
arxiv_id
stringlengths 11
13
| markdown
stringlengths 2.09k
423k
| paper_doi
stringlengths 13
47
⌀ | paper_authors
sequencelengths 1
1.37k
| paper_published_date
stringdate 2014-06-03 19:36:41
2024-08-02 10:23:00
| paper_updated_date
stringdate 2014-06-27 01:00:59
2025-04-23 08:12:32
| categories
sequencelengths 1
7
| title
stringlengths 16
236
| summary
stringlengths 57
2.54k
|
|---|---|---|---|---|---|---|---|---|
1408.0363v1 | ## Comment on 'Observation of a quantum Cheshire Cat in a matter-wave interferometer experiment', Nature Comm. 5 , 4492
## Antonio Di Lorenzo
Instituto de F´ ısica, Universidade Federal de Uberlˆndia, a 38400-902 Uberlˆndia, Minas Gerais, Brazil a
August 5, 2014
## Abstract
It is shown that a classical experiment using an ordinary cat can reproduce the same results and it is argued that the quantum nature of the phenomenon could be revealed instead by making an experiment that detects cross-moments.
In the recent paper [1], the authors claim to have separated the mass of a neutron from its polarization, implementing the proposal of Aharonov et al. [2]. We prove that the experimental data do not support the claim, as they could be reproduced classically, but that, with a suitable change of the apparatus, it would be possible to prove uncontroversially that a neutron inside an interferometer is simultaneously in the two arms.
Let us make a classical experiment. I send my cat to a bifurcation. I measure her passage in either direction with two very noisy apparatuses. In each repetition, either apparatus can give me outputs like -200, or +10, or 3.14 cats have passed here, because of a large random bias in the initial position of the pointer. Precisely, if the cat is present, the pointer is shifted by 1, but the initial value x 0 of the pointer is not zero, as one would expect from an ordinary measurement; rather, it is distributed around 0 with a widespread probability distibution. I repeat the measurements N times. Then, I change the apparatus, so that now it measures how many times a
tail pointing up or down is present in either path. Again, the apparatuses are very noisy. I repeat another N times. The first average gives me that there is 1 cat in the left path and 0 cats on the right path. The second average yields 0 tails in the left path and 1 tail in the right path.
Can I claim that I have separated the tail (or, better, the direction of the tail) from my cat (without hurting the cat)? Given that the random bias in the apparatuses averages to zero, I would conclude so, if the number of repetitions is sufficiently large and if I used all of the experimental data, i.e. if I did not make a post-selection. However, the post-selection can yield a biased subset of data.
Indeed, let us say that after the measurement my cat can either eat her food or hide inside a box. The post-selection is considered successful when the cat hides inside the box. The initial preparation of the cat consisted in letting her starve for some time. Therefore, most of the times the cat will choose the food over the box, with the exception of a few cases when the cat demonstrates her volatile nature. Now, with a small probability, the measuring apparatus can make a scary noise that will cause the cat to hide inside the box, the fear prevailing over the hunger. This probability is a function of the initial random bias of the probe. As the probability of the scary noise being produced is always small, the measurement apparatus does not disturb significantly the state of the cat. However, the rules of probability theory establish that the subset of events in which the postselection was successful correspond to an initial bias of the detector close to the maximum of the likelihood prob noise amount of bias ( | ). Therefore, if I consider only the subset of events with a successful post-selection, I can have an average number of cat in the left path equal to 1, and the same average number of tail-up in the right path. This does not allow me to conclude that my experimental data showed a disembodiment of the tail from the cat. This gedankenexperiment can be performed with a classical system, and reproduce the situation that the authors of the article have realized with neutrons.
Differently from the cat in the above example, the neutron can be thought of as simultaneously present in both arms of the interferometer. However, measuring weakly its average presence and its average polarization, as was done in the paper, provides no evidence of this, as we just demonstrated. Instead, we have suggested elsewhere [3, 4] that a good quantifier of this ubiquity is the sum of the signed cross-moment ∑ ± ±〈 xy 〉 ± , where x is the output of the detector measuring the presence of the neutron in the left arm and y it the output of the detector measuring simultaneously (and not in a
separate run, as was done in the experiment) the polarization in the right arm, while the sign ± denotes a successful or unsuccessful post-selection. This quantity was shown to be related to the entanglement between the two detectors, which is created due to the neutron being simultaneously in both arms.
In conclusion, the experiment does not demonstrate a quantum Cheshire cat yet, but it could do so with some appropriate changes.
## Quantifying our thesis
We provide an explicit example. The cat enters either path of the bifurcation with probability 1 / 2, and its tail is either up or down with probability 1 / 2, irrespectively of the path chosen. The cat detector has an initial distribution of the pointer variable
$$\Pi _ { 0 } ( x ) = \frac { 1 } { \sqrt { 2 \pi } \Delta } \exp [ - x ^ { 2 } / 2 \Delta ^ { 2 } ],$$
with ∆ /greatermuch 1. The pointer x , when the cat chooses the left path, is shifted deterministically from its initial value by 1, otherwise it stays the same. Analogously, in the right path we put a tail detector, with an initial distribution
$$\Pi _ { 0 } ( y ) = \frac { 1 } { \sqrt { 2 \pi } \Delta } \exp [ - y ^ { 2 } / 2 \Delta ^ { 2 } ].$$
If the cat chooses the right path and its tail is up, y shifts deterministically by +1, it its tail is down, y shifts by -1, and if the cat is not there, y does not vary. After the measurement, if the value of the pointer is x , the cat detector makes a scary noise with the probability
$$p _ { c } ( x ) \equiv P _ { c } ( n o i s e | x ) = \varepsilon _ { c } \exp [ - ( x - u ) ^ { 2 } / 2 \delta ^ { 2 } ],$$
with ε c /lessmuch 1, and u , δ parameters that we shall fix appropriately. Analogously, the tail detector can produce a noise with probability
$$p _ { t } ( y ) \equiv P _ { t } ( n o i s e | y ) = \varepsilon _ { t } \exp [ - ( y - v ) ^ { 2 } / 2 \delta ^ { 2 } ].$$
The detectors are acustically insulated from each other, so that if the cat detector makes a noise but the cat is interacting with the tail detector, the cat
won't hear any noise. We are assuming this to exclude a non-local feedback process. After the measurement, if no noise was produced, the cat will either eat its food or hide in the box, with a probability q = 3 4 and / p = 1 4, / respectively. However, in the rare cases when a noise is produced in the proximity of the cat, she will hide in the box with probability 1.
We can calculate the joint probability of observing an output x from the detector and later post-selecting the cat inside the box (which we denote by the symbol b ) by applying Bayes' rule
$$\text{$me$ symbol $y$ applying Days $rue$} \\ \Pi ( x, y, b ) = & \int d x _ { 0 } d y _ { 0 } \Pi ( x, y, b | x _ { 0 }, y _ { 0 } ) \Pi _ { 0 } ( x _ { 0 }, y _ { 0 } ) \\ = & \int d x _ { 0 } d y _ { 0 } P ( b | x, y, x _ { 0 }, y _ { 0 } ) \Pi ( x, y | x _ { 0 }, y _ { 0 } ) \Pi _ { 0 } ( x _ { 0 }, y _ { 0 } ) \\ = & \int d x _ { 0 } d y _ { 0 } P ( b | x, y, x _ { 0 }, y _ { 0 } ) \Pi ( x, y | x _ { 0 }, y _ { 0 } ) \Pi _ { 0 } ( x _ { 0 } ) \Pi _ { 0 } ( y _ { 0 } ), \quad ( 5 ) \\ \text{where. in the last line. we used the independence of the initial values of $x$}$$
where, in the last line, we used the independence of the initial values of x and y , Π ( 0 x , y 0 0 ) = Π ( 0 x 0 )Π ( 0 y 0 ). Now, the probability density of observing a final shift x , given that the initial value of the pointer was x 0 , is obtained by considering the two classical alternatives: either the cat went left, thus increasing x 0 by 1 and leaving y 0 to its original value, or the cat went right, leaving x 0 untouched and either increasing or decreasing y 0 by one unit. Namely,
$$\Pi ( x, y | x _ { 0 }, y _ { 0 } ) & = \frac { 1 } { 2 } \delta ( x - x _ { 0 } - 1 ) \delta ( y - y _ { 0 } ) + \frac { 1 } { 4 } \delta ( x - x _ { 0 } ) \delta ( y - y _ { 0 } - 1 ) + \frac { 1 } { 4 } \delta ( x - x _ { 0 } ) \delta ( y - y _ { 0 } + 1 ). \\ \cap \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \colon$$
On the other hand, the conditional probability of post-selection is
$$\text{On the other hand, the conditional probability of post-selection is} \\ P ( b | x, y, x _ { 0 }, y _ { 0 } ) = & \sum _ { n _ { c }, n _ { t } = 0 } ^ { 1 } P ( b, n _ { c }, n _ { t } | x, y, x _ { 0 }, y _ { 0 } ) \\ = & \sum _ { n _ { c }, n _ { t } = 0 } ^ { 1 } P ( b | n _ { c }, n _ { t }, x, y, x _ { 0 }, y _ { 0 } ) P ( n _ { c }, n _ { t } | x, y, x _ { 0 }, y _ { 0 } ) \\ = & P ( b | 1 ) p _ { c } ( x ) p _ { t } ( y ) + [ P ( b | 1 ) \delta _ { y, y _ { 0 } } + P ( b | 0 ) \delta _ { x, x _ { 0 } } ] p _ { c } ( x ) [ 1 - p _ { t } ( y ) ] \\ & + [ P ( b | 0 ) \delta _ { y, y _ { 0 } } + P ( b | 1 ) \delta _ { x, x _ { 0 } } ] [ 1 - p _ { c } ( x ) ] p _ { t } ( y ) + P ( b | 0 ) [ 1 - p _ { c } ( x ) [ 1 - p _ { t } ( y ) ] \\ \text{where } n _ { c }, n _ { t } = 0 \text{ indicates that no scary noise was produced, and } n _ { c }, n _ { t } = 1$$
where n , n c t = 0 indicates that no scary noise was produced, and n , n c t = 1 that the detector made the scary noise. In the last equality, we exploited
the fact that the probability of the cat going into the box depends only on her hearing the noise, all the other parameters being superfluous, and we considered that it may happen that a detector makes a noise when the cat is not there, hence the Kronecker deltas. We recall that we defined p = P b ( | 0) the probability that the cat will go inside the box when undisturbed; on the other hand P b n ( | = 1) = 1.
Finally, substituting into Eq. (5), we have
$$\Pi ( x, y, b ) & = \frac { 1 } { 2 } \Pi _ { 0 } ( x - 1 ) \Pi _ { 0 } ( y ) \{ p [ 1 - p _ { c } ( x ) ] + p _ { c } ( x ) \} \\ & \quad + \frac { 1 } { 4 } \Pi _ { 0 } ( x ) \left [ \Pi _ { 0 } ( y - 1 ) + \Pi _ { 0 } ( y + 1 ) \right ] \{ p [ 1 - p _ { t } ( y ) ] + p _ { t } ( y ) \}. \quad ( 8 )$$
The conditional average outputs are then and
$$\langle x \rangle _ { b } & = \frac { \int d x d y \, x \Pi ( x, y, b ) } { \int d x d y \Pi ( x, y, b ) } \\ & \quad \hat { \ }. \quad \hat { \ }.$$
$$\langle y \rangle _ { b } = \frac { \int d x d y \ y \Pi ( x, y, b ) } { \int d x d y \Pi ( x, y, b ) }. \text{ } & \text{(10)} \\ \text{or in these expressions is the probability of post-selection}$$
The denominator in these expressions is the probability of post-selection
$$P ( b ) & = \int d x d y \Pi ( x, y, b ) \\ & = p + \frac { q } { 4 } \frac { \Delta _ { R } } { \Delta } \left \{ 2 \varepsilon _ { c } G ( u - 1 ) + \varepsilon _ { t } \left [ G ( v - 1 ) + G ( v + 1 ) \right ] \right \} \\ & \simeq p + O ( \varepsilon ) = \frac { 1 } { 4 } + O ( \varepsilon ), \\ \text{where we introduced the reduced variance}$$
where we introduced the reduced variance
$$\Delta _ { R } ^ { 2 } = \frac { \Delta ^ { 2 } \delta ^ { 2 } } { \Delta ^ { 2 } + \delta ^ { 2 } },$$
and we defined
$$G ( x ) = e ^ { - x ^ { 2 } / [ 2 ( \Delta ^ { 2 } + \delta ^ { 2 } ) ] }.$$
The post-selected averages, after some straightforward albeit tedious calculations, are
$$\langle x \rangle _ { b } \simeq & \frac { 1 } { 2 } + \frac { 3 } { 2 } \frac { \Delta _ { R } } { \Delta } \varepsilon _ { c } u ^ { \prime } ( 1 ) G ( u - 1 )$$
and
$$\langle y \rangle _ { b } \simeq & \frac { 3 } { 4 } \frac { \Delta _ { R } } { \Delta } \varepsilon _ { t } \left [ v ^ { \prime } ( 1 ) G ( v - 1 ) + v ^ { \prime } ( - 1 ) G ( v + 1 ) \right ],$$
where we introduced the notation
$$u ^ { \prime } ( z ) = \frac { \delta ^ { 2 } z + \Delta ^ { 2 } u } { \Delta ^ { 2 } + \delta ^ { 2 } }$$
and
$$v ^ { \prime } ( z ) = \frac { \delta ^ { 2 } z + \Delta ^ { 2 } v } { \Delta ^ { 2 } + \delta ^ { 2 } }.$$
Inspection of Eqs. (13) and (14) reveals that the correction to the average values, even though they are proportional to ε c /lessmuch 1 , ε t /lessmuch 1, can be nonnegligible if u, v ∼ ∆ and if 1 /ε j /lessorsimilar δ /lessmuch ∆. For instance, we are able to reproduce the theoretical values 〈 x 〉 b = 1, 〈 y 〉 b = 1, P b ( ) /similarequal 0 251, choosing . ∆ = 1000, δ = 10 -2 ∆, ε c = e/ 3 δ /similarequal 0 091, . ε t = 2 e/ 3 δ /similarequal 0 181, . u /similarequal 0 402∆, . v /similarequal 0 400∆. . On the other hand, the cross-moment 〈 xy 〉 b for this classical model is 0, while the corresponding quantum mechanical realization has, according to the theory, a non-zero value. This concludes the proof that a classical experiment with post-selection can reproduce the quantum Cheshire cat, as far as local averages are concerned.
## Acknowledgments
This work was performed as part of the Brazilian Instituto Nacional de Ciˆ encia e Tecnologia para a Informa¸˜o Quˆntica (INCT-IQ). ca a
## References
- [1] Denkmayr T, Geppert H, Sponar S, Lemmel H, Matzkin A, Tollaksen J, and Hasegawa Y 2013 Observation of a quantum Cheshire Cat in a matter-wave interferometer experiment Nature Comm. 5 , 4492
- [2] Aharonov Y, Popescu S, Rohrlich D, and Skrzypczyk P 2013 Quantum Cheshire Cats New J. Phys. 15 113015
- [3] Di Lorenzo A 2012 Hunting for the Quantum Cheshire Cat pre-print (arXiv:1205.3755 [quant-ph]) http://arxiv.org/abs/1205.3755
- [4] Di Lorenzo A 2014 Postselection induced entanglement swapping from a vacuum-excitation entangled state to separate quantum systems preprint (arXiv:1406.1064 [quant-ph]) http://arxiv.org/abs/1406.1064 | null | [
"Antonio Di Lorenzo"
] | 2014-08-02T12:17:32+00:00 | 2014-08-02T12:17:32+00:00 | [
"quant-ph"
] | Comment on `Observation of a quantum Cheshire Cat in a matter-wave interferometer experiment', Nature Comm. 5, 4492 | It is shown that a classical experiment using an ordinary cat can reproduce
the same results and it is argued that the quantum nature of the phenomenon
could be revealed instead by making an experiment that detects cross-moments. |
1408.0364v3 | ## Rare transition event with self-consistent theory of large-amplitude collective motion
Kyosuke Tsumura, Yoshitaka Maeda, Hiroyuki Watanabe Analysis Technology Center, Research & Development Management Headquarters,
Fujifilm Corporation, Kanagawa 250-0193, Japan
## Abstract
A numerical simulation method, based on Dang et al. 's self-consistent theory of large-amplitude collective motion, for rare transition events is presented. The method provides a one-dimensional pathway without knowledge of the final configuration, which includes a dynamical effect caused by not only a potential but also kinetic term. Although it is difficult to apply the molecular dynamics simulation to a narrow-gate potential, the method presented is applicable to the case. A toy model with a high-energy barrier and/or the narrow gate shows that while the Dang et al. treatment is unstable for a changing of model parameters, our method stable for it.
Keywords: PACS: 82.20.-w, 87.10.Tf
Rare transition event, Collective path
## 1. Introduction
Transition events with long timescales are of great importance in many fields of molecular science. In particular, examples in biology range from conformational changes in proteins associated with ligand binding [1] to allosteric transitions that occur throughout the global protein domain [2, 3]. Their typical timescales are the order of 10 -5 -1 sec [4]. Such rare transition events are due to the separation between the initial and final configurations in phase space. The separation is caused by the existence of a high energy barrier or a narrow gate in a potential energy surface; schematic examples of such separations are shown in Fig. 1.
Email address: [email protected] (Kyosuke Tsumura)
Figure 1: Schematic examples of the separations in the potential energy surface. (a) A high energy barrier or (b) a narrow gate separate the initial and final configurations represented by the circle and cross, respectively. The thin lines denote the contours of the potential energy surfaces.
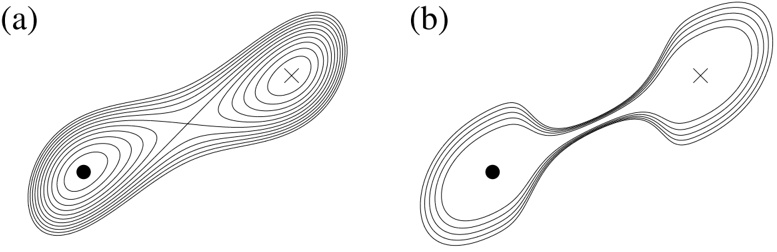
Numerical simulation is an essential tool to elucidate the rare transition event and obtain the final configuration. There exist two kinds of approaches to the problem. The first one is to find a pathway determined only by the geometrical feature of the potential energy together with some criteria. The second one is to obtain a trajectory which respects both the potential energy and the kinetic energy. In this work, we employ the latter one because the rare transition events are generated by the potential and kinetic effects.
A standard method for the latter one is molecular dynamics (MD). However, the computational time requirement of conventional MD makes this method insufficient for simulation of these rare transition events. A number of efficient methods that use artificial forces to overcome high energy barriers have been proposed [5, 6, 7, 8]. Most of the previous methods, however, are not efficient for rare transition events caused by a narrow gate. This is because the transition rate through the narrow gate is determined by a frequency factor and has a weak (at most power-law) dependence on the magnitude of the artificial forces as shown in chemical kinetics. Both the high energy barrier and the narrow gate are of significance for rare transition events especially in biology [4].
In this paper, we describe the development of a method to simulate rare transition events caused by not only the high energy barrier but also the narrow gate; we are interested in transitions between local minima in a potential energy surface. Typical thermally fluctuating motions are confined in space near the initial configuration; the motions have complex multi-
dimensional structures. On the other hand, the motion in the rare transition event moves along a simple sharp curve for the following reasons. For the narrow gate, coordinates of the system are limited to specific values as a result of the narrowness of the potential energy surface. For the high energy barrier, the coordinates must obtain large momenta to overcome the barrier, and the momenta restrict the direction of motion to a specific one. From this discussion, the method to be developed is one that can separate one relevant coordinate, which parametrizes the curve, from other coordinates orthogonal to the relevant one. We call the coordinate a collective coordinate and the curve a collective path . Many construction methods for the collective path have been proposed over the past five or more decades [9, 10, 11, 12, 13, 14, 15, 16, 17, 18, 19]. This approach includes both the potential energy and the kinetic energy as we shall see in Appendix A.
The self-consistent theory of large-amplitude collective motion developed by Dang et al. [15, 16, 17, 18] is one of the powerful methods, which is a pioneering work in applications to molecular systems. Central to their theory are decoupling conditions given by four equations whose solution gives the collective path. Because exact decoupling is not anticipated for realistic systems, that is, the four equations cannot have a simultaneous solution in general, the problem becomes that of defining a constructive procedure for the approximate collective path. In Refs. [15, 16, 17, 18], two approximations based on a subset of the four equations have been proposed.
However, which approximations in the theory of Dang et al. give a transition event between local minima in a potential energy surface depends highly on the details of the potential parameters, as will be demonstrated in Sec. 2.3. Owing to the lack of the robustness in the previous works, defining a unique approximation to the decoupling conditions and a method for evaluating the quality of it is a central issue for development of the collective path theory.
A natural improvement of the approximations proposed by Dang et al. is a construction of the collective path as an optimal solution to all the four decoupling condition equations rather than a subset of them. To manipulate this approximation and evaluate the quality of the resultant collective path, we introduce a unique scalar quantity that measures the deviations from the equalities in the four decoupling condition equations. We then minimize this quantity to formulate the proper construction method of the collective path. The resultant method is based on a first-order differential equation whose solubility algorithm requires calculation of the first and second derivatives of
the potential energy at each step for a stepwise construction of the collective path. We show this method can robustly construct the collective path even if the initial and final configurations are separated by a high energy barrier or narrow gate as shown in Fig. 1.
This paper is organized as follows: In Sec. 2, we introduce the decoupling conditions in the theory of Dang et al. [15, 16, 17, 18] and demonstrate that the two approximations cannot work as a robust construction method of the collective path. A detailed derivation of the decoupling conditions is presented in Appendix A. In Sec. 3, we define the scalar quantity and then formulate the proper method for the construction of the collective path by minimizing this quantity. In Sec. 4, we use two simple Hamiltonians to demonstrate the ability of our method to construct the collective path. We devote Sec. 5 to a summary and concluding remarks.
## 2. Preliminary
In this section, we present a brief account of the self-consistent theory of large-amplitude collective motion developed by Dang et al. [15, 16, 17, 18]. First, we present an explicit form of the decoupling conditions, and prove that there exists no simultaneous solution to them in the generic case. Then, we introduce the two approximations to the decoupling conditions that Dang et al. [15, 16, 17, 18] have proposed. Furthermore, we demonstrate that whether the two approximations can detect the collective path connecting local minima depends highly on the shape of a potential energy surface. We note that the proof of the absence of the solution and the demonstration of the lack of the robustness property are original arguments of this work.
## 2.1. Decoupling conditions
Because we are interested in the applications to molecular systems, we start with a Hamiltonian defined by
$$H = \sum _ { i = 1 } ^ { N } \, \frac { 1 } { 2 \, m _ { i } } \, p _ { i } ^ { 2 } + V ( x _ { 1 }, \, \cdots, \, x _ { N } ),$$
where N is the total number of degrees of freedom, x i , p i , and m i denote the coordinate, conjugate momentum, and mass of the i -th degree of freedom, respectively, and V ( x , 1 · · · , x N ) is the potential energy.
We introduce the decoupling conditions that define the collective path in the Hamiltonian (1). A detailed derivation of the decoupling conditions is presented in Appendix A. When we write the collective path as
$$x _ { i } = x _ { i } ( q ),$$
where q denotes the collective coordinate, the decoupling conditions to determine the explicit q -dependence of x i [15, 16, 17, 18] are
$$\frac { \mathrm d x _ { i } } { \mathrm d q } = \varphi _ { i } / \sqrt { m _ { i } },$$
where ϕ i are given as a solution to the following equations:
$$\sum _ { j = 1 } ^ { N } \left ( V _ {, i j } - \lambda \, \delta _ { i j } \right ) \varphi _ { j } \ = \ 0, \quad & & ( 4 ) \\ \nu, \quad & & \nu \searrow$$
$$V _ {, i } \ = \ \gamma \, \varphi _ { i },$$
$$\sum _ { i = 1 } ^ { N } \varphi _ { i } \, \varphi _ { i } \ = \ 1.$$
$$V _ {, i } \ \equiv \ \frac { 1 } { \sqrt { m _ { i } } } \, \frac { \partial V ( \boldsymbol x ) } { \partial x _ { i } }, \quad \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \$$
$$V _ {, i j } \ \equiv \ \frac { \cdot } { \sqrt { m _ { i } } \sqrt { m _ { j } } } \frac { \partial ^ { 2 } V ( \boldsymbol x ) } { \partial x _ { i } \, \partial x _ { j } },$$
with x = ( x , 1 · · · , x N ). We note that Eqs. (3)-(6) show that ϕ / i √ m i is a tangent vector to the collective path x = x ( q ) at the collective coordinate q , ϕ i should be an eigenvector of the matrix V ,ij , be proportional to the vector V ,i , and be normalized and that λ and γ denote an eigenvalue of the eigenvector ϕ i and a proportionality factor, respectively. By solving the decoupling conditions given by Eq. (3) together with Eqs. (4)-(6), we can construct the collective path x = x ( q ). We use the obtained x ( q ) to reduce the Hamiltonian (1) into a Hamiltonian that governs the dynamics of the collective coordinate q [15, 16, 17, 18].
where
## 2.2. Proof for absence of solution to decoupling conditions
We emphasize that for a generic potential energy function V ( x ), there exists no ϕ i that satisfies Eqs. (3)-(6), except for the local minima or saddle points defined by V ,i = 0. To explain this fact in an explicit manner, first we identify ( x , ϕ , λ, γ i i ) with would-be independent variables and consider an infinitesimal expansion of these variables around ( x , ϕ , λ, γ i i ), which satisfies Eqs. (4)-(6). Substituting x ′ i = x i + d x i , ϕ ′ i = ϕ i + d ϕ i , λ ′ = λ + d λ , and γ ′ = γ +d γ into Eqs. (4)-(6), we have equations governing (d x , i d ϕ , i d λ, d γ ), which are necessary for ( x , ϕ , λ , γ ′ i ′ i ′ ′ ) to remain the solution to Eqs. (4)-(6). Then, by dividing the equations by d q and incorporating Eq. (3) with them, we reduce the decoupling conditions (3)-(6) into a compact set of equations given by
$$\frac { \mathrm d } { \mathrm d q } ( x _ { i }, \varphi _ { i }, \lambda, \gamma ) = ( X _ { i } / \sqrt { m _ { i } }, \sum _ { a = 1 } ^ { N - 1 } \varphi _ { \perp i } ^ { a } \Phi _ { a }, \Lambda, \Gamma ),$$
where ϕ a ⊥ i with a = 1 , · · · , N -1 denote a complete set of the vectors orthogonal to ϕ i with the normalizations
$$\sum _ { i = 1 } ^ { N } \varphi _ { \perp i } ^ { a } \varphi _ { \perp i } ^ { b } \ = \ \delta ^ { a b },$$
and Y ≡ t ( X , i Φ a , Λ Γ) are defined as the solution to ,
$$A \, Y - b = 0,$$
with where
$$V _ {, i j k } \equiv \frac { 1 } { \sqrt { m _ { i } } \sqrt { m _ { j } } \sqrt { m _ { k } } } \frac { \partial ^ { 3 } V ( \boldsymbol x ) } { \partial x _ { i } \, \partial x _ { j } \, \partial x _ { k } }.$$
Here, we have used the Einstein summation convention for the dummy indices. We note that the matrix A is a (3 N ) × (2 N + 1) matrix. Because
$$A \ \equiv \ \left ( \begin{array} { c c c } V _ {, i j k } \varphi _ { k } & ( V _ {, i j } - \lambda \, \delta _ { i j } ) \, \varphi _ { \perp j } ^ { a } & - \varphi _ { i } & 0 \\ V _ {, i j } & - \gamma \, \varphi _ { \perp i } ^ { a } & 0 & - \varphi _ { i } \\ \delta _ { i j } & 0 & 0 & 0 \end{array} \right ), \quad \ \ ( 1 2 ) \\ \cdot \quad t / \sim \ \sim \ \, \end{array}$$
$$b \ \equiv \ ^ { t } ( 0, 0, \varphi _ { i } ),$$
the number of the equations is obviously larger than that of the variables, Eq. (11) has no solution with respect to Y = ( t X , i Φ a , Λ Γ) in general, and , hence the collective path x ( q ) also cannot be constructed as a solution to Eq. (9).
/negationslash
We prove that Eq. (11) has a definite solution of Y = ( t X , i Φ a , Λ Γ) , when x i agrees with x eq i , satisfying V ,i ( x eq ) = 0. We write Y obtained at x eq i as Y eq = ( t X eq i , Φ eq a , Λ eq , Γ eq ). To obtain an explicit form of Y eq , first we construct ϕ i , λ , γ , and ϕ a ⊥ i which are necessary to build the matrix elements of A and b in Eq. (11). Substituting V ,i ( x eq ) = 0 into Eq. (5), we have γ = 0. Furthermore, because Eq. (4) requires ϕ i and λ to be eigenvectors and eigenvalues of V ,ij ( x eq ), respectively, we have ϕ i = φ 0 i and λ = λ 0 . Here, we have introduced φ µ i and λ µ with µ = 0 , · · · , N -1 as the eigenvectors and eigenvalues of V ,ij ( x eq ), respectively. We suppose that λ 0 = λ a for any a = 1 , · · · , N -1. Using the eigenvectors φ a i orthogonal to φ 0 i , we have ϕ a ⊥ i = φ a i . Then, we use ( x , ϕ , λ, γ, ϕ i i a ⊥ i ) = ( x eq i , φ , λ , 0 i 0 0 , φ a i ) to construct A and b . After substituting these into Eq. (11), we come to the solution that
$$X _ { i } ^ { \text{eq} } \ = \ \phi _ { i } ^ { 0 },$$
$$\Phi _ { a } ^ { \text{eq} } & \ = \ \frac { 1 } { \lambda ^ { 0 } - \lambda ^ { a } } \, V _ {, i j k } ( x ^ { \text{eq} } ) \, \phi _ { i } ^ { 0 } \, \phi _ { j } ^ { 0 } \, \phi _ { k } ^ { a }, \\ \Lambda ^ { \text{eq} } & \ = \ V _ {, i j k } ( x ^ { \text{eq} } ) \, \phi _ { i } ^ { 0 } \, \phi _ { i } ^ { 0 },$$
$$\Lambda ^ { \text{eq} } \ = \ V _ {, i j k } ( \boldsymbol x ^ { \text{eq} } ) \, \phi _ { i } ^ { 0 } \, \phi _ { j } ^ { 0 } \, \phi _ { k } ^ { 0 },$$
$$\Gamma ^ { \text{eq} } \ = \ \lambda ^ { 0 }.$$
Indeed, Y = ( t X , i Φ a , Λ Γ) has been constructed as a definite solution to , Eq. (11) at a stationary point.
## 2.3. Approximations to decoupling conditions
It is a significant task to obtain an approximate solution to Eqs. (3)-(6). In Refs. [17, 18], Dang et al. proposed two methods. One respects Eqs. (4)-(6), but not (3), which is an approximation 1 (Approx1) method. The other takes into account Eqs. (3), (4), and (6), but not (5), which we call an approximation 2 (Approx2) method.
We examine whether the Approx1 method or the Approx2 method can construct the collective path connecting local minima, by using the following two-dimensional Hamiltonian ( N = 2):
$$H = \frac { 1 } { 2 } \, ( p _ { 1 } ^ { 2 } + p _ { 2 } ^ { 2 } ) + V _ { \text{MB} } ( x _ { 1 }, \, x _ { 2 } ).$$
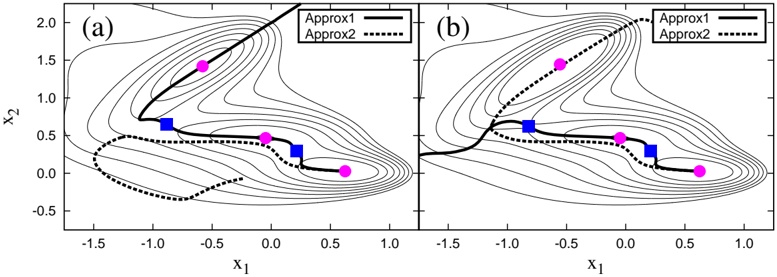
Figure 2: The potential energy surfaces made by the M¨ller-Brown potential [20], i.e., u (a) the modified one V ( a ) MB and (b) the original one V ( b ) MB , together with the collective paths extracted by the Approx1 and Approx2 methods. The circles denote the local minima and the squares the saddle points. The solid (dashed) line represents the collective path calculated by the Approx1 (Approx2) method, which starts from one of the local minima. The thin lines denote the contours of the potential energy surfaces.
Here, V MB ( x , x 1 2 ) is the M¨ller-Brown potential [20], u
$$V _ { \text{MB} } ( x _ { 1 }, x _ { 2 } ) = \sum _ { \alpha = 1 } ^ { 4 } C ^ { \alpha } \, \exp \left [ \frac { 1 } { 2 } \, \sum _ { i, j = 1 } ^ { 2 } \left ( x _ { i } - \bar { x } _ { i } ^ { \alpha } \right ) M _ { i j } ^ { \alpha } \left ( x _ { j } - \bar { x } _ { j } ^ { \alpha } \right ) \right ], \quad \ ( 2 0 )$$
where ( C , x α ¯ α i , M α ij ) with α = 1 , · · · , 4 and i, j = 1 , 2 denote parameters. The parameters are set equal to [20]
$$C ^ { \alpha } \ & = \ ( - 2 0 0, \, - 1 0 0, \, - 1 7 0, \, 1 5 ), \quad \ ( 2 1 ) \\ \bar { \tau } ^ { \alpha } \ & = \ ( 1 \, \ 0 \, \ = 0 \, 5 \, \ = 1 \, \L )$$
$$\bar { x } _ { 2 } ^ { \alpha } \ = \ ( 0, \, 0. 5, \, 1. 5, \, 1 ),$$
$$\bar { x } _ { 1 } ^ { \alpha } \ & = \ ( 1, \, 0, \, - 0. 5, \, - 1 ), \\ \bar { r } _ { \mu } ^ { \alpha } \ & = \ ( 0 \, 0 \, 5 \, 1 \, 5 \, 1 )$$
$$M _ { 1 1 } ^ { \alpha } \ & = \ ( - 2, \, - 2, \, - 1 3, \, 1. 4 ), \\ M _ { \alpha } ^ { \alpha } \ & = \ M _ { \alpha } ^ { \alpha } = \left ( 0 \ 0 \ 1 1 \ 0 \ 6 \right )$$
$$M _ { 1 2 } ^ { \alpha } \ = \ M _ { 2 1 } ^ { \alpha } = ( 0, \, 0, \, 1 1, \, 0. 6 ),$$
$$M _ { 2 2 } ^ { \alpha } \ = \ ( - 2 0, \, - 2 0, \, - 1 3, \, 1. 4 ).$$
The potential energy produced by this parameter set is denoted as V ( b ) MB and the set modified by altering C 3 from -170 to -120 is denoted V ( a ) MB .
In Fig. 2, we summarize four collective paths that are extracted from the Hamiltonians with V ( a ) MB and V ( b ) MB by the Approx1 and Approx2 methods. In
Figure 3: All the paths derived by the Approx1 method for (a) V ( a ) MB and (b) V ( b ) MB .
Refs. [17, 18], the Approx1 method was thought to be a better method than the Approx2 method. For V ( a ) MB , indeed, the Approx1 method can produce the collective path between local minima, while the Approx2 method is not the case. For V ( b ) MB , however, the approximation that extracts the transition event is not the Approx1 method but the Approx2 method. Figure 3 depicts all paths based on the Approx1 method. We note that, in contrast to V ( a ) MB , V ( b ) MB has no single path connecting the local minima. It turns out that whether the Approx1 method or the Approx2 method can extract the transition event sensitively depends on the shape of the potential energy surface, and hence both the Approx1 and Approx2 methods have not been a robust construction method of the collective path.
## 3. Improvement of approximations to decoupling conditions in self-consistent theory of large-amplitude collective motion
In this section, we develop the numerical simulation method that can robustly construct the collective path connecting local minima, which is an improvement of the Approx1 and Approx2 methods. A key point for the development of the method is the construction of Y = ( t X , i Φ a , Λ Γ) as an , optimal solution to Eq. (11).
By constructing the optimal solution Y and substituting Y into Eq. (9), we can obtain a first-order differential equation to determine ( x , ϕ , λ, γ i i ) as a solution to an initial-value problem.
We shall construct a procedure to obtain the optimal solution to Eq. (11).
To this end, first we define a vector ∆, which represents a deviation from the equality in Eq. (11), that is,
$$\Delta \equiv A Y - b.$$
Here, we treat the problem to minimize the magnitude of ∆ to derive an equation for the construction of the optimal Y .
## 3.1. Measure of deviation from exact decoupling
We introduce three new vectors d i , e i , and f i to represent ∆ as a form of the modification into ϕ i in the elements of A and b . Indeed, by parameterizing ∆ as
$$\Delta = \left ( \begin{array} { c } G _ { i j } \left ( d _ { j } - \varphi _ { j } \right ) \\ \Gamma \left ( e _ { i } - \varphi _ { i } \right ) \\ f _ { i } - \varphi _ { i } \end{array} \right ),$$
with
$$G _ { i j } \equiv \Lambda \, \delta _ { i j } - V _ {, i j k } \, X _ { k },$$
we can convert Eq. (27) into the same form as Eq. (11):
$$\tilde { A } Y - \tilde { b } = 0,$$
where
$$\begin{array} {$$
$$\begin{array} {$$
Here, ˜ and ˜ are obtained by the replacement of A b ϕ i in the first and second rows of A and the third row of b to d i , e i , and f i , respectively. Because the condition d i = e i = f i = ϕ i reproduces the exact decoupling conditions, we can reach the following natural definition of the scalar quantity that measures the deviation from exact decoupling:
$$Q = \sum _ { i = 1 } ^ { N } \, \left ( w _ {$$
where w d , w e , and w f denote weight parameters to determine which decoupling conditions (3)-(5) are respected. Because we are interested in the case where all of the decoupling conditions (3)-(5) are respected equivalently, we must set
$$( w _ { d }, w _ { e }, w _ { f } ) = ( 1$$
By definition, the set of ( w , w , w d e f ) = (1 , 1 , 0) corresponds to the Approx1 method, while the set of ( w , w , w d e f ) = (1 , 0 , 1) leads to the Approx2 method.
To make clear a geometrical meaning of Q , we rewrite Q as
$$Q = { ^ { t } } \Delta \, C \, \Delta = { ^ { t$$
This representation means that Q is identical to the norm, i.e., the square of the length of the vector ∆ = AY -b measured on the metric C given by
$$C \equiv \left ( \begin{array} { c c c } \left [ ^ { t } ( G ^ { - 1 } ) \, G ^ { - 1 } \right ] _ { i j } & 0 & 0 \\ 0 & \Gamma ^ { - 2 } \, \delta _ { i j } & 0 \\ 0 & 0 & \delta _ { i j } \end{array} \right ).$$
It is obvious that C has a dependence on ( X , i Λ Γ) that is not yet deter-, mined.
As shown in Eqs. (15)-(18), Y = ( t X , i Φ a , Λ Γ) can be obtained without , reference to C at the local minima and saddle points x eq i . If we take x eq i as a starting point to detect the collective path, we can carry out a straightforward construction of C by substituting ( X , i Λ Γ) in Eqs. (15), (17), and (18) into , Eq. (36). Here, we refer to C constructed at the starting point x eq i as C eq .
In this work, we use this metric C eq as a substitute for C in the course of the detection of the collective path;
$$C = C ^ { \text{eq} }.$$
Thanks to the metric C being constant, Q is a function bilinear with respect to Y , which is easily minimized. It is left to future work to carry out the nonlinear optimization of Q with respect to Y by taking into account the Y -dependence in C .
## 3.2. Basic equation of proper construction method of collective path
By applying the minimization (stationary) condition ∂Q/∂Y = 0 to Q with C = C eq , we arrive at
$$( ^ { t } A \, C ^ { \text{eq} } \, A ) \, Y - ^ { t } A \, C ^ { \text{eq} } \, b = 0.$$
We note that in contrast to Eq. (11), Eq. (38) can have a definite solution in general because t AC eq A is a (2 N +1) × (2 N +1) matrix and the number of the equations agrees with that of the variables. We stress that Eq. (9) combined with Y that is a solution to Eq. (38) is the main equation for the construction of the collective path, which is one of the results in this work.
A few remarks are in order here: (i) The basic equation of our method given by the set of Eqs. (9) and (38) is a first-order differential equation with respect to ( x , ϕ , λ, γ i i ), which can be solved with a single iteration for the stepwise construction of the collective path by repeating the calculation of the elements of the matrix A . In fact, we can construct A without an iteration procedure, because the elements of A are given by only the first, second, and third derivatives of the potential energy with respect to the coordinate variables, which can be calculated at a given structure of the system. Furthermore, we note that the elements associated with the third derivatives of V ( x ) in the matrix A in Eq. (38) can be calculated in the same computational cost as that in the case of the second derivative terms because the third derivative terms enter into A as a form of V ,ijk ϕ k . Indeed, we can construct V ,ijk ϕ k from the two second derivatives on the basis of the formula
$$V _ {, i j k } ( x ) \, \varphi _ { k } \sim \frac { V _ {, i j } ( x + n \, \Delta x ) - V _ {, i j } ( x - n \, \Delta x ) } { 2 \, \Delta x },$$
with n ≡ ( ϕ / 1 √ m , 1 · · · , ϕ N / √ m N ). Here, ∆ x denotes an infinitesimal value. We note that the calculations of the two second derivatives can be run in parallel. Thanks to Eq. (39), the resultant method requires only the numerical calculation of the first and second derivatives in each step of the single iteration. This property reduces the computational costs considerably. (ii) As mentioned in the final paragraph in Sec. 2.2, we suppose that the initial value of ( x , ϕ , λ, γ i i ) is set equal to ( x eq i , φ , λ , 0 i 0 0). Here, we present an account of the eigenvalue λ 0 and eigenvector φ 0 i . In this work, we adopt the smallest eigenvalue as λ 0 . This is because we are interested in the rare transition event of molecular systems where the amplitude of the collective
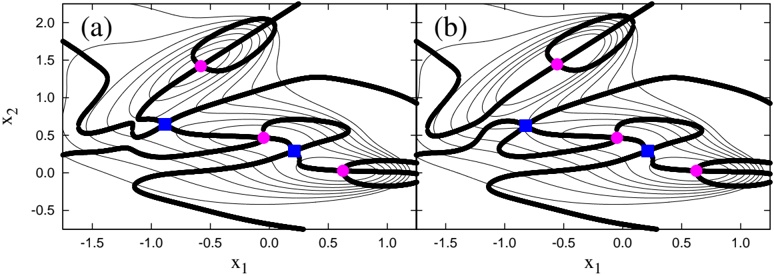
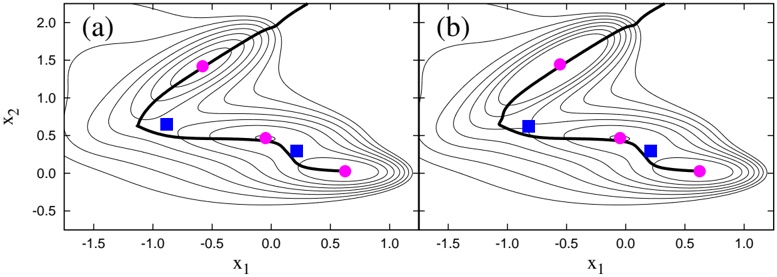
Figure 4: The collective paths constructed by the method based on the set of Eqs. (9) and (38). The potential energy surfaces are the same as those in Fig. 2, and the solid line represents the collective path.
coordinate is large compared to those of the other coordinates, which can be translated to the requirement to use the smallest eigenvalues of V ,ij . We note that the direction of the construction of the collective path from the initial configuration depends on the sign of φ 0 i , because φ 0 i gives the step from the initial structure to the next one.
## 4. Applications of self-consistent theory of large-amplitude collective motion to simple Hamiltonians
In this section, first we examine our method's ability to construct the collective path connecting local minima. Then, we elucidate the ability of the method to extract the rare transition event by using potential energy surfaces with either a high energy barrier or a narrow gate to separate the two local minima as shown in Fig. 1.
## 4.1. M¨ uller-Brown potential
To examine the robustness property of the numerical simulation method based on the set of Eqs. (9) and (38), we utilize the Hamiltonians with the M¨ uller-Brown potential [20], which are the same as those presented in Fig. 2.
In Fig. 4, we show the resultant collective paths. Both of them are shown as trajectories that connect almost all the local minima and saddle points. As that it is not the case in the collective paths obtained with the Approx1
and Approx2 methods, shown in Fig. 2, we conclude that our method is a robust construction method of the collective path describing the transition between local minima, in contrast to the Approx1 and Approx2 methods.
We now make one remark here. The collective paths depicted in Fig. 4 pass close to but not exactly through the saddle points. This is a critical problem for the studies of minimum energy path [21, 22]. However, the path studied in this paper is the one including not only the potential energy but also the kinetic energy. In this case, that the path passes exactly through the saddle points is not necessarily required. A further examination of this point is a future problem.
## 4.2. Barrier and gate potential
We consider a Hamiltonian given by
$$H = \frac { 1 } { 2 } \, ( p _ { 1 } ^ { 2 } + p _ { 2 } ^ { 2 } ) + V _ { \text{BG} } ( x _ { 1 }, \, x _ { 2 } ).$$
Here, V BG ( x , x 1 2 ) denotes the barrier and gate potential defined by
$$V _ { \text{BG} } ( x _ { 1 }, x _ { 2 } ) = - \frac { 1 } { 2 } \, a \, x _ { 1 } ^ { 2 } + \frac { 1 } { 4 } \, b \, x _ { 1 } ^ { 4 } + ( x _ { 2 } - c \, x _ { 1 } ) ^ { 2 } \left [ \alpha \, x _ { 1 } ^ { 2 } + \beta \, e ^ { - \gamma x _ { 1 } ^ { 2 } } + \delta \right ], \ \ ( 4 1 )$$
with ( a, b, c, α, β, γ, δ ) being parameters. The parameters ( a, b, c ) determine locations and energy values of stationary points. Indeed, this potential energy surface has two local minima and one saddle point located at ( ± √ a/b, ± c √ a/b ) and (0 , 0), respectively, and the activation energy in the transition between the two local minima is given by a / 2 (4 b ). The parameters ( α, β, γ, δ ) determine the narrowness of the pathway connecting the local minima and the saddle point.
To show the ability of the method developed to simulate the rare transition event, we introduce three potential energy surfaces: a potential energy surface containing neither a high energy barrier nor a narrow gate V ( a ) BG , a surface with a high energy barrier V ( b ) BG , and a surface with a narrow gate V ( c ) BG . The parameters ( a, b, c, α, β, γ, δ ) which create V ( a ) BG , V ( b ) BG , and V ( c ) BG read (80 , 80 , 3 , 0 0045 . , 10 , 10 , 1), (240 , 240 , 3 , 0 , 0 , 10 , 20), and (80 , 80 , 3 , 0 31 . , 690 , 10 , 9 7), . respectively. All the potential energies have the same locations of the local minima as ( ± 1 , ± 3).
In Fig. 5, we show the collective paths corresponding to V ( a ) BG , V ( b ) BG , and V ( c ) BG together with trajectories obtained by the conventional MD method.
Figure 5: The collective paths obtained by the method developed in this work and the trajectories obtained by the MD method on the V ( a ) BG , V ( b ) BG , and V ( c ) BG potential energy surfaces. The solid lines in (a-1) and (a-2) ((b-1) and (b-2) or (c-1) and (c-2)) show the collective path and the MD trajectory derived from V ( a ) BG ( V ( b ) BG or V ( c ) BG ), respectively. In (a-1) and (a-2) ((b-1) and (b-2) or (c-1) and (c-2)), the thin lines denote the contours of V ( a ) BG ( V ( b ) BG or V ( c ) BG ), the circles the local minima, and the squares the saddle point.
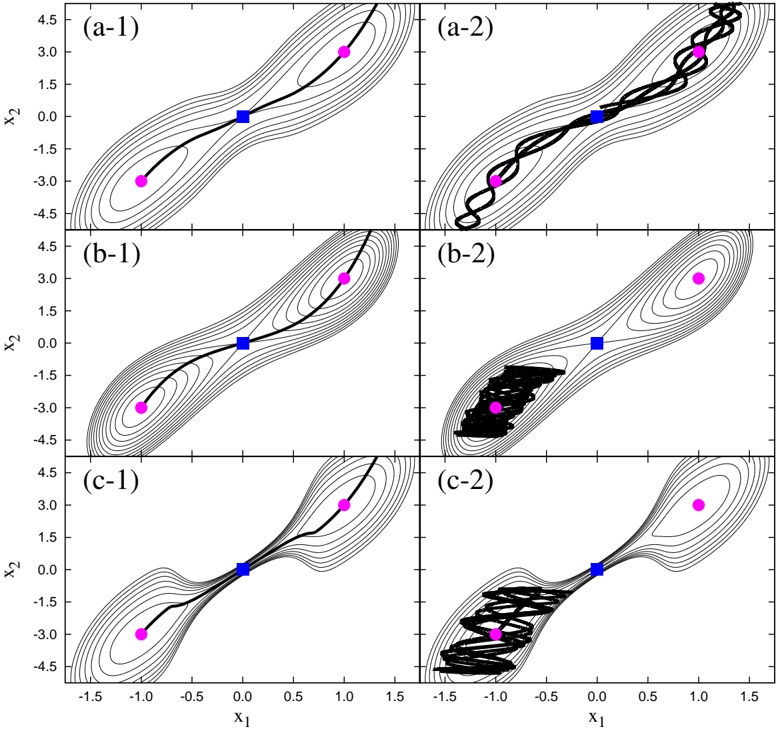
We find that the collective paths provide pathways connecting the two local minima even if a high energy barrier or narrow gate exists between the two local minima. Conversely, the MD method applied to V ( a ) BG can provide a trajectory near the collective path, but the trajectories obtained for the V ( b ) BG and V ( c ) BG cases are seen to be trapped near one local minimum and cannot reach the other local minimum. We note that the qualitatively same results are obtained with less symmetric potentials, e.g., V BG ( x , x 1 2 )+ x 3 1 ; in Appendix B, the results for the potentials are discussed. We stress that in contrast to the MD method, our method works well as a simulation technique for the rare transition event.
## 5. Summary and concluding remarks
Basic notion adopted in this work is that simulation of rare transition events can reduce to construction of a collective path given as a simple sharp curve along which only one coordinate increases if the initial coordinates are adequately chosen. To detect the collective path, we have developed a method to separate a collective coordinate, which parametrizes the collective path, from the other coordinates orthogonal to the collective coordinate. The method has been formulated by constructing the collective path as an optimal solution to the decoupling conditions in the self-consistent theory of large-amplitude collective motion proposed by Dang et al. [15, 16, 17, 18]. A basic equation of the method is given by the set of Eqs. (9) and (38). We have found that the equation is a first-order differential equation that determines the collective path as a solution to an initial-value problem from an arbitrary point in the collective path with the use of the first and second derivatives of the potential energy with respect to the atomic coordinates. By using the M¨ller-Brown potential [20], we have demonstrated that the u method, which is an improvement of the theory of Dang et al. , can robustly construct the collective path connecting the local minima in the potential energy surface. We have used a simple potential energy surface to show that our method uses only the initial configuration to construct a pathway to the final configuration, even if the configurations are separated by a high energy barrier and/or a narrow gate.
We consider that our study can stimulate discussions about the rare transition events in various systems of interest. In fact, the method presented in this work can be applied to simulate the rare transition events of generic
molecular systems whose potential energy surfaces are well-defined. For example, by using a potential energy for biomolecules, e.g., the generalized amber force field [23], we will demonstrate [24] that our method can be applied to describe allosteric transitions [2, 3] which are typical rare transition events for protein systems. Furthermore, if we utilize potential energies calculated numerically using computer programs developed on the basis of quantum chemistry, we can describe a chemical reaction as a rare transition event. In fact, we will show [25] that combining this method with the density functional theory [26] allows simulation of an intermolecular proton transfer reaction, i.e., molecular dynamics with quantum tunneling. We will also show [27] that our method in combination with time-dependent density functional theory [28] can be applied to simulate photochemical reactions, i.e., the dynamics of molecular systems in electronic excited states.
Finally, we remark again the following study that should be reported in the near future. We apply the non-linear optimization to Eq. (35) to determine the collective path in a full consistent manner and compare it with the collective path obtained in the approximation (37).
## Acknowledgments
The authors are grateful to Dr. Furuya for his encouragement and support.
## Appendix A. Detailed derivation of decoupling conditions
In this section, we present a review of the derivation of the decoupling conditions in the self-consistent theory of large-amplitude collective motion developed by Dang et al. [15, 16, 17, 18]. We focus on the collective path parametrized by one collective coordinate, although Dang et al. [15, 16, 17, 18] have presented a construction method of a multi-dimensional collective path, i.e., the so-called collective surface. Basically, we obey the notation used in Refs. [17, 18] in this section. In the final stage, we convert the derived decoupling conditions into those introduced in Sec. 2.1.
We treat an N -body system whose Hamiltonian is
$$H = \frac { 1 } { 2 } \, \pi _ { \alpha } \, B ^ { \alpha \beta } \, \pi _ { \beta } + V ( \xi ^ { 1 }, \, \cdots, \, \xi ^ { N } ).$$
Here, α and β denote indices that vary from 1 to N ξ , α and π α are a coordinate and its conjugate momentum of the α -th degree of freedom, respectively,
B αβ is a reciprocal mass tensor, and V ( ξ 1 , · · · , ξ N ) is a potential energy. We suppose that B αβ is diagonalized as
$$B ^ { \alpha \beta } = \text{diag} ( 1 / m _ { 1 }, \cdots, 1 / m _ { N } ),$$
with m α being the mass of the α -th degree of freedom.
We use a canonical transformation to obtain conditions that define the collective path. In the canonical transformation, we consider mappings of the form
$$\xi ^ { \alpha } = g ^ { \alpha } ( q ^ { 1 }, \, \cdots, \, q ^ { N } ) \equiv g ^ { \alpha } ( q ),$$
whose inverse relations are given by
$$q ^ { \mu } = f ^ { \mu } ( \xi ^ { 1 }, \cdots, \xi ^ { N } ) \equiv f ^ { \mu } ( \xi ).$$
Using a chain rule relation, we find that g α ( q ) and f µ ( ξ ) satisfy the following relations:
$$\delta ^ { \alpha } _ { \ \beta } \ = \ \partial \xi ^ { \alpha } / \partial \xi ^ { \beta } = g ^ { \alpha } _ {, \mu } ( q ) \, f ^ { \mu } _ {, \beta } ( \xi ),$$
$$\delta ^ { \dot { \mu } } _ { \, \nu } \ = \ \partial q ^ { \mu } / \partial q ^ { \nu } = f ^ { \dot { \mu } } _ {, \, \alpha } ( \xi ) \, g ^ { \dot { \alpha } } _ {, \, \nu } ( q ),$$
where the comma indicates a partial derivative; F , α ( ξ ) ≡ ∂F ξ /∂ξ ( ) α and G , µ ( q ) ≡ ∂G q /∂q ( ) µ . The indices α, β, · · · represent those of the initial coordinates, and µ, ν, · · · those of the final coordinates, although each set has the same range 1 , · · · , N . The momentum p µ conjugate to q µ is given by
$$p _ { \mu } = g _ {, \mu } ^ { \alpha } ( q ) \, \pi _ { \alpha },$$
with inverse
$$\pi _ { \alpha } = f _ {, \alpha } ^ { \mu } ( \xi ) \, p _ { \mu }.$$
The Hamiltonian as described with the canonical coordinates ( q µ , p µ ) is
$$H = \frac { 1 } { 2 } \, p _ { \mu } \, \bar { B } ^ { \mu \nu } ( q ) \, p _ { \nu } + \bar { V } ( q ).$$
Here, ¯ B µν ( q ) is an inverse matrix of ¯ B -1 µν ( q ) given by
$$\bar { B } _ { \mu \nu } ^ { - 1 } ( q ) \equ$$
and ¯ ( V q ) is the potential energy written by q µ as
$$\bar { V } ( q ) \equiv V ( \xi ^ { 1 } = g ^$$
Equations of motion derived from the Hamiltonian (A.9) are
$$\dot { q } ^ { \mu } \ = \ \bar { B } ^ { \mu$$
$$\begin{array} {$$
In the new canonical coordinates, we identify the collective path as follows: We divide the set of ( q µ , p µ ) into two subsets, ( q 1 , p 1 ) and ( q a , p a ) with a = 2 , · · · , N , and suppose this division to ensure that if at time t = 0 both q a = 0 and p a = 0, then q a ( ) = 0 and t p a ( ) = 0. t The time evolution of q 1 and p 1 in the new canonical coordinates can be converted into that of ξ α and π α which takes place on a two-dimensional subspace
$$\begin{array} { r c l } \xi ^ { \alpha } & = & \hat$$
$$\pi _ { \alpha } \ = \ \hat { \pi } _ { \alpha } \equiv f _ {, \alpha } ^ { \mu } ( \hat { \xi } ) \, \hat { p } _ { \mu },$$
with
$$\hat { q } ^ { \mu } \ & \equiv \ ( q ^ { 1 }, \, 0, \, \cdots, \, 0 ), \\ \hat { n } \ & = \ ( n, \, 0 \, \dots \, \, \mathfrak { m } ) \quad \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \$$
$$\hat { p } _ { \mu } \ \equiv \ ( p _ { 1 }, \, 0, \, \cdots, \, 0 ).$$
We note that q 1 is the collective coordinate and ˆ ξ α is identical to the collective path parametrized by q 1 .
The requirements ( ˙ q a , ˙ p a ) = (0 , 0) can be compatible with the requirements ( q a , p a ) = (0 , 0) only if the equations
$$0 \ = \ \bar { B } ^ { a 1 } ( \hat { q } ) \, p _ { 1 },$$
$$0 \ = \ - \frac { 1 } { 2 } \, p _ { 1 } \, \bar { B } _ {, a } ^ { 1 1 } ( \hat { q } ) \, p _ { 1 } - \bar { V } _ {, a } ( \hat { q } ), \quad \ \ ( A. 1 9 )$$
are satisfied, as one sees from Eqs. (A.12) and (A.13). Equations (A.18) and (A.19) are equivalent to three conditions
$$\bar { B } ^ { a 1 } ( \hat { q } ) \ = \ 0,$$
$$\bar { V } _ {, a } ( \hat { q } ) \ = \ 0,$$
$$\bar { B } ^ { 1 1 } _ {, \, a } ( \hat { q } ) \ = \ 0.$$
Here, we have assumed that p 1 is not a constant of the motion. We emphasize that these equations determine an explicit form of ˆ . ξ α In fact, if g α , 1 (ˆ) q is obtained as a solution to Eqs. (A.20)-(A.22), we can construct ˆ ξ α = ˆ ( ξ α q 1 ) by solving a differential equation
$$\frac { \mathrm d } { \mathrm d q ^ { 1 } } \hat { \xi } ^ { \alpha } = g _ {, 1 } ^ { \alpha } ( \hat { q } ),$$
which has been derived from the definition (A.14).
From here on, we convert Eqs. (A.20)-(A.22) into convenient forms to obtain an explicit form of g α , 1 (ˆ). q For this purpose, first we introduce two scalar quantities
$$X ^ { ( 0 ) } ( \xi ) \ & \equiv \ V ( \xi ) \\ & = \bar { \ V } ( q ) \equiv \bar { X } ^ { ( 0 ) } _ { \hat { \ } } ( q ),$$
$$X ^ { ( 1 ) } ( \xi ) \ & \equiv \ \stackrel { \theta \, \stackrel { \theta \, \cdot \, } { \, } } { \, } \stackrel { \theta \, \stackrel { \theta \, \cdot \, } { \, } } { \, } \stackrel { \theta \, \stackrel { \theta \, \cdot \, } { \, } \, } \, \stackrel { \theta \, \stackrel { \theta \, \cdot \, } { \, } \, } \, } { \, } \, \stackrel { \theta \, \stackrel { \theta \, \cdot \, } { \, } \, } \, \stackrel { \theta \, \stackrel { \theta \, \cdot \, } { \, } \, } \, } \, \stackrel { \theta \, \stackrel { \theta \, \stackrel { \theta \, \cdot \, } \, } \, } { \, } \, \stackrel { \theta \, \stackrel { \theta \, \stackrel { \theta \, \stackrel { \theta \, \cdot \, } \, } \, } \, } \, \stackrel { \theta \, \stackrel { \theta \, \stackrel { \theta \, \stackrel { \theta \, \stackrel { \theta \, \stackrel { \theta \, \stackrel { \theta \, \stackrel { \theta \, \stackrel { \theta \, \stackrel { \theta \, \stackrel { \theta \, \stackrel { \theta \, \stackrel { \theta \, \stackrel { \theta \, \stackrel { \theta \, \stackrel { \theta \, \stackrel { \theta \, \stackrel { \theta \, \stackrel { \theta \, \stackrel { \theta \, \stackrel { \theta \, \stackrel { \theta \, \stackrel { \theta \colon \, \stackrel { \theta \, \stackrel { \theta \, \stackrel { \theta \, \stackrel { \theta \, \stackrel { \theta \, \stackrel { \theta \, \stackrel { \theta \, \stackrel { \theta \, \stackrel { \theta \, \stackrel { \theta \, \stackrel { \theta \, \stackrel { \theta \, \stackrel { \theta \, \stackrel { \theta \, \stackrel { \theta \, \stackrel { \theta \, \stackrel { \theta \, \stackrel { \theta \, \stackrel { \theta \, \stackrel { \theta \, \stackrel { \theta \, \stackrel { \theta \ch | \stackrel { \theta \, \stackrel { \theta \, \stackrel { \theta \, \stackrel { \theta \, \stackrel { \theta \, \stackrel { \theta \, \stackrel { \theta \, \stackrel { \theta \, \stackrel { \theta \, \stackrel { \theta \, \stackrel { \theta \, \stackrel { \theta \, \stackrel { \theta \, \stackrel { \theta \, \stackrel { \theta \, \stackrel { \theta \, \stackrel { \theta \, \stackrel { \theta \, \stackrel { \theta \, \stackrel { \theta \, \stackrel { \theta \, \stackrel { \theta \, \textrel \, \stackrel { \theta \, \stackrel { \theta \, \stackrel { \theta \, \stackrel { \theta \, \stackrel { \theta \, \stackrel { \theta \, \stackrel { \theta \, \stackrel { \theta \, \stackrel { \theta \, \stackrel { \theta \, \stackrel { \theta \, \stackrel { \theta \, \stackrel { \theta \, \stackrel { \theta \, \stackrel { \theta \, \stackrel { \theta \, \stackrel { \theta \, \stackrel { \theta \, \stackrel { \theta \, \stackrel { \theta \, \stackrel { \theta \, \stackrel { \theta \. \, \stackrel { \theta \, \stackrel { \theta \, \stackrel { \theta \, \stackrel { \theta \, \stackrel { \theta \, \stackrel { \theta \, \stackrel { \theta \, \stackrel { \theta \, \stackrel { \theta \, \stackrel { \theta \, \stackrel { \theta \, \stackrel { \theta \, \stackrel { \theta \, \stackrel { \theta \, \stackrel { \theta \, \stackrel { \theta \, \stackrel { \theta \, \stackrel { \theta \, \stackrel { \theta \, \stackrel { \theta \, \stackrel { \theta \, \stackrel { \theta \bar { \bar { \bar { \bar { \bar { \bar { \bar { \bar { \bar { \bar { \bar { \bar { \bar { \bar { \bar { \bar { \bar { \bar { \bar { \bar { \bar { \bar { \bar { \bar { \bar { \bar { \bar { \bar { \bar { \bar { \bar { \bar { \bar { \bar { \bar { \bar { \bar { \bar { \bar { \bar { \bar { \bar { \bar { \bar { \bar { \bar { \bar { \bar { \bar { \bar { \bar { \bar { \bar { \bar { \bar { \bar { \bar { \bar { \bar { \bar { \bar { \bar { \bar { \bar { \bar { \bar { \bar { \hat { \bar { \bar { \bar { \bar { \bar { \bar { \bar { \bar { \bar { \bar { \bar { \bar { \bar { \bar { \bar { \bar { \bar { \bar { \bar { \bar { \bar { \bar { \bar { \bar { \bar { \bar { \bar { \bar { \bar { \bar { \bar { \bar { \bar { \bar { \bar { \bar { \bar { \bar { \bar { \bar { \bar { \bar { \bar { \bar { \bar { \bar { \bar { \bar { \bar { \bar { \bar { \bar { \bar { \bar { \bar { \bar { \bar { \bar { \bar { \bar { \bar { \bar { \bar { \bar { \bar { \bar { { \bar { \bar { \bar { \bar { \bar { \bar { \bar { \bar { \bar { \bar { \bar { \bar { \bar { \bar { \bar { \bar { \bar { \bar { \bar { \bar { \bar { \bar { \bar { \bar { \bar { \bar { \bar { \bar { \bar { \bar { \bar { \bar { \bar { \bar { \bar { \bar { \bar { \bar { \bar { \bar { \bar { \bar { \bar { \bar { \bar { \bar { \bar { \bar { \bar { \bar { \bar { \bar { \bar { \bar { \bar { \bar { \bar { \bar { \bar { \bar { \bar { \bar { \bar { \bar { \bar { \bar {'\bar { \bar { \bar { \bar { \bar { \bar { \bar { \bar { \bar { \bar { \bar { \bar { \bar { \bar { \bar { \bar { \bar { \bar { \bar { \bar { \bar { \bar { \bar { \bar { \bar { \bar { \bar { \bar { \bar { \bar { \bar { \bar { \bar { \bar { \bar { \bar { \bar { \bar { \bar { \bar { \bar { \bar { \bar { \bar { \bar { \bar { \bar { \bar { \bar { \bar { \bar { \bar { \bar { \bar { \bar { \bar { \bar { \bar { \bar { \bar { \bar { \bar { \bar { \bar { \bar { \bar { \ } { \bar { \bar { \bar { \bar { \bar { \bar { \bar { \bar { \bar { \bar { \bar { \bar { \bar { \bar { \bar { \bar { \bar { \bar { \bar { \bar { \bar { \bar { \bar { \bar { \bar { \bar { \bar { \bar { \bar { \bar { \bar { \bar { \bar { \bar { \bar { \bar { \bar { \bar { \bar { \bar { \bar { \bar { \bar { \bar { \bar { \bar { \bar { \bar { \bar { \bar { \bar { \bar { \bar { \bar { \bar { \bar { \bar { \bar { \bar { \bar { \bar { \bar { \bar { \bar { \bar { \bar { } { \bar { \bar { \bar { \bar { \bar { \bar { \bar { \bar { \bar { \bar { \bar { \bar { \bar { \bar { \bar { \bar { \bar { \bar { \bar { \bar { \bar { \bar { \bar { \bar { \bar { \bar { \bar { \bar { \bar { \bar { \bar { \bar { \bar { \bar { \bar { \bar { \bar { \bar { \bar { \bar { \bar { \bar { \bar { \bar { \bar { \bar { \bar { \bar { \bar { \bar { \bar { \bar { \bar { \bar { \bar { \bar { \bar { \bar { \bar { \bar { \bar { \bar { \bar { \bar { \bar { \bar \bar { \bar { \bar { \bar { \bar { \bar { \bar { \bar { \bar { \bar { \bar { \bar { \bar { \bar { \bar { \bar { \bar { \bar { \bar { \bar { \bar { \bar { \bar { \bar { \bar { \bar { \bar { \bar { \bar { \bar { \bar { \bar { \bar { \bar { \bar { \bar { \bar { \bar { \bar { \bar { \bar { \bar { \bar { \bar { \bar { \bar { \bar { \bar { \bar { \bar { \bar { \bar { \bar { \bar { \bar { \bar { \bar { \bar { \bar { \bar { \bar { \bar { \bar { \bar { \bar { \bar { \ \bar { \bar { \bar { \bar { \bar { \bar { \bar { \bar { \bar { \bar { \bar { \bar { \bar { \bar { \bar { \bar { \bar { \bar { \bar { \bar { \bar { \bar { \bar { \bar { \bar { \bar { \bar { \bar { \bar { \bar { \bar { \bar { \bar { \bar { \bar { \bar { \bar { \bar { \bar { \bar { \bar { \bar { \bar { \bar { \bar { \bar { \bar { \bar { \bar { \bar { \bar { \bar { \bar { \bar { \bar { \bar { \bar { \bar { \bar { \bar { \bar { \bar { \bar { \bar { \bar { \bar { \ | \bar { \bar { \bar { \bar { \bar { \bar { \bar { \bar { \bar { \bar { \bar { \bar { \bar { \bar { \bar { \bar { \bar { \bar { \bar { \bar { \bar { \bar { \bar { \bar { \bar { \bar { \bar { \bar { \bar { \bar { \bar { \bar { \bar { \bar { \bar { \bar { \bar { \bar { \bar { \bar { \bar { \bar { \bar { \bar { \bar { \bar { \bar { \bar { \bar { \bar { \bar { \bar { \bar { \bar { \bar { \bar { \bar { \bar { \bar { \bar { \bar { \bar { \bar { \bar { \bar { \bar { \ { \bar { \bar { \bar { \bar { \bar { \bar { \bar { \bar { \bar { \bar { \bar { \bar { \bar { \bar { \bar { \bar { \bar { \bar { \bar { \bar { \bar { \bar { \bar { \bar { \bar { \bar { \bar { \bar { \bar { \bar { \bar { \bar { \bar { \bar { \bar { \bar { \bar { \bar { \bar { \bar { \bar { \bar { \bar { \bar { \bar { \bar { \bar { \bar { \bar { \bar { \bar { \bar { \bar { \bar { \bar { \bar { \bar { \bar { \bar { \bar { \bar { \bar { \bar { \bar { \bar { \bar { - \bar { \bar { \bar { \bar { \bar { \bar { \bar { \bar { \bar { \bar { \bar { \bar { \bar { \bar { \bar { \bar { \bar { \bar { \bar { \bar { \bar { \bar { \bar { \bar { \bar { \bar { \bar { \bar { \bar { \bar { \bar { \bar { \bar { \bar { \bar { \bar { \bar { \bar { \bar { \bar { \bar { \bar { \bar { \bar { \bar { \bar { \bar { \bar { \bar { \bar { \bar { \bar { \bar { \bar { \bar { \bar { \bar { \bar { \bar { \bar { \bar { \bar { \bar { \bar { \bar { \bar { \ - \bar { \bar { \bar { \bar { \bar { \bar { \bar { \bar { \bar { \bar { \bar { \bar { \bar { \bar { \bar { \bar { \bar { \bar { \bar { \bar { \bar { \bar { \bar { \bar { \bar { \bar { \bar { \bar { \bar { \bar { \bar { \bar { \bar { \bar { \bar { \bar { \bar { \bar { \bar { \bar { \bar { \bar { \bar { \bar { \bar { \bar { \bar { \bar { \bar { \bar { \bar { \bar { \bar { \bar { \bar { \bar { \bar { \bar { \bar { \bar { \bar { \bar { \bar { \bar { \bar { \bar { { { \bar { \bar { \bar { \bar { \bar { \bar { \bar { \bar { \bar { \bar { \bar { \bar { \bar { \bar { \bar { \bar { \bar { \bar { \bar { \bar { \bar { \ }$$
$$\overset { \cdot \, \mathbb { \upsilon } } { \bar { V } } ( q ) \equiv \bar { X } ^ { ( 0 ) } ( q ), & & ( \text{A.24} ) \\ V _ {, \alpha } ( \xi ) \, B ^ { \alpha \beta } \, V _ {, \beta } ( \xi ) \\ \bar { V } _ {, \mu } ( q ) \, \bar { B } ^ { \mu \nu } ( q ) \, \bar { V } _ {, \nu } ( q ) \equiv \bar { X } ^ { ( 1 ) } ( q ). & & ( \text{A.25} ) \\ \overset { \cdot \, \cdot \, \cdot \, \cdot \, \cdot \, \cdot \, \cdot \, \cdot \, \cdot \, \cdot \, \cdot \, \cdot \, \cdot \, \cdot \, \cdot \, \cdot \, \cdot \, \cdot \, \cdot \, \cdot \, \cdot \, \cdot \, \cdot \, \cdot \, \cdot \, \cdot \, \cdot \, \cdot \, \cdot \, \cdot \, \cdot \, \cdot \, \cdot \, \cdot \, \cdot \, \cdot \, \cdot \, \cdot \, \cdot \, \cdot \, \cdot \cdot \, \cdot \, \cdot \, \cdot \, \cdot \, \cdot \, \cdot \, \cdot \, \cdot \, \cdot \, \cdot \, \cdot \, \cdot \, \cdot \, \cdot \, \cdot \, \cdot \, \cdot \, \cdot \, \cdot \, \cdot \, \cdot \, \cdot \, \cdot \, \cdot \, \cdot \, \cdot \, \cdot \, \cdot \, \cdot \, \cdot \, \cdot \, \cdot \, \cdot \, \cdot \, \cdot \, \cdot \, \cdot \, \cdot \, \cdot \colon \, \cdot \, \cdot \, \cdot \, \cdot \, \cdot \, \cdot \, \cdot \, \cdot \, \cdot \, \cdot \, \cdot \, \cdot \, \cdot \, \cdot \, \cdot \, \cdot \, \cdot \, \cdot \, \cdot \, \cdot \, \cdot \, \cdot \, \cdot \, \cdot \, \cdot \, \cdot \, \cdot \, \cdot \, \cdot \, \cdot \, \cdot \, \cdot \, \cdot \, \cdot \, \cdot \, \cdot \, \cdot \, \cdot \, \cdot \, \cdots } { \dots \, \cdot \, \cdot \, \cdot \, \cdot \, \cdot \, \cdot \, \cdot \, \cdot \, \cdot \, \cdot \, \cdot \, \cdot \, \cdot \, \cdot \, \cdot \, \cdot \, \cdot \, \cdot \, \cdot \, \cdot \, \cdot \, \cdot \, \cdot \, \cdot \, \cdot \, \cdot \, \cdot \, \cdot \, \cdot \, \cdot \, \cdot \, \cdot \, \cdot \, \cdot \, \cdot \, \cdot \, \cdot \, \cdot \, \cdot \, \cd. \, \cdots \, \cdots \, \cdots \, \cdots \, \cdots \, \cdots \, \cdots \, \cdots \, \cdots \, \cdots \, \cdots \, \cdots \, \cdots \, \cdots \, \cdots \, \cdots \, \cdots \, \cdots \, \cdots \, \cdots \, \cdots \, \cdots \, \cdots \, \cdots \, \cdots \, \cdots \, \cdots \, \cdots \, \cdots \, \cdots \, \cdots \, \cdots \, \cdots \, \cdots \, \cdots \, \cdots \, \cdots \, \cdots \, \cdots \, \cdots \, \cdelta \, \cdots \, \cdots \, \cdots \, \cdots \, \cdots \, \cdots \, \cdots \, \cdots \, \cdots \, \cdots \, \cdots \, \cdots \, \cdots \, \cdots \, \cdots \, \cdots \, \cdots \, \cdots \, \cdots \, \cdots \, \cdots \, \cdots \, \cdots \, \cdots \, \cdots \, \cdots \, \cdots \, \cdots \, \cdots \, \cdots \, \cdots \, \cdots \, \cdots \, \cdots \, \cdots \, \cdots \, \cdots \, \cdots \, \cdots \, \cdets \, \cdots \, \cdots \, \cdots \, \cdots \, \cdots \, \cdots \, \cdots \, \cdots \, \cdots \, \cdots \, \cdots \, \cdots \, \cdots \, \cdots \, \cdots \, \cdots \, \cdots \, \cdots \, \cdots \, \cdots \, \cdots \, \cdots \, \cdots \, \cdots \, \cdots \, \cdots \, \cdots \, \cdots \, \cdots \, \cdots \, \cdots \, \cdots \, \cdots \, \cdots \, \cdots \, \cdots \, \cdots \, \cdots \, \cdots \, \cd!.$$
These quantities have an important property given by
$$\bar { X } _ {, a } ^ { ( \sigma ) } ( \hat { q } ) = 0, \ \sigma = 0, \, 1.$$
Here, we present a proof for the above equations. The proof for the case of σ = 0 is trivial as follows:
$$\bar { X } _ {, a } ^ { ( 0 ) } ( \hat { q } ) = \bar { V } _ {, a } ( \hat { q } ) = 0, & & ( \text{A.27} )$$
which is just Eq. (A.21). In the case of σ = 1, we simply compute
$$\begin{array} { r c l } \kappa & \ell & \ell & \ell & \ell & \ell \\ \bar { X } _ {, a } ^ { ( 1 ) } ( \hat { q } ) & = & 2 & \bar { X } _ {, \mu a } ^ { ( 0 ) } ( \hat { q } ) & \bar { X } _ {, \nu } ^ { ( 0 ) } ( \hat { q } ) & \bar { B } ^ { \mu \nu } ( \hat { q } ) + \bar { X } _ {, \mu } ^ { ( 0 ) } ( \hat { q } ) & \bar { X } _ {, \nu } ^ { ( 0 ) } ( \hat { q } ) & \bar { B } ^ { \mu \nu } _ {, a } ( \hat { q } ) \\ & = & 2 & \bar { X } _ {, b a } ^ { ( 0 ) } ( \hat { q } ) & \bar { X } _ {, 1 } ^ { ( 0 ) } ( \hat { q } ) & \bar { B } ^ { b 1 } ( \hat { q } ) + 2 & \bar { X } _ {, 1 a } ^ { ( 0 ) } ( \hat { q } ) & \bar { X } _ {, 1 } ^ { ( 0 ) } ( \hat { q } ) & \bar { B } ^ { 1 1 } ( \hat { q } ) \\ & & & + \bar { X } _ {, 1 } ^ { ( 0 ) } ( \hat { q } ) & \bar { X } _ {, 1 } ^ { ( 0 ) } ( \hat { q } ) & \bar { B } _ {, a } ^ { 1 1 } ( \hat { q } ) \\ & = & 0. & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & && & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & &
& & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & \end{array} \\ & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & - & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & \\ & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & \end{array} \\ & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & \ & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & &. & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & \\ & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & \ & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & \\ & & & & & \ & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & \ & & & & & \\ & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & \\ & & & & & \\ & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & &$$
In passing to the second equality, we have used ¯ X (0) , a (ˆ) = 0 proved in Eq. q (A.27). We have then used Eqs. (A.20) and (A.22) in the first and third terms, respectively, to make these vanish, whereas the second term vanishes because ¯ X (0) , 1 a (ˆ) = 0 which can be derived from q ¯ X (0) , a (ˆ) = 0. q
Then, we rewrite Eq. (A.26) as
$$B ^ { \alpha \beta } \, X _ {, \beta } ^ { ( \sigma ) } ( \hat { \xi } ) = \bar { X } _ {, 1 } ^ { ( \sigma ) } ( \hat { q } ) \, g _ {, 1 } ^ { \alpha } ( \hat { q } ) \, \bar { B } ^ { 1 1 } ( \hat { q } ), \ \sigma = 0, \, 1. \quad \text{(A.29)}$$
Here, we have used relations
$$X _ {, \alpha } ^ { ( \sigma ) } ( \hat { \xi } ) = \bar { X } _ {, \mu } ^ { ( \sigma ) } ( \hat { q } ) \, f _ {, \alpha } ^ { \mu } ( \hat { \xi } ) = \bar { X } _ {, 1 } ^ { ( \sigma ) } ( \hat { q } ) \, f _ {, \alpha } ^ { 1 } ( \hat { \xi } ),$$
$$B ^ { \alpha \beta } \, f ^ { 1 } _ {, \beta } ( \hat { \xi } ) = g ^ { \alpha } _ {, \mu } ( \hat { q } ) \, \bar { B } ^ { \mu 1 } ( \hat { q } ) = g ^ { \alpha } _ {, 1 } ( \hat { q } ) \, \bar { B } ^ { 1 1 } ( \hat { q } ),$$
which have been derived from the chain rule and Eqs. (A.5), (A.6), (A.10), and (A.24)-(A.26). We note that Eq. (A.29) is an alternative form of Eqs. (A.20)-(A.22) because Eq. (A.29) can be derived only if all of Eqs. (A.20)(A.22) are used.
Substituting the explicit forms
$$X _ {, \alpha } ^ { ( 0 ) } ( \hat { \xi } ) \ = \ V _ {, \alpha } ( \hat { \xi } ),$$
$$X _ {, \alpha } ^ { ( 1 ) } ( \hat { \xi } ) \ = \ 2 \, V _ {, \alpha \beta } ( \hat { \xi } ) \, B ^ { \beta \gamma } \, V _ {, \gamma } ( \hat { \xi } ),$$
into Eq. (A.29), we have
$$B ^ { \alpha \beta } \, V _ {, \beta } ( \hat { \xi } ) = \gamma ( \hat { q } ) \, g _ {, 1 } ^ { \alpha } ( \hat { q } ),$$
with
$$\left [ B ^ { \alpha \gamma } \, V _ {, \gamma \beta } ( \hat { \xi } ) \, - \lambda ( \hat { q } ) \delta ^ { \alpha } _ { \ \beta } \right ] g ^ { \beta } _ {, 1 } ( \hat { q } ) = 0,$$
$$\gamma ( \hat { q } ) \ \equiv \ \bar { X } _ {, 1 } ^ { ( 0 ) } ( \hat { q } ) \, \bar { B } ^ { 1 1 } ( \hat { q } ), \\ \bar { \nu } ^ { ( 1 ) \, / \, \hat { \varepsilon } \, }$$
$$\lambda ( \hat { q } ) \ \equiv \ \frac { \stackrel {, \cdot \cdot \cdot \cdot } { \bar { X } _ {, 1 } ^ { ( 1 ) } ( \hat { q } ) } } { 2 \, \bar { X } _ {, 1 } ^ { ( 0 ) } ( \hat { q } ) }. \quad \quad \quad$$
Owing to a scale indefiniteness in the definition of q 1 , there exists an ambiguity for the overall amplitude of g α , 1 (ˆ). q Without loss of generality, we can adopt the normalization
$$g _ {, 1 } ^ { \alpha } ( \hat { q } ) \, B _ { \alpha \beta } ^ { - 1 } \, g _ {, 1 } ^ { \beta } ( \hat { q } ) = 1.$$
We note that Eqs. (A.23), (A.34), (A.35), and (A.38) are identical to the decoupling conditions. By setting
$$\xi ^ { \alpha = i } \ = \ x _ { i },$$
$$\begin{array} {$$
$$\ q ^ { 1 } \ = \ q,$$
we find that Eqs. (A.23), (A.34), (A.35), and (A.38) correspond to Eqs. (3), (5), (4), and (6), respectively.
## Appendix B. Barrier and gate potential with less symmetry
A Hamiltonian we consider is given by
$$H = \frac { 1 } { 2 } \, ( p _ { 1 } ^ { 2 }$$
Here, V ′ BG ( x , x 1 2 ) denotes the barrier and gate potential with less symmetry defined by
$$V _ { \text{BG} } ^ { \prime } ( x _ { 1 }, \$$
where V BG ( x , x 1 2 ) has been given in Eq. (41). We note that the term associated with /epsilon1 breaks the symmetry with respect to x 1 → -x 1 . This potential energy surface has two local minima and one saddle point located at ( /epsilon1/ 2 b ± √ /epsilon1 2 / 4 b 2 + a/b, c/epsilon1/ 2 b ± c √ /epsilon1 2 / 4 b 2 + a/b ) ≡ ( x eq 1 ± , x eq 2 ± ) and (0 , 0), respectively, and the activation energies in the transitions from ( x eq 1+ , x eq 2+ ) to ( x eq 1 -, x eq 2 -) and from ( x eq 1 -, x eq 2 -) to ( x eq 1+ , x eq 2+ ) are given by a / 2 4 b + a/epsilon1 2 / 4 b 2 + /epsilon1 4 / 24 b 3 ± ( a/epsilon1/ 3 b + /epsilon1 3 / 12 b 2 ) √ /epsilon1 2 / 4 b 2 + a/b , respectively.
In Fig. B.6, we show the collective paths for V ′ ( a ) BG , V ′ ( b ) BG , and V ′ ( c ) BG . It reveals that the collective paths provide pathways connecting the two local minima. We stress that these results are qualitatively the same as those of the symmetric potentials V ( a ) BG , V ( b ) BG , and V ( c ) BG examined in Sec. 4.2.
We introduce three potential energy surfaces: a potential energy surface containing neither a high energy barrier nor a narrow gate V ′ ( a ) BG , a surface with a high energy barrier V ′ ( b ) BG , and a surface with a narrow gate V ′ ( c ) BG . The parameters ( a, b, c, α, β, γ, δ, /epsilon1 ) which create V ′ ( a ) BG , V ′ ( b ) BG , and V ′ ( c ) BG read (80 , 80 , 3 , 0 0045 . , 10 , 10 , 1 , 20), (240 , 240 , 3 , 0 , 0 , 10 , 20 , 60), and (80 , 80 , 3 , 0 31 . , 690 , 10 , 9 7 . , 20), respectively. All the potential energies have the same locations of the local minima as ((1 ± √ 65) / 8 , 3(1 ± √ 65) / 8).
## References
- [1] P. G. Debrunner and H. Frauenfelder, Ann. Rev. Phys. Chem. 33 (1982), 283.
- [2] Chou KC, Biophys. Chem. 20 (1984), 61.
- [3] O. Miyashita, J. N. Onuchic, and P. G. Wolynes, Proc. Natl. Acad. Sci. USA, 100 (2003), 12570.
Figure B.6: The collective paths obtained by the method developed in this work on the V ′ ( a ) BG , V ′ ( b ) BG , and V ′ ( c ) BG potential energy surfaces. The solid lines in (a) ((b) or (c)) show the collective path derived from V ′ ( a ) BG ( V ′ ( b ) BG or V ′ ( c ) BG ), respectively. In (a) ((b) or (c)), the thin lines denote the contours of V ′ ( a ) BG ( V ′ ( b ) BG or V ′ ( c ) BG ), the circles the local minima, and the squares the saddle point.
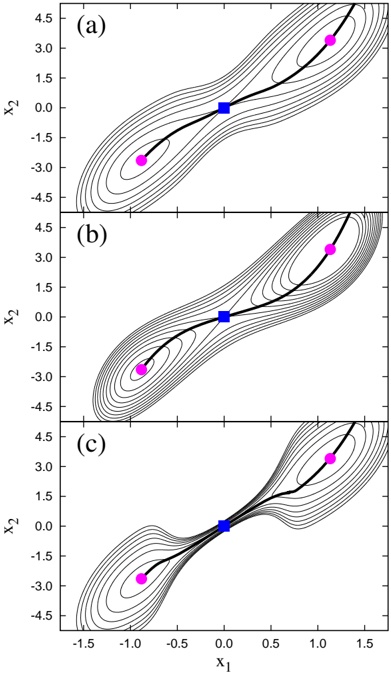
- [4] J. A. McCammon, Rep. Prog. Phys. 47 (1984), 1.
- [5] N. Nakajima, J. Phys. Chem. B 101 (1997), 817.
- [6] Y. Sugita and Y. Okamoto, Chemical Phys. Lett. 314 (1999), 141.
- [7] A. Laio and M. Parrinello, Proc. Natl. Acad. Sci. USA 99 (2002), 12562.
- [8] Y. Fukunishi, Y. Mikami, and H. Nakamura, J. Phys. Chem. B 107 (2003), 13201.
- [9] S. Tomonaga, Prog. Theor. Phys. 13 (1955), 467.
- [10] S. Tomonaga, Prog. Theor. Phys. 13 (1955), 482.
- [11] T. Marumori, T. Maskawa, F. Sakata, and A. Kuriyama, Prog. Theor. Phys. 64 (1980), 1294.
- [12] M. Matsuo and K. Matsuyanagi, Prog. Theor. Phys. 74 (1985), 288.
- [13] M. Matsuo, Prog. Theor. Phys. 76 (1986), 372.
- [14] M. Matsuo, T. Nakatsukasa and K. Matsuyanagi, Prog. Theor. Phys. 103 (2000), 959.
- [15] G. Do Dang, A. Bulgac, and A. Klein, Phys. Rev. C 36 (1987), 2661.
- [16] N. R. Walet, A. Klein, and G. Do Dang, J. Chem. Phys. 91 (1989), 2848.
- [17] A. Klein, N. R. Walet, and G. Do Dang, Ann. Phys. 208 (1991), 90.
- [18] G. D. Dang, A. Klein and N. R. Walet, Phys. Rep. 335 (2000), 93.
- [19] H. Aoyama and H. Kikuchi, Nucl. Phys. B 369 (1992), 219.
- [20] K. M¨ uller and L. D. Brown, Theor. Chim. Acta. 53 (1979), 75.
- [21] K. Fukui, S. Kato, and H. Fujimoto, J. Am. Chem. Soc. 97 (1975), 1.
- [22] G. Henkelman and H. J´nsson, J. Chem. Phys. o 113 (2000), 9978.
- [23] J. Wang, R. M. Wolf, J. W. Caldwell, P. A. Kollman, and D. A. Case, J. Comput. Chem. 25 (2004), 1157.
- [24] K. Tsumura et al. , in preparation.
- [25] K. Tsumura et al. , in preparation.
- [26] W. Kohn and L. J. Sham, Phys. Rev. 140 (1965), A1133.
- [27] K. Tsumura et al. , in preparation.
- [28] E. Runge and E. K. U. Gross, Phys. Rev. Lett. 52 (1984), 997. | 10.1016/j.aop.2015.04.001 | [
"Kyosuke Tsumura",
"Yoshitaka Maeda",
"Hiroyuki Watanabe"
] | 2014-08-02T12:29:23+00:00 | 2015-04-02T14:28:02+00:00 | [
"cond-mat.other",
"physics.comp-ph"
] | Rare transition event with self-consistent theory of large-amplitude collective motion | A numerical simulation method, based on Dang et al.'s self-consistent theory
of large-amplitude collective motion, for rare transition events is presented.
The method provides a one-dimensional pathway without knowledge of the final
configuration, which includes a dynamical effect caused by not only a potential
but also kinetic term. Although it is difficult to apply the molecular dynamics
simulation to a narrow-gate potential, the method presented is applicable to
the case. A toy model with a high-energy barrier and/or the narrow gate shows
that while the Dang et al. treatment is unstable for a changing of model
parameters, our method stable for it. |
1408.0365v1 | ## A new SATIRE-S spectral solar irradiance reconstruction for solar cycles 21-23 and its implications for stratospheric ozone
## William T. Ball, ∗
Physics Department, Blackett Laboratory, Imperial College London, SW7 2AZ, UK
## Natalie A. Krivova
Max-Planck-Institut f¨r Sonnensystemforschung, 37077 G¨ttingen, Germany u o
## Yvonne C. Unruh
Physics Department, Blackett Laboratory, Imperial College London, SW7 2AZ, UK
Joanna D. Haigh
Physics Department, Blackett Laboratory, Imperial College London, SW7 2AZ, UK Grantham Institute, Imperial College London, SW7 2AZ, UK
## Sami K. Solanki
Max-Planck-Institut f¨r Sonnensystemforschung, 37077 G¨ttingen, Germany u o School of Space Research, Kyung Hee University, Yongin, Gyeonggi 446-701, Korea
## ABSTRACT
We present a revised and extended total and spectral solar irradiance (SSI) reconstruction, which includes a wavelength-dependent uncertainty estimate, spanning the last three solar cycles using the SATIRE-S model. The SSI reconstruction covers wavelengths between 115 and 160 000 nm and all dates between August 1974 and October 2009. This represents the first full-wavelength SATIRE-S reconstruction to cover the last three solar cycles without data gaps and with an uncertainty estimate. SATIRE-S is compared with the NRLSSI model and SORCE/SOLSTICE ultraviolet (UV) observations. SATIRE-S displays similar cycle behaviour to NRLSSI for wavelengths below 242 nm and almost twice the variability between 242 and 310 nm. During the decline of last solar cycle, between 2003 and 2008, SSI from SORCE/SOLSTICE version 12 and 10 typically displays more than three times the variability of SATIRE-S between 200 and 300 nm. All three datasets are used to model changes in stratospheric ozone within a 2D atmospheric model for a decline from high solar activity to solar minimum. The different flux changes result in different modelled ozone trends. Using NRLSSI leads to a decline in mesospheric ozone, while SATIRE-S and SORCE/SOLSTICE result in an increase. Recent publications have highlighted increases in mesospheric ozone when considering version 10 SORCE/SOLSTICE irradiances. The recalibrated SORCE/SOLSTICE version 12 irradiances result in a much smaller mesospheric ozone response than when using version 10 and now similar in magnitude to SATIRE-S. This shows that current knowledge of variations in spectral irradiance is not sufficient to warrant robust conclusions concerning the impact of solar variability on the atmosphere and climate.
## 1. Introduction
There is substantial evidence to suggest that changes in the solar irradiance influence variations in the temperature and circulation of the Earth's atmosphere over the 11-year solar cycle. Many of these results are based on correlations with the 10.7 cm solar flux (e.g. Labitzke and van Loon (1995); van Loon and Shea (1999)) or the wavelengthintegrated, or total, solar irradiance (TSI); see Haigh (2003) and references therein. While TSI is a good indicator of the total solar forcing on the climate, it cannot be used to understand the physical interaction between the solar radiation and the atmosphere since spectral solar irradiance (SSI) variability, and the altitude in the atmosphere at which it is absorbed, is highly wavelength-dependent (Meier 1991; Lean et al. 1997; Krivova et al. 2006).
There is a growing body of evidence to suggest that TSI, and as a consequence SSI, may vary on secular timescales exceeding the 11-year solar cycle. Fr¨hlich (2009), o
Lockwood et al. (2010) and Ball et al. (2012) provide some evidence that TSI may have been slightly lower in the re- cent minimum compared to the two prior to that, though the PhysikalischMeteorologisches Observatorium Davos (PMOD) composite of TSI observations (Fr¨hlich o 2006) and the modelled TSI by Ball et al. (2012) are consistent, within the error bars, with no change between the last three minima. Estimates of the increase in TSI since the 17th century vary widely (see Schmidt et al. (2012) and Solanki and Unruh (2013) and references therein), though most recent estimates lie in the range ∼ 1-1.5 Wm -2
(Wang et al. 2005, Krivova et al. 2007, Steinhilber et al. 2009, Krivova et al. 2010), a change similar to solar cycle variability.
A large proportion of the variability in TSI is due to very much larger relative variations at UV wavelengths compared to the longer visible and infra-red (IR) wavelengths. Wavelengths shorter than 400 nm account for less than 10% of the absolute value of TSI, but contribute 3060% to TSI variability, according to models (Lean et al. 1997; Krivova et al. 2006) and measurements by the SOLar Stellar Irradiance Comparison Experiment (SOLSTICE) (Rottman et al. 2001) and the Solar Ultraviolet Spectral Irradiance Monitor (SUSIM) (Floyd et al. 2003; Morrill et al. 2011) on the Upper Atmosphere Research Satellite (UARS), made prior to 2006, and the SCanning Imaging Absorption SpectroMeter for Atmospheric CHartographY
(SCHIAMACHY) on the ENVIronmental SATellite (ENVISAT) (Pagaran et al. 2009). The data from the Spectral Irradiance Monitor (SIM) (Harder et al. 2005) and SOLSTICE (Snow et al. 2005) instruments on board the SOlar Radiation and Climate Experiment (SORCE) indicate that this contribution might be as high as 180% (Harder et al. 2009), though it should be noted that SIM is currently undergoing a reanalysis. A value larger than 100% is possible because the SSI in the visible measured by SIM varies in antiphase to that in the UV.
The UV radiation influences many processes in the atmosphere. Of particular interest is the interaction between solar UV radiation and ozone, which is the largest contributor to heating in the stratosphere. Variation of solar UV radiation over secular timescales may have an effect on global temperature trends and the impact is important to quantify.
Haigh et al. (2010) and Merkel et al. (2011) both investigated the potential impact that the SSI changes observed by SORCE (Rottman 2005; Harder et al. 2009) could have on stratospheric ozone concentrations, respectively using a coupled chemistry climate 2D atmospheric model and the fully 3D general circulation Whole Atmosphere Community Climate Model (WACCM). Both studies obtained qualitatively similar results when using hybrid SORCE data from SOLSTICE and SIM, though the two studies adopted different wavelengths to transition between SOLSTICE and SIM. While the magnitude and the exact heights varied, both studies found that between 2004 and 2007, when solar UV output was declining, ozone concentrations increased above ∼ 45 km while they decreased below ∼ 40 km. It is interesting to note that trends in O 3 from the Microwave Limb Sounder (MLS) on the Aura satellite and the Sounding of the Atmosphere using Broadband Emission Radiometry (SABER) on Thermosphere Ionosphere Mesosphere Energetics Dynamics (TIMED) observations presented by Haigh et al. (2010) and Merkel et al. (2011), respectively, suggest that SORCE SSI may better capture solar variability than models due to the negative response in mesospheric ozone that is out-of-phase with solar irradiance changes. On the other hand, Austin et al. (2008) did not find a negative ozone response to cycle changes of the Sun using combined data from several satellites prior to 2004. Dhomse et al. (2013) suggest that the negative response in the lower mesosphere cannot be used to distinguish between SSI datasets due to the large uncertainties in the ozone observations.
The significant differences in SSI variability between SORCE data and different models, the latter partly relying on earlier observations (see Ermolli et al., 2013), indicate that there is still much uncertainty in our knowledge of how the Sun's irradiance varies spectrally. The larger UV irradiance variability, and an inverse solar-cycle trend in the visible measured by the SIM instrument on the SORCE satellite (Harder et al. 2005, 2009), may indicate that the solar cycle variability observed by previous missions, and the models that reproduce similar behaviour, may be incorrect. It may also indicate a change in the Sun during the recent cycle. However, recent studies suggest that incomplete accounting for instrument degradation may contribute to the SSI trends suggested by SIM data (Ball et al. 2011, Deland and Cebula 2012, Lean and DeLand 2012, Ermolli et al. 2013).
This paper presents an extended and recalibrated data set using the Spectral And Total Irradiance REconstruction (SATIRE-S) model (Fligge et al. 2000; Krivova et al. 2003; Wenzler et al. 2004; Ball et al. 2012), for wavelengths between 115 and 160 000 nm and on all days between August 1974 and October 2009, for use by the climate and atmospheric research communities.
SATIRE-S is the most detailed of the SATIRE family of models, where 'S' refers to the model designed for the satellite era (Krivova et al. 2011), and provides the most reliable reconstruction of TSI and SSI. It does, however, rely on the availability of magnetograms and continuum intensity images, which restricts its applicability to a comparatively short period of time. In the past, the TSI and SSI reconstructed with SATIRE-S have been further limited by the fact that magnetograms obtained from different instruments do not have the same spatial resolution, noise level or magnetic field calibration. It requires careful intercalibrations between various magnetographs (and imagers) to allow a homogeneous reconstruction of TSI. This
has been successfully done by Wenzler et al. (2004, 2006) for Kitt Peak Solar Observatory (KP) 512-channel magnetograph (512) (Livingston et al. 1976a,b) and spectromagnetograph (SPM) (Jones et al. 1992) instruments and by Ball et al. (2012) for 512, SPM and MDI instruments (Scherrer et al. 1995), the latter of which is onboard the Solar and Heliospheric Observatory (SoHO) spacecraft.
Here we compute the SSI using magnetograms from all three instruments, thus extending the SSI reconstructed by SATIRE-S to fully cover the last three solar cycles including, for the first time, the extended solar minimum in 2008. The reconstruction is compared with the NRLSSI model (Lean 2000; Lean et al. 2005) and data from the SOLSTICE instrument (McClintock et al. 2005), onboard the SORCE satellite. We then show how the different spectral irradiances of these datasets affect changes in stratospheric O using the atmospheric model based on Harwood and Pyle 3 (1975).
## 2. Modelling solar irradiance with SATIRE
The SATIRE-S model (Fligge et al. 2000; Krivova et al. 2003; Wenzler et al. 2006; Krivova et al. 2011) assumes that all irradiance variations are the result of changes in the surface photospheric magnetic flux. SATIRE-S identifies four solar surface components in magnetograms and continuum intensity images: the background quiet sun; the dark penumbral and umbral components of sunspots; and small-scale magnetic features, that appear predominantly bright, called faculae.
Daily irradiance spectra are produced by summing the intensities of the four components weighted according to their surface distribution. The component intensities (as functions of wavelength and limb angle) are calculated with the spectral synthesis program ATLAS9 (Kurucz 1993) assuming local thermodynamic equilibrium (LTE) conditions. We use time-independent model atmospheres
(Fligge et al. 2000; Krivova et al. 2003; Solanki and Unruh 2013) with effective temperatures of 5777 K, 5450 K and 4500 K for quiet Sun, penumbral and umbral intensities, respectively. For faculae, we use the FAL-P model atmosphere (Fontenla et al. 1993), as modified by Unruh et al. (1999). The wavelength grid of the daily spectra from SATIRE-S has a resolution of 1 nm below 290 nm, 2 nm from 290 to 1000 nm, 5 nm from 1000 to 1600 nm, 10 nm from 1600 to 3200 nm, 20 nm from 3200 to 6400 nm, 40 nm from 6400 to 10 000 nm and 20 000 nm for the remainder of the spectrum up to 160 µ m.
The model has one free parameter; this relates the magnetic flux registered in a magnetogram pixel to the fraction of the pixel filled by faculae. The free parameter is set to a fixed value for each observatory (i.e., for KP and SoHO) as outlined in the next section.
## a. Method to combine reconstructions
In order to maximise the length of the SSI timeseries, magnetograms and continuum intensity images are taken from three instruments: two at KP that are based on spectropolarimetry of the Fe i 868.8 nm line (Livingston et al. 1976a), the KP/512 (Livingston et al. 1976b) and KP/SPM instrument (Jones et al. 1992), and the SoHO/MDI instrument that uses the Ni i 676.8 nm line (Scherrer et al. 1995). The free parameter for each instrument is fixed by comparing the reconstructed TSI to either TSI observations or to a TSI reconstruction made using images from a different instrument. Broadly, three steps are involved in the intercalibration, which are outlined below (see also Ball et al., 2012). The uncertainties arising in this process are outlined in section 2c.
In step (i), we fix the free parameter for the MDI reconstruction by requiring a regression slope of unity between the reconstructed TSI and the SORCE Total Irradiance Monitor (TIM) TSI observations (Kopp and Lawrence 2005). In step (ii), we combine the KP and MDI magnetogram and continuum images using the KP/SPM and SoHO/MDI overlap period of 895 days between 1999 and 2003. This requires fixing the free parameter for SPM, so that the reconstructed TSI during the overlap period agrees with the TSI derived from the MDI images. However, while the resulting spectral irradiances are very well correlated for the overlap period ( r c > 0 91 at all wavelengths), we see slightly dif-. ferent variability amplitudes in the two reconstructions at some wavelengths. The different instrument design, the use of different spectral lines with different magnetic sensitivities, as well as different telescope optics and detectors mean that there are non-linear, position-dependent differences in the KP and MDI instruments in response to magnetic flux that leads to the differing variability amplitude. The differences in amplitude of variability in the overlap period are typically 2% in the visible and near-IR and remain below 8% at all wavelengths. To avoid discontinuites in the SSI trends when changing between reconstructions based on MDI and KP magnetograms, we adjust the variability amplitudes of the KP reconstructions by rescaling them to those of the MDI reconstructions.
Step (iii) involves correcting for the change between the 512 and SPM instruments on KP. While the imaging quality for the KP/512 data is poorer, the two KP polarimeters show very similar flux registration so that the correction can be used to convert the KP/512 magnetogram signal to the KP/SPM level (see Wenzler et al., 2006, and Ball et al., 2012). Thus, the same filling factor can be used for both KP data sets. While the scaling factor introduces uncertainties regarding the long-term TSI behaviour, it does not affect its spectral distribution.
The ATLAS9 model intensities assume LTE conditions in the solar atmosphere; this can result in large errors
in the modelled irradiance variability in some wavelength regions, mainly below 270 nm and at the Mg I line at 285 nm. SATIRE-S does show, however, good agreement with SSI observations from the UARS satellite: the reconstructed SSI in the range 220-240 nm agrees well with UARS/SUSIM measurements (Krivova et al. 2006, 2009) and reasonably well with UARS/SOLSTICE measurements (Unruh et al. 2012).
To better reflect the spectral irradiance variability between 115 nm and 270 nm, we apply the empirical method outlined in Krivova et al. (2006). This method relies on the good agreement in the temporal variability of the 220 to 240 nm region as calculated by SATIRE-S and uses the scaling coefficients derived from spectral irradiance measurements, over the period 1997 to 2002, taken by the UARS/SUSIM instrument (Brueckner et al. 1993,
Floyd et al. 2003). Therefore, spectral regions in SATIRES below 220 nm and between 240 and 270 nm rely on SUSIM measurements and the close agreement in these regions is partly by design. In section c we show an example of this with the reconstructed Lyα irradiance, which is in agreement with the composite of Lyα measurements and proxy-models by Woods et al. (2000), and three integrated UV wavelength bands below 290 nm.
The TSI data set that is obtained by integrating our new SSI reconstruction is considered as an update of the TSI reconstruction presented in Ball et al. (2012). While both reconstructions are consistent within their uncertainty ranges, the updated TSI is now based upon the integral of the SSI that is self-consistent at every wavelength for the full reconstruction period. In Ball et al. (2012), the intercycle decline between 1996 and 2008 was estimated to be 0.20 +0 12 . -0 09 . Wm -2 , where the errors are one-sigma uncertainties. The new reconstruction revises this estimate down to 0.13 +0 07 . -0 10 . Wm -2 . Note that the reconstructions are calibrated using only the SORCE/TIM measurements and are thus independent of any TSI composite post-1990 and independent within the uncertainty range prior to this period (see Ball et al., 2012, for more details).
In a final step we adjust the absolute levels of SATIRE-S SSI so that the integrated SSI is in agreement with SORCE/ TIM at the solar minimum in December 2008. For this, the entire spectrum is multiplied by a factor of 1.0047. This small correction of 0.5% assures that the original variability as obtained directly from SATIRE-S, is not affected.
## b. Data gap filling
The new SATIRE-S SSI reconstruction now extends through the most recent and unusually long solar minimum period, whereas the previous version (Krivova et al. 2009) ended in 2007. For the period between 1974 December 10 and 2009 October 31, images are missing on ∼ 50% of dates, mostly within cycles 21 and 22; we fill these data gaps to provide fluxes on all dates over the entire period. To avoid any assumptions about the solar behaviour, we decompose each wavelength into short-term, or rotational, and longterm timeseries. The long-term timeseries is obtained by smoothing the original timeseries using a Gaussian window equivalent to a boxcar width of 135 days. We use this period, longer than the typical 81-days, to reduce the impact of short-term variability. The short-term timeseries, which captures rotational variability, is obtained by subtracting the long-term timeseries from the original.
Gaps in the long-term SATIRE-S time-series are filled by linear interpolation. Most gaps are short, with 90% of gaps being no longer than a solar rotation of 27 days in length, so the long-term trend is well approximated by a linear interpolation. Only five data gaps exceed two solar rotations, the longest of which is a 282 day period around the solar minimum of 1976.
Gaps in the detrended, rotational time series are filled using solar activity indices: the NOAA and LASP Mg II indices (Viereck et al. 2004; Snow et al. 2005), combined through linear regression; the Lyα composite by Woods et al. (2000); the Penticton F10.7 cm radio flux (data available through the National Geophysical Data Center at http://www.ngdc.noaa.gov/); the TSI from version d41 62 1003 of the PMOD composite (Fr¨hlich 2000) and o the sunspot area composite record by Balmaceda et al. (2009). Each index is indicative of the behaviour of some feature in the solar atmosphere, although it is not clear exactly how they relate to each wavelength of SSI (see Dudok de Wit et al., 2008, and supplementary material section b). Rotational variability at each wavelength is better approximated using multi-linear regression of two indices than using just one. We calculated the regression coefficient for every combination of two indices for each wavelength using dates when all indices and reconstructed SSI exist. Then, for each data gap, the available index-pair with the highest value of the coefficient of determination, r 2 c , at each wavelength is used to calculate the SSI in the missing gap.
Finally, the detrended and smoothed time series are added together to produce a spectral reconstruction that reflects the long-term variability of SATIRE-S while retaining rotational consistency (see supplementary material section b for examples). This procedure is expected to perform less well prior to 1978 because the TSI and the Mg II index, which generally have the highest combined correlation coefficients, are unavailable then. Also, this time period coincides with the longest data gaps in the reconstruction.
The change in SSI between maximum activity in solar cycle 23, in 2002, and the minimum in 2008 is plotted in Fig. 1. The blue curve indicates the final SATIRE-S reconstruction. This figure is described in greater detail and discussed in section 3a.
Figure 1 - The (top) percentage and (bottom) absolute change in flux between cycle 23 maximum and minimum, in terms of the maximum change in irradiance between three-month averages at February 2002 and December 2008 (see Fig. 2), for the SATIRE-S (blue) and NRLSSI (red) models; in the upper plot solid lines represent a decrease in flux while dotted lines represent an increase. The vertical dashed lines indicate 242 and 310 nm and the horizontal line marks no change in flux. (inset) The absolute change in flux in 10 nm bands between three month averages at May 1996 and February 2002 for SATIRE-S (blue), NRLSSI (red) and UARS/SUSIM (purple).
## c. Uncertainty estimate
An accurate error estimate for the modelled reconstruction is difficult to provide, since it depends partly on unknowns (such as the amount of magnetic flux missed by the magnetograms) and on uncertainties that cannot be precisely constrained within the scope of this paper (such as the accuracy of the model atmospheres employed, or the influence of neglecting non-LTE effects; see section c of the supplementary materials). Therefore, we attempt to provide a long-term SSI uncertainty range similar to the approach taken for TSI in Ball et al. (2012). This is an empirical approach that takes into account the uncertainties introduced in the calibration steps described in section 2a. Specifically, we account for step (i), the regression fitting between the TSI derived from MDI images and the SORCE/TIM measurements, step (ii), the regression fitting to combine the SATIRE-S reconstructions for MDI and KP data, and step (iii), the uncertainties in the correction factor for the KP/512 relative to the KP/SPM magnetograms.
For wavelengths below 270 nm we add, in quadrature, the uncertainty from the SATIRE-S reconstruction and the estimated relative uncertainty of the UARS/SUSIM measurements, which are estimated to be of the order of 5% below 142 nm and decreases to about 2% above 160 nm (Woods et al., 1996, and Linton Floyd, personal communication); we linearly interpolate the uncertainty between these wavelengths. These uncertainties are provided with the published reconstruction. We also flag a few wavelengths in the SATIRE-S spectrum, most notably the Mg I line at 285 nm, where our detailed comparisons with SORCE/SIM measurements on rotational time scales indicate that SATIRE-S overestimates the solar variability; see section c of the supplementary materials.
To summarise and illustrate the temporal behaviour of the uncertainties, we list the cycle amplitudes and their associated uncertainties in Tab. ?? for the TSI and for selected 'broadband' spectral irradiances. Column 4 lists the cycle amplitudes for cycle 23; these are based on reconstructions from SoHO/MDI images, i.e. these account for uncertainties in step (i) only. As shown in Ball et al. (2012), the error on the regression fitting for the SoHO/MDI free parameter is small and arises mainly from the longterm uncertainty in SORCE/
TIM. The uncertainty on the cycle amplitude (between sunspot maximum in March 2000 to the minimum in December 2008), is of the order of 100 ppm, comparable to the long-term uncertainty of SORCE/TIM. We note that the agreement between the TSI derived with SATIRE-S and the available composites is just as good as the agreement between the different composites (Ball et al. 2012).
Going back in time, the uncertainties increase, mainly due to the additional calibration steps (ii) and (iii). This is illustrated by the larger uncertainties for the amplitudes of cycles 21 and 22 (see columns 2 and 3 of Tab. ?? , respectively). As illustrated in Fig. 2 and Fig. 7 in Ball et al. (2012), the uncertainties are asymmetric and typically show slightly larger positive ranges. This is due to the different response of the magnetograms when connecting reconstructions from MDI and KP, as in step (ii), and the uncertainties in the correction factor from step (iii) that only lead to an increase in flux variability, not a decrease (see Ball et al., 2012).
While considerable progress has been made in determining the absolute value of the total solar irradiance (Kopp and Lean 2011), the absolute spectral solar irradiance is still poorly constrained and a number of different 'standard' absolute solar spectra are available (see Thuillier et al. (2003) for a discussion of this). For this reason, the uncertainties listed here and distributed with the reconstructions are for relative irradiances. Relative spectral irradiances in each band are much better constrained than the absolute accuracy, though the degradation of space instruments means that considerable uncertainties remain when going beyond rotational time scales (Unruh et al. 2012; Ermolli et al. 2013). If users of the SATIRE-S reconstruction wish to use a different absolute spectra as a basis upon which SATIRE-S variability is placed, we provide absolute spectra binned onto the SATIRES wavelength grid. We do this for the ATLAS 3 and Whole Heliosphere Interval solar reference spectra (Woods et al. 2009).
The SATIRE-S SSI data can be found at http://www. mps.mpg.de/projects/sun-climate/data.html.
## 3. Inter-comparison of SATIRE-S with other datasets
In this section, we compare the SATIRE-S model with the NRLSSI model (Lean 2000; Lean et al. 2005) and with SORCE/SOLSTICE observations. NRLSSI is the most widely used, empirically derived, model of SSI, so we perform a comparison with SATIRE-S here. The solar cycle spectral variability recorded by SORCE/SOLSTICE is larger than the variability seen by the UARS/SUSIM and UARS/SOLSTICE instruments. It is also larger than the variability inferred from the models. SORCE/SIM displays even larger variability than SORCE/SOLSTICE, for the overlapping range between 240-310 nm, and it is an interesting SSI dataset to consider. However, a comparison of SATIRE-S and an updated version of SORCE/SIM version 17 was made in Ball et al. (2011). The SORCE/SIM UV changes below 310 nm were up to five times larger than the changes seen in SATIRE-S. We note that Figure 11 of Ball et al. (2011) indicates that SORCE/SIM displays up to 10 times the variability of SATIRE-S at some wavelengths between 300 and 400 nm, though the integrated
Table 1 - Amplitude of flux variability over a solar cycle (SC) for selected wavelength bands and for total solar irradiance (TSI). The uncertainty of the amplitude is also given.
| λλ , nm | SC21, mWm - 2 | SC22, mWm - 2 | SC23, mWm - 2 |
|-----------|---------------------------------------------------------------------|-----------------|-----------------|
| 200-270 | 114 +25 - 8 509 +127 - 46 241 +141 - 72 138 +67 - 34 979 +394 - 183 | 114 +25 - 8 | 99 +4 - 4 |
| 270-400 | 114 +25 - 8 509 +127 - 46 241 +141 - 72 138 +67 - 34 979 +394 - 183 | 501 +135 - 47 | 445 +16 - 21 |
| 400-700 | 114 +25 - 8 509 +127 - 46 241 +141 - 72 138 +67 - 34 979 +394 - 183 | 190 +166 - 80 | 201 +37 - 51 |
| 700-1000 | 114 +25 - 8 509 +127 - 46 241 +141 - 72 138 +67 - 34 979 +394 - 183 | 116 +78 - 38 | 118 +18 - 24 |
| TSI | 114 +25 - 8 509 +127 - 46 241 +141 - 72 138 +67 - 34 979 +394 - 183 | 876 +445 - 195 | 837 +85 - 113 |
Figure 2 - Smoothed (solid) wavelength-integrated time series of SATIRE-S (blue), NRLSSI (red) and the PMOD composite of TSI (black) between 1978 and 2010. PMOD and NRLSSI have been normalised to the minimum of SATIRE-S in 1986. The SATIRE-S uncertainty range is shown by light blue shading and the PMOD error bars are given at the cycle minima. Grey shading highlights the periods where gaps exceeding three solar rotations have been filled.
variability of SORCE/SIM over this wavelength range was approximately 3.4 times larger than SATIRE-S. Ball et al. (2011) suggested that degradation of the instrument has not been properly accounted for and may be overestimating the long-term trends (see also Lean and DeLand (2012); Deland and Cebula (2012); Unruh et al. (2012); Ermolli et al. (2013)). SORCE/SIM is currently undergoing a reanalysis that may affect the cycle variability and its uncertainty estimates (Peter Pilewskie, personal communication). We, therefore, only consider SORCE/SOLSTICE in the following. We compare SATIRE-S and NRLSSI for wavelengths between 120 and 3000 nm and up to 310 nm when comparing with SORCE/SOLSTICE.
scribe the evolution of sunspots and faculae, respectively. For wavelengths < 400 nm, spectral irradiances are computed from multiple regression analysis with UARS/ detrended, rotational data to avoid instrumental degradawavelengths above 400 nm, facular and sunspot contrasts, from the models by Solanki and Unruh (1998), are scaled
SOLSTICE observations. This analysis is performed on tion effects and, therefore, assumes that rotational variability scales with solar cycle changes in irradiance. For to agree with solar cycle TSI observations. NRLSSI's integrated flux is ∼ 4 Wm -2 higher than SORCE/TIM so we normalise NRLSSI to SORCE/TIM, as was done for SATIRE-S in section 2a.
## a. Comparison with the NRLSSI model
NRLSSI is an empirical model that uses the diskintegrated Mg II and photospheric sunspot indices to de-
It is worth briefly considering how the TSI derived by integrating the SSI differs between the two models. In Fig. 2, the smoothed, wavelength-integrated SATIRE-S (blue), NRLSSI (red) and PMOD composite of TSI (black) (Fr¨hlich 2003) are plotted between 1978 and 2009. NRLSSI o
and PMOD have been normalised to the absolute value of SATIRE-S averaged over three months centred at the minimum of 1986. The SATIRE-S uncertainty range is plotted with light blue shading and the cycle minima error bars from PMOD are plotted as black bars (Fr¨hlich 2009). Alo though other TSI composites exist, PMOD is now generally accepted as the most accurate TSI composite of observations, which is why we consider only it here; see Ball et al. (2012) for comparisons with all TSI composites on rotational and cyclical timescales. We find correlation coefficients between NRLSSI and SATIRE-S TSI with PMOD, of 0.92 and 0.96, respectively; detrending the timeseries, as described in section 2b, yields correlation coefficients of 0.87 and 0.96 for the rotational variability. These statistics suggests that SATIRE-S reproduces the PMOD composite of observations better than NRLSSI. However, there are periods when NRLSSI matches PMOD better, on yearly and longer timescales, than SATIRE-S. For example, the large difference between SATIRE-S and PMOD around 19911993 is due to the remaining uncertainties in the crosscalibration of the KP 512 and SPM magnetograms (see also Wenzler et al., 2006, and Ball et al., 2012).
The inter-cycle trends of the three datasets are subtly different. Whereas PMOD and SATIRE-S show a decline of ∼ 0.20 +0 16 . -0 26 . and 0.13 +0 07 . -0 10 . Wm -2 , respectively, between 1996 and 2008, NRLSSI exhibits no change over this period. NRLSSI's behaviour is most likely due to the use of the Mg II index as a proxy for long-term changes; this index does not exhibit any strong inter-cycle variation (Fr¨hlich o 2009). Note, however, that the uncertainty of the cycle minima in PMOD and SATIRE-S also encompasses the NRLSSI model estimate of no change, though the Mg II record is not entirely free of long-term uncertainty either (Snow et al., 2005; Marty Snow, personal communication). We note that while accurate TSI is important to act as a constraint for the SSI in both NRLSSI and SATIRE-S (and SORCE/SIM, which is much less well constrained, see Ball et al. (2011)), it does not ensure that the SSI is correct, in either case, as higher variability at some wavelengths can be compensated by lower variability at other wavelengths.
For the SSI comparison between NRLSSI and SATIRES, in Fig. 1 we consider the change in flux, ∆F, between two 81-day averaged periods centred on: 2002 February 1, the second and highest peak of cycle 23; and the cycle 23/24 minimum on 2008 December 15. This provides the largest range of change in cycle 23.
In the upper plot of Fig. 1 the percentage change between the maximum and minimum of solar cycle 23 is plotted on a logarithmic scale while the lower plot depicts the absolute change in flux on a linear y-axis. The spectral uncertainty in SATIRE-S is very small for cycle 23 and is virtually invisible on the plotted scales. We, therefore, plot the spectral variability and the uncertainties for each cycle in section a of the supplementary materials. The wavelength spacings in the two models are different. Consequently, NRLSSI has been interpolated onto the SATIRES wavelength grid (see section 2). The regions below 242 nm and between 242 and 310 nm are important in ozone production and destruction processes in the stratosphere (see section 4), so these have been highlighted with vertical dashed lines.
Below 242 nm, the two models agree well in the change of flux, with larger differences apparent only below ∼ 150 nm; these result from the use of different instruments to define the cycle variability, i.e. UARS/SUSIM for SATIRES (see section 2c) and the scaled rotational variability of UARS/SOLSTICE for NRLSSI (see above). Integrating over 120-242 nm, a region important for the photodissociation of O 2 and O , we find that NRLSSI shows the same 3 solar cycle change as SATIRE-S, though we note that the SATIRE-S Lymanα has ∼ 6% larger cycle amplitude than NRLSSI during the descending phase of cycle 23, but which is generally larger for NRLSSI in earlier solar cycles (see section c and Fig. 4). These differences in Lymanα cycle changes will impact on OH chemistry that indirectly affect ozone concentrations. Between 242 and 310 nm, important in O 3 photodissociation, the integrated change in flux, ∆F, is more than 50% larger in SATIRE-S than NRLSSI.
SATIRE-S shows up to three times larger cycle variability than NRLSSI for wavelengths between 300 and 400 nm. At longer wavelengths, between 400 and 1250 nm, i.e. in the visible and near-IR, NRLSSI generally displays larger cycle variability than SATIRE-S. At yet longer wavelengths, both NRLSSI and SATIRE-S display negative variability in the IR, though this occurs over a wider range and with higher variability in SATIRE-S than NRLSSI, the latter of which only shows negative variability between 1500 and 1850 nm. Where this transition to negative variability occurs is highly dependent on the facular model used (see supplementary materials section c and Unruh et al. (1999, 2000, 2008)). We note that negative variability in the IR region is also seen in SORCE/SIM in the IR above 970 nm, but this change is much larger than both NRLSSI and SATIRE-S. In Ball et al. (2011), the integrated IR region of 972-1630 nm shows ∼ 0.00 Wm -2 change in SATIRE-S between 2004 and 2008, while SORCE/SIM increases by 0.24 Wm -2 . For all wavelengths between 200 and 1600 nm, detailed comparisons between SORCE/SIM and the SATIRE-S and NRLSSI models are made by Ball et al. (2011) and Lean and DeLand (2012), respectively.
## b. Comparison with SORCE/SOLSTICE
SORCE/SOLSTICE observations cover the UV region 115-310 nm. In Fig. 3, we compare the modelled SSI with SORCE/SOLSTICE between two 81-day average periods centred on 2003 August 15 and 2008 December 2008. This period constitutes ∼ 60% of the full cycle variation in TSI
and allows for a direct comparison with SORCE/SOLSTICE observations that started on 2003 May 14, i.e. some time after the maximum of cycle 23. The left plot of Fig. 3 shows the absolute change in flux, while the right is the change in absolute flux relative to SATIRE-S. We plot version 10 of SORCE/SOLSTICE data in addition to the latest version 12 as we consider version 10 in the next section. SORCE/SOLSTICEdata have a reported long-term uncertainty of 0.5% per year which amounts to ∼ 2.7% for the period considered in Fig. 3 and is shown with grey shading for version 12 only; version 12 data have additional degradation corrections to prior versions that result in a change to the absolute level and relative change in spectral irradiance (Marty Snow, personal communication). When not otherwise specified, version 12 is referred to in the following.
From Fig. 3, SORCE/SOLSTICE cycle variability is in reasonable agreement with the models below 140 nm and near 165, 180 and 255 nm. At most other wavelengths below 290 nm, cycle variability is larger in SORCE/SOLSTICE than in the models, typically by at least a factor of two: it is twice that of SATIRE-S at ∼ 170 and 200 nm; between 200 and 250 nm SORCE/SOLSTICE increases from two up to five times the change in SATIRE-S; and between 260 and 290 nm it typically ranges between 1.7 and 3.5 times larger than SATIRE-S. Above 290 nm the long-term uncertainty of SORCE/SOLSTICE exceeds the flux change, ∆F(Marty Snow, personal communication), so results cannot be considered realistic or useful in comparison to the models.
## c. Timeseries comparison with NRLSSI and SORCE/SOLSTICE
We show examples of timeseries for three different wavelength bands: Lymanα at ∼ 121 nm, 176-242 nm and 242290 nm.
In Fig. 4, we compare the Lymanα composite by Woods et al. (2000) (black) with SATIRE-S (blue), NRLSSI (red) and SORCE/SOLSTICE version 12 (green) and 10 (yellow, dashed). In this figure, SATIRE-S and NRLSSI are normalised to the Lymanα composite for the solar minimum of 1986 (as was done for the TSI plot with PMOD in Fig. 2), while both versions of SORCE/SOLSTICE are normalised to the three month averaged period around December 2008. The grey shading is an estimated 10% uncertainty (Woods et al. 2000) on the cycle amplitude, or approximately 0.22 mWm -2 at the 1 σ level. The Lymanα composite agrees with SORCE/SOLSTICE v10 almost exactly during the declining phase of cycle 23 because that version was used in the Lymanα composite. Light blue shading is the uncertainty range of SATIRE-S at 121.5 nm and is the quadrature sum of uncertainty from the SATIRE-S reconstruction and an estimated 5% uncertainty from UARS/SUSIM for the correction applied using the method by Krivova et al. (2006).
The nominal values of NRLSSI and SATIRE-S are at the lower end of the Lymanα uncertainty range. Considering that there is uncertainty at the cycle minima and maxima, SATIRE-S and NRLSSI absolute values could be shifted up and remain within the Lymanα composite uncertainty in all three solar cycles. Therefore, both models agree with the Lymanα observations, within the uncertainty, at almost all times on annual to decadal time scales.
UARS/SUSIM monitored spectral irradiance between
115 and 410 nm for the period 1991 to 2005 and suggested lower solar cycle changes in UV SSI than SORCE/ SOLSTICE. In Fig. 5, we show timeseries for two integrated regions, between 176-242 nm and 242-290 nm (important in the production and destruction of stratospheric ozone, respectively), for SATIRE-S (blue), NRLSSI (red), SORCE/SOLSTICE version 10 (yellow) and version 12 (green) and also UARS/SUSIM (purple). The absolute fluxes of NRLSSI and UARS/SUSIM are shifted to SATIRES for the average of the period between 1997 and 2000 and SORCE/SOLSTICE are shifted to SATIRE-S by the average over the period between June and November 2003. Both wavelength bands show similar solar cycle behaviour for UARS/SUSIM and the two models; SORCE/SOLSTICE show much larger solar cycle trends. We note that the degradation correction issue discussed by Krivova et al. (2006) can be seen just prior to the solar minimum of 1996. This would lead to a change of the cycle maximum in 1991 relative to that of 2000.
However, the two bands in Fig. 5 are broad spectral bands: selecting different wavelength ranges might lead to different conclusions as to which model is better at reconstructing SSI solar cycle changes based on UARS/SUSIM measurements. The inset in the lower plot of Fig. 1 shows the solar cycle change in flux from three month averages, centred on the solar minimum in 1996 and solar maximum in 2002, in 10 nm bands between 120 and 400 nm. This plot illustrates the wavelength dependence of the solar cycle changes. All three datasets show good agreement below 250 nm. Above 250 nm, UARS/SUSIM and SATIRE-S typically show larger solar cycle changes than NRLSSI; SATIRE-S shows closer solar cycle changes to UARS/SUSIM than NRLSSI.
Understanding the effect that the Sun has on Earth's atmosphere and climate requires reliable estimates of SSI variability. The differences between SATIRE-S, NRLSSI and SORCE/SOLSTICE lead to different predicted impacts on the Earth's atmosphere, e.g. heating and photodissociation rates, as the following example considering changes in ozone concentration shows.
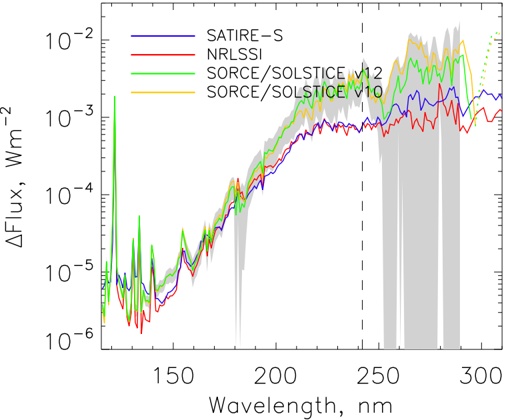
Figure 3 - The SSI change between two 81-day periods centred on 2003 August 15 and 2008 December 15 (left) in absolute flux and (right) relative to SATIRE-S, on a logarithmic scale. Plotted are SORCE/SOLSTICE version 10 (orange) and 12 (green), SATIRE-S (blue) and NRLSSI (red). Dotted lines indicate an inverse trend in flux between 2003 and 2008; flux variations at wavelengths longer than 290 nm cannot be considered reliable as the long-term uncertainty exceeds the flux change, ∆F, at these wavelengths (see main text). The uncertainty range for SORCE/SOLSTICE version 12 is shown in grey shading for wavelengths below 290 nm. Wavelengths are 1 nm width bins below 290 nm and 2 nm bins above. Dashed lines indicate the wavelength 242 nm.
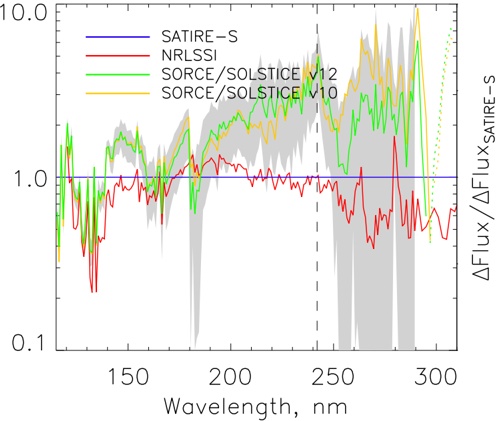
## 4. Modelled ∆ O from different input SSI 3
We employ the radiative-chemical transport atmospheric model based on that of Harwood and Pyle (1975) to compare the resultant change in ozone concentration, ∆O , 3 when using modelled and observational SSI data as a solar input. The atmospheric model has been used in many studies to investigate the dynamics and chemical interactions of the Earth's atmosphere (e.g. Bekki et al., 1996, Warwick et al., 2004, Haigh et al., 2010). It calculates the zonal mean temperature and winds and chemical-constituent concentration in a time-dependent 2D model with full radiative-chemical-dynamical coupling. The model considers a spherical Earth with seasons, but without land topography or oceans. The model is resolved into 19 latitudes and 29 pressure levels up to 95 km. In this study the only difference between model runs is the specification of the input SSI. Use of different input SSI affects photochemical reactions involved in ozone production and destruction which account for the largest contribution to heating in the stratosphere, through the absorption of solar flux below 310 nm. The spectral resolution of the input spectra for the atmospheric model decreases non-linearly from less than 1 nm at 116 nm to 5 nm at 300 nm; it remains at 5 nm resolution up to 650 nm, after which it has 10 nm resolution up to 730 nm.
The atmospheric model requires input SSI up to 730
nm. As SORCE/SOLSTICE data are not available above 310 nm, SATIRE-S fluxes are used. This is valid as there is little effect on ∆O 3 profiles from wavelengths above 310 nm. SORCE/SOLSTICE data show anomalous, large inverse trends in ∆F between 298 and 310 nm, indicated by the dotted lines in Fig. 3, but tests show that this narrow region also has very little impact on the magnitude and spatial distribution of ∆O 3 ; the results remain effectively unchanged if we use SATIRE-S at and above 298 nm, so we use the full wavelength range of SORCE/SOLSTICE in runs using SOLSTICE.
Tests show that the background spectrum (absolute flux) upon which the changes in SSI are superimposed makes very little difference to the O 3 results which depend more critically on the spectral shape of the change. This is because of the strong wavelength dependence of ozone production/destruction reactions. We therefore make no attempt to adjust fluxes to a common absolute level and we use the SSI data as published (see also section d of the supplementary material).
Using the same model that we use here, Haigh et al. (2010) investigated middle atmosphere ozone changes for SSI changes between 2004 and 2007 for NRLSSI and hybrid SORCEspectra with SIM data for λ > 200 nm and an older version of SOLSTICE below. Merkel et al. (2011) presented similar work using the WACCM model, but switched between an older version of SORCE/SOLSTICE and SORCE/
Figure 4 - The Lymanα composite (black) by Woods et al. (2000) with an uncertainty of 10% of the cycle amplitude (grey shading) compared with SATIRE-S (blue) with the uncertainty range (light blue shading), the NRLSSI model (red) and SORCE/SOLSTICE version 12 (green) and 10 (yellow). SATIRE-S and NRLSSI are normalised to the composite at the solar minimum of 1986 and SORCE/SOLSTICE datasets are normalised to the composite at the solar minimum of December 2008.
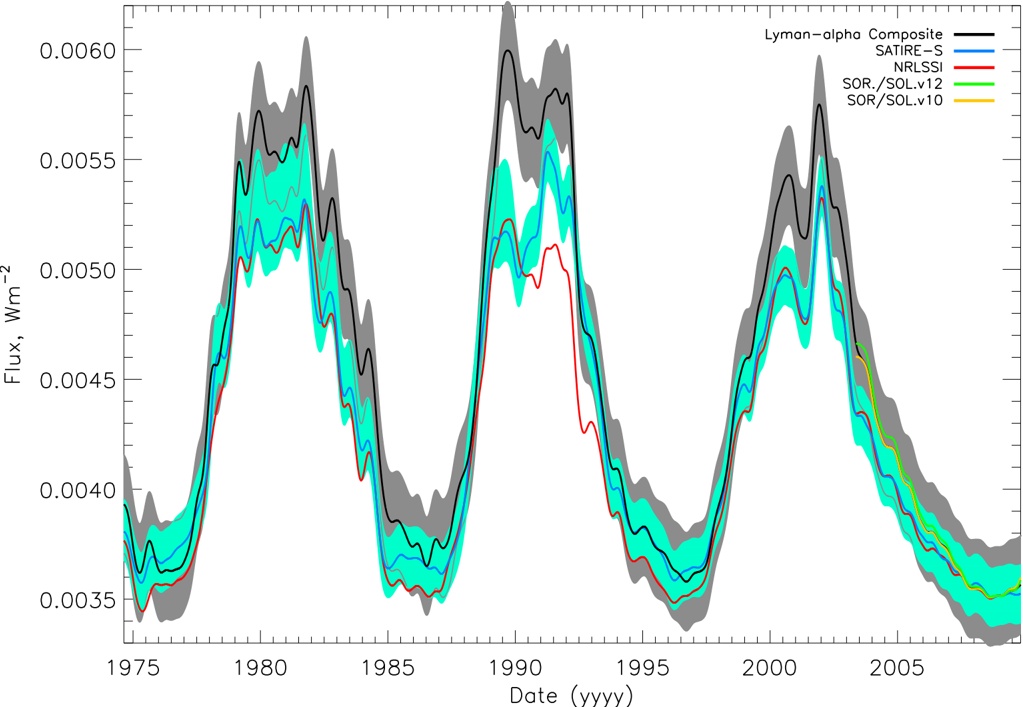
SIM datasets at 240 nm. The choice of wavelength at which to make the switch is somewhat arbitrary and makes a direct comparison with the runs we do here difficult. Also, the exact choice of dates over which SSI are averaged is different between Haigh et al. (2010) and Merkel et al. (2011). We do not try to reproduce their model setups exactly. Instead, we focus on making comparisons between the models and observations we present here. However, it is worth noting that the spatial distributions of ∆O 3 when using version 10 of SORCE/SOLSTICE show similar structure and magnitude to the results presented by Haigh et al. (2010) and Merkel et al. (2011). Both studies, when employing SORCE data between 2004 and 2007, found a negative response (i.e. an increasing ozone outof-phase with solar irradiance) in the mesosphere around 55 km, of 1.2% and 2% respectively. They also found a positive response in the middle stratosphere below 40 km, reaching ∼ 2%. Using NRLSSI in these studies resulted in a response in-phase with SSI changes at all altitudes between 30 and 60 km of up to ∼ 1%.
The input UV SSI for the atmospheric model are the 81-day average spectra as presented in Fig. 3. In Fig. 6 the change in ozone concentration produced by taking the difference between atmospheric model outputs that use SSI from 2003 and 2008 is shown for (a) NRLSSI, (b) SATIRES, (c) SORCE/SOLSTICE v10 and (d) SORCE/SOLSTICE v12. The period considered is during a decline in TSI and UV fluxes that is approximately 50% larger than for the 2004 to 2007 periods used by Haigh et al. (2010) and Merkel et al. (2011). In Fig. 6a the result for NRLSSI is qualitatively similar in spatial distribution to the NRLSSI result of Haigh et al. (2010), but values are approximately 50% larger, as expected for the larger UV change. Figure 6c, using SORCE/SOLSTICE version 10 also displays
Figure 5 - Timeseries of SATIRE-S (blue), NRLSSI (red), SORCE/SOLSTICE version 10 (yellow) and version 12 (green) and UARS/SUSIM (purple) are shown for the wavelength bands (top) 176-242 nm and (bottom) 242-290 nm between 1991 and 2009. UARS/SUSIM and NRLSSI are shifted to the mean of SATIRE-S for the period between 1997 and 2000 and SORCE/SOLSTICE v10 and v12 between June and November 2003.
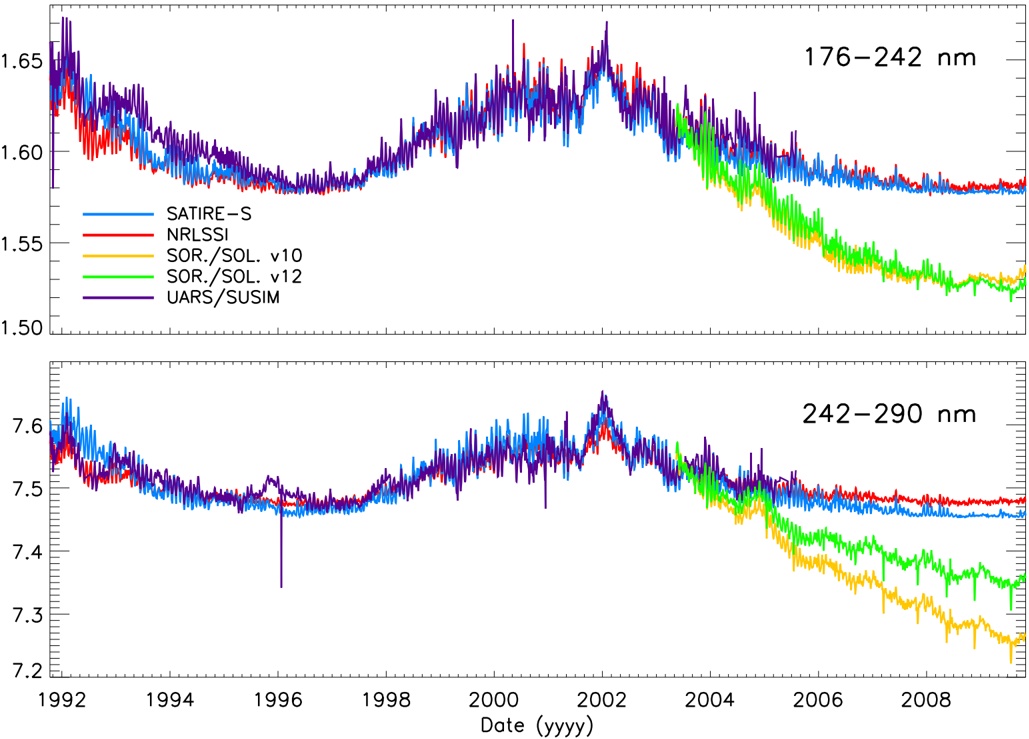
qualitatively similar ∆O 3 to those using SORCE presented by Haigh et al. (2010) and Merkel et al. (2011). The general spatial distribution of ∆O 3 in both versions of SORCE/ SOLSTICE presented in Figs. 6c and 6d are similar. However, there are two striking differences: the magnitude of ∆O 3 in the equatorial lower mesosphere is reduced by a factor of six at around 55 km, from -1.6% to -0.2%, for version 10 and 12, respectively; and the zero-line has also shifted up by ∼ 5 km in version 12 with an increased ∆O 3 maximum in the stratosphere at around 40 km. The change in ∆O 3 from version 10 to 12 reflects a general decrease of ∆F at wavelengths > 242 nm and competing increases and decreases in ∆F at wavelengths < 242 nm.
annum. So, even though there are these differences, in the ∆Fs of the two SORCE/SOLSTICE versions, they are within the stated uncertainty. Our work shows that knowledge of the detailed spectra to better than this accuracy is required to place any faith in derived atmospheric effects.
Despite showing different responses in the atmospheric model for these different datasets, version 10 and 12 of SORCE/SOLSTICE only differ at a small number of wavelengths by more than its stated uncertainty of 0.5% per
The run using SATIRE-S, in Fig. 6b, also displays a negative ∆O 3 above ∼ 50 km, though of lower magnitude than for SORCE/SOLSTICE. Relative to NRLSSI, the negative response in the mesosphere results mainly from the larger ∆F in SATIRE-S above 242 nm. The total concentration of O+O 3 is similar in SATIRE-S and NRLSSI due to similar ∆F for wavelengths < 242 nm. UV radiation at wavelengths between 242 and 310 nm photodissociates ozone to produce O( D) and O . 1 2 This has two effects: it reduces the O /O ratio and O( D) reacts with H O to pro3 1 2 duce OH which catalytically destroys O . 3 Both processes tend to decrease the O 3 concentration at these altitudes.
Figure 6 - Contour plots of the change in stratospheric ozone, ∆O , between 2003 and 2008 using SSI input from (a) 3 the NRLSSI model, (b) the SATIRE-S model, (c) SORCE/SOLSTICE version 10 and (d) version 12. All results are for December 25. Contours are given in 0.1% levels in (a) and (b) and 0.2% in (c) and (d) with negative changes, i.e. increases with decreasing solar activity, are shown with dotted contours. Blue and purple reflect negative changes, while green, yellow and red show positive changes.
Although NRLSSI and SATIRE-S show similar cycle variability below 242 nm, the reduction in ozone concentration at all altitudes and negative response in the mesosphere of SATIRE-S, with respect to NRLSSI, is a result of the larger flux change in SATIRE-S at wavelengths longer than 242 nm. SORCE/SOLSTICE shows very different flux changes compared to SATIRE-S and NRLSSI, but the similar response in the mesosphere relative to SATIRE-S is caused by competing effects on ozone concentration at all wavelengths.
ties that span the range of differences shown by the model runs here. It is therefore not possible, with datasets and methods currently available, to make unequivocal statements about the 'true' ozone response to solar cycle changes. The absolute calibration is less important than the longterm trends in spectral irradiance, the accuracy of which is limited by the stability of the instrument sensitivity. Accurate cycle trends in spectral irradiance are crucial to have confidence in the solar effect on the Earth. At the moment this is lacking.
The modelling study by Swartz et al. (2012) shows similar responses in O 3 to the NRLSSI and SORCE spectra as Haigh et al. (2010) and Merkel et al. (2011). Analysis of observational ozone data, e.g. SBUV, SAGE and HALOE
from Soukharev and Hood (2006), Aura/MLS from
Haigh et al. (2010) and TIMED/SABER from Merkel et al. (2011), suggests a range of changes in ozone with uncertain-
## 5. Discussion and conclusions
In this paper, we present SATIRE-S spectral solar irradiances covering fully the last three solar cycles spanning 1974 to 2009. SATIRE-S is a semi-empirical model that assumes all irradiance changes are the result of changes in surface magnetic flux (Fligge et al. 2000; Krivova et al.
2003). Data are available for all dates over the period with an accompanying error estimate.
We compare our new SATIRE-S spectral irradiances with the NRLSSI model and SORCE/ SOLSTICE observations. NRLSSI and SATIRE-S are in good agreement between ∼ 150-242 nm. Between 242 and 400 nm, the solar cycle change in flux in SATIRE-S is generally ∼ 50% larger than NRLSSI. Both models display significantly lower cycle variability than SORCE/SOLSTICE at almost all wavelengths between 190 and 290 nm.
Both models provide consistent, long-term reconstructions of solar irradiance with different cycle variability. At the moment there is insufficient reliable observational spectral irradiance data to identify which model is more accurate (on solar cycle time scales). While NRLSSI uses solar indices, SATIRE-S provides a direct translation from observed solar images to irradiances. The results presented in this paper show that SATIRE-S reproduces the PMOD TSI composite values better than NRLSSI (though the uncertainties of SATIRE-S and PMOD both encompass NRLSSI). Above 250 nm, the SATIRE-S spectral response is closer to that shown by UARS/SUSIM than NRLSSI (see inset of Fig 1). We suggest that the SATIRE-S spectral irradiances should be considered in future climate studies, either on its own or in addition to NRLSSI.
We present an example of the physical implications that these different SSI datasets have within the stratosphere. We calculate the ozone concentration resulting from the use of the three datasets within a 2D atmospheric model. We find that: (a) the magnitude of mesospheric ∆O 3 response when using SORCE/SOLSTICE versions 10 and 12 is very different; (b) SATIRE-S mimics the small negative mesospheric solar cycle change that SORCE/SOLSTICE version 12 produces; and (c) NRLSSI displays positive changes at all heights.
Interestingly, a recent study by Wang et al. (2013) suggests that modelled solar cycle changes in OH concentration in the stratosphere agree better with observations when using SORCE than NRLSSI data as a model input. We note that Wang et al. (2013) used hybrid SORCE datasets with SIM data either above 240 or above 210 nm and SOLSTICE below these wavelengths; this is different to the spectra we use here or that used by Haigh et al. (2010) and Merkel et al. (2011). However, the different ozone changes in the mesosphere resulting from SSI inputs from two different models and two versions of the same observational dataset in this study, highlights the need for a better understanding of solar cycle changes at wavelengths important for both O , O 2 3 and other atmospheric photochemistry such as OH as in Wang et al. (2013). If the solar effect on ozone is to be isolated correctly, it is imperative that greater certainty is established in SSI variability.
This raises an important point that should be considered when making comparisons of observed with modelled ozone changes which use different SSI datasets. Data are usually updated to make an improvement on previous releases. Unfortunately, the fast pace at which data revisions are made makes comparisons with previous publications difficult. In the case presented here, the change in ∆O 3 between version 10 and 12 of SORCE/SOLSTICE leads to a result in the mesosphere that is so different that it is not yet possible to make robust conclusions about SSI or ozone based on the negative ozone mesospheric response. Many previous investigations have used different SORCE/SIM spectral data, and hybrids with SORCE/SOLSTICE, to investigate the atmospheric response. This makes direct comparisons with the results published in the literature difficult. We have focused the investigation to highlight what is different about SATIRE-S and to only consider the effect of one SORCE dataset in each run. A major result is that significant uncertainties remain in how SSI affects the atmosphere on time scales longer than the solar rotation.
The SATIRE-S SSI data are available for download at http://www.mps.mpg.de/projects/sun-climate/data.html. The SSI reconstruction ends in October 2009. Work is currently underway to extend the reconstruction using fulldisk images from the Solar Dynamics Observatory Helioseismic and Magnetic Imager (Schou et al. 2012) and will be made available for download in the future.
## Acknowledgments.
We thank Marty Snow, Linton Floyd, Tom Woods, Peter Pilewskie and Judith Lean for helpful discussions. We acknowledge the use of the Ottawa/Penticton 2800 MHz Solar Radio Flux and version d41 62 1003 of the PMOD dataset from PMOD/WRC, Davos, Switzerland and the unpublished data from the VIRGO Experiment on SoHO, a project of international cooperation between ESA and NASA. This work has been partly supported by the NERC SolCli consortium grant, the STFC grant ST/I001972/1, the WCU grant number R31-10016 funded by the Korean Ministry of Education, Science and Technology and FP7 SOLID.
## REFERENCES
Austin, J., et al., 2008: Coupled chemistry climate model simulations of the solar cycle in ozone and temperature. Journal of Geophysical Research (Atmospheres) , 113 (D12) , D11306, doi:10.1029/2007JD009391.
Ball, W. T., Y. C. Unruh, N. A. Krivova, S. Solanki, and J. W. Harder, 2011: Solar irradiance variability: A sixyear comparison between SORCE observations and the SATIRE model. Astronomy & Astrophysics , 530 , A71, doi:10.1051/0004-6361/201016189.
Ball, W. T., Y. C. Unruh, N. A. Krivova, S. Solanki, T. Wenzler, D. J. Mortlock, and A. H. Jaffe, 2012: Reconstruction of total solar irradiance 1974-2009. Astronomy & Astrophysics , 541 , A27, doi:10.1051/0004-6361/ 201118702, 1202.3554 .
Balmaceda, L. A., S. K. Solanki, N. A. Krivova, and S. Foster, 2009: A homogeneous database of sunspot areas covering more than 130 years. Journal of Geophysical Research (Space Physics) , 114 (A13) , A07104, doi: 10.1029/2009JA014299, 0906.0942 .
Bekki, S., J. A. Pyle, W. Zhong, R. Toumi, J. D. Haigh, and D. M. Pyle, 1996: The role of microphysical and chemical processes in prolonging the climate forcing of the Toba eruption. Geophysical Research Letters , 23 , 2669-2672, doi:10.1029/96GL02088.
Brueckner, G. E., K. L. Edlow, L. E. Floyd, IV, J. L. Lean, and M. E. Vanhoosier, 1993: The solar ultraviolet spectral irradiance monitor (SUSIM) experiment on board the Upper Atmosphere Research Satellite (UARS). Journal of Geophysical Research , 98 , 10695, doi:10.1029/ 93JD00410.
Deland, M. T. and R. P. Cebula, 2012: Solar UV variations during the decline of Cycle 23. Journal of Atmospheric and Solar-Terrestrial Physics , 77 , 225-234, doi:10.1016/ j.jastp.2012.01.007.
Dhomse, S. S., et al., 2013: Stratospheric O 3 changes during 2001-2010: the small role of solar flux variations in a CTM. ACPD , 13 , 12263-12286, doi:10.5194/ acpd-13-12263-2013.
Dudok de Wit, T., M. Kretzschmar, J. Aboudarham, P.-O. Amblard, F. Auch` ere, and J. Lilensten, 2008: Which solar EUV indices are best for reconstructing the solar EUV irradiance? Advances in Space Research , 42 , 903-911, doi:10.1016/j.asr.2007.04.019, arXiv:astro-ph/0702053 .
Ermolli, I., et al., 2013: Recent variability of the solar spectral irradiance and its impact on climate modelling. ACP , 13 , 3945-3977, doi:10.5194/acp-13-3945-2013, 1303.5577 .
Fligge, M., S. K. Solanki, and Y. C. Unruh, 2000: Modelling irradiance variations from the surface distribution of the solar magnetic field. Astronomy & Astrophysics , 353 , 380-388.
Floyd, L. E., J. W. Cook, L. C. Herring, and P. C. Crane, 2003: SUSIM'S 11-year observational record of the solar UV irradiance. Advances in Space Research , 31 , 21112120, doi:10.1016/S0273-1177(03)00148-0.
Fontenla, J. M., E. H. Avrett, and R. Loeser, 1993: Energy balance in the solar transition region. III - Helium emission in hydrostatic, constant-abundance models with diffusion. The Astrophysical Journal , 406 , 319-345, doi: 10.1086/172443.
Fr¨hlich, C., 2000: o Observations of Irradiance Variations. Space Science Reviews , 94 , 15-24.
Fr¨hlich, C., 2003: Long-term behaviour of space radiomeo ters. Metrologia , 40 , 60, doi:10.1088/0026-1394/40/1/ 314.
Fr¨hlich, C., 2006: Solar Irradiance Variability Since 1978. o Revision of the PMOD Composite during Solar Cycle 21. Space Science Reviews , 125 , 53-65, doi:10.1007/ s11214-006-9046-5.
Fr¨hlich, C., 2009: o Evidence of a long-term trend in total solar irradiance. Astronomy & Astrophysics , 501 , L27L30, doi:10.1051/0004-6361/200912318.
Haigh, J. D., 2003: The effects of solar variability on the Earth's climate. Royal Society of London Philosophical Transactions Series A , 361 , 95, doi:10.1098/rsta.2002. 1111.
Haigh, J. D., A. R. Winning, R. Toumi, and J. W. Harder, 2010: An influence of solar spectral variations on radiative forcing of climate. Nature , 467 , 696-699.
Harder, J., G. Lawrence, J. Fontenla, G. Rottman, and T. Woods, 2005: The Spectral Irradiance Monitor: Scientific Requirements, Instrument Design, and Operation Modes. Solar Physics , 230 , 141-167, doi:10.1007/ s11207-005-5007-5.
Harder, J. W., J. M. Fontenla, P. Pilewskie, E. C. Richard, and T. N. Woods, 2009: Trends in solar spectral irradiance variability in the visible and infrared. Geophysical Research Letters , 36 , 7801, doi:10.1029/2008GL036797.
Harwood, R. S. and J. A. Pyle, 1975: A two-dimensional mean circulation model for the atmosphere below 80km. Quarterly Journal of the Royal Meteorological Society , 101 , 723-747, doi:10.1002/qj.49710143003.
Jones, H. P., T. L. Duvall, Jr., J. W. Harvey, C. T. Mahaffey, J. D. Schwitters, and J. E. Simmons, 1992: The NASA/NSO spectromagnetograph. Solar Physics , 139 , 211-232, doi:10.1007/BF00159149.
Kopp, G. and G. Lawrence, 2005: The Total Irradiance Monitor (TIM): Instrument Design. Solar Physics , 230 , 91-109, doi:10.1007/s11207-005-7446-4.
Kopp, G. and J. L. Lean, 2011: A new, lower value of total solar irradiance: Evidence and climate significance. Geophysical Research Letters , 38 , L01706, doi:10.1029/ 2010GL045777.
Krivova, N. A., L. Balmaceda, and S. K. Solanki, 2007: Reconstruction of solar total irradiance since 1700 from the surface magnetic flux. Astronomy & Astrophysics , 467 , 335-346, doi:10.1051/0004-6361:20066725.
Krivova, N. A., S. K. Solanki, M. Fligge, and Y. C. Unruh, 2003: Reconstruction of solar irradiance variations in cycle 23: Is solar surface magnetism the cause? Astronomy & Astrophysics , 399 , L1-L4, doi: 10.1051/0004-6361:20030029.
Krivova, N. A., S. K. Solanki, and L. Floyd, 2006: Reconstruction of solar UV irradiance in cycle 23. Astronomy & Astrophysics , 452 , 631-639, doi:10.1051/0004-6361: 20064809.
Krivova, N. A., S. K. Solanki, and Y. C. Unruh, 2011: Towards a long-term record of solar total and spectral irradiance. Journal of Atmospheric and Solar-Terrestrial Physics , 73 , 223-234, doi:10.1016/j.jastp.2009.11.013.
Krivova, N. A., S. K. Solanki, T. Wenzler, and B. Podlipnik, 2009: Reconstruction of solar UV irradiance since 1974. Journal of Geophysical Research , 114 (D13) , doi: 10.1029/2009JD012375, 0907.1500 .
Krivova, N. A., L. E. A. Vieira, and S. K. Solanki, 2010: Reconstruction of solar spectral irradiance since the Maunder minimum. Journal of Geophysical Research (Space Physics) , 115 (A14) , A12112, doi:10. 1029/2010JA015431.
Kurucz, R., 1993: ATLAS9 Stellar Atmosphere Programs and 2 km/s grid. ATLAS9 Stellar Atmosphere Programs and 2 km/s grid. Kurucz CD-ROM No. 13. Cambridge, Mass.: Smithsonian Astrophysical Observatory, 1993. , 13 .
Labitzke, K. and H. van Loon, 1995: Connection between the troposphere and stratosphere on a decadal scale. Tellus Series A , 47 , 275, doi:10.1034/j.1600-0870.1995. t01-1-00008.
Lean, J., 2000: Evolution of the Sun's spectral irradiance since the Maunder Minimum. Geophysical Research Letters , 27 , 2425-2428, doi:10.1029/2000GL000043.
Lean, J., G. Rottman, J. Harder, and G. Kopp, 2005: SORCE Contributions to New Understanding of Global Change and Solar Variability. Journal of Solar Physics , 230 , 27-53, doi:10.1007/s11207-005-1527-2.
Lean, J. L., G. J. Rottman, H. L. Kyle, T. N. Woods, J. R. Hickey, and L. C. Puga, 1997: Detection and parameterization of variations in solar mid- and near-ultraviolet radiation (200-400 nm). Journal of Geophysical Research , 102 , 29939-29956, doi:10.1029/97JD02092.
Lean, L., Judith and T. DeLand, Matthew, 2012: How Does the Sun's Spectrum Vary? . J. Climate , 25 , 25552560.
Livingston, W. C., J. Harvey, A. K. Pierce, D. Schrage, B. Gillespie, J. Simmons, and C. Slaughter, 1976a: Kitt Peak 60-cm vacuum telescope. Applied Optics , 15 , 3339, doi:10.1364/AO.15.000033.
Livingston, W. C., J. Harvey, C. Slaughter, and D. Trumbo, 1976b: Solar magnetograph employing integrated diode arrays. Applied Optics , 15 , 40-52, doi: 10.1364/AO.15.000040.
Lockwood, M., C. Bell, T. Woollings, R. G. Harrison, L. J. Gray, and J. D. Haigh, 2010: Top-down solar modulation of climate: evidence for centennial-scale change. Environmental Research Letters , 5 (3) , 034008, doi: 10.1088/1748-9326/5/3/034008.
McClintock, W. E., G. J. Rottman, and T. N. Woods, 2005: Solar-Stellar Irradiance Comparison Experiment II (Solstice II): Instrument Concept and Design. Solar Physics , 230 , 225-258, doi:10.1007/s11207-005-7432-x.
Meier, R. R., 1991: Ultraviolet spectroscopy and remote sensing of the upper atmosphere. Space Science Reviews , 58 , 1-185, doi:10.1007/BF01206000.
Merkel, A. W., J. W. Harder, D. R. Marsh, A. K. Smith, J. M. Fontenla, and T. N. Woods, 2011: The impact of solar spectral irradiance variability on middle atmospheric ozone. Geophysical Research Letters , 38 , L13802, doi:10.1029/2011GL047561.
Morrill, J. S., L. Floyd, and D. McMullin, 2011: The Solar Ultraviolet Spectrum Estimated Using the Mg II Index and Ca II K Disk Activity. Solar Physics , 269 , 253-267, doi:10.1007/s11207-011-9708-7.
Pagaran, J., M. Weber, and J. Burrows, 2009: Solar Variability from 240 to 1750 nm in Terms of Faculae Brightening and Sunspot Darkening from SCIAMACHY. The Astrophysical Journal , 700 , 1884-1895, doi:10.1088/0004-637X/700/2/1884.
Rottman, G., 2005: The SORCE Mission. Solar Physics , 230 , 7-25, doi:10.1007/s11207-005-8112-6.
Rottman, G., T. Woods, M. Snow, and G. Detoma, 2001: The solar cycle variation in ultraviolet irradiance. Advances in Space Research , 27 , 1927-1932, doi:10.1016/ S0273-1177(01)00272-1.
Scherrer, P. H., et al., 1995: The Solar Oscillations Investigation - Michelson Doppler Imager. Solar Physics , 162 , 129-188, doi:10.1007/BF00733429.
Schmidt, G. A., et al., 2012: Climate forcing reconstructions for use in PMIP simulations of the Last Millennium (v1.1). Geoscientific Model Development , 5 , 185191, doi:10.5194/gmd-5-185-2012.
Schou, J., et al., 2012: Design and Ground Calibration of the Helioseismic and Magnetic Imager (HMI) Instrument on the Solar Dynamics Observatory (SDO). Solar Physics , 275 , 229-259, doi:10.1007/s11207-011-9842-2.
Snow, M., W. E. McClintock, G. Rottman, and T. N. Woods, 2005: Solar Stellar Irradiance Comparison Experiment II (Solstice II): Examination of the Solar Stellar Comparison Technique. Solar Physics , 230 , 295-324, doi:10.1007/s11207-005-8763-3.
Solanki, S. K. and Y. C. Unruh, 1998: A model of the wavelength dependence of solar irradiance variations. Astronomy & Astrophysics , 329 , 747-753.
Solanki, S. K. and Y. C. Unruh, 2013: Solar irradiance variability. Astronomische Nachrichten , 334 , 145, doi: 10.1002/asna.201211752, 1210.5911 .
Soukharev, B. E. and L. L. Hood, 2006: Solar cycle variation of stratospheric ozone: Multiple regression analysis of long-term satellite data sets and comparisons with models. Journal of Geophysical Research (Atmospheres) , 111 (D10) , D20314, doi:10.1029/2006JD007107.
Steinhilber, F., J. Beer, and C. Fr¨hlich, 2009: o Total solar irradiance during the Holocene. Geophysical Research Letters , 361 , L19704, doi:10.1029/2009GL040142.
Swartz, W. H., R. S. Stolarski, L. D. Oman, E. L. Fleming, and C. H. Jackman, 2012: Middle atmosphere response to different descriptions of the 11-yr solar cycle in spectral irradiance in a chemistry-climate model. Atmospheric Chemistry & Physics , 12 , 5937-5948, doi: 10.5194/acp-12-5937-2012.
Thuillier, G., M. Hers´ e, D. Labs, T. Foujols, W. Peetermans, D. Gillotay, P. C. Simon, and H. Mandel, 2003: The Solar Spectral Irradiance from 200 to 2400 nm as Measured by the SOLSPEC Spectrometer from the Atlas and Eureca Missions. Solar Physics , 214 , 1-22, doi: 10.1023/A:1024048429145.
Unruh, Y. C., W. T. Ball, and N. A. Krivova, 2012: Solar Irradiance Models and Measurements: A Comparison in the 220-240 nm wavelength band. Surveys in Geophysics , 33 , 475-481, doi:10.1007/s10712-011-9166-7, 1111.2068 .
Unruh, Y. C., N. A. Krivova, S. K. Solanki, J. W. Harder, and G. Kopp, 2008: Spectral irradiance variations: comparison between observations and the SATIRE model on solar rotation time scales. Astronomy & Astrophysics , 486 , 311-323, doi:10.1051/0004-6361:20078421, 0802.4178 .
Unruh, Y. C., S. K. Solanki, and M. Fligge, 1999: The spectral dependence of facular contrast and solar irradiance variations. Astronomy & Astrophysics , 345 , 635-642.
Unruh, Y. C., S. K. Solanki, and M. Fligge, 2000: Modelling solar irradiance variations: Comparison with observations, including line-ratio variations. Space Science Reviews , 94 , 145-152.
van Loon, H. and D. J. Shea, 1999: A probable signal of the 11-year solar cycle in the troposphere of the northern hemisphere. Geophysical Research Letters , 26 , 28932896, doi:10.1029/1999GL900596.
Viereck, R. A., et al., 2004: A composite Mg II index spanning from 1978 to 2003. Space Weather , 2 , S10005, doi: 10.1029/2004SW000084.
Wang, S., et al., 2013: Midlatitude atmospheric oh response to the most recent 11-y solar cycle. PNAS , 110 , 1215-1220, doi:10.1073/pnas.1213389110.
Wang, Y.-M., J. L. Lean, and N. R. Sheeley, Jr., 2005: Modeling the Sun's magnetic field and irradiance since 1713. The Astrophysical Journal , 625 , 522-538, doi:10. 1086/429689.
Warwick, N. J., S. Bekki, E. G. Nisbet, and J. A. Pyle, 2004: Impact of a hydrogen economy on the stratosphere and troposphere studied in a 2-D model. Geophysical Research Letters , 31 , L05107, doi:10.1029/2003GL019224.
Wenzler, T., S. K. Solanki, N. A. Krivova, and D. M. Fluri, 2004: Comparison between KPVT/SPM and SoHO/MDI magnetograms with an application to solar irradiance reconstructions. Astronomy & Astrophysics , 427 , 1031-1043, doi:10.1051/0004-6361:20041313.
Wenzler, T., S. K. Solanki, N. A. Krivova, and C. Fr¨hlich, o 2006: Reconstruction of solar irradiance variations in cycles 21-23 based on surface magnetic fields. Astronomy & Astrophysics , 460 , 583-595, doi:10.1051/0004-6361: 20065752.
Woods, T. N., W. K. Tobiska, G. J. Rottman, and J. R. Worden, 2000: Improved solar Lyman α irradiance modeling from 1947 through 1999 based on UARS observations. Journal of Geophysical Research , 105 , 2719527216, doi:10.1029/2000JA000051.
Woods, T. N., et al., 1996: Validation of the UARS solar ultraviolet irradiances: Comparison with the ATLAS 1 and 2 measurements. Journal of Geophysical Research , 101 , 9541-9570, doi:10.1029/96JD00225.
Woods, T. N., et al., 2009: Solar Irradiance Reference Spectra (SIRS) for the 2008 Whole Heliosphere Interval (WHI). Geophysical Research Letters , 36 , L01101, doi:10.1029/2008GL036373.
-
## Supplementary Materials
## a. Cycle variability
The uncertainty of SATIRE-S is time-dependent and increases going backwards in time from 2008. This is due to the way the reconstructions from the different instruments are combined (see Ball et al., 2012, and section 2a of the main paper). We show the estimated cycle uncertainty, as a function of wavelength, for three solar cycles in Fig. S1. The bottom panel of Fig. S1 is similar to the bottom panel of Fig. 1 in the main paper, but is now between March 2000-December 2008 and has the 1 σ uncertainty estimate included as yellow shading. The uncertainty is very small in cycle 23 and is difficult to see. However, cycles 21 (top; December 1979-September 1986) and 22 (middle; July 1989-May 1996) show much larger uncertainty due to steps (ii) and (iii) of the construction method explained in section 2a. We note that even with the larger uncertainty in cycles 21 and 22, it does not generally encompass the cycle changes of NRLSSI for which there is no uncertainty estimate.
## b. Gap filling
We use five solar indices to fill gaps in the SATIRE-S time series. Here we detail the behaviour of these indices and show examples of the gap-filled time series in three spectral bands.
Each index is indicative of the behaviour of some feature (or combination of features) or source of radiative flux in the solar atmosphere, which in turn should correlate with activity and therefore variability in solar spectral irradiance. The variability of each index depends on the time scale being considered. We only use the detrended indices to avoid biasing the long-term SATIRE-S SSI behaviour to any index.
To account for the rotational variability and fill gaps in the detrended SSI time series, we compare each detrended index with each detrended SATIRE-S SSI wavelength. We do this for all wavelengths above 270 nm and for the integrated region between 220-240 nm. Below 270 nm, all time series are determined from the integrated 220-240 nm region so only this one time series needs to be filled to account for all wavelengths in this wavelength region (see section 2b of main paper). In Fig. S2, the coefficient of determination, r 2 c (the square of the correlation coefficient, r c ), shows how well each detrended index can account for the rotational variability at each wavelength. Colours are given in the legend. Also shown is the highest value r 2 c from the multi-linear regressions of all pairings of indices (black). The scale on the x-axis is linear between 115 and 2000 nm and logarithmic above. The constant value of r 2 c below 270 nm reflects the use of the 220-240 nm region, where the dots are located, to determine the wavelengths in this region.
Considering just the individual indices, we briefly describe the source of their variations (except for TSI), and why they agree with the SSI variability in various wavelength intervals. Below 300 nm, the Mg II index agrees best with SATIRE-S SSI wavelengths, accounting for around 70-80% of the rotational variability. The Mg II index is a measure of the ratio of the emission reversal in the line core of the Mg II line (at ∼ 280 nm) and the Mg II wings. The line core is formed higher up in the solar atmosphere than the wings and is associated with regions of strong magnetic flux, as found in faculae and plages. Faculae dominate spectral variability below 300 nm, so the agreement of the Mg II index with these wavelengths is to be expected.
Between 300 and 400 nm, there is a transition between the dominance of faculae and of sunspots on spectral variability. This is reflected in the behaviour of the indices over this spectral interval where correlation coefficients are highly variable and quite poor at some wavelengths. The lower rotational agreement is not so much of a concern for cycle-length changes in these wavelengths, which is more important in the analysis of the long-term impact of SSI on, e.g., stratospheric chemistry. By combining two proxies, which represent sunspot and facular variations, high agreement ( > 80%) with SATIRE-S wavelengths in this region can be maintained, as shown with the black line in Fig. S2.
The regions between 400 and 1300 nm and 2300 and 4000 nm are best represented by TSI, which can represent more than 80% of the variability at almost all of these wavelengths. TSI is replaced by the sunspot area (SSA) and F10.7 cm radio flux between 1400 and 2200 nm as being the best representative single index of rotational variability; this region contains the opacity minimum and represents the deepest directly observable layers of the photosphere where sunspots and pores dominate and where faculae are expected to appear dark. Where the transition to dark faculae occurs is dependent on the facular model atmosphere (Fontenla et al. 1993; Unruh et al. 1999, 2008). As the TSI includes facular brightening, its correlation with the near-IR SSI decreases. We thus find that the SSI is best represented by the SSA and F10.7 cm radio flux. The F10.7 cm radio flux is formed from plasma trapped in coronal loops anchored to sunspots, so, although it is not formed in the photosphere, the F10.7 cm radio flux is highly correlated with the SSA on rotational time scales and hence the modelled irradiance at these wavelengths. Between 4000 and 10 000 nm none of the indices agree well with rotational variability in SATIRE-S SSI. As in the 300-400 nm region, there is a transition between a stronger influence from pores and sunspots below 4500 nm and faculae above; the contrast of faculae increases monotonically from here while penumbral and umbral contrasts remain
Figure S1 - As for the lower panel of Fig. 1 of the main paper, but with cycle amplitude uncertainty included as yellow shading for SATIRE-S. This is given for cycles 21 (top), 22 (middle) and 23 (bottom). Cycle maximum and minimum dates are taken from the monthly sunspot numbers. Cycle 23 in this plot is for the 81-day average fluxes between March 2000 and December 2008, whereas Fig. 1 is between February 2002 and December 2008, which had a higher mean irradiance than around March 2000.
relatively constant. Once again, by combining two indices, good agreement with the SATIRE-S rotational variability is found.
In Fig. S3, we give three examples of the completed gapfilling process. The integrated region of 220-240 nm and the spectral regions centred at 501 (at 2 nm resolution) and 1605 nm (10 nm) are plotted with the original SATIRE-S time series (black) and the additional daily gap-filled data (blue). The time series is consistent on long- and shorttime scales.
ture of the solar atmosphere and are constrained using spatially resolved observations. Some of the differences between NRLSSI and SATIRE-S at wavelengths above 400 nm are due to the use of model atmospheres with slightly different atmospheric profiles. For example, the extent of the near-IR variability, and even its sign (correlated or anti-correlated with TSI), depends very sensitively on the adopted facular model. We note that the intensities are derived from one-dimensional plane parallel atmospheres and thus do not take the geometry of magnetic features into account.
## c. Uncertainties in model spectrum
The uncertainties we consider in the spectral reconstruction do not include an uncertainty in the model atmospheres themselves, which are estimates of the struc-
Another consideration is the assumption of local thermodynamic equilibrium (LTE) conditions in the solar atmosphere when employing the ATLAS9 code to calculate model intensities. This leads to errors in the modelled ir-
Figure S2 - The coefficient of determination, r 2 c , between the detrended, rotational variability of each wavelength in SATIRE-S and five solar indices: the Mg II index (blue), the PMOD TSI composite (red), the Lymanα composite (purple), the F10.7 cm radio flux (yellow) and the sunspot area (green). Also shown, in black, is the highest value of r 2 c from the multi-linear regression of all pairs of the indices.
radiance variability in some wavelength regions, mainly in the UV. In the data release, we flag the wavelength regions where the uncertainty due to the use of LTE is large, such as, e.g., Mg I line at 285 nm. In Fig. 8a of (Unruh et al. 2008), the variability of SATIRE-S and SORCE/SIM wavelengths between 220 and 290 nm is shown. Above 270 nm, only the Mg I line in SATIRE-S has much larger rotational variability than SORCE/SIM (more than four times); other lines showing much larger rotational variability in the UV below 270 nm are corrected using the method described in (Krivova et al. 2006) and section 2a of this paper. For wavelengths longer than 285 nm, we flag those that show rotational variability exceeding SORCE/SIM or the instrument noise by 25%. This includes the Ca II H and K lines and the wavelength region around 385 nm (see Fig. 8b of Unruh et al., 2008).
## d. Effect of absolute flux on ozone and temperature
We show here that the choice of absolute flux has very little impact on both the cycle change in ozone and temperature in the stratosphere and lower mesosphere. We do this to support the claim made in section 4 of the main paper that it is the relative change between cycle maximum and minimum that is more important when considering cycle changes in ozone. Figure S4 gives the mean absolute fluxes of SATIRE-S (blue), NRLSSI (red) and SORCE/SOLSTICE versions 12 (green) and 10 (yellow) for the three month period centred on December 2008. The left y-axis scale corresponds to wavelengths below 210 nm and the right scale is for wavelengths longer than this. We see that all four datasets show a difference in absolute flux, but the largest differences are above 290 nm, where relative cycle variability is lowest in the models. SATIRE-S has the largest absolute flux at these wavelengths, while SORCE/SOLSTICE (at 290-300 nm) and NRLSSI (at 300310 nm) show the lowest.
Figure S5 gives the change in temperature, in degrees Kelvin, between 2003 and 2008, corresponding to the same runs that produced Fig. 6 in the main paper. All plots in Fig. S5 show an increasing change in temperature with higher altitude, though NRLSSI and SATIRE-S both show about half the change in temperature compared to SORCE/ SOLSTICE. SORCE/SOLSTICE version 10 shows a slightly higher change in temperature than version 12 at all altitudes.
In Fig. S6, we show that the choice of absolute flux has little impact on the change in temperature and ozone concentration. We demonstrate this for three cases: (i) by putting the ∆F between 2003 and 2008 from NRLSSI on the absolute flux of SATIRE-S with the resulting ozone and temperature response given in Fig. S6a and b, respectively; (ii) by using the ∆F from SORCE/SOLSTICE v12 with the absolute flux of SATIRE-S in Fig. S6c and d; and (iii) the same as (ii), but with the absolute flux of SORCE/SOLSTICE version 10 in Fig. S6e and f. Comparing Fig. 6a of the main paper with Fig. S6a (for ozone concentration) and Fig. S5a with Fig. S6b (for temperature), it can be seen that the change resulting from using either the absolute flux of NRLSSI or SATIRE-S does make a small change to the contours, but these changes are much less than the difference between contour levels. Minor differences are more easily detectable for the examples using SORCE/SOLSTICE v12 changes with the ab-
Figure S3 - Time series for three wavelength regions from SATIRE-S showing both the reconstruction direct from the model (black) and the gaps in the data that have been filled with proxy data (blue). The top plot shows the integrated 220-240 nm flux, the middle plot is for the 2 nm band at 501 nm and the bottom plot is the 10 nm band at 1605
solute fluxes of SORCE/SOLSTICE v12 (Figs. 6d of the main paper and S5d), SATIRE-S (Figs. S6c and d) and SORCE/SOLSTICE v10 (Figs. S6e and f). However, once again, these differences are very small and only stand out at the winter pole at 0.3 hPa. It is, therefore, the case that the relative variations in the solar spectral irradiance have a much more significant effect on changes in ozone concentration and temperature in the stratosphere than the choice of absolute flux, at least for the range of absolute fluxes from datasets considered in this study.
Figure S4 - The absolute flux for the 81-day period centred on the solar minimum of December 2008 for SATIRE-S (blue), NRLSSI (red), SORCE/SOLSTICE v12 (yellow) and SORCE/SOLSTICE v10 (green).
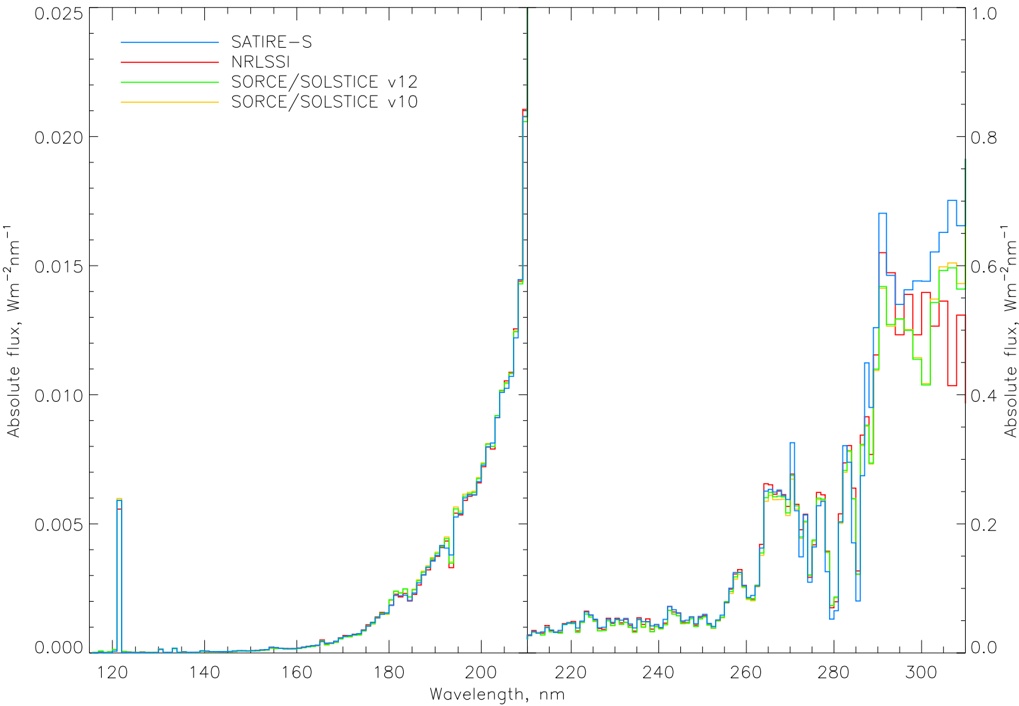
Figure S5 - The same as for Fig. 6 of the main paper, but showing the change in stratospheric temperature. Contours are given in 0.1 K levels.
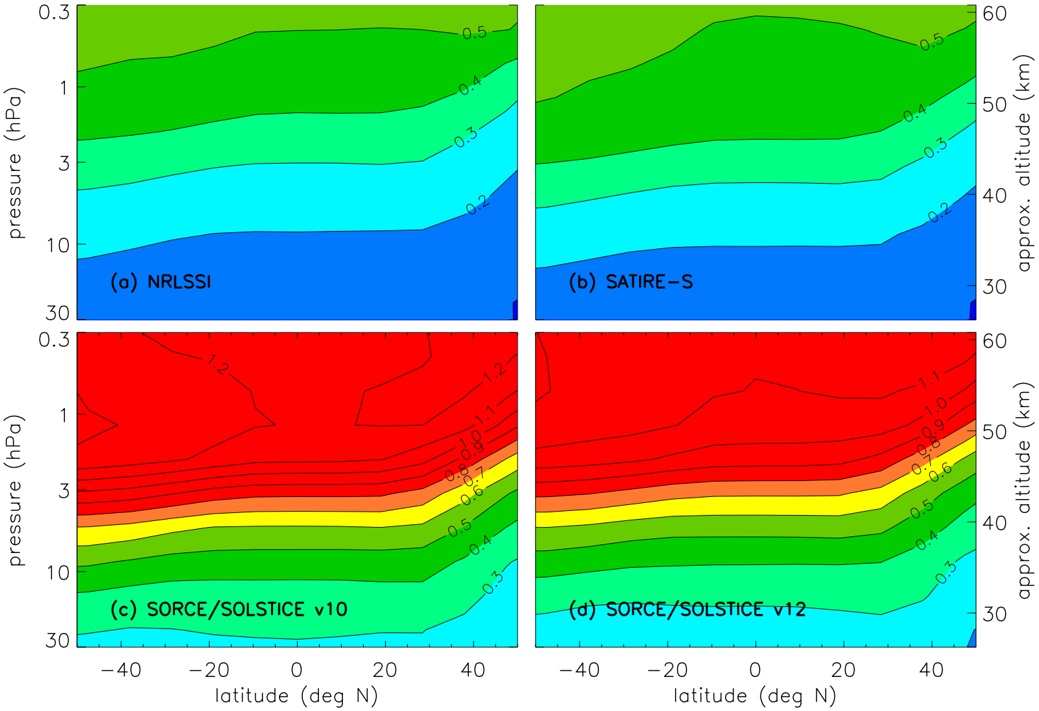
Figure S6 - As for Fig. 6 of the main paper and Fig. S5, contour plots of the change in stratospheric ozone (left panels) and the corresponding temperature change (right panels). The top row shows ozone and temperature changes when employing NRLSSI in the HP model with the absolute flux level of SATIRE-S. The middle row is using SORCE/SOLSTICE v12 change in flux with the absolute flux level of SATIRE-S. The bottom row is using SORCE/SOLSTICE v12 change in flux with the absolute flux of SORCE/SOLSTICE v10.
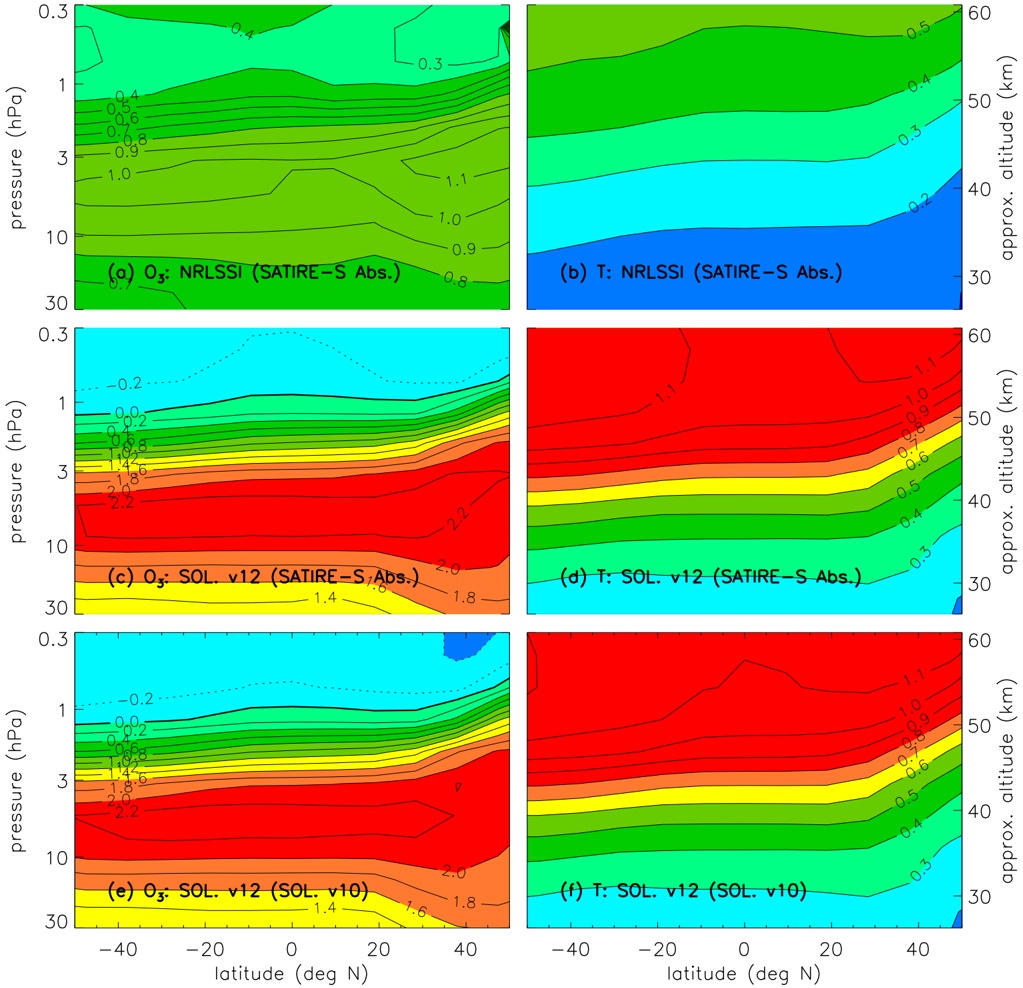 | 10.1175/JAS-D-13-0241.1 | [
"William T. Ball",
"Natalie A. Krivova",
"Yvonne C. Unruh",
"Joanna D. Haigh",
"Sami K. Solanki"
] | 2014-08-02T12:40:51+00:00 | 2014-08-02T12:40:51+00:00 | [
"physics.ao-ph",
"astro-ph.SR"
] | A new SATIRE-S spectral solar irradiance reconstruction for solar cycles 21--23 and its implications for stratospheric ozone | We present a revised and extended total and spectral solar irradiance (SSI)
reconstruction, which includes a wavelength-dependent uncertainty estimate,
spanning the last three solar cycles using the SATIRE-S model. The SSI
reconstruction covers wavelengths between 115 and 160,000 nm and all dates
between August 1974 and October 2009. This represents the first full-wavelength
SATIRE-S reconstruction to cover the last three solar cycles without data gaps
and with an uncertainty estimate. SATIRE-S is compared with the NRLSSI model
and SORCE/SOLSTICE ultraviolet (UV) observations. SATIRE-S displays similar
cycle behaviour to NRLSSI for wavelengths below 242 nm and almost twice the
variability between 242 and 310 nm. During the decline of last solar cycle,
between 2003 and 2008, SSI from SORCE/SOLSTICE version 12 and 10 typically
displays more than three times the variability of SATIRE-S between 200 and 300
nm. All three datasets are used to model changes in stratospheric ozone within
a 2D atmospheric model for a decline from high solar activity to solar minimum.
The different flux changes result in different modelled ozone trends. Using
NRLSSI leads to a decline in mesospheric ozone, while SATIRE-S and
SORCE/SOLSTICE result in an increase. Recent publications have highlighted
increases in mesospheric ozone when considering version 10 SORCE/SOLSTICE
irradiances. The recalibrated SORCE/SOLSTICE version 12 irradiances result in a
much smaller mesospheric ozone response than when using version 10 and now
similar in magnitude to SATIRE-S. This shows that current knowledge of
variations in spectral irradiance is not sufficient to warrant robust
conclusions concerning the impact of solar variability on the atmosphere and
climate. |
1408.0366v1 | ## 非可換群に基づく公開鍵暗号
## 寺澤 善博( Kryptism )
概要 1999 年、当時 16 歳の高校生だった少女セアラ・フラナリーによって行列を用いた公開鍵暗号が考案され、一時 RSA 暗号をもしのぐ強度を持つのではないかとうわさされ、日本でも本が出版され話題になった。しかし、フラナリーの論文が公 開される前に攻撃法が見つかり新型暗号発見のニュースは消えた。本稿では、同じ非可換群である置換群から暗号化関数を構 成し、実装を通してこの暗号系の可能性を探る。
## 0. 動機
新しい暗号を巡る動きは後を絶たない。日本では 著名なセキュリティ会社がほかの企業に合併吸収 される中、 暗号化ビジネスはセキュリティブームを 追い風に大きくなり、市場規模を増しているという のがイメージである。日本でも暗号の研究がおろそ かになったわけではないようだ。年に何回か最新の 暗号方式がどのくらいの時間で解かれたという報 告があるし、研究発表会も盛んに行われている。そ して何より、新しい暗号化方式が外注されずにメー カーやキャリアの独自、 ないしは共同開発という形 で行われていることだ。 これは市場規模とは関係な しに、 企業内で開発圧力が存在することを意味する。 暗号が提供できる機能が同じなら、 なぜ新しい方式 を開発する必要があるのだろうか?それは純粋に 研究者の楽しみである以外に実用的な要請でもあ る。まず既存の暗号方式のうち、数論的計算問題に 基づく方式は量子計算機によりいずれ破られる運 命にあるということ。これはすばわちさまざまな種 類の計算問題から多様な暗号系が構成でき、 実用的 なシステムとして選択可能であることを求められ ていることを意味している。そして計算機の性能が 上がるにつれ、暗号化処理時間は、増大する鍵サイ ズに引きずられる形で増しているということ。この ことは、次世代の暗号を設計する一つの指針を示し ているように思われる。 量子計算機にも攻撃不可能 で、鍵の大きさに暗号化に要する全体の処理速度が 影響されないような暗号系。設計の指針としては、
まず大きな数を使わずベクトルのような小さな数 を使って暗号化することである。現在の候補として は、NTRUなど格子暗号があげられるが、今回は他の 可能性として置換群を用いた公開鍵暗号を示す。
## 1. 対称群
対称群とは、n個の要素が入った配列の要素の位 置を入れ替えるという操作を演算に持つ群のこと である。一般に、n個の要素を扱う対称群を Sn と 書きn次の置換群という。
## 2. 対称群上の計算問題
CP アルゴリズムに置換群を適用することを考え る。置換群の積は自明である。ここで置換群の離散 対数問題を考える。しかしながら、置換群の離散対 数問題は容易に解けることがわかる。
そこで、ランダムビットパターンとして適度なさ を持つ乱数をとり、それを2つの群の言で表すこと を考える。すると、2つの元をそれぞれ0と1に割 り当てることで新たな群の元を計算できる。2つの 元に対して、それとは異なる3つ目の元を取り、そ れを秘密として群の共益問題を考える。 此処で共役 元とはxを秘密にしyが公開されているとして、z =xyx^-1を計算すると、zとyからxを計算する問 題である。
## 3. 暗号および認証系
## ・暗号系その 1
(公開鍵) (秘密鍵)
鍵生成 置換 D=A^aXA^-a,X,A ,a 暗号化 C=A^rD^mA^-r 、 E=A^rXA^-r
復号化 A^aEA^-a=A^r+aXA^-(a+r)=C^-m と C より、サイ クルに関する 1 元連立一次合同式を解いて、秘密指数m を得る。
## ・暗号系その 2
鍵生成 X を秘密鍵とし、 A,B,C=XAX^-1,D=XBX^-1 を公 開鍵とする。
暗号化 256 ビットランダムパターン R を A と B を用い て表したものを T,C と D を用いて表したものを U としm を暗号化すると、暗号文はm となる。ここで、 ( U T,mU ) を相手に送信する。
## 復号化
## XTX^-1=U
m U*U^-1=
より、 mとして、任意のベクトルを得る。
## 4 考察
この暗号化法は、置換群の離散対数問題と、共役 元の計算困難な問題の難しさを安全性の基礎にお いている。
この時のシステムパラメータは、公開鍵が2048 ビットである。この方式で暗号化できる平文のサイ ズは64*32ビットである。
メッセージ膨張率が小さく、鍵サイズも小さな公 開鍵暗号系の構成は難しいかもしれない。
## 寺澤 善博 (非会員) [email protected]
1996 年 電気通信大学大学院情報工学科卒業、 1999 年電気通信大学大学院博士前期課程情報工学専攻卒業、 フリーのエンジニア。暗号技術を用いたオンライプライ バシー保護に関心がある。
## 参考文献
1) 小林雅人(著) あみだくじの数学 共立出版 : , (2011). 2) セアラの暗号 , http://www2.cc.niigata-u.ac.jp/~takeuchi/tbasic/BackGround/cp.pdf 3) 16 歳のセアラが挑んだ世界最強の暗号 | null | [
"Yoshihiro Terasawa"
] | 2014-08-02T12:49:40+00:00 | 2023-08-13T11:46:31+00:00 | [
"cs.CR"
] | Publickey encryption by ordering | In 1999, public key cryptography using the matrix was devised by a hish
school student of 16 yesrs old girl Sarah Flannery. This cryptosystem seemed
faster than RSA, and it's having the strength to surpass even the encryption to
RSA. However, this encryption scheme was broken bfore har papers were
published. In this paper, We try to construct publickey encryption scheme from
permutation group that is equivalent to matrix as noncommutative group. And we
explore the potential of this cryptsystem through implementation. |
1408.0367v1 | ## Damped Electromagnetic fluctuations in the early universe?
Ian G. Moss ∗
School of Mathematics and Statistics, Newcastle University, Newcastle Upon Tyne, NE1 7RU, UK (Dated: August 5, 2014)
This short note considers the effects of quantum theory on the linear evolution of the magnetic fields during and after inflation. The analysis appears to show that the magnetic fields decay exponentially in the high-temperature radiation era due to a combination of ohmic dissipation and vacuum polarisation.
## I. INTRODUCTION
There have been many attemps to find a primordial origin for large-scale magnetic fields from physical processes taking place during the inflationary era. These have to overcome the natural tendency of magnetic fields to decay exponentially in an exponentially expanding universe. The key ingredient for a successful model is recognised as the necessity to break conformal invariance, and examples include higher derivative gravity-electromagnetic couplings [1], massive gauge fields [2], uncharged scalar-gravity couplings [3], charged scalar couplings [4]. (For a review of recent developments see, for example, [5].)
This short note considers the effects of quantum theory on the linear evolution of the magnetic fields during and after inflation. It appears that the magnetic fields decay exponentially in the high-temperature radiation era due to a combination of ohmic dissipation and vacuum polarisation. A similar decay process has been mentioned before by Berera et al. [6], but not yet investigated in any detail.
At leading order in the field strength, the main quantity of interest is magnetic field power spectrum. It therefore seems natural to use a formalism which puts this quantity centre stage. The formalism used here is based on the Schwinger-Dyson equations, and gives a rigorous treatment of the fluctuations at linearised level.
The rapid decay of magnetic fields in the radiation era seems likely to remove anything produced during inflation, but there are limitations to the analysis. If the fields are large enough, then they have to be analysed using a non-linear theory such as magnetohydrodynamics (MHD). (See [7] or [8] for reviews of early universe MHD). However, even in this case the vacuum polarisation effects have to be included and they will modify the MHD equations.
## II. PROPAGATOR THEORY
The central issue is how to track the evolution of the equal time fluctuations in the electromagnetic field. At a fundamental level, this can be derived if we can evaluate the ensemble average of the vector potential operator product,
$$\langle \widehat { A } _ { \mu } ( \mathbf x, t ) \widehat { A } _ { \nu } ( \mathbf x ^ { \prime }, t ) \rangle. & & ( 1 ) \\ \mathbf n \, \text{of this correlator in an expanding universe, taking into account interactions}.$$
We would like to follow the evolution of this correllator in an expanding universe, taking into account interactions with other fields, especially those which are charged.
The evolution of the components of the field operator in a comoveing coordinate frame and a gauge with ∇ µ A µ = 0 is described by
$$\widehat { A } _ { i } ^ { \ddot { \cdot } } & + H \widehat { A } _ { i } ^ { \cdot } + k ^ { 2 } \widehat { A } _ { i } = \widehat { j } _ { i }, \\ \text{ted non-linear operator depending on the vector potential and other charged field} \\.. \quad.. \quad.. \quad.. \quad.. \quad.. \quad.. \quad.. \quad........................................................................................................................................................................................................$$
where the current ̂ j i is a complicated non-linear operator depending on the vector potential and other charged field operators. The vector field obtained from (2) could in principle be fed back into the ensemble average (1), but this would be a formidable task.
If the field had a non-zero expectation value A µ , then the effective field equation derived from quantum field theory would have a linear approximation
$$\ddot { A } _ { i } + H \dot { A } _ { i } + \sigma \dot { A } _ { i } + k ^ { 2 } A _ { i } + \Pi _ { i } ^ { j } A _ { j } = 0,$$
∗ [email protected]
where σ is the plasma conductivity, and the non-dissipative part of the vacuum polarisation Π ij acts like an effective mass term. It is quite common to confuse the operator equation (2) with the effective field equation (3) to follow the time evolution of an operator which is then inserted into (1). Amore rigorous procedure, which we adopt here, uses the Schwinger-Dyson equation to follow the evolution of the two-point function (1). An account of the Schwinger-Dyson equations for non-equilibrium quantum field theory can be found in reviews such as [9].
The three two-point functions which are required are the retarded and advanced Green functions,
$$G _ { R i j } & = i \theta ( t - t ^ { \prime } ) \langle [ \widehat { A } _ { i } ( { \mathbf x }, t ), \widehat { A } _ { j } ( { \mathbf x } ^ { \prime }, t ^ { \prime } ) ] \rangle, \\ G _ { A i j } & = - i \theta ( t ^ { \prime } - t ) \langle [ \widehat { A } _ { i } ( { \mathbf x }, t ), \widehat { A } _ { j } ( { \mathbf x } ^ { \prime }, t ^ { \prime } ) ] \rangle,$$
and the anti-commutator function
$$G _ { A i j } ^ { \lambda } & = - i \theta ( t ^ { \prime } - t ) \langle [ \widehat { A } _ { i } ( { \mathbf x }, t ), \widehat { A } _ { j } ( { \mathbf x } ^ { \prime }, t ^ { \prime } ) ] \rangle, & \\ \intertext { r function }$$
$$G _ { S i j } = \frac { 1 } { 2 } \langle \{ \widehat { A } _ { i } ( { \mathbf x }, t ) \widehat { A } _ { j } ( { \mathbf x } ^ { \prime }, t ^ { \prime } ) \} \rangle. \quad & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & && & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & &
& & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & - & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & \\ & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & \ & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & _ & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & ; & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & } & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & &. & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & + & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & &, & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & = & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & &</ & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & b & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & ^ & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & | & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & &$$
These satisfy Schwinger-Dyson equations. At leading order in the two-point functions, these are
$$( - \nabla ^ { 2 } + \Pi _ { R } ) G _ { S } & = - \Pi _ { S } G _ { A }, & ( 7 ) \\ ( - \nabla ^ { 2 } + \Pi _ { N } \wr G _ { N } & = - 1 & ( 8 \wr$$
$$( - \nabla ^ { 2 } + \Pi _ { R } ) G _ { R } = - 1, \\ \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot$$
when written in a convenient condensed notation. The product terms in condensed notation translate into ordinary notation by
$$\Pi _ { S } G _ { A i j } ( x, x ^ { \prime } ) = \int \Pi _ { S i } ^ { k } ( x, y ) G _ { A k j } ( y, x ^ { \prime } ) \, \sqrt { g } d ^ { 4 } y,$$
and 1 ≡ g ij √ gδ 4 ( x -y ), where g ij is the spatial metric. A formal solution to the Schwinger-Dyson equation (7) is given by
$$G _ { S } = G _ { S } ^ { ( 0 ) } + G _ { R } \Pi _ { S } G _ { A }$$
where G (0) S is a solution to the homogeneous equation and represents the effects of initial conditions, whilst the second term represents induced fluctuations.
The vacuum polarisations Π R and Π S can be evaluated purturbatively by summing 1-particle-irreducible free Feynman diagrams. In the case of Π , the most important effects R are the ones that are localised in space and time, specifically effective mass and dissipation terms. On the other hand, for fluctuations on large length scales the small momentum contributions to Π R are the ones of interest. The methods for dealing with each of these vacuum polarisation terms are therefore different.
In Fourrier space, we can take advantage of the spatially homogeneous background to define the transverse symmetric fumction G S ( k , t, t ′ ) by
$$\langle \{ \widehat { A } _ { i } ( \mathbf k, t ) \widehat { A } _ { j } ^ { * } ( \mathbf k ^ { \prime }, t ^ { \prime } ) \} \rangle & = 2 \delta _ { k k ^ { \prime } } \pi _ { i j } G _ { S } ( \mathbf k, t, t ^ { \prime } ), & ( 1 1 ) \\ \mathfrak { c } - \mathbf k ^ { \prime } ) \text{ and for transverse fields } \pi _ { i j } & = \delta _ { i j } - k _ { i } k _ { j } / k ^ { 2 }. \text{ The electric and magnetic fields in an} \text{.}$$
where δ kk ′ = (2 π ) 3 δ ( k -k ′ ) and for transverse fields π ij = δ ij -k k /k i j 2 . The electric and magnetic fields in an orthonormal spatial frame (rather than the comoving coordinate frame) are B i = ia -2 /epsilon1 ijk k A j k and E i = -a -2 A ′ i , where /epsilon1 123 = 1 and prime denotes the conformal time derivative ∂ η = a∂ t . The equal-time magnetic power spectrum is defined by
$$\langle \widehat { B } _ { i } ( { \mathbf k }, t ) \widehat { B } _ { j } ^ { * } ( { \mathbf k } ^ { \prime }, t ) \rangle = \delta _ { k k ^ { \prime } } \pi _ { i j } P _ { B }. & & ( 1 2 ) \\ \text{the power spectrum to the vector Green function},$$
Comparison with (11) relates the power spectrum to the vector Green function,
$$P _ { B } = k ^ { 2 } a ^ { - 4 } G _ { S } ( { \mathbf k }, t, t ).$$
## III. FREE EVOLUTION
Solutions for the 'free' part of the anti-commutator function can be constructed from the solutions to the homogeneous field equation (3) or (8), u i ( k, t ) = u k, t e ( ) i , where e i is a transverse vector. If the initial state is a vaccum state, then the relevant solution is
$$G _ { S } ^ { ( 0 ) } ( k, t, t ^ { \prime } ) & = \frac { 1 } { 2 } \left ( u ( k, t ) \bar { u } ( k, t ^ { \prime } ) + u ( k, t ^ { \prime } ) \bar { u } ( k, t ) \right ),$$
where the modes are normalised by a uu ( ˙ ¯ -¯ ˙ ) = uu i at the initial time. We shall consider the case where the very long wavelength modes are not thermalised. The thermal symmetric Green function contains an extra factor 1 + 2 n T ( ), where n T ( ) is the thermal occupation number, and the conclusions we reach are similar if we begin with a thermal state.
## A. de Sitter space
In de Sitter space we define a negative conformal time τ such that dt = adτ . In the slow-roll approximation with H constant, τ = -1 / aH ( ) and τ = τ r at the end of reheating. The mode equation, which may include mass terms from quantum effects in the curved spacetime, becomes
$$u ^ { \prime \prime } + k ^ { 2 } u + a ^ { 2 } m _ { A } ^ { 2 } u = 0.$$
The solutions relevant for the de Sitter vacuum are Hankel functions of the first kind,
$$u _ { d S } = \frac { 1 } { 2 } \sqrt { \pi } ( - \tau ) ^ { 1 / 2 } H _ { 1 / 2 - \epsilon } ^ { ( 1 ) } ( - k \tau ),$$
where /epsilon1 = 1 2 / -(1 / 4 -m /H 2 A 2 ) 1 / 2 . In the large wavelength limit, using (14),
$$G _ { S } ^ { ( 0 ) } ( k, \eta ) \approx \frac { 1 } { 2 } k ^ { - 1 } ( k \tau ) ^ { 2 \epsilon }.$$
When /epsilon1 = 0 the maxwell fields become conformally invariant. In the language of conformal field theory the field operators have conformal weight zero. The magnetic field has conformal weight minus two and the power spectrum obtained from (13) decays rapidly. We can pull out a factor of k -3 for comparison with a scale invariant result,
$$\cdot \quad & P _ { B } = \frac { H ^ { 4 } } { 2 } \left ( \frac { k } { a H } \right ) ^ { 4 } k ^ { - 3 }.$$
As mentioned in the introduction, the rapid decay of the magnetic field can be overcome by interactions between the electromagnetic field and other fields which break the conformal invariance. One example, the coupling to charged scalar fields, will be considered in section IV A
## B. Radiation era
Suppose a significant amplitude of magnetic field fluctuations has been produced from one of the mechanisms mentioned in the introduction. The universe reheats and then enters the radiation era. In a linear approximation, the evolution of the field is subject to dissipation and other vacuum polarisation effects.
For temperatures larger than the lightest charged fermion mass, the dominant contribution to the vacuum polarisation comes from hard thermal fermion loops (i.e. from loop momenta larger than charged fermion masses), and standard flat-spacetime results for the vacuum polarisation are available (see appendix A). The vacuum polarisation can be decomposed into transverse and longitudinal components. For long vector wavelengths, both components reduce to a mass term,
$$m _ { A } ^ { 2 } = \frac { N _ { f } } { 6 } e ^ { 2 } T ^ { 2 },$$
where N f is the number of relativistic charged fermions. The conductivity of a relativistic plasma σ ∼ e -2 T , and so both aσ and am A are roughly constant. We use conformal time η , where dt = adη , and η = η r at the end of reheating. The mode equation becomes
$$u ^ { \prime \prime } + ( a \sigma ) u ^ { \prime } + k ^ { 2 } u + ( a m _ { A } ) ^ { 2 } u = 0.$$
The two solutions are now
$$u _ { 1 } = e ^ { - p _ { 1 } ( \eta - \eta _ { r } ) }, \quad u _ { 2 } = e ^ { - p _ { 2 } ( \eta - \eta _ { r } ) }.$$
where the conformal time η = 1 ( / aH ) and p 1 , p 2 are the roots of
$$p ^ { 2 } + ( a \sigma ) p + ( k ^ { 2 } + a ^ { 2 } m _ { A } ^ { 2 } ) = 0.$$
Since σ /greatermuch m A , and for long wavelengths m A /greatermuch k/a , we have p 1 ≈ am /σ 2 A ∼ e aT 4 and p 2 ≈ aσ ∼ e -2 aT . The unsourced electromagnetic fluctuations are strongly exponentially damped, with negative exponents of order e T/H 4 . The exponential damping only occurs when the ohmic dissipation and the electromagnetic mass term are both present.
The lightest fermion is the electron. For temperatures smaller than the electron mass, around 0 5MeV, the real . part of the vacuum polarisation drops suddenly due to thermal suppression factors in the fermion loop and it can be ignored. Then, p 1 ≈ ak /σ 2 ≈ 0, and the mode u 1 is frozen. The free magnetic field power spectrum P B defined by (13) falls off as a -4 . This is the familiar situation in which the r.m.s. magnetic field energy density also decays as a -4
## C. The reheating stage
Although the unsourced fluctuations are heavily damped and not capable of producing cosmological magnetic fields, it is interesting to follow their evolution through a short reheating stage following inflation. It has been claimed that there is a large growth of the magnetic field at the reheating time [ ? ]. Consider the modes
$$\alpha \cdots \cdots \cdots \cdots \cdots \cdots \cdots \\ u = \begin{cases} u _ { d S } & t < t _ { r } & & \\ \alpha u _ { 1 } + \beta u _ { 2 } & t > t _ { r } & & \\.. &.. &.. &.. &.. &.. &.. &.. &.. &.. &.. &.. \end{cases}$$
We obtain α and β by requiring the continuity of u and ˙ at reheating. Using these in (14) gives u
$$G _ { S } ^ { ( 0 ) } = \frac { 1 } { 2 } k ^ { - 1 } ( k \tau _ { r } ) ^ { 2 \epsilon } \frac { | \epsilon a _ { r } H ( u _ { 1 } - u _ { 2 } ) + p _ { 1 } u _ { 2 } - p _ { 2 } u _ { 1 } | ^ { 2 } } { | ( a \sigma ) ^ { 2 } - 4 ( a m _ { A } ) ^ { 2 } | } \\ \prod _ { \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \colon } \prod _ { \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdots }$$
If the dissipation and mass terms (after reheating) are ignored, then σ = 0 and am A is replaced by k . The numerator is dominated by the first term and the result would agree with Refs. [10, 11],
$$G _ { S } ^ { ( 0 ) } \approx \frac { 1 } { 2 } k ^ { - 1 } ( k \tau _ { r } ) ^ { 2 \epsilon - 2 } \epsilon ^ { 2 }.$$
This contains an enhancement factor 1 / kτ ( r ) 2 compared to the value before reheating. However, using the physical values for σ and m A gives
$$G _ { S } ^ { ( 0 ) } \approx \frac { 1 } { 2 } k ^ { - 1 } ( k \tau _ { r } ) ^ { 2 \epsilon } e ^ { - ( \alpha m _ { \lambda } ^ { 2 } / \sigma ) ( \eta - \eta _ { r } ) }.$$
There is no growth at reheating time, and the correllator decays after reheating.
## IV. SOURCED EVOLUTION
After finding that the free fluctuations in the magnetic fields are exponentially damped during the radiation era, we now turn to the fluctuations which arise from the source term. These depend on the retarded Green function G R and the vacuum polarisation Π S . We start with the retarded Green function.
In conformal time, the Fourrier space Green functions satisfy
$$G _ { i j } ^ { \prime \prime } + ( a \sigma ) G _ { i j } ^ { \prime } + k ^ { 2 } G _ { i j } + ( a m _ { A } ) ^ { 2 } G _ { i j } = - \pi _ { i j } \delta ( \eta - \eta ^ { \prime } ).$$
With this deffinition,
$$G _ { R } \Pi _ { S } G _ { A i j } ( \eta, \eta ^ { \prime } ) & = \pi _ { i j } \int d \rho d \rho ^ { \prime } \, a ^ { 2 } ( \rho ) a ^ { 2 } ( \rho ^ { \prime } ) G _ { R } ( \eta, \rho ) G _ { R } ( \eta ^ { \prime }, \rho ^ { \prime } ) \Pi _ { S } ^ { T } ( \rho, \rho ^ { \prime } ),$$
where Π T S is the transverse part of the vacuum polarisation, and all of the terms are evaluated at the same k . Using the modes (21), we get the retarded Green function
$$G _ { R i j } & = \pi _ { i j } \frac { 1 } { a \sigma } \left ( e ^ { - p _ { 1 } ( \eta - \eta ^ { \prime } ) } - e ^ { - p _ { 2 } ( \eta - \eta ^ { \prime } ) } \right ), \\. &. &. &. &. &. &. &. &. &. &. &. &. &. &. &. &. &. &. &. &. &. &. &. &. &. &. &. &. &. &. &. &. &. &. &. &. &. &. &. &. &. &. &. &. &. &. &. &. &. &. &. &. &. &. &. &. &. &. &. &. &. &. &. &. &. &. &. &. &. &. &. &. &. &. &. &. &. &. &. &. &. &. &. &. &. &. &. &. &. &. &. &. &. &. &. &. &. &. &. &.. &. &. &. &. &. &. &. &. &. &. &. &. &. &. &. &. &. &. &. &. &. &. &. &. &. &. &. &. &. &. &. &. &. &. &. &. &. &. &. &. &. &. &. &. &. &. &. &. &. &. &. &. &. &. &. &. &. &. &. &. &. &. &. &. &. &. &. &. &. &. &. &. &. &. &. &. &. &. &. &. &. &. &. &. &. &. &. &. &. &. &. &. &. &. &. &. &. &. &.$$
where p 1 and p 2 are given by (22). In some cases of interest, a 4 Π T S varies more slowly than the exponential terms, and we can take it out of the intergal (28),
$$G _ { R } \Pi _ { S } G _ { A i j } ( \eta, \eta ) & \approx \pi _ { i j } \frac { a ^ { 4 } \Pi _ { S } ^ { T } ( \eta, \eta ) } { ( k ^ { 2 } + a ^ { 2 } m _ { A } ^ { 2 } ) ^ { 2 } }.$$
The magnetic field fluctuations (13) sourced by Π T S are therefore
$$P _ { B } \approx k ^ { 2 } \frac { \Pi _ { S } ^ { T } ( \eta, \eta ) } { ( k ^ { 2 } + a m _ { A } ) ^ { 4 } }$$
In effect, the exponential damping of the vector modes localises the effect of the source term.
## A. Current fluctuations
As an example of possible source terms, consider charged scalar fields which produce long-wavelength current fluctuations during the de Sitter era, as originally suggested by Calzetta et al. [4, 12, 13]. The transverse current operators ˆ j T i couple to the gauge potentials in the Lagrangian and produce a vacuum polarisation,
$$\langle \{ \hat { j } _ { i } ^ { T } ( { \mathbf k }, t ), \hat { j } _ { j } ^ { T } ( { \mathbf k } ^ { \prime }, t ^ { \prime } ) \} \rangle & = 2 \pi _ { i j } \delta _ { k k ^ { \prime } } \Pi _ { S } ^ { T } ( { \mathbf k }, t, t ^ { \prime } ).$$
Consider a U (1) field φ for simplicity, with current operator
$$\stackrel { \dots } { \dots } \psi, \, \dots \, \dots \, \dots \, \dots \, \dots \, \dots \, \dots \, \dots \, \dots \, \dots \, \dots \, \dots \, \dots \, \dots \, \dots \, \dots \, \dots \, \dots \, \dots \, \dots \, \dots \, \dots \, \dots \, \dots \, \dots \, \dots \, \dots \, \dots \, \dots \, \dots \, \dots \, \dots \, \dots \, \dots \, \dots \, \dots \, \dots \, \dots \, \dots \, \dots \, \delta }$$
The leading order diagram contribution to the current correlations is
$$\dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \delta \delta \delta \delta \delta \delta \delta \delta \delta \delta \delta \delta \delta \delta \delta \delta \delta \delta \delta \delta \delta \delta \delta \delta \delta \delta \delta \delta \delta \delta \delta \delta \delta \delta \delta \delta \delta \delta \delta \delta \delta \delta \delta \delta \delta \delta \delta \delta \delta \delta \delta \delta \delta \delta \delta \delta \delta \delta \delta \delta \delta \delta \delta \delta \delta \delta \delta \Delta \delta \delta \delta \delta \delta \delta \delta \delta \delta \delta \delta \delta \delta \delta \delta \delta \delta \delta \delta \delta \delta \delta \delta \delta \delta \delta \delta \delta \delta \delta \delta \delta \delta \delta \delta \delta \delta \delta \delta \delta \delta \delta \delta \delta \delta \delta \delta \delta \delta \delta \delta \delta \delta \delta \delta \delta \delta \delta \delta \delta \delta \delta \delta \delta \delta \delta\delta \delta \delta \delta \delta \delta \delta \delta \delta \delta \delta \delta \delta \delta \delta \delta \delta \delta \delta \delta \delta \delta \delta \delta \delta \delta \delta \delta \delta \delta \delta \delta \delta \delta \delta \delta \delta \delta \delta \delta \delta \delta \delta \delta \delta \delta \delta \delta \delta \delta \delta \delta \delta \delta \delta \delta \delta \delta \delta \delta \delta \delta \delta \delta \delta \delta \dots \delta \delta \delta \delta \delta \delta \delta \delta \delta \delta \delta \delta \delta \delta \delta \delta \delta \delta \delta \delta \delta \delta \delta \delta \delta \delta \delta \delta \delta \delta \delta \delta \delta \delta \delta \delta \delta \delta \delta \delta \delta \delta \delta \delta \delta \delta \delta \delta \delta \delta \delta \delta \delta \delta \delta \delta \delta \delta \delta \delta \delta \delta \delta \delta \delta \ delta \delta \delta \delta \delta \delta \delta \delta \delta \delta \delta \delta \delta \delta \delta \delta \delta \delta \delta \delta \delta \delta \delta \delta \delta \delta \delta \delta \delta \delta \delta \delta \delta \delta \delta \delta \delta \delta \delta \delta \delta \delta \delta \delta \delta \delta \delta \delta \delta \delta \delta \delta \delta \delta \delta \delta \delta \delta \delta \delta \delta \delta \delta \delta \delta \delta \delta delta \delta \delta \delta \delta \delta \delta \delta \delta \delta \delta \delta \delta \delta \delta \delta \delta \delta \delta \delta \delta \delta \delta \delta \delta \delta \delta \delta \delta \delta \delta \delta \delta \delta \delta \delta \delta \delta \delta \delta \delta \delta \delta \delta \delta \delta \delta \delta \delta \delta \delta \delta \delta \delta \delta \delta \delta \delta \delta \delta \delta \delta \delta \delta \delta \delta \dia \delta \delta \delta \delta \delta \delta \delta \delta \delta \delta \delta \delta \delta \delta \delta \delta \delta \delta \delta \delta \delta \delta \delta \delta \delta \delta \delta \delta \delta \delta \delta \delta \delta \delta \delta \delta \delta \delta \delta \delta \delta \delta \delta \delta \delta \delta \delta \delta \delta \delta \delta \delta \delta \delta \delta \delta \delta \delta \delta \delta \delta \delta \delta \delta \delta \delta \ delta \ delta \delta \delta \delta \delta \delta \delta \delta \delta \delta \delta \delta \delta \delta \delta \delta \delta \delta \delta \delta \delta \delta \delta \delta \delta \delta \delta \delta \delta \delta \delta \delta \delta \delta \delta \delta \delta \delta \delta \delta \delta \delta \delta \delta \delta \delta \delta \delta \delta \delta \delta \delta \delta \delta \delta \delta \delta \delta \delta \delta \delta \delta \delta \delta \delta \delta$$
where G φ S is the anticommutator function for the charged scalar. If we assume that the fluctuations on large length scales are vacuum fluctuations, the anticommutator function can be expressed in terms of the scalar modes v and ¯, v
$$G _ { S } ^ { \phi } = \frac { 1 } { 2 } \left ( v ( k, t ) \bar { v } ( k, t ^ { \prime } ) + v ( k, t ^ { \prime } ) \bar { v } ( k, t ) \right ).$$
where
$$\ddot { v } + 3 H \dot { v } + \sigma _ { \phi } \dot { v } + k ^ { 2 } a ^ { - 2 } v + m _ { \phi } ^ { 2 } v = 0.$$
For large wavelengths, the effective mass is due curved space effects in de Sitter space, and to interaction with thermal radiation in the radiation era. The damping term is due to radiative damping and the decay of the charged scalar into charged fermion fields.
It is questionable whether the scalar correllators retain their vacuum form in the hot plasma, even on very long length scales. Giovannini et al. [13] have constructed a model where the occupance of the charged field modes is represented by a distribution function, and find a reduction in the induced magnetic fields.
## B. de Sitter space
In de Sitter space, with σ φ /lessmuch H , the scalar modes are
$$v = \frac { 1 } { 2 } \sqrt { \pi } H ( - \tau ) ^ { 3 / 2 } H _ { 3 / 2 - \delta } ^ { ( 1 ) } ( - k \tau ).$$
where δ = 3 2 / -(9 / 4 -m /H 2 φ 2 ) 1 / 2 . In the long-wavelength limit,
$$\L _ { \varphi ^ { \prime } } \, ^ { \prime } \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \ \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \ \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \ } \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \,\quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \,\ \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \ \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \,
\quad \quad \quad$$
after substituting this into the current-current correlations (34), we get
$$\langle \{ \hat { j } _ { i } ^ { T } ( { \mathbf k }, \tau ), \hat { j } _ { j } ^ { T } ( { \mathbf k } ^ { \prime }, \tau ^ { \prime } ) \} \rangle \approx 2 \delta _ { k k ^ { \prime } } \pi _ { i j } \frac { e ^ { 2 } } { 2 \pi } H ^ { 4 } k ^ { - 1 } ( k \tau ) ^ { 2 \delta } ( k \tau ^ { \prime } ) ^ { 2 \delta }.$$
The magnetic field fluctuations induced by these current fluctuations are obtained from Eq. (28) and Eq. (13). The scale factors in (28) compensate for the scale factors in (13) and the rapid decay of the magnetic field fluctuations is avoided.
## C. Radiation era
Consider what happens in the (unphysical) case with the radiation damping switched off, σ φ ≈ 0. Using a WKB approximation for the long-wavelength modes gives
$$v & = a ^ { - 1 } ( a m _ { \phi } ) ^ { - 1 / 2 } e ^ { - i \int m _ { \phi } d t }. & & ( 4 0 ) \\.. &. &. &. &. &. &. &. &. &. &. &. &. &. &. &. &. &. &. &. &. &. &. &. &. &. &. &. &. &. &. &. &. &. &. &. &. &. &. &. &. &. &. &. &. &. &. &. &. &. &. &. &. &. &. &. &. &. &. &. &. &. &. &. &. &. &. &. &. &. &. &. &. &. &. &. &. &. &. &. &. &. &. &. &. &. &. &. &. &. &. &. &. &. &. &. &. &. &. &. &.. &. &. &. &. &. &. &. &. &. &. &. &. &. &. &. &. &. &. &. &. &. &. &. &. &. &. &. &. &. &. &. &. &. &. &. &. &. &. &. &. &. &. &. &. &. &. &. &. &. &. &. &. &. &. &. &. &. &. &. &. &. &. &. &. &. &. &. &. &. &. &. &. &. &. &. &. &. &. &. &. &. &. &. &. &. &. &. &. &. &. &. &. &. &. &. &. &. &. &. &. &. &. &. &. &. &. &. &. &. &. &. &. &. &. &. &. &. &. &. &. &. &. &. &. &. &. &. &. &. &. &. &. &. &. &. &. &. &. &. &. &. &. &. &. &. &. &. &. &. &. &. &. &. &. &. &. &. &. &. &. &. &. &. &. &. &. &. &. &. &. &. &. &. &. &. &. &. &. &. &. &. &. &. &. &. &. &. &. &. &. &. &. &. &. &. &. &. &. &.. &. &. &. &. &. &. &. &. &. &. &. &. &. &. &. &. &. &. &. &. &. &. &. &. &. &. &. &. &. &. &. &. &. &. &. &. &. &. &. &. &. &. &. &. &. &. &. &. &. &. &. &. &. &. &. &. &. &. &. &. &. &. &. &. &. &. &. &. &. &. &. &. &. &. &. &. &. &. &. &. &. &. &. &. &. &. &. &. &. &. &. &. &. &. &. &. &. &. &.$$
Consequently, the scalar correlation function G φ S ∝ a -2 and the current-current correlations fall as a -4 . We can match to the de Sitter value (39) at reheating, and then
$$\langle \{ \hat { j } _ { i } ^ { T } ( \mathbf k, t ), \hat { j } _ { j } ^ { T } ( \mathbf k ^ { \prime }, t ^ { \prime } ) \} \rangle \approx 2 \delta _ { k k ^ { \prime } \pi i j } \frac { e ^ { 2 } } { 2 \pi } H _ { r } ^ { 4 } T _ { r } ^ { - 4 } T ^ { 4 } k ^ { - 1 } ( k \tau _ { r } ) ^ { 4 \delta }.$$
Combining with (31) when the temperature has dropped below the lightest fermion mass and m A = 0 gives
$$P _ { B } \approx \frac { e ^ { 2 } } { 2 \pi } H _ { r } ^ { 4 } T _ { r } ^ { - 4 } T ^ { 4 } ( k \tau _ { r } ) ^ { 4 \delta } \, k ^ { - 3 }.$$
This would be observationally significant. However, inserting a radiation damping term σ φ ∼ e -2 T gives a mode equation
$$v ^ { \prime \prime } + 2 H v ^ { \prime } + ( a \sigma _ { \phi } ) v ^ { \prime } + ( k ^ { 2 } + a ^ { 2 } m _ { \phi } ^ { 2 } ) v = 0$$
This is a similar situation to the vector modes, and v decays exponentially with negative exponent or order e T/H 4 . This feeds through into an exponential decay of the current so that the magnetic field fluctuations sourced by the de Sitter fluctuations decays exponentially, leaving nothing of significance behind.
## V. CONCLUSION
It appears that the combination of ohmic dissipation and real vacuum polarisation effects leads to an exponential decay of small magnetic field fluctuations during the radiation era at temperatures above 0 5MeV. . Any magnetic fields produced during inflation should be limited to have an energy density smaller than the vacuum energy driving inflation, and these fields would decay away during the radiation era.
For fields which are large enough to require an MHD treatment, the situation is unclear. The long-wavelength approximation to the vacuum energy applies when k /lessmuch | ω | . This can include sub-horizon scales, and the vacuum polarisation effects would have to be included in the MHD equations.
## ACKNOWLEDGMENTS
IGM is supported by STFC Consolidated Grant ST/J000426/1.
## Appendix A: Vacuum polarisation
The vacuum polarisation for an electromagnetic vector potential interacting with N f relativistic charged fermions in equilibrium at temperature T is a tensor with two spacetime indices. The spatial part decomposes into transverse and longitudinal terms,
$$\Pi _ { i j } & = \Pi ^ { T } \pi _ { i j } + \Pi ^ { E } q _ { i j }, & ( \text{A} 1 )$$
where π ij = δ ij -k k /k i j 2 and q ij ∝ k k i j . For temperatures large compared to the fermion mass, the one-loop contribution to the transverse component is given by
$$\text{e u a v e s e c o m p o u r e n } & \text{s g i v e n } \text{y} \\ \Pi ^ { T } & = m _ { A } ^ { 2 } \left \{ \frac { \omega ^ { 2 } } { k ^ { 2 } } + \frac { \omega } { 2 k } \left ( 1 - \frac { \omega ^ { 2 } } { k ^ { 2 } } \right ) \ln \left ( \frac { \omega + k + i \epsilon } { \omega - k + i \epsilon } \right ) \right \}, \\ \text{frofit max} \, & \text{g i v e n } \, &$$
where m A is an effective mass,
$$m _ { A } ^ { 2 } = \frac { 1 } { 6 } N _ { f } e ^ { 2 } T ^ { 2 }$$
Including the i/epsilon1 terms allows us to analytically continue the result off the real ω axis. When k /lessmuch | ω | , we find
$$\Pi ^ { T } & \approx m _ { A } ^ { 2 }.$$
The quantity appearing in the Schwinger-Dyson equation Eq. (7) is the retarded vacuum polarisation Π R ,
$$\psi _ { \quad } \, \psi _ { \quad } \, \psi _ { \quad } \, \psi _ { \quad } \, \psi _ { \quad } \, \psi _ { \quad } \, \psi _ { \quad } \, \psi _ { \quad } \, \psi _ { \quad } \, \psi _ { \quad } \, \psi _ { \quad } \, \psi _ { \quad } \, \psi _ { \quad } \, \psi _ { \quad } \, \psi _ { \quad } \, \psi _ { \quad } \, \psi _ { \quad } \, \psi _ { \quad } \, \psi _ { \quad } \, \psi _ { \quad } \, \psi _ { \quad } \, 0 \, 0 \, 0 \, 0 \, 0 \, 0 \, 0 \, 0 \, 0 \, 0 \, 0 \, 0 \, 0 \, 0 \, 0 \, 0 \, 0 \, 0 \, 0 \, 0 \, 0 \, 0 \, 0 \, 0 \, 0 \, 0 \, 0 \, 0 \, 0 \, 0 \, 0 \, 0 \, 0 \, 0 \, 0 \, 0 \, 0 \, 0 \, 0 \, 0 \, 0 \, 0 \, 0 \, 0 \, 0 \, 0 \, 0 \, 0 \, 0 \, 0 \, 0 \, 0 \, 0 \, 0 \, 0 \, 0 \, 0 \, 0 \, 0 \, 0 \, 0 \, 0 \, 0 \, 0 \, 0 \, 0 \, 0 \}$$
For k /lessmuch | ω | we can move the contour to lie entirely in the range k /lessmuch | ω ′ | , where Π T ≈ m 2 A . In the cosmological context, we use Fourrier components in conformal time and space, so that the physical frequency and wave numbers are ω/a and k/a . The vacuum polarisation depends on the ratio of these two, and reduces to a mass term when k /lessmuch | ω | .
The plasma conductivity ω is an imaginary contribution to the vacuum polarisation in the ω → 0 limit. For high temperatures, it has the form σ ∼ T 2 e / 2 Γ, where Γ is a decay width from one of the internal lines in the vacuum polarisation diagram. (This is not included in Eq. (A2) where the emphasis was on the real part of the vacuum polarisation.) The decay width is of order e T 4 , and so σ ∼ e -2 T [14]. Note that this result is perturbative, but just happens to have inverse powers in the leading term. Logarithmic corrections can also be calculated [15]. The conductivity is similar to the low temperature result obtained from classical Drude theory if we replace T by the electron mass.
- [1] M. S. Turner and L. M. Widrow, Phys.Rev. D37 , 2743 (1988).
- [2] K. Enqvist, A. Jokinen, and A. Mazumdar, JCAP 0411 , 001 (2004), arXiv:hep-ph/0404269 [hep-ph].
- [3] B. Ratra, Astrophys.J. 391 , L1 (1992).
- [4] E. A. Calzetta, A. Kandus, and F. D. Mazzitelli, Phys.Rev. D57 , 7139 (1998), arXiv:astro-ph/9707220 [astro-ph].
- [5] R. Durrer and A. Neronov, Astron.Astrophys.Rev. 21 , 62 (2013), arXiv:1303.7121 [astro-ph.CO].
- [6] A. Berera, T. W. Kephart, and S. D. Wick, Phys.Rev. D59 , 043510 (1999), arXiv:hep-ph/9809404 [hep-ph].
- [7] R. Banerjee and K. Jedamzik, Phys.Rev. D70 , 123003 (2004), arXiv:astro-ph/0410032 [astro-ph].
- [8] K. Subramanian, Astron.Nachr. 331 , 110 (2010), arXiv:0911.4771 [astro-ph.CO].
- [9] J. Berges, AIP Conf.Proc. 739 , 3 (2005), arXiv:hep-ph/0409233 [hep-ph].
- [10] O. Tornkvist, A.-C. Davis, K. Dimopoulos, and T. Prokopec, , 443 (2000), arXiv:astro-ph/0011278 [astro-ph].
- [11] K. Dimopoulos, T. Prokopec, O. Tornkvist, and A. Davis, Phys.Rev. D65 , 063505 (2002), arXiv:astro-ph/0108093 [astro-ph].
- [12] A. Kandus, E. A. Calzetta, F. D. Mazzitelli, and C. E. Wagner, Phys.Lett. B472 , 287 (2000), arXiv:hep-ph/9908524 [hep-ph].
- [13] M. Giovannini and M. E. Shaposhnikov, Phys.Rev. D62 , 103512 (2000), arXiv:hep-ph/0004269 [hep-ph].
- [14] M. L. Bellac, Thermal Field Theory , 1st ed. (Cambridge University Press, 1996) section 6.5.
- [15] P. B. Arnold, G. D. Moore, and L. G. Yaffe, JHEP 0011 , 001 (2000), arXiv:hep-ph/0010177 [hep-ph]. | null | [
"Ian G. Moss"
] | 2014-08-02T12:50:09+00:00 | 2014-08-06T06:55:32+00:00 | [
"hep-th"
] | Damped Electromagnetic fluctuations in the early universe? | This short note considers the effects of quantum theory on the linear
evolution of the magnetic fields during and after inflation. The analysis
appears to show that the magnetic fields decay exponentially in the
high-temperature radiation era due to a combination of ohmic dissipation and
vacuum polarisation. |
1408.0368v1 | ## Assessing complexity by means of maximum entropy models
Gregor Chliamovitch, 1, 2, ∗ Bastien Chopard, 1 and Lino Velasquez 1
1 (Dated: August 5, 2014)
Department of Computer Science, University of Geneva, Switzerland
2 Department of Theoretical Physics, University of Geneva, Switzerland
We discuss a characterization of complexity based on successive approximations of the probability density describing a system by means of maximum entropy methods, thereby quantifying the respective role played by different orders of interaction. This characterization is applied on simple cellular automata in order to put it in perspective with the usual notion of complexity for such systems based on Wolfram classes. The overlap is shown to be good, but not perfect. This suggests that complexity in the sense of Wolfram emerges as an intermediate regime of maximum entropybased complexity, but also gives insights regarding the role of initial conditions in complexity-related issues.
## I. INTRODUCTION
In the course of the last few decades, so many characterizations (sometimes at odds with each other) of complexity have appeared that it would be illusory to give a one-sentence statement encapsulating them all. Perhaps one of the most widely accepted such characterizations could be, in deliberately fuzzy terms, that 'complexity arises when a system is more than the collection of its parts' [1]. It is nonetheless far from easy to understand what 'being more than one's parts' really means. A similar idea is conveyed by the statement that 'a complex system cannot be fully understood by looking separately at its elements' which is barely more transparent but, as we shall see, paves the way to quantitative interpretations (see also [2]). As an historical aside, let us note that besides being the most popular, this notion of complexity also turns out to be one of the oldest since it can be traced back (in somewhat different terms) to Aristotle's writings [3]. For convenience, we shall refer to this definition of complexity as Aristotle's complexity or simply A-complexity .
gested building ME reconstructions on the knowledge of marginals up to a certain order [4, 6]. While this second approach is more general and certainly more in accordance with the spirit of information theory, it has the drawback that the models so generated are more difficult to investigate analytically than their correlation-based counterparts, often resulting in fairly abstract statements and conclusions.
In recent years, it has been proposed [4-6] to give a mathematical meaning to these abstract principles in a probabilistic framework by means of maximum entropy (ME) models . The ME approach provides a conceptually simple way to build generic models based on observational constraints. Following this line of reasoning, Aristotle's principle could be reformulated by asserting that a system is complex when its ME approximation built on the knowledge of small subparts provides a poor approximation of the system as a whole.
ME models come in different versions, depending on the observational constraints retained for consideration. Recently, impressive successes have been obtained in the study of neural networks by considering ME models based on constrained two-points correlations and firing rates [5]. However, little emphasis has been put on quantifying the limitations of this approach, and correlations are certainly not the only nor the most general quantity worth being considered. On another side, it has been sug-
The purpose of the present work is to display the ME method 'at work' by carrying through a numerical investigation of these marginal-based models. To this end we shall turn our attention to so-called one-dimensional elementary cellular automata (ECA) , since for this kind of system a notion of complexity is well established and may therefore serve as a benchmark. More precisely, ECA have long since raised a huge interest due to the fact that they may be classified in four classes ranging from trivial to complex behaviour, in a sense to be discussed further later on. While this classification scheme (essentially due to Wolfram [7], which is why we shall refer to this notion of complexity as W-complexity ) is the most famous one, many others have been proposed over time (see [8] and references therein). Some attention will also be devoted in this work to Langton's parameter [9], which, rather than a classification scheme, provides a parametrization of the CA space.
Despite innumerable attempts to apply usual information-theoretic tools to the study of cellular automata, inspired by the belief that complexity should, in the end, have something to do with information, we are not aware of a situation where these tools provide convincingly original and deep insights into these systems. It will turn out that ME tools give quite significant results in this context, namely by tying a link between W-complexity and the dependence of A-complexity on the size of the system, somewhat at odds with the idea that systems become more and more complex when they grow larger due to more and more room left for building synergistic interactions.
The outline of this paper is as follows. We start with a review of maximum entropy methods, and then show
how these tools may be used to cast Aristotle's intuition into a proper mathematical scheme. We continue with a reminder on ECA and discuss how to implement these systems in a way that fits our purpose, after what our results are presented.
## II. MAXIMUM ENTROPY APPROXIMATIONS
ing that the most general (that is the least structured) probability density is the one which has the largest entropy while still satisfying the observational constraints, which are usually provided by some set of observables f k ( k = 1 2 , , ..., K ) the average values of which are known, 〈 f k 〉 = µ k . Note that a drawback of this procedure lies in the fact that it only yields a probability density. An energy function can be deduced by analogy however, but this important point will not be of much concern in the present paper.
The philosophy underlying ME models is so to speak opposite to the constructive one, where a model is built and tuned to match observed properties ( top-down ). In the ME approach on the other side, we proceed by seeking the least structured model compatible with a given set of observations ( bottom-up ). This is done by not-
Assume we look for a probability distribution p on a set of N variables X ,..., X 1 N (collectively denoted by X ), such that H ( X ) = -∑ x p ( x ) ln p ( x ) is maximal, while making sure that the constraints 〈 f k 〉 := ∑ x f k ( x ) p ( x ) = µ k and ∑ x p ( x ) = 1 are enforced. Using Lagrange's method, the quantity we have to equate to zero is
$$\frac { \partial } { \partial p ( y ) } \left ( - \sum _ { x } p ( x ) \ln p ( x ) + \lambda _ { 0 } \left ( \sum _ { x } p ( x ) - 1 \right ) + \sum _ { k = 1 } ^ { K } \lambda _ { k } \left ( \sum _ { x } f _ { k } ( x ) p ( x ) - \mu _ { k } \right ) \right ),$$
where the λ 's are the multipliers.
Some straightforward algebra yields that the soughtafter distribution may be written as
$$p ( { \mathbf x } ) = \frac { 1 } { Z } \exp \left ( \sum _ { k = 1 } ^ { K } \lambda _ { k } f _ { k } ( { \mathbf x } ) \right ), \quad \quad ( 2 ) \text{ all}$$
ages. Fortunately, an appropriate use of delta functions allows generalizing the previous results in a straightforward way. Taking for illustration the case N = 4 ( i.e. x = ( w,x,y, z )), and assuming the tri-variate marginal p 123 ( a, b, c ) is known, putting f ( x ) = δ w, a δ x, b δ ( ) ( ) ( y, c ) allows writing where the multipliers have to be chosen to match the constraints. Dividing by the partition function Z := ∑ x exp ( ∑ K k =1 λ f k k ( x ) ) ensures that p is properly normalized. For instance in the most elementary case where no constraint besides normalization is imposed, the ME distribution is nothing but the uniform distribution (if the support of p is unbounded we have to impose finite mean and variance in order to recover a meaningful distribution, which turns out to be a Gaussian).
While in the present context we use the ME approach as a tool to investigate how well the reconstructed distribution matches the true one, which requires focussing on small systems whose distribution is known at any time, we should emphasize that the ME procedure may also be most usefully employed when the true probability density is unknown. In such a case, it is implicitly assumed that the observables providing the constraints are easier to determine with accuracy than the distribution itself, thereby providing a way to reconstruct this distribution. It is nevertheless difficult in this case to assess the accuracy of the reconstruction resulting from the ME procedure.
In this paper we shall deal with the case where the constraints are provided by marginals instead of aver-
$$\langle f \rangle & = \sum _ { x } f ( { \mathbf x } ) p ( { \mathbf x } ) \\ & = \sum _ { w, x, y } \delta ( w, a ) \delta ( x, b ) \delta ( y, c ) \sum _ { z } p ( { \mathbf x } ) \\ & = \sum _ { w, x, y } \delta ( w, a ) \delta ( x, b ) \delta ( y, c ) p _ { 1 2 3 } ( w, x, y ) \\ & = p _ { 1 2 3 } ( a, b, c ). \text{ (3)} \\ \text{Applying the result above to all possible values of the}$$
Applying the result above to all possible values of the arguments then yields
$$\underset { \text{time}, \quad } { \text{distri-} } \underset { \text{loss be} } { \text{distri-} } } \underset { \text{den-} } { \text{distri-} } \rightarrow \left ( \sum _ { a, b, c } \lambda ( a, b, c ) f ( \text{x} ) \right ) = \frac { 1 } { Z } \exp \left ( \lambda ( w, x, y ) \right ), \\ \underset { \text{den-} } { \text{den-} }. \quad \text{where $\lambda$ now denotes a well-choosen function $ \text{the}$} \text{$\text{$\text{$seen}$} }.$$
where λ now denotes a well-chosen function . This generalizes to any number of marginals in a straightforward way; for instance, if besides p 123 the marginals p 124 and p 34 are given we get
$$\Re \Re \Re ^ { \Re \Re } _ { \Re c e ^ { - } } \quad p ( \mathbf x ) = \frac { 1 } { Z } \exp \left ( \lambda _ { 1 } ( w, x, y ) + \lambda _ { 2 } ( w, x, z ) + \lambda _ { 3 } ( y, z ) \right ) \ ( 5 )$$
for some functions λ , λ 1 2 , λ 3 . Sadly, this elegant result is actually of little use since the determination of these
λ 's is a difficult problem. An important exception is the simple case in which constrained marginals are univariate. Then λ w ( ) = ln p 1 ( w ) (and λ x ( ) = ln p 2 ( x ), etc. ) obviously satisfies the requirements, so that the ME distribution compatible with given univariate marginals is the factorized distribution . In all other cases, we have to resort to the so-called iterative scaling algorithm which allows numerical calculations.
Brown [10] was among the first to describe this algorithm, the principle of which is, starting from some initial distribution, to consider all possible n -tuples of variables in sequence, each time adjusting the corresponding marginal. If we denote by p ( k ) the distribution obtained after k such adjustments, S k the subset considered at the k -th step and p S k the marginal distribution of this set, then the procedure is defined by
$$p ^ { ( k ) } \coloneqq p ^ { ( k - 1 ) } \frac { p _ { S _ { k } } } { p _ { S _ { k } } ^ { ( k - 1 ) } }.$$
The order in which the n -tuples are examined does not alter the distribution we converge to. From our experience, it seems that going twice through each n -tuple is enough to reach a satisfying solution. See [10] for proofs of convergence. This scheme is demanding due to the fact that the number of n -tuples in a set grows factorially.
## III. DECOMPOSING MULTI-INFORMATION
When looking at the ME reconstruction based on the knowledge of, say, tri-variate marginals, it is not easy a priori to know if it is accurate because it takes into account strong triplet-wise interactions between variables, or if the same could have been achieved by the reconstruction based on bi-variate marginals only. We need a way to disentangle different orders of interaction, as well as a tool to compare distributions.
Both are provided by the Kullback-Leibler (KL) divergence between two distributions p and q (living on the same support), which is defined as
$$D ( p, q ) \coloneqq \sum _ { x } p ( { \mathbf x } ) \ln \frac { p ( { \mathbf x } ) } { q ( { \mathbf x } ) }. \quad \quad ( 7 ) \quad \text{all} \epsilon \\ \text{con} \\ \text{how}$$
This quantity provides a pseudo-distance on the space of probability distributions [11].
The idea now is to use the KL divergence to compare the distribution we want to approximate with the ME distribution based on marginals of a certain order k by computing D p,p ( ( k ) ME ), where p ( k ) ME denotes the ME reconstruction based on k -marginals. It is intuitively clear that the larger the subsets considered, the more accurate the resulting ME approximation will be (indeed smaller-order marginals may be recovered from larger-order ones), whence the inequality D p,p ( ( k -1) ME ) ≥ D p,p ( ( k ) ME ). The difference may therefore be interpreted as the gain in accuracy when basing our guess on subsets of size k instead of k -1, and therefore quantifies specifically the role played by interactions of order k . We define accordingly
$$C _ { k } \coloneqq D ( p, p _ { M E } ^ { ( k - 1 ) } ) - D ( p, p _ { M E } ^ { ( k ) } ) \geq 0. \quad ( 8 )$$
This quantity is sometimes referred to as the connected multi-information of order k [4], but in our opinion this name is unfortunate (where does connectedness enter into the play ?) and will not be used here.
Performing the telescopic sum of all these coefficients gives
$$\sum _ { k = 2 } ^ { N } C _ { k } = D ( p, p _ { M E } ^ { ( 1 ) } ) - D ( p, p _ { M E } ^ { ( N ) } ). \quad \ ( 9 )$$
Since p ( N ) ME is trivially p itself (whence D p,p ( ( N ) ME ) = 0), and since, as mentioned above, p (1) ME = ∏ N i =1 p x ( i ), we get finally
$$\sum _ { k = 2 } ^ { N } C _ { k } & = D \left ( p ( { \mathbf x } ), \prod _ { i = 1 } ^ { N } p ( x _ { i } ) \right ) \\ & = \sum _ { \mathbf x } p ( { \mathbf x } ) \ln \frac { p ( { \mathbf x } ) } { \prod _ { i = 1 } ^ { N } p ( x _ { i } ) } \coloneqq M. \quad ( 1 0 ) \\ & \quad \cdot \.$$
The quantity M is known as the multi-information [12] and quantifies the total amount of interdependence inside a set of variables. (As an aside, note that the sum could be started from k = 1, in which case it would add up to the KL distance between p and the uniform distribution. The total amount of interdependence could indeed be defined that way, but it is usual to say that this quantity is given by the multi-information as defined above. Moreover, the standard convention attributes null interdependence to a set of independent variables which would not be the case otherwise, where only uniform distributions would be said to have no interdependence. This alternative way to define things could nevertheless be considered occasionally.) This formula shows, as could have been expected, that the total interdependence in a system is built by addition of pair-wise, triplet-wise, and so on, interactions.
An important question is whether all subsets of a given order should be treated on the same footing when there exists a notion of distance between variables, as would be the case for instance if the system were put on a graph and each variable assigned to a node (more generally, such a distance has to exist as soon as a focus is put on 'multi-scaleness'). Considering for instance the case of pairs, co-dependence between variables remote from each
other will intuitively be much smaller than between two neighbouring variables, so that it seems acceptable to discard pairs constituted by distant elements. On another side, these loose pairs are by far more numerous than tightly-bound ones, so that though their contribution is weak envisaged individually, it cannot be neglected anymore when considered globally. But this very fact that pairs (more generally n -tuples) are so many implies that considering them all becomes numerically difficult (factorial growth). Since in the experiments to follow we focus on systems which display such a notion of distance, provided by the topology of the graph on which we put our variables, our viewpoint will be to consider as admissible n -tuples only those consisting of connected variables ( i.e. n -tuples of which restricted graph is connected). A few checks (see below) tend to suggest than our conclusions are not drastically altered in the more general case where all subsets are retained. We have to admit that this simplification is questionable and intend to address more specifically this issue elsewhere.
## IV. ELEMENTARY CELLULAR AUTOMATA AND LANGTON'S PARAMETER
One-dimensional ECA have been very thoroughly investigated (see [13] for an introduction). Wolfram [7] noted that these may be classified in four different classes: class I regroups ECA converging to some homogeneous pattern; class II displays an inhomogeneous stable pattern or periodic behaviour; class III displays completely chaotic behaviour; finally class IV regroups automata which exhibit slowly building up and decaying subpatterns. It is believed that ECA belonging to class IV are the closest to our intuitive conception of complexity. While this classification is very widely used, many alternatives have been proposed (see [8] and references therein). One of these alternatives is to consider Langton's λ parameter , which provides a parametrization of the space of cellular automata. In the case of elementary one-dimensional automata, it is computed very easily as the percentage of configurations in the lookup table giving rise to a living cell ( i.e. a cell taking value 1), but this parameter may be generalized to any kind of automaton [9]. A leitmotiv of Langton's reflexion was to suggest that, while simple (classes I and II) automata correspond to small values of λ and chaotic ones (class III) to values close to λ = 1 2, complex CA should emerge somewhere / in between, at what has been popularized as the edge of chaos .
The idea of quantifying the role played by successive orders of interaction in the informational content of cellular automata has already been adressed by Lindgren and Nordahl [14, 15]. However, these authors do not resort to ME methods but use instead a simpler decomposition of the entropy rate, which makes this tool restricted to one-dimensional topologies (this limitation of their work was actually an important motivation for undertaking the present study).
## V. COMPUTATIONAL FRAMEWORK
Before moving on to discuss our results, we should say a few words about our computational framework and address how the temporal evolution of the probability density is handled. Often this is done by means of Monte-Carlo methods, by evolving copies of the system and reconstructing the probabilities by sampling trajectories (following this approach see [16] for a recent work on a closely related topic). Here we follow an alternative approach which is to determine the time evolution of the probability density exactly. Then we may, so to speak, follow simultaneously all trajectories down to the least probable ones. This amounts to a description in terms of Markov chains, where the knowledge of history allows to predict towards which states the system could evolve. We will restrict ourselves here to the case where the knowledge of a finite history is sufficient to predict possible futures. By suitably extending the state space, actually all such processes may be recast in the form of memoryless Markov chains (or simply Markov chains ), by what we mean that the probabilities of the forthcoming states may be predicted knowing the current state of the process only. In the case of ECA considered here, the Markov process is memoryless by construction.
While this approach seems to outperform sampling in terms of accuracy, it actually suffers from its numerical cost when the system's size increases. Assuming for instance we deal with a system constituted by N variables taking binary values, we have in this case 2 N possible configurations, while assuming the system is driven by a dynamics with a k -steps memory yields 2 kN possible histories to keep into consideration, which becomes soon untractable even for small values of N and k .
Nonetheless this formalism has some advantages which justify its adoption in this paper. In particular it allows a more straightforward transition from numerical exploration to theoretical investigation. Still more importantly, as we already mentioned, this approach does not require to select (arbitrarily) an initial configuration, but handles them all as long as they are not explicitly assigned probability zero from the beginning. This will turn out to be a crucial feature.
## VI. RESULTS
We first computed the time evolution of C k coefficients for ECA of size N = 10 put on a periodic stringlike topology, as well as the behaviour of the multiinformation. Two instances are presented below. Figure
FIG. 1: Time evolution of C k coefficients in rule 110 (adjacent subsets). Coefficients are displayed cumulatively, i.e. we show successively (from bottom to top) C 2 , C 2 + C 3 , etc. The sum converges to M (red curve).
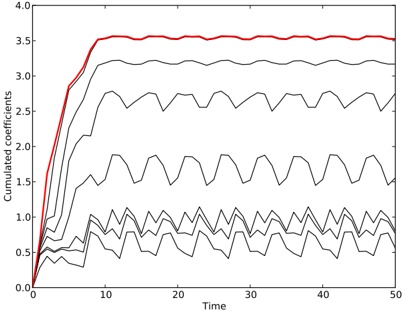
1 shows the result for rule 110, which is a most typical instance of a CA displaying W-complex behaviour. Note that all coefficients except C 9 and C 10 provide a significant contribution to the multi-information (note that the coefficients are displayed cumulatively; see caption). Remark that after a transient phase of around ten steps, the system enters a periodic regime. While the multi-information is almost constant in this regime, the respective contributions present a much stronger variability. C 4 , for instance, alternatively reaches significant value and then decays close to zero. On the contrary, the contribution of C 8 is nearly constant in the stationary regime after reaching a peak during the transient phase.
For comparison we show in figure 2 the corresponding picture when all subsets of a given order, instead of adjacent ones only, are taken into account. The main difference is that C 7 and C 8 play no significant role, but on the whole the behaviour of the remaining coefficients is not qualitatively altered. Note however how our decision to rule out non-adjacent subsets introduced spurious high-order dependences.
This behaviour is in sharp constrast with the one shown in figure 3, which displays the same plot for rule 90. This rule is characterized by the fact that the sole contribution to multi-information is provided by the coefficient C 9 , all other orders of interaction vanishing (admittedly this could hardly be guessed from the plot alone). Very interestingly, rule 90 is nothing but the dynamics obtained by applying the XOR operator on the two neighbours of a variable and assigning the result to the variable. This highlights the fact that the notion of 'order of interaction' as employed in the current context does not quite overlap what we could expect from, for instance, classical kinetic theory. There, 'interaction of order n ' would be understood in terms of the functional
FIG. 2: Time evolution of C k coefficients in rule 110 (all subsets)
FIG. 3: Time evolution of C k coefficients (adjacent subsets) in rule 90. Only C 9 contributes.
/negationslash form of the energy function (in the sense that the latter could not be decomposed as a sum of functions involving less than n variables). The case of rule 90 would then correspond to interactions of order two, and ECA in general to interactions of order three. It would then be difficult to justify the appearance of higher orders of interaction. An interesting question is to find a dynamics such that all informational content is brought in by interactions of order k , i.e. C k = M and C l = 0 ∀ l = k .
We should actually better get rid of the transient phase, details of which depend on the probabilities we initially assigned to each configuration. Moreover, in order to get more easily displayable results, we shall discard temporal variations of C k coefficients. From now on, coefficients will therefore be averaged (when necessary) over the stationary phase, so that all forthcoming statements about C k coefficients will be statements about the average value of these coefficients in the stationary regime.
FIG. 4: Size of subsets required to reconstruct a ME distribution recovering 50%, 70% and 90% of the multi-information respectively
Figure 4 displays, for each value of the Langton parameter λ , up to what size 〈〈 Σ 〉 T 〉 λ the subsets should be considered in order to recover, respectively, 50%, 70% and 90% of the multi-information in the stationary regime (while heavy, this notation has the merit to make clear that this is the size obtained from coefficients averaged over time and over all rules having the same λ ). We only consider the range λ ∈ [0 , 1 / 2] since any ECA with λ > 1 2 is mirrored by another one which is equivalent / but has λ ′ = 1 -λ . We observe that 〈〈 Σ 〉 T 〉 λ increases monotonically with λ , which means that A-complexity grows with λ , and this statement holds whatever the percentage of multi-information targeted.
We now turn to the dependence of 〈〈 Σ 〉 T 〉 λ on the size of the ECA, for the case where a 90% reconstruction of the multi-information is targeted. Results are displayed in figure 5. The curve for λ = 0 is special since it comprises only one rule (R0). For this rule considering individual elements -actually only one of themis enough to characterize the system, so that in this case 〈〈 Σ 〉 T 〉 λ =0 = 1 whatever the size of the system. For other values of λ , 〈〈 Σ 〉 T 〉 λ grows with N , in a way which is investigated below.
The fact that 〈〈 Σ 〉 T 〉 λ increases monotonically with λ seems to be common to all sizes, except for N = 4 and N = 8 by a small amount. Though it seems difficult to single out one specific cause for this inversion, the forthcoming discussion should make the issue clearer.
Figure 5 says nothing about possible heterogeneity inside the set of rules having the same λ . It will turn out that this intraλ variability is indeed extremely important, so that a discussion in terms of λ is actually rather irrelevant. We will therefore now discuss the question in detail by examining rules for themselves, without trying to tie links to the λ -parametrization.
A careful examination of the size of subsets required to
FIG. 5: Order of subsets required to recover 90% of the multi-information as a function of N , for each value of λ ( λ = 0: cyan; λ = 1 8: green; / λ = 1 4: blue; / λ = 3 8: red; / λ = 1 2: black) /
reconstruct at least 90% of the multi-information M for all 88 inequivalent rules separately allows to single out some representative behaviours typified by the rules displayed in figure 6 (the selection is arbitrary to a certain extent). The simplest behaviour is provided by rule 14, which belongs to Wolfram class II and exhibits a stable translating stationary configurational pattern (by configurational pattern we shall always mean the spatial pattern obtained by evolving some initial configuration). In this case the number of coefficients to take into account is seen to be the same (here 〈 Σ 〉 T = 5) whatever the size of the system, except for small sizes. This behaviour may be encountered in many rules, with some variations regarding the value of 〈 Σ 〉 T or the length of the transient phase (being meant as the transient in terms of N - recall that the time plays no role here since coefficients are averaged). Two interesting variations on this theme are to be found in rules 77 (reaching a stable inhomogeneous configuration and thus classified as class II) and 32 (reaching a stable homogeneous configuration and thus classified as class I). In the former case, 〈 Σ 〉 T seems to get stabilized at 〈 Σ 〉 T = 4, but jumps to 〈 Σ 〉 T = 3 when N increases from N = 8 to N = 9. This illustrates a weakness of our display of results, since 〈 Σ 〉 T changes abruptly when, say, the first three coefficients contribute to 89% of M , or when these same three coefficients reach 91% of M . 〈 Σ 〉 T would then jump from 〈 Σ 〉 T = 4 to 〈 Σ 〉 T = 3 although the change actually occurred almost smoothly. The case of rule 32 is more relevant to our purpose. There we oscillate between 〈 Σ 〉 T = 2 and 〈 Σ 〉 T = 3 depending on the parity of N . This may be explained by noting that there exists one initial configuration which does not converge to a stationary homogeneous pattern; namely, the alternate configuration 01010101010101 gets replicated again and again over time except for a one-cell shift at each it-
eration. Such an initial pattern is however only possible for even values of N . It therefore happens that while the dynamics is rightly classified as class I for odd values, it should not be so for even ones (at least not for all initial configurations). It is therefore no longer unexpected to detect a size-dependent amount of A-complexity.
A completely different behaviour is exemplified by rule 90 already discussed above. Here 〈 Σ 〉 T is close to its largest possible value 〈 Σ 〉 T = N whatever the value of N . This is in accordance with the temporal behaviour of C k 's observed in figure 3. Note the special case N = 8, for which 〈 Σ 〉 T drops to 〈 Σ 〉 T = 2. A similar behaviour may be found in rule 106, which is perhaps even more convincing due to the lack of drop. Interestingly, while rules 90 and 106 present similarities, they are usually assigned to different Wolfram classes (R90 is class III while R106 is class IV). We shall come back to this question later on.
Both types of behaviour analyzed so far constitute extreme situations: in one case (rules 14, 77 and 32), 〈 Σ 〉 T shows little or no dependance at all on the size of the system, while in the other (rules 90 and 106) 〈 Σ 〉 T seems to grow linearly with N . The following rules do not display such unambiguous behaviours. Rule 105, for instance, oscillates between a 'basis line' at 〈 Σ 〉 T = 2 and an 'upper bound' at 〈 Σ 〉 T = N , visiting intermediate values for some other values of N . Rule 15 behaves similarly, except that oscillations are sharper (intermediate values are never visited, at least for the range of sizes we were able to explore). Some other rules also exhibit what could be daringly (given the small range of sizes we were able to scan) characterized as sub-linear growth. Rule 22 illustrates this nicely, as well as rules 73, 110 and 54 (though in this latter case it is tempting to assert that 〈 Σ 〉 T eventually gets stabilized at 〈 Σ 〉 T = 8).
Before moving on to examine if and how these typical behaviours may be related to Wolfram's scheme of classification, let us have a side look on the situation where all subsets are considered instead of adjacent ones only. The counterpart of figure 6 is displayed in figure 7. It should first be noted that, as expected, the size of subsets to be considered in order to reconstruct a specified fraction of M is almost always smaller when all subsets may be considered than when unconnected ones are to be discarded. Even if the results obtained in these two cases are somewhat different, the distinctive features underlined above are preserved. In particular, low A-complexity expressed in terms of adjacent subsets is coherent with low A-complexity expressed in terms of all subsets, and similarly for high A-complexity.
The primary purpose of this study was to put alongside the notion of complexity promoted by ME methods applied to Aristotle's principle and complexity as meant in Wolfram's classification. We should therefore examine whether, or not, some behaviours can be found to be common to all rules pertaining to a given Wolfram
TABLE I: A compendium of the 88 inequivalent one-dimensional ECA

| CLASS | RULES |
|---------|----------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------|
| I | 0, 8, 32, 40, 128, 136, 160, 168 |
| II | 1, 2, 3, 4, 5, 6, 7, 9, 10, 11, 12, 13, 14, 15, 19, 23, 24, 25, 26, 27, 28, 29, 33, 34, 35, 36, 37, 38, 42, 43, 44, 46, 50, 51, 56, 57, 58, 72, 73, 74, 76, 77, 78, 104, 108, 130, 131, 132, 133, 134, 138, 140, 142, 152, 154, 156, 162, 164, 170, 172, 178, 184, 200, 204, 232 |
| III | 18, 22, 30, 45, 60, 90, 105, 129, 146, 150, 161 |
| IV | 41, 54, 106, 110 |
class. Table I lists all inequivalent rules and the class they belong to [8].
All eight rules in class I display the simple behaviour discussed above where 〈 Σ 〉 T = const . The value of 〈 Σ 〉 T varies from one rule to the other. The tricky case of rule 32 has already been discussed above, and R160 is very similar. This homogeneity of behaviours is in agreement with the simplicity of configurational patterns converged to in the stationary regime.
At the other end of the spectrum, 11 rules belong to class III. All of them display linear or sub-linear growth, possibly with drops for certain values of N ( cf. the discussion of R90 and R105 above). None of these rules shows the simple behaviour encountered in class I: here again, the ME approach is appropriate to catch the kind of complexity displayed by chaotic dynamics.
Things are no longer that clear when we come to considering classes II and IV. Class II regroups as much as 65 of the 88 inequivalent rules. At least 41 of them display the same simple type of behaviour already encountered in class I, which is fine since rules in class II are not expected to present a high level of complexity. Nonetheless, the remaining 24 rules behave in a way which is typical of class III. While this might suggest that classifications based on A-complexity on the one side and W-complexity on the other are definitively at odds with each other (which does not necessarily imply that one should be preferred to the other), it is also possible that the initial configuration plays an important role in this respect. We already met above a rule (R32) whose classification depended tightly on the initial configuration chosen, and, implicitly, on the size of the system. Another such instance is provided by rule 73, which is classified as class II due to the appearance of 'walls' splitting the configurations into sub-configurations which, being of finite size, will necessarily repeat themselves, whence the attribution to class II. It may however happen that the inital configuration is chosen in such a way as to forbid the appearance of such separating walls, in which case the dynamics should better be classified as class III.
Class IV, finally, regroups only four inequivalent rules. Among these, three of which are shown above, one (R106)
FIG. 6: A representative sample of rules. Horizontal axis displays the size of the automaton, vertical axis displays the required size of subsets to recover 90% of the informational content. The dotted line corresponds to maximal A-complexity 〈 Σ 〉 T = N .
shows linear growth while another (R54) seems to converge towards a constant value of 〈 Σ 〉 T = 8 as would dynamics in class I or II do (note however the large value of 〈 Σ 〉 T ). Rule 110 lies somewhere in between. The fourth rule (R41) in class IV is similar to R110.
## VII. CONCLUDING REMARKS
It should be noted that we did not actually take full advantage of the ME machinery in this study, focussing instead on averaged quantities; the case of rule 110 serves as an illustration, since obviously the interplay of various coefficients shown in figure 1 is much richer than
FIG. 7: The same picture as previously, now for the case where all subsets of a given size are taken as admissible. Only sizes up to N = 10 are considered.
the averaged values considered in most of our analysis. In spite of this, our results highlighted a tight relationship between A-complexity and W-complexity which is all the more remarkable. We cannot elude however that in some cases, namely in class II rules exhibiting very Acomplex behaviour, considerable discrepancies arose between these two schemes. In our opinion this may be interpreted in two different ways. Firstly, it might be that our study should indeed be refined by looking at more subtle quantities than averaged ones. Nonetheless, we have met several cases ( e.g. rules 32, 73, 160) where unexpected A-complexity could be explained by misattributions to such-and-such a class due to unsufficient attention paid to particular initial conditions. A great strength of our probabilistic approach is that we cannot be fooled by such effects since all possible initial config-
urations are considered in our framework. Moreover, if one wishes, it allows a separate treatment of these rogue configurations by simply assigning them probability zero. The issue lies in the determination of these special initial conditions, which would require a considerable amount of work.
Assuming all ambivalent rules may indeed be explained by an adequate splitting of initial configurations (which in itself would shed some light on the interplay between dynamics, initial conditions, and complexity of behaviour), it is very tempting to sketch the following global picture. 1) In automata converging to a stable or periodic configurational pattern the knowledge of subsets of some finite size is sufficient to reconstruct accurately (here up to a 10% error) the informational content of the system. 2) In chaotic automata the size of these subsets grows linearly with size, meaning that any inference based on small subsystems yields intrinsically flawed results. 3) Complex systems would then lie somewhere in between, perhaps exhibiting sub-linear growth of the required subsets . In other words, W-complexity corresponds to an intermediate regime of A-complexity, quite akin to Langton's edge of chaos which is therefore recovered starting from a completely different vantage point.
The behaviour encountered in classes I and II is somewhat reminiscent of the situation prevailing in classical kinetic theory, where the BBGKY hierarchy of equations may be truncated without too much harm after two steps for most gaseous or fluid systems of interest, neglecting in a sense the contribution of higher-order reduced densities. Pushing further this analogy, this would suggest that such systems cannot be characterized as 'complex' in the sense investigated here. This comparison is however made very conjectural by the fact that in the present study the criterion for truncation is provided by the informational content of the system, which is not the case in the context of kinetic theory where such a criterion is not so clearly stated. Actually, our criterion is rather arbitrary; indeed, reconstructing its informational content is but a first step towards the understanding of a system since there is no one-to-one relationship between probability distribution and multi-information.
This should remind us that the ME method employed is susceptible of several refinements, without even mentioning the fact that the cellular automata studied here are a very specific kind of system. As we already mentioned, different types of observational constraints may be used in the reconstruction of the probability density, and we see no reason why the C k coefficients could not be diversified accordingly, perhaps giving rise to tractable analytical expressions. We also emphasized that the selection of the subsets to take into account deserved careful attention. Lastly, it is unfortunate that these ME models are so difficult to handle analytically and computationally so demanding, precluding the exploration of larger systems; advances on the theoretical as well as on the numerical side are therefore mandatory if one wishes to gain insight into the underlying physics.
## ACKNOWLEDGMENTS
The authors would like to thank Joris Borgdorff, Christophe Charpilloz, Raphael Conradin, Alexandre Dupuis and Anton Golub for their helpful advices and comments. The research leading to these results has received funding from the European Union Seventh Framework Programme (FP7/2007-2013) under grant agreement 317534 (Sophocles).
- ∗ [email protected]
- [1] Y. Bar-Yam, Complexity 9 , 15 (2004)
- [2] Y. Bar-Yam, Advances in Complex Systems 7 , 47 (2004)
- [3] Aristotle, Metaphysics (Harvard University Press, Cambridge, Massachusetts, 1933)
- [4] E. Schneidman, S. Still, M. J. Berry, and W. Bialek, Physical Review Letters 91 (2003)
- [5] E. Schneidman, M. J. Berry, R. Segev, and W. Bialek, Nature 440 , 1007 (2006)
- [6] N. Ay, E. Olbrich, N. Bertschinger, and J. Jost, Chaos 21 (2011)
- [7] S. Wolfram, Reviews of Modern Physics 55 , 601 (1983)
- [8] G. Martinez, arXiv 1306-5577 (2013)
- [9] C. G. Langton, Physica D 42 , 12 (1990)
- [10] D. T. Brown, Information and Control 2 , 386 (1959)
- [11] T. Cover and J. Thomas, Elements of Information Theory (Wiley-Interscience, New York, 2006)
- [12] S. Watanabe, IBM Journal 14 , 66 (1960)
- [13] B. Chopard and M. Droz, Cellular Automata Modeling of Physical Systems (Cambridge University Press, Cambridge, 1998)
- [14] K. Lindgren, Complex Systems 1 , 529 (1987)
- [15] K. Lindgren and M. G. Nordahl, Complex Systems 2 , 409 (1988)
- [16] R. Quax, A. Apolloni, and P. M. A. Sloot, Journal of the Royal Society Interface 10 (2013) | null | [
"Gregor Chliamovitch",
"Bastien Chopard",
"Lino Velasquez"
] | 2014-08-02T12:53:01+00:00 | 2014-08-02T12:53:01+00:00 | [
"nlin.CG",
"cond-mat.stat-mech",
"physics.comp-ph"
] | Assessing complexity by means of maximum entropy models | We discuss a characterization of complexity based on successive
approximations of the probability density describing a system by means of
maximum entropy methods, thereby quantifying the respective role played by
different orders of interaction. This characterization is applied on simple
cellular automata in order to put it in perspective with the usual notion of
complexity for such systems based on Wolfram classes. The overlap is shown to
be good, but not perfect. This suggests that complexity in the sense of Wolfram
emerges as an intermediate regime of maximum entropy-based complexity, but also
gives insights regarding the role of initial conditions in complexity-related
issues. |
1408.0369v7 | ## A New Estimator of Intrinsic Dimension Based on the Multipoint Morisita Index
Jean GOLAY and Mikhail KANEVSKI
Institute of Earth Surface Dynamics, Faculty of Geosciences and Environment, University of Lausanne, 1015 Lausanne, Switzerland. Email: [email protected]. Phone: +41 21 692 35 41
## Abstract
The size of datasets has been increasing rapidly both in terms of number of variables and number of events. As a result, the empty space phenomenon and the curse of dimensionality complicate the extraction of useful information. But, in general, data lie on non-linear manifolds of much lower dimension than that of the spaces in which they are embedded. In many pattern recognition tasks, learning these manifolds is a key issue and it requires the knowledge of their true intrinsic dimension . This paper introduces a new estimator of intrinsic dimension based on the multipoint Morisita index. It is applied to both synthetic and real datasets of varying complexities and comparisons with other existing estimators are carried out. The proposed estimator turns out to be fairly robust to sample size and noise, unaffected by edge effects, able to handle large datasets and computationally efficient.
Keywords: Intrinsic dimension, Multipoint Morisita index, Fractal dimension, Multifractality, Dimensionality Reduction
## 1. Introduction
The 21 st century is more and more data-dependent and, in general, when collecting data for a particular purpose, it is not known which variables matter the most. This lack of knowledge leads to the emergence of high-dimensional datasets characterized by redundant features which artificially increase the volume of data to be processed. As a result, the empty space phenomenon [1] and the curse of dimensionality [2] make it challenging to conduct pattern recognition tasks such as clustering and classification.
The goal of Dimensionality Reduction (DR) [3, 4], sometimes called manifold learning, is to address this issue by mapping the N sampled data points into the lower dimensional space where they truly lie. Such a space is often considered as a manifold of intrinsic dimension M 1 embedded in a Euclidean space of dimension E with E ≥ M E . equals the number of variables of a dataset and the Intrinsic Dimension (ID) of a manifold is equal to the theoretical ID of the data. If a manifold is space-filling, its dimension M ≈ E . In contrast, if the Euclidean space is partially empty, M < E . The optimality of DR greatly depends on the accuracy of ID estimates. An underestimation of the theoretical ID will result in the implosion of the data manifold and information will be irreparably lost. On the contrary, an overestimation will lead to noise in the final mapping. From an application perspective, DR can be used to produce low dimensional syntheses of high dimensional datasets [5] and as a preprocessing tool for supervised learning [6, 7] and data visualization [8].
DR methods perform variable transformations to capture the complex dependencies which generate redundancy within datasets. Nevertheless, it is often important not to recast data. The Fractal Dimension Reduction (FDR) algorithm [9, 10, 11, 12] was designed to this end. The fundamental idea is to remove from a dataset all the variables which do not contribute to increasing its ID. FDR can also be adapted to supervised feature selection methods [13]. The goal is then to reject irrelevant or redundant variables (or features) according to a prediction task (i.e. regression or classification). Although ID estimation lies at the core of FDR, more traditional unsupervised [14, 15, 16] and supervised [17, 18, 19, 20, 21, 22] feature selection methods do not consider it. It has, however, a great potential in speeding up search strategies, such as those used in [23, 24, 25, 26].
These different approaches highlight that ID estimation is a fundamental problem when dealing with high-dimensional datasets. Unfortunately, ID estimators [27, 28] suffer from the curse of dimensionality as well. Their overall performance depends on many factors (to various degree), such as the number of data points, the theoretical ID of data and the shape of manifolds. The present research deals with a new ID estimator in order to provide a solution to the problems raised by these factors. It is based on the recently introduced multipoint Morisita index ( m -Morisita)[29, 30, 31].
1 In Physics, mainly, M is often referred to as the degrees of freedom of data
The m -Morisita index is a measure of global clustering closely related to the concept of multifractality and, so far, it has been successfully applied within the framework of (2-dimensional) spatial data analysis [29, 30].
The paper is organized as follows: In Section 2, traditional fractal-based and maximum likelihood methods of ID estimation are presented. Section 3 derives a new ID estimator from the m -Morisita index and introduces a new algorithm for its application to high-dimensional datasets. Section 4 is devoted to comparisons between the proposed estimator and those of Section 3. Their behaviour regarding sample sizes, noise and the dimension of manifolds is analysed. A special attention is also paid to their bias and variance by using Monte-Carlo simulations and real world case studies from the UCI machine learning repository are examined. Finally, conclusions are drawn in Section 5.
## 2. Existing Methods
Many ID estimation methods have been proposed [27, 28, 32, 33, 34] and they can be roughly divided into projection (e.g. PCA) and geometric methods (e.g. fractal, nearest-neighbor and maximum likelihood methods). This section focuses on fractal-based and maximum likelihood estimators. They are commonly used in a wide range of applications and they generally provide non-integer values as ID estimates.
## 2.1. Fractal-Based Estimation Methods
The word fractal was first coined by B. Mandelbrot [35] to describe scale-invariant sets. At small scales δ , for a given point pattern, one has that:
$$n _ { b o x } ( \delta ) \in \delta ^ { - D _ { 0 } }$$
where n box ( δ ) is the number of grid cells necessary to cover the whole pattern and D 0 is known as the box-counting dimension [35, 36, 37]. In practical applications, due to its simplicity, D 0 often replaces the Hausdorff dimension D (or fractal dimension) and it can be proved that D 0 is an upper bound of D [38].
In complex cases, the scaling behaviour of the moments of point distributions cannot be fully characterized by only one fractal dimension and a full spectrum of generalized dimensions, D q , is required. Such distributions
/negationslash are referred to as being multifractal [39, 40, 41, 42]. D q is generally obtained by using a generalization of the box-counting method [39, 40, 41, 43] based on Rényi's information, RI q ( δ ), of q th order [44]. The central scaling law of this approach can be written as follows for q = 1:
$$\exp ( R I _ { q } ( \delta ) ) \in \delta ^ { - D _ { q } }$$
where
$$R I _ { q } ( \delta ) = \frac { 1 } { 1 - q } \ \log ( \sum _ { i = 1 } ^ { n _ { b o x } ( \delta ) } p _ { i } ( \delta ) ^ { q } )$$
In this last equation, p i ( δ ) = n /N i is the value of the probability mass function in the i th grid cell of size δ ( n i is the number of points falling into the i th cell) and q ∈ R \{- } 1 . Finally, one has that:
$$D _ { q } = \lim _ { \delta \to 0 } \frac { R I _ { q } ( \delta ) } { \log ( \frac { 1 } { \delta } ) }$$
and
$$\lim _ { q \to 1 } D _ { q } = d f _ { i }$$
$$D _ { 2 } = d f _ { c o r }$$
where df i and df cor are, respectively, the information dimension [45, 39] and the correlation dimension [46].
Usually, df cor is computed with the Grassberger-Procaccia (GP) algorithm [46]. This algorithm is designed to better take advantage of the range of available pairwise distances between points. It can be introduced as follows: at small scales, for a point set, X N = { x , . . . , x 1 N } , one has that
$$C ( \delta ) \in \delta ^ { d f _ { c o r } }$$
where with ✶ being an indicator function and df cor can be expressed as
$$C ( \delta ) = \frac { 2 } { N ( N - 1 ) } \, \sum _ { i = 1 } ^ { N } \sum _ { j = i + 1 } ^ { N } \mathbb { 1 } _ { \{ \| x _ { i } - x _ { j } \| \leq \delta \} } \\ \text{being an indicator function and df} _ { c o r } \, \text{can be expressed as}$$
$$d f _ { c o r } = D _ { 2 } = \lim _ { \delta \to 0 } \frac { \log ( C ( \delta ) ) } { \log ( \delta ) }$$
4
The available values of RI q ( δ ) and log( C δ ( )) depend on the data resolution. A commonly used method for estimating D q consists in plotting RI q ( δ ) vs log( δ -1 ) for a chosen scale interval. The final estimate is then the slope of the linear regression fitting the linear part of the resulting chart. The procedure is the same for the GP algorithm, except that df cor and log( C δ ( )) replace, respectively, D q and RI q ( δ ). Eventually, both D q (in general 0 glyph[lessorequalslant] q glyph[lessorequalslant] 2) and df cor can be used as ID estimators.
Although these methods may entail some disadvantages due to the finiteness of datasets [33], they have been successfully applied in various fields, such as spatial [47, 48] and time series [49] analysis, cosmology [50], climatology [36, 51, 52] and pattern recognition [53, 54]. They have also been used in different procedures improving their overall performance [55].
## 2.2. Maximum Likelihood Estimation Methods
The Maximum Likelihood Estimation (MLE) of ID was introduced in [28]. The proposed method relies on the assumption that the k -nearest neighbors ( k -NN) of any point x i of a point set X N = { x , . . . , x 1 N } are stemming from a uniform probability density function f ( x i ). As a consequence, for a fixed x i , the observations are treated as a homogeneous Poisson process within a small sphere S x i ( R ) of radius R centred at x i . On this basis, the inhomogeneous binomial process { N t, x ( i ) , 0 ≤ t ≤ R } with
$$N ( t, x _ { i } ) & = \sum _ { j = 1 } ^ { N } \mathbb { 1 } _ { \left \{ x _ { j } \in S _ { x _ { i } } ( t ) \right \} } & & ( 1 0 ) \\ \text{ber of observations within the distance $t$ of $x_{i}$ and can be} \\ \text{$\mathfrak{ }u$} \cdots & \mathfrak{ }u \cdots & \mathfrak{ }u \cdots & \mathfrak{ }u \cdots & \mathfrak{ }u \cdots$$
counts the number of observations within the distance t of x i and can be approximated as a Poisson process. The rate of this process is:
$$\lambda ( t, x _ { i } ) = f ( x _ { i } ) \ V ( m ( x _ { i } ) ) \ m ( x _ { i } ) \ t ^ { m ( x _ { i } ) - 1 }$$
where m x ( i ) is the dimension of the manifold on which x i lies and V ( m x ( i )) is the volume of the unit sphere in R m x ( i ) centred at x i . The log-likelihood function of N t, x ( i ) can then be expressed as:
$$L ( m ( x _ { i } ), \theta ( x _ { i } ) ) = \int _ { 0 } ^ { R } \log ( \lambda ( t, x _ { i } ) ) \ d N ( t, x _ { i } ) - \int _ { 0 } ^ { R } \lambda ( t, x _ { i } ) \ d t \quad \ \ ( 1 2 )$$
where θ x ( i ) = log( f ( x i )). Finally, the MLE for m x ( i ) provides a local estimator of ID [28, 56, 57]:
$$\hat { \ m } _ { k } ( x _ { i } ) = \left [ \frac { 1 } { k - 2 } \sum _ { j = 1 } ^ { k - 1 } \log \left ( \frac { T _ { k } ( x _ { i } ) } { T _ { j } ( x _ { i } ) } \right ) \right ] ^ { - 1 }$$
where k > 2 is the number of NN taken into account and T k ( x i ) is the distance between x i and its k th NN.
If it is assumed that all the observations belong to the same manifold, one has that:
$$\hat { m } _ { k } = \frac { 1 } { N } \sum _ { i = 1 } ^ { N } \hat { m } _ { k } ( x _ { i } )$$
which is simply an average over the whole dataset and, for k ∈ { k , k 1 1 + 1 , ..., k 2 } with k 1 > 2, the final estimate of ID is provided in [28]:
$$\hat { m } = \frac { 1 } { k _ { 2 } - k _ { 1 } + 1 } \sum _ { k = k _ { 1 } } ^ { k _ { 2 } } \hat { m } _ { k }$$
A delicate issue which arises from Equations 13, 14 and 15 is the range of the values k to be chosen. In practical applications, this is similar to the choice of the scale interval in the fractal-based methods. Here, as well, the finiteness of datasets may greatly influence the final estimate of ID if the considered values k are not carefully selected. In [28], it is advocated to retain a range of small to moderate values, so that each S x i ( R ) is small enough to ensure f ( x i ) ≈ const and large enough to contain sufficiently many points.
In [58], a modified version of the MLE algorithm is proposed. It consists in averaging the inverse of the N estimators ˆ m x k ( i ) of Equation 14, so that the final estimator of Equation 15 is replaced with:
$$\hat { m } = \frac { 1 } { k _ { 2 } - k _ { 1 } + 1 } \sum _ { k = k _ { 1 } } ^ { k _ { 2 } } \left [ \frac { 1 } { N ( k - 1 ) } \sum _ { i = 1 } ^ { N } \sum _ { j = 1 } ^ { k - 1 } \log \left ( \frac { T _ { k } ( x _ { i } ) } { T _ { j } ( x _ { i } ) } \right ) \right ] ^ { - 1 } \quad ( 1 6 )$$
Although the second version of the algorithm is better for small values of k , both of them yield similar results [57] and have been successfully applied in various studies [28, 58, 56]. Finally, notice that, in the remainder of this paper, the estimators of Equations 15 and 16 will be named after their authors, ˆ m LB and ˆ m MG .
Figure 1: Computation of the m -Morisita index in two dimensions for m = 2 and m = 3 and for three benchmark patterns
## 3. A New Estimator of Intrinsic Dimension
## 3.1. The m -Morisita Index
The m -Morisita index [29, 30], I m,δ , is a global measure of clustering. It is a generalization of the Morisita index [31, 59] and it was first proposed in [30] for the analysis of population distributions in ecology. It was later modified in [29] to take into account the notion of scale in spatial data anal-
ysis and a relationship to multifractality was established.
For its computation, I m,δ , requires a dataset to be covered with a grid of Q quadrats (or cells) of changing size δ (see Figure 1). For a fixed δ , I m,δ measures how many times more likely it is that m m ( ≥ 2) randomly selected data points will be from the same quadrat than it would be if the N points of the dataset were distributed at random (see Figure 1). It is calculated as follows:
$$I _ { m, \delta } = Q ^ { m - 1 } \frac { \sum _ { i = 1 } ^ { Q } n _ { i } ( n _ { i } - 1 ) ( n _ { i } - 2 ) \cdots ( n _ { i } - m + 1 ) } { N ( N - 1 ) ( N - 2 ) \cdots ( N - m + 1 ) } \quad \ ( 1 7 )$$
where n i is the number of points in the i th quadrat and N is the total number of points. The computation of the index starts with a relatively large quadrat size δ . It is then reduced until it reaches a minimum value and a plot relating every I m,δ to its matching δ can be drawn.
Figure 1 illustrates the computation of the index in two dimensions for three benchmark point distributions (or patterns), for three different scales and for m = 2 and m = 3. For the highest possible δ , when only one quadrat is considered, I m,δ returns the same value for each pattern and m . As the number of quadrats increases, I m,δ adopts a specific behaviour for each of the three benchmark distributions. If the points are distributed at random, every computed I m,δ oscillates around the value of 1. If the points are clustered, the value of the index increases as δ decreases and, finally, if the points are dispersed, the index approaches 0 at small scales [29, 60]. Further, as m increases, I m,δ becomes more and more sensitive to the structure of the pattern under study. In complex situations, I m,δ computed with small m may miss structures which are detected with higher m .
## 3.2. The Morisita Estimator of Intrinsic Dimension
Several parallels can be drawn between the m -Morisita index and Rényi's information of q th order. In particular, it was established, for fractal point sets, that [29]:
$$\lim _ { \delta \to 0 } \frac { \log \left ( I _ { m, \delta } \right ) } { \log \left ( \frac { 1 } { \delta } \right ) } \frac { 1 } { m - 1 } \approx E - D _ { m } = C _ { m }$$
where m ∈ { 2 3 4 , , , · · · } , C m is the codimension of order q = m E , is the dimension of the Euclidean space where the dataset is embedded and D m is
Rényi's generalized dimension of order q = m . In practical applications, for finite datasets, it can be shown that Equation 18 is verified only under the condition that H := max n i ( i ) /greatermuch m [29]. If so, C m can be estimated from the slope, S m , of the straight line fitting the linear part of the plot relating log ( I m,δ ) to log ( 1 δ ) . Then, C m ≈ S m / m ( -1) and one has that:
$$D _ { m } \approx E - \left ( \frac { S _ { m } } { m - 1 } \right )$$
where m ∈ { 2 3 4 , , , · · · } .
In high-dimensional spaces, the condition H /greatermuch m is hardly ever met at small scales. In such situations, it is important to notice that the major difference between log ( I m,δ ) and RI m ( δ ) lies in the following inequality:
$$n _ { i } ^ { m } > n _ { i } ( n _ { i } - 1 ) \cdots ( n _ { i } - m + 1 )$$
Consequently, unlike log ( I m,δ ), RI m ( δ ) seriously overestimates the probability of randomly drawing m -tuples of points from grid cells characterized by a small n i . Such cells are numerous at small scales or when the sample size is limited and can greatly affect the accuracy of D m . From this perspective, it is possible to suggest a new ID estimator based on log ( I m,δ ) (for m ≥ 2):
$$M _ { m } \coloneqq E - \left ( \frac { S _ { m } } { m - 1 } \right )$$
which should be more robust to sample size than D m (see Equation 4). Notice that M m should only be computed under the condition that H > m at all considered scales. In the remainder of this paper, M m will be referred to as the Morisita estimator of ID. It will be thoroughly tested in Section 4 with synthetic datasets of various complexities and with real data from the UCI machine learning repository.
## 3.3. An Algorithm for Large Datasets
Algorithms used for handling large datasets should be affected as little as possible by the amount of main memory available. Regarding M m , the main issue concerns the way the number of points per quadrat is counted. A good algorithm must be able to effectively disregard empty quadrats. It is also more appealing if its implementation is straightforward in most programming environments (e.g. R and Matlab). To fulfil these requisites, the
Algorithm 1 The Morisita INDex for ID estimation (MINDID)
INPUT: a N × E matrix, D , with N points and E features; a vector L of values /lscript ; a vector M of contiguous values m . OUTPUT: a vector containing M m for each value m .
- 1: Rescale each variable to [0 , 1]
- 2: for all values /lscript do
- 3: Divide each element of D by /lscript and round the result to the next lowest whole number in a N × E matrix called D/lscript
- 4: Count the number, nbr \_ , l of different lines in D/lscript and store their frequency in a vector, ni , of size nbr \_ l
- 5: for all values m do
- 6: Compute log ( I m,δ ) (See Equation 23) using the vector ni and store the result in a | L | × | M | matrix called logMindex
- 7: end for
- 8: end for
- 9: Optional: Compute the values δ (See Equation 24) using the vector L and store the result in a vector ∆ of cardinality | L |
- 10: for all values m do
- 11: Compute M m (See Equation 21) using logMindex and ∆ (or L )
- 12: end for
MINDID algorithm (see Algorithm 1) incorporates a version of an algorithm suggested in [10]. It rescales each variable of a dataset D to [0 , 1] and takes advantage of the properties of the square cells of the hyper-grid covering the data: for a given cell size δ , each value of the dataset is divided by /lscript (see Figure 1) and rounded to the next lowest integer. In this way, in the resulting matrix, all the data points falling into the same cell are matched by as many equal lines.
Another issue concerns Q m -1 , since it is often given the value Inf (e.g. R and Matlab) for small values of /lscript when E /greatermuch 1. A way to overcome this problem is to resort to log ( I m,δ ) instead of I m,δ . Q m -1 is related to /lscript and E through:
$$Q ^ { m - 1 } = \left ( \frac { 1 } { \ell } \right ) ^ { E ( m - 1 ) }$$
and
$$\log \left ( I _ { m, \delta } \right ) = E ( 1 - m ) \log \left ( \ell \right ) + \log \left ( \frac { \sum _ { i = 1 } ^ { Q } n _ { i } ( n _ { i } - 1 ) \cdots ( n _ { i } - m + 1 ) } { N ( N - 1 ) \cdots ( N - m + 1 ) } \right ) \ ( 2 3 )$$
This solution is satisfactory, since the computation of M m (See Equation 21) only requires log ( I m,δ ). Consequently, the second part of the MINDID algorithm is devoted to the implementation of Equation 23.
Finally, the computation of M m is carried out using either log( ) /lscript or log δ ( ). In the rest of this paper, the second option will be preferred. Notice that /lscript and δ are related as follows:
$$\delta = \ell \sqrt { E }$$
## 4. Assessment of the Morisita Estimator of ID
## 4.1. Synthetic Data
Several datasets were built, so that each of them resides on a known manifold (or near a known manifold in the case of noisy data). They can be divided into four categories (see Figure 2):
- 1. Swiss rolls (e.g. [3]) of 1000, 5000 and 10 000 points. The theoretical ID of the data is equal to 2.
- 2. Noisy Swiss rolls of 1000, 5000 and 10 000 points. The noise is modelled as a Gaussian variable G ∼ N (0 , σ 2 ) where σ varies from 0 to 0 5. .
- 3. Uniform clouds of 1000, 5000 and 10 000 points. Each of the N distinct points x i , with i ∈ { 1 2 , , · · · , N } , is described by a E-dimensional vector [ x , x 1 i 2 i , · · · , x E T i ] ∈ R E , the components of which are sampled from E i.i.d. variables following a uniform distribution. E is gradually increased from 1 to 7 and is equal to the theoretical ID of the data.
- 4. This last category is based on the properties of the Cartesian product of some fractals [38, 61]. One-dimensional Cantor sets of 8192 and 65 536 points are first created. The resulting vectors are shuffled seven times to generate as many variables. A Euclidean space R E can then be constructed and E is gradually increased from 1 to 7. The dimension of the data manifold (i.e. the theoretical ID) is equal to log(2) log(3) E , where log(2) log(3) is the Hausdorff dimension of a one-dimensional Cantor set.
Figure 2: (a) A Cantor set of 512 points for E = 2; (b) a realization of a uniform cloud of 500 points for E = 2; (c) a Swiss roll of 10 000 points without noise and (d) a Swiss roll of 10 000 points with noise G ∼ N (0 , 0 25 . 2 )
## 4.2. Comparison Between M m and D m Using Synthetic Data
Two categories of datasets were used to compare M m with D m : the uniform point clouds and the Cantor sets. They were employed with varying N and E (see Subsection 4.1) and for each combination of these two parameters, 100 sets were generated. The results are displayed in Figures 3 and 4 and in Tables 1 and 2.
Figure 3: The results of the application of I 2 ,/lscript and RI 2 ( /lscript ) to 100 uniform point clouds of 10 000, 5000 and 1000 points. In the bottom-right table, the corresponding estimates of D 2 and M 2 are provided as follows: the mean (computed over the 100 sets) ± the standard deviation. The results written in bold script indicate that the theoretical ID falls within the mean value ± one standard deviation.
In the case of the uniform point clouds, RI 2 ( /lscript ) and log ( I 2 ,/lscript ) were computed by using an interval of the parameter /lscript -1 ranging from 1 to 15 (see Equation 24). Figure 3 shows the results for N = 10000, N = 5000 and N = 1000 and for increasing E . The points of each plot are the mean values yielded by the two indices over the 100 sets and the error bars correspond to the standard deviations.
Figure 4: The results of the application of I 2 ,/lscript (left) and RI 2 ( /lscript ) (right) to 100 Cantor sets of 8192 and 65 536 points. In the bottom table, the corresponding estimates of D 2 and M 2 are provided as follows: the mean (computed over the 100 sets) ± the standard deviation. The results written in bold script indicate that the theoretical ID falls within the mean value ± one standard deviation.
If the value of H (see Subsection 3.2) was smaller than 2 at certain scales /lscript for a given dimension E , the entire plots describing the corresponding behaviours of RI 2 ( /lscript ) and log ( I 2 ,/lscript ) were not drawn. This was motivated by the condition that H must be greater than m at all scales for M m to be computed.
In spite of this limitation, M m provides better ID estimates than D q when the same values of /lscript are considered. In Figure 3, this is highlighted, for the largest E , by the steady state reached by RI 2 ( /lscript ) at small scales, which shows a departure from the power law of Equation 2. As a consequence, D 2 cannot be derived from a linear regression calculated over the whole range of /lscript . In contrast, log ( I 2 ,/lscript ) follows, on average and throughout the scales, the power law which underlies Equation 21: all the plots are superimposed on a constant mean level of 0 as expected from a Poisson distribution (i.e. a random space-filling set). The cost of this near absence of bias is an increase in the variability of the values provided by log ( I 2 ,/lscript ) as /lscript decreases. As indicated in the table of Figure 3, this drawback has only a small impact on the variabilities of the final ID estimates which remain low.
Still with regard to the table of Figure 3, the means and standard deviations of the ID estimates 2 were calculated only if the dependence between log ( I 2 ,/lscript ) or RI 2 ( /lscript ) and /lscript could be reasonably approximated by using a linear regression over all the scales (i.e if only one slope could be distinguished in the different plots). The results show that D 2 becomes unreliable for E > 2, while M 2 works better and can even be used up to E = 6 for N = 10000.
The results of M 2 and D 2 were written in bold script if the theoretical ID fell within the mean value ± one standard deviation. Shapiro-Wilk tests were first conducted to check whether or not the estimates could be assumed to come from normal distributions (only if the standard deviations were not equal to 0 00). . At a 5% α level, the hypothesis of normality could not be rejected for any of the estimate distributions. The theoretical ID fell within the mean value ± one standard deviation for each result yielded by M 2 . Regarding D 2 , it only happened twice for high values of N and for E = 1. Notice that the same notation will be used throughout the section.
2 The linear slope of the plots must be multiplied by -1 to yield S m and D q , since the x-axis represents /lscript instead of /lscript -1
Table 1: The results of the application of M m and D m to 100 Cantor sets of 65 536 points for m = 2, m = 3 and m = 5. The mean ± the standard deviation is provided for each E -dimensional space. The results written in bold script indicate that the theoretical ID falls within the mean value ± one standard deviation.
| N = 65 536 | M 2 | D 2 | M 3 | D 3 | M 5 | D 5 |
|--------------|-----------------|-----------------|-----------------|-----------------|-----------------|-----------------|
| E = 1 | 0 . 63 ± 0 . 00 | 0 . 63 ± 0 . 00 | 0 . 63 ± 0 . 00 | 0 . 63 ± 0 . 00 | 0 . 63 ± 0 . 00 | 0 . 63 ± 0 . 00 |
| E = 2 | 1 . 26 ± 0 . 00 | 1 . 26 ± 0 . 00 | 1 . 26 ± 0 . 00 | 1 . 26 ± 0 . 00 | 1 . 26 ± 0 . 00 | 1 . 26 ± 0 . 00 |
| E = 3 | 1 . 89 ± 0 . 00 | 1 . 88 ± 0 . 00 | 1 . 89 ± 0 . 00 | 1 . 88 ± 0 . 00 | 1 . 89 ± 0 . 00 | 1 . 87 ± 0 . 00 |
| E = 4 | 2 . 52 ± 0 . 00 | 2 . 39 ± 0 . 00 | 2 . 52 ± 0 . 00 | 2 . 37 ± 0 . 00 | 2 . 53 ± 0 . 01 | 2 . 33 ± 0 . 00 |
| E = 5 | 3 . 16 ± 0 . 00 | - | 3 . 16 ± 0 . 02 | - | - | - |
| E = 6 | 3 . 79 ± 0 . 02 | - | - | - | - | - |
| E = 7 | 4 . 43 ± 0 . 07 | - | - | - | - | - |
Finally, the number of E -dimensional spaces, for which M 2 can be calculated, decreases as N is reduced. The reason is that it becomes less likely that at least two points will fall into the same cell at small scales when E /greatermuch 1. Nevertheless, whatever N , the bias affecting RI 2 ( /lscript ) is always noticeable for the greatest E and tends to lead to an underestimation of ID in any case.
Similar comments can be made about the results obtained for the Cantor sets (see Figure 4). For this second category of data, the interval of the parameter /lscript -1 follows a geometric series with ratio r = 3 and ranges from 1 to 81. In this way, the grid used for the computation of both log ( I 2 ,/lscript ) and RI 2 ( /lscript ) is in accordance with the mathematical construction of a Cantor set. For the same arguments as those previously set out, M 2 turns out to be a more reliable estimator of ID than D 2 : here as well, a bias affects the behaviour of RI 2 ( /lscript ) when the number of points in occupied cells is low. It is also interesting to notice that M 2 can be computed up to E = 5 for N = 8192, although the lowest considered scale /lscript is smaller than it was for the uniform point clouds. This is due to the dimension of the data manifold that is systematically less than E . As a consequence, a Cantor set is not space-filling and it is more likely that at least two points will fall into the same cell than it would be if the N data points were randomly distributed within the entire Euclidean space. This observation highlights that the curse of ID [12] (i.e. the problems induced by a high ID) is a central issue when studying high-dimensional spaces.
The Cantor sets were also used to assess the accuracy of M m and D m for m greater than 2. Tables 1 and 2 show the results for, respectively, N = 65536 and N = 8192. In both cases, M m provides results closer
Table 2: The results of the application of M m and D m to 100 Cantor sets of 8192 points for m = 2, m = 3 and m = 5. The mean ± the standard deviation is provided for each E -dimensional space. The results written in bold script indicate that the theoretical ID falls within the mean value ± one standard deviation.
| N = 8192 | M 2 | D 2 | M 3 | D 3 | M 5 | D 5 |
|------------|-----------------|-----------------|-----------------|-----------------|-----------------|-----------------|
| E = 1 | 0 . 63 ± 0 . 00 | 0 . 63 ± 0 . 00 | 0 . 63 ± 0 . 00 | 0 . 63 ± 0 . 00 | 0 . 63 ± 0 . 00 | 0 . 63 ± 0 . 00 |
| E = 2 | 1 . 26 ± 0 . 00 | 1 . 26 ± 0 . 00 | 1 . 26 ± 0 . 00 | 1 . 25 ± 0 . 00 | 1 . 26 ± 0 . 00 | 1 . 25 ± 0 . 00 |
| E = 3 | 1 . 90 ± 0 . 00 | 1 . 82 ± 0 . 00 | 1 . 90 ± 0 . 00 | 1 . 80 ± 0 . 00 | 1 . 90 ± 0 . 01 | 1 . 76 ± 0 . 00 |
| E = 4 | 2 . 53 ± 0 . 01 | - | 2 . 53 ± 0 . 03 | - | - | - |
| E = 5 | 3 . 16 ± 0 . 04 | - | - | - | - | - |
| E = 6 | - | - | - | - | - | - |
| E = 7 | - | - | - | - | - | - |
to the theoretical ID than those yielded by D m for E > 2. Nevertheless, the difference between the two estimators is lessened as the value of m is increased. This follows from Equation 20: when m m ( = q ) is high, the impact of the inequality is negligible, while the implementation of M m requires more data points than that of D m .
## 4.3. Comparison Between M 2 and the Distance-Based Estimators Using Synthetic Data
M 2 was also compared to the other estimators of ID presented in Section 2, namely d cor , ˆ m LB and ˆ m MG . The Swiss rolls and the uniform point clouds were used for this task. The parameters of each estimator were set using the Swiss rolls of 1000 points and stayed unchanged in the whole subsection. At each step, it was made sure that these parameters were close to the ideal ones. Regarding M 2 , the interval of the parameter /lscript -1 was chosen, so that it ranged from 5 to 15 and the two MLE estimators were computed with k going from 10 to 20. More challenging, the interval of the parameter δ of d cor turned out to be relatively complicated to set, since it tended to deviate from the ideal values as both N and E were increased. It was finally decided to resort to percentiles and the problem was empirically solved as follows: (a) 1 percent of the pairwise distances between points had to be lower than the smallest δ and 7 percent of them had to be lower than the largest one; (b) the range of the interval was divided by 100 to produce intermediate values of δ . It is also worth mentioning that each variable was rescaled, so that it ranged from 0 to 1. Such a transformation is mandatory when working with data of different nature. Regarding d cor , ˆ m LB and ˆ m MG , it amounts to using the Mahalanobis distance and, if the data are not noisy, it has, of course, no influence on M m (or D q ), since the grid employed in its computation is also transformed.
Table 3: The results of the application of the four estimators to Swiss rolls of N = 1000, N = 5000 and N = 10000 points (100 sets for each N ). The mean ± the standard deviation of the estimators, computed over the 100 sets, is provided for each N . The result written in bold script indicates that the theoretical ID falls within the mean value ± one standard deviation (the theoretical ID of the Swiss Roll is 2).
| Swiss Roll | N = 1000 | N = 5000 | N = 10 000 |
|--------------|-----------------|-----------------|-----------------|
| M 2 | 2 . 03 ± 0 . 03 | 2 . 03 ± 0 . 01 | 2 . 03 ± 0 . 00 |
| d cor | 1 . 95 ± 0 . 01 | 1 . 94 ± 0 . 00 | 1 . 94 ± 0 . 00 |
| ˆ m LB | 1 . 95 ± 0 . 02 | 1 . 98 ± 0 . 01 | 1 . 98 ± 0 . 01 |
| ˆ m MG | 1 . 95 ± 0 . 02 | 1 . 98 ± 0 . 01 | 1 . 98 ± 0 . 00 |
Tables 3 and 4 show the results (mean ± standard deviation computed over 100 sets) provided by the four estimators for, respectively, the Swiss rolls and the uniform point clouds. The values yielded by the four estimators are similar when the data points are densely distributed on their manifold. This situation is encountered for the Swiss rolls and for relatively low E and high N in the case of the uniform distributions. When the data points are sparse (low N and/or high theoretical ID) and provided that it can be calculated, M 2 provides better ID estimates. d cor , ˆ m LB and ˆ m MG are always able to yield a result, but, when the data are simply too sparse for M 2 to be computed, they tend to seriously underestimate the true ID of the data. The underestimation reduces as N increases and it can be assumed that it is caused (at least partially) by edge effects.
Several Edge effect corrections have been proposed and thoroughly studied in spatial data analysis [62], but the problem has often been overlooked in ID estimation methods. d cor appears to be more affected by this problem than the other estimators. Nevertheless, the case of d cor is difficult to deal with, since the ideal range of the parameter δ is very sensitive to N and E . Consequently, concerning the uniform distribution clouds, it was decided that a new series of 10 estimations would be carried out for N = 5000 and N = 10000 with improved parameters. The results appear in italics in Table 4 and reveal that the modifications have improved the estimates, even if ˆ m LB and ˆ m MG stay better.
| | M 2 | d cor | ˆ m LB | ˆ m MG |
|-------|-----------------|---------------------------------|-----------------|-----------------|
| E = 1 | 1 . 00 ± 0 . 00 | 0 . 99 ± 0 . 01 | 1 . 00 ± 0 . 01 | 1 . 00 ± 0 . 01 |
| E = 2 | 2 . 00 ± 0 . 01 | 1 . 91 ± 0 . 01 | 1 . 95 ± 0 . 02 | 1 . 95 ± 0 . 02 |
| E = 3 | 3 . 00 ± 0 . 05 | 2 . 74 ± 0 . 02 | 2 . 83 ± 0 . 02 | 2 . 83 ± 0 . 03 |
| E = 4 | 4 . 04 ± 0 . 19 | 3 . 51 ± 0 . 03 | 3 . 66 ± 0 . 03 | 3 . 65 ± 0 . 04 |
| E = 5 | - | 4 . 24 ± 0 . 04 | 4 . 45 ± 0 . 05 | 4 . 44 ± 0 . 05 |
| E = 6 | - | 4 . 93 ± 0 . 04 | 5 . 20 ± 0 . 06 | 5 . 20 ± 0 . 06 |
| E = 7 | - | 5 . 59 ± 0 . 04 | 5 . 92 ± 0 . 07 | 5 . 92 ± 0 . 07 |
| E = 1 | 1 . 00 ± 0 . 00 | 0 . 99 ± 0 . 00 1 . 00 ± 0 . 00 | 1 . 00 ± 0 . 00 | 1 . 00 ± 0 . 00 |
| E = 2 | 2 . 00 ± 0 . 00 | 1 . 91 ± 0 . 01 1 . 95 ± 0 . 00 | 1 . 98 ± 0 . 01 | 1 . 98 ± 0 . 01 |
| E = 3 | 3 . 00 ± 0 . 01 | 2 . 74 ± 0 . 01 2 . 84 ± 0 . 01 | 2 . 90 ± 0 . 01 | 2 . 90 ± 0 . 01 |
| E = 4 | 4 . 00 ± 0 . 04 | 3 . 51 ± 0 . 01 3 . 68 ± 0 . 01 | 3 . 78 ± 0 . 02 | 3 . 77 ± 0 . 02 |
| E = 5 | 5 . 02 ± 0 . 13 | 4 . 24 ± 0 . 01 4 . 47 ± 0 . 02 | 4 . 61 ± 0 . 02 | 4 . 60 ± 0 . 02 |
| E = 6 | - | 4 . 93 ± 0 . 01 5 . 22 ± 0 . 01 | 5 . 40 ± 0 . 03 | 5 . 40 ± 0 . 03 |
| E = 7 | - | 5 . 58 ± 0 . 01 5 . 94 ± 0 . 01 | 6 . 18 ± 0 . 03 | 6 . 17 ± 0 . 03 |
| E = 1 | 1 . 00 ± 0 . 00 | 0 . 99 ± 0 . 00 1 . 00 ± 0 . 00 | 1 . 00 ± 0 . 00 | 1 . 00 ± 0 . 00 |
| E = 2 | 2 . 00 ± 0 . 00 | 1 . 91 ± 0 . 00 1 . 97 ± 0 . 00 | 1 . 98 ± 0 . 00 | 1 . 98 ± 0 . 01 |
| E = 3 | 3 . 00 ± 0 . 00 | 2 . 74 ± 0 . 01 2 . 90 ± 0 . 01 | 2 . 93 ± 0 . 01 | 2 . 92 ± 0 . 01 |
| E = 4 | 4 . 00 ± 0 . 02 | 3 . 51 ± 0 . 01 3 . 78 ± 0 . 01 | 3 . 82 ± 0 . 01 | 3 . 81 ± 0 . 01 |
| E = 5 | 5 . 00 ± 0 . 08 | 4 . 24 ± 0 . 01 4 . 62 ± 0 . 01 | 4 . 66 ± 0 . 02 | 4 . 66 ± 0 . 02 |
| E = 6 | 6 . 06 ± 0 . 24 | 4 . 93 ± 0 . 01 5 . 42 ± 0 . 01 | 5 . 48 ± 0 . 02 | 5 . 47 ± 0 . 02 |
| E = 7 | - | 5 . 58 ± 0 . 01 6 . 19 ± 0 . 02 | 6 . 27 ± 0 . 02 | 6 . 26 ± 0 . 02 |
Table 4: The results of the application of the four estimators to uniform distribution clouds of N = 1000, N = 5000 and N = 10000 points (100 sets for each N ). The mean ± standard deviation, computed over the 100 sets, is provided for each N . The results written in bold script indicate that the theoretical ID falls within the mean value ± one standard deviation (the theoretical ID of a uniform point cloud is E ).
Figure 5: (left) Application of M 2 , ˆ m LB and ˆ m MG to noisy Swiss rolls of N = 1000; (right) Application of M 2 to noisy Swiss rolls of N = 1000, N = 5000 and N = 10000. The x-axis represents the standard deviation of the noise and, for each level, 100 sets are considered.
## 4.4. Comparison Between the Estimators Using Noisy Synthetic Data
The presence of noise implies that the data points are located near a manifold instead of being exactly on it [28]. Consequently, a robust ID estimator should be as insensitive to noise as possible. In order to test the robustness of M 2 , the noisy Swiss rolls, presented in Subsection 4.1, were used and the results are displayed in Figure 5. On the left, a comparison between M 2 , ˆ m LB and ˆ m MG was conducted to show how the mean and the standard deviation of the estimates (computed over 100 sets) change as the noise increases. Leaving aside the initial difference, the sensitivity of the three estimators appears to be similar. The right hand-side of the figure highlights that the number of points N has a low influence on the responsiveness of M 2 to noise. These results demonstrate that the behaviour of M 2 in presence of noise is not better or worse than that of the other two estimators.
## 4.5. Comparison Between the Estimators Using Real Data
M 2 , D 2 , ˆ m LB , ˆ m MG and d cor were used to estimate the ID of four real datasets from the UCI machine learning repository: (1) Housing values in suburbs of Boston, (2) Statlog (vehicle silhouettes), (3) Statlog (image segmentation) and (4) Combined cycle power plant. The output variables and
the duplicate events were removed. The number of points N and the number of variables E of the resulting datasets are indicated in Table 5. Notice that the true ID of real data is unknown and the goal of this subsection is to show that the results provided by M 2 are coherent with the theory and with the observations made for the synthetic data.
Figure 6: Application of I 2 ,/lscript and RI 2 ( /lscript ) to four real datasets
Figure 6 shows the linear regressions required for the computation of M 2 and D 2 . Here as well, RI 2 ( /lscript ) appears to converge to a constant value as /lscript decreases. The departure from the power law denoted by the dashed line is
Table 5: Application of the ID estimators to four real datasets from the UCI machine learning repository
| Real Data | Housing Values | Vehicle Silhouettes | Image Segmentation | Power Plant |
|-------------|--------------------------------------------|--------------------------------------------|---------------------------------------------|--------------------------------------------|
| N E | 506 13 | 846 18 | 2086 19 | 9527 4 |
| M 2 | 3 . 02 /lscript - 1 ∈ { 2 , 3 · · · , 19 } | 6 . 04 /lscript - 1 ∈ { 2 , 3 · · · , 10 } | 2 . 84 /lscript - 1 ∈ { 2 , 3 · · · , 19 } | 3 . 05 /lscript - 1 ∈ { 5 , 6 · · · , 19 } |
| D 2 | 2 . 73 /lscript - 1 ∈ { 2 , 3 , 4 } | 5 . 02 /lscript - 1 ∈ { 2 , 3 } | 2 . 99 /lscript - 1 ∈ { 2 , 3 , 4 , 5 , 6 } | 2 . 84 /lscript - 1 ∈ { 5 , 6 · · · , 19 } |
| ˆ m LB | 3 . 64 k ∈ { 4 , 5 , · · · , 20 } | 5 . 63 k ∈ { 3 , 4 , · · · , 11 } | 3 . 54 k ∈ { 10 , 11 , · · · , 20 } | 3 . 11 k ∈ { 4 , 5 , · · · , 20 } |
| ˆ m MG | 2 . 98 k ∈ { 4 , 5 , · · · , 20 } | 5 . 57 k ∈ { 3 , 4 , · · · , 11 } | 2 . 98 k ∈ { 4 , 5 , · · · , 20 } | 2 . 78 k ∈ { 4 , 5 , · · · , 20 } |
| d cor | 2 . 87 0 . 05 ≤ δ ≤ 0 . 5 | 4 . 98 0 . 1 ≤ δ ≤ 0 . 4 | 2 . 69 0 . 04 ≤ δ ≤ 0 . 15 | 2 . 97 0 . 02 ≤ δ ≤ 0 . 16 |
more pronounced when N is relatively low and the assumed ID rather high (according to the ID estimates of Table 5). This can be observed with the vehicle silhouette data. In contrast, the power plant dataset is characterized by a great number of points N and a relatively low ID (according to the final ID estimates of Table 5). As a result, the entire range of the parameter /lscript can be used to perform linear regression. But, regarding M 2 , in each of the case studies, the solid line is a good approximation of the behaviour of log ( I 2 ,/lscript ) and all the values of /lscript can be systematically retained for ID estimation. This primacy of M 2 over D 2 is in accordance with the results found for the synthetic data, for which the Morisita estimator always provided equivalent or better ID estimates than D q . The variability of log ( I 2 ,/lscript ) for small values of /lscript , observed in the case of the vehicle silhouettes, was also shown to have only a limited effect on the accuracy of M 2 (see Figures 3 and 4). Based on this examination of Figure 6, M 2 appears to adequately capture the scaling properties of the four real world datasets.
The final ID estimates of the real world datasets are given in Table 5. Although the results provided by D 2 were computed by using only the red points, they are less than those of M 2 , except for the image segmentation data. It is also worth mentioning that D 2 yields 3 09 for the power plant . dataset if it is calculated with only the three points on the right side of the plot, which is close to the estimate of M 2 . These observations are coherent with the conclusions drawn from the synthetic data: for the lowest considered values of /lscript , the behaviour of RI 2 ( /lscript ) can be evaluated by linear regression and the corresponding ID estimates tend to slightly underestimate both the ground truth and the values yielded by M 2 over the entire
range of examined scales. Besides, the difference between the two estimators fades away for rather large N and low theoretical ID (see Figures 3 and 4). The power plant and the vehicle silhouette datasets are real world illustrations of this last point. The number N of the former is large enough to fully characterize a 3-dimensional space (the assumed ID is about 3 and N = 9527), while the space where the latter resides is sparsely filled with points (the assumed ID is greater than 5 and N = 846). As a result, the range of /lscript and the final ID estimate of the two estimators differ more for the vehicle silhouette dataset than for the power plant one. In each plot of Figure 6, the difference is highlighted by the gap between the dashed line and the actual values of RI 2 ( /lscript ) at the lowest scales. It is large in the case of the vehicle silhouettes, while it is non-existent for the power plant data. The two remaining datasets (i.e. the housing values and the image segmentation) are in an intermediate situation, as it is confirmed by the values given in Table 5. Thus, the comparison between M 2 and D 2 using real world data shows an excellent consistency with what was expected from the theory and the synthetic data analysis.
Regarding the distance-based methods, the estimates of df cor are, as expected, lower than those provided by M 2 . In contrast, the results of ˆ m LB and ˆ m MG tend to be less similar than for the synthetic data and they do not systematically underestimate the values of M 2 . These slight differences, related to the complex specificities of the analysed datasets, do not question the good performance of the suggested estimator. Indeed, in each of the case studies, the values of M 2 are close to, at least, one of the two MLE-based results. And, finally, by comparison with the range of values yielded by all the other estimators, it can be definitely maintained that M 2 provides sensible ID estimates.
## 5. Conclusion
The Morisita estimator, M m , is a new tool for estimating the Intrinsic Dimension (ID) of data. It is related to Rényi's generalized dimensions, D q , for m = q ≥ 2. M m tended to provide better results than D q on the synthetic data used in this study. This turned out to be particularly true for order 2 (i.e. m = q = 2) when the data points were sparsely distributed. The application to four real datasets from the UCI machine learning repository confirmed the good properties of the suggested estimator. From the perspective of pattern recognition, M 2 might be of great interest, since it
could be a good replacement for D 2 in algorithms, such as the fractal dimension algorithm [9, 12]. It might also open a new door to fractal supervised feature selection [13] of large datasets (our current work in progress), since its accuracy is coupled with a high computational efficiency.
M 2 was also compared with three distance-based estimators, namely d cor , ˆ m LB and ˆ m MG . It yielded good results when applied to the synthetic data and, by comparison, the real world applications revealed that it was able to provide reasonable ID estimates in challenging case studies. Therefore, in addition to the above-mentioned application in feature selection, the Morisita estimator of ID can be considered as a new tool for conducting advanced data mining tasks (e.g. dimensionality reduction [3], monitoring network analysis [36]) in many varied fields where the other estimators are commonly used (e.g. pattern recognition [27], physics [46, 39], cosmology [50], climatology [52] and ecology [47]).
Finally, it is also worth mentioning that the multipoint Morisita index is a ratio of probabilities deep-rooted in the field of spatial clustering analysis. Consequently, M m can be viewed from a dual perspective, a fractal one and a statistical one, which helps to interpret the results.
## 6. Acknowledgements
The authors are grateful to the anonymous reviewers for their helpful and constructive comments that contributed to improving the paper. They also would like to thank Michael Leuenberger and Zhivko Taushanov for many fruitful discussions about machine learning and statistics.
## References
- [1] D. W. Scott, J. R. Thompson, Probability density estimation in higher dimensions, in: J. R. Gentle (Ed.), Proceedings of the Fifteenth Symposium on the Interface, Elsevier Science Publishers, North-Holland, 1983, pp. 173-179.
- [2] R. Bellman, Adaptive Control Processes: A Guided Tour, Princeton University Press, Princeton (NJ), 1961.
- [3] J. A. Lee, M. Verleysen, Nonlinear Dimensionality Reduction, Springer, New-York, 2007.
- [4] C. J. C. Burges, Dimension reduction: A guided tour, Foundations and Trends in Machine Learning 2 (4) (2009) 275-365.
- [5] J. B. Tenenbaum, V. de Silva, J. C. Langford, A global geometric framework for nonlinear dimensionality reduction, Science 290 (5500) (2000) 2319-2323.
- [6] A. Lendasse, J. A. Lee, V. Wertz, M. Verleysen, Time series forecasting using CCA and Kohonen maps - application to electricity consumption, in: M. Verleysen (Ed.), Proceedings of ESANN 2000, 8th European Symposium on Artificial Neural Networks, Bruges, 2000, pp. 329-334.
- [7] M. Kanevski, A. Pozdnoukhov, V. Timonin, Machine Learning for Spatial Environmental Data: Theory, Applications and Software, EPFL Press, Lausanne, 2009.
- [8] S. Kaski, J. Peltonen, Dimensionality reduction for data visualization, Signal Processing Magazine 28 (2) (2011) 100-104.
- [9] C. Traina Jr., A. J. M. Traina, L. Wu, C. Faloutsos, Fast feature selection using fractal dimension, in: Proceedings of the XV Brazilian Symposium on Databases (SBBD), 2000, p. 158-171.
- [10] H. Zhang, C. Perng, Q. Cai, An improved algorithm for feature selection using fractal dimension, in: Proceedings of the Second International Workshop on Databases, Documents, and Information Fusion, 2002.
- [11] E. P. M. De Sousa, C. Traina Jr., A. J. M. Traina, L. Wu, C. Faloutsos, A fast and effective method to find correlations among attributes in databases, Data Mining and Knowledge Discovery 14 (2007) 367-407.
- [12] C. Traina Jr., A. J. M. Traina, C. Faloutsos, Fast feature selection using fractal dimension - Ten years later, Journal of Information and Data Management 1 (1) (2010) 17-20.
- [13] D. Mo, S. H. Huang, Fractal-based intrinsic dimension estimation and its application in dimensionality reduction, IEEE Transactions on Knowledge and Data Engineering 24 (1) (2012) 59-71.
- [14] J. G. Dy, C. E. Brodley, Feature Selection for Unsupervised Learning, Journal of Machine Learning Research 5 (2004) 845-889.
- [15] J. G. Dy, Unsupervised feature selection, in: H. Liu, H. Motoda (Eds.), Computational Methods of Feature Selection, Chapman Hall/CRC, London/Boca Raton, 2013, pp. 29-55.
- [16] S. Alelyani, J. Tang, H. Liu, Feature Selection for Clustering: A Review, in: C. C. Aggarwal, C. K. Reddy (Eds.), Data Clustering: Algorithms and Applications, Chapman Hall/CRC, London/Boca Raton, 2013, pp. 29-55.
- [17] D. W. Aha, R. L. Bankert, A comparative evaluation of sequential feature selection algorithms, in: D. Fisher, H. J. Lenz (Eds.), Learning from Data: AI and Statistics, Springer, New-York, 1996, pp. 199-206.
- [18] A. K. Jain, D. Zongker, Feature selection: Evaluation, application and small sample performance, IEEE Transactions on Pattern Analysis and Machine Intelligence 19 (2) (1997) 153-158.
- [19] A. Blum, P. Langley, Selection of relevant features and examples in machine learning, Artificial Intelligence 97 (1-2) (1997) 245-271.
- [20] L. C. Molina, L. Belanche, A. Nebot, Feature selection algorithms: A survey and experimental evaluation, in: Proceedings of 2002 IEEE International Conference on Data Mining (ICDM'02), Japan, 2002, pp. 306-313.
- [21] I. Guyon, A. Elisseeff, An introduction to variable and feature selection, Journal of Machine Learning Research 3 (2003) 1157-1182.
- [22] I. Guyon, S. Gunn, M. Nikravesh, L. A. Zadeh, Feature extraction: Foundations and Applications, Springer, Berlin, 2006.
- [23] T. Marill, D. M. Green, On the effectiveness of receptors in recognition systems, IEEE Transactions on Information Theory 9 (1) (1963) 11-17.
- [24] P. Pudil, J. Novovičová, J. Kittler, Floating search methods in feature selection, Pattern Recognition Letters 15 (11) (1963) 1119-1125.
- [25] S. M. Vieira, M. C. Sousa, T. A. Runkler, Ant colony optimization applied to feature selection in fuzzy classifiers, Lecture Notes in Computer Science 4529 (2007) 778788.
- [26] X. Wang, J. Yang, X. Teng, W. Xia, R. Jensen, Feature selection based on rough sets and particle swarm optimization, Pattern Recognition Letters 28 (4) (2007) 459-471.
- [27] F. Camastra, Data dimensionality estimation methods: a survey, Pattern Recognition 36 (12) (2003) 2945 - 2954.
- [28] E. Levina, P. J. Bickel, Maximum likelihood estimation of intrinsic dimension 17, in: Advances in Neural Information Processing Systems, Vol. 17, The MIT Press, Cambridge (USA), 2004.
- [29] J. Golay, M. Kanevski, C. D. Vega Orozco, M. Leuenberger, The multipoint Morisita index for the analysis of spatial patterns, Physica A 406 (2014) 191-202.
- [30] S. H. Hurlbert, Spatial Distribution of the Montane Unicorn, Oikos 58 (3) (1990) 257-271.
- [31] M. Morisita, Measuring of the Dispersion of Individuals and Analysis of the Distributional Patterns, Memoires of the Faculty of Science (Serie E), Kyushu University 2 (4) (1959) 215-235.
- [32] A. K. Jain, R. C. Dubes, Algorithms for Clustering Data, Prentice-Hall, New-Jersey, 1988.
- [33] J. Theiler, Estimating fractal dimension, Journal of the Optical Society of America 7 (6) (1990) 1055 - 1073.
- [34] B. Kégl, Intrinsic dimension estimation using packing numbers, in: Advances in Neural Information Processing Systems, Vol. 14, The MIT Press, Cambridge (USA), 2002.
- [35] B. B. Mandelbrot, The Fractal Geometry of Nature, W.H. Freeman, San Francisco, 1983.
- [36] S. Lovejoy, D. Schertzer, P. Ladoy, Fractal Characterization of Inhomogeneous Geophysical Measuring Networks, Nature 319 (6048) (1986) 43-44.
- [37] T. G. Smith, W. B. Marks, G. D. Lange, W. H. Sheriff, E. A. Neale, A Fractal Analysis of Cell Images, Journal of Neuroscience Methods 27 (2) (1989) 173-180.
- [38] K. Falconer, Fractal Geometry: Mathematical Foundations and Applications, 2nd Edition, Wiley, Chichester (UK), 2003.
- [39] H. G. E. Hentschel, I. Procaccia, The Infinite Number of Generalized Dimensions of Fractals and Strange Attractors, Physica D 8 (3) (1983) 435-444.
- [40] P. Grassberger, Generalized Dimensions of Strange Attractors, Physics Letters A 97 (6) (1983) 227-230.
- [41] G. Paladin, A. Vulpiani, Anomalous Scaling Laws in Multifractal Objects, Physics Reports 156 (4) (1987) 147-225.
- [42] T. Tel, A. Fülöp, T. Vicsek, Determination of Fractal Dimensions for Geometrical Multifractals, Physica A 159 (1989) 155-166.
- [43] T. Vicsek, Fractal Growth Phenomena, World Scientific, Singapore, 1993.
- [44] A. Rényi, Probability Theory, Akadémiai Kiadò, Budapest, 1970.
- [45] J. Balatoni, A. Rényi, On the Notion of Entropy, Publ. Math. Inst. Hungarian Acad. Sci (1) (1956) 5-40, english translation in Selected Papers of A. Rényi , Budapest, vol. 1 (1976), 558.
- [46] P. Grassberger, I. Procaccia, Characterization of strange attractors, Physical Review Letters 50 (5) (1983) 346-349.
- [47] L. Seuront, Fractals and Multifractals in Ecology and Aquatic Science, CRC Press, Boca Raton (USA), 2010.
- [48] Y. Chen, Multifractals of central place systems: Models, dimension spectrums, and empirical analysis, Physica A 402 (2014) 266-282.
- [49] M. M. Dubovikov, N. V. Starchenko, M. S. Dubovikov, Dimension of the minimal cover and fractal analysis of time series, Physica A 339 (3-4) (2004) 591-608.
- [50] S. Borgani, G. Murante, A. Provenzale, R. Valdarnini, Multifractal Analysis of the Galaxy Distribution: Reliability of Results from Finite Data Sets, Physical Review E 47 (6) (1993) 3879-3888.
- [51] S. Lovejoy, D. Schertzer, A. Tsonis, Functional Box-counting and Multiple Elliptical Dimensions in Rain, Science 235 (4792) (1987) 1036-1038.
- [52] S. Lovejoy, D. Schertzer, The Weather and Climate, Cambridge University Press, New-York, 2013.
- [53] Q. Huang, J. R. Lorch, R. C. Dubes, Can the fractal dimension of images be measured?, Pattern Recognition 27 (3) (1994) 339-349.
- [54] J. B. Florindo, O. M. Bruno, Fractal descriptors based on the probability dimension: A texture analysis and classification approach, Pattern Recognition Letters 42 (2014) 107-114.
- [55] F. Camastra, A. Vinciarelli, Estimating the intrinsic dimension of data with a fractal-based method, IEEE Transactions on Pattern Analysis and Machine Intelligence 24 (10) (2002) 1404-1407.
- [56] J. Eberhardt, Estimating Intrinsic Dimension, University of Minnesota, Duluth, 2007.
- [57] A. Asensio Ramos, H. Socas-Navarro, A. López Ariste, M. J. Martínez González, The intrinsic dimensionality of spectropolarimetric data, The Astrophysical Journal 660 (2007) 1690-1699.
- [58] J. C. MacKay, D, Z. Ghahramani, Comments on "maximum likelihood estimation of intrinsic dimension" by E. Levina and P. Bickel @ONLINE (Jan. 2005).
- URL http://http://www.inference.phy.cam.ac.uk/mackay/dimension/
- [59] D. Tuia, M. Kanevski, Envrionmental Monitoring Network Charaterization and Clustering, in: M. Kanevski (Ed.), Advanced Mapping of Environmental Data: Geostatistics, Machine Learning and Bayesian Maximum Entropy, Iste/Wiley, London/Hoboken(USA), 2008, pp. 19-46.
- [60] M. Kanevski, M. Maignan, Analysis and Modelling of Spatial Environmental Data, EPFL Press, Lausanne, 2004.
- [61] Y. Shi, C. Gong, Multifractality of a cartesian product of two fractals, Communications in Theoretical Physics 23 (1995) 245-248.
- [62] D. B. Ripley, Spatial Statistics, Wiley, New-York, 1981. | null | [
"Jean Golay",
"Mikhail Kanevski"
] | 2014-08-02T12:59:28+00:00 | 2015-05-06T15:20:24+00:00 | [
"physics.data-an"
] | A New Estimator of Intrinsic Dimension Based on the Multipoint Morisita Index | The size of datasets has been increasing rapidly both in terms of number of
variables and number of events. As a result, the empty space phenomenon and the
curse of dimensionality complicate the extraction of useful information. But,
in general, data lie on non-linear manifolds of much lower dimension than that
of the spaces in which they are embedded. In many pattern recognition tasks,
learning these manifolds is a key issue and it requires the knowledge of their
true intrinsic dimension. This paper introduces a new estimator of intrinsic
dimension based on the multipoint Morisita index. It is applied to both
synthetic and real datasets of varying complexities and comparisons with other
existing estimators are carried out. The proposed estimator turns out to be
fairly robust to sample size and noise, unaffected by edge effects, able to
handle large datasets and computationally efficient. |
1408.0370v2 | ## Spectral Approximation for Quasiperiodic Jacobi Operators
Charles Puelz, Mark Embree and Jake Fillman
Abstract. Quasiperiodic Jacobi operators arise as mathematical models of quasicrystals and in more general studies of structures exhibiting aperiodic order. The spectra of these self-adjoint operators can be quite exotic, such as Cantor sets, and their fine properties yield insight into the associated quantum dynamics, that is, the one-parameter unitary group that solves the time-dependent Schr¨dinger equation. Quasiperio odic operators can be approximated by periodic ones, the spectra of which can be computed via two finite dimensional eigenvalue problems. Since long periods are necessary for detailed approximations, both computational efficiency and numerical accuracy become a concern. We describe a simple method for numerically computing the spectrum of a periodK Jacobi operator in O K ( 2 ) operations, then use the algorithm to investigate the spectra of Schr¨dinger operators with Fibonacci, peo riod doubling, and Thue-Morse potentials.
Mathematics Subject Classification (2010). Primary 47B36, 65F15, 81Q10; Secondary 15A18, 47A75.
Keywords. Jacobi operator, Schr¨dinger operator, quasicrystal, Fibonacci, o period doubling, Thue-Morse.
## 1. Introduction
For given sets of parameters { a n } { , b n } ∈ glyph[lscript] ∞ ( ❩ ), the corresponding Jacobi operator J : glyph[lscript] 2 ( ❩ ) → glyph[lscript] 2 ( ❩ ) is defined entrywise by
$$( \mathcal { O } \psi ) _ { n } = a _ { n - 1 } \psi _ { n - 1 } + b _ { n } \psi _ { n } + a _ { n } \psi _ { n + 1 } \quad \quad ( 1. 1 )$$
for all { ψ n } ∈ glyph[lscript] 2 ( ❩ ). When there exists a positive integer K such that
$$a _ { n } = a _ { n + K }, \ \ b _ { n } = b _ { n + K } \quad \text{for all } n \in \mathbb { Z },$$
the Jacobi operator is said to be periodic with period K . Here we are interested in computing the spectrum σ ( J ) of such an operator when the period K is very long, as a route to high fidelity numerical approximations of the
more intricate spectra of operators with aperiodic coefficients. These spectra are important, as they can help us understand the quantum dynamics of solutions to the time-dependent Schr¨dinger equation [31]. o
The spectrum of a periodK Jacobi operator can be calculated from classical Floquet-Bloch theory, the relevant highlights of which we briefly recapitulate for later reference. (Our presentation most closely follows Toda [48, Ch. 4]; see also, e.g., [44, Ch. 5], [46, Ch. 7],[49].) For a scalar E , any solution to J ψ = Eψ satisfies
$$\begin{bmatrix} \psi _ { p K + 1 } \\ \psi _ { p K } \end{bmatrix} = M _ { K } ^ { p } \begin{bmatrix} \psi _ { 1 } \\ \psi _ { 0 } \end{bmatrix}$$
for each p ∈ ❩ , where M K ≡ M K ( E ) denotes the 2 × 2 monodromy matrix
$$M _ { K } = \begin{bmatrix} \frac { E - b _ { K } } { a _ { K } } & - \frac { a _ { K - 1 } } { a _ { K } } \\ 1 & 0 \end{bmatrix} \cdots \begin{bmatrix} \frac { E - b _ { 2 } } { a _ { 2 } } & - \frac { a _ { 1 } } { a _ { 2 } } \\ 1 & 0 \end{bmatrix} \begin{bmatrix} \frac { E - b _ { 1 } } { a _ { 1 } } & - \frac { a _ { K } } { a _ { 1 } } \\ 1 & 0 \end{bmatrix}. \quad \text{ (1.3)}$$
Note that
$$\det _ { \substack { M _ { K } \\ \dots \, - \, - \, - \, - \, - \, - \, - \, - \, - \, - \, - \, - \, - \, - \, - \, - \, - \, - \, - \, - \, - \, - \, - \, - \, - \, - \, - \, - \, - \, - \, - \, - \, - \, - \, - \, - \, - \, - \, - \, - \, - \, - \, - \, - \, - \, - \, - \, - \, - \, - \, - \, - \, - \, - \, - \, - \, - \, - \, - \, - \, - \, - \, - \, - \, - \, - \, - \dots \, - \, - \, - \, - \, - \, - \, - \, - \, - \, - \, - \, - \, - \, - \, - \, - \, - \, - \, - \, - \, - \, - \, - \, - \, - \, - \, - \, - \, - \, - \, - \, - \, - \, - \, - \, - \, - \, - \, - \, - \, - \, - \, - \, - \, - \, - \, - \, - \, - \, - \, - \, - \, - \, - \, - \, - \, - \, - \, - \, - \, - \, - \, - \, - \, - \
\det _ { \substack { M _ { K } \\ \dots \, - \, - \, - \, - \, - \, - \, - \, - \, - \, - \, - \, - \, - \, - \, - \, - \, - \, - \, - \, - \, - \, - \, - \, - \, - \, - \, - \, - \, - \, - \, - \, - \, - \, - \, - \, - \, - \, - \, - \, - \, - \, - \, - \, - \, - \, - \, - \, - \, - \, - \, - \, - \, - \, - \, - \, - \, - \, - \, - \, - \, -. \, - \, - \, - \, - \, - \, - \, - \, - \, - \, - \, - \, - \, - \, - \, - \, - \, - \, - \, - \, - \, - \, - \, - \, - \, - \, - \, - \, - \, - \, - \, - \, - \, - \, - \, - \, - \, - \, - \, - \, - \, - \, - \, - \, - \, - \, - \, - \, - \, - \, - \, - \, - \, - \, - \, - \, - \, - \, - \, - \, - \, - \, - \, - \, - \, - \, - \. \, - \, - \, - \, - \, - \, - \, - \, - \, - \, - \, - \, - \, - \, - \, - \, - \, - \, - \, - \, - \, - \, - \, - \, - \, - \, - \, - \, - \, - \, - \, - \, - \, - \, - \, - \, - \, - \, - \, - \, - \, - \, - \, - \, - \, - \, - \, - \, - \, - \, - \, - \, - \, - \, - \, - \, - \, - \, - \, - \, - \, - \, - \, - \, - \, - \, - \: - \, - \, - \, - \, - \, - \, - \, - \, - \, - \, - \, - \, - \, - \, - \, - \, - \, - \, - \, - \, - \, - \, - \, - \, - \, - \, - \, - \, - \, - \, - \, - \, - \, - \, - \, - \, - \, - \, - \, - \, - \, - \, - \, - \, - \, - \, - \, - \, - \, - \, - \, - \, - \, - \, - \, - \, - \, - \, - \, - \, - \, - \, - \, - \, - \, - \, - - \, - \, - \, - \, - \, - \, - \, - \, - \, - \, - \, - \, - \, - \, - \, - \, - \, - \, - \, - \, - \, - \, - \, - \, - \, - \, - \, - \, - \, - \, - \, - \, - \, - \, - \, - \, - \, - \, - \, - \, - \, - \, - \, - \, - \, - \, - \, - \, - \, - \, - \, - \, - \, - \, - \, - \, - \, - \, - \, - \, - \, - \, - \, - \, - \, - \, -. \, - \, - \, - \, - \, -. \, - \, - \, - \, - \, - \, - \, - \, - \, - \, - \, - \, - \, - \, - \, - \, - \, - \, - \, - \, - \, - \, - \, - \, - \, - \, - \, - \, - \, - \, - \, - \, - \, - \, - \, - \, - \, - \, - \, - \, - \, - \, - \, - \, - \, - \, - \, - \, - \, - \, - \, - \, - \, - \, - \, - \, - \, - \, - \, - \, - \, - - \, - \, - \, - \, - \, -. \, - \, - \, - \, - \, - \, - \, - \, - \, - \, - \, - \, - \, - \, - \, - \, - \, - \, - \, - \, - \, - \, - \, - \, - \, - \, - \, - \, - \, - \, - \, - \, - \, - \, - \, - \, - \, - \, - \, - \, - \, - \, - \, - \, - \, - \, - \, - \, - \, - \, - \, - \, - \, - \, - \, - \, - \, - \, - \, - \, - \, \, - \, - \, - \, - \, - \, - \, - \, - \, - \, - \, - \, - \, - \, - \, - \, - \, - \, - \, - \, - \, - \, - \, - \, - \, - \, - \, - \, - \, - \, - \, - \, - \, - \, - \, - \, - \, - \, - \, - \, - \, - \, - \, - \, - \, - \, - \, - \, - \, - \, - \, - \, - \, - \, - \, - \, - \, - \, - \, - \, - \, - \, - \, - \, - \, - \, - \sigma _ { 1 } }$$
Now when J is periodic, E ∈ σ ( J ) provided J ψ = Eψ with bounded nontrivial ψ = { ψ n } , 1 which by (1.2) and (1.4) requires the eigenvalues of M K to have unit modulus. From
$$\det ( \gamma - M _ { K } ) = \gamma ^ { 2 } - \text{tr} ( M _ { K } ) \gamma + 1,$$
where tr( ) denotes the trace, the eigenvalues of · M K have unit modulus when
$$- \, 2 \leq \text{tr} ( M _ { K } ) \leq 2.$$
Since tr( M k ) is a degreeK polynomial in E , in principle we can find σ ( J ) by solving the two polynomial equations tr( M K ( E )) = ± 2, giving σ ( J ) as the union of K real intervals. For large K such numerical computations can incur significant errors, as illustrated in [14, Sec. 7.1]. Alternatively, note that if [ ψ , ψ 1 0 ] T is an eigenvector of M K associated with eigenvalue γ = e iθ , then by definition (1.1) and periodicity, J ψ = Eψ and ψ K j + = γψ j imply
$$\text{by comiton} \, ( 1. 1 ) \, \text{and peroicity}, \, \partial \psi = \mathcal { L } \psi \, \text{and} \, \psi _ { K + j } = \gamma \psi _ { j } \, \text{imply} \\ \begin{bmatrix} b _ { 1 } & a _ { 1 } & & e ^ { - i \theta } a _ { K } \\ a _ { 1 } & b _ { 2 } & \ddots & \\ & \ddots & \ddots & \ddots \\ e ^ { i \theta } a _ { K } & & a _ { K - 1 } & a _ { K - 1 } & b _ { K } \end{bmatrix} \begin{bmatrix} \psi _ { 1 } \\ \psi _ { 2 } \\ \vdots \\ \psi _ { K - 1 } \\ \psi _ { K } \end{bmatrix} = \mathcal { E } \begin{bmatrix} \psi _ { 1 } \\ \psi _ { 2 } \\ \vdots \\ \psi _ { K - 1 } \\ \psi _ { K } \end{bmatrix}, \\ \text{where all unspecified entries in the matrix equal zero. Solving} \, \text{$this $K\times K$}$$
where all unspecified entries in the matrix equal zero. Solving this K × K symmetric matrix eigenvalue problem for any θ ∈ [0 , 2 π ) gives K points in σ ( J ), one in each of the K intervals. We can compute σ ( J ) directly by noting
1 The spectrum of a Jacobi operator J is given by the closure of the set of E ∈ ❘ for which a nontrivial polynomially bounded solution to J ψ = Eψ exists. When J is periodic, one either has a bounded solution or all solutions grow exponentially on at least one half-line.
that θ = 0 and θ = π give the endpoints of these intervals. We shall thus focus on the two K × K symmetric matrices
$$\i \text{ the two $K\times K$ symmetric matrices} \\ \mathbf J _ { \pm } = \begin{bmatrix} b _ { 1 } & a _ { 1 } & & \pm a _ { K } \\ a _ { 1 } & b _ { 2 } & \ddots & \\ & \ddots & \ddots & \ddots \\ & & \ddots & b _ { K - 1 } & a _ { K - 1 } \\ \pm a _ { K } & & a _ { K - 1 } & b _ { K } \end{bmatrix}. \quad ( 1. 7 ) \\ \text{ecsly, enumerating the $2K\,eigenvalues of $J_{+}$ and $J_{-}$ such that}$$
More precisely, enumerating the 2 K eigenvalues of J + and J -such that
$$E _ { 1 } < E _ { 2 } \leq E _ { 3 } < E _ { 4 } \leq \dots \leq E _ { 2 K - 1 } < E _ { 2 K }$$
(strict inequalities separate eigenvalues from J + and J -), then
$$\sigma ( \mathfrak { J } ) = \bigcup _ { j = 1 } ^ { K } \, [ E _ { 2 j - 1 }, E _ { 2 j } ].$$
This discussion suggests three ways to compute the spectrum (1.9):
- 1. For a fixed E , test if E ∈ σ ( J ) by explicitly calculating tr( M E k ( )) and checking if (1.6) holds;
- 2. Construct the degreeK polynomial tr( M K ( E )) and find the roots of tr( M K ( E )) = ± 2;
- 3. Compute the eigenvalues of the two K × K symmetric matrices J ± .
The first method gives a fast way to test if E ∈ σ ( J ) for a given E , but is an ineffective way to compute the entire spectrum. The second method suffers from the numerical instabilities mentioned earlier. The third approach is most favorable, but O K ( 3 ) complexity and numerical inaccuracies in the computed eigenvalues become a concern for large K .
Jacobi operators with long periods arise as approximations to Schr¨o dinger operators with aperiodic potentials. For one special case (the almost Mathieu potential), Thouless [47] and Lamoureux [29] proposed an O K ( 2 ) algorithm to compute the spectra of J ± for the periodK approximation. Section 2 describes a simpler O K ( 2 ) algorithm that does not exploit special properties of the potential, and so applies to any periodK Jacobi operator. Section 3 addresses aperiodic potentials in some detail, showing how their spectra can be covered by those of periodic approximations. Section 4 shows application of our algorithm to estimate the fractal dimension of the spectrum for aperiodic operators with potential given by primitive substitution rules.
## 2. Algorithm
The conventional algorithm for finding all eigenvalues of a general symmetric matrix A first requires the application of unitary similarity transformations to reduce the matrix to tridiagonal form (in which all entries other than those on the main diagonal and the first super- and sub-diagonals are zero). This transformation is the most costly part of the eigenvalue computation: for a
Figure 1. The nonzero pattern of J ± for K = 32 (left) and an illustration of all the entries that are nonzero at some point in the transformation of J ± to tridiagonal form using the conventional plane rotation approach (right).
K × K matrix, the reduction takes O K ( 3 ) operations, while the eigenvalues of the tridiagonal matrix can be found to high precision in O K ( 2 ) further operations [38, § 8.15]. When many entries of A are zero, one might exploit this structure to perform fewer elementary similarity transformations. This is the case when A is banded: a j,k = 0 when | j -k | > b , where b is the bandwidth of A . For fixed b , the tridiagonal reduction takes O K ( 2 ) operations as K →∞ .
The matrix J ± in (1.7) is tridiagonal plus entries in the (1 , K ) and ( K, 1) positions that give it bandwidth b = K . One might still hope to somehow exploit the zero structure to quickly reduce J ± to tridiagonal form. Unfortunately, the transformation that eliminates the (1 , K ) and ( K, 1) entries creates new nonzero entries where once there were zeros, starting a cascade of new nonzeros whose sequential elimination leads again to O K ( 3 ) complexity. Figure 1 shows how the conventional approach to tridiagonalizing a sparse matrix (using Givens plane rotations) eventually creates O K ( 2 ) nonzero entries, requiring O K ( 2 ) storage and O K ( 3 ) floating point operations.
The challenge is magnified by the eigenvalues themselves. As described in Section 3, we approximate aperiodic operators whose spectra are Cantor sets, implying that the eigenvalues of σ ( J ± ) will be tightly clustered. The accuracy of these computed eigenvalues is critical to the applications we envision (e.g., estimating the fractal dimension of the Cantor sets), warranting use of extended (quadruple) precision arithmetic that magnifies the cost of O K ( 3 ) operations. Moreover, these studies often examine a family of operators over many parameter values (e.g., as the { b n } terms are scaled), so expedient algorithms are helpful even when K is tractable for a single matrix.
Thouless [47] and, in later, more complete work, Lamoureux [29] provide an explicit unitary matrix Q ± such that Q J Q ∗ ± ± ± is tridiagonal in the special case of the almost Mathieu potential,
$$a _ { n } = 1, \quad b _ { n } = 2 \lambda \cos ( 2 \pi ( n \alpha + \theta ) ),$$
where α is a rational approximation to an irrational parameter of true interest, and λ and θ are constants. This transformation gives an O K ( 2 ) algorithm for computing σ ( J ± ), but relies on the special structure of the potential.
glyph[negationslash]
Alternatively, we note that one can compute all eigenvalues of J ± in O K ( 2 ) time by simply reordering the rows and columns of J ± to yield a matrix with small bandwidth that is independent of K . Recall that the nonzero pattern of a symmetric matrix A can be represented as an undirected graph having vertices labeled 1 , . . . , K , with distinct vertices j and k joined by an edge if a j,k = a k,j = 0. (We suppress the loops corresponding to a j,j = 0.) The graph for J ± has a single cycle, shown in Figure 2 for K = 8. In the conventional labeling, the corner entries in the (1 , K ) and ( K, 1) positions give an edge between vertices 1 and K . To obtain a matrix with narrow bandwidth, simply relabel the vertices in a breadth-first fashion starting from vertex 1, as illustrated in Figure 2. Now each vertex only connects to vertices whose labels differ by at most two : if we permute the rows and columns of the matrix in accord with the relabeling, the resulting matrix will have bandwidth 2 (i.e., a pentadiagonal matrix). More explicitly, define glyph[negationslash]
$$p ( j ) = \begin{cases} \ 2 j - 1, & j \in \{ 1, \dots, \lceil K / 2 \rceil \} ; \\ 2 ( K - j - 1 ), & j \in \{ \lceil K / 2 \rceil + 1, \dots, K \}. \end{cases}$$
Let P = [ e p (1) , e p (2) , . . . , e p K ( ) ], where e j is the j th column of the K × K identity matrix; then PJ P ± ∗ has bandwidth b = 2. When K = 8,
$$y \, \text{ matrix} ; \, \text{ then } \mathbf P J _ { \pm } \mathbf P ^ { * } \, \text{ has bandwidth } b = 2. \, \text{ When } K = 8, \\ \mathbf J _ { \pm } = \, \left [ \begin{array} { c c c c } b _ { 1 } & a _ { 1 } & & & \pm a _ { 8 } \\ a _ { 1 } & b _ { 2 } & a _ { 2 } & & & \\ & a _ { 2 } & b _ { 3 } & a _ { 3 } & & \\ & a _ { 3 } & b _ { 4 } & a _ { 4 } & & \\ & & a _ { 4 } & b _ { 5 } & a _ { 5 } & \\ & & & a _ { 5 } & b _ { 6 } & a _ { 6 } \\ & & & & a _ { 6 } & b _ { 7 } & a _ { 7 } \\ \pm a _ { 8 } & & & & a _ { 7 } & b _ { 8 } \end{array} \right ] \\ \text{ dered to }$$
is reordered to
$$\text{$s$ reordered to} \\ \text{$PJ_{\pm}P^{*}=\left[\begin{matrix} b _ { 1 } & \pm a _ { 8 } & a _ { 1 } \\ \pm a _ { 8 } & b _ { 8 } & a _ { 7 } \\ a _ { 1 } & b _ { 2 } & a _ { 2 } \\ a _ { 7 } & b _ { 7 } & a _ { 6 } \\ a _ { 2 } & b _ { 3 } & a _ { 3 } \\ a _ { 6 } & b _ { 6 } & a _ { 5 } \\ a _ { 3 } & b _ { 4 } & a _ { 4 } \\ a _ { 5 } & a _ { 4 } & b _ { 5 } \end{matrix} \right ],$$
where unspecified entries are zero. The tridiagonal reduction of banded symmetric matrices has been carefully studied, starting with Rutishauser 2 [42]; see [10] for contemporary algorithmic considerations. Such matrices can be
2 Rutishauser was motivated by pentadiagonal matrices that arise in the addition of continued fractions.
Figure 2. The vertex reordering scheme for K = 8.
Figure 3. Analogue of Figure 1 for the pentadiagonal matrix from the breadth-first ordering (left) and the nonzeros that arise in reduction of this matrix to tridiagonal form using the bulge-chasing approach (right).
reduced to tridiagonal form using Givens plane rotations applied in a 'bulgechasing' procedure that increases the bandwidth by one; Figure 3 shows the nonzero entries introduced by this reduction. 3 Removing the ( j + 2 , j ) entry introduces a new entry in the third subdiagonal (a 'bulge') that is 'chased' toward the bottom right with O K ( ) additional Givens rotations, each of which requires O (1) floating point operations. Performing this exercise for j = 1 , . . . , K -2 amounts to O K ( 2 ) work and O K ( ) storage to reduce PJ P ± ∗ to tridiagonal form, an improvement over the usual O K ( 3 ) work and O K ( 2 ) storage. (Our application does not require the eigenvectors of J ± , so we do not store the transformations that tridiagonalize J ± .)
One can compute a banded tridiagonalization using the LAPACK software library's dsbtrd routine, or compute the eigenvalues directly with the
3 An alternative method that finds the eigenvalues of a banded symmetric matrix directly in its band form is described in [38, § 8.16]. This method, based on small Householder reflectors, is particularly effective when a small subset of the spectrum is sought.
Figure 4. Performance of LAPACK's standard ( dsyev ) and banded ( dsbev ) symmetric eigensolvers in double and quadruple precision, applied to the Fibonacci model.
banded eigensolver dsbev [2]. (If PJ P ± ∗ stored in sparse format, MATLAB's eig command will identify the band form and find the eigenvalues in O K ( 2 ) time.) We have benchmarked our computations in LAPACK with standard double precision arithmetic and a variant compiled for quadruple precision. 4 When a n = 1 and b n = 0 for all n , the eigenvalues of J ± are known in closed form [23]. With the reordering scheme described above, LAPACK returns the correct eigenvalues, up to the order of machine precision (roughly 10 -16 for double precision and 10 -34 for quadruple precision). Figure 4 compares the timing of the reordered scheme to the traditional dense matrix approach. In both double and quadruple precision, the O K ( 2 ) performance of the reordered approach offers a significant advantage. (These timings were performed on a desktop with a 3.30 GHz Intel Xeon E31245 processor, applied to the Fibonacci model described in the next section. The numbers in the legend indicate the slope of a linear fit of the last five data points, and each algorithm is averaged over the four Fibonacci parameters λ = 1 2 3 4.) , , ,
## 3. Spectral theory for quasiperiodic Schr¨dinger operators o
We focus on Jacobi operators that are discrete Schr¨dinger operators o , that is, those operators for which the off-diagonal terms satisfy a n = 1 for all n , and the potential { b n } varies in a deterministic but non-periodic fashion. 5
4 http://icl.cs.utk.edu/lapack-forum/viewtopic.php?f=2&t=2739 gives compilation instructions.
5 In off-diagonal models, b n = 0 for all n , while the a n coefficients vary aperiodically, see, e.g., [33, 50].
For several prominent examples the spectrum is a Cantor set; in other cases even a gross description of the spectral type has been elusive.
Periodic approximations lead to elegant covers of the spectra of the quasiperiodic operators, 6 and while the arguments that produce these covers are now standard, there is not such a direct venue in the literature where this framework is quickly summarized. Consequently, we recapitulate the essential arguments for the reader unfamiliar with this landscape; those seeking greater detail can consult the more extensive survey [13]. In Section 4 we shall apply our algorithm to numerically compute the spectral covers described here.
Avariety of quasiperiodic potentials have been investigated in the mathematical physics literature; for a survey, see, e.g., [18]. Most prominent is the almost Mathieu operator [25, 47], with potential
$$b _ { n } = 2 \lambda \cos ( 2 \pi ( n \alpha + \theta ) )$$
glyph[negationslash]
for irrational α , nonzero coupling constant λ , and phase θ ∈ ❘ . The spectrum of the almost Mathieu operator is a Cantor set for all irrational α , every θ , and every λ = 0 [3]. Moreover, the Lebesgue measure of the spectrum is precisely 4 1 ∣ ∣ - | λ | ∣ ∣ whenever α is irrational [4, Theorem 1.5]. Of particular interest is the Hausdorff dimension of the spectrum in the critical case λ = 1, about which very little is known; see [30] for some partial results.
Sturmian potentials take the form
$$b _ { n } = \lambda \chi _ { [ 1 - \alpha, 1 ) } ( ( n \alpha \, + \theta ) \bmod 1 ),$$
where χ S is the indicator function on the set S ⊂ ❘ and α , λ , and θ play the same role as in (3.1). For such potentials the spectrum is a Cantor set of zero Lebesgue measure for all irrational α , nonzero λ and phases θ [8]. It is conjectured that for a fixed nonzero coupling λ , the Hausdroff dimension of the spectrum is constant on a set of α 's of full Lebesgue measure; currently, this is only known for λ ≥ 24 [16, Theorem 1.2].
## 3.1. Quasiperiodic operators from substitution rules
Alternatively, aperiodic potentials can be constructed from primitive substitution rules. Unlike the almost Mathieu and Sturmian cases, the spectral type of the operators is not well-understood. Having spectrum of zero Lebesgue measure precludes the presence of absolutely continuous spectrum, a result known well before Damanik and Lenz proved zero-measure spectrum; see the main result of [28]. So far, numerous partial results exclude eigenvalues for particular substitution operators [8, 11, 12, 17, 26], and no results yet establish the existence of eigenvalues for any (two-sided) substitution operator. The construction is slightly more involved than previous examples, but since seeking a better understanding of substitution potentials is a motivation of this work, we describe these objects in detail.
6 Except for the Almost Mathieu operator, the potentials we describe are not quasiperiodic in the classical sense of being almost periodic sequences with finitely generated frequency modules. However, the terminology is completely standard at this point.
↦
↦
↦
↦
↦
↦
↦
Let A ⊂ ❘ be a finite set, called the alphabet . 7 A substitution on A is a rule that replaces elements of A by finite-length words over A . For example, the period doubling substitution, S PD , is defined by the rules a → ab and b → aa over the two-letter alphabet A = { a b , } [9]. The Thue-Morse substitution uses the rules a → ab and b → ba [7, 20]. The Fibonacci potential [27, 36] can be viewed as a Sturmian potential with α = ( √ 5 -1) / 2 and θ = 0, or as a primitive substitution potential with rules a → ab , b → a . (The equivalence of these definitions follows from [8, Lemma 1b].) One can also study substitutive sequences on larger alphabets; for example, the Rudin-Shapiro substitution is defined on the four-symbol alphabet A = { a b c d , , , } by the rules a → ab , b → ac , c → db , and d → dc [41, 43].
↦
↦
Each of the aforementioned examples enjoys a property known as primitivity, which can be described informally as the existence of an iterate which maps each letter to a word containing the full alphabet. More precisely, we say that a substitution S is primitive if there exists some k ∈ ❩ + so that for every a b , ∈ A , b is a subword of S k ( a ).
↦
We now describe how a primitive substitution rule leads to a quasiperiodic Schr¨dinger operator, focusing on period doubling as a concrete example. o To obtain an aperiodic sequence, start with the symbol a and form the sequence w k = S k PD ( a ) by iteratively applying the period doubling substitution rules, a → ab and b → aa . The result is a sequence of finite words: w 0 = a , w 1 = ab , w 2 = abaa , w 3 = abaaabab , and so on. Notice that w k is always a prefix of w k +1 . In particular, there is a well-defined limiting sequence,
↦
$$x _ { P D } = \lim _ { k \to \infty } S _ { P D } ^ { k } ( a ) = a b a a b a b a b a a a a \dots, \quad \quad ( 3. 3 )$$
with the property that x PD is fixed by the period doubling substitution; sequences with this property are called substitution words for the substitution.
From a substitution word x PD one can construct a quasiperiodic potential for a discrete Schr¨dinger operator. Given a coupling constant o λ , take
$$a = \lambda ; \quad b = 0 ; \quad b _ { n } = n t h \, \text{symbol of } x _ { P D }. \quad \quad ( 3. 4 )$$
One subtlety remains: the substitution word x PD is a one-sided sequence, while our potentials are two-sided, i.e., we should specify b n for all n ∈ ❩ . To generate two-sided potentials, one considers an accumulation point of leftshifts of x PD ; equivalently, one considers a two-sided sequence with the same local factor structure as x PD . The details of this construction follow.
Suppose S is a primitive substitution on the finite alphabet A ⊂ ❘ and x ∈ A ◆ is some substitution word thereof, i.e., S x ( ) = x . The subshift generated by S is the set of all two-sided sequences with the same local factor structure as x . More precisely,
Ω S = { ω ∈ A ❩ : ω n · · · ω m is a subword of x for every n ≤ m . } (3.5) Using primitivity of S , one can check that this definition of Ω S does not depend upon the choice of substitution word. One can also generate the set
7 We do not necessarily have to restrict our attention to alphabets consisting of real numbers, but this makes the definition of our subshift potentials in (3.7) somewhat simpler.
↦
Ω S via the following dynamical procedure. First, endow the sequence space A ❩ with some metric that induces the product topology thereupon, e.g.,
❩ where δ a,b denotes the usual Kronecker delta symbol. The sequences ω and ω ′ are close with respect to the metric in (3.6) if and only if they agree on a large window centered at the origin, so this metric does indeed induce the topology of pointwise convergence on Ω S . One can check that Ω S defined by (3.5) coincides precisely with the set of limits of convergent subsequences of the sequence ( T n x ) ∞ n =1 , where T denotes the usual left shift ( Tω ) n = ω n +1 . (There is a minor technicality here: since x is a one-sided sequence ( T n x ) k is only well-defined for n > | k | when k is negative.)
$$d ( \omega, \omega ^ { \prime } ) = \sum _ { n \in \mathbb { Z } } \frac { 1 - \delta _ { \omega _ { n }, \omega _ { n } ^ { \prime } } } { 2 ^ { | n | + 1 } },$$
Primitivity of S implies that the topological dynamical system (Ω S , T ) is strictly ergodic [39, Proposition 5.2 and Theorem 5.6]. For each ω ∈ Ω , S one obtains a Schr¨dinger operator o H ω on glyph[lscript] 2 ( ❩ ) defined via
$$( H _ { \omega } \psi ) _ { n } = \psi _ { n - 1 } + \omega _ { n } \psi _ { n } + \psi _ { n + 1 }$$
for each n ∈ ❩ . (The right hand side of (3.7) makes sense, since we chose A ⊆ ❘ .) Minimality of (Ω S , T ) implies ω -invariance of the spectrum.
Proposition 3.1. Given Ω S and H ω as above, there is a uniform compact set Σ with the property that σ H ( ω ) = Σ for every ω ∈ Ω S .
Proof. Given ω, ω ′ ∈ Ω , there is a sequence S { n k } ⊂ ❩ with the property that T n k ω → ω ′ as k →∞ . (This is a consequence of minimality of (Ω S , T ), which follows from [39, Proposition 4.7], for example.) In particular,
$$H _ { \omega ^ { \prime } } = s _ { \substack { k \rightarrow \infty \\ k \rightarrow \infty } } H _ { T ^ { n } _ { k } \omega }.$$
By a standard strong approximation argument (e.g., [40, Theorem VIII.24]),
$$\sigma ( H _ { \omega ^ { \prime } } ) \subseteq \bigcap _ { \ell = 1 } ^ { \infty } \overline { \bigcup _ { k = \ell } ^ { \infty } \sigma ( H _ { T ^ { n _ { k } } \omega } ) } = \sigma ( H _ { \omega } ).$$
By symmetry, we can run the previous argument with the roles of ω and ω ′ reversed, so σ H ( ω ) = σ H ( ω ′ ). glyph[square]
This is the upshot of the previous proposition: if we want to study the spectrum of a two-sided substitutive Schr¨dinger operator o as a set , then we can work with any member of the associated subshift.
One can avoid the construction needed to generate two-sided potentials by considering instead half-line Jacobi operators, J + : glyph[lscript] 2 ( ◆ ) → glyph[lscript] 2 ( ◆ ). These operators are defined entrywise by (1.1) for n ∈ ◆ with the normalization ψ 0 = 0 to make ( J + ψ ) 1 well defined. If J + denotes the Jacobi operator defined by a n ≡ 1 and (3.4), and J denotes a two-sided Jacobi operator generated in one of the two fashions just described, then by [44, Theorem 7.2.1],
$$\sigma _ { \text{ess} } ( \mathfrak { I } _ { + } ) = \sigma ( \mathfrak { I } ),$$
where σ ess ( ) · denotes the essential spectrum. In particular, σ ( J + ) and σ ( J ) have the same Hausdorff dimension, since (3.9) implies that they coincide up to a countable set of isolated points.
## 3.2. Periodic approximations
All the classes of quasiperiodic models we have described have natural periodic approximations. For the almost Mathieu and Sturmian cases: replace the irrational α with a rational approximant; for the substitution rules: pick a starting symbol, generate a string from finitely many applications of the substitution rules, and repeat that string periodically. We seek high fidelity numerical approximations to these periodic spectra, as a vehicle for understanding properties of quasiperiodic models, such as the fractal dimension of the spectrum.
In the case of substitution rules, we shall describe how periodic approximations lead to an upper bound on the spectrum of the quasiperiodic operator. Again we focus on the period doubling substitution. Fix S PD , x PD as before, choose some ω ∈ Ω PD , and put w a k = S k ( a ) and w b k = S k ( b ). We generate periodic Schr¨dinger operators o H a k and H b k by repeating the strings w a k and w b k periodically, giving H a k and H b k with coefficients having period 2 k . Moreover, we choose H a k and H b k in such a way that
$$H _ { \omega } = \underset { k \rightarrow \infty } { s \text{-} \lim } H _ { k } ^ { a } = \underset { k \rightarrow \infty } { s \text{-} \lim } H _ { k } ^ { \text{b} }.$$
Define Σ a k ≡ σ H ( a k ) and Σ b k ≡ σ H ( b k ) for all k ≥ 0. Application of strong approximation, as before, implies
$$\Sigma \subseteq \bigcap _ { n = 1 } ^ { \infty } \overline { \bigcup _ { k = n } ^ { \infty } \Sigma _ { k } ^ { a } }, \quad \Sigma \subseteq \bigcap _ { n = 1 } ^ { \infty } \overline { \bigcup _ { k = n } ^ { \infty } \Sigma _ { k } ^ { b } }.$$
These unions are too large to be computationally tractable, but the hierarchical structure of the periodic approximations saves the day. In these cases the monodromy matrices (1.3) take the forms
$$M _ { k } ^ { a } ( E ) \ & = \ \begin{bmatrix} E - w _ { k } ^ { a } ( 2 ^ { k } ) & - 1 \\ 1 & 0 \end{bmatrix} \cdots \begin{bmatrix} E - w _ { k } ^ { a } ( 1 ) & - 1 \\ 1 & 0 \end{bmatrix} \\ M _ { k } ^ { b } ( E ) \ & = \ \begin{bmatrix} E - w _ { k } ^ { b } ( 2 ^ { k } ) & - 1 \\ 1 & 0 \end{bmatrix} \cdots \begin{bmatrix} E - w _ { k } ^ { b } ( 1 ) & - 1 \\ 1 & 0 \end{bmatrix},$$
$$\dots$$
where now the subscript k denotes the k th iteration of the substitution rule, and hence a full period of length K = 2 . Recalling the discriminant condik tion (1.6), define
$$x _ { k } ( E ) \equiv \text{tr} ( M _ { k } ^ { a } ( E ) ), \ \ y _ { k } ( E ) \equiv \text{tr} ( M _ { k } ^ { b } ( E ) ).$$
As in (1.6), these functions encode the spectra of the periodic approximants, in that Σ a k = { E : | x k ( E ) | ≤ } 2 and Σ b k = { E : | y k ( E ) | ≤ } 2 . The rules of the
period doubling substitution imply
$$M _ { k + 1 } ^ { a } = M _ { k } ^ { \text{b} } M _ { k } ^ { a }$$
$$M _ { k + 1 } ^ { \flat } = M _ { k } ^ { a } M _ { k } ^ { a }.$$
Applying the Cayley-Hamilton theorem ( M 2 k -tr( M M k ) k + I = 0) to (3.11) and (3.12) yields
$$x _ { k + 1 } = x _ { k } y _ { k } - 2$$
$$y _ { k + 1 } = x _ { k } ^ { 2 } - 2,$$
given in [9, eq. (1.9)]. Now (3.13) and (3.14) imply Σ a k +1 ∪ Σ b k +1 ⊆ Σ a k ∪ Σ b k for all k ≥ 0, thus reducing (3.10) to the more tractable
$$[ \text{Period Doubling} ] \quad \ \ \Sigma \subseteq \left \{ \, \, \right \} \Sigma _ { k } ^ { a } \cup \Sigma _ { k } ^ { b }.$$
$$\Sigma \subseteq \bigcap _ { k = 1 } ^ { \infty } \Sigma _ { k } ^ { a } \cup \Sigma _ { k } ^ { b }.$$
The spectrum for the Thue-Morse substitution can be expressed in the same way, except that substitution rule replaces (3.13)-(3.14) with
$$x _ { k + 1 } = x _ { k - 1 } ^ { 2 } ( x _ { k } - 2 ) + 2 \quad \quad \quad$$
$$y _ { k + 1 } & = x _ { k + 1 }.$$
Reasoning as in the period doubling case, (3.16)-(3.17) implies
[Thue-Morse]
$$\Sigma \subseteq \bigcap _ { k = 1 } ^ { \infty } \Sigma _ { k } ^ { a } \cup \Sigma$$
Notice that (3.15) and (3.18) are not identical. In general, the covers of the spectrum obtained via this approach depend quite strongly on the chosen substitution. Note, however, that the same formula (3.18) holds for the Fibonacci substitution. The recursive relationships in (3.13)-(3.14) and (3.16)(3.17) are known as the trace maps for the period doubling and Thue-Morse potentials. Similar trace maps can be constructed for arbitrary substitutions; see [5, Theorem 1] and [6, Theorem 1] for their description.
Figure 5 depicts the covers Σ a k ∪ Σ b k for the period doubling potential and Σ a k ∪ Σ a k +1 for Thue-Morse as λ increases from zero with k = 7, giving an impression of how rapidly the covering intervals shrink as λ increases. Notice the quite different nature of the spectra obtained from these two substitution rules. Similar figures for the Fibonacci spectrum are shown in [14]. (The algorithm described in the last section enables such computations for much larger values of k , but the resulting figures become increasingly difficult to render due to the number and narrow width of the covering intervals.)
## 4. Numerical calculation of periodic covers
In this section, we apply the algorithm described in Section 2 to compute the spectral covers for quasiperiodic operators from substitution rules described in Section 3. We begin with some calculations that emphasize the need for
Figure 5. Spectral covers for the period doubling (Σ a k ∪ Σ ) b k and Thue-Morse (Σ a k ∪ Σ a k +1 ) potentials as a function of the coupling constant λ , for k = 7.
higher precision arithmetic to resolve the spectrum, then estimate various spectral quantities for these quasiperiodic operators.
## 4.1. Necessity for extended precision
High fidelity spectral approximations for quasiperiodic Schr¨dinger operators o are tricky to compute due not only to the complexity of the eigenvalue problem, but also considerations of numerical precision. The LAPACK symmetric eigenvalue algorithms are expected to compute eigenvalues of the K × K matrix J ± accurate to within p K ( ) ‖ J ± ‖ ε mach [2, p. 104], where p K ( ) is a 'modestly growing function of K ' and ε mach denotes the machine epsilon value for the floating point arithmetic system (on the order of 10 -16 for double precision and 10 -34 for quadruple precision [1]). Figure 6 shows the width of the smallest interval in the approximation Σ a k for the period doubling and Thue-Morse potentials, as computed in double and quadruple precision arithmetic for various values of λ . As λ increases, this smallest interval shrinks ever quicker. Comparing double and quadruple precision values, one sees that for even moderate values of K = 2 , double precision is unable to accurately k
k
Figure 6. Minimum interval length in Σ a k for a range of λ values (powers of two) for the period doubling and ThueMorse potentials. The solid line shows double precision, the dashed line quadruple precision. Black data points are believed to be correct to plotting accuracy; gray ones are not.
resolve the spectrum. 8 (Similar numerical errors will be observed for the original matrix J ± . Since it only permutes matrix entries, our algorithm does not introduce any new instabilities.)
8 The calculations of fractal dimension and gaps that follow were performed in quadruple precision arithmetic, and we generally restricted the values of λ and k to obtain numerically reliable results. In the event the numerical results violate the ordering of eigenvalues of J + and J -in (1.8), any offending interval is replaced by one of width 20 ε mach centered at the midpoint of the computed eigenvalues.
## 4.2. Approximating fractal dimensions
The quasiperiodic spectrum Σ is known to be a Cantor set for the Fibonacci, period doubling, and Thue-Morse potentials for all λ > 0, suggesting calculation of the fractal dimensions of these sets as functions of λ . We begin with two standard definitions; see, e.g., [22, 37].
Definition 4.1. Given A ⊂ ❘ and some α ∈ [0 , 1], let
$$h ^ { \alpha } ( A ) \equiv \lim _ { \Delta \to 0 } \inf _ { \Delta \text{-covers} } \sum$$
where a ∆-cover of A is defined to be collection { B m m } ≥ 1 of intervals such that A ⊂ ⋃ m ≥ 1 B m and | B m | < ∆ for each m . The Hausdorff dimension of A is then
$$\dim _ { H } ( A ) \equiv \inf \{ \alpha \, \colon h ^ { \alpha } ( A ) < \infty \}$$
Definition 4.2. Given A ⊂ ❘ , let N A ( ε ) denote the number of intervals of the form [ jε, ( j +1) ), ε j ∈ ❩ , that have a nontrivial intersection with A . The upper and lower box counting dimensions of A are
$$\dim _ { B } ^ { \pm } ( A ) \equiv \lim _ { \varepsilon \to 0 } \sup _ { \inf } \ \frac { \log N _ { A } ( \varepsilon ) } { \log 1 / \varepsilon } ;$$
when these agree, the result is the box-counting dimension of A , dim B ( A ).
The analysis in the last section provides natural covering sets for Σ, which we denote as C k (i.e., for period doubling, C k ≡ Σ a k ∪ Σ ; for Fibonacci b k and Thue-Morse, C k ≡ Σ a k ∪ Σ a k +1 ). We estimate dim H (Σ) using a heuristic proposed by Halsey et al. [24]. Enumerate the n k intervals in C k as { B k,m } :
$$C _ { k } = \bigcup _ { m = 1 } ^ { n _ { k } } B _ { k, m }.$$
## Approximating the Hausdorff dimension
- 1: Input : two consecutive covers C k,λ , C k +1 ,λ of the Cantor spectrum.
- 2: Construct the function f ( α ) ≡ ∑ n k m =1 | B k,m | α -∑ n k +1 m =1 | B k +1 ,m | α .
- 3: Compute root α k of f ( α ) in the interval [0 , 1].
- 4: Output : α k as the approximation to the dimension.
For the Fibonacci case, Damanik et al. [15] proved upper and lower bounds on dim H (Σ) for λ ≥ 8 in terms of the functions S u ( λ ) = 2 λ +22 and S l ( λ ) = 1 2 ( λ -4 + √ ( λ -4) 2 -12 . To benchmark our method, we compare ) the approximate dimension with the upper and lower bounds, as shown in Figure 7, indeed obtaining satisfactory results. Figure 8 shows estimates to dim H (Σ) drawn from spectral covers for k = 6 , . . . , 10, with good convergence in k in the small λ regime. The narrow covering intervals for large λ and k pose a significant numerical challenge, even in quadruple precision arithmetic.
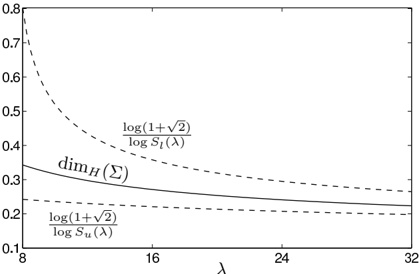
λ
Figure 7. Estimates of dim H (Σ) for the Fibonacci operator (solid line) computed from Σ a k ∪ Σ a k +1 ( k = 15 16), , obeying the upper and lower bounds from [15].
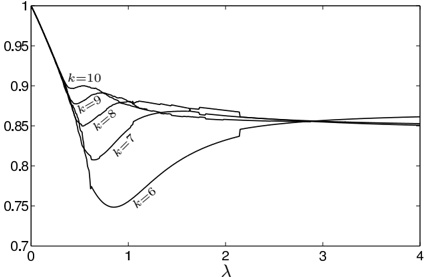
λ
Figure 8. Estimates of dim H (Σ) for the period-doubling operator using consecutive covers Σ a k ∪ Σ b k and Σ a k +1 ∪ Σ b k +1 , for k = 6 , . . . , 10. (The k = 9 and k = 10 plots do not show the full range of λ values, due to the numerical challenge of working with large k and λ .)
The bounds from [15] imply dim H (Σ) → 0 like log(1 + √ 2) / log( λ ) as λ →∞ for the Fibonacci case. In contrast, Liu and Qu [32] recently showed that for the Thue-Morse operator, dim H (Σ) is bounded away from zero as λ → ∞ . Interestingly, the approximation scheme described above does not yield consistent results for Thue-Morse, perhaps a reflection of the exotic behavior identified in [32]. As an alternative, in Figure 9 we show estimates of the box-counting dimension for Thue-Morse. Since for any finite k the covers comprise the finite union of real intervals, log( N C k ( ε )) / log(1 /ε ) → 1 as ε → 0. However, for finite ε the shape of the curves in Figure 9 can suggest rough values for dim B (Σ); cf. [45]. Figure 10 repeats the experiment for period doubling; note that the plot for λ = 4 shows good agreement with the estimate for dim H (Σ) seen in Figure 8. (The Hausdorff and box counting
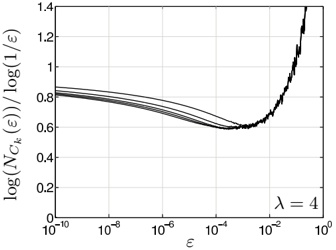
λ
ε
Figure 9. Estimates of dim B (Σ) for the Thue-Morse operator for λ = 4 8, using covers , C k with k = 5 , . . . , 9.
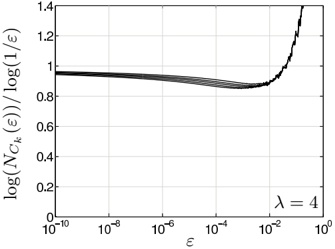
Figure 10. Estimates of dim B (Σ) for the period-doubling operator for λ = 4 8, using covers , C k with k = 5 , . . . , 9.
dimensions need not be equal; considerable effort was devoted over the years to showing dim H (Σ) = dim B (Σ) for all λ > 0 for the Fibonacci case, with the complete result obtained only recently [19].)
The spectral covers we have described can behave in rather subtle ways. To illustrate this fact, Figure 11 shows the largest gap in the Thue-Morse cover Σ a k ∪ Σ a k +1 as a function of the parameter λ . Bellisard [7] showed that, for the aperiodic model, this gap should behave like λ log 4 / log 3 as λ → 0. The covers satisfy this characterization for intermediate values of λ , but appear to behave instead like λ 2 as λ → 0. The larger the value of k (hence the longer the periodic approximations), the larger the range of λ values that are consistent with Bellisard's spectral asymptotics. This scenario provides another justification for the study of largek approximations: for this potential, one must consider large k to approximate the spectrum adequately for small λ .
Our algorithm also expedites study of the square Hamiltonians J sq acting on glyph[lscript] 2 ( ❩ ) × glyph[lscript] 2 ( ❩ ) via
$$( \mathfrak { I } _ { s q } \psi ) _ { m, n } = \psi _ { m - 1, n } + \psi _ { m, n - 1 } + ( b _ { m } + b _ { n } ) \psi _ { m, n } + \psi _ { m + 1, n } + \psi _ { m, n + 1 }.$$
= 8
Figure 11. Computed values of the largest gap in the cover Σ a k ∪ Σ a k +1 of the Thue-Morse spectrum, along with Bellisard's asymptotic description λ log 4 / log 3 . As k increases, the covers obey the asymptotics for smaller values of λ .
The spectrum of this operator is Σ + Σ, where Σ is the spectrum of the standard 1-dimensional operator with potential { b n } . When Σ is a Cantor set, Σ + Σ could be an interval, a union of intervals, a Cantorval , or a Cantor set; see, e.g., [34, 35, 37]. For further details and examples for the Fibonacci case, see [14] and the computations, based on σ ( J ± ), of Even-Dar Mandel and Lifshitz [21]. For the period doubling and Thue-Morse potentials, Figure 12 illustrates how the covers of the spectra for these square Hamiltonians develop in λ , revealing values of λ for which Σ + Σ cannot comprise a single interval.
## 5. Conclusion
We have presented a simple O K ( 2 ) algorithm to numerically compute the spectrum of a periodK Jacobi operator that can be implemented in a few lines of code, then we used this algorithm to estimate spectral quantities associated with quasiperiodic Schr¨dinger operators derived from substituo tion rules. The algorithm facilitates study of long-period approximations and extensive parameter studies across a family of operators. Yet even with the efficient algorithm, the accuracy of the numerically computed eigenvalues must be carefully monitored, or even enhanced with extended precision computations. This tool can expedite numerical experiments to help formulate conjectures about spectral properties for a range of quasiperiodic operators.
## Acknowledgments
We thank a referee for helpful comments that led us to study the largest Thue-Morse gap (Figure 11), and David Damanik, Paul Munger, Beresford Parlett, and Dan Sorensen for fruitful discussions. We especially thank May Mei for suggesting computations with substitution operators and sharing numerical results, and Adrian Forster for his Thue-Morse computations.
Figure 12. Spectral covers for the square Hamiltonian for period doubling and Thue-Morse substitutions, with k = 4.
## References
- [1] IEEE Standard for Floating-Point Arithmetic (IEEE Standard 754-2008). Institute of Electrical and Electronics Engineers, Inc., 2008.
- [2] E. Anderson, Z. Bai, C. Bischof, S. Blackford, J. Demmel, J. Dongarra, J. Du Croz, A. Greenbaum, S. Hammarling, A. McKenney, and D. Sorensen. LAPACK User's Guide . SIAM, Philadelphia, third edition, 1999.
- [3] A. Avila and S. Jitomirskaya. The ten martini problem. Ann. of Math. , 170:303-342, 2009.
- [4] A. Avila and R. Krikorian. Reducibility or nonuniform hyperbolicity for quasiperiodic Schr¨dinger cocycles. o Ann. of Math. , 164:911-940, 2006.
- [5] Y. Avishai and D. Berend. Trace maps for arbitrary substitution sequences. J. Phys. A , 26:2437-2443, 1993.
- [6] Y. Avishai, D. Berend, and D. Glaubman. Minimum-dimension trace maps for substitution sequences. Phys. Rev. Lett. , 72:1842-1845, 1994.
- [7] J. Bellissard. Spectral properties of Schr¨dinger's operator with a Thue-Morse o potential. In Number Theory and Physics , volume 47 of Springer Proceedings in Physics , pages 140-150. Springer-Verlag, Berlin, 1990.
- [8] J. Bellissard, B. Iochum, E. Scoppola, and D. Testard. Spectral properties of one-dimensional quasicrystals. Comm. Math. Phys. , 125:527-543, 1989.
- [9] Jean Bellissard, Anton Bovier, and Jean-Michel Ghez. Spectral properties of a tight binding Hamiltonian with period doubling potential. Comm. Math. Phys. , 135:379-399, 1991.
- [10] Christian H. Bischof, Bruno Lang, and Xiaobai Sun. A framework for symmetric band reduction. ACM Trans. Math. Software , 26:581-601, 2000.
- [11] D. Damanik. Singular continuous spectrum for a class of substitution Hamiltonians II. Lett. Math. Phys. , 54:25-31, 2000.
- [12] D. Damanik. Uniform singular continuous spectrum for the period doubling Hamiltonian. Ann. Henri Poincar´ e , 2:101-118, 2001.
- [13] D. Damanik. Strictly ergodic subshifts and associated operators. In Spectral Theory and Mathematical Physics: a Festschrift in Honor of Barry Simon's 60th Birthday , volume 76 of Proc. Sympos. Pure Math. , pages 539-563. American Mathematical Society, Providence, RI, 2007.
- [14] D. Damanik, M. Embree, and A. Gorodetski. Spectral properties of Schr¨dinger o operators arising in the study of quasicrystals, 2012. arXiv:1210.5753 [math.SP].
- [15] D. Damanik, M. Embree, A. Gorodetski, and S. Tcheremchantsev. The fractal dimension of the spectrum of the Fibonacci Hamiltonian. Comm. Math. Phys. , 280:499-516, 2008.
- [16] D. Damanik and A. Gorodetski. Almost sure frequency independence of the dimension of the spectrum of Sturmian Hamiltonians, 2014. arXiv:1406.4810 [math.SP].
- [17] D. Damanik and D. Lenz. Uniform spectral properties of one-dimensional quasicrystals, I. Absence of eigenvalues. Comm. Math. Phys. , 207:687-696, 1999.
- [18] David Damanik and Jake Fillman. Spectral Theory of Discrete OneDimensional Ergodic Schr¨dinger Operators o . In preparation.
- [19] David Damanik, Anton Gorodetski, and William Yessen. The Fibonacci Hamiltonian, 2014. arXiv:1403.7823 [math.SP].
- [20] F. Delyon and J. Peyri`re. Recurrence of the eigenstates of a Schr¨dinger ope o erator with automatic potential. J. Stat. Phys. , 64:363-368, 1991.
- [21] S. Even-Dar Mandel and R. Lifshitz. Electronic energy spectra of square and cubic Fibonacci quasicrystals. Phil. Mag. , 88:2261-2273, 2008.
- [22] Kenneth Falconer. Fractal Geometry: Mathematical Foundations and Applications . Wiley, Chichester, 2nd edition, 2003.
- [23] C. W. Gear. A simple set of test matrices for eigenvalue programs. Math. Comp. , 23:119-125, 1969.
- [24] Thomas C. Halsey, Mogens H. Jensen, Leo P. Kadanoff, Itamar Procaccia, and Boris I. Shraiman. Fractal measures and their singularities: the characterization of strange sets. Phys. Rev. A , 33:1141-1151, 1986.
- [25] P. G. Harper. Single band motion of conduction electrons in a uniform magnetic field. Proc. Phys. Soc. A , 68:874-878, 1955.
- [26] A. Hof, O. Knill, and B. Simon. Singular continuous spectrum for palindromic Schr¨dinger operators. o Comm. Math. Phys. , 174:149-159, 1995.
- [27] Mahito Kohmoto, Leo P. Kadanoff, and Chao Tang. Localization problem in one dimension: mapping and escape. Phys. Rev. Lett. , 50:1870-1872, 1983.
- [28] S. Kotani. Jacobi matrices with random potentials taking finitely many values. Rev. Math. Phys. , 1:129-133, 1989.
- [29] Michael P. Lamoureux. Reflections on the almost Mathieu operator. Integral Equations Operator Theory , 28:45-59, 1997.
- [30] Y. Last. Zero measure spectrum for the almost Mathieu operator. Comm. Math. Phys. , 164:421-432, 1994.
- [31] Yoram Last. Quantum dynamics and decompositions of singular continuous spectra. J. Funct. Anal. , 142:406-445, 1996.
- [32] Qinghui Liu and Yanhui Qu. Iteration of polynomial pair under Thue-Morse dynamic, 2014. arXiv:1403.2257 [math.DS].
- [33] Laurent Marin. On- and off-diagonal Sturmian operators: Dynamic and spectral dimension. Rev. Math. Phys. , 24(05):1250011, 2012.
- [34] Pedro Mendes and Fernando Oliveira. On the topological structure of the arithmetic sum of two Cantor sets. Nonlinearity , 7:329-343, 1994.
- [35] Carlos G. Moreira, Eduardo Mu˜oz Morales, and Juan Rivera-Letelier. On the n topology of arithmetic sums of regular Cantor sets. Nonlinearity , 13:2077-2087, 2000.
- [36] Stellan Ostlund, Rahul Pandit, David Rand, Hans Joachim Schellnhuber, and Eric D. Siggia. One-dimensional Schr¨dinger equation with an almost periodic o potential. Phys. Rev. Lett. , 50:1873-1876, 1983.
- [37] Jacob Palis and Floris Takens. Hyperbolicity and Sensitive Chaotic Dynamics at Homoclinic Bifurcations . Cambridge University Press, Cambridge, 1993.
- [38] Beresford N. Parlett. The Symmetric Eigenvalue Problem . SIAM, Philadelphia, SIAM Classics edition, 1998.
- [39] M. Queff´ elec. Substitution Dynamical Systems - Spectral Analysis . Springer, Berlin, 1987.
- [40] Michael Reed and Barry Simon. Methods of Modern Mathematical Physics I: Functional Analysis . Academic Press, San Diego, revised and enlarged edition, 1980.
- [41] W. Rudin. Some theorems on Fourier coefficients. Proc. Amer. Math. Soc. , 10:855-859, 1959.
- [42] H. Rutishauser. On Jacobi rotation patterns. In Experimental Arithmetic, High Speed Computing and Mathematics , volume 15 of Proceedings of Symposia in Applied Mathematics , pages 219-239. American Mathematical Society, Providence, RI, 1963.
- [43] H. S. Shapiro. Extremal problems for polynomials and power series. Master's thesis, Massachusetts Institute of Technology, 1951.
- [44] Barry Simon. Szeg˝'s o Theorem and Its Descendants . Princeton University Press, Princeton, NJ, 2011.
- [45] Tam´ as T´l, Agnes F¨l¨p, and Tam´s Vicsek. Determination of fractal dimene ´ u o a sions for geometrical multifractals. Physica A , 159:155-166, 1989.
- [46] Gerald Teschl. Jacobi Operators and Completely Integrable Nonlinear Lattices . American Mathematical Society, Providence, RI, 2000.
- [47] D. J. Thouless. Bandwidths for a quasiperiodic tight-binding model. Phys. Rev. B , 28:4272-4276, 1983.
- [48] Morikazu Toda. Theory of Nonlinear Lattices . Springer-Verlag, Berlin, 2nd edition, 1989.
- [49] Pierre van Moerbeke. The spectrum of Jacobi matrices. Inv. Math. , 37:45-81, 1976.
- [50] W.N. Yessen. Spectral analysis of tridiagonal Fibonacci Hamiltonians. J. Spectral Theory , 3:101-128, 2013.
## Charles Puelz
Department of Computational and Applied Mathematics
Rice University
6100 Main Street - MS 134
Houston, Texas
77005-1892
USA
e-mail:
[email protected]
## Mark Embree
Department of Mathematics
Virginia Tech
225 Stanger Street - 0123
Blacksburg, Virginia
24061
USA
e-mail:
[email protected]
Jake Fillman Department of Mathematics Rice University 6100 Main Street - MS 136 Houston, Texas 77005-1892 USA e-mail: [email protected] | null | [
"Charles Puelz",
"Mark Embree",
"Jake Fillman"
] | 2014-08-02T13:13:36+00:00 | 2014-12-28T17:13:19+00:00 | [
"math.SP",
"math.NA",
"47B36, 65F15, 81Q10"
] | Spectral Approximation for Quasiperiodic Jacobi Operators | Quasiperiodic Jacobi operators arise as mathematical models of quasicrystals
and in more general studies of structures exhibiting aperiodic order. The
spectra of these self-adjoint operators can be quite exotic, such as Cantor
sets, and their fine properties yield insight into associated dynamical
systems. Quasiperiodic operators can be approximated by periodic ones, the
spectra of which can be computed via two finite dimensional eigenvalue
problems. Since long periods are necessary to get detailed approximations, both
computational efficiency and numerical accuracy become a concern. We describe a
simple method for numerically computing the spectrum of a period-$K$ Jacobi
operator in $O(K^2)$ operations, and use it to investigate the spectra of
Schr\"odinger operators with Fibonacci, period doubling, and Thue-Morse
potentials. |
1408.0371v1 | ## A graph partition problem
Peter J. Cameron ∗ and Sebastian M. Cioab˘ a †
July 30, 2014
## Abstract
Given a graph G on n vertices, for which m is it possible to partition the edge set of the m -fold complete graph mK n into copies of G ? We show that there is an integer m 0 , which we call the partition modulus of G , such that the set M G ( ) of values of m for which such a partition exists consists of all but finitely many multiples of m 0 . Trivial divisibility conditions derived from G give an integer m 1 which divides m 0 ; we call the quotient m /m 0 1 the partition index of G . It seems that most graphs G have partition index equal to 1, but we give two infinite families of graphs for which this is not true. We also compute M G ( ) for various graphs, and outline some connections between our problem and the existence of designs of various types.
## 1 Introduction
The problem of interest in this paper is the following:
Given a graph G on n vertices, is it possible to partition the edge set of the complete graph K n into isomorphic copies of G ? If this is not possible, then we are interested in determining the set of integers m such that the edge set of the m -fold complete graph mK n can be partitioned into copies of G .
We will see that this seemingly simple problem has connections to algebra, combinatorics and geometry among others. Important open problems such
∗ Mathematical Institute, North Haugh, St. Andrews KY16 9SS, UK; [email protected]
† Department of Mathematical Sciences, University of Delaware, Newark, DE 197162553, USA; [email protected]
as the existence of finite projective planes are equivalent to edge partition problems into certain specified graphs.
Historically, perhaps the first instance of this type problem goes back to Walecki [8] who showed that the edge-set of the complete graph K n can be partitioned into copies of the cycle C n when n ≥ 3 is odd and the edge-set of the complete graph K n minus a perfect matching can be partitioned into copies of C n when n ≥ 4 is even. See Figure 1 for a partition of K 5 into edge disjoint copies of C 5 . This result shows the impossibility of decomposing the edge of K n into copies of C n , but also that the edge set of 2 K n can be partitioned into copies of C n , when n ≥ 4 is even.
Figure 1: Two edge disjoint cycles on 5 vertices on the same vertex set.
Figure 2 shows another instance of this problem where K 4 cannot be decomposed into edge disjoint copies of K 1 3 , , but 2 K 4 can be partitioned into 4 K 1 3 , s.
Figure 3 shows that it is possible to find two edge-disjoint copies of the Petersen graph on 10 vertices. But can we find three edge-disjoint copies, that is, a partition of the edges of the complete graph on 10 vertices into three Petersen graphs?
This problem was proposed by Allen Schwenk in the American Math Monthly in 1983. Elegant negative solutions by Schwenk and O. P. Lossers
Figure 2: Four stars K 1 3 , decomposing 2 K 4 .
Figure 3: Two edge disjoint Petersen graphs on the same vertex set.
appeared in the same journal in 1987 [13]. This result is described in many books on algebraic graph theory including Godsil and Royle [7, Section 9.2], and Brouwer and Haemers [3, Section 1.5.1]. Schwenk's argument plus some simple combinatorial ideas can be used to show that whenever we can arrange two edge disjoint Petersen graphs on the same vertex set, then the complement of their union must be the bipartite cubic graph on 10 vertices that is the bipartite complement of C 10 . In Figure 3, every missing edge goes from the set of 5 outer vertices to the set of 5 inner vertices, so the complement of the union of the two Petersen graphs is visibly bipartite (see [9] for a proof).
A generalization was posed by Rowlinson [12], and further variants have also been studied. ˇ iagiov´ S a and Meszka [14] obtained a packing of five Hoffman-Singleton graphs in the complete graph K 50 . At present time, it is not known if it is possible to decompose K 50 into seven Hoffman-Singleton graphs. Van Dam [5] showed that if the edge-set of the complete graph of order n can be partitioned into three (not necessarily isomorphic) strongly regular graphs of order n , then this decomposition forms an amorphic association scheme (see also van Dam and Muzychuk [6]).
At the Durham Symposium on Graph Theory and Interactions in 2013, the authors amused themselves by showing that, for every m > 1, the m -fold complete graph mK 10 (with m edges between each pair of vertices) can be partitioned into 3 m copies of the Petersen graph. Our purpose in this paper is to extend this investigation by replacing the Petersen graph by an arbitrary graph.
In fact, a stronger result for the Petersen graph was found by Adams, Bryant and Khodkar [1]; these authors allow n to be arbitrary, in other words, they allow adding arbitrary many isolated vertices to the Petersen graph. We do not consider this more general problem.
## 2 Partition Modulus
Definition For a graph G on n vertices, we let
M G ( ) = { m mK : n can be partitioned into copies of G . }
Example As mentioned in the Introduction, one of the earliest results on this concept is that of Walecki [8], according to which the complete graph K n can be partitioned into ( n -1) / 2 Hamiltonian cycles if (and only if) n is
odd; if n is even, then 2 K n can be partitioned into Hamiltonian cycles. If n is even, 2 K n can be partitioned into Hamiltonian cycles, but mK n cannot if m is odd, since n does not divide mn n ( -1) / 2 for n even and m odd. So
$$M ( C _ { n } ) = \begin{cases} \mathbb { N } & \text{if $n$ is odd,} \\ 2 \mathbb { N } & \text{if $n$ is even.} \end{cases}$$
Proposition 2.1 For any graph G , the set M G ( ) is non-empty. In fact, if G has e edges and Aut( G ) is its automorphism group, then
$$2 ( n - 2 )! e / | \, \text{Aut} ( G ) | \in M ( G ).$$
Proof The graph G has n / ! | Aut( G ) | images under the symmetric group S n , since S n acts transitively on the set of graphs on vertex set { 1 , . . . , n } which are isomorphic to G , and Aut( G ) is the stabiliser of one of these graphs. Each of the n n ( -1) / 2 pairs of points is covered equally often by an edge in one of these images, since S n is doubly transitive; double counting gives this number to be ( n / ! | Aut( G ) | ) /( e n n ( -1) / 2 ) , as required. glyph[square]
Our main result is a description of the set M G ( ).
Theorem 2.2 For any graph G , there is a positive integer m 0 and a finite set F of multiples of m 0 such that M G ( ) = m 0 N \ F .
We call the number m 0 the partition modulus of G , and denote it by pm( G ).
The theorem follows immediately from a couple of simple lemmas.
Lemma 2.3 The set M G ( ) is additively closed.
Proof Superimposing partitions of the edges of aK n and bK n gives a partition of ( a + ) b K n . glyph[square]
Lemma 2.4 An additively closed subset M of N has the form m N \ F , where F is a finite set of multiples of m .
Proof We have no convenient reference (though [11] is related), so we sketch the proof. We let m = gcd( M ). By dividing through by m , we obtain a set with gcd equal to 1, so it suffices to prove the result in this case.
First we observe that M is finitely generated, that is, there is a finite subset K such that any element M is a linear combination, with non-negative integer coefficients, of elements of K . Then we proceed by induction on | K | . It is well known that, if gcd( a, b ) = 1, then all but finitely many positive integers have the form xa + yb for some x, y ≥ 0. Assume that the result holds for generating sets smaller than K . Take a ∈ K , and let b = gcd( K \ { a } ). By induction, K \ { a } generates all but finitely many multiples of b . Also, gcd( a, b ) = 1, so that the result for sets of size 2 finishes the argument. glyph[square]
We have not tried to get an explicit bound here, since for most graphs the excluded set F seems to be much smaller than our general argument suggests.
Example As mentioned in Section ?? , if P is the Petersen graph, then M P ( ) = N \ { 1 } , so that the partition modulus of the Petersen graph is 1. It suffices to show that 2 , 3 ∈ M P ( ).
That 2 ∈ M P ( ) follows from a generalisation of Proposition 2.1:
Proposition 2.5 Suppose that G has n vertices and e edges, and that there is a doubly transitive group H of degree n for which | H : H ∩ Aut( G ) | = r . Then 2 re/n n ( -1) ∈ M G ( ) .
Proof The graph G has r images under H , whose re edges cover all pairs 2 re/n n ( -1) times. glyph[square]
Now Aut( P ) ∼ = S 5 , a subgroup of index 6 in S 6 (which acts as a 2transitive group on the vertex set of P ). So 6 · 15 45 = 2 / ∈ M P ( ).
A direct construction shows that 3 ∈ M P ( ). We do this by means of a 9-cycle on the vertex set of P , fixing a point ∞ and permuting the remaining points as (0 , 1 2 , , . . . , 8). It is clear that the images of the three edges of P containing ∞ cover all pairs of the form {∞ , x } three times. For the remaining pairs, we need to choose a drawing of P - ∞ on the vertices { 0 , . . . , 8 } in such a way that each of the distances 1 , 2 3 4 in the 9-cycle is , , represented three times by an edge, since these distances index the orbits of
the cycle on 2-sets. It takes just a moment by computer to find dozens of solutions. For example, the edges
$$& \{ \infty, 1 \}, \{ \infty, 4 \}, \{ \infty, 8 \}, \{ 0, 2 \}, \{ 0, 3 \}, \{ 0, 4 \}, \{ 1, 3 \}, \{ 1, 5 \}, \\ & \{ 2, 5 \}, \{ 2, 8 \}, \{ 3, 7 \}, \{ 4, 6 \}, \{ 5, 6 \}, \{ 6, 7 \}, \{ 7, 8 \}$$
have the required properties.
## 3 Partition index
As is common in problems of this kind, there are some divisibility conditions which are necessary for a partition to exist:
Proposition 3.1 Let G have n vertices and e edges. Then every element m of M G ( ) has the property that e divides mn n ( -1) / 2 , and the greatest common divisor of the vertex degrees of G divides m n ( -1) .
Proof If l copies of G partition mK n , then mn n ( -1) / 2 = le , proving the first assertion; and the m n ( -1) edges through a vertex in mK n are partitioned by the vertex stars in copies of G , from which the second assertion follows. glyph[square]
Let m 1 be the number for which these divisibility conditions are equivalent to the assertion that m 1 | m for all m ∈ M G ( ). Thus,
$$m _ { 1 } = \text{lem} \left ( \frac { e } { \gcd ( e, n ( n - 1 ) / 2 ) }, \frac { d } { \gcd ( d, n - 1 ) } \right ),$$
where d is the greatest common divisor of the vertex degrees.
We have that m 1 | m 0 = pm( G ). We define the partition index pi( G ) to be the quotient m /m 0 1 .
Proposition 3.2 Let G have n vertices and e edges, and let G denote its complement. Then m ∈ M G ( ) if and only if m n n ( ( -1) / 2 -e )/ e ∈ M G ( ) .
Proof If l copies of G cover kK n , then l copies of G cover ( l -k K ) n . Using l = kn n ( -1) / (2 e ) from the preceding Proposition gives the result. glyph[square]
Corollary 3.3 If G has n vertices and e edges, then
$$\text{pm} ( \overline { G } ) = \left ( \frac { n ( n - 1 ) / 2 - e } { e } \right ) \text{pm} ( G ).$$
The triangular graph T l ( ) is the line graph of K l , that is, its vertices are the 2-element subsets of an l -set, two vertices adjacent if they have non-empty intersection.
Example Since T (5) (the line graph of K 5 ) is the complement of the Petersen graph, we have M T ( (5)) = 2 N \ { 2 } .
Remark If the same relation held between the numbers m 1 for G and G defined earlier as for the partition moduli in Corollary 3.3, then we would have pi( G ) = pi( G ). But this is not true, as we will show using the graphs in Figure 4.
✉
✉
✉
✉
✉
✉
✉
✉
✉
Figure 4: An example
Let G be the graph with 6 vertices and 6 edges consisting of a triangle with a pendant edge at each vertex. Then G has 6 edges, and the gcd of the vertex degrees is 1, so m G 1 ( ) is the least common multiple of 6 / gcd(6 15) , and 1 / gcd(1 5), that is, , m G 1 ( ) = 2. However, G has 9 edges and all vertex degrees even; so m G 1 ( ) is the least common multiple of 9 / gcd(9 15) and , 2 / gcd(2 5), that is, , m G 1 ( ) = 6.
We have 4 ∈ M G ( ). This follows from Proposition 2.5, since Aut( G ), which is dihedral of order 6, is a subgroup of index 10 in the 2-transitive group
PSL(2 5). , So 6 ∈ M G ( ). It follows that M G ( ) = 6 N , and pm( G ) = 6 and pi( G ) = 1. But, by Corollary 3.3, we have M G ( ) = 4 N , so that pm( G ) = 4 and pi( G ) = 2.
## 4 Examples
In this section, we construct two families of examples of graphs which have partition index greater than 1. We are grateful to Mark Walters for the first of these.
Proposition 4.1 Let G be a star K 1 ,n -1 , with n > 2 . Then pm( G ) = 2 (and indeed M G ( ) = 2 N ); so
$$\text{pi} ( G ) = \begin{cases} 1 & \text{if $n$ is odd} \, \\ 2 & \text{if $n$ is even}. \end{cases}$$
Proof m G 1 ( ) is the least common multiple of ( n -1) / gcd( n -1 , n ( n -1) / 2) (which is equal to 1 if n is even, and 2 if n is odd) and 1 / gcd(1 , n -1) = 1.
glyph[negationslash]
Suppose that mK n is covered with copies of the star; let the vertex set be { 1 2 , , . . . , n } , and let x i be the number of stars with centre at the vertex i . Then the edge { i, j } is covered x i + x j times; so x i + x j = m for all i = . j This forces x i to have a constant value x , and m = 2 x . But we can achieve m = 2 by taking one star with each possible centre ( x i = 1 for all i ).
So the partition modulus of the star is 2, and the partition index is as claimed. glyph[square]
For the second construction, we observe that, if n is a multiple of 4, then the number n n ( -1) / 2 of edges of the complete graph is even, so there are graphs G and G each having n n ( -1) / 4 edges. So the first term in the lcm for both m G 1 ( ) and m G 1 ( ) is 1. Suppose we arrange that G has all degrees odd; then G will have all degrees even. If d and d are the least common multiples of these degrees, then d/ gcd( d, n -1) is odd, but d/ gcd( d, n -1) is even (since n -1 is odd). Thus, m G 1 ( ) is odd but m G 1 ( ) is even.
On the other hand, Proposition 3.3 shows that the partition moduli of the two graphs are equal, and so necessarily even. Thus, certainly, pi( G > ) 1.
The smallest example of this construction, for n = 4, has for G the star K 1 3 , and for G the graph K 3 ∪ K 1 . As we saw, the partition indices of these graphs are 2 and 1 respectively. For larger n , the construction gives many examples.
Problem Is there a simple method of calculating the partition modulus (and hence the partition index) of a graph G ? Is it true that almost all graphs have partition index 1?
## 5 Connection with design theory
For some special graphs, our partition problem is equivalent to the existence of certain 2-designs. A 2-( n, k, λ ) design consists of a set of n points and a collection of k -element subsets called blocks, such that any two points lie in exactly λ blocks. The design is resolvable if the blocks can be partitioned into classes of size n/k , each class forming a partition of the point set.
The existence of 2-designs has received an enormous amount of study; we refer to [2] for some results.
Now the following result is clear.
Theorem 5.1 (a) Let G 1 be the graph consisting of a k -clique and n -k isolated vertices. Then m ∈ M G ( 1 ) if and only if there exists a 2 -( n, k, m ) design.
- (b) Let k | n , and let G 2 be the graph consisting of n/k disjoint k -cliques. Then m ∈ M G ( 1 ) if and only if there exists a resolvable 2 ( -n, k, m ) design.
Figure 5 shows K 9 decomposed into four graphs, each the union of three disjoint triangles, otherwise known as the affine plane AG(2 , 3). To reduce clutter, we adopt the convention that a line through three collinear points represents a triangle.
In fact, a more general version of this theorem is true.
Proposition 5.2 Let G be a graph on n vertices whose edge-set can be partitioned into s complete graphs on k vertices. Then a necessary condition for λ ∈ M G ( ) is that there exists a 2 ( -n, k, λ ) design.
This class of graphs includes, for example, the point graphs of partial geometries and generalized polygons.
This result gives a proof that 1 / M T l ∈ ( ( )) (see Theorem 6.1 for another proof): for T l ( ) is the edge-disjoint union of l cliques of size l -1, and the resulting 2-( ( l l -1) / 2 , l -1 1) design would have ,
$$l ( l - 1 ) / 2 \cdot ( l + 1 ) ( l - 2 ) / 2 \, \Big / ( l - 1 ) ( l - 2 ) = l ( l + 1 ) / 4$$
✉
✉
✉
✉
✉
✉
✉
Figure 5: The affine plane AG(2 3) ,
blocks, and so would violate Fisher's inequality (asserting that a 2-design has at least as many blocks as points).
In some cases, the converse is true.
Proposition 5.3 Let L 2 ( q ) denote the line graph of K q,q , the q × q square lattice graph. Then 1 ∈ M L ( 2 ( q )) if and only if q is odd and there exists a projective plane of order q .
Proof We begin by noting that the existence of a projective plane of order q is equivalent to that of an affine plane of order q (a 2-( q , q, 2 1) design); such a design is necessarily resolvable, with q +1 parallel classes.
Now the necessity of the condition follows from our general results. If the affine plane exists, then partition the parallel classes into ( q +1) 2 sets / of size 2; each set, regarded as a set of 2 q complete graphs of size q , gives a copy of L 2 ( q ). glyph[square]
In Figure 5, if we identify red and black, and also blue and green, we obtain a decomposition of K 9 into two copies of L 2 (3).
The problem of determining M L ( 2 ( q )) in cases not covered by this result, especially those when the required plane does not exist, is open. For example, what is M L ( 2 (6))?
It is worth mentioning that the problem is solved for the unique strongly regular graph with the same parameters as L 2 ( q ) but not isomorphic to it. This is the 16-vertex Shrikhande graph . Darryn Bryant [4] found five copies of the Shrikhande graph S that cover the edges of K 16 twice; so M S ( ) = 2 N , and pi( S ) = 1.
## 6 Triangular graphs
Recall that the triangular graph T l ( ) is the line graph of K l , that is, its vertices are the 2-element subsets of an l -set, two vertices adjacent if they have non-empty intersection.
Now T l ( ) has l ( l -1) / 2 vertices and valency 2( l -2), and has l ( l -1)( l -2) / 2 edges. Thus e/ gcd( e, n ( n -1) / 2) = 4, 2 or 1 according as the power of 2 dividing l +1 is 1, 2 or at least 4. Also, d = l -2, so d/ gcd( d, n -1) is 1 or 2 according as l +1 is even or odd. So
$$m _ { 1 } ( T ( l ) ) = \begin{cases} 1 & \text{if $l \equiv 3$} \pmod{4}$}, \\ 2 & \text{if $l \equiv 1$} \pmod{4}, \\ 4 & \text{if $l$ is even}. \end{cases}$$
We conjecture that these are also the partition moduli of the triangular graphs, so that the partition indices are all 1. We saw this already for T (5).
$$\text{Theorem } 6. 1 \quad ( a ) \ I f \, l \geq 4, \, \text{ then } 1 \notin M ( T ( l ) ).$$
- (b) If l is odd, then 2 / M T l ∈ ( ( )) .
Proof (a) The graph T l ( ) has clique number l -1 and independence number glyph[floorleft] l/ 2 , so cannot be embedded into its complement. glyph[floorright]
(b) The proof is by contradiction and generalizes Schwenk's argument [13] showing that three Petersen graphs cannot partition K 10 . Assume that 2 ∈ M T l ( ( )) and consider a decomposition of 2 K ( ) l 2 into 2 (( ) l 2 -1 ) / 2( l -2) = ( l +1) 2 copies of / T l ( ). Let A , . . . , A 1 ( +1) l / 2 denote the adjacency matrices of these copies of T l ( ). For 1 ≤ i ≤ ( l +1) 2, denote by / E i the eigenspace of A i corresponding to -2. It is known that each E i is contained in the orthogonal complement of the all-one vector in R ( ) l 2 and that dim( E i ) = ( ) l 2 -l . Since the intersection of m subspaces each of codimension n in a vector space has codimension at most mn , we have
$$\dim \left ( \bigcap _ { i = 1 } ^ { ( l - 1 ) / 2 } \mathcal { E } _ { i } \right ) & \ \geq \ \binom { l } { 2 } - 1 - ( l - 1 ) \cdot ( l - 1 ) / 2 \\ & = \ ( l - 3 ) / 2 \\ & > \ 0.$$
Let x be a non-zero vector in ( l -1) / 2 ⋂ i =1 E i . Since A 1 + · · · + A ( l -1) / 2 + A ( +1) l / 2 = 2( J -I ), we deduce that
$$A _ { ( l + 1 ) / 2 } x \ & = \ ( 2 J - 2 I - A _ { 1 } - \cdots - A _ { ( l - 1 ) / 2 } ) x \\ & = \ - 2 x + ( ( l - 1 ) / 2 ) 2 x \\ & = \ ( l - 3 ) x. \quad \Box$$
Proposition 6.2 M T ( (6)) = 4 N , so that pi( T (6)) = 1 .
Proof The automorphism group Aut( T (6)) is S 6 and has a subgroup A 6 which has index 7 in the 2-transitive group A 7 of degree 15. So 7 copies of T (6) cover the edges of K 15 four times. glyph[square]
Thus 7 is the smallest value of m for which we don't know M T m ( ( )). Here are a few comments on this case. Let G = T (7).
- (a) By Theorem 6.1, we see that 1 2 , / M G ∈ ( ).
- (b) There does exist a 2-(21 , 6 4) design, namely the point residual of the , Witt design on 22 points. However, this design is not possible in our situation; for it has the property that any two blocks meet in 0 or 2 points, whereas T (7) has 6-cliques meeting in one point.
- (c) Applying Proposition 2.5, with H = PSL (3 , 4), we obtain 1440 ∈ M G ( ). This leaves a very big gap.
## Acknowledgments
The research of the first author is partially supported by National Security Agency grant H98230-13-1-0267. The authors are grateful to Steve Butler, Darryn Bryant, Alex Fink, and Mark Walters for helpful comments which have improved this paper and to Jason Vermette for Figure 1.
## References
- [1] P. Adams, D. E. Bryant and A. Khodkar, The spectrum problem for lambda-fold Petersen graph designs, J. Combin. Math. Combin. Comput. 34 (2000), 159-176.
| [2] | T. Beth, D. Jungnickel and H. Lenz, Design Theory (2 volumes), 2nd ed., Cambridge Univ. Press, Cambridge, 1990. |
|-------|-----------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------|
| [3] | A.E. Brouwer and W.H. Haemers, Spectra of Graphs , Universitext. Springer, New York, 2012. xiv+250pp. |
| [4] | http://cameroncounts.wordpress.com/2013/08/14/a-shrikhande-challenge/ |
| [5] | E. van Dam, Strongly regular decompositions of the complete graph, J. Algebraic Combinatorics 17 (2003), 181-201. |
| [6] | E. van Dam and M. Muzychuk, Some implications on amorphic associ- ation schemes, J. Combin. Theory Ser. A 117 (2010), 111-127. |
| [7] | C. Godsil and G. Royle, Algebraic Graph Theory , Graduate Texts in Mathematics, 207. Springer-Verlag, New York, 2001. xx+439pp. |
| [8] | E. Lucas, R´cr´ations e e Math´matiques e , Gauthier Villars, Paris (1891). |
| [9] | http://mathoverflow.net/questions/87886/decomposition-of-k-10- in-copies-of-thepetersen-graph/87900 |
| [10] | T.S. Michael, The decomposition of the complete graph into three, non- isomorphic strongly regular graphs, Congr. Numerantium 85 (1991), 177-183. |
| [11] | A. Nijenhuis and H. S. Wilf, Representations of integers by linear forms in nonnegative integers, J. Number Theory 4 (1972), 98-106. |
| [12] | P. Rowlinson, Certain 3-decompositions of complete graphs, Proc. Roy. Soc. Edinburgh (A) 99 (1985), 277-281. |
| [13] | A. J. Schwenk, Problem 6434, Amer. Math. Monthly 90 (1983), 408-412; solutions by A.J. Schwenk and O. P. Lossers, ibid. 94 (1987), 885-886. |
| [14] | J. ˇ Siagiov´ a and M. Meszka, A covering construction for packing dis- joint copies of the Hoffman-Singleton graph into K 50 , J. Combinatorial Designs 11 (2003), 408-412. |
| [15] | R.M. Wilson, Decompositions of complete graphs into subgraphs iso- morphic to a given graph, Proceedings of the Fifth British Combinatorial Conference (Univ. Aberdeen, Aberdeen, 1975), pp. 647-659. Congressus Numerantium, No. XV, Utilitas Math., Winnipeg, Man., 1976. | | null | [
"Peter J. Cameron",
"Sebastian M. Cioabă"
] | 2014-08-02T13:40:52+00:00 | 2014-08-02T13:40:52+00:00 | [
"math.CO",
"05C99, 05B25"
] | A graph partition problem | Given a graph $G$ on $n$ vertices, for which $m$ is it possible to partition
the edge set of the $m$-fold complete graph $mK_n$ into copies of $G$? We show
that there is an integer $m_0$, which we call the \emph{partition modulus of
$G$}, such that the set $M(G)$ of values of $m$ for which such a partition
exists consists of all but finitely many multiples of $m_0$. Trivial
divisibility conditions derived from $G$ give an integer $m_1$ which divides
$m_0$; we call the quotient $m_0/m_1$ the \emph{partition index of $G$}. It
seems that most graphs $G$ have partition index equal to $1$, but we give two
infinite families of graphs for which this is not true. We also compute $M(G)$
for various graphs, and outline some connections between our problem and the
existence of designs of various types. |
1408.0372v3 | ## GROMOV POSITIVE SCALAR CURVATURE CONJECTURE AND RATIONALLY INESSENTIAL MACROSCOPICALLY LARGE MANIFOLDS
MICHA/suppress L MARCINKOWSKI
Abstract. We give the first examples of rationally inessential but macroscopically large manifolds. Our manifolds are counterexamples to the Dranishnikov rationality conjecture. For some of them we prove that they do not admit a metric of positive scalar curvature, thus satisfy the Gromov positive scalar curvature conjecture. Fundamental groups of our manifolds are finite index subgroups of right angled Coxeter groups. The construction uses small covers of convex polyhedrons (or alternatively Davis complexes) and surgery.
## 1. Introduction
Let X be a metric space and let Y be a topological space. We say that a map f : X → Y is uniformly cobounded if there exists a real number C such that diam f ( -1 ( y )) < C for every y ∈ Y .
Definition 1. The macroscopic dimension of X , denoted dim mc ( X ) , is the smallest number k such that there exist a k -dimensional simplicial complex K and a continuous, uniformly cobounded map f : X → K .
Let M be a Riemannian manifold of topological dimension n , and let ˜ M be the universal cover of M with the pullback Riemannian metric. Note that since ˜ M can be given a structure of simplicial complex, dim mc ( ˜ M ) is never greater than the topological dimension.
Macroscopic dimension was defined by Gromov ([11]) in the search of topological obstructions for manifolds to admit a Riemannian metric with positive scalar curvature (briefly PSC). He conjectured that such manifolds tend to have deficiency of macroscopic dimension in the following sense
Gromov Conjecture. Let M be a closed n -dimensional manifold. If M admits a Riemannian metric of positive scalar curvature, then dim mc ( ˜ M ) ≤ n -2 .
We always assume that the metric on ˜ M is a pullback of some Riemannian metric on M . Macroscopic dimension of ˜ M does not depend on a metric chosen on M .
The n -2 in the conjecture comes from the following prototypical example: for any M n -2 , the manifold M ′ = M S × 2 admits a PSC metric. We have dim mc ( ˜ M ′ ) = dim mc ( ˜ M S × 2 ) = dim mc ( ˜ M ) ≤ n -2. Thus an inequality in the conjecture is sharp.
The work on this paper was conducted during the author's internship at the Warsaw Center of Mathematics and Computer Science. The author was supported by a scholarship of the Foundation for Polish Science and by the National Science Centre grant 2012/06/A/ST1/00259.
There is also a version of the Gromov Conjecture, called the weak Gromov conjecture, which asserts that if M admits a PSC metric, then dim mc ( ˜ M ) ≤ n -1.
The Gromov conjecture was proven for 3-dimensional manifolds ([10]) and for manifolds whose fundamental groups satisfy certain assumptions of analytical flavor ([2, 8]). In the present state of the art, the Gromov conjecture (and even its weak version) is considered to be out of reach. It implies other longstanding conjectures, e.g. the Gromov-Lawson conjecture, which asserts that no aspherical manifold admits a PSC metric.
An n -dimensional manifold M is called macroscopically large if dim mc ( ˜ M ) = n . Let us consider the following
Example 1. Let M be a closed oriented manifold, π = π 1 ( M ) , and let Bπ be a classifying space endowed with a structure of a simplicial complex. Denote by f : M → Bπ the map classifying the universal bundle. If f ∗ ([ M ]) = 0 ∈ H n ( Bπ ; Z ) , then there is a homotopy of f to some map g : M → Bπ [ n -1] . It follows, that there exist an equivariant homotopy of a lift ˜ f : ˜ M → Eπ to ˜ g : ˜ M → Eπ [ n -1] . Then ˜ g is a cobounded map, thus M cannot be macroscopically large.
One can ask if the property that a manifold M is large or not can be expressed in homological terms. To do that, let us introduce the following notions (we keep the notation from Example 1). We call M inessential if f ∗ ([ M ]) = 0 ∈ H n ( Bπ ; Z ) and rationally inessential if f ∗ ([ M ]) = 0 ∈ H n ( Bπ ; Q ). Note that M is rationally inessential if and only if f ∗ ([ M ]) ∈ H n ( Bπ ; Z ) is torsion. An example of rationally inessential but essential orientable manifold is RP 3 . Obviously dim mc ( ˜ RP 3 ) = 0, thus being essential is not enough to be macroscopically large. Gromov expected, that if M is rationally essential, then M is macroscopically large. A. Dranishnikov in [7] disproved this conjecture and found the right homology theory where one should place the fundamental class [ M ] to test if M is large just by checking if the class is non-trivial. Moreover, it is showed that [ M ] is large if and only if there exist a bounded homotopy from ˜ f : ˜ M → Eπ to some map which ranges in Eπ [ n -1] (these results are described in more details in 2.1). In [8] it is conjectured that
Rationality Conjecture. If M is rationally inessential, then it is macroscopically small.
It would imply the weak Gromov conjecture for rationally inessential manifolds. In the paper we give counterexamples to this conjecture. In terms of homotopy theory, they are rationally inessential manifolds such that ˜ f : ˜ M → Eπ can not be deformed by means of bounded homotopy to a map which ranges in Eπ [ n -1] . In the case when our manifolds are spin, we prove that they do not admit a PSC metrics. Thus they satisfy the Gromov Conjecture. If they are not spin, the conjecture is open.
Outline of the construction . Let K be an n -dimensional simple convex polyhedron, e.g. n -dimensional cube 1 . Assume that each maximal face of K is colored
1 By n -dimensional polyhedron we mean an intersection of finite number of half-spaces in the n -dimensional Euclidean space. A polyhedron K is simple if a neighborhood of every vertex of K looks like a neighborhood of a vertex in the n -dimensional symplex.
by one of n colors such that every pair of different non-disjoint faces have different colors 2 . To construct a manifold N out of K we use 'the reflection trick'. That is, we glue up 2 n copies of K along maximal faces. The way of how we glue them depends of the coloring of faces. To obtain a counterexample M to the Dranishnikov conjecture we attaching a bunch of handles and 'fill up' some loops in the connected sum N # N . This is made such that M is rationally inessential and π M ( ) is a finite index, torsion free subgroup of a Coxeter group. These properties are crucial in proving that M is macroscopically large and, if M is spin, does not admit a PSC metric.
## 2. Preliminaries
- 2.1. Homological characterisation of macroscopically large manifolds. A. Dranishnikov gave ([7]) a homological criterion one can use to detect if M is macroscopically large. We briefly discuss his result in the form we are going to use it.
- Let X be a locally finite simplicial complex. Let C lf ∗ ( X ; Z ) be the module of Z -valued simplicial chains on X . Here chains need not to be finitely supported nor bounded. The chain complex ( C lf ∗ ( X ; Z ) , ∂ ) with the standard differencial defines the locally finite homology groups H lf ∗ ( X, Z ) (see [9, Ch.11] for an exhaustive treatment of the locally finite homology). If A < X is a subcomplex of X , the notion of relative locally finite homology is defined as usual by the quotient chain complex C lf ∗ ( X ; Z ) /C lf ∗ ( A ; Z ). In [7] a more general definition (with an arbitrary coefficients) of coarsely equivariant homology is given. For Z coefficients, the coarsely equivariant homology is naturally isomorphic to the locally finite homology.
- Let ˜ X be the universal cover of X with the induced simplicial structure and let π = π 1 ( X ). Recall that H ∗ ( X ; Z ) = H π ∗ ( ˜ X ; Z ), where the last group is defined by means of π -equivariant chains C π ∗ ( ˜ X ; Z ). The inclusion i : C π ∗ ( ˜ X ; Z ) → C lf ∗ ( ˜ X ; Z ) induces the so called equivariant coarsening map ec ∗ : H ∗ ( X ; Z ) → H lf ∗ ( ˜ X ; Z ).
- Theorem 1. [7, Th.2.2 and Th.4.5] Let M be an n -dimensional, oriented, closed manifold and let Γ = π 1 ( M ) . Suppose that B Γ is realised by a finite simplicial complex. Let f : M → B Γ be a map classifying the universal cover.
/negationslash
- (2) We call a homotopy H M : ˜ × I → E Γ bounded, if for some number C and every x ∈ ˜ M we have diam H x ( [ × I ]) < C . On E Γ we consider any proper geodesic metric. Then M is macroscopically large if and only if there is no bounded homotopy from f to a map g : ˜ M → E Γ [ n -1] .
- (1) Then M is macroscopically large if and only if ec n f ([ M ]) = 0 ∈ H lf n ( E , Γ Z ) , where E Γ = ˜ B Γ .
- Remark 1. There is another notion of macroscopically large manifolds given by Gong and Yu. It is expressed in terms of non-vanishing of the fundamental class in the coarse homology group HX M, ∗ ( ˜ Q ) ([12, Def.8.2.2]). As it is shown in [8, Th. 4.2], this definition is equivalent to ours provided that the coefficient module is taken to be Z .
- 2.2. Small covers. The idea of a small cover of a simplicial complex is the main ingredient of the construction. They were investigated in the seminal paper of M. Davis and T. Januszkiewicz ([6]). Here we discuss the notion of a small cover and collect some facts we use later.
2 Due to Lemma 1 this assumption is not restrictive at all.
2.2.1. Basic definitions. Let L be an n -dimensional simplicial complex. By L b we denote its barycentric subdivision. By definition, it is the geometric realisation of the poset of nonempty simplices of L . It means that every ( l -1)-dimensional simplex τ ∈ L b is given by a chain τ = ( σ 1 < . . . < σ l ), σ i ∈ L . Let σ < L be a simplex. We define the face F σ to be the geometric realisation of the poset { σ ′ ∈ L | σ ≤ σ ′ < L } .
Thus F σ is a subcomplex of L b . If σ is k -dimensional, then F σ is n -k dimensional. If σ = [ v , . . . , v 0 k ], then F σ = F v 0 ∩ . . . ∩ F v k . The set of faces introduces on L a so called mirror structure. We use the notation L ∗ if we refer to L with this mirror structure. Note that if L is not a manifold, then a face need not be homeomorphic to the disc.
Let G be a Z 2 -linear space and let λ : L [0] → G . The function λ is defined on the set of vertices of L ; equivalently, it is defined on the n -dimensional faces of L ∗ . Let F be an ( n -k )-dimensional face, then F = F v 0 ∩ . . . ∩ F v k (i.e. F is dual to [ v , . . . , v 0 k ], for the unique set of vertices v i . We define G F = Span G 〈 λ F ( v 0 ) , . . . , λ ( F v k ) . 〉 We call λ a characteristic function if for each ( n -k )-dimensional face, linear dimension of G F equals k +1.
Now we define a 'cover space' associated to L ∗ and a characteristic function λ . Let p ∈ L ∗ . By F p ( ) denote the minimal face which contains p . Let C L ( ∗ ) be the cone over L ∗ . Note that C L ( ∗ ) contains L ∗ as the base of the cone. Consider the space M L = C L ( ∗ ) × G / ∼ λ , where p × g ∼ λ p ′ × g ′ if and only if p = p ′ ∈ L ∗ and g ′ -g ∈ G F p ( ) .
In this construction the copies of C L ( ∗ ) are glued along some n -dimensional faces, according to function λ . Note that on M L we have a natural G -action, which induces a quotient map p L : M L → C L ( ∗ ). If the linear dimension of G is equal to n +1, we call M L a small cover of C L ( ∗ ). For examples we advise to consult [6, Example 1.19].
Now we introduce a simplicial structure on M L . First we put on C L ( ∗ ) a simplicial structure given by L b . Since each face is a subcomplex of L b , the gluings between copies of C L ( ∗ ) are made along subcomplexes of this triangulations. Thus the simplicial structures on C L ( ∗ )'s carry to M L .
In the sequel, we will need a particular case of this construction. Let λ : L [0] → G be a characteristic function and let dim ( G ) = n +1. Let e i , i = 0 . . . n , be a basis of G . Later we simply write G = Z n +1 2 . We call λ folding on a simplex if λ v ( ) = e i for some i and every v ∈ L [0] . The name comes from the fact that such a λ defines a map f λ : L → ∆ , where ∆ is the n n dimensional simplex. Indeed, if we think of ∆ as a simplex spanned by the standard vectors e i in R n +1 , then for every v ∈ L [0] we define f λ ( v ) = λ v ( ) and extend f linearly to the whole of L .
/negationslash
Note that in this case being characteristic means that λ v ( ) = λ w ( ) if v and w are incident.
We end this section with the following lemma.
Lemma 1. Let L be an n -dimensional complex. There exists a folding on a simplex characteristic function for L b . Thus, having an arbitrary complex, we can always construct a folding on a simplex characteristic function after passing to the barycentric subdivision.
Proof. Every vertex v ∈ L b is a chain of length 1. Assume that v = ( σ ) and σ is i -dimensional. We can put λ v ( ) = e i . Indeed, if v 1 = ( σ 1 ) and v 2 = ( σ 2 ) are
connected by an edge e , then e = ( σ 1 < σ 2 ) or e = ( σ 2 < σ 1 ). Thus σ 1 and σ 2 have different dimensions. /square
2.2.2. Properties. Let L be a simplicial complex. The right angled Coxeter group W L associated to L is given by the presentation
$$W _ { L } = \langle L ^ { [ 0 ] } | \, v ^ { 2 }, [ v, w ] \text{ for } v, w \in L ^ { [ 0 ] } \text{ and } ( v, w ) \in L ^ { [ 1 ] } \rangle.$$
For any Coxeter group W L there exist a simplicial complex Σ W L , called the Davis complex of W L , with a proper, cocompact action of W L . The fundamental domain of the W L -action on Σ W L is simplicialy isomorphic to C L ( ). For infinite W L , the complex Σ W is contractible (see [5, ch.7]).
If λ is any function from L [0] to G , then Λ uniquely extends to a homomorphism from W L to G .
Fact 1. Let M L be a cover associated to some characteristic function λ . Then
- (1) π 1 ( M L ) = ker (Λ) is a torsion free finite index subgroup of W L .
- (2) M L is aspherical and its universal cover is homeomorphic to Σ W L .
- (3) If M S is a small cover associated to a sphere S , then it is an oriented manifold.
Proof. (1) The fact that π 1 ( M L ) = ker (Λ) is proved in [6, Col. 4.5]. To prove that π 1 ( M L ) is torsion free, assume that g ∈ π 1 ( M L ) is a nontrivial element of finite order. For T ⊂ L [0] define W T to be the subgroup of W L generated by T . In [3, Lemma 1.3] it is showed that every finite subgroup of W L is conjugate to a subgroup of finite W T , for some T . Since W T is finite, it follows that T spans a simplex in L . Indeed, otherwise W T would contain infinite dihedral group generated by non adjacent vertices. The element g generates a finite subgroup of W L and, thus there exist a simplex σ ∈ L such that g , up to conjugation, can be written in generators corresponding to the vertices of σ . Since Λ( g ) = 0, each of the generators has to appear even number of times. All the generators we used to express g pairwise commutes. Thus g = , which e gives a contradiction.
- (2) This is [6, Lemma 4.4].
- (3) This is [6, Prop. 1.7].
/square
Lemma 2. Let h : L 1 → L 2 be a simplicial map such that k -simplices are mapped to k -simplices for all k . Let G 1 < G 2 be a linear inclusion of Z 2 -linear spaces and let λ L i : L [0] i → G i be characteristic functions such that λ L 1 = λ L 2 h . Then G F p ( ) = G F h p ( ( )) for every p ∈ L 1 .
Proof. Let τ p be the minimal simplex in L b 1 containing p and let τ h p ( ) be the minimal simplex in L b 2 containing h p ( ). Notice that h τ ( p ) = τ h p ( ) . Let τ p = ( σ 1 < . . . < σ l ) and σ 1 = [ v , . . . , v 1 s ]. Since τ p is minimal, it is contained in each face F σ which contains p . Thus σ < σ 1 and F σ 1 ⊂ F σ . It means that F σ 1 is the minimal face containing p and G F p ( ) = Span G 1 〈 λ L 1 ( v 1 ) , . . . , λ L 1 ( v s ) . 〉 The same is true in L 2 ; i.e.: τ h p ( ) = h τ ( p ) = ( h σ ( 1 ) < .. . < h σ ( l )), where h σ ( 1 ) = [ h v ( 1 ) , . . . , h ( v s )] and G F h p ( ( )) = Span G 2 〈 λ L 2 h v ( 1 ) , . . . , λ L 2 h v ( s ) . 〉 Since λ L 1 = λ L 2 h , we have that G F h p ( ( )) = G F p ( ) . /square
Let us introduce the following notation. Recall that C X ( ) = X × I/ ∼ X , where I is the closed interval and ( x, t ) ∼ X ( y, s ) if and only if t = s = 1. Given a map h : A → B , we define C h : C A ( ) → C B ( ) by the formula C h ( a × t/ ∼ A ) = h a ( ) × t/ ∼ B .
Corollary 1. We use the notation from Lemma 2. Let w ∈ G 2 and let C h : C L ( 1 ) → C L ( 2 ) be the map induced from h to the cones. The function M h,w : M L 1 → M L 2 given by M h,w ( p × v/ ∼ λ 1 ) = C h ( p ) × ( v + w / ) ∼ λ 2 is well defined. If h is injective, then M h,w is injective.
/negationslash
/negationslash
/negationslash
/negationslash
Proof. Since M h,w is the composition of the action of w and M h, 0 , it is enough to prove Corollary for M h, 0 . The fact that M h, 0 is well defined follows from Lemma 2. Assume that h is injective. Take two different points x , x 1 2 ∈ M L 1 , let x i = p i × g / i λ 1 . We may assume that p i ∈ L 1 < C L ( 1 ), otherwise injectivity is trivial. If p 1 = p 2 , then h p ( 1 ) = h p ( 2 ) and M h, 0 ( x 1 ) = M h, 0 ( x 2 ). If p = p 1 = p 2 , then g g 1 -1 2 / G ∈ F p ( ) = G F h p ( ( )) and M h, 0 ( x 1 ) = M h, 0 ( x 2 ). /square
Let L n be a simplicial complex and M L its small cover associated to λ : L [0] → Z n +1 2 . If g ∈ Z n +1 2 , then by | g | we denote the number of nonzero coordinates of | g | . Let c be a simplicial chain in the barycentric subdivision L b , i.e. c is a formal sum of simplices of L b . Note that C c ( ), the cone over c , is itself a chain in C L ( b ). We define the lift of C c ( ) to M L by M c = ∑ g ∈ Z n +1 2 ( -1) | g | ( C c ( ) × g ).
Lemma 3. Let c be a chain in L b and let σ ∈ L b × g < M L for some g ∈ Z n +1 2 . Then σ does not appear in ∂M c .
Proof. Note that ∂M c = ∑ g ∈ Z n +1 2 ( -1) | g | ( ∂C c ( ) × g ). So the Lemma is clear if σ does not appear in ∂C c ( ) × g . Assume on the other hand that it appears in ∂C c ( ) × g and F is the smallest face containing σ . By the construction Stab σ ( ) = λ F ( ) and σ is glued exactly with the copies of σ contained in ∂C c ( ) × g ′ , where g ′ = g + x and x ∈ λ F ( ). Thus in M c , σ appears | λ F ( ) | = 2 k times (for some k ), the same number of times with the sign plus and minus. /square
2.3. Surgery. Let M be an ( n > 3)-dimensional manifold. The boundaries of H i = S i × D n -i and H n - -i 1 = D i +1 × S n - -i 1 are homeomorphic and equal to S i × S n - -i 1 . Thus every embedding (called framing) f : H i → M defines also an embedding ∂f : ∂H n - -i 1 → M . We consider a manifold M ′ = M f H \ ( i ) ∪ ∂f H n - -i 1 where ∂H n - -i 1 is glued to ∂ M f H ( \ ( i )) by ∂f . This procedure is called a surgery of index i +1. We present sketch of a proof of the following classical lemma.
Lemma 4. Let X be a topological space and let M be a compact, oriented, n -dimensional manifold, n > 3 . Assume that Γ X = π 1 ( X ) is finitely generated. Then for every map f M : M → X there exists a sequence of surgeries of index 1 and 2 , which results in a manifold M ′ such that: a) there exist a map f M ′ : M ′ → X such that π 1 ( f M ′ ) is an isomorphism, b) f M ([ M ]) = f M ′ ([ M ′ ]) .
Proof. First we modify the map f M to be an epimorphism. For this we use surgery of index 1, that is we attach handles. Let γ i be a set of loops in X which represents generators of Γ X . For each γ i we attach a handle to M . We call the new manifold M 0 . We can extend f M to f M 0 such that if we take a path which goes along the handle and connects its ends, it is mapped to γ i . The homology class of the image does not change and f M 0 is an epimorphism. Now we need to fill up some loops which are in N = ker π ( 1 ( f M 0 )). The subgroup N is normally finitely generated.
Let η i be a set of normal generators of N . Then we can perform a surgery of index 2 on M 0 along these loops, obtaining a manifold M ′ . Since images of loops are contractible in X , the map f M 0 can be extended to a map f M ′ . Moreover, the homology class does not change and f M ′ is an isomoprhism.
/square
## 3. Counterexamples
3.1. The construction. In this section we define manifolds M n k . It is done in three steps.
3.1.1. Step 1: The complex L n k . Let D 0 be an oriented ( n > 3)-dimensional closed disk. Let D ,. . . , D 1 k -1 ⊂ D 0 be a collection of pairwise disjoint subspaces of D 0 homeomorphic to closed n -discs. We define a complex L = L n k to be the following space: start with D 0 \ ( intD 1 ∪ . . . ∪ intD k -1 ) and glue each boundary ∂D i , i > 0, with ∂D 0 by orientation preserving homeomorphisms. Note that we have an inclusion i : ∂D 0 → L n k . The space L n k is a manifold except the singular sphere S = ( i ∂D 0 ) where we have a ramification of degree k . On S we have the orientation induced from ∂D 0 .
3.1.2. Step 2: Small covers. We pick a triangulation on L = L n k and assume that it admits a folding on a simplex characteristic function λ : L [0] → Z n +1 2 . By L ∗ we denote the complex dual to L . Moreover, assume that the restriction of λ to vertices of S is again a folding on a simplex characteristic function for the complex S , which ranges in the subspace spanned by the first n generators of Z n +1 2 . Such a triangulation exists. Indeed, having any triangulation on L we can pass to the barycentric subdivision and use the characteristic function defined in the proof of Lemma 1. It satisfies the above assumptions.
Let p L : M L → C L ( ∗ ) be the small cover defined by λ . Let p S : M S → C S ( ∗ ) be the small cover defined by λ S , where λ S is the restriction of λ to the vertices of S . Note that M S is an oriented manifold. By Corollary 1, in the complex M L we see two copies of M S . Namely they are
$$M _ { S } ^ { 0 } = C ( S ^ { * } ) \times ( \mathbf Z _ { 2 } ^ { n } \times 0 ) / _ { \sim _ { 0 } } < M _ { L } = C ( L ^ { * } ) \times \mathbf Z _ { 2 } ^ { n + 1 } / _ { \sim _ { \lambda } }$$
$$M _ { S } ^ { 1 } = C ( S ^ { * } ) \times ( \mathbf Z _ { 2 } ^ { n } \times 1 ) / _ { \sim _ { 1 } } < M _ { L } = C ( L ^ { * } ) \times \mathbf Z _ { 2 } ^ { n + 1 } / _ { \sim _ { \lambda } }.$$
By the relation ∼ i we mean the relation ∼ λ restricted to M i S . It coincides with ∼ λ S under the obvious identification with M S . The chain M 01 S = M 0 S -M 1 S is an n -dimensional cycle, thus defines a class [ M 01 S ] ∈ H n ( M L ; Z ). The signs were chosen so that M 01 S is the lift of C S ( b ) by p L , as described in the discussion before Lemma 3. We define an oriented manifold N = M 0 S #( -M 1 S ). Since M L is connected, there exists a map f N : N → M L such that the pushforward of the fundamental class equals [ M 01 S ].
3.1.3. Step 3: Surgery. Let M n k and f M n k : M n k → M L be an n -dimensional manifold and a map obtained by the procedure described in Lemma 4 applied to N and f N . From Fact 1(2) we know that M L is aspherical, thus f M n k classifies the universal cover. Moreover we have that the pushforward of the fundamental class of M n k equals [ M 01 S ].
## 3.2. M n k is a counterexample to the Dranishnikov rationality conjecture.
Lemma 5. Let S be as in the construction (Step 1). Then H n -1 ( L n k ; Z ) = Z k and [ S ] is a generator.
Proof. It follows from the Mayer-Vietors exact sequence. Let D = D 0 \ ( intD 1 ∪ . . . ∪ intD k -1 ). We have a quotient map
$$q \colon D \rightarrow L,$$
which glues the boundaries of ∂D i with ∂D 0 as in the construction. Let D k be another n -disk embedded in the interior of D . Let L · = L q intD \ ( k ). To use the Mayer-Vietoris sequence we decompose L as follows: L = L · ∪ q D ( k ).
Note that L · ∩ q D ( k ) = q ∂D ( k ) ∼ = S n -1 . The Mayer-Vietoris exact sequence reads:
We claim that L · is homotopy equivalent to the wedge of S n -1 and k -1 circles. Indeed, let γ i , i = 1 , . . . , k -1, be a collection of disjoint arcs in D intD \ k . Assume that each γ i connects a point on ∂D i with a point on ∂D 0 . The subspace X = ∂D 0 ∪ ( ∂D 1 ∪ γ 1 ) ∪ . . . ∪ ( ∂D k -1 ∪ γ k -1 ) is a deformation retract of D intD \ k . We can imagine that we start to inflate the disk D k such that at the end it fills up all the space between X . It is easy to see that the space q X ( ) is homotopy equivalent to the wedge of S n -1 and k -1 circles. Moreover, the retraction of D intD \ k to X carries down to a retraction of L · to q X ( ). This proves the claim.
$$H _ { n - 1 } ( q ( \partial D _ { k } ) ) \stackrel { i } { \longrightarrow } H _ { n - 1 } ( q ( D _ { k } ) ) \oplus H _ { n - 1 } ( L _ { \bullet } ) \stackrel { s } { \longrightarrow } H _ { n - 1 } ( L ) \\ \Big \downarrow _ { \begin{subarray} { c } H _ { n - 2 } ( q ( \partial D _ { k } ) ) \end{subarray} }$$
Thus s is an epimorphism. Let us take a closer look at i . Since L · ∼ = S n -1 ∨ S 1 ∨ . . . ∨ S 1 , we have that H n -1 ( q D ( k )) ⊕ H n -1 ( L · ) = Z . This group is generated by [ S ] = q ∗ [ ∂D 0 ]. Note that we can choose an orientation of D k such that the following holds:
$$\partial ( D \, \L D _ { k } ) = \partial D _ { 0 } + \partial D _ { 1 } + \dots + \partial D _ { k - 1 } - \partial D _ { k }.$$
After applying q to this equation we have that k S [ ] -q ∗ [ ∂D k ] = 0 in H n -1 ( L · ). To finish, we note that i ([ ∂D k ]) = q ∗ [ ∂D k ]. It follows that i is the multiplication by k , thus the Lemma.
/square
Now we are ready to prove the crucial lemma. The equivariant coarsening map ec ∗ : H ∗ ( X ; Z ) → H lf ∗ ( ˜ X ; Z ) and the locally finite homology H lf were defined in section 2.1.
Lemma 6. Let [ M 01 ] ∈ H n ( M L ; Z ) be as in the construction (Step 2). Then
S
- (1) k M [ 01 S ] = 0 ∈ H n ( M L ; Z ) .
/negationslash
- (2) ec n ([ M 01 S ]) = 0 ∈ H lf n ( ˜ M L ; Z ) .
Proof. (1) In Lemma 5 we defined D = D 0 \ ( intD 1 ∪ . . . ∪ intD k -1 ) and the quotient map
$$q \colon D \rightarrow L.$$
On D we consider the pullback simplicial structure. Let λ D be a folding on a simplex characteristic function for D defined by λ D = λq . Let p D : M D → C D ( ∗ ) be the small cover associated to λ D . By Corollary 1, the map q lifts to
$$M _ { q } \colon M _ { D } \rightarrow M _ { L }.$$
We recall the definition of this map: M p q ( × x/ ∼ λ D ) = C q ( p ) × x/ ∼ λ , for p ∈ C D ,x ( ) ∈ Z n +1 2 and C q : C D ( ) → C L ( ) is the map of cones induced by q . The complex D is oriented. The orientation defines an n -dimensional chain representing the relative to the boundary fundamental class of D . Abusing notation we call it D as well. Note that q ∗ ( ∂D ) = kS . Let M D be the lift of the chain D (for the definition see the discussion before Lemma 3).
To simplify the notation we write C D ( ) for C D ( ) × 0. Thus g.C D ( ) = C D ( ) × g , where by g.C D ( ) we denote the action of g ∈ Z n +1 2 on C D ( ). We have
$$\lambda \times \Delta / \cdots \varepsilon, \cdots \varepsilon \Delta \Delta \Delta \Delta \Delta \Delta \Delta \Delta \Delta \Delta \Delta \Delta \Delta \Delta \Delta \Delta \Delta \Delta \Delta \Delta \Delta \Delta \Delta \Delta \Delta \Delta \Delta \Delta \Delta \Delta \Delta \Delta \Delta \Delta \Delta \Delta \Delta \Delta \Delta \Delta \Delta \Delta \Delta \Delta \Delta \Delta \Delta \Delta \Delta \Delta \Delta \Delta \Delta \Delta \Delta \Delta \Delta \Delta \Delta \Delta \Delta \Delta \Delta \Delta \Delta \Delta \Delta \Delta \Delta \Delta \Delta \Delta \Delta \Delta \Delta \Delta \Delta \Delta \Delta \Delta \Delta \Delta \Delta \Delta \Delta \Delta \Delta \Delta \Delta \Delta \Delta \Delta \Delta \Delta \Delta \Delta \Delta \Delta \Delta \Delta \alpha \Delta \Delta \Delta \Delta \Delta \Delta \Delta \Delta \Delta \Delta \Delta \Delta \Delta \Delta \Delta \Delta \Delta \Delta \Delta \Delta \Delta \Delta \Delta \Delta \Delta \Delta \Delta \Delta \Delta \Delta \Delta \Delta \Delta \Delta \Delta \Delta \Delta \Delta \Delta \Delta \Delta \Delta \Delta \Delta \Delta \Delta \Delta \Delta \Delta \Delta \Delta \Delta \Delta \Delta \Delta \Delta \Delta \Delta \Delta \Delta \Delta \Delta \Delta \Delta \Delta \Delta \Delta \Delta \Delta \Delta \Delta \Delta \Delta \Delta \Delta \Delta \Delta \Delta \Delta \Delta \Delta \Delta \Delta \Delta \Delta \Delta \Delta \Delta \Delta \Delta \Delta \Delta \Delta \Delta \Delta \Delta \Delta \Delta \Delta \delta \Delta \Delta \Delta \Delta \Delta \Delta \Delta \Delta \Delta \Delta \Delta \Delta \Delta \Delta \Delta \Delta \Delta \Delta \Delta \Delta \Delta \Delta \Delta \Delta \Delta \Delta \Delta \Delta \Delta \Delta \Delta \Delta \Delta \Delta \Delta \Delta \Delta \Delta \Delta \Delta \Delta \Delta \Delta \Delta \Delta \Delta \Delta \Delta \Delta \Delta \Delta \Delta \Delta \Delta \Delta \Delta \Delta \Delta \Delta \Delta \Delta \Delta \Delta \Delta \Delta \Delta \Delta \Delta \Delta \Delta \Delta \Delta \Delta \Delta \Delta \Delta \Delta \Delta \Delta \Delta \Delta \Delta \Delta \Delta \Delta \Delta \Delta \Delta \Delta \Delta \Delta \Delta \Delta \Delta \Delta \Delta \Delta \Delta \Delta \Lambda \Delta \Delta \Delta \Delta \Delta \Delta \Delta \Delta \Delta \Delta \Delta \Delta \Delta \Delta \Delta \Delta \Delta \Delta \Delta \Delta \Delta \Delta \Delta \Delta \Delta \Delta \Delta \Delta \Delta \Delta \Delta \Delta \Delta \Delta \Delta \Delta \Delta \Delta \Delta \Delta \Delta \Delta \Delta \Delta \Delta \Delta \Delta \Delta \Delta \Delta \Delta \Delta \Delta \Delta \Delta \Delta \Delta \Delta \Delta \Delta \Delta \Delta \Delta \Delta \Delta \Delta \Delta \Delta \Delta \Delta \Delta \Delta \Delta \Delta \Delta \Delta \Delta \Delta \Delta \Delta \Delta \Delta \Delta \Delta \Delta \Delta \Delta \Delta \Delta \Delta \Delta \Delta \Delta \Delta \Delta \Delta \Delta \Delta \Delta \beta \Delta \Delta \Delta \Delta \Delta \Delta \Delta \Delta \Delta \Delta \Delta \Delta \Delta \Delta \Delta \Delta \Delta \Delta \Delta \Delta \Delta \Delta \Delta \Delta \Delta \Delta \Delta \Delta \Delta \Delta \Delta \Delta \Delta \Delta \Delta \Delta \Delta \Delta \Delta \Delta \Delta \Delta \Delta \Delta \Delta \Delta \Delta \Delta \Delta \Delta \Delta \Delta \Delta \Delta \Delta \Delta \Delta \Delta \Delta \Delta \Delta \Delta \Delta \Delta \Delta \Delta \Delta \Delta \Delta \Delta \Delta \Delta \Delta \Delta \Delta \Delta \Delta \Delta \Delta \Delta \Delta \Delta \Delta \Delta \Delta \Delta \Delta \Delta \Delta \Delta \Delta \Delta \Delta \Delta \Delta \Delta \Delta \Delta \Delta \Delta \Delta \Delta \Delta \Delta \Delta \Delta \Delta \Delta \Delta \Delta \Delta \Delta \Delta \Delta \Delta \Delta \Delta \Delta \Delta \Delta \Delta \Delta \Delta \Delta \Delta \Delta \Delta \Delta \Delta \Delta \Delta \Delta \Delta \Delta \Delta \Delta \Delta \Delta \Delta \Delta \Delta \Delta \Delta \Delta \Delta \Delta \Delta \Delta \Delta \Delta \Delta \Delta \Delta \Delta \Delta \Delta \Delta \Delta \Delta \Delta \Delta \Delta \Delta \Delta \Delta \Delta \Delta \Delta \Delta \Delta \Delta \Delta \Delta \Delta \Delta \Delta \Delta \Delta \Delta \Delta \Delta \Delta \Delta \Delta \Delta \Delta \Delta \Delta \Delta \Delta \Delta \Delta \Delta \Delta \Delta \Delta \Delta \Delta \Delta
\lambda \times \Delta / \Delta / \Delta / \Delta / \Delta / \Delta / \Delta / \Delta / \Delta / \Delta / \Delta / \Delta / \Delta / \Delta / \Delta / \Delta / \Delta / \Delta / \Delta / \Delta / \Delta / \Delta / \Delta / \Delta / \Delta / \Delta / \Delta / \Delta / \Delta / \Delta / \Delta / \Delta / \Delta / \Delta / \Delta / \Delta / \Delta / \Delta / \Delta / \Delta / \Delta / \Delta / \Delta / \Delta / \Delta / \Delta / \Delta / \Delta / \Delta / \Delta / \Delta / \Delta / \Delta / \Delta / \Delta / \Delta / \Delta / \Delta / \Delta / \Delta / \Delta / \Delta / \Delta / \Delta / \Delta / \Delta / \Delta / \Lambda \Delta / \Delta / \Delta / \Delta / \Delta / \Delta / \Delta / \Delta / \Delta / \Delta / \Delta / \Delta / \Delta / \Delta / \Delta / \Delta / \Delta / \Delta / \Delta / \Delta / \Delta / \Delta / \Delta / \Delta / \Delta / \Delta / \Delta / \Delta / \Delta / \Delta / \Delta / \Delta / \Delta / \Delta / \Delta / \Delta / \Delta / \Delta / \Delta / \Delta / \Delta / \Delta / \Delta / \Delta / \Delta / \Delta / \Delta / \Delta / \Delta / \Delta / \Delta / \Delta / \Delta / \Delta / \Delta / \Delta / \Delta / \Delta / \Delta / \Delta / \Delta / \Delta / \Delta / \Delta / \Delta / \Delta / \alpha \Delta / \Delta / \Delta / \Delta / \Delta / \Delta / \Delta / \Delta / \Delta / \Delta / \Delta / \Delta / \Delta / \Delta / \Delta / \Delta / \Delta / \Delta / \Delta / \Delta / \Delta / \Delta / \Delta / \Delta / \Delta / \Delta / \Delta / \Delta / \Delta / \Delta / \Delta / \Delta / \Delta / \Delta / \Delta / \Delta / \Delta / \Delta / \Delta / \Delta / \Delta / \Delta / \Delta / \Delta / \Delta / \Delta / \Delta / \Delta / \Delta / \Delta / \Delta / \Delta / \Delta / \Delta / \Delta / \Delta / \Delta / \Delta / \Delta / \Delta / \Delta / \Delta / \Delta / \Delta / \Delta / \Delta / \delta \Delta / \Delta / \Delta / \Delta / \Delta / \Delta / \Delta / \Delta / \Delta / \Delta / \Delta / \Delta / \Delta / \Delta / \Delta / \Delta / \Delta / \Delta / \Delta / \Delta / \Delta / \Delta / \Delta / \Delta / \Delta / \Delta / \Delta / \Delta / \Delta / \Delta / \Delta / \Delta / \Delta / \Delta / \Delta / \Delta / \Delta / \Delta / \Delta / \Delta / \Delta / \Delta / \Delta / \Delta / \Delta / \Delta / \Delta / \Delta / \Delta / \Delta / \Delta / \Delta / \Delta / \Delta / \Delta / \Delta / \Delta / \Delta / \Delta / \Delta / \Delta / \Delta / \Delta / \Delta / \Delta / \Delta / \D / \Delta / \Delta / \Delta / \Delta / \Delta / \Delta / \Delta / \Delta / \Delta / \Delta / \Delta / \Delta / \Delta / \Delta / \Delta / \Delta / \Delta / \Delta / \Delta / \Delta / \Delta / \Delta / \Delta / \Delta / \Delta / \Delta / \Delta / \Delta / \Delta / \Delta / \Delta / \Delta / \Delta / \Delta / \Delta / \Delta / \Delta / \Delta / \Delta / \Delta / \Delta / \Delta / \Delta / \Delta / \Delta / \Delta / \Delta / \Delta / \Delta / \Delta / \Delta / \Delta / \Delta / \Delta / \Delta / \Delta / \Delta / \Delta / \Delta / \Delta / \Delta / \Delta / \Delta / \Delta / \Delta / \Delta /\Delta / \Delta / \Delta / \Delta / \Delta / \Delta / \Delta / \Delta / \Delta / \Delta / \Delta / \Delta / \Delta / \Delta / \Delta / \Delta / \Delta / \Delta / \Delta / \Delta / \Delta / \Delta / \Delta / \Delta / \Delta / \Delta / \Delta / \Delta / \Delta / \Delta / \Delta / \Delta / \Delta / \Delta / \Delta / \Delta / \Delta / \Delta / \Delta / \Delta / \Delta / \Delta / \Delta / \Delta / \Delta / \Delta / \Delta / \Delta / \Delta / \Delta / \Delta / \Delta / \Delta / \Delta / \Delta / \Delta / \Delta / \Delta / \Delta / \Delta / \Delta / \Delta / \Delta / \Delta / \Delta / \Delta / \Delta \Delta \Delta \Delta \Delta \Delta \Delta \Delta \Delta \Delta \Delta \Delta \Delta \Delta \Delta \Delta \Delta \Delta \Delta \Delta \Delta \Delta \Delta \Delta \Delta \Delta \Delta \Delta \Delta \Delta \Delta \Delta \Delta \Delta \Delta \Delta \Delta \Delta \Delta \Delta \Delta \Delta \Delta \Delta \Delta \Delta \Delta \Delta \Delta \Delta \Delta \Delta \Delta \Delta \Delta \Delta \Delta \Delta \Delta \Delta \Delta \Delta \Delta \Delta \Delta \Delta \Delta \Delta \Delta \Delta \Delta \Delta \Delta \Delta \Delta \Delta \Delta \Delta \Delta \Delta \Delta \Delta \Delta \Delta \Delta \Delta \Delta \Delta \Delta \Delta \Delta \Delta \Delta \Delta \Delta \Delta \Delta \Delta \Delta \partial \Delta \Delta \Delta \Delta \Delta \Delta \Delta \Delta \Delta \Delta \Delta \Delta \Delta \Delta \Delta \Delta \Delta \Delta \Delta \Delta \Delta \Delta \Delta \Delta \Delta \Delta \Delta \Delta \Delta \Delta \Delta \Delta \Delta \Delta \Delta \Delta \Delta \Delta \Delta \Delta \Delta \Delta \Delta \Delta \Delta \Delta \Delta \Delta \Delta \Delta \Delta \Delta \Delta \Delta \Delta \Delta \Delta \Delta \Delta \Delta \Delta \Delta \Delta \Delta \Delta \Delta \Delta \Delta \Delta \Delta \Delta \Delta \Delta \Delta \Delta \Delta \Delta \Delta \Delta \Delta \Delta \Delta \Delta \Delta \Delta \Delta \Delta \Delta \Delta \Delta \Delta \Delta \Delta \Delta \Delta \Delta \Delta \Delta \Delta \Dep \Delta \Delta \Delta \Delta \Delta \Delta \Delta \Delta \Delta \Delta \Delta \Delta \Delta \Delta \Delta \Delta \Delta \Delta \Delta \Delta \Delta \Delta \Delta \Delta \Delta \Delta \Delta \Delta \Delta \Delta \Delta \Delta \Delta \Delta \Delta \Delta \Delta \Delta \Delta \Delta \Delta \Delta \Delta \Delta \Delta \Delta \Delta \Delta \Delta \Delta \Delta \Delta \Delta \Delta \Delta \Delta \Delta \Delta \Delta \Delta \Delta \Delta \Delta \Delta \Delta \Delta \Delta \Delta \Delta \Delta \Delta \Delta \Delta \Delta \Delta \Delta \Delta \Delta \Delta \Delta \Delta \Delta \Delta \Delta \Delta \Delta \Delta \Delta \Delta \Delta \Delta \Delta \Delta \Delta \Delta \Delta \Delta \Delta \Delta \Per \Delta \Delta \Delta \Delta \Delta \Delta \Delta \Delta \Delta \Delta \Delta \Delta \Delta \Delta \Delta \Delta \Delta \Delta \Delta \Delta \Delta \Delta \Delta \Delta \Delta \Delta \Delta \Delta \Delta \Delta \Delta \Delta \Delta \Delta \Delta \Delta \Delta \Delta \Delta \Delta \Delta \Delta \Delta \Delta \Delta \Delta \Delta \Delta \Delta \Delta \Delta \Delta \Delta \Delta \Delta \Delta \Delta \Delta \Delta \Delta \Delta \Delta \Delta \Delta \Delta \Delta \Delta \Delta \Delta \Delta \Delta \Delta \Delta \Delta \Delta \Delta \Delta \Delta \Delta \Delta \Delta \Delta \Delta \Delta \Delta \Delta \Delta \Delta \Delta \Delta \Delta \Delta \Delta \Delta \Delta \Delta \Delta \Delta \Delta \Log \colon$$
The last equality follows from the following: the class M 01 S is the lift of C S ( ) by λ S , thus equals ∑ ( -1) | g | g.C S ( ). Hence, if we show that ∑ ( -1) | g | g.D = 0, we are done. Note that D = ∂C D ( ) -C ∂D ( ). If we sum over Z n +1 2 action, we have
$$\sum _ { g \in \mathbf Z _ { 2 } ^ { n + 1 } } ( - 1 ) ^ { | g | } g. D = \partial M _ { D } - \sum _ { g \in \mathbf Z _ { 2 } ^ { n + 1 } } ( - 1 ) ^ { | g | } g. C ( \partial D ) = 0. \\. \quad \, \quad \, \quad \, - \cdot \quad \cdot \,,$$
Indeed, if σ < g.D for some g , then σ does not appear in ∑ ( -1) | g | g.C ∂D ( ) (every simplex of g.C ∂D ( ) lies inside the cone g.C D ( )) nor in ∂M D (Lemma 3). On the other hand, if σ ≮ g.D for every g , then it does not appear in ∑ ( -1) | g | g.D .
## (2) Consider the map
$$H _ { * } ( M _ { L } ; \mathbf Z ) \stackrel { e c _ { * } } { \longrightarrow } H _ { * } ^ { l f } ( \widetilde { M _ { L } } ; \mathbf Z ).$$
Let ˜ C be a lift of C L ( ) × 0 < M L to the universal cover ˜ M L . By ˜ L we denote the base of the cone ˜ C . We remark that ˜ M L is the Davis complex for W L and ˜ C is a fundamental domain of the W L action. Let intC ˜ = ˜ C -˜ L .
Let ρ be the homomorphism induced by the quotient map
$$\rho _ { * } \colon H _ { * } ^ { l f } ( \widetilde { M _ { L } } ; \mathbf Z ) \to H _ { * } ^ { l f } ( \widetilde { M _ { L } }, ( i n t \widetilde { C } ) ^ { c } ; \mathbf Z ).$$
Since ˜ C is a finite complex, it is straight-forward to prove that the locally finite homology of a pair ( ˜ M , intC L ( ˜ ) c ) is isomorphic to the standard homology.
The following equality holds by the excision theorem
$$H _ { * } ( \widetilde { M _ { L } }, ( i n t \widetilde { C } ) ^ { c } ; \mathbf Z ) = H _ { * } ( \widetilde { C }, \widetilde { L } ; \mathbf Z ).$$
Of course
$$H _ { * } ( \widetilde { C }, \widetilde { L } ; \mathbf Z ) = H _ { * } ( C ( L ), L ; \mathbf Z ). \quad \cdots \cdots \cdots. \quad \cdots$$
Thus we can write that (compare with [4], where such maps were used to compute the locally finite homology of Coxeter groups)
$$\rho _ { * } \colon H _ { * } ^ { l f } ( \widetilde { M _ { L } } ; \mathbf Z ) \to H _ { * } ( C ( L ), L ; \mathbf Z ).$$
From the definition of the comparision maps we see that ρ n ec n [ M 01 S ] = [ C S ( )] ∈ H n ( C L , L ( ) ; Z ). By the long exact sequence of the pair, the boundary map δ : H n ( C L , L ( ) ; Z ) → H n -1 ( L ; Z ) is an isomorphism. Moreover, δ ([ C S ( )]) = [ S ]. By Lemma 5, the class [ S ] is nonzero in H n -1 ( L ; Z ). Thus the class ec n ([ M 01 S ]) is nonzero.
/square
Remark 2. Let H ae ∗ ( M L ; Z ) be the almost equivariant homology defined in [7]. Let ae ∗ : H ∗ ( M L ; Z ) → H ae ∗ ( M L ; Z ). For Z coefficients, ae homology is isomorphic to the Block-Weinberger uniformly finite homology of π 1 ( M L ), defined in [1]. The map ec ∗ factors through H ae ∗ ( M L ; Z ), hence ae n ( M 01 S ) is nontrivial and torsion. To our knowledge, it is the first example of torsion class in the uniformly finite homology of a group.
Now we can prove that M n k are counterexamples to the Rationality Conjecture.
Theorem 2. Manifolds M n k are macroscopically large and rationally inessential.
Proof. By Step 3 of the construction, we have that ( f M n k ) ∗ [ M n k ] = [ M 01 S ]. From Lemma 6(2), ec ∗ ([ M 01 S ]) does not vanish and f M n k classifies the universal cover. We can apply Theorem 1. Thus M n k is macroscopically large. By Lemma 6(1) we have that M n k is rationally inessential.
/square
3.3. M n k and PSC metrics. Motivating by the Gromov conjecture, we address the following question: does M n k admit a PSC metric? In this section we make a small step towards answering this question. Namely, we prove using a result of Bolotov and Dranishnikov, that if M n k is spin, then it does not admit a PSC metric. Thus we support the Gromov conjecture in this case. We show as well, that our construction provides us with many examples of such manifolds.
3.3.1. Some remarks on spin structures. Let M be an oriented n -dimensional manifold. Let P SO ( TM ) be the principal SO n bundle associated to the tangent bundle of M . A spin structure on M is a two sheeted covering of P SO ( TM ) which is connected over a fiber of P SO ( TM ). There may be many spin structures on M . Such a structure exists if and only if the second Stiefel-Whitney class w 2 ( M ) vanishes. Let f : S i × D n -i → M be an embedding. One can always pick a framing f such that a given spin structure on M extends uniquely from M f S \ ( i × D n -i ) to the result of the surgery with respect to f . Since S i × D n -i admits an unique spin structure for i = 1, the choice of f is important only if i = 1.
/negationslash
Lemma 7. Let S be a triangulated n -dimensional sphere and λ : S [0] → Z n +1 2 be a folding on a simplex characteristic function. Let p : M S → C S ( ∗ ) be the small cover associated to λ . Then w i ( M S ) = 0 for i > 0 . In particular, M S is orientable and spin.
Proof. By [6, Cor. 6.10, Lemma 1.14] (compare as well [3, Prop. 1.4]) M S is stably parallelizable, i.e.: TM S ⊕ /epsilon1 r = /epsilon1 s for some r, s ≥ 0, where TM S is the tangent bundle of M S and /epsilon1 is the trivial bundle. Let w = ∑ i ≥ 0 w i be the total StiefelWhitney class. In the following we use the Whitney product formula and the fact that w /epsilon1 ( s ) = 1 ∈ H 0 ( M S ; Z 2 ):
$$w ( \epsilon ^ { r } ) = w ( T M _ { S } \oplus \epsilon ^ { s } ) = w ( T M _ { S } ) \cup w ( \epsilon ^ { s } ) = w ( T M _ { S } ).$$
By definition w M ( S ) = w TM ( S ), thus w i ( M S ) = w i ( /epsilon1 r ) = 0 for i > 0. /square
Corollary 2. Assume that the surgery we use in Step 3 of the construction allows us to extend spin structures. Then M n k is spin.
Proof. From Lemma 7 follows that M S is spin. A manifold N = M 0 S #( -M 1 S ) is spin as a connected sum of spin manifolds (surgery of index 1). The manifold M n k is the result of the surgery on N , which was arranged such that M n k is spin. /square
3.3.2. Positive scalar curvature. The crucial result which we use here is a theorem due to D. Bolotov and A. Dranishnikov
Theorem 3. [2, Col.4.4] The Gromov Conjecture holds for spin n-manifolds M , having the cohomological dimension cd π ( 1 ( M )) ≤ n +3 , and satisfying the Strong Novikov Conjecture.
Theorem 4. If M n k is spin, then it does not admit a Riemannian metric of positive scalar curvature.
Proof. We check that the assumptions of Theorem 3 are satisfied. It is well known that subgroups of Coxeter groups satisfy the Baum-Connes conjecture, which implies the Strong Novikov Conjecture. The inequality for cd π ( ) follows from the fact that M L is a classifying space of π , so cd π ( ) ≤ dim M ( L ) = n +1. We already know that M n k is macroscopically large, thus by Theorem 3, M n k can not admit a metric of positive scalar curvature. /square
## 4. Further examples
In this section we describe a construction of rationally inessential macroscopically large manifolds which generalizes that from Section 3.1. Instead of working with small covers, we start with a Davis complex. Then we find an appropriate subgroups of right angled Coxeter groups and pass to quotients.
Let X be a simplicial complex. By W X we denote the right angled Coxeter group associated to X (as in 2.2.2) and by Σ X its Davis complex. By g ∈ W X , l ( g ) we denote the minimal number of generators one needs to express g . Let W + X < W X be the subgroup of elements whose Coxeter length is even. We assume all complexes to be flag and associated Coxeter groups to be infinite. The usual fundamental domain of the action of W X on Σ X is homeomorphic to C X ( ) and is called the Davis cell.
Let S < L be a pair of compact simplicial complexes. We assume that S is an oriented null-bordant manifold such that [ S ] ∈ H L ( ; Z ) is a nontrivial k -torsion
class. Moreover, S can be of codimension bigger than one in L , but we assume that S is at least 3-dimensional. Let D be a simplicial chain in L such that ∂D = kS .
The inclusion S < L induces an inclusion on the level of Davis complexes: Σ S < Σ . L Let Γ S and Γ L be finite index torsion-free subgroups of W + S and W + L such that Γ S < Γ L and Γ L ∩ W S = Γ . S E.g. Γ S and Γ L can be taken to be the derived subgroups of W S and W L , respectively (the derived subgroup of a right angled Coxeter group is torsion free, the proof is analogous to that of Fact 1(1)). Then Γ S and Γ L act freely, orientation preserving and cocompactly on Σ S and Σ L , respectively. The group Γ L in this construction plays the role of π 1 ( M L ).
Notice that Σ L considered as a Γ S space, is a classifying bundle of Γ S . Since Σ S < Σ L is Γ -invariant (here we use the assumption that Γ S S < W + S ), it defines a class [Σ S / Γ ] S ∈ H ∗ (Σ L / Γ ; S Z ) = H ∗ (Γ S ; Z ).
Lemma 8. The class [Σ S / Γ ] S ∈ H ∗ (Γ S ; Z ) can be represented as a pushforward of the fundamental class of a manifold.
Proof. First, we consider the Davis cell C S ( ). By the assumption S is null-bordant, thus there exists a manifold B such that S = ∂B . The link of the apex of the cone C S ( ) is S , thus we can truncate the apex and glue in the manifold B , getting rid of the singularity. Now we take care of Σ S . The only points of Σ S which have noneuclidean neighborhoods are apexes of translates of the Davis cell. The group Γ S acts on Σ S freely and cocompactly. Thus the quotient Σ S / Γ S < Σ L / Γ S is compact and is a manifold except apexes of cones. We can do the above surgery for every apex of Σ S / Γ . S We obtain a manifold, denote it by M S , together with a map g : M S → Σ L / Γ , which collapses just glued copies of S B again to apexes of appropriate cones. We have that g ∗ ([ M S ]) = [Σ S / Γ ] S ∈ H ∗ (Γ S ; Z ). /square
Define a chain α = Σ g ∈ W L ( -1) l ( g ) g. Σ . S It is a Γ L -equivariant chain because Γ L < W + L . Thus it defines a class β = [ α/ Γ ] L ∈ H ∗ (Γ L ; Z ). Since Γ L ∩ W S = Γ S , the class β is a finite disjoint sum of ± Σ S / Γ S and it plays the role of M 01 S . The number of components in this sum equals [ W L : Γ ] L / W [ S : Γ ]. S Indeed, Σ S / Γ S consists of [ W S : Γ ] cones S C S ( ) and α/ Γ L consists of [ W L : Γ ] cones (in Section L 3.1 it was 2 = 2 n +1 / 2 n ). By Lemma 8, β is represented by a connected sum of manifolds ± M S . Denote this connected sum by N . The rest of the construction is the surgery procedure described in Step 3 of 3.1. We call the resulting manifold M L,S ( ).
Theorem 5. The manifold M L,S ( ) is rationally inessential and macroscopically large.
Proof. The proof of Lemma 6 goes through essentially without changes. Namely, the assumption that kS is the boundary of D allows to carry out the computations as in Lemma 6(1). The only difference is that we replace q ∗ ( M D ) with the lift of D to Σ L / Γ . That is, with L ∑ r ∈ R ( -1) l ( r ) r.C D ( ), where R is a set of representatives of the cosets of Γ L in W L . As well, Lemma 3 admits a straightforward generalisation to the situation when we lift a chain to a cover of C L ( ) of the form Σ L / Γ . L In Lemma 6(2) we really work with the universal cover of M L , which is the Davis complex for L . /square
Remark 3. The advantage of using small covers to construct our examples, except their intrinsic beauty, gives us a better insight into the (co)homology ring of M n k and possible spin structures. They are the simplest possible examples to deal with.
This paper leaves the following question open.
Question. Does M L,S ( ) admit a PSC metric? In particular, does M n k with no additional assumptions on Step 3, see 3.3.1, admit a PSC metric?
Acknowledgements. I wish to thank Tadeusz Januszkiewicz for his constant help and guidance throughout this project and Alexander N. Dranishnikov for helpful discussions and comments. I am also indebted to ´ wiatos/suppress law Gal and /suppress Lukasz GarS ncarek for their help in improving the presentation of the paper, and the anonymous referee for pointing out simpler proof of Lemma 7.
## References
- [1] Block, J., and Weinberger, S. Aperiodic tilings, positive scalar curvature and amenability of spaces. J. Amer. Math. Soc. 5 , 4 (1992), 907-918.
- [2] Bolotov, D. V., and Dranishnikov, A. N. On Gromov's scalar curvature conjecture. Proc. Amer. Math. Soc. 138 , 4 (2010), 1517-1524.
- [3] Davis, M. W. Some aspherical manifolds. Duke Math. J. 55 , 1 (1987), 105-139.
- [4] Davis, M. W. The cohomology of a Coxeter group with group ring coefficients. Duke Math. J. 91 , 2 (1998), 297-314.
- [5] Davis, M. W. The geometry and topology of Coxeter groups , vol. 32 of London Mathematical Society Monographs Series . Princeton University Press, Princeton, NJ, 2008.
- [6] Davis, M. W., and Januszkiewicz, T. L. Convex polytopes, Coxeter orbifolds and torus actions. Duke Math. J. 62 , 2 (1991), 417-451.
- [7] Dranishnikov, A. N. On macroscopic dimension of universal covering of closed manifolds. Tr. Mosk. Mat. Obs. 74:2 (2013), 279-296.
- [8] Dranishnikov, A. N. On Gromov's positive scalar curvature conjecture for duality groups. J. Topol. Anal. 6 , 3 (2014), 397-419.
- [9] Geoghegan, R. Topological methods in group theory , vol. 243 of Graduate Texts in Mathematics . Springer, New York, 2008.
- [10] Gromov, M., and Lawson, Jr., H. B. Positive scalar curvature and the Dirac operator on complete Riemannian manifolds. Inst. Hautes Etudes Sci. Publ. Math. ´ , 58 (1983), 83-196 (1984).
- [11] Gromov, M. L. Positive curvature, macroscopic dimension, spectral gaps and higher signatures. In Functional analysis on the eve of the 21st century, Vol. II (New Brunswick, NJ, 1993) , vol. 132 of Progr. Math. Birkh¨user Boston, Boston, MA, 1996, pp. 1-213. a
- [12] Nowak, P. W., and Yu, G. Large scale geometry . EMS Textbooks in Mathematics. European Mathematical Society (EMS), Z¨rich, 2012. u
Uniwersytet Wroc/suppress lawski & Instytut Matematyczny Polskiej Akademii Nauk, Warszawa E-mail address : [email protected] | 10.1112/jtopol/jtv037 | [
"Michał Marcinkowski"
] | 2014-08-02T13:54:09+00:00 | 2015-08-15T20:08:03+00:00 | [
"math.GT",
"math.AT",
"math.DG",
"math.GR",
"51F15, 20F55, 32Q10, 55N20"
] | Gromov positive scalar curvature conjecture and rationally inessential macroscopically large manifolds | We give the first examples of rationally inessential but macroscopically
large manifolds. Our manifolds are counterexamples to the Dranishnikov
rationality conjecture. For some of them we prove that they do not admit a
metric of positive scalar curvature, thus satisfy the Gromov positive scalar
curvature conjecture. Fundamental groups of our manifolds are finite index
subgroups of right angled Coxeter groups. The construction uses small covers of
convex polyhedrons (or alternatively Davis complexes) and surgery. |
1408.0373v2 | ## Nuclear magnetic resonance inverse spectra of InGaAs quantum dots: Atomistic level structural information
Ceyhun Bulutay, 1, ∗ E. A. Chekhovich, 2 and A. I. Tartakovskii 2
1 Department of Physics, Bilkent University, Ankara 06800, Turkey 2 Department of Physics and Astronomy, University of Sheffield, Sheffield S3 7RH, United Kingdom (Dated: November 21, 2014)
A wealth of atomistic information is contained within a self-assembled quantum dot (QD), associated with its chemical composition and the growth history. In the presence of quadrupolar nuclei, as in InGaAs QDs, much of this is inherited to nuclear spins via the coupling between the strain within the polar lattice and the electric quadrupole moments of the nuclei. Here, we present a computational study of the recently introduced inverse spectra nuclear magnetic resonance technique to assess its suitability for extracting such structural information. We observe marked spectral differences between the compound InAs and alloy InGaAs QDs. These are linked to the local biaxial and shear strains, and the local bonding configurations. The cation-alloying plays a crucial role especially for the arsenic nuclei. The isotopic line profiles also largely differ among nuclear species: while the central transition of the gallium isotopes have a narrow linewidth, those of arsenic and indium are much broader and oppositely skewed with respect to each other. The statistical distributions of electric field gradient (EFG) parameters of the nuclei within the QD are analyzed. The consequences of various EFG axial orientation characteristics are discussed. Finally, the possibility of suppressing the first-order quadrupolar shifts is demonstrated by simply tilting the sample with respect to the static magnetic field.
PACS numbers: 75.75.-c, 76.60.Gv, 76.60.Pc
## I. INTRODUCTION
The valuable expertise gained on nuclear spins in quantum dots (QDs) over the past decade has revolutionized the traditional research on semiconductor physics. 1-22 For instance, solid-state quantum memories, a vital component for quantum information technologies, count on the long coherence times of nuclear spins. 3 In addition to storing the quantum state, nuclear spins potentially can act as the central processing unit as in ensemble computing 23,24 that can also be extended to quadrupolar nuclei, 25 or, they can present an ideal testbed for quantum control as an integral part of an exciton-nuclei feedback loop. 5-8
Another emerging utility of QD nuclear spins is for the materials science as a targeted nanoscale diagnostic tool. On this front, there have been recent advances in analytical techniques such as cross-sectional scanning tunneling microscopy, 26 coherent x-ray diffraction-based three-dimensional mapping, 27,28 and the atom probe tomography. 29 Routinely, the nuclear magnetic resonance (NMR) had been one of the preferred choices in identifying below the parts-per-million-level concentration of rare constituents. 30 This, however works on macroscopic samples still of molar sizes. When it comes to probing a single QD, the applicability of the conventional NMR is hampered because of the insufficient equilibrium magnetizations within such small volumes. Added to this, is the low sensitivity inherent in detection by the magnetic induction of precessing magnetization. 9 If instead, the already proven optical orientation framework is pursued, the electron spin can efficiently polarize the nuclear spins within the QD through the contact hyper- fine interaction. 31 This nuclear polarization, known as the Overhauser field, acts back on the exciton and shifts its energy as it recombines, leaving a trace on the photoluminescence (PL). Overall, this makes up the recipe for the NMR of a single QD, which is termed as the optically detected NMR (ODNMR). 10 For the detection, it relies on the measurement of either the Overhauser field-shifted excitonic PL with a µ eV-resolution, 10 or the Faraday rotation in the reflected probe beam with a sensitivity below 1 mrad. 11
It is also desirable to use ODNMR on the widely accessible self-assembled QDs (SAQDs). However, an issue that is prevalent in SAQDs is that they inherently possess an inhomogeneous and anisotropic strain. 32 In a III-V semiconductor crystal lattice, such a strain field causes local electric field gradients (EFG) with which a quadrupolar spinI nucleus, i.e., with I ≥ 1, interacts because of its electric quadrupole moment. 33,34 This quadrupole interaction (QI) splits the nuclear spin degeneracy even in the absence of an external magnetic field, and severely broadens the resonances. This has posed a challenge for employing standard ODNMR in SAQDs giving rise to poor signal to noise ratio. Very recently the problem has been alleviated by introducing a so-called inverted radio frequency (rf) excitation scheme. 15 This increased substantially the fraction of nuclei participating in the Overhauser shift. A breakthrough not only for the atomistic level structural information on strained SAQDs, but also for the quantum information technologies. This is thanks to the crucial structural information it can supply, much needed both to engineer a noise-free nuclear spin bath and also to perform a coherent control over the Bloch sphere of relatively small number of
nuclear spins. 16,17
After this successful experimental demonstration of the ODNMR inverse spectra on strained QDs, 15 its full potential awaits to be explored on a theoretical level. Therefore, the aim of this work is to undertake a computational assessment, choosing InGaAs QDs as the test case. Primarily, we would like to address what kind of atomistic level information can possibly be extracted by the technique, and where to look for these. In particular we give special importance to the central transition lineshape as this is experimentally the most conspicuous spectral feature. Moreover, it carries important clues about the internal structure of the QD. Thus, we perform a detailed search over the parameter space of the inverse spectra technique. This sheds light on the line profiles and resolution trade offs, as well as experimentally more impracticable aspects such as the dependence of the sample orientation with respect to the magnetic field. By comparing a binary InAs QD with an identicalshape alloy In 0 2 . Ga 0 8 . As counterpart, we uncover key fingerprints of the alloy composition. Furthermore, we explain the basis of these behaviors in terms of available atomistic configurations. With this insight, we intend to unfold the prospects of the inverse spectra technique as a tool to resolve atomistic-level variations in strained nanostructures.
The paper is organized as follows: In Sec. II we present the theoretical setting of our atomistic analysis. In Sec. III we provide information about our benchmark cases, followed by our results. In Sec. IV we conclude by itemizing our major findings. In the interest of a lucid presentation, we defer additional technical supporting materials and figures to a number of appendixes. Appendix A discusses nuclear polarizations, and more specifically why it is harder to polarize the arsenic nuclei in a strained environment. Appendix B contains EFGrelated histograms for the alloy and the compound QDs. In Appendix C we consider the role of specific quadrupole parameters on the lineshape. The last appendix illustrates the effects of individual EFG parameters on spectral transitions of a single nucleus to authenticate some of the assertions in the main text.
## II. THEORY
## A. Three concomitant coordinate systems
The crux of our analysis is based on the simultaneous use of a number of coordinate systems. A QD has a native coordinate system set through the crystallographic axes where the QD growth axis usually coincides with one of them; in our test cases this is the z -axis and the [001] direction. The orientations of an external magnetic field and the optical beam with respect to the growth axis of the QD bear particular significance in terms of which Faraday/Voigt geometries and σ ± pumping are defined. Yet, there are at least two more relevant coordinate axes that gain importance in an atomistic treatment. Unlike the global crystal axes, these are local, i.e., they change orientation with position over the QD. They are defined through strain and the EFG tensors, denoted in cubic crystallographic xyz components by /epsilon1 ij and V ij , respectively. The two phenomena are linked through S , the fourth-rank gradient elastic tensor as
$$V _ { i j } \equiv \frac { \partial ^ { 2 } V } { \partial x _ { i } \partial x _ { j } } = \sum _ { k, l = 1 } ^ { 3 } S _ { i j k l } \epsilon _ { k l }, \text{ \quad \ \ } ( 1 )$$
where V is the crystal electric field potential. 35 In the socalled Voigt notation, the S tensor for cubic crystals is governed by only two independent components S 11 and S 44 , both of which are experimentally measurable. 36 In cubic crystallographic xyz axes, S 11 and S 44 relate the diagonal and off-diagonal strain and EFG components, respectively, like V zz = S 11 /epsilon1 B , V xy = 2 S 44 /epsilon1 xy , etc. where /epsilon1 B = /epsilon1 zz -( /epsilon1 xx + /epsilon1 yy ) / 2 is the so-called biaxial strain. Similarly, we find it necessary to introduce a shear strain measure as /epsilon1 S ≡ | /epsilon1 xy | + | /epsilon1 yz | + | /epsilon1 zx | to quantify the effectiveness of the off-diagonal components. 20
The strain and EFG tensors have their own distinct principal axes where each becomes diagonal, and within which working with that quantity becomes highly convenient. Among the three principal axes of a rank-2 quantity (such as strain or EFG), the one with the largest absolute value is named as the major principal axis. Hence, this brings three concomitant coordinate systems at one's disposal. Our primary interest in nuclear spin states in the presence of QI favors the explicit use of local EFG principal axes which we shall discriminate by the XYZ capital letters, 37 with axes being labeled so as to satisfy the inequalities | V XX | ≤ | V Y Y | ≤ | V ZZ | , making Z the major EFG axis.
## B. Fundamental Hamiltonian
In the local XYZ frame the strain-dependent part of the nuclear Hamiltonian responsible for the QI is given by
$$\mathcal { H } _ { Q } = \frac { e ^ { 2 } q Q } { 4 I ( 2 I - 1 ) } \left [ 3 \mathcal { I } _ { Z } ^ { 2 } - \mathcal { I } ^ { 2 } + \eta \frac { \mathcal { I } _ { + } ^ { 2 } - \mathcal { I } _ { - } ^ { 2 } } { 2 } \right ] \,, \quad ( 2 )$$
where /vector I is the dimensionless nuclear spin angular momentum vector operator, through which we define the above raising/lowering scalar operators I ± ≡ I X ± I i Y . As to the other variables, Q is the electric quadrupole moment of the nucleus, q ≡ V ZZ /e is the EFG parameter which is also the primary coupling constant of QI, with e > 0 being the electronic charge, and η = ( V XX -V Y Y ) /V ZZ is the biaxiality parameter, satisfying 0 ≤ η ≤ 1 by construction, and it determines the mixing between the free nuclear spin magnetic quantum numbers.
In the same local XYZ frame the static magnetic field vector B 0 will be in general oblique as described by the spherical polar angles θ , and φ so that its Hamiltonian becomes 34
$$\mathcal { H } _ { M } = - \hbar { \Omega } \left ( \mathcal { I } _ { X } \sin \theta \cos \phi + \mathcal { I } _ { Y } \sin \theta \sin \phi + \mathcal { I } _ { Z } \cos \theta \right ) \,, \quad \text{exit}$$
where Ω ≡ γB 0 , and γ is the nuclear gyromagnetic ratio. Hence, for each nucleus k under consideration,
$$\left ( \mathcal { H } _ { Q } + \mathcal { H } _ { M } \right ) | i \rangle _ { k } = h \nu _ { i } ^ { k } | i \rangle _ { k } \,,$$
needs to be solved, where we denote the resultant spectrum with ν k i , i = -I, -I +1 , . . . , I . Under sufficiently high magnetic fields, which we assume throughout our work, dipole-allowed transitions are i ↔ i + 1. Among these, the strongest one -1 / 2 ↔ +1 2 is referred to as / the central transition (CT), and the remaining weaker ones as the satellite transitions (STs). When the EFG major principal axis deviates from the B 0 direction, CT becomes broadened only as a second-order effect, hence stays quite narrow, whereas STs undergo extensive broadening as they are affected in first order. 33
## C. Optical orientation
We characterize the nuclear spin ensemble within the QDbya nuclear spin temperature T nuc which is a measure of the degree of optical orientation. The probability of occupancy of each nuclear spin state, i is governed by a thermal distribution of the form
$$p _ { i } ^ { \text{th} } = \frac { e ^ { - h \nu _ { i } ^ { k } / k _ { B } T _ { \text{unc} } } } { \sum _ { i = - I } ^ { I } e ^ { - h \nu _ { i } ^ { k } / k _ { B } T _ { \text{unc} } } } \,, \\ \text{is the Boltzmann constant.}$$
where k B is the Boltzmann constant.
The helicity of the absorbed optical orientation beam dictates the spin of the created electron and hole as a requirement of angular momentum conservation. Subsequently, through predominantly the contact hyperfine interaction between the electron and nuclear spins, depending on the absorbed photon helicity the nuclear spins are either pumped down or up within their individual spectrum ν k i , toward i →-I or i → + , respectively. I 1 In the absence of an rf excitation, and under continuous optical orientation this distribution will be sustained. Therefore, the steady-state is either normal for σ + , or inverted for σ -persistent pumping. We represent the former (latter) by using a positive (negative) nuclear spin temperature, i.e., T nuc > 0 ( T nuc < 0).
## D. rf Excitation
The novelty of the inverse spectra technique with respect to conventional saturation spectroscopy comes from its inverted excitation scheme, which has a white spectrum except for a frequency gap, f gap . 15 If this gap does not coincide with any of the dipole-allowed transitions ν k i ↔ ν k i +1 , then under a sufficiently long excitation, the population of all nuclear spin states will be equilibrated at the same value, p sat i = 1 (2 / I +1), giving rise to zero nuclear polarization, and hence no Overhauser shift on the excitonic PL. On the other hand when the gap coincides with one, or sometimes simultaneously with a number of transitions, the equilibration will only occur within the states that remain under the gap-free parts of the excitation. Therefore, the 2 I + 1 states will be split into multiple groups, 38 each internally reaching to an individual saturation value based on the preexisting thermal populations of the member states according to
$$p _ { i } ^ { \text{sat} } = \frac { \sum _ { i \in G } p _ { i } ^ { \text{th} } } { N _ { G } } \,, \quad \quad \quad ( 3 )$$
where G is the group index, and N G is the number of member spin states within that group.
The spin polarization of a nucleus k just after rf excitation will be based on the population of each state
$$\vec { P } _ { k } = \frac { 1 } { I } \sum _ { i = - I } ^ { I } _ { k } \langle i | \vec { \mathcal { I } } | i \rangle _ { k } \, p _ { i } ^ { \text{sat} } \,.$$
If we denote by ˆ the optical pumping direction along e which the electronic spin is aligned, which is usually, but not always the QD growth axis, then the parallel component of the nuclear polarization becomes P e k = ˆ e · /vector P k . In the experiments, the changes in the nuclear polarization are probed via the Overhauser energy shift in the excitonic PL signal 1 which is given by
$$E _ { O S } = \sum _ { k } \left | \psi ( \vec { R } _ { k } ) \right | ^ { 2 } A _ { k } I _ { k } P _ { k } ^ { e } \,, \quad \quad ( 5 ) \\ \intertext { A. ie t h o h m o r f i n o c o m l i n e c o n t } \, \text{and} \, \text{and} \, \text{and} \, \text{and} \, \text{and} \, \text{and} \, \text{and} \, \text{and} \, \text{and} \, \text{and} \, \text{and} \, \text{and} \, \text{and} \, \text{and} \, \text{and} \, \text{and} \, \text{and} \, \text{and} \, \text{and} \, \text{and} \, \text{and} \, \text{and} \, \text{and} \, \text{and} \, \text{and} \, \text{and} \, \text{and} \, \text{and} \, \text{and} \, \colon$$
where A k is the hyperfine coupling constant, and ψ /vector ( R k ) is the electronic wave function at the nuclear site. Here, we ignore the hole hyperfine interaction which is about an order of magnitude weaker. 22
## III. RESULTS
## A. Test QDs
The detailed chemical composition profile, i.e., local stoichiometry of InGaAs QDs is still an active and unresolved topic. 39 A critical factor that nontrivially affects the uniformity of the indium distribution within the QD is the annealing process. It has been reported that the annealed QDs become less uniform along the lateral, but more uniform along the growth direction; furthermore, the dots get 25% bigger with respect to their pre-annealed sizes in both lateral and growth directions as the indium atoms out-diffuse while the gallium atoms diffuse inward. 40 We base our comparative analysis on two test cases of lens-shaped QDs having a base diameter
FIG. 1. (Color online) Inverse NMR spectra of binary InAs, and alloy In 0 2 . Ga 0 8 . As QDs, under the conditions B 0 = 5 T, f gap =200 kHz, T nuc = 3 mK, σ + optical pumping. Inset shows corresponding QD atoms over the (100) cross section.
of 40 nm and a height of 6 nm. Both QDs have an InAs wetting layer and are embedded into a GaAs host matrix, but differ in their interior compositions, with one QD being InAs, whereas the other being the alloy In 0 2 . Ga 0 8 . As (see, inset of Fig. 1), where indium and gallium atoms are randomly distributed all over the QD region according to the given mole fraction. Admittedly, these constitute the two extremes, and intermediate cases like partially segregated alloy realizations are not addressed in this work. The uniform alloy composition considered here is expected under high growth rate conditions, where the landing atoms on the surface do not have time to segregate into binary compounds, as they quickly get covered by the next layer. 41 The rationale behind the selection of these two cases is based on their distinct strain, and hence quadrupolar characteristics. 20
The computational supercell contains more than 2 million atoms, most of them residing in the host matrix, and the QD itself has 171,884 atoms. We follow the procedure presented in Ref. 20 for the relaxation of the embedded QDs to their final structures, and the extraction of the atomistic strain distributions. The only exception in the present work is that we do not perform any nearestneighbor strain averaging as this would hinder the true linewidths of the isotope-dependent NMR spectra.
## B. General spectral aspects
The inverse spectra for both test cases are shown in Fig. 1 computed with the associated parameters of B 0 = 5 T, f gap =200 kHz, and T nuc = 3 mK, chosen to be representative of a realistic case. 15 The compound and alloy QD inverse spectra are strikingly different. The spectra in Fig. 1 is the cumulative result of all nuclei within the QD, under σ + optical pumping. In all cases,
✂
FIG. 2. (Color online) (Upper panel) The contribution of individual isotopic species under the same conditions as of Fig. 1. (Lower panel) The effect of optical pumping helicity ( σ + / σ -) on the inverse spectra, under the same conditions as Fig. 1 other than f gap =800 kHz.
unless stated otherwise, the static magnetic field vector, QD growth axis, and the optical pump beam directions are all collinear. Note that as we would like to develop a basic understanding of a typical InGaAs QD inverse spectra, throughout this work we use a simple uniformly distributed electron wave function that is confined within the lens-shaped QD region.
The contribution of individual isotopic species as well as the dependence on the light helicity with respect to external magnetic field are displayed in Fig. 2. Even though the number of arsenic nuclei is the largest, their CT resonance has the smallest peak, the reason for which is related to the hardness in polarizing the arsenic nuclei as elaborated further in Appendix A. The indium nuclei because of their 9/2 spins, have much extended STs as can be observed from the upper panel of Fig. 2. The spectrum asymmetry of the neighboring STs on either side of the CT are seen to be switched by changing pumping
Overhauser Shift (µeV)
Overhauser Shift (µeV)
14
12
10
8
6
4
2
0
20
15
10
5
0
75
32
48
34
A
36
38
40
Frequency (MHz)
Ga
50
52
54
20 kHz
200 kHz
400 kHz
600 kHz
800 kHz
1.2 MHz
42
44
20
kHz
200 kHz
400 kHz
600 kHz
800 kHz
1.2 MHz
56
Frequency (MHz)
115
42
In
44
46
48
50
20 kHz
200 kHz
400 kHz
600 kHz
800 kHz
1.2 MHz
52
54
25
20
15
10
5
0
Frequency (MHz)
FIG. 3. (Color online) The evolution of alloy In 0 2 . Ga 0 8 . As QD inverse spectra with respect to f gap for σ + optical pumping, B 0 = 5 T, T nuc = 3 mK.
helicity (see, Fig. 2 lower panel), as a matter of fact the contrast can be enhanced further by increasing the initial polarization which amounts to lowering of T nuc . Also note that to boost the small differences, here we prefer to use a larger f gap value of 800 kHz.
In experiments, the choice of f gap value can indeed become a crucial decision for the inverse spectra. To highlight the trade off between spectral resolution and the signal intensity, in Fig. 3 we display the spectral evolution as a function of f gap for each isotopic species. The resolution-limited flat-top profiles quickly emerge for the gallium nuclei indicating their narrow linewidths as will be analyzed below in more depth. On the other hand, for indium and especially arsenic nuclei, a large f gap value may still be preferred which is particularly beneficial to capture the relatively weak features associated with the STs. One example for this is the emergence under larger f gap values of an additional ST peak as indicated by an arrow on the top left arsenic panel of Fig. 3. For a spin-3/2 system only three peaks are expected, namely, 3/2 → 1/2, 1/2 → -1/2, and -1/2 → -3/2. Therefore, this fourth peak which unambiguously belongs to arsenic nuclei (see, Fig. 2, top panel) is rather curious. We identify it as the alloy peak with a reasoning based on an atomistic configuration analysis, however deferring its detailed discussion for now.
## C. Central transition linewidth and profile
The CT lineshape is one of the means to probe information on the nuclear spin environment. For this purpose, first we select a small f gap = 1 kHz, which is ultimately limited by the nuclear homogeneous linewidth. 42 Considering alloy In 0 2 . Ga 0 8 . As QD, CT line profiles at different magnetic fields are shown in Fig. 4. We should note that as there always remains some residual overlap from the ST of the other isotopic species, here the indi-
As
69
Overhauser Shift (µeV)
FIG. 4. (Color online) The dependence of CT line profiles on the external magnetic field for all the isotopes. Full width at half maximum (Γ) values are included in the legend boxes. To superimpose their peaks, curves for different magnetic fields are displaced in frequency. Alloy In 0 2 . Ga 0 8 . As QD is considered with f gap =1 kHz.
vidual isotopic contributions, and not the total signals are plotted. These isotopic line profiles display distinct features, namely, 69 Ga and 71 Ga both have quite narrow main peaks over a broad pedestal, while In and As have evidently opposite asymmetric lineshapes.
To quantify these trends, we make use of the mean, variance, skewness and kurtosis 43 of these distributions; for a sample { x j } of N data points these quantities are, respectively
$$\text{pectly} \\ \tilde { x } & = \frac { 1 } { N } \sum _ { j } x _ { j } \,, \\ \text{Var} ( x ) & = \frac { 1 } { N - 1 } \sum _ { j } \left ( x _ { j } - \bar { x } \right ) ^ { 2 } \,, \\ S _ { k p 1 } & = \frac { \tilde { x } - M } { \sigma } \,, \\ \text{Kurt} ( x ) & = \left [ \frac { 1 } { N } \sum _ { j } \left ( \frac { x _ { j } - \bar { x } } { \sigma } \right ) ^ { 4 } \right ] - 3 \,, \\ \text{ere among} \ a \text{ } a \text{ } \text{ number of alternatives } \, \text{ pre} \\ \underline { \text{person} } ^ { s ^ { 4 } } \text{ made skewness coefficient, } S _ { k p 1 }, \text{ with } \sigma$$
where among a number of alternatives we prefer Pearson's 44 mode skewness coefficient, S kp 1 , with σ = √ Var( x ) being the standard deviation, and M is the mode (peak value) of the distribution. Skewness is a dimensionless asymmetry parameter; for unimodal cases zero skewness corresponds to a symmetric distribution
FIG. 5. (Color online) Standard deviation ( σ ), skewness, and kurtosis of the CT for all isotopes contained in the alloy In 0 2 . Ga 0 8 . As QD. The inverse spectra are computed with f gap = 1 kHz.
around its mode so that tails on either side balance out. Kurtosis is a dimensionless measure of relative peakedness or flatness of a distribution; for a normal distribution it becomes zero.
We employ these shape quantifiers on the CT of alloy In 0 2 . Ga 0 8 . As QD for all isotopes as illustrated in Fig. 5 which not only corroborate well with the observations of Fig. 4 but also reveal some additional trends. For all isotopes the standard deviations diverge as the magnetic field decrease below 2 T into the QI-dominant regime. The 71 Ga isotope has the narrowest σ which is also matched by 69 Ga at high magnetic fields. Regarding skewness, 71 Ga monotonically changes its asymmetry from red- to blue-tailed making a transition at 5 T. As was qualitatively noted from Fig. 4, it is quantitatively asserted in Fig. 5 that In and As possess opposite skewness, a point which we shall discuss further after we lay out the atomistic structural analysis. Finally, from the kurtosis panel we observe that all isotopes start from a flat distribution within the QI-dominant regime at low magnetic fields which evolves to a peaked shape at higher fields. The gallium isotopes go through maxima around 4 T and 9 T for 71 Ga and 69 Ga, respectively.
## D. Alloy bonding and consequences of quadrupole axial tilting
As illustrated in Appendix B through a number of histograms, the spread of quadrupole axial tilting is most pronounced for the As nuclei among all elements. This can be linked to the combined effect of the large variation in the shear strain component, /epsilon1 S of As atoms, compounded by the particularly high S 44 value of As nuclei that is more than 2.5 times of those of Ga and In values; see, also Appendix C. The large variance in /epsilon1 S of As has a chemical origin which stems from the mixed cation neighbors in the tetrahedral bonding: center As atom is coordinated with a different number of Ga/In atoms depending on the local alloy realization. The corresponding tilt angles, θ of the major EFG axes in each bonding configuration are presented in Table I. This is in support of a recent NMR study which concludes that 75 As QI is highly sensitive to different cation coordinations. 45 In the case of In or Ga atoms their nearest neighbors are always As, thus, the local strain variation in the cations (Ga, In) is more of a next-nearest-neighbor effect.
What is the physical implication of large variance in quadrupole axial tilting? The nuclear dipole-dipole interaction is the main channel for nuclear spin diffusion via pairwise flip-flops. However, if the major quadrupolar alignment of each of the involved nuclei is significantly off, this inhibits a flip-flop event on the basis of energy mismatch. We noted above that the alloy QD and in particular the As nuclei have a much wider variation in quadrupole axial tilting due to change in the local neighborhood as compared to the compound QD case. Therefore, QDs with large variance in shear strain are ideal candidates for reduced nuclear spin diffusion, hence prolonged T 2 times, as validated by recent experiments (see, Ref. 17, and references therein). In fact, in resemblance to defect centers that receive wide attention for spintronics applications, 46,47 a random alloy In x Ga 1 -x As QD, especially of low molar fraction can be termed as a defect colony with so many indium atoms replacing the gallium of the host lattice.
## E. Hallmark for random alloying in ST band
We now return to the additional ST peak on the top left 75 As panel of Fig. 3 (marked with A and an arrow) which is unexpected for a spin-3/2 system. We attribute this A-peak to the cation-alloying present within the QD. Specifically we trace its origin to the As nuclei with their major quadrupolar EFG axes tilted perpendicular to the magnetic field. This can be observed from Fig. 6 where we analyze the contribution of nuclei tagged with respect to their EFG axial tilting. In the case of In nuclei (right panels), we do not see a particularly distinct feature coming from the nuclei (very few in number) that are close to perpendicular orientation ( θ = 90 ). ◦ In contrast, those for the case of As nuclei within the alloy In 0 2 . Ga 0 8 . As QD (left top panel) are clearly responsible for the Apeak. Because of the rather different strain environment of these nuclei, a distinct peak occurs (around 39 MHz) markedly separated in frequency from the neighboring ST peak (around 38 MHz). For the InAs QD, as there is only cation-alloying on the interfaces, there are almost no perpendicularly-tilted As nuclei (bottom left panel in Fig. 6), hence no contribution from them or an A-peak.
✁
✁
✁
✁
FIG. 6. (Color online) Contributions to inverse spectra from the nuclei as a function of their major EFG orientations with respect to static magnetic field, denoted by the angle θ . (Left panels) 75 As nuclei; (right panels) 115 In nuclei. (a) Alloy In 0 2 . Ga 0 8 . As QD, (b) InAs QD. For all cases B 0 = 5 T, f gap =200 kHz, and T nuc = 3 mK under σ + optical pumping. For the panels on the right, to improve visibility the color scale maxima are set to a quarter of their ordinary values.
## F. Opposite skewness of As and In CT lineshapes for the random alloy QD
Based on the foregoing analysis, we can now address the intriguing contrast between the CT lineshape asymmetries of the In and As nuclei as displayed in Figs. 4 and 5. That is, the CT profile of In has positive skew (blue-tailed), while that for As has negative skew (redtailed). The origin of these opposite behaviors is rooted in the corresponding disparity in their EFG characteristics manifested by two-dimensional histograms in Fig. 7. Specifically, for the case of As, the group of nuclei strongly tilted with θ /lessorsimilar 45 ◦ and V ZZ /lessorsimilar 0, and for the case of In those almost untilted θ /similarequal 0 ◦ but with large | V ZZ | are responsible for the opposite skewness. For the latter, this large | V ZZ | occurs from those In atoms resid- ing in a relatively large biaxial strain environment, unlike the As or Ga atoms in relation to their CT. To reconcile these features with the displayed skewness patterns we make use of a single-nucleus analysis. Refering to Appendix D, EFG axial tilt at a constant | V ZZ | causes a red shift of the CT as the tilt increases up to 45 ◦ ; on the other hand for the case of nearly untilted nuclei, increasing | V ZZ | and/or increasing EFG biaxiality, η both cause a blue shift of the CT.
To further substantiate these points, in Fig. 8 we present major EFG orientation-resolved inverse spectra analysis focusing on the CT. Here, the top left panel shows that the red-tailed skewness in As results from the tilted nuclei of an angle less than 45 ◦ , while on the top right panel the blue-tailed skewness of In is caused by almost untilted nuclei, θ < 3 ◦ (mind the different scales
❩
❩
❩
❩
✍
✍
✍
✍
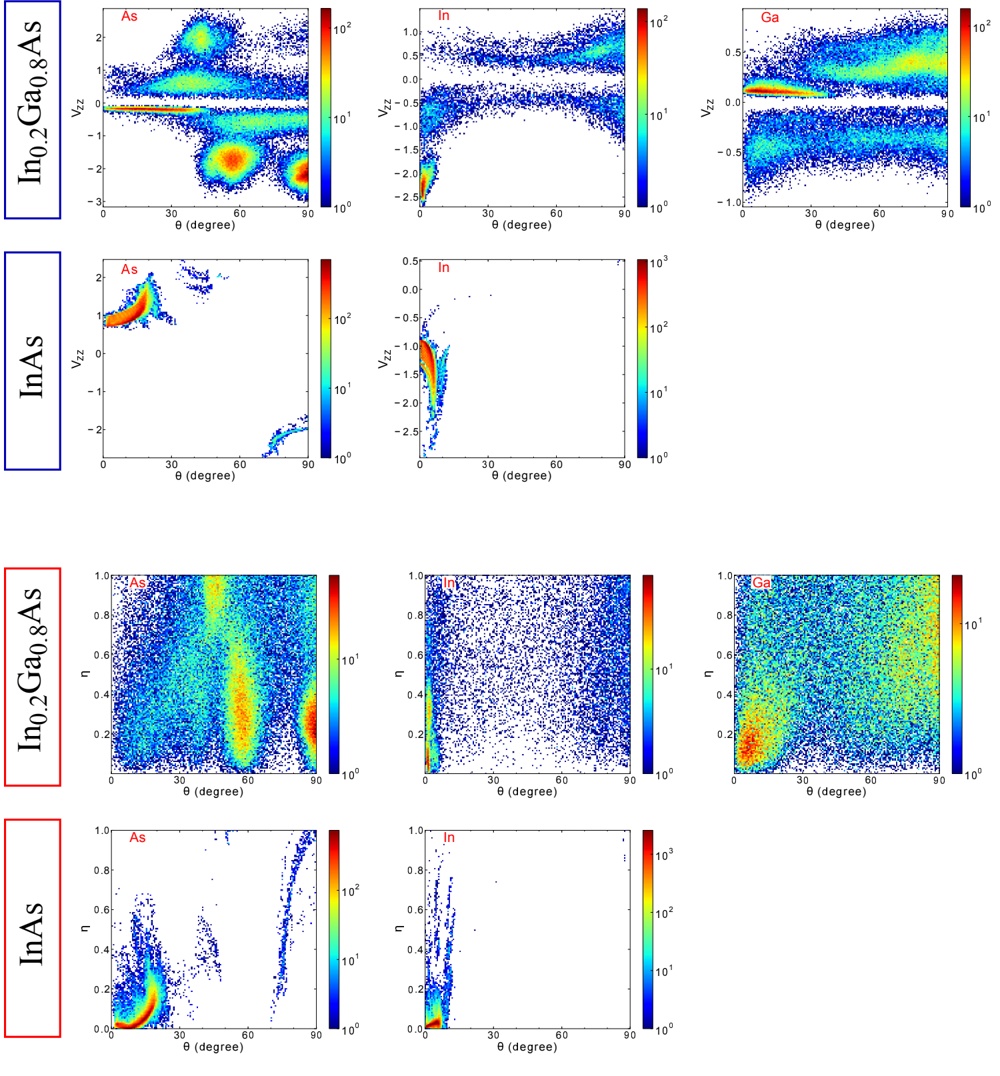
✍
FIG. 7. (Color online) Two-dimensional EFG histograms. (Top two rows) EFG axial tilting, θ versus the major EFG, V ZZ (in units of 3 × 10 21 V/m ). 2 (Bottom two rows) EFG axial tilting, θ versus the EFG biaxiality, η . In each group, (upper rows) In 0 2 . Ga 0 8 . As QD; (lower rows) binary InAs QD. Color code represents the number of nuclei in the logarithmic scale.
for the vertical axes). Note that the tilted In nuclei still give rise to red skew but they do not dominate. Indeed, in Fig. 9 we validate that if As (In) nuclei with tilt angle greater than 45 ◦ (3 ◦ ) are only considered, the red (blue) skewness disappears. Next, returning to the bottom row of Fig. 8 in the case of the binary InAs QD both As and In
CT are red skewed, which can also be inferred from their similar two-dimensional EFG histograms in Fig. 7 especially noting the fact that both ensembles have highly uniaxial EFG. Again invoking the single-nucleus insight from Appendix D, an increase in either the angular tilt or the | V ZZ | both work in the same direction leading to
✟
✆
✆
✆
✆
✡
✵
✆
✆
✵
FIG. 8. (Color online) Same as Fig. 6, but with B 0 = 8 T, f gap =1 kHz to focus on CT. The color scale maxima are set to a quarter of their ordinary values to improve visibility. For information purposes, full isotopic spectra, filled in red are placed on top; the vertical thin white line indicates the position of the pure Zeeman frequency for each case.
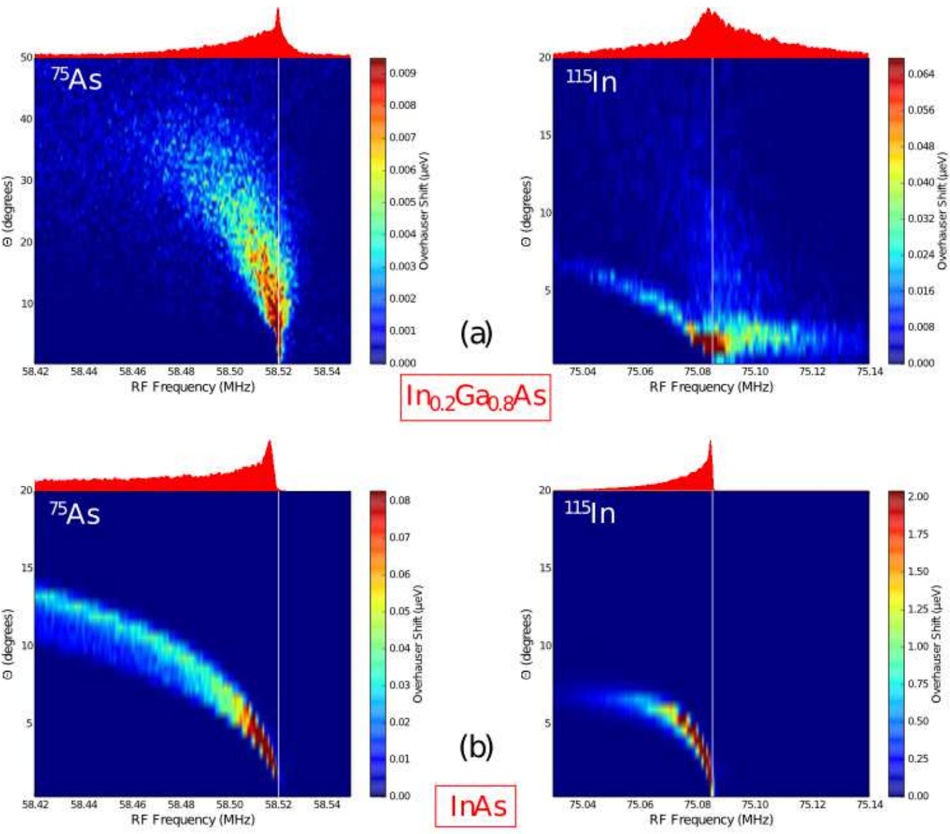
red shift of the CT.
The typical EFG configurations responsible for the In and As CT lineshapes are summarized in Fig. 10. In the alloy QD, strain inflates the EFG biaxiality of both indium and arsenic nuclei; at the same time, in the case of arsenic enhances tilting, and in the case of indium boosts the major EFG. The contrast between these two nuclei disappears in the compound QD. Both have quite uniaxial EFG with some axial tiltings: distribution's mode for In is ∼ 5 ◦ and for As it is ∼ 16 . ◦
## G. Satellite transition collapse under sample tilting
Other two-dimensional spectra can be generated with the added degree of freedom being the tilting of the sam- ple growth axis with respect to the static magnetic field which is also taken to be the direction of the optical pump beam. The resultant spectra for binary InAs, and alloy In 0 2 . Ga 0 8 . As QD are shown in Fig. 11, where we observe that around a tilting range of 50 ◦ -54 , the STs 'col-◦ lapse' on to CT, i.e., rendering all neighboring transitions energetically almost identical. Not surprisingly this is more distinctly the case for the compound InAs QD. To explain this behavior, in Appendix D we demonstrate on a single 115 In nucleus how the opposite ST shifts disappear at a tilting angle ranging between 45 ◦ and 54 5 . ◦ depending on the biaxiality, η (cf. Fig. 18). One outcome of this collapse is the reduction of the energy mismatch among the nuclei of the same isotope. Hence, especially for the indium nuclei which have the largest spin-9/2 manifold giving rise to the widest spread in en-
TABLE I. (Color online) Major quadrupole axis orientations, denoted by the angle θ with respect to the static magnetic field (in these figures, along the vertical direction), for all possible arsenic-centric configurations at their pre-relaxation stages. Note that consecutive local strain relaxation (cf. Fig. 14 in Appendix B) will result in a variance around these θ values.
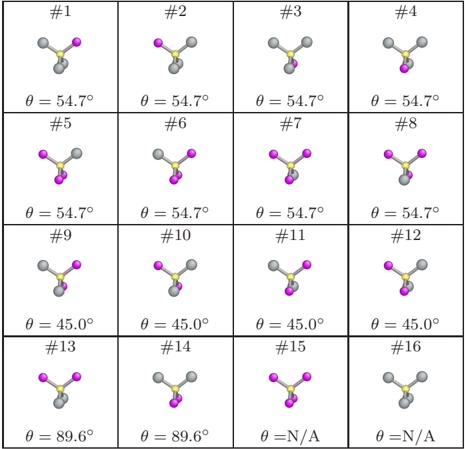
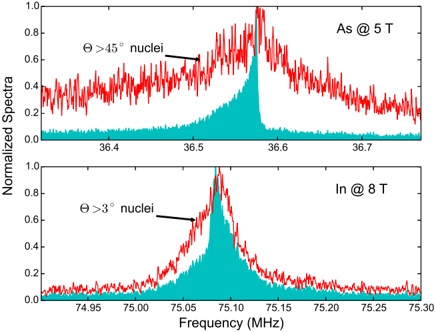
FIG. 9. (Color online) The effect of selected nuclei on the CT asymmetry based on their EFG axial tilting away from the static magnetic field, for the As nuclei at 5 T (top), and In nuclei at 8 T. Painted curves show the original contribution with all the nuclei. For each case maxima are normalized to unity to assist the asymmetry comparison. Alloy In 0 2 . Ga 0 8 . As QD is considered.
FIG. 10. (Color online) A schematic illustration for the typical EFG components and orientations for the indium (black/solid arrows) and arsenic (red/dashed arrows) nuclei of alloy In x Ga 1 -x As vs compound InAs QDs.
ergy, one can expect a shorter T 2 due to enhanced spin diffusion under the critically-tilted angle ( ∼ 52 ) ◦ with respect to no-tilted case. In a sense, sample tilting together with dipole-dipole interaction can act like a flush mechanism for evening out population imbalances among nuclear spin states brought and sustained by optical orientation.
## IV. CONCLUSIONS
This computational study demonstrates the power of the NMR inverse spectra technique as a tool for retrieving atomistic level structural information from strained SAQDs. Through a comparative assessment of alloy versus compound In(Ga)As QDs, as well as of the involved nuclear species, we unveil marked differences in their spectral features, and establish links with the local chemical structure, strain, and material properties. Our main findings are grouped as follows: (i) Strain and CT asymmetry ; In compound InAs QDs the dominant component is the compressive biaxial strain which causes quite a uniaxial and rather strong EFG. The shear strain has a secondary role being significant around the interfaces and results in a limited, yet still crucial EFG axial tilting. Indium and arsenic nuclei qualitatively both obey this picture. The situation becomes more complex with the sway of random alloying in the InGaAs QD. The shear strain spreads all throughout the core and plays a primary role. Moreover, EFG biaxiality of all elements get enhanced. An interesting aftermath of atomistic alloy strain is that the indium nuclei are mostly untilted but have large EFG values, whereas arsenic nuclei have low EFG values but with excessive axial tiltings. Under the realm of these different EFG conditions, the asymmetry of the CT in compound QDs gets red-skewed for both In and As, while for the alloy QD the In CT acquires a dominant blue tail arising from a large untilted In nuclear population residing in a relatively large biaxial strain environment.
✒✑
✒✑
✑ ✑
✑
Overhauser Shift (µeV)
FIG. 11. (Color online) The effect of sample tilting on the inverse spectra. (a) Binary InAs, (b) alloy In 0 2 . Ga 0 8 . As QD, both for B 0 = 5 T, f gap =200 kHz, T nuc = 3 mK. Faraday geometry is preserved, i.e., optical pumping and magnetic field are parallel, whereas the sample (growth axis) is tilted away from these, as shown in the inset. Upper row displays the two-dimensional spectra of the tilting angle versus RF frequency; lower row shows the one-dimensional spectra at zero and 52 ◦ tilting angles.
(ii) Arsenic and cation alloying ; Compared to In and Ga nuclei, As bares a number of distinctions. First, due to its low gyromagnetic ratio As nuclei are more prone to QI under a given magnetic field compared to In or Ga. Secondly, the shear strain is most operative on the arsenic nuclei. This stems from the large S 44 component of the gradient elastic tensor of arsenic nucleus, as well as nearest-neighbor variations because of cation alloying, not present for In and Ga categorically. An implication of these is that if there exists an alloy structure within the QD region, this can be identified, in principle by an additional peak in the arsenic ST. Specifically, it originates from those arsenic nuclei with their major quadrupolar EFG axes tilted perpendicular to the growth axis, a direct outcome of alloying. (iii) Sample tilt ; Finally, we predict the collapse of the STs onto CT which is most pronounced in compound InAs QDs, and the possibility of negating QI and restoring a monoenergetic distribution like a solitary Zeeman interaction, simultaneously for all isotopic nuclear spins by tilting the sample about
52 ◦ with respect to static magnetic field. These findings must be verified experimentally and superseded by further studies for the purposes of both atomistic material insights and also for the coherent control of a relatively small number of nuclear spins embedded in a strained confined environment.
## ACKNOWLEDGMENTS
C.B. would like to thank T ¨ B ˙ ITAK, T¨rkiye Bilimsel U u ve Teknolojik Ara¸ stırma Kurumu, for financial support through Project No. 112T148. E.A.C. was supported by a University of Sheffield Vice-Chancellor's Fellowship. All authors acknowledge the support of UK Royal Society International Exchanges. A.I.T. and E.A.C. thank the financial support of the EPSRC Programme Grant EP/J007544/1.
## APPENDIX A: NUCLEAR POLARIZATION ALONG THE STATIC MAGNETIC FIELD
In this appendix, we discuss the average nuclear spin orientation for each isotopic ensemble within the alloy In 0 2 . Ga 0 8 . As QD in the presence of both Zeeman and QI terms. Even though the results here are qualitatively along the normal expectations, the quantitative details and isotopic variations may still be worthwhile considering. In Fig. 12 we show the average nuclear polarization along the static magnetic field, P e for each isotopic ensemble as well as the total values, based on the weighted contribution of each isotope within the QD; in part (a), the upper plot depicts nuclear spin temperature dependence at a fixed magnetic field of 5 T, whereas the lower plot shows how it varies with respect to magnetic field at a fixed nuclear spin temperature, T nuc = 3 mK. The latter depends on the optical pumping and nuclear spin energetics. Qualitatively, in both cases all isotopes display the expected polarization trends under increased magnetic field or decreased nuclear spin temperature. On the quantitative side, there is a striking difference among the elements, namely arsenic nuclear ensemble's polarization is substantially lower than the other elements. This is the origin of the mentioned smallest CT peak of arsenic among all elements in Fig. 2. Stated quantitatively, at B 0 = 5 T and T nuc = 3 mK, arsenic nuclear spin polarization is about 44%, whereas 69 Ga → 58%, 71 Ga → 68%, and 115 In → 81%. With the largest population belonging to the arsenic nuclei due to alloy partitioning between cations, the overall average polarization value (denoted as total in Fig. 12) comes out as 55%, i.e., closer to that of the arsenic value.
Why is it harder to orient the arsenic nuclei? By far the most critical factor is the gyromagnetic ratio, γ which is substantially smaller for arsenic compared to other elements. To illustrate this point, we artificially increase γ for 75 As by 55% so that it reaches to the average value of the 69 Ga and 71 Ga ensemble. It can be observed in part (b) of Fig. 12 that arsenic as well as the total nuclear polarization now lie in between the 69 Ga and 71 Ga curves. In particular, for B 0 = 5 T and T nuc = 3 mK, the arsenic spin alignment increases from its actual value of 44% to 62%. The underlying reason is that QI has a bidirectional character; being an electrostatic interaction in nature, it cannot discriminate the states | ± m 〉 , whereas Zeeman interaction being unidirectional splits the | + m 〉 and | -m 〉 states thereby promoting nuclear spin polarization (see, Fig. 13). In other words, while the static magnetic field (Zeeman term) tries to polarize the nuclear spins, QI tries to erase this. Hence, with their low γ value, 75 As nuclei are more prone to the quadrupolar depolarization compared to other isotopes at the same external magnetic field. In the case for pure InAs QD (not shown), the trends are similar, however, as this QD is much more strained, here the relevant component is the biaxial strain, /epsilon1 B , 20 the quadrupolar effects are somewhat more pronounced.
✕
✖
/a80
✗
✖
/a80
✗
✕
✖
✗
✖
FIG. 12. (Color online) The isotope-resolved and total nuclear spin polarizations along the static magnetic field for the alloy In 0 2 . Ga 0 8 . As QD. (a) Using the original gyromagnetic ratio for arsenic, (b) with the 75 As gyromagnetic ratio artificially increased to the average value of 69 Ga and 71 Ga, i.e., γ As → γ Ga . Linestyle sets are the same for each panel.
## APPENDIX B: HISTOGRAMS FOR THE ALLOY AND THE COMPOUND QD
In this appendix, histograms for the three EFG parameters, namely, major quadrupole axial tilting away from the static magnetic field, θ , the value of the major EFG, V ZZ , and the EFG biaxiality, η are discussed comparatively for the alloy and compound QDs. Starting with axial tilting for the alloy In 0 2 . Ga 0 8 . As QD as displayed in the top row of Fig. 14, we observe a remarkable dissimilarity in the orientations of arsenic nuclei in comparison to cations (Ga, In). The latter display somewhat similar characteristics, that peaks either along or perpendicular to the magnetic field. As mentioned in the main text, for the cation nuclei (Ga, In) the quadrupole axial tilting is driven by a change in their next-nearest neigh-
✗
✕
✖
/a80
✗
✖
✗
✕
✖
/a80
✗
✖
✗
✓
✓
✙
FIG. 13. (Color online) Zeeman interaction having a unidirectional axis (left) versus QI with a bidirectional character (center). In actual QD samples the local major quadrupole axis is somewhat tilted because of shear strain with respect to magnetic field in Faraday geometry (right), which can accordingly reduce their competition.
borhoods. All together there are 144 configurations; we show in Fig. 15 two such gallium-centric instances where a change in the second-nearest neighbor atom switches the major EFG axis from parallel to perpendicular orientation with respect to growth axis. The distribution of the axial tilting of As nuclei has two peaks at 45 ◦ and 54.7 ◦ that coincide with those pre-relaxed configurations of Table I, even obeying the same 1:2 ratio of the relative weights of these cation-bonding orientations. Next, considering the binary InAs QD, due to lack of alloying for this case, both In and As nuclei's major EFG axes are more or less aligned along the magnetic field. The interface As atoms which are relatively low in number do still have mixed cation neighbors and this gives rise to some limited variance and axial tilting. Analyzing the middle rows, in the alloy QD major EFG values are evenly distributed on either side of zero, and grouped in a few bunches; for the compound QD, the nuclei are gathered around a single V ZZ value with opposite signs for In and As. The biaxiality parameters η (bottom rows) of the two QDs are also markedly different: They are spread over the full accessible range for the alloy QD, whereas the compound QD EFG is quite uniaxial, mainly restricted to lower than the 0.25 value.
## APPENDIX C: THE ROLE OF QUADRUPOLE PARAMETERS ON THE LINESHAPE
The aim of this appendix is to develop a feeling for the importance of the individual nuclear quadrupole parameters ( Q,S 11 , S 44 ) of As in regard to CT lineshape. As illustrated in Fig. 16, if we double the electric quadrupole moment Q , the red-tailed asymmetry is enhanced indicating that its origin is the QI. In particular, the S 44 component of the gradient elastic tensor primarily controls the asymmetric profile: Lowering this value to that of Ga (i.e., decreasing by about 2.5 times) drastically reduces the asymmetry, while setting it to zero totally removes and even reverses its direction. Since S 44 relates the off-diagonal entries of EFG and the strain tensors, its effectiveness directly invokes to the importance of shear strain on the CT asymmetry. On the other hand, the S 11 component is not functional, doubling its value virtually leaves the asymmetry unchanged.
Note that all of the above statements refer to the In 0 2 . Ga 0 8 . As QD. Additionally, in the bottom panel of Fig. 16 we compare the alloy QD with the binary InAs QD, where in the latter the CT asymmetry of As nuclei gets significantly enhanced. This is at odds with the established insight so far based on the prime importance of the shear strain, in conjunction with its small value for binary InAs QD. As a matter of fact as shown in the left column of Fig. 17, the interior of the In 0 2 . Ga 0 8 . As QD retains an exuberant shear strain profile due to random alloying, whereas this gets diminished in the core of the InAs QD and only becomes significant toward the interfaces. However, a change of roles is observed in the right column of the same figure where the compound QD has much stronger biaxial strain compared to alloy QD simply due to larger lattice mismatch between the core and the matrix regions. As we have stated in the atomistic analysis (see, also Appendix D), not only shear but also the biaxial strain component can cause a shift in CT; the former acts through EFG axial tilting as in alloy QD, and the latter via the major EFG value in the case of compound QD.
## APPENDIX D: SINGLE-NUCLEUS PARTICULAR EFG PARAMETER TRAITS
In this appendix considering a single nucleus governed by the general Hamiltonian, H Q + H M , we present how CT and ST frequencies shift under various combinations of the three EFG parameters: the major EFG value ( V ZZ ), the angular deviation of the major EFG axis from the static magnetic field ( θ ), and biaxiality ( η ). As the trends are qualitatively similar among the nuclear species of this work, for demonstration purposes we choose 115 In. The static magnetic field is taken as 8 T which is used in some of our calculations in the text. Within the STs, we consider the 3 / 2 ↔ 1 / 2 transition.
Figure 18 displays the variation with respect to each one of V ZZ , θ , η while keeping the other two parameters fixed. As the shift of CT is in second order under QI, 33 the dependence on V ZZ is quadratic, hence independent of its sign [Fig. 18(a)]; in contrast, ST shifts being firstorder are much stronger [Fig. 18(b)];. For both CT and ST the direction of shift depends on θ . In the case of CT for small angles there is a blue shift with increasing | V ZZ | , which becomes a red shift for larger angles, Fig. 18(a);, 10 ◦ curve. For the specific case considered here ( 115 In and η = 0 5) this transition occurs at . θ = 5 55 . . ◦ Yet, for even larger angles this reverts back to a blue shift,
1
FIG. 14. (Color online) For the alloy In 0 2 . Ga 0 8 . As and binary InAs QD histograms of the three EFG parameters. (Top row) The angular tilting of the major EFG axis away from the magnetic field, θ (inset). (Middle row) Major EFG, V ZZ in units of 3 × 10 21 V/m . (Bottom row) EFG biaxiality, 2 η . The results here refer to the case after the QD strain relaxation.
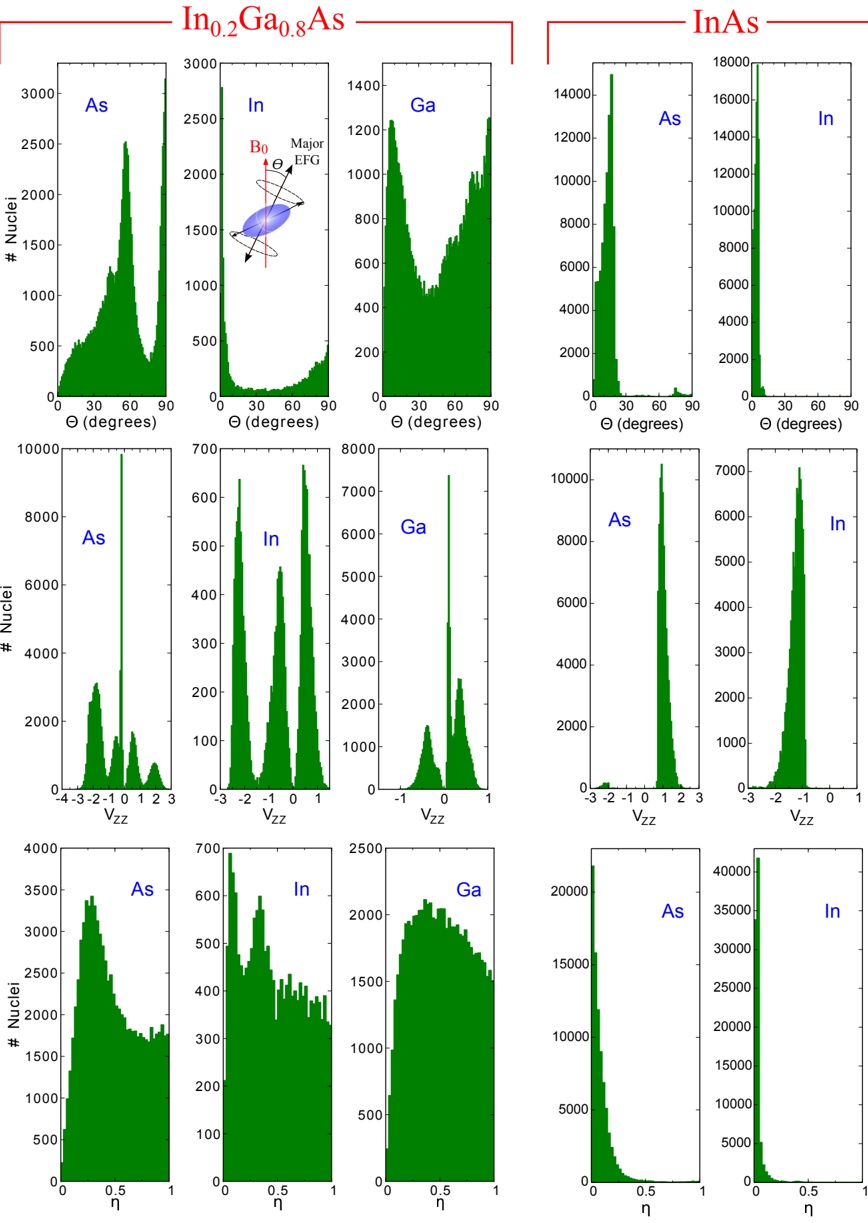
Major EFG axis along growth axis
Major EFG axis perpendicular to growth axis
FIG. 15. (Color online) The switching of the major EFG axis of the center gallium nuclei (indicated by black double arrows) from parallel (top) to perpendicular (bottom) orientation with respect to the growth axis (also the direction of the static magnetic field) by a change in a second-nearestneighbor atom. Color coding is as follows: indium in gray, gallium in purple, arsenic in yellow.
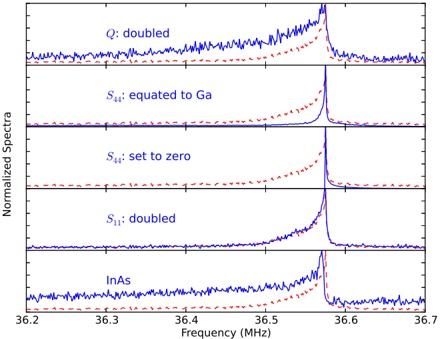
FIG. 16. (Color online) Dependence of arsenic resonance of CT asymmetry on the nuclear quadrupole parameters and alloy mole fraction. In all panels dotted (red) lines refer to original In 0 2 . Ga 0 8 . As QD with f gap =1 kHz, B 0 = 5 T, T nuc = 3 mK, σ + optical pumping. Solid (blue) lines demonstrate the cases after a modification in material parameters, Q,S 44 , S 11 , as well as the case for binary InAs QD. Each peak is set unity to compare the lineshapes.
FIG. 17. (Color online) Atomistic shear, /epsilon1 S (left) and biaxial, /epsilon1 B (right) strain distributions for the In 0 2 . Ga 0 8 . As (top) and InAs (bottom) QDs, cut through both (100) and (010) planes. The lens-shaped QD boundaries can easily be identified on the InAs QD from the enclosing bright shear strain regions corresponding to the interfaces with the host matrix as well as the wetting layer.
FIG. 18. (Color online) Demonstration on a single 115 In nucleus of the effects of various EFG parameter combinations on the CT (left) and ST (right) frequencies. For convenience Zeeman frequency is subtracted to highlight QI. The major EFG, V ZZ is in units of 3 × 10 21 V/m . (a)-(c) are for 2 η = 0 5; . (d) shows both η = 0 and η = 1 cases with the latter in dashdotted lines; (d) and (e) are for V ZZ = -1.
Fig. 18(a), 90 ◦ curve. The continuous variation of θ produces a cosine-type shift in either CT and ST, again with the effect being much stronger for the latter, Figs. 18(c) and (d). Observe that the shifts in ST for ± V ZZ cross each other at a θ value ranging between 45 ◦ and 54 5 . ◦ as η varies from 0 to 1. Other STs (for the case of In) display a similar pattern. It is this behavior that is harnessed in the collapse of STs at a convenient sample tilting around 52 . The bare dependence on ◦ η can be seen in Figs. 18(e)
and (f); in particular it shows a blue shift in CT for θ = 0. A rather inhomogeneous mixture of these single-nucleus
- ∗ [email protected]
- 1 B. Urbaszek, X. Marie, T. Amand, O. Krebs, P. Voisin, P. Maletinsky, A. H¨gele, and A. Imamoglu, Rev. Mod. Phys. o 85 , 79 (2013).
- 2 E. A. Chekhovich, M. N. Makhonin, A. I. Tartakovskii, A. Yacoby, H. Bluhm, K. C. Nowack, and L. M. K. Vandersypen, Nature Mater. 12 , 494 (2013).
- 3 J. M. Taylor, C. M. Marcus, and M. D. Lukin, Phys. Rev. Lett. 90 , 206803 (2003).
- 4 C. Deng and X. Hu, Phys. Rev. B 71 , 033307 (2005).
- 5 C. W. Lai, P. Maletinsky, A. Badolato, and A. Imamoglu, Phys. Rev. Lett. 96 , 167403 (2006).
- 6 A. H¨ ogele, M. Kroner, C. Latta, M. Claassen, I. Carusotto, C. Bulutay, and A. Imamoglu, Phys. Rev. Lett. 108 , 197403 (2012).
- 7 W. Yang and L. J. Sham, Phys. Rev. B 88 , 235304 (2013).
- 8 S. E. Economou and E. Barnes, Phys. Rev. B 89 , 165301 (2014).
- 9 J. A. Marohn, P. J. Carson, J. Y. Hwang, M. A. Miller, D. N. Shykind, and D. P. Weitekamp, Phys. Rev. Lett. 75 , 1364 (1995).
- 10 D. Gammon, S. W. Brown, E. S. Snow, T. A. Kennedy, D. S. Katzer, and D. Park, Science 277 , 85 (1997).
- 11 J. M. Kikkawa and D. D. Awschalom, Science 287 , 473 (2000).
- 12 M. N. Makhonin, E. A. Chekhovich, P. Senellart, A. Lemaˆ ıtre, M. S. Skolnick, and A. I. Tartakovskii, Phys. Rev. B 82 , 161309 (2010).
- 13 M. S. Kuznetsova, K. Flisinski, I. Ya. Gerlovin, M. Yu. Petrov, I. V. Ignatiev, S. Yu. Verbin, D. R. Yakovlev, D. Reuter, A. D. Wieck, and M. Bayer, Phys. Rev. B 89 , 125304 (2014).
- 14 M. Munsch, G. W¨ ust, A. V. Kuhlmann, F. Xue, A. Ludwig, D. Reuter, A. D. Wieck, M. Poggio, and R. J. Warburton, Nature Nanotech. 9 , 671 (2014).
- 15 E. A. Chekhovich, K. V. Kavokin, J. Puebla, A. B. Krysa, M. Hopkinson, A. D. Andreev, A. M. Sanchez, R. Beanland, M. S. Skolnick, and A. I. Tartakovskii, Nature Nanotech. 7 , 646 (2012).
- 16 M. N. Makhonin, K. V. Kavokin, P. Senellart, A. Lemaˆ ıtre, A. J. Ramsey, M. S. Skolnick, and A. I. Tartakovskii, Nature Mater. 10 , 844 (2011).
- 17 E. A. Chekhovich, M. Hopkinson, M. S. Skolnick, and A. I. Tartakovskii, arXiv:1403.1510v2 (unpublished).
- 18 R. I. Dzhioev and V. L. Korenev, Phys. Rev. Lett. 99 , 037401 (2007).
- 19 C. W. Huang and X. Hu, Phys. Rev. B 81 , 205304 (2010).
- 20 C. Bulutay, Phys. Rev. B 85 , 115313 (2012).
- 21 S. Yu. Verbin, I. Ya. Gerlovin, I. V. Ignatiev, M. S. Kuznetsova, R. V. Cherbunin, K. Flisinski, D. R. Yakovlev, and M. Bayer, J. Expt. Theor. Phys. 114 , 681 (2012).
- 22 P. Fallahi, S. T. Yilmaz, and A. Imamoglu, Phys. Rev. Lett. 105 , 257402 (2010).
- 23 D. G. Cory, A. F. Fahmy, and T. F. Havel, Proc. Natl. Acad. Sci. U.S.A. 94 , 1634 (1997).
- 24 L. M. K. Vandersypen, M. Steffen, G. Breyta, C. S. Yan-
traits as governed by the atomistic strain field gives rise to a unique fingerprint of the QD NMR.
- noni, M. H. Sherwood, and Isaac L. Chuang, Nature (London) 414 , 883 (2001).
- 25 G. Yusa, K. Muraki, K. Takashina, K. Hashimoto, and Y. Hirayama, Nature (London) 434 , 1001 (2005).
- 26 D. M. Bruls, J. W. A. M. Vugs, P. M. Koenraad, H. W. M. Salemink, J. H. Wolter, M. Hopkinson, M. S. Skolnick, F. Long, S. P. A. Gill, Appl. Phys. Lett. 81 , 1708 (2002).
- 27 I. Kegel, T. H. Metzger, A. Lorke, J. Peisl, J. Stangl, G. Bauer, J. M. Garc´ ıa, P. M. Petroff, Phys. Rev. Lett. 85 , 1694 (2000).
- 28 Y. Yacoby, M. Sowwan, E. Stern, J. Cross, D. Brewe, R. Pindak, J. Pitney, E. M. Dufresne, and R. Clarke, Nature Mater. 1 , 99 (2002).
- 29 T. F. Kelly, M. K. Miller, Rev. Sci. Instrum. 78 , 031101 (2007).
- 30 M. H. Levitt, Spin Dynamics , 2nd ed. (Wiley, New York, 2007).
- 31 D. Paget and V. L. Berkovits, in Optical Orientation , edited by F. Meier and B. P. Zakharchenya (NorthHolland, New York, 1984), Chap. 9.
- 32 P. Petroff, Top. Appl. Phys. 90 , 1 (2003).
- 33 M. H. Cohen and F. Reif, Solid State Phys. 5 , 321 (1957).
- 34 T. P. Das and E. L. Hahn, Nuclear Quadrupole Resonance Spectroscopy (Academic Press Inc., New York, 1958).
- 35 R. G. Shulman, B. J. Wyluda, and P. W. Anderson, Phys. Rev. 107 , 953 (1957).
- 36 R. K. Sundfors, Phys. Rev. B 10 , 4244 (1974).
- 37 An alternative notation in the literature is the use of lowercase subscripts, but with a ' P ' superscript, i.e., V P zz , to designate the EFG principal axis. As we would like to reserve the superscript for the element/isotope label when necessary, we prefer to use V ZZ .
- 38 In the presence of quadrupolar and Zeeman interactions the nuclear energy level spacings become non-monotonic, sometimes giving rise to more than two groups.
- 39 G. Biasiol and S. Heun, Phys. Rep. 500 , 117 (2011).
- 40 E. A. Zibik, W. H. Ng, L. R. Wilson, M. S. Skolnick, J. W. Cockburn, M. Gutierrez, M. J. Steer, and M. Hopkinson, Appl. Phys. Lett. 90 , 163107 (2007).
- 41 G. Vastola, V. B. Shenoy, J. Guo, and Y.-W. Zhang, Phys. Rev. B 84 , 035432 (2011).
- 42 D. Mao and P. C. Taylor, Phys. Rev. B 52 , 5665 (1995).
- 43 W. H. Press, S. A. Teukolsky, W. T. Vetterling, and B. P. Flannery, Numerical Recipes , 3rd ed. (Cambridge University Press, Cambridge, 2007), p. 721.
- 44 K. Pearson, Phil. Trans. R. Soc. Lond. A, 186 , 343 (1895).
- 45 P. J. Knijn, P. J. M. van Bentum, E. R. H. van Eck, C. Fang, D. L. A. G. Grimminck, R. A. de Groot, R. W. A. Havenith, M. Marsman, W. L. Meerts, G. A. de Wijs, and A. P. M. Kentgens, Phys. Chem. Chem. Phys. 12 , 11517 (2010).
- 46 P. M. Koenraad, and M. E. Flatt´ e, Nature Mater. 10 , 91 (2011).
- 47 M. W. Doherty, N. B. Manson, P. Delaney, F. Jelezko, J. Wrachtrup, and L. C. L. Hollenberg, Phys. Rep. 528 , 1 (2013). | 10.1103/PhysRevB.90.205425 | [
"Ceyhun Bulutay",
"E. A. Chekhovich",
"A. I. Tartakovskii"
] | 2014-08-02T14:01:06+00:00 | 2014-11-20T14:25:23+00:00 | [
"cond-mat.mes-hall",
"physics.atom-ph",
"quant-ph"
] | Nuclear magnetic resonance inverse spectra of InGaAs quantum dots: Atomistic level structural information | A wealth of atomistic information is contained within a self-assembled
quantum dot (QD), associated with its chemical composition and the growth
history. In the presence of quadrupolar nuclei, as in InGaAs QDs, much of this
is inherited to nuclear spins via the coupling between the strain within the
polar lattice and the electric quadrupole moments of the nuclei. Here, we
present a computational study of the recently introduced inverse spectra
nuclear magnetic resonance technique to assess its suitability for extracting
such structural information. We observe marked spectral differences between the
compound InAs and alloy InGaAs QDs. These are linked to the local biaxial and
shear strains, and the local bonding configurations. The cation-alloying plays
a crucial role especially for the arsenic nuclei. The isotopic line profiles
also largely differ among nuclear species: While the central transition of the
gallium isotopes have a narrow linewidth, those of arsenic and indium are much
broader and oppositely skewed with respect to each other. The statistical
distributions of electric field gradient (EFG) parameters of the nuclei within
the QD are analyzed. The consequences of various EFG axial orientation
characteristics are discussed. Finally, the possibility of suppressing the
first-order quadrupolar shifts is demonstrated by simply tilting the sample
with respect to the static magnetic field. |
1408.0374v2 | ## ORBITAL COUNTING OF CURVES ON ALGEBRAIC SURFACES AND SPHERE PACKINGS
## IGOR DOLGACHEV
To the memory of Andrey Todorov
Abstract. We realize the Apollonian group associated to an integral Apollonian circle packings, and some of its generalizations, as a group of automorphisms of an algebraic surface. Borrowing some results in the theory of orbit counting, we study the asymptotic of the growth of degrees of elements in the orbit of a curve on an algebraic surface with respect to a geometrically finite group of its automorphisms.
## 1. Introduction
Let Γ be a discrete subgroup of isometries of a hyperbolic space H n and O ( Γ x 0 ) be its orbit. Consider a family of compact subsets B T of H n whose volume tends to infinity as T →∞ . The problem of finding the asymptotic of #O Γ ( x 0 ) ∩B T is a fundamental problem in harmonic analysis, number theory, ergodic theory and geometry. In this paper we discuss an application of this problem to algebraic geometry.
Let X be a smooth projective algebraic surface and let Num( X ) be the group of divisor classes on X modulo numerical equivalence. For any divisor class D we denote by [ D ] its image in Num( X ). The intersection form on divisor classes defines a non-degenerate symmetric bilinear form on Num( X ) of signature (1 , n ). Let Γ ′ be a group of automorphisms of X such that its image Γ in the orthogonal group O(Num( X )) is an infinite group. This implies that X is birationally isomorphic to an abelian surface, a K3 surface, an Enriques surface or the projective plane.
For any divisor class D we denote by O Γ ( D ) the Γ-orbit of [ D ]. Fix an ample divisor class H and an effective divisor class C . For any positive real number T , let
N T ( H,C ) = # [ { C ′ ] ∈ O ( Γ C ) : H C · ′ ≤ T } = # { H ′ ∈ O ( Γ H ) : H ′ · C ≤ T } .
We are interested in the asymptotic of this function when T goes to infinity. As far as I know, this problem was first considered by Arthur Baragar in his two papers [3], [4]. 1
glyph[negationslash]
In the present paper we explain how does this problem relate to a general orbital counting problem in the theory of discrete subgroups of Lie groups. More precisely, we consider the group G = SO(1 , n ) 0 realized as the group of orientation preserving isometries of the hyperbolic space H n ⊂ P ( V ) associated with the real inner product vector space V = Num( X ) R of signature (1 , n ). We will represent points of H n (resp. points in its boundary ∂ H n , resp. the points in P n \ H n ) by vectors v ∈ V with ( v, v ) = 1 , ( v, h 0 ) > 0 (resp. positive rays of vectors with ( v, v ) = 0 , ( v, h 0 ) > 0, resp. vectors with ( v, v ) = -1 ( , v, h 0 ) > 0), where h 0 is a fixed vector with ( h , h 0 0 ) = 1. Let B T ( e ) be the set of points x in H n whose hyperbolic distance from the point e ∈ H n (resp. from a fixed horosphere with center at e if e ∈ ∂ H n , resp. from the orthogonal hyperplane H e with normal vector e if e ∈ H n ) is less than or equal to T . We use the following result (see [28]) which represents the state of the art in the study of orbital counting.
Theorem 1.1. Assume that Γ is a non-elementary geometrically finite discrete subgroup of orientation preserving isometries of H n . Let δ Γ be the Hausdorff dimension of the limit set Λ(Γ) of Γ . If ( e, e ) ≤ 0 , we additionally assume that the orbit O Γ ([ e ]) is a discrete set and δ Γ > 1 if ( e, e ) < 0 . Then there exists a positive constant c Γ ,h 0 ,e depending only on Γ [ , h ] and e such that
$$\lim _ { T \to \infty } \frac { \# O _ { \Gamma } ( h _ { 0 } ) \cap \mathcal { B } _ { T } } { \exp ( T ) ^ { \delta _ { \Gamma } } } = c _ { \Gamma, h _ { 0 }, e }.$$
We apply this theorem to our situation to obtain the following theorem.
Theorem 1.2. Let X be an abelian surface, or a K3 surface, or an Enriques surface, or a rational surface. Let Γ ′ be a group of automorphisms of X such that its image in O Num ( ( X )) is a non-elementary geometrically finite discrete group. Fix an ample numerical divisor class H ∈ Num ( X ) and an effective numerical divisor class C ∈ Num ( X ) . Assume that δ Γ > 1 if C 2 0 < 0 . Then there exists a positive constant c Γ ,H,C depending only on Γ [ , H ] and [ C ] such that
$$\lim _ { T \to \infty } \frac { N _ { T } ( H, C ) } { T ^ { \delta _ { \Gamma } } } = c _ { \Gamma, H, C }.$$
1 I thank Serge Cantat for these references.
As we see, the main ingredient of the asymptotic expression is the Hausdorff dimension δ Γ of the limit set Λ(Γ) ⊂ ∂ H n of Γ. One of the first and the most beautiful example where δ Γ was computed with many decimals is the example where Γ is an Apollonian group in H 3 whose limit set is the closure of a countable union of circles that intersect in at most one point, an Apollonian gasket . It was proved by D. Boyd [7] that the asymptotic of curvatures of circles in an Apollonian gasket is equal to c T ( ) T δ Γ for some function c T ( ) such that lim T →∞ c T ( ) T = 0. He also showed that 1 < δ Γ < 2. It is known now that δ is about 1 305686729 . ... [39]. An Apollonian sphere packing is a special case of a Boyd-Maxwell sphere packing defined by certain Coxeter groups of hyperbolic type introduced by G. Maxwell in [26]. . 2 The Hausdorff dimension of the limit set of the Boyd-Maxwell Coxeter groups coincides with the sphere packing critical exponent equal to
$$( 1. 1 ) \quad \inf \{ s \, \colon \sum _ { S \in \mathfrak { P } } r ( S ) ^ { s } < \infty \} = \sup \{ s \, \colon \sum _ { S \in \mathfrak { P } } r ( S ) ^ { s } = \infty \},$$
where r S ( ) denotes the radius of a sphere S in a sphere packing P . Although the Hausdorff dimension of the limit set of a geometrically finite group is usually difficult to compute, the bounds for sphere packing critical exponent is easier to find.
We give several concrete examples where the Boyd-Maxwell groups, and, in particular the Apollonian groups, are realized as automorphism groups of algebraic surfaces so that our counting problem can be solved in terms of the sphere packing critical exponent. Since this paper addresses a problem in algebraic geometry, we give a short introduction to the hyperbolic geometry and the theory of sphere packings in a language which we think is more suitable for algebraic geometers. Whenever the details or references are omitted, they can be found in [1], [2], [34], or [40].
It is my pleasure to thank Peter Sarnak for his inspiring talks in Ann Arbor, in April 2014, that gave rise to the present paper. The paper could never be written without the assitance of Jeffrey Lagarias who patiently answered my numerous questions on the theory of Apollonian sphere packings, of Boris Apanasov and Serge Cantat who helped me to correct some of my illiteracy in the theory of Kleinian groups, and of Hee Oh for explaining to me the state of the art in the general orbital counting problem.
2 We borrow the terminology from [9]
I am also thankful to the organizers of the conference at Schiermonnikoog2014 for giving me an opportunity to talk about the beautiful subject of Apollonian circle packings.
## 2. Hyperbolic space
Let R n, 1 denote the Minkowski space defined by the quadratic form (the fundamental quadratic form )
$$q = - t _ { 0 } ^ { 2 } + \sum _ { i = 1 } ^ { n } t _ { i } ^ { 2 }$$
of signature ( n, 1). 3 We denote by ( v, w ) the value of the associated symmetric form on two vectors v, w ∈ R n, 1 , so that q v ( ) = ( v, v ). Let
$$\mathbb { H } ^ { n } = \{ v \in \mathbb { R } ^ { n, 1 } \colon q ( v ) < 0 \} / \mathbb { R } ^ { * } \subset \mathbb { P } ^ { n + 1 } ( \mathbb { R } )$$
be the n -dimensional hyperbolic (or Lobachevsky ) space, a Riemannian space of constant negative curvature. Its points are lines [ v ] = R · v spanned by a vector v ∈ R n, 1 with ( v, v ) < 0. The set of real points of the fundamental quadric Q : q = 0 is called the absolute . The union of H n and the absolute is the closure H n of H n in P n ( R ). In affine coordinates y i = x /x i 0 , one represents H n by the interior of the n -dimensional ball
$$\cdot \stackrel { \dots } { \Phi } B _ { n } = \{ ( y _ { 1 }, \dots, y _ { n } ) \colon \sum _ { \substack { i = 1 \\ \Phi } } ^ { n } y _ { i } ^ { 2 } < 1 \}. \\ \cdot \stackrel { \dots } { \Phi } \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Psi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi\Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phis \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \ Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi$$
This is called the Klein model of H n . In this model the Riemannian metric of constant curvature -1 is given by
$$d s ^ { 2 } = \frac { ( 1 - | y | ^ { 2 } ) \sum _ { i = 1 } ^ { n } \bar { d y } _ { i } ^ { 2 } + ( \sum _ { i = 1 } ^ { n } y _ { i } d y _ { i } ) ^ { 2 } } { ( 1 - | y | ^ { 2 } ) ^ { 2 } },$$
where | y | 2 = ∑ n i =1 y 2 i . One can also represent any point in H n by a vector v = ( x , . . . , x 0 n ) ∈ R n, 1 with ( v, v ) = -1 , x 0 > 0. Thus, we obtain a model of H n as one sheet of a two-sheeted hyperboloid Y n in R n, 1
$$- t _ { 0 } ^ { 2 } + \sum _ { i = 1 } ^ { n + 1 } t _ { i } ^ { 2 } = - 1, \ t _ { 0 } > 0. \\......... \.. \.... \ e \prod _ { i = 1 } ^ { n + 1 } \ e \prod _ { i = 1 } ^ { n + 1 }.$$
This model is called the vector model of H n . The hyperbolic distance d v, w ( ) in this model between two points in H n satisfies
$$\cosh d ( v, w ) = - ( v, w ).$$
3 Note that we use the signature ( n, 1) instead of (1 , n ) to agree with the standard notations in hyperbolic geometry.
Here and later we use that, for any two vectors v, w in the vector model of H n , we have ( v, w ) < 0 (see [34], Theorem 3.1.1). The maps
↦
$$B ^ { n } \rightarrow Y ^ { n }, \ ( y _ { 1 }, \dots, y _ { n } ) \mapsto ( \frac { 1 } { \sqrt { 1 - | y | ^ { 2 } } }, \frac { y _ { 1 } } { \sqrt { 1 - | y | ^ { 2 } } }, \dots, \frac { y _ { n } } { \sqrt { 1 - | y | ^ { 2 } } } )$$
and
↦
$$Y ^ { n } \to B _ { n }, \ ( t _ { 0 }, \dots, t _ { n + 1 } ) \mapsto ( \frac { t _ { 1 } } { t _ { 0 } }, \dots, \frac { t _ { n } } { t _ { 0 } } )$$
are inverse to each other.
The induced metric of R n, 1 ds 2 = -dt 2 0 + ∑ n i =1 dt 2 i , after the scaling transformation y i = t /q i ( ) t 1 2 / , defines a Riemannian metric on H n of constant curvature -1
$$( 2. 2 ) \quad \ \ d s ^ { 2 } = \frac { 1 } { ( 1 - | y | ^ { 2 } ) ^ { 2 } } \left ( ( 1 - | y | ^ { 2 } ) \sum _ { i = 1 } ^ { n } d y _ { i } ^ { 2 } + ( \sum _ { i = 1 } ^ { n } y _ { i } d y _ { i } ) ^ { 2 } \right ),$$
where | y | 2 = y 2 1 + · · · + y 2 n . Consider the section of B n by the the hyperplane y n = 0. It is isomorphic to the n -1-dimensional ball
$$( 2. 3 ) \quad \ \ ^ { \prime } B _ { n - 1 } = \{ ( y _ { 1 }, \dots, y _ { n - 1 } ) \in \mathbb { R } ^ { n - 1 } \colon \sum _ { i = 1 } ^ { n - 1 } y _ { i } ^ { 2 } < 1 \}.$$
The restriction of the metric (2.2) to ′ B n -1 coincides with the metric of H n -1 . Thus we may view ′ B n -1 as a ball model of a geodesic hypersurface of B n = H n .
↦
Let p = [1 0 , , . . . , 0 , -1] ∈ Q ( R ) be the southern pole of the absolute. The projection P n glyph[axisshort]glyph[axisshort]glyph[arrowaxisright] P n -1 from this point is given by the formula [ t 0 , . . . , t n ] → [ t 1 , . . . , t n -1 , t 0 + t n ]. Since the hyperplanes t 0 + t n = 0 , t 0 = 0 do not intersect Q ( R ), Q ( R ) \ { p } maps bijectively onto R n -1 with coordinates u i = y i y n +1 . The rational map defined by the formula (2.4)
↦
Φ : P n -1 → Q , [ x , . . . , x 0 n -1 ] → [ x 2 0 + | x | 2 , 2 x x , . . . , 0 1 2 x x 0 n -1 , x 2 0 -| x | 2 ] , where | x | 2 = x 2 1 + · · · + x 2 n -1 , blows down the hyperplane x 0 = 0 to the point p and equals the inverse of the restriction of the projection Q ( R ) \{ } → p P n -1 ( R ). In affine coordinates u i = x /x i 0 in P n -1 \{ x 0 = 0 } and affine coordinates ( y , . . . , y 1 n ) in Q \{ t 0 = 0 } the map is defined by the formula (2.5)
↦
$$\lambda _ { \lambda } ^ { \dots \cdot \cdot \cdot / } ( u _ { 1 }, \dots, u _ { n - 1 } ) \mapsto ( y _ { 1 }, \dots, y _ { n } ) = ( \frac { 2 u _ { 1 } } { 1 + | u | ^ { 2 } }, \dots, \frac { 2 u _ { n - 1 } } { 1 + | u | ^ { 2 } }, \frac { 1 - | u | ^ { 2 } } { 1 + | u | ^ { 2 } } ),$$
where | u | 2 = u 2 1 + · · · + u 2 n -1 . Let Q + be the part of Q ( R ) where y n > 0 (the northern hemisphere). The preimage of Q + under the map Φ is the subset of R n -1 defined by the inequality | u | 2 < 1. It is a unit ball
B n -1 of dimension n -1. Consider the orthogonal projection α of Q + to the ball B n -1 from (2.3). The composition
↦
$$( 2. 6 ) \ \alpha \circ \Phi \, \colon B _ { n - 1 } \to ^ { \prime } B _ { n - 1 }, \ ( u _ { 1 }, \dots, u _ { n - 1 } ) \mapsto ( \frac { 2 u _ { 1 } } { 1 + | u | ^ { 2 } }, \dots, \frac { 2 u _ { n - 1 } } { 1 + | u | ^ { 2 } } )$$
with the inverse
↦
$$\overset { \prime } { B } _ { n - 1 } \to B _ { n - 1 }, \ ( y _ { 1 }, \dots, y _ { n - 1 } ) \mapsto ( \frac { y _ { 1 } } { 1 + \sqrt { 1 - | y | ^ { 2 } } }, \dots, \frac { y _ { n - 1 } } { 1 - \sqrt { 1 + | y | ^ { 2 } } } )$$
is a bijection which we can use to transport the metric on ′ B n -1 to a metric on B n -1 with curvature equal to -1. In coordinates u , . . . , u 1 n -1 , it is given by the formula
$$d s ^ { 2 } = 4 ( 1 - | u | ^ { 2 } ) ^ { - 2 } \sum _ { i = 1 } ^ { n - 1 } d u _ { i } ^ { 2 }.$$
This is a metric on B n -1 of constant curvature -1, called the Poincar´ e metric . The corresponding model of the hyperbolic space H n -1 is called a conformal or Poincar´ e model of H n -1 .
Yet, another model of H n is realized in the upper half-space
$$\mathcal { H } ^ { n } = \{ ( u _ { 1 }, \dots, u _ { n } ) \in \mathbb { R } ^ { n }, u _ { n } > 0 \}.$$
The isomorphism B n →H n is defined by
$$( u _ { 1 }, \dots, u _ { n } ) = \frac { 1 } { \rho ^ { 2 } } ( 2 y _ { 1 }, \dots, 2 y _ { n - 1 }, 2 ( y _ { n } + 1 ) - \rho ^ { 2 } ),$$
where ρ 2 = y 2 1 + · · · + y 2 n -1 +( y n +1) . The metric on 2 H n is given by
$$d s ^ { 2 } = \frac { 1 } { y _ { n } ^ { 2 } } \sum _ { i = 1 } ^ { n } d u _ { i } ^ { 2 }.$$
A k -plane Π in H n is the non-empty intersection of a k -plane in P n ( R ) with H n . We call it proper if its intersection with H n is nonempty, and hence, it is a geodesic submanifold of H n of dimension k isomorphic to H k .
A geodesic line corresponds to a 2-dimensional subspace U of signature (1 , 1). It has a basis ( f, g ) that consists of isotropic vectors with ( f, g ) = -1 (called a standard basis ). Thus any geodesic line glyph[lscript] intersects the absolute at two different points [ f ] and [ g ]. We can choose a parameterization γ : R → l of glyph[lscript] of the form γ t ( ) = 1 √ 2 ( e f t + e -t g ) so that γ ( -∞ ) = [ f ] and γ (+ ∞ ) = [ ]. g The hyperbolic distance d γ ( (0) , γ ( )) from the point t γ (0) = 1 √ 2 ( f + ) to the point g γ t ( ) satisfies d γ ( (0) , γ ( )) t = -( γ (0) , γ ( )) t = cosh t . Thus t = d γ ( (0) , γ ( )) t is the natural parameter of the geodesic line. The subgroup of SO( U ) 0 ∼ =
SU (1 , 1) 0 is isomorphic to R > 0 and consists of transformation g t given in the standard basis by the matrix ( e t 0 0 e -t ) . It can be extended to a group of isometries of R n, 1 that acts identically on U ⊥ . Comparing with the natural parameterization of l , we see that each transformation g t moves a point x ∈ l to a point g t ( x ) such that d x, g ( t ( x )) = t . For this reason, it is called the hyperbolic translate .
A n -1-plane H is called a hyperplane . We write it in the form
$$H _ { \mathfrak { e } } = \{ v \in \mathbb { R } ^ { n, 1 } \, \sum \{ 0 \} \, \colon ( v, \mathfrak { e } ) = 0, ( v, v ) \leq 0 \} / \mathbb { R } ^ { * }.$$
Since the signature of q is equal to ( n, 1), H n ∩ H e = ∅ if and only if ( e , e ) ≥ 0. If ( e , e ) = 0, the intersection with H n +1 consists of one point [ ]. e We assume that ( e , e ) ≥ 0 and ( e , e ) = 1 if ( e , e ) > 0. These properties define e uniquely, up to multiplication by a constant (equal to ± 1 if ( e , e ) = 1). A choice of one of the two rays of the line R e is called an orientation of the hyperplane. The complement of H e in H n consists of two connected components (half-spaces) defined by the sign of ( v, e ). We denote the closures of these components by H ± e , accordingly. Changing the orientation, interchanges the half-spaces.
Consider a hyperplane H e ′ in ′ B n -1 . It is given by an equation
$$a _ { 0 } t _ { 0 } + \sum _ { i = 1 } ^ { n - 1 } a _ { i } t _ { i } = 0$$
for some ( a , . . . , a 0 n -1 ) ∈ R n -1 1 , with norm 1.
Under the map (2.6), the pre-image of H e ′ is equal to the intersection S ( e ′ ) ∩ ¯ B n -1 , where
$$S ( \mathfrak { e } ^ { \prime } ) \coloneqq - a _ { 0 } \sum _ { i = 1 } ^ { n - 1 } u _ { i } ^ { 2 } + 2 \sum _ { i = 1 } ^ { n - 1 } a _ { i } u _ { i } - a _ { 0 } = 0.$$
glyph[negationslash]
If k = a 0 = 0, we can rewrite this equation in the form
$$k ^ { 2 } \sum _ { i = 1 } ^ { n - 1 } ( u _ { i } - a _ { i } / k ) ^ { 2 } = \sum _ { i = 1 } ^ { n - 1 } a _ { i } ^ { 2 } - a _ { 0 } ^ { 2 } = 1.$$
This is a sphere of radius r = 1 k with the center c = ( a /k, . . . , a 1 n -1 /k ). It is immediately checked that S ( e ′ ) intersects the boundary of B n -1 orthogonally (i.e the radius-vectors are perpendicular at each intersection point in the Euclidean inner product). The intersection of S ( e ′ ) with B n -1 is a hyperbolic codimension 1 subspace of the Poincar´ model of e H n -1 .
Assume k = 0, the equation of S ( e ′ ) becomes ∑ n -1 i =1 a u i i = 0 . The hyperplane S ( e ′ ) should be viewed as a sphere of radius r = ∞ with the center at the point at infinity corresponding to p in the compactification
R n ∪ {∞} ∼ = Q ( R ). For any k ≥ 0, the intersection S ( e ′ ) ∩ B n -1 is a geodesic hypersurface in H n -1 . It contains the center of the ball if and only if a 0 = 0.
Example 2.1. A one-dimensional hyperbolic space can be modeled by an open interval ( -1 1). , The Poincar´ e and the Klein metrics coincide and equal to dy / 2 (1 -y 2 ) 2 . It is isomorphic to the Euclidean onedimensional space in this case.
Assume n = 2. We have two models of a hyperbolic 2-dimensional space H 2 both realized in the unit disk B 2 . The the Klein model is defined by the metric
$$d s ^ { 2 } = \frac { y _ { 1 } d y _ { 2 } ^ { 2 } + y _ { 2 } d y _ { 1 } ^ { 2 } } { ( 1 - y _ { 1 } ^ { 2 } - y _ { 2 } ^ { 2 } ) ^ { 2 } }. \\. \quad. \quad. \quad.$$
The Poincar´ e model is defined by the metric
$$d s ^ { 2 } = \frac { d y _ { 1 } ^ { 2 } + d y _ { 2 } ^ { 2 } } { ( 1 - y _ { 1 } ^ { 2 } - y _ { 2 } ^ { 2 } ) ^ { 2 } }.$$
In the Klein model, a geodesic line in H 2 is a line joining two distinct points on the absolute. In the Poincar´ model, a geodesic line is a circle e arc intersecting the absolute orthogonally at two distinct points or a line passing through the center of the disk.
The group Iso( H n ) of isometries of H n is the index 2 subgroup O( n, 1) ′ of the orthogonal group of R n. 1 that preserves each sheet of the hyperboloid representing the vector model of H n . When n is even, we have O( n, 1) ′ = SO( n, 1). It is also isomorphic to the group PO( n, 1) of projective transformations of P n that leaves invariant the quadric Q = ∂ H n . It consists of two connected components, the connected component of the identity PO( n, 1) 0 is the group of isometries that preserve the orientation. It is isomorphic to the subgroup of SO( n, 1) 0 of elements of spinor norm 1.
Via the rational map (2.4), the group Iso( H n ) becomes isomorphic to the subgroup of the real Cremona group Cr R ( n -1) of P R n -1 . It is generated by affine orthogonal transformations of P R n -1 and the inversion birational quadratic transformation
↦
$$[ x _ { 0 }, \dots, x _ { n - 1 } ] \mapsto [ \sum _ { i = 1 } ^ { n - 1 } x _ { i } ^ { 2 }, x _ { 0 } x _ { 1 }, \dots, x _ { 0 } x _ { n - 1 } ].$$
This group is known classically as the Inversive group in dimension n -1. We can also identify Q with a one-point compactification ˆ E n -1 = R n -1 ∪ {∞} of the Euclidean space of dimension n -1. The point ∞ corresponds to the point on Q from which we project to P n -1 . In this
↦
↦
model the Inversive group is known as the M¨bius group M¨b( o o n -1). If we identify, in the usual way, the 2-dimensional sphere with the complex projective line P 1 ( C ), we obtain that the group M¨b(2) is isomorphic o to PSL ( 2 C ) and consists of M¨bius transformations o z → az + b cz + d . The inversion transformation (2.7) is conjugate to the transformation z → -1 /z .
It is known that the orthogonal group O( n, 1) is generated by reflections
↦
$$s _ { \alpha } \colon v \mapsto v - 2 \frac { ( v, \alpha ) } { ( \alpha, \alpha ) } \alpha,$$
glyph[negationslash]
where ( α, α ) = 0. If ( α, α ) < 0, then s α has only one fixed point in H n , the point [ α ] ∈ H n . If ( α, α ) > 0, then the fixed locus of s α is a hyperplane in H n . The pre-image of its intersection with the absolute ∂ H n is the sphere S α/ α, α ( ( ) 1 2 / ). The M¨ obius transformation corresponding to s α is the inversion transformation that fixes the sphere.
An isometry γ of a hyperbolic space H n is of the following three possible types:
- · hyperbolic if γ has no fixed points in H n but has two fixed points on the boundary;
- · parabolic if γ has no fixed points in H n but has one fixed point on the boundary;
- · elliptic if γ has a fixed point in H n .
An element is elliptic if and only if it is of finite order. In the ˆ E n -1 model of the absolute, a parabolic element corresponds to a translation in the affine orthogonal group AO( n -1).
A discrete subgroup Γ of Iso( H n ) is called a Kleinian group . It acts discontinuously on H n and the extension of this action to the absolute acts discontinuously on the set Ω(Γ) = ∂ H n \ Λ(Γ), where Λ(Γ) is the set of limit points of Γ, i.e. points on the boundary that belongs to the closure of the Γ-orbit of a point x in H n (does not matter which one). The set Ω(Γ) is called the discontinuity set of Γ. The set H n ∪ Ω(Γ) is the largest open subset of H n on which Γ acts discontinuously.
Following [34], § 12.2, we call a Kleinian group to be of the first kind (resp. of the second type ) if its discontinuity set is empty (resp. not empty).
A Kleinian group Γ is called elementary if it has a finite orbit in H n . It is characterized by the property that it contains a free abelian subgroup of finite index.
The limit set Λ(Γ) of an elementary Kleinian group is either empty or consists of at most two points, the fixed points of a parabolic or a
hyperbolic element in Γ. Otherwise Λ(Γ) is a perfect set, i.e. has no isolated points. A fixed point of a hyperbolic or a parabolic transformation is a limit point. The limit set of a non-elementary Kleinian group is equal to the closure of the set of fixed points of parabolic or hyperbolic elements [34], Theorem 12.2.2.
A Kleinian group in dimension 2 is called a Fuchsian group . Usually one assumes that Γ is contained in the connected component of Iso(2), i.e. it preserves the orientation. The discontinuity set Ω(Γ) is either empty, and then Γ is called of the first kind, or consists of the union of open intervals, then γ is of the second kind. The quotient X = H 2 ∪ Ω(Γ) Γ is a Riemann surface. / If Γ is of the first kind, one can compactify X by a finite set of orbits of cuspidal limit points. A Fuchsian group with H 2 / Γ of finite volume is of the first kind. If Γ is of the second kind, then X is a Riemann surface with possibly a non-empty boundary.
## 3. Geometrically finite Kleinian groups
A non-empty subset A of a metric space is called convex if any geodesic connecting two of its points is contained in A . Its closure is called a closed convex subset . A closed convex subset P of H n is equal to the intersection of open half-spaces H ,i e i ∈ I . It is assumed that none of the half-spaces H e i contains the intersection of other halfspaces. A maximal non-empty closed convex subset of the boundary of P is called a side . Each side is equal to the intersection of P with one of the bounding hyperplanes H e i . The boundary of P is equal to the union of sides and two different sides intersect only along their boundaries.
A convex polyhedron in H n is a convex closed subset P with finitely many sides. It is bounded by a finite set of hyperplanes H i .
We choose the vectors e i as in the previous section so that
$$P = \bigcap _ { i = 1 } ^ { N } H _ { \mathfrak { e } _ { i } } ^ { - }.$$
The dihedral angle φ H ,H ( e i e j ) between two proper bounding hyperplanes is defined by the formula
$$\cos \phi ( H _ { \mathfrak { e } _ { i } }, H _ { \mathfrak { e } _ { j } } ) \coloneqq - ( \mathfrak { e } _ { i }, \mathfrak { e } _ { j } ).$$
If | ( e i , e j ) | > 1, the angle is not defined, we say that the hyperplanes are divergent . In this case the distance between H e and H e ′ can be found from the formula
$$& ( 3. 2 ) & & \cosh d ( H _ { \mathfrak { e } }, H _ { \mathfrak { e } ^ { \prime } } ) = | ( \mathfrak { e }, \mathfrak { e } ^ { \prime } ) |.$$
For any subset J of { 1 , . . . , N } of cardinality n -k , such the intersection of H ,i e i ∈ J is a k -plane Π in H n , the intersection P ∩ Π is a polyhedron in Π. It is called a k -face of P . A ( n -1)-face of P is a side of P .
The matrix
$$G ( P ) = ( g _ { i j } ), \ \ g _ { i j } = ( \mathfrak { e } _ { i }, \mathfrak { e } _ { j } ),$$
is called the Gram matrix of P . There is a natural bijection between the set of its k -dimensional proper faces and positive definite principal submatrices of G P ( ) of size n -k . The improper vertices of P correspond to positive semi-definite principal submatrices of size n .
Recall that a closed subset D of a metric space X is called a fundamental domain for a group Γ of isometries of X if
- (i) the interior D o of D is an open set;
- (ii) γ D ( o ) ∩ D o = ∅ , for any γ ∈ Γ \ { 1 } ;
- (iii) the set of subsets of the form γ D ( ) is locally finite ; 4
- (iv) X = ∪ γ ∈ Γ γ D ( );
A group Γ admits a fundamental domain if and only if it is a discrete subgroup of the group of isometries of X . For example, one can choose D to be a Dirichlet domain
$$( 3. 3 ) \quad D ( x _ { 0 } ) = \{ x \in X \, \colon d ( x, x _ { 0 } ) \leq d ( \gamma ( x ), x _ { 0 } ), \text{ for any } \gamma \in \Gamma \},$$
glyph[negationslash]
where x 0 is fixed point in X and d x, y ( ) denotes the distance between two points. Assume X = H n . For any γ ∈ Γ \ Γ x 0 , let H γ be the hyperplane of points x such that d x , x ( 0 ) = ρ x, γ ( ( x 0 )). Then D x ( 0 ) = ∩ γ ∈ \ Γ Γ x 0 H -γ and, for any γ ∈ Γ x 0 , S = γ D x ( ( 0 )) ∩ D x ( 0 ) ⊂ H γ is a side in ∂D x ( 0 ). Each side of D x ( 0 ) is obtained in this way for a unique γ .
A fundamental domain D for a Kleinian group Γ in H n is called polyhedral if its boundary ∂D = D \ D o is contained in the union of a locally finite set of hyperplanes H i and each side S of the boundary is equal to D ∩ γ D ( ) for a unique σ S ∈ Γ. A Dirichlet domain is a convex polyhedral fundamental domain.
A choice of a polyhedral fundamental domain allows one to find a presentation of Γ in terms of generators and relations. The set of generators is the set of elements γ S ∈ Γ, where S is a side of D . A relation γ S t ◦· · ·◦ γ S 1 = 1 between the generators corresponds to a cycle
$$D _ { 0 } = D, D _ { 1 } = \gamma _ { S _ { 1 } } ( D _ { 0 } ), \dots, D _ { t } = \gamma _ { S _ { t } } \circ \dots \circ \gamma _ { S _ { 1 } } ( D _ { 0 } ) = D _ { 0 }.$$
Among various equivalent definitions of a geometrically finite Kleinian group we choose the following one (see [2], Chapter 4, § 1): A Kleinian
4 This means that every point x ∈ H n is contained in a finite set of subsets γ D ( )
group Γ is called geometrically finite if it admits a polyhedral fundamental domain with finitely many sides. 5 It follows from above that such a group is finitely generated and finitely presented. The converse is true only in dimension n ≤ 2. In dimensions n ≤ 3, one can show that Γ is geometrically finite if and only if there exists (equivalently any) a Dirichlet fundamental domain with finitely many sides (loc. cit., Theorem 4.4). On the other hand, for n > 3 there are examples of geometrically finite groups all whose Dirichlet domains have infinitely many sides (loc. cit. Theorem 4.5).
glyph[negationslash]
Example 3.1. A convex polyhedron P in H n is called a Coxeter polyhedron if each pair of its hyperplanes H ,H e i e j is either divergent or the dihedral angle between them is equal to π/m ij , where m ij ∈ Z or ∞ . The Coxeter diagram of a Coxeter polyhedron P is a labeled graph whose pairs of vertices corresponding to divergent hyperplanes are joined by a dotted edge, two vertices corresponding to hyperplanes forming the zero angle are joined by a solid edge or by putting ∞ over the edge, and two vertices corresponding to the hyperplanes with the dihedral angle π/m ij = 0 , π/ 2 are joined by an edge with the label m ij -2, the label is dropped if m ij = 3.
glyph[negationslash]
A Coxeter polyhedron is a fundamental polyhedron of the reflection Kleinian group Γ P generated by the reflections s e i . For each pair of reflections s e i , s e j with m ij = ∞ , the product s e i ◦ s e j is a rotation in angle 2 π/m ij around the codimension 2 face H e i ∩ H e j . It follows that ( s i ◦ s j ) m ij is one of the basic relations. In fact, these relations are basic relations. An abstract Coxeter group is a pair (Γ , S ) consisting of a group Γ and a set S of its generators s i such that ( s s i j ) m ij = 1 are the basic relations, where ( m ij ) is a matrix with diagonal elements equal to 1 and off-diagonal elements equal to integers ≥ 2 or the infinity symbol ∞ if the order of the product is infinite. A realization of a Coxeter group ( G,S ) in the form of Γ P , where P is a Coxeter polyhedron in a hyperbolic space H n is called a hyperbolic Coxeter group. It follows that the cardinality of the set S of generators must be equal to n +1. Compact Coxeter polytopes (resp. of finite volume) are described by Lanner (resp. quasi-Lanner) diagrams which can be found for example in [40], Chapter 5, Table 4.
Let Γ be any discrete group and Γ r be its subgroup generated by reflections. It is a Coxeter group with a fundamental Coxeter polyhedron P . Then Γ r is a normal subgroup of Γ and
$$\Gamma = \Gamma _ { r } \rtimes A ( P ),$$
5 Other equivalent definition is given in terms of the convex core of Γ, the minimal convex subset of H n that contains all geodesics connecting any two points in Λ(Γ).
where A P ( ) is the subgroup of Γ which leaves P invariant.
## 4. Sphere packings
Recall that a real n-sphere S in the projective space P R n over reals is the set of real points Q ( R ) of a quadric Q defined over R that contains a given nonsingular quadric Q 0 with Q 0 ( R ) = ∅ in a fixed hyperplane H ∞ . We fix the projective coordinates to assume that H ∞ : x 0 = 0 and Q 0 : x 0 = x 2 1 + · · · + x 2 n = 0. A 1-sphere is called a circle , it is a conic passing through the points [0 , 1 , ± i ] at infinity. We do not exclude the case n = 1 where H ∞ is the point ∞ = [0 1] and , Q 0 = ∅ . A 0-dimensional sphere is a set of two real points in P R 1 that may coincide.
Let
$$\mathbb { P } _ { \mathbb { R } } ^ { n } \dashrightarrow \mathbb { P } _ { \mathbb { R } } ^ { n + 1 }$$
be the rational map defined by the formula
↦
$$[ x _ { 0 }, \dots, x _ { n } ] & \mapsto [ 2 x _ { 0 } ^ { 2 }, - 2 x _ { 0 } x _ { 1 }, \dots, - 2 x _ { 0 } x _ { n }, \sum _ { i = 1 } ^ { n } x _ { i } ^ { 2 } ]. \\. \quad. \quad. \quad. \quad. \quad. \quad. \quad. \quad.$$
Its image is the quadric Q given by the equation
$$q & = 2 t _ { 0 } t _ { n + 1 } + t _ { 1 } ^ { 2 } + \dots + t _ { n } ^ { 2 } = 0.$$
This map is given by a choice of a basis in the linear system of quadrics containing the quadric Q 0 . Adifferent choice of a basis leads to the map (2.4) whose image is a quadric with equation -t 2 0 + ∑ n +1 i =1 t 2 i = 0. Let e = ( a , . . . , a 0 n +1 ) ∈ P n +1 1 , with ( e , e ) ≥ 0. We assume that ( e , e ) = 1 if ( e , e ) > 0. The pre-image of a hyperplane
$$H _ { \mathfrak { e } } \colon a _ { 0 } t _ { n + 1 } + a _ { n + 1 } t _ { 0 } + \sum _ { i = 1 } ^ { n + 1 } a _ { i } t _ { i } = 0$$
in P R n +1 is a quadric in P R n defined by the equation
$$\mu _ { 0 } \sum _ { i = 1 } ^ { n } x _ { i } ^ { 2 } - 2 a _ { n + 1 } x _ { 0 } ^ { 2 } - 2 x _ { 0 } \sum _ { i = 1 } ^ { n } a _ { i } x _ { i } = 0.$$
glyph[negationslash]
If a 0 = 0, we can rewrite this equation in the form
$$( 4. 2 ) \quad \ a _ { 0 } ^ { 2 } \sum _ { i = 1 } ^ { n } ( \frac { x _ { i } } { x _ { 0 } } - \frac { a _ { i } } { a _ { 0 } } ) ^ { 2 } = 2 a _ { 0 } a _ { n + 1 } + \sum _ { i = 1 } ^ { n } a _ { i } ^ { 2 } = 1.$$
So, we can identify its real points with a n -dimensional sphere S ( e ) in the Euclidean space P n ( R ) \ { x 0 = 0 } of radius square r 2 = 1 /a 2 0 and the center c = [ a 1 a 0 , . . . , a n a 0 ]. It is natural to call | a 0 | the curvature of the sphere. If a 0 = 0, we get the union of two hyperplanes H ∞ and S := ∑ n i =1 a x i i + a n +1 x 0 = 0. In this case we set r := ∞ . Note that if
glyph[negationslash]
we take e = ( a , . . . , a 0 n +1 ) in (4.2) with ( e , e ) = 0 , a 0 = 0, we obtain a quadratic cone with the vertex at c . Its set of real points consists only of the vertex.
One introduces the oriented curvature equal to a 0 . We agree that the positive curvature corresponds to the interior of the sphere S ( e ), i.e. an open ball B ( e ) of radius r . The negative curvature corresponds to the open exterior of the sphere, we also call it the ball corresponding to the oriented sphere S and continue to denote it B ( e ). It can be considered as a ball in the extended Euclidean space ˆ E n .
A sphere packing is an infinite set P = ( S i ) i ∈ I of oriented n -spheres such that any two of them are either disjoint or touch each other. We say that a sphere packing is strict if, additionally, no two open balls B i intersect. An example of a non-strict sphere packing is an infinite set of nested spheres. We assume also that the set P is locally finite in the sense that, for any t > 0, there exists only finitely many spheres of curvature at most t in any fixed bounded region of the space. The condition that two spheres S i and S j are disjoint or touch each other is easily expressed in terms of linear algebra. We have the following.
Lemma 4.1. Let S v ( ) and S w ( ) be two n -dimensional spheres corresponding to hyperplanes H v and H w . Then their interiors do not intersect if and only if
$$( v, w ) \leq - 1.$$
The equality takes place if and only if the spheres are tangent to each other, and hence intersect at one real point.
Proof. Consider the pencil of spheres λS v ( ) + µS w ( ) = H λv ( + µw ) (here, for brevity of notation, we do not normalize the normal vector defining the hyperplane λH v ( )+ µH µ ( )). It is clear that B v ( ) ∩ B w ( ) = ∅ if and only if S v ( ) = S w ( ) = ∅ or the pencil contains a cone with its vertex equal to the tangency points of the spheres. A point of intersection of two spheres is defined by a vector x such that ( x, v ) = ( x, w ) = ( x, x ) = 0. Such x exists if and only if the plane 〈 v, w 〉 spanned by v and w is positive or semi-positive definite. This happens if and only if ( v, v )( w, w ) -( v, w ) 2 ≥ 0. The equality takes place if and only x ∈ 〈 v, w 〉 . This is equivalent to that one of the spheres in the pencil is a degenerate sphere, i.e. a cone with its vertex equal to the tangency point of the two spheres. Thus we proved that | ( v, w ) | ≥ 1. As we noted before, ( v, w ) must be negative. glyph[square]
Let Γ be a geometrically finite Kleinian group in H n +1 that is identified with a subgroup of the M¨bius group M¨b( o o n ). We say that a sphere packing is a sphere Γ -packing if it is invariant with respect to
the action of Γ on spheres and has only finitely many orbits, say N , on the set. We also say that a sphere Γ-packing is clustered if one can choose representatives S , . . . , S 1 N of the orbits such that P is equal to the union of the sets { γ S ( 1 ) , . . . , γ ( S N ) } , γ ∈ Γ. Each such set is called a cluster of the sphere packing. We will see later than Apollonian sphere packings and, their generalizations, Boyd-Maxwell sphere packings, are examples of clustered sphere Γ-packings.
Let Γ i be the stabilizer subgroup of some sphere S i in a sphere Γpacking. The sphere corresponds to a geodesic hyperplane H i in H n +1 , hence the ball B i is the Klein model of H n on which Γ i acts as a geometrically finite Kleinian group. Its limit points are on S i . We know that they belong to the closure of the set of fixed points of nonelliptic elements in Γ , hence they are limit point of the whole Γ. i
Let us introduce the following assumptions.
- (A1) for any sphere S i , Λ(Γ ) = i S . i
- (A2) ⋃ i ∈ I ¯ B i = ˆ E . n
Assumption (A1) implies that
$$\overline { \bigcup _ { i \in I } ^ { S _ { i } } } \subset \Lambda ( \Gamma ).$$
Assumption (A2) means that the packing is maximal , i.e. one cannot find a sphere whose interior is disjoint from the interiors of all other spheres in the packing.
glyph[negationslash]
If the packing is strict, assumptions (A1) and (A1) imply the equality in (4.3). Indeed, suppose x is a limit point of Γ that does not lie in the closure of the union of the spheres. By (A2), it belongs to the closure of some open ball B i . Suppose x belongs to the open ball B i . We mentioned before that the limit set is the closure of the set of fixed points of non-elliptic elements of Γ. Thus we can find some open neighborhood of x inside B i that contains a fixed point of a non-elliptic element γ in Γ. The stabilizer subgroup Γ i of B i in Γ is a Kleinian group acting on B i . It cannot contain a non-elliptic element with a fixed point in the ball. This shows that γ ∈ Γ i and hence γ B ( i ) glyph[subsetnoteql] B i . Thus the set { γ n ( B ,n i ) ∈ Z } consists of nested spheres. This is excluded by the definition of a strict sphere packing.
In the next two sections we give examples of sphere Γ-packings satisfying assumptions (A1) and (A2).
## 5. Boyd-Maxwell sphere packings
Let P be a Coxeter polytope in H n +1 with the Gram matrix G P ( ). Let e 1 , . . . , e n +2 be the normal vectors of its bounding hyperplanes. We
can take the set ( e 1 , . . . , e n +2 ) to be a basis of the space R n +1 1 , with the fundamental quadric (4.1).
Let ω j be a vector in R n, 1 uniquely determined by the condition
$$( 5. 1 ) & & ( \omega _ { j }, \mathfrak { e } _ { i } ) = \delta _ { i j }.$$
We have
$$\sum ^ { n } g ^ { i j } \mathfrak { e } _ { i },$$
$$\omega _ { j } = \sum _ { i = 1 } ^ { \ell \ell } g ^ { i j } \mathfrak { e } _ { i },$$
where
$$G ( P ) ^ { - 1 } = ( g ^ { i j } ) = ( ( \omega _ { i }, \omega _ { j } ) ).$$
We call ω i real if ( ω , ω i i ) = g ii > 0 . In this case we can normalize it to set
$$\bar { \omega } _ { i } \coloneqq \omega _ { i } / \sqrt { g ^ { i i } }.$$
Let J = { j 1 < · · · < j r } be the subset of { 1 , . . . , n +2 } such that ¯ ω j is real if and only if j ∈ J . Consider the union
$$\mathfrak { P } ( P ) = \bigcup _ { k = 1 } ^ { r } O _ { \Gamma _ { P } } ( S ( \bar { \omega } _ { j _ { k } } ) ).$$
A Boyd-Maxwell sphere packing is a sphere packing of the form P ( P ), where P is a Coxeter polytope. By definition, it is clustered with clusters
$$( \gamma ( S ( \bar { \omega } _ { j _ { 1 } } ) ), \dots, \gamma ( S ( \bar { \omega } _ { j _ { r } } ) ) ) = ( S ( \gamma ( \bar { \omega } _ { j _ { 1 } } ) ), \dots, S ( \gamma ( \bar { \omega } _ { j _ { r } } ) ).$$
We call the cluster ( S ω ( j 1 ) , . . . , S ( ω j r )) the initial cluster . It is called non-degenerate if all ω i are real. This is equivalent to that all principal maximal minors of the matrix G P ( ) are negative.
glyph[negationslash]
Following G. Maxwell [26], we say that the Coxeter diagram is of level l if, after deleting any l of its vertices, we obtain a Coxeter diagram of Euclidean or of parabolic type describing a Coxeter polyhedron in an Euclidean or a spherical geometry. They can be characterized by the property that all m ij = ∞ (except in the case n = 1) and the symmetric matrix ( m ij ) is non-negative definite, definite in the Euclidean case, and having a one-dimensional radical in the parabolic case. Coxeter diagrams of level l = 1 correspond to Lanner and quasi-Lanner Coxeter groups. Coxeter diagrams of level 2 have been classified by G. Maxwell (with three graphs omitted, see [9]). They occur only in dimension n ≤ 10. For n ≥ 4 they are obtained from quasi-Lanner diagrams by adding one vertex.
For example, a Coxeter polyhedron in H 10 with Coxeter diagram of level 2

defines a sphere packing with only one real ω i corresponding to the extreme vertex on the right.
The following theorem is proven, under a certain assumption, in loc.cit., Theorem 3.3. The assumption had been later removed in [27], Theorem 6.1. 6
Theorem 5.1. Let P be a Coxeter polyhedron in H n . Then P ( P ) is a sphere Γ P -packing if and only if the Coxeter diagram of P is of level ≤ 2 .
If P is a quasi-Lanner Coxeter polytope, the Kleinian group Γ P has a fundamental polyhedron of finite volume. It follows that Γ P is a Kleinian group of the first kind ([34], Theorem 12.2.13). Thus any point on the absolute is its limit point. The stabilizer Γ P,i of each S ω (¯ ) i is the reflection group of the Coxeter group defined by the Coxeter diagram of level 1, hence the limit set of Γ P,i is equal to S ω (¯ ). i Thus the assumption (A1) is satisfied.
Let P ( P ) be a non-degenerate Boyd-Maxwell sphere packing and let k = ( k , . . . , k 1 n +2 ) be the vector of the curvatures of the spheres S v ( i ) in its cluster ( S v ( 1 ) , . . . , S ( v n +2 )).
Theorem 5.2. Let G P ( ) be the Gram matrix of P . Then
$$\ ^ { t } { \mathbf k } \cdot G ( P ) \cdot { \mathbf k } = 0.$$
Proof. Let J n +2 be the matrix of the symmetric bilinear form defined by the fundamental quadratic form q . It satisfies J n +2 = J -1 n +2 . Let X be the matrix whose j th column is the vector of coordinates of the vector v j . Recall that the first coordinate of each vector v j is equal to the curvature of the sphere S v ( j ) . Let v i = γ ω (¯ ) for some i γ ∈ Γ . We P have
$$( v _ { i }, v _ { j } ) = ( \gamma ( \bar { \omega } _ { i } ), \gamma ( \bar { \omega } _ { j } ) ) = ( \bar { \omega } _ { i }, \bar { \omega } _ { i } ).$$
Thus, hence
$$^ { t } X ^ { - 1 } \cdot G ( P ) ^ { - 1 } \cdot X ^ { - 1 } = J _ { n + 2 }.$$
6 I am grateful to Hao Chen for the reference.
$$^ { t } X \cdot J _ { n + 2 } \cdot X = G ( P ) ^ { - 1 },$$
Taking the inverse, we obtain
$$X \cdot G ( P ) \cdot ^ { t } X = J _ { n + 2 } ^ { - 1 } = J _ { n + 2 }.$$
The first entry a 11 of the matrix in the right-hand side is equal to zero. Hence
$$\L ^ { t } { \mathbf k } \cdot G ( P ) \cdot { \mathbf k } = 0,$$
It is clear that we have the following possibilities for a cluster in P ( P ).
Assume n ≥ 2. Suppose P ( P ) is a non-degenerate Boyd-Maxwell sphere packing. Let ¯ ω , . . . , ω 1 ¯ n +2 be defined as (5.2). Then the hyperplanes H ω (¯ ) bound a convex polyhedron with no proper vertices on i the absolute. Let us denote it by P ⊥ . Since P ( P ) is a sphere packing, no two bounding hyperplanes of P ⊥ have a common point in the absolute. By Lemma 4.1, glyph[negationslash]
$$( 5. 5 ) & & ( \bar { \omega } _ { i }, \bar { \omega } _ { j } ) \leq - 1, \ \ i \neq j.$$
Thus any two bounding hyperplanes of P ⊥ either diverge or have the dihedral angle equal to 0. In particular, we obtain that P ⊥ is a Coxeter polyhedron and hence its reflection group Γ ⊥ P := Γ P ⊥ is a Kleinian group. The Coxeter diagram of P ⊥ has either solid or dotted edges. As a non-weighted graph, it is a complete graph K n +2 with n + 2 vertices. It is clear that it is of level l ≤ 2 if and only if n ≤ 3. In this case we can define the dual Boyd-Maxwell sphere packing
$$\mathfrak { P } ( P ) ^ { \perp } \coloneqq \mathfrak { P } ( P ^ { \perp } ).$$
glyph[negationslash]
Note that the property ( e i , ω ¯ ) = 0 for k i = k is interpreted in terms of spheres as the property that the spheres S ( e i ) and S ω (¯ ) are orthogonal j to each other (see, for example, [13], Proposition 7.3). This implies that the dual sphere packing can be defined by a cluster that consists of spheres orthogonal to all spheres of a cluster defining P ( P ) except one.
Let A be the matrix of a transformation from Γ P ⊥ in a basis ( ω , . . . , ω 1 n +1 ). Then
$$^ { t } A \cdot G ( P ) ^ { - 1 } \cdot A = G ( P ).$$
Taking the inverse, we obtain
$$A ^ { - 1 } \cdot G ( P ) \cdot ^ { t } A ^ { - 1 } = G ( P ).$$
This shows that under the homomorphism A → t A -1 , the group Γ ⊥ P becomes isomorphic to a subgroup of the orthogonal group of the quadratic form defined by the matrix G P ( ).
The group Γ P is generated by the reflections s e i that act on the dual basis ( ω , . . . , ω 1 n +2 ) by the formula
$$& ( 5. 7 ) \quad s _ { \mathfrak { e } _ { i } } ( \omega _ { j } ) = \omega _ { j } - 2 ( \mathfrak { e } _ { i }, \omega _ { j } ) \mathfrak { e } _ { i } = \omega _ { j } - 2 \delta _ { i j } \mathfrak { e } _ { i } = \omega _ { j } - 2 \delta _ { i j } \sum _ { k = 1 } ^ { n + 2 } g _ { k i } \omega _ { k }, \\ & \cdot \quad. \quad. \quad. \quad. \quad. \quad. \quad. \quad. \quad. \quad. \quad. \quad.$$
where δ ij is the Kronecker symbol. This gives explicitly the action of Γ P on the clusters of the sphere packing and also on the set of their curvature vectors.
The group Γ P ⊥ is generated by the reflections s ω i = s ¯ ω i that act on the basis ( e 1 , . . . , e n +2 ) by the formula
$$s _ { \omega _ { i } } ( \mathfrak { c } _ { j } ) = \mathfrak { c } _ { j } - 2 ( \bar { \omega } _ { i }, \mathfrak { c } _ { j } ) \bar { \omega } _ { i } = \mathfrak { c } _ { j } - \frac { 2 \delta _ { i j } } { g ^ { i i } } \omega _ { i } = \mathfrak { c } _ { j } - \frac { 2 \delta _ { i j } } { g ^ { i i } } \sum _ { k = 1 } ^ { n + 2 } g ^ { k i } e _ { k }.$$
Example 5.3. This is the most notorious and widely discussed beautiful example of a Boyd-Maxwell sphere packing (see, for example, [18], [19], [20],[17],[36]).
We start with a set of pairwise touching non-degenerate n -spheres S v ( 1 ) , . . . , S ( v n +2 ) with positive radii that touch each other. By Lemma 4.1, the Gram matrix G = (( v , v i j )) has 1 at the diagonal and -1 off the diagonal. Thus,
$$G = c i r ( 1, - 1, \dots, - 1 ),$$
where cir( α , . . . , α 1 n +2 ) denotes the circulant matrix with the first row ( α , . . . , α 1 n +2 ). It is easy to compute the inverse of G to obtain
$$G ^ { - 1 } = \frac { 1 } { \varepsilon _ { n } } c i r ( n - 1, - 1, \dots, - 1 ).$$
$$^ {. 1 } = \frac { 1 } { 2 n } \text{cir} ( n - 1, - 1, \dots, - 1 ).$$
Assume n ≥ 2. Then
$$\frac { 2 n } { n - 1 } G ^ { - 1 } = \text{cir} ( 1, \frac { 1 } { 1 - n }, \dots, \frac { 1 } { 1 - n } ). \quad \ _ { - } \.$$
It is equal to the Gram matrix of a Coxeter polytope P if and only if n = 2 3. , The group Γ P is called the Apollonian group and will be denoted by Ap . It is a Kleinian group only for n n = 2 3. We call , P an
Apollonian polyhedron . Its Coxeter diagram is equal to the complete graph K 4 with solid edges if n = 2 and a complete graph K 5 with simple edges if n = 3. In each case the Coxeter diagram is of level 2. Thus, P defines a Boyd-Maxwell sphere packing in dimensions n = 2 or 3. In the case n = 2, we see that all circles in the cluster defined by the vectors ¯ ω , . . . , ω 1 ¯ n +2 mutually touch each other. So, all clusters in this packing define a set of n +2 mutually touching circles. Any two circles in the packing are either disjoint or touch each other.
We have G P ( ) -1 = n -1 2 n G , thus P ⊥ has the Gram matrix equal to G . It follows that P ⊥ is always a Coxeter polyhedron with Coxeter diagram equal to a complete graph K n +2 with solid edges. It defines a sphere packing only if n ≤ 3. Clearly, it is non-degenerate, and hence by Theorem 5.1, it is maximal. If n = 2 3, it is , the dual to the Apollonian packing. Its clusters consist of n +2 mutually tangent n -spheres. If n = 2, the dual of an Apollonian circle packing is an Apollonian circle packing. Its clusters are orthogonal to clusters of the original packing as shown on Figure 1 below. The group Ap ⊥ n is called the dual Apollonian group .
Figure 1. Dual Apollonian circle clusters (from [26])
Let H ¯ ω 1 , . . . , H ¯ ω n +2 be the bounding hyperplanes of an Apollonian Coxeter polyhedron and s e i be the corresponding reflections generating the Apollonian group Ap n . Let S ( e 1 ) , . . . , S ( e n +2 ) be the cluster of the dual Apollonian sphere packing. The formula (5.7) specializes to give
s e i (¯ ) = ¯ , and ω j ω j glyph[negationslash]
$$s _ { \mathfrak { e } _ { i } } ( \bar { \omega } _ { i } ) = - \bar { \omega } _ { i } + \frac { 2 } { n - 1 } \sum _ { j \neq i } \bar { w } _ { j }.$$
For example, s e 1 is represented in the basis (¯ ω , . . . , ω 1 ¯ n +2 ) by the matrix
$$\begin{array} { c c c c } \bullet & & \bullet & \bullet _ { \nu } \\ & & A _ { 1 } = \begin{pmatrix} - 1 & 0 & 0 & \dots & 0 \\ \frac { 2 } { n - 1 } & 1 & 0 & \dots & 0 \\ \vdots & \vdots & \vdots & \vdots \\ \frac { 2 } { n - 1 } & 0 & 0 & \dots & 1 \end{pmatrix}. \\ \bullet & & \bullet & \bullet & \bullet & \bullet & \end{array}$$
So, the Apollonian group is generated by n +2 matrices A , . . . , A 1 n +2 of this sort.
glyph[negationslash]
Formula (5.8) shows that the dual Apollonian group Ap ⊥ n acts on the Apollonian packing by acting on spheres S ( e i ) via the reflections s ¯ ω i . We have s ¯ ω i ( e j ) = e j if j = i and glyph[negationslash]
$$s _ { \bar { \omega } _ { i } } ( \mathfrak { e } _ { i } ) = - \mathfrak { e } _ { i } + 2 \sum _ { k = 1, k \neq i } ^ { n + 2 } \mathfrak { e } _ { j }$$
For example, s ¯ ω 1 is represented by the matrix
$$B _ { 1 } = \begin{pmatrix} - 1 & 2 & 0 & \dots & 2 \\ 0 & 1 & 0 & \dots & 0 \\ \vdots & \vdots & \vdots & \vdots \\ \dot { 0 } & \dot { 0 } & \dot { 0 } & \dots & 1 \end{pmatrix}.$$
The equation from Theorem 5.2 becomes
$$( 5. 1 0 ) \quad \ \ n ( k _ { 1 } ^ { 2 } + \dots + k _ { n + 2 } ^ { 2 } ) - ( k _ { 1 } + \dots + k _ { n + 2 } ) ^ { 2 } = 0.$$
It is known as Descartes's equation or Soddy's equation 7
glyph[negationslash]
Using (5.6), we see that Ap ⊥ n acts on the solutions of the equation (5.4) by the contragradient representations. It is generated by the matrices t A -1 = t A , . . . , 1 t A -1 n +2 = t A n +2 . However, if n = 2, it does not leave the Apollonian packing invariant.
Assume n > 1. Consider a solution ( k , . . . , k 1 n +2 ) of the Descartes' equation which we rewrite in the form
$$\sum _ { i = 1 } ^ { n + 2 } k _ { i } ^ { 2 } - \frac { 2 } { n - 1 } \sum _ { 1 \leq i \leq j \leq n + 2 } k _ { i } k _ { j } = 0.$$
7 From a 'poem proof' of the theorem in the case n = 2 in 'Kiss Precise' by Frederick Soddy published in Nature, 1930:
Four circles to the kissing come. / The smaller are the bender. / The bend is just the inverse of / The distance from the center. / Though their intrigue left Euclid dumb / Theres now no need for rule of thumb. / Since zero bends a dead straight line / And concave bends have minus sign, / The sum of the squares of all four bends / Is half the square of their sum.
Thus, k n +2 satisfies the quadratic equation
$$t ^ { 2 } - \frac { 2 t } { n - 1 } \sum _ { i = 1 } ^ { n + 1 } k _ { i } - \frac { 2 } { n - 1 } \sum _ { 1 \leq i < k \leq n + 1 } ^ { n + 2 } k _ { i } = 0.$$
It expresses the well-know fact (the Apollonian Theorem ) that, given n +1 spheres touching each other, there are two more spheres that touch them. Thus, starting from an Apollonian cluster ( S , . . . , S 1 n +2 ), we get a new Apollonian cluster ( S , . . . , S 1 n +1 , S ′ n +2 ) such that the curvatures of S n +2 and S ′ n +2 are solution of the above quadratic equation. The curvatures of S ′ n +2 is equal to
$$k _ { n + 2 } ^ { \prime } = - k _ { n + 2 } + \frac { 2 } { n - 1 } \sum _ { i = 1 } ^ { n + 1 } k _ { i }.$$
So the new cluster ( S , . . . , S 1 n +1 , S ′ n +2 ) is the cluster obtained from the original one by applying the transformation s e n +2 .
Figure 2. Apollonina circle cluster with curvature vector ( -10 18 23 27) , , ,
If we start with a cluster as in the picture, then all circles will be inclosed in a unique circle of largest radius, so our circle packing will look as in following Figure 3.
Another possibility is when we start with a cluster of three circles touching a line. Then, the circle packing will look like in the following Figure 4.
The following example is taken from [6].
Example 5.4. We take P with the Gram matrix
$$G ( P ) = \text{cir} ( 1, - 1, 0, - 1 ).$$
It is a Coxeter polyhedron with the Coxeter diagram
Figure 3. Apollonina circle packing
Figure 4. Apollonina circle packing in a band
$$\begin{smallmatrix} & & \infty & & \infty \\ \dddot { \longrightarrow } & & \infty & & \\ \end{smallmatrix}$$
The dual polyhedron P ⊥ has the Gram matrix G P ( ) -1
$$G ( P ) ^ { - 1 } = \frac { 1 } { 2 } \text{cir} ( 1, - 1, - 2, - 1 ).$$
Example 5.5. Let us consider the exceptional case of Apollonian packings when n = 1 (this case was briefly mentioned in [17]). Here 0dimensional spheres are sets of two or one points in P 1 ( R ) that we can identify with the boundary of the unit disk model of the hyperbolic plane H 2 . We start with three 0-dimensional spheres touching each other. This means that each pair has a common point. Let p 12 , p 13 , p 23 be the common points. We use the Poincar´ model of e H 2 . Then the corresponding hyperplanes H ω ( 1 ) , H ( ω 1 ) , H ( ω 1 ) are three geodesics joining pairs of these points. They form a ideal triangle with vertices on the boundary.
Figure 5. Ideal triangle

The Apollonian group is not defined in this case. However, the dual Apollonian group Ap ⊥ 1 is defined. It is a Coxeter group with Coxeter diagram equal to the complete graph K 3 with solid edges. It is a quasiLanner Coxeter group generated by the reflections in sides of the ideal triangle.
The fundamental polyhedron of Ap ⊥ 1 is equal to the closure of the interior of the triangle. Its Gram matrix is equal to cir(1 , -1 , -1). Since it is of finite volume, the group is a Fuchsian group of the first kind with 3 cusps. The limit set of Ap ⊥ 1 is the whole circle. However, the packing is not strict since the interiors of our 0-dimensional spheres are one of the two intervals in P 1 ( R ) with end points equal to the sphere. Obviously we have a nested family of intervals. The set of 0-dimensional spheres in the sphere Ap ⊥ 1 -packing is a proper subset of Λ(Ap ⊥ 1 ). It consists of cusp points and is countable.
The Descartes equation becomes
$$& ( 5. 1 2 ) & & k _ { 1 } k _ { 2 } + k _ { 1 } k _ { 3 } + k _ { 2 } k _ { 3 } = 0.$$
## 6. Integral packings
Let K ⊂ R be a totally real field of algebraic numbers of degree d = [ K : Q ] and o K be its ring of integers. A free o K -submodule L of rank n +2 of R n +1 1 , is called a o K -lattice. Let ( e 1 , . . . , e n +2 ) be a basis of L . Assume that the entries of its Gram matrix G = (( e i , e j )) = ( g ij ) belong to o K Let σ i : K ↪ → R , i = 1 , . . . , d -1 , be the set of nonidentical embeddings of K into R . We assume additionally that the matrices G σ i = ( σ i ( g ij )) are positive definite. Let
$$f = \sum _ { 1 \leq i, j \leq n + 2 } g _ { i j } t _ { i } t _ { j }$$
be the quadratic form defined by the matrix G and O( f, o K ) be the subgroup of GL n +2 ( o K ) of transformations that leave f invariant. The group O( f, o K ) is a discrete subgroup of O( R n +1 1 , ) with a fundamental polyhedron of finite volume, compact if f does not represent zero. By passing to the projective orthogonal group, we will view such groups as Kleinian subgroups of Iso( H n +1 ). A subgroup of Iso( H n +1 ) which is commensurable with a subgroup of the form PO( f, o K ) is called arithmetic . Two groups PO( f , ′ o ′ K ) and PO( f, o K ) are commensurable if and only if K = K ′ and f is equivalent to λf ′ for some positive λ ∈ K . In particular, any subgroup of finite index in PO( f, o K ) is an arithmetic group.
We will be interested in the special case of an integral lattice where K = Q . A Kleinian group Γ in H n +1 is called integral if it is commensurable with a subgroup of PO( f, Z ) for some integral quadratic form f of signature ( n + 1 1). , We will be dealing mostly with nonarithmetic geometrically finite Kleinian groups. However, it follows from [5], Proposition 1, that such a group is always Zariski dense in PSO( n +1 1) or PO( , n +1 1) if it acts irreducibly in , H n +1 . In terminology due to P. Sarnak, Γ is a thin group .
We will use the usual terminology of the theory of integral quadratic forms, or more abstractly, integral quadratic lattices , free abelian groups L of finite rank equipped with a symmetric bilinear form with values in Z . By tensoring with R , we embed L in L R := L ⊗ R . We assume that the quadratic form of L extends to a quadratic form on L R of signature ( n +1 1), this will identify , L with an integral lattice in the previous sense. The set L ∨ of all vectors in L R such that ( x, v ) ∈ Z for all x ∈ L is called the dual lattice . It is a free abelian group spanned by the dual basis of a basis of L in L R . The Gram matrix of this basis is the inverse of the Gram matrix of the basis of L . The quotient group L /L ∨ is called the discriminant group of L . Its order is equal to the minus of the determinant of the Gram matrix of any basis of L . Note that L ∨ ⊂ L R is not, in general, an integral lattice. However, it becomes integral if we multiply its quadratic form by the exponent of the discriminant group of L . We denote by O( L ) the orthogonal group of L , the subgroup of GL( L ) that preserves the bilinear form. A reflection isometry of R N defined by a vector v ∈ L belongs to O( L ) if and only if 2( v,x ) ( v,v ) ∈ Z for all x ∈ L .
Remark 6.1 . Let Γ be an integral Kleinian group of isometries of H n of finite covolume, for example, the orthogonal group of some integral quadratic lattice L . It is obviously geometrically finite, however, for
n > 3 it may contain finitely generated subgroups which are not geometrically finite. In fact, for any lattice L of rank ≥ 5 that contains a primitive sublattice defined by the quadratic form q = -x 2 0 + x 2 1 + x 2 2 + x 2 3 , the orthogonal group O( L ) contains finitely generated but not finitely presented subgroups (see [21]). 8
A sphere packing P = ( S i ) i ∈ I is called integral if the following conditions are satisfied.
- (i) The corresponding norm one vectors v i in R n +1 1 , span an integral lattice L ;
- (ii) There exists a positive integer λ such that λ v , v ( i j ) ∈ Z for all i, j ∈ I . The smallest such c is called the exponent .
- (iii) The curvatures of spheres S i are integers.
After multiplying the quadratic form of L , the restriction of the fundamental quadratic form to L , by the exponent we obtain an integral quadratic lattice int( L ). If Γ is a Kleinian group that leaves an integral sphere packing invariant, then it obviously leaves int( L ) invariant and becomes a subgroup of O(int( L )).
It follows from formula (5.7) that a Boyd-Maxwell sphere packing defined by a Coxeter polytope P with Gram matrix G P ( ) = ( g ij ) is integral if and only if the curvatures of the spheres from the initial cluster are integers and g ij ∈ Q . The quadratic lattice is defined by the matrix eG P ( ), where e is the smallest positive integer such that eg ij ∈ Z .
Example 6.2. Let P be an Apollonian polyhedron in H n +1 , n > 1. It is defined by the matrix cir(1 , 1 1 -n , . . . , 1 1 -n ) whose inverse is equal to n -1 2 n cir(1 , -1 , . . . , -1). Recall that it is a Coxeter polyhedron only for n = 2 3. , The Apollonian packing is an integral Coxeter packing with exponent 1. The Apollonian group Ap n becomes a subgroup of the orthogonal group O( A p n ( )), where A p n ( ) is an integral quadratic lattice of rank n +2 with the quadratic form
$$q _ { n } = \sum _ { i = 1 } ^ { n + 2 } t _ { i } ^ { 2 } - 2 \sum _ { 1 \leq i < j \leq n + 2 } t _ { i } t _ { j }.$$
Recall that an integral quadratic lattice is called even if all its values are even integers, it is called odd otherwise. Obviously, the lattice A p n ( ) is odd. For any lattice L , we denote by L ev its largest even sublattice. Obviously, O( L ) ⊂ O( L ev ). Let us find an orthogonal decomposition of the lattice A p n ( ) ev .
8 I thank Boris Apanasov who informed me about this fact.
The quadratic form (6.1) is given in a basis ¯ ω , . . . , ω 1 ¯ n +2 of A p n ( ). Consider a new basis f , . . . , f 1 n +2 formed by the vectors ¯ ω , ω 1 ¯ +¯ 1 ω , 2 -¯ ω 1 -¯ ω , ω 3 ¯ 1 + ¯ ω 2 + ¯ ω 3 -¯ ω , ω 4 ¯ 4 -¯ ω , . . . , ω 5 ¯ n +1 -¯ ω n +2 . The Gram matrix of this basis is the following matrix.
$$\begin{pmatrix} 1 \, 0 \, 0 \, 0 \, 0 \, 0 \, 0 \, 0 \, \dots \, 0 \, 0 \\ 0 \, 0 \, 2 \, 0 \, 0 \, 0 \, 0 \, 0 \, \dots \, 0 \, 0 \\ 0 \, 2 \, 0 \, 0 \, 0 \, 0 \, 0 \, \dots \, 0 \, 0 \\ 0 \, 0 \, 0 \, 4 \, - 2 \, 0 \, 0 \, \dots \, 0 \, 0 \\ 0 \, 0 \, 0 \, - 2 \, 4 \, - 2 \, 0 \, \dots \, 0 \, 0 \\ \vdots \vdots \vdots \vdots \vdots \vdots \vdots \vdots \vdots \vdots \vdots \vdots \\ \vdots \vdots \vdots \vdots \vdots \vdots \vdots \vdots \vdots \vdots \vdots \end{pmatrix}.$$
This shows that, for any n > 1,
$$\mathcal { A } p ( n ) & \cong \langle 1 \rangle \oplus U ( 2 ) \oplus \mathbf A _ { n - 1 } ( 2 ).$$
Here we use the standard notation from the theory of integral quadratic lattices: U is the integral hyperbolic plane, A n is the even positive definite root lattice defined by the Cartan matrix of type A n , 〈 k 〉 is the lattice of rank 1 spanned by a vector v with ( v, v ) = k , and M t ( ) denotes the quadratic lattice M with its integral quadratic form multiplied by a rational number t .
We have
$$( 6. 3 ) \quad \mathcal { A } p ( n ) ^ { e v } = \mathcal { A } _ { 1 } ( 2 ) \oplus \mathsf U ( 2 ) \oplus \mathsf A _ { n - 1 } ( 2 ) \cong ( \mathsf A _ { 1 } \oplus \mathsf U \oplus \mathsf A _ { n - 1 } ) ( 2 ).$$
The discriminant group of A p n ( ) (resp. A p n ( ) ev ) is isomorphic to ( Z / 2 Z ) n ⊕ Z / 2 n Z (resp. ( Z / 2 Z ) n ⊕ Z / 2 n Z ⊕ Z / 4 Z ).
Next we consider the dual Apollonian sphere packing. Its lattice is the dual lattice of A p n ( ) ∨ defined by the quadratic form from the left-hand side of (5.10) multiplied by n -1 2 n .
$$q _ { n } ^ { \perp } \coloneqq ( n - 1 ) \sum _ { i = 1 } ^ { n + 2 } t _ { i } ^ { 2 } - 2 \sum _ { 1 \leq i < j \leq n + 2 } t _ { i } t _ { j }.$$
Its exponent is equal to 2 n and coincides with the exponent of the discriminant group of A p n ( ). We have
$$\mathcal { A } p ( n ) ^ { \perp } \coloneqq \text{int} ( \mathcal { A } p ( n ) ^ { \vee } ) = \mathcal { A } p ( n ) ^ { \vee } ( 2 n ) \cong ( \langle 1 \rangle \oplus \mathsf U ( 1 / 2 ) \oplus \mathsf A ^ { \vee } _ { n - 1 } ( 1 / 2 ) ) ( 2 n )$$
$$= \langle 2 n \rangle \oplus \mathsf U ( n ) \oplus \mathsf A _ { n - 1 } ^ { \vee } ( n ).$$
The lattice A ∨ n -1 is generated by A n -1 and a vector
$$\beta = \frac { 1 } { n } ( \omega _ { 1 } + 2 \omega _ { 2 } + \cdots + ( n - 1 ) \omega _ { n - 1 } ),$$
where ω , . . . , ω 1 n -1 is the standard basis defined by simple roots. In the basis ( ω , . . . , ω 2 n -1 , β ), the matrix of A ∨ n -1 ( n ) is equal to
$$\begin{pmatrix} \dots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \\ ( 6. 4 ) & \left ( \begin{matrix} 2 n & - n & 0 & 0 & \dots & 0 & 0 & 0 \\ - n & 2 n & - n & 0 & \dots & 0 & 0 & 0 & 0 \\ 0 & - n & 2 & - n & \dots & 0 & 0 & 0 & 0 \\ \vdots & \vdots & \vdots & \vdots & \vdots & \vdots & \vdots & \vdots & \vdots \\ \vdots & \vdots & \vdots & \vdots & \vdots & \vdots & \vdots & \vdots \\ 0 & 0 & 0 & 0 & \dots & - n & 2 n & - n & 0 \\ 0 & 0 & 0 & 0 & \dots & 0 & - n & 2 n & n \\ 0 & 0 & 0 & 0 & \dots & 0 & 0 & n & n - 1 \end{matrix} \right ) \\ \vdots & \vdots & \vdots & \vdots & \vdots & \vdots & \vdots & \vdots & \vdots & \vdots & \vdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots. \end{pmatrix}$$
Thus we obtain that Ap ⊥ n is even if n is odd, and, for n even
$$( 6. 5 ) \quad \ \ ( \mathcal { A } p ( n ) ^ { \perp } ) ^ { \text{ev} } \cong \langle 2 n \rangle \oplus \mathbf U ( n ) \oplus ( A _ { n - 1 } ^ { \vee } ( n ) ) ^ { \text{ev} },$$
where ( A ∨ n -1 ( n )) ev is defined by the matrix (6.4) in which the submatrix ( 2 n n n n -1 ) is replaced with ( 2 n 2 n 2 n 4 n -4 ).
Note that the Apollonian packing in dimension n = 1 exists but it is not a Boyd-Maxwell sphere packing. We have
$$\mathcal { A } p _ { 1 } \cong \langle 1 \rangle \oplus U ( 2 ), \quad \mathcal { A } p _ { 1 } ^ { \text{ev} } \cong ( \mathbf A _ { 1 } \oplus U ) ( 2 ).$$
The lattice A p ev 1 (1 / 2) = A U 1 is from Nikulin's list of integral even hyperbolic quadratic lattices of rank 3 and signature (2 , 1) such that the subgroup of the orthogonal group generated by reflections s , v ( v, v ) = 2 is of finite index (a 2-reflexive lattice) [31]. Each such lattice is a sublattice of A 1 ⊕ U . According to Nikulin's classification of even 2reflexive hyperbolic lattices of rank ≥ 5, none of the lattices A p n ( ) ev or A p n ( ) ev is 2-reflexive [29].
If n = 2, the lattices A p 2 and A p ⊥ 2 are isomorphic. According to Vinberg's list of 2-reflexive even hyperbolic lattice of rank 4 [41], the lattice A p ev 2 is not 2-reflexive.
Note that all examples from [6] are examples of integral Boyd-Maxwell sphere packings.
## 7. Orbital counting
Let A be a subset of the Euclidean space R n . Recall that the Hausdorff dimension δ A ( ) of A is defined to be the infimum for all s ≥ 0 for which
$$\mu _ { s } ( A ) = \inf _ { A \subset \cup _ { j } B _ { j } } ( \sum _ { j } r ( B _ { j } ) ^ { s } ) = 0.$$
Here ( B j ) is a countable set of open balls of radii r B ( j ) which cover A . For example, if the Lebesque measure of A is equal to 0, then (7.1) holds for s = n , hence δ A ( ) ≤ n . The Hausdorff dimension coincides with the Lebesque measure if the latter is positive and finite. A countable set has the Hausdorff measure equal to zero. Also it is known that
the topological dimension of A is less than or equal to its Hausdorff dimension.
The Hausdorff dimension is closely related to the fractal dimension of a fractal set A , i.e. a set that can be subdivided in some finite number N λ ( ) of subsets, all congruent (by translation or rotation) to one another and each equal to a scaled copy of A by a linear factor λ . It is defined to be equal to log N s ( ) log(1 /λ ) . For example, the Cantor set consists of two parts A 1 and A 2 (contained in the interval [0 , 1 3] and / [1 / 3 1]), , each rescaled version of the set with the scaling factor 1 / 3. Thus its fractal dimension is equal to log 2 / log 3 < 1. It is clear that the Hausdorff dimension of a bounded fractal set of diameter D = 2 R is less than or equal than the fractal dimension. In fact, such a set can be covered by N λ ( ) balls of radius λR , or by N λ ( ) 2 balls of radius λ R 2 . Since λ < 1, we get µ s ( A ) = lim k →∞ N λ ( ) k ( λ R k ) s which is zero if N λ λ ( ) s < 1 or s > log N/ log(1 /λ ). In fact, the Hausdorff dimension of the Cantor set coincides with its fractal dimension log 2 / log 3.
By a theorem of D. Sullivan [37], for a geometrically finite nonelementary discrete group Γ, the Hausdorff dimension δ Γ of Λ(Γ) is positive and coincides with the critical exponent of Γ equal to
$$\inf \{ s > 0 \colon \sum _ { g \in \Gamma } e ^ { - s d ( x _ { 0 }, g ( x _ { 0 } ) ) } < \infty \},$$
where x 0 is any point on H n . Using this equality Sullivan shows that
$$\delta _ { \Gamma } = \overline { \lim _ { T \rightarrow \infty } } \frac { \log N _ { T } } { R },$$
where N T is the number of orbit points y with hyperbolic distance from x 0 less than or equal than R . He further shows in [38], Corollary 10, under the additional assumption that Γ has no parabolic fixed points, that there exists constants c, C such that, as T →∞ ,
$$C e ^ { T \delta _ { \Gamma } } \leq N _ { T } \leq C e ^ { T \delta _ { \Gamma } }.$$
In particular, asymptotically, as T →∞ ,
$$N _ { T } \sim c ( T ) e ^ { T \delta _ { \Gamma } },$$
where lim T →∞ c T ( ) T = 0.
If δ Γ > 1 2 ( n -1), then P. Lax and R. Phillips show that, for any geometrically finite non-elementary discrete group Γ, the function c T ( ) is a constant depending only on Γ. When Γ is of finite covolume, then δ Γ is known to be equal to n -1, and the result goes back to A. Selberg.
The assumption on δ Γ has been lifted by T. Roblin [35]. Applying (2.1), we will be able to obtain the assertion of Theorem 1.2 from the
introduction in the case when C 2 < 0. To do the remaining cases where ( e, e ) is non-negative we need to replace the family of hyperbolic balls with another family of sets of growing volume.
glyph[negationslash]
Let e be a nonzero vector in R n, 1 . We assume that ( e, e ) = ± 1 if ( e, e ) = 0 and we fix an isotropic e ′ with ( e, e ′ ) = -1 if ( e, e ) = 0. The group G = SO( n, 1) 0 acts in the projective space P R ( n, 1 ) with three orbits G · [ e ]. Let G [ e ] be the stabilizer subgroup of [ e ] in G . If ( e, e ) < 0, then G [ e ] is a maximal compact subgroup in K ⊂ G isomorphic to SO( n ) and the orbit G · [ e ] is the homogeneous space of left cosets G/K isomorphic to H n .
If ( e, e ) = 0, then G [ e ] is a parabolic subgroup of G . If we identify Q \{ [ e ] } with the Euclidean space E n -1 (via the projecting from [ e ]), we obtain a surjective homomorphism from G [ e ] to the group P of affine orthogonal transformations (motions) of the Euclidean space E n -1 . This homomorphism splits by a subgroup G ce of G [ e ] that stabilizes any nonzero vector ce on the line [ e ]. The kernel of the homomorphism is the group A l of hyperbolic translations along the hyperbolic line l corresponding to the subspace spanned by e and e ′ . This shows that G [ e ] = O n ( -1) · A N l · [ e ] , where O n ( -1) is the group of rotations around the line l and N [ e ] ∼ = R n -1 is the normal subgroup of translations of P , called a horospherical subgroup of G . The decomposition of G [ e ] from above is induced by the Iwasawa decomposition G = G x · A l · N [ e ] of G , where x is any point on l . The group G [ e ] acts transitively on the quadric Q and on H p .
If ( e, e ) > 0, then G [ e ] ∼ = SO( n -1 1) , the homogeneous space , 0 G [ e ] \ G is known as a de Sitter space . By taking the orthogonal complement of the line spanned by e , we identify the points of the de Sitter space with oriented hyperplanes H e in H n . For example, if n = 2, the de Sitter space is the set of oriented geodesic lines in the hyperbolic plane.
Let us consider the pencil of geodesic lines P ( e ) defined by indefinite planes U ⊂ R n, 1 containing e . If ( e, e ) < 0, then P ( e ) consists of geodesic lines containing the point x 0 = [ e ] ∈ H n . It is called an elliptic pencil . If ( e, e ) > 0, it consists of parallel geodesic lines perpendicular to the hyperplane H e . It is called a hyperbolic pencil . Finally, if ( e, e ) = 0, it consists of geodesic lines whose closure in H n contains the point [ e ]. The pencil is called parabolic pencil with center at [ e ].
The parametric equation of the geodesic line from the pencil P ( e ) is equal to
$$\lambda ^ { \dagger \dagger \dagger \dagger \dagger \dagger \dagger \dagger } _ { \L } \Big. \Big. \Big. \Big. \Big. \Big. \Big. \Big. \Big. \Big. \Big. \Big. \Big. \Big. \Big. \Big. \Big. \Big. \Big. \Big. \Big. \Big. \Big. \Big. \Big. \Big. \Big. \Big. \Big. \Big. \Big. \Big. \Big. \Big. \Big. \Big. \Big. \Big. \Big. \Big. \Big. \Big. \Big. \Big. \Big. \Big. \Big. \Big. \Big. \Big. \Big. \Big. \Big. \Big. \Big. \Big. \Big. \Big. \Big. \Big. \Big. \Big. \Big. \Big. \Big. \Big. \Big. \big. \Big. \Big. \Big. \Big. \Big. \Big. \Big. \Big. \Big. \Big. \Big. \Big. \Big. \Big. \Big. \Big. \Big. \Big. \Big. \Big. \Big. \Big. \Big. \Big. \Big. \Big. \Big. \Big. \Big. \Big. \Big. \Big. \Big. \Big. \Big. \Big. \Big. \Big. \Big. \Big. \Big. \Big. \Big. \Big. \Big. \Big. \Big. \Big. \Big. \Big. \Big. \Big. \Big. \Big. \Big. \Big. \Big. \Big. \Big. \Big. \Big. \Big. \Big. \Big. \Big. \Big.. \Big. \Big. \Big. \Big. \Big. \Big. \Big. \Big. \Big. \Big. \Big. \Big. \Big. \Big. \Big. \Big. \Big. \Big. \Big. \Big. \Big. \Big. \Big. \Big. \Big. \Big. \Big. \Big. \Big. \Big. \Big. \Big. \Big. \Big. \Big. \Big. \Big. \Big. \Big. \Big. \Big. \Big. \Big. \Big. \Big. \Big. \Big. \Big. \Big. \Big. \Big. \Big. \Big. \Big. \Big. \Big. \Big. \Big. \Big. \Big. \Big. \Big. \Big. \Big. \Big. \Big.
\gamma ( t ) = \begin{cases} v \sinh t + e \cosh t, ( v, e ) = 0, ( v, v ) = 1 & \text{if } ( e, e ) = - 1, \\ v \exp ( t ) + e \sinh t, ( v, e ) = 0, ( v, v ) = - 1 & \text{otherwise.} \end{cases}$$
(see [1], Chapter 4, 2.3). In the elliptic case, we have ( γ t , e ( ) ) = -cosh t , so that d γ t , ( ( ) [ e ]) = t . So, moving along the geodesic line for the distance t ≥ 0, we get the set of points in H n equidistant from [ e ]. This is a geodesic sphere
$$H _ { e } ^ { t } \coloneqq \{ [ v ] \in \mathbb { H } ^ { n } \, \colon - ( v, e ) = \cosh t \} = \{ [ v ] \in \mathbb { H } ^ { n } \, \colon d ( [ v ], [ e ] ) = t \}$$
with the center at x 0 = [ e ]. The group G [ e ] ∼ = SO( n ) acts transitively on each H t e and, projecting from [ e ] along the lines from the pencil P ( e ) identifies each geodesic sphere with the absolute as homogenous spaces with respect to G [ e ] . So, the orbits of G [ e ] in H n are Riemannian homogeneous spaces of constant positive curvature.
If ( e, e ) = 0, we have ( γ t , e ( ) ) = exp( ). t The orbits of N [ e ] are horospheres
$$H _ { e } ^ { t } \coloneqq \{ [ v ] \in \mathbb { H } ^ { n } \colon - ( v, e ) = \exp ( t ) \}.$$
In the vector model of H n , a horosphere is equal to the intersection of H n with a sphere in the Euclidean space tangent to Q at the point [ e ]. In the Klein model, they are ellipsoids tangent to the boundary of the ball. Any horosphere inherits a Riemannian metric of zero curvarure and hence isomorphic to an Euclidean space.
If ( e, e ) > 0, we have ( v, e ) = ( γ (0) , e ) = 0, i.e. [ γ (0)] ∈ H e . Since ( γ t , e ( ) ) = -sinh t , after time t we move from a point on the hyperplane H e to a point [ γ t ( )] on the hypersurface
$$H _ { e } ^ { t } = \{ [ w ] \in \mathbb { H } ^ { n } \, \colon - ( w, e ) = \sinh t \}.$$
The hypersurfaces of this form are called equidistant hypersurfaces . They are orbits of the group G [ e ] and inherit a Riemannian metric of constant negative curvature. In the Klein model, they are ellipsoids whose closures in H n intersect the closure ¯ H e of the hyperplane H e along its boundary. For example, if n = 2, they are ellipses tangent to the absolute at the two points in which the closure of the geodesic line H e intersects the absolute.
In each of the three cases, let us consider the following sets B T ( e ).
$$\text{If } ( e, e ) = - 1,$$
$$B _ { T } ( e ) = \bigcup _ { t = 0 } ^ { T } H _ { e } ^ { t } = \{ [ v ] \in \mathbb { H } ^ { n } \, \colon 1 \leq - ( v, e ) \leq \cosh T \}.$$
This is just a hyperbolic closed ball with center at [ e ] and radius T . If ( e, e ) = 0,
$$B _ { T } ( e ) = \bigcup _ { t = 0 } ^ { T } H _ { e } ^ { t } = \{ [ v ] \in \mathbb { H } ^ { n } \, \colon 1 \leq | ( v, e ) | \leq \exp ( T ) \}.$$
If ( e, e ) = 1,
$$B _ { T } ( e ) = \bigcup _ { t = 0 } ^ { T } H _ { e } ^ { t } = \{ [ v ] \in \mathbb { H } ^ { n } \colon | ( v, e ) | \leq \sinh ( T ) \}.$$
Fix a point x 0 = [ v 0 ] ∈ H n and let K = G x 0 so that G/K = H n . Let H = { } 1 (resp. N [ e ] , resp. G [ e ] if ( e, e ) = -1 (resp. ( e, e ) = 0, resp. ( e, e ) = 1).
Consider the following subsets of G/H
$$\mathcal { S } _ { T } ( e, x _ { 0 } ) \coloneqq G _ { x _ { 0 } } \cdot A _ { T } \cdot H / H,$$
where A T = { a t ∈ A : 0 ≤ t ≤ log T } .
The following result from [33], Theorem 1.2 and [28], Corollary 7.14 (see a nice survey of some of these results in [32]) is crucial for our applications.
Theorem 7.1. Let Γ be a torsion free geometrically finite non-elementary discrete subgroup of SO ( n, 1) 0 . Let [ e ] ∈ P R ( n, 1 ) . If ( e, e ) ≥ 0 , assume that the orbit O Γ ([ e ]) is a discrete set and also that δ Γ > 1 if ( e, e ) > 0 . Then
$$\lim _ { T \to \infty } \frac { \Gamma \cdot H / H \cap \mathcal { S } _ { T } ( e, x _ { 0 } ) } { T ^ { \delta _ { \Gamma } } } = c _ { \Gamma, x _ { 0 }, [ e ] }, \\. \quad \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \ dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots\dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dts \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \sigma \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \Dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots$$
where c Γ ,x 0 , [ e ] is a positive constant that depends only on Γ , x 0 , [ e ] .
Note that the results from [28] also give error terms.
Corollary 7.2. Keep the same assumptions. Fix a point x 0 ∈ H n .
Then
$$\lim _ { t \to \infty } \frac { \# \{ [ v ] \in O _ { \Gamma } ( x _ { 0 } ) \, \colon | ( e, v ) | \leq T \} } { T ^ { \delta _ { \Gamma } } } = c _ { \Gamma, x _ { 0 }, [ e ] }, \\ \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \colots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots$$
where c Γ ,x 0 , [ e ] is a positive constant that depends only on Γ , x 0 , [ e ] .
Remark 7.3 . The assumption δ Γ > 1 is not needed if the group Γ ∩ N [ e ] acts on ∂H e without parabolic fixed points. Also, the assumption that Γ is torsion free made in loc.cit. is needed only for an explicit formula for the constant.
Remark 7.4 . In the case when ( e, e ) < 0 (resp. ( e, e ) = 0 and n = 3), Theorem 7.1 follows from [33], Theorem 1.2 (resp. [22], Theorem 2.10) that gives an asymptotic of the number of orbit points in a ball { [ v ] ∈
H n : || v || ≤ T } , where || x || is the Euclidean norm. One has only use that if v = ( x , . . . , x 0 n ) with ∑ n i =0 x 2 i ≤ T 2 and -x 2 0 + ∑ n i =1 x 2 i = -1 (resp. = 0), then ( v, (1 , . . . , 0)) 2 = x 2 0 ≤ ( T 2 +1) 2 (resp. / ≤ T 2 ).
In the case ( e, e ) > 0, and Γ and Γ ∩ G [ e ] are of finite covolume (the second condition is always satisfied if n ≥ 3 [10]), Theorem (7.1) follows from [14], [15]. In this case δ Γ = n -1.
## 8. Algebraic geometrical realization
↦
Let X be a smooth projective algebraic surface over an algebraically closed field k . The group of its automorphisms defines a natural left action γ → ( g -1 ) ∗ ( γ ) on its lattice Num( X ) of algebraic cycles modulo numerical equivalence. As usual, we denote its rank by ρ X ( ), this is the Picard number of X . By the Hodge Index Theorem, the intersection form on algebraic cycles defines a symmetric bilinear form on Num( X ) of signature (1 , n ). We denote by V X the corresponding real vector space Num( X ) R equipped with the induced symmetric bilinear form of signature (1 , n ). We assume that the image Aut( X ) ∗ of the homomorphism Aut( X ) → O(Num( X )) is infinite. It is known that this could happen only if X is an abelian surface, a K3 surface, an Enriques surface, or a rational surface. Moreover, n must be larger than or equal to 2, and in the last case, n ≥ 9). All of this is rather well-known, see, for example, [11]. Let Γ be an infinite subgroup of Aut( X ) ∗ . Since the automorphism group preserves the connected component of { v ∈ Num( X ) R : ( v, v ) > 0 } containing an ample class on X , we obtain that Γ is a discrete subgroup in O( V X ) = O( ∼ n, 1). Also, since Γ preserves an integral lattice, its orbits are discrete sets. Thus, we can apply Theorem 7.1 to obtain the following.
Theorem 8.1. Assume that Γ is a geometrically finite non-elementary subgroup of Aut ( X ) ∗ . Let H,C be effective numerical divisor classes in Num ( X ) ′ such that H is ample. Then
$$( 8. 1 ) \quad \lim _ { t \to \infty } \frac { \# \{ C ^ { \prime } \in O _ { \Gamma } ( C ) \, \colon ( H, C ^ { \prime } ) / ( H, C ) \leq T \} } { T ^ { \delta _ { \Gamma } } } = c _ { \Gamma, C, H },$$
where c Γ ,H,C is a positive constant depending only on Γ [ , H , C ] [ ] but does not depend on C 2 and H 2 .
Now let us give some examples where we can apply the previous result. First, we note that we may always consider Γ up to a finite group, i.e. we either consider its subgroup of finite index, or extend it by a finite group, or do both. It affects only the constant in the asymptotic formula.
glyph[negationslash]
Let X be a complex algebraic K3 surface. It is known that the subgroup of O(Num( X )) generated by transformations g , g ∗ ∈ Aut( X ) and reflections s , r ( r, r ) = -2 is a subgroup of finite index (this is also true if the characteristic p = 2 [24]). Thus, if Num( X ) does not contain classes r with ( r, r ) = -2, then Aut( X ) is a Kleinian group of finite covolume. 9 The Hausdorff dimension δ Γ in this case is equal to n -1. So, it is more interesting to realize proper thin Kleinian groups of automorphisms.
Assume that we find a surface X and vectors α , . . . , α 1 r ∈ Num( X ) such that 2 ( α ,α i i ) α i ∈ Num( X ) ∨ , so that the reflections s α i define orthogonal transformations of Num( X ). Moreover, assume that there exist automorphisms g i ∈ Aut( X ) such that g ∗ i = s α i . Let P be the convex polyhedron with normal vectors e i = 1 ( α ,α i i ) 1 / 2 α i . Assume that it is a Coxeter polyhedron of level ≤ 2 with the reflection group Γ P generated by s α 1 , . . . , s α r . Then the limit set of Γ P is a Boyd-Maxwell sphere packing and its Hausdorff dimension δ Γ P is equal to the critical exponent (1.1). Now we can apply Theorem 8.1.
Example 8.2. Let M = A p (2) ev ∼ = ( A 1 ⊕ U )(2) be the even sublattice of the Apollonian lattice and Ap 2 be the Apollonian group. Let ω 1 = e 1 , . . . , ω 4 = e 4 be a basis in A p (2) with Gram matrix equal to G = cir(1 , -1 , -1 , -1) = ( g ij ). The lattice M ( -1 / 2) = ∼ A 1 ( -1) ⊕ U can be primitively embedded in the lattice Num( X ) = ∼ U ⊕ E 8 ( -1), where X is an Enriques surface. We identify the image with M ( -1 / 2). The group Ap 2 contains a subgroup of index 2 that consists of isometries of M ( -1 / 2) that extend to the whole lattice acting identically on the orthogonal complement. Thus the subgroup Γ = Ap ′ 2 ∩ O(Num( X ) ′ is realized by automorphisms of X . One can show that the index of Γ in Ap 2 is equal to 4. Now we can apply Theorem 8.1 with δ Γ = δ Ap 2 .
Of course, one can also realize A p (2)( -1) as the Picard lattice of a K3 surface X . Since the lattice does not represent -2, a subgroup of finite index of Ap 2 is realized as a group of automorphisms of a K3 surface. according to Vinberg's classification of 2-reflexive lattices of rank 4 [41], the 2-reflection group of the lattice A p (2) is of infinite index in the orthogonal group of the lattice. Thus Ap 2 is a thin group geometrically finite group of automorphisms of X .
The same is true for the group Ap ; 3 it contains a subgroup of finite index that can be realized as a thin geometrically finite group of automorphisms of either an Enriques or a K3 surface.
9 By Riemann-Roch theorem, such a divisor class is either effective or antieffective, and one of its irreducible component is a smooth rational curve.
Example 8.3. Consider the Coxeter group Γ( a, b, c ) of a Coxeter polyhedron P in H 2 with Gram matrix ( 1 -a -b -a 1 -c -b -c 1 ) , where a, b, c are rational numbers ≥ 1. If a = b = c = 1, the fundamental domain is an ideal triangle. If a, b, c > 2, the fundamental triangle is a pair of pants as on the following picture.
Figure 7: Hyperbolic triangle with no vertices
Let L be the quadratic form defined by the integral matrix A = -eG P ( ), where e is the exponent of the Coxeter matrix. Let L ∨ be the dual lattice. Suppose we can embed M = int( L ∨ ) ev in Num( X ) of some K3 surface and realize the reflection group Γ P as a group of automorphisms of X . Then we can apply Theorem 8.1 to any nef divisor class contained in the sublattice M .
For example, let us consider the case ( a, b, c ) = ( a, a, 1). The fundamental triangle has one ideal point and looks like in the following figure 8.3.
↦
Let H → 2 H 2 be the map from the upper-half plane to the unit disk given by the map z → z -i z + i . One can show that the pre-image of the sides of our triangle are the lines x = 1 , x = -1 and the upper halfcircle of radius r = 1 /a with center at the origin. Recall that a ≤ -1 so that the half-circle is between the vertical lines. Let us re-denote our group by Γ . r It was shown by C. McMullen in [25] that as r → 0, we have
$$\delta _ { \Gamma _ { r } } = \frac { r + 1 } { 2 } + O ( r ^ { 2 } ),$$
while for r → 1, we have
$$\delta _ { \Gamma _ { r } } \sim 1 - \sqrt { 1 - r }.$$
We have
$$G ( P ) ^ { - 1 } = \frac { 1 } { 4 a ^ { 2 } } \begin{pmatrix} 0 & - 2 a & - 2 a \\ - 2 a & a - 1 & - a - 1 \\ - 2 a & - a - 1 & a - 1 \end{pmatrix}$$
If a > 1 is odd, the matrix 2 a G P 2 ( ) -1 defines an even integral lattice L r . The group Γ r acts on this lattice as a reflection group in the sides of the triangle. The lattice L r ( -2) is realized as the Picard lattice of a K3 surface X . Since L r ( -2) does represent -2, the surface X does not contain smooth rational curves. This implies that a subgroup of finite index of Γ r acts on X by automorphisms. So, we may apply Theorems 8.1 with the Hausdorff dimension computed by McMullen. Note that when r = a = 1, the lattice L r is isomorphic to the Apollonian lattice A p 1 and the group Γ 1 is isomorphic to the Apollonian group Ap . 1
glyph[negationslash]
Let us give another example of a realizable group Γ( a, b, c ). It is taken from [3]. Let X be a K3 surface defined over an algebraically closed field of characteristic = 2 embedded in P 2 × P 2 as a complete intersection of hypersurfaces of multi-degree (1 , 1) and (2 2). , Let p , p 1 2 : X → P 2 be the two projections. They are morphisms of degree 2 branched along a plane curve B i of degree 6. We assume that B 1 is nonsingular and B 2 has a unique double point q 0 so that the fiber p -1 2 ( q 0 ) is a smooth rational curve R that is mapped isomorphically under p 1 to a line. We assume that X is general with these properties. More precisely, we assume that Pic( X ) has a basis ( h , h 1 2 , r ), where h i = p ∗ i (line) and r is
Figure 8: Hyperbolic triangle with one ideal point
the class of R . The intersection matrix of this basis is equal to
$$\begin{pmatrix} 2 & 4 & 1 \\ 4 & 2 & 0 \\ 1 & 0 & - 2 \end{pmatrix}.$$
Let s = p ∗ 1 (( p 1 ) ∗ ( r )) -r = h 1 -r . It is a class of smooth rational curve S on X . The pre-image of the pencil of lines through q 0 is an elliptic pencil | F | on X with [ F ] = h 2 -r . The curve S is a section of the elliptic fibration defined by the linear system | F | and the curve R is its 2-section that intersects S with multiplicity 3. Consider the following three automorphisms of X . The first two Φ 1 and Φ 2 are defined by the birational deck transformations of the covers p 1 and p 2 . The third one Φ 3 is defined by the negation automorphism of the elliptic pencil with the group law defined by the choice of S as the zero section.
It is easy to compute the matrix of each Φ i in the basis ( f, s, r ) = ([ F , ] [ S , ] [ R ]) with the Gram matrix
$$\begin{pmatrix} 0 & 1 & 2 \\ 1 & - 2 & 3 \\ 2 & 3 & - 2 \end{pmatrix}.$$
We have Φ ( ) = ∗ 1 s r, Φ ( ) = ∗ 1 r s and f ′ = Φ ( ∗ 1 f ) = af + bs + cr . Since Φ 2 i is the identity and ( f, f ) = 0, we get a = -1 and b = c . Since ( f , s ′ ) = ( f, r ) = 2, we easily get b = c = 3. The matrix of Φ , and 1 similarly obtained matrices of Φ 2 and Φ 3 are as follows.
$$A _ { 1 } = \begin{pmatrix} - 1 & 0 & 0 \\ 3 & 0 & 1 \\ 3 & 1 & 0 \end{pmatrix}, \quad A _ { 2 } = \begin{pmatrix} 1 & 4 & 0 \\ 0 & - 1 & 0 \\ 0 & 1 & 1 \end{pmatrix}, \quad A _ { 3 } = \begin{pmatrix} 1 & 0 & 1 4 \\ 0 & 1 & 4 \\ 0 & 0 & - 1 \end{pmatrix}.$$
The transformations Φ ′ 1 = Φ 1 ◦ Φ 2 ◦ Φ 1 , Φ 2 , Φ 3 are the reflections with respect to the vector α i , where
$$\alpha _ { 1 } = - 4 f + 1 3 s + 1 0 r, \ \alpha _ { 2 } = 4 f - 2 s + r, \ \alpha _ { 3 } = 7 f + 2 s - r.$$
The Gram matrix of the vectors α , α , α 1 2 3 is equal to
$$G = \begin{pmatrix} - 2 2 & 1 4 3 & 2 2 0 \\ 1 4 3 & - 2 2 & 2 2 \\ 2 2 0 & 2 2 & - 2 2 \end{pmatrix} = - 2 2 \begin{pmatrix} 1 & - \frac { 1 3 } { 2 } & - 1 0 \\ - \frac { 1 3 } { 2 } & 1 & - 1 \\ - 1 0 & - 1 & 1 \end{pmatrix}.$$
So, the group generated by Φ ′ 1 , Φ 2 , Φ coincides with the triangle group 3 Γ( 13 2 , 10 1). , The fundamental triangle P has one ideal vertex. The reflection group Γ P is a subgroup of infinite index of the group Γ of automorphisms of X generated by Φ 1 , Φ 2 , Φ . 3 Baragar proves that
Γ is isomorphic to Aut( X ) (for sufficiently general X ). He finds the following bounds for δ Γ
$$. 6 5 1 5 < \delta _ { \Gamma } <. 6 5 3 8.$$
This implies that
$$\delta _ { \Gamma _ { P } } <. 6 5 3 8.$$
Example 8.4. This is again due to Baragar [4]. We consider a nonsingular hypersurface X in P 1 × P 1 × P 1 of type (2 2 2). , , It is a K3 surface whose Picard lattice contains the Apollonian lattice A p (1). If X is general, then the Picard lattice coincides with this lattice. We assume that one of the projections p ij : X → P 1 × P 1 , say p 12 , contains the whole P 1 as its fiber over some point q 0 ∈ P 1 × P 1 . All the projections are degree 2 maps. Let F , i i = 1 2 3 , , , be the general fibers of the projections p i : X → P 1 . Each F i is an elliptic curve whose image under the map p jk is a divisor of type (2 , 2). Let f , f 1 2 , f 3 , r be the classes of the curves F , F , F , R 1 2 3 . We assume that X is general with these properties so that Pic( X ) is generated by these classes. The Gram matrix of this basis is equal to
$$\begin{pmatrix} 0 & 2 & 2 & 0 \\ 2 & 0 & 2 & 0 \\ 2 & 2 & 0 & 1 \\ 0 & 0 & 1 & - 2 \end{pmatrix}.$$
It is easy to see that
$$\text{Pic} ( X ) \cong \text{U} \oplus \left ( \begin{smallmatrix} - 4 & 2 \\ - 2 & - 8 \end{smallmatrix} \right ).$$
According to Vinberg's classification of 2-reflective hyperbolic lattices of rank 4 [1], the Picard lattice is not 2-reflective. Hence the image of the group Aut( X ) in O(Pic( X )) is of infinite index.
Let Φ ij be the automorphisms of X defined by the deck transformations of the projections p ij . Let Φ ′ 4 be defined as the transformation Φ in the previous example with respect to the elliptic pencil 3 | F 3 | with section R . The transformation Φ ∗ 12 leaves the vectors f , f 1 2 , r invariant, and transforms f 3 to 2 f 1 +2 f 2 -f 3 -r . Thus Φ ∗ 12 is the reflection with respect to the vector α 1 = -2 f 1 -2 f 2 +2 f 3 + . r
The transformation Φ ∗ 13 leaves f , f 1 3 invariant and transforms r in r ′ = f 1 -r . It also transforms f 2 to some vector f ′ 2 = af 1 + bf 2 + cf 3 + dr . Computing ( f , f ′ 2 1 ) = ( f , f 2 1 ) , ( f , f ′ 2 3 ) = ( f , f 2 3 ) , ( f , r ′ 2 ) = ( f , f 2 1 -r ), we find that f ′ 2 = 2 f 1 -f 2 + 2 f 3 . Similarly, we find that Φ ∗ 23 ( f 2 ) = f , 2 Φ ∗ 23 ( f 3 ) = f , 3 Φ ∗ 23 ( r ) = f 2 -r and Φ ∗ 23 ( f 2 ) = -f 1 +2 f 2 +2 f 3 .
It follows from the definition of a group law on an elliptic curve that
$$\Phi _ { 4 } ^ { \prime } ( f _ { 3 } ) = f _ { 3 }, \ \Phi _ { 4 } ^ { \prime } ( r ) = r, \ \Phi _ { 4 } ^ { \prime } ( f _ { i } ) = - f _ { i } + 8 f _ { 3 } + 4 r, \ i = 1, 2$$
Consider the transformations
$$\Phi _ { 1 } = \Phi _ { 1 2 }, \, \Phi _ { 2 } = \Phi _ { 1 3 } \circ \Phi _ { 1 2 } \circ \Phi _ { 1 3 }, \, \Phi _ { 3 } = \Phi _ { 2 3 } \circ \Phi _ { 1 2 } \circ \Phi _ { 2 3 }, \, \Phi _ { 4 } = \Phi ^ { \prime } _ { 4 } \circ \Phi _ { 1 2 } \circ \Phi ^ { \prime } _ { 4 }.$$
′ 4 ′ 4 .
These transformations act on Pic( X ) as the reflections with respect to the vectors
$$r.$$
$$\alpha _ { 1 } \ & = \ \ - 2 f _ { 1 } - 2 f _ { 2 } + 2 f _ { 3 } + r, \\ \alpha _ { 2 } \ & = \ \ \Phi _ { 1 3 } ^ { * } ( \alpha _ { 1 } ) = - 5 f _ { 1 } + 2 f _ { 2 } - 2 f _ { 3 } - r, \\ \alpha _ { 3 } \ & = \ \ \Phi _ { 2 3 } ^ { * } ( \alpha _ { 1 } ) = 2 f _ { 1 } - 5 f _ { 2 } - 2 f _ { 3 } - r, \\ \alpha _ { 4 } \ & = \ \ \Phi _ { 4 } ( \alpha _ { 1 } ) = 2 f _ { 1 } + 2 f _ { 2 } - 3 0 f _ { 3 } - 1 5 r. \\ \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot$$
The Gram matrix of these four vectors is equal to
$$\begin{pmatrix} - 1 4 & 1 4 & 1 4 & 2 1 0 \\ 1 4 & - 1 4 & 8 4 & 1 8 2 \\ 1 4 & 8 4 & - 1 4 & 1 8 2 \\ 2 1 0 & 1 8 2 & 1 8 2 & - 1 4 \end{pmatrix} = - 1 4 \begin{pmatrix} 1 & - 1 & - 1 & - 1 5 \\ - 1 & 1 & - 6 & - 1 3 \\ - 1 & - 6 & 1 & - 1 3 \\ - 1 5 & - 1 3 & - 1 3 & 1 \end{pmatrix}$$
Let P be the Coxeter polytope defined by this matrix. The Coxeter group Γ P is generated by the reflections Φ ∗ i , i = 1 2 3 4. , , ,
Baragar proves that the automorphisms Φ ij and Φ ′ 4 generate a subgroup Γ of Aut( X ) of finite index. His computer experiments suggest that
$$1. 2 8 6 < \delta _ { \Gamma } < 1. 3 0 6.$$
Our reflection group Γ P generated by Φ 1 , . . . , Φ 4 is of infinite index in Γ. So, we obtain
$$\delta _ { \Gamma _ { P } } < 1. 3 0 6.$$
Example 8.5. We consider a general Coble rational surface [8]. The orthogonal complement of the canonical class in Num( X ) is isomorphic to U ⊕ E 8 ( -1). One can prove that the automorphism group of X is isomorphic to the automorphism group of a general Enriques surface [8] (true in any characteristic). We do the same, as in Example 8.2 to realize Γ as an automorphism group of X . Since X is rational, it gives a realization of Γ as a group of Cremona transformations of P 2 . Taking the class of a line, we obtain the asymptotic of the growth of the function deg Φ, where deg Φ is the algebraic degree of a Cremona transformation Φ from Γ.
Remark 8.6 . Taking into account Remark 6.1, we see that, for any even hyperbolic lattice of rank > 4 that contains primitively the lattice M = U ⊕ A 1 ( -1) ⊕ A 1 ( -1), the orthogonal group O( L ) contains finitely generated subgroups which are not geometrically finite. Embedding M primitively in the lattice U ⊕ E 8 ( -1), we obtain that a general Enriques
surface contains finitely generated groups of automorphisms which are not geometrically finite.
## References
- [1] D. Alekseevskii, E. Vinberg, A. Solodovnikov, Geometry of spaces of constant curvature . Geometry, II, 1-138, Encyclopaedia Math. Sci., 29, Springer, Berlin, 1993.
- [2] B. Apanasov, Conformal geometry of discrete groups and manifolds . de Gruyter Expositions in Mathematics, 32. Walter de Gruyter, Berlin, 2000.
- [3] A. Baragar, Orbits of curves on certain K3 surfaces . Compositio Math. 137 (2003), 115-134.
- [4] A. Baragar, The ample cone for a K3 surface . Canad. J. Math. 63 (2011), 481-499.
- [5] Y. Benoist, P. de la Harpe, Adh´ erence de Zariski des groupes de Coxeter . Compos. Math. 140 (2004), 1357-1366.
- [6] D. Boyd, A new class of infinite sphere packings . Pacific J. Math. 50 (1974), 383-398
- [7] D. Boyd, The sequence of radii in an Apollonian packing , Math. Comp. 39 (1982) 249-254.
- [8] S. Cantat, I. Dolgachev, Rational surfaces with a large group of automorphisms . J. Amer. Math. Soc. 25 (2012), 863-905.
- [9] H. Chen, J.-Ph. Labb´ e, Lorentzian Coxeter systems and Boyd-Maxwell ball packings. arXiv:1310.8608, math.GR.
- [10] S. Dani, On invariant measures, minimal sets and a lemma of Margulis . Invent. Math. 51 (1979), 239-260.
- [11] I. Dolgachev, Reflection groups in algebraic geometry . Bull. Amer. Math. Soc. (N.S.) 45 (2008), 1-60.
- [12] I. Dolgachev, A brief introduction to Enriques surfaces , Development of moduli theory, Advanced Studies in Pure Mathematics, Math. Soc. Japan, to appear.
- [13] I. Dolgachev, B. Howard, Configuration spaces of complex and real spheres , Recent Advances in Algebraic Geometry, ed. C. Hacon, M. Mustata and M. Popa, London Math. Soc. Lect. Notes, 2014, 156-179 (to appear).
- [14] W. Duke, Z. Rudnick, P. Sarnak, P., Density of integer points on affine homogeneous varieties . Duke Math. J. 71 (1993), 143-179.
- [15] A. Eskin, C. McMullen, Mixing, counting, and equidistribution in Lie groups . Duke Math. J. 71 (1993), 181-209.
- [16] E. Fuchs, Counting problems in Apollonian packings . Bull. Amer. Math. Soc. (N.S.) 50 (2013), 229-266.
- [17] R. Graham, J. Lagarias, C. Mallows, A. Wilks, C. Yan, Apollonian circle packings: number theory . J. Number Theory 100 (2003), 1-45.
- [18] R. Graham, J. Lagarias, C. Mallows, A. Wilks, C. Yan, Apollonian circle packings: geometry and group theory. I. The Apollonian group . Discrete Comput. Geom. 34 (2005), 547-585.
- [19] R. Graham, J. Lagarias, C. Mallows, A. Wilks, C. Yan, Apollonian circle packings: geometry and group theory. II. Super-Apollonian group and integral packings . Discrete Comput. Geom. 35 (2006), 1-36.
- [20] R. Graham, J. Lagarias, C. Mallows, A. Wilks, C. Yan, Apollonian circle packings: geometry and group theory. III. Higher dimensions . Discrete Comput. Geom. 35 (2006), 37-72.
- [21] M. Kapovich, L. Potyagailo, E. Vinberg, Noncoherence of some lattices in Isom( H n ) . The Zieschang Gedenkschrift, 335-351, Geom. Topol. Monogr., 14, Geom. Topol. Publ., Coventry, 2008.
- [22] A. Kontorovich, H. Oh, Apollonian circle packings and closed horospheres on hyperbolic 3-manifolds . With an appendix by H.Oh and N. Shah. J. Amer. Math. Soc. 24 (2011), 603-648.
- [23] P. Lax, R. Phillips, The asymptotic distribution of lattice points in Euclidean and non-Euclidean spaces . J. Funct. Anal. 46 (1982), 280-350.
- [24] M. Lieblich, D. Maulik, A note on the cone conjecture for K3 surfaces in positive characteristic , math.AG arXiv:1102.3377.
- [25] C. McMullen, Hausdorff dimension and conformal dynamics. III. Computation of dimension . Amer. J. Math. 120 (1998), 691-721.
- [26] G. Maxwell, Sphere packings and hyperbolic reflection groups . J. Algebra 79 (1982), 78-97.
- [27] G. Maxwell, Wythoff's construction for Coxeter groups . J. Algebra 123 (1989), 351-377.
- [28] A. Mohammadi, H. Oh, Matrix coefficients, Counting and Primes for orbits of geometrically finite groups . arXiv:1208.4139 math.NT.
- [29] V. Nikulin, Integral quadratic forms and some of its geometric applications , Izv. Akad. Nauk SSSR, Ser. Math. 43 (1979), 111-177.
- [30] V. Nikulin, On the quotient groups of the automorphism groups of hyperbolic forms modulo subgroups generated by 2-reflections, Algebraic geometric applications , Current Problems of Mathematics, t. 18, VINITI, Moscow, 1981, pp. 3-114 [English translation:J. Soviet Math. 22 (1983), 1401-1476].
- [31] V. Nikulin, K3 surfaces with a finite group of automorphisms and a Picard group of rank three . Algebraic geometry and its applications. Trudy Mat. Inst. Steklov. 165 (1984), 119-142.
- [32] H. Oh, Harmonic analysis, Ergodic theory and Counting for thin groups, MSRI publication Vol. 61 (2014) 'Thin groups and Superstrong approximation' edited by E. Breuilliard and H. Oh,2014.
- [33] H. Oh, N. Shah, Equidistribution and counting for orbits of geometrically finite hyperbolic groups . J. Amer. Math. Soc. 26 (2013), 511-562.
- [34] J. Ratcliffe, Foundations of hyperbolic manifolds . Second edition. Graduate Texts in Mathematics, 149. Springer, New York, 2006.
- [35] T. Roblin, Ergodicit´ e et ´ equidistribution en courbure n´ egative , M´ em. Soc. Math. Fr. (N.S.) 95 (2003), vi+96 pp.
- [36] P. Sarnak, Integral Apollonian packings . Amer. Math. Monthly 118 (2011), 291-306.
- [37] D. Sullivan, Hausdorff measures old and new, and limit sets of geometrically finite Kleinian groups . Acta Math. 153 (1984), 259-277.
- [38] D. Sullivan, The density at infinity of a discrete group of hyperbolic motions . Inst. Hautes Etudes Sci. Publ. Math. ´ 50 (1979), 171-202.
- [39] P. Thomas, D. Dhar, The Hausdorff dimension of the Apollonian packing of circles . J. Phys. A 27 (1994), no. 7, 2257-2268.
42
- [40] E. Vinberg, O. Shvartsman, Discrete groups of motions of spaces of constant curvature . Geometry, II, 139-248, Encyclopaedia Math. Sci., 29, Springer, Berlin, 1993.
- [41] E. Vinberg, Classification of 2-reflective hyperbolic lattices of rank 4 . Tr. Mosk. Mat. Obs. 68 (2007), 44-76; translation in Trans. Moscow Math. Soc. 2007, 39-66.
Department of Mathematics, University of Michigan, 525 E. University Av., Ann Arbor, MI, 49109 E-mail address : [email protected] | null | [
"Igor Dolgachev"
] | 2014-08-02T14:02:59+00:00 | 2014-09-02T13:40:12+00:00 | [
"math.AG",
"math.DS"
] | Orbital counting of curves on algebraic surfaces and sphere packings | We realize the Apollonian group associated to an integral Apollonian circle
packings, and some of its generalizations, as a group of automorphisms of an
algebraic surface. Borrowing some results in the theory of orbit counting, we
study the asymptotic of the growth of degrees of elements in the orbit of a
curve on an algebraic surface with respect to a geometrically finite group of
its automorphisms. |
1408.0375v1 | ## CONFIGURATION SPACES OF COMPLEX AND REAL SPHERES
## IGOR DOLGACHEV AND BENJAMIN HOWARD
To Rob Lazarsfeld on the occasion of his 60th birthday
Abstract. We study the GIT-quotient of the Cartesian power of projective space modulo the projective orthogonal group. A classical isomorphism of this group with the Inversive group of birational transformations of the projective space of one dimension less allows one to interpret these spaces as configuration spaces of complex or real spheres.
## 1. Introduction
In this paper we study the moduli space of configurations of points in complex projective space with respect to the group of projective transformations leaving invariant a non-degenerate quadric. More precisely, if P n = P ( V ) denotes the projective space of lines in a linear complex space V equipped with a non-degenerate symmetric form 〈 v, w 〉 , we study the GIT-quotient
$$\cong \text{Proj} ( \bigoplus _ { d = 0 } ^ { \infty } ( S ^ { d } ( V ^ { * } ) ^ { \otimes m } ) ^ { O ( V ) }.$$
$$\text{symmetric from } \vee, w /, \, \text{we solve any one } \Pi \text{-} \text{-} \text{equation} \\ \text{O} _ { n } ^ { m } \coloneqq \mathbb { P } ( V ) ^ { m } \, \text{//PO} ( V ) = \text{Proj} ( \bigoplus _ { d = 0 } ^ { \infty } H ^ { 0 } ( \mathbb { P } ( V ) ^ { m }, \mathcal { O } _ { \mathbb { P } ( V ) } ( d ) ^ { \not \S m } ) ^ { O ( V ) } \\ \cong \text{Proj} ( \bigoplus _ { d = 0 } ^ { \infty } ( S ^ { d } ( V ^ { * } ) ^ { \otimes m } ) ^ { O ( V ) }.$$
If m ≥ n + 1 = dim V then generic point configurations have zero dimensional isotropy subgroups in O( V ), and since dim O( n +1) = 1 2 n n ( +1) we expect that dim O m n = mn -1 2 n n ( +1). Let
$$R ( n ; m ) = \bigoplus _ { d = 0 } ^ { \infty } ( S ^ { d } ( V ^ { * } ) ^ { \otimes m } ) ^ { O ( V ) }.$$
↦
It is a finitely generated graded algebra with graded part R n m ( ; ) d of degree d equal to ( S d ( V ∗ ) ⊗ m ) O( V ) . After polarization, R n m ( ; ) d becomes isomorphic to the linear space C [ V m ] O( V ) d,...,d of O( V )-invariant polynomials on V m which are homogeneous of degree d in each vector variable. The First Fundamental Theorem of Invariant theory (FFT) for the orthogonal group [19], Chapter 2, § 9 asserts that C [ V m ] O( V ) is generated by the bracket-functions [ ij ] : ( v , . . . , v 1 m ) → 〈 v , v i j 〉 . Using this theorem, our first result is the following.
Theorem 1.1. Let Sym m be the space of symmetric matrices of size m with the torus T m -1 = { ( z , . . . , z 1 m ) ∈ ( C ∗ ) m : z 1 · · · z m = 1 } acting by scaling each i -th row and i -th column by z i . Let S m be the toric variety P (Sym m ) //T m -1 . Then O m n is isomorphic to a closed subvariety of S m defined by the rank condition r ≤ n +1 .
For example, when m ≤ n +1, we obtain that O m n is a toric variety of dimension 1 2 n n ( +1).
The varieties O m 1 are special since the connected component of the identity of O(2) is isomorphic to SO(2) = ∼ C ∗ . This implies that O m 1 admits a double cover isomorphic to a toric variety ( P 1 ) m // SO(2). We compare this variety with the toric variety X A ( m -1 ) associated to the root system of type A m -1 (see [2], [15]). The variety X A ( m -1 ) admits a natural involution defined by the standard Cremona transformation of P m -1 and the quotient by this involution is a generalized Cayley 4-nodal cubic surface Cay m -1 (equal to the Cayley cubic surface if m = 3). We prove that O m 1 is isomorphic to Cay m -1 for odd m and equal to some blow-down of Cay m -1 when m is even.
The main geometric motivation for our work is the study of configuration spaces of complex and real spheres. It is known since F. Klein and S. Lie that the Inversive group 1 defining the geometry of spheres in dimension n is isomorphic to the projective orthogonal group PO( n + 1) (see, for example, [8], § 25). Thus any problem about configurations of m spheres in P n is equivalent to the problem about configurations of m points in P n +1 with respect to PO( n +1). The last two sections of the paper give some applications to the geometry of spheres.
## 2. The First Fundamental Theorem of Invariant theory
Let V be an n +1-dimensional quadratic complex vector space, i.e. a vector space together with a nondegenerate symmetric bilinear form whose values we denote by 〈 v, w 〉 . Let G = O( V ) be the orthogonal group of V and PO( V ) = O( V ) / {± } I . Consider the diagonal action of G on V m . The First Fundamental Theorem of Invariant theory for the orthogonal group (see [14], Chapter 11, 2.1, [19], Chapter 2, § 9) asserts that any G -invariant polynomial function on V m is a polynomial in the bracket-functions
$$[ i j ] \colon V ^ { m } \to \mathbb { C }, \ ( v _ { 1 }, \dots, v _ { m } ) \mapsto \langle v _ { i }, v _ { j } \rangle, \ \ 1 \leq i, j \leq m. \\ \cdot \quad \cdot \quad \ e \cap \cdot \quad \cdot \quad \cdot \quad \cdot \ e \quad \cdot \quad \ e t h r m { \mathcal { G } } \ \,, \quad \cdot \quad \cdot \quad \,.$$
↦
The algebra of G -invariant polynomial functions C [ V m G ] has a natural multigrading by N m with homogeneous part C [ V m G ] ( d ,...,d 1 m ) equal to the linear space of polynomials which are homogeneous of degree d i in each i -th vector variable. This grading corresponds to the natural action of the torus C ∗ m by scaling the vectors in each factor. The N -graded ring R n m ( ; ) in which we are interested is the subring ⊕ ∞ d =0 C [ V m G ] ( d,...,d ) . We have
$$R ( n ; m ) \cong \mathbb { C } [ V ^ { m } ] _ { \cdot } ^ { O ( V ) \times T },$$
$$\text{where $T=\{(z_{1},\dots,z_{m})\in\mathbb{C}^{*m}\colonz_{1}\cdotsz_{m}=1\}$.} \\ \text{Let Sym., done the linear space of complex symmet}$$
Let Sym m denote the linear space of complex symmetric m × m -matrices. If we view V m as the space of linear functions L ( C m , V ), then we can define a quadratic map by composing
$$\Phi \colon V ^ { m } \to \text{Sym} _ { m }, \ \ ( v _ { 1 }, \dots, v _ { m } ) \mapsto ( \langle v _ { i }, v _ { j } \rangle ),$$
↦
$$\mathbb { C } ^ { m } \stackrel { \phi } { \longrightarrow } V \stackrel { b } { \longrightarrow } V ^ { * } \stackrel { ^ { t } \phi } { \longrightarrow } ( \mathbb { C } ^ { m } ) ^ { * },$$
↦
1 Also called the Inversion group or the Laguerre group. It is a subgroup of the Cremona group of P n generated by the projective affine orthogonal group PAO( n + 1) and the inversion transformation [ x , . . . , x 0 n ] → [ x 2 1 + . . . + x 2 n , x 0 x , . . . , x 1 0 x n ].
where the middle map is defined by the symmetric bilinear form b associated to q . It is easy to see that, considering the domain and the range of Φ as affine spaces over C , the image of φ is the closed subvariety Sym m ( n + 1) ⊂ Sym m of symmetric matrices of rank ≤ n +1. Passing to the rings of regular functions, we get a homomorphism of rings
$$& ( 2. 1 ) & & \Phi \colon \mathbb { C } [ S y m _ { m } ] \to \mathbb { C } [ V ^ { m } ]. \\ & \infty \quad \pi \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \colon \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \dots \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \end{array}.$$
The map Φ is obviously T -equivariant if we make ( z , . . . , z 1 m ) act by multiplying the entry x ij of a symmetric matrix by z z i j . By passing to invariants, we obtain a homomorphism of graded rings
$$& \Phi _ { T } \colon \mathbb { C } [ & \text{Sym} _ { m } ] ^ { T } \to \mathbb { C } [ V ^ { m } ] ^ { T }. \\ & \tau \quad \tau \quad \tau \quad \cdots \cdots \cdots \cdots \cdots \cdots \cdots.$$
The FTT can be restated by saying that the image of this homomorphism is equal to the ring R n m ( ; ).
We identify C [Sym m ] with the polynomial ring in entries X ij of a general symmetric matrix X = ( X ij ) of size m m × . Note that the action of ( z , . . . , z 1 m ) ∈ ( C ∗ ) m on a symmetric matrix ( X ij ) is by multiplying each entry X ij by z z i j . The graded part C [Sym m d ] of C [Sym m ] consists of functions which under this action are multiplied by ( z 1 · · · z m d ) . They are obviously contained in C [Sym m T ] and define the grading of the ring C [Sym m T ] . The homomorphism Φ ∗ is a homomorphism of graded rings from C [Sym m T ] to R n m ( ; ).
Let
$$\det X = \sum _ { \sigma \in \mathfrak { S } _ { m } } \epsilon ( \sigma ) X _ { \sigma ( 1 ) 1 } \cdots X _ { \sigma ( N ) N }$$
be the determinant of X . The monomials d σ = X σ (1)1 · · · X σ N N ( ) will be called the determinantal terms. Note that the number k m ( ) of different determinantal terms is less than m !. It was known since the 19th century ([16], p. 46) that the generating function for the numbers k m ( ) is equal to
$$1 + \sum _ { m = 1 } ^ { \infty } \frac { 1 } { m! } k ( m ) t ^ { m } = \frac { e ^ { \frac { 1 } { 2 } t + \frac { 1 } { 4 } t ^ { 2 } } } { \sqrt { 1 - t } }. \\ \tilde { \tau } = \tilde { \tau } \cdots \quad \tilde { \varepsilon } = \tilde { \tau } \cdots \quad \varepsilon \circ \tilde { \tau } \cdots \quad \infty \circ.$$
For example, k (3) = 5 , k (4) = 17 , k (5) = 73 , k (6) = 338 .
Each permutation σ decomposes into disjoint oriented cycles. Consider the directed graph on m vertices which consists of the oriented cycles in σ ; i.e. we take a directed edge i → σ i ( ) for each vertex i . Suppose there is a cycle τ in σ of length ≥ 3. Write σ = τυ = υτ , and define σ ′ = τ -1 υ . Since our matrix is symmetric, the determinantal term d σ ′ corresponding to σ ′ has the same value as d σ , and furthermore σ ′ has the same sign as σ (so there is no canceling), and so we may drop the orientation on each cycle. We may therefore envision the determinantal terms as 2-regular un-directed graphs on m vertices (where 2-cycles and loops are admitted). Thus for each 2-regular graph having k cycles of length ≥ 3, there corresponds 2 k determinantal terms.
Proposition 2.1. The ring ⊕ ∞ d =0 C [Sym m T ] 2 d is generated by the determinantal terms.
Proof. A monomial X i 1 j 1 · · · X i k j k belongs to C [Sym m T ] d if and only if
$$z _ { i _ { 1 } } \cdots z _ { i _ { k } } z _ { j _ { 1 } } \cdots z _ { j _ { k } } = ( z _ { 1 } \cdots z _ { m } ) ^ { d }$$
for any z , . . . , z 1 m ∈ C ∗ . This happens if and only if each i ∈ { 1 , . . . , m } occurs exactly d times among i 1 , . . . , i k , j 1 , . . . , j k . Consider the graph with set of vertices equal to { 1 , . . . , m } and an edge from i to j if X ij enters into the monomial. The above property is equivalent to that the graph is a regular graph of valency d . The multiplication of monomials corresponds to the operation of adding graphs (in the sense that we add the sets of the edges). It remains to use that any regular graph of valency 2 d is equal to the union of regular graphs of valency 2 (this is sometimes called a '2-factorization' or Petersen's factorization theorem) [13], § 9. /square
Corollary 2.2. A set ([ v 1 ] , . . . , [ v m ]) is semi-stable for the action of O( V ) on ( P n m ) if and only if there exists σ ∈ S m such that 〈 v σ (1) , v 1 〉 · · · 〈 v σ m ( ) , v m 〉 is not equal to zero.
We can make it more explicit.
Proposition 2.3. A point set ([ v 1 ] , . . . , [ v m ]) is unstable if and only if there exists I ⊆ J ⊆ { 1 , . . . , m } such that | I | + | J | = m +1 and 〈 v , v i j 〉 = 0 for all i ∈ I and j ∈ J .
Proof. Since ( C [Sym m ] (2) ) T is generated by determinantal terms, we obtain that a matrix A = ( a ij ) has all determinantal terms equal to zero if and only if it represents an unstable point in P (Sym m ) with respect to the torus action. Now the assertion becomes a simple consequence of the Hilbert-Mumford numerical criterion of stability.
It is obvious that if such subsets I and J exist then all determinantal terms vanish. So we are left with proving the existence of the subsets I and J if we have an unstable matrix.
↦
Let r : t → ( t r 1 , . . . , t r m ) be a non-trivial one-parameter subgroup of the torus T . Permuting the points, we may assume that r 1 ≤ r 2 ≤ . . . ≤ r m . We also have r 1 + . . . + r m = 0. We claim that there exists i, j such that i + j = m + 1 and r i + r j ≤ 0. If not, then each of r 1 + r m , r 2 + r m -1 , . . . , r /floorleft m +1 2 /floorright + r /ceilingleft m +1 2 /ceilingright are strictly positive, which contradicts i r i = 0.
/negationslash
∑ Since our symmetric matrix A = ( a ij ) is unstable, by the Hilbert-Mumford criterion there must exist r such that min { r i + r j : a ij = 0 } > 0. Permute the points, if necessary, so that r 1 ≤ r 2 ≤ · · · ≤ r n . Let i 0 , j 0 be such that r i 0 + r j 0 ≤ 0 and i 0 + j 0 = m + 1. We may assume that i 0 ≤ j 0 since the above condition is symmetric in i 0 , j 0 . Now, since the entries of r are increasing, we have that r i + r j ≤ 0 for all i ≤ i 0 and j ≤ j 0 . Hence a ij = 0 for all i ≤ i 0 and j ≤ j 0 . Now let I = 1 { , . . . , i 0 } and let J = { 1 , . . . , j 0 } . /square
Similarly, we can prove the following.
Proposition 2.4. A point set ([ v 1 ] , . . . , [ v m ]) is semi-stable but not stable if and only if m = max {| I | + | J | : I ⊆ J ⊆ { 1 , . . . , m } and 〈 v , v i j 〉 = 0 for all i ∈ I, j ∈ J } .
Proof. Suppose that A = ( a ij = 〈 v , v i j 〉 ). Let m A ′ ( ) = max {| I | + | J | : I ⊆ J ⊆ { 1 , . . . , m } and 〈 v , v i j 〉 = 0 for all i ∈ I, j ∈ J } .
Suppose that A is semi-stable but not stable. Since A is not unstable, we know by the prior Proposition that m A ′ ( ) ≤ m . So we are left with showing that m A ′ ( ) = m .
/negationslash
Since A is not stable, there is a one parameter subgroup r : t → ( t r 1 , . . . , t r m ) such that r i + r j ≥ 0 whenever a ij = 0. We shall re-order the points so that r 1 ≤ r 2 ≤ · · · ≤ r n . Recall also that ∑ i r i = 0. Since some r i = 0, we know that r 1 < 0 < r n . We claim there is some i, j such that i + j = m and r i + r j < 0. Otherwise, each of r 1 + r m -1 , r 2 + r m -3 ,. . . , r /floorleft m 2 /floorright + r /ceilingleft m 2 /ceilingright would be non-negative. This implies that r 1 + · · · + r m -1 ≥ 0. But since r n > 0, we have that r 1 + · · · r m > 0, a contradiction. Hence, the claim is true. Now, take i 0 ≤ j 0 such that i 0 + j 0 = m and r i 0 + r j 0 < 0. Now, we must have that a ij = 0 for all i ≤ i 0 and j ≤ j 0 . Let I = { 1 , . . . , i 0 } and J = { 1 , . . . , j 0 } . Then I ⊆ J ⊆ { 1 , . . . , m } , | I | + | J | = m , and a ij = 0 for all i ∈ I , j ∈ J . Thus m A ′ ( ) = m .
↦
/negationslash
↦
/negationslash
Conversely suppose that m A ′ ( ) = m . Then A is not unstable (if A were unstable, Proposition 2.3 implies that m A ′ ( ) ≥ m +1). Let I ⊆ J ⊆ { 1 , . . . , m } , such that | I | + | J | = m , and a ij = 0 for all i ∈ I , j ∈ J . Re-order points if necessary so that I = 1 { , . . . , i 0 } and J = 1 { , . . . , j 0 } . Let r : t → ( t r 1 , . . . , t r m ) be defined as follows. Let r i = -1 for i ≤ i 0 , let r i = 1 for i > m -i 0 , and let r i = 0 otherwise. The sum ∑ i r i is zero and not all r i are zero, so this defines a one-parameter subgroup of the torus T . Also, if r i + r j < 0 and i ≤ j , then i ≤ i 0 and j ≤ j 0 , which implies that a ij = 0. Thus r i + r j ≥ 0 whenever a ij = 0. Hence A is not stable.
/square
The Second Fundamental Theorem (SFT) of Invariant Theory for the group O( V ) describes the kernel of the homomorphism (2.1) (see [14], p. 407, [19], Chapter 2, § 17).
Consider the ideal I ( n, m ) in C [ V n ] O( V ) generated by the Gram functions
↦
where I = (1 < i 1 < · · · < i n +2 ) , J = (1 < j 1 < · · · < j n +2 ) are subsets of [1 , m ]. We set γ I = γ I,I .
$$\cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \\ \gamma _ { I, J } \colon ( v _ { 1 }, \dots, v _ { m } ) \mapsto \det \begin{pmatrix} \langle v _ { i _ { 1 } }, v _ { j _ { 1 } } \rangle & \dots & \langle v _ { i _ { n + 2 } }, v _ { j _ { n + 2 } } \rangle \\ \vdots & \vdots & \vdots \\ \langle v _ { i _ { n + 2 } }, v _ { j _ { 1 } } \rangle & \dots & \langle v _ { i _ { n + 2 } }, v _ { j _ { n + 2 } } \rangle \end{pmatrix} \\ \text{where $I=(1<i_{1}<\cdots<i_{n+2}$)}, $J=(1<i_{1}<\cdots<i_{n+2}$)} \, \text{are subsets of $[1,m]$}$$
The pre-image of this ideal in C [Sym ( 2 V ∗ )] = ∼ C [Sym m ] is the determinant ideal D m ( n +1) of matrices of rank ≤ n +1. The SFT asserts that it is the kernel of the homomorphism (2.1). Then
$$\text{Ker} ( \Phi _ { T } ) = \mathcal { D } _ { m } ( n + 1 ) \cap \mathbb { C } [ \text{Sym} _ { m } ] ^ { T } \\ \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \sigma$$
and it is finitely generated by polynomials of the form m ∆ I,J , where m is a monomial in X ij of degree ( k, k, . . . , k ) -deg(∆ I,J ) for some k ≥ 2.
Our naive hope was that Ker(Φ T ) is generated only by polynomials of the form m ∆ I,J , for m having degree (2 2 , , . . . , 2) -deg(∆ I,J ). This is not true even if we restrict it to the open subset of semi-stable points in Sym m with respect to the torus action. The symmetric matrix
$$A = \begin{pmatrix} 0 & 0 & 1 & 1 & 1 \\ 0 & 0 & 1 & 1 & 1 \\ 1 & 1 & 1 & 0 & 0 \\ 1 & 1 & 0 & 1 & 0 \\ 1 & 1 & 0 & 0 & 1 \end{pmatrix} \\ i, j ) \text{ the product } a _ { i j } A _ { i j } \text{ (where }.$$
has rank 4, but for any ( i, j ) the product a ij A ij (where A ij is the complementary minor) is equal to zero. Thus our naive relations make it appear that A has rank
/negationslash
- 3. Also, a 31 a 42 a 13 a 24 a 55 = 0, so the matrix represents a semi-stable point. It can be shown that no counter-example exists with m< 5.
The following T -invariant polynomial vanishes on rank 3 matrices and is nonzero when evaluated on the matrix A above:
$$a _ { 1 3 } ^ { 2 } a _ { 1 4 } ^ { 2 } a _ { 2 5 } ^ { 2 } \Delta _ { \{ 2, 3, 4, 5 \}, \{ 2, 3, 4, 5 \} }.$$
Hence we need to consider higher degree relations. We can at least give a bound on the degree of such relations, again appealing to Petersen's factorization theorem.
Proposition 2.5. The ideal Ker(Φ T ) is generated by polynomials of the form m ∆ I,J , for m having degree at most (2( n +2) 2( , n +2) , . . . , 2( n +2)) -deg(∆ I,J ) .
Proof. It is clear that Ker(Φ T ) is generated by relations of the form m ∆ I,J where m is a monomial of degree (2 k, 2 k, . . . , 2 k ) -deg(∆ I,J ), for arbitrary k . Suppose that k > n +2. The monomial m corresponds to the multigraph Γ ′ with edges ij for each X ij dividing m , counting multiplicity. Choose any term from ∆ I,J ; similarly this term corresponds to a multigraph Γ ′′ . The graph Γ ′′ has exactly n +2 edges.
The union Γ = Γ ′ /unionsq Γ ′′ is a 2 k -regular graph. By Petersen's factorization theorem, we know that Γ completely factors into k disjoint 2-factors. Since k > n + 2, at least one of these 2-factors is disjoint from Γ ′′ . Hence, this 2-factor must be a factor of Γ . ′ This means that the monomial m is divisible by the T -invariant monomial m 0 corresponding to the 2-factor of Γ : ′
$$m = m _ { 0 } \cdot m ^ { \prime }.$$
Hence, the relation m ∆ I,J is equal to m 0 · ( m ′ ∆ I,J ), where m ′ ∆ I,J ∈ Ker(Φ T ) has smaller degree. /square
Conjecture 2.6 . A recent conjecture of Andrew Snowden (informal communication) implies that there is a bound d 0 ( n ) such that R n m ( ; ) is generated in degree ≤ d 0 ( n ) for all m . Further, after choosing a minimal set of generators (each of degree ≤ d 0 ( n )), his conjecture also implies that there is a bound d 1 ( n ) such that the ideal of relations is generated in degree ≤ d 1 ( n ) for all m . His conjecture applies to all GIT quotients of the form X m //G where G is linearly reductive and X is a G -polarized projective variety.
One of our goals was to prove (or perhaps disprove) his conjecture for this case of P ( V ) m // PO( V ). We were not able to do so. However, we have shown that the second Veronese subring is generated in lowest degree, providing small evidence of the first part of his conjecture. Furthermore, Proposition 2.5 is a small step towards proving an m -independent degree bound on the generating set of the ideal (again for the second Veronese subring only).
## 3. A toric variety
The variety S m = Sym m //T = Proj C [Sym m )] T is a toric variety of dimension m m ( -1) / 2. We identify the character lattice of C ∗ m with Z m . We have Sym m = ⊕ C X ij , where X ij is an eigenvector with the character e i + e j . The lattice M of characters of the torus ( C ∗ ) m m ( -1) / 2 acting on S m is equal to the kernel of the homomorphism Z m m ( +1) 2 / → Z m , e ij → e i + e j . It is defined by the matrix A with
↦
( ij )-spot in a k -th row equal
/negationslash
/negationslash
/negationslash
Let
$$a _ { k, i j } = \begin{cases} 0 & \text{if $k\neq i,j$,} \\ 1 & \text{if $k=i\neq j,or\,k=j\neq i$,} \\ 2 & \text{if $k=i=j$.} \end{cases} \\ x \in \mathbb { V } ^ { m ( m + 1 ) / 2 } \colon A x = 2 d ( \mathfrak { e } _ { 1 } + \dots + \mathfrak { e } _ { 2 } ). \text{for some $a$}$$
$$S = \{ x \in \mathbb { Z } _ { \geq 0 } ^ { m ( m + 1 ) / 2 } \colon A x = 2 d ( \mathbf e _ { 1 } + \dots + \mathbf e _ { m } ), \text{for some } d \geq 0 \} \\ \text{be the sacred semirquation } \text{Then}$$
be the graded semigroup. Then
$$\mathbb { C } [ \text{Sym} _ { m } ] ^ { T } = \mathbb { C } [ S ].$$
In other words, the toric variety S m is equal to the toric space P ∆ , where ∆ m is the convex polytope in { x ∈ R m m ( +1) 2 / : Ax = (2 , . . . , 2) } spanned by the vectors v σ , σ ∈ S m , such that a ij is equal to the number of edges from i to j in the regular graph corresponding to the determinantal term d σ . For example, if m = 3, σ = (12) defines the v σ with a 12 = 2 , a 33 = 1 and a ij = 0 otherwise. Thus the number of lattice points in the polytope ∆ is equal to the number k m ( ) of determinantal terms in a general symmetric matrix.
## Proposition 3.1.
$$\begin{array} { c } \# ( d \Delta _ { m } ) \cap M = \# \{ r e g u l a r \ g r a p h s \ w i t h \ v a l e n c y \ 2 d \}. \\ \dots \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \end{array}$$
$$\text{Proof. This follows easily from Proposition 2.1.}$$
## 4. Examples
Example 4.1. Let n = 2 and m = 3. We are interested in the moduli space of 3 points in P 2 modulo the group of projective transformations leaving invariant a nonsingular conic. The group PO(3) = PSL ∼ 2 is a 3-dimensional group. So, we expect a 3-dimensional variety of configurations.
We have five determinantal terms given by the following graphs:
Let t 0 , t 1 , t 2 , t 3 , t 4 be generators of the ring R (2; 3) corresponding, respectively, to the triangle, to the three graphs of the second type, and the one graph of the third type. We have the cubic relation:
$$t _ { 1 } t _ { 2 } t _ { 3 } - t _ { 0 } ^ { 2 } t _ { 4 } = 0. \\ \dots \ e q \colon \ e q \colon \ e q \colon \ e q \colon \ e q \colon$$
Thus our variety is a cubic threefold in P 4 . Its singular locus consists of three lines
$$t _ { 0 } = t _ { 1 } = t _ { 2 } = 0, \ t _ { 0 } = t _ { 1 } = t _ { 3 } = 0, \ t _ { 0 } = t _ { 2 } = t _ { 3 } = 0.$$
Let H i be hyperplane section of the cubic by the coordinate hyperplane t i = 0. Then
- · H 0 : point sets with two points conjugate with respect to the fundamental conic. H 0 is the union of three planes Λ i : t 0 = t i = 0 , i = 1 2 3. , ,
- · H 4 : one of the points lies on the fundamental conic. It is the union of three planes Π i : t 4 = t i = 0 , i = 1 2 3. , ,
8
- · H i is the union of two planes Λ i and Π i , i = 1 2 3. , ,
- · Λ i ∩ Λ j is a singular line on S 3 , the locus of point sets where one point is the intersection point of the polar lines of two other points;
- · Π i ∩ Π : two points are on the fundamental conic; j
/negationslash
- · Π i ∩ Λ : i two points are conjugate, the third point is on the conic;
- · Π i ∩ Λ j , i = j : one point is on the conic, and another point lies on the tangent to the conic at this point;
- · Λ 1 ∩ Λ 2 ∩ Λ 3 is the point representing the orbit of ordered self-conjugate triangles;
- · Π 1 ∩ Π 2 ∩ Π is the point representing the orbit of ordered sets of points on 3 the fundamental conic.
The singular point Λ 1 ∩ Λ 2 ∩ Λ 3 = [0 0 0 0 1] represents the orbit of ordered self-, , , , polar triangles. Recall that unordered self-conjugate triangles are parameterized by the homogeneous space PO(3) / S 4 . It admits a smooth compactification isomorphic to the Fano threefold of degree 5 and index 2 [11], Theorem (2.1) and Lemma (3.3) (see also [1], 2.1.3).
Example 4.2. Let us look at the variety O 3 1 . It isomorphic to the subvariety of O 3 2 representing collinear triples of points. The equation of the determinant of the Gram matrix of three points is
$$\begin{matrix} ( 4. 1 ) & & & 2 t _ { 0 } - t$$
It a hyperplane section of S 3 isomorphic to a cubic surface S in P 3 with equation
$$& ( 4. 2 ) & \quad \quad t _ { 1 } t _ { 2 } t$$
The surface is projectively isomorphic to the 4-nodal Cayley cubic surface given by the equation
$$x _ { 0 } x _ { 1 } x _ { 2 } + x _ { 0 } x$$
Its singular points are [ t 0 , t 1 , t 2 , t 3 ] = [1 1 1 1] [0 , , , , , 0 0 1] [0 , , , , 0 1 0] , , , [0 , 1 0 0]. Since , , the surface is irreducible, and all collinear sets of points satisfy (4.1), we obtain that the surface represents the locus of collinear point sets. It is also isomorphic to the variety O 3 1 of 3 points on P 1 . The additional singular point [1 , 1 1 1] not inherited , , from the singular locus of O 3 2 is the orbit of three collinear points [ v 1 ] , [ v 2 ] , [ v 3 ] such that the determinantal terms of the Gram matrix G v , v ( 1 2 , v 3 ) are all equal. This is equivalent to that all principal minors are equal to zero and the squares of the discriminant terms d (123) and d (321) are equal. This gives two possible points [ t 0 , t 1 , t 2 , t 3 ] = [ ± 1 1 1 1]. , , , We check that the point [ -1 1 1 1] does not satisfy , , , (4.2). Thus the point [1 1 1 1] is determined by the condition that the principal , , , minors of the Gram matrix G v , v ( 1 2 , v 3 ) are equal to zero. This implies that [ v 1 ] = [ v 2 ] = [ v 3 ]. It follows from the stability criterion that this point is not one of the two isotropic points.
It is immediate that R (1; 2) (2) is freely generated by two determinantal terms and hence O 2 1 ∼ = P 1 . The three projections O 3 1 to O 2 1 are regular map. If we realize S 3 as the image of the anti-canonical system of the blow-up of 6 vertices of a complete quadrilateral in the plane, then the three maps are defined by the linear system of conics through three subsets of 4 vertices no three lying on one side of the quadrilateral. One can show that these are the only regular maps from S 3 to P 1 .
❄
⑧ ⑧
Finally, observe, that we can use the conic to identify the plane with its dual plane. In this interpretation a triple of points becomes a triple of lines, the polar lines of the points with respect to the conic. Intersecting each line with the conic we obtain three ordered pairs of points on a conic.
Note that a set of six distinct points on a nonsingular conic can be viewed as the set of Weierstrass points of a hyperelliptic curve C of genus 2. An order on this set defines a symplectic basis of the F 2 -symplectic space Jac( C )[2] of 2-torsion points of its Jacobian variety Jac( C ). The GIT-quotient of the subvariety of ( P 2 ) 6 of ordered points on a conic by the group SL 3 is isomorphic to the Igusa quartic in P 4 (see [3], Chapter 1, Example 3). A partition of the set of Weierstrass points in three pairs defines a maximal isotropic subspace in Jac( C )[2]. An order of the three pairs chooses a basis in this space. The moduli space of principally polarized abelian surfaces A equipped with a symplectic basis in A [2] is isomorphic to the quotient of the Siegel space Z 2 = { X ∈ Sym 4 : Im( X > ) 0 } by the group Γ(2) = { M ∈ Sp(4 , Z ) : A ≡ I 4 mod 2 . The moduli space of principally polarized abelian surfaces together with a } choice of a basis in a maximal isotropic subspace of 2-torsion points is isomorphic
$$\begin{array} {$$
mod 2 . Thus, we obtain that our variety } O 3 2 is naturally birationally isomorphic to the quotient Z 2 / Γ (2) and this variety is isomorphic to the quotient of 1 Z 2 / Γ(2) by the group G = S 2 × S 2 × S 2 . The Satake compactification of Z 2 / Γ(2) is isomorphic to the Igusa quartic. In [12], S. Mukai shows that the Satake compactification of Z 2 / Γ (2) is isomorphic to the double cover of 1 P 3 branched along the union of four coordinate hyperplanes. It is easy to see that it is birationally isomorphic to the cubic hypersurface defining O 3 2 . A remarkable result of Mukai is that the Satake compactifications of Z 2 / Γ(2) and Z 2 / Γ (2) are isomorphic. 1
Remark 4.3 . Assume m = n + 1. Fix a volume form on V and use it to identify the linear spaces V ∗ and ∧ n V . This identification is equivariant with respect to the action of O( V ) on V and O( V ∗ ), where the orthogonal group of V ∗ is with respect to the dual quadratic form on V ∗ . Passing to the configuration spaces, we obtain a natural birational involution F : O n +1 n /axisshort/axisshort/arrowaxisright O n +1 n . If G is the Gram matrix of vectors v , 1 · · · , v n +1 , then the Gram matrix G ∗ of the vectors w i = v 1 ∧ · · · ∧ v i -1 ∧ v i +1 ∧ · · · ∧ v n +1 ∈ V ∗ is equal to the adjugate matrix of G (see [1], Lemma 10.3.2). In the case n = 2, the birational involution correspond to the involution defined by conjugate triangles (see loc.cit., 2.1.4). Using the modular interpretation of O 3 2 from the previous example, the involution F corresponds to the Fricke (or Richelot) involution of Z 2 / Γ (2) (see [12], Theorem 2). 1
Example 4.4. Now let us consider the variety O 4 1 of 4 points in P 1 modulo PO(2) = ∼ C ∗ × Z / 2 Z . It is another threefold. First we get the 5-dimensional toric variety of
symmetric matrices of size 4. The coordinate ring is generated by 17 (3+4+6+3+1) determinantal terms:
/c24/c25/c26/c27
/c31/c30/c29/c28
•
•

•
•
•
•
•
•
•
•
Let x , x 1 2 , x 3 , y 1 , y 2 , y 3 , y 4 , z 1 , . . . , z 6 , u 1 , u 2 , u 3 , v be the variables. We have additional equations expressing the condition that the rank of matrices is less than or equal to 2. One can show that the equations are all linear:
$$a _ { i j } \det A _ { i j } = 0.$$
Their number is equal to 10 but there are 3 linear dependencies found by expanding the determinant expression along columns.
We may also consider the spaces SO m n = P ( V ) m // O ( + V ), where O + ( V ) = O( V ) ∩ SL( V ) is the special orthogonal group. Note that PO( V ) ∼ = PO ( + V ) if dim V is odd. Thus we will be interested only in the case when dim V is even. In this case PO + ( V ) is a subgroup of index 2 in PO( V ), so the variety SO m n is a double cover of O m n . We have
$$\text{SO} _ { n } ^ { m } = \text{Proj} \ R ^ { + } ( n ; m ),$$
where R + ( n m ; ) = ⊕ ∞ d =0 ( S d ( V ) ∗⊗ m ) O ( + V ) . There are more invariants now. The additional invariants in C [ V m ] O ( + V ) are the Pl¨cker brackets u
$$p _ { i _ { 1 }, \dots, i _ { n + 1 } } \colon ( v _ { 1 }, \dots, v _ { m } ) \mapsto v _ { i _ { 1 } } \wedge \dots \wedge v _ { i _ { n + 1 } },$$
↦
where we have fixed a volume form on V . There are additional basic relations (see [19], Chapter 2, § 17)
$$& ( 4. 3 ) & & p _ { i _ { 1 }, \dots, i _ { n + 1 } } p _ { j _ { 1 }, \dots, j _ { n + 1 } } - \det ( [ i _ { \alpha }, i _ { \beta } ] ) _ { 1 \leq \alpha, \beta \leq n + 1 } = 0, \\ & & n + 1$$
$$\cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \\ ( 4. 4 ) \quad \sum _ { j = 1 } ^ { n + 1 } ( - 1 ) ^ { j } \sum p _ { i _ { 1 }, \dots, \hat { i } _ { j }, \dots, i _ { n + 1 } } [ i _ { j }, i _ { n + 2 } ] = 0.$$
The graded part R + ( n m ; ) d is spanned by the monomials p I 1 · · · p I k [ i 1 j 1 ] · · · [ i s , j s ] where each index j ∈ [1 , m ] appears exactly d times. Using the first relation in (4.3), we may assume that at most one Pl¨cker coordinate u p I appears. Also we see that the product of any two elements in R + ( n m ; ) d belongs to R N m ( ; ) 2 d .
## 5. Points in P 1 and generalized Cayley cubics
↦
↦
Recall that there is a Chow quotient ( P 1 ) m // C ∗ defined by the quotient fan of the toric variety ( P 1 ) m (see [6]).
The group SO(2) is isomorphic to the one-dimensional complex torus C ∗ . We choose projective coordinates in P 1 to identify a quadric in P 1 with the set Q = { 0 , ∞} so that SO(2) acts by λ : [ t 0 , t 1 ] → [ λt , λ 0 -1 t 1 ]. The points on Q are the fixed points of SO(2). The group O(2) is generated by SO(2) and the transformation [ t 0 , t 1 ] → [ t 1 , t 0 ].
Lemma 5.1. Consider ( P 1 ) m as a toric variety, the Cartesian product of the toric varieties P 1 . Then Chow quotient ( P 1 ) m // SO(2) is isomorphic to the toric variety X A ( m -1 ) associated to the root system of type A m -1 defined by the fan in the dual lattice of the root lattice of type A m -1 formed by the Weyl chambers.
Proof. The toric variety ( P 1 ) m is defined by the complete fan Σ in the lattice Z m with 1-skeleton formed by the rays R ≥ 0 e i and R ≤ 0 e , i i = 1 , . . . , m . The action of SO(2) on the torus ( C ∗ ) m ⊂ ( P 1 ) m is defined by the surjection of the lattices Z m → Z given by the map e i → e , i 1 = 1 , . . . , m . Thus the lattice M of characters of the torus ( C ∗ ) m -1 acting on ( C ∗ ) m / C ∗ can be identified with the sublattice of Z m spanned by the vectors α 1 = e 1 -e , . . . , α 2 m -1 = e m -1 -e m . This is the root lattice of type A m -1 . The dual lattice N is the lattice Z m / Z e , where e = e 1 + . . . + e m . The quotient fan is defined as follows. For any coset y ∈ N R = R m / R e , one considers the set
$$\mathcal { N } ( y ) = \{ \sigma \in \Sigma \, \colon y + \mathbb { R } e \cap \sigma \neq \emptyset \}. \\ \mathcal { I } _ { - } = \infty \, \infty \, \infty \, \infty \, \colon \, \mathbb { R } e \cap \mathbb { R } e \cap \mathbb { R } e \cap \mathbb { R } e \cap \mathbb { R } e \,.$$
/negationslash
A coset y + R e ∈ N R is called admissible if N ( φ ) = ∅ . Two admissible cosets y + R e and y ′ + R e are called equivalent if N ( y ) = N ( y ′ ). The closure if each equivalence class of admissible cosets is a rational polyhedral convex cone in N R and the set of such cones defines a fan Σ ′ in N R which is the quotient fan.
/negationslash
In our case, Σ consists of open faces σ I of the 2 m m -dimensional cones
$$\sigma _ { I, J } & = \{ ( x _ { 1 }, \dots, x _ { m } ) \in \mathbb { R } ^ { m } \colon ( - 1 ) ^ { \delta _ { I } } x _ { i } \geq 0, ( - 1 ) ^ { \delta _ { J } } x _ { i } \leq 0 \}, \\ r _ { \tau } & = \tau _ { \tau } + \tau _ { \tau } + \tau _ { \tau } + \tau _ { \tau } + \tau _ { \tau } + \tau _ { \tau } + \tau _ { \tau } + \tau _ { \tau } + \tau _ { \tau } + \tau _ { \tau } + \tau _ { \tau } + \tau _ { \tau } + \tau _ { \tau } + \tau _ { \tau } + \tau _ { \tau } + \tau _ { \tau } + \tau _ { \tau } + \tau _ { \tau } + \tau _ { \tau } + \tau _ { \tau } + \tau _ { \tau } - \tau _ { \tau } - \tau _ { \tau } - \tau _ { \tau } - \tau _ { \tau } - \tau _ { \tau } - \tau _ { \tau } - \tau _ { \tau } - \tau _ { \tau } - \tau _ { \tau } - \tau _ { \tau } - \tau _ { \tau } - \tau _ { \tau } - \tau _ { \tau } - \tau _ { \tau } - \tau _ { \tau } - \tau _ { \tau } - \tau _ { \tau } - \tau _ { \tau } - \tau _ { \tau } - \tau _ { \tau } + \tau _ { \tau } + \tau _ { \tau } + \tau _ { \tau } + \tau _ { \tau } + \tau _ { \tau } + \tau _ { \tau } + \tau _ { \tau } + \tau _ { \tau } + \tau _ { \tau } + \tau _ { \tau } + \tau _ { \tau } + \tau _ { \tau } + \tau _ { \tau } + \tau _ { \tau } + \tau _ { \tau } + \tau _ { \tau } + \tau _ { \tau } + \tau _ { \tau } + \tau _ { \tau } = \tau _ { \tau }.$$
where I, J are subsets of [1 , m ] such that I ∪ J = [1 , m ] and δ K is a delta-function of a subset K of [1 , m ]. The cones of maximal dimension correspond to pairs of complementary subsets I, J . The k -dimensional cones correspond to the pairs I, J with # I ∩ J = m -k .
Let y = ( y , . . . , y 1 m ) ∈ R m with y i = y , i j = j and let s ∈ S m be a unique permutation such that y s (1) > y s (2) > . . . > y σ m ( ) . Then y + R e intersects σ I,J if and only if s I ( ) = { 1 , . . . , k } for some k ≤ m or ∅ and J = [1 , m ] \ I . Since S m has only one orbit on the set of pairs of complementary subsets of [1 , m ], we see that the interiors of maximal cones in the quotient fan are obtained from the image of the subset
/negationslash
/negationslash
$$\left \{ y \in \mathbb { R } ^ { m } \colon y \cdot ( e _ { i } - e _ { i + 1 } ) \geq 0, i = 1, \dots, m - 1 \right \} \\ \text{hio is overwritten on a $f$} \, \text{the main home in $N_{\nu}$} \quad \text{all $other$} \, \infty$$
in N R . This is exactly one of the Weyl chambers in N R . All other cones in the quotient fan are translates of the faces of the closure of this chamber. This proves the assertion. /square
It is known that the toric variety X A ( m -1 ) is isomorphic to the blow-up of P m -1 of the faces of the coordinate simplex (see, for example, [2], Lemma 5.1). Let
$$\tau _ { m - 1 } \colon \mathbb { P } ^ { m - 1 } \, - \, \Phi ^ { m - 1 }, \, \left [ t _ { 0 }, \dots, t _ { m - 1 } \right ] & \mapsto \left [ 1 / t _ { 0 }, \dots, 1 / t _ { m - 1 } \right ] \\ \tau _ { 1 } \, \cdot \, \cdot \, \cdot \, \cdot \, \cdot \, \cdot \, \cdot \, \cdot \, \cdot \, \cdot \, \cdot \, \cdot \, \cdot \, \cdot \, \cdot \, \cdot \, \cdot \, \cdot \, \cdot \, \cdot \, \cdot \, \cdot \, \cdot \, \cdot \, \cdot \, \cdot \, \cdot \, \cdot \, \cdot \, \cdot \, \cdot \, \cdot \, \cdot \, \cdot \, \cdot \, \cdot \, \cdot \, \cdot \, \cdot \, \cdot \, \cdots$$
↦
be the standard Cremona transformation of P m -1 . The variety X A ( m -1 ) is isomorphic to a minimal resolution of indeterminacy points of
$$\begin{pmatrix} F _ { 0 } ( x ) & F _ { 1 } ( x ) & \dots & F _ { m - 1 } ( x ) \\ y _ { 0 } & y _ { 1 } & \dots & y _ { m - 1 } \end{pmatrix},$$
where F i ( x ) = ( x 0 · · · x m -1 ) /x i . It follows from this formula, that the standard involution τ m -1 of X A ( m -1 ) is induced by the switching involution ι of the factors of P m -1 × P m -1 . The image of composition of the embedding X A ( m -1 ) in P m -1 ×
P m -1 and the Segre embedding P m -1 × P m -1 ↪ → P m 2 -1 is equal to the intersection of the Segre variety with the linear subspace of dimension m -1 defined by
$$t _ { 0 0 } = t _ { 1 1 } = \dots = t _ { m - 1 m - 1 },$$
where we use the coordinates t ij = x y i j in P m 2 -1 . So X A ( m -1 ) is isomorphic to a closed smooth subvariety of P m m ( -1) of degree ( 2( m -1) m -1 ) .
Consider the embedding of ( P m -1 × P m -1 ) / ι 〈 〉 in P 1 2 ( m +2)( m -1) given by the linear system of symmetric divisors of type (1 1). , Its image is equal to the secant variety of the Veronese variety v 2 ( P m -1 ) isomorphic to the symmetric square Sym 2 P m -1 of P m -1 . The image of X A ( m -1 ) / τ 〈 m -1 〉 in P 1 2 ( m +2)( m -1) is equal to the intersection of the secant variety with a linear subspace L of codimension m -1 given by (5.1). It is known that the singular locus of the secant variety is equal to the Veronese variety. The singular locus of the embedded X A ( m -1 ) / τ 〈 m -1 〉 is equal to the intersection of L with the Veronese subvariety v 2 ( P m -1 ) and consists of 2 m -1 points. We have dim L = 1 2 m m ( -1) and deg Sym 2 P m -1 ) = 1 2 ( 2( m -1) m -1 ) . So X A ( m -1 ) / τ 〈 m -1 〉 embeds into P 1 2 m m ( -1) as a subvariety of degree 1 2 ( 2( m -1) m -1 ) with 2 m -1 singular points locally isomorphic to the singular point of the cone over the Veronese variety v 2 ( P m -2 ). We call it the generalized Cayley cubic and denote it by Cay m -1 .
It follows from above that Cay m -1 is isomorphic to the subvariety of the projective space of symmetric m × m -matrices with the conditions that the rank is equal to 2 and the diagonal elements are equal.
In the case when m = 3, the variety X A ( 2 ) is a Del Pezzo surface of degree 6, the blow up of 3 non-collinear points in P 2 and Cay 2 is isomorphic to the Cayley 4-nodal cubic surface in P 3 . The variety Cay 3 is a 3-dimensional subvariety of P 6 of degree 10 with 8 singular points locally isomorphic to the cone over the Veronese surface.
It is known that the Chow quotient birationally dominates all the GIT-quotients [7], Theorem (0.4.3). So we have a S m -equivariant birational morphism
$$\Phi _ { m } \colon X ( A _ { m - 1 } ) \to \text{so} _ { 1 } ^ { m }. \\ \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot$$
which, after dividing by the involution τ m -1 , defines a S m -equivariant birational morphism
$$\Phi _ { m } ^ { c } \colon & \text{Cay} _ { m - 1 } \to \text{O} _ { 1 } ^ { m }. \\ \omega _ { m } \dots \dots \dots \, \mathcal { C } _ { \dots } \cdots \cdots \, \mathcal { C } _ { \dots } \cdots \cdots$$
For example, take m = 3. The variety Cay 2 is the Cayley 4-nodal cubic, the morphism Φ m is an isomorphism. Take m = 4. We know from Proposition 2.4 that the variety SO 4 1 has 6 singular points corresponding to strictly semi-stable points defined by vanishing of two complementary principal matrices of the Gram matrix. They are represented by the point sets of the form ( a, a, b, b ), where a, b ∈ { 0 , ∞} . The morphism Φ 4 resolves these points with the exceptional divisors equal to the exceptional divisors of X A ( 3 ) → P 3 over the edges of the coordinate tetrahedron. The morphism Φ c 4 resolves 3 singular points of O 1 4 and leaves unresolved the 8 singular points coming from the fixed points of τ 3 . Altogether, the variety O 1 4 has 11 singular points: 8 points locally isomorphic to the cones of the Veronese surface and 3 conical double points. The latter three singular points correspond to strictly semi-stable orbits.
It is known that X A ( m -1 ) is isomorphic to the closure of a general maximal torus orbit in PGL m /B , where B is a Borel subgroup [9], Theorem 1. Let P be a parabolic subgroup containing B defined by a subset S of the set of simple roots, and W S be the subgroup of the Weil group S m generated by simple roots in S . Let φ S : PGL m /B ] → PGL m /P be the natural projection. The image of X A ( m -1 ) in PGL m /P is a toric variety X A ( m -1 ) S defined by the fan whose maximal cones are S m -translates of the cone W σ S , where σ a fundamental chamber ([4], Theorem 1). The morphism φ S : X A ( m -1 ) → X A ( m -1 ) S is a birational morphism which is easy to describe.
We believe, but could not find a proof, that for odd m , the morphism Φ m and Φ c m are isomorphisms. If m is even, then the morphism Φ m is equal to the morphism φ S , where S is the complement of the central vertex of the Dynkin diagram of type A m -1 .
## 6. Rational functions
First we shall prove the rationality of our moduli spaces.
Theorem 6.1. The varieties O m n are rational varieties.
↦
Proof. The assertion is trivial when m = n +1 because in this case the variety is isomorphic to the toric variety S m . If m < n +1, a general point set spans P ( W ), where W is a subspace of P ( V ) of dimension m . Since O( V ) acts transitively on a dense orbit of the Grassmannian G m,V ( ) (the subspaces containing an orthogonal basis), we may transform a general set to a subset of a fixed P ( W ). This shows that the varieties O m n and O m m -1 are birationally isomorphic. If m > n +1, we use the projection map O m n /axisshort/axisshort/arrowaxisright O m -1 n onto the first m -1 factors. It is a rational map with general fibre isomorphic to P n . Its geometric generic fibre is isomorphic to the projective space over the algebraic closure of the field K of rational functions of O m -1 n . In other words, the generic fibre is a Severi-Brauer variety over K (see [17], Ch. X, § 6). The rational map has a rational section ( x , . . . , x 1 m -1 ) → ( x , . . . , x 1 m -1 , x m -1 ). Thus the generic fibre is a Severi-Brauer variety with a rational point, hence isomorphic to the projective space over K (loc. cit., Exercise 1). Thus the field of rational functions on O m n is a purely transcendental extension of K , and by induction on m , we obtain that O m n is rational. /square
We know that the ring R n m ( ; ) (2) is generated by determinantal terms d σ of the Gram matrix of m points. If we take σ to be a transposition ( ab ), then the ratio d σ /d (12 ...m ) is equal to
$$R _ { a b } & = [ a b ] ^ { 2 } / [ a a ] [ b b ].$$
More generally for any cyclic permutation σ = ( a 1 . . . a k ) we can do the same to obtain the rational invariant function
$$& R _ { a _ { 1 } \dots a _ { k } } = \frac { [ a _ { 1 } a _ { 2 } ] \cdots [ a _ { k - 1 } a _ { k } ] [ a _ { k - 1 } a _ { k } ] [ a _ { k } a _ { 1 } ] } { [ a _ { 1 } a _ { 1 } ] \cdots [ a _ { k } a _ { k } ] }. \\ & \text{Writing any permutation as a product of cycles. we see that the field of}$$
Writing any permutation as a product of cycles, we see that the field of rational functions on O m n is generated by functions R a ...a 1 k . Note that
$$R _ { a _ { 1 } \dots a _ { k } } ^ { 2 } = R _ { a _ { 1 } a _ { 2 } } \cdots R _ { a _ { k } a _ { 1 } }. \\ \dots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots.$$
We do not know whether a transcendental basis of the field can be chosen among the functions R a ...a 1 k or their ratios.
## 7. Complex spheres
A ( n -1)-dimensional sphere is given by equation in R n of the form
$$\sum _ { i = 1 } ^ { n } & ( x _ { i } - a _ { i } ) ^ { 2 } = R ^ { 2 }. \\. & \quad. \quad. \quad \Xi = \Xi$$
After homogenizing, we get the equation in P n ( R )
$$& ( 7. 1 ) & \quad \cdot \quad \cdot \quad \cdot \quad \cdot \quad \cdot \quad \cdot \\ & & \mathbf Q \colon \sum _ { i = 1 } ^ { n } ( x _ { i } - a _ { i } x _ { 0 } ) ^ { 2 } - R ^ { 2 } x _ { 0 } ^ { 2 } = 0. \\ - \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot$$
The hyperplane section x 0 = 0 is a sphere in P n -1 ( R ) with equation
$$\begin{matrix} \cdots & \cdot & \cdot & \cdot & \cdot & \cdot \\ ( 7. 2 ) & & & & & Q _ { 0 } \colon \sum _ { i = 1 } ^ { n } x _ { i } ^ { 2 } = 0. & & \\ \infty & \cdots & \cdots & \cdots & \cdots & \cdots \end{matrix}.$$
The quadric has no real points, and for this reason, it is called the imaginary sphere. Now we abandon the real space and replace R with C . Equation (7.1) defines a complex sphere . A coordinate-free definition of a complex sphere is a nonsingular quadric hypersurface Q in P n intersecting a fixed hyperplane H 0 along a fixed nonsingular quadric Q 0 in H 0 . In the real case, we additionally assume that Q 0 ( R ) = ∅ . If we choose coordinates such that Q 0 is given by equation (7.2), then a quadric in P n +1 ( C ) containing the imaginary sphere has an equation
$$b ( \sum _ { i = 1 } ^ { n } x _ { i } ^ { 2 } ) - 2 x _ { 0 } ( \sum _ { i = 0 } ^ { n } a _ { i } x _ { i } ) = 0.$$
If b = 0, we may assume that b = 1 and rewrite the equation in the form
$$\lambda _ { 1 } ^ { n } ( x _ { i } - a _ { i } x _ { 0 } ) ^ { 2 } - ( 2 a _ { 0 } + \sum _ { i = 1 } ^ { n } a _ { i } ^ { 2 } ) x _ { 0 } ^ { 2 } = 0, \\ \cdot \quad \cdot \quad \sigma _ { 1 } ^ { n } \sigma _ { 2 } \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot$$
/negationslash so it is a complex sphere. Consider the rational map given by the linear system of quadrics in P n containing the fixed quadric Q 0 with equation (7.2). We can choose a basis formed by the quadric Q 0 and the quadrics V ( x x 0 i ) , i = 0 , . . . , n . This defines a rational map P n /axisshort/axisshort/arrowaxisright P n +1 given by formulae
↦
$$[ x _ { 0 }, \dots, x _ { n } ] \mapsto [ t _ { 0 }, \dots, t _ { n + 1 } ] & = [ - 2 x _ { 0 } ^ { 2 }, - 2 x _ { 0 } x _ { 1 }, \dots, - 2 x _ { 0 } x _ { n }, \sum _ { i = 1 } ^ { n } x _ { i } ^ { 2 } ].$$
The image of this map is a nonsingular quadric in P n +1 given by the equation Q = V ( q ), where
$$q & = 2 t _ { 0 } t _ { n + 1 } + \sum _ { i = 1 } ^ { n } t _ { i } ^ { 2 } = 0. \\ \dots & \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots.$$
We call Q the fundamental quadric . The quadratic form q defines a symmetric bilinear form on V whose value on vectors v, w ∈ V are denoted by 〈 v, w 〉 . The preimage of a hyperplane section ∑ A t i i = 0 is a complex sphere, or its degeneration. For example, the sphere corresponding to a hyperplane which is tangent to the quadric has the zero radius, and hence, it is defined by a singular quadric.
The idea of replacing a quadratic equation of a sphere by a linear equation goes back to Moebius and Chasles in 1850, but was developed by Klein and Lie twenty years later. The spherical geometry, as it is understood in Klein's Erlangen Program
becomes isomorphic to the orthogonal geometry. More precisely, the Inversive group of birational transformations of P n sending spheres to spheres or their degenerations is isomorphic to the projective orthogonal group PO( n +2).
Let us use the quadric Q to define a polarity duality between points and hyperplanes in P n +1 . If we use the equation of Q to define a symmetric bilinear form in C n +2 , the polarity is just the orthogonality of lines and hyperplanes with respect to this form. Under the polarity, hyperplanes become points, and hence spheres in P n can be identified with points in P n +1 .
Explicitly, a point α = [ α , . . . , α 0 n +1 ] ∈ P n +1 defines the sphere
$$S ( \alpha ) \colon \alpha _ { 0 } \sum _ { i = 1 } ^ { n } x _ { i } ^ { 2 } - 2 \sum _ { i = 1 } ^ { n } \alpha _ { i } x _ { 0 } x _ { i } - 2 \alpha _ { n + 1 } x _ { 0 } ^ { 2 } = 0.$$
By definition, its center is the point c = [ α , α 0 1 , . . . , α n ], its radius square R 2 is defined by the formula
$$\alpha _ { 0 } ^ { 2 } R ^ { 2 } = \sum _ { i = 1 } ^ { n } \alpha _ { i } ^ { 2 } + 2 \alpha _ { 0 } \alpha _ { n + 1 } = q ( \alpha _ { 0 }, \dots, \alpha _ { n + 1 } ).$$
Computing the discriminant D of the quadratic form in (7.4), we find
$$D & = \alpha _ { 0 } ^ { n - 1 } ( 2 \alpha _ { 0 } \alpha _ { n + 1 } + \sum _ { i = 1 } ^ { n } \alpha _ { i } ^ { 2 } ) = \alpha _ { 0 } ^ { n - 1 } q.$$
This proves the following.
/negationslash
Proposition 7.1. A complex sphere S α ( ) is singular if and only if a R 0 2 = 0 , or,equivalently, the point α ∈ P n +1 lies on the fundamental quadric Q . If a 0 = 0 , it contains the hyperplane at infinity. If a 0 = 0 and R 2 = 0 , the center is its unique singular point.
Remark 7.2 . Spheres of radius zero are points on the fundamental quadric. Thus the spaces O m n contain as its closed subsets the moduli space of m points on the fundamental quadric modulo the automorphism group of the quadric. For example, when n = 2, this is the moduli space P m 1 = ( P 1 ) m // SL(2) intensively studied in many papers (see, for example, [3], [5]).
Many geometrical mutual properties of complex spheres are expressed by vanishing of some orthogonal invariant of point sets in P n +1 . We give here only some simple examples.
We define two complex spheres in P n to be orthogonal to each other if the corresponding points in P n +1 are conjugate in the sense that one point lies on the polar hyperplane to another point.
Proposition 7.3. Two real spheres in R n are orthogonal to each other (i.e. the radius-vectors at their intersection points are orthogonal) if and only if the corresponding complex spheres are orthogonal in the sense of the previous definition.
Proof. Let
$$\sum _ { i = 1 } ^ { n } ( x _ { i } - a _ { i } ) ^ { 2 } = r ^ { 2 }, \ \sum _ { i = 1 } ^ { n } ( x _ { i } - b _ { i } ) ^ { 2 } = r ^ { \prime 2 },$$
be two orthogonal spheres. Let ( c 1 , . . . , c n ) be their intersection point. Then we have
$$\text{leave} \quad & \quad \cdot \quad \cdot \quad \cdot \quad \cdot \quad \cdot \quad \cdot \quad \cdot \\ 0 = \sum _ { i = 1 } ^ { n } ( c _ { i } - a _ { i } ) ( c _ { i } - b _ { i } ) = \sum _ { i = 1 } ^ { n } c _ { i } ^ { 2 } - \sum _ { i = 1 } ^ { n } ( a _ { i } + b _ { i } ) c _ { i } + \sum _ { i = 1 } ^ { n } a _ { i } b _ { i }, \\ \sum _ { i = 1 } ^ { n } ( c _ { i } - a _ { i } ) ^ { 2 } = r ^ { 2 }, \quad \sum _ { i = 1 } ^ { n } ( c _ { i } - b _ { i } ) ^ { 2 } = r ^ { \prime 2 }.$$
This gives the equality
$$\cdot \quad \begin{array} { c } \cdot & \cdot \\ & 2 \sum _ { i = 1 } ^ { n } a _ { i } b _ { i } - \sum _ { i = 1 } ^ { n } a _ { i } ^ { 2 } - \sum _ { i = 1 } ^ { n } b _ { i } ^ { 2 } + r ^ { 2 } + r ^ { \prime 2 } = 0. \\ & \cdot \end{array} \cdot \quad \begin{array} { c } \cdot & \cdot \\ & 2 \sum _ { i = 1 } ^ { n } a _ { i } b _ { i } ^ { 2 } + r ^ { 2 } + r ^ { \prime 2 } = 0. \\ & \cdot \end{array} \cdot \quad \begin{array} { c } \cdot & \cdot \\ & 2 \sum _ { i = 1 } ^ { n } a _ { i } b _ { i } ^ { 2 } + r ^ { \prime 2 } = 0. \\ & \cdot \end{array} \cdot \end{array}$$
It gives is a necessary and a sufficient condition that two spheres intersect orthogonally. It is clear that the condition does not depend on a choice of an intersection point. The corresponding complex spheres correspond to points [1 , a 1 , . . . , a n , 1 2 ( r 2 -∑ a 2 i )] and [1 , b 1 , . . . , b n , 1 2 ( r 2 -∑ b 2 i )]. The condition that two points [ α , . . . , α 0 n +1 ] and [ α , . . . , α 0 n +1 ] are conjugate is
$$\begin{array} { c } \psi \, \psi \\ \alpha _ { 0 } \beta _ { n + 1 } + \alpha _ { n + 1 } \beta _ { 0 } + \sum _ { i = 1 } ^ { n } \alpha _ { i } \beta _ { i } = 0. \\ \dots \end{array}$$
So we see that the two conditions agree.
/square
For convenience of notation, we denote x = C v ∈ P n by [ v ]. We use the symmetric form 〈 v, w 〉 in V defined by the fundamental quadric.
We have learnt the statements of the following two propositions from [10].
Proposition 7.4. Two complex spheres S ([ v ]) and S ([ w ]) are tangent at some point if and only if
$$\det \begin{pmatrix} \langle v, v \rangle & \langle v, w \rangle \\ \langle w, v \rangle & \langle w, w \rangle \end{pmatrix} = 0.$$
Proof. Let λφ 1 + µφ 2 be a one-dimensional space of quadratic forms in V and V ( λφ 1 + µφ 2 ) be the corresponding pencil of quadrics in P n . We assume that it contains a nonsingular quadric. Then the equation discr( λφ 1 + µφ 2 ) = 0 is a homogeneous form of degree n + 1 whose zeros define singular quadrics in the pencil. The quadrics V ( φ 1 ) and V ( φ 2 ) are tangent at some point p if and only if p is a singular point of some member of the pencil. It is well-known that the corresponding root [ λ, µ ] of the discriminant equation is of higher multiplicity. If V ( φ 1 ) = S ([ v ]) and V ( φ 2 ) = S ([ w ]) are nonsingular complex spheres, then the pencil V ( λq 1 + µq 2 ) corresponds to the line x, y in P n +1 spanned by the points x and y . A point [ λv + µw ] on the line defines a singular quadric if and only if
$$D ( \lambda v + \mu w ) = ( \lambda \alpha _ { 0 } + \mu \beta _ { 0 } ) ^ { n - 1 } q _ { 0 } ( \lambda v + \mu w ) = 0.$$
Our condition for quadrics V ( φ 1 ) and V ( φ 2 ) to be tangent to each other is that the equation q 0 ( λv + µw ) = 0 has a double root. We have
$$q _ { 0 } ( \lambda v + \mu w ) = \lambda ^ { 2 } \langle v, v \rangle + 2 \lambda \mu \langle v, w \rangle + \mu ^ { 2 } \langle w, w \rangle.$$
Thus the condition becomes
$$\det \begin{pmatrix} \langle v, v \rangle & \langle v, w \rangle \\ \langle w, v \rangle & \langle w, w \rangle \end{pmatrix} = 0.$$

Proposition 7.5. n +1 complex spheres S ([ v i ]) in P n have a common point if and only if
$$\det \begin{pmatrix} \langle w _ { 1 }, w _ { 1 } \rangle & \dots & \langle w _ { 1 }, w _ { n + 1 } \rangle \\ \langle w _ { 2 }, w _ { 1 } \rangle & \dots & \langle w _ { 2 }, w _ { n + 1 } \\ \vdots & \vdots & \vdots \\ \langle w _ { n + 1 }, w _ { 1 } \rangle & \dots & \langle w _ { n + 1 }, w _ { n + 1 } \rangle \end{pmatrix} = 0, \\ \L e t h e v e c t o r s \text{ of coordinates of the polar hyperplane of} \, [ v _ { i } ].$$
where w i are the vectors of coordinates of the polar hyperplane of [ v i ] .
Proof. We use the following known identity in the theory of determinants (see, for example, [1], Lemma 10.3.2). Let A = ( a ij ) , B = ( b ij ) be two matrices of sizes k × m and m × k with k ≤ m . Let | A , B I | | I | , I = ( i 1 , . . . , i k ) , 1 ≤ i 1 < . . . < i k ≤ m, be maximal minors of A and B . Then
$$| A \cdot B | & = \sum _ { I } | A _ { I } | | B _ { I } |.$$
Let H i := ∑ n +1 j =0 a ( ) i j t j = 0 be the polar hyperplanes of the complex spheres. We may assume that they are linearly independent, i.e. the vectors w i are linearly independent in V . Otherwise the determinant is obviously equal to zero. Thus the hyperplanes intersect at one point. The spheres have a common point if and only if the intersection point of the hyperplanes H i lies on the fundamental quadric. Let X be the matrix with rows equal to vectors w i = ( a ( ) i 0 , . . . , a ( ) i n +1 ). The projective coordinates of the intersection point are [ C , 1 -C , . . . , 2 ( -1) n +1 C n +2 ], where C j is the maximal minor obtained from X by deleting the j -th column. Let G be the symmetric matrix defining the fundamental quadric. We take in the above formula A = X · G,B = t X . Then the product A · B is equal to the left-hand side of the formula in the assertion of the proposition. The right-hand side is equal to ± ( C C 1 n +2 -∑ n +1 i =2 C 2 i ). It is equal to zero if and only if the intersection point lies on the fundamental quadric. /square
We refer to [18] for many other mutual geometrical properties of circles expressed in terms of invariants of the orthogonal group O(4).
## 8. Real points
We choose V to be a real vector space equipped with a positive definite inner product 〈- -〉 , . A real point in P ( V ) is represented by a nonzero vector v ∈ V . Since 〈 v, v 〉 > 0, we obtain from Propositions 2.3 and 2.4 that all real point sets ( x , . . . , x 1 m ) are stable points. Another nice feature of real point sets is the criterion for vanishing of the Gram functions: det G v , . . . , v ( 1 k ) = 0 if and only if v , . . . , v 1 k are linear dependent vectors in V .
It follows from the FFT and the SFT that the varieties O m n are defined over Q . In particularly, we may speak about the set O m N ( R ) of their real points.
Theorem 8.1. Let V be a real inner-product space. Consider the open subset U of linear independent point sets ( x , . . . , x 1 m ) in P ( V )( R ) . Then the map
$$U \rightarrow \mathbf O _ { n } ^ { m } ( \mathbb { R } )$$
is injective.
Proof. To show the injectivity of the map it suffices to show that
$$( 8. 1 ) & & ( g ( x _ { 1 } ), \dots, g ( x _ { m } ) ) = ( y _ { 1 }, \dots, y _ { m } )$$
for g ∈ PO( V C ) implies that ( g x ( 1 ) , . . . , g ( x m )) = ( y , . . . , y 1 m ) for some g ′ ∈ PO( V ). Choose an orthonormal basis in V to identify V with the Euclidean real space R n +1 . The transformation g is represented by a complex orthogonal matrix. If (8.1) holds, we can find some representatives v i and w i of points x , y i i , respectively, and a matrix A ∈ O( V C ) such that A v · i = w , i i = 1 , . . . , m . This is an inhomogeneous system of linear equations in the entries of A . Since the rank of the matrix [ v , . . . , v 1 n ] with columns v i is maximal, there is a unique solution for A and it is real. Thus g is represented by a transformation from O( n +1 , R ). /square
Let us look at the rational invariants R a ,...,a 1 k . Let φ ij , π -φ ij , denote the angles between basis vectors of the lines x i = R v i . Obviously,
$$R _ { i j } = \cos ^ { 2 } \phi _ { i j }$$
is well defined and does not depend on the choice of the bases. Also,
$$R _ { i j \dots k } = \cos \phi _ { i j } \cdots \cos \phi _ { k i } \\ \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \end{$$
are well defined too. Applying the previous theorem, we see that the cyclic products of the cosines determine uniquely the orbit of a linearly independent point set.
Finally, let us discuss configuration spaces of real spheres. For this we have to choose V = R n +2 to be a real space with quadratic form q 0 of signature ( n +1 1) , defined in (7.3). A real sphere with non-zero radius is defined by formula (7.4), where the coefficients ( α , . . . , α 0 n +1 ) belong to the set q -1 0 ( R > 0 ). It consists of two connected components corresponding to the choice of the sign of α 0 . Choose the component V + where α 0 > 0. The image V + / R > 0 of V + in the projective space P ( V + ) is, by definition, the hyperbolic space H n +1 . Each point in H n +1 can be uniquely represented by a unique vector v = ( α , . . . , α 0 n +1 ) with
$$\langle v, v \rangle = \sum _ { i = 1 } ^ { n } \alpha _ { i } ^ { 2 } + 2 \alpha _ { 0 } \alpha _ { n + 1 } = 1, \quad \alpha _ { 0 } > 0.$$
Each v ∈ H n +1 defines the orthogonal hyperplane
The cosine of the angle between the hyperplanes H v and H w is defined by
$$H _ { v } = \{ x \in \mathbb { H } ^ { n + 1 } \colon \langle x, v \rangle = 0, q ( x ) = 1 \}. \\ \intertext { a, c, c, c } \, \det \, \det \, \det \, \det \, \det \, \det \, \det \, \det \, \det \, \det \, \det \, \det \, \det \, \det \, \det \, \det \, \det \, \det \, \det \, \det \, \det \, \det \, \det \, \det \, \det \, \det \, \det \, \det \, \det \, \det \, \det \, \det \, \det \, \det \, \det \, \det \, \det \, \det \, \det \, \det \, \det \, \det \, \det \, \det \, \det \, \det \, \det \, \det \, \det \, \det \, \dot { \tau } } \, \det \, \det \, \det \, \det \, \det \, \det \, \det \, \det \, \det \, \det \, \det \det \det \det \det \det \det \det \det \det \det \det \det \det \det \det \det \det \det \det \det \det \det \det \det \det \det \det \det \det \det \det \det \det \det \det \det \det \det \det \det \det \det \det \det \det \det \det \det \det \det \det \det \det \det \det \det \det \det \det \det \det \det \det \det \det \det \det \det \det \det \det \det \det \det \det \det \det \det \det \det \det \det \det \det \det \det \det \det \det \det \det \det \det \det \det \det \det \det \det \dot { \tau } } \, \det \, \det \, \det \, \det \, \det \, \det \, \det \, \det \, \det \, \det \, \det \det \det \det \det \det \det \det \det \det \det \det \det \det \det \det \det \det \det \det \det \det \det \det \det \det \det \det \det \det \det \det \det \det \det \det \det \det \det \det \det \det \det \det \det \det \det \det \det \det \det \det \det \det \det \det \det \det \det \det \det \det \det \det \det \det \det \det \det \det \det \det \det \det \dot { \tau } } \, \det \, \det \, \det \, \det \, \det \, \det \det \det \det \det \det \det \det \det \det \det \det \det \det \det \det \det \det \det \det \det \det \det \det \det \det \det \det \det \det \det \det \det \det \det \det \det \det \det \det \det \det \det \det \det \det \det \det \det \det \det \det \det \det \det \det \det \det \det \det \det \det \det \det \det \det \det \det \det \det \det \det \det \det \det \det \det \det \det \det \det \det \det \det \det \det \det \det \dotdet \det \det \det \det \det \det \det \det \det \det \det \det \det \det \det \det \det \det \det \det \det \det \det \det \det \det \det \det \det \det \det \det \det \det \det \det \det \det \det \det \det \det \det \det \det \det \det \det \det \det \det \det \det \det \det \det \det \det \det \det \det \det \det \det \det \det \det \det \det \det \det \det \det \det \det \det \det \det \det \det \det \det \det \det \det \det \det \det \det \det \det \det \det \det \det \det \det \det \det\det \det \det \det \det \det \det \det \det \det \det \det \det \det \det \det \det \det \det \det \det \det \det \det \det \det \det \det \det \det \det \det \det \det \det \det \det \det \det \det \det \det \det \det \det \det \det \det \det \det \det \det \det \det \det \det \det \det \det \det \det \det \det \det \det \det \det \det \det \det \det \det \det \det \det \det \det \det \det \det \det \det \det \det \det \det \det \det \det \det \det \det \det \det \det \det \det \det \det \det \det \det \det \det \det \det \det \det \det \det \det \det \det \det \det \det \det \det \det \det \det \det \det \det \det \det \det \det \det \det \det \det \det \det \det \det \det \det \det \det \det \det \det \det \det \det \det \det \det \det \det \det \det \det \det \det \det \det \det \det \det \det \det \det \det \det \det \det \det \det \det \det \det \det \det \det \det \det \det \det \det \det \det \det \det \det \det \det \det \det \det \det \det \det \det \det \det \det \det \delta \, \det \det \det \det \det \det \det \det \det \det \det \det \det \det \det \det \det \det \det \det \det \det \det \det \det \det \det \det \det \det \det \det \det \det \det \det \det \det \det \det \det \det \det \det \det \det \det \det \det \det \det \det \det \det \det \det \det \det \det \det \det \det \det \det \det \det \det \det \det \det \det \det \det \det \det \det \det \det \det \det \det \det \det \det \det \det \det \det \det \det \det \det \det \det \det \det \det \det \dot \det \det \det \det \det \det \det \det \det \det \det \det \det \det \det \det \det \det \det \det \det \det \det \det \det \det \det \det \det \det \det \det \det \det \det \det \det \det \det \det \det \det \det \det \det \det \det \det \det \det \det \det \det \det \det \det \det \det \det \det \det \det \det \det \det \det \det \det \det \det \det \det \det \det \det \det \det \det \det \det \det \det \det \det \det \det \det \det \det \det \det \det \det \det \det \det \det \det \det \cot \det \det \det \det \det \det \det \det \det \det \det \det \det \det \det \det \det \det \det \det \det \det \det \det \det \det \det \det \det \det \det \det \det \det \det \det \det \det \det \det \det \det \det \det \det \det \det \det \det \det \det \det \det \det \det \det \det \det \det \det \det \det \det \det \det \det \det \det \det \det \det \det \det \det \det \det \det \det \det \det \det \det \det \det \det \det \det \det \det \det \det \det \det \det \det \det \det \det \det \end{c}$$
$$\cos \phi = - \langle v, w \rangle. \\ \dots \dots \cdots \cdots \cdots \cdots \colon \cdots.$$
If |〈 v, w 〉| > 1, the hyperplanes are divergent, i.e. they do not intersect in the hyperbolic space. In this case cosh( |〈 v, w 〉| ) is equal to the distance between the two divergent hyperplanes. If 〈 v, w 〉 = 1, the hyperplanes are parallel. By Proposition 2.1, the corresponding real spheres S v ( ) and S w ( ) are tangent to each other.
## References
- [1] I. Dolgachev, Classical algebraic geometry. A modern view . Cambridge University Press, Cambridge, 2012.
- [2] I. Dolgachev, V. Lunts, A character formula for the representation of a Weyl group in the cohomology of the associated toric variety . J. Algebra 168 (1994), 741-772.
- [3] I. Dolgachev, D. Ortland, Point sets in projective spaces and theta functions . Ast´ erisque No. 165 (1988), 210 pp.
- [4] H. Flaschka, L. Haine, Torus orbits in G/P . Pacific J. Math. 149 (1991), 251-292.
- [5] B. Howard, J. Millson, A. Snowden, R. Vakil, The equations for the moduli space of n points on the line . Duke Math. J. 146 (2009), 175-226.
- [6] M. Kapranov, B. Sturmfels, A. Zelevinsky, Quotients of toric varieties . Math. Ann. 290 (1991), 643-655.
- [7] M. Kapranov, Chow quotients of Grassmannians. I . I. M. Gelfand Seminar, 29-110, Adv. Soviet Math., 16, Part 2, Amer. Math. Soc., Providence, RI, 1993.
- [8] F. Klein, Vorlesungen ¨ber h¨here Geometrie u o . Dritte Auflage. Bearbeitet und herausgegeben von W. Blaschke. Die Grundlehren der mathematischen Wissenschaften, Band 22 SpringerVerlag, Berlin 1968.
- [9] A. Klyachko, A. Orbits of a maximal torus on a flag space . (Russian) Funktsional. Anal. i Prilozhen. 19 (1985), 77-78 [English transl.: Functional Analysis and its Applications, 19 (1985), 65-66].
- [10] E. Kranser, The invariant theory of the inversion group geometry upon a quadric surface , Trans. Amer. Math. Soc., 1 (1900), 430-498.
- [11] S. Mukai, H. Umemura, Minimal rational threefolds , Algebraic geometry (Tokyo/Kyoto, 1982), 490-518, Lecture Notes in Math., 1016, Springer, Berlin, 1983.
- [12] S. Mukai, Igusa quartic and Steiner surfaces . Compact moduli spaces and vector bundles, 205-210, Contemp. Math., 564, Amer. Math. Soc., Providence, RI, 2012.
- [13] J. Petersen, Die Theorie der regul¨ren graphs a , Acta Mathematica 15 (1891) 193-220.
- [14] C. Procesi, Lie groups: an approach through invariants and representations , Springer, 2007.
- [15] C. Procesi, The toric variety associated to Weyl chambers . Mots, 153-161, Lang. Raison. Calc., Herm` es, Paris, 1990.
- [16] G. Salmon, Lessons introductory to the modern higher algebra , Hodges and Smith, 1859, reprinted by Chelsea Publ. Co. 1964.
- [17] J.-P. Serre, Local fields , Springer-Verlag, 1979.
- [18] E. Study, Das Apollonische Problem , Math. Ann. 49 (1897), 497-542.
- [19] H. Weyl, The Classical groups, their invariants and representations , Princeton Univ. Press, 1939.
Department of Mathematics, University of Michigan, 525 E. University Av., Ann Arbor, MI, 49109
E-mail address :
[email protected]
Center for Communications Research, Institute for Defense Analysis, 805 Bunn Dr.,
Princeton, NJ, 08540
E-mail address : [email protected] | null | [
"Igor Dolgachev",
"Benjamin Howard"
] | 2014-08-02T14:10:33+00:00 | 2014-08-02T14:10:33+00:00 | [
"math.AG"
] | Configuration spaces of complex and real spheres | We study the GIT-quotient of the Cartesian power of projective space modulo
the projective orthogonal group. A classical isomorphism of this group with the
Inversive group of birational transformations of the projective space of one
dimension less allows one to interpret these spaces as configuration spaces of
complex or real spheres. |
1408.0377v1 | ## Layered, Exact-Repair Regenerating Codes Via Embedded Error Correction and Block Designs
Chao Tian, Senior Member, IEEE , Birenjith Sasidharan, Vaneet Aggarwal, Member, IEEE , Vinay A. Vaishampayan, Fellow, IEEE , and P. Vijay Kumar, Fellow, IEEE
## Abstract
A new class of exact-repair regenerating codes is constructed by stitching together shorter erasure correction codes, where the stitching pattern can be viewed as block designs. The proposed codes have the 'help-by-transfer' property where the helper nodes simply transfer part of the stored data directly, without performing any computation. This embedded error correction structure makes the decoding process straightforward, and in some cases the complexity is very low. We show that this construction is able to achieve performance better than space-sharing between the minimum storage regenerating codes and the minimum repair-bandwidth regenerating codes, and it is the first class of codes to achieve this performance. In fact, it is shown that the proposed construction can achieve a non-trivial point on the optimal functional-repair tradeoff, and it is asymptotically optimal at high rate, i.e., it asymptotically approaches the minimum storage and the minimum repair-bandwidth simultaneously.
## I. INTRODUCTION
Distributed data storage systems can encode and disperse information (a message) to multiple storage nodes (or disks) such that a user can retrieve it by accessing only a subset of them. Such systems are able to provide superior reliability and availability in the event of disk corruption or network congestion. In order to reduce the amount of storage overhead required to guarantee such performance, erasure correction codes can be used instead of simple replication of the data. Given the massive amount of data that is currently being stored, even a small reduction in storage overhead can translate into huge savings. For instance, Facebook currently stores 3 copies of all data, running 3000 nodes with a total of 100 PB of storage space. A 600 -node Hadoop [1] cluster at Facebook for performing data analytics on event logs from their website stores 2 petabytes of data, and grows about 15 TB every day [2].
When the data is encoded by an erasure code, data repair ( e.g. , due to node failure) becomes more involved, because the information stored at a given node may not be directly available from any one of the remaining storage nodes, but it can nevertheless be reconstructed since it is a function of the information stored at these nodes. One key issue that affects the system performance is the total amount of information that the remaining nodes need to transmit to the new node. Consider a storage system which has n storage nodes, and the data can be reconstructed by accessing any k of them. A failed node is
This paper was presented in part at 2013 IEEE International Symposium on Information Theory, Istanbul, Turkey.
repaired by requesting any d of the remaining nodes to provide information, and then using the received information to construct a new data storage node. A naive approach is to let these helper nodes transmit sufficient data such that the underlying data can be reconstructed completely, and then the information that needs to be stored at the new node can be subsequently generated. This approach is however rather wasteful, since the data stored at the new node is only a fraction of the complete data.
Dimakis et al. in [3] proposed the regenerating code framework to investigate the tradeoff between the amount of storage at each node ( i.e., data storage) and the amount of data transfer for repair ( i.e., repair bandwidth). It was shown that for the case when the regenerated new node only needs to fulfill the role of the failed node functionally ( i.e. , functional-repair), but not to replicate exactly the original content at the failed node ( i.e. , exact-repair), the problem can be converted to a network multicast problem, and thus the celebrated network coding result [4] can be applied. By way of this equivalence, the optimal tradeoff was completely characterized in [3] for this case. The two important extreme cases, where the data storage is minimized and the repair bandwidth is minimized, are referred to as minimum storage regenerating (MSR) codes and minimum bandwidth regenerating (MBR) codes, respectively. The functional-repair problem is well understood and constructions of such codes are available (see [3], [5], [6]).
The functional-repair framework implies that the coding rule evolves over time, which incurs additional system overhead. Furthermore, functional repair does not guarantee the data to be stored in systematic form, thus cannot satisfy this important practical requirement. In contrast, exact-repair regenerating codes do not suffer from such disadvantages. Exact-repair regenerating codes were investigated in [7]-[13], all of which address either the MBR case or the MSR case. Particularly, the optimal code constructions in [7] and [9] show that the more stringent exact-repair requirement does not incur any penalty for the MBR case; the constructions in [8], [9], [11] show that this is also true asymptotically for the MSR case. These results may lead to the impression that enforcing exact-repair never incurs any penalty compared to functional repair. However, it was shown in [7] that a large portion of the optimal tradeoffs achievable by functional-repair codes cannot be strictly achieved by exact-repair codes, and it was shown more recently in [14] that there exists a non-vanishing gap between the optimal functional-repair tradeoff and the exact-repair tradeoff, and thus the loss is not asymptotically diminishing. The characterization of the optimal tradeoff for exact-repair regenerating codes under general set of parameters remains open.
Codes achieving tradeoff other than the MBR point or the MSR point may be more suitable for systems employing exact-repair regenerating codes, which may have an acceptable storage-repair-bandwidth tradeoff and lower coding complexity. However, it is unknown whether there even exist codes that can achieve a storage-bandwidth tradeoff better than simply space-sharing between an MBR code and an MSR code. In this work, we provide a code construction based on stitching together shorter erasure correction codes through combinatorial block designs, which is indeed able to achieve such tradeoff points. We show that it can achieve a non-trivial point on the optimal functional-repair tradeoff for [ n, k, d = k = n -1] , and it is also asymptotically optimal at high rate while the space-sharing approach is strictly sub-optimal; moreover, space-sharing among this non-trivial tradeoff point, the MSR point, and the MBR point achieves the complete exact-repair tradeoff for the case [ n, k, d ] = [4 3 3] , , given in [14].
The conceptually straightforward code construction we propose has the property that the helper nodes in
the repair do not need to perform any computation, but can simply transmit certain stored information for the new node to synthesize and recover the lost information. This 'help-by-transfer' property is appealing in practice, since it reduces and almost completely eliminates the computation burden at the helper nodes. This property also holds in the constructions proposed in [7] and [15]. In fact our construction was partially inspired by and may be viewed as a generalization of these codes. Another closely related work is [16], where block designs were also used, however repetition is the main tool used in that construction, in contrast to the embedded erasure correction codes in our construction. The system model in [16] is also different, where the repair only needs to guarantee the existence of one particular d -helper-node combination (fix-access repair), instead of the more stringent requirement that the repair information can come from any d -helper-node combination (random-access repair).
The results presented here are the combination of two independent and concurrent works [17] and [18]. Given the surprising similarity between the code constructions found by the two groups, we decided to merge the results in the hope that the readers may gain a more coherent understanding from this effort . 1
The rest of the paper is organized as follows. In Section II, several relevant existing results are reviewed. Section III provides the construction of the canonical codes for the case [ n, k, d = k ] , and the performance is analyzed. Section IV provides the general code constructions. Finally Section V concludes the paper.
## II. PRELIMINARIES
In this section, we review some basics on regenerating codes, maximum separable codes, rank metric codes, and combinatorial block designs. We write { 1 2 , , . . . , n } as I n for simplicity.
## A. Exact-Repair Regenerating Codes
An [ n, k, d ] exact-repair regenerating code for a storage system with a total of n storage nodes satisfies the condition that any k of them can be used to reconstruct the original message, and to repair a lost node, the new node may access data from any d of the remaining nodes. Let the total amount of raw data stored be M units and let each storage site store α units, i.e., the redundancy of the system is nα -M . To repair a node failure (regenerate a new node), each helper node transmits β units of data to the new node, which results in a total of dβ units of data transfer. It is clear that the quantities α and β scale linearly with M , and thus we shall normalize the other two quantities using M , i.e.,
$$\bar { \alpha } \stackrel { \triangle } { = } \frac { \alpha } { M }, \quad \bar { \beta } \stackrel { \triangle } { = } \frac { \beta } { M },$$
and use them as the measure of performance from here on. The problem can be more formally defined using a set of encoding and decoding functions, which we omit here for conciseness (see [14]).
Fig. 1. The cut-set bound, the space-sharing line and the tradeoffs achieved by the proposed codes for [ n, k, d ] = [9 , 7 8] , .
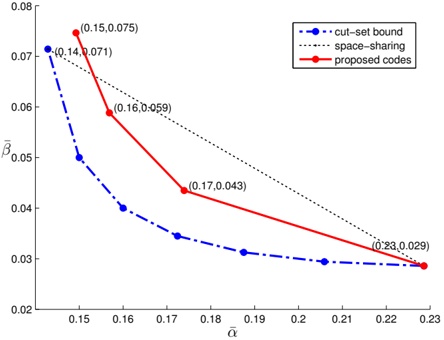
## B. Cut-Set Outer Bound, the MBR Point and the MSR Point
As mentioned earlier, a precise characterization of the optimal storage-bandwidth tradeoff under functional repair was obtained in [3], which is given by
$$\sum _ { i = 0 } ^ { k - 1 } \min ( \bar { \alpha }, ( d - i ) \bar { \beta } ) \geq 1.$$
Since exact-repair is a more stringent requirement than functional-repair, it provides an outer bound for exact-repair regenerating codes, which must also satisfy (2), possibly with strict inequality. It can be shown that the bound in (2) is equivalently to
$$p \bar { \alpha } + \sum _ { i = p } ^ { k - 1 } ( d - i ) \bar { \beta } \geq 1, \quad p = 0, 1, \dots, k - 1.$$
One extreme point of this outer bound is when the storage is minimized, i.e. , the minimum storage regenerating (MSR) point, which is
$$\bar { \alpha } = \frac { 1 } { k }, \quad \bar { \beta } = \frac { 1 } { k ( d - k + 1 ) }.$$
The other extreme case is when the repair bandwidth is minimized, i.e. , the minimum bandwidth regenerating (MBR) point, which is
$$\bar { \alpha } = \frac { 2 d } { k ( 2 d - k + 1 ) }, \quad \bar { \beta } = \frac { 2 } { k ( 2 d - k + 1 ) }.$$
Both of these extreme points (on the functional-repair tradefoff) are achievable (see [7]-[9], [11]) under
1 It should be noted that the 'layers' in [17] and [18] refer to different aspects of the construction: in the former it is used to refer the concatenation of two erasure correction coding steps, while in the latter it is used to refer to the way the component codes are arranged.
exact-repair, however the functional-repair outer bound is not tight in general (see [7] and [14]). The outer bound and the two extreme points are illustrated in Fig. 1 for [ n, k, d ] = [9 7 8] , , .
The space-sharing line between MSR and MBR points is characterized by the equation ( e.g., [7])
$$k \bar { \alpha } + k ( d - k + 1 ) \bar { \beta } \ = \ 2,$$
which when d = k , reduces to
$$k ( \bar { \alpha } + \bar { \beta } ) \ = \ 2.$$
It is sometimes convenient to view all the achievable (¯ α, β ¯ ) pairs together as a region, for which we introduce the following definition.
Definition 1: A pair (¯ α, β ¯ ) is said to be achievable for [ n, k, d ] exact-repair regenerating if there exists an exact-repair regenerating code with such a normalized storage and repair-bandwidth. The closure of the collection of all such pairs is the achievable (¯ α, β ¯ ) region, denoted as R n,k,d .
## C. Asymptotic Tradeoff Region
The proposed codes have performance better than space-sharing line in many cases, especially when k is close to n . It is insightful to consider the asymptote when k is driven to infinity while keeping n = k + τ 1 and d = k + τ 2 where τ 1 and τ 2 are fixed constant integers such that τ 1 > τ 2 ≥ 0 . For this purpose, define the following region
$$\mathcal { R } _ { \infty } \stackrel { \triangle } { = } \bigcup _ { k \to \infty } k \mathcal { R } _ { ( k + \tau _ { 1 }, k, k + \tau _ { 2 } ) },$$
where τ 1 and τ 2 are fixed integers as previously stated, and we have multiplied the components of elements in R ( k + τ 1 ,k,k + τ 2 ) by k . This k -fold expansion definition is partly motivated by observing k appears for both ¯ α and ¯ β terms in (6).
It is trivial to see that an outer bound for R ∞ is given by
$$k \bar { \alpha } \geq 1, \ \ k \bar { \beta } \geq 0,$$
by taking ¯ α at the MSR point, and ¯ β at the MBR point.
Space-sharing between the MSR point and the MBR point cannot achieve this outer bound due to (6). In Section III, we show that the proposed codes can achieve the entire region R ∞ when d = k .
## D. Maximum Distance Separable Code
A linear code of lengthn and dimension k is called an [ n, k ] code. The Singleton bound (see e.g. , [19]) is a well known upper bound on the minimum distance for any [ n, k ] code, given as
$$d _ { \min } \leq n - k + 1.$$
An [ n, k ] code that satisfies the Singleton bound with equality is called a maximum distance separable (MDS) code. A key property of an MDS code is that it can correct any ( n -k ) or fewer erasures. There
TABLE I EXAMPLE STEINER SYSTEMS S (2 3 7) , , , S (2 3 9) , , AND S (2 4 13) , , .
| S (3 , 7) | { (1 , 2 , 3) , (1 , 4 , 5) , (1 , 6 , 7) , (2 , 4 , 6) , (2 , 5 , 7) , (3 , 4 , 7) , (3 , 5 , 6) } |
|-------------|-------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------|
| S (3 , 9) | { (2 , 3 , 4) , (5 , 6 , 7) , (1 , 8 , 9) , (1 , 4 , 7) , (1 , 3 , 5) , (4 , 6 , 8) , (2 , 7 , 9) , (2 , 5 , 8) , (1 , 2 , 6) , (4 , 5 , 9) , (3 , 7 , 8) , (3 , 6 , 9) } |
| S (4 , 13) | { (1 , 2 , 4 , 10) , (2 , 3 , 5 , 11) , (3 , 4 , 6 , 12) , (4 , 5 , 7 , 13) , (5 , 6 , 8 , 1) , (6 , 7 , 9 , 2) , (7 , 8 , 10 , 3) , (8 , 9 , 11 , 4) , (9 , 10 , 12 , 5) , (10 , 11 , 13 , 6) , (11 , 12 , 1 , 7) , (12 , 13 , 2 , 8) , (13 , 1 , 3 , 9) } |
exist various ways to construct MDS codes for any given [ n, k ] values, and it is known that there exists an [ n, k ] MDS code in any finite field F q where q ≥ n ; see, e.g. , [19].
In coding literature, an [ n, k ] code with minimum distance d min is sometimes also referred to as an ( n, k, d min ) code. In the context of regenerating codes, the triple [ n, k, d ] instead specifies the total number of nodes, the number of nodes that together allow reconstruction of the data, and the number of helper nodes during a repair, respectively. In order to avoid possible confusion, we do not write the minimum distance d min explicitly for a linear code, and also use brackets instead of parentheses in this work.
## E. Linearized Polynomial and Gabidulin Codes
An important component in our construction is a code based on linearized polynomials, and the following lemma is particularly relevant to us; see, e.g., [20].
Lemma 1: A linearized polynomial
$$f ( x ) \ = \ \sum _ { i = 1 } ^ { M } v _ { i } x ^ { q ^ { i - 1 } }, \ v _ { i } \in \mathbb { F } _ { q ^ { \kappa } }$$
can be uniquely identified from evaluations at any M points, for which the input values are linearly independent over F q .
Another relevant property of linear polynomials is that they satisfy the following condition
$$f ( a x + b y ) \ = \ a f ( x ) + b f ( y ), \ a, b \in \mathbb { F } _ { q }, \ x, y \in \mathbb { F } _ { q ^ { \kappa } },$$
which is the reason that they are called 'linearized'.
Gabidulin [21] proposed a class of codes based on linearized polynomials, which is maximum distance separable in terms of rank metric. This class of codes can be viewed as a generalized version of the MDS codes, and it plays an instrumental role in our construction.
## F. Block Designs
A block design is a set together with a family of subsets ( i.e. , blocks) whose members are chosen to satisfy some properties. The blocks are required to all have the same number of elements, and thus a given block design with parameters ( r, n ) , where r < n , is specified by ( X, B ) where X is an n -element
TABLE II γ AND N
VALUES FOR THE TWO CLASSES OF BLOCK DESIGNS.
| | γ | N |
|------|-------------------|------------------------|
| DCBD | ν ( n - 1 r - 1 ) | ν ( n r ) |
| BIBD | λ ( n - 1) r - 1 | λn ( n - 1) r ( r - 1) |
set and B is a collection of r -element subsets of X . The blocks are usually allowed to repeat. We use N to denote the total number of blocks in a block design when the parameters are clear from the context. Two classes of block designs are particularly relevant to us:
- · The first is a restricted class of Steiner systems known in the literature. A Steiner system S t, r, n ( ) is a block design with parameters ( r, n ) where each element of X appears exactly γ times, and each t -element subset of X appears in exactly one block; in this work we shall restrict our attention to the case t = 2 , and thus refer to it as a restricted Steiner system and write it simply as S r, n ( ) . This design can be generalized to balanced incomplete block design (BIBD), S λ ( r, n ) , where each pair of elements of X appears in exactly λ blocks, instead of a single block. A restricted Steiner system is thus a BIBD with λ = 1 .
- · We refer the second class of block designs as duplicated combination block design (DCBD). An r -combination of a set X is a subset of r distinct elements of X . A duplicated combination block design C ν ( r, n ) is a block design with parameters ( r, n ) where each r -combination appears exactly ν times, which we write as C ν ( r, n ) .
It is clear that DCBDs can be viewed as BIBDs with λ = ν ( n -2 r -2 ) . This implies that for any ( r, n ) pair, a BIBD always exists (in fact even when we limit to ν = 1 ). However, for a fixed ( λ, r ) pair, a BIBD may not exist for all values of n . For the particularly well understood Steiner triple systems ( i.e. Steiner systems when t = 2 and r = 3 ), there exists an S (3 , n ) if and only if n = 0 , or n modulo 6 is 1 or 3 [22]. Examples of S (3 7) , , S (3 , 9) are given in Table I, where a design for S (4 , 13) is also included. The parameter γ and the total number of blocks N can be calculated straightforwardly (see [22]), and are listed in Table II for convenience. Without loss of generality, we assume X = I n from here on. More details on BIBDs, Steiner systems and other block designs can be found in, e.g. , [22] and [23].
## III. CANONICAL CODES FOR [ n, k, d = k ]
In this section, we present a set of exact-repair codes, referred to as the canonical codes, for the case d = k . The overall code is formed by stitching together shorter MDS codes, and the stitching patterns follow either BIBDs or DCBDs. This set of codes can be indexed by two auxiliary parameters m and r satisfying 1 ≤ m<r < n , where r is the same parameter as in the block designs being used. As will be seen, the parameters d and m are related as m = n -d , and the codes for m = 1 are particularly simple which will be presented first. The qualifier 'canonical' is used to describe the case of d = k because the construction in this case can be viewed as the basic form of a subsequent construction for the general case k < d .
/g1005 /g853/g1005
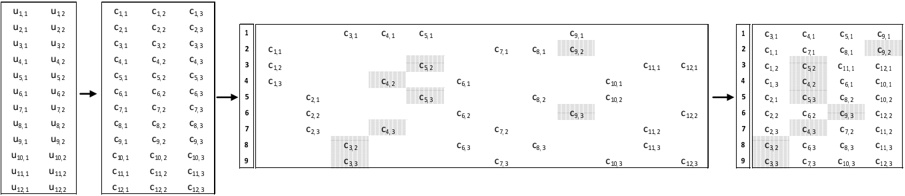
/g1005 /g853/g1006
/g1005 /g853/g1005
/g1005 /g853/g1006
/g1005 /g853/g1007
Fig. 2. For [ n, k, d ] = [9 8 8] , , , the parameter chosen here are m = 1 , r = 3 , and the block design is Steiner triple system shown on the second row of Table I. The data matrix is of dimension 12 × 2 , and after the first encoding step, c i = ( u i, 1 , u i, 2 , u i, 1 + u i, 2 ) are placed on the i -th column in the auxiliary matrix (the third matrix). The resulting code matrix is of dimension 9 × 4 , after the blank spaces are removed. The helper symbols to repair node1 are given in shade.
The canonical codes, together with known MSR codes and MBR codes, achieve the complete optimal tradeoff for [ n, k, d ] = [4 3 3] , , that was recently characterized in [14]. For [ n, k, d = k = n -1] , this construction is always able to achieve a non-trivial point on the cut-set bound, i.e., the optimal functionalrepair tradeoff, other than the MSR point and the MBR point. More generally, for [ n, k, d = k ] , it can achieve performance better than space-sharing between MSR and MBR in certain parameter range. For high rate regenerating codes, the canonical codes are asymptotically optimal, and essentially achieve the complete region R ∞ .
## A. Canonical Codes Using Restricted Steiner Systems and BIBDs
We use restricted Steiner Systems and BIBDs to construct canonical codes for the cases d = k = n -1 . Here the auxiliary parameter m = 1 , and it will become clear in the sequel why it is set as such. First fix a restricted Steiner system S r, n ( ) = { B , B , . . . , B 1 2 N } . The canonical code using this block design has M c = ( r -m N ) = ( r -1) N data symbols in certain finite field F q , arranged as an N × ( r -1) matrix U , whose rows are u 1 , u 2 , . . . , u N . The structure of the canonical code can be inferred from a two-step process (see Fig. 2) by which the data matrix U is encoded into an n × γ code array:
- 1) For i = 1 2 , , ..., N , the vector u i is encoded into c i = ( u i, 1 , u i, 2 , . . . , u i,r -1 , ∑ r -1 j =1 u i,j ) ;
- 2) The r symbols in c i , referred to together as a parity group, are placed in the rows specified in B i , i = 1 2 , , . . . , N , appended after any previous written symbols 2 .
After these encoding steps, each row in the resulting matrix corresponds to the symbols to be written on each node. Since the arrangement of the blocks is not unique, and the placement of the symbols in each parity group c i is also not unique, consequently the resulting code is not unique.
Since each component code c i has one parity symbol, it can withstand up to one erasure ( m = 1 ), and thus any single lost node can be repaired from the other n -1 nodes. More precisely, to repair node j , the helper node set is ∆ = I n \ { j } and the repair process has two steps (see Fig. 2):
2 All the symbols in c i together are sometimes called a parity group in the storage literature, and are referred to as a layer in [18]; we shall adopt the parity group terminology in the sequel.
- 1) Helper transmission: For i = 1 2 , , ..., N , if j ∈ B i , then the helper nodes in ∆ ∩ B i ( i.e., the helper nodes that have symbols in c i ) send the symbols in c i to the new node;
- 2) Symbol regeneration: For i = 1 2 , , ..., N , if j ∈ B i , with the r -1 symbols received from the helper nodes, the lost symbol in c i is regenerated.
Based on the construction, it can be seen that
$$M _ { c } = ( r - 1 ) N = \frac { n ( n - 1 ) } { r }, \quad \alpha = \gamma = \frac { ( n - 1 ) } { r - 1 }, \quad \beta = 1,$$
where the value of α is derived from the fact that in restricted Steiner systems each element appears in exactly γ blocks, and the value of β is derived from the fact that node j contributes one symbol to repair node i whenever ( i, j ) appears in a block in the block design, and the fact that each pair of elements appears in exactly one block. Clearly the alphabet here can be chosen as F 2 , i.e, , a binary code.
In the construction, the restricted Steiner system can be replaced with a more general BIBD without any essential change, resulting in the parameters
$$M _ { c } = ( r - 1 ) N = \frac { \lambda n ( n - 1 ) } { r }, \quad \alpha = \gamma = \frac { \lambda ( n - 1 ) } { r - 1 }, \quad \beta = \lambda.$$
## B. Canonical Codes Using DCBDs
As a natural generalization from the previous case, for d = k ≤ n -1 we set the auxiliary parameter m = n -d . Intuitively m is again the number of erasures that the component codes c i can withstand, and since having d = n -m helper nodes can be equivalently viewed as erasing the other m nodes, any lost symbols can be regenerated using only d = n -m helper nodes. For the repetition factor ν , let us for now choose ν = d = n -m , and we will revisit it later to discuss possibly reducing its value.
Fix a C ν ( r, n ) = { B , B , . . . , B 1 2 N } . We encode an N × ( r -m ) matrix into an n × γ code array in two steps (see Fig. 3):
- 1) For i = 1 2 , , ..., N , the vector u i is encoded using an [ r, r -m ] MDS code to yield c i
$$u _ { i } \in \mathbb { F } _ { q } ^ { r - m } \ \Rightarrow \ c _ { i } \in \mathbb { F } _ { q } ^ { r }.$$
- 2) The r symbols in c i are placed in the rows specified in B i ∈ C ν ( r, n ) , appended after any previous written symbols.
The only difference from the previous case is that the encoding from u i into c i now utilizes a general MDS code, instead of the single parity code (also an MDS code). The alphabet here can be chosen to be any F q where q ≥ r , in order for the component MDS code to exist. To repair node j , the helper node set is denoted as ∆ = { δ , δ 1 2 , . . . , δ d } , and the repair process is as follows (Fig. 3):
- 1) Helper transmission: For i = 1 2 , , ..., N , if j ∈ B i , some ( r -m ) helper nodes in the set ∆ ∩ B i send the symbols in c i to the new node;
- 2) Symbol regeneration: For i = 1 2 , , ..., N , if j ∈ B i , with the ( r -m ) symbols received from the helper nodes, the lost symbol in c i is regenerated.
The choice of m = n -d guarantees that the condition | ∆ ∩ B i | ≥ r -m holds as long as | ∆ = | d ≥ r -m , thus the repair will always succeed. However, it may occur that | ∆ ∩ B i | > r -m for some
/g1005

/g1005 /g853/g1005
/g1007 /g853/g1005
/g1008 /g853/g1005
/g1009 /g853/g1005
/g1005 /g1005 /g853/g1005
/g1005 /g1007 /g853/g1005
/g1005 /g1008 /g853/g1005
/g1005 /g1009 /g853/g1005
/g1010 /g853/g1005
/g1012 /g853/g1005
/g1013 /g853/g1005
/g1005 /g1004 /g853/g1005
Fig. 3. For [ n, k, d ] = [5 3 3] , , , the parameter is chosen as m = n -d = 2 , r = 4 , and the block design is 3 -DCBD with parameters (4 5) , , which duplicate the following blocks three times: { (1 2 3 4) (2 3 4 5) (1 3 4 5) (1 2 4 5) (1 2 3 5) , , , , , , , , , , , , , , , , , , , } . Only the auxiliary form in encoding step (2) is shown here. The data matrix is of size 15 × 2 and the resulting code matrix is of 5 × 12 (after removing the blank spaces). The helper symbols to repair node1 are highlighted.
cases, i.e., there may be more than one arrangement as to which ( r -m ) helper nodes should transmit the symbols to regenerate the lost symbol in c i ( e.g., in the first column of Fig. 3 we can also choose c 1 2 , and c 1 4 , to repair c 1 1 , ). Some combinations of the arrangements may result in transmissions being non-uniform among the helper nodes during repair. If we were to choose ν = 1 , the resulting code can still repair a lost node however with non-uniform repair transmissions from the d helper nodes, resulting in repair transmissions in the amounts of β = ( β , β 1 2 , . . . , β d ) ; it is clear that by using ν = d = n -m , the code symbols in the duplicate portions can be repaired with transmission amounts which are circularly shifted versions of β , and thus the total repair transmission amounts are uniform (see Fig. 3). In fact, the value of ν may be further reduced in some cases, as given in the following proposition whose proof can be found in the appendix.
Proposition 1: For every integer p , 1 ≤ p ≤ m<r , define
$$\theta _ { p } = ( d, r - p ) _ { g c d }, \quad \zeta _ { p } = \text{lcm} \left \{ \frac { \left ( \frac { \theta _ { p } } { s } \right ) } { \left ( \left ( \frac { \theta _ { p } } { s } \right ), r - m \right ) _ { g c d } } \, \colon s \, | \, \theta _ { p } \right \}, \quad \eta _ { p } = \frac { \zeta _ { p } } { ( \zeta _ { p }, \binom { m - 1 } { p - 1 } ) _ { g c d } },$$
where ( a, b ) gcd is the greatest common divisor of positive integers a and b , and a | b means a is divides b . Then, ν can be set as
$$\nu \ = \ \text{lcm} \{ \eta _ { p } \ | \ 1 \leq p \leq m \},$$
and there exists a repair pattern such that the transmissions are uniform among all the d helpers.
Note that ν is always a factor of d . Whenever d is a prime with r ≤ d , it can be checked that ν = 1 . Even when it is not, ν can become 1 in many cases. For example, when d = 8 , r = 6 , m = 2 , it can be checked that ν = 1 .
It is clear from the above discussion that
$$M _ { c } = ( r - m ) N = ( r - m ) \nu \binom { n } { r }, \quad \alpha = \gamma = \nu \binom { n - 1 } { r - 1 }, \quad \beta = \frac { ( r - m ) \alpha } { n - m } = \frac { ( r - m ) \nu } { n - m } \binom { n - 1 } { r - 1 },$$
where β is derived from the total amount of repair transmission and the fact it can be distributed uniformly among the d helper nodes.
For the case d = k = n -1 , DCBDs with parameters ( r, n ) can also be used to construct canonical codes even when restricted Steiner systems S r, n ( ) (or BIBDs S λ ( r, n ) ) indeed exist; it can be verified that such constructions in fact does not change the resultant (¯ α, β ¯ ) . The advantage of using restricted Steiner systems and BIBDs is that the codes have smaller α and β values, and thus practically more versatile. For example, the code in Fig. 2 has α = 4 and β = 1 ; on the other hand, the corresponding code using DCBDs in the same alphabet has α = 28 and β = 7 .
It should also be noted that for the case d < n -1 , we can utilize general Steiner systems ( i.e., when t > 2 ) or a more general class of block designs called t -designs, to construct canonical codes. However, the problem of non-uniform repair transmissions becomes rather intractable. Moreover, it was shown in [17] that the non-canonical codes based on such constructions may induce loss of performance in terms of the normalized storage-repair-bandwidth tradeoff, when compared to that based on DCBDs unless certain additional conditions are met (more precisely, the uniform-rank-accumulation property given in Section III-D). We thus do not pursue this route further.
## C. Performance Assessment of Canonical Codes
We next state several results pertaining to the performance of the canonical code. The first result characterizes the range of the auxiliary parameters ( r, m ) for which canonical codes outperform spacesharing between MSR and MBR points. Then we show that the canonical construction yields optimal codes operating on the functional-repair tradeoff when d = k = n -1 . The third result is regarding the asymptotic optimality of the canonical codes at high rates.
For canonical codes using DCBDs, the normalized storage and repair bandwidth (¯ α, β ¯ ) pair is
$$( \bar { \alpha }, \bar { \beta } ) = \left ( \frac { r } { n ( r - m ) }, \frac { r } { n ( n - m ) } \right ),$$
and it can be verified that taking m = 1 reduces (14) to that induced by codes based on BIBDs.
Proposition 2: The [ n, k, d = k ] -canonical code operates at an (¯ α, β ¯ ) -point that lies in between the MSR and MBR points, and improves upon space-sharing between the MSR and MBR points, whenever m<r -m<k .
Proof: Substituting (14) into the left hand side of (7), the performance is better than space-sharing as long as
$$\left ( \frac { k r } { n ( r - m ) } + \frac { r } { n } \right ) < 2,$$
which is equivalent to r > 2 m and n > r , and further equivalent to k > r -m > m , under which the performance of the canonical codes is strictly superior to space-sharing between MSR and MBR points.
Whenever n < 2 k -1 , there exists an ( r, m ) choice to satisfy the condition given above, consequently an [ n, k, d = k ] -canonical code that performs better than space-sharing between MSR and MBR points. Conversely, when n ≥ 2 k -1 , such choice of ( r, m ) does not exist, and thus the canonical codes do not provide any gain over the space-sharing approach.
β
0.34
0.32
0.3
0.28
0.26
¯
0.24
0.22
0.2
0.18
0.16
¯
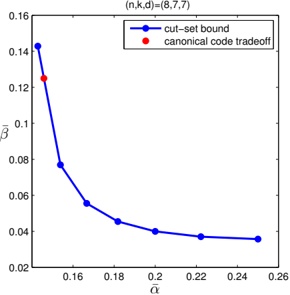
0.35
0.4
0.45
0.5
α
Fig. 4. The tradeoff points of the canonical codes for [ n, k, d ] = [4 , 3 3] , and [ n, k, d ] = [8 , 7 7] , that are on the cut-set bound.
Proposition 3: The [ n, k, d = k = n -1] -canonical code can achieve (¯ α, β ¯ ) = ( n -1 n n ( -2) , 1 n ) , which is on the functional-repair tradeoff but not the MSR point or the MBR point.
Proof: Choose m = 1 and r = n -1 in (14) gives the normalized (¯ α, β ¯ ) pair specified above. Setting p = k -1 in the left hand side of (3), and substituting the above (¯ α, β ¯ ) pair, we have,
$$( k - 1 ) \bar { \alpha } + \bar { \beta } = ( k -$$
i.e., it lies on the cut-set bound, however it is not the MSR or the MBR points.
In Fig. 4, two example cases of the tradeoff points achieved in Proposition 2 are given. For the particular case of [ n, k, d ] = [4 3 3] , , , space-sharing between the MSR point, the point achieved by the canonical code, and the MBR point characterizes the optimal exact-repair tradeoff, which was dervied in [14]. The non-achievability result established in [7] does not apply to a narrow line-segment close to the MSR point, and the point given the above lemma indeed lies in this region.
Proposition 4: The region R ∞ is given by the set of pairs satisfying (9), and it can be achieved using the canonical codes when d = k .
Proof: We show that the canonical codes can achieve asymptotically
$$k \bar { \alpha } \to 1, \ \ k \bar { \beta } \to$$
which is the only non-trivial corner point of the the outer bound region given in (9). √
Notice that by choosing r = k and m = n -d = τ 1 -τ 2 = τ 1 in this case, we have
$$\mathfrak { z } \cos \cos \mathfrak { z } - \mathf$$
and
$$\lim _ { k \to \infty } k \frac { r } { n ( n -$$
The proof is thus complete.
(n,k,d)=(4,3,3)
cut-set bound optimal exact-repair tradeoff
Fig. 5. The asymptotic tradeoff R ∞ .
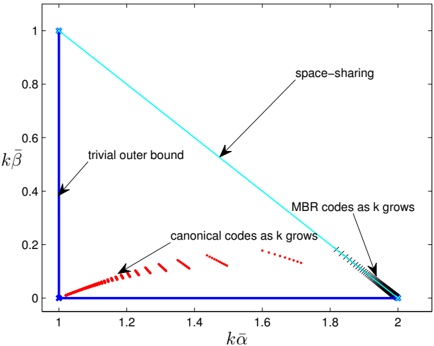
In Fig. 5 we plot the trivial outer bound for R ∞ , the MBR point cloud as k →∞ , the space-sharing line, and the tradeoff points achieved by the canonical codes using the parameters given in the proof above as k → ∞ . It should be noted that taking any sequence of r ∼ O k ( δ ) will result in the same asymptote given above, as long as δ ∈ (0 , 1) . This asymptote only captures the first order behavior, and the result implies that for this case, there is in fact no asymptotic difference between functional-repair and exact-repair.
## D. Property of Uniform Rank Accumulation
Thus far, we have described the canonical code in terms of the structure of the codeword. We now turn to a generator matrix viewpoint of the code, as the code is linear. To obtain a generator matrix, one needs to vectorize the code array, thus replace it with a vector of size nα = rN . The generator matrix then describes the linear relation between the M c = ( r -m N ) input symbols of the canonical code C can and the nα output symbols. Thus the generator matrix is of size ( M c × nα ) .
The ordering of columns within the generator matrix is clearly dependent upon the manner in which vectorization of the code matrix takes place. We will present two vectorizations and hence, two generator matrices:
- 1) From the distributed storage network point of view, each row of the ( n × α ) code matrix corresponds to a node in distributed storage network. Thus a natural vectorization is one in which the nα code symbols are ordered such that the first α symbols correspond to the elements of the first row vector (in left-to-right order), of the code matrix, the second α symbols correspond in order, to the elements of the second row vector, etc.. Thus, under this vectorization, the first α columns of the generator matrix correspond to the first row vector of the code array and so on. We will refer to this as the node-wise vectorization of the code. We will use G to denote the generator matrix of the canonical code C can under this vectorization. Each set of columns of G corresponding to a
node of the codeword array, will be referred to as a thick column . In other words, the code symbols associated to the i -th thick column of the generator matrix are the code symbols stored in the i -th storage node. In this context, we will refer to a single column of G as a thin column .
- 2) The code symbols in the code array of the canonical code C can can be vectorized in a second manner such that the resultant code vector is the serial concatenation of the N MDS codewords { c i } , each associated with a distinct message vector u i . We will refer to this as the parity-groupwise vectorization of the code. Let G b-d denote the associated generator matrix of C can . Clearly, G b-d has a block-diagonal structure:
$$\begin{array} {$$
Here G MDS denotes the generator matrix of the [ r, r -m ] -MDS code denoted by C MDS . It follows that the columns of G b-d associated with code symbols belonging to distinct parity groups span subspaces that are linearly independent. Also, any collection of ( r -m ) columns of G b-d associated with the same parity group are linearly independent.
We will now establish that the matrix G has the following t -uniform rank-accumulation property ( t URA) : if one selects a set T of t thick columns drawn from amongst the n thick columns of G , then the rank of the submatrix G | T of G is independent of the choice of T ; we call a code satisfying this property a t -URA code. Hence the rank of G | T may be denoted as ρ t , indicating that it does not depend on the specific choice of T of cardinality t . If a code is t -URA for all t = 1 2 , , . . . , n , then we say the code satisfies the universal-URA property, or that it is a universal-URA code.
The value of ρ t can be determined from how the collection of thin columns in T intersect with the blocks of G b-d . More specifically, due to the linear independence structure of columns of G b-d , we only need to count the total number of linear independent columns in G b-d that correspond to the thin columns of G | T . The values of ρ t for DCBDs and BIBDs can be derived as follows:
- · For the codes based on DCBDs, within each parity group, the number of columns chosen can range from 0 to r . If the intersection is of size p , the rank accumulated is min { p, r -m } , and thus it follows that
$$\rho _ { t } \ = \nu \sum _ { \substack { p = \max \{ 1, \\ r - ( n - t ) \} } } ^ { \min \{ t, r \} } \binom { t } { p } \binom { n - t } { r - p } \min \{ p, r - m \}.$$
These codes satisfy the universal-URA property, and it can be verified that ρ t = N r ( -m ) = M c for t ≥ k .
- · For the canonical codes based on restricted Steiner systems and BIBDs, the t -URA property holds
when t = n , n -1 or n -2 , but in general not for other values. It is straightforward to verify that
$$\rho _ { n } = \rho _ { n - 1 } = N ( r - 1 ) = \frac { \lambda n ( n - 1 ) } { r },$$
and
$$\rho _ { n - 2 } = N ( m - 1 ) - \lambda = \frac { \lambda n ( n - 1 ) } { r } - \lambda,$$
because the pair of indices of the lost nodes appears in exactly λ blocks in S λ ( r, n ) , and for each of the involved parity group, we only collect ( r -2) columns in G b-d , instead of ( r -1) .
## IV. CODE CONSTRUCTIONS FOR d > k
In this section, we first describe an explicit code construction for [ n, n -2 , n -1] code based on restricted Steiner systems S r, n ( ) . This construction however only applies to the case when a restricted Steiner system exists for such n , and as aforementioned, Steiner systems may not exist for all ( r, n ) pairs. Then construction using DCBDs for general values [ n, k, d ] are presented based on linearized polynomials. The alphabet size of the second class of codes can be quite large, and we show that it can be reduced significantly. The performance of the code is then discussed.
## A. Constructions Based on Restricted Steiner Systems and BIBDs for [ n, k = n -2 , d = n -1]
Given a restricted Steiner system S r, n ( ) , a canonical code can be constructed with [ n, k, d = k = n -1] as shown in the previous section. Next we construct a code with [ n, k = n -2 , d = n -1] by using an additional encoding step. The alphabet can be chosen to be F q , where q ≥ r , and the number of data symbols is M = N r ( -1) -1 . Let the data symbols be written in an ( r -1) × N matrix except the bottom-right entry u N,r -1 , which is parity symbol given the following value
$$u _ { N, r - 1 } = \sum _ { j = 1 } ^ { r - 2 } \phi _ { j } \sum _ { i = 1 } ^ { N } u _ { i, j } + \phi _ { r - 1 } \sum _ { i = 1 } ^ { N - 1 } u _ { i, r - 1 },$$
glyph[negationslash]
where φ j 's are distinct non-zero values in F q , and additionally φ j +1 = 0 for 1 ≤ j ≤ r -2 . With this new U data matrix, we then apply the canonical code encoding procedure to produce the n × γ code array. The repair procedure with d = n -1 helper nodes is precisely the same as in the previous section, and thus for this code
$$\alpha = \frac { n - 1 } { r - 1 }, \quad \beta = 1, \quad M = ( r - 1 ) N - 1 = \frac { n ( n - 1 ) } { r } - 1.$$
Note that these parameters are all integers for a valid Steiner system. Next we show that this code indeed can recover all the data symbols using any k = n -2 nodes. Recall that for a restricted Steiner system, any pair of nodes appears only once in the block design, and thus only a single parity group loses two symbols when any two nodes have failed. For parity groups losing only one symbol or less, all the symbols within them can be recovered, and thus only the parity group that loses exactly two symbols need to be considered. Taking this fact into consideration, the following cases need to be considered:
/g1005
Fig. 6. The (9 7 8) , , code based using the canonical code in Fig. 1. When node1 and node2 have failed, except parity group 9 , all other parity groups at least have two symbols remaining and thus can be completely recovered. To recover the symbols c 9 1 , and c 9 2 , , the parity symbols c 9 3 , and c 12 2 , provide sufficient information.
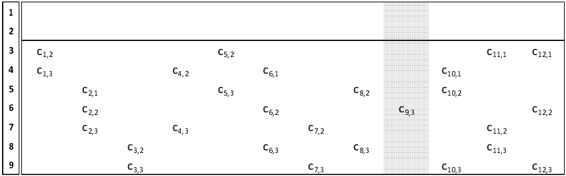
- 1) The i -th parity group c i , i < N , loses two symbols, one is a data symbol u i,j where j < r , and the other is the parity symbol c i,r . The only missing data symbol u i,j can be obtained by eliminating in (24) all the other data symbols.
glyph[negationslash]
- 2) The i -th parity c i , i < N , loses two symbols, which are both data symbols u i,j 1 and u i,j 2 , where j 1 < j 2 < r . Since u N,r -1 is available, by eliminating all other other data symbols, we obtain the value of φ j 1 u i,j 1 + φ j 2 u i,j 2 . Next by eliminating all other data symbols in c i,r = ∑ r -1 j =1 u i,j , we obtain the value of u i,j 1 + u i,j 2 . Since φ j 1 = φ j 2 and they are both non-zero, u i,j 1 and u i,j 2 can be solved using these two equations.
- 3) Parity group c N loses two symbols, which are u N,r -1 and c N,r . This case is trivial since all data symbols have been directly recovered.
- 4) Parity group c N loses two symbols, which are the parity symbols c N,r and a data symbol u N,j , 1 ≤ j ≤ r -2 . By eliminating the other data symbols in u N,r -1 using (24), we obtain u N,j .
- 5) Parity group c N loses two symbols, which are u N,r -1 and data symbol u N,j , 1 ≤ j ≤ r -2 . Note that
$$c _ { N, r } = \sum _ { j = 1 } ^ { r - 1 } u _ { N, j } = \sum _ { j = 1 } ^ { r - 2 } \phi _ { j } \sum _ { i = 1 } ^ { N } u _ { i, j } + \phi _ { r - 1 } \sum _ { i = 1 } ^ { N - 1 } u _ { i, r - 1 } + \sum _ { j = 1 } ^ { r - 2 } u _ { N, j }.$$
glyph[negationslash]
By eliminating all the other data symbols from c N,r , we obtain the value of ( φ j +1) u N.j . Since φ j +1 = 0 for 1 ≤ j ≤ r -2 , the only missing data symbol u N,i can be obtained.
There are essentially two MDS codes in this construction: the first code (referred to as the long MDS code) in the construction is an [ M +1 , M ] systematic MDS code whose parity symbol is specified by (24), and the component code (referred to as the short code) is an [ r, r -1] systematic MDS code. The key is to jointly design the two codes, and thus they are useful together. In the above construction, this is accomplished through the coefficients of the parity symbols. It should be noted that the coefficients in forming the parity symbols are not unique, and we have only given a convenient choice here.
There is an inherent connection between the construction given above and the URA property of the canonical codes. Let us denote the generator matrix of the long MDS code as G L , which is of size M × ( M +1) , and the generator matrix G of the canonical code in its node-wise vectorization form is
of size ( M +1) × nα . Because of the encoding procedure, the code we eventually obtain has generator matrix G L · G which is of size M × nα . To guarantee all data symbols recoverable from any n -2 nodes, we need the submatrix of G L · G formed by collecting any ( n -2) thick columns to have rank at least M , which is equivalent to having G L · G | T to have rank at least M , for any T ⊂ I n and | T | = n -2 . The ( n -2) -URA property of the canonical codes implies that that G | T has rank ρ n -2 , and thus ρ n -2 is an upper bound on M ; our code construction above is indeed able to achieve M = ρ n -2 .
To generalize the above construction and allow canonical codes based on BIBDs, we need to carefully choose the coding coefficients in the long MDS code such that the upper bound M ≤ ρ n -2 can be achieved with equality. In the following, an explicit construction based on rank-metric code is provided in the context of canonical codes using DCBDs, which can also be used with canonical codes based on BIBDs, and it leads to
$$\alpha = \frac { \lambda ( n - 1 ) } { r - 1 }, \quad \beta = \lambda, \quad M = ( r - 1 ) N - \lambda = \frac { \lambda n ( n - 1 ) } { r } - \lambda.$$
## B. A Construction Based on DCBDs for General [ n, k, d ]
For the more general settings of [ n, k, d ] that are not limited to [ n, k = n -2 , d = n -1] (or when the corresponding restricted Steiner system does not exist), the coding coefficients in the long MDS code need to chosen carefully such that the upper bound M ≤ ρ k of the canonical codes can be achieved with equality. The construction presented next utilizes Gabidulin codes to achieve this goal.
Let r -m ≤ k , and choose m = n -d . Fix a C ν ( r, n ) and the corresponding canonical code in F q , the number of data symbols M in this new code is chosen to be equal to the upper bound ρ k in the canonical code. The M message symbols { v i } M i =1 , v i ∈ F q κ are first used to construct a linearized polynomial
$$f ( x ) \ = \ \sum _ { i = 1 } ^ { M } v _ { i } x ^ { q ^ { i - 1 } },$$
where κ is any sufficiently large positive integer, and we shall provide a lower bound for its value in the sequel. The linearized polynomial is then evaluated at M c = ( r -m N ) elements { θ i,j } of F q κ , i = 1 2 , , . . . , N , j = 1 2 , , . . . , r , which when viewed as vectors over F q , are linearly independent. This coding step is not systematic, however a systematic version of the code can be obtained straightforwardly by equating the data symbols as the first ρ k outputs ( f ( θ 1 ) , f ( θ 2 ) , . . . , f ( θ ρ k )) , and then identifying the proper coefficients v i 's; from here on we do not distinguish these two cases.
We wish to feed these M c evaluations { f ( θ i,j ) } into an encoder for the afore-chosen canonical code by setting the elements of the input data matrix U ,
$$u _ { i, j } \ = \ f ( \theta _ { i, j } ), \quad 1 \leq i \leq N, \ \ 1 \leq j \leq r.$$
However, notice that in the original canonical code, the elements in the data matrix input u i,j ∈ F q , and the evaluations of the linearized polynomial f ( θ i,j ) ∈ F q κ . This discrepancy can be resolved by taking the standard convention of viewing { f ( θ i,j ) } as vectors over F q , and apply the canonical code encoder
over each of their components ; we use the same convention on the outputs, and thus obtain a code array 3 of n × α over F q κ through the canonical code encoding process.
It is clear that the repair procedure is precisely the same as the underlying canonical code, and thus we only need to show that it is possible to recover the message symbols { v i } M i =1 by connecting to an arbitrary set of k nodes.
Proposition 5: By connecting to an arbitrary set of k nodes, a data collector will be able to recover the message symbols { v i } M i =1 in the above code.
Proof: Let G denote the generator matrix of the canonical code when node-wise vectorization is employed. Observe that the entries in G belong to F q .
Let ( c 1 , c 2 , · · · , c nα ) denote the node-wise vectorized codeword of C . Then we have
$$( c _ { 1 }, c _ { 2 }, \cdots, c _ { n \alpha } ) \ = \ [ f ( \theta _ { 1 } ) \ f ( \theta _ { 2 } ) \ \cdots f ( \theta _ { M _ { c } } ) ] \cdot G.$$
Using linearity of f ( ) · , we can write this as
$$( c _ { 1 }, c _ { 2 }, \cdots, c _ { n \alpha } ) \ & = \ \ f ( [ \underbrace { \theta _ { 1 } \ \theta _ { 2 } \ \cdots \theta _ { M _ { c } } } ] \cdot G ] ) \\ & = \ \ f ( \underbrace { [ x _ { 1 } \ x _ { 2 } \cdots x _ { M _ { c } } ] } _ { ( N \times M _ { c } ) } \cdot G ] ),$$
in which x i ∈ F κ q is the vector representation of the element θ i ∈ F q M , with respect to some basis of F q κ over F q . Set
$$X \ = \ [ x _ { 1 } \ x _ { 2 } \cdots x _ { M _ { c } } ].$$
Now let A be the set of k thick columns of G , corresponding to the set of nodes to which the data collector is connecting to. Since { x i } M c i =1 are linearly independent over F q , it follows that
$$\text{Rank} \left ( X \cdot G | _ { A } \right ) & \ = \ \text{Rank} \left ( G | _ { A } \right ) \\ & \ = \ \rho _ { k } \ = \ M$$
Hence there are at least M linearly independent columns in the matrix product X G · | A . These columns correspond to linearly independent points of F q κ over F q . Thus f ( X G · | A ) yields the evaluations of f ( ) · at at least M linearly independent points of F q κ . By Lemma 1, f and thereby its coefficients can be uniquely identified from these M evaluations.
3 Equivalently, this is the field operation in F q κ when the canonical code coefficients are viewed as in the corresponding base field F q elements correctly embedded in the extended field.
It is clear that the performance of the code is given by
$$\dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \delta \delta \delta \delta \delta \delta \delta \delta \delta \delta \delta \delta \delta \delta \delta \delta \delta \delta \delta \delta \delta \delta \delta \delta \delta \delta \delta \delta \delta \delta \delta \delta \delta \delta \delta \delta \delta \delta \delta \delta \delta \delta \delta \delta \delta \delta \delta \delta \delta \delta \delta \delta \delta \delta \delta \delta \delta \delta \delta \delta \delta \delta \delta \delta \delta \delta \delta \ delta \delta \delta \delta \delta \delta \delta \delta \delta \delta \delta \delta \delta \delta \delta \delta \delta \delta \delta \delta \delta \delta \delta \delta \delta \delta \delta \delta \delta \delta \delta \delta \delta \delta \delta \delta \delta \delta \delta \delta \delta \delta \delta \delta \delta \delta \delta \delta \delta \delta \delta \delta \delta \delta \delta \delta \delta \delta \delta \delta \delta \delta \delta \delta \delta \delta \delta delta \delta \delta \delta \delta \delta \delta \delta \delta \delta \delta \delta \delta \delta \delta \delta \delta \delta \delta \delta \delta \delta \delta \delta \delta \delta \delta \delta \delta \delta \delta \delta \delta \delta \delta \delta \delta \delta \delta \delta \delta \delta \delta \delta \delta \delta \delta \delta \delta \delta \delta \delta \delta \delta \delta \delta \delta \delta \delta \delta \delta \delta \delta \delta \delta \delta \dta \delta \delta \delta \delta \delta \delta \delta \delta \delta \delta \delta \delta \delta \delta \delta \delta \delta \delta \delta \delta \delta \delta \delta \delta \delta \delta \delta \delta \delta \delta \delta \delta \delta \delta \delta \delta \delta \delta \delta \delta \delta \delta \delta \delta \delta \delta \delta \delta \delta \delta \delta \delta \delta \delta \delta \delta \delta \delta \delta \delta \delta \delta \delta \delta \delta \delta \Delta \delta \delta \delta \delta \delta \delta \delta \delta \delta \delta \delta \delta \delta \delta \delta \delta \delta \delta \delta \delta \delta \delta \delta \delta \delta \delta \delta \delta \delta \delta \delta \delta \delta \delta \delta \delta \delta \delta \delta \delta \delta \delta \delta \delta \delta \delta \delta \delta \delta \delta \delta \delta \delta \delta \delta \delta \delta \delta \delta \delta \delta \delta \delta \delta \delta \delta
\dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \ dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \delta delta \delta \delta \delta \delta \delta \delta \delta \delta \delta \delta \delta \delta \delta \delta \delta \delta \delta \delta \delta \delta \delta \delta \delta \delta \delta \delta \delta \delta \delta \delta \delta \delta \delta \delta \delta \delta \delta \delta \delta \delta \delta \delta \delta \delta \delta \delta \delta \delta \delta \delta \delta \delta \delta \delta \delta \delta \delta \delta \delta \delta \delta \delta \delta \delta \digma \delta \delta \delta \delta \delta \delta \delta \delta \delta \delta \delta \delta \delta \delta \delta \delta \delta \delta \delta \delta \delta \delta \delta \delta \delta \delta \delta \delta \delta \delta \delta \delta \delta \delta \delta \delta \delta \delta \delta \delta \delta \delta \delta \delta \delta \delta \delta \delta \delta \delta \delta \delta \delta \delta \delta \delta \delta \delta \delta \delta \delta \delta \delta \delta \delta \delta \ Delta \delta \delta \delta \delta \delta \delta \delta \delta \delta \delta \delta \delta \delta \delta \delta \delta \delta \delta \delta \delta \delta \delta \delta \delta \delta \delta \delta \delta \delta \delta \delta \delta \delta \delta \delta \delta \delta \delta \delta \delta \delta \delta \delta \delta \delta \delta \delta \delta \delta \delta \delta \delta \delta \delta \delta \delta \delta \delta \delta \delta \delta \delta \delta \delta \delta \delta\delta \delta \delta \delta \delta \delta \delta \delta \delta \delta \delta \delta \delta \delta \delta \delta \delta \delta \delta \delta \delta \delta \delta \delta \delta \delta \delta \delta \delta \delta \delta \delta \delta \delta \delta \delta \delta \delta \delta \delta \delta \delta \delta \delta \delta \delta \delta \delta \delta \delta \delta \delta \delta \delta \delta \delta \delta \delta \delta \delta \delta \delta \delta \delta \delta \delta \digma \delta
\dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \\ \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \ delta \delta \delta \delta \delta \delta \delta \delta \delta \delta \delta \delta \delta \delta \delta \delta \delta \delta \delta \delta \delta \delta \delta \delta \delta \delta \delta \delta \delta \delta \delta \delta \delta \delta \delta \delta \delta \delta \delta \delta \delta \delta \delta \delta \delta \delta \delta \delta \delta \delta \delta \delta \delta \delta \delta \delta \delta \delta \delta \delta \delta \delta \delta \delta \delta \delta \ delta
\dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \end{matrix} \min \{ k, r \choose k, r \choose k, r \choose k, r \choose k, r \choose k, r \choose k, r \choose k, r \choose k, r \choose k, r \choose k, r \choose k, r \choose k, r \choose k, r \choose k, r \choose k, r \choose k, r \choose k, r \choose k, r \choose k, r \choose k, r \choose k, r \choose k, r \choose k, r \choose k, r \choose k, r \choose k, r \choose k, r \choose k, r \choose k, r \choose k, r \choose k, r \choose k, r \choose k, r \choose k, r \choose k, r \choose k, r \choose k, r \choose k, r \choose k, r \choose k, r \choose k, r \choose k, r \choose k, r \choose k, r \choose k, r \choose k, r \choose k, r \choose k, r \choose k, r \choose k, r \choose k, r \choose k, r \choose k, r \choose k, r \choose k, r \choose k, r \choose k, r \choose k, r \choose k, r \choose k, r \choose k, r \choose k, r \choose k, r \choose k,$$
It should be noted that if we choose r = 2 , m = 1 , the construction reduces to the repair-by-transfer MBR code given in [7]. It is thus not surprising that the construction given here has the help-by-transfer property, since it includes the repair-by-transfer code as a special case.
Since the canonical code exists when q ≥ r , and F q κ must have at least M c = ν · ( n r ) ( r -m ) linearly independent elements over F q , we require κ ≥ M c . Hence a finite field of size r M c is sufficient in the above construction (exponential in r ). We show in the next subsection that there exist constructions of significantly lower field size (linear in r ).
For the case [ n, k = n -2 , d = n -1] , DCBD-based canonical codes can also be used even when the corresponding restricted Steiner systems exist. The advantages of the construction given in the previous subsection are that: firstly it induces smaller α and β values, secondly, the required alphabet size is smaller than the one specified above (and the one shown to exist in the sequel), and lastly the coding coefficients are more explicitly specified.
## C. Existence of Codes with Lower Field Size
As aforementioned in Section IV-A, the code for the general parameters has a generator matrix in the form G L · G , where G L is from the long MDS code, and G is from the canonical code (short MDS code), which is the node-wise vectorization version. We can alternatively consider the parity-group-wise vectorization version, which is G L · G b-d . Clearly the code corresponding to G L · G b-d is a subspace of the rowspace C of G b-d . In other words, the dual code of G L · G b-d is a superspace of the dual C ⊥ of C . Suppose
$$H _ { \text{b-d} } = \left [ \begin{array} { c c c c } H _ { \text{MD5} } & & & \\ & H _ { \text{MD5} } & & \\ & & \ddots & \\ & & & H _ { \text{MD5} } \end{array} \right ].$$
is a parity-check matrix of C . Here H MDS denotes the parity-check matrix of the [ r, r -m ] -MDS code C MDS . We need to enlarge the rowspace of H b-d by adding more rows to it in order to make it a paritycheck matrix of the code with generator matrix G L · G b-d . Let
$$H \ = \ \left [ \begin{array} { c } H _ { b - d } \\ H _ { 1 } \end{array} \right ]$$
be the resultant parity-check matrix. Conversely, any matrix H 1 essentially specifies a subspace of the canonical code that is the rowspace of G b-d . For any such subspace, there always exists a matrix G L such
that the rows of G L · G b-d span the chosen subspace. Hence specifying G L is equivalent to specifying H 1 . We denote the elements of H 1 as h i,j , which are to be determined; fix an [ r, r -m ] MDS code in the canonical code construction, which thus implies that the matrix H b-d is fixed.
For any set T ⊂ I n of nodes, where | T | = k , there are k thick columns in G L · G b-d corresponding to these nodes. If and only if the submatrix formed by collecting these k thick columns in G L · G has rank M = ρ k , can we recover all the M data symbols from these k nodes. Let us consider a submatrix G L · G ′ | T , where G ′ | T is formed by the following procedure: for each parity group c i , i = 1 2 , , . . . , N ,
- · When there are more than ( r -m ) thin columns corresponding to the same parity group c i in the k thick columns, then collecting any ( r -m ) of them;
- · Otherwise, collect all the thin columns corresponding to the remaining code symbols in this parity group.
It is clear that this results in ρ k columns. Let S T ⊂ I nα denote the indices of these ρ k thin columns. If this ρ k × ρ k matrix G L · G ′ | T has full rank, then all the M data symbols can be recovered from the k nodes. This is equivalent to having ( nα -ρ k ) × ( nα -ρ k ) submatrix H | T of H restricted to those thin columns indexed by I nα \ S T to have full rank. This requires the determinant of H | T be not zero, and we write the determinant as a polynomial f T ( { h i,j | i ∈ I nα -ρ k -Nm , j ∈ I nα } ) . Now, define
$$p ( \{ h _ { i, j } \} ) \ = \ \prod _ { T \subset I _ { n } ; | T | = k } f _ { T } ( \{ h _ { i, j } \ | \ i \in I _ { n \alpha - \rho _ { k } - N m }, j \in I _ { n \alpha } \} ).$$
If there exists an assignment for { h i,j } such that the polynomial p ( ) · evaluates to a non-zero value, then such an assignment will yield a G L that ensures the required data-collection property. We make use of the following lemma from [24] at this point.
glyph[negationslash]
Lemma 2: [24] ( Combinatorial Nullstellansatz ) Let F be a field, and let f = f ( x , 1 · · · , x n ) be a polynomial in F [ x , 1 · · · , x n ] . Suppose the degree deg ( f ) of f is expressible in the form ∑ n i =1 t i , where each t i is a non-negative integer and suppose that the coefficient of the monomial term ∏ n i =1 x t i i is nonzero. Then if S , . . . , S 1 n are subsets of F with sizes | S i | satisfying | S i | > t i , then there exist elements s 1 ∈ S , s 1 2 ∈ S . . . , s 2 n ∈ S n such that f ( s , s 1 2 , · · · , s n ) = 0 .
The condition that coefficient of the monomial term ∏ n i =1 x t i i is nonzero is equivalent to requiring f = f ( x , 1 · · · , x n ) is not identically zero. We note that f T ( { h i,j | i ∈ I nα -ρ k -Nm , j ∈ I nα } ) is indeed not identically zero, because the code construction given in the previous subsection essentially provides a non-zero assignment.
Since the degree of any indeterminate in each of f T ( { h i,j | i ∈ I nα -ρ k -Nm , j ∈ I nα } ) is 1 , the maximum among the degrees of a single indeterminate in p . ( ) is upper bounded by ( n k ) . Hence by Lemma 2, it is possible to find a suitable assignment for { h ij } , if the entries are picked from a finite field of size ≥ ( n k ) . Thus we have proved the following proposition.
Proposition 6: An [ n, k, d > k ] non-canonical regenerating code exists over F q with q ≥ ( n k ) .
It should be noted that to find such a code in the given alphabet is not trivial, and a possible approach is to randomly assign the coefficients and then check whether all the full rank conditions are satisfied.
Fig. 7. ¯ β vs ¯ α for different ( k, d ) parameters when n = 24 . The dashed blue lines are the cut-set bounds, the dotted black lines are the space-sharing lines, and the red solid lines are the tradeoff achieved by the proposed codes.
## D. Performance Assessment of the General Codes
There does not seem to be any simplification of (29) for specific [ n, k, d ] parameters. We provide a few examples to illustrate the performance of the codes. In Fig. 1, we have plotted the performance of the proposed codes for the case of [ n, k, d ] = [9 7 8] , , , together with the cut-set bound and space-sharing line. There are two values for parameter r = 3 or r = 4 that yield tradeoffs below the space-sharing line; the proposed code also achieves the MBR point. Here the code for r = 3 is based on Steiner systems, while for r ≥ 4 , the DCBD based design is used. The operating point (¯ α, β ¯ ) ≈ (0 15 . , 0 075) . is also worth noting, because although it is not as good as the MSR point, and in fact it is worse than the space-sharing line, the penalty is surprisingly small. This suggests that the proposed codes may even be a good albeit not optimal choice to replace an MSR code.
In Fig. 7 we plot the performance of codes for different parameters ( k, d ) when n = 24 . It can be seen that when d = n -1 = 23 , the performance is the most competitive, and often superior to the space-sharing line. As d value decreases, the method become less effective in terms of its (¯ α, β ¯ ) , and becomes worse than the space-sharing line. For the same d value, the code is most effective when k is
large, and becomes less so as k value decreases.
We can also consider the asymptotic performance of the code, however the derivation and result are almost identical to the canonical codes in the asymptotic regime we are considering ( i.e., asymptotically optimal in the sense that it achieves the complete R ∞ ), and thus we leave this simple exercise to interested readers. Another important asymptote is to keep the ratio of k and n constant, and letting n →∞ . However, in this case, the proposed codes are not optimal asymptotically, and such an analysis does not yield further useful insight beyond the example cases shown above.
## V. CONCLUSION
A new construction for [ n, k, d ] exact-repair regenerating codes is proposed by combining embedded error correction and block designs. The resultant codes have the desirable 'help-by-transfer' property where the nodes participating in the repair simply send certain stored data without performing any computation. We show that the proposed code is able to achieve performance better than the spacesharing between an MSR code and an MBR code for some parameters, and furthermore, the proposed construction can achieve a non-trivial tradeoff point on the functional repair tradeoff, and is in fact asymptotically optimal while the space-sharing scheme is suboptimal. For the case of d = n -1 and k = n -2 , an explicit construction is given in a finite field F q where q is greater or equal to the block size in the combinatorial block designs. For more general ( d, k ) parameters, a construction based on linearized polynomial is given, and it is further shown that there exist codes with significantly smaller alphabet sizes.
APPENDIX PROOF OF PROPOSITION 1
-
-
-
-
-
Fig. 8. A repair situation associated to a given parameter p .
Without loss of generality, we assume that the first node has failed (see Fig. 8) and that nodes 2 through ( d +1) are the helper nodes. Let us focus on those blocks that contain the integer 1 as an element. The number of elements within such a block, that are contained amongst the helper nodes can range from ( r -m ) to ( r -1) . We further focus on the blocks for which the number of elements contained amongst the helper nodes equals ( r -p ) , for a fixed value of p , where 1 ≤ p ≤ m . Denote the collection of such blocks as L , p 1 ≤ p ≤ m . The size of L p is given by
$$| L _ { p } | \ = \ \nu \binom { d } { r - p } \binom { m - 1 } { p - 1 }.$$
For each block in L p , consider its intersection with the helper node set I d +1 \ { 1 } , and denote the collection of all distinct such sub-blocks as J p , 1 ≤ p ≤ m . The cardinality of J p is given by,
$$| J _ { p } | \ = \ \binom { d } { r - p }.$$
A block in J p can equivalently be viewed as a binary vector of length d and Hamming weight ( r -p ) where the ( r -p ) locations of the 1 s correspond to these elements in the block. Thus the set J p can equivalently be mapped into a ( ( d r -p ) × d ) -binary array P , with each of its row vector mapping to an element in J p . Let M, i 1 ≤ i ≤ ( d r -p ) be the support of the i -th row of P . In any given repair strategy, each block will require to communicate ( r -m ) symbols to the failed node, to enable repair of the failed node. Thus a repair strategy within J p can be described by allocating
$$R _ { i } \subseteq M _ { i }, \ | R _ { i } | = ( r - m )$$
for every 1 ≤ i ≤ ( d r -p ) . If the number of elements in a column of P , that belong to R i for some i is equal to the same value irrespective of the choice of the column, then we refer to such a pattern of allocation for P a uniform allocation pattern . Clearly a uniform allocation pattern ensures uniform download from every helper node while repairing the failed node. Let Q be a binary matrix formed by stacking P vertically µ times. Here µ is referred to as the repetition number. Let M , ′ i 1 ≤ i ≤ µ ( d r -p ) be the support of the i -th row of Q . Suppose we can identify
$$R ^ { \prime } _ { i } \subseteq M ^ { \prime } _ { i }, \ | R ^ { \prime } _ { i } | = ( r - m )$$
such that the number of elements in a column of Q , that belong to R ′ i for some i is equal to the same value irrespective of the choice of the column. Then we say that the repetition number µ allows a uniform allocation pattern for P .
In what follows, we will identify a repetition number µ p for P that allows uniform allocation. We will verify that µ p | ν ( m -1 p -1 ) . Then it is clear that a repair strategy permitting uniform download from every helper node exists within the blocks of L p . Since this holds true for an arbitrary value of p , it follows that there exists a repair strategy ensuring uniform download from each of the helper nodes.
We consider allocation for P in two cases.
$$C a s e \, I \colon \theta _ { p } = 1$$
For any row vector v of P , let us call the set of all vectors that can be obtained through cyclic shifts of v , the orbit of v . The set J p can be partitioned into such orbits. When θ p = 1 , it can be shown that all orbits are of size d . Consider one such orbit, and let the ( d × d ) submatrix P 1 of P be the matrix formed of the vectors in the orbit arranged in such a way that the i -th row of P 1 , 0 ≤ i ≤ ( d -1) is the i -th periodic shift of the first row. For each i, 0 ≤ i ≤ ( d -1) , we proceed to identify a subset R 1 i of the support of the i -th row of P 1 . Let M 1 ⊂ [ d ] be the support of the first row of P 1 , and let R 10 ⊆ M 1 be such that | R 10 | = ( r -m ) . Let us define R , 1 i 0 ≤ i ≤ ( d -1) as the i -th periodic shift of R 10 . It is straightforward to see that the above choice of { R 1 i } results in an uniform allocation pattern for P 1 . The same strategy can be adopted for every orbit in J p . Thus in this case of θ p = 1 , the repetition factor
µ = 1 is sufficient.
glyph[negationslash]
$$\mu _ { p } = 1 \text{ is sufficient.} \\ C a s e \text{ } 2 \colon \theta _ { p } \neq 1$$
In this case also, J p can be partitioned into orbits. Let us focus our attention to a submatrix P 1 of P formed of the vectors in a fixed orbit. Unlike the previous case, the chosen orbit need not be of size d . However it can be shown that it will be of size
$$\left ( \frac { d } { \theta _ { p } } \right ) s \ = \colon \ \omega _ { p s }$$
for some s such that s | θ p . Thus P 1 is a ( ω ps × d ) binary matrix such that the i -th row of P 1 , 0 ≤ i ≤ ( ω ps -1) is the i -th periodic shift of the first row. Let
$$\lambda _ { p s } \ \coloneqq \ \frac { d } { \omega _ { p s } \left ( \frac { d } { \omega _ { p s } }, r - m \right ) _ { \gcd } } \ = \ \frac { \left ( \frac { \theta _ { p } } { s } \right ) } { \left ( \frac { \theta _ { p } } { s }, r - m \right ) _ { \gcd } }.$$
The integer λ ps is chosen as the smallest number such that d λ ps ω ps | ( r -m ) . Next, consider the ( ω ps λ ps × d ) -matrix Q formed by stacking P 1 vertically λ ps times. It shall be noted that the matrix Q has the property that its i -th row 0 ≤ i ≤ ω ps λ ps -1 is the i -th periodic shift of its first row. The matrix Q can be written as
$$Q \ = \ [ Q _ { 1 } \, | \, Q _ { 2 } \, | \, \dots \, | \, Q _ { ( \frac { d } { \omega _ { p s } \lambda _ { p s } } ) } ],$$
where Q , j 1 ≤ j ≤ d ω ps λ ps is a square matrix of dimension ω ps λ ps . It can be seen that each of { Q j } satisfies the following properties:
- · The Hamming weight of every row equals ( r -p ω ) ps λ ps d ;
- · The i -th row, 0 ≤ i ≤ ω ps λ ps -1 is the i -th periodic shift of the first row.
Let us now focus our attention on Q 1 , and we will describe a uniform allocation pattern for Q 1 . For each i, 0 ≤ i ≤ ( ω ps λ ps -1) , we proceed to identify a subset R 1 i of the support of the i -th row of Q 1 . Let M 1 ⊂ [ ω ps λ ps ] be the support of the first row of Q 1 , and let R 10 ⊆ M 1 be such that | R 10 | = ( r -m ω ) ps λ ps d . Let us define R , 1 i 0 ≤ i ≤ ( ω ps λ ps -1) as the i -th periodic shift of R 10 . It is not hard to see that the above choice of { R 1 i } results in a uniform allocation pattern for Q 1 . The same strategy can be adopted for Q , j 2 ≤ j ≤ ( d ω ps λ ps ) , permitting a uniform allocation for P 1 . Thus the repetition number of λ ps ensures uniform allocation for P 1 , an orbit within J p .
It still remains to determine a repetition number that will ensure uniform allocation for P . It can be shown that for every s | θ p , J p contains an orbit of size
$$\left ( \frac { d } { \theta _ { p } } \right ) s \ = \colon \ \omega _ { p s }.$$
For every such orbit, we have already shown that a repetiton factor of
$$\frac { \left ( \frac { \theta _ { p } } { s } \right ) } { \left ( \frac { \theta _ { p } } { s }, r - m \right ) _ { \gcd } }$$
will ensure uniform allocation within the orbit. Hence
$$\mu _ { p } \ = \ \zeta _ { p }$$
allows a uniform allocation for the entire matrix P .
Next, we observe that ν is chosen as the smallest number such that
$$\zeta _ { p } \, | \, \nu \binom { m - 1 } { p - 1 }$$
for every 1 ≤ p ≤ m . It follows that there exists a repair strategy ensuring uniform download from each of d helper nodes. This completes the proof.
We provide two examples to illustrate the design of matrix P as specified in the proof above.
Example 1: Suppose d = 7 , r -p = 5 , r -m = 3 . Then the binary matrix corresponding to an orbit is shown below. The bold one 1 represents the allocation of symbols to be transmitted for repair.
.

Example 2: Suppose d = 6 , r -p = 4 , r -m = 2 . Then the binary matrix corresponding to an orbit is shown below. The size of the orbit ω ps = 3 . Here we obtain λ ps = 1 . The bold one 1 represents the allocation of symbols to be transmitted for repair.
.
REFERENCES
- [1] 'Hadoop,' http://hadoop.apache.org.
- [2] M. Zaharia, D. Borthakur, J. Sen Sarma, K. Elmeleegy, S. Shenker, and I. Stoica, 'Delay scheduling: a simple technique for achieving locality and fairness in cluster scheduling,' in ACM Eurosys , 2010, pp. 265-278.
- [3] A. G. Dimakis, P. B. Godfrey, Y. Wu, M. Wainwright and K. Ramchandran, 'Network coding for distributed storage systems,' IEEE Trans. Information Theory , vol. 56, no. 9, pp. 4539-4551, Sep. 2010.
- [4] R. Ahlswede, Ning Cai, S.-Y.R. Li, and R. W. Yeung, 'Network information flow,' IEEE Trans. Information Theory , vol. 46, no. 4, pp. 1204-1216, Jul. 2000.
- [5] Y. Wu, 'Existence and construction of capacity-achieving network codes for distributed storage,' IEEE Journal on Selected Areas in Communications , vol. 28, no. 2, pp. 277-288, Feb. 2010.
- [6] A. G. Dimakis, K. Ramchandran, Y. Wu, C. Suh, 'A survey on network codes for distributed storage,' Proceedings of the IEEE , vol. 99, no. 3, pp. 476-489, Mar. 2011.
- [7] N. B. Shah, K. V. Rashmi, P. V. Kumar and K. Ramchandran, 'Distributed storage codes with repair-by-transfer and nonachievability of interior points on the storage-bandwidth tradeoff,' IEEE Transactions on Information Theory , vol. 58, no. 3, pp. 1837-1852, Mar. 2012.
- [8] N. B. Shah, K. V. Rashmi, P. V. Kumar and K. Ramchandran, 'Interference alignment in regenerating codes for distributed storage: necessity and code constructions,' IEEE Transactions on Information Theory , vol. 58, no. 4, pp. 2134-2158, Apr. 2012.
- [9] K. V. Rashmi, N. B. Shah, and P. V. Kumar, 'Optimal exact-regenerating codes for distributed storage at the MSR and MBR points via a product-matrix construction,' IEEE Transactions on Information Theory , vol. 57, no. 8, pp. 5227-5239, Aug. 2011.
- [10] I. Tamo, Z. Wang, and J. Bruck, 'Zigzag Codes: MDS array codes with optimal rebuilding,' IEEE Transactions on Information Theory , vol. 59, no. 3, pp. 1597-1616, Mar. 2013.
- [11] V. Cadambe, S. Jafar, H. Maleki, K. Ramchandran and C. Suh, 'Asymptotic interference alignment for optimal repair of MDS codes in distributed storage,' IEEE Transactions on Information Theory , vol. 59, no. 5, pp. 2974-2987, May 2013.
- [12] D. S. Papailiopoulos, A. G. Dimakis, and V. Cadambe, 'Repair optimal erasure codes through Hadamard designs,' IEEE Transactions on Information Theory , vol. 59, no. 5, pp. 3021-3037, May 2013.
- [13] V. R. Cadambe, C. Huang, S. A. Jafar, and J. Li, 'Optimal repair of MDS codes in distributed storage via subspace interference alignment,' arXiv:1106.1250.
- [14] C. Tian, 'Characterizing the rate region of the (4 3 3) , , exact-repair regenerating codes,' IEEE Journal on Selected Areas in Communications , vol. 32, no. 5, pp. 967-975, May 2014.
- [15] D. S. Papailiopoulos, J. Luo, A. G. Dimakis, C. Huang, and J. Li, 'Simple regenerating codes: network coding for cloud storage,' in Proceedings 2012 IEEE INFOCOM , Orlando FL, Mar. 2012, pp. 2801-2805.
- [16] S. El Rouayheb and K. Ramchandran, 'Fractional repetition codes for repair in distributed storage systems,' in Proceedings 48th Annual Allerton Conference on Communication, Control and Computation , Monticello, Sep. 2010.
- [17] C. Tian, V. Aggarwal and V. Vaishampayan, 'Exact-repair regenerating codes via layered erasure correction and block designs,' in Proceedings 2013 IEEE International Symposium on Information Theory , Istanbul, Turkey, Jul. 2013, pp. 14311435; also Arxiv: 1302.4670.
- [18] B. Sasidharan, P. V. Kumar, 'High-rate regenerating codes through layering,' in Proceedings 2013 IEEE International Symposium on Information Theory , Istanbul, Turkey, Jul. 2013, pp. 1611-1615; also Arxiv: 1301.6157.
- [19] S. Wicker, Error control systems for digital communication and storage , Prentice Hall, 1995.
- [20] R. Lidl and H. Niederreiter, Finite Fields (Encyclopedia of Mathematics and its Applications) . Cambridge University Press, 1997.
- [21] E. M. Gabidulin, 'Theory of codes with maximum rank distance,' Probl. Peredachi Inf. , vol. 21, no. 1, pp. 3-16, 1985.
- [22] C. J. Colbourn and J. H. Dinitz, Handbook of Combinatorial Designs, Second Edition (Discrete Mathematics and Its Applications) , Chapman and Hall/CRC, Nov. 2006.
- [23] R. C. Bose, 'On the construction of balanced incomplete block designs,' Annals of Eugenics , vol. 9, no. 4, Dec. 1939, pp. 353-399.
- [24] N. Alon, 'Combinatorial Nullstellensatz,' Combinatorics, Probability and Computing , 1999. | 10.1109/TIT.2015.2408595 | [
"Chao Tian",
"Birenjith Sasidharan",
"Vaneet Aggarwal",
"Vinay A. Vaishampayan",
"P. Vijay Kumar"
] | 2014-08-02T14:46:04+00:00 | 2014-08-02T14:46:04+00:00 | [
"cs.IT",
"math.IT"
] | Layered, Exact-Repair Regenerating Codes Via Embedded Error Correction and Block Designs | A new class of exact-repair regenerating codes is constructed by stitching
together shorter erasure correction codes, where the stitching pattern can be
viewed as block designs. The proposed codes have the "help-by-transfer"
property where the helper nodes simply transfer part of the stored data
directly, without performing any computation. This embedded error correction
structure makes the decoding process straightforward, and in some cases the
complexity is very low. We show that this construction is able to achieve
performance better than space-sharing between the minimum storage regenerating
codes and the minimum repair-bandwidth regenerating codes, and it is the first
class of codes to achieve this performance. In fact, it is shown that the
proposed construction can achieve a non-trivial point on the optimal
functional-repair tradeoff, and it is asymptotically optimal at high rate,
i.e., it asymptotically approaches the minimum storage and the minimum
repair-bandwidth simultaneously. |
1408.0378v3 | ## Cataloguing PL 4-manifolds by gem-complexity
Maria Rita Casali ∗
Paola Cristofori
Dipartimento di Scienze Fisiche, Informatiche e Matematiche Universit` di Modena e Reggio Emilia a Modena, Italy
[email protected]
[email protected]
November 18, 2015
## Abstract
We describe an algorithm to subdivide automatically a given set of PL n -manifolds (via coloured triangulations or, equivalently, via crystallizations ) into classes whose elements are PL-homeomorphic. The algorithm, implemented in the case n = 4, succeeds to solve completely the PL-homeomorphism problem among the catalogue of all closed connected PL 4-manifolds up to gem-complexity 8 (i.e., which admit a coloured triangulation with at most 18 4-simplices).
Possible interactions with the (not completely known) relationship among the different classifications in the TOP and DIFF=PL categories are also investigated. As a first consequence of the above PL classification, the non-existence of exotic PL 4-manifolds up to gem-complexity 8 is proved. Further applications of the tool are described, related to possible PL-recognition of different triangulations of the K 3-surface.
Keywords : 4-manifold, crystallization, coloured triangulation, gem-complexity, combinatorial move. 2000 Mathematics Subject Classification : 57Q15 - 57N13 - 57M15 - 57Q25.
## 1 Introduction and main results
One of the most interesting features of piecewise-linear (PL) topology is the possibility of representing manifolds by combinatorial structures; the main developed theories concern the
∗ Work supported by the 'National Group for Algebraic and Geometric Structures, and their Applications' (GNSAGA - INDAM) and by M.I.U.R. of Italy (project 'Strutture Geometriche, Combinatoria e loro Applicazioni').
3-dimensional case, where - thanks to recent advances in computing power - topologists succeeded in constructing exhaustive tables of 'small' 3-manifolds based on different representation methods (see [42] and its bibliography for successive results about closed orientable irreducible 3-manifolds up to Matveev's complexity 11, and [3], [12] for analogous studies about closed non-orientable P 2 -irreducible 3-manifolds up to Matveev's complexity 10).
In dimension four, fewer combinatorial tools are available to represent PL-manifolds. On the other hand, classification results for topological (TOP) simply-connected 4-manifolds are well-known, though more attention must be paid when considering equivalence of PLstructures.
Crystallization theory is a representation theory for PL-manifolds of arbitrary dimension by means of suitable edge-coloured graphs (called crystallizations ), which are dual to coloured triangulations. Together with the Italian school that gave rise to the graph-theoretical tool (see [43], [29], [35], [30], [4] and their references), many authors around the world concurred to its development, with recent significant contributions, too: for example, [8], [9], [44]. The totally combinatorial nature of the representing objects and the generality with respect to dimension are among the strong points of crystallization theory: topological and PL properties are reflected into combinatorial ones, and the problem of distinguishing manifolds (both in TOP and in PL category) can be simplified by combinatorial invariants computed on the graphs.
In particular, in dimension four and five the best achievements have been obtained as regards the attempts of classifying PL-manifolds via a suitable graph-defined invariant, called regular genus 1 : they concern both the case of 'low' regular genus, and the case of 'restricted gap' between the regular genus of the manifold and the regular genus of its boundary, and the case of 'restricted gap' between the regular genus and the rank of the fundamental group of the manifold (see, for example, [24], [14] and [26]).
More recently, the interest focused on other combinatorial invariants internal to crystallization theory, i.e. GM-complexity and gem-complexity , which are related in dimension three to Matveev's complexity, too (see [16], [18], [23], [21]). In particular, gem-complexity is the natural invariant used to create automatic catalogues of PL-manifolds via crystallizations: in fact, it is related to the minimum order of a crystallization of the manifold. On the other hand, suitable moves on edge-coloured graphs are defined, which preserve the represented manifold up to PL-homeomorphisms; even if they are not able to solve algorithmically the recognition problem for general PL-manifolds, they are a powerful tool to face the problem itself, for a given set of PL-manifolds. In dimension three, this approach already allowed the development of a classification algorithm, which succeeded to completely recognize PL-homeomorphism classes of all 3-manifolds up to gem-complexity 14 (i.e. representable by coloured triangulations with at most 30 tetrahedra): see [39], [18] and [19] for the orientable case and [15], [16] and [5] for the non-orientable one.
The present paper describes the n -dimensional extension of the above classifying algorithm, together with the results obtained by applying it to the crystallization catalogue representing all PL 4-manifolds up to gem-complexity 8 (i.e. whose associated coloured triangulations have at most 18 4-simplices).
1 In the orientable case, it is the minimum genus of a surface where a graph representing the manifold regularly embeds: see [35] for details.
The main classification results are collected into the following theorem, where k M ( 4 ) denotes the gem-complexity of M 4 ; the last statement makes use also of a partial analysis (whose completion is in progress) of the crystallization catalogue representing all PL 4-manifolds with gem-complexity 9, which has been generated, too.
Theorem 1 Let M 4 be a handle-free closed connected PL 4-manifold. Then:
- · k M ( 4 ) = 0 ⇐⇒ M 4 is PL-homeomorphic to S 4 ;
- · k M ( 4 ) = 3 ⇐⇒ M 4 is PL-homeomorphic to CP 2 ;
- · k M ( 4 ) = 6 ⇐⇒ M 4 is PL-homeomorphic to either S 2 × S 2 or CP 2 # CP 2 or CP 2 #( -CP 2 ) ;
- · k M ( 4 ) = 7 ⇐⇒ M 4 is PL-homeomorphic to RP 4 .
## Moreover:
- · no handle-free PL 4 -manifold M 4 exists with k M ( 4 ) ∈ { 1 2 4 5 8 , , , , } ;
- · no exotic PL 4 -manifold exists, with k M ( 4 ) ≤ 8;
- · any PL 4 -manifold M 4 with k M ( 4 ) = 9 is simply-connected (with second Betti number β 2 ≤ 3 ).
As far as the TOP category is concerned, the combinatorial properties of crystallizations, together with well-known results on TOP simply-connected 4-manifolds, yield the following interesting result related to the topological classification of simply-connected PL 4-manifolds with respect both to gem-complexity and to regular genus :
Theorem 2 Let M 4 be a simply-connected PL 4-manifold M 4 . If either gem-complexity k M ( 4 ) ≤ 65 or regular genus G ( M 4 ) ≤ 43 , then M 4 is TOP-homeomorphic to
$$( \# _ { r } \mathbb { C P } ^ { 2 } ) \# ( \# _ { r ^ { \prime } } ( - \mathbb { C P } ^ { 2 } ) ) \ \ o r \ \# _ { s } ( \mathbb { S } ^ { 2 } \times \mathbb { S } ^ { 2 } ),$$
where r + r ′ = β 2 ( M , s 4 ) = 1 2 β 2 ( M 4 ) and β 2 ( M 4 ) is the second Betti number of M 4 .
Theorem 2 summarizes Proposition 20 (for gem-complexity) and Proposition 23 (for regular genus) of Section 4.
As it is well-known, up to now there is no classification of smooth structures on any given smoothable topological 4-manifold; on the other hand, finding non-diffeomorphic smooth structures on the same closed simply-connected topological manifold has long been an interesting problem.
We hope that further advances in the generation and classification of crystallization catalogues for PL 4-manifolds, according to gem-complexity, could produce examples of nonequivalent PL-structures on the same topological 4-manifold. For example, if at least one among the infinitely many PL 4-manifolds TOP-homeomorphic but not PL-homeomorphic
to CP 2 # ( 2 -CP 2 ) (which are proved to exist in [1]) admits a so called simple crystallization (according to [9]), then it will appear in the catalogue of order 20 crystallizations.
Moreover, we point out that the program performing automatic recognition of PL-homeomorphic 4-manifolds may be a useful tool to approach open problems related to different triangulations of the same TOP 4-manifold, which are conjectured to represent the same PL 4-manifold, too. The first candidates are the two known 16-vertices and 17-vertices triangulations of the K 3-surface: see [27] and [45], together with the attempts to settle the conjecture described in [10], [11] and [9].
## 2 Basic notions of crystallization theory
As already pointed out, crystallization theory allows to represent combinatorially PL manifolds of arbitrary dimension, without restrictions concerning orientability, connectedness or boundary properties, by means of suitable edge-coloured graphs or - equivalently - by means of coloured triangulations . A detailed account of the theory may be found in [32], [39] and [4], together with their references.
In the present paper, when not otherwise stated, we will restrict our attention to the case of closed, connected PL n -manifolds.
Definition 3 An (n+1)-coloured graph is a pair (Γ , γ ) , where Γ = ( V (Γ) , E (Γ)) is a regular multigraph 2 of degree n +1 and γ : E (Γ) → ∆ = 0 1 n { , , . . . , n } is injective on adjacent edges.
The elements of the set ∆ n = { 0 1 , , . . . , n } are called colours ; moreover, for each i ∈ ∆ , n we denote by Γ ˆ i the n -coloured graph obtained from (Γ , γ ) by deleting all edges coloured by i .
Definition 4 An ( n + 1) -coloured graph (Γ , γ ) is said to be contracted if the subgraph Γ ˆ i is connected, for each i ∈ ∆ n .
Each ( n + 1)-coloured graph uniquely determines an n -dimensional CW-complex K (Γ), which is said to be associated to Γ:
- · for every vertex v ∈ V (Γ), take an n -ball σ v ( ) abstractly isomorphic to an n -simplex, and label injectively its n +1 vertices by the colours of ∆ n ;
- · for every i -coloured edge between v, w ∈ V (Γ), identify the ( n -1)-faces of σ v ( ) and σ w ( ) opposite to i -labelled vertices, so that equally labelled vertices coincide.
It is easy to check that the properties of (Γ , γ ) imply K (Γ) to be actually a pseudo-complex : in particular, its balls may intersect in more than one face, but self-identifications of faces are not allowed. 3
2 According to [47], this means that all vertices of V (Γ) have the same degree, that loops are forbidden, while multiple edges are allowed.
3 Even if, in general, K (Γ) fails to be a simplicial complex, we will always call h -simplices its h -balls, for every h ≤ n .
Definition 5 An ( n + 1) -coloured graph (Γ , γ ) is said to represent a PL n -manifold M n (briefly, it is a gem of M n ) if M n is PL-homeomorphic to | K (Γ) | . If, in addition, (Γ , γ ) is contracted, then it is called a crystallization of M n . In both cases, the pseudo-complex K (Γ) , equipped with the vertex-labelling inherited from γ , is said to be a coloured triangulation of M n .
Remark 6 It is easy to prove that each PL n -manifold admits an ( n + 1) -coloured graph representing it: just take the barycentric subdivision H ′ of any (simplicial) triangulation H of M n , label any vertex of H ′ with the dimension of the open simplex containing it in H , and then consider the 1-skeleton of the dual cellular complex of H ′ , with each edge coloured by i iff it is dual to an ( n -1) -face whose vertices are labelled by ∆ n -{ } i .
The following proposition collects some well-known facts in crystallization theory:
Proposition 7 Let (Γ , γ ) be an ( n +1) -coloured graph.
- (a) | K (Γ) | is orientable iff Γ is bipartite.
- (b) ∀B ⊂ ∆ n , with # B = h, there is a bijection between ( n -h )-simplices of K (Γ) whose vertices are labelled by ∆ n - {B} and connected components of the h -coloured graph Γ B = ( V (Γ) , γ -1 ( B )) (which are called h -residues involving colours B , or B -residues of Γ , and whose number will be denoted by g B ).
In particular: c -labelled vertices of K (Γ) are in bijection with connected components of Γ ˆ c = Γ ∆ n -{ } c .
- (c) If # (Γ) = 2 V p and ∑ # = B h g B denotes the total number of h -residues of Γ , then
$$\chi ( | K ( \Gamma ) | ) = ( - 1 ) ^ { n - 1 } \cdot p \cdot ( n - 1 ) + \sum _ { h = 2 } ^ { n } ( - 1 ) ^ { h } \cdot \sum _ { \# \mathcal { B } = h } g _ { \mathcal { B } }.$$
- (d) | K (Γ) | is an n -manifold if and only if, for every c ∈ ∆ n , each connected component of Γ ˆ c represents S n -1 .
- (e) If (Γ , γ ) is a crystallization of an n -manifold M n , then
$$\ r k ( \pi _ { 1 } ( M ^ { n } ) ) \leq \min \{ g _ { \mathcal { B } } - 1 \ | \ \# \mathcal { B } = n - 1 \}.$$
## Moreover:
Proposition 8 (Pezzana Theorem) Each PL n -manifold admits a crystallization.
It is not difficult to understand that, generally, many crystallizations of the same PL n -manifold exist; hence, it is a basic problem how to recognize crystallizations (or, more generally, gems) of the same PL n -manifold.
The easiest case is that of two colour-isomorphic gems, i.e. if there exists an isomorphism between the graphs, which preserves colours up to a permutation of ∆ n . It is quite trivial to check that two colour-isomorphic gems produce the same polyhedron.
The following result assures that colour-isomorphic graphs can be effectively detected by means of a suitably defined numerical code , which can be directly computed on each of them (see [25]).
Proposition 9 Two ( n +1) -coloured graphs are colour-isomorphic iff their codes coincide.
The problem of recognizing non-colour-isomorphic gems representing the same manifold is also solved, but not algorithmically: a finite set of moves - the so called dipole moves - is proved to exist, with the property that two gems represent the same manifold iff they can be related by a finite sequence of such moves. A dipole move consists in the insertion or elimination of particular configurations involving h parallel edges, called h -dipoles (1 ≤ h ≤ n ): see [30] for details, or Figure 1 for an example in dimension n = 4, with h = 2.
Figure 1: dipole move

In this paper, however, we will also make use of another set of moves, which appears to be more suitable for algorithmic procedures (see the notion of blob and flip in Section 5). Even if they still do not solve algorithmically the problem for general PL n -manifolds (nor for general PL 4-manifolds), nevertheless we will prove that a fixed sequence of blobs and flips is sufficient to classify - via PL-homeomorphism - all PL 4-manifolds admitting a coloured triangulation with at most 18 4-simplices (see Section 6).
In order to define the class of gems involved in our catalogues, further preliminary notions are required.
Definition 10 A pair ( e, f ) of equally coloured edges in an ( n + 1) -coloured graph (Γ , γ ) is said to form a ρ s -pair iff e and f both belong to exactly s common bicoloured cycles of Γ .
Figure 2 shows the combinatorial move called ρ -pair switching .
The effect of ρ -pair switching on crystallizations is explained by the following result, where H denotes an n -dimensional handle , i.e. either the orientable or non-orientable S n -1 -bundle over S 1 (respectively denoted by S 1 × S n -1 and S 1 ˜ × S n -1 ), according to the orientability of M n :
Proposition 11 ([7]) Let (Γ , γ ) be a crystallization of a PL n -manifold M n , n /greaterorequalslant 3 and let (Γ ′ , γ ′ ) be obtained by switching a ρ s -pair in Γ . Then:
- (a) if s = n -1 , (Γ ′ , γ ′ ) is a gem of M n , too;
- (b) if s = n, (Γ ′ , γ ′ ) is a gem of an n -manifold N n such that M n ∼ = PL N n # H .
Definition 12 An ( n +1) -coloured graph is said to be rigid (resp. rigid dipole-free) if it has no ρ s -pairs, with s ∈ { n -1 , n } (resp. if it is rigid and has no dipoles).
Figure 2: ρ -pair switching
Catalogues of PL n -manifolds are obviously constructed with respect to increasing 'complexity' of the representing combinatorial objects. Within crystallization theory, the following quite natural invariant is considered:
Definition 13 Given a PL n -manifold M n , its gem-complexity is the non-negative integer k M ( n ) = p -1 , where 2 p is the minimum order (i.e. the minimum number of vertices) of a crystallization of M n .
In order to generate an exhaustive catalogue of ( n + 1)-coloured graphs representing all closed connected PL n -manifolds up to a fixed gem-complexity, the restriction to the class of rigid dipole-free crystallizations yields no loss of generality, as Proposition 15 below proves.
In the following, # h M denotes the connected sum of h copies of a given n -manifold M .
Definition 14 A PL n -manifold M n is said to be handle-free if it admits no handles as connected summands.
Proposition 15 Let M n be a PL n -manifold ( n ≥ 3 ). Then:
- (a) If M n is handle-free, then a rigid dipole-free order 2 p crystallization (Γ , γ ) of M n exists, so that k M ( n ) = p -1 .
- (b) Otherwise, a rigid dipole-free order 2 p crystallization of a PL n -manifolds N n exists, so that M n ∼ = PL N n # h H ( h ≥ 0 ) and k M ( n ) = p -1 + n · h.
Proof. Statement (a) directly follows from [7, Theorem 5.3].
Let now M n ∼ = PL N n # h H be any connected sum decomposition of M n , with h ≥ 0. 4 Since a standard order 2( n +1) crystallization of S 1 × S n -1 (resp. S 1 ˜ × S n -1 ) is well-known (see [38]), and since the so called graph connected sum (see [32]) yields an order 2( p 1 + p 2 -1) gem of
4 Note that no assumption is made, both on h and on N n : the decomposition turns out to be 'trivial' in case h = 0 and N n = M n . Note also that in dimension n = 3, where the uniqueness of the decomposition under connected sum holds, the statement is already known: see [15, Proposition 8(b)].
N 1 # N 2 from any order 2 p 1 (resp. 2 p 2 ) gem of N 1 (resp. N 2 ), inequality k M ( n ) ≤ p -1 + n · h easily follows, 2 p being the order of any crystallization of N . n
Hence, if we set
$$\text{there, in we set} \\ \mathcal { S } = \left \{ p - 1 + n \cdot h \ | \ M ^ { n } \cong _ { P L } N ^ { n } \# _ { h } \mathbb { H }, \ 2 p = \# V ( \Gamma ), \\ \Gamma \text{ rigid dipole-free crystallization of } N ^ { n } \right \}, \\ \text{round to}$$
it is proved that
$$k ( M ^ { n } ) \, \leq \, \min \mathcal { S },$$
where the minimum is taken over all decompositions M n ∼ = PL N n # h H (with h ≥ 0) and over all rigid dipole-free crystallizations of N . n
In order to prove the reversed inequality (and hence statement (b)), let us consider an arbitrary crystallization ( ¯ Γ ¯) of , γ M n , with order 2¯. p If ( ¯ Γ ¯) is a rigid dipole-free crystallization, , γ then ¯ p -1 ∈ S (with respect to the trivial decomposition of M n ), and so ¯ p -1 ≥ min S trivially holds. If ( ¯ Γ ¯) contains , γ ρ n -1 -pairs and/or dipoles, a order 2¯ p ′ rigid dipole-free crystallization ( ¯ Γ ′ , γ ¯ ) ′ of M n is easily obtained via a suitable number of ρ n -1 -switching, each one followed by a 1-dipole elimination, and/or dipole eliminations; hence, ¯ p ′ -1 ∈ S (with respect to the trivial decomposition of M n ), and so ¯ p -1 > p ¯ ′ -1 ≥ min S trivially holds.
Finally, let us assume ( ¯ Γ ¯) to admit no , γ ρ n -1 -pairs, no dipoles and h ≥ 1 ρ n -pairs. After each ρ n -pair switching, n 1-dipoles appear, one for each colour not involved in the ρ -pair. Let ( ¯ Γ ′′ , γ ¯ ) be the order 2¯ ′′ p ′′ graph obtained by all ρ n -switchings and elimination of the resulting n · h 1-dipoles; according to Proposition 11(b), ( ¯ Γ ′′ , γ ¯ ) is a rigid dipole-free crystallization of a PL ′′ n -manifold ¯ N n such that M n ∼ = PL ¯ N n # h H . Hence, ¯ p ′′ -1+ n h · ∈ S . Relation ¯ p -1 = ¯ p ′′ -1+ n · h ≥ min S easily follows. ✷
Elementary notions of crystallization theory - and in particular the graph-connected sum quoted in the above proof - allow to easily extend to any dimension both the sphere-recognition property and the finiteness property and the sub-additivity (with respect to connected sum) of gem-complexity, already stated in [15, Proposition 10] for the 3-dimensional case.
Although the gem-complexity cannot be additive on the whole set of PL 4-manifolds, as a consequence of Wall theorem ([46]), nevertheless additivity is possible on restricted classes of manifolds: for example those with small values of gem-complexity ( ≤ 8 as shown by the results of the present paper) or those admitting simple crystallizations (as proved in [22]).
The invariant regular genus shares with the gem-complexity the properties of sphere recognition and subadditivity in any dimension. In dimension three it is additive but not finiteto-one (since it coincides with the Heegaard genus), while in the closed 4-dimensional case both finiteness and additivity are open problems. However, additivity holds within the class of 4-manifolds admitting simple crystallizations ([22]).
Remark 16 Note that, as pointed out in [31, Remark 1], additivity of the regular genus in dimension four would imply the Smooth Poincar´ Conjecture. e
$$\begin{matrix} 1 & 1 & 1 & 1 & 1 & 1 & 1 & 1 & 1 & 1 & 1 & 1 & 1 & 1 & 1 & 1 & 1 & 1 & 1 & 1 & 1 & 1 & 1 & 1 & 1 & 1 & 1 & 1 & 1 & 1 & 1 & 1 & 1 & 1 & 1 & 1 & 1 & 1 & 1 & 1 & 1 & 1 & 1 & 1 & 1 & 1 & 1 & 1 & 1 & 1 & 1 & 1 & 1 & 1 & 1 & 1 & 1 & 1 & 1 & 1 & 1 & 1 & 1 & 1 & 1 & 1 & 1 & 1 & 1 & 1 & 1 & 1 & 1 & 1 & 1 & 1 & 1 & 1 & 1 & 1 & 1 & 1 & 1 & 1 & 1 & 1 & 1 & 1 & 1 & 1 & 1 & 1 & 1 & 1 & 1 & 1 & 1 & 1 & 1 & 1 & 1 \\ \end{matrix}$$
## 3 4-dimensional generation algorithm
By Proposition 7(d), the generation of catalogues of crystallizations of n -manifolds with a fixed number of vertices 2 p is essentially inductive on dimension and requires the prior generation and recognition of all gems (with 2 p vertices) representing the ( n -1)-sphere.
It is therefore easy to understand why the first results have been obtained in dimension three, since 2-sphere recognition can be performed easily by computing the Euler characteristic, and null Euler characteristic characterizes closed 3-manifolds.
However, the generating algorithm, even in low dimension, becomes quickly very intensive as the number of vertices increases and requires large computing resources. A way to face this problem is to find combinatorial configurations in the graphs, which can be eliminated without changing the manifold. Examples of such configurations are dipoles and ρ -pairs.
Proposition 15 assures that restricting the catalogues to rigid dipole-free crystallizations does not affect their completeness.
Catalogues of 3-manifold rigid 5 crystallizations up to 32 vertices have already been generated and completely classified ([15], [18], [19], [5]). Complete classification was also obtained for genus two 3-manifolds admitting a crystallization with at most 42 vertices ([6]).
Let now fix our attention to the 4-dimensional case. For each p ≥ 1, we will denote by C (2 p ) (resp. ˜ C (2 p ) ) the catalogue of all not colour-isomorphic rigid dipole-free bipartite (resp. non-bipartite) crystallizations of 4-manifolds with 2 p vertices.
S (2 p ) will be the starting set of the procedure generating C (2 p ) and ˜ C (2 p ) , which consists essentially in adding 4-coloured edges to all elements of S (2 p ) , so as to obtain crystallizations of 4-manifolds.
Note that if Γ ∈ C (2 p ) ∪C ˜ (2 p ) , then Γ ˆ 4 is a (not necessarily contracted, nor rigid) 4-coloured graph representing S 3 and lacking in ρ 3 -pairs. Let S (2 p ) denotes the set of such 4-coloured graphs.
The set S (2 p ) is constructed by a suitable adaptation of the 3-dimensional generation algorithm; recognition of the 3-sphere is performed by cancelling dipoles and switching ρ -pairs in order to obtain a rigid crystallization and by comparing the resulting graph with the list of rigid crystallizations of S 3 , which appear in the 3-dimensional catalogue.
As a matter of fact, the recognition is very easy for p < 12, since the only rigid crystallization of S 3 up to this order is the standard one with two vertices.
So, the generating algorithm in dimension four runs as follows:
- 1) Construct the set S (2 p ) = { Σ (2 p ) 1 , Σ (2 p ) 2 , . . . , Σ (2 p ) n p } .
- 2) For each i = 1 2 , , . . . , n p :
- -add to Σ (2 p ) i 4-coloured edges in all possible ways so to produce 4-coloured graphs;
- -for each produced graph Γ, check absence of ρ -pairs and 2-dipoles;
- -for each c ∈ ∆ , check that Γ 3 ˆ c represents S 3 .
- 3) Compute and compare the codes in order to exclude colour-isomorphic duplicates.
5 It is easy to see that in dimension three, rigidity and contractedness imply absence of dipoles.
However, the above algorithm is practically useless due to the great computational time it requires; therefore it needs some modifications in order to be effective. More precisely, a branch and bound technique is used to prune the tree of possible attachments of edges on each element of S (2 p ) .
Let Γ be a 5-coloured ¯ graph obtained from an element of S (2 p ) by addition of r < p 4-coloured edges, then Γ will be kept for further additions if and only if: ¯
- (i) it contains no three edges with the same endpoints (otherwise there will be ρ -pairs in the final regular graph);
- (ii) for each i ∈ ∆ , ¯ 3 Γ represents a 3-sphere with holes. ˆ i
Unfortunately condition (ii) is very heavy to check, since it implies recognition of 3-spheres with holes. Instead, we use a weaker condition, which is equivalent to requiring Γ ¯ ˆ i to be a 3-manifold (with boundary), i.e.
- (ii ) ′ for each pair of colours i, j ∈ ∆ , each 3-residue of Γ not involving 3 ¯ colours i, j must represent a disjoint union of 2-spheres, possibly with holes.
Condition (ii ) can be checked by direct computation on Γ in the following way. ′ ¯
A 4-coloured graph (without boundary) ∂ ¯ Γ such that | K ∂ ( ¯ ) Γ | ∼ | = ∂K ( ¯ ) Γ | can be constructed as follows:
Note that Γ is a so-called ¯ 5-coloured graph with boundary , i.e. ¯ Γ ˆ 4 is a 4-coloured graph. Then K ( ¯ ), which is obtained exactly in the same way as in the closed case, is a pseudocomplex Γ with non-empty boundary. The 3-simplices which triangulate ∂K ( ¯ ) Γ correspond bijectively to the vertices of Γ missing the 4-coloured edge ( ¯ boundary vertices ).
- · V ( ∂ ¯ ) Γ is the set of boundary vertices of Γ; ¯
- · for each c ∈ ∆ , two vertices of 3 ∂ ¯ Γ are c -adjacent iff they are connected by a { c, 4 } -coloured path in Γ. ¯
Then, a suitable extension of the Euler characteristic computation of Proposition 7(c) implies that condition (ii') is equivalent to requiring the following equality to hold:
$$\sum _ { k, t \in \Delta _ { 4 } \, \langle i, j \} } g _ { k t } - \frac { \bar { p } } { 2 } = 2 g _ { i \hat { j } } - \bar { g } _ { i \hat { j } }$$
where g kt is the number of { k, t } -coloured cycles of Γ, ¯ is the number of boundary vertices of ¯ p ¯ and Γ g ˆˆ ij (resp. ¯ g ˆˆ ij ) is the number of (∆ 4 -{ i, j } )-residues of Γ (resp. ∂ Γ).
The above described restrictions succeed in reducing considerably both the computation time and the size of the resulting catalogues. Moreover, a parallelization strategy, which has been adopted in the implementation, has allowed to reduce further the computation time: see [41] for details.
As a consequence we could produce catalogues C (2 p ) and ˜ C (2 p ) for each p ≤ 10 (see Table 1 below).
Table 1
| 2p | 2 | 4 | 6 | 8 | 10 | 12 | 14 | 16 | 18 | 20 |
|--------------|-----|-----|-----|-----|------|------|-------|--------|-----------|------------|
| # S (2 p ) | 1 | 0 | 2 | 9 | 39 | 400 | 5.255 | 95.87 | 1.994.962 | 45.654.630 |
| # C (2 p ) | 1 | 0 | 0 | 1 | 0 | 0 | 1.109 | 4.511 | 44.803 | 47.623.129 |
| # ˜ C (2 p ) | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 1 | 0 | 0 |
Remark 17 We point out that the unique rigid dipole-free crystallization of C (2) (resp. of C (8) ) is the standard crystallization of S 4 (resp. CP 2 : see [36]), while the unique non-bipartite rigid dipole-free crystallization appearing up to 20 vertices is the standard one of RP 4 with 16 vertices ([37]).
Remark 18 A further restriction on the catalogues could be imposed: if Γ ∈ C (2 p ) ∪ C ˜ (2 p ) is a graph connected sum (see [32], or the proof of Proposition 15) of two graphs Γ 1 and Γ 2 , then | K (Γ) | ∼ = PL | K (Γ ) # 1 | | K (Γ ) 2 | and we call Γ splittable. The problem of recognizing the manifold | K (Γ) | is thus traced back to the (easier) problem of recognizing | K (Γ ) 1 | and | K (Γ ) 2 | . However, the low number of splittable crystallizations (about 0.6% of the elements for the catalogues with up to 18 vertices) forces to directly recognize the crystallizations by moves keeping the PL-homeomorphism of | K (Γ) | (see Section 5).
## 4 TOP classification via combinatorial invariants
Before describing the classification performed in our crystallization catalogues via suitable sequences of moves which realize PL-homeomorphisms of the represented PL 4-manifolds, we devote the present section to the much weaker problem of classifying the involved PL 4-manifolds within the TOP category.
The starting point is the direct computation of the Betti numbers and of the rank of the fundamental group for each PL 4-manifold represented by a crystallization of our catalogues.
Proposition 19 All orientable PL 4-manifolds represented by elements of C (2 p ) , 1 ≤ p ≤ 10 , are simply-connected. The unique elements of C (2) and C (8) are known crystallizations representing S 4 and CP 2 respectively. Moreover:
- (a) Among the 1 109 . crystallizations of C (14) :
- -exactly one represents a (simply-connected) PL 4-manifold M 4 with β 2 = 1;
- -all the remaining ones represent (simply-connected) PL 4-manifolds M 4 with β 2 = 2 .
- (b) All 4 511 . crystallizations of C (16) represent (simply-connected) PL 4-manifolds M 4 with β 2 = 2 .
- (c) Among the 44 803 . crystallizations of C (18) :
- -ten represent (simply-connected) PL 4-manifolds M 4 with β 2 = 1;
- -all the remaining ones represent (simply-connected) PL 4-manifolds M 4 with β 2 = 2 .
- (d) Among the 47 623 129 . . crystallizations of C (20) :
- -exactly one represents a (simply-connected) PL 4-manifold M 4 with β 2 = 0;
- -370 represent (simply-connected) PL 4-manifolds M 4 with β 2 = 1;
- -501 900 . represent (simply-connected) PL 4-manifolds M 4 with β 2 = 2;
- -all the remaining ones represent (simply-connected) PL 4-manifolds M 4 with β 2 = 3 .
Proof. In virtue of Proposition 7(e), an estimation of rk π ( 1 ( M 4 )), for each PL 4-manifold M 4 represented by our catalogues, may be obtained by computing the number g rst of 3-residues involving colours { r, s, t } , with 0 ≤ r < s < t ≤ 4, for each element of C (2 p ) , 1 ≤ p ≤ 10 . The calculation has been done by means of a suitable procedure of the program DUKE III 6 and the program output ensures that each crystallization of C (2 p ) , 1 ≤ p ≤ 10 , has g rst = 1 for at least a choice of distinct r, s, t ∈ ∆ 4 . Hence, the simply-connectedness of all involved orientable PL 4-manifolds is proved.
In order to calculate the Betti numbers of the same PL 4-manifolds, it is necessary to apply Proposition 7(c), yielding the Euler characteristic of M 4 by a direct computation on each order 2 p crystallization of M 4 7 :
$$\ y o w a m a { \varpropto \in \mathcal { O } } \, & \, \infty \, \begin{matrix} \,. \\ \, \chi ( M ^ { 4 } ) \end{matrix} & = 5 - \sum _ { i < j < k } g _ { i j k } + \sum _ { i < j } g _ { i j } - 3 p.$$
Now, the simply-connectedness implies χ M ( 4 ) = 2+ β 2 ( M 4 ); hence, β 2 ( M 4 ) follows by a direct computation of both the number of 3-residues and 2-residues, for each element of C (2 p ) , 1 ≤ p ≤ 10 . The statement is proved by making use of suitable procedures of the program DUKE III. ✷
The fact that all orientable PL 4-manifolds represented by crystallizations of our catalogues are simply-connected has important consequences as regards their classification in the TOP category.
In fact, the following result proves that, up to a significantly high gem-complexity, the classification of PL 4-manifolds up to TOP-homeomorphism is quite easy, at least in the simply-connected case (which - as a matter of fact - turns out to be the most frequent case): 8
6 'DUKE III: A program to handle edge-coloured graphs representing PL n-dimensional manifolds' is available on the Web: http://cdm.unimo.it/home/matematica/casali.mariarita/DUKEIII.htm
7 Recall that contractedness implies Γ to have exactly one 4-residue involving ∆ 4 -{ } i , for each i ∈ ∆ . 4 8 The statement of Proposition 20 was announced in [17] and in [20].
Proposition 20 Any simply-connected PL 4-manifold M 4 , with k M ( 4 ) ≤ 65 , is TOP-homeomorphic to
$$( \# _ { r } \mathbb { C P } ^ { 2 } ) \# ( \# _ { r ^ { \prime } } ( - \mathbb { C P } ^ { 2 } ) ) \ \ o r \ \# _ { s } ( \mathbb { S } ^ { 2 } \times \mathbb { S } ^ { 2 } ),$$
where r + r ′ = β 2 ( M , s 4 ) = 1 2 β 2 ( M 4 ) and β 2 ( M 4 ) ≤ k M ( 4 ) 3 is the second Betti number of M 4 .
Proof. Let Γ be an order 2 p crystallization of M 4 . As already recalled, formula (2) yields the direct computation of the Euler characteristic of M . 4
On the other hand, the planarity of each 3-residue of Γ yields (via Proposition 7(c), too) 2 g ijk = g ij + g ik + g jk -p for each triple ( i, j, k ) ∈ ∆ , from which the following relation is 4 obtained:
$$2 \sum _ { i < j < k } g _ { i j k } = 3 \sum _ { i < j } g _ { i j } - 1 0 p.$$
Hence, the Euler characteristic computation gives
$$1 - \beta _ { 1 } ( M ^ { 4 } ) + \beta _ { 2 } ( M ^ { 4 } ) - \beta _ { 3 } ( M ^ { 4 } ) + 1 = 5 - \frac { 1 } { 3 } \sum _ { i < j < k } g _ { i j k } + \frac { 1 } { 3 } p.$$
Now, if M 4 is assumed to be simply-connected, 6 + 3 β 2 ( M 4 ) = 15 + p -∑ i<j<k g ijk follows; since g ijk ≥ 1 trivially holds, we have 3 β 2 ( M 4 ) ≤ p -1 . So,
$$k ( M ^ { 4 } ) \geq 3 \beta _ { 2 } ( M ^ { 4 } )$$
may be stated, for each simply-connected PL 4-manifold M 4 .
Now, the classical theorems of Freedman and Donaldson ([33]) about the TOP classification of simply-connected closed 4-manifolds, together with more recent results by Furuta ([34]), ensure that intersection forms of type
$$\L v r \varsigma \pm 2 n E _ { 8 } \oplus s \begin{pmatrix} 0 & 1 \\ 1 & 0 \end{pmatrix}$$
do represent PL 4-manifolds only if s > 2 n ; hence, only PL 4-manifolds with β 2 ( M 4 ) ≥ 22 occur in this case. The thesis directly follows from the fact that k M ( 4 ) ≤ 65 implies β 2 ( M 4 ) ≤ 21; so, only intersection forms of the two simplest types are allowed:
$$r [ 1 ] \oplus r ^ { \prime } [ - 1 ] \quad o r \quad s \begin{pmatrix} 0 & 1 \\ 1 & 0 \end{pmatrix}$$
where r + r ′ = β 2 ( M 4 ) or s = 1 2 β 2 ( M . 4 )
✷
As a consequence of the above result, we can already deduce the complete TOP classification of all PL 4-manifolds represented in our cystallization catalogues, i.e. up to gemcomplexity 9.
We subdivide the results into two different statements, with respect to orientability assumptions; in fact, in the non-orientable case, the PL classification of all PL 4-manifolds up to gem-complexity 9 follows, too (Proposition 22), while in the orientable case the PL classification is possible only up to gem-complexity 5 (Proposition 21):
Proposition 21 Let M 4 be an orientable PL 4-manifold. Then:
- · k M ( 4 ) = 0 ⇐⇒ M 4 is PL-homeomorphic to S 4 ;
- · k M ( 4 ) = 3 ⇐⇒ M 4 is PL-homeomorphic to CP 2 ;
- · k M ( 4 ) = 4 ⇐⇒ M 4 is PL-homeomorphic to S 1 × S 3 ;
- · no orientable PL 4 -manifold M 4 exists with k M ( 4 ) ∈ { 1 2 5 , , } ;
- · k ( CP 2 #( S 1 × S 3 )) = 7 , k (# ( 2 S 1 × S 3 )) = 8 and no other PL 4-manifold with handles M 4 exists with k M ( 4 ) ∈ { 6 7 8 9 , , , } .
Moreover, if M 4 is assumed to be handle-free, then:
- · k M ( 4 ) ∈ { 6 7 8 , , } = ⇒ M 4 is TOP-homeomorphic to either S 2 × S 2 or CP 2 # CP 2 or CP 2 #( -CP 2 ) or CP 2 ;
- · k M ( 4 ) = 9 = ⇒ M 4 is TOP-homeomorphic to either S 2 × S 2 or (# r CP 2 )# (# r ′ ( -CP 2 )) , where 0 ≤ r + r ′ ≤ 3 .
Proof. In virtue of Proposition 15, the gem-complexity of a closed connected orientable PL 4-manifold M 4 is congruent mod 4 to p -1, 2 p being the order of a rigid dipole-free bipartite crystallization (i.e. an element of C (2 p ) ). Moreover, by Proposition 19, all elements of ⋃ 1 ≤ ≤ p 10 C (2 p ) represent simply-connected PL 4-manifolds, which are obviously handle-free. Hence (as far as the PL category is concerned):
- -the statements for k M ( 4 ) ≤ 3 are direct consequences of the generation algorithm output, for p ≤ 4 (see Proposition 19);
- -k ( S 1 × S 3 ) = 4 (resp. k ( CP 2 #( S 1 × S 3 )) = 7) (resp. k (# ( 2 S 1 × S 3 )) = 8) follows from Proposition 15(b), with N 4 = S 4 , h = 1 and s = 0 (resp. N 4 = CP 2 , h = 1 and s = 0) (resp. N 4 = S 4 , h = 2 and s = 0), since k ( S 4 ) = 0, k ( CP 2 ) = 3 and no element of ⋃ 1 ≤ ≤ p 9 C (2 p ) represents a PL 4-manifold with handles;
- -the statement regarding the non-existence of other PL 4-manifolds with handles (different from CP 2 #( S 1 × S 3 ) and # ( 2 S 1 × S 3 )) with k M ( 4 ) = k ∈ { 6 7 8 9 , , , } follows from Proposition 15(b), too, together with the previous analysis concerning gem-complexity k -4 and k -8.
- -for k M ( 4 ) ∈ { 4 5 , } , the statements follow from k ( S 1 × S 3 ) = 4 and from the fact that ⋃ 5 ≤ ≤ p 6 C (2 p ) = ∅ (see Table 1);
Finally, the statements involving TOP-homeomorphism follow immediately from Proposition 19 and Proposition 20. ✷
Proposition 22 Let M 4 be a non-orientable PL 4-manifold. Then:
- · k M ( 4 ) = 4 ⇐⇒ M 4 is PL-homeomorphic to S 1 ˜ × S 3 ; · k M ( 4 ) = 7 ⇐⇒ M 4 is PL-homeomorphic to either RP 4 or CP 2 #( S 1 ˜ × S 3 );
Moreover, no non-orientable PL 4 -manifold M 4 exists with k M ( 4 ) ∈ { 0 1 2 3 5 6 9 , , , , , , } .
- · k M ( 4 ) = 8 ⇐⇒ M 4 is PL-homeomorphic to # ( 2 S 1 ˜ × S 3 ) .
Proof. By Proposition 15, the gem-complexity of a closed connected non-orientable PL 4manifold M 4 is congruent mod 4 to p -1, 2 p being the order of a rigid dipole-free crystallization (i.e. an element of C (2 p ) ∪ C ˜ (2 p ) ). Moreover, the generation algorithm output (Table 1) and Proposition 19 ensure that all elements of ⋃ 1 ≤ ≤ p 10 ( C (2 p ) ∪ C ˜ (2 p ) ) , except the standard order 16 crystallization of RP 4 , represent simply-connected PL 4-manifolds; hence, no PL 4-manifold with handles appears.
Now, the arguments are exactly the same as in the proof of Proposition 21, when taking into account also the results of the generation algorithm for the non-bipartite case. ✷
Another interesting consequence of the quoted results by Freedman, Donaldson and Furuta ([33], [34]) is related to the topological classification of simply-connected PL 4-manifolds with respect to the invariant regular genus .
First, recall that the genus of a bipartite 9 ( n +1)-coloured graph (Γ , γ ) with respect to a cyclic permutation ε = ( ε , ε o 1 , . . . , ε n -1 , ε n = n ) of ∆ n is the genus ρ ε (Γ) of the surface F ε into which Γ regularly embeds (see [35] for details); moreover, ρ ε (Γ) may be directly computed by the following formula:
$$\ r m u a \colon \sum _ { i \in \mathbb { Z } _ { n + 1 } } g _ { \varepsilon _ { i } \varepsilon _ { i + 1 } } + ( 1 - n ) \cdot p = 2 - 2 \rho _ { \varepsilon } ( \Gamma ).$$
Then, the regular genus of Γ is defined as ρ (Γ) = min ε { ρ ε (Γ) } , while the regular genus of an orientable PL n -manifold M n is defined as:
$$\mathcal { G } ( M ^ { n } ) = \min \{ \rho ( \Gamma ) \ | \ ( \Gamma, \gamma ) \text{ crystallization of } M ^ { n } \}.$$
With the above notations, the following statement holds:
Proposition 23 Any simply-connected PL 4-manifold M 4 , with G ( M 4 ) ≤ 43 , is TOP-homeomorphic to
$$( \# _ { r } \mathbb { C P } ^ { 2 } ) \# ( \# _ { r ^ { \prime } } ( - \mathbb { C P } ^ { 2 } ) ) \ \ o r \ \# _ { s } ( \mathbb { S } ^ { 2 } \times \mathbb { S } ^ { 2 } ),$$
where r + r ′ = β 2 ( M , s 4 ) = 1 2 β 2 ( M 4 ) and β 2 ( M 4 ) is the second Betti number of M 4 .
Proof. Let Γ be a crystallization of a PL 4-manifold M 4 , and let ρ ε (resp. ρ ˆ ε i ) be the regular genus of Γ (resp. Γ ˆ ε i ) with respect to a given cyclic permutation ε of ∆ . 4 By applying formula (4) both to Γ and to each 4-residue of Γ, and by making use of formula (2), too, the following relations easily follow (see, for example, formulae (3)-(13) in the proofs of Lemma 1 and Lemma 2 in [13], where they are given in the more general setting of crystallizations of bounded PL 4-manifolds):
9 An analogous definition exists in the non-bipartite case, too (see [35]); for the purpose of the present work, however, the attention may be restricted to bipartite graphs.
- (a) g ε i -1 ,ε ,ε i i +1 = 1 + ρ ε -ρ ˆ ε i +1 -ρ ˆ ε i +3 ∀ i ∈ Z 4 ;
- (b) ∑ i ∈ Z 4 g ε i -1 ,ε ,ε i i +1 = 5 + 5 ρ ε -2 ∑ i ∈ Z 4 ρ ˆ ε i ;
Since g ε i -1 ,ε ,ε i i +1 ≥ 1 trivially holds, inequality 2 ∑ i ∈ Z 4 ρ ˆ ε i ≤ 5 ρ ε directly follows from (b). By substituting it into (c), with the additional hypothesis π 1 ( M 4 ) = 0 , we have 2 + β 2 ( M 4 ) = χ M ( 4 ) ≤ 2 + [ ρ ε 2 ] (where [ x ] means the integer part of x ), from which β 2 ( M 4 ) ≤ [ ρ ε 2 ] follows. As a consequence, relation
- (c) χ M ( 4 ) = 2 -2 ρ ε + ∑ i ∈ Z 4 ρ ˆ ε i .
$$\beta _ { 2 } ( M ^ { 4 } ) \leq \left [ \frac { \mathcal { G } ( M ^ { 4 } ) } { 2 } \right ]$$
(already obtained in [28, Proposition 2], too) is proved to hold.
Now, the thesis directly follows from the fact that G ( M 4 ) ≤ 43 implies β 2 ( M 4 ) ≤ 21, and from the already quoted well-known results about the classification of simply-connected closed 4-manifolds (exactly as in the proof of Proposition 20). ✷
As already pointed out, Proposition 20 and Proposition 23, together, prove Theorem 2 of Section 1, related to the TOP classification of the PL 4-manifolds represented by crystallizations.
The (more interesting!) PL classification will be independently achieved in Section 6, by making use of an implementation of the classifying algorithm described in Section 5.
## 5 Classification algorithm and possible applications
In order to complete the PL classification of the manifolds appearing in our catalogues of crystallizations, we exploit in the n -dimensional setting an idea already applied in dimension three.
First of all, let us call admissible a sequence of combinatorial moves which transforms a rigid dipole-free crystallization of a PL n -manifold M , into a rigid dipole-free crystallization of a PL n -manifold M ′ such that M ∼ = PL M ′ # h H ( h ≥ 0).
Let now X be a list of rigid dipole-free crystallizations; for any given set S of admissible sequences, it is possible to subdivide X into equivalence classes with regard to S .
More precisely, for each Γ ∈ X and for each /epsilon1 ∈ S , let θ /epsilon1 (Γ) denote the (rigid dipole-free) crystallization obtained from Γ by applying the admissible sequence /epsilon1 of moves, and let us define the class of Γ ∈ X with respect to S as:
$$c l _ { \mathcal { S } } ( \Gamma ) = \{ \Gamma ^ { \prime } \in X \ | \ \exists \epsilon, \epsilon ^ { \prime } \in \mathcal { S }, \ \theta _ { \epsilon } ( \Gamma ) \text{ and } \theta _ { \epsilon ^ { \prime } } ( \Gamma ^ { \prime } ) \text{ have the same code} \}$$
The following statement is a direct consequence of the above definition, together with Proposition 11:
Proposition 24 Given Γ Γ , ′ ∈ X , if cl S (Γ) = cl S (Γ ) ′ , then there exist h, k ∈ N ∪ { 0 } such that | K (Γ) | ∼ = PL M # h H and | K (Γ ) ′ | ∼ = PL M # k H (where the handles are orientable or not according to the bipartition of Γ and Γ ′ ).
Note that no theoretical proof exists ensuring that | K (Γ) | ∼ = PL | K (Γ ) ′ | implies cl S (Γ) = cl S (Γ ) (as well as its generalization: ′ | K (Γ) | ∼ = PL | K (Γ ) # ′ | h H ⇒ cl S (Γ) = cl S (Γ )). ′
Nevertheless, in dimension three, existence has been proven of a set of admissible moves which are sufficient to perform the topological (=PL) classification of all 3-manifolds admitting a coloured triangulation with at most 30 tetrahedra ([19], [5]).
As we will see in the next section, the same turns out to be true, in the 4-dimensional setting, for all elements of ⋃ 1 ≤ ≤ p 9 C (2 p ) , though with respect to a different set of moves.
In fact, the 3-dimensional classification algorithm employs dipole moves and ρ -pairs switchings (which are available in any dimension), together with generalized dipole moves ([30]), which are defined only for n = 3.
Instead, in the n -dimensional setting we make use of a further set of moves, introduced by Lins and Mulazzani in [40].
## Definition 25 Let Γ be a gem of a PL n -manifold M . n Then:
- · A blob is the insertion or cancellation of an n -dipole.
- · A t-flip is the switching of a pair ( e, f ) of equally coloured edges which are both incident to an h -dipole Ξ ( 1 ≤ h ≤ n -1 ). An s-flip is the inverse move, i.e. the switching of a pair ( e, f ) of equally coloured edges where either e or f belong to an h -dipole, which becomes an ( h -1) -dipole after the transformation. A flip is either an s- or a t-flip.
Figure 3: blob move

Figure 4: flip move

Flips and blobs on a gem do not change the represented manifold: [40, Proposition 3]. Actually, even if two crystallizations are known to represent the same manifold, there is no algorithmic procedure to determine a sequence of blobs and flips connecting them, nor an upper bound to the number of moves to be performed. However, in the next section we will show that such an algorithm exists for the crystallizations appearing in our catalogues and that only one blob is sufficient.
In order to define the set of admissible moves ¯ which have been chosen to work on the S catalogue ⋃ 1 ≤ ≤ p 9 C (2 p ) , let us introduce some definitions and notations.
Given an order 2 p ( n + 1) -coloured graph Γ there is a natural ordering of its vertices induced by the rooted numbering algorithm generating its code (see [25]); so we can write V (Γ) = { v , . . . , v 1 2 p } .
If Γ is a rigid dipole-free crystallization of a PL n -manifold, given i ∈ N 2 p = { 1 , . . . , 2 p } , c ∈ ∆ , an n n -tuple x = ( x , . . . , x 1 n ) with x i ∈ N 2 p and a permutation τ of ˆ = ∆ c n -{ } c , we denote by θ i,c, x ,τ (Γ) the rigid dipole-free crystallization obtained from Γ in the following way:
- -insert a blob over the c -coloured edge incident with v i ;
- -for each k ∈ ˆ, c consider, if exists, the s-flip on the pair of τ ( k )-coloured edges ( e, f ), where e belongs to the blob and f is incident to v x k ; then perform the sequence of all possible s-flips of this type for increasing values of the parameter k ;
- -cancel dipoles and switch ρ -pairs in the resulting graph.
θ i,c, x ,τ obviously defines an admissible sequence.
We denote by ¯ the set of all sequences S θ i,c, x ,τ , where i ∈ N 2 p , c ∈ ∆ n , x is an n -tuple of elements of N 2 p and τ is a permutation of ˆ. c
Remark 26 Note that the above definition of ¯ S , as well as the classification algorithm itself, are independent from dimension. As a consequence, the partition into equivalence classes with respect to ¯ S can be performed on any list of crystallizations of n -manifolds, in order to prove their PL-equivalence. Furthermore, note that the PL manifold represented by an equivalence class is completely identified once at least one of the crystallizations of the class is 'known'; hence the algorithm can be also effective for the PL recognition of the manifolds involved in the list.
Remark 27 It is not difficult to prove that ρ n -pairs cannot appear when the classification algorithm with respect to ¯ S is applied to a set of bipartite crystallizations representing simplyconnected n -manifolds (see Proposition 11(b)). Hence, in this case, cl S (Γ) = cl S (Γ ) ′ surely implies | K (Γ) | ∼ = PL | K (Γ ) ′ | .
In order to obtain PL classification results, the classification algorithm, with respect to ¯ S and for n = 4, has been implemented in a C++ program - called 'Γ4 -class '.
As already pointed out in Section 1, the program Γ4 -class can be applied to attempt to prove PL-equivalence between different (pseudo-)triangulations of the same topological 4manifold; in fact, it is very easy to produce automatically a rigid dipole-free crystallization starting from any (pseudo-)triangulation (see Remark 6 and Proposition 15).
In particular, an application of Γ4 -class to the case of the 16-vertices (resp. 17-vertices) triangulation of the K 3-surface (obtained in [27] and [45] respectively) is in progress. The idea is similar to the one described in [9], [10] and [11], but the elementary moves involved in the automatic procedures are different ( blob and flips , together with dipole eliminations and ρ -pair switching , instead of edge-contraction and bistellar moves ). Hence, it is possible that one sequence succeeds when the others fail, or viceversa, with equal computational time employed.
## 6 Classification results in PL=DIFF category
The application of the program Γ4 -class to the catalogue ⋃ 1 ≤ ≤ p 9 C (2 p ) yields the complete PL classification of the involved crystallizations (or, equivalently, of the dual contracted triangulations) as shown in the following proposition. 10
Proposition 28 There is a bijective correspondence between the partition obtained by the program Γ4-class and the set of PL 4-manifolds represented by ⋃ 1 ≤ ≤ p 9 ( C (2 p ) ∪ C ˜ (2 p ) ) . Moreover, the PL classification coincides with the TOP classification.
Proof. Since there is only one non-bipartite crystallization in all our catalogues, the statement is trivial for ⋃ 1 ≤ ≤ p 9 ˜ C (2 p ) .
Program Γ4 -class applied to the set ⋃ 1 ≤ ≤ p 9 C (2 p ) produces a partition into five classes, which coincides with the partition induced by the second Betti number. More precisely, all crystallizations with β 2 = 0 (resp. β 2 = 1) belong to the same class as the standard crystallization of S 4 (resp. CP 2 ), while the crystallizations with β 2 = 2 are subdivided into three classes, containing the standard crystallization of CP 2 # CP 2 , CP 2 #( -CP 2 ) and S 2 × S 2 respectively. ✷
The following proposition - whose statement already appeared in a partial and preliminary version in [17] and in [20] summarizes the complete PL classification of orientable (resp. non-orientable) PL 4-manifolds having gem-complexity up to 8 (resp. up to 9).
## Proposition 29 Let M 4 be a PL 4-manifold. Then:
- · k M ( 4 ) = 0 ⇐⇒ M 4 is PL-homeomorphic to S 4 ;
- · k M ( 4 ) = 3 ⇐⇒ M 4 is PL-homeomorphic to CP 2 ;
- · k M ( 4 ) = 4 ⇐⇒ M 4 is PL-homeomorphic to either S 1 × S 3 or S 1 ˜ × S 3 ;
- · k M ( 4 ) = 6 ⇐⇒ M 4 is PL-homeomorphic to either S 2 × S 2 or CP 2 # CP 2 or CP 2 #( -CP 2 );
- · k M ( 4 ) = 7 ⇐⇒ M 4 is PL-homeomorphic to either RP 4 or CP 2 #( S 1 × S 3 ) or CP 2 #( S 1 ˜ × S 3 );
## Moreover:
- · k M ( 4 ) = 8 ⇐⇒ M 4 is PL-homeomorphic to either # ( 2 S 1 × S 3 ) or # ( 2 S 1 ˜ × S 3 ) .
- · no PL 4 -manifold M 4 exists with k M ( 4 ) ∈ { 1 2 5 , , } ;
- · no exotic PL 4 -manifold exists, with k M ( 4 ) ≤ 8;
- · any PL 4 -manifold M 4 with k M ( 4 ) = 9 is simply-connected (with second Betti number β 2 ≤ 3 ).
10 The proof of Proposition 28 shows that the PL classification performed through Γ4 -class does not rely on the already stated results of Proposition 21.
Proof. The statements concerning PL 4-manifolds up to gem-complexity 8 are consequences of the previous Proposition 28, together with Proposition 15. The last statement, concerning gem-complexity 9, directly follows from Proposition 19. ✷
Note that the above Proposition 29 implies Theorem 1 (stated in Section 1), when the attention is restricted to the handle-free PL 4-manifolds.
As a consequence of the (partial) analysis of the 4-dimensional crystallization catalogue ⋃ 1 ≤ ≤ p 10 C (2 p ) , together with a suitable application of the classification program Γ4 -class , the following result may also be stated:
Proposition 30 A rigid crystallization of S 4 exists, with 20 vertices (see Figure 5). Apart from the standard order-two crystallization, it is the only rigid dipole-free crystallization of S 4 up to 20 vertices.
Proof. As already stated in Proposition 19, there exists exactly one crystallization ( ¯ Γ ¯) , γ ∈ ⋃ 7 ≤ ≤ p 10 C (2 p ) , with π 1 ( | K ( ¯ ) Γ | ) = 0 and β 2 ( | K ( ¯ ) Γ | ) = 0. Moreover, ¯ has order 20, while no eleΓ ment of ⋃ 2 ≤ ≤ p 6 C (2 p ) represents a PL 4-manifold with β 2 = 0 . Finally, by applying the program Γ4 -class to the crystallization Γ, the standard order two crystallization of ¯ S 4 is obtained; hence, | K ( ¯ ) Γ | ∼ = PL S 4 follows. ✷
Figure 5: The order 20 rigid dipole-free crystallization of S 4
In [9] the notion of simple crystallization of a (simply-connected) PL 4-manifold is introduced, which is equivalent to the assumption g rst = 1 for any distinct r, s, t ∈ ∆ ; moreover, 4
the existence of simple crystallizations for any 'standard' simply-connected PL 4-manifold (i.e. S 4 , CP 2 , S 2 × S 2 and the K 3-surface, together with the connected sums of them and/or their copies with opposite orientation) is proved.
As a consequence of our catalogues, we can state:
## Proposition 31
- · S 4 and CP 2 admit a unique simple crystallization;
- · S 2 × S 2 admits exactly 267 simple crystallizations;
- · CP 2 # CP 2 admits exactly 583 simple crystallizations;
- · CP 2 #( -CP 2 ) admits exactly 258 simple crystallizations.
✷
Moreover, known facts and open problems about exotic structures on 'standard' simplyconnected PL 4-manifolds have the following implications on the existence of simple crystallizations:
## Proposition 32
- (a) Let M 4 be S 4 or CP 2 or S 2 × S 2 or CP 2 # CP 2 or CP 2 #( -CP 2 ) ; if an exotic PL-structure on M 4 exists, then the corresponding PL-manifold does not admit a simple crystallization.
- (b) Let ¯ M be a PL 4 -manifold TOP-homeomorphic but not PL-homeomorphic to CP 2 # ( 2 -CP 2 ) ; then, either ¯ M does not admit a simple crystallization, or ¯ M admits an order 20 simple crystallization (i.e.: k M ( ¯ ) = 9 = k ( CP 2 # ( 2 -CP 2 )) ).
- (c) Let r ∈ { 3 5 7 9 11 13 , , , , , } ∪ { r = 4 n -1 | n ≥ 4 } ∪ { r = 4 n -2 | n ≥ 23 } ; then, infinitely many simply-connected PL 4 -manifolds with β 2 = r do not admit a simple crystallization.
Proof. Statements (a) and (b) directly follow from the fact - proved in [22] - that simplyconnected PL 4-manifolds admitting a simple crystallization are characterized by k M ( 4 ) = 3 β 2 ( M . 4 )
In order to prove statement (c), it is sufficient to recall the existence of infinitely many exotic structures TOP-homeomorphic to CP 2 # ( 4 -CP 2 ), # 3 CP 2 # ( k -CP 2 ) for k ∈ { 6 8 10 , , } and to # 2 n -1 CP 2 # 2 n ( -CP 2 ) for any integer n ≥ 1 (see [1]), as well as to # 2 n -1 CP 2 # 2 n -1 ( -CP 2 ) for n ≥ 23 (see [2]). Then, the statement follows from the above characterization of simplyconnected PL 4-manifolds admitting simple crystallizations (due to [22]), together with the (obvious) finiteness of PL 4-manifolds having a fixed gem-complexity. ✷
Proposition 32(b) suggests possible interesting consequences of the work in progress on the catalogue C (20) : in fact, the PL-characterization of all PL 4-manifolds represented by order 20
crystallizations could yield results about exotic structures on simply-connected 4-manifolds with β 2 ≤ 3 and/or about the existence of simple crystallizations, in case β 2 = 3.
More generally, we hope that further developments in the generation and classification of 4-dimensional crystallization catalogues, for increasing gem-complexity, could be useful to face open problems concerning different PL-structures on the same TOP 4-manifold.
## Acknowledgements
We thank the referee for his/her helpful comments. We acknowledge the CINECA award under the ISCRA initiative, for the availability of high performance computing resources and support.
## References
- [1] A. Akhmedov and B. Doug Park. Exotic smooth structures on small 4-manifolds with odd signatures . Invent. Math., 181:577-603, 2010.
- [2] A. Akhmedov, M. Ishida and B. Doug Park. Reducible smooth structures on 4-manifolds with zero signature . J. Topol., 7(3):607-616, 2014. DOI: 10.1112/jtopol/jtt043
- [3] G. Amendola and B. Martelli. Non-orientable 3-manifolds of complexity up to 7 . Topology Appl., 150:179-195, 2005.
- [4] P. Bandieri, M. R. Casali, P. Cristofori, L. Grasselli and M. Mulazzani. Computational aspects of crystallization theory: complexity, catalogues and classification of 3-manifolds . Atti Semin. Mat. Fis. Univ. Modena Reggio Emilia, 58:11-45, 2011.
- [5] P. Bandieri, P. Cristofori and C. Gagliardi. Nonorientable 3-manifolds admitting coloured triangulations with at most 30 tetrahedra . J. Knot Theory Ramifications, 18:381-395, 2009.
- [6] P. Bandieri, P. Cristofori and C. Gagliardi. A census of genus two 3-manifolds up to 42 coloured tetrahedra . Discrete Math., 310:2469-2481, 2010.
- [7] P. Bandieri and C. Gagliardi. Rigid gems in dimension n . Bol. Soc. Mat. Mex., 18(3):5567, 2012.
- [8] B. Basak and B. Datta. Minimal crystallizations of 3-manifolds . Electron. J. Combin., 21(1):#P1.61, 1-25, 2014.
- [9] B. Basak and J. Spreer. Simple crystallizations of 4-manifolds . To be published in Adv. Geom., 2014. Arxiv: 1407.0752
- [10] B. A. Burton and J. Spreer. Computationally proving triangulated 4-manifolds to be diffeomorphic . 29th ACM Symposium on Computational Geometry, Young Researchers Forum, Collections of abstracts, pages 15-16, 2013. Arxiv: 1403.2780
| [11] | B. Benedetti and F. H. Lutz. Random Discrete Morse Theory and a New Library of Triangulations . Exp. Math., 23(1):66-94, 2014. Arxiv: 1303.6422 |
|--------|------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------|
| [12] | B. A. Burton. Enumeration of non-orientable 3-manifolds using face-paring graphs and union-find . Discrete Comput. Geom., 38:527-571, 2007. |
| [13] | M. R. Casali. A combinatorial characterization of 4-dimensional handlebodies . Forum Math., 4:123-134, 1992. |
| [14] | M. R. Casali. Classifying PL 5-manifolds by regular genus: the boundary case . Canad. J. Math., 49:193-211, 1997. |
| [15] | M. R. Casali. Classification of non-orientable 3-manifolds admitting decompositions into ≤ 26 coloured tetrahedra . Acta Appl. Math., 54:75-97, 1999. |
| [16] | M. R. Casali. Computing Matveev's complexity of non-orientable 3-manifolds via crystal- lization theory . Topology Appl., 144:201-209, 2004. |
| [17] | M. R. Casali. Catalogues of PL-manifolds and complexity estimations via crystallization theory . Oberwolfach Rep. 24:58-61, 2012. DOI: 10.4171/OWR/2012/24 |
| [18] | M. R. Casali and P. Cristofori. Computing Matveev's complexity via crystallization theory: the orientable case . Acta Appl. Math., 92(2):113-123, 2006. |
| [19] | M. R. Casali and P. Cristofori. A catalogue of orientable 3-manifolds triangulated by 30 coloured tetrahedra . J. Knot Theory Ramifications, 17:1-23, 2008. |
| [20] | M. R. Casali and P. Cristofori. Coloured graphs representing PL 4-manifolds . Electron. Notes Discrete Math., 40:83-87, 2013. |
| [21] | M. R. Casali and P. Cristofori. A note about complexity of lens spaces . Forum Math., 2014. DOI: 10.1515/forum-2013-0185, published online February 19, 2014. |
| [22] | M. R. Casali, P. Cristofori and C. Gagliardi. PL 4-manifolds admitting simple crystal- lizations: framed links and regular genus . Arxiv: 1410.3321v2, 2015. |
| [23] | M. R. Casali, P. Cristofori and M. Mulazzani. Complexity computation for compact 3- manifolds via crystallizations and Heegaard diagrams . Topology Appl., 159(13):3042 - 3048, 2012. DOI: 10.1016/j.topol.2012.05.016 |
| [24] | M. R. Casali and C. Gagliardi. Classifying PL 5-manifolds up to regular genus seven Proc. Amer. Math. Soc., 120:275 -283, 1994. |
| [25] | M. R. Casali and C. Gagliardi. A code for m -bipartite edge-coloured graphs . Rend. Istit. Mat. Univ. Trieste, 32(Suppl. 1):55 -76, 2001. |
| [26] | M. R. Casali and L. Malagoli. Handle-decompositions of PL 4-manifolds . Cah. Topol. G´om. e Diff´r. e Cat´g., e 38:141-160, 1997. |
| [27] | M. Casella and W. K¨hnel. u A triangulated K 3 surface with the minimum number of vertices . Topology, 40(4):753-772, 2001. |
|--------|-----------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------|
| [28] | A. Cavicchioli. On the genus of smooth 4-manifolds . Trans. Amer. Math. Soc., 331(1):203- 214, 1992. |
| [29] | M. Ferri. Crystallisations of 2-fold branched coverings of S 3 . Proc. Amer. Math. Soc., 73:271-276, 1979. |
| [30] | M. Ferri and C. Gagliardi. Crystallization moves . Pacific J. Math., 100:85-103, 1982. |
| [31] | M. Ferri and C. Gagliardi. The only genus zero -manifold is S n . Proc. Amer. Math. Soc., 85:638-642, 1982. |
| [32] | M. Ferri, C. Gagliardi and L. Grasselli. A graph-theoretical representation of PL- manifolds. A survey on crystallizations . Aequationes Math., 31:121-141, 1986. |
| [33] | M. H. Freedman and F. Quinn. Topology of 4-manifolds . Princeton Mathematical Series, no. 39. Princeton University Press, Princeton, NJ, 1990. |
| [34] | M. Furuta. Monopole equation and the 11 8 conjecture . Math. Res. Lett., 8:279-291, 2001. |
| [35] | C. Gagliardi. Extending the concept of genus to dimension n . Proc. Amer. Math. Soc., 81:473-481, 1981. |
| [36] | C. Gagliardi. On the genus of the complex projective plane . Aequationes Math., 37:130- 140, 1989. |
| [37] | C. Gagliardi. How to deduce the fundamental group of a closed n -manifold from a con- tracted triangulation . J. Comb. Inf. Syst. Sci., 4:237-252, 1979. |
| [38] | C. Gagliardi and G. Volzone. Handles in graphs and sphere bundles over S 1 . European J. Combin., 8:151-158, 1987. |
| [39] | S. Lins. Gems, computers and attractors for 3-manifolds . Knots and Everything, no. 5. World Scientific, River Edge, NJ, 1995. |
| [40] | S. Lins and M. Mulazzani. Blobs and flips on gems . J. Knot Theory Ramifications, 15(8):1001-1035, 2006. |
| [41] | A. Marani, M. Rivi and P. Cristofori. Generation of Catalogues of PL n -manifolds: Computational Aspects on HPC Systems . Scalable Computing. Practice and Experience, 14(1):5-15, 2013. DOI: 10.12694/scpe.v14i1.823 |
| [42] | S. Matveev. Algorithmic Topology and Classification of 3-manifolds . Algorithms and Com- putation in Mathematics, no. 9. Springer-Verlag, 2007. |
| [43] | M. Pezzana. Sulla struttura topologica delle variet` a compatte . Atti Semin. Mat. Fis. Univ. Modena Reggio Emilia, 23:269-277, 1974. |
- [44] E. Swartz. The average dual surface of a cohomology class and minimal simplicial decompositions of infinitely many lens spaces . Arxiv: 1310.1991, 2013.
- [45] J. Spreer and W. K¨hnel. u Combinatorial properties of the K 3 surface, Simplicial blowups and slicings . Exp. Math., 20(2):201-216, 2011.
- [46] C. T.C. Wall. On simply connected 4-manifolds . J. Lond. Math. Soc., 39:141-149, 1964.
- [47] A. T. White. Graphs, groups and surfaces . North-Holland Mathematics Studies, no. 8, Elsevier, 1985. | null | [
"M. R. Casali",
"P. Cristofori"
] | 2014-08-02T14:47:27+00:00 | 2015-11-17T14:46:25+00:00 | [
"math.GT",
"57Q15 - 57N13 - 57M15 - 57Q25"
] | Cataloguing PL 4-manifolds by gem-complexity | We describe an algorithm to subdivide automatically a given set of PL
n-manifolds (via coloured triangulations or, equivalently, via
crystallizations) into classes whose elements are PL-homeomorphic. The
algorithm, implemented in the case n=4, succeeds to solve completely the
PL-homeomorphism problem among the catalogue of all closed connected PL
4-manifolds up to gem-complexity 8 (i.e., which admit a coloured triangulation
with at most 18 4-simplices). Possible interactions with the (not completely
known) relationship among different classification in TOP and DIFF=PL
categories are also investigated. As a first consequence of the above PL
classification, the non-existence of exotic PL 4-manifolds up to gem-complexity
8 is proved. Further applications of the tool are described, related to
possible PL-recognition of different triangulations of the K3-surface. |
1408.0379v1 | ## Bending strain-tunable magnetic anisotropy in Co FeAl Heusler thin film on 2 Kapton®
M. Gueye , B. M. Wague , F. Zighem , M. Belmeguenai , M. S. 1 1 1 1
Gabor , T. Petrisor jr , 2 2 C. Tiusan , 2 S. Mercone , and D. Faurie 1 1 ∗ 1 Laboratoire des Sciences des Procédés et des Matériaux, CNRS-Université Paris XIII, Sorbonne Paris Cité, Villetaneuse, France and 2 Center for Superconductivity, Spintronics and Surface Science, Technical University of Cluj-Napoca, Str. Memorandumului No. 28 RO-400114, Cluj-Napoca, Romania (Dated: July 29 th 2014)
Bending effect on the magnetic anisotropy in 20 nm Co 2 FeAl Heusler thin film grown on Kapton® has been studied by ferromagnetic resonance and glued on curved sample carrier with various radii. The results reported in this letter show that the magnetic anisotropy is drastically changed in this system by bending the thin films. This effect is attributed to the interfacial strain transmission from the substrate to the film and to the magnetoelastic behavior of the Co 2 FeAl film. Moreover two approaches to determine the in-plane magnetostriction coefficient of the film, leading to a value that is close to λ CFA = 14 × 10 -6 , have been proposed.
The functional properties of devices on non-planar substrates are receiving an increasing interest because of new flexible electronics based-technologies. Magnetic thin films deposited on polymer substrate show tremendous potentialities in new flexible spintronics basedapplications, such as magnetic sensors adaptable to nonflat surfaces. Indeed, several studies of giant magnetoresistance (GMR)-based devices, generally composed of metallic ferromagnetic materials deposited on a polymer substrate, have been made [1-3]. However, in order to develop flexible spintronic devices, materials with high spin polarization are highly desirable. Half metallic materials are known to be ideal candidates as high spin polarization current sources to realize a very large giant magnetoresistance (GMR) and to reduce the switching current densities in spin transfer based-devices according to the Slonczewski model [4]. Among half metallic materials, Co-based Heusler alloys [5] have generally high Curie temperature such as Co FeAl [6] in contrast to oxide half 2 metals, and thus are promising for spintronics-based applications at room temperature. However, the knowledge of the magnetoelastic properties of this Heusler alloys is poor while they could be submitted to high strains when integrated in flexible devices.
Among the overall flexible materials, polyimides are organic materials with an attractive combination of physical characteristics including low electrical conductivity, high tensile strength, chemical inertness, and stability at temperatures as high as 650 K. The most common commercially available (aromatic) polyimide has the DuPont de Nemours registered trademark Kapton® [9]. In addition to its widespread use in the microelectronics industry, Kapton® (PMDA-ODA) has an excellent thermal and radiation stability as evidenced by its routine use for vacuum windows at storage-ring sources.
∗ Electronic address: [email protected] ; [email protected]
Figure 1: Sketch of the microstripline resonator allowing for the resonance field detection of the bended CFA film deposited onto flexible substrate. I rf in and I rf out correspond to the injected and transmitted radio frequency current (fixed at 10 GHz thereafter). The static magnetic field glyph[vector] H is applied along the microstripline.
In the case of flexible sample made of polymers coated by a very thin layer, a very small bending effort can lead to relatively high stress in the layer, either compressive if it is at the inside edge either tensile if at the outside ones. Obviously, it depends on the adhesion between the layer and the Kapton® substrate that is generally good even if no buffer layer is deposited [7, 8]. In this paper, we will show that the magnetic anisotropy of 20 nm thick Co FeAl (CFA) film grown on Kapton® is significantly 2 changed through the magnetoelastic coupling by bending the sample glued on curved Aluminum blocks of different known radii.
The bending strain effect has been experimentally studied by microstripline ferromagnetic resonance (MSFMR), shown in Fig.1, through uniform precession mode resonance field. Indeed, the resonance field of the uniform precession mode is influenced by the magnetoelas-
tic behavior of the thin film. All the experimental MSFMR spectra analyzed in this work have been performed at room temperature at a fixed driving frequency of 10 GHz. In order to quantitatively study the magnetoelastic behavior of the thin film, we have analytically modeled the bending strain effect on the ferromagnetic resonance field through a magnetoelastic density of energy F me :
$$F _ { m e } = - \frac { 3 } { 2 } \lambda \left ( \gamma _ { x } ^ { 2 } - \frac { 1 } { 3 } \right ) \sigma _ { x x } \quad \quad ( 1 ) \quad \frac { 3 \lambda } { \lambda }$$
σ xx being the uniaxial stress due to bending while γ x correspond to the direction cosines of the in-plane magnetization. λ is the effective magnetostriction coefficient of the CFA film. The relation between the principal stress component ( σ xx ) and the radius curvature R is given by the following equation available when the film thickness is very small as compared to the substrate ones:
$$\sigma _ { x x } = E \frac { t } { 2 R } \quad \quad \ \ ( 2 ) \quad \ \cos _ { \mathfrak { m } }$$
where t is the whole sample thickness ( ∼ the substrate thickness in our case) and E is the Young's modulus.
In these conditions, the resonance field of the uniform precession mode evaluated at the equilibrium is obtained from the total magnetic energy density F as follows:
$$\left ( \frac { 2 \pi f } { \gamma } \right ) ^ { 2 } = \left ( \frac { 1 } { M _ { s } \sin \theta _ { M } } \right ) ^ { 2 } \left ( \frac { \partial ^ { 2 } F } { \partial \theta _ { M } ^ { 2 } } \frac { \partial ^ { 2 } F } { \partial \varphi _ { M } ^ { 2 } } - \left ( \frac { \partial ^ { 2 } F } { \partial \theta _ { M } \varphi _ { M } } \right ) ^ { 2 } \right ) \begin{array} { c } \ a l. \ [ 1 2 \\ \ t i o n s d \\ \text{The} \\ \text{substrata} } \end{array}$$
In the above expression, f is the microwave driving frequency, γ is the gyromagnetic factor ( γ = g × 8 794 . × 10 6 s -1 Oe -1 ) while θ M and ϕ M stand for the polar and the azimuthal angles of the magnetization. It should be noted here that the saturation magnetization ( M s ) has been measured by vibrating sample magnetometry ( M s glyph[similarequal] 820 emu.cm -3 ). The magnetic energy density F is the sum of several contributions including the Zeeman F zee , the dipolar F dip and the magnetoelastic F me and the out-of-plane magnetic anisotropy F perp = -K perp cos 2 θ M (where K perp is the out-of-plane anisotropy constant) contributions. Thereafter, ϕ H will correspond to the angle between the in-plane applied magnetic field and the bending axis ( x direction) as presented in Figure 1. In addition, an initial in-plane uniaxial anisotropy (measured on the unbended sample) has been put into evidence and is attributed to a non-equibiaxial residual stress inside the magnetostrictive film induced by a slight initial curvature of the sample after (or during) deposition. Thus, a magnetoelastic energy term ( F residual me ) will be added to take into account this initial anisotropy:
$$F _ { m e } ^ { r e s i d u a l } = - \frac { 3 } { 2 } \lambda \Big { ( } ( \gamma _ { x } ^ { 2 } - \frac { 1 } { 3 } ) \sigma _ { x x } ^ { r e s i d u a l } + ( \gamma _ { y } ^ { 2 } - \frac { 1 } { 3 } ) \sigma _ { y y } ^ { r e s i d u a l } \Big { ) } \quad \begin{array} { c } \stackrel { \stackrel { \stackrel { \stackrel { \stackrel { \stackrel { \stackrel { \stackrel { \stackrel { \stackrel { \stackrel { \stackrel { \stackrel { \stackrel \stackrel { \stackrel { \stackrel { \stackrel { \stackrel { \stackrel \stackrel \stackrel \stackrel \stackrel \stackrel { \stackrel \stackrel { \stackrel { \stackrel { \stackrel { \stackrel \stackrel \stackrel \stackrel \stackrel \stackrel \stackrel \stackrel { \stackrel \stackrel \stackrel \stackrel \stackrel \stackrel \stackrel \stackrel \stackrel \stackrel \stackrel \stackrel \stackrel \stackrel \stackrel \stackrel \stackrel \stackrel \stackrel \stackrel \stackrel \stackrel \stackrel \stackrel \stackrel \stackrel \stackrel \stackrel \stackrel \stackrel \stackrel \stackrel \stackrel \stackrel \stackrel \stackrel \stackrel \stackrel \stackrel \stackrel \stackrel \stackrel \stackrel \stackrel \stackrel \stackrel \stackrel \stackrel \stackrel \stackrel \stackrel \stackrel \stackrel \stackrel \stackrel \stackrel \stackrel \stackrel \stackrel \stackrel \stackrel \stackrel \stackrel \stackrel \stackrel \stackrel \stackrel \textrel { \stackrel \stackrel \stackrel \stackrel \stackrel \stackrel \stackrel \stackrel \stackrel \stackrel \stackrel \stackrel \stackrel \stackrel \stackrel \stackrel \stackrel \stackrel \stackrel \stackrel \stackrel \stackrel \stackrel \stackrel \stackrel \stackrel \stackrel \stackrel \stackrel \stackrel \stackrel \stackrel \stackrel \stackrel \stackrel \stackrel \stackrel \stackrel \stackrel \stackrel \stackrel \stackrel \stackrel \stackrel \stackrel \stackrel \stackrel \stackrel \stackrel \stackrel \stackrel \stackrel \stackrel \stackrel \stackrel \stackrel \stackrel \stackrel \stackrel \stackrel \stackrel \stackrel \stackrel \stackrel \stackrel \stack | \stackrel \stackrel \stackrel \stackrel \stackrel \stackrel \stackrel \stackrel \stackrel \stackrel \stackrel \stackrel \stackrel \stackrel \stackrel \stackrel \stackrel \stackrel \stackrel \stackrel \stackrel \stackrel \stackrel \stackrel \stackrel \stackrel \stackrel \stackrel \stackrel \stackrel \stackrel \stackrel \stackrel \stackrel \stackrel \stackrel \stackrel \stackrel \stackrel \stackrel \stackrel \stackrel \stackrel \stackrel \stackrel \stackrel \stackrel \stackrel \stackrel \stackrel \stackrel \stackrel \stackrel \stackrel \stackrel \stackrel \stackrel \stackrel \stackrel \stackrel \stackrel \stackrel \stackrel \stackrel \stackrel \stackrel \ \stackrel \stackrel \stackrel \stackrel \stackrel \stackrel \stackrel \stackrel \stackrel \stackrel \stackrel \stackrel \stackrel \stackrel \stackrel \stackrel \stackrel \stackrel \stackrel \stackrel \stackrel \stackrel \stackrel \stackrel \stackrel \stackrel \stackrel \stackrel \stackrel \stackrel \stackrel \stackrel \stackrel \stackrel \stackrel \stackrel \stackrel \stackrel \stackrel \stackrel \stackrel \stackrel \stackrel \stackrel \stackrel \stackrel \stackrel \stackrel \stackrel \stackrel \stackrel \stackrel \stackrel \stackrel \stackrel \stackrel \stackrel \stackrel \stackrel \stackrel \stackrel \stackrel \stackrel \stackrel \stackrel \stackrel \ } } } } } \\ \tilde { F } _ { m e } } ^ { r e s i d u a l } = - \frac { \stackrel { \stackrel { \stackrel { \stackrel { \stackrel { \stackrel { \stackrel { \stackrel { \stackrel { \stackrel { \stackrel { \stackrel { \stackrel { \stackrel { \stackrel { \stackrel { \stackrel { \stackrel { \stackrel { \stackrel { \stackrel { \stackrel { \stackrel { \stackrel { \stackrel { \stackrel { \stackrel \stackrel \stackrel \stackrel \stackrel \stackrel \stackrel \stackrel \stackrel \stackrel \stackrel \stackrel \stackrel \stackrel \stackrel \stackrel \stackrel \stackrel \stackrel \stackrel \stackrel \stackrel \stackrel \stackrel \stackrel \stackrel \stackrel \stackrel \stackrel \stackrel \stackrel \stackrel \stackrel \stackrel \stackrel \stackrel \stackrel \stackrel \stackrel \stackrel \stackrel \stackrel \stackrel \stackrel \stackrel \stackrel \stackrel \stackrel \stackrel \stackrel \stackrel \stackrel \stackrel \stackrel \stackrel \stackrel \stackrel \stackrel \stackrel \stackrel \stackrel \stackrel \stackrel \stackrel \stackrel } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } { } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } _ } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } ) } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } \ } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } & \\ } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } | } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } ( } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } }. } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } }, } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } \\ } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } \ \ } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } \$$
σ residual xx and σ residual yy being the in-plane principal residual stress tensor components and ϕ resi is the angle between x axis and the slight initial curvature. In these conditions, the resonance field can be extracted from the following expression: f 2 = ( γ 2 π ) 2 H H 1 2 where:
H
$$\text{occu} \\ \text{name} \\ \tilde { \ r m e } \colon \\ ( 1 ) \\ \cdots \cdots \cdots \\ \cdots \cdots \\ \cdots \cdots \\ \cdots \cdots \\ \cdots \cdots \\ \cdots \cdots \\ \cdots \cdots \\ \cdots \cdots \\ \cdots \cdots \\ \cdots \cdots \\ \cdots \cdots \\ \cdots \cdots \\ \cdots \cdots \\ \cdots \cdots \\ \cdots \cdots \\ \cdots \cdots \\ \cdots \cdots \\ \cdots \cdots \\ \cdots \cdots \\ \cdots \cdots \\ \cdots \cdots \\ \cdots \cdots \\ \cdots \cdots \\ \cdots \cdots \\ \cdots \cdots \\ \cdots \cdots \\ \cdots \cdots \\ \cdots \cdots \\ \cdots \cdots \\ \cdots \\ \cdots \cdots \\ \cdots \cdots \\ \cdots \cdots \\ \cdots \cdots \\ \cdots \cdots \\ \cdots \cdots \\ \cdots \cdots \\ \cdots \cdots \\ \cdots \cdots \\ \cdots \cdots \\ \cdots \cdots \\ \cdots \cdots \\ \cdots \cdots \\ \cdots \cdots \\ \cdots \cdots \\ \cdots \cdots \\ \cdots \cdots \\ \cdots \cdots \\ \cdots \cdots \\ \cdots \cdots \\ \cdots \cdots \\ \cdots \cdots \\ \cdots \cdots \\ \cdots \cdots \\ \cdots \cdots \\ \cdots \cdots \\ \cdots \cdots \\ \cdots \cdots
\\ \cdots \cdots \\ \cdots \cdots \\ \cdots \cdots \\ \cdots \cdots \\ \cdots \cdots \\ \cdots \cdots \\ \cdots \cdots \\ \cdots \cdots \\ \cdots \cdots \\ \cdots \cdots \\ \cdots \cdots \\ \cdots \cdots \\ \cdots \cdots \\ \cdots \cdots \\ \cdots \cdots \\ \cdots \cdots \\ \cdots \cdots \\ \cdots \cdots \\ \cdots \cdots \\ \cdots \cdots \\ \cdots \cdots \\ \cdots \cdots \\ \cdots \cdots \\ \cdots \cdots \\ \cdots \cdots \\ \cdots \cdots \\ \cdots \cdots \\ \cdots \cdots \\ \cd.. \cdots \\ \cdots \\ \cdots \\ \cdots \\ \cdots \\ \cdots \\ \cdots \\ \cdots \\ \cdots \\ \cdots \\ \cdots \\ \cdots \\ \cdots \\ \cdots \\ \cdots \\ \cdots \\ \cdots \\ \cdots \\ \cdots \\ \cdots \\ \cdots \\ \cdots \\ \cdots \\ \cdots \\ \cdots \\ \cdots \\ \cdots \\ \cdots \\ \cdots \\ \cdots \\ \cdots \\ \cdots \\ \cdots \\ \cdots \\ \cdots \\ \cdots \\ \cdots \\ \cdots \\ \cdots \\ \cdots \\ \cdots \\ \cdots \\ \cdots \\ \cdots \\ \cdots \\ \cdots \\ \cdots \\ \cdots \\ \cdots \\ \cdots \\ \cdots\\ \\ \cdots \\ \cdots \\ \cdots \\ \cdots \\ \cdots \\ \cdots \\ \cdots \\ \cdots \\ \cdots \\ \cdots \\ \cdots \\ \cdots \\ \cdots \\ \cdots \\ \cdots \\ \cdots \\ \cdots \\ \cdots \\ \cdots \\ \cdots \\ \cdots \\ \cdots \\ \cdots \\ \cdots \\ \cdots \\ \cdots \\ \cdots \\ \cdots \\ \cdots \\ \cdots \\ \cdots \\ \cdots \\ \cdots \\ \cdots \\ \cdots \\ \cdots \\ \cdots \\ \cdots \\ \cdots \\ \cdots \\ \cdots \\ \cdots \\ \cdots \\ \cdots \\ \cdots \\ \cdots \\ \cdots \\ \cdots \\ \cdots \\ \cd.. \\ \cdots \\ \cdots \\ \cdots \\ \cdots \\ \cdots \\ \cdots \\ \cdots \\ \cdots \\ \cdots \\ \cdots \\ \cdots \\ \cdots \\ \cdots \\ \cdots \\ \cdots \\ \cdots \\ \cdots \\ \cdots \\ \cdots \\ \cdots \\ \cdots \\ \cdots \\ \cdots \\ \cdots \\ \cdots \\ \cdots \\ \cdots \\ \cdots \\ \cdots \\ \cdots \\ \cdots \\ \cdots \\ \cdots \\ \cdots \\ \cdots \\ \cdots \\ \cdots \\ \cdots \\ \cdots \\ \cdots \\ \cdots \\ \cdots \\ \cdots \\ \cdots \\ \cdots \\ \cdots \\ \cdots \\ \cdots \\ \cdots \\ \cd. \\ \cdots \\ \cdots \\ \cdots \\ \cdots \\ \cdots \\ \cdots \\ \cdots \\ \cdots \\ \cdots \\ \cdots \\ \cdots \\ \cdots \\ \cdots \\ \cdots \\ \cdots \\ \cdots \\ \cdots \\ \cdots \\ \cdots \\ \cdots \\ \cdots \\ \cdots \\ \cdots \\ \cdots \\ \cdots \\ \cdots \\ \cdots \\ \cdots \\ \cdots \\ \cdots \\ \cdots \\ \cdots \\ \cdots \\ \cdots \\ \cdots \\ \cdots \\ \cdots \\ \cdots \\ \cdots \\ \cdots \\ \cdots \\ \cdots \\ \cdots \\ \cdots \\ \cdots \\ \cdots \\ \cdots \\ \cdots \\ \cdots \\ \cd: \\ \cdots \\ \cdots \\ \cdots \\ \cdots \\ \cdots \\ \cdots \\ \cdots \\ \cdots \\ \cdots \\ \cdots \\ \cdots \\ \cdots \\ \cdots \\ \cdots \\ \cdots \\ \cdots \\ \cdots \\ \cdots \\ \cdots \\ \cdots \\ \cdots \\ \cdots \\ \cdots \\ \cdots \\ \cdots \\ \cdots \\ \cdots \\ \cdots \\ \cdots \\ \cdots \\ \cdots \\ \cdots \\ \cdots \\ \cdots \\ \cdots \\ \cdots \\ \cdots \\ \cdots \\ \cdots \\ \cdots \\ \cdots \\ \cdots \\ \cdots \\ \cdots \\ \cdots \\ \cdots \\ \cdots \\ \cdots \\ \cdots \\ \cd> \\ \cdots \\ \cdots \\ \cdots \\ \cdots \\ \cdots \\ \cdots \\ \cdots \\ \cdots \\ \cdots \\ \cdots \\ \cdots \\ \cdots \\ \cdots \\ \cdots \\ \cdots \\ \cdots \\ \cdots \\ \cdots \\ \cdots \\ \cdots \\ \cdots \\ \cdots \\ \cdots \\ \cdots \\ \cdots \\ \cdots \\ \cdots \\ \cdots \\ \cdots \\ \cdots \\ \cdots \\ \cdots \\ \cdots \\ \cdots \\ \cdots \\ \cdots \\ \cdots \\ \cdots \\ \cdots \\ \cdots \\ \cdots \\ \cdots \\ \cdots \\ \cdots \\ \cdots \\ \cdots \\ \cdots \\ \cdots \\ \cdots \\ \cdjs \\ \cdots \\ \cdots \\ \cdots \\ \cdots \\ \cdots \\ \cdots \\ \cdots \\ \cdots \\ \cdots \\ \cdots \\ \cdots \\ \cdots \\ \cdots \\ \cdots \\ \cdots \\ \cdots \\ \cdots \\ \cdots \\ \cdots \\ \cdots \\ \cdots \\ \cdots \\ \cdots \\ \cdots \\ \cdots \\ \cdots \\ \cdots \\ \cdots \\ \cdots \\ \cdots \\ \cdots \\ \cdots \\ \cdots \\ \cdots \\ \cdots \\ \cdots \\ \cdots \\ \cdots \\ \cdots \\ \cdots \\ \cdots \\ \cdots \\ \cdots \\ \cdots \\ \cdots \\ \cdots \\ \cdots \\ \cdots \\ \cdots \\ \cd>] \\ \cdots \\ \cdots \\ \cdots \\ \cdots \\ \cdots \\ \cdots \\ \cd.. \\ \cdots \\ \cdots \\ \cd.. \\ \cdots \\ \cd.. \\ \cdots \\ \cdots \\ \cd.. \\ \cdots \\ \cd.. \\ \cd.. \\ \cd.. \\ \cd.. \\ \cd.. \\ \cd.. \\ \cd.. \\ \cd.. \\ \cd.. \\ \cd.. \\ \cd.. \\ \cd.. \\ \cd.. \\ \cd.. \\ \cd.. \\ \cd.. \\ \cd.. \\ \cd.. \\ \cd.. \\ \cd.. \\ \cd.. \\ \cd.. \\ \cd.. \\ \cd.. \\ \cd.. \\ \cd.. \\ \cd.. \\ \cd.. \\ \cd.. \\ \cd.. \\ \cd.. \\ \cd.. \\ \cd.. \\ \cd.. \\ \cd.. \\ \cd.. \\ \cd.. \\ \cd.. \\ \cd.. \\ \cd.. \\ \cd.. \\ \cd.. \\ \cd.. \\ \cd.. \\ \cd.. \\ \cd.. \\ \cd.. \\ \cd.. \\ \cd.. \\ \cd.. \\ \cd. \\ \cd.. \\ \cd.. \\ \cd.. \\ \cd.. \\ \cd.. \\ \cd.. \\ \cd.. \\ \cd.. \\ \cd.. \\ \cd.. \\ \cd.. \\ \cd.. \\ \cd.. \\ \cd.. \\ \cd.. \\ \cd.. \\ \cd.. \\ \cd.. \\ \cd.. \\ \cd.. \\ \cd.. \\ \cd.. \\ \cd.. \\ \cd.. \\ \cd.. \\ \cd.. \\ \cd.. \\ \cd.. \\ \cd.. \\ \cd.. \\ \cd.. \\ \cd.. \\ \cd.. \\ \cd.. \\ \cd.. \\ \cd.. \\ \cd.. \\ \cd.. \\ \cd.. \\ \cd.. \\ \cd.. \\ \cd.. \\ \cd.. \\ \cd.. \\ \cd.. \\ \cd.. \\ \cd.. \\ \cd.. \\ \cd.. \\ \cd.} \\ \cd.. \\ \cd.. \\ \cd.. \\ \cd.. \\ \cd.. \\ \cd.. \\ \cd.. \\ \cd.. \\ \cd.. \\ \cd.. \\ \cd.. \\ \cd.. \\ \cd.. \\ \cd.. \\ \cd.. \\ \cd.. \\ \cd.. \\ \cd.. \\ \cd.. \\ \cd.. \\ \cd.. \\ \cd.. \\ \cd.. \\ \cd.. \\ \cd.. \\ \cd.. \\ \cd.. \\ \cd.. \\ \cd.. \\ \cd.. \\ \cd.. \\ \cd.. \\ \cd.. \\ \cd.. \\ \cd.. \\ \cd.. \\ \cd.. \\ \cd.. \\ \cd.. \\ \cd.. \\ \cd.. \\ \cd.. \\ \cd.. \\ \cd.. \\ \cd.. \\ \cd.. \\ \cd.. \\ \cd.. \\ \cd.. \\ \cdots \\ \cd.. \\ \cd.. \\ \cd.. \\ \cd.. \\ \cd.. \\ \cd.. \\ \cd.. \\ \cd.. \\ \cd.. \\ \cd.. \\ \cd.. \\ \cd.. \\ \cd.. \\ \cd.. \\ \cd.. \\ \cd.. \\ \cd.. \\ \cd.. \\ \cd.. \\ \cd.. \\ \cd.. \\ \cd.. \\ \cd.. \\ \cd.. \\ \cd.. \\ \cd.. \\ \cd.. \\ \cd.. \\ \cd.. \\ \cd.. \\ \cd.. \\ \cd.. \\ \cd.. \\ \cd.. \\ \cd.. \\ \cd.. \\ \cd.. \\ \cd.. \\ \cd.. \\ \cd.. \\ \cd.. \\ \cd.. \\ \cd.. \\ \cd.. \\ \cd.. \\ \cd.. \\ \cd.. \\ \cd. \\ \cd.. \\ \cd. \\ \cd.. \\ \cd.. \\ \cd.. \\ \cd.. \\ \cd.. \\ \cd.. \\ \cd.. \\ \cd.. \\ \cd.. \\ \cd.. \\ \cd.. \\ \cd.. \\ \cd.. \\ \cd.. \\ \cd.. \\ \cd.. \\ \cd.. \\ \cd.. \\ \cd.. \\ \cd.. \\ \cd.. \\ \cd.. \\ \cd.. \\ \cd.. \\ \cd.. \\ \cd.. \\ \cd.. \\ \cd.. \\ \cd.. \\ \cd.. \\ \cd.. \\ \cd.. \\ \cd.. \\ \cd.. \\ \cd.. \\ \cd.. \\ \cd.. \\ \cd.. \\ \cd.. \\ \cd.. \\ \cd.. \\ \cd.. \\ \cd.. \\ \cd.. \\ \cd.. \\ \cd.. \\ \cd.. \\ \cd. \\
\\ \cd.. \\ \cd.. \\ \cd.. \\ \cd.. \\ \cd.. \\ \cd.. \\ \cd.. \\ \cd.. \\ \cd.. \\ \cd.. \\ \cd.. \\ \cd.. \\ \cd.. \\ \cd.. \\ \cd.. \\ \cd.. \\ \cd.. \\ \cd.. \\ \cd.. \\ \cd.. \\ \cd.. \\ \cd.. \\ \cd.. \\ \cd.. \\ \cd.. \\ \cd.. \\ \cd.. \\ \cd.. \\ \cd.. \\ \cd.. \\ \cd.. \\ \cd.. \\ \cd.. \\ \cd.. \\ \cd.. \\ \cd.. \\ \cd.. \\ \cd.. \\ \cd.. \\ \cd.. \\ \cd.. \\ \cd.. \\ \cd.. \\
\\
}$$
=
$$\overset { \text{or} } { \text{ess} } \quad & H _ { 2 } = \frac { 3 \lambda } { M _ { s } } \sigma _ { x x } \cos 2 \varphi _ { M } + H _ { r e s } \cos ( \varphi _ { M } - \varphi _ { H } ) + \\ \underset { \text{less} } { \text{ess} } \quad & \frac { 3 \lambda } { M _ { s } } \left ( \sigma _ { x x } ^ { r e s i d u a l } - \sigma _ { y y } ^ { r e s i d u a l } \right ) \cos 2 ( \varphi _ { M } - \varphi _ { r e s i } ) \quad ( 6 ) \\ \quad \cdot \ \dots \ \hat { \ } \quad \cdot \quad \cdot \quad \cdot \quad \cdot \quad \cdot$$
In this formalism, and because K perp and γ can be completely determined at zero applied stress [10], the main unknown is the magnetostriction coefficient λ since CFA single-crystal elastic constants can be found elsewhere ( C 11 = 253 GPa, C 12 = 165 GPa, C 44 = 153 GPa [11]). Indeed, in these conditions, the Young's modulus of a polycrystalline film (our case since it is deposited onto polymer substrate) can be estimated using suitable averaging (homogenization method detailed by Faurie et al. [12]), requiring the knowledge of the grain orientations distribution developed during film deposition.
The thin film has been placed on small pieces of circular Aluminum blocks of known radii R (13.2 mm, 32.2 mm, 59.2 mm and infinite (flat surface)) and analyzed by MS-FMR at 10 GHz driven frequency. In our conditions, these radii values correspond respectively to the following values of applied stress σ xx : 1.15 GPa, 0.47 GPa, 0.26 GPa, 0 GPa. Moreover we have stressed the thin film compressively (Fig.2-a) and tensily (Fig.2-b) so that we have studied three opposite stress states and the zero stress state (unbended sample). We can see in Fig.2 ( R = 32.2 mm) that the sign change for σ xx in the thin film induces a switching of the uniaxial anisotropy easy
The 20nm-thick CFA film was grown on Kapton® substrate (of thickness 127.5 µm ∼ t ) using a magnetron sputtering system with a base pressure lower than 3 × 10 -9 Torr. CFA thin film was deposited at room temperature by dc sputtering under an Argon pressure of 1 × 10 -3 Torr, at a rate of 0.1 nm.s -1 . The CFA film were then capped with a Ta (5 nm) layer. Finally the CFA film is mounted on curved Aluminum blocks of different radii after the characterization of the CFA thin film (unbended). Indeed the stacking film is widely thinner that the substrate (more than three order of magnitude) so that the uniaxial stress σ xx can be considered as homogeneous in the film thickness. X-ray diffraction measurements showed that no preferential orientation developed during film growth. Being given this random grain orientation distribution, we can estimate the Young's modulus to be E = 243 × 10 10 dyn.cm -2 ( ≡ 243 GPa).
Figure 2: Azimuthal angle dependance of the resonance field in polar representation with the corresponding bending effect on the stress state (either negative (a) or positive (b))for 20 nm thick CFA film placed on aluminum block with 32.2 mm radius.
Figure 3: Angular dependance of the resonance field (at 10 GHz) for R = ∞ (a), R = 59 2 . mm (b), R = 32 2 . mm (c), R = 13 2 . mm (d). In figures (b), (c) and (d) are shown the opposite stress states.
axis as revealed by the angular dependance of the resonance field for the two opposite stress values σ xx = -0 47 . GPa and σ xx = +0 47 . GPa. In our configuration, the x axis corresponds to ϕ H = 90 ° and 270° and y axis corresponds to ϕ H = 0 ° and 180° . We will see that the apparent slight misalignment between the easy axis and the x axis in Fig.2-a ( σ xx < 0 ) and the y axis in Fig.2-b ( σ xx < 0 ) respectively is mainly due to an initial uniaxial anisotropy in the thin film (before applied bending) at about 30° from the x axis.
Fig.3-a shows the angular dependance of the resonance field for unbended sample. This initial uniaxial anisotropy, which has been observed in previous work in magnetic thin films deposited on flexible substrates
[13, 14], is generally attributed to a slight initial unavoidable curvature of the sample after deposition when using such substrates. In Fig. 3-b, 3-c and 3-d are shown the angular dependencies of the resonance fields for all the applied stress states. Full symbols show the experimental data while continuous lines show the fit of the data using the formalism detailed below. Being given a saturation magnetization of 820 emu.cm -3 , the best fits to the whole angular dependencies (performed at f = 10 GHz) allowed for the determination of the following parameters: ∣ ∣ σ residual xx -σ residual yy ∣ ∣ = 90 MPa, ϕ resi = 30 °, K perp = 53 × 10 4 erg.cm -3 , γ = 1 835 . × 10 7 s -1 .Oe -1 and λ = 14 × 10 -6 . The first two parameters characterize the initial uniaxial anisotropy (magnetoelastic) which has an amplitude of around 25 Oe slightly misaligned with respect to the x axis (see Fig.3-a).
Interestingly, in-plane magnetostriction coefficient at saturation λ can be determined in a simplest way. Indeed, at ϕ H = 0 , the magnetization is aligned along the applied magnetic field ( ϕ H ∼ ϕ M ) and a linear resonance field-dependence of slope λ is derived as function of -3 σ xx M s :
$$H _ { r e s } ( \varphi _ { H } = 0 ) = H _ { 3 } - \frac { 3 \lambda } { M _ { s } } \sigma _ { x x } \quad \quad ( 7 )$$
H 3 being a term that is independent of the applied stress σ xx . Thus, by plotting the experimental resonance field as function of of -3 σ xx M s at ϕ H = 0 (Fig.4a), a simple linear fit gives in more a direct way the value of λ CFA = 13 8 . × 10 -6 . It should be noted that this fitting procedure does not require any knowledge on the residual stress state, the initial anisotropies or the gyromagnetic factor. The value found here is in good correlation with those found using the complete fit. This positive value means that a uniaxial tensile stress along the x axis will make easier this axis for the magnetization direction. This effect is illustrated in Fig. 4-b that shows the linear dependance of the effective bending-induced in-plane anisotropy field H U (where 2 H U glyph[similarequal] ( H res ( ϕ H = 0) -H res ( ϕ H = 90 )) ° ) as function of the applied stress σ xx . In our experimental conditions, the extreme values of H U are roughly -0.6 kOe and 0.6 kOe that are very high being given the small effort to bend this kind of flexible samples. Indeed, the anisotropy field induced by bending would be enough to compensate ones already present in patterned thin films showing sub-micronic lateral dimensions as encoutered in spin valve sensors for instance[15].
Finally, concerning the field of flexible spintronics, one difficulty will be to get materials with large GMR (or TMR [1, 2]) remaining almost constant during external loading, i.e. with very small in-plane magnetostriction coefficient (less than 10 -6 ). This would be either intrinsic to the material (depending on the alloying elements and stoichiometric) either due to microstructural features such as crystallographic texture since the in-plane magnetostriction coefficient of polycrystalline thin films depends on single-crystal coefficients ( λ 111 and λ 100 for
Figure 4: (a) Resonance field as function of ( -σ xx 3 M s ) . Here the slope of the linear curve is the magnetostriction coefficient λ CFA = 13 8 . × 10 -6 . (b) Anisotropy field as function of applied stress σ xx induced by bending.
cubic symmetry) and on grains orientations distribution [13, 16].
In conclusion, we have shown that the magnetization
- [1] A. Bedoya-Pinto, M. Donolato, M. Gobbi, L. E. Hueso, Paolo Vavassori, Appl. Phys. Lett. 104 , 062412 (2014)
- [3] M. Donolato, C. Tollan, J. M. Porro, A. Berger, and P. Vavassori, Adv. Mater. 25 , 623 (2013)
- [2] C. Barraud, C. Deranlot, P. Seneor, R. Mattana, B. Dlubak, S. Fusil, K. Bouzehouane, D. Deneuve, F. Petroff, and A. Fert, Appl. Phys. Lett. 96 , 072502 (2010)
- [4] J. C. Slonczewski, J. Magn. Magn. Mater. 159 , L1 (1996)
- [6] M. Belmeguenai, H. Tuzcuoglu, M. S. Gabor, T. Petrisor Jr, C. Tiusan, D. Berling, F. Zighem, T. Chauveau, S. M. Chérif, P. Moch, Phys. Rev. B 87 , 184431 (2013)
- [5] K. Inomata, N. Ikeda, N.Tezuka, R; Goto, S. Sugimoto, M. Wojcik and E. Jedryka Sci. Technol. Adv. Mater. 9 , 014101(2008)
- [7] G. Geandier, P.-O. Renault, E. Le Bourhis, Ph. Goudeau, D. Faurie, C. Le Bourlot, Ph. Djémia, O. Castelnau, and S. M. Chérif, Appl. Phys. Lett. 96 , 041905 (2010)
- [8] S. Djaziri, P. O. Renault, F. Hild, E. Le Bourhis, P. Goudeau, D. Thiaudière, D. Faurie, J. Appl. Cryst. 44 , 1071 (2011)
glyph<c=3,font=/TCZPNB+Calibri>
glyph<c=3,font=/TCZPNB+Calibri>
in CFA Heusler alloy deposited on flexible substrate can be easily manipulated by bending the sample. Obviously, a slight curvature of the sample induces an uniaxial anisotropy that is generally present in such flexible samples. Moreover, by modeling the bending strain effect, and by adjusting the analytical model to the FMR data, it has been possible to extract the in-plane magnetostriction coefficient: λ CFA = 13 8 . × 10 -6 . In order to be applied in GMR flexible systems, it is imperative to deposit Heusler alloys with lower coefficient (at least ten times lower), in order to keep a constant value of GMR if sample bending occurs.
## Acknowledgments
The authors gratefully acknowledge the CNRS for his financial support through the 'PEPS INSIS' program (FERROFLEX project) and by the Université Paris 13 through a 'Bonus Qualité Recherche' project (MULTIDYN). Tarik Sadat (PhD student at Paris 13th university) is thanked for helping us in programming our resonance field 'Mathematica-code'. Authors would like to thank Frédéric Lombardini, engineer-assistant at LSPMCNRS, for circular blocks machining. M.S.G, T.P. and C.T. acknowledge financial support through the Exploratory Research Project "SPINTAIL" PN-II-ID-PCE2012-4-0315.
- [9] http://www2.dupont.com/Kapton/en\_US/
- [11] M. S. Gabor, T. Petrisor Jr., C. Tiusan, M. Hehn, T. Petrisor, Phys. Rev. B 84 , 134413 (2011)
- [10] F. Zighem, Y. Roussigné, S. M. Chérif, P. Moch, J. Ben Youssef, F. Paumier, J. Phys.: Condens. Matter 22 406001 (2010)
- [12] D. Faurie, P. Djemia, E. Le Bourhis, P.-O. Renault, Y. Roussigné, S. M. Chérif, R. Brenner, O. Castelnau, G. Patriarche, Ph. Goudeau, Acta Mater. 58 , 4998-5008 (2010)
- [14] X. Zhang, Q. Zhan, G. Dai, Y. Liu, Z. Zuo, H. Yang, B. Chen, and R.-W. Li, J. App. Phys. 113 , 17A901 (2013)
- [13] F. Zighem, D. Faurie, S. Mercone, M. Belmeguenai, D. Faurie, J. Appl. Phys. 114 , 073902 (2013)
- [15] P. P. Freitas, R. Ferreira, S. Cardoso and F. Cardoso, J. Phys.: Condens. Matter 19 165221 (2007)
- [16] A. Bart k, L. Daniel and A. Razek, J. Phys. D: Appl. ´ o Phys. 44 , 135001 (2011) | 10.1063/1.4893157 | [
"M. Gueye",
"B. M. Wague",
"F. Zighem",
"M. Belmeguenai",
"M. S. Gabor",
"T. Petrisor jr",
"C. Tiusan",
"S. Mercon",
"D. Faurie"
] | 2014-08-02T14:54:13+00:00 | 2014-08-02T14:54:13+00:00 | [
"cond-mat.mtrl-sci"
] | Bending strain-tunable magnetic anisotropy in Co2FeAl Heusler thin film on Kapton | Bending effect on the magnetic anisotropy in 20 nm Co$_{2}$FeAl Heusler thin
film grown on Kapton\textregistered{} has been studied by ferromagnetic
resonance and glued on curved sample carrier with various radii. The results
reported in this letter show that the magnetic anisotropy is drastically
changed in this system by bending the thin films. This effect is attributed to
the interfacial strain transmission from the substrate to the film and to the
magnetoelastic behavior of the Co$_{2}$FeAl film. Moreover two approaches to
determine the in-plane magnetostriction coefficient of the film, leading to a
value that is close to $\lambda^{CFA}=14\times10^{-6}$, have been proposed. |
1408.0380v1 | ## Block Free Optical Quantum Banyan Network based on Quantum State
## Fusion and Fission *
Zhu Chang-Hua ( 朱畅华 ) † , Meng Yan-Hong (孟艳红) , Quan Dong-Xiao ( 权东晓 ),
Zhao Nan ( 赵楠 ), Pei Chang-Xing ( 裴昌幸
)
State Key Laboratory of Integrated Services Networks, Xidian University, Xi'an 710071, China
Abstract: Optical switch fabric plays an important role in building multiple-user optical quantum communication networks. Owing to its self-routing property and low complexity, Banyan network is widely used for building switch fabric. While, there is no efficient way to remove internal blocking in Banyan network by classical way. Quantum state fusion, by which the two-dimensional internal quantum state of two photons could be combined into four-dimensional internal state of a single photon, makes it possible to solve this problem. In this paper, we convert the output mode of quantum state fusion from spatial-polarization mode to time-polarization mode. By combining modified quantum state fusion, quantum state fission with quantum Fredkin gate, we propose a practical scheme to build an optical quantum switch unit which is block free. The scheme can be extended to build more complex units, four of which are shown in this paper.
Key words: optical switch fabric, quantum state fusion, quantum Fredkin gate, Linear optics
PACS: 03.67.Hk, 42.50.Ex
## 1. Introduction
Based on the principle of quantum mechanism and unique quantum mechanical effects (e. g. quantum entanglement), quantum information technology can enhance the transmission, processing and storage of information, and has been developing quickly. Single photon, for its
* This work was supported by the National Natural Science Foundation of China (No. 61372076 and No. 61301171), the 111 Project (No.B08038), the Fundamental Research Funds for the Central Universities (No. K5051201021), and the scholarship from China Scholarship Council (No. 201308615037).
† Corresponding author. [email protected]
low decoherence rate and easier manipulation, has been widely used in quantum information technology (e. g. quantum key distribution [1] ) and quantum computing (e.g. quantum logical gate [2][3] ). With the development of photon-based quantum key distribution system, several experimental multiple-user quantum communication networks were built [4]-[8] . In these networks, trusted relay were used to implement long distance quantum key distribution. The key factor is that relay should be trusted. In short distance quantum key distribution system, untrusted optical switch can be used to build multiple users network [4][7] .
In classical communication network, switch-based topology is widely applied. In optical fiber communication network, optical switch is used to build optical cross connect (OXC) by which different devices can be connected. For optical quantum, OXC can be also applied to build an end-to-end quantum channel for two quantum communication terminals. Various switch fabrics were proposed for OXC, e.g. Crossbar network, Banyan network, Beneš network, Clos network, et. al. [9] A higher performance OXC should be lower in block rate, smaller in insert loss and shorter in processing delay. Banyan network has self-routing property since a qubit can be routed by only knowing it's input and output addresses, as shown in Fig.1. Each 2×2 switch can be either in cross state or in through state. A qubit is routed to the lower output of a switch at the i th stage if the i th most significant bit is '1' and to the upper output if it is '0'. Although Banyan network has simple structure and short processing delay, it also has a shortcoming that block exists. In classical optical network, it is a difficult problem except for adopting a more complex structure. While, there exists efficient method to overcome block in Banyan network by quantum characteristics, e.g. quantum superposition [10] . Several quantum switch schemes were proposed [11]-[14] , but practical optical quantum circuit has not been proposed. Quantum state fusion and quantum state fission combining with quantum Fredkin gate may be one of efficient ways to remove block.
Quantum state fusion and quantum state fission are two processes proposed by Vitelli et. al. [15] . Quantum state fusion is defined as the physical process by which the internal quantum state of two particles (e.g. photons) is combined into four-dimensional internal state of a single particle (photon) [15] . For photons, the input photons may be in two-dimensional polarization mode, the output photon may be in four-dimensional spatial-polarization mode.
Fig. 1 Block in banyan network
An inverse process, quantum state fission, is defined as the physical process by which a higher-dimensional quantum state of a particle is split into two (or more) particles. By the quantum state fusion process, the blocking in Fig.1 can be efficiently removed. In the output of the second stage, a state fusion process could be applied to implement information fusion. Then in the third stage, a state fission process should be used to split them again. Although this is a good solution, the spatial-polarization mode still needs two output physical channels. We design a state conversion circuit to convert the spatial-polarization mode into time-polarization mode. The base states in time mode are one time instant and another time instant which is separated by a constant interval with the first one. This time interval is larger than the full-power bandwidth of optical pulse and dead time of single photon detector.
In this paper, we use this modified quantum state fusion scheme, quantum state fission scheme and quantum Fredkin gate to build block free optical quantum switch units. The rest of the paper is organized as follows: in section 2, a heralded linear optical quantum Fredkin gate is presented. In section 3, quantum state fusion scheme with time-polarization mode as output is given. A quantum state fission scheme with state conversion circuit is also given. In section 4, a block free optical quantum switch unit with two two-dimensional polarization states as inputs is proposed. Four types of switch fabric units are also proposed for four different scenarios with fused state (or states) as input. In section 5, we conclude the paper.
## 2. Heralded linear optical quantum Fredkin gate
Quantum Fredkin gate is also named as controlled swap gate, that is, if the control bit is in state 1 , then the two target qubits swap their states and otherwise, they remain in their initial states if the control bit is in state 0 . Quantum Fredkin gate can be built by three CNOT gates [16] . There are two types of optical methods to implement Quantum Fredkin gate. One is linear optical method by which the Fredkin gate is built by linear optical components [17] ; the other is nonlinear optical method by which nonlinear effect of optical components is used [18][19] . In linear optical quantum information processing, qubit could be implemented by the photon with special polarization direction. The schemes and experiments with linear optical method are developed quickly. Gong et. al. constructed a heralded Fredkin gate by using four CNOT gates and linear optical components [17] , they also simplified the methods to post-selection ones which operate in the coincidence basis and required ancillary photons in maximally entangled state.
Here, the state 0 is prepared by a photon with horizontal polarization, denoted by H and the state 1 is prepared by a photon with vertical polarization, denoted by V . The operation for optical quantum bit is converted to the operation of polarization of photon. For a Fredkin gate, the two input quantum bits are 1 1 1 1 1 h v a a a H V ψ β β = + and 2 2 2 2 2 h v a a a H V ψ β β = + , where 1 h β , 1 v β , 2 h β and 2 v β are arbitrary complexes, and 2 2 1 1 1, h v β β + = 2 2 2 2 1, h v β β + = 1 a and 2 a denote different space modes, as shown in Fig.2 [17] . So the joint state of the two input photons is
$$| \psi _ { i n } \rangle & = | \psi \rangle _ { _ { a _ { i } } } | \psi \rangle _ { _ { a _ { i } } } \\ & = \beta _ { i h } \beta _ { 2 i h } | H \rangle _ { _ { a _ { i } } } | H \rangle _ { _ { a _ { i } } } + \beta _ { i h } \beta _ { 2 i v } | H \rangle _ { _ { a _ { i } } } | V \rangle _ { _ { a _ { i } } } + \beta _ { i v } \beta _ { 2 i h } | V \rangle _ { _ { a _ { i } } } | H \rangle _ { _ { a _ { i } } } + \beta _ { i v } \beta _ { 2 i v } | V \rangle _ { _ { a _ { i } } } | V \rangle _ { _ { a _ { i } } }$$
Quantum Fredkin gate shown in Fig.2 can be in 'Cross' state or 'Through' state controlled by the control qubit in c . In 'Cross' state the two input qubits are swapped, the qubit 1 2 b a ψ ψ = and the qubit 2 1 b a ψ ψ = . In 'Through' state the two input qubits are
Fig.2. A linear optical implementation of quantum Fredkin gate [17] . (a)quantum circuit. (b) a simple model in which only inputs and outputs
## are given.
passed through directly, the qubit 1 1 b a ψ ψ = and the qubit 2 2 b a ψ ψ = . In Fig.2, 1 D and 2 D are two single photon detectors (SPD). CNOT gate can make the polarization direction of the photon rotate 0 90 . 1 HWP and 3 HWP are 22.5°-tilted half-wave plates(HWP), which act as Hadamard gates ( ( ) 2 , H H V → + ( ) 2 ). V H V → -2 HWP and 4 HWP are 67.5°-tilted half-wave plates which perform the transformation: ( ) 2 and H V H → -( ) 2 . Polarization beamsplitter (PBS) works as V H V → + follows: the horizontally polarized photon is passed through, while the vertically polarized
photon is reflected. If 1 in c V = = , and no photon arrives at 1 D and 2 D , the output state is
$$| \psi _ { c o u } \rangle = \beta _ { i n } \beta _ { 2 n } | H \rangle _ { n _ { 2 } } | H \rangle _ { n _ { 2 } } + \beta _ { i n } \beta _ { 2 v } | H \rangle _ { n _ { 2 } } | V \rangle _ { n _ { 2 } } + \beta _ { i v } \beta _ { 2 n } | V \rangle _ { n _ { 2 } } | H \rangle _ { n _ { 2 } } + \beta _ { i v } \beta _ { 2 v } | V \rangle _ { n _ { 2 } } | V \rangle _ { n _ { 2 } }.$$
In this case, the quantum Fredkin gate is in 'Cross' state. Otherwise, if 0 in c H = = and no photon arrives at 1 D and 2 D , the quantum Fredkin gate is in 'Through' state. If the quantum efficiency η of SPD is 100% and the dark count isn't taken into account, the success rate of the quantum Fredkin gate is 0.25.
A simple model of quantum Fredkin gate is shown in Fig. 2(b) in which only the inputs and outputs are given.
## 3. Quantum state fusion and fission
In this section, we introduce the schemes of quantum state fusion and state fission proposed by Vitelli et. al. [15] and our modification for applying to optical quantum switch unit.
## 3.1 Scheme of quantum state fusion
Vitelli et. al. proposed a schematic of quantum state fusion [15] , in which the two-dimensional quantum qubits of two input photons can be combined into a single output photon within a four-dimensional quantum space. Based on this scheme, we add a state conversion circuit and a control qubit in d c , as shown in Fig.3. In Fig.3, the half wave plates are all oriented at 22.5° with respect to the H direction except for 6 HWP which is oriented at -22.5°. Let 3 3 3 3 3 h v a a a H V ψ β β = + and 4 4 4 4 4 h v a a a H V ψ β β = + denote two input states, where 3 h β , 3 v β , 4 h β and 4 v β are arbitrary complexes, and 2 2 3 3 1 h v β β + = , 2 2 4 4 1. The ancillary photon enters the setup in h v β β + = H state, that is a H = . So the joint input state is
$$| \psi \rangle _ { _ { m } } = \left ( \beta _ { s h } \beta _ { 4 h } | H \rangle _ { _ { a _ { s } } } | H \rangle _ { _ { a _ { s } } } + \beta _ { s h } \beta _ { 4 v } | H \rangle _ { _ { a _ { s } } } | V \rangle _ { _ { a _ { s } } } + \beta _ { s v } \beta _ { 4 h } | V \rangle _ { _ { a _ { s } } } | H \rangle _ { _ { a _ { s } } } + \beta _ { s v } \beta _ { 4 v } | V \rangle _ { _ { a _ { s } } } | V \rangle _ { _ { a _ { s } } } \right ) | H \rangle _ { _ { a } } | c \rangle _ { _ { d _ { m } } }.$$
The quantum state fusion is successful if there is one and only one photon at each H-channel of 11 PBS and 12 PBS , no photon at each V-channel of 11 PBS and 12 PBS , one and only one photon at 3 b ′ and 4 b ′ . The detailed working process of quantum state fusion is shown in Ref. [15] and its supplementary materials. After quantum state fusion, the spatial-polarization state at 3 b ′ and 4 b ′ is
$$| \psi \rangle _ { _ { b _ { c } } i } = \beta _ { _ { 4 a } } \beta _ { _ { 3 b } } | H \rangle _ { _ { b _ { c } } i } + \beta _ { _ { 4 a b } } \beta _ { _ { 3 r } } | V \rangle _ { _ { b _ { c } } i } + \beta _ { _ { 4 r } } \beta _ { _ { 3 b } } | H \rangle _ { _ { b _ { c } } i } + \beta _ { _ { 4 r } } \beta _ { _ { 3 r } } | V \rangle _ { _ { b _ { c } } i } \,.$$
Fig.3 Quantum state fusion. (a)quantum circuit. (b)a simple model
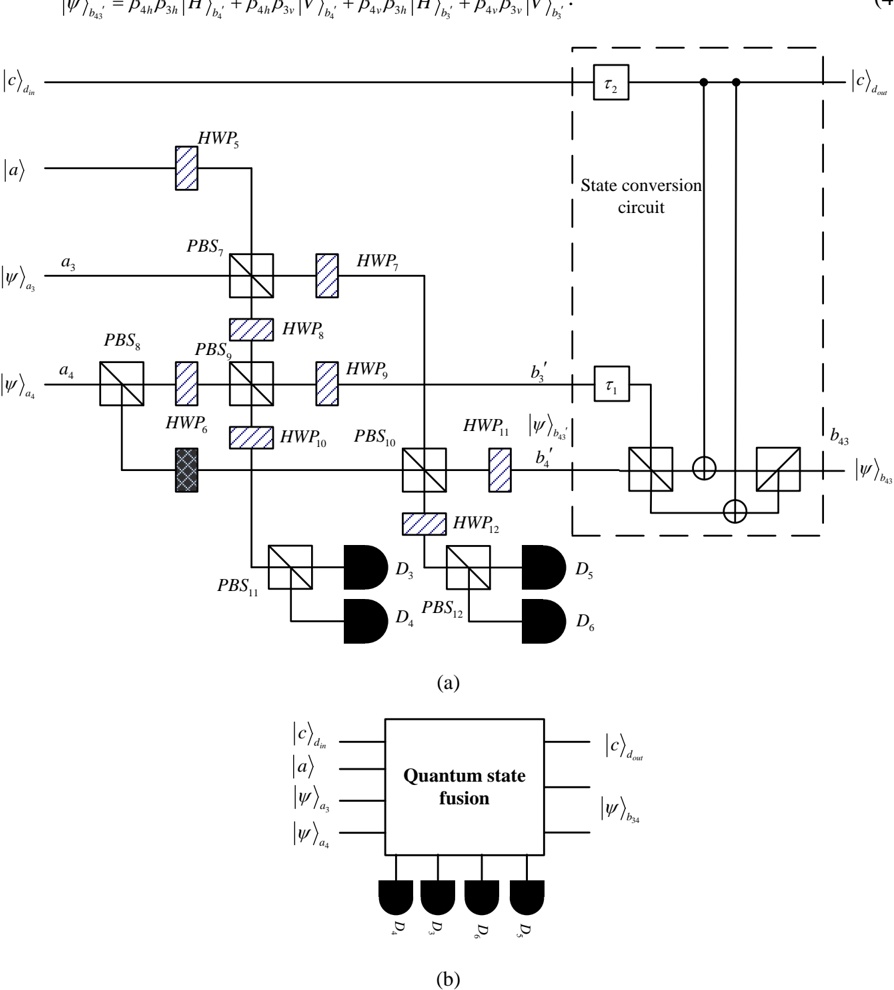
in which only inputs and outputs are given.
In Fig.3(a), state conversion circuit aims at converting the spatial-polarization mode to time-polarization mode. Here the state of a photon is in a four-dimensional Hilbert space obtained by time-polarization mode means that the photon may occur at one of the two time instants and may be in one of the two polarization directions. There are two time delay components with delay 1 τ and 2 τ , two CNOT gates and two PBS components in the conversion circuit. The spatial modes at 3 b ′ and 4 b ′ are combined to one path (spatial) mode at 43 b based on the two CNOT gates which perform NOT operation only on the photons from 3 b ′ by adjusting the values of 1 τ and 2 τ properly.
A simple model is shown as Fig. 3(b) in which only the inputs and outputs are shown.
## 3.2 Scheme of quantum state fission
Vitelli et. al. also proposed an inverse process of quantum state fusion, quantum state fission, in which the four-dimensional quantum state of a single photon is split into two two-dimensional states of two photons, each carrying a qubit [15] . We add a state conversion circuit on their scheme, as shown in Fig.4. There are four input states: one fused state 56 a ψ , one control state in d c under which state conversion circuit performs, and two ancillary states a and b which are in H at the inputs. In Fig.4, the half wave plates are all oriented at 22.5° with respect to the H direction, acting as Hadamard gates, except for 23 HWP and 24 HWP which are oriented at 45° so as to be equivalent to a NOT gate swapping states H and V .
The detailed working process can be obtained in the supplementary materials of Ref.[15]. The state conversion circuit added here aims at converting time-polarization mode to spatial-polarization mode. The CNOT gates work only on the photon at the second time mode. After state conversion, the spatial-polarization state at 5 a ′ and 6 a ′ is
$$| \psi \rangle _ { a _ { s _ { 6 } } ^ { ^ { \prime } } } = \beta _ { s h } \beta _ { 6 h } | H \rangle _ { a _ { s } ^ { ^ { \prime } } } + \beta _ { s h } \beta _ { 6 v } | V \rangle _ { a _ { s } ^ { ^ { \prime } } } + \beta _ { s v } \beta _ { 6 h } | H \rangle _ { a _ { s } ^ { ^ { \prime } } } + \beta _ { s v } \beta _ { 6 v } | V \rangle _ { a _ { s } ^ { ^ { \prime } } }$$
The quantum fission is successful if there is one and only one photon in the H-channel of
Fig. 4. Quantum state fission. (a) quantum circuit. (b) a simple model in which only inputs and outputs are given.
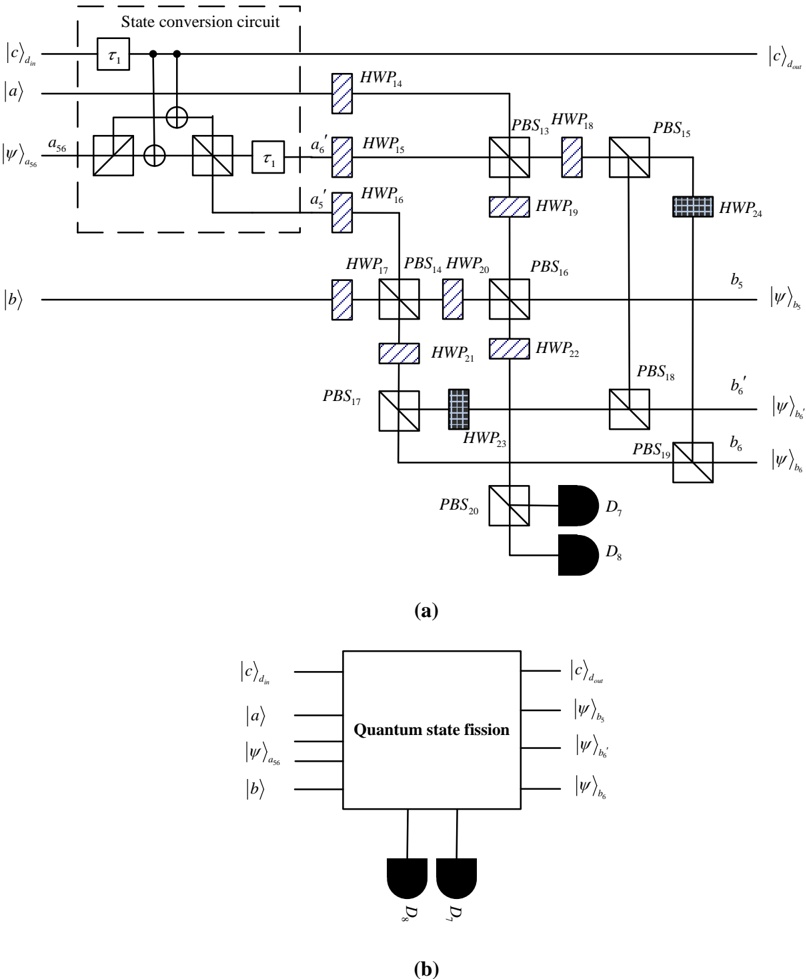
20 PBS , no photon in the V-channel of 20 PBS , one and only one photon in 5 b , one and only one photon in 6 b , no photon in 6 b ′ . A simplified version of the scheme is shown in Fig.4 (b).
## 4. Block free optical quantum switch units
Based on the heralded quantum Fredkin gate in section 2, quantum state fusion and
quantum state fission in section 3, we propose an optical quantum switch unit (OQSU) which is block free. Actually, the quantum state fusion schematic in section 3 can be directly applied to the scenario that two qubits which derive from two different inputs are switched to the same output at the same time. The two qubits can be fused and transmitted in the same quantum channel. Here, we propose a scheme in which the two input states may be fused or not.
## 4.1 Optical quantum switch unit (OQSU) with block free
The proposed optical quantum switch unit is shown in Fig. 5. There are two input information qubits at 7 a and 8 a , 7 a ψ and 8 a ψ , four control qubits in f c , in F c , in s c and in d c , and one ancillary qubit a . Let in f c denote the output competition. When 1 , it means that output competition exists and quantum state fusion works. When in f c = 0 , it means that there is no output competition and quantum Fredkin gate works. Let in f c = in F c denote the operation of quantum Fredkin gate which is in cross state when 1 , in F c = in through state when 0 . Let in F c = in s c denote the output port of the fused state which is 7 b when 1 , in s c = 8 b when 0 . Let in s c = in d c act as the control qubit of CNOT gate and is applied to combine the two spatial mode after delay of 2 τ . Let φ denote the vacuum state. The input-output relation under different control qubits is shown in the Table 1.
In Fig. 5, path selection circuit consists of two CNOT gates and two polarization beam splitters. When 1 , the two input states in f c = 7 a ψ and 8 a ψ are transmitted to the output ports at 7 a ′ ′ and 8 a ′ ′ . Otherwise, they are transmitted to the outputs at 7 a ′ and 8 a ′ . The two states at 7 a ′ and 8 a ′ are transmitted to quantum Fredkin gate. They are swapped or not under the control of qubit in F c . The two states at 7 a ′ ′ and 8 a ′ ′ are fused to a spatial-polarization mode. Then the spatial-polarization mode is converted into a time-polarizaiton mode by a converting circuit in which the time delay 1 τ and 2 τ are set properly. The output selection circuit is used to transmit the fused state to the expected output
Fig.5. An optical quantum switch unit with block free
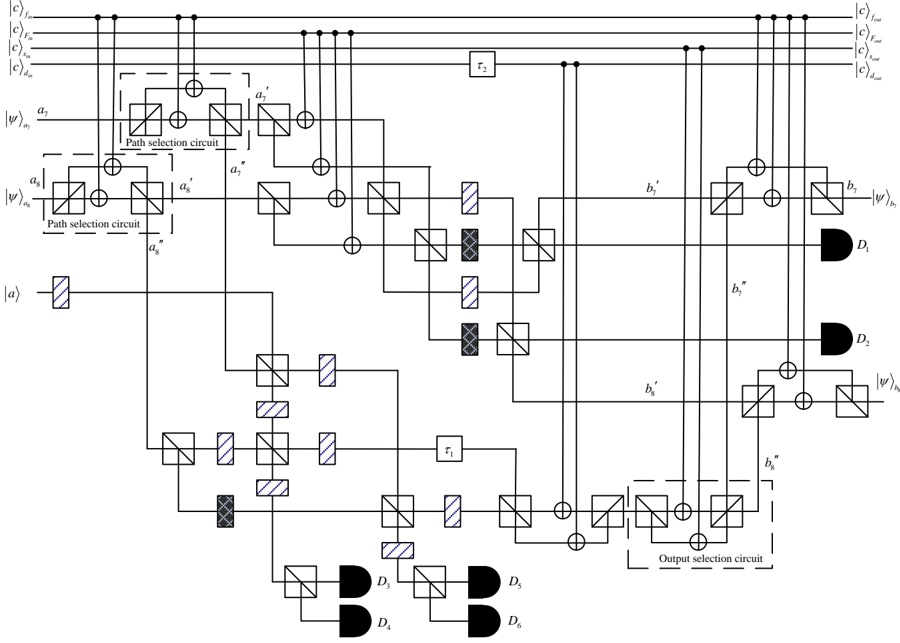
Table 1. The input-output relation under different control qubits
| in f c | in F c | in s c | 7 b ψ | 8 b ψ | Condition |
|----------|----------|----------|---------|---------|------------------------------------------|
| 0 | 0 | 0 | 7 a ψ | 8 a ψ | Both 1 D and 2 D have |
| 0 | 0 | 1 | 7 a ψ | 8 a ψ | Both 1 D and 2 D have |
| 0 | 1 | 0 | 8 a ψ | 7 a ψ | count. |
| 0 | 1 | 1 | 8 a ψ | 7 a ψ | Both 1 D and 2 D have |
| 1 | 0 | 0 | φ | f ψ | Both 3 D and 5 D detect one and only one |
| 1 | 0 | 1 | f ψ | φ | Both D |
| 1 | 1 | 0 | φ | f ψ | one photon |
| 1 | 1 | 1 | f ψ | φ | two time modes b . |
under the control of qubit in s c . So the two output states 7 b ψ and 8 b ψ can be a single
state or fused state. The operation is performed according the value of the control qubits as shown in Table 1.
According to Ref. [15] and its supplementary materials, the state fusion shown in Fig. 3 is successful with a probability of 1/32. By a suitable feed-forward, the success probability can be raised to 1/8. The state fission shown in Fig. 4 is the same as the state fusion. Since the Fredkin gate has a 1/4 success rate at ideal condition, and we assume the value of the control qubit in f c is 1 or 0 with equal probability, the average success probability of the unit is 1/2×1/8+1/2×1/4=3/16.
Since heralded quantum Fredkin gate, heralded quantum fusion process and quantum fission process are used in each switch unit, a network will fail if any one of the units in the network could not work successfully. In this scenario, the quantum bits should be retransmitted. How to overcome this deficiency will be our further work.
## 4.2 Optical quantum switch units with different input states
Besides the quantum circuit in the Fig. 5, there are other block free switch units which consist of one fusion circuit or more fusion circuits, one quantum Fredkin gate or more Fredkin gates, on fission circuit or more fission circuits. Here are four examples, as shown in Fig.6.
In Fig. 6(a), the input state is a fused state, which is splitted into two single qubits by quantum state fission operation. Then a quantum Fredkin gate follows. This network can be used in a scenario in which a multiplexed optical quantum signal is demultiplexed and the two resulted separate qubits can be sent to two outputs as they require. In Fig. 6(b), the input states are one fused state and a single state, one of the state after fission is fused with the input single state. This network can be used in a scenario in which a multiplexed optical quantum signal is demultiplexed into two separate qubits, in which one qubit is transmitted to the output directly and the other is multiplexed with the input single photon signal. In Fig. 6(c), the input are one fused state and one single state. A vacuum state is inserted into the input state at next time slot in order to perform Fredkin operation. This network can be used in a scenario in which one multiplexed quantum signal is swapped with a single qubit or not. In Fig. 6(d), the input states are two fused states. They are fissed and fused again. This network
Fig.6. Basic switch units based on the combinations of quantum state fusion, fission and Fredkin gate. (a)one fission and one Fredkin gate. (b) one fission and one fusion. (c) one Fredkin gate. (d) two fissions and two fusions.
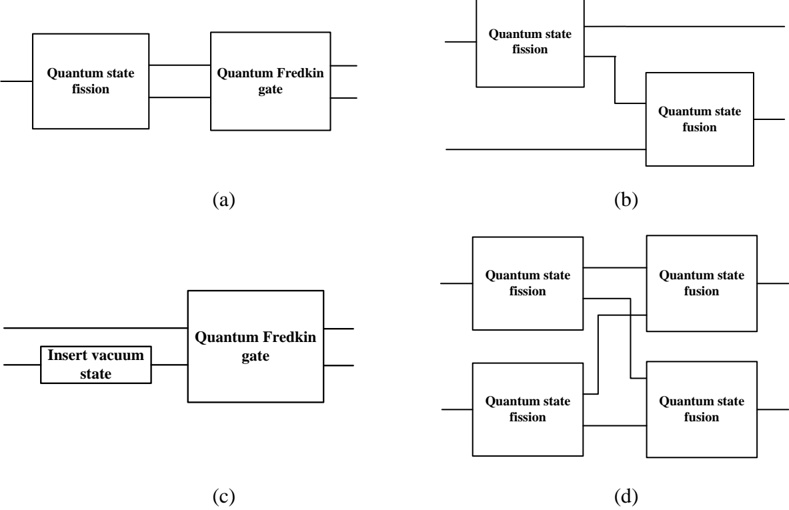
can be used in a scenario in which two multiplexed quantum signals are demultiplexed and mutilplexed again after exchanging one of the two qubits. In these four scenarios, the switch units are successful if the counts of the detectors in the quantum circuits meet with the conditions shown in section 3 and there is one and only one photon in each output for non-fused sate and one and only one photon in each time instant for fused state. Note that the some scenarios are not taken into account, e.g. a fused state might compete with another input state for same output port. These scenarios should be further discussed.
## 5 Conclusion
In this paper, we propose an optical quantum switch fabric with block free by using modified quantum state fusion, quantum state fission and quantum Fredkin gate. This switch fabric can be used to build a Banyan network with self-routing. We also propose schemes to build four types of switch fabric with block free. Since the photon loss in quantum circuit may decrease the fidelity of the switch fabric, we could improve its performance by using low-loss components and quantum nondemolition (QND) detectors.
Although quantum Fredkin gate, quantum fusion and fission processes are not be implemented with a success probability of 100%, the switch fabric proposed in this paper can be implemented without assisted classical control information and can be used to build all optical quantum information network. So, the side information leakage can be avoided.
With the development of integrated optics, large-scale optical quantum circuit or optical quantum computer may be built [20][21] . Our further works are to make experiment and to discuss how to implement it by integrated optics technology.
## References
- [1] Gisin N, Ribordy G, Tittel W and Zbinden H 2002 Rev. Mod. Phy. 74 145
- [2] Knill E, Laflamme R and Milburn G J 2001 Nature 409 46
- [3] Kok P, Munro W J, Nemoto K, Ralph T C, Dowling J P and Milburn G J 2007 Rev. Mod. Phy. 79 135
- [4] Elliott C, Pearson D and Troxel G 2003 Proceedings of the 2003 Conference on Applications, technologies, architectures and protocols for computer communications, Aug. 25, 2003 Karlsruhe, Germany, p.227
- [5] Peev M, Pacher C and Alléaume R et al. 2009 New J. Phys. 11 075001
- [6] Sasaki M., Fujiwara M. and Ishizuka H. 2011 Opt. Express 19 10387
- [7] Chen T Y, Liang H, Liu Y, Cai W Q, Ju L, Liu W Y, Wang J, Yin H, Chen K, Chen Z B, Peng C Z, Pan J W 2009 Opt. Express 17 6540
- [8] Xu F X, Chen W, Wang S, Yin Z Q, Zhang Y, Liu Y, Zhou Z, Zhao Y B, Li H W, Liu D, Han Z F and Guo G C 2009 Chinese Sci. Bull. 54 2277 (in Chinese)
- [9] Hui J Y 1990 Switching and Traffic Theory for Integrated Broadband Networks (New York: Springer Science+Business Media) p.64,126
- [10] Shukla M K, Ratan R and Oru ç A Y 2004 Proceedings of the 38th Annual Conference on Information Sciences and Systems March 17, 2004 Princeton, USA, p.484
- [11] Anwar S, Raja M Y A, Qazi S and IIyas M 2010 Nanotechnology for Telecommunications (Boca Raton: CRC press) p.373-384
- [12] Tsai I M and Kuo S Y 2002 IEEE Trans. Nanotechnol. 1 154
- [13] Cheng S T and Wang C Y 2006 IEEE Trans. Circ. Syst. I 53 316
- [14] Sue C C 2009 IEEE Trans. Comput. 58 238
- [15] Vitelli C, Spagnolo N, Aparo L, Sciarrino F, Santamato E and Marrucci L 2013 Nat. Photon. 7 521
- [16] Nielsen M A and Chuang I L 2000 Quantum Computation and Quantum Information (Cambridge: Cambridge University Press) pp.22-24
- [17] Gong Y X, Guo G C and Ralph T C 2008 Phys. Rev. A 78 012305
- [18] Lin Q 2009 Acta Phys. Sin. 58 5983 (in Chinese)
- [19] Shao X Q, Chen L and Zhang S 2009 Chin. Phys. B 18 3258
- [20] Politi A, Cryan M J, Rarity J G, Yu S and O'Brien J L 2008 Science 320 646
- [21] Marshall G D, Politi A, Matthews J C F, Dekker P, Ams M, Withford M J and O'Brien J L 2009 Opt. Express 17 12546 | 10.1088/1674-1056/23/12/120309 | [
"Chang-Hua Zhu",
"Yan-Hong Meng",
"Dong-Xiao Quan",
"Nan Zhao",
"Chang-Xing Pei"
] | 2014-08-02T15:09:16+00:00 | 2014-08-02T15:09:16+00:00 | [
"quant-ph"
] | Block Free Optical Quantum Banyan Network based on Quantum State Fusion and Fission | Optical switch fabric plays an important role in building multiple-user
optical quantum communication networks. Owing to its self-routing property and
low complexity, Banyan network is widely used for building switch fabric.
While, there is no efficient way to remove internal blocking in Banyan network
by classical way. Quantum state fusion, by which the two-dimensional internal
quantum state of two photons could be combined into four-dimensional internal
state of a single photon, makes it possible to solve this problem. In this
paper, we convert the output mode of quantum state fusion from
spatial-polarization mode to time-polarization mode. By combining modified
quantum state fusion, quantum state fission with quantum Fredkin gate, we
propose a practical scheme to build an optical quantum switch unit which is
block free. The scheme can be extended to build more complex units, four of
which are shown in this paper. |
1408.0381v1 | ## UNIQUENESS SETS FOR FOURIER SERIES
## ASHOT VAGHARSHAKYAN
Abstract. The paper discusses some uniqueness sets for Fourier series.
## 1. Introduction
In this paper the following problem is considered: to find conditions on a set E ∈ -[ π, π ] such that, if a function f ( x , ) -π < x < π, belongs to some space and its fourier series converges to zero at each point of the set E , then f ( x ) is identically zero.
The first nontrivial result, for trigonometric series, was proved by G. Cantor and W. Young, see [1], p. 191.
Theorem 1. Let c k → 0 and for each point x ∈ -[ π, π ] \ F we have
$$\lim _ { n \to \infty } \sum _ { k = - n } ^ { n } c _ { k } e ^ { i k x } = 0, \\ l e \ s e t \ \ T h e n \ c _ { n } = 0 \ \ k \in \mathcal { Z }$$
where F be a countable set. Then c k = 0 , k ∈ Z .
- D. Menshov, see [1], p. 806, construct a nonzero measure µ which has support of zero Lebesgue measure, and its Fourier coefficients tend to zero. The partial summs, of that Fourier series converges to zers out of supp µ ( ).
## 2. Auxliary definitions and results
More information, about the following quantities, related with Hausdorff's measures and capacities, one can find in [3], pp. 13 - 46. For convenient of the reader, we give some definitions.
Definition 2. Let 0 ≤ h x , ( ) 0 ≤ x ≤ 1 be a nonnegative, increasing function and h (0) = 0 . Let the subset E ⊂ { z ; | z | = 1 } be cover by the family of arcs { S k } ∞ k =1 , i.e.
$$E \subseteq \bigcup _ { \substack { k = 1 \\ 1 } } ^ { \infty } S _ { k }.$$
Then we put
$$M _ { h } ( E ) = \inf \left ( \sum _ { k = 1 } ^ { \infty } h ( | S _ { k } | ) \right ), \\ \text{length of the arc $S$ and the infinity} \,.$$
where | S | is the length of the arc S and the infimum is taken over all families of cover.
Definition 3. Let 0 < α < 1 and E be baunded Borel set. The C α ( E ) -capactiy of the set E is defined by formula
$$& \stackrel { \cdot } { C } _ { \alpha } ( E ) = \left ( \inf _ { \mu \prec E } \int _ { E } \int _ { E } \frac { d \mu ( x ) d \mu ( y ) } { | x - y | ^ { \alpha } } \right ) ^ { - 1 }, \\ \prec F \ m e a n s. \ t h a t \ u \ i s \ n r o b a l i t u \ m e a s u r e \ w i t h \ s u m o r t$$
where µ ≺ E means, that µ is probality measure with support in E .
For each 0 < α < 1 from Parseval's equality follows that there is a constant M such that,
$$\sum _ { k = - \infty } ^ { \infty } | \hat { f } _ { k } | ^ { 2 } | k | ^ { \alpha } & \leq M \, \int _ { - \pi } ^ { \pi } | f ( x ) | ^ { 2 } d x + M \, \int _ { - \pi } ^ { \pi } \int _ { \pi } ^ { \pi } \frac { | f ( x ) - f ( y ) | ^ { 2 } } { | x - y | ^ { 1 + \alpha } } d x d y. \\ \text{The following statement is a fragment of A. Zvggumd\'s theorem. see}$$
The following statement is a fragment of A. Zygmund's theorem, see [6], p.22. Let g ( -π ) = g π ( ) and g x , ( ) -π ≤ x ≤ π ] have a bounded variation. If
$$| g ( x ) - g ( y ) | \leq M \, \cdot h ( | x - y | ).$$
Then, there is a constant B such that the Fourier coefficients of the function g x ( ) satisfy the inequalities
$$\varphi ^ { \dots } \cdots \psi ^ { \dots } \cdots \psi ^ { \dots } \sum _ { 2 ^ { j } \leq | k | < 2 ^ { j + 1 } } | \hat { g } _ { k } | ^ { 2 } & \leq B \, 2 ^ { - j } h \left ( \frac { \pi } { 3 } 2 ^ { 1 - j } \right ). \\ \tau ^ { \dots } \cdots \psi ^ { \dots } \cdots \psi ^ { \dots } \cdots \psi ^ { \dots } \cdots \psi ^ { \dots } \cdots \psi ^ { \dots }.$$
Definition 4. Let us denote by Λ( n ) the known Mangold's function, equals
$$\Lambda \left ( p ^ { n } \right ) = \ln p,$$
where p is prime number and n is natural number. For other natural numbers m
$$\Lambda \left ( m \right ) = 0.$$
It is known, that for an arbitrary natural number n the equality
$$\ln n = \sum _ { d | n } \Lambda ( d ) \\ \cdot \alpha \text{from over all } \partial \text{$\partial$} \text{$\prime$},$$
holds, where the sum is taken over all positive divisors of n .
In the following theorem A. Broman, see [2], p. 851, gived the characterization of close exeptional sets.
Theorem 5. Let 0 < α < 1 and
Let F be close set and
$$\alpha \succ \iota \ u v o \\ \sum _ { n = - \infty } ^ { \infty } \frac { | c _ { n } | ^ { 2 } } { | n | ^ { \alpha } + 1 } < \infty.$$
$$& \underset { r \rightarrow 1 - 0 } { \ u v o } \\ & \lim _ { r \rightarrow 1 - 0 } \sum _ { k = - \infty } ^ { \infty } r ^ { | k | } c _ { k } e ^ { i k x } = 0, \\ - \pi. \ \pi | \, \bar { \ } F. \ T h e n \ c _ { \bullet } = 0. \ \ k \in Z.$$
for arbitrary x ∈ -[ π, π ] \ F . Then c k = 0 , k ∈ Z, if and only if C 1 -α ( F ) = 0 .
A. Zygmund, see [7], proved the following nontrivial result.
Theorem 6. Let /epsilon1 > 0 and /epsilon1 n > 0 , n = 1 2 , , . . . be an arbitrary decreasing sequence, tending to zero. Let | c n | ≤ /epsilon1 n , n = 1 2 , , . . . . There is a subset E ⊆ -[ π, π ] with measure, i. e. m E ( ) > 2 π -/epsilon1 , such that, if for each point x ∈ -[ π, π ] \ E we have then c k = 0 , k ∈ Z, .
$$\begin{array} { c c c }. & \nu ^ { 2 } \\ & \lim _ { n \to \infty } \sum _ { k = - n } ^ { n } c _ { k } e ^ { i k x } = 0, \end{array}$$
The proof of the following theorem one can find in [5].
Theorem 7. Let 0 ≤ α < 1 and
$$\dots \dots \dots \dots \dots \dots \\ \int _ { - \pi } ^ { \pi } | f ( x ) | d x + \int _ { - \pi } ^ { \pi } \int _ { - \pi } ^ { \pi } \frac { | f ( x ) - f ( y ) | } { | x - y | ^ { 1 + \alpha } } d x < \infty \\ \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \ dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots
\dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \delta \dots \delta \dots \delta \dots \delta \dots \delta \dots \delta \dots \delta \dots \delta \dots \delta \dots \delta \dots \delta \dots \delta \dots \delta \dots \delta \dots \delta \dots \delta \dots \delta \dots \delta \dots \delta \dots \delta \dots \delta \dots \delta \dots \delta \dots \delta \dots \delta \dots \delta \dots \delta \dots \delta \dots \delta \dots \delta \dots \delta \dots \delta \dots \delta \dots \delta \cdots \delta \dots \delta \dots \delta \dots \delta \dots \delta \dots \delta \dots \delta \dots \delta \dots \delta \dots \delta \dots \delta \dots \delta \dots \delta \dots \delta \dots \delta \dots \delta \dots \delta \dots \delta \dots \delta \dots \delta \dots \delta \dots \delta \dots \delta \dots \delta \dots \delta \dots \delta \dots \delta \dots \delta \dots \delta \dots \delta \dots \delta \dots \delta \dots \delta \dots delta \dots \delta \dots \delta \dots \delta \dots \delta \dots \delta \dots \delta \dots \delta \dots \delta \dots \delta \dots \delta \dots \delta \dots \delta \dots \delta \dots \delta \dots \delta \dots \delta \dots \delta \dots \delta \dots \delta \dots \delta \dots \delta \dots \delta \dots \delta \dots \delta \dots \delta \dots \delta \dots \delta \dots \delta \dots \delta \dots \delta \dots \delta \dots \delta \dots \delta
\dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots
\int _ { 1 } ^ { \pi } } & \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \Dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \\ \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \\ 0 } & \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \delta \ dots \delta \delta \dots \delta \dots \delta \dots \delta \dots \delta \dots \delta \delta \dots \delta \delta \dots \delta \delta \dots \delta \delta \dots \delta \delta \dots \delta \delta \dots \delta \delta \dots \delta \delta \delta \dots \delta \delta \delta \dots \delta \delta \delta \delta \delta \delta \delta \delta \delta \delta \delta \delta \delta \delta \delta \delta \delta \delta \delta \delta \delta \delta \delta \delta \delta \delta \delta \delta \delta \delta \delta \delta \delta \delta \delta \delta \delta \delta \delta \delta \delta \delta \delta \delta \delta \delta \delta \delta \delta \delta \delta \delta \delta \delta \delta \delta \delta \delta \delta \delta \delta \delta \delta \delta \delta \delta \delta \end{ \delta \delta \delta \delta \delta \delta \delta \delta \delta \delta \delta \delta \delta \delta \delta \delta \delta \delta \delta \delta \delta \delta \delta \delta \delta \delta \delta \delta \delta \delta \delta \delta \delta \delta \delta \delta \delta \delta \delta \delta \delta \delta \delta \delta \delta \delta \delta \delta \delta \delta \delta \delta \delta \delta \delta \delta \delta \delta \delta \delta \delta \delta \delta \delta \delta \delta \ delta \delta \delta \delta \delta \delta \delta \delta \delta \delta \delta \delta \delta \delta \delta \delta \delta \delta \delta \delta \delta \delta \delta \delta \delta \delta \delta \delta \delta \delta \delta \delta \delta \delta \delta \delta \delta \delta \delta \delta \delta \delta \delta \delta \delta \delta \delta \delta \delta \delta \delta \delta \delta \delta \delta \delta \delta \delta \delta \delta \delta \delta \delta \delta \delta \delta \delta
\dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \sigma \delta \delta \delta \delta \delta \delta \delta \delta \delta \delta \delta \delta \delta \delta \delta \delta \delta \delta \delta \delta \delta \delta \delta \delta \delta \delta \delta \delta \delta \delta \delta \delta \delta \delta \delta \delta \delta \delta \delta \delta \delta \delta \delta \delta \delta \delta \delta \delta \delta \delta \delta \delta \delta \delta \delta \delta \delta \delta \delta \delta \delta \delta \delta \delta \delta \delta \sigma \delta \delta \delta \delta \delta \delta \delta \delta \delta \delta \delta \delta \delta \delta \delta \delta \delta \delta \delta \delta \delta \delta \delta \delta \delta \delta \delta \delta \delta \delta \delta \delta \delta \delta \delta \delta \delta \delta \delta \delta \delta \delta \delta \delta \delta \delta \delta \delta \delta \delta \delta \delta \delta \delta \delta \delta \delta \delta \delta \delta \delta \delta \delta \delta \delta \end{ \ delta \delta \delta \delta \delta \delta \delta \delta \delta \delta \delta \delta \delta \delta \delta \delta \delta \delta \delta \delta \delta \delta \delta \delta \delta \delta \delta \delta \delta \delta \delta \delta \delta \delta \delta \delta \delta \delta \delta \delta \delta \delta \delta \delta \delta \delta \delta \delta \delta$$
Let E ⊂ -[ π, π ] be a subset such that for almost all points x 0 ∈ -[ π, π ] we have where
$$\sum _ { n = 1 } ^ { \infty } & 2 ^ { n ( 1 - \alpha ) } C _ { 1 - \alpha } ( E _ { n } ( x _ { 0 } ) ) = \infty, \\ & \cdot \quad.$$
If
$$E _ { n } ( x _ { 0 } ) = \left \{ x \in E ; \ \frac { 1 } { 2 ^ { n + 1 } } \leq | x - y | < \frac { 1 } { 2 ^ { n } } \right \}.$$
$$\lim _ { n \to \infty } \sum _ { k = - n } ^ { n } \hat { f } _ { k } e ^ { i k x } = 0, \ x \in E \\ \colon & \in [ - \pi, \ \pi ].$$
then f ( x ) = 0 , x ∈ -[ π, π ] .
In this paper we prove a new result of this type for other classes of functions.
## 3. New uniqueness result
The following result, in different form, one can find in the paper, see [4].
Theorem 8. Let f ( -π ) = f ( π ) be differetable function. Then
/negationslash
$$& \frac { 1 } { \pi } \sum _ { p \in P } \ln p \left ( \sum _ { n = 1 } ^ { \infty } \left [ \frac { 1 } { p ^ { n } } \sum _ { k = 1 } ^ { p ^ { n } } f \left ( \frac { 2 \pi k } { p ^ { n } } \right ) - \hat { f } _ { 0 } \right ] \right ) = \sum _ { n \neq 0, n = - \infty } ^ { \infty } \hat { f } _ { n } \ln | n |. \\ & P r o o f. \text{ We have}$$
Proof. We have
$$P r o o f. \text{ We have} \\ \sum _ { n = 1 } ^ { \infty } \Lambda ( n ) \left ( \frac { 1 } { n } \sum _ { k = 1 } ^ { n } \frac { 1 - | z | ^ { 2 } } { \left | 1 - z \exp \{ - \frac { 2 \pi i k } { n } \} \right | ^ { 2 } } - 1 \right ) = \\ = \sum _ { n = 1 } ^ { \infty } \Lambda ( n ) \frac { 1 } { n } \sum _ { k = 1 } ^ { n } \left ( \sum _ { j = - \infty } ^ { \infty } r ^ { | j | } \exp \left \{ i x j - \frac { 2 \pi i k j } { n } \right \} - 1 \right ) = \\ = \sum _ { j = 1 } ^ { \infty } r ^ { j } \left ( \sum _ { j / n } \Lambda ( n ) \right ) \cos ( j x ) = \sum _ { j = 1 } ^ { \infty } r ^ { j } \cos ( j x ) \ln j. \\ \text{where $z = r e ^ { i x }, $ 0 \leq r < 1$.Multiplying by the function $f(x)$ and after} \\ \text{integrating we get} \\ \sim \int _ { k = k } ^ { \infty } \hat { \lambda } \hat { \lambda } \hat { \lambda }$$
where z = re ix , 0 ≤ r < 1.Multiplying by the function f ( x ) and after integrating we get
$$\text{integrating we get} \\ \sum _ { n = 1 } ^ { \infty } \Lambda ( n ) \left ( \frac { 1 } { n } \sum _ { k = 1 } ^ { n } \frac { 1 } { 2 \pi } \int _ { - \pi } ^ { \pi } \frac { 1 - r ^ { 2 } } { \left | 1 - r \exp \{ i x - \frac { 2 \pi i k } { n } \} \right | ^ { 2 } } f ( x ) d x - \hat { f } _ { 0 } \right ) = \\ = \frac { 1 } { 2 } \sum _ { j \neq 0, j = - \infty } ^ { \infty } r ^ { | j | } \hat { f } _ { j } \ln | j |. \\ \text{Passing to the limit if } r \to 1 - 0 \text{ we get the required equality.} \quad \ \Box$$
/negationslash
Passing to the limit if r → -1 0 we get the required equality. /square
$$\sum _ { \begin{subarray} { c } 0, \, j = - \\ - \, 0 \ v \end{subarray} } ^ { \infty }$$
Remark. The getting result we can write in the form
/negationslash
This formula is a geralization of Poisson's well known formula:
$$& \frac { 1 } { \pi } \sum _ { p \in P } \ln p \left ( \sum _ { n = 1 } ^ { \infty } \left [ \frac { 1 } { p ^ { n } } \sum _ { k = 1 } ^ { p ^ { n } } \delta \left ( x - \frac { 2 \pi k } { p ^ { n } } \right ) - 1 \right ] \right ) = \sum _ { n \neq 0, \, n = - \infty } ^ { \infty } e ^ { i n x } \ln n. \\ & \text{This formula is a generalization of Poisson} ^ { s \, \text{well known formula} }.$$
$$\sum _ { n = - \infty } ^ { \infty } \delta ( x - 2 \pi n ) = \frac { 1 } { 2 \pi } \sum _ { n = - \infty } ^ { \infty } e ^ { i n x }, \, - \infty < x < \infty. \\ \text{hero rem} \, & 9. \, \text{ Let } 0 < \alpha < 1 \text{ and } a n o m n e a t i n e \, \text{ function } r < h ( r ) \text{ } 0$$
Theorem 9. Let 0 < α < 1 and a nonnegative function x ≤ h x , ( ) 0 ≤ x < 1 satisfy the condition
$$\int _ { 0 } ^ { 1 } \frac { h ( x ) } { x ^ { 2 - \alpha } } \ln _ { 4 } ^ { 2 } \frac { e } { x } d x < \infty.$$
Let for the function f ( x ) we have
$$\ell _ { - \pi } ^ { \ell } | f ( x ) | ^ { 2 } d x + \int _ { - \pi } ^ { \pi } \int _ { \pi } ^ { \pi } \frac { | f ( x ) - f ( y ) | ^ { 2 } } { | x - y | ^ { 1 + \alpha } } d x d y < \infty. \\ \text{etc. there is a subset $E\subset[-\pi,\pi]$ such that} \colon$$
Let there is a subset E ⊂ -[ π, π ] such that:
$$1. \ M _ { h } ( E ) \underset { - \ \mu } { > } 0,$$
- 2. if x ∈ E then an arbitrary point
$$x + \frac { 2 \pi k } { p ^ { n } },$$
where k ∈ Z, n ∈ N and p is prime number, by mod (2 π ) , belongs to the set E .
If for eavery x ∈ E we have
$$\sum _ { \substack { r \to 1 - 0 \\ r = - \infty } } ^ { \infty } r ^ { | k | } \hat { f } _ { k } e ^ { i k x } = 0, \\ f ( x ) \ i s \ i d e n t i c a l y \ z e r o.$$
then the function f ( x ) is identicaly zero.
Proof. By O. Frostman's theorem, see [3], p. 14, there is a probability measure dµ such that supp dµ ( ) ⊆ E ,
$$M _ { h } ( s u p p ( \mu ) ) > 0.$$
and for each 0 < δ the inequality
$$\overset { \bullet } { \int } _ { [ x, x + \delta ] } d \mu \leq A h ( \delta ) \\ \text{the noints } 0 \text{ and } 2 \pi \text{ the f}$$
hold. Let us assume at the points 0 and 2 π the function µ is continuous and µ (0) + 1 = µ (2 π ). Denote
Then we have
$$- \cdots _ { \prime } - \dots \cdots \\ f ( r e ^ { i x } ) = \sum _ { n = - \infty } ^ { \infty } r ^ { | n | } \hat { f } _ { n } e ^ { i n x }.$$
$$& \text{Then we have} \\ & \frac { 1 } { \pi } \sum _ { p \in P } \ln p \left ( \sum _ { n = 1 } ^ { \infty } \left [ \frac { 1 } { p ^ { n } } \sum _ { k = 1 } ^ { p ^ { n } } \int _ { E } f \left ( r \exp \left \{ \frac { 2 \pi i k } { p ^ { n } } + i x \right \} \right ) d \mu ( x ) - \hat { f } _ { 0 } \right ] \right ) = \\ & \quad = \sum _ { n = 2 } ^ { \infty } r ^ { n } \left [ \hat { f } _ { n } \int _ { E } e ^ { i n x } d \mu ( x ) + \hat { f } _ { - n } \int _ { E } e ^ { - i n x } d \mu ( x ) \right ] \ln n = \\ & \quad = 2 \pi i \sum _ { n = 2 } ^ { \infty } \left ( \hat { f } _ { n } \hat { g } _ { - n } - \hat { f } _ { - n } \hat { g } _ { - n } \right ) r ^ { n } n \ln n. \\ & \text{where} \\ & \quad g ( x ) = \mu ( x ) - \frac { x } { 2 \pi }.$$
$$g ( x ) = \mu _ { \substack { 5 } } ( x ) - \frac { x } { 2 \pi }.$$
Since the function f ( e ix ) vanish on the set E so, we have
$$\intertext { w o v e r a n d e r a n d e r a n d e r a n d e r a n d e r a n d e r a n d e r a n d e r a n d e r a n d e r a n d e r a n d e r a n d e r a n d e r a n d e r a n d e r a n d e r a n d e r a n d e r a n d e r a n d e r a n d e r a n d e r a n d e r a n d e r a n d e r a n d e r a n d e r a n d e r a n d e r a n d e r a n d e r a n d e r a n d e r a n d e r a n d e r a n d e r a n d e r a n d e r a n d e r a nd e r a n d e r a n d e r a n d e r a n d e r a n d e r a n d e r a n d e r a n d e r a n d e r a n d e r a n d e r a n d e r a n d e r a n d e r a n d e r a n d e r a n d e r a n d e r a n d e r a n d e r a n d e r a n d e r a n d e r a n d e r a n d e r a n d e r a n d e r a n d e r a n d e r a n d e r a n d e r a n d e r a n d e r a n d e r a n d e r a n d e r a n d e r a n d e r a n d e r a n n d e r a n d e r a n d e r a n d e r a n d e r a n d e r a n d e r a n d e r a n d e r a n d e r a n d e r a n d e r a n d e r a n d e r a n d e r a n d e r a n d e r a n d e r a n d e r a n d e r a n d e r a n d e r a n d e r a n d e r a n d e r a n d e r a n d e r a n d e r a n d e r a n d e r a n d e r a n d e r a n d e r a n d e r a n d e r a n d e r a n d e r a n d e r a n d e r a n d e r } \left | \frac { 1 } { \pi } \sum _ { p \in P } \hat { f } _ { 0 } \ln p \right | & \leq 2 2 \sum _ { n = 2 } ^ { \infty } ( | \hat { f } _ { - n } | | \hat { g } _ { n } | + | \hat { f } _ { n } | | \hat { g } _ { - n } | | ) n \ln n n. \\ \intertext { w o t u s n o t e } \in \quad \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ }$$
∣ Let us note
The inequality
$$\left | \frac { 1 } { \pi } \sum _ { p \in P } \hat { f } _ { 0 } \ln p \right | \leq 2 \sum _ { n = 2 } ^ { \infty } ( | \hat { f } _ { - n } | | \hat { g } _ { n } | + | \hat { f } _ { n } | | \hat { g } _ { - n } | ) n \ln n. \\ \text{Let us note} \sum _ { n = 2 } ^ { \infty } | \hat { f } _ { n } | | \hat { g } _ { - n } | n \ln n \leq \left ( \sum _ { n = 1 } ^ { \infty } | \hat { f } _ { n } | ^ { 2 } n ^ { \alpha } \right ) ^ { \frac { 1 } { 2 } } \left ( \sum _ { n = 1 } ^ { \infty } | \hat { g } _ { - n } | ^ { 2 } n ^ { 2 - \alpha } \ln ^ { 2 } n \right ) ^ { \frac { 1 } { 2 } } \leq \\ \leq \left ( \sum _ { n = 1 } ^ { \infty } | \hat { f } _ { n } | ^ { 2 } n ^ { \alpha } \right ) ^ { \frac { 1 } { 2 } } \left ( \sum _ { j = 1 } ^ { \infty } j ^ { 2 } 2 ^ { ( 2 - \alpha ) j } \sum _ { n = 2 ^ { j } } ^ { 2 j + 1 - 1 } | \hat { g } _ { - n } | ^ { 2 } \right ) ^ { \frac { 1 } { 2 } } \leq \\ \leq M \left ( \sum _ { j = 1 } ^ { \infty } j ^ { 2 } 2 ^ { ( 1 - \alpha ) j } h ( 2 ^ { - j } ) \right ) ^ { \frac { 1 } { 2 } } < \infty. \\ \text{The inequality} \quad \left | \frac { 1 } { - } \sum _ { j } \hat { f } _ { 0 } \ln p \right | < \infty$$
valid only if
$$\left | \frac { 1 } { \pi } \sum _ { p \in P } \hat { f } _ { 0 } \ln p \right | < \infty \\ \hat { f } _ { 0 } = 0. \\. \quad \underset { i n v } { i n v } \, e ^ { \prime } \, \cdots \, \cdots \, \cdots \, - \, \varepsilon$$
$$\hat { f } _ { 0 } = 0.$$
Considering the functions e inx f ( x , ) n ∈ Z we prove that ˆ ( f n ) = 0 , n ∈ Z. /square
## References
- [1] A. Bary, Trigonometric series, Moscow, 1961.
- [2] A. Broman, On two classes of trigonometrical series, Thesis, University of Upsala, Upsala, 1947.
- [3] L. Carleson, Selected Problems on Exceptional Sets, Princeton University Press, New Jersey, 1967.
- [4] A. Vagharshakyan, On a representation theorem for harmonic fonctions, Izvestiya National Akademii nauk Armenii, vol.28, no.4, 1993.
- [5] A. Vagharshakyan, On the uniqueness problem for Fourier series, Real Analysis Exchanges vol. 29(2), 2003/2004.
- [6] J.-P.Kahan, Series de Fourier absolutement convergentes, Springer -Verlag Berlin Heidelberg New York, 1970.
- [7] A. Zygmund, Contribution a l'unisite du developpement trigonometrique, MZ, 24 (1926).
Institute of Mathematics NAS of Armenia, Bagramian 24-b,
375019 Yerevan, Armenia | null | [
"Ashot Vagharshakyan"
] | 2014-08-02T15:13:08+00:00 | 2014-08-02T15:13:08+00:00 | [
"math.FA"
] | Uniqueness sets for Fourier series | The paper discusses some uniqueness sets for Fourier series. |
1408.0382v5 | ## Non Controllability to Rest of the Two-Dimensional Distributed System Governed by the Integrodifferential Equation
Igor Romanov 1 2 Alexey Shamaev 3 4
## Abstract
The paper deals with controllability problem for a distributed system governed by the twodimensional Gurtin-Pipkin equation. We consider a system with compactly supported distributed control and show that if the memory kernel is a twice continuously differentiable function, such that its Laplace transformation has at least one non-zero root, then the system cannot be driven to the equilibrium in a finite time.
Keyword: Lack controllability to rest, equation with memory, distributed control, moment problems MSC 2010: 45K05
## 1 Introduction
Integrodifferential equations with nonlocal terms of the convolution type often arise in applications such as mechanics of heterogeneous media, the theory of viscoelasticity, thermal physics, kinetic theory of gases and others.
For example, it was rigorously proved that in the case of heterogeneous two-phase medium, consisting of viscous fluid and elastic inclusions, the effective equation is integro-differential, and the corresponding convolution kernel is a finite of infinite sum of decreasing exponential functions.
If the viscosity of the liquid is small (big), the effective equation does contain (does not contain) the third order terms corresponding to Kelvin-Voigh friction, see [1].
In the theory of viscoelasticity, it is a common practice to approximate the relaxation kernels by the sum of exponents.
In thermal physics, laws of heat conduction with an integral memory are studied in many papers; note among them [2].
The presence of integral memory in the law of heat conduction might lead to the appearance of a thermal front which moves at a finite speed. This makes an important difference with the heat equation whose solution propagates at infinite speed.
In this paper, we give an outline of the results on the existence and uniqueness of solutions to these systems and consider the problem of controllability.
1 National Research University Higher School of Economics,
20 Myasnitskaya Ulitsa, Moscow 101000, Russia
2 E-mail: [email protected]
3 Institute for Problems in Mechanics RAS,
101 Prosp. Vernadskogo, Block 1, Moscow 119526, Russia 4 Lomonosov Moscow State University,
GSP-1, Leninskie Gory, Moscow 119991, Russia
## 2 Statement of the Problem
In this article, we consider the problem of non controllability of a system governed by the integrodifferential equation
$$\i o u \\ \theta _ { t } ( t, x, y ) - \int _ { 0 } ^ { t } K ( t - s ) \Delta \theta ( s, x, y ) d s & = u ( t, x, y ),$$
$$t > 0, \ ( x, y ) \in \Omega.$$
$$\theta | _ { t = 0 } = \xi ( x, y ),$$
$$\theta | _ { \partial \Omega } = 0,$$
hereinafter Ω ⊂ R 2 is a bounded domain, K t ( ) is an arbitrary twice continuously differentiable function such that K (0) = µ > 0, and u t, x, y ( ) is a control supported (in x, y ) on Ω. The kernel K t ( ) can be represented, for example, as a sum of decreasing exponential functions:
$$K ( t ) = \sum _ { j = 1 } ^ { N } c _ { j } e ^ { - \gamma _ { j } t },$$
c j , γ j are given positive constants.
For brevity, we write θ t ( ) and u t ( ) instead of θ t, x, y ( ) and u t, x, y ( ), respectively. This also means that θ t ( ), u t ( ) are functions of t with values in some suitable space.
The goal of the control is to drive this mechanical system to rest in a finite time. We say that the system (1)-(3) is controllable to rest if for every initial condition ξ we can find a control u with compact support (in t ) such that the corresponding solution θ t, u ( ) of the problem (1)-(3) has a compact support (in t ). Conversely, the system is uncontrollable to rest if there is the initial condition ξ such that for every control u ( u is in the suitable class of functions) the corresponding solution does not have compact support (in t ).
In this article, we prove that the system governed by two-dimensional Gurtin-Pipkin equation is uncontrollable to rest if the distributed control is supported on the subdomain which is properly contained in arbitrary bounded domain with a smooth boundary. This result is some generalization of the analogous theorem in [3] devoted to the similar one-dimensional problem. The method used in the paper can also apply to the case where the dimension of Ω is greater than 2. It will be discussed in Section 6.
## 3 Literature Review
The presence of nonlocal terms of the convolution type in the equations and systems leads to a number of interesting qualitative effects that are not observed in the case of differential equations and systems of equations. For instance, the systems of this type exhibit the properties of both parabolic and hyperbolic equations. In spectral problems for such equations and systems the spectrum is composed of two parts: real and complex. The former one corresponds to the energy dissipation in the heat equation; the later corresponds to vibrations. Such equations can be solved by means of the method similar to the Fourier method.
In addition, systems of this type are usually uncontrollable to rest, if we apply boundary control or control which is distributed on the part of the domain. Here we recall the well-known work [4] that deals with the equation of the vibration of a string. As was proved in this work, if we apply the control to the end of the string, then the system can be driven to rest. The author used the so-called moment method. The mentioned results were generalized to the multidimensional case in [5].
At the same time, if we use the control distributed on the whole domain then integral terms of the convolution type 'facilitate' the process of control. In this case, the control time is significantly reduced. It should be noted that the spectral method proposed in [6] can be successfully adapted to the case of systems with nonlocal terms of convolution type, see [7].
The uncontrollability mentioned above was justified in [3] for one-dimensional systems similar to (1). In most cases the property of controllability to rest is not observed. For example, in [3] it was proved that a solution to the heat equation with memory cannot be driven to rest in a finite time if some auxiliary function has roots. This result is valid both for boundary and distributed control. Moreover, the case of distributed control can be reduced to the case of boundary control. In our paper, we obtain similar results for the case of two-dimensional domains.
We should also mention the work [8], where the boundary non controllability was justified for the heat equation with memory.
Positive results on controllability of a one-dimensional wave equation with memory were obtained in [7]. It was shown that this equation can be driven to rest by applying a bounded distributed control. In this case, the kernel of the integral term in the equation is the sum of N decreasing exponential functions.
Problems similar to (1)-(3) for integrodifferential equations were widely studied in the existing literature. Equation (1) was originally derived in [2]. The questions of solvability and asymptotic behavior of solutions for equations of this type were investigated for example in [9], [10]. In [11] it was proved that the energy for some dissipative system decays polynomially, when the memory kernel decays exponentially.
Problems of solvability of system (1)-(3) were considered in [12]. It was proved that a solution belongs to some Sobolev space on the semi-axis (in t ) if the kernel K t ( ) is the sum of exponential functions, each of them tends to zero as t → + ∞ .
Interesting explicit formulas for the solution of (1)-(3) were obtained in [13] under the assumption that the kernel K t ( ) is also the sum of decreasing exponential functions. It follows from these formulas that solutions tend to zero when t → + ∞ . In all these works it is supposed that the kernels of integral terms in the studied equations are non increasing functions.
## 4 Preliminaries
Let A := ∆ be an operator acting on a space D A ( ) = H 2 (Ω) ∩ H 1 0 (Ω) where Ω ⊂ R 2 is a bounded domain with boundary of class C 2 . We consider now the control function u t ( ) ∈ C (0 + , ∞ ; L 2 (Ω)) and the initial condition ξ ∈ H 2 (Ω) ∩ H 1 0 (Ω).
Definition 1. The function
$$\theta ( t ) \in C ^ { 1 } ( 0, + \infty ; L _ { 2 } ( \Omega ) ) \cap C ( 0, + \infty ; H ^ { 2 } ( \Omega ) \cap H _ { 0 } ^ { 1 } ( \Omega ) )$$
is the solution of the problem (1)-(3) if θ t ( ) satisfies the equation (1) and initial condition (2).
We note that the boundary condition (3) makes sense because for any t glyph[greaterorequalslant] 0 θ t ( ) is a continuous (in x, y ) function. There are several theorems of existence and uniqueness dedicated to the problem (1)-(3) (see [15]).
Let us denote PW + as the linear space of the Laplace transforms of elements of L 2 (0 , + ∞ ) with compact support distributed on [0 , ∞ ). It is a well known fact that ϕ λ ( ) ∈ PW + if and only if it is an entire function such that
- 1) there are real numbers C and T such that | ϕ λ ( ) | ≤ Ce T λ | | . Note that C and T depend on ϕ λ ( ).
$$\mu _ { \nu } \stackrel { \nu } { \sup _ { x \geq 0 } } \underset { - \infty } { \overset { + \infty } { \sum } } | \varphi ( x + i y ) | ^ { 2 } d y < + \infty.$$
## 5 The main results
Now we consider an auxiliary boundary-value problem
$$\theta _ { t } ( t, x, y ) - \bigotimes _ { 0 } ^ { t } K ( t - s ) \Delta \theta ( s, x, y ) d s = 0,$$
t >
0
,
(
x, y
)
∈
Ω
0
=
{
(
x, y
) :
x
2
+
y
2
< R
2
}
,
$$\theta | _ { t = 0 } = \xi ( x, y ),$$
$$\theta | _ { \partial \Omega _ { 0 } } = v ( t, x, y ), \ ( x, y ) \in \partial \Omega _ { 0 }.$$
In this problem for each T > 0 ξ ∈ H 2 (Ω ), 0 v ∈ C (0 , T ; H 3 2 ( ∂ Ω )). 0
## Definition 2.
$$\theta ( t ) \in C ^ { 1 } ( 0, + \infty ; L _ { 2 } ( \Omega _ { 0 } ) ) \cap C ( 0, + \infty ; H ^ { 2 } ( \Omega _ { 0 } ) )$$
is the solution of the problem (4)-(6) if θ t ( ) satisfies the equation (4), initial condition (5) and the boundary condition (6) (in the sense of the trace).
Suppose there is a solution to the problem (4)-(6). We multiply (in the sense of the inner product in L 2 (Ω )) both parts of (4) by the function 0 ϕ such that ϕ ∈ H 2 (Ω ) 0 ∩ H 1 0 (Ω ). 0 Hereinafter ν is a normal vector to the domain boundary ∂ Ω . 0 After that, using Green's formula we replace the operator A from θ t ( ) to ϕ .
$$\nu \psi. \\ \frac { d } { d t } \langle \theta ( t ), \varphi \rangle - \int _ { 0 } ^ { t } K ( t - s ) \left ( \langle \theta ( s ), \Delta \varphi \rangle - \int _ { \partial \Omega _ { 0 } } v ( s ) \frac { \partial \varphi } { \partial \nu } d \sigma \right ) d s = 0,$$
where 〈· , ·〉 is the inner product in L 2 (Ω ). 0
The orthonormalized system of eigenvectors of A are the functions ϕ nm ( x, y ) which in polar coordinates x = r cos α y , = r sin α have the form
$$\tilde { \varphi } _ { n m } ( r, \alpha ) = \frac { J _ { m } \left ( \mu _ { n } ^ { m } \frac { r } { R } \right ) e ^ { i m \alpha } } { \sqrt { \pi } R J _ { m } ^ { \prime } ( \mu _ { n } ^ { m } ) }, \ \ m = 0, 1, 2, \dots, \ \ n = 1, 2, \dots,$$
where J m are Bessel functions, µ m n are positive roots of J m . It is a well-known fact that this system is a basis for L 2 (Ω ). We substitute 0 ϕ = ϕ nm in (7). Then using the notation θ nm ( ) = t 〈 θ t , ϕ ( ) nm 〉 we obtain
$$\frac { d \theta _ { n m } ( t ) } { d t } + \lambda _ { n m } ^ { 2 } \underset { 0 } { \overset { t } { \int } } K ( t - s ) \theta _ { n m } ( s ) d \sigma d s = - \underset { 0 } { \overset { t } { \int } } K ( t - s ) \left ( \underset { \partial \Omega _ { 0 } } { \int } v ( s ) \frac { \partial \varphi _ { n m } } { \partial \nu } \right ) d \sigma d s$$
where λ nm are the corresponding eigenvalues. If we use polar coordinates we have
$$\lambda _ { n m } ^ { 2 } = \frac { \left ( \mu _ { n } ^ { m } \right ) ^ { 2 } } { R ^ { 2 } }.$$
Let us make the Laplace transformation for both parts of (8) and express ˆ θ nm ( λ ):
$$\hat { \theta } _ { n m } ( \lambda ) = \frac { - \hat { K } ( \lambda ) \underset { \partial \Omega } { \int } \hat { v } ( \lambda ) \frac { \partial \hat { \varphi } _ { n m } } { \partial \nu } d \sigma + \xi _ { n m } } { \lambda + \lambda _ { n m } ^ { 2 } \hat { K } ( \lambda ) }.$$
glyph[negationslash]
Lemma 1. If in the problem (4)-(6) ˆ ( K λ ) has at least one root λ 0 = 0 in the domain of holomorphism (we require that this domain exists) then controllability to rest is impossible; that is, there exists the initial condition ξ ∈ H 2 (Ω ) 0 ∩ H 1 0 (Ω ) such that for any 0 T > 0 and for every control v ∈ C (0 , T ; H 3 2 ( ∂ Ω )) 0 the corresponding solution does not have compact support (in t).
Proof. Let us use the polar coordinates in the integral of the equality (9). Then the equality (9) takes the form:
$$\hat { \theta } _ { n m } ( \lambda ) = \frac { - \mu _ { n } ^ { m } \hat { K } ( \lambda ) \int _ { 0 } ^ { 2 \pi } \hat { v } _ { 0 } ( \lambda, \alpha ) e ^ { i m \alpha } d \alpha + \xi _ { n m } } { \sqrt { \pi } R \left ( \lambda + \lambda _ { n m } ^ { 2 } \hat { K } ( \lambda ) \right ) },$$
where ˆ ( v 0 λ, α ) := ˆ( v λ, R cos α, R sin α ).
The system of functions { e imα } m Z ∈ is an orthogonal basis in L 2 (0 , 2 π ). Thus we can expand
$$\hat { v } _ { 0 } ( \lambda, \alpha ) = \sum _ { j = - \infty } ^ { + \infty } \hat { v } _ { 0, j } ( \lambda ) e ^ { i j \alpha },$$
where
$$\hat { v } _ { 0, j } ( \lambda ) = \frac { 1 } { 2 \pi } \underset { 0 } { \overset { 2 \pi } { \int } } e ^ { - i j \alpha } \hat { v } _ { 0 } ( \lambda, \alpha ) d \alpha.$$
Hence we obtain
$$\hat { \theta } _ { n m } ( \lambda ) = \frac { - \mu _ { n } ^ { m } \hat { K } ( \lambda ) 2 \pi \hat { v } _ { 0, - m } ( \lambda ) + \xi _ { n m } } { \lambda + \lambda _ { n m } ^ { 2 } \hat { K } ( \lambda ) }.$$
We note that if the system is controllable to rest then θ nm ( ), t v 0 , -m ( ) have compact support. Thus t ˆ θ nm ( λ ) and ˆ v 0 , -m ( λ ) are in PW + .
As it follows from the definition of PW + , ˆ θ nm ( λ ) is an entire function then it can not have singularities at the roots of the denominator λ + λ 2 nm ˆ ( K λ ). Thus the control function ˆ v 0 , -m ( λ ) has to satisfy the following equalities:
$$\hat { v } _ { 0, - m } ( \lambda ) = - \frac { 1 } { 2 \pi } \frac { \lambda _ { n m } ^ { 2 } \xi _ { n m } } { \mu _ { n } ^ { m } \lambda } \quad \quad \quad ( 1 2 )$$
glyph[negationslash]
$$\hat { v } _ { 0, - m } ( \lambda ) = - \frac { 1 } { 2 \pi } \frac { \mu _ { n } ^ { m } \xi _ { n m } } { R ^ { 2 } \lambda }.$$
when λ = 0 is a root of the equation λ + λ 2 nm ˆ ( K λ ) = 0. As λ 2 nm = ( µ m n ) 2 /R 2 then (12) can be rewritten as follows
We note that equalities (13) can be presented in the following form:
$$\int _ { 0 } ^ { T } v _ { 0, - m } ( t ) e ^ { - \lambda t } d t = - \frac { 1 } { 2 \pi } \frac { \mu _ { n } ^ { m } \xi _ { n m } } { R ^ { 2 } \lambda }.$$
The latter equalities are the so-called moment problem.
We record now index m . Let m , for example, be equal to 1 and n changes from 1 to + ∞ . We get the subsystem of equalities for values of the function ˆ v 0 , -1 ( λ ) at such points λ that λ + λ 2 n 1 ˆ ( K λ ) = 0:
$$\hat { v } _ { 0, - 1 } ( \lambda ) = - \frac { 1 } { 2 \pi } \frac { \mu _ { n } ^ { 1 } \xi _ { n 1 } } { R ^ { 2 } \lambda }., \quad n = 1, 2, \dots.$$
glyph[negationslash]
glyph[negationslash]
We note that ˆ ( K λ ) has a root λ 0 = 0 (if K t ( ) is a series of decreasing exponentials then ˆ ( K λ ) has a countable number of roots, see [14]). Then applying methods used in [3] (in which Rouche's theorem was used) we can prove that there exists a sequence { λ n = 0 } of zeros of
$$\lambda + \frac { ( \mu _ { n } ^ { 1 } ) ^ { 2 } } { R ^ { 2 } } \hat { K } ( \lambda )$$
and it is important that this sequence is convergent to the non-zero complex number. Let us choose ξ 2 +1 1 j , = 0. Hence ˆ v 0 , -1 ( λ 2 n +1 ) = 0. As the sequence of zeros is convergent and ˆ v 0 1 , ( λ ) is an entire function, then ˆ v 0 , -1 ( λ ) ≡ 0. We get that for any n all ξ 2 n, 1 have to be zero. But we can always take some of them as non-zero numbers. Thus we come to the conclusion that there exists such initial condition ξ that for any control function v controllability to rest is impossible. Lemma is proved.
We consider the problem (1)-(3). The following theorem is the main result of this article.
glyph[negationslash]
Theorem. If the control function u ∈ C (0 , T ; L 2 (Ω)) in the equation (1) has compact support (in x, y ) on Ω and ˆ ( K λ ) has at least one root λ 0 = 0 in the domain of holomorphism then controllability to rest is impossible; that is, there exists the initial condition ξ ∈ H 2 (Ω) ∩ H 1 0 (Ω) such that for any T > 0 and for every control u ∈ C (0 , T ; L 2 (Ω)) (with compact support on Ω) the corresponding solution does not have compact support (in t).
Proof. Let u t, x, y ( ) at each time t > 0 be an arbitrary function in L 2 (Ω) with compact support D . As support of u is a closed and bounded set then we can consider a circle Ω 0 which is properly contained in Ω and does not intersect D (see figure 1). At each time t > 0 the solution θ t ( ) ∈ H 2 (Ω) ∩ H 1 0 (Ω). We restrict the solution θ t ( ) to Ω 0 (in this case θ t ( ) ∈ H 2 (Ω )) and consider a new initial boundary-value 0 problem on Ω . 0 In this problem the boundary condition is equal to the restriction (in the sense of the trace theorem) of the solution on the boundary of Ω 0 . As θ t ( ) ∈ H 2 (Ω ) this restriction can be computed 0 and at the each time t > 0 is an element of H 3 2 ( ∂ Ω ). We can consider the restriction of the solution to 0 ∂ Ω 0 as the control. Thus we obtain the boundary control problem on the circle Ω . The solution of this 0 problem exists automatically. Using the previous lemma we have proved that if controllability to rest of this new problem is impossible then it is impossible, to stop oscillations of the origin problem (1)-(3). The theorem is proved.
## 6 Some Generalization and Related Topics
To obtain analogous result for Gurtin-Pipkin equation in the case where the dimension of Ω is greater than 2, it is necessary to use the orthonormalized system of eigenvectors of A defined in Ω 0 , where Ω 0 is a ball. These eigenvectors, for example in R 3 , are constructed by means of spherical harmonics
$$Y _ { m } ^ { l } ( \alpha, \varphi ), \, 0 \leq \alpha \leq \pi, \, 0 \leq \varphi < 2 \pi, \, m = 0, 1, \dots, \, l = 0, \pm 1, \pm 2, \dots, \pm m,$$
while we use functions e imα , 0 ≤ α < 2 π , m = 0 1 , , ..., in case of two-dimensional domains. Using orthogonal property of spherical harmonics Y l m on the unit sphere we expand ˆ ( v 0 λ ) and after that all
steps of the proof remain unchanged (see proof of the lemma 1). We choose R 2 in present paper as the clearest and evident way to demonstrate the idea of the proof.
Most likely, it can be proved that if
$$K ( t ) = \sum _ { j = 1 } ^ { N } c _ { j } e ^ { - \gamma _ { j } t }$$
and the control function does not have compact support properly contained in Ω, then the problem (1)-(3) is controllable to rest. We note that if K t ( ) = C > 0 then the equation (1) is a classical wave equation and ˆ ( K λ ) does not have a null, and it is a well-known fact that using a control contained in a subdomain the system is controllable to rest. If K t ( ) = qe -γt , q, γ > 0 then the equation (1) can be reduced to the equation
$$\theta _ { t t } ( t, x, y ) - q \Delta \theta ( t, x, y ) + \gamma \theta _ { t } ( t, x, y ) = P ( t, x, y ),$$
where
$$P ( t, x, y ) = \frac { d u ( t, x, y ) } { d t } + \gamma u ( t, x, y )$$
and P can be considered as a new control. The latter equation is a damped wave equation. Let us consider the one-dimensional case then, instead of the Laplace operator ∆, we write the second derivative d 2 dx 2 :
$$\theta _ { t t } ( t, x ) - q \theta _ { x x } ( t, x ) + \gamma \theta _ { t } ( t, x ) = P ( t, x ).$$
It is proved (will be published later) that oscillations of the string governed by the equation (15) (let P t, x ( ) ≡ 0) can be stopped if we apply the control to the end of the string, the second end being fixed. Apparently, using this fact it can be proved (but it is not proved), that by means of a control P t, x ( ) contained in a subsegment (in x ), the system is also controllable to rest.
Finally, we also note a link between stability and controllability for the one-dimensional case. If we consider equation
$$\theta _ { t t } - \alpha \theta _ { x x } - q \theta _ { x x } * e ^ { - \gamma t } = 0,$$
where ∗ is convolution and α > 0, then solutions of this equation are stable if the parameter q ∈ [0 , αγ ], and unstable if q < 0 or q > αγ . Furthermore, if q = 0 or q = αγ then the system is controllable to rest.
## 7 Conclusions
In this article, we have proved that the system governed by the two-dimensional Gurtin-Pipkin equation is uncontrollable to rest if the distributed control is supported on the subdomain which is properly contained in arbitrary bounded domain with a smooth boundary. In this case, the memory kernel is a twice continuously differentiable function, such that its Laplace transformation has at least one non-zero root.
Figure 1:
## References
- [1] E. Sanchez-Palencia, Non-Homogeneous Media and Vibration Theory. Springer-Verlag, New York, (1980)
- [2] M. E. Gurtin, A. C. Pipkin, Theory of Heat Conduction with Finite Wave Speed, Arch. Ration. Mech. Anal. 31, pp. 113-126, (1968)
- [3] S. Ivanov, L. Pandolfi, Heat Equation with Memory: Lack of Controllability to Rest, Journal of Mathematical Analysis and Applications, 355(1), pp. 1-11 (2009)
- [4] A. G. Butkovskiy, Optimal Control Theory of Distributed Systems. Fizmatlit, Moscow (1965), (in Russian)
- [5] J. L. Lions, Exact Controllability. Stabilization and Perturbations for Distributed Systems, SIAM Review, 30(1), pp. 1-68 (1988)
- [6] F. L. Chernousko, Bounded Control in Distributed-Parameter Systems, Journal of Applied Mathematics and Mechanics, 56(5), pp. 707-723, (1992)
- [7] I. Romanov, A. Shamaev, Exact Controllability of the Distributed System Governed by String Equation with Memory, Journal of Dynamical and Control Systems, 19(4), pp. 611-623 (2013)
- [8] S. Guerrero, O. Yu. Imanuvilov, Remarks on non controllability of the heat equation with memory, ESAIM Control Optim. Calc. Var. 19(1), pp. 288-300 (2013)
- [9] C. M. Dafermos, Asimptotic Stability in Viscoelasticity, Arch. Ration. Mech. Anal. 37, pp. 297-308, (1970)
- [10] W. Desh, R. K. Miller, Exponential Stabilization of Volterra Integrodifferential Equations in Hilbert Space, Journal of Differential Equations, 70, pp. 366-389, (1987)
- [11] J. E. Munoz Rivera, M. G. Naso, F. M. Vegni, Asymptotic Behavior of the Energy for a Class of Weakly Dissipative Second-Order Systems With Memory, Journal of Mathematical Analysis and Applications, 286, pp. 692-704, (2003)
- [12] V. V. Vlasov, N. A. Rautian, A. S. Shamaev, Solvability and Spectral Analysis of Integro-Differential Equations Arising in the Theory of Heat Transfer and Acoustics, Doklady Mathematics, 82(2), pp. 684-687, (2010)
- [13] N. A. Rautian, On the Structure and Properties of Solutions of Integrodifferential Equations Arising in Thermal Physics and Acoustics, Mathematical Notes, 90(3), pp. 455-459, (2011)
- [14] S. Ivanov, T. Sheronova, Spectrum of the Heat Equation with Memory, arXiv. doi 0912.1818v3, 10 p. (2010)
- [15] L. Pandofi, The Controllability of the Gurtin-Pipkin Equations: a Cosine Operator Approach, Appl. Math. Optim. 52, pp. 143-165, (2005) | null | [
"Igor Romanov",
"Alexey Shamaev"
] | 2014-08-02T15:13:25+00:00 | 2016-03-08T14:17:02+00:00 | [
"math.AP",
"45K05"
] | Non Controllability to Rest of the Two-Dimensional Distributed System Governed by the Integrodifferential Equation | The paper deals with controllability problem for a distributed system
governed by the two-dimensional Gurtin-Pipkin equation. We consider a system
with compactly supported distributed control and show that if the memory kernel
is a twice continuously differentiable function, such that its Laplace
transformation has at least one non-zero root, then the system cannot be driven
to the equilibrium in a finite time. |
1408.0383v1 | Proceedings IAU Symposium No. 307, 2014
G. Meynet, C. Georgy, J.H. Groh & Ph.
Stee, eds.
## Magnetic fields and internal mixing of main sequence B stars
## G.A. Wade , C.P. Folsom , J. Grunhut , J.D. Landstreet 1 2 3 4 5 , , V. Petit 6
1 RMC, Canada, 2 IRAP, France, 3 ESO, Germany, 4 UWO, Canada, 5 Armagh, U.K., 6 U. Delaware, USA
Abstract. We have obtained high-quality magnetic field measurements of 19 sharp-lined B-type stars with precisely-measured N/C abundance ratios (Nieva & Przybilla 2012). Our primary goal is to test the idea (Meynet et al. 2011) that a magnetic field may explain extra drag (through the wind) on the surface rotation, thus producing more internal shear and mixing, and thus could provide an explanation for the appearance of slowly rotating N-rich main sequence B stars.
Keywords. stars: abundances, stars: early-type, stars: evolution, stars: magnetic fields
## 1. Introduction and motivation
Observations of chemically-enriched main sequence stars (e.g. Gies & Lambert 1992) have led to the idea that rotationally induced mixing may bring fusion products from the cores of massive stars to their surfaces during phases of core hydrogen burning. Measurements of surface chemical abundances - in particular those of light elements of early-type main sequence stars can therefore be leveraged to place constraints on the associated circulation currents. A surprising result of these studies is the identification of a significant population of stars with enhanced nitrogen abundances with apparently slow rotation (Hunter et al. 2008; Morel et al. 2006). The origin of the nitrogen enhancement in these stars is not understood, and may be related to various physical processes, e.g. true slow rotation, pulsation (Aerts et al. 2014), binarity (Langer 2008) or magnetic fields (Morel et al. 2008).
Figure 1. Left panel: HR diagram of the sample stars. Evolutionary tracks (Schaller et al. 1992) span 6-25 M /circledot . Right panel: Histogram of longitudinal magnetic field measurement standard errors.
## 2. The sample
Our sample consists of 19 of the the 20 nearby main sequence B stars for which Nieva & Przybilla (2012) determined precise, homogeneous abundances of CNO elements. All of the sample stars are sharp-lined, and 3 stars ( ζ Cas, τ Sco, and β Cep) are known magnetic stars. The HR diagram of the sample is shown in Fig. 1. We identify 6 N-rich stars, those with N/C differing by > 2 σ from the solar value of -0 60 . ± 0 07 (As-. plund et al. 2009): the 3 magnetic stars, as well as HD 61068 (N/C= -0 27, . σ B = 9 G), HD 16582 (N/C=+0 02, . σ B = 3 G) and HD 35708 (N/C= -0 08, . σ B = 8 G).
## 3. Magnetic diagnosis
Magnetic fields were diagnosed for 19 stars using high resolution Stokes V spectropolarimetry obtained using the ESPaDOnS, Narval and Harpspol spectropolarimeters. Some observations were obtained as part of the MiMeS Large Programs, while others were obtained from a dedicated PI program. Least-Squares Deconvolution (LSD) using tailored line masks was used to obtain high SNR mean Stokes I , V and diagnostic null line profiles for each star. Typically, 1-3 observations per target were obtained. The presence of a magnetic field was evaluated using the χ 2 detection criterion of Donati et al. (1997), as well as via measurement of the longitudinal magnetic field. No new magnetic stars are detected, with a median longitudinal field error bar of 13 G (see histogram in Fig. 1). We have also inferred upper limits on the surface dipole fields of the non-magnetic stars using the method of Petit & Wade (2012). All odds ratios favour the non-magnetic model, and all probability density functions characterizing the dipole field strength are consistent with zero within 68% confidence.
## 4. Results, conclusions and future work
We find that all magnetic stars in the sample show significant N enrichment. We therefore conclude that the proposed mechanism by which magnetic braking increases mixing from the deep interior (Meynet et al. 2011) does seem to be supported by our analysis. However, Morel (2011) reported normal N/C ratios for two magnetic early-type stars (NGC 2244-201, HD 57682), albeit with somewhat worse precision. Taking this at face value, the results appear presently to be ambiguous. Moreover, a small number of confidently non-magnetic stars in our sample are also observed to be significantly N-rich. In particular, the non-magnetic star HD 16582 (B2IV) shows the largest N/C enrichment of the sample. To explain the non-magnetic N-rich stars, additional mechanisms must be at play. Considering the small size of the current sample, an obvious extension will be to obtain similarly precise N/C ratios and magnetic data for a much larger sample of magnetic and non-magnetic early B/late O stars.
## References
Aerts, C., Molenberghs, G., Kenward, M. G., & Neiner, C. 2014, ApJ 781, 88
Donati, J.-F., Semel, M., Carter, B. D., Rees, D. E., & Collier Cameron, A. 1997, MNRAS 291, 658 Gies, D. R. & Lambert, D. L. 1992, ApJ 387, 673 Hunter, I., Brott, I., Lennon, D. J., et al. 2008, ApJ 676, L29 Langer, N. 2008, in L. Deng & K. L. Chan (eds.), IAU Symposium , Vol. 252 of IAU Symposium , pp 467-473 Meynet, G., Eggenberger, P., & Maeder, A. 2011, A&A 525, L11
Morel, T. 2011, in C. Neiner, G. Wade, G. Meynet, & G. Peters (eds.), IAU Symposium , Vol. 272 of IAU Symposium , pp 97-98
Morel, T., Butler, K., Aerts, C., Neiner, C., & Briquet, M. 2006, A&A 457, 651
Morel, T., Hubrig, S., & Briquet, M. 2008, A&A 481, 453
Nieva, M.-F. & Przybilla, N. 2012, A&A 539, A143
Petit, V. & Wade, G. A. 2012, MNRAS 420, 773
Schaller, G., Schaerer, D., Meynet, G., & Maeder, A. 1992, A&AS 96, 269 | 10.1017/S1743921314007273 | [
"G. A. Wade",
"C. P. Folsom",
"J. Grunhut",
"J. D. Landstreet",
"V. Petit"
] | 2014-08-02T15:15:52+00:00 | 2014-08-02T15:15:52+00:00 | [
"astro-ph.SR"
] | Magnetic fields and internal mixing of main sequence B stars | We have obtained high-quality magnetic field measurements of 19 sharp-lined
B-type stars with precisely-measured N/C abundance ratios. Our primary goal is
to test the idea that a magnetic field may explain extra drag (through the
wind) on the surface rotation, thus producing more internal shear and mixing,
and thus could provide an explanation for the appearance of slowly rotating
N-rich main sequence B stars. |
1408.0384v2 | ## Fast and Compact Distributed Verification and Self-Stabilization of a DFS Tree
Shay Kutten and Chhaya Trehan
Faculty of Industrial Engineering and Management, Technion, Haifa, Israel [email protected] , [email protected]
Abstract. We present algorithms for distributed verification and silentstabilization of a DFS(Depth First Search) spanning tree of a connected network. Computing and maintaining such a DFS tree is an important task, e.g., for constructing efficient routing schemes. Our algorithm improves upon previous work in various ways. Comparable previous work has space and time complexities of O n ( log ∆ ) bits per node and O nD ( ) respectively, where ∆ is the highest degree of a node, n is the number of nodes and D is the diameter of the network. In contrast, our algorithm has a space complexity of O (log n ) bits per node, which is optimal for silent-stabilizing spanning trees and runs in O n ( ) time. In addition, our solution is modular since it utilizes the distributed verification algorithm as an independent subtask of the overall solution. It is possible to use the verification algorithm as a stand alone task or as a subtask in another algorithm. To demonstrate the simplicity of constructing efficient DFS algorithms using the modular approach, we also present a (non-silent) self-stabilizing DFS token circulation algorithm for general networks based on our silent-stabilizing DFS tree. The complexities of this token circulation algorithm are comparable to the known ones.
Keywords: Fault Tolerance, Self-* Solutions, Silent-Stabilization, DFS, Spanning Trees
## 1 Introduction
A clear separation is common between the notions of computing and verification in sequential systems. A similar separation in the context of distributed systems has been emerging. Distributed verification of global properties like minimum spanning trees have been devised [21].
An area of distributed systems that can greatly benefit from this separation is that of self-stabilization. Self-stabilization is the ability of a system to recover from transient faults. A self-stabilizing distributed system can be started in any arbitrary configuration and must eventually converge to a desired legal behavior. Self-stabilizing algorithms can run a distributed verification algorithm repeatedly to detect the occurrence of faults in the system and take the necessary action for convergence to a legal behavior. This is the approach we take here in devising a silent-stabilizing DFS algorithm. The concept of first detecting a fault and
then taking the corrective measures for self-stabilization was first introduced by [20], [1] and [3]. The approach taken by Katz and Perry in [20] is that of global detection of faults by a leader node that periodically takes the snapshots of the global state of the network and resets the system if a fault is detected. Afek, Kutten and Yung [1], and Awebuch et al. [3] on the other hand, suggested that the faults in the global state of a system could sometimes be detected by local means - i.e., by having each node check the states of all its neighbors. G¨ o¨s and Suomela further formalized the idea of local detection of faults in [16]. o Korman, Kutten and Peleg [23] introduced the concept of proof labeling schemes . A proof labeling scheme works by assigning a label to every node in the input network. The collection of labels assigned to the nodes acts as a locally checkable distributed proof that the global state of the network satisfies a specific global predicate. A proof labeling scheme consists of a pair of algorithms ( M V , ), where M is a marker algorithm that generates a label for every node and V is a verifier algorithm that checks the labels of neighboring nodes. In this paper, we present a proof labeling scheme for detecting faults in the distributed representation of a DFS spanning tree. For self-stabilization, the DFS tree is computed afresh and new labels are assigned to the nodes by the marker on detection of faults.
## 1.1 Additional Related Work
Dijkstra introduced the concept of Self-stabilization [10] in distributed systems. Self-stabilization deals with the faults that entail an arbitrary corruption of the state of a system. These faults are rather severe in nature but do not occur very frequently in reality [31].
Table 1.1 summarizes the known complexity results for self-stabilizing DFS algorithms. Collin and Dolev presented a silent-stabilizing DFS tree algorithm in [6]. Their algorithm works by having each node store its path to the root node in the DFS tree. Since the path of a node to the root in a DFS tree can be as long as n , the number of nodes in the network, the space complexity of their algorithm is O n ( log ∆ ) per node, where ∆ is the highest degree of a node in the network. The time complexity of their algorithm under the contention time model is ( nD∆ ). We drop the multiplicative factor of ∆ from their time complexity here for the sake of comparison with all the other algorithms that do not count their time under the contention model. Cournier et al. presented a snap-stabilizing DFS wave protocol in [7] which snap stabilizes with a space complexity of O n ( log n ).
Considerable work has been invested in developing self-stabilizing depthfirst token circulation algorithms with multiple successive papers improving each other. All of these algorithms also generate a DFS tree in every token circulation round, however these algorithms are not silent. Self-stabilizing depth-first token circulation on arbitrary rooted networks was first considered by Huang and Chen in [17]. Their algorithm stabilizes in O nD ( ) time with a space complexity of O (log n ) bits per node. Subsequently several self-stabilizing DFS token circulation algorithms [9,19,18,26] were devised. All these papers worked on improving the space complexity of [17] from O (log n ) to a function of ∆ , the highest degree of a node in the network. The time complexity of all of the above token
Table 1. Comparing self-stabilizing DFS algorithms
| Algorithm | Space | Stabilization Time | Remarks |
|-------------|---------------|----------------------|-----------------------------------------------------------------------------|
| [6] | O ( n log ∆ ) | O ( nD ) | Silent |
| [7] | O ( n log n ) | 0 | Snap Stabilizing first DFS wave, needs Unique IDs |
| [8] | O (log n ) | 0 | Snap Stabilizing Wave takes O ( n 2 ) rounds |
| [17] | O (log n ) | O ( nD ) | Token Circulation, not silent |
| [25] | O (log n ) | O ( n ) | Token Circulation, not silent |
| [9] | O (log ∆ ) | O ( nD ) | Token Circulation, not silent |
| [19] | O (log ∆ ) | O ( nD ) | Token Circulation, not silent Requires neighbor of neighbor info |
| [18] | O ( ∆ ) | O ( nD ) | Token Circulation, not silent |
| [26] | O (log ∆ ) | O ( nD ) | Token Circulation, not silent |
| OUR RESULTS | O (log n ) | O ( n ) | Two algorithms: Silent and token circulation; both with the same complexity |
circulation algorithms [17,19,18,26] is O nD ( ) rounds, which is much more than the time it takes for one token circulation cycle on a given network. Petit improved the stabilization time complexity of depth-first token circulation to O n ( ) in [25] with a space complexity of O (log n ) bits per node. Petit and Villain [28] presented the first self-stabilizing depth-first token circulation algorithm that works in asynchronous message passing systems.
## 1.2 Our Contribution
The main contribution of the current paper is a silent self-stabilizing DFS spanning tree algorithm. The space complexity of our algorithm is O (log n ) bits per node. The only other silent-stabilizing DFS tree algorithm [6] has a space complexity of O n ( log ∆ ). Dolev et al. [12] established a lower bound of O (log n ) bits per node on the memory requirement of silent-stabilizing spanning tree algorithms. Thus, ours is the first memory optimal silent-stabilizing DFS spanning tree algorithm. The silent-stabilizing DFS construction algorithm is designed in a modular way consisting of separate modules for fault detection and correction. The distributed verification module of this algorithm can be considered a contribution in itself.
Composing self-stabilizing primitives using fair combination of protocols is a well-known technique(see e.g. [13,30]) to ensure that the resulting protocol is self-stabilizing. We use this approach of protocol combination to design a self-stabilizing depth-first token circulation algorithm which uses our silentstabilizing DFS tree as a module of the overall algorithm. The space and time complexities of our token circulation algorithm are as good as the previously published work on fast self-stabilizing depth-first token circulation [25].
## 1.3 Outline of the paper
In the next section (Section 2), we describe the model of distributed systems considered in this paper. That section also includes some basic definitions and notations. Section 3 addresses the distributed verification algorithm which acts as the Verifier V of the proof labeling scheme. The Marker M of the proof labeling scheme is presented in Section 4. Section 5 describes the technique used to make the algorithm self-stabilizing. Section 6 presents the correctness proofs and performance analysis. Section 7 describes a token circulation scheme based on the new silent-stabilizing DFS spanning tree.
## 2 Preliminaries
A distributed system is represented by a connected undirected graph G V,E ( ) without self-loops and parallel edges, where each node v ∈ V represents a processor in the network and each edge e ∈ E corresponds to a communication link between its incident nodes. Processors communicate by writing into their own shared registers and reading from the shared registers of the neighboring processors. The network is assumed to be asynchronous . We do not require processors to have unique identifiers. We do assume the existence of a distinguished processor, called the root of the network. Each node v ∈ V orders its edges by some arbitrary ordering α v as in [6]. For an edge ( u, v ), let α u ( v ) denote the index of the edge ( u, v ) in α u .
As opposed to Collin and Dolev [6], We use the (rather common) ideal time complexity which assumes that a node reads all of its neighbors in at most one time unit. Our results translate easily to an alternative, stricter, contention time complexity used by Collin and Dolev in [6], where a node can access only one neighbor in one time unit. The time cost of such a translation is a multiplicative factor of O ∆ ( ), the maximum degree of a node (it is not assumed that ∆ is known to nodes). As is commonly assumed in the case of self-stabilization, each node has only some bounded number of memory bits available to be used. Here, this amount of memory is O (log n ).
Self-stabilization and silent-stabilization: A distributed algorithm is selfstabilizing if it can be started in any arbitrary global state and once started, the algorithm converges to a legal state by itself and stays in the legal state unless additional faults occur [11]. A self-stabilizing algorithm is silent if starting from an arbitrary state it converges to a legal global state after which the values stored in the communication registers do not change, see e.g. [12]. While some problems like token circulation are non-silent by nature, many input/output algorithms allow a silent solution.
Spanning Tree: Distributed Representation: A spanning tree T of a connected, undirected graph G V,E ( ) is a tree composed of all the nodes and some of the edges of G . A spanning tree T of some graph G is represented in a distributed manner by having each node locally mark some of its incident edges such that the collection of marked edges of all the nodes forms a spanning tree
of G . Actually, it is enough that each node marks its edge leading to its parent on the tree in a local variable.
DFS Tree and the first DFS Tree of a Graph: A DFS Tree of a connected, undirected graph G V,E ( ) is the spanning tree generated by a depth first search traversal of G . In a DFS traversal, starting from a specified node called the root, all the nodes of the graph are visited one at a time, exploring as far as possible before backtracking, see e.g. [15]. The first DFS traversal is the one that acts as follows: whenever a node v has a set of unexplored edges to choose from, the chosen edge is the edge with the smallest port number in the port ordering α v . The tree thus generated is called the first DFS tree [6]. While a connected, undirected graph can have more than one DFS spanning trees, it can have only one first DFS spanning tree.
Lexicographic Ordering A simple path from the root of a graph G to some node v ∈ V can be represented as a string starting with a ⊥ followed by a sequence of the port numbers of the outgoing edges on the path [6]. Given such a string representation of a path, a lexicographic operator ≺ can be defined to compare multiple paths of a given node v from the root, where ⊥ is considered the minimum character. In the first DFS tree of a graph, the path leading from the root to some node v ∈ V is the lexicographically smallest (w.r.t. ≺ ) among all the simple paths from the root to v [6].
DFS Intervals In a DFS traversal, it is common to assign to each node an interval ( in, out ) corresponding to the discovery and finish time of exploration of that node. The discovery time or in is the time at which a node is discovered for the first time. The discovery time of a node v ∈ V is denoted as in v . The finish time of node v denoted by out v is the time at which a node has finished exploring all its neighbors. These intervals have the property that given any two intervals ( in, out ) and ( in , out ′ ′ ), either one includes the other or they are totally disjoint. Assuming without loss of generality that in < in ′ , we can write this formally as: either ( in < in ′ < out ′ < out ) or ( in < out < in ′ < out ′ ) [15]. In other words, the DFS intervals induce a partial order on the nodes of a graph.
## 2.1 Notation
We define the following notation to be used throughout:
- -η v ( ) denotes the set of neighbors of v in G . ∀ v ∈ V ( η v ( ) = { u u | ∈ V ∧ ( u, v ) ∈ E ) } ).
- -interval v denotes the ( in, out ) label of v .
- -in v denotes the in label of v and out v denotes the out label of v .
- -Relational operator ⊂ between two intervals ( in, out ) and ( in , out ′ ′ ) indicates the inclusion of of the first interval in the second one. For example: ( in, out ) ⊂ ( in , out ′ ′ ) indicates that ( in, out ) is included in ( in , out ′ ′ ).
- -Relational operator ⊃ is defined similarly.
## 3 DFS Verification: Verifier V
Given a graph G V,E ( ) and the distributed representation of a spanning tree T of G , the DFS verification algorithm is required to verify that T is the first DFS tree of G . The Verifier V takes as input a connected graph G V,E ( ) where each node v ∈ V bears an ( in v , out v ) label in addition to v 's parent on T . Note that V takes ( in, out ) labels of nodes as input and is not concerned with how they are generated.
We assume that each node can read the labels of all its neighbors in addition to its own label and state. A node cannot look at the state of any of its neighbors, however. Each node v ∈ V periodically reads the labels of all its neighbors and locally computes the following additional information from its own state and label as well as the labels of its neighbors.
## 3.1 Intermediate Computations
Each node computes the following macros to be used for verification.
- 1. There are zero or more neighbors of v whose interval includes v 's interval. Let us call the set of all such nodes the neighboring ancestors of v and denote this set by by anc l ( v ).
$$a n c _ { l } ( v ) = \{ w | w \in \eta ( v ) \ a n d \ i n t e r v a l _ { w } \supset i n t e r v a l _ { v } \}$$
glyph[negationslash]
- 2. The parent of v as perceived by the labels : parent l ( v ) = w w | ∈ anc l ( v ) ∧∀ u ∈ anc l ( v ) ( u = w → interval w ⊂ interval u ).
- 3. There are zero or more neighbors of v whose interval is included in v 's interval, let us call the set of all such nodes the neighboring descendants of v and denote this set by desc l ( v ).
$$d e s c _ { l } ( v ) = \{ w | w \in \eta ( v ) \ a n d \ i n t e r v a l _ { w } \subset i n t e r v a l _ { v } \}$$
- 4. A child neighbor of v is a neighboring descendant of v whose interval is not included in the interval of any other neighboring descendant of v .
glyph[negationslash]
- child l ( v ) = u u | ∈ desc l ( v ) ∧¬∃ u ′ ∈ desc l ( v )( u ′ = u ∧ interval u ′ ⊃ interval u )
- 5. children l ( v ) ⊆ desc l ( v ) is the set of all child neighbors of v .
The subscript l in anc l ( v ) above denotes that the set anc l ( v ) is computed by the node v by just looking at the labels of v and those of v 's neighbors. The same holds for all the other macros defined above. It is worth pointing out that all these are intermediate computations and the data they generate need not be stored on the node.
The verification is performed by having each node compute a set of predicates. If T is indeed the first DFS tree of G and the labels on all the nodes are proper (i.e. they are as if they were generated by an actual first DFS Traversal of the input graph); then the verifier accepts continuously on every node until a fault occurs. If a fault occurs either due to the corruption of the state of some nodes or due to some nodes having incorrect labels, at least one node rejects . The node that rejects is called a detecting node. The verifier self-stabilizes trivially since it runs periodically.
## 3.2 Local Interval Predicates
Let parent v denote the local variable used to store the parent of v in T . Following is the set of local predicates that each node has to compute:
## 3.2.1 Predicates for the root node r
- 1. parent r = null .
- 2. anc l ( r ) = φ .
## 3.2.2 Predicates for a non-root node v
glyph[negationslash]
- 1. parent v = null .
glyph[negationslash]
- 2. anc l ( v ) = φ .
- 3. parent v = parent l ( v ). The parent of v on T denoted by parent v is the same as v 's parent as computed by v from the labels of v and its neighbors.
- 4. interval v ⊂ interval parent v .
glyph[negationslash]
- 5. ∀ u ∈ anc l ( v ) such that u = parent v ( interval parent v ⊂ interval u ).
## 3.2.3 Predicates for every node(root as well as a non-root) v
- 1. out v > in v .
- 2. There is no neighbor of v such that its interval is totally disjoint with v . Formally
- ∀ u ∈ η v ( ) ( interval u ⊂ interval v ∨ interval u ⊃ interval v ).
- 3. if | children l ( v ) | = 0 then out v = in v +1.
- 4. if | children l ( v ) | > 0 and let childrenD l ( v ) denote the list of children of v sorted in ascending order of their in labels and firstChild l ( v ) and lastChild l ( v ) be the first and last members of childrenD l ( v ) then in firstChild l = in v +1 ∧ out v = out lastChild l +1.
- 5. if | children l ( v ) | > 1 and let childrenP l ( v ) denote the list of children of v sorted in the ascending order of their port numbers in v , then childrenD l ( v ) and childrenP l ( v ) sort the members of children l ( v ) in the same order.
glyph[negationslash]
- 6. Let u and w ∈ desc l ( v ), u = w , such that u ∈ children l ( v ) and w / ∈ children l ( v ) and in u < in w then α v ( u ) < α v ( w ).
- 7. ∀ ( u, w ) ∈ childrenD l ( v ) such that u and w are adjacent in childrenD l ( v ) and in u < in w , then in w = out u +1
Remark 1. The only predicates that deal with the order in which the neighbors of a node are explored are 5 and 6 of Section 3.2.3. Omitting these two Predicates leaves us with a set of predicates sufficient to verify that T is some DFS tree(may not be same as the initial input to the verifier) of G . If an algorithm that uses the verifier as a subtask is not concerned about the order, it can simply drop these predicates.
## 4 Generating the Labels: Marker M
A natural method for assigning the ( in, out ) labels is to perform an actual DFS traversal of the network starting from the root. The required labels can be generated by augmenting some known DFS tree construction algorithm (e.g. [4], [2], [5]) by adding new variables for the labels and specific actions for updating these label variables. We assume that the DFS construction algorithm of Awerbuch [2] can be easily translated to shared memory and the resulting algorithm can be easily augmented with actions to update the in and out labels. Note that translating [2] to shared memory is trivial and it decreases the memory from O ∆ ( ) to O log∆ ( ), if it changes memory at all, since a node does not need to store the VISITED message(the message broadcasted by a node to all its neighbors when it is visited for the first time, See [2]) of a neighbor, instead it can read the shared register of the neighbor.The pseudo code of the marker will appear in the full paper.
## 5 The Silent-Stabilizing DFS Construction Algorithm
We have constructed a proof labeling scheme ( M V , ) with a non-stabilizing marker M that takes as input a connected graph G and assigns ( in, out ) labels to every node in G . It also has a verifier V that takes as input a labeled (with ( in, out ) intervals) distributed data structure and verifies whether the input structure is the first DFS tree. The proofs for the correctness and the performance of ( M V , ) are presented in Section 6. In the meanwhile, we use them here assuming they are correct.
A simple way to stabilize any input/output algorithm is to run the algorithm repeatedly to maintain the correct output along with a self-stabilizing synchronizer [3]. This however would not be a silent algorithm. Still, let us use this approach to generate a non-silent self-stabilizing algorithm as an exercise, before presenting the silent one. Awerbuch and Varghese, in their seminal paper [3], present a transformer algorithm for converting a non-stabilizing input/output algorithm into its self-stabilizing version. Following theorem is taken from the paper of Awerbuch and Varghese [3]:
Theorem 1. Given a non-stabilizing distributed algorithm Π to compute an input/output relation with a space complexity of S Π and a time complexity of T Π . The Resynchronizer compiler produces a self-stabilizing version of Π whose time complexity is O T ( Π + ˆ ) D and whose space complexity is same as that of Π , where ˆ D is an upper bound on the diameter of the network.
Informally, the transformer that Awerbuch and Varghese developed to prove the above theorem is a self-stabilizing synchronizer. The transformer takes as input a non-stabilizing input/output algorithm Π whose running time and space requirement are T Π and S Π respectively. Another input it takes is ˆ which is an D upper bound on the actual diameter D of the network. Given these inputs, the transformer performs Π for T Π (recall that the transformer is a synchronizer and
transforms the network to be synchronous). Then it retains the results, performs Π again and compares the new results to the old ones. If they are the same, the old results are retained. if they differ, then some faults occurred, the new results are retained. This is repeated forever.
Since we do not assume the knowledge of n (required for input : T M ) or ˆ , D we use a slightly modified version of theorem 1 here, that appeared in [22]. The modified Awerbuch Varghese theorem presented in [22] is as follows:
Theorem 2. Given a non-stabilizing distributed algorithm Π to compute an input/output relation with a space complexity of S Π and a time complexity of T Π . The enhanced Resynchronizer compiler produces a self-stabilizing version of Π whose time complexity is O T ( Π + ) n for asynchronous networks and O T ( Π + D ) for synchronous networks with a space complexity of O S ( Π + logn ) .
Informally, Korman et al. used a better synchronizer plus a simple self-stabilizing algorithm that computes n and D to prove the above theorem. To obtain a nonsilent self-stabilizing DFS construction algorithm, we just plug the marker M of Section 4 into theorem 2 and obtain the following corollary.
Corollary 1. There exists a non-silent self-stabilizing DFS construction algorithm that can operate in a dynamic asynchronous network, with a time complexity of O T ( M + n ) and a space complexity of O S ( M +log n ) .
## 5.1 Achieving Silent-Stabilization
Before going into the details of achieving silence, let us go over how the selfstabilizing synchronizer of the enhanced transformer of theorem 2 helps coordinate repeated executions of the marker in the algorithm of corollary 1. A synchronizer simulates a synchronous protocol in an asynchronous network by using a pulse count at each node which is updated in increments of 1 subject to certain rules. A node u executes the i th step of the algorithm when pulse count at u , pulse u is equal to i . The synchronizer maintains the invariant that the pulse count of a node u differs from any of its neighbors by at most one. Since the synchronizer module is self-stabilizing, all the nodes may be initialized to an arbitrary pulse count and thus the network may not be synchronized in the beginning. The stabilization time of the synchronizer module of the enhanced transformer is O n ( ), thus starting from any arbitrary set of pulse counters, the network is guaranteed to be synchronized after O n ( ) time. The enhanced transformer waits for sufficient time for the nodes to get synchronized and then starts the execution of the algorithm to be stabilized, in our case, the marker M . If T e denotes the pulse count at which all the nodes are synchronized, the nodes run the marker from T e to T e + T M . Due to an allowed difference of at most 1 between pulse counts of neighboring nodes, the maximum difference between the pulse counts of any two nodes is D , the diameter of the network. Thus any node with a pulse count of T e + T M has to wait a maximum of D pulses to be sure that all the nodes in the network have written their output [3]. The node with a pulse count of T e + T M + D wraps around its pulse count to 0 which destroys
the synchronization. Essentially the first node(s) to wrap around invoke the reset module of the transformer which brings the nodes back in sync for the next execution of the marker. To make the algorithm silent-stabilizing, we execute the marker(along with the synchronizer) only once in the beginning to generate the labels. The silence is achieved by turning the synchronizer off after all the nodes have finished executing the marker. As explained above, the nodes can easily detect when the marker has finished by looking at their respective pulse counts. When a node reaches a pulse count of T e + T M + D , it stops updating its pulse count, thus turning the synchronizer off. When all the nodes in the neighborhood of a node have reached T e + T M + D , it turns on the verifier V . Since V can detect a fault in exactly one pulse, if one occurs, we can manage without running a synchronizer during the verification. The verifier keeps running repeatedly until a fault occurs. If a node v detects a fault, it invokes the synchronizer of the enhanced transformer again by dropping v 's pulse count to 0. Again, as in case of non-silent algorithm, this invokes a reset which resynchronizes the network and subsequently invokes the marker again. Note that the nodes need not know the T M a priori. The running time of M is a function of n , the number of nodes which can be computed in a self-stabilizing manner by the module of the enhanced transformer responsible for computing n .
Observation 1 The only communication that takes place at each node during verification is the reading of the shared registers of the neighbors. The computations performed during verification do not affect the contents of the shared registers at all, thus ensuring silence as defined in [12].
Thus we obtain a silent-stabilizing DFS construction algorithm. The following theorem summarizes our result:
Theorem 3. The proof labeling scheme ( M V , ) for a DFS tree implies a silentstabilizing DFS construction algorithm, that runs in O T ( M + ) n time with a space complexity of O S ( M + S V +log n ) .
## 6 Correctness and Performance Analysis
In this section, we establish the correctness of our algorithm. The proofs follow easily from the known properties of a DFS tree and the predicates of the verifier. Given a labeled (with ( in, out ) labels) graph G V,E ( ) and the distributed representation of a spanning subgraph T of G , the following lemmas holds on G , if the local interval predicates (Section 3.2) hold true at every node of G :
## Lemma 1. T is a spanning tree of G .
Proof. In order to prove that a graph is a tree, it is sufficient to prove that it has no cycles and its number of edges is n -1, where n is the number of nodes in this graph [15]. For the subgraph T of G to have a cycle, one of the ancestors of some node v ∈ V has to mark v as its parent. However, this leads to a contradiction by predicate 4 of Section: 3.2.2 which requires that the interval
of a node be included in the interval of its parent. Applying predicate 4 to v and v 's ancestors, implies that for an ancestor u of v which points to v as its parent, interval v ( ) ⊂ interval u ( ) ∧ interval u ( ) ∧ interval v ( ), a contradiction. The parent pointer of each node v ∈ V except the root comprises of a single incident edge of v and the parent pointer of the root is null , therefore there are exactly n nodes and n -1 edges in T .
Observation 2 The macros defined in Section 3.1 extract (periodically) a perceived tree T l from the ( in, out ) labels of the nodes in G .
While input tree T is encoded only by the collection of the parent pointers of the nodes, T l is extracted by having each node compute its perceived parent, denoted by parent l as well as its perceived children, denoted by the set children l on T l .
Lemma 2. For any node v ∈ V , the set of children of v in T is same as the set of perceived children of v in T l .
Proof. The predicate 3 of section 3.2.2, ensures that the parent pointer parent v of a node v on the input tree T is the same as v 's perceived parent parent l ( v ) on T l . The set of children of a node v on T is implicitly implied by the parent pointers of v 's children. Hence, it is sufficient to prove that the set of perceived children of v on T l is the same as those implied by the perceived parent pointers of perceived children of v , i.e., the collection of perceived parents is consistent with the collection of perceived children on T l . In what follows, we prove that if a node v has a node p as its perceived parent ( parent l ( v ) = p ), then v ∈ children l ( p ). Assume, for contradiction, that the above does not hold. Note that, by the definition of a perceived parent and simple inductive arguments, p has the narrowest interval of any node whose interval includes interval v , i.e., the interval of p does not include the interval of any other node whose interval includes interval v . Having v / children ∈ l ( p ) ∧ parent l ( v ) = p implies that there is a node x ∈ η p ( ) with interval x ⊃ interval v and moreover interval p ⊃ interval x . This implies that p can not be the parent of v . In a similar way, one can prove that if c ∈ children l ( v ) then v is the perceived parent of c .
Following lemma 2, in the discussion that follows, children l ( v ) implies the children of v in T and vice versa.
Lemma 3. For any two children u, w of a node v in T , the intervals of all the nodes in the subtree of u in T are disjoint from the intervals of all the nodes in the subtree of w in T .
Proof. The set childrenD l ( v ) is the set children l ( v ) sorted in the ascending order of the in labels of the nodes ∈ children l ( v ) as defined in Section 3.2.3. Let us assume, without loss of generality, that in w > in u . Consider a node u ′ ∈ η v ( ) such that u ′ is adjacent to u and appears after u in childrenD l ( v )(possibly u ′ = w ). Applying predicate 7 of Section 3.2.3 to u and u ′ , in u ′ = out u + 1. By predicate 1 of Section 3.2.3, out u ′ > in u ′ . Thus neither of the two intervals, interval u ( ) and interval u ( ′ ), includes the other, i.e. they are totally disjoint.
Applying predicate 4 of Section: 3.2.2 inductively, it is easy to see that the intervals of all the descendants of u in T are included in u 's own interval. Similarly, the intervals of all the descendants of u ′ are included in u ′ 's interval . Therefore, intervals of all the descendants of u are disjoint from the intervals of u ′ and all its descendants. By inductively applying the above argument to every adjacent pair of nodes in childrenD l ( v ) starting from u ′ to w , it is easy to show that the subtrees of any two children of a node have disjoint intervals.
Lemma 4. For any two children u, w of some node v in T , every simple path in G from some node in the subtree of u to any node in the subtree of w in T goes through either v or v 's ancestors.
Fig. 1. Figure for proof of lemma 4
(a) Case 1:path through a descendant of a sibling of u .
(b) Case 2: path through a descendant of a sibling of an ancestor of u and w
Proof. Let u ′ be some node in the subtree of u and w ′ be some node in the subtree of w . Let us assume, by way of contradiction, that there is a simple path P in G between u ′ and w ′ that does not go through v or v 's ancestors. There are two possibilities:
- -P goes through a descendant of a sibling of u (possibly w ).
- -or, it goes through a descendant of a sibling of an ancestor (possibly v ) of u and w .
Both these cases require an edge to exist in G that connects a pair of nodes in two sibling subtrees, known as a cross edge [15]. By lemma 3, the intervals of all the nodes in the subtree of some node x are disjoint from the intervals of all the nodes in the subtree of a sibling of x . Thus, the existence of any such edge in G is ruled out by predicate 2 of Section 3.2.3.
Observation 3 The proof of Lemma 4 shows that there are no cross edges in the input tree T which implies that T is a DFS(not necessarily the first DFS) tree of G .
Theorem 4. If a graph G V,E ( ) has every node v ∈ V labeled with its ( in, out ) interval and interval assignments are such that all the local interval predicates (Section 3.2) hold true at every node, then the spanning tree T encoded in a distributed manner in the states of all the nodes of G is the first DFS tree of G .
Proof. The problem of finding the first DFS Tree of a graph can be thought of as the one of selecting the lexicographically smallest simple path of every node v ∈ V out of all the simple paths from the root to v , see [6]. Let P T v denote the path leading from the root to some node v in T . We now prove that for any node v ∈ V , P T v is the lexicographically smallest among all the simple paths from the root to v in G . By way of contradiction, let us assume that there is another simple path P Alt v from the root to v which is smaller than P T v . Let us assume, w.l.o.g. , that P T v and P Alt v are the same up-to(and including) some node v m , the m th node of the common prefix. Let v T m +1 and v Alt m +1 denote the ( m +1) th node of P T v and P Alt v respectively.
Observation 4 For P Alt v to be lexicographically smaller than P T v , the edge index (as defined in Section 2) α v m ( v Alt m +1 ) must be smaller than the corresponding index α v m ( v T m +1 ) .
There are three possibilities for P Alt v based on how v Alt m +1 is related to v m :
- 1. v Alt m +1 is an ancestor of v m : This case is ruled out since any such path will not be a simple path.
- 2. v Alt m +1 is a child of v m : v Alt m +1 and v T m +1 are both children of v m . According to lemma 4, there is no simple path from v Alt m +1 to any node in the subtree of v T m +1 that does not go through v m or any of its ancestors. Since v T m +1 falls on P T v , v belongs to the subtree of v T m +1 in T . Thus, there is no simple path connecting v Alt m +1 to v that does not go through v m or its ancestors. The path from v Alt m +1 to v that goes through either v m or any of its ancestors would not be a simple path as in case 1. Therefore, this case is also ruled out.
- 3. v Alt m +1 is a descendant which is not a child of v m : This case can be further subdivided into two sub cases:
- (a) v Alt m +1 is also a descendant of V T m +1 in addition to being a descendant of v m : This implies that in v alt m +1 > in v T m +1 . Also, v T m +1 is a child of v m . This leads to a contradiction due to local interval predicate 6 (Section 3.2.3) which requires that the edge index of the edge ( v m , v T m +1 ) be smaller than the edge index of the edge ( v m , v Alt m +1 ) in alpha v m .
- (b) v Alt m +1 is a proper descendant of of v m , but not a descendant of v T m +1 : This case is similar to that of 2.
Theorem 5. The verifier V described in section 3 runs in one time unit and requires O (log n ) bits of memory per node.
Proof. The running time of V follows from the fact that each node needs to look only at the labels of its immediate neighbors in order to compute its predicates. Every node shares its ( in, out ) labels with its neighbors. The maximum value of a label is 2 n which can be encoded using O (log n ) bits.
The following theorem establishes the correctness and performance of the marker M :
Theorem 6. There exists a marker that constructs the first DFS tree and assigns ( in, out ) labels to all the nodes of the input graph G V,E ( ) in time O n ( ) using O (log n ) bits of memory per node.
Proof. As described in Section 4, it is easy to design a marker that adds new actions 1 to a standard DFS tree construction algorithm for computing the in and out labels. The standard DFS tree construction algorithm in shared memory model, without any actions for computing the ( in, out ) labels has a space complexity of O (log ∆ ) bits per node. The variables for updating the ( in, out ) labels require O (log n ) bits per node. Therefore the overall space complexity of such a marker is O logn ( ).
The actions for computing the labels do not change the values of any of the variables of the original algorithm. Also, these actions do not change the algorithm's flow of control. The addition of these actions cannot violate the correctness of the construction algorithm, nor change its time complexity of O n ( ).
It is easy to modify the algorithm such that a node v always picks the unvisited neighbor with the smallest port number. This ensures that the output of the algorithm is the first DFS tree of the input graph.
## 7 Self-stabilizing DFS token circulation
The silent-stabilizing DFS tree of Section 5.1 can be combined with a selfstabilizing mutual exclusion algorithm for tree networks to obtain a self-stabilizing token circulation scheme for general networks with a specified root. Self-stabilizing mutual exclusion algorithms that circulate a token in the DFS order on a tree network can be found in [14,24,27]. Petit and Villain presented a space optimal snap-stabilizing DFS token circulation algorithm for tree networks in [29] with a waiting time (See [29] for a definition of waiting time) of O n ( ). We can combine our silent-stabilizing DFS tree with the snap stabilizing DFS token circulation protocol of [29] using the fair composition method [13] to obtain a DFS token circulation for general networks. The space complexity of [29] is O (log ∆ ) and that of our silent-stabilizing DFS tree is O (log n ). Therefore the space complexity of the resulting self-stabilizing DFS token circulation algorithm is O (log n ).
Acknowledgements This research was supported in part by a grant from ISF and Technion TASP center.
1 Actually, these are just common actions of various versions of non-distributed DFS.
## References
- 1. Yehuda Afek, Shay Kutten, and Moti Yung. The local detection paradigm and its applications to self-stabilization.
- 2. Baruch Awerbuch. A new distributed depth-first-search algorithm. Information Processing Letters , 20(3):147-150, 1985.
- 3. Baruch Awerbuch and George Varghese. Distributed program checking: A paradigm for building self-stabilizing distributed protocols (extended abstract). In Proceedings of the 32Nd Annual Symposium on Foundations of Computer Science , SFCS '91, pages 258-267, Washington, DC, USA, 1991. IEEE Computer Society.
- 4. Imrich Chlamtac and Shay Kutten. Tree-based broadcasting in multihop radio networks. Computers, IEEE Transactions on , 100(10):1209-1223, 1987.
- 5. Isreal Cidon. Yet another distributed depth-first-search algorithm. Inf. Process. Lett. , 26(6):301-305, January 1988.
- 6. Zeev Collin and Shlomi Dolev. Self-stabilizing depth-first search. Information Processing Letters , 49(6):297 - 301, 1994.
- 7. Alain Cournier, Stephane Devismes, Franck Petit, and Vincent Villain. Snapstabilizing depth-first search on arbitrary networks. Comput. J , pages 268-280, 2006.
- 8. Alain Cournier, Stephane Devismes, and Vincent Villain. A snap-stabilizing dfs with a lower space requirement. In In Seventh International Symposium on SelfStabilizing Systems (SSS05 , pages 33-47, 2005.
- 9. Ajoy K. Datta, Colette Johnen, Franck Petit, and Vincent Villain. Self-stabilizing depth-first token circulation in arbitrary rooted networks. Distrib. Comput. , 13(4):207-218, November 2000.
- 10. Edsger W. Dijkstra. Self-stabilizing systems in spite of distributed control. Commun. ACM , 17(11):643-644, November 1974.
- 11. Shlomi Dolev. Self-stabilization . MIT Press, 2000.
- 12. Shlomi Dolev, Mohamed G. Gouda, and Marco Schneider. Memory requirements for silent stabilization. Acta Informatica , 36(6):447-462, 1999.
- 13. Shlomi Dolev, Amos Israeli, and Shlomo Moran. Self-stabilization of dynamic systems assuming only read/write atomicity. Distrib. Comput. , 7(1):3-16, November 1993.
- 14. Shlomi Dolev, Amos Israeli, and Shlomo Moran. Self-stabilization of dynamic systems assuming only read/write atomicity. Distrib. Comput. , 7(1):3-16, November 1993.
- 15. Shimon Even. Graph Algorithms . W. H. Freeman & Co., New York, NY, USA, 1979.
- 16. Mika G¨ o¨s and Jukka Suomela. o Locally checkable proofs. In Proceedings of the 30th Annual ACM Symposium on Principles of Distributed Computing, PODC 2011, San Jose, CA, USA, June 6-8, 2011 , pages 159-168, 2011.
- 17. Shing-Tsaan Huang and Nian-Shing Chen. Self-stabilizing depth-first token circulation on networks. Distributed Computing , 7(1):61-66, 1993.
- 18. Colette Johnen, Gianluigi Alari, Joffroy Beauquier, and Ajoy K Datta. Selfstabilizing depth-first token passing on rooted networks. In Distributed Algorithms , pages 260-274. Springer, 1997.
- 19. Colette Johnen and Joffroy Beauquier. Space-efficient, distributed and selfstabilizing depth-first token circulation. In In Proceedings of the Second Workshop on Self-Stabilizing Systems , pages 4-1, 1995.
- 20. Shmuel Katz and Kenneth J. Perry. Self-stabilizing extensions for meassage-passing systems. Distributed Computing , 7(1):17-26, 1993.
- 21. Amos Korman and Shay Kutten. Distributed verification of minimum spanning trees. In Proceedings of the twenty-fifth annual ACM symposium on Principles of distributed computing , PODC '06, pages 26-34, New York, NY, USA, 2006. ACM.
- 22. Amos Korman, Shay Kutten, and Toshimitsu Masuzawa. Fast and compact self stabilizing verification, computation, and fault detection of an mst. In Proceedings of the 30th Annual ACM SIGACT-SIGOPS Symposium on Principles of Distributed Computing , PODC '11, pages 311-320, New York, NY, USA, 2011. ACM.
- 23. Amos Korman, Shay Kutten, and David Peleg. Proof labeling schemes. Distributed Computing , 22(4):215-233, 2010.
- 24. Franck Petit. Highly space-efficient self-stabilizing depth-first token circulation for trees. In Euro-par'97 Parallel Processing, Proceedings LNCS , pages 47647-9. Springer-Verlag, 1997.
- 25. Franck Petit. Fast self-stabilizing depth-first token circulation. In Proceedings of the 5th International Workshop on Self-Stabilizing Systems , WSS '01, pages 200215, London, UK, UK, 2001. Springer-Verlag.
- 26. Franck Petit and Vincent Villain. Color optimal self-stabilizing depth-first token circulation. In ISPAN , pages 317-323. IEEE Computer Society, 1997.
- 27. Franck Petit and Vincent Villain. Optimality and self-stabilization in rooted tree networks. Parallel Processing Letters , 10(01):3-14, 2000.
- 28. Franck Petit and Vincent Villain. Self-stabilizing depth-first token circulation in asynchronous message-passing systems. Computers and Artificial Intelligence , 19(5), 2000.
- 29. Franck Petit and Vincent Villain. Optimal snap-stabilizing depth-first token circulation in tree networks. Journal of Parallel and Distributed Computing , 67(1):1 - 12, 2007.
- 30. F.A. Stomp. Structured design of self-stabilizing programs. In Theory and Computing Systems, 1993., Proceedings of the 2nd Israel Symposium on the , pages 167-176, Jun 1993.
- 31. George Varghese and Mahesh Jayaram. The fault span of crash failures. Journal of the ACM , 47:47-2, 2000. | null | [
"Shay Kutten",
"Chhaya Trehan"
] | 2014-08-02T15:19:46+00:00 | 2014-12-17T22:18:10+00:00 | [
"cs.DC"
] | Fast and Compact Distributed Verification and Self-Stabilization of a DFS Tree | We present algorithms for distributed verification and silent-stabilization
of a DFS(Depth First Search) spanning tree of a connected network. Computing
and maintaining such a DFS tree is an important task, e.g., for constructing
efficient routing schemes. Our algorithm improves upon previous work in various
ways. Comparable previous work has space and time complexities of $O(n\log
\Delta)$ bits per node and $O(nD)$ respectively, where $\Delta$ is the highest
degree of a node, $n$ is the number of nodes and $D$ is the diameter of the
network. In contrast, our algorithm has a space complexity of $O(\log n)$ bits
per node, which is optimal for silent-stabilizing spanning trees and runs in
$O(n)$ time. In addition, our solution is modular since it utilizes the
distributed verification algorithm as an independent subtask of the overall
solution. It is possible to use the verification algorithm as a stand alone
task or as a subtask in another algorithm. To demonstrate the simplicity of
constructing efficient DFS algorithms using the modular approach, We also
present a (non-sielnt) self-stabilizing DFS token circulation algorithm for
general networks based on our silent-stabilizing DFS tree. The complexities of
this token circulation algorithm are comparable to the known ones. |
1408.0386v1 | 
Prog. Theor. Exp. Phys. 2014 , 00000 (14 pages) DOI: 10.1093 / ptep/0000000000
## Study of hadron interactions in a lead-emulsion target
Hirokazu Ishida , Tsutomu Fukuda , Takafumi Kajiwara , Koichi Kodama , 1 1 1 2 Masahiro Komatsu , Tomokazu Matsuo , Shoji Mikado , Mitsuhiro Nakamura , 3 1 4 3 Satoru Ogawa , Andrey Sheshukov , Hiroshi Shibuya , Jun Sudou , Taira Suzuki , 1 5 1 1 1 Yusuke Tsuchida 1
- 1 Department of Physics, Toho University, Funabashi 274-8510, Japan
- 2 Aichi University of Education, Kariya 448-8542, Japan
- 3 Nagoya University, Nagoya 464-8602, Japan
- 4 Nihon University, Narashino 275-8576, Japan
- 5 JINR - Joint Institute for Nuclear Research, Dubna 141980, Russia
- ∗ E-mail: [email protected]
. . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . .
. . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . .
Topological and kinematical characteristics of hadron interactions have been studied using a lead-emulsion target exposed to 2, 4 and 10 GeV/ c hadron beams. A total length of 60 m π -tracks was followed using a high speed automated emulsion scanning system. A total of 318 hadron interaction vertices and their secondary charged particle tracks were reconstructed. Measurement results of interaction lengths, charged particle multiplicity, emission angles and momenta of secondary charged particles are compared with a Monte Carlo simulation and appear to be consistent. Nuclear fragments emitted from interaction vertices were also detected by a newly developed emulsion scanning system with wide-angle acceptance. Their emission angle distributions are in good agreement with the simulated distributions. Probabilities of an event being associated with at least one fragment track are found to be greater than 50% for beam momentum P > 4 GeV/ c and are well reproduced by the simulation. These experimental results validate estimation of the background due to hadron interactions in the sample of τ decay candidates in the OPERA ν µ → ν τ oscillation experiment.
Subject Index
C30, C32, H14, H16
## 1. Introduction and overview
The neutrino oscillation channel ν µ → ν τ is considered to be the dominant underlying process in the atmospheric neutrino sector. To prove this, the detection, in an initially pure ν µ beam, of the τ lepton produced in a ν τ charged current interaction is essential and provides a clear signature of the oscillation. The nuclear emulsion is the only particle detector which can detect τ decays by resolving their short flight path [1, 2]. The ongoing ν µ → ν τ oscillation experiment, OPERA [3-5], employs the emulsion cloud chamber (ECC) technique to provide both a large target mass and an excellent spatial resolution. Furthermore, ν τ appearance can be used to probe new physics, such as non-standard interactions and light sterile neutrino scenarios [6, 7]. An ECC brick is composed of layers of emulsion films interleaved with heavy material plates. In the ECC brick, a secondary hadron produced in neutrino interactions could interact with the heavy materials and mimic a hadronic decay of the τ lepton, as shown in Figure 1. Hence such a secondary hadron interaction could be a source of background
for τ decays. Expected number of hadron interactions as background in the sample of τ decay candidates is evaluated with a Monte Carlo simulation, which must be validated by experimental data 1 .
A high speed automated microscope system, S-UTS [8], has been developed to analyze particle tracks in emulsion films. This system allows to follow beam particle tracks for a long distance and measure their interactions with large statistics. In addition, a new type of automated emulsion scanning system [9] has recently been developed to detect nuclear fragments emitted with large angles.
We have studied hadron interactions in an ECC brick exposed to 2, 4 and 10 GeV/ c hadron beams and have compared experimental results with those of the Monte Carlo simulation.
Fig. 1 Left: a hadronic decay of the τ lepton produced in a ν τ charged current interaction. Right: an interaction of a secondary hadron ( h ) produced in a ν µ neutral current interaction.
## 2. Detectors and beam exposure
We exposed an ECC brick to 2, 4, 10 GeV/ c secondary hadron beams at CERN PS-T7 beam line in May 2001. The brick was composed of 29 emulsion films [10] (44 µ m thick emulsion layers on both sides of a 205 µ m thick plastic base) interleaved with 28 lead plates, 1 mm thick. The brick was 12.8 cm wide, 10.2 cm high and 3.7 cm thick. It was put on a turntable and tilted in the horizontal plane by an angle with respect to the beam of ± 50 mrad as shown in Figure 2. The relative beam momentum spread, ∆ P/P , is 1% [11]. The negatively (positively) charged beams are mainly composed of pions (pions and protons) with small contamination from electrons (positrons). The exposure conditions; composition, momentum, tilt angle, spot size, mean density integrated over the spot size are summarized in Table 1.
## 3. Measurement and analysis method
## 3.1. Beam tracks
We scanned the whole area of all the emulsion films by using S-UTS. Firstly track segments, so called micro tracks, were detected on each layer of emulsion films. Positions ( x, y ) and
1 The momentum region relevant to the hadron interaction background in the OPERA experiment is around 2 GeV/ c to 10 GeV/ . c
Table 1 Summary of beam exposures. For each beam spot, its composition, its momentum P , its angle with respect to the perpendicular of the emulsion film, its spot size, and its mean density integrated over the spot size are tabulated. For each spot, a tilt of -50 mrad corresponds to the positively charged hadron beam ( π + , p ) and +50 mrad to the negatively charged hadron beam ( π -).
| Spot | Composition | P [GeV/ c ] | Angle [mrad] | Spot size φ [mm] | Mean density [/cm |
|--------|---------------|---------------|----------------|--------------------|---------------------|
| 1 | π - | 10 | + 50 | ∼ 3 . 0 | 3 . 0 × 10 3 |
| 2 | π ± , p | 2 | ∓ 50 | ∼ 10 . 0 | 14 . 0 × 10 3 |
| 3 | π ± , p | 4 | ∓ 50 | ∼ 6 . 0 | 10 . 0 × 10 3 |
| 4 | π ± , p | 4 | ∓ 50 | ∼ 7 . 5 | 1 . 5 × 10 3 |
| 5 | π ± , p | 2 | ∓ 50 | ∼ 15 . 0 | 2 . 0 × 10 3 |
slopes (tan θ x , tan θ y ) of the micro tracks were measured. Base tracks were reconstructed by connecting two corresponding micro tracks (reconstructed in emulsion layers) across the plastic base. The slope acceptance of S-UTS is tan θ < 0 6, where . θ is the track angle with respect to the perpendicular of the emulsion film (the z axis). The track finding efficiency, the probability to find a base track in a film, is evaluated to be 94 8 . ± 0 2% by examining . whether a base track exists or not in the middle of 5 consecutive films.
The positions ( x, y ) and slopes (tan θ x , tan θ y ) of base tracks were measured with respect to the microscope's coordinate system. After connection of base tracks among emulsion films are performed, we adjust rotation, slant, parallel translation and distance between every pair of adjacent two emulsion films, so that differences of track positions and slopes in two films are minimized. Residuals of positions and slopes are ∼ 4 µ m and ∼ 0 004 respectively. .
Good quality beam tracks are selected by requiring they have track segments found in all 3 most upstream films and their slope in the most upstream film is compatible with the average slope within 0.004 (1 σ ) where the average is calculated from all the measured beam track slopes. For further analysis to be compared with the simulation, good negatively charged pion ( π -) tracks with these conditions were selected in the area of 1 0 . × 1 0 cm . 2 from 1st,
Fig. 2 Left: schematic view of the ECC brick structure. Right: beam spot positions on the ECC brick.
4th and 5th spots 2 , each corresponding to 10, 4 and 2 GeV/ , as shown in Figure 2. On the c other hand, positively charged hadron beams are mainly composed of π + s and protons, which cannot be differentiated in this momentum range. Relative abundance is not known precisely. Therefore positively charged hadrons are not easy to be compared with the simulation.
## 3.2. Interactions
The beam tracks in the ECC brick are composed of successive track segments and some of them are missing due to inefficiency or hadron interactions. The reconstructed tracks are followed down until no track segments found in 3 consecutive films (Figure 3, Left), then a beam particle is supposed to interact at the lead plate just downstream the film where the last track segment is found. The last track segment and its extrapolated position in the film downstream the supposed interaction position, the vertex film, are visually inspected. If the last track segment is confirmed that it is a real track and no track is found in the vertex film, the interaction is then considered as confirmed. If a track exists near the predicted position in the vertex film, we measure its position and slopes manually and the beam track is followed further downstream. For beam tracks escaping from the downstream face of the brick, a straight line fit is applied to detect a kink topology somewhere in the brick. If a kink with θ kink > 20 mrad is found, it is also considered as an interaction.
## 3.3. Secondary particles
Each confirmed interaction is subject to the secondary particle track search inside the area of 3 0 . × 3 0 cm . 2 in 6 downstream films of the interaction vertex. Secondary particle tracks are sought under the following conditions, as shown in Figure 3 right.
The angular acceptance of secondary particle track search is tan θ < 0 6, which is limited . by the ordinary S-UTS performance. For a secondary particle candidate found in at least 1 of the first 3 downstream films including the vertex film, we require the minimum distance MD of the candidate track with respect to the parent beam track to be less than (10 + 0 01 . × ∆ ) z µ m taking into account both the measurement error and the error due to the multiple Coulomb scattering (MCS) of the tracks, where the ∆ z ( µ m) is the z distance of the MD position from the nearest emulsion layer. The scanning data have a lot of fake tracks due to low energy Compton electrons and random noises. In order to reject such fake tracks, we demand the condition that base tracks exist in ≥ 3 out of the 6 downstream films and they can be reconstructed as a single secondary track. If base tracks matching with the secondary track candidate exist in ≥ 2 films out of the 3 upstream films, it is considered as a passing-through track which is not relevant to the interaction vertex.
Once a secondary track candidate is found, it is checked by visual inspection in 3 films: 1 upstream and 2 downstream films of the interaction vertex, in order to eliminate the possibility of a passing-through track or an electron track originated from γ conversion in a downstream lead plate. The efficiency of the secondary particle track search was evaluated to be 99.2% by applying the S-UTS track finding efficiency to the conditions in the whole procedure described above.
2 The 2nd and 3rd beam spots were not used because their mean densities were too high for the analysis.
Fig. 3 Left: detection method of beam interactions. Beam tracks are followed down until they are not found in three consecutive films. Extrapolated area (a), where a matching track is sought, becomes larger in the downstream films. Right: detection method of secondary particles. (b) A base track which satisfies the condition, MD< (10 + 0 01 . × ∆ ) z µ m, must exist in at least 1 of the first 3 downstream films. (c) The base track must exist in at least 3 out of the 6 downstream films. (d) If the track exists in ≥ 2 out of 3 upstream films, it is considered as a passing-through track.
Momenta of secondary tracks are estimated by measuring their multiple Coulomb scattering in the brick. There are two methods in the multiple scattering measurements, the coordinate method [12] and the angular method [13]. We use the coordinate method because it is more accurate when small multiple scattering signal is expected although it requires precise alignment among the emulsion films. We define the second difference δ i in one projection by:
$$\delta _ { i } = x _ { i + 2 } - x _ { i + 1 } - \frac { x _ { i + 1 } - x _ { i } } { z _ { i + 1 } - z _ { i } } \cdot ( z _ { i + 2 } - z _ { i + 1 } ) \quad \ \ ( 1 )$$
where the base track position at i th film ( i ∈ 1 , ..., n ) is ( x , z i i ), as shown in Figure 4. A similar expression can be written in the other projection, ( y , z i i ), and data in the two projections are used as independent measurements of the second difference. The multiple scattering signal ∆ sig is related to the momentum p by [14, 15]:
$$\Delta _ { \text{sig} } = \frac { t } { 2 \sqrt { 3 } } \frac { 0. 0 1 3 6 \, \text{GeV} } { p \, \beta \, c } \cdot \sqrt { \frac { t } { X _ { 0 } } } \left \{ 1 + 0. 0 3 8 \ln \left ( \frac { t } { X _ { 0 } } \right ) \right \}$$
where βc , t , and X 0 are the particle velocity, distance traversed, and radiation length in the material respectively. On the other hand, it is measured from second differences δ i and their errors /epsilon1 i :
$$< \delta _ { i } ^ { 2 } > = \Delta _ { s i g } ^ { 2 } + < \epsilon _ { i } ^ { 2 } >$$
where <> means the average over the available data. Since the multiple scattering measurement is statistical estimation of the particle momentum, it needs a sufficient number of data. To obtain reliable estimation, we apply the coordinate method only when at least 14 emulsion films are available for the position measurements.
Fig. 4 Schematic view of the multiple Coulomb scattering (MCS) measurement. The second differences of cell length = 1 and 2 are defined in top and bottom figures, respectively.
## 3.4. Nuclear fragments
If a secondary particle has a value of β < 0 7, the particle is observed as a heavily ionizing . track or a nuclear fragment, as shown in Figure 5. Nuclear fragments emitted from hadron interactions have also been sought by a newly developed automatic emulsion scanning system [9]. The acceptance to the track slopes are much improved up to | tan θ | < . 3 0. Since nuclear fragments are emitted almost isotropically, the new scanning system with a wider angular acceptance is suitable in order to detect the nuclear fragments with a good efficiency. The system has a large field of view, 352 × 282 µ m , and has a track finding efficiency of 2 practically 100% for nuclear fragments [9].
Searched area is defined as 3 5 . × 2 5 mm . 2 of both upstream and downstream films of each interaction vertex and its angular acceptance is | tan θ | < . 3 0. Since the nuclear fragments have low energy (few tens of MeV), they are expected to suffer large multiple scattering. Therefore the loose condition, IP < (100 + 0 01 . × ∆ ) z µ m is imposed. Here the 'Impact Parameter' IP is defined as the perpendicular distance between the path of a track and the vertex which is reconstructed by the beam and secondary tracks. The ∆ z ( µ m) is the distance between the vertex and the nearest emulsion layer where the nuclear fragment track is measured. A narrower condition, IP < (50 + 0 01 . × ∆ ) z µ m, is imposed in the case of 10 GeV/ c interactions because the beam density is high. To remove fake tracks, each found track candidate is required to be a base track and is confirmed by visual inspection.
## 4. FLUKA simulation
A FLUKA 3 [16, 17] based Monte Carlo simulation was employed for comparison. 30,000 negatively charged beam pions each were generated for momentum of P =2, 4 and 10 GeV/ . c The generated beam pions, of which directions were spread using observed distributions in this experiment, entered the brick. Some of them interacted with the brick material according to their cross sections and produced secondary particles including nuclear fragments by
3 The FLUKA version 2011.1 was used in this study.
Fig. 5 Photograph of a hadron interaction in an emulsion layer. Nuclear fragments are observed as black or gray tracks. Association of such highly ionizing particles is evidence of a hadron interaction.
using the PEANUT model [18] of hadron interactions. Exposed density, position and slope measurement errors, detection efficiency of base tracks were adjusted to be the same as real experimental conditions.
Then the simulation analysis has been performed by the same methods and tools that are used for the real data. Secondary particles with β ≥ 0 7 ( . β < 0 7) are defined as relativistic . particles (non-relativistic particles, i.e. nuclear fragments).
## 5. Results and discussion
## 5.1. Interaction length
In total, 318 interactions (77 for 2 GeV/ c , 68 for 4 GeV/ , 173 for 10 GeV/ ) have been found c c from the interaction measurements. Out of the found interactions of 2 GeV/ c (10 GeV/ ), c one (three) took place in the base of a film and one (one) in an emulsion layer of a film. All the others occurred in the lead plates. The statistics of the interaction measurements are summarized in Table 2 and evaluated interaction lengths are also presented. The interaction length, λ , is calculated as follows:
$$\lambda & = - \frac { L } { \ln ( 1 - \frac { N } { N _ { 0 } } ) } \\. \tilde { \epsilon } \, - \, \tilde { \epsilon } \, - \, \tilde { \epsilon } \, - \, \tilde { \epsilon } \, - \, \tilde { \epsilon } \, - \, \tilde { \epsilon } \, - \, \tilde { \epsilon } \, - \, \tilde { \epsilon } \, - \, \tilde { \epsilon } \, - \, \tilde { \epsilon } \, - \, \tilde { \epsilon } \, - \, \tilde { \epsilon } \, - \, \tilde { \epsilon } \, - \, \tilde { \epsilon } \, - \, \tilde { \epsilon } \, - \, \tilde{ \epsilon } \, - \, \tilde { \epsilon } \, - \, \tilde { \epsilon } \, - \, \tilde { \epsilon } \, - \, \tilde { \epsilon } \, - \, \tilde { \epsilon } \, - \, \tilde { \epsilon } \, - \, \tilde { \epsilon } \, - \, \tilde { \epsilon } \, - \, \tilde { \epsilon } \, - \, \tilde { \epsilon } \, - \, \tilde { \epsilon } \, - \, \tilde { \epsilon } \, - \, \tilde { \epsilon } \, - \, \tilde { \epsilicon } \, - \, \tilde { \epsilon } \, - \, \tilde { \epsilon } \, - \, \tilde { \epsilon } \, - \, \tilde { \epsilon } \, - \, \tilde { \epsilon } \, - \, \tilde { \epsilon } \, - \, \tilde { \epsilon } \, - \, \tilde { \epsilon } \, - \, \tilde { \epsilon } \, - \, \tilde { \epsilon } \, - \, \tilde { \epsilon } \, - \, \tilde { \epsilon } \, - \, \tilde { \epsilon } \, - \, \tilde { \epsilon } \, \ - \, \tilde { \epsilon } \, - \, \tilde { \epsilon } \, - \, \tilde { \epsilon } \, - \, \tilde { \epsilon } \, - \, \tilde { \epsilon } \, - \, \tilde { \epsilon } \, - \, \tilde { \epsilon } \, - \, \tilde { \epsilon } \, - \, \tilde { \epsilon } \, - \, \tilde { \epsilon } \, - \, \tilde { \epsilon } \, - \, \tilde { \epsilon } \, - \, \tilde { \epsilon } \, - \, \tilde { \epsilon } \, - \,$$
where L is the thickness of a lead plate and an emulsion film ( L = 1293 µ m), N is the number of found interactions and N 0 is the sum of the numbers of followed tracks in all analyzed films. Figure 6 shows momentum dependence of the interaction length, which is in good agreement with the Monte Carlo simulation within the statistical errors.
## 5.2. Topological characteristics
The multiplicity and kink angle distributions of relativistic charged secondary particles are shown in Figure 7. Topological characteristics are summarized in Table 3 and they are compared with those of simulated data. As the beam momentum increases, the average number of secondary particles < n > becomes larger. In the case of inelastic interactions, the higher is the momentum, the smaller is the emission angle. This tendency can be seen for 4 GeV/ c and 10 GeV/ c interactions, while it is not so for 2 GeV/ c interactions and
Table 2 Results of the interaction measurements and of the simulated data (MC) analysis. Number of tracks followed, total track length followed in the ECC brick, number of interactions in the ECC brick, evaluated interaction length for each momentum beam are presented.
| P [GeV/ c ] | 2 | 2 (MC) | 4 | 4 (MC) | 10 | 10 (MC) |
|---------------|--------------------------|------------------------|--------------------------|------------------------|--------------------------|------------------------|
| Tracks | 584 | 11301 | 913 | 9260 | 2205 | 13746 |
| Total L [mm] | 8506 | 191794 | 12620 | 162009 | 38534 | 240922 |
| Interactions | 77 | 1544 | 68 | 773 | 173 | 1040 |
| λ [mm] | 109 . 8 +14 . 1 - 11 . 4 | 123 . 6 +3 . 3 - 3 . 1 | 184 . 9 +24 . 2 - 20 . 1 | 208 . 9 +7 . 8 - 7 . 3 | 222 . 5 +18 . 4 - 15 . 8 | 231 . 0 +7 . 4 - 7 . 0 |
others. This might be explained by the fact that fraction of elastic interactions is larger in 2 GeV/ c interactions [14]. For the average multiplicity < n > , the agreement between the experimental data and the simulated data is not so good in 2 GeV/ c interactions. The other experimental data agree well with the simulation data.
## 5.3. Nuclear fragment association
We present measurement results of nuclear fragments for 1-prong and 3-prong events, which are relevant to topologies of the τ hadronic decay, and corresponding results for simulated data in Table 4. Here numbers of events associated with at least one heavily ionizing particle, pointing to the vertex, found in either the upstream film or the downstream film of the vertex are listed. The probability is the fraction of fragment associated events in the 1-prong or 3-prong events. Figure 8 shows the association probability as a function of the beam momentum, where data of 1-prong and 3-prong events are merged, together with simulation results. At least one nuclear fragment particle is associated with about a half of events for
Fig. 6 Interaction length as a function of beam momentum. Black dots with error bars (outlined circles) show experimental data (simulated data).
Table 3 Topological characteristics of experimental data and simulated data (MC). Number of events, average charged particle multiplicity < n > , number of 1-prong events, average kink angle for 1-prong events < θ kink > , number of 3-prong events, average of kink angle average for 3-prong events < θ kink > for 2, 4, 10 GeV/ c π -interactions are summarized.
| P [GeV/ c ] | 2 | 2 (MC) | 4 | 4 (MC) | 10 | 10 (MC) |
|------------------|------|----------|-------|----------|--------|-----------|
| Events | 77 | 1544 | 68 | 773 | 173 | 1040 |
| < n > | 0.48 | 0.65 | 0.93 | 1.03 | 2.45 | 2.41 |
| 1-prong events | 33 | 915 | 29 | 372 | 26 | 216 |
| < θ kink > [rad] | 0.13 | 0.13 | 0.23 | 0.21 | 0.2 | 0.15 |
| 3-prong events | 0 | 3 | 2 | 32 | 44 | 246 |
| < θ kink > [rad] | - | 0.36 | 0.32 | 0.3 | 0.27 | 0.24 |
Fig. 7 Multiplicity distributions of relativistic particle tracks in the forward hemisphere (Top) and kink angle distributions of 1-prong events (Bottom) for experimental data (dots with error bars) and simulated data (histogram). The simulated distributions are normalized to the real data.
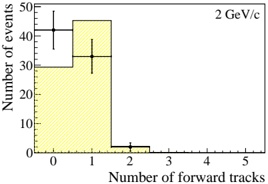
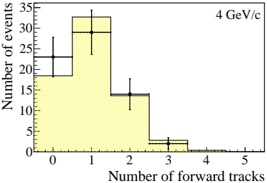
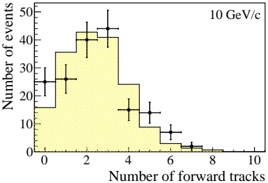
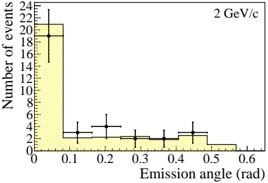
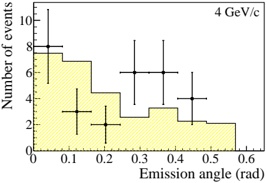
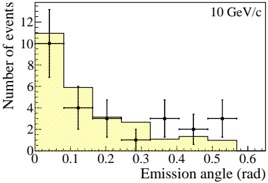
beam momentum greater than 4 GeV/ . The experimental data of the fragment associac tion probability are well reproduced by the simulation with differences less than 10%. The number of background nuclear fragment tracks was estimated to be 0.035 tracks/event by scanning around dummy vertices with the same conditions. Figure 9 shows good agreement in multiplicity and polar angle distributions of nuclear fragments between experimental data (dots with error bars) and simulated data (histogram).
Table 4 Results of nuclear fragment search (experimental data and simulated data). Lower limit of the probability shows the value at 90% confidence level.
| P [GeV/ c ] | 2 | 2 | 4 | 4 | 10 | 10 |
|--------------------------|-----------------------|-----|-----------------------|-----------------------|------------------------|-----------------------|
| Prong | 1 | 3 | 1 | 3 | 1 | 3 |
| Events | 32 | 0 | 29 | 2 | 25 | 41 |
| Fragment associated | 10 | 0 | 16 | 2 | 15 | 27 |
| Probability [%] | 31 . 3 +9 . 1 - 6 . 9 | - | 55 . 2 +8 . 6 - 9 . 3 | > 46 . 5 | 60 . 0 +8 . 9 - 10 . 2 | 65 . 9 +6 . 5 - 8 . 0 |
| Events (MC) | 908 | 0 | 372 | 32 | 214 | 246 |
| Fragment associated (MC) | 213 | 0 | 219 | 17 | 127 | 169 |
| Probability (MC) [%] | 23 . 5 +1 . 5 - 1 . 3 | - | 58 . 9 +2 . 5 - 2 . 6 | 53 . 1 +8 . 4 - 8 . 8 | 59 . 3 +3 . 3 - 3 . 5 | 68 . 7 +2 . 8 - 3 . 1 |
Fig. 8 Association probability of nuclear fragments as a function of beam momentum. Black dots with error bars (outlined circles) show experimental data (simulated data).
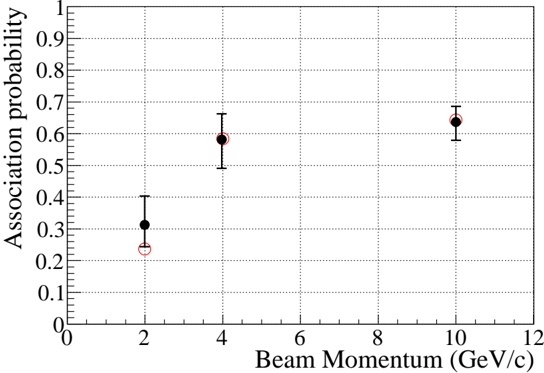
## 5.4. Kinematical characteristics
In OPERA, for τ candidates decaying into a single charged hadron, kinematical selection cuts; p > 2 GeV/ c and p T > . 0 6 GeV/ c are required [19, 20] 4 . Scatter plots of p T versus p of the secondary particles of 1-prong hadron interactions are shown together with those of simulated data in Figure 10. For comparison, scatter plots of p T versus p of the secondary particles of 10 GeV/ c 3-prong interactions are also shown in Figure 11. Statistics are limited because only secondary tracks for which more than 14 lead plates are available as scattering materials are able to be momentum-reconstructed. In this condition, error of the momentum measurement was estimated to be σ p = 45(55)% at p ≤ 4 GeV /c ( p > 4 GeV /c ) by using the multiple scattering measurements of beam pions with known momentum, i.e. 2, 4, 10 GeV/ , c
4 The cut on p T is 0.3 GeV/ c if there is a converted γ attached to the secondary vertex. In this analysis, no attempt is made to find γ s because the numbers of lead plates and emulsion films are limited.
Fig. 9 Top: multiplicity distributions of nuclear fragments for experimental data (dots with error bars) and simulated data (histogram). Bottom: polar angle distributions of nuclear fragments for experimental data (dots with error bars) and simulated data (histogram).
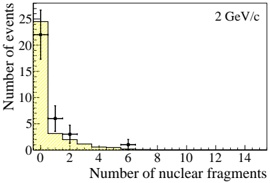
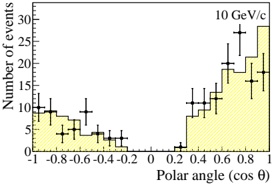
Table 5 Fraction of secondary particles in the selection domain of p > 2 GeV/ c and p T > . 0 6 GeV/ . c Numbers of secondary tracks for which the momentum is measurable and numbers of tracks in the selection domain are summarized. Upper limits are at 90% confidence level.
| P [GeV/ c ] | 2 | 2 | 4 | 4 | 10 | 10 |
|---------------------------------|----------------------|----------|----------------------|---------|------------------------|----------------------|
| Prong | 1 | 3 | 1 | 3 | 1 | 3 |
| Tracks p measurable | 12 | 0 | 7 | 0 | 10 | 54 |
| Tracks in selection domain | 0 | 0 | 0 | 0 | 1 | 1 |
| Fraction [%] | < 16 . 3 | - | < 25 . 0 | - | 10 . 0 +16 . 0 - 3 . 0 | 1 . 9 +3 . 7 - 0 . 4 |
| Tracks p measurable (MC) | 393 | 1 | 127 | 34 | 93 | 299 |
| Tracks in selection domain (MC) | 2 | 0 | 9 | 0 | 13 | 19 |
| Fraction (MC) [%] | 0 . 5 +0 . 7 - 0 . 2 | < 69 . 0 | 7 . 1 +3 . 0 - 1 . 7 | < 6 . 4 | 14 . 0 +4 . 4 - 2 . 9 | 4 . 8 +1 . 3 - 0 . 9 |
under the same condition. In Figure 10, the dark area defines the domain in which τ decay candidates are selected and the hatched area defines the domain rejected by the selection cuts ( θ kink > . 0 02 rad) and S-UTS angle acceptance (tan θ < 0 6). Table 5 summarizes the . fraction of secondary particles in the selection domain for the events in which secondary particle momenta are measurable. Comparisons between experimental and simulated data show generally good agreement, however the final statistics of the tracks in the selection domain are not sufficient to obtain quantitative results on how good the agreement is. We will therefore consider an alternative method to estimate the goodness of the agreement in the next subsection.
Fig. 10 Top: Scatter plot of p T vs. p of the secondary particle of 1-prong interactions (Experimental data). Bottom: Scatter plot of p T vs. p of the secondary particle of 1-prong interactions (Simulated data). On the figures the dark area defines the domain in which τ decay candidates are selected and the hatched area defines the domain rejected by the selection cuts.
## 5.5. Goodness of agreement between the experimental and the simulated data
The numbers of secondary particles in the domain where τ decay candidates are selected are too few to evaluate the goodness of the agreement between the experimental and the simulated data. So we try to widen the selection condition for comparison. We select 1-prong hadron interaction events with θ kink > 0.30, 0.15 and 0.06 rad for 2 GeV/ , 4 GeV/ c c and 10 GeV/ , respectively. These angles correspond to c p T > 0 6 GeV/ . . c
There are some events in the domains defined by these conditions, as shown in Table 6. We use these samples to check the agreement between the experimental and the simulated data.
Fig. 11 Left: Scatter plot of p T vs. p of the secondary particle of 10 GeV/ c 3-prong interactions (Experimental data). Right: Scatter plot of p T vs. p of the secondary particle of 10 GeV/ c 3-prong interactions (Simulated data). On the figures the dark area defines the domain in which τ decay candidates are selected and the hatched area defines the domain rejected by the selection cuts.
Table 6 Number of selected events for each momentum beam. We select 1-prong events with θ kink > 0.30, 0.15 and 0.06 rad for 2 GeV/ , 4 GeV/ c c and 10 GeV/ , respectively. For c the simulated data (MC), numbers of events normalized to the total track length followed in this experiment are shown. Relative differences δ sys between experimental data and simulated data are less than 30% and are within statistical errors δ stat of experimental data although statistics is not sufficient for 2 GeV/ c .
| P [GeV/ c ] | 2 | 2 (MC) | δ sys [%] | 4 | 4 (MC) | δ sys [%] | 10 | 10 (MC) | δ sys [%] |
|------------------|-----|----------|-------------|-----|----------|-------------|------|-----------|-------------|
| Events | 77 | 68.5 | 12 | 68 | 60.2 | 13 | 173 | 166 | 4 |
| 1-prong | 33 | 40.6 | -19 | 29 | 29.1 | 0 | 26 | 34.6 | -25 |
| After θ kink cut | 6 | 7.5 | -20 | 19 | 15.3 | 24 | 17 | 23.7 | -28 |
In Table 6, numbers of simulated data (MC) were normalized to the total track length followed for each beam momentum in this experiment. Then the statistical error δ stat and the relative difference δ sys are defined as follows,
$$\delta _ { \text{stat} } \ = \ \frac { 1 } { \sqrt { N _ { e v } } } \ \ _ { \quad \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \$$
$$\delta _ { s y s } \ = \ \frac { N _ { e v } - N _ { M C } } { N _ { M C } }$$
where N ev and N MC are numbers of the experimental data and the simulated data respectively. It is found that all the relative differences δ sys are less than 30% and can be understood within the statistical errors δ stat although statistics is not sufficient for 2 GeV/ c . We therefore conclude that the agreement between the experimental and the simulated data has been confirmed at the 30% level for beam momentum P ≥ 4 GeV/ . c
## 6. Conclusions
Topological and kinematical characteristics of hadron interactions have been studied by using an ECC brick exposed to 2, 4, 10 GeV/ c pion beams. High speed automated microscope system was employed to analyze the nuclear emulsion films. A total of 318 hadron interactions were found and reconstructed by following 60 m π -tracks in the brick. Secondary charged particle tracks from interaction vertices were also followed and reconstructed. Charged particle multiplicity of each event and emission angle of each secondary particle were measured and their distributions were found to be in good agreement with a FLUKA Monte Carlo simulation. Nuclear fragments were also searched for by newly developed automated microscope system with a wide view. We measured the probability for the interaction vertices to be associated with nuclear fragments and found it to be greater than 50% for beam momentum P > 4 GeV/ . The experimental data of the fragment association probability c are well reproduced by the simulation with differences less than 10%. When possible, the momentum of the secondary particle was measured by using the coordinate method. Fractions of 1-prong and 3-prong hadron interactions being in the domain where τ → hadron decays are selected are measured and found to be consistent with the simulation at the 30% level for beam momentum P ≥ 4 GeV/ . We conclude that the FLUKA based simulation c reproduces well the experimental distributions of 2, 4, and 10 GeV/ c π -interactions in the
ECC brick. This result can be applied in neutrino oscillation experiments to evaluate the hadronic background contaminations on τ lepton decays. Since the background contaminations originate from all charged hadron interactions, mainly π -, π + and proton interactions, positively charged hadron interactions should also be investigated. This will be the subject of further studies.
## Acknowledgments
We wish to thank P. Vilain for his careful reading of the manuscript and for his valuable comments. We wish to express our gratitude to the colleagues of the Fundamental Particle Physics Laboratory, Nagoya University for their cooperation. For the beam exposure, we gratefully acknowledge the support of the PS staff at CERN. We warmly acknowledge the financial support from the Japan Society for the Promotion of Science (JSPS), the Promotion and Mutual Aid Corporation for Private Schools of Japan, and Japan Student Services Organization.
## References
- [1] K. Kodama et al., (DONUT Collaboration), Phys. Lett. B, 504 , 218 (2001).
- [2] K. Kodama et al., (DONUT Collaboration), Nucl. Instrum. Methods Phys. Res., Sect. A 493 , 45 (2002).
- [3] M. Guler et al., (OPERA Collaboration), An appearance experiment to search for ν µ → ν τ oscillations in the CNGS beam: experimental proposal, CERN-SPSC-2000-028, LNGS P25/2000 (2000).
- [4] M. Guler et al., (OPERA Collaboration), Status Report on the OPERA Experiment, CERN/SPSC 2001-025, LNGS-EXP 30/2001 add. 1/01 (2001).
- [5] R. Acquafredda et al., (OPERA Collaboration), J. Instrum., 4 , P04018 (2009).
- [6] O. Yasuda, arXiv:1211.7175 [hep-ph].
- [7] T. Ota, J. Phys. Conf. Ser., 408 , 012021 (2013).
- [8] K. Morishima, T. Nakano, J. Instrum., 5 , P04011 (2010).
- [9] T. Fukuda et al., J. Instrum., 8 , P01023 (2013).
- [10] T. Nakamura et al., Nucl. Instrum. Methods Phys. Res., Sect. A 556 , 80 (2006).
- [11] D.J. Simon et al., SECONDARY BEAMS FOR TESTS IN THE PS EAST EXPERIMENTAL AREA, PS/PA-EP Note 88-26 (1988), PS/PA/Note 93-21 (1993), http://ps-div.web.cern.ch/ps-div/Reports/PA9321/.
- [12] K. Kodama et al., Nucl. Instrum. Methods Phys. Res., Sect. A 574 , 192 (2007).
- [13] N. Agafonova et al., (OPERA Collaboration), New J. Phys., 14 , 013026 (2012).
- [14] J. Beringer et al. (Particle Data Group), Phys. Rev. D, 86 , 010001 (2012).
- [15] M. Kimura et al., Nucl. Instrum. Methods Phys. Res., Sect. A 711 , 1 (2013).
- [16] A. Ferrari, P.R. Sala, A. Fass`, and J. Ranft, FLUKA: a multi-particle transport code, CERN-2005-10 o (2005), INFN/TC 05/11, SLAC-R-773.
- [17] G. Battistoni, S. Muraro, P.R. Sala, F. Cerutti, A. Ferrari, S. Roesler, A. Fass`, J. Ranft, The FLUKA o code: Description and benchmarking, Proceedings of the Hadronic Shower Simulation Workshop 2006, Fermilab 6-8 September 2006, M. Albrow, R. Raja eds., AIP Conference Proceeding 896, 31-49, (2007).
- [18] F. Ballarini et al., Nuclear models in FLUKA: present capabilities, open problems and future improvements, SLAC-PUB-10813 (2004).
- [19] N. Agafonova et al., (OPERA Collaboration), Phys. Lett. B, 691 , 138 (2010).
- [20] N. Agafonova et al., (OPERA Collaboration), New J. Phys., 14 , 033017 (2012). | 10.1093/ptep/ptu119 | [
"Hirokazu Ishida",
"Tsutomu Fukuda",
"Takafumi Kajiwara",
"Koichi Kodama",
"Masahiro Komatsu",
"Tomokazu Matsuo",
"Shoji Mikado",
"Mitsuhiro Nakamura",
"Satoru Ogawa",
"Andrey Sheshukov",
"Hiroshi Shibuya",
"Jun Sudou",
"Taira Suzuki",
"Yusuke Tsuchida"
] | 2014-08-02T15:36:02+00:00 | 2014-08-02T15:36:02+00:00 | [
"physics.ins-det",
"hep-ex"
] | Study of hadron interactions in a lead-emulsion target | Topological and kinematical characteristics of hadron interactions have been
studied using a lead-emulsion target exposed to 2, 4 and 10 GeV/c hadron beams.
A total length of 60 m $\pi^-$ tracks was followed using a high speed automated
emulsion scanning system. A total of 318 hadron interaction vertices and their
secondary charged particle tracks were reconstructed. Measurement results of
interaction lengths, charged particle multiplicity, emission angles and momenta
of secondary charged particles are compared with a Monte Carlo simulation and
appear to be consistent. Nuclear fragments emitted from interaction vertices
were also detected by a newly developed emulsion scanning system with
wide-angle acceptance. Their emission angle distributions are in good agreement
with the simulated distributions. Probabilities of an event being associated
with at least one fragment track are found to be greater than 50% for beam
momentum $P > 4$ GeV/c and are well reproduced by the simulation. These
experimental results validate estimation of the background due to hadron
interactions in the sample of $\tau$ decay candidates in the OPERA $\nu_{\mu}
\to \nu_{\tau}$ oscillation experiment. |
1408.0387v1 | ## Galaxy formation and chemical evolution
## S. Sahijpal
Department of Physics, Panjab University, Chandigarh, India Email: [email protected]
## ABSTRACT
The manner the galaxy accretes matter along with the star formation rates at different epochs, influence the evolution of the stable isotopic inventories of the galaxy. A detailed analysis is presented here to study the dependence of the galactic chemical evolution on the accretion scenario of the galaxy along with the star formation rate during the early accretionary phase of the galactic thick disk and thin disk. Our results indicate that a rapid early accretion of the galaxy during the formation of the galactic thick disk along with an enhanced star formation rate in the early stages of the galaxy accretion could explain the majority of the galactic chemical evolution trends of the major elements. Further, we corroborate the recent suggestions regarding the formation of a massive galactic thick disk rather than the earlier assumed low mass thick disk.
Keywords: Galactic chemical evolution, galaxy formation; solar neighborhood, solar elemental abundances.
## 1. Introduction
The big-bang origin of the universe occurred ~13.7 billion years (Gyr) ago. The onset of the accretion of the Milky-way galaxy along with the formation of the earliest generations of stars is considered to have commenced quite early. The various stellar nucleosynthetic processes that operate within the numerous generations of stars formed over the evolution of the galaxy established the galactic inventories of all the stable nuclides [1-5]. The gradual growth of the stable isotopic abundances of the galaxy critically depend upon the accretional growth scenario of the galaxy and the star formation rate at different epochs [1-5]. The traditional adopted approach for the formation of the Milky-way galaxy involves episodes of two exponentially declining accretionary growth related with the formation of the galactic thick and thin disks [1, 4, 5]. According to this scenario, the accretional growth of the galactic thick disk occurred over a timescale of the initial ~1 billion years, whereas, the accretional growth of the galactic thin disk occurred over a prolonged timescale of ~7 billion years. This scenario deals with the formation of a massive thin disk with the final surface mass density of ~44 Mʘ pc -2 subsequent to the accretion of the galactic thick disk with a final surface mass density of ~10 Mʘ pc -2 [see e.g. 4]. This adopted accretion scenario of the galaxy has been used in the previous GCE (galactic chemical evolution) models [1,3-5] to explain the majority of the observed features of the galaxy in terms of the elemental abundance evolution and the supernovae rates. An alternative scenario involving two main accretion episodes with both Gaussian infall rates has been also proposed for the formation of the galaxy [2]. The timescale for the accretion of the galactic thin disk was assumed to be ~4 Gyr in some of these models.
On the basis of the observed elemental composition of the F, G and K dwarf stars in the solar vicinity, two alternative scenarios for the formation of the galaxy have been recently proposed [6-8]. One of these scenarios involve episodes of three exponentially declining accretionary growth [6] involving the rapid accretion of the galactic halo and the thick disk over a timescale of ~0.2 and ~1.25 Gyr, respectively, followed by a prolonged accretion of the thin disk over a timescale of ~6 Gyr. On contrary to the traditional scenarios with a thick disk of low mass (~10 Mʘ pc -2 ) in comparison to a massive thin disk (~44 Mʘ pc -2 ) [1-5], the surface mass density of the thick and thin disks were optimized to ~24 and 30 Mʘ pc -2 , respectively, in order to explain the elemental abun-
dance evolutionary trends [6]. The star formation rate (SFR) in this scenario was evaluated on the basis of the prevailing total surface mass and gas densities [1-5].
An alternative scenario for the formation and the evolution of the galaxy has been recently proposed [7, 8] on the basis of the distribution of [Si/Fe] versus age of the F, G and K dwarf stars in the solar vicinity. This scenario is based on the closed box approximation for the GCE with no inflow or outflow of matter. The galaxy is assumed to have accreted matter rapidly in the early universe. A phase transition between the galactic thick and thin disk occurs ~8-9 Gyr ago. The thick disk acquires almost half of the mass. On contrary to all the previous works on GCE [1-6], the star formation rate was not estimated on the basis of the prevailing total and gas surface mass densities [7, 8]. It was rather considered as a fitting parameter to reproduce the distribution of [Si/Fe] versus age of the F, G and K dwarf stars in the solar vicinity. This work suggests the presence of large amounts of gas in the beginning of the formation of the galaxy and an enhanced early star formation rate.
Based on these two recent proposed scenarios [6-8], in the present work, we study the influence of the rapid early accretion and rapid early star formation history of the galaxy within the framework of episodes of two exponentially declining accretionary growth of the galactic thick and thin disks. We present results on the basis of our N-body numerical simulations of the evolution of the galaxy, whereby, we treat the formation and evolution of several generations of stars during the galactic evolution. The analysis was performed to reproduce the bulk elemental abundance of the sun [5, 9] at the time of its formation. The numerically deduced normalized elemental abundance distribution trends of some major elements were compared with the observed elemental abundance distribution of F, G and K dwarf stars in the solar vicinity. The essential aim is to parametrically impose constraint on the formation of the galactic thick and thin disks along with the star formation history.
## 2. Numerical simulations
The conventional approach of developing the GCE model deals with numerically solving the integro-differential equations dealing with the isotopic abundance evolution [1-4, 6]. An alternative approach of the N-body numerical simulation was developed [5, 10-13] to evolve the galaxy in terms of formation and evolution of numerically simulated stars of different generations. A detailed
parametric analysis of the GCE model was performed to constrain the galaxy formation scenario, the star formation rate, the stellar initial mass function and the supernova Ia (SN Ia) contributions to the GCE [5]. The analysis on the influence of the star formation rate and the SN Ia rate on GCE [10] indicated an enhanced star formation rate in the beginning of the formation of the galaxy. Further, it was also concluded [10] that a proposed normalized SN Ia delay distribution [14] corresponding to single degenerate SN Ia with a ~13 % contributions of the prompt SN Ia would adequately explain the SN Ia contributions to GCE. The inhomogeneous GCE models [11] further supported these deductions. A detailed analysis of SN II + SN Ib/c contributions on GCE indicated several limitations related with the use of specific set of stellar nucleosynthetic yields on the GCE models [12].
In the present work, we specifically study the role of the galaxy formation scenario and the star formation rate on GCE. The work is motivated by the recent developments [6-8] that present two distinct views regarding the formation of the galaxy. One of these works [6] deals with the prolonged formation of the galaxy [6] and the other one deal with the rapid accretion of the galaxy in the early universe [7, 8]. However, as mentioned earlier, both of these works indicate rapid formation of a massive thick disk.
Table 1. The assumed parameters related with the formation of the galactic thick and thin disks.
| Model | Final accreted surface mass density (M ʘ pc -2 ) | Final accreted surface mass density (M ʘ pc -2 ) | Simulation fitting parameters |
|---------|----------------------------------------------------|----------------------------------------------------|---------------------------------|
| | Thick disk | Thin disk | (x, f)* |
| Model A | 10 | 44 | (1.52, 0.04) |
| Model B | 30 | 24 | (1.57, 0.03) |
| Model C | 44 | 10 | (1.63, 0.02) |
| Model D | 30 | 24 | (1.56, 0.03) |
| Model E | 44 | 10 | (1.62, 0.02) |
The parameter 'υ' [10] related with the star formation rate during the initial 1 Gyr was assumed to be 1 and 3, respectively, in the case of Models A-C and Models D-E.
* 'x' is the power exponent of the stellar initial mass function in the mass rages 11-100 Mʘ [10-13]
'f' is the fraction of stars in the mass rages 3-16 Mʘ that evolve as binary systems to produce SN Ia
We have developed numerical simulations of GCE in the solar neighborhood using the formulation discussed elaborately in the earlier works [5, 10-13]. We have specifically adopted our recent models for the formulation of the SN Ia and the star formation rate [10]. We here avoid repetitive discussion of the details of the numerical simulations. We adopted the scenario related with two exponentially declining accretionary growth episodes associated with the formation of the galactic
thick and thin disks with the assumed timescales of 1 Gyr and 7 Gyr, respectively [1, 3-5]. The extent of the distribution of mass among the galactic thick and thin disks is treated as one of the simulation parameters to understand its dependence on GCE ( Table 1 ). The traditional galaxy accretion scenario deals with the formation of a galactic thick disk with a final surface mass density of ~10 Mʘ pc -2 ( Table 1 ). This is subsequently followed by the accretion of a massive thin disk with a final surface mass density of ~44 Mʘ pc -2 [see e.g. 4]. The Model A ( Table 1 ) refers to this specific scenario. We ran Model B & C by varying the final accreted mass distribution of the galactic thick and thin disks. The star formation rate in the present work was estimated on the basis of the prevailing total surface and gas baryonic matter density of the galaxy [4, 5, 10, 11]. This approach is identical to the recent work [6]. The Models A, B and C were run by assuming a value of 1 for the star formation rate parameter, 'υ' (see Equation 1 of [10]). The simulations, Model D and E were run with a value of 3 for υ. It has been demonstrated earlier [10, 11] that the GCE models with this particular value explain majority of the observed elemental abundances distribution of the F, G and K dwarf stars in the solar vicinity. It should be noted that the Models B and D ( Table 1 ) in the present work deals with the accretion of the galactic thick disk of substantial mass that is comparable to the thin disk. These scenarios are almost identical to the recent GCE scenario [6]. However, the Models C and E ( Table 1 ) deal with rapid accretion of substantial matter in the early evolution of the galaxy. Although, this scenario does not exactly correspond to the SFR and galaxy formation formulation that was adopted in the recent works [7, 8], the two distinct approaches however would eventually result in an early rapid growth of the galaxy and an early enhanced star formation.
During the evolution of the galaxy in the solar vicinity, the stars in the mass range 0.1-100 Mʘ were formed at the time of formation of stellar clusters of different generations according to an assumed piece-wise three step normalized stellar initial mass function (IMF) [5, 10-13]. The power exponent, x, of the IMF in the mass rages 11-100 Mʘ was considered as one of the simulation parameters ( Table 1 ) to reproduce the metallicity of 0.014 [9] and [Fe/H] ~ 0 at the time of formation of the solar system [10-13]. The stellar nucleosynthetic yields of SN II + SNI b/c [15], the low and the intermediate mass stars [16] and SN Ia [17] were used to deduce the stable isotopic abundance evolution of the various elements from hydrogen to zinc over the galactic timescales. We adopted the SN Ia formulation that involves a SN Ia normalized delay distribution [14] corresponding to single degenerate SN Ia with a ~13 % contributions of the prompt SN Ia [10]. A fraction, f, of stars
in the mass range 3-16 Mʘ from the IMF was considered as one of the other simulation parameters apart from the parameter, x ( Table 1 ). This fraction of stars evolves as binary stars and eventually produces SN Ia, the main contributors of the iron-peaked nuclides to the galaxy. The optimized values of the simulation fitting parameters are mentioned in Table 1 .
## 3. Results and Discussion
Numerical simulations were run to study the dependence of the galaxy formation scenario and the star formation rate on the galactic elemental abundance evolution ( Table 1 ). The star formation rates (SFR) inferred from the simulations are presented in Figure 1 . Compared to Model A, the Models B and C infer higher star formation rate during the early evolution of the galaxy. The star formation rate parameter, υ (see Equation 1 of [10]) in these models was assumed to be 1. It is interesting that the deduced SFR in the case of Model C follows almost an identical trend as observed in the recent work based on treating the SFR as a fitting parameter [7]. As mentioned earlier, even though, the present adopted approach is distinct from the recent work [7], the two approaches however identically invoke an early rapid accretion of the galaxy and a high SFR. An increase in the value of SFR parameter, υ to 3 results in a further enhancement of the SFR as is noticed in the case of simulations, Model D and Model E. This aspect was also noticed in the recent work [6]. It should be mentioned that the galactic thick disk is assumed to accrete over a timescale of 1 Gyr, and the parameter υ is taken to be unity during the accretion of galactic thin disk in all the simulations. The enhanced SRF during the early accretion of the galaxy results in a lower SRF during the latter evolutionary stages of the galaxy in all the simulations.
The numerically simulated total baryonic surface matter density accretion and distribution for the various models is presented in Figure 2 . Due to substantially more baryonic matter accretion during the galactic thick disk accretionary stage ( Table 1 ), the Models B and D acquire an earlier high matter accretion compared to the Model A. The Models C and E result in an even higher matter accretion during the early evolution of the galaxy. All the models eventually acquire an identical present day observed value of ~54 Mʘ pc -2 for the combined galactic thick and thin disks total baryonic matter surface density. The distributions of the baryonic matter among stars (+ stellar remnants) and interstellar gas are also presented in Figure 2 for the various models. Compared to the
Model A, the early enhanced star formation in the models B and C occurs due to the early rapid accretion of the galaxy. There is a sharp rise in the surface gas density prior to enhanced star formation. Compared to the Models B and C, in the case of the Models D and E, a further enhancement in the SFR during the initial couple of billion years is due to the choice of a higher value of 3 for the SFR parameter, υ ( Table 1 ). However, it should be noted that this does not significantly alter the SFR during the latter stages of the galaxy evolution.
The predicted supernovae rates for the various simulations are presented in Figure 3 . The SNII +SNIb/c supernovae rates follow the star formation rate temporal trends ( Figure 1 ). This is due to the fact that most of the massive (>11 Mʘ) stars explode as SNII +SNIb/c within a timescale of ~25 million years (Myr.) subsequent to their formation in a stellar cluster [11-13]. The enhancement in the star formation rate ( Figure 1 ) in the earlier stages of galaxy results in earlier enhanced SNII +SNIb/c rates. This would result in an earlier enrichment of the stellar nucleosynthetic yields of the massive stars. It should be also noted that the power exponent, x, of the stellar initial mass function increases due to the earlier rapid accretion of the galaxy or the enhancement in the SFR ( Table 1 ). Further, as mentioned earlier the SN Ia rates are according to the normalized delay distribution of single degenerate SN Ia with a ~13 % contributions of the prompt SN Ia [10, 14]. The fraction, f, of the stars in the mass range 3-16 Mʘ that eventually results in SN Ia decreases with the earlier rapid accretion of the galaxy or the enhancement of SFR ( Table 1 ).
The estimated evolutionary trends in the [Fe/H] versus age are presented in Figure 4 for all the models. As far as the earlier temporal evolutionary trend in the [Fe/H] are concerned, the Model D explains the best match with the observational data of the F, G and K dwarf stars in the solar vicinity. The Model D corresponds to the scenario dealing with the early rapid accretion of a galactic thick disk with a mass comparable to the galactic thin disk ( Table 1 ). This scenario also deals with an enhanced star formation rate with a value of 3 for the SFR parameter, υ [10-11]. Based on the comparison among the Models B-C and D-E ( Figure 4 ), it should be noted that a further increase in the mass of the galactic thick disk in comparison with the thin disk ( Table 1 ) makes the mismatch larger with the observational data in the earlier temporal evolutionary trends in [Fe/H].
The temporal normalized evolutionary trends of some major elements for the Models B, C, D and E are presented in Figure 5 . As mentioned earlier an enhanced SNII +SNIb/c rates in the early evolution of the galaxy result in an earlier enrichment of heavier elements due to the stellar nucleosynthetic yields of massive stars. Except for nitrogen, the Models D and E with an enhanced SFR in the early galaxy results in earlier high elemental yields compared to the Models B and C. The Models D and E provide a better match with the observational data. Further, except for carbon, nitrogen, copper and zinc, the elemental evolutionary trends among the Models B-C and D-E, having an identical value of the SFR parameter, υ, are not distinct. Based on the normalized [Si/Fe] versus [Fe/H] ( Figure 5 ) and [Fe/H] versus age ( Figure 4 ), it seems that the Model D could be most preferred choice for [Fe/H] > -1.0 [7]. Finally, as discussed in the earlier works it is impossible to match all the elemental evolutionary trends with the observational data [5, 10-12].
## 4. Conclusions
Based on the detailed numerical simulations of the galactic chemical evolution, we corroborate the recent findings [6, 7] that the formation of the galactic thick disk of mass comparable to the mass of the galactic thin disk occurred rapidly in the early universe. This was followed by the accretion of a galactic thin disk perhaps over a prolonged timescale. Further, we present predicted normalized elemental evolutionary trends for several elements for the first time.
## 5. Acknowledgements
This work is supported by a PLANEX (ISRO) grant
## REFERENCES
- [1] Chiappini, C., Matteucci, F. and Gratton, R., (1997) The chemical evolution of the galaxy: The two-Infall model. The Astrophysical Journal , 477 , 765-780.
- [2] Chang, R. X., Hou, J. L., Shu C. G. and Fu, C. Q. (1999) Two-component model for the chemical evolution of the Galactic disk. Astronomy and Astrophysics , 350 , 38-48.
- [3] Tutukov, A. V., Shustov, B. M. and Wiebe, D. S. (2000) The stellar epoch in the evolution of the galaxy. Astronomy Reports , 44 , 711-718.
- [4] Alibés, A., Labay, J. and Canal, R. (2001) Galactic chemical abundance evolution in the solar neighborhood up to the iron peak. Astronomy and Astrophysics , 370 , 1103-1121.
- [5] Sahijpal, S. and Gupta, G. (2013) Numerical simulation of the galactic chemical evolution: The revised solar abundance. Meteoritics and Planetary Science Journal , 48 , 1007-1033.
- [6] Micali, A., Matteucci, F. and Romano, D. (2013) The chemical evolution of the Milky Way: The three infall model. Monthly Notices of the Royal Astronomical , 436 , 1648-1658.
- [7] Snaith, O. N. et al. (2014) The dominant epoch of star formation in the milky way formed the thick disk. The Astrophysical Journal Letters , 781 , article id. L31.
- [8] Haywood, M. (2014) Galactic chemical evolution revisited. Memorie della Societa Astronomica Italiana Supplement , eprint arXiv:1401.1864
- [9] Asplund, M., Grevesse, N., Sauval, A. J. and Scott, P. (2009) The chemical composition of the Sun. Annual Review of Astronomy and Astrophysics , 47 , 481-522.
- [10] Sahijpal, S. (2013) Influence of supernova SN Ia rate and the early star formation rate on the galactic chemical evolution. International Journal of Astrophysics and Astronomy , 3 , 344-352.
- [11] Sahijpal, S. (2013) Inhomogeneous chemical evolution of the galaxy in the solar neighbourhood. Journal of Astrophysics and Astronomy , 34 , 297-316.
- [12] Sahijpal, S. (2014) Contributions of type II and Ib/c supernovae to Galactic chemical evolution. Research in Astronomy and Astrophysics , 14 , 693-704.
- [13] Sahijpal, S. (2014) Evolution of the galaxy and the birth of the solar system: The short-lived nuclides connection. Journal of Astrophysics and Astronomy , 35 , 121-142.
- [14] Matteucci, F. Spitoni, E., Recchi, S. and Valiante R. (2009) The effect of different type Ia supernova progenitors on Galactic chemical evolution. Astronomy and Astrophysics , 501 , 531-538.
- [15] Woosley, S. E. and Weaver, T. A. (1995) The Evolution and Explosion of Massive Stars. II. Explosive Hydrodynamics and Nucleosynthesis. The Astrophysical Journal Supplement , 101 , 181-235.
- [16] Karakas, A. I. and Lattanzio, (2007) Stellar models and yields of asymptotic giant branch stars. Publications of the Astronomical Society of Australia , 24 , 103-117.
- [17] Iwamoto, K. et al. (1999) Nucleosynthesis in Chandrasekhar mass models for type Ia supernovae and constraints on progenitor systems and burning-front propagation. The Astrophysical Journal Supplement , 125 , 439-462.
Figure 1.
Figure 2.
Figure 3.
Figure 4.
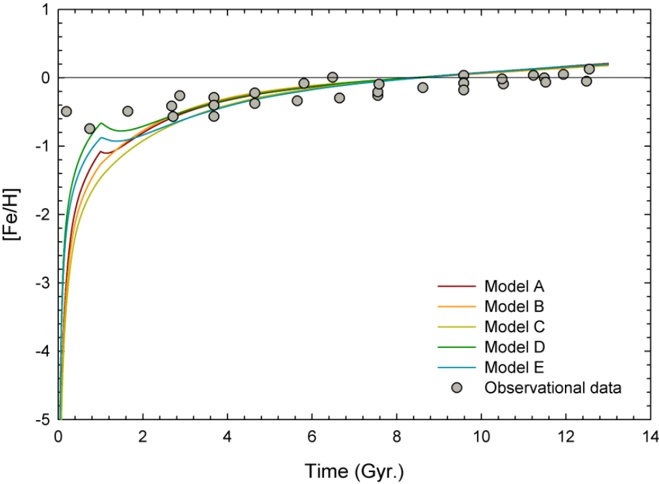
Figure 5.
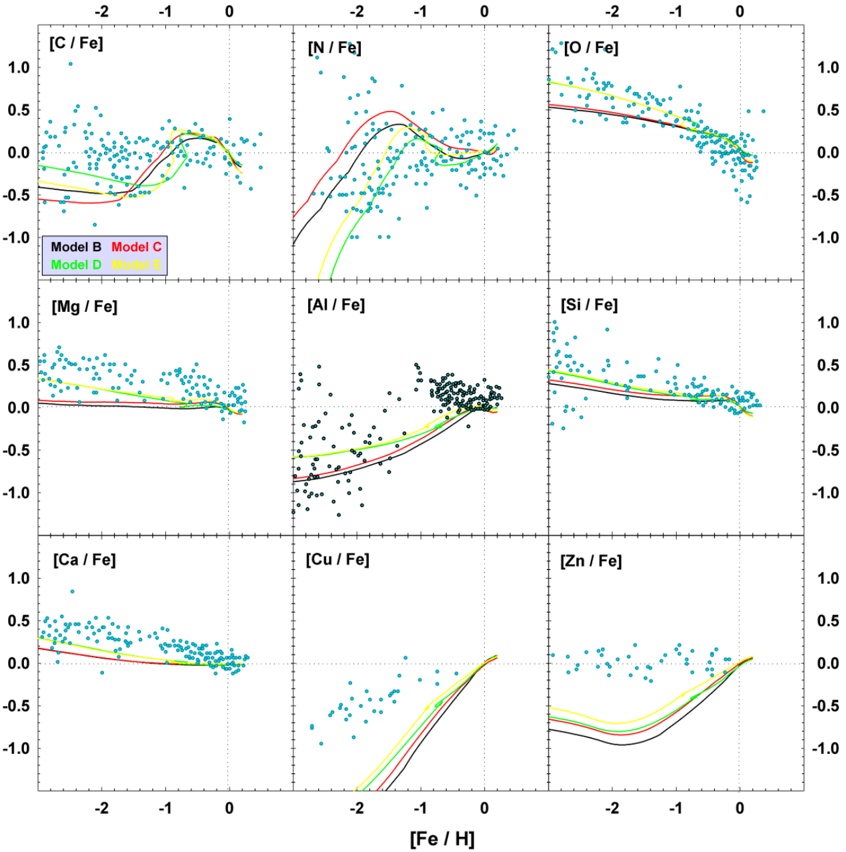
## Figure Caption
- Figure 1. The star formation rate (SFR, Mʘ pc -2 Myr -1 ) for the various GCE models.
- Figure 2. The estimated total baryonic surface mass density (Mʘ pc -2 ), the gas mass density, the stellar (+ stellar remnant) mass density, for the GCE models.
- Figure 3. The estimated supernova rates (in pc pc -2 Myr -1 ) for the various GCE models.
- Figure 4. The estimated evolution of [Fe/H] for the GCE models. The observational data of the F, G and K dwarf stars in the solar vicinity is also presented [4].
Figure 5. The estimated normalized elemental abundance evolution for the various simulations.The observational data of the F, G and K dwarf stars in the solar vicinity is also presented [5]. | null | [
"S. Sahijpal"
] | 2014-08-02T15:37:12+00:00 | 2014-08-02T15:37:12+00:00 | [
"astro-ph.GA"
] | Galaxy formation and chemical evolution | The manner the galaxy accretes matter along with the star formation rates at
different epochs, influence the evolution of the stable isotopic inventories of
the galaxy. A detailed analysis is presented here to study the dependence of
the galactic chemical evolution on the accretion scenario of the galaxy along
with the star formation rate during the early accretionary phase of the
galactic thick disk and thin disk. Our results indicate that a rapid early
accretion of the galaxy during the formation of the galactic thick disk along
with an enhanced star formation rate in the early stages of the galaxy
accretion could explain the majority of the galactic chemical evolution trends
of the major elements. Further, we corroborate the recent suggestions regarding
the formation of a massive galactic thick disk rather than the earlier assumed
low mass thick disk. |
1408.0388v1 | ## Computation of many-particle quantum trajectories with exchange interaction: Application to the simulation of nanoelectronic devices
## A. Alarc´n, S. Yaro, X. Cartoix` and X. Oriols o a
Departament d'Enginyeria Electr`nica, Universitat Aut`noma de Barcelona, 08193, o o Bellaterra, SPAIN
E-mail:
[email protected]
Abstract. Following Ref. [Oriols X 2007 Phys. Rev. Lett., 98 066803], an algorithm to deal with the exchange interaction in non-separable quantum systems is presented. The algorithm can be applied to fermions or bosons and, by construction, it exactly ensures that any observable is totally independent from the interchange of particles. It is based on the use of conditional Bohmian wave functions which are solutions of singleparticle pseudo-Schr¨dinger equations. o The exchange symmetry is directly defined by demanding symmetry properties of the quantum trajectories in the configuration space with a universal algorithm, rather than through a particular exchange-correlation functional introduced into the single-particle pseudo-Schr¨dinger equation. o It requires the computation of N 2 conditional wave functions to deal with N identical particles. For separable Hamiltonians, the algorithm reduces to the standard Slater determinant for fermions, or permanent for bosons. A numerical test for a two-particle system, where exact solutions for non-separable Hamiltonians are computationally accessible, is presented. The numerical viability of the algorithm for quantum electron transport (in a far-from equilibrium time-dependent open system) is demonstrated by computing the current and fluctuations in a nano-resistor, with exchange and Coulomb interactions among electrons.
## 1. Introduction
A system with N identical particles gives rise to a host of fascinating phenomena. Only those wave functions whose probability density remains unchanged under permutations of particles are a good description of such system. For separable Hamiltonians, these wave functions can be constructed from single-particle wave functions. However, for non-separable Hamiltonians, the computational burden associated with getting the N -particle wave function makes the exact solution inaccessible in most practical situations. This is known as the many-body problem [1].
There has been a constant effort among the scientific community to provide solutions to the many-body problem. The quantum Monte Carlo solutions of the Schr¨dinger o equation provide approximate solutions to exact many-particle Hamiltonians [2, 3]. The Hartree-Fock (HF) algorithm [4, 5] approximates the manyparticle wave function by a single Slater determinant of non-interacting single-particle wave functions. Although it is known that the Hartee-Fock wave function cannot approach the original many-particle wave function, it can provide useful information on the original ground state. Alternatively, density functional theory (DFT) shows that the charge density can be used to compute any observable without the explicit knowledge of the many-particle wave function [6, 7]. Practical computations within DFT make use of the Kohn-Sham theorem [8], which defines a system of N non-interacting single-particle wave functions that are able to provide a system of equations to find the exact charge density of the interacting system. However, the complexity of the many-body system is still present in the so called exchange-correlation functional, which is unknown and needs to be approximated. DFT has had a great success, mostly, in chemistry and material science [9], both, dealing with equilibrium systems. Similar ideas can also be used for non-equilibrium time-dependent scenarios, through the Runge-Gross theorem [10], leading to the time-dependent density functional theory (TDDFT). In contrast to the stationary-state DFT, where accurate exchange functionals exist, approximations to the time-dependent exchange-correlation functionals are still in their infancy. TDDFT has been reformulated in terms of the current density [11, 12] and extended into a stochastic time-dependent current density when the system is interacting with a bath [13].
The common strategy in all many-particle approximations is to obtain the observable result from mathematical entities defined in a real space, R 3 , (single-particle wave functions for HF and charge density for DFT) rather than from the many-particle wave function, whose support is defined in the configuration space R 3 N .
Bohmian mechanics [14, 15, 16, 17] is a consistent explanation of quantum phenomena based on the use of wave functions and trajectories. Apart from its ontological implications, Bohmian mechanics is nowadays used as a mathematical machinery that is able to reproduce the wave function evolution from fluid lines [18, 19, 20, 21, 22]. This is the point of view used in this work to study exchange interaction in many-particle systems [23]. In Bohmian mechanics one can naturally
find a single-particle wave function defined in R 3 , while still capturing many-particle features of the system. Such an entity is named conditional wave function [15], and it is built by substituting all degrees of freedom present in the many-particle wave function, except one, by its corresponding Bohmian trajectories. This substitution produces a single-particle wave function with a complicated time-dependence [18]. Recently, manyparticle Bohmian trajectories associated to the conditional wave function have been investigated by Oriols et al. [18, 24] and the idea of introducing exchange interaction into non-separable systems through conditional wave functions was briefly indicated in the seminal work of Ref. [18].
The purpose of this paper is to present an algorithm to introduce exchange interaction into non-separable systems through conditional wave functions following the idea of Ref. [18]. This paper includes physical discussions, technical details and numerical results, omitted in Ref. [18], that justifies the physical soundness of the proposal. The paper also includes the implementation of the exchange algorithm into a numerical simulator of quantum electron transport, justifying its numerical viability in practical systems. The paper is organized as follows. In section 2 we provide an introduction to many-particle wave functions and Bohmian mechanics. For such introduction, we will use many-particle wave functions for separable Hamiltonians. From a didactic point of view, these simple systems will be useful to discuss how the exchange interaction determines the behavior of the Bohmian trajectories of identical particles. In section 3, we will explain how to compute many-particle Bohmian trajectories for identical particles for non-separable Hamiltonians, without computing the manyparticle wave function. Ensemble results for the kinetic, classical and quantum potential energies will be discussed for systems with and without exchange interaction. Finally, in section 4, we show the numerical viability of the algorithm to include exchange and Coulomb interaction for electron transport simulators. In section 5 we present the conclusions and some additional discussions.
## 2. Many-particle trajectories from many-particle wave functions
In this section, we introduce many particle wave functions and Bohmian mechanics to explain general properties of Bohmian trajectories associated to identical particles. These discussions will be of great utility in the subsequent sections.
## 2.1. Summary of many-particle wave function
For non-relativistic open systems of N -particles, a general expression for a many-particle wave function, Φ ≡ Φ( /vector r , .., /vector 1 r N , t ), with or without exchange interaction, is:
$$\Phi & = C \sum _ { s _ { z j } } \Psi _ { s _ { z 1 }, \dots, s _ { z N } } ( \vec { r } _ { 1 },.., \vec { r } _ { N }, t ) \gamma ( s _ { z 1 },.., s _ { z N } ), & ( 1 ) \\ \intertext { h o r o c o n t e t h e n o i t i o n o f t h a t i o d e n d e n d e n d e n d e n d e n d e n d e n d e n d e n d e n d e n d e n d e n d e n d e n d e n d e n d e n d e n d e n d e n d e n d e n d e n d e n d e n d e n d e n d e n d e n d e n d e n d e n d e n d e n d e n d e n d e n d e n d e n d e n d e n d e n d e n d e n d e n d e n d e n d e n d e n d e n d e n d e n d e n d e n d e n d e n d e n d e n d e n d e n d e n d e n d e n d e n d e n d }$$
where /vector r j represents the position of the j -th particle and s zj is the z -component of its spin, which can take the value s zj = /planckover2pi1 / 2 (or ↑ j ) for spin up and s zj = -/planckover2pi1 / 2 (or ↓ j )
for spin down. The normalization constant is C . The sum in (1) is over all possible combinations of spin [25].
In most discussions of this paper (except the numerical results discussed in section 4) we will assume that the quantum system is described by just one of the terms in (1). In particular, we will consider the term where all spins are parallel, e.g., s zj = ↑ j for j = 1 , ...N . In order to simplify our notation, the orbital part of this term will be written as Ψ ≡ Ψ( /vector r , .., /vector 1 r N , t ), without any reference to the spins because their interchange becomes irrelevant. Therefore, the (orbital) wave function is solution of the following many-particle Schr¨dinger equation: o
$$\mu _ { \mu } ^ { \mu } & \quad i \hbar { \frac { } { } } \partial t = \left ( \sum _ { k = 1 } ^ { N } - \frac { \hbar { \ } ^ { 2 } } { 2 m } \nabla _ { k } ^ { 2 } + U ( \vec { r } _ { 1 },.., \vec { r } _ { N }, t ) \right ) \Psi, \\ \text{where $m$ is the free electron mass and $U(\vec{r}_{1},\dots,\vec{r}_{N},t)$ is a non-separable potential. By}$$
where m is the free electron mass and U /vector ( r , . . . , /vector 1 r N , t ) is a non-separable potential. By construction, we know that the solution of (2) satisfies the following continuity equation:
$$\text{there } \vec { I } _ { \infty } \, = \vec { I } _ { \infty } ( \vec { r } _ { k } ) \vec { J } _ { \vec { r } _ { k } } = 0, \\ \text{there } \vec { I } _ { \infty } \, = \vec { I } _ { \infty } ( \vec { r } _ { k } ) \quad \vec { r } _ { \infty } \, t ) \, \text{is the environment values of the current non-habilitiv} \, \text{density}$$
where /vector J /vector r k ≡ /vector J /vector r k ( /vector r , ..., /vector 1 r N , t ) is the expectation values of the current probability density [26] and | Ψ | 2 the presence probability density. This last result will be relevant in section 2.2 when presenting Bohmian trajectories.
Two particles are said to be identical if there are no experiments that can detect differences between them. This restriction on observable results can be satisfied by imposing the following property into the wave function Ψ of identical particles:
$$\Psi (., \vec { r } _ { j },., \vec { r } _ { h },., t ) = e ^ { i \gamma } \Psi (., \vec { r } _ { h },., \vec { r } _ { j },., t ),$$
for any j and h indices. We consider γ = 0 ( mod 2 π ) for bosons (symmetry) and γ = π ( mod 2 π ) for fermions (antisymmetry).
We say that the system has exchange interaction when the wave function satisfies (4). For physical systems of identical particles, the many-particle potential in (2) remains invariant under the permutation of two positions, i.e. U .,/vector ( r , ..., /vector j r h , ., t ) = U .,/vector ( r h , ..., /vector r , ., t j ) for any j and h , and the symmetry or antisymmetry property of the wave function in (4) for time t holds for all instants. Next, as a simple example of the difference between systems with and without exchange interaction, we discuss on the total energy, which will be useful later in section 4.
2.1.1. Example: The effect of exchange interaction on total energy We consider a system of N particles in free space. For simplicity, we consider 1D particles where its position is defined in R . Then, the many-particle wave function Ψ( x , ..., x 1 N , 0) at t = 0 can be constructed from the following single-particle Gaussian wave packets:
$$\psi _ { j } ( x _ { j }, 0 ) = \frac { \exp \left ( i k _ { o j } x _ { j } \right ) } { \left ( \pi \sigma _ { x _ { j } } ^ { 2 } \right ) ^ { 1 / 4 } } \exp \left ( - \frac { \left ( x _ { j } - x _ { o j } \right ) ^ { 2 } } { 2 \sigma _ { x _ { j } } ^ { 2 } } \right ),$$
where σ xj is the spatial dispersion, x oj the central position, E oj = ( /planckover2pi1 k oj ) 2 / (2 m ) the central energy of each wave packets and k oj the central wave vector.
In particular, the N -particle wave function Ψ( x , ..., x 1 N , 0) with exchange interaction can be defined from:
$$\Psi ( x _ { 1 },.., x _ { N }, 0 ) = C \, \sum _ { n = 1 } ^ { N! } \prod _ { j = 1 } ^ { N } \psi _ { j } ( x _ { p ( n ) _ { j } }, 0 ) \, \text{sign} ( \vec { p } _ { n } ), \\ \text{where the sum is over all $N$}! \, \text{permutations $\vec{p}_{n}$} \ = \ \{ p ( n ) _ { 1 } \dots p ( n ) _ { N } \} \text{ and } C \text{ is a}$$
where the sum is over all N ! permutations /vector p n = { p n ( ) 1 , ..., p ( n ) N } and C is a normalization constant. For fermions, the sign( /vector p n ) = ± 1 means the sign of the permutations, i.e. (6) is the Slater determinant. Alternatively, we will consider sign( /vector p n ) = 1 for bosons, meaning that (6) has to be interpreted as the permanent.
On the other hand, the wave function for particles without exchange interaction can be written as:
$$\Phi ( x _ { 1 }, \dots, x _ { N }, 0 ) = \prod _ { j = 1 } ^ { N } \psi _ { j } ( x _ { j }, 0 ), \\ \text{which, by construction, is already well normalized to unity. The ensemble value of the}$$
which, by construction, is already well normalized to unity. The ensemble value of the kinetic energy of the j -th particle belonging to a system of particles without exchange interaction is computed as:
$$\langle T _ { j } \rangle & = \int \dots \int \Psi ^ { * } \hat { T } _ { j } \Psi \ d x _ { 1 } \dots d x _ { N }, \\ \theta \, \text{line-interior over operator is } \hat { T }. \, - \frac { h ^ { 2 } } { } \frac { \partial ^ { 2 } } { } \text{ Horator
} \text{ \text{
\text{
\text{
\text{$$
The kinetic energy operator is ˆ T j = -/planckover2pi1 2 2 m∂x ∂ 2 2 j . Hereafter, unless specified, the spatial integrals are assumed to extend over the whole configuration space. The same expression (8) can be used for identical particles defined from the wave function in (6). Then, one can easily realize that 〈 T j 〉 = 〈 T h 〉 for any j and h indexes. As expected, one cannot discern between identical particles from the measurement of their kinetic energies.
We compute the behavior of the total kinetic energy 〈 T 〉 = 〈 T 1 〉 + 〈 T 2 〉 + 〈 T 3 〉 for three electrons (with parallel spins) with and without exchange interaction, as a function of the distance among the wave packets in the configuration space (see inset in figure 1). We define the normalized phase-space distance among the central positions and central wave vectors of two wave packets as [27]:
$$d ( 1, j ) ^ { 2 } & = \frac { ( k _ { o 1 } - k _ { o j } ) ^ { 2 } } { 2 \sigma _ { k } ^ { 2 } } + \frac { ( x _ { o 1 } - x _ { o j } ) ^ { 2 } } { 2 \sigma _ { x } ^ { 2 } } ; \ j = 2, 3, \\. &. &. &. &. &. &. &. &. &. &. &. &. &. &. &. &. &. &. &. &. &. &. &. &. &. &. &. &. &. &. &. &. &. &. &. &. &. &. &. &. &. &. &. &. &. &. &. &. &. &. &. &. &. &. &. &. &. &. &. &. &. &. &. &. &. &. &. &. &. &. &. &. &. &. &. &. &. &. &. &. &. &. &. &. &. &. &. &. &. &. &. &. &. &. &. &. &. &. &. &.. &. &. &. &. &. &. &. &. &. &. &. &. &. &. &. &. &. &. &. &. &. &. &. &. &. &. &. &. &. &. &. &. &. &. &. &. &. &. &. &. &. &. &. &. &. &. &. &. &. &. &. &. &. &. &. &. &. &. &. &. &. &. &. &. &. &. &. &. &. &. &. &. &. &. &. &. &. &. &. &. &. &. &. &. &. &. &. &. &. &. &. &. &. &. &. &. &. &. &.$$
where σ kj = 1 /σ xj is the wave vector dispersion. In figure 1, we plot, in a square (black) line, the mean value of the total kinetic energy of three electron (fermions) with exchange interaction, whose wave function is defined from (6). The result is repeated for different values of the distance d = d (1 , 2) = d (1 , 3) with the condition x o 1 -x o 2 = x o 3 -x o 1 and k o 2 -k o 1 = k o 3 -k o 1 seen in the inset of figure 1. Identically, we plot in up triangle (blue) line the total kinetic energy computed for three particles without exchange interaction, whose wave function is defined from (7). For large d , the values of the kinetic energy of the three electrons with and without exchange interaction are identical. For such large values of d , all electrons are placed far away from each other in the phase-space and
the exchange interaction has no effect. However, this is not true for small values of d . Then, the difference between the kinetic energy of electrons with or without exchange interaction increases as we place the three electrons closer inside the phase-space.
Figure 1: (Color online) Ensemble value of the kinetic energy for a 3-particle system with (square solid black line) and without (up triangle solid blue line) exchange interaction as function of their normalized phase-space distance d . The inset shows the positions of the central position and central wave vector of each wave packet in the phase-space, which are used to define the distance d among them.
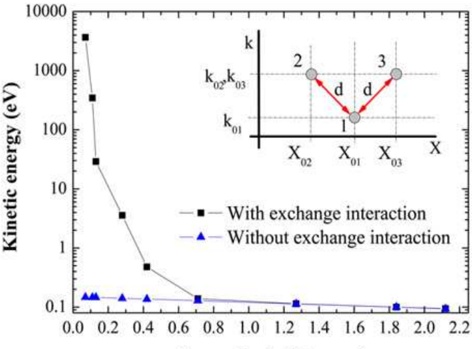
The result plotted in figure 1 is just (the wave packet version of) the celebrated Pauli exclusion principle: identical fermions cannot be in the same quantum state. The discussion has been done with three particles, instead of two, because in Appendix B we generalize the present example to three electrons with exchange interaction and different spins orientations.
## 2.2. Summary of many-particle trajectories
In Bohmian mechanics [14, 15, 16, 17], each particle of the system is represented by a trajectory guided by a wave. The wave is the many-particle wave function discussed above, Ψ( /vector r , ..., /vector 1 r N , t ), with all its computational difficulties. Such wave function satisfies the continuity equation, written in (3), that relates current and probability presence densities. From such continuity equation, one can easily define a (Bohmian) velocity /vector v j ( /vector r , ..., /vector 1 r N , t ) at each position of the configuration space as:
$$\psi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi\Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phis \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Psi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi
\Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Psilon \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \ Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phie \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi(\Phi)\Phi)\Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phip \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \psi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phis\Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \phie \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi\Psi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phis
\Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi\Phis\Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phis\Phis\Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Ph$$
The (Bohmian) trajectory of the j -th particle, /vector r l j [ t ], in real space can be defined by time-integrating (10) as:
$$\overset { \dots } { \dots } \overset { \dots } { \dots } \circ \overset { \dots } { \dots } \circ \overset { \dots } { \dots } \overset { \dots } { \dots } \overset { \dots } { \dots } \overset { \dots } { \dots } \overset { \dots } { \dots } \overset { \dots } { \dots } \overset { \dots } { \dots } \overset { \dots } { \dots } \overset { \dots } { \dots } \overset { \dots } { \dots } \overset { \dots } { \dots } \overset { \dots } { \dots } \overset { \dots } { \dots } \overset { \dots } \dots \\ \vec { r } _ { j } ^ { \prime } l t ] & = \vec { r } _ { j } ^ { \prime } [ 0 ] + \int _ { 0 } ^ { t } \vec { v } _ { j } ^ { \prime } ( \vec { r } _ { 1 } ^ { \dots } [ t ^ { \prime } ], \dots, \vec { r } _ { N } ^ { \dots } [ t ^ { \prime } ], t ^ { \prime } ) d t ^ { \prime }.$$
Obviously, one has to select the initial position /vector r l j [0] to perfectly specify the trajectory. The super-index l = 1 , ..., M on the trajectory accounts for the M →∞ different initial positions that can be selected. We refer to /vector r l j [ t ] as the Bohmian trajectory in R 3 , while we will refer to { /vector r l 1 [ t , .., /vector ] r l N [ t ] } as a many-particle (or N -particle) Bohmian trajectory in R 3 N .
The relevant property of these Bohmian trajectories that makes them meaningful for quantum computations is the fact that, by construction, a proper ensemble of them (with different initial positions) does exactly reproduce the time-evolution of the manyparticle wave function, at any time. A proper ensemble means that the initial positions, { /vector r l 1 [0] ..../vector r l N [0] } , are selected according to the probability distribution | Ψ( /vector r , ..., /vector 1 r N , 0) | 2 . This last condition is called 'quantum equilibrium hypothesis' [14, 28].
We can now deduce an important property of these trajectories that will be very relevant later. Since Ψ( /vector r , ..., /vector 1 r N , t ) is a single-valued wave function, the Bohmian velocity computed from (10) in each point of the configuration space is unique. This means that if two trajectories coincide at some point of the configuration space, then, they will coincide forever (because their velocities become identical). This well-known result can be summarized in a simple sentence: two many-particle Bohmian trajectories (with different initial positions) do not cross in the configuration space, either for bosons, fermions or non-identical particles [29].
Equivalently, the presentation of such trajectories can be done by introducing the polar form of the many-particle wave function ψ /vector ( r , .., /vector 1 r N , t ) = R /vector ( r , .., /vector 1 r N , t ) e iS /vector ( r 1 ,..,/vector r N ,t ) / /planckover2pi1 into (2). The modulus R ≡ R /vector ( r , .., /vector 1 r N , t ) and the phase S ≡ S /vector ( r , .., /vector 1 r N , t ) are real functions. Then, one obtains again, from the imaginary part of (2), the continuity equation defined in (3) in polar form:
$$\cdot \quad \frac { \partial R ^ { 2 } } { \partial t } + \sum _ { j = 1 } ^ { N } \vec { \nabla } _ { \vec { r } _ { j } } \left ( R ^ { 2 } \frac { \vec { \nabla } _ { \vec { r } _ { j } } S } { m } \right ) = 0,$$
where we recognize the velocity of the j -th particle as:
$$\vec { v } _ { j } ( \vec { r } _ { 1 },.., \vec { r } _ { N }, t ) & = \frac { \vec { \nabla } _ { \vec { r } _ { j } } S ( \vec { r } _ { 1 },.., \vec { r } _ { N }, t ) } { m }. \quad \ \. \quad \. \quad \. \quad \. \quad \. \quad \. \quad \. \quad \. \quad \. \quad \.$$
By construction [15], the velocity definition in (13) is identical to that in (10). On the other hand, the real part of the Schr¨dinger equation leads to a many-particle version o of the quantum Hamilton-Jacobi equation:
$$\bar { \ e r e s t e r e } \frac { \partial S } { \partial t } + U + \sum _ { j = 1 } ^ { N } \left ( K _ { j } + Q _ { j } \right ) = 0, \\ \intertext { r e r e $ U \equiv U ( \vec { r } _ { 1 }, \dots \vec { r } _ { s s. t } ) $ i s $ the $ \text{notential in (2)} $ and we have defined the (local)} $ \text{Bohmian}$$
where U ≡ U /vector ( r , .., /vector 1 r N , t ) is the potential in (2) and we have defined the (local) Bohmian kinetic energy as:
$$K _ { j } \equiv K _ { j } ( \vec { r } _ { 1 },.., \vec { r } _ { N }, t ) = \frac { 1 } { 2 } m \vec { v } _ { j } ( \vec { r } _ { 1 },.., \vec { r } _ { N }, t ) ^ { 2 },$$
and the (local) quantum potential energy:
$$Q _ { j } \equiv Q _ { j } ( \vec { r } _ { 1 },.., \vec { r } _ { N }, t ) = - \frac { \hbar { ^ { 2 } } } { 2 m } \frac { \vec { \nabla } _ { \vec { r } _ { j } } ^ { 2 } R ( \vec { r } _ { 1 },.., \vec { r } _ { N }, t ) } { R ( \vec { r } _ { 1 },.., \vec { r } _ { N }, t ) }.$$
When dealing with Bohmian trajectories, the ensemble kinetic energy defined in (8) is divided into two parts, 〈 ˆ T j 〉 = 〈 ˆ K j 〉 + 〈 ˆ Q j 〉 . The first part:
related to the local (Bohmian) kinetic energy K j ≡ K x ,...x j ( 1 N , t ), and the second part:
$$\left \langle \hat { K } _ { j } \right \rangle = \int \dots \int R ^ { 2 } \, K _ { j } \, d x _ { 1 } \dots d x _ { N }, \\ \text{lated to the local (Bohmian) kinetic energy } K _ { j } \equiv K _ { j } ( x _ { 1 }, \dots x _ { N }, t ), \, \text{and the second part} \colon$$
$$\left \langle \hat { Q } _ { j } \right \rangle = \int \dots \int R ^ { 2 } \, Q _ { j } \, d x _ { 1 } \dots d x _ { N }, \\ \mathbb { m } \text{ the quantum potential energy } Q _ { j } \equiv Q _ { j } ( x _ { 1 }, \dots, x _ { N }, t ).$$
to the quantum potential energy Q j ≡ Q x ,..., x j ( 1 N , t ).
2.2.1. Properties of many-particle Bohmian trajectories with exchange interaction Now, we can list a series of important properties for those ensembles of Bohmian trajectories that represents identical particles, i.e., when exchange interaction is present. In order to simplify the notation, we define /vector X = { /vector r , .., /vector 1 r N } . Identically, we define the N -particle Bohmian trajectory at time t = 0 as /vector X l [0] = { /vector r l 1 [0] , .., /vector r l N [0] } . Another set of initial conditions will be refereed as /vector X f [0] = { ., /vector r f h [0] , ., /vector r f j [0] , . } when it contains the same initials positions as /vector X l [0], but the two initial positions, /vector r l j [0] and /vector r l h [0], are interchanged. Because of (4), the modulus of the many-particle wave function satisfies:
$$R ( \vec { X } ^ { l } [ 0 ], 0 ) = R ( \vec { X } ^ { f } [ 0 ], 0 ),$$
for any such type of two set of initials conditions l and f . Identically, the phase satisfies:
$$S ( \vec { X } ^ { l } [ 0 ], 0 ) = \gamma + S ( \vec { X } ^ { f } [ 0 ], 0 ),$$
where γ = 0 ( mod 2 π ) for bosons (symmetry) and γ = π ( mod 2 π ) for fermions (antisymmetry). As discussed for the wave function, the requirements in (19) and (20) are satisfied at any time t . The property of (20) togther with the definition of the velocity in (13) implies:
$$\vec { v } _ { j } ( \vec { X } ^ { l } [ t ], t ) = \vec { v } _ { h } ( \vec { X } ^ { f } [ t ], t ).$$
This condition on the Bohmian velocities, which is valid for either bosons or fermions, has two relevant consequences. First, let us compare the two sets of many-particle trajectory with different initial positions mentioned above: the l -set and the f -set. Their difference are only /vector r l j [0] = /vector r f h [0] and /vector r l h [0] = /vector r f j [0]. Then, we realize from (21) that all Bohmian trajectories with identical initial conditions will be equal independently of the initial conditions, except the two trajectories which have their initial positions interchanged. For these trajectories, we get /vector r l j [ t ] = /vector r f h [ t ] and /vector r l h [ t ] = /vector r f j [ t ].
The second consequence of (21) is valid for those many-particle trajectories that have, at least, two equal components, i.e. /vector r l j [0] = /vector r l h [0] ≡ /vector a . Because of this coincidence,
we have /vector X l [0] = { ., /vector , a .,/vector , . a } and also /vector X f [0] = { ., /vector , a .,/vector , . a } which in fact are the same. Then, the condition /vector v j ( /vector X t , t l [ ] ) = /vector v h ( /vector X t , t f [ ] ) can be written as:
$$\vec { v } _ { j } ( \vec { X } ^ { l } [ t ], 0 ) = \vec { v } _ { h } ( \vec { X } ^ { l } [ t ], 0 ) \equiv v _ { a },$$
because /vector X l [0] = /vector X f [0]. Then, the trajectory /vector r l j [ t ] at the subsequent time /vector r l j [0 + dt ] = /vector a + /vector v dt a is identical to the other trajectory /vector r l h [0 + dt ] = /vector a + /vector v dt a . This result, means /vector r l j [ t ] = /vector r l h [ t ] at any time.
Because of the previous property and the non-crossing property of Bohmian trajectories discussed before [29], we have an important corollary. We define 'diagonal' many-particle trajectories as those trajectories where at least two components, /vector r l j [ t ] = /vector r l h [ t ], are identical (the rest of components can be different). Since other Bohmian trajectories cannot cross such 'diagonal' trajectories, all Bohmian trajectories are restricted to remain in subspaces of the configuration space. According to Ref. [30], Bohmian mechanics for identical particles can be described in a 'reduced' space R 3 N /S N , with S N the permutation space of N -particles.
Finally, we want to mention that in Bohmian computations, even with the symmetrization postulate, trajectories of particles are obviously distinguishable. One labels the trajectory of particle 1 as /vector r l 1 [ t ] and that of particle 2 as /vector r l 2 [ t ]. We have shown that, by construction, the Bohmian trajectories have special symmetry requirements. Then, all results for particle 1 computed from an ensemble of these trajectories will be identical to those computed for particle 2. In simple words, for a system of identical particles, Bohmian trajectories are distinguishable, while observable results associated to different particles become indistinguishable.
2.2.2. Example: The effect of exchange interaction on Bohmian trajectories Let us discuss, with some numerical examples, the previous properties of Bohmian trajectories of identical particles. In all the numerical examples of this subsection, we consider two free particles propagating, each one, in 1D physical space. The single-particle wave packets that will be used to construct the many-particle wave function at the initial time t = 0 are defined from (5).
First, we consider two electrons with a wave function Ψ( x , x 1 2 , t ) computed from (7), without any symmetry. See the initial modulus of the 2-particle wave function in figure 2. In particular, we consider E o 1 = 0 12 eV, . x o 1 = +50 nm and σ x 1 = 25 nm for the first wave packet, and E o 2 = 0 08 eV, . x o 2 = -50 nm and σ x 2 = 25 nm for the second. In order to see the spatial interaction of the two particles, the momentum of the first particle is negative and that of the second positive. We consider a free electron mass for both electrons. Once we know Ψ( x , x 1 2 , t ), we compute the (two-particle) Bohmian trajectory from (11) with different initial positions. As seen in figure 3, they correspond to roughly parallel lines.
In figure 4, we see that the quantum potential of either the first or the second particles are nearly zero. The total quantum potential, as the sum of the two particles, is plotted in dashed square (red) line. The ensemble (Bohmian) kinetic energy remains
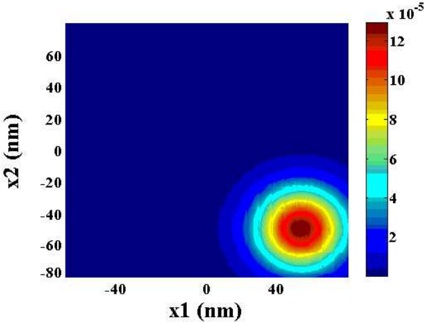
Figure 2: (Color online) Modulus of the wave function for two particles without exchange interaction in the 2D configuration space at t = 0 fs.
Figure 3: (Color online) Two-particles Bohmian trajectories with different initials conditions for particles without exchange interaction in a free space.
Figure 4: (Color online) Time evolution of the total and individual (ensemble average) energies of two-electron system without exchange interaction in free space.
equal to its initial value, 0 12 eV for the first wave packet in solid circle (blue) line and . 0 08 eV for the second in solid plus (blue) line. . The total energy in solid (green) line remains constant and equal to 0 2 eV, i.e., the sum of kinetic energies. . These simple Bohmian trajectories for non-identical particles move roughly like classical particles.
Next, we consider a wave function Ψ( x , x , t 1 2 ) of two identical electrons computed from the Slater determinant of (6) for N = 2. We use the same two initial gaussian wave packets discussed above. In figure 5(a), we plot the (symmetric) modulus of the manyparticle wave functions at t = 267 8 fs. . In particular, we get Ψ( a, a, t ) = 0 at any point { a, a } of the diagonal. In figure 6(a), we plot a set of Bohmian trajectories. The initials positions { x l 1 [0] , x l 2 [0] } are selected symmetrically with respect to the 'diagonal'. First, we observe that x l 1 [ t ] = x f 2 [ t ] and x l 2 [ t ] = x f 1 [ t ] when x l 1 [0] = x f 2 [0] and x l 2 [0] = x f 1 [0]. As discussed in section 2.2.1, the Bohmian trajectories corresponding to interchanged initial positions become symmetrical with respect to the diagonal points of the configuration space. Second, we observe that the Bohmian trajectories do not cross the diagonal.
In figure 7(a), we plot the energies of this two-particle fermion system. The total energy of the identical particles is equal to that of the particles without exchange interaction discussed in figure 4. The reason, as explained in section 2.1.1, is because the momentum of the wave packets are very different. One momentum is positive and the other negative and no Pauli effect is observed in the energy. However, since Bohmian trajectories are 'reflected' at the diagonal, their (bohmian) velocity becomes zero at that time. Then, the ensemble average of K x ,x ,t j ( 1 2 ) in (17) is almost zero, while the ensemble average of Q x ,x , t j ( 1 2 ) grows to keep the total energy constant. The same result can be argued by noting that the quantum potential in (16) depends on the curvature of the modulus, which becomes large at that points. In addition, in contrast to the two particles without exchange interaction discussed in figure 4, the (Bohmian kinetic plus quantum) energies of the first particle are identical to those of the second particle. The observable results of the energy of the individual particles are indistinguishable, while we can perfectly distinguish the trajectories in figure 5(a).
/negationslash
Finally, in figure 5(b), figure 6(b) and figure 7(b), we plot the same result as in the previous figures but considering two identical bosons. We use exactly the same parameters for the wave packets discussed in the previous figures. The only difference is that the initial wave function is computed from (6) when the sign( /vector p n ) is substituted by 1. Let us notice again the symmetric property of the modulus of the wave function in the configuration space. Although we have Ψ( a, a, t ) = 0 at the diagonal points { a, a } , we see in figure 6(b), that Bohmian trajectories do not cross that diagonal. This is an expected result because our discussions on the properties of Bohmian trajectories in section 2.2.1 do not depend on the bosonic or fermionic nature of particles. There is a Bohmian trajectory located along the diagonal points of the configuration space (not plotted) that does not allow to be crossed by other trajectories. The initials positions { x l 1 [0] , x l 2 [0] } are selected symmetrically with respect to the 'diagonal' and identical to the ones used for the fermions. Again, trajectories are symmetric under the exchange of initial positions. In figure 7(b), we plot the energies of the two-particle bosonic system.
The numerical results of the (Bohmian) kinetic energy for bosons (0.019 eV) are slightly lower than fermions (0.022 eV) when the wave packet is close to the diagonal of the configuration space. The reason is because there are more bosonic Bohmian trajectories that arrive closer to the diagonal in figure 5(b) and figure 6(b) than the fermionic ones in figure 5(a) and figure 6(a).
## 3. Many-particle trajectories without many-particle wave functions
As commented in the introduction, many attempts have been developed in the literature to provide accurate solutions to the many-body problem. Here, we briefly review one of this approximations presented by one of the authors in Ref. [18]. Then, we explain how the exchange interaction can be included in the mentioned approximation.
## 3.1. The conditional wave function
The main idea behind the many-body approximation mentioned in Ref. [18] is the fact that the computation of the Bohmian velocity for the /vector r a [ t ] trajectory from (10) only requires the spatial derivatives of Ψ( /vector r , .., /vector 1 r , .., /vector a r N , t ) on the /vector r a directions, and not on the rest of degrees of freedom. Thus, in principle, the trajectory /vector r a [ t ] can be equivalently computed from the many-body wave function Ψ( /vector r , ..., /vector 1 r N , t ) or from the following conditional wave function:
$$\Psi _ { a } ( \vec { r } _ { a }, t ) = \Psi ( \vec { r } _ { a }, \vec { X } _ { a } [ t ], t ),$$
where /vector X t a [ ] = { /vector r 1 [ t , /vector ] r a -1 [ t , /vector ] r a +1 [ t , /vector ] r N [ t ] } is a vector that contains all Bohmian trajectories except /vector r a [ t ]. We also use /vector X a = { /vector r , .../vector 1 r a -1 , /vector r a +1 , .., /vector r N } when referring to all the degrees of freedom except /vector r a . When not relevant, we avoid the superindex l in the Bohmian trajectory that specifies the initial positions of the trajectory. Certainly, the conditional wave function in (23) is defined in a much smaller configuration space, R 3 , than the many-body wave function. Thus, in principle, the conditional wave function needs much less computational effort than the explicit many-particle wave function. Following Ref. [18], the single-particle wave function Ψ ( a /vector r , t a ), that we will use to compute /vector r a [ t ], can be obtained as a solution of the single-particle Schr¨dinger equation: o
$$\text{unpow } r _ { a [ \nu ] }, \, \text{can use a non-zero} \, \text{on any} \, \text{equation}. \\ i \hbar { \frac { \partial \Psi _ { a } ( \vec { r } _ { a }, t ) } { \partial t } } & = \left ( - \frac { \hbar { ^ { 2 } } } { 2 m } \nabla _ { \vec { r } _ { a } } ^ { 2 } + U _ { a } ( \vec { r } _ { a }, \vec { X } _ { a } [ t ], t ) + G _ { a } ( \vec { r } _ { a }, \vec { X } _ { a } [ t ], t ) \\ + i J _ { a } ( \vec { r } _ { a }, \vec { X } _ { a } [ t ], t ) \right ) \Psi _ { a } ( \vec { r } _ { a }, t ). \\ \text{The exact definition of the terms } U _ { a } ( \vec { r } _ { a }, \vec { X } _ { a }, t ), \, G _ { a } ( \vec { r } _ { a }, \vec { X } _ { a }, t ) \text{ and } J _ { a } ( \vec { r } _ { a }, \vec { X } _ { a }, t ) \text{ can be}$$
The exact definition of the terms U a ( /vector r , X , t a /vector a ), G a ( /vector r , X a /vector a , t ) and J a ( /vector r , X a /vector a , t ) can be found in Ref. [18].
In brief, we have been able to decompose an irresolvable N -particle Schr¨dinger o equation into a set of N -single-particle Schr¨dinger o equation with time-dependent potentials [18]. At this point we realize that the extraordinary numerical simplification comes at the prize that there are terms in (24) which are unknown and need pertinent
Figure 5: (Color online) Modulus of the wave function for two identical particles in the 2D configuration space. (a) two fermions at t = 267 8 fs and (b) two bosons at . t = 178 5 fs. .
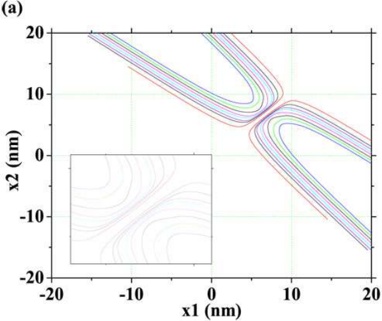
Figure 6: (Color online) Two-particle Bohmian trajectories with different initial conditions in free space. (a) Fermions and (b) bosons. The inset is a zoom of the diagonal non-crossing properties of Bohmian trajectories.
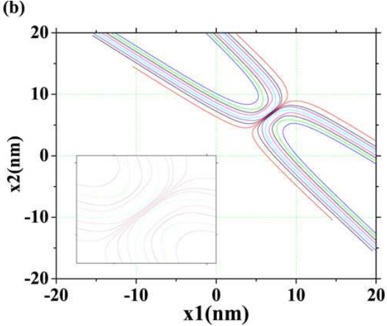
Figure 7: (Color online) Time evolution of the total and individual (ensemble average) energies of the two-particle system in a free space. (a) Fermions and (b) bosons.
approximations, G a ( /vector r , X a /vector a [ t , t ] ) and J a ( /vector r , X a /vector a [ t , t ] ). This is a similar situation to that in DFT discussed in the introduction.
3.1.1. Test for non-separable harmonic potentials without exchange interaction Next, in order to clarify the use of conditional (Bohmian) trajectories discussed above, we applied it to a simple system of two electrons without exchange interaction under a non-separable Hamiltonian. We consider two 1D particles so that the configuration space is R 2 . We use the non-separable potential energy:
$$U ( x _ { 1 }, x _ { 2 } ) = c ( x _ { 1 } - x _ { 2 } ) ^ { 2 },$$
where the factor c will allow us to modify arbitrarily the strength of the non-separable interaction. In particular, we will use c = 10 12 eV/m 2 . The many-body wave function Ψ( x , x , t 1 2 ) can be solved exactly from (2) with N = 2. Once the exact 2D wave function Ψ( x , x 1 2 , t ) is known, we can compute the exact 2D Bohmian trajectories straightforwardly from (10).
In figure 8, we have plotted the ensemble results of the (Bohmian) kinetic energy, (17), the quantum potential energy, (18), for the two electrons. We compute the results directly from the 2D exact wave function solution of (2). We emphasize that there is an interchange of kinetic energies between the first and second particles (see their kinetic energy in the first and second oscillations). This effect clearly manifests that the Hamiltonian of that quantum system is non-separable.
Alternatively, we can compute the trajectories used to compute figure 8 without knowing the many-particle wave function, but computing the conditional wave function Ψ ( a x , t a ) solution of (24) with the proper approximation for terms G a and J a . Here, we consider a zero order Taylor expansion around x a [ t ] for the unknown potentials terms G a and J a . In other words, we consider them as purely time-dependent potential terms, G a ( x , x a b [ t , t ] ) ≈ G ′′ a ( x a [ t , t ] ) and J a ( x , x a b [ t , t ] ) ≈ J ′′ a ( x a [ t , t ] ). This is the simplest approximation. Then, we know that the (complex) purely time-dependent terms G ′′ a ( x a [ t , X ] /vector a [ t , t ] ) and J ′′ a ( x a [ t , X ] /vector a [ t , t ] ) in the Hamiltonian of (24) only introduce a (complex) purely time-dependent phase. Then, we can write Ψ ( a x , t a ) as:
$$\Psi _ { a } ( x _ { a }, t ) = \tilde { \psi } _ { a } ( x _ { a }, t ) \exp ( z _ { a } ( t ) ),$$
where the term z a ( ) t is the (complex) purely time-dependent term that has no effect on the Bohmian trajectory x a [ t ], because this phase has no spatial dependence. Then, under the previous approximation, (24) can be simplified into the following equation for the computation of ˜ ( ψ a x , t a ):
$$i \hbar { \frac { \partial \tilde { \psi } _ { a } } { ( x _ { a }, t ) } } & = \left ( - \frac { \hbar { ^ { 2 } } } { 2 m } \frac { \partial ^ { 2 } } { \partial x _ { a } ^ { 2 } } + U _ { a } ( x _ { a }, x _ { b } [ t ] ) \right ) \tilde { \psi } _ { a } ( x _ { a }, t ), \\ \intertext { a r a b a t i o n i t i o n a r e i o n } \ e n \ h a \ I I I ( r _ { a }, r _ { b } [ t ] ) \, = \, \ e ( r _ { a }, \ e _ { b } [ t ] \vee 2 \ f o r \ a \ - \ 1 \ e n d }$$
Here, the potential energies can be U 1 ( x , x 1 2 [ t ]) = c x ( 1 -x 2 [ t ]) 2 for a = 1 and U 2 ( x , x 2 1 [ t ]) = c x ( 1 [ t ] -x 2 ) 2 for a = 2. The initial wave functions are ψ 1 ( x , 1 0) and ψ 2 ( x , 2 0) defined, both, form (5). In particular, we consider E o 1 = 0 06 eV, . x o 1 = 50 nm and σ x 1 = 25 nm for the first wave packet, and E o 2 = 0 04 eV, . x o 2 = -50 nm
and σ x 2 = 25 nm for the second. In general, we need N -conditional wave functions to compute one N -particle Bohmian trajectory. If we change the initials positions, we need new N -conditional wave functions.
Figure 8: (Color online) Time evolution of the total and individual (ensemble averaged) energies of two-electron system without exchange interaction under a non-separable potential.
In figure 9, we have plotted the same information than in figure 8 with our singleparticle 1D approximation algorithm explained in section 3.1. For this particular scenario, our simplest approximation for the unknown terms works perfectly and the agreement between 2D exact results and our 1D approximation is excellent. In general, potentials with small spatial variations are better adapted to the simplest 1 D approximation of the term G a and J a used in this work. We emphasize that the kinetic energy of the first and second particles are clearly distinguishable. We have compute the ensemble energies in order to justify that the algorithm is accurate not only for an arbitrarily selected set of Bohmian trajectory, but for most of them. In particular, the ensemble results are computed from 160000 two-particle Bohmian trajectories.
Figure 9: (Color online) Time evolution of individual (ensemble averaged) Bohmian kinetic energies of identical two-electron system without exchange interaction under non-separable potential computed from 2 D exact and 1 D approximate solutions.
3.2. Algorithm to include exchange interaction in many-particle Bohmian trajectories
Since (24) is valid for system with or without exchange interaction, one could look for approximations to the terms G a and J a different from the simplest one mentioned above in order to incorporate the exchange interaction directly into (24). However, from a computational point of view, such approximations seems quite difficult to implement. For example, in a system of fermions, we have seen that the wave function Ψ ( a /vector r , t a ) becomes zero everywhere /vector r a is equal to the position of another trajectory. At these positions, because of their dependence on the inverse of the modulus, we would obtain G a → ±∞ and J a → ±∞ . These infinities are difficult to treat numerically. In this subsection we present a different strategy that will be able to capture the exchange interaction avoiding the previous difficulties. The algorithm can be explained in four steps:
1.The first step is developing an expression for Ψ( /vector r , .../vector 1 r N , t ) as a sum of wave functions. Each one of these wave function without symmetry. For example, let us define Ψ ns ( /vector r , .../vector 1 r N , t ) as a many-particle wave function without any (bosonic or fermionic) symmetry. Then, we can construct a global wave function with exchange interaction using a sum of the term Ψ ns ( /vector r , .../vector 1 r N , t ) with all possible permutations of the positions:
$$\Psi & = C \sum _ { n = 1 } ^ { N! } \Psi _ { n s } ( \vec { r } _ { p ( n ) _ { 1 } },.., \vec { r } _ { p ( n ) _ { N } }, t ) \, \text{sign} \left ( \vec { p } ( n ) \right ), \\ \text{et us emphasize that each term } \Psi _ { n s } ( \vec { r } _ { n ( n ) },., \vec { r } _ { n ( n ) _ { n } },.., \vec { r } _ { n ( n ) _ { x } }, t ) \text{ is also a solution of}$$
Let us emphasize that each term Ψ ns ( /vector r p n ( ) 1 , /vector r p n ( ) 2 , ..., /vector r p n ( ) N , t ) is also a solution of a many-particle Schr¨dinger o equation for non-separable Hamiltonian without special exchange symmetry requirements. Finally, the conditional wave function Ψ ( a /vector r , t a ) extracted from (28) can be written as:
$$\Psi _ { a } ( \vec { r } _ { a }, t ) = C \sum _ { n = 1 } ^ { N! } \Psi _ { n s } ( \vec { r } _ { p ( n ) _ { 1 } } [ t ],., \vec { r } _ { p ( n ) _ { e } },., \vec { r } _ { p ( n ) _ { N } } [ t ], t ) \times \text{sign} \left ( \vec { p } ( n ) \right ). \quad \text{(29)} \\ \text{Ne have substituted all positions} \, \text{hv the corresponding trajectory event} \, \text{the degree of}$$
We have substituted all positions by the corresponding trajectory except the degree of freedom /vector r p n ( ) e = /vector r a .
2.- The second step is solving each wave function Ψ ns ( /vector r p n ( ) 1 [ t , ..., /vector ] r p n ( ) e , ..., /vector r p n ( ) N [ t , t ] ) present in (29) as a solution of (24). Since Ψ ns has no exchange interaction, we can look for a solution similar to the one mentioned in the example in section 3.1.1. Then, we can write Ψ ns ≡ Ψ ns ( /vector r p n ( ) 1 [ t , ..., /vector ] r p n ( ) e , ..., /vector r p n ( ) N [ t , t ] ) as:
$$\Psi _ { n s } = \tilde { \psi } _ { p ( n ) _ { e }, a } ( \vec { r } _ { a }, t ) \exp ( z _ { p ( n ) _ { e }, a } ( t ) ),$$
where the term z p n ( ) e ,a ( ) t is the (complex) purely time-dependent term related to G ′′ a ( /vector r a [ t , X ] /vector a [ t , t ] ) + J ′′ a ( /vector r a [ t , X ] /vector a [ t , t ] ). The subindex a in ˜ ψ p n ( ) e ,a ( /vector r , t a ) specifies which are the potential U a ( /vector r , X a /vector a [ t , t ] ) used when solving (27). The other subindex p n ( ) e identifies the initial wave function, as explained in next step.
3.- The third step is finding the initial wave function ˜ ψ p n ( ) e ,a ( /vector r , a 0). When dealing with quantum transport, we can assume that the initial many-particle wave function is
located far from the active region (deep inside the reservoirs in a free space region) where it can be written as a Slater determinant (or permanent) as in (6) only during the time t = 0. Then, we can easily realize that the initial state defining ˜ ψ p n ( ) e ,a ( /vector r , a 0) ≡ ψ /vector, l ( r 0) is the particular wave packet of the ones defined in (5) which accomplishes p n ( ) e = a (see Refs. [15] and [31]).
4.The fourth step, once we know all wave functions ˜ ψ p n ( ) e ,a ( /vector r , t a ), is to compute the many-particle wave function Ψ ( a /vector r , t a ) = Ψ( /vector r 1 [ t , .../vector ] r a -1 [ t , /vector ] r , /vector a r a +1 [ t , .. ] ) in (29) as:
$$\Psi _ { a } ( \vec { r } _ { a }, \vec { X } _ { a } [ t ], t ) & = C \sum _ { n = 1 } ^ { N! } \tilde { \psi } _ { \vec { p } ( n ), a } ( \vec { r } _ { a }, t ) \times \exp \left ( z _ { \vec { p } ( n ), a } ( t ) \right ) \, \text{sign} \left ( \vec { p } ( n ) \right ). \quad \text{$31$} \\ \text{We have to specify the values of the unknown hashes $z_{1}$} \ \ ( t \, \cdots \ \text{$We will $fv$}$$
We have to specify the values of the unknown phases z p n ( ) e ,a ( ). t We will fix these phases trying to satisfy the symmetry requirements of the Bohmian trajectories discussed in section 2.2.1. In particular, we will demand that the observable results associated to different particles are indistinguishable. The following phases z /vector p n ,a ( ) ( ) t accomplish the previous symmetry condition:
/negationslash
In the Appendix A we show that this condition is enough to ensure that ensemble results of different particles are identical.
$$\mu \quad & \quad \exp \left ( z _ { \vec { p } ( n ), a } ( t ) \right ) = \prod _ { k = 1, k \neq a } ^ { N } \tilde { \psi } _ { p ( n ) _ { e }, a } ( \vec { r } _ { k } [ t ], t ). \\ \intertext { the Appendix A we show that this condition is enough to ensure that ensemble results }$$
These are the four necessary steps needed to compute an N -particle Bohmian trajectory with exchange interaction for non-separable Hamiltonians. Let us discuss the number of conditional wave functions that we need for each N -particle Bohmian trajectory. We realize that we have N possible initial wave functions ψ /vector l ( r , a 0) in (31). Since the potential U a ( /vector r , X a /vector a [ t , t ] ) is invariant under the exchange of trajectories different than /vector r a [ t ], there are only N different potentials needed. Then, when computing the N ! functions ˜ ψ p n ( ) e ,a ( /vector r , t a ) present from (31), we realize that there are many repeated solutions. Therefore, there are N × N different wave functions ˜ ψ l,a ( /vector r , t a ) that we have to solve in order to compute (31). The N × N correspond to e = 1 , ..., N different potentials and a = 1 , ...., N different initial wave packets.
In addition, it is important to notice what is the result of our algorithm when the non-separability of the Hamiltonian becomes negligible but the exchange interaction is still present. Then, we directly recover the Slater determinant (or permanent) defined in (6). Finally, we want to emphasize that the algorithm for the inclusion of the exchange interaction is universal in the sense that exactly the same 4 steps have to be followed for any system.
3.2.1. Test for non-separable harmonic potentials with exchange interaction In order to clarify the explanation of the exchange algorithm, we applied it to the same system discussed in section 3.1.1 but with the exchange interaction included. In figure 10, we have plotted the ensemble results of the (Bohmian) kinetic energy, (17), the quantum
potential energy, (18), computed directly from the two-particle wave function 2D exact solution of (2) for two identical electrons (with parallel spins). In particular, we consider fermions with the some potential and initial wave packets that we discuss in section 3.1.1. Now, the energies of particle 1 and 2 become indistinguishable. In addition, we realize that the fact that Bohmian trajectories cannot cross the diagonal of the configuration space, implies a decrease/increase of the (Bohmian) kinetic/quantum energy when the wave function crosses the diagonal. This is the same effect discussed previously in section 2.2.2.
Figure 10: (Color online) Time evolution of the total and individual (ensemble averaged) energies of identical two-electron system with exchange interaction under non-separable potential.
Finally, we compute the same results as in figure 10 with the 1D approximated conditional wave functions discussed in section 3.2. Now, we have to compute 4 different functions, ˜ ψ l,a ( x , a 0). The wave function ˜ ψ 1 1 , ( x , 1 0) has initial wave function ψ 1 ( x , 1 0) defined from (5) and the potential U 1 ( x , x 1 2 [ t ]) = c x ( 1 -x 2 [ t ]) 2 . The wave function ˜ ψ 1 2 , ( x , t 2 ) has the same initial state ψ 1 ( x , 2 0) but different potential energy U 2 ( x , x 2 1 [ t ]) = c x ( 1 [ t ] -x 2 ) 2 . Finally, ˜ ψ /vector 2 1 , ( x , t 1 ) has initial state ψ 2 ( x , 1 0) and potential U 2 ( x , x 2 1 [ t ]) = c x ( 1 [ t ] -x 2 ) 2 , while ˜ ψ /vector 2 2 , ( x , t 2 ) has the same initial state ψ 2 ( x , 2 0) and U 1 ( x , x 1 2 [ t ]) = c x ( 1 -x 2 [ t ]) 2 . The final wave functions Ψ ( l 1 x , t 1 ) and Ψ ( l 2 x , t 2 ) for the computation of the Bohmian trajectory, x l 1 [ t ] and x l 2 [ t ] are, respectively:
$$\Psi _ { 1 } ^ { l } ( x _ { 1 }, t ) & = C \left ( \tilde { \psi } _ { 1, 1 } ^ { l } ( x _ { 1 }, t ) \tilde { \psi } _ { 2, 2 } ^ { l } ( x _ { 2 } [ t ], t ) \ - \tilde { \psi } _ { 2, 1 } ^ { l } ( x _ { 1 }, t ) \tilde { \psi } _ { 1, 2 } ^ { l } ( x _ { 2 } [ t ], t ) \right ), \\ \Psi _ { 2 } ^ { l } ( x _ { 2 }, t ) & = C \left ( \tilde { \psi } _ { 1. 1 } ^ { l } ( x _ { 1 } [ t ], t ) \tilde { \psi } _ { 2. 2 } ^ { l } ( x _ { 2 }, t ) - \tilde { \psi } _ { 2. 1 } ^ { l } ( x _ { 1 } [ t ], t ) \tilde { \psi } _ { 1. 2 } ^ { l } ( x _ { 2 }, t ) \right ).$$
We emphasize that we require four single-particle wave functions for each 2-particle trajectory { x l 1 [ t , x ] l 2 [ t ] } . As discussed previously, the algorithm with exchange scales as N 2 . In figure 11, we have plotted the information about the energies for the same electrons discussed in section 3.1.1. The agreement between the exact 2D results and the approximate 1D ones for identical particles is acceptable. Let us emphasize that the excellent agreement in figure 9 and the results of figure 11, both, have been computed
$$\Psi _ { 2 } ^ { l } ( x _ { 2 }, t ) = C \, \overset { \bullet } { \left ( \tilde { \psi } _ { 1, 1 } ^ { l } ( x _ { 1 } [ t ], t ) \tilde { \psi } _ { 2, 2 } ^ { l } ( x _ { 2 }, t ) - \tilde { \psi } _ { 2, 1 } ^ { l } ( x _ { 1 } [ t ], t ) \tilde { \psi } _ { 1, 2 } ^ { l } ( x _ { 2 }, t ) \right ) } ^ { \prime }. \quad \text{(34)} \\ \text{We emphasize that we require four single-particle wave functions for each $2$-particle}$$
with the mentioned approximations on the terms G a and J a in (24). However, the algorithm with exchange interaction is more sensible to the approximations because we have to deal with Ψ ( l a x , t a ) that are very close to zero at the diagonal of the configuration space. A small deviation (due to the approximate G a and J a ) in the value of the modulus close to zero becomes an amplified deviation in the velocity, as seen in (10), which is inversely proportional to the modulus. This difficulty is not present in the results of figure 9 because, there, trajectories are not forced to be closer to regions where the modulus is zero. This difficulty is also manifested in the quantum potential. See the importance of the quantum potential in the 2 D exact result with exchange interaction at 1100 fs in figure 10 (red lines), while the quantum potential is negligible in the 2 D exact results without exchange interaction, as seen in figure 8 (red lines).
All (ensemble) results presented in this work can be explained in terms of individual trajectories (each trajectory with different initial conditions). Thus, the error in the ensemble results in figure 11 is due to errors in some individual trajectories, not all (mainly those trajectories starting outside of the center of the wave packet and arriving at regions where the wave function is almost zero). The total number of trajectories is 2 × 160000 (computed from 4 × 160000 conditional wave functions). A wrong trajectory will never be converted into a correct one at a later time. On the contrary, one can expect that a correct trajectory at some particular time can become a wrong one at a later time due to the approximations in G a and J a . In any case, a better approximation of the unknown terms G a and J a in (24) for systems without exchange will improve the accuracy of the algorithm with exchange. An interesting path to improve the approximations in the unknown terms G a and J a of the equation of the conditional wave function can be obtained by following Ref. [35]. It is showed there that the terms G a and J a in (24) can be computed, in principle, from a (infinite) set of coupled differential equations. A practical implementation will certainly require cutting the infinite set somewhere.
Figure 11: (Color online) Time evolution of the individual (ensemble averaged) Bohmian kinetic energies of two-electron system with exchange interaction under non-separable potential computed from 2 D exact and 1 D approximate solutions.
The most relevant feature is that the ensemble results for the first and second particle become indistinguishable with our 1D approximated conditional wave functions (see circle, plus, cross and square symbols in figure 11), although we perfectly distinguish Bohmian trajectories labeled as { x l 1 [ t , x ] l 2 [ t ] } .
## 4. Numerical results for electron transport simulation
Now, we use the general algorithm (with exchange interactions in non-separable Hamiltonians) to study quantum electron transport. The numerical implementation of the algorithm has been included into our simulator BITLLES (Bohmian Interacting Transport for non-equiLibrium eLEctronic Structures) [32]. It is a general, versatile and time-dependent 3 D electron transport simulator that allows the computation of DC, AC, transient and current and voltage fluctuations (noise) for nanoelectronic devices [15]. We compute the influence of the exchange interaction on the static and dynamic performance of a simple nano-resistor. We consider explicitly the Coulomb and exchange interaction among electrons inside the device active region. No other scattering mechanics is considered in the simulations. The details of the injection model for electrons (with a Binomial distribution) are explained in Appendix C.
## 4.1. Definition of the simulation system with arbitrary spins
We consider a set of free electrons moving under the influence of the Coulomb and exchange interaction inside a device active region, when an external bias is applied between source and drain (see figure 12). Electrons are injected into the device with an arbitrary spin. Therefore, in principle, we would have to consider several terms (each one with different spin distributions) in the many-particle wave function (1) to treat properly the exchange interaction. The consideration of many terms in (1) would imply an intractable computational burden, as mentioned in Appendix B. Alternatively, we can assume that the effect of the exchange interaction on the dynamics of an electron with spin up ↑ (down ↓ ) is due only to the other electrons with spin up ↑ (down ↓ ). Therefore, in this work we will assume that the many-particle wave function can be separated into a product of spin-up and spin-down many-particle wave functions. For the example, we will consider that the wave function with arbitrary spins Ψ ↑ 1 , ↓ 2 , ↓ 3 , ↑ 4 ( /vector r , /vector 1 r , /vector 2 r , /vector 3 r , t 4 ) γ ( ↑ 1 , ↓ 2 , ↓ 3 , ↑ 4 ), can be approximated as the product Ψ ( ↑ /vector r , /vector 1 r , t 4 ) γ ( ↑ 1 , ↑ 4 ) by Ψ ( ↓ /vector r , /vector 2 r , t 3 ) γ ( ↓ 2 , ↓ 3 ):
$$& \Psi _ { \uparrow 1, \downarrow _ { 2 }, \downarrow _ { 3 }, \uparrow _ { 4 } } ( \vec { r } _ { 1 }, \vec { r } _ { 2 }, \vec { r } _ { 3 }, \vec { r } _ { 4 }, t ) \gamma ( \uparrow _ { 1 }, \downarrow _ { 2 }, \downarrow _ { 3 }, \uparrow _ { 4 } ) \approx \\ & \Psi _ { \uparrow } ( \vec { r } _ { 1 }, \vec { r } _ { 4 }, t ) \gamma ( \uparrow _ { 1 }, \uparrow _ { 4 } ) \Psi _ { \downarrow } ( \vec { r } _ { 2 }, \vec { r } _ { 3 }, t ) \gamma ( \downarrow _ { 2 }, \downarrow _ { 3 } ).$$
From this approximation, we can apply our algorithm presented in section 3.2 to Ψ ↑ and Ψ independently. However, there are some terms in the left hand side of (35) that are ↓ not present in the right hand side (see Appendix B). The approximation (35) has already
been tested in [33]. In the mentioned reference, it is shown that this approximation is almost an exact result when the normalized distance d defined in (9) is larger than 1. For closer electrons, d smaller than 1, an error appears in the computation of the Bohmian velocity [33]. On the other hand, we explicitly consider the Coulomb interaction among all the electrons, regardless of their spin. Therefore, we can expect that electrons try to be spatially separated, i.e. large d , because of the Coulomb repulsion among electrons. This argument provides an additional justification on the validity of (35) when study quantum electron transport (with Coulomb and exchange interaction). Finally, let us notice that the number of particles varies as the simulation progress, i.e., we are dealing with a more complex many-particle wave function than that represented in (1).
In figure 12 we show a scheme of the nano-resistor that we will simulate with two GaAs source/drain doped contacts with a Fermi level of 0 15 eV above the conduction . band and a device active region of intrinsic GaAs with length L x = 30 nm. Transport takes place in the x direction with room temperature in all simulations. A single spherical band with m ∗ GaAs = 0 067 . m 0 (and m 0 the electron free mass) is considered. Because of the geometry L x /greatermuch L , L y z , with L y = L z = 9 nm, energy confinement takes place in the lateral directions. We only take into account the first energy of the subband of GaAs with a value of E 1 = 0 13 eV just above the bottom of the conduction band. .
Figure 12: (Color online) Scheme of a nano-resistor with N + AsGa source/drain doped contacts and intrinsic AsGa in the device active region. The device dimension are L x = 30 nm, L y = L z = 9 nm. A Fermi level of 0 15 . eV and room temperature are considered.
## 4.2. Computation of I-V characteristic
In figure 13, we present the time-averaged current 〈 I 〉 as a function of the external bias for four different scenarios: Coulomb and exchange interactions (CEI), without exchange or Coulomb interactions (WI), with Coulomb interaction alone (CI) and with exchange interaction alone (EI). It is clear that the differences observed in the different curves are mainly a direct consequence of the Coulomb interaction. Somehow, for our particular device, the Coulomb interaction screens the effect of the exchange interaction because most of the electrons (not all) are already repelled by the Coulomb interaction. We emphasize that we are using Coulomb interaction beyond mean field, with selfinteraction correction [24]. The presence of Coulomb interaction tends to reduce the current because there are less electrons in the channel. Electrons repel each other.
For each simulated electron, we know when it enters the simulation box, t l in , and when it leaves t l out . The superindex l indicates which Bohmian trajectory is associated to the electron. Identically, we know whether the electron enters (leaves) the simulation box from the source (S) or drain (D) contacts. Then, we compute:
$$d _ { A / B } & = \sum _ { l _ { A / B } } \int \Theta ( t - t ^ { l } _ { i n } ) \Theta ( t ^ { l } _ { o u t } - t ) d t, \\ \intertext { w h o r o \ t h o \ H e a v i i d o \ e t o \ f n c t i o \ i e \ \Theta ( t ) } \, - \, 1 \ f o r \ \text{activo time and } \Theta ( t ) \, - \, 0 \ f o r$$
where the Heaviside step function is Θ( ) t = 1 for positive times and Θ( ) t = 0 for negatives ones. The time integral is over the whole simulation time. The sum is over all l -trajectories that have entered through the contact A = { S, D } and leave through B = { S, D } . In figure 14(a), we plot d S/D /d and d D/S /d , and in figure 14(b) d S/S /d and d D/D /d , where we have defined d = d S/D + d D/S + d S/S + d D/D . Electrons crossing the active region, d S/D and d D/S , are responsible for the DC (i.e. zero frequency) behavior. On the other hand, electrons that do not cross the device active region, d S/S and d D/D , do not contribute to DC, but only to high-frequency dynamics.
At zero bias, as seen in figure 14(a), without interaction (WI), half of electrons are transmitted from source to drain and half from drain to source. No reflected electrons. This is not true for the rest of scenarios. The EI simulation provides reflected electrons because of the effect seen in section 2.2.2, that forbids electrons from occupying the same positions (i.e. the diagonals points of the configuration space) and some of the electrons are finally bounced. Let us emphasize that the mean number of electrons in the active region of the quantum wire of figure 12 can be very small. From the current in figure 13, we can compute the rate of transmitted electrons which is quite similar to their transit time. The CI (and CEI) simulation shows reflected because of the Coulomb repulsion among electrons. Finally, we focus on set of plots d D/D /d (from drain to drain) in figure 14(b). At a 0.05 V, the EI simulation has a larger value d D/D /d than the others. This result does not implies a larger number of reflected particles with EI simulation, but only that these EI reflected particles spent more time inside the active region than, for example, the CI and CEI ones. The reflection in the EI simulation occurs when the particles are really very close, see figure 6(a), while the reflection in the CI simulation occurs for particles with a larger spatial separation. The Coulomb interaction has a longer range than the particular (exchange interaction) effect seen in figure 6(a). Thus, these CI and CEI particles spent less time in the active region. This result justifies again why the Coulomb interaction, somehow, screens the possible effects of the exchange interaction.
## 4.3. Computation of the noise
From the time-dependent current I ( ) provided by the Monte Carlo t BITLLES simulator we can also study the noise characteristics of this simple nano-resistor in a very simple way [34]. The fluctuations of the current can be easily obtained from the autocorrelation function R τ ( ) = ∆ I ( )∆ t I ( t + ) of the current fluctuations ∆ τ I ( ) = t I ( ) t -〈 〉 I being I ( ) t the instantaneous current provided by the quantum Monte Carlo BITLLES simulator
Figure 13: (Color online) The average current as a function of the applied bias for the simulated system in four different situations: Coulomb and exchange interactions, without interactions, Coulomb interaction, and exchange interaction.
Figure 14: (Color online) Normalized (mean) time spent by the electrons inside the simulating box as a function of the applied voltage for the four different scenarios discussed in figure 13. (a) from drain to source, d D/S /d , and from source to drain, d S/D /d . (b) from the drain that have been finally bounced, d D/D /d and from the source that have been finally bounced, d S/S /d
and 〈 I 〉 the time-average DC current computed above. The Fourier transform of this autocorrelation function R τ ( ) is the noise power spectral density of S f ( ) = ∫ ∞ -∞ R τ e ( ) -i 2 πfτ dτ . Finally, the Fano factor, defined as the ratio γ = S (0) /S schottky with S Schottky ( f ) = 2 q 〈 I 〉 , can be computed.
In figure 15 we show the noise power spectral density as a function of the frequency
Figure 15: (Color online) Noise power spectral density as a function of the frequency for four applied bias. (a) V DS = 0.01 V (b) V DS = 0.02 V (c) V DS = 0.1 V (d) and V DS = 0.2 V.
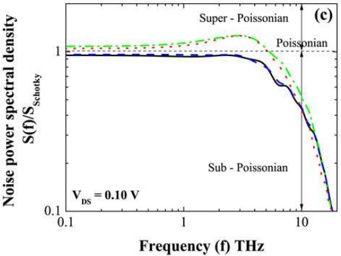
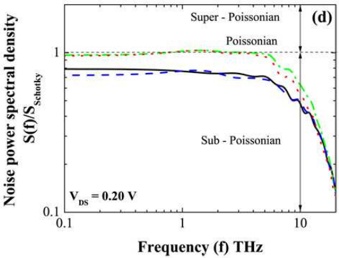
for four different bias. The Fano factor decreases as we increase the voltage. Since we are simulating at room temperature, for low bias tending to zero, the current tends to zero while the thermal noise is still present giving a Fano factor tending to infinite. For high bias, the fluctuations follows the Binomial distribution (C.2) that roughly tends to a Poissonian one for electrons with energy above the Fermi level (as is the case for the sample with confinement discussed here). Deviations from this behavior are due to correlations originated from Coulomb and exchange interactions. First, we observe in figure 15 that, similarly to DC, the the most important effect on the Fano factor is due to the Coulomb interaction (see CI and CEI in figure 15). As we see in figure 15(d), the Fano factor is lower than one with CEI or CI simulations. It is well-known that the Coulomb repulsion between electrons tends to space them more regularly rather than strictly at random, and to evidence a sub-Poissonian statistics [36, 37]. However, we see that the small deviations between the CEI and CI results are influenced by the exchange interaction present in the simulation box. When EI is larger than CI, the CEI is larger than CI, and vice-verse. Secondly, we observe that the effect of the exchange interaction in the noise is more important at low bias. This result has the same explanation that we explain in the previous figure 13 and figure 14. Thirdly, in figure 15(b) and (c), at intermediate bias, we see a peak of the noise power spectral density above 1THz. One can realize that this peak in the fluctuations appears when only WI or EI are considered. The origin of this peak is the increment of the number of reflected electrons because
they cannot occupy identical positions. These bounced electrons do not affect the zero (low) frequency fluctuations, but they affect the high-frequency values. This increment of reflected particles can be seen in figure 14(b).
Finally, as discussed in the injection process in Appendix C, we want to mention that wave packets with identical central positions and wave vectors are injected with a temporal separation between them equal to t 0 that tries to avoids relevant exchange interaction effects among them inside the simulating box.
## 5. Discussion and conclusions
In this work we have presented an algorithm for introducing the exchange interaction into the many-particle quantum (Bohmian) trajectories with an universal protocol valid for any quantum system, with separable or non-separable Hamiltonians, for either fermions or bosons. In principle, one could thought in introducing the exchange interaction into the terms G a and J a present in (24) that define the conditional wave function, in a similar way as the exchange-correlation functional is introduced into the Hamiltonian of a single-particle pseudo-Schr¨dinger equation used by DFT. However, There is no clear o prescription on how to define directly the terms G a and J a with exchange interaction. Alternatively, in this work we follow a different path. We compute N × N conditional wave function solutions of (24) [with a very simple approximation for G a and J a , leading to (27)] without symmetry requirements. However, the global conditional wave function constructed as a combination of them, (31), can satisfy the exchange requirements, after a proper guess for some phases. We have shown that the phases defined from (32) satisfy, by construction, three very satisfactory properties. First, in the case of separable Hamiltonians, it directly leads to the standard Slater determinants for computing manyparticle wave functions (or the permanent for bosons). Second, for fermions with nonseparable Hamiltonians, it guarantees that the probability presence of the many-particle wave function in the diagonal points of the configuration space is zero. Third, in any scenario, the Bohmian trajectories satisfies the expected symmetry property when initial positions are interchanged. This last property ensures that observable results computed from Bohmian trajectories are indistinguishable, as seen in figure 11. Note that the selection of the phases in (32) is not unique. In the Appendix A, we have shown another possibility, but it does not satisfy the second property discussed above.
An improvement on the simple approximation used to compute G a and J a when constructing the conditional (Bohmian) wave functions without exchange interaction would also improve the accuracy of the algorithm with exchange presented here.
As a practical demonstration of the numerical viability of the algorithm discussed here for quantum transport (in a far-from equilibrium open system), the current and its fluctuations are computed for a nano-resistor, with exchange and Coulomb interactions. For this simple device, the effects of the exchange interaction are mainly screened by the Coulomb interaction. In any case, the main conclusions that one can extract from these numerical results, applied to this very simple device, is that the algorithm explained in
this work can be perfectly implemented for a number of electrons on the order of 20-30. This requires solving 30 × 30 ≈ 1000 single particle conditional wave functions, which can still be handled with normal computing facilities and simulation times on the order of few hours for each simulation bias.
## acknowledgement
The present work have greatly beneficed from discussions with W. Struyve and G. Albareda. This work was supported through Spanish project MICINN TEC2012-31330.
## Appendix A. Indistinguishable results computed from the approximate conditional Bohmian wave functions using (32)
The requirement for ensuring that ensemble results computed from Bohmian trajectories are indistinguishable is that the N -particle Bohmian trajectories are symmetric under the interchange of their initial positions: We consider two different N -particle Bohmian trajectories, whose initial positions are /vector X l [0] and /vector X f [0]. In particular, we consider /vector r l k [0] = /vector r f k [0] for all k except /vector r l j [0] = /vector r f h [0] and /vector r l h [0] = /vector r f j [0]. Then, the sufficient condition to ensure that observable results of different particles are indistinguishable is ensuring that /vector r l k [ t ] = /vector r f k [ t ] = /vector r k [ t ] for all k except /vector r l j [ t ] = /vector r f h [ t ] and /vector r l h [ t ] = /vector r f j [ t ]. In this appendix, we show that this last property is guaranteed by our proposal of using (32) for fixing the unknown phases z p n ( ) e ,a ( ). t
At the initial time, by construction (see step 3 in section 3.2), it is obvious that (32) provides Bohmian trajectories with the desired property. Let us demonstrate that this relation between trajectories at the initial time is also true at a later time. We assume that the Bohmian trajectories have the desired property at the time t ′ (for example, t ′ = 0). Then, we want to demonstrate that /vector r l j [ t ] = /vector r f h [ t ] and /vector r l h [ t ] = /vector r f j [ t ] at a later time t = t ′ + dt . In fact, we only have to demonstrate that the velocities of the particles j and h at t ′ are interchanged. According to (32), the conditional wave function used to compute the velocity /vector v l j ( /vector X,t ′ ) | /vector X = /vector X t l [ ′ ] with the initial positions /vector X t l [ ′ ] = { /vector r 1 [ t ′ ] , ..., /vector r α [ t ′ ] , ..., /vector r β [ t ... ] } is:
$$\Psi _ { j } ^ { l } ( \vec { r } _ { j }, t ^ { \prime } ) & = C \sum _ { n = 1 } ^ { N! } \tilde { \psi } _ { p ( n ) _ { e }, \alpha } ( \vec { r } _ { 1 } [ t ], t ^ { \prime } ),.., \tilde { \psi } _ { p ( n ) _ { e }, \alpha } ( \vec { r } _ { j }, t ^ { \prime } ) \\ &,.., \tilde { \psi } _ { p ( n ) _ { e }, \alpha } ( \vec { r } _ { \beta } [ t ], t ^ { \prime } ).., \tilde { \psi } _ { p ( n ) _ { e }, \alpha } ( \vec { r } _ { N } [ t ], t ^ { \prime } ) \times \text{sign} \left ( \vec { p } ( n ) \right ), \quad \quad \quad$$
where we have defined /vector r l j [ t ] = /vector r f h [ t ] ≡ /vector r α [ t ] and /vector r l h [ t ] = /vector r f j [ t ] ≡ /vector r β [ t ]. Identically, we have /vector v l h ( /vector X,t ′ ) | /vector X = /vector X t l [ ′ ] :
$$\Psi _ { h } ^ { t } ( \vec { r } _ { h }, t ^ { \prime } ) & = C \sum _ { n = 1 } ^ { N! } \tilde { \psi } _ { p ( n ) _ { e }, \beta } ( \vec { r } _ { 1 } [ t ], t ^ { \prime } ),.., \tilde { \psi } _ { p ( n ) _ { e }, \beta } ( \vec { r } _ { \alpha } [ t ], t ^ { \prime } ) \\ &,.., \tilde { \psi } _ { p ( n ) _ { e }, \beta } ( \vec { r } _ { h }, t ^ { \prime } ).., \tilde { \psi } _ { p ( n ) _ { e }, \beta } ( \vec { r } _ { N } [ t ], t ^ { \prime } ) \times \text{sign} \left ( \vec { p } ( n ) \right ).$$
On the other hand, for the many-particle Bohmian trajectory with initial conditions /vector X f [0] = { /vector r 1 [0] , ..., /vector r β [0] , ..., /vector r α [0] ... } , we have for /vector v f j ( /vector X,t ′ ) | /vector X = /vector X f [ t ′ ] :
$$\Psi _ { j } ^ { f } ( \vec { r } _ { j }, t ^ { \prime } ) & = C \sum _ { n = 1 } ^ { N! } \tilde { \psi } _ { p ( n ) _ { e }, \beta } ( \vec { r } _ { 1 } [ t ], t ^ { \prime } ),.., \tilde { \psi } _ { p ( n ) _ { e }, \beta } ( \vec { r } _ { j }, t ^ { \prime } ) \\ &,.., \tilde { \psi } _ { p ( n ) _ { e }, \beta } ( \vec { r } _ { \alpha } [ t ], t ^ { \prime } ).., \tilde { \psi } _ { p ( n ) _ { e }, \beta } ( \vec { r } _ { N } [ t ], t ^ { \prime } ) \times \text{sign} \left ( \vec { p } ( n ) \right ).$$
and for /vector v f h ( /vector X,t ′ ) | /vector X = /vector X f [ t ′ ] :
$$\Psi _ { h } ^ { f } ( \vec { r } _ { h }, t ^ { \prime } ) & = C \sum _ { n = 1 } ^ { N! } \tilde { \psi } _ { p ( n ) _ { e }, \alpha } ( \vec { r } _ { 1 } [ t ], t ^ { \prime } ),.., \tilde { \psi } _ { p ( n ) _ { e }, \alpha } ( \vec { r } _ { \beta } [ t ], t ^ { \prime } ) \\ &,.., \tilde { \psi } _ { p ( n ) _ { e }, \alpha } ( \vec { r } _ { h }, t ^ { \prime } ).., \tilde { \psi } _ { p ( n ) _ { e }, \alpha } ( \vec { r } _ { N } [ t ], t ^ { \prime } ) \times \text{sign} \left ( \vec { p } ( n ) \right ). \\ & \dots \dots$$
As expected, it becomes obvious that /vector v l j ( /vector r , t j ′ ) = /vector v f h ( /vector r h , t ′ ) and /vector v l h ( /vector r h , t ′ ) = /vector v f j ( /vector r , t j ′ ). Q.E.D.
/negationslash
/negationslash
The use of expression (32) does also provide the additional property that Ψ ( l j /vector r , t j ) becomes zero whenever /vector r j = /vector r k [ t ] for j = k . It can also be shown that exp ( z /vector p n ,a ( ) ( )) = t ∏ N k =1 ,k = a ˜ ψ p n ( ) e ,k ( /vector r k [ t , t ] ) does also provide the required symmetry condition for the trajectories, but it does not guarantee that the conditional wave function is zero for fermions at the coincident points. Thus, (32) is preferred. Let us emphasize that ensuring that observable results become indistinguishable is not enough to ensure that our algorithm provides the correct results. Apart from the requirement mentioned here, Bohmian trajectories have to satisfy other properties as for example their non-crossing property discussed in section 2.2.1.
## Appendix B. Exchange interaction for electrons with different spin
Even for systems without spin-orbit interaction and when we are not interested in the time evaluation of the spins, we cannot neglect the spin degrees of freedom of the electrons (with arbitrary spins) because the symmetry of the overall wave function depends on the exchange properties of the orbital part and spin component. To understand the complexity of computing the antisymmetry wave function with spins in different directions, we present an example for three electrons, one with spin up ( ↑ j ) and the others two with spin down ( ↓ j ). Then, the global antisymmetric wave function in (1), for this particular case, can be written as:
$$\wedge \cdot \cdot \cdot \cdot \cdot \cdot \cd$$
We define the orbital wave functions ψ l ( x l ) as the Gaussian wave packets of (5). Equation (B.1) has 3! terms, each one composed of the product of an orbital function by
a spin function. Next, we compute the total norm taking into account the 3!3! products of permutations. For this purpose we have to multiply the orbital parts and the spin parts separately. Due to orthogonality, the product of the spin part can be either 0 and 1. The final result is:
$$\begin{array} { l l$$
Let us notice that, in principle, we had to keep 3!3! = 6 2 = 36 terms. However, only these terms whose product of spin parts is 1 are present in (B.3). The evaluation of the product of the spin parts have to be done explicitly, term by term, with no possibility of simplification. For example, the product of γ ( ↑ 1 , ↓ 2 , ↓ 3 ) by γ ( ↑ 1 , ↓ 3 , ↓ 2 ) is 1, while the product of γ ( ↑ 1 , ↓ 2 , ↓ 3 ) by γ ( ↓ 2 , ↑ 1 , ↓ 3 ) is 0. However, if we increase the number of electrons, the practical computation of the previous expression is computationally inaccessible. Note that N = 8 gives 8! 2 = 40320 2 terms.
In (35) we provide a (computationally accessible) approximation to treat wave functions with spin of different orientations. For example, if we assume that there is no exchange interaction between spin up and spin down components, then:
$$& \bar { \Phi } ( x _ { 1 }, x _ { 2 }, x _$$
Now, the norm would be:
$$\text{row, the norm would be: } \\ & \left | \bar { \Phi }$$
where there are terms on (B.3) that are not present in (B.4). However, in Ref. [33] we show that the approximation (35) provides a quite reasonable approximation for the computation of the Bohmian velocity. Expression (B.3) keep the most relevant terms of the exchange interaction.
## Appendix C. Electron injection probability
Our Bohmian algorithm requires each electron to be described by a (conditional) wave function plus a Bohmian trajectory. Every time an electron with a particular initial wave function is selected to enter the device active region, an initial position for the Bohmian trajectory associated to this wave packet has to be randomly selected according to 'quantum equilibrium hypothesis' [14, 28] discussed in section 2.2. Accordingly, this initial position is more frequently found to be around the center of the wave packet than in the borders. Next, we explain how the wave packets are selected.
The (central) kinetic energy E o of the wave packet is related to the (central) wave vectors k o by E o = ( /planckover2pi1 k o ) 2 / (2 m ∗ ) with m ∗ the effective mass. For each contact, we select a flat potential region in an (non-physical) extension of the simulation box (for x < 0 in the source and x > L x in the drain of figure 12). Let us notice that in a flat potential region without interaction, a single-particle wave packets is exactly the normalized conditional (Bohmian) wave function discussed in this work. The initial Gaussian wave packet is defined in this flat potential region (deep inside the contact) following the analytical expression (5). In particular, the central position of all wave packets is selected x o = 100 nm far from the border of the active region (inside the contacts) and the spatial dispersion of the wave packet is σ x = 25 nm (i.e. the wave packet is somehow similar to a scattering state). The only two additional parameters that we still have to fix to fully define the wave packet are the central kinetic energy E o of the wave packet and the injecting time when the electron effectively enters the simulation box. The selection of the energy E o has to satisfy the Fermi-Dirac occupation function f ( E o ) that depends on the (quasi) Fermi energy and temperature. The selection of the time when the electron is injected is a a bit more complex.
Let us define t 0 as the minimum temporal separation between the injection of two wave packets whose central wave vectors and central positions fit into the following particular phase-space cell k o ∈ [ k , b k b + ∆ ) and k x c ∈ [ x , x b b + ∆ ), being x x b the left border of the simulation region. For a 1D system, the value of t 0 can be easily estimated. The number of electrons n 1 D in the particular phase space cell ∆ k · ∆ x is n 1 D = 2 · ∆ k · ∆ x/ (2 π ) where the factor 2 takes into account the spin degeneracy. These electrons have been injected into ∆ x during the time interval ∆ t defined as the time needed for electrons with velocity v x = ∆ x/ ∆ = t /planckover2pi1 k /m o to travel a distance ∆ x . Therefore, the minimum temporal separation, t 0 , between the injection of two electrons
into the previous cell is ∆ t divided by the maximum number n 1 D of electrons:
$$t _ { 0 } = \frac { \Delta t } { n _ { 1 D } } = \$$
It is very instructive to understand the minimum temporal separation t 0 in (C.1) as a consequence of the wave packet version of the Pauli principle discussed in section 2.1.1. The simultaneous injection of two electrons with similar central positions and central momentums would require such a huge amount of energy that its probability is almost zero (see figure 1). In other words, a subsequent electron with central position and central momentum equal to the preceding ones can only be injected after a time interval given by t 0 .
The injection of electrons (from the mentioned phase-space cell) at multiple times of t o depends finally on the statistics imposed by the Fermi-Dirac function mentioned above. During each attempt of injection at multiples of t o , we select a random number r , and the electron is effectively injected only if f ( E o ) > r . The mathematical definition of the rate and randomness of the injection process are given by the following binomial probability P E , N , τ ( o τ ) (See Ref. [38]):
$$P ( E _ { o }, N _ { \tau }, \tau ) = \frac { M _ { \tau }! } { N _ { \tau }! \cdot ( M _ { \tau } - N _ { \tau } )! } f ( E _ { o } ) ^ { N _ { \tau } } \left ( 1 - f ( E _ { o } ) \right ) ^ { M _ { \tau } - N _ { \tau } }.$$
This expression defines the probability that N τ electrons (from the mentioned phasespace cell) are effectively injected into the active region during the time interval τ . The parameter M τ is the number of attempts of injecting electrons during this time interval τ , defined as a natural number that rounds the quotient τ/t o to the nearest natural number towards zero. The number of injected electrons can be N τ = 1 2 , , .... ≤ M τ . More details can be found in Ref. [38]. Finally, let us clarify that (C.2) does only specify the injecting probability. The transmission probability with a certain energy depends on the injecting probability and also on all complex (Coulomb and exchange) phenomena explained along the text.
## References
- [1] 'The general theory of quantum mechanics is now almost complete. The underlying physical laws necessary for the mathematical theory of a large part of physics and the whole of chemistry are thus completely known,f and the difficulty is only that the exact application of these laws leads to equations much too complicated to be soluble.' Dirac P A M 1929 Proceedings of the Royal Society of London A 123 714
- [2] Nightingale M P Umrigar C J 1999 Quantum Monte Carlo Methods in Physics and Chemistry (Springer)
- [3] Suzuki M 1993 Quantum Monte Carlo Methods in Condensed Matter Physics (World Scientific)
- [4] Hartree D R 1928 The Wave Mechanics of an Atom with a Non-Coulomb Central Field. Part II. Some Results and Discussion Mathematical Proceedings of the Cambridge Philosophical Society 24 (01) 111
- [5] Fock V 1930 N¨herungsmethode zur L¨sung des quanten mechanichanischen Mehrk¨rperproblems a o o Z. Phys. 61 126
- [6] Kohn W 1998 Reviews of Modern Physics 71(5) 1253
- [7] Hohenberg P and Kohn W 1964 Inhomogeneous electron gas Physical Review 136 B864
- [8] Kohn W and Sham L J 1965 Phys.Rev. A 140 1163
- [9] Soler J M Artacho E Gale J D Garcia A Junquera J Ordejon P and Sanchez-Portal D 2002 Journal of Physics: Condensed Matter 14 2745
- [10] Runge E and Gross E K U 1984 Physical Review Letters 52 12 997
- [11] Giuliani G F and Vignale G 2005 Quantum Theory of electron Liquid (Cambridge University Press)
- [12] Capelle K and Gross E K U 1997 Phys. Rev. Lett. 78(10) 1872
- [13] Di Ventra M and D'Agosta R 2007 Phys. Rev. Lett. 98 22 226403
- [14] Holland P R 1993 The Quantum Theory of Motion (Cambridge University Press Cambridge)
- [15] Oriols X and Mompart J 2011 Applied Bohmian Mechanics: From Nanoscale Systems to Cosmology (Pan Stanford Publishing Singapore)
- [16] Bell J S 1987 Speakable and Unspeakable in Quantum Mechanics (Cambridge University Press Cambridge)
- [17] D¨ urr D and Teufel S 2009 Bohmian Mechanics: The Physics and Mathematics of Quantum Theory (Spinger Germany)
- [18] Oriols X 2007 Phys. Rev. Let. 98 066803
- [19] Wyatt R E 2005 Quantum Dynamics with Trajectories: Introduction to Quantum Hydrodynamics (Springer New York)
- [20] Wyatt R E and Bittner E R 2000 Journal of Chemical Physics 113 22
- [21] Goldfarb Y Degani I and Tannor D J 2006 Journal of Chemical Physics 125 231103
- [22] Gindensperger E Meier C and Beswick J A 2002 Journal of Chemical Physics 116 8
- [23] In this work, the quantum trajectories are only used to reproduce ensemble results without any ontological implication. Then, the adjective Bohmian and hydrodynamic are fully interchangeable in this work. However, we use the first one only because the concept of conditional wave function, which is fundamental in this work, is mainly developed for Bohmian mechanics.
- [24] Albareda G Su˜´ e J and Oriols X 2009 n Phys. Rev. B 79 075315
- [25] We use the basis of individual spins instead of the basis of the total spin because we are interested in open systems, where particles (spins) are interchanged with reservoirs. Then, the requirement of constant total spin (implicit in the total spin basis) is not at all evident.
- [26] Cohen-Tannoudji C Diu B and Laloe F 1978 Quantum Mechanics (Vol I and II) (Wiley, John and Sons)
- [27] Oriols X 2004 Nanotechnology 15 S167
- [28] D¨ urr D et al. 2004 Journal of Statistical Physics 116 9595
- [29] Oriols X Mart´ ın F and Su˜´ J 1996 ne Physical Review A 54 2595
- [30] Brown H R Sj¨ oqvist E 1999 Physics Letters A 251(4) 229
- [31] For example, the permutation /vector p n ( ) = { 3 2 1 , , } on the conditional wave function used to compute the trajectory /vector r 1 [ t ] has the initial wave packet ψ 3 ( /vector r 1 , t ) because p n ( ) 3 = 1.
- [32] http://europe.uab.es/bitlles
- [33] Alarc´n A Cartoix` X and Oriols X 2010 o a Physica Status Solidi C 7 11
- [34] By construction, an ensemble of Bohmian trajectories reproduces the probability presence of the many-particle wave function at any time and also the correlations. The only approximation in our computations of the current is that the (continuous) time-dependent measurement of the current provides a negligible back-action on the simulated system [15].
- [35] Norsen T 2010 Foundations of Physics 40 1858
- [36] Nazarov Y V and Blanter Y M 2009 Quantum Transport: Introduction to Nanoscience (Cambridge University press,f Cambridge)
- [37] Bulashenko O M Mateos J Pardo D and Gonz´ alez T Reggiani L Rub´ ı J M 1998 Phys. Rev. B 57 1366.
- [38] Oriols X Fernandez-Diaz E Alvarez A Alarc´n A 2007 o Solid State Electronics 51 306 | 10.1088/0953-8984/25/32/325601 | [
"A. Alarcón",
"S. Yaro",
"X. Cartoixà",
"X. Oriols"
] | 2014-08-02T15:37:19+00:00 | 2014-08-02T15:37:19+00:00 | [
"quant-ph",
"81V70"
] | Computation of many-particle quantum trajectories with exchange interaction: Application to the simulation of nanoelectronic devices | Following Ref. [Oriols X 2007 Phys. Rev. Lett., 98 066803], an algorithm to
deal with the exchange interaction in non-separable quantum systems is
presented. The algorithm can be applied to fermions or bosons and, by
construction, it exactly ensures that any observable is totally independent
from the interchange of particles. It is based on the use of conditional
Bohmian wave functions which are solutions of single-particle
pseudo-Schr\"odinger equations. The exchange symmetry is directly defined by
demanding symmetry properties of the quantum trajectories in the configuration
space with a universal algorithm, rather than through a particular
exchange-correlation functional introduced into the single-particle
pseudo-Schr\"odinger equation. It requires the computation of N^2 conditional
wave functions to deal with N identical particles. For separable Hamiltonians,
the algorithm reduces to the standard Slater determinant for fermions, or
permanent for bosons. A numerical test for a two-particle system, where exact
solutions for non-separable Hamiltonians are computationally accessible, is
presented. The numerical viability of the algorithm for quantum electron
transport (in a far-from equilibrium time-dependent open system) is
demonstrated by computing the current and fluctuations in a nano-resistor, with
exchange and Coulomb interactions among electrons. |
1408.0389v2 | ## Bifix codes and interval exchanges
Val´ erie Berth´ e 1 , Clelia De Felice , Francesco Dolce , Julien Leroy , 2 3 4 Dominique Perrin , Christophe Reutenauer , Giuseppina Rindone 3 5 3
1 2
CNRS, Universit´ e Paris 7, Universit` degli Studi di Salerno, a 3 Universit´ Paris Est, LIGM, e 4 Universit´ du Luxembourg, e 5 Universit´ du Qu´ ebec ` Montr´al e a e
February 23, 2015 1 h 28
## Abstract
We investigate the relation between bifix codes and interval exchange transformations. We prove that the class of natural codings of regular interval echange transformations is closed under maximal bifix decoding.
## Contents
| 1 | Introduction | 2 |
|-----|-----------------------------------|----------------------------------------------------------------------------|
| 2 | Interval exchange transformations | 3 |
| | 2.1 | Regular interval exchange transformations . . . . . . . . . . . . . 4 |
| | 2.2 | Natural coding . . . . . . . . . . . . . . . . . . . . . . . . . . . . 5 |
| | 2.3 | Uniformly recurrent sets . . . . . . . . . . . . . . . . . . . . . . . 6 |
| | 2.4 | Interval exchange sets . . . . . . . . . . . . . . . . . . . . . . . . 7 |
| 3 | Bifix codes and interval exchange | 9 |
| | 3.1 | Prefix codes and bifix codes . . . . . . . . . . . . . . . . . . . . . 9 |
| | 3.2 | Maximal bifix codes . . . . . . . . . . . . . . . . . . . . . . . . . 10 |
| | 3.3 | Bifix codes and regular transformations . . . . . . . . . . . . . . 13 |
| 4 | Tree sets | 16 |
| | 4.1 | Extension graphs . . . . . . . . . . . . . . . . . . . . . . . . . . . 16 |
| | 4.2 | Interval exchange sets and planar tree sets . . . . . . . . . . . . . 17 |
| | 4.3 | Exchange of pieces . . . . . . . . . . . . . . . . . . . . . . . . . . 18 |
| | 4.4 | Subgroups of finite index . . . . . . . . . . . . . . . . . . . . . . . 21 |
## 1 Introduction
This paper is part of a research initiated in [2] which studies the connections between the three subjects formed by symbolic dynamics, the theory of codes and combinatorial group theory. The initial focus was placed on the classical case of Sturmian systems and progressively extended to more general cases.
The starting point of the present research is the observation that the family of Sturmian sets is not closed under decoding by a maximal bifix code, even in the more simple case of the code formed of all words of fixed length n . Actually, the decoding of the Fibonacci word (which corresponds to a rotation of angle α = (3 -√ 5) / 2) by blocks of length n is an interval exchange transformation corresponding to a rotation of angle nα coded on n +1 intervals. This has lead us to consider the set of factors of interval exchange transformations, called interval exchange sets. Interval exchange transformations were introduced by Oseledec [15] following an earlier idea of Arnold [1]. These transformations form a generalization of rotations of the circle.
The main result in this paper is that the family of regular interval exchange sets is closed under decoding by a maximal bifix code (Theorem 3.13). This result invited us to try to extend to regular interval exchange transformations the results relating bifix codes and Sturmian words. This lead us to generalize in [4] to a large class of sets the main result of [2], namely the Finite Index Basis Theorem relating maximal bifix codes and bases of subgroups of finite index of the free group.
Theorem 3.13 reveals a close connection between maximal bifix codes and interval exchange transformations. Indeed, given an interval exchange transformation T each maximal bifix code X defines a new interval exchange transformation T X . We show at the end of the paper, using the Finite Index Basis Theorem, that this transformation is actually an interval exchange transformation on a stack, as defined in [7] (see also [19]).
The paper is organized as follows.
In Section 2, we recall some notions concerning interval exchange transformations. We state the result of Keane [12] which proves that regularity is a sufficient condition for the minimality of such a transformation (Theorem 2.3).
We study in Section 3 the relation between interval exchange transformations and bifix codes. We prove that the transformation associated with a finite S -maximal bifix code is an interval exchange transformation (Proposition 3.8). We also prove a result concerning the regularity of this transformation (Theorem 3.12).
We discuss the relation with bifix codes and we show that the class of regular interval exchange sets is closed under decoding by a maximal bifix code, that is, under inverse images by coding morphisms of finite maximal bifix codes (Theorem 3.13).
In Section 4 we introduce tree sets and planar tree sets. We show, reformulating a theorem of [9], that uniformly recurrent planar tree sets are the regular interval exchange sets (Theorem 4.3). We show in another paper [5] that, in the same way as regular interval exchange sets, the class of uniformly recurrent
tree sets is closed under maximal bifix decoding.
In Section 4.3, we explore a new direction, extending the results of this paper to a more general case. We introduce exchange of pieces, a notable example being given by the Rauzy fractal. We indicate how the decoding of the natural codings of exchange of pieces by maximal bifix codes are again natural codings of exchange of pieces. We finally give in Section 4.4 an alternative proof of Theorem 3.13 using a skew product of a regular interval exchange transformation with a finite permutation group.
Acknowledgements This work was supported by grants from R´ egion Ile-deFrance, the ANR projects Eqinocs and Dyna3S, the Labex Bezout, the FARB Project 'Aspetti algebrici e computazionali nella teoria dei codici, degli automi e dei linguaggi formali' (University of Salerno, 2013) and the MIUR PRIN 20102011 grant 'Automata and Formal Languages: Mathematical and Applicative Aspects'. We thank the referee for his useful remarks on the first version of the paper which was initially part of the companion paper [4].
## 2 Interval exchange transformations
Let us recall the definition of an interval exchange transformation (see [8] or [6]).
A semi-interval is a nonempty subset of the real line of the form [ α, β [= { z ∈ R | α ≤ z < β } . Thus it is a left-closed and right-open interval. For two semi-intervals ∆ Γ, we denote ∆ , < Γ if x < y for any x ∈ ∆ and y ∈ Γ.
Let ( A,< ) be an ordered set. A partition ( I a ) a ∈ A of [0 , 1[ in semi-intervals is ordered if a < b implies I a < I b .
Let A be a finite set ordered by two total orders < 1 and < 2 . Let ( I a ) a ∈ A be a partition of [0 , 1[ in semi-intervals ordered for < 1 . Let λ a be the length of I a . Let µ a = ∑ b ≤ 1 a λ b and ν a = ∑ b ≤ 2 a λ b . Set α a = ν a -µ a . The interval exchange transformation relative to ( I a ) a ∈ A is the map T : [0 , 1[ → [0 , 1[ defined by
$$T ( z ) & = z + \alpha _ { a } \quad \text{if } z \in I _ { a }. \\ \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot$$
Observe that the restriction of T to I a is a translation onto J a = T I ( a ), that µ a is the right boundary of I a and that ν a is the right boundary of J a . We additionally denote by γ a the left boundary of I a and by δ a the left boundary of J a . Thus
$$I _ { a } = [ \gamma _ { a }, \mu _ { a } [, \ J _ { a } = [ \delta _ { a }, \nu _ { a } [.$$
Note that a < 2 b implies ν a < ν b and thus J a < J b . This shows that the family ( J a ) a ∈ A is a partition of [0 , 1[ ordered for < 2 . In particular, the transformation T defines a bijection from [0 , 1[ onto itself.
An interval exchange transformation relative to ( I a ) a ∈ A is also said to be on the alphabet A . The values ( α a ) a ∈ A are called the translation values of the transformation T .
Example 2.1 Let R be the interval exchange transformation corresponding to A = { a, b } , a < 1 b , b < 2 a , I a = [0 1 , -α [, I b = [1 -α, 1[. The transformation R is the rotation of angle α on the semi-interval [0 , 1[ defined by R z ( ) = z + α mod 1.
Since < 1 and < 2 are total orders, there exists a unique permutation π of A such that a < 1 b if and only if π a ( ) < 2 π b ( ). Conversely, < 2 is determined by < 1 and π and < 1 is determined by < 2 and π . The permutation π is said to be associated with T .
If we set A = { a , a 1 2 , . . . , a s } with a 1 < 1 a 2 < 1 · · · < 1 a s , the pair ( λ, π ) formed by the family λ = ( λ a ) a ∈ A and the permutation π determines the map T . We will also denote T as T λ,π . The transformation T is also said to be an s -interval exchange transformation.
It is easy to verify that if T is an interval exchange transformation, then T n is also an interval exchange transformation for any n ∈ Z .
Example 2.2 A3-interval exchange transformation is represented in Figure 2.1. One has A = { a, b, c } with a < 1 b < 1 c and b < 2 c < 2 a . The associated permutation is the cycle π = ( abc ). µ µ µ
Figure 2.1: A 3-interval exchange transformation.
## 2.1 Regular interval exchange transformations
The orbit of a point z ∈ [0 , 1[ is the set { T n ( z ) | n ∈ Z } . The transformation T is said to be minimal if, for any z ∈ [0 , 1[, the orbit of z is dense in [0 , 1[.
Set A = { a , a 1 2 , . . . , a s } with a 1 < 1 a 2 < 1 . . . < 1 a s , µ i = µ a i and δ i = δ a i . The points 0 , µ 1 , . . . , µ s -1 form the set of separation points of T , denoted Sep( T ). Note that the singular points of the transformation T (that is the points z ∈ [0 , 1[ at which T is not continuous) are among the separation points but that the converse is not true in general (see Example 3.9).
An interval exchange transformation T λ,π is called regular if the orbits of the nonzero separation points µ , . . . , µ 1 s -1 are infinite and disjoint. Note that the orbit of 0 cannot be disjoint of the others since one has T µ ( i ) = 0 for some i with 1 ≤ i ≤ s -1. The term regular was introduced by Rauzy in [17]. A regular interval exchange transformation is also said to be without connections or to satisfy the idoc condition (where idoc stands for infinite disjoint orbit condition).
Note that since δ 2 = T µ ( 1 ) , . . . , δ s = T µ ( s -1 ), T is regular if and only if the orbits of δ 2 , . . . , δ s are infinite and disjoint.
As an example, the 2-interval exchange transformation of Example 2.1 which is the rotation of angle α is regular if and only if α is irrational.
Note that if T is a regular s -interval exchange transformation, then for any n ≥ 1, the transformation T n is an n s ( -1)+1-interval exchange transformation. Indeed, the points T i ( µ j ) for 0 ≤ i ≤ n -1 and 1 ≤ j ≤ s -1 are distinct and define a partition in n s ( -1) + 1 intervals.
The following result is due to Keane [12].
Theorem 2.3 (Keane) A regular interval exchange transformation is minimal.
The converse is not true. Indeed, consider the rotation of angle α with α irrational, as a 3-interval exchange transformation with λ = (1 -2 α, α, α ) and π = (132). The transformation is minimal as any rotation of irrational angle but it is not regular since µ 1 = 1 -2 α µ , 2 = 1 -α and thus µ 2 = T µ ( 1 ).
The following example shows that the indecomposability of π is not sufficient for T to be minimal.
The following necessary condition for minimality of an interval exchange transformation is useful. A permutation π of an ordered set A is called decomposable if there exists an element b ∈ A such that the set B of elements strictly less than b is nonempty and such that π B ( ) = B . Otherwise it is called indecomposable . If an interval exchange transformation T = T λ,π is minimal, the permutation π is indecomposable. Indeed, if B is a set as above, the set S = ∪ a ∈ B a I is closed under T and strictly included in [0 , 1[.
Example 2.4 Let A = { a, b, c } and λ be such that λ a = λ c . Let π be the transposition ( ac ). Then π is indecomposable but T λ,π is not minimal since it is the identity on I b .
## 2.2 Natural coding
Let A be a finite nonempty alphabet. All words considered below, unless stated explicitly, are supposed to be on the alphabet A . We denote by A ∗ the set of all words on A . We denote by 1 or by ε the empty word. We refer to [3] for the notions of prefix, suffix, factor of a word.
Let T be an interval exchange transformation relative to ( I a ) a ∈ A . For a given real number z ∈ [0 , 1[, the natural coding of T relative to z is the infinite word Σ T ( z ) = a a 0 1 · · · on the alphabet A defined by
$$a _ { n } = a \quad \text{if} \quad T ^ { n } ( z ) \in I _ { a }.$$
For a word w = b 0 b 1 · · · b m -1 , let I w be the set
$$I _ { w } = I _ { b _ { 0 } } \cap T ^ { - 1 } ( I _ { b _ { 1 } } ) \cap \dots \cap T ^ { - m + 1 } ( I _ { b _ { m - 1 } } ). \quad \quad ( 2. 1 )$$
Note that each I w is a semi-interval. Indeed, this is true if w is a letter. Next, assume that I w is a semi-interval. Then for any a ∈ A T I , ( aw ) = T I ( a ) ∩ I w is a
semi-interval since T I ( a ) is a semi-interval by definition of an interval exchange transformation. Since I aw ⊂ I a , T I ( aw ) is a translate of I aw , which is therefore also a semi-interval. This proves the property by induction on the length. m
$$\text{Set } J _ { w } = T ^ { m } ( I _ { w } ). \text{ Thus}$$
$$J _ { w } = T ^ { m } ( I _ { b _ { 0 } } ) \cap T ^ { m - 1 } ( I _ { b _ { 1 } } ) \cap \dots \cap T ( I _ { b _ { m - 1 } } ). \text{ \quad \ \ } ( 2. 2 )$$
In particular, we have J a = T I ( a ) for a ∈ A . Note that each J w is a semiinterval. Indeed, this is true if w is a letter. Next, for any a ∈ A , we have T -1 ( J wa ) = J w ∩ I a . This implies as above that J wa is a semi-interval and proves the property by induction. We set by convention I ε = J ε = [0 1[. , Then one has for any n ≥ 0
$$a _ { n } a _ { n + 1 } \cdots a _ { n + m - 1 } = w \Longleftrightarrow T ^ { n } ( z ) \in I _ { w }$$
and
$$a _ { n - m } a _ { n - m + 1 } \cdots a _ { n - 1 } = w \Longleftrightarrow T ^ { n } ( z ) \in J _ { w }. \quad \quad ( 2. 4 ) \\ \cdots \quad, \quad. \quad, \quad. \quad, \quad e \, \sum \, \mathbb { s } \,. \quad. \quad e \quad.$$
Let ( α a ) a ∈ A be the translation values of T . Note that for any word w ,
$$J _ { w } & = I _ { w } + \alpha _ { w } & ( 2. 5 )$$
with α w = ∑ m -1 j =0 α b j as one may verify by induction on | w | = m . Indeed it is true for m = 1. For m ≥ 2, set w = ua with a = b m -1 . One has T m ( I w ) = T m -1 ( I w )+ α a and T m -1 ( I w ) = I w + α u by the induction hypothesis and the fact that I w is included in I u . Thus J w = T m ( I w ) = I w + α u + α a = I w + α w . Equation (2.5) shows in particular that the restriction of T | w | to I w is a translation.
## 2.3 Uniformly recurrent sets
A set S of words on the alphabet A is said to be factorial if it contains the factors of its elements.
A factorial set is said to be right-extendable if for every w ∈ S there is some a ∈ A such that wa ∈ S . It is biextendable if for any w ∈ S , there are a, b ∈ A such that awb ∈ S .
A set of words S = { } ε is recurrent if it is factorial and if for every u, w ∈ S there is a v ∈ S such that uvw ∈ S . A recurrent set is biextendable. It is said to be uniformly recurrent if it is right-extendable and if, for any word u ∈ S , there exists an integer n ≥ 1 such that u is a factor of every word of S of length n . A uniformly recurrent set is recurrent.
/negationslash
We denote by A N the set of infinite words on the alphabet A . For a set X ⊂ A N , we denote by F X ( ) the set of factors of the words of X .
Let S be a set of words on the alphabet A . For w ∈ S , set R w ( ) = { a ∈ A | wa ∈ S } and L w ( ) = { a ∈ A | aw ∈ S } . A word w is called right-special if Card( R w ( )) ≥ 2 and left-special if Card( L w ( )) ≥ 2. It is bispecial if it is both right and left-special.
An infinite word on a binary alphabet is Sturmian if its set of factors is closed under reversal and if for each n there is exactly one right-special word of length n .
An infinite word is a strict episturmian word if its set of factors is closed under reversal and for each n there is exactly one right-special word w of length n , which is moreover such that Card( R w ( )) = Card( A ).
A morphism f : A ∗ → A ∗ is called primitive if there is an integer k such that for all a, b ∈ A , the letter b appears in f k ( a ). If f is a primitive morphism, the set of factors of any fixpoint of f is uniformly recurrent (see [10, Proposition 1.2.3], for example).
Example 2.5 Let A = { a, b } . The Fibonacci word is the fixpoint x = f ω ( a ) = abaababa . . . of the morphism f : A ∗ → A ∗ defined by f ( a ) = ab and f ( b ) = a . It is a Sturmian word (see [13]). The set F x ( ) of factors of x is the Fibonacci set .
Example 2.6 Let A = { a, b, c } . The Tribonacci word is the fixpoint x = f ω ( a ) = abacaba · · · of the morphism f : A ∗ → A ∗ defined by f ( a ) = ab , f ( b ) = ac , f ( c ) = a . It is a strict episturmian word (see [11]). The set F x ( ) of factors of x is the Tribonacci set .
## 2.4 Interval exchange sets
Let T be an interval exchange set. The set F (Σ T ( z )) is called an interval exchange set . It is biextendable.
/negationslash
If T is a minimal interval exchange transformation, one has w ∈ F (Σ T ( z )) if and only if I w = ∅ . Thus the set F (Σ T ( z )) does not depend on z . Since it depends only on T , we denote it by F T ( ). When T is regular (resp. minimal), such a set is called a regular interval exchange set (resp. a minimal interval exchange set).
Let T be an interval exchange transformation. Let M be the closure in A N of the set of all Σ ( ) for T z z ∈ [0 , 1[ and let σ be the shift on M . The pair ( M,σ ) is a symbolic dynamical system , formed of a topological space M and a continuous transformation σ . Such a system is said to be minimal if the only closed subsets invariant by σ are ∅ or M (that is, every orbit is dense). It is well-known that ( M,σ ) is minimal if and only if F T ( ) is uniformly recurrent (see for example [13, Theorem 1.5.9] ).
We have the following commutative diagram (Figure 2.2).
Figure 2.2: The transformations T and σ .
The map Σ T is neither continuous nor surjective. This can be corrected by embedding the interval [0 , 1[ into a larger space on which T is a homeomophism (see [12] or [6, page 349]). However, if the transformation T is minimal, the symbolic dynamical system ( M,S ) is minimal (see [6, page 392]). Thus, we obtain the following statement.
Proposition 2.7 For any minimal interval exchange transformation T , the set F T ( ) is uniformly recurrent.
Note that for a minimal interval exchange transformation T , the map Σ T is injective (see [12] page 30).
The following is an elementary property of the intervals I u which will be used below. We denote by < 1 the lexicographic order on A ∗ induced by the order < 1 on A .
Proposition 2.8 One has I u < I v if and only if u < 1 v and u is not a prefix of v .
Proof. For a word u and a letter a , it results from (2.1) that I ua = I u ∩ T -| u | ( I a ). Since ( I a ) a ∈ A is an ordered partition, this implies that ( T | u | ( I u ) ∩ I a ) a ∈ A is an ordered partition of T | u | ( I u ). Since the restriction of T | u | to I u is a translation, this implies that ( I ua ) a ∈ A is an ordered partition of I u . Moreover, for two words u, v , it results also from (2.1) that I uv = I u ∩ T -| u | ( I v ). Thus I uv ⊂ I u .
Conversely, assume that I u < I v . Since I u ∩ I v = ∅ , the words u, v cannot be comparable for the prefix order. Set u = /lscriptas and v = /lscriptbt with a, b two distinct letters. If b < 1 a , then I v < I u as we have shown above. Thus a < 1 b which implies u < 1 v .
Assume that u < 1 v and that u is not a prefix of v . Then u = /lscriptas and v = /lscriptbt with a, b two letters such that a < 1 b . Then we have I /lscripta < I /lscriptb , with I u ⊂ I /lscripta and I v ⊂ I /lscriptb whence I u < I v .
We denote by < 2 the order on A ∗ defined by u < 2 v if u is a proper suffix of v or if u = waz and v = tbz with a < 2 b . Thus < 2 is the lexicographic order on the reversal of the words induced by the order < 2 on the alphabet.
We denote by π the morphism from A ∗ onto itself which extends to A ∗ the permutation π on A . Then u < 2 v if and only if π -1 (˜) u < 1 π -1 (˜), v where ˜ u denotes the reversal of the word u .
The following statement is the analogue of Proposition 2.8.
Proposition 2.9 Let T λ,π be an interval exchange transformation. One has J u < J v if and only if u < 2 v and u is not a suffix of v .
Proof. Let ( I ′ a ) a ∈ A be the family of semi-intervals defined by I ′ a = J π a ( ) . Then the interval exchange transformation T ′ relative to ( I ′ a ) with translation values -α a is the inverse of the transformation T . The semi-intervals I ′ w defined by Equation (2.1) with respect to T ′ satisfy I ′ w = J π w ( ˜) or equivalently J w =
I ′ π -1 ( ˜) w . Thus, J u < J v if and only if I ′ π -1 (˜) u < I ′ π -1 (˜) v if and only if (by Proposition 2.8) π -1 (˜) u < π 1 -1 (˜) or equivalently v u < 2 v .
## 3 Bifix codes and interval exchange
In this section, we first introduce prefix codes and bifix codes. For a more detailed exposition, see [3]. We describe the link between maximal bifix codes and interval exchange transformations and we prove our main result (Theorem 3.13).
## 3.1 Prefix codes and bifix codes
A prefix code is a set of nonempty words which does not contain any proper prefix of its elements. A suffix code is defined symmetrically. A bifix code is a set which is both a prefix code and a suffix code.
A coding morphism for a prefix code X ⊂ A + is a morphism f : B ∗ → A ∗ which maps bijectively B onto X .
Let S be a set of words. A prefix code X ⊂ S is S -maximal if it is not properly contained in any prefix code Y ⊂ S . Note that if X ⊂ S is an S -maximal prefix code, any word of S is comparable for the prefix order with a word of X .
A map λ : A ∗ → [0 , 1] such that λ ε ( ) = 1 and, for any word w
$$\sum _ { a \in A } \lambda ( a w ) = \sum _ { a \in A } \lambda ( w a ) = \lambda ( w ),$$
is called an invariant probability distribution on A ∗ .
Let T λ,π be an interval exchange transformation. For any word w ∈ A ∗ , denote by | I w | the length of the semi-interval I w defined by Equation (2.1). Set λ w ( ) = | I w | . Then λ ε ( ) = 1 and for any word w , Equation (3.1) holds and thus λ is an invariant probability distribution.
The fact that λ is an invariant probability measure is equivalent to the fact that the Lebesgue measure on [0 1[ is invariant by , T . It is known that almost all regular interval exchange transformations have no other invariant probability measure (and thus are uniquely ergodic, see [6] for references).
Example 3.1 Let S be the set of factors of the Fibonacci word (see Example 2.5). It is the natural coding of the rotation of angle α = (3 -√ 5) / 2 with respect to α (see [13, Chapter 2]). The values of the map λ on the words of length at most 4 in S are indicated in Figure 3.1.
The following result is a particular case of a result from [2] (Proposition 3.3.4).
Proposition 3.2 Let T be a minimal interval exchange transformation, let S = F T ( ) and let λ be an invariant probability distribution on S . For any finite S -maximal prefix code X , one has ∑ x ∈ X λ x ( ) = 1 .
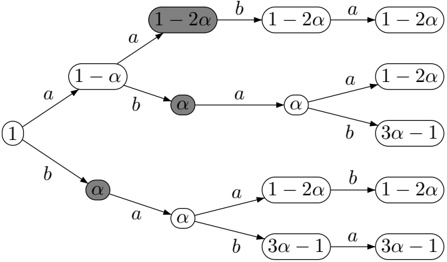
-
-
Figure 3.1: The invariant probability distribution on the Fibonacci set.
The following statement is connected with Proposition 3.2.
Proposition 3.3 Let T be a minimal interval exchange transformation relative to ( I a ) a ∈ A , let S = F T ( ) and let X be a finite S -maximal prefix code ordered by < 1 . The family ( I w w ) ∈ X is an ordered partition of [0 , 1[ .
Proof. By Proposition 2.8, the sets ( I w ) for w ∈ X are pairwise disjoint. Let π be the invariant probability distribution on S defined by π w ( ) = | I w | . By Proposition 3.2, we have ∑ w X ∈ π w ( ) = 1. Thus the family ( I w w ) ∈ X is a partition of [0 , 1[. By Proposition 2.8 it is an ordered partition.
Example 3.4 Let T be the rotation of angle α = (3 -√ 5) / 2. The set S = F T ( ) is the Fibonacci set. The set X = { aa, ab, b } is an S -maximal prefix code (see the grey nodes in Figure 3.1). The partition of [0 , 1[ corresponding to X is
$$I _ { a a } = [ 0, 1 - 2 \alpha [, \ \ I _ { a b } = [ 1 - 2 \alpha, 1 - \alpha [, \ \ I _ { b } = [ 1 - \alpha, 1 [.$$
The values of the lengths of the semi-intervals (the invariant probability distribution) can also be read on Figure 3.1.
A symmetric statement holds for an S -maximal suffix code, namely that the family ( J w w ) ∈ X is an ordered partition of [0 , 1[ for the order < 2 on X .
## 3.2 Maximal bifix codes
Let S be a set of words. A bifix code X ⊂ S is S -maximal if it is not properly contained in a bifix code Y ⊂ S . For a recurrent set S , a finite bifix code is S -maximal as a bifix code if and only if it is an S -maximal prefix code (see [2, Theorem 4.2.2]).
A parse of a word w with respect to a bifix code X is a triple ( v, x, u ) such that w = vxu where v has no suffix in X u , has no prefix in X and x ∈ X ∗ . We denote by δ X ( w ) the number of parses of w with respect to X .
The number of parses of a word w is also equal to the number of suffixes of w which have no prefix in X and the number of prefixes of w which have no suffix in X (see Proposition 6.1.6 in [3]).
By definition, the S -degree of a bifix code X , denoted d X ( S ), is the maximal number of parses of a word in S . It can be finite or infinite.
The set of internal factors of a set of words X , denoted I ( X ), is the set of words w such that there exist nonempty words u, v with uwv ∈ X .
Let S be a recurrent set and let X be a finite S -maximal bifix code of S -degree d . A word w ∈ S is such that δ X ( w ) < d if and only if it is an internal factor of X , that is,
$$I ( X ) = \{ w \in S \, | \, \delta _ { X } ( w ) < d \} \\ \mathbb { m } \ \, \infty \ \, \begin{array} { c } I ( X ) & \delta _ { X } ( w ) < d \} \\ \mathbb { m } \ \, \infty \ \, \end{array} \dots \, \cdot \ \end{array}.$$
(Theorem 4.2.8 in [2]). Thus any word of S which is not a factor of X has d parses. This implies that the S -degree d is finite.
Example 3.5 Let S be a recurrent set. For any integer n ≥ 1, the set S ∩ A n is an S -maximal bifix code of S -degree n .
The kernel of a bifix code X is the set K X ( ) = I ( X ) ∩ X . Thus it is the set of words of X which are also internal factors of X . By Theorem 4.3.11 of [2], a finite S -maximal bifix code is determined by its S -degree and its kernel.
Example 3.6 Let S be the Fibonacci set. The set X = { a, baab, bab } is the unique S -maximal bifix code of S -degree 2 with kernel { a } . Indeed, the word bab is not an internal factor and has two parses, namely (1 , bab, 1) and ( b, a, b ).
The following result shows that bifix codes have a natural connection with interval exchange transformations.
Proposition 3.7 If X is a finite S -maximal bifix code, with S as in Proposition 3.3 , the families ( I w w ) ∈ X and ( J w w ) ∈ X are ordered partitions of [0 , 1[ , relatively to the orders < 1 and < 2 respectively.
Proof. This results from Proposition 3.3 and its symmetric and from the fact that, since S is recurrent, a finite S -maximal bifix code is both an S -maximal prefix code and an S -maximal suffix code.
Let T be a regular interval exchange transformation relative to ( I a ) a ∈ A . Let ( α a ) a ∈ A be the translation values of T . Set S = F T ( ). Let X be a finite S -maximal bifix code on the alphabet A .
Let T X be the transformation on [0 , 1[ defined by
$$T _ { X } ( z ) = T ^ { | u | } ( z ) \ \text{ if } \ z \in I _ { u }$$
with u ∈ X . The transformation is well-defined since, by Proposition 3.7, the family ( I u u ) ∈ X is a partition of [0 , 1[.
Let f : B ∗ → A ∗ be a coding morphism for X . Let ( K b ) b ∈ B be the family of semi-intervals indexed by the alphabet B with K b = I f ( b ) . We consider B as
ordered by the orders < 1 and < 2 induced by f . Let T f be the interval exchange transformation relative to ( K b ) b ∈ B . Its translation values are β b = ∑ m -1 j =0 α a j for f ( b ) = a a 0 1 · · · a m -1 . The transformation T f is called the transformation associated with f .
Proposition 3.8 Let T be a regular interval exchange transformation relative to ( I a ) a ∈ A and let S = F T ( ) . If f : B ∗ → A ∗ is a coding morphism for a finite S -maximal bifix code X , one has T f = T X .
Proof. By Proposition 3.7, the family ( K b ) b ∈ B is a partition of [0 , 1[ ordered by < 1 . For any w ∈ X , we have by Equation (2.5) J w = I w + α w and thus T X is the interval exchange transformation relative to ( K b ) b ∈ B with translation values β b .
In the sequel, under the hypotheses of Proposition 3.8, we consider T f as an interval exchange transformation. In particular, the natural coding of T f relative to z ∈ [0 , 1[ is well-defined.
Example 3.9 Let S be the Fibonacci set. It is the set of factors of the Fibonacci word, which is a natural coding of the rotation of angle α = (3 -√ 5) / 2 relative to α (see Example 3.1). Let X = { aa, ab, ba } and let f be the coding morphism defined by f ( u ) = aa , f ( v ) = ab , f ( w ) = ba . The two partitions of [0 , 1[ corresponding to T f are
$$I _ { u } = [ 0, 1 - 2 \alpha [, \ \ I _ { v } = [ 1 - 2 \alpha, 1 - \alpha [ \ \ I _ { w } = [ 1 - \alpha, 1 [ \ \ }$$
and
$$J _ { v } = [ 0, \alpha [, \ \ J _ { w } = [ \alpha, 2 \alpha [ \ \ J _ { u } = [ 2 \alpha, 1 [.$$
The transformation T f is represented in Figure 3.2. It is actually a representa-
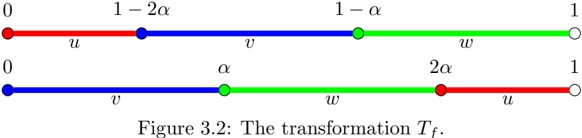
tion on 3 intervals of the rotation of angle 2 α . Note that the point z = 1 -α is a separation point which is not a singularity of T f . The first row of Table 3.1 gives the two orders on X . The next two rows give the two orders for each of the two other S -maximal bifix codes of S -degree 2 (there are actually exactly three S -maximal bifix codes of S -degree 2 in the Fibonacci set, see [2]).
Let T be a minimal interval exchange transformation on the alphabet A . Let x be the natural coding of T relative to some z ∈ [0 , 1[. Set S = F x ( ). Let X be a finite S -maximal bifix code. Let f : B ∗ → A ∗ be a morphism which maps bijectively B onto X . Since S is recurrent, the set X is an S -maximal
Table 3.1: The two orders on the three S -maximal bifix codes of S -degree 2.
| ( X,< 1 ) | ( X,< 2 ) |
|--------------|--------------|
| aa, ab, ba | ab, ba, aa |
| a, baab, bab | bab, baab, a |
| aa, aba, b | b, aba, aa |
prefix code. Thus x has a prefix x 0 ∈ X . Set x = x x 0 ′ . In the same way x ′ has a prefix x 1 in X . Iterating this argument, we see that x = x x 0 1 · · · with x i ∈ X . Consequently, there exists an infinite word y on the alphabet B such that x = f ( y ). The word y is the decoding of the infinite word x with respect to f .
Proposition 3.10 The decoding of x with respect to f is the natural coding of the transformation associated with f relative to z : Σ ( ) = T z f (Σ T f ( z )) .
Proof. Let y = b 0 b 1 · · · be the decoding of x with respect to f . Set x i = f ( b i ) for i ≥ 0. Then, for any n ≥ 0, we have
$$T _ { f } ^ { n } ( z ) = T ^ { | u _ { n } | } ( z )$$
with u n = x 0 · · · x n -1 (note that | u n | denotes the length of u n with respect to the alphabet A ). Indeed, this is is true for n = 0. Next T n +1 f ( z ) = T f ( ) with t t = T n f ( z ). Arguing by induction, we have t = T | u n | ( z ). Since x = u x x n n n +1 · · · , t is in I x n by (2.3). Thus by Proposition 3.8, T f ( ) t = T | x n | ( ) t and we obtain T n +1 f ( z ) = T | x n | ( T | u n | ( z )) = T | u n +1 | ( z ) proving (3.2). Finally, for u = f ( b ) with b ∈ B ,
$$b _ { n } = b \Longleftrightarrow x _ { n } = u \Longleftrightarrow T ^ { | u _ { n } | } ( z ) \in I _ { u } \Longleftrightarrow T _ { f } ^ { n } ( z ) \in I _ { u } = K _ { b }$$
showing that y is the natural coding of T f relative to z .
Example 3.11 Let T, α, X and f be as in Example 3.9. Let x = abaababa · · · be the Fibonacci word. We have x = Σ T ( α ). The decoding of x with respect to f is y = vuwwv · · · .
## 3.3 Bifix codes and regular transformations
The following result shows that, for the coding morphism f of a finite S -maximal bifix code, the map T → T f preserves the regularity of the transformation.
↦
Theorem 3.12 Let T be a regular interval exchange transformation and let S = F T ( ) . For any finite S -maximal bifix code X with coding morphism f , the transformation T f is regular.
Proof. Set A = { a , a 1 2 , . . . , a s } with a 1 < 1 a 2 < 1 · · · < 1 a s . We denote δ i = δ a i . By hypothesis, the orbits of δ 2 , . . . , δ s are infinite and disjoint. Set X = { x , x 1 2 , . . . , x t } with x 1 < x 1 2 < 1 · · · < x 1 t . Let d be the S -degree of X .
/negationslash
For x ∈ X , denote by δ x the left boundary of the semi-interval J x . For each x ∈ X , it follows from Equation (2.2) that there is an i ∈ { 1 , . . . , s } such that δ x = T k ( δ i ) with 0 ≤ k < | x | . Moreover, we have i = 1 if and only if x = x 1 . Since T is regular, the index i = 1 and the integer k are unique for each x = x 1 . And for such x and i , by (2.4), we have Σ T ( δ i ) = u Σ ( T δ x ) with u a proper suffix of x .
/negationslash
/negationslash
We now show that the orbits of δ x 2 , . . . , δ x t for the transformation T f are infinite and disjoint. Assume that δ x p = T n f ( δ x q ) for some p, q ∈ { 2 , . . . , t } and n ∈ Z . Interchanging p, q if necessary, we may assume that n ≥ 0. Let i, j ∈ { 2 , . . . , s } be such that δ x p = T k ( δ i ) with 0 ≤ k < | x p | and δ x q = T /lscript ( δ j ) with 0 ≤ /lscript < x | q | . Since T k ( δ i ) = T n f ( T /lscript ( δ j )) = T m /lscript + ( δ j ) for some m ≥ 0, we cannot have i = j since otherwise the orbits of δ , δ i j for the transformation T intersect. Thus i = j . Since δ x p = T k ( δ i ), we have Σ T ( δ i ) = u Σ ( T δ x p ) with | u | = k , and u a proper suffix of x p . And since δ x p = T n f ( δ x q ), we have Σ ( T δ x q ) = x Σ ( T δ x p ) with x ∈ X ∗ . Since on the other hand δ x q = T /lscript ( δ i ), we have Σ T ( δ i ) = v Σ ( T δ x q ) with | v | = /lscript and v a proper suffix of x q . We obtain
$$\Sigma _ { T } ( \delta _ { i } ) \ & = \ u \Sigma _ { T } ( \delta _ { x _ { p } } ) \\ & = \ v \Sigma _ { T } ( \delta _ { x _ { q } } ) = v x \Sigma _ { T } ( \delta _ { x _ { p } } ).$$
Since | u | = | vx | , this implies u = vx . But since u cannot have a suffix in X , u = vx implies x = 1 and thus n = 0 and p = . This concludes the proof. q
Let f be a coding morphism for a finite S -maximal bifix code X ⊂ S . The set f -1 ( S ) is called a maximal bifix decoding of S .
Theorem 3.13 The family of regular interval exchange sets is closed under maximal bifix decoding.
Proof. Let T be a regular interval exchange transformation such that S = F T ( ). By Theorem 3.12, T f is a regular interval exchange transformation. We show that f -1 ( S ) = F T ( f ), which implies the conclusion.
Let x = Σ T ( z ) for some z ∈ [0 , 1[ and let y = f -1 ( x ). Then S = F x ( ) and F T ( f ) = F y ( ). For any w ∈ F y ( ), we have f ( w ) ∈ F x ( ) and thus w ∈ f -1 ( S ). This shows that F T ( f ) ⊂ f -1 ( S ). Conversely, let w ∈ f -1 ( S ) and let v = f ( w ). Since S = F x ( ), there is a word u such that uv is a prefix of x . Set z ′ = T | u | ( z ) and x ′ = Σ T ( z ′ ). Then v is a prefix of x ′ and w is a prefix of y ′ = f -1 ( x ′ ). Since T f is regular, it is minimal and thus F y ( ′ ) = F T ( f ). This implies that w ∈ F T ( f ).
Since a regular interval exchange set is uniformly recurrent, Theorem 3.13 implies in particular that if S is a regular interval exchange set and f a coding morphism of a finite S -maximal bifix code, then f -1 ( S ) is uniformly recurrent.
This is not true for an arbitrary uniformly recurrent set S , as shown by the following example.
Example 3.14 Set A = { a, b } and B = { u, v } . Let S be the set of factors of ( ab ) ∗ and let f : B ∗ → A ∗ be defined by f ( u ) = ab and f ( v ) = ba . Then f -1 ( S ) = u ∗ ∪ v ∗ which is not recurrent.
We illustrate the proof of Theorem 3.12 in the following example.
Example 3.15 Let T be the rotation of angle α = (3 -√ 5) / 2. The set S = F T ( ) is the Fibonacci set. Let X = { a, baab, babaabaabab, babaabab } . The set X is an S -maximal bifix code of S -degree 3 (see [2]). The values of the µ x i (which are the right boundaries of the intervals I x i ) and δ x i are represented in Figure 3.3.
µ

µ
µ
µ
Figure 3.3: The transformation associated with a bifix code of S -degree 3.
The infinite word Σ T (0) is represented in Figure 3.4. The value indicated on the word Σ T (0) after a prefix u is T | u | (0). The three values δ x 4 , δ x 2 , δ x 3 correspond to the three prefixes of Σ T (0) which are proper suffixes of X .
Figure 3.4: The infinite word Σ T (0).
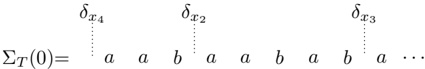
The following example shows that Theorem 3.13 is not true when X is not bifix.
Example 3.16 Let S be the Fibonacci set and let X = { aa, ab, b } . The set X is an S -maximal prefix code. Let B = { u, v, w } and let f be the coding morphism for X defined by f ( u ) = aa , f ( v ) = ab , f ( w ) = b . The set W = f -1 ( S ) is not an interval exchange set. Indeed, we have vu, vv, wu, wv ∈ W . This implies that both J v and J w meet I u and I v , which is impossible in an interval exchange transformation.
## 4 Tree sets
We introduce in this section the notions of tree sets and planar tree sets. We first introduce the notion of extension graph which describes the possible two-sided extensions of a word.
## 4.1 Extension graphs
Let S be a biextendable set of words. For w ∈ S , we denote
$$L ( w ) = \{ a \in A \ | \ a w \in S \}, \ \ R ( w ) = \{ a \in A \ | \ w a \in S \}$$
and
$$E ( w ) = \{ ( a, b ) \in A \times A \ | \ a w b \in S \}. \\. \ \. \ \. \ \. \ \. \ \. \ \. \ \. \ \. \ \.. \ \..$$
For w ∈ S , the extension graph of w is the undirected bipartite graph G w ( ) on the set of vertices which is the disjoint union of two copies of L w ( ) and R w ( ) with edges the pairs ( a, b ) ∈ E w ( ).
Let < 1 and < 2 be two orders on A . For a set S and a word w ∈ S , we say that the graph G w ( ) is compatible with the orders < 1 and < 2 if for any ( a, b ) , ( c, d ) ∈ E w ( ), one has
Recall that an undirected graph is a tree if it is connected and acyclic. Let S be a biextendable set. We say that S is a tree set if the graph G w ( ) is a tree for all w ∈ S .
$$a < _ { 1 } c \Longrightarrow b \leq _ { 2 } d.$$
Thus, placing the vertices of L w ( ) ordered by < 1 on a line and those of R w ( ) ordered by < 2 on a parallel line, the edges of the graph may be drawn as straight noncrossing segments, resulting in a planar graph.
We say that a biextendable set S is a planar tree set with respect to two orders < 1 and < 2 on A if for any w ∈ S , the graph G w ( ) is a tree compatible with < , < 1 2 . Obviously, a planar tree set is a tree set.
The following example shows that the Tribonacci set is not a planar tree set.
Example 4.1 Let S be the Tribonacci set (see Example 2.6). The words a, aba and abacaba are bispecial. Thus the words ba, caba are right-special and the words ab, abac are left-special. The graphs G ε , G a ( ) ( ) and G aba ( ) are shown in Figure 4.1. One sees easily that it not possible to find two orders on A making
Figure 4.1: The graphs G ε , G a ( ) ( ) and G aba ( ) in the Tribonacci set.

the three graphs planar.
## 4.2 Interval exchange sets and planar tree sets
The following result is proved in [9] with a converse (see below).
Proposition 4.2 Let T be an interval exchange transformation on A ordered by < 1 and < 2 . If T is regular, the set F T ( ) is a planar tree set with respect to < 2 and < 1 .
Proof. Assume that T is a regular interval exchange transformation relative to ( I a , α a ) a ∈ A and let S = F T ( ).
Since T is minimal, w is in S if and only if I w = ∅ . Thus, one has
/negationslash
- (ii) a ∈ L w ( ) if and only if J a ∩ I w = . ∅
/negationslash
- (i) b ∈ R w ( ) if and only if I w ∩ T -| w | ( I b ) = ∅ and
/negationslash
Condition (i) holds because I wb = I w ∩ T -| w | ( I b ) and condition (ii) because I aw = I a ∩ T -1 ( I w ), which implies T I ( aw ) = J a ∩ I w . In particular, (i) implies that ( I wb b ) ∈ R w ( ) is an ordered partition of I w with respect to < 1 .
/negationslash
We say that a path in a graph is reduced if it does not use consecutively the same edge. For a, a ′ ∈ L w ( ) with a < 2 a ′ , there is a unique reduced path in G w ( ) from a to a ′ which is the sequence a , b 1 1 , . . . a n with a 1 = a and a n = a ′ with a 1 < 2 a 2 < 2 · · · < 2 a n , b 1 < 1 b 2 < 1 · · · < 1 b n -1 and J a i ∩ I wb i = ∅ , J a i +1 ∩ I wb i = ∅ for 1 ≤ i ≤ n -1 (see Figure 4.2). Note that the hypothesis that T is regular is needed here since otherwise the right boundary of J a i could be the left boundary of I wb i . Thus G w ( ) is a tree. It is compatible with < , < 2 1 since the above shows that a < 2 a ′ implies that the letters b 1 , b n -1 such that ( a, b 1 ) , ( a , b ′ n -1 ) ∈ E w ( ) satisfy b 1 ≤ 1 b n -1 .
/negationslash
Figure 4.2: A path from a 1 to a n in G w ( ).

By Proposition 4.2, a regular interval exchange set is a planar tree set, and thus in particular a tree set. Note that the analogue of Theorem 3.13 holds for the class of uniformly recurrent tree sets [5].
The main result of [9] states that a uniformly recurrent set S on an alphabet A is a regular interval exchange set if and only if A ⊂ S and there exist two orders < 1 and < 2 on A such that the following conditions are satisfied for any word w ∈ S .
- (i) The set L w ( ) (resp. R w ( )) is formed of consecutive elements for the order < 2 (resp. < 1 ).
- (ii) For ( a, b ) , ( c, d ) ∈ E w ( ), if a < 2 c , then b ≤ 1 d .
- (iii) If a, b ∈ L w ( ) are consecutive for the order < 2 , then the set R aw ( ) ∩ R bw ( ) is a singleton.
It is easy to see that a biextendable set S containing A satisfies (ii) and (iii) if and only if it is a planar tree set. Actually, in this case, it automatically satisfies also condition (i). Indeed, let us consider a word w and a, b, c ∈ A with a < 1 b < 1 c such that wa,wc ∈ S but wb / S ∈ . Since b ∈ S there is a (possibly empty) suffix v of w such that vb ∈ S . We choose v of maximal length. Since wb / S ∈ , we have w = uv with u nonempty. Let d be the last letter of u . Then we have dva, dvc ∈ S and dvb / S ∈ . Since G v ( ) is a tree and b ∈ R v ( ), there is a letter e ∈ L v ( ) such that evb ∈ S . But e < 2 d and d < 2 e are both impossible since G v ( ) is compatible with < 2 and < 1 . Thus we reach a contradiction.
This shows that the following reformulation of the main result of [9] is equivalent to the original one.
Theorem 4.3 (Ferenczi, Zamboni) A set S is a regular interval exchange set on the alphabet A if and only if it is a uniformly recurrent planar tree set containing A .
We have already seen that the Tribonacci set is a tree set which is not a planar tree set (Example 4.1). The next example shows that there are uniformly recurrent tree sets which are neither Sturmian nor regular interval exchange sets.
Example 4.4 Let S be the Tribonacci set on the alphabet A = { a, b, c } and let f : { x, y, z, t, u } ∗ → A ∗ be the coding morphism for X = S ∩ A 2 defined by f ( x ) = aa , f ( y ) = ab , f ( z ) = ac , f ( ) = t ba , f ( u ) = ca . By Theorem 7.1 in [5], the set W = f -1 ( S ) is a uniformly recurrent tree set. It is not Sturmian since y and t are two right-special words. It is not either a regular interval exchange set. Indeed, for any right-special word w of W , one has Card( R w ( )) = 3. This is not possible in a regular interval exchange set T since, Σ T being injective, the length of the interval J w tends to 0 as | w | tends to infinity and it cannot contain several separation points. It can of course also be verified directly that W is not a planar tree set.
## 4.3 Exchange of pieces
In this section, we show how one can define a generalization of interval exchange transformations called exchange of pieces. In the same way as interval exchange is a generalization of rotations on the circle, exchange of pieces is a generalization of rotations of the torus. We begin by studying this direction starting from the Tribonacci word. For more on the Tribonacci word, see [17] and also [14, Chap. 10].
The Tribonacci shift The Tribonacci set S is not an interval exchange set but it is however the natural coding of another type of geometric transformation, namely an exchange of pieces in the plane, which is also a translation acting on the two-dimensional torus T 2 . This will allow us to show that the decoding of
the Tribonacci word with respect to a coding morphism for a finite S -maximal bifix code is again a natural coding of an exchange of pieces.
The Tribonacci shift is the symbolic dynamical system ( M ,σ x ), where M x = { σ n ( x ) : n ∈ N } is the closure of the σ -orbit of x where x is the Tribonacci word. By uniform recurrence of the Tribonacci word, ( M ,σ x ) is minimal and M x = M y for each y ∈ M x ([16, Proposition 4.7]). The Tribonacci set is the set of factors of the Tribonacci shift ( M ,σ x ).
↦
Natural coding Let Λ be a full-rank lattice in R d . We say that an infinite word x is a natural coding of a toral translation T t : R d / Λ → R d / Λ , x → x + t if there exists a fundamental domain R for Λ together with a partition R = R 1 ∪·· ·∪ R k such that on each R i (1 ≤ i ≤ k ), there exists a vector t i such that the map T t is given by the translation along t i , and x is the coding of a point x ∈ R with respect to this partition. A symbolic dynamical system ( M,σ ) is a natural coding of ( R d / Λ , T t ) if every element of M is a natural coding of the orbit of some point of the d -dimensional torus R d / Λ (with respect to the same partition) and if, furthermore, ( M,σ ) and ( R d / Λ , T t ) are measurably conjugate.
↦
↦
Definition of the Rauzy fractal Let β stand for the Perron-Frobenius eigenvalue of the Tribonacci substitution. It is the largest root of z 3 -z 2 -z -1. Consider the translation R β : T 2 → T 2 , x → x +(1 /β, 1 /β 2 ). Rauzy introduces in [18] a fundamental domain for a two-dimensional lattice, called the Rauzy fractal (it has indeed fractal boundary), which provides a partition for the symbolic dynamical system ( M ,σ x ) to be a natural coding for R β . The Tribonacci word is a natural coding of the orbit of the point 0 under the action of the toral translation in T 2 : x → x + ( 1 β , 1 β 2 ). Similarly as in the case of interval exchanges, we have the following commutative diagram
The Abelianization map f of the free monoid { 1 2 3 , , } ∗ is defined by f : { 1 2 3 , , } ∗ → Z 3 , f ( w ) = | w | 1 e 1 + | w | 2 e 2 + | w | 3 e , 3 where | w | i denotes the number of occurrences of the letter i in the word w , and ( e , e 1 2 , e 3 ) stands for the canonical basis of R 3 .
↦
↦
↦
$$\text{``\nu`` *} \quad \mathbb { N } \vee \mathbb { N } / \mathbb { N } / ( \mathfrak { t }, \mathfrak { j } ) \in \mathbb { A } ^ { \prime } \ \dashv \cdots \quad \mathbb { N } \vee \mathbb { N } / \mathbb { N } \ \dashv \cdots \quad \mathbb { N } \ \dashv \cdots \quad \mathbb { N } \ \dashv \cdots \quad \mathbb { N } \ \dashv \cdots \quad \mathbb { N } \ \dashv \cdots \quad \mathbb { N } \ \dashv \cdots \quad \mathbb { N } \ \dashv \cdots \quad \mathbb { N } \ \dashv \cdots \quad \mathbb { N } \ \dashv \cdots \quad \mathbb { N } \ \dashv \cdots \quad \mathbb { N } \ \dashv \cdots \quad \mathbb { N } \ \dashv \cdots \quad \mathbb { N } \ \dashv \cdots \quad \mathbb { N } \ \dashv \cdots \quad \mathbb { W } \ \mathbb { N } \ \mathbb { N } \ \mathbb { N } \ \mathbb { N } \ \mathbb { N } \ \mathbb { N } \ \mathbb { N } \ \mathbb { N } \ \mathbb { N } \ \mathbb { N } \ \mathbb { N } \ \mathbb { N } \ \mathbb { N } \ \mathbb { N } \ \mathbb { N } \ \mathbb { N } \ \mathbb { N } \ \mathbb { N } \ \mathbb { N } \ \mathbb { N } \ \mathbb { N } \ \mathbb { N } \ \mathbb { N } \ \mathbb { N } \ \mathbb { N } \ \mathbb { N } \ \mathbb { N } \ \mathbb { N } \ \mathbb { N } \ \matrix \cdots \quad \mathbb { N } \ \mathbb { N } \ \mathbb { N } \ \mathbb { N } \ \mathbb { N } \ \mathbb { N } \ \mathbb { N } \ \mathbb { N } \ \mathbb { N } \ \mathbb { N } \ \mathbb { N } \ \mathbb { N } \ \mathbb { N } \ \mathbb { N } \ \mathbb { N } \ \mathbb { N } \ \mathbb { N } \ \mathbb { N } \ \mathbb { N } \ \mathbb { N } \ \mathbb { N } \ \mathbb { N } \ \mathbb { N } \ \mathbb { N } \ \mathbb { N } \ \mathbb { N } \ \mathbb { N } \ \mathbb { N } \ \mathbb{ N } \ \mathbb { N } \ \mathbb { N } \ \mathbb { N } \ \mathbb { N } \ \mathbb { N } \ \mathbb { N } \ \mathbb { N } \ \mathbb { N } \ \mathbb { N } \ \mathbb { N } \ \mathbb { N } \ \mathbb { N } \ \mathbb { N } \ \mathbb { N } \ \mathbb { N } \ \mathbb { N } \ \mathbb { N } \ \mathbb { N } \ \mathbb { N } \ \mathbb { N } \ \mathbb { N } \ \mathbb { N } \ \mathbb { N } \ \mathbb { N } \ \mathbb { N } \ \mathbb { N } \ \mathbb { N } \ \mathbb { N } \ \\ \text{letter} \, i \, in \, f ( j ). \, One has \, F = \left [ \begin{array} { c c c } 1 & 1 & 1 & 1 \\ 1 & 0 & 0 \\ 0 & 1 & 0 \end{array} \right ]. \, The incidence matrix \, F \, \text{admits} \, as$$
Let f be the morphism a → ab, b → ac, c → a such that the Tribonacci word is the fixpoint of f (see Example 2.6). The incidence matrix F of f is defined by F = ( | f ( j ) | i ) ( i,j ) ∈A 2 , where | f ( j ) | i counts the number of occurrences of the eigenspaces in R 3 one expanding eigenline (generated by the eigenvector with positive coordinates v β = (1 /β, 1 /β , 2 1 /β 3 ) associated with the eigenvalue β ).
We consider the projection π onto the antidiagonal plane x + y + z = 0 along the expanding direction of the matrix F .
One associates with the Tribonacci word x = ( x n n ) ≥ 0 a broken line starting from 0 in Z 3 and approximating the expanding line v β as follows. The Tribonacci broken line is defined as the broken line which joins with segments of length 1 the points f ( x x 0 1 · · · x n -1 ) , n ∈ N . In other words we describe this broken line by starting from the origin, and then by reading successively the letters of the Tribonacci word x , going one step in direction e i if one reads the letter i . The vectors f ( x x 0 1 · · · x n ), n ∈ N , stay within bounded distance of the expanding line (this comes from the fact that β is a Pisot number). The closure of the set of projected vertices of the broken line is called the Rauzy fractal and is represented on Figure 4.3. We thus define the Rauzy fractal R as
$$\mathcal { R } \coloneqq \overline { \{ \pi ( \mathbf f ( x _ { 0 } \cdots x _ { n - 1 } ) ) ; \ n \in \mathbb { N } \} },$$
where x 0 . . . x n -1 stands for the empty word when n = 0.
Figure 4.3: The Rauzy fractal
The Rauzy fractal is divided into three pieces, for i = { 1 2 3 , , }
$$\begin{array} { c c c } \mathcal { R } ( i ) & \coloneqq & \overline { \{ \pi ( \mathbf f ( x _ { 0 } \cdots x _ { n - 1 } ) ) ; \ x _ { n } = i, n \in \mathbb { N } \} }, \\ \mathcal { R } ^ { \prime } ( i ) & \coloneqq & \overline { \{ \pi ( \mathbf f ( x _ { 0 } \cdots x _ { n } ) ) ; \ x _ { n } = i, n \in \mathbb { N } \} }. \end{array}$$
It has been proved in [18] that these pieces have non-empty interior and are disjoint up to a set of zero measure. The following exchange of pieces E is thus well-defined
$$E \, \colon \text{Int } \mathcal { R } _ { 1 } \cup \text{Int } \mathcal { R } _ { 2 } \cup \text{Int } \mathcal { R } _ { 3 } \to \mathcal { R }, \, x \mapsto x + \pi ( e _ { i } ), \, \text{when } x \in \text{Int } \mathcal { R } _ { i }.$$
↦
One has E ( R i ) = R ′ i , for all i .
/negationslash
/negationslash
We consider the lattice Λ generated by the vectors π e ( i ) -π e ( j ), for i = . j The Rauzy fractal tiles periodically the plane, that is, ∪ γ ∈ Λ γ + R is equal to the plane x + y + z = 0, and for γ = γ ′ ∈ Λ, γ + R and γ ′ + R do not intersect (except on a set of zero measure). This is why the exchange of pieces is in fact measurably conjugate to the translation R β . Indeed the vector of coordinates of π ( f ( x x 0 1 · · · x n -1 )) in the basis ( π e ( 3 ) -π e ( 1 ) , π ( e 3 ) -π e ( 2 )) of the plane x + y + z = 0 is n · (1 /β, 1 /β 2 ) - | ( x x 0 1 · · · x n -1 1 | , | x x 0 1 · · · x n -1 2 | ) . Hence the coordinates of E n (0) in the basis ( p i ( e 3 ) -π e ( 1 ) , p i ( e 3 ) -p i ( e 2 )) are equal to R n β (0) modulo Z 2 .
Bifix codes and exchange of pieces Let ( R a ) a ∈ A and ( R ′ a ) a ∈ A be two families of subsets of a compact set R incuded in R d . We assume that the families ( R a ) a ∈ A and ( R ′ a ) a ∈ A both form a partition of R up to a set of zero measure. We assume that there exist vectors e a such that R ′ a = R a + e a for any a ∈ A . The exchange of pieces associated with these data is the map E defined on R (except a set of measure zero) by E z ( ) = z + e a if z ∈ R a . The notion of natural coding of an exchange of pieces extends here in a natural way.
Assume that E is an exchange of pieces as defined above. Let S be the set of factors of the natural codings of E . We assume that S is uniformly recurrent.
By analogy with the case of interval exchanges, let I a = R a and let J a = E ( R a ). For a word w ∈ A ∗ , one defines similarly as for interval exchanges I w and J w .
Let X be a finite S -maximal prefix code. The family I w , w ∈ X , is a partition (up to sets of zero measure) of R . If X is a finite S -maximal suffix code, then the family J w is a partition (up to sets of zero measure) of R . Let f be a coding morphism for X . If X is a finite S -maximal bifix code, then E X is the exchange of pieces E f (defined as for interval exchanges), hence the decoding of x with respect to f is the natural coding of the exchange of pieces associated with f . In particular, S being the Tribonacci set, the decoding of S by a finite S -maximal bifix code is again the natural coding of an exchange of pieces. If X is the set of factors of length n of S , then E f is in fact equal to R n β (otherwise, there is no reason for this exchange of pieces to be a translation). The analogues of Proposition 3.8 and 3.10 thus hold here also.
## 4.4 Subgroups of finite index
We denote by F A the free group on the set A .
Let S be a recurrent set containing the alphabet A . We say that S has the finite index basis property if the following holds: a finite bifix code X ⊂ S is an S -maximal bifix code of S -degree d if and only if it is a basis of a subgroup of index d of F A .
The following is a consequence of the main result of [4].
Theorem 4.5 A regular interval exchange set has the finite index basis property.
Proof. Let T be a regular interval exchange transformation and let S = F T ( ). Since T is regular, S is uniformly recurrent and by Proposition 4.2, it is a tree set. By Theorem 4.4 in [4], a uniformly recurrent tree set has the finite index basis property, and thus the conclusion follows.
Note that Theorem 4.5 implies in particular that if T is a regular s -interval exchange set and if X is a finite S -maximal bifix code of S -degree d , then Card( X ) = d s ( -1) + 1. Indeed, by Schreier's Formula a basis of a subgroup of index d in a free group of rank s has d s ( -1) + 1 elements.
We use Theorem 4.5 to give another proof of Theorem 3.12. For this, we recall the following notion.
Let T be an interval exchange transformation on I = [0 1[ , relative to ( I a ) a ∈ A . Let G be a transitive permutation group on a finite set Q . Let ϕ : A ∗ → G be a morphism and let ψ be the map from I into G defined by ψ z ( ) = ϕ a ( ) if z ∈ I a . The skew product of T and G is the transformation U on I × Q defined by
$$U ( z, q ) = ( T ( z ), q \psi ( z ) )$$
(where qψ z ( ) is the result of the action of the permutation ψ z ( ) on q ∈ Q ). Such a transformation is equivalent to an interval exchange transformation via the identification of I × Q with an interval obtained by placing the d = Card( Q ) copies of I in sequence. This is called an interval exchange transformation on a stack in [7] (see also [19]). If T is regular, then U is also regular.
Let T be a regular interval exchange transformation and let S = F T ( ). Let X be a finite S -maximal bifix code of S -degree d = d X ( S ). By Theorem 4.5, X is a basis of a subgroup H of index d of F A . Let G be the representation of F A on the right cosets of H and let ϕ be the natural morphism from F A onto G . We identify the right cosets of H with the set Q = { 1 2 , , . . . , d } with 1 identified to H . Thus G is a transitive permutation group on Q and H is the inverse image by ϕ of the permutations fixing 1.
The transformation induced by the skew product U on I × { } 1 is clearly equivalent to the transformation T f = T X where f is a coding morphism for the S -maximal bifix code X . Thus T X is a regular interval exchange transformation.
Example 4.6 Let T be the rotation of Example 3.1. Let Q = 1 2 3 { , , } and let ϕ be the morphism from A ∗ into the symmetric group on Q defined by ϕ a ( ) = (23) and ϕ b ( ) = (12). The transformation induced by the skew product of T and G on I ×{ } 1 corresponds to the bifix code X of Example 3.15. For example, we have U : (1 -α, 1) → (0 , 2) → ( α, 3) → (2 α, 2) → (3 α -1 1) (see Figure 4.4) , and the corresponding word of X is baab .
b
Figure 4.4: The transformation U .
## References
- [1] Vladimir I. Arnold. Small denominators and problems of stability of motion in classical and celestial mechanics. Uspehi Mat. Nauk , 18(6 (114)):91-192, 1963.
- [2] Jean Berstel, Clelia De Felice, Dominique Perrin, Christophe Reutenauer, and Giuseppina Rindone. Bifix codes and Sturmian words. J. Algebra , 369:146-202, 2012.
- [3] Jean Berstel, Dominique Perrin, and Christophe Reutenauer. Codes and Automata . Cambridge University Press, 2009.
- [4] Val´ erie Berth´, Clelia De Felice, Francesco Dolce, Julien Leroy, Dominique e Perrin, Christophe Reutenauer, and Giuseppina Rindone. The finite index basis property. J. Pure Appl. Algebra , 219:2521-2537, 2015.
- [5] Val´ erie Berth´, Clelia De Felice, Francesco Dolce, Julien Leroy, Dominique e Perrin, Christophe Reutenauer, and Giuseppina Rindone. Maximal bifix decoding. Discrete Math. , 338:725-742, 2015.
- [6] Val´ erie Berth´ e and Michel Rigo, editors. Combinatorics, automata and number theory , volume 135 of Encyclopedia of Mathematics and its Applications . Cambridge University Press, Cambridge, 2010.
- [7] Michael D. Boshernitzan and C. R. Carroll. An extension of Lagrange's theorem to interval exchange transformations over quadratic fields. J. Anal. Math. , 72:21-44, 1997.
- [8] Isaac P. Cornfeld, Sergei V. Fomin, and Yakov G. Sina˘ ı. Ergodic theory , volume 245 of Grundlehren der Mathematischen Wissenschaften [Fundamental Principles of Mathematical Sciences] . Springer-Verlag, New York, 1982. Translated from the Russian by A. B. Sosinski˘ ı.
- [9] S´ ebastien Ferenczi and Luca Q. Zamboni. Languages of k -interval exchange transformations. Bull. Lond. Math. Soc. , 40(4):705-714, 2008.
- [10] N. Pytheas Fogg. Substitutions in dynamics, arithmetics and combinatorics , volume 1794 of Lecture Notes in Mathematics . Springer-Verlag, Berlin, 2002. Edited by V. Berth´, S. Ferenczi, C. Mauduit and A. Siegel. e
- [11] Jacques Justin and Laurent Vuillon. Return words in Sturmian and episturmian words. Theor. Inform. Appl. , 34(5):343-356, 2000.
- [12] Michael Keane. Interval exchange transformations. Math. Z. , 141:25-31, 1975.
- [13] M. Lothaire. Algebraic Combinatorics on Words . Cambridge University Press, 2002.
- [14] M. Lothaire. Applied combinatorics on words , volume 105 of Encyclopedia of Mathematics and its Applications . Cambridge University Press, Cambridge, 2005.
- [15] V. I. Oseledec. The spectrum of ergodic automorphisms. Dokl. Akad. Nauk SSSR , 168:1009-1011, 1966.
- [16] Martine Queff´ elec. Substitution dynamical systems-spectral analysis , volume 1294 of Lecture Notes in Mathematics . Springer-Verlag, Berlin, second edition, 2010.
- [17] G´ erard Rauzy. ´ changes d'intervalles E et transformations induites. Acta Arith. , 34(4):315-328, 1979.
- [18] G´ erard Rauzy. Nombres alg´ ebriques et substitutions. Bull. Soc. Math. France , 110(2):147-178, 1982.
- [19] William A. Veech. Finite group extensions of irrational rotations. Israel J. Math. , 21(2-3):240-259, 1975. Conference on Ergodic Theory and Topological Dynamics (Kibbutz Lavi, 1974). | null | [
"Valérie Berthé",
"Clelia De Felice",
"Francesco Dolce",
"Julien Leroy",
"Dominique Perrin",
"Christophe Reutenauer",
"Giuseppina Rindone"
] | 2014-08-02T15:53:41+00:00 | 2015-02-20T18:52:18+00:00 | [
"math.CO"
] | Bifix codes and interval exchanges | We investigate the relation between bifix codes and interval exchange
transformations. We prove that the class of natural codings of regular interval
echange transformations is closed under maximal bifix decoding. |
1408.0391v3 | ## RiPKI: The Tragic Story of RPKI Deployment in the Web Ecosystem
Matthias Wählisch Freie Universität Berlin [email protected]
Robert Schmidt Freie Universität Berlin [email protected]
Thomas C. Schmidt HAW Hamburg [email protected]
Olaf Maennel Tallinn U. of Technology [email protected]
Steve Uhlig Queen Mary Univ. London [email protected]
## ABSTRACT
Gareth Tyson Queen Mary Univ. London [email protected]
## Keywords
Web content delivery is one of the most important services on the Internet. Access to websites is typically secured via TLS. However, this security model does not account for prefix hijacking on the network layer, which may lead to traffic blackholing or transparent interception. Thus, to achieve comprehensive security and service availability, additional protective mechanisms are necessary such as the RPKI, a recently deployed Resource Public Key Infrastructure to prevent hijacking of traffic by networks. This paper argues two positions. First, that modern web hosting practices make route protection challenging due to the propensity to spread servers across many different networks, often with unpredictable client redirection strategies; and, second, that we need a better understanding why protection mechanisms are not deployed. To initiate this, we empirically explore the relationship between web hosting infrastructure and RPKI deployment. Perversely, we find that less popular websites are more likely to be secured than the prominent sites. Worryingly, we find many large-scale CDNs do not support RPKI, thus making their customers vulnerable. This leads us to explore business reasons why operators are hesitant to deploy RPKI, which may help to guide future research on improving Internet security.
## Categories and Subject Descriptors
C.2.2 [ Computer-Communication Networks ]: Network ProtocolsRouting Protocols ; C.2.5 [ Computer-Communication Networks ]: Local and Wide-Area NetworksInternet
General Terms
Security, Measurement
Permission to make digital or hard copies of all or part of this work for personal or classroom use is granted without fee provided that copies are not made or distributed for profit or commercial advantage and that copies bear this notice and the full citation on the first page. To copy otherwise, to republish, to post on servers or to redistribute to lists, requires prior specific permission and/or a fee.
HotNets '15 November 16-17 2015, Philadelphia, PA USA Copyright 2015 ACM 978-1-4503-4047-2 ...$15.00. DOI: http://dx.doi.org/10.1145/2834050.2834102
BGP, RPKI, secure inter-domain routing, deployment, hosting infrastructure, CDN
## 1. INTRODUCTION
Website security is a long pursued and rather esoteric goal. Traditionally, it has been approached from an end-to-end perspective ( e.g. TLS), largely because this is easily within the sphere of control of any web provider. However, as evidenced by many prominent attacks, this is frequently insufficient. This is because various third party infrastructure dependencies exist that maybe vulnerable to attack, e.g. within BGP, DNS, certificate authorities, operating systems.
Take, for example, BGP, which manages inter-domain connectivity. If BGP is misconfigured, websites can become severed from the network, regardless of the security measures taken at the application layer [4,27,33]. Thus, true security requires multi-layer and multi-stakeholder cooperation. In this paper, we focus on the importance of routing layer security for ensuring reliable website provision.
Routing security is a topic that is discussed widely among network operators, yet (anecdotally) receives far less attention from web service providers. This is despite the availability of technologies that mitigate attacks. For example, the Resource Public Key Infrastructure (RPKI) is a recently standardized framework that enables BGP routers to perform prefix origin validation. When activated, this can prevent incidents such as the Pakistan Telecom hijacking of traffic destined to YouTube. It works by crytographically validating the right of an AS to advertise a prefix. Although clearly attractive as a security measure, it is unclear to what extent networks and content providers have engaged with RPKI. The complexity of this question is particularly exacerbated by the unusual way websites are often hosted. Generally, they rely on third party networks to host their servers with many services spreading their content among multiple networks and CDNs. Enabling RPKI is therefore not just a matter of flipping a switch. Although this could dissuade websites from utilising RPKI, it does not reduce its importance.
In this paper, we argue that websites should take a holistic approach to securing their services by extending security provisions beyond traditional end-to-end concerns. Although there are many third party dependencies that websites should secure, we focus on BGP due to the recency of several attacks in this realm. We conduct the first quantitative analysis of the deployment of RPKI by web providers. We make several worrying discoveries, revealing a lack of awareness of the importance of securing BGP among those hosting websites. Perversely, this ranges from huge international players such as Google to small regional websites. We then explore the reasons for this, as well as intuitive steps that should be taken. Our findings can be summarized as follows:
- 1. Less popular websites are commonly better secured than websites with many visitors.
- 2. CDNs tend to ignore RPKI, whereas ISPs and webhosters have started RPKI deployment.
- 3. CDN servers that are placed in third party networks benefit from RPKI deployment that these networks perform.
- 4. CDN deployment policies are the principle cause for a reduced security level at prominent websites.
The remainder of this paper is structured as follows. § 2 details the problem space. § 3 introduces a first proposal of a broadly reproducible measurement methodology and § 4 presents our first findings. § 5 sheds light on business reasons why operators do not deploy RPKI and sketches a research agenda. § 6 briefly surveys related work. § 7 concludes with our outlook.
## 2. BACKGROUND
## 2.1 Primer on RPKI
The Border Gateway Protocol (BGP) [23] governs the interdomain routing of the Internet. BGP exchanges announcements that advertise the ability to reach IP prefixes between Autonomous Systems (ASes). An AS represents a set of prefixes that it originates and is identified by unique AS Number (ASN). Unfortunately, a BGP speaker may announce any IP prefix, allowing a malicious or misconfigured party to disrupt routing. To undermine access to a website, a malicious BGP speaker could, for example, advertise the website's IP prefix and 'steal' traffic destined to it.
To address the above problem, the Resource Public Key Infrastructure (RPKI) [18] has been designed. It is a PKI framework dedicated to securing the Internet routing infrastructure. It uses cryptographic certificates to prove the ownership of Internet number resources ( i.e. ASNs and IP prefixes). However, the Internet decouples the ownership of resources and their routing. Hence, the RPKI introduces Route Origin Authorization (ROA) objects. A correctly signed ROA authorizes an AS to originate one or more prefixes.
Using ROA data, an RPKI-enabled router is able to validate the BGP updates it receives. There are three states for BGP updates when validated using the RPKI, valid, invalid, and not found. Rejecting an invalid route announcement helps to suppress incorrectly announced prefix, thus preventing route hijacking of websites for example. Of course, invalid announcements do not necessarily indicate malicious behaviour, e.g. it could be misconfiguration of ROAs [32]. However, from a website operator's perspective, this is irrelevant.
## 2.2 RPKI and the Web
To successfully access a webpage, there are usually two key requisites: ( ) retrieve a valid domain i → IP address mapping via DNS; and ( ii ) establish valid end-to-end routing from the client to the mapped IP address. DNSSEC [1] can ensure valid name to address mapping. This paper focuses on the routing layer.
To secure the routing layer (via RPKI), a website operator must take certain steps. In the simplest case, a web page is hosted on a single web server situated in a single AS. The prefix owner therefore needs to create a single RPKI entry for the prefix-AS pair, which hosts the domain. However, highly popular webpages are often distributed among several web servers to increase availability and performance. With the advent of Content Delivery Networks (CDNs), these web servers are not only reachable via different IP prefixes but also placed in different ASes. To fully secure the web server infrastructure of the domain, all prefix-AS pairs need to be included into the RPKI. It is worth noting that content provided by CDNs is not necessarily located in the AS of the CDN, in which case the CDN has no control over the authorization of this AS.
## 2.3 Attacker Model: Beyond DoS
Having clarified that the current Web ecosystem complicates the success of countermeasures to correctly access content on the network layer, we now introduce an attacker model which lacks sufficient attention in our community. We assume an attacker who is able to redirect network traffic destined to the web server by manipulating Internet routing, i.e. sending malicious route updates related to the web server infrastructure. Compared to very common DoS attacks against web servers, this threat might seem less likely. However, even difficult attacks find their way into the real world, sooner or later. A simple example we refer to the Great Cannon attack beginning this year [20], where an ISP injected on-path malicious JavaScript code into live network traffic to disturb connectivity to GitHub. Note that TLS does not necessarily protect against such an attack when prefix hijacking is in place [9].
There are political as well as commercial reasons that motivates an attacker to attack a web server. Leveraging prefix hijacking has several attractive advantages. First, the attacker can intercept the network traffic, which enables him to drop, monitor, or modify packets. Second, the attack does not necessarily need to affect all clients-when malicious route propagation is restricted locally, the attacker can harm specific subset of clients. Third, the attack can be performed without notifying the website under attack. In the follow-
Relative frequency
1.0
Figure 1: Comparison of IP deployment for www and w/o www domain names.
ing, we explore the severity of this threat and the level of countermeasures currently deployed via RPKI.
## 3. PRELIMINARY METHODOLOGY
Our measurement study proceeds in four steps: (1) selection of websites; (2) mapping domain names to IP addresses; (3) mapping these IP addresses to IP prefixes routed in the Internet and their origin ASes; and (4) validating if these ASes support RPKI. The purpose is to explore how widely deployed RPKI is among web providers. We now describe our methodology, which is meant to be simple and widely reproducible. All data will be made available.
- (1) Selecting Domain Names. To explore RPKI deployment among websites, it is necessary to first select a sample set. To achieve this, we extract the top 1 million websites from the Alexa list [3]. This is the default approach taken by most web measurements ( e.g. [2, 5, 19, 25]), and allows us to explore how RPKI deployment varies across popularity ranks.
- (2) Mapping Domains to IP Addresses. To map domain names taken from the Alexa into IP addresses, we utilise several public resolvers (to improve reproducibility). Using Google DNS, we collect all A AAAA , , and CNAME records for all the Alexa domain names, including the names appended with the prefix www . We refer to the former as a 'w/o www domain'. The measurements were performed from Berlin repeatedly over several weeks in 2014 and 2015. We also used Open DNS and us01 of the DNS Looking Glass [8] to verify that the results returned from Google DNS were not miscellaneous. We obtain similar results from all three datasets. We exclude all invalid DNS answers, i.e. all specialpurpose IPv4 and IPv6 addresses reserved by the IANA.
Note that, although the distributed nature of DNS may lead to answers that vary between locations, we delay exploration of CDN redirection strategies to future work. This is because we are primarily interested in checking whole ASes, rather than where individual clients are redirected to. In Section 4, we show that our main results remain independent of the DNS server selection because CDNs are reluctant to create ROAs at all. Analyzing the effects of many vantage points will be part of our future work.
To briefly analyze the overlap between www and w/o www domains, we quantify the amount of equal prefixes per do- main. Figure 1 shows that for the first 100k domains more than 76% of the IP prefixes are equal for both names. For the remaining domains, more than 94% of the names refer to the same prefix. As a side observation, in future work it should be explored how this fact can help accelerate continuous DNS measurements.
- (3) Mapping IP Addresses to Prefixes and ASNs. To map addresses to ASNs, we take dumps of the active tables of the RIPE RIS route servers. For each IP address of a domain name, we extract all covering prefixes and derive the origin AS from the AS path (i.e., the right most ASN in the AS path). Note that entries with an AS\_SET are excluded from our study as this leads to an ambiguity of the attribute, which is why the function is deprecated with the deployment of RPKI [16].
- (4) RPKI Validation. For the validation of the BGP data, we follow the necessary steps to perform origin validation at BGP routers. ROA data of all trust anchors (APNIC, AfriNIC, ARIN, LACNIC, and RIPE) are collected and validated. Only cryptographically correct ROAs are further used to check the IP prefixes obtained from the BGP table dumps.
The outcome of this process is a comprehensive list of all Alexa websites that ( ) can be resolved from our DNS vantage i point and ( ii ) mapped to an IP prefix AS pair. This list is ( iii ) annotated with RPKI origin validation outcome.
## 4. RESULTS
We have used the above methodology to collect data on RPKI deployment for all 1 million Alexa domains. After excluding 0.07% incorrect DNS answers, we gathered 1,167,086 IP addresses for the www domains and 1,154,170 IP addresses for the w/o www domains. These addresses map to 1,369,030 and 1,334,957 different prefix-AS pairs respectively. 0.01% of the IP addresses are not reachable from our BGP vantage points.
In the following subsections, we present the core RPKI validation outcomes, and explore reasons for the observed deployment state. For better visibility, we do not present results per domain but apply a binning of 10k domains in all graphs, after experimenting with different bin sizes. As a domain name may refer to multiple IP addresses, which may belong to different IP prefixes and ASes, several RPKI states may exist per domain. To represent heterogeneous RPKI deployment, we assign corresponding probabilities to domain names ( e.g. 3/5 or 60% RPKI coverage of foo.bar ).
## 4.1 Less Popular Content is More Secured
We first explore how many websites are secured via RPKI, shown in Figure 2. On average, only 6% of the web server prefixes are covered by RPKI (either correctly or incorrectly announced in the BGP). This is somewhat worrying considering the international prominence of the websites under study. However, it also effectively illustrates that web operation and network operation are decoupled. Roughly 0.09% of the
Figure 2: RPKI validation outcome for the 1 million Alexa domains ( valid = the origin AS is allowed to announce the prefix, invalid = the origin AS is not allowed to announce the prefix, and not found = the announced prefix is not covered by the RPKI).
prefixes are invalid according to the RPKI prefix origin validation, spread evenly across all Alexa ranks. This observation is in qualitative agreement with the general RPKI deployment. Note that the current invalid BGP announcements do not necessarily indicate hijacking, but rather potential misconfiguration [32]. The amount of invalids is evenly distributed among all web domains.
Perhaps more interesting is the distribution of RPKI support across the different popularity rankings. By inspecting Figure 2, distinct trends can be seen. Perversely, domains with a high rank ( i.e. popular sites in the top 100k) are less likely to be secured than less popular sites. Among the first 100k domains ( e.g. google.com blogspot.com , ), only ≈ 4.0% of web server prefixes are secured via RPKI. In contrast, for the last 100k domains, ≈ 5.5% are secured. The absolute numbers are small, but a clear trend is visible and may reflect the deployment strategy of different stakeholders.
Table 1 shows the first top 10 domains that have RPKI support, i.e. either all or at least one prefix which is associated with the domain name is part of the RPKI. It is clearly visible that ( ) almost all of the very popular sites are unsecured; and i ( ii ) sometimes there is differing RPKI support for a website's www and w/o www domains; and ( iii ) most of the content is only partially secured. We now analyze the deployment by CDNs in more detail.
## 4.2 CDNContent Benefits from 3 rd Party ISPs
CDNs are a critical part of modern web delivery. Many websites rely on them to deliver their content. Next, we focus on the RPKI deployment of CDNs. To study this, we search the RPKI repository for attestation objects that belong to the ASes of well-known CDNs. Specifically, we inspect the infrastructures of Akamai, Amazon, Cdnetworks, Chinacache,
Table 1: Top 10 Alexa domains that have partial ( GLYPH<218> ) or full ( 3 ) RPKI coverage, including number of prefixes.
| | RPKI Coverage | RPKI Coverage |
|-----------------------------|-------------------|-------------------|
| Alexa Rank &Domain Name | www | w/o www |
| 2 facebook.com | 3 (3/3) | 3 (2/2) |
| 70 cdncache1-a.akamaihd.net | n/a | GLYPH<218> (1/3) |
| 73 huffingtonpost.com | GLYPH<218> (1/3) | 8 (0/3) |
| 92 cnet.com | GLYPH<218> (1/3) | 8 (0/2) |
| 95 dailymail.co.uk | GLYPH<218> (1/3) | 8 (0/1) |
| 117 indiatimes.com | GLYPH<218> (1/3) | 8 (0/1) |
| 120 kickass.to | GLYPH<218> (1/10) | GLYPH<218> (1/10) |
| 130 booking.com | 3 (4/4) | 3 (2/2) |
Chinanet, Cloudflare, Cotendo, Edgecast, Highwinds, Instart, Internap, Limelight, Mirrorimage, Netdna, Simplecdn, and Yottaa. It is worth noting that the results of this approach do not depend on DNS measurements and thus do not include a bias that might result from any DNS measurement point.
To derive the AS numbers of these CDNs, we apply keyword spotting on common AS assignment lists. This leads to a lower bound for the current state of deployment. We discover 199 ASes operated by these CDNs. From these, we find only four entries in the RPKI. These four prefixes are owned by Internap and are tied to three origin ASes. One might mistakenly think that Internap has therefore engaged widely with RPKI. However, Internap operates at least 41 ASes, the bulk of which are not secured via RPKI. No other CDN has made any deployment. Thus, these CDNs do not actively participate in the creation of RPKI attestation objects. This is in contrast to web hosters or common ISPs that, as shown previously, have far higher levels of penetration ( > 5% ).
Another interesting trend has been for CDNs to place caches in third party networks ( e.g. eyeball ISPs). This allows the CDN to 'inherit' RPKI support from the third party network. Based on our previous observation, i.e. these CDNs do not create ROAs, we know that every RPKI-enabled CDNcontent is served by a third party network.
## 4.3 Are the CDNs to blame?
To quantify the impact that CDNs have on global website support for RPKI, we conduct a basic classification of CDN domains. Generally, CDNs use CNAME chains (Canonical Names) to redirect DNS requests to their caches. We exploit this fact to identify how many of our Alexa domains use CDNs. We say a domain is served by a CDN, if the IP address of its domain name is indirectly accessed via two or more CNAMEs ( e.g. www.huffingtonpost.com → www.huffingtonpost.com.\edgesuite.net → a495. g.akamai.net → 212.201.100.136 ). We confirm this rough heuristic by comparing its results with an independent classification provided by HTTPArchive. HTTPArchive classifies the first 300k Alexa domains based on DNS pattern matching of CNAMEs, which is distinct from our test of DNS indirections. Furthermore, the HTTPArchive monitoring agent is located in Redwood City, CA, USA, and thus a geographically separated vantage point.
Relative Frequency
Figure 3: Popularity of CDNs-comparison of CDN detection heuristics for 1M Alexa domains.
Figure 3 compares the distributions of CDN-hosted web domains as determined by our classification approach and HTTPArchive (in 10k bins). The two almost identically shaped curves clearly indicate that popular websites are more likely to be served by CDNs. Quantitatively, our approach indicates fewer CDNs than HTTPArchive. This is not surprising, since there are CDN deployments without CNAME chains. However, a conservative (under)-estimate of CDN domains sharpens our view on the RPKI-protection of CDN domains: (Over-)enlarging the set of CDN domains will mix deployment cases and diffuse the overall picture.
Integrating the above results, we now explore why highly ranked websites do not support RPKI. Specifically, we focus on the relation between RPKI-enabled and CDN-served websites. Figure 4 depicts the distribution of RPKI-enabled websites across the Alexa rankings. The figure separates websites into those that utilise a CDN and those that do not. In contrast to the Alexa domains at large, RPKI deployment is fairly independent of the rank for CDNs. Results fluctuate around an average of ≈ 0 9% . . This is almost an order of magnitude lower than the overall RPKI deployment rate, which is plotted for comparison.
Combining the lines of argument, we have shown that ( ) i CDN deployment is strongly enhanced for popular domains, but ( ii ) RPKI deployment for CDNs is low-independent of content popularity. As a result, a high density of CDN sites reduces the RPKI-enabled portion of domains. This holds for those ranks of the Alexa list where CDNs are more common: at the top ranks. In summary, the observable degradation of routing security for popular websites is caused by the resistance of CDN operators to adopt RPKI in their ASes.
## 5. DISCUSSIONANDRESEARCHAGENDA
After ( ) identifying a new attacker model, which has subi stantial potential to threaten the Web, and ( ii ) analysing the current deployment of the state-of-the-art countermeasure, we are left with a surprisingly basic but still unanswered question: How can a content owner easily verify that his content is reliably and securely delivered in the current Web ecosystem?
## 5.1 Securing Web Architectures
First and foremost, we call for a more elegant and approachable web architecture. We currently see a complex ecosystem
Figure 4: RPKI deployment statistics on CDNs and for the unconditioned Web.
built by a broad set of (sometimes competing) stakeholders. These include many network operators, content providers, and CDNs, largely underpinned by an abused DNS infrastructure. At each stage in the content delivery chain, different security protocols are being employed, making a comprehensive understanding virtually impossible for most web startups. For instance, a key finding of our work is the poor awareness that web providers have regarding routing security. Despite its importance, only a small fraction of websites have any deployment of RPKI.
The above observations are unlikely to change in the near future as the deployment of such mechanisms require notable effort. As of yet, we have not witnessed events critical enough to shake most web providers into action. However, we should not be sitting and waiting for a major event to disrupt the Internet content delivery ecosystem, as we have already many examples hinting at its potential impact [4, 27, 30]. A key part of our future research agenda is expanding our work from RPKI to include other security mechanisms that web providers should be aware of ( e.g. DNSSEC). Ultimately, we argue that new systems should be devised that increase transparency and thus make the comprehensive understanding and deployment of e2e security much more straightforward.
## 5.2 Incentivizing RPKI Deployment
Returning to our key contribution, we also argue that the need for RPKI must be more critically communicated to web providers-particularly large CDNs that serve disproportionate amounts of web traffic. This is largely a process of minimising barriers ( e.g. cost), alongside offering incentives. During our study, we have spoken to many network operators to gauge their opinion of RPKI. We have found several reasons why operators have not deployed it ( e.g. [10]). Often this relates to a lack of perceived need, combined with insufficient manpower and expertise in the area. This is common across many technologies. More interestingly, we also have discovered RPKI-specific factors that dissuade adoption.
RPKI is a proactive security solution that implements a positive attestation model. As such, RPKI exposes information that organisations may be wary of revealing. Most worrying to some is the potential of revealing their business relations. In RPKI, prefix owners must proactively create ROAs before any attack occurs. As soon as at least one ROA for an IP prefix exists, all valid origin ASes for this IP prefix need to be assigned in the RPKI before route updates are processed (otherwise a BGP update including the prefix and missing ASes becomes invalid). Although a prefix owner can assign any AS without asking for approval, it is very likely that the ROA information indicates a business relation between prefix owner and authorized origin AS. This might be a serious concern, from our discussions with several operators.
To illustrate a business policy conflict, imagine that two large CDNs serve secretly as backups for each other. As changes within the DNS are slow, they could quickly redirect traffic using BGP. Similarly, smaller CDNs that rely on third party networks ( e.g. using Verisign for external DoS mitigation) may see such information as damaging to their reputation. Despite this, in both cases, RPKI would publicly reveal these setups.
It is worth noting that RPKI data differs from public routing data such as BGP collectors or looking glasses. Those sources also provide insights into peering relations but only after the event has occurred. Furthermore, the data analysis follows an exploratory approach because not all vantage points report the same. In contrast to this, the RPKI represents a catalog which does not only allow for easy browsing but also documents information in advance. In case of a very unlikely or never occurring event (e.g., a backup incident), the RPKI exposes more information. We therefore argue for changes to RPKI that address these business concerns. Whereas privacyaware protocols are rife in other fields ( e.g. Tor), they have always been seen as less important in the routing layer. The above observations undermine this assumption. Arguably, not recognising this issue could be extremely damaging to RPKI deployment.
## 5.3 Web Measurement Methodology
A tangential observation from our work is the daunting complexity of launching web measurement campaigns. Compiling a generalised and comprehensive methodology for dealing with this still eludes the web community. Questions that remain open include: ( ) which websites should be queried; i ( ii ) where should they be queried from; ( iii ) how these should be distributed over time. For instance, selecting Alexa websites is a typical approach, however, results differ for www and w/o www domains; complexity is also greatly increased when considered the tendency to shard content across multiple subdomains in a website. Some might say that security incidents in the past [4, 27, 33] have showed that routing failures usually affect complete web pages instead of just subdomains. However, a commercially motivated attacker may explicitly target subdomains, e.g. those hosting adverts.
Exhaustive crawls may be suitable for small sets of websites, but scalability quickly becomes a challenge particularly when duplicating crawls across regions. Answering these questions at scale is not trivial, and should be explored further. We plan to use such insights to expand our methodology in a generalised way that can help others to perform web measurements too. Without better methodologies in this field, web measurements may become increasingly infeasible and unreproducible as web complexity increases.
## 6. RELATED WORK
The deployment of RPKI started in 2011. Several looking glasses and tools exist [15, 17, 21, 24, 29, 31] to inspect the current state of deployment or to do experiments, but up until now only few publications studied the current state of deployment in detail. [14, 32] analyze the RPKI validation outcome of entire BGP tables trying to better understand invalid BGP announcements. [7] discusses the risk when RPKI authorities misbehave, and [12] explores the general limitations of current secure inter-domain routing protocols. Nevertheless, large ISPs such as Deutsche Telekom and ATT added their IP prefixes to the RPKI, which motivates the relevance of this new protocol framework. The motivation to adapt new Internet protocols is analyzed in [22], with a special focus on secure inter-domain routing in [6,11]. Our work complements these insights by clarifying that CDNs can benefit from early RPKI-adoption in third party networks where their servers are hosted.
Several measurement studies discovered the content distribution space ( e.g. [2, 13, 26, 28]). We emphasize that the aim of this paper is not to reveal the hosting infrastructure completely but to present a trend analyse of RPKI adoption in the wild and its interplay with the web ecosystem by applying a very basic methodology.
## 7. CONCLUSION AND OUTLOOK
In this paper, we analyzed the RPKI-protection of websites. We resolved 1M domain names from the Alexa ranking, mapped the IP addresses to IP prefixes and origin ASes visible in the global BGP routing table, and validate each prefix-AS pair against the currently deployed RPKI data.
We found that RPKI security deployment is significantly degraded for the more popular websites, which led us to apply a new, initial methodology for discovering its reasons. Our findings revealed that CDN hosters are the likely cause for this operational bias. Their enhanced provenience at prominent web domains on the one hand, and their obvious reluctance towards RPKI deployment on the other hand strongly indicate that prominent websites would be better protected against routing attacks without CDNs.
In future work, we will aim to explore in more detail why CDNs implement this operational behavior. Furthermore, we will compare RPKI deployment with the adoption of other core protocols such as DNSSEC.
## Acknowledgements
We would like to thank Eric Osterweil and Andy Newton for very fruitful discussions. This work was partially supported by the BMBF within the project Peeroskop.
## 8. REFERENCES
- [1] D. E. E. 3rd. Domain Name System Security Extensions. RFC 2535, IETF, March 1999.
- [2] B. Ager, W. Mühlbauer, G. Smaragdakis, and S. Uhlig. Web Content Cartography. In Proc. of ACM SIGCOMM IMC , pages 585-600, New York, NY, USA, 2011. ACM.
- [3] Alexa Internet Inc. Top 1M Sites.
- [4] M. A. Brown. Pakistan hijacks YouTube - Renesys Blog, February 2008.
- [5] S. Calzavara, G. Tolomei, M. Bugliesi, and S. Orlando. Quite a Mess in My Cookie Jar!: Leveraging Machine Learning to Protect Web Authentication. In Proc. of the 23rd WWW , pages 189-200, New York, NY, USA, 2014. ACM.
- [6] H. Chan, D. Dash, A. Perrig, and H. Zhang. Modeling Adoptability of Secure BGP Protocol. In Proc. ACM SIGCOMM , pages 279-290, New York, NY, USA, 2006. ACM.
- [7] D. Cooper, E. Heilman, K. Brogle, L. Reyzin, and S. Goldberg. On the Risk of Misbehaving RPKI Authorities. In Proc. of HotNets-XII , New York, NY, USA, 2013. ACM.
- [8] Frederic Cambus. Multilocation DNS Looking Glass.
- [9] A. Gavrichenkov. Breaking HTTPS with BGP Hijacking. In Black Hat. Briefings , 2015.
- [10] W. George. Adventures in RPKI (non)Deployment. In NANOG 62 . NANOG, 2015.
- [11] P. Gill, M. Schapira, and S. Goldberg. Let the Market Drive Deployment: A Strategy for Transitioning to BGP Security. In Proc. of ACM SIGCOMM , pages 14-25, New York, NY, USA, 2011. ACM.
- [12] S. Goldberg, M. Schapira, P. Hummon, and J. Rexford. How secure are secure interdomain routing protocols. In Proc. of ACM SIGCOMM , pages 87-98, New York, NY, USA, 2010. ACM.
- [13] C. Huang, A. Wang, J. Li, and K. W. Ross. Measuring and Evaluating Large-scale CDNs. In Proc. of the ACM IMC , pages 15-29, New York, NY, USA, 2008. ACM.
- [14] D. Iamartino, C. Pelsser, and R. Bush. Measuring BGP route origin registration validation. In Proc. of PAM , LNCS, pages 28-40, Berlin, 2015. Springer.
- [15] S. Knight, H. X. Nguyen, O. Maennel, I. Phillips, N. J. G. Falkner, R. Bush, and M. Roughan. An Automated System for Emulated
Network Experimentation. In Proc. of ACM CoNEXT , pages 235-246, New York, NY, USA, 2013. ACM.
- [16] W. Kumari and K. Sriram. Recommendation for Not Using AS\_SET and AS\_CONFED\_SET in BGP. RFC 6472, IETF, December 2011.
- [17] L. Labs. Origin Validation Looking Glass, 2014.
- [18] M. Lepinski and S. Kent. An Infrastructure to Support Secure Internet Routing. RFC 6480, IETF, February 2012.
- [19] R. Lychev, S. Goldberg, and M. Schapira. Bgp security in partial deployment: Is the juice worth the squeeze? In Proc. of ACM SIGCOMM , pages 171-182, New York, NY, USA, 2013. ACM.
- [20] B. Marczak, N. Weaver, J. Dalek, R. Ensafi, D. Fifield, S. McKune, A. Rey, J. Scott-Railton, R. Deibert, and V. Paxson. China's Great Cannon. Technical report, Citizen Lab, University of Toronto, April 2015.
- [21] NIST. Global Prefix/Origin Validation using RPKI, 2014.
- [22] S. Ratnasamy, S. Shenker, and S. McCanne. Towards an Evolvable Internet Architecture. In Proc. of ACM SIGCOMM , pages 313-324, New York, NY, USA, 2005. ACM.
- [23] Y. Rekhter, T. Li, and S. Hares. A Border Gateway Protocol 4 (BGP-4). RFC 4271, IETF, January 2006.
- [24] A. Reuter, M. Wählisch, and T. C. Schmidt. RPKI MIRO: Monitoring and Inspection of RPKI Objects. SIGCOMM Comput. Commun. Rev. , 45(5):107-108, 2015.
- [25] F. Roesner, T. Kohno, and D. Wetherall. Detecting and Defending Against Third-party Tracking on the Web. In Proc. of the 9th USENIX NSDI , Berkeley, CA, USA, 2012. USENIX Association.
- [26] C. A. Shue, A. J. Kalafut, and M. Gupta. The Web is Smaller Than It Seems. In Proc. of ACM IMC , pages 123-128, New York, NY, USA, 2007. ACM.
- [27] D. M. Slane, C. Bartholomew, et al. 2010 Report to Congress. Annual report, U.S.-China Economic and Security Review Commission, November 2010.
- [28] A.-J. Su, D. R. Choffnes, A. Kuzmanovic, and F. E. Bustamante. Drafting behind akamai: Inferring network conditions based on cdn redirections. IEEE/ACM Trans. Netw. , 17(6):1752-1765, 2009.
- [29] Surfnet. RPKI Dashboard, 2014.
- [30] A. Toonk. http://www.bgpmon.net/the-canadian-bitcoin-hijack/.
- [31] M. Wählisch, F. Holler, T. C. Schmidt, and J. H. Schiller. RTRlib: An Open-Source Library in C for RPKI-based Prefix Origin Validation. In Proc. of USENIX Security Workshop CSET'13 , Berkeley, CA, USA, 2013. USENIX Assoc.
- [32] M. Wählisch, O. Maennel, and T. C. Schmidt. Towards Detecting BGP Route Hijacking using the RPKI. In Proc. of ACM SIGCOMM, Poster Session , pages 103-104, New York, August 2012. ACM.
- [33] E. Zmijewski. Indonesia Hijacks the World - Renesys Blog, May 2014. | 10.1145/2834050.2834102 | [
"Matthias Wählisch",
"Robert Schmidt",
"Thomas C. Schmidt",
"Olaf Maennel",
"Steve Uhlig",
"Gareth Tyson"
] | 2014-08-02T16:12:43+00:00 | 2015-11-02T10:41:33+00:00 | [
"cs.NI",
"cs.CR",
"C.2.2, C.2.5"
] | RiPKI: The Tragic Story of RPKI Deployment in the Web Ecosystem | Web content delivery is one of the most important services on the Internet.
Access to websites is typically secured via TLS. However, this security model
does not account for prefix hijacking on the network layer, which may lead to
traffic blackholing or transparent interception. Thus, to achieve comprehensive
security and service availability, additional protective mechanisms are
necessary such as the RPKI, a recently deployed Resource Public Key
Infrastructure to prevent hijacking of traffic by networks. This paper argues
two positions. First, that modern web hosting practices make route protection
challenging due to the propensity to spread servers across many different
networks, often with unpredictable client redirection strategies, and, second,
that we need a better understanding why protection mechanisms are not deployed.
To initiate this, we empirically explore the relationship between web hosting
infrastructure and RPKI deployment. Perversely, we find that less popular
websites are more likely to be secured than the prominent sites. Worryingly, we
find many large-scale CDNs do not support RPKI, thus making their customers
vulnerable. This leads us to explore business reasons why operators are
hesitant to deploy RPKI, which may help to guide future research on improving
Internet security. |
1408.0392v1 | ## UNIVERSAL SPACES FOR UNRAMIFIED GALOIS COHOMOLOGY
## FEDOR BOGOMOLOV AND YURI TSCHINKEL
Abstract. We construct and study universal spaces for birational invariants of algebraic varieties over algebraic closures of finite fields.
## Introduction
Let /lscript be a prime. Recall that in topology, there exist unique (up to homotopy) topological spaces K( Z //lscript n , m ) such that
- · K( Z //lscript n , m ) is homotopically trivial up to dimension m -1, in particular,
$$\mathbf H ^ { i } ( \mathbf K ( \mathbb { Z } / \ell ^ { n }, m ), \mathbb { Z } / \ell ^ { n } ) = 0, \quad \text{for} \quad i < m ;$$
- · H (K( m Z //lscript n , m , ) Z //lscript n ) is cyclic, with a distinguished generator κ m ;
- · for every topological space X and every α ∈ H ( m X, Z //lscript n ) there is a unique, up to homotopy, continuous map
$$\mu _ { X, \alpha } \, \colon \, X \to K ( \mathbb { Z } / \ell ^ { n }, m )$$
such that
$$\mu _ { X, \alpha } ^ { * } ( \kappa _ { m } ) = \alpha.$$
This reduces many questions about singular cohomology to the study of these universal spaces. Analogous theories exist for other contravariant functors, for example, topological K-theory, or the theory of cobordisms. The study of moduli spaces in algebraic geometry can be viewed, broadly speaking, as an incarnation of the same idea of universal spaces.
Here we propose a similar theory for unramified cohomology, developed in connection with the study of birational properties of algebraic varieties [4], [16]. The Bloch-Kato conjecture proved by Voevodski, Rost, and Weibel, combined with techniques and results from birational anabelian geometry in [10], implies that an unramified class in the cohomology of a function field K = k X ( ) of an algebraic variety X over an algebraic closure of a finite field k = ¯ , with finite constant F p
Key words and phrases. Galois groups, function fields.
coefficients, is induced from the cohomology of a finite abelian group G a . Our main result is:
Theorem. Let /lscript and p be distinct primes, K = k X ( ) the function field of an algebraic variety X of dimension ≥ 2 over k = ¯ F p , G K its absolute Galois group, and α K ∈ H ∗ nr ( G , K Z //lscript n ) an unramified class. Then there exists a finite set J of finite-dimensional k -vector spaces V , j j ∈ J , such that α K is induced, via a rational map, from an unramified class in the cohomology of an explicit open subset of the quotient of
$$\mathbb { P } \coloneqq \prod _ { j \in J } \mathbb { P } ( V _ { j } ) \\ \mathcal { \cdot } G ^ { a }. \ a c t i n a \ n r o i e c t$$
by a finite abelian /lscript -group G a , acting projectively on each factor.
Thus, the spaces P /G a serve as universal spaces for all finite birational invariants of algebraic varieties over k = ¯ . F p
Actions of finite abelian groups G a on products of projective spaces are described by central extensions of G a , i.e., by subspaces in ∧ 2 ( G a ). This allows to present unramified classes of X in terms of configurations of subspaces of skew-symmetric matrices. For example, if the unramified Brauer group of X is trivial, then all finite birational invariants of X are encoded already in the combinatorics of configurations of liftable subgroups in finite abelian quotients of the absolute Galois group G K (see Section 1 for the definition).
Similar ideas were first put forward in [4] and [5], however, the recent proof of the Bloch-Kato conjecture allows us to formulate a more precise and constructive theory. This approach to birational invariants leads to many new questions:
- · Is there a smaller class of configurations with this universal property?
- · How does this structure interact with Sylow subgroups of G K ?
- · Is there an extention to cohomology with Z /lscript -coefficients? An equally simple description of models for /lscript -adic invariants would provide insights into higher-dimensional Langlands correspondence.
- · What are the analogs of universal spaces for varieties over k = ¯ ? Q Counterexamples to our main result arise from bad reduction places, already for abelian varieties [4].
Here is the roadmap of the paper: In Section 1 we recall basic facts about stable and unramified cohomology. In Section 3 we provide some background on valuation theory. In Section 5 we investigate Galois cohomology groups of function fields of higher-dimensional algebraic varieties over k = ¯ F p and their images in cohomology of finite groups.
In Section 6 we introduce and study unramified cohomology of algebraic varieties. Section 7 contains the proof of our main theorem, modulo geometric considerations presented in Sections 8 and 9.
Acknowledgments. We are grateful to A. Pirutka for her interest and insightful comments. The first author was supported by NSF grant DMS-1001662 and by AG Laboratory GU-HSE grant RF government ag. 11 11.G34.31.0023. The second author was partially supported by NSF grants DMS-0739380, 0901777, and 1160859.
## 1. Stable cohomology
Let G be a pro-finite group. We will write
$$G ^ { a } = G / [ G, G ] \quad \text{and} \quad G ^ { c } = G / [ [ G, G ], G ]$$
for the abelianization, respectively, the second lower central series quotient of G . We have a canonical central extension
$$1 \to Z \to G ^ { c } \stackrel { \pi _ { a } } { \longrightarrow } G ^ { a } \to 1.$$
Let M be a topological G -module and H ( i G,M ) its (continuous) i -cohomology group. These groups are contravariant with respect to G and covariant with respect to M . In this paper, G is either a finite group or a Galois group (see [1] for background on group cohomology and [28] for background on Galois cohomology) and M either Z //lscript n or Q Z / , with trivial G -action. We will sometimes omit the coefficient module M from the notation.
Our goal is to investigate incarnations of Galois cohomology of function fields in cohomology of finite groups. For example, let K = k X ( ) be a function field of an algebraic variety X over an algebraically closed field k ; varieties birational to X are called models of K . Let G K be the absolute Galois group of K and ˆ ( π 1 X ) the ´tale fundamental group of e X , with respect to some basepoint. The choice of a base point will not affect our considerations and we omit it from our notation. We have natural homomorphisms
$$H ^ { * } ( \hat { \pi } _ { 1 } ( X ) ) \stackrel { \kappa _ { X } ^ { * } } { \longrightarrow } H _ { e t } ^ { * } ( X ) \stackrel { \tilde { \eta } _ { X } ^ { * } } { \longrightarrow } H ^ { * } ( G _ { K } ),$$
where the right arrow arises from the embedding of the generic point X η → X . We will write
$$\eta _ { X } \colon G _ { K } \rightarrow \hat { \pi } _ { 1 } ( X )$$
and
$$\eta _ { X } ^ { * } = \tilde { \eta } _ { X } ^ { * } \circ \kappa _ { X } ^ { * } \colon \mathrm H ^ { * } ( \hat { \pi } _ { 1 } ( X ) ) \to \mathrm H ^ { * } ( G _ { K } )$$
for the corresponding map in cohomology.
We say that a class α K ∈ H ( ∗ G K ) is defined (or represented) on a model X of K if there exists a class α X ∈ H ( ∗ et X ) such that
$$\alpha _ { K } = \tilde { \eta } _ { X } ^ { * } ( \alpha _ { X } ).$$
Let G be a finite group. A continuous homomorphism
$$\chi \colon \hat { \pi } _ { 1 } ( X ) \rightarrow G$$
gives rise to homomorphisms in cohomology
$$H ^ { * } ( G ) \stackrel { \chi ^ { * } } { \longrightarrow } H ^ { * } ( \hat { \pi } _ { 1 } ( X ) ) \stackrel { \eta ^ { * } _ { X } } { \longrightarrow } H ^ { * } ( G _ { K } ).$$
Conversely, every α K ∈ H ( ∗ G K ) arises in this way: there exist
- · a model X of K ,
- · a continuous homomorphism χ as above,
- · and a class α G ∈ H ( ∗ G )
such that
$$\alpha _ { K } = \eta _ { X } ^ { * } ( \chi ^ { * } ( \alpha _ { G } ) ).$$
This follows from the description of ´ etale cohomology of points, see [22]. In such situations we say that α K is defined on X and is induced from χ .
A version of this construction arises as follows: assume that the characteristic of k does not divide the order of G . Let V be a faithful representation of G over k , and X an algebraic variety over k with function field
$$K = k ( X ) \simeq k ( V ) ^ { G },$$
the field of invariants; we will write X = V/G and call it a quotient . Even more generally, let Y be an algebraic variety over k with a generically free action of G X , = Y/G a quotient. This situation gives rise to a natural surjective continuous homomorphism
$$G _ { K } \rightarrow G$$
and induced homomorphisms on cohomology
$$s _ { K } ^ { i } \, \colon \, \mathrm H ^ { i } ( G ) \to \mathrm H ^ { i } ( G _ { K } ).$$
The following lemma shows that we have many choices in realizing a class α K ∈ H ( i G K ):
Lemma 1.1. [4] Assume that α K ∈ H ( i G K ) is represented by a class α X ∈ H ( i et X ) on some affine irreducible model X of K and is induced from a surjective continuous homomorphism χ : ˆ ( π 1 X ) → G and a class α G ∈ H ( i G ) . Let V be a faithful representation of G over k and
V ◦ ⊂ V the locus where the action is free. Then, for every x ∈ X and v ∈ V ◦ there exists a map
$$f = f _ { x } \colon X \rightarrow V / G$$
such that
- · f ( x ) = v and
- · the restriction of α X to X ◦ = f -1 ( V ◦ /G ) ⊂ X is equal to f ∗ ( α G ) .
Proof. We follow the proof in [4]. The homomorphism χ : ˆ ( π 1 X ) → G defines a finite ´tale covering e π : ˜ X → X , by an affine variety ˜ . X The ring k X [ ˜ ] is a k G [ ] -module. Every finite-dimensional k G [ ]-submodule W ∗ ⊂ k X [ ˜ ] defines a G -equivariant map ˜ X → W := Spec( W ∗ ).
Let e ∈ k G [ ] be the unit element of G . For any G -orbit G · y ∈ V there is a G -linear homomorphism
$$l _ { y } \colon k [ G ] \to V,$$
which maps the orbit G e · to G y · . Let ˜ x ∈ π -1 ( x ). Choose h ∈ k X [ ˜ ] such that
/negationslash
$$h ( \tilde { x } ) = 1, \ \ h ( g \cdot \tilde { x } ) = 0, \ \ g \neq e.$$
Then h generates a k G [ ]-submodule W ⊂ k X [ ˜ ] and defines a regular G -map h : ˜ X → W = k G [ ], with h x (˜) = e ∈ k G [ ]. The map f := l y ◦ h is a regular G -map satisfying the first property.
Let X ◦ = f -1 ( V ◦ /G ) ⊂ X . It is a nonempty affine subvariety. We have a compatible diagram of G -maps
/d111
/d111
/d15
/d15
/d15
/d15
/d15
/d15
/d111
$$\begin{array} { c c c c } \text{file diagram of $G$-maps} \\ V ^ { \circ } \xleftarrow { \leftarrow \leftarrow \leftarrow \leftarrow \rightarrow \leftarrow \leftarrow \rightarrow \leftarrow \rightarrow \leftarrow \rightarrow \leftarrow \rightarrow \leftarrow \rightarrow \leftarrow \rightarrow \leftarrow \rightarrow \rightarrow \leftarrow \rightarrow \leftarrow \rightarrow \rightarrow \leftarrow \rightarrow \rightarrow \leftarrow \rightarrow \rightarrow \leftarrow \rightarrow \rightarrow \leftarrow \rightarrow \rightarrow \leftarrow \rightarrow \rightarrow \leftarrow \rightarrow \rightarrow \leftarrow \rightarrow \rightarrow \rightarrow \leftarrow \rightarrow \rightarrow \rightarrow \rightarrow \leftarrow \rightarrow \rightarrow \rightarrow \rightarrow \rightarrow \rightarrow \rightarrow \rightarrow \rightarrow \rightarrow \rightarrow \rightarrow \rightarrow \rightarrow \rightarrow \rightarrow \rightarrow \rightarrow \rightarrow \rightarrow \rightarrow \rightarrow \rightarrow \rightarrow \rightarrow \rightarrow \rightarrow \rightarrow \rightarrow \rightarrow \rightarrow \rightarrow \rightarrow \rightarrow \rightarrow \rightarrow \rightarrow \rightarrow \rightarrow \rightarrow \rightarrow \rightarrow \rightarrow \rightarrow \rightarrow \rightarrow \rightarrow \rightarrow \rightarrow \rightarrow \rightarrow \rightarrow \rightarrow \rightarrow \rightarrow \rightarrow \rightarrow \rightarrow \rightarrow \rightarrow \rightarrow \rightarrow \rightarrow \rightarrow \rightarrow \rightarrow \rightarrow
} } \pi _ { G } \right | \Big | \Big | \Big | \Big | \Big | \Big | \Big | \Big | \Big | \Big | \Big | \Big | \Big | \Big | \Big | \Big | \Big | \Big | \Big | \Big | \Big | \Big | \Big | \Big | \Big | \Big | \Big | \Big | \Big | \Big | \Big | \Big | \Big | \Big | \Big | \Big | \Big | \Big | \Big | \Big | \Big | \Big | \Big | \Big | \Big | \Big | \Big | \Big | \Big | \Big | \Big | \Big | \Big | \Big | \Big | \Big | \Big | \Big | \Big | \Big | \Big | \Big | \Big | \Big | \Big | \Big | \Big |
V ^ { \circ } / G \xleftarrow { \leftarrow \leftarrow \leftarrow \rightarrow \leftarrow \rightarrow \leftarrow \rightarrow \leftarrow \rightarrow \rightarrow \leftarrow \rightarrow \leftarrow \rightarrow \rightarrow \leftarrow \rightarrow \rightarrow \leftarrow \rightarrow \rightarrow \rightarrow \leftarrow \rightarrow \rightarrow \rightarrow \rightarrow \rightarrow \rightarrow \rightarrow \rightarrow \rightarrow \rightarrow \rightarrow \rightarrow \rightarrow \rightarrow \rightarrow \rightarrow \rightarrow \rightarrow \rightarrow \rightarrow \rightarrow \rightarrow \rightarrow \rightarrow \rightarrow \rightarrow \rightarrow \rightarrow \rightarrow \rightarrow \rightarrow \rightarrow \rightarrow \rightarrow \rightarrow \rightarrow \rightarrow \rightarrow \rightarrow \rightarrow \rightarrow \rightarrow \rightarrow \rightarrow \rightarrow \rightarrow \rightarrow \rightarrow \rightarrow \rightarrow \rightarrow \rightarrow \rightarrow \rightarrow \rightarrow \rightarrow \rightarrow \rightarrow \rightarrow \rightarrow \rightarrow \rightarrow
\pi _ { G } \text{ and } \pi \text{ induce the same cover } \pi _ { G } \text{ } \text{Th} \end{array}$$
/d111
and the maps π G and π induce the same cover π 0 . This implies the second claim. /square
We can achieve even more flexibility for G -maps, under a projectivity conditions on V : we say that a G -module V is projective if for every finite-dimensional representation W of G with a G -surjection
$$\mu \, \colon W \rightarrow V$$
there exists a G -section
$$\theta \, \colon V \to W \quad \text{with} \quad \mu \circ \theta = \text{id}.$$
This condition holds, for example, for regular representations over arbitrary fields or when the order of G is coprime to the characteristic of the ground field k .
Now let { S j } j ∈ J be a finite set of G -orbits in Y with stabilizers H j so that S j /similarequal G/H j . Consider a faithful representation V of G and a subset { T j } j ∈ J of G -orbits in V with stabilizers Q j , with H j ⊂ Q j , T j = G/Q j . Consider regular G -maps f j : S j → T j , for j ∈ J .
Lemma 1.2. Assume that V is a projective G -module. Then there is a regular G -map f : Y → V such that f = f j , for all j ∈ J .
We return to our setup: X = Y/G , K = k X ( ), and χ : G K → G , inducing
$$s _ { K } ^ { i } \colon \mathrm H ^ { * } ( G ) \to \mathrm H ^ { * } ( G _ { K } ).$$
The groups
$$H ^ { i } _ { s, K } ( G ) \coloneqq H ^ { i } ( G ) / \text{Ker} ( s ^ { i } _ { K } )$$
are called stable cohomology groups with respect to K = k X ( ). Let
$$\text{Ker} ( s ^ { i } ) \coloneqq \bigcap _ { K } \text{Ker} ( s ^ { i } _ { K } ), \\ \text{|ds $K=k(X)\text{ as above. In fact}$}$$
over all function fields K = k X ( ) as above. In fact,
$$\text{Ker} ( s ^ { i } ) = \text{Ker} ( s ^ { i } _ { k ( V / G ) } ),$$
for some faithful representation V of G over k , in particular, this is independent of the choice of V (see [8, Proposition 4.3]). The groups
$$H _ { s } ^ { i } ( G ) \coloneqq H ^ { i } ( G ) / \text{Ker} ( s ^ { i } )$$
are called stable cohomology groups of G (with coefficients in M = Z //lscript n or Q Z / ); they depend on the ground field k . These define contravariant functors in G . For example, for a subgroup H ⊂ G we have a restriction homomorphism
$$\text{res} _ { G / H } \colon \text{H} _ { s } ^ { * } ( G ) \rightarrow \text{H} _ { s } ^ { * } ( H ).$$
## Furthermore:
- · While usual group cohomology H ( i G ) can be nontrivial for infinitely many i (even for cyclic groups), stable cohomology groups H ( i s G ) = 0 for i > dim( V ), where V is a faithful representation.
- · We have
$$H _ { s } ^ { i } ( G ) \subseteq H _ { s } ^ { i } ( S y l _ { \ell } ( G ) ) ^ { N _ { G } ( S y l _ { \ell } ( G ) ) },$$
where N G ( H ) is the normalizer of H in G and Syl ( /lscript G ) an /lscript -Sylow subgroup of G .
## UNIVERSAL SPACES
The determination of the stable cohomology ring
$$H _ { s } ^ { * } ( G ) \coloneqq \oplus _ { i } H _ { s } ^ { i } ( G )$$
is a nontrivial problem, see, e.g., [7] for a computation of stable cohomology of alternating groups. For finite abelian groups G , we have
$$H _ { s } ^ { * } ( G ) = \wedge ^ { * } ( { \mathrm H } ^ { 1 } ( G ) ).$$
For central extensions of finite groups as in (1.1), the kernel of
$$\pi _ { a } ^ { * } \colon H _ { s } ^ { * } ( G ^ { a } ) \to H _ { s } ^ { * } ( G ^ { c } )$$
is the ideal I = I( G c ) generated by
(see, for example, [12, Section 8]). We will identify
$$R ^ { 2 } = R ^ { 2 } ( G ^ { c } ) \coloneqq & \, \text{Ker} \left ( H _ { s } ^ { 2 } ( G ^ { a } ) \to H _ { s } ^ { 2 } ( G ^ { c } ) \right ). \\ \text{r example, [12, Section 8]}). \, \text{We will identify}$$
$$H _ { s } ^ { * } ( G ^ { a } ) / I$$
with its image in H ( ∗ s G c ). An important role in the computation of this subring of H ( ∗ s G c ) is played by the fan
$$\Sigma = \Sigma ( G ^ { c } ) = \{ \sigma \},$$
the set of noncyclic liftable subgroups σ of G a , and the complete fan
$$\bar { \Sigma } = \bar { \Sigma } ( G ^ { c } ) = \{ \sigma \},$$
consisting of all liftable subgroups σ ⊂ G c : a subgroup σ is liftable if and only if the full preimage ˜ of σ σ in G c is abelian. The fan Σ defines a subgroup R (Σ) 2 ⊆ H ( 2 s G a ) as the set of all elements which vanish upon restriction to every σ ∈ Σ. We have
$$R ^ { 2 } \subseteq R ^ { 2 } ( \Sigma ).$$
Lemma 1.3. For every α ∈ I( G c ) ⊆ H ( ∗ s G a ) and every σ ∈ Σ( G c ) the restriction of α to σ is trivial.
## Definition 1.4. Let
$$1 \to Z \to G ^ { c } \to G ^ { a } \to 1$$
be a central extension. A ∆-pair ( I, D ) of G a is a set of subgroups
$$I \subseteq D \subseteq G ^ { a }$$
a
## such that
- · I ∈ ¯ ( Σ G c ),
- · D is noncyclic,
- · for every δ ∈ D , the subgroup 〈 I, δ 〉 ∈ ¯ ( Σ G c ).
This definition depends on G c . Assume we have a commutative diagram of central extensions
/d47
/d47
/d47
/d47
/d47
/d47
/d47
/d47
/d15
/d15
/d15
/d15
/d15
/d15
/d15
/d15
/d15
/d15
/d47
/d47
/d47
/d47
/d47
/d47
/d47
/d47
.
Definition 1.5. A ∆-pair ( ˜ I, D ˜ ) of ˜ G a surjects onto a ∆-pair ( I, D ) of G a if γ I ( ˜ ) = I and γ D ( ˜ ) = D .
Definition 1.6. A class α ∈ H ( i s G a ) is unramified with respect to a ∆-pair if its restriction to D is induced from D/I , i.e., there exists a β ∈ H ( i s D/I ) such that φ α ( ) = ψ β ( ), for the natural homomorphisms in the diagram:
/d47
$$\mathbf H _ { s } ^ { * } ( G ^ { a } ) \xrightarrow { \phi } \mathbf H _ { s } ^ { * } ( D ) \xrightarrow { \psi } \mathbf H _ { s } ^ { * } ( D / I )$$
/d47
/d111
/d111
By Lemma 1.3 we have a similar notion for
$$\mathsf H _ { s } ^ { * } ( G ^ { a } ) / \mathsf I ( G ^ { c } ) \subseteq \mathsf H _ { s } ^ { * } ( G ^ { c } ).$$
Lemma 1.7. Consider a homomorphism
$$\gamma \colon \tilde { G } ^ { a } \rightarrow G ^ { a }$$
and a class α ∈ H ( i G a ) . Let ˜ := α γ ∗ ( α ) ∈ H ( ˜ i G a ) be the induced class. Let ( ˜ I, D ˜ ) be a ∆ -pair in ˜ G a . Assume that one of the following holds:
- · γ I ( ˜ ) = 0 ,
- · γ D ( ˜ ) is cyclic,
- · γ induces a surjection of ∆ -pairs
$$( \tilde { I }, \tilde { D } ) \rightarrow ( I, D )$$
and α ∈ H ( i s G a ) is unramified with respect to ( I, D ) .
Then ˜ α ∈ H ( ˜ i s G a ) is unramified with respect to ( ˜ I, D ˜ ) .
Proof. The first two cases are evident. Consider the third condition. By assumption, γ induces a homomorphism ˜ D/I ˜ → D/I . Passing to cohomology we get a commuting diagram
/d47
/d47
/d15
/d15
/d15
/d15
and thus the claim.
/d47
/d47
## UNIVERSAL SPACES
## 2. Central extensions and isoclinism
Let G a and Z be finite abelian /lscript -groups. Central extensions of G a by Z are parametrized by H ( 2 G , Z a ); for α ∈ H ( 2 G , Z a ) we let G c α be the corresponding central extension:
$$1 \to Z \to G _ { \alpha } ^ { c } \stackrel { \pi _ { a } } { \longrightarrow } G ^ { a } \to 1$$
Fix an embedding Z ↪ → ( Q Z / ) r , consider the exact sequence
$$1 \rightarrow Z \rightarrow ( \mathbb { Q } / \mathbb { Z } ) ^ { r } \rightarrow ( \mathbb { Q } / \mathbb { Z } ) ^ { r } \rightarrow 1,$$
and the induced long exact sequence in cohomology
$$\mathbf H ^ { 1 } ( G ^ { a }, ( \mathbb { Q } / \mathbb { Z } ) ^ { r } ) \stackrel { \delta } { \longrightarrow } \mathbf H ^ { 2 } ( G ^ { a }, Z ) \rightarrow \mathbf H ^ { 2 } ( G ^ { a }, ( \mathbb { Q } / \mathbb { Z } ) ^ { r } ).$$
We say that α, α ˜ ∈ H ( 2 G , Z a ) and the corresponding extensions are isoclinic if
$$\alpha - \tilde { \alpha } \in \delta ( { \mathsf H } ^ { 1 } ( G ^ { a }, ( { \mathbb { Q } } / { \mathbb { Z } } ) ^ { r } ) ).$$
This notion does not depend on the chosen embedding Z ↪ → ( Q Z / ) r and coincides with the standard definition of isoclinic in the theory of /lscript -groups.
Lemma 2.1. If α, α ˜ ∈ H ( 2 G , Z a ) are isoclinic then the corresponding extensions of G a define the same set of ∆ -pairs in G a .
Proof. A pair of subgroups ( I, D ) is a ∆-pair in G a , with respect to a central extension G c , if their preimages commute in G c , i.e.,
$$[ \pi _ { a } ^ { - 1 } ( I ), \pi _ { a } ^ { - 1 } ( D ) ] = 0 \quad \text{in} \quad Z.$$
Consider the homomorphism
$$\pi _ { a } ^ { * } \colon \mathrm H ^ { 2 } ( G ^ { a }, \mathbb { Q } / \mathbb { Z } ) \to \mathrm H ^ { 2 } ( G ^ { c }, \mathbb { Q } / \mathbb { Z } ),$$
and note that Ker( π ∗ a ) only depends on the isoclinism class of the extension. Furthermore, H ( 2 G , a Q Z / ) is dual to ∧ 2 ( G a ). Let R ⊂ ∧ 2 ( G a ) be the subgroup which is dual to Ker( π ∗ a ). It remains to observe that ( I, D ) is a ∆-pair for G c if and only if π -1 a ( I ) ∧ π -1 a ( D ) intersects R trivially; thus the notion of a ∆-pair is an invariant of the isoclinism class of the extension. /square
Lemma 2.2. If α, α ˜ ∈ H ( 2 G , Z a ) are isoclinic then
$$R ^ { 2 } ( G _ { \alpha } ^ { c } ) = R ^ { 2 } ( G _ { \tilde { \alpha } } ^ { c } ),$$
in particular
$$\mathsf H _ { s } ^ { * } ( G ^ { a }, \mathbb { Z } / \ell ^ { n } ) / \mathsf I ( G _ { \alpha } ^ { c } ) = \mathsf H _ { s } ^ { * } ( G ^ { a }, \mathbb { Z } / \ell ^ { n } ) / \mathsf I ( G _ { \tilde { \alpha } } ^ { c } ).$$
Proof.
See Section 2 and Theorem 3.2 in [6]. /square
Lemma 2.3. If R = R (Σ) 2 2 then Σ determines G c up to isoclinism.
Example 2.4 . Consider G a = F 2 m /lscript , as a vector-space over F /lscript 2 of dimension m . Let Σ be the set of F /lscript -linear subspaces of the form F /lscript 2 . Then
$$H _ { s } ^ { i } ( G ^ { c }, \mathbb { Z } / \ell ^ { n } ) = 0, \quad \text{for} \quad i > 2.$$
Lemma 2.5. If α, α ˜ ∈ H ( 2 G , Z a ) are isoclinic then there exist faithful representations V, V ˜ of G c α and G c ˜ α over k such that V/G c α and ˜ V /G c ˜ α are birational.
Proof. Explicit construction: Let χ , . . . , χ 1 r be a basis of Hom( Z, k × ) and put
$$V \coloneqq \oplus _ { j = 1 } ^ { r } V _ { j } \quad \text{and} \quad \tilde { V } = \oplus _ { j = 1 } ^ { r } \tilde { V } _ { j },$$
where
$$V _ { j } = \text{Ind} _ { Z } ^ { G _ { \alpha } ^ { c } } ( \chi _ { j } ) \quad \text{and} \quad \tilde { V } _ { j } = \text{Ind} _ { Z } ^ { G _ { \bar { \alpha } } ^ { c } } ( \chi _ { j } ).$$
Note that the projectivizations P ( V j ) and P ( ˜ V j ) are canonically isomorphic as G a -representations. The group ( k × ) r acts on V and ˜ , V and both V/G c α and V/G c ˜ α are birational to
$$\bar { \bar { \mu } } ^ { \dots \dots } \cdot \bar { \bar { \mu } } ^ { \dots \dots \dots \dots \dots \cdot \cdot } \cdot \\ \left ( \prod _ { j = 1 } ^ { r } \mathbb { P } ( V _ { j } ) \right ) / G ^ { a } \times \left ( \prod _ { j = 1 } ^ { r } k ^ { \times } / \chi _ { j } ( Z ) \right ).$$
Lemma 2.6. Consider a central extension of finite /lscript -groups
$$1 \to Z \to G ^ { c } \stackrel { \pi _ { a } } { \longrightarrow } G ^ { a } \to 1$$
and fix a primitive g ∈ G a . Then there exists an isoclinic extension
$$1 \rightarrow \tilde { Z } \rightarrow \tilde { G } ^ { c } \stackrel { \tilde { \pi } _ { a } } { \longrightarrow } G ^ { a } \rightarrow 1$$
and a lift ˜ g c ∈ ˜ G c of g such that the order of ˜ g c in ˜ G c equals the order of g ∈ G a .
Proof. Since H ( 2 Z //lscript n , ( Q Z / ) r ) = 0 we can modify the sequence (2.2) by an element in δ (H ( 1 G , a ( Q Z / ) r )) to split the induced extension
$$1 \to Z \to Z _ { g } \to \langle g \rangle \to 1, \quad Z _ { g } \coloneqq ( \pi _ { a } ) ^ { - 1 } ( \langle g \rangle ),$$
this provides a lift of g of the same order.
/square
Corollary 2.7. If for some g ∈ Z the restriction of π a to 〈 g 〉 defines an embedding π a : 〈 g 〉 → ↪ G a then G c is isoclinic to G / g c 〈 〉 × 〈 g 〉 .
Proof. Consider the central extension
$$1 \to \langle g \rangle \to G ^ { c } \to G ^ { c } / \langle g \rangle \to 1.$$
It is defined by an element α g ⊂ H ( 2 G / g , c 〈 〉 〈 g 〉 ). Consider the embedding 〈 g 〉 ⊂ Q Z / . Then the image of α g in H ( 2 G / g , c 〈 〉 Q Z / ) is 0.
Indeed, the extension is induced from a central extensions of abelian quotient groups
$$1 \to \pi _ { a } ( \langle g \rangle ) \to G ^ { a } \to G ^ { a } / \pi _ { a } ( \langle g \rangle ) \to 1,$$
which is isoclinic to the trivial central extension; the same holds for the exact sequence (2.3). /square
Lemma 2.8. Consider a central extension of finite /lscript -groups
$$1 \rightarrow Z \rightarrow G ^ { c } \rightarrow G ^ { a } \rightarrow 1,$$
let α ∈ H ( 2 G , Z a ) be the corresponding class, and assume that there exists a g ∈ G a lifting to a g c ∈ G c of the same order. Let Z g ⊂ G c be the centralizer of g c . Then the central extension
$$0 \rightarrow \langle g ^ { c } \rangle \rightarrow Z _ { g } \rightarrow Z _ { g } / \langle g ^ { c } \rangle \rightarrow 0$$
is induced from the extension
$$0 \rightarrow \langle g \rangle \rightarrow G ^ { a } \rightarrow G ^ { a } / \langle g \rangle \rightarrow 0.$$
If V is a faithful representation of G c as in the proof of Lemma 2.5 then V/Z g is a vector bundle over ˜ V / Z / g ( g 〈 c 〉 ) , for some faithful representation ˜ V of Z / g g 〈 c 〉 . Furthermore, if K := k V/Z ( g ) and
$$s _ { K } ^ { 2 } \colon \mathrm H ^ { 2 } ( G ^ { a }, \mathbb { Z } / \ell ^ { n } ) \to \mathrm H ^ { 2 } ( G _ { K }, \mathbb { Z } / \ell ^ { n } )$$
is the corresponding homomorphism, then s 2 K ( α ) is induced from G / g a 〈 〉 . Proof. Immediate from the definitions. /square
Lemma 2.9. Consider a central extension of finite groups
$$1 \rightarrow Z \rightarrow G ^ { c } \stackrel { \pi _ { a } } { \longrightarrow } G ^ { a } \rightarrow 1$$
and let V = ⊕ j V j be a faithful representation of G c as in Lemma 2.5, i.e., each V j = Ind G c Z ( χ j ) , where { χ j } j ∈ J is a basis of Hom( Z, k × ) . Let P := ∏ j ∈ J P ( V j ) . Then: (1) G a acts faithfully on P .
- (2) For any subgroup σ ⊂ G a the subset of σ -fixed points P σ ⊂ P is nonempty if and only if σ ∈ ¯ ( Σ G c ) .
- (3) Each irreducible component of P σ is a product of projective subspaces of P ( V j ) , corresponding to different eigenspaces of σ in V j , and distinct irreducible components are disjoint.
- (5) The action of G a on P ◦ := P \ ∪ σ ∈ ¯ Σ P σ is free.
- (4) Each irreducible component of P σ is stable under the action of H σ ⊂ G c , the maximal subgroup such that [ H ,π σ -1 a ( σ )] = 0 in G c ; the action of G /H c σ on the set of components of P σ is free.
Proof. Since the order of G c is coprime to the characteristic of k , every g ⊂ G c is semi-simple and we can decompose
$$V _ { j } = \oplus _ { i } V _ { j } ( \lambda _ { i } ( g ) ),$$
as a sum of eigenspaces. The subset of g -fixed points splits as a product ∏ ij P ( V j ( λ i ( g ))), where the product runs over different eigenvalues in different V j . It follows that the subset of g -fixed points P g ⊂ P is a union of products of projective subspaces of P ( V j ).
Let σ := 〈 g, h 〉 ⊂ G a be a subgroup such that σ / ∈ ¯ . Σ Then the same holds for the images of g, h in GL( V j ), for at least one j ∈ J . Thus the commutator [ g, h ] ∈ GL( V j ) is a nontrivial scalar matrix, hence they have no common eigenvectors, i.e., no common fixed points in P ( V j ). Thus if σ / ∈ ¯ then Σ σ has no fixed points in ∏ j P ( V j ). Note that projective subspaces corresponding to different eigenvalues of g do not intersect in P ( V j ) and hence P σ splits into a disjoint union of products of projective subspaces of different P ( V j ).
If σ ∈ ¯ then its elements can be simultaneously diagonalized. Hence Σ the subset of fixed points in P = ∏ j P ( V j ) is a union of products of projective subspaces, and there is a Zariski open subvariety of P stable under the action of the preimage ˜ := σ π -1 a ( σ ) ⊂ G c .
Assume that [ h, σ ˜] = 0 in G c for some h ∈ G c . Then 〈 h, σ ˜ 〉 has a fixed point in each component of P σ and h maps every component of P σ into itself. Thus a subgroup H ⊂ G c , with [ H,σ ˜] = 0 maps every component of P σ into itself.
Assume that 〈 h, γ 〉 ∈ / ¯ , for some Σ γ ∈ σ . Then for some j , the images of h, γ in GL( V j ) have nonintersecting invariant subvarieties in P ( V j ). In particular, h does not preserve any component of P σ . /square
Lemma 2.10. Let K = k X ( ) be a function field with Galois group G K . Given a surjection G K → G c , onto some finite central extension of an abelian group G a , let P = ∏ j P ( V j ) be the space constructed in Lemma 2.9. Then there is a rational map /rho1 : X → P /G a such that
- · /rho1 maps the generic point of X into P ◦ /G a ;
- · the homomorphism
$$s _ { K } \colon \mathbf H _ { s } ^ { * } ( G ^ { a }, \mathbb { Z } / \ell ^ { n } ) \to \mathbf H ^ { * } ( G _ { K }, \mathbb { Z } / \ell ^ { n } )$$
factors through the cohomology of P ◦ /G a .
Proof. Let X ◦ ⊂ X be an open affine subvariety such that π 1 ( X ◦ ) surjects onto G c . Let ˜ X ◦ → X ◦ be the induced unramified G c covering. Then k X [ ˜ ◦ ] decomposes into an infinite direct sum of G c -representations.
Fix a point ˜ X ◦ and consider its orbit. The restriction of k X [ ˜ ◦ ] to this orbit defines a regular quotient G c -representation isomorphic to k G [ ]; this admits homomorphisms to k V [ ], corresponding to maps X → V/G c . /square
## 3. Basic valuation theory
/negationslash
Let X be a variety over k = ¯ , F p K = k X ( ) its function field, and G K the absolute Galois group of K . We write V K for the set of valuations of K and DV K for the subset of divisorial valuations. The corresponding residue fields will be denoted by K ν . For ν ∈ V K , let D ν ⊂ G K denote a decomposition group of ν and I ν ⊂ D ν the inertia subgroup; we have G K ν = D /I ν ν . The pro- -quotients of these groups will be /lscript denoted by G K , D ν , and I ν , respectively. We will always assume that p = /lscript . The corresponding abelianizations will be denoted by G a K , D a ν , and I a ν ; their canonical central extensions by G c K , D c K , and I c K . Under our assumptions, G a K is a free Z /lscript -module of infinite rank.
Lemma 3.1. For ν ∈ V K consider the commutative diagram
/d47
/d47
/d15
/d15
/d15
/d15
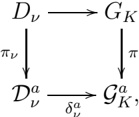
/d47
/d47
ν
where π v and π are the canonical projections and δ a ν is the induced homomorphism. Then δ a ν is injective with primitive image. In particular, δ a ν embeds I a ν as a primitive subgroup of D a ν .
Let Σ( G c K ) be the set of primitive topologically noncyclic subgroups of G a K whose preimage in G c K is abelian. By [9, Section 6], we have:
Theorem 3.2. Assume that dim( X ) ≥ 2 . Then
$$\text{rk} _ { \mathbb { Z } _ { \ell } } ( \sigma ) \leq \dim ( X ), \ \ \text{ for all } \ \sigma \in \Sigma ( \mathcal { G } _ { K } ^ { c } ).$$
The following key result gives a valuation-theoretic interpretation of liftable subgroups in G a K ; it is crucial for the reconstruction of function fields in [10] and [11].
Theorem 3.3. [9, Corollary 6.4.4] Assume that dim( X ) ≥ 2 and let σ ∈ Σ( G c K ) . Then there exists a valuation ν ∈ V K such that I a ν is a subgroup of σ of Z /lscript -corank at most one and σ ⊆ D a ν .
We recall some background from valuation theory. For ν ∈ V K let Γ ν = ν K ( × ) be its value group. We have a fundamental inequality
$$( 3. 1 ) \quad \ \ \ t r \deg _ { k } ( K ) \geq \text{tr} \deg _ { k } ( K _ { \nu } ) + \dim _ { \mathbb { Q } } ( \Gamma _ { \nu } \otimes \mathbb { Q } ).$$
A valuation ν is called algebraic of rank r if its value group Γ ν := ν K ( × ) is isomorphic to Z r and admits a filtration
$$\mathbb { Z } ^ { r } \simeq \Gamma _ { \nu } = \Gamma _ { \nu _ { r } } \supsetneq \dots \supsetneq \Gamma _ { \nu _ { 1 } } \simeq \mathbb { Z }$$
by free abelian subgroups Γ ν j corank j which are value groups of embedded compatible valuations ν j . Such valuations arise from flags of irreducible subvarieties c j of codimension j
$$\mathfrak { c } _ { r } \subsetneq \mathfrak { c } _ { r - 1 } \subsetneq \dots \subsetneq \mathfrak { c } _ { 1 } \subsetneq X.$$
A valuation is called an Abhyankar valuation if equality holds in (3.1) (alternatively, ν is said to be without transcendence defect); every algebraic valuation is an Abhyankar valuation.
Let ν be an Abhyankar valuation of K . By [19, Theorem 3.4(a)],
$$\Gamma _ { \nu } \simeq \mathbb { Z } ^ { r },$$
for some r . By [19, Theorem 1.1], for any F := { f , . . . , f 1 m } ⊂ o ν there exists a projective model X of K such that
- · the center c = c X ( ν ) of ν is a generically smooth subvariety of X of dimension dim Q (Γ ν ⊗ Q );
- · there exists a regular parameter system ( a , . . . , a 1 r ) of O X, c such that each f j , j = 1 , . . . , m , is an O X, c -monomial in { a , . . . , a 1 r } .
We say that ν admits a smooth monomial uniformization on X with respect to F . In particular, we have:
Proposition 3.4. Let K be a function field of an algebraic variety over k = ¯ F p . Let ν be an algebraic valuation of rank r . Then there exists a projective model X of K over k such that the centers c j of ν j on X are irreducible subvarieties of codimension j which are smooth at the general point of c r .
The following statement has been proved in [20, Theorem 1.2 and Corollary 1.3].
Proposition 3.5. Let K be a function field of an algebraic variety over k = ¯ F p , ν ∈ V K , and F = { f , . . . , f 1 m } ⊂ o ν a finite set of functions. Then there exists a finite separable Galois extension ˜ K/K , an extension of ν to a valuation ˜ ν ∈ V ˜ K , and a projective model ˜ X of ˜ K such that
- (1) the extension of residue fields ˜ K ˜ ν / ˜ K ˜ ν is purely inseparable;
- (2) Γ ˜ ν / Γ ν is a finite p -group;
- (3) ˜ ν admits a smooth monomial uniformization on ˜ X with respect to F .
Proposition 3.6. Let K be a function field of an algebraic variety over k = ¯ F p and I a ν , D a ν ⊂ G a K the abelianized inertia, resp. decomposition subgroup of some valuation ν ∈ V K . Let
$$\gamma _ { K } \, \colon \, \mathcal { G } _ { K } ^ { a } \rightarrow G ^ { a }$$
be a continuous surjective homomorphism onto a finite abelian /lscript -group G a . Assume that γ K ( I a ν ) is nontrivial. Then for any primitive cyclic subgroup I ⊂ γ K ( I a ν ) there exists a divisorial valuation ν ′ ∈ DV K such that
$$I \subseteq \gamma _ { K } ( \mathcal { I } ^ { a } _ { \nu ^ { \prime } } ) \quad a n d \quad \gamma _ { K } ( \mathcal { D } ^ { a } _ { \nu } ) \subseteq \gamma _ { K } ( \mathcal { D } ^ { a } _ { \nu ^ { \prime } } ).$$
Proof. Assume that /lscript n annihilates G a = ⊕ j Z //lscript n j , i.e., n j ≤ n . By Kummer theory, the homomorphism
$$\gamma _ { K } \in \text{Hom} ( \mathcal { G } _ { K } ^ { a } / \ell ^ { n }, G ^ { a } ) = \oplus _ { j } \text{Hom} ( \mathcal { G } _ { K } ^ { a }, \mathbb { Z } / \ell ^ { n _ { j } } ) = \oplus _ { j } K ^ { \times } / ( K ^ { \times } ) ^ { \ell ^ { n _ { j } } }$$
is defined by a finite set of elements F = { f j } , with f j ∈ K / K × ( × ) /lscript n j . We lift these to a set of elements of K × , denoted by the same letter, and we may assume that these are in o ν . We apply Proposition 3.5 and pass to a finite separable Galois extension ˜ K of K over which ˜, the ν extension of ν , admits a smooth uniformization on a projective model ˜ X of ˜ with respect to K F . Properties (1) and (2) in Proposition 3.5 insure that the image in G a of the corresponding inertia and decomposition group is unchanged, i.e., we have a diagram
/d15
/d15
/d47
/d47
/d47
/d47
Thus we may assume that K = ˜ . K Let c = ( ) be the center of the c ν (the lift of) ν on X . The regular parameter system ( a , . . . , a 1 r ) of O X, c defines an algebraic valuation ν ′ = ( ν , . . . , ν ′ 1 ′ r ) of rank r of K and
$$\rho ( \mathcal { I } _ { \nu } ^ { a } ) = \rho ( \mathcal { I } _ { \nu ^ { \prime } } ^ { a } ) \subseteq \rho ( \mathcal { D } _ { \nu } ^ { a } ) = \rho ( \mathcal { D } _ { \nu ^ { \prime } } ^ { a } ).$$
We have reduced the proof to the case of algebraic valuations, where it is straightforward: If ρ ( I a ν ′ 1 ) is nontrivial in G a then we are done since
$$\rho ( \mathcal { I } ^ { a } _ { \nu ^ { \prime } _ { 1 } } ) \subset \rho ( \mathcal { I } ^ { a } _ { \nu ^ { \prime } } ) = \rho ( \mathcal { I } ^ { a } _ { \nu ^ { \prime } _ { 1 } } ) \subset \rho ( \mathcal { D } ^ { a } _ { \nu ^ { \prime } } ).$$
/negationslash
Otherwise, we can assume that ρ ( I a ν ′ 1 ) and ρ ( I a ν ′ j ) = 0 , j > i but ρ ( I a ν ′ i ) = 0. We blow up the general point of the center of ν ′ i and let E be the exceptional divisor, it is generically smooth by Proposition 3.4. Then
16
we have
/negationslash
$$0 \neq \rho ( \mathcal { I } _ { E } ^ { a } ) \subset \rho ( \mathcal { I } _ { \nu ^ { \prime } } ^ { a } / \mathcal { I } _ { \nu ^ { \prime } _ { i + 1 } } ^ { a } ) \subset \rho ( \mathcal { D } _ { \nu ^ { \prime } } ^ { a } ) / \rho ( \mathcal { I } _ { \nu ^ { \prime } _ { i + 1 } } ^ { a } ) \subset \rho ( \mathcal { D } _ { E } ^ { a } )$$
and ρ ( I a E ) coincides with ρ ( I a ν ′ i / I a ν ′ i +1 ), which is nontrivial by assumption. /square
Remark 3.7 . The proof is essentially an application of the general result that algebraic valuations (or Abhyankar valuations) are dense in the patch-topology on V K .
## 4. Liftable subgroups and their configurations
Let K = k X ( ) be the function field of an algebraic variety over k = ¯ . In this section, we compare the structure of the fan Σ( F p G c K ) with fans in its finite quotients. Consider the canonical central extension
$$\mathcal { C } _ { \cdot \cdot } ^ { c } \rightarrow \mathcal { C } _ { \cdot \cdot } ^ { a }.$$
$$1 \to \mathcal { Z } _ { K } \to \mathcal { G } _ { K } ^ { c } \to \mathcal { G } _ { K } ^ { a } \to 1.$$
Lemma 4.1. We have
$$\mathcal { Z } _ { K } = [ \mathcal { G } _ { K } ^ { c }, \mathcal { G } _ { K } ^ { c } ].$$
Proof. This holds for function fields of curves since the corresponding pro- -quotients of their absolute Galois groups are free. /lscript In higher dimensions, G a K embedds into the product ∏ E G a E , where E ranges over function fields of curves E ⊂ K . Under the projection to G c K → G a E , the center of G c K maps to zero, hence the claim. /square
Lemma 4.2. Consider commutative diagrams of continuous homomorphisms
/d47
/d47
/d47
/d47
/d47
/d47
/d47
/d47
/d15
/d15
/d15
/d15
/d15
/d15
/d15
/d15
/d15
/d15
/d15
/d15
/d47
/d47
/d47
/d47
/d47
/d47
/d47
/d47
,
where G c is finite, with fixed surjective γ K . Assume that Z is the maximal quotient of Z K giving rise to such a diagram. Then G c is unique, modulo isoclinism.
Proof. Assume that G , G c 1 c 2 are two such extensions of G a with Z , Z 1 2 , respectively, and put G := G c 1 × G a G c 2 . We have a natural surjection G → G a and an inclusion Z 1 × Z 2 ↪ → G . Moreover, [ G,G ] ⊆ Z 1 × Z 2 . By Lemma 4.1, Z K is generated by commutators in G c K , thus Z 1 × Z 2 is also generated by commutators in G . It follows that G = G c . If both projections [ G , G c c ] → Z , Z 1 2 are isomorphisms then G c 1 and G c 2 are isoclinic. Otherwise, we have a contradiction to the maximality assumption. Since G a is finite, G c is also finite, as it is bounded by ∧ 2 ( G a ) ∗ . /square
We proceed to investigate the properties of fans under such factorizations. Let
$$\gamma _ { K } \colon \mathcal { G } _ { K } ^ { a } \to G ^ { a }$$
be a continuous surjective homomorphism onto a finite group. We choose a maximal finite central extension G c of G a as in Lemma 4.2.
## Corollary 4.3. Given continuous surjective homomorphisms
$$\mathcal { G } _ { K } ^ { a } \stackrel { \tilde { \gamma } _ { K } } { \longrightarrow } \tilde { G } ^ { a } \stackrel { \gamma } { \longrightarrow } G ^ { a },$$
with ˜ G a a finite group, there is a unique (modulo isoclinism of lower rows) diagram of central extensions
/d47
/d47
/d47
/d47
/d47
/d47
/d47
/d47
/d15
/d15
/d15
/d15
/d15
/d15
/d15
/d15
/d15
/d15
/d47
/d47
/d47
/d47
/d47
/d47
/d47
/d47
with surjective ˜ γ c K , γ c and maximal ˜ Z , Z .
Proof.
$$P r o o f. \text{ Evident}.$$
We will use the following observation:
Lemma 4.4. Let G a be a profinite abelian group and
$$\mathcal { G } ^ { a } \stackrel { \gamma _ { j } } { \longrightarrow } \tilde { G } ^ { a } _ { j }, \ \ j = 1, \dots, n,$$
a collection of continuous surjective homomorphisms onto finite groups. Then there exists a continuous surjection
$$\gamma \, \colon \mathcal { G } ^ { a } \rightarrow \tilde { G } ^ { a }$$
onto a finite group such that each γ j factors through γ :
$$\gamma _ { j } \colon \mathcal { G } ^ { a } \stackrel { \gamma } { \longrightarrow } \tilde { G } ^ { a } \rightarrow \tilde { G } ^ { a } _ { j }.$$
Proof. We can choose ˜ G a to be the image of G a in the direct product
$$\tilde { G } _ { 1 } \times \dots \times \tilde { G } _ { n }.$$
/square
We are interested in factorizations (4.2), with finite ˜ G a , preserving liftable subgroups and their configurations. Throughout we will be
/d47
/d47
/d47
/d47
/d47
/d47
/d15
/d15
/d47
/d47
working with the canonical, modulo isoclinism, diagram as in Corollary 4.3, i.e., a factorization as in Equation (4.2) will canonically determine Σ( ˜ G c ) and the set of ∆-pairs in ˜ G a , by Lemma 2.1. Let
$$\Sigma _ { E } ( G ^ { c } ) \coloneqq \{ \sigma \in \Sigma ( G ^ { c } ) \, | \, \sigma = \gamma _ { K } ( \sigma _ { K } ), \quad \text{for some} \quad \sigma _ { K } \in \Sigma ( \mathcal { G } _ { K } ^ { c } ) \}$$
be the subset of extendable subgroups.
Lemma 4.5. Given a continuous surjective homomorphism
$$\gamma _ { K } \colon \mathcal { G } _ { K } ^ { a } \to G ^ { a }$$
onto a finite abelian group there exists a factorization
$$\mathcal { G } _ { K } ^ { a } \stackrel { \tilde { \gamma } _ { K } } { \longrightarrow } \tilde { G } ^ { a } \stackrel { \gamma } { \longrightarrow } G ^ { a }, \ \ \gamma _ { K } = \gamma \circ \tilde { \gamma } _ { K },$$
with finite ˜ G a , such that for all σ ∈ Σ( G c ) we have: if σ is nonextendable then there is no ˜ σ ∈ Σ( ˜ G c ) with γ σ (˜) = σ .
Moreover, this holds for every finite ¯ G a fitting into
$$\mathcal { G } _ { K } ^ { a } \rightarrow \bar { G } ^ { a } \rightarrow \tilde { G } ^ { a }.$$
Proof. First we prove the statement for one nonextendable σ . Write
$$( 4. 3 ) \quad \ \mathcal { G } _ { K } ^ { a } = \text{projlim} G _ { \iota \in I } ^ { a }, \quad \gamma _ { \iota \iota ^ { \prime } } \colon G _ { \iota } ^ { a } \longrightarrow G _ { \iota ^ { \prime } } ^ { a }, \quad \iota ^ { \prime } \preceq \iota,$$
where the limit is over finite continuous quotients of G a K . Assume that for all ι , there is some σ ι ∈ Σ( G c ι ) surjecting onto σ ; this implies that there exist such σ ι ′ , for all ι ′ /precedesequal ι , with γ ιι ′ ( σ ι ) = σ ι ′ .
By compactness of G a K , there exists a closed liftable σ K ⊂ G a K surjecting onto σ . This contradicts our assumption that σ is nonextendable. Thus there is a required factorization
$$\mathcal { G } _ { K } ^ { a } \rightarrow \tilde { G } ^ { a } \stackrel { \gamma } { \longrightarrow } G ^ { a }.$$
Let
For each j , let
$$\mathcal { G } _ { K } ^ { a } \longrightarrow \tilde { G } _ { j } ^ { a } \stackrel { \gamma _ { j } } { \longrightarrow } G ^ { a }$$
be the factorization constructed above. Now we apply Lemma 4.4, combined with Corollary 4.3, and obtain factorizations of γ j :
$$\mathcal { G } _ { K } ^ { a } \to \tilde { G } ^ { a } \to \tilde { G } _ { j } \to G ^ { a }, \quad \gamma \, \colon \tilde { G } ^ { a } \to G ^ { a },$$
Assume that there is some j for which there exists a ˜ σ ∈ Σ( ˜ G c ) surjecting onto σ j . Then image ˜ in σ ˜ G j must be liftable, contradicting the construction in the first part. /square
$$\{ \sigma _ { 1 }, \dots, \sigma _ { n } \} = \Sigma ( G ^ { c } ) \, \wedge \Sigma _ { E } ( G ^ { c } ).$$
Let
$$I \subseteq D \subseteq G ^ { a }.$$
be a ∆-pair (see Definition 1.4). Throughout, we assume that G a arises as a finite quotient of the Galois group of some function field G K , in particular, the corresponding G c is determined as in Lemma 4.2, up to isoclinism. We say that ( I, D ) is extendable if there exists a valuation ν ∈ V K and subgroups
$$I ^ { a } \subseteq \mathcal { I } ^ { a } _ { \nu }, \ \ D ^ { a } \subseteq \mathcal { D } ^ { a } _ { \nu }$$
such that
$$\gamma _ { K } ( I ^ { a } ) = I, \ \gamma _ { K } ( D ^ { a } ) = D.$$
Recall that a ∆-pair ( ˜ I, D ˜ ) is said to surject onto ( I, D ) if
$$\gamma ( \tilde { I } ) = I, \ \gamma ( \tilde { D } ) = D.$$
We will need the following strengthening of Lemma 4.5
Proposition 4.6. Given a continuous surjective homomorphism
$$\mathcal { G } _ { K } ^ { a } \rightarrow G ^ { a }$$
onto a finite abelian group there exists a factorization
$$\mathcal { G } _ { K } ^ { a } \rightarrow \tilde { G } ^ { a } \rightarrow G ^ { a },$$
with finite ˜ G a , such that for all ∆ -pairs ( I, D ) in G a we have: if ( I, D ) nonextendable then there is no ∆ -pair ( ˜ I, D ˜ ) in ˜ G a surjecting onto ( I, D ) .
Proof. As in the proof of Lemma 4.5, it suffices to establish the statement for one nonextendable ∆-pair; indeed, there are only finitely many ∆-pairs in G a and the same application of Lemma 4.4 will then establish it for all.
Assume that there is no finite quotient of G a K with the desired property. We start with a factorization
$$\mathcal { G } _ { K } ^ { a } \rightarrow \tilde { G } ^ { a } \stackrel { \gamma } { \longrightarrow } G ^ { a }$$
such that ˜ G a satisfies the conclusions of Lemma 4.5, i.e., no σ ∈ Σ( G c ) \ Σ ( E G c ) is the image of a ˜ σ ∈ Σ( ˜ G c ).
Let ( I, D ) be a nonextendable ∆-pair. By our assumption, there exists a ∆-pair ( ˜ I, D ˜ ) in ˜ G a surjecting onto ( I, D ). Choose representatives g , . . . , g 1 n ∈ D for D/I and their preimages ˜ g j := γ -1 ( g j ) ∈ ˜ . D Note that for each j ,
$$\sigma _ { j } \coloneqq \langle g _ { j }, I \rangle \in \Sigma ( G ^ { c } ), \ \tilde { \sigma } _ { j } \coloneqq \langle \tilde { g } _ { j }, \tilde { I } \rangle \in \Sigma ( G ^ { c } ).$$
and that ˜ σ j surject onto σ j . By Lemma 4.5 and our choice of ˜ G a , all σ j are extendable. Moreover,
$$\tilde { I } = \cap _ { j = 1 } ^ { n } \tilde { \sigma } _ { j }.$$
We replace and rename the original ˜ D by
$$\tilde { D } \coloneqq \cup _ { j = 1 } ^ { n } \tilde { \sigma } _ { j }.$$
Then ( ˜ I, D ˜ ) is a ∆-pair in ˜ G a surjecting onto ( I, D
).
Now we consider a projective system of finite continuous quotients
$$\mathcal { G } _ { K } ^ { a } \to \tilde { G } _ { \iota } ^ { a } \to \tilde { G } ^ { a } \to G ^ { a }, \quad \gamma _ { \iota \iota ^ { \prime } } \colon G _ { \iota } ^ { a } \longrightarrow G _ { \iota ^ { \prime } } ^ { a }, \ \iota ^ { \prime } \preceq \iota.$$
Assume that for each ι there exists a ∆-pair ( ˜ I , D ι ˜ ) in ι ˜ G a ι surjecting onto ( I, D ). Iterating the construction above, we construct, for each ι , a collection of liftable subgroups
$$\tilde { \sigma } _ { \iota, 1 }, \dots, \tilde { \sigma } _ { \iota, n }$$
and a ∆-pair ( ˜ I , D ι ˜ ) of the form ι
$$\tilde { I } _ { \iota } = \cap _ { j = 1 } ^ { n } \tilde { \sigma } _ { \iota, j }, \quad \tilde { D } _ { \iota } \coloneqq \cup _ { j = 1 } ^ { n } \tilde { \sigma } _ { \iota, j },$$
such that
- · ( ˜ I , D ι ˜ ) surjects onto ( ˜ ι I ι ′ , D ˜ ι ′ ), for each ι ′ /precedesequal ι ,
and in particular onto ( I, D ). By compactness of G a K (see Lemma 4.5), there exist closed subgroups
$$\sigma _ { K, 1 }, \dots, \sigma _ { K, n } \in \Sigma ( \mathcal { G } _ { K } ^ { c } ) ;$$
the closed subgroups
$$\mathcal { I } ^ { a } \coloneqq \cap \sigma _ { K, j }, \quad \mathcal { D } ^ { a } \coloneqq \cup \sigma _ { K, j }$$
of G a K surject onto I , resp. D . On the other hand, by the theory of liftable pairs (see [9, Section 6] and [11, Corollary 4.3]), there exists a valuation ν ∈ V K such that
$$\mathcal { I } ^ { a } \subseteq \mathcal { I } ^ { a } _ { \nu }, \ \mathcal { D } ^ { a } \subseteq \mathcal { D } ^ { a } _ { \nu }.$$
This contradicts our assumption that ( I, D ) is not extendable. /square
## 5. Galois cohomology of function fields
/negationslash
In [10], [11] we proved that if k = ¯ , with F p p = /lscript , and X is an algebraic variety over k of dimension ≥ 2 then K = k X ( ) is encoded, up to purely inseparable extensions, by G c K , the second lower series quotient of G K . Related reconstruction results have been obtained in [24], [23], [25].
The proof of the Bloch-Kato conjecture by Voevodsky, Rost, and Weibel, substantially advanced our understanding of the relations between fields and their Galois groups, in particular, their Galois cohomology. Indeed, consider the diagram
/d127
/d127
/d31
/d31
/d47
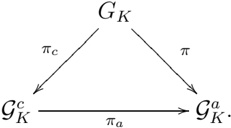
/d47
.
The following theorem relates the Bloch-Kato conjecture to statements in Galois-cohomology, with coefficients in Z //lscript n (see also [13], [14], [26]).
/negationslash
Theorem 5.1. [3] , [12, Theorem 11] Let k = ¯ F p , p = /lscript , and K = k X ( ) be the function field of an algebraic variety of dimension ≥ 2 . The Bloch-Kato conjecture for K is equivalent to:
- (1) The map
$$\pi ^ { * } \colon \mathrm H ^ { * } ( \mathcal { G } _ { K } ^ { a }, \mathbb { Z } / \ell ^ { n } ) \to \mathrm H ^ { * } ( G _ { K }, \mathbb { Z } / \ell ^ { n } )$$
is surjective and
- (2) Ker( π ∗ a ) = Ker( π ∗ ) .
This implies that the Galois cohomology of the pro- - quotient /lscript G K of the absolute Galois group G K encodes important birational information of X . For example, in the case above, G c K , and hence K , modulo purelyinseparable extensions, can be recovered from the cup-products
$$\mathsf H ^ { 1 } ( \mathcal { G } _ { K }, \mathbb { Z } / \ell ^ { n } ) \cup \mathsf H ^ { 1 } ( \mathcal { G } _ { K }, \mathbb { Z } / \ell ^ { n } ) \to \mathsf H ^ { 2 } ( \mathcal { G } _ { K }, \mathbb { Z } / \ell ^ { n } ), \ \ n \in \mathbb { N }.$$
From now on, we will frequently omit the coefficient ring Z //lscript n from notation.
The first part of the Bloch-Kato theorem says that every α K ∈ H ( i G K ) is induced from a cohomology class α a ∈ H ( i G a ) of some finite abelian quotient G K → G a . An immediate application of this is the following proposition:
Proposition 5.2. Let α K ∈ H ( i G K ) be defined on a model X of K and induced from a continuous surjective homomorphism χ : ˆ ( π 1 X ) → G onto a finite group. Let α = α X ∈ H ( i et X ) be the class representing α K on X . Then there exists a finite cover X = ∪ j X j by Zariski open subvarieties such that, for each j , the restriction α j := α | X j is induced from a continuous surjective homomorphism χ j : ˆ ( π 1 X j ) → G a onto a finite abelian group and a class α a ∈ H ( i s G a ) = ∧ i (H ( 1 G a )) .
Proof. We first apply the Bloch-Kato theorem to V ◦ /G and find a Zariski open subset U := U ◦ α such that the restriction α U is as claimed, i.e., induced from a class α a ∈ H ( i s G a ) = ∧ i (H ( 1 G a )), for some homomorphism χ a : G K → G a to a finite abelian group.
By Lemma 1.1, for every x ∈ X there exists a map f = f x such that f ( x ) ⊂ U and the restriction of α to f -1 ( U ) ⊂ X equals f ∗ ( χ ∗ a ( α a )). The claim follows by choosing a finite cover by open subvarieties with these properties. /square
The second part implies the following:
Corollary 5.3. Let α K ∈ H ( i G K ) . Assume that we are given finitely many quotients
$$\chi _ { j } \colon G _ { K } \to G _ { j } ^ { a }$$
onto finite abelian groups and classes
$$\alpha _ { j } ^ { a } \in \mathrm H ^ { i } ( G _ { j } ^ { a } )$$
with χ ∗ j ( α a j ) = α K , for all j . Then there exists a continuous finite quotient G K → G c onto a finite central extension of an abelian group G a such that
- · χ j factor through G c , i.e., there exist surjective homomorphisms ψ j : G c → G a j , for all j ;
- · there exists a class α c ∈ H ( i G c ) with
$$\alpha ^ { c } = \psi _ { j } ^ { * } ( \alpha _ { j } ^ { a } ), \ \ \ f o r \ a l l \ \ \ j.$$
Lemma 5.4. Let Z ⊂ X be an affine subset, Z = Spec( o Z ) , and ν ∈ V K . The general point of ν is contained in Z ,
$$\mathfrak { c } _ { X } ( \nu ) ^ { \circ } \subseteq Z$$
if and only if ν f ( ) ≥ 0 , for all f ∈ o Z .
Lemma 5.5. Let X be a normal variety with function field K . Assume that α K ∈ H ( i G K ) is defined on X and induced from a homomorphism χ : ˆ ( π 1 X ) → G to a finite group G . Consider the sequence
$$\chi _ { K } \colon G _ { K } \to \hat { \pi } _ { 1 } ( X ) \stackrel { \chi } { \longrightarrow } G.$$
Then χ K ( I ν ) = 0 , for every ν such that c X ( ν ) ◦ ⊂ X .
Proof. An ´ etale cover of X induces an ´tale cover of the generic point e of c X ( ν ), thus the cover is unramified in ν , i.e., χ K ( I ν ) = 0. /square
Corollary 5.6. Let α K ∈ H ( i G K ) . Let X be a normal projective model of K and ∪ j X j a finite cover by open subvarieties such that α K is defined on X j , for each j , and is induced from a class α a j ∈ H ( i G a j ) , via a homomorphism χ j : ˆ ( π 1 X j ) → G a j to some finite abelian group.
Then there exists a quotient χ K : G K → G a and a class α a ∈ H ( i G a ) such that
- · α a induces α K and
- · α a is unramified on every extendable ∆ -pair ( I, D ) in G a .
Proof. Each α a j is unramified on all ν such that the generic point c X ( ν ) ◦ ⊂ X j , by Lemma 5.5. Since the classes α j define the same element α K ∈ H ( i G K ), there exists an intermediate quotient G a and a class in α a ∈ H ( i G a ) inducing α K . /square
## 6. Unramified cohomology
An important class of birational invariants of algebraic varieties are unramified cohomology groups, with finite constant coefficients (see [4], [16]). These are defined as follows: Let ν be a divisorial valuation of K . We have a natural homomorphism
$$\partial _ { \nu } \, \colon \, H ^ { i } ( G _ { K } ) \to H ^ { i - 1 } ( G _ { K _ { \nu } } ).$$
Classes in ker( ∂ ν ) are called unramified with respect to ν . The unramified cohomology is
$$H ^ { i } _ { n r } ( G _ { K } ) \coloneqq \bigcap _ { \nu \in \mathcal { D } \mathcal { V } _ { K } } \text{Ker} ( \partial _ { \nu } ) \subset H ^ { i } ( G _ { K } ). \\ \text{thic ie the unramified Rrature around which was dead}$$
For i = 2 this is the unramified Brauer group which was used to provide counterexamples to Noether's problem, i.e., nonrational varieties of type V/G , where V is a faithful representation of a finite group G (see [27], [2]).
Generally, for ν ∈ V K and α ∈ H ( G K
$$\alpha _ { \nu } \in \mathrm H ^ { i } ( D _ { \nu } )$$
$$H ^ { i } ( G _ { K } ) & \text{ let } \\ H ^ { i } ( D _ { \nu } )$$
be the restriction of α to the decomposition subgroup D ν ⊂ G K of ν .
Lemma 6.1. A class α ∈ Ker( ∂ ν ) ⊆ H ( i G K ) , for ν ∈ DV K , if and only if α ν is induced from the quotient G K ν = D /I ν ν . In particular, α ν is well-defined as an element in H ( i G K ν ) .
Proof. The exact sequence
$$1 \to I _ { \nu } \to D _ { \nu } \to G _ { \mathcal { K } _ { \nu } } \to 1$$
admits a noncanonical splitting, i.e., D ν is noncanonical direct product of G K ν = D /I ν ν with the corresponding inertia group, which is a torsion-free central procyclic subgroup of D ν . Thus
$$H ^ { * } ( D _ { \nu } ) = H ^ { * } ( G _ { \mathbf K _ { \nu } } ) \otimes \wedge ^ { * } H ^ { 1 } ( I _ { \nu } ).$$
We have and
Thus
$$\mathsf H ^ { i } ( D _ { \nu } ) = \mathsf H ^ { i - 1 } ( G ^ { a } _ { K _ { \nu } } ) \otimes \wedge ^ { * } ( \mathsf H ^ { 1 } ( I _ { \nu } ) ) \oplus \mathsf H ^ { i } ( G ^ { a } _ { K _ { \nu } } )$$
and the differential ∂ ν coincides with the projection onto the first summand. Hence ∂ ν ( α ) = 0 is equivalent to α ν being induced from G a K ν = D /I ν ν . /square
Let K be a function field over k = ¯ . F p By Theorem 5.1, a class α ∈ H ( i G K ) is induced from α a K ∈ G a K , which in turn is induced from a finite quotient G a K → G a . Applying Proposition 3.6 we obtain an alternative characterization unramified classes.
Corollary 6.2. A class α K ∈ H ( i G K ) is unramified if and only if for every ν ∈ V K the restriction of α c K := π ∗ a ( α a K ) ∈ H ( i G c K ) to D c ν is induced from D c ν / I c ν .
Proof. Assuming that for every ν ∈ DV K , the restriction of α a K to D a ν is induced from D a ν / I a ν we need to show this property for every ν . This follows from Proposition 3.6. /square
This allows to extend the notion of unramified to arbitrary valuations.
Combining the considerations above we obtain the notion of unramified stable cohomology
$$H _ { s, n r } ^ { * } ( G )$$
of a finite group G : a stable cohomology class α ∈ H ( i s G ) is unramified if and only if it is contained in the kernel of the composition
$$H _ { s } ^ { i } ( G ) \rightarrow H ^ { i } ( G _ { K } ) \stackrel { \partial _ { \nu } } { \longrightarrow } H ^ { i - 1 } ( G _ { K _ { \nu } } ),$$
/negationslash for every valuation ν ∈ DV K , where K = k V/G ( ) for some faithful representation of G . This does not depend on the choice of V , provided /lscript = char( k ). These groups are contravariant in G and form a subring
$$H _ { s, n r } ^ { * } ( G ) \subset H _ { s } ^ { * } ( G ).$$
## Furthermore:
- · If V/G is stably rational then H i s,nr ( G ) = 0, for all i ≥ 2.
- · We have
$$\mathsf H ^ { i } _ { s, n r } ( G ) \subseteq \mathsf H ^ { i } _ { s, n r } ( \text{Syl} _ { \ell } ( G ) ) ^ { N _ { G } ( \text{Syl} _ { \ell } ( G ) ) }.$$
$$\mathsf H ^ { 1 } ( I _ { \nu }, \mathbb { Z } / \ell ^ { n } ) = \mathsf H ^ { 0 } ( I _ { \nu }, \mathbb { Z } / \ell ^ { n } ) = \mathbb { Z } / \ell ^ { n }$$
$$\wedge ^ { * } ( \mathbf H ^ { 1 } ( I _ { \nu }, \mathbb { Z } / \ell ^ { n } ) ) = \mathbf H ^ { 1 } ( I _ { \nu }, \mathbb { Z } / \ell ^ { n } ) \oplus \mathbf H ^ { 0 } ( I _ { \nu }, \mathbb { Z } / \ell ^ { n } ).$$
Remark 6.3 . In [8], we proved that H i s,nr ( G ) = 0, i ≥ 1, for most quasisimple groups of Lie type. A complete result for quasi-simple groups and i = 2 was obtained in [21].
Note that the /lscript -Sylow-subgroups of finite simple groups often have stably-rational fields of invariants; this provides an alternative approach to our vanishing theorem.
## Lemma 6.4. Let
$$1 \rightarrow Z \rightarrow G ^ { c } \stackrel { \pi } { \longrightarrow } G ^ { a } \rightarrow 1$$
be a central extension of finite /lscript -groups and α a ∈ H ( 2 s G a ) . Then α c := π ∗ a ( α ) ∈ H 2 s,nr ( G c ) if and only if for all σ ∈ Σ := Σ( G c ) the restriction of α a to σ is trivial, i.e., α a ∈ R (Σ) 2 .
## Lemma 6.5. Let
$$\gamma _ { K } \colon \mathcal { G } _ { K } ^ { a } \to G ^ { a }$$
be a continuous surjective homomorphism and α a K = γ ∗ K ( α a ) ∈ H ( i G a K ) , for some α a ∈ H ( i s G a ) . Assume that α a K is unramified and let ( I, D ) be an extendable ∆ -pair in G a . Then α a is unramified with respect to ( I, D ) .
Conversely, if α a is unramified with respect to every extendable ∆ -pair in G a then α a K ∈ H i nr ( G a K ) .
Proof. For the converse, for ν ∈ DV K , let D := γ K ( D a ν ) and I := γ K ( I a ν ). Then either D is cyclic or ( D,I ) is an extendable ∆-pair in G a . We have a commutative diagram
/d47
/d47
/d111
/d111
/d15
/d15
/d15
/d15
/d15
/d15
/d47
$$\begin{array} { c } \mathbf H ^ { i } _ { s } ( G ^ { a } ) \xrightarrow { \phi } \mathbf H ^ { i } _ { s } ( D ) \xleftarrow { \psi } \mathbf H ^ { i } _ { s } ( D / I ) \\ \gamma ^ { * } _ { K } \Big | \Big | \Big \downarrow \Big \downarrow \\ \mathbf H ^ { i } ( \mathcal { G } ^ { a } _ { K } ) \xrightarrow { \Big | \Big | \Big | \Phi ^ { a } _ { \nu } ) \xleftarrow { \Big | \Big | \Phi ^ { a } _ { \nu } / \mathcal { I } ^ { a } _ { \nu } ) \\ a \cdot \cdot \cdot c \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \, \end{array}$$
/d47
/d111
/d111
In either case, α a K is unramified with respect to ν , by Lemma 1.7. /square
## 7. Main theorem
/negationslash
Theorem 7.1. Let K = k X ( ) be a function field over k = ¯ F p of tr deg k ( K ) ≥ 2 and α K ∈ H i nr ( G K ) , with /lscript = p and i > 1 . Then there exist a continuous homomorphism G K → ˜ G a onto a finite /lscript -group, fitting into a diagram
/d15
/d15
/d47
/d47
/d47
/d47
/d47
/d47
/d47
/d47
- (1) α K is induced from ˜ α a ,
- (2) ˜ α c := π ∗ a (˜ ) α a ∈ H ∗ s,nr ( ˜ G c ) .
Conversely, every α K ∈ H ( i G K ) induced from ∧ ∗ (H ( ˜ 1 G a )) and unramified on some ˜ G c as above is in H i nr ( G K ) .
In this section we begin the proof of Theorem 7.1, reducing it to geometric statements addressed in Sections 8 and 9.
Fix an unramified class
$$\alpha _ { K } \in \mathbf H ^ { i } _ { n r } ( G _ { K } ) \subset \mathbf H ^ { i } ( G _ { K } ).$$
By Theorem 5.1, we have a surjection
$$\pi ^ { * } \colon \mathsf H ^ { i } ( \mathcal { G } _ { K } ^ { a } ) \rightarrow \mathsf H ^ { i } ( G _ { K } ),$$
let α a K ∈ H ( i G a K ) be the unramified class such that π ∗ ( α a K ) = α K . Let
$$\gamma _ { K } \colon \mathcal { G } _ { K } ^ { a } \rightarrow G ^ { a }$$
be a continuous quotient onto a finite abelian /lscript -group such that α a K is induced from a class α a ∈ H ( i s G a ) = ∧ i (H ( 1 G a )). We have a diagram of central extensions:
/d47
/d47
/d47
/d47
/d47
/d47
/d47
/d47
/d15
/d15
/d15
/d15
/d15
/d15
/d15
/d15
/d47
/d47
/d47
/d47
/d47
/d47
/d47
/d47
1
where the lower row is uniquely defined, up to isoclinism, as in Lemma 4.2. The group G a might be too small, i.e., it may happen that
$$\pi _ { a } ^ { * } ( \alpha ^ { a } ) \notin \mathbf H _ { s, n r } ^ { i } ( G ^ { c } ).$$
Our goal is to pass to an intermediate finite quotient G a K → ˜ G a fitting into a commutative diagram below
/d47
/d47
/d47
/d47
/d47
/d47
/d47
/d47
/d15
/d15
/d15
/d15
/d47
/d47
/d47
/d47
/d47
/d47
/d47
/d47
/d15
/d15
/d47
/d47
/d47
/d47
/d15
/d15
/d47
/d47
/d47
/d47
where the vertical arrows are surjections onto finite /lscript -groups, and such that α a K is induced from a class ˜ α a ∈ H ( ˜ ∗ G a ) with
$$\tilde { \pi } _ { a } ^ { * } ( \tilde { \alpha } ^ { a } ) \in \mathbf H _ { s, n r } ^ { i } ( \tilde { G } ^ { c } ).$$
There are two possibilities:
- (1) There exists a finite quotient G K → G a such that α K is induced from α a ∈ H ( i s G a ) which is unramified with respect to every extendable ∆-pair ( I, D ) in G a . This case is treated in Lemma 7.2.
- (2) On every finite quotient, the class α a inducing α K is ramified on some extendable ∆-pair ( I, D ). This possibility is eliminated by Lemma 7.3.
Lemma 7.2. Assume that α a ∈ H ( i s G a ) is unramified with respect to every extendable ∆ -pair ( I, D ) in G a . Then there is a factorization
$$\mathcal { G } _ { K } ^ { a } \stackrel { \tilde { \gamma } _ { K } } { \longrightarrow } \tilde { G } ^ { a } \stackrel { \gamma } { \longrightarrow } G ^ { a }, \quad \gamma _ { K } = \gamma \circ \tilde { \gamma } _ { K },$$
with finite ˜ G a , such that
$$\pi _ { a } ^ { * } ( \tilde { \alpha } ^ { a } ) \in \mathbf H ^ { i } _ { s, n r } ( \tilde { G } ^ { c } ), \quad \tilde { \alpha } ^ { a } \coloneqq \gamma ^ { * } ( \alpha ^ { a } ).$$
Proof. Let ˜ G a be the quotient constructed in Proposition 4.6, i.e., if ( I, D ) is not an extendable ∆-pair in G a then no ∆-pair ( ˜ I, D ˜ ) surjects onto ( I, D ). Thus, for each ∆-pair ( ˜ I, D ˜ ) in ˜ G a one of the following holds:
- · either γ I ( ˜ ) = 0 or γ D ( ˜ ) cyclic,
- · or ( γ I ( ˜ ) , γ ( ˜ )) D is an extendable ∆-pair in G a .
By Lemma 1.7, combined with Lemma 6.5, ˜ α a := γ ∗ ( α a ) is unramified with respect to ( I, D ). /square
Lemma 7.3. There exists a finite quotient G K → G a such that α a ∈ H ( i G a ) induces α K and is unramified on every extendable ∆ -pair ( I, D ) in G a .
The proof of this lemma is presented in Section 8, in the case when K admits a smooth projective model; a reduction to the smooth case is postponed until Section 9.
## 8. The smooth case
Let X be a smooth projective irreducible variety over an algebraically closed field k with function field K = k X ( ). By the Bloch-Ogus theorem, there is an isomorphism
$$\mathsf H ^ { i } _ { n r } ( G _ { K } ) = \mathsf H ^ { 0 } _ { Z a r } ( X, \mathcal { H } ^ { i } _ { e t } ( X ) ),$$
where H i et is an ´ etale cohomology sheaf (see also Theorem 4.1.1 in [15]). In particular, a class α K ∈ H i nr ( G K ) can be represented by a finite collection of classes { α n } n ∈ N , with α n defined on some Zariski open affine X n ⊂ X , with X = ∪ n X n , such that the restrictions of α n to some common open affine subvariety X ◦ ⊂ ∩ n X n coincide. We will need the following strengthening:
Lemma 8.1. Let X be a smooth variety with function field K and S = { x , . . . , x 1 r } ⊂ X a finite set of points. Given a class α K ∈ H i nr ( G K ) there exist
- · a Zariski open subset U S ⊂ X , containing S , and
- · a class α S ∈ H ( i et U S )
such that α K and α S coincide on some dense Zariski open subset U ◦ S ⊂ U S , i.e., for every representation of α K by { α n } n ∈ N as above there exists some dense Zariski open U ◦ S ⊂ U S such that the restrictions of α S and all α n to U ◦ S coincide.
Proof. Fix a representation of α K by { α n } n ∈ N as above; in particular α n -α n ′ = 0 on X n ∩ X n ′ , for all n, n ′ ∈ N . Every point in S is contained in some X n ; refining the cover by Zariski open subsets, we can achieve that each point in S is contained in exactly one such subset; i.e., after relabeling, we may assume that x n ⊂ X n , for n = 1 , . . . , r . Put
X ◦ S := ∩ r n =1 X n and X ◦ n := X n \ [(( X \ X n ) ∪ ( X \ X n ′ )) ∩ ( X \ X ◦ S )] If x n ∈ X n then x n ∈ X ◦ n . Moreover,
$$X _ { S } ^ { \circ } = X _ { n } ^ { \circ } \cap X _ { n ^ { \prime } } ^ { \circ }, \text{ \ for all \ } n, n ^ { \prime } \in [ 1, \dots, r ].$$
Define
$$U _ { S } \coloneqq \cup _ { n = 1 } ^ { r } X _ { n } ^ { \circ }.$$
The restrictions of α n to X ◦ n can be glued to a unique class α S ∈ H ( i et U S ), via the Mayer-Vietoris exact sequence. This is the required class. /square
Fix a representation of α K ∈ H i nr ( G K ) by { α n } n ∈ N as above. Each class α n ∈ H ( i et X n ) is represented by a finite collection { X nm } of affine charts X nm , with ∪ X nm = X n and finite ´tale covers e
$$\psi _ { n m } \colon \tilde { X } _ { n m } \rightarrow X _ { n m },$$
.
such that the restrictions α nm := α n X | nm are induced from homomorphisms χ nm : ˆ ( π 1 X nm ) → G nm onto finite groups. Proposition 5.2 implies that there is further refinement of the cover by affine subcovers
$$X = \cup _ { j } X _ { j },$$
such that for each j there exist
- · a finite abelian group G a j
- · a class α j ∈ H ( i G a j ) inducing α via χ K,j .
- · a surjection χ K,j : G K → G a j , and
Corollary 5.3 implies that there exists a finite quotient π c : G K → G c onto a central extension of an abelian group G a such that the projections χ K,j factor through G c and the images of α j in H ( i G c ) coincide. In particular, α K is induced from α c ∈ H ( i G c ).
We claim that α c is unramified on every pair ( π c ( I ν ) , π c ( D ν )), for ν ∈ V K . Indeed, for each ν , χ K,j ( I ν ) = 0 on at least one of the charts X j , thus α j is induced from χ K,j ( D /χ ν ) K,j ( I ν ); since α c ∈ H ( i G c ) is induced from α j , we have the same property for α c , with respect to the pair ( π c ( I ν ) , π c ( D ν )).
The rest of the argument is similar to the proof of Lemma 7.2. Let G K → G a be an intermediate quotient surjecting onto each G a j and
$$G _ { K } \rightarrow \tilde { G } ^ { a } \rightarrow G ^ { a }$$
the intermediate finite quotient constructed in Proposition 4.6. In particular, the projection of every ∆-pair in ˜ G a to G a j is either of the form ( π a,j ( I ν ) , π a,j ( D ν )), for some ν ∈ V K , or cyclic . Let ˜ G c be a central extension as in Corollary 4.3, surjecting onto G c . We have classes ˜ α a j ∈ H ( ˜ j G a ), induced by α a j constructed above, and mapping to the same class ˜ α c ∈ H ( ˜ j G c ).
We claim that ˜ α c ∈ H j s,nr ( ˜ G c ). Indeed, for every ∆-pair ( ˜ I, D ˜ ) in ˜ G a either ˜ projects to a cyclic group in D G a or it is extendable, i.e., image of some ( I ν , D ν ). In the first case, all elements ˜ α j are unramified on ( ˜ I, D ˜ ). In the second case, at least one of the ˜ α j is unramified on it.
## 9. Reduction to the smooth case
In absense of resolution of singularities in positive characteristic, we reduce to the smooth case via the de Jong-Gabber alterations theorem (see [17]): The Galois group G K contains a subgroup G ˜ K of finite index, coprime to /lscript , such that
- · The function field ˜ K corresponding to G ˜ K admits a smooth model, i.e., there exists a finite cover
$$\rho \colon \tilde { X } \rightarrow X,$$
of degree | G /G K ˜ K | with ˜ X smooth and ˜ K = k X ( ˜ ).
Let α K ∈ H n nr ( G K ) be an unramified class. Its restriction α ˜ K to a class in H n ( G ˜ K ) is also unramified. By results in Section 8, there exists a surjection
$$( 9. 1 )$$
$$G _ { \tilde { K } } \rightarrow \tilde { G } ^ { c }$$
onto a finite abelian /lscript -group such that α ˜ K is unduced from a class in ˜ α c ∈ H n s,nr ( ˜ G c ).
## Lemma 9.1. There exists a diagram
/d47
/d47
/d15
/d15
/d15
/d15
/d47
/d47
where the vertical arrows are injections, with image of index coprime to /lscript , ˜ G and G are finite groups, and α K is induced from an element α G ∈ H n nr ( G ) . In particular, Syl ( /lscript G ) /similarequal Syl ( ˜ ) /lscript G .
Proof. Fix a finite continuous quotient G K → G ′ such that α K is induced from some α G ′ ∈ H ( i G ′ ). Note that for every intermediate quotient
$$G _ { K } \rightarrow G \rightarrow G ^ { \prime }$$
there exists an α G ∈ H ( i G ) inducing α K . It suffices to find a sufficiently large G such that the sujection (9.1) factors through a subgroup of G . This is a standard fact in Galois theory.
Since ˜ α c ∈ H i s,nr ( G c ) its image ˜ α ∈ H ( ˜ ) is i G also unramified. Since the index ( G : ˜ ) is coprime to G /lscript , and since the unramified ˜ is induced α from an element α G ∈ H ( i G ), α G is also unramified, as claimed. /square
At this stage, we cannot yet guarantee that G is a central extension of an abelian group, nor that it is an /lscript -group. However, we know that
$$\text{tr} ( \text{res} _ { G _ { K } / G _ { \tilde { K } } } ( \alpha _ { K } ) ) = \alpha _ { K } \in \text{H} _ { n r } ^ { i } ( G _ { K } ),$$
modulo multiplication by an element in ( Z //lscript n ) × .
We need the following version of resolution of singularities in positive characteristic:
/d47
/d47
/d47
/d47
Theorem 9.2. [18] Let G be a finite /lscript -group and Y a smooth variety with a generically free action of G . Then there exists a G -variety ˜ Y with a proper G -equivariant birational map ˜ Y → Y such that ˜ Y /G is smooth.
We are very grateful to D. Abramovich for providing the reference and indicating the main steps of the proof in [18]:
- · Theorem VIII.1.1 gives an equivariant modification Y ′ of Y with a regular log structure on Y ′ such that the action is very tame , i.e., the stabilizers in G of points in Y ′ are abelian and act as subgroups of tori in toroidal charts of the log structure Y ′ .
- · By Theorem VI.3.2, the quotient Y /G ′ of a log regular variety by a very tame action is log regular.
- · By Theorem VIII.3.4.9, which is a step in Theorem VIII.1.1, a log regular variety has a resolution of singularities.
We return to the proof of Theorem 7.1. Start with a suitable faithful representation V of G , and thus of Syl ( /lscript G ) = Syl ( ˜ ), and construct a /lscript G diagram
/d47
/d47
)
/d15
/d15
where Y = ˜ Y / Syl ( /lscript G ) is the smooth projective variety from Theorem 9.2, and π Y is a Syl ( /lscript G )-equivariant map from a G -equivariant projective closure of V . Let L = k Y ( ) be the function field of Y . Given a class α L ∈ H i nr ( G L ) we have a covering of Y = ∪ n Y n by affine Zariski open subsets and a finite set of classes { α n } representing α L , as considered in Section 8.
Pick a point v ∈ ¯ . V The image S := π Y ( G · b ) of its G -orbit is a finite set of points. By Lemma 8.1, there exist a dense Zariski open subset U S and a class α S ∈ H ( i et U S ) coinciding with α L on some dense Zariski open subset U ◦ S ⊂ U S . Its preimage
$$\bar { U } _ { S } ^ { \circ } \coloneqq \pi _ { Y } ^ { - 1 } ( U _ { S } ^ { \circ } ) \subset \bar { V }$$
is a dense Zariski open subset containing G v · . Put
$$\bar { U } _ { v } \coloneqq \cap _ { g \in G } g ( \bar { U } _ { S } ^ { \circ } ) \subset \bar { V },$$
it is a G -stable dense Zariski open subvariety containing v . Its image π G ( ¯ U v ) ⊂ ¯ V /G is a Zariski open subset containing π G ( G v · ). Note that
π v : ¯ U / v Syl ( /lscript G ) → U S is a birational morphism to an open subset and π ∗ v ( α S ) is well-defined in ´tale e cohomology of ¯ U / v Syl ( /lscript G ). It follows that the trace
$$\text{tr} _ { \pi _ { G } } ( \pi _ { v } ^ { * } ( \alpha _ { S } ) ) \in \text{H} _ { e t } ^ { i } ( \bar { U } _ { v } / G )$$
is well-defined and coincides with ( G : Syl ( /lscript G )) · α S at the generic point of ¯ V /G .
Thus we have a covering of ¯ V /G by Zariski open subsets of the form ¯ U /G v , v ∈ ¯ , V with cohomology classes representing α K on each chart. There exists a finite subcovering by ¯ U /G v with extensions of α S to each ¯ U /G v . We can now apply Proposition 5.2 to produce a finite subcover such that on each chart, the class is induced from homomorphisms onto finite abelian groups, and proceed as in Section 8.
## References
- [1] A. Adem and R. J. Milgram. Cohomology of finite groups , volume 309 of Grundlehren der Mathematischen Wissenschaften [Fundamental Principles of Mathematical Sciences] . Springer-Verlag, Berlin, second edition, 2004.
- [2] F. Bogomolov. The Brauer group of quotient spaces of linear representations. Izv. Akad. Nauk SSSR Ser. Mat. , 51(3):485-516, 688, 1987.
- [3] F. Bogomolov. On two conjectures in birational algebraic geometry. In Algebraic geometry and analytic geometry (Tokyo, 1990) , ICM-90 Satell. Conf. Proc., pages 26-52. Springer, Tokyo, 1991.
- [4] F. Bogomolov. Stable cohomology of groups and algebraic varieties. Mat. Sb. , 183(5):3-28, 1992.
- [5] F. Bogomolov. Stable cohomology of finite and profinite groups. In Algebraic groups , pages 19-49. Universit¨tsverlag G¨ttingen, G¨ttingen, 2007. a o o
- [6] F. Bogomolov and Chr. B¨hning. Isoclinism and stable cohomology of wreath o products, 2012. arXiv:1204.4747 .
- [7] F. Bogomolov and Chr. B¨ ohning. Stable cohomology of alternating groups. Cent. Eur. J. Math. , 12(2):212-228, 2014.
- [8] F. Bogomolov, T. Petrov, and Y. Tschinkel. Unramified cohomology of finite groups of Lie type. In Cohomological and geometric approaches to rationality problems , volume 282 of Progr. Math. , pages 55-73. Birkh¨user Boston Inc., a Boston, MA, 2010.
- [9] F. Bogomolov and Y. Tschinkel. Commuting elements of Galois groups of function fields. In Motives, polylogarithms and Hodge theory, Part I (Irvine, CA, 1998) , volume 3 of Int. Press Lect. Ser. , pages 75-120. Int. Press, Somerville, MA, 2002.
- [10] F. Bogomolov and Y. Tschinkel. Reconstruction of function fields. Geom. Funct. Anal. , 18(2):400-462, 2008.
- [11] F. Bogomolov and Y. Tschinkel. Reconstruction of higher-dimensional function fields. Mosc. Math. J. , 11(2):185-204, 406, 2011.
- [12] F. Bogomolov and Y. Tschinkel. Introduction to birational anabelian geometry. In Current developments in algebraic geometry , volume 59 of Math. Sci. Res. Inst. Publ. , pages 17-63. Cambridge Univ. Press, Cambridge, 2012.
- [13] S. K. Chebolu, I. Efrat, and J. Min´ˇ c. Quotients of absolute Galois groups a which determine the entire Galois cohomology. Math. Ann. , 352(1):205-221, 2012.
- [14] S. K. Chebolu and J. Min´ˇ c. Absolute Galois groups viewed from small quoa tients and the Bloch-Kato conjecture. In New topological contexts for Galois theory and algebraic geometry (BIRS 2008) , volume 16 of Geom. Topol. Monogr. , pages 31-47. Geom. Topol. Publ., Coventry, 2009.
- [15] J.-L. Colliot-Th´l`ne. Birational invariants, purity and the Gersten conjecture. e e In K-Theory and Algebraic Geometry : Connections with Quadratic Forms and Division Algebras, AMS Summer Research Institute, Santa Barbara 1992 , volume 58, Part I of Proceedings of Symposia in Pure Mathematics , pages 1-64. 1995.
- [16] J.-L. Colliot-Th´l`ne e e and M. Ojanguren. Vari´t´s e e unirationnelles non rationnelles: au-del` de l'exemple d'Artin et Mumford. a Invent. Math. , 97(1):141158, 1989.
- [17] J.-L. Illusie. On Gabber's refined uniformization, talks at the University of Tokyo, 2008. preprint.
- [18] L. Illusie, Y. Laszlo, and F. Orgogozo. Travaux de Gabber sur l'uniformisation locale et la cohomologie etale des schemas quasi-excellents. Seminaire a l'Ecole polytechnique 2006-2008, 2012. arXiv:1207.3648 .
- [19] H. Knaf and F.-V. Kuhlmann. Abhyankar places admit local uniformization in any characteristic. Ann. Sci. Ecole Norm. Sup. (4) ´ , 38(6):833-846, 2005.
- [20] H. Knaf and F.-V. Kuhlmann. Every place admits local uniformization in a finite extension of the function field. Adv. Math. , 221(2):428-453, 2009.
- [21] B. Kunyavski˘ ı. The Bogomolov multiplier of finite simple groups. In Cohomological and geometric approaches to rationality problems , volume 282 of Progr. Math. , pages 209-217. Birkh¨user Boston Inc., Boston, MA, 2010. a
- [22] J. Milne. ´ tale cohomology E . Princeton Mathematical Series 33. Princeton University Press, 1980.
- [23] Sh. Mochizuki. The local prop anabelian geometry of curves. Invent. Math. , 138(2):319-423, 1999.
- [24] F. Pop. On Grothendieck's conjecture of birational anabelian geometry. Ann. of Math. (2) , 139(1):145-182, 1994.
- [25] F. Pop. On the birational anabelian program initiated by Bogomolov I. Invent. Math. , 187(3):511-533, 2012.
- [26] L. Positselski. Koszul property and Bogomolov's conjecture. Int. Math. Res. Not. , (31):1901-1936, 2005.
- [27] D. J. Saltman. Noether's problem over an algebraically closed field. Invent. Math. , 77(1):71-84, 1984.
- [28] J.-P. Serre. Galois cohomology . Springer Monographs in Mathematics. Springer-Verlag, Berlin, 2002.
Courant Institute of Mathematical Sciences, N.Y.U., 251 Mercer str., New York, NY 10012, U.S.A., Laboratory of Algebraic Geometry, National Research University Higher School of Economics, 7 Vavilova str., Moscow, 117312, Russia
E-mail address : [email protected]
Courant Institute of Mathematical Sciences, N.Y.U., 251 Mercer str., New York, NY 10012, U.S.A.
E-mail address :
[email protected]
Simons Foundation, 160 Fifth Avenue, New York, NY 10010, USA | null | [
"Fedor Bogomolov",
"Yuri Tschinkel"
] | 2014-08-02T16:15:19+00:00 | 2014-08-02T16:15:19+00:00 | [
"math.AG"
] | Universal spaces for unramified Galois cohomology | We construct and study universal spaces for birational invariants of
algebraic varieties over algebraic closures of finite fields. |
1408.0393v1 | ## Standards for Graph Algorithm Primitives
Tim Mattson (Intel Corporation), David Bader (Georgia Institute of Technology), Jon Berry (Sandia National Laboratory), Aydin Buluc (Lawrence Berkeley National Laboratory), Jack Dongarra (University of Tennessee), Christos Faloutsos (Carnegie Melon University), John Feo (Pacific Northwest National Laboratory), John Gilbert (University of California at Santa Barbara), Joseph Gonzalez (University of California at Berkeley), Bruce Hendrickson (Sandia National Laboratory), Jeremy Kepner (Massachusetts Institute of Technology), Charles Leiserson (Massachusetts Institute of Technology), Andrew Lumsdaine (Indiana University), David Padua (University of Illinois at Urbana-Champaign), Stephen Poole (Oak Ridge National Laboratory), Steve Reinhardt (Cray Corporation), Mike Stonebraker (Massachusetts Institute of Technology), Steve Wallach (Convey Corporation), Andrew Yoo (Lawrence Livermore National Laboratory)
Abstract -
It
is
our
view
that
the
state
of
the
art
in constructing
a
large
collection
of
graph
algorithms
in terms
of
linear
algebraic
operations
is
mature
enough
to support
the
emergence
of
a
standard
set
of
primitive building
blocks.
This
paper
is
a
position
paper
defining the
problem
and
announcing
our
intention
to
launch
an open
effort
to
define
this
standard.
critical that we move quickly so as new research groups enter this field we can prevent needless and ultimately damaging diversity at the level of the basic primitives supporting this research; thereby freeing up researchers to innovate and diversify at the level of higher level algorithms and graph analytics applications.
## II. THE STATE-OF-THE-ART
The standardization of sparse linear algebra historically begins with the NIST Sparse Basic Linear Algebra Subprograms (BLAS) [3] and consists of Sparse Vector (Level 1), Matrix Vector (Level 2), and Matrix Matrix (Level 3) operations. These BLAS were designed for solving the kinds of sparse linear algebra operations that arise in finite element simulation techniques that are widely used in engineering. In particular, the operations are limited to traditional multiplication and addition operations and, in the case of matrix-matrix multiply, usually one of the arguments is dense.
We can extend the BLAS to address the needs of graph algorithms by generalizing the pair of operations involved in the computations to define a semiring. For example, in semiring notation we could write the most common operations found in the exiting Sparse BLAS as
$$C = \mathbf A + * \mathbf B$$
where +.* denotes standard matrix multiply. In the case of the NIST Sparse BLAS, A is a sparse matrix, and B and C are usually tall skinny dense matrices. In graph algorithms, a fundamental operation is matrix-matrix multiply where both matrices are sparse. This operation represents multi source 1hop breadth first search (BFS) and combine, which is the foundation of many graph algorithms. In addition, it is often the case that operations other than standard matrix multiply are desired, for example:
C = A max.+ B
C = A min.max B
C = A |.& B
C = A f().g() B
Keywords-component; Graphs; Algorithms; Linear Algebra; Software Standards
## I. PROBLEM STATEMENT
Data analytics and the closely related field of Òbig dataÓ have emerged as a leading research topics in both applied and theoretical computer science. While it has been shown that many problems can be addressed with a Òmap-reduceÓ style framework, as we move to the next level of sophistication in data analytics applications, graph algorithms that demand more than Òmap-reduceÓ will play an increasingly vital role. There are many ways to organize a collection of graph algorithms into a high level library to support data analytics. It is probably premature to standardize these graph APIs. The low level building blocks of graph algorithms, however, are well understood and we believe a suitable target for standardization. In particular, the representation of graphs as sparse matrices allows many graph algorithms to be represented in terms of a modest set of linear algebra operations [1,2,5].
Our concern, however, is that as new researchers enter this expanding field of research, the linear algebraic foundation of this class of graph algorithms will fragment. Diversity at the level of the primitive building blocks of graph algorithms will not help advance the field of graph algorithms. It will hinder progress as groups create different overlapping variants of what should be common low level building blocks. Furthermore, diverse sets of primitives will complicate the ability of the vendor community to support this research with math tuned to the needs of these algorithms.
It is our view that the state of the art in constructing a large collection of graph algorithms in terms of linear algebraic operations is mature enough to support the emergence of a standard set of primitive building blocks. We believe it is
With this more general case of sparse matrix multiply, a wide range of graphs algorithms can be implemented [1]. An implementation of this approach is found in the combinatorial BLAS [2]. The combinatorial BLAS provides implementations of nine functions: matrix-matrix multiply (multi source BFS combine), matrix-vector multiply (single source BFS combine), element wise matrix-matrix multiply (edge weighting), reduce (in/out degree), sub reference (sub-graph selection), sub assign (sub-graph insertion), scale matrix (edge weighting), scale vector (vertex weighting), and apply unary operator (edge transformation). These functions are a reasonable basis for graph algorithms primitives, and the combinatorial BLAS demonstrate that they can be effectively implemented in a parallel.
The data types and storage formats are also an important consideration. The values should be able to handle all the standard types: float, double, complex, boolean, signed/unsigned integers of various lengths, and pointers to external user defined data structures. There should be a concept of a symmetric matrix to handle undirected graphs. Internal formats should include at least Compressed Sparse Rows (CSR) and Compressed Sparse Columns (CSC). Other formats such as tuples and more complex formats [4] should also be considered.
## III. RECOMMENDATIONS
We believe the research community working on graph algorithms expressed as linear algebra should come together now and define a common API they can use in their research. The combinatorial BLAS are an excellent starting point for this work. We propose the formation of an ongoing combinatorial BLAS forum to finalize the specification and take ownership of its ongoing evolution.
## REFERENCES
- [1] Graph Algorithms in the Language of Linear Algebra, Edited by J. Kepner and J. Gilbert, SIAM, 2011
- [2] A. Buluc and J. Gilbert ,The Combinatorial BLAS: Design, Implementation and Applications, http://www.cs.ucsb.edu/research/tech\_reports/reports/2010-18.pdf
- [3]
- http://math.nist.gov/spblas/
- [4] D. Ediger, K. Jiang, J. Riedy, and D.A. Bader, ``Massive Streaming Data Analytics: A Case Study with Clustering Coefficients,'' 4th Workshop on Multithreaded Architectures and Applications (MTAAP), Atlanta, GA, April 23, 2010
- [5] U Kang, C. Tsourakakis, and C. Faloutsos, ``PEGASUS: A Peta-Scale Graph Mining System - Implementation and Observations,ÕÕ IEEE International Conference on Data Mining (ICDM) 2009, Miami, Florida, USA. | 10.1109/HPEC.2013.6670338 | [
"Tim Mattson",
"David Bader",
"Jon Berry",
"Aydin Buluc",
"Jack Dongarra",
"Christos Faloutsos",
"John Feo",
"John Gilbert",
"Joseph Gonzalez",
"Bruce Hendrickson",
"Jeremy Kepner",
"Charles Leiserson",
"Andrew Lumsdaine",
"David Padua",
"Stephen Poole",
"Steve Reinhardt",
"Mike Stonebraker",
"Steve Wallach",
"Andrew Yoo"
] | 2014-08-02T16:17:40+00:00 | 2014-08-02T16:17:40+00:00 | [
"cs.MS",
"cs.DM",
"cs.DS"
] | Standards for Graph Algorithm Primitives | It is our view that the state of the art in constructing a large collection
of graph algorithms in terms of linear algebraic operations is mature enough to
support the emergence of a standard set of primitive building blocks. This
paper is a position paper defining the problem and announcing our intention to
launch an open effort to define this standard. |
1408.0394v1 | ## Destroyed quantum Hall effect in graphene with [0001] tilt grain boundaries
Anders Bergvall, 1 Johan M. Carlsson, 2 and Tomas L¨ ofwander 1
1 Department of Microtechnology and Nanoscience - MC2,
Chalmers University of Technology, SE-412 96 G¨ oteborg, Sweden
2 Accelrys Ltd, Cambridge Science Park 334, Cambridge CB4 OWN, United Kingdom
(Dated: August 5, 2014)
The reason why the half-integer quantum Hall effect (QHE) is suppressed in graphene grown by chemical vapor deposition (CVD) is unclear. We propose that it might be connected to extended defects in the material and present results for the quantum Hall effect in graphene with [0001] tilt grain boundaries connecting opposite sides of Hall bar devices. Such grain boundaries contain 5-7 ring complexes that host defect states that hybridize to form bands with varying degree of metallicity depending on grain boundary defect density. In a magnetic field, edge states on opposite sides of the Hall bar can be connected by the defect states along the grain boundary. This destroys Hall resistance quantization and leads to non-zero longitudinal resistance. Anderson disorder can partly recover quantization, where current instead flows along returning paths along the grain boundary depending on defect density in the grain boundary and on disorder strength. Since grain sizes in graphene made by chemical vapor deposition are usually small, this may help explain why the quantum Hall effect is usually poorly developed in devices made of this material.
PACS numbers: 73.50.Jt 72.80.Vp 85.75.Nn
The half-integer quantum Hall effect (QHE) [1, 2] in monolayer graphene grown on silicon-carbide substrates has been observed to metrological accuracy [3-5]. Very high breakdown currents have been recorded, and quantization remains accurate also at elevated temperatures. This material may therefore be the next choice for an improved resistance standard. On the other hand, QHE plateaux have not been measured to the same level of accuracy on Hall bars made of graphene grown by chemical vapor deposition (CVD) [6, 7]. The reason for this disparity is unclear, but it may be due to extrinsic effects, such as defects and inhomogeneity introduced in the process of graphene transfer from substrates used in the growth to other substrates used for devices, or due to defects in the material itself, such as grain boundaries that usually are found in graphene made by CVD [8].
In a recent experiment [7], it was indeed argued that grain boundaries may be the source of reduced quantization in devices made of CVD graphene. A clear theoretical picture of how the QHE is destroyed in graphene with grain boundaries is however still lacking. One particular and very special type of grain boundary has been considered theoretically in the literature before [7, 9]. The grain boundary consists of a perfect row of 5-8-5 ring complexes that separates two perfect armchair ribbons oriented along the same axis. To join the armchair ribbons to the grain boundary, the ribbons are cut at 90 ◦ to their armchair edges so that perfect zigzag edges are formed. These zigzag edges can be attached to the grain boundary. In a magnetic field, a picture appears of current flowing along an armchair edge in the ribbon and along a zigzag edge along the grain boundary over to the opposite edge of the ribbon where the current can flow back in the opposite direction. This special type of grain boundary is not the only or typical grain boundary in graphene [8, 10-13] and a more extensive investigation of other grain boundaries is called for.
Here, we report an investigation of the influence of [0001] tilt grain boundaries on the QHE in graphene. We show by numerical simulation that electronic states at dislocation cores (5-7 ring complexes), which form several 1D metallic bands along the grain boundary, can in a strong externally applied magnetic field connect two edge states on opposite sides of the Hall bar and thereby destroy quantization. The resulting conductance fluctuations depend on the number of dislocation cores in the grain boundary, which is related to the grain boundary tilt angle and its physical length. This is similar to the situation for graphene grown on silicon-carbide substrates, where it has been shown by numerical simulation [14] and experiment [15] that bilayer stripe defects connecting Hall bar edges destroy the QHE in that material.
FIG. 1. The first three in a series of grain boundaries with decreasing misiorientation angle θ . The grain boundaries contain 5-7 ring defects on a line with an increasing number of hexagons (hatched) between neighboring defects.
Only in samples without such large bilayer defects one may expect the precise quantization reported in [5].
The grain boundary models were constructed by the coincidence site lattice (CSL) theory according to the method presented in Ref. [16]. We focus on a series of grain boundaries for which the Burger's vector is one lattice vector long ( n d = 1 series in Ref.( [16]), meaning that we limit ourselves to a class of [0001] tilt grain boundaries with one 5-7 ring complex per grain boundary unit cell, but an increasing number of hexagons per unit cell for decreasing grain boundary angles. This means that the distance between 5-7 ring defects increases by one hexagon as we move along the n d =1 series towards smaller tilt angles, see Fig. 1. We consider the first six grain boundaries in the series, which we enumerate by m = 1 2 , , ..., 6, for which the grain boundary angles are θ = 21 8 , 13 2 . ◦ . ◦ , 9 4 . ◦ , 7 3 . ◦ , 6 0 . ◦ , and 5 1 . ◦ . The geometry was optimized by a force field calculation using the Dreiding Force Field as implemented in the Forcite module in Materials Studio [17]. We aim to model graphene grown on a substrate, so the graphene sheet was kept flat even at the grain boundaries by fixing the atomic relaxation perpendicular to the sheet during the relaxation. Using the atomic positions of the relaxed grain boundary, we create a two-terminal zigzag nanoribbon of varying width and study electron transport in a magnetic field.
In the transport simulations, the system is modeled by a tight-binding Hamiltonian
$$H = \sum _ { i } \epsilon _ { i } c _ { i } ^ { \dagger } c _ { i } + \sum _ { i j } t _ { i j } c _ { i } ^ { \dagger } c _ { j }. \quad \quad ( 1 ) \quad \text{$\text{$fere}$} \\ \text{$\text{$int}$}$$
The onsite energies are either put to zero, as in defect-free graphene, or we include Andersson disorder by putting glyph[epsilon1] i to random numbers uniformly distributed between [ -W/ ,W/ 2 2], where W is the disorder strength. The atomic positions determine the hopping elements t ij through an approximative formula for π -orbital overlap at different carbon sites j and i separated by R j -R i = r = ( x, y ) T ,
$$t _ { i j } = t ( \mathbf r ) = - \gamma _ { 0 } \frac { x ^ { 2 } + y ^ { 2 } } { r ^ { 2 } } e ^ { - \lambda ( | \mathbf r | - a _ { c c } ) }, \quad \ \ ( 2 ) \quad \text{ all s} \\ \text{mea}$$
where γ 0 is the nearest neighbor hopping parameter, a cc is the carbon-carbon distance, and the exponent is λ ≈ 3 /a cc . The formula in Eq. (2) is applied for atomic distances r = | r | reaching a cut-off R c , beyond which t ij = 0. For the present problem, a good description is obtained for small R c glyph[greaterorsimilar] a cc -2 a cc . Going beyond the nearest neighbor approximation means that the Dirac point in the bandstructure obtained from the model in Eq. (1) is shifted from zero to a higher energy E Dirac ≈ 0 3 . γ 0 . The applied magnetic field enters the hopping parameters through a standard Peierls substitution, t ij → exp [ ie ∫ R i R j A dl · / glyph[planckover2pi1] ] t ij . The magnetic field enters naturally as an applied magnetic flux
FIG. 2. (a) A nanoribbon with a m = 1 grain boundary. Current flows along the upper edge (color scale denotes the absolute value of the current in units of G V 0 , where V is the applied voltage between source and drain) at energy E = 0 45 . γ 0 for which the conductance is quantized, G = G 0 . (b) Conductance at zero temperature for nanoribbons with one grain boundary including 10 defects as function of energy. The different curves (shifted by 3 G 0 for clarity) correspond to different grain boundary angles and therefore also different ribbon widths since the defect density varies with grain boundary angle. The dashed orange line is the quantized conductance of an ideal ribbon without grain boundary shifted by 3 G 0 . The magnetic field corresponds to a flux Φ = 0 01Φ . 0 per hexagon in all cases. In (a) the Anderson disorder strength is W = 0 25 . γ 0 , while it is W = 0 in (b).
per hexagon (hexagon area of perfect graphene) in units of the flux quantum Φ 0 = h/e . The magnetic field defines the magnetic length through glyph[lscript] B = √ glyph[planckover2pi1] / ( | e B | ), which in all simulations is smaller than the ribbon width, which means that the spectrum is dominated by Landau levels E n -E Dirac = √ 2 n v /glyph[lscript] glyph[planckover2pi1] f B = √ nω c , where n ≥ 0 is an integer, and v f if the electron velocity of graphene in the absence of magnetic field. In the ribbon geometry, Landau level bands acquire dispersive parts corresponding to the well known edge states which carry the current in the quantum Hall regime (see for instance Fig. 2 in Ref. [14] for an illustration).
In a magnetic field the two-terminal conductance equals the transverse conductivity σ xy in a Hall bar geometry when the contacts are perfect (as is the case in these simulations). The two-terminal conductance at zero temperature G = G T E 0 ( ) is given in terms of the conductance quantum G 0 = 2 e /h 2 and the lin-
ear response transmission function T E ( ). The latter is computed through the retarded propagator of the system G R ij ( E ) and self-energies of the lead surfaces Σ R glyph[lscript] ( E ), which remain after the leads have been eliminated in favor of the system in a standard way, see for instance Ref. [18]. The leads are enumerated by the index glyph[lscript] ( glyph[lscript] = 1 and 2 for source and drain). The formula for the transmission is then
$$T ( E ) = \text{Tr} \left [ \Gamma _ { 1 } ( E ) G _ { 1 2 } ^ { R } ( E ) \Gamma _ { 2 } ( E ) G _ { 2 1 } ^ { A } ( E ) \right ] \quad ( 3 ) \quad \ _ { 2 }$$
where Γ glyph[lscript] = [Σ i R glyph[lscript] -(Σ R glyph[lscript] ) † ], and G R 12 symbolises the propagator between leads 1 and 2. The advanced propagator G A 21 ( E ) is the hermitian conjugate of the retarded propagator and the trace is over the surface sites.
For local current flow patterns we need the lesser Green's function G < . In the absence of electron correlations, the lesser Green's function is reduced to the form
$$G _ { i j } ^ { < } ( E ) = \sum _ { \ell } f _ { \ell } ( E ) \sum _ { c \tilde { c } } G _ { i c } ^ { R } ( E ) \left [ \Gamma _ { \ell } ( E ) \right ] _ { c \tilde { c } } G _ { \tilde { c } j } ^ { A } ( E ), \ \ ( 4 ) \quad \stackrel { \sim } { \succ } _ { 5 } \right |$$
which involves the distribution functions of the leads f glyph[lscript] ( E ). Surface sites of the leads are labeled by c and ˜. c Local charge current flow in the device (bond current between sites i and j ) is then written as
$$I _ { i j } = e \int _ { - \infty } ^ { \infty } \left [ t _ { i j } G _ { j i } ^ { < } ( E ) - t _ { j i } G _ { i j } ^ { < } ( E ) \right ] d E = \int _ { \infty } ^ { \infty } I _ { i j } ( E ) d E. \quad & \quad \quad 5 \\ \tau _ { 1 } \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \ dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots.$$
The retarded Green's function G R ij ( E ) of the system is computed numerically through our own implementation of a recently developed recursive algorithm [19] within which sites are added one by one. Below we present the spectral current flow pattern I ij ( E ) assuming zero temperature and current injection from one contact.
In Fig. 2(a) we display a narrow nanoribbon with an m = 1 grain boundary with ten 5-7 ring defect complexes. In a strong magnetic field, the current enters for instance from the top left corner and flows along the edge. Without scattering against defects, as in Fig. 2(a), the current reaches the right contact and is absorbed. Depending on the electron density, i.e. the location of the Fermi energy, we have different number of Landau levels occupied and the corresponding number of edge states. Each edge state carries a unit of conductance including spin degeneracy, G 0 , since we neglect the Zeeman effect. The n = 0 level is special in that valley degeneracy in the bulk is broken in the finite size ribbon for the dispersive (edge state) parts of the spectrum. Higher Landau levels have valley degenerate edge states. The conductance sequence at zero temperature is therefore G = (2 n + 1) G 0 for energies above the Dirac point (electron doping), and the same sequence for increasing hole doping. This sequence of plateaux is illustrated in Fig. 2(b) by the orange dashed line for electron doping (energies E > E Dirac ≈ 0 3 . γ 0 ).
FIG. 3. (a) Evolution of the conductance in Fig. 2(b) for the m = 6 grain boundary with increasing Anderson disorder strength W (other model parameters are held fixed). (b)-(d) Examples of local current flow patterns near the grain boundary for (b) W = 0, (c) W = 0 25 . γ 0 , and (d) W = 0 5 . γ 0 . The energies where these current flow patterns appear are marked in (a) by vertical arrows. Disorder are distributed randomly across the whole displayed systems, with ideal source and drain contacts attached to the left and right ribbons.
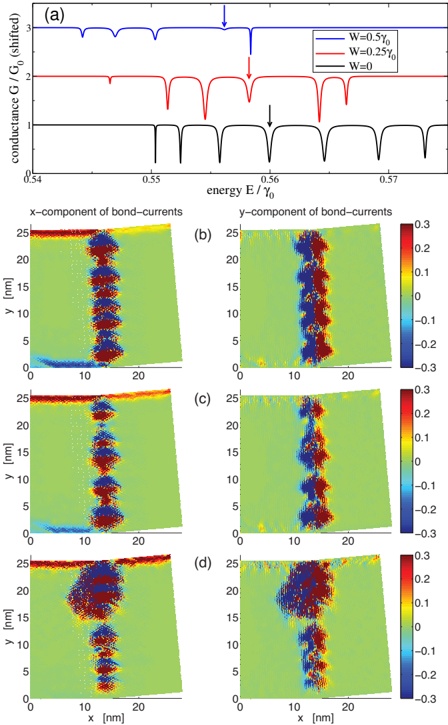
Let us now discuss the influence of the grain boundaries. It is well known that at each 5-7 defect, there are defect states. They may hybridize along the grain boundary, which then becomes metallic, as has been discussed in several papers [20-23]. In a magnetic field, with the grain boundary connecting the upper and lower edges, the question arises what will happen with the edge state current flow. In Fig. 2(b) we present the conductance as function of energy, corresponding to the Fermi energy at zero temperature (which can be controlled by a back gate in a real device). For large grain boundary misorientation angles, m = 1 and 2 in Fig. 2(b), the metallicity of the grain boundary is apparent as the plateaux are not quantised. Edge states at opposite edges (which
carry current in opposite directions) are connected by the metallic grain boundary which causes partial reflection of current and destruction of the plateaux. For lower grain boundary angles, the 5-7 defects are further apart and hybridization is less effective. In a magnetic field, a more pronounced reflection resonance pattern then develops, see for instance the m = 6 grain boundary conductance curve in Fig. 2(b) (brown line). This resonance behavior is particularly clear for the n = 0 plateau, where a comb of resonances are well defined near E ≈ 0 56 . γ 0 . The number of resonances (size of the comb) depends on the number of defects along the grain boundary. In Fig. 2(b) the ribbon width is varying so that the grain boundaries always hold ten 5-7 defects. The comb is present for all grain boundary angles, but the enhanced hybridization and enhanced metallicity for grain boundaries with more dense defect densities is clear in Fig. 2(b) when comparing the combs' shapes for grain boundaries with decreasing m . For higher energies, many more resonances appear and quantization for higher Landau levels is completely destroyed.
We can gain additional insight into the nature of the conductance fluctuations by looking at the local current flow patterns. In Fig. 3(a) we display a zoom of the resonance comb on the n = 0 plateau for the m = 6 grain boundary (black curve for W = 0). For the energy indicated by the vertical black arrow, we present the local current flow pattern in Fig. 3(b). The current flows in a circular fashion around each 5-7 ring defect and at the same time displays an envelope pattern across the entire grain boundary from the upper to the lower ribbon edges. The envelope contains a varying number of nodes for the different resonances in the comb. Each resonance, therefore, corresponds to a particular hybridization of the defect states along the grain boundary.
In Fig. 3(a), we study the evolution of the resonance comb with increasing Anderson disorder strength W . For W = 0 25 . γ 0 ( ∼ 0 68 eV for . γ 0 ≈ 2 7 eV), the resonances . are shifted and some are weakened. For W = 0 5 . γ 0 this effect is more pronounced, and at higher W resonances disappear. The current flow patterns for the conductance dips marked by the red arrow ( W = 0 25 . γ 0 ) and the blue arrow ( W = 0 5 . γ 0 ) are shown in Fig. 3(c) and (d), respectively. For increasing disorder strength, the current flows chaotically down the grain boundary but eventually [for strong W , Fig. 3(d)] a situation resembling localization along the grain boundary appears and quantization is improved. This picture of localization agrees with the recent results in Ref. [7] for the special 5-8-5 line defect mentioned in the introduction.
In Fig. 4, we study the effect of Andersson disorder for a 50 nn wide ribbon with a m = 1 grain boundary. This grain boundary has the most dense defect density and display for W = 0 non-quantized conductance reflecting the metallicity of the grain boundary (black wavy curve in the figure). Introducing weak Andersson dis-
FIG. 4. Conductance on the lowest plateau at zero temperature for a 50 nm wide nanoribbon with a m = 1 grain boundary for varying Anderson impurity disorder strength. The different curves are shifted by G 0 for clarity and the magnetic field corresponds to a flux Φ = 0 01Φ . 0 per hexagon.
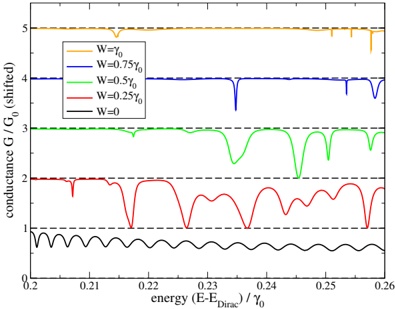
order W = 0 25 . γ 0 , leads to development of more sharp resonances (dips with zero conductance; red curve in the figure). For larger W , also these resonances disappear. The sensitivity of resonances to disorder depends on the grain boundary angle. Smaller grain boundary angles correspond to less defect density, sharper resonances, and higher sensitivity to disorder. For system sizes that we have considered, higher plateaux are however always destroyed, while the first plateau is more robust.
In conclusion, we have studied the influence of [0001] tilt grain boundaries on the quantum Hall effect in granular graphene. We find that electronic states formed at dislocation cores (5-7 complexes) in the grain boundary form metallic bands that in a magnetic field can short circuit counter propagating edge states on opposite sides of the Hall bar. The QHE is thereby destroyed. Depending on the defect density along the grain boundary, weak Andersson disorder can lead to recovery of at least the n = 0 plateau. This indicates that the fact that the QHE so far has not been observed to metrological accuracy in CVD graphene could be due to the granularity of this material.
We acknowledge financial support from the EU through FP7 STREP ConceptGraphene, the Swedish Foundation for Strategic Research, and the Knut and Alice Wallenberg foundation.
- [1] K. S. Novoselov et al. , Nature 438 , 197 (2005).
- [2] Y. Zhang et al. , Nature 438 , 201 (2005).
- [3] A. Tzalenchuk et al. , Nature Nanotech. 5 , 186 (2010).
- [4] W. Poirier et al. , Comptes Rendus Physique 12 , 347 (2011)
- [5] T. J. B. M. Janssen et al. , Metrologia 49 , 294 (2012).
- [6] Y. Nam et al. , Appl. Phys. Lett. 103 , 233110 (2013).
- [7] F. Lafont et al. , arXiv:1404.2536 [cond-mat.mes-hall]
- [8] See e.g. the review in F. Banhart, J. Kotakoski, and A.V. Krasheninnikov, ACS Nano 5 , 26 (2011).
- [9] H.-B. Yao, X.-L. L¨, and Y.-S. Zheng, Phys. Rev. B u 88 , 235419 (2013).
- [10] P. Y. Huang, et al. , Nature 469 , 389 (2011).
- [11] K. Kim et al. , ACS Nano 5 , 2142 (2011)
- [12] J. An et al. , ACS Nano 5 , 2433 (2011)
- [13] P. Nemes-Incze et al. Carbon 64 , 178 (2013).
- [14] T. L¨fwander, P. San Jos´, and E. Prada, Phys. Rev. B o e 87 , 205429 (2013).
- [15] T. Yager, A. Lartsev et al. , Nano Lett. 13 , 4217 (2013).
- [16] J. M. Carlsson, L. M. Ghiringhelli, and A. Fasolino, Phys. Rev. B 84 , 165423 (2011).
- [17] Materials Studio release 7.0 , Accelrys Software Inc., San Diego, USA (2013).
- [18] S. Datta, Electronic Transport in Mesoscopic Systems (Cambridge University Press, Cambridge, UK, 1997).
- [19] K. Kazymyrenko and X. Waintal, Phys. Rev. B 77 , 115119 (2008).
- [20] J. Lahiri et al. , Nature Nanotech. 5 , 326 (2010).
- [21] O. V. Yazyev, Solid State Comm. 152 , 1431 (2012).
- [22] S. Ihnatsenka and I. V. Zozoulenko, Phys. Rev B 88 , 085436 (2013).
- [23] F. Gargiulo and O. V. Yazyev, Nano Lett. 14 , 250 (2014) | 10.1103/PhysRevB.91.245425 | [
"Anders Bergvall",
"Johan M. Carlsson",
"Tomas Lofwander"
] | 2014-08-02T16:38:22+00:00 | 2014-08-02T16:38:22+00:00 | [
"cond-mat.mes-hall"
] | Destroyed quantum Hall effect in graphene with [0001] tilt grain boundaries | The reason why the half-integer quantum Hall effect (QHE) is suppressed in
graphene grown by chemical vapor deposition (CVD) is unclear. We propose that
it might be connected to extended defects in the material and present results
for the quantum Hall effect in graphene with [0001] tilt grain boundaries
connecting opposite sides of Hall bar devices. Such grain boundaries contain
5-7 ring complexes that host defect states that hybridize to form bands with
varying degree of metallicity depending on grain boundary defect density. In a
magnetic field, edge states on opposite sides of the Hall bar can be connected
by the defect states along the grain boundary. This destroys Hall resistance
quantization and leads to non-zero longitudinal resistance. Anderson disorder
can partly recover quantization, where current instead flows along returning
paths along the grain boundary depending on defect density in the grain
boundary and on disorder strength. Since grain sizes in graphene made by
chemical vapor deposition are usually small, this may help explain why the
quantum Hall effect is usually poorly developed in devices made of this
material. |
1408.0395v2 | ## HSkip+: A Self-Stabilizing Overlay Network for Nodes with Heterogeneous Bandwidths
Matthias Feldotto Heinz Nixdorf Institute & Department of Computer Science University of Paderborn, Germany Email: [email protected]
Christian Scheideler Theory of Distributed Systems Group Department of Computer Science University of Paderborn, Germany Email: [email protected]
## Kalman Graffi
Technology of Social Networks Group Department of Computer Science University of D¨sseldorf, Germany u Email: [email protected] ∗
## Abstract
In this paper we present and analyze HSkip+, a self-stabilizing overlay network for nodes with arbitrary heterogeneous bandwidths. HSkip+ has the same topology as the Skip+ graph proposed by Jacob et al. [10] but its self-stabilization mechanism significantly outperforms the self-stabilization mechanism proposed for Skip+. Also, the nodes are now ordered according to their bandwidths and not according to their identifiers. Various other solutions have already been proposed for overlay networks with heterogeneous bandwidths, but they are not self-stabilizing. In addition to HSkip+ being self-stabilizing, its performance is on par with the best previous bounds on the time and work for joining or leaving a network of peers of logarithmic diameter and degree and arbitrary bandwidths. Also, the dilation and congestion for routing messages is on par with the best previous bounds for such networks, so that HSkip+ combines the advantages of both worlds. Our theoretical investigations are backed by simulations demonstrating that HSkip+ is indeed performing much better than Skip+ and working correctly under high churn rates.
∗ This work was partially supported by the German Research Foundation (DFG) within the Collaborative Research Centre 'On-The-Fly Computing' (SFB 901).
This is a long version of a paper published by IEEE in the Proceedings of the 14-th IEEE International Conference on Peer-to-Peer Computing, available at http://dx.doi.org/10.1109/P2P.2014.6934300.
c 2014 © IEEE. Personal use of this material is permitted. Permission from IEEE must be obtained for all other uses, in any current or future media, including reprinting/republishing this material for advertising or promotional purposes, creating new collective works, for resale or redistribution to servers or lists, or reuse of any copyrighted component of this work in other works.
## 1 Introduction
Peer-to-peer systems have become very popular for a variety of reasons. For example, the fact that peer-topeer systems do not need a central server means that individuals can search for information or cooperate without fees or an investment in additional high-performance hardware. Also, peer-to-peer systems permit the sharing of resources (such as computation and storage) that otherwise sit idle on individual computers. However, the absence of any trusted anchor like a central server also has its disadvantages since churn and adversarial behavior has to be managed by the peers without outside help. One promising approach that has been investigated in recent years is to use topological self-stabilization, i.e., the overlay network of the peerto-peer system can recover its topology from any state, as long as it is initially weakly connected. Various topologies have already been considered, but so far mostly the case has been studied that the peers have the same resources (concerning speed, storage, and bandwidth) whereas in reality the available resources may differ significantly from peer to peer. An exception is a self-stabilizing system for peers with non-uniform storage [13], but no self-stabilizing peer-to-peer system for peers with non-uniform bandwidth has been proposed yet. Due to the current development, especially with mobile devices, this property becomes more important and is often the bottleneck in the system. This paper is the first to propose a system which considers the bandwidth in its design.
## 1.1 Our model
## 1.1.1 Network model
Similar to Nor et al. [16], we assume that we have a (potentially dynamic) set V of n nodes with unique identifiers. Each node v maintains a set of variables (determined by the protocol) that define the state of node v . For each pair of nodes u and v we have a channel C u,v that holds messages that are currently in transit from u to v . We assume that the channel capacity is unbounded, there is no message loss, and the messages are delivered asynchronously to v in FIFO order. The sequence of all messages stored in C u,v constitutes the state of C u,v .
Whenever a node u stores a reference of node v , we consider that as an explicit edge ( u, v ), and whenever a channel C u,v holds a message with a reference of node w , we consider that as an implicit edge ( v, w ). Node references are assumed to be atomic and read-only, i.e., they cannot be split, encoded, or altered. They can only be deleted or copied to produce new references that can be sent to other nodes. If there is a reference of a node that is not in the system any more, we assume that this can be detected by the nodes, so that without loss of generality we can assume that only references of nodes that are still in the system are present in the nodes and the channels. Whenever a message in C u,v contains a node reference w , it also contains w 's bandwidth and identifier so that this information can be corrected in v if needed (though it might initially be wrong). Only point-to-point communication is possible, and the nodes can only send messages along explicit edges (since they are not yet aware of the endpoint of an implicit edge). Whenever node u sends a message along an explicit edge ( u, v ), it is transferred to C u,v . Let E e denote the set of all explicit edges and E i denote the set of all implicit edges. The overlay network formed by the system is defined as a directed graph G = ( V, E ) with E = E e ∪ E i . With G e = ( V, E e ) respectively G i = ( V, E i ) we define the network which only consists of the explicit respectively implicit edges. The degree of a node v in G is equal to its degree in G e (i.e., the number of explicit edges of the form ( v, w )), and the diameter of G is equal to the diameter of G e . We define the specific state of the network at a time t with G t ,E ( ) ( ) t , E e ( ) and t E i ( ). t
## 1.1.2 Computational model
A program is composed of a set of variables and actions. An action has the form 〈 label 〉 : 〈 guard 〉 → 〈 command 〉 . label is a name to differentiate between actions, guard can be an arbitrary predicate based on the state of the node executing the action, and command represents a sequence of commands. A guard of the form received m ( ) is true whenever a message m has been received (and not yet processed) by the corresponding node. An action is enabled if its guard is true and otherwise disabled .
The node state of the system is the combination of all node states, and the channel state of the system is the combination of all channel states. Both states together form the (program) state of the system. A computation is an infinite fair sequence of states such that for each state s t , the next state s t +1 is obtained by executing the commands of an action that is enabled in s t . So for simplicity we assume that only one action can be executed at a time, but our results would also hold for the distributed scheduler, i.e., only one action can be executed per node at a time. We assume two kinds of fairness of computation: weak fairness for action execution and fair message receipt. Weak fairness of action execution means that no action will be enabled without being executed for an infinite number of states (i.e., no action will starve, and actions that are enabled for an infinite number of states will be executed infinitely often). Fair message receipt means that every message will eventually be received (and therefore processed due to weak fairness).
## 1.1.3 Topological self-stabilization
Next we define topological self-stabilization, which goes back to the idea by Dijkstra [6] and is summarized by Schneider [19]. In the topological self-stabilization problem we start with an arbitrary state (with a finite number of nodes, channels, and messages) in which G is weakly connected, and a legal state is any state where the topology of G e has the desired form and the information that the nodes have about their neighbors is correct. We assume without loss of generality that G is initially weakly connected, because if not, then we would just focus on any of the weakly connected components of G and would prove topological self-stabilization for that component. In order to show topological self-stabilization, two properties need to be shown:
Definition 1 (Convergence) . For any initial state in which G is weakly connected, the system eventually reaches a legal state.
Definition 2 (Closure) . Whenever the system is in a legal state, then it is guaranteed to stay in a legal state, provided that no faults or changes in the node properties (in our case, the bandwidth) happen.
## 1.2 Related work
Topological self-stabilization has recently attracted a lot of attention. Various topologies have been considered such as simple line and ring networks (e.g., [20, 9]), skip lists and skip graphs (e.g., [16, 10]), expanders [8], the Delaunay graph [11], the hypertree [7], and Chord [12]. Also a universal protocol for topological self-stabilization has been proposed [3]. However, none of these works consider nodes with heterogeneous bandwidths.
Various network topologies have been suggested to interconnect nodes with heterogeneous bandwidths. While [15, 21] do not provide any formal guarantees and just evaluate their constructions via experiments, [4, 18] give formal guarantees, but (like for the experimental papers) no self-stabilizing protocol has been proposed for these networks. There has also been extensive work on networks with heterogeneous bandwidths in the context of streaming applications (see, e.g., [14] and the references therein) but the focus is more on coding schemes and optimization problems, so it does not fit into our context.
Probabilistic approaches like ours have the advantage of better graph properties (e.g., a logarithmic expansion) compared to deterministic variants (e.g., [2]).
## 1.3 Our Contribution
We modified the protocol proposed for the self-stabilizing Skip+ graph [10] to organize the nodes in a more effective way using the same topology. However, the nodes are not ordered according to their labels but according to their bandwidths. Due to this we call our graph the HSkip+ graph. Improvements of our construction over previous work are:
- · We prove self-stabilization under the asynchronous message passing model whereas in [10] it was only shown for the synchronous message passing model.
- · In simulations, our Skip+ protocol has basically the same self-stabilization time as the original Skip+ protocol, but it spends significantly less work (in terms of messages that are exchanged between the nodes) in order to reach a legal state. Furthermore, our overlay is working correctly under a churn rate of nearly 50%.
- · When a node joins or leaves in a legal state, then the worst case work in [10] is O (log 4 n ) w.h.p. whereas our protocol just needs a worst case work of O (log 2 n ) w.h.p., and a worst-case time of O (log n ) w.h.p. in the synchronous message passing model, to get back to a legal state. The work and time bounds are on par with the previously best (non-self-stabilizing) network of logarithmic diameter and degree for peers with heterogeneous bandwidths [18].
- · Also the competitiveness concerning the congestion of arbitrary routing problems in HSkip+ is on par with the previously best (non-self-stabilizing) network of logarithmic diameter and degree for peers with heterogeneous bandwidths [4].
Hence, our HSkip+ construction combines the best results of both worlds (self-stabilizing networks and scalable networks for heterogeneous nodes).
## 1.4 Organization of the Paper
This paper is structured as follows: In Section 2 we present our topology and the associated self-stabilizing algorithm. We show its convergence and closure. Furthermore, we look at the handling of external dynamics and routing in our network. Section 3 presents our simulation results, especially the comparison of Skip+ and HSkip+. Finally, we end the paper in Section 4 with a conclusion.
## 2 Theoretical Analysis
## 2.1 HSkip+ Topology
We now present the desired topology for our problem which we call HSkip+ . It is the same as the Skip+ topology introduced by Jacob et al. [10], which is based on skip graphs [1], but the ordering of the nodes is different. Instead of using fixed node labels for the ordering, the bandwidth values are used. Also, new rules are used since they turned out to consume clearly less work than the rules proposed for Skip+ .
As stated in our network model (cf. Sec. 1.1.1), the system forms a directed graph G = ( V, E ). Each node v ∈ V has several internal variables which define the internal state of the node v :
- · v.id is the unique, immutable identifier of node v .
- · v.rs is an immutable pseudo-random bit string of node v .
- · v.bw is the current bandwidth of node v , which is modifiable during the execution. W.l.o.g., we assume that all bandwidths are unique (which is easy to achieve given that the node identifiers are unique).
- · v.nh is the neighborhood of node v , i.e., the set of all nodes whose references are stored in v .
We introduce some auxiliary functions for the internal variables, and especially for the bit string v.rs :
- · prefix( v, i ) = v.rs [0 . . . i -1] is the prefix of length i of v.rs .
- · commonPrefix( v, w ) = argmax i { prefix( v, i ) = prefix( w,i ) } is the length of the maximal common prefix of v.rs and w.rs .
- · level( v ) = max w v.nh ∈ { commonPrefix( v, w ) } is called the current level of node v and will be used later for the grouping of the nodes.
- · deg( v ) = | v.nh | is called the current degree of node v , the number of neighbors.
As mentioned before, we are aiming at maintaining the HSkip+ graph among the nodes. For the HSkip+ graph we need a series of definitions.
Definition 3 (Component of HSkip+) . Two nodes v and w belong to the same component at level i of HSkip+ if their bit values v.rs and w.rs share the same prefix of length i , formally component( v, i ) = { w ∈ V | commonPrefix( v, w ) ≥ } i . The nodes in each component are ordered according to their bandwidths. A component is called trivial if there is only one node in the component.
Components exist at each level as long as they are non-trivial, which means there would be only one node in a component. Therefore, we can define the level of HSkip+ as the number of levels needed to represent all non-trivial components:
glyph[negationslash]
Definition 4 (Level of HSkip+) . The level of the network G = ( V, E ) is defined by the maximum level i such that two nodes share a common prefix of length i . Formally, level( G ) = max v,w ∈ V,v = w commonPrefix( v, w ).
In addition to the regular linked list for each component we have further edges to get a more stable neighborhood and to allow local checking of the correctness. Each node v is connected at level i to at least one node w 0 and one node w 1 which share the same prefix of length i and have the next bit as 0 respectively 1:
Definition 5 (Farthest Neighbors of HSkip+) . We define the farthest predecessors of node v as
$$\text{farthestPred} ( v, i, b ) \ = \ \argmax_{u\in\{u\in V|u.bw>v.bw\} \choose \text{prefix} ( v, i) \cdot b = prefix} ( u, i + 1)\} \text{farthestPred} ( v, i ) \ = \ \argmax_{u\in\{u\in V|u.bw>v.bw\} \choose \min_{b\in\{0,1\} } \ \{prefix} ( v, i) \cdot b = prefix} ( u, i + 1)\}$$
and the farthest successors as
$$\begin{array} { l l l } \text{farthestSucc} ( v, i, b ) & = & \argmin _ { w \in \{ w \in V | w. b w < v. b w \} } \\ & & \{ \text{prefix} ( v, i ) \cdot b = \text{prefix} ( w, i + 1 ) \} \\ \text{farthestSucc} ( v, i ) & = & \argmin _ { w \in \{ w \in V | w. b w < v. b w \} } \\ & & \max _ { b \in \{ 0, 1 \} } \{ \text{prefix} ( v, i ) \cdot b = \text{prefix} ( w, i + 1 ) \} \end{array}$$
Also, all nodes between the farthest predecessor and successor in each level are connected. This property aims at a stable neighborhood which prepares the next higher level as the linked list of level i +1 is already available. Formally we can define the neighborhood range at level i with the help of the components:
Definition 6 (Range of HSkip+) . The node v is connected at level i to all nodes w ∈ component( v, i ) with w.bw ≤ farthestPred( v, i ) .bw and w.bw ≥ farthestSucc( v, i ) .bw , which we call the range or neighbors of node v at level i .
Furthermore, we define different neighborhood shortcuts:
## Definition 7 (Neighbors of HSkip+) . Let
- · preds( v, i ) = { u ∈ neighbors( v, i ) | u.bw > v.bw }
- · succs( v, i ) = { w ∈ neighbors( v, i ) | w.bw < v.bw }
- · closestPred( v, i ) = argmin u ∈ preds(v i) , u.bw
- · closestSucc( v, i ) = argmax w ∈ succs(v i) , w.bw
With the three definitions of components, level and range (cf. Def. 3, 4 and 6) in the HSkip+ topology we can now define the desired network. See Fig. 1 for an example.
$$\text{Definition $8$ (HSkip+)}. \text{ The HSkip+ network is defined by $G^{HSkip+}=\left(\mathcal{ }V,E^{HSkip+} \right)$ with}$$
$$E ^ { H S k i p + } = \{ ( v, w ) | \exists i \in [ 0, \text{level} ] \, \colon w \in \text{range} ( v, i ) \}$$
Figure 1: Example for the HSkip+ topology with eight nodes.
Figure 1 shows an example network with 8 nodes and 4 levels. The image visualizes the edges caused by the different levels in the HSkip+ topology.
## 2.2 HSkip+ Algorithm
To reach the presented topology, we now introduce a self-stabilizing algorithm whose correctness we will prove afterwards. All following operations are executed at node v . The algorithm works in the asynchronous message passing model presented in Section 1. We just use two types of guards: true and received m ( ). true means that the action is continuously enabled, which implies that it is executed infinitely often. In addition to the definitions in Sec. 2.1 we take use of local variants (e. g. localFarthestPred( v, i )) which represent the cached information at node v .
true →
CheckNeighborhood()
IntroduceNode()
IntroduceClosestNeighbors()
LinearizeNeighbors()
Figure 2: Action called periodically by node v .
The CheckNeighborhood() function checks if all nodes which are in the neighborhood of the node v are needed for the topology (cf. Fig. 3). If a node w is no longer needed in any level, it is removed from
the neighborhood of v and forwarded to another node x , concretely the node in the neighborhood with the longest common prefix, because it is the most promising node which could include the node in its own neighborhood at any level.
```
function CHECKNEIGHBORHOOD
for all w in v.nh do
if CheckNode(w) = false then
v.nh = v.nh\{w}
send m = (build, w)
to node argmax_x in v.nh commonPrefix(w, x)
end if
end for
end function
```
Figure 3: CheckNeighborhood() inspects the nodes in v.nh .
The test if a node w is really needed for node v is done by the CheckNode() function (cf. Fig. 4). For the node w in each level i it is checked if the node w is in the range (cf. Def. 6) of node v . If this is the case for at least one level, the node w is needed in the neighborhood of v .
```
<_Julia_>
```
Figure 4: CheckNode() tests if a node w is needed in v.nh .
```
function INTRODUCENODE
for all w in v.nh do
send m = (build,v) to node w
end for
end function
```
Figure 5: IntroduceNode() introduces the node v to all neighbors.
The other three periodic actions introduce new neighbors to each other to reach the desired topology. In the first function IntroduceNode() , node v introduces itself to all of its neighbors to create backward edges (cf. Fig. 5). In the second function IntroduceClosestNeighbors() , node v introduces the two direct neighbors, the closest predecessor and the closest successor, in each level to all other neighbors in this level (cf. Fig. 6). The last function LinearizeNeighbors() linearizes the neighborhood (cf. Fig. 7), i.e., each neighbor is introduced to the subsequent neighbor.
In addition to the periodic actions we have different reactive actions triggered by the received m ( ) guard. Depending on the message type of the message m received by a node v , the Build , Remove or Lookup operation is called (cf. Fig. 8).
The Build() function of a node v must handle two cases (cf. Fig. 9): The node x which is given as argument is already in the neighborhood or not. If it is already included, its information (especially its
glyph[negationslash]
glyph[negationslash]
```
function INTRODUCECLOSESTNEIGHBORS
for i = 0 to level(v) do
if localClosestPred(v, i) \neq \t then
for all w in localNeighbors(v, i) do
send m = (build, localClosestPred(v, i))
to node w
end for
end if
if localClosestSucc(v, i) \neq \t then
for all w in localNeighbors(v, i) do
send m = (build, localClosestSucc(v, i))
to node w
end for
end if
end for
end function
```
Figure 6: IntroduceClosestNeighbors() introduces the closest neighbors.
```
function LINEARIZENEIGHBORS
for i = 0 to level(v) do
for j = 0 to |localPredecessors(v, i)| - 1 do
send m = (build, localPredecessors(v, i)[j + 1])
```
Figure 7: LinearizeNeighbors() introduces the neighbors to each other.
current bandwidth) is updated. Then the CheckNeighborhood() operation is called to check if the modified node x and all other nodes are still needed for the node. In the case that the node x is not yet in the neighborhood, it is checked by the CheckNode() function (cf. Fig. 4) if the node should be integrated in the neighborhood. If the node is needed in one level, it will be included in the neighborhood and the whole neighborhood will be checked if there is an unnecessary node now. If the new node is not needed by the node, it will be forwarded to the next node w with the longest common prefix.
With these self-stabilizing rules the desired topology can be reached and maintained in a finite number of steps.
```
received(m)
if m = (build, x) then
Build(x)
else if m = (remove, x) then
Remove(x)
else if m = (lookup, x) then
Lookup(x)
end if
```
Figure 8: The incoming messages at node v are handled.
```
function BUILD(node x)
if x in v.nh then
update neighbor information
CheckNeighborhood()
else
v.nh = v.nh \u {x}
if CheckNode(x) = true then
CheckNeighborhood()
else
v.nh = v.nh\{x}
send m = (build, x)
to node argmax_w \in v.nh commonPrefix(x, w)
end if
end if
end function
```
Figure 9: Build handles an incoming build message.
```
)
```
## 2.3 Correctness
Next we show the convergence and the closure of the algorithm, which implies that it is a self-stabilizing algorithm for the HSkip+ topology. Most of the proofs are skipped due to space constraints, but we dissected the self-stabilization process into sufficiently small pieces so that it is not too difficult to verify them with the help of the protocols.
## 2.3.1 Convergence
Here, we prove the following theorem:
Theorem 9 (Convergence) . If G t ( ) = ( V, E ) is weakly connected at time t , then G e ( t ′ ) = G HSkip + for some time t ′ > t and all node information is correct.
Proof. To prove this theorem we will show different lemmas which lead to the convergence. But first, we give an overview of the whole proof: Starting with any weakly connected graph we first show that the network stays connected over time (cf. Lem. 10). Furthermore, we show that all wrong information about nodes in the network will be removed over time (cf. Lem. 11). Having reached this state, we will show the creation of the correct linked list at the bottom level (cf. Lem. 12) and the maintenance of it (cf. Lem. 13). The next step is the proof of the creation of the HSkip+ topology at the bottom level (cf. Lem. 14) and its maintenance (cf. Lem. 15). By showing the inductive creation of the HSkip+ topology at all levels (cf. Lem. 16) we can finish the convergence proof.
Note that edges are only deleted if there already exist other edges concerning the desired topology. Otherwise, edges are only added or delegated in a sense that a node u holding an identifier of v may forward that identifier to one of its neighbors w , which also preserves connectivity. Hence, we get:
Lemma 10 (Weakly Connected) . If G t ( ) = ( V, E ) is weakly connected at time t , then G t ( ′ ) is weakly connected at any time t ′ > t .
Proof. To show the connectivity, we have to prove that for all edges ( x, y ) ∈ E t ( ) there is the same edge in the next time step, ( x, y ) ∈ E t ( +1), or there is a path from x to y which uses other edges. If the edge is still available in the next time step, G t ( +1) obviously stays weakly connected, so we only have to consider the case that ( x, y ) / E t ∈ ( +1). Here we distinguish between two different cases: Either the removed edge was an explicit edge or it was an implicit edge at time t .
So let us first consider the case where ( x, y ) is an explicit edge in the graph and therefore y is in the neighborhood of x . In our algorithm there is only one operation which removes nodes from the neighborhood: The CheckNeighborhood() function removes nodes which are not needed for the correct neighborhood. But in this case, a message with the removed node y is sent by the current node x to another node v in its
neighborhood (the one with the longest common prefix). Therefore, we have a new implicit edge ( v, y ) and together with the existing explicit edge ( x, v ) as v is in the neighborhood of x , there exists a path from x to y over v .
We now look at the case where ( x, y ) is an implicit edge at time t which means that we have the reference to node y in an incoming Build message at node x . The message is handled by the Build() operation and two cases can occur. On the one hand, the node y can be useful in the neighborhood of x , then y is integrated in the neighborhood and at time t +1, y ∈ x.nh . So we have an explicit edge instead of the implicit one. On the other hand, the node y can be useless for the node x . Then y is delegated to another node v in its neighborhood (the one with the longest common prefix) and x stays connected with y over the node v and the explicit edge ( x, v ) ( v is in the neighborhood of x ) as well as the new implicit edge ( v, y ).
Due to our FIFO delivery and fair message receipt assumption, all messages initially in the system will eventually be processed. Moreover, the distance (w.r.t. the sorted ordering of the nodes) of wrong information in the network can be shown to monotonically decrease. Once it is equal to one, the periodic self-introduction (cf. Figure 5) ensures that the node information is corrected, which implies the following lemma.
Lemma 11 (Wrong Information) . If G t ( ) = ( V, E ) is weakly connected at time t , then there is a time point t ′ at which all node information in G t ( ′′ ) is correct for any t ′′ > t ′ .
Proof. We assume, that there is a wrong information in the network. This wrong information can be contained in a message or in an internal variable of a node. A message is only delegated a finite number of steps because it decreases the distance to its target in each step by choosing as next hop a node with a longer common prefix. Eventually, the information is integrated in the internal variables of a node, so we only have to consider this case. Therefore at a time ˆ , there is no wrong information in any message, but t there can be wrong information in the internal variables of a node.
Assume that a node x has wrong information about node y at time ˆ . t If node x is connected to node y by an explicit edge, eventually also node y is connected to node x because of the periodic call of IntroduceNode() . Periodically, y sends a build message to x in the IntroduceNode() function. This message is handled by the Build() operation in the first case ( y ∈ x.nh ). The information about y in the internal variables of x is updated and all wrong information is removed.
Furthermore, no new wrong information is produced in the network without any operations from outside, as only correct information is sent. Therefore at a time t ′ > t we have only correct information in the whole network.
From now on, let us only consider time steps in which all node information is correct. Next to the edge set of the desired topology E HSkip + we define the edge set E HSkip + i which contains all edges belonging to the topology at level i and the edge set E list i which contains all edges needed for a linked list at level i . Then it follows from arguments in [10] for the edge set E list 0 at level 0:
Lemma 12 (List Creation) . If G t ( ) = ( V, E ) is weakly connected, then E e ( t ′ ) ⊇ E list 0 at some time t ′ > t .
Proof. As the graph is weakly connected at time t , there exists an undirected path from v to w for all pairs ( v, w ) ∈ V 2 . Now we look at two nodes v and w which should be direct neighbors: If v and w are already direct neighbors regarding their bandwidth values, then we only need one periodic message of the IntroduceNode() operation and we have the linked list completed at this point.

Figure 10: Path which connects v with w over intermediate nodes y , x , u , z .
Let us now assume without loss of generality, that the path from v to w is through other nodes (cf. Fig. 10). We will show that the length of the path from v to w does not increase and finally becomes shorter
that in the end v and w are directly connected. At first, we will show that the length of the path does not increase: For each edge ( x, y ) in the path it yields, that the edge is only replaced by two edges which are in the range of ( x, y ). We distinguish two cases:
(a) x and y are connected with an implicit edge ( x, y ).
(b) x and y are connected with an explicit edge ( x, y ).
Figure 11: Edge ( x, y ) is only replaced by two edges that are within the range of ( x, y ).
- 1. ( x, y ) is an implicit edge (cf. Fig. 11a): If the edge ( x, y ) is not needed by x , there has to be a closer node z in the neighborhood of x . As consequence, y can be delegated to z and the edge ( x, y ) is replaced by the two edges ( x, z ) and ( z, y )
which fulfills the condition to stay in the range.
- 2. ( x, y ) is an explicit edge (cf. Fig. 11b): The edge ( x, y ) is only replaced if x has a closer neighbor z in its neighborhood. But than y can be delegated to z and the edge ( x, y ) is replaced by the two edges ( x, z ) and ( z, y ) which fulfills the condition to stay in the range.
If x has no further outgoing edge ( x, z ), the edge ( x, y ) is kept or integrated as explicit one since x does not know about closer neighbors.
We now show that border nodes in the path (the leftmost and rightmost nodes) will eventually be eliminated. Therefore, we assume that the path from v to w contains a border node x . Without loss of generality, we assume that x has the maximum bandwidth in the path, x.bw > v.bw > w.bw . There are various cases, how x is connected with two edges to the path: Explicit or implicit, the edges may point to x or away from x . The undirected path from v to w contains somewhere the successive sequence of the nodes y , x and z (w.l.o.g. x.bw > y.bw > z.bw ). We want to exclude node x , so that the path only uses the nodes y and z . We will now consider theses cases one by one:
Figure 12: The border node x can be excluded from the path.

- 1a) x has explicit edges to y and to z (cf. Fig. 12a): With the LinearizeNeighbors() operation of node x , a new implicit edge ( y, z ) is added since y and z are successive neighbors of x . We have a direct connection between y and z and x can be excluded.
- 1b) x has an explicit edge to y and an implicit one to z (cf. Fig. 12b): Node x integrates z in its neighborhood, as it needs at least two successors. The edge ( x, z ) is converted to an explicit edge and we have case a.
in its neighborhood since it needs at least two successors.
- 1c) x has an implicit edge to y and an explicit edge to z (cf. Fig. 12c): As in the previous case, Node x integrates y The edge ( x, y ) is also converted to an explicit one and we have case a.
- 1d) x has implicit edges to y and to z (cf. Fig. 12d): Depending on the order of processing, y or z is integrated in the neighborhood of x since it has no successor. As consequence this case is reduced to case b or c.
Additionally, we have to consider the cases in which there is another node u to which node x has an explicit edge to:
Figure 13: The border node x can be excluded with the use of node u .

2a) x.bw > u.bw > y.bw > z.bw (cf. Fig. 13a): The results depends on the execution order: If the edge ( x, y ) is considered first, y is integrated in the neighborhood of x . In the next step with the LinearizeNeighborhood() operation, a new implicit edge ( u, y ) is added since u and y are successive neighbors of x . We can treat u as new y and the case 1b holds. added with
- If ( x, z ) is considered first, z is integrated in the neighborhood, the implicit edge ( u, z ) is the LinearizeNeighborhood() operation and with u as new z , the case 1b also holds.
- 2b) x.bw > y.bw > u.bw > z.bw (cf. Fig. 13b):
The same argumentation as in case 2a reduces to case 1b or 1c.
- 2c) x.bw > y.bw > z.bw > u.bw (cf. Fig. 13c): The same argumentation as in case 2a reduces to case 1b or 1c.
For the cases in which the edges point to x , a similar argumentation is possible to exclude the border node x . The exclusion of border nodes is executed for all border nodes on the undirected path from v to w until v and w are directly connected by an edge ( v, w ) or ( w,v ). Eventually, for each pair of direct neighbors v and w it yields that there is an edge ( v, w ) ∈ E or ( w,v ) ∈ E . As the direct neighbors are always needed in our topology, the edges will be converted to explicit edges, if they are still implicit ones. By using one IntroduceNode() operation, the backward edges will be created for each pair and also integrated as explicit edges. Since now the double-linked list is completed at the base level, G e ( t ′ ) ⊇ G list 0 e at time t ′ > t .
Moreover, it follows from the algorithm that the set of linked lists at level i , E list i , is maintained over time.
Lemma 13 (List Maintenance) . If E e ( ) t ⊇ E list i at time t , then E e ( t ′ ) ⊇ E list i at any time t ′ > t .
Proof. We start with a correct list G list i e at time t . As there are no external dynamics, no nodes enter or leave the system. To destroy the correct list, a node has to be removed from the neighborhood of any other node. The only removal happens in the CheckNeighborhood() operation after the check if the node is needed. But this check always returns true for the closest neighbors of a node because they are always needed. They are always in the range at level i and CheckNode() returns true . Therefore no edges are removed and it follows that G e ( t ′ ) ⊇ G e ( ) t ⊇ G list i e .
Starting with a linked list at a level i we can show the creation of the HSkip+ links at the same level, E HSkip + i :
Lemma 14 (HSkip+ Creation) . If E e ( ) t ⊇ E list i at time t , then eventually E e ( t ′ ) ⊇ E HSkip + i at time t ′ > t .
Proof. We start with a correct linked list G list i e which is created and obtained (cf. Lem. 12 and 13). We look at an arbitrary node v . It is connected to its direct predecessor u 1 and successor w 1 , formally localClosestPred( v, i ) = closestPred( v, i ) and localClosestSucc( v, i ) = closestSucc( v, i ) (cf. Fig. 14a). The same holds for all other nodes, they are all connected to their direct predecessors and successors.

(a) Double-linked list in the environment of node v at a level i .

- (c) Node v and node w 2 are connected through skip edges.

(b) Node v and node w 2 are introduced each other by node w 1 .

(e) Node v is connected to node w 3 and introduces itself to node w 3 .


(f) Node v and node w 3 are connected through skip edges.

(g) Node v is connected to nodes w , . . . w 1 k ; node w k +1 is introduced to node v by node w k .
Figure 14: The correct creation of the skip+ edges for node v at level i .
First we only look at the successors of node v . With the IntroduceClosestNeighbors() operation, node w 1 introduces the nodes v and w 2 to each other and the implicit edges ( v, w 2 ) and ( w , v 2 ) are created (cf. Fig. 14b). As both edges are needed in the neighborhood of the nodes v and w 2 , they are both converted to explicit edges (cf. Fig. 14c).
Now node w 2 introduces w 3 to v (cf. Fig. 14d). As the node w 3 is needed in the neighborhood of v it is also converted to the explicit edge ( v, w 3 ) and with the IntroduceNode() operation the implicit edge ( w , v 3 ) is created (cf. Fig. 14e). Also this edge is converted to an explicit edge (cf. Fig. 14f).
The same procedure is continued for the nodes w , . . . , w 4 k which are all needed neighbors for node v . Then the last neighbor w k introduces w k +1 to node v (cf. Fig. 14g). As it is not needed, it is not integrated in the neighborhood. This implicit edge is also created in the future by the IntroduceClosestNeighbors() operation of node w k , but never converted to an explicit edge at level i . The successors are created correctly and the same observation can be made for the predecessors. Therefore, we eventually have all needed edges for the topology and G e ( ) t ⊇ G HSkip + i e .
Additionally, it follows from our rules that the HSkip+ topology at a level i is maintained over time.
Lemma 15 (HSkip+ Maintenance) . If E e ( ) t ⊇ E HSkip + i at time t , then E e ( t ′ ) ⊇ E HSkip + i at any time t ′ > t .
Proof. The proof is equivalent to the list maintenance (cf. Lem. 13): Explicit edges are only removed during the CheckNeighborhood() operation. As all neighbors are needed, no edge is removed and we get G e ( t ′ ) ⊇ G e ( ) t ⊇ G HSkip + i e .
Using the simple observation that E list i +1 ⊆ E HSkip + i , we can then conclude:
Lemma 16 (HSkip+ Induction) . If E e ( ) t ⊇ E HSkip + i at time t , then E e ( t ′ ) ⊇ E HSkip + i +1 at some time t ′ > t .
Proof. Starting with G HSkip + i e , each node has an edge to the previous and one to next node with 0 and 1 as next bit of the bit string (cf. Fig. 15a). Each component of level i is separated into two components of level i +1 according to the i +1-th bit. Furthermore, the components of the next level are already connected and they already form a double-linked list (cf. Fig. 15b). Now we can apply Lemma 14 and the correct HSkip+ topology is formed at level i +1 and maintained over the time (cf. Lem. 15).
The previous lemmas immediately imply Theorem 9.
Figure 15: The inductive step from level i to level i +1.

## 2.3.2 Closure
After proving the convergence of our algorithm we need to show its closure. This means that the network stays in a legal state once it has reached one. Formally, we show (cf. Def. 2):
$$\text{Theorem } 1 7 \ ( \text{Closure} ). \ I f \, G _ { e } ( t ) = G ^ { H S k i p + } \ a t \ t i m e \, t, \, \text{then } G _ { e } ( t ^ { \prime } ) = G ^ { H S k i p + } \ a t \ a n y \ t i m e \, t ^ { \prime } > t.$$
glyph[negationslash]
Proof. Suppose that at time t we have a network which forms the desired topology with its explicit edges, i.e., E e ( ) = t E HSkip + . If E e ( t +1) = E e ( ), then at least one explicit edge is added or removed. t Edges are only removed in the CheckNeighborhood() operation if they are not needed and edges are only added in the Build() operation if they are needed for the neighborhood. However, G e ( ) already forms the correct neighborhood t at time t at all levels (cf. Def. 8). As there are no external changes and faults, the neighborhood is still correct at time t +1. Therefore, no edge is removed or added, so G e ( t +1) = G e ( ) = t G HSkip + .
The convergence and closure together show the correctness of the self-stabilizing algorithm. In other words we have designed an algorithm which creates the HSkip+ topology and ensures that it stays correct.
## 2.4 External Dynamics
As external dynamics of a network we consider all events which can have an influence on the network. Two typical events for a peer-to-peer system are arrivals and departures of nodes. The network has to adapt the topology in this case. In our HSkip+ network we will also consider changes in the bandwidths of the nodes because also this will have an influence on the network topology. To handle these events we need a Join, Leave, and Change operation.
## 2.4.1 Join
The Join operation in our network is very simple. If a node v wants to join the network, it just has to introduce itself to some node w . The rest will be handled by the self-stabilization. Hence, it suffices to execute the code in Fig. 16.
```
function JOIN
send m = (build, v) to a known node w
end function
```
Figure 16: The Join operation of node v sends a build message to w .
## 2.4.2 Leave
We distinguish between two cases: A scheduled Leave and a Leave caused by a failure. In the first case (cf. Fig. 17) the node v which wants to leave the network simply sends a remove message to all of its neighbors. The receivers of these messages remove the node v from their neighborhood (cf. Fig. 18). The leaving node also deletes its entire neighborhood.
The Remove() operation removes a given node from the neighborhood if it is present (cf. Fig. 18). It is executed as reaction to a remove message. A neighborhood check is not needed, as there cannot be too much information after removing some information.
```
function LEAVE
for all w \in v.nh do
send m = (remove, v) to node w
end for
v.nh = 0
end function
```
Figure 17: The Leave() operation of node v sends remove messages.
```
function REMOVE(node x)
if x \in u.nh then
u.nh = u.nh\{x}
end if
end function
```
Figure 18: The Remove() operation removes the node x from v.nh .
```
end function
```
Additionally, we can have a Leave in the network caused by a node failure. In this case, we assume the existence of a failure detector at the nodes which checks periodically the existence of the neighbor nodes. Therefore, the outcome of a failed node is the same as for a scheduled Leave : all neighboring nodes invalidate their links to the failed node.
## 2.4.3 Change
The Change operation updates the bandwidth value of a node v and therefore the order in our topology has to be updated. The operation itself only needs to update its internal variable of the bandwidth (cf. Fig. 19).
```
function CHANGE(new bandwidth bw)
v.bw = bw
end function
```
Figure 19: The Change() operation updates the bandwidth value of v .
The correct recovery of the topology after no more external dynamics are happening follows directly from the convergence.
Theorem 18 (Recovery from External Dynamics) . If G e ( ) = t G HSkip + at time t and a node v joins or a node u leaves or a node u changes its bandwidth, then eventually G e ( t ′ ) = G HSkip + at time t ′ > t .
Proof. If the node v joins the network by sending a build message to some node w , the graph has a new node v and a new implicit edge ( w,v ). Therefore G t ( +1) = ( V ( t +1) = V ( ) t ∪ { v } , E ( t +1) = E t ( ) ∪ { ( w,v ) } ). G t ( + 1) is obviously weakly connected. As there are no further external dynamics, we can apply the theorem about the convergence of our self-stabilizing algorithm (cf. The. 9). After a finite number of steps, we eventually reach the correct topology, formally G e ( t ′ ) = G HSkip + at a time t ′ > t .
It is easy to see that the worst case number of structural changes in a level does not exceed O (log 2 n ) w.h.p., but with more refined arguments one can also show the following result:
Theorem 19 (Structural Changes after External Dynamics) . If G e ( ) = t G HSkip + at time t and a node v joins or a node u leaves or a node u changes its bandwidth, then G e ( t ′ ) = G HSkip + after O (log 2 n ) structural changes, w.h.p.
Proof. To analyze the structural changes which are needed after node v joins the network, we will look at the obsolete edges which have to be removed and at the new edges which need to be created during the self-stabilization.
As the degree of the network is limited by O (log n ), each node w has only O (log n ) neighbors in w.nh . So each node can only remove at most O (log n ) edges. Furthermore only O (log n ) nodes can be affected from any changes as the new node v can be in at most O (log n ) neighborhoods and cause changes. Therefore at most O (log 2 n ) edges can be removed.
In addition, the new node v has O (log n ) other nodes in its neighborhood. As already stated in the removing part, only O (log n ) other nodes are affected by the Join , each one can create at most O (log n ) new edges. Therefore O (log n ) + O (log 2 n ) new edges can be created.
Altogether we have at most O (log 2 n ) structural changes in the network after a Join
.
With some effort, one can also show that this is an upper bound for the number of additional messages (i.e., messages beyond those periodically created by the true guard).
Theorem 20 (Workload of External Dynamics) . If G e ( ) = t G HSkip + at time t and a node v joins or a node u leaves or a node u changes its bandwidth, then G e ( t ′ ) = G HSkip + after O (log 2 n ) additional messages, w.h.p.
Proof. Firstly, the build message for the Join from node v to node w has to be forwarded to a node x which can include the new node v in its neighborhood. This needs at most O (log n ) additional messages because the diameter of the network is at most O (log n ) and the message will be forwarded closer to the target in each step as the bit string is adjusted at least one bit in each step.
At the position we need several further build messages to introduce and linearize the neighborhood. We have to create at most O (log 2 n ) structural changes (cf. Lem. 19). For each new edge, a message is created and integrated as an explicit edge in the next step. Therefore with O (log 2 n ) messages we can create all new edges. Altogether we have a workload of at most O (log 2 n ) additional messages to complete the Join operation.
## 2.5 Routing
The routing of a message to a target node x is handled by the message m = ( lookup , x ). The Lookup() operation handles the forwarding of lookup messages (cf. Alg. 20). If the lookup target is equal to the current node, the lookup has finished. This is checked with the help of the identifiers of the nodes. If this is not the case, the lookup is forwarded to the next better node.
glyph[negationslash]
```
<_Julia_>
```
Figure 20: The Lookup() operation of v handles the build messages.
The next hop is determined by the random bit strings of the involved nodes: In each step we want to have at least one bit more in common with the target node x . Formally, if at the current node v the bit string has i bits in common with the target (commonPrefix( v, x ) = i ), at the next step at node w we want
at least i +1 bits in common (commonPrefix( w,x ) ≥ i +1). In our topology such a node is always present in level i of a node v in both the successors and the predecessors (unless there is no such higher level) as every node is connected at every level i to at least one predecessor and successor with 0 and one with 1 as next bit. First, the routing is done along predecessors so that the message is guaranteed to follow a sequence of nodes of monotonically increasing bandwidth. Once the node with the highest bandwidth defined by this rule has been reached, we use the successor nodes until the target node is reached. From the routing protocol it follows:
Theorem 21 (Correctness of Routing) . If G e = G HSkip + , then a message m = (lookup , w ) sent by a node u eventually reaches node w .
Proof. We prove the correctness inductive such that at each step the random bit string v.rs of the current node v is more similar to the target bit string x.rs . As inductive hypothesis it holds that at step i at node v : prefix( v, i ) = prefix( x, i ). As induction base we look at step i = 0 at the source node s , here at least the prefix of length 0 should be equal to the target bit string, which obviously is the case. In the induction step we start from node v with an equal prefix of length i and the message has to reach a node w with an equal prefix of length i +1. In the correct HSkip+ topology, each node has a predecessor and a successor with 0 and 1 as next bit. Only at the border nodes, the successor or predecessor could be absent, but at least one of the sides is complete. Therefore the length of the equal prefix is extended. As the target node x exists in the network and is included in the HSkip+ topology it will eventually be reached by the message.
We can also guarantee the following critical property, this is important to keep the congestion low.
Lemma 22 (Involved Nodes in Routing) . If G e = G HSkip + , the routing from some node u to w only uses nodes v with v.bw ≥ min { u.bw, w.bw } .
The dilation is defined as the longest path which is needed to route a packet from an arbitrary source to an arbitrary target node. Since it just takes a single hop to climb up one level and there are at most O (log n ) levels w.h.p., we get:
Theorem 23 (Dilation of Routing) . In HSkip+ the dilation is at most O (log n ) w.h.p.
Proof. In each routing step we use the edges of a higher level to forward the message to the next hop. As we have at most O (log n ) levels, after O (log n ) steps we have reached the highest level. At each step we have adjusted the bit string to reach the target bit string. At the highest level we have connections to all nodes with the same bit string and reach our target node directly. If this were not the case a further level would be included in the network because there would be a non trivial component (cf. Def. 4). Therefore, we need O (log n ) steps to route a message from an arbitrary source to an arbitrary target and our dilation is O (log n ).
Finally, we analyze the congestion of our routing strategy. The congestion of a node v is equal to the total volume of the messages passing it divided by its bandwidth. Let us consider the following routing problem: Each node u selects a target bitstring x independently and uniformly at random and sends a message of volume min { u.bw, w.bw } to the node w with the longest prefix match with x . Of course, u may not know that volume in advance. Our goal will just be to show that the expected congestion of this routing problem is O (log n ). If this is the case, then one can show similar to [4] that the expected congestion of routing any routing problem in HSkip+ is by a factor of at most O (log n ) worse than the congestion of routing that routing problem in any other topology of logarithmic degree, which matches the result in [4].
Theorem 24 (Congestion of Routing) . In the HSkip+ topology, we can route messages with the presented routing algorithm (cf. Alg. 20) and the defined routing problem with an expected congestion of O (log n ) .
To prove the congestion we divide the routing process of a message from an arbitrary source node u to an arbitrary target node w into two parts: On the one hand the routing from u along predecessor edges to an intermediate node v which has no better predecessors and on the other hand the routing back over successors from node v to the target node w . We will start with the first part of the routing process, and initially we separately look at each level i in the network at node v . Later, we will sum it up for all levels.
Figure 21: Stabilization Time.
Figure 22: Overall Used Messages Total.
Figure 23: Stabilization Time after Join.
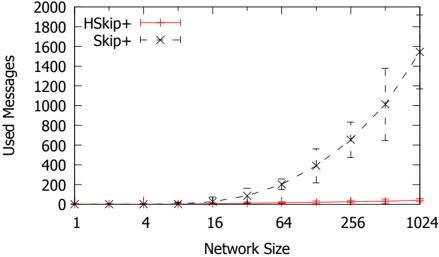
Figure 24: Used Messages after Join.
Lemma 25 (Congestion of node v at level i ) . In our routing problem (cf. The. 24), every node v has an expected congestion of O (1) at every level i ≥ 1 .
Proof. We assume w.l.o.g. that the first i bits of v.rs are 1. So messages with the target bitstring starting with 1 . . . 1 as the first i bits will be sent through the node v as long as they start at a node w that, at level 0, is between v and the closest successor w ′ of v whose first i bits are also 1. We calculate the probability that there are m nodes between v and w ′ . For each node in between we have the probability (1 -( 1 2 ) ) that one of i its first i bits differs from 1, and for w ′ we get a probability of ( 1 2 ) i that its first i bits are 1. Altogether, we
$$E \left [ X _ { v } ^ { i } \right ] = \sum _ { m = 0 } ^ { \infty } \frac { ( 2 ^ { i } - 1 ) ^ { m } } { ( 2 ^ { i } ) ^ { m + 1 } } \cdot ( m + 1 ) \cdot \frac { 1 } { 2 ^ { i } } \cdot v. b w = O ( v. b w )$$
get a probability that there are m sources that may send their messages to v of (1 -( 1 2 ) ) i m · ( 1 2 ) i = (2 i -1) m (2 ) i m +1 . Furthermore, we have to estimate the fraction of messages which will be sent through v . Each message is sent through v if the first i bits are 1, which has a probability of 1 2 i . Since we have m possible sources (excluding v ), a fraction of ( m +1) · 1 2 i messages will be sent through v . Lastly, we have to look at the volume sent by a single source. We know that a node s can send at most a volume of s.bw . As we have only successors of v as sources and for all successors s it holds that s.bw < v.bw , we can upper bound the volume sent by each source by v.bw . Altogether, if we have m nodes between v and w ′ , the total expected volume through v at level i is at most ( m +1) · 1 2 i · v.bw . Let the random variable X i v be the total volume sent through v at level i . Then
$$\begin{matrix} \end{matrix}$$
Summing up the congestion over all levels, we get:
Lemma 26 (Congestion of node v ) . In our routing problem (cf. The. 24), an arbitrary node v has an expected congestion of O (log n ) .
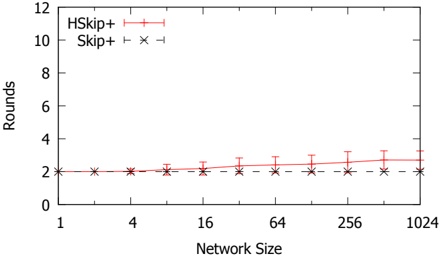
Figure 25: Stabilization Time after Leave.
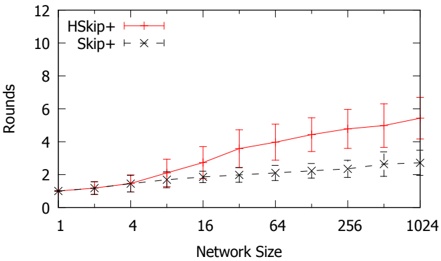
Figure 26: Used Messages after Leave.
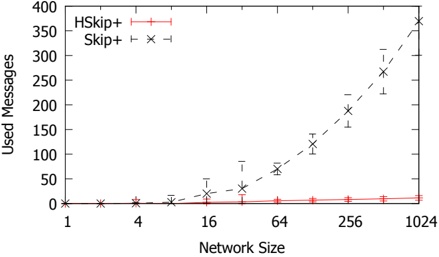
Figure 27: Stabilization Time after Change.
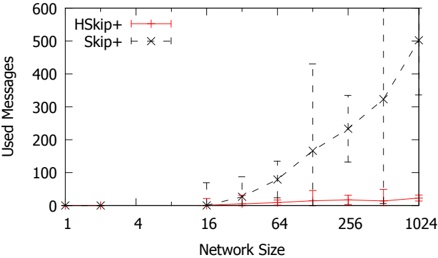
Figure 28: Used Messages after Change.
Proof of Theorem 24. With the previous lemmas (cf. Lem. 25 and Lem. 26) we have calculated the congestion caused by the first part of the routing process. For the second part, we can argue in a similar way by looking at the routing path backwards from the target node x to the intermediate node v and we also get an expected volume of O (log n ) · v.bw at node v . Both routing parts together yield an expected congestion of O (log n ) at every node v .
## 3 Simulations
In this section we present simulation results for the HSkip+ network in comparison to the Skip+ graph. We simulated both protocols starting from randomly generated trees. The bandwidths were assigned randomly
Figure 29: Routing Congestion of Flow Problem.
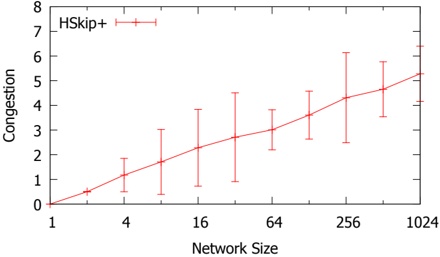
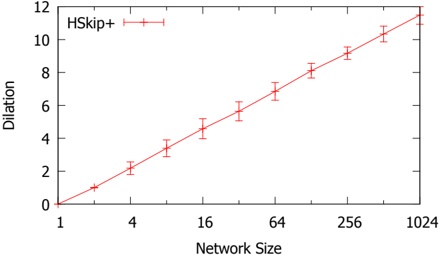
Figure 30: Routing Dilation of Flow Problem.
Figure 31: Stabilization after Crash and Attack.
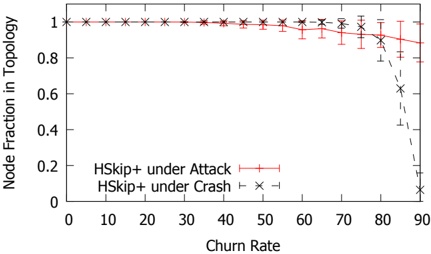
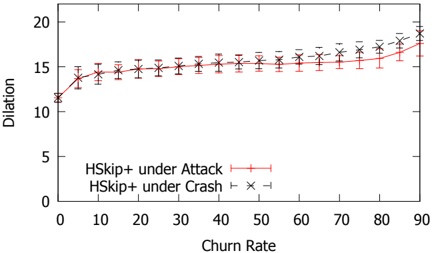
Figure 32: Routing Dilation during Crash and Attack.
to the peers according to measurements of the connections in Germany [5]. All simulations are run 100 times with different seeds for network configurations with up to 1024 participating nodes. Since both networks are self-stabilizing, we focus on the stabilization costs in terms of rounds (in each round every node is allowed to process all received messages) until the desired topology is constructed from an initial weakly connected network and the number of messages which were used in this process. The simulator can be found in the ancillary files of this paper on arXiv.org.
## 3.1 Self-Stabilization
If we look at the self-stabilization time for Skip+ and HSkip+ (cf. Fig. 21), we see asymptotically similar results. Both networks need O (log n ) rounds for the self-stabilization, whereas the Skip+ has slightly better results. In contrast, if we look at the used messages (cf. Fig. 22), we see a big difference between both networks. While Skip+ uses O (log 4 n ) messages for the self-stabilization process, the HSkip+ topology requires only O (log 2 n ) messages.
## 3.2 External Dynamics
As the next step, we look at the external dynamics in the network, namely joining and leaving nodes, as well as bandwidth changes. We start with the needed rounds after a new node joined the network (cf. Fig. 23). The result is similar to the self-stabilization we have seen before. Both networks are stabilized again after O (log n ) rounds, where the Skip+ network is slightly faster. Also the overall used messages for this process reflect the already seen result (cf. Fig. 24). While the Skip+ network consumes O (log 4 n ) messages, the rules of HSkip+ need only O (log 2 n ) messages. The concrete number of messages are not directly comparable to the numbers in Fig. 22 as there are further messages in the system which cannot be excluded from counting.
Also the other two operations show similar results. The self-stabilization after a node left the network or changed its bandwidth can be finished in O (log n ) rounds and nearly in constant time (cf. Fig. 25 and 27). This tendency yields also for the used messages. The work consumed by HSkip+ is clearly less than in the case of Skip+ (cf. Fig. 26 and 28).
## 3.3 Routing
For evaluating the routing performance of the topology we look at a flow problem: For each node pair u, v ∈ V node u sends an amount of data of u.bw v.bw · ∑ w V ∈ w.bw to node v . The average normalized congestion (according to the nodes' bandwidth) is logarithmic in the network size (cf. Fig. 29). The same yields for the dilation of the routing process (cf. Fig. 30). Both results agree with the theoretical findings as proved in Sec. 2.5.
## 3.4 Behavior under Churn
As last aspect we look at the network behavior under churn. In a practical usage scenario of a peer-topeer system nodes can arbitrary join and leave the network. Usual churn behavior as it was studied in several papers (i.e. [17, 22]) has no influence on the topology as the stabilization times of our network are significantly smaller than the session and intersession times of peers in a network. Therefore, we focus on two exceptional scenarios: On the one hand we examined a crash and on the other hand an adversarial attack. In the first scenario x% randomly chosen nodes are leaving from a network with 1024 nodes at the same time and the same number of new nodes join the network (to have a comparable size of the network). In the second scenario the leaving nodes are no longer randomly chosen, but all from a neighboring area.
The number of leaving nodes has no remarkable influence on the stabilization time as we have seen it in Fig. 23, Fig. 25 and Fig. 27. Hence, we concentrate on the topology after stabilization and especially how many nodes are still connected correctly (cf. Fig. 31). Up to a churn rate of about 35% all nodes stay in the topology, under a random crash even up to a rate of 60%. Over this limit, the topology looses nodes which are no longer reachable. As for the second evaluation, we concentrate on the dilation. We have used the same flow problem as in Sec. 3.3 starting at the same round as the attack and crash. In a stable network with 1024 nodes, it is about 11 hops (cf. Fig. 30). During the attack or crash it is just a little increased to about 14 or 15 hops; only at a very high churn rate (when we also have lost many nodes) the dilation increases noticeable.
## 4 Conclusion
In this paper, we presented HSkip+, a self-stabilizing overlay network based on Skip+. We showed by simulations that the self-stabilization time is nearly identical in O (log n ) while the improved version uses only O (log 2 n ) messages for the process compared to the originally used O (log 4 n ) messages. Also the dealing with external dynamics can be managed in the same time bounds and with the same work. Furthermore, we have extended the network to deal with heterogeneous bandwidths where we reach a logarithmic congestion and dilation in the routing process. Finally, the practical usage was shown by simulations under churn behavior.
## References
- [1] J. Aspnes and G. Shah. Skip graphs. In Proceedings of the ACM-SIAM Symposium on Discrete Algorithms (SODA '03) , pages 384-393. Society for Industrial and Applied Mathematics, 2003.
- [2] B. Awerbuch and C. Scheideler. The hyperring: a low-congestion deterministic data structure for distributed environments. In Proceedings of the fifteenth annual ACM-SIAM symposium on Discrete algorithms , SODA '04, pages 318-327, Philadelphia, PA, USA, 2004. Society for Industrial and Applied Mathematics.
- [3] A. Berns, S. Ghosh, and S. V. Pemmaraju. Building self-stabilizing overlay networks with the transitive closure framework. In Proceedings of the International Conference on Stabilization, Safety, and Security of Distributed Systems (SSS '11) , pages 62-76, 2011.
- [4] A. Bhargava, K. Kothapalli, C. Riley, C. Scheideler, and M. Thober. Pagoda: a dynamic overlay network for routing, data management, and multicasting. In Proceedings of the ACM Symposium on Parallelism in Algorithms and Architectures (SPAA '04) , pages 170-179, 2004.
- [5] Bundesnetzagentur f¨r Elektrizit¨t, Gas, Telekommunikation, Post und Eisenbahnen. T¨tigkeitsbericht u a a 2012/2013, 2013.
- [6] E. W. Dijkstra. Self-stabilizing systems in spite of distributed control. Communications of the ACM , 17(11):643-644, Nov. 1974.
| [7] | S. Dolev and R. I. Kat. HyperTree for Self-Stabilizing Peer-to-Peer Systems. In Proceedings of the IEEE International Symposium on Network Computing and Applications (NCA '04) , pages 25-32, 2004. |
|-------|--------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------|
| [8] | S. Dolev and N. Tzachar. Spanders: Distributed spanning expanders. Sci. Comput. Program. , 78(5):544- 555, May 2013. |
| [9] | D. Gall, R. Jacob, A. Richa, C. Scheideler, S. Schmid, and H. T¨ubig. a Time complexity of distributed topological self-stabilization: the case of graph linearization. In Proceedings of the Latin American Conference on Theoretical Informatics (LATIN '10) , pages 294-305, 2010. |
| [10] | R. Jacob, A. Richa, C. Scheideler, S. Schmid, and H. T¨ubig. a A distributed polylogarithmic time algorithm for self-stabilizing skip graphs. In Proceedings of the ACM Symposium on Principles of Distributed Computing (PODC '09) , pages 131-140, 2009. |
| [11] | R. Jacob, S. Ritscher, C. Scheideler, and S. Schmid. Towards higher-dimensional topological self- stabilization: A distributed algorithm for Delaunay graphs. Theor. Comput. Sci. , 457:137-148, Oct. 2012. |
| [12] | S. Kniesburges, A. Koutsopoulos, and C. Scheideler. Re-Chord: a self-stabilizing chord overlay network. In Proceedings of the ACM Symposium on Parallelism in Algorithms and Architectures (SPAA '11) pages 235-244, 2011. |
| [13] | S. Kniesburges, A. Koutsopoulos, and C. Scheideler. CONE-DHT: A Distributed self-stabilizing algo- rithm for a heterogeneous storage system. In Proceedings of the International Symposium on Distributed Computing (DISC'13) , 2013. |
| [14] | R. Meier and R. Wattenhofer. Peer-to-Peer Streaming in Heterogeneous Environments. Signal Process- ing: Image Communication , 27(5):457-469, March 2012. |
| [15] | W. Nejdl, M. Wolpers, W. Siberski, C. Schmitz, M. Schlosser, I. Brunkhorst, and A. L¨ser. o Super- peer-based routing and clustering strategies for RDF-based peer-to-peer networks. In Proceedings of the ACM International Conference on World Wide Web (WWW '03) , pages 536-543, 2003. |
| [16] | R. M. Nor, M. Nesterenko, and C. Scheideler. Corona: a stabilizing deterministic message-passing skip list. In Proceedings of the International Conference on Stabilization, Safety, and Security of Distributed Systems (SSS '11) , pages 356-370, 2011. |
| [17] | K. Pussep, C. Leng, and S. Kaune. Modeling User Behavior in P2P Systems. In K. Wehrle, M. G¨nes, u and J. Gross, editors, Modeling and Tools for Network Simulation , pages 447-461. Springer, 2010. |
| [18] | C. Scheideler and S. Schmid. A Distributed and Oblivious Heap. In Proceedings of the Internatilonal Collogquium on Automata, Languages and Programming (ICALP '09) , pages 571-582, 2009. |
| [19] | M. Schneider. Self-stabilization. ACM Computing Surveys , 25(1):45-67, Mar. 1993. |
| [20] | A. Shaker and D. S. Reeves. Self-Stabilizing Structured Ring Topology P2P Systems. In Proceedings of the IEEE International Conference on Peer-to-Peer Computing (P2P '05) , pages 39-46, 2005. |
| [21] | M. Srivatsa, B. Gedik, and L. Liu. Scaling Unstructured Peer-to-Peer Networks With Multi-Tier Capacity-Aware Overlay Topologies. In Proceedings of the IEEE Parallel and Distributed Systems, Tenth International Conference (ICPADS '04) , 2004. |
| [22] | M. Steiner, T. En-Najjary, and E. W. Biersack. Long term study of peer behavior in the KAD DHT. IEEE/ACM Trans. Netw. , 17(5):1371-1384, 2009. | | 10.1109/P2P.2014.6934300 | [
"Matthias Feldotto",
"Christian Scheideler",
"Kalman Graffi"
] | 2014-08-02T16:51:56+00:00 | 2014-11-27T14:08:54+00:00 | [
"cs.DC",
"cs.DS",
"cs.NI"
] | HSkip+: A Self-Stabilizing Overlay Network for Nodes with Heterogeneous Bandwidths | In this paper we present and analyze HSkip+, a self-stabilizing overlay
network for nodes with arbitrary heterogeneous bandwidths. HSkip+ has the same
topology as the Skip+ graph proposed by Jacob et al. [PODC 2009] but its
self-stabilization mechanism significantly outperforms the self-stabilization
mechanism proposed for Skip+. Also, the nodes are now ordered according to
their bandwidths and not according to their identifiers. Various other
solutions have already been proposed for overlay networks with heterogeneous
bandwidths, but they are not self-stabilizing. In addition to HSkip+ being
self-stabilizing, its performance is on par with the best previous bounds on
the time and work for joining or leaving a network of peers of logarithmic
diameter and degree and arbitrary bandwidths. Also, the dilation and congestion
for routing messages is on par with the best previous bounds for such networks,
so that HSkip+ combines the advantages of both worlds. Our theoretical
investigations are backed by simulations demonstrating that HSkip+ is indeed
performing much better than Skip+ and working correctly under high churn rates. |
1408.0396v1 | ## Two-dimensional C/BN core/shell structures
S. Cahangirov 1 and S. Ciraci 1, 2, ∗
1 UNAM-Institute of Materials Science and Nanotechnology, Bilkent University, Ankara 06800, Turkey 2 Department of Physics, Bilkent University, Ankara 06800, Turkey (Dated: August 5, 2014)
Single layer core/shell structures consisting of graphene as core and hexagonal boron nitride as shell are studied using first-principles plane wave method within density functional theory. Electronic energy level structure is analysed as a function of the size of both core and shell. It is found that the confinement of electrons in two dimensional graphene quantum dot is reduced by the presence of boron nitride shell. The energy gap is determined by the graphene states. Comparison of round, hexagonal, rectangular and triangular core/shell structures reveals that their electronic and magnetic states are strongly affected by their geometrical shapes. The energy level structure, energy gap and magnetic states can be modified by external charging. The core part acts as a two-dimensional quantum dot for both electrons and holes. The capacity of extra electron intake of these quantum dots is shown to be limited by the Coulomb blockade in two-dimension.
PACS numbers: 73.21.Fg, 68.65.Hb, 75.75.-c
## I. INTRODUCTION
Synthesis of the graphene structure 1 provided a new perspective to scientific community. This monoatomic layer of carbon atoms is the best media for investigating exciting physical phenomena in two-dimensions (2D). Graphene is a semimetal with unique electronic and mechanical properties. The intensive study on graphene structure rouse interest also in other 2D materials. 2,3 One of these materials is 2D honeycomb structure of boron nitride (BN). While few atomic layers of BN honeycomb structure was synthesized using micromechanical cleavage technique, 4 a single layer was obtained by electron irradiation. 5 The mechanical properties of graphene and BN are very similar. They have only 3 % of lattice mismatch and BN is the stiffest honeycomb structure after graphene. 3 The electronic structure, however, is very different. Graphene is a semimetal, while BN is a wide band gap material. 6-8
Due to their structural similarity and distinct electronic properties hexagonal BN (h-BN) and graphite structures are considered to be good candidates for fabricating composite B/N/C materials offering new functionalities. 9 Interesting phenomena like electron confinement, itinerant ferromagnetism and half metallicity was predicted theoretically in quasi-one-dimensional BN/C nanowire, nanotube/nanoribbon superlattices and hybrid BN/C nanoribbons/nanotubes. 10-16 Also nanotubes of BN/C in various patterns were synthesized experimentally. 17-19 Owing to synthesis of single layer composite structures consisting of adjacent BN and graphene domains, 20 C/BN core/shell (CS) structures have been a focus of interest. These structures can find novel technological applications in electronics and photonics in the view of the recent realization of nanoscale meshes or periodically patterned nanostructures. 21-24 Despite the ongoing intensive work on quasi-one-dimensional BN/C structures, 0D and 2D counterparts of these materials are not enough explored yet.
This paper investigates the CS structures of C and BN formed by their commensurate 2D hexagonal lattice. We report the variation of energy gap with respect to geometric parameters of the structures and link these results to quantum confinement phenomena. The shape of the CS structures, in particular whether they have round or rectangular shape, causes crucial effects in the electronic structure. We reveal the nature of the band edge states by analyzing the charge density profiles projected on those states. C/BN CS structure considered here constitutes a planar quantum dot. The effect of charging on these 2D quantum dots is investigated and the role of Coulomb blockade is discussed in detail.
## II. METHODS
Our predictions are obtained from the state-of-the-art first-principles plane wave calculations carried out within the spin-polarized density functional theory (DFT) using the projector augmented wave (PAW) potentials. 25 The exchange correlation potential is approximated by generalized gradient approximation (GGA) using PerdewBurke-Ernzerhof functional. 26 A plane-wave basis set with kinetic energy cutoff of 500 eV is used. All structures are treated within the supercell geometry; the lattice constants, as well as the positions of all atoms in the supercell are optimized by using the conjugate gradient method, where the total energy and atomic forces are minimized. 27 The convergence criterion for energy is chosen as 10 -5 eV between two steps. In the course of ionic relaxation, the maximum Hellmann-Feynman forces acting on each atom is kept less than 0.01 eV/ ˚ . The A vacuum separation between the structures in the adjacent unit cells is taken to be at least 10 ˚ . For charged A structures this value is at least 15 ˚. Also, A the necessary corrections 28,29 needed in calculations with charged cells were included in the fashion they are implemented
in the simulation package VASP, that we use. To calculate the energy gaps of large graphene patches we use the nearest neighbor tight-binding technique. Here the self energies of carbon atoms are set to zero and the nearest neighbor hopping integral is taken to be t = 2 7 eV. The . hopping integral between hydrogen and carbon atoms at the edges are taken to be zero. Although we mention the quantitative energy gap of the structures throughout the paper, there can be errors due to the lack of the selfenergy corrections in the method that we use. We think that, inclusion of these corrections would not result in a qualitative change in the observed trends.
## III. HEXAGONAL C/BN CS STRUCTURES: EFFECTS OF SIZE
In the Fig. 1(a) we present the geometric parameters used to define the hexagonal CS structures. Starting with a single hexagonal atomic structure we call its radius r = 1 then adding a new hexagonal ring to this structure we get a structure with a radius defined as r = 2. According to this definition we have investigated all hexagonal CS structures having total radius from r 2 = 2 to r 2 = 5 and inner radius from r 1 = 0 to r 1 = r 2 . This means that we also investigate structures composed of only C and only BN, which provide data for comparison. Note that, the low coordinated edge atoms are passivated by H atoms in all structures.
Figure 1(b) presents the calculated energy difference between the highest occupied (HOMO) and the lowest unoccupied (LUMO) molecular orbitals for all hexagonal CS structures investigated here. Due to the threefold symmetry of these structures, both the HOMO and the LUMO states are doubly degenerate. One can find several trends in Fig. 1(b). For instance, r 1 = 0 corresponds to hexagonal BN patches. As the radius r 2 of these structures is varied from 2 to 5 the energy gap is reduced by 0.6 eV. For comparison we can look at structures with r 1 = r 2 = 2 to 5 which corresponds to hexagonal C patches. This time the energy gap is lowered by 2.9 eV. This large difference as compared to BN occurs because in the graphene structure the π -orbitals of adjacent carbon atoms have the same energy and thus interact strongly. This leads to dispersive bands. In BN structure, however, π -orbitals of adjacent B and N atoms have large energy difference and have weaker interaction. This results in rather flat bands. In fact, the charge density projected on the HOMO states of BN structure is composed of weakly interacting (second nearest neighbor) π -states of N atoms. For graphene, the band edge states are composed of strongly interacting π -states of neighboring C atoms. Since the energy gap of BN and C structures with a certain finite size corresponds to certain folding of periodic band profiles, the dispersion of these bands are mirrored in the LUMO-HOMO gap variation of the finite structures with their size.
Now let r 1 = 2, when r 2 goes from 2 to 3 we add a
FIG. 1. (Color Online) (a) Ball and stick representation of single layer C/BN CS structure. The presented structure is denoted as CS( r 1 = 3, r 2 = 5). Here radii r 1 and r 2 are defined as number of hexagonal atomic rings formed by C atoms and total number of hexagonal rings, respectively. Note that, for r 2 ≤ 5 the atoms enclosed by a circle of this radius make a hexagonal structure. (b) The energy gap between the HOMO and the LUMO levels for hexagonal structures having various r 1 and r 2 values. (c) Energy gap trends for round graphene patches with various radii and edge patterns calculated from the first-principles and using the nearest neighbor tight-binding approximation. Ball and stick representation of these round structures are presented in the inset.
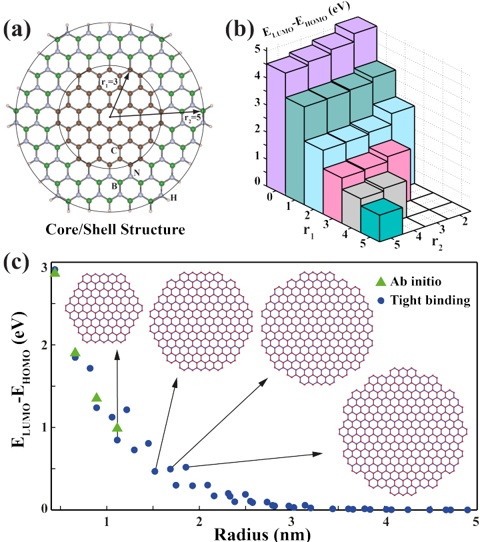
BN layer to hexagonal C structure. r 2 = 4 and 5 correspond to adding further BN layers to this CS structure. By adding one BN layer the energy gap decreases by 0.4 eV, however adding two more layers the energy gap decreases further by only 0.1 eV. Either surrounded by vacuum or BN layers, the graphene structure acts as a quantum well. Thus, the band edge states are confined in the graphene region. When the graphene structure is surrounded by the vacuum, these states are confined in higher potential barrier than when it was surrounded by BN structure. Buffering BN layer reduces the confinement strength, thereby reducing the energy gap. However this reduction in energy gap is low, compared to that when r 1 parameter of CS structure is increased. This again shows that the band edge states are determined by the core part, and the shell part has a minor effect on them.
We have to note that, the structures mentioned so far are very small and hard to be synthesized experimen-
tally, but larger structures compatible with experiment cannot be treated from the first-principles. For example, the size of BN domains in the recently synthesized BN/graphene heterostructure is estimated to range from 2 nm to 42 nm. 20 Also, graphene nanoflakes with sizes in the order of 10 nm have been synthesized by both bottom-up 30 and top-down 31 approaches.
Here we extrapolate our results obtained for the smaller structures using a single parameter nearest neighbor tight-binding calculation. Since the band edge states are determined by the core graphene structure, we have only performed tight-binding calculations of graphene patches saturated by hydrogen atoms at the edges. The results of these calculations are presented in Fig. 1(c). One can see that, for smaller structures the tight binding and ab initio calculations are in a good agreement. One can clearly see that the energy gaps decrease as the radii of the structures increase, which is due to the quantum size effect. However, this trend is sometimes breaks down due to the dominating effect of edge termination in smaller patches. This kind of behavior is highlighted in Fig. 1(c). Here one can see the increase in the energy gap with increasing radius, which is accompanied with different edge patterns shown in the inset. As the radius increases further, the effect of the edges ceases and the energy gap approaches zero. In fact, the calculated energy gap for round graphene patches having radii more than 4.5 nm is lower than 1 meV.
Figure 2 presents the energy level diagram for core, shell and CS structures individually. This figure does not include a band offset information; the first two columns are presented only for the sake of comparison. As mentioned in the previous paragraph, adding a shell reduces confinement of electrons in the core structure. This squeezes the energy levels slightly, but still the HOMO and the LUMO states of core structures are present in the CS structure, because the shell structure by itself has a large energy gap. Charge densities of the HOMO and the LUMO shown in the Fig. 2 clearly corroborate this fact. One can see the bonding and antibonding states of the doubly degenerate HOMO and LUMO confined in the core part. The nondegenerate state below the HOMO is confined at the interface of the core and the shell structure. However, this state is also attributed to the core structure, because core structures by themselves possess this state as an edge state. Moving deeper to the filled molecular orbitals one can also find states spread both on the core and shell parts. Also as shown in the bottom charge density plot of Fig. 2, deep down the filled orbitals there are states which are confined in the shell part.
## IV. ROUND, RECTANGULAR AND TRIANGULAR C/BN CS STRUCTURES: EFFECTS OF GEOMETRY
We now investigate the effect of shape on the electronic properties of the CS structures. Here we compare the en-
FIG. 2. (Color Online) Energy level diagram for fully relaxed hexagonal structure of C atoms, hexagonal shell structure of BN and CS structure which is formed by the combination of the first two structures. Isosurface charge densities projected on specific states of CS(2,4) structure. Single arrows correspond to the nondegenerate states. Charge densities of the doubly degenerate band edge states are shown by two arrows. The '+' sign between these two arrows denotes that the plotted charge density profile is the average values of two degenerate states. All plots have the same isosurface values. Zero of energy is set to the middle of the gap between HOMO and LUMO. The energy gap region is shaded.
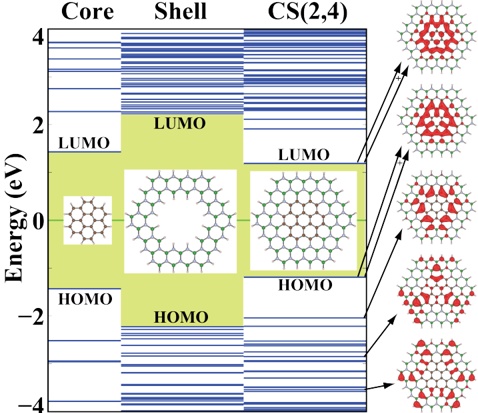
ergy levels and charge densities of the band edge states of round, rectangular and triangular CS structures with that of the hexagonal structures mentioned in the previous section. We start with the analysis of the large (C 204 B 123 N 123 H 54 ) structure, which is composed of 504 atoms and mimics a round CS structure. This way we can contrast hexagonal and round CS structures. The core radius of this structure is 12.7 A while the total radius ˚ is 19.4 ˚ . Unlike the hexagonal structures having linear A boundaries composed of zigzag edges, this structure has round boundaries with armchair and zigzag edges at both core and shell parts. Similar to hexagonal structures, the round structure also has threefold symmetry which results in the doubly degenerate band edge states. These states are confined in the core part of the round structure. The energy gap between its HOMO and LUMO states is calculated to be 0.77 eV. Moreover, as hexagonal structures, the round CS structures also have a nondegenerate state below the HOMO level, which is confined at the interface of the core and shell parts. Note that, both hexagonal and round structures have equal number of C atoms in each sublattice and, as expected by Lieb's theorem, 32 have a nonmagnetic ground state.
Figure 3 presents a comparison of the electronic energy levels of hexagonal, rectangular and triangular CS structures. To explore the effect of the shape we try
to compare structures having similar stoichiometry. Energy level diagram and charge densities projected to HOMO states of hexagonal (C 54 B 48 N 48 H 30 ) and rectangular (C 54 B 46 N 46 H 32 ) CS structures are presented in Fig. 3(a). Here we again see that the hexagonal CS structure have twofold degenerate HOMO states confined in the core part. HOMO states of rectangular CS structure are also confined in the core region, but upon the removal of the threefold symmetry the twofold degeneracy is lifted. One of the band edge states of rectangular structure remains at the same level as that of the hexagonal structure. This is attributed to nearly the same area of core parts which enclose the same number of carbon atoms and also that the charge density of this state is spread over the whole rectangular core part. The other band edge state, however, is shifted close to the Fermi level, thereby decreasing the band gap. The charge density of this state is confined at the zigzag edges of the core part of the rectangular structure. We have also calculated the electronic structure of the (C 54 H 20 ) structure which is composed of only core part of presented rectangular CS structure, namely rectangular core structure. Compared to rectangular CS structure, the states that are spread over whole rectangular core structure are located further apart from the Fermi level. In the previous section, similar effect was mentioned about the HOMO-LUMO gap of the hexagonal core structure, compared to hexagonal CS structure with the same core size. Conversely, HOMO and LUMO states of rectangular core structure are closer (0.03 eV) to Fermi level than those of the rectangular CS structure (0.15 eV). In fact, the HOMO and the LUMO states of the rectangular core structure are very similar and confined at both zigzag edges. Adding the shell, which consists of the dipolar BN, breaks the symmetry of the effective electronic potential of the rectangular core structure. The resulting effective potential of the rectangular CS structure is deeper in the left hand side, which further confines the bonding HOMO states towards left and the antibonding LUMO states towards right. This increase in the confinement strength explains the increase in the energy gap of the rectangular CS structure compared to that of the rectangular core structure. Rectangular CS structures presented here have the same number of C atoms in each sublattice and thus have total magnetic moment of zero.
In Fig. 3(b) the energy level diagram and charge densities of HOMO of hexagonal (C 24 B 36 N 36 H 24 ) and triangular (C 24 B 36 N 36 H 24 ) CS structures are presented. Note that, the hexagonal structure presented in this figure is also CS(2,4). Thus, the sum of the charge densities of the twofold degenerate band edge states of this structure can be compared to that in Fig. 2. Since the threefold symmetry is preserved in triangular CS structures, the band edge states are again doubly degenerate. But this time the difference between the number of atoms in each sublattice of the core structure is nonzero, being equal to two. Unpaired π -orbitals result in the breaking of the spin degeneracy and hence the structure gains a net
FIG. 3. (Color Online) (a) Comparison of hexagonal (C 54 B 48 N 48 H 30 ) and rectangular (C 54 B 46 N 46 H 32 ) CS structures. C and BN regions are delineated on the isosurface charge density plots. Band edge states of hexagonal structure is doubly degenerate, while in rectangular structure this degeneracy is lifted. (b) Comparison of hexagonal (C 24 B 36 N 36 H 24 ) and triangular (C 22 B 36 N 36 H 24 ) CS structures. Split majority and minority spin states of triangular structure are shown side by side. Band edge states of both hexagonal and triangular structures are doubly degenerate. Zero of energy is set at the middle of the energy gap between HOMO and LUMO and is shown by a dashed dotted lines. The energy gap region is shaded.
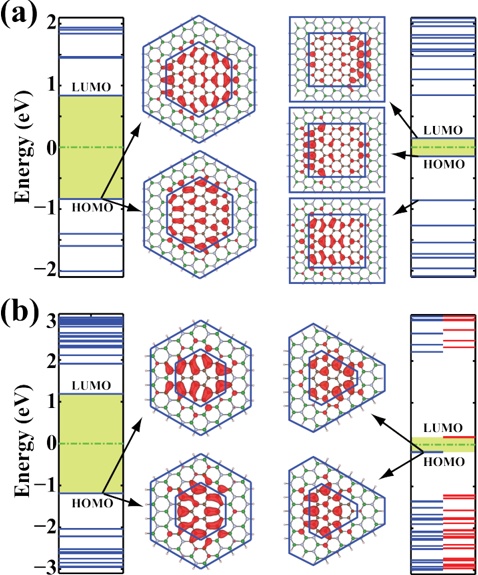
magnetic moment of 2 µ B . The difference in the number of atoms in each sublattice is proportional to the perimeter of the triangular core structures having zigzag edges. Thus, the magnitude of the magnetization is expected to increase with increasing size of the triangular core structures. 32-34 Because of the comparable core area, the HOMO-LUMO gap of the majority spins of the triangular CS structure is close to the gap of the hexagonal CS structure. However, the overall HOMO-LUMO gap of the triangular CS structure is diminished to 0.4 eV as compared to 2.4 eV gap of the hexagonal CS structure. Actually, the spin degenerate tight-binding and DFT calculations give zero energy gap for triangular core structures. Spin polarized tight-binding calculation 35 of triangular core structure results in 0.8 eV energy gap, and our DFT calculation gives 0.6 eV, while the net magnetic moment is 2 µ B . Note that, the energy gap, which is caused by the magnetization, is decreased upon the
inclusion of the shell structure. Similarly, while the magnetic state of the triangular core structure is favourable over the nonmagnetic state by 0.27 eV, in the triangular CS structure this energy difference is diminished to 0.15 eV. From these trends we deduce that, including the shell structure weakens the magnetization of the system, while preserving the total magnetic moment.
## V. EFFECTS OF CHARGING
From previous sections one can deduce that the CS structures of C/BN can be used as a quantum dot with core structure behaving as a quantum well for both electrons and holes. One can trap both positive and negative charges in these quantum dots. 36,37 To explore the effect of charging we have calculated the electronic structure of CS(2,4) structure when one or two electrons are added to or removed from the system.
Upon the removal of one electron the CS(2,4) +1 structure is formed. Minority spin part of one of the doubly degenerate HOMO is emptied and the system gains a magnetic moment of 1 µ B . The CS(2,4) +2 , which is formed upon the removal of the second electron has a doubly degenerate HOMO composed of majority spins. This situation gives rise to a total magnetic moment of 2 µ B . The LUMO is composed of doubly degenerate minority spin states located 0.2 eV above the HOMO. When one electron is added to pristine CS(2,4) structure the energy of the system lowers and a magnetic moment of 1 µ B is acquired. However, upon the injection of the second electron, the energy of the system is not lowered further, but increased. This is interpreted as the electron intake of the CS(2,4) structure being limited to only one. The forthcoming analysis corroborates this conclusion.
Figure 4(a) presents the energy level diagram for pristine and charged CS(2,4) structure with one or two electrons added or removed. One can see the levels shifting up as the electron is injected in the system. This is mainly attributed to increase in the Coulomb repulsion term on the electrons as the number of electrons is increased in the system. The magnitude of the shift is ∼ 1.6 eV per injected electron for both HOMO and LUMO levels. This can be explained by similar charge density distribution in HOMO and LUMO, both of which are confined in the core part. This shift sets a limit to the electron intake of the CS structure. As seen in Fig. 4(a), the LUMO of the CS(2,4) -1 structure is 0.9 eV below the vacuum level. This is the first available state for the second electron injection, but due to the shift of approximately 1.6 eV, the state will move above the vacuum level. This means that the second electron will stay in the vacuum, rather than filling the LUMO level of CS(2,4) -1 . This limitation of electron intake is a reminiscent of Coulomb blockade phenomena in 2D quantum dots. 38
Zero of energy in the level diagram of CS(2,4) -2 is not set to the local potential value at the most distant point
FIG. 4. (Color Online) (a) Energy level diagram for pristine and charged CS(2,4) structure. The minority and majority spin levels are shown at the left and right side of the same plot, respectively. The filled states are shown by dark (red) and the empty states are shown by light (green) lines. The energy level of edge and vacuum states mentioned in the text are shown by dashed dotted (blue) and dashed (black) lines, respectively. In all plots except the two electron injected case, zero of energy is set to the local potential value at the farthest place from the surface. The reason for this exception and the definition of zero energy for this plot is explained in the text. (b) Top panel: planarly averaged local potential difference between charged and pristine structures, plotted along the axis perpendicular to the surface. Bottom panel: planarly averaged linear charge density for specific states, plotted along the axis perpendicular to the structures. Contour plots of specific states averaged along this axis are shown on the honeycomb structure.
to the CS structure in the unit cell. This is because the second electron injected to the system fills the vacuum state, which is a state that is mainly spread far from the CS structure. Since such state is filled, the local potential at the vacuum region becomes ill-defined. This is seen in the top panel of Fig. 4(b), where we present the planarly averaged plot of local potential of charged structure minus that of the pristine structure. Here one can see that extracting two electrons from the system doubles the change of local potential profile formed upon extraction of only one electron. This linearity holds also in the case of injecting one electron to the system, where the change of local potential profile has the mirror symmetry of that of extracting one electron. However, injecting second electron does not give rise to practically any change in the local potential calculated for single electron injected case. Here the second electron is escaped into the vacuum, far from the CS atomic plane, thereby reducing the depth of potential, which otherwise should be two times deeper than that of one electron injected case. Also the height of local potential difference averaged on the CS plane is not doubled because the second electron is not confined in the core part of CS structure as the first one does. For the reasons stated here, we have not set zero of energy according to the ill-defined local potential of CS(2,4) -2 structure. Instead, we have extrapolated the position of slow varying vacuum level state of CS(2,4) and CS(2,4) -1 structures to set the vacuum level of CS(2,4) -2 structure.
The bottom panel of Fig. 4(b) presents the planarly averaged linear charge density for specific states. 39 The linear charge densities of pristine HOMO and LUMO states have a node at the plane of the CS structure with two symmetric rapidly decaying gaussians. This indicates the π nature of these states. The linear charge density of the vacuum state of pristine structure have nearly constant profile which indicates that this state barely interacts with the neutral CS structure. As seen in the charge density contour plots presented by inset, this state is spread throughout the vacuum part of the unit cell. The energy of vacuum states is indicated by dashed black lines in Fig. 4(a). Below these dashed lines there are no states with charge density spread throughout the vacuum. Note that, the energy of vacuum states are very close to the vacuum level determined by the local potential (zero of energy). When two electrons are injected to the system, the second electron fills the vacuum state. This time the CS structure is negatively charged and thus pushes the vacuum state away. This is clearly seen in both linear charge density and planar contour plot of this state.
Below the vacuum state of pristine structure there is an empty state which is localized around the CS structure but with a significant extension in the vacuum region. Such states were investigated in bulk graphite 40 and hexagonal BN 41 structures and were referred as interlayer states. Nevertheless, they were then observed also in isolated graphene 42 and BN 43 sheets. In fact, this state forms the conduction band edge of bulk and 2D
hexagonal structure of BN and makes these structures an indirect gap material. 43 Carbon 44 and BN 45 nanotubes also possess unoccupied free-electron-like states originating from 'interlayer' state of their 2D counterparts. 46 In the bottom panel of Fig. 4(b) we present the linear charge density and planar contour plots of 'interlayer' states of pristine and +2 e charged CS structures. We refer to these states as edge states. The location of edge states are delineated by dashed dotted lines in Fig. 4(a). One can see that these states also shift up upon injection of electron to the system. The magnitude of shift is ∼ 1.0 eV per injected electron, which is lower compared to that of the HOMO and LUMO, because this state has large extension in the vacuum region. The vacuum state itself shifts by only ∼ 0.1 eV upon injection of one electron.
We can readily say that the number of electrons that can be injected in quantum dots formed by C/BN CS structures are mainly limited by electron-electron Coulomb interactions. This is, so called, Coulomb blockade in 2D. It should be noted that, the charging capacity of CS structures can be increased by increasing their size. The larger the core part of the CS structure the more states will be available. Also since electrons will be spread in a larger core area, the Coulomb interaction between electrons will decrease. 38 This will decrease the magnitude of the shift in the states due to electron injection. We have performed the electron injection analyses on larger structures to test these trends. Upon injection of one electron into both hexagonal and rectangular CS structures, presented in the Fig. 3(a), the energy levels were shifted up by ∼ 1.1 eV. In CS(2,4) structure, this shift is ∼ 1.5 eV, which corroborates the trend. Our calculations also show that, the intake capacity of both hexagonal and rectangular CS structures presented in Fig. 3(a) is two electrons. This is also expected, since the core part of these structures are larger than that of the CS(2,4) structure. We should note that, the shape of the CS structures have minor effect on the magnitude of the shift of the energy levels upon charging and thus have minor effect on the electron intake capacity.
## VI. DISCUSSIONS AND CONCLUSIONS
We presented a theoretical analysis of a single layer, composite structure consisting of graphene as core and hexagonal BN as shell, which can make a pseudomorphic heterostructure with a 3% lattice mismatch. Graphene being a semimetal or semiconductor and BN being a wide band gap insulator the graphene/BN CS structure can function as a quantum dot. Recent studies 20 reporting the synthesis of composite structures consisting of adjacent hexagonal BN and graphene domains herald the realization of graphene/BN CS structures. In this study, we examined the effects of size, geometry and charging on the electronic and magnetic properties of graphene/BN CS structures. Unexpectedly, the confinement of states in graphene core is relaxed by the presence of BN shell.
The band gap decreases with increasing the size of the graphene core. The energy level structure, HOMOLUMO gap and magnetic state of C/BN CS structures can be tuned by engineering their size and shape, which may lead to interesting applications. Another recent progress in nanotechnology reporting the fabrication of periodically repeating patterns, or simply nanomeshes, 22 can be combined with the fabrication of C/BN CS structures to realize arrays of graphene domains in BN layer. Here BN layer can play the role of a dielectric holding multiple and periodic domains of graphene. In visa versa BN dielectric domains in semimetallic graphene layer can be an interesting structure for photonic applications.
- ∗ [email protected]
- 1 K. S. Novoselov, A. K. Geim, S. V. Morozov, D. Jiang, Y. Zhang, S. V. Dubonos, I. V. Grigorieva, and A. A. Firsov, Science 306 , 666 (2004).
- 2 S. Cahangirov, M. Topsakal, E. Akt¨rk, H. Sahin, and S. u ¸ Ciraci, Phys. Rev. Lett. 102 , 236804 (2009).
- 3 H. S ¸ahin, S. Cahangirov, M. Topsakal, E. Bekaroglu, E. Akt¨ urk, R. T. Senger, and S. Ciraci, Phys. Rev. B 80 , 155453 (2009).
- 4 D. Pacil´, e J. C. Meyer, C. O. Girit, and A. Zettl, Appl. ¸ ¨ Phys. Lett. 92 , 133107 (2008).
- 5 C. Jin, F. Lin, K. Suenaga, and S. Iijima, Phys. Rev. Lett. 102 , 195505 (2009).
- 6 K. Novoselov, Nature Mater. 6 , 720 (2007).
- 7 K. Watanabe, T. Taniguchi, and H. Kanda, Nature Mater. 3 , 404 (2004).
- 8 C. Ataca and S. Ciraci, Phys. Rev. B 82 , 165402 (2010).
- 9 M. Kawaguchi, Adv. Mater. 9 , 615 (1997).
- 10 J. Choi, Y. H. Kim, K. J. Chang, and D. Tom´nek, Phys. a Rev. B 67 , 125421 (2003).
- 11 H. Sevin¸ cli, M. Topsakal, and S. Ciraci, Phys. Rev. B 78 , 245402 (2008).
- 12 A. Du, Y. Chen, Z. Zhu, G. Lu, and S. C. Smith, J. Am. Chem. Soc. 131 , 1682 (2009).
- 13 Y. Ding, Y. Wang, and J. Ni, Appl. Phys. Lett. 95 , 123105 (2009).
- 14 Z. Y. Zhang, Z. Zhang, and W. Guo, J. Phys. Chem. C 113 , 13108 (2009).
- 15 J. M. Pruneda, Phys. Rev. B 81 , 161409(R) (2010).
- 16 B. Huang, C. Si, H. Lee, L. Zhao, J. Wu, B. Gu, and W. Duan, Appl. Phys. Lett. 97 , 043115 (2010).
- 17 W. L. Wang, X. D. Bai, K. H. Liu, Z. Xu, D. Golberg, Y. Bando, and E. G. Wang, J. Am. Chem. Soc. 128 , 6530 (2006).
- 18 S. Y. Kim, J. H. Park, H. C. Choi, J. P. Han, J. Q. Hou, and H. S. Kang, J. Am. Chem. Soc. 129 , 1705 (2007).
- 19 S. Enouz, O. St´phan, J.-L. Colliex, and A. Loiseau, Nano e Lett. 7 , 1856 (2007).
- 20 L. Ci, L. Song, C. Jin, D. Jariwala, D. Wu, Y. Li, A. Srivastava, Z. F. Wang, K. Storr, L. Balicas, F. Liu, and P. M. Ajayan, Nature Mater. 9 , 430 (2010).
- 21 A. Rubio, Nature Mater. 9 , 379 (2010).
- 22 J. Bai, X. Zhong, S. Jiang, Y. Huang, and X. Duan, Nature Nanotech. 5 , 190 (2010).
## VII. ACKNOWLEDGEMENT
This work is partially supported by TUBA. We thank the DEISA Consortium (www.deisa.eu), funded through the EU FP7 project RI-222919, for support within the DEISA Extreme Computing Initiative. Also, part of the computations have been provided by UYBHM at Istanbul Technical University through a Grant No. 2-0242007. We thank Hasan Sahin for fruitful discussions. ¸
- 23 A. Goriachko and H. Over, Zeitschrift f¨r u Physikalische Chemie 223 , 157 (2009).
- 24 H. Ma, M. Thomann, J. Schmidlin, S. Roth, M. Morscher and T. Greber, Frontiers of Physics in China 5 , 387 (2010).
- 25 P. E. Bl¨chl, Phys. Rev. B o 50 , 17953 (1994).
- 26 J. P. Perdew, K. Burke, and M. Ernzerhof, Phys. Rev. Lett. 77 , 3865 (1996).
- 27 G. Kresse and J. Furthmuller, Phys. Rev. B 54 , 11169 (1996).
- 28 G. Makov and M. C. Payne, Phys. Rev. B 51 , 4014 (1995).
- 29 J. Neugebauer and M. Scheffler, Phys. Rev. B 46 , 16067 (1992).
- 30 X. Yan, X. Cui, B. Li, and L. Li, Nano Lett. 10 , 1869 (2010).
- 31 L. C. Campos, V. R. Manfrinato, J. D. Sanchez-Yamagishi, J. Kong, and P. Jarillo-Herrero, Nano Lett. 10 , 2600 (2009).
- 32 E. H. Lieb, Phys. Rev. Lett. 62 , 1201 (1989).
- 33 W. L. Wang, S. Meng, and E. Kaxiras, Nano Lett. 8 , 241 (2008).
- 34 H S ¸ahin, R. T. Senger and S. Ciraci J. Appl. Phys. 108 , 074301 (2010).
- 35 O. V. Yazyev, Rep. Prog. Phys. 73 056501 (2010).
- 36 A. D. G¨¸ cl¨, P. Potasz, O. Voznyy, M. Korkusinski, and u u P. Hawrylak, Phys. Rev. Lett. 103 , 246805 (2009).
- 37 J. M. Pereira , V. Mlinar, F. M. Peeters, and P. Vasilopoulos, Phys. Rev. B 74 , 045424 (2006).
- 38 M. Ezawa, Phys. Rev. B 77 , 155411 (2008).
- 39 The planarly averaged linear charge density is defined as λ z ( ) = ∫ ∫ | Ψ( x, y, z ) | 2 dxdy , where z is perpendicular to the CS structure.
- 40 M. Posternak, A. Baldereschi, A. J. Freeman, and E. Wimmer, Phys. Rev. Lett. 52 , 863 (1984).
- 41 A. Catellani, M. Posternak, and A. Baldereschi, H. J. F. Jansen and A. J. Freeman, Phys. Rev. B 32 , 6997 (1985).
- 42 D. Pacile, M. Papagno, A. Fraile Rodriguez, M. Grioni, L. Papagno, C. O. Girit, J. C. Meyer, G. E. Begtrup, and A. ¸ ¨ Zettl, Phys. Rev. Lett. 101 , 066806 (2008).
- 43 X. Blase, A. Rubio, S. G. Louie, and M. L. Cohen, Phys. Rev. B 51 , 6868 (1995).
- 44 S. Okada, A. Oshiyama, and S. Saito, Phys. Rev. B 62 , 7634 (2000).
- 45 X. Blase, A. Rubio, S. G. Louie, and M. L. Cohen, Europhys. Lett. 28 , 335 (1994).
- 46 V. M. Silkin, J. Zhao, F. Guinea, E. V. Chulkov, P. M. Echenique, and H. Petek, Phys. Rev. B 80 , 121408(R) (2009). | 10.1103/PhysRevB.83.165448 | [
"S. Cahangirov",
"S. Ciraci"
] | 2014-08-02T16:54:42+00:00 | 2014-08-02T16:54:42+00:00 | [
"cond-mat.mes-hall",
"physics.comp-ph"
] | Two-dimensional C/BN core/shell structures | Single layer core/shell structures consisting of graphene as core and
hexagonal boron nitride as shell are studied using first-principles plane wave
method within density functional theory. Electronic energy level structure is
analysed as a function of the size of both core and shell. It is found that the
confinement of electrons in two dimensional graphene quantum dot is reduced by
the presence of boron nitride shell. The energy gap is determined by the
graphene states. Comparison of round, hexagonal, rectangular and triangular
core/shell structures reveals that their electronic and magnetic states are
strongly affected by their geometrical shapes. The energy level structure,
energy gap and magnetic states can be modified by external charging. The core
part acts as a two-dimensional quantum dot for both electrons and holes. The
capacity of extra electron intake of these quantum dots is shown to be limited
by the Coulomb blockade in two-dimension. |
1408.0397v2 | 
Nuclear Physics A

Nuclear Physics A 00 (2014) 1-4
## Transverse energy (E T ) distributions at mid-rapidity in p + p , d + Au and Au + Au collisions at p s NN = 200 GeV and implications for particle production models
M. J. Tannenbaum (for the PHENIX Collaboration) 1
Physics Department, Brookhaven National Laboratory, Upton, NY 11973-5000, USA
## Abstract
Measurements of the mid-rapidity transverse energy distribution d E T = d GLYPH<17> are presented for p + p , d + Au, and Au + Au collisions at p s NN = 62.4-200 GeV. The E T distributions are compared with the number of participants, N part , the number of constituent-quark participants, Nqp , and the number of color-strings (Additive Quark Model - AQM) calculated from a Glauber model. For Au + Au, h d E T = d GLYPH<17> i = (0 5 : N part ) increases with N part , while h d E T = d GLYPH<17> i = Nqp is approximately constant vs. centrality for p s NN GLYPH<21> 62 4 GeV. This : indicates that the two component ansatz, d E T AA = d GLYPH<17> = ( d E T pp = d GLYPH<17> ) [(1 GLYPH<0> x ) N part = 2 + x N coll ], which has been used to represent E T distributions, is simply a proxy for Nqp , and that the N coll term does not represent a hard-scattering component in E T distributions. The d E T = d GLYPH<17> distributions of d + Au, and Au + Au are calculated from the measured p + p E T distribution using two models (AQM and Nqp ) that both reproduce the Au + Au data. For the asymmetric d + Au system, the Nqp model reproduces the data while the AQMdoes not.
Keywords: Transverse energy, Constituent-quarks, RHIC
## 1. Introduction
Recent PHENIX measurements of mid-rapidity transverse energy distributions d E T = d GLYPH<17> (more properly d E T = d GLYPH<17> j GLYPH<17> = 0 , measured in an electromagnetic calorimeter and corrected to total hadronic E T within a reference acceptance of GLYPH<1> GLYPH<17> = 1 0 : ; GLYPH<1> GLYPH<30> = 2 GLYPH<25> [1]) are presented for p + p , d + Au and Au + Au collisions at p s NN = 200 GeV and Au + Au collisions at p s NN = 62.4 and 130 GeV. The transverse energy E T is a multiparticle variable defined as the sum
$$E _ { T } = \sum _ { i } E _ { i } \, \sin \theta _ { i } \quad d E _ { T } ( \eta ) / d \eta = \sin \theta ( \eta ) \, d E ( \eta ) / d \eta,$$
where GLYPH<18> is the polar angle, GLYPH<17> = GLYPH<0> ln tan GLYPH<18>= 2 is the pseudorapidity, Ei is by convention taken as the kinetic energy for baryons, the kinetic energy + 2 mN for antibaryons, and the total energy for all other particles, and the sum is taken over all particles emitted into a fixed solid angle for each event.
The transverse energy, E T , was introduced by high energy physicists [2, 3] as an improved method to detect and study the jets from hard-scattering compared to high pT single particle spectra by which hard-scattering was discovered in p + p collisions and used as a hard-probe in Au + Au collisions at RHIC. However, it didn't work as expected: E T distributions are dominated by soft particles near h pT i [4].
1 A list of members of the PHENIX Collaboration and acknowledgements can be found at the end of this issue.
The significance of systematic measurements of mid-rapidity d E T = d GLYPH<17> and the closely related charged particle multiplicity distributions, dN ch = d GLYPH<17> , in A + B collisions is that they provide excellent characterization of the nuclear geometry (hence centrality) of the reaction on an event-by-event basis, and are also sensitive to the underlying reaction dynamics. For instance, measurements of dN ch = d GLYPH<17> in Au + Au collisions at the Relativistic Heavy Ion Collider (RHIC), as a function of centrality expressed as the number of participating nucleons, N part , do not depend linearly on N part but have a nonlinear increase of h dN ch = d GLYPH<17> i with increasing N part . The nonlinearity has been explained by a two component model [5, 6] proportional to a linear combination of N coll and N part , with the implication that the N coll term represents a contribution from hard-scattering. Alternatively, it has been proposed that dN ch = d GLYPH<17> is linearly proportional to the number of constituent-quark participants (NQP) model [7], without need to introduce a hard-scattering component. For symmetric systems such as Au + Au, the NQP model is identical to another model from the 1980s, the Additive Quark Model (AQM) [8], which is actually a model of particle production by color-strings in which only one colorstring can be attached to a constituent-quark participant. The models can be distinguished for asymmetric systems such as d + Au, since in the AQM the maximum number of color-strings is limited to the number of constituent-quarks in the lighter nucleus, or six for d + Au, while the NQP allows all the quark participants in both nuclei to emit particles. The two-component ansatz, the NQP model and the AQM will be tested with the present data.
## 2. Extreme independent models
The models mentioned above are examples of Extreme Independent Models in which the e GLYPH<11> ect of the nuclear geometry of the interaction can be calculated independently of the dynamics of particle production which can be taken directly from experimental measurements. The nuclear geometry is represented by the relative probability, wn per B + A interaction for a given number n of fundamental elements, in the present case, number of collisions ( N coll ), number of nucleon participants (wounded nucleon model - WNM [10]), number of constituent-quark participants ( Nqp ), number of color-strings (AQM). The dynamics of particle production, the N ch or E T distribution of the fundamental element, is taken from the measured p + p data in the same detector: e.g. the measured N ch distribution for a p + p collision represents: 1 collision; 2 participants (WNM); a predictable convolution of constituent-quark participants (NQP), or projectile-quark participants (AQM). Glauber calculations of the nuclear geometry ( wn ) and the p + p measurement provide a prediction for the B + A measurement in the same detector as the result of particle production by multiple independent fundamental elements. www.annualreviews.org/aronline Annual Reviews
I became acquainted with these models in my first Quark Matter talk (QM1984), in which I presented measurements of E T distributions from p + p and GLYPH<11> + GLYPH<11> interactions at p s NN = 31 GeV at the CERN-ISR (Fig. 1a [11, 12]). It was claimed at the meeting that the deviation from the WNM was due to jets [13], but in both proceedings [12, 13] it was demonstrated that 'there is no . . . sign of jets. This indicates that soft processes are still dominant, and that we are still legimately testing the WNM at these high values of E T .' [13]. As shown in Fig. 1a, the WNM did not follow the data but the AQM did [9]. Jets do appear in E T distributions as a break < GLYPH<24> 10 GLYPH<0> 5 down in cross section (Figs. 1b,c). JETS IN HADRONIC COLLISIONS 111 clear peak at A~o12 = 180 is observed, which ndicates that the two clusters ¡ i are coplanar with the beam irection. d The emergence f two-cluster structures in events with large ~ ET is even o more dramatically illustrated by inspecting the transverse energy distribution over the calorimeter ells. c Figure 4 shows uch a distribution for four s typical events having ~ ET > 100 GeV. The transverse energy appears to be concentrated within two (or, more rarely, three) small angular regions. These energy clusters appear to be associated with collimated multiparticle systems (jets), as found by reconstructing the charged-particle tracks these events (see Figure 5). Furthermore, longitudinal shower develop- ments, as measured n the calorimeter, are found to be inconsistent,
i
in general, with those of single particles,
but consistent with those of jets containing both charged hadrons and photons (from o d ecay).
Annu. Rev. Nucl. Part. Sci. 1985.35:107-134. Downloaded from arjournals.annualreviews.org the UA2
central calorimeter.
Figure 1. (a) E T distributions in p + p , GLYPH<11> + GLYPH<11> [11] at p s NN = 31 GeV, with AQM and WNM calculations [9]. (b),(c) E T distributions with breaks indicating jets: (b) p + p p s = 62.3 GeV [14]; (c) d GLYPH<27>= d E T (nb GeV) vs. E / T for ¯ p + p p s = 540 GeV [15].
## 3. E T and N ch distributions cut on centrality
At RHIC, following the style of the CERN SpS rather than the BNL-AGS fixed target heavy ion program, E T and N ch distributions were not generally shown. The measurements were presented cut in centrality in the form h dN ch AA = d GLYPH<17> i = ( h N part i = 2) vs. h N part i (Fig. 2), which would be a constant equal to h dN ch pp = d GLYPH<17> i if the WNM worked. The measurements clearly deviate from the WNM (Fig. 2a) [16]; so the PHENIX collaboration, inspired by the
c)
Figure 2. (a) PHENIX, Au + Au, p s NN = 130 GeV [16]; (b) ALICE, Pb + Pb, p s NN = 2.76 TeV [17]; (c) PHENIX preliminary Au + Au, p s NN = 7.7 GeV compared to the data at larger p s NN [18].
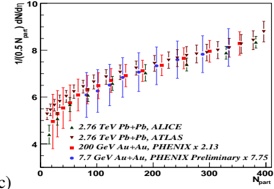
preceding article in the journal [5], fit their data to the two-component ansatz:
$$d N _ { \text{ch} } ^ { A A } / d \eta = \left ( d N _ { \text{ch} } ^ { p p } / d \eta \right ) \left [ \left ( 1 - x \right ) \langle N _ { \text{part} } \rangle / 2 + x \langle N _ { \text{coll} } \rangle \right ]$$
where the N coll term implied a hard-scattering component for E T and N ch , known to be absent in p-p collisions 2 (recall Fig. 1). A decade later, the first measurement from Pb + Pb collisions with p s NN = 2.76 TeV at the LHC Fig. 2b [17], showed exactly the same shape vs. N part as the RHIC Au + Au data at p s NN = 200 GeV, although h N coll i is a factor of 1.6 larger and the hard-scattering cross section is more than a factor of 20 larger. This strongly argued against a hard-scattering component and for a nuclear geometrical e GLYPH<11> ect, which was reinforced by a PHENIX preliminary measurement in Au + Au at p s NN = 7.7 GeV (Fig. 2c) [18] which also showed the same shape for the evolution of h dN ch AA = d GLYPH<17> i = ( h N part i = 2) with N part as the p s NN = 200 and 2760 GeV measurements. It had previously been proposed that the number of constituent-quark participants provided the nuclear geometry that could explain the RHIC Au + Au data without the need to introduce a hard-scattering component [7]. However an asymmetric system is necessary in order to distinguish the NQP model from the AQM so the two models were applied to the RHIC d + Au data.
## 4. The number of constituent-quark participant model (NQP)
The massive constituent-quarks [19], which form mesons and nucleons (e.g. a proton = uud ), are relevant for static properties and soft physics with pT < 2 GeV c. / They are complex objects or quasiparticles [21] made of the massless partons (valence quarks, gluons and sea quarks) of DIS [20] such that the valence quarks acquire masses GLYPH<25> 1 3 the nucleon mass with radii = GLYPH<25> 0 3 fm when bound in the nucleon. : With smaller resolution one can see inside the bag to resolve the massless partons which can scatter at large angles according to QCD. At RHIC, hardscattering is distinguishable from soft (exponential) particle production only for pT GLYPH<21> 2 GeV c at mid-rapidity, where / Q 2 = 2 p 2 T = 8 (GeV c) 2 / which corresponds to a distance scale (resolution) < 0 07 fm. :
Astandard Monte Carlo Glauber calculation is used to assemble the initial positions of all the nucleons. Then three quarks are distributed around the center of each nucleon according to the proton charge distribution GLYPH<26> ( ~ r ) / e GLYPH<0> p 12 r = r rms , where r rms = 0 81 fm is the rms charge radius of the proton [22]. : The q -q inelastic scattering cross section is adjusted to 9.36 mb at p s = 200 GeV to give the correct p + p inelastic cross section (42 mb) and then used in the B A calculations. + Fig. 3a shows the deconvolution of the p + p E T distribution to the sum of 2-6 constituent-quark participants from which the E T distribution of a constituent-quark is determined and applied to d + Au (Fig. 3b) and
2 It was noted in Ref. [16] that hard-scattering was not a unique interpretation. The shape of the centrality dependences of d E T AA = d GLYPH<17> parameterized as N part GLYPH<11> were the same for Pb + Pb at p s NN = 17.6 GeV at the CERN SpS and Au + Au at p s NN = 130 GeV, with GLYPH<11> = 1 1 and : GLYPH<11> = 1 16 : GLYPH<6> 0 04, : respectively. The LHC data 10 years later [17] gave GLYPH<11> = 1 19 : GLYPH<6> 0 02 for Pb : + Pb at p s NN = 2760 GeV, again the same shape.
]
-1
1
[GeV
(a)
10
-1
200 GeV p+p
T
Au + Au (Fig. 3c) reactions in the same detector. The NQP calculations closely follow the measured d + Au and Au + Au E T distributions in shape and magnitude over a range of more than 1000 in cross section. A complete calculation was also done for the AQM which fails to describe the d + Au data (Fig. 3b). The conclusion is that it is the number of constituent-quark participants that determine the N ch and E T distributions and that the AQM calculation which describes the GLYPH<11> -GLYPH<11> data at p s NN = 31 GeV (Fig. 1a) is equivalent to the NQP in the symmetric system. 0 20 40 60 dY/dE -6 10 -5 10 -4 10 -3 10 -2 10 1 color-string 2 color-strings 3 color-strings
=0.538
AQM
∈
AQM fit sum,
E
[GeV]
T
Figure 3. PHENIX NQP calculations [1] for (a) p + p , (b) d + Au (also AQM), (c) Au + Au E T distributions at p s NN = 200 GeV.
The NQP model was also applied to the centrality cut PHENIX data with the result that d E T = d GLYPH<17> is strictly proportional to Nqp (Fig 4a) so that d E T = d GLYPH<17>= ( Nqp = 2) vs. Nqp is a constant for p s NN > GLYPH<24> 27 GeV (Fig 4b). As a final touch, the ratio of the two-component ansatz with x = 0 08 to the : Nqp as a function of centrality was found to be constant to better than 1% at p s NN = 200 GeV (Fig 4c), which indicates that the ansatz works because the particular linear combination of N part and N coll turns out to be an empirical proxy for Nqp and not because the N coll term implies hard-scattering.
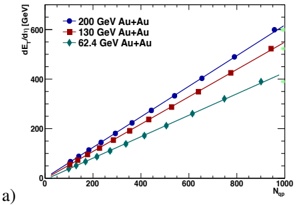
b)
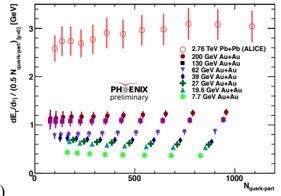
c)
Figure 4. PHENIX [1]: (a) d E T = d GLYPH<17> vs. Nqp ; (b) d E T = d GLYPH<17>= ( Nqp = 2) vs. Nqp ; (c) ( Nqp / ansatz) / h Nqp = ansatz i vs. N part .
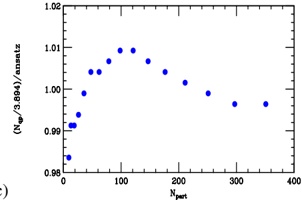
## References
- [1] PHENIX Collaboration, S.S.Adler et al., Phys. Rev. C 89 (2014) 044905 .
- [2] W. J. Willis, Report CRISP-72-15, BNL-16841, Upton, NY, 1972.
- [3] J.D.Bjorken, Phys. Rev. D 8 (1973) 4098 .
- [4] E.g. see Jan Rak and Michael J. Tannenbaum, High pT Physics in the Heavy Ion Era, Cambridge University Press, Cambridge, 2013.
- [5] X.-N. Wang and M. Gyulassy, Phys. Rev. Lett. 86 (2001) 3496 .
- [6] D. Kharzeev and M. Nardi, Phys. Lett. B 507 (2001) 121 .
- [7] S. Eremin and S. Voloshin, Phys. Rev. C 67 (2003) 064905 .
- [8] A. Bialas, W. Czyz, and L. Lesniak, Phys. Rev. D 25 (1982) 2328 .
- [9] T. Ochiai, Z. Phys. C 35 (1987) 209 .
- [10] A. Białas, M. Bleszy´ nski, and W. Czy˙ z, Nucl. Phys. B 111 (1976) 461 .
- [11] BCMOR Collaboration, A.L.S. Angelis et al., Phys. Lett. B 141 (1984) 140 .
- [12] BCMOR Collaboration, Michael J. Tannenbaum et al., Lect. Notes Phys. 221 (1985) 174 .
- [13] AFS Collaboration, Bruce Callen et al., Lect. Notes Phys. 221 (1985) 133 .
- [14] CMOR Collaboration, A.L.S. Angelis et al., Nucl. Phys. B 244 (1984) 1 .
- [15] L. DiLella, Annu. Rev. Nucl. Part. Sci. 35 (1985) 107 .
- [16] PHENIX Collaboration, K. Adcox et al., Phys. Rev. Lett. 86 (2001) 3500 .
- [17] ALICE Collaboration, K. Aamodt et al., Phys. Rev. Lett. 106 (2011) 032301 .
- [18] PHENIX Collaboration J. T. Mitchell et al., PoS CPOD2013 (2013) 003.
- [19] M. Gell-Mann, Phys. Lett. 8 (1964) 214 .
- [20] M. Breidenbach et al., Phys. Rev. Lett. 23 (1969) 935 .
- [21] E. V. Shuryak, Nucl. Phys. B 203 (1982) 116 .
- [22] R. Hofstadter, F. Bumiller, and M. R. Yerian, Rev. Mod. Phys. 30 (1958) 482 . | 10.1016/j.nuclphysa.2014.07.048 | [
"M. J. Tannenbaum"
] | 2014-08-02T16:58:20+00:00 | 2014-08-13T16:25:44+00:00 | [
"nucl-ex"
] | Transverse Energy ($E_T$) distributions at mid-rapidity in $p$$+$$p$, $d$$+$Au and Au$+$Au collisions at $\sqrt{s_{_{NN}}}$=200 GeV and implications for particle production models | Measurements of the midrapidity transverse energy distribution $d{\rm
E}_T/d\eta$ are presented for $p$$+$$p$, $d$$+$Au, and Au$+$Au Collisions at
$\sqrt{s_{_{NN}}}$=62.4--200 GeV. The ${\rm E}_T$ distributions are compared
with the number of participants, $N_{\rm part}$, the number of
constituent-quark participants, $N_{qp}$, and the number of color-strings
(Additive Quark Model-AQM) calculated from a Glauber model. For Au$+$Au,
$\langle d{\rm E}_T/d\eta/(0.5 N_{\rm part})\rangle$ increases with $N_{\rm
part}$, while $\langle d{\rm E}_T/d\eta/N_{qp}\rangle$ is approximately
constant vs. centrality for $\sqrt{s_{_{NN}}} \geq 62.4$ GeV. This indicates
that the two component ansatz, $d{\rm E}_T^{\rm AA}/d\eta=(d{\rm E}_T^{\rm
pp}/d\eta)\ [(1-x)\, N_{\rm part}/2 + x\, N_{\rm coll}]$, which has been used
to represent ${\rm E}_T$ distributions, is simply a proxy for $N_{qp}$, and
that the $N_{\rm coll}$ term does not represent a hard-scattering component in
${\rm E}_T$ distributions. The $d{\rm E}_T/d\eta$ distributions of $d$$+$Au,
and Au$+$Au are calculated from the measured $p$$+$$p$ ${\rm E}_T$ distribution
using two models (AQM and $N_{qp}$) that both reproduce the Au$+$Au data. For
the asymmetric $d$$+$Au system, the $N_{qp}$ model reproduces the data while
the AQM does not. |
1408.0398v1 | ## Study of Antigravity in an F(R) Model and in Brans-Dicke Theory with Cosmological Constant
V.K. Oikonomou ∗
Department of Theoretical Physics, Aristotle University of Thessaloniki, 54124 Thessaloniki, Greece
†
N. Karagiannakis Polytechnic School, Aristotle University of Thessaloniki, 54124 Thessaloniki, Greece
August 5, 2014
## Abstract
We study antigravity, that is having an effective gravitational constant with a negative sign, in scalar-tensor theories originating from F R ( )-theory and in a Brans-Dicke model with cosmological constant. For the F R ( ) theory case, we obtain the antigravity scalar-tensor theory in the Jordan frame by using a variant of the Lagrange multipliers method and we numerically study the time dependent effective gravitational constant. As we shall demonstrate by using a specific F R ( ) model, although there is no antigravity in the initial model, it might occur or not in the scalar-tensor counterpart, mainly depending on the parameter that characterizes antigravity. Similar results hold true in the Brans-Dicke model.
## Introduction
During the last two decades our perception about the universe has changed drastically owing to the discovered late time acceleration that our universe has. Particularly, it can be thought as one of the most striking astrophysical observations with another striking observation being the verification of the inflating period of our universe. Actually, moving from time zero to present time, inflation came first, with the late time acceleration occurring at present epoch. One of the greater challenges in cosmology is to model this late time acceleration in a self consistent way. According to the new Planck telescope observational data for the present epoch, the universe is consistently described by the ΛCDM model, according to which the universe is nearly spatially flat, and consists of ordinary matter ( ∼ 4 9%), cold dark matter ( . ∼ 26 8%) and dark energy ( . ∼ 68 3%). . The dark energy is
∗ [email protected]
† [email protected]
actually responsible for late time acceleration and current research on the field is mostly focused on this issue.
One of the most promising and theoretically appealing descriptions of dark energy and late time acceleration issues, is provided by the F R ( ) modified theories of gravity and related modifications. For important review articles and papers on the vast issue of F R ( ) theories, the reader is referred to [1-20] and references therein. For some alternative theories to modified gravity that model dark energy, see [21-26]. The most appealing characteristic of modified gravity theories theories is that, what is actually changed is not the left hand side of the Einstein equations, but the right hand side. Late time acceleration then, requires a negative w fluid, which can be consistently incorporated in the energy momentum tensor of these theories. This feature naturally appears in F R ( ) theories and also late time acceleration solutions of the Friedmann-Robertson-Walker equations, naturally occur in these theoretical frameworks [1-20,27]. In addition, inflation, the first accelerating period of our universe, is also consistently described by some F R ( ) theories, rendering the latter a very elegant and economic description of nature at large scales, where General Relativity fails to describe phenomena consistently. Particularly, the possibility to theoretically describe in a consistent and elegant way, early-time inflation and late-time acceleration in F R ( ) gravity was explicitly demonstrated in the NojiriOdintsov model [27]. For studies on specific solutions in several strong curved backgrounds see [28-33]. Remarkable possibilities, like modified gravitational theories with non-minimal curvature-matter coupling, were given in [34-37] and references therein.
In principle, every consistent generalizations of general relativity inevitably has to be confronted with the successes of general relativity. Since general relativity is a successful description of nature in strong gravitational environments, there exist a large number of constraints need to be satisfied, in order an F R ( ) modified gravity theory can be considered as viable. The constraints to be satisfied are mainly imposed from local tests of general relativity, for example from planetary and star formation tests and moreover from various cosmological bounds. In addition, since each F R ( ) theory has a Jordan frame scalartensor gravitational theory counterpart, with ω zero and a potential, the scalarons of this counterpart theory must be classical, in order to ensure quantum-mechanical stability (see [1-7]).
In theories of modified gravity a longstanding debatable theoretical problem exists, related to Jordan and Einstein frames [38,39], since the physics coming out from the two frames can be quite different in principle. In view of this, we shall focus on the physics of Jordan frame and demonstrate that it is possible to have antigravity. [40-43] For the possibility of antigravity regimes in scalar-tensor theories consult [40-42] and for antigravity in F R ( ) theories see [43]. In this paper we shall study antigravity regimes coming from F R ( ) theories and from Brans-Dicke theories in the Jordan frame. In reference to the F R ( ) theories, we shall find the Jordan frame antigravity scalar-tensor counterpart, using a modified method of the Lagrange multipliers, as we shall see in the following sections. The interesting feature about these theories is that, although the F R ( ) theory has no antigravity, the resulting Jordan frame scalar-tensor theory may or may not have antigravity. We exemplify this by numerically working out an example. In the case of Brans-Dicke antigravity, we introduce by hand an antigravity term and numerically solve
the cosmological equations and as we shall demonstrate, similar results hold true, that is, antigravity may exist or not, depending on the parameters of the theory.
This paper is organized as follows: In section 1 we briefly recall the essentials of F R ( ) theories, in section 2 we get to the core of the paper and introduce a modification of the Lagrange multipliers method in order to get antigravity from F R ( ) theories. Accordingly we apply the technique to one quite known F R ( ) model and present the result of our analysis. The study of antigravity is performed in section 3 and the conclusions follow in the end of the paper.
## 1 General Features of F R ( ) Dark Energy Models in the Jordan Frame
In this section in order to maintain the article self-contained, we briefly review the main features of F R ( ) gravity theories in the Jordan frame in the theoretical framework of the metric formalism. For an important stream of review papers and articles see [1-20] and references therein.
The geometrical background of the manifolds used here is pseudo-Riemannian and is described locally by a Lorentz metric (the FRW metric in our case), in addition to a torsion-less, symmetric, and metric compatible affine connection, the so-called Levi-Civita connection. In such a geometric background, the Christoffel symbols are
$$\Gamma ^ { k } _ { \mu \nu } = \frac { 1 } { 2 } g ^ { k \lambda } ( \partial _ { \mu } g _ { \lambda \nu } + \partial _ { \nu } g _ { \lambda \mu } - \partial _ { \lambda } g _ { \mu \nu } )$$
and the Ricci scalar becomes
$$R = g ^ { \mu \nu } ( \partial _ { \lambda } \Gamma _ { \mu \nu } ^ { \lambda } - \partial _ { \nu } \Gamma _ { \mu \rho } ^ { \rho } - \Gamma _ { \sigma \nu } ^ { \sigma } \Gamma _ { \mu \lambda } ^ { \sigma } + \Gamma _ { \mu \rho } ^ { \rho } g ^ { \mu \nu } \Gamma _ { \mu \nu } ^ { \sigma } ).$$
The F R ( ) theories of modified gravity are described by a modification of the EinsteinHilbert action, with the four dimensional action being equal to:
$$\mathcal { S } = \frac { 1 } { 2 \kappa ^ { 2 } } \int \mathrm d ^ { 4 } x \sqrt { - g } F ( R ) + S _ { m } ( g _ { \mu \nu }, \Psi _ { m } ),$$
where κ 2 = 8 πG and S m the matter action containing the matter fields Ψ m . For simplicity in this section it shall be assumed that the form of the F R ( ) theory that will be used is F R ( ) = R + ( f R ) and in addition the metric formalism framework shall be used. Varying the action (3) with respect to the metric g µν , we get the following equations of motion:
$$F ^ { \prime } ( R ) R _ { \mu \nu } ( g ) - \frac { 1 } { 2 } F ( R ) g _ { \mu \nu } - \nabla _ { \mu } \nabla _ { \nu } F ^ { \prime } ( R ) + g _ { \mu \nu } \Box F ^ { \prime } ( R ) = \kappa ^ { 2 } T _ { \mu \nu }.$$
In the above equation, F ′ ( R ) = ∂F R /∂R ( ) and also T µν is the energy momentum tensor.
What is the most striking feature of the F R ( ) modified gravity theories is that, what actually changes in reference to the usual Einstein-Hilbert gravity equations, is the right
hand side of the Einstein equations and not the left, which remains the same. Indeed, the equations of motion (4) can be cast in the following form:
$$R _ { \mu \nu } - \frac { 1 } { 2 } R g _ { \mu \nu } = \frac { \kappa ^ { 2 } } { F ^ { \prime } ( R ) } \left ( T _ { \mu \nu } + \frac { 1 } { \kappa } \left [ \frac { F ( R ) - R F ^ { \prime } ( R ) } { 2 } g _ { \mu \nu } + \nabla _ { \mu } \nabla _ { \nu } F ^ { \prime } ( R ) - g _ { \mu \nu } \Box F ^ { \prime } ( R ) \right ] \right ).$$
Therefore we get an additional contribution for the energy momentum tensor, coming from the term:
$$\text{ne term} \colon \quad & T _ { \mu \nu } ^ { e f f } = \frac { 1 } { \kappa } \left [ \frac { F ( R ) - R F ^ { \prime } ( R ) } { 2 } g _ { \mu \nu } + \nabla _ { \mu } \nabla _ { \nu } F ^ { \prime } ( R ) - g _ { \mu \nu } \Box F ^ { \prime } ( R ) \right ]. \quad & ( 6 ) \\ \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \end{cases}$$
It is this term that actually models the dark energy in F R ( ) theories of modified gravity. Taking the trace of equation (4) we straightforwardly obtain the following equation:
$$3 \Box F ^ { \prime } ( R ) + R F ^ { \prime } ( R ) - 2 F ( R ) = \kappa ^ { 2 } T,$$
where T stands for the trace of the energy momentum tensor T = g µν T µν = -ρ + 3 P , and, additionally, ρ and P stand for the matter energy density and pressure respectively.
There exists another degree of freedom in F R ( ) theories, as can be easily seen by observing equation (7). This degree of freedom is actually a scalar degree of freedom, called scalaron, described by the function F ′ ( R ), with equation (7) being the equation of motion of this scalar field. In a flat Friedmann-Lemaitre-Robertson-Walker spacetime, the Ricci scalar is equal to:
$$R = 6 ( 2 H ^ { 2 } + \dot { H } ),$$
with H being the Hubble parameter and the 'dot' indicating differentiation with respect to time. The cosmological equations of motion are given by the following set of equations:
$$3 F ^ { \prime } ( R ) H ^ { 2 } & = \kappa ^ { 2 } ( \rho _ { m } + \rho _ { r } ) + \frac { ( F ^ { \prime } ( R ) R - F ( R ) ) } { 2 } - 3 H \dot { F } ^ { \prime } ( R ), \text{ and } \quad \quad \quad ( 9 a ) \\ \quad \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \$$
$$- 2 F ^ { \prime } ( R ) \dot { H } = \kappa ^ { 2 } ( p _ { m } + 4 / 3 \rho _ { r } ) + F \ddot { F } ^ { \prime } ( R ) - H \dot { F } ^ { \prime } ( R ),$$
with ρ r and ρ m standing for the radiation and matter energy density respectively. Thereby, the total effective energy density and pressure of matter and geometry are [1-7]:
$$\rho _ { e f f } = \frac { 1 } { F ^ { \prime } ( R ) } \left [ \rho _ { m } + \frac { 1 } { \kappa ^ { 2 } } \left ( F ^ { \prime } ( R ) R - F ( R ) - 6 H \dot { F } ^ { \prime } ( R ) \right ) \right ], \text{ and } \quad \ \..$$
$$p _ { e f f } = \frac { \overset { \cdot } { 1 } } { F ^ { \prime } ( R ) } \left [ p _ { m } + \frac { 1 } { \kappa ^ { 2 } } \left ( - F ^ { \prime } ( R ) R + F ( R ) + 4 H \dot { F } ^ { \prime } ( R ) + 2 \ddot { F } ^ { \prime } ( R ) \right ) \right ], \quad \ ( 1 0 b )$$
where ρ m , P m denote the total matter energy density and matter pressure respectively.
## 2 Antigravity in F R ( ) Models
The possibility of antigravity sectors in F R ( ) theories was firstly pointed out in [43] and also in various scalar-tensor models in references [40-42]. In most cases, a passing from
antigravity to a gravity regime always occurs, with a singularity existing at the transition between these two different gravitational regimes. At the transition, the effective gravitational constant and also several invariants of the geometry, such as the Weyl invariant, become singular quantities [40-43]. In the present article, we are interested in studying the time dependence of the effective gravitational constant and see how this behaves for both an F R ( ) theory related antigravity scalar-tensor model and an antigravity version of the Brans-Dicke model with cosmological constant. In reference to F R ( ) theories, we shall explicitly demonstrate in the next subsection how to find the antigravity scalar-tensor theory in the Jordan frame. By doing so, we will have at hand an antigravity scalar-tensor theory with a potential term and we shall explicitly find how the scalar field, along with the gravitational constant and the energy density, behaves for various values of the model dependent and cosmological variables. Then we study the Brans-Dicke model in which we shall make a by hand modification in order to render it an antigravity model. As we shall see, in both cases, there exist several gravity-antigravity regimes, depending on the values of the model dependent and cosmological variables. Moreover, for the F R ( )-model, although the model per-se has no antigravity, the corresponding scalar-tensor model gives rise to antigravity regimes. However, there exist values of the variables for which the model describes gravity regimes. In the following subsections we shall study in detail these models.
## 2.1 A General Way to Obtain Antigravity Scalar-Tensor Models from F R ( ) models
It is a quite well known fact that scalar-tensor theories are equivalent to F R ( ) theories. In the literature one starts from an F R ( ) theory and ends up to a non-minimally coupled scalar-tensor theory and more specifically to a Brans-Dicke theory with ω BD equal to zero. This is practically the Lagrange multipliers method (see [1-7] and particularly Odintsov and Nojiri (2007) and Felice and Tsujikawa (2010)).
In this paper we shall use a variant but quite similar method to obtain an antigravity scalar-tensor theory starting from a given F R ( ) theory. Consider the general F R ( ) theory with matter, which is described by the action
$$\mathcal { S } = \int \mathrm d ^ { 4 } x \sqrt { - g } F ( R ) + S _ { m } ( g _ { \mu \nu }, \Psi _ { m } ).$$
Introducing an auxiliary field χ , which acts as a Lagrange multiplier, the action (11)
becomes
$$\underset { - \, \cdot \, \cdot \, \cdot \, \cdot \, \cdot \, \cdot \, \cdot \, \cdot \, \cdot \, \cdot \, \cdot \, \cdot \, \cdot \, \cdot \, \cdot \, \cdot \, \cdot \, \cdot \, \cdot \, \cdot \, \cdot \, \cdot \, \cdot \, \cdot \, \cdot \, \cdot \, \cdot \, \cdot \, \cdot \, \cdot \, \cdot \, \cdot \, \cdot \, \cdot \, \cdot \, \cdot \, \cdot \, \cdot \, \cdot \, \cdot \, \cdots \, \cdots \, \cdots \, \cdots \, \cdots \, \cdots \, \cdots \, \cdots \, \cdots \, \cdots \, \cdots \, \cdots \, \cdots \, \cdots \, \cdots \, \cdots \, \cdots \, \cdots \, \cdots \, \cdots \, \cdots \, \cdots \, \cdots \, \cdots \, \cdots \, \cdots \, \cdots \, \cdots \, \cdots \, \cdots \, \cdots \, \cdots \, \cdots \, \cdots \, \cdots \, \cdots \, \cdots \, \cdots \, \cdots \, \cdots \, \cdot \, \cdots \, \cdots \, \cdots \, \cdots \, \cdots \, \cdots \, \cdots \, \cdots \, \cdots \, \cdots \, \cdots \, \cdots \, \cdots \, \cdots \, \cdots \, \cdots \, \cdots \, \cdots \, \cdots \, \cdots \, \cdots \, \cdots \, \cdots \, \cdots \, \cdots \, \cdots \, \cdots \, \cdots \, \cdots \, \cdots \, \cdots \, \cdots \, \cdots \, \cdots \, \cdots \, \cdots \, \cdots \, \cdots \, \cdot \, \cdot \, \cdots \, \cdots \, \cdots \, \cdots \, \cdots \, \cdots \, \cdots \, \cdots \, \cdots \, \cdots \, \cdots \, \cdots \, \cdots \, \cdots \, \cdots \, \cdots \, \cdots \, \cdots \, \cdots \, \cdots \, \cdots \, \cdots \, \cdots \, \cdots \, \cdots \, \cdots \, \cdots \, \cdots \, \cdots \, \cdots \, \cdots \, \cdots \, \cdots \, \cdots \, \cdots \, \cdots \, \cdots \, \cdot \, \cdots \, \cdot \, \cdots \, \cdots \, \cdots \, \cdots \, \cdots \, \cdots \, \cdots \, \cdots \, \cdots \, \cdots \, \cdots \, \cdots \, \cdots \, \cdots \, \cdots \, \cdots \, \cdots \, \cdots \, \cdots \, \cdots \, \cdots \, \cdots \, \cdots \, \cdots \, \cdots \, \cdots \, \cdots \, \cdots \, \cdots \, \cdots \, \cdots \, \cdots \, \cdots \, \cdots \, \cdots \, \cdots \, \cdots \, \cdot \, \cdot \, \cdot \, \cdots \, \cdots \, \cdots \, \cdots \, \cdots \, \cdots \, \cdots \, \cdots \, \cdots \, \cdots \, \cdots \, \cdots \, \cdots \, \cdots \, \cdots \, \cdots \, \cdots \, \cdots \, \cdots \, \cdots \, \cdots \, \cdots \, \cdots \, \cdots \, \cdots \, \cdots \, \cdots \, \cdots \, \cdots \, \cdots \, \cdots \, \cdots \, \cdots \, \cdots \, \cdots \, \cdots \, \cdot \, \cdots \, \cdots \, \cdot \, \cdots \, \cdots \, \cdots \, \cdots \, \cdots \, \cdots \, \cdots \, \cdots \, \cdots \, \cdots \, \cdots \, \cdots \, \cdots \, \cdots \, \cdots \, \cdots \, \cdots \, \cdots \, \cdots \, \cdots \, \cdots \, \cdots \, \cdots \, \cdots \, \cdots \, \cdots \, \cdots \, \cdots \, \cdots \, \cdots \, \cdots \, \cdots \, \cdots \, \cdots \, \cdots \, \cdots \, \cdot \, \cdots \, \cdot \, \cdot \, \cdots \, \cdots \, \cdots \, \cdots \, \cdots \, \cdots \, \cdots \, \cdots \, \cdots \, \cdots \, \cdots \, \cdots \, \cdots \, \cdots \, \cdots \, \cdots \, \cdots \, \cdots \, \cdots \, \cdots \, \cdots \, \cdots \, \cdots \, \cdots \, \cdots \, \cdots \, \cdots \, \cdots \, \cdots \, \cdots \, \cdots \, \cdots \, \cdots \, \cdots \, \cdots \, \cdots \, \cd> \, \cdots \, \cdots \, \cdots \, \cdots \, \cdots \, \cdots \, \cdots \, \cdots \, \cdots \, \cdots \, \cdots \, \cdots \, \cdots \, \cdots \, \cdots \, \cdots \, \cdots \, \cdots \, \cdots \, \cdots \, \cdots \, \cdots \, \cdots \, \cdots \, \cdots \, \cdots \, \cdots \, \cdots \, \cdots \, \cdots \, \cdots \, \cdots \, \cdots \, \cdots \, \cdots \, \cdots \, \cdots \, \cdots \, \cdots \, \cd> \, \cdots \, \cdots \, \cd> \, \cdots \, \cdots \, \cdots \, \cdots \, \cdots \, \cdots \, \cdots \, \cdots \, \cdots \, \cdots \, \cdots \, \cdots \, \cdots \, \cdots \, \cdots \, \cdots \, \cdots \, \cdots \, \cdots \, \cdots \, \cdots \, \cdots \, \cdots \, \cdots \, \cdots \, \cdots \, \cdots \, \cdots \, \cdots \, \cdots \, \cdots \, \cdots \, \cdots \, \cdots \, \cdots \, \cdots \, \cd> \, \cdots \, \cdots \, \cd>.$$
with F ,χ ( χ ) being the first derivative of the function F χ ( ) with respect to χ . By varying the action (12) with respect to χ we obtain:
$$F _ {, \chi \chi } ( \chi ) ( R - \chi ) = 0.$$
/negationslash
Given that F ,χχ ( χ ) = 0, which is actually true for most viable F R ( ) theories, we may conclude that R = χ . Hence, the action (12) actually recovers the initial F R ( )-gravity
action (11). We define,
$$\varphi - \mathcal { B } & = F _ {, \chi } ( \chi ) \\ \psi \infty \cdot \quad \psi \quad \psi \quad \psi \quad \psi \quad \psi \quad \psi \quad \psi \quad \psi \quad \psi \quad \psi \quad \psi \quad \psi \quad \psi \quad \psi \quad \psi \quad \psi \quad \psi \quad \psi \quad \psi \quad \psi \quad \psi \quad \psi \quad \psi \quad \psi \quad \psi \quad \psi \quad \psi \quad \psi \quad \psi \quad \psi \quad \psi \quad \psi \quad \psi \quad \psi \quad \psi \quad \psi \quad \psi \quad \psi \quad \psi \quad \psi \quad \psis \quad \psi \quad \psi \quad \psi \quad \psi \quad \psi \quad \psi \quad \psi \quad \psi \quad \psi \quad \psi \quad \psi \quad \psi \quad \psi \quad \psi \quad \psi \quad \psi \quad \psi \quad \psi \quad \psi \quad \psi \quad \psi \quad \psi \quad \psi \quad \psi \quad \psi \quad \psi \quad \psi \quad \psi \quad \psi \quad \psi \quad \psi \quad \psi \quad \psi \quad \psi \quad \psi \quad \psi \quad \psi \quad \psi \quad \psi \quad \psus \quad \psi \quad \psi \quad \psi \quad \psi \quad \psi \quad \psi \quad \psi \quad \psi \quad \psi \quad \psi \quad \psi \quad \psi \quad \psi \quad \psi \quad \psi \quad \psi \quad \psi \quad \psi \quad \psi \quad \psi \quad \psi \quad \psi \quad \psi \quad \psi \quad \psi \quad \psi \quad \psi \quad \psi \quad \psi \quad \psi \quad \psi \quad \psi \quad \psi \quad \psi \quad \psi \quad \psi \quad \psi \quad \psi \quad \psi \quad \psu \quad \psi \quad \psi \quad \psi \quad \psi \quad \psi \quad \psi \quad \psi \quad \psi \quad \psi \quad \psi \quad \psi \quad \psi \quad \psi \quad \psi \quad \psi \quad \psi \quad \psi \quad \psi \quad \psi \quad \psi \quad \psi \quad \psi \quad \psi \quad \psi \quad \psi \quad \psi \quad \psi \quad \psi \quad \psi \quad \psi \quad \psi \quad \psi \quad \psi \quad \psi \quad \psi \quad \psi \quad \psi \quad \psi \quad \psi \quad \psigma \quad \psi \quad \psi \quad \psi \quad \psi \quad \psi \quad \psi \quad \psi \quad \psi \quad \psi \quad \psi \quad \psi \quad \psi \quad \psi \quad \psi \quad \psi \quad \psi \quad \psi \quad \psi \quad \psi \quad \psi \quad \psi \quad \psi \quad \psi \quad \psi \quad \psi \quad \psi \quad \psi \quad \psi \quad \psi \quad \psi \quad \psi \quad \psi \quad \psi \quad \psi \quad \psi \quad \psi \quad \psi \quad \psi \quad \psi \quad \psid \quad \psi \quad \psi \quad \psi \quad \psi \quad \psi \quad \psi \quad \psi \quad \psi \quad \psi \quad \psi \quad \psi \quad \psi \quad \psi \quad \psi \quad \psi \quad \psi \quad \psi \quad \psi \quad \psi \quad \psi \quad \psi \quad \psi \quad \psi \quad \psi \quad \psi \quad \psi \quad \psi \quad \psi \quad \psi \quad \psi \quad \psi \quad \psi \quad \psi \quad \psi \quad \psi \quad \psi \quad \psi \quad \psi \quad \psi \quad \psp \quad \psi \quad \psi \quad \psi \quad \psi \quad \psi \quad \psi \quad \psi \quad \psi \quad \psi \quad \psi \quad \psi \quad \psi \quad \psi \quad \psi \quad \psi \quad \psi \quad \psi \quad \psi \quad \psi \quad \psi \quad \psi \quad \psi \quad \psi \quad \psi \quad \psi \quad \psi \quad \psi \quad \psi \quad \psi \quad \psi \quad \psi \quad \psi \quad \psi \quad \psi \quad \psi \quad \psi \quad \psi \quad \psi \quad \psi \quad \pss \quad \psi \quad \psi \quad \psi \quad \psi \quad \psi \quad \psi \quad \psi \quad \psi \quad \psi \quad \psi \quad \psi \quad \psi \quad \psi \quad \psi \quad \psi \quad \psi \quad \psi \quad \psi \quad \psi \quad \psi \quad \psi \quad \psi \quad \psi \quad \psi \quad \psi \quad \psi \quad \psi \quad \psi \quad \psi \quad \psi \quad \psi \quad \psi \quad \psi \quad \psi \quad \psi \quad \psi \quad \psi \quad \psi \quad \psi \quad \psh \quad \psi \quad \psi \quad \psi \quad \psi \quad \psi \quad \psi \quad \psi \quad \psi \quad \psi \quad \psi \quad \psi \quad \psi \quad \psi \quad \psi \quad \psi \quad \psi \quad \psi \quad \psi \quad \psi \quad \psi \quad \psi \quad \psi \quad \psi \quad \psi \quad \psi \quad \psi \quad \psi \quad \psi \quad \psi \quad \psi \quad \psi \quad \psi \quad \psi \quad \psi \quad \psi \quad \psi \quad \psi \quad \psi \quad \psi \quad \psim \quad \psi \quad \psi \quad \psi \quad \psi \quad \psi \quad \psi \quad \psi \quad \psi \quad \psi \quad \psi \quad \psi \quad \psi \quad \psi \quad \psi \quad \psi \quad \psi \quad \psi \quad \psi \quad \psi \quad \psi \quad \psi \quad \psi \quad \psi \quad \psi \quad \psi \quad \psi \quad \psi \quad \psi \quad \psi \quad \psi \quad \psi \quad \psi \quad \psi \quad \psi \quad \psi \quad \psi \quad \psi \quad \psi \quad \psi \quad \psing \quad \psi \quad \psi \quad \psi \quad \psi \quad \psi \quad \psi \quad \psi \quad \psi \quad \psi \quad \psi \quad \psi \quad \psi \quad \psi \quad \psi \quad \psi \quad \psi \quad \psi \quad \psi \quad \psi \quad \psi \quad \psi \quad \psi \quad \psi \quad \psi \quad \psi \quad \psi \quad \psi \quad \psi \quad \psi \quad \psi \quad \psi \quad \psi \quad \psi \quad \psi \quad \psi \quad \psi \quad \psi \quad \psi \quad \psi \quad \psj \quad \psi \quad \psi \quad \psi \quad \psi \quad \psi \quad \psi \quad \psi \quad \psi \quad \psi \quad \psi \quad \psi \quad \psi \quad \psi \quad \psi \quad \psi \quad \psi \quad \psi \quad \psi \quad \psi \quad \psi \quad \psi \quad \psi \quad \psi \quad \psi \quad \psi \quad \psi \quad \psi \quad \psi \quad \psi \quad \psi \quad \psi \quad \psi \quad \psi \quad \psi \quad \psi \quad \psi \quad \psi \quad \psi \quad \psi \quad \psig \quad \psi \quad \psi \quad \psi \quad \psi \quad \psi \quad \psi \quad \psi \quad \psi \quad \psi \quad \psi \quad \psi \quad \psi \quad \psi \quad \psi \quad \psi \quad \psi \quad \psi \quad \psi \quad \psi \quad \psi \quad \psi \quad \psi \quad \psi \quad \psi \quad \psi \quad \psi \quad \psi \quad \psi \quad \psi \quad \psi \quad \psi \quad \psi \quad \psi \quad \psi \quad \psi \quad \psi \quad \psi \quad \psi \quad \psi \quad \psiv \quad \psi \quad \psi \quad \psi \quad \psi \quad \psi \quad \psi \quad \psi \quad \psi \quad \psi \quad \psi \quad \psi \quad \psi \quad \psi \quad \psi \quad \psi \quad \psi \quad \psi \quad \psi \quad \psi \quad \psi \quad \psi \quad \psi \quad \psi \quad \psi \quad \psi \quad \psi \quad \psi \quad \psi \quad \psi \quad \psi \quad \psi \quad \psi \quad \psi \quad \psi \quad \psi \quad \psi \quad \psi \quad \psi \quad \psi \quad \psilon \quad \psi \quad \psi \quad \psi \quad \psi \quad \psi \quad \psi \quad \psi \quad \psi \quad \psi \quad \psi \quad \psi \quad \psi \quad \psi \quad \psi \quad \psi \quad \psi \quad \psi \quad \psi \quad \psi \quad \psi \quad \psi \quad \psi \quad \psi \quad \psi \quad \psi \quad \psi \quad \psi \quad \psi \quad \psi \quad \psi \quad \psi \quad \psi \quad \psi \quad \psi \quad \psi \quad \psi \quad \psi \quad \psi \quad \psi \quad \ps } \psi \quad \psi \quad \psi \quad \psi \quad \psi \quad \psi \quad \psi \quad \psi \quad \psi \quad \psi \quad \psi \quad \psi \quad \psi \quad \psi \quad \psi \quad \psi \quad \psi \quad \psi \quad \psi \quad \psi \quad \psi \quad \psi \quad \psi \quad \psi \quad \psi \quad \psi \quad \psi \quad \psi \quad \psi \quad \psi \quad \psi \quad \psi \quad \psi \quad \psi \quad \psi \quad \psi \quad \psi \quad \psi \quad \psi \quad \psi \ \psi \quad \psi \quad \psi \quad \psi \quad \psi \quad \psi \quad \psi \quad \psi \quad \psi \quad \psi \quad \psi \quad \psi \quad \psi \quad \psi \quad \psi \quad \psi \quad \psi \quad \psi \quad \psi \quad \psi \quad \psi \quad \psi \quad \psi \quad \psi \quad \psi \quad \psi \quad \psi \quad \psi \quad \psi \quad \psi \quad \psi \quad \psi \quad \psi \quad \psi \quad \psi \quad \psi \quad \psi \quad \psi \quad \psi \quad \psi \cdot \psi \quad \psi \quad \psi \quad \psi \quad \psi \quad \psi \quad \psi \quad \psi \quad \psi \quad \psi \quad \psi \quad \psi \quad \psi \quad \psi \quad \psi \quad \psi \quad \psi \quad \psi \quad \psi \quad \psi \quad \psi \quad \psi \quad \psi \quad \psi \quad \psi \quad \psi \quad \psi \quad \psi \quad \psi \quad \psi \quad \psi \quad \psi \quad \psi \quad \psi \quad \psi \quad \psi \quad \psi \quad \psi \quad \psi \quad \psi \pmi \quad \psi \quad \psi \quad \psi \quad \psi \quad \psi \quad \psi \quad \psi \quad \psi \quad \psi \quad \psi \quad \psi \quad \psi \quad \psi \quad \psi \quad \psi \quad \psi \quad \psi \quad \psi \quad \psi \quad \psi \quad \psi \quad \psi \quad \psi \quad \psi \quad \psi \quad \psi \quad \psi \quad \psi \quad \psi \quad \psi \quad \ps$$
and the action of equation (12) is expressed as a function of the field ϕ in the following way:
$$\mathcal { S } = \int \mathrm d ^ { 4 } x \sqrt { - g } \left [ ( \varphi - \mathcal { B } ) R - U ( \varphi ) \right ] + S _ { m } ( g _ { \mu \nu }, \Psi _ { m } ). \quad \ \ ( 1 5 ) \\ \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \ dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 1 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0.$$
Comparing the non-minimal coupling term ( ϕ -B ) R to the corresponding term 1 16 πG R of the standard Einstein-Hilbert action, we get the relation for the effective gravitational constant
It is easy to see that if ϕ t ( ) - B = F ,χ ( χ ) < 0 there emerges antigravity. The potential term U ϕ ( ) is equal to
$$G _ { e f f } = \frac { 1 } { 1 6 \pi \left ( \varphi - \mathcal { B } \right ) }. \quad & ( 1 6 ) \\ \partial ( t ) - \mathcal { B } = \ F.. ( \nu ) < 0 \text{ there emroses anti-gravity} \text{ } The \text{ notential}$$
$$\mu _ { \ }. \mu _ { \ }. \mu _ { \ }. \mu _ { \ }. \mu _ { \ }. \mu _ { \ }. \mu _ { \ }. \mu _ { \ }. \mu _ { \ }. \mu _ { \ }. \mu _ { \ }. \mu _ { \ }. \mu _ { \ }. \mu _ { \ }. \mu _ { \ }. \mu _ { \ }. \mu _ { \ }. \mu _ { \ }. \mu _ { \ }. \mu _ { \ }. \mu _ { \ }. \mu _ { \ }. \mu _ { \ }. \mu _ { \ }. \mu _ { \ }. \mu _ { \ }. \mu _ { \ }. \mu _ { \ }. \mu _ { \ }. \mu _ {\ }. \mu _ { \ }. \mu _ { \ }. \mu _ { \ }. \mu _ { \ }. \mu _ { \ }. \mu _ { \ }. \mu _ { \ }. \mu _ { \ }. \mu _ { \ }. \mu _ { \ }. \mu _ { \ }. \mu _ { \ }. \mu _ { \ }. \mu _ { \ }. \mu _ { \ }. \mu _ { \ }. \mu _ { \ }. \mu _ { \ }. \mu _ { \ }. \mu _ { \ }. \mu _ { \ }. \mu _ { \ }. \mu _ { \ }. \mu _ { \ }. \mu _ { \ }. \mu _ { \ }. \mu _ { \ }. \mu _ { \ }. \nu _ { \ }. \mu _ { \ }. \mu _ { \ }. \mu _ { \ }. \mu _ { \ }. \mu _ { \ }. \mu _ { \ }. \mu _ { \ }. \mu _ { \ }. \mu _ { \ }. \mu _ { \ }. \mu _ { \ }. \mu _ { \ }. \mu _ { \ }. \mu _ { \ }. \mu _ { \ }. \mu _ { \ }. \mu _ { \ }. \mu _ { \ }. \mu _ { \ }. \mu _ { \ }. \mu _ { \ }. \mu _ { \ }. \mu _ { \ }. \mu _ { \ }. \mu _ { \ }. \mu _ { \ }. \mu _ { \ }. \mu _ { \}. \mu _ { \ }. \mu _ { \ }. \mu _ { \ }. \mu _ { \ }. \mu _ { \ }. \mu _ { \ }. \mu _ { \ }. \mu _ { \ }. \mu _ { \ }. \mu _ { \ }. \mu _ { \ }. \mu _ { \ }. \mu _ { \ }. \mu _ { \ }. \mu _ { \ }. \mu _ { \ }. \mu _ { \ }. \mu _ { \ }. \mu _ { \ }. \mu _ { \ }. \mu _ { \ }. \mu _ { \ }. \mu _ { \ }. \mu _ { \ }. \mu _ { \ }. \mu _ { \ }. \mu _ { \ }. \mu _ { \ }. \mu_{ \ }. \mu _ { \ }. \mu _ { \ }. \mu _ { \ }. \mu _ { \ }. \mu _ { \ }. \mu _ { \ }. \mu _ { \ }. \mu _ { \ }. \mu _ { \ }. \mu _ { \ }. \mu _ { \ }. \mu _ { \ }. \mu _ { \ }. \mu _ { \ }. \mu _ { \ }. \mu _ { \ }. \mu _ { \ }. \mu _ { \ }. \mu _ { \ }. \mu _ { \ }. \mu _ { \ }. \mu _ { \ }. \mu _ { \ }. \mu _ { \ }. \mu _ { \ }. \mu _ { \ }. \mu _ { \ }. \mu _ { \ }.. \mu _ { \ }. \mu _ { \ }. \mu _ { \ }. \mu _ { \ }. \mu _ { \ }. \mu _ { \ }. \mu _ { \ }. \mu _ { \ }. \mu _ { \ }. \mu _ { \ }. \mu _ { \ }. \mu _ { \ }. \mu _ { \ }. \mu _ { \ }. \mu _ { \ }. \mu _ { \ }. \mu _ { \ }. \mu _ { \ }. \mu _ { \ }. \mu _ { \ }. \mu _ { \ }. \mu _ { \ }. \mu _ { \ }. \mu _ { \ }. \mu _ { \ }. \mu _ { \ }. \mu _ { \ }. \mu _ { \ }. \mu_ { \ }. \mu _ { \ }. \mu _ { \ }. \mu _ { \ }. \mu _ { \ }. \mu _ { \ }. \mu _ { \ }. \mu _ { \ }. \mu _ { \ }. \mu _ { \ }. \mu _ { \ }. \mu _ { \ }. \mu _ { \ }. \mu _ { \ }. \mu _ { \ }. \mu _ { \ }. \mu _ { \ }. \mu _ { \ }. \mu _ { \ }. \mu _ { \ }. \mu _ { \ }. \mu _ { \ }. \mu _ { \ }. \mu _ { \ }. \mu _ { \ }. \mu _ { \ }. \mu _ { \ }. \mu _ { \ }. \mu _ { \ } }. \mu _ { \ }. \mu _ { \ }. \mu _ { \ }. \mu _ { \ }. \mu _ { \ }. \mu _ { \ }. \mu _ { \ }. \mu _ { \ }. \mu _ { \ }. \mu _ { \ }. \mu _ { \ }. \mu _ { \ }. \mu _ { \ }. \mu _ { \ }. \mu _ { \ }. \mu _ { \ }. \mu _ { \ }. \mu _ { \ }. \mu _ { \ }. \mu _ { \ }. \mu _ { \ }. \mu _ { \ }. \mu _ { \ }. \mu _ { \ }. \mu _ { \ }. \mu _ { \ }. \mu _ { \ }. \mu _ { \ }. \alpha _ { \ }. \alpha _ { \ }. \alpha _ { \ }. \alpha _ { \ }. \alpha _ { \ }. \alpha _ { \ }. \alpha _ { \ }. \alpha _ { \ }. \alpha _ { \ }. \alpha _ { \ }. \alpha _ { \ }. \alpha _ { \ }. \alpha _ { \ }. \alpha _ { \ }. \alpha _ { \ }. \alpha _ { \ }. \alpha _ { \ }. \alpha _ { \ }. \alpha _ { \ }. \alpha _ { \ }. \alpha _ { \ }. \alpha _ { \ }. \alpha _ { \ }. \alpha _ { \ }. \alpha _ { \ }. \alpha _ { \ }. \alpha _ { \ }. \alpha _ { \ }. \alpha _ { \}. \alpha _ { \ }. \alpha _ { \ }. \alpha _ { \ }. \alpha _ { \ }. \alpha _ { \ }. \alpha _ { \ }. \alpha _ { \ }. \alpha _ { \ }. \alpha _ { \ }. \alpha _ { \ }. \alpha _ { \ }. \alpha _ { \ }. \alpha _ { \ }. \alpha _ { \ }. \alpha _ { \ }. \alpha _ { \ }. \alpha _ { \ }. \alpha _ { \ }. \alpha _ { \ }. \alpha _ { \ }. \alpha _ { \ }. \alpha _ { \ }. \alpha _ { \ }. \alpha _ { \ }. \alpha _ { \ }. \alpha _ { \ }. \alpha _ { \ }. \alpha _ { \ }. \alpha. \alpha _ { \ }. \alpha _ { \ }. \alpha _ { \ }. \alpha _ { \ }. \alpha _ { \ }. \alpha _ { \ }. \alpha _ { \ }. \alpha _ { \ }. \alpha _ { \ }. \alpha _ { \ }. \alpha _ { \ }. \alpha _ { \ }. \alpha _ { \ }. \alpha _ { \ }. \alpha _ { \ }. \alpha _ { \ }. \alpha _ { \ }. \alpha _ { \ }. \alpha _ { \ }. \alpha _ { \ }. \alpha _ { \ }. \alpha _ { \ }. \alpha _ { \ }. \alpha _ { \ }. \alpha _ { \ }. \alpha _ { \ }. \alpha _ { \ }. \alpha _ { \ }. \alpha_{ \ }. \alpha _ { \ }. \alpha _ { \ }. \alpha _ { \ }. \alpha _ { \ }. \alpha _ { \ }. \alpha _ { \ }. \alpha _ { \ }. \alpha _ { \ }. \alpha _ { \ }. \alpha _ { \ }. \alpha _ { \ }. \alpha _ { \ }. \alpha _ { \ }. \alpha _ { \ }. \alpha _ { \ }. \alpha _ { \ }. \alpha _ { \ }. \alpha _ { \ }. \alpha _ { \ }. \alpha _ { \ }. \alpha _ { \ }. \alpha _ { \ }. \alpha _ { \ }. \alpha _ { \ }. \alpha _ { \ }. \alpha _ { \ }. \alpha _ { \ }. \alpha _ { \ }.. \alpha _ { \ }. \alpha _ { \ }. \alpha _ { \ }. \alpha _ { \ }. \alpha _ { \ }. \alpha _ { \ }. \alpha _ { \ }. \alpha _ { \ }. \alpha _ { \ }. \alpha _ { \ }. \alpha _ { \ }. \alpha _ { \ }. \alpha _ { \ }. \alpha _ { \ }. \alpha _ { \ }. \alpha _ { \ }. \alpha _ { \ }. \alpha _ { \ }. \alpha _ { \ }. \alpha _ { \ }. \alpha _ { \ }. \alpha _ { \ }. \alpha _ { \ }. \alpha _ { \ }. \alpha _ { \ }. \alpha _ { \ }. \alpha _ { \ }. \alpha _ { \ }. \alpha._ \alpha _ { \ }. \alpha _ { \ }. \alpha _ { \ }. \alpha _ { \ }. \alpha _ { \ }. \alpha _ { \ }. \alpha _ { \ }. \alpha _ { \ }. \alpha _ { \ }. \alpha _ { \ }. \alpha _ { \ }. \alpha _ { \ }. \alpha _ { \ }. \alpha _ { \ }. \alpha _ { \ }. \alpha _ { \ }. \alpha _ { \ }. \alpha _ { \ }. \alpha _ { \ }. \alpha _ { \ }. \alpha _ { \ }. \alpha _ { \ }. \alpha _ { \ }. \alpha _ { \ }. \alpha _ { \ }. \alpha _ { \ }. \alpha _ { \ }. \alpha _ { \ }. \alpha _ }. \alpha _ { \ }. \alpha _ { \ }. \alpha _ { \ }. \alpha _ { \ }. \alpha _ { \ }. \alpha _ { \ }. \alpha _ { \ }. \alpha _ { \ }. \alpha _ { \ }. \alpha _ { \ }. \alpha _ { \ }. \alpha _ { \ }. \alpha _ { \ }. \alpha _ { \ }. \alpha _ { \ }. \alpha _ { \ }. \alpha _ { \ }. \alpha _ { \ }. \alpha _ { \ }. \alpha _ { \ }. \alpha _ { \ }. \alpha _ { \ }. \alpha _ { \ }. \alpha _ { \ }. \alpha _ { \ }. \alpha _ { \ }. \alpha _ { \ }. \alpha _ { \ }. \beta _ { \ }. \alpha _ { \ }. \alpha _ { \ }. \alpha _ { \ }. \alpha _ { \ }. \alpha _ { \ }. \alpha _ { \ }. \alpha _ { \ }. \alpha _ { \ }. \alpha _ { \ }. \alpha _ { \ }. \alpha _ { \ }. \alpha _ { \ }. \alpha _ { \ }. \alpha _ { \ }. \alpha _ { \ }. \alpha _ { \ }. \alpha _ { \ }. \alpha _ { \ }. \alpha _ { \ }. \alpha _ { \ }. \alpha _ { \ }. \alpha _ { \ }. \alpha _ { \ }. \alpha _ { \ }. \alpha _ { \ }. \alpha _ { \ }. \alpha _ { \ }. \alpha _ { \ }. \alpha _ { \ }. \alpha _ { \ }. \alpha _ { \ }. \alpha _ { \ }. \alpha _ { \ }. \alpha _ { \ }. \alpha _ { \ }. \alpha _ { \ }. \alpha _ { \ }. \alpha _ { \ }. \alpha _ { \ }. \alpha _ { \ }. \alpha _ { \ }. \alpha _ { \ }. \alpha _ { \ }. \alpha _ { \ }. \alpha _ { \ }. \alpha _ { \ }. \alpha _ { \ }. \alpha _ { \ }. \alpha _ { \ }. \alpha _ { \ }. \alpha _ { \ }. \alpha _ { \ }. \alpha _ { \ }. \alpha _ { \ }. \alpha _ { \ }. \alpha _ { \ }. \mu _ { \ }. \alpha _ { \ }. \alpha _ { \ }. \alpha _ { \ }. \alpha _ { \ }. \alpha _ { \ }. \alpha _ { \ }. \alpha _ { \ }. \alpha _ { \ }. \alpha _ { \ }. \alpha _ { \ }. \alpha _ { \ }. \alpha _ { \ }. \alpha _ { \ }. \alpha _ { \ }. \alpha _ { \ }. \alpha _ { \ }. \alpha _ { \ }. \alpha _ { \ }. \alpha _ { \ }. \alpha _ { \ }. \alpha _ { \ }. \alpha _ { \ }. \alpha _ { \ }. \alpha _ { \ }. \alpha _ { \ }. \alpha _ { \ }. \alpha _ { \}. \alpha _ { \}. \alpha _ { \ }. \alpha _ { \ }. \alpha _ { \ }. \alpha _ { \ }. \alpha _ { \ }. \alpha _ { \ }. \alpha _ { \ }. \alpha _ { \ }. \alpha _ { \ }. \alpha _ { \ }. \alpha _ { \ }. \alpha _ { \ }. \alpha _ { \ }. \alpha _ { \ }. \alpha _ { \ }. \alpha _ { \ }. \alpha _ { \ }. \alpha _ { \ }. \alpha _ { \ }. \alpha _ { \ }. \alpha _ { \ }. \alpha _ { \ }. \alpha _ { \ }. \alpha _ { \ }. \alpha _ { \ }. \alpha _ { \ }. \alpha _ { \ }.$$
where the function χ ϕ ( ) is directly obtained by solving the algebraic equation (14) with respect to χ , so that χ is an explicit function of ϕ . Therefore as result, starting from an F R ( ) theory and using the technique we just presented, one obtains Jordan frame antigravity scalar-tensor theories.
## 2.2 The Model F R ( ) = R -R -p with p a Positive Integer
As an application of the method we just presented, let us use a viable F R ( ) model a modified version of which is quite frequently used in F R ( ) cosmology [1-7]. The model has the following form as a function of the curvature scalar R :
$$F ( R ) = R - R ^ { - p },$$
with p being some positive integer number. This form of the F R ( ) function ensures that the first derivative of the F R ( ) function with respect to R is positive definite for R ≥ R D , with R D being the final de-Sitter attractor solution of the theory, that is
$$\frac { \mathrm d F ( R ) } { \mathrm d R } > 0.$$
The condition (19) assures that no antigravity occurs for the F R ( ) model [1-7]. However, as we shall demonstrate, antigravity might occur in the Jordan frame scalar-tensor model. The action corresponding to the F R ( ) action (18) is the following,
$$\mathcal { S } = \int \mathrm d ^ { 4 } x \sqrt { - g } ( R - R ^ { - p } ) + S _ { m } ( g _ { \mu \nu }, \Psi _ { m } ). \quad \ \ ( 2 0 ) \\ \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \end{$$
Using the Lagrange multipliers method we introduced in the previous section, we obtain the corresponding scalar-tensor antigravity theory, with the Jordan frame action being equal to:
$$\mathcal { S } = \int \mathrm d ^ { 4 } x \sqrt { - g } \left [ ( \varphi - \mathcal { B } ) R - U _ { F ( R ) } ( \varphi ) \right ] + S _ { m } ( g _ { \mu \nu }, \Psi _ { m } ).$$
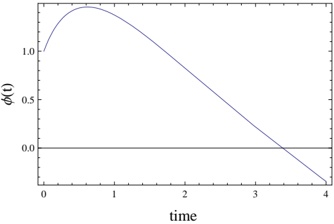
time
Figure 1: F R ( ) model: Time dependence of the scalar field ϕ t ( ) (left), the effective gravitational constant G eff ( ) t (right) and the matter energy density ρ t ( ) (bottom), for w = 1 3 , p = 3, B = 1
The potential U F R ( ) ( ϕ ) for the present F R ( ) model is equal to
$$U _ { F ( R ) } ( \varphi ) = \left ( \frac { p } { \varphi - \mathcal { B } - 1 } \right ) ^ { \frac { 1 } { p + 1 } } ( \varphi - \mathcal { B } ) - \left ( \frac { p } { \varphi - \mathcal { B } - 1 } \right ) ^ { \frac { 1 } { p + 1 } } + \left ( \frac { p } { \varphi - \mathcal { B } - 1 } \right ) ^ { - \frac { p } { p + 1 } }. \quad ( 2 2 ) \\ \intertext { H o r i n a t i o n } \, \infty \, \text{at hand a loan with national term } ( 2 2 ) \, \text{ was an entire $r$} \, \text{the contribution}.$$
Having action (21) at hand, along with potential term (22), we can study the antigravity scalar-tensor model in a straightforward way. By varying action (21) with respect to the metric and the scalar field, we get the Einstein equations that describe the cosmic evolution of the antigravity F R ( )-related scalar-tensor model. Assuming a flat FRW metric of the form
$$d s ^ { 2 } = - d t ^ { 2 } + a ^ { 2 } ( t ) \sum _ { i } d x _ { i } ^ { 2 }$$
the cosmological equations are equal to
$$3 ( \varphi - \mathcal { B } ) H ^ { 2 } & = \rho + U _ { F ( R ) } ( \varphi ) - 3 H \dot { \varphi } & & ( 2 4 \tt a ) \\ \omega \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \colon$$
$$- R + 2 \frac { \mathrm d U _ { F ( R ) } ( \varphi ) } { \mathrm d \varphi } = 0,$$
$$- & 2 ( \varphi - \mathcal { B } ) \dot { H } = \rho + P + \ddot { \varphi } - H \dot { \varphi } & & ( 2 4 b ) \\ & \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \ \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \ \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \,$$
where ˙ ϕ denotes differentiation of the scalar field function ϕ t ( ), with respect to the time variable t:
$$\dot { \varphi } = \frac { d \varphi } { d t }. \quad \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \$$
In addition P = wρ and also the continuity equation for matter, stemming from T µν ; µ = 0, holds true:
$$\dot { \rho } + 3 H ( 1 + w ) \rho = 0.$$
Figure 2: F R ( ) model: The effective gravitational constant G eff ( ) as a function of time, t for non-relativistic matter w = 0, with B = 0 001, . p = 2 (left) and B = 1, p = 2 (right)
From equation (21), it easily follows that the effective gravitational constant of the Jordan frame scalar-tensor theory, is equal to:
$$G _ { e f f } ( t ) & = \frac { 1 } { 1 6 \pi ( \varphi ( t ) - \mathcal { B } ) }. \quad \quad \quad ( 2 7 ) \\ \dots \quad \cdot \dots \quad \cdot \dots \quad \cdot \dots \quad \cdot \dots \quad \cdot \dots$$
We numerically solved the cosmological equations (24) and in Figures 1 and 2 we present the results which we will now analyze in detail. As a general comment let us note that, depending on the value of the antigravity parameter B , the Jordan frame scalar-tensor theory may or may not have antigravity. Therefore, although we started with an F R ( ) theory with no antigravity solutions, the Jordan frame counterpart exhibits antigravity for some values of the parameter B . In order for the time dependent functions ϕ , ρ and G eff to vary smoothly, we chose the initial conditions to be
$$\rho ( 1 ) = 1, \ \ \varphi ( 1 ) = 1, \ \ \dot { \varphi } ( 1 ) = 0, \ \ \text{ and } \ t \times H ( 1 ) \sim 1,$$
which are similar to those used in reference [44] (check also [39]). We also performed the following rescaling for time:
$$\Phi _ { 1 } \Phi _ { 2 } \Phi _ { 3 } \Phi _ { 4 } \Phi _ { 5 } \Phi _ { 6 } \Phi _ { 7 } \Phi _ { 8 } \Phi _ { 9 } \Phi _ { 9 } \Phi _ { 9 } \Phi _ { 9 } \Phi _ { 9 } \Phi _ { 9 } \Phi _ { 9 } \Phi _ { 9 } \Phi _ { 9 } \Phi _ { 9 } \Phi _ { 9 } \Phi _ { 9 } \Phi _ { 9 } \Phi _ { 9 } \Phi _ { 9 } \Phi _ { 9 } \Phi _ { 9 } \Phi _ { 9 } \Phi _ { 9 } \Phi _ { 9 } \Phi _ { 9 } \Phi _ { 9 } \Phi _ { 9 } \Phi _ { 9 } \Phi _ { 9 } \Phi _ { 9 } \Phi _ { 9 } \Phi _ { 9 } \Phi _ { 9 } \Phiconacci \Phi _ { 9 } \Phi _ { 9 } \Phi _ { 9 } \Phi _ { 9 } \Phi _ { 9 } \Phi _ { 9 } \Phi _ { 9 } \Phi _ { 9 } \Phi _ { 9 } \Phi _ { 9 } \Phi _ { 9 } \Phi _ { 9 } \Phi _ { 9 } \Phi _ { 9 } \Phi _ { 9 } \Phi _ { 9 } \Phi _ { 9 } \Phi _ { 9 } \Phi _ { 9 } \Phi _ { 9 } \Phi _ { 9 } \Phi _ { 9 } \Phi _ { 9 } \Phi _ { 9 } \Phi _ { 9 } \Phi _ { 9 } \Phi _ { 9 } \Phi _ { 9 } \Phi_ { 9 } \Phi _ { 9 } \Phi _ { 9 } \Phi _ { 9 } \Phi _ { 9 } \Phi _ { 9 } \Phi _ { 9 } \Phi _ { 9 } \Phi _ { 9 } \Phi _ { 9 } \Phi _ { 9 } \Phi _ { 9 } \Phi _ { 9 } \Phi _ { 9 } \Phi _ { 9 } \Phi _ { 9 } \Phi _ { 9 } \Phi _ { 9 } \Phi _ { 9 } \Phi _ { 9 } \Phi _ { 9 } \Phi _ { 9 } \Phi _ { 9 } \Phi _ { 9 } \Phi _ { 9 } \Phi _ { 9 } \Phi _ { 9 } \Phi _ { 9 } \Phi _ { 9 } \\ \Phi _ { 2 } \Phi _ { 3 } \Phi _ { 4 } \Phi _ { 5 } \Phi _ { 6 } \Phi _ { 7 } \Phi _ { 8 } \Phi _ { 9 } \Phi _ { 9 } \Phi _ { 9 } \Phi _ { 9 } \Phi _ { 9 } \Phi _ { 9 } \Phi _ { 9 } \Phi _ { 9 } \Phi _ { 9 } \Phi _ { 9 } \Phi _ { 9 } \Phi _ { 9 } \Phi _ { 9 } \Phi _ { 9 } \Phi _ { 9 } \Phi _ { 9 } \Phi _ { 9 } \Phi _ { 9 } \Phi _ { 9 } \Phi _ { 9 } \Phi _ { 9 } \Phi_ _ { 9 } \Phi _ { 9 } \Phi _ { 9 } \Phi _ { 9 } \Phi _ { 9 } \Phi _ { 9 } \Phi _ { 9 } \Phi _ { 9 } \Phi _ { 9 } \Phi _ { 9 } \Phi _ { 9 } \Phi _ { 9 } \Phi _ { 9 } \Phi _ { 9 } \Phi _ { 9 } \Phi _ { 9 } \Phi _ { 9 } \Phi _ { 9 } \Phi _ { 9 } \Phi _ { 9 } \Phi _ { 9 } \Phi _ { 9 } \Phi _ { 9 } \Phi _ { 9 } \Phi _ { 9 } \Phi _ { 9 } \Phi _ { 9 } \Phi _ { 9 } \Phi _ { 9} \Phi _ { 9 } \Phi _ { 9 } \Phi _ { 9 } \Phi _ { 9 } \Phi _ { 9 } \Phi _ { 9 } \Phi _ { 9 } \Phi _ { 9 } \Phi _ { 9 } \Phi _ { 9 } \Phi _ { 9 } \Phi _ { 9 } \Phi _ { 9 } \Phi _ { 9 } \Phi _ { 9 } \Phi _ { 9 } \Phi _ { 9 } \Phi _ { 9 } \Phi _ { 9 } \Phi _ { 9 } \Phi _ { 9 } \Phi _ { 9 } \Phi _ { 9 } \Phi _ { 9 } \Phi _ { 9 } \Phi _ { 9 } \Phi _ { 9 } \Phi _ { 9 } \Phi_{ 9 } \Phi _ { 9 } \Phi _ { 9 } \Phi _ { 9 } \Phi _ { 9 } \Phi _ { 9 } \Phi _ { 9 } \Phi _ { 9 } \Phi _ { 9 } \Phi _ { 9 } \Phi _ { 9 } \Phi _ { 9 } \Phi _ { 9 } \Phi _ { 9 } \Phi _ { 9 } \Phi _ { 9 } \Phi _ _ { 9 } \Phi _ { 9 } \Phi _ { 9 } \Phi _ _ { 9 } \Phi _ { 9 } \Phi _ { 9 } \Phi _ _ { 9 } \Phi _ { 9 } \Phi _ _ { 9 } \Phi _ { 9 } \Phi _ _ { 9 } \Phi _ { 9 } \Phi _ { 9 } \Phi _ _ { 9 } \Phi _ _ { 9 } \Phi _ { 9 } \Phi _ _ { 9 } \Phi _ _ { 9 } \Phi _ _ { 9 } \Phi _ _ { 9 } \Phi _ _ { 9 } \Phi _ _ { 9 } \Phi _ _ { 9 } \Phi _ _ { 9 } \Phi _ _ { 9 } \Phi _ _ { 9 } \Phi _ _ { 9 } \Phi _ _ { 9 } \Phi _ _ { 9 } \Phi _ _ { 9 } \Phi _ _ { 9 } \Phi _ _ { 9 } \Phi _ _ { 9 } \Phi _ _ { 9 } \Phi _ _ { 9 } \Phi _ _ { 9 } \Phi _ _ { 9 } \Phi _ _ { 9 } \Phi _ _ { 9 } \Phi _ _ { 9 } \Phi _ _ { 9 } \Phi }$$
in favor of the simplicity of the plots. The above initial conditions and time scaling are used for all the plots in this article. The results obtained by the numerical analysis are qualitatively robust towards the change of the initial conditions, meaning that the only thing that changes is not the whole phenomenon, but the exact time point when the singularity occurs; in all cases the transition singularity occurs long before the beginning of inflation at t = 10 10 → 10 -36 sec. In Figure 1 we provide plots of the scalar field ϕ t ( ), the energy density ρ t ( ), and the effective gravitational constant G eff ( ) as a function of t the time t , with the time axis properly rescaled. We have chosen the numerical values to be w = 1 3 , p = 3, and B = 1, that is in a radiation dominated universe. The same behavior however is observed for B = 1 and different values for w . Therefore, we observe that the parameter B critically affects the antigravity behavior. In the present case, the occurring antigravity can be seen in the right part of Figure 1; as can be seen, there appears a gravity dominated period for 0 < t < 1 7 and after the singularity at . t = 1 7 antigravity .
occurs. In Figure 2, we present the time dependence of the effective gravitational constant G eff ( ), t for two different values of B , namely B = 0 001 (left) . and B = 1 (right). We assumed a universe filled with non-relativistic matter, that is w = 0, and also p = 2. As we can see in this case, for B = 0 001 there is no antigravity and conversely for . B = 1 there is. This is the expected behavior of the Jordan frame theory, since as B increases, the possibility that the term ( ϕ t ( ) -B ) becomes negative increases, depending, of course, on the initial conditions and on the other parameters' values.
The model we studied in this section is similar to the one studied in [43], in which case the antigravity scalar-tensor model was the following:
$$S = \int \mathrm d x ^ { 4 } \sqrt { - g } \left [ \frac { 1 - \varphi ^ { 2 } } { 1 2 } R - \frac { 1 } { 2 } g ^ { \mu \nu } \partial _ { \mu } \varphi \partial _ { \nu } \varphi - J ( \varphi ) \right ].$$
The corresponding F R ( ) gravity action,following the technique presented in [43] is easily found to be
$$S = \int \mathrm d x ^ { 4 } \sqrt { - g } F ( R ),$$
where F R ( ) stands for:
$$F ( R ) = \frac { e ^ { \eta ( \varphi ( R ) ) } } { 1 2 } \left ( 1 - \varphi ^ { 2 } ( R ) \right ) R - e ^ { 2 \eta ( \varphi ( R ) ) } J ( \varphi ( R ) ).$$
Moreover, the real function η ϕ ( ) satisfies
$$( 1 + 2 \varphi ^ { 2 } ) \eta ^ { \prime } ( \varphi ) ^ { 2 } - 4 \eta ^ { \prime } ( \varphi ) - 4 = 0$$
and, as a result, the kinetic term of the scalar field vanishes. This antigravity model clearly provides us with regimes governed by a negative gravitational constant for some values of the scalar field ϕ , clearly indicating a highly non-smooth, big crunch-big bang transition in the theoretical context of [43].
Before we close this section, we discuss an important issue. Reasonably, it can be argued that since the effective gravitational constant G eff ( ) diverges at some time, this t could imply some sort of instability of the F R ( ) theory. Indeed, this is true to some extend. Actually, the singularity of the gravitational constant is a spacetime one, since spacetime geometric invariants like the Kretschmann scalar R abcd R abcd seriously diverge. In a mathematical context, this singularity is also a naked Cauchy horizon, not 'dressed' by some event horizon, which, in turn, would imply the loss of predictability and also signal a spacetime singularity. Therefore, it is better if these singularities occur in the very early universe. As for the issue of stability of the initial F R ( ) theory, this is an involved question, since the quantum mechanical stability of the F R ( ) theory is examined in the Einstein frame and not in the Jordan frame [1]. In the case of an occurring singularity, the Einstein frame is not consistently defined, since this singularity also introduces another singularity in the scalar field redefinition necessary for the definition of the canonical transformation in the Einstein frame (see the book of Faraoni for more details on this [38]). A very thorough analysis of the stability of a, similar to ours, scalar-tensor model was studied in
reference [45] (see equation (1) of [45]), in which case the model can exhibit antigravity if the non-minimal coupling term becomes negative. The model in [45] can be identical to our Brans-Dicke model if the potential is zero and the non-minimal coupling contains terms of the order of ∼ ϕ .
## 3 Antigravity in Brans-Dicke Models
As we saw in the previous section, even though we started from an F R ( ) theory with no antigravity, the antigravity Jordan frame action may or may not have antigravity solutions. In this section, we shall study a minor modification of the Brans-Dicke model with cosmological constant. The antigravity term will be introduced by hand and will be of the form ( ϕ -B ) R , with B being the extra term introduced by hand. The general
2.0
1.5
1.0
0.5
0.0
Figure 3: Brans-Dicke Model with Cosmological constant: Time dependence of the scalar field ϕ t ( ) (left), the effective gravitational constant G eff ( ) t (right) and the matter energy density ρ t ( ) (bottom), for w = 1 3 , B = 1, and the cosmological constant Λ = 10 -49 .
0
1
2
3
4
time action in the Jordan frame that describes a general Brans-Dicke model with cosmological constant, potential U ϕ ( ), and matter is:
$$S = \int \mathrm d x ^ { 4 } \sqrt { - g } \left [ \frac { 1 } { 2 } \varphi ( R - 2 \Lambda ) - \frac { \omega _ { B D } } { \varphi } g ^ { \mu \nu } \partial _ { \mu } \varphi \partial _ { \nu } \varphi - U ( \varphi ) \right ] + \int \mathrm d x ^ { 4 } \sqrt { - g } L _ { m a t t e r }.$$
In the following, we shall assume that initially, the scalar potential U ϕ ( ) is zero and also that the cosmological constant is positive and has the value Λ = 10 -49 GeV . 4 The antigravity model we shall study is obtained from the original Brand-Dicke model with cosmological constant (34) if we modify by hand the action in the following way:
$$S = \int \mathrm d x ^ { 4 } \sqrt { - g } \left [ \frac { 1 } { 2 } ( \varphi - \mathcal { B } ) R - \frac { \omega _ { B D } } { \varphi } g ^ { \mu \nu } \partial _ { \mu } \varphi \partial _ { \nu } \varphi - \varphi \lambda \right ] + \int \mathrm d x ^ { 4 } \sqrt { - g } L _ { m a t t e r }.$$
/RParen1
/LParen1
t
Ρ
Figure 4: Brans-Dicke Model with Cosmological constant: The effective gravitational constant G eff ( ) as a function of time, for non-relativistic matter t w = 0, with Λ = 10 -49 , and B = 2 (left) and B = 1 (right)
The term ϕλ acts as a potential term and hence we have at hand an antigravity BransDicke model with potential U BD ( ϕ ) = ϕ Λ. By varying 35 with respect to the metric and the scalar field, we obtain the Einstein equations describing the cosmological evolution of the antigravity Brans-Dicke model, which for a flat FRW metric are equal to
$$3 ( \varphi - \mathcal { B } ) H ^ { 2 } & = \rho ^ { ( m ) } + \frac { \omega _ { B D } } { 2 } \left ( \dot { \varphi } \right ) ^ { 2 } + \varphi \Lambda - 3 H \dot { \varphi }, \quad \quad \quad ( 3 6 a ) \\ \cap & \quad \tilde { \nu } \quad \dot { \nu } \quad ( m ) \ \cdot \ \tilde { \nu } ^ { ( m ) } \ \cdot \ \quad \ \tilde { \nu } \cdot \ \cdot \ \cdot \ \cdot \ \quad \ \tilde { \nu } \cdot \ \cdot \ \cdot \ \cdot \ \cdot \ \cdot \ \quad \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \$$
$$\ddot { \varphi } + 3 H \dot { \varphi } + \frac { 1 } { 2 \omega _ { B D } } \left [ \, - \, R + 2 \Lambda \right ] = 0.$$
$$- 2 \left ( \varphi - \mathcal { B } \right ) \dot { H } = \rho ^ { ( m ) } + \stackrel { \tau } { P ^ { ( m ) } } + \stackrel { \tau } { \omega _ { B D } } \left ( \dot { \varphi } \right ) ^ { 2 } + \ddot { \varphi } - H \dot { \varphi }, \text{ and } \quad ( 3 6 b ) \\. \tau r \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \colon$$
In the following, we shall take ω BD = 1 2. / As in the previous case, the effective gravitational constant varies with time in the Jordan frame model and its value is given by
$$G _ { e f f } ( t ) & = \frac { 1 } { 1 6 \pi ( \varphi ( t ) - \mathcal { B } ) }. & & ( 3 7 ) \\ \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot$$
We have solved numerically the cosmological equations (36) and as a general remark let us note that the model has both gravity and antigravity solutions, depending on the values of the parameters and specifically on the value of the antigravity parameter B . In Figures 3 and 4 we have presented the results of our numerical analysis for various parameter values and we now discuss in detail. In Figure 1 appears the time dependence of the scalar field ϕ t ( ), the energy density ρ t ( ), and the effective gravitational constant G eff ( ), t where again we have properly rescaled the time axis. The numerical values we used in Figure 3 are w = 1 3 , B = 1, and Λ = 10 -49 . Changing the value of w does not drastically affect the solutions, which crucially depend on the value of the antigravity parameter B . As can be seen from the time dependence of the effective gravitational constant G eff ( ) t in Figure 3, antigravity occurs along with a singularity between the transition from gravity to antigravity. This latter feature is quite common in antigravity models (see for example [40-43]). Accordingly, in Figure 4 we have provided the plots of the effective gravitational constant as a function of time, for w = 0, Λ = 10 -49 , and
B = 2(1) for the left (right) plot. Obviously, for B = 2 (left) a complex antigravity pattern occurs, while for B = 1 (right) there is no antigravity at all. This result validates our observation that antigravity crucially depends on the values of the B .
## 4 A Brief Discussion
Before closing this section, we discuss a last issue of some importance. It is generally known that a general F R ( ) theory with the method of Lagrange multipliers can be transformed to a Brans-Dicke theory with ω BD = 0 and non zero potential. Indeed, it is easy to see this and we demonstrate it shortly. Consider a general F R ( ) theory described by the following action:
$$\mathcal { S } = \int \mathrm d ^ { 4 } x \sqrt { - g } F ( R ) + S _ { m } ( g _ { \mu \nu }, \Psi _ { m } )$$
We introduce an auxiliary field χ , which actually is the Lagrange multiplier. Using this field, the action (38) becomes:
$$\mathcal { S } = \int \mathrm d ^ { 4 } x \sqrt { - g } \Big { ( } F ( \chi ) + F _ {, \chi } ( \chi ) ( R - \chi ) \Big { ) } + S _ { m } ( g _ { \mu \nu }, \Psi _ { m } ),$$
with F ,χ ( χ ) being the first derivative of the function F χ ( ) with respect to χ . Varying the action (39), with respect to the auxiliary field χ , we get,
$$F _ {, \chi \chi } ( \chi ) ( R - \chi ) = 0.$$
/negationslash
Recalling that F ,χχ ( χ ) = 0, which actually holds true for most viable F R ( ) theories, we get R = χ . Therefore, the action (39) recovers the initial F R ( )-gravity action (39). If we define,
$$\varphi = F _ {, \chi } ( \chi ),$$
then the action appearing in equation (39) becomes actually a function of the field ϕ , as can be seen below:
$$\mathcal { S } = \int \mathrm d ^ { 4 } x \sqrt { - g } \left [ \varphi R - U ( \varphi ) \right ] + S _ { m } ( g _ { \mu \nu }, \Psi _ { m } )$$
The scalar potential term U ϕ ( ) is equal to the following expression:
$$U ( \varphi ) & = \chi ( \varphi ) \varphi - F ( \chi ( \varphi ) ). & ( 4 3 ) \\ \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \end{cases}$$
By solving the algebraic equation (41) with respect to χ , will actually give us in closed form the function χ ϕ ( ) (at least in most cases), as a function of ϕ . Therefore, it is a straightforward way to obtain a Brans-Dicke theory with ω BD zero and non-zero potential by starting from a general F R ( ) theory. A question naturally springs to mind, that is, whether it is possible to have any sort of coincidence between F R ( ) gravity and BransDicke with a non-zero potential and zero ω BD and the answer is actually yes, but only when the potential of the Brans-Dicke is exactly the one of equation (43). Now, one has to be cautious, however, because this coincidence is 'one way' only, meaning that if we
start with the Brans-Dicke theory with ω BD = 0 and we try to find the corresponding F R ( ) theory by using a conformal transformation, then we may end up with a different F R ( ) theory, which we denote for example f ( R ). This requires a much deeper study that extends beyond the purpose of this article and we defer this interesting issue to a near future work. However, the reader is referred to the method in four dimensions used by the authors in [43]. There, it can be seen that, when starting from a general scalar-tensor theory, we end up with a certain class of F R ( ) theories determined by a constraint which the scalar field has to obey. It is not obvious, however, that starting from a Brans-Dicke theory with ω BD = 0 and non-zero potential, we will end up to the original F R ( ) theory we started with. We hope to answer this issue in a future publication.
## 5 Conclusions
In this paper we studied antigravity in scalar-tensor theories originating from F R ( ) theories and also antigravity in the Brans-Dicke model with cosmological constant. In the case of the F R ( ) theories we used a variant of the Lagrange multipliers method leading to antigravity scalar-tensor model in the Jordan frame, with ω = 0 and a scalar potential. We applied the technique and studied numerically the time-dependence of the gravitational constant. As we exemplified, although the initial F R ( ) model has no antigravity, guaranteed by the condition F ′ ( R > ) 0, the scalar-tensor Jordan frame counterpart may or may not have antigravity. This latter feature strongly depends on the parameters of the theory and particularly on the antigravity parameter B . In the case of the Brans-Dicke model with cosmological constant, we studied a by hand introduced antigravity modification of the model in the Jordan frame. The numerical analysis of the cosmological equations showed that the model exhibits antigravity depending on the numerical values of the parameters and particularly on the B antigravity parameter, like in the F R ( ) model case. In both cases, there exist regimes in the cosmic evolution in which either gravity or antigravity prevails and when going from antigravity to gravity and vice versa a singularity occurs, like in most antigravity contexts [40-43]. It worths searching theoretical constructions in which such a singularity is avoided. This would probably require some sort of singular conformal transformations between frames, or some singularity of the Lagrangian, a task we hope to address in the near future.
Finally, it is worth discussing the results and also the cosmological implications of our results. The main goal of this article was to demonstrate all possible cases in which antigravity might appear in modified theories of gravity. As we explicitly demonstrated, in the case of F R ( ) theories, although the initial Jordan frame F R ( ) theory had no antigravity (recall the condition F ′ ( R > ) 0 which actually guarantees this), antigravity might show up when the Jordan frame equivalent theory is considered, modified in the way we explicitly showed in the text. This is one of the new and notable results of this article. In the case of Brans-Dicke model, introducing by hand a term that causes antigravity, then antigravity might or not appear in the resulting theory. The latter depends strongly on the value of the antigravity parameter B . In principle, antigravity is a generally unwanted feature in modified theories of gravity and thus it can be considered less harmful if it occurs in the
very early universe, prior to inflation. Indeed, this is exactly what happens in all the cases we explicitly demonstrated in the text. However, antigravity is rather difficult to detect experimentally, unless there exists some mechanism of creation of a primordial black hole during the antigravity regime that could retain some information in terms of some sort of gravitational memory [46]. The evaporation of this black hole could reveal the value of the gravitational constant at the time it was created. A well posed question may be to ask how such a compact gravitational object could be created in an antigravity regime. The answer to this could be that antimatter behaves somehow different in antigravity regimes, so it could probably play a prominent role in such a scenario. However, we have to admit that this is just a speculation, since after antigravity occurs, the universe experiences a gravitational regime with a spacetime singularity at the moment of transition. We cannot imagine how a compact gravitational object (if any) could react under such severe conditions.
## References
- [1] S. Nojiri, S. D. Odintsov, Int. J. Geom. Meth. Mod.Phys. 4 (2007) 115
- [2] A. Felice, Shinji Tsujikawa, Living Rev.Rel. 13 (2010) 3
- [3] T. P. Sotiriou, V. Faraoni, Rev.Mod.Phys. 82 (2010) 451
- [4] T. P. Sotiriou, V. Faraoni, Rev.Mod.Phys. 82 (2010) 451
- [5] S. Nojiri, S. D. Odintsov, Phys.Rept. 505 (2011) 59
- [6] K. Bamba, S. Capozziello, S. Nojiri, S. D. Odintsov, Astrophys. Space Sci. 342, 155 (2012)
- [7] S. Capozziello, M. De Laurentis, Phys.Rept. 509 (2011) 167
- [8] S. Capozziello, S. Nojiri, S.D. Odintsov, A. Troisi, Phys.Lett. B639 (2006) 135
- [9] S. Nojiri, S. D. Odintsov, Gen.Rel.Grav. 36 (2004) 1765
- [10] S. Nojiri, S. D. Odintsov, Phys.Rev. D74 (2006) 086005
- [11] S. Tsujikawa, Phys.Rev. D77 (2008) 023507
- [12] S. Nojiri, S. D. Odintsov, Phys.Lett. B657 (2007) 238
- [13] A. A. Starobinsky, JETP Lett. 86 (2007) 157
- [14] S. M. Carroll, V. Duvvuri, M. Trodden, M. S. Turner, Phys.Rev. D70 (2004) 043528
- [15] O. Bertolami, R. Rosenfeld, Int.J.Mod.Phys. A23 (2008) 4817
- [16] A. Capolupo, S. Capozziello, G. Vitiello, Int.J.Mod.Phys. A23 (2008) 4979
- [17] P. K.S. Dunsby, E. Elizalde, R. Goswami, S. Odintsov, D. S. Gomez, Phys.Rev. D82 (2010) 023519
- [18] E.I. Guendelman, A.B. Kaganovich, Int.J.Mod.Phys. A21 (2006) 4373
- [19] G. Cognola, E. Elizalde, S. Nojiri, S.D. Odintsov, L. Sebastiani, S. Zerbini, Phys.Rev. D77 (2008) 046009
- [20] S.K. Srivastava, Int.J.Mod.Phys. A22 (2007) 1123
- [21] K. Bamba, S. Capozziello, S. Nojiri, S. D. Odintsov, Astrophys.Space Sci. 342 (2012) 155
- [22] S. Capozziello, V.F. Cardone, S. Carloni, A. Troisi, Int.J.Mod.Phys. D12 (2003) 1969
- [23] S. Capozziello, Int.J.Mod.Phys. D11 (2002) 483
- [24] P.J.E. Peebles, Bharat Ratra, Rev.Mod.Phys. 75 (2003) 559
- [25] V. Faraoni, Int.J.Mod.Phys. D11 (2002) 471
- [26] Edmund J. Copeland, M. Sami, Shinji Tsujikawa, Int.J.Mod.Phys. D15 (2006) 1753
- [27] S. Nojiri, S. D. Odintsov, Phys.Rev. D68 (2003) 123512
- [28] J.P. Morais Graca, V.B. Bezerra, Mod.Phys.Lett. A27 (2012) 1250178
- [29] M. Sharif, S. Arif, Mod.Phys.Lett. A27 (2012) 1250138
- [30] S. Asgari, R. Saffari, Gen.Rel.Grav. 44 (2012) 737
- [31] K. A. Bronnikov, M.V. Skvortsova, A.A. Starobinsky, Grav.Cosmol. 16 (2010) 216
- [32] E.V. Arbuzova, A.D. Dolgov, Phys. Lett. B 700 (2011) 289
- [33] Chung-Chi Lee, Chao-Qiang Geng, L. Yang, Prog. Theor. Phys. 128 (2012) 415
- [34] Harko, T., Lobo, F.S.N., Nojiri, S. and Odintsov, S.D., Phys. Rev. D 84(2011)024020
- [35] Bertolami, O., Boehmer, C.G. Harko, T. and Lobo, F.S.N., Phys. Rev. D 75 (2007) 104016
- [36] Haghani, Z., Harko, T., Lobo, F.S.N., Sepangi, H.R. and Shahidi, S., Phys. Rev. D 88 (2013) 044023
- [37] Sharif, M. and Zubair, M.: Astrophys. Space Sci. 349(2014)457
- [38] Valerio Faraoni, 'Cosmology in Scalar-Tensor Gravity', Kluwer Academic Publishers, 2004, Netherlands
- [39] Yasunori Fujii, Kei-Ichi Maeda, 'The Scalar-Tensor Theory of Gravitation', Cambridge University Press, 2004, Cambridge UK
- [40] P. Caputa, S. S. Haque, J. Olson and B. Underwood, Class. Quant. Grav. 30, 195013 (2013)
- [41] I. Bars, S. H. Chen, P. J. Steinhardt, N. Turok, Phys. Lett. B 715, 278 (2012)
- [42] J. J. M. Carrasco, W. Chemissany, R. Kallosh, arXiv:1311.3671
- [43] K. Bamba, Shin'ichi Nojiri, S. D. Odintsov, Diego Saez-Gomez, Phys. Lett. B 730 (2014) 136
- [44] Y. Fujii, Prog. Theor. Phys. 99 (1998) 599
- [45] M. A. Skugoreva, A. V. Toporensky, S. Yu. Vernov, arXiv:1404.6226
- [46] J. D. Barrow, Phys.Rev. D46 (1992) R3227-R3230 | null | [
"V. K. Oikonomou",
"N. Karagiannakis"
] | 2014-08-02T17:00:50+00:00 | 2014-08-02T17:00:50+00:00 | [
"gr-qc"
] | Study of Antigravity in an F(R) Model and in Brans-Dicke Theory with Cosmological Constant | We study antigravity, that is having an effective gravitational constant with
a negative sign, in scalar-tensor theories originating from $F(R)$-theory and
in a Brans-Dicke model with cosmological constant. For the $F(R)$ theory case,
we obtain the antigravity scalar-tensor theory in the Jordan frame by using a
variant of the Lagrange multipliers method and we numerically study the time
dependent effective gravitational constant. As we shall demonstrate by using a
specific $F(R)$ model, although there is no antigravity in the initial model,
it might occur or not in the scalar-tensor counterpart, mainly depending on the
parameter that characterizes antigravity. Similar results hold true in the
Brans-Dicke model. |
1408.0400v1 | ## Frictional figures of merit for single layered nanostructures
S. Cahangirov, 1, 2 C. Ataca, 1, 2, 3 M. Topsakal, 1, 2 H. Sahin, 1, 2 and S. Ciraci 1, 2, 3, ∗ 1 UNAM-National Nanotechnology Research Center, Bilkent University, 06800 Ankara, Turkey 2 Institute of Materials Science and Nanotechnology, Bilkent University, Ankara 06800, Turkey 3 Department of Physics, Bilkent University, Ankara 06800, Turkey (Dated: August 5, 2014)
We determined frictional figures of merit for a pair of layered honeycomb nanostructures, such as graphane, fluorographene, MoS 2 and WO 2 moving over each other, by carrying out ab-initio calculations of interlayer interaction under constant loading force. Using Prandtl-Tomlinson model we derived critical stiffness required to avoid stick-slip behavior. We showed that these layered structures have low critical stiffness even under high loading forces due to their charged surfaces repelling each other. The intrinsic stiffness of these materials exceed critical stiffness and thereby avoid the stick-slip regime and attain nearly dissipationless continuous sliding. Remarkably, tungsten dioxide displays much better performance relative to others and heralds a potential superlubricant. The absence of mechanical instabilities leading to conservative lateral forces is also confirmed directly by the simulations of sliding layers.
PACS numbers: 68.35.Af, 62.20.Qp, 81.40.Pq
Advances in atomic scale friction 1-3 have provided insight on dissipation mechanisms. The stick-slip phenomena is the major process, which contributes to the dissipation of the mechanical energy through sudden or non-adiabatic transitions between bi-stable states of the sliding surfaces. 4-7 During a sudden transition from one state to another, the velocities of the surface atoms exceed the center of mass velocity sometimes by orders of magnitudes. 8 Local vibrations are created thereof evolve into the non-equilibrium system phonons via anharmonic couplings 9 within picoseconds. 10 In specific cases, even a second state in stick-slip can coexist. 7
In Fig.1, two regimes of sliding friction are summarized within the framework of Prandtl-Tomlinson model, 4,5,8 where an elastic tip(+cantilever) moves over a sinusoidal surface potential. The curvature of this potential at its maximum gives the value of the critical stiffness k c . If the intrinsic stiffness of the tip k s is higher than this critical stiffness i.e. k /k s c > 1, the total energy of the tip-surface system always has one minimum. The sliding tip gradually follows this minimum, which results in the continuous sliding regime. Conversely, if the tip is softer than the critical value, then it is suddenly slipped from one of the bi-stable states to the other. This slip event can be activated by thermal fluctuations even before the local minimum point becomes unstable. 11 Experimentally, using friction force microscope, Socoliuc et al. 12 showed that the transition from stick-slip regime to continuous sliding attaining ultralow friction coefficient can be achieved by tuning the loading force on the contact.
In this Letter, the sliding friction between two same pristine layers of nanostructures, such as graphane, 13,14 fluorographene, 15,16 molybdenum disulfide 17 and tungsten dioxide, 18 (abbreviated according to their stoichiometry as CH, CF, MoS 2 and WO 2 respectively) is investigated using the Density Functional Theory 19 . We find that these nanostructures avoid stick-slip even under high
FIG. 1. (Color Online) Schematic representation of stick-slip regime (left), critical transition (middle) and continuous sliding regime (right) in Prandtl-Tomlinson model. Upper part: the potential energy curves of the surface (green lines) and of the tip(+cantilever) (red lines) ; lower part: force variation of the surface (green lines) and of the tip (red lines). Blue lines represent the potential energy of the tip and surface. The magenta dot shows the position of the tip on the surface, while its other end is positioned at the minimum of the parabola shown with red lines in the upper part. The dotted, dashed and solid lines correspond to three different tip positions moving to the right.
loadings and execute continuous sliding. Consequently, the sliding occurs without friction that would originate from the generation of non-equilibrium phonons. Our approach mimics the realistic situation, where the total energy and forces are calculated from first-principles as two-dimensional (2D) two layers undergo a 3D sliding motion under a constant (normal) loading force. This is the most critical and difficult aspect of our study. In this respect, our results provide a 3D rigorous quantum mechanical treatment for the 1D and empirical PrandtlTomlinson model. 4,5
The nanostructures considered in the present study are recently discovered insulators having honeycomb structure, which can form suspended single layers as well as multilayers. The unusual electronic, magnetic and elastic properties of these layers have been the subject of recent numerous studies. In particular, they have large band
gaps to hinder the dissipation of energy through electronic excitation and have high in-plane stiffness 16-18,21 ( C = (1 /A ∂ E /∂glyph[epsilon1] ) 2 s 2 , i.e. the second derivative of the strain energy relative to strain per unit area, A being the area of the unit cell). Analysis based on the optimized structure, phonon and finite temperature molecular dynamics calculations demonstrate that each suspended layer of these nanostructures are planarly stable. 14,16-18 In graphane, positively charged three hydrogen atoms from the top side and another three from the bottom are bound to the alternating and buckled carbon atoms at the corners of hexagons in graphene to form a uniform hydrogen coverage at both sides (See Fig.2(a)). Recently synthesized CF 15 is similar to CH, but F atoms are negatively charged. Tribological properties of carbon based fluorinated structures have been the focus of interest. 22,23 In the layers of MoS 2 or WO , the plane of positively 2 charged transition metal atoms is sandwiched between two negatively charged outer S or O atomic planes. It was shown that MoS 2 structure can have ultralow friction. 24 Theoretically, the static energy surfaces are calculated during sliding at MoS (001) surfaces. 2 25 Apparently, the interaction energy between two single layers of these nanostructures is mainly repulsive due to charged outermost planes except very weak Van der Waals attractive interaction around the equilibrium distance. In Fig.2, each layer being a large 2D sheet consisting of three atomic planes mimics one of two sliding surfaces. In practice, sliding surfaces can be coated by these single layer nanostructures as one achieved experimentally. 26
We consider two layers of the same nanostructures in relative motion, where the spacing z between the bottom atomic plane of the bottom layer and the top atomic plane of the top layer is fixed. Here the frictional behavior of the system is dictated mainly by C-H(F), Mo-S and W-O bonds and their mutual interactions. These layers are represented by periodically repeating rectangular unit cells. We calculate the value of the equilibrium lattice constants, which increase as z decreases. For each value of z the fixed atomic layer at the top is displaced by x and y on a mesh within the quarter of the rectangular unitcell. Then all possible relative positions (displacements) between fixed atomic layers are deduced using symmetry. At each mesh point all atoms of the system except those of fixed top and bottom planes are relaxed and the total energy of the system E T ( x, y, z ) (comprising both layers) is calculated. We have also derived ∆ ( x x, y, z ) and ∆ y x, y, z ( ) data which correspond to the shear (deflection) from the equilibrium position of the relaxed atomic planes relative to the fixed atomic plane of the same layer as illustrated in Fig.2(c). The matrices of these data are arranged for each nanostructure using the mesh spacing of ∼ 0.2 ˚ in A x and y directions. The forces exerting on the displacing top layer in the course of relative motion of layers are calculated from the gradient of the total energy of the interacting system, namely glyph[vector] F x, y, z ( ) = -∇ glyph[vector] E T ( x, y, z ) at each mesh point ( x, y ). These forces are in agreement with the resultant of the
FIG. 2. (Color Online) (a) Ball and stick model showing the honeycomb structure of graphane CH (fluorographene CF) (top) and MoS 2 (WO ) (bottom). 2 Calculated values of energy gaps E g and in-plane stiffness C are also given in units of eV and J/m 2 respectively. (b) Two MoS 2 layers sliding over each other have the distance z between their outermost atomic planes. (c) Each layer is treated as a separate elastic block. Lateral F L and normal (loading) F z o forces, the shear of bottom atomic plane relative to top atomic plane in each layer ∆ x y ( ), and the width of the layer w , are indicated.
atomic forces calculated for the top layer using HellmanFeynman theorem. Eventually, the matrices of all data, namely E T ( x, y, z ), ∆ x x, y, z ( ), ∆ y x, y, z ( ) and glyph[vector] F x, y, z ( ) are made finer down to mesh spacing of ∼ 0.05 ˚ using A spline interpolation.
The properties affecting the friction between layers should be derived under a given constant loading force. First of all we preset the value of applied loading, F z o , which corresponds to the operation pressure when divided by the cell area A , namely σ N = F z o /A . We obtain the normal force from F z ( x, y, z ) = -∂E T ( x, y, z ) /∂z and for each x and y we calculate the value of z where F z ( x, y, z ) = F z o and abbreviate it as z o ( x, y ). Then by using spline interpolation in z direction we calculate the x and y dependence of F x o [ x, y, z o ( x, y )] and F y o [ x, y, z o ( x, y )], as well as ∆ x o [ x, y, z o ( x, y )] and ∆ y o [ x, y, z o ( x, y )] for a given F z o . The lateral force is then glyph[vector] F L [ x, y, z o ( x, y )] = F x o ˆ + i F y o ˆ . j Integrating the lateral force over the rectangular unitcell we obtain,
$$E _ { I } [ x, y, z _ { o } ( x, y ) ] = \int _ { 0 } ^ { x } \int _ { 0 } ^ { y } \vec { F } _ { L } ( x, y, z _ { o } ( x, y ) ) \cdot \vec { \mathrm d r }$$
where E x,y,z I [ o ( x, y )] is the interaction energy for displacement ( x, y ) in the cell under applied constant loading force F z o . It should be noted that E I is different from E T ( x, y, z ) (but E I → E T for z >> 1) and is essential to reveal the friction coefficient. Contour plots of E I of two sliding MoS 2 layers calculated for σ N =15 GPa are shown in Fig.3(a) and those of CH, CF, WO 2 in SupplementalMaterial-A. 27 The profile of E I is composed of hills arranged in a triangular lattice. These hills correspond to the relative positions when the charged atoms of adjacent layers have the minimum distance. The hills are surrounded by two kind of wells. The difference between these two wells is enhanced with increasing pressure. The wells form a honeycomb structure and are connected to
each other through the saddle points (SP). When the layers are moved over each other they will avoid the relative positions corresponding to the hills. For example, if the layers are pulled in the y -direction they will follow the curved F x = 0 path passing through the wells and SP but not the straight one passing through the hills as shown in the Fig.3(b). This makes SP very important because moving from one well to the adjacent one requires to overcome the barriers at these points. We note that the critical stiffness can be calculated from the curvature of E o I , which is obtained by subtracting the strain energies of two sliding MoS 2 layers, namely E o I = E I -k s (∆ x 2 o +∆ y 2 o ) and by replacing x by x -2∆ x o . While the SP serves as a barrier in the direction joining the nearby wells it acts as a well in the perpendicular direction joining the hills. Since we are interested in the curvature of the SP in the former direction we have made a plot along the F y = 0 line which passes through the hill, the wells and the SP in between as shown in the Fig.3(b). We derive two critical stiffness values from E o I curve for a given normal loading force; namely k c 1 at the SP and k c 2 at the hill by fitting the curve at the maxima of the barriers to a parabola. Although the hills will be avoided during sliding motion the curvature at these points are calculated for completeness. In Fig.3 (c) the variation of k c 1 and k c 2 of CH, CF, MoS 2 and WO 2 with loading pressure σ N is presented. Generally, the critical stiffness, in particular k c 1 is low due to repulsive interaction between sliding layers. This facilitates the transition to continuous sliding.
Next we calculate the intrinsic stiffness k s of individual MoS 2 layers using the force and the displacement data. For each x and y the lateral forces F x o [ x, y, z o ( x, y )] and F y o [ x, y, z o ( x, y )] versus the displacements ∆ x o [ x, y, z o ( x, y )] and ∆ y o [ x, y, z o ( x, y )], respectively are plotted. As shown in Fig.3(b) as inset, this data falls on a straight line having a negative slope as expected from Hook's law of elasticity. We note that the elastic properties of layers having honeycomb structure is uniform and is independent of the direction of displacement and force. 21 The magnitude of the slope, k s = -F x y ( ) o / ∆ ( ) x y o gives us the stiffness of the layers. 20 Calculated intrinsic stiffness values of CH, CF, MoS 2 and WO in the range of 2 σ N from 5GPa to 30 GPa are found to be 6.15 ± 0.15 eV/ ˚ A , 4.5 eV/ ˚ 2 A , 10.0 2 ± 0.3 eV/ ˚ A 2 and 15.2 ± 0.3 eV/ ˚ A , respectively. 2 Clearly, these values of k s , in particular those of MoS 2 and WO 2 are rather high.
Based on the discussion at the beginning, the ratios k /k s c 1 and k /k s c 2 give us a dimensionless measure of performance of our layered structures in sliding friction. When these ratios are above two (since both layers in relative motion contribute), the stick-slip process is replaced by continuous sliding, whereby the dissipation of mechanical energy through phonons is ended. Under these circumstances the friction coefficient diminish, if other mechanisms of energy dissipation were neglected. For this reason one may call these ratios as a frictional figures of merit of the layered materials. In Fig.3 (d) we present the variations of the ratios k /k s c 1 and k /k s c 2 with
FIG. 3. (Color Online) (a) The contour plot of interaction energy E I of two sliding layers of MoS 2 . The zero of energy is set to E I [0 , 0 , z o (0 0)]. , The energy profile is periodic and here we present the rectangular unitcell of it. The width of this unitcell in y -direction is equal to the lattice constant a of the hexagonal lattice. Forces in x -( y -) direction is zero along the red (green) dashed lines, respectively. There are several points at which the lateral force glyph[vector] F L , is zero. The arrows at these critical points indicate the directions where the energy decreases. (b) The energy profiles of E I (blue line) and E o I (red line) along the horizontal line with F y = 0 for MoS . 2 The inset presents force versus shear values along x -and y -directions for each mesh point by red and green dots, respectively, which fall on the same line. Loading pressure in all cases is σ N =15 GPa. (c) The variation of k c 1 and k c 2 with loading pressure. (d) The variation of the ratios of k /k s c 1 and k /k s c 2 , i.e. frictional figures of merit with loading pressure calculated for CH, CF, MoS 2 and WO . 2
FIG. 4. (Color Online) Calculated lateral force variation of two single layer SiH under two different σ N . The top layer is moving to the right or to the left between two wells. Atomic positions of two SiH layers in stick and slip stages are shown by inset. The movement of SiH layers under loading pressure of σ N = 8 GPa is presented in Supplemental-Material-B. 30
normal loading forces. Even for very large σ N , k /k s c 1 > 2 and k /k s c 2 > 2. For usual loading pressures, the stiffness of MoS , CF and CH is an order of magnitude higher than 2 corresponding critical values. Interestingly, for WO 2 this ratio can reach to two orders of magnitudes at low pressures. The absence of mechanical instabilities has been also tested by performing extensive simulations of the sliding motion of layers in very small displacements. CH, C-F, Mo-S and W-O bonds in each case of two layers in relative motion under significant loading force did not display the stick-slip motion.
Conversely, we now examine the sliding of two silicane 28 layers (abbreviated as SiH and composed of silicene 29 saturated by hydrogen atoms from both sides, like graphane) with k s = 2 1 . ± 0 1 . eV/˚ A 2 for 2 GPa ≤ σ N ≤ 8 GPa. This is an interesting material because the onset of stick-slip occurs already at low loading pressures and exhibits a pronounced asymmetry in the direction of sliding between two wells. In Fig.4 we present the lateral force variation calculated for two different loading pressures. For small loading pressure, σ N =2 GPa the stick-slip is absent since approaching the SP from Well-I, the curvature is k c,I = 0 28 eV/ ˚ . A 2 and from
- ∗ [email protected]
- 1 C. M. Mate et al ., Phys. Rev. Lett. 59 , 1942 (1987).
- 2 B. N. J. Persson, Sliding Friction: Physical Principles and Applications (Springer, Berlin, 1998).
- 3 M. Urbakh and E. Meyer, Nature Mat. 9 , 8 (2010).
- 4 L. Prandtl, Z. Angew. Math. Mech. 8 , 85 (1928).
- 5 G. A. Tomlinson, Philos. Mag., 7 , 905 (1929).
- 6 D. Toman´ ek, W. Zhong, and H. Thomas, Europhys. Lett. 15 , 887 (1991).
- 7 A. Buldum and S. Ciraci, Phys. Rev. B 55 , 2606 (1997).
- 8 M. H. Mueser, M. Urbakh, and M. O. Robbins, Advances in Chem. Phys. 126 , 187 (2003).
- 9 V. L. Gurevich, Transport in phonon systems (NorthHolland, Amsterdam, 1986).
- 10 A. Buldum, D.M. Leitner and S. Ciraci, Phys. Rev. B 59 ,
Well-II it is k c,II = 0 16 eV/ ˚ . A 2 , thus k /k s c,IorII > 2 for both directions. Whereas, once the pressure is raised to σ N =8 GPa stick-slip already governs the sliding friction, since k c,I reaches 1.38 eV/ ˚ A 2 . Interestingly, since k c,II is only 0.28 eV/ ˚ A 2 for σ N =8 GPa, going from Well-II to Well-I a slip event occurs at SP. Eventually, one sees in Fig.4 a hysteresis in the variation of F L leading to energy dissipation.
Earlier, the sliding motion of the diamond like carbon coatings exposed to hydrogen plasma resulted in a very low friction coefficient. 31 Ultralow friction was attributed to repulsive Coulomb forces between DLC films facing each other in sliding. However, when exposed to open air in ambient conditions, positively charged H atoms was replaced by negatively charged O and hence the uniformity in the charging was destroyed. In the present study, graphane coating is reminiscent of the hydrogenated DLC and accordingly is found to have ultralow friction, but vulnerable to degradation by oxygen atoms. Unlike graphane coating, WO 2 coating consists of negatively charged oxygens and hence immune to oxidation.
In conclusion, using a criterion for the transition from stick-slip to dissipationless continuous sliding regime, which is calculated from the first-principles, we showed that two sliding layered nanostructures, such as CH, CF, MoS 2 and WO , execute continuous sliding with ultralow 2 friction. The minute variation of the amplitude of the interaction potential due to the repulsive interaction, as well as stiff C-H(F), Mo-S and W-O bonds underlie the frictionless sliding predicted in the present study. Our predictions put forward an important field of application as ultralow friction coating for the layered honeycomb structures, which can be achieved easily to hinder energy dissipation and wear in sliding friction.
This work is supported by TUBITAK through Grant No:108T234 also by EFS EUROCORE programme FANAS. All the computational resources have been provided by TUBITAK ULAKBIM, High Performance and Grid Computing Center (TR-Grid e-Infrastructure).
- 16042 (1999); H. Sevincli et al ., Phys. Rev. B 76 , 205430 (2007).
- 11 E. Gnecco et al ., Phys. Rev. Lett. 84 , 1172 (2000).
- 12 A. Socoliuc et al ., Phys. Rev. Lett. 92 , 134301 (2004).
- 13 D. C. Elias et al ., Science 323 , 610 (2009).
- 14 H. Sahin, C. Ataca, and S. Ciraci, Phys. Rev. B ¸ 81 , 205417 (2010).
- 15 R. R. Nair et al ., Small 6 , 2877 (2010).
- 16 H. S ¸ahin, M. Topsakal, and S. Ciraci, Phys. Rev. B 83 , 115432 (2011).
- 17 C. Ataca et al ., J. Phys. Chem. C 115 , 16354 (2011).
- 18 C. Ataca, H. Sahin and S. Ciraci, to be published in J. Phys. Chem. C.
- 19 We have performed first-principles plane wave calculations within the Generalized Gradient Approximation (GGA)
- [J. P. Perdew, K. Burke, and M. Ernzerhof, Phys. Rev. Lett. 77 , 3865 (1996)] including van der Waals corrections [S. Grimme, J. Comp. Chem. 27 , 1787 (2006)] using PAW potentials [P.E. Blochl, Phys. Rev. B 50 , 17953 (1994)]. All structures have been treated within supercell geometry using the periodic boundary conditions. A plane-wave basis set with kinetic energy cutoff of 400 eV and 500 eV is used for transition metal and carbon based structures respectively. In the self-consistent potential and total energy calculations the BZ is sampled by (10 × 18 × 1) for graphane and was scaled in this manner for other structures. All atomic positions and lattice constants are optimized by using the conjugate gradient method where total energy and atomic forces are minimized. The convergence for energy is chosen as 10 -5 eV between two steps, and the maximum force allowed on each atom is less than 10 -4 eV/˚. NumerA ical plane wave calculations have been performed by using VASP package [G. Kresse and J. Hafner, Phys. Rev. B 47 , 558 (1993); G. Kresse and J. Furthm¨ller, Phys. Rev. B u 54 , 11169 (1996)].
- 20 Note that, normally the stiffness is defined as stress over strain and has units of energy per volume. Here we only need the ratio of material stiffness to the critical stiffness and should have the same units. The critical stiffness was
- calculated as second order spatial derivative of energy in the unitcell and it has units of energy per unitcell per unit area. As defined above, the stiffness of layers, k s , also has units of energy per unitcell per unit area.
- 21 M. Topsakal, S. Cahangirov, S. Ciraci, App. Phys. Lett. 96 , 091912 (2010).
- 22 S. Miyake et al ., J. Tribol., 113 , 384 (1991).
- 23 P. Thomas et al ., J. Phys. Chem. Solids 67 , 1095 (2006).
- 24 J. M. Martin et al ., Phys. Rev. B 48 , 10583 (1993).
- 25 T. Liang, et al ., Phys. Rev. B 77 , 104105 (2008).
- 26 S. Chen, et al ., ACS Nano, 5 , 1321 (2011).
- 27 See Supplemental-Material-A at [URL] for E I profiles of CH, CF and WO 2 under σ N = 15 GPa and variation of E 0 I in MoS 2 with applied loading pressure.
- 28 L. C. Lew Yan Voon, et al ., Appl. Phys. Lett. 97 , 163114 (2010); M. Houssa, et al ., Appl. Phys. Lett. 98 , 223107 (2011).
- 29 S. Cahangirov, et al ., Phys. Rev. Lett. 102 , 236804 (2009).
- 30 See Supplemental-Material-B at [URL] for the deformation and sudden jumps of SiH bonds during the stick-slip motion.
- 31 A. Erdemir, Surface and Coatings Technology 146 , 292 (2001). | 10.1103/PhysRevLett.108.126103 | [
"S. Cahangirov",
"C. Ataca",
"M. Topsakal",
"H. Sahin",
"S. Ciraci"
] | 2014-08-02T17:08:05+00:00 | 2014-08-02T17:08:05+00:00 | [
"cond-mat.mes-hall",
"cond-mat.mtrl-sci",
"physics.comp-ph"
] | Frictional figures of merit for single layered nanostructures | We determined frictional figures of merit for a pair of layered honeycomb
nanostructures, such as graphane, fluorographene, MoS$_2$ and WO$_2$ moving
over each other, by carrying out ab-initio calculations of interlayer
interaction under constant loading force. Using Prandtl-Tomlinson model we
derived critical stiffness required to avoid stick-slip behavior. We showed
that these layered structures have low critical stiffness even under high
loading forces due to their charged surfaces repelling each other. The
intrinsic stiffness of these materials exceed critical stiffness and thereby
avoid the stick-slip regime and attain nearly dissipationless continuous
sliding. Remarkably, tungsten dioxide displays much better performance relative
to others and heralds a potential superlubricant. The absence of mechanical
instabilities leading to conservative lateral forces is also confirmed directly
by the simulations of sliding layers. |
1408.0403v2 | ## Heavy Flavour Physics at the LHC
T. Gershon , M. Needham a b
a
Department of Physics, University of Warwick, Coventry, United Kingdom b School of Physics and Astronomy, University of Edinburgh, Edinburgh, United Kingdom
## Abstract
A summary of results in heavy flavour physics from Run 1 of the LHC is presented. Topics discussed include spectroscopy, mixing, CP violation and rare decays of charmed and beauty hadrons.
Un r´ esum´ des r´sultats e e du run 1 du LHC sur la physique des saveurs lourdes est pr´sent´. e e Les sujets discut´s incluent la spectroscopie, le m´lange ene e tre m´ esons et anti-m´sons, la violation de e CP et les d´ esint´grations e rares des hadrons charm´ es et de beaut´. e
Keywords: quark flavour physics, spectroscopy, CP violation, rare decays, Large Hadron Collider
Mots-cl´s: e physique des saveurs lourdes, spectroscopie, violation de CP , d´ esint´grations rares, Grand collisionneur de hadrons (LHC). e
## 1. Introduction
Within the Standard Model of particle physics, there are six 'flavours' of quark. Hadrons containing charm ( ) or beauty ( ) quarks or antiquarks are c b known as heavy flavoured particles. By a quirk of convention, the heaviest flavoured particle, the top quark, is not usually included with discussions of 'heavy flavour physics', and thus it is not within the scope of this review.
The high energy proton-proton collisions at the Large Hadron Collider are the world's most copious source of heavy flavoured particles. For example, the production cross-sections for cc ¯ and bb ¯ quark-antiquark pairs are O (1 mb) and O (100 µ b) respectively. Specific values depend on the kinematic region in which the measurement is made, with the production peaking at pseudorapidity values | η | ∼ 3, and are an increasing function of centre-of-mass energy. Therefore, per fb -1 of data collected at, for example, LHCb, over 10 11 bb ¯ quark pairs are, in principle, available, with the corresponding number for charm pairs an order of magnitude larger. The number that is actually recorded by each experiment depends critically on the trigger used for online selection.
Email addresses: [email protected] (T. Gershon), [email protected] (M. Needham)
The availability of such large samples enables a new era of precision flavour physics and discovery. Measurements of the properties of heavy flavoured hadrons - including those of states that had not previously been observed - provide tests of the theory of the strong interaction, quantum chromodynamics (QCD), in a regime where it is not well understood. In addition, heavy flavour phenomena such as mixing and rare decays are mediated by loop processes involving virtual particles, and are sensitive to possible non-Standard Model physics at high scales. In fact, precision measurements in the quark sector can be sensitive to new particles with masses much higher than the reach of the LHC collisions. Studies of these processes therefore provide a complementary approach to discover 'new physics', and form a key part of the LHC programme to search beyond the Standard Model.
One particularly enticing aspect of this programme is the possibility to learn more about the origin of the asymmetry between matter and antimatter in the Universe. Violation of the combined CP symmetry, that is symmetry under inversion of parity ( P ) and of all internal quantum numbers (charge conjugation, C ) is a prerequisite for the evolution of an asymmetric Universe. Within the Standard Model, CP violation arises due to a complex phase in the CabibboKobayashi-Maskawa (CKM) quark mixing matrix [1, 2] that describes the relative coupling strengths of the charged-current weak interaction transitions between different flavours of quarks. While this gives a consistent description of all the CP violation effects that have been observed to date, additional sources of asymmetry must exist to explain the observed Universe. One of the highest priorities in contemporary particle physics is to discover new sources of CP violation, which may be present in the quark sector or may be manifest in other areas, for example neutrino oscillations.
## 2. Detectors
All the main LHC detectors have considerable potential to study heavy flavour physics, and ATLAS [3], CMS [4] and LHCb [5] have extensive programmes in this area. Although ALICE can study production at low luminosity, it cannot perform competitive studies of the processes that are the main focus of this review, and therefore is not discussed further.
Precision tracking is a key requirement in a hadronic environment in order to reduce combinatorial background to an acceptable level. All the LHC detectors have well aligned and calibrated tracking detectors delivering performance close to design expectations. An important performance indicator of the tracking system is the mass resolution for the Υ resonances decaying to the dimuon final state, shown in Fig. 1. ATLAS, CMS and LHCb have Υ(1 S ) mass resolutions of ∼ 120 MeV /c 2 , ∼ 70 MeV /c 2 and ∼ 45 MeV /c 2 respectively.
The key signatures that allow decays of heavy flavoured particles to be distinguished from random combinations of tracks are the presence of muons with comparatively large transverse momentum, and a displaced vertex due to the non-negligible lifetimes of the weakly decaying hadrons. ATLAS and CMS exploit only the former in their online selections, while LHCb makes extensive use
3
Figure 1: Dimuon invariant mass resolution in the region of the Υ resonances for (left) ATLAS [6] (middle) CMS [7] (right) LHCb [8].

in its trigger [9] of information from its vertex locator [10]. This, together with the particle identification capability provided by its ring-imaging Cherenkov detectors [11], gives LHCb a broader heavy flavour physics programme than ATLAS and CMS. However, ATLAS and CMS benefit from higher integrated luminosities ( ∼ 5 fb -1 of √ s = 7TeV and ∼ 20 fb -1 of √ s = 8TeV pp collisions collected in 2011 and 2012, respectively, for each experiment) and are therefore highly competitive for final states containing dimuon signatures. LHCb operates at a lower instantaneous luminosity to avoid saturating its trigger and causing over-occupancy of its subdetectors: the corresponding integrated luminosities are 1 fb -1 (2011) and 2 fb -1 (2012). The LHCb upgrade [12] will enable higher luminosity operation.
## 3. Spectroscopy
The large datasets collected at the LHC have allowed studies of the properties of b -hadrons with unprecedented precision. This is a wide field of research, in which three particularly interesting areas, discussed below, are exotic spectroscopy, the B + c meson and b -baryons.
In addition to conventional mesons and baryons, the QCD Lagrangian allows for more exotic possibilities such as tetraquark and molecular states. The unexpected discovery of the X (3872) state by the Belle collaboration [13] led to a resurgence of interest in exotic spectroscopy and subsequently many new 'XYZ' states have been claimed.
The X (3872) state has been studied in detail both at the e + e -B factories [14, 15] and the Tevatron [16, 17] but the nature of this particle remains unclear. Its properties do not match the predictions for the conventional charmonium states and it has been interpreted as a candidate for a tetraquark state or a loosely bound deuteron-like D ∗ 0 D 0 'molecule' (reviews can be found in Refs. [18, 19]). At the LHC the X (3872) is produced both directly in pp collisions and also in b -hadron decays. Inclusive studies are challenging due to the large combinatorial background from other particles produced in the pp interaction. Nevertheless, both LHCb and CMS have studied inclusive X (3872) production in pp collisions at √ s = 7TeV [20, 21]. The cross-sections measured by both ex-
Figure 2: (Left) J/ψπ + π -mass spectrum observed by CMS (with 10 < p T < 50 GeV and | y | < . 1 2). Clear signals for both the X (3872) and ψ (2 S ) states are seen. (Right) Differential cross-section for prompt X (3872) versus p T compared to the NRQCD predictions [22]. Both plots are taken from Ref. [21].
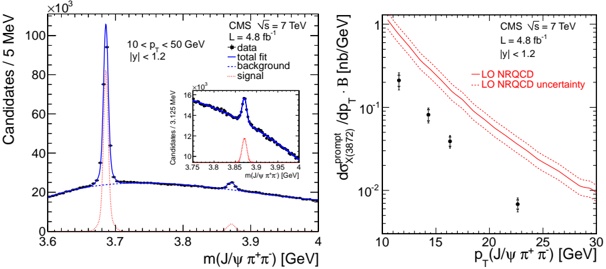
periments are significantly less than those expected from leading-order NRQCD predictions [22], as shown in Fig. 2.
In addition, LHCb has measured the X (3872) quantum numbers by performing a five-dimensional angular analysis of the B + → X (3872) K + , X (3872) → J/ψπ + π -decay chain [23]. To distinguish between the possible hypotheses for the quantum numbers a likelihood ratio test is performed. The data favour the J PC = 1 ++ hypothesis and the 2 -+ hypothesis is rejected with a significance of 8 4 . σ . This assignment favours the hypothesis that the X (3872) is exotic in nature. However, the relative decay rates of the X (3872) to the ψ (2 S γ ) and J/ψγ final states [24] are inconsistent with the prediction for a pure molecule. Further studies are still needed to understand the nature of the X (3872) particle.
The large datasets collected by the LHC experiments have allowed studies of other 'XYZ' states. One very important result is the confirmation by LHCb [25] of the existence and resonant nature of the Z (4430) + state first seen by the Belle collaboration [26-28]. As this state is charged its minimal quark content is ccud , and thus it provides clear evidence for the existence of nonqq mesons. A puzzle that remains open concerns the existence of the X (4140) state. Evidence for this putative J/ψφ resonance was reported by the CDF collaboration based on studies of the B + → J/ψφK + decay chain [29]. However, a subsequent LHCb study found no evidence for this state and set upper limits on its existence [30]. An analysis by CMS [31] confirmed the existence of a peaking structure in the same region, and in addition found evidence for a second structure with m J/ψφ ( ) ∼ 4300 MeV /c 2 , in same decay mode. Further study is needed to clarify whether these structures are resonant in nature.
The B + c meson, the ground state of the bc system, is unique as it is the only weakly decaying heavy quarkonium system. It was first observed by the CDF collaboration [32, 33], but with the advent of the LHC studies of the B + c meson have entered a new precision era. LHCb has reported observations of many
new decay modes [34-39], while signals for the B + c → J/ψπ + π + π -decay have also been reported by ATLAS [40] and CMS [41]. One particularly important observation is that of the decay B + c → B π 0 s + [42], which is mediated by the decay of the constituent c quark. Such decays are expected to dominate the B + c width, but had never previously been observed. It will be of interest to search for decay modes in which the b and c annihilate in the near future. The fundamental properties of the B + c meson have also been determined, with significant improvements in precision compared to prior results. The most precise measurement of the B + c mass to date is obtained by LHCb in the J/ψD + s decay mode [36],
$$m ( B _ { c } ^ { + } ) = 6 2 7 6. 2 8 \pm 1. 4 4 \, ( \text{stat} ) \pm 0. 3 6 \, ( \text{syst} ) \, \text{MeV} / c ^ { 2 } \,.$$
In addition, LHCb has used semileptonic B + c decays to measure the lifetime [43]
$$\tau ( B _ { c } ^ { + } ) = 5 0 9 \pm 1 2 \, ( \text{stat} ) \pm 8 \, ( \text{syst} ) \, \text{fs} \,.$$
The observation of a candidate B c (2 S ) + state by ATLAS [44], shown in Fig. 3(left), demonstrates the possibility for more detailed understanding of the spectroscopy in the B + c sector.
The large data samples collected by the LHC experiments has also allowed to explore in detail the properties of the b -baryon sector for the first time. One puzzle from studies at LEP and the Tevatron concerned the lifetime of the Λ 0 b baryon. Theoretical predictions based on the Heavy Quark Expansion (HQE) give the ratio of the Λ 0 b and B 0 lifetimes to be consistent with unity at the level of a few percent [45-47]. However, early measurements gave considerably smaller values. ATLAS, CMS and LHCb have all made measurements of this quantity [48-50] and find values more consistent with theory. The most precise measurements of the Λ 0 b lifetime are obtained by LHCb with decays to the J/ψΛ [51] and J/ψpK -[52] final states. These give
$$\tau ( \Lambda _ { b } ^ { 0 } ) = 1. 4 6 8 \pm 0. 0 0 9 \pm 0. 0 0 8 \, \text{ps} \,,$$
within a few percent of the measured B 0 lifetime [53] as predicted by the HQE. Measurements of the lifetimes of other b -baryons also start to approach the percent level [54, 55].
First observations of excited b -baryons have also been made. CMS has observed an excited Ξ b state [56] whilst LHCb has observed two excited Λ 0 b states [57], as shown in Fig. 3(right). Further new discoveries in this area can be anticipated with more data and refined analysis techniques.
## 4. Mixing
There are four ground-state neutral flavoured mesons: the K 0 (¯ ), sd D 0 ( cu ¯), B 0 ( ¯ bd ) and B 0 s ( ¯ bs ) particles. Each of these can mix with its antiparticle, through diagrams that either contain virtual heavy particles or have on-shell
Figure 3: Invariant mass distributions of: (left) B π ± c + π -candidates from ATLAS [44]; (right) Λ π 0 b + π -candidates from LHCb [57].
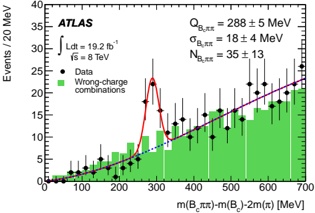
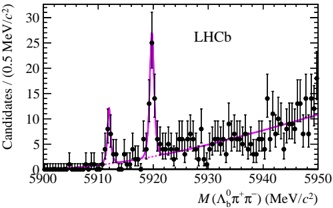
intermediate states. These are often referred to as short-distance (or dispersive) and long-distance (or absorptive) processes, respectively.
As a result of the mixing, physical states with definite masses and lifetimes are formed. When the amplitudes of the mixing processes are calculated, theoretical predictions for the mass and width differences (∆ m and ∆Γ), and for the parameter of CP violation in the mixing ( a sl ), are obtained. Since, at least for the short-distance diagrams, the uncertainties related to the theory prediction are under good control, comparison of the measurements (particularly ∆ m and a sl ) to the predictions provide strong tests of the Standard Model.
The first data from the LHC has led to significant improvement in knowledge of the D 0 and B 0 s mixing parameters. The measurement of the mass difference in the B 0 s system, ∆ m s , had proved challenging for previous experiments because its large value causes fast oscillations between B 0 s and B 0 s that are hard to resolve. The CDF collaboration did, however, succeed to determine the value of ∆ m s with 5 σ significance [58].
Due to the LHCb detector's excellent vertex resolution, which allows to resolve the oscillations, and flavour tagging capability [59, 60], from which initial state B 0 s and B 0 s mesons can be distinguished, major improvement in the determination of ∆ m s has been achieved [61-63]. The single most precise result, based on a sample of B 0 s → D π -s + decays selected from LHCb's 2011 data sample, illustrated in Fig. 4 (left), gives [62]
$$\Delta m _ { s } = \left ( 1 7. 7 6 8 \pm 0. 0 2 3 \left ( \text{stat} \right ) \pm 0. 0 0 6 \left ( \text{syst} \right ) \right ) p s ^ { - 1 } \,.$$
The width difference in the B 0 s system, ∆Γ , can be measured either by s comparing the lifetimes for CP -even ( e.g. K K + -[64-66] or D D + s -s [67]) and CP -odd ( e.g. J/ψπ + π -[68] or J/ψK 0 S [69]) final states or from analysis of decays to a final state that contains an admixture of both ( e.g. J/ψφ ). The most precise measurements come from the latter approach [70-74], which also has the advantage that it is not necessary to make assumptions concerning CP violation parameters since they can be determined simultaneously (as discussed
›3
Figure 4: Mixing in (left) the B 0 s -B 0 s system [62]; (right) the D 0 -D 0 system [79].
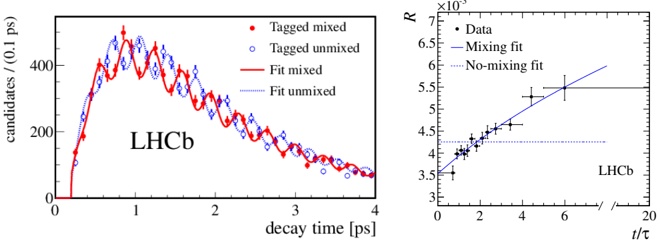
below). The single most precise measurement gives [74]
$$\Delta \Gamma _ { s } = \left ( 0. 1 0 0 \pm 0. 0 1 6 \left ( \text{stat} \right ) \pm 0. 0 0 3 \left ( \text{syst} \right ) \right ) p s ^ { - 1 } \,.$$
In this channel, by studying the variation of the strong phase difference between the J/ψφ and J/ψK + K -(S wave) components, the sign of ∆Γ s has been confirmed to be positive [74, 75].
In stark contrast to the large values of ∆ m s and ∆Γ , the mixing parameters s in the charm sector are small. Indeed, while previous experiments had seen evidence for charm oscillations [76-78], no single measurement exceeded the 5 σ threshold for discovery. LHCb has taken the precision of the measurements far past that threshold using D 0 → K π ± ∓ decays [79, 80] as shown in Fig. 4 (right). The world averages of the charm mixing parameters are now [81]
$$x _ { D } = \Delta m _ { D } / \Gamma _ { D } = ( 0. 3 9 ^ { + 0. 1 6 } _ { - 0. 1 7 } ) \% \,, \quad y _ { D } = \Delta \Gamma _ { D } / ( 2 \Gamma _ { D } ) = ( 0. 6 7 ^ { + 0. 0 7 } _ { - 0. 0 8 } ) \% \,,$$
where Γ D is the average width of the neutral charm mesons. As the value of x D is still consistent with zero, further improvement of precision is well motivated.
## 5. Mixing-related CP violation
CP violation phenomena in charm oscillations are expected to be negligible. Now that charm mixing is definitively established, precise experimental searches to test this Standard Model prediction are imperative. Results from LHCb with the D 0 → K π ∓ ± [80] and D 0 → K K + -and D 0 → π + π -[82] decays have significantly improved the precision of prior measurements, but not yet revealed any discrepancy with the Standard Model. Further improvements in precision are anticipated as all measurements are updated to the full Run I data sample, and results from additional channels such as D 0 → K π 0 S + π -become available.
Mixing-induced CP violation in the B 0 sector has been studied extensively by the e + e -B factories. The benchmark measurement is from the asymmetry in B 0 → J/ψK 0 S decays, which gives sin 2 β = 0 665 . ± 0 024 [81, 83, 84], where . β ≡
Figure 5: Compilation of data on φ s and ∆Γ s [81]. The latest results from LHCb [88] and CMS [72] are not included.
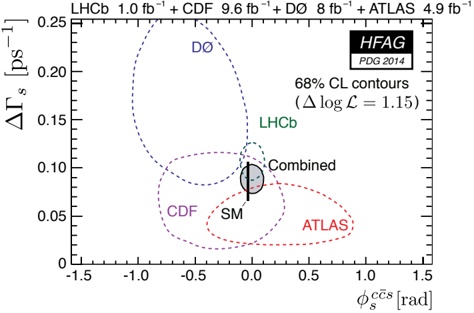
arg [ -V cd V ∗ cb / V ( td V ∗ tb )] and V ij represent elements of the CKM matrix. Using its 2011 dataset LHCb has measured sin 2 β = 0 73 . ± 0 07 (stat) . ± 0 04 (syst) [85], . in agreement with the world average though less precise. Results with the full Run I precision should be competitive with the individual measurements from BaBar and Belle.
The LHC era has allowed the first high precision searches for CP violation in the B 0 s sector. In the Standard Model the prediction for the CP violation effect in B 0 s → J/ψφ decays is φ s ≡ -2arg [ -V ts V ∗ tb / V ( cs V ∗ cb )] = -0 036 . ± 0 002. . Extensions of the Standard Model typically give additional phases which can make the measured value of φ s differ from this prediction. Hence, precise measurements of φ s test models of new physics. Prior to LHC running, first measurements from the Tevatron experiments hinted towards a deviation with the Standard Model, though with large uncertainties [86, 87]. Significant improvement in precision has been achieved by LHCb with the B 0 s → J/ψφ channel [73, 74]. ATLAS [71] and CMS [72] have also released preliminary measurements from flavour-tagged time-dependent angular analyses of B 0 s → J/ψφ decays, using their 2011 and 2012 data samples, respectively.
It is of interest to make φ s measurements using additional channels. LHCb has released results based on the B 0 s → J/ψπ + π -decay [88-90]. This final state has a large contribution from J/ψf 0 (980) decays, but the whole phase-space can be used inclusively since it has been shown to be dominantly CP -odd [91, 92]. The most recent LHCb analysis of B 0 s → J/ψπ + π -using the full Run I data sample gives currently the single most precise measurement [88]
φ s = 0 07 . ± 0 07 (stat) . ± 0 01 (syst) rad . .
Further improvement in precision is anticipated with the update of the B 0 s → J/ψφ analysis to the full Run I sample. Figure 5 summarises the current knowl-
Figure 6: Compilation of data on a sl in the B 0 and B 0 s system [81]. The vertical and horizontal bands show the averages of a sl ( B 0 ) and a sl ( B 0 ) measured individually, the green ellipse is the D0 measurement with inclusive same-sign dileptons, and the red ellipse is the world average of all measurements. The Standard Model prediction (red point) is indistinguishable from the origin.
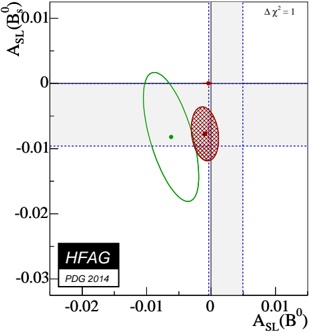
edge of φ s : the measurements are consistent with the Standard Model, suggesting that any new physics effects are small.
In addition, LHCb has measured φ s with the B 0 s → φφ channel [93, 94]. As this decay is dominated by the b → s loop transition, it can be used to search for new physics effects in the decay amplitude as well as in mixing. In the near future it will be interesting to obtain also values of φ s from B 0 s → K ∗ 0 K ∗ 0 which is similarly sensitive to possible new physics effects.
The semileptonic (or flavour-specific) asymmetry a sl is sensitive to CP violation in mixing. It is expected to be negligibly small in the Standard Model, but the D0 collaboration has reported an anomalous asymmetry between positive and negative like-sign muon pairs [95]. The effect, which deviates from the Standard Model predictions by 3 6 . σ , could be caused by non-zero a sl in either or both the B 0 and B 0 s systems. LHCb has measured a sl ( B 0 s ) using B 0 s → D µ X -s + decays reconstructed in its 2011 data sample [96]. The result is the single most precise measurement of this quantity, and is in agreement with the Standard Model prediction, as are all other measurements of a sl ( B 0 ) and a sl ( B 0 s ) individually. The current situation is summarised in Fig. 6. Further improvements in precision are needed to shed light on whether the D0 result indicates new physics.
## 6. Direct CP violation and the determination of γ
The term 'direct CP violation' is used to refer to asymmetries that cannot be caused by CP violation in the mixing amplitude. Historically, this categorisation was important to test so-called 'superweak' models. Direct CP violation can be observed as a difference in mixing-related CP violating effects in neutral meson decays to different final states, as seen in the kaon system [97, 98]. Alternatively, if a sl is known to be small, direct CP violation can be seen in flavour-specific decays of neutral mesons, for example as an asymmetry in the yields of B 0 → K π + -and B 0 → K π -+ decays [99, 100]. This approach allowed LHCb to make the first observation of CP violation in the B 0 s system through the decay rate asymmetry of B 0 s → K π -+ and B 0 s → K π + -decays, [101, 102]
$$A _ { C P } ( B _ { s } ^ { 0 } \to K ^ { - } \pi ^ { + } ) = 0. 2 7 \pm 0. 0 4 \left ( \text{stat} \right ) \pm 0. 0 1 \left ( \text{syst} \right ).$$
Among other results on direct CP violation, particularly striking are the phase-space dependent effects seen in B + decays to the final states π + π -K + , K K K + -+ , π + π -π + and K K π + -+ [103, 104], illustrated in Fig. 7. The asymmetries are larger than 50 % in some regions away from resonant peaks. This appears to indicate that interference effects play a crucial role in generating the asymmetries, although further investigation is necessary to obtain a clear understanding.
The main objective in CP violation studies is to understand whether all observed effects arise from the complex phase of the CKM quark mixing matrix. To interpret results such as those in charmless B meson decays mentioned above, it is necessary to have a benchmark determination of the Standard Model phase γ ≡ arg [ -V ud V ∗ ub / V ( cd V ∗ cb )]. This can be achieved using decays such as B → DK , where interference between amplitudes leading to final state D 0 and D 0 mesons is possible when they are reconstructed in a common final state such as K K + -. As no loop contributions are possible these decays are very clean theoretically, and moreover all hadronic parameters can be determined from the data by considering several different D meson decays. LHCb has reported results on B + → DK + using D → K K ,π + -+ π -, K ∓ π ± [105], K π π ∓ ± + π -[106], K π 0 S + π -, K 0 S K K + -[107, 108] and K K 0 S ± π ∓ [109] decays. The combination of these results gives [110, 111]
$$\gamma = ( 6 7 \pm 1 2 ) ^ { \circ } \,.$$
Since most of the inputs are yet to be updated to include all Run I data, and results on B 0 → DK ∗ 0 [112, 113], B + → DK π π + + -[114] and B 0 s → D K ∓ s ± [115] can also be included, there are excellent prospects for further improvement.
Since the Standard Model predicts only small or vanishing CP asymmetries in charm decays, searches for direct CP violation provide useful null tests. A measurement of the parameter ∆ A CP , describing the difference between the asymmetries for D 0 → K K + -and D 0 → π + π -decays, that differed from zero by 3.5 standard deviations [116], prompted a great deal of theoretical activity (reviewed in Ref. [117]) to examine whether or not a percent level asymmetry
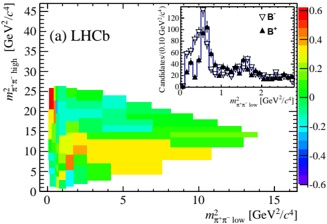
0
(b) LHCb
10
1
20
-
B
+
B
2.5
2
2
K
/
[GeV
-
K
+
30
m
]
c
/
[GeV
-
]
4
c
4
2
1.5
2
K
K
+
Figure 7: Direct CP violation effects in the phase space of (left) B + → π + π -π + and (right) B + → K K π + -+ decays [104]. The z -axis ( y -axis on inset) shows the raw asymmetry, without correction for background, or instrumental efficiencies and asymmetries.
could be accommodated within the Standard Model. More recent measurements, however, bring the world average closer to zero [118-120]. In addition searches for CP violation in D + and D + s decays have yielded null results [121125], so that currently there is no evidence for CP violation in the charm system.
## 7. Rare decays
A powerful way to search for new physics is to study decays which are either forbidden or suppressed due to features of the Standard Model that may not be present in a more general theory. The flavour sector of the Standard Model presents several such features: there are no flavour changing neutral currents at tree-level, vertices involving quarks of different families are suppressed by CKM quark mixing matrix elements, and the V -A structure of the weak interaction leads to distinctive effects. Rare decays of B mesons to final states containing leptons or photons are particularly useful for Standard Model tests since observables can be calculated with reduced theoretical uncertainty compared to fully hadronic final states.
Perhaps the most powerful of all Standard Model tests with rare B decays is the search for B 0 ( s ) → µ + µ -decays. The decay rate is suppressed by all three of the features mentioned above, and in particular the helicity suppression due to the V -A structure of the weak interaction is expected to be alleviated in models with extended Higgs sectors, such as supersymmetry. Prior to LHC data taking, experimental limits [126, 127] still allowed the B 0 s → µ + µ -rate to be enhanced by more than a factor of ten compared to its Standard Model prediction of (3 35 . ± 0 28) . × 10 -9 . However, a series of results from LHCb [128-130], CMS [131] and ATLAS [132] progressively reduced the phase space for new physics signals. In late 2012, LHCb announced the first evidence for the B 0 s → µ + µ -decay [133], and this was subsequently confirmed by both LHCb [134] and CMS [135] with their full Run I data sets. The signals, shown in Fig. 8, when combined now reach the 5 σ threshold for observation [136]. The combined result for the branching
2
]
4
/
c
2
[GeV
-
p
-
2
K
m
40
35
30
25
20
15
10
5
0
)
4
/c
2
Candidates/(0.10 GeV
70
60
50
40
30
20
10
0
m
0.6
0.4
0.2
0
-0.2
-0.4
-0.6
Figure 8: Signals for B 0 s → µ + µ -decays from (left) LHCb [134] with only the most signal-like candidates included, and (right) CMS [135], with all candidates weighted by their probability to be signal.
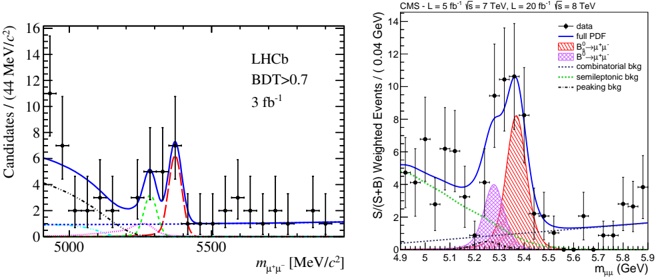
## fraction
$$\mathcal { B } ( B _ { s } ^ { 0 } \rightarrow \mu ^ { + } \mu ^ { - } ) = ( 2. 9 \pm 0. 7 ) \times 1 0 ^ { - 9 }$$
is consistent with the Standard Model prediction. Future updates with more statistics are nonetheless of great interest to reduce the uncertainty, to search for the B 0 → µ + µ -decay and to test the Standard Model prediction for the effective lifetime of the B 0 s → µ + µ -decay.
New physics can also be searched for using B 0 → K ∗ 0 µ + µ -decays, or similar b → sµ + µ -transitions. Such decays offer a wealth of asymmetries and angular observables that can be studied as functions of the dimuon invariant mass squared, q 2 , several of which have been shown to have reduced theoretical uncertainty. For example, although the absolute values of the branching fractions are hard to predict precisely, isospin and CP asymmetries, between B + and B 0 or B and B decays respectively, provide powerful null tests of the Standard Model. Evidence of isospin asymmetry in B → Kµ µ + -decays [137] has not been confirmed in an update with larger statistics [138], and all CP asymmetry measurements in B → K ( ∗ ) µ + µ -decays are also consistent with zero [139, 140].
Among other angular observables, the forward-backward asymmetry in B 0 → K ∗ 0 µ + µ -decays, i.e. the difference in the average directions of the µ + and µ -particles in the rest frame of the decay, has received considerable interest. In the Standard Model such an asymmetry arises, and varies with q 2 in a predictable way, due to interference between diagrams where the dimuon system is produced by virtual γ and Z 0 bosons. While previous measurements had shown evidence for a net forward-backward asymmetry when integrated over q 2 [141143], a measurement from LHCb [144], shown in Fig. 9, was the first to pin down the shape of the variation and measure the q 2 at which the asymmetry crosses zero. LHCb has additionally extended the analysis to study further angular
Figure 9: Measurements of the (left) forward-backward asymmetry [144] and (right) the observable P ′ 5 [145] from LHCb.
observables that have reduced theoretical uncertainty [145]. In one of them, labelled P ′ 5 , an interesting discrepancy with the Standard Model prediction is seen. This result is based on the 2011 data sample, and an update with the full Run I statistics together with improved theoretical predictions will help to determine whether the discrepancy is robust. Further results on this topic are also anticipated from CMS [146] and ATLAS [147]. As more data is collected similar observables can also be studied in B 0 s → φµ + µ -[148] and Λ 0 b → Λµ + µ -[149] decays as well as in b → dµ + µ -transitions such as B + → π + µ + µ -[150].
The study of the lowest region of the q 2 spectrum is of particular interest since the strong polarisation of the emitted photon in b → sγ ( ∗ ) transitions that is predicted in the Standard Model can be probed. The non-negligible muon mass implies that it is preferable to carry out such studies with either b → sγ or b → se + e -decays. The trigger capability of LHCb has allowed it to measure branching fractions and CP asymmetries of B 0 → K ∗ 0 γ and B 0 s → φγ decays [151, 152]. The latter channel is particularly interesting because with more data the CP violating parameters of its decay time distribution can be used to probe the photon polarisation with low theoretical uncertainty. Angular distributions in B 0 → K ∗ 0 e + e -[153] and B + → K π π + + -γ [154] decays provide complementary ways to test this Standard Model prediction, with the latter mode giving the first observation of non-zero photon polarisation.
## 8. Summary and outlook
The large data samples collected from high-energy pp collisions during Run I of the Large Hadron Collider have enabled dramatic progress in heavy flavour physics. Significant advances have been achieved in understanding spectroscopy, CP violation and rare decays. The results are consistent with Standard Model predictions, although several puzzles and hints of discrepancies demand further investigation with larger data samples. Since many of the results to date are based on data collected in 2011 only, further progress can be anticipated in the near future as the analyses are updated to the full Run 1 samples.
Substantial further improvement in precision will be possible with the data from the LHC Run II. The increased centre-of-mass energy of the collisions is expected to result in higher production cross-sections for heavy-flavoured particles, and therefore more useful events can in principle be recorded per fb -1 of data collected. The actual gain will be determined by the trigger algorithms used for online event selection.
Beyond Run II, the LHCb detector will be upgraded [12] to allow improved trigger efficiencies with higher luminosity operation. With the LHCb upgrade, and the ongoing capability of ATLAS and CMS in the field of heavy flavour physics, this topic will remain a priority throughout the high luminosity LHC era.
## Acknowledgements
This work was supported by the Science and Technology Facilities Council (UK) and the European Research Council under FP7. The authors are grateful to Sascha Turczyk for pointing out an error in a draft of the manuscript.
## References
## References
- [1] N. Cabibbo, Unitary symmetry and leptonic decays, Phys. Rev. Lett. 10 (1963) 531. doi:10.1103/PhysRevLett.10.531 .
- [2] M. Kobayashi, T. Maskawa, CP violation in the renormalizable theory of weak interaction, Prog. Theor. Phys. 49 (1973) 652. doi:10.1143/PTP. 49.652 .
- [3] G. Aad, et al., The ATLAS Experiment at the CERN Large Hadron Collider, JINST 3 (2008) S08003. doi:10.1088/1748-0221/3/08/S08003 .
- [4] S. Chatrchyan, et al., The CMS experiment at the CERN LHC, JINST 3 (2008) S08004. doi:10.1088/1748-0221/3/08/S08004 .
- [5] A. A. Alves Jr., et al., The LHCb detector at the LHC, JINST 3 (2008) S08005. doi:10.1088/1748-0221/3/08/S08005 .
- [6] G. Aad, et al., Measurement of Upsilon production in 7 TeV pp collisions at ATLAS, Phys. Rev. D87 (2013) 052004. arXiv:1211.7255 , doi:10. 1103/PhysRevD.87.052004 .
- [7] S. Chatrchyan, et al., Measurement of the Υ(1 S , ) Υ(2 S ), and Υ(3 S ) cross sections in pp collisions at √ s = 7 TeV, Phys. Lett. B727 (2013) 101. arXiv:1303.5900 , doi:10.1016/j.physletb.2013.10.033 .
- [8] R. Aaij, et al., Production of J/ψ and Υ mesons in pp collisions at √ s = 8 TeV, JHEP 06 (2013) 064. arXiv:1304.6977 , doi:10.1007/ JHEP06(2013)064 .
- [9] R. Aaij, et al., The LHCb trigger and its performance in 2011, JINST 8 (2013) P04022. arXiv:1211.3055 , doi:10.1088/1748-0221/8/04/ P04022 .
- [10] R. Aaij, et al., Performance of the LHCb Vertex Locator, JINST 9 (2014) P09007. arXiv:1405.7808 , doi:10.1088/1748-0221/9/09/P09007 .
- [11] M. Adinolfi, et al., Performance of the LHCb RICH detector at the LHC, Eur. Phys. J. C73 (2013) 2431. arXiv:1211.6759 , doi:10.1140/epjc/ s10052-013-2431-9 .
- [12] LHCb collaboration, Framework TDR for the LHCb Upgrade: Technical Design Report, LHCB-TDR-012 (2012).
- [13] S.-K. Choi, et al., Observation of a narrow charmoniumlike state in exclusive B ± → K π π ± + -J/ψ decays, Phys. Rev. Lett. 91 (2003) 262001. arXiv:hep-ex/0309032 , doi:10.1103/PhysRevLett.91.262001 .
- [14] S.-K. Choi, et al., Bounds on the width, mass difference and other properties of X (3872) → π + π -J/ψ decays, Phys. Rev. D84 (2011) 052004. arXiv:1107.0163 , doi:10.1103/PhysRevD.84.052004 .
- [15] B. Aubert, et al., Study of the B -→ J/ψK -π + π -decay and measurement of the B -→ X (3872) K -branching fraction, Phys. Rev. D71 (2005) 071103. arXiv:hep-ex/0406022 , doi:10.1103/PhysRevD.71.071103 .
- [16] V. M. Abazov, et al., Observation and properties of the X (3872) decaying to J/ψπ + π -in pp ¯ collisions at √ s = 1 96 TeV, Phys. Rev. Lett. . 93 (2004) 162002. arXiv:hep-ex/0405004 , doi:10.1103/PhysRevLett.93. 162002 .
- [17] D. Acosta, et al., Observation of the narrow state X (3872) → J/ψπ + π -in pp ¯ collisions at √ s = 1 96 TeV, Phys. Rev. Lett. 93 (2004) 072001. . arXiv:hep-ex/0312021 , doi:10.1103/PhysRevLett.93.072001 .
- [18] E. S. Swanson, The new heavy mesons: a status report, Phys. Rept. 429 (2006) 243. arXiv:hep-ph/0601110 , doi:10.1016/j.physrep.2006.04. 003 .
- [19] S. Godfrey, S. L. Olsen, The exotic XYZ charmonium-like mesons, Ann. Rev. Nucl. Part. Sci. 58 (2008) 51. arXiv:0801.3867 , doi:10.1146/ annurev.nucl.58.110707.171145 .
- [20] R. Aaij, et al., Observation of X (3872) production in pp collisions at √ s = 7 TeV, Eur. Phys. J. C72 (2011) 1972. arXiv:1112.5310 , doi: 10.1140/epjc/s10052-012-1972-7 .
- [21] S. Chatrchyan, et al., Measurement of the X (3872) production cross section via decays to J/ψπ + π -in pp collisions at √ s = 7 TeV, JHEP 04 (2013) 154. arXiv:1302.3968 , doi:10.1007/JHEP04(2013)154 .
- [22] P. Artoisenet, E. Braaten, Production of the X (3872) at the Tevatron and the LHC, Phys. Rev. D81 (2010) 114018. arXiv:0911.2016 , doi: 10.1103/PhysRevD.81.114018 .
- [23] R. Aaij, et al., Determination of the X (3872) meson quantum numbers, Phys. Rev. Lett. 110 (2013) 222001. arXiv:1302.6269 , doi:10.1103/ PhysRevLett.110.222001 .
- [24] R. Aaij, et al., Evidence for the decay X (3872) → ψ (2 S γ ) , Nucl. Phys. B886 (2014) 665. arXiv:1404.0275 , doi:10.1016/j.nuclphysb.2014. 06.011 .
- [25] R. Aaij, et al., Observation of the resonant character of the Z (4430) -state, Phys. Rev. Lett. 112 (2014) 222002. arXiv:1404.1903 , doi:10. 1103/PhysRevLett.112.222002 .
- [26] S. Choi, et al., Observation of a resonance-like structure in the π ± ψ ′ mass distribution in exclusive B → Kπ ψ ± ′ decays, Phys. Rev. Lett. 100 (2008) 142001. arXiv:0708.1790 , doi:10.1103/PhysRevLett.100.142001 .
- [27] R. Mizuk, et al., Dalitz analysis of B → Kπ ψ + ′ decays and the Z (4430) + , Phys. Rev. D80 (2009) 031104. arXiv:0905.2869 , doi: 10.1103/PhysRevD.80.031104 .
- [28] K. Chilikin, et al., Experimental constraints on the spin and parity of the Z (4430) + , Phys. Rev. D88 (2013) 074026. arXiv:1306.4894 , doi: 10.1103/PhysRevD.88.074026 .
- [29] T. Aaltonen, et al., Evidence for a narrow near-threshold structure in the J/ψφ mass spectrum in B + → J/ψφK + decays, Phys. Rev. Lett. 102 (2009) 242002. arXiv:0903.2229 , doi:10.1103/PhysRevLett.102. 242002 .
- [30] R. Aaij, et al., Search for the X (4140) state in B + → J/ψφK + decays, Phys. Rev. D85 (2012) 091103(R). arXiv:1202.5087 doi:10.1103/ , PhysRevD.85.091103 .
- [31] S. Chatrchyan, et al., Observation of a peaking structure in the J/ψφ mass spectrum from B ± → J/ψφK ± decays, Phys. Lett. B734 (2014) 261. arXiv:1309.6920 , doi:10.1016/j.physletb.2014.05.055 .
- [32] F. Abe, et al., Observation of the B + c meson in pp ¯ collisions at √ s = 1 8 TeV, Phys. Rev. Lett. 81 (1998) 2432. . arXiv:hep-ex/9805034 , doi: 10.1103/PhysRevLett.81.2432 .
- [33] A. Abulencia, et al., Evidence for the exclusive decay B ± c → J/ψπ ± and measurement of the mass of the B + c meson, Phys. Rev. Lett. 96 (2006) 082002. arXiv:hep-ex/0505076 , doi:10.1103/PhysRevLett.96. 082002 .
- [34] R. Aaij, et al., First observation of the decay B + c → J/ψπ + π -π + , Phys. Rev. Lett. 108 (2012) 251802. arXiv:1204.0079 , doi:10.1103/ PhysRevLett.108.251802 .
- [35] R. Aaij, et al., Observation of the decay B + c → ψ (2 S π ) + , Phys. Rev. D87 (2013) 071103(R). arXiv:1303.1737 , doi:10.1103/PhysRevD.87. 071103 .
- [36] R. Aaij, et al., Observation of B + c → J/ψD + s and B + c → J/ψD ∗ + s decays, Phys. Rev. D87 (2013) 112012. arXiv:1304.4530 , doi:10.1103/ PhysRevD.87.112012 .
- [37] R. Aaij, et al., First observation of the decay B + c → J/ψK + , JHEP 09 (2013) 075. arXiv:1306.6723 , doi:10.1007/JHEP09(2013)075 .
- [38] R. Aaij, et al., Observation of the decay B + c → J/ψK + K π -+ , JHEP 11 (2013) 094. arXiv:1309.0587 , doi:10.1007/JHEP11(2013)094 .
- [39] R. Aaij, et al., Evidence for the decay B + c → J/ψ π 3 + 2 π -, JHEP 05 (2014) 148. arXiv:1404.0287 , doi:10.1007/JHEP05(2014)148 .
- [40] ATLAS collaboration, Observation of the B ± c meson in the decay B ± c → J/ψ µ ( + µ -) π ± with the ATLAS detector at the LHC, ATLAS-CONF2012-028 (2012).
- [41] V. Khachatryan, et al., Measurement of the ratio of the production cross sections times branching fractions of B ± c → J/ψπ ± and B ± → J/ψK ± and B ( B ± c → J/ψπ ± π ± π ∓ ) / B ( B ± c → J/ψπ ± ) in pp collisions at √ s = 7 TeV, JHEP 01 (2015) 063. arXiv:1410.5729 , doi: 10.1007/JHEP01(2015)063 .
- [42] R. Aaij, et al., Observation of the decay B + c → B π 0 s + , Phys. Rev. Lett. 111 (2013) 181801. arXiv:1308.4544 , doi:10.1103/PhysRevLett.111. 181801 .
- [43] R. Aaij, et al., Measurement of the B + c meson lifetime using B + c → J/ψµ + ν µ X decays, Eur. Phys. J. C74 (2014) 2839. arXiv:1401.6932 , doi:10.1140/epjc/s10052-014-2839-x .
- [44] G. Aad, et al., Observation of an excited B ± c meson state with the ATLAS detector, Phys. Rev. Lett. 113 (2014) 212004. arXiv:1407.1032 , doi: 10.1103/PhysRevLett.113.212004 .
- [45] H.-Y. Cheng, A phenomenological analysis of heavy hadron lifetimes, Phys. Rev. D56 (1997) 2783. arXiv:hep-ph/9704260 , doi:10.1103/ PhysRevD.56.2783 .
- [46] M. Neubert, C. T. Sachrajda, Spectator effects in inclusive decays of beauty hadrons, Nucl. Phys. B483 (1997) 339. arXiv:hep-ph/9603202 , doi:10.1016/S0550-3213(96)00559-7 .
- [47] N. Uraltsev, On the problem of boosting nonleptonic b baryon decays, Phys. Lett. B376 (1996) 303. arXiv:hep-ph/9602324 , doi:10.1016/ 0370-2693(96)00305-X .
- [48] G. Aad, et al., Measurement of the Λ 0 b lifetime and mass in the ATLAS experiment, Phys. Rev. D87 (2013) 032002. arXiv:1207.2284 , doi:10. 1103/PhysRevD.87.032002 .
- [49] S. Chatrchyan, et al., Measurement of the Λ 0 b lifetime in pp collisions at √ s = 7 TeV, JHEP 07 (2013) 163. arXiv:1304.7495 , doi:10.1007/ JHEP07(2013)163 .
- [50] R. Aaij, et al., Precision measurement of the Λ 0 b baryon lifetime, Phys. Rev. Lett. 111 (2013) 102003. arXiv:1307.2476 , doi:10.1103/ PhysRevLett.111.102003 .
- [51] R. Aaij, et al., Measurements of the B + , B 0 , B 0 s meson and Λ 0 b baryon lifetimes, JHEP 04 (2014) 114. arXiv:1402.2554 , doi:10.1007/ JHEP04(2014)114 .
- [52] R. Aaij, et al., Precision measurement of the ratio of the Λ 0 b to ¯ B 0 lifetimes, Phys. Lett. B734 (2014) 122. arXiv:1402.6242 , doi:10.1016/j. physletb.2014.05.021 .
- [53] J. Beringer, et al., Review of particle physics, Phys. Rev. D86 (2012) 010001, and 2013 partial update for the 2014 edition. doi:10.1103/ PhysRevD.86.010001 .
- [54] R. Aaij, et al., Measurement of the Ξ -b and Ω -b baryon lifetimes, Phys. Lett. B736 (2014) 154. arXiv:1405.1543 , doi:10.1016/j.physletb. 2014.06.064 .
- [55] R. Aaij, et al., Precision measurement of the mass and lifetime of the Ξ 0 b baryon, Phys. Rev. Lett. 113 (2014) 032001. arXiv:1405.7223 , doi: 10.1103/PhysRevLett.113.032001 .
- [56] S. Chatrchyan, et al., Observation of a new Ξ b baryon, Phys. Rev. Lett. 108 (2012) 252002. arXiv:1204.5955 , doi:10.1103/PhysRevLett.108. 252002 .
- [57] R. Aaij, et al., Observation of excited Λ 0 b baryons, Phys. Rev. Lett. 109 (2012) 172003. arXiv:1205.3452 , doi:10.1103/PhysRevLett.109. 172003 .
- [58] A. Abulencia, et al., Observation of B 0 s -B 0 s oscillations, Phys. Rev. Lett. 97 (2006) 242003. arXiv:hep-ex/0609040 , doi:10.1103/PhysRevLett. 97.242003 .
- [59] R. Aaij, et al., Opposite-side flavour tagging of B mesons at the LHCb experiment, Eur. Phys. J. C72 (2012) 2022. arXiv:1202.4979 , doi:10. 1140/epjc/s10052-012-2022-1 .
- [60] LHCb collaboration, Optimization and calibration of the same-side kaon tagging algorithm using hadronic B 0 s decays in 2011 data, LHCb-CONF2012-033 (2012).
- [61] R. Aaij, et al., Measurement of the B 0 s -¯ B 0 s oscillation frequency ∆ m s in B 0 s → D -s (3) π decays, Phys. Lett. B709 (2012) 177. arXiv:1112.4311 , doi:10.1016/j.physletb.2012.02.031 .
- [62] R. Aaij, et al., Precision measurement of the B 0 s - ¯ B 0 s oscillation frequency in the decay B 0 s → D π -s + , New J. Phys. 15 (2013) 053021. arXiv:1304. 4741 , doi:10.1088/1367-2630/15/5/053021 .
- [63] R. Aaij, et al., Observation of B 0 s - ¯ B 0 s mixing and measurement of mixing frequencies using semileptonic B decays, Eur. Phys. J. C73 (2013) 2655. arXiv:1308.1302 , doi:10.1140/epjc/s10052-013-2655-8 .
- [64] R. Aaij, et al., Measurement of the effective B 0 s → K K + -lifetime, Phys. Lett. B707 (2012) 349. arXiv:1111.0521 , doi:10.1016/j.physletb. 2011.12.058 .
- [65] R. Aaij, et al., Measurement of the effective B 0 s → K K + -lifetime, Phys. Lett. B716 (2012) 393. arXiv:1207.5993 , doi:10.1016/j.physletb. 2012.08.033 .
- [66] R. Aaij, et al., Effective lifetime measurements in the B 0 s → K K + -, B 0 → K π + -and B 0 s → π + K -decays, Phys. Lett. B736 (2014) 446. arXiv:1406.7204 , doi:10.1016/j.physletb.2014.07.051 .
- [67] R. Aaij, et al., Measurement of the ¯ B 0 s → D D -s + s and ¯ B 0 s → D D -+ s effective lifetimes, Phys. Rev. Lett. 112 (2014) 111802. arXiv:1312.1217 , doi:10.1103/PhysRevLett.112.111802 .
- [68] R. Aaij, et al., Measurement of the ¯ B 0 s effective lifetime in the J/ψf 0 (980) final state, Phys. Rev. Lett. 109 (2012) 152002. arXiv:1207.0878 , doi: 10.1103/PhysRevLett.109.152002 .
- [69] R. Aaij, et al., Measurement of the effective B 0 s → J/ψK 0 S lifetime, Nucl. Phys. B873 (2013) 275. arXiv:1304.4500 , doi:10.1016/j.nuclphysb. 2013.04.021 .
- [70] G. Aad, et al., Time-dependent angular analysis of the decay B 0 s → J/ψφ and extraction of ∆Γ s and the CP -violating weak phase φ s by ATLAS, JHEP 12 (2012) 072. arXiv:1208.0572 , doi:10.1007/JHEP12(2012) 072 .
- [71] G. Aad, et al., Flavor tagged time-dependent angular analysis of the B s → J/ψφ decay and extraction of ∆Γ s and the weak phase φ s in ATLAS, Phys. Rev. D90 (2014) 052007. arXiv:1407.1796 , doi:10.1103/PhysRevD.90. 052007 .
- [72] CMS collaboration, Measurement of the decay width ∆Γ s and the CP -violating phase φ s in the B 0 s → J/ψφ decays at CMS, CMS-BPH-13-012 (2014).
- [73] R. Aaij, et al., Measurement of the CP -violating phase φ s in the decay B 0 s → J/ψφ , Phys. Rev. Lett. 108 (2012) 101803. arXiv:1112.3183 , doi:10.1103/PhysRevLett.108.101803 .
- [74] R. Aaij, et al., Measurement of CP violation and the B 0 s meson decay width difference with B 0 s → J/ψK + K -and B 0 s → J/ψπ + π -decays, Phys. Rev. D87 (2013) 112010. arXiv:1304.2600 , doi:10.1103/ PhysRevD.87.112010 .
- [75] R. Aaij, et al., Determination of the sign of the decay width difference in the B 0 s system, Phys. Rev. Lett. 108 (2012) 241801. arXiv:1202.4717 , doi:10.1103/PhysRevLett.108.241801 .
- [76] B. Aubert, et al., Evidence for D 0 -D 0 mixing, Phys. Rev. Lett. 98 (2007) 211802. arXiv:hep-ex/0703020 , doi:10.1103/PhysRevLett.98. 211802 .
- [77] M. Staric, et al., Evidence for D 0 -D 0 mixing, Phys. Rev. Lett. 98 (2007) 211803. arXiv:hep-ex/0703036 , doi:10.1103/PhysRevLett.98. 211803 .
- [78] T. Aaltonen, et al., Evidence for D 0 -D 0 mixing using the CDF II detector, Phys. Rev. Lett. 100 (2008) 121802. arXiv:0712.1567 , doi:10.1103/ PhysRevLett.100.121802 .
- [79] R. Aaij, et al., Observation of D 0 - ¯ D 0 oscillations, Phys. Rev. Lett. 110 (2013) 101802. arXiv:1211.1230 , doi:10.1103/PhysRevLett.110. 101802 .
- [80] R. Aaij, et al., Measurement of D 0 - ¯ D 0 mixing parameters and search for CP violation using D 0 → K π + -decays, Phys. Rev. Lett. 111 (2013) 251801. arXiv:1309.6534 , doi:10.1103/PhysRevLett.111.251801 .
- [81] Y. Amhis, et al., Averages of b -hadron, c -hadron, and τ -lepton properties as of early 2012, updated results and plots available at http://www.slac.stanford.edu/xorg/hfag/ . arXiv:1207.1158 .
- [82] R. Aaij, et al., Measurements of indirect CP asymmetries in D 0 → K K -+ and D 0 → π -π + decays, Phys. Rev. Lett. 112 (2014) 041801. arXiv: 1310.7201 , doi:10.1103/PhysRevLett.112.041801 .
- [83] B. Aubert, et al., Measurement of time-dependent CP asymmetry in B 0 → ccK ¯ ( ∗ )0 decays, Phys. Rev. D79 (2009) 072009. arXiv:0902.1708 , doi: 10.1103/PhysRevD.79.072009 .
- [84] I. Adachi, et al., Precise measurement of the CP violation parameter sin 2 φ 1 in B 0 → ( cc K ¯) 0 decays, Phys. Rev. Lett. 108 (2012) 171802. arXiv:1201.4643 , doi:10.1103/PhysRevLett.108.171802 .
- [85] R. Aaij, et al., Measurement of the time-dependent CP asymmetry in B 0 → J/ψK 0 S decays, Phys. Lett. B721 (2013) 24. arXiv:1211.6093 , doi:10.1016/j.physletb.2013.02.054 .
- [86] T. Aaltonen, et al., First flavor-tagged determination of bounds on mixinginduced CP violation in B 0 s → J/ψφ decays, Phys. Rev. Lett. 100 (2008) 161802. arXiv:0712.2397 , doi:10.1103/PhysRevLett.100.161802 .
- [87] V. Abazov, et al., Measurement of B 0 s mixing parameters from the flavortagged decay B 0 s → J/ψφ , Phys. Rev. Lett. 101 (2008) 241801. arXiv: 0802.2255 , doi:10.1103/PhysRevLett.101.241801 .
- [88] R. Aaij, et al., Measurement of the CP -violating phase φ s in ¯ B 0 s → J/ψπ + π -decays, Phys. Lett. B736 (2014) 186. arXiv:1405.4140 , doi:10.1016/j.physletb.2014.06.079 .
- [89] R. Aaij, et al., Measurement of the CP violating phase φ s in ¯ B 0 s → J/ψf 0 (980), Phys. Lett. B707 (2012) 497. arXiv:1112.3056 , doi:10. 1016/j.physletb.2012.01.017 .
- [90] R. Aaij, et al., Measurement of the CP -violating phase φ s in ¯ B 0 s → J/ψπ + π -decays, Phys. Lett. B713 (2012) 378. arXiv:1204.5675 , doi:10.1016/j.physletb.2012.06.032 .
- [91] R. Aaij, et al., Analysis of the resonant components in ¯ B 0 s → J/ψπ + π -, Phys. Rev. D86 (2012) 052006. arXiv:1204.5643 , doi:10.1103/ PhysRevD.86.052006 .
- [92] R. Aaij, et al., Measurement of resonant and CP components in ¯ B 0 s → J/ψπ + π -decays, Phys. Rev. D89 (2014) 092006. arXiv:1402.6248 , doi: 10.1103/PhysRevD.89.092006 .
- [93] R. Aaij, et al., First measurement of the CP -violating phase in B 0 s → φφ decays, Phys. Rev. Lett. 110 (2013) 241802. arXiv:1303.7125 , doi: 10.1103/PhysRevLett.110.241802 .
- [94] R. Aaij, et al., Measurement of CP violation in B 0 s → φφ decays, Phys. Rev. D90 (2014) 052011. arXiv:1407.2222 , doi:10.1103/PhysRevD.90. 052011 .
- [95] V. M. Abazov, et al., Study of CP -violating charge asymmetries of single muons and like-sign dimuons in pp ¯ collisions, Phys. Rev. D89 (2014) 012002. arXiv:1310.0447 , doi:10.1103/PhysRevD.89.012002 .
- [96] R. Aaij, et al., Measurement of the flavour-specific CP -violating asymmetry a s sl in B 0 s decays, Phys. Lett. B728 (2014) 607. arXiv:1308.1048 , doi:10.1016/j.physletb.2013.12.030 .
| [97] | V. Fanti, et al., A new measurement of direct CP violation in two pion decays of the neutral kaon, Phys. Lett. B465 (1999) 335. arXiv:hep-ex/ 9909022 , doi:10.1016/S0370-2693(99)01030-8 . |
|--------|---------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------|
| [98] | A. Alavi-Harati, et al., Observation of direct CP violation in K 0 S,L → ππ decays, Phys. Rev. Lett. 83 (1999) 22. arXiv:hep-ex/9905060 , doi: 10.1103/PhysRevLett.83.22 . |
| [99] | B. Aubert, et al., Observation of direct CP violation in B 0 → K + π - decays, Phys. Rev. Lett. 93 (2004) 131801. arXiv:hep-ex/0407057 , doi: 10.1103/PhysRevLett.93.131801 . |
| [100] | Y. Chao, et al., Evidence for direct CP violation in B 0 → K + π - decays, Phys. Rev. Lett. 93 (2004) 191802. arXiv:hep-ex/0408100 , doi:10. 1103/PhysRevLett.93.191802 . |
| [101] | R. Aaij, et al., First evidence of direct CP violation in charmless two- body decays of B 0 s mesons, Phys. Rev. Lett. 108 (2012) 201601. arXiv: 1202.6251 , doi:10.1103/PhysRevLett.108.201601 . |
| [102] | R. Aaij, et al., First observation of CP violation in the decays of B 0 s mesons, Phys. Rev. Lett. 110 (2013) 221601. arXiv:1304.6173 , doi: 10.1103/PhysRevLett.110.221601 . |
| [103] | R. Aaij, et al., Measurement of CP violation in the phase space of B ± → K ± π + π - and B ± → K ± K + K - decays, Phys. Rev. Lett. 111 (2013) 101801. arXiv:1306.1246 , doi:10.1103/PhysRevLett.111.101801 . |
| [104] | R. Aaij, et al., Measurement of CP violation in the phase space of B ± → K + K - π ± and B ± → π + π - π ± decays, Phys. Rev. Lett. 112 (2014) 011801. arXiv:1310.4740 , doi:10.1103/PhysRevLett.112.011801 . |
| [105] | R. Aaij, et al., Observation of CP violation in B ± → DK ± decays, Phys. Lett. B712 (2012) 203. arXiv:1203.3662 , doi:10.1016/j.physletb. 2012.04.060 . |
| [106] | R. Aaij, et al., Observation of the suppressed ADS modes B ± → [ π ± K ∓ π + π - ] D K ± and B ± → [ π ± K ∓ π + π - ] D π ± , Phys. Lett. B723 (2013) 44. arXiv:1303.4646 , doi:10.1016/j.physletb.2013.05.009 . |
| [107] | R. Aaij, et al., A model-independent Dalitz plot analysis of B ± → DK ± with D → K 0 S h + h - ( h = π, K ) decays and constraints on the CKM angle γ , Phys. Lett. B718 (2012) 43. arXiv:1209.5869 , doi:10.1016/j. physletb.2012.10.020 . |
| [108] | R. Aaij, et al., Measurement of the CKM angle γ using B ± → DK ± with D → K 0 S π + π - , K 0 S K + K - decays, JHEP 10 (2014) 097. arXiv: 1408.2748 , doi:10.1007/JHEP10(2014)097 . |
| [109] | R. Aaij, et al., A study of CP violation in B ± → DK ± and B ± → Dπ ± decays with D → K 0 S K ± π ∓ final states, Phys. Lett. B733 (2014) 36. arXiv:1402.2982 , doi:10.1016/j.physletb.2014.03.051 . |
|---------|--------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------|
| [110] | R. Aaij, et al., A measurement of the CKM angle γ from a combination of B ± → Dh ± analyses, Phys. Lett. B726 (2013) 151. arXiv:1305.2050 , doi:10.1016/j.physletb.2013.08.020 . |
| [111] | LHCb collaboration, A measurement of γ from a combination of B ± → DK ± analyses including first results using 2 fb - 1 of 2012 data, LHCb- CONF-2013-006 (2013). |
| [112] | R. Aaij, et al., Measurement of CP observables in B 0 → DK ∗ 0 with D → K + K - , JHEP 03 (2013) 067. arXiv:1212.5205 , doi:10.1007/ JHEP03(2013)067 . |
| [113] | R. Aaij, et al., Measurement of CP violation parameters in B 0 → DK ∗ 0 decays, Phys. Rev. D90 (2014) 112002. arXiv:1407.8136 , doi:10.1103/ PhysRevD.90.112002 . |
| [114] | LHCb collaboration, First observation of B - → D 0 K - π + π - decays to CP even final states, LHCb-CONF-2012-021 (2012). |
| [115] | R. Aaij, et al., Measurement of CP asymmetry in B 0 s → D ∓ s K ± decays, JHEP 11 (2014) 060. arXiv:1407.6127 , doi:10.1007/JHEP11(2014) 060 . |
| [116] | R. Aaij, et al., Evidence for CP violation in time-integrated D 0 → h - h + decay rates, Phys. Rev. Lett. 108 (2012) 111602. arXiv:1112.0938 , doi: 10.1103/PhysRevLett.108.111602 . |
| [117] | R. Aaij et al. , and A. Bharucha, et al., Implications of LHCb measure- ments and future prospects, Eur. Phys. J. C73 (2013) 2373. arXiv: 1208.3355 , doi:10.1140/epjc/s10052-013-2373-2 . |
| [118] | LHCb collaboration, A search for time-integrated CP violation in D 0 → K - K + and D 0 → π - π + decays, LHCb-CONF-2013-003 (2013). |
| [119] | R. Aaij, et al., Search for direct CP violation in D 0 → h - h + modes using semileptonic B decays, Phys. Lett. B723 (2013) 33. arXiv:1303.2614 , doi:10.1016/j.physletb.2013.04.061 . |
| [120] | R. Aaij, et al., Measurement of CP asymmetry in D 0 → K - K + and D 0 → π - π + decays, JHEP 07 (2014) 041. arXiv:1405.2797 , doi:10. 1007/JHEP07(2014)041 . |
| [121] | R. Aaij, et al., Search for CP violation in D + → K - K + π + decays, Phys. Rev. D84 (2011) 112008. arXiv:1110.3970 , doi:10.1103/PhysRevD.84. 112008 . |
| [122] | R. Aaij, et al., Search for CP violation in D + → φπ + and D + s → K 0 S π + decays, JHEP 06 (2013) 112. arXiv:1303.4906 , doi:10.1007/ JHEP06(2013)112 . |
|---------|------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------|
| [123] | R. Aaij, et al., Model-independent search for CP violation in D 0 → K - K + π + π - and D 0 → π - π + π - π + decays , Phys. Lett. B726 (2013) 623. arXiv:1308.3189 , doi:10.1016/j.physletb.2013.09.011 . |
| [124] | R. Aaij, et al., Search for CP violation in the decay D + → π - π + π + , Phys. Lett. B728 (2014) 585. arXiv:1310.7953 , doi:10.1016/j.physletb. 2013.12.035 . |
| [125] | R. Aaij, et al., Search for CP violation in D ± → K 0 S K ± and D ± s → K 0 S π ± decays, JHEP 10 (2014) 025. arXiv:1406.2624 , doi:10.1007/ JHEP10(2014)025 . |
| [126] | V. M. Abazov, et al., Search for the rare decay B 0 s → µ + µ - , Phys. Lett. B693 (2010) 539. arXiv:1006.3469 , doi:10.1016/j.physletb.2010. 09.024 . |
| [127] | T. Aaltonen, et al., Search for B 0 s → µ + µ - and B 0 → µ + µ - decays with CDF II, Phys. Rev. Lett. 107 (2011) 191801. arXiv:1107.2304 , doi:10.1103/PhysRevLett.107.191801 . |
| [128] | R. Aaij, et al., Search for the rare decays B 0 s → µ + µ - and B 0 → µ + µ - , Phys. Lett. B699 (2011) 330. arXiv:1103.2465 , doi:10.1016/ j.physletb.2011.04.031 . |
| [129] | R. Aaij, et al., Search for the rare decays B 0 s → µ + µ - and B 0 → µ + µ - , Phys. Lett. B708 (2012) 55. arXiv:1112.1600 , doi:10.1016/ j.physletb.2012.01.038 . |
| [130] | R. Aaij, et al., Strong constraints on the rare decays B 0 s → µ + µ - and B 0 → µ + µ - , Phys. Rev. Lett. 108 (2012) 231801. arXiv:1203.4493 , doi:10.1103/PhysRevLett.108.231801 . |
| [131] | S. Chatrchyan, et al., Search for B 0 s → µ + µ - and B 0 → µ + µ - decays, JHEP 04 (2012) 033. arXiv:1203.3976 , doi:10.1007/JHEP04(2012) 033 . |
| [132] | G. Aad, et al., Search for the decay B 0 s → µ + µ - with the ATLAS de- tector, Phys. Lett. B713 (2012) 387. arXiv:1204.0735 , doi:10.1016/j. physletb.2012.06.013 . |
| [133] | R. Aaij, et al., First evidence for the decay B 0 s → µ + µ - , Phys. Rev. Lett. 110 (2013) 021801. arXiv:1211.2674 , doi:10.1103/PhysRevLett.110. 021801 . |
- [134] R. Aaij, et al., Measurement of the B 0 s → µ + µ -branching fraction and search for B 0 → µ + µ -decays at the LHCb experiment, Phys. Rev. Lett. 111 (2013) 101805. arXiv:1307.5024 , doi:10.1103/PhysRevLett.111. 101805 .
- [135] S. Chatrchyan, et al., Measurement of the B 0 s → µ + µ -- branching fraction and search for B 0 → µ + µ -with the CMS experiment, Phys. Rev. Lett. 111 (2013) 101804. arXiv:1307.5025 , doi:10.1103/PhysRevLett.111. 101804 .
- [136] CMS and LHCb collaborations, Combination of results on the rare decays B 0 ( s ) → µ + µ -from the CMS and LHCb experiments, CMS-PAS-BPH-13007, LHCb-CONF-2013-012 (2013).
- [137] R. Aaij, et al., Measurement of the isospin asymmetry in B → K ( ∗ ) µ + µ -decays, JHEP 07 (2012) 133. arXiv:1205.3422 doi:10.1007/ , JHEP07(2012)133 .
- [138] R. Aaij, et al., Differential branching fractions and isospin asymmetries of B → K ( ∗ ) µ + µ -decays, JHEP 06 (2014) 133. arXiv:1403.8044 , doi: 10.1007/JHEP06(2014)133 .
- [139] R. Aaij, et al., Measurement of the CP asymmetry in B 0 → K ∗ 0 µ + µ -decays, Phys. Rev. Lett. 110 (2013) 031801. arXiv:1210.4492 , doi: 10.1103/PhysRevLett.110.031801 .
- [140] R. Aaij, et al., Measurement of the CP asymmetry in B + → K µ µ + + -decays, Phys. Rev. Lett. 111 (2013) 151801. arXiv:1308.1340 , doi: 10.1103/PhysRevLett.111.151801 .
- [141] B. Aubert, et al., Measurements of branching fractions, rate asymmetries, and angular distributions in the rare decays B → Kglyph[lscript] + glyph[lscript] -and B → K glyph[lscript] ∗ + glyph[lscript] -, Phys. Rev. D73 (2006) 092001. arXiv:hep-ex/0604007 , doi:10.1103/PhysRevD.73.092001 .
- [142] J.-T. Wei, et al., Measurement of the differential branching fraction and forward-backward asymmetry for B → K ( ∗ ) glyph[lscript] + glyph[lscript] -, Phys. Rev. Lett. 103 (2009) 171801. arXiv:0904.0770 , doi:10.1103/PhysRevLett.103. 171801 .
- [143] T. Aaltonen, et al., Measurements of the angular distributions in the decays B → K ( ∗ ) µ + µ -at CDF, Phys. Rev. Lett. 108 (2012) 081807. arXiv:1108.0695 , doi:10.1103/PhysRevLett.108.081807 .
- [144] R. Aaij, et al., Differential branching fraction and angular analysis of the decay B 0 → K ∗ 0 µ + µ -, JHEP 08 (2013) 131. arXiv:1304.6325 , doi:10.1007/JHEP08(2013)131 .
- [145] R. Aaij, et al., Measurement of form-factor-independent observables in the decay B 0 → K ∗ 0 µ + µ -, Phys. Rev. Lett. 111 (2013) 191801. arXiv: 1308.1707 , doi:10.1103/PhysRevLett.111.191801 .
- [146] S. Chatrchyan, et al., Angular analysis and branching fraction measurement of the decay B 0 → K ∗ 0 µ + µ -, Phys. Lett. B727 (2013) 77. arXiv:1308.3409 , doi:10.1016/j.physletb.2013.10.017 .
- [147] ATLAS collaboration, Angular analysis of B d → K ∗ 0 µ + µ -with the ATLAS experiment, ATLAS-CONF-2013-038 (2013).
- [148] R. Aaij, et al., Differential branching fraction and angular analysis of the decay B 0 s → φµ + µ -, JHEP 07 (2013) 084. arXiv:1305.2168 , doi: 10.1007/JHEP07(2013)084 .
- [149] R. Aaij, et al., Measurement of the differential branching fraction of the decay Λ 0 b → Λ µ + µ -, Phys. Lett. B725 (2013) 25. arXiv:1306.2577 , doi:10.1016/j.physletb.2013.06.060 .
- [150] R. Aaij, et al., First observation of the decay B + → π + µ + µ -, JHEP 12 (2012) 125. arXiv:1210.2645 , doi:10.1007/JHEP12(2012)125 .
- [151] R. Aaij, et al., Measurement of the ratio of branching fractions B ( B 0 → K ∗ 0 γ / ) B ( B 0 s → φγ ), Phys. Rev. D85 (2012) 112013. arXiv:1202.6267 , doi:10.1103/PhysRevD.85.112013 .
- [152] R. Aaij, et al., Measurement of the ratio of branching fractions B ( B 0 → K ∗ 0 γ / ) B ( B 0 s → φγ ) and the direct CP asymmetry in B 0 → K ∗ 0 γ , Nucl. Phys. B867 (2013) 1. arXiv:1209.0313 , doi:10.1016/j.nuclphysb. 2012.09.013 .
- [153] R. Aaij, et al., Measurement of the B 0 → K ∗ 0 e + e -branching fraction at low dilepton mass, JHEP 05 (2013) 159. arXiv:1304.3035 , doi:10. 1007/JHEP05(2013)159 .
- [154] R. Aaij, et al., Observation of photon polarization in the b → sγ transition, Phys. Rev. Lett. 112 (2014) 161801. arXiv:1402.6852 , doi:10.1103/ PhysRevLett.112.161801 . | 10.1016/j.crhy.2015.04.001 | [
"T. Gershon",
"M. Needham"
] | 2014-08-02T17:58:35+00:00 | 2015-06-06T09:26:55+00:00 | [
"hep-ex"
] | Heavy Flavour Physics at the LHC | A summary of results in heavy flavour physics from Run 1 of the LHC is
presented. Topics discussed include spectroscopy, mixing, CP violation and rare
decays of charmed and beauty hadrons. |
1408.0404v1 | ## Random matrix study for a three-terminal chaotic device
A. M. Mart´ ınez-Arg¨ello, u E. Casta˜o, n and M. Mart´ ınez-Mares
Departamento de F´ ısica, Universidad Aut´noma Metropolitana-Iztapalapa, 09340 M´xico Distrito Federal, Mexico o e
We perform a study based on a random-matrix theory simulation for a three-terminal device, consisting of chaotic cavities on each terminal. We analyze the voltage drop along one wire with two chaotic mesoscopic cavities, connected by a perfect conductor, or waveguide, with one open mode. This is done by means of a probe, which also consists of a chaotic cavity that measure the voltage in different configurations. Our results show significant differences with respect to the disordered case, previously considered in the literature.
## I. INTRODUCTION
In the last thirty years there have been much theoretical and experimental work concerning electronic transport through multiterminal devices (see Refs. [1, 2] there in). Nowadays, the interest to study the electronic transport properties on these devices has been renewed [3-8], due to the fact that they are very useful in experimental measurements in several configurations [9-11].
The earlier experiments were done with normal metal conductors, whose random distribution of impurities in their microscopic structure, give rise to interference that is reflected in the relevant physical observables, like resistance or voltage measurements. Moreover, those quantities show sample to sample fluctuations [12-14]. More recently, the interest on these systems has resurged due to recent advances in technology, that allow to access to clean devices, where the typical size is smaller than the elastic mean free path. Therefore, the electrons propagate ballistically and scattering is produced only by the device boundaries, which have important consequences in the electronic transport through the device [6, 15, 16]. For instance, when the geometry is such that the classical dynamics in the system is chaotic, the transport properties fluctuates too [17-19]. What is very important is to know how are the fluctuations with respect to the disordered case.
In this work, by numerical simulation, we analyze the statistical distribution of the voltage drop along a chaotic wire, which consists of two chaotic mesoscopic cavities connected by a perfect conductor with one open mode. The probe is a chaotic cavity that measure the voltage in different configurations. The presence and absence of time reversal invariance are considered. We compare our results with the ones obtained in an equivalent three terminal device but with disordered, instead of chaotic, wires, previously studied in the literature, where the distribution of the voltage drop was determined in the presence of time reversal invariance only [12, 13]. There, a remarkable difference in the distribution of the voltage drop between the ballistic regime and the strong disordered limit, has been found. The position of the probe has a stronger effect than in the disordered case.
First, we summarize the scattering formalism for the voltage drop in a three terminal device, proposed by B¨ uttiker [10, 11]. Then, we construct the scattering matrix for our system, in terms of the scattering matrices of the individual cavities, as well as of the scattering matrix associated to the junction, for which we assume the simplest model introduced by B¨ttiker, that couple the probe symmetrically to the horizontal wire [9]. For the statisu tical analysis, we make an ensemble of systems by assuming that the scattering matrix of each cavity is chosen from a Circular Ensemble, Orthogonal or Unitary, depending on the presence or absence of time reversal invariance. We present our conclusions at the end.
## II. ELECTRONIC TRANSPORT IN A THREE-TERMINAL SYSTEM
In the formulation of Landauer-B¨ttiker, the electronic transport is reduced to a scattering problem. u In a single mode multiprobe devices, the current I i in a lead i can be written into two components, one being the reflection to the same lead and the transmission from the others leads to the lead i . That is, I i is given in terms of the reflection and transmission coefficients, according to [11]
/negationslash
$$I _ { i } = \frac { e } { h } \left [ ( 1 - R _$$
where µ j is the chemical potential in lead j , R ii is the reflection coefficient to the lead i , and T ij represent the transmission from lead j to lead i . These coefficients are given by the scattering matrix S as R ii = | S ii | 2 and T ij = | S ij | 2 .
3
FIG. 1: A scattering system consisting of three one-dimensional wires converging to a junction. The thin lines represent perfect conductors that connect the wave guides to the chemical reservoirs. The amplitude of the incoming (outgoing) wave in wire i is denoted by a i ( b i ), while a ′ i ( b ′ i ) denotes the amplitude at the junction. Each wire is described by a 2 × 2 scattering matrix S j and the junction by a 3 × 3 matrix, S 0 .
The voltage along a horizontal wire, connected via perfect leads to two reservoirs of fixed chemical potentials, µ 1 and µ 2 , can be measured in a three terminal device, where the third wire is in a voltage measurement configuration (see Fig. 1); that is, the chemical potential µ 3 is such that the current through it is equal to zero, I 3 = 0. In such a case [11],
$$\mu _ { 3 } = \frac { 1 } { 2 } ( \mu _ { 1 }$$
where f is given by
$$f = \frac { T _ { 3 1 } - T _ { 3 2 } } { T _$$
Equation (2) shows that the chemical potential µ 3 has an averaged part, that comes from the effect of the resorvoirs µ 1 and µ 2 only. The second part gives the deviation from the averaged part, and depends on the intrinsic nature of the conductors through the quantity f , that contains all the relevant information about the multiple scattering in the device. If the conductors are disordered or chaotic, f fluctuates between -1 and 1, since µ 3 can not reach the values µ 1 nor µ 2 due to the contact resistance [11]. The disordered three terminal device was studied in Refs. [12, 13].
In what follows we will consider a three terminal device where the conductors are chaotic. Since f depends on the scattering matrix S of the whole system, we construct S in terms of the scattering matrices of each conductor and the scattering matrix of the splitter, that we will assume to be known. For the splitter we assume a simple model, while the scattering matrices of the chaotic conductors are chosen from an ensemble of random matrices that satisfy certain symmetry requirements.
## III. THE S MATRIX FOR A THREE TERMINAL DEVICE
Let us consider the three terminal system shown in Fig. 1. The system is described by the scattering matrix S which relates the incoming plane waves amplitudes on each terminal, a 1 , a 2 , and a 3 , to the outgoing ones, b 1 , b 2 , and b 3 , by
$$\begin{array} {$$
where we assume that S contains all the information that from the system we can obtain. Of course, S depends on the scattering process inside the system, due to scattering elements.
Let assume that the splitter is represented by the scattering matrix S 0 , that couples the three terminals; therefore, the amplitudes at the junction are related as
$$\left ( \begin{array} { c } b _ { 1 } ^ { \prime }$$
If the conductors on each terminal are represented by the scattering matrices S j ( j = 1 2 3), the amplitudes are , , related as follows:
$$\left ( \begin{smallmatrix} b _ { 1 } \\ a ^ { \prime } _ { 1 } \end{smallmatrix} \right ) = S _ { 1 } \left ( \begin{smallmatrix} a _ { 1 } \\ b ^ { \prime } _ { 1 } \end{smallmatrix} \right ), \quad \left ( \begin{smallmatrix} a ^ { \prime } _ { 2 } \\ b _ { 2 } \end{smallmatrix} \right ) = S _ { 2 } \left ( \begin{smallmatrix} b ^ { \prime } _ { 2 } \\ a _ { 2 } \end{smallmatrix} \right ), \quad \left ( \begin{smallmatrix} a ^ { \prime } _ { 3 } \\ b _ { 3 } \end{smallmatrix} \right ) = S _ { 3 } \left ( \begin{smallmatrix} b ^ { \prime } _ { 3 } \\ a _ { 3 } \end{smallmatrix} \right ),$$
where each matrix S j is a 2 × 2 matrix with the general structure
$$S _ { j } = \left ( \begin{array} { c c } r _ { j } & t ^ { \prime } _ { j } \\ t _ { j } & r ^ { \prime } _ { j } \end{array} \right ),$$
with r j , t j are the reflection and transmission amplitudes when the incidence is from the left (or below for j = 3) of the j th conductor, and r ′ j , t ′ j when the incidence is from the other side. Flux conservation implies that S j is unitary,
$$S _ { j } S _ { j } ^ { \dagger } = I _ { 2 },$$
where I 2 stands for the 2 × 2 identity matrix. Equation (8) is the only requirement in absence of any symmetry, while in the presence of time reversal invariance , S j is a unitary and symmetric ,
$$S _ { j } = S _ { j } ^ { T },$$
where T stands for the transposed.
Through Eqs. (5), (7) and (6) we arrive to the scattering matrix S that describes the full system, which is given by
$$S = S _ { P P } + S _ { P Q } S _ { 0 } \frac { 1 } { 1 - S _ { Q Q } S _ { 0 } } S _ { Q P },$$
where we have defined
$$S _ { P P } = \left ( \begin{array} { c c c } r _ { 1 } & 0 & 0 \\ 0 & r _ { 2 } ^ { \prime } & 0 \\ 0 & 0 & r _ { 3 } ^ { \prime } \end{array} \right ), \quad S _ { P Q } = \left ( \begin{array} { c c c } t _ { 1 } ^ { \prime } & 0 & 0 \\ 0 & t _ { 2 } & 0 \\ 0 & 0 & t _ { 3 } \end{array} \right ), \quad S _ { Q P } = \left ( \begin{array} { c c c } t _ { 1 } & 0 & 0 \\ 0 & t _ { 2 } ^ { \prime } & 0 \\ 0 & 0 & t _ { 3 } ^ { \prime } \end{array} \right ), \quad S _ { Q Q } = \left ( \begin{array} { c c c } r _ { 1 } ^ { \prime } & 0 & 0 \\ 0 & r _ { 2 } & 0 \\ 0 & 0 & r _ { 3 } \end{array} \right ).$$
Equation (10) has a nice interpretation: the first term on the right hand side, S PP , represents the reflected parts of the waves that reach the conductors, while the second term comes from the multiple scattering in the system. Here, S QP gives the transmission from outside to inside, S PQ gives the transmission from inside to outside of the system, and S QQ represents the internal reflections.
Notice that S is also a unitary matrix once we ensure that S 0 is chosen as a unitary matrix too, and the symmetry conditions are fixed by the symmetry properties of the S j 's. Although our result is general, in what follows we adopt a simple model for S 0 and we choose S j from an ensemble of scattering matrices that simulates chaotic cavities.
## A. A simple model for the splitter
A simple model for the S -matrix of the splitter, real and symmtric, that couples the probe symmetrically , was proposed by B¨ttiker [9], namely u
$$S _ { 0 } & = \left ( \begin{array} { c c } a & b & \sqrt { \varepsilon } \\ b & a & \sqrt { \varepsilon } \\ \sqrt { \varepsilon } & \sqrt { \varepsilon } & - ( a + b ) \end{array} \right ), \\ \text{ith $0<\varepsilon < 1/2$. which evices the coupling strength. and}$$
where ε is a real parameters with 0 ≤ ε ≤ 1 / 2, which gives the coupling strength, and
When the coupling vanishes ( ε → 0), a → 0 and b → 1 which means that the probe is decoupled and there is complete transmission between the terminals 1 and 2. On the contrary, when the probe is perfectly coupled ( ε = 1 2), / a = -1 / 2 and b = 1 2, nothing is reflected to the probe. /
$$a = - \frac { 1 } { 2 } \left ( 1 - \sqrt { 1 - 2 \varepsilon } \right ), \quad b = + \frac { 1 } { 2 } \left ( 1 + \sqrt { 1 - 2 \varepsilon } \right ). & & ( 1 3 ) \\ \text{vanishes} \left ( \varepsilon \rightarrow 0 \right ). & a \rightarrow 0 \text{ and } b \rightarrow 1 \text{ which means that the nrobe is decoumled and there is complete}$$
## IV. THE VOLTAGE MEASUREMENT
We assume that the conductors in our device are in fact chaotic cavities, such that the voltage measurement, and any other transport properties, shows sample to sample fluctuations, although macroscopically seems to be identical; this is due to the difficulty of control of the shape of the cavity microscopically. Of course, the fluctuations also arise with respect to external parameters like the chemical potentials and magnetic field. Therefore, we require to make a statistical study for the voltage measurement. We do this for two kind of ensembles for the S j matrices: in presence and absence of time reversal symmetry. In the Dyson's scheme these correspond to the orthogonal and unitary cases, labeled by β = 1 and β = 2, respectively [20].
## A. Presence of time reversal invariance
In the β = 1 symmetry, an S j matrix can be parameterized in a 'polar representation' as [17]
$$S _ { j } = & \left ( \begin{smallmatrix} e ^ { i \phi _ { j } } & 0 \\ 0 & e ^ { i \psi _ { j } } \end{smallmatrix} \right ) \left ( \begin{smallmatrix} - \sqrt { 1 - \tau _ { j } } & \sqrt { \tau _ { j } } \\ \sqrt { \tau _ { j } } & \sqrt { 1 - \tau _ { j } } \end{smallmatrix} \right ) \left ( \begin{smallmatrix} e ^ { i \phi _ { j } } & 0 \\ 0 & e ^ { i \psi _ { j } } \end{smallmatrix} \right ), \\ \intertext { l \psi _ { i } } \, \text{are random numbers, uniformly distributed in the interval } [ 0, 2 \pi ], \, \text{and} \, \tau _ { i } \, \text{is randomly distributed in}$$
where φ j and ψ j are random numbers, uniformly distributed in the interval [0 , 2 π ], and τ j is randomly distributed in [0 , 1]. The probability distribution for S j is [17]
$$d P _ { 1 } ( S _ { j } ) = \frac { d \tau _ { j } } { 2 \sqrt { \tau _ { j } } } \frac { d \phi _ { j } } { 2 \pi } \frac { d \psi _ { j } } { 2 \pi },$$
which defines the Circular Orthogonal Ensemble , which can be generated numerically. Once this is done, we substitute the elements of the S j matrices in the expressions given in Eq. (11), and then in Eq. (10) from which we obtain the transmission coefficients T 31 and T 32 , needed to determine f through Eq. (3).
The numerical results for the distribution of f , for several values of the coupling strength ε , are shown in Fig. 2 for different measurement configurations. Panels (a), (b), and (c) of this figure are the most general cases of voltage measurements with respect to the position, where all conductors are chaotic. We can observe a clear dependence on the position of the probe. In panel (a), the probe is in the middle of the horizontal wire, and the distribution of f is symmetric around zero, which means that µ 3 fluctuates symmetrically around the average ( µ 1 + µ 2 ) / 2. However, when the position of the probe changes to one end of the horizontal wire, the distribution of f is no more symmetric with respect to zero, as can be seen in panels (b) and (c) of Fig. 2; in fact, µ 3 tends to be closer to the chemical potential of that terminal. We also note that the distribution of f is independent of the coupling parameter. However, when the probe is asymmetrically located in the horizontal wire, the distribution of f reminds that of the probe in the midpoint. We can see that our results contrast with the disordered case of Refs. [12, 13] in both limits of weak and strong disorder.
## B. Absence of time reversal invariance
The scattering matrix S j for the β = 2 symmetry has the following parametrization [17],
$$S _ { j } = \left ( \begin{smallmatrix} e ^ { i \phi _ { j } } & 0 \\ 0 & e ^ { i \psi _ { j } } \end{smallmatrix} \right ) \left ( \begin{smallmatrix} - \sqrt { 1 - \tau _ { j } } & \sqrt { \tau _ { j } } \\ \sqrt { \tau _ { j } } & \sqrt { 1 - \tau _ { j } } \end{smallmatrix} \right ) \left ( \begin{smallmatrix} e ^ { i \phi ^ { \prime } _ { j } } & 0 \\ 0 & e ^ { i \psi ^ { \prime } _ { j } } \end{smallmatrix} \right ). \\ \text{babilitv distribution of $S$ is given $bv_{[17]$} }$$
Here, the probability distribution of S j is given by [17]
$$d P _ { 2 } ( S _ { j } ) = d \tau _ { j } \frac { d \phi _ { j } } { 2 \pi } \frac { d \psi _ { j } } { 2 \pi } \frac { d \phi _ { j } ^ { \prime } } { 2 \pi },$$
which defines the Circular Unitary Ensemble .
In Fig. 2, panels (d), (e) and (f), we show the results for the distribution of f for the same values of ε and configurations as in the β = 1 case. The dependence on the intensity of the coupling, as well as in the position of the probe, is also observed. As in the β = 1 case, the distribution of f is independent of ε and has memory with respect to the measurement in the midpoint of the horizontal wire. What is important to note here is that the distribution of f is strongly affected by the broken symmetry of time reversal.
1
FIG. 2: Distribution of f for a chaotic three terminal device for different values of ε and configurations (insets), (a), (b) and (c) in the presence, and (d), (e) and (f) in the absence, of time reversal invariance.
## V. CONCLUSIONS
We studied the voltage drop along a horizontal wire with one open mode, consisting of chaotic conductors, in a three terminal device. This was done by using a probe which is chaotic. Our analysis was based on random matrix theory simulations for the chaotic elements, in the presence and absence of time reversal invariance. We found a clear dependence of the position of the probe in the horizontal wire. Also, we found a strong dependence of the time reversal symmetry.
## Acknowledgments
The authors thank the organizers of the V Leopoldo Garc´ ıa-Col´ ın Mexican Meeting for their kind invitation. AMMA acknowledges financial support from CONACyT, Mexico. MM-M is a fellow of Sistema Nacional de Investigadores, Mexico; he also thanks MA Torres-Segura for her encouragement.
- [1] S. Datta, Electronic Transport in Mesoscopic Systems , Cambridge University Press, Cambridge, 1995.
- [2] S. Goodnick, IEEE Transactions on Nanotechnology 2 , 368 (2003).
- [3] R. de Picciotto, H. L. Stormer, L. N. Pfeiffer, K. W. Baldwin, and K. W. West, Nature 411 , 51 (2001).
- [4] A. M. Chang, Nature 411 , 39 (2001).
- [5] R. Fleischmann and T. Geisel, Phys. Rev. Lett. 89 , 016804 (2002).
- [6] S. de Haan, A. Lorke, J. P. Kotthaus, W. Wegscheider, and M. Bichler, Phys. Rev. Lett. 92 , 056806 (2004).
- [7] B. Gao, Y. F. Chen, M. S. Fuhrer, D. C. Glattli, and A. Bachtold Phys. Rev. Lett. 95 , 196802 (2005).
- [8] H. Aita, L. Arrachea, and C. Naom, Physica B-Condensed Matter 47 , 3158 (2012).
- [9] M. B¨ uttiker, Y. Imry, and Y. Azbel, Phys. Rev. A 30 , 1982 (1984).
- [10] M. B¨ uttiker, Phys. Rev. Lett. 57 , 1761 (1986).
- [11] M. B¨ uttiker, IBM J. Res. Dev. 32 , 317 (1988).
- [12] S. Godoy and P. A. Mello, Europhys. Lett. 17 , 243 (1992).
- [13] S. Godoy and P. A. Mello, Phys. Rev. B 46 , 2346 (1992).
- [14] V. A. Gopar, M. Mart´ ınez, and P. A. Mello, Phys. Rev. B 50 , 2502 (1994).
- [15] A. M. Song, A. Lorke, A. Kriele, J. P. Kotthaus, W. Wegscheider, and M. Bichler, Phys. Rev. Lett. 80 , 3831 (1998).
- [16] A. M. Song, Phys. Rev. B 59 , 9806 (1999).
- [17] P. A. Mello, Theory of Random Matrices: Spectral Statistics and Scattering Problems in Mesoscopic Quantum Physics , edited by E. Akkermans, G. Montambaux, J.-L. Pichard, and J. Zinn-Justinm, Elsevier, Amsterdam, 1995.
- [18] C. W. J. Beenakker, Rev. Mod. Phys. 69 , 731 (1997).
- [19] Y. Alhassid, Rev. Mod. Phys. 72 , 895 (2000).
- [20] F. J. Dyson, J. Math. Phys. 3 , 140 (1962). | 10.1063/1.4862416 | [
"A. M. Martínez-Argüello",
"E. Castaño",
"M. Martínez-Mares"
] | 2014-08-02T18:03:03+00:00 | 2014-08-02T18:03:03+00:00 | [
"cond-mat.mes-hall"
] | Random matrix study for a three-terminal chaotic device | We perform a study based on a random-matrix theory simulation for a
three-terminal device, consisting of chaotic cavities on each terminal. We
analyze the voltage drop along one wire with two chaotic mesoscopic cavities,
connected by a perfect conductor, or waveguide, with one open mode. This is
done by means of a probe, which also consists of a chaotic cavity that measure
the voltage in different configurations. Our results show significant
differences with respect to the disordered case, previously considered in the
literature. |
1408.0406v2 | ## Shaping Social Activity by Incentivizing Users
Mehrdad Farajtabar 1 , Nan Du 1 , Manuel Gomez Rodriguez 2 , Isabel Valera , Hongyuan Zha , and 3 1 Le Song 1
1 Georgia Institute of Technology, { mehrdad,dunan } @gatech.edu, { zha,lsong } @cc.gatech.edu 2 Max Plank Institute for Intelligent Systems, [email protected] 3 University Carlos III in Madrid, [email protected]
## Abstract
Events in an online social network can be categorized roughly into endogenous events, where users just respond to the actions of their neighbors within the network, or exogenous events, where users take actions due to drives external to the network. How much external drive should be provided to each user, such that the network activity can be steered towards a target state? In this paper, we model social events using multivariate Hawkes processes, which can capture both endogenous and exogenous event intensities, and derive a time dependent linear relation between the intensity of exogenous events and the overall network activity. Exploiting this connection, we develop a convex optimization framework for determining the required level of external drive in order for the network to reach a desired activity level. We experimented with event data gathered from Twitter, and show that our method can steer the activity of the network more accurately than alternatives.
## 1 Introduction
Online social platforms routinely track and record a large volume of event data, which may correspond to the usage of a service ( e.g. , url shortening service, bit.ly). These events can be categorized roughly into endogenous events, where users just respond to the actions of their neighbors within the network, or exogenous events, where users take actions due to drives external to the network. For instance, a user's tweets may contain links provided by bit.ly, either due to his forwarding of a link from his friends, or due to his own initiative to use the service to create a new link.
Can we model and exploit these data to steer the online community to a desired activity level? Specifically, can we drive the overall usage of a service to a certain level ( e.g. , at least twice per day per user) by incentivizing a small number of users to take more initiatives? What if the goal is to make the usage level of a service more homogeneous across users? What about maximizing the overall service usage for a target group of users? Furthermore, these activity shaping problems need to be addressed by taking into account budget constraints, since incentives are usually provided in the form of monetary or credit rewards.
Activity shaping problems are significantly more challenging than traditional influence maximization problems, which aim to identify a set of users, who, when convinced to adopt a product, shall influence others in the network and trigger a large cascade of adoptions [1, 2]. First, in influence maximization, the state of each user is often assumed to be binary, either adopting a product or not [1, 3, 4, 5]. However, such assumption does not capture the recurrent nature of product usage, where the frequency of the usage matters. Second, while influence maximization methods identify a set of users to provide incentives, they do not typically provide a quantitative prescription on how much incentive should be provided to each user. Third, activity shaping concerns about a larger variety of target states, such as minimum activity requirement and homogeneity of activity, not just activity maximization.
In this paper, we will address the activity shaping problems using multivariate Hawkes processes [6], which can model both endogenous and exogenous recurrent social events, and were shown to be a good fit for such data in a number of recent works ( e.g. , [7, 8, 9, 10, 11, 12]). More importantly, we will go beyond model fitting, and derive a novel predictive formula for the overall network activity given the intensity of exogenous events in individual users, using a connection between the processes and branching processes [13, 14, 15, 16]. Based on this relation, we propose
a convex optimization framework to address a diverse range of activity shaping problems given budget constraints. Compared to previous methods for influence maximization, our framework can provide more fine-grained control of network activity, not only steering the network to a desired steady-state activity level but also do so in a time-sensitive fashion. For example, our framework allows us to answer complex time-sensitive queries, such as, which users should be incentivized, and by how much, to steer a set of users to use a product twice per week after one month?
In addition to the novel framework, we also develop an efficient gradient based optimization algorithm, where the matrix exponential needed for gradient computation is approximated using the truncated Taylor series expansion [17]. This algorithm allows us to validate our framework in a variety of activity shaping tasks and scale up to networks with tens of thousands of nodes. We also conducted experiments on a network of 60,000 Twitter users and more than 7,500,000 uses of a popular url shortening service. Using held-out data, we show that our algorithm can shape the network behavior much more accurately.
## 2 Modeling Endogenous-Exogenous Recurrent Social Events
We model the events generated by m users in a social network as a m -dimensional counting process N ( ) t = ( N 1 ( ) t , N 2 ( ) t , . . . , N m ( )) t glyph[latticetop] , where N t i ( ) records the total number of events generated by user i up to time t . Furthermore, we represent each event as a tuple ( u , t i i ) , where u i is the user identity and t i is the event timing. Let the history of the process up to time t be H t := { ( u , t i i ) | t i glyph[lessorequalslant] t } , and H t -be the history until just before time t . Then the increment of the process, d N ( ) t , in an infinitesimal window [ t, t + dt ] is parametrized by the intensity λ ( ) = ( t λ 1 ( ) t , . . . , λ m ( )) t glyph[latticetop] glyph[greaterorequalslant] 0 , i.e. ,
$$\mathbb { E } [ d N ( t ) | \mathcal { H } _ { t - } ] = \lambda ( t ) \, d t.$$
Intuitively, the larger the intensity λ ( ) t , the greater the likelihood of observing an event in the time window [ t, t + dt ] . For instance, a Poisson process in [0 , ∞ ) can be viewed as a special counting process with a constant intensity function λ , independent of time and history. To model the presence of both endogenous and exogenous events, we will decompose the intensity into two terms
$$\begin{smallmatrix} \cdot & & \cdot \\ & & \text{overall event intensity} & & = & \underbrace { \lambda ^ { ( 0 ) } ( t ) } _ { \text{exogenous event intensity} } & & + & \underbrace { \lambda ^ { * } ( t ) } _ { \text{endogenous event intensity} }, & & \\ \end{smallmatrix}$$
where the exogenous event intensity models drive outside the network, and the endogenous event intensity models interactions within the network. We assume that hosts of social platforms can potentially drive up or down the exogenous events intensity by providing incentives to users; while endogenous events are generated due to users' own interests or under the influence of network peers, and the hosts do not interfere with them directly. The key questions in the activity shaping context are how to model the endogenous event intensity which are realistic to recurrent social interactions, and how to link the exogenous event intensity to the endogenous event intensity. We assume that the exogenous event intensity is independent of the history and time, i.e. , λ (0) ( ) = t λ (0) .
## 2.1 Multivariate Hawkes Process
Recurrent endogenous events often exhibit the characteristics of self-excitation, where a user tends to repeat what he has been doing recently, and mutual-excitation, where a user simply follows what his neighbors are doing due to peer pressure. These social phenomena have been made analogy to the occurrence of earthquake [18] and the spread of epidemics [19], and can be well-captured by multivariate Hawkes processes [6] as shown in a number of recent works ( e.g. , [7, 8, 9, 10, 11, 12]).
More specifically, a multivariate Hawkes process is a counting process who has a particular form of intensity. More specifically, we assume that the strength of influence between users is parameterized by a sparse nonnegative influence matrix A = ( a uu ′ ) u,u ′ ∈ [ m ] , where a uu ′ > 0 means user u ′ directly excites user u . We also allow A to have nonnegative diagonals to model self-excitation of a user. Then, the intensity of the u -th dimension is
$$\kappa _ { u } ^ { \quad \lambda } ( t ) = \sum _ { i \colon t _ { i } < t } a _ { u u _ { i } } \, g ( t - t _ { i } ) = \sum _ { u ^ { \prime } \in [ m ] } a _ { u u ^ { \prime } } \, \overset { \cdot } { \int _ { 0 } ^ { t } g ( t - s ) \, d N _ { u ^ { \prime } } ( s ) },$$
Figure 1: (a) an example social network where each directed edge indicates that the target node follows , and can be influenced by, the source node. The activity in this network is modeled using Hawkes processes, which result in branching structure of events in (b). Each exogenous event is the root node of a branch ( e.g. , top left most red circle at t 1 ), and it occurs due to a user's own initiative; and each event can trigger one or more endogenous events (blue square at t 2 ). The new endogenous events can create the next generation of endogenous events (green triangles at t 3 ), and so forth. The social network in (a) will constrain the branching structure of events in (b), since an event produced by a user ( e.g. , user 1 ) can only trigger endogenous events in the same user or one or more of her followers ( e.g. , user 2 or user 3 ).
where g s ( ) is a nonnegative kernel function such that g s ( ) = 0 for s ≤ 0 and ∫ ∞ 0 g s ( ) ds < ∞ ; the second equality is obtained by grouping events according to users and use the fact that ∫ t 0 g t ( -s ) dN u ′ ( s ) = ∑ u i = u ,t <t ′ i g t ( -t i ) . Intuitively, λ ∗ u ( ) t models the propagation of peer influence over the network - each event ( u , t i i ) occurred in the neighbor of a user will boost her intensity by a certain amount which itself decays over time. Thus, the more frequent the events occur in the user's neighbor, the more likely she will be persuaded to generate a new event.
For simplicity, we will focus on an exponential kernel, g t ( -t i ) = exp( -ω t ( -t i )) in the reminder of the paper. However, multivariate Hawkes processes and the branching processed explained in next section is independent of the kernel choice and can be extended to other kernels such as power-law, Rayleigh or any other long tailed distribution over nonnegative real domain. Furthermore, we can rewrite equation (3) in vectorial format
$$\lambda ^ { * } ( t ) = \int _ { 0 } ^ { t } G ( t - s ) \, d N ( s ), \quad \begin{array} { c } \cdot & \cdot \\ \lambda ^ { * } ( t ) = \int _ { 0 } ^ { t } G ( t - s ) \, d N ( s ), \quad \begin{array} { c } \cdot & \cdot \\ \lambda ^ { * } ( t ) = \int _ { 0 } ^ { t } \end{array} \cdot \\ \cdot & \cdot & \cdot \end{array} \cdot \begin{array} { c } \cdot & \cdot \\ \lambda ^ { * } ( t ) = \int _ { 0 } ^ { t } \end{array} \cdot$$
by defining a m × m time-varying matrix G ( ) = ( t a uu ′ g t ( )) u,u ′ ∈ [ m ] . Note that, for multivariate Hawkes processes, the intensity, λ ( ) t , itself is a random quantity, which depends on the history H t . We denote the expectation of the intensity with respect to history as
$$\mu ( t ) \coloneqq \mathbb { E } _ { \mathcal { H } _ { t - } } \left [ \lambda ( t ) \right ]$$
## 2.2 Connection to Branching Processes
A branching process is a Markov process that models a population in which each individual in generation k produces some random number of individuals in generation k + 1 , according some distribution [20]. In this section, we will conceptually assign both exogenous events and endogenous events in the multivariate Hawkes process to levels (or generations), and associate these events with a branching structure which records the information on which event triggers which other events (see Figure 1 for an example). Note that this genealogy of events should be interpreted in probabilistic terms and may not be observed in actual data. Such connection has been discussed in Hawkes' original paper on one dimensional Hawkes processes [21], and it has recently been revisited in the context of multivariate Hawkes processes by [11]. The branching structure will play a crucial role in deriving a novel link between the intensity of the exogenous events and the overall network activity.
More specifically, we assign all exogenous events to the zero-th generation, and record the number of such events as N (0) ( ) t . These exogenous events will trigger the first generation of endogenous events whose number will be
recorded as N (1) ( ) t . Next these first generation of endogenous events will further trigger a second generation of endogenous events N (2) ( ) t , and so on and so forth. Then the total number of events in the network is the sum of the numbers of events from all generations
$$N ( t ) = N ^ { ( 0 ) } ( t ) + N ^ { ( 1 ) } ( t ) + N ^ { ( 2 ) } ( t ) + \dots$$
Furthermore, denote all events in generation k -1 as H ( k -1) t . Then, independently for each event ( u , t i i ) ∈ H ( k -1) t in generation k -1 , it triggers a Poisson process in its neighbor u independently with intensity a uu i g t ( -t i ) . Due to the additivity of independent Poisson processes [22], the intensity, λ ( k ) u ( ) t , of events at node u and generation k is simply the sum of conditional intensities of the Poisson processes triggered by all its neighbors, i.e. , λ ( k ) u ( ) t = ∑ ( u ,t i i ) ∈H ( k -1) t a uu i g t ( -t i ) = ∑ u ′ ∈ [ m ] ∫ t 0 g t ( -s ) d N ( k -1) u ′ ( s . ) Concatenate the intensity for all u ∈ [ m ] , and use the time-varying matrix G ( ) t (4), we have
$$\Phi \Phi _ { \Phi } \Phi _ { \Phi } \Phi _ { \Phi } \Phi _ { \Phi } \Phi _ { \Phi } \Phi _ { \Phi } \Phi _ { \Phi } \Phi _ { \Phi } \Phi _ { \Phi } \Phi _ { \Phi } \Phi _ { \Phi } \Phi _ { \Phi } \Phi _ { \Phi } \Phi _ { \Phi } \Phi _ { \Phi } \Phi _ { \Phi } \Phi _ { \Phi } \Phi _ { \Phi } \Phi _ { \Phi } \Phi _ { \Phi } \Phi _ { \Phi } \Phi _ { \Phi } \Phi _ { \Phi } \Psi _ { \Phi } \Phi _ { \Phi } \Phi _ { \Phi } \Phi _ { \Phi } \Phi _ { \Phi } \Phi _ { \Phi } \Phi _ { \Phi } \Phi _ { \Phi } \Phi _ { \Phi } \Phi _ { \Phi } \Phi _ { \Phi } \Phi _ { \Phi } \Phi _ { \Phi } \Phi _ { \Phi } \Phi _ { \Phi } \Phi _ { \Phi } \Phi _ { \Phi } \Phi _ { \Phi } \Phi _ { \Phi } \Phi _ { \Phi } \Phi _ { \Phi } \Phi _ { \Phi } \Phi_ { \Phi } \Phi _ { \Phi } \Phi _ { \Phi } \Phi _ { \Phi } \Phi _ { \Phi } \Phi _ { \Phi } \Phi _ { \Phi } \Phi _ { \Phi } \Phi _ { \Phi } \Phi _ { \Phi } \Phi _ { \Phi } \Phi _ { \Phi } \Phi _ { \Phi } \Phi _ { \Phi } \Phi _ { \Phi } \Phi _ { \Phi } \Phi _ { \Phi } \Phi _ { \Phi } \Phi _ { \Phi } \Phi _ { \Phi } \Phi _ { \Phi } \Phi _ { \Phi } \Phi _ {\Phi } \Phi _ { \Phi } \Phi _ { \Phi } \Phi _ { \Phi } \Phi _ { \Phi } \Phi _ { \Phi } \Phi _ { \Phi } \Phi _ { \Phi } \Phi _ { \Phi } \Phi _ { \Phi } \Phi _ { \Phi } \Phi _ { \Phi } \Phi _ { \Phi } \Phi _ { \Phi } \Phi _ { \Phi } \Phi _ { \Phi } \Phi _ { \Phi } \Phi _ { \Phi } \Phi _ { \Phi } \Phi _ { \Phi } \Phi _ { \Phi } \Phi _ { \Phi } \Phi _ { \Philon } \Phi _ { \Phi } \Phi _ { \Phi } \Phi _ { \Phi } \Phi _ { \Phi } \Phi _ { \Phi } \Phi _ { \Phi } \Phi _ { \Phi } \Phi _ { \Phi } \Phi _ { \Phi } \Phi _ { \Phi } \Phi _ { \Phi } \Phi _ { \Phi } \Phi _ { \Phi } \Phi _ { \Phi } \Phi _ { \Phi } \Phi _ { \Phi } \Phi _ { \Phi } \Phi _ { \Phi } \Phi _ { \Phi } \Phi _ { \Phi } \Phi _ { \Phi } \Phi _ { \Phi }$$
where λ ( k ) ( ) = ( t λ ( k ) 1 ( ) t , . . . , λ ( k ) m ( )) t glyph[latticetop] is the intensity for counting process N ( k ) ( ) t at k -th generation. Again, due to the additivity of independent Poisson processes, we can decompose the intensity of N ( ) t into a sum of conditional intensities from different generation
$$\lambda ( t ) = \lambda ^ { ( 0 ) } ( t ) + \lambda ^ { ( 1 ) } ( t ) + \lambda ^ { ( 2 ) } ( t ) + \dots$$
Next, based on the above decomposition, we will develop a closed form relation between the expected intensity µ ( ) t = E H t -[ λ ( )] t and the intensity, λ (0) ( ) t , of the exogenous events. This relation will form the basis of our activity shaping framework.
## 3 Linking Exogenous Event Intensity to Overall Network Activity
Our strategy is to first link the expected intensity µ ( k ) ( ) t := E H t -[ λ ( k ) ( )] t of events at the k -th generation with λ (0) ( ) t , and then derive a close form for the infinite series sum
$$\mu ( t ) = \mu ^ { ( 0 ) } ( t ) + \mu ^ { ( 1 ) } ( t ) + \mu ^ { ( 2 ) } ( t ) + \dots$$
Define a series of auto-convolution matrices, one for each generation, with G ( glyph[star] 0) ( ) = t I and
$$G ^ { ( * k ) } ( t ) = \int _ { 0 } ^ { t } G ( t - s ) \, G ^ { ( * k - 1 ) } ( s ) \, d s = G ( t ) * G ^ { ( * k - 1 ) } ( t ) \, \sum _ { \lambda \lambda } ^ { t } \,,$$
Then the expected intensity of events at the k -th generation is related to exogenous intensity λ (0) by
$$L e m m a { 1 } \ \mu ^ { ( k ) } ( t ) = G ^ { ( * k ) } ( t ) \, \lambda ^ { ( 0 ) }.$$
Next, by summing together all auto-convolution matrices,
$$\Psi ( t ) \coloneqq I + G ^ { ( * 1 ) } ( t ) + G ^ { ( * 2 ) } ( t ) + \dots$$
we obtain a linear relation between the expected intensity of the network and the intensity of the exogenous events, i.e. , µ ( ) t = Ψ ( ) t λ (0) . The entries in the matrix Ψ ( ) t roughly encode the 'influence' between pairs of users. More precisely, the entry Ψ uv ( ) t is the expected intensity of events at node u due to a unit level of exogenous intensity at node v . We can also derive several other useful quantities from Ψ ( ) t . For example, Ψ · v ( ) t := ∑ u Ψ uv ( ) t can be thought of as the overall influence user v on has on all users. Surprisingly, for exponential kernel, the infinite sum of matrices results in a closed form using matrix exponentials. First, let ̂ · denote the Laplace transform of a function, and we have the following intermediate results on the Laplace transform of G ( glyph[star]k ) ( ) t .
$$L e m a \, 2 \ \widehat { G } ^ { ( * k ) } ( z ) = \int _ { 0 } ^ { \infty } G ^ { ( * k ) } ( t ) \, d t = \frac { 1 } { z } \cdot \frac { A ^ { k } } { ( z + \omega ) ^ { k } }$$
With Lemma 2, we are in a position to prove our main theorem below:
$$\text{Theorem} \, 3 \ \mu ( t ) = \Psi ( t ) \lambda ^ { ( 0 ) } = \left ( e ^ { ( A - \omega I ) t } + \omega ( A - \omega I ) ^ { - 1 } ( e ^ { ( A - \omega I ) t } - I ) \right ) \lambda ^ { ( 0 ) }.$$
Theorem 3 provides us a linear relation between exogenous event intensity and the expected overall intensity at any point in time but not just stationary intensity. The significance of this result is that it allows us later to design a diverse range of convex programs to determine the intensity of the exogenous event in order to achieve a target intensity.
In fact, we can recover the previous results in the stationary case as a special case of our general result. More specifically, a multivariate Hawkes process is stationary if the spectral radius
$$\Gamma \coloneqq \overset { \cdot } { \int _ { 0 } ^ { \infty } } G ( t ) \, d t = \left ( \overset { \cdot } { \int _ { 0 } ^ { \infty } } g ( t ) \, d t \right ) \left ( a _ { u u ^ { \prime } } \right ) _ { u, u ^ { \prime } \in [ m ] } = \frac { A } { \omega } \\ \dots \dots \wedge \overset { \cdot } { \wedge }$$
is strictly smaller than 1 [6]. In this case, the expected intensity is µ = ( I -Γ ) -1 λ (0) independent of the time. We can obtain this relation from theorem 3 if we let t →∞ .
$$\text{Corollary } 4 \ \mu = \left ( \mathbf I - \Gamma \right ) ^ { - 1 } \lambda ^ { ( 0 ) } = \lim _ { t \to \infty } \Psi ( t ) \, \lambda ^ { ( 0 ) }.$$
Refer to Appendix A for all the proofs.
## 4 Convex Activity Shaping Framework
Given the linear relation between exogenous event intensity and expected overall event intensity, we now propose a convex optimization framework for a variety of activity shaping tasks. In all tasks discussed below, we will optimize the exogenous event intensity λ (0) such that the expected overall event intensity µ ( ) t is maximized with respect to some concave utility U ( ) · in µ ( ) t , i.e. ,
$$\underset { \substack { \max \lim i z e _ { \mu ( t ), \lambda ^ { ( 0 ) } } \\ \text{subject to} } } { \max \lim i z e _ { \mu ( t ), \lambda ^ { ( 0 ) } } } \ \ \ U ( \mu ( t ) ) \ \ \ c ^ { \top } \lambda ^ { ( 0 ) } \leqslant C, \quad \lambda ^ { ( 0 ) } \geqslant 0$$
where c = ( c 1 , . . . , c m ) glyph[latticetop] glyph[greaterorequalslant] 0 is the cost per unit event for each user and C is the total budget. Additional regularization can also be added to λ (0) either to restrict the number of incentivized users (with glyph[lscript] 0 norm ‖ λ (0) ‖ 0 ), or to promote a sparse solution (with glyph[lscript] 1 norm ‖ λ (0) ‖ 1 , or to obtain a smooth solution (with glyph[lscript] 2 regularization ‖ λ (0) ‖ 2 ). We next discuss several instances of the general framework which achieve different goals (their constraints remain the same and hence omitted).
Capped Activity Maximization. In real networks, there is an upper bound (or a cap) on the activity each user can generate due to limited attention of a user. For example, a Twitter user typically posts a limited number of shortened urls or retweets a limited number of tweets [23]. Suppose we know the upper bound, α u , on a user's activity, i.e. , how much activity each user is willing to generate. Then we can perform the following capped activity maximization task
$$\maximize _ { \mu ( t ), \lambda ^ { ( 0 ) } } \sum _ { u \in [ m ] } \min \left \{ \mu _ { u } ( t ), \alpha _ { u } \right \}$$
Minimax Activity Shaping. Suppose our goal is instead maintaining the activity of each user in the network above a certain minimum level, or, alternatively make the user with the minimum activity as active as possible. Then, we can perform the following minimax activity shaping task
$$\maximize _ { \mu ( t ), \lambda ^ { ( 0 ) } } \min _ { u } \mu _ { u } ( t )$$
Least-Squares Activity Shaping. Sometimes we want to achieve a pre-specified target activity levels, v , for users. For example, we may like to divide users into groups and desire a different level of activity in each group. Inspired by these examples, we can perform the following least-squares activity shaping task
$$\maximize _ { \mu ( t ), \lambda ^ { ( 0 ) } } \ - \| B \mu ( t ) - v \| _ { 2 } ^ { 2 }$$
↦
where B encodes potentially additional constraints ( e.g. , group partitions). Besides Euclidean distance, the family of Bregman divergences can be used to measure the difference between Bµ ( ) t and v here. That is, given a function f ( ) : · R m → R convex in its argument, we can use D ( Bµ ( ) t ‖ v ) := f ( Bµ ( )) t -f ( v ) -〈∇ f ( v ) , Bµ ( ) t -v 〉 as our objective function.
Activity Homogenization. Many other concave utility functions can be used. For example, we may want to steer users activities to a more homogeneous profile. If we measure homogeneity of activity with Shannon entropy, then we can perform the following activity homogenization task
$$\maximize _ { \mu ( t ), \lambda ^ { ( 0 ) } } - \sum _ { u \in [ m ] } \mu _ { u } ( t ) \ln \mu _ { u } ( t )$$
## Algorithm 1: Average Instantaneous Intensity
```
\
\
```
return v 1 + ω v 3 ;
## 5 Scalable Algorithm
All the activity shaping problems defined above require an efficient evaluation of the instantaneous average intensity µ ( ) t at time t , which entails computing matrix exponentials to obtain Ψ ( ) t . In small or medium networks, we can rely on well-known numerical methods to compute matrix exponentials [24]. However, in large networks with sparse graph structure A , the explicit computation of Ψ ( ) t quickly becomes intractable.
Fortunately, we can exploit the following key property of our convex activity shaping framework: the instantaneous average intensity only depends on Ψ ( ) t through matrix-vector product operations. In particular, we start by using Theorem 3 to rewrite the multiplication of Ψ ( ) t and a vector v as Ψ ( ) t v = e ( A -ω I ) t v + ( ω A -ω I ) -1 ( e ( A -ω I ) t v -v ) . We then get a tractable solution by first computing e ( A -ω I ) t v efficiently, subtracting v from it, and solving a sparse linear system of equations, ( A -ω I ) x = ( e ( A -ω I ) t v -v ) , efficiently. The steps are illustrated in Algorithm 1. Next, we elaborate on two very efficient algorithms for computing the product of matrix exponential with a vector and for solving a sparse linear system of equations.
For the computation of the product of matrix exponential with a vector, we rely on the iterative algorithm by AlMohy et al. [17], which combines a scaling and squaring method with a truncated Taylor series approximation to the matrix exponential.
For solving the sparse linear system of equation, we use the well-known GMRES method [25], which is an Arnoldi process for constructing an l 2 -orthogonal basis of Krylov subspaces. The method solves the linear system by iteratively minimizing the norm of the residual vector over a Krylov subspace. In detail, consider the n th Krylov subspace for the problem Cx = b as K n = span { b Cb A b , , 2 , . . . , C n -1 b } . GMRES approximates the exact solution of Cx = b by the vector x n ∈ K n that minimizes the Euclidean norm of the residual r n = Cx n -b . Because the span consists of orthogonal vectors, the Arnoldi iteration is used to find an alternative basis composing rows of Q n . Hence, the vector x n ∈ K n can be written as x n = Q y n n with y n ∈ R n . Then, y n can be found by minimizing the Euclidean norm of the residual r n = ˜ H y n n -β e 1 , where ˜ H n is the Hessenberg matrix produced in the Arnoldi process, e 1 = (1 0 0 , , , . . . , 0) T is the first vector in the standard basis of R n +1 , and β = ‖ b -Cx 0 ‖ . Finally, x n is computed as x n = Q y n n . The whole procedure is repeated until reaching a small enough residual.
Perhaps surprisingly, we will now show that it is possible to compute the gradient of the objective functions of all our activity shaping problems using the algorithm developed above for computing the average instantaneous intensity. We only need to define the vector v appropriately for each problem, as follows: (i) Activity maximization: g λ ( (0) ) = Ψ ( ) t glyph[latticetop] v , where v is defined such that v j = 1 if α j > µ j , and v j = 0 , otherwise. (ii) Minimax activity shaping: g λ ( (0) ) = Ψ ( ) t glyph[latticetop] e , where e is defined such that e j = 1 if µ j = µ min , and e j = 0 , otherwise. (iii) Least-squares activity shaping: g λ ( (0) ) = 2 Ψ ( ) t glyph[latticetop] B glyph[latticetop] ( B Ψ ( ) t λ (0) -v ) . (iv) Activity homogenization: g λ ( (0) ) = Ψ ( ) t glyph[latticetop] ln ( Ψ ( ) t λ (0) ) + Ψ ( ) t glyph[latticetop] 1 , where ln( ) · on a vector is the element-wise natural logarithm. Since the activity maximization and the minimax activity shaping tasks require only one evaluation of Ψ ( ) t times a vector, Algorithm 1 can be used directly. However, computing the gradient for least-squares activity shaping and activity homogenization is slightly more involved and it requires to be careful with the order in which we perform the operations. Algorithm 2 includes the efficient procedure to compute the gradient in the least-squares activity shaping task. Since B is usually sparse, it includes two multiplications of a sparse matrix and a vector, two matrix exponentials multiplied by a vector, and two sparse linear systems of equations. Algorithm 3 summarizes the steps for efficient computation of the gradient in the activity homogenization task. Assuming again a sparse B , it consists of two multiplication of a matrix exponential and a vector and two sparse linear systems of equations.
Equipped with an efficient way to compute of gradients, we solve the corresponding convex optimization problem for each activity shaping problem by applying the projected gradient descent [26] optimization framework with the
## Algorithm 2: Gradient For Least-squares Activity Shaping
input : A , ω t , , v λ , (0) output : g λ ( (0) ) v 1 = Ψ ( ) t λ (0) ; //Application of algorithm 1 v 2 = Bv 1 ; //Sparse matrix vector product v 3 = B glyph[latticetop] ( v 2 -v ) ; //Sparse matrix vector product v 4 = Ψ ( ) t v 3 ; //Application of algorithm 1 return 2 v 4
## Algorithm 3: Gradient For Activity Homogenization
input : A , ω t , , v λ , (0) output : g λ ( (0) ) v 1 = Ψ ( ) t λ (0) ; //Application of algorithm 1 v 2 = ln( v 1 ) ; v 3 = Ψ ( ) t glyph[latticetop] v 2 ; //Application of algorithm 1 v 4 = Ψ ( ) t glyph[latticetop] 1 ; //Application of algorithm 1 return v 3 + v 4
appropriate gradient . Algorithm 4 summarizes the key steps of the algorithm. 1
## 6 Experimental Evaluation
We evaluate our activity shaping framework using both simulated and real world held-out data, and show that our approach significantly outperforms several baselines.
## 6.1 Experimental Setup
Here, we briefly present our data, evaluation schemas, and settings.
Dataset description and network inference. We use data gathered from Twitter as reported in [27], which comprises of all public tweets posted by 60,000 users during a 8-month period, from January 2009 to September 2009. For every user, we record the times she uses any of the following six url shortening services: Bitly , TinyURL, Isgd, TwURL, SnURL, Doiop (refer to Appendix B for details). We evaluate the performance of our framework on a subset of 2,241 active users, linked by 4,901 edges, which we call 2K dataset, and we evaluate its scalability on the overall 60,000 users, linked by ∼ 200,000 edges, which we call 60K dataset. The 2K dataset accounts for 691,020 url shortened service uses while the 60K dataset accounts for ∼ 7.5 million uses. Finally, we treat each service as independent cascades of events.
In the experiments, we estimated the nonnegative influence matrix A and the exogenous intensity λ (0) using maximum log-likelihood, as in previous work [8, 9, 12]. We used a temporal resolution of one minute and selected the bandwidth ω = 0 1 . by cross validation. Loosely speaking, ω = 0 1 . corresponds to loosing 70% of the initial influence after 10 minutes, which may be explained by the rapid rate at which each user' news feed gets updated.
Evaluation schemes. We focus on three tasks: capped activity maximization, minimax activity shaping, and least square activity shaping. We set the total budget to C = 0 5 . , which corresponds to supporting a total extra activity equal to 0 5 . actions per unit time, and assume all users entail the same cost. In the capped activity maximization, we set the upper limit of each user's intensity, α , by adding a nonnegative random vector to their inferred initial intensity. In the least-squares activity shaping, we set B = I and aim to create three groups of users, namely less-active, moderate, and super-active users. We use three different evaluation schemes, with an increasing resemblance to a real world scenario:
1 For nondifferential objectives, subgradient algorithms can be used instead.
Figure 2: Row 1: Capped activity maximization. Row 2: Minimax activity shaping. Row 3: Least-squares activity shaping. * means statistical significant at level of 0.01 with paired t-test between our method and the second best
Theoretical objective : We compute the expected overall (theoretical) intensity by applying Theorem 3 on the optimal exogenous event intensities, λ (0) opt , to each of the three activity shaping tasks, as well as the learned A and ω . We then compute and report the value of the objective functions.
Simulated objective : We simulate 50 cascades with Ogata's thinning algorithm [28], using the optimal exogenous event intensities, λ (0) opt , to each of the three activity shaping tasks, and the learned A and ω . We then estimate empirically the overall event intensity based on the simulated cascades, by computing a running average over nonoverlapping time windows, and report the value of the objective functions based on this estimated overall intensity.
Appendix C provides a comparison between the simulated and the theoretical objective.
Held-out data : The most interesting evaluation scheme would entail carrying out real interventions in a social platform. However, since this is very challenging to do, instead, in this evaluation scheme, we use held-out data to simulate such process, proceeding as follows. We first partition the 8 -month data into 50 five-day long contiguous intervals. Then, we use one interval for training and the remaining 49 intervals for testing. Suppose interval 1 is used for training, the procedure is as follows:
- 1. We estimate A 1 , ω 1 and λ (0) 1 using the events from interval 1 . Then, we fix A 1 and ω 1 , and estimate λ (0) i for all other intervals, i = 2 , . . . , 49 .
- 2. Given A 1 and ω 1 , we find the optimal exogenous event intensities, λ (0) opt , for each of the three activity shaping task, by solving the associated convex program. We then sort the estimated λ (0) i ( i = 2 , . . . , 49 ) according to their similarity to λ (0) opt , using the Euclidean distance ‖ λ (0) opt -λ (0) i ‖ 2 .
- 3. Weestimate the overall event intensity for each of the 49 intervals ( i = 2 , . . . , 49 ), as in the 'simulated objective' evaluation scheme, and sort these intervals according to the value of their corresponding objective function.
- 4. Last, we compute and report the rank correlation score between the two orderings obtained in step 2 and 3. 2 The larger the rank correlation, the better the method.
We repeat this procedure 50 times, choosing each different interval for training once, and compute and report the average rank correlations.
It is beneficial to emphasize that the held-out experiments are essentially evaluating prediction performance on test sets. For instance, suppose we are given a diffusion network and two different configuration of incentives. We will shortly show our method can predict more accurately which one will reach the activity shaping goal better. This means, in turn, that if we incentivize the users according to our method's suggestion, we will achieve the target activity better than other heuristics.
Alternatively, one can understand our evaluation scheme like this: if one applies the incentive (or intervention) levels prescribed by a method, how well the predicted outcome coincides with the reality in the test set? A good method should behavior like this: the closer the prescribed incentive (or intervention) levels to the estimated base intensities in test data, the closer the prediction based on training data to the activity level in the test data. In our experiment, the closeness in incentive level is measured by the Euclidean distance, the closeness between prediction and reality is measured by rank correlation.
## 6.2 Activity Shaping Results
In this section, the results for three activity shaping tasks evaluated on the three schemas are presented.
Capped activity maximization (CAM). We compare to a number of alternatives. XMU: heuristic based on µ ( ) t without optimization; DEG and WEI: heuristics based on the degree of the user; PRANK: heuristic based on page rank (refer to Appendix B for further details). The first row of Figure 2 summarizes the results for the three different evaluation schemes. We find that our method (CAM) consistently outperforms the alternatives. For the theoretical objective, CAM is 11 % better than the second best, DEG. The difference in overall users' intensity from DEG is about 0 8 . which, roughly speaking, leads to at least an increase of about 0 8 . × 60 × 24 × 30 = 34 560 , in the overall number of events in a month. In terms of simulated objective and held-out data, the results are similar and provide empirical evidence that, compared to other heuristics, degree is an appropriate surrogate for influence, while, based on the poor performance of XMU, it seems that high activity does not necessarily entail being influential. To elaborate on the interpretability of the real-world experiment on held-out data, consider for example the difference in rank correlation between CAM and DEG, which is almost 0 1 . . Then, roughly speaking, this means that incentivizing users based on our approach accommodates with the ordering of real activity patterns in 0 1 . × 50 × 49 2 = 122 5 . more pairs of realizations.
Minimax activity shaping (MMASH). We compare to a number of alternatives. UNI: heuristic based on equal allocation; MINMU: heuristic based on µ ( ) t without optimization; LP: linear programming based heuristic; GRD: a greedy approach to leverage the activity (see Appendix B for more details). The second row of Figure 2 summarizes the results for the three different evaluation schemes. We find that our method (MMASH) consistently outperforms
2 rank correlation = number of pairs with consistent ordering / total number of pairs.
the alternatives. For the theoretical objective, it is about 2 × better than the second best, LP. Importantly, the difference between MMASH and LP is not trifling and the least active user carries out 2 × 10 -4 × 60 × 24 × 30 = 4 3 . more actions in average over a month. As one may have expected, GRD and LP are the best among the heuristics. The poor performance of MINMU, which is directly related to the objective of MMASH, may be because it assigns the budget to a low active user, regardless of their influence. However, our method, by cleverly distributing the budget to the users whom actions trigger many other users' actions (like those ones with low activity), it benefits from the budget most. In terms of simulated objective and held-out data, the algorithms' performance become more similar.
Least-squares activity shaping (LSASH). We compare to two alternatives. PROP: Assigning the budget proportionally to the desired activity; LSGRD: greedily allocating budget according the difference between current and desired activity (refer to Appendix B for more details). The third row of Figure 2 summarizes the results for the three different evaluation schemes. We find that our method (LSASH) consistently outperforms the alternatives. Perhaps surprisingly, PROP, despite its simplicity, seems to perform slightly better than LSGRD. This is may be due to the way it allocates the budget to users, e.g. , it does not aim to strictly fulfill users' target activity but benefit more users by assigning budget proportionally. Refer to Appendix D for additional experiments.
In all three tasks, longer times lead to larger differences between our method and the alternatives. This occurs because the longer the time, the more endogenous activity is triggered by network influence, and thus our framework, which models both endogenous and exogenous events, becomes more suitable.
## 6.3 Sparsity and Activity Shaping
In some applications there is a limitation on the number of users we can incentivize. In our proposed framework, we can handle this requirement by including a sparsity constraint on the optimization problem. In order to maintain the convexity of the optimization problem, we consider a l 1 regularization term, where a regularization parameter γ provides the trade-off between sparsity and the activity shaping goal:
$$\underset { \substack { \max \lim i z e _ { \mu ( t ), \lambda ^ { ( 0 ) } } \\ \text{subject to} } } \underset { \mu ( t ) = \Psi ( t ) \lambda ^ { ( 0 ) }, \quad c ^ { \top } \lambda ^ { ( 0 ) } \leqslant C, \quad \lambda ^ { ( 0 ) } \geqslant 0 } } \sum ( 1 7 )$$
Tables 1 and 2 demonstrate the effect of different values of regularization parameter on capped activity maximization and minimax activity shaping , respectively. When γ is small, the minimum intensity is very high. On the contrary, large values of γ imposes large penalties on the number of non-zero intensities which results in a sparse and applicable manipulation. Furthermore, this may avoid using all the budget. When dealing with unfamiliar application domains, cross validation may help to find an appropriate trade-off between sparsity and objective function.
Table 1: Sparsity properties of capped activity maximization.
| γ | # Non-zeros | Budget consumed | Sum of activities |
|-----|---------------|-------------------|---------------------|
| 0.5 | 2101 | 0.5 | 0.69 |
| 0.6 | 1896 | 0.46 | 0.65 |
| 0.7 | 1595 | 0.39 | 0.62 |
| 0.8 | 951 | 0.21 | 0.58 |
| 0.9 | 410 | 0.18 | 0.55 |
| 1 | 137 | 0.13 | 0.54 |
## 6.4 Scalability
The most computationally demanding part of the proposed algorithm is the evaluation of matrix exponentials, which we scale up by utilizing techniques from matrix algebra, such as GMRES and Al-Mohy methods. As a result, we are able to run our methods in a reasonable amount of time on the 60K dataset, specifically, in comparison with a naive implementation of matrix exponential evaluations. The naive implementation of the algorithm requires computing the matrix exponential once, and using it in (non-sparse huge) matrix-vector multiplications, i.e. ,
$$T _ { n a i v e } = T _ { \Psi } + k T _ { p r o d }.$$
Table 2: Sparsity properties of minimax activity shaping.
| γ ( × 10 - 3 ) | # Non-zeros | Budget Consumed | u min ( × 10 - 3 ) |
|------------------|---------------|-------------------|----------------------|
| 0.6 | 1941 | 0.49 | 0.38 |
| 0.7 | 881 | 0.17 | 0.22 |
| 0.8 | 783 | 0.15 | 0.21 |
| 0.9 | 349 | 0.09 | 0.16 |
| 1 | 139 | 0.06 | 0.12 |
| 1.1 | 102 | 0.04 | 0.11 |
Figure 3: Scalability of least-squares activity shaping.
Here, T Ψ is the time to compute Ψ ( ) t , which itself comprised of three parts; matrix exponential computation, matrix inversion and matrix multiplications. T prod is the time for multiplication between the large non-sparse matrix and a vector plus the time to compute the inversion via solving linear systems of equation. Finally, k is the number of gradient computations, or more generally, the number of iterations in any gradient-based iterative optimization. The dominant factor in the naive approach is the matrix exponential. It is computationally demanding and practically inefficient for more than 7000 users.
In contrast, the proposed framework benefits from the fact that the gradient depends on Ψ ( ) t only through matrixvector products. Thus, the running time of our activity shaping framework will be written as
$$T _ { o u r } = k T _ { g r a d },$$
where T grad is the time to compute the gradient which itself comprises the time required to solve a couple of linear systems of equations and the time to compute a couple of exponential matrix-vector multiplication.
Figure 3 demonstrates T our and T naive with respect to the number of users. For better visualization we have provided two graphs for up to 10,000 and 50,000 users, respectively. We set k equal to the number of users. Since the dominant factor in the naive computation method is matrix exponential, the choice of k is not that determinant. The time for computing matrix exponential is interpolated for more than 7000 users; and the interpolated total time, T naive , is shown in red dashed line. These experiments are done in a machine equipped with one 2.5 GHz AMD Opteron Processor. This graph clearly shows the significance of designing an scalable algorithm.
Figure 4 shows the results of running our large-scale algorithm on the 60K dataset evaluated via theoretical objective function. We observe the same patterns as 2K dataset. Especially, the proposed method consistently outperforms the heuristic baselines. Heuristic baselines provide similar performance as for the 2K dataset. DEG shows up again as a reasonable surrogate for influence, and the poor performance of XMU on activity maximization shows that high activity does not necessarily mean being more influential. For minimax activity shaping we observe MMASH is superior to others in 2 × 10 -5 actions per unit time, which means that the person with minimum activity uses the service 2 × 10 -5 × 60 ∗ 24 ∗ 30 = 0 864 . times more compared to the best heuristic baseline. An increase in the activity per month of 0 864 . is not a big deal itself, however, if we consider the scale at which the network's activity is steered, we can deduce that now the service is guaranteeing, at least in theory, about 60000 × 0 864 = 51840 . more adoptions monthly. As shown by the experiments on real-world held-out data, our approach for activity shaping outperforms all
(a) Capped activity maximization.
(c) Least-square activity shaping.
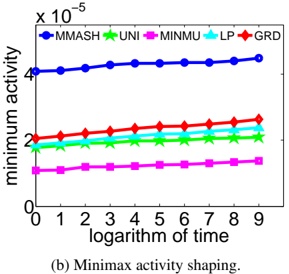
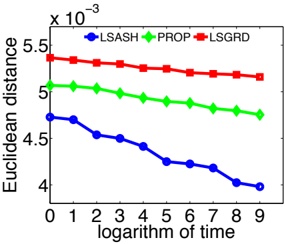
Figure 4: Activity shaping on the 60K dataset.
the considered heuristic baselines.
## 7 Summary and Discussion
In this paper, we introduced the activity shaping problem, which is a generalization of the influence maximization problem, and it allows for more elaborate goal functions. Our model of social activity is based on multivariate Hawkes processs, and via a connection to branching processes, we manage to derive a linear connection between the exogenous activity ( i.e. , the part that can be easily manipulated via incentives) and the overall network activity. This connection enables developing a convex optimization framework for activity shaping, deriving the necessary incentives to reach a global activity pattern in the network. The method is evaluated on both synthetic and real-world held-out data and is shown to outperform several heuristics.
We acknowledge that our method has indeed limitations. For example, our current formulation assumes that exogenous events are constant over time. Thus, subsequent evolution in the point process is a mixture of endogenous and exogenous events. However, in practice, the shaping incentives need to be doled out throughout the evolution of the process, e.g. , in a sequential decision making setting. Perhaps surprisingly, our framework can be generalized to time-varying exogenous events, at the cost of stating some of the theoretical results in a convolution form, as follows:
- · Lemma 1 needs to be kept in convolution form, i.e. , µ ( k ) ( ) = t G ( glyph[star]k ) ( ) t glyph[star] λ (0) ( ) t . The sketch of the proof is very similar, and we only need to further exploit the associativity property of the convolution at the inductive step, to prove the hypothesis holds for k +1 :
$$\mu ^ { ( k + 1 ) } ( t ) = \int _ { 0 } ^ { t } G ( t - s ) \, \left ( G ^ { ( * k ) } ( s ) \, * \, \lambda ^ { ( 0 ) } ( s ) \right ) \, d s = G ^ { ( * k ) } ( t ) * G ( t ) * \lambda ^ { ( 0 ) } ( t ) = G ^ { ( * k + 1 ) } ( t ) * \lambda ^ { ( 0 ) } ( t ) \, \ ( 1 8 )$$
- · Lemma 2 is responsible for finding a closed form for ̂ G ( glyph[star]k ) ( z ) and thus is not affected by a time-varying exogenous intensity. It remains unchanged.
- · Theorem 3 derives the instantaneous average intensity µ ( ) t and, therefore, needs to be updated accordingly using the modified Lemma 1:
$$\mu ( t ) = \Psi ( t ) * \lambda ^ { ( 0 ) } ( t ) = \left ( e ^ { ( A - \omega I ) t } + \omega ( A - \omega I ) ^ { - 1 } ( e ^ { ( A - \omega I ) t } - I ) \right ) * \lambda ^ { ( 0 ) } ( t ).$$
Many simple parametrized incentive functions, such as exponential incentives λ (0) ( ) t = λ (0) exp( -αt ) with constant decay α or constant incentives within a window λ (0) ( ) = t λ (0) I [ t 1 < t < t 2 ] , for a fixed window [ t 1 , t 2 ] , result in linear closed form expressions between the exogenous event intensity and the expected overall intensity. Nonparameteric functions result in a non-closed form expression, however, we still benefit the fact that the mapping from λ 0 ( ) t to µ ( ) t is linear, and hence the activity shaping problems can still be cast as convex optimization problems. In this case, the optimization can still be done via functional gradient descent (or variational calculus), though with some additional challenge to tackle.
There are many other interesting venues for future work. For example, considering competing incentives, discovering the branching structure and using it explicitly to shape the activities, exploring other possible kernel functions or even learning them using non-parametric methods.
## Acknowledgement
The research was supported in part by NSF/NIH BIGDATA 1R01GM108341, NSF IIS-1116886, NSF CAREER IIS1350983 and a Raytheon Faculty Fellowship to L.S.
## References
- [1] David Kempe, Jon Kleinberg, and Eva Tardos. Maximizing the spread of influence through a social network. In ´ KDD , pages 137-146. ACM, 2003.
- [2] Matthew Richardson and Pedro Domingos. Mining knowledge-sharing sites for viral marketing. In KDD , pages 61-70. ACM, 2002.
- [3] Wei Chen, Yajun Wang, and Siyu Yang. Efficient influence maximization in social networks. In KDD , pages 199-208. ACM, 2009.
- [4] Manuel G. Rodriguez and Bernard Sch¨ olkopf. Influence maximization in continuous time diffusion networks. In ICML , 2012.
- [5] Nan Du, Le Song, Manuel Gomez Rodriguez, and Hongyuan Zha. Scalable influence estimation in continuous-time diffusion networks. In NIPS 26 , 2013.
- [6] Thomas .J. Liniger. Multivariate Hawkes Processes . PhD thesis, SWISS FEDERAL INSTITUTE OF TECHNOLOGY ZURICH, 2009.
- [7] Charles Blundell, Jeff Beck, and Katherine A Heller. Modelling reciprocating relationships with Hawkes processes. In NIPS , 2012.
- [8] Ke Zhou, Hongyuan Zha, and Le Song. Learning social infectivity in sparse low-rank networks using multi-dimensional Hawkes processes. In AISTATS , 2013.
- [9] Ke Zhou, Hongyuan Zha, and Le Song. Learning triggering kernels for multi-dimensional Hawkes processes. In ICML , 2013.
- [10] Tomoharu Iwata, Amar Shah, and Zoubin Ghahramani. Discovering latent influence in online social activities via shared cascade poisson processes. In KDD , pages 266-274. ACM, 2013.
- [11] Scott W Linderman and Ryan P Adams. Discovering latent network structure in point process data. arXiv preprint arXiv:1402.0914 , 2014.
- [12] Isabel Valera, Manuel Gomez-Rodriguez, and Krishna Gummadi. Modeling adoption of competing products and conventions in social media. arXiv preprint arXiv:1406.0516 , 2014.
- [13] Ian Dobson, Benjamin A Carreras, and David E Newman. A branching process approximation to cascading load-dependent system failure. In System Sciences, 2004. Proceedings of the 37th Annual Hawaii International Conference on , pages 10-pp. IEEE, 2004.
- [14] Jakob Gulddahl Rasmussen. Bayesian inference for Hawkes processes. Methodology and Computing in Applied Probability , 15(3):623-642, 2013.
- [15] Alejandro Veen and Frederic P Schoenberg. Estimation of space-time branching process models in seismology using an em-type algorithm. JASA , 103(482):614-624, 2008.
- [16] Jiancang Zhuang, Yosihiko Ogata, and David Vere-Jones. Stochastic declustering of space-time earthquake occurrences. JASA , 97(458):369-380, 2002.
- [17] Awad H Al-Mohy and Nicholas J Higham. Computing the action of the matrix exponential, with an application to exponential integrators. SIAM journal on scientific computing , 33(2):488-511, 2011.
[18] David Marsan and Olivier Lengline. Extending earthquakes' reach through cascading. Science , 319(5866):1076-1079, 2008.
[19] Shuang-Hong Yang and Hongyuan Zha. Mixture of mutually exciting processes for viral diffusion. In ICML , pages 1-9, 2013.
[20] Theodore E Harris. The theory of branching processes . Courier Dover Publications, 2002.
[21] Alan G Hawkes. Spectra of some self-exciting and mutually exciting point processes. Biometrika , 58(1):83-90, 1971.
[22] John Frank Charles Kingman. Poisson processes , volume 3. Oxford university press, 1992.
[23] Manuel Gomez-Rodriguez, Krishna Gummadi, and Bernhard Schoelkopf. Quantifying Information Overload in Social Media and its Impact on Social Contagions. In ICWSM , 2014.
[24] Gene H Golub and Charles F Van Loan. Matrix computations , volume 3. JHU Press, 2012.
- [25] Youcef Saad and Martin H Schultz. Gmres: A generalized minimal residual algorithm for solving nonsymmetric linear systems. SIAM Journal on scientific and statistical computing , 7(3):856-869, 1986.
[26] Stephen Boyd and Lieven Vandenberghe. Convex Optimization . Cambridge University Press, Cambridge, England, 2004.
- [27] Meeyoung Cha, Hamed Haddadi, Fabricio Benevenuto, and P Krishna Gummadi. Measuring User Influence in Twitter: The Million Follower Fallacy. In ICWSM , 2010.
- [28] Yosihiko Ogata. On lewis' simulation method for point processes. Information Theory, IEEE Transactions on , 27(1):23-31, 1981.
## A Proofs
$$L e m m a { 1 } \ \mu ^ { ( k ) } ( t ) = G ^ { ( * k ) } ( t ) \, \lambda ^ { ( 0 ) }.$$
Proof We will prove the lemma by induction. For generation k = 0 , µ (0) ( ) t = E H t [ λ (0) ] = G ( glyph[star] 0) ( ) t λ (0) . Assume the relation holds for generation k : µ ( k ) ( ) = t G ( glyph[star]k ) ( ) t λ (0) . Then for generation k +1 , we have µ ( k +1) ( ) = t E H t [ ∫ t 0 G ( t -s ) d N ( k ) ( s )] = ∫ t 0 G ( t -s ) E H t [ d N ( k ) ( s )] . Bydefinition E H t [ d N ( k ) ( s )] = E H s -[ E [ d N ( k ) ( s ) |H s -]] = E H s -[ λ ( k ) ( s ) ds ] = µ ( k ) ( s ) ds , then substitute it in and we have
$$\cdot \quad \cdot \quad \cdot \quad \mu ^ { ( k + 1 ) } ( t ) = \int _ { 0 } ^ { t } G ( t - s ) \, G ^ { ( * k ) } ( s ) \, \lambda ^ { ( 0 ) } \, d s = G ^ { ( * k + 1 ) } ( t ) \lambda ^ { ( 0 ) },$$
which completes the proof.
$$L e m a \, 2 \ \widehat { G } ^ { ( * k ) } ( z ) = \int _ { 0 } ^ { \infty } G ^ { ( * k ) } ( t ) \, d t = \frac { 1 } { z } \cdot \frac { A ^ { k } } { ( z + \omega ) ^ { k } }$$
Proof We will prove the result by induction on k . First, given our choice of exponential kernel, G ( ) = t e -ωt A , we have that ̂ G ( z ) = 1 z + w A . Then for k = 0 , G ( glyph[star] 0) ( ) = t I and ̂ I ( z ) = ∫ ∞ -0 e zt I dt = 1 z I . Now assume the result hold for a general k -1 , then ̂ G ( glyph[star]k -1) ( z ) = 1 z · A k -1 ( z + ) ω k -1 . Next, for k , we have ̂ G ( glyph[star]k ) ( z ) = ∫ ∞ -0 e zt ( G ( ) t glyph[star] G ( glyph[star]k -1) ( ) t ) dt = ̂ G ( z ) ̂ G ( glyph[star]k -1) ( z ) , which is ( 1 z + ω A )( A k -1 ( z + ) ω k -1 · 1 z ) = 1 z · A k ( z + ) ω k , and completes the proof.
$$\text{Theorem $3$ } \mu ( t ) = \Psi ( t ) \lambda ^ { ( 0 ) } = \left ( e ^ { ( A - \omega I ) t } + \omega ( A - \omega I ) ^ { - 1 } ( e ^ { ( A - \omega I ) t } - I ) \right ) \lambda ^ { ( 0 ) }.$$
Proof We first compute the Laplace transform ̂ Ψ ( z ) := ∫ ∞ -0 e zt Ψ ( ) t dt . Using lemma 2, we have
$$\dot { \Phi } ( z ) = \frac { 1 } { z } \sum _ { i = 0 } ^ { \infty } \frac { \dot { \ A } ^ { i } } { ( z + w ) ^ { i } } = \frac { ( z + w ) } { z } \sum _ { i = 0 } ^ { \infty } \frac { \dot { \ A } ^ { i + 1 } } { ( z + w ) ^ { i } }$$
Second, let ̂ F ( z ) := ∑ ∞ i =0 A i z i +1 and its inverse Laplace transform be F ( ) = t ∫ ∞ 0 e zt ̂ F ( z ) dz = ∑ ∞ i =0 ( A t ) i i ! = e A t , where e A t is a matrix exponential. Then, it is easy to see that ̂ Ψ ( z ) = ( z + ) w z ̂ F ( z + w ) = ̂ F ( z + w )+ w z ̂ F ( z + w . ) Finally, we perform inverse Laplace transform for ̂ Ψ ( z ) , and obtain Ψ ( ) = t e ( A -ω I ) t + ω ∫ t 0 e ( A -ω I ) s ds = e ( A -ω I ) t + ω ( A -ω I ) -1 ( e ( A -ω I ) t -I ) , where we made use of the property of Laplace transform that dividing by z in the frequency domain is equal to an integration in time domain, and F z ( + w ) = e -ωt e A t = e ( A -ω I ) t .
$$\text{Corollary $4\,\mu=\left(\mathbf I-\Gamma\right)^{-1}\lambda^{(0)}=\lim_{t\to\infty}\Psi(t)\lambda^{(0)}$.}$$
Proof If the process is stationary, the spectral radius of Γ = A w is smaller than 1, which implies that all eigenvalues of A are smaller than ω in magnitude. Thus, all eigenvalues of A -ω I are negative. Let PDP -1 be the eigenvalue decomposition of A -ω I , and all the elements (in diagonal) of D are negative. Then based on the property of matrix exponential, we have e ( A -ω I ) t = P e D t P -1 . As we let t →∞ , the matrix e D t → 0 and hence e ( A -ω I ) t → 0 . Thus lim t →∞ Ψ ( ) = t -ω ( A -ω I ) -1 , which is equal to ( I -Γ ) -1 , and completes the proof.
## B More on Experimental Setup
Table 3 shows the number of adopters and usages for the six different URL shortening services. It includes a total of 7,566,098 events (adoptions) during the 8-month period.
Table 3: # of adopters and usages for each URL shortening service.
| Service | # adopters | # usages |
|-----------|--------------|---------------|
| Bitly | 55 , 883 | 5 , 046 , 710 |
| TinyURL | 46 , 577 | 1 , 682 , 459 |
| Isgd | 28 , 050 | 596 , 895 |
| TwURL | 15 , 215 | 197 , 568 |
| SnURL | 4 , 462 | 41 , 823 |
| Doiop | 88 | 643 |
In the following, we describe the considered baselines proposed to compare to our approach for i) the capped activity maximization; ii) the minimax activity shaping; and iii) the least-squares activity shaping problems.
For capped activity maximization problem, we consider the following four heuristic baselines:
- · XMUallocates the budget based on users' current activity. In particular, it assigns the budget to each of the half top-most active users proportional to their average activity, µ ( ) t , computed from the inferred parameters.
- · WEI assigns positive budget to the users proportionally to their sum of out-going influence ( ∑ u a uu ′ ). This heuristic allows us (by comparing its results to CAM) to understand the effect of considering the whole network with respect to only consider the direct (out-going) influence.
- · DEG assumes that more central users, i.e. , more connected users, can leverage the total activity, therefore, assigns the budget to the more connected users proportional to their degree in the network.
- · PRK sorts the users according to the their pagerank in the weighted influence network ( A ) with the damping factor set to 0 85% . , and assigns the budget to the top users proportional their pagerank value.
In order to show how network structure leverages the minimax activity shaping we implement following four baselines:
- · UNI allocates the total budget equally to all users.
- · MINMU divides uniformly the total budget among half of the users with lower average activity µ ( ) t , which is computed from the inferred parameters.
- · LP finds the top half of least-active users in the current network and allocates the budget such that after the assignment the network has the highest minimum activity possible. This method uses linear programming to learn exogenous activity of the users, but, in contrast to the proposed method, does not consider the network and propagation of adoptions.
- · GRD finds the user with minimum activity, assigns a portion of the budget, and computes the resulting µ ( ) t . It then repeats the process to incentivize half of users.
We compare least-square activity shaping with the following baselines:
- · PROP shapes the activity by allocating the budget proportional to the desired shape, i.e. , the shape of the assignment is similar to the target shape.
- · LSGRD greedily finds the user with the highest distance between her current and target activity, assigns her a budget to reach her target, and proceeds this way to consume the whole budget.
Each baseline relies on a specific property to allocate the budget ( e.g. connectedness in DEG). However, most of them face two problems: The first one is how many users to incentivize and the second one is how much should be paid to the selected users. They usually rely on heuristics to reveal these two problems ( e.g. allocating an amount proportional to that property and/or to the top half users sorted based on the specific property). In contrast, our framework is comprehensive enough to address those difficulties based on well-developed theoretical basis. This key factor accompanied with the appropriate properties of Hawkes process for modeling social influence ( e.g. mutually exciting) make the proposed method the best.
## C Temporal Properties
For the experiments on simulated objective function and held-out data we have estimated intensity from the events data. In this section, we will see how this empirical intensity resembles the theoretical intensity. We generate a synthetic network over 100 users. For each user in the generated network, we uniformly sample from [0 , 0 1] . the exogenous intensity, and the endogenous parameters a uu ′ are uniformly sampled from [0 , 0 1] . . A bandwidth ω = 1 is used in the exponential kernel. Then, the intensity is estimated empirically by dividing the number of events by the length of the respective interval.
We compute the mean and variance of the empirical activity for 100 independent runs. As illustrated in Figure 5, the average empirical intensity (the blue curve) clearly follows the theoretical instantaneous intensity (the red curve) but, as expected, as we are further from the starting point ( i.e. , as time increases), the standard deviation of the estimates (shown in the whiskers) increases. Additionally, the green line shows the average stationary intensity. As it is expected, the instantaneous intensity tends to the stationary value when the network has been run for sufficient long time.
Figure 5: Evolution in time of empirical and theoretical intensity.
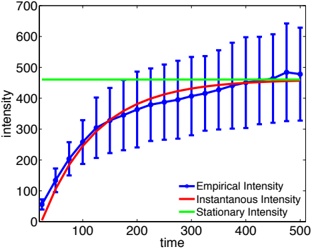
## D Visualization of Least-squares Activity Shaping
To get a better insight on the the activity shaping problem we visualize the least-squares activity shaping results for the 2K and 60K datasets. Figure 6 shows the result of activity shaping at t = 1 targeting the same shape as in the experiments section. The red line is the target shape of the activity and the blue curve correspond to the activity profiles of users after incentivizing computed via theoretical objective. It is clear that the resulted activity behavior resembles the target shape.
Figure 6: Activity shaping results.
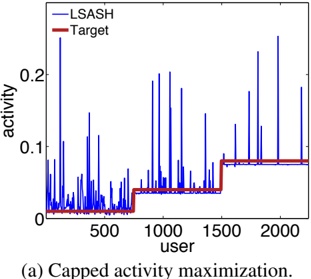
 | null | [
"Mehrdad Farajtabar",
"Nan Du",
"Manuel Gomez Rodriguez",
"Isabel Valera",
"Hongyuan Zha",
"Le Song"
] | 2014-08-02T18:23:55+00:00 | 2014-08-19T13:06:37+00:00 | [
"cs.SI"
] | Shaping Social Activity by Incentivizing Users | Events in an online social network can be categorized roughly into endogenous
events, where users just respond to the actions of their neighbors within the
network, or exogenous events, where users take actions due to drives external
to the network. How much external drive should be provided to each user, such
that the network activity can be steered towards a target state? In this paper,
we model social events using multivariate Hawkes processes, which can capture
both endogenous and exogenous event intensities, and derive a time dependent
linear relation between the intensity of exogenous events and the overall
network activity. Exploiting this connection, we develop a convex optimization
framework for determining the required level of external drive in order for the
network to reach a desired activity level. We experimented with event data
gathered from Twitter, and show that our method can steer the activity of the
network more accurately than alternatives. |
1408.0407v1 | ## Triple Patterning Lithography (TPL) Layout Decomposition using End-Cutting
## Bei Yu a 1 , Subhendu Roy a , Jhih-Rong Gao , b David Z. Pan a
a ECE Department, University of Texas at Austin, Austin, Texas, United States 78712 b Cadence Design Systems, 12515-7 Research Boulevard, Austin, Texas, United States 78759
Abstract. Triple patterning lithography (TPL) is one of the most promising techniques in the 14nm logic node and beyond. Conventional LELELE type TPL technology suffers from native conflict and overlapping problems. Recently, as an alternative process, triple patterning lithography with end cutting (LELE-EC) was proposed to overcome the limitations of LELELE manufacturing. In LELE-EC process the first two masks are LELE type double patterning, while the third mask is used to generate the end-cuts. Although the layout decomposition problem for LELELE has been well-studied in the literature, only few attempts have been made to address the LELE-EC layout decomposition problem. In this paper we propose the comprehensive study for LELE-EC layout decomposition. Conflict graph and end-cut graph are constructed to extract all the geometrical relationships of both input layout and end-cut candidates. Based on these graphs, integer linear programming (ILP) is formulated to minimize the conflict number and the stitch number. The experimental results demonstrate the effectiveness of the proposed algorithms.
Keywords: triple/multiple patterning, end-cutting, layout decomposition, integer linear programming.
Address all correspondence to : Bei Yu, E-mail: [email protected]
## 1 Introduction
As the semiconductor process further scales down to the 14 nanometer logic node and beyond, the industry encounters many lithography-related issues. Triple patterning lithography (TPL) 1 is one of the most promising candidates as next generation lithography techniques, along with extreme ultraviolet lithography (EUVL), electron beam lithography (EBL), directed self-assembly (DSA), and nanoimprint lithography (NIL). 2, 3 However, all these new techniques are challenged by some problems, such as tremendous technical barriers, or low throughput. Therefore, TPL earns more attentions recently from both industry and academia.
One conventional process of TPL, called LELELE, is with the same principle of litho-etchlitho-etch (LELE) type double patterning lithography (DPL). Here 'L' and 'E' represent one lithography process and one etch process, respectively. Although LELELE process has been widely studied by industry and academia, there are twofold issues derived. On one side, even with stitch insertion, there are some native conflicts in LELELE, like 4-clique conflict. 4 For example, Fig. 1 illustrates a 4-clique conflict among features a , b , c , and d . No matter how to assign the colors, there is at least one conflict. Since this 4-clique structure is common in advanced standard cell design, LELELE type TPL still suffers from the native conflict problem. On the other side, compared with LELE type double patterning, there are more serious overlapping problem in LELELE. 5
To overcome all these limitations from LELELE, recently Lin 6 proposed a new TPL manufacturing process, called LELE-end-cutting (LELE-EC). As a TPL, this new manufacturing process contains three mask steps, namely first mask, second mask, and trim mask. Fig. 2 illustrates an
1 The preliminary version of this work appeared in Proc. SPIE 8684, Design for Manufacturability through DesignProcess Integration VII.
Fig 1 Process of LELELE type triple patterning lithography (a) Target features; (b) Layout decomposition with one conflict introduced.
Fig 2 Process of LELE-EC type triple patterning lithography (a) Target features; (b) First and second mask patterns; (c) Trim mask, and final decomposition without conflict.
example of the LELE-EC process. To generate target features in Fig. 2(a), the first and second masks are used for pitch splitting, which is similar to LELE type DPL process. These two masks are shown in Fig. 2(b). Finally, a trim mask is applied to trim out the desired region as in Fig. 2(c). In other words, the trim mask is used to generate some end-cuts to further split feature patterns. Although the target features are not LELELE-friendly, they are LELE-EC process friendly that with LELE-EC the features can be decomposed without any conflict. In addition, if all cuts are properly designed or distributed, LELE-EC can introduce better printability then conventional LELELE process. 6
For a design with four short features, Fig. 3 and Fig. 4 present its simulated images through LELELE and LELE-EC processes, respectively. The lithography simulations are computed based on the partially coherent imaging system, where the 193nm illumination source is modeled as a kernel matrix given by [7]. To model the photoresist effect with the exposed light intensity, we use the constant threshold model with threshold 0 225 . . We can make several observations from these simulated images. First, there are some round-offs around the line ends (see Fig. 3 (c)). Second, to reduce the round-off issues, as illustrated in Fig. 4 (b), in LELE-EC process the short lines can be merged into longer lines, then the trim mask is used to cut off some spaces. It shall be noted that there might be some corner roundings due to the edge shorting of trim mask patterns. However, since the line shortening or rounding is a strong function of the line width, 8 and we observe that usually trim mask patterns can be much longer than line-end width, thus we assume the rounding caused by the trim mask is insignificant. This assumption is demonstrated as in Fig. 4 (c).
Many research have been carried out to solve the corresponding design problems for LELELE type TPL. The layout decomposition problem has been well studied. 4, 9-15 In addition, the related constraints have been considered in early physical design stages, like routing, 16,17 standard cell
Fig 3 LELELE process example. (a) Decomposed result; (b) Simulated images for different masks; (c) Combined simulated image as the final printed patterns.
Fig 4 LELE-EC process example. (a) Decomposed result; (b) Simulated images for different masks, where orange pattern is trim mask; (c) Combined simulated image as the final printed patterns.
design, 18,19 and detailed placement. 19 However, only few attempts have been made to address the LELE-EC layout decomposition problem. It shall be noted that although trim mask can bring about better printability, it does introduce more design challenge, especially in layout decomposition stage.
In this paper, we propose a comprehensive study for LELE-EC layout decomposition. Given a layout which is specified by features in polygonal shapes, we extract the geometrical relationships and construct the conflict graphs. Furthermore, the compatibility of all end-cuts candidates are also modeled in the conflict graphs. Based on the conflict graphs, integer linear programming (ILP) is formulated to assign each vertex into one layer. Our goal in the layout decomposition is to minimize the conflict number, and at the same time minimize the overlapping errors.
The rest of the paper is organized as follows. Section 2 provides some preliminaries, and discusses the problem formulation. Section 3 provides the overall flow of our layout decomposer. Section 4 explains the details of end-cut candidate generation. Section 5 presents a set of algorithms to solve the layout decomposition problem. Section 6 discusses several speed-up techniques. Section 7 presents the experimental results, followed by conclusions in Section 8.
## 2 Preliminary and Problem Formulation
## 2.1 Layout Graph
Given a layout which is specified by features in polygonal shapes, layout graph 4 is constructed. As shown in Fig. 5, The layout graph is an undirected graph with a set of vertices V and a set of conflict edges CE . Each vertex in V represents one input feature. There is an edge in CE if and
Fig 5 Layout graph construction. (a) Input layout; (b) Layout graph with conflict edges;
only if the two features are within minimum coloring distance dis m of each other. In other words, each edge in CE is a conflict candidate. Fig. 5(a) shows one input layout, and the corresponding layout graph is in Fig. 5(b). Here the vertex set V = { 1 2 3 4 5 6 7 , , , , , , } , while the conflict edge set CE = { (1 , 2) , (1 , 3) , (1 , 4) , (2 , 4) , (3 , 4) , (3 , 5) , (3 , 6) , (4 , 5) , (4 , 6) , (5 , 6) , (5 , 7) , (6 , 7) } . For each edge (conflict candidate), we check whether there is an end-cut candidate. For each end-cut candidate i -j , if it is applied, then features i and j will be merged into one feature. By this way the corresponding conflict edge can be removed. If stitch is considered in layout decomposition, some vertices in layout graph can be split into several segments. The segments in one layout graph vertex are connected through stitch edges . All these stitch edges are included in a set, called SE . Please refer to [20] for the details of stitch candidate generation.
## 2.2 End-Cut Graph
Fig 6 End-cut graph construction. (a) Input layout; (b) Generated end-cut candidates. (c) End-cut graph.
Since all the end-cuts are manufactured through one single exposure process, they should be distributed far away from each other. That is, two end-cuts have conflict if they are within minimum end-cut distance dis c of each other. Note that these conflict relationships among end-cuts are not available in layout graph, therefore we construct end-cut graph to store the relationships. Fig. 6(a) gives an input layout example, with all end-cut candidates pointed out in Fig. 6 (b); and the corresponding end-cut graph is shown in Fig. 6 (c). Each vertex in the end-cut graph represents one end-cut. There is an solid edge if and only if the two end-cuts conflict to each other. There is an dash edge if and only if they are close to each other, and they can be merged into one larger end-cut.
## 2.3 Problem Formulation
Here we give the problem formulation of layout decomposition for triple patterning with EndCutting (LELE-EC).
Problem 1 (LELE-EC Layout Decomposition). Given a layout which is specified by features in polygonal shapes, the layout graph and the end-cut graph are constructed. The LELE-EC layout decomposition assigns all vertices in layout graph into one of two colors, and select a set of endcuts in end-cut graph. The objectives is to minimize the number of conflict and/or stitch.
With the end-cut candidates generated, the LELE-EC layout decomposition is more complicated since more constraints are derived. Even there is no end-cut candidate, LELE-EC layout decomposition is similar to the LELE type DPL layout decomposition. Sun et al. in Ref. [21] showed that LELE layout decomposition with minimum conflict and minimum stitch is NP-hard, thus it is not hard to see that LELE-EC layout decomposition is NP-hard as well. NP-hard problem is a set of computational search problems that are difficult to solve. 22 Aproblem is NP-hard if solving it in polynomial time would make it possible to solve all problems in class NP in polynomial time. In other words, unless 'P=NP', there is no polynomial time algorithm to solve an NP-hard problem optimally.
## 3 Overall Flow
Fig 7 Overall flow of our layout decomposer.
The overall flow of our layout decomposer is illustrated in Fig. 7. First we generate all end-cut candidates to find out all possible end-cuts. Then we construct the layout graph and the end-cut graph to transform the original geometric problem into a graph problem, and thus the LELEEC layout decomposition can be modeled as a coloring problem in layout graph and the end-cut selection problem in end-cut graph. Both the coloring problem and the end-cut selection problem can be solved through one ILP formulation. Since the ILP formulation may suffer from runtime overhead problem, we propose a set of graph simplification techniques. Besides, to further reduce the problem size, some end-cut candidates are pre-selected before ILP formulation. All the steps in the flow are detailed in the following sections.
## 4 End-Cut Candidate Generation
In this section we will explain the details of our algorithm to generate all end-cut candidates. An end-cut candidate is generated between two conflicting polygonal shapes. It should be stressed that compared with the end-cut generation in Ref. [23], our methodology has the following two differences.
Fig 8 An end-cut can have multiple end-cut boxes.
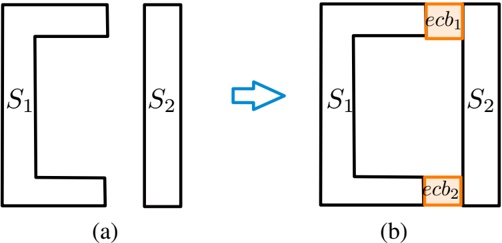
- · An end-cut can be a collection of multiple end-cut boxes depending on the corresponding shapes. For instance, two end-cut boxes ( ecb 1 and ecb 2 ) need to be generated between shapes S 1 and S 2 as shown in Fig 8. We propose a shape-edge dependent algorithm to generate the end-cuts with multiple end-cut boxes.
- · Weconsider the overlapping and variations caused by end-cuts. Two lithography simulations are illustrated in Fig. 9 and Fig. 10, respectively. In Fig. 9 we find some bad patterns or hotspots, due to the cuts between two long edges. In Fig. 10 we can see that the final patterns are in better shape. Therefore, to reduce the manufacturing hotspot from trim mask, during end-cut candidate generation we avoid the cuts along two long edges.
Fig 9 (a) Decomposition example where cuts are along long edges; (b) Simulated images for different masks; (c) Combined simulated image with some hotspots.
Algorithm 1 presents the key steps of generating end-cut between two polygonal shapes S 1 and S 2 . A polygonal shape consists of multiple edges. For each of the shape-edge-pair, one taken from S 1 and another from S 2 , the possibility of generation of end-cut box ( ecBox ) is explored and we store all such end-cut boxes in ecBoxSet (Lines 2 9 -). The function 'generateEndCutBox( se 1 , se 2 )' generates an end-cut box ecBox between the shape-edges se 1 and se 2 .
Fig 10 (a) Decomposition example where cuts are between line ends; (b) Simulated images for different masks; (c) Combined simulated image with good printability.
Fig. 11 shows how end-cut boxes are generated between two shape-edges under different situations. In Fig. 11(a), the end-cut box is between two shape-edges which are oriented in same direction and overlap in its x-coordinates. This type of end-cut box is called as edge-edge end-cut box. For Fig. 11(b) the shape edges are in same direction but they do not overlap, and in Fig. 11(c), the shape-edges are oriented in different directions. The end-cut boxes generated in these two cases are called corner-corner end-cut boxes. No end-cut box is generated in case of Fig. 11(d). In addition, end-cut boxes are not generated for the following cases: (i) the end-cut box is overlapping with any existing polygonal shape in the layout, (ii) the height ( h ) or width ( w ) of the box is not within some specified range, i.e. , when h w , do not obey the following constraints h low ≤ h ≤ h high and w low ≤ w ≤ w high .
Then all generated end-cut boxes between two shapes are divided into independent components IC (Line 10 ) based on finding connected components of a graph G = ( V, E ) with V = { v i } = set of all end-cut boxes and ( v , v i j ) ∈ E , if v i overlaps with v j . The overlap between two end-cut boxes is classified into type 1 and type 2 overlaps. When two boxes overlap only in an edge or in a point but not in space, we call this type 1 overlap, where as the overlap in space is termed as type 2 overlap as shown in Fig. 12. Each of the ic ∈ IC may contain multiple end-cut boxes. If the total number of end-cut-boxes ( | V | ) is equal to | IC | , that implies there is no overlap between the end-cut boxes and we generate all of them (Lines 11 14 -).
For multiple boxes in each ic , if there is an overlap between corner-corner and edge-edge endcut boxes, the corner-corner end-cut box is removed (Line 16 ). After doing this, either there will be a set of type 1 overlaps or a set of type 2 overlaps in each ic . In case of type 2 overlaps, the end-cut box with minimum area is chosen as shown in Fig. 13. For type 1 overlaps in each ic , all end-cut boxes are generated (Line 20 ).
Algorithm 1 Shape-edge dependent end-cut generation algorithm between two shapes S 1 and S 2
- 1: Procedure generateEndCut ( S 1 , S 2 );
- 2: for all se 1 ∈ edges( S 1 ) do
- 3: for all se 2 ∈ edges( S 2 ) do
- 4: ecBox = generateEndCutBox ( se 1 , se 2 );
glyph[negationslash]
- 5: if ecBox = NULL then
- 6: Store ecBox in ecBoxSet ;
- 7: end if
- 8: end for
9:
end for
- 10: Divide ecBoxSet into independent components ( IC );
11:
if
|
ecBoxSet
|
=
|
V
|
then
- 12: Print all boxes;
- 13: return true;
14:
end if
- 15: for all ic ∈ IC do
- 16: Remove corner-corner end-cut boxes overlapping with edge-edge end-cut box;
- 17: if ∃ set of type 2 overlaps then
- 18: Generate minimum area box;
- 19: else
20:
Generate all end-cut boxes
- 21: end if
22:
end for
- 23: return true;
- 24: end Procedure
Fig 12 Types of overlaps between end-cut boxes
## 5 ILP Formulations
After the construction of layout graph and end-cut graph, LELE-EC layout decomposition problem can be transferred into a coloring problem on layout graph and a selection problem on end-cut graph. At the first glance the coloring problem is similar to that in LELE layout decomposition. However, since the conflict graph can not be guaranteed to be planar, the face graph based methodology 24 cannot be applied here. Therefore, we formulate integer linear programming (ILP) to solve both coloring problem and selection problem simultaneously. For convenience, some notations in the ILP formulation are listed in Table 1.
Fig 13 Minimum area end-cut box is chosen for type 2 overlaps
Table 1 Notations in LELE-EC Layout Decomposition
| CE | set of conflict edges |
|-------|------------------------------------------------------------|
| EE | set of end-cut conflict edges |
| SE | set of stitch edges. |
| n | number of input layout features. |
| r i | the i th layout feature |
| x i | variable denoting the coloring of r i |
| ec ij | 0-1 variable, ec ij = 1 when a end-cut between r i and r j |
| c ij | 0-1 variable, c ij = 1 when a conflict between r i and r j |
| s ij | 0-1 variable, s ij = 1 when a stitch between r i and r j |
## 5.1 ILP Formulation w/o. Stitch
In this subsection we discuss the ILP formulation when no stitch candidate is generated in layout graph. Given a set of input layout features { r , . . . , r 1 n } , we construct layout graph, and end-cut graph. Every conflict edge e ij is in CE , while each end-cut candidate ec ij is in SE x . i is a binary variable representing the color of r i . c ij is a binary variable for conflict edge e ij ∈ CE . To minimize the conflict number, our objective function to minimize ∑ e ij ∈ CE c ij .
To evaluate the conflict number, we provide the following constraints:
glyph[negationslash]
glyph[negationslash]
$$\begin{cases} \begin{array} { c c } x _ { i } + x _ { j } \leq 1 + c _ { i j } + e c _ { i j } & \text{if $\exists\ ec_{ij}\in EE$} \\ ( 1 - x _ { i } ) + ( 1 - x _ { j } ) \leq 1 + c _ { i j } + e c _ { i j } & \text{if $\exists\ ec_{ij}\in EE$} \\ x _ { i } + x _ { j } \leq 1 + c _ { i j } & \text{if $\not\,\ A\ ec_{ij}\in EE$} \\ ( 1 - x _ { i } ) + ( 1 - x _ { j } ) \leq 1 + c _ { i j } & \text{if $\not\,\ A\ ec_{ij}\in EE$} \end{array} \end{cases}$$
glyph[negationslash]
Here ec ij is a binary variable for end-cut candidate. If there is no end-cut candidate between adjacent features r i and r j , if x i = x j then one conflict would be reported ( c ij = 1 ). Otherwise, we will try to enable the end-cut candidate ec ij first. If the end-cut candidate ec ij cannot be applied ( ec ij = 0 ), then one conflict will be also reported.
If end-cuts ec ij and ec pq are conflict with each other, at most one of them will be applied. To enable this, we introduce the following constraint.
$$\ e c _ { i j } + e c _ { p q } \leq 1, \ \forall e _ { i j p q } \in E E$$
To forbid useless end-cut, we introduce the following constraints. That is, if features x i and x j
are in different colors, ec ij = 0 .
$$\begin{cases} \ e c _ { i j } + x _ { i } - x _ { j } \leq 1 & \forall e _ { i j } \in C E \\ \ e c _ { i j } + x _ { j } - x _ { i } \leq 1 & \forall e _ { i j } \in C E \end{cases}$$
Therefore, without the stitch candidate, the LELE-EC layout decomposition can be formulated as shown in Eq. (4).
$$\min _ { e _ { i j } \in C E } c _ { i j } \\ s. t. \ ( 1 ), ( 2 ), ( 3 )$$
## 5.2 ILP Formulation w. Stitch
If the stitch insertion is considered, the ILP formulation is as in Eq. (5). Here the objective is to simultaneously minimize both the conflict number and the stitch number. The parameter α is a user-defined parameter for assigning relative importance between the conflict number and the stitch number. The constraints (5a) - (5b) are used to calculate the stitch number.
$$\min _ { \ e _ { i j } \in C E } c _ { i j } + \alpha \times \sum _ { \ e _ { i j } \in S E } s _ { i j } \\ s. t. \ x _ { i } - x _ { j } & \leq s _ { i j } & \forall e _ { i j } \in S E \\ x _ { j } - x _ { i } & \leq s _ { i j } & \forall e _ { i j } \in S E \\ ( 1 ), ( 2 ), ( 3 )$$
## 6 Graph Simplification Techniques
ILP is a classical NP-hard problem, i.e., there is no polynomial time optimal algorithm to solve it. 22 Therefore, for large layout cases, solving ILP may suffer from long runtime penalty to achieve the results. In this section, we provide a set of speed-up techniques. Note that these techniques can keep optimality. In other words, with these speed-up techniques, ILP formulation can achieve the same results comparing with those not applying speed-up.
## 6.1 Independent Component Computation
The first speed-up technique is called independent component computation . By breaking down the whole layout graph into several independent components, we partition the initial layout graph into several small ones. Then each component can be resolved through ILP formulation independently. At last, the overall solution can be taken as the union of all the components without affecting the global optimality. Note that this is a well-known technique which has been applied in many previous studies ( e.g., Ref. [20, 25, 26]).
## 6.2 Bridge Computation
A bridge of a graph is an edge whose removal disconnects the graph into two components. If the two components are independent, removing the bridge can divide the whole problem into two independent sub-problems. We search all bridge edges in layout graph, then divide the whole layout graph through these bridges. Note that all bridges can be found in O V ( | | + | E | ) , where | V | is the vertex number, and | E | is the edge number in the layout graph.
## 6.3 End-Cut Pre-Selection
Some end-cut candidates have no conflict end-cuts. For the end-cut candidate ec ij that has no conflict end-cut, it would be pre-selected in final decomposition results. That is, the features r i and r j are merged into one feature. By this way, the problem size of ILP formulation can be further reduced. End-cut pre-selection can be finished in linear time.
## 7 Experimental Results
We implement our algorithms in C++ and test on an Intel Xeon 3.0GHz Linux machine with 32G RAM. 15 benchmark circuits from Ref. [4] are used. GUROBI 27 is chosen as the ILP solver. The minimum coloring spacing min s is set as 120 for the first ten cases and as 100 for the last five cases, as in Ref. [4] and Ref. [10]. The width threshold w th , which is used in end-cut candidate generation, is set as dis m .
## 7.1 With Stitch or Without Stitch
Table 2 Comparison between w. stitch and w/o. stitch
| Circuit | Wire# | Comp# | ILP w/o. stitch | ILP w/o. stitch | ILP w/o. stitch | ILP w/o. stitch | ILP w. stitch | ILP w. stitch | ILP w. stitch | ILP w. stitch |
|-----------|---------|---------|-------------------|-------------------|-------------------|-------------------|-----------------|-----------------|-----------------|-----------------|
| Circuit | Wire# | Comp# | conflict# | stitch# | cost | CPU(s) | conflict# | stitch# | cost | CPU(s) |
| C1 | 1109 | 123 | 1 | 0 | 1 | 1.19 | 1 | 0 | 1 | 1.32 |
| C2 | 2216 | 175 | 1 | 0 | 1 | 2.17 | 1 | 0 | 1 | 2.89 |
| C3 | 2411 | 270 | 0 | 0 | 0 | 3.11 | 0 | 0 | 0 | 3.62 |
| C4 | 3262 | 467 | 0 | 0 | 0 | 3.2 | 0 | 0 | 0 | 3.75 |
| C5 | 5125 | 507 | 4 | 0 | 4 | 8.72 | 4 | 0 | 4 | 8.81 |
| C6 | 7933 | 614 | 1 | 0 | 1 | 11.24 | 1 | 0 | 1 | 11.1 |
| C7 | 10189 | 827 | 2 | 0 | 2 | 14.57 | 2 | 0 | 2 | 15.98 |
| C8 | 14603 | 1154 | 2 | 0 | 2 | 21.2 | 2 | 0 | 2 | 23.07 |
| C9 | 14575 | 2325 | 23 | 0 | 23 | 24.36 | 12 | 12 | 13.2 | 28.06 |
| C10 | 21253 | 1783 | 7 | 0 | 7 | 28.42 | 7 | 0 | 7 | 32.02 |
| S1 | 4611 | 272 | 0 | 0 | 0 | 6.23 | 0 | 0 | 0 | 7.04 |
| S2 | 67696 | 5116 | 166 | 0 | 166 | 179.05 | 166 | 1 | 166.1 | 218.37 |
| S3 | 157455 | 15176 | 543 | 0 | 543 | 506.55 | 530 | 13 | 531.3 | 563.65 |
| S4 | 168319 | 15354 | 443 | 0 | 443 | 464.84 | 436 | 7 | 436.7 | 494.4 |
| S5 | 159952 | 12626 | 419 | 0 | 419 | 464.11 | 415 | 6 | 415.6 | 514.56 |
| avg. | - | - | 107.5 | 0 | 107.5 | 115.9 | 105.1 | 2.6 | 105.4 | 128.6 |
| ratio | - | - | - | - | 1.0 | 1.0 | - | - | 0.98 | 1.10 |
In the first experiment, we show the decomposition results of the ILP formulation. Table 2 compares two ILP formulations ' ILP w/o. stitch ' and ' ILP w. stitch '. Here 'ILP w/o. stitch' is the ILP formulation based on the graph without stitch edges, while 'ILP w. stitch' considers the stitch insertion in the ILP. Note that all speed-up techniques are applied to both. Columns
'Wire#' and 'Comp#' reports the total feature number, and the divided component number, respectively. For each method we report the conflict number, stitch number, and computational time in seconds('CPU(s)'). 'Cost' is the cost function, which is set as conflict# +0 1 . × stitch#.
From Table 2 we can see that compared with 'ILP w/o. stitch', when stitch candidates are considered in the ILP formulation, the cost can be reduced by 2%, while the runtime is increased by 5%. It shall be noted that stitch insertion has been shown to be an effective method to reduce the cost for both LELE layout decomposition and LELELE layout decomposition. However, we can see that for LELE-EC layout decomposition, stitch insertion is not that effective. In addition, due to the overlap variation derived from stitch, stitch insertion for LELE-EC may not be an effective method.
## 7.2 Effectiveness of Speed-up Techniques
In the second experiment, we analyze the effectiveness of the proposed speed-up techniques. Fig. 14 compares two ILP formulations ' w/o. stitch w/o. speedup ' and ' w/o. stitch w. speedup ', where 'w/o. stitch w/o. speedup' only applies independent component computation, while 'w. speedup' involves all three speed-up techniques. Besides, none of them consider the stitch in layout graph. From Fig. 14 we can see that with speed-up techniques (bridge computation and end-cut pre-selection), the runtime can be reduced by around 60%.
Fig 14 Effectiveness of Speed-up techniques when no stitch is introduced.
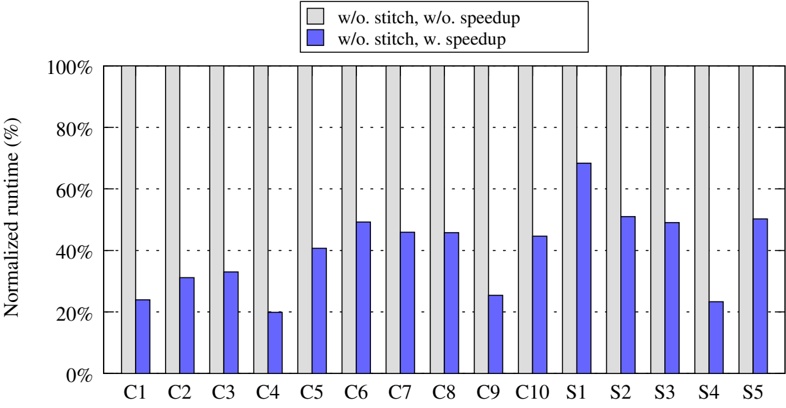
Fig. 15 demonstrates the similar effectiveness of speed-up techniques between ' w. stitch w. speedup ' and ' w/o. stitch w. speedup '. Here stitch candidates are introduced in layout graph. Wecan see that for these two ILP formulation the bridge computation and the end-cut pre-selection can reduce runtime by around 56%.
## 7.3 Conflict Analysis
Fig. 16 shows four conflict examples in decomposed layout, where conflict pairs are labeled with red arrows. We can observe that some conflicts (see Fig. 16 (a) and (c)) are introduced due to the end-cuts existing in neighboring. For these two cases, the possible reason is the patterns are
Fig 15 Effectiveness of Speed-up techniques when stitch is introduced.
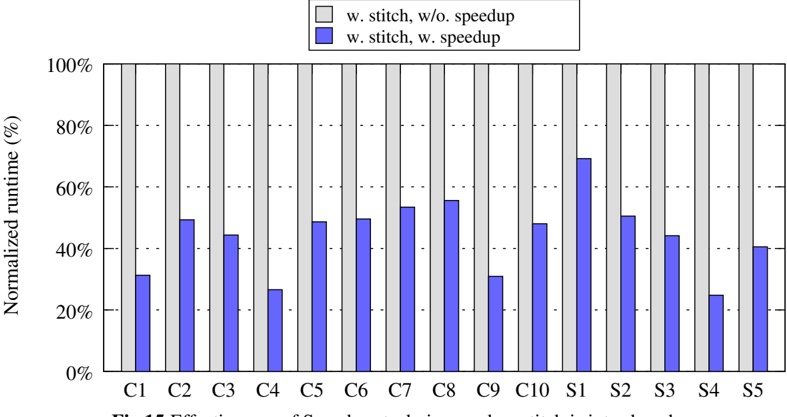
irregular, therefore some end-cuts that close to each other cannot be merged into a larger one. We can also observe some conflicts (see Fig. 16 (b) and (d)) come from via shapes. For these two cases, one possible reason is that it is hard to find end-cut candidates around via, comparing with long wires.
## 8 Conclusions
In this paper we have proposed an improved framework and algorithms to solve the LELE-EC layout decomposition problem. New end-cut candidates are generated considering potential hotspots. The layout decomposition is formulated as an integer linear programming (ILP). The experimental results show the effectiveness of our algorithms. It shall be noted that our framework is very generic that it can provide high quality solutions to both uni-directional and bi-directional layout patterns. However, if all the layout patterns are uni-directional, there might be some faster solutions. Since end-cutting can provide better printability than traditional LELELE process, we expect to see more works on the LELE-EC layout decomposition and LELE-EC aware design.
## References
- 1 K. Lucas, C. Cork, B. Yu, G. Luk-Pat, B. Painter, and D. Z. Pan, 'Implications of triple patterning for 14 nm node design and patterning,' in Proc. of SPIE , 8327 (2012).
- 2 D. Z. Pan, B. Yu, and J.-R. Gao, 'Design for manufacturing with emerging nanolithography,' IEEE Transactions on Computer-Aided Design of Integrated Circuits and Systems (TCAD) 32 (10), 1453-1472 (2013).
- 3 B. Yu, J.-R. Gao, D. Ding, Y. Ban, J.-S. Yang, K. Yuan, M. Cho, and D. Z. Pan, 'Dealing with IC manufacturability in extreme scaling,' in IEEE/ACM International Conference on Computer-Aided Design (ICCAD) , 240-242, ACM (2012).
- 4 B. Yu, K. Yuan, B. Zhang, D. Ding, and D. Z. Pan, 'Layout decomposition for triple patterning lithography,' in IEEE/ACM International Conference on Computer-Aided Design (ICCAD) , 1-8, ACM (2011).
Fig 16 Conflict examples in decomposed results. (a)(c) Conflicts because no additional end-cut can be inserted due to the existing neighboring end-cuts. (b)(d) Conflicts because no end-cut candidates between irregular vias.
- 5 C. Ausschnitt and P. Dasari, 'Multi-patterning overlay control,' in Proc. of SPIE , 6924 (2008).
- 6 B. J. Lin, 'Lithography till the end of Moore's law,' in ACM International Symposium on Physical Design (ISPD) , 1-2, ACM (2012).
- 7 S. Banerjee, Z. Li, and S. R. Nassif, 'ICCAD-2013 CAD contest in mask optimization and benchmark suite,' in IEEE/ACM International Conference on Computer-Aided Design (ICCAD) , 271-274, ACM (2013).
- 8 C. Mack, Fundamental principles of optical lithography: the science of microfabrication , John Wiley & Sons (2008).
- 9 C. Cork, J.-C. Madre, and L. Barnes, 'Comparison of triple-patterning decomposition algorithms using aperiodic tiling patterns,' in Proc. of SPIE , 7028 (2008).
- 10 S.-Y. Fang, W.-Y. Chen, and Y.-W. Chang, 'A novel layout decomposition algorithm for triple patterning lithography,' in IEEE/ACM Design Automation Conference (DAC) , 1185-1190, ACM (2012).
- 11 H. Tian, H. Zhang, Q. Ma, Z. Xiao, and M. Wong, 'A polynomial time triple patterning algorithm for cell based row-structure layout,' in IEEE/ACM International Conference on Computer-Aided Design (ICCAD) , 57-64, ACM (2012).
- 12 J. Kuang and E. F. Young, 'An efficient layout decomposition approach for triple patterning lithography,' in IEEE/ACM Design Automation Conference (DAC) , 69:1-69:6, ACM (2013).
- 13 B. Yu, Y.-H. Lin, G. Luk-Pat, D. Ding, K. Lucas, and D. Z. Pan, 'A high-performance triple patterning layout decomposer with balanced density,' in IEEE/ACM International Conference on Computer-Aided Design (ICCAD) , 163-169, ACM (2013).
- 14 Y. Zhang, W.-S. Luk, H. Zhou, C. Yan, and X. Zeng, 'Layout decomposition with pairwise coloring for multiple patterning lithography,' in IEEE/ACM International Conference on Computer-Aided Design (ICCAD) , 170-177, ACM (2013).
- 15 B. Yu and D. Z. Pan, 'Layout decomposition for quadruple patterning lithography and beyond,' in IEEE/ACM Design Automation Conference (DAC) , 1-6, ACM (2014).
- 16 Q. Ma, H. Zhang, and M. D. F. Wong, 'Triple patterning aware routing and its comparison with double patterning aware routing in 14nm technology,' in IEEE/ACM Design Automation Conference (DAC) , 591-596, ACM (2012).
- 17 Y.-H. Lin, B. Yu, D. Z. Pan, and Y.-L. Li, 'TRIAD: A triple patterning lithography aware detailed router,' in IEEE/ACM International Conference on Computer-Aided Design (ICCAD) , 123-129, ACM (2012).
- 18 H. Tian, Y. Du, H. Zhang, Z. Xiao, and M. Wong, 'Constrained pattern assignment for standard cell based triple patterning lithography,' in IEEE/ACM International Conference on Computer-Aided Design (ICCAD) , 57-64, ACM (2013).
- 19 B. Yu, X. Xu, J.-R. Gao, and D. Z. Pan, 'Methodology for standard cell compliance and detailed placement for triple patterning lithography,' in IEEE/ACM International Conference on Computer-Aided Design (ICCAD) , 349-356, ACM (2013).
- 20 A. B. Kahng, C.-H. Park, X. Xu, and H. Yao, 'Layout decomposition for double patterning lithography,' in IEEE/ACM International Conference on Computer-Aided Design (ICCAD) , 465-472, ACM (2008).
- 21 J. Sun, Y. Lu, H. Zhou, and X. Zeng, 'Post-routing layer assignment for double patterning.,' in IEEE/ACM Asia and South Pacific Design Automation Conference (ASPDAC) , 793-798, IEEE Press (2011).
- 22 T. T. Cormen, C. E. Leiserson, and R. L. Rivest, Introduction to algorithms , MIT Press, Cambridge, MA, USA (1990).
- 23 B. Yu, J.-R. Gao, and D. Z. Pan, 'Triple patterning lithography (TPL) layout decomposition using end-cutting,' in Proc. of SPIE , 8684 (2013).
- 24 Y. Xu and C. Chu, 'A matching based decomposer for double patterning lithography,' in ACM International Symposium on Physical Design (ISPD) , 121-126, ACM (2010).
- 25 K. Yuan, J.-S. Yang, and D. Z. Pan, 'Double patterning layout decomposition for simultaneous conflict and stitch minimization,' in ACM International Symposium on Physical Design (ISPD) , 107-114, ACM (2009).
- 26 J.-S. Yang, K. Lu, M. Cho, K. Yuan, and D. Z. Pan, 'A new graph-theoretic, multi-objective layout decomposition framework for double patterning lithography,' in IEEE/ACM Asia and South Pacific Design Automation Conference (ASPDAC) , 637-644, IEEE Press (2010).
- 27 Gurobi Optimization Inc., 'Gurobi optimizer reference manual.' http://www.gurobi. com (2014). | null | [
"Bei Yu",
"Subhendu Roy",
"Jhih-Rong Gao",
"David Z. Pan"
] | 2014-08-02T19:19:36+00:00 | 2014-08-02T19:19:36+00:00 | [
"cs.OH"
] | Triple Patterning Lithography (TPL) Layout Decomposition using End-Cutting (JM3 Special Session) | Triple patterning lithography (TPL) is one of the most promising techniques
in the 14nm logic node and beyond. Conventional LELELE type TPL technology
suffers from native conflict and overlapping problems. Recently, as an
alternative process, triple patterning lithography with end cutting (LELE-EC)
was proposed to overcome the limitations of LELELE manufacturing. In LELE-EC
process the first two masks are LELE type double patterning, while the third
mask is used to generate the end-cuts. Although the layout decomposition
problem for LELELE has been well-studied in the literature, only few attempts
have been made to address the LELE-EC layout decomposition problem. In this
paper we propose the comprehensive study for LELE-EC layout decomposition.
Conflict graph and end-cut graph are constructed to extract all the geometrical
relationships of both input layout and end-cut candidates. Based on these
graphs, integer linear programming (ILP) is formulated to minimize the conflict
number and the stitch number. The experimental results demonstrate the
effectiveness of the proposed algorithms. |
1408.0408v1 | ## Enomoto and Ota's conjecture holds for large graphs
Vincent Coll, Alexander Halperin, Colton Magnant, Pouria Salehi-Nowbandegani ∗ † ‡ §
August 5, 2014
## Abstract
In 2000, Enomoto and Ota conjectured that if a graph G satisfies σ 2 ( G ) ≥ n + k -1, then for any set of k vertices v , . . . , v 1 k and for any positive integers n , . . . , n 1 k with ∑ n i = | G | , there exists a partition of V ( G ) into k paths P , . . . , P 1 k such that v i is an end of P i and | P i | = n i for all i . We prove this conjecture when | G | is large. Our proof uses the Regularity Lemma along with several extremal lemmas, concluding with an absorbing argument to retrieve misbehaving vertices.
## 1 Introduction
For all basic definitions and notation, see [1]. Let σ 2 ( G ) denote the minimum degree sum of a graph G . In 2000, Enomoto and Ota conjectured the following and proved several cases.
Conjecture 1 (Enomoto and Ota [4]) . Given an integer k ≥ 3 , let G be a graph of order n and let n , n 1 2 , . . . , n k be a set of k positive integers with ∑ n i = n . If σ 2 ( G ) ≥ n + k -1 , then for any k distinct vertices x , x 1 2 , . . . , x k in G , there exists a set of vertex-disjoint paths P , P 1 2 , . . . , P k such that | P i | = n i and P i starts at x i for all i with 1 ≤ i ≤ k .
A partial solution was provided by Magnant and Martin in the sense that the path lengths could only be prescribed within a small fraction of n .
Theorem 1 (Magnant and Martin [7]) . Given an integer k ≥ 3 , for every set of k positive real numbers η , . . . η 1 k with ∑ k i =1 η i = 1 , and for every /epsilon1 > 0 , there exists n 0 such that for every graph G of order n ≥ n 0 with σ 2 ( G ) ≥ n + k -1 and for every choice of k vertices S = { x , . . . , x 1 k } ⊆ V ( G ) , there exists a set of vertex disjoint paths P , . . . , P 1 k which span V ( G ) with P i beginning at the vertex x i and ( η i -/epsilon1 ) n < | P i | < η ( i + ) /epsilon1 n . Also the condition on σ 2 ( G ) is sharp.
When n is sufficiently large relative to k , we prove that Conjecture 1 holds.
Theorem 2. Given an integer k ≥ 3 , let G be a graph of sufficiently large order n and let n , n 1 2 , . . . , n k be a set of k positive integers with ∑ n i = n . If σ 2 ( G ) ≥ n + k -1 , then for any k distinct vertices x , x 1 2 , . . . , x k in G , there exists a set of vertex disjoint paths P , P 1 2 , . . . , P k such that | P i | = n i and P i starts at x i for all i with 1 ≤ i ≤ k .
Our proof utilizes several extremal lemmas based on the structure of the reduced graph provided by the Regularity Lemma. Our lemmas deal with the cases where the minimum degree is small, the reduced graph has a large independent set and the connectivity of the reduced graph is small.
## 2 Preliminaries
Given two sets of vertices A and B , let E A,B ( ) denote set of edges with one end in A and one end in B and let e A, B ( ) = | E A,B ( ) . | Define the density between A and B to be
$$d ( A, B ) = \frac { e ( A, B ) } { | A | | B | }.$$
∗ Department of Mathematics, Lehigh University, Bethlehem, PA, USA. [email protected]
† Department of Mathematics and Computer Science, Salisbury University, Salisbury, MD, USA. [email protected]
‡ Department of Mathematical Sciences, Georgia Southern University, Statesboro, GA, USA. [email protected] §
Department of
Mathematical
Sciences,
Georgia
Southern
University,
Statesboro,
GA,
pouria [email protected]
USA.
Definition 1. Let /epsilon1 > 0 . Given a graph G and two nonempty disjoint vertex sets A,B ⊂ V , we say that the pair ( A,B ) is /epsilon1 -regular if for every X ⊂ A and Y ⊂ B satisfying
$$| X | > \epsilon | A | \ a n d \ | Y | > \epsilon | B |$$
we have
$$| d ( X, Y ) - d ( A, B ) | < \epsilon.$$
We will also use the following one-sided but stronger version of regularity.
Definition 2. Let /epsilon1, d > 0 . Given a graph G and two nonempty disjoint vertex sets A,B ⊂ V , we say that the pair ( A,B ) is ( /epsilon1, d )-super-regular if for every X ⊂ A and Y ⊂ B satisfying
$$| X | > \epsilon | A | \ \ a n d \ \ | Y | > \epsilon | B |,$$
we have
$$e ( X, Y ) > d | X | | Y |,$$
and furthermore d B ( a ) > d B | | for all a ∈ A and d A ( b ) > d A | | for all b ∈ B .
The following is the famous Regularity Lemma of Szemer´ edi.
Lemma 1 (Regularity Lemma - Szemer´ edi [11]) . For every /epsilon1 > 0 and every positive integer m , there is an M = M /epsilon1 ( ) such that if G is any graph and d ∈ (0 , 1) is any real number, then there is a partition of V ( G ) into r +1 clusters V , V 0 1 , . . . , V r , and there is a subgraph G ′ ⊆ G with the following properties:
- (1) m ≤ r ≤ M ,
- (2) | V 0 | ≤ /epsilon1 | V ( G ) | ,
- (3) | V 1 | = · · · = | V r | = L ≤ | /epsilon1 V ( G ) | ,
- (4) deg G ′ ( v ) > deg G ( v ) -( d + ) /epsilon1 | V ( G ) | for all v ∈ V ( G ) ,
- (5) e G ( ′ [ V i ]) = 0 for all i ≥ 1 ,
- (6) for all 1 ≤ i < j ≤ r the graph G V , V ′ [ i j ] is /epsilon1 -regular and has density either 0 or greater than d .
Given a graph G and appropriate choices of /epsilon1 and d , let G ′ be a spanning subgraph of G obtained from Lemma 1. The reduced graph R = R G,/epsilon1, d ( ) of G contains a vertex v i for each cluster V i in G ′ \ V 0 and has an edge between v i and v j if and only if d V , V ( i j ) > d . Hence, V ( R ) = { v i | 1 ≤ i ≤ } r and E R ( ) = { v v i j | 1 ≤ i, j ≤ r, d V , V ( i j ) > d } .
Throughout this work, we let r = | R | .
This next lemma allows the creation of a super-regular pair from an /epsilon1 -regular pair by simply removing some vertices.
Lemma 2 (Diestel [3], Lemma 7.5.1) . Let ( A,B ) be an /epsilon1 -regular pair of density d and let Y ⊆ B have size | Y | ≥ /epsilon1 | B | . Then all but at most /epsilon1 | A | of the vertices in A each have at least ( d -/epsilon1 ) | Y | neighbors in Y .
We use a simple corollary of this result.
Lemma 3. Let ( A,B ) be an /epsilon1 -regular pair of density d . There exist subsets A ′ ⊆ A and B ′ ⊆ B with | A ′ | ≥ (1 -/epsilon1 ) | A | and | B | ≥ (1 -/epsilon1 ) | B | such that the pair ( A , B ′ ′ ) is ( /epsilon1, d -2 ) /epsilon1 -super-regular.
Our next lemma follows trivially from the definition of super-regular pairs.
Lemma 4. Given an ( /epsilon1, d ) -super-regular pair ( A,B ) and a pair of vertices a ∈ A and b ∈ B , there exists a path of length at most 3 from a to b in ( A,B ) .
The following lemma provides very strong structure in super-regular pairs.
Lemma 5 (Blow-Up Lemma - Koml´ os, S´rk¨zy and Szemer´ edi [5]) a o . Given a graph R of order r and positive parameters d, ∆ , there exists a positive /epsilon1 = /epsilon1 ( d, ∆ , r ) such that the following holds. Let { n , n 1 2 , . . . , n r } be an arbitrary set of positive integers and replace the set of vertices { v , v 1 2 , . . . , v r } of R with pairwise disjoint sets V , V 1 2 , . . . , V r -1 and V r of sizes n , n 1 2 , . . . , n r -1 and n r respectively (blowing up). We construct two graphs on the same vertex-set V = ∪ V i . The first graph R is obtained by replacing each edge v , v i j of R with the complete bipartite graph between the corresponding vertex-sets V i and V j . A sparser graph G is constructed by replacing each edge v , v i j arbitrarily with an ( /epsilon1, d ) -super-regular pair between V i and V j . If a graph H with ∆( H ) ≤ ∆ is embeddable into R then it is also embeddable into G .
The following theorem gives us a degree sum condition on R based on our assumed degree sum condition on G .
Theorem 3 (K¨ uhn, Osthus and Treglown [6]) . Given a constant c , if σ 2 ( G ) ≥ cn , then σ 2 ( R ) ≥ ( c -2 d -4 ) /epsilon1 | R | .
We also use the following theorem of Ore.
Theorem 4 (Ore [10]) . If G is 2 -connected, then G contains a cycle of length at least σ 2 ( G ) .
We use the following result of Williamson. Recall that a graph is called panconnected if, between every pair of vertices, there is a path of every possible length from 2 up to n -1.
Theorem 5. Let G be a graph of order n . If δ G ( ) ≥ n +2 2 , then G is panconnected.
## 3 Proof Outline
Given an integer k ≥ 3 and desired path orders n , n 1 2 , . . . , n k , we choose constants /epsilon1 and d as follows:
$$0 < \epsilon \ll d \ll \frac { 1 } { k },$$
where a /lessmuch b is used to indicate that a is chosen to be sufficiently small relative to b . Let n be sufficiently large to apply Lemma 1 with constant /epsilon1 to get large clusters and let R be the corresponding reduced graph. Note that, when applying Lemma 1, there are at least 1 -/epsilon1 /epsilon1 clusters so | R | ≥ 1 -/epsilon1 /epsilon1 .
We use a sequence of lemmas to eliminate extremal cases of the proof. Without loss of generality, we assume n 1 ≤ n 2 ≤ · · · ≤ n k . Our first lemma establishes the case when δ G ( ) is small.
## Lemma 6. Conjecture 1 holds when δ G ( ) ≤ n k 8 .
Lemma 6 is proven in Section 5. By Lemma 6, we may assume δ G ( ) ≥ n k 8 ≥ n 8 k . Our next lemma establishes the case when κ R ( ) ≤ | /epsilon1 R | , where R is the reduced graph of G after applying Lemma 1.
Lemma 7. Given a positive integer k , let /epsilon1 = /epsilon1 k , d = d k > 0 , and let G be a graph of order n ≥ n /epsilon1, ( d, k ) with σ 2 ( G ) ≥ n + k -1 and δ G ( ) ≥ n k 8 . If κ R ( ) ≤ 1 , then the conclusion of Conjecture 1 holds.
Lemma 7 is proven in Section 7. Our final lemma establishes the case where G contains a large independent set.
Lemma 8. Given a positive integer k , let /epsilon1 = /epsilon1 k > 0 be small, and let G be a graph of order n ≥ n /epsilon1 ( ) . If σ 2 ( G ) ≥ n + k -1 and α G ( ) ≥ ( 1 2 -/epsilon1 ) n , then G satisfies Conjecture 1. Lemma 8 is proven in Section 6.
With all these lemmas in place, we use Ore's Theorem (Theorem 4) to construct a long cycle in the reduced graph of G . Alternating edges of this cycle are then made into super-regular pairs of G . This structure is then used to construct the desired paths. The complete proof of our main result, assuming the above lemmas, is presented in the following section.
## 4 Proof of Theorem 2
By Lemma 7, we may assume R is 2-connected. By Theorem 3, we know that σ 2 ( R ) ≥ (1 -2 d -4 ) /epsilon1 | R | . Thus, we may apply Theorem 4 to obtain a cycle C of length at least (1 -2 d -4 ) /epsilon1 | R | in R . Define a 'garbage set' to include V 0 and those clusters not used in C .
Color the edges of C with red and blue such that no two red edges are adjacent and as few blue edges as possible are adjacent. Note that if C is even, then the colors will alternate, and if C is odd, then there will be only one consecutive pair of blue edges while all others are alternating. Apply Lemma 3 on the pairs of clusters in G corresponding to the red edges of R to obtain super-regular pairs where the two sets of each super-regular pair have the same order. All vertices discarded in this process are added to the garbage set and define the clusters C i to be the original clusters without the removed vertices. Note that we have added a total of at most /epsilon1n vertices to the garbage set.
If C is odd, then let c 0 be the vertex in R with two blue edges, let C 0 be the corresponding cluster in G , and let C + 0 and C -0 be the neighboring clusters in G . Since the pairs ( C -0 , C 0 ) and ( C , C 0 + 0 ) are both large and /epsilon1 -regular, there exists a set of at least k vertices T 0 ⊆ C 0 with a matching to each of C -0 and C + 0 . We will use these vertices as transportation and move all of C 0 \ T 0 to the garbage set.
Let G C denote the graph on the set of vertices remaining in clusters associated with C that have not been moved to the garbage set, and let D denote the garbage set. Then V ( G ) = ⋃ | i =1 C C | i ∪ C 0 ∪ D (if C 0 exists), with | D | ≤ (2 d +7 ) /epsilon1 n .
By Lemma 6, we may assume δ G ( ) ≥ n k 8 . In particular, the vertices in D each have at least n k 8 - | ( D | -1) /greatermuch /epsilon1n edges to G C .
A path is said to balance the super-regular pairs in G C if for every super-regular pair the path visits, it uses an equal number of vertices from each set in the pair. Note that the removal of a balancing path preserves the fact that if a pair of clusters is super-regular, then the two clusters have the same order. Let ( A,B ) be a super-regular pair of clusters in G C . A balancing path starting in A and ending in B which contains a vertex v ∈ D is called v -absorbing .
Claim 1. Avoiding any selected set of at most /epsilon1r clusters and any set of at most 16(2 d +7 ) /epsilon1 n /epsilon1r vertices in each of the remaining clusters, there exists a v -absorbing path of order at most 17 . Otherwise the desired path partition already exists.
Proof. Absorbing paths are constructed iteratively, one for each vertex of D , in an arbitrary order. Suppose some number of such absorbing paths have been created. If we have created one for each vertex of D within the restrictions of the claim, the proof is complete so suppose we have constructed at most | D | -1 absorbing paths. Vertices that have already been used and clusters that have lost at least 16(2 d +7 ) /epsilon1 n /epsilon1r vertices removed from consideration in following iterations.
Recall that L is the order of each non-garbage cluster of G in Lemma 1.
Fact 1. If we have created at most | D | -1 such paths, at most /epsilon1r clusters would have order at most L -16(2 d +7 ) /epsilon1 n /epsilon1r .
Proof. Since each absorbing path constructed in this claim has order at most 16 (other than the vertex v ), we lose at most 16 vertices from G C for each vertex of D . The result follows.
Let v ∈ D such that there is no absorbing path for v of order at most 16. Since d v ( ) ≥ n k 8 , v must have edges to at least r 8 k clusters. Let A and B be two clusters which are not already ignored to which v has at least two edges to vertices that are not already in a path or an absorbing path. For convenience, we call two clusters X and Y a couple or spouses if X and Y are consecutive on C and the pair ( X,Y ) is super-regular.
The following facts are easily proven using the structure we have provided and the lemmas proven before.
## Fact 2. A and B are not a couple.
Otherwise it would be trivial to produce a v -absorbing path.
Let A ′ and B ′ denote the spouses of A and B , respectively, let a , b ′ ′ ∈ R correspond to A ′ and B ′ , respectively, and define the following sets of clusters:
- · X A := { all couples ( P, Q ) of clusters such that pa ′ and qa ′ are edges in R } ,
- · X B := { all couples of clusters such that both clusters have an edge to B ′ in R } , and
- · X AB := { all couples of clusters such that one spouse has an edge to both A ′ and B ′ in R } . In particular, let X ′ AB denote the clusters in X AB that are not the neighbors of A ′ and B ′ .
Since we are considering two neighbors of v in A (and two neighbors of v in B ), say v 1 and v 2 , if X A (or similarly X B ) contains even a single couple ( Q,R ), then we can absorb v using a path of the form v vv 1 2 -A ′ -Q -R -A ′ . Thus, we may actually assume X A = X B = ∅ .
Our next fact follows from the fact that σ 2 ( R ) ≥ (1 -2 d -4 ) /epsilon1 | R | .
## Fact 3. There are at most (2 d -4 ) /epsilon1 | R | clusters in C which are not in X AB .
If there is an edge xy between two (non-used) vertices in clusters in X ′ AB , then there is a v -absorbing path of the form v vv 1 2 -A ′ -( X AB \ X ′ AB ) -xy -( X AB \ X ′ AB ) -A ′ . Thus, the graph induced on the vertices in clusters in X ′ AB contains no edges. By Lemma 8, we have the desired set of paths. This completes the proof of Claim 1.
For each chosen vertex x i , if x i / G ∈ C , use Menger's Theorem [9] to construct a shortest path to a vertex, say x ′ i , in G C . Using an edge of a super-regular pair first, construct a balancing path from x ′ i through every cluster of G C . Note that, since the pairs are either /epsilon1 -regular or ( /epsilon1, d )-super-regular, using Lemma 4, this path can be constructed to use at most 2 vertices from each cluster.
First suppose the path starting at x i already has order at least n i -16. In this case, we add at most 16 vertices using a super-regular pair (and Lemma 4) or discard any excess vertices to obtain the desired path. If a coupled pair of clusters in G C is left unbalanced by this process, we simply remove a vertex from the larger cluster to D . Note that repeating this for each short path adds at most k -1 vertices to D .
By Claim 1, since | D | ≤ (2 d +7 ) /epsilon1 n , we can construct an absorbing path for each vertex v ∈ D where these paths are all disjoint. Let P v be an absorbing path for v with ends of P v in clusters C i and C i +1 . Suppose uw is the edge of P k from C i to C i +1 . Then using Lemma 4, we can replace the edge uw with the path P v with the addition of at most 4 extra vertices at either end. Note that absorbing a vertex v ∈ D into a path P i using the absorbing path will always correct the parity of the length of P i .
For each path P i that is not already completed and not the correct parity, absorb a single vertex from D into P i . This will correct the parity of the path.
Recall the assumption (without loss of generality) that n 1 ≤ · · · ≤ n k . By the same process, all remaining vertices of D can be absorbed into P k . This makes | P k | larger but since | D | ≤ (2 d +7 ) /epsilon1 n and each absorbing path P v for v ∈ D has order at most 17, we get | P k | ≤ | 3 C | +17(2 d +7 ) /epsilon1 n < n k .
The following lemma, stated in [8], is an easy exercise using the definitions of ( /epsilon1, d )-super-regular pairs.
Lemma 9 (Magnant and Salehi [8]) . Let U and V be two clusters forming a balanced ( /epsilon1, d ) -super-regular pair with | U | = | V | = L . Then for every pair of vertices u ∈ U and v ∈ V , there exist paths of all odd lengths /lscript between u and v satisfying
- (a) 3 ≤ /lscript ≤ dL and
- (b) (1 -d L ) ≤ /lscript ≤ L .
For each i with n i small, absorb a few pairs of vertices from each super-regular pair, using Lemma 9, until P i has the desired order. For each remaining index i , using Lemma 9 absorb entire super-regular pairs at a time (along with possibly a few vertices from other super-regular pairs) until each path P i has the desired order to complete the proof.
## 5 Proof of Lemma 6
Recall that Lemma 6 claims Conjecture 1 holds when δ G ( ) ≤ n k 8 .
Proof. Let a ∈ V ( G ) with | N a ( ) | = ( δ G ) ≤ n k 8 , and partition V ( G ) as follows:
$$\L ^ { \prime } \quad \L ^ { \prime } \quad \L ^ { \prime } \quad \L ^ { \prime } - \S ^ { \prime } \quad \L ^ { \prime } \quad \L ^ { \prime } \\ B \ \ & = \ \ G \, \left ( a \cup N ( a ) \right ) \\ A \ \ & = \ \left \{ v \in a \cup N ( a ) \, \colon | N ( v ) \cap V ( B ) | < \frac { 1 } { 8 } ( n + k - \delta ( G ) - 1 ) \right \} \\ C \ \ & = \ \left \{ v \in a \cup N ( a ) \, \colon | N ( v ) \cap V ( B ) | \geq \frac { 1 } { 8 } ( n + k - \delta ( G ) - 1 ) \right \} \\ \text{ce} \, \sigma _ { 2 } ( G ) \geq n + k - 1, \, \text{the set $A$ induces a complete graph. Furthermore, the set $B$ has ord},$$
Note that, since σ 2 ( G ) ≥ n + k -1, the set A induces a complete graph. Furthermore, the set B has order n - -1 δ G ( ), and A is nonempty since a ∈ A . Since σ 2 ( G ) ≥ n + k -1 and a has no edges to B , each vertex in B has degree at least n + k -1 -δ G ( ) which means δ G B ( [ ]) ≥ n + k -1 -2 ( δ G ). Note that also G is at least ( k +1)-connected. First, a claim about subsets of B .
Claim 2. Every subset of B of order at least 3 n k 8 is panconnected.
Proof. With | B | = n -δ G ( ) -1 and δ G B ( [ ]) ≥ n + k -1 -2 ( δ G ), we see that δ G B ( [ ]) ≥ | B | -δ G ( ) ≥ | B | -n k 8 . Therefore, for any subset B ′ ⊆ B with | B ′ | ≥ 3 n k 8 , we have δ G B ( [ ′ ]) ≥ | B ′ | -n k 8 > | B ′ | +2 2 . By Theorem 5, we see that B ′ is panconnected.
Consider k selected vertices X = { x , . . . , x 1 k } ⊆ V ( G ). Let X A denote the (possibly empty) set X ∩ A and let X ′ A denote X A ∪ v where v ∈ A \ X A if such a vertex v exists. If no such vertex v exists, then let X ′ A = X A . The vertices of X ′ A will serve as start vertices for paths that will be used to cover all of A . By Menger's Theorem, since κ G ( ) ≥ k +1, there exists a set of disjoint paths P A starting at the vertices of X ′ A and ending in B and avoiding all other vertices of X . Choose P A so that each path is as short as possible, contains only one vertex in B and, by construction, has order at most 4. If any of the paths in P A begins at a selected vertex x i and has order at least n i , we call this desired path completed and remove the first n i vertices of the path from the graph and continue the
/negationslash construction process. If A \ V ( P A ) = ∅ , let P v be a path using all remaining vertices and ending at v . This path P v together with the path of P A corresponding to v provides a single path that cleans up the remaining vertices of A and ends in B . The ending vertices of these paths, the vertices of B , will serve as proxy vertices for the start vertices ( v or x i ∈ X ∩ A ). Thus far, we have constructed paths that cover all of A , start at vertices of X ∩ A (when such vertices exist) and end in B .
As vertices of B are selected and used on various paths, we continuously call the set of vertices in B that have not already been prescribed or otherwise mentioned the remaining vertices in B . For example, so far, we have B \ ( X ∪ V ( P A )) are the remaining vertices of B . Our goal is to maintain at least 3 n k 8 +1 remaining vertices to be able to apply Claim 2 as needed within these remaining vertices.
Since | C | ≤ δ G ( ) ≤ n k 8 and d B ( u ) ≥ 1 8 ( n + k -δ G ( ) -1) for all u ∈ C , there exists a set of two distinct neighbors in B \ ( X ∪ V ( P A )) for each vertex in C . For each vertex x i ∈ X ∩ C , select one such vertex to serve as a proxy for x i and leave the other aforementioned neighbor in the remaining vertices of B . By Claim 2, there exists a path through the remaining vertices of B with at most one intermediate vertex from one neighbor of a vertex of C to a neighbor of another vertex of C . Since | C | ≤ n k 8 , such paths can be built and strung together into a single path P C starting and ending in B , containing all vertices of C \ X with | P C | < 4 | C | ≤ n k 2 .
We may now construct what is left of the desired paths within B . The paths P , P 1 2 , . . . , P k -1 can be constructed in any order starting at corresponding proxy vertices and ending at arbitrary remaining vertices of B using Claim 2 in the remaining vertices of B . Finally, there are at least
$$| B | - | B \cap ( \cup _ { i = 1 } ^ { k - 1 } V ( P _ { i } ) ) | - | B \cap V ( \mathcal { P } _ { A } ) | - | B \cap V ( P _ { C } ) | \ & \geq \ ( n - 1 - \delta ( G ) ) - ( k + 1 ) - ( 3 | C | ) \\ & \ > \ \frac { 3 n _ { k } } { 8 } + 1 \\ \cdot \ \cdot \ \cdot \ \cdot \ \, \ e n d { \Phi } { \Phi } { \Phi } { \Phi } { \Phi } { \Phi } { \Phi } { \Phi } { \Phi } { \Phi } { \Phi } { \Phi } { \Phi } { \Phi } { \Phi } { \Phi } { \Phi } { \Phi } { \Phi } { \Phi } { \Phi } { \Phi } { \Phi } { \Phi } { \Phi } { \Phi } { \Phi } { \Phi } { \Phi } { \Phi } { \Phi } { \Phi } { \Phi } { \Phi } { \Phi } { \Phi } { \Phi } { \Phi } { \Phi } { \Phi } { \Phi { \Phi } { \Phi } { \Phi } { \Phi } { \Phi } { \Phi } { \Phi } { \Phi } { \Phi } { \Phi } { \Phi } { \Phi } { \Phi } { \Phi } { \Phi } { \Phi } { \Phi } { \Phi } { \Phi } { \Phi } { \Phi } { \Phi } { \Phi } { \Phi } { \Phi } { \Phi } { \Phi } { \Phi } { \Phi } { \Phi } { \Phi } { \Phi } { \Phi } { \Phi } { \Phi } { \Phi } { \Phi } { \Phi } { \Phi } { \Phi} { \Phi } { \Phi } { \Phi } { \Phi } { \Phi } { \Phi } { \Phi } { \Phi } { \Phi } { \Phi } { \Phi } { \Phi } { \Phi } { \Phi } { \Phi } { \Phi } { \Phi } { \Phi } { \Phi } { \Phi } { \Phi } { \Phi } { \Phi } { \Phi } { \Phi } { \Phi } { \Phi } { \Phi } { \Phi } { \Phi } { \Phi } { \Phi } { \Phi } { \Phi } { \Phi } { \Phi } { \Phi } { \Phi } { \Phi } { \Phi \Phi } { \Phi } { \Phi } { \Phi } { \Phi } { \Phi } { \Phi } { \Phi } { \Phi } { \Phi } { \Phi } { \Phi } { \Phi } { \Phi } { \Phi } { \Phi } { \Phi } { \Phi } { \Phi } { \Phi } { \Phi } { \Phi } { \Phi } { \Phi } { \Phi } { \Phi } { \Phi } { \Phi } { \Phi } { \Phi } { \Phi } { \Phi } { \Phi } { \Phi } { \Phi } { \Phi } { \Phi } { \Phi } { \Phi } { \Phi } }$$
remaining vertices in B . With these and Claim 2, we construct a path with at most one internal vertex from an end of P C to the proxy of v (if such a vertex exists) and a path containing all remaining vertices of B from x k (or its proxy) to the other end of P C . This completes the construction of the desired paths and thereby completes the proof of Lemma 6.
## 6 Proof of Lemma 8
Recall that Lemma 8 says for a positive integer k , a small /epsilon1 = /epsilon1 k > 0, and a graph G of order n ≥ n /epsilon1 ( ), if σ 2 ( G ) ≥ n + k -1 and α G ( ) ≥ ( 1 2 -/epsilon1 ) n , then G satisfies Conjecture 1.
Proof. Let A be a maximum independent set of G , and let B = V ( G ) \ A . By the assumption on σ 2 ( G ), we have | B | ≥ 1 2 ( n + k -1). This implies and
$$\left ( \frac { 1 } { 2 } - \epsilon \right ) n \leq | A | \leq \frac { 1 } { 2 } ( n - k + 1 )$$
$$\frac { 1 } { 2 } ( n + k - 1 ) \leq | B | \leq \left ( \frac { 1 } { 2 } + \epsilon \right ) n. \\ \text{erefore we have}$$
Let t = | B | - | A | + ; therefore, we have k
$$2 k - 1 \leq t \leq 2 \epsilon n + k.$$
Let C denote the set of vertices in B with fewer than t -1 2 neighbors in B . Since 1 2 ( n + k -1) -| A | ≤ | B |-| A | + k -1 2 = t -1 2 , we see C is necessarily a clique on at most t -1 2 vertices.
Claim 3. Let B ′ be the set of vertices in B with at least | A |-1 | B | · 1 2 ( n + k -1) > ( 1 2 -1 100 k ) n neighbors in A . Then | B ′ | ≥ 1 2 ( n + k -1) .
Proof. Each vertex in A (except possibly one) has at least 1 2 ( n + k -1) neighbors in B , which means there are at least ( | A | -1) · 1 2 ( n + k -1) edges between A and B . By the Pigeonhole Principle, we have our result.
A bipartite graph U ∪ V is bipanconnected if for every pair of vertices x, y ∈ U ∪ V , there exist ( x, y )-paths of all possible lengths at least 2 of appropriate parity in U ∪ V . That is, for every pair of vertices x ∈ U and y ∈ V , there exist ( x, y )-paths of every possible odd length except 1, and for every pair of vertices x, y ∈ U (and V ), there exist ( x, y )-paths of every even length. Note that we must exclude the value 1 from our definition in order to allow graphs U ∪ V that are not complete bipartite. Also observe that the partite sets of a bipanconnected graph must have order within one of each other.
Lemma 10 (Coll, Halperin and Magnant [2]) . If G U [ ∪ V ] is a balanced bipartite graph of order 2 m with δ G U ( [ ∪ V ]) ≥ 3 m 4 , then G U [ ∪ V ] is bipanconnected.
Our next claim shows that any reasonably large subsets of B ′ induce bipanconnected subgraphs when paired with any corresponding subset of A .
Claim 4. For all m ≥ n 25 k , the m -subsets U ⊆ A and V ⊆ B ′ induce a bipanconnected subgraph of order 2 m .
Proof. For m ≥ n 25 k , let U and V be m -subsets of A and B ′ , respectively. Each vertex in U has at least | V | -/epsilon1n + k -1 2 > 3 m 4 neighbors in V . Each vertex in B ′ has greater than | U | -( | A | -( 1 2 -1 100 k ) n ) > 3 m 4 neighbors in U . It follows from Lemma 10 that G U [ ∪ V ] is bipanconnected.
Let D = B \ B ′ , and let D ′ be the set of vertices in B with fewer than n 100 neighbors in A . Note that every vertex in D ′ has well over n 3 neighbors in B ′ .
Claim 5. The sets D and D ′ satisfy D ′ ⊆ D and
$$| D ^ { \prime } | \leq | D | \leq \frac { t - 2 k + 1 } { 2 }.$$
$$\overline { 2 }$$
Proof. By the definition of D , we have D ′ ⊆ D . By Claim 3, we observe
$$- \quad \cdot \quad \cdot \\ | D | & \leq | B | - \frac { 1 } { 2 } ( n + k - 1 ) \\ & = | B | - \frac { n } { 2 } - \frac { k - 1 } { 2 } \\ & = \frac { | B | - | A | } { 2 } - \frac { k - 1 } { 2 } ;$$
$$\frac { 1 } { 2 } - \frac { 1 } { 2 }$$
it follows that | D ′ | ≤ | D | ≤ t -2 k +1 2 .
When creating the desired path partition of G , we must make sure that all vertices in G are included. In particular, since | B > A | | | , we must ensure that each vertex in B may be included in some path. We show this by creating a path Q that contains more vertices in B than in A . The path Q will contain all vertices in D ′ and roughly (but not necessarily exactly) the appropriate number of additional vertices in B . We make this discrepancy exact by considering Q ′ , the collection of paths including Q and all vertices in D .
Before we create Q and Q ′ , we first specify the necessary value τ , the number of additional vertices in B that we must account for before creating our desired paths. Let X = { x , . . . , x 1 k } be the set of arbitrarily chosen endpoints for the desired paths. Let O A be the set of vertices x i ∈ A ∩ X such that n i is odd. Let O ′ B be the set of vertices x i ∈ B ′ ∩ X such that n i is even. Recall that D ′ ⊆ D is the set of vertices in B with fewer than 2 | D | neighbors in A . Let E ′ D be the set of vertices x i ∈ D ′ ∩ X such that n i is even. Lastly, let P ′ D be the path containing
- · all vertices in D ′ \ X ,
- · two unique neighbors b , β ′ j ′ j ∈ B ′ \ X of d ′ j , and
- · for j ≥ 1, the unique neighbor a j ∈ A \ X of β ′ j and b j +1 .
To ensure τ ≥ 0 (see Claim 7) or that our desired path Q , an extension of P ′ D , always begins in B and ends in A , we may need to drop the first vertex b ′ 1 of P ′ D so that P ′ D begins at d ′ 1 . As a result, the path P ′ D contains either 2 | D ′ \ X | or 2 | D ′ \ X | -1 more vertices in B than in A and of course only exists if D ′ \ X is nonempty. Thus, we have P ′ D = { ( b ′ 1 ) , d ′ 1 , β ′ 1 , a 1 , b ′ 2 , . . . , b ′ | D ′ \ X | , d ′ | D ′ \ X | , β ′ | D ′ \ X | , a | D ′ \ X | } , with the vertex b ′ 1 in parentheses to denote that b ′ 1 is not always included in P ′ D .
Claim 6. Let G = A ∪ B as defined in Lemma 8. Then
$$\tau = \begin{cases} | B | - | A | + | O _ { A } | - | O ^ { \prime } _ { B } | - | D ^ { \prime } \cap X | - | E ^ { \prime } _ { D } | & \text{if } | D ^ { \prime } \, \L X | = 0 \\ | B | - | A | + | O _ { A } | - | O ^ { \prime } _ { B } | - | D ^ { \prime } \cap X | - | E ^ { \prime } _ { D } | - ( | P ^ { \prime } _ { D } \cap B | - | P ^ { \prime } _ { D } \cap A | ) & \text{if } | D ^ { \prime } \, \L X | \geq 1. \end{cases}$$
Proof. We prove this statement by showing that each term in (3) accounts for a necessary quantity. Since | B > A | | | and A is an independent set, it is clear that we must account for | B | - | A | additional vertices in B . For each x i ∈ O A (symmetrically x i ∈ O ′ B ), the path beginning at x i that alternates between A and B uses one additional vertex in A (symmetrically B ′ ). This accounts for the term | O A | - | O ′ B | . Next, we cannot assume e D , A ( ′ ) > 0 and hence must use at least one additional vertex in B to account for each vertex in D ′ . By Claim 3, every vertex in D ′ contains sufficiently many neighbors in B ′ \ X and hence, two unique neighbors in B ′ \ X . For all x i ∈ D ′ ∩ X , reserve the unique vertex b i ∈ B ′ \ X and its unique neighbor a i ∈ A \ X . Hence, for each x i ∈ D ′ ∩ X , we have used one additional vertex in B , which accounts for the term -| D ′ ∩ X | . Now, if x i ∈ E ′ D , then the desired path starting at x i and alternating between A and B will contain an extra additional vertex in B since the first two vertices and the last vertex of the path are all in B . This accounts for the term -| E ′ D | . Lastly, the only way we can be guaranteed to include the vertices in D ′ \ X = { d , . . . , d ′ 1 ′ | D ′ \ X | } in a path is to create P ′ D containing either 2 | D ′ \ X | or 2 | D ′ \ X | -1 more vertices in B than in A .
Hence, we have (3).
Claim 7. 0 ≤ t -2 k ≤ τ ≤ t - | 2 D ′ ∩ X | ≤ t .
Proof. First note that -k ≤ | O A | -| O ′ B | ≤ k , and that | D ′ | ≤ | D | ≤ | B |-| A |-k +1 2 . Also, we have | D ′ ∩ X | + | O ′ B | ≤ k and | D ′ ∩ X | + | O A | ≤ k . Similarly, we have | E ′ D | + | O ′ B | ≤ k and | E ′ D | + | O A | ≤ k . It is clear that a situation where | O A | = k and | O B | = | D | = 0 results in a maximum value for τ . It follows from (3) that we have
$$\tau & \leq | B | - | A | + ( k - | D ^ { \prime } \cap X | ) - 0 - | D ^ { \prime } \cap X | - 0 \\ & \leq t - 2 | D ^ { \prime } \cap X | \\ & \leq t.$$
It also is clear that a situation where | O A | = 0, E ′ D = D ′ ∩ X , and | D ′ ∩ X | + | O ′ B | = k results in a minimum value for τ . By (3), this gives
$$\tau \geq \begin{cases} | B | - | A | + 0 - ( k - | D ^ { \prime } \cap X | ) - | D ^ { \prime } \cap X | - | D ^ { \prime } \cap X | & \text{if} \ | D ^ { \prime } \ \, X | = 0 \\ | B | - | A | + 0 - ( k - | D ^ { \prime } \cap X | ) - | D ^ { \prime } \cap X | - | D ^ { \prime } \cap X | - ( | P _ { D } ^ { \prime } \cap B | - | P _ { D } ^ { \prime } \cap A | ) & \text{if} \ | D ^ { \prime } \ \, X | \geq 1, \end{cases}$$
which reduces to
$$\ x u c e s \, \text{to} \\ \tau \geq \begin{cases} t - 2 k - | D ^ { \prime } \cap X | & \text{if} \ | D ^ { \prime } \, \| \, X | = 0 \\ t - 2 k - | D ^ { \prime } \cap X | - ( | P ^ { \prime } _ { D } \cap B | - | P ^ { \prime } _ { D } \cap A | ) & \text{if} \ | D ^ { \prime } \, \| \, X | \geq 1. \end{cases}$$
First consider the case where | D ′ \ X | = 0. Recall from Lemma 5 that | D ′ | ≤ | D | ≤ t -2 k +1 2 . Then
$$t - 2 k - | D ^ { \prime } \cap X | & \geq t - 2 k - | D ^ { \prime } | \\ & \geq t - 2 k - \frac { t - 2 k + 1 } { 2 } \\ & = \frac { t - 2 k - 1 } { 2 }. \\ \cdot \, \alpha \, \ e n \dots \, \dots \, \dots \, \ e n \dots \, \alpha \, \ e n \dots \, \alpha \, \ e n \dots \, \alpha.$$
Hence, if t -2 k ≥ 1, then τ ≥ 0. However, we can still have t -2 k = 0 or t -2 k = -1. If t -2 k = 0, then | A | = 1 2 ( n -k ) and | B | = 1 2 ( n + ), which implies k | D | = | D ′ ∩ X | = 0, and hence, that τ ≥ t -2 k -| D ′ ∩ X | = 0. If t -2 k = -1, then | A | = 1 2 ( n -k +1) and | B | = 1 2 ( n + k -1), which implies | D | = 0. It follows that n + k -1 is even, and that either n is odd and k is even, or that n is even and k is odd. Either way, we must have | O B | ≤ k -1 or else the parities of n and k are violated. Since | O B | = k -| D ′ ∩ X | , we must have | D ′ ∩ X | ≥ 1, which contradicts | D | = 0. Hence, we have τ ≥ 0.
Now consider the case where | D ′ \ X | ≥ 1. Again recalling Lemma 5, we have
$$t - 2 k - | D ^ { \prime } \cap X | - ( | P ^ { \prime } _ { D } \cap B | - | P ^ { \prime } _ { D } \cap A | ) \geq t - 2 k - 2 | D ^ { \prime } |.$$
It follows that t -2 k -| D ′ ∩ X | -( | P ′ D ∩ B | -| P ′ D ∩ A | ) if and only if | P ′ D ∩ B | -| P ′ D ∩ A | = 2 | D ′ \ X | and | D ′ ∩ X | = 0. Letting | P ′ D ∩ B | - | P ′ D ∩ A | = 2 | D ′ \ X | -1 ensures τ ≥ 0.
The fact that τ ≥ 0 ensures that, no matter what, the set B contains enough vertices to account for a (relatively) large D ′ and/or any number of odd-ordered paths beginning in B .
Claim 8. If G is a graph of sufficiently large order n with δ G ( ) ≥ ω , then for all γ > 0 , the graph G either contains
- 1. γω independent edges, or
- 2. /ceilingleft ω /ceilingright vertices of degree at least n 2 γ +1 .
Proof. Consider a graph G of sufficiently large order n with δ G ( ) ≥ ω . If there exist γω independent edges in G , then we are done, so suppose not. Consider the largest collection of c < γω independent edges, i.e., the largest matching in G . Call this set of edges M c . Then G = M c ∪ A , where A must induce an independent set of n -2 c vertices. Since δ G ( ) ≥ ω , each vertex in A must be adjacent to ω vertices in M c . This means there are at least ω n ( -2 ) edges c from A to M c . Therefore, there are at least ω vertices in M c with degree at least ωn -2 cω 2 c = ( ω c ) n 2 -ω > n 2 γ +1 .
/negationslash
Recall from before that there may exist a small clique C ⊂ B of vertices in B with fewer than t -1 2 neighbors in B . If C = ∅ , then we can only be guaranteed that δ G B ( [ ]) ≥ | C | -1. For each vertex c ∈ C , attach t -1 2 -d c ( ) edges to c to create the graph G B ′ [ ]. Then δ G ( ′ [ B ]) ≥ t -1 2 . Let γ = 10; by Claim 8, the graph G B ′ [ ] contains either 10( t -1) independent edges or ⌈ t -1 2 ⌉ vertices of degree at least n 21 . Case 1. G B [ ] contains at least 5( t -1) independent edges.
This immediately implies G B [ ] contains 10( t -1 -| C | ) ≥ 5( t -1) independent edges.
Let M = { e , . . . , e 1 | M | } be a maximum set of independent edges in G B [ ]. Disregard all edges in M whose endpoints are both in X ; there are at most k 2 < t -1 2 such edges.
Let M ′ X be the set of edges in M ′ that contain a single vertex in X as an endpoint. For all edges x β i i ∈ M ′ X , let α i ∈ A be a unique neighbor of β i . In a similar fashion to the way we constructed P ′ D , we may extend P ′ D into a path Q by adjoining as many edges in M ′ \ M ′ X as necessary so that we have
If t = 1, then consider an edge Q = bβ ∈ G B [ ], and skip to the construction of R . Now suppose t > 1. As noted in the definition of D ′ , every vertex d ′ j ∈ D ′ contains sufficiently many neighbors in B ′ . As such, for some unique neighbor β ′ j of each d ′ j , choose a new matching M ′ to include every edge d β ′ j ′ j and all other edges in M , removing as many as 2 | D ′ | edges from M if necessary. Hence, we have e M ( ′ ) ≥ e M ( ) -k 2 - | 2 D ′ | + | D ′ | > 2( t -1) since t > 1. Construct the path P ′ D . Then P ′ D ⊃ D ′ \ X and | P ′ D ∩ B |-| P ′ D ∩ A | = 2 | D ′ \ X |-1 or | P ′ D ∩ B |-| P ′ D ∩ A | = 2 | D ′ \ X | .
$$| Q \cap B | - | Q \cap A | = \tau - | X \cap D ^ { \prime } |.$$
The inequalities | M ′ | > 2( t -1) > t ≥ τ ensure that M ′ contains enough edges to extend P ′ D into Q (we are still assuming t > 1). Construct Q so that the last vertex in Q is in A , so that Q begins in B and ends in A .
Note that all vertices in D D \ ′ have enough neighbors in A so that each vertex in D D \ ′ has two unique neighbors in A X \ . For all x i ∈ ( D D \ ′ ) ∩ X , simply consider the unique neighbor α i . We may string all vertices in D \ ( D ′ ∪ X ) into a path R so that R contains as many vertices in D \ ( D ′ ∪ X ) as in A . We do this as follows. For all d j ∈ D \ ( D ′ ∪ X ), choose the unique neighbors a , α j j ∈ A \ X . For each j ≥ 1, the vertices α j and a j +1 share a common neighbor b ′ j ∈ B ′ . This gives a path R = { d , a 1 1 , b ′ 1 , α 1 , d 2 , a 2 , b ′ 2 , α 2 , . . . , d | D \ ( D ′ ∪ X ) | , a | D \ ( D ′ ∪ X ) | , b ′ | D \ ( D ′ ∪ X ) | , α | D \ ( D ′ ∪ X ) | } . Hence, the collection of paths satisfies
$$Q ^ { \prime } = Q \cup R \cup \left ( \bigcup _ { x _ { i } \in D ^ { \prime } \cap X } \{ x _ { i }, \beta _ { i }, \alpha _ { i } \} \right ) \cup \left ( \bigcup _ { x _ { j } \in ( D \vee D ^ { \prime } ) \cap X } \{ x _ { j }, \alpha _ { j } \} \right )$$
$$| Q ^ { \prime } \cap B | - | Q ^ { \prime } \cap A | = \tau$$
and contains all vertices in D .
Case 2. G B [ ] contains at least ⌈ t -1 2 ⌉ vertices of degree at least n 21 .
This immediately implies G B [ ] contains ⌈ t -1 2 ⌉ stars with greater than n 21 -| C > | n 22 vertices in G B [ ] \ C . Call this collection of stars S , and for each star in S , consider the smaller star S j = { b , c ′ j j , β ′ j } with center c j and unique neighbors b , β ′ j ′ j ∈ B ′ \ X , which we may choose due to the large neighborhoods of all c j . Then there exists a unique a j in the neighborhoods of both b j and β j . Construct P ′ D ; then P ′ D ⊇ D ′ \ X , and | P ′ D ∩ B | - | P ′ D ∩ A | = 2 | D ′ \ X | -1. Extend P ′ D to Q by adjoining as many stars S j as necessary (and of course the necessary common neighbors in A ).
Claim 9. There exist enough stars S j so that we have
$$| Q \cap B | - | Q \cap A | = \tau - | D ^ { \prime } \cap X |$$
with Q beginning in B and ending in A .
Proof. By assumption, we have at least ⌈ t -1 2 ⌉ -| D ′ ∩ X | disjoint stars S j in B \ X . Since each star and an adjacent vertex in A contribute 3 vertices in B and 1 vertex in A , we have at least 2 (⌈ t -1 2 ⌉ -| D ′ ∩ X | ) ≥ t -1 - | 2 D ′ ∩ X | additional vertices in B as a result of adjoining the stars S j with a neighbor in A .
Recall from Claim 7 that 0 ≤ τ ≤ t - | 3 D ′ ∩ X | ≤ t . It follows that we need
$$| Q \cap B | - | B \cap A | & = \tau - | D ^ { \prime } \cap X | \\ & \leq ( | B | - | A | + ( k - | D ^ { \prime } \cap X | ) - 0 - | D ^ { \prime } \cap X | - 0 ) - | D ^ { \prime } \cap X | \\ & \leq t - 3 | D ^ { \prime } \cap X |. \\.. \quad. \quad.. -.. \ \........................................................................................................................................................................................................$$
Since we may construct Q to give us as many as t -1 - | 2 D ′ ∩ X | additional vertices in B , we are done unless | D ′ ∩ X | = 0 and t is odd. (If t is even, then ⌈ t -1 2 ⌉ = t 2 , and we have t - | 2 D ′ ∩ X | ≥ t - | 3 D ′ ∩ X | ≥ τ -| D ′ ∩ X | additional vertices in B .) If | D ′ ∩ X | = 0 and t is odd, then either n is odd and k is even, or n is even and k is odd. Either way, we have | O A | ≤ k -1, which implies τ -| D ′ ∩ X | ≤ | B | - | A | + k -1 - | 2 D ′ ∩ X < t | - | 3 D ′ ∩ X | . Therefore, we can always construct Q to satisfy (7). Furthermore, we can always have Q end in A by either starting P ′ D at d ′ 1 or at b ′ 1 . This avoids a possible parity issue, as each star contributes 2 additional vertices in B .
For all x i ∈ D ′ ∩ X , consider the unique neighbor β i , which in turn has the unique neighbor α i . For all vertices d j ∈ D \ ( D ′ ∪ X ), let α j and a j be the unique neighbors in A \ X .
As in Case 1, create the path R containing all vertices in D \ ( D ′ ∪ X ); naturally, this implies R contains as many vertices in A as in B . Then the collection satisfies
$$Q ^ { \prime } = Q \cup R \cup \left ( \bigcup _ { x _ { i } \in D ^ { \prime } } \{ x _ { i }, \beta _ { i }, \alpha _ { i } \} \right ) \cup \left ( \bigcup _ { x _ { j } \in ( D \vee D ^ { \prime } ) \cap X } \{ x _ { j }, \alpha _ { j } \} \right )$$
$$| Q ^ { \prime } \cap B | - | Q ^ { \prime } \cap A | = \tau$$
and contains all vertices in D .
In both Cases 1 and 2, we have created Q ′ , a collection of paths that contains the necessary number of extra vertices in B than in A and all vertices in D ′ .
We use induction to construct all desired paths P , . . . , P 1 k with desired lengths n , . . . , n 1 k . Without loss of generality, assume n 1 ≤ · · · ≤ n k .
Let X i = X \ { x , . . . , x 1 i } = { x i +1 , . . . , x k } , let m i = max ⌈ { n , i n 25 k }⌉ , and let P i = ⋃ i j =1 P j . Now consider the inductive step for 1 < i < k . We have
For the base case, let i = 1. Choose two sets U 1 ⊂ A and V 1 ⊂ B , each of order max { n 25 k , ⌈ n 1 2 ⌉} , and so that U 1 or V 1 contains x 1 and no other vertices in Q ′ ∪ X . By Lemma 10, the balanced bipartite graph U 1 ∪ V 1 is bipanconnected, and so there exists a path P 1 beginning at x 1 of length n 1 within U 1 ∪ V 1 .
$$n - | \mathcal { P } ^ { i - 1 } \cup Q \cup X ^ { i } | & \geq \frac { ( k - i + 1 ) n } { k } - ( k - i + 1 ) - \frac { n } { 2 5 k } \\ & > \frac { n } { k }.$$
Hence, there are always enough vertices to create a balanced bipartite graph U i ∪ V i ⊂ ( A ∪ B ) \ ( P i -1 ∪ Q ∪ X i ) that includes x i with m i vertices. By Lemma 10, we may construct a path P i in U i ∪ V i beginning at x i with n i vertices.
Finally, for i = k , we wish for P k to contain all vertices in V ( G ) \ P k -1 . Note that this final path must include Q and R . We have X k = ∅ , and hence
$$n - | \mathcal { P } ^ { k - 1 } \cup Q \cup R \cup X ^ { k } | & > n - \left ( \frac { n } { 2 5 k } + \frac { k - 1 } { k } \right ) n \\ & > \frac { 2 4 n } { 2 5 k }.$$
By the definition of Q and R , the graph G \ ⋃ k -1 i =1 P i is within a single vertex of being a balanced bipartite graph, and | Q | + | R | ≤ 4 τ +2 | D | /lessmuch n 25 k . Also note that Q and R both start in A and end in B ; hence, we may adjoin Q and R using Lemma 10 and some vertices { a , b q r } . Similarly, the amalgamation Q ∪ { a , b q r } ∪ R still begins in B and ends in A , allowing us to perform a similar process in adjoining { x , k ( β k ) , α k } (if β k exists) to Q ∪{ a , b q r } ∪ R . Lastly, use Lemma 10 to adjoin Q ∪ { a , b q r } ∪ R to a remaining vertex in G -P k -1 , possibly adding on one last vertex if V ( G -P k -1 ) is odd. This results in a path P k that begins at x k and necessarily contains n k vertices.
We have therefore created disjoint paths beginning at x i on n i vertices for all 1 ≤ i ≤ k that together cover V ( G ).
## 7 Proof of Lemma 7
We begin with a lemma ensuring that low connectivity in the reduced graph R results in at most two components in the original graph G .
Lemma 11. Let /epsilon1, d > 0 be small reals and k be a positive integer. If G is a graph with σ 2 ( G ) ≥ n + k -1 and reduced graph R with connectivity at most ( 1 10 -3 5 ( d +2 ) /epsilon1 ) | R | , then R consists of only two components ( and a cutset if κ R ( ) > 0) .
Proof. Applying Lemma 1 to G , let G ′′ = G V G ′ [ ( ) \ V 0 ]. Since d G ′′ ( v ) > d G ( v ) -( d +2 ) /epsilon1 n , it immediately follows that σ 2 ( R > ) (1 -2( d +2 )) /epsilon1 | R | . Let D be a cutset of R (if one exists). Suppose R (or R \ D ) contains at least 3 components, three of which being A B , , and C . Let a ∈ A b , ∈ B and c ∈ C . Then d a ( ) + d b ( ) > (1 -2( d +2 )) /epsilon1 | R | , which implies | A | + | B > | (1 -2( δ + 2 )) /epsilon1 | R | -2 | D | . Similarly, the same is true for | B | + | C | and | A | + | C | . So 2( | A | + | B | + | C | ) > 3(1 -2( d +2 )) /epsilon1 | R | -6 | D | , or | D > | ( 1 10 -3 5 ( d +2 ) /epsilon1 ) | R | , a contradiction.
Note that the connectivity of R may be considerably larger than /epsilon1 | R | . Also note that A B , , C , and D were vertex sets in R . In the following remark, the same symbols are used to denote vertex sets in G .
Remark 1. Given small real numbers /epsilon1, d > 0 and a positive integer k , let G be a graph of order n = ∑ k i =1 n i ≥ n /epsilon1, ( d, k ) with σ 2 ( G ) ≥ n + k -1 and δ G ( ) ≥ n k 8 . If the reduced graph of G has connectivity at most /epsilon1 | R | , then let D ⊂ V ( G ) be the cluster corresponding to a cut vertex of R . (If R contains no cut vertices, then D = ∅ .) Let V 0 be the garbage cluster of G resulting from Lemma 1, and let C be a minimum cutset of G . Then C ⊆ D ∪ V 0 . By Lemma 1, each vertex of R corresponds to a cluster in G of order L = ξn . Hence, we have k +1 ≤ | C | ≤ | D | + | V 0 | ≤ /epsilon1ξ | R n | + /epsilon1n . By Lemma 11, we may define A and B to be the components of G \ C and write G = A ∪ C ∪ B . It immediately follows from σ 2 ( G ) ≥ n + k -1 that
$$\delta ( G [ A ] ) & > | A | - | C | > | A | - ( \epsilon \xi | R | + \epsilon ) n, \\ \delta ( G [ B ] ) & > | B | - | C | > | B | - ( \epsilon \xi | R | + \epsilon ) n.$$
From the condition δ G ( ) ≥ n k 8 ≥ n 2 k , we know | A , | | B | ≥ n k 8 -| C | ≥ ( 1 8 k -/epsilon1ξ | R | -/epsilon1 ) n > n 8( k +1) .
Note that /epsilon1ξ | R | /lessmuch 1.
While panconnected sets give paths of arbitrary length, only the endpoints are specified. Hence, to create disjoint paths of arbitrary length, we must create sets using vertices that are not part of an already existing desired path. Fortunately, even small subsets of A and B induce panconnected graphs.
Lemma 12. Let /epsilon1 , d , k , and G = A ∪ C ∪ B be defined as in Remark 1. Then the induced graph on any subgraph of A or B of order at least 2( /epsilon1ξ | R | + ) /epsilon1 n is panconnected.
Proof. We see from (8) that δ G A ( [ ]) > A | | - | C | > A | | -( /epsilon1ξ | R | + ) . /epsilon1 n Then for all U ⊂ A of order at least 2( /epsilon1ξ | R | + ) /epsilon1 n , we have
$$\delta ( G [ U ] ) & \geq | S | - ( \epsilon \xi | R | + \epsilon ) n + 1 \\ & \geq \frac { | S | + 2 } { 2 }. \\. \quad. \quad. \quad.$$
By Theorem 5, the graph G U [ ] is panconnected. A symmetric argument shows that if U ⊂ B has order at least ( /epsilon1ξ | R | + ) /epsilon1 n , then G U [ ] is panconnected.
With this information, we prove the following lemma which is a bit stronger than Lemma 7.
Lemma 13. Given small real numbers /epsilon1, d > 0 and a positive integer k , let G be a graph of order n = ∑ k i =1 n i ≥ n /epsilon1, ( d, k ) with σ 2 ( G ) ≥ n + k -1 and δ G ( ) ≥ n k 8 . If κ R ( ) ≤ | /epsilon1 R | , then the conclusion of Conjecture 1 holds.
Proof. Suppose κ R ( ) ≤ | /epsilon1 R | , and let G = A ∪ C ∪ B as in Remark 1. As noted before (8), we know k +1 ≤ | C | ≤ ( /epsilon1ξ | R | + ) . /epsilon1 n As noted after (8), we know | A , | | B > | n 8( k +1) . For each c ∈ C , we may reserve 2 unique neighbors a c ∈ A and b c ∈ B . Call A C = { a c ∈ A \ X | c ∈ C } (symmetrically B C = { b c ∈ B \ X | c ∈ C } ) the set of proxy vertices in A (symmetrically B ). Then we have
$$| C | = | A _ { C } | = | B _ { C } |.$$
Given a vertex x , let an x -path be a path containing x as an endpoint. Namely, each desired path P i in G is an x i -path. Recall that X = { x i | n i ≤ n i +1 } . For some i ≤ k , let
$$A ^ { * } & = A \, \smallsetminus \bigcup _ { j = 1 } ^ { i - 1 } P _ { j }, \\. \quad. \quad. \quad. \quad. \quad. \quad.$$
and define B ∗ and C ∗ similarly. In particular, note that A ∗ = A for i = 1. Let
$$A ^ { v } & = ( A ^ { * } \, \langle A _ { C } \cup X ) ) \cup v, \\ B ^ { v } & = ( B ^ { * } \, \langle B _ { C } \cup X ) ) \cup v ;$$
i.e., if v = x i or v = a c , then A v ∩ ( X ∪ A C ) = v , and symmetrically for B v and B C . For the sake of notation, if v = x i for some i , then we write A x and B x . This will never cause an issue, as we never discuss A ∗ or x i for different values of i at the same time.
We induct on i to prove our result. Consider the base case i = 1. If x 1 ∈ A and n 1 ≤ | A x | -4( /epsilon1ξ | R | + ) /epsilon1 n , then use Lemma 12 to construct an x 1 -path P 1 ⊂ A x containing n 1 vertices. If x 1 ∈ A and n 1 > A | x |-4( /epsilon1ξ | R | + ) /epsilon1 n , then let c ∈ C with proxy vertices a ∈ A C and b ∈ B C . Use Lemma 12 to create an x , a 1 -path P A consisting of all but 4( /epsilon1ξ | R | + ) /epsilon1 n vertices of x 1 ∪ A a . Also create a b -path P B ⊆ B b with n 1 -| P A | -1 vertices. Then P 1 = P A ∪ c ∪ P B is an x 1 -path with n 1 vertices. If x 1 ∈ B , then a symmetric argument works. Lastly, if x 1 ∈ C , then suppose without loss of generality that | A \ ( A C ∪ X ) | ≥ | B \ ( B C ∪ X ) . | Since | C | + | A C ∪ X | ≤ 2( /epsilon1ξ | R | + ) /epsilon1 n + k < 4( /epsilon1ξ | R | + ) /epsilon1 n and n 1 ≤ n k , this implies n 1 < A | x ∪ a | -4( /epsilon1ξ | R | + ) /epsilon1 n . Let a ∈ A C be the proxy vertex of x 1 , and use Lemma 12 to create an a -path P A ⊂ A a with n 1 -1 vertices. Then P 1 = x 1 ∪ P A is an x 1 -path with n 1 vertices.
Now suppose 1 < i < k and that the disjoint x j -paths P , . . . , P 1 i -1 have been constructed in G . If x i ∈ A ∗ ∪ C ∗ and n i ≤ | A x | -4( /epsilon1ξ | R | + ) , then use Lemma 12 to construct an /epsilon1 n x i -path P i ⊂ A x containing n i vertices. If x i ∈ A ∗ ∪ C ∗ and n i > A | x | -4( /epsilon1ξ | R | + ) /epsilon1 n , then
$$\cup C ^ { * } \text{ and } n _ { i } > | A ^ { z } | - 4 ( \epsilon \xi | R | + \epsilon ) n, \text{ then} \\ | B ^ { b } | & = n - | A ^ { * } | - | C ^ { * } | - | \{ x _ { i }, \dots, x _ { k } \} | - \left | \bigcup _ { j = 1 } ^ { i - 1 } P _ { j } \right | \\ & \geq n - n _ { i } - 4 ( \epsilon \xi | R | + \epsilon ) n - ( \epsilon \xi | R | + \epsilon ) n - ( k - i + 1 ) - \sum _ { j = 1 } ^ { i - 1 } n _ { j } \\ & \geq \sum _ { j = i + 1 } ^ { k } n _ { j } - 6 ( \epsilon \xi | R | + \epsilon ) n. \\ f i < k - 1, \text{ then } | B ^ { b } | > n _ { i + 1 } \geq n _ { i }. \text{ If } i = k - 1, \text{ then by the Pigeonhole Principle, we have}$$
Hence, if i < k -1, then | B b | > n i +1 ≥ n i . If i = k -1, then by the Pigeonhole Principle, we have
$$| B ^ { b } | & > n _ { k } - 6 ( \epsilon \xi | R | + \epsilon ) n \\ & > \frac { n } { k } - 6 ( \epsilon \xi | R | + \epsilon ) n$$
Furthermore, since | C ∗ \ x i | ≥ k +1 -( i -1) -1 ≥ 2, we know there exists c ∈ C ∗ with proxy vertices a ∈ A C and b ∈ B C . If | A x | > 4( /epsilon1ξ | R | + ) , then use Lemma 12 to create an /epsilon1 n x , a i -path P A consisting of all but 4( /epsilon1ξ | R | + ) /epsilon1 n vertices of a ∪ A x . If | A x | ≤ 4( /epsilon1ξ | R | + ) /epsilon1 n and a ∈ A ∗ , then use Lemma 12 to create an x , a i -path P A consisting of three vertices in a ∪ A x . If | A x | ≤ 4( /epsilon1ξ | R | + ) /epsilon1 n and a ∈ C ∗ , then let P A = ∅ . Regardless of the initial size of A x , we now have
$$3 ( \epsilon \xi | R | + \epsilon ) n < | A ^ { x } \, \sum P _ { A } | \leq 4 ( \epsilon \xi | R | + \epsilon ) n.$$
From (9) and (10), we may similarly use Lemma 12 to create a b -path P B ⊂ B b with n i -| P A | -1 vertices. Then P i = P A ∪ c ∪ P B is an x i -path with n i vertices. If x i ∈ B ∗ , then a symmetric argument works.
Finally, suppose i = k and that the disjoint x j -paths P , . . . , P 1 k -1 have been constructed in G . From (10) and (11), we know
$$| A ^ { * } \, \slash \, ( X \cup A _ { C } ) | & > 3 ( \epsilon \xi | R | + \epsilon ) n, \\ | B ^ { * } \, \slash \, ( X \cup B _ { C } ) | & > 3 ( \epsilon \xi | R | + \epsilon ) n.$$
From the Pigeonhole Principle, we also know
$$n _ { k } \geq \frac { n } { k } \gg | A _ { C } | + | C ^ { * } | + | B _ { C } |.$$
Without loss of generality, assume x k ∈ A ∗ ∪ C ∗ . Note that | C ∗ \ x k | ≥ 1, and hence, that we must have n k > A | x | . Define A ∗ C and B ∗ C similarly to the way A ∗ and B ∗ are defined. Use Lemma 12 repeatedly | C ∗ | ≤ ( /epsilon1ξ | R | + ) /epsilon1 n times within A ∗ and within B ∗ each to create a path P C that strings together all vertices in C ∗ by using all proxy vertices in A ∗ C and B ∗ C . Since A ∗ C , B ∗ C , and C ∗ each have at most ( /epsilon1ξ | R | + ) /epsilon1 n vertices, and since | C ∗ \ x k | ≥ 1, we know 7 ≤ | P C | < 5( /epsilon1ξ | R | + ) /epsilon1 n . Given the high value of δ G ( ), we may ensure that P C starts with a proxy vertex in A ∗ and ends with a proxy vertex in B ∗ by including an additional vertex in A ∗ or B ∗ adjacent to some vertex in C ∗ . Let the endpoints of P C be a ∈ A ∗ and b ∈ B ∗ . Noting (12), we may use Lemma 12 in A ∗ and B ∗ to create an x , a k -path P A that contains all vertices in A ∗ \ P C . Similarly, use (12) and Lemma 12 to create a b -path P B that contains all vertices in B ∗ \ P C . Then P k = P A ∪ P C ∪ P B is an x k -path that contains all remaining n k vertices in G .
We have created k paths P , . . . , P 1 k in G , with each path P i starting at x i and having n i vertices.
## References
- [1] Gary Chartrand, Linda Lesniak, and Ping Zhang. Graphs & digraphs . CRC Press, Boca Raton, FL, fifth edition, 2011.
- [2] V. Coll, A. Halperin, and C. Magnant. Graph linkage with prescribed lengths. Manuscript , 2013.
- [3] R. Diestel. Graph theory , volume 173 of Graduate Texts in Mathematics . Springer, Heidelberg, fourth edition, 2010.
- [4] H. Enomoto and K. Ota. Partitions of a graph into paths with prescribed endvertices and lengths. J. Graph Theory , 34(2):163-169, 2000.
- [5] J. Koml´ os, G. N. S´rk¨zy, and E. Szemer´di. Blow-up lemma. a o e Combinatorica , 17(1):109-123, 1997.
- [6] D. K¨ uhn, D. Osthus, and A. Treglown. An Ore-type theorem for perfect packings in graphs. SIAM J. Discrete Math. , 23(3):1335-1355, 2009.
- [7] C. Magnant and D. M. Martin. An asymptotic version of a conjecture by Enomoto and Ota. J. Graph Theory , 64(1):37-51, 2010.
- [8] C. Magnant and P. Salehi Nowbandegani. Note on lengths of cycles containing a specified edge. Manuscript , 2014.
- [9] Karl Menger. Zur allgemeinen kurventheorie. Fundamenta Mathematicae , 10(1):96-115, 1927.
- [10] O. Ore. Note on Hamilton circuits. Amer. Math. Monthly , 67:55, 1960.
- [11] E. Szemer´ edi. Regular partitions of graphs. In Probl`mes combinatoires et th´orie des graphes (Colloq. Internat. e e CNRS, Univ. Orsay, Orsay, 1976) , volume 260 of Colloq. Internat. CNRS , pages 399-401. CNRS, Paris, 1978. | null | [
"Vincent Coll",
"Alexander Halperin",
"Colton Magnant",
"Pouria Salehi Nowbandegani"
] | 2014-08-02T19:30:51+00:00 | 2014-08-02T19:30:51+00:00 | [
"math.CO",
"05C35"
] | Enomoto and Ota's conjecture holds for large graphs | In 2000, Enomoto and Ota conjectured that if a graph $G$ satisfies
$\sigma_{2}(G) \geq n + k - 1$, then for any set of $k$ vertices $v_{1}, \dots,
v_{k}$ and for any positive integers $n_{1}, \dots, n_{k}$ with $\sum n_{i} =
|G|$, there exists a partition of $V(G)$ into $k$ paths $P_{1}, \dots, P_{k}$
such that $v_{i}$ is an end of $P_{i}$ and $|P_{i}| = n_{i}$ for all $i$. We
prove this conjecture when $|G|$ is large. Our proof uses the Regularity Lemma
along with several extremal lemmas, concluding with an absorbing argument to
retrieve misbehaving vertices. |
1408.0409v1 | ## Vertex Fault Tolerant Additive Spanners
Merav Parter ∗
August 5, 2014
## Abstract
A fault-tolerant structure for a network is required to continue functioning following the failure of some of the network's edges or vertices. In this paper, we address the problem of designing a fault-tolerant additive spanner, namely, a subgraph H of the network G such that subsequent to the failure of a single vertex, the surviving part of H still contains an additive spanner for (the surviving part of) G , satisfying dist( s, t, H \ { v } ) ≤ dist( s, t, G \ { v } ) + β for every s, t, v ∈ V . Recently, the problem of constructing fault-tolerant additive spanners resilient to the failure of up to f edges has been considered [8]. The problem of handling vertex failures was left open therein. In this paper we develop new techniques for constructing additive FT-spanners overcoming the failure of a single vertex in the graph. Our first result is an FT-spanner with additive stretch 2 and ˜ O n ( 5 / 3 ) edges. Our second result is an FT-spanner with additive stretch 6 and ˜ O n ( 3 / 2 ) edges. The construction algorithm consists of two main components: (a) constructing an FT-clustering graph and (b) applying a modified path-buying procedure suitably adopted to failure prone settings. Finally, we also describe two constructions for fault-tolerant multi-source additive spanners , aiming to guarantee a bounded additive stretch following a vertex failure, for every pair of vertices in S × V for a given subset of sources S ⊆ V . The additive stretch bounds of our constructions are 4 and 8 (using a different number of edges).
## 1 Introduction
An ( α, β )-spanner H of an unweighted undirected graph G is a spanning subgraph satisfying for every pair of vertices s, t ∈ V that dist( s, t, H ) ≤ α · dist( s, t, G ) + β . When β = 0, the spanner is termed a multiplicative spanner and when α = 1 the spanner is additive . Clearly, additive spanners provide a much stronger guarantee than multiplicative ones, especially for long distances. Constructions of additive spanners with small number of edges are currently known for β = 2 4 6 , , with O n ( 3 2 / ) , O ˜ ( n 7 5 / ) and O n ( 4 3 / ) edges respectively [1, 2, 5, 11, 14, 15]. This paper considers a network G that may suffer single vertex failure events, and looks for fault tolerant additive spanners that maintain their additive stretch guarantee under failures. Formally, a subgraph H ⊆ G is a β -additive FT-spanner iff for every ( s, t ) ∈ V × V and for every failing vertex v ∈ V , dist( s, t, H \ { v } ) ≤ dist( s, t, G \ { v } ) + β . As a motivation for such structures, consider a situation where it is required to lease a subnetwork of a given network, which will provide short routes from every source s and every target t with additive stretch 2. In a failure-free environment one can
∗ Department of Computer Science and Applied Mathematics, The Weizmann Institute of Science, Rehovot, Israel. E-mail: { merav.parter @ } weizmann.ac.il . Recipient of the Google European Fellowship in distributed computing; research is supported in part by this Fellowship. Supported in part by the Israel Science Foundation (grant 894/09).
simply lease a 2-additive spanner H 0 of the graph with Θ( n 3 2 / ) edges. However, if one of the vertices in the graph fails, some s -t routes in H 0 \ { v } might be significantly longer than the corresponding route in the surviving graph G \ { v } . Moreover, s and t are not even guaranteed to be connected in H 0 \ { v } . One natural approach towards preparing for such eventuality is to lease a larger set of links, i.e., an additive FT-spanner.
The notion of fault-tolerant spanners for general graphs was initiated by Chechik at el. [10] for the case of multiplicative stretch. Specifically, [10] presented algorithms for constructing an f -vertex fault tolerant spanner with multiplicative stretch (2 k -1) and O f k ( 2 f +1 · n 1+1 /k log 1 -1 /k n ) edges. Dinitz and Krauthgamer presented in [13], a randomized construction attaining an improved tradeoff for vertex fault-tolerant spanners, namely, f -vertex fault tolerant k -spanner with ˜ O f ( 2 · n 1+2 ( / k +1) ) edges. Constructions of fault-tolerant spanners with additive stretch resilient to edge failures were recently given by Braunschvig at el. [8]. They establish the following general result. For a given n -vertex graph G , let H 1 be an ordinary additive (1 , β ) spanner for G and H 2 be a ( α, 0) fault tolerant spanner for G resilient against up to f edge faults. Then H = H 1 ∪ H 2 is a (1 , β ( f )) additive fault tolerant spanner for G (for up to f edge faults) for β f ( ) = O f α ( ( + β )). In particular, fixing the number of H edges to be O n ( 3 2 / ) and the number of faults to f = 1 yields an additive stretch of 14. Hence, in particular, there is no construction for additive stretch < 14 and o n ( 2 ) edges. In addition, note that these structures are resilient only to edge failures as the techniques of [8] cannot be utilized to protect even against a single vertex failure event. Indeed, the problem of handling vertex failures was left open therein.
In this paper, we make a first step in this direction and provide additive FT-structures resilient to the failure of a single vertex (and hence also edge) event. Our constructions provide additive stretch 2 and 6 and hence provide an improved alternative also for the case of a single edge failure event, compared to the constructions of [8].
The presented algorithms are based upon two important notions, namely, replacement paths and the path-buying procedure , which have been studied extensively in the literature. For a source s , a target vertex t and a failing vertex v ∈ V , a replacement path is the shortest s -t path P s,t,v that does not go through v . The vast literature on replacement paths (cf. [7, 16, 19, 21]) focuses on time-efficient computation of the these paths as well as their efficient maintenance in data structures (a.k.a distance oracles ).
Fault-resilient structures that preserve exact distances for a given subset of sources S ⊆ V have been studied in [17], which defines the notion of an FT-MBFS structure H ⊆ G containing the collection of all replacement paths P s,t,v for every pair ( s, t ) ∈ S × V for a given subset of sources S and a failing vertex v ∈ V . Hence, FT-MBFS structures preserve the exact s -t distances in G \ { v } for every failing vertex v , for every source s ∈ S .
It is shown in [17] that for every graph G and a subset S of sources, there exists a (poly-time constructible) 1-edge (or vertex) FT-MBFS structure H with O ( √ | S | · n 3 2 / ) edges. This result is complemented by a matching lower bound showing that for sufficiently large n , there exist an n -vertex graph G and a source-set S ⊆ V , for which every FT-MBFS structure is of size Ω( √ | S | · n 3 2 / ). Hence exact FT-MBFS structures may be rather expensive. This last observation motivates the approach of resorting to approximate distances, in order to allow the design of a sparse subgraph with properties resembling those of an FT-MBFS structure.
The problem of constructing multiplicative approximation replacement paths ˜ P s,t,v (i.e., such that | ˜ P s,t,v | ≤ α · | P s,t,v | ) has been studied in [3, 9, 6]. In particular its single source variant has been studied in [4, 18]. In this paper, we further explore this approach. For a given subset of
sources S , we focus on constructions of subgraphs that contain an approximate BFS structure with additive stretch β for every source s ∈ S that are resistant to a single vertex failure.
Indeed, the construction of additive sourcewise FT-spanners provides a key building block of additive FT-spanner constructions (in which bounded stretch is guaranteed for all pairs). We present two constructions of sourcewise spanners with different stretch-size tradeoffs. The first construction ensures an additive stretch 4 with ˜ O (max { n · | S , | ( n/ S | | ) 3 } ) edges and the second construction guarantees additive stretch 8 with ˜ O (max { n · | S , | ( n/ S | | ) 2 } ). As a direct consequence of these constructions, we get an additive FT-spanner with stretch 6 and ˜ O n ( 3 2 / ) edges and an additive sourcewise FT-spanner with additive stretch 8 and ˜ O n ( 4 3 / ) for at most ˜ O n ( 1 3 / ) sources.
Our constructions employ a modification of the path-buying strategy, which was originally devised in [5] to provide 6-additive spanners with O n ( 4 3 / ) edges. Recently, the path-buying strategy was employed in the context of pairwise spanners, where the objective is to construct a subgraph H ⊆ G that satisfies the bounded additive stretch requirement only for a subset of pairs [12]. The high-level idea of this procedure as follows. In an initial clustering phase, a suitable clustering of the vertices is computed, and an associated subset of edges is added to the spanner. Then comes a path-buying phase, where they consider an appropriate sequence of paths, and decide whether or not to add each path into the spanner. Each path P has a cost , given by the number of edges of p not already contained in the spanner, and a value , measuring P 's help in satisfying the considered set of constraints on pairwise distances. The considered path P is added to the spanner iff its value is sufficiently larger than its cost. In our adaptation to the FT-setting, an FT-clustering graph is computed first, providing every vertex with a sufficiently high degree (termed hereafter a heavy vertex) two clusters to which it belongs. Every cluster consists of a center vertex v connected via a star to a subset of its heavy neighbors. In our design not all replacement paths are candidates to be bought in the path-buying procedure. Let π s, t ( ) be an s -t shortest-path between a source s and a heavy vertex t (in our constructions, all heavy vertices are clustered). We divide the failing events on π s, t ( ) into two classes depending on the position of the failing vertex on π s, t ( ) with respect to the least common ancestor (LCA) glyph[lscript] ( s, t ) of t 's cluster members in the BFS tree rooted at s . Specifically, a vertex fault π s, t ( ) that occurs on glyph[lscript] ( s, t ) is handled directly by adding the last edge of the corresponding replacement path to the spanner. Vertex failures that occur strictly below the LCA, use the shortest-path π s, x ( ) between s and some member x in the cluster of t whose failing vertex v does not appear on its π s, x ( ) path. The approximate replacement path will follow π s, x ( ) and then use the intercluster path between x and t . The main technicality is when concerning the complementary case when that failing events occur strictly above glyph[lscript] ( s, t ). These events are further divided into two classes depending on the structure of their replacement path. Some of these replacement paths would again be handled directly by collecting their last edges into the structure and only the second type paths would be candidate to be bought by the path-buying procedure. Essentially, the structure of these paths and the cost and value functions assigned to them would guarantee that the resulting structure is sparse, and in addition, that paths that were not bought have an alternative safe path in the surviving part of the structure.
Contributions. This paper provides the first constructions for additive spanners resilient upon single vertex failure. In addition, it provides the first additive FT-structures with stretch guarantee as low as 2 or 6 and with o n ( 2 ) edges.
The main technical contribution of our algorithms is in adapting the path-buying strategy to the vertex failure setting. Such an adaptation has been initiated in [18] for the case of a single-
source s and a single edge failure event. In this paper, we extend this technique in two senses: (1) dealing with many sources and (2) dealing with vertex failures. In particular, [18] achieves a construction of single source additive spanner with O n ( 4 3 / ) edges resilient to a single edge failure. In this paper, we extend this construction to provide a multiple source additive spanners resilient to a single vertex failure, for O n ( 1 3 / ) sources, additive stretch 8 and ˜ O n ( 4 3 / ) edges. In summary, we show the following.
Theorem 1.1 (2-additive FT-spanner) For every n -vertex graph G = ( V, E ) , there exists a (polynomially constructible) subgraph H ⊆ G of size ˜ O n ( 5 3 / ) such that dist( s, t, H \{ v } ) ≤ dist( s, t, G \ { v } ) + 2 for every s, t, v ∈ V .
Theorem 1.2 (6-additive FT-spanner) For every n -vertex graph G = ( V, E ) , there exists a (polynomially constructible) subgraph H ⊆ G of size ˜ O n ( 3 2 / ) such that dist( s, t, H \{ v } ) ≤ dist( s, t, G \ { v } ) + 6 for every s, t, v ∈ V .
Theorem 1.3 (8-additive sourcewise FT-spanner) For every n -vertex graph G = ( V, E ) and a subset of sources S ⊂ V where | S | = ˜ O n ( 1 3 / ) , there exists a (polynomially constructible) subgraph H ⊆ G of size ˜ O n ( 4 3 / ) such that dist( s, t, H \ { v } ) ≤ dist( s, t, G \ { v } ) + 8 for every s ∈ S and t, v ∈ V .
## 2 Preliminaries
Notation. Given a graph G = ( V, E ), a vertex pair s, t and an edge weight function W : E G ( ) → R + , let SP s,t, G, W ( ) be the set of s -t shortest-paths in G according to the edge weights of W . Throughout, we make use of (an arbitrarily specified) weight assignment W that guarantees the uniqueness of the shortest paths . 1 Hence, SP s,t, G , W ( ′ ) contains a single path for every s, t ∈ V and for every subgraph G ′ ⊆ G , we override notation and let SP s,t, G, W ( ) be the unique s -t path in G according to W . When the shortest-path are computed in G , let π s, t ( ) = SP s,t, G, W ( ). To avoid cumbersome notation, we may omit W and simply refer to π s, t ( ) = SP s,t, G, W ( ). For a subgraph G ′ ⊆ G , let V ( G ′ ) (resp., E G ( ′ )) denote the vertex set (resp. edge set) in G ′ .
For a given source node s , let T 0 ( s ) = ⋃ t ∈ V π s, t ( ) be a shortest paths (or BFS) tree rooted at s . For a set S ⊆ V of source nodes, let T 0 ( S ) = ⋃ s ∈ S T 0 ( s ) be a union of the single source BFS trees. For a vertex t ∈ V and a subset of vertices V ′ ∈ V , let T t, V ( ′ ) = ⋃ u ∈ V ′ π u, t ( ) be the union of all { } × t V ′ shortest-paths (by the uniqueness of W T t,V , ( ′ ) is a subtree of T 0 ( )). t Let Γ( v, G ) be the set of v 's neighbors in G . Let E v, G ( ) = { ( u, v ) ∈ E G ( ) } be the set of edges incident to v in the graph G and let deg ( v, G ) = | E v, G ( ) | denote the degree of node v in G . For a given graph G = ( V, E ) and an integer ∆ ≤ n , a vertex v is ∆-heavy if deg ( v, G ) ≥ ∆, otherwise it is ∆-light . When ∆ is clear from the context, we may omit it and simply refer to v as heavy or light . For a graph G = ( V, E ) and a positive integer ∆ ≤ n , let V ∆ = { v | deg ( v, G ) ≥ ∆ } be the set of ∆-heavy vertices in G . (Throughout, we sometimes simplify notation by omitting parameters which are clear from the context.) For a subgraph G ′ = ( V , E ′ ′ ) ⊆ G (where V ′ ⊆ V and E ′ ⊆ E ) and a pair of vertices u, v ∈ V , let dist( u, v, G ′ ) denote the shortest-path distance in edges between u and v in G ′ . For a path P = [ v , . . . , v 1 k ], let LastE ( P ) be the last edge of P , let | P | denote its length and let P v , v [ i j ] be the subpath of P from v i to v j . For paths P 1 and P 2 , denote by P 1 ◦ P 2
1 The role of the weights W is to perturb the edge weights by letting W e ( ) = 1+ glyph[epsilon1] for a random infinitesimal glyph[epsilon1] > 0.
the path obtained by concatenating P 2 to P 1 . For 'visual' clarity, the edges of these paths are considered throughout, to be directed away from the source node s . Given an s -t path P and an edge e = ( x, y ) ∈ P , let dist( s, e, P ) be the distance (in edges) between s and y on P . In addition, for an edge e = ( x, y ) ∈ T 0 ( s ), define dist( s, e ) = i if dist( s, x, G ) = i -1 and dist( s, y, G ) = i . A vertex w is a divergence point of the s -v paths P 1 and P 2 if w ∈ P 1 ∩ P 2 but the next vertex u after w (i.e., such that u is closer to v ) in the path P 1 is not in P 2 .
Basic Tools. We consider the following graph structures.
Definition 2.1 ( ( α, β, S ) -AMBFS FT-spanners) A subgraph H ⊆ G is an ( α, β, S ) -FT-AMBFS (approximate multi-BFS) structure with respect to S if for every ( s, t ) ∈ S × V and every v ∈ V , dist( s, t, H \ { v } ) ≤ α · dist( s, t, G \ { v } ) + β .
Definition 2.2 ( ( α, β ) FT-spanners) A subgraph H ⊆ G is an ( α, β ) FT-spanner if it is an ( α, β, V ) -FT-AMBFS structure for G with respect to V .
Throughout, we restrict attention to the case of a single vertex fault. When α = 1, H is termed ( β, S ) -additive FT-spanner. In addition, in case where S = V , H is an β -additive FT-spanner.
FT-Clustering Graph. A subset Z ⊆ V is an FT-center set for V if every ∆heavy vertex v has at least two neighbors in Z , i.e., | Γ( v, G ) ∩ Z | ≥ 2. For every heavy vertex v ∈ V ∆ , let Z v ( ) = { z 1 ( v , z ) 2 ( v ) } be two arbitrary neighbors of v in Z . The clustering graph G ∆ ⊆ G consists of the edges connecting the ∆-heavy vertices v to their two representatives in Z as well as all edges incident to the ∆-light vertices. Formally,
$$G _ { \Delta } = \bigcup _ { v \in V _ { \Delta } } \{ ( v, z _ { 1 } ( v ) ), ( v, z _ { 2 } ( v ) ) \} \cup \bigcup _ { v \notin V _ { \Delta } } E ( v, G ).$$
The ∆heavy vertices are referred hereafter as clustered , hence every missing edge in G \ G ∆ is incident to a clustered vertex.
For every center vertex z ∈ Z , let C z be the cluster consisting of z and all the ∆-heavy vertices it represents, i.e., C z = { z } ∪ { v ∈ V ∆ | z ∈ Z v ( ) } . Note that every center z is connected via a star to each of the vertices in its cluster C z , hence the diameter of each cluster C z in G ∆ is 2.
glyph[negationslash]
For a failing vertex v and a heavy vertex t , let z v ( ) t ∈ Z t ( ) \{ } v be a cluster center of t in G \{ } v . In particular, if z 1 ( ) = t v , then z v ( ) = t z 1 ( ), t else z v ( ) = t z 2 ( ). t Let C v ( ) be the cluster centered t at z v ( ). t Note that since every heavy vertex has two cluster centers z 1 ( ) t and z 2 ( ), t we have the guarantee that at least one of them survives the single vertex fault event. The next observation summarizes some important properties of the clustering graph.
## Observation 2.3 (1) | E G ( ∆ ) | = O (∆ · n ) .
- (2) Every missing edge is incident to a clustered vertex in V ∆ .
- (3) The diameter of every cluster C z is 2 .
- (4) There exists an FT-center set Z ⊆ V of size | Z | = ˜ O n/ ( ∆) .
Obs. 2.3(4) follows by a standard hitting set argument.
Replacement Paths. For a source s , a target vertex t and a vertex v ∈ G , a replacement path is the shortest s -t path P s,t,v ∈ SP s,t, G ( \ { v } ) that does not go through v .
Observation 2.4 Every path P s,t,v contains at most 3 n/ ∆ ∆ -heavy vertices.
Proof: Note that
$$3 n \, \geq \, 3 \cdot \left | \bigcup _ { x \in P _ { s, t, v } \cap V _ { \Delta } } \Gamma ( x, G \, \{ v \} ) \right | \geq \sum _ { x \in P _ { s, t, v } \cap V _ { \Delta } } \deg ( x, G \, \{ v \} ) \geq | P _ { s, t, v } \cap V _ { \Delta } | \cdot \Delta$$
where the second inequality follows by the fact the every vertex u ∈ V \{ } v has at most 3 neighbors on P s,t,v . The observation follows.
New-ending replacement paths . Areplacement path P s,t,v is called new-ending if its last edge is different from the last edge of the shortest path π s, t ( ). Put another way, a new-ending replacement path P s,t,v has the property that once it diverges from the shortest-path π s, t ( ) at the vertex b , it joins π s, t ( ) again only at the final vertex t . It is shown in [17] that for a given graph G and a set S of source vertices, a structure H ⊆ G containing a BFS tree rooted at each s ∈ S plus the last edge of each new-ending replacement path P s,t,v for every ( s, t ) ∈ S × V and every v ∈ V , is an FT-MBFS structure with respect to S . Our algorithms exploit the structure of new-ending replacement paths to construct ( β, S )-additive FT-spanners. Essentially, a key section in our analysis concerns with collecting the last edges from a subset of new-ending replacement paths as well as bounding the number of new-ending paths P s,t,v whose detour segments intersect with π s , t ( ′ ) \{ } t for some other source s ′ ∈ S .
The basic building block. Our constructions of β -additive FT-spanners, for β ≥ 2, consist of the following two building blocks: (1) an FT-clustering graph G ∆ for some parameter ∆, and (2) an ( β -2 , Z )-additive FT-spanner where Z is an FT-center set (i.e., cluster centers) for the vertices.
Lemma 2.5 Let β ≥ 2 and H = G ∆ ∪ H β -2 ( Z ) where Z is an FT-center set for V ∆ . Then H is an β additive FT-spanner.
Proof: Consider vertices u , u 1 2 , u 3 ∈ V . Let P ∈ SP u ,u ,G ( 1 2 \ { u 3 } ) be the u 1 -u 2 replacement path in G \ { u 3 } and let ( x, y ) be the last missing edge on P \ H (i.e., closest to u 2 ). Since G ∆ ⊆ H , by Obs. 2.3(2), y is a clustered vertex. Let z = z u 3 ( y ) be the cluster center of y in G \ { u 3 } , and consider the following u 1 -u 2 path P 3 = P 1 ◦ P 2 where P 1 ∈ SP u ,z,H ( 1 \ { u 3 } ) and P 2 = ( z, y ) ◦ P y, u [ 2 ]. Clearly, P 3 ⊆ H \{ u 3 } , so it remains to bound its length. Since H β -2 ( Z ) ⊆ H , it holds that | P 1 | ≤ dist( u , z, G 1 \ { u 3 } ) + β -2. Hence,
$$\text{dist} ( u _ { 1 }, u _ { 2 }, H \, \langle \{ u _ { 3 } \} ) & \ \leq \ \ | P _ { 3 } | \ = \ | P _ { 1 } | + | P _ { 2 } | \\ & \ \leq \ \text{dist} ( u _ { 1 }, z, G \, \langle \{ u _ { 3 } \} ) + \beta - 2 + \text{dist} ( y, u _ { 2 }, G \, \langle \{ u _ { 3 } \} ) \\ & \ \leq \ \text{dist} ( u _ { 1 }, y, G \, \langle \{ u _ { 3 } \} ) + \text{dist} ( y, u _ { 2 }, G \, \langle \{ u _ { 3 } \} ) + \beta \\ & \ \leq \ \ | P | + \beta \ = \ \text{dist} ( u _ { 1 }, u _ { 2 }, G \, \langle \{ u _ { 3 } \} ) + \beta$$
where the second inequality follows by the triangle inequality using the fact that the edge ( z, y ) exists in H \ { u 3 } . The lemma follows.
## 3 Additive Stretch 2
We begin by considering the case of additive stretch 2. We make use of the construction of FT-MBFS structures presented in [17].
Fact 3.1 ([17]) There exists a polynomial time algorithm that for every n -vertex graph G = ( V, E ) and source set S ⊆ V constructs an FT-MBFS structure H S 0 ( ) from each source s i ∈ S , tolerant to one edge or vertex failure, with a total number of O ( √ | S | · n 3 2 / ) edges.
Set ∆ = glyph[ceilingleft] n 2 3 / glyph[ceilingright] and let Z be an FT-center set for V ∆ as given by Obs. 2.3(4). Let H Z 0 ( ) be an FT-MBFS structure with respect to the source set Z as given by Fact 3.1. Then, let H = G ∆ ∪ H Z . 0 ( ) Thm. 1.1 follows by Lemma 2.5, Obs. 2.3 and Fact 3.1.
## 4 Sourcewise additive FT-spanners
In this section, we present two constructions of (4 , S ) and (8 , S ) additive FT-spanners with respect to a given source set S ⊆ V . The single source case (where | S | = 1) is considered in [18], which provides a construction of a single source FT-spanner 2 with O n ( 4 3 / ) edges and additive stretch 4. The current construction increases the stretch to 8 to provide a bounded stretch for ˜ O n ( 1 3 / ) sources with the same order of edges, ˜ O n ( 4 3 / ).
## 4.1 Sourcewise spanner with additive stretch 4
Lemma 4.1 There exists a subgraph H S 4 ( ) ⊆ G with ˜ O (max {| S | · n, ( n/ S | | ) 3 } ) edges satisfying dist( s, t, H 4 ( S ) \ { v } ) ≤ dist( s, t, G \ { v } ) + 4 for every ( s, t ) ∈ S × V and v ∈ V .
The following notation is useful in our context. Let C = { C z | z ∈ Z } be the collection of clusters corresponding to the FT-centers Z . For a source s ∈ S and a cluster C z ∈ C rooted at FT-center z ∈ Z , let LCA ( s, C z ) be the least common ancestor (LCA) of the cluster vertices of C z in the BFS tree T 0 ( s ) rooted at s . Let π s, C ( z ) be the path connecting s and LCA ( s, C z ) in T 0 ( s ).
## 4.1.1 Algorithm Cons4SWSpanner for constructing H S 4 ( ) spanner
Step (0): Replacement-path definition. For every ( s, t ) ∈ S × V and every v ∈ V , let P s,t,v = SP s,t, G ( \ { v } , W ).
Step (1): Clustering. Set ∆ = | S | and let Z ⊆ V be an FT-center set of size ˜ O n/ ( ∆) (by Obs. 2.3(4) such set exists). Let C = { C z | z ∈ Z } be the collection of | Z | clusters. For a heavy vertex t , let C 1 ( ) t , C 2 ( ) be its two clusters in t C corresponding to the centers z 1 ( ) and t z 2 ( ) respectively. t
2 The construction of [18] supports a single edge failure, yet, it can be modified to overcome a single vertex failure as well.
Step (2): Shortest-path segmentation. For every ( s, t ) ∈ S × V ∆ , the algorithm uses the first cluster of t , C 1 ( ), to segment the path t π s, t ( ). Define
$$\pi ^ { f a r } ( s, t ) = \pi ( s, \ell ( s, t ) ) \, \sum \{ \ell ( s, t ) \} \ \text{ and } \ \pi ^ { n e a r } ( s, t ) = \pi ( \ell ( s, t ), t ) \, \sum \{ \ell ( s, t ) \},$$
where glyph[lscript] ( s, t ) = LCA ( s, C 1 ( )) t is the LCA of the cluster C 1 ( ) t in the tree T 0 ( s ). Hence, π s, t ( ) = π far ( s, t ) ◦ glyph[lscript] ( s, t ) ◦ π near ( s, t ). The algorithm handles separately vertex faults in the near and far segments. Let V near ( s, t ) = V ( π near ( s, t )) and V far ( s, t ) = V ( π far ( s, t )).
## Step (3): Handling faults in the cluster center and the LCA. Let
$$E ^ { l o c a l } ( t ) = \{ \text{Last} \, E ( P _ { s, t, v } ) \ | \ s \in S, v \in \{ z _ { 1 } ( t ), \text{LCA} ( s, C _ { 1 } ( t ) ) \} \} \text{ and } E ^ { l o c a l } = \bigcup _ { t \in V _ { \Delta } } E ^ { l o c a l } ( t ),$$
be the last edges of replacement-paths protecting against the failure of the primary cluster center z 1 ( ) and the least common ancestor t LCA ( s, C 1 ( )). t
Step (4): Handling far vertex faults V far ( s, t ) . A replacement path P s,t,v is new-ending if its last edge is not in ( T 0 ( S ) ∪ G ∆ ). For a new-ending path P s,t,v , let b s,t,v be the unique divergence point of P s,t,v from π s, t ( ) (in the analysis we show that such point exists). Let D s,t,v = P s,t,v [ b s,t,v , t ] denote the detour segment and let D + s,t,v = D s,t,v \{ b s,t,v } denote the detour segment excluding the divergence point. For every clustered vertex t , let P far ( ) be the collection of new-ending t s -t paths protecting against vertex faults in the far segments, i.e., P far ( ) = t { P s,t,v | s ∈ S, LastE ( P s,t,v ) / ∈ T 0 ( S ) and v ∈ V far ( s, t ) } .
The algorithm divides this set into two subsets P far dep ( ) and t P far indep ( ) depending on the structure t of the partial detour segment D + s,t,v . A new-ending path P s,t,v is dependent if D + s,t,v intersects π s , t ( ′ ) \ { } t for some s ′ ∈ S , i.e., for a dependent path P s,t,v , it holds that glyph[negationslash]
$$V ( D _ { s, t, v } ^ { + } ) \cap V ( T ( t, S ) ) \neq \{ t \} \.$$
Otherwise, it is independent . Let glyph[negationslash]
$$\mathcal { P } _ { d e p } ^ { f a r } ( t ) = \{ P _ { s, t, v } \in \mathcal { P } ^ { f a r } ( t ) \ | \ s \in S, v \in V ^ { f a r } ( s, t ) \text{ and } V ( D _ { s, t, v } ^ { + } ) \cap V ( T ( t, S ) ) \neq \{ t \} \}$$
be the set of all S ×{ } t dependent paths and let P far indep ( ) = t P far \P far dep ( ) be the set of independent t paths.
Step (4.1): Handling dependent new-ending paths. The algorithm simply takes the last edges E far dep ( ) of all dependent replacement paths where t E far dep ( ) = t { LastE ( P ) | P ∈ P far dep ( ) t } . (In the analysis section, we show that the E far dep ( ) sets are sparse.) t Let E far dep = ⋃ t ∈ V ∆ E far dep ( ). t
Step (4.2): Handling independent new-ending paths. The algorithm employs a modified path-buying procedure on the collection P far indep = ⋃ t ∈ V ∆ P far indep ( ) of new-ending independent paths. t The paths of P far indep are considered in some arbitrary order. A path P ∈ P far indep is bought, if it improves the pairwise cluster distances in some sense. Starting with
$$G _ { 0 } = T _ { 0 } ( S ) \cup G _ { \Delta } \cup E ^ { l o c a l } \cup E ^ { f a r } _ { d e p }$$
at step τ ≥ 0, the algorithm is given G τ ⊆ G and considers the path P τ = P s,t,v . Let e = ( x, y ) be the first missing edge on P τ \ E G ( τ ) (where x is closer to s ). Note that since G ∆ ⊆ G 0 , both x and t are clustered. Recall that for a clustered vertex u and a failing vertex v , C v ( u ) is the cluster of u centered at z v ( u ) ∈ Z u ( ) \{ } v . For every cluster C , let V f ( C ) be the collection of vertices appearing on the paths π s, C ( ) = π s, ( LCA ( s, C )) for every s ∈ S excluding the vertices of the clusters. That is,
$$V _ { f } ( C ) = \bigcup _ { s \in S } V ( \pi ( s, C ) ) \, \langle \, C.$$
The path P τ is added to G τ resulting in G τ +1 = G τ ∪ P τ , only if
$$\text{dist} ( x, t, P _ { \tau } ) < \text{dist} ( C _ { v } ( x ), C _ { v } ( t ), G _ { \tau } \, \langle V _ { f } ( C _ { v } ( t ) ) ).$$
Let τ ′ = |P far indep | be the total number of independent paths considered to be bought by the algorithm. Then, the algorithm outputs H S 4 ( ) = G . τ ′ This completes the description of the algorithm.
Analysis. Throughout the discussion, we consider a P s,t,v paths of clustered vertices t ∈ V ∆ . A path P s,t,v is a new-ending path, if LastE ( P s,t,v ) / G ∈ 0 (see Eq. (2)). Let b s,t,v be the first divergence point of P s,t,v and π s, t ( ).
Lemma 4.2 For every vertex u ∈ P s,t,v such that LastE ( P s,t,v [ s, u ]) / T ∈ 0 ( S ) , it holds that: (a) v ∈ π s, u ( ) . (b) V ( P s,t,v [ b s,t,v , u ]) ∩ V ( π s, u ( )) = { b s,t,v , u } .
Proof: Begin with (a). Assume towards contradiction otherwise. By the uniqueness of the weight assignment W , we get that P s,t,v [ s, u ] = SP s,u,G ( \ { v } , W ) = π s, u ( ). Leading to contradiction to the fact that LastE ( P s,t,v ) not in T 0 ( S ). We next prove (b) and show that the divergence point b s,t,v is unique. By the definition of b s,t,v , it occurs on π s, t ( ) above the failing vertex v . Since by Lemma 4.2, v ∈ π s, u ( ), it also holds that b s,t,v ∈ π s, u ( ). Assume towards contradiction that there exists an additional point
$$w \in ( P _ { s, t, v } [ b _ { s, t, v }, u ] \cap \pi ( s, u ) ) \, \langle \{ b _ { s, t, v }, u \}.$$
There are two cases to consider (b1) v ∈ π b ( s,t,v , w ), in such a case, v / π w, u ∈ ( ) and hence π w, u ( ) = SP w,u,G ( \ { v } ) = P s,t,v [ w,u ], contradiction that LastE ( P s,t,v [ s, u ]) / T ∈ 0 ( S ). (b2) v ∈ π w, u ( ). In such a case, v / ∈ π b ( s,t,v , w ) and hence π b ( s,t,v , w ) = SP b ( s,t,v , w, G \ { v } ) = P s,t,v [ b s,t,v , w ], contradiction to the fact the b s,t,v is a divergence point from π s, t ( ). The claim holds.
The next claim shows that a new-ending P s,t,v path whose last edge is not in G 0 (see Eq. (2)), protecting against faults in the near segment, has a good approximate replacement ˜ P s,t,v in T 0 ∪ G ∆ .
Lemma 4.3 If LastE ( P s,t,v ) / G ∈ 0 and v ∈ π near ( s, t ) , then dist( s, t, ( G 0 ∪ G ∆ ) \{ } v ) ≤ dist( s, t, G \ { v } ) + 4 .
glyph[negationslash]
glyph[negationslash]
Proof: Since v ∈ π near ( s, t ), i.e., the failing vertex occurs strictly below LCA ( s, C 1 ( )) t on π s, t ( ), there exists a vertex w ∈ C 1 ( ) t such that v / π s, w ∈ ( ) (hence in particular w = v ). See Fig. 1. Since LastE ( P s,t,v ) / ∈ E local , it holds that v = z 1 ( ). t Consider the following s -w path P = π s, w ( ) ◦ [ w,z 1 ( ) t , t ]. Clearly, P ⊆ ( T 0 ( S ) ∪ G ∆ ) \ { v } . By the triangle inequality, as the diameter of the cluster C 1 ( ) is 2, it holds that t dist( s, t, ( T 0 ( S ) ∪ G ∆ ) \ { v } ) ≤ dist( s, w, G ) + 2 ≤ dist( s, t, G ) + 4 ≤ dist( s, t, G \ { v } ) + 4 .
Figure 1: Handling near vertex faults. Schematic illustration of an approximate replacement path in ( T 0 ∪ G ∆ ) \{ } v . Shown is an π s, t ( ) whose failing vertex v occurs strictly below the least common ancestor LCA ( s, C 1 ( )). t The alternative replacement path exploits the surviving π s, w ( ) ⊆ T 0 ( S ) path for w ∈ C 1 ( ) and the intracluster path connecting t w and v through z = z v ( ). t
The claim follows.
For every new-ending path P s,t,v , recall that D + s,t,v = D s,t,v \ { b s,t,v } . Let ( x, y ) be the first missing in P s,t,v \ G 0 (where x is closer to y ). The following auxiliary claims are useful.
Lemma 4.4 For every vertex u ∈ P s,t,v such that LastE ( P s,t,v [ s, u ]) / ∈ G 0 , it holds that: (a) C v ( u ) = C 1 ( u ) . (b) P s,t,v [ x, t ] ⊆ D + s,t,v .
glyph[negationslash]
glyph[negationslash]
Proof: Begin with (a). By the definition of the weight assignment W , it holds that P s,t,v [ s, u ] = P s,u,v = SP s,u,G ( \ { v } , W ). Since LastE ( P s,t,v [ s, u ]) / E ∈ local , it holds that v = z 1 ( u ), concluding that z v ( u ) = z 1 ( u ) and hence C v ( u ) = C 1 ( u ). Claim (a) follows. Consider claim (b). Let b = b s,t,v . We show that x = b , which implies the claim. By 4.2, v ∈ π s, y ( ). Since b appears above v on π s, t ( ), b is mutual to π s, t ( ) and π s, y ( ). Hence, the s -y shortest path has the following form: π s, y ( ) = π s, b ( ) ◦ π b, v ( ) ◦ π v, y ( ). Since b = v = y , dist( y, b, G ) ≥ 2, and hence also dist( y, b, G \ { v } ) ≥ 2, concluding that b = x . The lemma follows.
glyph[negationslash]
glyph[negationslash]
glyph[negationslash]
Corollary 4.5 Let t ∈ V ∆ . For every P s,t,v ∈ P far indep ( ) t , P s,t,v [ x, t ] ∩ V f ( C v ( )) = t ∅ where x is the first vertex of D + s,t,v .
Proof: Since P s,t,v is independent, by Eq. 1, D + s,t,v ∩ T t, S ( ) = { } t . Since t ∈ C v ( ), t by Eq. (3), t / V ∈ f ( C v ( )) and hence t D + s,t,v ∩ V f ( C v ( )) = t ∅ . The corollary follows by combining with Lemma 4.4(b).
Correctness analysis of H S 4 ( ) . We now show that H S 4 ( ) is a (4 , S ) FT-spanner.
Lemma 4.6 H S 4 ( ) is a (4 , S ) FT-spanner.
Proof: Let H = H S 4 ( ). The proof is by contradiction. Assume that there exists a vertex s ∈ S , a target vertex t and a failing vertex v such that dist( s, t, H \ { v } ) > dist( s, t, G \ { v } ) + 4. Let
$$B P = \{ ( t, v ) \ | \ t \in V, v \in ( V \cup \{ \emptyset \} ) \ \text{ and} \\ \text{dist} ( s, t, H \, \searrow \{ v \} ) > \text{dist} ( s, t, G \, \searrow \{ v \} + 4 \}$$
glyph[negationslash]
be the set of 'bad pairs' namely, vertex pair ( t, v ) whose additive stretch in H is greater than 4 with respect to s ∈ S . By the contradictory assumption BP = ∅ . Since the BFS tree T 0 ( s ) is in H , it holds that the failing vertex v ∈ π s, t ( ) for every pair ( t, v ) ∈ BP .
For every bad pair ( t, v ) ∈ BP define e t,v to be the last missing edge of P s,t,v = SP s,t, G ( \ { v } , W ) in H . Let d t, v ( ) = dist( s, e t,v , P s,t,v ) be the distance of the last missing edge from s on P s,t,v . Finally, let ( t 0 , v 0 ) ∈ BP be the pair that minimizes d t, v ( ), and let ee t 0 ,v 0 = ( u, t i ). Note that e t 0 ,v 0 is the shallowest 'deepest missing edge' over all bad pairs ( t, v ) ∈ BP .
## Lemma 4.7 The pair ( t , v i 0 ) ∈ BP .
Proof: Assume towards contradiction that ( t , v i 0 ) / BP ∈ and let P ′′ ∈ SP s,t , H ( i \ { v 0 } ). Hence, since ( t , v i 0 ) / BP ∈ , it holds that
$$| P ^ { \prime \prime } | \ & \leq \ \text{dist} ( s, t _ { i }, G \, \langle v _ { 0 } \} ) + 4 \\ & = \ \ | P _ { s, t _ { 0 }, v _ { 0 } } [ s, t _ { i } ] | + 4.$$
We now consider the following s -t 0 replacement path Q = P ′′ ◦ P s,t 0 ,v 0 [ t , t i 0 ]. By definition of ( t , v i 0 ) (last missing edge on P s,t i ,v 0 ), Q ⊆ H \ { v 0 } . In addition,
$$| Q | \ & = \ | P ^ { \prime \prime } | + | P _ { t _ { 0 }, v _ { 0 } } [ t _ { i }, t _ { 0 } ] | \leq | P _ { s, t _ { 0 }, v _ { 0 } } [ s, t _ { i } ] | + 4 + | P _ { s, t _ { 0 }, v _ { 0 } } ( t _ { i }, t _ { 0 } ) | \\ & = \ | P _ { s, t _ { 0 }, v _ { 0 } } | + 4 \ = \ \text{dist} ( s, t _ { 0 }, G \, \langle v _ { 0 } \} ) + 4$$
where the inequality follows by Eq. (5). This contradicts the fact that ( t 0 , v 0 ) ∈ BP .
Since π s, t ( i ) ⊆ H , by the fact that ( t , v i 0 ) ∈ BP , we have that the failing vertex v 0 occurs on the shortest-path π s, t ( i ). Since the last edge of P s,t i ,v 0 = P s,t 0 ,v 0 [ s, t i ] is missing, by the fact that the clustering graph G ∆ is in H , by Obs. 2.3(2), it holds that t i is clustered (i.e., t i ∈ V ∆ ). By step (2), since E local ⊆ H , it holds that v 0 / ∈ { z 1 ( t i ) , LCA ( s, C 1 ( t i )) } . Combining with Lemma 4.3, it holds that v 0 / V ∈ near ( s, t i ). Hence, v 0 ∈ V far ( s, t i ). There are further two cases. Case (1) P s,t i ,v 0 is dependant. By step (4.1), we then have that LastE ( P s,t i ,v 0 ) ∈ E far dep ( ), contradiction to the fact t that LastE ( P s,t i ,v 0 ) is missing in H .
Consider case(2) where P s,t i ,v 0 is an independent path, i.e., P s,t i ,v 0 ∈ P far indep ( ) and hence it was t considered to be bought in the path-buying procedure of Step (4.2). By the fact that the pair ( t , v i 0 ) is a bad pair (i.e., ( t , v i 0 ) ∈ BP ), we conclude that the algorithm did not buy the path. Let τ be the iteration at which P τ = P s,t i ,v 0 was considered to be purchased in the path-buying procedure. Let G τ be the current spanner in iteration τ . Let x be the vertex incident to the first missing edge on P τ \ E G ( τ ).
Let C 0 = C v 0 ( t i ) be the cluster of t i in G ∆ \ { v 0 } . Since LastE ( P τ ) / E ∈ local , by Lemma 4.4(a) C 0 = C 1 ( t i ) and z v 0 ( t i ) = z 1 ( t i ). By definition,
$$v _ { 0 } \in \pi ^ { f a r } ( s, t _ { i } ) = \pi ( s, C _ { 0 } ) \, \wedge \, \{ \text{LCA} ( s, C _ { 0 } ) \}.$$
Hence, in particular failing vertex is not in the cluster C 0 , i.e., v 0 / C ∈ 0 and by Eq. (3),
$$v _ { 0 } \in V _ { f } ( C _ { 0 } ).$$
Since P τ was not bought by the algorithm, by Eq. (4), we have that
$$\text{dist} ( C _ { v _ { 0 } } ( x ), C _ { 0 }, G _ { \tau } \, \sum V _ { f } ( C _ { 0 } ) ) \leq \text{dist} ( x, t _ { i }, P _ { \tau } ).$$
Let w 1 ∈ C v 0 ( x ) and w 2 ∈ C 0 be an arbitrary closest pair in G τ \ V f ( C 0 ) from the clusters C v 0 ( x ) and C 0 respectively satisfying that dist( w , w , G 1 2 τ \ V f ( C 0 )) = dist( C v 0 ( x , C ) 0 , G τ \ V f ( C 0 )).
glyph[negationslash]
Let z 1 (resp., z 2 ) be the cluster center of C v 0 ( x ) (resp., C 0 ). Consider the following s -t i replacement path in H \ { v 0 } , P 5 = P 1 ◦ P 2 ◦ P 3 ◦ P 4 where P 1 = P τ [ s, x ], P 2 = [ x, z 1 , w 1 ] and P 3 ∈ SP w ,w ,G ( 1 2 τ \ V f ( C 0 )) and P 4 = [ w , z 2 2 , t i ]. For an illustration see Fig. 2. We first claim that P 5 ⊆ H \ { v 0 } . Since x incident to the first missing edge on P τ , P 1 is in H \ { v 0 } . By Eq. (6), v 0 ∈ V f ( C 0 ) and since w , w 1 2 ⊆ G τ \ V f ( C 0 ) it also holds that w , w 1 2 = v 0 . Finally note that G ,G τ ∆ ⊆ H , hence P , P 2 4 ⊆ H \ { v 0 } . We next bound the length of P 5 .
$$\text{dist} ( s, t _ { i }, H \, \{ v _ { 0 } \} ) \ & \ \leq \ \ P _ { 5 } \ \leq \ \text{dist} ( s, x, G \, \{ v _ { 0 } \} ) + 2 + \text{dist} ( w _ { 1 }, w _ { 2 }, G _ { \tau } \, \| \vee \| _ { f } ( C _ { 0 } ) ) + 2 \\ & \ \leq \ \text{dist} ( s, x, G \, \{ v _ { 0 } \} ) + \text{dist} ( C _ { v _ { 0 } } ( x ), C _ { 0 }, G _ { \tau } \, \| \vee \| _ { f } ( C _ { 0 } ) ) + 4 \\ & \ \leq \ \text{dist} ( s, x, G \, \{ v _ { 0 } \} ) + \text{dist} ( x, t _ { i }, P _ { \tau } ) + 4 \\ & \ \leq \ \left | P _ { s, t _ { i }, v } \right | + 4 = \text{dist} ( s, t _ { i }, G \, \{ v _ { 0 } \} ) + 4, \\ \quad.. \ \quad \..$$
where Eq. (8) follows by Eq. (7). We end with contradiction to the fact that the pair ( t , v i 0 ) is a bad pair. The claim follows.
Size analysis of H S 4 ( ) . We proceed with the size analysis.
$$\text{Lemma } 4. 8 \text{ for every } t \in V _ { \Delta }, \, | E ^ { l o c a l } ( t ) | = O ( | S | ), \, \text{ hence } | E ^ { l o c a l } | = O ( | S | \cdot n ).$$
Bounding the number of last edges in E far dep ( ) t . We now turn to bound the number of edges added due to step (4.1), i.e., the last edges of new-ending dependent paths P s,t,v protecting against the faults in the far segment π far ( s, t ). To bound the number of edges in E far dep ( ), t consider the partial BFS tree rooted at t , T t, S ( ) ⊆ T 0 ( T ), whose leaf set is contained in the vertex set S where T t, S ( ) = ⋃ s ∈ S π s, t ( ). It is convenient to view this tree as going from the leafs towards the root, where the root t is at the bottom and the leafs are on the top of the tree. Let V + = S ∪ { u ∈ T t, S ( ) | deg ( u, T ( t, S )) ≥ } 3 , be the union of S and the vertices with degree at least 3 in the tree T t, S ( ). We have that | V + | < 2 | S | . A pair of vertices x, y ∈ V + is adjacent if their shortest-path π x, y ( ) is contained in the tree T t, S ( ) and it is free from any other V + vertex, i.e, π x, y ( ) ⊆ T t, S ( ) and π x, y ( ) ∩ V + = { x, y } . Let Π( V + ) = { π x, y ( ) | x, y ∈ V + and x, y are adjacent } be the collection of paths between adjacent pairs.
Observation 4.9 (1) T t, S ( ) = Π( V + ) . (2) Π( V + ) consists of at most 2 | S | +1 paths π x, y ( ) (i.e., there are at most 2 | S | adjacent pairs).
4-additive sourcewise FT-spanner.
Figure 2: Schematic illustration of the path-buying procedure of Alg. Cons4SWSpanner . Shown is an s -t path P τ = P s,t,v considered to be bought in time τ . The green paths correspond to shortest-paths in T 0 ( s ) and the red edges correspond to missing edges on P τ \ E G ( τ ). The first missing edge on P τ \ E G ( τ ) is incident to x . If P τ was not bought, then there exists a short route between a pair of vertices w 1 and w 2 belonging to C v ( x ) and C v ( ) (respectively) in t H \ { v } .
We now show the following.
Lemma 4.10 For every t ∈ V ∆ , | E far dep ( ) t | = O S ( | | ) .
We first claim that every two dependent replacement paths with the same divergence point have the same last edge.
Lemma 4.11 For every two dependent paths P s 1 ,t,v 1 , P s 2 ,t,v 2 ∈ P far dep ( ) t , if b s 1 ,t,v 1 = b s 2 ,t,v 2 then LastE ( P s 1 ,t,v 1 ) = LastE ( P s 1 ,t,v 2 ) .
Proof: Let b = b s 1 ,t,v 1 = b s 2 ,t,v 2 . Since b ∈ π s , t ( 1 ) ∩ π s , t ( 2 ) it holds that π s , t ( i ) = π s , b ( i ) ◦ π b, t ( ) for i ∈ { 1 2 , } . In addition, since P s ,t,v i i [ s , b i ] = π s , b ( i ) for i ∈ { 1 2 , } , it holds that both failing vertices v 1 and v 2 occur in the common segment π b, t ( ). Recall that P s ,t,v i i is a newending path, hence by the definition of the divergence point b (see Lemma 4.2(b)), it holds that V ( P s ,t,v i i [ b, t ]) ∩ V ( π b, t ( )) = { b, t } and hence both detours are free from the failing vertices. Hence, P s 1 ,t,v 1 [ b, t , P ] s 1 ,t,v 1 [ b, t ] = SP b,t, G ( \ { v , v 1 2 } ). We get that LastE ( P s 1 ,t,v 1 ) = LastE ( P s 2 ,t,v 2 ) as needed.
Since our goal is to bound the number of last edges of the new ending dependent paths P far dep ( ), t to avoid double counting, we now restrict attention to Q far ( ), a collection of representative paths in t P far dep ( ) each ending with a distinct new edge from t E far dep ( ). t Formally, for each new edge e ∈ E far dep ( ), t let P e ( ) be an arbitrary path in P far dep ( ) satisfying that t LastE ( P e ( )) = e . Let Q far ( ) = t { P e , e ( ) ∈ E far dep ( ) t } (hence |Q far ( ) t | = | E far dep ( ) ). t | From now on, we aim towards bounding the cardinality of
Q far ( ). t Let DP = { b s,t,v | P s,t,v ∈ Q far ( ) t } be the set of divergence points of the new ending paths in Q far ( ). t By Lemma 4.11, it holds that in order to bound the cardinality of P far dep ( ), it t is sufficient to bound the number of distinct divergence points. To do that, we show that every path π x, y ( ) of two adjacent vertices x, y ∈ V + , contains at most one divergence point in DP \ V + .
## Lemma 4.12 | π x, y ( ) ∩ ( DP \ V + ) | ≤ 1 for every π x, y ( ) ∈ Π( V + ) .
glyph[negationslash]
Proof: Assume, towards contradiction, that there are two divergence points b s 1 ,t,v 1 and b s 2 ,t,v 2 on some path π x, y ( ) for two adjacent vertices x, y ∈ V + . For ease of notation, let P i = P s ,t,v i i , b i = b s ,t,v i i , D i = D s ,t,v i i and D + i = D i \ { b i } for i ∈ { 1 2 , } . Without loss of generality, assume the following: (1) y is closer to t than x and (2) b 2 is closer to t than b 1 . By construction, the vertices s 1 and s 2 are in the subtree T x ( ) ⊆ T t, S ( ). For an illustration see Fig. 3. We now claim that the failing vertices v , v 1 2 occur on π y, t ( ). Since D + 1 and D + 2 are vertex disjoint with π y, t ( ) \{ } t , it would imply that both detour segments D 1 and D 2 are free from the failing vertices and hence at least one of the two new edges LastE ( P 1 ) , LastE ( P 2 ) could have been avoided. We now focus on v 1 and show that v 1 ∈ π y, t ( ), the exact same argumentation holds for v 2 . Since P 1 is a new-ending dependent path, by Eq. (1), there exists some source s 3 ∈ s \ { s 1 } satisfying that ( D + 1 ∩ π s , t ( 3 ) ) \ { } glyph[negationslash] t = ∅ . Let w ∈ ( D + 1 ∩ π s , t ( 3 ) ) \{ } t be the first intersection point (closest to s 1 ). See Fig. 3 for schematic illustration. We first claim that s 3 is not in the subtree T x ( ) ⊆ T t, S ( ) rooted at x . To see why this holds, assume, towards contradiction, that s 3 ∈ T x ( ). It then holds that the replacement path P 1 has the following form P 1 = π s , x [ 1 ] ◦ π x, b ( 1 ) ◦ P 1 [ b 1 , w ] ◦ P 1 [ w,t ]. Recall, that since b 1 ∈ DP \ V + , b 1 = x and also b 1 = w . Since P 1 [ x, w ] goes through b 1 , by the optimality of P 1 , it holds that glyph[negationslash]
$$\text{dist} ( x, w, G \, \sum \{ v _ { 1 } \} ) > \text{dist} ( b _ { 1 }, w, G \, \sum \{ v _ { 1 } \} ) \.$$
glyph[negationslash]
On the other hand, the path π s , t ( 3 ) has the following form: π s , t ( 3 ) = π s , w ( 3 ) ◦ π w, x ( ) ◦ π x, b ( 1 ) ◦ π b , t ( 1 ). Hence, π w, b ( 1 ) goes through x . Since the failing vertex v 1 ∈ π b , t ( 1 ) is not in π w, b ( 1 ), by the optimality of π w, b ( 1 ), we get that dist( w,b , G 1 \ { v 1 } ) > dist( x, w, G \ { v 1 } ), leading to contradiction with Ineq. (9). Hence, we conclude that s 3 / T ∈ ( x ) (in particular this implies that s 3 = s 2 ). Note that π w, t ( ) is a segment of π s , t ( 3 ) and hence it is contained in the tree T t, S ( ). Since P 1 is a new-ending path (i.e., LastE ( P 1 ) / ∈ T t, S ( )), we have that P 1 [ w,t ] = π w, t ( ) are distinct w -t paths. We next claim that the failing vertex v 1 must occur on π w, t ( ) and hence also on π s , t ( 3 ). To see this, observe that if π w, t ( ) would have been free from the failing vertex v 1 , then it implies that π w, t ( ) = SP w,t,G ( \{ v 1 } ) = P 1 [ w,t ], contradiction as LastE ( P 1 ) = LastE ( π w, t ( )). Finally, we show that v 1 ∈ π y, t ( ). By the above, the failing vertex v 1 is common to both paths π s , t ( 1 ) and π s , t ( 3 ), i.e., v 1 ∈ π s , t ( 1 ) ∩ π s , t ( 3 ). By the definition of the path π x, y ( ), all its internal vertices u have degree 2 and hence ( π x, y ( ) ∩ π s , t ( 3 )) \{ } y = ∅ , concluding that v 1 ∈ π y, t ( ). By the same argumentation, it also holds that v 2 is in π y, t ( ). As the detours D 1 and D 2 are vertex disjoint with π y, t ( ) \ { } t , it holds that they are free from the two failing vertices, i.e., v , v 1 2 / D ∈ 1 ∪ D 2 . Since P , P 1 2 ∈ Q far ( ), it holds that t LastE ( P 1 ) = LastE ( P 2 ), and hence there are two b 1 -t distinct shortest paths in G \{ v , v 1 2 } , given by D 1 and π b , b ( 1 2 ) ◦ D 2 . By optimality of these paths, they are of the same lengths. Again, we end with contradiction to the uniqueness of the weight assignment W . The claim follows.
glyph[negationslash]
glyph[negationslash]
glyph[negationslash]
By Lemma 4.11 there are at most | V + | replacement paths with divergence point in V + . By Lemma 4.12, there is at most one divergence point on each segment π x, y ( ) of an adjacent pair ( x, y ). Combining with Obs. 4.9(2), we get | E far ( ) t | = |Q far ( ) t | = O S ( | | ). The lemma follows.
Figure 3: Schematic illustration of new-ending dependent paths. Shown is the tree T t, S ( ) with the root t at the bottom and leaf set is contained in the set of sources S . (a) The two replacement paths have the same divergence point b , hence one of the new last edges is redundant. (b) A newending s 1 -t dependant path P s 1 ,t,v 1 with a divergence point b 1 ∈ π x, y ( ) intersects with π s , t ( 3 ) at the vertex w / ∈ { b 1 , t } . Since P s 1 ,t,v is a new-ending path (i.e., its last edges is not on T t, S ( )), the failing vertex v must occur on the path π w, t ( ). Hence v 1 ∈ π s , t ( 1 ) ∩ π s , t ( 3 ), implying that v 1 ∈ π y, t ( ). Since this holds for any new-ending path with a divergence point in π x, y ( ), we get that only one new edge from all these paths is needed.
We complete the size analysis and proves Lemma 4.1, by bounding the number of edges added by the path-buying procedure of Step (4.2).
Bounding the number of edges added due to the path-buying procedure. Finally, it remains to bound the number of edges added due to the path-buying procedure of step (4.2).
$$\text{Lemma } 4. 1 3 \ | H _ { 4 } ( S ) \, \sum G _ { 0 } | = \widetilde { O } ( ( n / | S | ) ^ { 3 } ).$$
Proof: Let B ⊆ P far indep ( ) be the set of paths bought in the path-buying procedure of Step (4.2). t For every ordered pair of clusters C , C 1 2 ∈ C , let B ( C , C 1 2 ) ⊆ B be the set of paths that were added since they improved the distance of C 1 and C 2 , that is
$$\mathcal { B } ( C _ { 1 }, C _ { 2 } ) = \{ P _ { \tau } \in \mathcal { B } \ | \ C _ { 1 } ( \tau ) = C _ { 1 } \text{ and } C _ { 2 } ( \tau ) = C _ { 2 } \}$$
Clearly, B = ⋃ C ,C 1 2 ∈C B ( C , C 1 2 ). We next use the fact that the diameter of each cluster C ∈ C is small, to bound the cardinality of the set B ( C , C 1 2 ).
$$\text{Lemma } 4. 1 4 \ | \mathcal { B } ( C _ { 1 }, C _ { 2 } ) | \leq 5 \text{ for every } C _ { 1 }, C _ { 2 } \in \mathcal { C }.$$
Proof: Fix C , C 1 2 ∈ C and order the paths of B ( C , C 1 2 ) according to the time step they were added to the spanner B ( C , C 1 2 ) = { P τ 1 , . . . , P τ N } where τ 1 < τ 2 < . . . < τ N where N = |B ( C , C 1 2 ) . | Since P τ k ∈ P far indep , it is a new-ending path, i.e., LastE ( P τ k ) / ∈ T 0 ( S ). Let P τ k = P s k ,t k ,v k and D τ k = D s k ,t k ,v k denote the detour segment of this path. Let x k be the vertex adjacent to the first missing edge on P τ k . Hence, C 1 = C v k ( x k ) and C 2 = C v k ( t k ) for every k ∈ { 1 , . . . , N } and also V f ( C v k ( t k )) = V f ( C 2 ) for every k ∈ { 1 , . . . , N } . Since T 0 ( S ) ⊆ G 0 , the missing edges of P τ k are restricted to the detour segment D τ k .
In addition, since P τ k ∈ P far indep , it holds that the failing vertex v k occurs on the far segment π far ( s k , t k ) and in particular, v k / C ∈ 2 (i.e., v k occurs strictly above the least common ancestor LCA ( s k , C 2 ) and since all cluster members appears on T 0 ( s k ) in the subtree rooted at LCA ( s k , C 2 ), the far segment π far ( s k , t k ) is free from cluster members). We therefore have
$$\{ v _ { 1 }, \dots, v _ { N } \} & \subseteq V _ { f } ( C _ { 2 } ) \.$$
Note that π s , C ( k 2 ) ⊆ π s , t ( k k ) and hence it is contained in T t , S ( k ) for every k ∈ { 1 , . . . , N } . By the definition of independent paths (see Eq. (1) for the definition of dependent paths), we have that
$$D _ { s _ { k }, t _ { k }, v _ { k } } ^ { + } \cap T ( t _ { k }, S ) = \left \{ t _ { k } \right \} \,.$$
Consequently, by Lemma 4.4(b),
$$P _ { \tau _ { k } } [ x _ { k }, t _ { k } ] \subseteq D _ { \tau _ { k } } ^ { + } \subseteq G \, \sum V _ { f } ( C _ { 2 } ) \.$$
glyph[negationslash]
where the last inclusion holds by the fact that t k / ∈ V f ( C 2 ) and V f ( C 2 ) ⊆ ⋃ s ∈ S π s, C ( 2 ) ⊆ ⋃ s ∈ S π s, t ( ) = T t, S ( ). Let z i ∈ Z be the cluster center of C i for i ∈ { 1 2 , } . We therefore have that z 1 = z v 1 ( x 1 ) = . . . = z v N ( x N ) and z 2 = z v 1 ( t 1 ) = . . . = z v N ( t N ) and hence z 2 = v k for every k ∈ { 1 , . . . , N } . Hence,
$$z _ { 1 }, z _ { 2 } & \notin \{ v _ { 1 }, \dots, v _ { N } \}.$$
For every k ∈ { 1 , . . . , N } , denote
$$X _ { k } = \text{dist} ( x _ { k }, t _ { k }, G _ { \tau _ { k + 1 } } \, \langle V _ { f } ( C _ { 2 } ) ).$$
We now show that X < X k k -1 for every k ∈ { 2 , . . . N } .
Since the path P τ k is purchased at time τ k , we have that
$$X _ { k } \ \leq \ \text{dist} ( x _ { k }, t _ { k }, P _ { \tau _ { k } } \, \langle V _ { f } ( C _ { 2 } ) )$$
$$= \text{ dist} ( x _ { k }, t _ { k }, P _ { \tau _ { k } } )$$
$$< \text{ dist} ( C _ { 1 }, C _ { 2 }, G _ { \tau _ { k } } \, \langle V _ { f } ( C _ { 2 } ) )$$
$$\leq \ X _ { k - 1 } \,,$$
where Eq. (14) follows by the fact that P τ k ⊆ G τ k +1 , Eq. (15) follows by Eq. (12). Eq. (16) follows by the fact that P τ k was bought and by Eq. (4), and Eq. (41) follows by the fact that x k -1 ∈ C 1 and t k -1 ∈ C 2 .
Therefore, we have that
$$X _ { N } \leq X _ { 1 } - ( N - 1 ) \.$$
Conversely, we have that
$$X _ { N } \ \geq \ \text{dist} ( x _ { N }, t _ { N }, G \, \sum \{ v _ { 1 }, \dots, v _ { N } \} )$$
$$\geq \text{ dist} ( x _ { 1 }, t _ { 1 }, G \, \sum \{ v _ { 1 }, \dots, v _ { N } \} ) - 4$$
$$= \ \text{dist} ( x _ { 1 }, t _ { 1 }, P _ { \tau _ { 1 } } ) - 4 = \text{dist} ( x _ { 1 }, t _ { 1 }, P _ { \tau _ { 1 } } \, \langle \, V _ { f } ( C _ { 2 } ) ) - 4$$
$$\geq \ X _ { 1 } - 4$$
where Eq. (19) follows as G τ N +1 ⊆ G and by Eq. (10), { v , . . . , v 1 N } ⊆ V f ( C 2 ). To see Eq. (20), we need to prove the existence of the intracluster paths R 1 = [ x , z 1 1 , x N ] and R 2 = [ t 1 , z 2 , t N ] in
G \{ v , . . . , v 1 N } where z 1 (resp., z 2 ) is the cluster center of C 1 (resp., C 2 ). By definition, x , x 1 N ∈ C 1 and t 1 , t N ∈ C 2 . Hence, z 1 (resp., z 2 ) is a common neighbor of both x 1 and x N (resp., t 1 and t N ). By (13), z , z 1 2 / ∈ { v , . . . , v 1 N } .
In addition, by Eq. (12), x , t k k ∈ G \ V f ( C 2 ) for every k ∈ { 1 , . . . , N } and by Eq. (10), it also holds that x , t k k / ∈ { v , . . . , v 1 N } for every k ∈ { 1 , . . . , N } . Hence, R 1 and R 2 exists in G \ { v , . . . , v 1 N } and Eq. (20) follows by the triangle inequality. Eq. (21) follows by Eq. (12) and Eq. (10). Finally, Eq. (22) follows by the fact that P τ 1 was added at step τ 1 , hence P τ 1 ⊆ G τ 2 . We get that N ≤ 5. The claim follows.
By Obs. 2.3(2) and Obs. 2.4, every path P τ k contains at most O n/ ( | ∆ ) = | O n/ S ( | | ) missing edges in G \ G ∆ . Hence,
$$| E ( G _ { \tau ^ { \prime } } \, \langle \, G _ { 0 } ) | \ = \ O ( n / | S | ) \cdot | \mathcal { B } |$$
$$\lq ^ { \prime } _ { \tau ^ { \prime } } \, \sum \, G _ { 0 } ) | \ & = \ \ & O ( n / | S | ) \cdot | \mathcal { B } | \\ & = \ \ & O ( n / | S | ) \cdot \sum _ { C _ { 1 }, C _ { 2 } \in \mathcal { C } } | \mathcal { B } ( C _ { 1 }, C _ { 2 } ) | \\ & \leq \ \ & O ( n / | S | ) \cdot | \mathcal { C } | ^ { 2 } = \widetilde { O } ( ( n / | S | ) ^ { 3 } ) \. \\ & \quad \quad \quad$$
where the last equality follows by the fact that |C| = ˜ O n/ S ( | | ). The claim follows.
## 4.2 Sourcewise spanner with additive stretch 8
In this section, we present Alg. Cons8SWSpanner for constructing a sourcewise additive FT-spanner with additive stretch 8. The size of the resulting spanner is smaller (in order) than the H S 4 ( ) spanner of Alg. Cons4SWSpanner , at the expense of larger stretch. The algorithm is similar in spirit to Alg. Cons4SWSpanner and the major distinction is in the path-buying procedure of step (4.2).
Lemma 4.15 There exists a subgraph H S 8 ( ) ⊆ G with ˜ O (max {| S |· n, ( n/ S | | ) 2 } ) edges s.t. dist( s, t, H 8 ( S ) \ { v } ) ≤ dist( s, t, G \ { v } ) + 8 for every ( s, t ) ∈ S × V and every v ∈ V .
## 4.2.1 Algorithm Cons8SWSpanner for constructing H S 8 ( ) spanner
Step (0-4.1): Same as in Alg. Cons4SWSpanner . Let E local , E far dep be the set of last edges obtained at the end of step (3) and set (4.1) respectively. Let P far indep be the set of new-ending independent paths.
Step (4.2): Handling independent new-ending paths. Starting with G 0 as in Eq. (2), the paths of P far indep are considered in an arbitrary order. At step τ , we are given G τ ⊆ G and consider the path P τ = P s,t,v . Let D τ = P τ \ π s, t ( ) be the detour segment of P τ (since π s, t ( ) ⊆ T 0 ( S ) is in G 0 , all missing edges of P τ occur on its detour segment).
To decide whether P τ should be added to G τ , the number of pairwise cluster 'distance improvements' is compared to the number of new edges added due to P τ . To do that we compute the set ValSet ( P τ ) containing all pairs of clusters that achieves a better distance if P τ is bought. The value and cost of P τ are computed as follows. Let Val ( P τ ) = | ValSet ( P τ ) | as the number of distance improvements as formally defined later. We next define a key vertex φ τ ∈ V ∆ on the path P τ .
Definition 4.16 Let φ s,t,v (or φ τ for short) be the last vertex on P τ (closest to t ) satisfying that: (N1) LastE ( P τ [ s, φ τ ]) / G ∈ τ , and (N2) v ∈ π near ( s, φ τ ) = π glyph[lscript], ( φ τ ) \ { glyph[lscript] } where glyph[lscript] = LCA ( s, C v ( φ τ )) . If there is no vertex on P τ that satisfies both (N1) and (N2), then let φ τ be the first vertex incident to the first missing edge on P τ \ E G ( τ ) (i.e., such that P τ [ s, φ τ ] is the maximal prefix that is contained in G τ ).
Let Q τ = P τ [ φ , t τ ] and define Cost ( P τ ) = | E Q ( τ ) \ E G ( τ ) | be the number of edges of Q τ that are missing in the current subgraph G τ . Thus Cost ( P τ ) represents the increase in the size of the spanner G τ if the procedure adds Q τ . Our algorithm attempts to buy only the suffix Q τ of P τ when considering P τ . We now define the set ValSet ( P τ ) ⊆ C × C which contains a collection ordered cluster pairs. Let C 1 ( τ ) = C v ( φ τ ) and C 2 ( τ ) = C v ( ) be the clusters of t φ τ and t in G ∆ \ { v } . Let κ = Cost ( P τ ). The candidate P τ is said to be cheap if κ ≤ 4, otherwise it is costly . The definition of ValSet ( P τ ) depends on whether or not the path is cheap. In particular, if P τ is cheap, then let ValSet ( P τ ) = { ( C 1 ( τ ) , C 2 ( τ )) } only if
$$\text{dist} ( \phi _ { \tau }, t, P _ { \tau } ) < \text{dist} ( C _ { 1 } ( \tau ), C _ { 2 } ( \tau ), G _ { \tau } \, \sum V _ { f } ( C _ { 2 } ( \tau ) ) )$$
where V f ( C 2 ( τ )) is as given by Eq. (3), and let ValSet ( P τ ) = ∅ otherwise. Alternatively, if P τ is costly, we do the following.
Definition 4.17 Let U s,t,v = { u 3 +1 glyph[lscript] | glyph[lscript] ∈ { 0 , . . . , glyph[floorleft] ( κ -1) / 3 glyph[floorright]}} ⊆ Q τ be some representative endpoints of missing edges on Q τ satisfying that
$$\text{LastE} ( Q _ { \tau } [ \phi _ { \tau }, u _ { \ell } ] ) \notin G _ { \tau } \text{ for every } u _ { \ell } \in U _ { s, t, v } \text{ and dist} ( u _ { \ell }, u _ { \ell ^ { \prime } }, Q _ { \tau } ) \ \geq \ 3$$
for every u , u glyph[lscript] glyph[lscript] ′ ∈ U s,t,v .
Define
$$\text{valSet} _ { 1 } ( P _ { \tau } ) \ = \ \{ ( C _ { 1 } ( \tau ), C _ { \ell } ) \ | \ C _ { \ell } = C _ { v } ( u _ { \ell } ), u _ { \ell } \in U _ { s, t, v } \\ \text{and dist} ( \phi _ { \tau }, u _ { \ell }, P _ { \tau } ) < \text{dist} ( C _ { 1 } ( \tau ), C _ { \ell }, G _ { \tau } \, \searrow \, V _ { f } ( C _ { \ell } ) ) \}$$
and
$$\text{valSet} _ { 2 } ( P _ { \tau } ) \ = \ \{ ( C _ { \ell }, C _ { 2 } ( \tau ) ) \ | \ C _ { \ell } = C _ { v } ( u _ { \ell } ), u _ { \ell } \in U _ { s, t, v } \\ \text{ and dist} ( u _ { \ell }, t, P _ { \tau } ) < \text{dist} ( C _ { \ell }, C _ { 2 } ( \tau ), G _ { \tau } \, \sum V _ { f } ( C _ { 2 } ( \tau ) ) ) \}$$
Let ValSet ( P τ ) = ValSet 1 ( P τ ) ∪ ValSet 2 ( P τ ). The subpath Q τ is added to G τ resulting in G τ +1 only if
$$\text{Cost} ( P _ { \tau } ) \leq 4 \cdot \text{Val} ( P _ { \tau } )$$
where Val ( P τ ) = | ValSet ( P τ ) . | (Note that when P τ is cheap, Eq. (29) holds iff Eq. (26) holds.) The output of Alg. Cons8SWSpanner is the subgraph H S 8 ( ) = G τ ′ where τ ′ = |P far indep | . This completes the description of the algorithm.
Analysis. Throughout the discussion, a path P s,t,v is a new-ending path, if LastE ( P s,t,v ) / G ∈ 0 (see Eq. (2)). Hence, we consider only P s,t,v ∈ P far indep ( ) paths for clustered vertices t t ∈ V ∆ .
For a new-ending path P s,t,v , recall that b s,t,v is the unique divergence point of P s,t,v and π s, t ( ) and let D s,t,v be the detour segment, i.e., D s,t,v = P s,t,v [ b s,t,v , t ] and D + s,t,v = D s,t,v \ { b s,t,v } . Let Q s,t,v = P s,t,v [ φ s,t,v , t ] be the path segment that was considered to be bought in step (4.2) (see Def. 4.16).
## Observation 4.18 Q s,t,v ⊆ D + s,t,v .
Proof: Let x be the first vertex incident to a new-edge on P s,t,v (such that P s,t,v [ s, x ] is the maximal prefix that is contained in G 0 ). Since φ s,t,v occurs not before x on P s,t,v the observation follows by Lemma 4.4(b).
Lemma 4.19 Let P s,t,v ∈ P far indep ( ) t be a new-ending replacement path. Then for every u k ∈ U s,t,v ∪ { } t with C k = C v ( u k ) it holds that:
- (a) C k = C 1 ( u k ) .
- (b) V ( P s,t i ,v [ b s,t,v , u k ]) ∩ V ( T u , S ( k )) = { b s,t,v , u k } .
- (c) Q s,t,v [ φ s,t,v , u k ] ∩ V f ( C k ) = {∅} .
- (d) v ∈ V f ( C k ) .
Proof: We begin with (a). By the uniqueness of the weight assignment W P , s,t i ,v [ s, u k ] = P s,u k ,v = SP s,u ,G ( k \{ } v , W ). By the uniqueness of the divergence point b s,t,v and in particular by Lemma 4.2(b),
$$b _ { s, t, v } = b _ { s, u _ { k }, v } \.$$
glyph[negationslash]
Since LastE ( P s,u k ,v ) / E ∈ local , concluding that v = z 1 ( u k ) and hence z v ( u k ) = z 1 ( u k ) and (a) holds. Consider (b). By the definition of the set U s,t,v (see Def. 4.17), it holds LastE ( P s,u k ,v ) / G ∈ 0 . Since u k ∈ Q s,t,v occurs strictly after φ s,t,v , by the definition Def. 4.16, it holds that u k did not satisfy property (N2). Hence, since LastE ( P s,u k ,v ) / E ∈ local , v / ∈ { z 1 ( u k ) , LCA ( s, C 1 ( u k )) } and hence v ∈ π far ( s, u k ). As LastE ( P s,u k ,v ) / E ∈ far dep ( u k ), we get that P s,u k ,v is a new-ending independent path. By Eq. (1), V ( P s,u k ,v [ b s,u k ,v , u k ]) ∩ V ( T u , S ( k )) = { b s,u k ,v , u k } . Hence (b) holds by Eq. (30).
glyph[negationslash]
We now turn to consider claim (c). By Eq. (3), V f ( C v ( u k )) ⊆ T u , S ( k ). Since C v ( u k ) ∩ V f ( C v ( u k )) = ∅ , it holds that u k / V ∈ f ( C v ( u k )), and hence by combining with claim (a), we get that P s,u k ,v [ b s,u k ,v , u k ] ∩ V f ( C v ( u k )) = { b s,u k ,v } . Since by the proof of Lemma 4.4(b), φ s,t,v = b s,u k ,v , hence Q s,t,v [ φ s,t,v , u k ] ∩ V f ( C v ( u k )) = ∅ .
Consider claim (d). By the above, v occurs on the far segment π s, C ( k ) \ { LCA ( s, C k ) } , hence v / C ∈ k . Since ( π s, C ( k ) \ C k ) ⊆ V f ( C k ), (d) holds.
The next observation is useful in our analysis.
Observation 4.20 If φ s,t,v satisfies (N1) and (N2), then there exists a vertex x ∈ C v ( φ s,t,v ) satisfying that v / π s, x ∈ ( ) .
Proof: Let P τ = P s,t,v and φ τ = φ s,t,v . By the uniqueness of the weight assignment W P s,φ , τ [ τ ] = P s,φ τ ,v = SP s,φ ,G ( τ \ { v } , W ). Since φ τ satisfies (N2), it holds that the failing vertex v occurs on π near ( s, φ τ ), strictly below (i.e., closer to φ τ ) the least common ancestor LCA ( s, C v ( φ τ )) on π s, φ ( τ ). Hence, there must exist a vertex x ∈ C v ( φ τ ) such that v / π s, x ∈ ( ) (otherwise, if v is shared by
π s, u ( ) for all cluster members u , then we end with contradiction to the definition of the least common ancestor LCA ( s, C v ( φ τ ))).
We proceed by showing correctness.
Theorem 4.21 H S 8 ( ) is a (8 , S ) FT-spanner.
Proof: Let H = H S 8 ( ). It is required to show that dist( s, t, H \ { v } ) ≤ dist( s, t, G \ { v } ) + 8 for every ( s, t ) ∈ S × V and v ∈ V . By the analysis of Alg. Cons4SWSpanner (Lemma 4.6), it remains to consider the case of independent new-ending paths where P s,t,v ∈ P far indep ( ) for t t ∈ V ∆ .
Let τ be the iteration at which P τ = P s,t,v was considered to be added to the spanner at step (4.2), and let κ = Cost ( P τ ) denote its cost. Let φ τ be as defined in Def. 4.16 and recall that Q τ = P τ [ φ , t τ ] is the candidate suffix to be bought by the procedure. (In particular, Cost ( P τ ) counts the number of edges on Q τ \ E G ( τ ).)
Case (1): Q τ was bought. If φ τ did not satisfy neither properties (N1), (N2) (or both), then P τ [ s, φ τ ] ⊆ G τ . Since P τ = P τ [ s, φ τ ] ◦ Q τ and Q τ was added to the spanner, we get that P τ ⊆ H \{ v } . By Obs.
It remains to consider the complementary case where φ τ satisfies both (N1) and (N2). 4.20, we get that there exist x ∈ C v ( φ τ ) satisfying that v / π s, x ∈ ( ).
Consider the path P = π s, x ( ) ◦ ( x, z v ( φ τ ) , φ τ ). By definition, P ⊆ H \{ } v and by the existence of the intracluster path connecting x and φ τ in G \ { v } , it holds that | P | = dist( s, x, G \ { v } ) + 2 ≤ dist( s, φ τ , G \ { v } ) + 4. Hence, letting P ′ = P ◦ Q τ (where Q τ = P τ [ φ , t τ ]), since Q τ ⊆ H \ { v } , it holds that P ′ ⊆ H \ { v } and | P ′ | ≤ | P τ | +4, as required.
Case (2): Q τ was not bought. Let x ∈ C v ( φ τ ) be defined as follows. If φ τ satisfies both properties (N1) and (N2) of Def. 4.16, then using Obs. 4.20, let x ∈ C v ( φ τ ) be the vertex satisfying that v / π s, x ∈ ( ). Otherwise, if φ τ did not satisfy (N1) or (N2) (or both), let x = φ τ . Note that in any case, it holds that x, φ τ ∈ C v ( φ τ ). We have the following.
## Lemma 4.22 P s,x,v ⊆ H \ { v } .
Proof: If x = φ τ , then it implies that φ τ did not satisfy both of the properties (N1,N2). By Def. 4.16, in such a case φ τ is the vertex incident to the first missing edge on P s,t,v \ E G ( τ ) and hence P s,t,v [ s, x ] = P s,x,v ⊆ G τ \ { v } .
glyph[negationslash]
Otherwise, if x = φ τ , then x ∈ C v ( φ τ ) and by the selection of x , v / π s, x ∈ ( ). Hence, P s,x,v = π s, x ( ) ⊆ H \ { v } .
Recall that C 1 ( τ ) = C v ( φ τ ) and C 2 ( τ ) = C v ( ). t In addition, since v ∈ π far ( s, t ), it holds that v ∈ V f ( C 2 ( τ )).
Case (2.1): P τ is cheap. Since Q τ was not added, Eq. (26) did not hold and hence
$$\text{dist} ( \phi _ { \tau }, t, P _ { \tau } ) \geq \text{dist} ( C _ { 1 } ( \tau ), C _ { 2 } ( \tau ), G _ { \tau } \, \sum V _ { f } ( C _ { 2 } ( \tau ) ) ) \.$$
Let w 1 ∈ C 1 ( τ ) and w 2 ∈ C 2 ( τ ) be a closest pair satisfying that dist( w , w , G 1 2 τ \ V f ( C 2 ( τ ))) = dist( C 1 ( τ ) , C 2 ( τ ) , G τ \ V f ( C 2 ( τ ))). Since the failing vertex v is in V f ( C 2 ( τ )), both auxiliary vertices w 1 and w 2 are in G \{ } v . Consider the following s -t path: P = P 0 ◦ P 1 ◦ P 2 ◦ P 3 where P 0 = P s,x,v , P 1 = [ x, z v ( φ τ ) , w 1 ], P 2 ∈ SP w ,w ,G ( 1 2 τ \ V f ( C 2 ( τ ))), and P 3 = [ w , z 2 v ( ) t , t ]. For an illustration see
Fig. 4. By Lemma 4.22, P 0 ⊆ H \{ } v . Note that since x, w 1 ∈ C v ( φ τ ), the path P 1 exists in H \{ } v . Combining with the definitions of the vertices z v ( x , z ) v ( ) t , w 1 , w 2 , it holds that P ⊆ H \ { v } . So, it remains to bound the length of the path.
$$\text{dist} ( s, t, H \, \{ v \} ) & \ \leq \ \, | P _ { 0 } | + | P _ { 1 } | + | P _ { 2 } | + | P _ { 3 } | \\ & \ = \ \, \text{dist} ( s, x, G \, \{ v \} ) + \text{dist} ( w _ { 1 }, w _ { 2 }, G _ { \tau } \, \| \, V _ { f } ( C _ { 2 } ( \tau ) ) ) + 4 \\ & \ \leq \ \, \text{dist} ( s, \phi _ { \tau }, G \, \| \, \{ v \} ) \\ & \ \, + \ \, \text{dist} ( w _ { 1 }, w _ { 2 }, G _ { \tau } \, \| \, V _ { f } ( C _ { 2 } ( \tau ) ) ) + 6 \\ & \ \leq \ \, \text{dist} ( s, \phi _ { \tau }, G \, \| \, \{ v \} ) + \text{dist} ( \phi _ { \tau }, t, P _ { \tau } ) + 6 \, = | P _ { \tau } | + 6, \\ \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot$$
where Eq. (32) follows by the fact that x, φ τ ∈ C v ( φ τ ) and since G ∆ ⊆ H , it holds that the intracluster path R = [ x, z v ( φ τ ) , φ τ ] exists in G \ { v } , Eq. (33) follows by Eq. (31).
Case (2.2): P τ is costly. Let U s,t,v = { u , . . . , u 1 κ ′ } ⊆ Q τ for κ ′ = glyph[floorleft] κ/ 3 glyph[floorright] ≥ 1 be as defined by Def. 4.17. Since by Obs. 2.3, the diameter of each cluster is 2, each u k ∈ U s,t,v belongs to a distinct cluster C k = C v ( u k ) ∈ C . Hence there are at least κ ′ distinct clusters on Q τ .
Acluster C k = C v ( u k ) is a contributor if adding Q τ to G τ improves either the C 1 ( τ ) -C k distance (i.e., ( C 1 ( τ ) , C k ) ∈ ValSet 1 ( P τ )) or the C 2 ( τ ) -C k distance (i.e., ( C , C k 2 ( τ )) ∈ ValSet 2 ( P τ )) in the corresponding appropriate graph. Otherwise, C k is neutral . There are two cases to consider. If all clusters are contributors (i.e., there is no neutral cluster) then all the κ ′ clusters contribute to Val ( P τ ) (either with C 1 ( τ ) or with C 2 ( τ ) or both). It then holds that Val ( P τ ) ≥ κ ′ ≥ Cost ( P τ ) / 4. Hence, by Eq. (29), we get a contradiction to the fact that the suffix Q τ was not added to G τ .
In the other case, there exists at least one neutral cluster C glyph[lscript] such that
$$\text{dist} ( C _ { 1 } ( \tau ), C _ { k }, \widehat { H } _ { 1 } ) \ & \leq \ \text{dist} ( \phi _ { \tau }, u _ { k }, P _ { \tau } ) \ \text{ and } \\ \text{dist} ( C _ { k }, C _ { 2 } ( \tau ), \widehat { H } _ { 2 } ) \ & \leq \ \text{dist} ( u _ { k }, t, P _ { \tau } )$$
where ̂ H 1 = G τ \ V f ( C k ) and ̂ H 2 = G τ \ V f ( C 2 ( τ )). Let w 1 ∈ C 1 ( τ ) and w 2 ∈ C k be the pair of vertices satisfying dist( w , w , H 1 2 ̂ 1 ) = dist( C 1 ( τ ) , C k , H ̂ 1 ). In addition, let y 1 ∈ C k and y 2 ∈ C 2 ( τ ) be the pair satisfying dist( y , y 1 2 , H ̂ 2 ) = dist( C , C k 2 ( τ ) , H ̂ 2 ).
Let Q 1 = [ x, z v ( φ τ ) , w 1 ], Q 2 = [ w , z 2 v ( u k ) , y 1 ] and Q 3 = [ y , z 2 v ( ) t , t ] be the intracluster paths in C 1 ( τ ) , C k and C 2 ( τ ) respectively. Note that by definition x, w 1 ∈ C v ( φ τ ).
Since by Lemma 4.19(c), v ∈ V f ( C k ) ∩ V f ( C 2 ( τ )), it also holds that Q , Q , Q 1 2 3 ⊆ H \ { v } . Let P ′ = P 0 ◦ Q 1 ◦ P 1 ◦ Q 2 ◦ P 2 ◦ Q 3 where P 0 = P s,x,v , P 1 ∈ SP w ,w ,H ( 1 2 ̂ 1 ) and P 2 ∈ SP y ,y , H ( 1 2 ̂ 2 ). By Lemma 4.22, P 0 ⊆ H \ { v } and by the above explanation, P ′ ⊆ H \ { v } . So, it remains to bound the length of the s -t path P ′ .
$$\text{bound the length of the $s-t$ path $P$}. \\ \text{dist} ( s, t, H \, \{ v \} ) \, & \, \leq \, & | P ^ { \prime } | = | P _ { 0 } | + | P _ { 1 } | + | P _ { 2 } | + 6 \\ & \, = \, & \text{dist} ( s, x, G \, \{ v \} ) + \text{dist} ( w _ { 1 }, w _ { 2 }, \widehat { H } _ { 1 } ) + \text{dist} ( y _ { 1 }, y _ { 2 }, \widehat { H } _ { 2 } ) + 6 \\ & \, \leq \, & \text{dist} ( s, \phi _ { \tau }, G \, \{ v \} ) + \text{dist} ( w _ { 1 }, w _ { 2 }, \widehat { H } _ { 1 } ) + \text{dist} ( y _ { 1 }, y _ { 2 }, \widehat { H } _ { 2 } ) + 8 \\ & \, = \, & \text{dist} ( s, \phi _ { \tau }, G \, \{ v \} ) + \text{dist} ( C _ { 1 } ( \tau ), C _ { k }, \widehat { H } _ { 1 } ) \\ & \, + \, & \text{dist} ( C _ { k }, C _ { 2 } ( \tau ), \widehat { H } _ { 2 } ) + 8 \\ & \, \leq \, & \text{dist} ( s, \phi _ { \tau }, G \, \{ v \} ) + \text{dist} ( \phi _ { \tau }, u _ { k }, P _ { \tau } ) + \text{dist} ( u _ { k }, t, P _ { \tau } ) + 8 \\ & \, = \, & | P _ { s, t, v } | + 8 \, \\ & \, \quad \quad \quad$$
where the first inequality follows by the fact that x, φ τ ∈ C v ( φ τ ) and hence the intraclusrer path R = [ x, z v [ φ τ ] , φ τ ] exists in G \ { v } and last inequality follows Eq. (34). The claim follows.
8-additive sourcewise FT-spanner.
Figure 4: Schematic illustration of the path-buying procedure of Alg. Cons8SWSpanner . The horizontal path is P τ = P s,t,v whose segment Q s,t,v = P s,t,v [ φ s,t,v , t ] was considered to be bought at time τ . The green paths correspond to the shortest paths in T 0 ( s ). Red edges correspond to missing edges on P s,t,v \ E G ( τ ). The vertex φ s,t,v satisfies properties (N1) and (N2), hence it is incident to a missing edge and the failing vertex v occurs on π s, φ ( s,t,v ) strictly below the LCA vertex LCA ( φ s,t,v ) = LCA ( s, C v ( φ s,t,v )). The vertex x ∈ C v ( φ s,t,v ) satisfies that v / π s, x ∈ ( ). The s -t replacement path in H \ { v } is given by traveling from s to x on π s, x ( ) and then use the closest vertex pairs w , w 1 2 and y , y 1 2 .
Finally, we turn to bound the size of H S 8 ( ) and claim the following.
$$\text{Lemma } 4. 2 3 \ | E ( H _ { 8 } ( S ) ) | = \widetilde { O } ( \max \{ | S | \cdot n, n ^ { 2 } / | S | ^ { 2 } \} ).$$
Proof: Let H = H S 8 ( ). By the size-analysis of Alg. Cons4SWSpanner , it remains to bound the number of edges added due to the path-buying procedure of step (4.2).
Let B ⊆ P far indep be the set of paths corresponding to the paths segments that were bought in the path-buying phase. For every ordered pair of clusters, C , C 1 2 ∈ C let B ( C , C 1 2 ) = { P τ ∈ B | ( C , C 1 2 ) ∈ ValSet ( P τ ) } .
Clearly, B = ⋃ C ,C 1 2 ∈C B ( C , C 1 2 ). We next claim that since the diameter of each cluster is small, it holds that the cardinality of each subset B ( C , C 1 2 ) is small as well.
Lemma 4.24 |B ( C , C 1 2 ) | ≤ 5 for every C , C 1 2 ∈ C .
Proof: Fix C , C 1 2 ∈ C and let B ( C , C 1 2 ) = { P τ 1 , . . . , P τ N } be sorted according to the time τ k their segment Q τ was added to the spanner, for every k ∈ { 1 , . . . , N } where N = |B ( C , C 1 2 ) . | Let P τ k = P s k ,t k ,v k . Let p , q k k ∈ P τ k be such that p k is closer to the source s k , and C v k ( p k ) = C 1 and C v k ( q k ) = C 2 .
glyph[negationslash]
Recall that φ τ k is the first vertex of Q τ k (see Def. 4.16). Let C glyph[lscript] = C v k ( u glyph[lscript] ) be the cluster of u glyph[lscript] for every u glyph[lscript] ∈ U s k ,t k ,v k (see Def. 4.17). By Obs. 2.3, it holds that C glyph[lscript] = C glyph[lscript] ′ for every u , u glyph[lscript] glyph[lscript] ′ ∈ U s k ,t k ,v k . Recall that for every u glyph[lscript] ∈ U s k ,t k ,v k , P s,u ,v glyph[lscript] = P s,t,v [ s, u glyph[lscript] ]. Since LastE ( P s,u ,v glyph[lscript] ) / E ∈ local , it holds that v / ∈ { z 1 ( u glyph[lscript] ) , LCA ( s, C 1 ( u glyph[lscript] )) } . Combining that with the fact that u glyph[lscript] ∈ U s k ,t k ,v k did not satisfy property (N2) (see Def. 4.16 and Def. 4.17), we conclude that v k ∈ π far ( s k , u glyph[lscript] ). Since q k ∈ U s k ,t k ,v k ∪ { t k } , using Lemma 4.19(c), it holds that
$$v _ { k } \in V _ { f } ( C _ { 2 } ) \text{ for every } k \in \{ 1, \dots, N \}$$
and by Lemma 4.19(b),
$$P _ { \tau _ { k } } [ p _ { k }, q _ { k } ] \subseteq Q _ { \tau _ { k } } [ p _ { k }, q _ { k } ] \subseteq G \, \sum V _ { f } ( C _ { 2 } ) \.$$
Since C 1 = C v k ( p k ) and C 2 = C v k ( q k ), for every k ∈ { 1 , . . . , N } , it holds that z v 1 ( p 1 ) = ... = z v N ( p N ) and also z v 1 ( q 1 ) = ... = z v N ( q N ). Hence, letting z 1 = z v 1 ( p 1 ) and z 2 = z v 1 ( q 1 ), it holds that
$$z _ { 1 }, z _ { 2 } & \notin \{ v _ { 1 }, \dots, v _ { N } \}.$$
Denote
$$X _ { k } = \text{dist} ( p _ { k }, q _ { k }, G _ { \tau _ { k + 1 } } \, \langle V _ { f } ( C _ { 2 } ) ).$$
We now show that X < X k k -1 for every k ∈ { 2 , . . . N } .
Each time a path segment Q τ k is purchased at time τ k , it implies that
$$X _ { k } \ \leq \ \text{dist} ( p _ { k }, q _ { k }, P _ { \tau _ { k } } \, \langle V _ { f } ( C _ { 2 } ) )$$
$$= \text{ dist} ( p _ { k }, q _ { k }, P _ { \tau _ { k } } )$$
$$< \text{ dist} ( C _ { 1 }, C _ { 2 }, G _ { \tau _ { k } } \, \langle V _ { f } ( C _ { 2 } ) )$$
$$\leq \ X _ { k - 1 }$$
where Eq. (38) follows by the fact that P τ k [ p , q k k ] ⊆ Q τ k ⊆ G τ k +1 , Eq. (39) follows by Eq. (36), Eq. (40) follows by the fact that Q τ k was bought and by Eqs. (27) and (28), and Eq. (41) follows by the fact that p k -1 ∈ C 1 and q k -1 ∈ C 2 .
Therefore, we have that
$$X _ { N } \leq X _ { 1 } - ( N - 1 ) \.$$
Conversely, we have that
$$X _ { N } \ \geq \ \text{dist} ( p _ { N }, q _ { N }, G \, \langle \, \{ v _ { 1 }, \dots, v _ { N } \} )$$
$$\geq \ \text{dist} ( p _ { 1 }, q _ { 1 }, G \, \sum \{ v _ { 1 }, \dots, v _ { N } \} ) - 4$$
$$= \ \text{dist} ( p _ { 1 }, q _ { 1 }, P _ { \tau _ { 1 } } ) - 4 = \text{dist} ( p _ { 1 }, q _ { 1 }, P _ { \tau _ { 1 } } \ \| \ V _ { f } ( C _ { 2 } ) ) - 4$$
$$\geq \ X _ { 1 } - 4$$
where Eq. (43) follows as G τ N +1 ⊆ G and by Eq. (35), { v , . . . , v 1 N } ⊆ V f ( C 2 ). To see Eq. (44), note that p , p 1 N ∈ C 1 and q , q 1 N ∈ C 2 and by Obs. 2.3(3) the diameter of the cluster is 2. It remains to show that the intracluster paths R 1 = [ p , z 1 1 , p N ] , R 2 = [ q , z 1 2 , q N ] exist in the surviving graph G \ { v , . . . , v 1 N } . This holds since by Eq. (37), z , z 1 2 / ∈ { v , . . . , v 1 N } , and by Eq. (35) and (36). Eq. (45) follows by Eq. (36). Finally, Eq. (46) follows by the fact that P τ 1 [ p , q 1 1 ] ⊆ Q τ 1 was added at step τ 1 , hence P τ 1 [ p , q 1 1 ] ⊆ G τ 2 . By combining with Eq. (42), we get that N ≤ 5. The claim follows.
Finally, since for every path P ∈ B , it holds that Cost ( P ) ≤ 4 · Val ( P ), we get that
$$| E ( G _ { \tau ^ { \prime } } ) \, \sum \, E ( G _ { 0 } ) | \ & = \ \sum _ { P \in \mathcal { B } } \cosh ( P ) \leq 4 \sum _ { P \in \mathcal { B } } \text{vat} ( P ) \leq 4 \sum _ { C _ { 1 }, C _ { 2 } \in \mathcal { C } } | \mathcal { B } ( C _ { 1 }, C _ { 2 } ) | \\ & \leq \ O ( | \mathcal { C } | ^ { 2 } ) = \widetilde { O } ( ( n / | S | ) ^ { 2 } ) \.$$
where the last equality follows by the fact that there are |C| = | Z | = ˜ O n/ S ( | | ) clusters. The claim follows.
Additive stretch 6 (for all pairs). Thm. 1.2 follows immediately by Lemma 4.1. This should be compared with the single source additive FT-spanner H 4 ( { } s ) of [18] and the (all-pairs, non FT) 6-additive spanner, both with ˜ O n ( 4 3 / ) edges.
## References
- [1] D. Aingworth, C. Chekuri, P. Indyk, and R. Motwani. Fast estimation of diameter and shortest paths (without matrix multiplication). SIAM J. Comput. , 28(4):1167-1181, 1999.
- [2] Mathias Bæk Tejs Knudsen. Additive Spanners: A Simple Construction. In SWAT , 277-281, 2014.
- [3] S. Baswana and S. Sen. Approximate distance oracles for unweighted graphs in expected O n ( 2 ) time. ACM Trans. Algorithms , 2(4):557-577, 2006.
- [4] S. Baswana and N. Khanna. Approximate Shortest Paths Avoiding a Failed Vertex: Optimal Size Data Structures for Unweighted Graph. In STACS , 513-524, 2010.
- [5] S. Baswana, T. Kavitha, K. Mehlhorn, and S. Pettie. Additive spanners and ( α, β )-spanners. ACM Trans. Algo. 7, A.5, 2010.
- [6] A. Bernstein. A nearly optimal algorithm for approximating replacement paths and k shortest simple paths in general graphs. In Proc. 21st ACM-SIAM Symp. on Discrete Algorithms , 2010.
- [7] A. Bernstein and D. Karger. A nearly optimal oracle for avoiding failed vertices and edges. In Proc. 41st ACM Symp. on Theory of Computing , 101-110, 2009.
- [8] G. Braunschvig, S. Chechik and D. Peleg. Fault tolerant additive spanners. In WG , 206-214, 2012.
- [9] S. Chechik, M. Langberg, D. Peleg, and L. Roditty. f -sensitivity distance oracles and routing schemes. Algorithmica 63 , (2012), 861-882.
- [10] S. Chechik, M. Langberg, D. Peleg, and L. Roditty. Fault-tolerant spanners for general graphs. In STOC , 435-444, 2009.
- [11] S. Chechik. New Additive Spanners. In SODA , 2013.
- [12] M. Cygan, F. Grandoni and T. Kavitha. On Pairwise Spanners. In STACS , 209-220, 2013.
- [13] M. Dinitz and R. Krauthgamer. Fault-tolerant spanners: better and simpler. In PODC , 2011, 169-178.
- [14] D. Dor, S. Halperin, and U. Zwick. All-pairs almost shortest paths. SIAM J. Computing , 29(5):17401759, 2000.
- [15] M. Elkin and D. Peleg. (1 + ε, β )-Spanner Constructions for General Graphs. SIAM Journal on Computing , 33(3): 608-631, 2004.
- [16] F. Grandoni and V.V Williams. Improved Distance Sensitivity Oracles via Fast Single-Source Replacement Paths. In FOCS , 2012.
- [17] M. Parter and D. Peleg. Sparse Fault-tolerant BFS trees. In ESA , 2013.
- [18] M. Parter and D. Peleg. Fault Tolerant Approximate BFS Structures. In SODA , 2014.
- [19] L. Roditty and U. Zwick. Replacement paths and k simple shortest paths in unweighted directed graphs. ACM Trans. Algorithms ,2012.
- [20] M. Thorup and U. Zwick. Spanners and emulators with sublinear distance errors. In SODA , 802-809, 2006.
- [21] O. Weimann and R. Yuster. Replacement paths via fast matrix multiplication. FOCS , 2010.
- [22] D.P Woodruff. Lower bounds for additive spanners, emulators, and more. In FOCS , 389-398, 2006.
- [23] D.P Woodruff. Additive spanners in nearly quadratic time. In ICALP , 463-474, 2010. | null | [
"Merav Parter"
] | 2014-08-02T19:51:30+00:00 | 2014-08-02T19:51:30+00:00 | [
"cs.DS"
] | Vertex Fault Tolerant Additive Spanners | A {\em fault-tolerant} structure for a network is required to continue
functioning following the failure of some of the network's edges or vertices.
In this paper, we address the problem of designing a {\em fault-tolerant}
additive spanner, namely, a subgraph $H$ of the network $G$ such that
subsequent to the failure of a single vertex, the surviving part of $H$ still
contains an \emph{additive} spanner for (the surviving part of) $G$, satisfying
$dist(s,t,H\setminus \{v\}) \leq dist(s,t,G\setminus \{v\})+\beta$ for every
$s,t,v \in V$. Recently, the problem of constructing fault-tolerant additive
spanners resilient to the failure of up to $f$ \emph{edges} has been considered
by Braunschvig et. al. The problem of handling \emph{vertex} failures was left
open therein. In this paper we develop new techniques for constructing additive
FT-spanners overcoming the failure of a single vertex in the graph. Our first
result is an FT-spanner with additive stretch $2$ and $\widetilde{O}(n^{5/3})$
edges. Our second result is an FT-spanner with additive stretch $6$ and
$\widetilde{O}(n^{3/2})$ edges. The construction algorithm consists of two main
components: (a) constructing an FT-clustering graph and (b) applying a modified
path-buying procedure suitably adopted to failure prone settings. Finally, we
also describe two constructions for {\em fault-tolerant multi-source additive
spanners}, aiming to guarantee a bounded additive stretch following a vertex
failure, for every pair of vertices in $S \times V$ for a given subset of
sources $S\subseteq V$. The additive stretch bounds of our constructions are 4
and 8 (using a different number of edges). |
1408.0410v1 | ## Slow ground state molecules from matrix isolation sublimation
A. N. Oliveira ∗ 1 2 , , R. L. Sacramento , B. X. Alves , B. A. Silva 1 1 1 , W. Wolff 1 and C. L. Cesar 1
1 Instituto de F´ ısica, Universidade Federal do Rio de Janeiro, Caixa Postal 68528, 21941-972 Rio de Janeiro, RJ, Brazil 2 INMETRO, Av. Nossa Senhora das Gra¸ cas, 50 Duque de Caxias - RJ, Brazil ∗ [email protected] (Dated: August 5, 2014)
We describe the generation and properties of a cryogenic beam of 7 Li 2 dimers from sublimation of a neon matrix where lithium atoms have been implanted via laser ablation of solid precursors of metallic lithium or lithium hydride (LiH). Different sublimation regimes lead to pulsed molecular beams with different temperatures, densities and forward velocities. With laser absorption spectroscopy these parameters were measured using the molecular 7 Li 2 (R) transitions A Σ 1 + u ( v ′ = 4 , J ′ = J ′′ +1) ← X Σ 1 + g ( v ′′ = 0 , J ′′ = 0 1 3). In a typical regime, sublimating a matrix , , at 16 K, translational temperatures of 6-8 K with a drift velocity of 130 m s -1 in a free expanding pulsed beam with molecular density of 10 9 cm -3 , averaged along the laser axis, were observed. Rotational temperatures around 5-7 K were obtained. In recent experiments we were able to monitor the atomic Li signal - in the D2 line - concomitantly with the molecular signal in order to compare them as a function of the number of ablation pulses. Based on the data and a simple model, we discuss the possibility that a fraction of these molecules are being formed in the matrix, by mating atoms from different ablation pulses, which would open up the way to formation of other more interesting and difficult molecules to be studied at low temperatures. Such a source of cryogenic molecules have possible applications encompassing fundamental physics tests, quantum information studies, cold collisions, chemistry, and trapping.
## I. INTRODUCTION
The production of cold samples or beams of molecules is an ongoing research field since it has many important potential applications as discussed in [1]. Among the interesting applications there is the prospective use in quantum information and computation [2, 3] and basic physics tests, such as the search for a permanent electric dipole moment of the electron [4, 5] with its corresponding parity and time reversal symmetries violations. Some molecular species are complex to make in an environment compatible with low temperatures [6], requiring the use of hot ovens. Low velocities and particularly low temperatures are important for long or precise interaction times - with lasers or microwave - in high precision experiments. As an illustration, in precision experiments, the work in [4] used a supersonic beam of YbF with a forward velocity of 590 m s -1 while the work in [5] used a buffer gas precooled beam of ThO with forward velocity of 200 m s -1 and temperatures of ∼ 10 K.
matrix [9]. Optical absorptions due to molecular lines have been observed, albeit with large frequency broadening and shifts from their transition values in free space. Fajardo and coworkers [9-11] report an annealing treatment to the matrix resulting in better resolved molecular lines.
The study of ultracold collisions in magneto-optical traps (MOT) and photo-association experiments have produced large amounts of ultracold molecules, but only with a few atomic species which are amenable to be trapped in a MOT [1, 7, 8]. A whole field of cold chemistry will benefit from the availability of different species of cold molecules. The easier the technique to produce cold molecules, trapped or as beams, the more applications will be found, from sensors, to basic physics and chemistry.
In the field of Matrix Isolation Spectroscopy (MIS), molecules have been studied inside the inert-gas solid matrix [9-13], including rotating molecules in a solid H 2
In the present work we expand our research program on Matrix Isolation Sublimation (MISu) - where intense cryogenic atomic beams of Cr and Li originating from Ne or H 2 matrices have been studied [14-17] - to demonstrate a cryogenic beam of 7 Li 2 dimers sublimated from a Ne matrix. The transitions in 7 Li 2 dimers are accessible by the experimental setup and diode lasers built in the laboratory and also allow for a simultaneous comparison of the molecular signal to the atomic signal which has been extensively studied. Thus, the choice of 7 Li 2 dimers, while circumstantial, serves as a first demonstration and evidence of the possibilities of the MISu technique. Most importantly, it enabled us to start probing the nature of the molecular formation process and answer questions such as: would the molecules be released in a variety of rovibrational states due to possible strains in the matrix? And, what is its temperature and velocity distribution? The pulsed molecular beam resulting from the MISu technique appears attractive in terms of density, temperatures and forward velocities for many applications. One of its main advantage may be the easiness by which one could form molecules which are not accessible by the other techniques.
There are three non-excluding possibilities for formation of the molecules detected in our experimental procedure: (i) they are implanted as molecules from the laser ablation process [18] ; (ii) they are formed in the matrix
when the implanted atoms fall adjacent to each other; (iii) they are formed during the matrix sublimation, in flight. While all three processes could be involved, process (ii) is clearly very attractive as it would open up the way to produce interesting heteronuclear molecules that are difficult to produce in compatibility with high precision measurements, with low temperatures and forward velocities. We discuss, in view of the data and some simple models, these three processes pointing to evidence that a relevant fraction of the molecules we detect should be formed by the second process.
This first molecular MISu study leave interesting open questions: -what is the percentage of molecules formed in the matrix as opposed to implanted directly from ablation, and how does that depend on the size, or composition, of the molecule? -what is the limit on the number of molecules formed (we did not reach beyond 5% of laser absorption)? -will softer molecules suffer from strains in the matrix leaving a low population in the ground rovibrational state upon sublimation? - what will be the effect of a controlled annealing of the matrix to the number of molecules?
## II. EXPERIMENTAL SETUP
The experimental setup has been described in detail elsewhere [14, 15] and a diagram is shown in figure 1. The system consists of a closed-cycle cryostat, with optical access, that reaches 3 K at its cold plate with 1 W cooling power at 4 K. A sapphire substrate, with a deposited resistive film of NiCr, is thermally connected, through a chosen thermal link, to the cold plate. This configuration permits large and fast variations of the sapphire substrate temperature without affecting the cryostat temperature. The Ne gas that forms the matrix is delivered through a 2 mm inner diameter tube whose exit points towards the sapphire substrate. The flow rate of the gas is controlled by the pressure in a reservoir followed by a high impedance line, achieving 1-10 mmol/hr. The growth of the Ne matrix film is monitored by two CW laser beams - called 'atomic' (LA) and 'molecular' (LM) lasers through the interference fringes (with 10-12% visibility) off the etalon formed by the Ne film together with the ∼ 40% reflectivity of the NiCr resistive film on the sapphire substrate. These beams come from the bottom upwards, with slightly different angle, reflect off the Ne film and sapphire mirror at near normal incidence, and are monitored by photodiodes as indicated in figure 1. A typical time for growing a λ/ 2 thick Ne layer in the data here presented is 40 s, but it can be reduced to less than 1 s.
The lasers are tuned to the atomic D2 transition in 7 Li (at 670.776 nm - air wavelength is used throughout the paper) and the molecular 7 Li 2 (R) transitions A Σ 1 + u ( v ′ = 4 , J ′ = J ′′ +1) ← X Σ 1 + g ( v ′′ = 0 , J ′′ = 0 1 3) , , (at 665.948 nm, 665.924 nm, 665.927 nm, respectively). The Franck-Condon factor for this molecular transition
[19] is 0.158. The transitions energies have been calculated by taking [20, 21] T e (A-X) = 14068.185 cm -1 , G = 175.029 cm 0 -1 and B =0.669 cm 0 -1 for the X Σ 1 + g state and G =1117.918 cm 4 -1 and B =0.4732 cm 4 -1 for the A Σ 1 + u state and checked against the data of D. Hsu [22]. The laser beams have a diameter around 4 mm and powers of tens of microwatts to avoid much saturation.
The experiment proceeds in a sequence as follows. Allowing Ne to flow into the cryostat a desired layer of Ne solid matrix is formed. Then, a pulsed laser, at 1 Hz repetition rate and up to 25 mJ of energy per pulse, promotes ablation of the solid precursor (metallic lithium or LiH), implanting atoms, and possibly molecules, into the matrix. The laser is focused onto the solid precursor by a 75 mm lens. The number of ablation pulses is varied from 1 to 300. Special care should taken to avoid Ne matrix loss - which could be observed by the laser interference fringes - due to the temperature increase when absorbing ablation energy. For some experimental conditions we had to lower substantially the energy of the pulsed laser to avoid this matrix loss. During ablation, very large absorptions on the atomic spectral line are seen, while no absorption on the molecular line is observed. This is expected from the high temperatures achieved during the laser ablation phase which would diminish the population of the particular molecular ground-state seen by the laser. For some data - in the case of thinner matrices (13 -60 nm /lessmuch λ/ 2) - the cycle above is repeated up to 5 times.
After the matrix is completed, a heat pulse is applied to the sapphire NiCr resistor causing the matrix to sublimate into vacuum while the absorption spectra is recorded by scanning the lasers' frequencies. The sublimation time depends on the heat pulse energy and was typically between 60-240 µ s. At longer sublimation times, we reach the limit of sensitivity of our detection for molecules, while with atoms we have seen signals even at sublimation times of seconds, reaching a quasi-CW operation. During this period the sample expands and its center-of-mass moves in ˆ x direction (see figure 1). This flight direction leads to a splitting of the resonance lines due to a positive and a negative Doppler effect, since the laser beams are both co-propagating and counterpropagating with the sublimation plume. This allows for a direct measure of the sample's forward velocity. The Doppler profile enables the measurement of the sample's longitudinal temperature (in other studies we have investigated the transverse temperature as well [14, 15]). The lasers frequency scans are monitored using two 1 GHz free spectral range Fabry-Perot interferometers.
The whole experiment can be repeated in time scales of one minute, but with a lower gas impedance this time can be brought down to a couple of seconds. The data analysis starts by finding the best fit for the atomic and molecular Fabry-Perot signals - disregarding the small peaks (modes other then the fundamental) - thus allowing a plot of photodiode signals as a function of frequency. Then, we can subtract the lasers amplitude modulation,
by fitting it at longer times, in absence of atomic or molecular absorption, and extending to the earlier times. The interference fringe from the Ne matrix sublimation at early times can also be subtracted by a complex thermal model [14] or by a simple linearization near the absorption peaks. Finally, the spectrum is adjusted by a double gaussian yielding several parameters, such as: peak optical density, forward velocity and temperature of the molecular and the atomic beams.
FIG. 1. Schematics of the experimental apparatus showing the sapphire substrate, the NiCr film resistor and the deposited matrix of Ne which comes from the gas tube. Li atoms, and perhaps molecules, are implanted via laser ablation (shown in dashed green) on a solid Li or LiH precursor. The spectroscopy laser beams (shown in red and identified as L A and L M ), propagate along the direction of the sublimation plume expansion and are also used to monitor the matrix film thickness.
## III. EXPERIMENTAL DATA AND DISCUSSION
Following the experimental procedure, a typical data is presented in figure 2. The laser power transmitted through the sample upwards and backwards to the photodiode is also sensitive to the Ne matrix sublimation, which is evident in the large amplitude variation in the first 0.2 ms. In this figure, a single scan captures two transition lines A Σ 1 + u ( v ′ = 4 , J ′ = 2) ← X Σ 1 + g ( v ′′ = 0 , J ′′ = 1) and A Σ 1 + u ( v ′ = 4 , J ′ = 4) ← X Σ 1 + g ( v ′′ = 0 , J ′′ = 3) (at 665.924 nm and 665.927 nm, respectively).
The distance between peaks in each doublet in figure 2 - (i) and (ii) - accounts for the forward (centerof-mass) velocity, while the gaussian profile, once fitted in frequency domain, measures the longitudinal translational temperature as shown in figure 3. We fit the gaussian standard deviation ∆ ν σ = √ k B T long /M Li 2 /λ , and
FIG. 2. Raw data for laser scan around 665.924 - 665.927 nm, showing the laser transmission (a), the Fabry-Perot signal (b) with a fit (c). The laser transmission signal is offset in the figure. It has a residual amplitude modulation due to the laser PZT scan, and it is affected by the Ne matrix sublimation, displaying a fraction of an interference fringe. In a single scan we are able to observe two rotational levels: J'=1 (i) and J'=3 (ii). See text for more details.
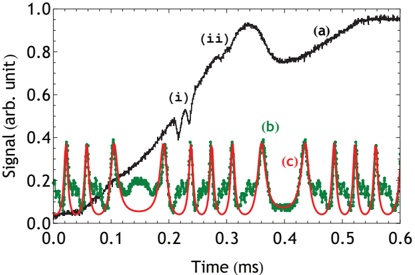
the Doppler shift between the two components δν DS = v CM /λ , obtaining the forward velocity v CM and the longitudinal temperature T long , where M Li 2 is the mass of the lithium dimmer, k B is Boltzmann's constant, and λ is the wavelength.
A typical signal in the A Σ 1 + u ( v ′ = 4 , J ′ = 1) ← X Σ 1 + g ( v ′′ = 0 , J ′′ = 0) transition at 665.949 nm is shown in figure 4.
In order to reach a reasonable signal-to-noise ratio in the molecular signal we resorted to fast sublimations. In most of the experiments, the matrix was sublimated within 60 to 240 µ s. The laser resonance condition was often met at a later time, after the full matrix had sublimated. As can be easily imagined and corroborated with a Monte-Carlo simulation, there is a dynamical reduction of temperature for times after the full matrix has sublimated, both in the molecular and the atomic samples. Essentially, the fast atoms or molecules go quickly outside the laser beam and towards the walls where they stick, while the slower species remain longer within the laser beam. This effect can be avoided with atoms, where the large signal-to-noire ratio allows for a slow sublimation with the laser interacting with a freshly released sample, giving a more instantaneous measurement. In this time delayed process we can observe temperatures of the atomic beam down to 1-2 K.
Most of our data was obtained using a cell of 75 mm diameter and a distance between the sapphire substrate and the bottom window of 65 mm. With a forward velocity of ∼ 130 ms -1 , the sample's center-of-mass would reach the window at 500 µ s (longer than the typical time at which we get our signals). Moreover, as the atoms or
FIG. 3. Treated data for the peaks (i) and (ii) from figure 2 showing visual fits and their parameters [14]. Taking into account a similar set of data and using mainly the information on the strongest signal we find the parameters to be compatible with the following values: forward velocity v CM ≈ 130 - 140 m s -1 and longitudinal translational temperature T long ≈ 6 -8 K. From the sublimation time we infer a sapphire temperature T S ≈ 16 K. From the optical densities one can obtain the molecular density along the laser path.
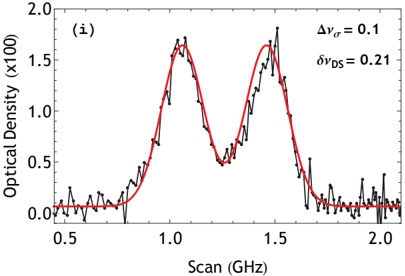
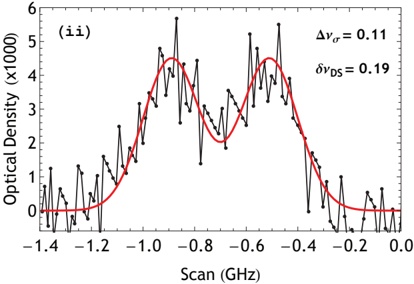
molecules move away from the sapphire they have smaller probability of passing through the laser beam, this being true for all the directions. We did a quick test on the atomic signal with an experimental cell 4 times larger in all the dimensions and got identical results. So, our quoted results are not influenced with collisions to the surfaces. Only in special experiments, after many cycles and having released a large quantity of Ne in the cell and with large atomic signals, we can observe very small 'revival' signals from Li atoms reflecting off the Ne coated cell windows.
The longitudinal translational temperature measured for the molecules is in accordance to our predicted 1d or 3-d thermalization models [14]. For example, for the data in figure 2 (and figure 3), where the sublimation temperature is T S ∼ 16 K and the molecular signal is seen during the sublimation, the 1-d thermalization model would predict a translational longitudinal temper-
FIG. 4. A spectrum at 665.949 nm at two subsequent scans during the same sublimation. In the second one we can see a lower density and also lower velocity and temperature.
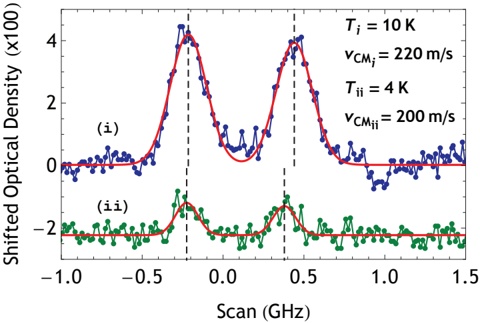
ature T 1 d = T S (4 -π / ) 2 ∼ 7 K which is in agreement with the measured temperature.
On the other hand, the forward velocity seems higher than our previous models would indicate. We can deduce the substrate temperature from the sublimation time. For the data in figure 2 (and figure 3) we obtain a substrate temperature of 16 K, and we measured forward velocities around ∼ 130 ms -1 , which is more than the expected full entrained value, which would be Ne velocity at 104 m s -1 , and still higher than that expected from Li 2 being released without entrainment, which would be around 124 ms -1 . We do not know where this discrepancy come from.
From the data presented in figure 3 we can obtain the rotational temperature ( T rot ) from the relative absorption line strength for different transitions by considering not just the degeneracy of the initial state, g J ( ′′ ) = 2 J ′′ + 1, but also taking into account the final J' value by using the average [23] 〈 J ′′ 〉 → ( J ′ + J ′′ ) / 2. Herzberg's [23] equation (III.169) reads:
$$\overset { \circ \mu \mu } { \text{our} } \quad I _ { \text{abs} } = \frac { C _ { \text{abs} } v ^ { \prime \prime } } { Q _ { r } } ( J ^ { \prime } + J ^ { \prime \prime } + 1 ) \exp \left [ - \frac { B _ { v ^ { \prime \prime } } J ^ { \prime \prime } ( J ^ { \prime \prime } + 1 ) } { k _ { \text{B} } T _ { \text{rot} } } \right ],$$
where C abs v ′′ /Q r does not depend on J ′′ or J ′ , B v ′′ J ′′ ( J ′′ +1) gives the energy of the ( v ′′ , J ′′ ) level, and k B is the Boltzmann constant. The relative strength of these two lines point to a rotational temperature T rot ≈ 4 -5 K, even slightly below the translational temperature. This temperature range is compatible if we also include the A Σ 1 + u ( v ′ = 4 , J ′ = 1) ← X Σ 1 + g ( v ′′ = 0 , J ′′ = 0) (at 665.948 nm) transition signal, with its typical higher optical density maximum, from different experimental runs in the same day and conditions. But since the experiment did not have a very good reproducibility from run to run, we avoid extending the analysis, obtaining more precise values, to other lines which were not accessible in a single run.
The fact that the rotational temperature seems lower than the translational temperature suggests that it would not be decreasing from a very high value towards equilibration with the translational temperature, which would probably be the case if the molecules were being formed during the sublimation: in this case, due to the larger phase-space of recombination, a wide variety of rovibrational states were expected to be populated and the rotational temperature would be high.
The peak molecular density can be estimated, using equation 8.7-10 of [24], from a peak absorption of 5% at a linewidth of 0.2 GHz and taking into account the Franck-Condon factor. The decay rate of the molecular electronic state is approximately the same as the atomic state [25]. If we average over the whole path length of the laser (6.5 cm) we get an under-estimated value of over 10 9 cm -3 .
We were also interested in testing the dependency of the molecular signal as a function of the number of ablation pulses. But it was soon realized that there were large variations in the signal due to the ablation process burning a hole in the solid precursor. By also monitoring the atomic signal, in the same runs, we do get some qualitative information on these dependencies. If the molecules were being formed in the evaporation of the area surround the ablation pulse [26] and the process was repetitive, we would expect both the atomic and molecular signals to increase with the number of ablation pulses and there would be a linear correlation between these absorption signals. If the molecules are formed by collisions in the ablation plume, and if this is a repetitive process one would still observe a linear growth of the atomic and molecular signals with the number of ablation pulses, while from pulse to pulse, the dependence of molecules number to atoms number would show a more rich dependence, as it involves the collision of two Li atoms with a third body that could be H, Li, or LiH. Rather than seeing a linear, or perhaps monotonic, growth of the signals with the number of ablation pulses, we do see a clear saturation towards the disappearance of both signals. If the molecules are being formed in the matrix, we would expect an initial quadratic dependence on the number of molecules to number of atoms and a saturation of the signals as the number of ablation pulses is increased as it is discussed in the next section. The lack of good reproducibility and the noise in the data did not allow us to to quantify the linear and quadratic dependencies between the molecular and atomic signals. The data on the dependence of the signals with the number of ablation pulses, as well as the correlation between molecular and atomic signal is shown in figure 5. This data can be better understood within the discussion in the next section.
In some series we started off saturated and saw only a decrease of the signal as a function of the number of ablation pulses. In these series we took special care to monitor the matrix thickness so that a possible matrix loss would not be accountable for this loss of signal. In some conditions we do notice the matrix evaporating away as we deposit more and more ablation pulses. In those cases the ablation laser energy was lowered and a new series attempted, until this problem disappeared. It is clear that there is a saturation process in the matrix that leads to a decrease of both the atoms and molecules signals as the number of ablation pulses increases. We discuss a model regarding this issue in the next section.
FIG. 5. Dependency of atomic and molecular optical densities as a function of implanted atoms (ablation pulse) in the top, showing a clear saturation. In the bottom, the molecular signal is plotted as a function of the atomic signal parametrized by the number of ablation pulses. The top graph is made with averaged signals while the bottom one employs no average. The solid lines are included just to guide the eyes. See text for discussion.
## IV. MODELS FOR MOLECULAR FORMATION
Lithium dimers have been observed directly from laser ablation of a metallic Li precursor using the technique of cavity ring-down spectroscopy [18]. Experiments from the same group [26] have detected heteronuclear molecules with alloys. Another group [27] have produced CaH and other molecules from laser ablation of a solid that contains the molecules, sometimes in a more complex form, such as CaH 2 for the case of CaH. So, clearly,
dimer formation does occur during the ablation phase. We interpret that the work in [26] would suggest that lithium dimers could be formed even from the ablation of solid LiH.
Molecular formation during the ablation process can occur via two possibilities: the dimers being formed by evaporation of the surrounding hot spot, or being recombined in the ablation plume. In both cases the total number of dimers produced would be proportional to the number of ablation pulses, if the ablation results would be stable. If some dimers are recombining in the ablation plume, since it is a more than a one-body body process their number would show higher order dependency on the number of atoms produced in each ablation pulse, but the total number would still scale linearly with the number of ablation pulses, if they were similar.
In a regime of very low dilution of the atomic and molecular species in the Ne matrix, one would expect the atomic and molecular signal to grow indefinitely with the number of ablation pulses. Clearly this is not physical and has to fail at higher dilutions. The saturation of this process leads us to consider the possibility of forming molecules in the matrix, by atoms being implanted side-by-side.
We have simulated a very simple model where we consider the Ne matrix as a set of boxes, where atoms and molecules could be trapped. For a simple qualitative picture one could consider one box for each unit cell in the solid. A Monte-Carlo simulation throws atoms randomly at the boxes and one can then count the number of empty boxes, or boxes with 1 atom, or with 2 atoms, and so on. We consider 2 atoms in a box as a dimer formation, and 3 atoms as a trimer. The simulation counts the number of empty boxes, with 1 Li atom, or with 1 Li 2 dimer as a function of the number of atoms evaporated. We can also take into account molecules emitted directly by evaporation from the ablation by considering that a percentage of the ablation happens in molecular form. The result of one such simulation is shown in figure 6, where we consider ablation from LiH emitting one hydrogen atom for each lithium atom, and one H 2 molecule for each Li 2 , but these molecules being emitted with a 20% probability. The inset show the molecular population in the boxes as a function of the atomic population. The higher the probability of emitting molecules, the more linear is the growth of the molecular population in the low dilution regime. As this probability decreases, the initial growth of the molecular signal becomes fully quadratic in the number of atoms, and the inset would show a more round shape(keeping the choice of scale where the maxima atomic and molecular - fill the scales).
With the formation of molecules in the matrix, the atomic signal (boxes with 1 atom) grows with the number of ablations, reaches a maximum and start decreasing. The molecular signal, will reach a maximum after the atomic passed through its maximum, and both signals go to zero in the limit of very high dilution (atoms ablated compared to the number of boxes). In the case shown in figure 6, we used 100 boxes. At about 50 atoms ablated, the atomic signal reaches a maximum, and one can see a deviation from a linear behavior down to 10-15 atoms, or 1/8 of the number of boxes So, this model predicts a significant deviation from a linear behavior once about 1/8 of the boxes have been filled.
One can easily get an order of magnitude estimate for the number of boxes in our case of Li in the Ne matrix. We have previously measured [14] the penetration depth of laser ablated Li atoms reaching a maximum at 6-10 atomic monolayers and extends up to 20-30 monolayers. We take 20 monolayers as typical penetration depth for uniform population. The average distance between Ne atoms in the solid matrix is 2.8 ˚ . A The sapphire area, of order of 8 mm 2 would lead to about 10 14 monolayers squared. Thus, one gets about 2 × 10 15 boxes. This is a typical number of atoms that can be obtained in a single laser ablation pulse in our conditions. Therefore, one can be in a saturated regime (high dilution) even with a single ablation pulse.
The saturation of the atomic and the molecular signals with number of ablations, without the loss of Ne matrix does indicate that some atoms have to be recombining in the matrix. The fact that the numbers fall in the right estimate for saturation also indicates that this process might be happening. On the other hand, clearly our model cannot be considered valid in the regime of very high saturations as the matrix would loose its characteristics (if the impurities reach a level of 50% one cannot speak of a Ne matrix anymore, it has become another solid). This change in character might be a limiting factor to the density of molecules we can observe, since the molecular signal is a factor of 10-50 lower than our very simple model would predict from the atomic signal (even considering the fact that in some experiments the atoms can interact more than once with the laser beam through absorption and emission cycles, while the molecules, due to the decay to other states only interact once, we still find a factor of 10 lower molecular signal).
Other questions remain unclear to us: -how does the matrix dissipate the ∼ 8600 cm -1 binding energy when atoms recombine? - does that lead to some evaporation of the matrix as we have seen, specially in the case of thin matrices? -do atoms recombine into molecules if they cross near another in the matrix on their way through the matrix (then a 'cone' or 'cylinder' model would describe better than an independent boxes model)? -would an annealing of the matrix help in the molecular formation, to what temperature and for how long? It would be interesting to see these questions answered by Molecular Dynamics simulations.
Finally, a third possibility by which molecules could be formed in present experimental setup is by atomic combination during the sublimation. If Li atomic density is high, with Ne atoms serving as a third body, Li dimers could be formed. In this case, we expect that they would be initially in high vibrational and rotational states due to the larger phase-space for recombination
at high quantum numbers. Thermalization towards low ro-vibrational temperatures, where they would be detectable by the laser, would require a large number of collisions and the translational temperature would be approached from above. In this case, in contrast to what was observed, one would expect a rotational temperature exceeding the translational temperature. We are confident, therefore, that molecules we detect have not been formed during sublimation, but have come as molecules out of Ne solid matrix.
FIG. 6. A Monte-Carlo simulation of n a atoms thrown randomly at n b boxes or sites. In this case, n b =100, and n a varies from 0 to 500. The number of sites with 0 atoms decrease monotonically while the ones with 1, 2 or more atoms grow to a maximum and then decrease with the number of implanted atoms. In a very simple model we identify sites with 2 atoms as having formed dimers, or trimers with 3 atoms, and so on. The process of forming molecules in the matrix from this simple model would grow quadratically initially - after all it is a 2-body process - and would eventually saturate and decrease.
A major concern during the long search for this molecular signal was the possibility that the molecules could be found in some sort of stretched or compressed configuration within the solid Ne and, therefore, they could be sent off in several vibrational and rotational states upon release. In that case, the narrow laser, tuned to a particular rovibrational state, would not have enough sensitivity to detect the molecules in an absorption experiment. On the other hand, it may happen that the stretched or compressed molecules could adiabatically relax to its free configuration during the sublimation process. Indeed the density is high during sublimation and the dissipation of this energy could happen very quickly. In fact, we have not attempted to detect transitions starting from other vibrational states away from the ground state ( v ′′ = 0). Thus, we have no upper limit on the vibrational temperature and cannot rule out the possibility of this process. But, by obtaining a rotational temperature slightly lower than the translational one, we have an indication that the initial rotational temperature is low and that this concern may not be happening, or at least it did not prevent us from observing the ground state molecules. In retrospect, the 7 Li 2 quantum of vibration corresponds to about 500 K (G 1 -G 0 for the X Σ 1 + g state [21]), much more than the typical Ne-Ne binding energy. Thus, it is expected that the Ne solid should conform to the 7 Li 2 configuration, rather than the opposite. While this is the case for 7 Li , it may not be the case for some loosely 2 bound molecules.
## V. CONCLUSION AND PROSPECTS
In this study we report the first pulsed beam of cryogenic molecules ( 7 Li 2 dimers) from Matrix Isolation Sublimation. We measured temperatures as low as 4-6 K, which is understood from a dynamical cooling (higher loss of the faster species) after the full matrix have sublimated. The maximum laser absorption, at 5% with line width of 0.2 GHz, points to a 7 Li 2 molecular density around 10 9 cm -3 averaged along the full laser path. By studying the A Σ 1 + u ( v ′ = 4 , J ′ = J ′′ + 1) ← X Σ 1 + g ( v ′′ = 0 , J ′′ = 0 1 3) transitions we measured a rotational tem-, , perature around 4-5 K, slightly lower than the longitudinal translational temperature of 6-8 K for the same series. The translational temperatures are in agreement with previous models [14], while the forward velocities of the beam seem higher, around ∼ 130 ms -1 for a sublimation temperature of 16 K, for this same set of data. but these values show that it is a competitive technique for performing high precision measurements on ground state molecules.
We have seen, in all the series attempted, a clear saturation of the atomic and the molecular signals which go through a maximum and decay with increasing number of sublimation pulses. By considering a simple model where the Ne matrix serves as a set of boxes where atoms are thrown randomly, and by considering a box with 2 atoms as a formation of a dimer in the matrix, we can mimic this observation. Clearly there is a saturation in the matrix and a detailed balance of the number of implanted atoms with the number of sites in the Ne matrix, together with our previous measurements of the depth of penetration of the lithium atoms, make a compatible picture with observation of this saturation. If indeed a relevant fraction of the molecules are being formed in the matrix, this may turn out a powerful technique to produce other species of more interest which are difficult to be made in a way compatible to high precision experiments. We are preparing an experiment with heteronuclear molecules to confirm this preliminary evidence that the molecules can be formed in the matrix and to carry on a physics program, in precision tests of physics, quantum information and scientific metrology with these molecules.
While we see no evidence that the molecules would be released in a variety of vibrational states due to a possi-
ble stretch or compression in the solid Ne matrix, we cannot rule out completely this possibility for other loosely bound molecules. Observing a rotational temperature lower than the translational is suggestive that the solid Ne matrix is accommodating itself to the ground state
- [1] Carr L, DeMille D, Krems R V and Ye J 2009 Cold and ultracold molecules: science, technology and applications New J. Phys. 11 055049
- [2] DeMille D 2002 Quantum computation with trapped polar molecules Phys. Rev. Lett. 88 067901
- [3] Rabl P, DeMille D, Doyle J M, Lukin M D, Schoelkopf R J and Zoller P 2006 Hybrid quantum processors: molecular ensembles as quantum memory for solid state circuits Phys. Rev. Lett. 97 033003
- [4] Hudson J J, Kara D M, Smallman I J, Sauer B E, Tarbutt M R and Hinds E A 2011 Improved measurement of the shape of the electron Nature 473 493-6
- [5] Baron J et al 2014 Order of magnitude smaller limit on the electric dipole moment of the electron Science 343 269-72
- [6] Walker K A, Hedderich H G and Bernath P F 1993 High resolution vibration-rotation emission spectroscopy of BaH Mol. Phys. 78 577-89
- [7] Mancini M W, Telles G D, Caires A R L, Bagnato V S and Marcassa L G 2004 Observation of ultracold groundstate heteronuclear molecules Phys. Rev. Lett. 92 133203
- [8] Ulmanis J, Deiglmayr J, Repp M, Wester R and Weidem¨ uller M 2012 Ultracold molecules formed by photoassociation: heteronuclear dimers, inelastic collisions, and interactions with ultrashort laser pulses Chem. Rev. 112 4890-927
- [9] Lee Y -P, Wu Y -J, Lees R M, Xu L -H and Hougen J T 2006 Internal rotation and spin conversion of CH 3 OH in solid para-hydrogen Science 311 365-8
- [10] Fajardo M E and Tam S 1998 Rapid vapor deposition of millimeters thick optically transparent parahydrogen solids for matrix isolation spectroscopy J. Chem. Phys. 108 4237
- [11] Tam S and Fajardo M E 1999 Ortho/para hydrogen converter for rapid deposition matrix isolation spectroscopy Rev. of Sci. Instrum. 70 1926
- [12] Cradock S and Hinchcliffe A J 1975 Matrix Isolation. A Technique For The Study Of Reactive Inorganic Species (Cambridge: Cambridge University Press)
- [13] Ball D W, Kafafi Z H, Fredin L, Hauge R H and Margrave J L 1988 A Bibliography of Matrix Isolation Spectroscopy (Houston: Rice University Press) pp 1954-85
- [14] Sacramento R L, Alves B X, Almeida D T, Wolff W, Li M S and Cesar C L 2012 Source of slow lithium atoms from Ne or H2 matrix isolation sublimation J. Chem. Phys. 136 154202
7 Li 2 conformation, rather than the other way around.
We acknowledge the work of Douglas Teixeira, Henrique Bergallo in some phases of this study as well as a help from Ivan Silva and Mauricio Lima from INMETRO. This work is partially supported by the Brazilian institutions CNPq, CAPES, and INCT-IQ.
- [15] Sacramento R L, Scudeller L A, Lambo R, Crivelli P and Cesar C L 2011 Spectroscopy of lithium atoms sublimated from isolation matrix of solid Ne J. Chem. Phys. 135 134201
- [16] Crivelli P, Cesar C L and Lambo R 2009 Ortho/para hydrogen converter for rapid deposition matrix isolation spectroscopy Can. J. Phys. 87 799-806
- [17] Lambo R, Rodegheri C C, Silveira D M and Cesar C L 2007 Spectroscopy of low-energy atoms released from a solid noble-gas matrix: proposal for a trap-loading technique Phys. Rev. A 76 061401(R)
- [18] Labazan I and Milosevic S 2002 Observation of lithium dimers in laser produced plume by cavity ring-down spectroscopy Chem. Phys. Lett. 352 226-33
- [19] Barakat B, Bacis R, Carrot F, Churassy S, Crozet P, Martin F and Verges J 1986 Extensive analysis of the X Σ 1 + g ground state of 7 Li 2 by laser-induced fluorescence Fourier transform spectrometry Chem. Phys. 102 215-27
- [20] Le Roy R J, Dattani N S, Coxon J A, Ross A J, Crozet P, and Linton C 2009 Accurate analytic potentials for Li 2 (X Σ 1 + g ) and Li 2 (A Σ 1 + u ) from 2 to 90 A, and the ˚ radiative lifetime of Li(2p) J. Chem. Phys. 131 204309
- [21] Coxon J A and Melville T C 2006 Application of direct potential fitting to line position data for the image X 1 Σ + g and A Σ 1 + u image states of Li 2 J. Mol. Spec. 235 235-47
- [22] We thank Dr. Donald K. Hsu for providing us with a hard copy listing of the data obtained as part of his Ph.D thesis: Hsu D K 1975 The absorption spectra of the A ← X and C ← X transitions of the 7 Li 2 lithium molecule (Fordham University)
- [23] Herzberg G 2008 Molecular Spectra and Molecular Structure ( Spectra of Diatomic Molecules vol I) (Princeton: D. Van Nostrand Company INC)
- [24] Yariv A 1989 Quantum Electronics (New York: John Wiley & Sons) p 178
- [25] Chung H -K, Kirby K and Babb J F 1999 Theoretical study of the absorption spectra af the lithium dimer Phys. Rev. A 60 2002-8
- [26] Labazan I, Vrbanek E, Milosevic S and D¨ren R 2005 u Laser ablation of lithium and lithium/cadmium alloy studied by time-of-flight mass spectrometry Appl. Phys. A 80 569-74
- [27] Lu H, Rasmussen J, Wright M J, Patterson D and Doyle J M 2011 A cold and slow molecular beam Phys. Chem. Chem. Phys. 13 18986-90 | 10.1088/0953-4075/47/24/245302 | [
"Alvaro N. Oliveira",
"Rodrigo L. Sacramento",
"Bruno X. Alves",
"Bruno A. Silva",
"Wania Wolff",
"Claudio L. Cesar"
] | 2014-08-02T19:52:36+00:00 | 2014-08-02T19:52:36+00:00 | [
"physics.atom-ph"
] | Slow ground state molecules from matrix isolation sublimation | We describe the generation and properties of a cryogenic beam of $^7$Li$_2$
dimers from sublimation of a neon matrix where lithium atoms have been
implanted via laser ablation of solid precursors of metallic lithium or lithium
hydride (LiH). Different sublimation regimes lead to pulsed molecular beams
with different temperatures, densities and forward velocities. With laser
absorption spectroscopy these parameters were measured using the molecular
$^7$Li$_2$ (R) transitions A$^1\Sigma_u^+(v'=4,J'=J''+1)\leftarrow
$X$^1\Sigma_g^+ (v''=0,J''=0,1,3)$. In a typical regime, sublimating a matrix
at 16 K, translational temperatures of 6--8 K with a drift velocity of 130
m$\,$s$^{-1}$ in a free expanding pulsed beam with molecular density of 10$^9$
cm$^{-3}$, averaged along the laser axis, were observed. Rotational
temperatures around 5--7 K were obtained. In recent experiments we were able to
monitor the atomic Li signal -- in the D2 line -- concomitantly with the
molecular signal in order to compare them as a function of the number of
ablation pulses. Based on the data and a simple model, we discuss the
possibility that a fraction of these molecules are being formed in the matrix,
by mating atoms from different ablation pulses, which would open up the way to
formation of other more interesting and difficult molecules to be studied at
low temperatures. Such a source of cryogenic molecules have possible
applications encompassing fundamental physics tests, quantum information
studies, cold collisions, chemistry, and trapping. |
1408.0411v1 | ## The LOFAR Pilot Surveys for Pulsars and Fast Radio Transients ?
Thijs Coenen 1 2 ; , Joeri van Leeuwen 2 ?? ; 1 , Jason W. T. Hessels 2 1 ; , Ben W. Stappers 3 , Vladislav I. Kondratiev 2 4 ; , A. Alexov 1 5 ; , R. P. Breton 6 , A. Bilous 7 , S. Cooper 3 , H. Falcke 7 2 ; , R. A. Fallows 2 , V. Gajjar 8 3 , , J.-M. Grießmeier 9 10 ; , T. E. Hassall 6 , A. Karastergiou 11 , E. F. Keane 12 13 ; , M. Kramer 14 3 ; , M. Kuniyoshi 14 , A. Noutsos 14 , S. Osłowski 14 15 ; , M. Pilia 2 , M. Serylak 11 , C. Schrijvers 16 , C. Sobey 2 , S. ter Veen 7 , J. Verbiest 15 , P. Weltevrede , S. Wijnholds , 3 2 K. Zagkouris 11 , A.S. van Amesfoort 2 , J. Anderson 17 18 ; , A. Asgekar 2 19 ; , I. M. Avruch 20 21 ; , M. E. Bell 22 , M. J. Bentum 2 23 ; , G. Bernardi 24 , P. Best 25 , A. Bonafede 26 , F. Breitling 18 , J. Broderick 6 , M. Brüggen 26 , H. R. Butcher 27 , B. Ciardi 28 , A. Corstanje , A. Deller 7 2 , S. Duscha 2 , J. Eislö GLYPH<11> el 29 , R. Fender 11 , C. Ferrari 30 , W. Frieswijk 2 , M. A. Garrett 2 31 ; , F. de Gasperin 26 , E. de Geus 2 32 ; , A. W. Gunst 2 , J. P. Hamaker 2 , G. Heald 2 , M. Hoeft 29 , A. van der Horst , E. Juette 1 33 , G. Kuper 2 , C. Law 34 1 ; , G. Mann 18 , R. McFadden 2 , D. McKay-Bukowski 35 36 , J. P. McKean 2 21 ; ; , H. Munk 2 , E. Orru 2 , H. Paas 37 , M. Pandey-Pommier 38 , A. G. Polatidis 2 , W. Reich 14 , A. Renting 2 , H. Röttgering 31 , A. Rowlinson 1 , A. M. M. Scaife 6 , D. Schwarz 15 , J. Sluman 2 , O. Smirnov 39 40 ; , J. Swinbank 1 , M. Tagger 9 , Y. Tang 2 , C. Tasse 41 , S. Thoudam 7 , C. Toribio 2 , R. Vermeulen 2 , C. Vocks 18 , R. J. van Weeren 24 , O. Wucknitz 14 , P. Zarka 41 , and A. Zensus 14
(A GLYPH<14> liations can be found after the references)
August 5, 2014
## ABSTRACT
We have conducted two pilot surveys for radio pulsars and fast transients with the Low-Frequency Array (LOFAR) around 140 MHz and here report on the first low-frequency fast-radio burst limit and the discovery of two new pulsars. The first survey, the LOFAR Pilot Pulsar Survey (LPPS), observed a large fraction of the northern sky, GLYPH<24> 1 4 : GLYPH<2> 10 4 deg 2 , with 1-hr dwell times. Each observation covered GLYPH<24> 75 deg 2 using 7 independent fields formed by incoherently summing the high-band antenna fields. The second pilot survey, the LOFAR Tied-Array Survey (LOTAS), spanned GLYPH<24> 600 deg 2 , with roughly a 5-fold increase in sensitivity compared with LPPS. Using a coherent sum of the 6 LOFAR 'Superterp' stations, we formed 19 tied-array beams, together covering 4 deg 2 per pointing. From LPPS we derive a limit on the occurrence, at 142 MHz, of dispersed radio bursts of < 150 day GLYPH<0> 1 sky GLYPH<0> 1 , for bursts brighter than S > 107 Jy for the narrowest searched burst duration of 0.66 ms. In LPPS, we re-detected 65 previously known pulsars. LOTAS discovered two pulsars, the first with LOFAR or any digital aperture array. LOTAS also re-detected 27 previously known pulsars. These pilot studies show that LOFAR can e GLYPH<14> ciently carry out all-sky surveys for pulsars and fast transients, and they set the stage for further surveying e GLYPH<11> orts using LOFAR and the planned low-frequency component of the Square Kilometer Array.
## 1. Introduction
The Low-Frequency Array (LOFAR; van Haarlem et al. 2013), with its high sensitivity and flexible observing configurations, is set to open the lowest radio frequencies to e GLYPH<14> cient pulsar surveys. Its operating frequency of 10 GLYPH<0> 240 MHz means a return to the long-wavelength range at which pulsars were originally discovered. The first pulsars were detected at 81 5 MHz, with the : Cambridge Inter Planetary Scattering array (Hewish et al. 1968). Since then, however, most pulsar surveys have avoided low radio frequencies ( < 300 MHz) because of a number of e GLYPH<11> ects that scale strongly with decreasing frequency and severely a GLYPH<11> ect pulsar detectability (Stappers et al. 2011). First, at low frequencies, dispersion correction requires many more, narrower frequency channels (Lorimer & Kramer 2005), and searches need a much finer grid of trial dispersion measures (DMs). Second, multi-path propagation caused by interstellar scattering broadens the intrinsically short duration pulses, scaling with frequency GLYPH<23> as GLYPH<23> GLYPH<0> 3 9 : (Bhat et al. 2004). Lastly, the sky background temperature T sky increases at low frequencies as GLYPH<23> GLYPH<0> 2 6 : (Lawson et al. 1987).
These drawbacks are partially compensated for by the steep pulsar spectral indices, S / GLYPH<23> GLYPH<0> 1 8 : on average (Maron et al. 2000; interpreted further in Bates et al. 2013), with outliers of S / GLYPH<23> GLYPH<0> 2 -GLYPH<23> GLYPH<0> 4 (Hassall et al. 2014). Furthermore, as many pulsar spectra turn over toward lower frequencies, flux densities typically peak in the 100-200 MHz band (Malofeev et al. 2000; Hassall et al. 2014). Finally, for some pulsars only the wider, low-frequency beam may cross Earth (Stappers et al. 2011). Overall these make a compelling low-frequency search case.
? http://www.astron.nl/pulsars/lofar/surveys/lotas/
?? e-mail: [email protected]
A number of low-frequency surveys have recently been performed between 16 and 400 MHz: The Ukrainian UTR-2 radio telescope carried out a pulsar census in the 16 5 : GLYPH<0> 33 0 MHz band : (Zakharenko et al. 2013). A 34.5-MHz pulsar survey undertaken with the Gauribidanur telescope resulted in the first (potential) radio detection of Fermi pulsar J1732 GLYPH<0> 3131 (Maan et al. 2012) - a source that might only be detectable below 50 MHz. The Cambridge array performed a second pulsar survey at 81.5 MHz but did not discover any new pulsars (Shrauner et al. 1998). The ongoing Arecibo drift survey for pulsars at 327 MHz discovered 24 new pulsars (Deneva et al. 2013). A survey of the Cygnus region using the Westerbork Synthesis Radio Telescope (WSRT) at 328 MHz led to the discovery of 3 new pulsars (Janssen et al. 2009), also demonstrating the use of a dish-based radio interfer-
ometer for pulsar searching. Perhaps most importantly, several 300 GLYPH<0> 400 MHz surveys have recently been conducted using the Green Bank Telescope (GBT). Through their high time and frequency resolution, these surveys have discovered over 100 normal and millisecond pulsars so far (Hessels et al. 2008; Boyles et al. 2013; Lynch et al. 2013; Stovall et al. 2014).
Low-frequency surveys can also achieve large instantaneous sky coverage and sensitivity. That is important, as over the last decade it has become increasingly apparent that the various subtypes of radio-emitting neutron stars show a wide range of activity - from the classical, steady pulsars to the sporadic pulses of the rotating radio transients (RRATs; McLaughlin et al. 2006), and the o GLYPH<11> -on intermittent pulsars (Kramer et al. 2006). Other cases of transient millisecond radio pulsars (Archibald et al. 2009; Papitto et al. 2013; Bassa et al. 2014; Stappers et al. 2014) and radio magnetars (Camilo et al. 2006; Eatough et al. 2013) also give strong motivation for pulsar surveys that permit large on-sky time and repeated observations of the same survey area. Furthermore, the recent discovery of the fast radio bursts (FRBs, also known as 'Lorimer Bursts'; Lorimer et al. 2007; Keane et al. 2012; Thornton et al. 2013; Spitler et al. 2014; Petro GLYPH<11> et al. 2014) provides even more impetus for wide-field radio surveys with sub-millisecond time resolution.
LOFAR operates in two observing bands by using two di GLYPH<11> erent types of antennas: the LOFAR low-band antennas (LBA; 10 GLYPH<0> 90 MHz) and the LOFAR high-band antennas (HBA; 110 GLYPH<0> 240 MHz), which together cover the lowest 4 octaves of the radio window observable from Earth. It has a dense central core in the north of the Netherlands. Core HBA stations consist of two identically sized 'sub-stations' (Fig. 4 in van Haarlem et al. 2013). LOFAR uses digital electronics and high-speed fiber networks to create a low-frequency interferometric array that is more versatile and scientifically capable than its predecessors. In particular, through the use of multi-beaming techniques LOFAR can achieve very large (tens of square degrees) fields-of-view, which are ideal for performing e GLYPH<14> cient pulsar and fast transient surveys. The wide fractional bandwidth and capability to store and process hundreds of terabytes of high-resolution data make it an even more powerful instrument. A general overview of LOFAR's pulsar observing capabilities is provided in Stappers et al. (2011), while LOFAR pulsar-survey strategies are outlined and simulated in van Leeuwen & Stappers (2010).
During the 2008 GLYPH<0> 2012 commissioning of LOFAR, we performed two pilot pulsar surveys. E GLYPH<14> cient pulsar surveys ideally combine high sensitivity, a large total field-of-view (FoV) and a high angular resolution per FoV element. LOFAR's beamformed modes (Stappers et al. 2011) can form up to hundreds of beams simultaneously (Romein et al. 2010), and thus provide such a wide view ( > 10 deg 2 ) as well as the ability to constrain positions to a few arcminutes. The first survey, employing incoherent beam-forming, is called the LOFAR Pilot Pulsar Survey (LPPS; Fig. 1, left panel), while the second survey, the LOFAR Tied-Array Survey (LOTAS; Fig. 1, middle panel) employed coherent or tied-array beam forming. Incoherent beamforming (Backer 2000) provides lower raw sensitivity, with pulsar signal-to-noise (S N) increasing only as the square root of the / number of stations being added. But it does allow one to observe bright, rare events because of its large FoV, clear from Fig. 1. Coherent beam-forming, in contrast, permits maximum instantaneous sensitivity, scaling linearly with the number of stations summed. The resulting tied-array beams have limited FoV, however, scaling as the inverse of the maximum distance between stations (Stappers et al. 2011).
## LPPS (2010)
Fig. 1. The single-pointing footprints of LPPS (left) and LOTAS (middle). Circles denote the half-power beam widths at the respective central frequencies (Table 1). For comparison (right) is the single-pointing footprint of the ongoing LOFAR Tied-array All-sky Survey LOTAAS (Section 5). The LOTAAS pointings use both incoherent (large circles) and coherent (clusters of small circles) beams.
In this paper, we present the setup of these two surveys (Sect. 2 and 3). In Section 4 we then report on the new and known pulsars that were detected and present limits for the rate of fast radio transients in general. Section 5 contains overall conclusions, and looks forward to currently ongoing and future work. Profiles and parameters for the detected and discovered pulsars can be found in Appendices A and B. These sections are all described in greater detail in Coenen (2013, henceforth C13), and throughout this paper we will refer the interested reader to specific sections of C13.
## 2. Observations
In LPPS we incoherently added as many LOFAR stations as were available; For LOTAS we only coherently combined stations from the 300-m-wide LOFAR 'Superterp', which has a much higher filling factor (Backer 2000; van Leeuwen & Stappers 2010) than the rest of the array (Table 1).
## 2.1. LPPS Survey
The LPPS survey was conducted in 2010 December, using notyet-calibrated Dutch LOFAR HBA stations (cf. §4.7 in van Haarlem et al. 2013). Initial observations used 13 core sub-stations and 4 remote stations, which increased to 38 core and 6 remote stations at the end of the survey. As remote stations are twice as sensitive as core stations, the antenna gain G for a certain LPPS configuration scales as G / ( n core + 2 n remote ) = p n core + n remote . As detailed in Ch. 3 of C13 these stations were combined to form sets of 7 incoherent-sum station beams (Table 1).
Full-wave electro-magnetic simulations on HBA stations (Arts et al. 2013), modeling the incoherent summation of the sets of stations used, produced the FoV listed in Table 1. The modeled LPPS beam proved well-behaved and circular in the zenith, with a full width at half maximum (FWHM) of 3.7 GLYPH<14> (Fig. 3.1 in C13). The large FoV per pointing (Table 1) allowed the survey to cover 34% of the celestial sphere (Fig. 2). Combined with the long dwell times, e GLYPH<11> ectively up to 1 hr, LPPS provided the equivalent of 9.7 minutes of all-sky coverage.
| Observation | Pointings | Beams / P | FoV / P deg 2 | Res. deg | t int min | BW MHz | f MHz | N ch | t samp ms | Coh. | R d TB / hr |
|--------------------|-------------|-----------------|-----------------|------------|----------------|----------|---------|--------|-------------|--------|----------------|
| LPPS Survey | 246 | 7 | 75 | 3.7 | 57 | 6.8 | 142 | 560 | 0.655 | I | 0.09 |
| LOTAS Survey | 206 | 19 | 3.9 | 0.5 1 | 17 | 48 | 143 | 3904 | 1.3 | C | 0.8 |
| LOTAS Confirmation | GLYPH<0> | 61 GLYPH<0> 217 | GLYPH<0> | < 0.1 | 27 | 80 | 150 | 6576 | 0.49 | C | 12 GLYPH<0> 42 |
| LOTAS Timing | GLYPH<0> | 1 | GLYPH<0> | GLYPH<0> | 15 GLYPH<0> 30 | 80 | 150 | 6576 | 1.3 | C | 0.07 |
1 With the 2011 beam-former, beams at higher declinations were spaced more closely in right ascension (§4.2.1 in C13).
Table 1. The di GLYPH<11> erent observational setups used in this work. Listed are the number of pointings over the survey; the number of beams per pointing Beams P, the field of view per pointing FoV P, the angular resolution (FWHM of each beam), integration time tint, bandwidth BW, central / / frequency f, number of channels Nch, sampling time tsamp, whether beamforming was (I)ncoherent or (C)oherent, and the data rate Rd.
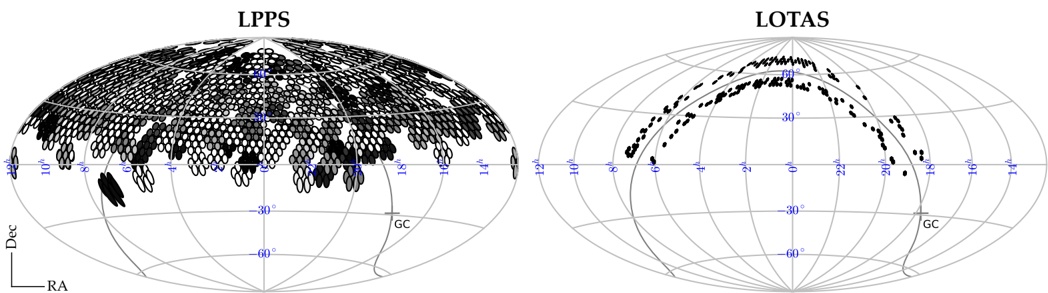
Fig. 2. The total sky coverage achieved by LPPS (left) and LOTAS (right). The Galactic plane and Center are shown with a grey line and cross, respectively. The grayscale of the individual beams shows the usable observation length, where white is 0 min, and black the full 57 min for LPPS and 17 min for LOTAS.
## 2.2. LOTAS Survey
## 3.1. Pipeline processing
In May 2011 we carried out LOTAS, a tied-array survey of GLYPH<24> 600 deg 2 . By that time the 6 HBA stations on the central Superterp shared a single clock signal 1 (van Haarlem et al. 2013), which allowed for reliable tied-array beamforming (§4.2.1 in C13). This resulted in 19-beam observations covering 3.9 deg 2 per 17 min pointing (Fig. 1; Table 1). The expected tied-array beam shapes were validated through a series of characterization observations (Fig. 27 in van Haarlem et al. 2013). LOTAS sparsely surveyed two strips of sky 5 GLYPH<14> < j b j < 15 , just o GLYPH<14> GLYPH<11> the Galactic plane, to maximize the potential for new pulsar discoveries while avoiding high scattering and background sky emission (Fig. 2).
## 2.3. LOTAS Confirmations and Timing
Confirmation observations on pulsar candidates from the LOTAS survey were performed late 2012. The availability of 24 core stations, and ability to form many tens of tied-array beams together enabled significantly higher sensitivity and angular resolution (Table 1). Confirmed candidates were timed until early 2014 with a similar but single-beam setup (Table 1).
## 3. Analysis
Survey data were processed to detect periodic pulsar signals and individual, dispersed bright radio bursts. This processing included data quality checks. As the implementation of this pipeline and quality control is detailed in C13, only its essentials are summarized here.
1 This signal is now distributed to all 24 core stations.
Search processing was handled by a parallelized Python pipeline, based on PRESTO 2 (Ransom 2001). It automated the process of radio frequency interference (RFI) excision and dedispersion (with survey specific settings, described below). It next handled periodicity searches including accounting for acceleration, single-pulse searching, as well as sifting and folding of the best candidates.
We first performed periodicity searches assuming no acceleration. Binary motion, however, can cause the intrinsically periodic signals to drift in the Fourier domain. Therefore we next performed an 'acceleration' search (Ransom et al. 2002) up to a maximum number of bins, or zmax , of 50. For a pulsar with, e.g., a 40-ms period in a relativistic binary, LPPS is sensitive up to binary accelerations of 51 m s GLYPH<0> 2 (C13). We summed up to 16 harmonics, a technique where through recursive stretching and summing, the power contained in all harmonics can be recovered (Ransom 2001); and included 'polishing', an extra step to reject RFI peaks acting as spurious harmonics.
The dedispersed time series were inspected for single, dispersed bursts by convolving the time series with a running boxcar function and inspecting the correlation coe GLYPH<14> cient. We used box-cars 1-4, 6, 9, 14, 20 and 30 bins long, making the search sensitive to bursts between 0.655 ms and 19.5 ms at low DMs and, because of down-sampling during dedispersion, to between 41.9 ms and 1.26 s at the very highest DMs. Data that were affected by RFI were discarded. For the remaining good-quality data, the PRESTO detections per individual trial-DM were next associated or 'grouped' (§3.3.3 in C13) across all DMs. This freely available 3 single-pulse post-processing script looked for
2 https://github.com/scottransom/presto
3 https://github.com/tcoenen/singlepulse-search
astrophysical signals by demanding that each single-pulse detection (or 'group') had a minimum of 7 members, that it had a minimum signal-to-noise ratio of 8 and that at least 8 such pulses occurred at roughly the same peak DM. Through trials, these numbers generally appeared to be the best heuristics to distinguish astrophysical signals from man-made ones. For each instance where these criteria were met, a plot like Fig. 3 was created for inspection. Beyond these, two-dimensional histograms of the number of detections in the time-DM plane (Fig. 3.5 in C13) were used to assess data quality and detect bright pulsars.
## 3.1.1. LPPS
The LPPS data were reduced on the Hydra cluster at the University of Manchester. We dedispersed our data in 3487 trial-DMs up to 3000 pc cm GLYPH<0> 3 , and applied zero-DM filtering (Eatough et al. 2009). That technique removes all broad-band signals from DM 0pc cm = GLYPH<0> 3 , which are assumed to be RFI. This proved useful in limiting the number of spurious single-pulse detections without negatively impacting the periodicity search results. At the lowest DMs no downsampling in time was performed and the trial-DM spacing was 0.05 pc cm GLYPH<0> 3 . At the very highest DMs the data were downsampled 64 times, to match the increased intra-channel dispersive smearing, and the trial-DMs are spaced in steps of 5 pc cm GLYPH<0> 3 . Because of this heavy downsampling in time, the high-DM part of the search added only a few percent to the total processing time.
Acceleration candidates for all 7 beams were sorted by significance, and duplicates in period and DM, across beams and across zmax values, were removed. To minimize spurious (RFI) detections, only candidates with periods 5 ms < P < 15 s and DM > 2 pc cm GLYPH<0> 3 were processed further. The prepfold routine from PRESTO folded each candidate and optimized in period and period derivative. Because this folding was done on the raw data, which includes frequency information, the DM could also be optimized. The resulting candidates were ranked. Two neural nets (Eatough et al. 2010), trained on the folds of LPPS pulsar re-detections and RFI instances, helped prioritize candidates.
## 3.1.2. LOTAS
LOTAS data were transferred from Groningen over a three-point 'bandwidth-on-demand' 1 GLYPH<0> 10 Gbps network, to the grid storage cluster at SURFsara 4 Amsterdam, and to Hydra. The availability of a large grid compute cluster, operated by SURFsara and part of the European grid infrastructure coordinated by EGI , al5 lowed processing of the full survey data set to proceed relatively quickly. In all, the search ran on 200 8-core servers for a little over a month, for a total of 1.3 million core hours used.
For LOTAS, the DM search covered 0 GLYPH<0> 1000 pc cm GLYPH<0> 3 with spacings increasing from 0 02 : GLYPH<0> 0 30 pc cm : GLYPH<0> 3 for a total of either 16845 or 18100 DM trials (cf. §4.2.3 in C13). No zero-DM filtering was used. All time series were searched at the full 1.3 ms resolution.
LOTAS contained little RFI and no neural-net candidate preselection was used. We manually inspected all acceleration candidates with GLYPH<31> 2 > 2 0. That reduced : GLYPH<31> 2 , reported by prepfold , is the result of fitting a straight line to the profile - noisy profiles can be fit with such a straight line and will produce low GLYPH<31> 2 , while strong pulsars deviate and produce high GLYPH<31> 2 . A GLYPH<31> 2 > 2 0 corre-: sponds to a signal-to-noise ratio & 6. We also inspected those
4
5
https://www.surfsara.nl/nl/systems/grid/description http://www.egi.eu/
with 1 5 : < GLYPH<31> 2 < 2 0, DM : < 250 pc cm GLYPH<0> 3 and period derivative ˙ P < 10 GLYPH<0> 8 s s GLYPH<0> 1 . That choice of parameter space e GLYPH<14> ciently excludes RFI, which often shows large P. ˙
## 3.2. Telescope validation and data quality
The LPPS data were taken during LOFAR's early commissioning period and data quality issues were expected. Stations had not yet been calibrated and contained faulty initial elements that generated RFI. This a GLYPH<11> ected the quality of the array beam, and a significant fraction of the data was unusable 6 .
In the single-pulse search, RFI instances could sometimes overwhelm the PRESTO diagnostics. We developed a condensed version of the single-pulse diagnostic plots, where the singlepulse candidates are shown as a 2-dimensional, color-coded histogram on the time-DM plane (Ch. 5 in C13). Our removal of all 10-s blocks of data containing more than 500 single-pulse candidates considerably cleaned the LPPS data set.
We obtained a first indication of the sensitivity of this uncalibrated LOFAR setup from the sample of pulsars blindly detected in LPPS (§4.1). As detailed in §3.4.4 in C13, we extrapolated the ATNF catalog 400-MHz fluxes of this set to the LOFAR band. From an ensemble comparison to our measured signal-to-noise-ratio we found the maximum LPPS gain to be G = 0 60 : GLYPH<6> 0 13 K Jy. That is an appreciable fraction ( : = GLYPH<24> 40%) of LOFAR's theoretical, calibrated sensitivity.
Compared to LPPS, the LOTAS data were already found to be much cleaner of both internally generated artifacts and external RFI. This was due to both the much more mature state of the deployed stations, and the fact that the narrow, coherently formed beams are less susceptible to RFI. The wider bandwidth of LOTAS, too, helped di GLYPH<11> erentiate interference - which typically peaks at DM = 0 pc cm GLYPH<0> 3 - from pulsar signals.
## 4. Results and Discussion
LPPS is a shallow survey that covered 34% of the sky and detected 65 known pulsars (§4.1). In §4.2, we compare this yield with a simulation of the Galactic population. LPPS also sets a stringent upper limit on the rate of low-frequency Fast Radio Bursts (§4.3). LOTAS, with its higher sensitivity, detected the first two LOFAR pulsars (§4.4).
## 4.1. LPPS pulsar search
The LPPS blind periodicity search yielded the re-detection of 54 pulsars. Their profiles are shown in Figs. A.1 and A.2. Folding of known pulsars within the survey footprint (§4.2.4 in C13) led to the detection of a further 9. The single-pulse search resulted in 20 pulsar re-detections. This means that we were able to detect about one third of our periodicity search detections in singlepulse searches of the same data. This is in line with predictions from Stappers et al. (2011). Two pulsars, PSRs B0154 + 61 and B0809 + 74, were only detected through their individual pulses. In Table A.1 we list the detection parameters of all 65 pulsars.
The brightest pulsar in the Northern hemisphere, B0329 + 54, was detected in the side lobes for many observations, from up to 109 degrees away from the pointing center (Fig. 3.14 in C13).
Pulsar J2317 + 68 is a 813-ms pulsar at a DM of 71.158 pc cm GLYPH<0> 3 , which we independently discovered. This source had only months earlier been discovered in the 350-MHz
6 With system health monitoring now in place, the quality of current LOFAR data is much improved.
Fig. 3. A detection plot of PSR J0243 + 6257 (Beam 1, top row), as produced by our single-pulse post processing scripts. For each of the seven beams in this observation, the single-pulse detections are plotted between DMs of 0.5 cm GLYPH<0> 3 pc and 10 cm GLYPH<0> 3 pc (left panels). The two right-most columns of panels show the events collapsed in time, in DM versus cumulative signal-to-noise ratio (S N) and number of events (N), respectively. / The top panel of the plot shows PSR J0243 + 6257 clearly detected whilst the other beams show no detection, only some RFI. The pulsar is visible in the main top-row DM versus time panel as a series of individual pulses with a DM GLYPH<24> 3 9 pc cm : GLYPH<0> 3 . In post-processing, our automated pulse grouping algorithm (C13) has colored events that are judged to be of an astrophysical origin in red (the black points were automatically judged to be either statistical noise or RFI).
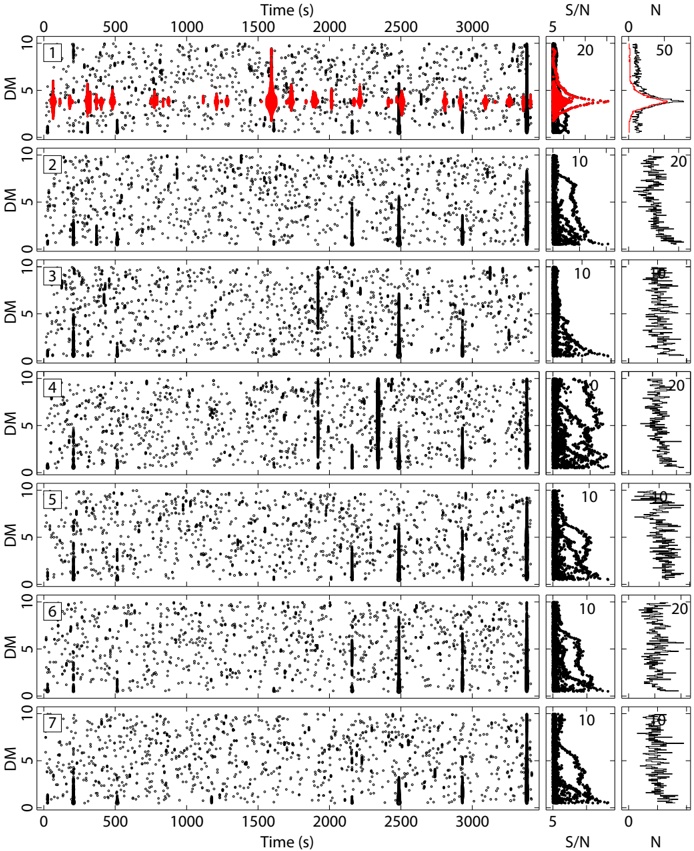
## GBT Northern Celestial Cap (GBNCC) survey (Stovall et al. 2014).
Pulsar J0243 + 6257 was discovered by the GBT350 Survey (Hessels et al. 2008, there known as J0240 + 62). It was detected in both the LPPS periodicity and single pulse search. In many ways this source is a prototype for the nearby, low-DM, perhaps intermittent, sources that LOFAR is best equipped to discover. The single-pulse discovery observation (Fig. 3) showed that PSR J0243 + 6257 has a broad pulse-energy distribution. In a 1-hr follow-up observation taken with the full LOFAR HBA core and bandwidth, the large pulse-to-pulse intensity variations in PSR J0243 + 6257 become even more clear. In Fig. 4 we show that some bright bursts outshine the average pulse by a factor 25. In most of the well-studied pulsars this ratio is much lower (e.g., a factor of only 2 in PSR B0809 + 74; van Leeuwen et al. 2002). It is only higher in RRATs and PSR B0656 + 14 (where it is of or- der 100; Weltevrede et al. 2006). Using LOFAR's multi-beaming confirmation method (§2.3) this observation was also used to determine the position to RAJ = 02:42:35(3), DECJ = 62:56:5(4). With the long dwell times that can be a GLYPH<11> orded by the huge FoV of LOFAR's incoherent beam-forming mode, there are prospects for discovering other intermittent but occasionally bright sources like PSR J0243 + 6257.
The detection of 54 pulsars in the blind search of the LPPS data demonstrated that LOFAR is a capable pulsar search instrument. The further detection of 9 pulsars by folding on their known ephemerides means that our processing can still be improved for better extraction of pulsars from spurious, RFIrelated candidates. As LOFAR now routinely produces bettercalibrated, more sensitive data, the prospects for achieving a significantly deeper all-sky survey using the same incoherent beamforming technique as LPPS is very good.
Fig. 4. Pulse energy histogram for PSR J0243 + 6257. Shown are the individual pulse energies for 6000 pulses, compared to their average. The dashed line, filled in dark gray, represents the o GLYPH<11> -pulse noise distribution. The light gray histogram is the energy present in the on-pulse region. That distribution peaks near zero and has significant overlap with the background histogram. In those pulses no pulsar emission is detected.
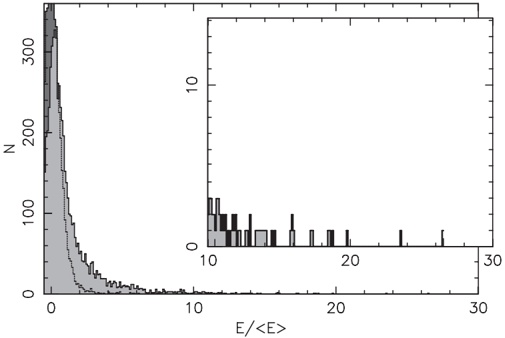
## 4.1.1. Comparison to recent low-frequency or wide-field surveys
Two features that make LPPS stand out from other recent pulsar survey e GLYPH<11> orts (e.g. the Parkes multi-beam pulsar survey, Manchester et al. 2001; the GBT driftscan survey, Boyles et al. 2013), are the very low observing frequency and the large dwell time. Two surveys that each did share one of these characteristics are the second Cambridge pulsar survey and the Allen Telescope Array (ATA) 'Fly's Eye' experiment.
The second Cambridge survey at 81.5 MHz (see Shrauner et al. 1998) scanned the same northern sky as LPPS and detected 20 pulsars. The blind periodicity search of LPPS data did not detect 3 of those (B0809 + 74, B0943 + 10, B1133 + 16) because their LPPS pointings were corrupted. B1642 GLYPH<0> 03 fell outside our survey area.
Notable features of LPPS are its large FoV, and 57-min dwell time. It shares these features with the 'Fly's Eye' experiment carried out with the ATA (Welch et al. 2009) at a frequency of 1.4 GHz. Its single-pulse searches were the L-Band equivalent of those in LPPS. Down to a signal-to-noise ratio of 8 no astronomical single pulses were detected beyond those from PSR B0329 + 54 (Siemion et al. 2012).
## 4.2. Modeling the pulsar population that underlies LPPS
On completion LPPS was the deepest large-area survey in the 100 MHz regime to date. The 65 pulsar detections constitute a low-frequency sample that is adequate in size to serve as input for a pulsar population model.
In modeling LPPS we used the dynamic, evolving model approach developed in Hartman et al. (1997). We populated the modeled Galaxy with a population of pulsars that in van Leeuwen & Stappers (2010) best reproduced the survey results of 6 large surveys. We implemented a survey model of LPPS that takes into account the total footprint on the sky, including overlapping regions (Fig. 2); the distribution of usable integration times; the sensitivity variation between pointings using di GLYPH<11> erent sets of stations; and the gain determined in §3.2. Based on the cumulative signal-to-noise-ratio values determined for our detected sample (Table A.1), any simulated pulsar producing a S N / over 15 was labeled detected. That S N value is higher than the / common value of 8 GLYPH<0> 10 (cf. van Leeuwen & Stappers 2010) to account for the deleterious e GLYPH<11> ect that RFI had on blindly identifying pulsar signals in LPPS.
In our simulation, 2.7 million pulsars formed throughout the Galaxy. Of these, 50,000 were above the death line at the present day and beamed toward Earth; 9,000 are in our survey FoV. For 1,200 of these, the scatter and dispersion broadening exceeds their rotational period, making them undetectable. Of the remaining 8,000 pulsars, 80 are bright enough to be detected in LPPS (Fig. 5). Running the simulation over the error range on the derived gain of 0.60 GLYPH<6> 0.13 K Jy produces a LPPS detected = sample containing 80 GLYPH<6> 20 simulated pulsars. That is in reasonable agreement with the actual number of blind detections of 54. Some of the di GLYPH<11> erence between these numbers could be in either the modeled survey (e.g., remaining incomplete understanding of the incoherent-addition of these commissioning era data) or the modeled population (e.g., the low-frequency spectrum turn-over behaving di GLYPH<11> erently than simulated). Overall, these simulations confirm that our best pulsar population models (van Leeuwen & Stappers 2010) can accurately predict lowfrequency surveys.
## 4.3. LPPS limit on the rate of fast radio bursts
The detection of a bright, highly dispersed radio burst of apparent extra-galactic origin was first reported by Lorimer et al. (2007) and further detections have since been reported by Keane et al. (2011), Thornton et al. (2013) and Spitler et al. (2014). As the LPPS survey provides both long dwell times and large FoV, the survey data can be used to either detect or limit FRBs at low radio frequencies.
We searched the single-pulse data (§3.1) down to a signalto-noise ratio of 10 at DMs between 2-3000 cm GLYPH<0> 3 pc. This is a much larger DM than predicted for any typical line-of-sight through our Galaxy away from the Galactic center (Cordes & Lazio 2002). Signals with such high DMs may also be highly scattered at low frequencies. Although there is an observed relation between DM and scattering delay in the Galaxy (Bhat et al. 2004), this relation has more than an order-of-magnitude scatter and any single line-of-sight may deviate significantly from the average relation. Furthermore, it is unlikely that the ionized inter-galactic medium is distributed in a similar way to the Galactic inter-stellar medium. Such highly dispersed signals may thus continue to be detectable at LOFAR frequencies (Serylak et al. 2013; Macquart & Koay 2013; Hassall et al. 2013; Lorimer et al. 2013), making a detection possible and a limit useful.
We visually inspected all pulses that crossed this threshold of S N / > 10. All were associated with either a known pulsar or RFI (as evidenced by detections across multiple beams, or across multiple trial DMs with no peak in S N) which was particularly / present at low DMs. Thus, no FRBs were detected in LPPS.
For bursts that are not a GLYPH<11> ected by intra-channel dispersion smearing, the resulting fast-transient limit then depends on the telescope sensitivity and the sky coverage in both time and area. We define the sky coverage as being out to the FWHM of each beam and use the e GLYPH<11> ective time coverage determined in §3.2.
We use the peak gain derived from the LPPS pulsar redetections (§3.2) to calculate the sensitivity. For each LPPS observation this was adjusted for the number of used (sub-)stations and the zenith angle, and was multiplied by 0.73 to produce the
Fig. 5. The modeled pulsars in our Galaxy. Pulsars that are still emitting at the current time, and are beamed toward us, are marked with dots (only 10% of these shown). Simulated pulsars that are detected in LPPS are marked with blue open circles. The Earth is marked with a ' + ', the Galactic center with a '*'. On the left a projection onto the plane of the Galaxy is plotted, including spiral arms, with the Galactic centre at y = GLYPH<0> 8.5 kpc from the Earth. The right hand panel shows the projection of the detections onto the vertical plane through the Galactic centre and the Earth.
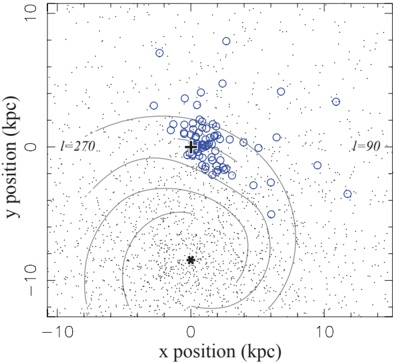
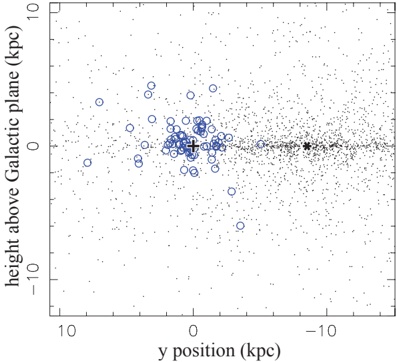
average over the FoV. Use of the gain average, not its minimum at FWHM, is common in determining survey sensitivity (e.g. Edwards et al. 2001). Finally, we derived a flux limit for each pointing using a T sys + T sky of 500 K. We removed from consideration any beam with a flux limit above 200 Jy, which was likely caused by RFI and or calibration issues. The LPPS average flux / limit is then Smin = 107 Jy (Fig. 3.15 in C13).
That limit is valid when the observed burst, after dedispersion, falls within a single 0.66 ms sample. For bursts that are wider, either intrinsically or by intra-channel or step-size dispersion smearing, the burst flux is spread over a width w . The fluence F = S w is preserved when a pulse is smeared out (e.g. Thornton et al. 2013) but the sensitivity of our single-pulse searches over boxcars of up to 1.26 s (§3.1) decreases by the square root of this width w .
We thus find a rate limit R on FRBs that were detectable by LPPS of
$$R _ { \text{FRB} } ( S > 1 0 7 \sqrt { \frac { w } { 0. 6 6 \, m s } } \, J y ) < 1. 5 \times 1 0 ^ { 2 } \, \text{sky} ^ { - 1 } \text{day} ^ { - 1 }. \ ( 1 ) \quad \text{fig. 6. }.$$
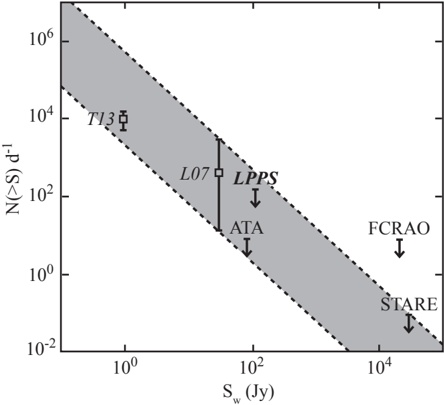
In Fig. 6 we compare our rate to the extrapolated occurrence based on the detection of the first FRB (Lorimer et al. 2007), to the FRB rate reported in Thornton et al. (2013) and to limits set by other surveys. These other surveys were all performed at higher frequencies, 270-1400 MHz. The low observing frequency used in LPPS means that any steep spectrum sources would appear much brighter, and consequently that a flux limit obtained with LOFAR would be much more constraining when extrapolated to higher observing frequencies. The original detection of the Lorimer burst had an apparently steep spectrum (Lorimer et al. 2007), while one of the bursts reported in Thornton et al. (2013) instead showed 100-MHz-wide, bright bands. Given our limited knowledge at this time, we simply assume a flat spectral index.
We can convert this celestial rate to a volumetric event frequency. We start from the assumptions that FRB emission is intrinsically shorter than our sampling time of 0.655 ms, has a luminosity at 1.3 GHz of 1 Jy Gpc 2 (Thornton et al. 2013), and follows a power-law scaling of the fluence F ( GLYPH<23> ) / GLYPH<23> GLYPH<11> . We as-
Fig. 6. The limits on transient occurrence per day N versus widthadjusted minimum flux S w = S = p w 0 66 ms : , on a logarithmic scale, comparing previous fast-transient surveys (Kulkarni et al. 2008) with LPPS. The burst rates reported by Lorimer et al. (2007, L07) and Thornton et al. (2013, T13) are plotted with their errors. The area between the dashed lines represents a N ( > S ) / S GLYPH<0> 3 2 = prediction from a homogeneous, stationary population of objects. The LPPS limit, which assumes a flat spectral index for the purposes of comparing with surveys at other frequencies, is seen near the center.
sume our intra-channel dispersion smearing dominates over scatter smearing.
For each LPPS beam we determine at which distance the decreasing flux of such an FRB falls under the minimum detectable flux for the increasingly dispersion-smeared pulse. As the distance to a simulated FRBs increases, we calculate its flux S , which falls per the inverse-square law based on the co-moving distance. At each step in redshift z , we calculate the expected DMby adding the maximum Galactic contribution in this direction (Cordes & Lazio 2002), a host contribution, and an intergalactic matter (IGM) component. We assume an intrinsic host
DM of 100 pc cm GLYPH<0> 3 and a reduction of the e GLYPH<11> ective time smearing with redshift as 1 (z / + 1). From Fig. 1 in Ioka (2003) we estimate DMIGM ' 1100 z , for z < 4. We assume the intrinsic dispersion in the burst is negligible. From the combined e GLYPH<11> ective DM we determine the number of time bins n the burst is smeared over. After also taking into account the average expected mismatch with the closest box-car length (§3.1) this results in an increase of the previously determined minimum detectable flux Smin by a factor p 1 125 : n . The distance at which this S min > S determines the volume this beam has searched. This is multiplied by the pointing integration time. Given our non-detection, the reciprocal of the resulting summed flux-limited volume over all such beams then produces a rate upper limit of
$$\Phi _ { F R B } < 2. 5 \times 1 0 ^ { 5 } \left ( \frac { 1 4 2 } { 1 3 0 0 } \right ) ^ { - 1. 3 ( \alpha + 2 ) } \text{Gpc} ^ { - 3 } \, \text{yr} ^ { - 1 }. \quad ( 2 ) \quad \underset { \infty } { \circ } \, \left | \right |$$
Here the dependence of the deleterious dispersion smearing on frequency causes the power-law index to deviate from the GLYPH<0> 1 5( : GLYPH<11> + 2) expected for a purely flux-limited cosmological population. For GLYPH<11> = GLYPH<0> 2 our upper limit of 2 5 : GLYPH<2> 10 5 Gpc GLYPH<0> 3 yr GLYPH<0> 1 is higher than, and thus consistent with, the Thornton et al. FRB rate at 1.3 GHz of 2 4 : GLYPH<2> 10 4 Gpc GLYPH<0> 3 yr GLYPH<0> 1 as derived in Kulkarni et al. (2014). For shallower spectral indexes our rate upper limit increases further and becomes less constraining.
The limits we find are in line with those derived from other surveys. In ongoing LOFAR transient searches, we are continuing to improve on this limit and better constrain the spectra and scattering properties of such bursts. These searches will either soon detect such signals or show that the higher-frequency ( GLYPH<24> 1.4 GHz) window is ideal for their detection.
## 4.4. LOTAS pulsar search
The LOTAS periodicity search resulted in the detection of 23 pulsars, including LOFAR's first two pulsar discoveries: PSRs J0140 + 5622 and J0613 + 3731 (Fig. 7). The parameters of all detections are listed in Table B.1. Of the 21 redetections, 17 were available in the ATNF pulsar catalog. A further four, J0216 + 52, J0338 + 66, J0358 + 42 and J2243 + 69, were independent discoveries that had only recently been found in the ongoing GBNCC survey (Stovall et al. 2014).
To judge the completeness of our blind search, we directly folded at the periods of all known pulsars within a 5-degree radius of the LOTAS pointing centers. Inspecting these folds yielded the re-detection of a further 6 pulsars. These are marked 'd" in Table B.1.
The LOTAS single-pulse search output su GLYPH<11> ered from temporal misalignment between subsequent DM trials, which prevented automatic separation of astrophysical pulses from RFI. By manually inspecting the condensed plots produced by the single-pulse search (§3.2) we identified 8 bright pulsars. In Table B.1 we mark these 's" and list the S N of the brightest pulse. We / then checked for all known pulsars within a 7 degrees radius of the LOTAS pointing, but we did not detect any.
For the two discoveries, PSRs J0140 + 5622 and J0613 + 3731, confirmation and follow-up observations (§2.3) were combined to determine the rotational ephemerides. These data sets span two years. This timing analysis was performed using PSRCHIVE (Hotan et al. 2004; van Straten et al. 2012) and TEMPO2 (Hobbs et al. 2006) and followed standard techniques (detailed in C13).
The resulting timing solutions are given in Table 2.
When the most recent of these timing observations were carried out in 2014 January, the LOFAR sensitivity was well de-
Fig. 7. Discovery plots of PSRs J0140 + 5622 (left) and J0613 + 3731 (right). The bottom panels shows the signal strength as a function of time and rotational phase. Some RFI is masked, showing up as whiteouts. The top panels shows the folded profiles, repeated twice for clarity.
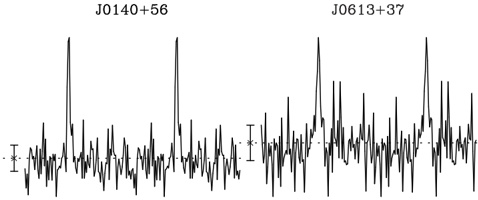
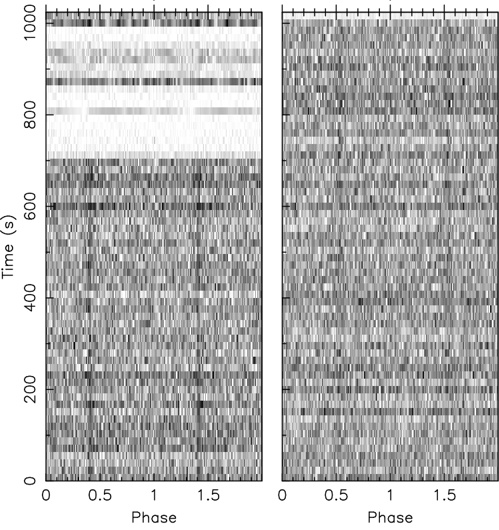
scribed and characterized, allowing for the flux measurements also listed in Table 2. As detailed in Kondratiev et al. (2014), these take into account e.g., the actual number of healthy dipoles used, the empirical scaling of sensitivity versus number of coherently added stations, and the exact fraction of masking due to RFI.
## 4.4.1. PSR J0140+5622
LOFAR's first pulsar discovery, PSR J0140 + 5622, has a spin period P = 1 8 s and DM : = 101.8 pc cm GLYPH<0> 3 . Its discovery profile is shown in Fig. 7. Our timing campaign allowed us to derive a period derivative P of 7 9 ˙ : GLYPH<2> 10 GLYPH<0> 14 s s GLYPH<0> 1 . The values derived for the characteristic age GLYPH<28> c and the surface magnetic field B surf are respectively 3.5 GLYPH<2> 10 5 yr and 1.2 GLYPH<2> 10 13 G. This surface magnetic field is at the high end of the known population (Fig. 4.14 in C13). The best-fit timing model for PSR J0140 + 5622 is presented in Table 2. The estimated distance to this pulsar is 3.8 kpc, based on the NE2001 model (Cordes & Lazio 2002).
Fig. 8. The confirmation observation of PSR J0613 + 3731, establishing it had been discovered in a side-lobe of the original survey observation. The initially derived position was between beams 15 and 30 in this figure. Two of the 217 specified beams did not process due to a cluster hardware issue. Each beam is color coded according to the reduced chisquared of the average pulse profile in that beam, compared to a straight line (cf. §3.1.2). The actual size of the individual tied-array beams is shown bottom left. The cross shows the pulsar's best-fit position.
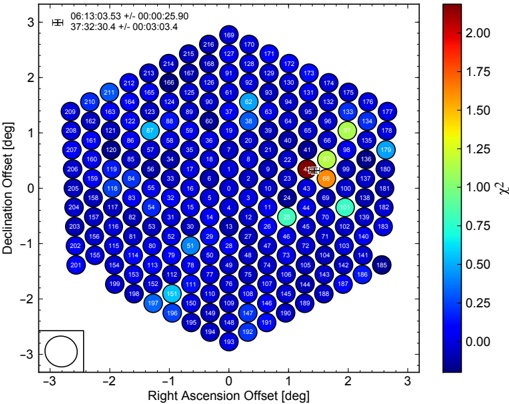
## 4.4.2. PSR J0613+3731
The second LOTAS pulsar discovery is PSR J0613 + 3731 (Fig. 7), with P = 0 62 s and DM : = 19.0 pc cm GLYPH<0> 3 . While this pulsar was quickly confirmed in a multi-beam observation, its observed position appeared to vary, and it was only visible at the bottom of the observing band. Side-lobe detections of bright known pulsars showed similar behavior. As the LOTAS fractional bandwidth is large, the FWHM of a tied-array beam changes by GLYPH<24> 40% over the band, and the size and position of the side lobes follow. A further localization observation performed as part of the timing campaign for PSR J0613 + 3731, this time using 215 beams spread over an area much larger than the 19-beam footprint of a LOTAS survey observation, established the fact that PSR J0613 + 3731 was indeed initially discovered in a side-lobe (Fig. 8). The timing campaign along with the initial discovery and confirmation observations allowed us to derive values for ˙ , P B surf and a GLYPH<28> c , which are respectively 3 2 : GLYPH<2> 10 GLYPH<0> 15 s s GLYPH<0> 1 , 1 4 : GLYPH<2> 10 12 G and 3 0 : GLYPH<2> 10 6 yr. Table 2 contains the precise values for these derived quantities and also contains information about the timing solutions. The DM-derived distance to PSR J0613 + 3731 is 0.64 kpc.
## 4.4.3. Follow-up
High-frequency confirmation attempts were carried out at 1532 MHz with the Lovell telescope at Jodrell Bank Observatory. Both pulsars were ultimately detected. Pulsar J0613 + 3731 was seen easily, although in follow-up timing it showed considerable flux variation possibly caused by scintillation, explaining why it was missed in previous 1.4 GHz surveys. Pulsar J0613 + 3731 thus showcases the benefit of a low-frequency survey, where the observed bandwidth greatly exceeds the scintillation bandwidth. From a 4-hr integrated profile we estimate an L-Band mean flux density of 0.13(6) mJy, using the radiometer equation (Eq. 3.3 in C13) to scale to the o GLYPH<11> -pulse noise. Pul- sar J0140 + 5622 is much fainter at 1.4 GHz. Only after a total of 6 hrs of integration this pulsar was detected at a S N of 10 -/ clearly illustrating the importance of low-frequency surveys for finding steep-spectrum sources. The resulting average flux density is listed in Table 2.
Next, both sources were weakly detected in the expected archive pointings from GBNCC (Stovall et al. 2014), by folding at their now-known periods. The resulting 350 MHz mean flux densities, derived using the radiometer equation, are listed in Table 2. Between each of the derived fluxes at 150, 350 and 1400 MHz we derived the spectral index GLYPH<11> from a fit to S GLYPH<23> / GLYPH<23> GLYPH<11> , where S GLYPH<23> is the flux density at observing frequency GLYPH<23> . Table 2 shows these are steeper than GLYPH<0> 2 at the low-frequency end, for both pulsars.
## 5. Conclusions and future work
LPPS re-detected 54 pulsars in the periodicity search, and 20, mostly overlapping, in single pulse searches. A further 9 pulsars were retrieved from the data by folding on known ephemerides (Table A.1). That detected sample agrees well with the outcome of a simulation of the Galactic pulsar population and the LOFAR telescope response. Making use of the large LPPS footprint, in both sky coverage and time, we derived a limit on the occurrence of FRBs of width w and flux density S > 107 q w 0 66 ms : Jy of no GLYPH<0> 1 GLYPH<0> 1
more than 1 5 : GLYPH<2> 10 2 day sky at 142 MHz.
LOTAS produced the first two pulsars ever discovered with LOFAR. Periodicity searching also found 21 known pulsars. Of these, 8 were also re-detected through single-pulse searches. A further 6 pulsars were detected by folding data on known ephemerides.
LPPS and LOTAS were surveys in their own right - discovering new pulsars and setting the first low-frequency FRB limit. They were also critical learning steps towards a proper LOFAR pulsar survey. The full LOFAR pulsar search, the LOFAR TiedArray All-Sky (LOTAAS, 'with double A' ) survey, includes aspects of both LPPS and LOTAS; it simultaneously creates both large incoherently formed beams and many tied-array beams using the 6 Superterp stations (Fig. 1, right panel). This setup allows the best of both worlds; the large FoV a GLYPH<11> orded through incoherent beam-forming and its concomitant sensitivity to rare bright bursts, and the raw sensitivity a GLYPH<11> orded by coherent beamforming.
LOTAAS is using many more tied-array beams than LOTAS, as well as a much more complicated pointing strategy that takes better advantage of LOFAR's flexible multi-beaming capabilities. Each survey pointing is comprised of three sub-array pointings (i.e. three beams generated at station level). An incoherent array beam is generated for each of these sub-array pointings, and together these cover GLYPH<24> 60 square degrees of sky at a sensitivity roughly twice that of LPPS. Within the FoV of each incoherent beam we also form a Nyquist-sampled, hexagonal grid of 61 tied-array beams. Together, this set of 3 GLYPH<2> 61 tied-array beams covers a survey area of GLYPH<24> 12 square degrees at a sensitivity roughly twice that of LOTAS and the GBNCC. Through 3 interlinked overlapping survey passes our sensitivity for intermittent or transient sources is greatly improved. Processing for LOTAAS has begun at the University of Manchester and on the new Dutch national supercomputer Cartesius . Extrapolating from the pilot 7 surveys, LOTAAS could discover at least 200 new pulsars over the whole northern hemisphere.
7 https://www.surfsara.nl/nl/systems/cartesius
Table 2. Measured and derived quantities for the two newly discovered pulsars. Figures in parentheses are the nominal 1 GLYPH<27> TEMPO2 uncertainties in the least-significant digits quoted. For the fluxes, errors are estimated to be 50%. The pulse widths are quoted as fraction of the pulsar period P .
| Measured and derived quantities | Measured and derived quantities | Measured and derived quantities |
|-----------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------|---------------------------------------------|-------------------------------------------|
| Pulsar name . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . ascension (J2000), GLYPH<11> . . . . . . . . . . . . . . . . . . . . . . (J2000), GLYPH<14> . . . . . . . . . . . . . . . . . . . . . . . . . . . Latitude, l (degrees) . . . . . . . . . . . . . . . . . . . . Longitude, b (degrees) . . . . . . . . . . . . . . . . . . frequency, GLYPH<23> (s GLYPH<0> 1 ) . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . | J0140 + 5622 | J0613 + 3732 06:13:12.149(11) + |
| Right | 01:39:38.561(19) | |
| Declination | + 56:21:36.82949(1) | 37:31:38.30520(1) |
| Galactic | 129.6090 | 175.3357 |
| Galactic | GLYPH<0> 5.8853 | 9.2388 |
| Pulse | 0.56327117338(3) | 1.61499182415(16) |
| Frequency derivative, ˙ GLYPH<23> (s GLYPH<0> 2 ) . | GLYPH<0> 2.50951(8) GLYPH<2> 10 GLYPH<0> 14 | GLYPH<0> 8.463(5) GLYPH<2> 10 GLYPH<0> 15 |
| Dispersion measure, DM (cm GLYPH<0> 3 pc) . . . . . . . . . . . . . . . | 101.842(32) | 18.990(12) |
| Reference epoch (MJD) . . . . . . . . . . . . . . . . . . . . . . . . | 56000 | 56000 |
| MJD range . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . | 55693.4 GLYPH<0> 56691.7 | 55693.6 GLYPH<0> 56665.9 |
| Number of TOAs . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . | 25 | 74 |
| Rms timing residual ( GLYPH<22> s ). . . . . . . . . . . . . . . . . . . . . . . . | 1151.7 | 996.9 |
| Flux density at 0.15 GHz, S 0 : 15 (mJy) . . . . . . . . . . . . . | 4(1) | 13(1) |
| Flux density at 0.35 GHz, S 0 : 35 (mJy) . . . . . . . . . . . . . | 0.7(3) | 1.6(8) |
| Flux density at 1.4 GHz, S 1 : 4 (mJy) . . . . . . . . . . . . . . . | 0.02(1) | 0.13(6) |
| Spectral index 0.15 GLYPH<0> 0.35 GHz, GLYPH<11> 0 : 15 GLYPH<0> 0 : 35 . . . . . . . . . | GLYPH<0> 2.1(1.0) | GLYPH<0> 2.5(1.3) |
| Spectral index 0.35 GLYPH<0> 1.4 GHz, GLYPH<11> 0 : 35 GLYPH<0> 1 : 4 . . . . . . . . . . . | GLYPH<0> 2.6(1.7) | GLYPH<0> 1.8(1.2) |
| Fractional pulse width w 50 . . . . . . . . . . . . . . . . . . . . . . | 0.024 | 0.017 |
| Characteristic age, log 10 ( GLYPH<28> c (yr)) . . . . . . . . . . . . . . . . . | 5.55 | 6.48 |
| Surface magnetic field, log 10 ( B surf (G)) . . . . . . . . . . . | 13.08 | 12.16 |
## 5.1. The Square Kilometre Array
- Deneva, J. S., Stovall, K., McLaughlin, M. A., et al. 2013, ApJ, 775, 51
- Eatough, R. P., Keane, E. F., & Lyne, A. G. 2009, MNRAS, 395, 410
- Eatough, R. P., Molkenthin, N., Kramer, M., et al. 2010, MNRAS, 407, 2443
- Eatough, R. P., Falcke, H., Karuppusamy, R., et al. 2013, Nature, 501, 391
- Edwards, R. T., Bailes, M., van Straten, W., & Britton, M. C. 2001, MNRAS, 326, 358
- Garrett, M. A., Cordes, J. M., Deboer, D. R., et al. 2010, in ISKAF2010 Science Meeting
- Hartman, J. W., Bhattacharya, D., Wijers, R., & Verbunt, F. 1997, A&A, 322, 477
- Hassall, T. E., Keane, E. F., & Fender, R. P. 2013, MNRAS, 436, 371
- Hassall, T. E. et al. 2014, A&A, in prep.
- Hessels, J. W. T., Ransom, S. M., Kaspi, V. M., et al. 2008, in American Institute of Physics Conference Series, Vol. 983, 40 Years of Pulsars: Millisecond Pulsars, Magnetars and More, ed. C. Bassa, Z. Wang, A. Cumming, & V. M. Kaspi, 613
- Hewish, A., Bell, S. J., Pilkington, J. D. H., Scott, P. F., & Collins, R. A. 1968, Nature, 217, 709
- Hobbs, G. B., Edwards, R. T., & Manchester, R. N. 2006, MNRAS, 369, 655 Hotan, A. W., van Straten, W., & Manchester, R. N. 2004, PASA, 21, 302 Ioka, K. 2003, ApJ, 598, L79
- Janssen, G. H., Stappers, B. W., Braun, R., et al. 2009, A&A, 498, 223
- Keane, E. F., Kramer, M., Lyne, A. G., Stappers, B. W., & McLaughlin, M. A. 2011, MNRAS, 415, 3065
- Keane, E. F., Stappers, B. W., Kramer, M., & Lyne, A. G. 2012, MNRAS, 425, L71
- Kondratiev, V. I., et al. 2014, A&A, in prep.
- Kramer, M., Lyne, A. G., O'Brien, J. T., Jordan, C. A., & Lorimer, D. R. 2006, Science, 312, 549
- Kulkarni, S., Ofek, E., Juric, M., Neill, J., & Zheng, Z. 2008, http://www. astro.caltech.edu/~srk/sparker.pdf [retrieved 2010-08-19]
- Kulkarni, S. R., Ofek, E. O., Neill, J. D., Zheng, Z., & Juric, M. 2014, ArXiv e-prints, arXiv:1402.4766 [astro-ph.HE]
- Lawson, K. D., Mayer, C. J., Osborne, J. L., & Parkinson, M. L. 1987, MNRAS, 225, 307
- Lorimer, D. R., Bailes, M., McLaughlin, M. A., Narkevic, D. J., & Crawford, F. 2007, Science, 318, 777
- Lorimer, D. R., Karastergiou, A., McLaughlin, M. A., & Johnston, S. 2013, MNRAS, 436, L5
- Lorimer, D. R., & Kramer, M. 2005, Handbook of Pulsar Astronomy, ed. Lorimer, D. R. & Kramer, M. (Cambridge University Press)
- Lynch, R. S., Boyles, J., Ransom, S. M., et al. 2013, ApJ, 763, 81
- Maan, Y., Aswathappa, H. A., & Deshpande, A. A. 2012, MNRAS, 425, 2 Macquart, J.-P., & Koay, J. Y. 2013, ApJ, 776, 125
- Malofeev, V. M., Malov, O. I., & Shchegoleva, N. V. 2000, Astronomy Reports, 44, 436
- Manchester, R. N., Lyne, A. G., Camilo, F., et al. 2001, MNRAS, 328, 17
Looking beyond LOFAR, the two pulsar discoveries reported here are the first ever using a sparse digital aperture array. We are confident that these discoveries validate our approach to pulsar surveys, an important point as the upcoming Phase I of the Square Kilometre Array (SKA) will feature a LOFAR-like lowfrequency aperture array of GLYPH<24> 250,000 dipole antennas (Garrett et al. 2010), more than an order-of-magnitude more collecting area than LOFAR. These will be beam-formed into stations in a LOFAR-like way. The LPPS and LOTAS surveys act as a proving ground for such flexible digital beam-forming capabilities. The techniques pioneered by LOFAR and presented here will thus be important as precursors to the eventual pulsar surveys with the SKA.
Acknowledgements. We thank J. Green and P. Abeyratne for help with LPPS processing. This work was supported by grants from the Netherlands Research School for Astronomy (NOVA3-NW3-2.3.1) and by the European Commission (FP7-PEOPLE-2007-4-3-IRG #224838) to JVL; an NWO Veni Fellowship to JWTH; and Agence Nationale de la Recherche grant ANR-09-JCJC-0001-01 to CF. LOFAR is designed and constructed by ASTRON, and is operated by the International LOFAR Telescope (ILT) foundation. LOTAS 'bandwidth-ondemand' was provided by SURFnet. LOTAS processing was carried out on the Dutch grid infrastructure supported by the BiGGrid project.
## References
Archibald, A. M., Stairs, I. H., Ransom, S. M., et al. 2009, Science, 324, 1411 Arts, M. J., Kant, G. W., & Wijnholds, S. J. 2013, SKA-ASTRON-RP-473
- Backer, D. C. 2000, in Perspectives on Radio Astronomy: Science with Large Antenna Arrays, ed. M. P. van Haarlem, 285
- Bassa, C. G., Patruno, A., Hessels, J. W. T., et al. 2014, MNRAS, 441, 1825
- Bates, S. D., Lorimer, D. R., & Verbiest, J. P. W. 2013, MNRAS, 431, 1352
- Bhat, N. D. R., Cordes, J. M., Camilo, F., Nice, D. J., & Lorimer, D. R. 2004, ApJ, 605, 759
- Boyles, J., Lynch, R. S., Ransom, S. M., et al. 2013, ApJ, 763, 80
- Camilo, F., Ransom, S. M., Halpern, J. P., et al. 2006, Nature, 442, 892
- Coenen, T. 2013, PhD thesis, University of Amsterdam, http://dare.uva. nl/en/record/459730
- Cordes, J. M., & Lazio, T. J. W. 2002, ArXiv Astrophysics e-prints, arXiv:astroph/0207156
Maron, O., Kijak, J., Kramer, M., & Wielebinski, R. 2000, A&AS, 147, 195 McLaughlin, M. A., Lyne, A. G., Lorimer, D. R., et al. 2006, Nature, 439, 817 Papitto, A., Hessels, J. W. T., Burgay, M., et al. 2013, The Astronomer's Telegram, 5069, 1
- Petro GLYPH<11> , E., van Straten, W., Johnston, S., et al. 2014, ArXiv e-prints, arXiv:1405.5945 [astro-ph.HE]
- Ransom, S. M. 2001, PhD thesis, Harvard University
- Ransom, S. M., Eikenberry, S. S., & Middleditch, J. 2002, AJ, 124, 1788
- Romein, J. W., Broekema, P. C., Mol, J. D., & van Nieuwpoort, R. V. 2010,
- in ACM Symposium on Principles and Practice of Parallel Programming (PPoPP'10), Bangalore, India, 169
- Serylak, M., Karastergiou, A., Williams, C., et al. 2013, in IAU Symposium, Vol. 291, IAU Symposium, ed. J. van Leeuwen, 492
- Shrauner, J. A., Taylor, J. H., & Woan, G. 1998, ApJ, 509, 785
- Siemion, A. P. V., Bower, G. C., Foster, G., et al. 2012, ApJ, 744, 109
- Spitler, L. G., Cordes, J. M., Hessels, J. W. T., et al. 2014, ArXiv e-prints, arXiv:1404.2934 [astro-ph.HE]
- Stappers, B. W., Hessels, J. W. T., Alexov, A., et al. 2011, A&A, 530, A80
Stappers, B. W., Archibald, A. M., Hessels, J. W. T., et al. 2014, ApJ, 790, 39
- Stovall, K., Lynch, R. S., Ransom, S. M., & et al. 2014, ApJ, in prep.
- Thornton, D., Stappers, B., Bailes, M., et al. 2013, Science, 341, 53
- van Haarlem, M. P., Wise, M. W., Gunst, A. W., et al. 2013, A&A, 556, A2
- van Leeuwen, J., Kouwenhoven, M. L. A., Ramachandran, R., Rankin, J. M., & Stappers, B. W. 2002, A&A, 387, 169
- van Leeuwen, J., & Stappers, B. W. 2010, A&A, 509, 7
- van Straten, W., Demorest, P., & Oslowski, S. 2012, Astronomical Research and Technology, 9, 237
- Welch, J., Backer, D., Blitz, L., et al. 2009, IEEE Proceedings, 97, 1438
- Weltevrede, P., Wright, G. A. E., Stappers, B. W., & Rankin, J. M. 2006, A&A, 458, 269
- Zakharenko, V. V., Vasylieva, I. Y., Konovalenko, A. A., et al. 2013, MNRAS, 431, 3624
- 1 Anton Pannekoek Institute for Astronomy, University of Amsterdam, Science Park 904, 1098 XH Amsterdam, The Netherlands
- 2 ASTRON, the Netherlands Institute for Radio Astronomy, Postbus 2, 7990 AA, Dwingeloo, The Netherlands
- 3 Jodrell Bank Center for Astrophysics, School of Physics and Astronomy, University of Manchester, Manchester M13 9PL, UK
4
Astro Space Center of the Lebedev Physical Institute, Profsoyuznaya str. 84 32, Moscow 117997, Russia
/
- 5 Space Telescope Science Institute, 3700 San Martin Drive, Baltimore, MD 21218, USA
- 6 School of Physics and Astronomy, University of Southampton, Southampton, SO17 1BJ, UK
- 7 Department of Astrophysics IMAPP, Radboud University Nijmegen, P.O. Box 9010, 6500 GL Nijmegen, The Netherlands /
- 8 National Centre for Radio Astrophysics, Post Bag 3, Ganeshkhind, Pune 411 007, India
- 9 Laboratoire de Physique et Chimie de l'Environnement et de l'Espace, LPC2E UMR 7328 CNRS, 45071 Orléans, France
- 10 Station de Radioastronomie de Nançay, Observatoire de Paris, CNRS INSU, 18330 Nançay, France /
- 11 Astrophysics, University of Oxford, Denys Wilkinson Building, Keble Road, Oxford OX1 3RH
- 12 Centre for Astrophysics and Supercomputing, Swinburne University of Technology, Mail H30, PO Box 218, VIC 3122, Australia
- 13 ARC Centre of Excellence for All-sky Astrophysics (CAASTRO).
- 14 Max-Planck-Institut für Radioastronomie, Auf dem Hügel 69, 53121 Bonn, Germany
- 15 Fakultät für Physik, Universität Bielefeld, Postfach 100131, D-33501 Bielefeld, Germany
- 16 SURFsara, PO Box 94613, NL-1090 GP Amsterdam, the Netherlands
- 17 Helmholtz-Zentrum Potsdam, DeutschesGeoForschungsZentrum GFZ, Department 1: Geodesy and Remote Sensing, Telegrafenberg, A17, 14473 Potsdam, Germany
- 18 Leibniz-Institut für Astrophysik Potsdam (AIP), An der Sternwarte 16, 14482 Potsdam, Germany
- 19 Shell Technology Center, Bangalore, India
- 20 SRON Netherlands Insitute for Space Research, PO Box 800, 9700 AV Groningen, The Netherlands
- 21
- Kapteyn Astronomical Institute, PO Box 800, 9700 AV Groningen, The Netherlands
- 22 CSIRO Australia Telescope National Facility, PO Box 76, Epping NSW 1710, Australia
- 23 University of Twente, The Netherlands
- 24 Harvard-Smithsonian Center for Astrophysics, 60 Garden Street, Cambridge, MA 02138, USA
- 25 Institute for Astronomy, University of Edinburgh, Royal Observatory of Edinburgh, Blackford Hill, Edinburgh EH9 3HJ, UK
- 26 University of Hamburg, Gojenbergsweg 112, 21029 Hamburg, Germany
- 27 Research School of Astronomy and Astrophysics, Australian National University, Mt Stromlo Obs., via Cotter Road, Weston, A.C.T. 2611, Australia
- 28 Max Planck Institute for Astrophysics, Karl Schwarzschild Str. 1, 85741 Garching, Germany
- 29 Thüringer Landessternwarte, Sternwarte 5, D-07778 Tautenburg, Germany
- 30 Laboratoire Lagrange, UMR7293, Universitè de Nice Sophia-Antipolis, CNRS, Observatoire de la Cóte d'Azur, 06300 Nice, France
- 31 Leiden Observatory, Leiden University, PO Box 9513, 2300 RA Leiden, The Netherlands
- 32 SmarterVision BV, Oostersingel 5, 9401 JX Assen
- 33 Astronomisches Institut der Ruhr-Universität Bochum, Universitaetsstrasse 150, 44780 Bochum, Germany
- 34 Radio Astronomy Lab, UC Berkeley, CA, USA
- 35 Sodankylä Geophysical Observatory, University of Oulu, Tähteläntie 62, 99600 Sodankylä, Finland
- 36 STFC Rutherford Appleton Laboratory, Harwell Science and Innovation Campus, Didcot OX11 0QX, UK
- 37 Center for Information Technology (CIT), University of Groningen, The Netherlands
- 38 Centre de Recherche Astrophysique de Lyon, Observatoire de Lyon, 9 av Charles André, 69561 Saint Genis Laval Cedex, France
- 39 Department of Physics and Elelctronics, Rhodes University, PO Box 94, Grahamstown 6140, South Africa
- 40 SKA South Africa, 3rd Floor, The Park, Park Road, Pinelands, 7405, South Africa
- 41 LESIA, UMR CNRS 8109, Observatoire de Paris, 92195 Meudon, France
## Appendix A: LPPS detections and profiles
Table A.1. All pulsars detected in the LPPS data. Sources marked with an asterisk were used to derive an estimate for the LPPS gain (see §3.2). The column headed by an M (method) lists how the pulsar was detected - through a periodicity search (p), through a direct fold using a known ephemeris (d), or through single-pulse searches (s). The next column, headed by GLYPH<11> , lists the distance to the beam center in degrees at which the pulsar was detected (based on the ATNF pulsar database positions). The DM and period columns list the values as reported by PRESTO (without errors or digit significance) after folding the data on the known ephemeris using 256 bins. The next two columns report the peak and the cumulative signal-to-noise ratio derived from the pulse profiles. For profiles where the o GLYPH<11> -pulse baseline is not flat (because of RFI), the signal-to-noise ratios are left blank. The last column shows the peak signal-to-noise ratio of the brightest pulse found in the single-pulse search as reported by PRESTO (not corrected for zero-DM filtering).
| Pulsar | M | GLYPH<11> (deg) | DM(pccm GLYPH<0> 3 ) | Period (ms) | S / N p | S / N cum | S / N s |
|---------------------|-----|-------------------|------------------------|---------------|-----------|-------------|-----------|
| B0045 + 33 | p | 1.53 | 39.94 | 1217.0 | 14 | - | - |
| B0105 + 65 | d | 1.99 | 30.46 | 1283.6 | 9 | 93 | - |
| B0136 + 57 GLYPH<3> | p | 2.57 | 73.779 | 272.4 | 7 | 74 | - |
| B0138 + 59 GLYPH<3> | p,s | 2.67 | 34.797 | 1222.9 | 9 | 29 | 7 |
| B0144 + 59 | d | 1.61 | 40.111 | 196.3 | 7 | 64 | - |
| B0154 + 61 | s | 1.37 | 30 | - | - | - | 9 |
| J0243 + 6257 | p,s | - | 3.903 | 591.7 | 9 | 36 | 31 |
| B0329 + 54 GLYPH<3> | p,s | 2.44 | 26.833 | 714.5 | 606 | 2137 | - |
| B0355 + 54 GLYPH<3> | p,s | 1.10 | 57.142 | 156.3 | 32 | 352 | 7 |
| B0402 + 61 | p | 1.65 | 65.303 | 594.5 | 8 | 82 | - |
| B0450 + 55 GLYPH<3> | p | 2.20 | 14.495 | 340.7 | 32 | 237 | - |
| J0540 + 3207 | p | - | 62.371 | 524.2 | 9 | - | - |
| B0523 + 11 | p | 0.85 | 79.345 | 345.4 | 7 | 149 | - |
| B0611 + 22 GLYPH<3> | p | 1.53 | 96.91 | 334.9 | 10 | 208 | - |
| B0626 + 24 | d | 2.03 | 84.195 | 476.6 | 4 | 35 | - |
| B0655 + 64 GLYPH<3> | p | 0.59 | 8.771 | 195.6 | 81 | 550 | - |
| B0809 + 74 | s | 2.66 | 5.75 | - | - | - | 14 |
| B0823 + 26 GLYPH<3> | p,s | 1.66 | 19.454 | 530.6 | 120 | 560 | 22 |
| B0834 + 06 GLYPH<3> | p | 1.50 | 12.889 | 1273.7 | 226 | 347 | - |
| B0917 + 63 | p,s | 0.50 | 13.158 | 1567.9 | 20 | 243 | 11 |
| B0919 + 06 GLYPH<3> | p | 2.09 | 27.271 | 430.6 | 92 | 618 | - |
| B0950 + 08 GLYPH<3> | p,s | 2.23 | 2.958 | 253.0 | 60 | 658 | 21 |
| B1112 + 50 | p,s | 1.68 | 9.195 | 1656.4 | - | - | 24 |
| B1237 + 25 GLYPH<3> | p,s | 1.92 | 9.242 | 1382.4 | 27 | 46 | 31 |
| B1322 + 83 | p | 1.61 | 31.312 | 670.0 | 7 | - | - |
| B1508 + 55 GLYPH<3> | p | 2.10 | 19.613 | 739.6 | 303 | 1451 | - |
| B1530 + 27 | p,s | 1.41 | 14.698 | 1124.8 | - | - | 10 |
| B1541 + 09 GLYPH<3> | p | 1.67 | 35.24 | 748.4 | 26 | 247 | - |
| B1604 GLYPH<0> 00 | p | 2.70 | 10.682 | 421.8 | - | - | - |
| B1633 + 24 | p | 1.73 | 24.32 | 490.5 | - | - | - |
| J1758 + 3030 | p | 1.33 | 34.9 | 947.2 | - | - | - |
| B1811 + 40 GLYPH<3> | p | 0.94 | 41.487 | 931.0 | 30 | 309 | - |
| B1821 + 05 GLYPH<3> | p | 1.65 | 66.775 | 752.9 | 25 | 192 | - |
| B1839 + 09 | p | 0.75 | 49.107 | 381.3 | 12 | - | - |
| B1839 + 56 | p | 2.58 | 26.298 | 1652.8 | - | - | - |
| B1842 + 14 GLYPH<3> | p | 1.55 | 41.51 | 375.4 | 29 | 147 | - |
| B1905 + 39 GLYPH<3> | p,s | 1.55 | 30.96 | 1235.7 | 11 | 38 | 12 |
| B1918 + 26 | p | 0.39 | 27.62 | 785.5 | 18 | 136 | - |
| B1919 + 21 | p,s | 2.39 | 12.455 | 1337.3 | - | - | 32 |
| B1929 + 10 | p | 2.14 | 3.18 | 226.5 | - | - | - |
| B1949 + 14 | d | 1.44 | 31.46 | 275.0 | 4 | 39 | - |
| B1951 + 32 | d | 0.54 | 45.006 | 39.5 | 8 | 223 | - |
| B1953 + 50 GLYPH<3> | p,s | 1.29 | 31.974 | 518.9 | 28 | 96 | 12 |
| B2016 + 28 GLYPH<3> | p,s | 0.72 | 14.172 | 557.9 | 124 | 156 | 14 |
| B2020 + 28 GLYPH<3> | p | 0.43 | 24.64 | 343.4 | 50 | 314 | - |
| B2021 + 51 GLYPH<3> | p,s | 0.71 | 22.648 | 529.1 | 18 | 182 | 30 |
Table A.1. Continued
| Pulsar | M | GLYPH<11> (deg) | DM(pccm GLYPH<0> 3 ) | Period (ms) | S / N p | S / N cum | S / N s |
|-------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------|-----------------------------------|----------------------------------------------------------------------------|--------------------------------------------------------------------------------------------------------------|-------------------------------------------------------------------------------------------------|---------------------------------------|--------------------------------------------------|---------------------------------|
| B2022 + 50 GLYPH<3> J2043 + 2740 GLYPH<3> B2110 + 27 B2111 + 46 GLYPH<3> J2139 + 2242 B2154 + 40 B2217 + 47 GLYPH<3> B2224 + 65 GLYPH<3> B2227 + 61 B2255 + 58 J2302 + 6028 B2303 + 30 B2306 + 55 GLYPH<3> B2310 + 42 GLYPH<3> B2315 + 21 | p p p p,s p p p,s p d p d p p p p | 1.64 1.42 2.95 1.66 0.79 2.09 1.80 2.86 0.71 1.26 2.20 1.14 2.75 1.78 2.11 | 33.021 21.000 25.113 141.260 44.100 70.857 43.519 36.079 124.614 151.082 156.700 49.544 46.538 17.276 20.906 | 372.6 96.1 1202.8 1014.6 1083.5 1525.2 538.4 682.5 443.0 368.2 1206.4 1575.8 475.0 349.4 1444.6 | 9 22 36 24 11 - 447 7 5 - 6 - 5 25 23 | 28 276 199 483 114 - 1976 55 178 - 76 - 13 215 - | - - - 12 - - 12 - - - - - - - - |
Fig. A.1. LPPS pulsar profiles. For each pulsar, the catalog name, detected pulse period, detected DM, and reduced chi-squared significance (in parentheses) from the automated search fold are given. One full rotational cycle is shown. Some of the brightest pulsars were detected multiple times; only the highest signal-to-noise detection is shown here. Several of the pulse profiles show scattering tails, e.g. PSRs B0523 + 11, B0611 + 22, B2111 + 46, making them excellent sources for studies of the interstellar medium. In many cases the o GLYPH<11> -pulse baseline is not flat due to RFI that could not be completely excised.
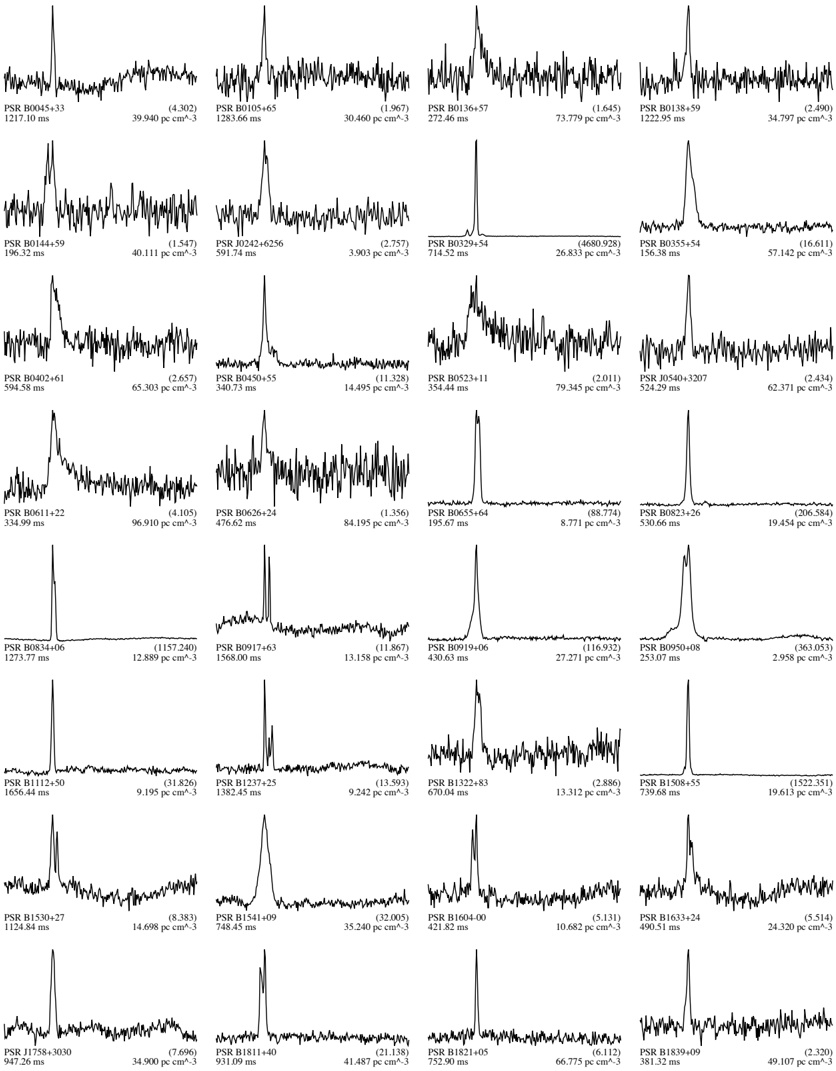
Fig. A.2. LPPS pulsar profiles - continued.
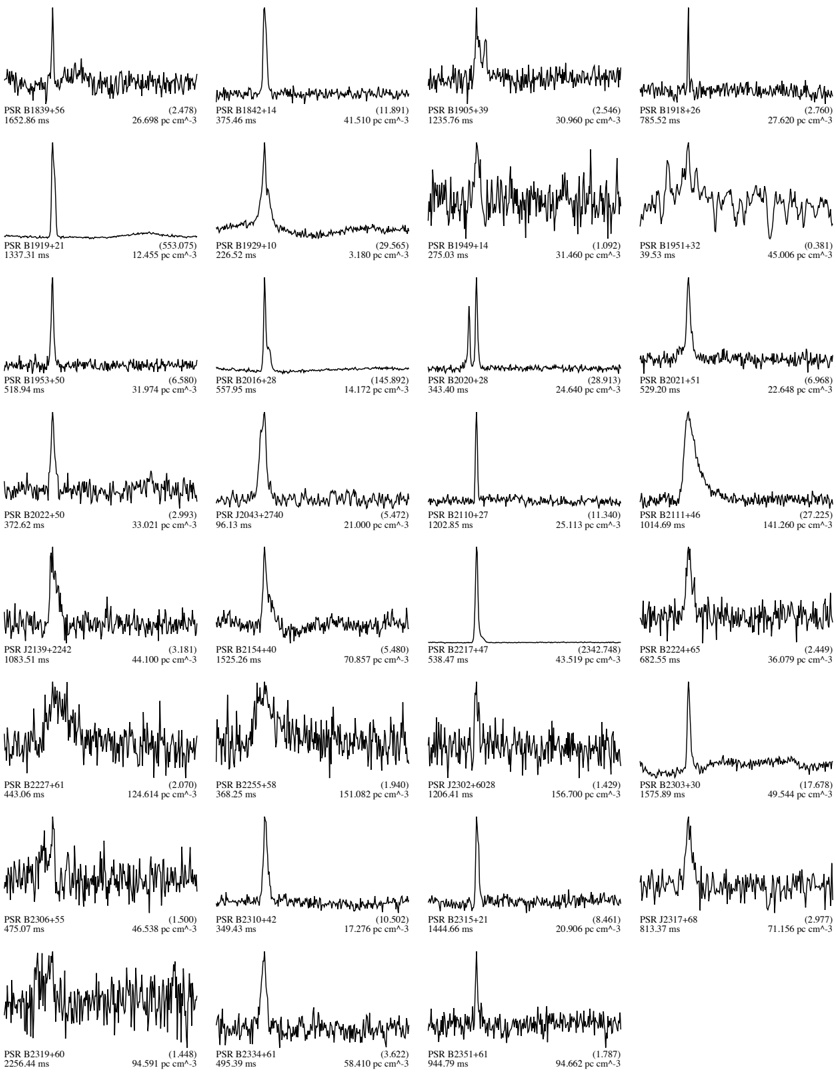
## Appendix B: LOTAS detections and profiles
| Pulsar | M | GLYPH<11> (deg) | DM(pccm GLYPH<0> 3 ) | Period (ms) | S / N p | S / N cum | S / N s |
|---------------------------|-----|-------------------|------------------------|---------------|-----------|-------------|-----------|
| J0140 + 5622 J0613 + 3731 | p p | 0.16 1.52 | 101.637 19.106 | 1775.4 619.1 | 9 5 | 40 42 | - - |
| B0037 + 56 | d | 0.19 | 92.480 | 1118.1 | 10 | 85 | - |
| B0105 + 65 | d | 3.32 | 30.681 | 1283.6 | 5 | 22 | - |
| B0136 + 57 | p | 3.00 | 73.894 | 272.4 | 9 | 44 | - |
| J0216 + 52 | p | - | 22.030 | 24.5 | 20 | 94 | - |
| B0329 + 54 | p,s | 4.09 | 26.785 | 714.5 | 19 | 73 | 10 |
| J0338 + 66 | p | - | 66.577 | 1761.9 | 6 | - | - |
| J0358 + 42 | p | - | 46.308 | 226.4 | 5 | 56 | - |
| B0402 + 61 | p | 0.82 | 65.360 | 594.5 | 8 | 40 | - |
| B0450 + 55 | p,s | 0.10 | 14.600 | 340.7 | 138 | 512 | 35 |
| B0525 + 21 | p,s | 2.80 | 51.133 | 3745.5 | 9 | - | 17 |
| J0611 + 30 | p | 1.95 | 45.320 | 1412.2 | 3 | - | - |
| B0609 + 37 | d | 1.37 | 27.084 | 297.9 | 3 | 10 | - |
| B0626 + 24 | d | 2.80 | 83.523 | 476.6 | 4 | - | - |
| B1821 + 05 | p,s | 0.87 | 66.754 | 752.9 | 40 | 70 | 8 |
| J1822 + 0705 | p | 0.20 | 62.282 | 1362.8 | 8 | 39 | - |
| B1839 + 09 | d | 3.20 | 49.146 | 381.2 | 4 | 22 | - |
| B1911 GLYPH<0> 04 | p | 2.40 | 89.380 | 825.9 | 37 | 132 | - |
| B1918 + 26 | p,s | 0.07 | 27.673 | 785.5 | 51 | 100 | 10 |
| B1919 + 21 | p | 3.74 | 12.394 | 1337.2 | 19 | 26 | - |
| J1942 + 01 | p | 0.09 | 52.267 | 217.3 | 5 | 43 | - |
| B1953 + 50 | p | 1.29 | 32.036 | 518.9 | 11 | 6 | - |
| J2007 + 0910 | d | 3.08 | 47.291 | 458.6 | 5 | 38 | - |
| B2154 + 40 | p,s | 0.88 | 71.281 | 1525.2 | 23 | 68 | 9 |
| B2217 + 47 | p,s | 1.45 | 43.463 | 538.4 | 400 | 913 | 43 |
| B2224 + 65 | p | 2.02 | 36.333 | 682.5 | 23 | 112 | - |
| B2241 + 69 | p,s | 0.17 | 40.820 | 1664.4 | 31 | 43 | 10 |
| J2243 + 69 | p | - | 67.732 | 855.4 | 5 | 35 | - |
Table B.1. A list of all LOTAS pulsar detections. Pulsar names in bold are newly discovered pulsars, the first two rows contain unique LOFAR discoveries and the other pulsars with bold names signify independent discoveries - i.e. unpublished sources recently found by competing surveys such as the GBNCC (Stovall et al. 2014). The M column contains the method through which the pulsar was detected: (p) in the blind periodicity search, (d) through folding on a known ephemeris, and (s) by inspecting condensed single-pulse plots. The GLYPH<11> column gives the distance to the center of the nearest tied-array beam. These distances are based on the ATNF catalog value. For the LOTAS discoveries the timing position was used. The DMs and periods quoted are taken from the PRESTO diagnostics of the folds; these values were optimized during the folding process in order to maximize the signal-to-noise ratio. There is no error or digit significance information for these. The columns S Np / and S Ncum / quote respectively the peak and cumulative signal-to-noise ratios if they could be derived automatically. The signal-to-noise ratios were derived from profiles with 100 bins. The S Ns / column contains the signal-to-noise ratio of the brightest single pulse detected, possibly in another beam than the periodicity search detection.
Fig. B.1. Average pulse profiles for pulsars re-detected in LOTAS. Both pulsars found in the blind periodicity search and pulsars re-detected by folding on previously known ephemerides are shown. For each pulsar the name, period, reduced chi-squared (in brackets) and DM are quoted. The reduced chi-squared is a proxy for the signal-to-noise of the pulse profile and is reported by PRESTO . Periods marked with '(topo)' are topocentric values as produced by the direct folding feature of the pipeline (§4.4).
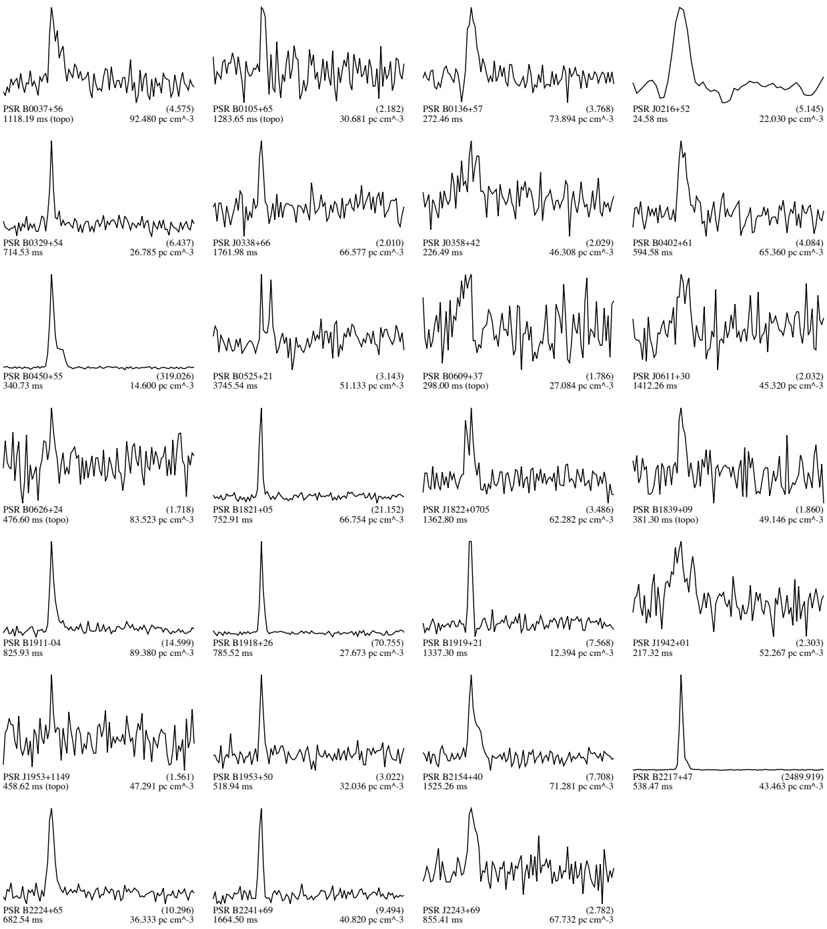 | 10.1051/0004-6361/201424495 | [
"Thijs Coenen",
"Joeri van Leeuwen",
"Jason W. T. Hessels",
"Ben W. Stappers",
"Vladislav I. Kondratiev",
"A. Alexov",
"R. P. Breton",
"A. Bilous",
"S. Cooper",
"H. Falcke",
"R. A. Fallows",
"V. Gajjar",
"J. -M. Grießmeier",
"T. E. Hassall",
"A. Karastergiou",
"E. F. Keane",
"M. Kramer",
"M. Kuniyoshi",
"A. Noutsos",
"S. Osłowski",
"M. Pilia",
"M. Serylak",
"C. Schrijvers",
"C. Sobey",
"S. ter Veen",
"J. Verbiest",
"P. Weltevrede",
"S. Wijnholds",
"K. Zagkouris",
"A. S. van Amesfoort",
"J. Anderson",
"A. Asgekar",
"I. M. Avruch",
"M. E. Bell",
"M. J. Bentum",
"G. Bernardi",
"P. Best",
"A. Bonafede",
"F. Breitling",
"J. Broderick",
"M. Brüggen",
"H. R. Butcher",
"B. Ciardi",
"A. Corstanje",
"A. Deller",
"S. Duscha",
"J. Eislöffel",
"R. Fender",
"C. Ferrari",
"W. Frieswijk",
"M. A. Garrett",
"F. de Gasperin",
"E. de Geus",
"A. W. Gunst",
"J. P. Hamaker",
"G. Heald",
"M. Hoeft",
"A. van der Horst",
"E. Juette",
"G. Kuper",
"C. Law",
"G. Mann",
"R. McFadden",
"D. McKay-Bukowski",
"J. P. McKean",
"H. Munk",
"E. Orru",
"H. Paas",
"M. Pandey-Pommier",
"A. G. Polatidis",
"W. Reich",
"A. Renting",
"H. Röttgering",
"A. Rowlinson",
"A. M. M. Scaife",
"D. Schwarz",
"J. Sluman",
"O. Smirnov",
"J. Swinbank",
"M. Tagger",
"Y. Tang",
"C. Tasse",
"S. Thoudam",
"C. Toribio",
"R. Vermeulen",
"C. Vocks",
"R. J. van Weeren",
"O. Wucknitz",
"P. Zarka",
"A. Zensus"
] | 2014-08-02T19:54:55+00:00 | 2014-08-02T19:54:55+00:00 | [
"astro-ph.SR",
"astro-ph.HE"
] | The LOFAR Pilot Surveys for Pulsars and Fast Radio Transients | We have conducted two pilot surveys for radio pulsars and fast transients
with the Low-Frequency Array (LOFAR) around 140 MHz and here report on the
first low-frequency fast-radio burst limit and the discovery of two new
pulsars. The first survey, the LOFAR Pilot Pulsar Survey (LPPS), observed a
large fraction of the northern sky, ~1.4 x 10^4 sq. deg, with 1-hr dwell times.
Each observation covered ~75 sq. deg using 7 independent fields formed by
incoherently summing the high-band antenna fields. The second pilot survey, the
LOFAR Tied-Array Survey (LOTAS), spanned ~600 sq. deg, with roughly a 5-fold
increase in sensitivity compared with LPPS. Using a coherent sum of the 6 LOFAR
"Superterp" stations, we formed 19 tied-array beams, together covering 4 sq.
deg per pointing. From LPPS we derive a limit on the occurrence, at 142 MHz, of
dispersed radio bursts of < 150 /day/sky, for bursts brighter than S > 107 Jy
for the narrowest searched burst duration of 0.66 ms. In LPPS, we re-detected
65 previously known pulsars. LOTAS discovered two pulsars, the first with LOFAR
or any digital aperture array. LOTAS also re-detected 27 previously known
pulsars. These pilot studies show that LOFAR can efficiently carry out all-sky
surveys for pulsars and fast transients, and they set the stage for further
surveying efforts using LOFAR and the planned low-frequency component of the
Square Kilometer Array. |
1408.0413v3 | ## Smooth models of motivic spheres and the clutching construction
Aravind Asok ∗
Brent Doran †
Jean Fasel
## Abstract
We study the representability of motivic spheres by smooth varieties. We show that certain explicit 'split' quadric hypersurfaces have the A 1 -homotopy type of motivic spheres over the integers and that the A 1 -homotopy types of other motivic spheres do not contain smooth schemes as representatives. We then study some applications of these representability/nonrepresentability results to the construction of new exotic A 1 -contractible smooth schemes. Then, we study vector bundles on even dimensional 'split' quadric hypersurfaces by developing an algebro-geometric variant of the classical construction of vector bundles on spheres via clutching functions.
## Contents
| 1 | Introduction 1 |
|---------------------------------------------------------------------|------------------|
| 2 Geometric models of motivic spheres | 5 |
| 3 A 1 -contractible subvarieties of quadrics | 10 |
| 4 Clutching functions for principal G -bundles on algebraic spheres | 13 |
## 1 Introduction
This note is concerned with several results about spheres in the Morel-Voevodsky A 1 -homotopy theory [MV99], also known as motivic spheres. First, we make precise the idea that (split) smooth affine quadric hypersurfaces are motivic spheres. Second, we try to better understand the situations in which motivic spheres admit models as smooth schemes. Finally, we use homotopic ideas in an attempt to understand how to explicitly construct all vector bundles on split smooth affine quadrics. We now explain our results more precisely.
Given a commutative ring k , the Morel-Voevodsky A 1 -homotopy category H ( k ) is constructed by first enlarging the category Sm k of schemes smooth over Spec k to a category Spc k of spaces over Spec k and then performing a categorical localization. The category Spc k has all small limits and colimits, but the functor Sm k → Spc k does not preserve all colimits that exist in Sm k , e.g., quotients in Sm k that exist need not coincide with quotients computed in Spc k .
∗ Aravind Asok was partially supported by National Science Foundation Award DMS-1254892.
† Brent Doran was partially supported by Swiss National Science Foundation Award 200021 138071.
The resulting homotopy theory of schemes bears a number of similarities to the classical homotopy category. For example, there are two objects of Spc k that play a role analogous to that played by the circle in classical homotopy theory. On the one hand, one can view the circle as I/ { 0 1 , } where I is the unit interval [0 , 1] . If we view A 1 as analogous to the unit interval, we can form the quotient space A 1 / { 0 1 , } (pointed by the image of { 0 1 , } in the quotient), and we call this space S 1 s . This quotient does exist as a singular scheme (i.e., a nodal curve). However, it is not a priori clear whether S 1 s is isomorphic in H ( k ) to a smooth scheme. On the other hand, if we emphasize the fact that S 1 has a group structure, then we could also think of G m (pointed by 1 ) as a version of the circle. Of course, G m is a smooth k -scheme.
General motivic spheres are obtained by taking smash products (this notion makes sense in Spc k because of existence of colimits) of copies of S 1 s and G m [MV99, § 3.2]; by convention, we set S 0 s to be the disjoint union of two copies of Spec k . While in classical topology spheres are by construction smooth manifolds, the example of S 1 s shows that, in stark contrast, the following question in A 1 -homotopy theory has no obvious answer.
Question 1. Which motivic spheres S i s ∧ G ∧ j m have the A 1 -homotopy type of a smooth scheme?
Throughout this paper, we consider the smooth affine quadric hypersurfaces
$$\text{Throughout this paper, we consider the smooth affine quadric hypersurfaces} \\ Q _ { 2 m - 1 } \coloneqq & \text{Spec} k [ x _ { 1 }, \dots, x _ { m }, y _ { 1 }, \dots, y _ { m } ] / \langle \sum _ { i } x _ { i } y _ { i } - 1 \rangle, \text{ and} \\ Q _ { 2 m } \coloneqq & \text{Spec} k [ x _ { 1 }, \dots, x _ { m }, y _ { 1 }, \dots, y _ { m }, z ] / \langle \sum _ { i } x _ { i } y _ { i } - z ( 1 + z ) \rangle. \\ \text{immediately verifies that all of these hypersurfaces are in fact smooth over Spec} k.$$
One immediately verifies that all of these hypersurfaces are in fact smooth over Spec k .
Note that Q 0 is the subscheme of A 1 given by the two points 0 1 , and thus coincides with S 0 s . The hypersurface Q 2 m -1 is well-known to be A 1 -weakly equivalent to A m \ 0 (by projection onto x , . . . , x 1 m ) and the latter is A 1 -weakly equivalent to the motivic sphere S m -1 s ∧ G ∧ m m [MV99, Example 2.20]. Our first result provides an explicit description of the A 1 -homotopy type of the other family of quadrics, thus answering Question 1 in a collection of cases.
Theorem 2 (See Theorem 2.2.5) . Let k be a commutative unital ring and n ≥ 0 an integer. There are explicit A 1 -weak equivalences
$$Q _ { n } \sim _ { \mathbb { A } ^ { 1 } } & \begin{cases} S _ { s } ^ { m - 1 } \wedge \mathbf G _ { m } ^ { \wedge m } & \text{if $n=2m-1$ and} \\ S _ { s } ^ { m } \wedge \mathbf G _ { m } ^ { \wedge m } & \text{if $n=2m$} \end{cases}$$
of spaces over Spec k .
Remark 3 . The interesting part of Theorem 2 is the case where n = 2 m , and the result was known previously for m = 1 2 , by special geometric considerations. On the other hand, the S 1 -stable homotopy types of the quadrics Q 2 m were known over fields having characteristic unequal to 2 by unpublished work of Morel [Mor08], and Dugger and Isaksen [DI08]. We emphasize that Theorem 2 is an unstable result. In contrast to the corresponding proof for n odd, it uses the Nisnevich topology in an essential way, via the Morel-Voevodsky homotopy purity theorem.
While Theorem 2 tells us that some motivic spheres do have the A 1 -homotopy type of smooth schemes, the following result shows that not all motivic spheres have this property.
Proposition 4 (See Proposition 2.3.1) . If i, j are integers with i > j , the spheres S i s ∧ G ∧ j m do not have the A 1 -homotopy type of smooth (affine) schemes.
Classically, S n admits an open cover by two contractible subspaces homemorphic to R n (via stereographic projection), namely S n \{ N } and S n \{ S } , where N and S are the North and South poles. The intersection of these two open sets is homeomorphic to the total space of a line bundle over S n -1 and, in particular, homotopy equivalent to S n -1 . Pursuing the analogy between the classical spheres and the quadrics further, one can ask whether analogous covers exist in algebraic geometry. We begin by establishing the existence of A 1 -contractible open subschemes covering Q 2 n ; the main results are summarized in the following theorem (see Subsection 2.1 and Remark 3.1.2 for detailed explanations of the connections with [AD07]).
Theorem 5 (See Theorem 3.1.1 and Corollary 3.2.3) . Suppose k is a commutative unital ring. Write X 2 m for the open subscheme of Q 2 m defined as the complement of x 1 = · · · = x m = 0 , z = -1 .
- 1. The variety X 2 m is A 1 -contractible over Spec k .
- 2. For m ≥ 3 , X 2 m cannot be realized as a quotient of an affine space by a (scheme-theoretically) free action of a unipotent k -group scheme.
The identification of the A 1 -homotopy type of spheres has a number of applications. Pursing the analogy with the classical geometry of S n further, recall that the open cover of S n described above also yields the 'clutching construction' which provides a bijection between pointed homotopy classes of maps S n -1 → GL n ( R ) and isomorphism classes of real vector bundles on S n . We pursue an analogous construction in algebraic geometry. The open subscheme X 2 m has an 'opposite' defined as the complement of x 1 = · · · = x m = z = 0 ; this subscheme is A 1 -contractible as well (if 2 is a unit in k , then X 2 m and its opposite are isomorphic algebraic varieties). When m = 1 , the intersection of X 2 m and its opposite is isomorphic to A 1 × G m . For m ≥ 2 , the situation is more complicated as the intersection of X 2 m and its opposite is a quasi-affine but not affine variety, so every regular function on the intersection extends to Q 2 m itself. As a consequence, considering the intersection of X 2 m and its opposite does not produce a reasonable analog of the clutching construction.
Instead, we produce two variants (abstract and concrete) of the clutching construction (see Theorems 4.1.6 and 4.3.6). The abstract clutching construction works rather generally and, roughly speaking, yields a surjection from the set of 'naive' A 1 -homotopy classes of pointed maps from Q 2 m -1 to GL r to the set of isomorphism classes of rank r vector bundles on Q 2 m ; this result holds over Z (or, more generally, any base ring that is smooth over a Dedekind domain with perfect residue fields).
The concrete clutching construction refines the abstract clutching construction and shows how to produce explicit GL m -valued 1 -cocycles on a suitable open cover of Q 2 m realizing any rank r vector bundle, at least under suitable additional restrictions on the base k . More precisely, consider the open affine subschemes V 0 2 m := D z ⊂ Q 2 m and V 1 2 m := D 1+ z ⊂ Q 2 m . The subschemes V 1 2 m and V 0 2 m are not A 1 -contractible. Nevertheless, there is an explicit morphism ψ m : V 0 2 m ∩ V 1 2 m → Q 2 m -1 such that the vector bundle on Q 2 m attached to a pointed morphism f : Q 2 m -1 → GL r is obtained by gluing copies of the trivial bundle of rank r on V i 2 m along V 0 2 m ∩ V 1 2 m via the composite map f ◦ ψ m . One consequence of this construction is the following result, which is perhaps of independent interest.
Theorem 6 (See Theorem 4.3.6(2)) . If k is a regular ring, then for every integer n ≥ 1 , there exists an explicit matrix β m : Q 2 m -1 → GL m , constructed by Suslin, such that the rank n vector bundle on Q 2 m obtained by gluing trivial bundles via the automorphism β m ◦ ψ m yields a generator of the rank 1 free K k 0 ( ) -module ˜ K Q 0 ( 2 m ) .
These results have a number of applications which will be developed elsewhere, but which we mention here for the sake of context. Naive homotopy classes of maps from a smooth affine k -scheme X to Q 2 n appear in problems related to complete intersection ideals [Fas15, § 2]. On the other hand, the set of naive A 1 -homotopy classes of maps from a smooth affine scheme to Q 2 n was identified, at least if k is an infinite field having characteristic unequal to 2 , with [ X,Q 2 n ] A 1 in [AHW15b, Theorem 4.2.2]. These ideas will be put together with the results established here in [AF15]. Among other things, the set [ X,Q 2 m ] A 1 is a 'motivic cohomotopy group' (provided the dimension of X is 'small' compared to m ): it can be equipped with a functorial abelian group structure and this additional structure can be used to study various classical problems, e.g., related to comparison of 'Euler class groups.'
## Note on prerequisites
We close this introduction with a warning: the prerequisites required to read this paper are nonuniform. The proofs of Theorem 2 and (the first part of) Theorem 5 use only basic algebraic geometry, standard results about cofiber sequences in pointed model categories [Hov99, Chapter 6] and knowledge of the basic aspects of [MV99] (see the preliminaries for further discussion regarding relaxation of hypotheses on the base); we have attempted to make them as accessible as possible. The proofs of Proposition 4 and the second part of Theorem 5 are slightly more algebrogeometrically involved: the first requires some knowledge of properties of motivic cohomology [MVW06] while the second requires knowledge about Cousin complexes for coherent sheaves. The results of Section 4 on the clutching construction require some familiarity with some of the results of [AHW15a, AHW15b] (which we review), together with some ideas from [Mor12]. The proof of Theorem 6 requires familiarity with some results of Suslin.
## Acknowledgements
Some of the results claimed in this paper were announced in talks by first and second named authors as early as 2007. For example, the original proof of Theorem 2 we envisioned, specifically the description of A 1 -homotopy types of Q n for n even ≥ 6 , was an elementary geometric argument that was supposed to work over Spec Z ; this argument contained a gap. The authors would also like to thank Paul Balmer, Dan Isaksen, Christian Haesemeyer, and Fabien Morel, for useful discussions over the course of the project and Matthias Wendt for a number of useful comments on a first draft of this note. Finally, we thank Marc Hoyois for helpful discussions about the A 1 -homotopy category over non-Noetherian base schemes.
## Preliminaries/Notation
Throughout the paper the phrase ' k is a ring' will always mean ' k is a commutative unital ring'. We write Sm k for the category of schemes that are separated, finite type and smooth over Spec k ,
and Spc k , i.e., the category of 'spaces over k ', is the category of simplicial presheaves on Sm k . We write H Nis s ( k ) (resp. H Nis s, · ( k ) ) for the Nisnevich local homotopy category (as in [MV99, § 2.1]) and H ( k ) (resp. H · ( k ) ) for the (pointed) Morel-Voevodsky A 1 -homotopy category [MV99].
The assumptions here require further discussion if k is not Noetherian of finite Krull dimension, which are the explicit assumptions on k used in [ MV99 in the construction of the Morel-Voevodsky ] A 1 -homotopy category. In contrast to [MV99], but following [AHW15a], we define the Nisnevich topology on Sm k to be the topology generated by finite families of ´ etale maps { U i → X } admitting a splitting sequence by finitely presented closed subschemes, in the sense of [MV99, § 3, p. 97]. This definition, which is equivalent to the 'standard' definition [MV99, § 3 Definition 1.2] if k is Noetherian by [MV99, § 3 Lemma 1.5], is studied in more detail in [Lur11, § 1]. We refer the reader to [Hoy14, Appendix C] for a 'good' version of the A 1 -homotopy category over a quasi-compact, quasi-separated base scheme. We note here that arbitrary affine schemes are quasicompact and quasi-separated. In addition, in the construction of the A 1 -homotopy category when k is not Noetherian, one imposes Nisnevich descent (not hyperdescent) as discussed in [AHW15a, § 3.1] and A 1 -invariance.
As usual, smooth schemes are, via the Yoneda embedding, identified with their corresponding representable (simplicially constant) presheaves. If X ∈ Spc k , we write X + for the pointed space X ∐ Spec k , pointed by the disjoint copy of Spec k . If Y → X is a closed immersion of smooth scheme, we write ν Y/X for the normal bundle to Y in X . In that case, Th ν ( Y/X ) is the Thom space of the vector bundle ν Y/X as in [MV99, § 3 Definition 2.16].
↦
Suppose ( X , x ) and ( Y , y ) are pointed spaces. We use the notation Σ i s X := S i s ∧ X for simplicial suspension, and suppress the base-point. Likewise, we write R Ω 1 s X for the derived simplicial loops of X : i.e., first apply Nisnevich fibrant replacement and then apply Ω 1 s . We set [( X , x ) , ( Y , y )] s := Hom H Nis s, · ( k ) (( X , x ) , ( Y , y )) , [( X , x ) , ( Y , y )] A 1 := Hom H · ( k ) (( X , x ) , ( Y , y )) [ X Y , ] s := Hom H Nis s ( k ) ( X Y , ) and [ X Y , ] A 1 := Hom H ( k ) ( X Y , ) . Finally, if ( X , x ) is a pointed space, we write π A 1 i ( X , x ) for the Nisnevich sheaf associated with the presheaf U → Hom H · ( k ) ( S i s ∧ U , + ( X , x )) (such sheaves are typically denoted with boldface symbols).
## 2 Geometric models of motivic spheres
This section is devoted to establishing Theorem 2 from the introduction. The argument proceeds by induction. Subsection 2.1 gives an elementary geometric argument showing that Q 2 is A 1 -weakly equivalent to P 1 , and a related (mostly elementary) argument showing that Q 4 is A 1 -weakly equivalent to ( P 1 ) ∧ 2 ; the first computation is the base-case for the induction argument. Subsection 2.2 contains the proof of the main result, which is Theorem 2.2.5. Finally, Subsection 2.3 establishes some non-geometrizability results for motivic spheres.
## 2.1 On the A 1 -homotopy types of Q 2 and Q 4
Proposition 2.1.1. If k = Z , then there is a (pointed) A 1 -weak equivalence Q 2 ∼ → P 1 .
Proof. We can identify Q 2 as the quotient of SL 2 by its maximal torus T := diag t, t ( -1 ) = ∼ G m acting by right multiplication; this follows from a straightforward computation of invariants. If B
is the linear algebraic group of upper triangular matrices with determinant 1 , then the closed immersion group homomorphism T ↪ → B induces a morphism of homogeneous spaces SL /T 2 → SL /B 2 . This morphism of homogeneous spaces is Zariski locally trivial with fibers isomorphic to A 1 (use the standard open cover of P 1 by two copies of A 1 ), in particular an A 1 -weak equivalence. To conclude, we observe that the quotient SL /B 2 is isomorphic to P 1 , and we can make this morphism a pointed morphism by picking any k -point in SL /T 2 and looking at the image of this k -point in P 1 .
There are two 'natural' (pointed) A 1 -weak equivalences of Q 2 → P 1 that we know. In the previous proof, the A 1 -weak equivalence we wrote down arose from the structure of Q 2 as a homogeneous space, but as we now explain this seems to be an 'exceptional' low-dimensional phenomenon. If k is a ring in which 2 is invertible, the varieties Q 2 n are all isomorphic to homogeneous spaces for suitable orthogonal groups, but this seems false if 2 is not invertible in k .
The other 'natural' (pointed) A 1 -weak equivalence arises as follows. The locus of points where x 1 = 0 and z = -1 is a closed subscheme of Q 2 isomorphic to A 1 ; the open complement of this closed subscheme is isomorphic to A 2 . The normal bundle to this embedding of A 1 comes equipped with a prescribed trivialization, and we can use homotopy purity together with A 1 -contractibility of A 2 to construct another A 1 -weak equivalence of Q 2 with P 1 . We now explain how to identify the A 1 -homotopy type of Q 4 using the method just sketched.
Proposition 2.1.2. If k = Z , then there is a (pointed) A 1 -weak equivalence Q 4 ∼ → P 1 ∧ 2 .
Proof. Let E 2 be the closed subscheme of Q 4 defined by x 1 = x 2 = 0 and z = -1 . Observe that E 2 is isomorphic to A 2 . The normal bundle to E 2 is trivial, and we fix a choice of trivialization. Let X 4 := Q 4 \ E 2 . The homotopy purity theorem gives a cofiber sequence of the form
$$X _ { 4 } \longrightarrow Q _ { 4 } \longrightarrow T h ( \nu _ { E _ { 2 } / Q _ { 4 } } ) \longrightarrow \cdots.$$
The choice of trivialization determines an isomorphism Th ν ( E /Q 2 4 ) ∼ = P 1 ∧ 2 ∧ ( E 2 ) + . The map E 2 → Spec k is an A 1 -weak equivalence, it follows that Th ν ( E /Q 2 4 ) ∼ = P 1 ∧ 2 in H · ( k ) . We showed in [AD08, Corollary 3.1 and Remark 3.3] that X 4 is A 1 -contractible over Spec Z (indeed, it is the base of a Zariski locally trivial morphism with total space A 5 and fibers isomorphic to A 1 ). Properness of the A 1 -local model structure [MV99, § 2 Theorem 3.2] guarantees that pushouts of A 1 -weak equivalences along cofibrations are A 1 -weak equivalences. Applying this fact to the diagram ∗ ← X 4 → Q 4 , one concludes that the map Q 4 → Th ν ( E /Q 2 4 ) is an A 1 -weak equivalence and the proposition follows by combining the stated isomorphisms.
Remark 2.1.3 . The variety Q 4 is isomorphic to the variety HP 1 studied in [PW10, § 3]. The variety we call X 4 appears in the 'cell decomposition' of HP 1 described in [PW10, Theorem 3.1] (it is the variety they call X 0 ).
## 2.2 On the A 1 -homotopy type of Q 2 n , n ≥ 3
## The 'octahedral' axiom in a pretriangulated category
If C is a pointed model category, then recall that one can understand the homotopy cofiber of a composite in terms of the homotopy cofibers of the constituents by means of the following result,
which is sometimes called the 'octahedral' axiom, by analogy with a corresponding result for stable model categories [Hov99, Proposition 6.3.6].
Proposition 2.2.1. Suppose given a sequence of maps in a pointed model category C of the form:
$$X \stackrel { u } { \longrightarrow } Y \stackrel { v } { \longrightarrow } Z.$$
If U = hocofib( u ) , V = hocofib( uv ) , W = hocofib( v ) , then there is a commutative diagram of the form
u
/d47
/d47
/d47
/d47
/d15
/d15
/d15
/d15
/d15
/d15
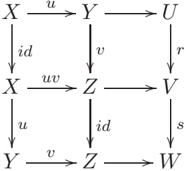
/d15
/d15
/d15
/d15
/d15
/d15
/d47
/d47
/d47
/d47
where the rows and the third column are cofiber sequences, and the maps r and s are the maps induced by functoriality of the homotopy cofiber construction.
## The induction step
Consider the quadric Q 2 n introduced in the introduction over Z . The open subscheme U n defined by the non-vanishing of x n is isomorphic to A 2 n -1 × G m (with coordinates ( x , . . . , x 1 n -1 , y 1 , . . . , y n -1 , z ) on the first factor and x n on the second factor). The closed complement of this open subscheme, which we will call Z n , is isomorphic to Q 2 n -2 × A 1 , with coordinates x , . . . , x 1 n -1 , y 1 , . . . , y n -1 , z on the first factor and y n on the second factor. The subvariety Z n has a distinguished point '0' corresponding to x 1 = · · · = x n = y 1 = · · · = y n = z = 0 . Moreover, the normal bundle to Z n in Q 2 n is a line bundle equipped with a chosen trivialization (coming from x n ).
The closed subscheme of U n defined by x 1 = · · · = x n -1 = y 1 = · · · = y n -1 = z = 0 is isomorphic to G m with coordinate x n and the inclusion map
$$G _ { \text{m} } \longrightarrow U _ { n }$$
is a cofibration and A 1 -weak equivalence (it even admits a retraction). The closed subscheme of Q 2 n defined by x 1 = · · · = x n -1 = y 1 = · · · = y n -1 is isomorphic to Q 2 . Imposing further the condition y n = 0 , the resulting variety is isomorphic to two copies of A 1 (corresponding to z = 0 and z = -1 ). Imposing yet further the condition z = 0 gives a subvariety of Q 2 n isomorphic to A 1 with coordinate x n . Note that, by construction, the intersection of this copy of the affine line with Z n is precisely the point '0', i.e., there is a pullback square (of smooth schemes) of the form:
/d47
/d47
/d15
/d15
/d15
/d15
/d47
/d47
Moreover, the natural map from the pullback of the normal bundle to Z n in Q 2 n to the normal bundle of 0 in A 1 is an isomorphism compatible with the specified trivializations.
/d47
/d47
/d47
/d47
It follows from the construction of the purity isomorphism [MV99, § 3 Theorem 2.23] that, given a pullback square as in the previous paragraph, the diagram
/d47
/d47
/d15
/d15
/d15
/d15
/d47
$$\mathbb { A } ^ { 1 } / \mathbf G _ { \text{m} } & \xrightarrow { T h ( \nu _ { 0 / \mathbb { A } ^ { 1 } } ) } \\ \Big \downarrow \\ Q _ { 2 n } / U _ { n } & \xrightarrow { T h ( \nu _ { Z _ { n } } / Q _ { 2 n } ) }$$
/d47
is commutative in H · ( k ) (cf. [Voe03a, Lemma 2.1]). Moreover, the specified trivializations yield A 1 -weak equivalences of the form Th ν ( 0 / A 1 ) = ∼ P 1 and Th ν ( Z /Q n 2 n ) = ∼ P 1 ∧ ( Z n ) + by [MV99, § 3 Proposition 2.17.2] and their compatibility ensures that the diagram
/d47
/d47
/d15
/d15
/d15
/d15
/d47
$$T h ( \nu _ { 0 / \mathbb { A } ^ { 1 } } ) \xrightarrow { \mathbb { P } ^ { 1 } } \mathbb { P } ^ { 1 } \\ \downarrow \downarrow _ { T h ( \nu _ { Z _ { n } / Q _ { 2 n } } ) \xrightarrow { \mathbb { P } ^ { 1 } } \wedge ( Z _ { n } ) _ { + } }$$
/d47
commutes (this time in the category of pointed spaces). Furthermore, under these identifications, we can make the right vertical map in the diagram very explicit. Indeed, consider the map S 0 s → ( Z n ) + sending the base-point of S 0 s to the base-point of ( Z n ) + and the point 1 of S 0 s to the point ' 0 ' in Z n described above; the right hand vertical map is the P 1 -suspension of this map.
Now, we apply Proposition 2.2.1 to the composition
$$( G _ { m } ) _ { + } \stackrel { u } { \longrightarrow } ( \mathbb { A } ^ { 1 } ) _ { + } \stackrel { v } { \longrightarrow } ( Q _ { 2 n } ) _ { + }.$$
Observe that the cofiber of v is Q 2 n pointed with the image of '0' , while the cofiber of u is, by means of the purity isomorphism, P 1 . It remains to identify the cofiber of ( G m + ) → ( Q 2 n ) + , which is the content of the next lemma.
Lemma 2.2.2. If k = Z , then the cofiber of the map ( G m + ) → ( Q 2 n ) + is A 1 -weakly equivalent to P 1 ∧ ( Q 2 n -2 ) + .
Proof. The projection map Z n → Q 2 n -2 is an A 1 -weak equivalence, it follows that it induces an A 1 -weak equivalence P 1 ∧ ( Z n ) + ∼ → P 1 ∧ ( Q 2 n -2 ) + . On the other hand, by the purity isomorphism, the space P 1 ∧ ( Z n ) + is A 1 -weakly equivalent to Q 2 n /U n . Since the map G m → U n described above is an A 1 -weak equivalence and cofibration and since the induced map G m → Q 2 n is a cofibration, it follows that the induced map of cofibers
$$Q _ { 2 n } / G _ { \mathfrak { m } } \rightarrow Q _ { 2 n } / U _ { n }$$
is an A 1 -weak equivalence. Moreover, the same statement remains true for the cofibers of the pointed morphisms ( G m + ) → ( Q 2 n ) + and ( U n ) + → ( Q 2 n ) + .
Combining Proposition 2.2.1 and Lemma 2.2.2, we deduce the following result.
Corollary 2.2.3. If k = Z , then for any integer n ≥ 1 , there is a cofiber sequence of the form
$$\mathbb { P } ^ { 1 } \longrightarrow \mathbb { P } ^ { 1 } \wedge ( Q _ { 2 n - 2 } ) _ { + } \longrightarrow Q _ { 2 n } \longrightarrow \cdots.$$
To finish, we provide an alternative identification of the cofiber of P 1 → P 1 ∧ ( Q 2 n -2 ) + . Recall that this map is induced by P 1 -suspension of a map S 0 s → ( Z n ) + . We prove a more general statement about smashing this map with the identity map.
Proposition 2.2.4. Assume ( X , x ) is a pointed space, and X + is X with a disjoint base-point attached. Let ι : S 0 s → X + be the map that sends the base-point of S 0 s to the (disjoint) basepoint of X + and the non-base-point to x ∈ X ( k ) . If ( Y , y ) is a pointed space, then the map Y ∼ = S 0 s ∧ Y -→ X ι ∧ id + ∧ Y fits into a split cofiber sequence of the form
$$\mathcal { Y } \stackrel { \iota \wedge i d } { \longrightarrow } \mathcal { X } _ { + \wedge } \mathcal { Y } \longrightarrow \mathcal { X } _ { \wedge } \mathcal { Y }.$$
Proof. The splitting is given by the map X + → S 0 s that collapses the non base-point component of X + to the non-base-point of S 0 s . In particular, the map ι ∧ id is a cofibration. The homotopy cofiber of this map is then computed by the actual quotient.
The quotient X + ∧ Y is, by definition, the quotient X + × Y by X + ∨ Y , where the latter is the disjoint union of X × + y and Spec k ×Y . Identify X ×Y + as ( X×Y ) ∐ (Spec k ×Y ) . Wedescribe the quotient in two steps. First, we collapse Spec k ×Y to the base-point and then the image of X + × y to the base-point. We conclude that there is an isomorphism of spaces X + ∧ Y ∼ = ( X ×Y ) / ( X × y ) . To conclude, we simply observe that X × Y / ( X × y ) modulo the image of x ×Y is X Y ∧ .
Theorem 2.2.5. For any base ring k , there is an isomorphism in H · ( k ) of the form Q 2 n ∼ → P 1 ∧ n .
Proof. Since both sides of the weak equivalence are preserved by base-change, it suffices to prove the result for k = Z . In that case, by Proposition 2.1.1, we know that Q 2 ∼ → P 1 in H · ( k ) . Combining Proposition 2.2.4 and Corollary 2.2.3, we conclude that for every n ≥ 2 that there is an isomorphism in H · ( k ) of the form Q 2 n ∼ = Q 2 n - ∧ 2 P 1 . The result follows by a straightforward induction.
## 2.3 Non-geometric motivic spheres
Proposition 2.3.1. If k is a base ring, and if i > j are integers, then S i s ∧ G ∧ j m does not have the A 1 -homotopy type of a smooth scheme.
Proof. Assume to the contrary that X is a smooth k -scheme having the A 1 -homotopy type of S i s ∧ G ∧ j m . By picking a a geometric point of Spec k , we can, without loss of generality, assume k is an algebraically closed field, in particular perfect. Then, by A 1 -representability of motivic cohomology (see, e.g., [V oe03b, § 2]), we know that for arbitrary integers p, q
$$H ^ { p, q } ( X, \mathbb { Z } ) = [ X, K ( \mathbb { Z } ( q ), p ) ] _ { \mathbb { A } ^ { 1 } }.$$

Next, observe that by the cancellation theorem [Voe10, Corollary 4.10] and the (simplicial) suspension isomorphism, there is a non-trivial morphism S i s ∧ G ∧ j m → K ( Z ( j ) , i + ) j , giving a non-trivial class in H i + j,j ( X, Z ) . However, if X is a smooth scheme, and i > j , then this latter group must vanish by [MVW06, Theorem 19.3].
Remark 2.3.2 . One can obtain another more 'homotopic' proof of the proposition at the expense of introducing slightly different terminology; we freely use the conventions of [AF14a] and some terminology from [Mor12]. Consider an Eilenberg-Mac Lane space K ( K M j , i ) , i.e., a space with exactly 1 non-vanishing A 1 -homotopy sheaf in degree j , in which degree it is isomorphic to the unramified Milnor K-theory sheaf K M j . If X is a smooth scheme, the explicit Gersten resolution of K M j shows that H X, i ( K M j ) vanishes for i > j . On the other hand, there is a non-trivial (pointed) morphism S i s ∧ G ∧ j m → K ( K M j , i ) . Indeed, by [Mor12, Theorem 6.13], we have π A 1 i,j ( K ( K M j , i )) = ∼ ( K M j ) -j and by applying, e.g., [AF14a, Lemma 2.7] we deduce ( K M j ) -j ∼ = Z .
The following conjecture summarizes our expectations regarding representability of the remaining motivic spheres by smooth schemes.
Conjecture 2.3.3. If k is a base ring, and if i, j ∈ N with i < j -1 , the sphere S i s ∧ G ∧ j m does not have the A 1 -homotopy type of a smooth k -scheme.
## 3 A 1 -contractible subvarieties of quadrics
A smooth k -scheme X is A 1 -contractible if the structure map X → Spec k is an isomorphism in H ( k ) , i.e., an A 1 -weak equivalence. The affine space A n k is A 1 -contractible by construction of the A 1 -homotopy category. An exotic A 1 -contractible smooth scheme is an A 1 -contractible smooth scheme that is not isomorphic to an affine space. In [AD07] the first two authors constructed many exotic A 1 -contractible smooth schemes as quotients of an affine space by a free action of the additive group G a (or, more generally, free actions of unipotent groups on affine spaces). All of the examples constructed in [AD07] could be realized as open subschemes of affine schemes with complement of codimension ≤ 2 .
Let E n ⊂ Q 2 n be the closed subscheme defined by x 1 = · · · = x n = 0 and z = -1 . Observe that E n ∼ = A n and has codimension n in Q 2 n . Set
$$X _ { 2 n } \coloneqq Q _ { 2 n } \, \bigwedge E _ { n }.$$
It is straightforward to check that X 2 ∼ = A 2 , and we recalled in the proof of Proposition 2.1.2 that X 4 is A 1 -contractible. The main results of this section are Theorem 3.1.1, which shows that X 2 n is A 1 -contractible for n ≥ 1 , and Corollary 3.2.3, which establishes that X 2 n is not a unipotent quotient of affine space for n ≥ 3 .
## 3.1 On the A 1 -contractibility of X 2 n
If k = C , one can check that X 2 m ( C ) is a contractible complex manifold. Over C , the variety Q 2 m is isomorphic to the variety defined by ∑ 2 m +1 i =1 x 2 i = 1 . Wood explains [Woo93, § 2] how to identify the last variety with the tangent bundle of a sphere. Under this isomorphism, the variety E m can be identified with the tangent space at a point. The complement of E m is then a contractible topological space diffeomorphic to R 4 m . Here is the generalization of this result to A 1 -homotopy theory.
Theorem 3.1.1. If k is a base ring, then the variety X 2 n is A 1 -contractible over Spec k .
Proof. Once more, since both sides are preserved by base-change, it suffices to prove the result with k = Z . We continue with the notation of Subsection 2.2. The proof is essentially a repeat of the Proof of Theorem 2.2.5, so we will explain only the changes required. Consider the closed subvariety Z n ⊂ Q 2 n defined by x n = 0 . Wesaw that Z n ∼ = Q 2 n -2 × A 1 and that the normal bundle to Z n comes equipped with a specified trivialization. Observe that, by construction E n ⊂ Z n and therefore we see that X 2 n := Q 2 n \ E n contains U n := Q 2 n \ Z n as an open subscheme. Moreover, the subvariety Z n \ E n is isomorphic to X 2 n -2 × A 1 .
Recall that U n ∼ = A 2 n -1 × G m with coordinates x , . . . , x 1 n -1 , y 1 , . . . , y n -1 , z on the first factor and x n on the last factor. The closed subscheme G m ↪ → U n is defined by x 1 = · · · = x n -1 = y 1 = · · · y n -1 = 0 and z = 0 . The intersection of X 2 n and Q 2 , viewed as a subvariety of Q 2 n by imposing x 1 = · · · = x n -1 = y 1 = · · · = y n -1 = 0 is isomorphic to A 2 . The copy of A 1 ⊂ Q 2 identified by further imposing the conditions y n = z = 0 is disjoint from E n and therefore contained in X 2 n . Note that the point '0' of Q 2 n is contained in X 2 n .
We therefore have a diagram of the form
$$G _ { m } \stackrel { u } { \longrightarrow } \mathbb { A } ^ { 1 } \stackrel { v } { \longrightarrow } X _ { 2 n }.$$
We understand the cofiber of this composite map using Proposition 2.2.1 again. In particular, repeating the proofs of Lemma 2.2.2 and Corollary 2.2.3 with all instances of Q 2 i replaced by X 2 i , we deduce the existence of a cofiber sequence of the form
$$\mathbb { P } ^ { 1 } \stackrel { \iota } { \longrightarrow } ( X _ { 2 n - 2 } ) _ { + } \wedge \mathbb { P } ^ { 1 } \longrightarrow X _ { 2 n } \longrightarrow \cdots$$
Now, applying Proposition 2.2.4, we conclude that the cofiber of ι is A 1 -weakly equivalent to X 2 n - ∧ 2 P 1 . The induction hypothesis guarantees that X 2 n -2 is A 1 -contractible, so the smash product X 2 n - ∧ 2 P 1 is A 1 -contractible as well. Since X 2 n - ∧ 2 P 1 is A 1 -weakly equivalent to X 2 n , it follows that X 2 n is A 1 -contractible.
Remark 3.1.2 . Theorem 3.1.1 gives an alternative proof of Theorem 2.2.5, this time repeating the argument of Proposition 2.1.2. In this case, the map Q 2 n → Th ν ( E /Q n 2 n ) obtained by collapsing X 2 n to a point and then using the homotopy purity theorem is an A 1 -weak equivalence by properness of the A 1 -local model structure, as explained in the proof of Proposition 2.1.2. The explicit trivialization of the normal bundle to E n that arises by its presentation as a (connected component of a) complete intersection defined by a regular sequence of Q 2 n yields an isomorphism Th ν ( E /Q n 2 n ) ∼ = P 1 ∧ n ∧ ( E n ) + , and the projection map E n → Spec k then yields an A 1 -weak equivalence Q 2 n ∼ → P 1 ∧ n that is perhaps slightly more explicit than the one arising in the proof of Theorem 2.2.5.
## 3.2 A 1 -contractibles that are not unipotent quotients
We will now see that for m ≥ 3 , the varieties X 2 m studied in Theorem 3.1.1 cannot be realized as quotients of affine space by free actions of unipotent groups U . We begin by proving a general 'excision' style result (Theorem 3.2.1) for (Zariski) cohomology with coefficients in a unipotent group; the main result then follows from this excision result when applied in the special case of degree 1 cohomology (Corollary 3.2.2). Indeed, the degree 1 cohomology group in question can be
identified as the (pointed) set of U -torsors on the scheme X . We warn the reader that, contrary to 'understood' prior conventions, the letter U in this section stands for a unipotent group, as opposed to an open subscheme; we refer the reader to [Bor91, § 15 (Definition 15.1)] for general information on split unipotent groups.
Theorem 3.2.1 (Excision for unipotent groups) . Let d ≥ 3 be an integer. Suppose X is a regular scheme over a field and j : W ↪ → X is an open immersion whose closed complement has codimension ≥ d . Suppose U is a (not necessarily commutative) split unipotent group. The restriction map
$$j ^ { * } \colon H ^ { 1 } _ { Z \text{ar} } ( X, U ) \longrightarrow H ^ { 1 } _ { Z \text{ar} } ( W, U )$$
is a pointed bijection, i.e., every U -torsor on W extends uniquely to a U -torsor on X .
Proof. Since U is split, by definition it admits an increasing filtration by normal subgroups 1 = U 0 ⊂ U 1 ⊂ · · · U n = U with subquotients U i +1 /U i isomorphic to G a . We first show that, working inductively with respect to the dimension of U , it suffices to prove the result in the case U = G a .
Indeed, suppose we know the result holds true for all unipotent groups of dimension n and all open immersions of regular schemes with closed complement of codimension d ≥ 3 . In that case, suppose U has dimension n + 1 and we are given a U -torsor ϕ : P → W . We know that there is a normal subgroup U ′ of U such that U/U ′ ∼ = G a . In that case, the quotient map U → G a gives rise to a G a -torsor W ′ := P × U G a → W ; note that W ′ is again regular. The pullback of ϕ along W ′ → W gives a U ′ -torsor on W ′ . Now, again by induction, we also know that the G a -torsor W ′ → W extends (uniquely) to a G a -torsor X ′ → X ; again, X ′ is regular. Moreover, working over a Zariski trivialization of X ′ → X , we conclude that W ′ ⊂ X ′ is open with closed complement having codimension ≥ 3 as well. However, the induction hypothesis guarantees that the U ′ -torsor over W ′ extends uniquely to a U ′ -torsor on X ′ , and this extension provides the required extension of ϕ over W .
Now, assume U = G a . In this case, one knows that by definition H q ( X, G a ) = H q ( X, O X ) . We will show that the map
$$j ^ { * } \colon H ^ { q } ( X, \mathcal { O } _ { X } ) \longrightarrow H ^ { q } ( W, \mathcal { O } _ { W } )$$
induced by pull-back along j is an isomorphism for q ≤ d -2 .
To prove the last fact, we use the Cousin complex for O X as discussed in, e.g., [Har66, IV.2]. Under the assumption that X is regular, the Cousin complex provides an injective resolution of O X (see especially ibid. p. 239). If X ( p ) denote the set of codimension p points in X (recall this means dim O X,x = p ), the p -th term of the Cousin complex is
$$\coprod _ { x \in X ^ { ( p ) } } ( i _ { x } ) _ { * } ( H _ { x } ^ { p } ( \mathcal { O } _ { X } ) ). \\ \dots \dots \dots.$$
Since j is an open immersion, it is an affine morphism and the Leray spectral sequence for j degenerates to yield isomorphisms j ∗ : H q ( W, O W ) ∼ → H q ( X,j ∗ O W ) . Adjunction gives rise to a morphism O X → j ∗ O W . The push-forward of the Cousin complex for O W to X by j remains a flasque resolution of j ∗ O W on X . Since the inclusion W ↪ → X is, by definition, an isomorphism on points of codimension d -1 , it follows that the cokernel of the induced morphism of Cousin complexes, which provides a flasque resolution of the cone of the map O X → j ∗ O X , only depends
on points of codimension ≥ d and the isomorphism of the theorem statement follows immediately from the long exact sequence in cohomology.
Corollary 3.2.2. If X is a regular affine scheme and W ⊂ X is an open subscheme whose complement has codimension d ≥ 3 , then every torsor under a split unipotent group over W is trivial. In particular, the varieties X 2 m cannot be realized as quotients of affine space by free actions of split unipotent groups.
Proof. BySerre's vanishing theorem [Gro61, Th´ eor` eme 1.3.1], we know that all higher cohomology of a quasi-coherent sheaf on an affine scheme vanishes. By Theorem 3.2.1, we conclude that if W is as in the the theorem statement, and if U is a (split) unipotent group, then H 1 ( W,U ) = ∗ , so every U -torsor over W is trivial. In particular, the total space of any U -torsor over W is of the form W × U , which is itself a quasi-affine variety that is not affine.
Corollary 3.2.3. If k is a base ring, and m ≥ 3 is an integer, then X 2 m is not a quotient of an affine space by the free action of a unipotent group.
Proof. Pick an algebraically closed field F such that Spec k has a Spec F -point. Assume that X 2 m is a quotient of A n by the free action of a unipotent group. By base change, we conclude that the unipotent group is necessarily smooth. Base-change to Spec F then allows us to assume that the unipotent group in question is also split. For m ≥ 3 , X 2 m has codimension m ≥ 3 in Q 2 m , so the result then follows immediately from Corollary 3.2.2.
Question 3.2.4. If Z → X 2 n is a Jouanolou device, then Z is an affine A 1 -contractible variety. Is Z ∼ = A m for some integer m ?
Remark 3.2.5 . If k is a field having characteristic p > 0 , work of N. Gupta [Gup14, Gup13] shows that there exist smooth affine k -varieties of every dimension d ≥ 3 that are stably isomorphic to affine k -space, yet which are not isomorphic to affine k -space. Such varieties are necessarily exotic smooth affine A 1 -contractible varieties. At the moment, we do not have any examples of exotic smooth affine A 1 -contractible varieties over a fields having characteristic 0 . Nevertheless, it seems reasonable to ask: if k is an arbitrary field, is every smooth affine A 1 -contractible k -variety a retract of an affine k -space?
## 4 Clutching functions for principal G -bundles on algebraic spheres
In this section, we provide an algebro-geometric analog of the clutching construction of vector bundles on even-dimensional spheres. As an application, we provide an explicit vector bundle yielding a generator of ˜ K Q 0 ( 2 n ) for n ≥ 1 . For n = 1 2 , , such explicit generators are given by classical geometric constructions (Hopf bundles). For n ≥ 3 , while it is easy to write down virtual vector bundle representatives, writing down explicit vector bundles is more complicated.
The main results of this section are Theorem 4.1.6, which provides a version of the clutching construction for any smooth affine scheme Y whose (simplicial) suspension has the A 1 -homotopy type of a smooth affine scheme. Making the abstract clutching construction explicit depends on the choice of weak equivalence Σ 1 s Y with an affine scheme X . In the special case where Y = Q 2 n -1 in
Theorem 4.2.3, we construct an explicit weak equivalence Σ 1 s Q 2 n -1 → Q 2 n , at least under suitable additional hypotheses. Finally in Theorem 4.3.6, we combine these two observations to obtain a version of the clutching construction that gives explicit cocycle representatives of vector bundles.
## 4.1 The abstract clutching construction
We begin by providing an abstract analog of the clutching construction in algebraic geometry. Let us begin by quickly reviewing the topological situation, where the clutching construction is sometimes phrased as follows. Suppose M is a pointed finite CW complex, and consider the (reduced) suspension Σ M . The usual identification G ∼ = Ω BG together with the loop-suspension adjunction yield a canonical bijection between sets of pointed homotopy classes of maps of the form [ M,G ] · ∼ = [Σ M,BG ] · . By the representability theorem for principal G -bundles, the forgetful map [Σ M,BG ] · → [Σ M,BG ] from based to free homotopy classes yields a surjection from [Σ M,BG ] · to the set of isomorphism classes of principal G -bundles on Σ M . If G is furthermore connected, then BG is necessarily 1 -connected, then the set of pointed homotopy classes of maps [ M,G ] · is actually in bijection with the set of isomorphism classes of principal G -bundles on Σ M . By Theorem 2.2.5, we find ourselves in an analogous situation. Indeed, we know that Q 2 n ∼ = P 1 ∧ n in H · ( k ) for n ≥ 0 . Using the standard identification Q 2 n -1 ∼ = Σ n -1 s G ∧ n m , we can then conclude that Q 2 n is A 1 -weakly equivalent to Σ 1 s Q 2 n -1 if n ≥ 1 , though providing an explicit A 1 -weak equivalence of this form is more complicated. More abstractly, we are given a (pointed) smooth affine scheme Y such that Σ 1 s Y has the A 1 -homotopy type of a smooth affine scheme. (If k is a regular ring, using Jouanolou-Thomason devices, it suffices to assume that Σ 1 s Y has the A 1 -homotopy type of a smooth scheme).
We would like to link principal G -bundles on a smooth affine model of Σ 1 s Y with 'clutching functions' on Y itself. As Σ 1 s Y only has the A 1 -homotopy type of a smooth affine scheme, we appeal to the results of [AHW15a, AHW15b] on A 1 -representability results for principal G -bundles (which themselves extend results of F. Morel [Mor12] and M. Schlichting [Sch15]). We break the argument into three pieces along the lines of what is sketched above: (i) adjunction, to obtain a bijection of A 1 -homotopy classes of maps, (ii) connectivity statements, to obtain a suitable surjectivity statement, and (iii) representability, to connect A 1 -homotopy classes with actual geometric objects (i.e., morphisms on the one side and bundles on the other). These three pieces are put together in the main result of this section, Theorem 4.1.6.
Webegin by recalling some notation. Recall that a presheaf F on Sm k is called A 1 -invariant on affines if, for any smooth affine k -scheme X , the map F ( X ) → F ( X × A 1 ) induced by pullback along the projection X × A 1 → X is a bijection. Write Sing A 1 ( -) for the singular construction of [MV99, p. 87]; briefly, this space is the diagonal of the bisimplicial object obtained by considering the internal hom Hom(∆ · k , X ) . Write R Zar for a Zariski fibrant replacement functor on the category of simplicial presheaves. With this notation, we can recall the results from [AHW15a, AHW15b] that we need.
Lemma4.1.1. Suppose k is a base ring, G is a smooth k -group scheme and assume that the presheaf H 1 Nis ( -, G ) on Sm k is A 1 -invariant on affines.
- 1. The spaces R Zar Sing A 1 BG and R Zar Sing A 1 G are Nisnevich local and A 1 -invariant.
- 2. For any smooth affine k -algebra A , the maps Sing A 1 BG A ( ) → R Zar Sing A 1 BG A ( ) and Sing A 1 G A ( ) → R Zar Sing A 1 G A ( ) are weak equivalences.
- 3. For any smooth affine k -algebra A , the canonical map Sing A 1 R Ω 1 s BG A ( ) → R Ω Sing 1 s A 1 BG A ( ) is a weak equivalence.
Proof. The first two statements are contained in [AHW15b, Theorems 2.2.5 and 2.3.2]. The third statement follows from [AHW15b, Corollary 2.1.2].
We begin by establishing the 'adjunction' part of the clutching construction.
Lemma4.1.2. Suppose k is a base ring, G is a smooth k -group scheme and assume that the presheaf H 1 Nis ( -, G ) on Sm k is A 1 -invariant on affines. If ( Y, y ) is a (pointed) smooth affine scheme such that Σ 1 s Y has the A 1 -homotopy type of a smooth affine scheme, then for any (pointed) smooth affine model ( X,x ) of Σ 1 s Y there is a pointed bijection
$$[ ( Y, y ), ( G, 1 ) ] _ { \mathbb { A } ^ { 1 } } \longrightarrow [ ( X, x ), ( B G, * ) ] _ { \mathbb { A } ^ { 1 } }.$$
Proof. By Lemma 4.1.1(1), we know that R Zar Sing A 1 G is Nisnevich local and A 1 -invariant, i.e., A 1 -fibrant [MV99, § 2 Proposition 3.19]. By Lemma 4.1.1(2), we know that the map Sing A 1 G → R Zar Sing A 1 G is a Nisnevich local weak equivalence. In particular, we know that Sing A 1 ( G ) is A 1 -local and thus that [( Y, y ) , ( G, 1)] A 1 ∼ = [( Y, y ) , (Sing A 1 ( G , ) 1)] s .
The evident map G → R Ω 1 s BG is a Nisnevich local weak equivalence, e.g., by [AHW15b, Lemma 2.2.2(iii)]. It follows that the induced map Sing A 1 G → Sing A 1 R Ω 1 s BG , which can be written as a homotopy colimit of Nisnevich local weak equivalences, is again a Nisnevich local weak equivalence. On the other hand, Lemma 4.1.1(3) allows us to conclude that the map Sing A 1 R Ω 1 s BG → R Ω Sing 1 s A 1 BG is a Nisnevich local weak equivalence. Combining these two observations, we deduce that the induced map Sing A 1 G → R Ω Sing 1 s A 1 BG is a Nisnevich local weak equivalence. Together with the conclusion of the previous paragraph, we deduce that
$$[ ( Y, y ), ( \text{Sing} ^ { A ^ { 1 } } ( G ), 1 ) ] _ { s } \longrightarrow [ ( Y, y ), \text{R} \Omega _ { s } ^ { 1 } \text{Sing} ^ { A ^ { 1 } } B G ] _ { s }$$
is a bijection.
By the using the loop-suspension adjunction, we conclude that [( Y, y ) , R Ω Sing 1 s A 1 BG ] s ∼ = [Σ ( 1 s Y, y ) , Sing A 1 BG ] s . However, arguing as in the first paragraph, we also know that Sing A 1 BG is A 1 -local, i.e., [Σ ( 1 s Y, y ) , Sing A 1 BG ] s ∼ = [Σ ( 1 s Y, y ) , Sing A 1 BG ] A 1 = [Σ ( 1 s Y, y ) , BG ] A 1 . Thus, combining all these identifications, we conclude that [( Y, y ) , ( G, 1)] A 1 ∼ → [Σ ( 1 s Y, y ) , BG ] A 1 . Now, since Σ 1 s Y has the A 1 -homotopy type of a smooth scheme X (and explicitly writing base-points for BG ), we conclude that
$$[ ( Y, y ), ( G, 1 ) ] _ { \mathbb { A } ^ { 1 } } = [ ( X, x ), ( B G, * ) ] _ { \mathbb { A } ^ { 1 } },$$
which is precisely what we wanted to show.
Next, we establish the analog of the surjectivity and bijectivity statements in the topological clutching construction.
Lemma4.1.3. Suppose k is a base ring, G is a smooth k -group scheme and assume that the presheaf H 1 Nis ( -, G ) on Sm k is A 1 -invariant on affines. If ( X,x ) is a pointed smooth affine scheme, then the evident map [( X,x , ) ( BG, ∗ )] A 1 → [ X,BG ] A 1 is surjective; if G is furthermore A 1 -connected, then this map is bijectictive.
Proof. As in the Proof of Lemma 4.1.2 we know that Sing A 1 G and Sing A 1 BG are A 1 -local and that Sing A 1 G → R Ω Sing 1 s A 1 BG is a Nisnevich local weak equivalence. Therefore, we conclude there are identifications of homotopy sheaves π A 1 0 ( G ) = π 0 (Sing A 1 G ) = ∼ π 0 ( R Ω Sing 1 s A 1 BG ) = ∼ π 1 (Sing A 1 BG ) = π A 1 1 ( BG ) .
The space BG is always 0 -connected by construction, and therefore by [MV99, § 2 Corollary 3.22] it is always A 1 -connected. In particular, Sing A 1 BG is always 0 -connected. Since X is a pointed smooth scheme, any morphism X → R Zar Sing A 1 BG can be pointed and this yields the surjectivity statement. If G is A 1 -connected, then we similarly conclude that BG is A 1 -1 -connected. In that case, the map of the theorem statement is a bijection by [AF14a, Lemma 2.1].
Remark 4.1.4 . The space BGL n is not A 1 -1 -connected in general, and thus the map from pointed to free homotopy classes is not a bijection in general; see [AF14a, Corollary 4.12] for an explicit example to see that injectivity can indeed fail in this case. On the other hand, the set of pointed homotopy classes of maps [( X,x , ) ( BG, ∗ )] A 1 also has a 'concrete' description in terms of pairs consisting of a G -torsor P on X equipped with a trivialization of x ∗ P ; we will not need this description.
Now, we give a concrete description of elements of [( Y, y ) , ( G, 1)] A 1 in terms of pointed morphisms of smooth schemes Y → G . Suppose Y = Spec A , where A is a k -algebra, a choice of k -point y of Y corresponds to a homomorphism y : A → k . This homomorphism induces a surjective morphism res y of simplicial groups res y : G A ( [∆ ]) · → G k ( [∆ ]) · , and we set
$$\text{Sing} ^ { \mathbb { A } ^ { 1 } } G ( Y, y ) \coloneqq \ker ( r e s _ { y } ) \colon G ( A [ \Delta ^ { \bullet } ] ) \longrightarrow G ( k [ \Delta ^ { \bullet } ] ).$$
Equivalently, Sing A 1 G Y,y ( ) is the (pointed) subsimplicial set of Sing A 1 G Y ( ) consisting of morphisms Y × ∆ n → G whose restriction to { y }× ∆ n are constant with image 1 ∈ G , which explains the choice of terminology.
Lemma4.1.5. Suppose k is a base ring, G is a smooth k -group scheme and assume that the presheaf H 1 Nis ( -, G ) on Sm k is A 1 -invariant on affines. Assume ( Y, y ) is a (pointed) smooth affine scheme.
- 2. There is a pointed bijection [ Y, BG ] A 1 ∼ = H 1 Nis ( Y, G ) .
- 1. The map π 0 (Sing A 1 G Y,y ( )) → [( Y, y ) , ( G, 1)] A 1 is a bijection, i.e., [( Y, y ) , ( G, 1)] A 1 coincides with the set of naive homotopy classes of pointed maps from Y to G .
Proof. For Point (1), we proceed as follows. The map Sing A 1 G → R Zar Sing A 1 G is a morphism of pointed simplicial presheaves and upon evaluation at any smooth affine scheme Y is a weak equivalence. We can assume that R Zar commutes with finite limits (it has a model given by the 'Godement resolution' [MV99, § 2 Theorem 1.66]). Therefore, R Zar Sing A 1 G is again a simplicial group and R Zar res y : R Zar Sing A 1 G Y ( ) → R Zar Sing A 1 G k ( ) is a homomorphism; this homomorphism is surjective because res y admits a set-theoretic section corresponding to the structure morphism. We set F y := ker( R Zar res y ) .
By functoriality, we obtain the following commutative diagram:
/d47
/d47
/d47
/d47
/d15
/d15
/d15
/d15
/d15
/d15
/d47
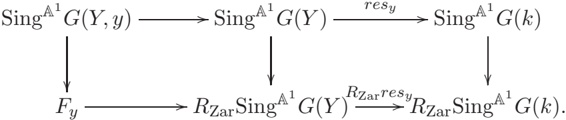
/d47
/d47
/d47
The two right vertical maps in this diagram are weak equivalences by Lemma 4.1.1(2). On the other hand, as res y and R Zar res y are both surjective group homomorphism, they are fibrations, with fibers isomorphic to the respective kernels, i.e., the diagram is a morphism of homotopy fiber sequences [Cur71, Lemma 3.2]. Therefore, we conclude that the leftmost vertical map Sing A 1 G Y,y ( ) → F y is also a (pointed) weak equivalence.
On the other hand, π 0 ( F y ) coincides with the quotient of the group of pointed morphisms Y → R Zar Sing A 1 G by the homotopy relation. Then, since R Zar Sing A 1 G is Nisnevich local and A 1 -fibrant by Lemma 4.1.1(1), we conclude that [( Y, y ) , ( G, 1)] A 1 coincides with π 0 ( F y ) . Bythe results of the previous paragraphs, we conclude that π 0 ( F y ) = ∼ π 0 (Sing A 1 G Y,y ( )) , which is precisely what we wanted to show.
$$<_Python_>$$
The simplicial weak equivalence G ∼ = R Ω 1 s BG yields, by adjunction, a canonical morphism Σ 1 s G → BG . If ( Y, y ) is a pointed smooth scheme, a pointed morphism f : Y → G then determines a morphism ˜ cl G ( f ) : Σ 1 s Y → Σ 1 s G → BG . If Σ 1 s Y has the A 1 -homotopy of a smooth scheme X , then fixing an A 1 -weak equivalence Σ 1 s Y ∼ = X , the element ˜ cl G ( f ) determines an element of [ X,BG ] A 1 by forgetting the base-point. The resulting assignment factors through naive A 1 -weak equivalence and determines a 'clutching' function
$$c l _ { G } \colon \pi _ { 0 } ( \text{Sing} ^ { \mathbb { A } ^ { 1 } } G ( Y, y ) ) \longrightarrow [ X, B G ] _ { \mathbb { A } ^ { 1 } }.$$
Regarding this clutching function, we have the following result, which puts everything above together.
↦
Theorem 4.1.6. Suppose k is a base ring, G is a smooth k -group scheme and assume that the presheaf H 1 Nis ( -, G ) on Sm k is A 1 -invariant on affines. If Y is a (pointed) smooth affine scheme such that Σ 1 s Y has the A 1 -homotopy type of a smooth affine scheme, then the assignment f → cl G ( f ) yields a surjective 'clutching' function of the form
$$c l _ { G } \colon \pi _ { 0 } ( \text{Sing} ^ { \mathbb { A } ^ { 1 } } G ( Y, y ) ) \longrightarrow H ^ { 1 } _ { \text{Nis} } ( \Sigma ^ { 1 } _ { s } Y, G ) ;$$
this assignment is functorial in both G and Y , and bijective if G is A 1 -connected. Moreover, the A 1 -invariance on affines hypothesis is satisified if:
- (i) G is GL ,SL n n or Sp 2 n , and k is smooth over a Dedekind domain with perfect residue fields, or
- (ii) k is an infinite field, and G is an isotropic reductive k -group (in the sense of [AHW15b, Definition 3.3.4] );
and the A 1 -connectedness hypothesis is satisfied if, e.g., G = SL n or Sp 2 n .
Proof. For the first statement, simply combine Lemmas 4.1.2, 4.1.3 and 4.1.5. Points (i) and (ii) are a consequence of [AHW15a, Theorem 5.2.1] and [AHW15a, Theorems 3.3.1, 3.3.2 and 3.3.6]. The A 1 -connectedness of SL n or Sp 2 n if k is infinite follows from existence of elementary matrix factorizations combined with [Mor05, Lemma 6.1.3].
Remark 4.1.7 . One criticism of Theorem 4.1.6 is that, given an explicit pointed map f : Y → G , we have only 'abstractly' produced the bundle cl G ( f ) as an A 1 -homotopy class of maps. While we will see this is sufficient to make interesting existence statements, to 'concretely' produce a bundle, say in terms of a suitable G -valued 1 -cocycle on a smooth affine model X of Σ 1 s Y , requires specifying an A 1 -weak equivalence Σ 1 s Y ∼ = X .
## 4.2 Mayer-Vietoris cofiber sequences and an explicit weak equivalence
We now turn our attention to producing an explicit A 1 -weak equivalence Q 2 n ∼ → Σ 1 s Q 2 n -1 ; this is accomplished in Theorem 4.2.3 below. We begin with some preliminaries on Mayer-Vietoris cofiber sequences. Suppose ( X , x ) and ( Y , y ) are pointed spaces. Write C ( X ) for the usual cone on X , i.e., X ∧ ∆ 1 s , where the latter is pointed by 1 . If f : X → Y , the map collapsing Y to a point yields a morphism of diagrams:
/d111
/d111
/d47
/d47
/d15
/d15
/d15
/d15
/d111
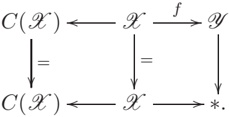
/d15
/d15
/d111
/d47
/d47
The induced map of homotopy pushouts along the rows yields a morphism C f ( ) -→ Σ 1 s X , functorial in all the inputs.
Now, suppose we are given a smooth scheme X and a Nisnevich distinguished square of the form
/d47
/d47
/d15
/d15
/d15
/d15
/d47
/d47
Let us assume that ( U × X V )( k ) is non-empty and fix a base-point; we point U V , and X by the image of this base-point under the various maps. In that case, the morphism ¯ : ψ V/ U ( × X V ) → X/U induced by ψ is an isomorphism by [MV99, § 3 Lemma 1.6]. On the other hand, since all horizontal morphism in the diagram are cofibrations, the quotients V/ U ( × X V ) and X/U are models for the homotopy cofibers of j and j ′ . Thus, ψ -1 provides a weak equivalence C j ( ) → C j ( ′ ) . On the other hand, there is a map C j ( ′ ) → Σ ( 1 s U × X V ) by the discussion of the previous paragraph. Therefore, one obtains a composite morphism of the form
$$X \longrightarrow C ( j ^ { \prime } ) \stackrel { \sim } { \longrightarrow } C ( j ) \longrightarrow \Sigma _ { s } ^ { 1 } ( U \times _ { X } V ) ;$$
we use this connecting morphism below.
Example 4.2.1 . If X is a smooth scheme, and X = U ∪ V is a Zariski cover of X by two open subschemes such that ( U ∩ V )( k ) is non-empty, then the construction just described yields a morphism
$$X \longrightarrow \Sigma _ { s } ^ { 1 } ( U \cap V ).$$
As we will see below, the assumption ( U ∩ V )( k ) = ∅ is a non-trivial restriction.
/negationslash
Let us now specialize the constructions just made taking X = Q 2 n . Before proceeding, recall that the scheme Q 2 n -1 has a standard base-point (1 0 , , . . . , 0 1 0 , , , . . . , 0) . Consider the two principal open subschemes V 0 2 n := D z and V 1 2 n := D 1+ z . The intersection V 0 2 n ∩ V 1 2 n is the principal open subscheme D z (1+ ) z ⊂ Q 2 n on which the 2 n sections
$$( x _ { 1 } / z, \dots, x _ { n } / z, y _ { 1 } / ( 1 + z ), \dots, y _ { n } / ( 1 + z ) )$$
satsify the equation defining the quadric Q 2 n -1 . We thus obtain a morphism ψ n : V 0 2 n ∩ V 1 2 n → Q 2 n -1 .
Remark 4.2.2 . The set ( V 0 2 n ∩ V 1 2 n )( k ) can be empty if, e.g., k = F 2 .
If ( V 0 2 n ∩ V 1 2 n )( k ) is non-empty, then we can pick a base-point here. Up to post-composing with an automorphism of Q 2 n -1 , we can assume that this base-point is mapped to the standard base-point of Q 2 n -1 . Therefore, we obtain a morphism Σ ( 1 s V 0 2 n ∩ V 1 2 n ) -→ Σ 1 s Q 2 n -1 . Then, the connecting homomorphism in the Mayer-Vietoris cofiber sequence as in Example 4.2.1 composed with the morphism of the previous sentence yields a morphism
$$\varphi _ { n } \colon Q _ { 2 n } \longrightarrow \Sigma _ { s } ^ { 1 } ( V _ { 2 n } ^ { 0 } \cap V _ { 2 n } ^ { 1 } ) \longrightarrow \Sigma _ { s } ^ { 1 } Q _ { 2 n - 1 }.$$
Regarding this composite morphism, we have the following result:
Theorem 4.2.3. If the base k is an (infinite) perfect field, then, for any integer n ≥ 2 , the morphism ϕ n : Q 2 n → Σ 1 s Q 2 n -1 is an A 1 -weak-equivalence.
Remark 4.2.4 . The careful reader will note that the results of Morel to which we appeal only require k to be perfect. However, the precise results to which we appeal, specifically [Mor12, Theorem 5.46] and [Mor12, Theorem 6.1] implicitly make use of [Mor12, Lemma 1.15], which is a form of a presentation lemma of Gabber. Morel does not provide a proof for this statement; the published version of Gabber's presentation lemma [CTHK97] requires that base field is infinite and so we have made this assumption as well.
Proof. In the proof, we appeal to the results of [ Mor12 and this is the reason we require the base to ] be an (infinite) perfect field. The assumption that k is infinite also guarantees that ( V 0 2 n ∩ V 1 2 n )( k ) is non-empty. By Theorem 2.2.5, we have an explicit weak-equivalence Q 2 n → ( P 1 ) ∧ n . In particular, by [Mor12, Corollary 6.38], Q 2 n is A 1 -( n -1) -connected. On the other hand, we know that Q 2 n -1 /similarequal S n -1 ∧ G ∧ n m by [MV99, § 3 Example 2.20]. Since n ≥ 2 , Σ 1 s Q 2 n -1 is at least A 1 -1 -connected, and it follows from [AF14a, Lemma 2.1] that for any pointed space ( X , x ) the map [( X , x ) , Σ 1 s Q 2 n -1 ] A 1 → [ X , Σ 1 s Q 2 n -1 ] is a bijection (this bijection allows us to be sloppy with pointed and free homotopy classes below). Combining this observation with the conclusion of [Mor12, Corollary 6.43], which computes [( Q 2 n , 0) Σ , 1 s Q 2 n -1 ] A 1 , we conclude that
[ Q 2 n , Σ 1 s Q 2 n -1 ] ∼ = K MW 0 ( k ) . Then, it suffices then to show that the class of the morphism ϕ n corresponds to an invertible element of K MW 0 ( k ) under the previous identifications.
Observe that any morphism f : Q 2 n → Σ 1 s Q 2 n -1 yields a function
$$[ \Sigma _ { s } ^ { 1 } Q _ { 2 n - 1 }, Q _ { 2 n } ] _ { \mathbb { A } ^ { 1 } } \longrightarrow [ Q _ { 2 n }, Q _ { 2 n } ] _ { \mathbb { A } ^ { 1 } }$$
by precomposing with f . Identifying both terms with K MW 0 ( k ) , this map is precisely the multiplication by the class of f in [ Q 2 n , Σ 1 s Q 2 n -1 ] A 1 = K MW 0 ( k ) .
Next, we claim that [ Q 2 n , Q 2 n ] A 1 ∼ → H n Nis ( Q 2 n , K MW n ) . Indeed, we know Q 2 n is A 1 -( n -1) -connected and π A 1 n ( Q 2 n ) ∼ = K MW n by [Mor12, Theorem 6.40]. Therefore, we conclude that there is an A 1 -weak equivalence Q ( n ) 2 n ∼ = K ( K MW n , n ) between the n -th stage of the A 1 -Postnikov tower (see [AF14b, Theorem 6.1]) of Q 2 n , and the Eilenberg-Mac Lane space K ( K MW n , n ) . The functorial morphism Q 2 n → Q ( n ) 2 n thus yields a homomorphism
$$[ Q _ { 2 n }, Q _ { 2 n } ] _ { \mathbb { A } ^ { 1 } } \longrightarrow H _ { \text{Nis} } ^ { n } ( Q _ { 2 n }, \mathbf K _ { n } ^ { M W } ).$$
By [AF14a, Lemma 4.5] and the suspension isomorphism, for any strictly A 1 -invariant sheaf A there are isomorphisms of the form
$$H ^ { i } _ { \text{Niis} } ( Q _ { 2 n }, \mathbf A ) \cong H ^ { i } _ { \text{Niis} } ( \Sigma ^ { 1 } _ { s } Q _ { 2 n - 1 }, \mathbf A ) \cong H ^ { i - 1 } _ { \text{Niis} } ( Q _ { 2 n - 1 }, \mathbf A ) = 0$$
if i > n . Thus, arguing as in [AF14b, Proposition 6.2], this vanishing implies that the map [ Q 2 n , Q 2 n ] A 1 → [ Q 2 n , Q ( n ) 2 n ] A 1 ∼ = [ Q 2 n , K ( K MW n , n )] A 1 is a bijection. Reading through the above, one has also deduced that [Σ 1 s Q 2 n -1 , Q 2 n ] A 1 ∼ → H n -1 Nis ( Q 2 n -1 , K MW n ) .
To establish the theorem, it suffices to prove that ϕ n : Q 2 n → Σ 1 s Q 2 n -1 yields an isomorphism
$$H _ { \text{Ni} } ^ { n - 1 } ( Q _ { 2 n - 1 }, \mathbf K _ { n } ^ { M W } ) \longrightarrow H _ { \text{Ni} } ^ { n } ( Q _ { 2 n }, \mathbf K _ { n } ^ { M W } ).$$
Now, by construction, the morphism induced by ϕ n is the composite
$$H _ { N i s } ^ { n - 1 } ( Q _ { 2 n - 1 }, \mathbf K _ { n } ^ { M W } ) \longrightarrow H _ { N i s } ^ { n - 1 } ( V _ { 2 n } ^ { 0 } \cap V _ { 2 n } ^ { 1 }, \mathbf K _ { n } ^ { M W } ) \longrightarrow H _ { N i s } ^ { n } ( Q _ { 2 n }, \mathbf K _ { n } ^ { M W } )$$
where the first morphism is the pull-back along the map ϕ n : V 0 2 n ∩ V 1 2 n → Q 2 n -1 and the second morphism is the connecting homomorphism in the Mayer-Vietoris exact sequence. The result then rests on the explicit cohomological computations performed in Lemmas 4.2.5, 4.2.6 and 4.2.7.
We recall a few consequences of [Mor12, Corollary 5.43] concerning cohomology with coefficients in the sheaves K MW n , which will be helpful in performing the necessary computations. For any smooth scheme X , the canonical map H i Zar ( X, K MW n ) ∼ → H i Nis ( X, K MW n ) is an isomorphism, and the groups H i Zar ( X, K MW n ) can be computed using an explicit flasque resolution; the degree m term of this complex takes the form
$$\Re s u e \, \text{forml} \\ x \in X ^ { ( m ) } \\ \dots \colon = \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \ dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 1 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0.$$
where Λ x = ∧ m m x / m 2 x , m x is the maximal ideal in the local ring O X,x and Λ ∗ x is the set of nonzero elements in the (one dimensional) k x ( ) -vector space Λ x (usually, one considers the dual of m x / m 2 x but this makes no difference in our analysis [Mor12, § 5.1] and we drop it to lighten the notation). In particular, in the lemmas below, cohomology could be taken either with respect to the Zariski or Nisnevich topologies.
Lemma 4.2.5. For any n ≥ 1 , the group H n -1 Zar ( Q 2 n -1 , K MW n ) is a free K MW 0 ( k ) -module of rank one generated by the class of the cycle [ x n ] ⊗ x 1 ∧ . . . ∧ x n -1 in K MW 1 ( k s ( )) ⊗ Z [ k s ( ) × ] Z [Λ ]) ∗ s where s is the complete intersection given by the equations x 1 = . . . = x n -1 = 0 (and s is the generic point if n = 1 ).
Proof. See [Fas11, § 3.3].
Lemma 4.2.6. For any n ≥ 1 , the group H n Zar ( Q 2 n , K MW n ) is a free K MW 0 ( k ) -module of rank one generated by the class of the cycle 〈 1 〉 ⊗ x 1 ∧ . . . ∧ x n in K MW 0 ( k t ( )) ⊗ Z [ k t ( ) × ] Z [Λ ]) ∗ t where t is the closed subscheme defined by the vanishing locus of the sections x , . . . , x 1 n , 1 + z .
Proof. By Theorem 3.1.1, we know that the open subscheme X 2 n ⊂ Q 2 n is A 1 -contractible and has closed complement E n /similarequal A n . It suffices then to use the long exact sequence associated with this embedding, together with homotopy invariance of cohomology with coefficients in Milnor-Witt K-theory sheaves to obtain the result.
## Lemma 4.2.7. The composite
$$H _ { Z a r } ^ { n - 1 } ( Q _ { 2 n - 1 }, \mathbf K _ { n } ^ { M W } ) \longrightarrow H _ { Z a r } ^ { n - 1 } ( V _ { 2 n } ^ { 0 } \cap V _ { 2 n } ^ { 1 }, \mathbf K _ { n } ^ { M W } ) \longrightarrow H _ { Z a r } ^ { n } ( Q _ { 2 n }, \mathbf K _ { n } ^ { M W } )$$
induced by ϕ n maps the generator of Lemma 4.2.5 to 〈 -( 1) n 〉 times the generator of Lemma 4.2.6 .
Proof. Pulling-back the generator of Lemma 4.2.5 to V 0 2 n ∩ V 1 2 n we find the cycle [ x /z n ] ⊗ x /z 1 ∧ . . . ∧ x n -1 /z . Its image under the boundary map H n -1 Zar ( V 0 2 n ∩ V 1 2 n , K MW n ) → H n 1+ z ( V 0 2 n , K MW n ) is the cycle 〈 1 〉 ⊗ x /z 1 ∧ . . . ∧ x /z n in K MW 0 ( k t ( )) ⊗ Z [ k t ( ) × ] Z [Λ ]) ∗ t . As z = -1 in k t ( ) , the above cycle corresponds to 〈 -( 1) n 〉⊗ x 1 ∧ . . . ∧ x n , which can be seen as an element of H n 1+ z ( Q 2 n , K MW n ) . The result follows.
## 4.3 The concrete clutching construction
We now apply the results of the abstract clutching construction with Y = Q 2 n -1 and X = Q 2 n ∼ = Σ 1 s Y . Assume k = Z momentarily. In that case, Theorem 4.1.6 yields a surjective function
$$c l _ { G L _ { m } } \colon \pi _ { 0 } ( \text{Sing} ^ { \mathbb { A } ^ { 1 } } G L _ { m } ( Q _ { 2 n - 1 }, 1 ) ) \longrightarrow \mathcal { V } _ { m } ( Q _ { 2 n } ).$$
In particular, all rank m vector bundles on Q 2 n are obtained from pointed morphisms from the quadric to GL m .
We are particularly interested in the clutching function in the case where m = n . The weak equivalence Q 2 n ∼ = P 1 ∧ n of Theorem 2.2.5, together with A 1 -representability of algebraic K-theory [MV99, § 4 Theorem 3.13], determines an isomorphism of reduced K-theory ˜ K Q 0 ( 2 n ) = ∼ K 0 ( Z ) = ∼ Z . In fact if k is (Noetherian) regular, then we conclude that ˜ K Q 0 ( 2 n ) is a free K k 0 ( ) -module of rank 1 . 1 Our goal, accomplished in Theorem 4.3.4, is to describe an explicit vector bundle generator for this K k 0 ( ) -module.
1 Note: these kinds of representability statements continue to hold if k is not Noetherian. As observed in [Hoy14, Appendix C], algebraic K-theory is representable in the version of H ( k ) we use. Likewise, the proof of geometric representability (by the Grassmannian) goes through in this setting; one may modify [ST15, Theorem 4] as necessitated by [ST15, Remark 2] to check it when k = Z and then use base-change to treat the general case.
Example 4.3.1 . For small values of n , the generator of ˜ K Q 0 ( 2 n ) are given by classical geometric constructions. For n = 1 , the generator is simply the class of O (1) , viewed as an element of Pic Q ( 2 ) . Alternatively, this line bundle is the line bundle associated with Hopf map η : Q 3 → Q 2 , which is a G m -torsor. Similarly, for n = 2 , a generator is given by a Hopf bundle. Indeed, consider the associated vector bundle to the SL 2 -torsor corresponding with the motivic Hopf map ν : Q 7 → Q 4 . The map ν can can be defined as follows: given a pair of 2 × 2 -matrices ( M ,M 1 2 ) such that det M 1 -det M 2 = 1 , send ( M ,M 1 2 ) to ( M M , 1 2 det M 2 ) . A corresponding generator can also be given for Q 8 in terms of the motivic Hopf map σ , which can be defined using split octonion algebras.
Remark 4.3.2 . For n ≥ 3 , it is easy to write down generators using the isomorphism K Q 0 ( 2 n ) = ∼ G 0 ( Q 2 n ) and taking the pushforward i ∗ [ O Q 2 n \ X 2 n ] , but an explicit projective resolution of this class yields only a virtual vector bundle representative.
If x = ( x , . . . , x 1 n ) and y = ( y , . . . , y 1 n ) be elements of a ring A such that xy t = 1 . Attached to such a pair, Suslin inductively defined matrices α n ( x y , ) ∈ GL 2 n -1 [Sus77, § 5]. The universal such example corresponds to a morphism α n : Q 2 n -1 → GL 2 n -1 . By means of elementary row operations, the matrix α n can be reduced to an invertible n × n -matrix (non-uniquely). Equivalently, the morphism Q 2 n -1 → GL 2 n -1 lifts (non-uniquely) up to (naive) A 1 -homotopy to a morphism β n : Q 2 n -1 → GL n [Sus77, p. p. 489 Point (b)].
Remark 4.3.3 . A more topologically inclined reader may prefer the following description of the matrices α n . Atiyah-Bott and Shapiro constructed an explicit generator of the topological K-theory group ˜ K S 0 ( n ) in terms of Clifford algebras [ABS64]. Suslin's matrix α can be thought of as an algebraic version of Clifford multiplication; this has been worked out in more detail in [Chi15]. The morphisms α n (resp. β n ) are closely related to algebraic K-theory. Indeed, for any integer i , there is an isomorphism of reduced K-theory ˜ ( K Q i 2 n -1 ) = ∼ ˜ K i -1 ( Z ) using the fact that Q 2 n -1 ∼ = Σ n -1 s G ∧ n m and A 1 -representability of algebraic K -theory. Suslin showed [Sus82, Theorem 2.3] that this isomorphism is given by multiplication by α n (or, equivalently, β n ); see [AF14c, § 3] for more discussion of Suslin matrices in the context of A 1 -homotopy theory.
Theorem 4.3.4. If k is a (Noetherian) regular base ring, then for every n ≥ 1 , cl GL n ( β n ) determines a rank n vector bundle on Q 2 n ; the stable isomorphism class of this vector bundle yields a generator of K Q 0 ( 2 n ) .
For the second statement, recall that under these hypotheses ˜ K Q 0 ( 2 n ) is a free K k 0 ( ) -module of rank 1 . By functoriality, it suffices to produce a generator over Spec Z . In that case, we appeal to functoriality of the clutching construction for the map GL n → GL , the fact that the clutching construction is given by suspension and appeal to Suslin's results. Indeed, it suffices to show that cl GL ( β n ) is a generator of ˜ K Q 0 ( 2 n ) . However, Suslin showed that the map β n : Q 2 n -1 → GL is a generator of [ Q 2 n -1 , GL ] A 1 ∼ = Z ; this is contained in [Sus82, Theorem 2.3], but see [AF14c, Theorem 3.4.1] for a translation in this language. The statement then follows from the suspension isomorphism in K-theory together with the identification [ Q 2 n -1 , GL ] A 1 ∼ = [ Q 2 n , BGL ] A 1 ∼ = ˜ K Q 0 ( 2 n ) .
˜ Proof. The first statement follows from Theorem 4.1.6(i). Indeed, cl GL n ( β n ) gives a vector bundle on Q 2 n over Spec Z , which we may then pullback to Q 2 n over Spec k .
Remark 4.3.5 . The results of [AF14c, Proposition 3.3.3] together with obstruction theory arguments can be used to show that the generators of ˜ K Q 0 ( 2 n ) described in Theorem 4.3.4 admit reductions of structure group in certain situations: if n ≡ 0 mod 4 , then the vector bundle cl GL n ( β n ) admits a reduction of structure group to the split orthogonal group, while if n ≡ 2 mod 4 , then it admits a reduction of structure group to the symplectic group.
Now, using Theorem 4.2.3, we show how to refine Theorem 4.1.6 to obtain explicit cocycles representing vector bundles on Q 2 n from the associated clutching functions. To this end, assume that k is an (infinite) perfect field, and consider the commutative diagram
/d111
/d47
/d47
/d111
/d15
/d15
/d15
/d15
/d15
/d15
/d111
/d111
/d47
/d47
The induced map of homotopy pushouts gives a reinterpretation of the map ϕ n and thus is an A 1 -weak equivalence by Theorem 4.2.3. Moreover, the induced A 1 -weak equivalence Q 2 n → Σ 1 s Q 2 n -1 factors through a morphism Q 2 n → Σ ( 1 s V 0 2 n ∩ V 1 2 n ) → Σ 1 s Q 2 n -1 . The following result, which can be viewed as a refinement of some of the results in [NRS10, § 6], is our concrete version of the clutching construction in the case of Q 2 n .
Theorem 4.3.6. Assume k is a field, and n, r ≥ 2 are integers and G is an isotropic reductive k -group (in the sense of [AHW15b, Definition 3.3.4] ).
- 1. If k is infinite and perfect, given a pointed k -morphism f : Q 2 n -1 → G , the G -torsor cl G ( f ) on Q 2 n attached to f is obtained, up to isomorphism, by gluing the trivial G -torsor on V 0 2 n with a trivial G -torsor on V 1 2 n along the function f ◦ ψ n .
- 2. For arbitrary k , the rank n vector bundle on Q 2 n corresponding to cl GL n ( β n ) is that associated with β n ◦ ψ n by the construction of the previous point.
Proof. Here the assumption that k is infinite is used in conjunction with the assumption that G is isotropic to appeal to Theorem 4.1.6(ii). Considering the diagram above, point (1) follows from the functoriality assertion in Theorem 4.1.6 combined with Theorem 4.2.3. In more detail, given a vector bundle on [ Q 2 n , BG ] A 1 , we can lift it to a pointed homotopy class [( Q 2 n , 0) ( , BG, ∗ )] A 1 . Since the weak equivalence Q 2 n → Σ 1 s Q 2 n -1 factors through V 0 2 n ∩ V 1 2 n , every element of [( Q 2 n , 0) ( , BG, ∗ )] A 1 corresponds to an element of [Σ 1 s Q 2 n -1 , ( BG, ∗ )] A 1 and thus determines an element of [Σ ( 1 s V 0 2 n ∩ V 1 2 n ) , ( BG, ∗ )] A 1 . The adjoints to these elements are precisely a pointed map f : Q 2 n -1 → G and the composite map f ◦ ψ n .
The clutching construction proceeds by composing Σ 1 s f with the canonical morphism Σ 1 s G → BG . The factorization through V 0 2 n ∩ V 1 2 n in the previous paragraph, then corresponds, by contemplating the diagram before the statement, to gluing two homotopically constant maps V i 2 n → ∗ → BG , i.e., trivial G -torsors on V i 2 n along the morphism f ◦ ψ n as claimed.
For Point (2), begin by observing that the function cl GL n ( β n ) over the field k is obtained by base-change from a morphism of schemes over Spec Z . In particular, the function cl GL n ( β n ) over k is obtained by extending scalars from a function defined over the prime field F ⊂ k , which is perfect. Now, since an algebraic closure ¯ F of the prime field is infinite and perfect, Point (2) follows by combining Theorem 4.3.4 with the conclusion of Point (1). However, by Galois descent,
there is an equivalence between vector bundles over F and Gal F/F ( ¯ ) -invariant cocycles over ¯ F . Therefore, the vector bundle corresponding to cl GL n ( β n ) over ¯ F descends to a vector bundle over F . Pulling back this bundle to k yields the required vector bundle.
Remark 4.3.7 . Note that Point (2) makes sense even if the intersection V 0 2 n ∩ V 1 2 n is empty. More generally, using faithfully flat descent techniques, it is possible to build G -torsors over fields that arise from clutching functions given by k -morphisms f : Q 2 n -1 → G defined over perfect subfields F ⊂ k . For example, if k is a finite field, every G -torsor over Q 2 n under an isotropic reductive G is described by means of a clutching function Q 2 n -1 → G . Lacking any applications of the result in this form at the moment, we leave the proof of this fact to the reader.
Example 4.3.8 . Unwinding the definitions, the Suslin matrix Q 3 → SL 2 corresponds to the identity map SL 2 → SL 2 under the isomorphism of Q 3 with SL 2 given by sending ( x , x 1 2 , y 1 , y 2 ) to the 2 × 2 -matrix, ( x 1 x 2 -y 2 y 1 ) . From this, one can see that the resulting vector bundle on Q 4 is precisely the Hopf bundle.
We close with one final application of our results. Recall that, since the inclusion X 2 n ↪ → Q 2 n has complement of codimension n , whenever n ≥ 2 the restriction functor on categories of vector bundles is fully-faithful [AD08, Lemma 2.4]. Combining this fact with Theorem 4.3.4 one obtains the following result, which is a generalization of [AD08, Corollary 3.1].
Corollary 4.3.9. If k is a (Noetherian) regular base ring, then for every n ≥ 2 , the A 1 -contractible k -scheme X 2 n has a non-trivial vector bundle.
## References
| [ABS64] | M. F. Atiyah, R. Bott, and A. Shapiro. Clifford modules. Topology , 3(suppl. 1):3-38, 1964. 22 |
|-----------|-----------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------|
| [AD07] | A. Asok and B. Doran. Unipotent groups and some A 1 -contractible smooth schemes. Int. Math. Res. Pap. , 5, 2007. Art. ID rpm005. 3, 10 |
| [AD08] | A. Asok and B. Doran. Vector bundles on contractible smooth schemes. Duke Math. J. , 143(3):513-530, 2008. 6, 24 |
| [AF14a] | A. Asok and J. Fasel. Algebraic vector bundles on spheres. J. Topology , 7(3):894-926, 2014. doi:10.1112/jtopol/jtt046. 10, 16, 19, 20 |
| [AF14b] | A. Asok and J. Fasel. A cohomological classification of vector bundles on smooth affine threefolds. Duke Math. J. , 163(14):2561-2601, 2014. 20 |
| [AF14c] | A. Asok and J. Fasel. An explicit KO -degree map and applications. Preprint , available at http://arxiv.org/abs/1403.4588 , 2014. 22, 23 |
| [AF15] | A. Asok and J. Fasel. Euler class groups are motivic cohomotopy groups. In preparation , 2015. 4 |
| [AHW15a] | A. Asok, M. Hoyois, and M. Wendt. Affine representability results in A 1 -homotopy theory I: vector bundles. Preprint , available at http://arxiv.org/abs/1506.07093 , 2015. 4, 5, 14, 18 |
| [AHW15b] | A. Asok, M. Hoyois, and M. Wendt. Affine representability results in A 1 -homotopy theory II: principal bun- dles and homogeneous spaces. Preprint , available at http://arxiv.org/abs/1507.08020 , 2015. 4, 14, 15, 17, 23 |
| [Bor91] | A. Borel. Linear algebraic groups , volume 126 of Graduate Texts in Mathematics . Springer-Verlag, New York, 1991. 12 |
| [Chi15] | V. Chintala. On Suslin matrices and their connection to spin groups. Doc. Math. , 20:531-550, 2015. 22 |
| [CTHK97] | J.-L. Colliot-Th´l`ne, e e R. T. Hoobler, and B. Kahn. The Bloch-Ogus-Gabber theorem. In Algebraic K -theory (Toronto, ON, 1996) , volume 16 of Fields Inst. Commun. , pages 31-94. Amer. Math. Soc., Providence, RI, 1997. 19 |
|------------|--------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------|
| [Cur71] | E. B. Curtis. Simplicial homotopy theory. Advances in Math. , 6:107-209 (1971), 1971. 17 |
| [DI08] | D. Dugger and D. Isaksen. Unpublished work , 2008. 2 |
| [Fas11] | J. Fasel. Some remarks on orbit sets of unimodular rows. Comment. Math. Helv. , 86(1):13-39, 2011. 21 |
| [Fas15] | J. Fasel. On the number of generators of ideals in polynomial rings. Preprint , available at http://arxiv.org/abs/1507.05734 , 2015. 4 |
| [Gro61] | A. Grothendieck. ´ El´ments e de g´om´trie e e alg´brique. e III. ´ Etude cohomologique des faisceaux coh´rents. e I. Inst. Hautes ´ Etudes Sci. Publ. Math. , 11:167, 1961. 13 |
| [Gup13] | N. Gupta. On Zariski's cancellation problem in positive characteristic. Adv. Math. , 264:296-307, 2013. 13 |
| [Gup14] | N. Gupta. On the cancellation problem for the affine space A 3 in characteristic p . Invent. Math. , 195(1):279- 288, 2014. 13 |
| [Har66] | R. Hartshorne. Residues and duality . Lecture notes of a seminar on the work of A. Grothendieck, given at Harvard 1963/64. With an appendix by P. Deligne. Lecture Notes in Mathematics, No. 20. Springer-Verlag, Berlin, 1966. 12 |
| [Hov99] | M. Hovey. Model Categories , volume 63 of Math. Surveys and Monographs . American Mathematical Society, Providence, RI, 1999. 4, 7 |
| [Hoy14] | M. Hoyois. A quadratic refinement of the Grothendieck-Lefschetz-Verdier trace formula. Algebr. Geom. Topol. , 14(6):3603-3658, 2014. 5, 21 |
| [Lur11] | J. Lurie. Derived algebraic geometry XI: Descent theorems. 2011. Preprint, available at http://www.math.harvard.edu/˜lurie/papers/DAG-XI.pdf . 5 |
| [Mor05] | F. Morel. The stable A 1 -connectivity theorems. K -Theory , 35(1-2):1-68, 2005. 18 |
| [Mor08] | F. Morel. Personal communication dated April 3, 2008. 2 |
| [Mor12] | F. Morel. A 1 -algebraic topology over a field , volume 2052 of Lecture Notes in Mathematics . Springer, Heidelberg, 2012. 4, 10, 14, 19, 20 |
| [MV99] | F. Morel and V. Voevodsky. A 1 -homotopy theory of schemes. Inst. Hautes ´ Etudes Sci. Publ. Math. , 90:45- 143 (2001), 1999. 1, 2, 4, 5, 6, 8, 14, 15, 16, 18, 19, 21 |
| [MVW06] | C. Mazza, V. Voevodsky, and C. Weibel. Lecture notes on motivic cohomology , volume 2 of Clay Mathe- matics Monographs . American Mathematical Society, Providence, RI, 2006. 4, 9 |
| [NRS10] | M. V. Nori, R. A. Rao, and R. G. Swan. Non-self-dual stably free modules. In J.-L. Colliot-Th´l`ne, e e S. Garibaldi, R. Sujatha, and V. Suresh, editors, Quadratic forms, linear algebraic groups, and cohomology , volume 18 of Dev. Math. , pages 315-324. Springer, New York, 2010. 23 |
| [PW10] | I. Panin and C. Walter. Quaternionic grassmannians and pontryagin classes in algebraic geometry. Preprint available at http://arxiv.org/abs/1011.0649 , 2010. 6 |
| [Sch15] | M. Schlichting. Euler class groups, and the homology of elementary and special linear groups. Preprint , available at http://arxiv.org/abs/1502.05424 , 2015. 14 |
| [ST15] | M. Schlichting and G. S. Tripathi. Geometric models for higher Grothendieck-Witt groups in A 1 -homotopy theory. Math. Ann. , 362(3-4):1143-1167, 2015. 21 |
| [Sus77] | A. A. Suslin. Stably free modules. Mat. Sb. (N.S.) , 102(144)(4):537-550, 632, 1977. 22 |
| [Sus82] | A. A. Suslin. Mennicke symbols and their applications in the K -theory of fields. In Algebraic K -theory, Part I (Oberwolfach, 1980) , volume 966 of Lecture Notes in Math. , pages 334-356. Springer, Berlin-New York, 1982. 22 |
| [Voe03a] | V. Voevodsky. Motivic cohomology with Z / 2 -coefficients. Publ. Math. Inst. Hautes ´ Etudes Sci. , 98:59-104, 2003. 8 |
[Voe03b]
V. Voevodsky. Reduced power operations in motivic cohomology. Publ. Math. Inst. Hautes Etudes Sci. ´ ,
- 98:1-57, 2003. 9
[Voe10]
V. Voevodsky. Cancellation theorem. Doc. Math. , Extra volume: Andrei A. Suslin sixtieth birthday:671-685, 2010. 9
[Woo93] R.M.W. Wood. Polynomial maps of affine quadrics. Bull. London Math. Soc. , 25(5):491-497, 1993. 10
- A. Asok, DEPARTMENT OF MATHEMATICS, UNIVERSITY OF SOUTHERN CALIFORNIA, 3620 S. VERMONT AVE. KAP 104, LOS ANGELES, CA 90089-2532, UNITED STATES; E-mail address: [email protected]
- B. Doran, DEPARTEMENT MATHEMATIK, EIDGEN ¨SSISCHE TECHNISCHE HOCHSCHULE, R ¨MISTRASSE 101, O A 8092 Z ¨RICH SWITZERLAND; U E-mail address: [email protected]
- J. Fasel, INSTITUT FOURIER - UMR 5582, UNIVERSIT´ E GRENOBLE ALPES, 100 RUE DES MATH´ EMATIQUES BP 74, F-38000 GRENOBLE; E-mail address: [email protected] | null | [
"Aravind Asok",
"Brent Doran",
"Jean Fasel"
] | 2014-08-02T20:19:55+00:00 | 2015-11-27T12:56:27+00:00 | [
"math.KT",
"math.AG",
"math.AT",
"14F42, 57R60"
] | Smooth models of motivic spheres | We study the representability of motivic spheres by smooth varieties. We show
that certain explicit "split" quadric hypersurfaces have the $\mathbb
A^1$-homotopy type of motivic spheres over the integers and that the $\mathbb
A^1$-homotopy types of other motivic spheres do not contain smooth schemes as
representatives. We then study some applications of these
representability/non-representability results to the construction of new exotic
$\mathbb A^1$-contractible smooth schemes. Then, we study vector bundles on
even dimensional "split" quadric hypersurfaces by developing an
algebro-geometric variant of the classical construction of vector bundles on
spheres via clutching functions. |
1408.0414v2 | 

Nuclear Physics A
Nuclear Physics A 00 (2014) 1-8
## Overview of ALICE Results at Quark Matter 2014
Jan Fiete Grosse-Oetringhaus (for the ALICE Collaboration) 1
CERN, 1211 Geneva 23, Switzerland
## Abstract
The results released by the ALICE collaboration at Quark Matter 2014 address topics from identified-particle jet fragmentation functions in pp collisions, to the search for collective signatures in p-Pb collisions to precision measurements of jet quenching with D mesons in Pb-Pb collisions. This paper gives an overview of the contributions (31 parallel talks, 2 flash talks and 80 posters) by the ALICE collaboration at Quark Matter 2014.
Keywords: heavy-ion collisions, proton-lead collisions, quark-gluon plasma, jet quenching, elliptic flow, heavy flavour
## 1. Introduction
The ALICE collaboration has presented numerous new results at Quark Matter 2014 which advance our knowledge about the dynamics of ultrarelativistic proton and heavy-ion collisions in various directions. Among the main topics are precision measurements of jet quenching in heavy-ion collisions as well as further understanding of possible collectivity in proton-lead collisions. These proceedings can only present a subset of the results, for more information the reader is referred to [1-33]. These discuss light flavour [2, 3, 6, 18, 25], heavy flavour [5, 8, 15, 21, 28], jet [1, 13, 23, 32], photon [10, 24], quarkonia [4, 9, 11, 12, 20], dielectron [19] and correlation [7, 14, 16, 22, 26, 30, 33] measurements as well as ultra-peripheral collisions [27], event characterization [31] and the ALICE upgrade [17, 29].
## 2. Results from Proton-Lead Collisions
Proton-lead collisions at the LHC, initially thought of just as a control experiment for Pb-Pb collisions, have triggered significant interest when it became clear that non-trivial (potentially final-state) e GLYPH<11> ects were present as compared to an incoherent superposition of nucleon-nucleon collisions. In particular, the behavior of the h p T i as a function of multiplicity [34], the multiplicity dependence of identified-particle spectra [35] and the discovery of long-range correlation structures [36] as well as their dependence on particle type [37] should be noted. These structures are typically found in heavy-ion collisions where they are interpreted as a signature of collectivity. A new measurement using fourparticle cumulants has established that higher-order correlations contribute to these long-range correlations [30, 38].
## 2.1. Nuclear Modification Factor
While the observations discussed in the previous paragraph hint at novel e GLYPH<11> ects in p-Pb collisions, observables sensitive to energy loss in a hot and dense medium show no significant deviation from an incoherent superposition
1 A list of members of the ALICE Collaboration and acknowledgements can be found at the end of this issue.
T
Figure 1. Nuclear modification factor R pPb of forward muons from heavy-flavour decays measured in p-going (black) and Pb-going (green) directions (left panel) and of GLYPH<25> (blue), K (orange), p (red) and GLYPH<4> (green) measured at mid-rapidity (right panel).
of nucleon-nucleon collisions. This can be seen for example in measurements of the nuclear-modification factor R pPb defined as the ratio of p T spectra in p-Pb collisions and in pp collisions scaled by the number of nucleonnucleon collisions. Results from minimum-bias collisions for charged particles up to 50 GeV / c [18, 39], for jets up to 90 GeV / c [1, 13], for D mesons up to about 20 GeV / c [28, 40], for muons from heavy-flavour decays measured at forward rapidities up to 16 GeV / c [21] as well as for electrons from beauty decays up to about 6 GeV / c show no deviation from unity at high p T. As an example the nuclear modification factor of muons measured at forward rapidities is shown in the left panel of Fig. 1 for p-going and Pb-going directions. No significant energy loss seems to be at play in minimum-bias p-Pb collisions. The centrality dependence of these e GLYPH<11> ects and the related di GLYPH<14> culties encountered are discussed further below (Section 2.4).
The minimum-bias nuclear-modification factor for charged particles shows an increase up to about 1.1 at 34 GeV / c . It is interesting to note that such an enhancement has already been observed at lower energies and is referred to as Cronin e GLYPH<11> ect [41]. This peak shows a strong particle-type dependence [18], presented in the right panel of Fig. 1: it is not observed for GLYPH<25> and K, while it is rather strong for p and GLYPH<4> where R pPb reaches values of 1.5-1.7. Such a behavior has been interpreted as a consequence of radial flow which alters the p T spectra. This can be further understood by analyzing the particle spectra within blast-wave models which are a proxy for hydrodynamic modeling. Within these models one finds that the extracted average radial-flow expansion velocity h GLYPH<12> T i is larger in p-Pb collisions than in Pb-Pb collision at the same multiplicity [3]. This can be interpreted as indication that a larger density gradient is prevailing in p-Pb collisions. However, applying blast-wave fits to pp collisions, large values of h GLYPH<12> T i are also found in measured pp events and PYTHIA [42] generated pp events underlining that there may be other mechanisms than the expansion of a hot and dense fireball producing signatures compatible with radial expansion.
## 2.2. Jet Modification at low p T
The measurements presented in the previous paragraphs have shown that there are no significant modifications of particle production at high p T as compared to pp collisions while at low p T spectra are modified and long-range correlation structures appear in high-multiplicity events. Two-particle correlations can assess if jet yields in this lowp T region are modified [26, 43]. Figure 2 (left panel) shows the near-side jet-like associated yield as a function of forward multiplicity after subtraction of the long-range contribution estimated at large pseudorapidity di GLYPH<11> erences. The yield is basically independent of multiplicity except at low multiplicity where a reduction is observed. This observation is similar on the away side. This finding is consistent with a picture in which the minijet yields in p-Pb collisions stem from a superposition of nucleon-nucleon collisions with incoherent fragmentation, while the longrange double-ridge correlation appears unrelated to minijet production. The reduction at low multiplicities may be related to event selection biases, see Section 2.4.
〉
N
〈
Figure 2. Left panel: Near-side jet-like associated yield as a function of multiplicity class (measured with the forward V0A detector, 2 8 : < GLYPH<17> lab
Right panel: GLYPH<3> S ratio as a function of their p T (denoted with p T V 0 ; ) within charged jets for di GLYPH<11> erent cone radii compared to the inclusive ratio (black filled circles). Data is shown as points while lines show results from MC generators.
< 5 1) after subtraction of the long-range contribution for several : p T ranges [43]. to K 0
## 2.3. Particle Content of Jets
In Pb-Pb collisions, the inclusive GLYPH<3> = K 0 S ratio is significantly larger in central collisions than in peripheral collisions which is interpreted as a sign of the partonic degrees of freedom and the collective expansion in a quark-gluon plasma. In p-Pb collisions, the GLYPH<3> = K 0 S ratio is also larger in high-multiplicity than in low-multiplicity collisions [44]. The track-based reconstruction of jets allows us to study if this enhancement is also present within jets [32]. Figure 2 (right panel) presents the GLYPH<3> = K 0 S ratio within charged jets for jet p T above 10 GeV / c for high-multiplicity events. This ratio does not exceed about 0.3 within the jet compared to about 0.7 for the inclusive ratio at 3-4 GeV / c . These low values are consistent with results from PYTHIA pp collisions and low-multiplicity p-Pb collisions showing that the fragmentation seems to occur in a similar way in p-Pb and pp collisions.
## 2.4. Centrality Determination in p-Pb Collisions
The division of events into centrality classes with the aim of measuring observables as a function of impact parameter is not straightforward in p-Pb collisions as several biases occur [31]: the number of nucleons participating in the collision is rather modest, leading to a large influence of fluctuations; due to the lower multiplicity, event selection biases play a larger role in p-Pb than in Pb-Pb collisions (such as the suppression of events with jets when low-multiplicity events are selected); furthermore, in peripheral collisions geometric biases are present which reduce the number of parton-parton interactions per nucleon-nucleon collision.
These biases can be illustrated with a simple model where a Glauber calculation of the number of nucleonnucleon collisions N coll is coupled with PYTHIA (called G-PYTHIA); for each nucleon-nucleon collision a PYTHIA pp minimum-bias collision is generated. Subsequently, the events are divided into classes based on the multiplicity at mid-rapidity and the 'standard' nuclear-modification factor is calculated with respect to minimum-bias PYTHIA events. N coll is determined based on the distribution of the event multiplicity. To underline that this observable is biased we call it Q pPb instead of the 'standard' R pPb. A value close to unity is expected for such an incoherent superposition. Figure 3 (left panel) shows the so-obtained Q pPb compared to the measured quantity. Surprisingly, the Q pPb of G-PYTHIA is between 0.1 and 1.8 at high p T depending on the event class and shows a p T dependence contrary to the expectation of unity. The data agrees overall well with this simple model, in particular the large di GLYPH<11> erence between the di GLYPH<11> erent event classes at high p T as well as the slopes are reproduced showing the significant influence of the event selection.
CL1
pPb
Q
2.5
2
1.5
1
0.5
0
= 5.02 TeV
NN
s
p›Pb
CL1
ALICE PRELIMINARY
Syst. on
〉
T
〈
pA
Syst. on normalization
5
10
15
0›5%
5›10%
10›20%
20›40%
20
40›60%
60›80%
80›100%
25
30
p
(GeV/c)
ALI-PREL-79629
T
Figure 3. Left panel: Q pPb as a function of p T for charged particles using a mid-rapidity detector (denoted with CL1) to slice the events in classes. The data is shown as points while the G-PYTHIA model (see text) is shown as lines. The systematic error on the spectra is only shown for the 0-5% bin and is the same for all others.
Right panel: Q pPb as a function of p T for D mesons using the hybrid centrality method, for details see text.
A hybrid method is proposed with the aim of reducing the discussed biases. In this method events are sliced into classes based on the signal in the zero-degree neutron detectors (ZN), introducing a maximal pseudorapidity gap between the detector used for the event selection and the detectors used to measure the event activity under study. Then, the average number of nucleon-nucleon collisions in a class is obtained by assuming a scaling of the multiplicity with N part (the number of nucleons participating in the collision). The resulting Q pPb are consistent with unity at highp T for all event classes. The hybrid method allows us to compute the Q pPb for other particles as a function of event activity. As an example, Figure 3 (right panel) presents the Q pPb of D mesons which shows no significant dependence
Figure 4. Inclusive Q pPb for J / (green diamonds) and (2S) (red circles) as a function of event activity class in p-going direction (left panel) and Pb-going direction (right panel).
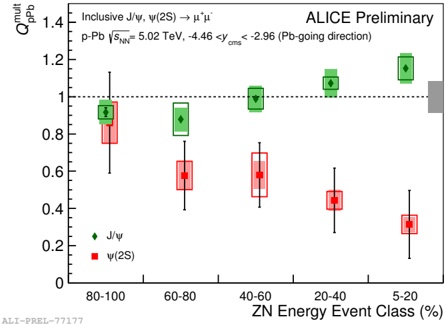
Figure 5. Elliptic-flow coe GLYPH<14> cient v 2 f SP g as a function of p T for GLYPH<25> (black open circles), K (orange upward-pointing triangles), p + ¯ (green squares), p GLYPH<30> (red filled circles), GLYPH<3> (blue filled stars), GLYPH<4> (violet downward-pointing triangles) and GLYPH<10> (pink open stars) measured in central 10-20% (left panel) and 30-40% (right panel) Pb-Pb collisions [45].
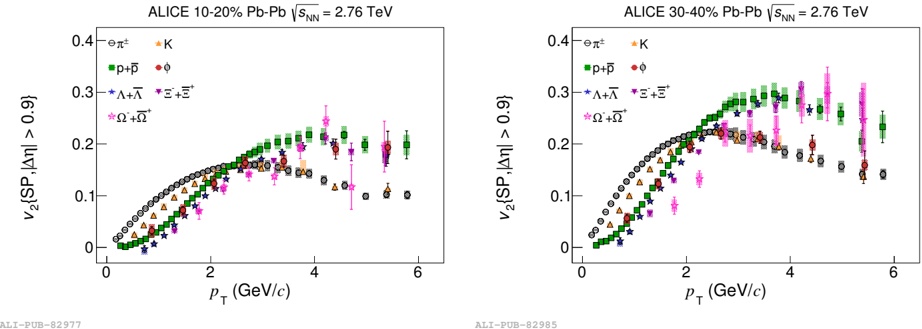
on event class: the production of D mesons scales with N coll .
## 2.5. Surprising Nuclear Modification Factor of J / and (2S)
The nuclear modification factor of inclusive J / and (2S) production is found to show an interesting pattern. Figure 4 presents Q pPb as a function of event class for the p-going and Pb-going directions [4, 9, 20]. Both have been measured in the dimuon channel at forward rapidities. The J / shows a suppression in the p-going direction, which increases with event activity, while no significant modification is observed in the Pb-going direction. These findings are consistent with the expectation from the nuclear modification of the parton distribution functions (shadowing). The (2S) shows a similar suppression pattern as the J / in the p-going direction. In the Pb-going direction, however, contrary to the J / , the (2S) is also suppressed. The expectation from shadowing though is that both should show a similar suppression, suggesting that additional, e.g. final state, e GLYPH<11> ects are a GLYPH<11> ecting the observed yields.
## 3. Results from Pb-Pb Collisions
As discussed in previous Quark Matter conferences, the hot and dense medium produced at LHC is larger and hotter than observed previously at lower-energy collisions, which results in stronger jet quenching and medium e GLYPH<11> ects. Newly presented results quantify these e GLYPH<11> ects with high precision and for numerous particle species.
## 3.1. Jet Quenching in the Heavy-Flavour Sector
The study of heavy-flavour decays allows the measurement of the R AA of combined D 0 , D + and D GLYPH<3> + [15] and their elliptic-flow coe GLYPH<14> cient v 2 [5, 49]. The fact that the R AA is significantly below 1 at high p T and that a non-zero v 2 is measured shows the sizable interactions of c quarks and D mesons with the hot and dense medium. These high-precision R AA and v 2 measurements provide significant constraints to models since both have to be reproduced simultaneously.
## 3.2. Elliptic Flow
Elliptic flow has been measured as a function of p T and centrality for eight di GLYPH<11> erent particle species: GLYPH<25> , K , K 0 GLYPH<6> S , p + ¯, p GLYPH<30> , GLYPH<3> , GLYPH<4> and GLYPH<10> [14, 45]. Figure 5 presents the v 2 extracted with the scalar-product method for two centrality classes. The measured v 2 values of the di GLYPH<11> erent particles are found to be ordered according to their particle masses for p T < 2 5 GeV : = c . Comparisons to hydrodynamic calculations with VISHNU [46] show a good agreement for GLYPH<25> and K while the p v 2 is underestimated and that of GLYPH<3> and GLYPH<4> are overestimated. Dividing the obtained v 2 as well as the p T by the number of constituent quarks ( n q ) allows us to assess the so-called NCQ scaling [47]. This scaling, where v 2 = n q as a function of p T = n q is expected to be universal for all particle species, is violated by about 20% in central collisions.
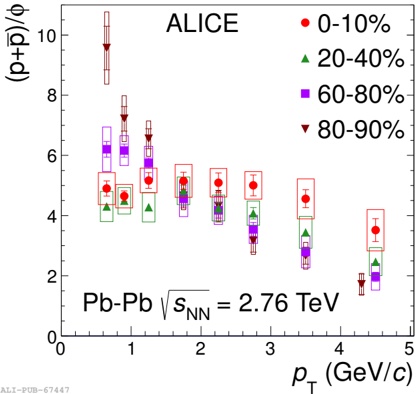
T
Figure 6. Left panel: Proton to GLYPH<30> ratio as a function of p T for di GLYPH<11> erent Pb-Pb centrality classes [48].
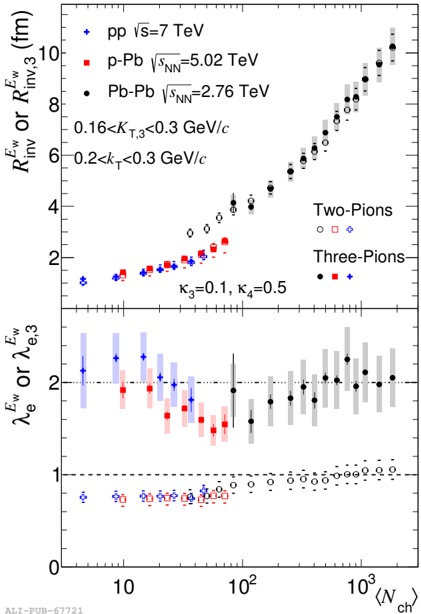
Right panel: Femtoscopic radii extracted from two- and three-pion cumulants together with the associated GLYPH<21> parameters [51].
## 3.3. The GLYPH<30> Meson
The v 2 of the GLYPH<30> shows an interesting pattern: below a p T of 2.5 GeV / c it follows mass ordering while at higher p T the behavior depends on centrality: in central collisions, its v 2 is close to that of the p, while in mid-central collisions its v 2 is closer to the one of the GLYPH<25> (see Fig. 5). Comparing the p T spectra of GLYPH<30> and p reveals that they have a similar shape in central collisions up to about 4 GeV / c (left panel of Fig. 6) [6, 48]. This is expected in a picture where the spectral shape is driven by radial flow. Combining this finding with that for the v 2 suggests that the mass (and not the number of constituent quarks) drives v 2 and spectra in central Pb-Pb collisions for p T < 4 GeV = c . It is interesting to note that also in p-Pb collisions the shape of the p T spectra of GLYPH<30> and p become more similar for high-multiplicity events [3].
## 3.4. Identified-Particle Spectra
The ALICE collaboration has presented yields and spectra for 12 particle species ( GLYPH<25> , K , K , K 0 GLYPH<6> GLYPH<3> , p, GLYPH<30> , GLYPH<3> , GLYPH<4> , GLYPH<10> , d, 3 He, 3 GLYPH<3> H) in up to 3 collision systems (and, for pp collisions, 3 di GLYPH<11> erent center of mass energies). In particular the measurement of the p T and centrality dependence of the d and the nuclei ( He, 3 3 GLYPH<3> H) spectra should be pointed out [25]. It is interesting to note that the yields of d, 3 He and 3 GLYPH<3> H are correctly calculated in equilibrium thermal models. Furthermore, the yields of multi-strange baryons have been measured as a function of event multiplicity showing a smooth evolution from pp over p-Pb to Pb-Pb collisions for the yield ratios to GLYPH<25> or p [2]. The large amount of data allows a stringent comparison to thermal models which describe particle production on a statistical basis [50].
Figure 7. d GLYPH<27>= dy for coherent (2S) photoproduction measured in ultra-peripheral Pb-Pb collisions compared to model predictions.
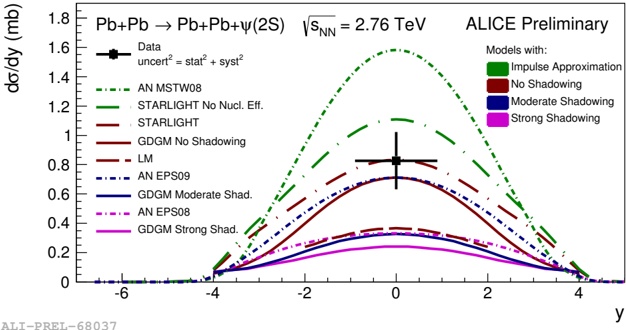
## 3.5. Source Sizes
For the first time, femtoscopic radii were extracted with three-pion cumulants [16, 51]. This approach reduces non-femtoscopic e GLYPH<11> ects contributing to the extracted radii significantly. Figure 6 (right panel) presents the extracted radii using an Edgeworth expansion [52] compared to results using two-pion correlations for pp, p-Pb and Pb-Pb collisions. The size of the system extracted in this way is 35-45% larger in Pb-Pb collisions than in p-Pb collisions at the same multiplicity showing that there are di GLYPH<11> erences between high-multiplicity p-Pb collisions and peripheral Pb-Pb collisions. On the contrary, the radii in p-Pb collisions are only 5-15% larger than in pp collisions at the same multiplicity. The radii in pp and p-Pb collisions can be reproduced in a CGC initial-state model (IP-GLASMA) without a hydrodynamic phase [53] while such calculations underestimate the radii measured in Pb-Pb collisions.
## 3.6. Exclusive Production of the (2S) State
In ultra-peripheral Pb-Pb collisions particles can be produced exclusively. The first measurements of coherent GLYPH<26> and (2S) photoproduction in a nuclear target have been performed [27]. This required a special trigger and event selection where the decay products of the produced state are the only objects observed in the detector. For the (2S), two di GLYPH<11> erent channels have been studied: the decay to two leptons as well as the decay to two leptons and two GLYPH<25> . For each channel about 20 candidates were found. Figure 7 shows the extracted cross section compared to model predictions. Despite the present uncertainties, the measurement allows us to conclude that models including strong shadowing as well as those without any nuclear e GLYPH<11> ects are disfavored.
## 4. Results from pp Collisions
The ALICE collaboration has also presented several measurements in pp collisions. In particular, there is an interesting measurement of the particle-type dependence of jet fragmentation functions for GLYPH<25> , K and p in jets of 5-20 GeV / c and constituent p T between 0.2 and 20 GeV / c [23]. Such measurements provide important constraints on fragmentation functions at low p T. Furthermore, a direct photon measurement has been presented for 1 < p T < 4 GeV / c consistent with next-to-leading order pQCD [19].
## 5. Conclusions
In Pb-Pb collisions, the presented results significantly improve the precision of previous measurements in various areas. In particular, a measurement of elliptic flow with identified particles shows a clear mass ordering for light and strange hadrons for p T < 2.5 GeV / c . Spectra and v 2 measurements of the GLYPH<30> meson suggests that the mass (and not
the number of constituent quarks) drives the spectral shape and the size of the elliptic flow in central collisions for p T < 4 GeV / c . While there are several observables which are approximately consistent with a description of p-Pb collisions as incoherent superposition of nucleon-nucleon collisions at high p T, some measurements hint to novel e GLYPH<11> ects at low p T which are potentially of collective origin. Furthermore, the suppression pattern of (2S) compared to J / indicates that significant final-state e GLYPH<11> ects are at play. These findings still need to be reconciled theoretically and promise that p-Pb collisions will continue to be a very exciting field in the future.
## References
- [1] S. Aiola for the ALICE collaboration, other proceedings in this volume
- [2] D. Alexandre for the ALICE collaboration, other proceedings in this volume
- [3] C. Andrei for the ALICE collaboration, other proceedings in this volume
- [4] R. Arnaldi for the ALICE collaboration, other proceedings in this volume
- [5] R. Bailhache for the ALICE collaboration, other proceedings in this volume
- [6] F. Bellini for the ALICE collaboration, other proceedings in this volume
- [7] R. Belmont for the ALICE collaboration, other proceedings in this volume
- [8] S. Bjelogrlic for the ALICE collaboration, other proceedings in this volume
- [9] J. Blanco for the ALICE collaboration, other proceedings in this volume
- [10] F. Bock for the ALICE collaboration, other proceedings in this volume
- [11] J. Book for the ALICE collaboration, other proceedings in this volume
- [12] J. Castillo for the ALICE collaboration, other proceedings in this volume
- [13] M. Connors for the ALICE collaboration, other proceedings in this volume
- [14] A. Dobrin for the ALICE collaboration, other proceedings in this volume
- [15] A. Festanti for the ALICE collaboration, other proceedings in this volume
- [16] D. Gangadharan for the ALICE collaboration, other proceedings in this volume
- [17] T. Gunji for the ALICE collaboration, other proceedings in this volume
- [18] M. Knichel for the ALICE collaboration, other proceedings in this volume
- [19] M. Kohler for the ALICE collaboration, other proceedings in this volume
- [20] I. Lakomov for the ALICE collaboration, other proceedings in this volume
- [21] S. Li for the ALICE collaboration, other proceedings in this volume
- [22] V. Loggins for the ALICE collaboration, other proceedings in this volume
- [23] X. Lu for the ALICE collaboration, other proceedings in this volume
- [24] A. Marin for the ALICE collaboration, other proceedings in this volume
- [25] N. Martin for the ALICE collaboration, other proceedings in this volume
- [26] L. Milano for the ALICE collaboration, other proceedings in this volume
- [27] J. Nystrand for the ALICE collaboration, other proceedings in this volume
- [28] R. Russo for the ALICE collaboration, other proceedings in this volume
- [29] S. Siddhanta for the ALICE collaboration, other proceedings in this volume
- [30] A. Timmins for the ALICE collaboration, other proceedings in this volume
- [31] A. Toia for the ALICE collaboration, other proceedings in this volume
- [32] X. Zhang for the ALICE collaboration, other proceedings in this volume
- [33] Y. Zhou for the ALICE collaboration, other proceedings in this volume
- [34] B. B. Abelev et al. [ALICE Collaboration], Phys. Lett. B 727 (2013) 371 [arXiv:1307.1094 [nucl-ex]].
- [35] B. B. Abelev et al. [ALICE Collaboration], Phys. Lett. B 728 (2014) 25 [arXiv:1307.6796 [nucl-ex]].
- [36] B. Abelev et al. [ALICE Collaboration], Phys. Lett. B 719 (2013) 29 [arXiv:1212.2001 [nucl-ex]].
- [37] B. B. Abelev et al. [ALICE Collaboration], Phys. Lett. B 726 (2013) 164 [arXiv:1307.3237 [nucl-ex]].
- [38] B. B. Abelev et al. [ALICE Collaboration], arXiv:1406.2474 [nucl-ex].
- [39] B. B. Abelev et al. [ALICE Collaboration], arXiv:1405.2737 [nucl-ex].
- [40] B. B. Abelev et al. [ALICE Collaboration], arXiv:1405.3452 [nucl-ex].
- [41] J. W. Cronin, H. J. Frisch, M. J. Shochet, J. P. Boymond, R. Mermod, P. A. Piroue and R. L. Sumner, Phys. Rev. D 11 (1975) 3105.
- [42] T. Sjostrand, S. Mrenna and P. Z. Skands, JHEP 0605 (2006) 026 [hep-ph 0603175]. /
- [43] B. B. Abelev et al. [ALICE Collaboration], arXiv:1406.5463 [nucl-ex].
- [44] B. B. Abelev et al. [ALICE Collaboration], Phys. Lett. B 728 (2014) 25 [arXiv:1307.6796 [nucl-ex]].
- [45] B. B. Abelev et al. [ALICE Collaboration], arXiv:1405.4632 [nucl-ex].
- [46] H. Song, S. A. Bass, U. Heinz, T. Hirano and C. Shen, Phys. Rev. Lett. 106 (2011) 192301 [Erratum-ibid. 109 (2012) 139904] [arXiv:1011.2783 [nucl-th]].
- [47] S. A. Voloshin, Nucl. Phys. A 715 (2003) 379 [nucl-ex 0210014]. /
- [48] B. B. Abelev et al. [ALICE Collaboration], arXiv:1404.0495 [nucl-ex].
- [49] B. B. Abelev et al. [ALICE Collaboration], arXiv:1405.2001 [nucl-ex].
- [50] M. Floris, other proceedings in this volume
- [51] B. B. Abelev et al. [ALICE Collaboration], arXiv:1404.1194 [nucl-ex].
- [52] T. Csorgo and A. T. Szerzo, hep-ph 9912220. /
- [53] A. Bzdak, B. Schenke, P. Tribedy and R. Venugopalan, Phys. Rev. C 87 (2013) 6, 064906 [arXiv:1304.3403 [nucl-th]]. | 10.1016/j.nuclphysa.2014.10.003 | [
"Jan Fiete Grosse-Oetringhaus"
] | 2014-08-02T20:20:57+00:00 | 2014-10-07T07:28:09+00:00 | [
"nucl-ex",
"hep-ex"
] | Overview of ALICE Results at Quark Matter 2014 | The results released by the ALICE collaboration at Quark Matter 2014 address
topics from identified-particle jet fragmentation functions in pp collisions,
to the search for collective signatures in p-Pb collisions to precision
measurements of jet quenching with D mesons in Pb-Pb collisions. This paper
gives an overview of the contributions (31 parallel talks, 2 flash talks and 80
posters) by the ALICE collaboration at Quark Matter 2014. |
1408.0416v1 | ## The large level limit of Kazama-Suzuki models
Stefan Fredenhagen, Cosimo Restuccia
Max-Planck-Institut f¨r Gravitationsphysik u Albert-Einstein-Institut Am M¨ uhlenberg 1 14476 Golm, Germany
## Abstract
Limits of families of conformal field theories are of interest in the context of AdS/CFT dualities. We explore here the large level limit of the two-dimensional N = (2 2) superconformal , W n +1 minimal models that appear in the context of the supersymmetric higher-spin AdS /CFT 3 2 duality. These models are constructed as Kazama-Suzuki coset models of the form SU n ( +1) /U n ( ). We determine a family of boundary conditions in the limit theories, and use the modular bootstrap to obtain the full bulk spectrum of N = 2 superW n +1 primaries in the theory. We also confirm the identification of this limit theory as the continuous orbifold C n /U n ( ) that was discussed recently.
E-mail: [email protected]
## Contents
| 1 Introduction | 1 Introduction | 1 Introduction | 2 |
|------------------------------------------------|------------------------------------------------|-----------------------------------------------------------------|-----|
| 2 Kazama-Suzuki Grassmannian cosets | 2 Kazama-Suzuki Grassmannian cosets | 2 Kazama-Suzuki Grassmannian cosets | 3 |
| 3 Boundary conditions in the large level limit | 3 Boundary conditions in the large level limit | 3 Boundary conditions in the large level limit | 5 |
| | 3.1 | Boundary conditions and spectrum . . . . . . . . . . . . . | 5 |
| | 3.2 | Limit of coset characters . . . . . . . . . . . . . . . . . . . | 6 |
| | 3.3 | Match with the continuous orbifold . . . . . . . . . . . . . | 8 |
| | 3.4 | Explicit expressions for SU (3) /U (2) . . . . . . . . . . . . | 9 |
| 4 | Bulk spectrum in the limit | Bulk spectrum in the limit | 10 |
| | 4.1 | Ground states . . . . . . . . . . . . . . . . . . . . . . . . . | 11 |
| | 4.2 | Full coset spectrum in the limit . . . . . . . . . . . . . . . | 11 |
| | 4.3 | The example of SU (3) /U (2) . . . . . . . . . . . . . . . . . | 13 |
| 5 | Modular bootstrap | Modular bootstrap | 13 |
| | 5.1 | Modular transformation of the boundary partition function | 14 |
| | 5.2 | Limit of boundary state overlaps . . . . . . . . . . . . . . | 15 |
| A | Decomposition of representations | Decomposition of representations | 17 |
## 1 Introduction
Limits of rational conformal field theories in two dimensions play an important role for the proposed higher-spin AdS /CFT 3 2 dualities. After the observation that higher-spin gauge theories on asymptotically Anti-de Sitter backgrounds have large asymptotic symmetry W -algebras [1, 2], a concrete proposal for the dual of the bosonic Prokushkin-Vasiliev model [3] was formulated [4], which is given by a certain limit of bosonic W n -minimal models. This has been generalised to duality proposals for N = 2 [5, 6, 7] and N = 4 [8] supersymmetric situations. In a very interesting recent development [9] it was shown that a certain large level limit of the models occurring in the N = 4 case is related to a conjectured conformal field theory dual of tensionless strings on AdS 3 × S 3 × T 4 , thus pointing towards an understanding how higher-spin gauge theories are related to a tensionless limit of string theory.
In this article we want to investigate the large level limit of the N = 2 superconformal models that appear in the N = 2 higher-spin AdS /CFT 3 2 duality. These are the Grassmannian Kazama-Suzuki models [10, 11] that are realised as coset models of the form
$$\frac { \ s u ( n + 1 ) _ { k } \oplus \mathfrak { s o } ( 2 n ) _ { 1 } } { \mathfrak { s u } ( n ) _ { k + 1 } \oplus \mathfrak { u } ( 1 ) _ { n ( n + 1 ) ( k + n + 1 ) } } \.$$
Similarly to what happens for the bosonic models in the large level limit [12], for n = 1 it was shown in [13] that the limit theory coincides with the continuous orbifold C /U (1). Analogously, it was conjectured in [14] that the large level limit for general n is given by the continuous orbifold C n /U n ( ). Recently evidence for this conjecture has been given in [15], where the untwisted sector as well as the ground states of the twisted sectors of the orbifold theory were identified in the limit theory. In the present work we on the one hand give further support to the conjecture by an analysis of boundary conditions and boundary partition functions, and on the other hand we provide a complete description of the spectrum of N = 2 W n +1 -primaries in the limit theory, which is based on the modular bootstrap.
The paper is organised as follows. Section 2 contains a short summary of the facts about Kazama-Suzuki models that we will need in this paper. In section 3 we study boundary conditions in Kazama-Suzuki models in the large level limit. We determine the boundary partition functions for discrete boundary conditions in the limit theory, and show that they coincide with the boundary partition functions of fractional boundary conditions in the orbifold C n /U n ( ). We present in section 4 a proposal how the full continuous bulk spectrum of N = 2 W n +1 primaries arises from the Kazama-Suzuki spectra in the limit. We confirm this proposal by the modular bootstrap that we discuss in section 5.
## 2 Kazama-Suzuki Grassmannian cosets
We are interested in the Kazama-Suzuki models [10, 11], which are rational N = (2 2) super-, conformal field theories based on the coset
$$\frac { \mathfrak { g } _ { k } \oplus \mathfrak { s o } ( \dim [ \mathfrak { g } ] - \dim [ \mathfrak { h } ] ) _ { 1 } } { \mathfrak { h } _ { k + g _ { G } - g _ { H } } }$$
where g G , g H indicate the dual Coxeter numbers of the numerator and denominator algebra, respectively. A particular class of Kazama-Suzuki models are the Grassmannian cosets, which are specified by two positive integers, the rank n and the level k of the model, and whose explicit coset description reads
$$\frac { \mathfrak { s u } ( n + 1 ) _ { k } \oplus \mathfrak { s o } ( 2 n ) _ { 1 } } { \mathfrak { s u } ( n ) _ { k + 1 } \oplus \mathfrak { u } ( 1 ) _ { \kappa } } \. & & ( 2. 2 ) \\ \cdots \cdots & \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \colon$$
Here, κ = n n ( + 1)( k + n + 1) and the central charge is c = 3 nk k + +1 n . The theories are rational with respect to an extension of the N = 2 superconformal algebras, the so-called N = 2 W n +1 -algebras.
The map of the denominator into the numerator group in equation (2.2) is specified by the following group homomorphisms (see e.g. [6]):
$$i _ { 1 } \quad \colon U ( n ) & \longrightarrow S U ( n + 1 ) \, \quad \quad i _ { 1 } ( h, \xi ) = \begin{pmatrix} h \xi & 0 \\ 0 & \xi ^ { - n } \end{pmatrix} \quad & \in S U ( n + 1 ) \, \\ i _ { 2 } \quad \colon U ( n ) & \longrightarrow S O ( 2 n ) \, \quad \quad i _ { 2 } ( h, \xi ) = \begin{pmatrix} \mathrm R e ( h \xi ^ { n + 1 } ) & \text{Im} ( h \xi ^ { n + 1 } ) \\ - \text{Im} ( h \xi ^ { n + 1 } ) & \text{Re} ( h \xi ^ { n + 1 } ) \end{pmatrix} \quad & \in S O ( 2 n )$$
where h ∈ SU n ( ) is a n × n -matrix, and ξ ∈ U (1) is a phase.
Following the usual coset construction [16, 17], the spectrum of the theory is given by the branching of the decomposition of the representations of the numerator algebra in terms of representations of the denominator algebra,
$$\mathcal { H } ^ { \Lambda } _ { \text{su} ( n + 1 ) } \otimes \mathcal { H } ^ { \Sigma } _ { \text{so} ( 2 n ) } = \sum _ { \lambda, \mu } \mathcal { H } ^ { \Lambda, \Sigma } _ { \lambda, \mu } \otimes \left [ \mathcal { H } ^ { \lambda } _ { \text{su} ( n ) } \otimes \mathcal { H } ^ { \mu } _ { \text{u} ( 1 ) } \right ] \.$$
The representations H Λ Σ , λ,µ are labelled by (Λ Σ; , λ, µ ), where Λ = (Λ 1 , . . . , Λ ) is a dominant n weight of su ( n +1) k (where we display only the corresponding weight of the finite-dimensional algebra), Σ one of the four dominant weights of so (2 n ) 1 (Σ = 0 singlet, Σ = v vector, Σ = s spinor, Σ = c co-spinor), λ = ( λ , . . . , λ 1 n -1 ) labels dominant weights of su ( n ) k +1 , and µ is an integer ( κ -periodic) labelling the primaries of the free boson compactified at radius √ κ .
We are here only interested in the Neveu-Schwarz sector where Σ = 0 or Σ = v . Also we are usually interested in representations of the full N = 2 W n +1 -algebra and not only in representations of the bosonic part of it. To get those in the Neveu-Schwarz sector we have to consider in so (2 n ) 1 the representation H 0 so (2 n ) ⊕H v so (2 n ) .
We can get the full N = 2 Neveu-Schwarz characters Ξ Λ λ,µ ( q ) of the coset representations by decomposing the product of a su ( n +1) k character and the character for the so (2 n ) 1 -part,
$$\chi _ { \Lambda } ^ { s u ( n + 1 ), k } ($$
where χ su ( n +1) ,k Λ and χ su ( n ,k ) +1 λ are the characters of the representations of su ( n + 1) k and of su ( n ) k +1 , respectively, Ξ is the coset character, Θ are u (1) κ characters; the squared bracket expression on the right hand side is altogether a u ( n ) affine character. θ NS is the character of 2 n Neveu-Schwarz Majorana fermions, given by
$$\theta ^ { \text{NS} } ( q ) = & \chi _ { 0 }$$
Note that i 2 ( h, ξ ) given in (2.3) has eigenvalues h ξ j n +1 and ¯ h ξ j - -n 1 , where h j are the eigenvalues of h ∈ SU n ( ).
Being class functions, the characters depend only on the coordinates of the Cartan torus T n of U n ( ), which we parameterise as
$$\mathbb { T } ^ { n } \ni \text{Diag} ( e ^ {$$
The spectrum obtained in this way is subject to selection rules, since some of the representations of the denominator do not appear as subsectors of the numerator. Only those representations occur for which
$$\frac { | \Lambda | } { n + 1 } - \frac { | \lambda$$
where for su ( n ) and su ( n +1) the symbol |D| denotes the number of boxes of the Young diagram associated with the finite dimensional representation D .
Furthermore, some states in the spectrum have to be identified, because of the outer automorphisms of the numerator and denominator chiral algebras. The group of outer automorphisms of the affine algebra su ( n ) k is isomorphic to the centre of the group SU n ( ), which is Z n . The automorphism acts therefore by permuting the Dynkin labels of the representations on both the special unitary numerator and denominator algebras, resulting in a Z n n ( +1) group. Under the automorphisms the u (1) label gets shifted by k + +1. The identifications among representations n are accordingly:
$$\begin{array} {$$
Conformal weights can be determined from the knowledge of the L 0 eigenvalues for the representations in the numerator and in the denominator. The U (1)-charge can be obtained by a careful definition of the fields which generate the N = 2 superconformal algebra [10]. The conformal dimension h and the U (1) charge Q of the Neveu-Schwarz representation (Λ; λ, µ ) are then
$$h = \ \frac { 1 } { k + n + 1 } \left [ C ^ { ( n + 1 ) } ( \Lambda ) - C ^ { ( n ) } ( \lambda ) - \frac { \mu ^ { 2 } } { 2 n ( n + 1 ) } \right ] + h _ { \Sigma } \mod \frac { 1 } { 2 } \quad \quad ( 2. 1 0 )$$
$$Q = \ - \frac { \mu } { n \, + \, l ^ { * } \, + \, 1 } + Q _ { \Sigma } \mod 1$$
$$\ = \ - \frac { \mu } { n + k + 1 } +$$
where C ( n ) and C ( n +1) denote the quadratic Casimir, which for su ( n ) reads
$$C ^ { ( n ) } ( \lambda ) = \sum _ { 1 \leq i < j \leq n - 1 } \lambda _ { i } \lambda _ { j } \ \frac { i ( n - j ) } { n } + \frac { 1 } { 2 } \sum _ { j = 1 } ^ { n - 1 } \lambda _ { j } ^ { 2 } \ \frac { j ( n - j ) } { n } + \frac { 1 } { 2 } \sum _ { j = 1 } ^ { n - 1 } \lambda _ { j } \ j ( n - j ) \.$$
## 3 Boundary conditions in the large level limit
In this section we analyse the behaviour of boundary states of the coset theory in the large level limit. We show how one can obtain a certain discrete class of boundary conditions for the limit theory, and we study their boundary partition functions. We then give support to the claim that the limit theory can be described by the N = (2 2) superconformal continuous orbifold , C n /U n ( ).
## 3.1 Boundary conditions and spectrum
The Grassmannian coset models su ( n +1) / u ( n ) are rational with respect to the N = 2 W n +1 -algebras. With the Cardy construction [18] one can define rational boundary states, i.e. those that preserve one copy of the chiral algebra of the theory. Depending on the gluing conditions for the supercurrents, one can distinguish A-type and B-type boundary conditions - here we
want to focus on A-type conditions. For a diagonal bulk spectrum, A-type boundary conditions are labelled by the same set of representations as the bulk fields, i.e. by tuples (Λ , Σ; λ, µ ), with Λ Σ , , λ dominant weights of su ( n +1) k , so (2 n ) 1 , su ( n ) k +1 respectively, and µ the U (1) label of the free boson on the circle of radius √ κ . We want to use a particular choice for the gluing condition for the fermions, this restricts the so -label to Σ = 0 or Σ = v .
From the analysis of boundary renormalisation group flows in coset models [19, 20, 21] one knows that a boundary state with su ( n +1) label (Λ 1 , . . . Λ ) can be obtained by a flow from a n superposition of boundary states with su ( n +1) label (0 , . . . , 0). These boundary renormalisation group flows become shorter and shorter as k grows, and in the limit k →∞ the initial and final fixed-point coincide. We therefore expect that in the limit theory the elementary boundary conditions are labelled by the tuples (0 , S L M ; , ). This fact generalises what we observed in the case n = 1 of N = 2 minimal models [22, 13].
The boundary partition function for two boundary conditions (0 , S i ; L i , M i ) ( i = 1 2) in the , model at level k is given by
$$Z _ { ( 0, \mathcal { S } _ { 1 } ; \mathcal { L } _ { 1 }, \mathcal { M } _ { 1 } ) ( 0, \mathcal { S } _ { 2 } ; \mathcal { L } _ { 2 }, \mathcal { M } _ { 2 } ) } ( \tilde { \tau } ) = \sum _ { \Sigma, \lambda } N _ { \Sigma \mathcal { S } _ { 1 } } ^ { s o ( 2 n ) _ { 1 } \mathcal { S } _ { 2 } } N _ { \lambda \mathcal { L } _ { 1 } } ^ { s \mathfrak { m } ( n ) _ { k + 1 } \mathcal { L } _ { 2 } } \, \chi _ { ( 0, \Sigma ; \lambda, \mathcal { M } _ { 2 } - \mathcal { M } _ { 1 } ) } ( \tilde { q } )$$
where ˜ = q e 2 πiτ ˜ , and the symbols N denote the fusion coefficients. In the expression above, the characters of the bosonic subalgebra of the coset algebra appear. To simplify our analysis we want to study the supersymmetric partition functions with the full superW n characters Ξ Λ λ,µ (the unprojected partition function). Then we can forget about the so -label S in the boundary conditions, and the unprojected partition function reads
$$Z _ { ( 0 ; \mathcal { L } _ { 1 }, \mathcal { M } _ { 1 } ) ( 0 ; \mathcal { L } _ { 2 }, \mathcal { M } _ { 2 } ) } ( \tilde { \tau } ) = \sum _ { \lambda } N _ { \lambda \mathcal { L } _ { 1 } } ^ { \mathfrak { s u } ( n ) _ { k + 1 } \mathcal { L } _ { 2 } } \Xi _ { \lambda, \mathcal { M } _ { 2 } - \mathcal { M } _ { 1 } } ^ { 0 } ( \tilde { q } ) \. \quad \quad ( 3. 2 ) \\. \. \. \. \. \. \. \. \. \. \. \. \. \. \. \. \. \. \. \. \. \. \. \.$$
To obtain the large level limit k of this boundary partition function we have to identify the limit of the coset characters, which we will do in the following subsection.
## 3.2 Limit of coset characters
We want to evaluate the coset characters Ξ 0 λ,µ in the limit k →∞ while keeping the labels λ, µ fixed. This has been worked out in [6, 15] (see [23] for a similar analysis for the bosonic models) by using large level expansions of the individual character that enter (2.5) as we will review below.
The su ( n ) k +1 character is given by the Weyl-Kaˇ formula c
$$\chi _ { \lambda } ^ { \mathfrak { s u } ( n ) _ { k + 1 } } = q ^ { - \frac { ( n + 1 ) ( n - 1 ) ( k + 1 ) } { 2 4 ( k + n + 1 ) } } \frac { \sum _ { w \in \hat { W } } \text{sgn} ( w ) e ^ { w ( \lambda + \rho ) } } { \sum _ { w \in \hat { W } } \text{sgn} ( w ) e ^ { w ( \rho ) } } \quad & ( 3. 3 ) \\ \text{persents the affine Weyl group, which is given by the semidirect product of finite Weyl}$$
where ˆ W represents the affine Weyl group, which is given by the semidirect product of finite Weyl reflections with translations of elements of the root lattice. The affine translations contribute with terms of order q k +1 -∑ i λ i (see e.g. [24]), which are suppressed as k becomes large. It is
therefore possible to write down an expansion of the form
/negationslash
$$\chi _ { \lambda } ^ { \text{su} ( n ) _ { k + 1 } } ( q ; h ) = q ^ { - \frac { ( n + 1 ) ( n - 1 ) ( k + 1 ) } { 2 4 ( k + n + 1 ) } + \frac { C ^ { ( n ) } ( \lambda ) } { n + k + 1 } } \frac { \text{ch} _ { \lambda } ^ { \text{su} ( n ) } ( h ) + \mathcal { O } ( q ^ { k + 1 - \sum _ { i } \lambda _ { i } } ) } { \overset { \infty } { \prod } _ { m = 0 } \left [ ( 1 - q ^ { m + 1 } ) ^ { n - 1 } \prod _ { i \neq j } ^ { n - 1 } ( 1 - h _ { 4 } \bar { h } _ { j } q ^ { m + 1 } ) \right ] } \, \quad ( 3. 4 ) \\ \text{where} \, \text{where} \, \text{$ch} ^ { \text{su} ( n ) } ( t \rangle \text{is the finite $\alpha(n)\,character} for the transformation $\lambda$ and $\mathcal{C}(n)\,(\lambda)\,is the mathematical}$$
where ch su ( n ) λ ( ) is the finite t su ( n ) character for the representation λ , and C ( n ) ( λ ) is the quadratic Casimir (see (2.12)).
Similarly, the vacuum character of su ( n +1) k for large level k becomes (see e.g. [15])
$$\chi _ { 0 } ^ { \text{su} ( n + 1 ), k } ( q, i _ { 1 } ( h ; \xi ) )$$
/negationslash
$$\lambda _ { 0 } & = \frac { \langle \bar { q }, \epsilon _ { 1 } \langle \bar { n }, \S \rangle \rangle } { q ^ { - \frac { n ( n + 2 ) k } { 2 4 ( k + n + 1 ) } } ( 1 + \mathcal { O } ( q ^ { k } ) ) } \left ( 1 + \mathcal { O } ( q ^ { k } ) \right ) } \left ( 1 - \bar { q } ^ { - \frac { n ( n + 2 ) k } { 2 4 ( k + n + 1 ) } } ( 1 + \mathcal { O } ( q ^ { k } ) ) \right ) \\ & \prod _ { m = 0 } ^ { n - 1 } \left [ ( 1 - q ^ { m + 1 } ) ^ { n } \prod _ { i \neq j } ^ { n - 1 } ( 1 - h _ { i } \bar { h } _ { j } q ^ { m + 1 } ) \prod _ { k = 1 } ^ { n } ( 1 - h _ { k } \xi ^ { n + 1 } q ^ { m + 1 } ) ( 1 - \bar { h } _ { k } \xi ^ { - ( n + 1 ) } q ^ { m + 1 } ) \right ] \right )$$
Analogously the u (1) character can be expanded as
$$\Theta _ { \mu, \kappa } ( q ; \xi ) = q ^ { - \frac { 1 } { 2 4 } + \frac { \mu ^ { 2 } } { 2 \kappa } } \frac { \xi ^ { - \mu } + \mathcal { O } \left ( q ^ { \frac { \kappa } { 2 } - | \mu | } \right ) } { \prod _ { m = 0 } ^ { \infty } \left ( 1 - q ^ { m + 1 } \right ) } \. \\ \text{avisous expansions into equation } ( 2. 5 ), \, \text{we arrive at the following large $k$ expression}$$
Plugging the previous expansions into equation (2.5), we arrive at the following large k expression for the coset characters:
$$\Xi _ { \lambda, \mu } ^ { 0 } ( q ) & = q ^ { \frac { n ( n + 1 ) } { 8 ( k + n + 1 ) } - \frac { C ^ { ( n ) } ( \lambda ) } { n + k + 1 } - \frac { \mu ^ { 2 } } { 2 \kappa } } \left [ A _ { \lambda, \mu } ( q ) + \mathcal { O } \left ( q ^ { k - \sum _ { i } \lambda _ { i } } \right ) + \mathcal { O } \left ( q ^ { \frac { \kappa } { 2 } - | \mu | } \right ) \right ] \, \\ \text{where } A \times.. is \, \text{given} \, \text{hv}$$
where A λ,µ is given by
$$\cdots \cdots \cdots \cdots \cdots \cdots \\ \sum _ { \lambda, \mu } A _ { \lambda, \mu } ( q ) \, \mathfrak { c h } _ { \lambda } ^ { \mathfrak { s u } ( n ) } ( h ) \, \xi ^ { - \mu } & = q ^ { - \frac { n } { 1 2 } } \frac { \theta ^ { \text{NS} } ( q ) } { \prod _ { m = 0 } ^ { n } \prod _ { j = 1 } ^ { n } ( 1 - h _ { j } \xi ^ { n + 1 } q ^ { m + 1 } ) ( 1 - \bar { h } _ { j } \xi ^ { - ( n + 1 ) } q ^ { m + 1 } ) } \\ & = \prod _ { j = 1 } ^ { n } \left ( 2 \sin \frac { \theta _ { j } } { 2 } \right ) \frac { \vartheta _ { 3 } ( q, \frac { \theta _ { j } } { 2 \pi } ) } { \vartheta _ { 1 } ( q, \frac { \theta _ { j } } { 2 \pi } ) } \,, \\ \text{and the angles $\theta_{i}$ are defined in analogy with (2.7). The branching function $A_{\lambda,\mu}$ can be isolated}$$
and the angles θ i are defined in analogy with (2.7). The branching function A λ,µ can be isolated using the orthogonality of the finite characters, and we conclude
$$A _ { \lambda, \mu } ( q ) & = \frac { 1 } { | \mathbb { T } ^ { n } | } \int _ { \mathbb { T } ^ { n } } d \mu ( t ) \, \text{ch} _ { \lambda, \mu } ^ { u ( n ) } ( t, \xi ) \prod _ { j = 1 } ^ { n } \left ( 2 \sin \frac { \theta _ { j } } { 2 } \right ) \frac { \vartheta _ { 3 } ( q, \frac { \theta _ { j } } { 2 \pi } ) } { \vartheta _ { 1 } ( q, \frac { \theta _ { j } } { 2 \pi } ) } \,, \\ \dots \quad. \quad. \quad. \quad. \quad. \quad.$$
where T n is the Cartan torus of U n ( ).
From (3.7) we see that the limit of the coset characters Ξ 0 λ,µ with fixed labels λ, µ is simply
given by A λ,µ ,
$$\lim _ { k \to \infty } \Xi _ { \lambda, \mu } ^ { 0 } ( q ) = A _ { \lambda, \mu } ( q ) \.$$
This provides us with an expression for the boundary partition function (3.2) in the limit.
## 3.3 Match with the continuous orbifold
We will now show that the boundary partition functions in the limit theory coincide with the corresponding partition functions in the orbifold model C n /U n ( ).
The boundary conditions in an orbifold conformal field theory arise from superpositions of conformal boundary conditions of the parent theory that are invariant under the action of the orbifold group. A boundary condition that is by itself invariant splits into 'fractional boundary conditions'. In a continuous orbifold the only relevant boundary conditions are these fractional boundary conditions, because they couple to twisted sectors of the orbifold, which outnumber the untwisted sector in case of continuous groups (see the discussions in [12, 13, 14]). Fractional boundary conditions are labelled by irreducible representations of the orbifold group (if the original boundary condition is invariant under the full orbifold group). In our case we consider the boundary condition corresponding to a point-like brane at the origin. The boundary partition function between fractional boundary conditions labelled by the U n ( ) multi-indices r, r ′ then reads
$$Z _ { r r ^ { \prime } } ( \tilde { \tau } ) = \frac { 1 } { | G | } \int _ { G } d \mu ( g ) \, \text{ch} _ { r } ^ { u ( n ) } ( g ) \, \text{ch} _ { r ^ { \prime } } ^ { u ( n ) } ( g ) \, \text{tr} _ { \mathcal { H } _ { 0 } } \left ( U ( g ) \tilde { q } ^ { L _ { 0 } - \frac { n } { 8 } } \right ) \, \quad G = U ( n ) \, \quad \quad ( 3. 1 1 )$$
where H 0 is the Hilbert space of the boundary spectrum of a point-like brane in C n , ch u ( n ) r is the finite character of the U n ( ) representation labelled by r , U g ( ) is the action of g ∈ U n ( ) on the space of states H 0 , and | G | is the volume of U n ( ) measured with respect to the Haar measure dµ g ( ).
The expression in equation (3.11) can be simplified by noting that
$$\text{ch} _ { r } ^ { u ( n ) } ( g ) \, \text{ch} _ { r ^ { \prime } } ^ { u ( n ) } ( g ) = \sum _ { s } N _ { r r ^ { \prime } } ^ { u ( n ) s } \, \text{ch} _ { s } ^ { u ( n ) } ( g )$$
where N u ( n s ) rr ′ are u ( n ) Clebsch-Gordan coefficients. This implies that any boundary partition function can be realised as a combination of elementary Z r 0 (˜) amplitudes. τ
Every group element is conjugate to some element of the Cartan torus (quotiented by the Weyl group). Using the cyclicity of the trace we can rewrite the integral as an integral over the Cartan torus of U n ( ) parameterised as in section 2 by n angles θ i as Diag( e iθ 1 , . . . , e iθ n ). The trace becomes
We conclude that
$$& \text{es} \\ & \text{tr} _ { \mathcal { H } _ { 0 } } \left ( U ( g ) \tilde { q } ^ { L _ { 0 } - \frac { n } { 8 } } \right ) = \prod _ { i = 1 } ^ { n } \left ( 2 \sin \frac { \theta _ { i } } { 2 } \right ) \frac { \vartheta _ { 3 } ( \tilde { \tau }, \frac { \theta _ { i } } { 2 \pi } ) } { \vartheta _ { 1 } ( \tilde { \tau }, \frac { \theta _ { i } } { 2 \pi } ) } \,. \\ & \text{e that}.$$
$$Z _ { \mathcal { L } \mathcal { M }, 0 } ( \tilde { \tau } ) = \frac { 1 } { | \mathbb { T } ^ { n } | } \int _ { \mathbb { T } ^ { n } } d \mu ( t ) \, \text{ch} _ { \mathcal { L } \mathcal { M } } ^ { u ( n ) } ( t ) \, \prod _ { i = 1 } ^ { n } \left ( 2 \sin \frac { \theta _ { i } } { 2 } \right ) \frac { \vartheta _ { 3 } ( \tilde { \tau }, \frac { \theta _ { i } } { 2 \pi } ) } { \vartheta _ { 1 } ( \tilde { \tau }, \frac { \theta _ { i } } { 2 \pi } ) } \,,$$
where we have labelled the u ( n ) representation by representation labels of su ( n ) and u (1), r → L M ( , ). Comparing (3.14) with equation (3.10) we find
$$Z _ { \mathcal { L } \mathcal { M }, 0 } ( \tilde { \tau } ) \equiv A _ { \mathcal { L }, \mathcal { M } } ( \tilde { q } ) \.$$
Hence the boundary partition functions of type-A Cardy boundary conditions on the coset coincide in the limit k → ∞ with the boundary partition functions of fractional boundary conditions in the continuous orbifold. This provides further evidence that the k → ∞ limit of the Grassmannian Kazama-Suzuki models is equivalent to the continuous orbifold C n /U n ( ).
## 3.4 Explicit expressions for SU (3) /U (2)
The boundary partition functions (3.15) in the limit theory have been explicitly analysed in [13, 14] for the case n = 1. We present here the explicit characters that appear in the boundary functions in the limit for the second simplest example, n = 2, namely for the A-type boundary conditions of the large level limit of su (3) / u (2) Grassmannian coset.
In the su (3) / u (2) case the integral (3.14) reads
$$Z _ { \mathcal { L } \mathcal { M }, 0 } ( \tilde { \tau } ) & = \frac { 1 } { | \mathbb { T } ^ { 2 } | } \int _ { \mathbb { T } ^ { 2 } } d \mu ( t ) \, \text{ch} _ { \mathcal { L } \mathcal { M } } ^ { u ( 2 ) } ( t ) \prod _ { i = 1 } ^ { 2 } \left ( 2 \sin \frac { \theta _ { i } } { 2 } \right ) \frac { \vartheta _ { 3 } ( \tilde { \tau }, \frac { \theta _ { i } } { 2 \pi } ) } { \vartheta _ { 1 } ( \tilde { \tau }, \frac { \theta _ { i } } { 2 \pi } ) } \,, \\. & \quad. & \quad. & \quad. & \quad - \lambda \, \dashv \, - \lambda \, \dashv \, - \dots \, \cdots \, \cdots \, \cdots \, \cdots \, \cdots \, \cdots \,.$$
where the angles θ 1 and θ 2 parameterise the Cartan torus T 2 . The finite U (2) character has the form
$$\text{ch} _ { \mathcal { L }, \mathcal { M } } ^ { u ( 2 ) } = \frac { \sin ( 1 + \mathcal { L } ) \frac { \theta _ { 1 } - \theta _ { 2 } } { 2 } } { \sin \frac { \theta _ { 1 } - \theta _ { 2 } } { 2 } } e ^ { i \mathcal { M } \frac { \theta _ { 1 } + \theta _ { 2 } } { 2 } } \.$$
The induced measure on the Cartan torus is
$$& \frac { d \mu ( t ) } { | \mathbb { T } ^ { 2 } | } = \frac { d \theta _ { 1 } d \theta _ { 2 } } { 8 \pi ^ { 2 } } \left ( 2 \sin \frac { \theta _ { 1 } - \theta _ { 2 } } { 2 } \right ) ^ { 2 } \,. \\. & \quad \cdot \quad \cdot \quad \cdot \quad \cdot \quad \cdot \quad \cdot$$
Using the following expansion (see e.g. [25, appendix A])
$$\frac { \vartheta _ { 3 } ( \tau, \frac { \theta _ { i } } { 2 \pi } ) } { \vartheta _ { 1 } ( \tau, \frac { \theta _ { i } } { 2 \pi } ) } & = - i \frac { \vartheta _ { 3 } ( \tau, 0 ) } { \eta ^ { 3 } ( \tau ) } \sum _ { n \in \mathbb { Z } } \frac { e ^ { i \theta _ { i } ( n + \frac { 1 } { 2 } ) } } { 1 + q ^ { n + \frac { 1 } { 2 } } } \, \\. \quad. \quad. \quad. \quad. \quad. \quad. \quad.$$
we can explicitly solve the integral (3.16). We find
$$A _ { \mathcal { L }, \mathcal { M } } ^ { c = 6 } ( q ) & = q ^ { - \frac { 5 } { 2 } + \frac { 3 } { 2 } \mathcal { M } - \frac { 1 } { 2 } \mathcal { L } } \left [ \frac { \vartheta _ { 3 } ( \tau, 0 ) } { \eta ^ { 3 } ( \tau ) } \right ] ^ { 2 } \frac { ( 1 - q ) ^ { 3 } ( 1 + q ) ( 1 - q ^ { 1 + \mathcal { L } } ) } { \prod _ { j = 0 } ^ { 2 } \left ( 1 + q ^ { ( \frac { 1 } { 2 } - j ) + \frac { M - \mathcal { L } } { 2 } } \right ) \left ( 1 + q ^ { ( j - \frac { 1 } { 2 } ) + \frac { M + \mathcal { L } } { 2 } } \right ) } \, \quad ( 3. 2 0 ) \\ \text{recalling that $\mathcal{ L } + \mathcal{ M }$ must be even $(\mathcal{ L }. \mathcal{M}$ are $\mathcal{u}(2)$ representation labels). In the special case}$$
recalling that L + M must be even ( L M , are u (2) representation labels). In the special case
L = M = 0 we find the vacuum character,
$$A _ { 0, 0 } ^ { c = 6 } ( q ) & = q ^ { - \frac { 1 } { 4 } } \prod _ { n = 0 } ^ { \infty } \frac { \left ( 1 + q ^ { n + \frac { 3 } { 2 } } \right ) \left ( 1 + q ^ { n + \frac { 3 } { 2 } } \right ) \left ( 1 + q ^ { n + \frac { 5 } { 2 } } \right ) } { \left ( 1 - q ^ { n + 1 } \right ) \left ( 1 - q ^ { n + 2 } \right ) ^ { 2 } \left ( 1 - q ^ { n + 3 } \right ) } = \left [ \frac { \vartheta _ { 3 } ( \tau, 0 ) } { \eta ^ { 3 } ( \tau ) } \right ] ^ { 2 } \frac { \left ( 1 - q ^ { \frac { 1 } { 2 } } \right ) ^ { 4 } \left ( 1 + q \right ) } { \left ( 1 + q ^ { \frac { 3 } { 2 } } \right ) ^ { 2 } } \. \\ \text{The expression presented in (3.21) and (3.20) are the characters of irreducible representations of}$$
The expression presented in (3.21) and (3.20) are the characters of irreducible representations of the unprojected Neveu-Schwarz spectrum of the discrete boundary conditions in the large level limit of su (3) / u (2) Kazama-Suzuki Grassmannian cosets. Analogously they describe point-like fractional branes in the N = 2 supersymmetric continuous orbifold C 2 /U (2).
The value of the conformal weight of the ground states above the vacuum can be recognised as the leading exponent of the characters of equation (3.20) (when we take out the overall factor q -1 4 / ), and one finds [14]
| range | leading term | |
|-------------|-------------------------------|--------|
| M = L = 0 | q 0 | |
| |M| ≤ L- 2 | q L- 1 | (3.22) |
| |M| = L > 0 | q L- 1 2 | |
| |M| = L +2 | q L +1 | |
| > +2 | q - 5 2 - 1 2 ( - 3 |M| + L ) | |
|M|
L
## 4 Bulk spectrum in the limit
We now want to explore the bulk spectrum of the limit theory. If one keeps the representation labels (Λ; λ, µ ) of a bulk field fixed while taking the limit k →∞ , the corresponding conformal weight will tend to zero (or at least to a (half-)integer) (see eq. (2.10)). If on the other hand one looks at the complete spectrum of conformal weights of primaries, there are many fractional weights, and in the limit the conformal weights that appear even become dense on the positive real line, so that one expects a continuous spectrum.
This behaviour is well-known from other limit theories [26, 27, 28, 29, 22, 13]. To obtain the spectrum in the limit theory one has to study which fields contribute to some given conformal weight (or better to a small neighbourhood of this conformal weight). 1 The representations that contribute to some finite non-integer conformal weight arise from coset representations where the labels scale with the level k . The precise analysis is complicated by the fact that one does not know all the conformal weights in the Kazama-Suzuki models explicitly, and in general only its fractional part can be computed (by eq. (2.10)). 2
In [15] a class of coset fields was identified whose conformal weights, which could be computed exactly, precisely match the conformal weights we expect for the ground states of the twisted
1 In addition one should also specify the charges with respect to the other currents in the W -algebra.
2 Only for n = 1 one can bring all coset fields by field identifications to some standard range for which one can determine the conformal weights directly.
sector of the continuous orbifold theory that is supposed to describe the limit theory. We take this identification as a starting point to formulate a proposal for what happens to the complete bulk spectrum in the limit. We can perform some checks to our proposal in the SU (3) /U (2) model. In section 5 we will then see that our proposal precisely matches with the modular bootstrap.
## 4.1 Ground states
We expect that in the limit the representation labels of bulk fields have to be scaled with k . Following [15], we write the labels λ, µ of the denominator group as 3
$$\lambda ( \alpha ) = ( k + n + 1 ) \left ( \alpha _ { 2 } - \alpha _ { 1 }, \dots, \alpha _ { n } - \alpha _ { n - 1 } \right ) \ \, \quad \mu ( \alpha ) = ( k + n + 1 ) \sum _ { i = 1 } ^ { n } \alpha _ { i } \. \quad ( 4. 1 ) \\ \intertext { n } \quad \cdot \ \cdot \ \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \colon }$$
By using field identification the α i can be brought to the range -1 2 ≤ α i ≤ 1 2 . Note also that by definition they satisfy
$$\alpha _ { 1 } \leq \alpha _ { 2 } \leq \cdots \leq \alpha _ { n } \.$$
For a given denominator label we expect that we have to tune the numerator label in a precise way to obtain a finite conformal weight in the limit. In [15] it was proposed to choose the numerator labels as
$$\Lambda ( \alpha ) = ( k + n + 1 ) \left ( \alpha _ { 2 } - \alpha _ { 1 }, \dots, \alpha _ { m } - \alpha _ { m - 1 }, - \alpha _ { m }, \alpha _ { m + 1 }, \alpha _ { m + 2 } - \alpha _ { m + 1 }, \dots, \alpha _ { n } - \alpha _ { n - 1 } \right ) \,, \, ( 4. 3 ) \\ \text{where the integer } m \text{ with } 0 \, \leq \, m \, \leq \, n \text{ is the number of negative } \alpha _ { i }. \text{ For those labels the}$$
$$h _ { ( \Lambda ( \alpha ) ; \lambda ( \alpha ), \mu ( \alpha ) ) } = \frac { 1 } { 2 } \sum _ { i = 1 } ^ { n } | \alpha _ { i } | + \mathcal { O } ( 1 / k ) \. & & ( 4. 4 ) \\ \text{mulate a nonosal for the complete spectrum of cost primaries.}$$
where the integer m with 0 ≤ m ≤ n is the number of negative α i . For those labels the conformal weight can be determined exactly, because there appears no integer shift in the formula (2.10) (the representation ( λ α ( ); µ α ( )) occurs in the decomposition of Λ( α ) as can be seen from the explicit decomposition described in appendix A). If we consider the representations (Λ( α ); λ α , µ α ( ) ( )) for which the parameters α i have a finite limit, the conformal weight is given by
We will now formulate a proposal for the complete spectrum of coset primaries.
## 4.2 Full coset spectrum in the limit
For given denominator labels λ α , µ α ( ) ( ) we have seen that one obtains a finite conformal weight in the limit if one chooses the numerator label as Λ( α ). Except for the selection rules the numerator labels and denominator labels run independently, so there are many more coset fields in the spectrum. On the other hand, as emphasised before, to get a finite limit of the conformal weight the scaling of the labels has to be tightly correlated, and we expect that to get a finite result the numerator labels Λ should deviate from Λ( α ) in the limit only by a finite amount.
3 In [15] the prefactor is k instead of k + n +1, in the limit k →∞ this difference does not play a role.
Taking the selection rules into account, such Λ are of the form
$$\Lambda ( \alpha, N ) = \Lambda ( \alpha ) + \left ( N _ { 1 } - N _ { 2 }, \dots, N _ { m - 1 } - N _$$
where m again denotes the number of negative α i and N i are integers, and
$$N = \sum _ { i = 1 } ^ { m } N _ { i } - \sum _ { i = m + 1 } ^ { n } N _ { i } \. \quad \quad \quad$$
The N i will be kept fixed in the limit. One can show (see appendix A) that for non-negative N i the U n ( ) representation ( λ α , µ α ( ) ( )) is contained in the decomposition of Λ( α, N ), therefore there is no shift for the conformal weight when using the formula (2.10). The result is
$$h = \sum _ { i = 1 } ^ { n } | \alpha _ { i } | \left ( \frac { 1 } { 2 } + N _ { i } \right ) + \mathcal { O }$$
For negative N i we propose to shift the conformal weight by | N i | -1 2 so that the conformal weight in the limit is
$$h = \sum _ { i } ^ { + } | \alpha _ { i } | \left ( \frac { 1 } { 2 } + N _ { i } \right ) + \sum _ { i } ^ {$$
where the sum with superscript '+' runs over those i for which N i ≥ 0, and the one with the superscript ' -' over those with N < i 0.
We cannot give a proof of the proposed shift in the conformal weight, but we can give some justifications. First of all there has to be a shift, because ( λ α , µ α ( ) ( )) does not occur in the decomposition of Λ( N,α ) if any of the N i is negative (see appendix A). In [15] it was argued that finite changes of Λ away from Λ( α ) would result in representations belonging to the same twisted sector labelled by the α i in the orbifold description. In the twisted sector we expect all conformal weights of primaries to be half-integer multiples of | α i | and (1 -| α i | ), and the shift we propose is the only choice that is consistent with these orbifold expectations.
Also let us look at a simple example. Choose all α i negative, such that m = n . Furthermore we choose N 1 = -1 and all other N i = 0. Then the numerator label is
$$\Lambda = \Lambda ( \alpha, N ) = \left ( \lambda _ { 1 } - 1, \lambda _ { 2 }, \dots, \lambda _ { n - 1 }, -$$
In its decomposition to representations of U n ( ) one finds among others the representation
$$\left ( \lambda - \mathfrak { f }, \mu + ( n + 1 ) \right ) \,, & & ( 4. 1 0 ) \\ \intertext { l weight of $su(n)$. On the other hand the vector representation $v$ of }$$
where f is the fundamental weight of su n ( ). On the other hand the vector representation v of so (2 n ) decomposes into the u n ( ) representation ( f , n +1) ⊕ ( ¯ f , - -n 1), so that ( λ, µ ) is contained in Λ ⊗ v . The formula for the conformal weight therefore has to be shifted by the conformal weight h ( v ) = 1 / 2 of the vector representation of so (2 n ) 1 .
We give some more evidence in the next subsection in the example of SU (3) /U (2). Another justification for our proposal is provided by the modular bootstrap analysis in section 5.
## 4.3 The example of SU (3) /U (2)
We now consider the Kazama-Suzuki model based on SU (3) /U (2) (i.e. the case n = 2). We consider negative α , α 1 2 (i.e. m = n = 2), and coset label ( Λ( α, N ); λ α , µ α ( ) ( ) ) with
$$\lambda ( \alpha ) & = ( k + 3 ) ( \alpha _ { 2 } - \alpha _ { 1 } ) \\.. / \wedge \wedge & = \omega _ { 1 } + \omega _ { 2 } \wedge / \wedge \omega _ { 3 } + \wedge \wedge$$
$$\Lambda ( \alpha, N ) & = \left ( ( k + 3 ) ( \alpha _ { 2 } - \alpha _ { 1 } ) + N _ { 1 } - N _ { 2 }, - ( k + 3 ) \alpha _ { 2 } + N _ { 1 } + 2 N _ { 2 } \right ) \quad & ( 4. 1 1 ) \\ \lambda ( \alpha ) & = ( k + 3 ) ( \alpha _ { 2 } - \alpha _ { 1 } ) \\ \tau \cdots \tilde { \lambda } \cdots \tilde { \lambda } \cdots \tilde { \lambda } \cdots \tilde { \lambda } \cdots \tilde { \lambda } \cdots \tilde { \lambda } \cdots \tilde { \lambda } \cdots \tilde { \lambda } \cdots \tilde { \lambda } \cdots \tilde { \lambda } \cdots \tilde { \lambda } \cdots \tilde { \lambda } \cdots \tilde { \lambda } \cdots \tilde { \lambda } \cdots \tilde { \lambda } \cdots \tilde { \lambda } \cdots \tilde { \lambda } \cdots \tilde { \lambda } \cdots \tilde { \lambda } \cdots \tilde { \lambda } \cdots \tilde { \lambda \cdots \tilde { \lambda } \cdots \tilde { \lambda } \cdots \tilde { \lambda } \cdots \tilde { \lambda } \cdots \tilde { \lambda } \cdots \tilde { \lambda } \cdots \tilde { \lambda } \cdots \tilde { \lambda } \cdots \tilde { \lambda } \cdots \tilde { \lambda } \cdots \tilde { \lambda } \cdots \tilde { \lambda } \cdots \tilde { \lambda } \cdots \tilde { \lambda } \cdots \tilde { \lambda } \cdots \tilde { \lambda } \cdots \tilde { \lambda } \cdots \tilde { \lambda } \cdots \tilde { \lambda } \cdots \tilde { \lambda. }$$
$$\mu ( \alpha ) = ( k + 3 ) ( \alpha _ { 1 } + \alpha _ { 2 } ) \.$$
For non-negative N i the conformal weight can be computed using the coset formula (2.10) without (half-)integer shift, and the result is (compare eq. (4.7))
$$h = | \alpha _ { 1 } | \left ( N _ { 1 } + \frac { 1 } { 2 } \right ) + | \alpha _ { 2 } | \left ( N _ { 2 } + \frac { 1 } { 2 } \right ) + \mathcal { O } ( 1 / k ) \.$$
For one or both N i negative there have to be shifts because the U (2) representation ( λ α , µ α ( ) ( )) does not appear in the decomposition of Λ( α, N ). We consider now the case where N < 1 0 and N 2 ≥ 0. Then we make use of the field identification (see (2.9)) and shift the labels by the action of the simple current
$$\Lambda ( \alpha, N ) & \to \Lambda ^ { ( 1 ) } ( \alpha, N ) = \left ( - ( k + 3 ) \alpha _ { 2 } + N _ { 1 } + N _ { 2 }, ( k + 3 ) ( 1 + \alpha _ { 1 } ) - 2 N _ { 1 } - N _ { 2 } - 3 \right ) \quad ( 4. 1 5 ) \\ \lambda ( \alpha ) & \to \lambda ^ { ( 1 ) } ( \alpha ) = ( k + 3 ) ( 1 - \alpha _ { 2 } + \alpha _ { 1 } ) - 2 \quad ( 4. 1 6 ) \\ u ( \alpha ) & \to u ^ { ( 1 ) } ( \alpha ) = ( k + 3 ) ( \alpha _ { 2 } + \alpha _ { 2 } + 1 ) \quad ( 4 \ 1 7 )$$
$$\mu ( \alpha ) \rightarrow \mu ^ { ( 1 ) } ( \alpha ) = ( k + 3 ) ( \alpha _ { 1 } + \alpha _ { 2 } + 1 ) \.$$
Using the explicit branching described in appendix A one can now show that ( λ (1) ( α , µ ) (1) ( α )) is contained in the decomposition of Λ (1) ( α, N ) if N < 1 0 and N 2 ≥ 0. Therefore we can use the formula for the conformal weight (2.10) without any (half-)integer shift, and we obtain
$$h & = \left ( 1 - | \alpha _ { 1 } | \right ) \left ( | N _ { 1 } | - \frac { 1 } { 2 } \right ) + | \alpha _ { 2 } | \left ( N _ { 2 } + \frac { 1 } { 2 } \right ) + \mathcal { O } ( 1 / k ) \. \quad & ( 4. 1 8 ) \\ \tau _ { 1 } & = \tilde { 1 } \cdot \tilde { 1 } \cdot \tilde { 1 } \cdot \tilde { 1 }.$$
## 5 Modular bootstrap
In the last section we formulated a proposal for the bulk spectrum of N = 2 W n +1 -primaries in the large level limit. One way of testing it is by comparing it against the modular bootstrap: a boundary partition function after modular transformation results in the overlap of boundary states, which should be expressible as a sum/integral over the contributions of the different bulk fields.
We consider the boundary partition function Z 00 ( q ) for the simplest boundary condition labelled by (0; 0 , 0), the vacuum representation. For this we know the expression in the large level limit (see (3.14)), and we can determine its modular transformation. On the other hand,
we can also determine the modular transformation at finite level and express it as a sum over the bulk spectrum. In the limit this has to approach the modular transform of the limit of the boundary partition function. From the comparison we can identify the bulk characters in the limit theory and verify that their leading exponent matches the expectations for the conformal weight that we formulated in the previous section.
## 5.1 Modular transformation of the boundary partition function
The boundary partition function for the simplest boundary condition is given by
$$Z _ { 0 0 } ( \tilde { \tau } ) = \frac { 1 } { | U ( n ) | } \int d \mu ( g ) \ t r _ { \mathcal { H } _ { 0 } } \left ( U ( g ) \tilde { q } ^ { L _ { 0 } - \frac { n } { 8 } } \right ) \. \\ \cdots \. \. \. \. \. \. \. \. \. \. \. \. \. \. \. \. \. \. \. \. \. \. \. \. \. \. \. \. \. \. \. \. \. \. \. \. \. \. \. \. \. \. \. \. \. \. \. \. \. \. \. \. \. \. \. \. \. \. \. \. \. \. \. \. \. \. \. \. \. \. \. \. \. \. \. \. \. \. \. \. \. \. \. \. \. \. \. \. \. \. \. \. \. \. \. \. \. \. \. \. \$$
The integral can be rewritten as an integral over the Cartan torus which as in section 2 we parameterise by Diag( e iθ 1 , . . . , e iθ n ). The trace is then given by
$$\text{tr} \mathcal { H } _ { 0 } \left ( U ( g ) \tilde { q } ^ { L _ { 0 } - \frac { n } { 8 } } \right ) = ( 2 \sin \frac { \theta _ { 1 } } { 2 } ) \cdots ( 2 \sin \frac { \theta _ { n } } { 2 } ) \frac { \vartheta _ { 3 } ( \tilde { \tau }, \frac { \theta _ { 1 } } { 2 \pi } ) \cdots \vartheta _ { 3 } ( \tilde { \tau }, \frac { \theta _ { n } } { 2 \pi } ) } { \vartheta _ { 1 } ( \tilde { \tau }, \frac { \theta _ { 1 } } { 2 \pi } ) \cdots \vartheta _ { 1 } ( \tilde { \tau }, \frac { \theta _ { n } } { 2 \pi } ) } \,. \\ \text{Tha individual macro on the terms is the way to information formula} \, \right )$$
The induced measure on the torus is (Weyl's integration formula)
$$& \frac { 1 } { | U ( n ) | } \int d \mu ( g ) f ( g ) = \frac { 1 } { ( 2 \pi ) ^ { n } n! } \int d \theta _ { 1 } \cdots d \theta _ { n } \prod _ { i < j } \left ( 2 \sin \frac { \theta _ { i } - \theta _ { j } } { 2 } \right ) ^ { 2 } f ( \text{Diag} ( e ^ { i \theta _ { 1 } }, \dots, e ^ { i \theta _ { n } } ) ) \, \ ( 5. 3 ) \\ &. \quad \, \, \,$$
where f is some class function on U n ( ). Therefore the partition function can be written as
$$Z _ { 0 0 } ( \tilde { \tau } ) & = \frac { 1 } { ( 2 \pi ) ^ { n } n! } \int d \theta _ { 1 } \cdots d \theta _ { n } \prod _ { i < j } \left ( 2 \sin \frac { \theta _ { i } - \theta _ { j } } { 2 } \right ) ^ { 2 } \prod _ { i = 1 } ^ { n } \left ( 2 \sin \frac { \theta _ { i } } { 2 } \frac { \vartheta _ { 3 } ( \tilde { \tau }, \frac { \theta _ { i } } { 2 \pi$$
The modular transformation of the theta-functions is well known,
$$\vartheta _ { 3 } & ( \tilde { \tau }, \frac { \theta } { 2 } ) = \sqrt { - i \tau } \, e ^ { i \pi \tau \left ( \frac { \theta } { 2 \pi } \right ) ^ { 2 } } \vartheta _ { 3 } \left ( \tau, \tau \frac { \theta } { 2 \pi } \right ) \\ \wedge \, \tau \, \wedge \, a \, \quad. \, \longmapsto \, i \pi \tau \, \underline { \theta } \, \cup ^ { 2 } \, \wedge \$$
where ˜ = τ -1 τ , and we obtain
$$\vartheta _ { 3 } ( \tilde { \tau }, \frac { \theta } { 2 } ) & = \sqrt { - i \tau } \, e ^ { i \pi \tau \left ( \frac { \theta } { 2 \pi } \right ) ^ { 2 } } \vartheta _ { 3 } ( \tau, \tau \frac { \theta } { 2 \pi } ) \\ \vartheta _ { 1 } ( \tilde { \tau }, \frac { \theta } { 2 } ) & = - i \sqrt { - i \tau } \, e ^ { i \pi \tau \left ( \frac { \theta$$
$$Z _ { 0 0 } ( \tilde { \tau } ) = \frac { 1 } { ( 2 \pi ) ^ { n } n! } \int d \theta _ { 1 } \cdots d \theta _ { n } \prod _ { i < j } \left ( 2 \sin \frac { \theta _ { i } - \theta _ { j } } { 2 } \right ) ^ { 2 } \prod _ { j = 1 } ^ { n } \left ( 2 \sin \frac { \theta _ { j } } { 2 \pi } \, \frac { i \vartheta _ { 3 } \left ( \tau, \tau \frac { \theta _ { j } }$$
Now we can expand the ratio of the theta-functions,
$$\sin \frac { \theta } { 2 \pi } \, \frac { \vartheta _ { 3 } ( \tau, \tau \frac { \theta } { 2 \pi } ) } { \vartheta _ { 1 } ( \tau, \tau \frac { \theta } { 2 \pi } ) } = - i \sin \frac { | \theta | } { 2 \pi } \, \frac { \vartheta _ { 3 } ( \tau, 0 ) } { \eta ^ { 3 } ( \tau ) } \sum _ { N \in Z } \frac { e ^ { i \tau | \theta | ( N + \frac { 1 } { 2 } ) } } { 1 + q ^ { N + \frac { 1 } { 2 } } } \quad \text{for } - 2 \pi \leq \theta \leq 2 \pi \, \quad ( 5. 8 )$$
to find
$$& \cdots \cdots \\ & Z _ { 0 0 } ( \tilde { \tau } ) = \int d \theta _ { 1 } \cdots d \theta _ { n } \sum _ { N _ { 1 }, \dots, N _ { n } \in \real { Z } } \frac { 1 } { ( 2 \pi ) ^ { n } n! } \prod _ { i < j } \left ( 2 \sin \frac { \theta _ { i } - \theta _ { j } } { 2 } \right ) ^ { 2 } \prod _ { j = 1 } ^ { n } \left ( 2 \sin \frac { | \theta _ { j } | } { 2 } \right ) \\ & \quad \times \left ( \frac { \vartheta _ { 3 } ( \tau, 0 ) } { \eta ^ { 3 } ( \tau ) } \right ) ^ { n } \prod _ { j = 1 } ^ { n } \frac { q ( N _ { j } + \frac { 1 } { 2 } ) \frac { | \theta _ { j } | } { 2 \pi } } { 1 + q ^ { N _ { j } + \frac { 1 } { 2 } } } \,. \quad ( 5. 9 ) \\ & \quad \text{The integrand is invariant under permutation of the $\theta$}, \text{therefore we can assume them to be}$$
The integrand is invariant under permutation of the θ j , therefore we can assume them to be ordered and multiply the expression by n !. After introducing the variables α j = θ j 2 π , we finally arrive at
$$Z _ { 0 0 } ( \tilde { \tau } ) & = \int _ { - \frac { 1 } { 2 } \leq \alpha _ { 1 } \leq \cdots \leq \alpha _ { n } \leq \frac { 1 } { 2 } } d \alpha _ { 1 } \cdots d \alpha _ { n } \sum _ { N _ { 1 }, \dots, N _ { n } \in Z } \prod _ { i < j } ( 2 \sin \pi ( \alpha _ { i } - \alpha _ { j } ) ) ^ { 2 } \prod _ { j = 1 } ^ { n } ( 2 \sin \pi | \alpha _ { j } | ) \\ & \quad \times \prod _ { j = 1 } ^ { n } \left ( \frac { \vartheta _ { 3 } ( \tau, 0 ) } { \eta ^ { 3 } ( \tau ) } \frac { q ^ { ( N _ { j } + \frac { 1 } { 2 } ) | \alpha _ { j } | } } { 1 + q ^ { N _ { j } + \frac { 1 } { 2 } } } \right ) \,. \quad ( 5. 1 0 ) \\ \text{We want to interpret this expression as an integral/sum over the bulk sectors labelled by the } \alpha _ { i }$$
We want to interpret this expression as an integral/sum over the bulk sectors labelled by the α j and N j ,
$$\L ^ { \prime \prime } _ { 9 }, \\ Z _ { 0 0 } ( \tilde { \tau } ) = \underset { - \frac { 1 } { 2 } \leq \alpha _ { 1 } \leq \cdots \leq \alpha _ { n } \leq \frac { 1 } { 2 } } { \int } d \alpha _ { 1 } \cdots d \alpha _ { n } \underset { N _ { 1 }, \dots, N _ { n } \in \mathbb { Z } } { \sum } \ S _ { \{ \alpha, N \} } \, \chi _ { \{ \alpha, N \} } ( q )$$
where the character of the corresponding representation is given by
$$& \chi _ { \{ \alpha, N \} } ( q ) = \prod _ { j = 1 } ^ { n } \left ( \frac { \vartheta _ { 3 } ( \tau, 0 ) } { \eta ^ { 3 } ( \tau ) } \frac { q ^ { ( N _ { j } + \frac { 1 } { 2 } ) | \alpha _ { j } | } } { 1 + q ^ { N _ { j } + \frac { 1 } { 2 } } } \right ) \. & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & && & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & &
& & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & \\ & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & - & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & ; & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & } & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & \ & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & _ & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & &. & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & . & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & &
{ & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & = & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & { & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & &. &. & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & &. & \\ & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & &$$
The coefficient that appears in front of the character,
$$S _ { \{ \alpha, N \} } = \prod _ { i < j } \left ( 2 \sin \pi ( \alpha _ { i } - \alpha _ { j } ) \right ) ^ { 2 } \prod _ { j = 1 } ^ { n } \left ( 2 \sin \pi | \alpha _ { j } | \right ) \,, \\. \quad. \quad \sim \,. \quad. \quad. \quad. \quad. \quad. \quad. \quad..$$
is interpreted as the coefficient of the disc one-point function of the corresponding bulk field in the presence of the boundary condition (0; 0 0) , (note that it does not depend on the N i ). We confirm this interpretation by an analysis of the limit of the boundary states overlap in the following subsection.
## 5.2 Limit of boundary state overlaps
For finite k , the modular S-transformation of the vacuum character reads
$$\Xi _ { 0, 0 } ^ { 0 } ( \tilde { q } ) = \sum _ { \Lambda, \lambda, \mu } S _ { ( 0 ; 0, 0 ) ( \Lambda ; \lambda, \mu ) } \, \Xi _ { \lambda, \mu } ^ { \Lambda } ( q )$$
where Λ , λ, µ are the labels of the bulk representation, and the sum must be performed taking care of identifications and selection rules. The modular S-matrix is given by
$$S _ { ( 0 ; 0, 0 ) ( \Lambda ; \lambda, \mu ) } = n ( n + 1 ) \, S _ { 0 \Lambda } ^ { s u ( n + 1 ) } S _ { 0 \lambda } ^ { s u ( n ) } S _ { 0 \mu } ^ { u ( 1 ) }$$
as a product of S-matrices for su ( n +1), su ( n ) and u (1), which read
$$S _ { 0 \Lambda } ^ { s u ( n + 1 ) } & = \frac { ( k + n + 1 ) ^ { - \frac { n } { 2 } } } { \sqrt { n + 1 } } \, \prod _ { 1 \leq i < j \leq n + 1 } \left ( \sum _ { 1 } ^ { j - 1 } \Lambda _ { k } + ( j - i ) } { k + n + 1 } \right ) \quad \left ( \sum _ { 1 } ^ { j - 1 } \lambda _ { k } + ( j - i ) \right )$$
$$S _ { 0 \mu } ^ { u ( 1 ) } & = \frac { 1 } { \sqrt { n ( n + 1 ) ( k + n + 1 ) } } \,. & \quad & \quad & \quad & ( 5. 1 8 ) \\ \intertext { w e a l u a t e $ S _ { 0 \lambda } ^ { s u ( n ) } $ for $ \lambda = \lambda ( \alpha ) $ given in $ ( 4. 1 ), $ and $ w e $ find }$$
$$S _ { 0 \lambda } ^ { s \bar { u } ( n ) } & = \frac { ( k + n + 1 ) ^ { \frac { 1 - n } { 2 } } } { \sqrt { n + 1 } } \, \prod _ { 1 \leq i < j \leq n } \left ( \sum _ { \substack { 2 \sin \pi \frac { k = i } { k + n + 1 } \\ k + n + 1 } } ^ { j - 1 } \right ) ^$$
We now evaluate S su ( n ) 0 λ for λ = λ α ( ) given in (4.1), and we find
$$S _ { 0 \lambda ( \alpha ) } ^ { \text{su} ( n ) } & = \frac { ( k + n + 1 ) ^ { \frac { 1 - n } { 2 } } } { \sqrt { n } } \prod _ { 1 \leq i < j \leq n } \left ( 2 \sin \pi ( \alpha _ { j } - \alpha _ { i } ) + \mathcal { O } ( 1 / k ) \right ) \,. \quad \quad \quad$$
Similarly we evaluate S su ( n +1) 0Λ( α,N ) for Λ( α, N ) given in (4.5), and we arrive at
$$S _ { 0 \Lambda ( \alpha, N ) } ^ { \mathfrak { u } ( n + 1 ) } & = \frac { ( k + n + 1 ) ^ { - \frac { n } { 2 } } } { \sqrt { n + 1 } } \prod _ { 1 \leq i < j \leq n } \left ( 2 \sin \pi ( \alpha _ { j } - \alpha _ { i } ) \right ) \prod _ { i = 1 } ^ { n } \$$
where the leading term is independent of the N j . Our final expression for the S-matrix is then
$$S _ { ( 0 ; 0, 0 ) ( \Lambda ( \alpha, N ) ; \lambda ( \alpha ), \mu ( \alpha ) ) } = ( k + n + 1 ) ^ { - n } \, S _ { \{ \alpha, N \} } \left ( 1 + \mathcal { O } ( 1 / k ) \right )$$
where S { α,N } is the coefficient that we obtained from the modular transformation of the limit of Z 00 (see (5.13)). We want to reparameterise the sum over Λ , λ and µ in (5.14) by α j and N j . The sum over λ and µ can be replaced by an integral for large k , and when we do a variable transformation to α j , we get a factor n k ( + n +1) n from the variable transformation. Because of the selection rules not all combinations of λ and µ are allowed, which reduces the integral by a factor of 1 /n , so that we find
$$\sum _ { \stackrel { \lambda, \mu } { \text{allowed} } } \longrightarrow ( k + n + 1 ) ^ { n } \underset { - \frac { 1 } { 2 } \leq \alpha _ { 1 } \leq \cdots \leq \alpha _ { n } \leq \frac { 1 } { 2 } } { \int } d \alpha _ { 1 } \cdots d \alpha _ { n } \.$$
We can then write down the limit of the modular transformed boundary partition function Z 00 as
$$Z _ { 0 0 } ( \tilde { \tau } ) = \lim _ { k \to \infty } \Xi _ { 0, 0 } ^ { 0 } ( \tilde { q } )$$
$$= \lim _ { k \to \infty } \sum _ { \Lambda, \lambda, \mu } S _ { ( 0 ; 0, 0 ) ( \Lambda ; \lambda, \mu ) } \, \Xi _ { \lambda, \mu } ^ { \Lambda } ( q ) \, & \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \$$
$$= \underset { - \frac { 1 } { 2 } \leq \alpha _ { 1 } \leq \cdots \leq \alpha _ { n } \leq \frac { 1 } { 2 } } { \overset { \cdots, \cdots r } { \int } } d \alpha _ { 1 } \cdots d \alpha _ { n } \sum _ { N _ { 1 }, \dots, N _ { n } \in Z } S _ { \{ \alpha, N \} } \, \chi _ { \{ \alpha, N \} } ( q )$$
where χ { α,N } is the limit of the character of the representation (Λ( α, N ); λ α , µ α ( ) ( )) when α is kept fixed. By comparison with the result of the modular transformation of the limit of Z 00 in (5.10) we can read off the character χ { α,N } , which confirms our identification in eq. (5.12). Note also that the leading exponent of the character χ { α,N } (see (5.12)),
$$\chi _ { \{ \alpha, N \} } = q ^ { - \frac { n } { 8 } + \sum _ { j } ^ { + } | \alpha _ { j } | ( N _ { j } + \frac { 1 } { 2 } ) + \sum _ { j } ^ { - } ( 1 - | \alpha _ { j } | ) ( | N _ { j } | - \frac { 1 } { 2 } ) } + \cdots$$
confirms the conformal weight for the representation (Λ( α, N ); λ α ( )) , µ ( α ) that we determined in (4.8). This gives another evidence that our prescription for the shifts of the conformal weights that we used in section 4.2 is correct.
We arrive therefore at our final result that the primary spectrum of the limit theory is labelled by the continuous parameters α j as well as the integers N j . The N = 2 W n +1 -characters of the corresponding representations are given in (5.12).
## A Decomposition of representations
A representation of su ( n +1) labelled by the weight Λ = (Λ 1 , . . . , Λ ) (with Dynkin labels Λ ) n i decomposes into representations ( λ, µ ) of su ( n ) ⊕ u (1) embedded as described in (2.3) in the following way (see e.g. the appendix of [15]),
$$\Lambda & \to \bigoplus _ { a _ { 1 } = 0 } ^ { \Lambda _ { 1 } } \dots \bigoplus _ { a _ { n } = 0 } ^ { \Lambda _ { n } } \left ( \left ( \Lambda _ { 1 } - a _ { 1 } + a _ { 2 }, \dots, \Lambda _ { n - 1 } - a _ { n - 1 } + a _ { n } \right ), \, - | \Lambda | + ( n + 1 ) \sum _ { i } a _ { i } \right ) \,. \quad ( \Lambda _ { 1 } ) \\ \text{--} \quad \dots \quad \longrightarrow \, \dots \, \cdot \quad \dots \, \cdot \quad \dots \, \dots \, \dots \,. \quad \dots$$
Here, | Λ = | ∑ j j Λ j is the number of boxes of the corresponding Young diagram. As an example we test whether the representation ( λ α , µ α ( ) ( )) (defined in (4.1)) is contained in the su ( n +1) representation Λ( α, N ) given in (4.5). If it occurs on the right hand side of (A.1),
the corresponding numbers a i are determined by the following equations:
$$\text{the corresponding numbers} \, a _ { i } \, \text{ are determined by the following equations: } \\ & N _ { 1 } - N _ { 2 } - a _ { 1 } + a _ { 2 } = 0 \\ & \vdots \\ & N _ { m - 1 } - N _ { m } - a _ { m - 1 } + a _ { m } = 0 \\ - ( k + n + 1 ) \alpha _ { m + 1 } + N _ { m } + N - a _ { m } + a _ { m + 1 } = 0 \\ ( k + n + 1 ) ( 2 \alpha _ { m + 1 } - \alpha _ { m + 2 } ) + N _ { m + 1 } - N - a _ { m + 1 } + a _ { m + 2 } = 0 \\ ( k + n + 1 ) ( - \alpha _ { m + 1 } + 2 \alpha _ { m + 2 } - \alpha _ { m + 3 } ) + N _ { m + 2 } - N _ { m + 1 } - a _ { m + 2 } + a _ { m + 3 } = 0 \\ & \vdots \\ ( k + n + 1 ) ( - \alpha _ { n - 2 } + 2 \alpha _ { n - 1 } - \alpha _ { n } ) + N _ { n - 1 } - N _ { n - 2 } - a _ { n - 1 } + a _ { n } = 0 \\ - | \Lambda ( \alpha, N ) | - ( k + n + 1 ) \sum _ { j } \alpha _ { j } + ( n + 1 ) \sum _ { j } a _ { j } = 0 \. \\ \text{The last equation comes from comparing } \mu ( \alpha ) \text{ with the } u ( 1 ) \text{ entry of } ( A. 1 ). \text{ To proceed we} \\ \text{evaluate} | \Lambda ( \alpha, N ) |, \text{ and we find}$$
The last equation comes from comparing µ α ( ) with the u (1) entry of (A.1). To proceed we evaluate | Λ( α, N ) , | and we find
$$| \Lambda ( \alpha, N ) | = \begin{cases} ( k + n + 1 ) \left ( - \sum _ { i } \alpha _ { i } + ( n + 1 ) \alpha _ { n } \right ) + ( n + 1 ) N _ { n } & m \leq n - 1 \\ ( k + n + 1 ) \left ( - \sum _ { i } \alpha _ { i } \right ) + ( n + 1 ) \sum _ { j } N _ { j } & m = n \end{cases} \\ \text{Let us first consider the case $m=n$. Then the last equation of (A.2) becomes simply}$$
Let us first consider the case m = n . Then the last equation of (A.2) becomes simply
$$( n + 1 ) \sum _ { j } a _ { j } - ( n + 1 ) \sum _ { j } N _ { j } = 0$$
and together with the remaining equations of (A.2) it follows that
$$a _ { i } = N _ { i } \ \text{ for } m = n \.$$
Let us now consider the case m ≤ n -1. Then the last equation of (A.2) implies
$$\sum _ { j } a _ { j } - ( k + n + 1 ) \alpha _ { n } - N _ { n } = 0 \.$$
As one can check straightforwardly, the solution to this and the remaining equations of (A.2) is given by
$$a _ { 1 } = N _ { 1 } \, \ \cdots \, \ a _ { m } = N _ { m } \, \ a _ { m + 1 } = \Lambda _ { m + 1 } ( \alpha, N ) - N _ { m + 1 } \, \ \cdots \, \ a _ { n } = \Lambda _ { n } ( \alpha, N ) - N _ { n } \. \ \ ( \text{A.7} )$$
Comparing with (A.5) we see that this solution also applies in the case m = n . The condition on the coefficients a j is 0 ≤ a j ≤ Λ ( j α, N ). For large k one therefore concludes that the representation ( λ α , µ α ( ) ( )) appears in the decomposition of Λ( α, N ) precisely if N i ≥ 0.
## References
- [1] A. Campoleoni, S. Fredenhagen, S. Pfenninger and S. Theisen, 'Asymptotic symmetries of three-dimensional gravity coupled to higher-spin fields' , JHEP 1011, 007 (2010) , arxiv:1008.4744 .
- [2] M. Henneaux and S.-J. Rey, 'Nonlinear W infinity as Asymptotic Symmetry of Three-Dimensional Higher Spin Anti-de Sitter Gravity' , JHEP 1012, 007 (2010) , arxiv:1008.4579 .
- [3] S. Prokushkin and M. A. Vasiliev, 'Higher spin gauge interactions for massive matter fields in 3-D AdS space-time' , Nucl.Phys. B545, 385 (1999) , hep-th/9806236 .
- [4] M. R. Gaberdiel and R. Gopakumar, 'An AdS 3 Dual for Minimal Model CFTs' , Phys.Rev. D83, 066007 (2011) , arxiv:1011.2986 .
- [5] T. Creutzig, Y. Hikida and P. B. Rønne, 'Higher spin AdS 3 supergravity and its dual CFT' , JHEP 1202, 109 (2012) , arxiv:1111.2139 .
- [6] C. Candu and M. R. Gaberdiel, 'Supersymmetric holography on AdS 3 ' , JHEP 1309, 071 (2013) , arxiv:1203.1939 .
- [7] C. Candu and M. R. Gaberdiel, 'Duality in N=2 Minimal Model Holography' , JHEP 1302, 070 (2013) , arxiv:1207.6646 .
- [8] M. R. Gaberdiel and R. Gopakumar, 'Large N=4 Holography' , JHEP 1309, 036 (2013) , arxiv:1305.4181 .
- [9] M. R. Gaberdiel and R. Gopakumar, 'Higher Spins & Strings' , arxiv:1406.6103 .
- [10] Y. Kazama and H. Suzuki, 'Characterization of N=2 Superconformal Models Generated by Coset Space Method' , Phys. Lett. B216, 112 (1989) .
- [11] Y. Kazama and H. Suzuki, 'New N=2 superconformal field theories and superstring compactification' , Nucl. Phys. B321, 232 (1989) .
- [12] M. R. Gaberdiel and P. Suchanek, 'Limits of Minimal Models and Continuous Orbifolds' , JHEP 1203, 104 (2012) , arxiv:1112.1708 .
- [13] S. Fredenhagen and C. Restuccia, 'The geometry of the limit of N=2 minimal models' , J.Phys. A46, 045402 (2013) , arxiv:1208.6136 .
- [14] C. Restuccia, 'Limit theories and continuous orbifolds' , arxiv:1310.6857 .
- [15] M. R. Gaberdiel and M. Kelm, 'The Continuous Orbifold of N=2 Minimal Model Holography' , arxiv:1406.2345 .
- [16] P. Goddard, A. Kent and D. I. Olive, 'Virasoro algebras and coset space models' , Phys. Lett. B152, 88 (1985) .
- [17] P. Goddard, A. Kent and D. I. Olive, 'Unitary Representations of the Virasoro and Supervirasoro Algebras' , Commun. Math. Phys. 103, 105 (1986) .
- [18] J. L. Cardy, 'Boundary conditions, fusion rules and the Verlinde formula' , Nucl. Phys. B324, 581 (1989) .
- [19] S. Fredenhagen and V. Schomerus, 'D-branes in coset models' , JHEP 0202, 005 (2002) , hep-th/0111189 .
- [20] S. Fredenhagen and V. Schomerus, 'On boundary RG-flows in coset conformal field theories' , Phys. Rev. D67, 085001 (2003) , hep-th/0205011 .
- [21] S. Fredenhagen, 'Organizing boundary RG flows' , Nucl. Phys. B660, 436 (2003) , hep-th/0301229 .
- [22] S. Fredenhagen, C. Restuccia and R. Sun, 'The limit of N=(2,2) superconformal minimal models' , JHEP 1210, 141 (2012) , arxiv:1204.0446 .
- [23] M. R. Gaberdiel, R. Gopakumar, T. Hartman and S. Raju, 'Partition Functions of Holographic Minimal Models' , JHEP 1108, 077 (2011) , arxiv:1106.1897 .
- [24] J. Fuchs and C. Schweigert, 'Symmetries, Lie algebras and representations: A graduate course for physicists' .
- [25] Y. Sugawara, 'Thermodynamics of Superstring on Near-extremal NS5 and Effective Hagedorn Behavior' , JHEP 1210, 159 (2012) , arxiv:1208.3534 .
- [26] I. Runkel and G. Watts, 'A Nonrational CFT with c = 1 as a limit of minimal models' , JHEP 0109, 006 (2001) , hep-th/0107118 .
- [27] S. Fredenhagen and V. Schomerus, 'Boundary Liouville theory at c = 1 ' , JHEP 0505, 025 (2005) , hep-th/0409256 .
- [28] S. Fredenhagen and D. Wellig, 'A common limit of super Liouville theory and minimal models' , JHEP 0709, 098 (2007) , arxiv:0706.1650 .
- [29] S. Fredenhagen, 'Boundary conditions in Toda theories and minimal models' , JHEP 1102, 052 (2011) , arxiv:1012.0485 . | null | [
"Stefan Fredenhagen",
"Cosimo Restuccia"
] | 2014-08-02T20:27:38+00:00 | 2014-08-02T20:27:38+00:00 | [
"hep-th"
] | The large level limit of Kazama-Suzuki models | Limits of families of conformal field theories are of interest in the context
of AdS/CFT dualities. We explore here the large level limit of the
two-dimensional N=(2,2) superconformal W_{n+1} minimal models that appear in
the context of the supersymmetric higher-spin AdS3/CFT2 duality. These models
are constructed as Kazama-Suzuki coset models of the form SU(n+1)/U(n). We
determine a family of boundary conditions in the limit theories, and use the
modular bootstrap to obtain the full bulk spectrum of N=2 super-W_{n+1}
primaries in the theory. We also confirm the identification of this limit
theory as the continuous orbifold C^n/U(n) that was discussed recently. |
1408.0418v1 | ## McCool groups of toral relatively hyperbolic groups
Vincent Guirardel and Gilbert Levitt
August 5, 2014
## Abstract
The outer automorphism group Out( G ) of a group G acts on the set of conjugacy classes of elements of G . McCool proved that the stabilizer Mc( C ) of a finite set of conjugacy classes is finitely presented when G is free. More generally, we consider the group Mc( H ) of outer automorphisms Φ of G acting trivially on a family of subgroups H i , in the sense that Φ has representatives α i with α i equal to the identity on H i .
When G is a toral relatively hyperbolic group, we show that these two definitions lead to the same subgroups of Out( G ), which we call 'McCool groups'of G. We prove that such McCool groups are of type VF (some finite index subgroup has a finite classifying space). Being of type VF also holds for the group of automorphisms of G preserving a splitting of G over abelian groups.
We show that McCool groups satisfy a uniform chain condition: there is a bound, depending only on G , for the length of a strictly decreasing sequence of McCool groups of G . Similarly, fixed subgroups of automorphisms of G satisfy a uniform chain condition.
## 1 Introduction
Mapping class groups of punctured surfaces may be viewed as subgroups of Out( F n ) for some n (with F n denoting the free group of rank n ). Indeed, they consist of automorphisms of F n fixing conjugacy classes corresponding to punctures. More generally, the group of automorphisms of F n fixing a finite number of conjugacy classes was studied by McCool, who proved in particular that such groups are finitely presented [McC75]. We therefore define:
Definition 1.1. Let G be a group. Let C be a set of conjugacy classes [ c i ] of elements of G . We denote by Mc( ) C the subgroup of Out( G ) consisting of outer automorphisms fixing each [ c i ] . If C is finite, we say that Mc( ) C is an elementary McCool group of G (or of Out( G ) ).
Work on automorphisms suggests a more general definition:
Definition 1.2. Let G be a group. Let H = { H i } be an arbitrary family of subgroups of G . We say that ϕ ∈ Aut( G ) , and its image Φ ∈ Out( G ) , act trivially on H if ϕ acts on each H i as conjugation by some g i ∈ G . Note that Φ acts trivially if and only if it has representatives ϕ i ∈ Aut( G ) with ϕ i equal to the identity on H i .
We denote by Mc( H ) , or Mc ( G H ) , the subgroup of Out( G ) consisting of all Φ acting trivially on H .
If H is a finite family of finitely generated subgroups, we say that Mc( H ) is a McCool group of G (or of Out( G ) ).
Elementary McCool groups correspond to McCool groups with H a finite family of cyclic groups. Mc( H ) does not change if we replace the H i 's by conjugate subgroups, so it is really associated to a family of conjugacy classes of subgroups.
For a topological analogy, one may think of Mc( H ) as the group of automorphisms of G = π 1 ( X ) induced by homeomorphisms of X equal to the identity on subspaces Y i with π 1 ( Y i ) = H i .
McCool groups are relevant for automorphisms for the following reason (see [GL12]). Consider a splitting of a group ˆ G as a graph of groups in which G is a vertex group, and the H i 's are the incident edge groups. Then any element of Mc G ( H ) extends 'by the identity' to an automorphism of ˆ . G Topologically, if X is a vertex space in a graph of spaces ˆ , X and edge spaces are attached to subspaces Y i ⊂ X , then any homeomorphism of X equal to the identity on the Y i 's extends to ˆ X by the identity.
In this paper we will consider McCool groups when G is a toral relatively hyperbolic group : G is torsion-free, and hyperbolic relative to a finite set of finitely generated abelian subgroups. This includes in particular torsion-free hyperbolic groups, limit groups, and groups acting freely on R n -trees.
We will show (Corollary 1.6) that in this case any Mc( H ) is an elementary McCool group Mc( C ); in other words, it is equivalent for a subgroup of Out( G ) to be an elementary McCool group Mc( C ), or to be a McCool group Mc( H ) with H a finite family of finitely generated groups, or to be Mc( H ) with H arbitrary. We will not always make the distinction in the statements given below.
It was proved by McCool [McC75] that (elementary) McCool groups of a free group are finitely presented. Culler-Vogtmann [CV86, Corollary 6.1.4] proved that they are of type VF : they have a finite index subgroup with a finite classifying space (i.e. there exists a classifying space which is a finite complex). We proved in [GL12] that Out( G ) is of type VF if G is toral relatively hyperbolic (in particular, Out( G ) is virtually torsion-free). Our first main results extend this to certain naturally defined subgroups of Out( G ).
Theorem 1.3. If G is a toral relatively hyperbolic group, then any McCool group Mc( H ⊂ ) Out( G ) is of type VF.
Theorem 1.4. If G is a toral relatively hyperbolic group, and T is a simplicial tree on which G acts with abelian edge stabilizers, then the group of automorphisms Out( T ) ⊂ Out( G ) leaving T invariant is of type VF.
Our most general result in this direction (Corollary 6.3) combines these two theorems; it implies in particular that Mc( H ∩ ) Out( T ) is of type VF if T is as above and H is any family of subgroups, each of which fixes a point in T .
Remark. Some of these results may be extended to groups which are hyperbolic relative to virtually polycyclic subgroups, but with the weaker conclusion that the automorphism groups are of type F ∞ (see [GLa]). On the other hand, one can show that, if there exists a hyperbolic group which is not residually finite, then there exists a hyperbolic group with Out( G ) not virtually torsion-free (hence not VF).
Our second main result is the following:
Theorem 1.5. Let G be a toral relatively hyperbolic group. McCool groups of G satisfy a uniform chain condition: there exists C = C G ( ) such that, if
$$\text{Mc} ( \mathcal { H } _ { 0 } ) \supsetneq \text{Mc} ( \mathcal { H } _ { 1 } ) \supsetneq \dots \supsetneq \text{Mc} ( \mathcal { H } _ { p } )$$
is a strictly decreasing chain of McCool groups in Out( G ) , then p ≤ C .
This is based, among other things, on the vertex finiteness proved in [GL13]: if G is toral relatively hyperbolic, then all vertex groups occurring in splittings of G over abelian groups lie in finitely many isomorphism classes.
The chain condition, proved in Section 5 for McCool groups Mc( H ) with H a finite family of finitely generated groups, implies:
Corollary 1.6. Let G be a toral relatively hyperbolic group. If H is a (possibly infinite) family of (possibly infinitely generated) subgroups H i ⊂ G , there exists a finite set of conjugacy classes C such that Mc( H ) = Mc( ) C . In particular, any Mc( H ) is a McCool group, and any McCool group is an elementary McCool group Mc( ) C .
The chain condition also implies that no McCool group Mc( H ⊂ ) Out( G ) is conjugate to a proper subgroup. Note, however, that McCool groups may fail to be co-Hopfian (they may be isomorphic to proper subgroups). To illustrate the variety of McCool groups, we show:
Proposition 1.7. Out( F n ) contains infinitely many non-isomorphic McCool groups if n ≥ 4 ; it contains infinitely many non-conjugate McCool groups if n ≥ 3 .
It may be shown that the bounds on n are sharp (see the appendix). We will also show in the appendix that, if G is a torsion-free one-ended hyperbolic group, then Out( G ) only contains finitely many McCool groups up to conjugacy.
Say that J ⊂ G is a fixed subgroup if there is a family of automorphisms α i ∈ Aut( G ) such that J = ∩ i Fix α i , with Fix α = { g ∈ G | α g ( ) = g } . The chain condition also implies:
Theorem 1.8. Let G be a toral relatively hyperbolic group. There is a constant c = ( c G ) such that, if J 0 /notsubsetoreql J 1 /notsubsetoreql . . . /notsubsetoreql J p is a strictly ascending chain of fixed subgroups, then p ≤ c .
This was proved by Martino-Ventura [MV04] for G free, with c F ( n ) = 2 n . In [GLb], we will apply Theorems 1.3 and 1.8 to the study of stabilizers for the action of Out( G ) on spaces of R -trees.
As explained above, one does not get new groups by allowing the set C in Definition 1.1 to be infinite, or by considering arbitrary subgroups as in Definition 1.2. The following definition provides a genuine generalization.
Definition 1.9. Let G be a group, and C a finite set of conjugacy classes [ c i ] . We write C -1 for the set of classes [ c -1 i ] . Let ̂ Mc( ) C be the subgroup of Out( G ) consisting of automorphisms leaving C ∪ C -1 globally invariant; it contains Mc( ) C as a normal subgroup of finite index. We say that ̂ Mc( ) C is an extended elementary McCool group of G .
More generally, if H is a finite family of subgroups, one can define finite extensions of Mc( H ) by allowing the H i 's to be permuted, or the action on H i to be only 'almost' trivial.
Proposition 1.10. Given a toral relatively hyperbolic group G , there exists a number C such that, if a subgroup ̂ M ⊂ Out( G ) contains a group Mc( H ) with finite index, then the index [ M : Mc( H )] is bounded by C .
̂ In particular, for C finite, the index of Mc( ) C in ̂ Mc( ) C is bounded by a constant depending only on G .
It follows that extended elementary McCool groups satisfy a uniform chain condition as in Theorem 1.5 (see Corollary 6.4). We also have:
Corollary 1.11. Let G be a toral relatively hyperbolic group. Let A be any subgroup of Out( G ) , and let C A be the (possibly infinite) set of conjugacy classes of G whose A -orbit is finite. The image of A in the group of permutations of C A is finite, and its order is bounded by a constant depending only on G . In other words, there is a subgroup A 0 ⊂ A of bounded finite index such that every conjugacy class in G is fixed by A 0 or has infinite orbit under A 0 .
When G is free, one may take for A 0 the intersection of A with a fixed finite index subgroup of Out( G ) (independent of A ) [HM13].
One may also consider subgroups of Aut( G ).
Definition 1.12. Let H be a family of (conjugacy classes of) subgroups, and H 0 < G another subgroup. Let Ac( H , H 0 ) ⊂ Aut( G ) be the group of automorphisms acting trivially on H (in the sense of Definition 1.2) and fixing the elements of H 0 .
Proposition 1.13. If G is a non-abelian toral relatively hyperbolic group, then Ac( H , H 0 )
is an extension
$$1 \to K \to \text{Ac} ( \mathcal { H }, H _ { 0 } ) \to \text{Mc} ( \mathcal { H } ^ { \prime } ) \to 1$$
where Mc( H ′ ) ⊂ Out( G ) is a McCool group, and K is the centralizer of H 0 (isomorphic to G or to Z n for some n ≥ 0 ).
Corollary 1.14. Theorems 1.3 and 1.5 also hold in Aut( G ) : groups of the form Ac( H , H 0 ) are of type VF and satisfy a uniform chain condition.
Theorems 1.3 and 1.4 are proved in Section 3, and Theorem 1.5 is proved in Section 5. All other results are proved in Section 6.
Acknowledgements The first author acknowledges support from ANR-11-BS01-013, the Institut Universitaire de France, and from the Lebesgue center of mathematics. The second author acknowledges support from ANR-10-BLAN-116-03.
## 2 Preliminaries
In this paper, G will always denote a toral relatively hyperbolic group. Any non-trivial abelian subgroup A of G is contained in a unique maximal abelian subgroup. The maximal abelian subgroups are malnormal ( G is CSA), finitely generated, and there are finitely many non-cyclic ones up to conjugacy. Two subgroups of A which are conjugate in G are equal.
The center of a group H will be denoted by Z H ( ). We write N K ( H ) for the normalizer of a group H in a group K , with N H ( ) = N G ( H ). Centralizers are denoted by Z K ( H ).
We say that Φ ∈ Out( G ) preserves a subgroup H , or leaves H invariant, if its representatives ϕ ∈ Aut( G ) map H to a conjugate. If ϕ ∈ Aut( G ) equals the identity on H , we say that it fixes H .
Definition 2.1. If H is a family of subgroups, we let Out( G ; H ⊂ ) Out( G ) be the group of automorphisms preserving each H ∈ H , and ̂ Out( G ; H ) the group of automorphisms preserving H globally (possibly permuting groups in H ).
We denote by
$$O u t ( G ; \mathcal { H } ^ { ( t ) } ) = \text{Mc} ( \mathcal { H } ) \subset O u t ( G )$$
the group of automorphisms acting trivially on groups in H (as in Definition 1.2).
We write
$$\text{Out} ( G ; \mathcal { H } ^ { ( t ) }, \mathcal { K } ) \coloneqq \text{Out} ( G ; \mathcal { H } ^ { ( t ) } ) \cap \text{Out} ( G ; \mathcal { K } ),$$
and
$$O u t ( G ; \mathcal { H }, \mathcal { K } ) \coloneqq O u t ( G ; \mathcal { H } \cup \mathcal { K } ).$$
Remark. Out( G ; H (t) ) and Mc( H ) denote the same group. The notation Out( G ; H (t) ) is more flexible and will be convenient in Section 3.
We will often view a set of conjugacy classes C = [ { c i ] } as a family of cyclic subgroups H = {〈 c i 〉} , since Mc( C ) = Mc( H ). Note that Out( G ; H ) is larger than Mc( C ) = Mc( H ) since c i may sent to a conjugate of c -1 i .
For example, suppose that H < G = Z n is the subgroup generated by the first k basis elements, and H = { H } . Then Out( G ) = GL n, ( Z ); the group Out( G ; H ) consists of block triangular matrices, and Out( G ; H (t) ) = Mc( H ) is the group of matrices fixing the first k basis vectors.
̂ Given a family H and a subgroup J , we denote by H | J the J -conjugacy classes of subgroups of J conjugate to a group of H . We view H | J as a family of subgroups of J , each defined up to conjugacy in J . In the next subsection we will define a closely related notion H || J when J = G v is a vertex stabilizer in a tree.
There are inclusions Out( G ; H (t) ) ⊂ Out( G ; H ⊂ ) ̂ Out( G ; H ). Note that Out( G ; H (t) ) has finite index in Out( G ; H ) and Out( G ; H ) if H is a finite family of cyclic groups.
If C is a set of conjugacy classes [ c i ], viewed as a set of cyclic subgroups, C | J is the set of J -conjugacy classes of elements of J representing elements in C .
Now suppose that subgroups of J which are conjugate in G are conjugate in J ; this holds for instance if J is malnormal (in particular if J is a free factor), and also if J is abelian. In this case we may view H | J as a subset of H ; it is finite if H is.
## 2.1 Trees and splittings
A tree will be a simplicial tree T with an action of G without inversions. A tree T is relative to H (resp. to C ) if any group in H (resp. any element representing a class in C ) fixes a point in T .
Two trees are considered to be the same if there is a G -equivariant isomorphism between them. In this paper, all trees will have abelian edge stabilizers.
Unless mentioned otherwise, we assume that the action is minimal (there is no proper invariant subtree). We usually assume that there is no redundant vertex (if T \ { x } has two components, some g ∈ G interchanges them). If a finitely generated subgroup H ⊂ G acts on T with no global fixed point, there is a smallest H -invariant subtree called the minimal subtree of H .
The tree T is trivial if there is a global fixed point (minimality then implies that T is a point). An element of G , or a subgroup, is elliptic if it fixes a point in T . Conjugates of elliptic subgroups are elliptic, so we also consider elliptic conjugacy classes.
An action of G on a tree T gives rise to a splitting of G , i.e. a decomposition of G as the fundamental group of the quotient graph of groups Γ = T/G . Conversely, T is the Bass-Serre tree of Γ. All definitions given here apply to both splittings and trees. In particular, a splitting is relative to H if every H ∈ H has a conjugate contained in a vertex group.
Minimality implies that the graph Γ is finite. There is a one-to-one correspondence between vertices (resp. edges) of Γ and G -orbits of vertices (resp. edges) of T . We denote by V the set of vertices of Γ, and by G v the group carried by a vertex v ∈ V . We also view v as a vertex of T with stabilizer G v . Similarly, we denote by e an edge of Γ or T , by G e the corresponding group (always abelian in this paper), and by E the set of non-oriented edges of Γ.
Edge groups being abelian, hence relatively quasiconvex, every vertex group G v is toral relatively hyperbolic (see for instance [GL12]).
The edge groups carried by edges of Γ incident to a given vertex v will be called the incident edge groups of G v . We denote by Inc v the family of incident edge groups (we view it as a finite family of subgroups of G v , each well-defined up to conjugacy).
If H is a finite family of subgroups of G , and v is a vertex stabilizer of T , we denote by H || G v the family of subgroups H ⊂ G v which are conjugate to a group of H and fix no other point in T . Two such groups are conjugate in G v if they are conjugate in G ([GL12], Lemma 2.2 where the notation H | G v is used instead), so we may also view H || G v as a subset of H (it contains some of the groups of H having a conjugate in G v ), or as a finite family of subgroups of G v , each well-defined up to conjugacy ( H || G v may be smaller than H | G v because we do not include subgroups of edge groups).
Any splitting of G v relative to Inc v extends to a splitting of G . If T is relative to H , any splitting of G v relative to Inc v ∪H || G v is relative to H | G v and extends to a splitting of G relative to H .
If C is a set of conjugacy classes, we view C || G v as the subset of C consisting of classes having a representative that fixes v and no other vertex. In particular, C || G v is finite if C is.
A tree T ′ is a collapse of T if it is obtained from T by collapsing each edge in a certain G -invariant collection to a point; conversely, we say that T refines T ′ . In terms of graphs of groups, one passes from Γ = T/G to Γ ′ = T /G ′ by collapsing edges; for each vertex v ′ ∈ Γ , the vertex group ′ G v ′ is the fundamental group of the graph of groups Γ v ′ occuring as the preimage of v ′ in Γ.
All maps between trees will be G -equivariant. Given two trees T and T ′ , we say that T dominates T ′ if there is a map f : T → T ′ , or equivalently if every subgroup which is elliptic in T is also elliptic in T ′ ; in particular, T dominates any collapse T ′ . We sometimes say that f is a domination map. Minimality implies that it is onto.
Two trees belong to the same deformation space if they dominate each other. In other words, a deformation space D is the set of all trees having a given family of subgroups as their elliptic subgroups. We say that D dominates D ′ if trees in D dominate those in D ′ .
## 2.2 JSJ decompositions [GL09, GL10]
Let H be a family of subgroups of G . Recall that a tree T is relative to H if all groups of H are elliptic in T .
We denote by H + ab the family obtained by adding to H all non-cyclic abelian subgroups of G .
/negationslash
The group G is freely indecomposable relative to H if it does not split over the trivial group relative to H ; equivalently, G cannot be written non-trivially as A ∗ B with every group of H contained in a conjugate of A or B (if H is trivial, we also require G = Z , as we consider Z as freely decomposable). Non-cyclic abelian groups being one-ended, being freely indecomposable relative to H is the same as relative to H + ab .
Let A be another family of subgroups (in this paper, A consists of the trivial group or is the family of all abelian subgroups). Once H and A are fixed, we only consider trees relative to H , with edge stabilizers in A . We also assume that trees are minimal.
Atree T (with edge stabilizers in A , relative to H ) is universally elliptic (with respect to H ) if its edge stabilizers are elliptic in every tree. It is a JSJ tree if, moreover, it dominates every universally elliptic tree. The set of JSJ trees is called the JSJ deformation space (over A relative to H ). All JSJ trees have the same vertex stabilizers, provided one restricts to stabilizers not in A .
When A consists of the trivial group, the JSJ deformation space is called the Grushko deformation space (relative to H ). The group G has a relative Grushko decomposition G = G 1 ∗· · · ∗ G n ∗ F p , with F p free, every H ∈ H contained in some G i (up to conjugacy), and G i freely indecomposable relative to H | G i . Vertex stabilizers of the relative Grushko deformation space D are precisely conjugates of the G i 's. The deformation space is trivial (it only contains the trivial tree) if and only if G is freely indecomposable relative to H . Writing G = { G ,. . . , G 1 n } , note that Out( G ; H ∪ G ) has finite index in Out( G ; H ), because automorphisms in Out( G ; H ) leave D invariant and therefore permute the G i 's (up to conjugacy).
Now suppose that A consists of all abelian subgroups, and G is freely indecomposable relative to a family H . Then [GL10, 11.1] the JSJ deformation space relative to H + ab contains a preferred tree T can ; this tree is invariant under Out( ̂ G ; H ) (the group of automorphisms preserving H ).
It is obtained as a tree of cylinders . We describe this construction in the case that will be needed here (see Proposition 6.3 of [GL11] for details). Let T be any tree with non-trivial abelian edge stabilizers, relative to all non-cyclic abelian subgroups. Say that two edges e, e ′ belong to the same cylinder if their stabilizers commute. Cylinders are subtrees intersecting in at most one point.
The tree of cylinders T c is defined as follows. It is bipartite, with vertex set V 0 ∪ V 1 . Vertices in V 0 are vertices of T belonging to at least two cylinders. Vertices in V 1 are cylinders of T . A vertex v ∈ V 0 is joined to a vertex Y ∈ V 1 if v (viewed as a vertex of T ) belongs to Y (viewed as a subtree of T ). Equivalently, one obtains T c from T by replacing each cylinder Y by the cone on its boundary (points of Y belonging to at least one other cylinder).
The tree T c only depends on the deformation space D containing T , and it belongs to D . Like T , it has non-trivial abelian edge stabilizers, and is relative to all non-cyclic abelian subgroups. It is minimal if T is minimal, but vertices in V 1 may be redundant vertices.
The stabilizer of a vertex v 1 ∈ V 1 is a maximal abelian subgroup. The stabilizer of a vertex in V 0 is non-abelian and is the stabilizer of a vertex of T . The stabilizer of an edge v v 0 1 with v i ∈ V i is an infinite abelian subgroup, it is a maximal abelian subgroup of G v 0 (but it is not always maximal abelian in G v 1 ).
The Out( ̂ G ; H )-invariant tree T can mentioned above is the tree of cylinders of JSJ trees relative to H + ab . It is a JSJ tree, and the tree of cylinders of T can is T can itself.
Let Γ can = T can /G be the quotient graph of groups, and let v ∈ V 0 /G be a vertex with G v non-abelian. If G v does not split over an abelian group relative to incident edge groups and to H || G v , it is universally elliptic (with respect to both H and H + ab ); we say that G v (or v ) is rigid . Otherwise it is flexible .
A key fact here is that every flexible vertex v of Γ can is quadratically hanging (QH) . The group G v is the fundamental group of a compact (possibly non-orientable) surface
Σ, and incident edge groups are boundary subgroups of π 1 (Σ) (i.e. fundamental groups of boundary components of Σ); in particular, incident edge groups are cyclic. At most one incident edge group is attached to a given boundary component (groups carried by distinct incident edges are non-conjugate in G v ). If H is conjugate to a group of H , then H ∩ G v is contained in a boundary subgroup. Conversely, every boundary subgroup is an incident edge group or has a finite index subgroup which is conjugate to a group of H .
As in [Sze08], we denote by PM + (Σ) the group of isotopy classes of homeomorphisms of Σ mapping each boundary component to itself in an orientation-preserving way. We view PM + (Σ) as a subgroup of Out( π 1 (Σ)) = Out( G v ), indeed PM + (Σ) = Out( G v ; Inc (t) v , H (t) || G v ).
## 2.3 Automorphisms of trees
There is a natural action of Out( G ) on the set of trees, given by precomposing the action on T with an automorphism of G . We denote by Out( T ) the stabilizer of a tree T . We write Out( T, H ) for Out( T ) ∩ Out( G ; H ), and so on.
If T is a point, Out( T ) = Out( G ). If G is abelian and T is not a point, then T is a line on which G acts by integral translations, and Out( T ) is the group of automorphisms of G preserving the kernel of the action.
We now study Out( T ) in the general case, following [Lev05a].
We always assume that edge stabilizers are abelian. This implies that all vertex or edge stabilizers H have the property that the normalizer N H ( ) acts on H by inner automorphisms: indeed, N H ( ) is abelian if H is abelian, equal to H if H is not abelian.
One first considers the action of Out( T ) on the finite graph Γ = T/G . We always denote by Out ( 0 T ) the finite index subgroup consisting of automorphisms acting trivially. We study it through the natural map
$$\underset { v \in V } { \text{qu} \, \in \, \max \, \partial \, \max \, \rho } } \\ \rho & = \prod _ { v \in V } \rho _ { v } \colon \text{Out} ^ { 0 } ( T ) \to \prod _ { v \in V } \text{Out} ( G _ { v } )$$
recording the action of automorphisms on vertex groups (see Section 2 of [Lev05a]); recall that V is the vertex set of Γ. Since N G ( v ) acts on G v by inner automorphisms, ρ v (Φ) is simply defined as the class of α | G v , where α ∈ Aut( G ) is any representative of Φ ∈ Out ( 0 T ) leaving G v invariant.
The image of ρ is contained in ∏ v ∈ V Out( G v ; Inc v ) (the family of incident edge groups at a given v is preserved). It contains the subgroup ∏ v ∈ V Out( G v ; Inc (t) v ) because automorphisms of G v acting trivially on incident edge groups extend 'by the identity' to automorphisms of G preserving T .
The kernel of ρ is the group of twists T , a finitely generated abelian group when no edge group is trivial (bitwists as defined in [Lev05a] belong to T because the normalizer of an abelian subgroup is its centralizer). We therefore have an exact sequence
$$\omega _ { \text{group} } & \in \infty \cos \Gamma \Gamma \Gamma \Gamma \cos \Gamma \Gamma \cos \Gamma \Gamma \Gamma \cos \Gamma \Gamma \cos \Gamma \cos \Gamma \cos \Gamma \cos \Gamma \cos \Gamma \cos \Gamma \cos \Gamma \cos \Gamma \cos \Gamma \cos \Gamma \cos \Gamma \cos \Gamma \cos \Gamma \cos \Gamma \cos \Gamma \cos \Gamma \cos \Gamma \cos \Gamma \cos \Gamma \cos \Gamma \cos \Gamma \cos \Gamma \cos \Gamma \cos \Gamma \cos \Gamma \cos \Gamma \cos \Gamma \cos \Gamma \cos \Gamma \cos \Gamma \cos \Gamma \cos \Gamma \cos \Gamma \cos \Gamma \cos \Gamma \cos \Gamma \cos \Gamma \cos \Gamma \cos \Gamma \cos \Gamma \sin \Gamma \cos \Gamma \cos \Gamma \cos \Gamma \cos \Gamma \cos \Gamma \cos \Gamma \cos \Gamma \cos \Gamma \cos \Gamma \cos \Gamma \cos \Gamma \cos \Gamma \cos \Gamma \cos \Gamma \cos \Gamma \cos \Gamma \cos \Gamma \cos \Gamma \cos \Gamma \cos \Gamma \cos \Gamma \cos \Gamma \cos \Gamma \cos \Gamma \cos \Gamma \cos \Gamma \cos \Gamma \cos \Gamma \cos \Gamma \cos \Gamma \cos \Gamma \cos \Gamma \cos \Gamma \cos \Gamma \cos \Gamma \cos \Gamma \cos \Gamma \cos \Gamma \cos \Gamma \tan \Gamma \cos \Gamma \cos \Gamma \cos \Gamma \cos \Gamma \cos \Gamma \cos \Gamma \cos \Gamma \cos \Gamma \cos \Gamma \cos \Gamma \cos \Gamma \cos \Gamma \cos \Gamma \cos \Gamma \cos \Gamma \cos \Gamma \cos \Gamma \cos \Gamma \cos \Gamma \cos \Gamma \cos \Gamma \cos \Gamma \cos \Gamma \cos \Gamma \cos \Gamma \cos \Gamma \cos \Gamma \cos \Gamma \cos \Gamma \cos \Gamma \cos \Gamma \cos \Gamma \cos \Gamma \cos \Gamma \cos \Gamma \cos \Gamma \cos \Gamma \cos \Gamma \cos \Gamma \ cos \Gamma \cos \Gamma \cos \Gamma \cos \Gamma \cos \Gamma \cos \Gamma \cos \Gamma \cos \Gamma \cos \Gamma \cos \Gamma \cos \Gamma \cos \Gamma \cos \Gamma \cos \Gamma \cos \Gamma \cos \Gamma \cos \Gamma \cos \Gamma \cos \Gamma \cos \Gamma \cos \Gamma \cos \Gamma \cos \Gamma \cos \Gamma \cos \Gamma \cos \Gamma \cos \Gamma \cos \Gamma \cos \Gamma \cos \Gamma \cos \Gamma \cos \Gamma \cos \Gamma \cos \Gamma \cos \Gamma \cos \Gamma \cos \Gamma \cos \Gamma \cos \Gamma \cos \Gamma \osigma \Gamma \Gamma \cos \Gamma \cos \Gamma \Gamma \cos \Gamma \cos \Gamma \cos \Gamma \cos \Gamma \cos \Gamma \cos \Gamma \cos \Gamma \cos \Gamma \cos \Gamma \cos \Gamma \cos \Gamma \cos \Gamma \cos \Gamma \cos \Gamma \cos \Gamma \cos \Gamma \cos \Gamma \cos \Gamma \cos \Gamma \cos \Gamma \cos \Gamma \cos \Gamma \cos \Gamma \cos \Gamma \cos \Gamma \cos \Gamma \cos \Gamma \cos \Gamma \cos \Gamma \cos \Gamma \cos \Gamma \cos \Gamma \cos \Gamma \cos \Gamma \cos \Gamma \cos \Gamma \cos \Gamma \cos \gamma \cos \Gamma \Gamma \cos \Gamma \cos \Gamma \cos \Gamma \cos \Gamma \cos \Gamma \cos \Gamma \cos \Gamma \cos \Gamma \cos \Gamma \cos \Gamma \cos \Gamma \cos \Gamma \cos \Gamma \cos \Gamma \cos \Gamma \cos \Gamma \cos \Gamma \cos \Gamma \cos \Gamma \cos \Gamma \cos \Gamma \cos \Gamma \cos \Gamma \cos \Gamma \cos \Gamma \cos \Gamma \cos \Gamma \cos \Gamma \cos \Gamma \cos \Gamma \cos \Gamma \cos \Gamma \cos \Gamma \cos \Gamma \cos \Gamma \cos \Gamma \cos \Gamma \cos \Gamma\cos \Gamma \cos \Gamma \cos \Gamma \cos \Gamma \cos \Gamma \cos \Gamma \cos \Gamma \cos \Gamma \cos \Gamma \cos \Gamma \cos \Gamma \cos \Gamma \cos \Gamma \cos \Gamma \cos \Gamma \cos \Gamma \cos \Gamma \cos \Gamma \cos \Gamma \cos \Gamma \cos \Gamma \cos \Gamma \cos \Gamma \cos \Gamma \cos \Gamma \cos \Gamma \cos \Gamma \cos \Gamma \cos \Gamma \cos \Gamma \cos \Gamma \cos \Gamma \cos \Gamma \cos \Gamma \cos \Gamma \cos \Gamma \cos \Gamma \cos \Gamma \cos \Gamma \cos \Gamma
1 & 1 & \to \mathcal { T } \to \text{Out} ^ { 0 } ( T ) \xrightarrow \longrightarrow \text{Up} \prod _ { v \in V } \text{Out} ( G _ { v } ; \text{Inc} _ { v } ).$$
Now suppose that T is relative to families H and K (i.e. each H i , K j fixes a point in T ). A trivial but important remark is that T ⊂ Out( G ; H (t) , K (t) ). As pointed out in Lemma 2.10 of [GL12], we have
$$& \text{Lemina $Z.tv$ or $[\mathbb{o} L 1 z ], we have} \\ & \prod _ { v \in V } \text{Out} ( G _ { v } ; \text{Inc} _ { v } ^ { ( t ) }, \mathcal { H } _ { \| G _ { v } } ^ { ( t ) }, \mathcal { K } _ { \| G _ { v } } ) \subset \rho \left ( \text{Out} ^ { 0 } ( T ) \cap \text{Out} ( G ; \mathcal { H } ^ { ( t ) }, \mathcal { K } ) \right ) \subset \prod _ { v \in V } \text{Out} ( G _ { v } ; \text{Inc} _ { v }, \mathcal { H } _ { \| G _ { v } } ^ { ( t ) }, \mathcal { K } _ { \| G _ { v } } )$$
(see Subsection 2.1 for the definition of H || G v ; groups of H || G v that are conjugate in G are necessarily conjugate in G v ).
Given an edge e of Γ, there is a natural map ρ e : Out ( 0 T ) → Out( G e ), defined in the same way as ρ v above. If v is an endpoint of e , the inclusion of G e into G v induces a homomorphism ρ v,e : Out( G v ; Inc v ) → Out( G e ) with ρ e = ρ v,e ◦ ρ v (it is well-defined because the normalizer N G v ( G e ) acts on G e by inner automorphisms).
The fact noted above that the image of Out ( 0 T ) by ρ contains ∏ v ∈ V Out( G v ; Inc (t) v ) expresses that automorphisms Φ v ∈ Out( G v ) acting trivially on incident edge groups may be combined into a global Φ ∈ Out( G ). In Subsection 3.2.4 we will need a more general result, where we only assume that the Φ v 's have compatible actions on edge groups.
Lemma 2.2. Consider a family of automorphisms Φ v ∈ Out( G v ; Inc v ) such that, if e = vw is any edge of Γ , then ρ v,e (Φ ) v = ρ w,e (Φ w ) . There exists Φ ∈ Out ( 0 T ) such that ρ v (Φ) = Φ v for every v .
We leave the proof to the reader. The lemma applies to any graph of groups such that, for every vertex or edge group H , the normalizer N H ( ) acts on H by inner automorphisms. Φ is not unique, it may be composed with any element of T .
In Subsection 3.2.4 we will have a family of automorphisms Φ e ∈ Out( G e ), and we will want Φ ∈ Out ( 0 T ) such that ρ e (Φ) = Φ e for every e . By the lemma, it suffices to find automorphisms Φ v ∈ Out( G v ; Inc v ) inducing the Φ 's. e
## 2.4 Rigid vertices
We now specialize to the case when T = T can is the canonical JSJ decomposition relative to H + ab discussed in Subsection 2.2.
If v is a QH vertex, the image of Out ( 0 T ) ∩ Out( G ; H (t) ) in Out( G v ) contains PM + (Σ) = Out( G v ; Inc (t) v , H (t) || G v ) with finite index (see [GL12], Proposition 4.7).
If v is a rigid vertex, then G v does not split over an abelian group relative to Inc v ∪ H || G v . By the Bestvina-Paulin method and Rips theory, one deduces that the image of Out ( 0 T ) ∩ Out( G ; H (t) ) in Out( G v ) is finite if H is a finite family of finitely generated subgroups (see [GL12], Theorem 3.9 and Proposition 4.7).
Lemma 2.3. Let H K , be finite families of finitely generated subgroups, with each group in K abelian. Assume that G is one-ended relative to H∪K , and let T can be the canonical JSJ tree relative to ( H∪K ) + ab .
The image of
$$O u t ^ { 0 } ( T ) \cap O u t ( G ; \mathcal { H } ^ { ( t ) }, \mathcal { K } )$$
by ρ v : Out ( 0 T ) → Out( G v ) is finite if v is a rigid vertex of T can . Its image by ρ e : Out ( 0 T ) → Out( G e ) is finite if e is any edge.
Proof. Define K Z by removing all non-cyclic groups from K . Being freely indecomposable relative to H∪K is the same as being freely indecomposable relative to H∪K Z , and a tree is relative to ( H∪K ) + ab if and only if it is relative to ( H∪K Z ) + ab . We may therefore view T can as the canonical JSJ tree relative to ( H∪K Z ) + ab .
Let v be a rigid vertex. The group Out( G ; H (t) , K ) is contained in Out( G ; H (t) , K Z ), which contains Out( G ; H (t) , K (t) Z ) with finite index. As explained above, the image of Out ( 0 T ) ∩ Out( G ; H (t) , K (t) Z ) in Out( G v ) is finite ([GL12], Prop. 4.7). The first assertion of the lemma follows.
Since T can is bipartite, every edge e is incident to a vertex v which is QH or rigid. In the first case G e is cyclic, so there is nothing to prove. In the second case the map ρ e : Out ( 0 T ) → Out( G e ) factors through Out( G v ), and the second assertion follows from the first.
## 3 Finite classifying space
In this section, we prove that McCool groups of a toral relatively hyperbolic group have type VF (Theorem 1.3), and that so does the stabilizer of a splitting (Theorem 1.4). In the course of the proof, we will describe the automorphisms of a given maximal abelian subgroup which are restrictions of an automorphism of G belonging to a given McCool group (Proposition 3.10).
We start by recalling some standard facts about groups of type VF.
A group has type F if it has a finite classifying space, type VF if some finite index subgroup is of type F. A key tool for proving that groups have type F is the following statement:
Theorem 3.1 (see for instance [Geo08, Th. 7.3.4]) . Suppose that G acts simplicially and cocompactly on a contractible simplicial complex X . If all point stabilizers have type F, so does G . In particular, being of type F is stable under extensions.
If G has a finite index subgroup acting as in the theorem, then G has type VF. In particular:
Corollary 3.2. Given an exact sequence 1 → N → G → Q → 1 , suppose that Q has type VF, and G has a finite index subgroup G < G 0 such that G 0 ∩ N has type F. Then G has type VF.
Remark 3.3 . Suppose that G acts on X as in Theorem 3.1. If point stabilizers are only of type VF, one cannot claim that G has type VF, even if G is torsion-free. This subtlety was overlooked in Theorem 5.2 of [GL07b] (we will give a corrected statement in Corollary 3.8), and it introduces technical complications (which would not occur if we only wanted to prove that the groups under consideration have type F ∞ ). In particular, to study the stabilizer of a tree with non-cyclic edge stabilizers in Subsection 3.2.3, we have to prove more precise versions of certain results (such as the 'moreover' in Theorem 3.4).
## 3.1 McCool groups are VF
In this subsection we prove the following strengthening of Theorem 1.3.
Theorem 3.4. Let G be a toral relatively hyperbolic group. Let H and K be two finite families of finitely generated subgroups, with each group in K abelian. Then Out( G ; H (t) , K ) is of type VF.
Morerover, if groups in H are also abelian, there exists a finite index subgroup Out ( 1 G ; H K , ) ⊂ Out( G ; H K , ) such that Out ( 1 G ; H K ∩ , ) Out( G ; H (t) , K ) is of type F .
Recall (Definition 2.1) that Out( G ; H (t) , K ) consists of classes of automorphisms acting trivially on each group H i ∈ H (i.e. as conjugation by some g i ∈ G ), and leaving each K j ∈ K invariant up to conjugacy.
It will follow from Corollary 1.6 that the main assertion of Theorem 3.4 holds if H is an arbitrary family of subgroups (see Corollary 6.3), but finiteness is needed at this point in order to apply Lemma 2.3.
Convention 3.5. In this section, a superscript -1 , as in Out ( 1 G ; H K , ) , always indicates a subgroup of finite index. The superscript -0 refers to a trivial action on a quotient graph of groups (see Section 2.3).
## 3.1.1 The abelian case
The following lemma deals with the case when G = Z n .
Lemma 3.6. Let H and K be finite families of subgroups of Z n . Let A = Out( Z n ; H (t) , K ) be the subgroup of GL n, ( Z ) consisting of matrices acting as the identity on groups H i ∈ H and leaving each K j ∈ K invariant. Then A is of type VF. More precisely, every torsionfree subgroup of finite index A ′ ⊂ A is of type F.
Recall that GL n, ( Z ) is virtually torsion-free, so groups such as A ′ exist.
Proof. The set of endomorphisms of Z n acting as the identity on H i and preserving K j is a linear subspace defined by linear equations with rational coefficients. It follows that the groups A and A ′ are arithmetic: they are commensurable with a subgroup of GL n, ( Z ) defined by Q -linear equations. By Borel-Serre [BS73], every torsion-free arithmetic subgroup of GL n, ( Q ) is of type F.
To deduce Theorem 3.4 when G is abelian, we simply define Out ( 1 G ; H K , ) as any torsion-free finite index subgroup of Out( G ; H K , ).
If G is not abelian, we shall distinguish two cases.
## 3.1.2 The one-ended case
We first assume that G is freely indecomposable relative to H∪K : one cannot write G = A ∗ B with each group of H∪K contained in a conjugate of A or B . We then consider the canonical tree T can as in Subsection 2.2 (it is a JSJ tree relative to H K , , and to non-cyclic abelian subgroups). It is invariant under Out( G ; H K , ), so Out( G ; H K , ) ⊂ Out( T can ).
We write Out ( 0 T can ) for the finite index subgroup consisting of automorphisms acting trivially on the finite graph Γ can = T can /G , and
$$O u ^ { 0 } ( G ; \mathcal { H }, \mathcal { K } ) = O u t ( G ; \mathcal { H }, \mathcal { K } ) \cap O u t ^ { 0 } ( T _ { \text{can} } ) ;$$
it has finite index in Out( G ; H K , ).
Recall that non-abelian vertex stabilizers G v of T can (or vertex groups of Γ can ) are rigid or QH. Also recall from Subsection 2.3 that, for each vertex v , there is a map ρ v : Out ( 0 T can ) → Out( G v ; Inc v ), with Inc v the family of incident edge groups (see Subsection 2.1).
We define a subgroup Out ( r G ; H K , ) ⊂ Out( G ; H K , ) by restricting to automorphisms Φ ∈ Out ( 0 G ; H K , ), and imposing conditions on the image of Φ by the maps ρ v .
- · If G v is rigid, we ask that ρ v (Φ) be trivial.
- · If G v is abelian, we fix a torsion-free subgroup of finite index Out ( 1 G v ) ⊂ Out( G v ), and we ask that ρ v (Φ) belong to Out ( 1 G v ).
- · If G v is QH, it is the fundamental group of a compact surface Σ. Each boundary component is associated to an incident edge or a group in H ∪ K (see Subsection 2.2), so ρ v (Φ) preserves the peripheral structure of π 1 (Σ) and may therefore be represented by a homeomorphism of Σ. Since groups in H∪K , and their conjugates, only intersect G v along boundary subgroups, the image of Out ( 0 G ; H K , ) by ρ v contains the mapping class
group PM + (Σ) = Out( G v ; Inc (t) v , H (t) || G v , K (t) || G v ) (see Subsection 2.2); the index is finite. We fix a finite index subgroup PM + 1 , (Σ) of type F, and we require ρ v (Φ) ∈ PM + 1 , (Σ). In particular, Φ acts trivially on all boundary subgroups of Σ.
Let Out ( r G ; H K , ) consist of automorphisms Φ ∈ Out ( 0 G ; H K , ) whose images ρ v (Φ) satisfy the conditions stated above. These automorphisms act trivially on edge stabilizers.
It follows from Lemma 2.3 that Out ( r G ; H K ∩ , ) Out( G ; H (t) , K ) always has finite index in Out( G ; H (t) , K ). If groups in H are abelian, then Out ( r G ; H K , ) has finite index in Out( G ; H K , ). It therefore suffices to prove that
$$O \coloneqq \text{Out} ^ { r } ( G ; \mathcal { H }, \mathcal { K } ) \cap \text{Out} ( G ; \mathcal { H } ^ { ( t ) }, \mathcal { K } )$$
is of type F (this argument, based on Lemma 2.3, is the only place where we use the assumptions on H and K ).
Every edge of T can has an endpoint v with G v rigid or QH, so elements of O act trivially on edge stabilizers of T can . Consider an abelian vertex stabilizer G v . Elements in ρ v ( O ) are the identity on incident edge groups and groups in H || G v , and leave groups in K || G v invariant. By Lemma 3.6 these conditions define a group B v ⊂ Out( G v ) which is of type VF, and C v := B v ∩ Out ( 1 G v ) is a group of type F containing ρ v ( O ).
Recall from Subsection 2.3 the exact sequence
We claim that the image of O by ρ is a direct product ∏ v ∈ V C v , with C v as above if G v is abelian, C v = PM + 1 , (Σ) if v is QH, and C v trivial if v is rigid. The image is contained in the product. Conversely, given a family (Φ v ) v ∈ V , with Φ v ∈ C v , the automorphisms Φ v act trivially on incident edge groups, so there is Φ ∈ Out ( 0 T can ) with ρ v (Φ) = Φ . v Since Φ v acts trivially on Inc v ∪ H || G v and preserves K || G v , this automorphism is in O . This proves the claim.
$$\underset { v \in V } { \text{subsection $2.0$ the exact sequence} } \\ 1 \to \mathcal { T } \to \text{Out} ^ { 0 } ( T _ { \text{can} } ) \overset { \rho } { \longrightarrow } \prod _ { v \in V } \text{Out} ( G _ { v } ; \text{Inc} _ { v } ).$$
It follows that ρ O ( ) is of type F. The group of twists T is contained in O , because twists act trivially on vertex groups and T is relative to H∪K , so we can conclude that O is of type F by Theorem 3.1 if we know that T is of type F. The group T is a finitely generated abelian group. It is torsion-free, hence of type F, as shown in Section 4 of [GL12] (alternatively, one can replace Out ( r G ; H K , ) by its intersection with a torsion-free finite index subgroup of Out( G ), which exists by Corollary 4.4 of [GL12]).
This proves Theorem 3.4 in the freely indecomposable case. To prove it in general, we need to study automorphisms of free products.
## 3.1.3 Automorphisms of free products
In this subsection, G does not have to be relatively hyperbolic.
Let G = { G i } be a family of subgroups of G . We have defined Out( G ; G ) as automorphisms leaving the conjugacy class of each G i invariant, and Out( G ; G (t) ) as automorphisms acting trivially on each G i .
More generally, consider a group of automorphisms Q ⊂ i Out( G i ) and Q = {Q } i . We would like to define Out( G ; G ( Q ) ) ⊂ Out( G ; G ) as the automorphisms Φ acting on each G i as an element of Q i . To be precise, given Φ ∈ Out( G ; G ), choose representatives ϕ i of Φ in Aut( G ) with ϕ i ( G i ) = G i . We say that Φ belongs to Out( G ; G ( Q ) ) if every ϕ i represents an element of Q i . This is well-defined (independent of the chosen ϕ i 's) if each G i is a free factor (more generally, if the normalizer of G i acts on G i by inner automorphisms).
The goal of this subsection is to show:
Proposition 3.7. Let G = G 1 ∗ · · · ∗ G n ∗ F p , with F p free of rank p , and let G = { G i } . Assume that all groups G i and G /Z G i ( i ) have type F.
Let Q = {Q } i be a family of subgroups Q ⊂ i Out( G i ) . If every Q i is of type VF, then Out( G ; G ( Q ) ) has type VF.
More precisely, there exists a finite index subgroup Out ( 1 G ; G ) ⊂ Out( G ; G ) , independent of Q , such that, if every Q i is of type F, then Out ( 1 G ; G ) ∩ Out( G ; G ( Q ) ) has type F.
The 'more precise' assertion implies the first one, since Out( G ; G ( Q ′ ) ) has finite index in Out( G ; G ( Q ) ) if every Q ′ i is a finite index subgroup of Q i .
Assume that G i and G /Z G i ( i ) have type F. The proposition says in particular that the Fouxe-Rabinovitch group Out( G ; G (t) ) is of type VF, and that Out( G ; G ) is of type VF if every Out( G i ) is. If we consider the Grushko decomposition of G , then Out( G ; G ) has finite index in Out( G ) and we get:
Corollary 3.8 (Correcting [GL07b], Theorem 5.2) . Let G = G 1 ∗ · · · ∗ G n ∗ F p , with F p free, G i non-trivial, not isomorphic to Z , and not a free product. If every G i and G /Z G i ( i ) has type F, and every Out( G i ) has type VF, then Out( G ) has type VF.
Proof of Proposition 3.7. We prove the 'more precise' assertion, so we assume that Q ⊂ i Out( G i ) has type F. We shall apply Theorem 3.1 to the action of Out( G ; G ( Q ) ) on the outer space defined in [GL07b]. We let D be the Grushko deformation space relative to G , i.e. the JSJ deformation space of G over the trivial group relative to G (see Subsection 2.2). Trees in D have trivial edge stabilizers, and non-trivial vertex stabilizers are conjugates of the G i 's.
Like ordinary outer space [CV86], the projectivization ˆ of D D is a complex consisting of simplices with missing faces, and the spine of ˆ is a simplicial complex. D It is contractible for the weak topology [GL07a].
The group Out( G ; G ) acts on D , hence on the spine, and the action of the FouxeRabinovitch group Out( G ; G (t) ) ⊂ Out( G ; G ( Q ) ) is cocompact because there are finitely many possibilities for the quotient graph T/G , for T ∈ D . In order to apply Theorem 3.1, we just need to show that stabilizers are of type F.
Out( G ; G ) also acts on the free group (isomorphic to F p ) obtained from G by killing all the G i 's (it may be viewed as the topological fundamental group of Γ = T/G , for any T ∈ D ). In other words, there is a natural map Out( G ; G ) → Out( F p ). We fix a torsionfree finite index subgroup Out ( 1 F p ) ⊂ Out( F p ), and we define Out ( 1 G ; G ) ⊂ Out( G ; G ) as the pullback of Out ( 1 F p ).
Given T ∈ D , we let S be its stabilizer for the action of Out 1 ( G ; G ), and S Q its stabilizer for the action of Out ( 1 G ; G ) ∩ Out( G ; G ( Q ) ). We complete the proof by showing that S Q has type F.
We first claim that S equals Out ( 0 T ), the group of automorphisms of G leaving T invariant and acting trivially on Γ = T/G . Clearly Out ( 0 T ) ⊂ S . Conversely, we have to show that any Φ ∈ S acts as the identity on Γ. First, Φ fixes all vertices of Γ carrying a nontrivial group G v , because G v is a G i (up to conjugacy) and the G i 's are not permuted. In particular, by minimality of T , all terminal vertices of Γ are fixed. Also, by our definition of Out ( 1 G ; G ), the image of Φ in Out( π 1 (Γ)) is trivial or has infinite order. The claim follows because any non-trivial symmetry of Γ fixing all terminal vertices maps to a non-trivial element of finite order in Out( π 1 (Γ)) if Γ is not a circle.
The map ρ (see Subsection 2.3) maps S onto ∏ i Out( G i ), and the image of S Q is ∏ i Q i , a group of type F. The kernel is the group of twists T , which is contained in S Q ,
so it suffices to check that T has type F. Since edge stabilizers are trivial, T is a direct product ∏ i K i , with K i = G n i i /Z G ( i ); here n i is the valence of the vertex carrying G i in Γ, and the center Z G ( i ) is embedded diagonally (see [Lev05a]). There are exact sequences
$$1 \to G _ { i } ^ { n _ { i } - 1 } \to G _ { i } ^ { n _ { i } } / Z ( G _ { i } ) \to G _ { i } / Z ( G _ { i } ) \to 1,$$
so the assumptions of the proposition ensure that T is of type F.
## 3.1.4 The infinitely-ended case
We can now prove Theorem 3.4 in full generality. We let G = G 1 ∗ · · · ∗ G n ∗ F p be the Grushko decomposition of G relative to H∪K (see Subsection 2.2), and G = { G i } . Each G i is toral relatively hyperbolic, so has type F by [Dah03]. Its center is trivial if G i is nonabelian, so G /Z G i ( i ) also has type F. This will allow us to use Proposition 3.7.
Lemma 3.9. Let Q = {Q } i , with Q i = Out( G i ; H (t) | G i , K | G i ) , and let R = {R } i with R i = Out( G i ; H | G i , K | G i ) .
Then
$$O u t ( G ; \mathcal { G } ^ { ( \mathcal { Q } ) } ) = O u t ( G ; \mathcal { H } ^ { ( \mathfrak { t } ) }, \mathcal { K } ) \cap O u t ( G ; \mathcal { G } ),$$
and
$$O u t ( G ; \mathcal { G } ^ { ( \mathcal { R } ) } ) = O u t ( G ; \mathcal { H }, \mathcal { K } ) \cap O u t ( G ; \mathcal { G } ).$$
Moreover, Out( G ; G ( Q ) ) has finite index in Out( G ; H (t) , K ) , and Out( G ; G ( R ) ) has finite index in Out( G ; H K , ) .
Proof. If Φ belongs to Out( G ; G ( Q ) ), it belongs to Out( G ; H (t) , K ) because every group in H∪K has a conjugate contained in some G i . Conversely, automorphisms in Out( G ; H (t) , K ) preserve the Grushko deformation space relative to H∪K and therefore permute the G i 's, so Out( G ; G ) ∩ Out( G ; H (t) , K ) has finite index in Out( G ; H (t) , K ). If ϕ ∈ Aut( G ) leaves G i invariant and maps a non-trivial H ⊂ G i to a conjugate gHg -1 , then g ∈ G i because G i is a free factor. This shows
$$O u t ( G ; \mathcal { H } ^ { ( t ) }, \mathcal { K } ) \cap O u t ( G ; \mathcal { G } ) \subset O u t ( G ; \mathcal { G } ^ { ( \mathcal { Q } ) } ),$$
completing the proof for Out( G ; G ( Q ) ). The proof for Out( G ; G ( R ) ) is similar.
The first assertion of Theorem 3.4 now follows immediately from the one-ended case together with Proposition 3.7, since Out( G ; H (t) , K ) contains Out( G ; G ( Q ) ) with finite index. There remains to prove the 'moreover'.
Each G i is freely indecomposable relative to H | G i ∪K | G i , so we may apply the 'moreover' of Theorem 3.4 to G i . We get a finite index subgroup R ⊂ R 1 i i such that Q 1 i := R ∩Q 1 i i has type F. Let R 1 = {R } 1 i , and Q 1 = {Q } 1 i .
By Proposition 3.7, there is a finite index subgroup Out ( 1 G ; G ) ⊂ Out( G ; G ) such that Out ( 1 G ; G ) ∩ Out( G ; G ( Q 1 ) ) has type F . Now write
$$O u t ^ { 1 } ( G ; \mathcal { G } ) \cap O u t ( G ; \mathcal { G } ^ { ( \mathcal { Q } ^ { 1 } ) } ) = O u t ^ { 1 } ( G ; \mathcal { G } ) \cap O u t ( G ; \mathcal { G } ^ { ( \mathcal { R } ^ { 1 } ) } ) \cap O u t ( G ; \mathcal { G } ^ { ( \mathcal { Q } ) } ).$$
By Lemma 3.9, we may replace the last term Out( G ; G ( Q ) ) by Out( G ; H (t) , K ). Defining
$$O u t ^ { 1 } ( G ; \mathcal { H }, \mathcal { K } ) \coloneqq O u t ^ { 1 } ( G ; \mathcal { G } ) \cap O u t ( G ; \mathcal { G } ^ { ( \mathcal { R } ^ { 1 } ) } ),$$
we have shown that Out ( 1 G ; H K ∩ , ) Out( G ; H (t) , K ) has type F. There remains to check that Out ( 1 G ; H K , ) is a finite index subgroup of Out( G ; H K , ).
Since Out ( 1 G ; G ) has finite index in Out( G ; G ), and R 1 i is a finite index subgroup of R i , the group Out ( 1 G ; H K , ) has finite index in Out( G ; G ) ∩ Out( G ; G ( R ) ), which equals Out( G ; G ( R ) ) and has finite index in Out( G ; H K , ) by Lemma 3.9.
This completes the proof of Theorem 3.4.
## 3.1.5 The action on abelian groups
We study the action of Out( G ) on abelian subgroups. The result of this subsection (Proposition 3.10) will be needed in Subsection 3.2.4.
A toral relatively hyperbolic group has finitely many conjugacy classes of non-cyclic maximal abelian subgroups. Fix a representative A j in each class. Automorphisms of G preserve the set of A j 's (up to conjugacy), so some finite index subgroup of Out( G ) maps to ∏ j Out( A j ). We shall show in particular that the image of a suitable finite index subgroup Out ( ′ G ) ⊂ Out( G ) is a product of McCool groups ∏ j Out( A j ; { F j } (t) ) ⊂ ∏ j Out( A j ).
̂ In fact, we will work with two (possibly empty) finite families H K , of abelian subgroups, and we will restrict to Out( G ; H (t) , K ). We shall therefore define a finite index subgroup Out ( ′ G ; H (t) , K ⊂ ) Out( G ; H (t) , K ).
This product structure expresses the fact that automorphisms of non-conjugate maximal non-cyclic abelian subgroups do not interact. Indeed, consider a family of elements Φ j ∈ Out( A j ), and suppose that each Φ , taken individually, extends to an automorphism j Φ j ∈ Out ( ′ G ); then there is Φ ∈ Out ( ′ G ) inducing all Φ 's simultaneously. j
First assume that G is freely indecomposable relative to H∪K . As in Subsection 3.1.2, we consider the canonical JSJ tree T can , we restrict to automorphisms Φ ∈ Out( G ; H (t) , K ) acting trivially on Γ can = T can /G , and we define Out ( ′ G ; H (t) , K ) by imposing conditions on the action on non-abelian vertex groups G v : if G v is QH, the action should be trivial on all boundary subgroups of Σ (i.e. ρ v (Φ) ∈ PM + (Σ)); if G v is rigid, then ρ v (Φ) should be trivial. We have explained in Subsection 3.1.2 why this defines a subgroup of finite index Out ( ′ G ; H (t) , K ) in Out( G ; H (t) , K ). Note that Out ( ′ G ; H (t) , K ) acts trivially on edge groups of T can .
If G is not freely indecomposable relative to H∪K , let G = G 1 ∗ · · · ∗ G n ∗ F p be the relative Grushko decomposition. To define Out ( ′ G ; H (t) , K ), we require that Φ maps G i to G i (up to conjugacy), and the induced automorphism belongs to Out ( ′ G i ; H (t) | G i , K | G i ) as defined above.
Elements of Out ( ′ G ; H (t) , K ) leave every A j invariant (up to conjugacy), and we denote by
$$\theta \colon \text{Out} ^ { \prime } ( G ; \mathcal { H } ^ { ( t ) }, \mathcal { K } ) \to \prod _ { j } \text{Out} ( A _ { j } )$$
the natural map.
We can now state:
Proposition 3.10. Let H K , be two finite families of abelian subgroups, and let Out ( ′ G ; H (t) , K ) be the finite index subgroup of Out( G ; H (t) , K ) defined above.
Recall that the A j 's are representatives of conjugacy classes of non-cyclic maximal abelian subgroups.
There exist subgroups F j ⊂ A j such that the image of θ : Out ( ′ G ; H (t) , K → ) ∏ j Out( A j ) equals ∏ j Out( A j ; { F j } (t) , K | A j ) .
Proof. The A j 's are contained (up to conjugacy) in factors G i of the Grushko decomposition relative to H ∪ K , and the G i 's are invariant under Out ( ′ G ; H (t) , K ). Since any family of automorphisms Φ i ∈ Out ( ′ G i ; H (t) | G i , K | G i ) extends to an automorphism Φ ∈ Out ( ′ G ; H (t) , K ), we may assume that G is freely indecomposable relative to H∪K .
Consider T can as above. If A j is contained in a rigid vertex stabilizer, then Out ( ′ G ; H (t) , K ) acts trivially on A j and we define F j = A j . If not, A j is a vertex stabilizer G v . Vertex stabilizers adjacent to v are rigid or QH, and because of the way we defined Out ( ′ G ; H (t) , K ) it leaves A j invariant and acts trivially on incident edge groups. It also acts trivially on the groups belonging to H | A j .
Defining F j as the subgroup of A j generated by incident edge groups and groups in H | A j , we have proved that the image of θ is contained in ∏ j Out( A j ; { F j } (t) , K | A j ). Conversely, choose a family Φ j ∈ Out( A j ; { F j } (t) , K | A j ). As explained in Subsection 2.3, there exists Φ ∈ Out ( 0 T can ) acting trivially on cyclic, rigid, and QH vertex stabilizers, and inducing Φ j on A j . We check that Φ acts trivially on any H ∈ H . Such a group H fixes a vertex v ∈ T can . If G v is cyclic, rigid, or QH, the action of Φ on H is trivial. If not, G v is (conjugate to) an A j and the action is trivial because H ⊂ F j . A similar argument shows that Φ preserves K up to conjugacy, so Φ ∈ Out( G ; H (t) , K ). Since Φ acts trivially on rigid and QH vertex stabilizers, Φ ∈ Out ( ′ G ; H (t) , K ).
## 3.2 Automorphisms preserving a tree
We now study the stabilizer of a tree. The following theorem clearly implies Theorem 1.4.
Theorem 3.11. Let G be a toral relatively hyperbolic group. Let T be a simplicial tree on which G acts with abelian edge stabilizers. Let K be a finite family of abelian subgroups of G , each of which fixes a point in T . Then Out( T, K ) = Out( T ) ∩ Out( G ; K ) is of type VF.
The group Out( T, K ) is the subgroup of Out( G ) consisting of automorphisms leaving T invariant and mapping each group of K to a conjugate (in an arbitrary way). The tree T is assumed to be minimal, but it may be a point, it may have trivial edge stabilizers, and non-cyclic abelian subgroups need not be elliptic.
Theorem 3.4 proves Theorem 3.11 when T is a point. Also note that, if G is abelian and T is not a point, then T is a line on which G acts by integral translations, and Out( T, K ) is of type VF because it equals Out( G ; K∪{ N } ), with N the kernel of the action of G on T .
Thus, we assume from now on that G is not abelian. We will prove Theorem 3.11 when T has cyclic edge stabilizers before treating the general case. This special case is much easier because Out( G e ) is finite for every edge stabilizer G e , and we may apply Proposition 2.3 of [Lev05a].
## 3.2.1 Cyclic edge stabilizers
In this subsection we prove Theorem 3.11 when all edge stabilizers G e of T are cyclic (possibly trivial); this happens in particular if G is hyperbolic.
As in Subsection 2.3, we consider the exact sequence
$$1 \to \mathcal { T } \to \text{Out} ^ { 0 } ( T ) \stackrel { \rho } { \longrightarrow } \prod _ { v \in V } ^ { \bullet } \text{Out} ( G _ { v } ; \text{Inc} _ { v } ).$$
The image of ρ contains ∏ v ∈ V Out( G v ; Inc (t) v ), and the index is finite because all groups Out( G e ) are finite (see [Lev05a], where Out( G v ; Inc (t) v ) is denoted PMCG G ( v )). The preimage of ∏ v ∈ V Out( G v ; Inc (t) v ) is thus a finite index subgroup Out ( 1 T ) ⊂ Out( T ).
We want to prove that Out( T, K ) is of type VF, so we restrict the preceding discussion to Out( T, K ). Let
$$O u t ^ { 1 } ( T, \mathcal { K } ) = O u t ^ { 1 } ( T ) \cap O u t ( G ; \mathcal { K } ),$$
a finite index subgroup. We show that Out ( 1 T, K ) is of type VF (this will not use the assumption that edge stabilizers are cyclic).
The image of Out ( 1 T, K ) by ρ is contained in ∏ v ∈ V Out( G v ; Inc (t) v , K || G v ), with K || G v as in Subsection 2.1, and arguing as in Subsection 2.3 one sees that equality holds. On the other hand, Out ( 1 T, K ) contains T because twists act trivially on vertex stabilizers, hence on K since groups of K are elliptic in T . We therefore have an exact sequence
$$\lambda ^ { \cdot } _ { 1 } \rightarrow \mathcal { T } \rightarrow \text{Out} ^ { 1 } ( T, \mathcal { K } ) \rightarrow \prod _ { v \in V } \text{Out} ( G _ { v } ; \text{Inc} _ { v } ^ { ( t ) }, \mathcal { K } _ { | | G _ { v } } ) \rightarrow 1.$$
Vertex stabilizers are toral relatively hyperbolic, so the product is of type VF by Theorem 3.4 applied to the G v 's. We conclude the proof by showing that T is of type F. This will imply that Out ( 1 T, K ), hence Out( T, K ), is VF.
We claim that T is isomorphic to the direct product of a finitely generated abelian group and a finite number of copies of non-abelian vertex groups G v . We use the presentation of T given in Proposition 3.1 of [Lev05a]. It says that T can be written as a quotient
$$\mathcal { T } = \prod _ { e, v } Z _ { G _ { v } } ( G _ { e } ) / \langle \mathcal { R } _ { V }, \mathcal { R } _ { E } \rangle,$$
the product being taken over all pairs ( e, v ) where e is an edge incident to v ; here R E = ∏ e Z G ( e ) is the group of edge relations, and R V = ∏ v Z G ( v ) is the group of vertex relations, both embedded naturally in ∏ e,v Z G v ( G e ). Every group Z G v ( G e ) is abelian, unless G e is trivial and G v is non-abelian. In this case Z G v ( G e ) = G v , and it is not affected by the edge and vertex relations since both Z G ( v ) and Z G ( e ) are trivial. Our claim follows.
It follows that T is of type F provided that it is torsion-free. One may show that this is always the case, but it is simpler to replace Out ( 1 T, K ) by its intersection with a torsion-free finite index subgroup of Out( G ).
## 3.2.2 Changing T
We shall now prove Theorem 3.11 in the general case.
The first step, carried out in this subsection, is to replace T by a better tree ˆ (satifsT fying the second assertion of the lemma below). When all edge stabilizers are non-trivial, ˆ may be viewed as the smallest common refinement (called lcm in [GL10]) of T T and its tree of cylinders (see Subsection 2.2). Here is the construction of ˆ . T
Consider edges of T with non-trivial stabilizer. We say that two such edges belong to the same cylinder if their stabilizers commute. Cylinders are subtrees and meet in at most one point. A vertex v with all incident edge groups trivial belongs to no cylinder. Otherwise v belongs to one cylinder if G v is abelian, to infinitely many cylinders if G v is not abelian. To define ˆ , T we shall refine T at vertices x belonging to infinitely many cylinders.
Given such an x , let S x be the set of cylinders Y such that x ∈ Y . We replace x by the cone T x on S x : there is a central vertex, again denoted by x , and vertices ( x, s Y ) for Y ∈ S x , with an edge between x and ( x, s Y ). Edges e of T incident to x are attached to T x as follows: if the stabilizer of e is trivial, we attach it to the central vertex x ; if not, e is contained in a cylinder Y and we attach e to the vertex ( x, s Y ), noting that G e leaves Y invariant.
Performing this operation at each x belonging to infinitely many cylinders yields a tree ˆ . T The construction being canonical, there is a natural action of G on ˆ , T and Out( T ) ⊂ Out( ˆ ). T
Lemma 3.12. 1. Edge stabilizers of ˆ T are abelian, ˆ T is dominated by T , and Out( ˆ ) = T Out( T ) .
- 2. Let G v be a non-abelian vertex stabilizer of ˆ T . Non-trivial incident edge stabilizers G e are maximal abelian subgroups of G v . If e 1 , e 2 are edges of ˆ T incident to v with G e 1 , G e 2 equal and non-trivial, then e 1 = e 2 .
Proof. Let Y be a cylinder in S x (viewed as a subtree of T ). The setwise stabilizer G Y of Y is the maximal abelian subgroup of G containing stabilizers of edges of Y . The stabilizer of the vertex ( x, s Y ) of ˆ , T and also of the edge between ( x, s Y ) and x , is G x ∩ G Y ; it is non-trivial (it contains the stabilizer of edges of Y incident to x ), and is a maximal abelian subgroup of G x . This proves that edge stabilizers of ˆ are abelian, since the other edges T have the same stabilizer as in T .
Consider two edges e 1 and e 2 incident to v in ˆ , T with the same non-trivial stabilizer. They join v to vertices ( v, s Y i ), and we have seen that G e 1 = G e 2 is maximal abelian in G v . The groups G Y 1 and G Y 2 are equal because they both contain G e 1 = G e 2 . Edges of Y i have stabilizers contained in G Y i , so have commuting stabilizers. Thus Y 1 = Y 2 , so e 1 = e 2 .
Every vertex stabilizer of T is also a vertex stabilizer of ˆ , T so T dominates ˆ . T Edges of ˆ which are not edges of T T (those between ( x, s Y ) and x ) are characterized as those having non-trivial stabilizer and having an endpoint v with G v non-abelian. One recovers T from ˆ by collapsing these edges, so Out( ˆ ) T T ⊂ Out( T ).
Remark 3.13 . If G e 1 , G e 2 are conjugate in G v , rather than equal, we conclude that e 1 and e 2 belong to the same G v -orbit. On the other hand, edges belonging to different G v -orbits may have stabilizers which are conjugate in G (but not in G v ).
## 3.2.3 The action on edge groups
In Subsection 3.2.1 we could neglect the action of Out ( 0 T ) on edge groups because all groups Out( G e ) were finite. We now allow edge stabilizers of arbitrary rank, so we must take these actions into account. We denote Out ( 0 T, K ) = Out ( 0 T ) ∩ Out( G ; K ).
Recall that, for each edge e of Γ = T/G , there is a natural map ρ e : Out ( 0 T ) → Out( G e ) (see Section 2.3). The collection of all these maps defines a map
$$\text{mean} \, \sl o n \, \sl a n \, \sl a n \, \sl a n \, \sl a n \, \sl a n \, \sl a n \, \sl a n \, \sl a n \, \sl a n \, \sl a n \, \sl a n \, \sl a n \, \sl a n \, \sl a n \, \sl a n \, \sl a n \, \sl a n \, \sl a n \, \sl a n \, \sl a n \, \sl a n \, \sl a n \, \sl a n \, \sl a n \, \sl a n \, \sl a n \, \sl a n \, \sl a n \, \sl a n \, \sl a n \, \sl a n \, \sl a n \, \sl a n \, \sl a n n \, \sl a n \, \sl a n \, \sl a n \, \sl a n \, \sl a n \, \sl a n \, \sl a n \, \sl a n \, \sl a n \, \sl a n \, \sl a n \, \sl a n \, \sl a n \, \sl a n \, \sl a n \, \sl a n \, \sl a n \, \sl a n \, \sl a n \, \sl a n \, \sl a n \, \sl a n \, \sl a n \, \sl a n \, \sl a n \, \sl a n \, \sl a n \, \sl a n \, \sl a n \, \sl a n \, \sl a n \, \sl a n \, \sl a n, \sl a n \, \sl a n \, \sl a n \, \sl a n \, \sl a n \, \sl a n \, \sl a n \, \sl a n \, \sl a n \, \sl a n \, \sl a n \, \sl a n \, \sl a n \, \sl a n \, \sl a n \, \sl a n \, \sl a n \, \sl a n \, \sl a n \, \sl a n \, \sl a n \, \sl a n \, \sl a n \, \sl a n \, \sl a n \, \sl a n \, \sl a n \, \sl a n \, \sl a n \, \sl a n \, \sl a n \, \sl a n \, \sl a n \, \smile \, \text{$\psi$} \, \colon & \text{$\psi$} \colon & \text{$\psi$} \colon & \text{$\psi$} \colon & \text{$\psi$} \colon & \text{$\psi$} \colon & \text{$\psi$} \colon & \text{$\psi$} \colon & \text{$\psi$} \colon & \text{$\psi$} \colon & \text{$\psi$} \colon & \text{$\psi$} \colon & \text{$\psi$} \colon & \text{$\psi$} \colon & \text{$\psi$} \colon & \text{$\psi$} \colon & \text{$\psi$} \colon &\text{$\psi$} \colon & \text{$\psi$} \colon & \text{$\psi$} \colon & \text{$\psi$} \colon & \text{$\psi$} \colon & \text{$\psi$} \colon & \text{$\psi$} \colon & \text{$\psi$} \colon & \text{$\psi$} \colon & \text{$\psi$} \colon & \text{$\psi$} \colon & \text{$\psi$} \colon & \text{$\psi$} \colon & \text{$\psi$} \colon & \text{$\psi$} \colon & \text{$\PSi$} \colon & \text{$\psi$} \colon & \text{$\psi$} \colon & \text{$\psi$} \colon & \text{$\psi$} \colon & \text{$\psi$} \colon & \text{$\psi$} \colon & \text{$\psi$} \colon & \text{$\psi$} \colon & \text{$\psi$} \colon & \text{$\psi$} \colon & \text{$\psi$} \colon & \text{$\psi$} \colon & \text{$\psi$} \colon & \text{$\psi$} \colon & \text{$\psi$} \text{$\psi$} \colon & \text{$\psi$} \colon & \text{$\psi$} \colon & \text{$\psi$} \colon & \text{$\psi$} \colon & \text{$\psi$} \colon & \text{$\psi$} \colon & \text{$\psi$} \colon & \text{$\psi$} \colon & \text{$\psi$} \colon & \text{$\psi$} \colon & \text{$\psi$} \colon & \text{$\psi$} \colon & \text{$\psi$} \colon & \text{$\psi$} \colon & \text{$%$} \colon & \text{$%$} \colon & \text{$%$} \colon & \text{$%$} \colon & \text{$%$} \colon & \text{$%$} \colon & \text{$%$} \colon & \text{$%$} \colon & \text{$%$} \colon & \text{$%$} \colon & \text{$%$} \colon & \text{$%$} \colon & \text{$%$} \colon & \text{$%$} \colon & \text{$%$} \colon & \text{$%$} \colon & \text{$%$} \colon & \text{$%$} \colon & \text{$%$}\colon & \text{$%$} \colon & \text{$%$} \colon & \text{$%$} \colon & \text{$%$} \colon & \text{$%$} \colon & \text{$%$} \colon & \text{$%$} \colon & \text{$%$} \colon & \text{$%$} \colon & \text{$%$} \colon & \text{$%$} \colon & \text{$%$} \colon & \text{$%$} \colon & \text{$%$} \colon & \text{$%$} \colon & \text{$%$} \colon & \text{$%$} \colon & \text{$%$} \col: & \text{$%$} \colon & \text{$%$} \colon & \text{$%$} \colon & \text{$%$} \colon & \text{$%$} \colon & \text{$%$} \colon & \text{$%$} \colon & \text{$%$} \colon & \text{$%$} \colon & \text{$%$} \colon & \text{$%$} \colon & \text{$%$} \colon & \text{$%$} \colon & \text{$%$} \colon & \text{$%$} \colon & \text{$%$} \colon & \text{$%$} \colon & \text{$%$} \colon &\text{$%$} \colon & \text{$%$} \colon & \text{$%$} \colon & \text{$%$} \colon & \text{$%$} \colon & \text{$%$} \colon & \text{$%$} \colon & \text{$%$} \colon & \text{$%$} \colon & \text{$%$} \colon & \text{$%$} \colon & \text{$%$} \colon & \text{$%$} \colon & \text{$%$} \colon & \text{$%$} \colon & \text{$%$} \colon & \text{$%$} \colon & \text{$%$} \colon & \text{\psi$} \colon & \text{$%$} \colon & \text{$%$} \colon & \text{$%$} \colon & \text{$%$} \colon & \text{$%$} \colon & \text{$%$} \colon & \text{$%$} \colon & \text{$%$} \colon & \text{$%$} \colon & \text{$%$} \colon & \text{$%$} \colon & \text{$%$} \colon & \text{$%$} \colon & \text{$%$} \colon & \text{$%$} \colon & \text{$%$} \colon & \text{$%$} \colon & \text{$\psi$} \colon & \text{$%$} \colon & \text{$%$} \colon & \text{$%$} \colon & \text{$%$} \colon & \text{$%$} \colon & \text{$%$} \colon & \text{$%$} \colon & \text{$%$} \colon & \text{$%$} \colon & \text{$%$} \colon & \text{$%$} \colon & \text{$%$} \colon & \text{$%$} \colon & \text{$%$} \colon & \text{$%$} \colon & \text{$%$} \colon & \text{$\psi$} \colon & \text{$\psi$} \colon & \text{$%$} \colon & \text{$%$} \colon & \text{$%$} \colon & \text{$%$} \colon & \text{$%$} \colon & \text{$%$} \colon & \text{$%$} \colon & \text{$%$} \colon & \text{$%$} \colon & \text{$%$} \colon & \text{$%$} \colon & \text{$%$} \colon & \text{$%$} \colon & \text{$%$} \colon & \text{$%$} \colon & \text{\psi$} \colon & \text{$%$} \colon & \text{$%$}\colon & \text{$%$} \colon & \text{$%$} \colon & \text{$%$} \colon & \text{$%$} \colon & \text{$%$} \colon & \text{$%$} \colon & \text{$%$} \colon & \text{$%$} \colon & \text{$%$} \colon & \text{$%$} \colon & \text{$%$} \colon & \text{$%$} \colon & \text{$%$} \colon & \text{$%$} \colon & \text{$%$} \colon & \text{$%$}$$
the product being over all non-oriented edges of Γ. We denote by Q the image of Out ( 0 T, K ) by ψ , so that we have the exact sequence
$$1 \to \ker \psi \to O u t ^ { 0 } ( T, \mathcal { K } ) \to Q \to 1.$$
Lemma 3.14. If T satisfies the second assertion of Lemma 3.12, then the group Q is of type VF.
This lemma will be proved in the next subsection. We first explain how to deduce Theorem 3.11 from it. The first assertion of Lemma 3.12 implies that the theorem holds for T if it holds for ˆ , T so we may assume that T satisfies the second assertion of Lemma 3.12.
The kernel of ψ is the group discussed in Subsection 3.2.1 under the name Out ( 1 T, K ), but now (contrary to Convention 3.5) Out ( 1 T, K ) may be of infinite index in Out( T, K ); indeed, Out( T, K ) is virtually an extension of Out ( 1 T, K ) by Q . To avoid confusion, we use the notation ker ψ rather than Out ( 1 T, K ).
We proved in Subsection 3.2.1 that ker ψ is of type VF, and Q is of type VF by the lemma, but this is not quite sufficient (see Remark 3.3). We shall now construct a finite index subgroup Out ( 2 T, K ⊂ ) Out ( 0 T, K ) such that ker ψ ∩ Out ( 2 T, K ) has type F . Applying Corollary 3.2 to Out ( 0 T, K ) then completes the proof of Theorem 3.11.
We argue as in Subsection 3.2.1. Recall from Subsection 2.3 the exact sequence
$$1 \to \mathcal { T } \to O u t ^ { 0 } ( T, \mathcal { K } ) \overset { \rho } { \longrightarrow } \prod _ { v \in V } O u t ( G _ { v } ; \text{Inc} _ { v }, \mathcal { K } _ { | | G _ { v } } )$$
whose restriction to ker ψ is the exact sequence
$$1 \stackrel { ^ { \prime } } { \to } \mathcal { T } \to \ker \psi \stackrel { \rho } { \longrightarrow } \prod _ { v \in V } ^ { ^ { \prime } } \text{Out} ( G _ { v } ; \text{Inc} _ { v } ^ { ( t ) }, \mathcal { K } _ { | | G _ { v } } ) \to 1.$$
Using the 'more precise' statement of Theorem 3.4 we get, for each v ∈ V , a finite index subgroup Out ( 1 G v ; Inc v , K || G v ) ⊂ Out( G v ; Inc v , K || G v ) such that
$$\text{Out} ^ { 1 } ( G _ { v } ; \text{Inc} _ { v }, \mathcal { K } _ { | | G _ { v } } ) \cap \text{Out} ( G _ { v } ; \text{Inc} _ { v } ^ { ( t ) }, \mathcal { K } _ { | | G _ { v } } )$$
is of type F. Define the finite index subgroup Out ( 2 T, K ⊂ ) Out ( 0 T, K ) as the preimage of ∏ v ∈ V Out ( 1 G v ; Inc v , K || G v ) under ρ , intersected with a torsion-free finite index subgroup of Out( G ).
Restricting the exact sequence above, we get an exact sequence
$$1 \to \mathcal { T } ^ { \prime } \to \ker \psi \cap O \text{ut} ^ { 2 } ( T, \mathcal { K } ) \stackrel { \rho } { \longrightarrow } L \to 1$$
where L has finite index in the product of the groups
$$\text{Out} ^ { 1 } ( G _ { v } ; \text{Inc} _ { v }, \mathcal { K } _ { | | G _ { v } } ) \cap \text{Out} ( G _ { v } ; \text{Inc} _ { v } ^ { ( t ) }, \mathcal { K } _ { | | G _ { v } } ),$$
hence has type F. The group T ′ is a torsion-free subgroup of finite index of T , so has type F as in Subsection 3.2.1. We conclude that ker ψ ∩ Out ( 2 T, K ) has type F. As explained above, this completes the proof of Theorem 3.11 (assuming Lemma 3.14).
## 3.2.4 Proof of Lemma 3.14
There remains to prove Lemma 3.14. We let E j be representatives of conjugacy classes of maximal abelian subgroups containing a non-trivial edge stabilizer. Note that E j is allowed to be cyclic, and maximal abelian subgroups of G containing no non-trivial G e are not included.
Inside each E j we let B j be the smallest direct factor containing all edge groups included in E j (it equals E j if E j is cyclic). It is elliptic in T , because it is an abelian group generated (virtually) by elliptic subgroups.
Each automorphism Φ ∈ Out ( 0 T, K ) induces an automorphism of E j , which preserves B j and all the edge groups it contains. This defines a map
$$\mu _ { 0 } \quad \psi ^ { \prime } \, \colon \text{Out} ^ { 0 } ( T, \mathcal { K } ) \to \prod _ { j } \, \text{Out} ( B _ { j } )$$
having the same kernel as the map ψ : Out ( 0 T, K → ) ∏ e ∈ E Out( G e ) defined in Subsection 3.2.3. Thus, it suffices to prove that the image of Out ( 0 T, K ) by ψ ′ is of type VF. We do so by finding a finite index subgroup Out ( 1 T, K ) (not the same as in Subsection 3.2.1) whose image is a product ∏ j Q j with each Q j of type VF.
Consider a non-abelian vertex group G v . Define Inc v, Z ⊂ Inc v by keeping only the incident edge groups which are infinite cyclic, and denote by E nc ( v ) the set of edges e of Γ with origin v and G e non-cyclic (if e is a loop, we subdivide it so that it counts twice in E nc ( v )). By Lemma 3.12 and Remark 3.13, the edge groups G e , for e ∈ E nc ( v ), are non-conjugate maximal abelian subgroups of G v .
We apply Proposition 3.10, describing the action on non-cyclic maximal abelian subgroups, to Out( G v ; Inc (t) v, Z , K || G v ). We get a subgroup of finite index Out ( ′ G v ; Inc (t) v, Z , K || G v ), and a subgroup F v e ⊂ G e for each edge e ∈ E nc ( v ), such that the image of Out ( ′ G v ; Inc (t) v, Z , K || G v ) in ∏ e ∈ E nc ( v ) Out( G e ) is the product ∏ e ∈ E nc ( v ) Out( G e ; { F v e } (t) , K | G e ).
We let Out ( 1 T, K ) ⊂ Out ( 0 T, K ) be the subgroup consisting of automorphisms acting trivially on cyclic edge stabilizers, and acting on non-abelian vertex stabilizers as an element of Out ( ′ G v ; Inc (t) v, Z , K || G v ). It has finite index because
$$\text{Out} ( G _ { v } ; \text{Inc} _ { v, \mathbb { Z } } ^ { ( \mathfrak { t } ) }, \mathcal { K } _ { | | G _ { v } } ) \subset \rho _ { v } ( \text{Out} ^ { 0 } ( T, \mathcal { K } ) ) \subset \text{Out} ( G _ { v } ; \text{Inc} _ { v, \mathbb { Z } }, \mathcal { K } _ { | | G _ { v } } ),$$
with all indices finite.
We now define Q j ⊂ Out( B j ) as consisting of automorphisms Φ j such that:
- 1. if G e is a cyclic edge stabilizer contained in B j , then Φ j acts trivially on G e ;
- 2. if B j contains a non-cyclic G e , and v is an endpoint of e with G v non-abelian, then Φ j acts trivially on F v e ;
- 3. non-cyclic edge stabilizers, and abelian vertex stabilizers, contained in B j are Φ j invariant;
- 4. Φ extends to an automorphism of j E j leaving K | E j invariant; in particular, subgroups of B j conjugate to a group of K are Φ -invariant. j
This definition was designed so that the image of Out ( 1 T, K ) by ψ ′ is contained in ∏ j Q j . We claim that equality holds:
Proof. We fix automorphisms Φ j ∈ Q j ⊂ Out( B j ), and we have to construct an automorphism Φ ∈ Out ( 1 T, K ). By items 1 and 3 above, the Φ 's induce automorphisms Φ j e of edge stabilizers (each non-trivial edge group G e lies in a unique E j , so there is no ambiguity in
## Lemma 3.15. The image of Out ( 1 T, K ) by ψ ′ equals ∏ j Q j .
the definition of Φ ). e As explained after Lemma 2.2, it suffices to find automorphisms Φ v of vertex groups inducing the Φ 's. e We distinguish several cases.
If G v is contained in some B j (up to conjugacy), it is Φ -invariant by item 3, so we let j Φ v be the restriction.
If G v is abelian, but not contained in any B j , we may assume that some incident G e is non-cyclic (otherwise we let Φ v be the identity). This G e is contained in some B j , and G v ⊂ E j . In fact G v = E j : since G v is not contained in B j , it fixes only v , and E j fixes v because it commutes with G v . We may thus extend Φ j to G v using item 4.
If G v is not abelian, we construct Φ v in Out ( ′ G v ; Inc (t) v, Z , K || G v ) as follows. If e ∈ E nc ( v ), the automorphism Φ e acts trivially on F v e by item 2, and preserves K | G e by item 4. Thus, the collection of automorphisms Φ e lies in ∏ e ∈ E nc ( v ) Out( G e ; { F v e } (t) , K | G e ). Proposition 3.10 guarantees that Out ( ′ G v ; Inc (t) v, Z , K || G v ) contains an automorphism Φ v inducing Φ e for all e ∈ E nc ( v ) (and acting trivially on all cyclic incident edge groups).
We have now constructed automorphisms Φ v ∈ Out( G v ) inducing the Φ 's, so Lemma e 2.2 provides an automorphism Φ ∈ Out ( 0 T ) whose image in ∏ j Out( B j ) is the product of the Φ 's because j B j is virtually generated by edge stabilizers. We show Φ ∈ Out ( 1 T, K ). By construction it acts trivially on cyclic edge groups and acts on non-abelian vertex stabilizers as an element of Out ( ′ G v ; Inc (t) v, Z , K || G v ). We just have to check that Φ leaves any K ∈ K invariant.
The group K is contained in some G v . If K is contained in some B j , it is Φ-invariant by item 4. Otherwise, K fixes no edge. If G v is abelian, we have seen that either all incident edge groups are cyclic (and Φ v is the identity), or G v equals some E j and our choice of Φ v using item 4 guarantees that K is invariant. If G v is not abelian, then K belongs to K || G v because it fixes no edge. It is invariant because we chose Φ v ∈ Out ( ′ G v ; Inc (t) v, Z , K || G v ).
We have seen that the group Q of Lemma 3.14 is isomorphic to the image of Out ( 0 T, K ) by ψ ′ , hence contains ∏ j Q j with finite index. To show that Q is of type VF, there remains to show that each Q j is of type VF.
We defined Q j inside Out( B j ) by four conditions. As in Lemma 3.6, the first three define an arithmetic group. To deal with the fourth one, we consider the group ˜ Q j consisting of automorphisms of E j leaving B j and K | E j invariant, with the restriction to B j satisfying the first three conditions. This is an arithmetic group. It consists of blocktriangular matrices, and one obtains Q j by considering the upper left blocks of matrices in ˜ Q j . It follows that K j is arithmetic, as the image of an arithmetic group by a rational homomorphism [Bor66, Th. 6], hence of type VF by Lemma 3.6.
This completes the proof of Lemma 3.14, hence of Theorem 3.11.
## 4 A finiteness result for trees
The goal of this section is Proposition 4.8, which gives a uniform bound for the size of certain sets of relative JSJ decompositions of G . This an essential ingredient in the proof of the chain condition for McCool groups. We will have to restrict to root-closed (RC) trees, which are introduced in Definitions 4.3 and 4.7 (they are closely related to the primary splittings of [DG08]).
Definition 4.1. Let H be a subgroup of a group G . Its root closure e H,G ( ) , or simply e H ( ) , is the set of elements of G having a power in H . If e H ( ) = H , we say that H is root-closed .
If G is toral relatively hyperbolic and H is abelian, e H ( ) is a direct factor of the maximal abelian subgroup containing H , and H has finite index in e H ( ). Also note that, given h ∈ G and n ≥ 2, there exists at most one element g such that g n = h .
The following fact is completely general.
Lemma 4.2. Let T be a tree with an action of an arbitrary group. The following are equivalent:
- · Vertex stabilizers of T are root-closed.
- · Edge stabilizers of T are root-closed.
Proof. If g n fixes an edge e = vw , it fixes v and w . If vertex stabilizers are root-closed, g fixes v and w , hence fixes e , so edge stabilizers are root-closed.
Conversely, if g n fixes a vertex v , then g is elliptic hence fixes a vertex w . Edges between v and w (if any) are fixed by g n , hence by g if edge stabilizers are root-closed. Thus g fixes v .
We now go back to a toral relatively hyperbolic group G .
Definition 4.3. A tree T is an RC -tree if:
- · all non-cyclic abelian subgroups fix a point in T ;
- · edge stabilizers of T are abelian and root-closed.
When G is hyperbolic, RC -trees are the Z max -trees of [DG11]: non-trivial edge stabilizers are maximal cyclic subgroups.
Lemma 4.4. 1. Let T be an RC -tree with all edge stabilizers non-trivial. Its tree of cylinders T c (see Subsection 2.2) is an RC -tree belonging to the same deformation space as T .
- 2. If T 1 and T 2 are RC -trees relative to some family H , and edge stabilizers of T 1 are elliptic in T 2 , there is an RC -tree ˆ T 1 relative to H which refines T 1 and dominates T 2 . Moreover, the stabilizer of any edge of ˆ T 1 fixes an edge in T 1 or in T 2 .
Proof. Non-triviality of edge stabilizers ensures that T c is defined. The vertex stabilizers of T c are vertex stabilizers of T or maximal abelian subgroups, so are root-closed. The deformation space does not change because T is relative to non-cyclic abelian subgroups (see [GL11], prop. 6.3). This proves 1.
We define a refinement ˆ T 1 of T 1 dominating T 2 as in Lemma 3.2 of [GL09], by blowing up each vertex v of T 1 into a G v -invariant subtree of T 2 . We just have to check that its edge stabilizers are root-closed. As in the proof of Lemma 4.9 of [DG11], an edge stabilizer of ˆ T 1 is an edge stabilizer of T 1 or is the intersection of a vertex stabilizer of T 1 with an edge stabilizer of T 2 , so is root-closed.
Proposition 4.5. Let G be toral relatively hyperbolic. In each of the following two cases, there is a bound for the number of orbits of edges of a minimal tree T with abelian edge stabilizers:
- 1. T is bipartite: each edge has exactly one endpoint with abelian stabilizer (redundant vertices are allowed);
## 2. T is an RC -tree with no redundant vertex.
Here, and below, the bound has to depend only on G (it is independent of the trees under consideration).
Case 1 applies in particular to trees of cylinders.
Proof. We cannot apply Bestvina-Feighn's accessibility theorem [BF91] directly because T does not have to be reduced in the sense of [BF91]: Γ = T/G may have a vertex v of valence 2 such that an incident edge carries the same group as v . We say that such a v is a non-reduced vertex. The assumptions rule out the possibility that Γ contains long segments consisting of non-reduced vertices (as in the example on top of page 450 in [BF91]).
If T is bipartite, consider all non-reduced vertices of Γ and collapse exactly one of the incident edges. This yields a reduced graph of groups, and at most half of the edges of Γ are collapsed, so [BF91] gives a bound.
If T is an RC -tree with no redundant vertex, every non-reduced vertex v of Γ = T/G has exactly two adjacent edges e v and f v , whose groups satisfy G e v /notsubsetoreql G v = G f v . Among all edges incident to a non-reduced vertex, consider the set E m consisting of those with G e of minimal rank. No two edges of E m are adjacent at a non-reduced vertex, because T is an RC -tree. Now collapse the edges in E m .
If I = e 1 ∪ e 2 ∪··· ∪ e k is a maximal segment in the complement of the set of vertices of Γ having degree 3 or carrying a non-abelian group, we never collapse adjacent edges e , e i i +1 (and we do not collapse e 1 if k = 1; we may collapse e 1 and e 3 if k = 3). It follows that at least one third of the edges of Γ remain after the collapse.
Repeat the process. Denote by M the maximal rank of abelian subgroups of G . After at most M steps one obtains a graph of groups which is reduced in the sense of [BF91], hence has at most N edges for some fixed N . The number of edges of Γ is bounded by 3 M N .
Proposition 4.6. Given a toral relatively hyperbolic group G , there exists a number M such that, if T 1 → T 2 → ··· → T p is a sequence of maps between RC -trees belonging to distinct deformation spaces, then p ≤ M .
Proof. There are two steps.
- · The first step is to reduce to the case when no edge stabilizer is trivial. Consider the tree ¯ T i (possibly a point) obtained from T i by collapsing all edges with non-trivial stabilizer. A map T i → T i +1 cannot send an arc with non-trivial stabilizer to the interior of an edge with trivial stabilizer, so ¯ T i dominates ¯ T i +1 . Vertex stabilizers of ¯ T i are free factors, there are finitely many possibilities for their isomorphism type.
Using Scott's complexity, it is shown in Section 2.2 of [Gui08] that the number of times that the deformation space D i of ¯ T i differs from that of ¯ T i +1 is uniformly bounded. We may therefore assume that D = D i is independent of i .
Let H ,.. . , H 1 k be representatives of conjugacy classes of non-trivial vertex stabilizers of trees in D . They are free factors of G , hence toral relatively hyperbolic, and k is bounded.
Consider the action of H j on its minimal subtree T j i ⊂ T i (we let T j i be any fixed point if the action is trivial). It is an RC -tree, and no edge stabilizer is trivial. The deformation space of T i is completely determined by D and the deformation spaces D j i of the trees T j i (viewed as trees with an action of H j ). It therefore suffices to bound (by
a constant depending only on H j ) the number of times that D j i changes in a sequence T j 1 → T j 2 →··· → T j p , so we may continue the proof under the additional assumption that the T i 's have non-trivial edge stabilizers.
- · Now that edge stabilizers are non-trivial, the tree of cylinders of T i is defined. By the first assertion of Lemma 4.4, we may assume that it equals T i .
Since all trees are trees of cylinders, Proposition 4.11 of [GL11] lets us assume that all domination maps T i → T i +1 send vertex to vertex, and map an edge to either a point or an edge. Such a map may collapse an edge to a point, or identify edges belonging to different orbits, or identify edges in the same orbit. The first two phenomena are easy to control since they decrease the number of orbits of edges; controlling the third one requires more care (and restricting to RC -trees).
We associate a complexity ( n, -s ) to each T i , with n the number of edges of T /G i , and s the sum of the ranks of its edge groups; complexities are ordered lexicographically. We claim that the complexity of T i +1 is strictly smaller than that of T i . This gives the required uniform bound on p , since n (hence also s ) is bounded by the first case of Proposition 4.5.
Let f i : T i → T i +1 be a domination map as above. Complexity clearly cannot increase when passing from T i to T i +1 . If n does not decrease, no edge of T i is collapsed in T i +1 . Since T i and T i +1 belong to distinct deformation spaces, there exist distinct edges e, e ′ identified by f i . They have to belong to the same orbit (otherwise n decreases), so e ′ = ge for some g ∈ G . The group 〈 g, G e 〉 fixes the edge f i ( e ) = f i ( e ′ ) of T i +1 , so is abelian. It has rank bigger than the rank of G e because G e is root-closed and g / G ∈ e . Thus s increases, and the complexity decreases.
Let A be the family of all abelian subgroups. Let H be a family of subgroups of G . A JSJ tree (over A ) relative to H may be defined as a tree T such that T is relative to H , edge stabilizers of T are elliptic in every tree which is relative to H , and T dominates every tree satisfying the previous conditions (all trees are assumed to have abelian edge stabilizers). This motivates the following definition, where we require that T be an RC -tree (compare Section 4.4 of [DG11]). Recall that H + ab is obtained by adding all non-cyclic abelian subgroups to H .
Definition 4.7. Let G be a toral relatively hyperbolic group, and H a family of subgroups. A tree T is an RC -JSJ tree relative to H + ab if:
- 1. T is relative to H + ab , and is an RC -tree;
- 2. edge stabilizers of T are elliptic in every tree with abelian edge stabilizers (not necessarily an RC -tree) which is relative to H + ab ;
- 3. T dominates every tree satisfying 1 and 2.
We will construct RC -JSJ trees in Section 5. Note that non-cyclic edge stabilizers always satisfy 2.
Proposition 4.8. Let G be a toral relatively hyperbolic group. Let H 1 ⊂ . . . ⊂ H i ⊂ . . . be an increasing sequence (finite or infinite) of families of subgroups, with G freely indecomposable relative to H 1 . For each i , let U i be an RC -JSJ tree relative to H + ab i . There exists a number q , depending only on G , such that the trees U i belong to at most q distinct deformation spaces.
Proof. Let U i be as in the proposition. Note that U i satisfies condition 1 of Definition 4.7 with respect to H + ab j if j ≤ i , and condition 2 with respect to H + ab j if j ≥ i . But cyclic edge stabilizers of U i do not necessarily satisfy 2 with respect to H + ab j if j < i .
In general, there is no domination map U i → U i +1 , so we cannot apply Proposition 4.6 directly. The easy case is when, for each i , every cyclic edge stabilizer of U i +1 is contained in an edge stabilizer of U i . Indeed, this implies that U i +1 satisfies condition 2 with respect to H + ab i (not just to H + ab i +1 ). By condition 3, U i dominates U i +1 , so Proposition 4.6 applies.
/negationslash
Next, assume that there is an RC -tree T relative to H 1 such that, for all i , there is a domination map T → U i that collapses no edge. Each cyclic edge stabilizer G e of U i +1 contains an edge stabilizer G e ′ of T (take for e ′ any edge whose image contains a subarc of e ). Since G is freely indecomposable relative to H 1 , and T is relative to H 1 , one has G e ′ = 1, and G e ′ = G e because G e ′ is root closed. Since the map T → U i collapses no edge, G e fixes an edge in U i , and we conclude as above.
We now construct such a tree T . By condition 2 of Definition 4.7, edge stabilizers of U 1 are elliptic in U 2 , so by Lemma 4.4 there is an RC -tree T 1 relative to H 1 which refines U 1 and dominates U 2 ; we remove redundant vertices of T 1 if needed. Edge stabilizers of T 1 fix an edge in U 1 or U 2 , so are elliptic in U 3 and one may iterate. One obtains RC -trees T i relative to H 1 such that T i refines T i -1 and dominates U i +1 . By Proposition 4.5, all trees T i for i large enough are equal to a fixed RC -tree T . We have no control over how large i has to be, but we have a uniform bound for the number of orbits of edges of T .
By construction, there are domination maps f i : T → U i , but f i may collapse some G -invariant set of edges. There are only a bounded number of possibilities for the set E i of edges of T that are collapsed by f i , so we may assume that E = E i is independent of i . Collapsing all edges of E then gives a tree T as wanted.
## 5 The chain condition
We prove Theorem 1.5. In this section we only consider groups of the form Out( G ; H (t) ), so we use the simpler notation Mc( H ). Since we do not yet know that every Mc( H ) is a McCool group, we assume that every H i is a finite set of finitely generated subgroups (this is needed to apply Lemma 2.3).
Since Mc( H ′ ) = Mc( H∪H ′ ) if Mc( H ⊃ ) Mc( H ′ ), we may assume H ⊂ H i i +1 . We will use the following procedure several times. We associate an invariant to each family H i , and we show that, as i varies, the number of distinct values of the invariant is bounded (by which we mean that there is a bound depending only on G ). We then continue the proof under the additional asssumption that the value of the invariant is independent of i .
- · The first invariant is the Grushko deformation space D i relative to H i (see Subsection 2.2). The assumption H i ⊂ H i +1 implies that D i dominates D i +1 . As in the proof of Proposition 4.6, it follows from [Gui08] that the number of times that D i changes is bounded. We may therefore assume that D i is constant.
Let G ,. . . , G 1 n be the free factors in a Grushko decomposition G = G 1 ∗ · · · ∗ G n ∗ F p relative to H i (they do not depend on i up to conjugation since D i is constant). The subgroup of Mc( H i ) consisting of automorphisms sending each factor G j to a conjugate has bounded index, and it is determined by the McCool groups Mc G j ( H i | G j ), so we are reduced to the case when G is freely indecomposable relative to H i .
- · We then consider the canonical JSJ tree T i (over abelian subgroups) relative to H + ab i , i.e. to H i and all non-cyclic abelian subgroups (see Subsection 2.2); it is Mc( H i )-invariant.
We cannot use Proposition 4.8 to say that the number of distinct T i 's is bounded, because they are not RC -trees, so we shall now replace T i by an RC -JSJ tree U i .
Any edge e of T i joins a vertex v 1 whose stabilizer is a maximal abelian subgroup to a vertex v 0 with non-abelian stabilizer. The group G e is a maximal abelian subgroup of G v 0 , but not necessarily of G v 1 . Let ¯ G e be the root-closure of G e in G v 1 (hence also in G ). As in Section 4.3 of [DG11], we can fold all edges in the ¯ G e -orbit of e together. Doing this for all edges of T i yields an RC -tree U i which is Mc( H i )-invariant.
This construction may also be described in terms of graphs of groups, as follows. We now view e = v v 0 1 as an edge of T /G i . Subdivide it by adding a midpoint u carrying ¯ G e . This creates two edges v u 0 and uv 1 , carrying G e and ¯ G e respectively. Do this for every edge e of T /G i . Collapsing all edges uv 1 yields T /G i , whereas collapsing all edges v u 0 yields U /G i .
The quotient graph U /G i is the same as T /G i , but labels are different. Edge groups are replaced by their root-closure, and non-abelian vertex groups have gotten bigger (roots have been adjoined: each fold replaces some G v 0 by G v 0 ∗ G e ¯ G e ). Just like T i , the tree U i is equal to its tree of cylinders because folding only occurs within cylinders; in particular, U i is determined by its deformation space.
Note that U i may have redundant vertices, and is not necessarily minimal (this happens if T /G i has a terminal vertex carrying an abelian group, and the incident edge group has finite index). In this case we replace U i by its minimal subtree.
We claim that U i is an RC -JSJ tree relative to H + ab i , in the sense of Definition 4.7. It satisfies conditions 1 and 2 since its edge stabilizers are finite extensions of edge stabilizers of T i . Any tree satisfying these two conditions is dominated by T i because T i is a JSJ tree. But any RC -tree dominated by T i is also dominated by U i (with notations as above, e and ge must have the same image if g ∈ ¯ G e ).
- · Proposition 4.8 lets us assume that U i is a fixed tree U . It is invariant under every Mc( H i ). We let Out ( 0 U ) be the finite index subgroup of Out( U ) consisting of automorphisms preserving U and acting trivially on Γ = U/G . The number of edges of Γ is uniformly bounded by Proposition 4.5, so the index of Out ( 0 U ) in Out( U ) is bounded, and it is enough to prove the chain condition for Mc ( 0 H i ) := Mc( H i ) ∩ Out ( 0 U ).
Let V be the set of vertices of Γ. As recalled in Subsection 2.3, there are maps ρ v : Out ( 0 U ) → Out( G v ) and a product map ρ : Out ( 0 U ) → ∏ v ∈ V Out( G v ). Since U is relative to H i , the group of twists T = ker ρ is contained in Mc ( 0 H i ).
Lemma 5.1. There exist subgroups Out ( 1 G v ) ⊂ Out( G v ) , independent of i , such that:
- 1. ∏ v ∈ V Out ( 1 G v ) is contained in ρ (Mc ( 0 H i )) for every i ;
- 2. the index of Out ( 1 G v ) in ρ v (Mc ( 0 H i )) is uniformly bounded.
This lemma implies Theorem 1.5 because Mc ( 0 H i ) contains ρ -1 ( ∏ v ∈ V Out ( 1 G v )) with bounded index.
Proof of Lemma 5.1. Let H i,v := ( H i ) || G v be the set of (conjugacy classes of) subgroups of G v which are conjugate to an element of H i , and which fix no other point in T (see Subsection 2.1). Since two such subgroups are conjugate in G v if and only if they are conjugate in G , we may view H i,v as a subset of H i .
Since ρ (Mc ( 0 H i )) contains ∏ v ∈ V Mc(Inc v ∪ H i,v ), as explained in Subsection 2.3, it suffices to fix v ∈ V and to construct Out ( 1 G v ), with Out ( 1 G v ) ⊂ Mc(Inc v ∪H i,v ) and the index of Out ( 1 G v ) in ρ v (Mc ( 0 H i )) uniformly bounded. We distinguish several cases.
- · First suppose that G v /similarequal Z k is abelian, so Out( G v ) = Aut( G v ) = GL k, ( Z ). Let A i be the root-closure of the subgroup of G v generated by incident edge groups and subgroups in H i,v . It is a direct factor and increases with i , so we may assume that it is independent of i . We define Out ( 1 G v ) ⊂ Out( G v ) as the subgroup consisting of automorphisms equal to the identity on A i . It is equal to Mc(Inc v ∪ H i,v ) and contained in ρ v (Mc ( 0 H i )). We must show that the index is bounded.
The group A i is invariant under ρ (Mc ( 0 H i )), and we have to bound the order of the image of Mc ( 0 H i ) in Out( A i ). Any incident edge group ¯ G e of G v contains an edge stabilizer G e of T i with finite index, and the image of the map ρ e : Mc ( 0 H i ) → Out( G e ) is finite by Lemma 2.3. Since A i is generated by incident edge groups and elements which are fixed by Mc ( 0 H i ), this implies that the image of Mc 0 ( H i ) in Out( A i ) is finite. Its cardinality is uniformly bounded because there is a bound for the order of finite subgroups of GL k, ( Z ), so the index of Out ( 1 G v ) in ρ v (Mc ( 0 H i )) is bounded.
- · We now consider a non-abelian vertex stabilizer G v . It follows from the way U i was constructed that G v is, for each i , the fundamental group of a graph of groups Λ i,v . This graph is a tree. It has a central vertex v i , which may be viewed as a vertex of T /G i with G v i non-abelian. All edges e join v i to a vertex u e carrying a root-closed abelian group, and the index of G e in G u e is finite. The graph of groups Λ i,v is invariant under the action of Mc ( 0 H i ) on G v .
We say that G v (or v ) is rigid with sockets , or QH with sockets , depending on the type of v i as a vertex of T i (since the number of vertices of T /G i is bounded, we may assume that this type is independent of i ).
- · If G v is rigid with sockets, we define Out ( 1 G v ) as the trivial group, and we have to explain why ρ v (Mc ( 0 H i )) is a finite group of bounded order. Assume first that U = T i (i.e. U is also a regular JSJ tree). Lemma 2.3 then implies that ρ v (Mc ( 0 H i )) is a finite subgroup of G v , but we need to bound its order only in terms of G (independently of the sequence H i ). To get this uniform bound, we note that there are only finitely many possibilities for G v up to isomorphism by [GL13]. Moreover Out( G v ) is virtually torsion-free by [GL12, Cor 4.5], so there is a bound for the order of its finite subgroups.
In general (i.e. without assuming U = T i ), we study ρ v (Mc ( 0 H i )) through its action on the graph of groups Λ i,v as in Subsection 2.3 (note that edges are not permuted). The group of twists is trivial because edge groups are maximal abelian in G v i and terminal vertex groups are abelian (see Proposition 3.1 of [Lev05a]), so we only have to control the action of Mc ( 0 H i ) on vertex groups of Λ i,v .
Applying Lemma 2.3 to the JSJ decomposition T i , we get finiteness of the image of Mc ( 0 H i ) in Out( G v i ), and in Out( G e ) for every edge e of T i , and hence of Λ i,v . The action of an automorphism on the edge groups of Λ i,v determines the action on the abelian vertex groups because they contain the incident edge group with finite index. This proves that ρ v (Mc ( 0 H i )) is finite, and boundedness follows as above.
- · There remains the case when G v is QH with sockets. The group G v i is then isomorphic to the fundamental group of a compact surface Σ , and incident edge groups are boundary i subgroups. The topology of Σ i may vary with i , but the number of boundary components of Σ i is bounded (by a simple accessibility argument, or because the rank of G v i as a free group is bounded by [GL13]).
- If J is a subgroup of G , denote by U i ( J ) the set of elements of J that are H + ab i -universally elliptic (i.e. elliptic in every G -tree with abelian edge stabilizers which is relative to H i and non-cyclic abelian subgroups). We view it as a union of J -conjugacy classes. Since H ⊂ H i i +1 , we have U i ( J ) ⊂ U i +1 ( J ). We shall show that the sequence U i ( G v )
stabilizes.
We first study U i ( G v i ): we claim that U i ( G v i ) is the union of the conjugacy classes of boundary subgroups of G v i = π 1 (Σ ). i Indeed, any boundary subgroup is an incident edge group of v i (up to conjugacy) or has a finite index subgroup conjugate to a group in H i (otherwise, G would be freely decomposable relative to H i , see Proposition 7.5 of [GL09]). It follows that U i ( G v i ) contains all boundary subgroups (incident edge groups are H + ab i -universally elliptic because T i is a JSJ tree relative to H + ab i ). Conversely, by Proposition 7.6 of [GL09], any g ∈ U i ( G v i ) is contained in a boundary subgroup of π 1 (Σ ). i This proves our claim, and shows in particular that U i ( G v i ) is the union of a bounded number of conjugacy classes of maximal cyclic subgroups L j ( ) of i G v i .
Elements of ρ v (Mc ( 0 H i )) send each cyclic group in U ( G v ) to a conjugate (conjugacy classes are not permuted because the action on T /G i is trivial). They act trivially on groups in H i,v , but they may map an element g belonging to a terminal vertex group of Λ v,i to g -1 (geometrically, they correspond to homeomorphisms of Σ i which may reverse orientation on boundary components).
We now consider U i ( G v ). The H + ab i -universally elliptic elements of G v are contained (up to conjugacy) in G v i or in one of the terminal vertex groups of Λ i,v , so U i ( G v ) is the union of the conjugates of the root-closures (in G v ) of the groups L j ( ). i Since H ⊂ H i i +1 , we have U i ( G v ) ⊂ U i +1 ( G v ). As U i ( G v ) is the union of the conjugates of a bounded number of cyclic subgroups, we may assume that U i ( G v ) = U ( G v ) does not depend on i .
We define Out ( 1 G v ) ⊂ Out( G v ) as the group of automorphisms acting trivially on each cyclic group in U ( G v ) (geometrically, we restrict to homeomorphisms of Σ i equal to the identity on the boundary). It is contained in Mc(Inc v ∪ H i,v ), because U i ( G v ) contains the incident edge groups of G v in U , hence contained in ρ v (Mc ( 0 H i )), and the index is bounded in terms of the number of conjugacy classes of cyclic subgroups in U ( G v ).
Remark 5.2 . Groups of the form Out( G ; H ), with H a finite family of abelian groups, do not satisfy the descending chain condition: consider G = Z 2 = 〈 x, y 〉 , and H i = {〈 x, y 2 i 〉} .
## 6 Proof of the other results
We first note the following consequence of the chain condition:
Proposition 6.1. If C is an infinite family of conjugacy classes, there exists a finite subfamily C ′ ⊂ C such that Mc( ) = Mc( C C ′ ) .
Recall that Mc( C ) is the group of outer automorphisms fixing all conjugacy classes belonging to C .
Proof. Write C as an increasing union of finite families C i and note that Mc( C ) is the intersection of the descending chain Mc( C i ).
To prove Corollary 1.6, saying in particular that every McCool group is an elementary McCool group, we need the following fact:
Lemma 6.2. Let G be a toral relatively hyperbolic group. Let H be a subgroup, and α ∈ Aut( G ) . If α h ( ) and h are conjugate in G for every h ∈ H , then α acts on H as conjugation by some g ∈ G .
Proof. We may assume that there is a non-trivial h ∈ H such that α h ( ) = h . If H is abelian, malnormality of maximal abelian subgroups implies that α is the identity on H . If not, the result follows from Lemma 5.2 of [MO10] (which is valid for any homomorphism ϕ : H → G , not just automorphisms of H ), see also Corollary 7.4 of [AMS13].
Corollary (Corollary 1.6) . Let G be a toral relatively hyperbolic group. If H is any family of subgroups of G , there exists a finite set of conjugacy classes such that Mc( H ) = Mc( C ) .
Recall that Mc( H ) is also denoted Out( G ; H (t) ). We favor the notation Mc( H ) in this section.
Proof. Given an arbitrary family H , let C H be the set of all conjugacy classes having a representative belonging to some H i . By Lemma 6.2, Mc( H ) = Mc( C H ). We apply Proposition 6.1 to get Mc( H ) = Mc( C ) with C finite.
Together with Theorem 3.11, this implies our most general finiteness result.
Corollary 6.3. Let G be a toral relatively hyperbolic group. Let H be an arbitrary collection of subgroups of G . Let K be a finite collection of abelian subgroups of G . Let T be a simplicial tree on which G acts with abelian edge stabilizers, with each group in H∪K fixing a point.
Then the group Out( T, H (t) , K ) = Out( T ) ∩ Out( G ; H (t) , K ) of automorphisms leaving T invariant, acting trivially on each group of H , and sending each K ∈ K to a conjugate (in an arbitrary way), is of type VF.
Proof. By Corollary 1.6, we may write Out( G ; H (t) ) = Mc( ) for some finite family of C conjugacy classes [ c i ], with each c i belonging to a group of H hence elliptic in T . Defining L = {〈 c i 〉} , we see that Mc( C ) is a finite index subgroup of Out( G ; L ), so Out( T, H (t) , K ) is a finite index subgroup of Out( T, K ∪ L ). By Theorem 3.11, this group has type VF, and therefore so does Out( T, H (t) , K ).
Proposition 1.7 and Theorem 1.8 will be proved at the end of the section.
Proposition (Proposition 1.10) . Given a toral relatively hyperbolic group G , there exists a number C such that, if a subgroup ̂ M ⊂ Out( G ) contains a group Mc( H ) with finite index, then the index [ ̂ M : Mc( H )] is bounded by C .
Proof of Proposition 1.10. By Corollary 1.6, we may write Mc( H ) = Mc( C ′ ) for some finite set C ′ . Let C be the orbit of C ′ under ̂ M . Since Mc( C ′ ) fixes C ′ , this is a finite ̂ M -invariant collection of conjugacy classes. We thus have
$$\text{Mc} ( \mathcal { C } ) & \subset \text{Mc} ( \mathcal { C } ^ { \prime } ) \subset \widehat { M } \subset \widehat { \text{Mc} } ( \mathcal { C } ), \\ \text{I the index } [ \widehat { \text{Mc} } ( \mathcal { C } ) \colon \text{Mc} ( \mathcal { C } ) ].$$
and it suffices to bound the index [Mc( ̂ C ) : Mc( C )]. As in the beginning of Section 5, let G = G 1 ∗· · · ∗ G n ∗ F r be a Grushko decomposition of G relative to C , and G = { G ,. . . G 1 n } . The group Mc( ̂ C ) permutes the conjugacy classes of the groups in G . Since the cardinality of G is bounded, and G has finitely many free factors up to isomorphism, we may assume that G is one-ended relative to C .
We now consider the JSJ decomposition T can over abelian groups relative to C and non-cyclic abelian groups. It is invariant under Mc( ̂ C ), so we may study Mc( ̂ C ) through its action on T can (see Subsection 2.3).
The number of edges of Γ can = T can /G being bounded by the first case of Proposition 4.5, we may replace Mc( ̂ C ) and Mc( C ) by their subgroups Mc ( ̂ 0 C ) and Mc ( 0 C ) acting trivially on Γ. The group of twists T is contained in Mc ( 0 C ), so as in the proof of Lemma 5.1 it suffices to construct Out 1 ( G v ) ⊂ Mc G v (Inc v ∪ C || G v ) with the index of Out ( 1 G v ) in ρ v (Mc ( ̂ 0 C )) uniformly bounded. We distinguish the same cases as in the proof of Lemma 5.1.
If G v is rigid, we let Out 1 ( G v ) be trivial. The image of Mc ( ̂ 0 C ) in Out( G v ) is finite by Lemma 2.3, and bounded by [GL13] as in the proof of Lemma 5.1.
If G v is abelian, isomorphic to Z k with k ≥ 2, let H < G v be the set of elements whose orbit under ρ v (Mc ( ̂ 0 C )) is finite. This is a subgroup of G v , isomorphic to some Z p , which is invariant under ρ v (Mc ( ̂ 0 C )) and contains the incident edge groups by Lemma 2.3. We define Out ( 1 G v ) = Mc G v ( { H } ). It is contained in Mc G v (Inc v ∪ C || G v ). The image of ρ v (Mc ( ̂ 0 C )) in Aut( H ) = GL p, ( Z ) is finite, and its order bounds the index of Out ( 1 G v ) in ρ v (Mc ( ̂ 0 C )). This concludes the proof in this case since there is a bound for the order of finite subgroups of GL p, ( Z ).
If G v = π 1 (Σ) is QH, we define Out ( 1 G v ) = PM + (Σ) = Mc G v (Inc v ∪C || G v ). Elements of ρ v (Mc ( ̂ 0 C )) may reverse orientation, or permute boundary components of Σ.
Proof. Given a descending chain Mc( ̂ C i ), define C ′ i = C 0 ∪ · · · ∪ C i and note that
Corollary 6.4. Extended elementary McCool groups ̂ Mc( ) C of G satisfy a uniform chain condition.
$$\text{Mc} ( \mathcal { C } _ { i } ^ { \prime } ) = \cap _ { j \leq i } \text{Mc} ( \mathcal { C } _ { j } ) \subset \widehat { \text{Mc} } ( \mathcal { C } _ { i } ) = \cap _ { j \leq i } \widehat { \text{Mc} } ( \mathcal { C } _ { j } ) \subset \widehat { \text{Mc} } ( \mathcal { C } _ { i } ^ { \prime } ). \\ \text{rollary follows from Theorem 1.5, since by Proposition 1.10 the index of $Mc$}$$
We now prove Corollary 1.11 stating that, for any A < Out( G ), there is a subgroup A 0 < A of bounded finite index such that, for the action of A 0 on the set of conjugacy classes of G , every orbit is a singleton or is infinite.
The corollary follows from Theorem 1.5, since by Proposition 1.10 the index of Mc( C ′ i ) in ̂ Mc( C ′ i ) is bounded.
Proof of Corollary 1.11. Let C A be the (possibly infinite) set of conjugacy classes of G whose A -orbit is finite. Partition C A into A -orbits, and let C p be the union of the first p orbits. The image of A in the group of permutations of C p is contained in that of Mc( ̂ C p ), so by Proposition 1.10 its order is bounded by some fixed C . This C also bounds the order of the image of A in the group of permutations of C A .
Recall that Ac( H , H 0 ) ⊂ Aut( G ) is the group of automorphisms acting trivially on H (in the sense of Definition 1.2, i.e. by conjugation) and fixing the elements of H 0 . Proposition 1.13 states that, if G is non-abelian, then Ac( H , H 0 ) is an extension
$$1 \to K \to \text{Ac} ( \mathcal { H }, H _ { 0 } ) \to \text{Mc} ( \mathcal { H } ^ { \prime } ) \to 1$$
with Mc( H ′ ) ⊂ Out( G ) a McCool group, and K the centralizer of H 0 . Corollary 1.14 states that the groups Ac( H , H 0 ) are of type VF and satisfy a uniform chain condition.
Proof of Proposition 1.13. Let H ′ = H∪{ H 0 } . Map Ac( H , H 0 ) ⊂ Aut( G ) to Out( G ). The image is Mc( H ′ ). The kernel K is the set of inner automorphisms equal to the identity on H 0 . Since G has trivial center, it is isomorphic to the centralizer of H 0 .
Proof of Corollary 1.14. The group Mc( H ′ ) has type VF by Theorem 1.3. The group K is abelian or equal to G , so has type F because G does [Dah03]. Proposition 1.13 and Corollary 3.2 imply that Ac( H , H 0 ) has type VF. Moreover, a chain of centralizers has length at most 2 since the centralizer of H 0 is trivial, G , or a maximal abelian subgroup. The uniform chain condition for McCool groups (Proposition 1.5) then implies the uniform chain condition for groups of the form Ac( H , H 0 ).
We now deduce the bounded chain condition for fixed subgroups.
Proof of Theorem 1.8. Let J 0 /notsubsetoreql J 1 /notsubsetoreql . . . /notsubsetoreql J p be a strictly ascending chain of fixed subgroups. Let Ac( ∅ , J i ) be the subgroup of Aut( G ) consisting of automorphisms equal to the identity on J i . Since J i is a fixed subgroup, Ac( ∅ , J i ) /supersetnoteql Ac( ∅ , J i +1 ). Corollary 1.14 then gives a bound on the length on the chain.
Remark. One can adapt the arguments of Section 5 to prove Theorem 1.8 directly (without passing through McCool groups).
We now prove Proposition 1.7 saying that Out( F n ) contains infinitely many nonisomorphic McCool groups for n ≥ 4, and infinitely many non-conjugate McCool groups for n ≥ 3.
Proof of Proposition 1.7. Let H be the free group on three generators a, b, c . Given a nontrivial element w ∈ 〈 a, b 〉 , let P w be the cyclic HNN extension P w = 〈 a, b, c, t | tct -1 = w 〉 . It is free of rank 3, with basis a, b, t . Let ϕ w be the automorphism of P w fixing a and b , and mapping t to wt (it equals the identity on H since it fixes c = t -1 wt ). The image Φ w of ϕ w in Out( P w ) preserves the Bass-Serre tree T of the HNN extension (it belongs to its group of twists T ).
We apply this construction with w = a b k k , for k a positive integer. As k varies, the cyclic subgroups 〈 Φ w 〉 are pairwise non-conjugate in Out( P w ) /similarequal Out( F 3 ), as seen by considering the action on the abelianization.
We shall now prove the second assertion of the proposition for n = 3, by showing that 〈 Φ w 〉 is a McCool group of P w , namely 〈 Φ w 〉 = Mc P w ( { H } ) ⊂ Out( F 3 ). The extension to n > 3 is straightforward, by adding generators to H .
Consider splittings of P w over abelian (i.e. cyclic) subgroups relative to H . The tree T is a JSJ tree because its vertex stabilizers are universally elliptic [GL09, lemma 4.7]; in particular, P w is freely indecomposable relative to H . Moreover, T equals its tree of cylinders (up to adding redundant vertices) because w is not a proper power, so T is the canonical JSJ tree T can . The McCool group Mc P w ( { H } ) therefore leaves T invariant, and it is easily checked using [Lev05a] that Mc P w ( { H } ) = T = Φ 〈 w 〉 .
To prove the first assertion of the proposition, consider R w = P w ∗ 〈 d 〉 /similarequal F 4 , the family H = { H, d 〈 〉} , and the McCool group Mc R w ( H ⊂ ) Out( F 4 ). The decomposition R w = P w ∗ 〈 d 〉 is a Grushko decomposition of R w relative to H because P w is freely indecomposable relative to H . This decomposition is invariant under Mc R w ( H ) because it is a one-edge splitting (see [For02], cor 1.3).
The stabilizer Out( T ) of the Bass-Serre tree T in Out( R w ) is naturally isomorphic to
$$\text{Aut} ( P _ { w } ) \times \text{Aut} ( \langle d \rangle ) \simeq \text{Aut} ( P _ { w } ) \times \mathbb { Z } / 2 \mathbb { Z }$$
(see [Lev05a]); the natural map Out( T ) → Out( P w ) kills the factor Z / 2 Z and coincides with the quotient map Aut( P w ) → Out( P w ) on the other factor. The McCool group
Mc R w ( H ) is isomorphic to the preimage of Mc P w ( { H } ) = 〈 Φ w 〉 in Aut( P w ), hence to the mapping torus
$$Q _ { w } = \langle a, b, t, u \ | \ u a = a u, u b = b u, u t u ^ { - 1 } = a ^ { k } b ^ { k } t \rangle.$$
The abelianization of Q w is Z 3 × Z /k Z , so the isomorphism type of Q w changes when k varies. This proves the first assertion of the proposition or n = 4. The extension to larger n is again straightforward.
## 7 Appendix: groups with finitely many McCool groups
In this appendix we describe cases when Out( G ) only contains finitely many McCool subgroups. In particular, we show that the values of n given in Proposition 1.7 are optimal.
Proposition 7.1. If G is a torsion-free one-ended hyperbolic group, then Out( G ) only contains finitely many McCool groups up to conjugacy.
Proposition 7.2. Out( F 2 ) only contains finitely many McCool groups up to conjugacy.
Proposition 7.3. Out( F 3 ) only contains finitely many McCool groups up to isomorphism.
The proof of Proposition 7.1 requires the fact that Out( G ), and more generally extended McCool groups Mc( ̂ C ), only contain finitely many conjugacy classes of finite subgroups. This will appear in [GLa].
Proof of Proposition 7.1. We assume that Out( G ) contains infinitely many non-conjugate elementary McCool groups Mc( C i ), and we derive a contradiction (this implies the proposition by Corollary 1.6).
It is proved in [Sel97, Corollary 4.9] that there are only finitely many minimal actions of G on trees with cyclic edge stabilizers, up to the action of Out( G ), so we may assume that the canonical cyclic JSJ tree relative to C i (the tree T can of Subsection 2.2) is a given tree T . This tree is invariant under all groups Mc( C i ), so Mc( C i ) ⊂ Out( T ). In this proof, we cannot restrict to Out ( 0 T ).
Given a vertex v of T , we define C i,v as the restriction C i | G v if G v is cyclic, as C i || G v if G v is not cyclic (recall from Subsection 2.1 that conjugacy classes represented by elements fixing an edge of T do not belong to C i || G v ). The tree being bipartite, C i is the disjoint union of the C i,v 's.
We say that v is used if C i,v is non-empty. Since there are finitely many G -orbits of vertices, we may assume that usedness is independent of i ; we let V u be a set of representatives of orbits of used vertices. We may also assume that the type of vertices with non-cyclic stabilizer (rigid or QH) is independent of i (QH vertices with Σ a pair of pants are rigid, we do not consider them as QH).
We claim that QH vertices G v of T are not used. Indeed, any boundary subgroup of G v is an incident edge stabilizer of T : otherwise, G v would split as a free product relative to Inc , contradicting one-endedness of v G . Elements in C i are universally elliptic (relative to C i ), and the only universally elliptic subgroups of G v are contained in boundary subgroups of G v because G v is flexible (see [GL09], Proposition 7.6), so C i || G v is empty.
For v ∈ V u , define Out ( i G v ) ⊂ Out( G v ) as the set of automorphisms which fix each conjugacy class in C i,v and leave the set of incident edge stabilizers globally invariant. Any automorphism in Mc( C i ) is an automorphism of T which leaves G v invariant (up to conjugacy), and induces an automorphism belonging to Out ( i G v ). Conversely, any
automorphism of T satisfying these properties for every v ∈ V u lies in Mc( C i ). This means that Mc( C i ) is completely determined by the knowledge of the groups Out ( i G v ), for v ∈ V u .
We complete the proof by showing that there are only finitely many possibilities for each Out ( i G v ). This is clear if G v is cyclic, and QH vertices are not used, so there remains to consider the case where G v is rigid.
In this case, Out ( i G v ) is finite by Lemma 2.3 (otherwise G v would have a cyclic splitting relative to Inc v and C i,v , contradicting rigidity). Since G v is hyperbolic, Out( G v ) has finitely many conjugacy classes of finite subgroups [GLa]. We deduce that there are finitely many possibilities for Out ( i G v ), up to conjugacy in Out( G v ). Unfortunately, this is not enough to get finiteness for Mc( C i ) up to conjugacy in Out( G ), because the conjugator may fail to extend to an automorphism of G .
To remedy this, we consider Mc(Inc ) and Mc(Inc ), with Inc v ̂ v v the family of incident edge groups as in Subsection 2.1, and Mc(Inc ̂ v ) = Out( ̂ G v ; Inc v ) the set of outer automorphisms of G v preserving Inc v (see Definition 2.1; edge groups may be permuted, and the generator of an edge group may be mapped to its inverse).
The group Out ( i G v ) ⊂ Out( G v ) is finite and contained in Mc(Inc ) (but not neces-̂ v sarily in Mc(Inc v )). By [GLa], Mc(Inc ) has only finitely many conjugacy classes of finite ̂ v subgroups. It follows that there are only finitely many possibilities for Out ( i G v ) up to conjugation by an element of Mc(Inc ), hence also up to conjugation by an element of ̂ v Mc(Inc ) since Mc(Inc ) has finite index in Mc(Inc v v v ).
̂ We may therefore assume that Out ( i G v ) is independent of i if G v is cyclic and v ∈ V u , and that all groups Out ( i G v ) are conjugate by elements of Mc(Inc ) if v v ∈ V u is rigid. Any element of Mc(Inc ) extends 'by the identity' to an automorphism of v G which leaves T invariant and acts trivially (as conjugation by an element of G ) on G w if w is not in the orbit of v . Since Mc( C i ) is determined by the groups Out ( i G v ) for v ∈ V u , we conclude that all groups Mc( C i ) are conjugate in Out( G ).
Proof of Proposition 7.2. We view Out( F 2 ) /similarequal GL (2 , Z ) as the mapping class group of a punctured torus Σ (with orientation-reversing maps allowed). Let c be a peripheral conjugacy class (representing the commutator of basis elements of F 2 ).
We consider a McCool group Mc( H ) ⊂ Out( F 2 ). We may assume that Mc( H ) is infinite. By the classification of elements of GL (2 , Z ), or by the Bestvina-Paulin method and Rips theory, F 2 then splits over a cyclic group relative to H and c (see for instance Theorem 3.9 of [GL12]). Such a splitting is dual to a non-peripheral simple closed curve γ ⊂ Σ.
If there are two different splittings, they are dual to curves γ, γ ′ whose union fills Σ, so H only contains peripheral subgroups. It follows that Mc( H ) is either Out( F 2 ) /similarequal GL (2 , Z ) or SL (2 , Z ). If the splitting is unique, Mc( H ) fixes γ (viewed as an unoriented curve up to isotopy). Since the splitting dual to γ is relative to H , the Dehn twist T γ around γ is contained in Mc( H ). The stabilizer Stab( γ ) of γ in the mapping class group contains 〈 T γ 〉 with finite index (the index is 4 because a homeomorphism may reverse the orientation of Σ and/or of γ ). We thus have 〈 T γ 〉 ⊂ Mc( H ) ⊂ Stab( γ ), with both indices finite. Finiteness of Mc( H ) up to conjugacy follows, since γ is unique up to the action of the mapping class group.
The remainder of this appendix is devoted to the proof of Proposition 7.3. We first record a few useful facts.
Lemma 7.4. Fix n . Up to isomorphism, Out( F n ) only contains finitely many virtually solvable subgroups.
Proof. Virtually solvable subgroups are virtually abelian ([Ali02, BFH04]). More precisely, they contain Z k with k ≤ 2 n -3 as a subgroup of bounded index (see [BFH04], proof of Theorem 1.1 page 94). This implies finiteness, for instance by [Seg83, Th. 6 p. 176].
Lemma 7.5. Let A be virtually cyclic, and B be virtually F n for some n . Up to isomorphism, there are only finitely many groups which are extensions of A by B .
Proof. This follows from standard extension theory ([Bro82], sections III.10 and IV.6), noting that Out( A ) is finite and B has a finite index subgroup with trivial H 2 .
Now consider a McCool group Mc( H ⊂ ) Out( F 3 ). The first step is to reduce to the case where F 3 is freely indecomposable relative to H . If this does not hold, let Γ be a Grushko decomposition relative to H (see Subsection 2.2). It is not unique, we choose one with as few edges as possible.
If all vertex groups are cyclic, groups in H are generated (up to conjugacy) by powers of elements belonging to some fixed basis of F 3 , and finiteness holds. Otherwise, there is a vertex group G v /similarequal F 2 . Our choice of Γ implies that Γ has a single edge (it is an HNN extension, or an amalgam F 2 ∗ Z with a finite index subgroup of Z belonging to H ). It follows that Γ is Mc( H )-invariant ([For02, Lev05b]), and Mc( H ) is determined by its image in Out( F 2 ). This image is the McCool group Mc( H | F 2 ), so finiteness follows from Proposition 7.2.
We continue the proof under the assumption that F 3 is freely indecomposable relative to H . Let Γ can be the canonical Mc( H )-invariant cyclic JSJ decomposition relative to H (see Subsection 2.2). Vertex groups G v are cyclic, rigid, or QH.
One easily checks the formula ∑ v (rk G v -1) = 2. In particular, rk G v ≤ 3 for all v , and if some G v is isomorphic to F 3 , then all other vertex groups are cyclic.
If G v /similarequal π 1 (Σ) is a QH vertex group, it is isomorphic to F 2 or F 3 , so there are 9 possibilities for the compact surface Σ:
- 1. pair of pants
- 2. sphere with 4 boundary components
- 3. projective plane with 2 boundary components
- 4. projective plane with 3 boundary components
- 5. torus with 1 boundary component
- 6. torus with 2 boundary components
- 7. Klein bottle with 1 boundary component
- 8. Klein bottle with 2 boundary components
- 9. non-orientable surface of genus 3 with 1 boundary component.
Each incident edge group G e is (up to conjugacy) a boundary subgroup of π 1 (Σ). Conversely, there are two possibilities for a boundary subgroup C . If it is an incident edge group, it equals G e for a unique incident edge. If not, we say that the corresponding boundary component of Σ is free ; in this case some finite index subgroup of C belongs to H .
As in Subsection 2.3, the finite index subgroup Mc ( 0 H ) of Mc( H ) acting trivially on Γ can maps to ∏ v Out( G v ) with kernel the group of twists T . The image in Out( G v ) is finite if G v is cyclic or rigid, virtually the mapping class group of Σ if G v is QH, and T is isomorphic to some Z k (see Subsection 4.3 of [GL12]).
By mapping class group, we mean the group of isotopy classes of homeomorphisms of a compact surface Σ mapping each boundary component to itself in an orientationpreserving way. We denote it by PM + (Σ) as in Subsection 2.2.
By Lemma 7.4, we may assume that there is a QH vertex v with PM + (Σ) non-solvable. As explained above, there are 9 possibilities for Σ. Cases 1, 3, 7 are ruled out because PM + (Σ) is virtually cyclic (see [Sze08], or argue as in the proof of Proposition 7.2, noting that a finite index subgroup of PM + (Σ) fixes a conjugacy class of F 2 which is not a power of the commutator).
If Γ can is trivial (i.e. if the QH subgroup G v is the whole group), Mc( H ) is the mapping class group of Σ. We therefore assume that Γ can is non-trivial.
## Lemma 7.6. If G v has rank 3, then Σ has a free boundary component.
Proof. This follows from Lemma 4.1 of [BF], a generalization of the standard fact that a cyclic amalgam A ∗ 〈 c 〉 B of free groups is free only if c belongs to a basis in A or B .
This lemma rules out case 9.
Now suppose that all vertices of Γ can other than v are terminal vertices carrying Z (by Lemma 7.6, this holds in cases 6 and 8). In this case the group of twists T is trivial (see Proposition 3.1 of [Lev05a]). The group Mc( H ) contains PM + (Σ) with finite index, and there are finitely many possibilities: they depend on whether edges of Γ can may be permuted, and whether elements in edge groups may be mapped to their inverse.
We must now deal with cases 2, 4, 5. We start with 4. The only possibility left is that Γ can has two vertices v, w joined by 2 edges, with G w cyclic. Every automorphism leaving Γ can invariant maps G v to itself (up to conjugacy), and we consider the natural map from Mc( H ) to Out( G v ). As above, the image contains PM + (Σ) with finite index, and there are finitely many possibilities. The kernel is the group of twists T , which is isomorphic to Z . Since PM + (Σ) is isomorphic to F 3 by Theorem 7.5 of [Sze08], we conclude by Lemma 7.5.
The argument in case 2 is similar. Besides v and w , there may be another vertex w ′ , with G w ′ cyclic and a single edge between v and w ′ . The group PM + (Σ) is again free, it is isomorphic to F 2 (see for instance [FM12], 4.2.4).
In case 5 (once-punctured torus), there is a single edge incident to v . Collapsing all other edges yields an Mc( H )-invariant decomposition as an amalgam F 3 = G v ∗ 〈 a 〉 G w with G w /similarequal F 2 . By the standard fact recalled above, a belongs to a basis of G w (and is equal to a commutator in G v ). The group Mc( H ) acts trivially on the graph underlying this amalgam, and the map ρ (see Subsection 2.3) maps Mc( H ) to Out( G v ) × Out( G w ), with kernel the group of twists T , isomorphic to Z . The image in Out( G v ) is isomorphic to GL (2 , Z ) or SL (2 , Z ).
We now consider the image L of Mc( H ) in Out( G w ). It preserves the conjugacy class of 〈 a 〉 . If L is finite (necessarily of order ≤ 6), then Mc( H ) maps onto GL (2 , Z ) or SL (2 , Z ) with virtually cyclic kernel K ; there are finitely many possibilities for K up to isomorphism (it maps to L with cyclic kernel), and we conclude by Lemma 7.5. As explained in the proof of Proposition 7.2, if L is infinite, it is virtually cyclic, contains a 'Dehn twist' T a , and has index at most 4 in the stabilizer of the conjugacy class of 〈 a 〉 in Out( G w ). Since Mc( H ) is determined by its image in Out( G v ) × Out( G w ), and this image contains SL (2 , Z ) ×〈 T a 〉 , this leaves only finitely many possibilities.
## References
| [Ali02] | Emina Alibegovi´. c Translation lengths in Out( F n ). Geom. Dedicata , 92:87-93, 2002. Dedicated to John Stallings on the occasion of his 65th birthday. |
|-----------|---------------------------------------------------------------------------------------------------------------------------------------------------------------------------|
| [AMS13] | Yago Antolin, Ashot Minasyan, and Alessandro Sisto. Commensurating endomorphisms of acylindrically hyperbolic groups and applications. arXiv:1310.8605, 2013. |
| [BF91] | Mladen Bestvina and Mark Feighn. Bounding the complexity of simplicial group actions on trees. Invent. Math. , 103(3):449-469, 1991. |
| [BF] | Mladen Bestvina and Mark Feighn. Outer limits. Preprint (1992), http://andromeda.rutgers.edu/~{}feighn/papers/outer.pdf . |
| [BFH04] | Mladen Bestvina, Mark Feighn, and Michael Handel. Solvable subgroups of Out( F n ) are virtually Abelian. Geom. Dedicata , 104:71-96, 2004. |
| [Bor66] | Armand Borel. Density and maximality of arithmetic subgroups. J. Reine Angew. Math. , 224:78-89, 1966. |
| [BS73] | A. Borel and J.-P. Serre. Corners and arithmetic groups. Comment. Math. Helv. , 48:436- 491, 1973. |
| [Bro82] | Kenneth S. Brown. Cohomology of groups , volume 87 of Graduate Texts in Mathematics . Springer-Verlag, New York, 1982. |
| [CV86] | Marc Culler and Karen Vogtmann. Moduli of graphs and automorphisms of free groups. Invent. Math. , 84(1):91-119, 1986. |
| [Dah03] | Fran¸ois c Dahmani. Classifying spaces and boundaries for relatively hyperbolic groups. Proc. London Math. Soc. (3) , 86(3):666-684, 2003. |
| [DG08] | Fran¸ois c Dahmani and Daniel Groves. The isomorphism problem for toral relatively hyperbolic groups. Publ. Math. Inst. Hautes ´ Etudes Sci. , 107:211-290, 2008. |
| [DG11] | Fran¸ois c Dahmani and Vincent Guirardel. The isomorphism problem for all hyperbolic groups. Geom. Funct. Anal. , 21(2):223-300, 2011. |
| [FM12] | Benson Farb and Dan Margalit. A primer on mapping class groups , volume 49 of Prince- ton Mathematical Series . Princeton University Press, Princeton, NJ, 2012. |
| [For02] | Max Forester. Deformation and rigidity of simplicial group actions on trees. Geom. Topol. , 6:219-267 (electronic), 2002. |
| [Geo08] | Ross Geoghegan. Topological methods in group theory , volume 243 of Graduate Texts in Mathematics . Springer, New York, 2008. |
| [Gui08] | Vincent Guirardel. Actions of finitely generated groups on R -trees. Ann. Inst. Fourier (Grenoble) , 58(1):159-211, 2008. |
| [GL07a] | Vincent Guirardel and Gilbert Levitt. Deformation spaces of trees. Groups Geom. Dyn. , 1(2):135-181, 2007. |
| [GL07b] | Vincent Guirardel and Gilbert Levitt. The outer space of a free product. Proc. Lond. Math. Soc. (3) , 94(3):695-714, 2007. |
| [GL09] | Vincent Guirardel and Gilbert Levitt. JSJ decompositions: definitions, existence and uniqueness. I: The JSJ deformation space. arXiv:0911.3173 v2 [math.GR], 2009. |
| [GL10] | Vincent Guirardel and Gilbert Levitt. JSJ decompositions: definitions, existence and uniqueness. II: Compatibility and acylindricity. arXiv:1002.4564 v2 [math.GR], 2010. |
| [GL11] | Vincent Guirardel and Gilbert Levitt. Trees of cylinders and canonical splittings. Geom. Topol. , 15(2):977-1012, 2011. |
| [GL12] | Vincent Guirardel and Gilbert Levitt. Splittings and automorphisms of relatively hy- perbolic groups, 2012. Geometry Groups and Dynamics , to appear. arXiv:1212.1434 [math.GR]. |
|----------|----------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------|
| [GL13] | Vincent Guirardel and Gilbert Levitt. Vertex finiteness for splittings of relatively hyper- bolic groups. arXiv:1311.2835, 2013 |
| [GLa] | Vincent Guirardel and Gilbert Levitt. Extension finiteness for relatively hyperbolic groups. In preparation. |
| [GLb] | Vincent Guirardel and Gilbert Levitt. Strata and canonical subtrees of R -trees. In preparation. |
| [HM13] | Michael Handel and Lee Mosher. Subgroup decomposition in Out ( F n ): Introduction and research announcement. arXiv:1302.2681, 2013. |
| [Lev05a] | Gilbert Levitt. Automorphisms of hyperbolic groups and graphs of groups. Geom. Dedicata , 114:49-70, 2005. |
| [Lev05b] | Gilbert Levitt. Characterizing rigid simplicial actions on trees. In Geometric methods in group theory , volume 372 of Contemp. Math. , pages 27-33. Amer. Math. Soc., Providence, RI, 2005. |
| [MV04] | A. Martino and E. Ventura. Fixed subgroups are compressed in free groups. Comm. Algebra , 32(10):3921-3935, 2004. |
| [McC75] | James McCool. Some finitely presented subgroups of the automorphism group of a free group. J. Algebra , 35:205-213, 1975. |
| [MO10] | A. Minasyan and D. Osin. Normal automorphisms of relatively hyperbolic groups. Trans. Amer. Math. Soc. , 362(11):6079-6103, 2010. |
| [Seg83] | Daniel Segal. Polycyclic groups , volume 82 of Cambridge Tracts in Mathematics . Cam- bridge University Press, Cambridge, 1983. |
| [Sel97] | Z. Sela. Acylindrical accessibility for groups. Invent. Math. , 129(3):527-565, 1997. |
| [Sze08] | B/suppressazej l ˙ Szepietowski. A presentation for the mapping class group of a non-orientable surface from the action on the complex of curves. Osaka J. Math. , 45(2):283-326, 2008. |
## Vincent Guirardel
Institut de Recherche Math´matique de Rennes e Membre de l'institut universitaire de France Universit´ de Rennes 1 et CNRS (UMR 6625) e 263 avenue du G´ en´ral Leclerc, CS 74205 e F-35042 RENNES C´ edex e-mail: [email protected]
## Gilbert Levitt
Laboratoire de Math´ ematiques Nicolas Oresme Universit´ de Caen et CNRS (UMR 6139) e BP 5186 F-14032 Caen Cedex France e-mail:
[email protected] | 10.2140/agt.2015.15.3485 | [
"Vincent Guirardel",
"Gilbert Levitt"
] | 2014-08-02T20:56:20+00:00 | 2014-08-02T20:56:20+00:00 | [
"math.GR",
"20F28, 20F65, 20F67, 20F34, 20E08, 57M07, 20J06"
] | McCool groups of toral relatively hyperbolic groups | The outer automorphism group Out(G) of a group G acts on the set of conjugacy
classes of elements of G. McCool proved that the stabilizer $Mc(c_1,...,c_n)$
of a finite set of conjugacy classes is finitely presented when G is free. More
generally, we consider the group $Mc(H_1,...,H_n)$ of outer automorphisms
$\Phi$ of G acting trivially on a family of subgroups $H_i$, in the sense that
$\Phi$ has representatives $\alpha_i$ with $\alpha_i$ equal to the identity on
$H_i$.
When G is a toral relatively hyperbolic group, we show that these two
definitions lead to the same subgroups of Out(G), which we call "McCool groups"
of G. We prove that such McCool groups are of type VF (some finite index
subgroup has a finite classifying space). Being of type VF also holds for the
group of automorphisms of G preserving a splitting of G over abelian groups.
We show that McCool groups satisfy a uniform chain condition: there is a
bound, depending only on G, for the length of a strictly decreasing sequence of
McCool groups of G. Similarly, fixed subgroups of automorphisms of G satisfy a
uniform chain condition. |
1408.0419v3 | ## MATROID TORIC IDEALS: COMPLETE INTERSECTION, MINORS AND MINIMAL SYSTEMS OF GENERATORS
## IGNACIO GARCÍA-MARCO* AND JORGE LUIS RAMÍREZ ALFONSÍN
ABSTRACT. In this paper, we investigate three problems concerning the toric ideal associated to a matroid. Firstly, we list all matroids M such that its corresponding toric ideal I M is a complete intersection. Secondly, we handle the problem of detecting minors of a matroid M from a minimal set of binomial generators of I M . In particular, given a minimal set of binomial generators of I M we provide a necessary condition for M to have a minor isomorphic to U d, 2 d for d ≥ 2 . This condition is proved to be sufficient for d = 2 (leading to a criterion for determining whether M is binary) and for d = 3 . Finally, we characterize all matroids M such that I M has a unique minimal set of binomial generators.
## 1. INTRODUCTION
Let M be a matroid on a finite ground set E = { 1 , . . . , n } , we denote by B the set of bases of M ∈ B . Let k be an arbitrary field and consider k x , . . . , x [ 1 n ] a polynomial ring over k . For each base B , we introduce a variable y B and we denote by R the polynomial ring in the variables y B , i.e., R := k y [ B | B ∈ B ] . A binomial in R is a difference of two monomials, an ideal generated by binomials is called a binomial ideal .
↦
We consider the homomorphism of k -algebras ϕ : R -→ k x , . . . , x [ 1 n ] induced by y B → ∏ i ∈ B x . i The image of ϕ is a standard graded k -algebra, which is called the bases monomial ring of the matroid M and it is denoted by S M . By [23, Theorem 5], S M has Krull dimension dim( S M ) = n -c +1 , where c is the number of connected components of M . The number c of connected components is the largest integer k such that E is the disjoint union of the nonempty sets E , . . . , E 1 k and M is the direct sum of some matroids M 1 , . . . , M k , where M i has ground set E i . The kernel of ϕ , which is the presentation ideal of S M , is called the toric ideal of M and is denoted by I M . It is well known that I M is a prime, binomial and homogeneous ideal, see, e.g., [20]. Since R/I M /similarequal S M , it follows that the height of I M is ht( I M ) = |B| dim( S M ) .
In [24], White posed several conjectures concerning basis exchange properties on matroids. One of these combinatorial conjectures turned out to be equivalent to decide if I M is always generated by quadratics. This algebraic version of the conjecture motivated several authors to study I M . Despite this conjecture is still open, it has been proved to be true by means of this algebraic approach for several families of matroids (see [13] and the references there). Even more, it is not even known if for every matroid its corresponding toric ideal admits a quadratic Gröbner basis.
In this paper we study the algebraic structure of toric ideals of matroids. We study three different problems concerning I M .
Date : September, 2015.
2010 Mathematics Subject Classification. 05B35, 20M25, 05E40, 14M25.
Key words and phrases. Matroid, toric ideal, complete intersection, minimal set of generators, minor, binary matroid.
* Corresponding Author: Phone: +33-624564368. Email: [email protected]
The authors were supported by the ANR TEOMATRO grant ANR-10-BLAN 0207.
The first author was partially supported by Ministerio de Educación y Ciencia - España MTM2010-20279- C02-02.
- 1.1. Complete intersection. The first problem is to characterize the matroids M such that I M is a complete intersection. The toric ideal I M is a complete intersection if µ I ( M ) = ht( I M ) , where µ I ( M ) denotes the minimal number of generators of I M . Equivalently, I M is a complete intersection if and only if there exists a set of homogeneous binomials g , . . . , g 1 s ∈ R such that s = ht( I M ) and I M = ( g , . . . , g 1 s ) .
Complete intersection toric ideals were first studied by Herzog in [11]. Since then, they have been extensively studied by several authors. In the context of toric ideals associated to combinatorial structures, the complete intersection property has been widely studied for graphs, see, e.g., [2, 22, 10]. In this work we address this problem in the context of toric ideals of matroids and prove that there are essentially three matroids whose corresponding toric ideal is a complete intersection; namely, the rank 2 matroids without loops or coloops on a ground set of 4 elements.
- 1.2. Minors. Many of the most celebrated results on matroids make reference to minors, for this reason it is convenient to have tools to detect whether a matroid has a certain minor or not. In this work we study the problem of detecting whether a matroid M has a minor isomorphic to U d, 2 d with d ≥ 2 , where U r,n denotes the uniform matroid of rank r on E = { 1 , . . . , n } . More precisely, we prove that whenever a matroid contains a minor isomorphic to U d, 2 d , then there exist B , B 1 2 ∈ B such that ∆ { B ,B 1 2 } = ( 2 d -1 d ) ; where, for every B , B 1 2 ∈ B , ∆ { B ,B 1 2 } denotes the number of pairs of bases { D , D 1 2 } such that B 1 ∪ B 2 = D 1 ∪ D 2 as multisets. This condition is also proved to be sufficient for d = 2 and d = 3 . Since U 2 4 , is the only excluded minor for a matroid to be binary, the result for d = 2 provides a new criterion for detecting whether a matroid is binary. Moreover, we provide an example to show that for d = 5 this condition is no longer sufficient. These results are presented in purely combinatorial terms, nevertheless whenever one knows a minimal set of binomials generators of I M , one can easily compute ∆ { B ,B 1 2 } for all B , B 1 2 ∈ B . Thus, these results give a method to detect if a matroid has a minor isomorphic to U 2 4 , or U 3 6 , provided one knows a minimal set of binomial generators of I M .
- 1.3. Minimal systems of generators. Minimal systems of binomial generators of toric ideals have been studied in several papers; see, e.g., [4, 8]. In general, for a toric ideal it is possible to have more than one minimal system of generators formed by binomials. Given a toric ideal I , we denote by ν I ( ) the number of minimal sets of binomial generators of I , where the sign of a binomial does not count. A recent problem arising from algebraic statistics (see [21]) is to characterize when a toric ideal I possesses a unique minimal system of binomial generators; i.e., when ν I ( ) = 1 . The problems of determining ν I ( ) and characterizing when ν I ( ) = 1 for a toric ideal I were studied in [6, 15], also in [9, 12] in the context of toric ideals associated to affine monomial curves and in [16, 19] for toric ideals of graphs. In this paper we also handle these problems in the context of toric ideals of matroids. More precisely, we characterize all matroids M such that ν I ( M ) = 1 . This result follows as a consequence of a lower bound we obtain for ν I ( M ) . This bound turns to be an equality whenever I M is generated by quadratics.
The paper is organized as follows. In the next section, we recall how the operations of deletion and contraction on a matroid M reflect into I M . We prove that the complete intersection property is preserved under taking minors (Proposition 2.1). We then give a complete list of all matroids whose corresponding toric ideal is a complete intersection (Theorem 2.3). To this end, we first give such a list for matroids of rank 2 (Proposition 2.2), which is based on results given in [2]. In Section 3, we provide a necessary condition for a matroid to contain a minor isomorphic to U d, 2 d for d ≥ 2 in terms of the values ∆ { B ,B 1 2 } for B , B 1 2 ∈ B (Proposition 3.3). We also prove that this condition is also sufficient when d = 2 or d = 3 (Theorems 3.4 and 3.5). Moreover, we show that this condition is no longer sufficient for d = 5 . In the last section we focus on giving formulas for the values µ I ( M ) and ν I ( M ) . In particular, we give a lower bound for these in terms of the values ∆ { B ,B 1 2 } for B , B 1 2 ∈ B (Theorem 4.1). Moreover, this lower bound turns to be exact provided
MATROID TORIC IDEALS: COMPLETE INTERSECTION, MINORS AND MINIMAL SYSTEMS OF GENERATORS3
I M is generated by quadratics. Finally, we characterize all those matroids whose toric ideal has a unique minimal binomial generating set (Theorem 4.2).
## 2. COMPLETE INTERSECTION TORIC IDEALS OF MATROIDS
We begin this section by setting up some notation and recalling some results about matroids which are useful in the sequel. For a general background on matroids we refer the reader to [18].
Let M be a matroid on the ground set E = { 1 , . . . , n } and rank r . Let B denote the set of bases of M . By definition B is not empty and satisfies the following exchange axiom :
For every B , B 1 2 ∈ B and for every e ∈ B 1 \ B 2 , there exists f ∈ B 2 \ B 1 such that ( B 1 ∪ { f } ) \ { e } ∈ B .
Brualdi proved in [5] that the exchange axiom is equivalent to the symmetric exchange axiom :
For every B , B 1 2 in B and for every e ∈ B 1 \ B 2 , there exists f ∈ B 2 \ B 1 such that both ( B 1 ∪ { f } ) \ { e } ∈ B and ( B 2 ∪{ } e ) \ { f } ∈ B .
Now we recall some basic facts and results over toric ideals of matroids needed later on. Firstly, we observe that for B , . . . , B 1 s , D , . . . , D 1 s ∈ B , the homogeneous binomial y B 1 · · · y B s -y D 1 · · · y D s belongs to I M if and only if B 1 ∪··· ∪ B s = D 1 ∪··· ∪ D s as multisets. Since I M is a homogeneous binomial ideal, it follows that
I M = ( { y B 1 · · · y B s -y D 1 · · · y D s | B 1 ∪ · · · ∪ B s = D 1 ∪ · · · ∪ D as multisets s } ) .
From this expression one easily derives that whenever r ∈ { 0 1 , , n -1 , n } , then I M = (0) and I M is a complete intersection. Thus, we only consider the case 2 ≤ r ≤ n -2 .
Now we prove that the operations of taking duals, deletion, contraction and taking minors of M preserve the property of being a complete intersection on I M . For more details on how these operations affect I M we refer the reader to [3, Section 2].
↦
We denote by M ∗ the dual matroid of M . It is straightforward to check that σ I ( M ) = I M ∗ , where σ is the isomorphism of k -algebras σ : R -→ k y [ E B \ | B ∈ B ] induced by y B → y E B \ . Thus, I M is a complete intersection if and only if I M ∗ also is.
For every A ⊂ E , M\ A denotes the deletion of A from M and M /A denotes the contraction of A from M . For E ′ ⊂ E , the restriction of M to E ′ is denoted by M| E ′ .
Proposition 2.1. Let M ′ be a minor of M . If I M is a complete intersection, then I M ′ also is.
Proof. Take e ∈ E and let us prove that I M\{ } e is a complete intersection. If e is a loop, then B is the set of bases of both M and M\{ } e and, hence, I M = I M\{ } e . Assume that e is not a loop and take G a binomial generating set of I M . By [2, Lemma 2.2] or [17], I M\{ } e is generated by the set G ′ := G ∩ k y [ B | e / B ∈ ∈ B ] . Hence, I M\{ } e is a complete intersection (see [2, Proposition 2.3]). An iterative application of this result proves that for all A ⊂ E I , M\ A is a complete intersection.
For every A ⊂ E , it suffices to observe that M /A = ( M \ ∗ A ) ∗ to deduce that I M /A is also a complete intersection whenever I M is. Thus, the result follows. /square
↦
As we mentioned in the proof of Proposition 2.1, if e is a loop then I M = I M\{ } e . Moreover, if e is a coloop of M , then I M is essentially equal to I M { } / e . Indeed, if one considers the isomorphism of k -algebras τ : R -→ k y [ B \{ } e | B ∈ B ] induced by y B → y B \{ } e , then τ ( I M ) = I M { } / e . For this reason we may assume without loss of generality that M has no loops or coloops.
Now we study the complete intersection property for I M when M has rank 2 . In this case, we associate to M the graph H M with vertex set E and edge set B . It turns out that I M coincides with the toric ideal of the graph H M (see, e.g., [2]). In particular, from [2, Corollary 3.9], we have that whenever I M is a complete intersection, then H M does not contain K 2 3 , as subgraph, where
K 2 3 , denotes the complete bipartite graph with partitions of sizes 2 and 3 . The following result characterizes the complete intersection property for toric ideals of rank 2 matroids.
Proposition 2.2. Let M be a rank 2 matroid on a ground set of n ≥ 4 elements without loops or coloops. Then, I M is a complete intersection if and only if n = 4 .
Proof. ( ⇒ ) Assume that n ≥ 5 and let us prove that I M is not a complete intersection. Since M has rank 2 and has no loops or coloops, we may assume that it has two disjoint basis, namely B 1 = { 1 2 , } , B 2 = { 3 4 , } ∈ B . Moreover, 5 is not a coloop, so we may also assume that B 3 = { 1 5 , } ∈ B . Since B , B 1 2 ∈ B , by the symmetric exchange axiom, we can also assume that B 4 = { 1 3 , } , B 5 = { 2 4 , } ∈ B . If { 4 5 , } ∈ B , then H M has a subgraph K 2 3 , and I M is not a complete intersection. Let us suppose that { 4 5 , } ∈ B / . By the exchange axiom for B 2 and B 3 we have B 6 := { 3 5 , } ∈ B . Again by the exchange axiom for B 5 and B 6 we get that B 7 := { 2 5 , } ∈ B . Thus, H M has K 2 3 , as a subgraph and I M is not a complete intersection.
( ⇐ ) There are three non isomorphic rank 2 matroids without loops or coloops and n = 4 . Namely, M }} 1 with set of bases B 1 = {{ 1 2 , } { , 3 4 , } { , 1 3 , } { , 2 4 , }} , M 2 with set of bases B 2 = B 1 ∪ {{ 1 4 , and M 3 = U 2 4 , . For i = 1 2 , one can easily check that ht( I M i ) = 1 and that I M i = ( y { 1 2 , } y { 3 4 , } -y { 1 3 , } y { 2 4 , } ) ; thus both I M 1 and I M 2 are complete intersections. Moreover, ht( I M 3 ) = 2 and a direct computation with SINGULAR [7] or COCOA [1] yields that I M 3 = ( y { 1 2 , } y { 3 4 , } -y { 1 3 , } y { 2 4 , } , y { 1 4 , } y { 2 3 , } -y { 1 3 , } y { 2 4 , } ) ; thus I M 3 is also a complete intersection. /square
Now, we apply Proposition 2.2 to give the list of all matroids M such that I M is a complete intersection.
Theorem 2.3. Let M be a matroid without loops or coloops and with 2 ≤ r ≤ n -1 . Then, I M is a complete intersection if and only if n = 4 and M is the matroid whose set of bases is:
- (1) B = {{ 1 2 , } { , 3 4 , } { , 1 3 , } { , 2 4 , }} ,
- (2) B = {{ 1 2 , } { , 3 4 , } { , 1 3 , } { , 2 4 , } { , 1 4 , }} , or
- (3) B = {{ 1 2 , } { , 3 4 , } { , 1 3 , } { , 2 4 , } { , 1 4 , } { , 2 3 , }} , i.e., M = U 2 4 , .
Proof. By Proposition 2.2 it only remains to prove that I M is not a complete intersection provided r ≥ 3 . Since n > r + 1 and M has no loops or coloops, we can take B , B 1 2 ∈ B such that | B 1 \ B 2 | = 2 and consider f ∈ B 1 ∩ B 2 . Since f is not a coloop, there exists B ′ ∈ B such that f / B ∈ ′ . Moreover, since B , B 1 ′ ∈ B , by the exchange axiom there exists e ∈ B ′ such that B 3 := ( B 1 \{ f } ) ∪{ } ∈ B e . We observe that | B 2 \ B 3 | ∈ { 2 3 , } . Setting A := B 1 ∩ B 2 ∩ B 2 , we can assume without loss of generality that f = 1 and that B 1 = A ∪{ 1 2 3 , , } , B 2 = A ∪{ 1 4 5 , , } and B 3 = A ∪ { 2 3 , , e } , where e ∈ { 5 6 , } . We have two cases.
Case 1: e = 5 . We consider the matroid ( M { ′ ) ∗ , the dual matroid of M ′ := ( M /A ) | E ′ , with E ′ = { 1 2 3 4 5 , , , , } . We observe that { 1 2 3 , , } , 1 4 5 , , } { , 2 3 5 , , } are bases of M ′ and hence { 4 5 , } { , 2 3 , } { , 1 4 , } are bases of ( M ′ ) ∗ . Thus ( M ′ ) ∗ is a rank 2 matroid without loops or coloops and, by Proposition 2.2, I ( M ′ ) ∗ is not a complete intersection. Hence, by Proposition 2.1, we conclude that I M is not a complete intersection.
Case 2: e = 6 . We consider the minor M ′ := ( M /A ) | E ′ , where E ′ = { 1 2 3 4 5 6 , , , , , } and observe that { 1 4 5 , , } { , 1 2 3 , , } { , 2 3 6 , , } are bases of M ′ . By the symmetric exchange axiom, we may also assume that { 1 2 4 , , } { , 1 3 5 , , } are also bases of M ′ . We claim that for every base B of M , either 1 ∈ B or 6 ∈ B , but not both. Indeed, if there exists a base B of M ′ such that { 1 6 , } ⊂ B then the rank 2 matroid M 1 := M { } ′ / 1 on the set E ′ \ { 1 } has no loops or coloops. Thus, by Proposition 2.2, I M 1 is not a complete intersection and, by Proposition 2.1, neither is I M . If there exists a base of M ′ such that 1 / B ∈ and 6 / B ∈ , the rank 2 matroid M 2 := ( M\{ } ′ 6 ) ∗ on the set E ′ \ { 6 } has no loops or coloops. Thus again by Proposition 2.2, we get that I M 1 is not a complete intersection and, by Proposition 2.1, neither is I M . Analogously, one can prove that for every base B of M ′ either 2 ∈ B or 5 ∈ B but not both, and that either 3 ∈ B or 4 ∈ B but not
both. Hence, M ′ is the transversal matroid with presentation ( { 1 6 , } { , 2 5 , } { , 3 4 , } ) . Since M ′ has 8 bases and 3 connected components, then I M ′ has height 4 . Moreover, a direct computation yields that I M ′ is minimally generated by 9 binomials; thus, I M ′ is not a complete intersection and the proof is finished. /square
## 3. FINDING MINORS IN A MATROID
In this section we investigate a characterization for a matroid to contain certain minors in terms of a set of binomial generators of its corresponding toric ideal. In particular, we focus our attention to detect if a matroid M contains a minor U d, 2 d for d ≥ 2 . We consider the following binary equivalence relation ∼ on the set of pairs of bases:
$$\{ B _ { 1 }, B _ { 2 } \} \sim \{ B _ { 3 }, B _ { 4 } \} \iff B _ { 1 } \cup B _ { 2 } = B _ { 3 } \cup B _ { 4 } \text{ as multisets},$$
and we denote by ∆ { B ,B 1 2 } the cardinality of the equivalence class of { B , B 1 2 } .
For two sets A, B we denote by A /triangle B the symmetric difference of A and B , i.e., A /triangle B := ( A \ B ) ∪ ( B \ A . )
We now introduce two lemmas concerning the values ∆ { B ,B 1 2 } . The first one provides some bounds on the values of ∆ { B ,B 1 2 } . In the proof of this lemma we use the so called multiple symmetric exchange property (see [25]):
For every B , B 1 2 in B and for every A 1 ⊂ B 1 , there exists A 2 ⊂ B 2 such that ( B 1 ∪ A 2 ) \ A 1 ∈ B and ( B 2 ∪ A 1 ) \ A 2 are in B .
Lemma 3.1. For every B , B 1 2 ∈ B , then 2 d -1 ≤ ∆ { B ,B 1 2 } ≤ ( 2 d -1 d ) , where d := | B 1 \ B 2 | .
Proof. Take e ∈ B 1 \ B 2 . By the multiple symmetric exchange property, for every A 1 such that e ∈ A 1 ⊂ ( B 1 \ B 2 ) , there exists A 2 ⊂ B 2 such that both B ′ 1 := ( B 1 ∪ A 2 ) \ A 1 and B ′ 2 := ( B 2 ∪ A 1 ) \ A 2 are bases. Since B 1 ∪ B 2 = B ′ 1 ∪ B ′ 2 as multisets, we derive that ∆ { B ,B 1 2 } is greater or equal to the number of sets A 1 such that e ∈ A 1 ⊂ ( B 1 \ B 2 ) , which is exactly 2 d -1 .
We set A := B 1 ∩ B 2 , C := B 1 /triangle B 2 and take e ∈ B 1 \ B 2 . Take B , B 3 4 ∈ B such that B 1 ∪ B 2 = B 3 ∪ B 4 as multisets and assume that e ∈ B 4 . Then, B 3 \ A ⊂ C \ { e } with | B 3 \ A | = | B 1 \ B 2 | = d elements; thus, ∆ { B ,B 1 2 } ≤ ( 2 d -1 d ) . /square
Moreover, the bounds of Lemma 3.1 are sharp for every d ≥ 2 . Indeed, if one considers the transversal matroid on the set { 1 , . . . , 2 d } with presentation ( { 1 , d + 1 } , . . . , { d, 2 d } ) , and takes the bases B 1 = { 1 , . . . , d } , B 2 = { d +1 , . . . , 2 d } , then | B 1 \ B 2 | = d and ∆ { B ,B 1 2 } = 2 d -1 . Also, if we consider the uniform matroid U d, 2 d then for any base B we have that ∆ { B,E B \ } = ( 2 d -1 d ) .
The second lemma interprets the values of ∆ { B ,B 1 2 } in terms of the number of bases-cobases of a certain minor of M . Recall that a base B ∈ B is a base-cobase if E \ B is also a base of M .
Lemma 3.2. Let B , B 1 2 ∈ B of a matroid M and consider the matroid M ′ := ( M / B ( 1 ∩ B 2 )) | ( B 1 /triangle B 2 ) on the ground set B 1 /triangle B 2 . Then, the number of bases-cobases of M ′ is equal to 2∆ { B ,B 1 2 } .
Proof. Set t := ∆ { B ,B 1 2 } and consider B , B , . . . , B 3 4 2 t ∈ B such that B 1 ∪ B 2 = B 2 i -1 ∪ B 2 i as multisets for all i ∈ { 1 , . . . , t } . Take i ∈ { 1 , . . . , t } , then B 1 ∩ B 2 ⊂ B 2 i -1 , B 2 i ⊂ B 1 ∪ B 2 and, thus, B 2 i -1 \ ( B 1 ∩ B 2 ) and B 2 i \ ( B 1 ∩ B 2 ) are complementary bases-cobases of M ′ . This proves that 2 t is less or equal to the number of bases-cobases of M ′
Conversely, take D ′ 1 a base-cobase of M ′ and denote by D ′ 2 its complementary base-cobase of M ′ , i.e., D ′ 1 ∪ D ′ 2 = B 1 /triangle B 2 . Moreover, if we set D i := D ′ i ∪ ( B 1 ∩ B 2 ) ∈ B for i = 1 2 , , then D 1 ∪ D 2 = B 1 ∪ B 2 as multisets. This proves that 2 t is greater or equal to the number of bases-cobases of M ′ . /square
The following result provides a necessary condition for a matroid to have a minor isomorphic to U d, 2 d .
Proposition 3.3. If M has a minor M /similarequal ′ U d, 2 d for some d ≥ 2 , then there exist B , B 1 2 ∈ B such that ∆ { B ,B 1 2 } = ( 2 d -1 d ) .
Proof. Let A, C ⊂ E be disjoint sets such that M ′ := ( M\ A /C ) /similarequal U d, 2 d and denote E ′ := E \ ( A ∪ C ) . Since M ′ = ( M\ A /C ) , then there exist e , . . . , e 1 r -d ∈ A ∪ C such that B ′ ∪ { e , . . . , e 1 r -d } ∈ B for every B ′ base of M ′ (notice that the set { e , ...e 1 r -d } might not only have elements of C ). Wetake any D ⊂ E ′ with d elements, we have that B 1 = D ∪{ e , . . . , e 1 r -d } ∈ B , B 2 = ( E ′ \ D ) ∪ { e , . . . , e 1 r -d } ∈ B and B 1 ∪ B 2 = E ′ ∪ { e , . . . , e 1 r -d } . Thus, ∆ { B ,B 1 2 } ≥ ( 2 d d ) / 2 = ( 2 d -1 d ) . Since | B 1 \ B 2 | = d , by Lemma 3.1 we are done. /square
Since U 2 4 , is the only forbidden minor for a matroid to be binary, (see, e.g., [18, Theorem 6.5.4]) the following result gives a criterion for M to be binary by proving the converse of Proposition 3.3 for d = 2 .
/negationslash
## Theorem 3.4. M is binary if and only if ∆ { B ,B 1 2 } = 3 for every B , B 1 2 ∈ B .
Proof. ( ⇒ ) Assume that there exist B , B 1 2 ∈ B such that ∆ { B ,B 1 2 } = 3 . Let us denote d := | B 1 \ B 2 | . By Lemma 3.1 we observe that d = 2 . If we set C := B 1 ∩ B 2 and A = E \ ( B 1 ∪ B 2 ) , then M ′ := ( M\ A /C ) is a rank 2 matroid on a ground set of 4 elements and, by Lemma 3.2, it has 6 bases-cobases, thus M /similarequal ′ U 2 4 , and M is not binary.
( ⇐ ) Assume that M is not binary, then M has a minor M /similarequal ′ U 2 4 , and the result follows from Proposition 3.3. /square
We also prove that the converse of Proposition 3.3 also holds for d = 3 . In order to prove this we make use of the database of matroids available at
/negationslash www-imai.is.s.u-tokyo.ac.jp/ ∼ ymatsu/matroid/index.html which is based on [14]. This database includes all matroids with n ≤ 9 and all matroids with n = 10 and r = 5 .
Theorem 3.5. M has a minor M /similarequal ′ U 3 6 , if and only if ∆ { B ,B 1 2 } = 10 for some B , B 1 2 ∈ B .
Proof. ( ⇒ ) It follows from Proposition 3.3.
( ⇐ ) Assume that there exist B , B 1 2 ∈ B such that ∆ { B ,B 1 2 } = 10 . We denote d := | B 1 \ B 2 | and, by Lemma 3.1, we observe that d ∈ { 3 4 , } . We set C := B 1 ∩ B 2 , A = E \ ( B 1 ∪ B 2 ) and M ′ := ( M\ A /C ) , the rank d matroid on the ground set E ′ = ( B 1 ∪ B 2 ) \ C with 2 d elements. Moreover, by Lemma 3.2, M ′ has exactly 20 bases-cobases. An exhaustive computer aided search among the 940 non-isomorphic rank 4 matroids on a set of 8 elements proves that there does not exist such a matroid. Therefore d = 3 , and M ′ is a rank 3 matroid on a ground set of 6 elements with 20 bases-cobases, thus M /similarequal ′ U 3 6 , . /square
In view of Theorems 3.4 and 3.5, one might wonder if the condition ∆ { B ,B 1 2 } = ( 2 d -1 d ) for some B , B 1 2 ∈ B is also sufficient to have U d, 2 d as a minor. For d = 4 , we do not know it is true or not. Nevertheless, Example 3.6 shows that for d = 5 this is no longer true. That is to say, there exists a matroid M with two bases B , B 1 2 such that ∆ { B ,B 1 2 } = ( ) 9 5 = 126 and M has not a minor isomorphic to U 5 10 , . To prove this result we use the fact that there exist rank 3 matroids with exactly k bases-cobases for k = 14 and for k = 18 . We have found these matroids by an exhaustive search among the 36 non-isomorphic matroids of rank 3 on a set of 6 elements.
Example 3.6. Let M M 1 , 2 be rank 3 matroids on the sets E 1 and E 2 with exactly 14 and 18 basescobases respectively. Consider the matroid M := M ⊕M 1 2 , i.e., the direct sum of M 1 and M 2 .
It is easy to check that M has exactly 14 18 = 252 · bases-cobases. Therefore, if we take B a basecobase of M and denote by B ′ its complementary base-cobase, then ∆ { B,B ′ } = 252 2 = 126 / . Let us see now that M M\ has not a minor isomorphic to U 5 10 , . Suppose that there exist A, B ⊂ E 1 ∪ E 2 such that U 5 10 , /similarequal ( A /B ) . Weobserve that A ∪ B has two elements and if we denote A i := A ∩ E i and B i := B ∩ E i for i = 1 2 , , then U 5 10 , /similarequal ( M\ A /B ) = (( M \ 1 A 1 ) /B 1 ) ⊕ (( M \ 2 A 2 ) /B 2 ) , but this is not possible since U 5 10 , has only one connected component.
One of the interests in Proposition 3.3 and Theorems 3.4 and 3.5 comes from the fact that for every B , B 1 2 ∈ B , the values of ∆ { B ,B 1 2 } can be directly computed from a minimal set of generators of I M formed by binomials. The following proposition can be obtained as a consequence of [6, Theorems 2.5 and 2.6]. However, we find it convenient to include a direct proof of this fact.
Proposition 3.7. Let { g , . . . , g 1 s } be a minimal set of binomial generators of I M . Then,
∆ { B ,B 1 2 } = 1 + |{ g i = y B i 1 y B i 2 -y B i 3 y B i 4 | B i 1 ∪ B i 2 = B 1 ∪ B 2 as a multiset }| for every B , B 1 2 ∈ B .
↦
Proof. Set H := { g , . . . , g 1 s } and take B , B 1 2 ∈ B . Assume that g , . . . , g 1 t ∈ H are of the form g i = y B i 1 y B i 2 -y B i 3 y B i 4 with B i 1 ∪ B i 2 = B 1 ∪ B 2 as a multiset. We consider the graph G with vertices { B , B j k } ⊂ B such that B j ∪ B k = B 1 ∪ B 2 as multisets and, for every i ∈ { 1 , . . . , t } , if g i = y B i 1 y B i 2 -y B i 3 y B i 4 then f i is the edge connecting { B ,B i 1 i 2 } and { B ,B i 3 i 4 } . We observe that G has ∆ { B ,B 1 2 } vertices and t edges; to conclude that ∆ { B ,B 1 2 } = t +1 we prove that G is a tree. Assume that G has a cycle and suppose that the sequence of edges ( f , . . . , f 1 k ) forms a cycle. After replacing g i by -g i if necessary, we get that g 1 + · · · + g k = 0 , which contradicts the minimality of H . Assume now that G is not connected and denote by G 1 one of its connected components. We take { B ,B j 1 j 2 } a vertex of G 1 , { B k 1 , B k 2 } a vertex which is not in G 1 and consider q := y B j 1 y B j 2 -y B k 1 y B k 2 ∈ I M . We claim that q can be written as a combination of g , . . . , g 1 t , i.e., q = ∑ t i =1 q g i i for some q , . . . , q 1 t ∈ R . Indeed, the matroid M { induces a grading on R by assigning to y B the degree deg M ( y B ) := ∑ i ∈B e i ∈ N n , where e , . . . , e 1 n } is the canonical basis of Z n . Since I M is a graded ideal with respect to this grading, whenever q ∈ I M one may assume that q can be written as a combination of the g i such that deg M ( g i ) is componentwise less or equal to deg M ( q ) . By construction of q , we have that deg M ( g i ) is componentwise less or equal to deg M ( q ) if and only if i ∈ { 1 , . . . , t } and the claim is proved. Moreover, if we consider B 1 := ∪ { B,B ′ }∈ V ( G 1 ) { B,B ′ } and the homomorphism of k -algebras ρ : R → k y [ B | B ∈ B 1 ] induced by y B → y B if B ∈ B 1 , or y B → 0 otherwise, then y B j 1 y B j 2 = ρ q ( ) = ∑ f i ∈ E ( G 1 ) ρ q ( i ) g i , which is not possible. Thus, we conclude that G is connected and that ∆ { B ,B 1 2 } = t +1 . /square
↦
## 4. MATROIDS WITH A UNIQUE SET OF BINOMIAL GENERATORS
In general, for a toric ideal it is possible to have more than one minimal system of generators formed by binomials. For example, as we saw in the proof of Proposition 2.2, the matroid U 2 4 , is minimally generated by { f , f 1 2 } , where f 1 := y { 1 2 , } y { 3 4 , } -y { 1 3 , } y { 2 4 , } and f 2 := y { 1 4 , } y { 2 3 , } -y { 1 3 , } y { 2 4 , } ; nevertheless, if we consider f 3 := y { 1 2 , } y { 3 4 , } -y { 1 4 , } y { 2 3 , } one can easily check that I M is also minimally generated by { f , f 1 3 } and by { f , f 2 3 } . Thus, µ I ( U 2 4 , ) = 2 and ν I ( U 2 4 , ) ≥ 3 .
In this section we begin by giving some bounds for the values of µ I ( M ) and ν I ( M ) in terms of the values ∆ { B ,B 1 2 } for B , B 1 2 ∈ B . Moreover, this lower bounds turn out to be the exact values if I M is generated by quadratics.
Theorem 4.1. Let R = {{ B , B 1 2 } , . . . , { B 2 s -1 , B 2 s }} be a set of representatives of ∼ and set r i := ∆ { B 2 i -1 ,B 2 i } for all i ∈ { 1 , . . . , s } . Then,
$$\begin{array} { c } ( I ) \stackrel { \cdot \cdot \cdot \cdot } { \mu } ( I _ { \mathcal { M } } ) \stackrel { \cdot \cdot \cdot } { \geq } ( b ^ { 2 } - b - 2 s ) / 2, w h e r e \, b \coloneqq | \mathcal { B } |, \, a n d \\ ( 2 ) \, \nu ( I _ { \mathcal { M } } ) \stackrel { \cdot } { \geq } \prod _ { i = 1 } ^ { s } r _ { i } ^ { r _ { i } - 2 }. \end{array}$$
Moreover, in both cases equality holds whenever I M is generated by quadratics.
Proof. From Proposition 3.7, we deduce that µ I ( M ) ≥ ∑ s i =1 (∆ { B 2 i -1 ,B 2 i } -1) with equality if and only if I M is generated by quadratics. It suffices to observe that ∑ s i =1 ∆ { B 2 i -1 ,B 2 i } = ( b b -1) / 2 to prove (1) .
For each i ∈ { 1 , . . . , s } we consider the complete graph G i with vertices { B ,B j 1 j 2 } such that B 2 i -1 ∪ B 2 i = B j 1 ∪ B j 2 as multiset. We consider T i a spanning tree of G and define H i := { y B j 1 y B j 2 -y B j 3 y B j 4 | the vertices { B ,B j 1 j 2 } and { B ,B j 3 j 4 } are connected by an edge in T } i and H := ∪ s i =1 H i . Since H is formed by degree 2 polynomials which are k -linearly independent, then H can be extended to a minimal set of generators of I M . Since G i has exactly r i vertices, then there are exactly r r i -2 i different spanning trees of G i that lead to different minimal systems of generators and, thus, ν I ( M ) ≥ ∏ s i =1 r r i -2 i . Moreover, if I M is generated by quadratics, let us see that the set H is a set of generators itself. Indeed, let f ∈ I M be a binomial of degree two, then f = y B k 1 y B k 2 -y B k 3 y B k 4 . We take i ∈ { 1 , . . . , s } such that { B k 1 , B k 2 } /similarequal { B k 3 , B k 4 } /similarequal { B 2 i -1 , B 2 i } and there exists a path in T i connecting the vertices { B k 1 , B k 2 } and { B k 3 , B k 4 } , the edges in this path correspond to binomials in H and f is a combination of these binomials. /square
We end by characterizing all matroids whose toric ideal has a unique minimal binomial generating set. We recall that the basis graph of a matroid M is the undirected graph G M with vertex set B and edges { B,B ′ } such that | B \ B ′ | = 1 . We also recall that the diameter of a graph is the maximum distance between two vertices of the graph.
Theorem 4.2. Let M be a rank r ≥ 2 matroid. Then, ν I ( M ) = 1 if and only if M is binary and the diameter of G M is at most 2 .
Proof. ( ⇒ ) By Theorem 4.1,we have that ∆ { B ,B 1 2 } ∈ { 1 2 , } for all B , B 1 2 ∈ B . By Lemma 3.1 and Theorem 3.4, this is equivalent to M is binary and | B 1 \ B 2 | ∈ { 1 2 , } for all B , B 1 2 ∈ B . Clearly this implies that the diameter of G M is less or equal to 2 .
( ⇐ ) Assume that the diameter of G M is ≤ 2 , we claim that M is strongly base orderable. Recall that a matroid is strongly base orderable if for any two bases B 1 and B 2 there is a bijection π : B 1 → B 2 such that ( B 1 \ C ) ∪ π C ( ) is a basis for all C ⊂ B 1 . Wetake B , B 1 2 ∈ B and observe that | B 1 \ B 2 | ∈ { 1 2 , } . If B 1 \ B 2 = { } e and B 2 \ B 1 = { f } if suffices to consider the bijection π : B 1 → B 2 which is the identity on B 1 ∩ B 2 and π e ( ) = f . Moreover, if B 1 \ B 2 = { e , e 1 2 } and B 2 \ B 1 = { f , f 1 2 } , we denote A := B 1 ∩ B 2 and, by the symmetric exchange axiom, we can assume that both A ∪ { e , f 1 1 } and A ∪ { e , f 2 2 } are basis of M ; then it suffices to consider π : B 1 → B 2 the identity on A π e , ( 1 ) = f 2 and π e ( 2 ) = f 1 to conclude that M is strongly base orderable. So, by [13, Theorem 2], I M is generated by quadratics. Moreover, from Lemma 3.1 and Theorem 3.4 we deduce that ∆ { B ,B 1 2 } ∈ { 1 2 , } for all B , B 1 2 ∈ B . Hence, the result follows by Theorem 4.1. /square
## REFERENCES
- [1] J. Abbott, A. M. Bigatti, G. Lagorio, CoCoA-5: a system for doing Computations in Commutative Algebra. Available at http://cocoa.dima.unige.it .
- [2] I. Bermejo, I. García-Marco, E. Reyes, Graphs and comple te intersection toric ideals, J. Algebra Appl. 14 (2015), no. 9, 1540011, 37 pp.
- [3] S. Blum, Base-sortable matroids and Koszulness of semigroup rings, European J. Combin. 22(7) (2001), 937951.
- [4] E. Briales, A. Campillo, C. Marijuán, P. Pisón, Minimal sstems of generators for ideals of semigroups. J. Pure y Appl. Algebra 124 (1998), no. 1-3, 7-30.
- [5] R. A. Brualdi, Comments on bases in dependence structures, Bull. Austral. Math. Soc. 1 (1969), 161-167.
- [6] H. Charalambous, A. Katsabekis, A. Thoma, Minimal systems of binomial generators and the indispensable complex of a toric ideal. Proc. Amer. Math. Soc. 135 (2007), no. 11, 3443-3451.
- [7] W. Decker, G.-M. Greuel, G. Pfister, H. Schoenemann, SINGULAR 4-0-2, a Computer Algebra System for Polynomial Computations. Available at http://www.singular.uni-kl.de (2015).
MATROID TORIC IDEALS: COMPLETE INTERSECTION, MINORS AND MINIMAL SYSTEMS OF GENERATORS9
- [8] P. Diaconis, B. Sturmfels, Algebraic algorithms for sampling from conditional distributions, Ann. Statist. 26 (1998), no. 1, 363-397.
- [9] P. A. García-Sánchez, I. Ojeda, Uniquely presented finit ly generated commutative monoids, Pacific J. Math. e 248 (2010), no. 1, 91-105.
- [10] I. Gitler, E. Reyes, J. A. Vega, Complete intersection toric ideals of oriented graphs and chorded-theta subgraphs, J. Algebraic Combin. 38 (2013), no. 3, 721-744.
- [11] J. Herzog, Generators and relations of abelian semigroups and semigroup rings, Manuscripta Math. 3 (1970) 175-193.
- [12] A. Katsabekis, I. Ojeda, An indispensable classification of monomial curves in A 4 ( k ) , Pacific J. Math. 268 (2014), no. 1, 96-116.
- [13] M. Laso´ n, M. Michałek, On the toric ideal of a matroid, Adv. Math. 259 (2014), 1-12.
- [14] Y. Matsumoto, S. Moriyama, H. Imai, D. Bremner, Matroid enumeration for incidence geometry, Discrete and Computational Geometry, 47 (2012), issue 1, pp. 17-43.
- [15] I. Ojeda, A. Vigneron-Tenorio, Indispensable binomials in semigroup ideals, Proc. Amer. Math. Soc. 138 (2010), no. 12, 4205-4216.
- [16] H. Ohsugi, T. Hibi, Indispensable binomials of finite graphs, J. Algebra Appl. 4 (2005), no. 4, 421-434.
- [17] H. Ohsugi, J. Herzog, T. Hibi, Combinatorial pure subrings, Osaka J. Math. 37 (2000), 745-757.
- [18] J. Oxley, Matroid theory. Second edition. Oxford Graduate Texts in Mathematics 21. Oxford University Press, Oxford, 2011. xiv+684 pp.
- [19] E. Reyes, C. Tatakis, A. Thoma, Minimal generators of toric ideals of graphs. Adv. in Appl. Math. 48 (2012), no. 1, 64-78.
- [20] B. Sturmfels, Gröbner Bases and Convex Polytopes , University Lecture Series 8, American Mathematical Society, Providence, RI, 1996.
- [21] A. Takemura, S. Aoki, Some characterizations of minimal Markov basis for sampling from discrete conditional distributions, Ann. Inst. Statist. Math., 56(1) (2004), 1-17.
- [22] C. Tatakis, A. Thoma, On complete intersection toric ideals of graphs, J. Algebraic Combin. 38 (2013), no. 2, 351-370.
- [23] N. White, The bases monomial rings of a matroid. Adv. Math. 24 (1977), 292-297.
- [24] N. White, A Unique Exchange Property for Bases. Linear Algebra Appl. 31 (1980), 81-91.
- [25] D. R. Woodall, An exchange theorem for bases of matroids, J. Combin. Theory Ser. B 16 (1974), 227-228.
UNIVERSITÉ DE MONTPELLIER, INSTITUT MONTPELLIÉRAIN ALEXANDER GROTHENDIECK, CASE COURRIER 051, PLACE EUGÈNE BATAILLON, 34095 MONTPELLIER CEDEX 05, FRANCE
E-mail address : [email protected]
E-mail address : [email protected] | null | [
"Ignacio García-Marco",
"Jorge Luis Ramírez Alfonsín"
] | 2014-08-02T21:07:20+00:00 | 2015-09-18T11:10:41+00:00 | [
"math.AC",
"math.CO",
"05B35, 20M25, 05E40, 14M25"
] | Matroid toric ideals: complete intersection, minors and minimal systems of generators | In this paper, we investigate three problems concerning the toric ideal
associated to a matroid. Firstly, we list all matroids $\mathcal M$ such that
its corresponding toric ideal $I_{\mathcal M}$ is a complete intersection.
Secondly, we handle with the problem of detecting minors of a matroid $\mathcal
M$ from a minimal set of binomial generators of $I_{\mathcal M}$. In
particular, given a minimal set of binomial generators of $I_{\mathcal M}$ we
provide a necessary condition for $\mathcal M$ to have a minor isomorphic to
$\mathcal U_{d,2d}$ for $d \geq 2$. This condition is proved to be sufficient
for $d = 2$ (leading to a criterion for determining whether $\mathcal M$ is
binary) and for $d = 3$. Finally, we characterize all matroids $\mathcal M$
such that $I_{\mathcal M}$ has a unique minimal set of binomial generators. |
1408.0420v2 | ## PRIMES IN THE INTERVALS BETWEEN PRIMES SQUARED
## KOLBJØRN TUNSTRØM
Abstract. The set of short intervals between consecutive primes squared has the pleasant-but seemingly unexploited-property that each interval s k := { p 2 k , . . . , p 2 k +1 - } 1 is fully sieved by the k first primes. Here we take advantage of this essential characteristic and present evidence for the conjecture that π k ∼ | s k | / log p 2 k +1 , where π k is the number of primes in s k ; or even stricter, that y = x 1 / 2 is both necessary and sufficient for the prime number theorem to be valid in intervals of length y . In addition, we propose and substantiate that the prime counting function π x ( ) is best understood as a sum of correlated random variables π k . Under this assumption, we derive the theoretical variance of π p ( 2 k +1 ) = ∑ k j =1 π j , from which we are led to conjecture that | π x ( ) -li( x ) | = O ( √ li( x )). Emerging from our investigations is the view that the intervals between consecutive primes squared hold the key to a furthered understanding of the distribution of primes; as evidenced, this perspective also builds strong support in favour of the Riemann hypothesis.
## 1. Introduction
An important theme in analytic number theory is the distribution of primes in short intervals. Notably, it is still an open question for what exact interval lengths the prime number theorem is valid or breaks down, as it eventually does for short enough intervals. The problem, formally stated, is to identify for which functions y = y x ( ), as x →∞ ,
$$\pi ( x + y ) - \pi ( x ) \sim \frac { y } { \log x }.$$
Currently, the gulf between the known upper and lower bounds of y is huge. The best unconditional estimate of the upper bound, proved by Heath-Brown [HeathBrown 1988], is y = x 7 / 12+ ( glyph[epsilon1] x ) , where glyph[epsilon1] ( x ) → 0 as x → ∞ , an estimate that is lowered to y = x 1 / 2+ glyph[epsilon1] assuming the Riemann hypothesis (RH). In contrast, Selberg, also assuming RH, proved that as long as y/ (log x ) 2 →∞ when x →∞ , then (1) holds for almost all x , understood in the sense that the set of x ∈ [0 , X ] for which (1) is not true is o X ( ) as X →∞ . Unconditionally, this almost-all result has been proven to hold with y = x 1 / 6 -glyph[epsilon1] [Zaccagnini 1998]. It was long thought that Selberg's result would be true even in the case of all x [Granville 1995b], but Maier [Maier 1985] made it clear that there are indeed infinitely many exceptions to Selberg's result, for any function of the form y = (log x ) λ , with λ > 1. It is not known whether there exist exceptions that are larger than (log x ) λ , but it has been conjectured that y > x glyph[epsilon1] will suffice for (1) to hold for all x , see e.g. [Granville 1995b] or [Soundararajan 2007].
In this paper we draw attention to the short intervals between consecutive primes squared, defined by s k := { p , . . . p 2 k 2 k +1 - } 1 for k ≥ 1. These intervals naturally occur in the context of the sieve of Eratosthenes, and in particular, each s k has
the specific quality of being fully sieved by the k first primes; any element in s k is either divisible by some p ∈ P k := { p , . . . , p 1 k } or else is a prime p / ∈ P k . In addition, the exact distribution of primes in s k is in its entirety build up of the periodic sequences
$$\rho _ { k } ( n ) \coloneqq \begin{cases} p _ { k } & \text{if $p_{k} \, | \, n$,} \\ 1 & \text{otherwise}, \end{cases}$$
which we visualise for the specific example of s 3 by the following table:
| n | 25 | 26 | 27 | 28 | 29 | 30 | 31 | 32 | 33 | 34 | 35 | 36 | 37 | · · · | 48 |
|-----------|------|------|------|------|------|------|------|------|------|------|------|------|------|---------|------|
| ρ 1 ( n ) | 1 | p 1 | 1 | p 1 | 1 | p 1 | 1 | p 1 | 1 | p 1 | 1 | p 1 | 1 | · · · | p 1 |
| ρ 2 ( n ) | 1 | 1 | p 2 | 1 | 1 | p 2 | 1 | 1 | p 2 | 1 | 1 | p 2 | 1 | · · · | p 2 |
| ρ 3 ( n ) | p 3 | 1 | 1 | 1 | 1 | p 3 | 1 | 1 | 1 | 1 | p 3 | 1 | 1 | · · · | 1 |
Together with the fact that these intervals make up a complete subdivision of the natural numbers, these insights allow us to argue for the range in which the prime number theorem is valid, as well as providing a rudimentary explanation of the behaviour of the prime counting function π x ( ). Specifically, we present a heuristic as to why the following conjecture should hold:
Conjecture. The choice of y = x 1 / 2 is necessary and sufficient for
$$\pi ( x + y ) - \pi ( x ) \sim \frac { y } { \log ( x + y ) }$$
to hold for all x as x →∞ .
Furthermore, we present evidence that the set of π k s satisfies a conjecture of Montgomery and Soundararajan [Montgomery and Soundararajan 2004], that the number of primes in s k , denoted π k , is expected to follow a normal distribution with mean
$$\mu _ { k } = \frac { | s _ { k } | } { \log p _ { k + 1 } ^ { 2 } }$$
and standard deviation
$$\sigma _ { k } = \frac { \sqrt { | s _ { k } | \log ( p _ { k + 1 } ^ { 2 } / | s _ { k } | ) } } { \log p _ { k + 1 } ^ { 2 } }.$$
Because of the periodic structure of the sequences ρ k ( n ), the number of primes in two intervals s i and s j are not independent, but correlated. Following from this, we demonstrate that:
Remark. The prime counting function π x ( ) behaves -and should be understoodas a sum of correlated random variables π k , each normally distributed with mean µ k and standard deviation σ k .
Building on this insight, we formulate a random model of the primes, where the random variables are the number of primes in each interval s k , and where these variables derive from drawing random translations of the sequences ρ k ( n ). This construction naturally preserves the observed correlations between π k s. Moreover, assuming this model, we calculate the theoretical variance of π p ( 2 k +1 ) = ∑ k j =1 π j , which in turn suggests the conjecture
Conjecture. The error term in the prime number theorem satisfies
$$| \pi ( x ) - \text{li} ( x ) | = O \left ( \sqrt { \text{li} ( x ) } \right ).$$
In sum, it emerges that the apparent random behaviour of the primes and the prime counting function π x ( ) can be fundamentally understood in terms of the intervals s k and the underlying periodic sequences ρ k ( n ). Through Koch's equivalence criterium [von Koch 1901], our results also strongly support the correctness of the Riemann hypothesis, and as such might pave the way towards a complete technical proof.
## 2. Notation and definitions
We write the set consisting of the k first primes as P k := { p , . . . , p 1 k } , the intervals between consecutive primes squared as s k := { p , . . . , p 2 k 2 k +1 - } 1 , and the length of s k as l k := | s k | = p 2 k +1 -p 2 k , where k ≥ 1. As usual, the number of primes less than or equal to x is given by π x ( ), but in addition, since the number of primes in s k will appear frequently, we establish the shorthand notation
$$\pi _ { k } \coloneqq \pi ( p _ { k + 1 } ^ { 2 } ) - \pi ( p _ { k } ^ { 2 } ).$$
For the same reason, in the case when we apply the logarithmic integral,
$$\text{li} ( x ) \coloneqq \int _ { 2 } ^ { x } \frac { d t } { \log t },$$
to the interval s k , we write
$$\text{li} _ { k } \coloneqq \text{li} ( p _ { k + 1 } ^ { 2 } ) - \text{li} ( p _ { k } ^ { 2 } ).$$
Moreover, we need notation for the expected number of primes in s k -understood as the expected number of coprimes to p k #in a random interval of length l k (where p k # := ∏ p ∈P k p is the primorial of p k ). The probability of a random integer being coprime to p k # is given by the Euler product ∏ p ∈P k ( 1 -1 p ) , and multiplying this by l k produces the expected number of primes in s k , which we denote
$$\tilde { \pi } _ { k } \coloneqq l _ { k } \cdot \prod _ { p \in \mathcal { P } _ { k } } \left ( 1 - \frac { 1 } { p } \right ).$$
We now use this definition to construct a probabilistic prime counting function ˜( π x )-the expected number of primes less than or equal to x . By assuming k to be the integer such that p 2 k ≤ x < p 2 k +1 , we define ˜( π x ) simply as the sum taken over the individual estimates ˜ π j , 1 ≤ j ≤ k , namely
$$\tilde { \pi } ( x ) \coloneqq \sum _ { j = 1 } ^ { k - 1 } \tilde { \pi } _ { j } + \frac { x - p _ { k } ^ { 2 } } { l _ { k } } \, \tilde { \pi } _ { k }.$$
The last term on the right side adjusts for the fact that x in general reaches only partially into the last interval s k .
Finally, we emphasise the fact that the distribution of primes within any interval s k can be viewed as a construction of k periodic sequences. To make this structure
apparent, we first define an arithmetic function that picks out the integers n coprime to a given prime p k ,
$$\rho _ { k } ( n ) \coloneqq \begin{cases} p _ { k } & \text{if $p_{k} \, | \, n$,} \\ 1 & \text{otherwise.} \end{cases}$$
Then we apply this definition to construct a second arithmetic function that locates all n coprime to p k #,
$$R _ { k } ( n ) \coloneqq \prod _ { 1 \leq i \leq k } \rho _ { i } ( n ).$$
By these definitions R k ( n ) = 1 whenever ( n, p k #) = 1, and both ρ k ( n ) and R k ( n ) are periodic, satisfying for any integer m the equalities
$$\rho _ { k } ( n + m p _ { k } ) = \rho _ { k } ( n ) \text{ \ and \ } R _ { k } ( n + m p _ { k } \# ) = R _ { k } ( n ).$$
Since s k is sieved completely by the k first primes, the primes within s k align with the 1s in R k , and therefore the number of primes in s k equals the number of 1s in R k across the interval. We visualise this for the specific example of s 3 by the following table:
| n | 25 | 26 | 27 | 28 | 29 | 30 | 31 | 32 | 33 | 34 | 35 | 36 | 37 | · · · | 48 |
|-----------|------|------|------|------|------|-------------|------|------|------|------|------|---------|------|---------|---------|
| ρ 1 ( n ) | 1 | p 1 | 1 | p 1 | 1 | p 1 | 1 | p 1 | 1 | p 1 | 1 | p 1 | 1 | · · · | p 1 |
| ρ 2 ( n ) | 1 | 1 | p 2 | 1 | 1 | p 2 | 1 | 1 | p 2 | 1 | 1 | p 2 | 1 | · · · | p 2 |
| ρ 3 ( n ) | p 3 | 1 | 1 | 1 | 1 | p 3 | 1 | 1 | 1 | 1 | p 3 | 1 | 1 | · · · | 1 |
| R 3 ( n ) | p 3 | p 1 | p 2 | p 1 | 1 | p 1 p 2 p 3 | 1 | p 1 | p 2 | p 1 | p 3 | p 1 p 2 | 1 · | · · | p 1 p 2 |
But in general, if we pick a random interval ˜ s k of length l k , the 1s in R k across ˜ s k are not necessarily primes; all we know is that they are coprime to p k #. And because R k is periodic with period p k #, the number of coprimes to p k # in ˜ s k can take any out of p k # (non-unique) values; the probabilistic counting function ˜ π k is the mean value of these.
The last statement can be made explicit by applying sieve notation. Consider therefore an arbitrary interval A and denote the number of coprimes to p k # in A by
$$S ( A, p _ { k } \# ) \coloneqq | \{ n \, \colon n \in A, R _ { k } ( n ) = 1 \} |.$$
It follows from the periodicity of R k that S A,p ( k #) is periodic as well; if A j denotes A left-shifted j times, the equality
$$S ( A ^ { m \cdot p _ { k } \# }, p _ { k } \# ) = S ( A, p _ { k } \# )$$
holds for any integer m. Using this notation, it is obvious that we can restate the probabilistic prime counting function ˜ π k as the mean value taken over the sample space
$$\Omega _ { k } \coloneqq \{ S ( s _ { k } ^ { j }, p _ { k } \# ) \} _ { j = 0 } ^ { p _ { k } \# - 1 }.$$
In other words,
$$\tilde { \pi } _ { k } = \frac { 1 } { p _ { k } \# } \sum _ { j = 0 } ^ { p _ { k } \# - 1 } S ( s _ { k } ^ { j }, p _ { k } \# ).$$
The actual number of primes in s k coincides with the specific element in Ω k corresponding to j = 0,
$$\pi _ { k } = S ( s _ { k } ^ { 0 }, p _ { k } \# ) = S ( s _ { k }, p _ { k } \# ).$$
The prime counting function π k is therefore just one instance out of p k # elements in the sample space underlying ˜ π k . The crucial point, nonetheless, is that all elements in Ω k , π k inclusive, stem from the same underlying structure of k periodic sequences.
## 3. Approximate expressions for ˜ π k and ˜( π x )
From (2), we know that the expected number of primes in the interval s k can be expressed exactly in terms of
$$\tilde { \pi } _ { k } = l _ { k } \cdot \prod _ { p \in \mathcal { P } _ { k } } \left ( 1 - \frac { 1 } { p } \right ).$$
Applying Merten's product theorem, we attain the following approximation:
## Lemma 3.1.
$$\tilde { \pi } _ { k } \sim 2 e ^ { - \gamma } \frac { l _ { k } } { \log p _ { k + 1 } ^ { 2 } }.$$
$$\begin{smallmatrix} \\ \end{smallmatrix}$$
Proof. Assume that x is a real number within the interval s k , so that p 2 k ≤ x < p 2 k +1 . Then we can state Merten's product theorem [Mertens 1874] as
$$\prod _ { p \in \mathcal { P } _ { k } } ( 1 - \frac { 1 } { p } ) = e ^ { - \gamma + \delta } \frac { 1 } { \log \sqrt { x } } = 2 e ^ { - \gamma + \delta } \frac { 1 } { \log x },$$
where γ is the Euler-Mascheroni constant and δ is a measure of the uncertainty of the approximation, satisfying
$$| \delta | < \frac { 4 } { \log ( \sqrt { x } + 1 ) } + \frac { 2 } { \sqrt { x } \log \sqrt { x } } + \frac { 1 } { 2 \sqrt { x } }.$$
By combining (2) and (5), it follows immediately that
$$\tilde { \pi } _ { k } = 2 e ^ { - \gamma + \delta } \frac { l _ { k } } { \log x }.$$
Additionally, (6) implies that in order to minimize the error we should choose x as large as possible-that is, x = p 2 k +1 -glyph[epsilon1] , where glyph[epsilon1] > 0 is infinitesimal-by which we obtain (4). glyph[square]
Note that by the choice of x = p 2 k +1 in the proof above, the estimate of ˜ π k reflects the characteristic property of the sieving process; sieving by the k first primes removes all composites less than p 2 k +1 .
Similarly, we obtain an approximate expression for ˜( π x ):
## Lemma 3.2.
$$\tilde { \pi } ( x ) \sim 2 e ^ { - \gamma } \, \text{li} ( x ).$$
Proof. First, applying Lemma 3.1 to (3) we immediately have that
$$\tilde { \pi } ( x ) \sim 2 \mathrm e ^ { - \gamma } \left ( \sum _ { j = 1 } ^ { k - 1 } \frac { l _ { j } } { \log p _ { j + 1 } ^ { 2 } } + \frac { x - p _ { k } ^ { 2 } } { l _ { k } } \, \frac { l _ { k } } { \log p _ { k + 1 } ^ { 2 } } \right ).$$
The expression within parentheses is nothing but a Riemann sum, which in the continuum limit can be approximated by the logarithmic integral li( x ): The logarithmic integral taken over the interval s k satisfies
$$\frac { l _ { k } } { \log p _ { k } ^ { 2 } } > \text{li} _ { k } > \frac { l _ { k } } { \log p _ { k + 1 } ^ { 2 } },$$
and also,
We therefore have that
$$\tilde { \pi } _ { k } \sim 2 e ^ { - \gamma } \, \text{li} _ { k },$$
and eventually,
$$\tilde { \pi } ( x ) \sim 2 e ^ { - \gamma } \left ( \sum _ { j = 1 } ^ { k - 1 } \text{li} _ { j } + \frac { x - p _ { k } ^ { 2 } } { l _ { k } } \text{ li} _ { k } \right ) = 2 e ^ { - \gamma } \text{ li} ( x ).$$
We emphasise here again that the above results are derived under the sole assumption that s k is sieved by the k first primes. In this case, the best we can do is to assign a uniform probability of finding a prime in any position across s k . This probability is given exactly by ∏ p ∈P k ( 1 -1 p ) , or approximately by 2e -γ / log p 2 k +1 , Obviously, there is more to say about s k -illustrated with a few examples in the next section-and this additional information is what eventually will close the gap between ˜ π k and π k , where the latter is anticipated to satisfy
$$\pi _ { k } \sim \frac { l _ { k } } { \log p _ { k + 1 } ^ { 2 } }.$$
It is also worth noting that the expression 2e -γ li( x ) emerges as the continuum approximation to the discrete sum 2e -γ ∑ k j =1 l j / log p 2 j +1 , and not the other way around. This fact hints to the possibility that even the prime counting function π x ( ) is best approximated by ∑ k j =1 l j / log p 2 j +1 rather than li( x ). We examine this in closer detail in Section 6.
## 4. Shrinking the gap between ˜ π k and π k
Recall from Section 2 that the probabilistic prime counting function ˜ π k can be stated as
$$\tilde { \pi } _ { k } = \frac { 1 } { p _ { k } \# } \sum _ { j = 0 } ^ { p _ { k } \# - 1 } S ( s _ { k } ^ { j }, p _ { k } \# ),$$
while π k is given by
$$\pi _ { k } = S ( s _ { k } ^ { 0 }, p _ { k } \# ).$$
To close in on an estimate for π k , we need to shrink the sample space Ω k in such a way that it still contains S s , p ( 0 k k #). Of course, S s , p ( 0 k k #) is completely determined by where in the natural numbers the interval s k is situated (allowing for shifts that are multiples of p k #), so the constraints on Ω k must reflect this fact. While defining the right constraints is an essential part of sieve theory, our point
$$\frac { l _ { k } } { \log p _ { k } ^ { 2 } } \sim \frac { l _ { k } } { \log p _ { k + 1 } ^ { 2 } }.$$
here is only to illustrate with a few numerical examples how imposing constraints affect the probabilistic estimate ˜ π k .
The most obvious constraint is that all elements in R k ( n ) must be strictly smaller than p 2 k +1 whenever n ∈ s k . We can observe the effect of this constraint by expanding the Euler product (2) in terms of the the M¨bius function, which is defined o by
$$( 7 ) \quad \ \mu ( n ) \coloneqq \begin{cases} 1 & \text{if $n=1$,} \\ ( - 1 ) ^ { k } & \text{if $n$ is a product of $k$ distinct primes,} \\ 0 & \text{if $n$ has one or more repeated prime factors.} \end{cases}$$
It follows that we can rewrite (2) as
$$\tilde { \pi } _ { k } = l _ { k } \cdot \sum$$
Adding the constraint produces a truncated version, which we denote
$$\tau _ { k } = l _ { k } \cdot \sum _ { \sub$$
Numerically-as seen in Figure 1-we verify that the truncated expression amounts to a significant reduction of the sample space Ω k , resulting in τ k / l ( k / log p 2 k +1 ) ≈ 1 03, as opposed to ˜ . π / l k ( k / log p 2 k +1 ) ∼ 2e -γ ≈ 1 12. . In addition, the error term, which is O (2 k ) in the case of ˜ π k , reduces to O k ( 2 32 . ) in the case of τ k .
Figure 1. The ratios of π k , ˜ π k , and τ k to l k / log p 2 k +1 . The values are plotted at x = p 2 k +1 , 1 ≤ k ≤ 1000 . The three horizontal lines illustrate the limits tended to by each ratio.
Our second example is a set of constraints on the internal structure of s k : Within s k , the first appearance of a composite divisible by p i , for i < k , is in one of the positions p i -m +1, where m> 0 is an element in the residue class of n 2 (mod p i ), j > i ( m = 0 is not included, since the first position in s k is always occupied by
p 2 k ). For instance, given the primes p , . . . , p 1 6 , these are the possible positions of first appearance when k > 6:
| Prime | Candidate positions of first appearance in s k |
|---------|--------------------------------------------------|
| p 1 | 2 |
| p 2 | 3 |
| p 3 | 2, 5 |
| p 4 | 4, 6, 7 |
| p 5 | 3, 7, 8, 9, 11 |
| p 6 | 2, 4, 5, 10, 11, 13 |
The outcome is that these constraints bound the possible positions of sequences ρ i ( n ) across s k , 1 ≤ i ≤ k , effectively halving the sample space Ω k .
To get an impression of how these constraints impact the probabilist prime counting function ˜ π k , we randomly sample sequences of ρ i of length l k , 1 ≤ i ≤ k , with first appearance of p i in each sequence constrained as explained above, and count the number of 1s in the resulting R k -denoted η k . We observe in Figure 2 that the mean value of η k in fact appears to lie slightly above ˜ π k , while still satisfying η k ∼ ˜ π k . Note that in the figure we plot ∑ k j =1 η j rather than η k as the accumulation of biases is more visible than the individual biases in each interval. It appears therefore that the statistical properties of the reduced sample space do not change significantly from the original one, which can be understood from the fact that these constraints do not restrain the position of s k within the natural numbers.
GLYPH<142>
Figure 2. Comparison of ∑ k j =1 η j and ∑ k j =1 ˜ π j , with values plotted at x = p 2 k +1 , 1 ≤ k ≤ 500 . A) 200 samples of ∑ k j =1 ( η j -˜ ) π j (grey) shown together with the mean value 〈 ∑ k j =1 ( η j -˜ ) π j 〉 (black), demonstrating a statistical bias of η k > π ˜ k . B) 200 samples of ∑ k j =1 η / j ∑ k j =1 ˜ π j (grey) shown together with the mean value 〈 ∑ k j =1 η / j ∑ k j =1 ˜ π j 〉 (black), indicating that η k ∼ ˜ π k .
## 5. Conjectures on the distribution of primes in short intervals
The prime number theorem, proven independently by Hadamard and de la Vall´e-Poussin in 1896, is usually stated by either of the equivalent relations e
$$\mu _ { 0 } \quad \pi ( x ) \sim \frac { \mu _ {$$
The results so far, however, motivates an alternative formulation of the prime number theorem, in the form of the conjecture:
## Conjecture 1. As k →∞ , we have that
$$\pi _ { k } \sim \frac { l _ { k } } { \log p _$$
From this perspective-as in the probabilistic case in Section 3-we should view π x ( ) ∼ li( x ) as originating from a continuum approximation of ∑ k j =1 l j / log p 2 j +1 .
Proving Conjecture 1 rigorously is out of reach for this paper, but we present a heuristic justification that hopefully can seed a complete proof. Specifically, we argue that the following conjecture holds, which in turn implies Conjecture 1:
## Conjecture 2. The choice of y = x 1 / 2 is necessary and sufficient for
$$\begin{array} {$$
to hold for all x as x →∞ .
To start with, let us consider what happens to an interval that grows slower than y = x 1 / 2 . For this purpose we define y glyph[epsilon1] = y glyph[epsilon1] ( x ) to be a function that grows arbitrarily slower than y . Naturally, no matter how large y glyph[epsilon1] is initially, as x increases, y glyph[epsilon1] eventually becomes infinitesimal compared to y . This has the effect that for any given integer q > 0, we can find an x such that y glyph[epsilon1] ≤ y/ 2 . q It then follows from Bertrand's postulate-which says there is always a prime p such that n < p < 2 n -that
$$\pi ( y ) - \pi ( y _ { \epsilon } ) \geq \pi ( y ) - \pi ( y / 2 ^ { q } ) = q.$$
And because q can be arbitrarily large,
$$\lim _ { x \to \infty } \pi ( y ) - \pi ( y _ { \epsilon } ) = \infty.$$
Therefore, across s k we will always find that p k ≤ y < p k +1 , while y glyph[epsilon1] lags behind and ultimately turns infinitesimal relative to infinitely many primes smaller than p k .
Let us explore the consequence of the last statement: As described earlier, an essential property of the distribution of primes in s k is that we can view it as a construction of the periodic sequences ρ j ( n ), 1 ≤ j ≤ k . From this perspective, it is clear that if we want to sample correctly the distribution of primes within s k , we need to choose y such that the interval [ x, x + ] spans at least the largest y underlying period, that is, y ≥ p k whenever x ∈ s k ; the slowest growing function that satisfies this criteria is y = x 1 / 2 . The interval [ x, x + y glyph[epsilon1] ], on the other hand, is in general only long enough to provide valid samples from the distribution of coprimes to p m #, where p m is the greatest prime smaller or equal to y glyph[epsilon1] across s k . Since, from our argument above, p m eventually grows infinitesimal relative to arbitrarily many primes smaller than p k , we should expect [ x, x + y glyph[epsilon1] ] to ultimately move repeatedly across regions where the density of primes deviates significantly from that predicted by the prime number theorem.
What this suggests is that y = x 1 / 2 is the sharp barrier below which the prime number theorem breaks down for all x , contradicting previous conjectures that this barrier lies close to y = x glyph[epsilon1] , glyph[epsilon1] > 0 [Granville 1995b, Soundararajan 2007]. Furthermore, taking this reasoning to its conclusion, it seems logical to conjecture
a variation of Maier's theorem [Maier 1985] applied to any interval growing slower than x 1 / 2 :
Conjecture 3. Let y glyph[epsilon1] = y glyph[epsilon1] ( x ) satisfy lim x →∞ y /y glyph[epsilon1] = 0 , where y = x 1 / 2 . Then
$$\lim _ { x \to \infty } \frac { \pi ( x + y _ { \epsilon } ) - \pi ( x ) } { y _ { \epsilon } / \log x } > 1 \quad a n d \quad \liminf _ { x \to \infty } \frac { \pi ( x + y _ { \epsilon } ) - \pi ( x ) } { y _ { \epsilon } / \log x } < 1.$$
So far, we have argued that y = x 1 / 2 is a necessary condition for (8) to hold for all x . To substantiate that y = x 1 / 2 is also sufficient, we make the observation that the lengths of the intervals s k are of the form l k = 2 p k +1 g k -g 2 k , where g k := p k +1 -p k , and hence lie on the curves 2 √ xg -g 2 , with g = 2 n , n ≥ 1. Therefore, l k grows as O x ( 1 / 2 ). Let us further define y δ = y δ ( x ) to be a function that grows arbitrarily faster than y = x 1 / 2 , so that lim x →∞ y /y δ = ∞ . As a consequence, the interval [ x, x + y δ ] will eventually cover arbitrarily many intervals s k ; that is, for any m , we can always choose k so that y δ ( p 2 k ) ≥ ∑ k + m i = k l i . The problem we encounter now, however, is that the estimate
$$\pi ( p _ { k } ^ { 2 } + y _ { \delta } ) - \pi ( p _ { k } ^ { 2 } ) \sim \frac { y _ { \delta } } { \log ( p _ { k } ^ { 2 } + y _ { \delta } ) }$$
assumes a uniform distribution of primes in the interval [ p , p 2 k 2 k + y δ ], given by the density of primes in s m . But this assumption is inaccurate; the largest intervals across which we can suppose a uniform distribution are the intervals s k . Subdividing the natural numbers into intervals of length y δ and estimating the number of primes up to x from these results in an underestimate of the prime counting function π x ( ). At its most extreme, this is exemplified by the estimate π x ( ) ∼ x/ log x , which is well known to be an inferior guess of the number of primes up to x compared to π x ( ) ∼ li( x ), a fact that was established in 1899 by de la Vall´e-Poussin [de la e Vall´e-Poussin 1899]. e
One final note about this heuristic. We have only argued for what lengths y can take, in order for the interval [ x, x + ] to correctly sample the distribution of primes, y but not what is the correct limiting value of π x ( + ) y -π x ( ). The asymptotic limit in Conjecture 2 should therefore be considered as an assumption of the heuristic as well.
## 6. Numerical results on the distribution of primes
With the purpose of providing clues about how to understand the apparent random behaviour of the primes, we here examine the distribution of primes both locally and globally. We start by noting that since l k = 2 p k +1 g k -g 2 k , where g k = p k +1 -p k , we have that
$$\pi _ { k } \sim \frac { l _ { k } } { \log p _ { k + 1 } ^ { 2 } } = \frac { 2 p _ { k + 1 } g _ { k } - g _ { k } ^ { 2 } } { \log p _ { k + 1 } ^ { 2 } }.$$
Naturally, g k is not unique, suggesting that we can subdivide the set of intervals s k according to what the corresponding gap g k is. Hence, the subset of intervals s k all with corresponding gap g will be distributed along the curve
$$\begin{matrix} \sim \dots \dots \dots \dots \dots \dots \dots \dots \dots \\ \frac { 2 \sqrt { x } g - g ^ { 2 } } { \log x }, \end{matrix}$$
where g takes the values 2 n n , ≥ 1. This structure becomes apparent when plotting the values of π k as a function of p 2 k +1 , as illustrated in Figure 3, where all values of π k are plotted for 1 ≤ k ≤ 6 × 10 . 5
While this perspective clearly reveals how the intervals s k define an underlying pattern of the distribution of primes, it is possible to provide an even more compact viewpoint. According to a conjecture of Montgomery and Soundararajan [Montgomery and Soundararajan 2004], we should expect the primes in s k to follow a normal distribution with mean
$$\mu _ { k } = \frac { l _ { k } } { \log p _ { k + 1 } ^ { 2 } }$$
and standard deviation
$$\sigma _ { k } = \frac { \sqrt { l _ { k } ( \log ( p _ { k + 1 } ^ { 2 } / l _ { k } ) + B ) } } { \log p _ { k + 1 } ^ { 2 } }, \\. \quad. \quad.$$
where B = 1 -γ -log 2 π . Actually,
$$\frac { \sqrt { l _ { k } ( \log ( p _ { k + 1 } ^ { 2 } / l _ { k } ) + B ) } } { \log p _ { k + 1 } ^ { 2 } } \sim \frac { \sqrt { l _ { k } \log ( p _ { k + 1 } ^ { 2 } / l _ { k } ) } } { \log p _ { k + 1 } ^ { 2 } }, \\ \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \end{array}$$
but the latter expression does not give the same numerical accuracy for the data we have available, so we stick with σ k as defined.
Next, we apply Montgomery and Soundararajan's conjecture to generate normalised versions of the prime counting functions π k :
$$\overline { \pi } _ { k } \coloneqq \frac { \pi _ { k } - \mu _ { k } } { \sigma _ { k } }.$$
Assuming the conjecture holds, the result of this step should be that π k is normally distributed with mean 0 and standard deviation 1. This expectation is accurately confirmed by Figure 4, where we (A) plot π k as a function of k and (B) display a histogram revealing the probability distribution of π k . As such, this result lends support to Montgomery and Soundararajan's conjecture. But more importantly, it promotes the fundamental idea that we can view π k as a random variable with variance µ k and standard deviation σ k .
We turn now to the global distribution of primes, where we want to examine the behaviour of the prime counting function π x ( ) when it is expressed in terms of the individual prime counting functions π k :
$$\pi ( p _ { k + 1 } ^ { 2 } ) = \sum _ { j = 1 } ^ { k } \pi _ { j }.$$
To best get an impression of how π x ( ) behaves, we plot-rather than π x ( ) itselfthe error function
$$\epsilon ( x ) \coloneqq \pi ( x ) - \text{li} ( x ),$$
which produces the result seen in Figure 5. The first observation we make is that the error function starts out being negative-a famed bias that continues for the full stretch of our data set. Nonetheless, as Littlewood proved [Littlewood 1914], if we persist in moving x towards infinity, the error term will eventually shift sign, and it will continue to do so infinitely many times over. When that happens for the first time, however, no one knows, though it has been proved that x = 1 39822 . × 10 316 is
Figure 3. The number of primes π k in each interval s k plotted at the values x = p 2 k +1 , 1 ≤ k ≤ 6 × 10 5 (black dots). The emerging curves relate to the specific gap values g , g ∈ { 2 4 , , . . . } , where the bottom curve corresponds to the set of intervals s k where g k = 2 , the second bottom g k = 4 , etc. The red curves show the corresponding theoretical estimates (2 √ xg -g 2 ) / log x .
Figure 4. (A) The normalised prime counting functions π k plotted as a function of k , 1 ≤ k ≤ 6 × 10 5 . (B) A histogram displaying the numerical probability distribution of π k , overlaid with the PDF of the normal distribution N (0 1) , (black). The measured mean and standard deviation of π k are 0 000(7) . and 1 000(8) . , respectively.
an upper bound for the event [Bays and Hudson 2000]. A probabilistic measure of the bias was provided in 1994, when Rubinstein and Sarnak [Rubinstein and Sarnak 1994]-assuming the Riemann hypothesis- calculated the logarithmic density of those x such that π x ( ) -li( x ) > 0 to be around 0 00000026. .
According to Conjecture 1, however, li( x ) is a continuum approximation to the discrete sum ∑ k j =1 l j / log p 2 j +1 , and therefore we should expect the latter to be a better estimate of π x ( ). As we can tell from Figure 5, where we also have included curves of ∑ k j =1 ( l j / log p 2 j -li j ) and ∑ k j =1 ( l j / log p 2 j +1 -li j ), the statistical evidence
Figure 5. The error function glyph[epsilon1] ( x ) plotted at the values x = p 2 k +1 , 1 ≤ k ≤ 6 × 10 5 (black). Also shown are the differences ∑ k j =1 ( l j / log p 2 j -li j ) (red), and ∑ k j =1 ( l j / log p 2 j +1 -li j ) (blue), as well as one realisation of the sum ∑ k j =1 ω j (grey), where the ω k s are independent random variables each satisfying N (0 , σ k ) .
seems to indicate that the truth lies somewhere in between,
$$\sum _ { j = 1 } ^ { k } \frac { l _ { j } } { \log p _ { j + 1 } ^ { 2 } } < E [ \pi ( p _ { k + 1 } ^ { 2 } ) ] < \text{li} ( p _ { k + 1 } ^ { 2 } ).$$
To more accurately interpret this observation, we normalise the curves in Figure 5 by
$$\Delta _ { k } \coloneqq \frac { 1 } { 2 } \sum _ { j = 1 } ^ { k } \left ( \frac { l _ { j } } { \log p _ { j } ^ { 2 } } - \frac { l _ { j } } { \log p _ { j + 1 } ^ { 2 } } \right ),$$
which places the normalised differences
$$\left [ \sum _ { j = 1 } ^ { k } \left ( \frac { l _ { j } } { \log p _ { j + 1 } ^ { 2 } } - \text{li} _ { j } \right ) \right ] / \Delta _ { k } \text{ \ and \ } \left [ \sum _ { j = 1 } ^ { k } \left ( \frac { l _ { j } } { \log p _ { j } ^ { 2 } } - \text{li} _ { j } \right ) \right ] / \Delta _ { k }$$
approximately at the constant lines -1 and 1 respectively. We also normalise the error function, defined by
$$E _ { k } \coloneqq \frac { \epsilon ( p _ { k + 1 } ^ { 2 } ) } { \Delta _ { k } }.$$
The resulting curves are shown in Figure 6A, plotted as functions of k . We note that on the scale of the data available, E k fluctuates fairly stable around a mean value of -0 60. . This becomes even more apparent if we display the data in histogram form, as done in Figure 6B, where we see that the empirical probability distribution of E k resembles a normal distribution. A natural speculation therefore, is whether there in fact exists a constant c such that
$$\mathbf E \left [ \pi \left ( p _ { k + 1 } ^ { 2 } \right ) \right ] = c \cdot \mathbf l i \left ( p _ { k + 1 } ^ { 2 } \right ) - \left ( 1 - c \right ) \cdot \sum _ { j = 1 } ^ { k } \frac { l _ { j } } { \log p _ { j + 1 } ^ { 2 } }.$$
Figure 6. The normalised error function E k plotted as a function of k , 1 ≤ k ≤ 6 × 10 5 (A), as well as a probability density histogram of all values of E k (B). Also displayed in (B) is the PDF for a normal distribution with mean -0 60(4) . and standard deviation 0 12(1) . estimated from all E k .
Returning to Figure 5, we end with one final important observation: The error function glyph[epsilon1] ( x ) does not conform to a sum of independent random variables. This is clearly visible when comparing with an example of an actual sum of independent random variables ω k , where ω k ∼ N (0 , σ k ); the error function does not display the same scale of fluctuations as ∑ k ω k , and as already discussed, lingers more densely around a mean value. As will be apparent later, what causes the discrepancy between the error function glyph[epsilon1] ( x ) and ∑ k j =1 ω j are correlations between the prime counting functions π k . These correlations even grow stronger for larger interval lengths l k , possibly explaining why the normalised error function E k in Figure 6A seems to fluctuate more slowly as k becomes large. Explaining these correlations and their effect on the error function will be the focus of the next sections. But for now, we summarise the numerical insights by the following remark:
Remark 1. The prime counting function π x ( ) behaves-and should be understoodas a sum of correlated random variables π k , each normally distributed with mean µ k and standard deviation σ k as conjectured in [Montgomery and Soundararajan 2004].
## 7. A random model for the distribution of primes
With the understanding we have developed so far, we now have in hand enough information to construct a random model of the prime counting function π x ( ). We start with emphasising the fundamental observation underlying the model; the exact distribution of primes up to p 2 k +1 is in its entirety build up of the k periodic sequences ρ j ( n ), 1 ≤ j ≤ k , each having the property that ρ j (0) = p j . We visualise this in the following table:
Importantly-and already discussed at length-within s k , only the k first sequences
| n | 0 | 1 | 2 | 3 | 4 | 5 | 6 | 7 | 8 | 9 | 10 | 11 | 12 | 13 | 14 | 15 | · · · |
|-------------|-------|-----|-----|-----|-----|-----|-----|-----|-----|-----|------|------|------|------|------|------|---------|
| ρ 1 ( n ) | p 1 | 1 | p 1 | 1 | p 1 | 1 | p 1 | 1 | p 1 | 1 | p 1 | 1 | p 1 | 1 | p 1 | 1 | · · · |
| ρ 2 ( n ) | p 2 | 1 | 1 | p 2 | 1 | 1 | p 2 | 1 | 1 | p 2 | 1 | 1 | p 2 | 1 | 1 | p 2 | · · · |
| ρ 3 ( n ) | p 3 | 1 | 1 | 1 | 1 | p 3 | 1 | 1 | 1 | 1 | p 3 | 1 | 1 | 1 | 1 | p 3 | · · · |
| . | . | . | . | . | . | . | . | . | . | . | . | . | . | . | . | . | |
| . | . | . | . | . . | . | . | . . | . . | . | . | . . | . . | . . | . . | . . | . . | · · · |
| . ρ k ( n ) | . p k | . 1 | . 1 | 1 | . 1 | . 1 | 1 | 1 | . 1 | . 1 | 1 | 1 | 1 | 1 | 1 | 1 | · · · |
ρ j , 1 ≤ j ≤ k , are needed to completely determine the distribution of primes. Note also that the distribution of primes in s k correlates with the distribution of primes in all previous intervals s i , 1 ≤ i < k , due to the periodicities of ρ j , 1 ≤ j ≤ i .
In formulating the model-which we hereafter refer to as the correlated random model -the essential idea is to keep the intervals s k , but to allow translations of the sequences ρ j , 1 ≤ j ≤ k . By this approach, we stay close to the original structure of the primes, but will eventually be able to get a theoretical grip on the correlations between intervals; as becomes apparent, this is exactly what we need to give a proper explanation of the error function glyph[epsilon1] ( x ).
The central object in the model is the random variable Π( ˜ p 2 k +1 ), which is defined in terms of a sum over the random variables Π : ˜ j
$$\tilde { \Pi } ( p _ { k + 1 } ^ { 2 } ) \coloneqq \sum _ { j = 1 } ^ { k } \tilde { \Pi } _ { j }.$$
To generate the random variables Π , 1 ˜ j ≤ j ≤ k , we randomly choose k corresponding integers m j , where m j ∈ { 0 1 , , . . . , p j - } 1 and then define the translated sequences
$$\hat { \rho } _ { j } ( n ) \coloneqq \rho _ { k } ( n + m _ { j } ).$$
As in Section 2, we construct a second arithmetic function; here with the purpose of locating all n such that n + m i , 1 ≤ i ≤ j , is coprime to p j #:
$$\hat { R } _ { j } ( n ) \coloneqq \prod _ { 1 \leq i \leq j } \hat { \rho } _ { i } ( n ).$$
The random variables Π ˜ j are now obtained by
$$\tilde { \Pi } _ { j } \coloneqq | \{ n \, \colon n \in s _ { j }, \hat { R } _ { j } ( n ) = 1 \} |.$$
Since the sequences ˆ , ρ j 1 ≤ j ≤ k , are drawn independent from each other, the expectation value of Π ˜ j is given by
$$E \left [ \tilde { \Pi } _ { j } \right ] = \tilde { \pi } _ { j } = l _ { j } \cdot \prod _ { p \in \mathcal { P } _ { j } } \left ( 1 - \frac { 1 } { p } \right ) \sim 2 e ^ { - \gamma } \frac { l _ { j } } { \log p _ { j + 1 } ^ { 2 } } \sim 2 e ^ { - \gamma } \, \text{li} _ { j },$$
and correspondingly,
$$E \left [ \tilde { \Pi } ( p _ { k + 1 } ^ { 2 } ) \right ] = \sum _ { j = 1 } ^ { k } \tilde { \pi } _ { j } \sim 2 e ^ { - \gamma } \sum _ { j = 1 } ^ { k } \text{li} _ { j } = 2 e ^ { - \gamma } \text{li} ( p _ { i + 1 } ^ { 2 } ).$$
Note that the model as stated does not produce the correct mean. This can easily be overcome be introducing the random variables
$$\Pi _ { j } \coloneqq \frac { e ^ { \gamma } } { 2 } \tilde { \Pi } _ { j } \ \text{ and } \ \Pi ( p _ { k + 1 } ^ { 2 } ) \coloneqq \sum _ { j = 1 } ^ { k } \Pi _ { j }.$$
However, our interest is not in the mean, but in the variance produced by this model, and for that purpose it is not essential whether the mean differs by a constant; we still expect the primes to be constrained by the same variance.
To continue, we write the variance of Π( ˜ p 2 k +1 ) as
$$\text{$to$ continue, we write $neq variance of $m(\psi_{k+1})$ as} \\ \text{Var} \left [ \tilde { \Pi } ( p _ { k + 1 } ^ { 2 } ) \right ] & = E \left [ \left ( \sum _ { j = 1 } ^ { k } \left ( \tilde { \Pi } _ { j } - \tilde { \pi } _ { j } \right ) \right ) ^ { 2 } \right ] \\ & = \sum _ { j = 1 } ^ { k } E \left [ \left ( \tilde { \Pi } _ { j } - \tilde { \pi } _ { j } \right ) ^ { 2 } \right ] + 2 \sum _ { 1 \leq i < j \leq k } E \left [ \left ( \tilde { \Pi } _ { i } - \tilde { \pi } _ { i } \right ) \cdot \left ( \tilde { \Pi } _ { j } - \tilde { \pi } _ { j } \right ) \right ]. \\ \text{As we see, the first expression after the last equality is a sum over the individual}$$
As we see, the first expression after the last equality is a sum over the individual variances, while the second expression contains all covariance terms; they are all appearing twice, thereby explaining the factor 2. Crucially, we can express the variance theoretically, and will do so in the next section.
For comparison, we also consider what we will refer to as the uncorrelated random model , where the sequences ˆ , 1 ρ j ≤ j ≤ k , are drawn anew for each interval s k . We formulate this model in terms of the random variables
$$\hat { \Pi } _ { j }, \, 1 \leq j \leq k, \quad \text{and} \quad \hat { \Pi } ( p _ { k + 1 } ^ { 2 } ) \coloneqq \sum _ { j = 1 } ^ { k } \hat { \Pi } _ { j }.$$
The expectation values of these random variables are the same as above for the correlated random model, but now the covariances between intervals are zero, so that the variance is simply
$$\text{Var} \left [ \hat { \Pi } ( p _ { k + 1 } ^ { 2 } ) \right ] = \sum _ { j = 1 } ^ { k } \text{E} \left [ \left ( \hat { \Pi } _ { j } - \tilde { \pi } _ { j } \right ) ^ { 2 } \right ].$$
To illustrate the behaviour of the random models, we generate 275 realisations of Π( ˜ p 2 k +1 ), as well as 275 realisations of Π( ˆ p 2 k +1 ), for 1 ≤ k ≤ 10 . 4 The result is displayed in Figure 7, where the different realisations are plotted with their mean subtracted. Notable is that the correlated random model exhibits less variance than the uncorrelated model, indicating that the covariance terms in the correlated model in general are negative. In the same figure, we also plot the error function
$$\epsilon ( p _ { k + 1 } ^ { 2 } ) \coloneqq \pi ( p _ { k + 1 } ^ { 2 } ) - \text{li} ( p _ { k + 1 } ^ { 2 } )$$
as well as the adjusted error function
$$\epsilon _ { 0 } ( p _ { k + 1 } ^ { 2 } ) \coloneqq \pi ( p _ { k + 1 } ^ { 2 } ) - \left [ c \cdot \text{li} \left ( p _ { k + 1 } ^ { 2 } \right ) - ( 1 - c ) \cdot \sum _ { j = 1 } ^ { k } \frac { l _ { j } } { \log p _ { j + 1 } ^ { 2 } } \right ],$$
where c ≈ 1 -0 604. . It is evident that both of these error functions display a behaviour that is closer to that of the correlated model.
It is worth contrasting the correlated random model with the famous Cramer random model [Cram´ er 1936] (see also [Granville 1995a] for a thorough review of Cramer's work). In Cramer's model each integer n , 1 ≤ n ≤ x , has the probability 1 / log n of being prime, which gives a correct estimate of the number of primes across long enough intervals. While the model has proved very valuable in conjecturing different properties of the prime numbers, for example on the distribution of prime gaps, it also has the apparent weakness that it does not preserve certain central characteristics of the primes, such as the fact that an even number other than 2 can never be prime. In our suggested model, on the other hand, we move away from
Figure 7. The error function glyph[epsilon1] ( x ) (black) and the adjusted error function glyph[epsilon1] 0 ( x ) (blue) plotted at the values x = p 2 k +1 , 1 ≤ k ≤ 10 4 , together with 275 realisations of the correlated random model (red) and 275 realisations of the uncorrelated random model (grey).
looking at each integer. Rather, the number of primes in each interval s k is treated as a random variable, and the correlation structure between intervals emerging from the underlying periodicities of ρ k is kept intact. In this sense, we expect our choice of model to better describe the behaviour of the prime counting function π x ( ).
## 8. Theoretical expressions for the variance of ˜ Π ( p 2 k +1 )
In an elementary calculation, Hausman and Shapiro [Hausman and Shapiro 1973] derived the variance of the number of reduced residues modulo n in an arbitrary interval of length h . We here extend to the general case of the covariance between two intervals A 1 and A 2 with corresponding lengths h 1 and h 2 that are separated by a distance q , and where in A 1 we regard the number of reduced residues modulo n 1 , and in A 2 the number of reduced residues modulo n 2 . The resulting expressions for the covariance we present here follows from a straight forward adaption of Hausman and Shapiro's proof.
Let
$$f _ { n } ( m ) \coloneqq \begin{cases} 1 & \text{if} \quad ( m, n ) = 1, \\ 0 & \text{if} \quad ( m, n ) > 1. \end{cases}$$
The function of f n ( m ) is to weed out coprimes to n . To count the number of such in an interval of length h , we define
$$F _ { n } ( m, h ) \coloneqq \sum _ { r = m } ^ { m + h - 1 } f _ { n } ( r ).$$
From a probabilistic perspective, the expected number of coprimes to n in an interval of length h is given by
$$h \frac { \Phi ( n ) } { n },$$
where Φ( n ) is Euler's totient function.
Denote now the number of coprimes to n 1 in A 1 and the number of coprimes to n 2 in A 2 by F n 1 ( m,h 1 ) and F n 2 ( m + q, h 2 ), respectively, where we assume n 1 ≤ n 2 and q ≥ 1. Then the covariance between F n 1 ( m,h 1 ) and F n 2 ( m + q, h 2 ) is given by
$$& \Gamma _ { n } \geq 1. \ \lim e \, \text{$covariance veuween $r_{n}\{m,n_{1}$} \, \text{and} \, r_{n_{2}\{m}+q,n_{2}$} \, $ \text{is given by} \\ & \quad G ( n _ { 1 }, n _ { 2 }, h _ { 1 }, h _ { 2 }, q ) \\ & \coloneqq \frac { 1 } { n _ { 1 } n _ { 2 } } \sum _ { m = 1 } ^ { n _ { 1 } n _ { 2 } } \left ( F _ { n _ { 1 } } ( m, h _ { 1 } ) - h _ { 1 } \frac { \Phi ( n _ { 1 } ) } { n _ { 1 } } \right ) \left ( F _ { n _ { 2 } } ( m + q, h _ { 2 } ) - h _ { 2 } \frac { \Phi ( n _ { 2 } ) } { n _ { 2 } } \right ) \\ & \quad = \frac { 1 } { n _ { 1 } n _ { 2 } } \sum _ { m = 1 } ^ { n _ { 1 } n _ { 2 } } F _ { n _ { 1 } } ( m, h _ { 1 } ) F _ { n _ { 2 } } ( m + q, h _ { 2 } ) - h _ { 1 } h _ { 2 } \frac { \Phi ( n _ { 1 } n _ { 2 } ) } { n _ { 1 } n _ { 2 } }. \\ & \text{Note that $G$ is periodic with respect to $q$ and has periodicity $n_{1}$,}$$
Note that G is periodic with respect to q and has periodicity n 1 ,
$$G ( n _ { 1 }, n _ { 2 }, h _ { 1 }, h _ { 2 }, q + n _ { 1 } ) = G ( n _ { 1 }, n _ { 2 }, h _ { 1 }, h _ { 2 }, q ).$$
For brevity, we only continue with the case when h 2 > h 1 and n 1 and n 2 are both even. Similar expressions can be derived in the other cases. Under this assumption, and introducing the abbreviation
$$Q ( n _ { 1 }, n _ { 2 } ) \coloneqq \frac { 1 } { 2 } n _ { 1 } n _ { 2 } \prod _ { p | \left ( n _ { 1 } n _ { 2 } / ( n _ { 1 }, n _ { 2 } ) ^ { 2 } \right ) } \left ( 1 - \frac { 1 } { p } \right ) \prod _ { p | ( n _ { 1 }, n _ { 2 } ) ^ { \prime } } \left ( 1 - \frac { 2 } { p } \right ),$$
where n ′ denotes the largest odd divisor of n , we can express the sum after the last equality in (9) as
$$\text{where} \, n ^ { \prime } \text{ denotes the largest odd divisor of } n, \, \text{we can express the sum after the last} \\ \text{equality in } ( 9 ) \, & \text{as} \\ \sum _ { m = 1 } ^ { n _ { 1 } n _ { 2 } } F _ { n _ { 1 } } ( m, h _ { 1 } ) F _ { n _ { 2 } } ( m + q, h _ { 2 } ) = \\ Q ( n _ { 1 }, n _ { 2 } ) \sum _ { \substack { k = 1 \\ 2 | q + k - 1 } } ^ { h _ { 2 } - h _ { 1 } + 1 } h _ { 1 } \prod _ { \substack { p | ( n _ { 1 }, n _ { 2 } ) ^ { \prime } \\ p | ( q + k - 1 ) } } \left ( 1 + \frac { 1 } { p - 2 } \right ) + \\ Q ( n _ { 1 }, n _ { 2 } ) \sum _ { \substack { k = 1 \\ 2 | ( q + h _ { 2 } - h _ { 1 } + k ) } } ^ { h _ { 1 } - 1 } ( h _ { 1 } - k ) \prod _ { \substack { p | ( n _ { 1 }, n _ { 2 } ) ^ { \prime } \\ p | ( q + h _ { 2 } - h _ { 1 } + k ) } } \left ( 1 + \frac { 1 } { p - 2 } \right ) + \\ Q ( n _ { 1 }, n _ { 2 } ) \sum _ { \substack { k = 1 \\ 2 | ( q - k ) } } ^ { h _ { 1 } - 1 } ( h _ { 1 } - k ) \prod _ { \substack { p | ( n _ { 1 }, n _ { 2 } ) ^ { \prime } \\ p | ( q - k ) } } \left ( 1 + \frac { 1 } { p - 2 } \right ). \\ \text{For computational purposes, } G ( n _ { 1 }, n _ { 2 }, h _ { 1 }, h _ { 2 }, q ) \, \text{is most efficiently calculated using} \\ \text{this expression, and it underlies later numerical examples. } \text{ But it is possible to}$$
For computational purposes, G n , n , h ( 1 2 1 , h 2 , q ) is most efficiently calculated using this expression, and it underlies later numerical examples. But it is possible to derive a more compact theoretical expression in terms of the M¨bius function [see o (7)]. We also need the following definitions: For any square-free integer n ,
$$\rho ( n ) \coloneqq \prod _ { p | n } ( p - 2 ) ;$$
$$\gamma ^ { + } ( h, q, d ) \coloneqq \begin{cases} 0 & \text{if $d\nmid q+i$ for all $i$, where $1\leq i\leq d\left\{\frac{h}{d}\right\}$}, \\ 1 & \text{if $d\nmid q+i$ for some $i$, where $1\leq i\leq d\left\{\frac{h}\right\}$} ; \end{cases}$$
and
$$\left \{ \frac { q } { d } \right \} _ { 1 } \coloneqq \begin{cases} \left \{ \frac { q } { d } \right \} \quad \text{if $d\nmid q$}, \\ 1 \quad \text{if $d\,|\,q$}. \end{cases}$$
Then we can write the covariance G n , n , h ( 1 2 1 , h 2 , q ) on the equivalent form
$$( 1 0 ) \quad G ( n _ { 1 }, n _ { 2 }, h _ { 1 }, h _ { 2 }, q ) = \frac { 1 } { n _ { 1 } n _ { 2 } } Q ( n _ { 1 }, n _ { 2 } ) \sum _ { d | ( n _ { 1 }, n _ { 2 } ) ^ { \prime } } \frac { \mu ^ { 2 } ( d ) } { \rho ( d ) } \mathcal { B } ( h _ { 1 }, h _ { 2 }, q, d ),$$
where
$$\text{where} \quad & \mathcal { B } ( h _ { 1 }, h _ { 2 }, q, d ) \\ & = h _ { 1 } \left ( \frac { 1 } { 2 d } - \left \{ \frac { h _ { 2 } - h _ { 1 } + 1 } { 2 d } \right \} + \left \{ \frac { q + h _ { 2 } - h _ { 1 } } { 2 d } \right \} - \left \{ \frac { q } { 2 d } \right \} _ { 1 } \right ) \\ & - 2 d \left \{ \frac { h _ { 1 } } { 2 d } \right \} \left ( \left \{ \frac { h _ { 1 } } { 2 d } \right \} + \left \{ \frac { q + h _ { 2 } - h _ { 1 } } { 2 d } \right \} - \left \{ \frac { q } { 2 d } \right \} _ { 1 } \right ) \\ & + \gamma ^ { + } ( h _ { 2 } - h _ { 1 } + 1, q - 1, 2 d ) h _ { 1 } \\ & + \gamma ^ { + } ( h _ { 1 }, q + h _ { 2 } - h _ { 1 }, 2 d ) 2 d \left ( \left \{ \frac { h _ { 1 } } { 2 d } \right \} - \left ( 1 - \left \{ \frac { q + h _ { 2 } - h _ { 1 } } { 2 d } \right \} \right ) \right ) \\ & + \gamma ^ { - } ( h _ { 1 }, q, 2 d ) 2 d \left ( \left \{ \frac { h _ { 1 } } { 2 d } \right \} - \left \{ \frac { q } { 2 d } \right \} _ { 1 } \right ). \\ & \quad \cdots \quad. &. &. &. &. &. &. &. &. &. &. &. &. &.$$
Numerical investigations hints to a possible simplification of this expression, as some of the terms appear to always cancel each other, but this remains to be shown theoretically.
Whenever A 1 = A 2 , so that h 1 = h 2 = h and n 1 = n 2 = n , we can write H n,h ( ) := G n,n,h,h, ( 0), and (10) reduces to the variance derived in [Hausman and Shapiro 1973],
$$H ( n, h ) = \prod _ { p | n ^ { \prime } } \left ( 1 - \frac { 2 } { p } \right ) \sum _ { d | n ^ { \prime } } \frac { \mu ^ { 2 } ( d ) } { \rho ( d ) } d \left \{ \frac { h } { 2 d } \right \} \left ( 1 - \left \{ \frac { h } { 2 d } \right \} \right ).$$
Note that if we apply the inequality { x } (1 -{ } x ) ≤ x , we obtain the upper bound
$$H ( n, h ) \leq h \frac { \Phi ( n ) } { n }.$$
Returning to the random models in Section 7, we can now express the variance of the correlated model as
$$& \text{or use coverage} \text{ move as} \\ & \text{Var} \left [ \tilde { \Pi } ( p _ { k + 1 } ^ { 2 } ) \right ] = \sum _ { j = 1 } ^ { k } E \left [ \left ( \tilde { \Pi } _ { j } - \tilde { \pi } _ { j } \right ) ^ { 2 } \right ] + 2 \sum _ { 1 \leq i < j \leq k } E \left [ \left ( \tilde { \Pi } _ { i } - \tilde { \pi } _ { i } \right ) \cdot \left ( \tilde { \Pi } _ { j } - \tilde { \pi } _ { j } \right ) \right ] \\ & \quad = \sum _ { j = 1 } ^ { k } H ( p _ { j } \#, l _ { j } ) + 2 \sum _ { 1 \leq i < j \leq k } G ( p _ { i } \#, p _ { j } \#, l _ { i }, l _ { j }, p _ { j + 1 } ^ { 2 } - p _ { i + 1 } ^ { 2 } ).$$
$$\gamma ^ { - } ( h, q, d ) \coloneqq \begin{cases} 0 & \text{if $d\nmid q - i$ for all $i$, where $1\leq i\leq d\left\{frac{\hbar{d}}{\}$} \right\}$}, \\ 1 & \text{if $d\left|q-i$ for some $i$, where $1\leq i\leq d\left\{frac{\hbar{d}}{\}$} \right\}$} ; \end{cases}$$
Likewise, for the uncorrelated model,
$$\text{Var} \left [ \hat { \Pi } ( p _ { k + 1 } ^ { 2 } ) \right ] = \sum _ { j = 1 } ^ { k } \text{E} \left [ \left ( \hat { \Pi } _ { j } - \tilde { \pi } _ { j } \right ) ^ { 2 } \right ] = \sum _ { j = 1 } ^ { k } H ( p _ { j } \#, l _ { j } ).$$
From (11) it follows that
$$H ( p _ { j } \#, l _ { j } ) \leq l _ { j } \cdot \frac { \Phi ( p _ { j } \# ) } { p _ { j } \# } = l _ { j } \cdot \prod _ { p \in \mathcal { P } _ { j } } \left ( 1 - \frac { 1 } { p } \right ) \sim 2 e ^ { - \gamma } \frac { l _ { j } } { \log p _ { j + 1 } ^ { 2 } } \sim 2 e ^ { - \gamma } \, \text{li} _ { j },$$
which results in the variance of the uncorrelated model having the upper bound
$$\text{Var} \left [ \hat { \Pi } ( p _ { k + 1 } ^ { 2 } ) \right ] \leq 2 e ^ { - \gamma } \sum _ { j = 1 } ^ { k } \text{li} _ { j } = 2 e ^ { - \gamma } \text{ li} \left ( p _ { k + 1 } ^ { 2 } \right ).$$
## 9. Properties of the covariance function
In this section we present some general considerations on the behaviour of the covariance function G n , n , h ( 1 2 1 , h 2 , q ). Let us first have a look at the role of the relative position q of two intervals, when both are assumed to be sieved by the k first primes. As an example of this scenario, we show in Figure 8A a plot of G p ( 100 # , p 100 # , h 1 , 2 h , q 1 ) as a function of q for different values of h 1 . We observe that in each case, the covariance function reaches a negative minimum value when q = h 1 -the exact situation when the two intervals are adjacent-before slowly climbing towards zero again. In addition, the minimum values grow in size as the length of the intervals increases. While not shown in Figure 8A, this result also holds for arbitrary values of h 2 . Note, however, that the observed minimum values are not unique, as shown in Figure 8B, where we have plotted G p ( k # , p k # , h 1 , h 1 , q ) across its full period p k # for two values of h 1 .
The reason why q = h 1 corresponds to a minimum value of the covariance function can be understood in terms of the following heuristic: For the sake of argument, assume that A 1 and A 2 are both sieved by p k only, and that their lengths h 1 and h 2 satisfy h 1 + h 2 ≤ p k . Then we have that
$$F _ { p _ { k } } ( m, h _ { 1 } ) = h _ { 1 } - 1 \ \text{ or } \ F _ { p _ { k } } ( m, h _ { 1 } ) = h _ { 1 },$$
depending respectively on whether the interval A 1 lies across a multiple of p k or not. Likewise in the case of A 2 :
$$F _ { p _ { k } } ( m, h _ { 2 } ) = h _ { 2 } - 1, \text{ \ or \ } F _ { p _ { k } } ( m, h _ { 2 } ) = h _ { 2 }.$$
Under these assumptions, we have that
$$G ( p _ { k }, p _ { k }, h _ { 1 }, h _ { 2 }, q ) = \frac { 1 } { p _ { k } } \sum _ { m = 1 } ^ { p _ { k } } F _ { p _ { k } } ( m, h _ { 1 } ) F _ { p _ { k } } ( m + q, h _ { 2 } ) - h _ { 1 } h _ { 2 } \left ( \frac { p _ { k } - 1 } { p _ { k } } \right ) ^ { 2 }.$$
When A 1 and A 1 do not overlap, that is, q ≥ h 1 , we can write the sum after the equality in terms of three contributions,
$$\begin{array} { l } \text{equity in terms of unree contributions}, \\ \sum _ { m = 1 } ^ { p _ { k } } & F _ { p _ { k } } ( m, h _ { 1 } ) F _ { p _ { k } } ( m + q, h _ { 2 } ) \\ & = ( p _ { k } - h 1 - h _ { 2 } ) \cdot [ h _ { 1 } h _ { 2 } ] + h _ { 1 } \cdot [ h _ { 2 } ( h _ { 1 } - 1 ) ] + h _ { 2 } \cdot [ h _ { 1 } ( h _ { 2 } - 1 ) ] \\ & = h _ { 1 } h _ { 2 } ( p _ { k } - 2 ). \end{array}$$
Figure 8. Covariance plots: (A) G p ( 100 # , p 100 # , h 1 , 2 h , q 1 ) plotted for four different values of h 1 as a function of q . In each case, the covariance function is minimum at q = h 1 . (B) G p ( 4 # , p 4 # , h 1 , h 1 , q ) plotted for two different values of h 1 as a function of q across its full period. The plot illustrates that the minimum found at q = h 1 is in general not unique.
And if A 1 and A 2 do overlap, that is, 0 ≤ q < h 1 , in terms of four contributions,
$$& \text{And if } A _ { 1 } \text{ and } A _ { 2 } \text{ do overlap, that is, } 0 \leq q < h _ { 1 }, \text{ in terms of four contributions,} \\ & \sum _ { m = 1 } ^ { p _ { k } } F _ { p _ { k } } ( m, h _ { 1 } ) F _ { p _ { k } } ( m + q, h _ { 2 } ) \\ & \quad = ( p _ { k } - h _ { 2 } - q ) \cdot [ h _ { 1 } h _ { 2 } ] + q \cdot [ ( h _ { 1 } - 1 ) h _ { 2 } ] + ( h _ { 1 } - q ) \cdot [ ( h _ { 1 } - 1 ) ( h _ { 2 } - 1 ) ] \\ & \quad \quad + ( h _ { 2 } - h _ { 1 } + q ) \cdot [ h _ { 1 } ( h _ { 2 } - 1 ) ] \\ & \quad = - q + h _ { 1 } + h _ { 1 } h _ { 2 } ( p _ { k } - 2 ). \\ & \text{Cmnaring these two sums } \text{ we see that } G ( n. \text{ $n$}. \text{ $h$}. \text{ $h$}. \text{ $a$} \text{ is minimised whenever}$$
Comparing these two sums, we see that G p , p ( k k , h 1 , h 2 , q ) is minimised whenever q ≥ h 1 , in which case
$$G ( p _ { k }, p _ { k }, h _ { 1 }, h _ { 2 }, q ) = - \frac { h _ { 1 } h _ { 2 } } { p _ { k } ^ { 2 } } < 0.$$
Note that the larger the product h h 1 2 is, the larger the absolute value of the covariance at its minimum, as we observe in Figure 8A.
Letting go of the restriction that h 1 + h 2 ≤ p k complicates the heuristic, since more careful accounting is needed; as does sieving the intervals by multiple primes. It seems realistic, however, that a proof can be produced to show that in general, G p ( k # , p k # , h 1 , h 2 , q ) takes on a negative minimum value whenever q = h 1 .
Aside the relative positions of intervals, a second aspect to consider is what primes each interval is sieved by. Again, assume two intervals, now with lengths h 1 and h 2 , where the first is sieved by the i first primes, and the second by the j first primes. Then we can write the covariance function as
$$G ( p _ { i } \#, p _ { j } \#, h _ { 1 }, h _ { 2 }, q ) = c _ { 1 } \prod _ { p | ( p _ { j } \# / p _ { i } \# ) } \left ( 1 - \frac { 1 } { p } \right ) - c _ { 2 } \prod _ { p \in \mathcal { P } _ { j } } \left ( 1 - \frac { 1 } { p } \right ),$$
where c 1 and c 2 are constants. Both products approaches 0 as j →∞ , and therefore we have that
$$\lim _ { j \to \infty } G ( p _ { i } \#, p _ { j } \#, h _ { 1 }, h _ { 2 }, q ) = 0.$$
Figure 9. The covariance function G p ( 10 # , p k # 100 100 , , , q ) plotted for two different values of q as a function of 10 ≤ k ≤ 1000 .
This limit behaviour is illustrated in Figure 9; G p ( i # , p j # , h 1 , h 2 , q ) is plotted for two values of q , and in both cases it moves slowly towards 0 as j increases.
Combining these two insights-the covariance function is minimised for adjacent intervals and approaches zero as the difference in sieving steps between intervals increases- we anticipate that G p ( i # , p j # , l i , l j , p 2 j +1 -p 2 i +1 ) is negative when j -i is small, increasingly so when i and j both become large, and grows smaller in absolute value as the difference j -i increases. Hence, the sum
$$\sum _ { 1 \leq i < j \leq k } G ( p _ { i } \#, p _ { j } \#, l _ { i }, l _ { j }, p _ { j + 1 } ^ { 2 } - p _ { i + 1 } ^ { 2 } )$$
should be dominated by negative terms, implying that the variance of the correlated random model is bounded by the same upper bound as the uncorrelated random model. Thus,
$$\text{Var} \left [ \tilde { \Pi } ( p _ { k + 1 } ^ { 2 } ) \right ] \leq \sum _ { i = 1 } ^ { k } H ( p _ { i } \#, l _ { i } ) \leq 2 e ^ { - \gamma } \text{ li} ( p _ { k + 1 } ^ { 2 } ).$$
## 10. Comparing random models and empirical data
In order to verify the predictions stated in the previous section we now consider four cases: 1) The theoretical variance of the correlated random model; 2) The variance of the correlated random model estimated from sampled realisations of ˜ Π ( p 2 k +1 ) ; 3) The estimated variance of the prime counting function π x ( ) under the assumption that E π x [ ( )] = li( x ); and 4) The estimated variance of the prime counting function π x ( ) under the assumption that
$$E [ \pi \left ( p _ { k + 1 } ^ { 2 } \right ) ] = c \cdot \text{li} \left ( p _ { k + 1 } ^ { 2 } \right ) - ( 1 - c ) \cdot \sum _ { i = 1 } ^ { k } l _ { i } / \log p _ { i + 1 } ^ { 2 }.$$
Let us start with the separate contribution from the covariance terms between intervals. In the theoretical case, we write the sum
$$\sum _ { 1 \leq i < j \leq k } G ( p _ { i } \#, p _ { j } \#, l _ { i }, l _ { j }, p _ { j + 1 } ^ { 2 } - p _ { i + 1 } ^ { 2 } )$$
on the equivalent form
$$\sum _ { j = 1 } ^ { k - 1 } \left ( \sum _ { i = 1 } ^ { k - j } G ( p _ { i } \#, p _ { i + j } \#, l _ { i }, l _ { i + j }, p _ { i + j + 1 } ^ { 2 } - p _ { i + 1 } ^ { 2 } ) \right ),$$
and denote the expression in parentheses by
$$\kappa _ { \text{th} } ( j ) \coloneqq \sum _ { i = 1 } ^ { k - j } G ( p _ { i } \#, p _ { i + j } \#, l _ { i }, l _ { i + j }, p _ { i + j + 1 } ^ { 2 } - p _ { i + 1 } ^ { 2 } ),$$
where the label 'th' is short for theory. κ th ( j ) is therefore the sum over all covariance terms originating from j th nearest intervals. For example, κ th (1) gives the sum over all covariance terms for neighbouring intervals. We also need the total remaining contribution to the covariance for all j larger than some value d , which we obtain by
$$\sum _ { j > d } ^ { k - 1 } \kappa _ { \text{th} } ( j ).$$
Now to the second case, where we draw samples of Π ˜ ( p 2 k +1 ) = ∑ k i =1 ˜ Π . k We define the error function in each interval j as glyph[epsilon1] sim ,j := Π ˜ j -˜ , π j where the label 'sim' is short for simulation, and write the global error function as
$$\epsilon _ { \sin } ( p _ { k + 1 } ^ { 2 } ) \coloneqq \sum _ { j = 1 } ^ { k } ( \tilde { \Pi } _ { j } - \tilde { \pi } _ { j } ) = \sum _ { j = 1 } ^ { k } \epsilon _ { \sin, j }.$$
Then the measured variance of one realisation of Π ˜ ( p 2 k +1 ) can be expressed as
$$\text{Var} \left [ \tilde { \Pi } \left ( p _ { k + 1 } ^ { 2 } \right ) \right ] = \left ( \sum _ { j = 1 } ^ { k } \epsilon _ { \text{sim}, j } \right ) ^ { 2 } = \sum _ { j = 1 } ^ { k } \epsilon _ { \text{sim}, j } ^ { 2 } + 2 \sum _ { 1 \leq i < j \leq k } \epsilon _ { \text{sim}, i } \cdot \epsilon _ { \text{sim}, j }.$$
Similar to the theoretical case, we rewrite the sum
$$\sum _ { 1 \leq i < j \leq k } \epsilon _ { \sin, i } \cdot \epsilon _ { \sin, j }$$
as
$$\sum _ { j = 1 } ^ { k - 1 } \left ( \sum _ { i = 1 } ^ { k - j } \epsilon _ { \sin, i } \cdot \epsilon _ { \sin, i + j } \right ).$$
Since we are interested in the average taken over many realisations, we define
$$\kappa _ { \sin } ( j ) \coloneqq \left \langle \sum _ { i = 1 } ^ { k - j } \epsilon _ { \sin, i } \cdot \epsilon _ { \sin, i + j } \right \rangle,$$
and the total remaining contribution to the covariance for all j larger than some value d , by
$$\sum _ { j > d } ^ { k } \kappa _ { \sin } ( j ).$$
Finally, in the cases of the primes, we define
$$\epsilon _ { p r, j } \coloneqq \pi _ { j } - \text{li} _ { j } \text{ \ and \ } \epsilon _ { a d, j } \coloneqq \pi _ { j } - \left [ c \cdot \text{li} _ { j } - ( 1 - c ) \cdot \frac { l _ { j } } { \log p _ { j + 1 } ^ { 2 } } \right ],$$
where 'pr' and 'ad' denote primes and primes with adjusted mean, and obtain
$$\epsilon _ { p r } \left ( p _ { k + 1 } ^ { 2 } \right ) \coloneqq \sum _ { j = 1 } ^ { k } \epsilon _ { p r, j } \text{ \ and \ } \epsilon _ { a d } \left ( p _ { k + 1 } ^ { 2 } \right ) \coloneqq \sum _ { j = 1 } ^ { k } \epsilon _ { a d, j }.$$
Then, entirely analogous to the previous cases, we obtain
$$\kappa _ { \text{pr} } ( j ) \coloneqq \sum _ { i = 1 } ^ { k - j } \epsilon _ { p r, i } \cdot \epsilon _ { p r, i + j } \text{ \ and \ } \sum _ { j > d } ^ { k } \kappa _ { \text{pr} } ( j ),$$
and
$$\kappa _ { \text{ad} } ( j ) \coloneqq \sum _ { i = 1 } ^ { k - j } \epsilon _ { a d, i } \cdot \epsilon _ { a d, i + j } \text{ \ and \ } \sum _ { j > d } ^ { k } \kappa _ { \text{ad} } ( j ).$$
We now plot κ th ( j ), κ sim ( j ), κ pr ( j ), and κ ad ( j ) for different values of j up to a maximum d , as well as the remainder terms, all shown in Figure 10. The different plots are across different ranges of k -limited to smaller k in the first two cases due to increasing computational cost for large k -but we observe that they are all qualitatively similar, confirming that the primes behave according to the correlated random model. For direct comparison, we include κ pr (1) and κ pr (2) also in the plots of κ th ( j ) and κ sim ( j ). At this short range, however, the fluctuations of κ pr (1) and κ pr (2) are rather significant, so we are not able to determine whether κ pr ( j ) converges to the theoretical value of the correlated random model in the limit of large k . In fact, as will be evident when we plot the total variance in each case, it appears that the covariance functions κ pr ( j ) and κ ad ( j ) in general lie below κ th ( j ) as k grows large, and this might be what we actually observe in Figure 10A and more convincingly in Figure 10B.
As we anticipated in the previous section, the contribution to the covariance is largest when j is small; κ a (1) is more than a factor two larger than κ a (2) (here 'a' denotes any of 'th', 'sim', 'pr', or 'ad'). And as j grows larger, κ a ( j ) approaches zero in absolute value. Note though that while we can observe some κ a ( j ) being positive, the remainder terms in all cases add up to negative values.
Comparing Figure 10C and Figure 10D, we see that for small j , κ pr ( j ) and κ ad ( j ) are almost identical. However, for j large the remainder terms differ significantly. Assuming li( x ) to be the correct expectation value of π x ( ) produces large fluctuations in the remainder term, while a much smoother curve results from assuming the adjusted expectation value.
k
k
Figure 10. The covariance sums κ th ( j ) (A), κ sim ( j ) (B), κ pr ( j ) (C), and κ ad ( j ) (D) plotted at the values x = p 2 k +1 . The legend applies for all three covariance sums. In (A), 1 ≤ k ≤ 300 , and data are plotted for each value of k , d 1 = 10 , and d 2 = 50 ; In (B), 1 ≤ k ≤ 10 3 , and data are plotted for every 10th value of k , d 1 = 10 , and d 2 = 200 . The curves are obtained by averaging over 275 individual samples; In (C) and (D), 1 ≤ k ≤ 6 × 10 5 , and data are plotted for every 500th value of k , d 1 = 10 , and d 2 = 1000 . In (A) and (B), κ pr (1) and κ pr (2) are included for comparison (dashed black and red, respectively).
Next, we continue by examining the total variance in each case, or rather, the standard deviations, that are given by
$$\text{s.s.s.s.s.s.s.s.s.s.s.s.s.s.s.s.s.s.s.s.s.s.s.s.s.s.s.s.s.s.s.s.s.s.s.s.s.s.s.s.s.s.s.s.s.s.s.s.s.s.s.s.s.s.s.s.s.s.s.s.s.s.s.s.s.s.s.s.s.s.s.s.s.s.s.s.s.s.s.s.s.s.s.s.s.s.s.s.s.s.s.s.s.s.s.s.s.s.s.s.s.}$$
In addition, we consider the standard deviations under the assumption that all covariance terms are zero, that is, corresponding to the uncorrelated random model. Hence,
$$\begin{array} { l } \text{re zero, that is, corresponding to the uncorrelat} \\ \\ \sigma _ { t h, 0 } \left ( p _ { k + 1 } ^ { 2 } \right ) \coloneqq \sqrt { \sum _ { j = 1 } ^ { k } H ( p _ { j } \#, l _ { j } ) }, \\ \\ \sigma _ { \text{sim}, 0 } \left ( p _ { k + 1 } ^ { 2 } \right ) \coloneqq \sqrt { \left \langle \sum _ { j = 1 } ^ { k } \epsilon _ { \text{sim}, j } ^ { 2 } \right \rangle }, \\ \\ \sigma _ { \text{pr}, 0 } \left ( p _ { k + 1 } ^ { 2 } \right ) \coloneqq \sqrt { \sum _ { j = 1 } ^ { k } \epsilon _ { \text{pr}, j } ^ { 2 } }, \quad \text{and} \\ \\ \sigma _ { \text{ad}, 0 } \left ( p _ { k + 1 } ^ { 2 } \right ) \coloneqq \sqrt { \sum _ { j = 1 } ^ { k } \epsilon _ { \text{ad}, j } ^ { 2 } }. \\ \\ \text{ide the upper bound we found earlier for the s} \\ \text{random model}. \end{array}$$
Finally, we include the upper bound we found earlier for the standard deviation of the uncorrelated random model:
$$\sigma _ { \text{ub} } \left ( p _ { k + 1 } ^ { 2 } \right ) \coloneqq \sqrt { 2 e ^ { - \gamma } \, \text{li} \left ( p _ { k + 1 } ^ { 2 } \right ) }.$$
The different standard deviations are plotted in Figure 11. Under the assumption of the uncorrelated model, we observe that the curves of σ pr 0 , and σ ad 0 , lie on top of each other and are not visibly different. They also lie close to the theoretical value σ th 0 , , as shown in Figure 11A, and in fact seems to converge to σ sim 0 , , as evidenced in Figure 11B.
Including correlations, we note in Figure 11A that σ pr starts out larger than σ th , but seems to stabilise below σ sim in Figure 11B. It appears that this trends continues in Figure 11C, but without comparison with the correlated random model, we cannot state this with certainty. In all cases, σ ad is small compared to σ pr .
As expected from the covariance contribution being negative, the total variance is always smaller than the variance of the uncorrelated model, which again is bounded by σ ub , placed far above any of the other curves.
## 11. The distribution of primes and the Riemann hypothesis
Considered an outstanding challenge in number theory, the Riemann hypothesis states that the real part of every non-trivial zero of the Riemann zeta function is 1/2, where the Riemann zeta function is defined by
$$\zeta ( s ) \coloneqq \sum _ { n = 1 } ^ { \infty } \frac { 1 } { n ^ { s } }.$$
The Riemann zeta function ties in tightly with the distribution of primes through the Euler product formula, which states that
$$\zeta ( s ) = \prod _ { p \in \mathcal { P } } \left ( 1 - \frac { 1 } { p ^ { s } } \right ) ^ { - 1 }.$$
Figure 11. Different standard variance functions plotted at the values x = p 2 k +1 (calculated from theory, samples from the correlated random model, and from the prime counting function π x ( ) ). The legends in (C) also applies to (A) and (B). In (A), 1 ≤ k ≤ 300 , and data are plotted for each value of k ; In (B), 1 ≤ k ≤ 10 3 , and data are plotted for every 10th value of k . The curves for σ sim and σ sim, 0 are obtained by averaging over 275 individual samples; In (C), 1 ≤ k ≤ 6 × 10 5 , and data are plotted for every 100th value of k .
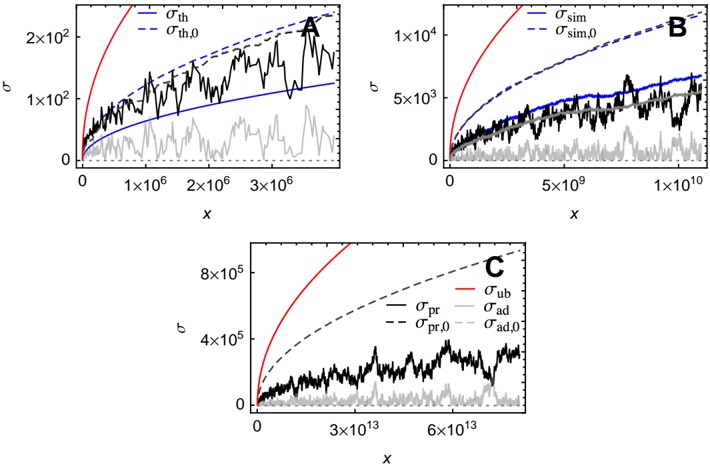
Our particular interest is in the fact that the Riemann hypothesis is equivalent to the upper bound on the error function being
$$\mu _ { \mu } \mu _ { \mu } \mu _ { \mu } \mu _ { \mu } \mu _ { \mu } \mu _ { \mu } \mu _ { \mu } \mu _ { \mu } \mu _ { \mu } \mu _ { \mu } \mu _ { \mu } \mu _ { \mu } \mu _ { \mu } \mu _ { \mu } \mu _ { \mu } \mu _ { \mu } \mu _ { \mu } \mu _ { \mu } \mu _ { \mu } \mu _ { \mu } \mu _ { \mu } \mu _ { \mu } \mu _ { \mu } \mu _ { \mu } \mu _ { \mu } \mu _ { \mu } \mu _ { \mu } \mu _ { \mu } \mu _ { \mu } \mu _ {\mu } \mu _ { \mu } \mu _ { \mu } \mu _ { \mu } \mu _ { \mu } \mu _ { \mu } \mu _ { \mu } \mu _ { \mu } \mu _ { \mu } \mu _ { \mu } \mu _ { \mu } \mu _ { \mu } \mu _ { \mu } \mu _ { \mu } \mu _ { \mu } \mu _ { \mu } \mu _ { \mu } \mu _ { \mu } \mu _ { \mu } \mu _ { \mu } \mu _ { \mu } \mu _ { \mu } \mu _ { \mu } \mu _ { \mu } \mu _ { \mu } \mu _ { \mu } \mu _ { \mu } \mu _ { \mu } \mu _ { \mu } \nu _ { \mu } \nu _ { \mu } \nu _ { \mu } \nu _ { \mu } \nu _ { \mu } \nu _ { \mu } \nu _ { \mu } \nu _ { \mu } \nu _ { \mu } \nu _ { \mu } \nu _ { \mu } \nu _ { \mu } \nu _ { \mu } \nu _ { \mu } \nu _ { \mu } \nu _ { \mu } \nu _ { \mu } \nu _ { \mu } \nu _ { \mu } \nu _ { \mu } \nu _ { \mu } \nu _ { \mu } \nu _ { \mu } \nu _ { \mu } \nu _ { \mu } \nu _ { \mu } \nu _ { \mu } \nu _ { \mu } \nu _ { \nu } \nu _ { \mu } \nu _ { \mu } \nu _ { \mu } \nu _ { \mu } \nu _ { \mu } \nu _ { \mu } \nu _ { \mu } \nu _ { \mu } \nu _ { \mu } \nu _ { \mu } \nu _ { \mu } \nu _ { \mu } \nu _ { \mu } \nu _ { \mu } \nu _ { \mu } \nu _ { \mu } \nu _ { \mu } \nu _ { \mu } \nu _ { \mu } \nu _ { \mu } \nu _ { \mu } \nu _ { \mu } \nu _ { \mu } \nu _ { \mu } \nu _ { \mu } \nu _ { \mu } \nu _ { \mu } \nu _ { \mu } \nu ^ { \prime } \nu _ { \mu } \nu _ { \mu } \nu _ { \mu } \nu _ { \mu } \nu _ { \mu } \nu _ { \mu } \nu _ { \mu } \nu _ { \mu } \nu _ { \mu } \nu _ { \mu } \nu _ { \mu } \nu _ { \mu } \nu _ { \mu } \nu _ { \mu } \nu _ { \mu } \nu _ { \mu } \nu _ { \mu } \nu _ { \mu } \nu _ { \mu } \nu _ { \mu } \nu _ { \mu } \nu _ { \mu } \nu _ { \mu } \nu _ { \mu } \nu _ { \mu } \nu _ { \mu } \nu _ { \mu } \nu _ { \mu } \nu } \nu _ { \mu } \nu _ { \mu } \nu _ { \mu } \nu _ { \mu } \nu _ { \mu } \nu _ { \mu } \nu _ { \mu } \nu _ { \mu } \nu _ { \mu } \nu _ { \mu } \nu _ { \mu } \nu _ { \mu } \nu _ { \mu } \nu _ { \mu } \nu _ { \mu } \nu _ { \mu } \nu _ { \mu } \nu _ { \mu } \nu _ { \mu } \nu _ { \mu } \nu _ { \mu } \nu _ { \mu } \nu _ { \mu } \nu _ { \mu } \nu _ { \mu } \nu _ { \mu } \nu _ { \mu } \nu _ { \mu }$$
a statement proven by von Koch in 1901 [von Koch 1901].
Koch's criteria is far from being a tight upper bound; it is much wider than what we have conjectured-and justified-in the previous sections, namely that for x large enough,
$$| \pi ( x ) - \text{li} ( x ) | < 2 e ^ { - \gamma } \sqrt { \text{li} ( x ) }.$$
In fact, we know enough to conjecture an even tighter upper bound, expressed discretely at the values x = p 2 k +1 , as
$$| \pi \left ( p _ { k + 1 } ^ { 2 } \right ) - \text{li} \left ( p _ { k + 1 } ^ { 2 } \right ) | < \sqrt { \sum _ { j = 1 } ^ { k } \frac { l _ { j } \log \left ( p _ { j + 1 } ^ { 2 } / l _ { j } \right ) } { \left ( \log p _ { j + 1 } ^ { 2 } \right ) ^ { 2 } } }.$$
This statement follows from Montgomery and Soundararajan's conjecture discussed in Section 6; the expression on the right side of the inequality is an estimate of the standard deviation of the uncorrelated random model. Due to the negative
contribution to the variance from the covariance terms between intervals, this bound holds stance for the correlated random model and hence the primes. Furthermore, since Montgomery and Soundararajan's conjecture holds empirically, we should expect that the bound should align with the sum of squares of the error functions in each interval,
$$\sum _ { j = 1 } ^ { k } ( \pi _ { j } - \text{li} _ { j } ) ^ { 2 }.$$
We can also express (13) in continuous form. Observe that under the assumption of Cramer's conjecture [Cram´r 1936]-that is, e g j := p j +1 -p j = O ( (log p j ) 2 ) -we have that
$$\log \left ( p _ { j + 1 } ^ { 2 } / l _ { i } \right ) = \log p _ { j + 1 } ^ { 2 } - \log \left ( 2 g _ { j } p _ { j + 1 } - g _ { j } ^ { 2 } \right ) \sim \frac { 1 } { 2 } \log p _ { j + 1 } ^ { 2 },$$
which further implies
$$\sum _ { j = 1 } ^ { k } \frac { l _ { j } \log \left ( p _ { j + 1 } ^ { 2 } / l _ { j } \right ) } { \left ( \log p _ { j + 1 } ^ { 2 } \right ) ^ { 2 } } \sim \frac { 1 } { 2 } \sum _ { j = 1 } ^ { k } \frac { l _ { j } } { \log p _ { j + 1 } ^ { 2 } } \sim \frac { 1 } { 2 } \, \text{li} \left ( p _ { k + 1 } ^ { 2 } \right ).$$
We can therefore restate (13) as
$$| \pi ( x ) - \text{li} ( x ) | < \sqrt { \frac { 1 } { 2 } \text{ li} ( x ) }.$$
Neglecting any constant coefficients, we state this conjecture more generally as
Conjecture 4. The error term in the prime number theorem satisfies
$$| \pi ( x ) - \text{li} ( x ) | = O \left ( \sqrt { \text{li} ( x ) } \right ).$$
We continue by plotting the error function | π x ( ) -li( x ) | together with the different upper bounds, as shown in Figure 12. Note that because Koch's criteria is much larger than the other bounds, we use a logarithmic scale on the y -axis. As expected, we find that the discrete estimate in (13), corresponding to the uncorrelated random model, lies on top of the sum of squares (14) (in the plot we include the lower order term for higher accuracy), while the error function | π x ( ) -li( x ) | is placed well below these bounds. The continuous estimate (15) lies close to the discrete estimate (13), but a bit higher, since the lower order terms are not accounted for here; nonetheless, as x →∞ , we expect their relative distance to decrease. Slightly above these curves we find the upper bound of the uncorrelated random model (12). And finally, we observe that Koch's criteria for the Riemann hypothesis is residing high above all the other curves, leaving plenty of room below it.
Essentially then, by considering the prime counting function π x ( ) as a sum over correlated random variables, we have arrived at a fundamental explanation of why the Riemann hypothesis must be correct, as illustrated by the different theoretical bounds displayed in Figure 12. A purely technical proof still awaits, but perhaps what we have presented here can serve as a stepping stone towards one.
## References
C Bays and R H Hudson. A new bound for the smallest x with π x ( ) > li x ( ). Math. Comput. , 69:1285-1296, 2000.
Figure 12. The error function | π x ( ) -li( x ) | and different upper bounds plotted at the values x = p 2 k +1 for every 100th value of k , 1 ≤ k ≤ 6 × 10 5 .
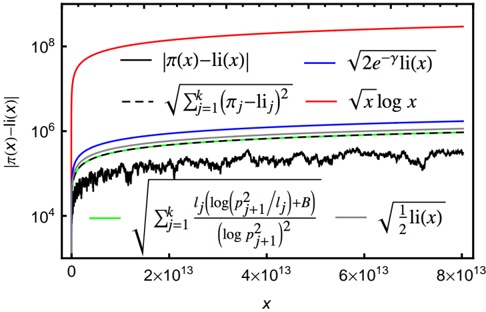
- H Cram´ er. On the Order of Magnitude of the Difference Between Consecutive Prime Numbers. Acta Arith. , 2:23-46, 1936.
- C J de la Vall´e-Poussin. Recherches analytiques sur la thorie des nombers premiers. e Ann. Soc. Sci. Bruxelles , 20:183-256, 1899.
- A Granville. Harald Cram´ er and the distribution of prime numbers. Scand. Actuarial J. , 1995(1):12-28, January 1995a.
- AGranville. Unexpected irregularities in the distribution of prime numbers. In Proceedings of the International Congress of Mathematicians (Z¨rich, 1994) u , volume 1,2, pages 388399. Basel, B¨rkhauser, 1995b. u
- M Hausman and H N Shapiro. On the mean square distribution of primitive roots of unity. Commun. Pure App. Math. , 26:539-547, 1973.
- D R Heath-Brown. The number of primes in a short interval. J. Reine Angew. Math. , 389:22-63, 1988.
- J W Littlewood. Distribution des Nombres Premiers. C. R. Acad. Sci. Paris , 158:18691872, 1914.
- H Maier. Primes in short intervals. Michigan Math. J. , 32(2):221-225, 1985.
- F Mertens. Ein Beitrag zur analytischen Zahlentheorie. J. Reine Angew. Math. , 78:46-62, 1874.
- H L Montgomery and K Soundararajan. Primes in short intervals. Commun. Math. Phys. , 252:589-617, 2004.
- M Rubinstein and P Sarnak. Chebyshev's bias. Exper. Math. , 3(3):173-197, 1994.
- K Soundararajan. The distribution of prime numbers. In Equidistribution in number theory, an introduction , pages 59-83. Springer, Dordrecht, 2007.
- H von Koch. Sur la distribution des nombres premiers. Acta Math. , 24(1):159-182, 1901.
- A Zaccagnini. Primes in almost all short intervals. Acta Arith. , 84(3):225-244, 1998.
E-mail address : [email protected]
Complex Systems Group, Department of Energy and Environment, Chalmers University of Technology, 41296 Gothenburg, Sweden | null | [
"Kolbjørn Tunstrøm"
] | 2014-08-02T21:22:22+00:00 | 2014-08-12T09:23:25+00:00 | [
"math.NT"
] | Primes in the intervals between primes squared | The set of short intervals between consecutive primes squared has the
pleasant---but seemingly unexploited---property that each interval
$s_k:=\{p_k^2, \dots,p_{k+1}^2-1\}$ is fully sieved by the $k$ first primes.
Here we take advantage of this essential characteristic and present evidence
for the conjecture that $\pi_k \sim |s_k|/ \log p_{k+1}^2$, where $\pi_k$ is
the number of primes in $s_k$; or even stricter, that $y=x^{1/2}$ is both
necessary and sufficient for the prime number theorem to be valid in intervals
of length $y$. In addition, we propose and substantiate that the prime counting
function $\pi(x)$ is best understood as a sum of correlated random variables
$\pi_k$. Under this assumption, we derive the theoretical variance of
$\pi(p_{k+1}^2)=\sum_{j=1}^k \pi_j$, from which we are led to conjecture that
$|\pi({x})-\textrm{li}(x)| =O(\sqrt{\textrm{li}(x)})$. Emerging from our
investigations is the view that the intervals between consecutive primes
squared hold the key to a furthered understanding of the distribution of
primes; as evidenced, this perspective also builds strong support in favour of
the Riemann hypothesis. |
1408.0421v1 | ## Height distribution of equipotential lines in a region confined by a rough conducting boundary
## C. P. de Castro
Instituto de F´ ısica, Universidade Federal da Bahia, Campus Universit´rio da a Federa¸ c˜o, Rua Bar˜o de Jeremoabo s/n, 40170-115, Salvador, BA, Brazil a a
E-mail:
[email protected]
## T. A. de Assis
Instituto de F´ ısica, Universidade Federal da Bahia, Campus Universit´rio da a Federa¸ c˜o, Rua Bar˜o de Jeremoabo s/n, 40170-115, Salvador, BA, Brazil a a
E-mail: [email protected]
## C. M. C. de Castilho
Instituto de F´ ısica, Universidade Federal da Bahia, Campus Universit´rio da a Federa¸ c˜o, Rua Bar˜o de Jeremoabo s/n, 40170-115, Salvador, BA, Brazil a a Instituto Nacional de Ciˆncia e Tecnologia em Energia e Ambiente, Universidade e Federal da Bahia Campus Universit´rio da Federa¸ c˜o, 40170-115, Salvador, BA, a a Brazil
E-mail:
[email protected]
## R. F. S. Andrade
Instituto de F´ ısica, Universidade Federal da Bahia, Campus Universit´rio da a Federa¸ c˜o, Rua Bar˜o de Jeremoabo s/n, 40170-115, Salvador, BA, Brazil a a
E-mail:
[email protected]
## Abstract.
This work considers the behavior of the height distributions of the equipotential lines in a region confined by two interfaces: a cathode with an irregular interface and a distant flat anode. Both boundaries, which are maintained at distinct and constant potential values, are assumed to be conductors. The morphology of the cathode interface results from the deposit of 2 × 10 4 monolayers that are produced using a single competitive growth model based on the rules of the Restricted Solid on Solid and Ballistic Deposition models, both of which belong to the Kadar-Parisi-Zhang (KPZ) universality class. At each time step, these rules are selected with probability p and q = 1 -p . For several irregular profiles that depend on p , a family of equipotential lines is evaluated. The lines are characterized by the skewness and kurtosis of the height distribution. The results indicate that the skewness of the equipotential line increases when they approach the flat anode, and this increase has a non-trivial convergence to a delta distribution that characterizes the equipotential line in a uniform electric field. The morphology of the equipotential lines is discussed; the discussion emphasizes their features for different ranges of p that correspond to positive, null and negative values of the coefficient of the non-linear term in the KPZ equation.
Height distribution of equipotential lines in a region confined by a rough conducting boundary 2
PACS numbers: 68.55.-a, 68.35.Ct, 81.15.Aa , 05.40.-a
## 1. Introduction
Growth phenomena in non-equilibrium conditions [1, 2] are an important subject of condensed matter physics. Many properties of specific devices depend on rough surfaces that are produced under such non-equilibrium conditions. Technological applications such as conducting-field emitter devices that operate in Ultra High Vacuum (UHV) conditions, require the control of several properties such as the surface morphology. It is well known that large values of the current intensity on field emitter devices are connected to extremely small values of the effective emitting area [3]. One method to increase the effective area of emission is to use surfaces with an ending fractal boundary with self-affine scale invariance instead of considering structurally regular tips. In fact, the connection between the morphology of irregular surfaces including sharp conducting tips and the field emission properties has been a subject of intense research [4, 5]. In a recent work [6], Cabrera et al. measured experimentally the current-voltage (I-V) of a tunnel junction consisting of a sharp electron emitting metallic tip at a variable distance ('∆') from a planar collector and emitting electrons using electric field assisted emission. Their results showed scale invariance of the tunnel junction with respect to changes in ∆ (from few mm to several nm ), which means that the physical laws governing the flow of current are invariant with respect the changes of the length scale ∆. However, this behavior fails when ∆ was only a few nanometers as showed in reference [7]. The reported scale invariance for a single tip can be regarded as a preliminary study of the more general problem of field emission by an irregular conducting interface that will be considered in this work.
In the statistical mechanics framework, macroscopic laws that emerge in surface growth can be explained at different spatial and temporal scales considering a theoretical microscopic description that involves simple probabilistic laws. An interesting related point is the possibility of modeling these systems so that in the large-scale limit (i.e., where the scale invariance arises), they do not depend on the corresponding details but only on symmetries and the corresponding conservation laws.
Previous theoretical works related to the emitting properties of rough surfaces [8, 9, 10, 11, 12] have studied the behavior of the electric potential in a region bounded by a rough conducting profile/surface and a smooth conducting line/plane, which is held to a constant voltage bias. In particular, the references [9, 10] analyzed the roughness exponent of the equipotential lines (surfaces) in 2 (3)-dimensional systems. However, to our knowledge, no previous work discussed the properties of equipotential lines/surfaces under the perspective of its height distribution properties.
In this work, we investigate the height distribution properties of a family of equipotential lines in a region that is confined by a rough profile, which is regarded as an electron-emitting cathode, and a flat anode which is placed sufficiently away from it. The profile results from a numerical simulation of the deposition and growth surface models, whereas the cathode and the anode are subject to an electric potential difference. Our results are mainly based on the model that was introduced by Silva and Moreira [13, 14], which is compared to those obtained for the simpler Family model [15] in some limiting cases. We emphasize two consequences of our results for the following aspects: the height distribution presents a more detailed characterization of the equipotential lines than that provided by the roughness exponents and such investigation of equipotential lines offers a much more reliable method to characterize the surface. For particular applications, our work can contribute to elucidate the image
distortions in probe microscopies such as Electrostatic Force Microscopy (EFM), where the knowledge of the electric field distribution along the tip probe is relevant to extract morphological information about the real irregular surface. This main conclusion from our work is particularly useful to study surfaces under the influence of non-linear mechanisms in the growth phase, where the surface width is not expressed as a power law with a single growth exponent for a large number of deposited monolayers.
This investigation is also motivated by the quoted experimental aspects related to the electronic properties of rough surfaces and the recent theoretical advances regarding the solution of the Kardar-Parisi-Zhang (KPZ) equation [16] in d = 1+1, where, in general, d = n + 1 indicates that a system composed by a n-dimensional substrate (here, 1-dimensional) and an extra dimension to where an important effect produced by the substrate is propagated.
The remainder of the paper is organized as follows. In Sec. 2, we describe the main features of the used models and emphasize the conditions under which they reproduce the typical features of the KPZ and Edwards-Wilkinson (EW) [17] growth dynamics. In Sec. 3, we describe the methodology to calculate and characterize of the equipotential lines. In Sec. 4, we discuss our results for the morphological properties of equipotential lines and analyze the corresponding behavior of the skewness and kurtosis with the electric potential. In Sec. 5, we summarize the results and present our conclusions.
## 2. Models
It is convenient to discuss the properties of the computational surface growth models that are used in this work with those of the KPZ equation in 1 + 1 dimensions
$$\partial _ { t } h ( x, t ) = \mu _ { 0 } + \nu \triangle h + \frac { \lambda } { 2 } ( \nabla h ) ^ { 2 } + \eta ( x, t ),$$
where h x, t ( ) represents the height of the profile in the y direction with respect to the line, h x, t ( = 0) = 0, that describes the flat profile at t = 0. Eq. 1 comprises several terms that consider the essential features of a stochastic surface growth. These features include irreversibility and locality, which enhance the surface roughness. In eq. 1 µ 0 corresponds to a constant driving force, ν is the diffusion coefficient of the deposited atoms on the surface, and η x, t ( ) is a white Gaussian noise that mimics the stochastic nature of the growth process. The non-linear term accounts for a considerable number of experimental results [18, 19] for the height distribution. Many of them cannot be described by a Gaussian function, which is the solution of the linear EW equation, which corresponds to setting λ = 0 in eq. 1.
The investigated model depends on a parameter p , which describes the probability that the deposited particle follows the Restricted Solid on Solid (RSOS) local rule, whereas q = 1 -p is the probability related to the Ballistic Deposition (BD) rule. Both RSOS and BD discrete models belong to the universality class that is defined by the KPZ equation but are characterized by negative and positive values of the parameter λ , respectively. Although the used model has not been proved to be equivalent to a KPZ equation, recent numerical investigations suggest that a change in the probability p changes the value of λ in a KPZ equation, which may be suitable to describe the competitive model [20, 21].
For almost all ranges of p , a growing profile first experiences a transient phase before attaining a stationary growth regime, where its width W scales with the
number of monolayers with the typical exponent β KPZ = 1 3 of the KPZ universality / class. For finite profiles, this regime is interrupted when W exponentially relaxes to a saturation regime and becomes constant. In this work, we analyze only rough interfaces in the growth regime, which corresponds to typical experimental conditions. In the first transient phase, depending on p , the growth exponent can reach values close to those typical of EW dynamics. Starting from p = 0, the length of the transient phase increases until a specific value p ∗ ≈ 0 83, where the EW typical value is always . valid. For p > p ∗ , the model reaches KPZ scaling again after a decreasing transient time [22]. Because the condition p = p ∗ is very special, we find it wise to compare the properties of the profiles and equipotential lines with those obtained when the cathode is represented by Family-model produced profile [15], which shows the EW properties notably clearly.
The interesting behavior of the competitive model makes it suitable to investigate how the equipotential lines change when p is selected to reproduce either KPZ or EW dynamics, and for a fixed value of p , how the magnitude of the non-linear terms affects the EW-KPZ crossover as a function of time [22], which is particularly important for experimental interests. Indeed, the competition between physical mechanisms is present in many real processes in thin-film science. Then, the actual study clearly advances on the previously one where single models were considered, and the roughness exponent of equipotential lines were evaluated without a perspective for height distribution properties.
The distribution of height fluctuations of the KPZ equation, for a flat initial condition, can be expressed by Gaussian Orthogonal Ensemble (GOE) Tracy-Widom (TW) distributions [23]. Therefore our results can be better appreciated by comparing the skewness ( S ) and kurtosis ( K ) of the equipotential height distributions with the typical TW values for the corresponding quantities. Both S and K depend on the average distance from the equipotential lines to the cathode and anode. Such dependence has intrinsic features according to whether p < p ∗ or p > p ∗ . A third distinct behavior is observed at p = p ∗ , when the profile falls into an EW universality class.
We emphasize again that our investigation opens the possibility of analyzing the effects on the behavior of equipotential lines of distinct surfaces with growth exponents near those that feature an EW class. This possibility is important because of the emergence of local growth exponents in the first transient growth phase, which is near the phase that characterizes the EW dynamics when p ≈ p ∗ . As shown in Sec. 4, our results indicate that the height distributions of equipotential lines for such transient patterns are clearly different from those obtained for an actual EW profile , no matter whether they are produced using the competitive model at p = p ∗ or the Family model.
## 3. Methodology: Determination and Characterization of Equipotential Lines
The current investigation starts by constructing the rough profile h x ( ), which acts as the cathode and results from one of the quoted deposition models. Here, x and y are integer numbers that represent distance measured in terms of some basic unit distance u , the precise size of which is not important in a theory of the kind under discussion. The growth process along the y direction of the considered 1 + 1 system (one-dimensional substrate + height, as mentioned in Sec.1) starts with a flat substrate
h x, t ( = 0) = 0, where x is an integer number, and x ∈ [1 , L ]. The column height h x ( ) is the y coordinate of the topmost adatom at position x . We have used profiles with lateral size up to L = 10 6 and up to T = 2 × 10 4 deposited monolayers (ML). For such parameter values, finite-size effects no longer influence the interpretation of our results and can be neglected. During the growth process, the number of monolayers is also referred to as the integration time t ; in this way, each time unit corresponds to the deposition of L particles. For the convenience of using a unified notation for all profiles and equipotential lines, let us switch from h x ( ) to h x, t ( ) = h p,φ ( x, t ), where we emphasize the dependence of h x ( ) on t . The subscript p stands for the probability of choosing the RSOS rule in the competitive model. Finally, the subscript φ is used to identify the constant value of the equipotential line. In this work, φ = 0 and φ = A correspond to the cathode and anode surfaces, respectively.
The flat anode, which is defined by h p,A , is placed at a distance 〈 d 〉 away from the cathode. 〈 d 〉 is measured by the number of vertical spacings between the average
$$\text{and cause} \, \underbrace { y } \, \text{in some or very one or even} \, \text{with} \, \text{with} \, \text{if} \, \text{the profile} \, \overline { h } _ { p, 0 } = \frac { 1 } { L } \sum _ { x = 1 } ^ { L } \left [ h _ { p, 0 } ( x, T ) \right ] \text{ and the flat anode, i.e:} \\ \langle d \rangle = h _ { p, A } - \overline { h } _ { p, 0 }.$$
$$\langle d \rangle = h _ { p, A } - \overline { h } _ { p, 0 }.$$
As previously indicated, h p, 0 is evaluated at t = T , except if explicitly indicated.
To compare the results for different rough profiles, we fixed the value of 〈 d 〉 . As a consequence h p,A , which is measured with respect to the substrate where the film is grown, changes with p . In this way, to select a proper and fixed value of 〈 d 〉 , such that for any value of p the anode is sufficiently away from the cathode, we first determined the value of p for which the roughness W (defined in eq. 4) attains its maximum, which is p = 0 when W ≈ 37 3. . Next, we identified the vertical coordinate of the highest peak h p =0 max for this value of p and set h 0 ,A = h p =0 max +∆, which result, using eq. 2, in:
$$\langle d \rangle = h _ { m a x } ^ { p = 0 } + \Delta - \overline { h } _ { 0, 0 },$$
where ∆ corresponds to the distance defined on the second paragraph of Sec.1. At this point, let us comment on the reasons to choose the particular value of ∆ used in this work. For ∆ >> h p =0 max , the results are expected to be largely independent of the precise value of ∆, but the computational work is largely increased. We have observed that, for all the rough profiles, the equipotential lines become flat and parallel to the x axis very rapidly after the value of y surpasses the highest peak. Therefore, we choose the value ∆ = 10, which corresponds to 〈 d 〉 = 198. We use this average distance for all p , because it is already sufficient large to have very smooth equipotential lines (with roughness exponent, α , near to unity [10]) that are observed at the flat anode. If we consider the basic unit distance u = 5 nm, we obtain ∆ = 50 nm for p = 0, and 〈 d 〉 /similarequal 1 µ m, which correspond to the typical scale used in the non-contact mode in atomic force microscopy (like EFM) where the electrostatic force is probed. Then, the results of this work can motivate experimental realizations in this regime.
Observed at this angle, the geometrical set up depends on two different scales (expressed by L and H ) along the horizontal and vertical directions. However, the rough profile has its own length scale in the vertical direction, which is the roughness
$$W _ { p, 0 } ( L, t ) = \left [ L ^ { - 1 } \sum _ { x = 1 } ^ { L } \left ( h _ { p, 0 } ( x, t ) - \overline { h } _ { p, 0 } ( t ) \right ) ^ { 2 } \right ] ^ { 1 / 2 }$$
Height distribution of equipotential lines in a region confined by a rough conducting boundary 7
$$\text{where} \, \overline { h } _ { p, 0 } ( t ) = L ^ { - 1 } \sum _ { \substack { x = 1 \\ x = 1 } } ^ { L } [ h _ { p, 0 } ( x, t ) ]. \\ \text{When} \, \ t \ = \ T, \ \text{the profiles that} \\ \text{are in the assumntotic growth response}$$
When t = T , the profiles that are grown using the competitive model are in the asymptotic growth regime ( W ∼ t β KPZ ) for p ∈ [0 , 0 75) . ⋃ (0 9 . , 1]. This regime corresponds to typical experimental conditions, in contrast to the exponential relaxation that is observed in steady-state (long-time) properties. For p ∈ [0 75 . , p ∗ ) ⋃ ( p , ∗ 0 90], the asymptotic growth KPZ regime has not yet been reached, . and the system is in the EW-KPZ crossover [24, 25]. For p = p ∗ ≈ 0 83, the system . is in the critical point and the corresponding growth regime is such that W ∼ t β EW , where β EW = 1 4 is the EW growth exponent. /
The next step is to compute the equipotential lines, h p,φ ( x ). Hence, we numerically solve Laplace's equation
$$\nabla ^ { 2 } \phi = 0,$$
/negationslash for the electric potential φ in the region between the two conductors, which are held at constant potential values of φ C and φ A for the rough cathode and the flat anode that is parallel to the x axis, respectively. The equation is solved using Liebmann's method and the appropriate Dirichlet conditions. The geometrical characterization of the equipotential lines is insensitive to the choice of φ C and φ A = φ C = 0. However, to directly compare some experimental devices, we choose the typical values φ C = 0 and φ A = 10 . 3
Then, the domain is divided into a two-dimensional grid, and the potential is iteratively calculated at each grid point for fixed boundary conditions at the rough cathode, which is described by the function h p, 0 ( x ) and the anode at h p,A . Periodic boundary conditions are imposed on the lateral borders. To determine the coordinates of the equipotential lines, we define the following difference,
$$D _ { \phi } = \frac { \phi _ { x, y + 1 } - \phi _ { x, y } } { \Delta y } > 0,$$
where x, y are integer numbers, and ∆ y =1 /lessmuch L . For any equipotential line h p,φ ( x ) where φ x,y < φ < φ x,y +1 , the corresponding coordinates are computed by evaluating h p,φ ( x ) = h x ( ) + dh φ , with
$$d h _ { \phi } = D _ { \phi } ^ { - 1 } [ \phi - \phi _ { x, y } ].$$
To illustrate the geometry of our problem, Figure 1 shows the substrate (or cathode) and a family of equipotential lines that were calculated using Eqs. (5), (6) and (7) for p = 0 (a) and p = 1 (b).
Next, we characterize the height distributions of the corresponding equipotential lines. In particular, the skewness, S φ ( ) = L -1 L =1 h p,φ ( x ) -h p,φ 3 /W 3 and kurtosis
$$\begin{array} { c } K ( \phi ) = \left [ L ^ { - 1 } \sum _ { x = 1 } ^ { L } \left ( h _ { p, \phi } ( x ) - \overline { h } _ { p, \phi } \right ) ^ { 4 } / W ^ { 4 } \right ] - 3 \, \text{are used throughout this work. Here, } W \\ \text{is a shorthand notation for } W _ { p, 0 } ( L, t ), \, \text{which is defined in } Eq. \, ( 4 ). \end{array}$$
∑ ( x )
## 4. Results and Discussion
Before discussing the results for the Family and the competitive models, we emphasize that in this last case, our results are based on a single profile for each distinct value of p . This usage is justified by the following facts: for each profile, our procedure amounts
/s32
/s32
Figure 1. Geometry of the problem for a substrate that was formed using an irregular profile, which was defined by (a) p=0 and (b) p=1. The equipotential lines h p,φ ( x ) for φ = 50 100 300 500 and 900 are shown. , , , The top panel shows the equipotential line h p, 900 ( x ) in a magnified scale.
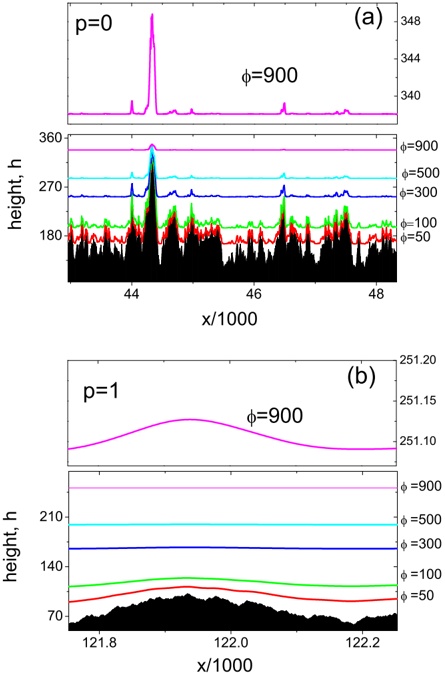
to considering an entire set of equipotential lines, which demands a considerably numerical effort; we have found that, in the interval p /lessorsimilar 0 75 and . p /greaterorsimilar 0 9, . at time T , the height distribution of the cathode and the resulting equipotential lines are almost insensitive to p , which can be observed by comparing the values of S and K . Therefore, our procedure is equivalent to replacing several realizations for one value of p with a set of independent realizations at slightly different values of this parameter. This method can also be justified when we move to the close neighborhood of p = p ∗ . Here, S and K vary smoothly even for the results that are produced using 1 profile realization.
The first illustrated aspect in Figure 2 refers to the relative positions of the profile with respect to the anode, which can be expressed by the ratio 〈 d 〉 W ( 〈 d 〉 = 198) as a function of p . In units of the roughness W , the curve in Figure 2 represents the height where the anode is maintained above the average height of the corresponding rough
/s32
/s32
Figure 2. Ratio 〈 d 〉 W as function of probability p . 〈 d 〉 is the average distance between the anode and the irregular cathode (see Eq.2) while W ≡ W p, 0 ( L, t ) is the roughness of the irregular cathode (see Eq.4). The results are presented considering 〈 d 〉 =198, and it is possible to observe that the global roughness decreases at the interval 0 < p < 0 83 and increases for . p > 0 83. . The global roughness is minimum at the point p = 0 83( . ≈ p ∗ )
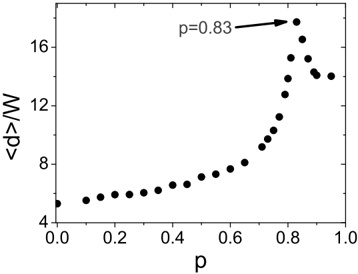
.
profile. It is possible to observe that the smoother rough profile occurs at p = 0 83, . i.e., near the critical point. Moreover, it is expected that in the infinite-size limit, the peak becomes more pronounced.
Next, we characterize the height distribution of the equipotential lines based on the behavior of S and K as a function of φ . These quantities vary in a wide interval, so that it becomes convenient to draw some of the graphs in the logarithmic scale. Because both quantities may assume negative values, we shift S and K by a fixed value 0 5, which leads to the functions . S ∗ ( φ ) = S φ ( ) + 0 5 and . K ∗ ( φ ) = K φ ( ) + 0 5 . illustrated in Figure 3. To better interpret the results, we draw the horizontal lines S ∗ = 0 5 and . K ∗ = 0 5, which delimitate the regions of negative and positive values . of S and K . The overall behavior of S ∗ ( φ ) is characterized by its monotonic increase with respect to the value of φ , as displayed in panel (a). This result is consistent with the convergence of S to a δ function, which is expected for a flat equipotential line. Furthermore, for p /lessorsimilar 0 75, the results in Figure 3 reveal that . S φ ( /lessorsimilar 10) ∼ 0 29 . (a) and K φ ( /lessorsimilar 10) ∼ 0 16. . Therefore, in the growth regime where the fluctuations in the surface height distribution is described using the GOE-TW distribution, the equipotential lines close to the profile follow a similar height distribution. The values of S ∗ and K ∗ do not significantly change until φ ≈ 10. However, for φ /greaterorsimilar 10, the derivative dS/dφ significantly grows, which indicates a non-uniform convergence to the δ function. This aspect can be observed by the analysis of Figure 3 (c), which shows the scaled height distribution P { [ h p,φ ( x, T ) -h T ( )] /W } of the equipotential lines for φ = 1 5 50 and 500. , , In fact, our results show that the large deviations of h T ( ) ≡ h p,φ ( T ) for each equipotential line determine the behavior of S . For p = 0 83, . the behavior of S φ ( ) has similar but less pronounced features, which indicates a weaker dependence of dS/dφ at this value of λ .
For p > 0 90, . S φ ( ) becomes negative for h p,φ ( x ) near the rough conducting profiles h p, 0 ( x ). In this region, the absolute value of S is also near that typical of a GOE TW
/s41
/s40
/s42
/s49/s48
/s49
/s83
/s48/s46/s49
/s48/s46/s49
/s49
/s49/s48
/s49/s48/s48
/s49/s48/s48/s48
/s32
/s40/s120/s44/s84/s41/s45/s104/s40/s84/s41/s93/s47/s87/s125
/s112/s44
/s80/s123/s91/s104
/s48/s46/s49
/s48/s46/s48/s49
/s49/s69/s45/s51
/s91/s104
/s112/s61/s48/s46/s50/s48
/s45/s52
/s45/s50
/s48
/s50
/s40/s99/s41
/s52
/s61/s49
/s61/s53/s48
/s61/s53
/s61/s53/s48/s48
/s54
/s112/s44
/s40/s120/s44/s84/s41/s45/s104/s40/s84/s41/s93/s47/s87
Figure 3. Shifted skewness S ∗ (a) and kurtosis K ∗ (b) for a family of equipotential lines h p,φ ( x ) as a function of φ for different values of p . Three distinct regimes can be identified: for λ > 0 ⇔ p = 0 0 20 and 0 50, , . . λ ≈ 0 ⇔ p = 0 83, and . λ < 0 ⇔ p = 0 90 0 95 and . , . p = 1 0. . The inset details the behavior in a region where the rough profile morphologies are blurred because of finite time effects. The horizontal dashed line defines S ∗ ( φ ) = 0 5 . ⇒ S φ ( ) = 0 and K ∗ ( φ ) = 0 5 . ⇒ K φ ( ) = 0. (c) Scaled height distributions for the equipotential lines considering φ = 1 5 50 and 500 for a rough conducting profile grown with , , p = 0 20. . The vertical dashed line defines [ h p,φ ( x, T ) -h T ( ) ] /W = 0.
distribution. The important aspect is that S φ ( ) crosses the null value at φ ≈ 15, which coincides with the point where K ∗ ( φ ) exhibits a minimum value (see Figure
/s32
/s48/s46/s49
/s32/s112/s61/s48/s46/s56/s51
/s49
/s49/s48
/s32
/s49/s48/s48
/s32
/s49/s48/s48/s48
/s49/s48
/s49
/s48/s46/s49
/s32
/s40/s97/s41
/s32
/s32
/s32
/s32
/s32
/s112/s61/s48
/s32
/s112/s61/s48/s46/s50/s48
/s32
/s112/s61/s48/s46/s53/s48
/s32
/s112/s61/s48/s46/s56/s51
/s32
/s112/s61/s48/s46/s57/s48
/s32
/s112/s61/s48/s46/s57/s53
/s32
/s112/s61/s49
/s32
/s32
/s32
/s32
Figure 4. Dependence of the local growth exponent β t ( )( ≡ d ln W/d ln t ) for p = 0 8 and . p = 0 825. . The dashed and solid lines indicate the exact EW and KPZ values.
3 (b)). This result indicates that, for conducting surfaces where λ < 0, there is an equipotential line near the surface that presents a symmetric asymptotic behavior at the tails of the height distributions. This result suggests that the height distribution of the equipotential lines changes in a different manner (for positive and negative fluctuations) with respect to that of the actual conducting profile.
In the insets of Figures 3 (a) and 3 (b), we focus on the behavior of S ∗ ( φ ) and K ∗ ( φ ) for p = 0 80, 0 81, 0 87 and 0 89, where for . . . . L and t = T , the system presents morphologic features in the crossover EW-KPZ. Interestingly, the results indicate that similar features do not appear for the values of S ∗ ( φ ) and K ∗ ( φ ). We notice no appreciable differences for t = T , in the values of S ∗ ( φ ) and K ∗ ( φ ) for p ∈ [0, 0.75] and p ∈ (0.75, 0.83) or p ∈ (0.83, 0.9) and p ∈ [0.9, 1]. Our results suggest that the potential variation does not feel the consequences of these finite time effects (KPZEW crossover), following the typical values for models that obey the KPZ statistics. The analysis of equipotential lines appears as a better estimator to uncover the actual geometric features of the growing system.
Let us proceed with a closer discussion of our results for p ∈ (0 75 . , 0 83) and . p ∈ (0 83 . , 0 9) at times where the EW features are believed to exist. . It is well known [24, 25] that in this region, the duration of the transient phase EW-KPZ increases quickly. More specifically, it is claimed that the time to reach the asymptotic limit (i.e. the KPZ class) scales with λ -4 [22]. In competitive models, λ grows at least linearly with the difference p -p ∗ [26], and the crossover time is expect to depend on p with ( p -p ∗ ) -4 . This result is corroborated by evaluating the local growth exponent β t ( ) ≡ d ln W/d ln t (or effective growth exponent) illustrated in Figure 4. Let us first recall that, for any growing profile, a single growth exponent β can only be defined if a strict linear dependence between log( W L,t ( )) and log( ) is observed. t Because this dependence is not verified for a large interval of values of t when 0 75 . /lessorsimilar p /lessorsimilar 0 9, we . analyze the behavior of β t ( ), which is computed by numerically evaluating the local slope of this curve. We consider two conditions for which linear features should prevail in the morphology of conducting rough profiles as p = 0 8 and . p = 0 825. . Figure 4
shows the time evolution of β t ( ), which indicates the presence of a minimum that hints the value of t where the profile should be closer to one grown using a pure EW dynamics (this minimum was estimated at the times t = 347 and t = 1652 for p = 0 8 . and p = 0 825, respectively). .
To show that the analysis of equipotential lines helps elucidating the fine differences between profiles, we also explicitly consider a rough profile that is grown using the well-know linear Family model. Then, we compare the resulting behavior of the corresponding equipotential lines with those for the competitive model for p = 0 83 . ≈ p ∗ and p ∼ 0 83 ( . p = 0 8 and . p = 0 825 at times . t = 347 and t = 1652, respectively). In Figure 5 (a) and (b), we observe a similar behavior for S ∗ and K ∗ , respectively, as a function of φ for the Family model and as p = 0 83 . ≈ p ∗ . This result is interesting because modeling the condition p = 0 83 provides vacancies in . the volume, but these features are not reflected in the behavior of the equipotential lines, as we can observe by directly comparing with the results obtained using the Family model. However, for p ∼ 0 83, we do not observe a similar behavior for the . equipotential lines, which now exhibit different morphologies from the previous ones. This result indicates that β t ( ) of the competitive model close to those that characterize the EW dynamic (minimum of β t ( )), is not a reliable measure to confirm the electrical features of the rough devices that are similar to that grown using the EW dynamics. Moreover, we observe that for p = 0 8, . S ∗ exhibits low values for far equipotential lines, compared with the other models ( S ∗ ∼ 1 for φ = 900). Finally we can observe that a notable convergence for the limit p → p ∗ and for values of t that correspond to the minimum of β t ( ), to the behavior of S ∗ and K ∗ of equipotential lines, which are associated to EW features. At these values of t , the misinterpretations of small differences in β t ( ) compared to β EW can significantly affect the design of electrical devices, where roughness is an important tool.
At this point, let us remark that the height distribution of the equipotential lines becomes a reliable criterion to analyze the morphological differences that are produced by distinct rough cathodes. Indeed, the previous results, which were only based on the local roughness exponent (see reference [9]), have not produced such clear-cut differences in the local roughness exponent of the equipotential lines that are produced by rough cathodes generated by a ballistic ( λ > 0) and random deposition with surface relaxation (RDSR) ( λ = 0). In the current work, such differences become clear when we consider the height distributions of equipotential lines for all three regimes, which are characterized by λ ( > 0 = 0 , , < 0) and p ( < p , ∗ = p , > p ∗ ∗ ).
Further morphological aspects of the profile have been revealed by our results. Let us define the set of peaks P p,φ in an equipotential line. A point x ∈ P p,φ , where its associated vertical coordinate is larger than those of its first lateral neighbors, i.e., h p,φ ( x -1 , T ) < h p,φ ( x, T ) > h p,φ ( x +1 , T ). In a similar way, let us define F + p,φ , the set of peaks of an equipotential line that are also characterized by positive fluctuations. A point x ∈ F + p,φ when x ∈ P p,φ and h p,φ ( x, T ) > h p,φ ( T ). Finally, let us define f + as the fraction of the number of points x ∈ P p,φ that also satisfy x ∈ F + p,φ . It is possible to show that a relation h 3 p,φ ( T ) ∼ ( h + p,φ ( T )) 3 f p should be valid, where h + p,φ ( T ) is the average value of h p,φ ( x, T ) that was restricted to points x ∈ F + p,φ .
This regime identifies the regions for equipotential lines where the small fluctuations quickly disappear and large fluctuations with lower wavelengths prevail when the electric potential grows. In fact, for equipotential lines that are far from the rough profile, we find that h + p,φ ( T ) >> h p,φ ( T ) (For example, the main peaks in
/s32
/s32
/s32
Figure 5. Shifted (a) skewness S ∗ and (b) kurtosis K ∗ of equipotential lines as functions of the electric potential for the rough profiles that were grown according to the Family model and the competitive model at p = 0 8, . p = 0 825 and . p = 0 83 . ≈ p ∗ . For p = 0 8 and . p = 0 825, . the rough cathode surfaces were considered at times when the β t ( ) is minimum (See Figure 4). This minimum was estimated when t = 347 and t = 1652 for p = 0 8 and . p = 0 825, respectively. . It is possible to observe the convergence to EW behavior in the p → p ∗ limit.
Figure 1 (a) for φ = 300 and 500). Therefore, the corresponding global roughness can be written as
$$W ^ { 3 } \sim f _ { + } ^ { - 3 / 2 } ( \overline { h } _ { p, \phi } ^ { + } ( T ) ) ^ { 3 }.$$
Additionally, S should depend on f + as:
$$S \sim f _ { + } ^ { - 1 / 2 },$$
so that S >> 1 for equipotential lines that are far from the cathode. This result is observed in Figure 3 (a), where S ∗ ∼ 10 as φ = 900 for p < 0 83. . It is worth noting that such behavior is observed in the large roughness limit ( p << 1) of the conducting profile. In Figure 6, we show that these theoretical predictions are confirmed by numerical calculations for the rough conducting profile that were generated for p = 0 1 . and 0 2. . It is clearly observed that in the regime where h + p,φ ( T ) >> h p,φ ( T ), the exponent of f P tends to -1 / 2. In this region, dS/dφ quickly grows for 300 < φ < 500 immediately before the inflexion point (see Figure 3 (a)).
/s32
/s32
/s32
Figure 6. Skewness as a function of the fraction of peaks for equipotential lines that are calculated in the region bounded by a rough profile and the flat line for p = 0 10 0 20 and 0 95. . , . . In the inset, we show a magnified region where the scale relation S ∼ f -1 / 2 P holds.
If we only consider the cases where the equipotential lines have S > 0, the predictions by Eqs. (8) and (9) fail for p = 0 95, i.e., in the case of smooth surfaces, . where the values of the skewness of distant equipotential lines are S ∗ ∼ 4 as p → 1 (For example, see Figure 3 (a) for p > 0 83). . In that case, dS/dφ grows slowly before the inflexion point mainly because of the variations of fluctuations, which are associated to longer wavelengths (See Figure 1 (b)). For p = 0 95, the region before . the inflection point corresponds to -3 0 . /lessorsimilar log 10 ( f P ) /lessorsimilar -2 5. . However, Figure 6 shows that, in this region, the absolute value of the exponent of f + is greater than 1 / 2. This result explains the rapid disappearance of roughness with lower wavelengths (which do not corresponds to pronounced peaks). Then, we encounter another regime with the absolute value of the exponent of f + less than 1 / 2, which explains the limit dS/dφ → 0 in Figure 3 (a) for p = 0 95. .
## 5. Summary and Conclusions
In this paper, we study the behavior of the height distributions of the equipotential lines and focus the behavior of their skewness and kurtosis. We used rough profiles that were grown following a competitive model with KPZ components, which show opposite signals of λ . Our results show a non-trivial behavior of S and K as a function of φ . We conducted our investigation for profiles with a lateral extension L = 10 6 grown until a time t = 2 × 10 , which considerably reduces (but not eliminate) the presence 4 of finite time effects for any p = 0.83.
/negationslash
For all KPZ profiles with λ > 0, an almost invariant behavior of S and K on φ was found. The same behavior occurs to families for which λ < 0, where S and K for the height distribution of the equipotential lines have an invariant behavior with respect to φ , although they are different from the previous families with λ > 0. For families with λ ≈ 0, our results show a third distinct behavior for S and K . These results suggest that the electric potential variation can identify the signal of λ ,
which provides the signal of the skewness of the rough conducting profile. However, the height distribution statistics of equipotential lines far from the conducting profile were shown as being notably different.
The particular behavior of S and K as a function of φ when p ≈ p ∗ motivated the comparison of these parameters with the corresponding ones that were obtained for substrates that are characterized by identical EW values of growth exponents. This comparison was conducted considering the equipotential lines of rough profiles: (i) which are defined by p = 0 83, (ii) for . the case of a Family model, and (iii) at the time in the competitive model (for p =0.80 and p =0.825) where the effective growth exponent nearly 1 / 4. The results show similar behaviors for p = 0 83 and the Family . model but clearly different results when the effective growth exponent is nearly 1 / 4. At these values of t , where thin-film technology arises, the misinterpretations of small differences in β t ( ) (if experimentally reliable) compared with β EW can significantly affect the design of the electrical devices.
Finally, our results can provide new insights for cases where the rough morphologies are an important tool to construct devices where electrical properties play a fundamental role. For example in the design of devices for the flexible stacked resistive random access memory (RRAM) applications the rough surface leads to a local electric field enhancement which accelerates the oxygen ion back-drift by the external positive bias (reset process) [27]. Radio-frequency absorption and electric field enhancements due to surface roughness are also subjects of theoretical research [28]. However, there are situations where high roughness is an important tool, such as when the deposited surface is combined with metallic and nonmetallic materials. In that case, understanding the evolution of the surface morphology and the electric potential distribution along an irregular shape during electrodeposition phenomena is greatly significant [29].
Moreover, in our viewpoint, the current study has called the attention to interesting characteristics that help one more systematically interpret of images from probe microscopies, such as the Electrostatic Force Microscopy. In that case, the tip must be maintained far enough from the rough surface to avoid unwanted short-range interactions (which may result from van der Waals forces) and close enough to not loose important morphologic information about the real profile.
## Acknowledgements
This work has the financial support of CNPq and FAPESB (Brazilian agencies). C. P. de Castro acknowledges specific support from Funda¸ c˜o CAPES. a
## References
- [1] Barabasi A L, Stanley H E 1995 Fractal Concepts in Surface Growth (Cambridge - Cambridge U. Press).
- [2] Krug J, 1997 Adv. Phys. 46 , 139.
- [3] Forbes R G, 2012 Nanotech. 23 , 095706.
- [4] Du J, Zhang Y, Deng S, Xu N, Xiao Z, She J, Wu Z and Cheng H, 2013 Carbon , 61 , 507.
- [5] de Assis T A, Benito R M, Losada J C, Andrade R F S, Miranda J G V, de Souza N C, de Castilho C M C, Mota F de b and Borondo F, 2013 J. Phys:. Cond. Matt. , 25 , 285106.
- [6] Cabrera H, Zanin D A, De Pietro L G, Michaels Th, Thalmann P, Ramsperger U, Vindigni A, Pescia D, Kyritsakis A, Xanthakis J P, Fuxiang Li and Abanov Ar, 2013 Phys. Rev. B , 87 , 115436.
- [7] Kyritsakis A, Xanthakis J P, Pescia D, 2014 Proc. R. Soc. A , 470 , 20130795.
Height distribution of equipotential lines in a region confined by a rough conducting boundary 16
- [8] Cajueiro D O, Sampaio V A de A, de Castilho C M C and Andrade R F S, 1999 J. Phys.: Condens. Matter , 18 , 4985.
- [9] Filho H de O D, de Castilho C M C, Miranda J G V and Andrade R F S, 2004 Physica A , 342 , 388.
- [10] de Assis T A, Mota F de B, Miranda J G V, Andrade R F S, Filho H de O D and de Castilho C M C, 2006 J. Phys.: Condens. Matter , 18 , 3393.
- [11] de Assis T A, Mota F de B, Miranda J G V, Andrade R F S and de Castilho C M C, 2007 J. Phys.: Condens. Matter , 19 , 476215.
- [12] Budaev V P and Yakovlev M, 2008 Plasma and Fusion Ressearch (R) , 3 , 1.
- [13] da Silva T J and Moreira J G, 2001 Phys. Rev. E , 63 , 041601.
- [14] da Silva T J and Moreira J G, 2002 Phys. Rev. E , 66 , 061604.
- [15] Family F, 1986 J. Phys. A , 19 , l441.
- [16] Kardar M, Parisi G and Zhang Y C, 1986 Phys. Rev. Lett. , 56 , 889.
- [17] Edwards S F and Wilkinson D R, 1982 Proc. R. Soc. London , 381 , 17.
- [18] Takeuchi K A, Sano M, Sasamoto T and Spohn H, 2011 Sci. Rep. , 1 , 34.
- [19] Yunker P J, Lohr M A, Still T, Borodin A, Durian D J and Yodh A G, 2013 Phys. Rev. Lett. , 110 , 035501.
- [20] Muraca D, Braunstein L A and Buceta R C, 2004 Phys. Rev. E , 69 , 065103(R).
- [21] Silveira F A and Aar˜o Reis F D A, 2012 a Phys. Rev. E , 85 , 011601.
- [22] Oliveira T J, Dechoum K, Redniz J A and Aar˜o Reis F D A, 2006 a Phys. Rev. E , 74 , 011604.
- [23] Sasamoto T and Spohn H, 2010 Phys. Rev. Lett. , 104 , 230602.
- [24] de Assis T A, de Castro C P, de Brito Mota F, de Castilho C M C and Andrate R F S, 2012 Phys. Rev. E , 86 051607.
- [25] Oliveira T J , 2013 Phys. Rev. E 87 , 034401.
- [26] Silveira F A and Aar˜o Reis F D A, 2012 a Phys. Rev. E , 85 , 011601.
- [27] Hu Young Jeong, Yong In Kim, Lee J Y and Sung-Yool Choi, 2010 Nanotech. , 21 , 115203.
- [28] Zhang P, Lau Y Y and Gilgenbach R M, 2009 J. Appl. Phys. 105 , 114908.
- [29] Gamburg Y D and Zangari G 2011 Theory and Practice of Metal Electrodeposition (Springer, New York, USA). | 10.1088/0953-8984/26/44/445007 | [
"C. P. de Castro",
"T. A. de Assis",
"C. M. C. de Castilho",
"R. F. S. Andrade"
] | 2014-08-02T21:24:17+00:00 | 2014-08-02T21:24:17+00:00 | [
"physics.comp-ph"
] | Height distribution of equipotential lines in a region confined by a rough conducting boundary | This work considers the behavior of the height distributions of the
equipotential lines in a region confined by two interfaces: a cathode with an
irregular interface and a distant flat anode. Both boundaries, which are
maintained at distinct and constant potential values, are assumed to be
conductors. The morphology of the cathode interface results from the deposit of
$2 \times 10^{4}$ monolayers that are produced using a single competitive
growth model based on the rules of the Restricted Solid on Solid and Ballistic
Deposition models, both of which belong to the Kadar-Parisi-Zhang (KPZ)
universality class. At each time step, these rules are selected with
probability $p$ and $q = 1 - p$. For several irregular profiles that depend on
$p$, a family of equipotential lines is evaluated. The lines are characterized
by the skewness and kurtosis of the height distribution. The results indicate
that the skewness of the equipotential line increases when they approach the
flat anode, and this increase has a non-trivial convergence to a delta
distribution that characterizes the equipotential line in a uniform electric
field. The morphology of the equipotential lines is discussed; the discussion
emphasizes their features for different ranges of $p$ that correspond to
positive, null and negative values of the coefficient of the non-linear term in
the KPZ equation. |
1408.0422v2 | ## EXISTENCE AND UNIQUENESS OF GLOBAL SOLUTIONS TO FULLY NONLINEAR FIRST ORDER ELLIPTIC SYSTEMS
## NIKOS KATZOURAKIS
Abstract. Let F : R n × R N × n → R N be a Carath´ eodory map. In this paper we consider the problem of existence and uniqueness of weakly differentiable global strong a.e. solutions u : R n -→ R N to the fully nonlinear PDE system R n
$$F ( \cdot, D u ) \, = \, f, \text{ a.e. on } \mathbb { R } ^ { n },$$
when f ∈ L 2 ( R n N ) . By introducing an appropriate notion of ellipticity, we prove existence of solution to (1) in a tailored Sobolev 'energy' space (known also as the J.L. Lions space) and a uniqueness a priori estimate. The proof is based on the solvability of the linearised problem by Fourier transform methods and a 'perturbation device' which allows to use of Campanato's notion of near operators, an idea developed for the 2nd order case.
## 1. Introduction
Let n, N ≥ 2 and let also
$$F \ \colon \ \mathbb { R } ^ { n } \times \mathbb { R } ^ { N \times n } \longrightarrow \mathbb { R } ^ { N },$$
be a Carath´ eodory map, namely
↦
↦
$$\begin{cases} \ x \mapsto F ( x, Q ) \text{ is measurable, for every } Q \in \mathbb { R } ^ { N \times n }, \\ Q \mapsto F ( x, Q ) \text{ is continuous, for almost every } x \in \mathbb { R } ^ { n }. \end{cases}$$
In this paper we consider the problem of existence and uniqueness of global strong a.e. solutions u : R n -→ R N to the fully nonlinear PDE system
$$F ( \cdot, D u ) \, = \, f, \text{ \ a.e. on } \mathbb { R } ^ { n }.$$
To the best of our knowledge, the above problem has not been considered before in this generality. We will assume that our right hand side f is an L 2 vector function, i.e. f ∈ L 2 ( R n N ) . By introducing an appropriate ellipticity assumption on F , we will prove unique solvability of (1.1) for a weakly differentiable map u , together with a strong a priori estimate. In the above, Du x ( ) ∈ R N × n denotes the gradient matrix of of u = u e α α , namely Du = ( D u i a ) e α ⊗ e i and D i = ∂/∂x i . Here and in the sequel we employ the summation convention when i, j, k, ... run in { 1 , ..., n } and α, β, γ, ... run in { 1 , ..., N } . Evidently, { e i } , { e α } and { e α ⊗ e i } denote the standard bases of R n , R N and R N × n respectively.
2010 Mathematics Subject Classification. Primary 35J46, 35J47, 35J60; Secondary 35D30, 32A50, 32W50.
Key words and phrases. Cauchy-Riemann equations, fully nonlinear systems, elliptic first order systems, Calculus of Variations, Campanato's near operators, Cordes' condition, Compensated compactness, Baire Category method, Convex Integration.
The simplest case of (1.1) is when F is independent of x and linear in P , that is when
$$F ( x, P ) \, = \, \Lambda _ { \alpha \beta j } P _ { \beta j } e ^ { \alpha },$$
for a linear operator A : R N × n -→ R N . Then (1.1) becomes
$$\mathbf A _ { \alpha \beta j } D _ { j } u _ { \beta } \, = \, f _ { \alpha },$$
which we will write compactly as
$$A \, \colon D u \, = \, f.$$
The appropriate notion of ellipticity in this case is that the nullspace of the operator A contains no (non-trivial) rank-one lines. This means glyph[negationslash]
$$| \mathbf A \, \colon \eta \otimes a | \, > \, 0, \ \eta \neq 0, \ a \neq 0.$$
glyph[negationslash]
The prototypical example is the operator A : R 2 × 2 -→ R 2 given by
$$\mathbf A \, = \, \left [ \begin{array} { c c c } 1 & 0 & 0 & 1 \\ 0 & - 1 & 1 & 0 \end{array} \right ]$$
which corresponds to the Cauchy-Riemann differential operator. Linear elliptic first order systems with constant coefficients have been extensively studied in several contexts, since they play an important role in Complex and Harmonic Analysis (see e.g. Buchanan-Gilbert [BG], Begehr-Wen [BW]), Compensated Compactness and Differential Inclusions (Di Perna [DP], M¨ller [Mu]), regularity theory of PDE u (see chapter 7 in [Mo] for Morrey's exposition of the Agmon-Douglis-Nirenberg theory) and Geometric Analysis with differential forms (Csat´-Dacorogna-Kneuss o [CDK]).
The fully nonlinear case of (1.1) is much less studied. When F is coercive instead of elliptic , the problem is better understood. By using the analytic Baire category method of the Dacorogna-Marcellini [DM] which is the 'geometric counterpart' of Gromov's Convex Integration, one can prove that, under certain structural and compatibility assumptions, the Dirichlet problem
$$\begin{cases} \ F ( \cdot, D u ) & = \ f, \quad \text{in } \Omega, \\ u & = g, \quad \text{on } \partial \Omega, \end{cases}$$
has infinitely many strong a.e. solutions in the Lipschitz space, for Ω ⊆ R n and g Lipschitz. However, ellipticity and coercivity of F are, roughly speaking, mutually exclusive. In particular, the Dirichlet problem (1.4) is not well posed when F is either linear or elliptic. For example, the equation u ′ -1 = 0 has no Lipschitz solution on (0 , 1) for which u (0) = u (1) = 0.
Herein we focus on the general system (1.1) and we consider the problem of finding an ellipticity condition which guarantees existence as well as uniqueness of a strong a.e. weakly differentiable solution. In order to avoid the compatibility difficulties which arise in the case of the Dirichlet problem on bounded domains, we will consider the case of global solutions on the whole space. We will also restrict attention to the case of f in L 2 ( R n N ) and n ≥ 3. This is mostly for technical simplicity and since the case of n = 2 has been studied much more extensively. We will prove unique solvability of (1.1) in the 'energy' Sobolev space 1
$$( 1. 5 ) \quad \ \ W ^ { 1 ; 2 ^ { * }, 2 } ( \mathbb { R } ^ { n } ) ^ { N } \ \coloneqq \left \{ u \in L ^ { 2 ^ { * } } ( \mathbb { R } ^ { n } ) ^ { N } \ | \ D u \in L ^ { 2 } ( \mathbb { R } ^ { n } ) ^ { N n } \right \}$$
1 We would like to thank the referee of this paper who pointed out to us that (1.5) is called in the literature the 'J.L. Lions space'.
where n ≥ 3 and 2 ∗ is the conjugate Sobolev exponent:
$$2 ^ { * } \, = \, \frac { 2 n } { n - 2 }.$$
The technique we follow for (1.1) is based on the solvability of the linear constant coefficient equation (1.2) via the Fourier transform. In Section 2 we prove existence and uniqueness of a strong global solution u ∈ W 1;2 ∗ , 2 ( R n N ) to (1.2), for which we also have an explicit integral representation formula for the solution (Theorem 2). The essential idea in order to go from the linear to the fully nonlinear case is a perturbation device inspired from the work of Campanato [C0]-[C5] on the second order case of
$$F ( \cdot, D ^ { 2 } u ) \, = \, f.$$
Campanato introduced a notion of strict ellipticity which requires that the nonlinear operator F u [ ] := F ( · , D 2 u ) is 'near' the Laplacian ∆ u (see also Tarsia [Ta1]-[Ta3]). This implies unique solvability of (1.6) in H 2 ∩ H 1 0 , by the unique solvability of the Poisson equation ∆ u = f in H 2 ∩ H 1 0 and a fixed point argument. This notion can be also seen equivalently as a sort of strict pseudo-monotonicity, related to the Cordes condition (see Cordes [Co1, Co2] and also Talenti [T] and Landis [L]). That such a stringent notion is required in order to guarantee well posedness is evident by counter-examples which are valid even in the linear scalar case of the second order elliptic equation
$$A _ { i j } ( x ) D _ { i j } ^ { 2 } u ( x ) \, = \, f ( x )$$
with A measurable and A ≥ λI for λ > 0 (see e.g. Pucci [P], and also GiaquintaMartinazzi [GM]). We also note that Campanato's notion has been weakened by Buica-Domokos in [BD] to a notion of 'weak nearness', which still retains most of the features of (strong) nearness. In the same paper, the authors also use an idea similar to ours, namely a fully nonlinear operator being 'near' a general linear operator, but they implement this idea in the scalar case of 2nd order elliptic equations.
In Section 3 we introduce a notion of strict ellipticity which is inspired by Campanato's ellipticity, the latter being referred to as 'Condition A' in the literature (Definition 4). Loosely speaking, our notion requires that F is 'not too far' form a constant coefficient operator A. We also introduce a related notion which we call pseudo-monotonicity and examine their connection (Lemma 8). Finally, we prove existence and uniqueness of solutions to (1.1) when F is elliptic (Theorem 9). This is based on the solvability of the linear system, our ellipticity assumption and the fixed point theorem in the guises of Campanato's result of 'near operators' taken from [C0], which we recall herein for the convenience of the reader (Theorem 11). A byproduct of our method is a strong uniqueness estimate in the form of a comparison principle for the distance of any solutions in terms of the distance of the right hand sides of the equations (Corollary 10).
## 2. Existence-uniqueness-representation in the linear case
In this section we prove existence and uniqueness of solutions to the linear constant coefficient system
$$\text{A} \, \colon D u \, = \, f, \text{ a.e. on } \mathbb { R } ^ { n },$$
when A : R N × n -→ R N is elliptic, that is the nullspace does not contain lines spanned by rank-one directions. This means that all rank-one lines are transversal to the nullspace:
glyph[negationslash]
$$\text{A} \, \colon \eta \otimes a \, \neq \, 0, \ \text{when } \, \eta \neq 0, \ a \neq 0.$$
glyph[negationslash]
glyph[negationslash]
By compactness of the torus S N -1 × S n -1 ⊆ R N × R n , this is equivalent to
$$| A \, \colon \eta \otimes a | \, \geq \, \nu \, | \eta | | a |, \ \eta \in \mathbb { R } ^ { N }, \, a \in \mathbb { R } ^ { n },$$
for some ν > 0, which can be taken to be the ellipticity constant of A :
$$\nu ( A ) \ \coloneqq \ \min _ { | \eta | = | a | = 1 } | A \, \colon \eta \otimes a |.$$
It is easy to see that (2.1) is equivalent to
$$\min _ { a \in \mathbb { S } ^ { n - 1 } } \left | \det ( A a ) \right | > 0,$$
where A a is the N × N matrix
$$\Lambda a \, \coloneqq \, ( \Lambda _ { \alpha \beta j } \, a _ { j } ) \, e ^ { \alpha } \otimes e ^ { \beta }.$$
Example 1. An example of A : R 2 × 2 -→ R 2 satisfying the above type of ellipticity is
$$A \, = \, \left [ \begin{array} { c c } \kappa &$$
where κ, λ, µ, ν > 0 . A higher dimensional example of elliptic A : R 4 × 3 -→ R 4 is given by
$$A = \left [ \begin{array} { c c c c c c c c c } 1$$
and corresponds to the electron equation of Dirac in the case where is no external force, the mass is zero and we are in the static case without time dependence. For a pair of complex functions φ, ψ : R 3 -→ C , the relevant system reads
$$\begin{cases} \, ( D _ { 1 } \, - \, i D _ {$$
and in real coordinates becomes
$$o r u n u a v e s & \ o c o m e s \\ \begin{cases$$
In order to see that the tensor A is indeed is elliptic, we have that for any a = ( a , a 1 2 , a 3 ) glyph[latticetop] ∈ R 3 with a 2 1 + a 2 2 + a 2 3 = 1 , a quick calculation gives
$$\begin{array} {$$
and the rows (or the columns) of the 4 × 4 matrix A a form an orthomornal frame of vectors in R 4 . Hence, A a is an orthogonal matrix in O (4 , R ) , from which it follows that det( A a ) = ± 1 .
The next theorem is the main result of this section. Before the statement and for the reader's convenience, we note that the elementary ideas of Fourier Analysis we use herein can be found e.g. in Folland [F] and we follow the same notations as therein. In particular, for the Fourier transform and its inverse we use the conventions
$$\widehat { u } ( z ) = \int _ { \mathbb { R } ^ { n } } u ( x ) e ^ { - 2 \pi i x \cdot z } d x \, \ \stackrel { \vee } { u } ( x ) = \int _ { \mathbb { R } ^ { n } } u ( z ) e ^ { 2 \pi i x \cdot z } d z.$$
glyph[negationslash]
Here ' ' is the inner product of · R n . With 'sgn' we denote the sign function on R n , that is sgn( x ) = x/ x | | when x = 0 and sgn(0) = 0. With 'cof( X )' we denote the cofactor matrix of X ∈ R N × N and we will tacitly use the identity
$$X \text{cof} ( X ) ^ { \top } \ = \ \text{cof} ( X ) ^ { \top } X \ = \ \text{det} ( X ) I.$$
Theorem 2 (Existence-Uniqueness-Representation) . Let n ≥ 3 , N ≥ 2 and A : R N × n -→ R N a constant map satisfying (2.1) . Let also f ∈ L 2 ( R n N ) . Then, the problem
$$\text{A} \, \colon D u \, = \, f, \ \ a. e. \ o n \, \mathbb { R } ^ { n },$$
has a unique solution u in the space W 1;2 ∗ , 2 ( R n N ) (see (1.5) ), which also satisfies the estimate
$$\| u \| _ { L ^ { 2 ^ { * } } ( \mathbb { R } ^ { n } ) } \, + \, \| D u \| _ { L ^ { 2 } ( \mathbb { R } ^ { n } ) } \, \leq \, C \| f \| _ { L ^ { 2 } ( \mathbb { R } ^ { n } ) }$$
for some C > 0 depending only on A .
Moreover, we have the following representation formula for the solution:
$$u \, = \, - \frac { 1 } { 2 \pi i } \lim _ { m \to \infty } \left \{ \widehat { h _ { m } } \, * \left [ \frac { \text{cof} \, ( \text{As} g n ) ^ { \top } \vee } { \det ( \text{As} g n ) } f \right ] ^ { \wedge } \right \}.$$
In (2.5) ( h m ) ∞ 1 ⊆ S ( R n ) is any sequence of even functions in the Schwartz class for which
$$0 \, \leq \, h _ { m } ( x ) \, \leq \, \frac { 1 } { | x | } \quad a n d \quad h _ { m } ( x ) \longrightarrow \frac { 1 } { | x | }, \text{ for } a. e. \ x \in \mathbb { R } ^ { n }, \ \ a s \ m \to \infty.$$
The limit in (2.5) is meant in the weak L 2 ∗ sense as well as a.e. on R n , and u is independent of the choice of sequence ( h m ) ∞ 1 .
Remark 3. The solution u above is vectorial but real , although the formula (2.5) involves complex quantities. Moreover, ' L 2 ∗ ' above means ' L p for p = 2 ', not ∗ '( L 2 ) ∗ '.
Formal derivation of the representation formula. Before giving the rigorous proof of Theorem 2, it is very instructive to derive formally a representation formula for the solution of A : Du = f . By applying the Fourier transform to the PDE, we have
$$\text{A} \, \colon \widehat { D } u \, = \, \widehat { f }, \text{ a.e. on } \mathbb { R } ^ { n },$$
and hence,
$$2 \pi i \, \text{A} \, \colon \widehat { u } ( z ) \otimes z \, = \, \widehat { f } ( z ), \text{ \ for a.e. } z \in \mathbb { R } ^ { n }.$$
For clarity, let us also rewrite this equation in index form:
$$( \mathbf A _ { \alpha \beta j } z _ { j } ) \, \widehat { u _ { \beta } } ( z ) \, = \, \frac { 1 } { 2 \pi i } \widehat { f _ { \alpha } } ( z ).$$
Hence, we have
$$\left ( \mathbf A \frac { z } { | z | } \right ) \widehat { u } ( z ) \, = \, \frac { 1 } { 2 \pi i | z | } \widehat { f } ( z )$$
and by using the identity
$$\left ( A s g n ( z ) \right ) ^ { - 1 } = \frac { \text{cof} \left ( A s g n ( z ) \right ) ^ { \top } } { \det \left ( A s g n ( z ) \right ) }$$
we get
$$\widehat { u } ( z ) \, & = \, \frac { 1 } { 2 \pi i | z | } \left ( \text{Asgn} ( z ) \right ) ^ { - 1 } \widehat { f } ( z ) \\ & = \, \frac { 1 } { 2 \pi i | z | } \frac { \text{cof} \left ( \text{Asgn} ( z ) \right ) ^ { \top } } { \det \left ( \text{Asgn} ( z ) \right ) } \widehat { f } ( z ).$$
$$= \frac { 1 } { 2 \pi i | z | } \frac { \tilde { \ } o f \left ( A s g n ( z ) \right ) ^ { \top } } { \det \left ( A s g n ( z ) \right ) } \widehat { f } ( z ).$$
By the Fourier inversion formula and the identity f ∨ ( z ) = ̂ f ( -z ) = ( f ( -· ) ) ∧ , we obtain
$$\vee$$
$$\begin{smallmatrix} \\ \end{smallmatrix}$$
$$u & \, = \, \frac { 1 } { 2 \pi i } \left \{ \frac { 1 } { | \cdot | } \frac { \text{cof} ( \text{Asgn} ) ^ { \top } } { \det \left ( \text{Asgn} \right ) } \widehat { f } \right \} ^ { \vee } \\ & \, = \, - \frac { 1 } { 2 \pi i } \left \{ \frac { 1 } { | \cdot | } \frac { \text{cof} ( \text{Asgn} ) ^ { \top } } { \det \left ( \text{Asgn} \right ) } \widehat { f } \right \} ^ { \wedge }.$$
Hence, we get the formula
$$\hat { \nu } \quad \ \ \ u \, = \, - \frac { 1 } { 2 \pi i } \left \{ \widehat { \frac { 1 } { | \cdot | } } \, \ast \left [ \frac { \, \text{cof} \, \text{Asgn} \, } ^ { \top } \, \vee } { \det \, \text{Asgn} \, } \hat { f } \right ] ^ { \wedge } \right \}.$$
Formula (2.7) is 'the same' as (2.5), if we are able to pass the limit inside the integrals of the convolution and the Fourier transform. However, this may not be possible since h = 1 / | · | is only in the weak L 1 space L 1 , ∞ ( R n ). Convergence needs to be rigorously justified, and this is the content of the proof of Theorem 2. Further, by using the next identity (which follows by the properties of the Riesz potential)
$$\left ( \frac { 1 } { | \cdot | } \right ) ^ { \wedge } = \gamma _ { n - 1 } \frac { 1 } { | \cdot | ^ { n - 1 } }$$
where the constant γ α equals
$$\gamma _ { \alpha } \, = \, \frac { 2 ^ { \alpha } \, \pi ^ { n / 2 } \, \Gamma ( \alpha / 2 ) } { \Gamma ( n / 2 - \alpha / 2 ) }, \ \ 0 \, < \, \alpha \, < \, n,$$
we may rewrite (2.7) as
$$\hat { \Phi } _ { 0 } \quad \ \ u = - \frac { \gamma _ { n - 1 } } { 2 \pi i | \cdot | ^ { n - 1 } } \ast \left [ \frac { \text{cof} ( \text{Asgn} ) ^ { \top } \vee } { \det \left ( \text{Asgn} \right ) } \hat { f } \right ] ^ { \wedge }.$$
Formula (2.8) is the formal interpretation of the expression (2.5), which we will now establish rigorously.
Proof of Theorem 2. We begin by assuming that a solution of A : Du = f exists, and we derive the a priori estimate. By applying the Fourier transform and arguing as above, we have
$$2 \pi i \, \mathbf A \, \colon \widehat { u } ( z ) \otimes z \, = \, \dot { f } ( z ),$$
for a.e. z ∈ R n . Let ν ≡ ν (A) be the ellipticity constant of A (see (2.2)). We then get
$$\begin{array} { c c c } 2 \pi \nu \left | \widehat { u } ( z ) \right | \left | z \right | & \leq & 2 \pi \left | \mathbf A \, \colon \widehat { u } ( z ) \otimes z \right | = & \left | \widehat { f } ( z ) \right | \end{array}$$
and hence we have
$$\left | \widehat { D } u ( z ) \right | ^ { 2 } \, & = \, \left | 2 \pi i \, \widehat { u } ( z ) \otimes z \right | ^ { 2 } \\ & = \, \left | \widehat { u } ( z ) \right | ^ { 2 } | 2 \pi z | ^ { 2 } \\ & \leq \, \frac { 1 } { \nu ^ { 2 } } \left | \widehat { f } ( z ) \right | ^ { 2 }, \\ \text{orat} \, \text{the above inequality on the w}$$
for a.e. z ∈ R n . By integrating the above inequality on the whole space, Plancherel's theorem gives
$$\| D u \| _ { L ^ { 2 } ( \mathbb { R } ^ { n } ) } \leq \frac { 1 } { \nu } \| f \| _ { L ^ { 2 } ( \mathbb { R } ^ { n } ) }.$$
Further, since n ≥ 3, the Gagliardo-Nirenberg-Sobolev inequality gives that there exists C = C n,N ( ) > 0 such that
$$\| u \| _ { L ^ { 2 ^ { * } } ( \mathbb { R } ^ { n } ) } \, \leq \, C \| D u \| _ { L ^ { 2 } ( \mathbb { R } ^ { n } ) } \, \leq \, \frac { C } { \nu } \| f \| _ { L ^ { 2 } ( \mathbb { R } ^ { n } ) }.$$
Hence, (2.9) implies (2.4). Now we prove existence of u and the desired formula (2.7). Let ( h m ) ∞ 1 ⊆ S ( R n ) be any sequence of even functions in the Schwartz class for which
$$( 2. 1 0 ) \quad 0 \leq h _ { m } ( x ) \leq \frac { 1 } { | x | } \text{ and } h _ { m } ( x ) \longrightarrow \frac { 1 } { | x | }, \text{ for a.e. } x \in \mathbb { R } ^ { n }, \text{ as } m \to \infty.$$
We set:
$$u _ { m } \, \coloneqq \, - \frac { 1 } { 2 \pi i } \widehat { h _ { m } } \, * \left [ \frac { \, \text{cof} \, ( \text{Asgn} ) ^ { \top } } { \, \det ( \text{Asgn} ) } \, \overset { \vee } { f } \right ] ^ { \wedge }.$$
We will now show that the function u m of (2.11) satisfies
$$u _ { m } \, \in \, L ^ { 2 } ( \mathbb { R } ^ { n } ) ^ { N } \cap L ^ { \infty } ( \mathbb { R } ^ { n } ) ^ { N }.$$
Indeed, observe first that since h m ∈ S ( R n ) and the Fourier transform is bijective on the Schwartz class, we have
$$\widehat { h _ { m } } \, \in \, \mathcal { S } ( \mathbb { R } ^ { n } ) \, \subseteq \, L ^ { 1 } ( \mathbb { R } ^ { n } ) \cap L ^ { 2 } ( \mathbb { R } ^ { n } ).$$
Let now p ∈ [1 , 2] and define r by
$$r \ \coloneqq \ \frac { 2 p } { 2 - p }.$$
Then, we have
$$1 \, + \, \frac { 1 } { r } \, = \, \frac { 1 } { p } \, + \, \frac { 1 } { 2 }, \quad 1 \leq p \leq 2,$$
and by Young's inequality and Plancherel's theorem, we obtain
$$\i u y \, \text{using} \, \text{using} \, \text{and} \, \text{alternate} \, \text{s} \, \text{even} \,, \, \text{we odd} \, \\ \| u _ { m } \| _ { L ^ { r } ( \mathbb { R } ^ { n } ) } \ & \leq \ \frac { 1 } { 2 \pi } \| \widehat { h _ { m } } \| _ { L ^ { p } ( \mathbb { R } ^ { n } ) } \left \| \left [ \frac { \text{cof} \, ( \text{Asgn} ) ^ { \top } } { \text{det} ( \text{Asgn} ) } \, \dot { f } \right ] ^ { \cap } \right \| _ { L ^ { 2 } ( \mathbb { R } ^ { n } ) } \\ & \leq \ \frac { 1 } { 2 \pi } \| \widehat { h _ { m } } \| _ { L ^ { p } ( \mathbb { R } ^ { n } ) } \left \| \frac { \text{cof} \, ( \text{Asgn} ) ^ { \top } } { \text{det} ( \text{Asgn} ) } \, \dot { f } \right \| _ { L ^ { 2 } ( \mathbb { R } ^ { n } ) }.$$
We now recall that the estimate (2.3) implies
$$\underset { z \in \mathbb { R } ^ { n } } { \text{ess inf} } \left | \det ( \text{Asgn} ( z ) ) \right | > 0$$
and hence we get
$$\| u _ { m } \| _ { L ^ { r } ( \mathbb { R } ^ { n } ) } \ & \leq \ \frac { 1 } { 2 \pi } \| \widehat { h _ { m } } \| _ { L ^ { p } ( \mathbb { R } ^ { n } ) } \left \| \frac { \text{cof} \left ( \text{Asgn} \right ) } { \det ( \text{Asgn} ) } \right \| _ { L ^ { \infty } ( \mathbb { R } ^ { n } ) } \| ^ { \vee } _ { \ } f \| _ { L ^ { 2 } ( \mathbb { R } ^ { n } ) } \\ & \leq \ C \| \widehat { h _ { m } } \| _ { L ^ { p } ( \mathbb { R } ^ { n } ) } \, \| f \| _ { L ^ { 2 } ( \mathbb { R } ^ { n } ) } \,, \\ \quad \sim \ \cdot \ \cdot \ \cdot \ \cdot \ \cdot \ \cdot \ \cdot \ \cdot \ \cdot \ \cdot \ \cdot \ \cdot \ \cdot \ \cdot \ \cdot \ \cdot \ \cdot \ \cdot \ \cdot \ \cdot \ \cdot \ \cdot \ \cdot \ \cdot \ \cdot \ \cdot \ \cdot \ \cdot \ \cdot \ \cdot \ \cdot \ \cdot \ \cdot \ \cdot \ \cdot \ \cdot \ \cdot \ \cdot \ \cdot \ \cdot \ \cdot \ \cdot \ \cdot \ \cdot \ \cdot \ \cdot \ \cdot \ \cdot \ \cdot \ \cdot \ \cdots \ \ n.$$
for some C > 0 depending only on | A and | ν (A). Consequently, u m ∈ L r ( R n N ) for all r ∈ [2 , ∞ ].
Next, by (2.11) and the properties of convolution, we obtain
$$u _ { m } = - \frac { 1 } { 2 \pi i } \left [ h _ { m } \frac { \text{cof} \left ( \text{Asgn} \right ) ^ { \top } } { \det ( \text{Asgn} ) } \stackrel { \vee } { f } \right ] ^ { \wedge },$$
a.e. on R n . The Fourier inversion theorem gives
$$\overset { \vee } { u } _ { m } \, = \, - \$$
a.e. on R n . Since h m ( -z ) = h m ( z ) for all z ∈ R n , we get
$$\begin{array} {$$
$$\begin{array} { c } \cdot & \cdot \\ \quad = - \frac$$
Hence, by the identity (2.6), we deduce
$$\widehat { u _ { m } } ( z ) \, = \, \frac { 1$$
a.e. on R n , which we rewrite as
$$A \, \colon \widehat { u _ { m } } ( z ) \otimes$$
Equivalently,
(2.13)
By (2.12) we have that
$$( 2. 1 4 )$$
$$0 \, \leq \, h _ { m } ( z ) | z | \, \leq \, 1$$
and hence by (2.14), (2.12), (2.13), (2.10) and in view of (2.1), we may argue again as in the derivation of (2.9) to obtain that each u m satisfies the estimate (2.4). Hence, there is a subsequence of m 's and a map u ∈ W 1;2 ∗ , 2 ( R n N ) such that, along the subsequence,
$$\cdot$$
$$D u _ { m ^ { \mu } }$$
$$\iota ^ { \dots \dots }, & u _ { m } \longrightarrow u, \quad \text{in $L^{2}(\mathbb{R}^{n})^{N}$ as $m\to\infty$}, \\ u _ { m } \longrightarrow u, \quad \text{a.e. and in $L^{2}_{\text{oc}(\mathbb{R}^{n})^{N}$ as $m\to\infty$}, \\ D u _ { m } \longrightarrow D u, \ \text{in $L^{2}(\mathbb{R}^{n})^{N}$ as $m\to\infty$}.$$
$$\mathbf A \colon \widehat { D u _ { m } } ( z ) \, = \, \left ( h _ { m } ( z ) | z | \right ) \widehat { f } ( z ).$$
By (2.14) and since h m ( z ) | z | → 1 for a.e. z ∈ R n , the Dominated Convergence theorem implies
$$| h _ { m } | \cdot | | \widehat { f } \longrightarrow \widehat { f }, \text{ in } L ^ { 2 } ( \mathbb { R } ^ { n } ) ^ { N } \text{ as } m \rightarrow \infty.$$
By passing to the limit as m →∞ in (2.13), since both Du and f are L 2 maps, the Fourier inversion formula implies that u solves
$$\mathbf A \, \colon D u \, = \, f$$
a.e. on R n . By passing to the limit as m → ∞ in (2.11), we obtain the desired representation formula (2.5). Uniqueness of the limit u (and hence independence from the choice of sequence h m ) follows from the a priori estimate (2.4) and linearity. The theorem ensues. glyph[square]
## 3. Strict ellipticity and Existence-uniqueness in the fully nonlinear case
In this section we focus on the derivation of the appropriate condition allowing to prove existence and uniqueness of solution in the fully nonlinear case of the PDE system
$$F ( \cdot, D u ) \, = \, f, \quad \text{a.e. on } \mathbb { R } ^ { n }.$$
Here and subsequently F : R n × R N × n -→ R N is a Carath´odory map, namely e
↦
↦
$$( 3. 2 ) \quad \begin{cases} \ x \mapsto F ( x, P ) \text{ is measurable, for every } P \in \mathbb { R } ^ { N \times n }, \\ P \mapsto F ( x, P ) \text{ is continuous, for a.e. } x \in \mathbb { R } ^ { n }. \end{cases}$$
The crucial assumption in order to prove unique solvability of (3.1) is the next strict ellipticity condition.
Definition 4 (Strict ellipticity) . Let F : R n × R N × n -→ R N satisfy (3.2). We say that (3.1) is an elliptic system (or that F is elliptic) when there exists a linear map
$$A \, \colon \, \mathbb { R } ^ { N \times n } \longrightarrow \mathbb { R } ^ { N }$$
such that glyph[negationslash]
$$( 3. 3 ) \quad \text{ess} \sup _ { x \in \mathbb { R } ^ { n } } \sup _ { P, Q \neq 0 } \left | \frac { F ( x, P + Q ) - F ( x, P ) - \text{A } \colon Q } { | Q | } \right | \, < \, \min _ { | \eta | = | a | = 1 } | A \, \colon \eta \otimes a |.$$
We recall that for the right hand side we have the notation ν (A) of (2.2).
Remark 5. In the sequel we will assume that
$$\nu ( \mathbf A ) \, > \, 0,$$
which means that the linear map A : R N × n -→ R N assumed above is elliptic in the sense of (2.1). Otherwise, if ν (A) = 0, it easy to see that we have F x, P ( ) = A : P and then we reduce to the linear case studied in Section 2.
Remark 6. Loosely speaking, the meaning of (3.3) is that the difference quotient of F x, ( · ) is uniformly close to an elliptic constant tensor A, and 'how close' is determined by 'how much elliptic' A is. That is, the larger the value of the ellipticity constant ν (A) of A, the larger the deviation of F from this A is allowed to be.
In particular, in the linear non-constant case of
$$F ( x, P ) \, = \, A ( x ) \, \colon P, \quad A \, \colon \, \mathbb { R } ^ { n } \longrightarrow \mathbb { R } ^ { N } \otimes \mathbb { R } ^ { N \times n }, \ \text{ measurable},$$
which corresponds to the linear system
$$& ( 3. 4 ) & & \text{A} ( x ) \colon D u ( x ) \, = \, f ( x ),$$
the ellipticity assumption (3.3) simplifies to
$$( 3. 5 ) \quad \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \
\quad \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \
\ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \\ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \\ \quad \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \\ \
\ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \
\quad \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \
\quad \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \
\quad \\ \quad \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \
\ \quad \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \\ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \. \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ } \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \
\ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \quad \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \. \. \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \
\
\ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \\ \\ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \$$
Hence, by using the norm
$$\| A \| \, \coloneqq \, \sup _ { | Q | = 1 } | A \, \colon Q | \, = \, \sup _ { | \xi | = | Q | = 1 } \left | A _ { \alpha \beta j } \xi _ { \alpha } Q _ { \beta j } \right |$$
on R N ⊗ R N × n , assumption (3.3) says
$$\underset { x \in \mathbb { R } ^ { n } } { \text{ess} } \sup \left \| A ( x ) - A \right \| \, < \, \min _ { | \eta | = | a | = 1 } \left | A \, \colon \eta \otimes a \right |.$$
Hence, the linear system (3.4) is elliptic when there is a constant elliptic tensor A such that the distance ‖ A ( x ) -A ‖ is slightly smaller than the ellipticity constant of the tensor A.
Remark 7. Nontrivial fully nonlinear examples of maps F which are elliptic in the sense of the Definition 4 above are easy to find. Consider any fixed tensor A ∈ R N ⊗ R N × n for which ν (A) > 0 and any Carath´ eodory map
$$f \ \colon \ \mathbb { R } ^ { n } \times \mathbb { R } ^ { N \times n } \longrightarrow \mathbb { R } ^ { N }$$
which is Lipschitz with respect to the second variable and whose Lipschitz constant is essentially uniformly strictly smaller than the ellipticity constant of A:
$$\left \| f ( x, \cdot ) \right \| _ { C ^ { 0, 1 } ( \mathbb { R } ^ { N \times n } ) } \, \leq \, \lambda \, \nu ( A ), \text{ for a.e. } x \in \mathbb { R } ^ { n }, \ 0 < \lambda < 1.$$
Then, the map F : R n × R N × n -→ R N given by
$$F ( x, Q ) \, \coloneqq \, A \, \colon Q \, + \, f ( x, Q )$$
satisfies
$$\left | F ( x, P + Q ) - F ( x, P ) - \mathbf A \, \colon Q \right | & = \left | f ( x, P + Q ) - f ( x, P ) \right | \\ & \leq \, \lambda \, \nu ( \mathbf A ) | Q |,$$
and hence is elliptic in the sense of (3.3).
Thus, every Lipschitz perturbation of an elliptic constant tensor gives a fully nonlinear elliptic map, when the Lipschitz constant of the perturbation is strictly smaller than the ellipticity constant of the tensor.
↦
We now show that the ellipticity assumption can be seen an a notion of pseudomonotonicity, coupled by Lipschitz continuity of Q → F x, Q ( ).
Lemma 8 (Relation of ellipticity and pseudo-monotonicity) . Suppose that the map F : R n × R N × n -→ R N satisfies (3.2) . Consider the statements
- (1) There exists A ∈ R N ⊗ R N × n with ν ( A ) > 0 such that F is strictly elliptic, namely satisfies the inequality (3.3) .
↦
- (2) · Q → F x, Q ( ) is globally Lipschitz continuous on R N × n , essentially uniformly in x ∈ R n .
- · (Pseudo-Monotonicity) There exists an A ∈ R N ⊗ R N × n for which ν ( A ) > 0 and also a λ ∈ (0 , 1) such that, for all P, Q ∈ R N × n and a.e. x ∈ R n ,
$$( 3. 7 ) \quad \ \ & ( A \, \colon Q ) ^ { \top } \left [ F ( x, P + Q ) - F ( x, P ) \right ] \ \geq \ \frac { 1 } { 2 } | A \, \colon Q | ^ { 2 } \, - \, \frac { \lambda ^ { 2 } } { 2 } \nu ( A ) ^ { 2 } | Q | ^ { 2 },$$
where ν ( A ) is given by (2.2) .
↦
Then, (1) implies (2) . Conversely, (2) implies (1) when in addition the Lipschitz constant of Q → F x, Q ( ) is small enough:
$$\underset { x \in \mathbb { R } ^ { n } } { \ e s s \sup } \left \| F ( x, \cdot ) \right \| _ { C ^ { 0, 1 } ( \mathbb { R } ^ { N \times n } ) } \, < \, \sqrt { 1 - \lambda ^ { 2 } } \, \nu ( A ).$$
Proof of Lemma 8. Assume (1). By (3.3) we have
$$\left | F ( x, P + Q ) - F ( x, P ) \right | \, \leq \, \left ( \nu ( \mathbf A ) + \| \mathbf A \| \right ) | Q |,$$
for a.e. x ∈ R n and all P, Q ∈ R N × n . Hence, F x, ( · ) is Lipschitz, essentially uniformly in x . Again by (3.3), we have that there exists λ ∈ (0 , 1) such that
$$\left | F ( x, P + Q ) - F ( x, P ) - A \, \colon Q \right | \leq \, \lambda \nu ( A ) | Q |.$$
Hence,
$$\text{me}, \quad \lambda ^ { 2 } \nu ( \mathbf A ) ^ { 2 } | Q | ^ { 2 } & \geq \left | F ( x, P + Q ) - F ( x, P ) \right | ^ { 2 } + \left | \mathbf A \colon Q \right | ^ { 2 } \\ & \quad - \, 2 \left ( \mathbf A \colon Q \right ) ^ { \top } \left [ F ( x, P + Q ) - F ( x, P ) \right ] \\ & \geq \left | \mathbf A \colon Q \right | ^ { 2 } - \, 2 \left ( \mathbf A \colon Q \right ) ^ { \top } \left [ F ( x, P + Q ) - F ( x, P ) \right ].$$
$$\begin{smallmatrix} \\ \end{smallmatrix}$$
The above inequality implies (3.7), and (2) ensues. Conversely, assume (2) and also (3.8). Then, by (3.8) there exists δ ∈ (0 1) such that ,
$$\left | F ( x, P + Q ) - F ( x, P ) \right | ^ { 2 } \leq \delta ^ { 2 } ( 1 - \lambda ^ { 2 } ) \nu ( \Lambda ) ^ { 2 } | Q | ^ { 2 }.$$
By adding this inequality to
$$| \mathbf A \, \colon Q | ^ { 2 } \, - \, 2 ( \mathbf A \, \colon Q ) ^ { \top } \left [ F ( x, P + Q ) - F ( x, P ) \right ] \, \leq \, \lambda ^ { 2 } \nu ( \mathbf A ) ^ { 2 } | Q | ^ { 2 }$$
we get
$$\left | F ( x, P + Q ) - F ( x, P ) - \mathbf A \, \colon Q \right | \leq \sqrt { \lambda ^ { 2 } + \, \delta ^ { 2 } ( 1 - \lambda ^ { 2 } ) } \, \nu ( \mathbf A ) | Q |.$$
Since λ 2 + δ 2 (1 -λ 2 ) < 1, we see that the above inequality implies (3.3) and hence (1) ensues, as desired. glyph[square]
The main result of this paper is the next theorem:
Theorem 9 (Existence-Uniqueness) . Assume that n ≥ 3 , N ≥ 2 and let F : R n × R N × n -→ R N be a Carath´odory map, satisfying e (3.3) and also F x, ( 0) = 0 for a.e. x ∈ R n . Let also f ∈ L 2 ( R n N ) . Then, the problem
$$F ( \cdot, D u ) \, = \, f, \ \ a. e. \ o n \, \mathbb { R } ^ { n },$$
has a unique solution u in the space W 1;2 ∗ , 2 ( R n N ) (see (1.5) ), which also satisfies the estimate
$$\| u \| _ { L ^ { 2 ^ { * } } ( \mathbb { R } ^ { n } ) } \, + \, \| D u \| _ { L ^ { 2 } ( \mathbb { R } ^ { n } ) } \, \leq \, C \| f \| _ { L ^ { 2 } ( \mathbb { R } ^ { n } ) }$$
for some C > 0 depending only on F .
In the course of the proof we will establish the following strong uniqueness estimate, which is a form of 'comparison principle in integral norms':
Corollary 10 (Uniqueness estimate) . Assume that n ≥ 3 , N ≥ 2 and let F : R n × R N × n -→ R N be a Carath´odory map, satisfying e (3.3) . Then, for any two maps w,v ∈ W 1;2 ∗ , 2 ( R n N ) , we have
$$( 3. 1 0 ) \ \| w - v \| _ { L ^ { 2 ^ { * } } ( \mathbb { R } ^ { n } ) } \ + \ \| D w - D v \| _ { L ^ { 2 } ( \mathbb { R } ^ { n } ) } \, \leq \, C \| F ( \cdot, D w ) - F ( \cdot, D v ) \| _ { L ^ { 2 } ( \mathbb { R } ^ { n } ) }.$$
In particular, any two global strong a.e. solutions of the PDE system F ( · , Du ) = f coincide.
The proofs of Theorem 9 and Corollary 10 utilise the following result of Campanato taken from [C0], whose short proof is given for the sake of completeness at the end of the section:
glyph[negationslash]
Theorem 11 (Campanato's near operators) . Let F, A : X -→ X be two maps from the set X = ∅ to the Banach space ( X, ‖ · ‖ ) . Suppose there exists 0 < K < 1 such that
$$\left \| F [ u ] - F [ v ] - \left ( A [ u ] - A [ v ] \right ) \right \| \, \leq \, K \| A [ u ] - A [ v ] \|,$$
for all u, v ∈ X . Then, if A is a bijection, F is a bijection as well.
Campanato defined the inequality (3.11) above as the 'nearness of F to A ', using also a multiplicative constant of front of (either A or) F . Such a constant has no bearing in the generality we are working in, so we normalise it to one in the definition.
Proof of Theorem 9 ( and Corollary 10). By our assumption (3.3) on F and that F x, ( 0) = 0, Lemma 8 implies that there exists an M > 0 depending only on F , such that for any u ∈ W 1;2 ∗ , 2 ( R n N ) , we have
$$( 3. 1 2 ) \quad \left \| F ( \cdot, D u ) \right \| _ { L ^ { 2 } ( \mathbb { R } ^ { n } ) } & \leq \left \| F ( \cdot, 0 ) \right \| _ { L ^ { 2 } ( \mathbb { R } ^ { n } ) } + M \| D u \| _ { L ^ { 2 } ( \mathbb { R } ^ { n } ) } \\ & = M \| D u \| _ { L ^ { 2 } ( \mathbb { R } ^ { n } ) } \\ & \leq M \left ( \| D u \| _ { L ^ { 2 } ( \mathbb { R } ^ { n } ) } + \| u \| _ { L ^ { 2 } ^ { * } ( \mathbb { R } ^ { n } ) } \right ).$$
Let also A ∈ R N ⊗ R N × n be the tensor given by assumption (3.3), which satisfies ν (A) > 0, with ν (A) as in (2.2). Then, we have
$$\| \mathbf A \, \colon D u \| _ { L ^ { 2 } ( \mathbb { R } ^ { n } ) } & \, \leq \, \| \mathbf A \| \, \| D u \| _ { L ^ { 2 } ( \mathbb { R } ^ { n } ) } \\ & \, \leq \, \| \mathbf A \| \left ( \| D u \| _ { L ^ { 2 } ( \mathbb { R } ^ { n } ) } \, + \, \| u \| _ { L ^ { 2 ^ { * } } ( \mathbb { R } ^ { n } ) } \right ).$$
By (3.12) and (3.13) we obtain that the operators
$$\begin{cases} \ A [ u ] \ \coloneqq \ A \colon D u, \\ \ F [ u ] \ \coloneqq \ F ( \cdot, D u ), \end{cases}$$
map W 1;2 ∗ , 2 ( R n N ) into L 2 ( R n N ) . If u, v ∈ W 1;2 ∗ , 2 ( R n N ) , then (2.1) and Plancherel's theorem give (below we denote the identity map by ' Id ', that is Id x ( ) := x ):
$$\text{theorem give (below we denote the identity map by `I d ^ { \prime }, that is I d} ( x ) \coloneqq x ) \colon \\ \left \| A \colon D u - A \colon D v \right \| _ { L ^ { 2 } ( \mathbb { R } ^ { n } ) } & = \left \| A \colon \widehat { D u } - A \colon \widehat { D v } \right \| _ { L ^ { 2 } ( \mathbb { R } ^ { n } ) } \\ & = \left \| A \colon ( \widehat { u } - \widehat { v } ) \otimes ( 2 \pi i I d ) \right \| _ { L ^ { 2 } ( \mathbb { R } ^ { n } ) } \\ \geq \nu ( A ) \right \| ( \widehat { u } - \widehat { v } ) \otimes ( 2 \pi i I d ) \right \| _ { L ^ { 2 } ( \mathbb { R } ^ { n } ) } \\ & = \nu ( A ) \right \| \widehat { D u } - \widehat { D v } \right \| _ { L ^ { 2 } ( \mathbb { R } ^ { n } ) } \\ & = \nu ( A ) \right \| D u - D v \right \| _ { L ^ { 2 } ( \mathbb { R } ^ { n } ) }. \\ \text{We now set}$$
We now set glyph[negationslash]
$$\nu ( F, A ) \, \coloneqq \, \text{ess} \sup _ { x \in \mathbb { R } ^ { n } } \sup _ { P, Q \neq 0 } \left | \frac { F ( x, P + Q ) - F ( x, P ) - A \, \colon Q } { | Q | } \right |.$$
In view of (2.2), we may rewrite (3.3) as
$$0 < \nu ( F, A ) < \nu ( A ).$$
By employing (3.3), for u, v ∈ W 1;2 ∗ , 2 ( R n N ) we have glyph[negationslash]
$$\text{By employing } ( 3. 3 ), \, \text{for } u, v \in W ^ { 1 ; 2 ^ { * }, 2 } ( \mathbb { R } ^ { n } ) ^ { N } \, \text{ we have} \\ \left \| F ( \cdot, D u ) & - F ( \cdot, D v ) - A \, \colon ( D u - D v ) \right \| _ { L ^ { 2 } ( \mathbb { R } ^ { n } ) } \\ & \leq \left ( \, \text{ess} \, \sup _ { \mathbb { R } ^ { n } } \, \sup _ { P, Q \neq 0 } \, \left | \frac { F ( \cdot, P + Q ) - F ( \cdot, P ) - A \, \colon Q } { | Q | } \right | \right ) \, \| D u - D v \| _ { L ^ { 2 } ( \mathbb { R } ^ { n } ) } \\ & = \nu ( F, A ) \| D u - D v \| _ { L ^ { 2 } ( \mathbb { R } ^ { n } ) } \\ & \stackrel { ( 3. 1 3 ) } { \leq } \, \frac { \nu ( F, A ) } { \nu ( A ) } \| A \, \colon ( D u - D v ) \| _ { L ^ { 2 } ( \mathbb { R } ^ { n } ) } \\ \text{and hence we obtain the inequality}$$
and hence we obtain the inequality (3.15)
$$\overset { \cdot } { \left \| F ( \cdot, D u ) - F ( \cdot, D v ) - A \, \colon ( D u - D v ) \right \| } _ { L ^ { 2 ( \mathbb { R } ^ { n } ) } } \leq \, \frac { \nu ( F, \mathbf A ) } { \nu ( \mathbf A ) } \| \mathbf A \, \colon ( D u - D v ) \| _ { L ^ { 2 ( \mathbb { R } ^ { n } ) } }.$$
We now recall that since ν (A) > 0, Theorem 2 implies that the linear operator
$$A \ \colon \, W ^ { 1 ; 2 ^ { * }, 2 } ( \mathbb { R } ^ { n } ) ^ { N } \longrightarrow L ^ { 2 } ( \mathbb { R } ^ { n } ) ^ { N }$$
is a bijection. Hence, in view of the inequalities (3.14) and (3.15), Campanato's Theorem 11 implies that F is a bijection as well. As a result, for any f ∈ L 2 ( R n N ) , the PDE system
$$F ( \cdot, D u ) \, = \, f, \text{ a.e. on } \mathbb { R } ^ { n },$$
has a unique solution u ∈ W 1;2 ∗ , 2 ( R n N ) . Moreover, by (3.15) we deduce the estimate
$$\left \| F ( \cdot, D u ) - F ( \cdot, D v ) \right \| _ { L ^ { 2 } ( \mathbb { R } ^ { n } ) } \, & \geq \, \left ( 1 - \frac { \nu ( F, \mathbb { A } ) } { \nu ( \mathbb { A } ) } \right ) \| \mathbf A \, \colon ( D u - D v ) \| _ { L ^ { 2 } ( \mathbb { R } ^ { n } ) } \\ & \geq \, \left ( \nu ( \mathbf A ) - \nu ( F, \mathbf A ) \right ) \, \left \| D u - D v \right \| _ { L ^ { 2 } ( \mathbb { R } ^ { n } ) }.$$
This last estimate together with the fact that n ≥ 3 and the Gagliardo-NirenbergSobolev inequality, imply both (3.9) and (3.10). The theorem ensues, and so does Corollary 10. glyph[square]
We conclude this section with the proof of Campanato's theorem on near operators taken from [C0], which we provide for the convenience of the reader.
Proof of Theorem 11. It suffices to show that for any f ∈ X , there is a unique u ∈ X such that
$$F [ u ] \, = \, f.$$
In order to prove that, we first turn X into a complete metric space, by pulling back the structure from X via A : for, we define the distance
$$d ( u, v ) \, \coloneqq \, \left \| A [ u ] - A [ v ] \right \|.$$
Next, we fix an f ∈ X and define the map
$$T \ \colon \, \mathfrak { X } \longrightarrow \mathfrak { X } \, \ \ T [ u ] \ \coloneqq \, A ^ { - 1 } \Big ( A [ u ] - \Big ( F [ u ] - f ) \Big ).$$
We conclude by showing that T is a contraction on ( X , d ), and hence has a unique u ∈ X such that T u [ ] = u . The latter equality is equivalent to F u [ ] = f , and then we will be done. Indeed, we have that
$$d \left ( T [ u ], T [ v ] \right ) & \stackrel { ^ { \prime } } { = } \left \| \left ( A [ u ] - \left ( F [ u ] - f \right ) \right ) - \left ( A [ v ] - \left ( F [ v ] - f \right ) \right ) \right \| \\ & = \left \| A [ u ] - A [ v ] - \left ( F [ u ] - F [ v ] \right ) \right \|, \\ \dots$$
and hence
$$d \left ( T [ u ], T [ v ] \right ) ^ { ( 3. 1 1 ) } & \leq \, K \| A [ u ] - A [ u ] \| \\ & = \, K \, d ( u, v ).$$
Since K < 1, the conclusion follows and the theorem ensues.
glyph[square]
Acknowledgement. I would like to thank Jan Krinstensen and Bernard Dacorogna for their share of expertise on the status of the subject. I am also indebted to Tristan Pryer and Beatrice Pelloni for our inspiring scientific discussions. Finally, I would like to thank the referee of this paper who's suggestions improved the content and the appearance of this work.
## References
- BG. J. L. Buchanan, R.P. Gilbert, First Order Elliptic Systems: A Function Theoretic Approach , Mathematics in Science & Engineering, Vol. 163, 1983.
- BW. H. Begehr, G. C. Wen, Nonlinear Elliptic Boundary Value Problems and Their Applications , Pitman Monographs and Surveys in Pure and Applied Mathematics 80, Addison Welsey Longman, 1996.
- BD. A. Buica, A. Domokos, Nearness, Accretivity and the Solvability of Nonlinear Equations , Numer. Funct. Anal. Optim. 23, 477 - 497 (2002).
- C0. S. Campanato, On the condition of nearness between operators , Analli di Mat. Pura Appl. IV, Vol. CLXVII, 243 - 256 (1994).
- C1. S. Campanato, Sistemi ellittici in forma divergenza - Regolarit´ all' interno a , Quaderni della Sc. Norm. Sup. di Pisa (1980).
- C2. S. Campanato, A Cordes type condition for nonlinear non variational systems , Rendiconti Accad. Naz. delle Scienze detta dei XL, vol. 198 (1989).
- C3. S. Campanato, L 2 ,λ theory for nonlinear non variational differential systems , Rendiconti di Matematica, vol. 10, Roma (1990).
- C4. S. Campanato, Nonvariational basic parabolic systems of second order , Atti Accad. Naz. Lincei, Cl. Sci. Fis. Mat. Nat., IX Ser., Rend. Lincei, Mat. Appl. 2, No.2, (1991), 129 - 136.
- C5. S. Campanato, A history of Cordes Condition for second order elliptic operators , in 'Boundary value problems for partial differential equations and applications', J.L. Lions et al (editors), Paris: Masson. Res. Notes Appl. Math 29, (1983), 319 - 325.
- Co1. H. O. Cordes, Uber die erste Randwertaufgabe bei quasilinerian Differentialgleichun-gen zweiter Ordnung in mehr als zwei Variablen , Math. Ann. 131 (1956), 278 - 312.
- Co2. H. O. Cordes, Zero order a priori estimates for solutions of elliptic differential equation s, Proc. Sympos. Pure Math. 4 (1961), 157 - 166.
- D. A. Domokos, Remarks on some equivalent conditions for nearness , Fixed Point Theory, Vol. 4 (2003), 213-221.
- CDK. G. Csat´ o, B. Dacorogna, O. Kneuss, The Pullback Equation for Differential Forms , Progress in Nonlinear Differential Equations and Their Applications, Birkh´user, 2012. a
- DM. B. Dacorogna, P. Marcellini, Implicit Partial Differential Equations , Progress in Nonlinear Differential Equations and Their Applications, Birkh¨user, 1999. a
- DP. R. J. Di Perna, Compensated Compactness and General Systems of Conservation Laws , Transactions of the AMS 292, (1985), 383 - 420.
- F. G. B. Folland, Real Analysis: Modern Techniques and Their Applications , Pure and Applied Mathematics: A Wiley Series of Texts, Monographs and Tracts, 2nd edition, 1999.
- GM. M. Giaquinta, L. Martinazzi, An Introduction to the Regularity Theory for Elliptic Systems, Harmonic Maps and Minimal Graphs , Publications of the Scuola Normale Superiore 11, Springer, 2012.
- L. E. M. Landis, Second Order equations of elliptic and parabolic Type , vol. 171, AMS Providence, English Translations of Math. Monographs, 1998.
- Le. S. Leonardi, On Campanato's nearness condition , Le Matematiche, Vol. XLVIII (1993), 179181.
- Mo. C. B. Morrey, Multiple Integrals in the Calculus of Variations Series: Classics in Mathematics, reprint of the 1966 edition.
- Mu. S. M¨ uller, Variational models for microstructure and phase transitions , in Calculus of Variations and Geometric Evolution Problems, Springer Lecture Notes in Mathematics, Vol. 1713 (1999), 85 - 210.
- P. C. Pucci, Limitazioni per soluzioni di equazioni ellittiche , Annali di Matematica Pura ed Applicata 74 (1966), 15 - 30.
- T. G. Talenti, Sopra una classe di equazioni elilitticche a coeffcienti misurabili , Ann. Math. Pure. Appl. 69 (1965), 285 - 304.
- Ta1. A. Tarsia, Recent Developments of the Campanato Theory of Near Operators , Le Matematiche LV, Supplemento n. 2 (2000), 197 - 208.
- Ta2. A. Tarsia, Near operators theory and fully nonlinear elliptic equations , J. Global Optim. 40 (2008), 443 453.
- Ta3. A. Tarsia, Differential equations and implicit functions: A generalisation of the near operators theorem , Topological Methods in Nonlinear Analysis, Vol. 11 (1998), 115133.
Department of Mathematics and Statistics, University of Reading, Whiteknights, PO Box 220, Reading RG6 6AX, Berkshire, UK
E-mail address : [email protected] | null | [
"Nikos Katzourakis"
] | 2014-08-02T21:25:55+00:00 | 2014-12-08T00:46:15+00:00 | [
"math.AP",
"math.CV",
"math.FA"
] | Existence and Uniqueness of Global Solutions to Fully Nonlinear First Order Elliptic Systems | Let $F : \mathbb{R}^n \times \mathbb{R}^{N\times n} \rightarrow \mathbb{R}^N$
be a Caratheodory map. In this paper we consider the problem of existence and
uniqueness of weakly differentiable global strong a.e. solutions $u:
\mathbb{R}^n \longrightarrow \mathbb{R}^N$ to the fully nonlinear PDE system
\[\label{1} \tag{1} F(\cdot,Du ) \,=\, f, \ \ \text{ a.e. on }\mathbb{R}^n, \]
when $ f\in L^2(\mathbb{R}^n)^N$. This problem has not been considered before.
By introducing an appropriate notion of ellipticity, we prove existence of
solution to \eqref{1} in a tailored Sobolev "energy" space (known also as the
J.L. Lions space) and a uniqueness a priori estimate. The proof is based on the
solvability of the linearised problem by Fourier transform methods and a
"perturbation device" which allows to use of Campanato's notion of near
operators, an idea developed for the 2nd order case. |
1408.0423v2 | ## STABILITY IN CONDUCTIVITY IMAGING FROM PARTIAL MEASUREMENTS OF ONE INTERIOR CURRENT
## CARLOS MONTALTO AND ALEXANDRU TAMASAN
Abstract. We prove a stability result in the hybrid inverse problem of recovering the electrical conductivity from partial knowledge of one current density field generated inside a body by an imposed boundary voltage. The region where interior data stably reconstructs the conductivity is well defined by a combination of the exact and perturbed data.
## 1. Introduction
We consider the problem of recovering the electrical conductivity of a body from partial interior measurements of one current density field generated by an imposed boundary voltage. Originally, one sought to recover the conductivity solely from boundary measurements. Most generally formulated by Calder´n [9], the problem has been extensively o studied: the unique determination results [5,8,30,31,35] are known to have weak (of logarithmic type) stability estimates [2], which cannot be, in general, improved [21]. The need for determining the conductivity by more robust methods has lead to considering new problems in the conductivity imaging, which employ some interior data. Such interior knowledge is obtained by coupling the electromagnetic model with the physics of some high resolution imaging method. For example, magnetic resonance measurements are employed in [18,19] to determine (one component) of the magnetic field inside, or in [13, 20, 40] to obtain the current density field inside, whereas ultrasound measurements are employed in [6, 10, 11] to obtain the interior knowledge of power densities; see [29,34,36,39] for some recent reviews.
This work concerns the problem of stability in determining the conductivity from partial knowledge of one current density inside. The interior data can be obtained from Magnetic Resonance measurements
2000 Mathematics Subject Classification. 35R30, 35J65, 65N21.
Key words and phrases. hybrid inverse problems, current density imaging, magnetic resonance, electrical impedance tomography, 1-Laplacian.
A. Tamasan was supported by the NSF Grant DMS 1312883.
as discovered in [33]. A first attempt to image the conductivity from the interior data of current density fields goes back to [40]. Since then several mathematical methods have been proposed, see [15, 19, 26-28] for the isotropic case, and [7,22,23] for the anisotropic case.
Of interest here, the work in [26, 27] shows that interior knowledge of the magnitude of one current density field generated by an imposed boundary voltage uniquely determine the conductivity inside. A general approach in [17] shows that using multiple measurements (two in the planar case) the linearized problem is stable, up to a finite dimensional kernel. Stability for the linear and non-linear problem from knowledge of the magnitude of one current density field was proved in [24]. The second author would like to point out a small omission in [24, Theorem 1.2], were the assumption that the voltage potentials must be equal at the boundary needs to be added. This is a natural assumption and it was clearly used in Equation (21) in there, but unfortunately omitted in the final version of the paper.
When the entire current density field is known, a stability result has been obtained in [16]. For the anisotropic conductivities we mention the work in [7] which a proved stability in two dimensions from full knowledge of four current density fields. All these stability results assume perturbations within the range of the data, locally near a given conductivity. If one assumes general perturbations in the interior data, the recent uniqueness result in [25] combined with the structural stability in [32] shows that the voltage potential can still be stably recovered inside. However, the class of smoothness is insufficient to further yield stability for the conductivity.
In the case of partial interior data, unique determination of planar conductivity have been showed to be possible in certain subdomains (see the injectivity region defined below) in [29], but the stability question has been left open. While the voltage potential can be stably recovered in certain subregions from partial interior data the stability estimates obtained in [37] do not guarantee the necessary regularity to extend to estimates for the conductivity.
In this paper we assume that knowledge of the current density field is only partially available inside. In fact we will show that knowledge of a certain component of the field suffices. We identify the specific subregions where conductivity can be stably recovered from partial interior and boundary data. The boundary voltage potential imposed to generate the current density field is assumed unperturbed, but need not be known everywhere. In general the stability region is a subset of the injectivity region as illustrated in Figure 2. However, if the accessible part of the boundary (where the voltage potential is known)
is simply connected, then the injectivity region and the stability region coincide under some geometric (strict convexity) assumptions on the shape of the boundary.
Different from the work in [24] we use a non-linear version of the decomposition of the data operator and identify a natural component of the current density field sufficient to yield stability. To authors' knowledge, this is the first result where either injectivity or stability is established from knowledge of just one component of the current density. The required component depends both on the measured and on the exact data.
Similar to all the works in the hybrids methods, we also work with voltages free of singular points inside the domain. In dimension two, the condition of no critical points can be satisfied under the assumption that the boundary illumination is almost two-to-one [1,26]. In dimensions n ≥ 3, it is still unclear if similar conditions exists; the recent results in [4, 14] describing the set of singular points assume nonzero frequencies.
## 2. Statement of the results
Let Ω ⊂ R n be a bounded domain C 2 ,α -diffeomorphic with the unit ball, 0 < α < 1. This assumption can be relaxed as explained in the proofs. Let σ be a positive function in C 2 ,α (Ω) and let f ∈ C 2 ,α ( ∂ Ω). From Schauder's regularity theory we know that the unique solution u of the Dirichlet problem
$$\left ( 1 \right ) \quad \nabla \cdot \sigma \nabla u = 0 \ \text{ in } \Omega, \quad \ \ u | _ { \partial \Omega } = f.$$
is in C 2 ,α (Ω), see e.g. [12, Theorem 6.18]. We refer to such a u as being σ -harmonic. The corresponding current density vector field J : C 1 ,α (Ω) → C 1 ,α ( ¯ ) Ω is defined by
$$\mathbf J ( \sigma ) = - \sigma \nabla u.$$
In order to state our partial data results we introduce the following notation. For some u ∈ C 1 (Ω) arbitrary (not necessarily σ -harmonic) with |∇ u | > 0 in Ω, and p an arbitrary point in Ω, let γ p denote the integral curve starting at p in the direction of ∇ u . Since |∇ u | > 0, there exist a first time, denoted by t + p (resp. t -p ), such that the integral curve starting at p and moving in the direction ±∇ u hits the boundary. We denote by
$$l _ { p } ^ { \pm } = \{ \gamma _ { p } ( t ) \, \colon t \in [ 0, t _ { p } ^ { \pm } ] \}$$
the segment of the integral curve from t = 0 to t = t ± p . Also, let
$$\Sigma _ { p } = \{ x \in \overline { \Omega } \, \colon u ( x ) = u ( p ) \}$$
denote the level curve of u passing through p , see Figure 1.
Figure 1. Illustration of the segment l p and the surface Σ p .
Let Γ be an open subset of the boundary to denote the accessible part. The following definitions specify the interior subdomains, where the unique and stable determination of the conductivity can be guaranteed.
Definition 2.1. Let Ω ⊂ R n be a bounded domain C 2 ,α -diffeomorphic to the unit ball and let u ∈ C 2 ,α (Ω) , where 0 < α < 1 .
Injectivity region: We say that a point p ∈ Ω is visible from Γ along the equipotential set if
$$\Sigma _ { p } \cap \partial \Omega \subset \Gamma.$$
The set I (Γ , u ) of points in Ω that are visible from Γ along equipontential sets is called the injectivity region ,
$$\mathcal { I } ( \Gamma, u ) \, \coloneqq \, \{ p \in \overline { \Omega } \, \colon \Sigma _ { p } \cap \partial \Omega \subset \Gamma \}.$$
Stability region: We say that the trajectory through p along ∇ u is visible from Γ if either l + p ⊂ I (Γ , u ) or l -p ⊂ I (Γ , u ) . The set S (Γ , u ) of points in Ω for which the corresponding trayectories along ∇ u are visible from Γ is called the stability region , i.e.,
$$( 4 ) \quad \mathcal { S } ( \Gamma, u ) \coloneqq \{ p \in \mathcal { I } ( \Gamma, u ) \colon l _ { p } ^ { + } \subset \mathcal { I } ( \Gamma, u ) \text{ or } l _ { p } ^ { - } \subset \mathcal { I } ( \Gamma, u ) \}.$$
Clearly S (Γ , u ) ⊆ I (Γ , u ) and, if Γ is connected, the equality can hold as illustrated in Figure 3. In Figure 2 we illustrate the injectivity and stability regions, when Γ is not connected.
Figure 2. The injectivity region I (Γ , u ) is the light grey region that contains the stability region S (Γ , u ) in dark grey.
Figure 3. When Γ is connected the visible region and the trajectory region can be the same.
Let ˜ be the voltage potential corresponding to some perturbed conu ductivity ˜ σ ∈ C 1 ,α (Ω),
$$\nabla \cdot \tilde { \sigma } \nabla \tilde { u } = 0 \quad \text{in } \Omega, \quad \ \tilde { u } | _ { \partial \Omega } = f,$$
and let J (˜) := σ - ∇ ˜ σ ˜ be the corresponding current density field. u Let
$$\delta \sigma \coloneqq \sigma - \tilde { \sigma } \quad \text{and} \quad \delta \mathbf J \coloneqq \mathbf J - \tilde { \mathbf J }$$
denote the corresponding perturbations.
We prove that δσ is controlled by the component of δ J in the direction ∇ ( u + ˜) throughout u S (Γ , u + ˜). u To the author's knowledge the result below is the first stability result from partial interior data. It is
also the first time the recovery is done from just one component of the current density field.
For a vector field w 0 in Ω we denote the orthogonal projection onto w 0 by Π w 0 , and onto the orthogonal complement (both in the Euclidean metric) by Π ⊥ w 0 := Id -Π w 0 the orthogonal projection; i.e., for an arbitrary vector field w ,
$$\Pi _ { w _ { 0 } } \mathbf w = \frac { \mathbf w _ { 0 } \cdot \mathbf w } { | \mathbf w _ { 0 } | ^ { 2 } } \mathbf w _ { 0 } \quad \text{and} \quad \Pi _ { w _ { 0 } } ^ { \perp } \mathbf w = \mathbf w - \Pi _ { w _ { 0 } } \mathbf w.$$
Figure 4. From knowledge to the scalar component of w = Π ∇ ( u +˜) u ( δ J ) we can stably recover the difference in the conductivities σ -˜. σ Here δ J represents the difference J ( σ ) -J (˜). σ
Theorem 2.1 (Stability with Partial Data) . Let Ω ⊂ R n be C 2 ,α -diffeomorphic to the unit ball, and σ, σ ˜ ∈ C 1 ,α (Ω) be positive on Ω , for some 0 < α < 1 . Let u (respectively ˜ u ) in C 2 ,α (Ω) be σ (respectively ˜ σ )-harmonic. Let Γ ⊆ ∂ Ω be the union of finitely many open connected components, and Γ ′ ⊂⊂ Γ be a open subset compactly contained in Γ . Assume that
$$\sigma | _ { \Gamma } = \tilde { \sigma } | _ { \Gamma }, \, u | _ { \Gamma } = \tilde { u } | _ { \Gamma },$$
and
$$| \nabla ( u + \tilde { u } ) | > 0, \quad i n \ \overline { \mathcal { I } ( \Gamma ^ { \prime }, u + \tilde { u } ) }.$$
Then there exist C > 0 dependent on a lower bound ot |∇ ( u + ˜) u | in I (Γ ′ , u + ˜) u , the domain Ω , and the C 1 (Ω) - norm of σ and ˜ σ , such that (10)
$$\stackrel { \dots } { \left \| \sigma - \tilde { \sigma } \right \| } _ { L ^ { 2 } ( \mathcal { S } ( \Gamma ^ { \prime }, u + \tilde { u } ) ) } \leq C \left | \left | \nabla \cdot \left ( \Pi _ { \nabla ( u + \tilde { u } ) } ( \mathbf J ( \sigma ) - \mathbf J ( \tilde { \sigma } ) ) \right ) \right | \right | _ { L ^ { 2 } ( \mathcal { I } ( \Gamma ^ { \prime }, u + \tilde { u } ) ) } ^ { \frac { \alpha } { 2 + \alpha } }.$$
In particular,
$$( 1 1 ) \ \| \sigma - \tilde { \sigma } \| _ { L ^ { 2 } ( \mathcal { S } ( \Gamma ^ { \prime }, u + \tilde { u } ) ) } \leq C \left | \left | \Pi _ { \nabla ( u + \tilde { u } ) } ( \mathbf J ( \sigma ) - \mathbf J ( \tilde { \sigma } ) ) \right | \right | _ { H ^ { 1 } ( \mathcal { I } ( \Gamma ^ { \prime }, u + \tilde { u } ) ) } ^ { \frac { \alpha } { 2 + \alpha } }.$$
The proof of the Theorem 2.1 is presented in Section 4.
A few remarks are in order. Note first, that the estimates (10) and (11) concern norms over (possibly) different domains. However, in many interesting situation S (Γ ′ , u + ˜) = u I (Γ ′ , u + ˜) as illustrated in u Figure 3. In particular, in the full data case with Γ = ∂ Ω, we have S (Γ ′ , u + ˜) = u I (Γ ′ , u + ˜) = Ω, and the estimate (11) yields u
$$\| \sigma - \tilde { \sigma } \| _ { L ^ { 2 } ( \Omega ) } \leq C \| \mathbf J ( \sigma ) - \mathbf J ( \tilde { \sigma } ) \| | _ { H ^ { 1 } ( \Omega ) } ^ { \frac { \alpha } { 2 + \alpha } }.$$
The stability estimate requires knowledge of a component of J in a direction ∇ ( u +˜) that is well defined by the exact and perturbed data u due to the uniqueness results in [27]. However, if ˜ is σ a priori close to σ then the level curves of ˜ will be close to the level curves u u , and it will suffice to project δ J onto the ∇ u with a penalty term that will depend on the apriori closeness assumption, as illustrated in Figure 5. More precisely, we have the following local stability result.
Figure 5. We illustrate how we can controlled the visible region and the projection of the current density. The underlying idea is to chose voltages potential f at the boundary to induced specific level curves u 0 =const. By doing so, we get a better understanding of the required direction of the current density to obtain an stable reconstruction. Here, δ J 0 denote J ( σ ) -J ( σ 0 ) and w 0 = Π ∇ ( u 0 ) ( δ J 0 ).
Theorem 2.2. Let σ ∈ C 1 ,α (Ω) , 0 < α < 1 , be positive in Ω and u be σ -harmonic with |∇ u | > 0 in Ω . There exists an glyph[epsilon1] > 0 depending on Ω and some C > 0 depending on glyph[epsilon1] , such that the following holds: If ˜ σ ∈ C 1 ,α (Ω) with
$$\| \sigma - \tilde { \sigma } \| _ { C ^ { 1, \alpha } ( \overline { \Omega } ) } < \epsilon \ \ a n d \ \sigma | _ { \partial \Omega } = \tilde { \sigma } | _ { \partial \Omega },$$
and ˜ u is the ˜ σ -harmonic map with
$$\tilde { u } | _ { \partial \Omega } = u | _ { \partial \Omega },$$
then
$$\| \sigma - \tilde { \sigma } \| _ { L ^ { 2 } ( \Omega ) } \leq C \, \| \nabla \cdot \left ( \Pi _ { \nabla u } ( \mathbf J ( \sigma ) - \mathbf J ( \tilde { \sigma } ) ) \| _ { L ^ { 2 } ( \Omega ) } ^ { \frac { \alpha } { 2 + \alpha } } \,.$$
In particular,
$$\| \sigma - \tilde { \sigma } \| _ { L ^ { 2 } ( \Omega ) } \leq C \, | | \Pi _ { \nabla u } ( \mathbf J ( \sigma ) - \mathbf J ( \tilde { \sigma } ) ) | | _ { H ^ { 1 } ( \Omega ) } ^ { \frac { \alpha } { 2 + \alpha } } \,.$$
As a consequence of Theorem 2.2 let us consider the problem of determining a perturbation from a constant conductivity: If the boundary voltage is uniform in the z -direction, the equipotential surfaces are planes perpendicular to the z -direction and we only need two components of the magnetic field B = ( B , B , B x y z ) to stably recover the conductivity, as exemplified below.
Example 1 . For simplicity assume that σ ≡ 1 and f ( x, y, z ) = z . Then u x, y, z ( ) = z and, by Amp` ere's law,
$$\delta J ^ { z } = \nabla u \cdot \delta \mathbf J = \frac { 1 } { \mu _ { 0 } } \nabla u \cdot ( \nabla \times \delta \mathbf B ) = \frac { 1 } { \mu _ { 0 } } \left ( \frac { \partial } { \partial x } \delta B ^ { y } - \frac { \partial } { \partial y } \delta B ^ { x } \right ).$$
By Theorem 2.2, we can stably recover a sufficiently small pertubation of the conductivity from δB x and δB y .
## 3. Preliminaries
The stability result relies on the following decomposition of the perturbation δ J in the data.
glyph[negationslash]
Proposition 3.1. Let u and ˜ u be σ -harmonic and ˜ σ -harmonic, respectively. If ∇ ( u + ˜) = 0 u in V , for some open subset V of Ω , then
$$2 \nabla \cdot \Pi _ { \nabla ( u + \tilde { u } ) } ( \mathbf J ( \sigma ) - \mathbf J ( \tilde { \sigma } ) ) = L ( u - \tilde { u } ) \quad i n \ V.$$
where L is the differential operator defined by
$$( 1 7 ) \ L v \coloneqq - \nabla \cdot ( \sigma + \tilde { \sigma } ) \nabla v + \nabla \cdot \left ( ( \sigma + \tilde { \sigma } ) \frac { \nabla ( u + \tilde { u } ) \cdot \nabla v } { | \nabla ( u + \tilde { u } ) | ^ { 2 } } \nabla ( u + \tilde { u } ) \right ).$$
Proof. Consider the difference of two internal measurements
$$( 1 8 ) \quad \ 2 ( \mathbf J ( \sigma ) - \mathbf J ( \tilde { \sigma } ) ) = ( \sigma - \tilde { \sigma } ) \nabla ( u + \tilde { u } ) + ( \sigma + \tilde { \sigma } ) \nabla ( u - \tilde { u } ).$$
If we dot product with ∇ ( u + ˜) we obtain u
(19)
$$\dot { 2 } ( \mathbf J ( \sigma ) - \mathbf J ( \tilde { \sigma } ) ) \cdot \nabla ( u + \tilde { u } ) = ( \sigma - \tilde { \sigma } ) | \nabla ( u + \tilde { u } ) | ^ { 2 } + ( \sigma + \tilde { \sigma } ) \nabla ( u - \tilde { u } ) \cdot \nabla ( u + \tilde { u } ).$$
Solving for σ -˜ we have σ
$$( 2 0 ) \ \sigma - \tilde { \sigma } = \frac { 2 ( \mathbf J ( \sigma ) - \mathbf J ( \tilde { \sigma } ) ) \cdot \nabla ( u + \tilde { u } ) } { | \nabla ( u + \tilde { u } ) | ^ { 2 } } - ( \sigma + \tilde { \sigma } ) \frac { \nabla ( u + \tilde { u } ) \cdot \nabla ( u - \tilde { u } ) } { | \nabla ( u + \tilde { u } ) | ^ { 2 } }$$
On the other hand it follows easily from (1)
$$( 2 1 ) \quad \nabla \cdot ( \sigma + \tilde { \sigma } ) \nabla ( u - \tilde { u } ) = - \nabla \cdot ( \sigma - \tilde { \sigma } ) \nabla ( u + \tilde { u } ) \ \text{ in } \Omega.$$
Using (20) we substitute σ -˜ in (21) and we get σ
$$\text{Using} \, ( 2 0 ) \, \text{we substitute} \, \sigma - \tilde { \sigma } \, \text{ in} \, ( 2 1 ) \, \text{and} \, \text{we get} \\ L ( u - \tilde { u } ) & = - \nabla \cdot ( \sigma + \tilde { \sigma } ) \nabla ( u - \tilde { u } ) \\ & \quad + \nabla \cdot ( \sigma + \tilde { \sigma } ) \frac { \nabla ( u + \tilde { u } ) \cdot \nabla ( u - \tilde { u } ) } { | \nabla ( u + \tilde { u } ) | ^ { 2 } } \nabla ( u + \tilde { u } ) \\ & = \nabla \cdot \left ( \frac { 2 ( \mathbf J ( \sigma ) - \mathbf J ( \tilde { \sigma } ) ) \cdot \nabla ( u + \tilde { u } ) } { | \nabla ( u + \tilde { u } ) | ^ { 2 } } \nabla ( u + \tilde { u } ) \right ) \\ & = 2 \nabla \cdot \Pi _ { \nabla ( u + \tilde { u } ) } ( \mathbf J ( \sigma ) - \mathbf J ( \tilde { \sigma } ) ) \\ \quad \text{We remark that} \, ( 1 6 ) \, \text{is the non-linear version of the decomposition}$$
We remark that (16) is the non-linear version of the decomposition obtained in the linearized case in [24]. The representation of the operator L in local coordinates can then be obtained similarly as in [24]:
glyph[negationslash]
Proposition 3.2. Let u, u ˜ ∈ C 2 (Ω) , with ∇ ( u + ˜)( u x 0 ) = 0 for x 0 ∈ Ω . Then locally near Σ x 0 , the operator L in (17) is the restriction of ∇ ( σ + ˜) σ ∇ onto the level surfaces ( u + ˜) = u const. Moreover, if y n = u + ˜ u , and y ′ = ( y , . . . , y 1 n -1 ) are any local coordinates of the level set Σ x 0 , then in a neighborhood of Σ x 0 the Euclidean line element d s is given by
$$( 2 2 ) \quad \text{d} s ^ { 2 } = c ^ { 2 } ( \text{d} y ^ { n } ) ^ { 2 } + g _ { \alpha \beta } \text{d} y ^ { \alpha } \text{d} y ^ { \beta }, \ \ g _ { \alpha, \beta } \coloneqq \sum _ { i } ^ { n - 1 } \frac { \partial x ^ { i } } { \partial y ^ { \alpha } } \frac { \partial x ^ { i } } { \partial y ^ { \beta } },$$
where c = |∇ ( u + ˜) u | -1 . In this coordinates the operator L becomes
$$L = - \sum _ { \alpha, \beta } \frac { 1 } { \sqrt { \det g } } \frac { \partial } { \partial y ^ { \beta } } ( \sigma + \tilde { \sigma } ) g ^ { \alpha \beta } \sqrt { \det g } \frac { \partial } { \partial y ^ { \alpha } },$$
where the Greek super/subscripts run from 1 to n -1 .
Proof. Let Σ x 0 be the level set of u + ˜ passing through u x 0 . On Σ x 0 choose local coordinates y ′ = ( y , . . . , y 1 n -1 ) and set y n = ( u + ˜)( u x ). Then y = ( y , y ′ n ) = ϕ x ( ) define local coordinates in a neighborgood of Σ x 0 . In the new coordinates, the Euclidean metric becomes
$$( 2 4 ) \quad \text{d} s ^ { 2 } = c ^ { 2 } ( \text{d} y ^ { n } ) ^ { 2 } + g _ { \alpha \beta } \text{d} y ^ { \alpha } \text{d} y ^ { \beta }, \text{ where } g _ { \alpha \beta } \coloneqq \sum _ { i = 1 } ^ { n - 1 } \frac { \partial x ^ { i } } { \partial y ^ { \alpha } } \frac { \partial x ^ { i } } { \partial y ^ { \beta } },$$
where c = |∇ ( u + ˜) u | -1 . This follows easily by noticing that u + ˜ u trivially solves the eikonal equation c 2 |∇ φ | 2 = 1 for the speed c = |∇ ( u + ˜) u | -1 . Then, near x 0 , u + ˜ is the signed distance from the u x to the level surface Σ x 0 and the Euclidean metric has block structure given by (24). Denote by g be metric after the change of variables, i.e.,
$$g = \left [ \begin{array} { c c } [ g _ { \alpha, \beta } ] & 0 \\ 0 & c ^ { 2 } \end{array} \right ]$$
Let φ ∈ C ∞ 0 (Ω) be a test function supported near some ˆ x 0 ∈ Σ x 0 . We have
$$\langle L v, \phi \rangle & = \langle ( \sigma + \tilde { \sigma } ) \nabla v, \nabla \phi \rangle - \langle ( \sigma + \tilde { \sigma } ) \Pi _ { \nabla ( u + \tilde { u } ) } \nabla v, \nabla \phi \rangle, \\ & = \langle ( \sigma + \tilde { \sigma } ) \Pi _ { \nabla ( u + \tilde { u } ) } ^ { \perp } \nabla v, \Pi _ { \nabla ( u + \tilde { u } ) } ^ { \perp } \nabla \phi \rangle \,,$$
where 〈· , ·〉 denotes the scalar product in L 2
(Ω).
From (24), we get that for any function v ∈ C 1 (Ω)
$$\Pi _ { \nabla ( u + \tilde { u } ) } \nabla _ { x } v = \left ( 0, \dots, 0, c ^ { 2 } \frac { \partial v } { \partial y ^ { n } } \right ).$$
and
$$\Pi ^ { \perp } _ { \nabla ( u + \tilde { u } ) } \nabla _ { x } v = \left ( \frac { \partial v } { \partial y ^ { 1 } }, \dots, \frac { \partial v } { \partial y ^ { n - 1 } }, 0 \right ).$$
thus in ( y , y ′ n ) coordinates (25) becomes
(26)
$$\langle L v, \phi \rangle & = \sum _ { \alpha, \beta } \int _ { \varphi ^ { - 1 } ( \Omega ) } ( \sigma + \tilde { \sigma } ) \left ( g ^ { \alpha \beta } \frac { \partial v } { \partial y ^ { \alpha } } \frac { \partial \phi } { \partial y ^ { \beta } } \right ) \sqrt { \det g } \, d y \\ & = - \sum _ { \alpha, \beta } \int _ { \varphi ^ { - 1 } ( \Omega ) } \frac { 1 } { \sqrt { \det g } } \left ( \frac { \partial } { \partial y ^ { \beta } } ( \sigma + \tilde { \sigma } ) g ^ { \alpha \beta } \sqrt { \det g } \frac { \partial } { \partial y ^ { \alpha } } \right ) \phi ( y ) d y \\ \circ \dots \dots \lambda \sim \lambda \not \sim \lambda \not \sim \lambda \not \sim \lambda \not \sim \lambda \not \sim \lambda \not \sim \lambda \not \sim \lambda \not \sim \lambda \not \sim \lambda \not \sim \lambda \not \sim \lambda \not \sim \lambda \not \sim \lambda \not \sim \lambda \not \sim \lambda \not \sim \lambda \not \sim \lambda \not \sim \lambda \not \sim \lambda \not \sim \lambda \not \sim \lambda \not \sim \lambda \not \sim \lambda \not \sim \lambda \not \sim \lambda \not \sim \lambda \not \sim \lambda \not \sim \lambda \not \sim \lambda \not \sim \lambda \not \sim \lambda \not \sim \lambda \not \sim \lambda \not \, \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \ dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots$$
Since φ and ˆ x 0 ∈ Σ x 0 were arbitrarily we conclude that
$$L = - \sum _ { \alpha, \beta } \frac { 1 } { \sqrt { \det g } } \left ( \frac { \partial } { \partial y ^ { \beta } } ( \sigma + \tilde { \sigma } ) g ^ { \alpha \beta } \sqrt { \det g } \frac { \partial } { \partial y ^ { \alpha } } \right ).$$
near Σ . 0 glyph[square]
We note that Proposition 3.2 shows L to be an elliptic differential operator acting onto the level sets of u +˜, for which the normal comu ponent becomes a parameter.
## 4. Stability estimates for partial data
In this section we prove Theorem 2.1 and its corollary. The proof is based on establishing separate estimates for u -˜ and for the operator u L in (16). For points in S (Γ ′ , u + ˜) the visibility from Γ u ′ parallel to ∇ ( u + ˜) will allow us to control u u -˜, while the the visibility along u the equipotential sets will be used for estimates on L .
Recall that S (Γ ′ , u + ˜) = u S + (Γ ′ , u + ˜) u ∪ S -(Γ ′ , u + ˜), where u
$$\mathcal { S } ^ { \pm } ( \Gamma ^ { \prime }, u ) = \{ p \in \overline { \Omega } \, \colon \Sigma _ { p } \cap \partial \Omega \subset \Gamma ^ { \prime } \text{ and } l _ { p } ^ { \pm } \subset \mathcal { I } ( \Gamma, u ) \}.$$
We will show that
(28)
$$\stackrel { \llcorner } { \sigma } - \tilde { \sigma } \| _ { L ^ { 2 } ( \mathcal { S } ^ { \pm } ( \Gamma ^ { \prime }, u + \tilde { u } ) ) } \leq C \left | \left | \nabla \cdot \left ( \Pi _ { \nabla ( u + \tilde { u } ) } ( \mathbf J ( \sigma ) - \mathbf J ( \tilde { \sigma } ) ) \right ) \right | ^ { \frac { \alpha } { 2 + \alpha } } _ { L ^ { 2 } ( \mathcal { I } ( \Gamma ^ { \prime }, u + \tilde { u } ) ) }.$$
We prove (28) for S + (Γ ′ , u + ˜). u The corresponding inequality for S -(Γ ′ , u + ˜) follows similarly. u
To simplify notation, let
$$( 2 9 ) \ \mathcal { S } \coloneqq \mathcal { S } ^ { + } ( \Gamma, u + \tilde { u } ), \quad \mathcal { S } ^ { \prime } \coloneqq \mathcal { S } ^ { + } ( \Gamma ^ { \prime }, u + \tilde { u } ), \text{and} \ \mathcal { I } ^ { \prime } \coloneqq \mathcal { I } ( \Gamma ^ { \prime }, u + \tilde { u } ).$$
We assume w.l.o.g. that S ′ and S are connected. Notice that, since there are only finitely many components, we can add the estimates that we obtain for the single-component case, to the more general case.
We will make use of the following two technical estimates in the Lemmas below.
Lemma 4.1. There exist C > 0 dependent on the domain Ω such that
$$\| \sigma - \tilde { \sigma } \| _ { L ^ { 2 } ( \mathcal { S } ^ { \prime } ) } \leq C \| u - \tilde { u } \| _ { H ^ { 2 } ( \mathcal { S } ^ { \prime } ) },$$
where for simplicity we denote S ′ := S + (Γ ′ , u + ˜) u .
glyph[negationslash]
Proof. Since ∇ ( u + ˜) = 0 in Ω, without loss of generality (otherwise u work with a diffeormorphic image of Ω, and, possibly, with -( u + ˜)), u we may assume that
$$\min _ { \overline { \Omega } } \frac { \partial ( u + \tilde { u } ) } { \partial x ^ { n } } > 0.$$
Since the n -th coordinate now plays a special role, to simplify notation, let x ′ := ( x , . . . , x 1 n -1 ), so that x = ( x , x ′ n ).
Let Z be the set (possibly empty) of boundary points , where ∇ ( u +˜) u is tangential to the boundary,
$$Z \coloneqq \{ x \in \partial \Omega \, \colon \, n ( x ) \cdot \nabla ( u + \tilde { u } ) ( x ) = 0 \}.$$
The regularity assumptions on the boundary of the domain, and on u, u ˜ yield that Z is closed and confined to a co-dimension 1 variety of the boundary, in particular, Z is negligible with respect to the induced area measure on the boundary.
Let Γ ′ ⊂⊂ Γ \ Z , x 0 ∈ S ′ = S + (Γ ′ , u + ˜), u and Σ 0 := { x ∈ Ω : ( u + ˜)( u x ) = ( u + ˜)( u x 0 ) } be the level set passing through x 0 .
glyph[negationslash]
↦
Since ∂ u ( +˜) u ∂x n ( x , x ′ 0 n 0 ) = 0, by the implicit function theorem, in a neighborhood O ⊂ R n of x ′ 0 there is a local representation of Σ : 0 O glyph[owner] x ′ → ( x , g ′ ( x ′ )), for some C 1 ,α -smooth coordinate map g : O ⊂ R n -1 → R with g x ( ′ 0 ) = x n 0 .
We define next a tubular neighborhood T x 0 by flowing along ∇ ( u +˜) u the points on O ⊂ Σ 0 until the boundary is met. More precisely, we consider the family (indexed in x ′ ∈ O ) of the initial value problems
$$( 3 3 ) \quad \frac { d } { d t } \gamma ( t ; x ^ { \prime } ) = \frac { \nabla ( u + \tilde { u } ) } { | \nabla ( u + \tilde { u } ) | } ( \gamma ( t ; x ^ { \prime } ) ), \ \ \gamma ( 0 ) = ( x ^ { \prime }, g ( x ^ { \prime } ) ), \ x ^ { \prime } \in O.$$
Since x 0 ∈ S ′ , for the solution γ ( ; · x ′ 0 ) of (33) with parameter x ′ = x ′ 0 meets the boundary transversally, hence there exists a smallest time t x ′ 0 such that γ t ( x ′ 0 ; x ′ 0 ) ∈ Γ , and ′ γ t ( ; x ′ 0 ) ∈ Ω for 0 ≤ t < t x ′ 0 .
↦
The continuous dependence with parameters of solutions of initial value problems for ODE's shows that, by possibly shrinking the neighborhood O , we have that t → γ t, x ( ′ ) are defined on a maximal interval with γ ( · , x ′ ) : [0 , t x ′ ) → Ω and γ t ( x ′ ; x ′ ) ∈ Γ . ′
We consider the following change of coordinates ( x , x ′ n ) → ( y , y ′ n ), where y ′ = x ′ and x n = γ y ( n ; y ′ ). In the new coordinates, the tubular neighborhood T x 0 rewrites
$$T _ { x _ { 0 } } = \{ ( y ^ { \prime }, y ^ { n } ) \in \mathbb { R } ^ { n } \, \colon y ^ { \prime } \in O, \, 0 \leq y ^ { n } \leq t _ { y ^ { \prime } } \}.$$
Let J y , y ( ′ n ) denotes the absolute value of the Jacobian determinant of the change of coordinates above at some ( y , y ′ n ) ∈ T x 0 , and let β > 0 denote an upper bound on the quotient
$$\beta \coloneqq \frac { \max _ { T _ { x _ { 0 } } } J } { \min _ { T _ { x _ { 0 } } } J } < \infty$$
Recall the equation (1) interpreted as a transport equation for δσ = ( σ -˜): σ
$$( 3 5 ) \quad \ \nabla ( u + \tilde { u } ) \cdot \nabla ( \delta \sigma ) + ( \delta \sigma ) \Delta ( u + \tilde { u } ) = G \ \text{ in } \Omega,$$
where, for brevity, we let
$$G \coloneqq - \nabla \cdot ( \sigma + \tilde { \sigma } ) \nabla ( u - \tilde { u } ).$$
In the local coordinates in the interior of T x 0 , the equation (35) becomes
$$\frac { 1 } { c ^ { 2 } } \frac { \partial ( \delta \sigma ) } { \partial y ^ { n } } + ( \delta \sigma ) \Delta ( u + \tilde { u } ) = G,$$
where c = |∇ ( u + ˜) u | -1 . By (9),
$$\max _ { \overline { \Omega } } c < \infty.$$
By hypothesis (13) we also have that
$$( \delta \sigma ) ( y ^ { \prime }, t _ { y ^ { \prime } } ) = 0, \quad \forall y ^ { \prime } \in O.$$
Using an integral factor we can solve (37) and (39) to get
$$( 4 0 ) \quad \ \ ( \delta \sigma ) ( y ^ { \prime }, y ^ { n } ) = \left ( \frac { 1 } { \mu ( y ^ { \prime }, y ^ { n } ) } \int _ { t _ { y ^ { \prime } } } ^ { y ^ { n } } c ^ { 2 } G ( y ^ { \prime }, t ) \mu ( y ^ { \prime }, t ) d t \right ),$$
where
$$\mu ( y ^ { \prime }, y ^ { n } ) = \exp \left ( - \int _ { y ^ { n } } ^ { t _ { y ^ { \prime } } } c ^ { 2 } \Delta ( u + \tilde { u } ) ( y ^ { \prime }, t ) d t \right ).$$
Let m,M (not necessarily positive) be such that
$$m \leq c ^ { 2 } \Delta ( u + \tilde { u } ) ( x ) \leq M, \quad \forall x \in \overline { \Omega }.$$
Then, it is easy to see that, for y ′ ∈ O and 0 ≤ t ≤ y n ≤ t y ′ , we have
$$e ^ { - | M | d i a m ( \Omega ) } \leq \frac { \mu ( y ^ { \prime }, t ) } { \mu ( y ^ { \prime }, y ^ { n } ) } \leq e ^ { | m | d i a m ( \Omega ) }.$$
For a constant ˜ C > 0 depending on the bounds in (42) and (38), and β in (34), we estimate
(43)
$$\beta \text{ in (34), we estimate } \cdot \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \
\| \delta \sigma \| _ { L ^ { 2 } ( T _ { x _ { 0 } } ) } & = \int _ { y ^ { \prime } \in O } \int _ { 0 } ^ { t _ { y ^ { \prime } } } \left | \int _ { 0 } ^ { y ^ { n } } c ^ { 2 } G ( y ^ { \prime }, t ) \frac { \mu ( y ^ { \prime }, t ) } { \mu ( y ^ { \prime }, y ^ { n } ) } d t \right | ^ { 2 } J ( y ^ { \prime }, y ^ { n } ) d y ^ { n } d y ^ { \prime } \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \ \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \ \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \cdots \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \end{array} \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \ = \, \, \,$$
Since S ′ can be covered by finitely many tubular neighborhoods, and the norm in the right hand side of (43), we conclude that
$$( 4 4 ) \quad \| \delta \sigma \| _ { L ^ { 2 } ( \mathcal { S } ^ { \prime } ) } ^ { 2 } \leq C \| \nabla \cdot ( \sigma + \tilde { \sigma } ) \nabla ( u - \tilde { u } ) \| _ { L ^ { 2 } ( \mathcal { S } ^ { \prime } ) } \leq C \| u - \tilde { u } \| _ { H ^ { 2 } ( \mathcal { S } ^ { \prime } ) },$$
for a constant C depending on u, u ˜ and the domain Ω, and a priori bounds on C 1 -norm of σ and ˜. This finishes the proof of (30). σ
glyph[square]
Lemma 4.2. There exists C > 0 dependent on Ω and a lower bound on σ + ˜ σ , such that,
$$\| u - \tilde { u } \| _ { L ^ { 2 } ( \mathcal { I } ^ { \prime } ) } \leq C \| L ( u - \tilde { u } ) \| _ { L ^ { 2 } ( \mathcal { I } ^ { \prime } ) },$$
where, for simplicity we denote by I ′ := I (Γ ′ , u + ˜) u .
Proof. Let x 0 be arbitrarily fixed in the injectivity region I ′ . Assume first that the level set Σ 0 of u + ˜ passing through u x 0 intersects the boundary in Γ , transversally at any point of intersection. ′ Consider the local coordinates ( y , y ′ n ) for the equipotential set Σ , introduced in 0 Proposition 3.2. By continuity of y n = u + ˜ w.r.t. u y ′ , for sufficiently small glyph[epsilon1] , the neighborhood U glyph[epsilon1] of Σ 0 defined by
$$U _ { \epsilon } \coloneqq \{ ( y ^ { \prime }, y ^ { n } ) \in \mathcal { I } ^ { \prime } \colon y ^ { \prime } \in \Sigma _ { 0 }, \text{and} \ y ^ { n } \in ( - \epsilon, \epsilon ) \}$$
is visible from Γ ′ along the equipotential sets of u + ˜. u
Using the local representation of L obtained in (***) and local representation the metric g on U glyph[epsilon1] we estimate L δu ( ). We denote by g ′ the restriction of the metric to y ′ , i.e., g ′ = [ g α,β ] for 1 ≤ α, β ≤ n -1. Let δu = u -˜. u Note that in U glyph[epsilon1] , ( u -˜) u | ∂ Ω = 0, hence Poincar´'s inequality e is valid in Σ . 0 We estimate
$$\begin{array} { l } \text{is valid in $\Sigma_{0}$. We estimate} \\ \\ \langle L \delta u \cdot \delta u \rangle | _ { U _ { \epsilon } } = & \int _ { - \epsilon } ^ { \epsilon } \left ( \frac { 1 } { \sqrt { \det g } } \frac { \partial \delta u } { \partial y ^ { \beta } } ( \sigma + \vec { \sigma } ) g ^ { \alpha \beta } \sqrt { \det g } \frac { \partial \delta u } { \partial y ^ { \alpha } } \right ) \cdot \delta u \sqrt { \det g } \, d y ^ { \prime } d y ^ { n } \\ \\ = & \int _ { - \epsilon } ^ { \epsilon } \int ( \sigma + \vec { \sigma } ) g ^ { \alpha \beta } \frac { \partial \delta u } { \partial y ^ { \alpha } } \frac { \partial \delta u } { \partial y ^ { \beta } } \sqrt { \det g } \, d y ^ { n } \\ \\ \geq \delta \int _ { - \epsilon } ^ { \epsilon } \int _ { \Sigma _ { 0 } } | \nabla _ { y } \delta u | ^ { 2 } \, \ d y ^ { \prime } d y ^ { n }, \\ \\ \geq \delta \int _ { - \epsilon } ^ { \epsilon } \int _ { \Sigma _ { 0 } } | \delta u | ^ { 2 } \, \ d y ^ { \prime } d y ^ { n } \\ \\ ( 4 6 ) & = \delta \| \delta u \| _ { L ^ { 2 } ( U _ { \epsilon } ) }, \\ \text{where} \, \delta > 0 \, \text{depends on an a priori lower bound of $\sigma + \vec { \sigma }$ and of $g^{\alpha,\beta}$ on} \\ \Omega \text{ for $1\leq\alpha$, $\beta\leq n$. The second inequality is the Poincaré inequality.} \end{array}$$
where δ > 0 depends on an a priori lower bound of σ +˜ and of σ g α,β on Ω for 1 ≤ α, β ≤ n . The second inequality is the Poincar´ inequality. e Since U glyph[epsilon1] ⊂ I ′ we obtain from (46)
$$\| \delta u \| _ { L ^ { 2 } ( U _ { \epsilon } ) } ^ { 2 } \leq C \langle L ( \delta u ), \delta u \rangle _ { L ^ { 2 } ( \mathcal { I } ^ { \prime } ) },$$
By compactness, we can get a finite covering of I ′ with neighborhoods U glyph[epsilon1] . Summing (47) over the covering of U glyph[epsilon1] we obtain
$$\| u - \tilde { u } \| _ { L ^ { 2 } ( \mathcal { I } ^ { \prime } ) } ^ { 2 } \leq C ( L ( u - \tilde { u } ), u - \tilde { u } ) _ { L ^ { 2 } ( \mathcal { I } ^ { \prime } ) },$$
for some constant C which depends on Ω, and the lower bound on σ + ˜. Finally from Cauchy-Schwartz inequality (45) follows. σ
Finally the level set Σ 0 intersects tangentially the boundary of Ω as some point then the analysis presented above could fail depending on the degeneracy of such interseccion. In particular it is not clear how to justify integration by parts on U glyph[epsilon1] in the intersection is degenerate. To avoid this difficulty we will extend σ, σ, u ˜ and ˜ in two different u ways to an open domain Ω 1 containing I ′ . The first extension takes advantage of the boundary information while the second extension uses the regularity of the functions to extend the geometry and the operators in decomposition (16).
Since Γ ′ is compactly supported in Γ it follows that I ′ ⊂ I . Thus there exists an open bounded Ω 1 with smooth boundary, such that I ′ ⊂ Ω 1 and Ω 1 ∩ Ω ⊂ I . First, using the fact that ( σ -˜) σ | Γ = 0 we
can find H 1 (Ω ) extensions 1 σ 1 and ˜ σ 1 of σ and ˜, respectively, σ such that ( σ 1 -˜ ) = 0 in Ω σ 1 1 \ Ω; (e.g., extend first σ to some σ 1 ∈ C 2 (Ω ), 1 and define ˜ σ 1 := σ 1 in Ω 1 \ Ω. Since ˜ σ 1 coincide with σ 1 on ∂ Ω, the difference ˜ σ 1 -σ 1 , and thus ˜ σ 1 lie in H 1 (Ω ). 1 Moreover, since σ and ˜ are positive in Ω, we may assume that σ σ 1 and ˜ σ 1 are positive in Ω . 1 Second, denote by σ , σ 2 ˜ 2 ∈ C 2 (Ω ) extensions of 1 σ and ˜, respectively. σ We can take Ω 1 close enough to the boundary of Ω so that σ 2 and ˜ σ 2 are positive in Ω . 1
glyph[negationslash]
In a similar way we extend u and ˜ as follows. u Since ( u -˜) u | Γ = 0, we can find H 1 (Ω ) extensions 1 u 1 and ˜ u 1 of u and ˜, respectively, such u that ( u 1 -˜ ) u 1 | Ω 1 \ Ω = 0. Also denote by u , u 2 ˜ 2 ∈ C 2 (Ω ) extensions of 1 u and ˜ respectively. u We can take Ω 1 close enough to the boundary of Ω so that ∇ ( u 2 + ˜ ) = 0 on Ω . u 2 1 Finally we denote by g 1 a C 1 (Ω ) 1 extension to Ω 1 of the metric g obtained in (22).
We then define U glyph[epsilon1] in Ω 1 instead of I ′ by
$$U _ { \epsilon } \coloneqq \{ ( y ^ { \prime }, y ^ { n } ) \in \Omega _ { 1 } \, \colon y ^ { \prime } \in \Sigma _ { 0 }, \text{and} \, y ^ { n } \in ( - \epsilon, \epsilon ) \}$$
Now, even if the intersection of Σ 0 with ∂ Ω 1 is tangential the function that we are integrating is compactly supported, so we can justify integration by parts in (47). glyph[square]
Using the estimates in Lemmas 4.1 and 4.2 we proceed to proving (10). Recall from Schauder theory that u, u ˜ ∈ C 2 ,α (Ω). By using in order the estimate (30), an interpolation estimate in [38, Sec. 4.3.1 ], (45), and Proposition 3.1 we obtain
(49)
$$\| \sigma - \tilde { \sigma } \| _ { L ^ { 2 } ( V ^ { \prime } ) } & \leq C \| u - \tilde { u } \| _ { H ^ { 2 } ( V ^ { \prime } ) } \\ & \leq C \| u - \tilde { u } \| _ { L ^ { 2 } ( V ^ { \prime } ) } ^ { \frac { \alpha } { 2 + \alpha } } \cdot \| u - \tilde { u } \| _ { H ^ { 2 } + \alpha } ^ { \frac { 2 } { 2 + \alpha } } ( V ^ { \prime } ) \leq C \| u - \tilde { u } \| _ { L ^ { 2 } ( \mathcal { T } ^ { \prime } ) } ^ { \frac { \alpha } { 2 + \alpha } } \\ & \leq C \| L ( u - \tilde { u } ) \| _ { L ^ { 2 } ( \mathcal { T } ^ { \prime } ) } ^ { \frac { \alpha } { 2 + \alpha } } \\ & = C \left | \left | 2 \nabla \cdot \Pi _ { \nabla ( u + \tilde { u } ) } ( \mathbf J ( \sigma ) - \mathbf J ( \tilde { \sigma } ) ) \right | _ { L ^ { 2 } ( \mathcal { T } ^ { \prime } ) } ^ { \frac { \alpha } { 2 + \alpha } } \\ \tau \infty \cdot \ e \cdot \ e \cdot \ e \cdot \ e \cdot \ e \cdot \ e \cdot \ e \cdot \ e \cdot \ e \cdot \ e \cdot \ e \cdot \ e \cdot \ e \cdot \ e \cdot \ e \cdot \ e \cdot \ e \cdot \ e \cdot \ e \cdot \ e \cdot \ e \cdot \ e \cdot \ e \cdot \ e \cdot \ e \cdot \ e \cdot \ e \cdot \ e \cdot \ e \cdot \ e \cdot \ e \cdot \ e \cdot \ e \cdot \ e \cdot \ e \cdot \ e \cdot \ e \cdot \ e \cdot \ e \cdot \ e \cdot \end{array}$$
This finishes the proof of Theorem 2.1.
Proof of Theorem 2.2. Recall glyph[epsilon1] > 0 in (13). The Schauder stability estimates for solutions of elliptic equations with C α (Ω)-coefficients and C 2 ,α traces on the boundary, yield
$$\| u - \tilde { u } \| _ { C ^ { 2, \alpha } ( \overline { \Omega } ) } \leq M \epsilon,$$
for a constant M dependent only on Ω and a lower bound of σ . In particular, for glyph[epsilon1] < 1 /M we have that
$$\| \tilde { u } \| _ { C ^ { 2 } ( \overline { \Omega } ) } & \leq \| u \| _ { C ^ { 2 } ( \overline { \Omega } ) } + 1.$$
Moreover, since m := min Ω |∇ u > | 0, for glyph[epsilon1] < m/M , we also have
$$( 5 2 ) \quad \ | \nabla ( u + \tilde { u } ) | \geq 2 | \nabla u | - | \nabla ( u - \tilde { u } ) | \geq 2 m - M \epsilon \geq m > 0.$$
Denote by δ J = J ( σ ) -J (˜). σ From Theorem 2.1 we have that there exist a C > 0 independent of glyph[epsilon1] , such that
$$\| \sigma - \tilde { \sigma } \| _ { L ^ { 2 } ( \Omega ) } \leq C \left | \left | \frac { \delta \mathbf J \cdot \nabla ( u + \tilde { u } ) } { | \nabla ( u + \tilde { u } ) | } \right | \right | _ { H ^ { 1 } ( \Omega ) }.$$
Write
$$\frac { \delta \mathbf J \cdot \nabla ( u + \tilde { u } ) } { | \nabla ( u + \tilde { u } ) | } = 2 \frac { | \nabla u | } { | \nabla ( u + \tilde { u } ) | } \left ( \frac { \delta \mathbf J \cdot \nabla u } { | \nabla u | } \right ) + \frac { \delta \mathbf J \cdot \nabla ( \tilde { u } - u ) } { | \nabla ( u + \tilde { u } ) | }.$$
Note that all the terms in (54) are C 1 (Ω)-regular.
By using the identity (19), the second term in the right hand side of (54) rewrites as
$$( 5 5 ) \quad \frac { \delta \mathbf J \cdot \nabla ( \tilde { u } - u ) } { | \nabla ( u + \tilde { u } ) | } = \frac { 1 } { 2 } ( \sigma - \tilde { \sigma } ) | \nabla ( u - \tilde { u } ) | + \frac { 1 } { 2 } ( \sigma + \tilde { \sigma } ) \frac { | \nabla ( u - \tilde { u } ) | ^ { 2 } } { | \nabla ( u + \tilde { u } ) | }.$$
Using (21), (51), and the Cauchy-Schwartz inequality we obtain
$$\dots \circ \dots \circ \dots \circ \dots \circ \dots \circ \dots \circ \dots \circ \dots \circ \dots \\ \langle ( \sigma + \tilde { \sigma } ) \nabla ( \tilde { u } - u ), \nabla ( \tilde { u } - u ) \rangle _ { L ^ { 2 } ( \Omega ) } & = - \langle \nabla \cdot ( \sigma + \tilde { \sigma } ) \nabla ( \tilde { u } - u ), \tilde { u } - u \rangle _ { L ^ { 2 } ( \Omega ) } \\ & = \langle \nabla \cdot ( \tilde { \sigma } - \sigma ) \nabla ( u + \tilde { u } ), \tilde { u } - u \rangle _ { L ^ { 2 } ( \Omega ) } \\ & \leq \| ( \tilde { \sigma } - \sigma ) \nabla ( u + \tilde { u } ) \| _ { L ^ { 2 } ( \Omega ) } \| \nabla ( \tilde { u } - u ) \| _ { L ^ { 2 } ( \Omega ) } \\ ( 5 6 ) & \leq C \| \tilde { \sigma } - \sigma \| _ { L ^ { 2 } ( \Omega ) } \| \nabla ( \tilde { u } - u ) \| _ { L ^ { 2 } ( \Omega ) }, \\ \epsilon \quad \sim \cdots \quad \cdots \quad \cdots \circ \dots \circ \dots \circ \dots \circ \dots \circ \dots \circ \dots \circ \dots \circ \dots \circ \dots \circ \dots \circ \dots \end{array}$$
for C dependent on the C 1 -norm of u but independent of glyph[epsilon1] . From (56), for
$$\delta \coloneqq \min _ { \overline { \Omega } } ( \sigma + \tilde { \sigma } ) > 0,$$
we obtain
$$\left ( 5 7 \right ) \right ) \left ( \left ( \left ( \left ( \left ( \left ( \left ( \left ( \left ( \left ( \left ( \left ( \left ( \left ( \left ( \left ( \left ( \left ( \left ( \left ( \left ( \left ( \left ( \left ( \left ( \left ( \left ( \left ( \left ( \left ( \left ( \left ( \left ( \left ( \left ( \left ( \left ( \left ( \left ( \left ( \left ( \left ( \left ( \left ( \left ( \left ( \left ( \left ( \left ( \left ( \left ( \left ( \left ( \left ( \left ( \left ( \left ( \left ( \left ( \left ( \left ( \left ( \left ( \left ( \left ( \left ( \left ( \right ) \right ) \right ) \right ) \right ) } \right ) \right ) } \right ) \right ) } \left ( \left ( \left ( \left ( \left ( \left ( \left ( \left ( \left ( \left ( \left ( \left ( \left ( \left ( \left ( \left ( \left ( \left ( \left ( \left ( \left ( \left ( \left ( \left ( \left ( \left ( \left ( \left ( \left ( \left ( \left ( \left ( \left ( \left ( \left ( \left ( \left ( \left ( \left ( \left ( \left ( \left ( \left ( \left ( \left ( \left ( \left ( \left ( \left ( \left ( \left ( \left ( \left ( \left ( \left ( \left ( \left ( \left ( \left ( \left ( \left ( \left ( \left ( \left ( \left ( \left ( \ \left ( \left ( \left ( \left ( \left ( \left ( \left ( \left ( \left ( \left ( \left ( \left ( \left ( \left ( \left ( \left ( \left ( \left ( \left ( \left ( \left ( \left ( \left ( \left ( \left ( \left ( \left ( \left ( \left ( \left ( \left ( \left ( \left ( \left ( \left ( \left ( \left ( \left ( \left ( \left ( \left ( \left ( \left ( \left ( \left ( \left ( \left ( \left ( \left ( \left ( \left ( \left ( \left ( \left ( \left ( \left ( \left ( \left ( \left ( \left ( \left ( \left ( \left ( \left ( \left ( \left ( \bottom \right ) \right ) \right ) \right ) \right ) } \right ) \right ) } \right ) } \right ) \right ) } \right ) \right ) \right ) \right ) \right ) \right ) \right ) \right ) \right ) \right ) \right ) \right ) \right ) \right ) \right ) \right ) \right ) \right ) \right ) \right ) \right ) \right ) \right ) \right ) \right ) \right ) \right ) \right ) \right ) \right ) \right ) \right ) \right ) \right ) \right ) \right ) \right ) \right ) \right ) \right ) \right ) \right ) \right ) \right ) \right ) \right ) \right ) \right ) \right ) \right ) \right ) \right ) \right ) \right ) \right ) \right ) \right ) \right ) \right ) \right ) \right ) \right ) \right ) \right ) \right ) \right ) \right ) \left ( \left ( \left ( \left ( \left ( \left ( \left ( \left ( \left ( \left ( \left ( \left ( \left ( \left ( \left ( \left ( \left ( \left ( \left ( \left ( \left ( \left ( \left ( \left ( \left ( \left ( \left ( \left ( \left ( \left ( \left ( \left ( \left ( \left ( \left ( \left ( \left ( \left ( \left ( \left ( \left ( \left ( \left ( \left ( \left ( \left ( \left ( \left ( \left ( \left ( \left ( \left ( \left ( \left ( \left ( \left ( \left ( \left ( \left ( \left ( \left ( \left ( \left ( \left ( \right ) \right ) \left ) \right ) \right ) \right ) \right ) \right ) \right ) \right ) \right ) } \right ) \right ) \right ) \right ) \right ) \right ) \right ) \right ) \right ) \right ) \right ) \right ) \right ) \right ) \right ) \right ) \right ) \right ) \right ) \right ) \right ) \right ) \right ) \right ) \right ) \right ) \right ) \right ) \right ) \right ) \right ) \right ) \right ) \right ) \right ) \right ) \right ) \right ) \right ) \right ) \right ) \right ) \right ) \right ) \right ) \right ) \right ) \right ) \right ) \right ) \right ) \right ) \right ) \right ) \right ) \right ) \right ) \right ) \right ) \right ) \right ) \right ) \right ) \right )$$
We claim that
$$\left \| \frac { \delta \mathbf J \cdot \nabla ( u - \tilde { u } ) } { | \nabla ( u + \tilde { u } ) | } \right \| _ { H ^ { 1 } ( \Omega ) } \leq C \epsilon \| \sigma - \tilde { \sigma } \| _ { L ^ { 2 } ( \Omega ) }.$$
for some C independent of glyph[epsilon1] . Indeed: one differentiation in (55) in any variable, which for simplicity we denote by subscript x , yields four terms. We treat each term individually, the appearing constants are
independent of glyph[epsilon1] . To bound the first term we use (13), the Cauchy inequality and (57) to obtain
$$\int _ { \Omega } | ( \sigma - \tilde { \sigma } ) _ { x } | \, | \nabla ( u - \tilde { u } ) | d x \leq C _ { 1 } \epsilon \| \sigma - \tilde { \sigma } \| _ { L ^ { 2 } ( \Omega ) }.$$
To bound the second term we use the Cauchy inequality and uniform bounds (dependent on u only via (51)) on the second derivatives of u and ˜ and obtain u
$$\int _ { \Omega } | \sigma - \tilde { \sigma } | \left ( | \nabla ( u - \tilde { u } ) | \right ) _ { x } d x \leq C _ { 2 } \epsilon \| \sigma - \tilde { \sigma } \| _ { L ^ { 2 } ( \Omega ) }.$$
To bound the third term we use uniform bounds on the second derivatives of u (and implicitly on ˜ via (51)) and on the first derivatives of u σ (and implicitly of ˜ via (13)), (52) and (57) and obtain σ
$$\int _ { \Omega } \left ( \frac { \sigma + \tilde { \sigma } } { | \nabla ( u + \tilde { u } ) | } \right ) _ { x } | \nabla ( u - \tilde { u } ) | ^ { 2 } d x \leq C _ { 3 } \epsilon \| \sigma - \tilde { \sigma } \| _ { L ^ { 2 } ( \Omega ) }.$$
To bound the fourth term we use the Cauchy inequality and uniform bounds on σ, σ ˜, and C 2 -bounds on u (and implicitly via on ˜ (51)), u (52), and (57) and obtain
$$\int _ { \Omega } \frac { \sigma + \tilde { \sigma } } { | \nabla ( u + \tilde { u } ) | } ( | \nabla ( u - \tilde { u } ) | ) _ { x } | \nabla ( u - \tilde { u } ) | d x \leq C _ { 4 } \epsilon \| \sigma - \tilde { \sigma } \| _ { L ^ { 2 } ( \Omega ) }.$$
This finishes the proof of (58).
From Equations (53), (54) and (58) we get
$$\| \sigma - \tilde { \sigma } \| _ { L ^ { 2 } ( \Omega ) } \leq C \left \| \frac { \delta \mathbf J \cdot \nabla u } { | \nabla u | } \right \| _ { H ^ { 1 } ( \Omega ) } + C \epsilon \| \sigma - \tilde { \sigma } \| _ { L ^ { 2 } ( \Omega ) },$$
for a constant C independent of glyph[epsilon1] .
Finally, using (59) for glyph[epsilon1] < 1 /C we obtain
$$\| \sigma - \tilde { \sigma } \| _ { L ^ { 2 } ( \Omega ) } \leq \frac { C } { 1 - C \epsilon } \left \| \frac { \delta \mathbf J \cdot \nabla u } { | \nabla u | } \right \| _ { H ^ { 1 } ( \Omega ) }$$
which implies (15) and proves Theorem 2.2.
glyph[square]
## Acknowledgments
We would express our gratitute to Plamen Stefanov for his valuable suggestions during the writing of this paper.
## References
- 1. Giovanni Alessandrini, Critical points of solutions of elliptic equations in two variables , Annali della Scuola Normale Superiore di Pisa-Classe di Scienze 14 (1987), no. 2, 229-256. 3
- 2. , Stable determination of conductivity by boundary measurements , in Appl. Anal. [3], 153-172. MR 922775 (89f:35195) 1
- 3. , Stable determination of conductivity by boundary measurements , Appl. Anal. 27 (1988), no. 1-3, 153-172. MR 922775 (89f:35195) 19
- 4. , Global stability for a coupled physics inverse problem , arXiv preprint arXiv:1404.1275 (2014). 3
- 5. Kari Astala and Lassi P¨ aiv¨rinta, a Calder´n's o inverse conductivity problem in the plane , Ann. of Math. (2) 163 (2006), no. 1, 265-299. MR 2195135 (2007b:30019) 1
- 6. Guillaume Bal, Eric Bonnetier, Fran¸ cois Monard, and Faouzi Triki, Inverse diffusion from knowledge of power densities , Inverse Problems and Imaging 7 (2013), no. 2, 353-375. 1
- 7. Guillaume Bal, Chenxi Guo, and Fran¸ cois Monard, Inverse anisotropic conductivity from internal current densities , Inverse Problems 30 (2014), no. 2, 025001. 2
- 8. AL Bukhgeim, Recovering a potential from cauchy data in the two-dimensional case , Journal of Inverse and Ill-posed Problems jiip 16 (2008), no. 1, 19-33. 1
- 9. A. P. Calder´n, o On an inverse boundary value problem , in Seminar on Numerical Analysis and its Applications to Continuum Physics, Soc. Brasiliera de Matemarica, Rio de Janeiro, 1980, article republished in Comp. Appl. Math 25 (2006), no. 2-3. 1
- 10. Y. Capdeboscq, J.e Fehrenbach, F. De Gournay, and O. Kavian, Imaging by modification: numerical reconstruction of local conductivities from corresponding power density measurements , SIAM Journal on Imaging Sciences 2 (2009), 1003. 1
- 11. B. Gebauer and O. Scherzer, Impedance-acoustic tomography , SIAM J. Appl. Math. 69 (2008), no. 2, 565-576. MR 2465856 (2009j:35381) 1
- 12. David Gilbarg and Neil S. Trudinger, Elliptic Partial Differential Equations of Second Order , Springer, 2001. 3
- 13. K.F. Hasanov, A.W. Ma, R.S. Yoon, A.I. Nachman, and M.L. Joy, A new approach to current density impedance imaging , Engineering in Medicine and Biology Society, 2004. IEMBS '04. 26th Annual International Conference of the IEEE, vol. 1, Sept 2004, pp. 1321-1324. 1
- 14. N. Honda, J. McLaughlin, and G. Nakamura, Conditional stability for single interior measurement , Inverse Problems 30 (2013), no. 5. 3
- 15. Sungwhan Kim, Ohin Kwon, Jin Keun Seo, and Jeong-Rock Yoon, On a nonlinear partial differential equation arising in magnetic resonance electrical impedance tomography , SIAM journal on mathematical analysis 34 (2002), no. 3, 511-526. 2
- 16. Yong-Jung Kim and Min Gi Lee, Well-posedness of the conductivity reconstruction from an interior current density in terms of Schauder theory , Quart. Appl. Math. 2
- 17. Peter Kuchment and Dustin Steinhauer, Stabilizing inverse problems by internal data , Inverse Problems 28 (2012), no. 8, 084007, 20. MR 2956563 2
- 18. O. Kwon, E.J. Woo, J. R. Yoon, and J. K. Seo, Magnetic resonance electrical impedance tomography (MREIT): Simulation study of J-substitution algorithm , IEEE Transactions on Biomedical Engineering 49 (2002), no. 2, 160-167. 1
- 19. Ohin Kwon, June-Yub Lee, and Jeong-Rock Yoon, Equipotential line method for magnetic resonance electrical impedance tomography , Inverse Problems 18 (2002), no. 4, 1089. 1, 2
- 20. June-Yub Lee, A reconstruction formula and uniqueness of conductivity in mreit using two internal current distributions , Inverse Problems 20 (2004), no. 3, 847. 1
- 21. Niculae Mandache, Exponential instability in an inverse problem for the Schr¨dinger equation o , Inverse Problems 17 (2001), no. 5, 1435. 1
- 22. Fran¸ cois Monard and Guillaume Bal, Inverse anisotropic diffusion from power density measurements in two dimensions , Inverse Problems 28 (2012), no. 8, 084001. 2
- 23. , Inverse anisotropic conductivity from power densities in dimension n 3 , Communications in Partial Differential Equations 38 (2013), no. 7. 2
- 24. Carlos Montalto and Plamen Stefanov, Stability of coupled-physics inverse problems with one internal measurement , Inverse Problems 29 (2013), no. 12, 125004. 2, 3, 9
- 25. A. Moradifam, A. Nachman, and A. Tamasan, Uniqueness of minimizers of weighted least gradient problems arising in conductivity imaging , preprint (2014). 2
- 26. Adrian Nachman, Alexandru Tamasan, and Alexandre Timonov, Conductivity imaging with a single measurement of boundary and interior data , Inverse Problems 23 (2007), no. 6, 2551-2563. MR 2441019 (2009k:35325) 2, 3
- 27. , Recovering the conductivity from a single measurement of interior data , Inverse Problems 25 (2009), no. 3, 035014, 16. MR 2480184 (2010g:35340) 2, 7
- 28. , Reconstruction of planar conductivities in subdomains from incomplete data , SIAM Journal on Applied Mathematics 70 (2010), no. 8, 3342-3362. 2
- 29. , Current density impedance imaging , Tomography and inverse transport theory, Contemp. Math., vol. 559, Amer. Math. Soc., Providence, RI, 2011, pp. 135-149. MR 2885199 1, 2
- 30. Adrian I Nachman, Reconstructions from boundary measurements , Annals of Mathematics (1988), 531-576. 1
- 31. , Global uniqueness for a two-dimensional inverse boundary value problem , Annals of Mathematics (1996), 71-96. 1
- 32. M. Z. Nashed and A. Tamasan, Structural stability in a minimization problem and applications to conductivity imaging , Inverse Probl. Imaging 4 (2010). 2
- 33. G. C. Scott, M. L. G. Joy, R. L. Armstrong, and R. M. Henkelman, Measurement of nonuniform current density by magnetic resonance , IEEE Transactions on Medical Imaging 10 (1991), no. 3, 362-374, cited By (since 1996) 141. 2
- 34. Jin Keun Seo and Eung Je Woo, Magnetic resonance electrical impedance tomography (MREIT) , SIAM Rev. 53 (2011), no. 1, 40-68. MR 2785879 (2012d:35412) 1
- 35. John Sylvester and Gunther Uhlmann, A global uniqueness theorem for an inverse boundary value problem , Ann. of Math. (2) 125 (1987), no. 1, 153-169. MR 873380 (88b:35205) 1
- 36. A. Tamasan and Timonov A., Coupled physics electrical conductivity imaging , Eurasian J. Math. Comp. Appl. 2 (2014), no. 3-4, 5-29. 1
- 37. A. Tamasan, A. Timonov, and J. Veras, Stable reconstruction of regular 1harmonic maps with a given trace at the boundary , Appl. Anal 94 (2015), no. 6, 1098-1115. 2
- 38. Hans Triebel, Interpolation theory, function spaces, differential operators , 2nd ed., Johann Ambrosius Barth, Heidelberg, 1995. MR 1328645 (96f:46001) 16
- 39. Thomas Widlak and Otmar Scherzer, Hybrid tomography for conductivity imaging , Inverse Problems 28 (2012), no. 8, 084008. 1
- 40. Nanping Zhang, Electrical impedance tomography based on current density imaging , 1992. 1, 2
Department of Mathematics, University of Washington, Seattle, WA 98195-4350, USA
E-mail address : [email protected]
Department of Mathematics, University of Central Florida, Orlando, Florida 32816
E-mail address : [email protected] | null | [
"Carlos Montalto",
"Alexandru Tamasan"
] | 2014-08-02T21:32:34+00:00 | 2016-02-16T00:23:45+00:00 | [
"math-ph",
"math.MP",
"35R30, 35J65, 65N21"
] | Stability in Conductivity Imaging from Partial Measurements of One Interior Current | We prove a stability result in the hybrid inverse problem of recovering the
electrical conductivity from partial knowledge of one current density field
generated inside a body by an imposed boundary voltage. The region where
interior data stably reconstructs the conductivity is well defined by a
combination of the exact and perturbed data. |
1408.0426v1 | ## An Electrohydrodynamics Model for Non-equilibrium Electron and
## Phonon Transport in Metal Films after Ultra-short Pulse Laser Heating
Jun Zhou, 1,2 Nianbei Li, and Ronggui Yang 2 1, ♥
1 Department of Mechanical Engineering and Materials Science and Engineering Program,
University of Colorado, Boulder, CO 80309, USA
2 Center for Phononics and Thermal Energy Science, School of Physics Science and Engineering, Tongji University, Shanghai 200092, People's Republic of China
## ABSTRACT
The electrons and phonons in metal films after ultra-short pulse laser heating are in highly non-equilibrium states not only between the electron sub-system and the phonon sub-system but also within the electron sub-system. An electrohydrodynamics model consisting of the balance equations of electron density, energy density of electrons, and energy density of phonons is derived from the coupled non-equilibrium electron and phonon Boltzmann transport equations to study the nonlinear transport phenomena, such as the electron density fluctuation and the transient electrical current in metal films, after ultra-short pulse laser heating. The time-dependent temperature distributions is calculated by the coupled electron and phonon Boltzmann transport equations, the electrohydrodynamics model derived in this work, and the two-temperature model for different laser pulse durations, film thicknesses, and laser fluences. We find that the twotemperature model overestimates the electron temperature at the front surface of the film and underestimates the damage threshold when the nonlinear thermal transport of
♥ Email: [email protected]
electrons is important. The electrohydrodynamics model proposed in this work could be a more accurate prediction tool to study the non-equilibrium electron phonon transport process than the two-temperature model and it is much easier to be solved than the coupled electron and phonon Boltzmann transport equations.
KEYWORDS: electron-phonon coupling, laser-material interaction, metal thin film, electrohydrodynamics model, Boltzmann transport equation, two-temperature model
PACS numbers: 63.20.kd, 66.10.cd, 44.10.+i, 68.60.Dv
## I. INTRODUCTION
The study of the interaction of ultra-short pulse laser with materials has a wide range of applications in the fields of fundamental physics of electron-phonon (EP) interaction, 1,2,3 hot electron dynamics, 4,5,6,7,8 superconductivity, 9,10 and laser-material processing. 11,12,13,14,15,16 The energy deposited from ultra-short pulse laser could drive electrons and phonons to a highly nonequilibrium state. For laser-metal interaction, the energy temporarily stored in the electron sub-system is conducted away through two channels: i) electron transport and ii) coupling of electron lattice to the lattice which is then conducted away by phonons. 17 , 18 The interplay between these two processes determines the evolutions of both electrons and phonons.
The research on this topic can be traced back to as early as 1957. Kaganov et al . 17 presented a model for EP energy exchange which is still quite widely used. This phenomenological two-temperature model (TTM) assumes that the sub-systems of electrons and phonons can be described by their own temperatures and both the electron and phonon temperatures are much higher than the Debye temperature. The EP energy exchange rate can then be linearized as ) where ( p e T T G -e T is the electron temperature, p T is the phonon temperature, and G is the EP coupling constant. The coupled electron and phonon thermal transport could thus be described by the energy balance equations 18,19
$$C _ { e } ( T _ { e } ) \, \frac { \partial T _ { e } } { \partial t } = - \nabla \cdot \mathbf J _ { e, E } - G ( T _ { e } - T _ { p } ) + Q ( \mathbf r, t ) \,,$$
$$C _ { p } ( T _ { p } ) \frac { \partial T _ { p } } { \partial t } = - \nabla \cdot \mathbf J _ { p, E } + G ( T _ { e } - T _ { p } ) \,.$$
Here ) is the electronic heat capacity, ( e e T C ) is the lattice heat capacity, and ( p p T C ) is the energy deposition by the ultra-short pulse laser, , ( t Q r E e , J and E p , J are the energy current densities of electrons and phonons, respectively. The TTM follows closely the Fourier's law of heat conduction e p e e E e T T T ∇ -κ = ) , ( , J and p p p E p T T ∇ -κ = ) ( , J , where ) , ( p e e T T κ is the electronic thermal conductivity and ) ( p p T κ is the lattice (phononic) thermal conductivity.
Although the TTM has been widely used by many researchers, there are quite some limitations of TTM to describe the ultra-short pulse laser-material interaction, especially with the recent advances of femtosecond and attosecond lasers. One of the obvious drawback is not considering the transient electrical current flow due to non-equilibrium electrons:
- (1) e p e e E e T T T ∇ -κ = ) , ( , J used in TTM is valid only when the electrical current and the chemical potential gradient can be ignored.
- (2) The divergence of energy current density of electrons E e , J ⋅ ∇ -consists of not only Fourier's heat conduction but also the electron density accumulation, the Thomson effect, and the Joule heat generation. 20 The TTM considers the heat conduction and neglects the other mechanisms.
- (3) The approximation e p e e e p e e T T T T T T 2 ) , ( ] ) , ( [ ∇ ≈ ∇ ⋅ ∇ κ κ is used in the TTM. It is valid only when the thermal conductivity are temperature-independent. In addition, the electronic heat capacity is usually chosen to be proportional to the electron temperature which is valid only when the temperature is lower than Fermi temperature.
Currently, there have been a few works which address the non-equilibrium transport that considers transient electrical current and chemical potential gradient. Chen et al. 21 added an additional conservation equation of electron momentum which is derived from the BTE into the TTM to study the effect of electronic kinetic pressure on the electron and phonon temperature evolutions. As a result, they obtain significantly different electron and phonon temperature response from the TTM. The larger laser fluence is and shorter laser pulse duration is, the larger the difference between their model and the TTM is.
In this paper, we derive an electrohydrodynamics (EHD) model based on the coupled electron and phonon BTE to investigate the electron and phonon transport in metals after the ultra-short pulse laser heating. In this model, the energy current is driven by both the temperature gradient and the chemical potential gradient. The contributions to E e , J ⋅ ∇ -from the heat conduction, the electron density accumulation, the Thomson effect, and the Joule heat generation are considered. The paper is organized as follows. After a brief introduction of the BTE in Sec. IIA, we derive the EHD model in detail in Sec. IIB. In Sec. III, the results of the calculation of the electron density fluctuation, the transient electrical current, the evolutions of electron temperature and phonon temperature, and the laser fluence damage threshold are presented. Section IV concludes this work.
## II. THEORETICAL MODELS
Figure 1 shows the coupled non-equilibrium electron and phonon transport mechanisms in a metal film after ultra-short pulse laser heating. The surface of the film is
in x-y plane (perpendicular to z -direction) and the film thickness is L . The photon energy of the ultra-short pulse laser can be absorbed by electrons near the front surface ( x = 0) of the film. The intensity of absorption exponentially decays with the depth where δ is the optical absorption depth. Highly non-equilibrium states between the electron sub-system and the phonon sub-system are induced because the electrons are excited by ultra-short pulse laser to higher energy states. The highly non-equilibrium electrons will dissipate their energy through two channels: i) electron transport and ii) coupling of electron lattice to the lattice which is then conducted away by phonons. Diffusive reflection boundary conditions are used in this study by assuming that electrons and phononsare reflected back randomly when they reach the front surface or the rear surface of the film.
## A. Coupled electron and phonon BTE model
We can write the coupled electron and phonon BTE as follows: 22
$$\frac { \partial f _ { \mathbf k } ( \mathbf r, t ) } { \partial t } + \mathbf v _ { e, \mathbf k } \cdot \nabla f _ { \mathbf k } ( \mathbf r, t ) - \frac { e } { \hbar } \, \mathbf E \cdot \nabla _ { \mathbf k } f _ { \mathbf k } ( \mathbf r, t ) = \frac { \partial f _ { \mathbf k } ( \mathbf r, t ) } { \partial t } \Big | _ { c } + s ( \mathbf r, \mathbf k, t ) \,,$$
$$\frac { \partial n _ { \mathfrak { q } } ( \mathbf r, t ) } { \partial t } + \mathbf v _ { p } \cdot \nabla n _ { \mathfrak { q } } ( \mathbf r, t ) = \frac { \partial n _ { \mathfrak { q } } ( \mathbf r, t ) } { \partial t } \Big | _ { c },$$
where ) is the electron distribution function in the phase space with wave vector , ( t f r k k and position ) at time , , ( z y x = r t , ) is the phonon distribution function in the , ( t n r q phase space with wave vector q 23 and position r at time t . k ∇ is the wave vector gradient operator, and E is the external electric field. k e ε k k v ∇ = h 1 , is the electron velocity, where k ε is the kinetic energy of electron and h is the Planck constant. p v is
the phonon velocity. ) is the source term due to laser heating. , , ( t s k r 24 c t t f | / ) , ( ∂ ∂ r k is the electron collision term which includes the EP scattering term ep t t f | / ) , ( ∂ ∂ r k and the electron-electron scattering term ee t t f | / ) , ( ∂ ∂ r k . c t t n | / ) , ( ∂ ∂ r q is the phonon collision term which includes the EP scattering term ep t t n | / ) , ( ∂ ∂ r q and the phonon-phonon scattering term pp t t n | / ) , ( ∂ ∂ r q .
The EP scattering terms in Eq. (2) are calculated from a microscopic approach: 9
$$\frac { \partial f _ { \mathbf k } } { \partial t } \Big | _ { e p } = & - \frac { 2 \pi } { \hbar } \sum _ { \mathbf q } | \, M _ { \mathbf q } | ^ { 2 } \, \Big \{ \delta ( \varepsilon _ { _ { k } } - \varepsilon _ { _ { k ^ { \prime } } } - \hbar { \omega } _ { _ { q } } ) \Big [ n _ { \mathbf q } ( f _ { \mathbf k } - f _ { \mathbf k ^ { \prime } } ) + f _ { \mathbf k } ( 1 - f _ { \mathbf k } ) \Big ] \\ & - \delta ( \varepsilon _ { _ { k } } - \varepsilon _ { _ { k ^ { \prime } } } + \hbar { \omega } _ { _ { q } } ) \Big [ n _ { \mathbf q } ( f _ { \mathbf k ^ { \prime } } - f _ { \mathbf k } ) + f _ { \mathbf k ^ { \prime } } ( 1 - f _ { \mathbf k } ) \Big ] \Big ],$$
$$\frac { \partial n _ { \mathbf q } } { \partial t } \Big | _ { e p } = - \frac { 4 \pi } { \hbar } \sum _ { \mathbf k } | \, M _ { \mathbf q } \, | ^ { 2 } \ f _ { \mathbf k } ( 1 - f _ { \mathbf k } ) [ n _ { \mathbf q } \delta ( \varepsilon _ { _ { k } } - \varepsilon _ { _ { k } } + \hbar { \omega } _ { _ { q } } ) \\ - ( n _ { \mathbf q } + 1 ) \delta ( \varepsilon _ { _ { k } } - \varepsilon _ { _ { k } } - \hbar { \omega } _ { _ { q } } ) \Big ]$$
We drop ( , ) in the rest of this paper for simplification. Here t r q M is the EP scattering matrix elements, q ω h is the energy of phonons whose wave vector equals to the wave vector change of electron after the scattering ' k k q -= . Delta functions denote the energy conservation of the scattering processes. Electron spin degeneracy has been taken into account by the factor 2 in Eq. (3b).
To calculate the EP scattering terms in Eq. (3) in metal without doing the summation over three dimensional momentum space, the Eliashberg function 25 ) ( 2 ω α F is introduced similar as shown in Ref. [9]. We then have
$$\frac { \partial f _ { \mathbf k } } { \partial t } \Big | _ { \mathrm e p } = - 2 \pi \int d \omega \alpha _ { i } ^ { 2 } F ( \omega ) \int & d \varepsilon ^ { \left \{ } \delta ( \varepsilon _ { i } - \varepsilon ^ { \prime } - \hbar { \omega } ) \Big [ n _ { 0, \omega } ( f _ { 0, \varepsilon _ { i } } - f _ { 0, \varepsilon ^ { \prime } } ) + f _ { 0, \varepsilon _ { i } } ( 1 - f _ { 0, \varepsilon ^ { \prime } } ) \right ] \\ & - \delta ( \varepsilon _ { k } - \varepsilon ^ { \prime } + \hbar { \omega } ) \Big [ n _ { 0, \omega } ( f _ { 0, \varepsilon ^ { \prime } } - f _ { 0, \varepsilon _ { i } } ) + f _ { 0, \varepsilon ^ { \prime } } ( 1 - f _ { 0, \varepsilon _ { i } } ) \right ],$$
$$\frac { \partial n _ { \mathbf q } } { \partial t } \Big | _ { \mathrm e p } = - 2 \pi \Xi ( \mu ) \Big | \, d \varepsilon \Big | \, d \varepsilon ^ { \prime } \frac { \alpha ^ { 2 } F ( \omega ) } { F ( \omega ) } ( f _ { 0, \varepsilon } - f _ { 0, \varepsilon } ) \\ & \Big [ n _ { 0, \omega } \delta ( \varepsilon - \varepsilon ^ { + } \hbar { \omega } ) - ( n _ { 0, \omega } + 1 ) \delta ( \varepsilon - \varepsilon ^ { \prime } - \hbar { \omega } ) \Big ] \Big | _ { \omega = \omega _ { \mathbf q } },$$
where ) is the electron density states (DOS) at the chemical potential and ( µ Ξ ) is ( ω F the phonon DOS. k f ε , 0 is the equilibrium Fermi-Dirac distribution of electrons and ω , 0 n is the equilibrium Bose-Einstein distribution of phonons.
In non-equilibrium systems, the electron-electron scattering and the phonon-phonon scattering drive the non-equilibrium electron and phonon sub-systems towards to equilibrium ones, respectively. Therefore, we assume [ ] ) ( / | / , 0 k f f t f ee ee k τ ε --= ∂ ∂ k k 24 and [ ] ) using relaxation time approximation where ( / | / , 0 q n n t n pp pp q τ ω --= ∂ ∂ q q ) is ( k ee τ the electron-electron relaxation time and ) is the phonon-phonon relaxation time. In ( q pp τ this work, ) and ( k ee τ ) are assumed to be constants so that we could focus on the ( q pp τ EP scattering on the energy transfer pathway.
With the scattering terms explicitly written as above, the coupled electron and phonon BTE model shown in Eq. (2) can be solved iteratively for both directions ( 0 > z k and 0 ) by using finite difference method with a numerical scheme similar to that < z k described in Ref. [26]. In our calculation, the Eliashberg function is taken from Ref. [27] and the phonon DOS is taken from Ref. [28]. Both the front surface and rear surface are assumed to be rough so that the equilibrium distribution function due to diffusive reflection of electrons and phonons can be written at the boundaries: 29
$$f _ { \mathbf k } ( z = 0, t ) = f _ { 0, \varepsilon _ { \mathbf k } } ( z = 0, t ) \,, \ f _ { \mathbf k } ( z = L, t ) = f _ { 0, \varepsilon _ { \mathbf k } } ( z = L, t ) \,,$$
$$n _ { \mathfrak { q } } ( z = 0, t ) = n _ { 0, \omega _ { \mathfrak { q } } } ( z = 0, t ) \,, \ n _ { \mathfrak { q } } ( z = L, t ) = n _ { 0, \omega _ { \mathfrak { q } } } ( z = L, t ) \,.$$
Table I lists all the parameters used in the calculation of BTE.
## B. Electrohydrodynamics (EHD) Model
The coupled electron and phonon BTE is a set of multi-variable integral-differential equations in the phase space where the scattering integral is very complicated to be solved. 30 A convenient approach to simplify the problem is to use balance equations, instead of directly solving the BTE to obtain the distribution function of electrons and phonons, where the macroscopic variables such as electron density, electron temperature, and phonon temperature are calculated. The computational cost is remarkably reduced in spite of the losing of some detailed information in distribution functions. Here, we write a set of EHD equations with the electron density and energy density of electrons as macroscopic variables by multiplying 1/ V and V k / ε in Eq. (2a) and then summing over k , where V is the unit volume. 22
$$\frac { \partial N } { \partial t } = - \nabla \cdot { \mathbf J } _ { e, n } \,,$$
$$\frac { \partial U _ { e } } { \partial t } = - \nabla \cdot \mathbf J _ { e, E } - e \mathbf E \cdot \mathbf J _ { e, n } - G ( T _ { e } - T _ { p } ) + Q ( \mathbf r, t ) \,.$$
Here ∑ = k k f N 2 is the local electron density and ∑ = k k k v J f e n e , , 2 is the particle current density of electrons (n e e , J is the electrical current density). ∑ = k k f Ue k ε 2 is the energy
density of electrons and ∑ = k k k v J f k e E e ε , , 2 is the energy current density of electrons.
The factor 2 comes from electron spin degeneracy. ∑ = q v J q q p p n ω h is the thermal
current density carried by phonons. We focus our study on noble metals, the photoelectric
effect and inter-band transition which excites d - or -electrons to be itinerant electrons in f transition metals are not considered. Therefore, 2 0 since there is no net ) , , ( = ∑ k k r t s photon )
electron generated or annihilated in electron intra-band transition due to absorption as shown in Fig. 1. The electron energy source term is ∑ = k k r , , ( 2 t s Q k ε
which is assumed to be independent on the temperature. 19 The balance equation which is the same as Eq. 1(b) can also be obtained by multiplying V q / ω h in Eq. (2b) and then summing over q .
Under the free electron approximation, the left side of Eq. (6b) can be written as:
$$\frac { \partial U _ { e } } { \partial t } = \frac { \partial U _ { e } } { \partial \mu } \frac { \partial \mu } { \partial t } + \frac { \partial U _ { e } } { \partial T _ { e } } \frac { \partial T _ { e } } { \partial t } = \frac { \partial U _ { e } } { \partial \mu } \left ( \frac { \partial N } { \partial \mu } \right ) ^ { - 1 } \frac { \partial N } { \partial t } + C _ { e } ( T _ { e } ) \frac { \partial T _ { e } } { \partial t } \,,$$
where the electronic heat capacity is defined as e e e e e e T N N U T U T C ∂ ∂ ⎟ ⎟ ⎠ ⎞ ⎜ ⎜ ⎝ ⎛ ∂µ ∂ ∂µ ∂ -∂ ∂ = -1 ) ( which can be calculated as
$$C _ { e } ( T _ { e } ) = \gamma T _ { e } \left [ 1 - \frac { 3 } { 1 0 } \left ( \frac { k _ { B } T _ { e } } { \mu _ { 0 } } \right ) ^ { 2 } + O \left ( \frac { k _ { B } T _ { e } } { \mu _ { 0 } } \right ) ^ { 4 } \right ],$$
where 0 µ is the chemical potential at zero temperature. 31 See Appendix A for detailed derivations.
n e , J and E e , J in Eqs. (6a) and (6b) can be obtained by solving the BTE under the relaxation time approximation 22 as shown in Appendix B for details:
$$\mathbf J _ { e, n } = - \frac { \sigma } { e } \mathbf E - D _ { n } \nabla N - S _ { n } \nabla T _ { e },$$
$$\mathbf J _ { e, E } = - \left ( - T _ { e } \sigma \alpha + \frac { \mu \sigma } { e } \right ) \mathbf E - D _ { E } \nabla N - S _ { E } \nabla T _ { e } \,. \quad \quad \quad ( 9 b )$$
Here σ is the electrical conductivity, 0 0 2 3 2 N e Dn µ σ = is the diffusion coefficient of electron,
$$S _ { n } = - \frac { \sigma \alpha } { e } \frac { 2 \lambda - 1 } { 2 \lambda } \quad \text{is} \quad \text{the} \quad \text{Soret} \quad \text{coefficient}, \quad \alpha \quad \text{is} \quad \text{the} \quad \text{Seebeck}$$
$$\text{coefficient}, \ \ D _ { E } = - \frac { T _ { e } \sigma \alpha } { e } \frac { 2 \mu _ { 0 } } { 3 N _ { 0 } } + \mu D _ { n } \quad, \quad \text{and} \quad S _ { E } = \kappa _ { e } ^ { 0 } - T _ { e } \sigma \alpha ^ { 2 } \frac { 1 } { 2 \lambda } + \mu S _ { n } \quad, \quad \text{where}$$
$$\kappa _ { e } ^ { 0 } = \kappa _ { e } + T _ { e } \sigma \alpha ^ { 2 } \,. \, \text{Here } \, N _ { 0 } \text{ is the electron density without fluctuation} \, \lambda = - \alpha \left ( \frac { \pi ^ { 2 } k _ { B } ^ { 2 } T _ { e } } { 3 e \mu _ { 0 } } \right ) ^ { - 1 }$$
is almost a constant for given metal. 32
Then n e , J ⋅ ∇ -and E e , J ⋅ ∇ -in Eqs. (6a) and (6b) can be calculated as follows (see detailed derivation in Appendix C):
$$- \nabla \cdot \mathbf J _ { e, n } \approx D _ { n } \nabla ^ { 2 } N + S _ { n } \nabla ^ { 2 } T _ { e } - \frac { D _ { n } } { 3 N _ { 0 } } ( \nabla N ) ^ { 2 } - \frac { 2 S _ { n } ^ { \bullet } } { T _ { e } } ( \nabla T _ { e } ) ^ { 2 } - \frac { 2 D _ { n } } { T _ { e } } ( \nabla N \cdot \nabla T ),$$
$$- \nabla \cdot \mathbf J _ { e, E } \approx D _ { E } \nabla ^ { 2 } N + S _ { E } \nabla ^ { 2 } T _ { e } - \frac { D _ { E } } { 3 N _ { 0 } } \left ( \nabla N \right ) ^ { 2 } - \frac { 2 S _ { E } ^ { \prime } } { T _ { e } } \left ( \nabla T _ { e } \right ) ^ { 2 } - \frac { 2 D _ { E } } { T _ { e } } \left ( \nabla N \cdot \nabla T _ { e } \right ).$$
$$\text{Here } \, S _ { \, _ { n } } ^ { \prime } = - \frac { \sigma \alpha } { \ e } \frac { 4 \lambda - 1 } { 4 \lambda } \text{ and } S _ { \, _ { E } } ^ { \prime } = \kappa _ { _ { e } } ^ { 0 } - T _ { _ { e } } \sigma \alpha ^ { 2 } \frac { 1 } { 4 \lambda } + \mu S _ { \, _ { n } } ^ { \prime } \,.$$
In the rest of this work, we do not consider the external electric field for simplification. By substituting Eq. (10) into Eq. (6), the EHD model can finally be written as (see Appendix D for details):
$$\frac { \partial N } { \partial t } = D _ { n } \nabla ^ { 2 } N + S _ { n } \nabla ^ { 2 } T _ { e } - \frac { D _ { n } } { 3 N _ { 0 } } \left ( \nabla N \right ) ^ { 2 } - \frac { 2 S _ { n } ^ { \prime } } { T _ { e } } \left ( \nabla T _ { e } \right ) ^ { 2 } - \frac { 2 D _ { n } } { T _ { e } } \left ( \nabla N \cdot \nabla T \right ),$$
$$C _ { e } ( T _ { e } ) \frac { \partial T _ { e } } { \partial t } & = D \nabla ^ { 2 } N + S \nabla ^ { 2 } T _ { e } - \frac { D } { 3 N _ { o } } \left ( \nabla N \right ) ^ { 2 } - \frac { 2 S ^ { \prime } } { T _ { e } } \left ( \nabla T _ { e } \right ) ^ { 2 } - \frac { 2 D } { T _ { e } } \left ( \nabla N \cdot \nabla T _ { e } \right ) \\ & \quad - G ( T _ { e } - T _ { p } ) + Q,$$
$$C _ { p } ( T _ { p } ) \, \frac { \partial T _ { p } } { \partial t } = \kappa _ { p } ( T _ { p } ) \nabla ^ { 2 } T _ { p } + \frac { \partial \kappa _ { p } ( T _ { p } ) } { \partial T _ { p } } ( \nabla T _ { p } ) ^ { 2 } + G ( T _ { e } - T _ { p } ) \,,$$
$$\text{where } D = - \frac { T _ { e } \sigma \alpha } { e } \frac { 2 \mu _ { 0 } } { 3 N _ { 0 } } \frac { 2 \lambda - 1 } { 2 \lambda } \,, \, S = \kappa _ { e } ^ { 0 } - T _ { e } \sigma \alpha ^ { 2 } \frac { 4 \lambda - 1 } { 4 \lambda ^ { 2 } } \,, \, \text{and } S ^ { 0 } = \kappa _ { e } ^ { 0 } - T _ { e } \sigma \alpha ^ { 2 } \frac { 6 \lambda - 1 } { 8 \lambda ^ { 2 } } \,.$$
The models for the temperature dependence of the transport coefficients are chosen as
$$\text{follows in our calculation: } \sigma = \sigma _ { r n } \frac { T _ { r n } } { T _ { p } } \,, \, \alpha = \alpha _ { r n } \frac { T _ { e } } { T _ { r n } } \,, ^ { 3 2 } \, \kappa _ { e } ^ { 0 } = \kappa _ { e, r n } ^ { 0 } \frac { T _ { e } \, \vdash 1 8 } { T _ { p } } \, \text{ where } \sigma _ { r n } \,, \, \alpha _ { r n } \,, \, \text{ and}$$
0 , rt e κ are the transport coefficients when both electron temperature and phonon temperature are at room temperature K . The electron energy source term is 300 = rt T written as 19
$$Q ( { \mathbf r }, t ) = 0. 9 4 ( 1 - R ) I \frac { 1 } { \tau _ { p } \delta } \exp \left [ - \frac { z } { \delta } - 2. 7 7 \frac { t ^ { 2 } } { \tau _ { p } ^ { 2 } } \right ],$$
where R is the reflectivity, I is the fluence of laser pulse, and p τ is the laser pulse time duration. The time zero is noted as the center of laser pulse, 0. = t
The thermal-insulation boundary conditions for temperature and zero electrical current boundary conditions are used:
$$\nabla T _ { e } \Big | _ { z = 0 } = \nabla T _ { e } \Big | _ { z = L } = 0 \,, \quad \nabla T _ { p } \Big | _ { z = 0 } = \nabla T _ { p } \Big | _ { z = L } = 0 \,, \ \nabla N _ { e } \Big | _ { z = 0 } = \nabla N _ { e } \Big | _ { z = L } = 0 \,.$$
The parameters used in the EHD model calculation in gold thin film are listed in Table I.
## C. Comparison between TTM and EHD Model
By comparing TTM in Eq. (1) with EHD model in Eq. (11), the major differences between the proposed EHD model and the TTM are as follows:
(1). The addition of the balance equation on electron density in the EHD model (Eq. (11a)) enables us to study the electron density fluctuation and transient electrical current induced by ultra-short pulse laser heating. The chemical potential gradient µ ∇ is considered as the driving force for current flow in the EHD model, which is not even considered in the TTM model. A complete energy current density of electron n e Q e E e , , , J J J µ + = is considered in the EHD while n e , J µ is not included in TTM.
- (2). The divergence of energy current density of electron in the presence of electrical current is 20
$$- \nabla \cdot \mathbf J _ { e, E } = \nabla \cdot [ \mathcal { K } _ { e } ( T _ { e }, T _ { p } ) \nabla T _ { e } ] - \mu \nabla \cdot \mathbf J _ { e, n } - \xi \mathbf J _ { e, n } \cdot \nabla T _ { e } + \frac { 1 } { \sigma } [ e \mathbf J _ { e, n } ] ^ { 2 },$$
where ξ is the Thomson coefficient. Comparing to the TTM model, the EHD model considers the electron accumulation, the Thomson effect, and the Joule heat generation through the last three terms on the right side of Eq. (14)
- (3). The divergence of heat current of electrons is
$$\nabla \cdot [ \kappa _ { e } ( T _ { e }, T _ { p } ) \nabla T _ { e } ] = \kappa _ { e } ( T _ { e }, T _ { p } ) \nabla ^ { 2 } T _ { e } + \left [ \frac { \partial \kappa _ { e } ( T _ { e }, T _ { p } ) } { \partial T _ { e } } \right ] \nabla T _ { e } \right ) ^ { 2 } + \left [ \frac { \partial \kappa _ { e } ( T _ { e }, T _ { p } ) } { \partial T _ { p } } \right ] \nabla T _ { p } \cdot \nabla T _ { e } \,, \ ( 1 5 )$$
where the first term on the right side in describes the linear thermal transport due to the electron temperature gradient while the last two terms are additional nonlinear thermal transport terms. The TTM model only explicitly considers the linear transport term/ 19 Empirically, the nonlinear terms can be calculated when one has an explicit analytical temperature dependence of ) . Anisimov and Rathfeld , ( p e e T T κ 33 showed that p e e T T / ∝ κ
when F e T T << and 2 / 5 e e T ∝ κ when F e T T ~ , where TF is the Fermi temperature of material (usually over 10 K in metals). A more complicated analytical expression of 4 e κ is given by Refs. [34,35]. The question here is whether it is correct to directly substitute the above temperature dependence of e κ into Eq. (15)? A revisit is needed from more basic approaches such as the BTE. We assume p e e T T / ∝ κ as an example and set the Seebeck coefficient 0 which means = α 0 and = D e e S S κ κ = = = 0 ' , then the divergence of heat current in Eq. (11b) becomes
$$\kappa _ { e } ( T _ { e }, T _ { p } ) \nabla ^ { 2 } T _ { e } - \frac { 2 \kappa _ { e } ( T _ { e }, T _ { p } ) } { T _ { e } } \left ( \nabla T _ { e } \right ) ^ { 2 }.$$
In contrast, the divergence of heat current in Eq. (1a) in the TTM can be rewritten as:
$$\kappa _ { e } ( T _ { e }, T _ { p } ) \nabla ^ { 2 } T _ { e } + \frac { \kappa _ { e } ( T _ { e }, T _ { p } ) } { T _ { e } } ( \nabla T _ { e } ) ^ { 2 } - \frac { \kappa _ { e } ( T _ { e }, T _ { p } ) } { T _ { p } } \nabla T _ { p } \cdot \nabla T _ { e } \,.$$
The coefficients of linear term e T 2 ∇ in Eq. (16) and Eq. (17) are the same, and the coefficient of nonlinear term ( ) 2 e T ∇ in Eq. (16) is e e T / 2 κ -which is different from e e T / κ in Eq. (17), and there is one more term e p p e T T T ∇ ⋅ ∇ -κ in Eq. (17). The difference between the EHD model and the TTM can be neglected only when ( ) e e e T T T 2 2 / ∇ << ∇ and ( ) e p e p T T T T 2 / ∇ << ∇ ⋅ ∇ . When (∇ ) e e e T T T 2 2 ~ / ∇ and ( ) e p e p T T T T 2 ~ / ∇ ∇ ⋅ ∇ one have to directly solve the BTE or solve the EHD model instead.
## III. RESULTS AND DISCUSSIONS
In the following, we compare the calculation results from the coupled electron and phonon BTE model, the proposed EHD model and the classical TTM for the coupled electron and phonon transport in gold thin films after ultra-short pulse heating, as show in Fig. 1.
## A. Electron density fluctuation and transient electrical current
We first compare the evolution of electron temperature at the front surface for a 50nmthick gold film after an ultra-short pulse laser heating with fluence 2 1mJ/cm = I and pulse duration 96fs calculated from the BTE model, the EHD model, and the TTM. = p τ The EP coupling constant is chosen to be K throughout this paper W/m 3 10 1 . 2 16 × = G which is obtained by fitting the experimental data measured by Brorson et al. in Ref. [8], which is close to the values in literature, 2 2 K. W/m 3 10 4 -K W/m 3 10 . 16 16 × × Error! Bookmark not defined. As shown in Fig. 2(a), the electron temperature at the front surface calculated from the EHD model is in good agreement with the prediction from the BTE while the TTM overestimates the electron temperature.
The large temperature gradient due to the non-equilibrium ultra-short pulse laser heating can induce electron density redistribution and transient electrical current due to electron diffusion and thermoelectric effect. Such electron density fluctuation and transient electrical current after ultra-short pulse laser heating can be calculated by the BTE model and the EHD model while the Fourier-like TTM model is not able to. Figure 2(b) shows the electron density fluctuation in gold film at different time delays, =0.05ps, t 0.1ps, and 0.2ps. At the beginning, the amplitude of the electron density fluctuation is on the order of 10 3 24 /m , which is about 1% of the electron density near Fermi surface
0 0 / µ T k N B . Figure 2(c) shows the particle current density of electrons in gold film at different time delays, =0ps, 0.1ps, 0.2ps. At the beginning, a negative particle current is t noted due to flow of particles towards the front surface as a result of thermoelectric effect. However, the particle current density becomes positive, i.e., flow away from the front surface at =0.1ps, due to the diffusion of electrons driven by electron density gradient as t shown in Fig. 2(b). The maximum amplitude of the particle current density is about 2 30 /sm 10 which results an electrical current density on the order of 10 2 11 A/m . After t =0.2ps, the particle current density becomes negligible. In our calculation, the Seebeck coefficient of gold is positive 36 which results in a negative Soret coefficient ( 0) in < n S Eq. (9a). This negative Soret coefficient results in the flow of electrons towards the front surface driven by temperature gradient. In other metals with negative Seebeck coefficient and positive Soret coefficient (for example, Al, Pb et al. ), the electrons would flow away from the front surface driven by temperature gradient.
## B. Dependence of temperature evolution on laser pulse duration, laser fluence and film thickness
The time scale that the laser-deposited energy is conducted away from the front surface is on the order of sub-picosecond. When the laser pulse time duration is smaller than this time scale, most energy absorbed from laser is stored at the front surface and the interior of the film is not heated up yet at the beginning of the time evolution. This results in an abrupt temperature drop near the front surface. In other words, e T ∇ is very large and ( ) e e e T T T 2 2 ~ / ∇ ∇ is satisfied which means that the nonlinear thermal transport could be important as we discussed in Sec. IIC. Figure 2(a), Fig. 3(a), and Fig. 3(b) show
the evolution of electron temperature at the front surface of the film with thickness 50nm for different laser pulse time durations, = L fs , 150fs, and 200fs , when the 96 = p τ laser fluence is 2 1mJ/cm . For all these three time durations, the electron temperature = I calculated from the EHD model is closer to that calculated from BTE while the TTM overestimate the electron temperature. The maximum electron temperatures for the BTE and the EHD model are almost the same when 96fs . The calculated maximum = p τ electron temperatures are 634K from the BTE, 660K from the EHD model, and 686K from the TTM when the pulse duration is 150fs. When the duration time increases = p τ to 200fs, the maximum electron temperatures become 621K from the BTE, 653K from the EHD model, and 672K from the TTM. The reason is that ( ) e e e T T T 2 2 ~ / ∇ ∇ for shorter time duration and the nonlinear thermal transport must be considered.
When the electrons are heated by the laser pulse, they would transport inside the film with the Fermi velocity F v (about 1 4 m/s in gold), and then be reflected back by 10 . 6 × the rear surface. These hot electrons return to the front surface after a time interval, F v L / 2 ~ . When this time interval is smaller than the laser pulse duration, the temperature evolution at the front surface can be affected by the boundary reflection from the rear surface which results in highly nonlinear transport. Therefore, the thickness of film is another important parameter in our study. Figures 3(c) and 3(d) show the evolution of electron temperature at front surface of the film for different thicknesses, 40nm and 60nm , when the laser fluence is = L 2 1mJ/cm and the laser pulse duration = I is 96fs . Figure 2(a) also shows the results with = p τ 50nm while other conditions = L are the same. For all these three film thickness, the electron temperature calculated from
the EHD model is closer to that from the BTE, and the TTM overestimates the electron temperature. The calculated maximum electron temperatures are 696K from the BTE, 723K from the EHD model, and 750K from the TTM when 40nm. When the film = L thickness increases to 50nm , the electron temperature calculated from the EHD model is almost the same as that from the BTE. When the film thickness is 60nm , the electron temperature calculated from the EHD model is slightly smaller than that from the BTE.
Larger laser fluence results in higher electron temperature at the front surface and the electron distribution is farther away from the equilibrium distribution. Therefore, the electron transport is highly nonlinear for large laser fluence. Figures 4(a) and 4(b) show the evolution of electron temperature at front surface of the film for different laser fluences, 2 5mJ/cm and 10mJ/cm = I 2 when the film thickness is 50nm and the laser = L pulse time duration is 96fs , respectively. Figure 2(a) also shows the results with = p τ 2 1mJ/cm when other conditions are the same. For = I 2 1mJ/cm and 5mJ/cm = I 2 , the electron temperature calculated from the EHD model is close to that calculated from the BTE for all the time delays considered. The TTM overestimates the electron temperature. For higher laser fluence 2 10mJ/cm , both the EHD model and the TTM underestimate = I the electron temperature in comparison with the BTE at the beginning of the time evolution (time delay<1.5ps). The reason is that both the EHD model and the TTM assume that the electron distribution is slightly deviated from the Fermi-Dirac distribution which does not hold at the beginning of the time evolution for high laser fluence. When time delay>1.5ps, the electron temperatures calculated from the EHD model and the BTE become getting closer since the electron-electron scattering drives the
electron sub-system from non-equilibrium distribution to equilibrium one which is called thermalization process. Error! Bookmark not defined.
From Fig. 3 and Fig. 4, we find that the EHD model is more accurate than TTM in thinner film and shorter laser pulse time duration because of the contribution from transient electrical current and nonlinear thermal transport. When the thermalization process is important for higher laser fluence, both the EHD model and the TTM underestimate the electron temperature at the beginning of the time evolution.
## C. Damage thresholds
We now study the laser damage threshold calculated from the EHD model and the TTM with high laser fluences. We do not show the results from the BTE calculations due to the computational cost. The BTE model calculates the distribution functions in wave vector and position phase-space. Larger laser fluence requires larger truncation wave vector that significantly increases the computational cost. Figure 5(a) shows that the time evolutions of both electron temperature and phonon temperature at the front surface of the film calculated from the EHD model slightly differ from that calculated from the TTM when nm . Therefore, the converged temperature (electron temperature 25 = L becomes equal to phonon temperature) calculated from the EHD model is also slightly smaller than that from TTM. When the film thickness increases to 50nm, the maximum electron temperature calculated from the EHD model could be 800K lower than that from TTM and the converged temperature calculated from EHD model is 100K higher than that from TTM as shown in Fig. 5(b). Overall, the EHD model gives a lower converged
temperature than the TTM, which means that more energy at the front surface is conducted away from the surface.
When the laser fluence is large enough, the phonon temperature at the front surface can reach the melting point of the metal, which is 1337K for gold. Such laser fluence is called damage fluence threshold. As we shown in Fig. 5, the converged temperature depends on the film thickness. Therefore, the damage fluence threshold is also a function of film thickness. Figure 6 shows the calculated damage fluence thresholds from the EHD model and the TTM for an ultra-short pulse laser for different film thickness with a laser pulse duration 96fs . As shown in Figs. 5 and 6, the TTM overestimates the = p τ converged temperature at front surface of the film and the difference of this overestimation increases with the film thickness. Therefore, the EHD model gives a larger damage fluence threshold in comparison with the TTM. For example, when the film thickness is smaller than 25nm, the damage fluence thresholds calculated from the EHD model and the TTM are both around 125mJ/cm 2 . When the film thickness is increased to 60nm, the damage fluence threshold calculated from the EHD model is 2 mJ/cm which is much larger than that calculated from the TTM, 236mJ/cm . 375 2
## IV. CONCLUSIONS
In summary, we established an EHD model which consists of the balance equations of electron density, energy density of electrons, and energy density of phonons to investigate the coupled non-equilibrium electron and phonon transport in thin metal films after the ultra-short pulse laser heating. The non-equilibrium transport of electrons such as the electron density fluctuation and transient electrical current are considered in the
EHD model beyond the phenomenological TTM. By comparing the calculated results from the BTE for different laser pulse time durations, film thicknesses, and laser fluences, we found that the EHD model is more accurate than the TTM which usually overestimates the surface electron temperature when the nonlinear thermal transport in electron transport is important. We find that shorter laser pulse duration and thinner metal film result in stronger nonlinear transport. This model gives a more accurate tool to study the non-equilibrium coupled electron and phonon transport process than the TTM and it is much easier to be solved than the BTE.
Acknowledgements : J. Z. would like to thank Dr. J. L. Cheng and Dr. Y . Y . Wang for valuable discussions. R. Y. would like to acknowledge the support from AFOSR (Grant No. FA9550-11-1-0109) and NSF (Grant No. 0846561). J. Z. and B. L. are supported by the National Natural Science Foundation of China grant no. 11334007. J. Z. is also supported by the program for New Century Excellent Talents in Universities grant no. NCET-13-0431.
## APPENDIX A. ELECTRONIC HEAT CAPACITY
We calculate the temperature-dependent electronic heat capacity by using the Sommerfeld expansion method under the free electron approximation and local equilibrium approximation, the local electron density and energy density can be written as:
$$N = \chi \overset { \infty } { \int } d \varepsilon _ { k } \, \frac { \varepsilon _ { k } ^ { 1 / 2 } } { \exp [ ( \varepsilon _ { k } - \mu ) / k _ { B } T _ { e } + 1 ] } = \chi ( k _ { B } T _ { e } ) ^ { 3 / 2 } \, F _ { 1 / 2 } ( \eta ) \,, \quad \quad ( \text{A1a} )$$
$$U _ { e } = \chi \overset { \infty } { \int } d \varepsilon _ { k } \, \frac { \varepsilon _ { k } ^ { 3 / 2 } } { \exp [ ( \varepsilon _ { k } - \mu ) / k _ { B } T _ { e } + 1 ] } = \chi ( k _ { B } T _ { e } ) ^ { s / 2 } \, F _ { 3 / 2 } ( \eta ) \,, \quad \, \quad ( \text{A1b} )$$
where T k / , ) ( F is the dimensionless integral e B µ η = η j
( ) ∫ ∞ --+ -η = 0 1 ] 1 ) / /[exp( ) ( ε ε ε η e B k j k k j e B j T k d T k F , the electron density of states is
2 / 1 ) ( k k χε ε = Ξ , 2 / 3 2 2 2 2 ⎟ ⎠ ⎞ ⎜ ⎝ ⎛ = h m V π χ , V is the unit volume, m is the electron mass, and
$$j = - 1 / 2, 1 / 2, 3 / 2 \,.$$
The derivatives in Eq. (7) can be calculated as
$$\frac { \partial N } { \partial \mu } = \frac { 1 } { 2 } \, \chi ( k _ { _ { B } } T _ { e } ) ^ { 1 / 2 } \, F _ { - 1 / 2 } ( \eta )$$
$$\frac { \partial N } { \partial T _ { e } } = \frac { 1 } { 2 T _ { e } } \, \chi ( k _ { B } T _ { e } ) ^ { 3 / 2 } \left [ 3 F _ { _ { 1 / 2 } } ( \eta ) - \frac { \mu } { k _ { B } T _ { e } } \, F _ { _ { - 1 / 2 } } ( \eta ) \right ],$$
$$\frac { \partial U _ { e } } { \partial \mu } = \frac { 3 } { 2 } \, \chi ( k _ { _ { B } } T _ { e } ) ^ { 3 / 2 } \, F _ { _ { 1 / 2 } } ( \eta ) \,,$$
$$\frac { \partial U _ { e } } { \partial T _ { e } } = \frac { 1 } { 2 T _ { e } } \, \chi ( k _ { B } T _ { e } ) ^ { 5 / 2 } \left [ 5 F _ { 3 / 2 } ( \eta ) - \frac { \mu } { k _ { B } T _ { e } } 3 F _ { 1 / 2 } ( \eta ) \right ].$$
$$\text{Here we used } \frac { d F _ { 1 / 2 } ( \eta ) } { d \eta } = \frac { 1 } { 2 } F _ { - 1 / 2 } ( \eta ) \, \ \frac { d F _ { 3 / 2 } ( \eta ) } { d \eta } = \frac { 3 } { 2 } F _ { 1 / 2 } ( \eta ) \. \ \text{The Taylor expansion of}$$
) can be found in Ref. [31] ( η j F
$$F _ { 3 / 2 } ( \eta ) = \frac { 2 } { 5 } \eta ^ { 5 / 2 } \left [ 1 + \frac { 5 \pi ^ { 2 } } { 8 } \eta ^ { - 2 } - \frac { 7 \pi ^ { 4 } } { 3 8 4 } \eta ^ { - 4 } + O ( \eta ^ { - 6 } ) \right ],$$
$$F _ { 1 / 2 } ( \eta ) = \frac { 2 } { 3 } \eta ^ { 3 / 2 } \left [ 1 + \frac { \pi ^ { 2 } } { 8 } \eta ^ { - 2 } + \frac { 7 \pi ^ { 4 } } { 6 4 0 } \eta ^ { - 4 } + O ( \eta ^ { - 6 } ) \right ],$$
$$F _ { - 1 / 2 } ( \eta ) = 2 \eta ^ { 1 / 2 } \left [ 1 - \frac { \pi ^ { 2 } } { 2 4 } \eta ^ { - 2 } - \frac { 7 \pi ^ { 2 } } { 3 8 4 } \eta ^ { - 4 } + O ( \eta ^ { - 6 } ) \right ].$$
By ignoring the high order terms, the electronic heat capacity defined for Eq. (7) can be written as
$$C _ { e } ( T _ { e } ) & = \frac { \partial U _ { e } } { \partial T _ { e } } - \frac { \partial U _ { e } } { \partial \mu } \left ( \frac { \partial N } { \partial \mu } \right ) ^ { - 1 } \frac { \partial N } { \partial T _ { e } } \\ & = \frac { 1 } { 2 T _ { e } } \, \chi ( k _ { b } T _ { e } ) ^ { 5 / 2 } \left [ 5 F _ { 3 / 2 } ( \eta ) - 9 F _ { 1 / 2 } ^ { 2 } ( \eta ) / F _ { - 1 / 2 } ( \eta ) \right ] \\ & \approx \frac { 1 } { 3 } \, \chi \pi ^ { 2 } k _ { b } ^ { 2 } \mu ^ { 1 / 2 } T _ { e } \left [ 1 - \frac { 3 1 \pi ^ { 2 } } { 1 2 0 } \left ( \frac { k _ { b } T _ { e } } { \mu } \right ) ^ { 2 } \right ] \\ & \approx \gamma T _ { e } \left [ 1 - \frac { 3 \pi ^ { 2 } } { 1 0 } \left ( \frac { k _ { b } T _ { e } } { \mu _ { 0 } } \right ) ^ { 2 } \right ] \\ & \quad \lceil \quad \longrightarrow \frac { \pi ^ { 2 } \left ( \left ( \left ( \right ) ^ { 2 } \right ) } { \nu ^ { 2 } } \right ] \quad \left ( \left ( \left ) ^ { 2 } \right ) \right )$$
Here, we use the relation ⎥ ⎥ ⎦ ⎤ ⎢ ⎢ ⎣ ⎡ ⎟ ⎟ ⎠ ⎞ ⎜ ⎜ ⎝ ⎛ -≈ 2 0 2 0 12 1 ) ( µ π µ µ e B e T k T and replace µ e B T k 31 in the square bracket by 0 µ e B T k where the higher order terms are ignored. 2 2 0 0 2 / 1 0 2 2 2 3 1 B B k N k π µ µ χπ γ = =
is the ideal heat capacity constant.
## APPENDIX B. PARTICLE CURRENT DENSITY AND ENERGY CURRENT DENSITY OF ELECTRONS
The particle current density and energy current density of electrons are calculated by solving electron BTE under relaxation time approximation. The distribution function in the BTE can be written into two parts k k k , 1 , 0 f f f + = , 22 where 1 1 / ) ( , 0 + = -µ e B T k k e f ε k is the equilibrium Fermi-Dirac distribution. The non-equilibrium part driven by thermodynamic force along z-direction can be written as:
$$f _ { 1, k } = e E _ { z } \frac { \hbar { k } _ { z } \tau _ { k } } { m } \frac { \partial f _ { 0, k } } { \partial \varepsilon _ { k } } - \frac { \hbar { k } _ { z } \tau _ { k } } { m } \frac { \partial f _ { 0, k } } { \partial z } \,,$$
with k , 1 f under the relaxation time approximation. The particle current density and the energy current density of electrons alone -direction are defined as z
$$J _ { e, n, z } = \sum _ { k } v _ { e, k, z } f _ { 1, k }$$
$$J _ { e, E, z } = \sum _ { k } v _ { e, k, z } \mathcal { E } _ { k } f _ { 1, k } \,,$$
We replace 2 z v by 2 m k 3 / ε using isotropic condition, and substitute Eq. (B1) into Eq. (B2).
$$J _ { e, n, z } = & \frac { 2 e } { 3 m } \sum \tau _ { k } \varepsilon _ { k } \left [ \frac { \partial f _ { 0, k } } { \partial \varepsilon _ { k } } \, E _ { z } - \frac { 1 } { e } \frac { \partial f _ { 0, k } } { \partial z } \right ] \\ = & - \frac { N } { e } \langle \tau _ { k } \varepsilon _ { k } ^ { 3 / 2 } \rangle \Big ( e E _ { z } + \frac { \partial \mu } { \partial z } \Big ) - \frac { N } { e T _ { e } } \langle \tau _ { k } \varepsilon _ { k } ^ { 3 / 2 } ( \varepsilon _ { k } - \mu ) \rangle \frac { \partial T _ { e } } { \partial z },$$
$$J _ { e, E, z } = & \frac { 2 e } { 3 m } \sum \tau _ { k } \varepsilon _ { k } ^ { 2 } \left [ \frac { \partial f _ { 0, k } } { \partial \varepsilon _ { k } } E _ { z } - \frac { 1 } { e } \frac { \partial f _ { 0, k } } { \partial z } \right ] \\ = & - \frac { N } { e } \langle \tau _ { k } \varepsilon _ { k } ^ { s / 2 } \rangle \left ( e E _ { z } + \frac { \partial \mu } { \partial z } \right ) - \frac { N } { e T _ { e } } \langle \tau _ { k } \varepsilon _ { k } ^ { s / 2 } ( \varepsilon _ { k } - \mu ) \rangle \frac { \partial T _ { e } } { \partial z },$$
where the relation ⎥ ⎦ ⎤ ⎢ ⎣ ⎡ ∂ ∂ -µ + ∂ ∂µ ∂ε ∂ -= ∂ ∂ z T e T e z f z f k k k ε , 0 , 0 is used for the derivation. The bracket
) ( k A ε denotes the integration of arbitrary function ) ( k A ε
$$\left \langle A ( \varepsilon _ { k } ) \right \rangle = - \frac { 2 e } { 3 m N } \chi \overset { \infty } { \int } d \varepsilon _ { k } A ( \varepsilon _ { k } ) \frac { \partial f _ { 0, k } } { \partial \varepsilon _ { k } } \,,$$
The derivative of chemical potential z ∂ ∂µ can be transformed to the derivative of electron density z N ∂ ∂ and electron temperature z T e ∂ ∂ as follows:
$$\frac { \partial \mu } { \partial z } & = \left ( \frac { \partial N } { \partial \mu } \right ) ^ { - 1 } \frac { \partial N } { \partial z } - \frac { \partial N } { \partial T _ { e } } \left ( \frac { \partial N } { \partial \mu } \right ) ^ { - 1 } \frac { \partial T _ { e } } { \partial z } \\ & = \frac { 2 } { \chi ( k _ { B } T _ { e } ) ^ { 1 / 2 } F _ { - 1 / 2 } ( \eta ) } \frac { \partial N } { \partial z } - \left [ \frac { 3 k _ { B } F _ { 1 / 2 } ( \eta ) } { F _ { - 1 / 2 } ( \eta ) } - \frac { \mu } { T _ { e } } \right ] \frac { \partial T _ { e } } { \partial z }. \\ & \approx \frac { 1 } { \chi \mu ^ { 1 / 2 } } \frac { \partial N } { \partial z } - \frac { \pi ^ { 2 } k _ { B } ^ { 2 } T _ { e } } { 6 \mu } \frac { \partial T _ { e } } { \partial z } \\ \longrightarrow \lambda \cdot \quad \cdot \quad \cdot \quad \cdot \quad \cdot \quad \cdot \quad \cdot \quad \cdot \quad \cdot \quad \cdot \quad \cdot \quad \cdot \quad \cdot$$
Then Eqs. (B3a) and (B3b) can be rewritten by substituting Eq. (B5) into them
$$\int n \in \psi \colon \infty \, \infty \, \frac { 1 } { 2 } \, \infty \, \infty \, \frac { 1 } { 3 } \, \infty \, \infty \, \frac { 1 } { 4 } \, \infty \, \infty \, \infty \, \infty \, \infty \, \infty \, \infty \, \infty \, \infty \, \infty \, \infty \, \infty \, \infty \, \infty \, \infty \, \infty \, \infty \, \infty \, \infty \, \infty \, \infty \, \infty \, \infty \, \infty \, \infty \, \infty \, \infty \, \infty \, \infty \, \infty \, \infty \, \infty \, \infty \, \infty \, \infty \, \infty \, \infty \, \infty \, \infty \, \infty \, \incolon \\ J _ { e, n, z } = & - \frac { N } { e T _ { e } } \left \langle \tau _ { k } \varepsilon _ { k } ^ { 3 / 2 } \right \rangle e E _ { z } - \frac { N } { e \chi \mu ^ { 1 / 2 } } \left \langle \tau _ { k } \varepsilon _ { k } ^ { 3 / 2 } \right \rangle + \left \langle \tau _ { k } \varepsilon _ { k } ^ { 3 / 2 } \left ( \varepsilon _ { k } - \mu \right ) \right \rangle \right ] \frac { \partial T _ { e } } { \partial z } \\ = & - \frac { \sigma } { e } E _ { z } - D _ { n } \frac { \partial N } { \partial z } - S _ { n } \, \frac { \partial T _ { e } } { \partial z }, \\ = & - \frac { \sigma } { e } E _ { z } - D _ { n } \frac { \partial N } { \partial z } - S _ { n } \, \frac { \partial T _ { e } } { \partial z }, \\ = & \quad \varepsilon \quad \varepsilon \quad \varepsilon \quad \varepsilon \, \quad \infty \, \infty \, \infty \, \infty \, \infty \, \infty \, \infty \, \infty \, \infty \, \infty \, \infty \, \infty \, \infty \, \infty \, \infty \, \infty \, \infty \, \infty \, \infty \, \infty \, \infty \, \infty \, \infty \, \infty \, \infty \, \infty \, \infty \, \infty \, \infty \, \infty \, \infty \, \infty \, \infty \, \infty \, \infty \, \infty \, \infty \, \infty \, \infty \, \infty \. \infty \, \infty \, \infty \, \infty \, \infty \, \infty \, \infty \, \infty \, \infty \, \infty \, \infty \, \infty \, \infty \, \infty \, \infty \, \infty \, \infty \, \infty \, \infty \, \infty \, \infty \, \infty \, \infty \, \infty \, \infty \, \infty \, \infty \, \infty \, \infty \, \infty \, \infty \, \infty \, \infty \, \infty \, \infty \, \infty \, \infty \, \infty \, \infty \, \infty \: \infty \, \infty \, \infty \, \infty \, \infty \, \infty \, \infty \, \infty \, \infty \, \infty \, \infty \, \infty \, \infty \, \infty \, \infty \, \infty \, \infty \, \infty \, \infty \, \infty \, \infty \, \infty \, \infty \, \infty \, \infty \, \infty \, \infty \, \infty \, \infty \, \infty \, \infty \, \infty \, \infty \, \infty \, \infty \, \infty \, \infty \, \infty \, \infty \, \infty \infty \, \infty \, \infty \, \infty \, \infty \, \infty \, \infty \, \infty \, \infty \, \infty \, \infty \, \infty \, \infty \, \infty \, \infty \, \infty \, \infty \, \infty \, \infty \, \infty \, \infty \, \infty \, \infty \, \infty \, \infty \, \infty \, \infty \, \infty \, \infty \, \infty \, \infty \, \infty \, \infty \, \infty \, \infty \, \infty \, \infty \, \infty \, \infty \, \infty \numpy \, \infty \, \infty \, \infty \, \infty \, \infty \, \infty \, \infty \, \infty \, \infty \, \infty \, \infty \, \infty \, \infty \, \infty \, \infty \, \infty \, \infty \, \infty \, \infty \, \infty \, \infty \, \infty \, \infty \, \infty \, \infty \, \infty \, \infty \, \infty \, \infty \, \infty \, \infty \, \infty \, \infty \, \infty \, \infty \, \infty \, \infty \, \infty \, \infty \, \inosity \, \infty \, \infty \, \infty \, \infty \, \infty \, \infty \, \infty \, \infty \, \infty \, \infty \, \infty \, \infty \, \infty \, \infty \, \infty \, \infty \, \infty \, \infty \, \infty \, \infty \, \infty \, \infty \, \infty \, \infty \, \infty \, \infty \, \infty \, \infty \, \infty \, \infty \, \infty \, \infty \, \infty \, \infty \, \infty \, \infty \, \infty \, \infty \, \infty \, \inocity \, \infty \, \infty \, \infty \, \infty \, \infty \, \infty \, \infty \, \infty \, \infty \, \infty \, \infty \, \infty \, \infty \, \infty \, \infty \, \infty \, \infty \, \infty \, \infty \, \infty \, \infty \, \infty \, \infty \, \infty \, \infty \, \infty \, \infty \, \infty \, \infty \, \infty \, \infty \, \infty \, \infty \, \infty \, \infty \, \infty \, \infty \, \infty \, \infty \, \inclusive \, \inclusive \, \inclusive \, \inclusive \, \inclusive \, \inclusive \, \inclusive \, \inclusive \, \inclusive \, \inclusive \, \inclusive \, \inclusive \, \inclusive \, \inclusive \, \inclusive \, \inclusive \, \inclusive \, \inclusive \, \inclusive \, \inclusive \, \inclusive \, \inclusive \, \inclusive \, \inclusive \, \inclusive \, \inclusive \, \inclusive \, \inclusive \, \inclusive \, \inclusive \, \inclusive \, \inclusive \, \inclusive \, \inclusive \, \inclusive \, \inclusive \, \inclusive \, \inclusive \, \inclusive \, \inclusive \, \invisible \, \inclusive \, \inclusive \, \inclusive \, \inclusive \, \inclusive \, \inclusive \, \inclusive \, \inclusive \, \inclusive \, \inclusive \, \inclusive \, \inclusive \, \inclusive \, \inclusive \, \inclusive \, \inclusive \, \inclusive \, \inclusive \, \inclusive \, \inclusive \, \inclusive \, \inclusive \, \inclusive \, \inclusive \, \inclusive \, \inclusive \, \inclusive \, \inclusive \, \inclusive \, \inclusive \, \inclusive \, \inclusive \, \inclusive \, \inclusive \, \inclusive \, \inclusive \, \inclusive \, \inclusive \, \inclusive \, \inulative \, \inclusive \, \inclusive \, \inclusive \, \inclusive \, \inclusive \, \inclusive \, \inclusive \, \inclusive \, \inclusive \, \inclusive \, \inclusive \, \inclusive \, \inclusive \, \inclusive \, \inclusive \, \inclusive \, \inclusive \, \inclusive \, \inclusive \, \inclusive \, \inclusive \, \inclusive \, \inclusive \, \inclusive \, \inclusive \, \inclusive \, \inclusive \, \inclusive \, \inclusive \, \inclusive \, \inclusive \, \inclusive \, \inclusive \, \inclusive \, \inclusive \, \inclusive \, \inclusive \, \inclusive \, \inclusive \, \inexclusive \, \inclusive \, \inclusive \, \inclusive \, \inclusive \, \inclusive \, \inclusive \, \inclusive \, \inclusive \, \inclusive \, \inclusive \, \inclusive \, \inclusive \, \inclusive \, \inclusive \, \inclusive \, \inclusive \, \inclusive \, \inclusive \, \inclusive \, \inclusive \, \inclusive \, \inclusive \, \inclusive \, \inclusive \, \inclusive \, \inclusive \, \inclusive \, \inclusive \, \inclusive \, \inclusive \, \inclusive \, \inclusive \, \inclusive \, \inclusive \, \inclusive \, \inclusive \, \inclusive \, \inclusive \, \inclusive \, \inlike \, \inclusive \, \inclusive \, \inclusive \, \inclusive \, \inclusive \, \inclusive \, \inclusive \, \inclusive \, \inclusive \, \inclusive \, \inclusive \, \inclusive \, \inclusive \, \inclusive \, \inclusive \, \inclusive \, \inclusive \, \inclusive \, \inclusive \, \inclusive \, \inclusive \, \inclusive \, \inclusive \, \inclusive \, \inclusive \, \inclusive \, \inclusive \, \inclusive \, \inclusive \, \inclusive \, \inclusive \, \inclusive \, \inclusive \, \inclusive \, \inclusive \, \inclusive \, \inclusive \, \inclusive \, \inclusive \, \inless \, \inclusive \, \inclusive \, \inclusive \, \inclusive \, \inclusive \, \inclusive \, \inclusive \, \inclusive \, \inclusive \, \inclusive \, \inclusive \, \inclusive \, \inclusive \, \inclusive \, \inclusive \, \inclusive \, \inclusive \, \inclusive \, \inclusive \, \inclusive \, \inclusive \, \inclusive \, \inclusive \, \inclusive \, \inclusive \, \inclusive \, \inclusive \, \inclusive \, \inclusive \, \inclusive \, \inclusive \, \inclusive \, \inclusive \, \inclusive \, \inclusive \, \inclusive \, \inclusive \, \inclusive \, \inclusive \, \inclusively \inclusive \, \inclusive \, \inclusive \, \inclusive \, \inclusive \, \inclusive \, \inclusive \, \inclusive \inclusive \, \inclusive \, \inclusive \, \inclusive \, \inclusive \, \inclusive \, \inclusive \, \inclusive \, \inclusive \, \inclusive \, \inclusive \, \inclusive \, \inclusive \, \inclusive \, \inclusive \, \inclusive \, \inclusive \, \inclusive \, \inclusive \, \inclusive \, \inclusive \, \inclusive \, \inclusive \, \inclusive \, \inclusive \, \inclusive \, \inclusive \, \inclusive \, \inclusive \, \inclusive \, \inclusive \, \inclusive \, \inclusive \inclusive \, \inclusive \, \inclusive \, \inclusive \, \inclusive \, \inclusive \, \inclusive \, \inclusive \, \inclusive \, \inclusive \, \inclusive \, \inclusive \, \inclusive \, \inclusive \, \inclusive \, \inclusive \, \inclusive \, \inclusive \, \inclusive \, \inclusive \, \inclusive \, \inclusive \, \inclusive \, \inclusive \, \inclusive \, \inclusive \, \inclusive \, \inclusive \, \inclusive \, \inclusive \, \inclusive \, \inclusive \, \begin{matrix} \, \inclusive \, \inclusive \, \inclusive \, \inclusive \, \inclusive \, \inclusive \, \inclusive \, \inclusive \, \inclusive \, \inclusive \, \inclusive \, \inclusive \, \inclusive \, \inclusive \, \inclusive \, \inclusive \, \inclusive \, \inclusive \, \inclusive \, \inclusive \, \inclusive \, \inclusive \, \inclusive \, \inclusive \, \inclusive \, \inclusive \, \inclusive \, \inclusive \, \inclusive \, \inclusive \, \inclusive \, \inclusive \, \inclusive \, \inclusive \, \inclusive \, \inclusive \, \inclusive \, \inclusive \, \inclusive \, \inwikipedia \, \inclusive \, \$$
$$& \varepsilon \quad \varnothing _ { \sigma } \quad \varnothing _ { \sigma } \\ J _ { _ { e, E, \tau } } = & - \frac { N } { e } \langle \tau _ { _ { k } } \varepsilon _ { _ { k } } ^ { 5 / 2 } \rangle e E _ { \tau } - \frac { N } { e \chi \mu ^ { 1 / 2 } } \langle \tau _ { _ { k } } \varepsilon _ { _ { k } } ^ { 5 / 2 } \rangle \frac { \partial N } { \partial z } \\ & - \frac { N } { e T _ { e } } \left [ - \frac { \pi ^ { 2 } ( k _ { _ { B } } T _ { e } ) ^ { 2 } } { 6 \mu } \langle \tau _ { _ { k } } \varepsilon _ { _ { k } } ^ { 5 / 2 } \rangle + \langle \tau _ { _ { k } } \varepsilon _ { _ { k } } ^ { 5 / 2 } ( \varepsilon _ { _ { k } } - \mu ) \rangle \right ] \frac { \partial T _ { e } } { \partial z } \\ = & - \left ( - T _ { e } \sigma \alpha + \frac { \mu \sigma } { e } \right ) E _ { \tau } - D _ { E } \frac { \partial N } { \partial z } - S _ { E } \frac { \partial T _ { e } } { \partial z }.$$
The transport coefficients are defined as follows: the electrical conductivity is 2 / 3 k k Ne ε τ σ = , the diffusion constant of electron 0 0 2 2 / 1 2 3 2 1 N e e Dn µ σ χµ σ ≈ = , the Soret
$$\text{coefficient is } S _ { n } = - \frac { \sigma \alpha } { e } \frac { 2 \lambda - 1 } { 2 \lambda } \,, \text{ the Seebeck coefficient is } \alpha = - \frac { 1 } { e T _ { e } } \frac { \left \langle \tau _ { t } \varepsilon _ { k } ^ { 3 / 2 } \left ( \varepsilon _ { k } - \mu \right ) \right \rangle } { \left \langle \tau _ { k } \varepsilon _ { k } ^ { 3 / 2 } \right \rangle } \,,$$
$$D _ { E } = - \frac { T _ { e } \sigma \alpha } { e } \frac { 2 \mu _ { 0 } } { 3 N _ { 0 } } + \mu D _ { n } \ \, \ \text{ and } \ S _ { E } = \kappa _ { e } ^ { 0 } - T _ { e } \sigma \alpha ^ { 2 } \frac { 1 } { 2 \lambda } + \mu S _ { n } \ \. \ \text{ The thermal }$$
conductivity is 2 0 σα κ κ e e e T -= where ( ) 2 2 / 3 0 µ ε ε τ κ -= k k k e e eT N . The relations
λ µ π α = 0 2 2 3 e T e k B , 2 / 3 0 0 3 2 χµ = N , and 0 µ µ ≈ are also used 31 where λ is a material parameter. 32 Mathematical tricks
$$\text{ics} \quad \left \langle \tau _ { k } \varepsilon _ { k } ^ { 5 / 2 } \right \rangle = \left \langle \tau _ { k } \varepsilon _ { k } ^ { 3 / 2 } \left ( \varepsilon _ { k } - \mu \right ) \right \rangle + \mu \left \langle \tau _ { k } \varepsilon _ { k } ^ { 3 / 2 } \right \rangle \quad \text{and}$$
$$\left \langle \tau _ { k } \mathcal { E } _ { k } ^ { 5 / 2 } ( \mathcal { E } _ { k } - \mu ) \right \rangle = \left \langle \tau _ { k } \mathcal { E } _ { k } ^ { 3 / 2 } ( \mathcal { E } _ { k } - \mu ) ^ { 2 } \right \rangle + \mu \left \langle \tau _ { k } \mathcal { E } _ { k } ^ { 3 / 2 } ( \mathcal { E } _ { k } - \mu ) \right \rangle \text{ are use} \right \rangle$$
are used in the calculation.
The current components in x and y direction can be calculated in the same way. We can then extend Eqs. (B6a) and (B6b) to three dimension equations
$$\mathbf J _ { e, n } = - \frac { \sigma } { e } \mathbf E - D _ { n } \nabla N - S _ { n } \nabla T _ { e } \,,$$
$$\mathbf J _ { e, E } = - \left ( - T _ { e } \sigma \alpha + \frac { \mu \sigma } { e } \right ) \mathbf E - D _ { E } \nabla N - S _ { E } \nabla T _ { e } \,.$$
## APPENDIX C. DIVERGENCES OF ELECTRON DENSITY AND ENERGY DENSITY OF ELECTRONS
The divergences of electron density and energy density of electrons can be calculated as:
$$- \nabla \cdot \mathbf J _ { e, n } = - \frac$$
$$- \nabla \cdot \mathbf J _ { e, E } = - \frac$$
when the thermodynamic forces such as temperature gradient and chemical potential gradient are alone z -direction, i.e. 0 , , , , = ∂ ∂ -= ∂ ∂ -y n e x n e J y J x and
$$- \frac { \partial } { \partial x } J _ { e, E, x } =$$
We assume that only the equilibrium distribution function in k , 1 f vary with position and the external electric field is absent. Eqs. (C1a) and (C1b) become
$$\sum _ { \substack { w a t i n d e s t i n d e s$$
$$\begin{array} {$$
Here the second order derivative of distribution function is
$$\frac { \partial ^ { 2 } f _ { 0, k } } { \partial z ^ { 2 } } = & - \frac { \partial f _ { 0, k } } { \partial \varepsilon _ { k } } \left [ \frac { 1 } { k _ { 2 } T _ { e } } \frac { e ^ { ( e _ { k } + \mu ) / k _ { 2 } T _ { e } } } { e ^ { ( e _ { k } - \mu ) / k _ { 2 } T _ { e } } } + 1 } \right ] \left ( \frac { \partial \mu } { \partial z } + \frac { \varepsilon _ { k } - \mu } { T _ { e } } \frac { \partial T _ { e } } { \partial z } \right ) ^ { 2 } \\ & + \frac { \partial f _ { 0, k } } { \partial \varepsilon _ { k } } \frac { 2 } { T _ { e } } \frac { \partial T _ { e } } { \partial z } \left ( \frac { \partial \mu } { \partial z } + \frac { \varepsilon _ { k } - \mu } { T _ { e } } \frac { \partial T _ { e } } { \partial z } \right ) - \frac { \partial f _ { 0, k } } { \partial \varepsilon _ { k } } \left ( \frac { \partial ^ { 2 } \mu } { \partial z ^ { 2 } } + \frac { \varepsilon _ { k } - \mu } { T _ { e } } \frac { \partial ^ { 2 } T _ { e } } { \partial z ^ { 2 } } \right )$$
The first term on the right in Eq. (C3) is symmetric on the chemical potential, its contribution to z n e J z , , ∂ ∂ -and z E e J z , , ∂ ∂ -is negligible. That is why we use ' ≈ ' in Eqs.
(C2a) and (C2b). 2 2 z ∂ ∂ µ in Eqs. (C2a) and (C2b) can be transformed to
$$\frac { \partial ^ { 2 } \mu } { \partial z ^ { 2 } } = \left ( \frac { \partial N } { \partial \mu } \right ) ^ { - 1 } \left [ \frac { \partial ^ { 2 } N } { \partial z ^ { 2 } } - \frac { \partial N } { \partial T _ { e } } \frac { \partial ^ { 2 } T _ { e } } { \partial z ^ { 2 } } - \frac { \partial } { \partial z } \left ( \frac { \partial N } { \partial \mu } \right ) \frac { \partial \mu } { \partial z } - \frac { \partial } { \partial z } \left ( \frac { \partial N } { \partial T _ { e } } \right ) \frac { \partial T _ { e } } { \partial z } \right ].$$
And z ∂ ∂µ in Eqs. (C2a), (C2b), and (C4) can be transformed to z N ∂ ∂ and z T e ∂ ∂ using Eq.
(B5). Then Eqs. (C2a) and (C2b) are rewritten as
$$( B 5 ). \text{ Then Eqs. } ( C 2 a ) \text{ and } ( C 2 b ) \text{ are rewritten as } \\ - \frac { \partial } { \partial z } J _ { e, n, z } \left ( \frac { N } { \exp } \frac { N } { \exp } \langle \tau _ { k } \varepsilon _ { k } ^ { 3 / 2 } \rangle \frac { \partial ^ { 2 } N } { \partial z ^ { 2 } } + \frac { N } { \exp } \left [ - \frac { \pi ^ { 2 } ( k _ { b } T _ { e } ) ^ { 2 } } { 6 \mu } \langle \tau _ { k } \varepsilon _ { k } ^ { 3 / 2 } \rangle + \langle \tau _ { k } \varepsilon _ { k } ^ { 3 / 2 } ( \varepsilon _ { - } \mu ) \rangle \right ] \frac { \partial ^ { 2 } T _ { e } } { \partial z ^ { 2 } } \\ & - \frac { N } { 2 e \chi ^ { 2 } \mu ^ { 2 } } \langle \tau _ { k } \varepsilon _ { k } ^ { 3 / 2 } \rangle \left ( \frac { \partial N } { \partial z } \right ) ^ { 2 } - \left [ \frac { 2 N } { \exp } \langle \tau _ { k } \varepsilon _ { k } ^ { 3 / 2 } ( \varepsilon _ { - } \mu ) \rangle - \frac { \pi ^ { 2 } k _ { b } } { 6 \mu } \langle \tau _ { k } \varepsilon _ { k } ^ { 3 / 2 } \rangle \right ] \left ( \frac { \partial T _ { e } } { \partial z } \right ) ^ { 2 } \\ & - \frac { 2 N } { e T _ { e } \chi \mu ^ { 1 / 2 } } \langle \tau _ { k } \varepsilon _ { k } ^ { 3 / 2 } \rangle \frac { \partial N } { \partial z } \frac { \partial T _ { e } } { \partial z } \\ & = D _ { n } \frac { \partial ^ { 2 } N } { \partial z ^ { 2 } } + S _ { n } ^ { \ } \frac { \partial ^ { 2 } T _ { e } } { \partial z ^ { 2 } } - \frac { D _ { n } } { 3 N _ { 0 } } \left ( \frac { \partial N } { \partial z } \right ) ^ { 2 } - \frac { 2 S ^ { \prime } _ { n } } { T _ { e } } \left ( \frac { \partial T _ { e } } { \partial z } \right ) ^ { 2 } - \frac { 2 D _ { n } } { T _ { e } } \frac { \partial N } { \partial z } \frac { \partial T _ { e } } { \partial z }, \\ \Delta \quad \lambda ^ { \prime } \quad \Delta ^ { 2 } \lambda ^ { \prime } \quad \lambda ^ { \prime } \Gamma \quad \mu ^ { 2 } ( \L _ { k } \ \ T \ \L ^ { 2 } \. \.$$
$$\Lambda ^ { \prime } \, \dot { \ } d z ^ { \prime } \quad \Lambda ^ { \prime } \, \dot { \ } d z ^ { \prime } \quad \Lambda ^ { \prime } \quad T _ { e } \, \left \{ \, \dot { \ } d z \, \right \} \quad T _ { e } \, \left \{ \, \dot { \ } d z \, \right \} \quad T _ { e } \, \left \{ \, \dot { \ } d z \, \right \} \, \\ - \frac { \partial } { \partial } J _ { e, E, \varepsilon } \approx \frac { N } { e \chi \mu ^ { \prime 2 } } \left \langle \tau _ { e } \varepsilon _ { k } ^ { s / 2 } \right \rangle \frac { \partial ^ { 2 } N } { \partial z ^ { 2 } } + \frac { N } { e T _ { e } } \left [ - \frac { \pi ^ { 2 } ( k _ { B } T _ { e } ) ^ { 2 } } { 6 \mu } \left \langle \tau _ { e } \varepsilon _ { k } ^ { s / 2 } \right \rangle + \left \langle \tau _ { e } ^ { s / 2 } _ { k } ( e _ { k } - \mu ) \right \rangle \right ] \frac { \partial ^ { 2 } T _ { e } } { \partial z ^ { 2 } } \\ - \frac { N } { 2 e \chi ^ { 2 } \mu ^ { 2 } } \left \langle \tau _ { e } ^ { s / 2 } _ { k } \right \rangle \left ( \frac { \partial N } { \partial z } \right ) ^ { 2 } - \left [ \frac { 2 N } { e T _ { e } ^ { 2 } } \left \langle \tau _ { e } ^ { s / 2 } _ { k } ( e _ { k } - \mu ) \right ) - \frac { \pi ^ { 2 } k _ { B } ^ { 2 } } { 6 \mu } \left \langle \tau _ { e } ^ { s / 2 } _ { k } \right \rangle \right ) \left ( \frac { \partial T _ { e } } { \partial z } \right ) ^ { 2 } \\ - \frac { 2 N } { e T _ { \chi } \mu ^ { \prime 2 } } \left \langle \tau _ { e } ^ { s / 2 } _ { k } \right \rangle \frac { \partial N } { \partial z } \frac { \partial T _ { e } } { \partial z } \\ = & \, D _ { E } \frac { \partial ^ { 2 } N } { \partial z ^ { 2 } } + S _ { E } \frac { \partial ^ { 2 } T _ { e } } { \partial z ^ { 2 } } \frac { D _ { E } } { 3 N _ { 0 } } \left ( \frac { \partial N } { \partial z } \right ) ^ { 2 } - \frac { 2 S _ { E } } { T _ { e } } \left ( \frac { \partial T _ { e } } { \partial z } \right ) ^ { 2 } - \frac { 2 D _ { E } } { T _ { e } } \frac { \partial N } { \partial z } \frac { \partial T _ { e } } { \partial z }, \\ \\ \tau \alpha \alpha \, 4 \lambda - 1 \quad \Lambda ^ { \prime } \quad \Lambda ^ { \prime } \quad \Lambda ^ { \prime } \quad \Lambda ^ { \prime } \quad \Lambda ^ { \prime } \quad \Lambda ^ { \prime } \quad \Lambda ^ { \prime }$$
$$\text{where } S _ { \, _ { n } } ^ { \prime } = - \frac { \sigma \alpha } { e } \frac { 4 \lambda - 1 } { 4 \lambda } \text{ and } S _ { \, _ { E } } ^ { \prime } = \kappa _ { e } ^ { 0 } - T _ { e } \sigma \alpha ^ { 2 } \frac { 1 } { 4 \lambda } + \mu S _ { \, _ { n } } ^ { \prime } \,.$$
Eqs. (C5a) and (C5b) can be extended to three dimension form
$$- \nabla \cdot \mathbf J _ { e, n } \approx D _ { n } \nabla ^ { 2 } N + S _ { n } \nabla ^ { 2 } T _ { e } - \frac { D _ { n } } { 3 N _ { 0 } } ( \nabla N ) ^ { 2 } - \frac { 2 S _ { n } ^ { \prime } } { T _ { e } } ( \nabla T _ { e } ) ^ { 2 } - \frac { 2 D _ { n } } { T _ { e } } ( \nabla N \cdot \nabla T ) \,,$$
$$- \nabla \cdot \mathbf J _ { e, E } \approx D _ { E } \nabla ^ { 2 } N + S _ { E } \nabla ^ { 2 } T _ { e } - \frac { D _ { E } } { 3 N _ { 0 } } ( \nabla N ) ^ { 2 } - \frac { 2 S _ { E } } { T _ { e } } ( \nabla T _ { e } ) ^ { 2 } - \frac { 2 D _ { E } } { T _ { e } } ( \nabla N \cdot \nabla T _ { e } ).$$
## APPENDIX D. BALANCE EQUATION OF ENERGY DENSITY OF ELECTRONS
$$\text{Using the relation in } \text{ } \text{ } \text{ } \text{ } \text{ } \text{ } \text{ } \text{ } \text{ } \text{ } \text{ } \text{ } \text{ } \text{ } \text{ } \text{ } \text{ } \text{ } \text{ } \text{ } \text{ } \text{ } \text{ } \text{ } \text{ } \text{ } \text{ } \text{ } \text{ } \text{ } \text{ } \text{ } \text{ } \text{ } \text{ } \text{ } \text{ } \text{ } \text{ } \text{ } \text{ } \text{ } \text{ } \text{ } \text{ } \text{ } \text{ } \text{ } \text{ } \text{ } \text{\ } \text{ } \text{ } \text{ } \text{ } \text{ } \text{ } \text{ } \text{ } \text{ } \text{ } \text{ } \text{ } \text{ } \text{ } \text{ } \text{ } \text{ } \text{ } \text{ } \text{ } \text{ } \text{ } \text{ } \text{ } \text{ } \text{ } \text{ } \text{ } \text{ } \text{ } \text{ } \text{ } \text{ } \text{ } \text{ } \text{ } \text{ } \text{ } \text{ } \text{ } \text{ } \text{ } \text{ } \text{ } \text{ } \text{ } \text{ } \text{ } \text{ } \text
\text{ } \text{ } \text{ } \text{ } \text{ } \text{ } \text{ } \text{ } \text{ } \text{ } \text{ } \text{ } \text{ } \text{ } \text{ } \text{ } \text{ } \text{ } \text{ } \text{ } \text{ } \text{ } \text{ } \text{ } \text{ } \text{ } \text{ } \text{ } \text{ } \text{ } \text{ } \text{ } \text{ } \text{ } \text{ } \text{ } \text{ } \text{ } \text{ } \text{ } \text{ } \text{ } \text{ } \text{ } \text{ } \text{ } \text{ } \text{ } \text{ } \text{ the balance}$$
equation Eq. (9b) in the absence of external electric field becomes
$$\frac { \partial U _ { e } } { \partial t } = \frac { \partial U _ { e } } { \partial \mu } \left ( \frac { \partial N } { \partial \mu } \right ) ^ { - 1 } \frac { \partial N } { \partial t } + C _ { e } ( T _ { e } ) \, \frac { \partial T _ { e } } { \partial t } = - \nabla \cdot \mathbf J _ { e, E } \, - \, G ( T _ { e } \, - \, T _ { p } ) \, + \, Q ( \mathbf r, t ) \,.$$
Eq. (D1) can be rewritten as
$$C _ { e } ( T _ { e } ) \frac { \partial T _ { e } } { \partial t } = - \nabla \cdot \mathbf J _ { e, E } - \frac { \partial U _ { e } } { \partial \mu } \left ( \frac { \partial N } { \partial \mu } \right ) ^ { - 1 } \frac { \partial N } { \partial t } - G ( T _ { e } - T _ { p } ) + Q ( \mathbf r, t ) \,.$$
Using the divergences of electron density and energy density of electrons obtained in Eqs.
(C6a) and (C6b), the first two terms on the right side of Eq. (D2) are
$$- \nabla \cdot \mathbf J _ { e, E } - \frac { \partial U _ { e } } { \partial \mu } \left ( \frac { \partial N } { \partial \mu } \right ) ^ { - 1 } \frac { \partial N } { \partial t } \approx - \nabla \cdot \mathbf J _ { e, E } + \mu \left [ 1 + \frac { \pi ^ { 2 } \left ( k _ { b } T _ { e } \right ) ^ { 2 } } { 6 \mu ^ { 2 } } \right ] \nabla \cdot \mathbf J _ { e, n } \\ = D \nabla ^ { 2 } N + S \nabla ^ { 2 } T _ { e } - \frac { D } { 3 N _ { 0 } } \left ( \nabla N \right ) ^ { 2 } - \frac { 2 S ^ { \prime } } { T _ { e } } \left ( \nabla T _ { e } \right ) ^ { 2 } - \frac { 2 D } { T _ { e } } \left ( \nabla N \cdot \nabla T _ { e } \right ),$$
$$\text{where } \ D = - \frac { T _ { e } \sigma \alpha } { e } \frac { 2 \mu _ { 0 } } { 3 N _ { 0 } } \frac { 2 \lambda - 1 } { 2 \lambda } \,, \, S = \kappa _ { e } ^ { 0 } - T _ { e } \sigma \alpha ^ { 2 } \, \frac { 4 \lambda - 1 } { 4 \lambda ^ { 2 } } \,, \, \text{and } S ^ { \prime } = \kappa _ { e } ^ { 0 } - T _ { e } \sigma \alpha ^ { 2 } \, \frac { 6 \lambda - 1 } { 8 \lambda ^ { 2 } } \,. \text{ The}$$
$$\text{relations} \ \frac { \partial N } { \partial t } = - \nabla \cdot \mathbf J _ { e, \eta } \text{ and } \ \frac { \partial U _ { e } } { \partial \mu } \left ( \frac { \partial N } { \partial \mu } \right ) ^ { - 1 } = 3 k _ { _ { B } } T _ { e } \frac { F _ { 1 / 2 } ( \eta ) } { F _ { - 1 / 2 } ( \eta ) } \approx \mu \left [ 1 + \frac { \pi ^ { 2 } \left ( k _ { _ { B } } T _ { e } \right ) ^ { 2 } } { 6 \mu ^ { 2 } } \right ] \text{ are } \text{ used.}$$
Combining Eqs. (D2) and (D3), the balance equation of energy density of electrons is finally written as:
$$C _ { e } ( T _ { e } ) \frac { \partial T _ { e } } { \partial t } & = D \nabla ^ { 2 } N + S \nabla ^ { 2 } T _ { e } - \frac { D } { 3 N _ { 0 } } \left ( \nabla N \right ) ^ { 2 } - \frac { 2 S } { T _ { e } } \left ( \nabla T _ { e } \right ) ^ { 2 } - \frac { 2 D } { T _ { e } } \left ( \nabla N \cdot \nabla T _ { e } \right ) \\ & \quad - G ( T _ { e } - T _ { p } ) + Q ( { \mathbf r }, t ).$$
Table I. Parameters used in the calculation of the BTE model and the EHD model.
| R a | 0.93 | δ a | 15.3 nm |
|--------------|---------------------|--------|----------------------|
| rt σ b | m / 10 52 . 4 7 Ω × | rt α c | μ V/K 94 . 1 |
| 0 , rt e κ a | W/mK 315 | λ c | -1.48 |
| 0 µ b | 5.5 eV | 0 N b | 3 28 m / 10 86 . 5 × |
| γ a | 2 3 K J/m 9 . 62 | p C a | K J/m 70 3 |
| p v b | 3240m/s | ee τ d | 0.04ps |
| pp τ d | 0.08ps | | |
a Ref. [19]; [28]; [32]; Ref. [37] b c d
## Figure Captions
FIG. 1 (Color online) Schematic diagram of the coupled non-equilibrium electron and phonon transport in metal film after ultra-short pulse laser heating. The film thickness is L and the surface of the metal film is in x-y plane. The low energy electrons (black dot) near the front surface are excited to be higher energy ones (red dot) after absorbing a photon. The absorption intensity exponentially decays with the radiation penetration depth δ . The hot electrons release energy through two channels: transport to the rear surface and colliding with the lattice to emit phonons, i.e. EP scattering. When the electrons reach both the front and rear surfaces, they are scattered back randomly if a rough surface is assumed. In this work, diffusive reflection boundary conditions of electrons and phonons are used.
FIG. 2 (Color online) (a) Time-dependent electron temperature at the front surface of gold film calculated from the BTE, the EHD model, and theTTM. Evolution of (b) electron density fluctuation and (c) particle current density of electrons in the film calculated from the BTE and the EHD models at different delay time, respectively. The calculations use a laser fluence 2 mJ/cm and film thickness 1 = I nm as input parameters. 50 = L
FIG. 3 (Color online) Time-dependent electron temperature at the front surface of the film calculated from the BTE, the EHD model, and the TTM after ultra-short pulse laser heating with different thicknesses and laser durations of (a) nm and 50 = L fs , (b) 150 = p τ nm and 50 = L fs , (c) 200 = p τ nm and 40 = L fs , (d) 96 = p τ nm and 60 = L fs . 96 = p τ The calculations use laser fluence 2 mJ/cm 1 = I as input parameter.
FIG. 4 (Color online) Time-dependent electron temperature at front surface of the film calculated from the BTE, the EHD model, and the TTM for different laser fluences of 2 mJ/cm 5 and 10mJ/cm 2 . The calculations use laser duration fs and film 96 = p τ thickness nm as input parameters. 50 = L
FIG. 5 (Color online) Time-dependent electron and phonon temperature at the front surface calculated from the EHD model and the TTM for different film thicknesses of 25nm and 50nm for a high laser fluence 2 mJ/cm with a laser duration 100 = I fs . 96 = p τ
FIG. 6 (Color online) Comparison of the damage threshold for a fs laser pulse as 96 = p τ a function of film thickness, calculated from the EHD model and the TTM.
Figure 1
FIG. 1 (Color online) Schematic diagram of the coupled non-equilibrium electron and phonon transport in metal film after ultra-short pulse laser heating. The film thickness is L and the surface of the metal film is in x-y plane. The low energy electrons (black dot) near the front surface are excited to be higher energy ones (red dot) after absorbing a photon. The absorption intensity exponentially decays with the radiation penetration depth δ . The hot electrons release energy through two channels: transport to the rear surface and colliding with the lattice to emit phonons, i.e. EP scattering. When the electrons reach both the front and rear surfaces, they are scattered back randomly if a rough surface is assumed. In this work, diffusive reflection boundary conditions of electrons and phonons are used.
Figure 2
FIG. 2 (Color online) (a) Time-dependent electron temperature at the front surface of gold film calculated from the BTE, the EHD model, and the TTM. Evolution of (b) electron density fluctuation and (c) particle current density of electrons in the film calculated from the BTE and the EHD models at different delay time, respectively. The calculations use a laser fluence 2 mJ/cm and film thickness 1 = I nm as input parameters. 50 = L
Figure 3
FIG. 3 (Color online) Time-dependent electron temperature at the front surface of the film calculated from the BTE, the EHD model, and the TTM after ultra-short pulse laser heating with different thicknesses and laser durations of (a) nm and 50 = L fs , (b) 150 = p τ nm and 50 = L fs , (c) 200 = p τ nm and 40 = L fs , (d) 96 = p τ nm and 60 = L fs . 96 = p τ The calculations use laser fluence 2 mJ/cm 1 = I as input parameter.
Figure 4
FIG. 4 (Color online) Time-dependent electron temperature at front surface of the film calculated from the BTE, the EHD model, and the TTM for different laser fluences of 2 mJ/cm 5 and 10mJ/cm 2 . The calculations use laser duration fs and film 96 = p τ thickness nm as input parameters. 50 = L
Figure 5
FIG. 5 (Color online) Comparison of time-dependent electron and phonon temperature at the front surface calculated from the EHD model and the TTM for different film thicknesses of 25nm and 50nm for a high laser fluence 2 mJ/cm 100 = I with a laser duration fs . 96 = p τ
Figure 6
FIG. 6 (Color online) Comparison of the damage threshold for a fs laser pulse as 96 = p τ a function of film thickness, calculated from the EHD model and the TTM.
## REFERENCES
| 1 P. B. Corkum, F. Brunel, N. K. Sherman, and T. Srinivasan-Rao, Phys. Rev. Lett. 61 , |
|---------------------------------------------------------------------------------------------|
| 2886 (1988). |
| 2 J. G. Fujimoto, J. M. Liu, E. P. Ippen, and N. Bloembergen, Phys. Rev. Lett. 53 , 1837 |
| (1984). |
| 3 H. E. Elsayed-Ali, T. B. Norris, M.A. Pessot, and G. A. Mourou, Phys. Rev. Lett. 58 , |
| 1212 (1986). |
| 4 G. L. Eesley, Phys. Rev. Lett. 51 , 2140 (1983). |
| 5 C. Suarez, W. E. Bron, and T. Juhasz, Phys. Rev. Lett. 75 , 4536 (1995). |
| 6 W. S. Fann, R. Storz, H. W. K. Tom, and J. Bokor, Phys. Rev. Lett. 68 , 2834 (1992). |
| 7 R. W. Schoenlein, W. Z. Lin, J. G. Fujimoto, and G. L. Eesley, Phys. Rev. Lett. 58 , 1680 |
| (1987). |
| 8 S. D. Brorson, J. G. Fujimoto, and E. P. Ippen, Phys. Rev. Lett. 59 , 1962 (1987). |
| 9 P. B. Allen, Phys. Rev. Lett. 59 , 1460 (1987). |
| 10 S. D. Brorson, A. Kazeroonian, J. S. Moodera, D. W. Face, T. K. Cheng, E. P. Ippen, M. |
| S. Dresselhaus, and G. Dresselhaus, Phys. Rev. Lett. 64 , 2172 (1990). |
| 11 M. Bass, Laser Materials Processing (North-Holland, Amsterdam, 1993). |
| 12 H. Häkkinen and U. Landman, Phys. Rev. Lett. 71 , 1023 (1993). |
| 13 C. L. Cleveland, U. Landman, and R. N. Barnett, Phys. Rev. Lett. 49 , 790 (1982). |
| 14 C. Schäfer, H. M. Urbassek, and L. V. Zhigilei, Phys. Rev. B 66 , 115404 (2002). |
| 15 K. Sokolowski-Tinten, J. Bialkowski, A. Cavalleri, D. von der Linder, A. Opatin, J. |
| Meyer-ter-Vehn, and S. I. Anisimov, Phys. Rev. Lett. 81 , 224 (1998). |
| 16 V. Schmidt, W. Husinsky, and G. Zetz, Phys. Rev. Lett. 85 , 3516 (2000). |
|---------------------------------------------------------------------------------------------|
| 17 M. I. Kaganov, I. M. Lifshits, and L. V. Tanatarov, Sov. Phys. JETP 4 , 173 (1957). |
| 18 S. I. Anisimov, B. L. Kapeliovich, and T. L. Perel'man, Sov. Phys. JETP 39 , 375 (1974). |
| 19 T. Q. Qiu and C. L. Tien, Int. J. Heat Mass Transfer 35 , 719 (1992). |
| 20 Z. C. Wang, Thermodynamics and Statistical Physics , (Higher Education Press, Beijing, |
| 1993) |
| 21 J. K. Chen, D. Y. Tzou, and J. E. Beraun, Int. J. Heat Mass Transfer, 49, 307 (2006). |
| 22 M. Lundstrom, Fundmentals of Carrier Transport (Cambridge University Press, |
| Cambridge, 2000). |
| 23 The phonon branch index is absorbed into the wave vector for simplification. |
| 24 L. D. Pietanza, G. Colonna, S. Longo, and M. Capitelli, Eur. Phys. J. D 45 , 369 (2007). |
| 25 W. L. McMillan, Phys. Rev. 167 ,331 (1968). |
| 26 J. L. Cheng and M. W. Wu, J. Appl. Phys. 101 , 073702 (2007). |
| 27 R. Bauer, A. Schmid, P. Pavone, and D. Strauch, Phys. Rev. B 57 , 11276 (1998). |
| 28 H. R. Schober, P. H. Dederichs, Au , Landolt-Börnstein Vol.III/13A, edited by K.-H. |
| Hellwege, J. L. Olsen (Springer-Verlag, Berlin, 1981). |
| 29 J. M. Ziman, Electrons and Phonons , (Oxford University Press, London,1962, p. 456) |
| 30 L. D. Pietanza, G. Colonna, and M. Capitelli, AIP Conf. Proc. 762 , 1241 (2004). |
| 31 N. W. Ashcroft and N. D. Mermin, Solid State Physics (Holt, Rinehart and Winston, |
| New York, 1976). |
| 32 N. F. Mott and H. Jones, The Theory of the Properties of Metals and Alloys , (Dover |
| Publications, Inc., New York, 1958). |
- 33 S. I. Anisimov and B. Rethfeld, Proc. SPIE 3093 , Nonresonant Laser-Matter Interaction (NLMI-9) , 192 (1997).
- 34 D. G. Yakovlev and V. A. Urpin, Sov. Astron. J., 24 , 303 (1980).
- 35 Yu. V. Martynenko and Yu. N. Yavlinskii, Sov. Phys. Doklady, 28 , 391 (1983).
- 36 D. K. C. MacDonald, Thermoelectricity: an Introduction to the Principles , (Dover Publication, Inc., New York, 2006)
- 37 A. Pattamata and C. K. Madnia, J. Heat Trans. 131 , 082401 (2009). | null | [
"Jun Zhou",
"Nianbei Li",
"Ronggui Yang"
] | 2014-08-02T21:49:20+00:00 | 2014-08-02T21:49:20+00:00 | [
"cond-mat.mtrl-sci"
] | An Electrohydrodynamics Model for Non-equilibrium Electron and Phonon Transport in Metal Films after Ultra-short Pulse Laser Heating | The electrons and phonons in metal films after ultra-short pulse laser
heating are in highly non-equilibrium states not only between the electron
sub-system and the phonon sub-system but also within the electron sub-system.
An electrohydrodynamics model consisting of the balance equations of electron
density, energy density of electrons, and energy density of phonons is derived
from the coupled non-equilibrium electron and phonon Boltzmann transport
equations to study the nonlinear transport phenomena, such as the electron
density fluctuation and the transient electrical current in metal films, after
ultra-short pulse laser heating. The time-dependent temperature distributions
is calculated by the coupled electron and phonon Boltzmann transport equations,
the electrohydrodynamics model derived in this work, and the two-temperature
model for different laser pulse durations, film thicknesses, and laser
fluences. We find that the two-temperature model overestimates the electron
temperature at the frontsurface of the film and underestimates the damage
threshold when the nonlinear thermal transport of electrons is important. The
electrohydrodynamics model proposedin this work could be a more accurate
prediction tool to study the non-equilibrium electron phonon transport process
than the two-temperature model and it is much easier to be solved than the
coupled electron and phonon Boltzmann transport equations. |
1408.0427v1 | ## Homesick L´ evy walk: A mobility model having Ichi-go Ichi-e and scale-free properties of human encounters
Akihiro Fujihara 1 and Hiroyoshi Miwa 2 1 Department of Management Information Science, Fukui University of Technology, 3-6-1 Gakuen Fukui Fukui 910-8505, JAPAN Email: [email protected] 2 Graduate School of Science and Technology, Kwansei Gakuin Univ. 2-1 Gakuen Sanda Hyogo 669-1337, JAPAN
Email: [email protected]
Abstract -In recent years, mobility models have been reconsidered based on findings by analyzing some big datasets collected by GPS sensors, cellphone call records, and Geotagging. To understand the fundamental statistical properties of the frequency of serendipitous human encounters, we conducted experiments to collect long-term data on human contact using short-range wireless communication devices which many people frequently carry in daily life. By analyzing the data we showed that the majority of human encounters occur once-in-an-experimentalperiod: they are Ichi-go Ichi-e. We also found that the remaining more frequent encounters obey a power-law distribution: they are scale-free. To theoretically find the origin of these properties, we introduced as a minimal human mobility model, Homesick L´ evy walk, where the walker stochastically selects moving long distances as well as L´ evy walk or returning back home. Using numerical simulations and a simple mean-field theory, we offer a theoretical explanation for the properties to validate the mobility model. The proposed model is helpful for evaluating long-term performance of routing protocols in delay tolerant networks and mobile opportunistic networks better since some utilitybased protocols select nodes with frequent encounters for message transfer.
In parallel with the understanding of human mobility patterns, recently, many researchers become actively engaged in studies on mobility models, and many mobility models have been proposed [3], [4]. Traditional mobility models, such as Random Walk (RW), (truncated) L´ evy Walk (LW), Random WayPoint (RWP), are simple and basic: they can easily be used for numerical simulations in general purposes, but they are far from real human mobility patterns. Therefore, newly proposed models have become more realistic and complicated : They includes more parameters to explain many statistical properties on human mobility patterns and social effects, thus they resultingly consume more memory space as simulation time progresses, such as SLAW [5]. The more a model explains, however, the harder it gets to use for the simulations with a large number of walkers in general.
Keywords -Mobility models, Contact frequency, Ichi-go Ichi-e, Power law, and Delay Tolerant Networks.
## I. INTRODUCTION
In recent years, many kinds of human-carried mobile devices, such as smartphones and tablets, that enable many high-tech sensors and wireless communications have been increasingly pervasive throughout the world. Because most of the people in the world usually carry these devices in their lives, their activity logs, such as places where they visit and persons who they are connected with, can be easily recorded using GPS, cellphone call, and Geotagging. We are living in the era of Big data: by analyzing collections of data on people's activity, big companies can take advantage of success in their businesses. Also, academic researchers can investigate human activities and social behaviours in more details than ever. For example, some recent studies based on the analysis of Big data of human mobility patterns have revealed that human behavior is easily predictable because human mobility is biased in general [1], [2]. This result shows that human mobility is far from random, but is ordered.
These mobility models are often used for evaluating performance of routing protocols in Delay Tolerant Networks (DTNs) [19] and Mobile Opportunistic Networks (MON) [6], [7]. To evaluate the performance in systems with a large number of mobile nodes, we need to select a balanced mobility model properly. Because the above routing protocols are often contact-based ones, the model doesn't necessarily preserve real mobility patterns, but it must have real contact patterns. In the context of information communication networks, many researchers frequently mention statistical properties on intercontact time (or inter-meeting time) to select the model. But, we would argue in this paper that statistical properties on contact frequency is also an important factor to properly select the mobility model.
By the way, there is a famous Japanese proverb closely related with the frequency of human contacts which is called Ichi-go Ichi-e . This proverb is literally translated as 'One chance in a lifetime' or more specifically as 'Treasure every encounter, for it will never recur.' This phrase is closely associated with the history of the tea ceremony of Japan. Sen no riky¯ u (1522-1591), the famous tea master during the age of the provincial wars, originally taught this proverb to his pupils in the spirit of good service. Later, at the end of the Edo Period, Ii Naosuke (1815-1860), an accomplished practitioner of the Japanese tea ceremony, rediscovered and reconsidered this lesson as it is known today.
We know from experience that to meet with someone (or something) is sometimes very precious, and we might wonder about how often we have once-in-a-lifetime meetings in our daily lives or whether there is any statistical law that governs our meetings with people (or things). To the best of our knowledge, no scientific study has answered these questions because of the difficulty of collecting long-term data concerning human contact. However, given the recent advances in mobile wireless communication technologies, studies on the statistical physics of serendipitous human encounters can now be undertaken.
Our research group collected data concerning daily human contact using Bluetooth and Wi-Fi wireless communication technologies. Today, billions of electronic devices equipped with Bluetooth and Wi-Fi are used throughout the world. Most of these devices are light and mobile, including mobile PCs and phones, PDAs, tablets, and portable game machines. Therefore, they tend to be carried at almost all times. In addition, the communication range of Bluetooth and Wi-Fi is usually on the order of several meters, which is nearly the same as the range that humans can see when observing those around them. Thus, by scanning and logging nearby Bluetooth and Wi-Fi devices, we can collect reasonably well-sampled data concerning human encounters. In this case, here, encounter should be defined as a state that other humans having the device happen to come close within several dozen of meters at a maximum distance of its communicable range. In our experiment, we used PDAs and smartphones to continuously scan once every twenty seconds and to record pairs of time stamps and MAC addresses of detected devices, which indicated when a participant of the experiment encountered other people. A sample data logging software that our group uses is available as an open-access application for Android OS [8]. To calculate the contact frequency, we need to give a threshold value θ m where two consecutive device detections whose interval time is less than the threshold value are within the same encounter. In this research, we give θ m = 1[ hour ] as a choice, but we also have checked that varying the choice of the threshold from some minutes to some hours is not sensitive for the whole contact frequency. After conducting our experiment, we obtained Long data (rather than a recent buzzword Big data ) whose experimental period is between a minimum of several months and a maximum of more than two years. (See Table I and II). A dozen of people (university teachers, students, and company workers) participated and in total more than 50,000 different devices are detected in the experiment.
In this paper, by analyzing the collected experimental data, we exhibit two basic statistical properties of human contact frequency in the long data of human serendipitous encounters: (1) the property of Ichi-go Ichi-e, under which most human encounters occur once-in-a-experimental-period, and (2) the scale-free property of the remaining more frequent meetings. We can find that these properties clearly emerge for each individual when analyzing the Long Data. Inversely, it is difficult to observe these properties by analyzing shortterm data even if they are categorized into the Big Data. To theoretically explain the origin of these statistical properties observed in the experiment, we furthermore propose 'Homesick L´ evy Walk' as a simple mobility model. This is a minimal stochastic model of human mobility that traces whether the walker stochastically selects moving long distances as well as the L´ evy walk [9], or returning back home as a minimum social effect. In order to validate the mobility model, we offer a theoretical explanation for the properties of human contact using numerical simulations and a simple mean-field theory, which is the main contribution of the paper.
The rest of the paper is organized as follows. In Section II, we show the experimental results of analyzing collected data with Bluetooth and Wi-Fi opportunistic communications. In Section III, we propose a minimal stochastic model of human mobility patterns as a way to simultaneously explain both the two basic statistical properties. In Section IV, we perform numerical simulations to show that the minimal model can explain these properties. Section V demonstrates a simple meanfield theory to explain the emergence of these properties. We summarize our work, discuss future directions, and comment on an application of the model to performance evaluation of routing protocols in Delay Tolerant Networks in Sections VI and VII.
## II. EXPERIMENTAL RESULTS
First, we define R t ( ) as the ratio of one-time meetings to all meetings until time t . The ratio of Ichi-go Ichi-e (once-in-a-lifetime meetings) to all encounters can also be denoted as R t ( ) at t = T where T is the end of life. Some typical time variations in R t ( ) during the experiment are shown in Fig. 1. Although the initial patterns of R t ( ) vary strongly from one individual to the next, all of them stabilize as time progresses. Therefore, we may roughly assume that each of the time variations in R t ( ) converges to some fixed point around the ratio R T ( ) . Under this assumption, we may consider the time-averaged ratio over the experimental period denoted as 〈 R 〉 t to be approximately equivalent to the ratio R T ( ) . We present the time-averaged ratio using Bluetooth, 〈 R bt 〉 t , and Wi-Fi, 〈 R wf 〉 t , in Tables I and II, respectively. Averaged over all participants, the percentages of Ichi-go Ichie meetings using Bluetooth and Wi-Fi are approximately 8090%, meaning that the majority of human encounters occur once-in-an-experimental-period.
We also considered the complementary cumulative distribution function (CCDF) for human contact frequency. As illustrated in Fig. 2, the CCDF clearly follows a power-law distribution,
$$F ( X \geq x ) \equiv \bar { F } ( x ) \sim x ^ { - k }, \text{ \quad \ \ } ( 1 )$$
where k is a scaling exponent. Note that this power law is satisfied only for the remaining 10-20% of encounters, those that occur more than once for each individual. In other words, a large gap exists between x = 1 and x ≥ 2 in ¯ ( F x ) . The estimated scaling exponents of Bluetooth, k bt , and WiFi, k wf , which were determined using the experimental data, are summarized in Tables I and II, respectively. For almost all the participants, the estimated scaling exponents are lower than two. Because of this, the variance of the CCDF tends to diverge during a long experimental period. This divergence indicates that the number of encounters that the participants meet with people in their experimental periods has no characteristic scale. In other words, meetings inherently exhibit extreme inequality, making it difficult to predict how many opportunities are left to encounter someone (or something).
Fig. 1. Time variations in the ratio R t ( ) for individual participants using (a) Bluetooth and (b) Wi-Fi (line with points) and their time-averaged ratios 〈 R 〉 t over the experimental time (solid line). In the legends, those of four participants (E, C, B, and A in Tables I and II) are described.
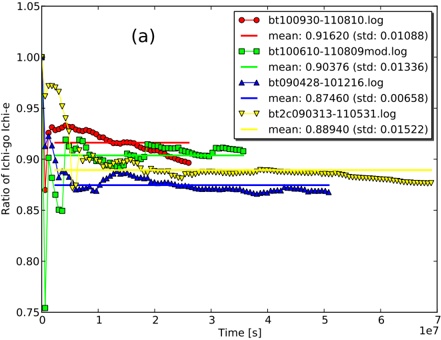
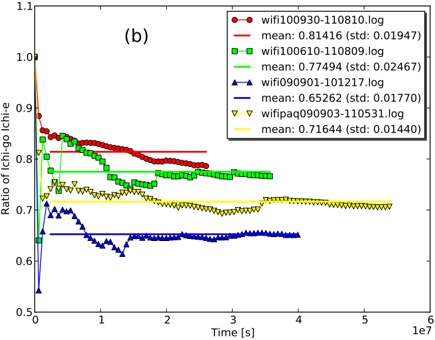
TABLE I. THE TIME-AVERAGED RATIO OF ICHI-GO ICHI-E 〈 R bf 〉 t AND THE SCALING EXPONENT k bf FOR HUMAN CONTACT FREQUENCY OBTAINED FROM THE BLUETOOTH DATA FOR THE TEN PARTICIPANTS.
| Participant ID | Experimental period | 〈 R bt 〉 t | k bt |
|------------------|-----------------------|-----------------|--------|
| A | 2009/03/13-2011/05/31 | 0 . 89 ± 0 . 02 | 1.63 |
| B | 2009/04/28-2010/12/16 | 0 . 87 ± 0 . 01 | 1.34 |
| C | 2010/06/10-2011/08/09 | 0 . 90 ± 0 . 01 | 1.42 |
| D | 2010/09/01-2011/08/08 | 0 . 87 ± 0 . 01 | 1.25 |
| E | 2010/09/30-2011/08/10 | 0 . 92 ± 0 . 01 | 1.32 |
| F | 2010/10/18-2011/02/22 | 0 . 93 ± 0 . 01 | 1.24 |
| G | 2010/10/19-2011/03/09 | 0 . 93 ± 0 . 01 | 1.29 |
| H | 2010/10/21-2011/01/27 | 0 . 89 ± 0 . 01 | 1.39 |
| I | 2010/10/21-2011/02/03 | 0 . 87 ± 0 . 02 | 1.17 |
| J | 2010/11/10-2011/03/31 | 0 . 84 ± 0 . 03 | 2.23 |
## III. HOMESICK L´ EVY WALK
Next, we propose a minimal stochastic model of human mobility patterns as a way to simultaneously explain both the Ichi-go Ichi-e and scale-free properties of human encounters. A number of researchers have recently reported that human mobility traces statistically exhibit the L´vy walk (LW) [10]e [13]. A L´ evy walker in d -dimensional space determines his or
CCDF
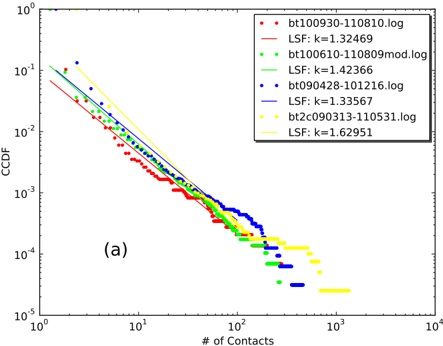
0
CCDF
# of Contacts
Fig. 2. CCDF for human contact frequency ¯ ( F x ) using (a) Bluetooth and (b) Wi-Fi (dots). Least squares fitting (LSF) of each CCDF (solid line). In the legends, those of four participants (E, C, B, and A in Tables I and II) are described.
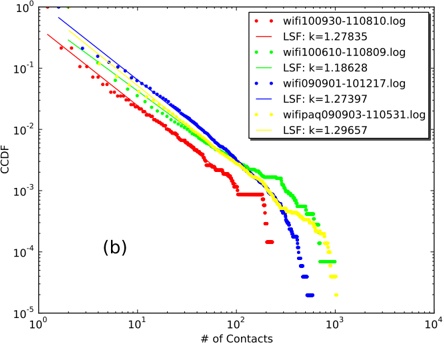
TABLE II. THE TIME-AVERAGED ICHI-GO ICHI-E RATIO 〈 R wf 〉 t AND THE SCALING EXPONENT k wf FOR HUMAN CONTACT FREQUENCY OBTAINED FROM THE WI-FI DATA FOR THE TEN PARTICIPANTS.
| Participant ID | Experimental period | 〈 R wf 〉 t | k wf |
|------------------|-----------------------|-----------------|--------|
| A | 2009/09/03-2011/05/31 | 0 . 72 ± 0 . 01 | 1.3 |
| B | 2009/09/01-2010/12/17 | 0 . 65 ± 0 . 02 | 1.27 |
| C | 2010/06/10-2011/08/09 | 0 . 77 ± 0 . 02 | 1.19 |
| D | 2010/09/01-2011/08/08 | 0 . 87 ± 0 . 01 | 1.25 |
| E | 2010/09/30-2011/08/10 | 0 . 81 ± 0 . 02 | 1.28 |
| F | 2010/10/18-2011/02/22 | 0 . 80 ± 0 . 03 | 0.94 |
| G | 2010/10/19-2011/03/09 | 0 . 82 ± 0 . 01 | 0.9 |
| H | 2010/10/21-2011/01/27 | 0 . 73 ± 0 . 02 | 1.4 |
| I | 2010/10/21-2011/02/03 | 0 . 73 ± 0 . 01 | 1.42 |
| J | 2010/11/10-2011/03/31 | 0 . 63 ± 0 . 01 | 1.42 |
her destination; the travel distance from the present location l is governed by an independently and identically distributed power-law distribution,
$$p ( l ) \sim l ^ { - ( 1 + \beta ) },$$
where 0 < β ≤ 2 is the L´ evy index. The direction from the present location to the next destination location is usually
Fig. 3. Typical sample traces for L´ evy walk (LW) and homesick L´ evy walk (HLW). The initial position of each walker is indicated by the grey circle, which is assumed to be the hub of activity (or home) in the HLW scenario.
determined by the uniform distribution. This feature has been found to be common to the mobility of humans and animals in two-dimensional space [14]-[17].
However, the scale-free property of walk lengths is insufficient to explain the statistical properties of human contact frequency. We numerically confirmed that the CCDF of contact frequency for L´ evy walkers in bounded two-dimensional space generally decays exponentially at the tail. Let us consider what is lacking in the ordinary L´ evy walk scenario. A L´ evy walke r easily travels long distances, but has difficulty returning to his or her original position (refer to Fig. 3). In real life, however, each participant typically frequents his or her own hub of social activity (or his or her own home). This reality strongly determines most of the topology of human mobility traces. Taking into consideration the role of the hub, we propose an extended version of the L´ evy walk named the 'Homesick L´ evy Walk (HLW).' In this model, after arriving at the destination determined by the power-law walk length in Eq. (2), there exists a certain fixed probability α that the L´ evy walker will become homesick and return home; otherwise, according to probability (1 -α ) , the walker will determine his or her next destination using Eq. (2) and continue travelling. By definition, HLW with a homesick probability of α = 0 reduces to LW. For the sake of convenience, we define the initial position of HLW as home. The detailed procedure to move two-dimensional HLW is shown in Motion Control 1. The difference between the sample traces associated with the (simple) L´ evy walk and the homesick L´ evy walk is illustrated in Fig. 3.
In the name of this model, we use the word walk but not flight . In general, walk means that a walker moves with a finite velocity to the destination, but flight means that a walker jump instantly to the destination, which is the difference between these words. Because we also consider serendipitous encounters on the way to the destination, we introduce homesick L´ evy walk here. But, Homesick L´ evy Flight (HLF) can be defined by a similar way with changing from walk to flight in the model.
## IV. NUMERICAL SIMULATIONS
We performed numerical simulations for N homesick L´ evy walkers in a bounded two-dimensional space. Initially, N = 1000 walkers were uniformly distributed within a 1726[ m ] × 1726[ m squared region. The number of the walkers ] N does not change in the simulations. The density of the walk-
## Motion Control 1 : (Two-dimensional) Homesick L´ evy Walk
Require: Initial position: Hub of activity (or home) x home (The current position x now = x home ), Initial state: State == Stop; the homesick probability α ; the scaling exponent of the CCDF of contact frequency β
while TRUE (The walker is alive.) do if
State == Stop then
State == Move if Probability: α then
Destination == Hub of activity ( x dest = x home )
else
New destination x dest = x now + l × ( cos θ , sin θ ), where l is determined by Eq. (2) and the angle θ is given by the uniform distribution on [0 , 2 π ) .
end if
## end if
Start moving to the destination x now ← x now + ∆ l × ( cos θ , sin θ ), where ∆ l is the distance that the walker moves in a single step.
if
x
now
==
x
home or
x
dest then
State == Stop
(The walker may wait for a while.)
end if end while
ers was determined based on the average population density of Japan, approximately 336[ km -2 ] , because all of the study participants live mainly in Japan. The distance between the present position and the next destination described using the polar coordinate l = ( r cos θ, r sin θ ) is randomly generated from the probability distribution function, p l ( ) ≡ p r p θ ( ) ( ) , where
$$\underset { \substack { \text{rere} \\ \text{will} \\ \text{$2$ to} \\ \text{next} \quad \text{end} \quad \text{the} \quad \text{milliseconds} \quad \text{end} \quad \text{end} \quad \text{end} \quad \text{end} \quad \text{end} \quad \text{end} \quad \text{end} \quad \text{end} \quad \text{end} \quad \text{end} \quad \text{end} \quad \text{end} \quad \text{end} \quad \text{end} \quad \text{end} \quad \text{end} \quad \text{end} \quad \text{end} \quad \text{end} \quad \text{end} \quad \text{end} \quad \text{end} \quad \text{end} \quad \text{end} \quad \text{end} \quad \text{end} \quad \text{end} \quad \text{end} \quad \text{end} \quad\text{end} \quad \text{end} \quad \text{end} \quad \text{end} \quad \text{end} \quad \text{end} \quad \text{end} \quad \text{end} \quad \text{end} \quad \text{end} \quad \text{end} \quad \text{end} \quad \text{end} \quad \text{end} \quad \text{end} \quad \text{end} \quad \text{end} \quad \text{end} \quad \text{end} \quad \text{end} \quad \text{end} \quad \text{end} \quad \text{end} \quad \text{end} \quad \text{end} \quad \text{end} \quad \text{end} \quad \text{end} \quad \text{end},$$
and the minimum travelling distance r m = 1[ m . ] These equations are derived from Eq. (2) to satisfy the normalization condition ∫ ∞ r m p l ( ) dl = 1 . We assumed that for each time-step, all of the walkers move with a constant speed v = 1[ m/s , and ] a small number of walkers meet together if they are within a fixed communication radius c = 1[ m . We also assumed that ] after a walker arrive at a destination, the walker waits a single time-step to determine the next destination.
Next, we considered the effects of the homesick property and long-distance travelling on the time-averaged Ichi-go Ichie ratio 〈 R 〉 t and the scaling exponent of the CCDF of the contact frequency k , varying α and β . The typical time evolution of R t ( ) is illustrated in Fig. 4 (a). As observed in Fig. 1, each R t ( ) tends to converge as time progresses. The time-averaged ratio 〈 R 〉 t , calculated by averaging R t ( ) over the simulation time, is also plotted for the ranges 0 ≤ α < 1 and 0 ≤ β ≤ 1 in Fig. 4 (b). We numerically confirmed that 〈 R 〉 t tends to decrease with increases in α and β . Also, we observe that by roughly tuning parameters α and β to sufficiently small values, we obtain a value of more than 80% for 〈 R 〉 t and the numerical results becomes consistent with the experimental ones.
In Fig. 5(a), we also present some typical CCDFs for contact frequency based on the numerical results. We can clearly
/a0
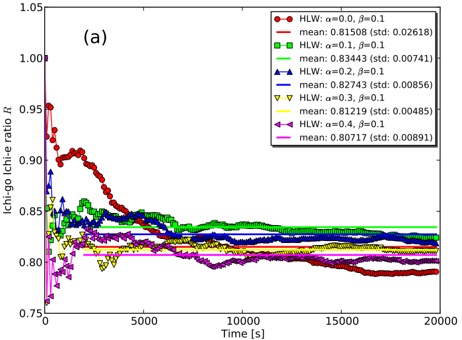
✁
✄
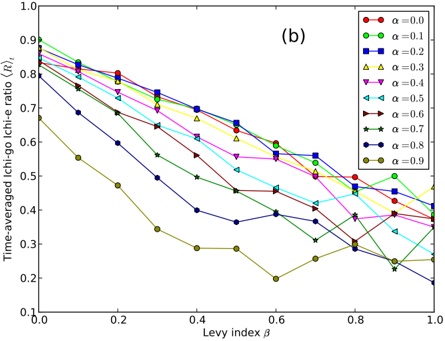
☎
✆
Fig. 4. (a) The typical time evolution of R t ( ) in the L´vy walk ( e α = 0 ) and the homesick L´ evy walk ( α > 0 ) determined using numerical simulations for N = 10 3 , T = 2 0 . × 10 [ ] 4 s , α = 0 0 1 0 2 0 3 0 4 , . , . , . , . , and β = 0 1 . (lines with dots). The time-averaged Ichi-go Ichi-e ratios 〈 R 〉 t are also included (solid line). (b) Relationship between 〈 R 〉 t and α and β over the ranges 0 ≤ α < 1 and 0 ≤ β ≤ 1 .
see that the CCDF created using HLW for α > 0 obeys a power-law distribution, whereas that created using LW ( α = 0 ) decays exponentially at the tail, as we mentioned before. This exponential decay for α = 0 was observed for the entire range, 0 ≤ β ≤ 1 . The results indicate that the homesickness component of HLW is essential to the scale-free property of contact frequencies. We also consider the relationship between the scaling exponent k for contact frequency and for α and β calculated using least-squares fitting. As observed in Fig. 5(b), k has a weak decreasing trend with increasing α and β for 0 < α < 1 and 0 ≤ β ≤ 1 . The most important point is that the value of k matches the experimental values of k bt and k wf in Tables I and II when we keep α > ( 0 ) and β small, as shown in Fig. 5(b). As a result, we numerically demonstrate that the HLW stochastic model can explain human contact frequency.
It should be emphasized that the contact frequencies of Homesick Random Walk (HRW) and Homesick Random WayPoint (HRWP) seem to be different from that of HLW as shown
✝
✝
CCDF
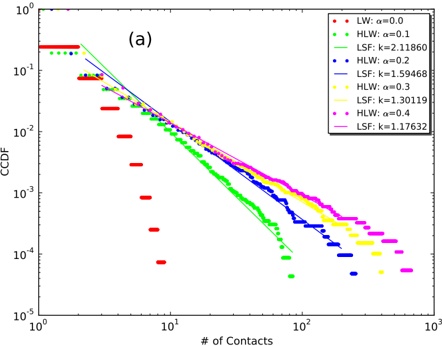
✟
Scaling exponent k
Fig. 5. (a) Typical CCDFs for contact frequency values ¯ ( F x ) employing LW and HLW in numerical simulations where N = 10 3 , T = 10 [ ] 5 s , and α = 0 0 1 0 2 0 3 , . , . , . , 0 4 . , β = 0 (dots) with least squares fitting (LSF) for the CCDFs (solid line). (b) Relationship between the estimated scaling exponent k from the CCDFs for contact frequency and α and β for 0 < α < 1 and 0 ≤ β ≤ 1 .
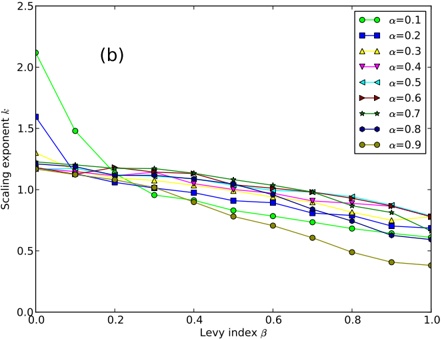
in Figs. 6 and 7, thus tail's fatness of these distribution is less than that of the power-law distribution.
## V. MEAN-FIELD THEORY
Finally, we use a simple mean-field theory of HLW to explain the emergence of these phenomena. We focus on one walker whose home is fixed at the origin of the twodimensional space, whereas the other walkers are assumed to be spatially fixed and uniformly distributed in the space. We also define the mean-free path λ as the averaged moving distance that one traverses before encountering the next walker. Because the walker continues to repeatedly travel around and return home, the spatial existence probability of the focused walker tends to increase as the distance from home decreases. With this viewpoint in mind, we assume that the contact frequency for this walker and others depends only on the distance from home r ′ and that the walker meets the same walker at the same distance. Taking into consideration all of
✠
Fig. 6. Typical CCDFs for contact frequency values ¯ ( F x ) employing RW and HRW in numerical simulations where N = 10 3 , T = 10 [ ] 5 s , and α = 0 0 2 0 5 , . , . (dots).
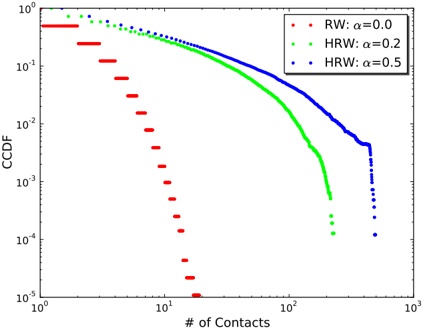
Fig. 7. Typical CCDFs for contact frequency values ¯ ( F x ) employing RWP and HRWP in numerical simulations where N = 10 3 , T = 10 [ ] 5 s , and α = 0 0 2 0 5 , . , . (dots).
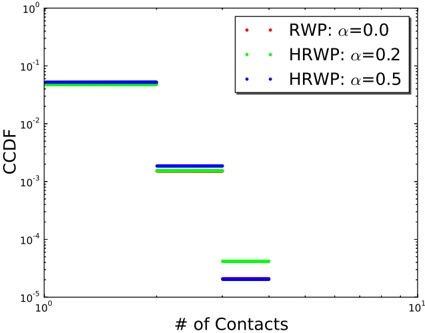
the above definitions and assumptions, we envision a scenario in which the walker encounters a new walker whenever he walks away from the concentric rings of width λ whose centre is his home. This image of meetings with walkers is used to separate the space into many ring-shaped concentric zones in which the walker in question meets others, as shown in Fig. 8. We call this the concentric zone hypothesis .
In Fig. 9(a), we present numerical results for the CCDF of the walker's frequency of contact with others with respect to his distance from home and the location at which he encounters those other individuals, ¯ H . We observe that the function ¯ H generally obeys a power-law distribution for α > 0 , especially for the lower range of r ,
$$\bar { H } ( r ^ { \prime } \geq r ) \sim r ^ { - \tilde { \beta } }, \text{ \quad \ \ } ( 4 )$$
where ˜ β is the power index. The cut-off of the power law at the tail arises from the effect of spatial boundedness. For
Fig. 8. Schematic illustration of the concentric zone hypothesis.
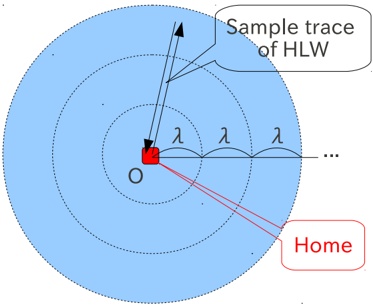
α = 0 , however, ¯ H is more likely to behave like a uniform distribution than it is to behave like a power law. Therefore, the spatial existence probability ¯ H appears to be qualitatively different for HLW and LW.
In Fig. 9 (b), we showed the numerical results indicating how the power index ˜ β behaves given changes in α and β . We can see that a proportional relationship between ˜ β and β ,
$$\tilde { \beta } \simeq c \beta + d,$$
is approximately satisfied for small α and 0 ≤ β ≤ 1 . The proportionality coefficient c α ( ) in Eq. (5), which seems to have a particular value when α is fixed, tends to gradually decrease with increasing α . These values of c α ( ) for α = 0 1 . , 0 2 . , 0 3 . , 0 4 . , 0 5 . varies around one.
Applying the power-law distribution of ¯ H to the concentric zone hypothesis allows us to calculate the contact frequency of the walker in the j -th concentric ring zone, denoted as x j . For this purpose, we use h r ( ) ≡ -dH r ¯ ( ′ ≥ r /dr ) as follows:
$$x _ { j } & \ \stackrel {. } { \approx } \ \int _ { j \lambda } ^ { ( j + 1 ) \lambda } h ( r ) r d r \sim \int _ { j \lambda } ^ { ( j + 1 ) \lambda } r ^ { - ( 1 + \tilde { \beta } ) } r d r \\ & \ \stackrel {. } { \approx } \ \lambda ^ { 2 } j / ( j \lambda ) ^ { 1 + \tilde { \beta } } \ \in j ^ { - \tilde { \beta } }.$$
This equation directly indicates that the rank distribution of the contact frequencies also obeys a power-law distribution whose power index is ˜ β . When β remains within its small range 0 ≤ β < (1 -d /c ) , the power index of the rank distribution ˜ β becomes less than one by Eq. (5). In this case, therefore, the tail of the rank distribution is generally so wide that the number of low-ranked walkers is divergent, which provides a simple explanation of why the majority of human encounters is Ichigo Ichi-e.
We also consider the relationship between the rank distribution and the CCDF for contact frequency. It is well-known that if a rank distribution obeys a power law, then its frequency also becomes a power law. Thus, for the rank distribution x j , we can obtain the scale-free human contact frequency. In this case, it is also known that an inverse relationship exists between k and ˜ β :
$$k = 1 / \tilde { \beta } \simeq 1 / ( c \beta + d ).$$
We checked whether this inverse relation is numerically supported in Fig. 10. We can see that Eq. (7) roughly explains
✍
✌
Fig. 9. (a) A typical spatial existence probability distribution ¯ ( H r ′ ≥ r ) for HLWs where N = 10 3 , T = 10 [ ] 5 s , α = 0 0 1 0 2 0 3 0 4 , . , . , . , . , and β = 0 2 . (dots). The power index ˜ β is also shown using the least-square fits for the distribution (solid line). (b) The relationship between the parameters α = 0 1 0 2 0 3 0 4 . , . , . , . , 0 5 . and 0 ≤ β ≤ 1 and the estimated power index ˜ β (line with dots) and their least-square fits (line).
the trend between k and ˜ β . Substituting controlled values of 0 ≤ β < (1 -d /c ) into Eq. (7) yields values of k ( > 1 ) that are consistent with the experimental presented in Tables I and II.
## VI. CONCLUSION
In summary, we investigated the general statistical properties of serendipitous human encounters in daily life using portable wireless communication devices. We experimentally determined that we can universally apply the following statistical principles to human contact frequencies among individuals:
- 1) The majority of human encounters occur once during one's experimental period and this feature seems to continue during one's lifetime (the property of Ichigo Ichi-e)
- 2) The remaining, more frequent encounters obey the power-law distribution in terms of contact frequency and its variance diverges (the scale-free property)
✏
Fig. 10. Relation between k and ˜ β for α = 0 1 0 2 0 3 0 4 0 5 . , . , . , . , . and 0 ≤ β ≤ 1 (dots) and the exact inverse relationship in Eq. (7) (solid line).
Because this long tail principle of human contact frequency is universal, it is difficult to predict how many times we will have additional opportunities to meet with people over long periods of time. This further validates the principle of Ichi-go Ichi-e, which teaches us to 'treasure every encounter.'
To facilitate a fundamental theoretical understanding of these principles, we introduced a novel stochastic model of human mobility traces called the 'homesick L´ evy walk.' We used numerical simulations to demonstrate that this model can successfully explain both of the principles. Furthermore, using simple mean-field theory, we determined that the origin of the principles arises from the following two opposing mechanisms that inherently underlie human mobility patterns:
- 1) Long-distance travelling ( 0 ≤ β < (1 -d /c ) in HLW)
- 2) Homesickness ( α > 0 in HLW)
Although we have proposed this model in [22], [23] for evaluation our proposed routing method, the origin of the above properties is first explained in this paper. Balancing the two mechanisms leads the statistical principles of human contact frequency to emerge. Note that according to violating the first mechanism, 'Homesick Random Walk (HRW)' whose walk length to the next destination is determined by a distribution with a finite variance does not have the scale-free property of contact frequency, which we have also checked numerically.
It should be noted that we have introduced home as a minimum social effect. Because homesick L´ evy walkers periodically return to their home, they tend to stay longer around their homes. Therefore, they meet with each other more frequently as the distance between their homes is closer, which naturally includes social relations between the walkers.
## VII. DISCUSSIONS
In this paper, we focused on contact frequency for humans . However, that of animals might also obey the same principles because the above two mechanisms are common to animals and humans: animals usually have nests that are similar to our homes, and they also travel to distant feeding sites.
For future works, it is also important to consider effects of non-uniformity of population density. In the simulations, we used the average population density of Japan, but the density of people highly varies by the size of city where they live. Effects of the density on contact frequency, inter-contact time, and contact duration is an interesting task to investigate.
Recently, Song et al. has proposed 'preferential return' to explain spatial visitation properties of human mobility patterns using their individual mobility model [18]. Our homesick L´ evy walk model seems to be similar to their model, but there are some differences: Since they consider the visitation frequency of locations, their model needs multiple locations where one can return preferentially by flight . Since we consider the contact frequency between humans, on the other hand, our model does not necessarily assume multiple locations, but only one hub location where one can return with a fixed probability by walk . By experiment, we empirically know that the serendipitous human contacts occur on the way to destination more frequently rather than duration of visit at destination. Therefore, theoretical results given by their model does not cover statistical properties of the majority of human contacts. To understand the relation between these models is left for future work.
We think our mobility model is useful for performance evaluation of routing protocols in Delay Tolerant Networks (DTN) [19] since some protocols selects routing paths with frequent encounters in utility-based routing protocols, such as PRoPHET [20], MAXPROP [21], and so on. We also have proposed our algorithm for routing in DTN and have shown some results regarding the comparison between LW and HLW [22], [23], which indicates that the arrival rate of transferred messages tends to be much lower as increasing the homesick probability α . It is also important to take into consideration the effect of Ichi-go Ichi-e since the large number of human encounters is rare. Therefore, the majority of human encounters usually doesn't contribute to the performance of the utility-based routing, but they only consume much memory in vain for memorizing the history of encounters with many nodes that will never be encountered again. After understanding the properties of the frequency of human contact well, the routing protocols for message transfer could be improved.
## ACKNOWLEDGMENT
This work is partially supported by Japan Society for the Promotion of Science through Grant-in-Aid for Scientific Research (C) (23500105) and Grant-in-Aid for Young Scientists (B) (25870958).
## REFERENCES
- [1] Song, C., et al. Limits of Predictability in Human Mobility, Science, vol. 327, no. 5968, pp.1018-1021 (2010).
- [2] Y.-A. de Montjoye, et al. , Unique in the Crowd: The privacy bounds of human mobility, Scientific Reports, vol. 3, no. 1376 (2013).
- [3] Roy, R. R. Handbook of Mobile Ad Hoc Networks for Mobility Models (Springer, 2011).
- [4] Santi, P. Mobility Models for Next Generation Wireless Networks: Ad Hoc, Vehicular and Mesh Networks (Wiley, 2012).
- [5] Lee, K. et al. SLAW: Self-Similar Least-Action Human Walk, IEEE/ACM Transactions on Networking, vol. 20, no.2, (2012).
- [6] Denko, M. K. Mobile Opportunistic Networks: Architectures, Protocols and Applications (Auerbach Publications, 2011).
- [7] Woungang, I., et al. Routing in Opportunistic Networks (Springer, 2013).
- [8] http://tech.pokutuna.com/android-wireless-device-logger/
- [9] ben-Avraham, D. & Havlin, S. Diffusion and Reactions in Fractals and Disordered Systems (Cambridge University Press, 2000).
- [10] Barab´ asi, A.-L. Bursts: The Hidden Pattern Behind Everything We Do (Dutton Adult, 2010).
- [11] Brockmann, D. et al. The scaling laws of human travel. Nature 439 462-465 (2006).
- [12] Gonz´ alez, M. C. et al. Understanding individual human mobility patterns. Nature 453 , 779-782 (2008).
- [13] Rhee, I. et al. On the Levy-walk Nature of Human Mobility: Do Humans Walk like Monkey? The 27th IEEE International Conference on Computer Communications (IEEE INFOCOM 2008), 924-932 (2008).
- [14] Viswanathan, G. M. et al. Optimizing the success of random searches. Nature 401 , 911914 (1999).
- [15] Edwards, A. M. et al. Revisiting L´ evy flight search patterns of wandering albatrosses, bumblebees and deer. Nature 449 , 1044-1048 (2007).
- [16] David W. Sims et al. Scaling laws of marine predator search behaviour. Nature 451 , 1098-1102 (2008).
- [17] Viswanathan, G. M. et al. The Physics of Foraging: An Introduction to Random Searches and Biological Encounters (Cambridge University Press, 2011).
- [18] C. Song et al. , Modelling the scaling properties of human mobility, Nature Physics (Advanced Online Publications) 7, 713 (2010).
- [19] A. Vasilakos, Y. Zhang, and T. V. Spyropoulos, Delay Tolerant Networks: Protocols and Applications , Wireless Networks and Mobile Communications Series, CRC Press, 2012.
- [20] A. Lindgren, A. Doria, and O. Schel´ en, 'Probabilistic routing in intermittently connected networks,' ACM SIGMOBILE Mobile Computing and Communications Review, Vol. 7 Issue 3, pp.19-20(2003).
- [21] J. Burgess, B. Gallagher, D. Jensen, and B. N. Levine, 'MaxProp: Routing for vehicle-based disruption-tolerant networks,' In Proc. IEEE INFOCOM, 398-408 (2006).
- [22] A. Fujihara, S. Ono, and H. Miwa 'Optimal Forwarding Criterion of Utility-based Routing under Sequential Encounters for Delay Tolerant Networks,' Third International Conference on Intelligent Networking and Collaborative Systems (INCoS) 2011, 279-286 (2011).
- [23] A. Fujihara and H. Miwa, 'Homesick L´ evy Walk and Optimal Forwarding Criterion of Utility-based Routing under Sequential Encounters,' Internet of things and inter-cooperative computational technologies for collective intelligence, Studies in Computational Intelligence, vol. 460, pp. 207-231 (2013). | 10.1109/COMPSAC.2014.81 | [
"Akihiro Fujihara",
"Hiroyoshi Miwa"
] | 2014-08-02T21:53:22+00:00 | 2014-08-02T21:53:22+00:00 | [
"physics.soc-ph",
"cs.SI"
] | Homesick Lévy walk: A mobility model having Ichi-go Ichi-e and scale-free properties of human encounters | In recent years, mobility models have been reconsidered based on findings by
analyzing some big datasets collected by GPS sensors, cellphone call records,
and Geotagging. To understand the fundamental statistical properties of the
frequency of serendipitous human encounters, we conducted experiments to
collect long-term data on human contact using short-range wireless
communication devices which many people frequently carry in daily life. By
analyzing the data we showed that the majority of human encounters occur
once-in-an-experimental-period: they are Ichi-go Ichi-e. We also found that the
remaining more frequent encounters obey a power-law distribution: they are
scale-free. To theoretically find the origin of these properties, we introduced
as a minimal human mobility model, Homesick L\'evy walk, where the walker
stochastically selects moving long distances as well as L\'evy walk or
returning back home. Using numerical simulations and a simple mean-field
theory, we offer a theoretical explanation for the properties to validate the
mobility model. The proposed model is helpful for evaluating long-term
performance of routing protocols in delay tolerant networks and mobile
opportunistic networks better since some utility-based protocols select nodes
with frequent encounters for message transfer. |
1408.0428v1 | ## ANOTHER DIMINIMAL MAP ON THE TORUS
## THOM SULANKE
Abstract. This note adds one diminimal map on the torus to the published set of 55. It also raises to 15 the number of vertices for which all diminimal maps on the torus are known.
## 1. Introduction
Riskin [4][5] found two diminimal maps on the torus (denoted R1 and R2 in this note). Henry [2][3], using a computer found 53 more (H1 through H53). All diminimal maps on the torus with fewer than 10 vertices or fewer than 10 faces were found using this technique. But Henry was not able to complete the generation process due to time constraints.
Using a completely different computer technique we generated all polyhedral maps on the torus with 15 or fewer vertices and checked each to see if it was diminimal. While this technique found all diminimal maps on the torus with 15 or fewer vertices, there may be other diminimal maps on the torus with more than 15 vertices.
## 2. Definitions
Following [3] we use these definitions. We consider only graphs with no multiple edges and no loops. If G is a graph embedded in a surface, then the closure of each connected component of the complement of the graph is called a face . An embedded graph together with its embedding is called a map if each vertex of the graph has degree at least 3 and each face is a closed 2-cell.
If the intersection of two distinct faces of a map is empty, a vertex, or an edge then the faces are said to meet properly . If each face is simply connected and each pair of faces meet properly, then the map is a polyhedral map . We refer to a polyhedral map on the torus as a toroidal polyhedral map or TPM.
The operation edge removing is the process of obtaining one map from another by removing a single edge. If the removal creates a vertex of degree 2 then the two edges adjacent to that vertex are coalesced into one edge in the new map. Let G be a TPM and let G ′ be the map obtained from G by removing edge e from G . If G ′ is also a TPM, then edge e is called removable .
The operation edge shrinking is the process of obtaining one map from another by contracting an edge so that edge's two vertices become one vertex. If the contraction creates a two-sided face in the new map then the two edges of the two-sided face are replaced with a single edge. Let G be a TPM and let G ′ be the map obtained from G by shrinking edge e in G . If G ′ is also a TPM, then edge e is called shrinkable .
If G is a TPM with no shrinkable edges and no removable edges then G is called diminimal .
## 3. Generating TPMs
The author has developed the program surftri [6] for generating embeddings on surfaces. This program is based on the program plantri [1] written by Brinkmann and McKay which generates planar graphs. It is easy to restrict surftri to generate only polyhedral maps . As a test of surftri we checked that all the known diminimal TPMs were among the TPMs with 15 or fewer vertices. The number of TPMs checked is shown in Table 1. About three CPU years were required to generate the TPMs with up to 15 vertices. In the process we discovered an additional diminimal TPM (S1). All the known diminimal TPMs are shown in Figs. 2, 3, and 4.
A list of the 56 known diminimal TPMs (H1, . . . , H53, R1, R2, S1) is in Figure 1. Each line of the list represents one diminimal TPM. The format used is taken from surftri [6] which generalizes the format in plantri [1]. The vertices are labeled by single letters. The number is the number of vertices for the embedding. For each vertex there is a list of its neighbors in cyclic order. So
## 7 bcdefg agdfec abegfd acfbge adgcbf aebdcg afcedb , , , , , ,
represents K 7 embedded on the torus. This embedding has 7 vertices. The vertex a has 6 neighbors bcdefg in cyclic order. The vertex b also has 6 neighbors agdfec in cyclic order. The final vertex g has neighbors afcedb .
Table 1. Counts of TPMs and diminimal TPMs by number of vertices
| Vertices | TPMs | Diminimal TPMs |
|------------|----------------|------------------|
| 7 | 1 | 1 |
| 8 | 33 | 2 |
| 9 | 4713 | 11 |
| 10 | 442429 | 19 |
| 11 | 28635972 | 15 |
| 12 | 1417423218 | 5 |
| 13 | 58321972887 | 2 |
| 14 | 2102831216406 | 1 |
| 15 | 68781200467456 | 0 |
- 7 bcdefg,agdfec,abegfd,acfbge,adgcbf,aebdcg,afcedb
- 8 bcde,aefgdh,ahgf,afhbg,aghfb,behdcg,bfced,bdfec
- 8 bcd,aefgh,ahegf,afhge,bdgchf,behdcg,bfcedh,bgdfec
- 9 bcde,afghi,aifh,ahge,adihf,becg,bfid,bdcei,bhegc
- 9 bcd,aefgh,ahei,aihge,bdgcf,behi,biedh,bgdfc,cgfd
- 9 bcd,aefgh,ahig,afhe,bdhgi,bidg,bfceh,bgedic,chfe
- 9 bcd,aefgh,aheg,agfi,bicf,behdg,bfdcih,bgifc,dhge
- 9 bcd,aefgh,aig,afhe,bdhgif,beidg,bfceh,bgedi,chfe
- 9 bcde,afghi,aifd,achg,agihf,behcg,bfied,bdfei,bhegc
- 9 bcd,aefgh,ahegf,afhge,bdgci,bidcg,bfcedh,bgdic,ehf
- 9 bcd,aefgh,ahig,agfhe,bdhgi,bihdg,bfdceh,bgedfc,cfe
- 9 bcd,aefgh,ahfi,agfhe,bdhif,bechdg,bfdih,bgedfc,ceg
- 10 bcde,afgh,ahfi,aihg,agif,becj,bjed,bdjc,cejd,fhig
- 10 bcd,aefgh,ahij,ajhe,bdgi,bihj,bjeh,bgdfc,cfe,cgfd
- 10 bcd,aefg,ahei,aihj,bjcf,behi,bijh,cgdf,cjgfd,dgie
- 10 bcd,aefgh,ahij,afhe,bdgi,bidj,bjeh,bgdic,chfe,cgf
- 10 bcd,aefgh,ahig,afhe,bdji,bidg,bfcj,bjdic,chfe,ehg
- 10 bcd,aefgh,ahei,aihj,bjcf,behi,bijh,bgdfc,cgfd,dge
- 10 bcd,aefgh,aig,afhe,bdjif,beidg,bfcj,bjdi,chfe,ehg
- 10 bcd,aefgh,aig,afje,bdjif,behdg,bfcj,bjfi,che,dhge
- 10 bcd,aefg,ahi,ajge,bdgihj,bji,biedh,cgje,cegf,dfeh
- 10 bcd,aefgh,aig,afj,bjif,behdg,bfcjh,bgjfi,che,dhge
- 10 bcd,aefg,aghi,aije,bdgih,bhji,biejc,cjfe,cegfd,dfhg
- 10 bcd,aefgh,ahfi,agje,bdhif,becjg,bfdih,bgejc,ceg,dfh
- 10 bcd,aefgh,ahig,agfj,bjgi,bihdg,bfdceh,bgjfc,cfe,dhe
- 10 bcde,aefgh,ahif,ajhg,aijb,bjcg,bfid,bdjic,cheg,dfeh
- 10 bcd,aefg,aghi,afhj,bjih,bhdig,bfjhc,cgdfe,cejf,dgie
- 10 bcd,aefgh,ahfi,ajhe,bdhif,bechj,bjih,bgedfc,ceg,dgf
- 10 bcd,aefg,ahif,ajgi,bihj,bjcig,bfidh,cgje,cedgf,dfeh
- 10 bcd,aefgh,ahfi,agfj,bjif,bechdg,bfdih,bgjfc,ceg,dhe
- 10 bcd,aefgh,aij,afhge,bdgif,behdj,bjedh,bgdfi,che,cgf
- 11 bcd,aefg,ahf,aigj,bji,bick,bkdh,cgij,dfeh,dkhe,fjg
- 11 bcd,aefg,ahf,aij,bjhi,bick,bkih,cgej,dfeg,dkhe,fjg
- 11 bcd,aefgh,aig,afhe,bdjk,bkdg,bfcj,bjdi,chk,ehg,eif
11 bcd,aefgh,aij,afhe,bdgk,bkdj,bjeh,bgdi,chk,cgf,eif
- 11 bcd,aefgh,aig,afj,bjgk,bkdg,bfceh,bgji,chk,dhe,eif
- 11 bcd,aefgh,ahig,ajhe,bdki,bihj,bjck,bkdfc,cfe,dgf,ehg
- 11 bcd,aefg,aghi,aije,bdhk,bihj,bjkc,cejf,cfkd,dgfh,egi
- 11 bcd,aefgh,ahei,afhj,bjck,bkdi,bijh,bgdkc,cgf,dge,ehf
- 11 bcd,aefgh,aij,afke,bdgif,behdj,bjek,bkfi,che,cgf,dhg
- 11 bcd,aefg,ahi,ajk,bkif,behj,bjikh,cgkf,cegj,digf,dhge
- 11 bcd,aefg,ahi,ajk,bkhf,beji,bikjh,cgje,ckgf,dfhg,dgie
- 11 bcd,aefg,aghi,ajgk,bkh,bjig,bfkdhc,cgje,ckf,dfh,dgie
- 11 bcd,aefgh,aij,afhk,bkif,behdj,bjkh,bgdfi,che,cgf,dge
- 11 bcd,aefgh,aij,agfk,bkjf,beidg,bfdjh,bgki,chf,ceg,dhe
- 11 bcde,afgh,ahfi,aijk,akif,becj,bjik,bkjc,cegd,dgfh,dhge
- 12 bcd,aefg,ahf,aij,bki,bicl,blih,cgk,dfeg,dlk,ejh,fjg
- 12 bcd,aefg,ahi,ajkl,blj,bilk,bkjh,cgl,cfj,dieg,dgf,dfhe
- 12 bcd,aefg,ahi,ajk,bkhl,bikg,bfjh,cgek,cfl,dlg,dfhe,eji
12 bcd,aefg,ahi,ajk,bkhf,beji,bikl,cle,ckgf,dfl,dgie,gjh
- 12 bcd,aefgh,aij,akl,blif,bekj,bjlh,bgki,che,cgf,dfh,dge
- 13 bcd,aefg,ahi,ajk,blm,bikg,bfjh,cgl,cfm,dmg,dfl,ekh,eji
- 14 bcd,aef,agh,aij,bkl,bmn,cnk,cml,dln,dmk,ejg,eih,fhj,fig
- 9 bcde,afdg,ageh,ahbi,aicf,begi,bhfc,cigd,dfhe
- 9 bcde,afdg,agfh,ahbi,aihf,beci,bhic,cegd,dfge
- 13 bcde,afgh,ahij,ajkl,almf,beji,biml,blkc,ckgf,cfmd,dmih,dhge,egkj
Figure 1. List of Diminimal Maps on the Torus in plantri format
H1 and dual H53
H4 and dual H32
H7 and dual H35
H2 and dual H47
H5 and dual H33
H8 and dual H36
H3 and dual H52
H6 and dual H34
H9 and dual H48
H10 and dual H49
H11 and dual H50
H12 and dual H51
Figure 2. Diminimal Maps on the Torus with duals, 1 of 3
H13 and self dual
H17 and self dual
H21 and self dual
H16 and self dual
H19 and dual H20
H23 and dual H38
H14 and dual H15
H18 and self dual
H22 and self dual
H24 and dual H41
H25 and dual H42
H26 and dual H37
Figure 3. Diminimal Maps on the Torus with duals, 2 of 3
H27 and dual H39
H30 and dual H44
H28 and dual H43
H31 and dual H45
H29 and dual H40
H46 and self dual
R1 and self dual
R2 and self dual
S1 and self dual
Figure 4. Diminimal Maps on the Torus with duals, 3 of 3
## References
- 1. Gunnar Brinkmann and Brendan D. McKay, plantri, program for generation of certain types of planar graph , http://cs.anu.edu.au/ ~ bdm/plantri/ .
- 2. Jennifer Henry, On generating a diminimal set of polyhedral maps on the torus , arXiv:math/0107123.
- 3. , On generating a diminimal set of polyhedral maps on the torus , ProQuest LLC, Ann Arbor, MI, 2001, Thesis (Ph.D.)-University of California, Davis. MR 2702268
- 4. Adrian Riskin, Type 3 diminimal maps on the torus , Israel J. Math. 75 (1991), no. 2-3, 371-379. MR 1164599 (93d:57048)
- 5. , On type 2 diminimal maps on the torus , J. Combin. Inform. System Sci. 17 (1992), no. 3-4, 288-301. MR 1317680 (95k:05059)
- 6. Thom Sulanke, Source for surftri and lists of irreducible triangulations , http://hep.physics.indiana.edu/ ~ tsulanke/graphs/surftri/ .
Department of Physics, Indiana University, Bloomington, Indiana 47405 USA E-mail address : [email protected] | null | [
"Thom Sulanke"
] | 2014-08-02T22:03:20+00:00 | 2014-08-02T22:03:20+00:00 | [
"math.CO",
"05C10, 05c30, 05C35"
] | Another Diminimal Map on the Torus | This note adds one diminimal map on the torus to the published set of 55. It
also raises to 15 the number of vertices for which all diminimal maps on the
torus are known. |
1408.0430v1 | Titel: Artificial Left Ventricle
Authors: Saeed Ranjbar , Ph.D, Tohid Emami Meybodi , MD, , Mahmood emami Meybodi , MD
## Research institute:
- 1Modarres Hospital, Institute of Cardiovascular Research, Shahid Beheshti University of Medical Science, Tehran, Iran.
- 2Shahid sadoughi university of medical sciences, Yazd, Iran
## *Corresponding Author: Saeed Ranjbar
The full postal address of the corresponding author:
Modarres Hospital, Institute of Cardiovascular Research, Shahid Beheshti University of Medical Science, Tehran, Iran
E-mail: [email protected]
Tel/FAX: +9821 22083106
## Artificial Left Ventricle
Saeed Ranjbar , Ph.D, Tohid Emami Meybodi , MD, , Mahmood emami Meybodi , MD
## Abstract
This Artificial left ventricle is based on a simple conic assumption shape for left ventricle where its motion is made by attached compressed elastic tubes to its walls which are regarded to electrical points at each nodal .This compressed tubes are playing the role of myofibers in the myocardium of the left ventricle. These elastic tubes have helical shapes and are transacting on these helical bands dynamically. At this invention we give an algorithm of this artificial left ventricle construction that of course the effect of the blood flow in LV is observed with making beneficiary used of sensors to obtain this effecting, something like to lifegates problem. The main problem is to evaluate powers that are interacted between elastic body (left ventricle) and fluid (blood). The main goal of this invention is to show that artificial heart is not just a pump, but mechanical modeling of LV wall and its interaction with blood in it (blood movement modeling) can introduce an artificial heart closed to natural heart.
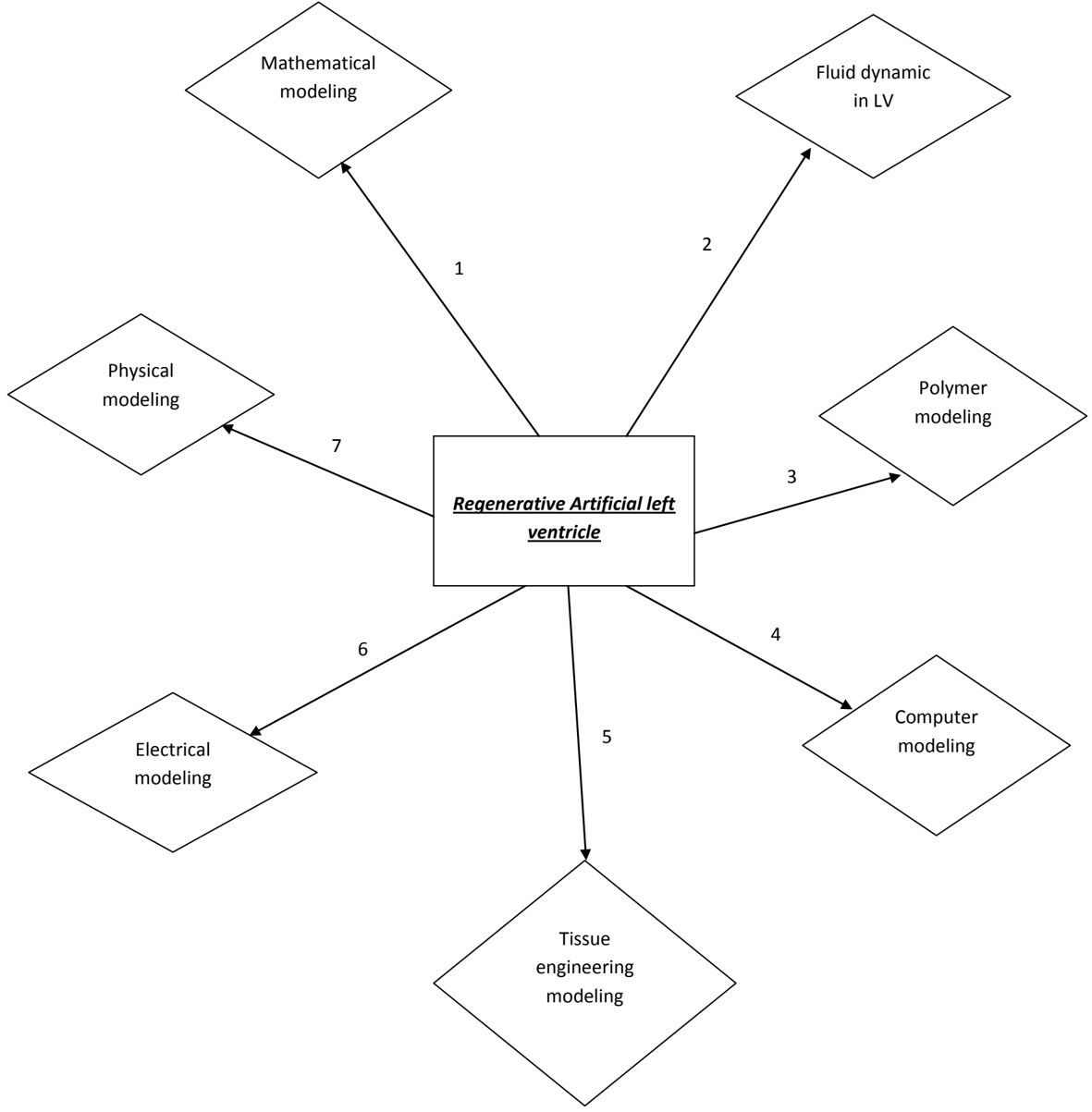
These bands initiate from the posterior-basal region of the heart continues through the left ventricle free wall, reaches the septum, loops around the apex, ascends, and ends to the superioranteriorsection of the left ventricle.
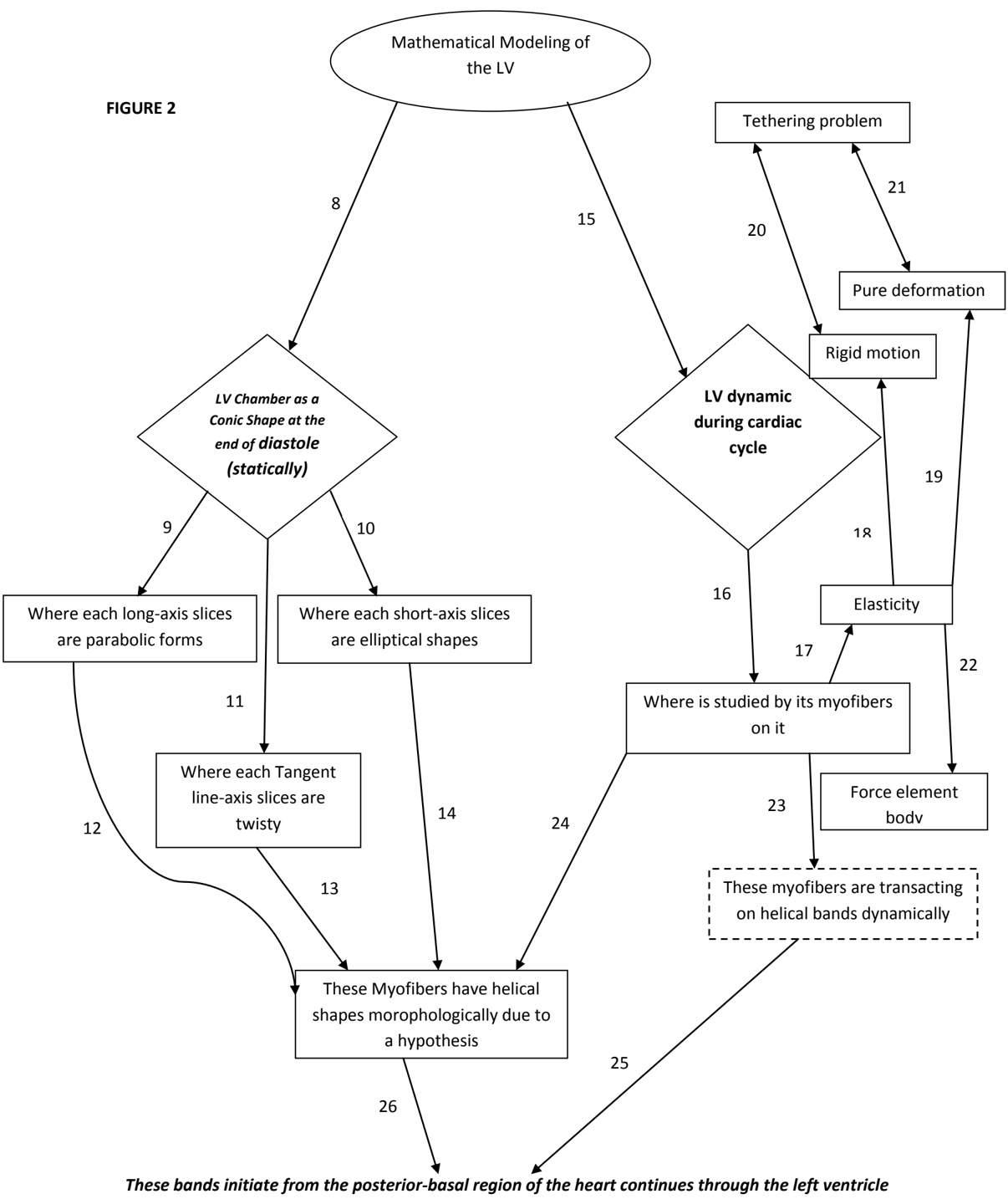
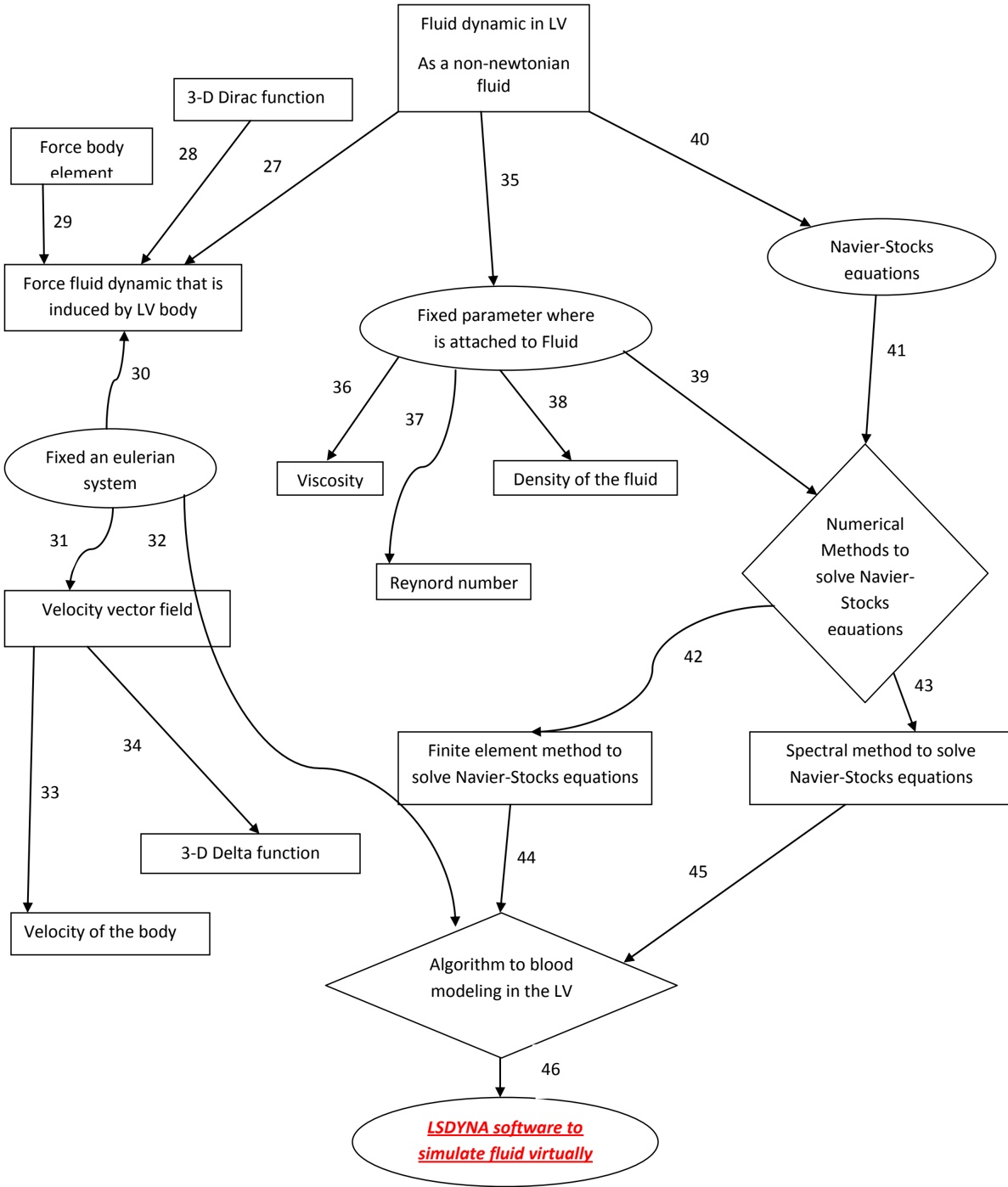
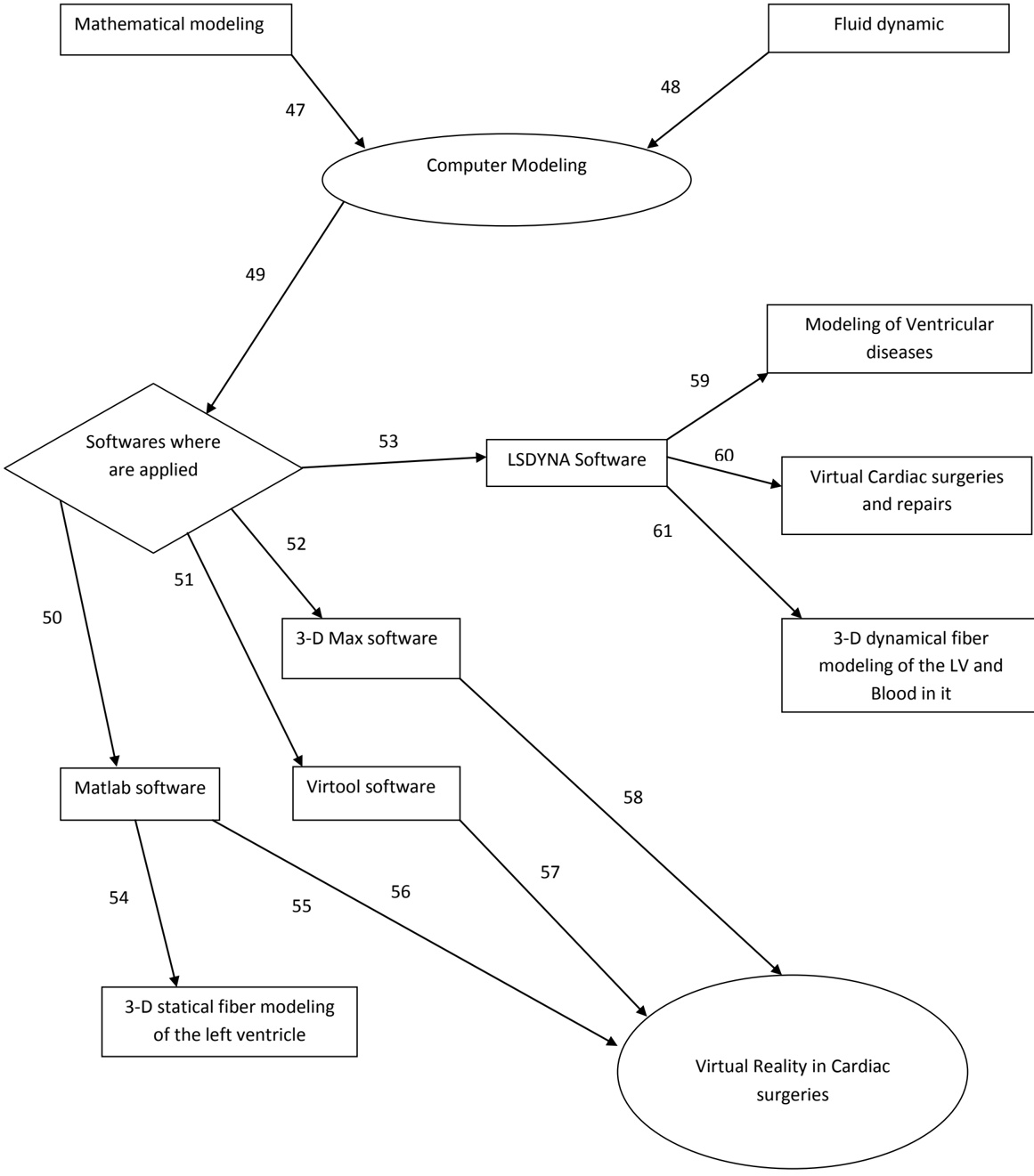
Polymer motion by power effecting where are applied on micro actuators that have been situated at nodal points on elastic tubes.
FIGURE 6
Figure 7
Figure 8
FIGURE 9
Having used sensors at each nodal point, blood force on the LV wall is considered.
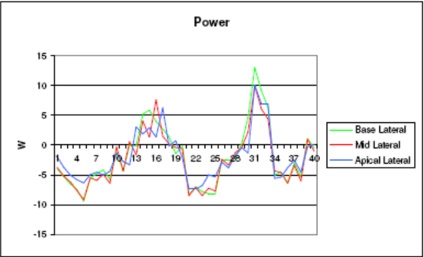
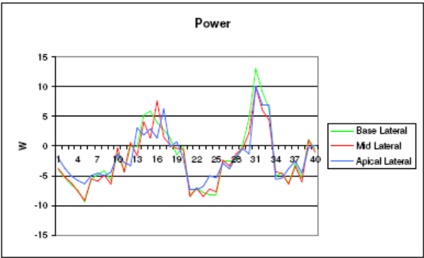
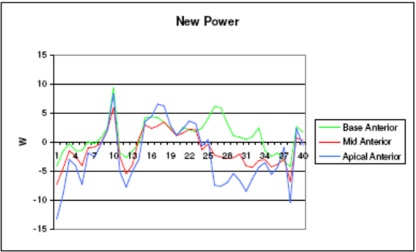
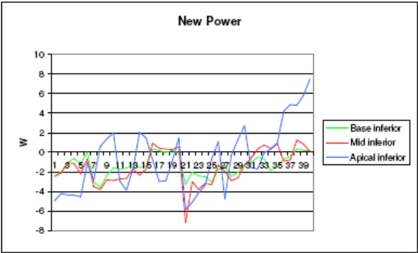
FIGURE 12

FIGURE 13

Figure 14
## Background of the invention
All recent artificial left ventricles are just miniature pumps. The pump Electric coils cause a rotor with an embedded magnet to spin. Fins on the rotor push Oxygen-rich blood (red arrows) from the heart through a tube in to the aorta. On October 27, 2008, French professor and leading heart transplant specialist Alain F. Carpentier announced that a fully implantable artificial heart will be ready for clinical trial by 2011 and for alternative transplant in 2013. It was developed and will be manufactured by him, Biomedical firm Carmat, and venture capital firm Truffle. The prototype uses electronic sensors and is made from chemically treated animal tissues, called "biomaterials", or a "pseudoskin" of biosynthetic, microporous materials. Another US team with a prototype called 2005 MagScrew Total Artificial Heart, including Japan and South Korea researchers are racing to produce similar projects. But at this presentation the main goal is to advance recent attempts on artificial left ventricles by these point of views where using compressed elastic tubes with helical shapes toward microprous materials which are applied to nodal points of these elastic tubes. At this invention these elastic tubes are replaced with the fibers of the myocardium in the left ventricle where this is needed to find a good understanding of these fibers not only statically but also dynamically at the same time. A fiber in the myocardium means to follow the curve of the motion of a muscle volume sample in the myocardium from the end of diastole to the end of systole. Characterization of local and global contractile activities in the myocardium is essential for a better understanding of cardiac form and function. The spatial distribution of regions that contribute the most to cardiac function plays an important role in defining the pumping parameters of the myocardium like ejection fraction and dynamic aspects such as twisting and untwisting. In general Myocardial shortening and lengthening, tangent to the wall , and ventricular wall thickening are important parameters that characterize the regional contribution within the myocardium to the global function of the heart.
We calculated these parameters using vector bundles of myocardium deformation, which were captured through the displacement encoding with stimulated echoes in 50 normal volunteers. High spatial resolution of the acquired data revealed transmural changes of wall thickening and tangential shortening with high fidelity in beating hearts during a cycle. By filtering myocardium regions that showed a tangential shortening of < 0.23, we were able to identify the complete or a portion of a macrostructure composed of connected regions in the form of a helical bundle within the left ventricle mass. In this study, we present a represetative case that shows the complete morophology of a helical myocardial band due to a famous hypothesis about fibers transaction in the LV as well as cases that present ascending and descending portions of the helical myocardial band.
A better understanding the structure and function of the heart continues to challenge modern medicine and physiology. Despite the remarkable advances in the understanding of myocardial cell function and its complex molecularstructure, the role of cardiac sarcomeres and myofibers in generating contractile forces in the normal heart baffles us at all levels. A better understanding of the spatial distribution of regions with elevated contractile dynamics within the myocardium mass would perhaps help to resolve this issue. As it can also be observed in the morophology of the LV, our hypothesis is that if myofibers of the left ventricle form a gross macroscopic structure in the form of a band, its importance in the dynamics of the heart must be revealed in characterized regional and global function of the myocardium. Based on our hypothesis, such an anatomic structure should act like a physical pathway for the maximum transmission of systolic contractile force and should facilitate the spatial coordination of relaxation and diastolic recoil. The effective of this approach depends on the proper indentification of the cardiac regions that exhibit higher contractile activity and the nature of their linkage and inner connectivity. In this presentation, we implement an approach that enable us to map regions of intense and directional contractile activities within myocardium to examine the nature of gross morophology suggests that a band in the form of elleptical characterizes the most intense contractile activities within the ventricular mass.
The other assessment to gain a necessary understanding of the local contractility, in contrast with chemical and electrical reasons of the cardiac muscle contraction would be followed by a new notion of the intrinsic power of myocytes resulting in the sufficient energy to the cardiac motion and deformation. If we follow myofiber's transactions from the end diastole to the end systole, they would show us helical curves that intrinsic power is made to move myofibers on these bands. The other values must be calculated is the local power of the fluid (blood) which is transfered to the myocardium.
It would therefore be desirable to design a method and system to fully applying myofiber transactions in the myocardium and their interactions with the fluid through the LV for this assistant devise where it has the central role in the cardiac function.
## Summary
This invention includes a method and system that is applied to an elastic conic shape where here is a miniature of the left ventricle.
In fact our elastic material of the left ventricle is a plastic modeling of a simple mathematical modeling of the left ventricle in compared with its physical modeling.
The motion and deformation of the LV are forced by studying of the behaviors of fibers in LV, statically and dynamically. Our evidence not only in cardiac imaging but also in the mathematical modeling show that the most of these fibers move on helical bands. Here these fibers in the myocardium are replaced with compressed elastic tubes where are deformed to helical shapes. For each part of LV wall, they set somehow in the myocardium where their nodal points pass from the LV free wall, the mid of the septum, the apex, the mid of the lateral and the base of the anterior respectively.
Electrical sensors which are made by microprous materials are used at these nodal points to push elastic tubes on their helical curves. The powers which are recharged by these microprouses save from the evaluation of the power of the local myocardium at our LV mathematical modeling. And by these sensors and having used evaluated powers of the blood when comes in to the LV, we can observe effecting of the blood to body movement of the left ventricle.
## Brief Description of the Drawings
The drawings illustrate one preferred embodiment presently contemplated for carrying out the invention.
In the drawings:
- FIG. 1 is a general flowchart of a regenerative artificial left ventricle where states what models are involved to pose a good structure of an artificial left ventricle near real left ventricle.
- FIG. 2 is a flowchart of the mathematical modeling of the left ventricle function not only statically but dynamically at the same time where data are evaluated by electrocardiogram data in compare with the other cardiac imaging tools.
- FIG. 3 is a flowchart of the fluid (the blood) dynamic as a nonnewtonian fluid in the left ventricle where is studied as fluid-wall interaction. samples for solving partial differential equations come from Echo ( as one of tools in cardiac imaging by ultrasound method).
- FIG. 4 and 5 are flowcharts of computer and polymer modeling at this invention.
- FIG. 6 shows a simple mathematical conic assumption of the left ventricle at the end of diastole where is constructible by an elastic polymer.
- FIG. 7 is a mesh file of this conic shape at the Matlab software.
- FIG. 8 shows nodal points in a compressed elastic twisty tube. Micro actuators are applied at these points to transfer enough energy that we have explicitly computed these values of energy.
- FIG. 9 is a scheme of using sensors at nodal points to evaluate the effect of the blood though the mitral valve and left ventricle.
- FIG. 10 is a short-axis view of the left ventricle toward landmarks of experimental samples.
- FIG. 11 is the diagrams of power local values of the myocardium where have been tested on 50 normal cases by Vivid 7 Echo.
- FIG. 12 is a scheme of a muscle volume sample toward a myofiber on it in the myocardium at the end of diastole.
- FIG. 13 is the same muscle volume sample after passing 0.2s from the end of diastole.
- FIG. 14 is a scheme of a muscle volume sample in the myocardium with a distribution of its fibers in it. And a scheme of three vectors of deformations where is attached to this volume sample.
## Detailed Description of the prefferd of embodiment:
Referring to FIG. 1 , the major components of a regenerative artificial left ventricle 1-6 incorporating the present invention are shown. The operation of this regenerative artificial left ventricle is locally designed
Srr mathematically to FIG. 2, 8 and 15 in compared with its real physical modeling of the left ventricle. Behavior of the left ventricle is basically divided to statical modeling of the LV 9-14 and to dynamical studying of the LV 16-25. Having assumed LV as a conic shape 8 at the end of diastole and look at shapes of its sections 9-11 , we can gain a good understanding of the local geometrical shape of the myocardium at the left ventricle. These local mathematical shapes are attached to each muscle volume samples and the main theme is to follow these samples on the curves where they are the fibers of a deformation flat map 1619 . In FIG. 14 , left ventricle can be realized as a vector bundle of deformation components radial strain longitudinal strain and Circumferential strain that are evaluated by Echo techniques for each landmarks at our samples. And the curves of myofibers transactions are iso-curves of a deformation map which is defined by the following way:
)
fibers (as an outputs of an algorithm where is running co-images of the deformations map) of this map have a twisty shape geometrically 12-14 , and fiber transactions on such these bands where are on isocurves of the deformation map give us a fiber modeling of the myocardium at the left ventricle 23-25 . The advantage of this modeling is due to ultrasound method where is really accessible and our algorithm as a software can also be applied to develop imaging in echocardiography at this invention. Since left ventricle function is not just an elastic body movement but is a problem in fluid (blood)-wall interaction. Having used ultrasound method in echocardiography, fluid dynamic in the left ventricle is the major goal in FIG. 2 , as a fluid-wall interaction problem we are dealing to solve a system of partial differential equations one by continuum motions 27-34 , and the others are related to Navier-Stocks equations 35-40 . One of the major investigation is to solve discretely Navier-Stocks equations by experimental electrocardiogram data 41 , two main methods have been applied on electrocardiogram data at this invention 42-43 , that after a manipulating of these data, they can be considered as inputs of an algorithm where simulates blood through the left ventricle in LSDYNA software as a fluid dynamical simulation software 45 . Referring to FIG. 2 and FIG. 3 we give a detailed description of our method to solve of equations by using ultrasound method. One of the main attempts at this invention serves to study an arbitrary piece of the myocardium while is mechanically contracted, from the end-diastole to the end-systole. This finding can be posed to gain a good understanding of the local contractility, in contrast with chemical and electrical reasons of the cardiac muscle contraction. This assessment would be followed by a new notion of the power of myocytes resulting in the sufficient energy to the cardiac motion and deformation. This power was measured through 50 normal cases for each muscle volume samples in the myocardium at peak systolic. Case data included velocity, displacement, strain and strain rate. For instance, passing 0.2s from end diastole for a case in a piece with unit volume of his/her base lateral, 2.72w power is needed to
get 4.5cm/s, 0.83cm, 25% and 1.85 1/s, in velocity , displacement, strain and strain rate respectively. This option is also considered as a remodeling index of the ventricles that as an example of this include due to vavular stenosis or regurgitation, coronary artery disease with associated decreased contractility and fibrosis leading to ventricular dilatation, genetic abnormalities resulting in hypertrophy, and progressive development of local fibrosis, severe hypertension, conduction abnormalities, etc. in fact this remodeling is a response to a problem with either the muscle itself or the environment in which it has to work and is an attempt to keep on fulfilling the heart's task-circulating the blood. However, since this is an abnormal situation with inherent mechanical disadvantages, in the long term, this will lead to irreversible damage to the muscle which evolves into ventricular dysfunction and heart failure. The early detection and follow-up of change in cardiac function and myocardial properties is thus of major importance.
The strain-stress relationship is a common concept used to investigate the mechanical properties of materials and has recently been applied to the analysis of cardiac tissue properties. The concept of strain (ε) corresponds to the deformation of an object as a function of an applied force stress (s). It represents the precentage of change of the unstressed dimension after the application of stress. And hold for both expansion (positive strains) and compression (negative strains). Considering a one dimensional object. The possible stress deformations are lengthening and shortening. In this case the strain can be expressed as the difference between the original length ( ) and the length (L) after deformation. Normalized by the original length ( ). As shown in the following equation:
$$\varepsilon = \frac { \left ( \frac { \left ( \frac { \left ( \frac { \left ( \left ( \pi _ { 0 } } { r } } } { r } } { \right ) }$$
As shown, the strain is a dimensionless parametr and, by convention, positive correspond to lengthening and negative strains to shortening.
In some cases the length of the object is known during the deformation process, in that case we can define the instantaneous strain as:
$$= \frac { L ( t ) - L ( t _ { 0 } ) } { L ( t _ { 0 } ) }$$
Where (L(t)) is the length at a given instant (t) and (L( )) is the original length.
The strain rate is measurement of the rate of deformation and corresponds to the velocity of the deformation process. Taking into account equation (1) and (2) the latter definition, the instantaneous strain rate is expressed as the temporal strain derivative:
$$\dot { \varepsilon } ( t ) = \frac { d \varepsilon ( t ) } { d t } = \frac { d L ( t ) } { d t. L ( t ) } = \frac { L ^ { ^ { \prime } } ( t ) } { L ( t ) }$$
With being the rate of deformation and L(t) the instantaneous length. The strain rate units are . Compared with the rate of deformation unites m. . As a conclusion, both strain rate and strain are closely related and they can be derived one from each other as we will discuss later.
Different approaches have been proposed to calculate the strain and strain rate parameters; some preliminary studies have been carried out to evaluate their precision and clinical usefulness. Two main methods have been proposed: the Crosscorrelation method and the velocity gradient method. The Cross-correlation method is based on the principles of elastography where two consecutive radiofrequency signals are compared to extract information about the tissue elasticity properties. Considering two consecutive radiofrequency signals applied to a tissue under deformation, the resultant backscatter signals received have similar patterns, except for a temporal shift related to the actual deformation. Cross-correlation analysis provides the temporal shift or delay introduced due to the object motion. From this analysis, different parameters such as the change in distance, local motion, velocities, etc., can be derived. The principal limitation of this technique is its high computational cost and the need of very high temporal resolution to avoid noisy estimates. That limits its application to M-mode acquisition. On the other hand, Fleming et al and Uematsu et al . introduced the concept of myocardial velocity gradient as an indicator of local contraction and relaxation. This concept is directly related to the already formulated strain rate parameter (3) under the assumption of linear and uniform strain (homogeneous, isotropic and incompressible material) as can be shown in the following expression:
$$\dot { \epsilon } ( \mathbf t ) = \frac { d \varepsilon ( t ) } { d t } = \frac { d L ( t ) } { d t. L ( t ) } = \frac { L ^ { ( } ( t ) } { L ( t ) } \\ ( 4 )$$
where and are the local instantaneous velocities at two myocardial points separated an L t ( ) distance. This formulation allows to compute myocardial strain rate as the spatial gradient of myocardial velocities, which can be obtained by Doppler echocardiography. Since the computational load is not high it can be implemented as a postprocessing step after acquiring Doppler Tissue images or in real-time from digitally stored tissue velocity information . The axial natural strain component can be calculated from the strain rate curve time-integration expressed by:
$$\dot { \varepsilon } ( t ) d t$$
When using myocardial motion and deformation to assess (dys-) function, it is important to understand the relation between intrinsic power and the resulting motion and deformation. In fact by roughly speaking, how much mechanical power is needed to make these dynamical deformations for each cardiac muscle volume? This matter would give the best information of cardiac function. In summary, the main factors influencing to the cardiac function mechanically are: 1) Regional myocardial motion and deformation. 2) Intrinsic power, i.e. the sufficient energy force developed by myocardium, resulting in motion and deformation. Having applied ViVid7 setting, for 50 normal cases, we got velocity, displacement, strain and strain rate at peak systolic, for each part of the myocardium, i.e. at the base, Middle and Apical of Septal, Lateral, Anterior and inferior FIG. 10 .
And using these data and applying them in the "Power formula", we could compute intrinsic power values at peak systolic, for each local part of the myocardium where these values have been presented at the diagrams in FIG. 11 , for instance, the value of this new option at the base septal for a case is 6.5w that means, 6.5w is needed to make a necessary motion and deformation of this part at the peak systolic. And with removing the general motion of the heart, this value for that case at the base septal is less than 6.5w where this states, tethering helps that piece of myocardium to handle the matter.
We pick a cardiac muscle volume sample, for instance from the basal septum and follow-up its motion and deformation during the end diastole to the end systole FIG 12 .
Passing time" t" after the end diastole, radial strain rate for the fiber AB is:
$$s t r a i n \ r a t e = V _ { B }$$
Let are displacement and velocity of the above muscle volume element at time t.
By classical mechanic we set :
$$D _ { t } + L _ { A B } ( t ) - L ( t _ { 0 } ) = \frac { 1 } { 2 } \, a _ { t } t ^ { 2 } + W _ { t } \mathbf t$$
is the time and is the length of the fiber AB respectively at the end diastole.
Having used the 1-D deformation definition we rewrite the above formula by the following way:
$$\frac { D _ { t } } { t } + \frac { L _ { A B } ( t ) } { t } - \frac { L ( t _ { 0 } ) } { t } = \frac { 1 } { 2 } \, a _ { t } t \,.$$
By radial strain rate and strain of the fiber AB at time "t" we have:
$$\frac { D _ { t } } { t } + \ s t r a i n \ r a t e ( t ). ( \ s t r a i n ( t ) + 1 ) L ( t _ { 0 } ) = \frac { 1 } { 2 } a _ { t } t + W _ { 1 }$$
Thus we can reformulate in below:
$$a _ { t } = 2 \frac { D _ { t } } { t ^ { 2 } } + 2 s t r a i n \, r a t e ( t ). \frac { ( s t r c ) } { - \frac { 2 W _ { t } } { j } }$$
Now if µ be the density and Volume(t) (8) be the volume respectively of our muscle volume sample after the contraction during the time "t". the power which is needed to result in this motion and deformation at time "t" would be FIG. 13 :
$$& P ( t ) \\ & = \mu. \text{Volume} ( t ). a _ { t }. \, D _ { t } / _ { 1 }$$
Decreased or increased in power, for a muscle volume sample can be caused a maker of myocardial ischemia, LV dysfunction, or LV hypertrophy FIG. 4, 59 . Inasmuch as intrinsic power has simultaneously been contributed by some codependent factors such as motion and deformation FIG. 2, 18,19 , and 22 , it is realized as a remodeling index to keep up normal conditions. For instance failure to achieve adequate wall thickening (at radial deformation) and lengthening/shortening (at longitudinal deformation) of a fiber can be made by power. Having increased in wall thickening of a piece of left ventricle, motivate us to inhibit widely dilate with a hypertrophic wall, by a reduction in power of that part. Particularly when power tends to zero for a muscle volume, it may be a factor that shows myofibers of that section, have died. So it would be a criterion, where we can make use of stern cell method to improve cardiac? FIG. 1 and 5
On the other hand, this power shows its influence on red blood cell flow by change in volume FIG. 3, 27 , In fact when a unit volume of red blood cell is dealing with a piece of ventricles, has a simple description of its change in volume, i.e. it can calculate by:
∆V(t)= Local change in volume of RBC with unit volume from end diastole to end systole , where
## ∆V(t)= (Radial deformation(t))x(Longitudinal deformation(t)) x Displacement(t) (8)
From this point of view, one can locally compute myocardial pressure which is a very valuable measure for many normal and pathological conditions of the heart, particularly right ventricular function and interrelationship of the right and left heart. This pressure is directly measured by the following way:
## Local myocardial pressure (t) =
.
## (9)
If we follow myofiber's transactions from the end diastole to the end systole, they would show us curves FIG. 2, 23 , that intrinsic power is made to move myofibers on these bands.
Referring to FIG. 4 , the present invention includes algorithms that are applied to softwares 50 and 53 to follow a muscle volume sample in the myocardium and its interaction with a red blood cell within the LV contractions. Experimental samples are evaluated by electrocardiogram data and mathematical formulations will be also applied on these data to disclose images of a fiber modeling of the left ventricle motions and blood through it. Referring to a ventricular disease in terms of its electrocardiogram data, we can also do the same work to give a fiber modeling for this disease 59 , that it would basically be hard to diagnosis it by echo techniques. By a technical manipulating of electrocardiogram data therein as inputs of our algorithms we can do cardiac surgeries virtually 53 and 60 . Having made the beneficiary used of fiber modeling of the LV where had been modeled by echocardiography tool and referring to FIG. 4 , and 51, 52 we can make a program to virtual reality in cardiac surgery and follow new techniques and repairs for cardiac surgical tasks.
Due to FIG. 5 , the best mathematical modeling at this invention was the main goal where it can be applied on an elastic polymer for an artificial left ventricle 64 and 65 . In fact dynamical properties of this polymer are made by representing elastic tubes (as myofibers in the left ventricle) where have been equipped to micro actuators in their nodal points to charge enough powers 66-69 .
The present study has been described in terms of a mathematical modeling that all mathematical formulations are stated from ultrasound methods in compared with the other cardiac imaging tools.
Disclosure:
There is no disclosure .
## References:
- 1Saeed Ranjbar , Mersedeh Karvandi. System and method for modeling left ventricle of heart. US Patent Number: 8,414,490.
- 2Saeed Ranjbar , Mersedeh Karvandi Solution Navier-stocks equations of the blood as a . non-newtonian fluid in the left ventricle. US Patent number: 8805663 | null | [
"Saeed Ranjbar",
"Tohid Emami Meybodi",
"Mahmood Emami Meybodi"
] | 2014-08-02T22:28:45+00:00 | 2014-08-02T22:28:45+00:00 | [
"physics.med-ph"
] | Artificial Left Ventricle | This Artificial left ventricle is based on a simple conic assumption shape
for left ventricle where its motion is made by attached compressed elastic
tubes to its walls which are regarded to electrical points at each nodal .This
compressed tubes are playing the role of myofibers in the myocardium of the
left ventricle. These elastic tubes have helical shapes and are transacting on
these helical bands dynamically. At this invention we give an algorithm of this
artificial left ventricle construction that of course the effect of the blood
flow in LV is observed with making beneficiary used of sensors to obtain this
effecting, something like to lifegates problem. The main problem is to evaluate
powers that are interacted between elastic body (left ventricle) and fluid
(blood). The main goal of this invention is to show that artificial heart is
not just a pump, but mechanical modeling of LV wall and its interaction with
blood in it (blood movement modeling) can introduce an artificial heart closed
to natural heart. |
1408.0431v1 | ## Solar modulations by the regular heliospheric electromagnetic field
## Paolo Lipari
INFN, sezione di Roma, Piazzale Aldo Moro 2, 00185 Roma, Italy.
August 2, 2014
## Abstract
The standard way to model the cosmic ray solar modulations is via the Parker equation, that is as the effect of diffusion in the turbulent magnetic of an expanding solar wind. Calculations performed with this method that do not include a description of the regular magnetic field in the heliosphere predict, in disagreement with the observations, equal modulations for particles and antiparticles. The effects of the regular heliospheric field, that break the the particle/anti-particle symmetry, have been included in the Parker equation adding convection terms associated to the magnetic drift velocity of charged particles moving in non-homogeneous magnetic field. In this work we take a completely different approach and study the propagation of charged particles in the heliosphere assuming only the presence of the regular magnetic field, and completely neglecting the random component. Assuming that the field is purely magnetic in the wind frame, one can deduce the existence of a large scale electric field, that results in important energy losses for charged particles that traverse the heliosphere and reach the Earth. The energy loss ∆ E due to the large scale regular electric field depends on the particle electric charge, is proportional to the absolute value of the electric charge, and to a good approximation is independent from the particle energy and direction. We speculate that this deterministic energy loss is an important, or perhaps even the leading contribution to the solar modulation effects.
## 1 Introduction
The fluxes of galactic cosmic rays observed near the Earth are different from those present in the local interstellar space because the particles lose energy and are deviated when they penetrate the heliosphere. These effects are time dependent because the heliospheric environment is not static. The time variations have several different characteristic time scales with a prominent 22 years periodicity associated to the solar magnetic activity. The solar modulations of the cosmic rays energy spectra have been extensively studied experimentally for many years using ground and space based detectors, and has been the subject of many theoretical studies [1].
Following the pioneering work of Parker [2], the usual way to study theoretically the solar modulations is to model the propagation of cosmic rays in the heliosphere as a diffusion
process in a turbulent magnetic field, accompanied by convection (because of the motions of the plasma - the solar wind - that fills the heliosphere) and adiabatic energy losses associated to the expansion of the plasma. The effects of diffusion, convection and adiabatic energy loss in particle propagation are included in the Parker equation that has been used as the standard instrument to study solar modulations (for a recent reviews see [4]).
In the first studies of the solar modulations (such as [3]) the calculated effects were identical for particles of opposite electric charge. The data however show that the modulations effects differ for particles of opposite electric charge. The dependence of the modulations on the sign of the electric charge can be attributed to the presence of a regular magnetic field in the heliosphere. In the presence of such a field, the average trajectories of particles with opposite charge differ, and the particles can have different energy losses.
The effects of the regular heliospheric field was first included in the Parker equation by Jokipii [5] introducing an additional convection term associated to the average 'drift velocity' of the gyration center of charged particles moving in a non-homogeneous magnetic field. The direction of the drift velocity is reversed when the electric charge of a particle changes sign, and therefore the drift velocity convection term breaks the particle/antiparticle symmetry in the Parker equation [6, 7, 8].
In this work we will discuss the propagation of charged particles in the heliosphere assuming that only the regular electromagnetic field is present, neglecting completely the effects of the random component of the field. This approach is complementary to the traditional method (where it is the regular field that is completely neglected), and a comparison of the results can be instructive to clarify the physical mechanisms that generate the solar modulations.
To keep the discussion as simple as possible we will assume that the heliospheric magnetic field glyph[vector] B ( glyph[vector] x ) has the simple Parker spiral form (discussed below), and that the speed of the solar wind is constant, and its direction is radial ( glyph[vector] w glyph[vector] ( x ) = wr ˆ). The magnetic field and the solar wind will be also considered as stationary during the time necessary for charged particles to reach the Earth from the boundary of the heliosphere.
If the conductivity of the plasma in the heliosphere is sufficiently high, the condition of stationarity implies that the net force on an electrically charged particle moving with the wind must vanish. It follows that in a frame where the Sun is at rest there is a non vanishing electric field given by the well known expression:
$$\vec { E } ( \vec { x } ) = - \frac { \vec { w } ( \vec { x } ) } { c } \wedge \vec { B } ( \vec { x } ) \.$$
Equation (1) can be also derived requiring that the electric field vanishes in a frame where the plasma of the solar wind is at rest.
Under the assumptions we have outlined above, the propagation of a charged particle in the heliosphere, is completely deterministic and can be calculated integrating the classical equations of motion:
$$\frac { d \vec { x } } { d t } = \vec { v } = \frac { \vec { p } } { \sqrt { p ^ { 2 } + m ^ { 2 } } } \\ \frac { d \vec { p } } { d t } = q \, \left ( \vec { E } + \frac { \vec { v } } { c } \wedge \vec { B } \right ) \,.$$
In the following we will show that charged particles of sufficiently low energy ( E glyph[lessorsimilar] 1 TeV) propagating from the boundary of the heliosphere to the Earth will always lose energy, and discuss the properties and consequences of this energy loss.
This paper is organized as follows: in the next section we describe the model of the heliospheric electromagnetic fields used in this work. In section 3 we discuss the magnetic drift velocities in the motion of charged particles in our heliospheric model. In section 4 we discuss some examples of trajectories of charged particles in the heliosphere. Section 5 discusses the energy loss suffered by particles that arrive at the Earth. Section 6 discusses the relation between the interstellar spectra of cosmic rays at the boundary of the heliosphere, and the energy spectra observable at the Earth. The last section gives a summary and outlook.
## 2 Electromagnetic fields in the heliosphere
In the following we will assume that the solar magnetic field has the Parker spiral form:
$$\vec { B } = A \ B _ { 0 } \ \left ( \frac { r _ { 0 } } { r } \right ) ^ { 2 } \, \left [ \hat { r } - \frac { \Omega } { w } \, r \, \sin \theta \, \hat { \varphi } \right ] \, S ( \vec { r } )$$
In this equation r , θ and ϕ are spherical coordinates in a frame centered on the Sun, ˆ and r ˆ ϕ are versors, r 0 is the radius of the Earth orbit (approximated as a circle), Ω is the (equatorial) frequency of the solar rotation, w is the speed of the solar wind that we will assume is radial and constant ( glyph[vector] w = w r ˆ), B 0 is a normalization constant, A = ± 1 give the polarity of the solar cycle (that is reversed approximately every 11 years), and S glyph[vector] ( r ) is ± 1:
$$S ( \vec { r } ) = \begin{cases} + 1 & \text{if $\cos\theta>\cos\theta^{*}$} \\ - 1 & \text{if $\cos\theta\leq\cos\theta^{*}$} \end{cases}$$
with
$$\cos \theta ^ { * } = - \sin \alpha \, \sin \left ( \varphi + \frac { \Omega } { w } \, r \right ) \.$$
The set of points that satisfy the equation cos θ = cos θ ∗ forms a surface known as the Heliospheric Current Sheet (HCS) where the magnetic field is discontinuous. The 'tilt angle' α can take values in the interval [0 , π/ 2]. For α = 0 the HCS coincides with the xy equatorial plane, more in general the surface has the wavy form of a 'ballerina skirt'. The shape of the current sheet is illustrated in fig.1, 2 and 3.
It is convenient to introduce the characteristic length:
$$R = \frac { w } { \Omega } \simeq 0. 9 3 \ \left [ \frac { w } { 4 0 0 \, \text{km/s} } \right ] A \text{U}$$
that will enter in several expressions in the following. The modulus of the magnetic field is:
$$| B ( \vec { x } ) | = B _ { 0 } \, \left ( \frac { r _ { 0 } } { r } \right ) ^ { 2 } \sqrt { 1 + \frac { \Omega ^ { 2 } } { w ^ { 2 } } \, ( r ^ { 2 } - z ^ { 2 } ) } \.$$
When r increases for a fixed direction ˆ, the field decreases in general n ∝ r -1 , with the only exception of the ± ˆ directions, when the field is z ∝ r -2 . The field at the Earth is:
$$B _ { \oplus } = B _ { 0 } \, \sqrt { 1 + \left ( \frac { \Omega r _ { 0 } } { w } \right ) ^ { 2 } } \.$$
The magnetic field lines have the form of clockwise Archimedes spirals that are enveloped on a cone with vertical axis and vertex at the origin of the coordinates. The field line that passes through the point with polar coordinates { r, θ, ϕ } can be parametrized in terms of the azimuth angle ϕ of the points along the line:
$$\theta ( \varphi ) \ = \ \bar { \theta }$$
$$r ( \varphi ) \ = \ \overline { r } + R \times [ \overline { \varphi } - \varphi ]$$
with the angle ϕ in the interval:
$$- \infty < \varphi \leq \varphi _ { \max } = \overline { \varphi } + \frac { \bar { r } } { R } \.$$
The range of variation of ϕ in the previous equations shows that each field line extends to infinity in one direction and reaches the origin at r = 0 after a finite length in the opposite direction. The distance from the origin of a point on the line grows linearly with ϕ max -ϕ , and the quantity ϕ max gives the azimuth angle of the field line direction at the origin.
For positive polarity ( A > 0) the magnetic lines are outward (inward) in the hemisphere above (below) the heliospheric current sheet. For negative polarity ( A < 0) the direction of all field lines is reversed.
The heliospheric electric field can be calculated using equation (1). In cartesian components one has:
$$\max \colon \\ \vec { E } ( x, y, z ) = \pm A \, B _ { 0 } \, \frac { \Omega r _ { 0 } ^ { 2 } } { c \, r ^ { 3 } } \left \{ x \, z, y \, z, - ( x ^ { 2 } + y ^ { 2 } ) \right \}$$
where the + ( -) sign applies above (below) the heliospheric current sheet. Note that the near the heliospheric equator the electric field is vertical, and points toward the HCS for A > 0, and away from the HCS for A < 0. The streamlines of the electric field are shown in fig.4. The modulus of the electric field is
$$\left | \vec { E } ( x, y, z ) \right | = B _ { 0 } \, \frac { \Omega r _ { 0 } ^ { 2 } } { c } \, \frac { \sqrt { x ^ { 2 } + y ^ { 2 } } } { r ^ { 2 } }$$
The divergence and rotor of glyph[vector] E are:
$$\nabla \cdot \vec { E } = \pm A \, B _ { 0 } \, \frac { \Omega \, r _ { 0 } ^ { 2 } } { c } \, \frac { 2 z } { r ^ { 3 } }$$
and
$$\nabla \wedge \vec { E } = 0 \.$$
Equation (13) implies that a non vanishing electric charge density must be present in the heliosphere to satisfy the Maxwell equations. Equation (14) has very important consequences, because it implies that the electric field can be written as the gradient of a potential function:
$$\vec { E } ( x, y, z ) = - \nabla V ( x, y, z ) \.$$
Choosing the constant so that the potential vanishes at the heliospheric equator z = 0, the electric potential V is:
$$V ( x, y, z ) = \mp A \, B _ { 0 } \, \frac { \Omega \, r _ { 0 } ^ { 2 } } { c } \, \frac { z } { r }$$
glyph[negationslash]
where the ∓ sign is valid above (below) the heliospheric current sheet. Note that on the HCS the electric potential V (as also the electric and magnetic fields) is discontinuous for all points that have z = 0. A z = 0, when the HCS coincides with the equatorial plane, the potential vanishes and is continuous (but the electric and magnetic fields are discontinuous).
The limits of the potential for z ±∞ (with x and y finite) are equal to each other, and independent from the values of x and y :
$$\lim _ { z \pm \infty } V ( x, y, z ) = V _ { \infty } = - A \ | V _ { \infty } | = - A \ B _ { 0 } \ \frac { \Omega r _ { 0 } ^ { 2 } } { c } \.$$
Note that V ∞ , the asymptotic value of the potential for | z | → ∞ , changes sign with the polarity of the solar phase (is negative for A > 0, and positive for A < 0). The existence of the electric field potential and the result that all points with large | z | have the same potential have important consequences that will be discussed later.
It should be noted that the Parker spiral expression of equation (3) cannot be a good description of the magnetic field in all space, and it must fail both for very small and very large distances from the origin of the coordinates. This can be verified computing the total energy of the magnetic field. Integrating the energy density B / 2 (8 π ) of the Parker spiral field in the volume contained between radii r min and r max one obtains:
$$E _ { \text{magnetic} } = \frac { B _ { 0 } ^ { 2 } \, r _ { 0 } ^ { 4 } } { 2 } \, \left [ \frac { 1 } { r _ { \min } } - \frac { 1 } { r _ { \max } } + \frac { 2 } { 3 } \, \frac { ( r _ { \max } - r _ { \min } ) } { ( w / \Omega ) ^ { 2 } } \right ] \,.$$
This expression diverges in the limits r min → 0 and r max →∞ demonstrating that a Parker spiral magnetic field that extends to all space is unphysical. The extension of the Parker spiral form to r → ∞ would in fact correspond to the assumption of a solar wind emitted with constant velocity for an infinitely long time in the past.
The expression (3) for the heliospheric magnetic field should therefore be considered as approximately valid only in a finite volume outside an inner spherical surface of few solar radii, and inside the termination shock, a roughly spherical surface with a radius of approximately 100 AU where the solar wind suffers an abrupt deceleration.
In this work we will not attempt to model the magnetic field outside the termination shock, that is in fact only very poorly known. The results shown here are not very sensitive to the size of the volume where the field is well described as a Parker spiral, if it extends to a radius equal or larger than ∼ 100 AU.
## 3 Drift velocity
The motion of a particle in a non homogeneous magnetic field can be decomposed into the gyration around the field lines accompanied by the drift of the gyration center in a direction orthogonal to the lines [9]. The drift velocity is given by the well known expression:
$$\vec { v } _ { \text{drift} } = \frac { \vec { B } \wedge \vec { \nabla } | B | } { 2 \, q \, | B | ^ { 3 } } \, E \, c \, \left ( \beta _ { \perp } ^ { 2 } + 2 \, \beta _ { \| } ^ { 2 } \right )$$
where q and E are the charge and energy of the particle, and β ⊥ and β ‖ are the components of the particle velocity orthogonal and parallel to the magnetic field. The two terms proportional to β 2 ⊥ and β 2 ‖ are known as the gradient and curvature contributions to the drift velocity.
For a magnetic field of the Parker spiral form the drift velocity can be calculated explicitely as:
$$\vec { v } _ { \text{diff} } = \pm A \, \frac { q } { | q | } \, V _ { \beta } \, \left [ \, \hat { \rho } \, \frac { 2 \, \rho \, z } { R ^ { 2 } + z ^ { 2 } } + \hat { \varphi } \, \frac { R \rho z \, \sqrt { \rho ^ { 2 } + z ^ { 2 } } } { ( R ^ { 2 } + z ^ { 2 } ) ^ { 2 } } - \hat { z } \, \frac { \rho ^ { 2 } \, ( 2 R ^ { 2 } + \rho ^ { 2 } - z ^ { 2 } ) } { ( R ^ { 2 } + z ^ { 2 } ) ^ { 2 } } \right ] \quad ( 2 0 )$$
where again the ± sign applies above (below) the heliospheric current sheet, ˆ, ρ ˆ and ˆ are ϕ z versors in the three directions of cylindrical coordinates (with ρ = √ x 2 + y 2 ), the length R was defined in equation (6) and V β , with the dimensions of a velocity, is:
$$V _ { \beta } = V _ { 0 } \, \left ( \beta _ { \perp } ^ { 2 } + 2 \, \beta _ { \| } ^ { 2 } \right )$$
with
$$V _ { 0 } = \frac { E } { 2 | q | \, B _ { 0 } } \, \frac { w } { \Omega } \, \frac { c } { r _ { 0 } ^ { 2 } } \simeq c \, \left ( 1. 0 4 \times 1 0 ^ { - 3 } \right ) \, \left [ \frac { E } { \text{GeV} } \right ] \, \left [ \frac { 1 0 ^ { - 4 } \, G } { B _ { 0 } } \right ] \, \left [ \frac { w } { 4 0 0 \, \text{km/s} } \right ]$$
The direction of the drift velocity is inverted when the electric charge of the particle changes sign, and also when the polarity of the solar phase is reversed. In the equatorial plane ( z = 0) the drift velocity is parallel to the ± ˆ direction and has the simple expression: z
$$\vec { v } _ { \text{drift} } ( z = 0 ) = \mp A \ V _ { \beta } \left [ 1 - \frac { R ^ { 4 } } { ( R ^ { 2 } + \rho ^ { 2 } ) ^ { 2 } } \right ] \, \hat { z } \.$$
The term in square parenthesis vanishes for ρ = 0 and grows monotonically with ρ , reaching an asymptotic value of one when ρ → ∞ . For qA > 0 (positive solar polarity and positive electric charge, or negative polarity and negative charge) the z component of glyph[vector] v drift is negative above the HCS, and positive below the HCS, in other words the drift velocity transports the particles toward the current sheet. In the opposite case ( qA < 0) the effect is reversed and the drift transports the particles away from the current sheet.
The streamlines of the drift velocity are shown in fig.5. Comparing these figure with the streamlines of the electric field shown in fig.4 one can notice that the directions of the drift velocity and of the electric force appear to be always antiparallel. In fact the scalar product of the drift velocity and the electrical force can be calculated explicitely with a result:
$$\left \langle \frac { d E } { d t } \right \rangle = q \, \vec { E } \cdot \vec { v } _ { \text{drift} } = - \frac { | q | } { 2 } E \, w \, \frac { \rho ^ { 2 } ( 2 R ^ { 2 } + \rho ^ { 2 } ) } { ( R ^ { 2 } + \rho ^ { 2 } ) ^ { 2 } \, r } \, \left ( \beta _ { \perp } ^ { 2 } + 2 \, \beta _ { \| } ^ { 2 } \right )$$
that is manifestly negative. This result is valid for any sign of the electric charge and of the solar polarity, because reversing the sign of q or A inverts the directions of both the electrical force and of the drift velocity, leaving the scalar product of the two vectors invariant. The scalar product q glyph[vector] E · glyph[vector] v drift , as indicated in equation (24), is equal to the energy variation of a charged particle that moves in the heliosphere on a trajectory controled by the electromagnetic field (after averaging over the fast gyration around the magnetic field lines). Equation (24) therefore states that the average energy variation is always negative, it is an energy loss .
It is instructive to compare equation (24) with the expression of the adiabatic energy loss used in the Parker equation for a relativistic particle diffusing in a spherically expanding wind:
$$- \left \langle \frac { d E } { d t } \right \rangle = | q | \, E \, \vec { \nabla } \cdot \vec { w } = \frac { 2 | q | \, E \, w } { r } \.$$
The expressions (24) and (25) are very similar, with identical dependences ( ∝ | q | Ew ) on the wind velocity and on the charge and energy of the particle, and similar dependence on the space coordinates (approximately ∝ r -1 in both cases). This similarity emerges because the expression of the adiabatic energy loss can be derived with magnetohydrodynamics consideration for the random magnetic field that are very similar to those developed here for the large scale regular field. The important difference between expression (24) and (25) is that the first case the energy loss can be associated to an electric potential, while in the other this is not possible. This point will be illustrated more extensively in section 5.
## 4 Space trajectories in the heliosphere
For a qualitative understanding of the problem we are discussing, it is very instructive to inspect some examples of trajectories of charged particles in the heliosphere, obtained with a numerical integration of the equation of motions (2). In the following calculations we will use a coordinate system where the Sun is at the origin and the z axis is parallel to the Sun rotation axis; the orientation of the x and y axis with respect to the pattern of the HCS is chosen as shown in fig.3. One example of trajectory is shown in fig.6 for an electron that is 'observed' at the Earth with energy E = 10 GeV and direction with polar angles { cos θ = 2 3 / , ϕ = 3 π/ 4 . } At the 'detection' time the phase of the Earth with respect to the pattern of the heliospheric current sheet was ϕ ⊕ = 0, when the Earth (see fig.3) is above the heliospheric current sheet. The trajectory is calculated from this initial condition integrating the equations of motion both forward and backward in time. In the calculation the solar polarity is positive ( A > 0) and the parameters that describe the Sun magnetic field are B 0 = 10 -4 Gauss, w = 400 km/s and sin α = 0 05. . Reversing simultaneously the polarity A of the heliospheric magnetic field and the electric charge q of the particle the trajectory remains identical and therefore the example of fig.6 refers more in general to the condition qA > 0.
The particle of this example reaches the Earth, traveling on a down-going spiral that wraps around a surface of approximately paraboloidal shape, and then leaves the heliosphere traveling close to the equatorial plane, or more accurately close to the heliospheric current sheet.
For a better visualization, fig.7 and fig.8 show (with different scales) the projections of the
trajectory in the equatorial { x, y } plane, while fig.9 shows the projection in the { √ x 2 + y , z 2 } space. In fig.7 one can best see (in the { x, y } projection) the trajectory in the inner part of the heliosphere. It is clear that, in first approximation, the particle gyrates around a magnetic field line (one such line is shown as a dashed curve in the figure). The trajectory also undergoes a 'bounce', (or a 'reflection') at the point of closest approach to the Sun, an example of the well known magnetic mirror effect, present when the magnetic field lines converge. Fig.8 and fig.9 allow to visualize the 'in' part of the particle trajectory as a spiral wrapped around a paraboloid, and the 'out' part as propagation close to the wavy heliospheric current sheet.
The main qualitative features of the trajectory we have just presented: the spiral, the bounce, and the outgoing travel close to the HCS, are in fact general features that are present in all trajectories when the product of the particle electric charge and of the solar polarity is positive ( qA > 0). The spiral is downgoing (as in our example) when the Earth is located above the HCS, but it is upgoing when the Earth is below the HCS. In the opposite case ( qA < 0) the trajectories have the same three features, but in reversed order. The particles enter the heliosphere traveling close to HCS, undergo a bounce at a point of closest approach to the Sun, and then exit the heliosphere traveling on a (upgoing or downgoing) spiral.
The qualitative features of the trajectories, are determined by the structure of magnetic field, (note that in the equations of motion the effects of the electric field are suppressed by a factor w/c , and can be considered as a as small perturbation), and are easy to understand qualitatively, using the results on the properties of the magnetic field lines and of the drfit velocity derived in the previous sections. The key points are the facts that the magnetic field lines are spirals around vertical cones, and that the drift velocity points toward (away from) the current sheet for qA > 0 ( qA < 0).
For qA > 0, when the drift 'pushes' the particle toward the HCS, the charged particle can enter the heliosphere only traveling along a trajectory that starts at large | z | , and spirals around the z axis following the behavior of the field lines. Since all magnetic field lines converge at the origin, and the convergence acts as a magnetic mirror, the particle trajectory will stop approaching the Sun, and will be reflected outward, undergoing a 'bounce'. The qualitative behavior of the trajectory changes dramatically when the particle reaches the HCS. The magnetic drift effects (for the case qA > 0 we are discussing now) always push the particle toward the HCS, so that it remains 'trapped' close to the sheet (crossing it multiple times) while it travels out of the heliosphere.
A similar discussion can be applied to the case qA < 0 to show that the trajectory is formed by the sequence of an 'in' section, where the particle reaches the Earth traveling near the HCS, a bounce, and an 'out' section that is an (upgoing or dowgoing) spiral around the z axis.
The properties of the 'out' ('in') part of the trajectories of charged particles for the case qA > 0 ( qA < 0), depend strongly on the shape of the HCS, and in particular on the tilt angle α , because the particle remains close the sheet, and follows its shape. This is illustrated in fig.10 that shows (for the case qA < 0) the past (or 'in') trajectories of e ± observed at the Earth with E = 10 GeV. The trajectories are shown in two projections ( { x, y } ) and ( { √ x 2 + y , z 2 } ), for four different values of the tilt angle (sin α = 0 02, 0.2, 0.5 . and 0.8). For small tilt angle (as already shown in the example of fig. 6-9) the past trajectory is approximately radial and confined to the heliospheric equatorial plane. For large tilt angle
the trajectory undergoes oscillations around the the equatorial plane with an amplitude that increases with sin α and √ x 2 + y 2 reflecting the shape of the heliospheric current sheet; at the same time the trajectory rotates around the z axis following the shape of the field lines.
The spirals that form the 'in' trajectories when qA > 0 and the 'out 'trajectories when qA < 0 have a shape that is independent from the tilt angle of the HCS, because they remain on one side of the HCS. The projection of the spiral in the { √ x 2 + y , z 2 } plane has a quasiparabolic shape that depends on the particle momentum as illustrated in fig.11, that shows this projection for three particle momenta. The energy dependence of the shape can be understood as the consequence of a drift velocity that is proportional to the particle energy.
Note that the asymptotic direction (for t →-∞ ) of the particle has polar angle θ that is approximately 0 or π , for upgoing or down going spirals. This property is also illustrated in fig.12 and 13 that show the past trajectories of particles observed at the Earth with 12 GeV, and different directions that span the entire solid angle at the detector point. One can see that for t → -∞ the directions of all particles converge to the same one (that is approximately θ = 0).
## 5 Energy Loss
The equations of motion for the propagation of a charged particle in the heliosphere imply an energy variation given by:
$$\frac { d E } { d t } = q \, \frac { d \vec { x } } { d t } \cdot \vec { E } \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \ \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \cdots \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \end{cases}$$
Two examples of this energy evolution, for an e ± observed at the Earth with E = 12 GeV are shown in fig.14 that plots the energy as a function of the length along the trajectory. The portion of the trajectories closest to the Earth is also shown on an enlarged in fig.15. In the example the parameters of the heliospheric field are: B 0 = 10 -4 Gauss, w = 400 km/s and sin α = 0 05. .
Inspecting the figures, one can see that after averaging for the small, fast oscillations (produced by the gyration motion around the magnetic field lines, that rapidly change the orientation of the particle velocity with respect to the electric field), the particles continuosly lose energy, both entering and exiting the heliosphere. This behavior was predicted in section 3 and with equation (24). The initial energy of the particle E i = E obs + ∆ E can be obtained as the limit of E t ( ) for t → -∞ , and depends on the sign of the particle. For qA > 0 one has ∆ E + glyph[similarequal] 0 42 GeV for . qA < 0, ∆ E -glyph[similarequal] 0 12 GeV. .
Figure 16 shows (for the same configuration of the heliospheric fields) the past time evolution of four particles (in the case qA > 0) that reach the Earth with energy 1, 3, 10 and 30 GeV. The remarkable thing, that is immediately apparent inspecting the figure, is that the energy loss suffered by all particles (in this case for qA > 0) that reach the Earth is equal, (and with value 0.42 GeV). From fig.16 one can also see that the time needed by a charghed particle to reach the Earth from the boundary of the heliosphere has the energy dependence E -1 , reflecting a drift velocity proportional to E . On the other hand, as shown in equation (24), the energy loss -dE/dt is proportional to E . Combining the two effects one arrives to a total energy loss that is independent from energy.
The result that the energy loss of particles that reach the Earth for qA > 0 is a constant (for fixed values of B 0 and w ) can be easily seen as an elementary consequence of the existence
of an electric field potential (as given in equation (16)), and of the fact that the trajectories are spirals around the heliospheric z axis.
The energy variation of a charged particle that follows a trajectory T can be calculated performing the line integral:
$$E _ { f } = E _ { i } + q \int _ { T } d \vec { \ell } \cdot \vec { E } ( \ell )$$
Because of the existence of the electric potential, if the trajectory never crosses the heliospheric current sheet (where the electric potential is discontinuos), the energy loss ∆ E = E i -E f is given by:
$$\Delta E = q \left [ V ( \vec { x } _ { f } ) - V ( \vec { x } _ { i } ) \right ] \.$$
and is proportional to the difference between the electric potential calculated at the initial and final point on the trajectory.
More in general, for a trajectory that crosses n times the heliospheric current sheet, one has:
$$\Delta E = q \left [ V ( \vec { x } _ { f } ) - V ( \vec { x } _ { i } ) \right ] + q \, \left [ \sum _ { k = 1 } ^ { n } \Delta V _ { \text{disc} } ( \vec { x } _ { k } ) \right ]$$
where the summation is over all points { glyph[vector] x k } of intersection of the trajectory with the HCS, and ∆ V disc ( glyph[vector] x k ) is the potential jump at the discontinuity.
An alternative way to write the result (29) is:
$$\Delta E = - q \, \left [ \sum _ { j = 1 } ^ { n + 1 } \Delta V _ { j } \right ] \,,$$
that is as the sum of the contributions as in equation (28) of the ( n +1) trajectory segments that divide the trajectory, having the points of discontinuity for the potential only at the boundaries.
The result (28) is sufficient to compute the energy variation in the case qA > 0. In this case the charged particles reach the Earth traveling on a (downgoing or upgoing) spiral, starting from a very large value of | z | , and (with very few exceptions) arrive at the Earth without ever crossing the HCS. The energy loss can then be estimated as:
$$\Delta E | _ { q A > 0 } \ & = \ q \left [ V ( z = 0 ) - V ( | z | \to \infty ) \right ] \\ & = \ + q \, A \, | V _ { \infty } | = + | q | \, | V _ { \infty } | \.$$
In the the first step in the second line we have used the fact that the potential at z = 0 vanishes, and equation (17) for the value of the potential at | z | large. In the final step we have used the condition qA > 0. Substituting the expression of the potential at large z | V ∞ | given in equation (17) one finds the energy loss:
$$\Delta E | _ { q A > 0 } = Z \left | q _ { e } \right | B _ { 0 } \, \frac { \Omega \, r _ { 0 } ^ { 2 } } { c } \simeq 0. 4 2 2 \ Z \, \left ( \frac { B _ { 0 } } { 1 0 ^ { - 4 } \ G auss s } \right ) \, \text{GeV} \.$$
It is less straightforward to estimate the energy loss for the case qA < 0. In this case the magnetic drift pushes the particle away from the heliospheric current sheet, and therefore
the particles can arrive at the Earth only traveling close the heliospheric equator. Since the points glyph[vector] x f (the Earth position) and glyph[vector] x i (where the particle enters the heliosphere) have both z coordinate close to zero, one has V ( glyph[vector] x i ) glyph[similarequal] V ( glyph[vector] x f ) glyph[similarequal] 0, and the first term in the right hand side of equation (29) vanishes. On the other hand the particles traveling close to the HCS will cross it several times, and the second term in the equation (that sums the potential jumps at the discontinuities) contributes to the energy variation.
It is easy to see that also in this case one has an energy loss , because the drift is always against the direction of the electric force. The energy loss for the case qA < 0 is however sensitive to the value of the HCS tilt angle, and in fact depends approximately linearly on sin α .
Having defined the electric potential with the convention that V = 0 for points on the heliospheric equator, one has the potential on the two sides of the HCS are equal and opposite. Using equation (16) one has:
$$V _ { \pm } = \mp A \left | V _ { \infty } \right | \frac { z } { r }$$
The points on the sheet have | z /r | in the interval 0 ≤ | z /r | ≤ sin α , so that the each crossing of the HCS gives a contribution to the energy loss in the interval:
$$0 \leq \Delta E _ { k } = q \, \Delta V _ { \text{disc} } ( \vec { x } _ { k } ) \leq 2 | q | \, | V _ { \infty } | \, \sin \alpha \.$$
The points on the HCS that satisfy the condition V = ±| V ∞ | sin α are those on the crests of the waves in the ondulating HCS (see fig.2). Equation (34) implies that for small tilt angle, when the HCS nearly coincides with the equatorial plane, all ∆ E k (and therefore ∆ E ) are small.
For a visualization of the energy loss in the case qA < 0 one can inspect fig.17 that illustrates schematically the propagation of a charged particle (in the case qA < 0) from a point A on the heliospheric equator to point E (the Earth). Both the starting and final points of the trajectory are at z = 0 and have electric potential ( V = 0), therefore the line integral of the electric field along any trajectory (like T 1 in the figure) that does not cross the HCS vanishes. On the other hand the dynamically possible trajectories that connects the points A and E, looks schematically like T 2 . The magnetic drift pushes the particle toward + z ( -z ) when the particle is above (below) the HCS, however the trajectory meets and crosses several time the HCS because of the waviness of its shape. In each segment of the trajectory between HCS crossings, the particle loses energy because it moves against the electric force that always points in a direction opposite to the drift, that is toward -z (+ ) above (below) z the HCS, so that the particle continuously loses energy.
The total energy loss of the particles that reach the Earth in the case qA < 0 is not unique, because it depends on how many times and at what points a particle crosses the HCS. Numerical studies indicate however that the loss has a surprisigly small dispersion. As it is intuitive looking at equation (34) the average energy loss is proportional to the product | V ∞ | sin α , so that
$$\langle \Delta E \rangle | _ { q A < 0 } = f \ | q | \ | V _ { \infty } | \ \sin \alpha$$
Numerical experiments suggest a value f glyph[similarequal] 1 5-2.5. .
The results (31) and (35) can be summarized as:
$$\Delta E \simeq \begin{cases} | q | \, | V _ { \infty } | & \text{for } q A > 0 \, \\ | q | \, | V _ { \infty } | \ f \sin \alpha & \text{for } q A < 0 \. \end{cases}$$
The quantity f is of order 2, and the potential of V ∞ , given in equation (17), depends on the absolute normalization of the heliospheric magnetic field. Numerically one has:
$$| q | \, | V _ { \infty } | = Z \, | q _ { e } | \, B _ { 0 } \, \frac { \Omega \, r _ { 0 } ^ { 2 } } { c } \simeq 0. 4 2 2 \, \left ( \frac { B _ { 0 } } { 1 0 ^ { - 4 } \ G a w s } \right ) \, \text{GeV} \.$$
Both B 0 and the tilt angle α depend on the solar magnetic activity and vary with time.
The energy loss depends on the sign of the electric charge, and the role of particles with positive or negative charge is exchanged when the solar polarity is reversed. The energy loss is larger for the case qA > 0 when the tilt angle is small (sin α glyph[lessorsimilar] 0 5), and is larger for the . case qA < 0 when the tilt angle is large (sin α glyph[greaterorsimilar] 0 5). .
## 6 Energy Spectra
The fundamental problem in the study of solar modulations is to relate the energy spectra observed near the Earth at different times, to one unmodulated spectrum that gives the distribution at the boundary of the heliosphere. The unmodulated spectrum is assumed to be approximately stationary (on a time scale of order 10-100 years) and is commonly called the 'Local Interstellar Spectrum' (or LIS).
In the model described here, and with the approximation that charged particles lose a well defined energy ∆ E ± ( ) (given by equation (36)) the problem has a simple closed form t solution. Calling φ obs ( E,t ) the observable flux at the Earth, and φ 0 ( E ) the LIS, one has:
$$\phi _ { \text{obs} } ( E, t ) = \phi _ { 0 } [ E + \Delta E ( t ) ] \ \left [ \frac { E ^ { 2 } - m ^ { 2 } } { [ E + \Delta E ( t ) ] ^ { 2 } - m ^ { 2 } } \right ] \.$$
This result is also the well known expression of the so called 'Force Field Approximation' (FFA) for the solar modulations [10].
The remarkable point is that in the context of the discussion here the 'Force Field' is real, and is due to the electric field that fills the heliosphere, and the FFA expression of equation (38) is an exact (for qA > 0) or nearly exact (for qA < 0) result.
Equation (38) can be derived as a simple consequence of the Liouville theorem, that states that if the Lagrangian of a physical system is time independent, the phase space density of an ensemble of particles remains constant along a particle trajectory. More formally, denoting as ρ glyph[vector] , ( x glyph[vector], p t ) = d N/ d xd p 6 ( 3 3 ) the phase space density, one has that if { glyph[vector] x t ( 1 ) , glyph[vector] p t ( 1 ) } and { glyph[vector] x t ( 2 ) , glyph[vector] p t ( 2 ) } are two points on one solution of the equations of motion then:
$$\rho [ \vec { x } ( t _ { 1 } ), \vec { p } ( t _ { 1 } ), t _ { 1 } ] = \rho [ \vec { x } ( t _ { 2 } ), \vec { p } ( t _ { 2 } ), t _ { 2 } ] \.$$
The FFA expression (38) follows from (39) and the assumptions that the interstellar spectrum at the boundary of the heliosphere is stationary and isotropic. The flux (differential
in energy) is related to the phase space density by the equation:
$$\phi ( E, \hat { p }, \vec { x }, t ) \equiv \frac { d N } { d E \ d A \, d t \, d \Omega } = v \, p ^ { 2 } \, \frac { d N } { d ^ { 3 } p \, d ^ { 3 } x } \, \frac { d p } { d E } = p ^ { 2 } \, \rho ( \vec { x }, \vec { p }, t )$$
(with E = √ p 2 + m 2 ). The particle velocity cancels in the last equality because the Jacobian factor is dp/dE = 1 /v . From the condition that the phase densities of the particles at the Earth and outside the heliosphere are equal, one obtains a relation between the LIS and the observed spectrum. Using equation (40) and the assumptions that the phase space density at the boundary of the heliosphere is isotropic one then obtains:
$$\phi _ { \text{obs} } ( E ) \, p _ { i } ^ { 2 } = \phi _ { 0 } ( E _ { i } ) \, p ^ { 2 }$$
where E and p are the energy and momentum at the Earth, and E i and p i the same quantities outside the heliosphere. Equation (38) follows from the condition E i = E +∆ . E
The FFA algorithm of (38) is symmetric, and it can be used to compute the observable flux at the Earth from the LIS spectrum, or viceversa, to reconstruct the unmodulated LIS spectrum from the observations. For this purpose (dropping the time dependence of ∆ E in the notation) one can recast the equation in the form:
$$\phi _ { 0 } ( E ) = \phi _ { \text{obs} } [ E - \Delta E ] \ \left [ \frac { E ^ { 2 } - m ^ { 2 } } { [ E - \Delta E ] ^ { 2 } - m ^ { 2 } } \right ] \.$$
In this case there is obviously a limitation, since equation (42), even in the case of a perfect meaurement, allows to determine the interstellar spectrum only above a minimum kinetic energy ∆ E , because for lower energy the argument of φ obs in (42) becomes unphysical, and the equation meaningless. This simply reflects the fact that particles with a kinetic energy lower than ∆ E in interstellar space cannot reach the Earth.
It is interesting to note that equation (38) predicts that in the limit of small kinetic energy the observable flux at the Earth φ obs ( E ) is linear in E kin . In fact, in the limit E kin → 0 (and for E kin glyph[lessmuch] m ) the observable flux has the behavior:
$$\phi _ { \text{obs} } ( m + E _ { \text{kin} } ) \simeq \phi _ { 0 } ( m + \Delta E ) \ \frac { 2 m \, E _ { \text{kin} } } { \Delta E ^ { 2 } + 2 m \, \Delta E } + O ( E _ { \text{kin} } ^ { 2 } ) \simeq \text{const} \times E _ { \text{kin} } \. \quad ( 4 3 )$$
As it will shown in the following, the linear dependence of the fluxes is the observed behavior of the fluxes, and insures that the estimate of the interstellar flux φ 0 ( m +∆ ) from equation E (42) is finite.
More in general, it is possible to use expression (38) to relate spectra measured at different times. If for example the spectrum φ 1 ( E ), measured at time t 1 , is related to the LIS spectrum by the FFA expression with parameter ∆ E 1 , and similarly the spectrum φ 2 ( E ), measured at time t 2 , is related to the LIS spectrum using the same relation with the parameter ∆ E 2 , then the spectra φ 2 ( E ) can be obtained from the flux φ 1 ( E ) with the one parameter transformation:
$$\phi _ { 2 } ( E ) = \phi _ { 1 } [ E + \Delta E _ { 2 1 } ] \ \left [ \frac { E ^ { 2 } - m ^ { 2 } } { [ E + \Delta E _ { 2 1 } ] ^ { 2 } - m ^ { 2 } } \right ] \.$$
where
$$\Delta E _ { 2 1 } = \Delta E _ { 2 } - \Delta E _ { 1 }$$
or symmetrically φ 1 ( E ) can be obtained from φ 2 ( E ) by the same transformation with parameter ∆ E 12 = -∆ E 21 . Equation (44) can be used to test experimentally the validity of the FFA, measuring two spectra for different conditions in the heliosphere, and studying if the spectra satisfy equation (44) for some value of the parameter ∆ E 21 .
An illustration of the FFA algorithm applied to measurements of the cosmic ray proton spectrum is given in fig.18 and 19 that show measurements of the proton flux measured at different times by the BESS [11, 12] and PAMELA [13] detectors. The BESS measurements were performed during (approximately one day long) balloon flights in 1997, 1998, 1999, 2000 and 2002. During all this time the polarity of the heliospheric magnetic field was positive ( A > 0). The measurements of PAMELA are averages of data collected in 2006, 2007, 2008 and 2009, when the polarity of the heliospheric field was negative ( A < 0).
Fig.18 shows the five measurements of the BESS spectrometer [12]. In the figure the thick (red) line was chosen to give a good description of the data collected by BESS in 1998, the other lines are calculated using the FFA algorithm of equation (44) using the 1998 flux as starting point and fitting the parameter ∆ E for the other BESS measurements of the proton flux performed in 1997, 1999, 2000 and 2002. The best fit values of ∆ E (relative to the 1998 measurement) for the four spectra are -100, 67, 709 and 518 MeV. The parameter ∆ E is positive (negative) when the fitted spectrum is lower (higher) than the reference flux.
Figure 19 shows the measurements of the proton flux obtained by PAMELA [13] in 2006, 2007, 2008 and 2009. The lines in the figure are one parameter fits to the four spectra with the FFA algorithm of equation (44), calculated using as starting flux the parametrization of the measurement performed by BESS in 1998. The best fit values for ∆ E are -7, -84, -115 and -178 MeV (in all years the flux measured by PAMELA is higher than the one measured by BESS in 1998). The FFA fits give a very good description of the proton spectra.
In summary, the measurements of the proton flux performed by BESS and PAMELA during nine years (that include an inversion of the solar magnetic phase) exhibit time variations that are reasonably well described by the Force Field Approximation algorithm.
In the discussion above, we have studied the validity of the FFA algorithm comparing measurements performed at different times, without attempting to reconstruct the unmodulated interstellar flux. Previous studies have used use the approach to relate the observed flux to the interstellar spectrum. For example, in [12] the BESS collaboration have shown the time dependence of their proton flux measurements also using the FFA algorithm, but starting from a model of the unmodulated LIS spectrum. This LIS spectrum (shown in fig.18 as a dashed line), is then used to estimate an energy loss ∆ E (relative to the unmodulated flux) for each proton flux measurement. The two procedures (the one performed by the BESS collaboration, and the one discussed in this work) are perfectly consistent, because one has:
$$\Delta E _ { j, 1 9 9 8 } = \Delta E _ { j, \text{LIS} } - \Delta E _ { 1 9 9 8, \text{LIS} }$$
where j is an index that runs through the five measurements, ∆ E j, 1998 is the energy loss with respect to the 1998 measurement estimated in this work, and ∆ E j, LIS the energy loss with respect to the LIS spectrum estimated by the BESS collaboration in [12]. In the BESS study the total energy loss of protons at the time of the 1998 measurement was estimated as 591 MeV.
The point we want to make here is that it is possible to verify the validity (or nonvalidity) of the FFA without making any assumption on the shape and properties of the
interstellar flux, simply comparing measurements taken at different times, and testing if they are consistent with the one parameter transformation of equation (44). If this test is succesful, then one can conclude that all measurements are the results of the time dependent modulations of a unique interstellar flux described by the FFA algorithm.
Having established the validity (or approximate validity) of the FFA, the reconstruction of the unmodulated flux requires additional theoretical assumptions, because the FFA algorithm has in fact infinite solutions, parametrized by ∆ E LIS , that are mathematically all equally valid. To select the physically correct solution there are in principle two different methods. In the first, one starts from a theoretical prediction for the shape of the interstellar energy spectrum, and then use equation (42) to determine ∆ E LIS , as ther parameter that reproduces the observed spectrum, starting from the interstellarone. This method allows to obtain an estimate of the total size of the modulation effects from the cosmic ray flux measurement.
The alternative approach is to have a complete model for propagation in the heliosphere that allows to compute from first principles the value of ∆ E LIS at different epochs. Inserting this value into equation (42) one can then calculate the of the interstellar energy spectrum from the observations of the spectral shape at the Earth.
The main point want to make in this section is that the FFA algorithm is quite successful in describing the time variations of the cosmic rays fluxes. This implies that the cosmic rays that arrive at the Earth lose a (time dependent) ∆ E that is approximately equal for all energies and has a small dispersion.
In general one can expect that the relation between the observed and the interstellar flux is more complicated that the FFA algorithm of equation (38). For example, the energy variation ∆ E could be a function of E (or equivalently of E i ). Also in general the energy loss of particles that traverse the heliosphere will not be unique, but can have a distribution with a certain (possibly energy dependent) width and shape. The point os that the approximate validity of the FFA is non trvila result, that gives important constraints on the construction of a model of the solar modulations.
## 7 Summary and outlook
In this work we have studied the propagation of charged particles in the heliosphere assuming only the presence of the regular magnetic field, completely neglecting the random magnetic field generated by turbulent motions in the heliospheric plasma. The presence of a magnetic field in the solar wind, a moving plasma with good electrical conductivity, generates an electric field that plays an important role in the propagation of charged particles in the heliosphere, and results in significant solar modulations.
The combined effect of the large scale heliospheric magnetic and electric fields is that charged particles that reach the Earth from the boundary of the heliosphere always lose energy. The energy loss ∆ E , to a good approximation, is independent from the energy and direction of the particle, and is determined only by the structure of the heliospheric fields. The energy loss is proportional to the absolute value of the electric charge of the particle, but depends on the sign of the charge.
It might appear surprising that the same field configuration can generate energy losses for particles of opposite electric charge, but this is possible because particles of opposite charge
reach the Earth traveling on different trajectories. In all cases the electric field results in a force that, after averaging over fast gyrations around the magnetic field lines, is anti-parallel to the particle velocity, and causes an energy loss.
The shape and properties of the trajectories are determined by the structure of the heliospheric magnetic field, with the electric field that acts effectively only as a small perturbation. When the product qA of the particle electric charge and the solar magnetic polarity is positive particles arrive at the Earth traveling along spirals around the heliosphere polar axis, in the opposite case the particles arrive traveling close to the heliospheric current sheet (HCS) and the the heliospheric equator.
The energy loss is always linear with the value pof the magnetic field, but in the case qA < 0 it also depends on the tilt angle of the HCS, and is also linear with sin α . The energy loss is larger for qA > 0 when the tilt angle of the HCS is small (sin α glyph[lessorsimilar] 0 5), and it is larger . for qA < 0 when the tilt angle is large (sin α glyph[greaterorsimilar] 0 5). . A quantitative estimate of the energy loss is given in equations (36) and (37), and is of order of a few hundred MeV.
All the results discussed in this work have been obtained for a very simple model of the heliosphere (a magnetic field that is a Parker spiral, and a solar wind that is purely radial, and of constant velocity), but one can expect that they will remain valid for a more general description of the heliospheric magnetic field and of the solar wind.
In conclusion, in this work we have demonstrated that the deterministic propagation of charged particles in the heliosphere results in an energy loss that is sufficient to generate important solar modulations.
Modern calculations of solar modulations effects do include a description of the regular heliospheric magnetic field, but only as a convection term associated to the magnetic drift velocity. The drift velocity inverts its direction for the transformation q →-q , and introduce a dependence on the sign of the electric charge. This treatment does not take into account properly of the important fact, outlined in this work, that the heliosphere contains a regular electric field, with a large scale structure. In the standard treatment of the solar modulations particles lose energy adiabatically, that is they suffer an energy loss proportional to energy and to the divergence of the wind velocity ( -dE/dt ∝ E ∇· glyph[vector] w ). This implies that the total energy loss of a particle observed at the Earth is proportional to the time that a particle takes to penetrate the heliosphere, independently from the characteristics of the trajectories.
The phenomenological success of the Force Field Approximation (as discussed in section 6) suggests that charged particles penetrate the heliosphere losing an amount of energy ∆ E that is approximately independent from E and has a small dispersion. This is a suprising result when seen in the framework of the Parker equation, because it implies that the time needed by a particle to reach the Earth has the energy dependence t ∝ E -1 , and therefore that the diffusion coefficient (that describes the effects of the turbulent magnetic field) has the energy dependence D E ( ) ∝ E . This energy dependence of the diffusion coefficient is not seen in other astrophysical environments, for example when studying the escape of cosmic rays from the Milky Way, where one estimate a power law dependence D E ( ) ∝ E δ with δ = 0 3-0.6. . Also the apparent narrowness of the ∆ E distribution appears to be problematic.
These difficulties could perhaps be solved assuming that a large fraction of the energy loss for cosmic rays that travel in the heliosphere is caused by a large scale electric field that permeates the solar wind. The existence of this electric field emerges as a simple and well known magnetohydrodynamical effect when a conducting and moving fluid (such as the solar
wind) contains a magnetic field. The investigation of this hypothesis clearly requires detailed numerical studies of the propagation of particles in the heliosphere that take into account the presence of both the regular and random components of the electromagnetic fields.
The existence of the regular electromagnetic fields in the heliosphere has very important consequences for studies on anisotropy of cosmic rays at the Earth, because it clearly has effects on the angular distribution of particles observed at the Earth. his problem will be discussed in a separate work [14].
In conclusion, the results outlined in this work point to the need of a profound revision of the treatment of solar modulations that properly include the regular electromagnetic fields present in the heliosphere.
## References
- [1] M. Potgieter, Living Rev. Solar Phys. 10 , 3 (2013) [arXiv:1306.4421 [physics.space-ph]].
- [2] E.N. Parker Planetary and Space Science 13, 9 (1965).
- [3] M. L. Goldstein, L. A. Fisk and R. Ramaty, Phys. Rev. Lett. 25 , 832 (1970).
- [4] R. D. Strauss, M. S. Potgieter and S. E. S. Ferreira, Adv. Space Res. 49 , 392 (2012).
- [5] J. R. Jokipii, E. H. Levy & W. B. Hubbard, Ap.J. 213 , 861 (1977).
- [6] P. Bobik et al. , Astrophys. J. 745 , 132 (2012) [arXiv:1110.4315 [astro-ph.SR]].
- [7] L. Maccione, Phys. Rev. Lett. 110 , no. 8, 081101 (2013) [arXiv:1211.6905 [astroph.HE]].
- [8] M. S. Potgieter, Adv. Space Res. 53 , 1415 (2014).
- [9] J.D. Jackson, 'Classical Electrodynamics//, 3rd ed. Wiley, 1998.
- [10] L. J. Gleeson and W. I. Axford, Astrophys. J. 154 , 1011 (1968).
- [11] T. Sanuki et al. [BESS Collaboration] Astrophys. J. 545 , 1135 (2000) [astroph/0002481].
- [12] Y. Shikaze et al. [BESS Collaboration] Astropart. Phys. 28 , 154 (2007) [astroph/0611388].
- [13] O. Adriani et al. [PAMELA Collaboration] Astrophys. J. 765 , 91 (2013) [arXiv:1301.4108 [astro-ph.HE]].
- [14] Paolo Lipari, in preparation.
Figure 1: Representation of the heliospheric current sheet for tilt angle sin α = 0 2. .
Figure 2: Section xz of the heliospheric current sheet. For positive polarity ( A > 0) the field lines enter (exit) the plane of the figure in the white (shaded) area. The dashed lines correspond to the condition cos θ = ± sin α (with θ is the standard the polar angle and α the tilt angle of the heliospheric field). For a negative polarity phase the field directions are inverted.
Figure 3: Section xy of the inner part of the heliosphere. The Sun is at the center of the image, the circles indicate the orbits of the five inner planets (Mercury, Venus, Earth, Mars and Jupiter). The spiral that separates the darker and lighter regions marks the intersection of the heliospheric current sheet with the Earth's orbital plane. In the darker (lighter) region the current sheet is below (above) the plane. In a positive polarity solar phase the magnetic field lines are directed toward (away from) the Sun below (above) the current sheet. For a negative polarity phase the field directions are inverted.
Figure 4: Streamlines of the electric field in the heliosphere. The thick line represents the heliospheric current sheet. The electric field glyph[vector] Ef has cylindrical symmetry and vanishes along the line x = 0. The figure is valid for A > 0. For A < 0 the field direction is reversed.
Figure 5: Projection in the plane ( x, z ) of the streamlines of the drift velocity of charged particles moving in the heliosphere. The figure is valid for qA > 0. The direction Changing the sign of the electric charge or the polarity of the solar phase the direction of the drift is reversed.
Figure 6: Space Trajectory of an electron in the heliosphere. The particle is observed at the Earth with energy 10 GeV. The thick (thin) line shows the trajectory before (after) the observation. The green circles are the trajectories of the planets.
Figure 7: Projection in the { x, y } plane of the space trajectory shown in fig.6. The thick (thin) line corresponds the portion of the trajectory before (after) the observation at the Earth. The dashed red line shows the magnetic field line that passes through the observation point.
Figure 8: Same as fig.7 but with an enlarged scale.
Figure 9: Projection in the { √ x 2 + y , z 2 } space of the trajectory shown in fig.6 (a particle with observed energy 10 GeV). The thick (thin) line corresponds the portion of the trajectory before (after) the observation at the Earth.
Figure 10: Projections of the past trajectory of an electron observed at the Earth with energy 10 GeV. The calculations are for qA < 0. The trajectory is calculated for four different values of the tilt angle: sin α = 0 02, . 0.2, 0.5 and 0.8.
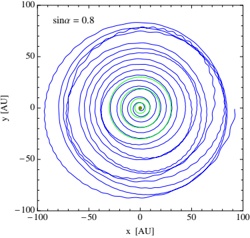
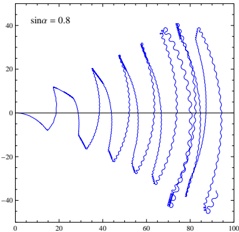
Figure 11: Projection of the 'in' part of the space trajectories of e ± observed at the Earth with energy E = 2 5, 5 and 10 GeV. The calculation is for . qA > 0.
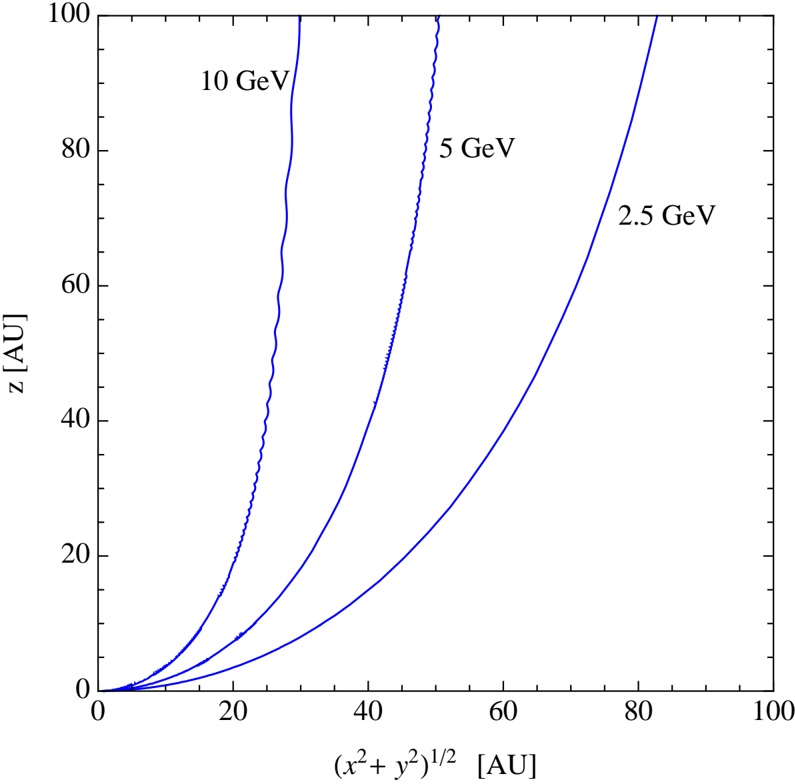
Figure 12: Past trajectories of e ± that arrive at the Earth with energy 12 GeV and different directions. The calculation is valid for qA > 0.
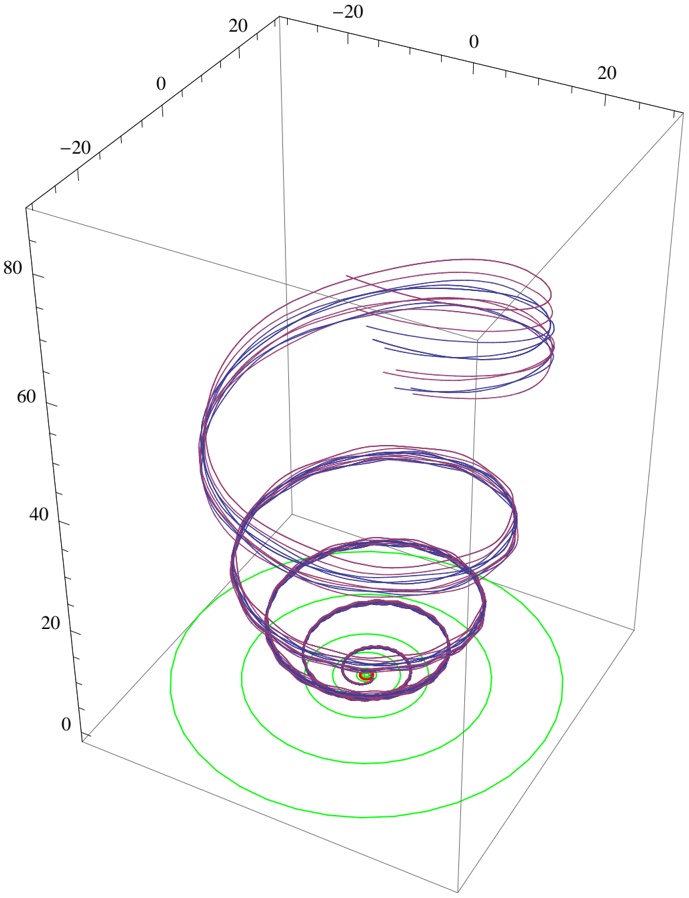
Figure 13: Projection in the equatorial plane of the 'in' part of the trajectories of e ± that arrive at the Earth with energy 12 GeV and different directions. The calculation is valid for qA > 0.
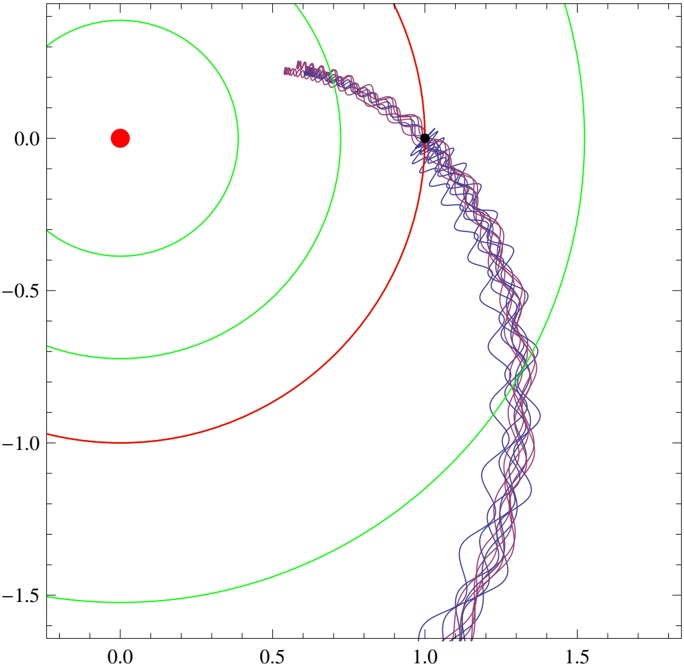
12.4
12.2
12.0
11.8
11.6
1000
-
-
500
0
500
1000
L
@
AU
D
Figure 14: Energy evolution of an e ± particle observed at the Earth with energy 12 GeV plotted as a function of the length L = cβ t (in astronomical units) along the trajectory. The top (bottom) panel is for qA > 0 ( qA < 0). The space trajectory for the case qA > 0 is shown in figures 6-10.
D
GeV
@
L
H
p L
Figure 15: Energy evolution of an e ± particle observed at the Earth with energy 12 GeV (the space trajectory is shown in fig.6) plotted as a function of the length L = cβ t (in astronomical units) along the trajectory. The top (bottom) panel is for qA > 0 ( qA < 0).
Figure 16: Time evolution (in the past) of the energy of e ± observed at the Earth with energy of 1, 3, 10 and 30 GeV. for the case qA > 0. The direction of the particle at the Earth and the position of the Earth is equal for all particles.
Figure 17: The figure shows an ρz section of the heliosphere. The wavy line is the heliospheric current sheet that separates regions of space where the field lines enter and exit the page. Note that the points on the current sheet that also satisfy the condition z = sin αx (or z = -sin αx ) have equal potential. Points A and E have the same potential. The line integral of the electric field along the trajectory T 1 is zero, while the line integral along T 2 that crosses several times the current sheet is non vanishing.
GLYPH<242>
Figure 18: Proton spectra measured by the BESS collaboration at different times. [11, 12]. The thick red line is the fit to the 1998 BESS proton given in [12]. The other lines are one parameter fits to data, distorting the curve that describes the 1998 data the algorithm of the Force Field approximation. The best fit parameter of the curves is given in the figure.
GLYPH<230>
GLYPH<242>
GLYPH<242>
GLYPH<224>
GLYPH<236>
Figure 19: Proton spectra measured by the PAMELA collaboration [13]. The thick red line is the fit to the 1998 BESS proton data shown in fig.18. The other lines are one parameter fit to the PAMELA data, where the fitting curve is the fit to the BESS-1998 data, distorted with the algorithm of the Force Field approximation. The parameter of the fit is shown in the figure. | null | [
"Paolo Lipari"
] | 2014-08-02T22:58:09+00:00 | 2014-08-02T22:58:09+00:00 | [
"astro-ph.HE"
] | Solar modulations by the regular heliospheric electromagnetic field | The standard way to model the cosmic ray solar modulations is via the Parker
equation, that is as the effect of diffusion in the turbulent magnetic of an
expanding solar wind. Calculations performed with this method that do not
include a description of the regular magnetic field in the heliosphere predict,
in disagreement with the observations, equal modulations for particles and
antiparticles. The effects of the regular heliospheric field, that break the
the particle/anti-particle symmetry, have been included in the Parker equation
adding convection terms associated to the magnetic drift velocity of charged
particles moving in non--homogeneous magnetic field. In this work we take a
completely different approach and study the propagation of charged particles in
the heliosphere assuming only the presence of the regular magnetic field, and
completely neglecting the random component. Assuming that the field is purely
magnetic in the wind frame, one can deduce the existence of a large scale
electric field, that results in important energy losses for charged particles
that traverse the heliosphere and reach the Earth. The energy loss (Delta E)
due to the large scale regular electric field depends on the particle electric
charge, is proportional to the absolute value of the electric charge, and to a
good approximation is independent from the particle energy and direction. We
speculate that this deterministic energy loss is an important, or perhaps even
the leading contribution to the solar modulation effects. |
1408.0432v1 | ## Mapping accretion and its variability in the young open cluster NGC 2264: a study based on u-band photometry ? ?? ,
L. Venuti 1 2 3 ; ; , J. Bouvier 1 2 ; , E. Flaccomio 4 , S. H. P. Alencar 5 , J. Irwin 6 , J. R. Stau GLYPH<11> er 7 , A. M. Cody 7 , P. S. Teixeira 8 , A. P. Sousa 5 , G. Micela 4 , J.-C. Cuillandre 9 , and G. Peres 3
- 1 Univ. Grenoble Alpes, IPAG, F-38000 Grenoble, France
- 2 CNRS, IPAG, F-38000 Grenoble, France
- e-mail: [email protected]
- 3 Dipartimento di Fisica e Chimica, Università degli Studi di Palermo, Piazza del Parlamento 1, 90134 Palermo, Italy
- 4 Istituto Nazionale di Astrofisica, Osservatorio Astronomico di Palermo G.S. Vaiana, Piazza del Parlamento 1, 90134 Palermo, Italy
- 5 Departamento de Física - ICEx - UFMG, Av. Antônio Carlos, 6627, 30270-901 Belo Horizonte, MG, Brazil
- 6 Harvard-Smithsonian Center for Astrophysics, 60 Garden Street, Cambridge, MA 02138, USA
- 7 Spitzer Science Center, California Institute of Technology, 1200 E California Blvd., Pasadena, CA 91125, USA
- 8 Universität Wien, Institut für Astrophysik, Türkenschanzstrasse 17, 1180, Vienna, Austria
- 9 Canada - France - Hawaii Telescope Corporation, 65-1238 Mamalahoa Highway, Kamuela, HI, 96743, USA
Received 7 March 2014 / Accepted 29 July 2014
## ABSTRACT
Context. The accretion process has a central role in the formation of stars and planets.
Aims. We aim at characterizing the accretion properties of several hundred members of the star-forming cluster NGC 2264 (3 Myr). Methods. We performed a deep ugri mapping as well as a simultaneous u -band + r -band monitoring of the star-forming region with CFHT MegaCam in order to directly probe the accretion process onto the star from UV excess measurements. Photometric properties / and stellar parameters are determined homogeneously for about 750 monitored young objects, spanning the mass range GLYPH<24> 0.1-2 M GLYPH<12> . About 40% of the sample are classical (accreting) T Tauri stars, based on various diagnostics (H GLYPH<11> , UV and IR excesses). The remaining non-accreting members define the (photospheric + chromospheric) reference UV emission level over which flux excess is detected and measured.
Results. We revise the membership status of cluster members based on UV accretion signatures, and report a new population of 50 CTTS candidates. A large range of UV excess is measured for the CTTS population, varying from a few times 0.1 to GLYPH<24> 3 mag. We convert these values to accretion luminosities and accretion rates, via a phenomenological description of the accretion shock emission. We thus obtain mass accretion rates ranging from a few 10 GLYPH<0> 10 to GLYPH<24> 10 GLYPH<0> 7 M yr. Taking into account a mass-dependent GLYPH<12> / detection threshold for weakly accreting objects, we find a > GLYPH<27> 6 correlation between mass accretion rate and stellar mass. A powerlaw fit, properly accounting for censored data (upper limits), yields ˙ Macc / M 1 4 : GLYPH<6> 0 3 : GLYPH<3> . At any given stellar mass, we find a large spread of accretion rates, extending over about 2 orders of magnitude. The monitoring of the UV excess on a timescale of a couple of weeks indicates that its variability typically amounts to 0.5 dex, i.e., much smaller than the observed spread in accretion rates. We suggest that a non-negligible age spread across the star-forming region may e GLYPH<11> ectively contribute to the observed spread in accretion rates at a given mass. In addition, di GLYPH<11> erent accretion mechanisms (like, e.g., short-lived accretion bursts vs. more stable funnel-flow accretion) may be associated to di GLYPH<11> erent ˙ Macc regimes.
Conclusions. A huge variety of accretion properties is observed for young stellar objects in the NGC 2264 cluster. While a definite correlation seems to hold between mass accretion rate and stellar mass over the mass range probed here, the origin of the large intrinsic spread observed in mass accretion rates at any given mass remains to be explored.
Key words. Accretion, accretion disks - Stars: formation - Stars: low-mass - Stars: pre-main sequence - open clusters and associations: individual: NGC 2264 - Ultraviolet: stars
## 1. Introduction
The disk accretion phase assumes a pivotal role in the scenarios of early stellar evolution and planetary formation. Circumstellar
- ? Based on observations obtained with MegaPrime MegaCam, a joint / project of CFHT and CEA DAPNIA, at the Canada-France-Hawaii / Telescope (CFHT) which is operated by the National Research Council (NRC) of Canada, the Institut National des Sciences de l'Univers of the Centre National de la Recherche Scientifique (CNRS) of France, and the University of Hawaii.
- ?? Tables 2, 3 and 4 are only available in electronic form at the CDS via anonymous ftp to cdsarc.u-strasbg.fr (130.79.128.5) or via http: // cdsweb.u-strasbg.fr cgi-bin qcat?J A / / / + A /
disks are the ubiquitous result of the earliest stages of star formation, surrounding the vast majority of solar-type protostars at an age of GLYPH<24> 1 Myr. Mass accretion from the inner disk to the central star regulates the star-disk interaction over the few subsequent million years; this process has a direct, long-lasting impact on the basic properties of the system, by providing at the same time mass and angular momentum. Angular momentum transport and mass infall have a most important part in dictating the dynamical evolution of protoplanetary disks, hence setting the environmental conditions which eventually lead to the formation of planetary systems (Armitage 2011).
The widely accepted paradigm for mass accretion in young stellar objects (YSOs) is that of magnetospheric accretion (Camenzind 1990; Königl 1991). A cavity of a few stellar radii extends from the stellar surface to the inner disk rim, as an e GLYPH<11> ect of the inner disk truncation by the stellar magnetosphere (B GLYPH<24> 2 kG). Accretion columns, channeled along the magnetic field lines, regulate the transport of material from the disk inner edge to the central star; as the accreting material impacts onto the stellar surface at near free-fall velocity, accretion shocks are produced near the magnetic poles. This picture is strongly supported by its predictive capability of the main observational features of accreting young solar-type stars (classical T Tauri stars, or CTTS): UV, optical and IR excess compared to the photospheric flux; spectral 'veiling'; broad emission lines; inverse P Cygni profiles; pronounced spectroscopic and photometric variability (e.g. Bouvier et al. 2007b).
Several studies (e.g. Muzerolle et al. 2003; Rigliaco et al. 2011) have shown that the rates ( ˙ Macc ) at which mass accretion occurs tend to scale with the mass of the central object (M ). GLYPH<3> Notwithstanding this general trend, a large spread in the ˙ Macc values at a given M GLYPH<3> appears to be a constant feature (e.g. Hartmann et al. 2006); this is indicative of a complex and dynamic picture, shaped by a variety of parameters and concurrent processes. Similarly, observations suggest a progressive decrease of ˙ Macc over the age of the systems (Hartmann et al. 1998; SiciliaAguilar et al. 2010), following the time evolution and dispersal of circumstellar disks (Haisch et al. 2001; Hillenbrand 2005). The large spread associated with the e GLYPH<11> ective relationship attests that a multiplicity of elements concur to the disk dissipation; moreover, the initial conditions in which stars are formed (e.g. Dullemond et al. 2006) and local environmental properties (e.g. Guarcello et al. 2007) are likely to significantly a GLYPH<11> ect the evolutionary pattern of individual star-disk systems.
Statistical surveys of the accretion properties of young stars provide essential insight into the dynamics of accretion. Large, homogeneously characterized samples of objects, spanning several ranges of parameters, are crucial to achieve a proper understanding of the physics governing the disk accretion history of forming stars and to explore di GLYPH<11> erent facets of the accretion mechanisms. To this respect, extensive mapping surveys of wellpopulated star-forming regions at UV wavelengths (e.g. Rigliaco et al. 2011; Manara et al. 2012) provide a most interesting standpoint, as they allow to directly probe accretion for large samples of stars from the excess emission produced in the shocked impact layer at the base of the accretion column.
Such single epoch surveys e GLYPH<14> ciently trace the instantaneous spread of accretion properties in a given star-forming region; however, they are unable to probe the nature of such a spread, i.e. to determine whether this is due to variability of individual objects or to an intrinsic spread amongst objects. And yet, a key aspect of the accretion dynamics is the intrinsic variability profile of the process (i.e., the amplitude and characteristic timescales of the variability in ˙ Macc ). The enhanced variability typical of young stars, cornerstone of the very definition of the T Tauri class (Joy 1945), is manifest over a broad range of wavelengths (X-rays, UV, optical, IR) and of time baselines (hours, days, years); a variety of processes concur to shape the variability pattern of individual objects, with a significant contribution coming from the geometry of the system. Understanding to which extent and on which timescales the accretion process is intrinsically variable, and characterizing its variability on a statistical basis compared to individual cases, is of utmost importance in order to accurately interpret the information provided by large accretion surveys and thus infer a detailed picture of the accretion process.
Multi-epoch surveys hence provide a more accurate description of the accretion process, as they allow to probe the time evolution of single snapshots of the accretion properties and, thus, to investigate how accretion occurs. This has been addressed in a few recent studies (e.g. Nguyen et al. 2009; Fang et al. 2013), which explored the variability of spectral accretion diagnostics for tens of objects with a few observing epochs over several months. Such e GLYPH<11> orts provided very valuable constraints on the average accretion variability shown by typical CTTS. However, a much tighter time sampling is needed in order to recover an estimate of the e GLYPH<11> ective intrinsic accretion variability, isolated from geometric contributions which are simply due to a varying visible portion of the accretion spots during stellar rotation.
We have recently conducted an extensive observational program specifically aimed at addressing the issue of YSOs variability over the full spectrum. The Coordinated Synoptic Investigation of NGC 2264 (CSI 2264; Cody et al. 2013) project was devised as a coordinated multi-wavelength exploration of the hours-to-weeks variability of the pre-Main Sequence (PMS) population of the star-forming region NGC 2264. The space telescopes CoRoT and Spitzer provided the backbone of the optical and IR investigations, with simultaneous continuous monitoring over 40 and 30 days respectively; the Flames multi-object spectrograph at the Very Large Telescope (VLT) provided a full set of spectra covering 20 di GLYPH<11> erent epochs for GLYPH<24> 100 young stars, while multi-band optical + UV photometric monitoring obtained at the Canada-France-Hawaii Telescope (CFHT) provided contemporaneous, synoptic measures of the accretion rates and their variability from the direct diagnostics of the UV excess, with an overall time coverage of 14 consecutive days and several measurements per night. The targeted region, NGC 2264, has long been a benchmark for star formation studies, thanks to its youth ( GLYPH<24> 3 Myr), its richness ( GLYPH<24> 1500 known members, both CTTS and non-accreting, weak-lined T Tauri stars, or WTTS), its relative proximity (d GLYPH<24> 800 pc), the low extinction on the line of sight and the association with a molecular cloud complex that significantly reduces the contamination from background stars (see Dahm 2008 for a recent review on the region).
As part of the CSI 2264 campaign, this paper specifically focuses on the issue of accretion properties and accretion variability in the PMS population of NGC 2264. Sect. 2 describes the photometric dataset obtained at CFHT, on which the study reported here is based. Sect. 3 reports on the characterization of photometric accretion signatures, which allowed us to perform a new, accretion-driven census of NGC 2264 members; an extensive, homogeneous investigation of individual stellar properties is also reported. In Sect. 4, we describe the procedure adopted to convert the UV excess measurement to a ˙ Macc estimate; we analyze the ˙ Macc over M GLYPH<3> distribution thus inferred and compare this picture with the amount of variability registered over a baseline of two weeks; we further probe the origin of this variability and infer a specific estimate of the intrinsic accretion variability as opposed to rotational modulation detected during the monitoring. Results are discussed in Sect. 5; our conclusions are synthetized in Sect. 6. This provides a complete picture of a whole star-forming region and its several hundred members at short wavelengths, from a specifically accretion-oriented perspective. A more detailed characterization of the variability properties monitored at CFHT and their relation to the underlying physics will be addressed in a forthcoming paper (Venuti et al., in preparation).
Fig. 1. CFHT MegaCam / u g r color image of NGC 2264.
## 2. Observations and data reduction
2.1. CFHT MegaCam surveys of NGC 2264: data reduction and photometric calibration
Wesurveyed NGC 2264 in two multiwavelength observing campaigns at the CFHT, using the wide-field optical camera MegaCam; the camera has a field of view (FOV) of GLYPH<24> 1 deg. 2 (Boulade et al. 2003), thus fitting the whole region in a single telescope pointing. Five broad-band filters ( u GLYPH<3> ; g ; 0 r 0 ; i 0 ; z 0 ) are adopted at the camera; their design, close to the Sloan Digital Sky Survey (SDSS) photometric system (Fukugita et al. 1996), ensures high e GLYPH<14> ciency for faint object detection and deep sky mapping.
## 2.1.1. Mapping survey
The first MegaCam survey of NGC 2264, held on Dec. 12, 2010, consisted of a deep u GLYPH<3> g 0 r 0 mapping of the region. In the r 0 -band, five short exposures (10 s) were obtained, using a dithering pattern in order to compensate for the presence of bad pixels and small gaps on the CCD mosaic. In the u GLYPH<3> -band and g 0 -band, the same 5-step dithering procedure was repeated in two di GLYPH<11> erent exposure modes, short (10 s) and long (60 s), in order to obtain a good signal noise (S N) for the whole sample of objects with-/ / out saturating the brightest sources. All images were obtained over a continuous temporal sequence within the night. On Feb. 28, 2012, concurrently with the monitoring survey reported in Sect. 2.1.2, we additionally obtained a deep i 0 -band mapping, in order to reconstruct a full 4-band picture of NGC 2264 together with the u GLYPH<3> g 0 r 0 survey of Dec. 2010. Similarly to previous observations, a dithering pattern was used, along with two di GLYPH<11> erent exposure times: 180 s, to detect all sources in the FOV, and 5 s, to recover the bright sources saturated in the long exposure.
Raw data have been preliminarily processed at the CFHT, in order to correct for instrumental signatures across the whole CCD mosaic (i.e., bad pixel clusters or columns, dark current, bias, non-uniformity in the response), and a first astrometric and photometric calibration has been performed. The subsequent photometric processing of the images obtained during the survey has been handled as described below.
For each spectral band and each exposure time, single dithered images have been combined, in order to discard spurious signal detections (e.g., cosmic rays) and correct for small CCD gaps. The photometric images thus assembled (one in the r 0 -band and two for each other filter, corresponding to the two di GLYPH<11> erent exposure times) have then been processed using the SExtractor (Bertin & Arnouts 1996) and PSFEx (Bertin 2011) tools, in order to identify true sources in the field of view and extract the relevant photometry. At first, we run a preliminary aperture photometry procedure with a detection threshold of 10 GLYPH<27> above the local background, in order to extract only brighter sources; this selection of objects has been used as input to run a pre-PSF fitting routine, aimed at testing the optimal parameters for the PSF function to be used for analyzing the images. A final, complete single-band catalog has eventually been produced from each image processed with SExtractor by performing a new PSF-fitting run with a lower detection threshold of 3 GLYPH<27> , thus recovering the fainter component of the population.
A first filtering of each catalog population, based on the properties of the extracted sources and on the relevant extraction flags, allowed us to discard the stellar component potentially a GLYPH<11> ected by saturation or other detection problems. Long and short exposure catalogs corresponding to the same spectral band, when present, have then been merged, in order to obtain a unique photometric catalog for each spectral band and avoid duplicates. The sample of objects common to both the longexposure and short-exposure catalogs has been used to evaluate the photometric accuracy, to correct the short-exposure photometry for small magnitude o GLYPH<11> sets with photometry obtained from the long exposures and to define a confidence magnitude threshold below which photometry could begin to be a GLYPH<11> ected by saturation. Objects have been preferentially taken from the long-exposure catalog; sources brighter than the long-exposure threshold have been retrieved from the short-exposure catalog, when available; sources brighter than the short-exposure threshold have been discarded.
A complete calibration of the CFHT instrumental magnitudes to the SDSS photometric system, including a correction for both o GLYPH<11> set and color e GLYPH<11> ect, has then been performed. The calibration procedure has not been anchored to a sample of standard stars in the field of view; instead, we used an ensemble of around 3000 stars, present in the CFHT FOV, for which SDSS photometry was available from the seventh SDSS Data Release (Abazajian et al. 2009), to statistically calibrate the CFHT magnitudes to the SDSS system. The matching of sources between the SDSS and the CFHT catalogs has been performed using the TOPCAT (Taylor 2005) tool, fixing a matching radius of 1 arcsec and retaining only closest matches. The statistical ensemble of stars used for the calibration has been selected among the objects with complete CFHT u GLYPH<3> g 0 r i 0 0 photometry and that matched the magnitude limits for 95% detection repeatability for point sources defined for the SDSS photometric survey (Abazajian et al. 2004). The calibration procedure adopted is based on the results of the photometric calibration study of the CFHT MegaCam photom-/ etry to the SDSS system performed by Regnault et al. (2009). We compared the distribution of SDSS colors over the ensemble of stars with the SDSS dwarf color loci tabulated in literature (Covey et al. 2007; Lenz et al. 1998) and retained, for calibration purposes, only objects whose colors matched the tabulated ranges. After checking their consistency with the observed trends, Regnault's linear calibration relations have then been used to fit the ( m CFHT GLYPH<21> GLYPH<0> m S DSS GLYPH<21> ) vs. ( m S DSS GLYPH<21> GLYPH<0> m S DSS GLYPH<21> + 1 ) distri-
butions in u GLYPH<3> , g 0 and r 0 , by keeping the angular coe GLYPH<14> cient fixed and adapting the intercept value. In the i 0 -band, for which the filter in use at MegaPrime has been changed, due to accidental breakage, after the epoch of acquisition of data used in Regnault et al. (2009)'s study, no evident color dependence of the o GLYPH<11> set between the two photometric systems has been observed; the i 0 -band photometry has therefore been uniquely corrected for a constant o GLYPH<11> set. The system of 4 calibration equations thus obtained (one for each spectral band; Eq. 1-4) has then been solved to obtain the final conversion from CFHT instrumental magnitudes to SDSS photometry.
$$u _ { C F H T } - u _ { S D S S } = - 0. 2 1 1 \, ( u _ { S D S S } - g _ { S D S S } ) - 0. 6 3 \, \quad \ \ ( 1 )$$
$$g _ { C F H T } - g _ { S D S S } = - 0. 1 5 5 \, ( g _ { S D S S } - r _ { S D S S } ) - 0. 5 1 \, \quad \ \ ( 2 ) \, \quad \ w e \, \text{exam}$$
$$r _ { C F H T } - r _ { S D S S } & = - 0. 0 3 \left ( r _ { S D S S } - i _ { S D S S } \right ) & ( 3 ) \underset { \text{sequenc} } { \text{$\text{$\text{$max\infty$} } } }$$
$$i _ { C F H T } - i _ { S D S S } & = - 0. 0 2 & ( 4 ) \quad \text{to the } \mathfrak { m } _ { \mathfrak { a. c. d. } }$$
Acomplete u GLYPH<3> g 0 r i 0 0 catalog of NGC 2264, containing GLYPH<24> 9000 sources in the field of view, has been built by cross-correlating the single-band catalogs on TOPCAT. A matching radius of 1 arcsec has been fixed for identifying common sources detected in the u GLYPH<3> ; g ; 0 r 0 concurrent observations, while a larger matching radius of 2 arcsecs has been introduced to match u GLYPH<3> g 0 r 0 sources with their i 0 -band counterpart, to account for a lower astrometric accuracy (lower angular resolution) characterizing the i 0 -band field, due to poorer seeing conditions at the time of acquisition of the i 0 -band images. Sources have been identified by retaining only best matches; we address potential problems in the derived colors associated with misidentifications and multiple matches in Sect. 2.2. Final SDSS u 0 g 0 r i 0 0 (hereafter u g ri ) photometry has then been associated to each source in the catalog using the derived calibration relations.
## 2.1.2. Monitoring survey
The second MegaCam survey of NGC 2264, performed in Feb. 2012, consisted in monitoring the u GLYPH<3> -band and r 0 -band variability of the entire stellar population of the region over a mid-term timescale (Feb.14-28, i.e., 2 weeks), as a part of the CSI 2264 project. On each observing night during the run, the region was imaged repeatedly, with a temporal cadence varying from 20 min to 1.5 h. Each u r GLYPH<3> 0 observing block was performed using a 5-step dithering pattern, with single exposures of 3 s in the r 0 -band and 60 s in the u GLYPH<3> -band.
The procedure adopted for the photometric processing of the images obtained during the u r GLYPH<3> 0 monitoring survey is similar to that applied to the mapping survey images, but each exposure has been individually processed in order to retrieve the luminosity variations over di GLYPH<11> erent timescales. The i -band image (Sect. 2.1.1) has been used as the astrometric reference exposure, as the nebulosity component was the least conspicuous in this image compared to the other filters; for each source, an aperture has been placed down on each u GLYPH<3> and r 0 image at the position predicted from the i -band source detection and the amount of flux within this aperture has been extracted to build the light curve.
A preliminary quality check on the CFHT light curves consisted in closely examining a sample of NGC 2264 members with known periodicities, in order to attempt to recover their periods from the phase-folded CFHT light curves. This allowed us to ascertain the global accuracy of the u r GLYPH<3> 0 time series photometry, albeit occasionally a GLYPH<11> ected by isolated discrepant points and non-negligible scatter due to poorer observing conditions. In order to locate the potentially problematic observing sequences,
Table 1. Detection limits and completeness in the CFHT u g ri survey of NGC 2264.
| (mag) | u | g | r | i |
|------------------|---------|---------|-----------|---------|
| mag range * | 15-23.5 | 14-21.5 | 13.5-20.5 | 13-19.5 |
| Saturation start | < 12.5 | < 13 | < 13.5 | 12.5 |
| Detection limit | 23.5 | 21.5 | 20.5 | 19.5 |
| Completeness | 21.5 | 19.5 | 18.5 | 17.5 |
Notes. Values reported are conservative estimates.
( * ) Values referred to the main body of the magnitude distribution of the catalog population.
we examined the time series photometry for the whole sample of field stars in the CFHT FOV and derived, for each observing sequence, the distribution of median zero-point o GLYPH<11> sets referred to the master frame. The zero-point o GLYPH<11> set, for a given object, is defined as the mag di GLYPH<11> erence between the frame of interest and the master frame; in case of large deviation from zero, the zeropoint o GLYPH<11> set distribution associated to an observing sequence thus signals that the observation has been carried out through clouds. This translates to significantly lower than average S N for a given / source, which implies that, even for the brightest stars, no accurate measurements can be inferred from that specific observation; hence, epochs matching this description have not been used for any subsequent analysis.
As done earlier for the u g ri snapshot survey, the instrumental light curve photometry has been calibrated to the SDSS system, referring the procedure to the calibrated photometry from the first CFHT survey. No o GLYPH<11> sets and color e GLYPH<11> ects have been noticed in the r 0 -band (hereafter r -band) photometry, while a correction for both contributions has been applied to the u GLYPH<3> -band photometry from the ( u GLYPH<3> CFHT lc \_ GLYPH<0> u ) vs. ( u GLYPH<0> r ) plane:
$$u _ { C F H T _ { - l c } } ^ { * } - u = - 0. 1 3 4 3 \ ( u - r ) - 0. 1 0 0 9$$
## 2.2. The CFHT catalog of NGC 2264
Fig. 1 shows a MegaCam color picture of the field imaged at CFHT during the NGC 2264 campaign. The star-forming region extends over the central part of the field, with the most active sites of star formation located at the center of the image, northward of the Cone Nebula (cf. Dahm 2008).
We obtained a complete u g ri dataset and photometric monitoring for GLYPH<24> 9000 sources in the field, exploring the area projected onto the star-forming region as well as the periphery of the cluster and background foreground sky. Table 1 provides some de-/ tails on the photometric properties of the population of the CFHT catalog. The survey is complete down to u GLYPH<24> 21.5 and r GLYPH<24> 18.5 and the monitored objects span a range of GLYPH<24> 7 mags. The photometry is globally accurate up to a few GLYPH<2> 10 GLYPH<0> 2 mag and the relative accuracy rises up to order of 10 GLYPH<0> 3 mag for brighter objects.
In order to evaluate the probability of misidentifications as a result of the procedure adopted for matching sources in different catalogs, and thus evaluate the potential impact on the photometric properties inferred for individual sources, we reconsidered all multiple identifications within the allowed matching radii and closely examined their spatial distribution. The sources with potentially multiple identifications amount to GLYPH<24> 2.9% of the population of the catalog. The di GLYPH<11> erence in o GLYPH<11> set distance between the best match and the next best match is less than 0.5 arcsec for only 23% of these cases. Less than 20% of the multiply matched sources are located within the region occupied by
Fig. 2. ( r GLYPH<0> i , g GLYPH<0> r ) color-color diagram for objects monitored at CFHT. Empirical dwarf color sequences from Covey et al. (2007) and Kraus & Hillenbrand (2007) are shown as black crosses and blue triangles, respectively. The reddening vector is traced based on the reddening parameters in the SDSS system provided by the Asiago Database on Photometric Systems (ADPS; Fiorucci & Munari 2003).
most NGC 2264 members. For the statistical purposes of this study, this component is assumed to be negligible.
## 3. The PMS population of NGC 2264
A global picture of the photometric properties of the stellar population can be achieved from the analysis of color-color diagrams, as shown in Figs. 2-3. Empirical dwarf SDSS color sequences (Covey et al. 2007; Kraus & Hillenbrand 2007) have been overplotted to the diagrams in order to follow the observed color distribution and investigate the relationship between color loci and stellar properties.
In Fig. 2, earlier-type field stars are located along the diagonal ellipse, with foreground or slightly reddened objects on the lowermost part of the distribution and background stars at the uppermost end; M-type stars are predominantly located on the horizontal branch, whose g GLYPH<0> r position is in good agreement with the value of GLYPH<24> 1.4 mentioned in previous studies (Covey et al. 2007; Finlator et al. 2000; Fukugita et al. 1996; Annis et al. 2011). A number of objects can be located to the left (i.e., blueward) of the standard locus in r GLYPH<0> i ; only for a part of them this displacement may be ascribed to photometric inaccuracies. The most likely explanation for these objects is that they are highly variable, and the inferred r GLYPH<0> i color is spurious due to the large epoch di GLYPH<11> erence between the r -band and i -band photometry (the over one year time lapse between the u g r and the i -band mappings of the region, as discussed in Sect. 2).
Similarly, a progression of increasing spectral types and reddening e GLYPH<11> ects can be observed from left to right along the ellipse in Fig. 3; an interesting locus is defined by the point dispersion at 0.5 GLYPH<20> g GLYPH<0> r GLYPH<20> 2.0, below the main body of the color distribution, as it shows u GLYPH<0> g color excesses presumably linked with the YSO accretion activity, manifest at UV wavelengths with a flux ex-
Fig. 3. ( g GLYPH<0> r , u GLYPH<0> g ) color-color diagram for objects monitored at CFHT. Empirical dwarf color sequences from Covey et al. (2007) and Kraus & Hillenbrand (2007) are shown as black crosses and blue triangles, respectively. The reddening vector is traced based on the reddening parameters in the SDSS system provided by the ADPS (Fiorucci & Munari 2003).
cess compared to the photospheric emission. An o GLYPH<11> set of a few tenths of a mag is observed between the mean locus of field stars in our survey and the sequences of Covey et al. (2007) and Kraus & Hillenbrand (2007). This o GLYPH<11> set cannot be explained with imprecisions in our calibration. A possible explanation may lie in a lower than solar standards metallicity of the field population probed here; at any rate, this disagreement has no impact on our analysis, as we uniquely used our internal reference sequence to probe the photometric accretion signatures of members, as illustrated in the following sections.
We further pursued the color signatures of di GLYPH<11> erent YSO types in the SDSS filters by analyzing the color properties of known members of the region with respect to the loci traced on the diagrams by the large population of field stars. Known members were identified amidst the population of the region based on a wide collection of photometric spectroscopic data available / in the literature from various surveys of the cluster; membership and further information on the WTTS (no disk evidence) vs. CTTS (disk-accreting) nature of selected members have been inferred based on one or more of the following criteria: i) H GLYPH<11> emitter from narrow-band photometry and variability from the data of Lamm et al. (2004) and following their criteria; ii) X-ray detection (Ramírez et al. 2004; Flaccomio et al. 2006) and location on the cluster sequence in the (I, R-I) diagram when R,I photometry is available; iii) H GLYPH<11> emitter from spectroscopy (H GLYPH<11> EW > 10 Å, H GLYPH<11> width at 10% intensity > 270 km s GLYPH<0> 1 ); iv) radial velocity member according to F˝ urész et al. (2006); v) member according to Sung et al. (2008) (cf. criteria enumerated earlier) and Sung et al. (2009) (Spitzer Class I Class II). It is worth remarking that / this preliminary analysis of membership and TTS classification is not based on direct accretion criteria.
Around 700 known members have been matched in the CFHT catalog within a matching radius of 1 arcsec; among
Fig. 4. ( r GLYPH<0> i , g GLYPH<0> r ) color-color diagram for NGC 2264 members monitored at CFHT. Field stars, non-accreting cluster members (WTTS) and accreting cluster members (CTTS) are depicted as grey dots, blue triangles and red circles, respectively. The reddening vector is traced based on the reddening parameters reported in the ADPS (Fiorucci & Munari 2003).
these, GLYPH<24> 60% are classified as WTTS. Fig. 4 and 5 show the color properties of these groups of objects respectively in the ( r GLYPH<0> i , g GLYPH<0> r ) and ( g GLYPH<0> r , u GLYPH<0> g ) diagrams.
In redder filters, as shown in Fig. 4, both CTTS and WTTS define a single color sequence following the one traced by field stars. A few CTTS appear well blueward of this sequence, reflecting multi-year variability that is evidently more common in the CTTS than the WTTS. Conversely, accreting and nonaccreting stars define two clear distinct distributions on the ( g GLYPH<0> r , u GLYPH<0> g ) diagram in Fig. 5, with the latter displaying colors consistent with the photometric properties of field stars and the former located at smaller (i.e., bluer) u GLYPH<0> g values compared to the main color locus defined by dwarfs.
These distinctive features are well observed in Fig. 6, which shows how members distribute on the ( u GLYPH<0> r , r ) color-magnitude diagram. There, the cluster sequence is clearly traced by WTTS, while CTTS appear broadly scattered to the left as a result of their u -band excess, indicative of active accretion activity, compared to WTTS. A number of presumed non-accreting members show a non-negligible displacement blueward redward of / the main locus; these two groups of objects are discussed further in Sect. 3.2.2.
Two main inferences can be drawn from these diagrams:
- 1. CTTS and WTTS members do di GLYPH<11> erentiate in the SDSS colors on the basis of photometric accretion signatures at short wavelengths (UV flux excess);
- 2. the UV excess linked with accretion, detected in the u -band, does not a GLYPH<11> ect significantly the observations in filters at longer wavelengths, as emphasized by the substantial agreement of the CTTS and WTTS color sequences in Fig. 4 and the color saturation at g GLYPH<0> r GLYPH<24> 1.4, a behavior common to field stars.
Fig. 5. ( g GLYPH<0> r , u GLYPH<0> g ) color-color diagram for NGC 2264 members monitored at CFHT. Field stars, WTTS and CTTS are depicted as grey dots, blue triangles and red circles, respectively. The reddening vector is traced based on the reddening parameters reported in the ADPS (Fiorucci & Munari 2003).
These photometric properties, observed for di GLYPH<11> erent ensembles of stars, enable us to perform a new membership and population study on an individual basis, from an accretion-driven per-
Fig. 6. ( u GLYPH<0> r , r ) color-magnitude diagram for NGC 2264 members monitored at CFHT. Field stars, WTTS and CTTS are depicted as grey dots, blue triangles and red circles, respectively. The reddening vector is traced based on the reddening parameters reported in the ADPS (Fiorucci & Munari 2003).
spective. This analysis has the twofold purposes of investigating the presence, in the CFHT FOV, of additional objects that are new candidate members, and of re-examining the classification of known members, looking in both cases for classification outliers in the diagram loci dominated by accretion.
## 3.1. UV excess vs. different accretion diagnostics
In order to ascertain the coherence of the classification based on the UV excess detection on these diagrams and define some confidence limits for a reliable identification of accreting members, we compared the u -band excess information drawn from CFHT photometry with di GLYPH<11> erent diagnostics commonly used to investigate accretion, such as the equivalent width and the width at 10% intensity in the H GLYPH<11> emission line, probing the accretion funnel, or the mid-infrared emission, that signals the presence of material in the inner disk when a flux excess compared to the photospheric level is detected.
Fig. 7 shows the same color-color diagram as in Fig. 5 with additional information on the H GLYPH<11> EW values measured for the subsample of objects having VLT Flames spectra from the / CSI 2264 campaign (A. Sousa, UFMG). A threshold value commonly adopted to identify accreting YSOs from H GLYPH<11> emission is H GLYPH<11> EW GLYPH<21> 10 Å (Herbig & Bell 1988), while a more robust scheme relating the threshold value to the stellar spectral type has been introduced by White & Basri (2003). As can be observed in Fig. 7, the UV excess and the H GLYPH<11> EW diagnostics are fully consistent, with the objects having the least H GLYPH<11> EWs located on the color locus traced by WTTS and field stars, while a region of the diagram dominated by accretion can clearly be delimited below the field stars distribution and identified from the detection of a UV excess.
A useful tool for characterizing presence and properties of a circumstellar disk is the examination of the infrared spectral
Fig. 7. u GLYPH<0> g vs. g GLYPH<0> r colors for NGC 2264 members are compared to the H GLYPH<11> EW. Asterisks mark members for which H GLYPH<11> EW is available from the CSI 2264 campaign (see text). Asterisk colors and sizes are scaled according to the value of H GLYPH<11> EW.
energy distribution (SED) of the system. A particularly interesting indicator of the SED morphology is the measure of its slope in the spectral range of interest (i.e., the spectral index GLYPH<11> first introduced by Lada 1987): smaller amounts of material in the inner disk result in smaller contributions, i.e. smaller flux excesses, at mid-IR wavelengths and hence more negative values of the GLYPH<11> -index, which approaches the slope of a reddened blackbody, while positive values of the mid-IR SED slope are specific to deeply embedded, Class I sources. In Lada et al. (2006), the GLYPH<11> -index diagnostics for disks is applied to the mid-IR emission sampling between 3.6 and 8 GLYPH<22> m performed with the Spitzer instrument IRAC for the young cluster IC 348; the same tool has been adopted by Teixeira et al. (2012) to characterize the evolutionary state of NGC 2264 members based on the inner disk properties. We compare their results to the colors of NGC 2264 YSOs in the ( g GLYPH<0> r , u GLYPH<0> g ) diagram in Fig. 8. Following the classification proposed in Table 2 of Teixeira et al. (2012), values of GLYPH<11> IRAC < GLYPH<24> GLYPH<0> 2 are indicative of objects with anaemic disks or naked photospheres, while objects with thick disks (hence likely to be actively accreting) are characterized by GLYPH<11> IRAC > GLYPH<0> 2. Indeed, as can be observed in Fig. 8, objects in the first GLYPH<11> IRAC group are mainly located on the WTTS dwarf locus in / u GLYPH<0> g vs. g GLYPH<0> r , while objects showing a UV excess (and thus actively accreting stars) have the largest values of GLYPH<11> IRAC , as globally expected.
## 3.2. UV census of the NGC 2264 population
## 3.2.1. New CTTS candidates in NGC 2264
A most interesting locus to identify accreting members is the data points dispersion below the main body of the distribution in Fig. 5. In fact, this allows easy detection and measurement of the u -band excess with respect to WTTS. The inferred color excess estimate is independent of distance and has no significant dependence on visual extinction A V , as WTTS define a color
Fig. 8. u GLYPH<0> g vs. g GLYPH<0> r colors for NGC 2264 members are compared to the GLYPH<11> IRAC diagnostics, which probes the inner disk properties (see text). Colors and sizes of symbols are scaled according to the value of GLYPH<11> IRAC from the data of Teixeira et al. (2012).
Fig. 9. Selection of new CTTS candidates from the ( g GLYPH<0> r , u GLYPH<0> g ) diagram. The grey dashed line traces a conservative boundary separating the accretion-dominated region of the diagram from the color locus of non-accreting stars (see text). Field stars, WTTS and known CTTS are depicted as grey dots, blue triangles and red circles, respectively; the new CTTS candidates selected from this diagram are marked as green crosses. The purple line fitting the upper envelope of the WTTS distribution traces the reference sequence of photospheric colors that has been adopted for measuring the UV excess of accreting stars (see Sect. 4).
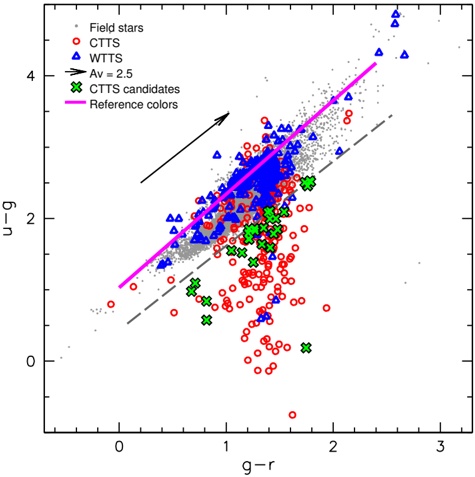
sequence nearly parallel to the reddening vector down to GLYPH<24> M0 spectral type. For later-type stars, the color sequence traced by WTTS turns down, saturating at g GLYPH<0> r GLYPH<24> 1.4 (cf. Fig. 4); the implications of this for the UV excess measurement are discussed in Sect. 4. In order to minimize the contamination, we traced a straight line, parallel to the reddening vector, bordering the accretion-dominated area below the lower envelope of the dwarf color locus (Fig. 9); we then selected as new CTTS candidates all the objects lying in this region and marked as field stars. For all these objects, a preliminary check of the photometry on the CFHT field images has been performed, in order to discard the sources whose flux measurements could be a GLYPH<11> ected by detection issues (e.g., too faint source, presence of two close sources, partial projection of the source on CCD gaps or bad pixel rows).
A second group of new CTTS candidates has been extracted from the color distribution in Fig. 4, namely among the color outliers located to the left and, to a smaller extent, below the main color distribution. Similarly to the procedure adopted for the selection of objects on the diagram in Fig. 5, a check on the photometry quality for all the objects of interest has preceded the identification of new candidates.
A third color-color diagram of interest for the analysis of membership is the one depicting u GLYPH<0> g vs. r GLYPH<0> i (Fig. 10); as a 'transitional' diagram between u GLYPH<0> g vs. g GLYPH<0> r (Fig. 5; direct UV excess detection) and g GLYPH<0> r vs. r GLYPH<0> i (Fig. 4; nearly horizontal photospheric color sequence for late-type stars, with no color saturation on r GLYPH<0> i ), this diagram provides a greater sensitivity to the UV excess for spectral types GLYPH<21> M0. Additional, later-type CTTS candidates have then been identified on this diagram, and
Fig. 10. ( r GLYPH<0> i , u GLYPH<0> g ) diagram for cluster members and field stars in the NGC 2264 field. Field stars, WTTS and known CTTS are depicted as grey dots, blue triangles and red circles, respectively. Grey dots encircled in red correspond to new CTTS candidates selected on di GLYPH<11> erent diagrams (Fig. 9 or Fig. 4.) Green crosses mark the additional CTTS candidates selected on this diagram.
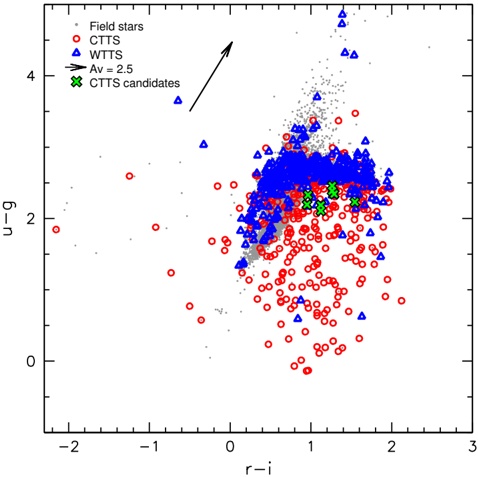
their photometric properties inspected similarly to what done for the candidate members extracted earlier.
A second aspect of our selection of new candidate, actively accreting YSOs concerns the group of already known members which had previously been considered WTTS (that is, YSOs without evidence of significant, ongoing accretion at the time of the previous surveys). We examined the locations of these putative WTTS in our several diagrams (Figures 4 through 9) and identified a significant number whose colors fell generally within the UV-bright regions - for example, the small group of blue points located below the normal dwarf locus in Fig. 5. This procedure allowed us to re-classify 19 WTTS members as CTTS, which add to the 50 newly accretion-identified candidates; this varied status does not necessarily reflect an erroneous previous classification, but may as well be the result of a long-term ( GLYPH<24> years) variability in the accretion activity of the objects.
The results of our UV-based membership investigation are provided in Table A.1 (new CTTS candidates) and Table A.2 (re-classified CTTS). This revised census of accreting members we infer for NGC 2264 likely encompasses all objects showing a strong UV excess, hence a significant amount of accretion. However, our sample might not be exhaustive regarding the weakly-accreting CTTS component. Indeed, a non-negligible overlap between the CTTS and WTTS populations can be seen in Figs. 5-6, which cannot be e GLYPH<14> ciently probed with our diagnostics. Hence, we do identify some new CTTS, but we might be missing a number of lower accretors, showing a smaller UV excess that cannot be easily separated from the color properties of WTTS field stars. /
The wide FOV of CFHT MegaCam allowed us to probe a / quite extended region around the cluster, encompassing most of the fields of view adopted in previous surveys. It is thus of interest to examine the spatial distribution of the new CTTS candi-
Fig. 11. Spatial distribution of the new CTTS candidates from the CFHT u -band survey. Field stars, known cluster members and new CTTS candidates are depicted as small grey dots, blue dots and black crosses, respectively.
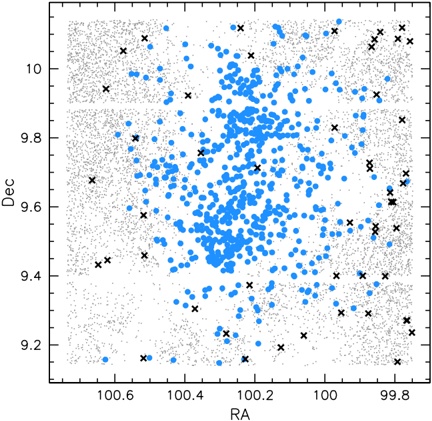
dates, selected as described in Sect. 3.2.1, compared to the distribution of known NGC 2264 members on the CFHT field of view. This comparison is shown in Fig. 11. A fraction of the object positions are projected onto the main cluster region, while a significant part are located on the periphery or beyond. This provides evidence for a wider spatial spread of the PMS population associated with NGC 2264, and attests to the presence of actively accreting members far from the original sites of star formation, currently known to be located towards the north and the center of the field imaged at CFHT (Dahm 2008).
## 3.2.2. Field stars contamination in the NGC 2264 sample
Based on the discussion in Sect. 3.2.1, another potentially interesting location for our accreting members census is the data point dispersion to the left of the cluster sequence (WTTS distribution) in Fig. 6. A direct search for candidate members in this color-magnitude locus would hardly be straightforward, due to the distance-dependence and to the vast preponderance of field stars; on the other hand, this diagram provides an additional test bench for investigating the nature of individual groups of objects.
Similarly to Fig. 5, we can identify on Fig. 6 a group of putative non-accreting members with inferred u GLYPH<0> r colors bluer than expected. This feature, suggestive of ongoing accretion activity for a young cluster member, is consistently observed on di GLYPH<11> erent color-magnitude diagrams ( g vs. u GLYPH<0> g , i vs. u GLYPH<0> i ) for several of these objects; interestingly, these objects populate the thin lower branch of the WTTS distribution, below the main WTTS locus, on the lower part of the dwarf locus in Fig. 5 ( u GLYPH<0> g vs. g GLYPH<0> r diagram). Little spectroscopic information is available for this group of stars; contrary to what is expected for objects clearly showing accretion activity, the level of variability exhibited by many of these objects during our monitoring is not significant over the noise level defined, as a function of magnitude, by field stars in our survey (see Venuti et al., in prep.). Additionally, several of these putative members would be located close to or onto the MS-turno GLYPH<11> (or below) in the HR diagram of the region
(Fig. 12). We therefore suspect at least a part of these objects to possibly be misclassified dwarfs instead. A list of objects with questioned membership, of the relevant CFHT photometry and of the original selection criteria is provided in Table A.3.
Another interesting group of objects in Fig. 6 is the sample of WTTS displaced redward of the main cluster sequence. Most of these objects consistently appear significantly reddened through all CFHT photometric diagrams; in several cases, they display little variability. While contamination by field stars might be partly reflected in the observed properties, most of the objects in this stellar group would actually look like very young, or equivalently overluminous, objects on the HR diagram of the region (i.e., they are located on the upper right envelope of the data point distribution in Fig. 12). This would rather suggest binarity and or earlier (i.e., more embedded) evolutionary status as pos-/ sible explications of the distinctive properties of these objects.
## 3.3. NGC 2264 members in the CFHT survey: individual extinction and stellar parameters
The sample of PMS stars retrieved or newly identified in the CFHT survey amounts to about 750 objects. Based on the multiband photometry obtained during our campaign, as well as on the collection of previous literature data in di GLYPH<11> erent spectral bands, we performed an extensive investigation of individual stellar parameters (like extinction, mass and radius); this is aimed at characterizing the properties of members in a uniform and selfconsistent manner.
Extinction towards NGC 2264 is known to be low (cf. Dahm 2008, for a review of literature results), with a typical value of < GLYPH<24> 0.4 mag for the visual extinction A V . Indeed, the good agreement of the cluster sequence with the color locus traced by foreground stars on Fig. 4 and the color saturation at GLYPH<24> 1.4 in g GLYPH<0> r (cf. discussion at the beginning of Sect. 3) is consistent with a low value of the average A V . We use the photometric properties displayed in this diagram to derive an estimate of the individual A V for late-type stars, i.e. the group of members located on the horizontal branch in the color locus. For this group of objects, A V is determined by displacing each point along the reddening direction until the lowermost envelope of the branch distribution defined by field stars is reached and computing the corresponding amount of reddening. This procedure has the advantage of relying solely on observed quantities, without involving the comparison with an external reference sequence that would intrinsically introduce an additional source of uncertainty on the result.
For earlier-type stars ( < GLYPH<24> M0), the cluster sequence is nearly parallel to the reddening direction in Fig. 4, thus preventing a direct A V determination from the object location on the diagram. For this group of objects, we derive a first estimate of the individual A V from the analysis of the infrared photometry in the JHK S filters, as measured in the 2MASS survey (Skrutskie et al. 2006). This consists in comparing their infrared colors with the JHK S color sequence for dwarfs (Covey et al. 2007) and with the CTTS infrared locus defined in Meyer et al. (1997) and converted to the 2MASS photometric system as in Covey et al. (2010) (K. Covey, private communication). Additional A V estimates for a part of these sources are available from previous, similar studies (e.g., Rebull et al. 2002, where A V is investigated from the color excess on R-I, or Cauley et al. 2012, where A V is computed by fitting stellar spectra with spectral templates) and or derived / from our optical photometry collection (from the measurement of the color excess on R-I, V-I or B-V in order of preference). In the absence of a direct A V estimate from CFHT photometry, all available A V derivations have been examined and their con-
sistency checked on the color properties displayed in the CFHT diagrams, in order to discard discrepant estimates; an average value has then been adopted as a final estimate.
In order to evaluate the uncertainty on our individual A V estimates, we collected all available A V determinations for any object in our sample, and measured the amount of scatter observed among values inferred from di GLYPH<11> erent authors methods. / This comparison allowed us to conclude that di GLYPH<11> erent A V estimates are typically consistent within a radius of a few 0.1 mag, which then provides an order-of-magnitude uncertainty on the A V values adopted in this study.
Of the sample of CFHT members, spectral type is known for around 50% and has been retrieved, in order of preference, from the studies of Dahm & Simon (2005), Rebull et al. (2002) or Walker (1956). For the remaining objects, the spectral type has been derived from the comparison of the dereddened colors with the empirical optical color sequence of Covey et al. (2007). We used the dereddened photometry of members with known spectral type, earlier than M1, to recalibrate the empirical spectral type-color sequence onto CFHT photometry. Spectral types were converted to e GLYPH<11> ective temperatures T e f f following the scale of Cohen & Kuhi (1979), checked for consistency against the scale of Luhman et al. (2003).
Bolometric luminosities have been derived from the dereddened J-band photometry retrieved from the 2MASS catalog, adopting T e f f -dependent J-band bolometric corrections (BC ) J obtained as a fit to the T e f f -BC J scales of Pecaut & Mamajek (2013) and Bessell et al. (1998). A cluster distance value of 760 pc (Sung et al. 1997) has been adopted for the conversion to absolute magnitudes; this commonly adopted estimate of distance has been recently strengthened by the results of Gillen et al. (2014), who performed a detailed characterization of a newly identified, well sampled low-mass PMS eclipsing binary in NGC 2264, with strong evidence of membership and an inferred distance of 756 GLYPH<6> 96 pc. For a few tens of objects, for which J-band photometry from the 2MASS survey was not available, L bol has been derived using an empirical calibration relationship between the dereddened r -band photometry and L bol , which has been inferred from the distribution of dereddened r -band magnitudes vs. L bol values derived from the J-band photometry over the whole sample.
Stellar masses have been determined by placing each object on the Hertzsprung-Russell diagram and comparing their position with the mass tracks of the PMS model grid of Siess et al. (2000) (Fig. 12). A track-fitting tool provided by L. Siess on his webpage has been used to interpolate the mass value between two mass tracks. CFHT members span a wide range of masses, varying from 0.1 to 2 M GLYPH<12> . Stellar radii have been determined from the estimates of L bol and T e f f as
$$R _ { * } = \sqrt { \frac { L _ { b o l } } { 4 \pi \sigma T _ { e f f } ^ { 4 } } }$$
where GLYPH<27> is the Stefan-Boltzmann constant.
Photometric data and stellar parameters for the whole population of NGC 2264 members monitored at CFHT are reported in Table 2 and Table 3, respectively.
## 4. UV excess and accretion in NGC 2264
The investigation of YSOs at short wavelengths o GLYPH<11> ers a unique window on the accretion mechanisms: it provides one of the most direct probes to the hot emission from the impact layer
Fig. 12. HR diagram for NGC 2264 members. Mass tracks and isochrones from Siess et al. (2000)'s models are plotted over the point distribution.
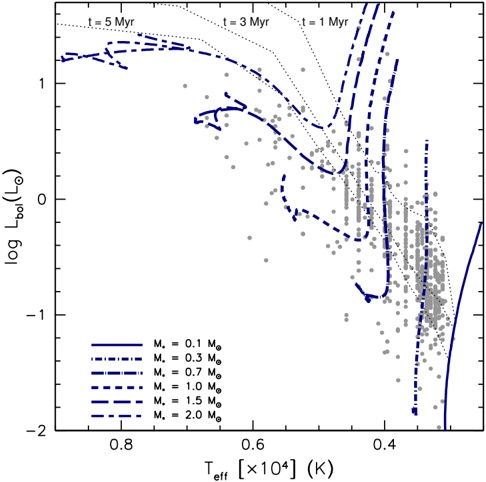
where the accreting material hits the stellar surface at near freefall velocities, producing a shocked area up to several GLYPH<2> 10 3 K hotter than the stellar photosphere. This enhanced luminosity at UV wavelengths is reflected in the characteristic color properties of accretion-dominated objects compared to non-accreting young stars (cf. Figs. 5 and 6) and hence provides a direct proxy to the accretion luminosity, which in turn enables the investigation of the rates of mass accretion in individual systems.
The u -band flux excess is trivially given by
$$\underset { \text{and} \, \text{mag} } { \text{mag} } \underset { \text{and} } { \text{mag} } \underset { \text{and} } { \text{mag} } F _ { u } ^ { e x c } = F _ { u } ^ { o b s } - F _ { u } ^ { p h o t },$$
where F obs u is the measured flux in the u -band and F phot u is the amount of flux that would be expected from a purely photospheric emission. It is important to remark that, in order to isolate the component of additional flux produced in the accretion shock and thus probe accretion onto the star, the flux excess (compared to dwarfs) due to the enhanced chromospheric activity of T Tauri stars has to be included in the photospheric emission. This issue is addressed by taking the photometric properties observed for the WTTS population as the reference for the definition of the UV excess. The color excess will thus correspond to the di GLYPH<11> erence between the observed stellar colors and the expected photospheric colors based on the properties of the non-accreting counterparts of the objects of interest:
$$E ( u - m ) = ( u - m ) _ { o b s } - ( u - m ) _ { p h o t + c h r o m }$$
As discussed in Sect. 3, no significant impact of the accretion luminosity is observed on the stellar flux detected at filters redder than the u -band; hence, the color excess of Eq. 7 basically corresponds to the u -band excess revealing the presence of accretion, E u ( ) ' E u ( GLYPH<0> m ).
We measured the UV color excess of accreting stars in two di GLYPH<11> erent ways, from the properties displayed on the u GLYPH<0> g vs. g GLYPH<0> r and r vs. u GLYPH<0> r diagrams (Fig. 5 and Fig. 6, respectively), as detailed below.
Table 2. Photometry for NGC 2264 members monitored at CFHT.
| Mon-ID 1 | RA | Dec | u | g | r | i |
|------------|---------|----------|--------|--------|--------|--------|
| Mon-000007 | 100.471 | 9.96755 | 15.85 | 14.807 | 14.674 | 14.192 |
| Mon-000008 | 100.452 | 9.90322 | 19.656 | 17.083 | 15.839 | 19.887 |
| Mon-000009 | 100.538 | 9.80134 | 18.208 | 16.043 | 15.011 | 14.532 |
| Mon-000011 | 100.322 | 9.909 | 18.548 | 16.808 | 15.531 | 14.535 |
| Mon-000014 | 100.528 | 9.69214 | 18.895 | 15.879 | 14.28 | 13.445 |
| Mon-000015 | 100.538 | 9.9841 | 19.427 | 16.172 | 14.589 | 13.786 |
| Mon-000017 | 100.383 | 10.0068 | 18.402 | 15.972 | 14.93 | 14.496 |
| Mon-000018 | 100.305 | 9.91909 | 19.311 | 16.526 | 15.366 | 14.613 |
| Mon-000020 | 100.538 | 9.73427 | 19.964 | 17.213 | 15.891 | 15.267 |
| Mon-000021 | 100.248 | 9.99594 | 18.174 | 15.835 | 14.81 | 14.452 |
Notes. A full version of the Table is available in electronic form at the CDS. A portion is shown here for guidance regarding its form and content. Uncertainties on the photometric measurements are estimated to range from GLYPH<24> 0.15 to GLYPH<24> 0.004 from the faintest to the brightest objects in u and g , from GLYPH<24> 0.015 to GLYPH<24> 0.0015 in r and 5-10 times smaller in i .
( 1 ) Object identifiers adopted within the CSI 2264 project (see Cody et al. 2014).
Table 3. Spectral type, extinction and stellar parameters for NGC 2264 members monitored at CFHT.
| Mon-ID | Status 1 | SpT | SpT_ref. 2 | A V | L bol (L GLYPH<12> ) | M GLYPH<3> (M GLYPH<12> ) | R GLYPH<3> (R GLYPH<12> ) | log t(yr) |
|------------|------------|---------|--------------|-------|------------------------|-----------------------------|-----------------------------|-------------|
| Mon-000007 | c | K7 | s | | 1.28 | 0.69 | 2.36 | 6.09 |
| Mon-000008 | w | K5 | s | 0.3 | 0.241 | 0.8 | 0.85 | |
| Mon-000009 | w | F5 | p | 2.3 | 2.31 | 1.3 | 1.24 | |
| Mon-000011 | c | K7 | s | 0.3 | 0.79 | 0.7 | 1.86 | 6.34 |
| Mon-000014 | w | K7:M0 | p | 1.2 | 3.9 | 0.66 | 4.22 | 5.68 |
| Mon-000015 | w | K7:M0 | p | 1.0 | 2.7 | 0.65 | 3.5 | |
| Mon-000017 | c | K5 | s | 0.2 | 0.71 | 1.13 | 1.45 | |
| Mon-000018 | w | K3:K4.5 | p | 0.6 | 1.7 | 1.47 | 2.03 | 6.60 |
| Mon-000020 | w | K7 | s | 0.4 | 0.44 | 0.71 | 1.39 | 6.70 |
| Mon-000021 | c | K5 | s | 0.4 | 0.96 | 1.2 | 1.69 | 6.69 |
A full version of the Table is available in electronic form at the CDS. A portion is shown here for guidance regarding its form and content.
Notes. ( 1 ) 'c' = CTTS; 'w' = WTTS; 'cc' = CTTS candidate.
( 2 ) 's' = spectroscopic SpT estimate (retrieved from literature); 'p' = photometric SpT estimate (from CFHT optical colors).
- -In the first case (Fig. 5), we referred the color excess measurement to a straight line nearly parallel to the reddening vector and following the upper part of the WTTS distribution, as shown in Fig. 9. E u ( ) is thus measured as
$$E ( u ) & = ( u - g ) _ { o b s } - ( u - g ) _ { r e f } \,, & ( 8 ) & \quad \text{the } \varsigma$$
where ( u GLYPH<0> g ) re f is the reference (i.e., expected) color at the observed g GLYPH<0> r level, ( u GLYPH<0> g ) re f = 1 312 ( : g GLYPH<0> r ) obs + 1 03. The : WTTS color sequence is in good agreement with the reference line until spectral type GLYPH<24> M0, and hence the adoption of this reference sequence allows us to derive a UV excess estimate essentially una GLYPH<11> ected by reddening. For later-type stars, however, the real WTTS color sequence turns down on the diagram; this implies that the extrapolation of the WTTS trend at spectral types earlier than M0 to the whole sample yields an excess overestimation (i.e., more negative values of E u ( )) for M-type stars. As the bulk of M-type WTTS lies about 0.2 mag below the reference line, we corrected for this bias by adding a constant o GLYPH<11> set of 0.2 mag to the E u ( ) estimates derived for this group of objects.
- -In the second case, as can be observed on Fig. 6, WTTS nicely trace the cluster sequence over the whole range of magnitude. We thus dereddened the u r ; photometry and defined the sequence of reference colors as the least-squares fit polynomial to the resulting WTTS distribution. The UV
excess is thus provided by
$$\underset { \text{ibu-} } { \text{mag} } \quad E ( u ) = ( u - r ) _ { o b s } - ( u - r ) _ { r e f } \,,$$
where ( u GLYPH<0> r ) re f is the reference color at brightness robs . Due to the small number of point and the large scatter a GLYPH<11> ecting the definition of the sequence at the brighter end, we decided to restrict our UV excess analysis to objects fainter than 14.5 in r .
This second method, compared to the first, has the disadvantage of being intrinsically more uncertain, as it is subject to errors in A V determination (while the first method is essentially A V -independent); on the other hand, the application of this method to u - and r -band observations taken during the monitoring survey allows us to derive both a global picture of accretion in NGC 2264 from the average photometry, and a variability range for the UV excess on a timescale of a few weeks (cf. Sect. 4.2).
An average rms error of GLYPH<24> 0.16 mag has been associated to the UV excess determinations, in order to account for the scatter of the WTTS distribution around the reference sequence.
From Eq. 6 and
$$\underset { \text{range of} } { \text{$E(u)=u_{obs}-u_{phot}$} }$$
## we obtain
$$\tilde { \text{The UV} } \ \ F _ { u } ^ { e x c } = F _ { u } ^ { o b s } \left ( 1 - 1 0 ^ { + 0. 4 E ( u ) } \right ) = F _ { u } ^ { 0 } \, 1 0 ^ { - 0. 4 u } \left ( 1 - 1 0 ^ { + 0. 4 E ( u ) } \right ), \ \ ( 1 1 )$$
Article number, page 11 of 24
Fig. 13. UV excess luminosity measurements obtained in this study are compared to Rebull et al. (2002)'s for objects in common to both samples (L. Rebull, private communication). On the x-axis, dots correspond to the median L exc u detected during the 2 week-long CFHT monitoring, while variability bars depict the actual range in L exc u values measured at di GLYPH<11> erent observing epochs during the survey. The equality line is traced as a solid line to guide the eye.
where u is the (dereddened) apparent u -band magnitude of the object, E u ( ) is the UV excess computed as in Eqs. 8-9 and Fu 0 is the SDSS u -band zero-point flux ( Fu 0 = 3767.2 Jy).
We used Eq. 11 (cf. also Rigliaco et al. 2011) to measure the u -band flux excess over the whole sample and then converted F exc u to L exc u using a distance of 760 pc.
The results of a similar, single epoch photometric survey to detect and measure mass accretion in NGC 2264 from the UV excess diagnostics have been reported in Rebull et al. (2002). The authors measured the UV excess displayed by accreting stars from U-band and V-band photometry, by comparing the observed colors with colors expected based on the spectral type of individual objects. In Fig. 13, we compare their measured UVexcess luminosities (L. Rebull, private communication) with both the median L exc u values and the relevant variability ranges we detect here, on a timescale of a couple of weeks, for CTTS targeted in both surveys (about 100). As can be observed, data points result to be well distributed around the equality line; the rms scatter measured about the line, amounting to 0.5 dex, is quite consistent with the average amount of variability on L exc u (about 0.6 dex) detected across the sample from CFHT monitoring.
## 4.1. Accretion luminosity and mass accretion rates
The u -band excess luminosity represents a single component of the total excess emission over the whole spectral range. In order to characterize the properties of the accretion process, it is therefore necessary to also take into account the flux excess at unobserved wavelengths, i.e., to apply a bolometric correction.
Gullbring et al. (1998) showed that a direct correlation exists between the total accretion luminosity L acc and the excess luminosity observed in the U-band. This is indeed expected, since the excess emission likely dominates the observed flux at wavelengths < 4500 Å (i.e., below the g -band filter). In order to achieve this result, they measured the excess emission from spectra covering the range 3200-5400 Å, for a sample of 26 CTTS. They modeled the excess spectrum from the accretion spot assuming a region of constant temperature and density (slab model) and used this model fit to estimate the amount of excess emission at unobserved wavelengths. The authors eventually resolved to adopt a uniform correction factor, across the whole sample, for the ratio of total-to-observed excess flux, corresponding to a T GLYPH<24> 10 000 K. For each object, they subsequently synthetized a U-band magnitude from the observed spectrum and computed the corresponding flux excess. The comparison of the two quantities (L acc and L exc U ) enabled the authors to yield a well-determined calibration equation, log( Lacc = L GLYPH<12> ) = 1 09 : + 0 04 : GLYPH<0> 0 18 : log( L exc U = L GLYPH<12> ) + 0 98 : + 0 02 : GLYPH<0> 0 07 : , that was ultimately consistent with the model predictions of Calvet & Gullbring (1998), who introduced a detailed description of the accretion shock region.
Here we adopt a simple phenomenological approach to derive a direct relationship between the u -band excess luminosity and the total accretion luminosity L acc . In a first approximation, we describe the stellar emission as a blackbody emission at the photospheric temperature T phot . Similarly, the emission from the accretion spot is approximated by a blackbody at T = T spot . The excess emission linked with accretion is thus given by the difference between the flux emitted by the distribution of accretion spots and the flux emitted by a corresponding area, of the same extension, on the stellar photosphere. In terms of blackbodies, this becomes the di GLYPH<11> erence between a blackbody flux density at T = T spot and a blackbody flux density at T = T phot , both integrated over the same area. In this picture, the ratio r of total-to-observed flux excess in the u -band, i.e. the corrective factor to be introduced to derive the total L acc from L exc u , can be estimated as
$$& \text{sure the} \\ & \text{onverted} \quad r = \frac { \sigma T _ { s p o t } ^ { 4 } - \sigma T _ { p h o t } ^ { 4 } } { \pi \int _ { u } ( B _ { T _ { s p o t } } ( \lambda ) - B _ { T _ { p h o t } } ( \lambda ) ) \, d \lambda } \,, & ( 1 2 ) \\ & \text{urvey to} \quad \int _ { u } ( B _ { T _ { s p o t } } ( \lambda ) - B _ { T _ { p h o t } } ( \lambda ) ) \, d \lambda \\ & \text{under the UV}$$
where the integration is performed over the u -band window. No assumptions on the filling factor are needed in this description.
In order to investigate the relationship between L exc u and L acc , we selected a subsample of 44 CTTS, covering the spectral type range M3.5:K2 (or equivalently the mass range GLYPH<24> 0.2-1.8 M GLYPH<12> ) and whose variability, monitored in the u -band ( GLYPH<21> e f f = 3557 Å) and r -band ( GLYPH<21> e f f = 6261 Å) at CFHT, is likely accretion-dominated. An extensive spot modeling (cf. Bouvier et al. 1993) of the simultaneous u + r variability amplitudes has been performed in order to assess the dominating features of the variability displayed by individual objects; accretion-dominated sources have been identified as well-represented variables in terms of a surface spot distribution GLYPH<24> 10 3 to several GLYPH<2> 10 3 Khotter than the stellar photosphere. A full description of the variability analysis for the CFHT NGC 2264 members will be provided in a forthcoming paper (Venuti et al., in prep.).
For each of the selected objects, we adopted the individual T spot estimate inferred from spot models, that corresponds, for a given object, to the color temperature of the spot distribution that best reproduces the simultaneous flux variations observed at di GLYPH<11> erent wavelengths; T phot is derived from the spectral type as described in Sect. 3.3. We then derived, for each object, the ratio r of Eq. 12, through a numerical integration of B( GLYPH<21> ) in the spectral range 3257-3857 Å (cf. Fukugita et al. 1996); an uncertainty
on the value of r has been inferred correspondingly to the uncertainty on the spot temperature T spot . Based on these estimates, the percentage of the total excess flux detectable in the u -band is on average GLYPH<24> 10%. The accretion luminosity L acc is then computed as Lacc = r L exc u .
A least-squares fit to the log GLYPH<0> L exc u = L GLYPH<12> GLYPH<1> vs. log ( Lacc = L GLYPH<12> ) distribution inferred as previously described provided us with the following calibration relationship:
$$\log \left ( \frac { L _ { a c c } } { L _ { \odot } } \right ) = ( 0. 9 7 \pm 0. 0 3 ) \, \log \left ( \frac { L _ { u } ^ { e x c } } { L _ { \odot } } \right ) + ( 1. 0 9 \pm 0. 0 7 ) \quad \ ( 1 3 ) \, \begin{array} { c } \text{ } \text{ } \text{ } \text{ } \text{ } \text{ } \text{ } \text{ } \text{ } \text{ } \text{ } \text{ } \text{ } \text{ } \text{ } \text{ } \text{ } \text{ } \text{ } \text{ } \text{ } \text{ } \text{ } \text{ } \text{ } \text{ } \text{ } \text{ } \text{ } \text{ } \text{ } \text{ } \text{ } \text{ } \text{ } \text{ } \text{ } \text{ } \text{ } \text{ } \text{ } \text{ } \text{ } \text{ } \text{ } \text{ } \text{ } \text{ } \text{ } \text{ } \text{\quad \text{ } \text{ } \text{ } \text{ } \text{ } \text{ } \text{ } \text{ } \text{ } \text{ } \text{ } \text{ } \text{ } \text{ } \text{ } \text{ } \text{ } \text{ } \text{ } \text{ } \text{ } \text{ } \text{ } \text{ } \text{ } \text{ } \text{ } \text{ } \text{ } \text{ } \text{ } \text{ } \text{ } \text{ } \text{ } \text{ } \text{ } \text{ } \text{ } \text{ } \text{ } \text{ } \text{ } \text{ } \text{ } \text{ } \text{ } \text{ } \text{ } \text{ \text{ } \text{ } \text{ } \text{ } \text{ } \text{ } \text{ } \text{ } \text{ } \text{ } \text{ } \text{ } \text{ } \text{ } \text{ } \text{ } \text{ } \text{ } \text{ } \text{ } \text{ } \text{ } \text{ } \text{ } \text{ } \text{ } \text{ } \text{ } \text{ } \text{ } \text{ } \text{ } \text{ } \text{ } \text{ } \text{ } \text{ } \text{ } \text{ } \text{ } \text{ } \text{ } \text{ } \text{ } \text{ } \text{ } \text{ } \text{ } \text{ } \text{$$
Fig. 14 compares our result with the calibration inferred from the study of Gullbring et al. (1998); the parameters of the two calibrations are fairly consistent within the error bars. The locus traced by our point distribution is globally consistent with the prediction of Gullbring et al.'s study, albeit showing a systematic shift above their calibration line. Our estimates result to be larger by a factor of . 2 to 4, corresponding to a di GLYPH<11> erence from GLYPH<24> 0.2 dex at the highest ˙ Macc regimes ( GLYPH<24> 10 GLYPH<0> 7 M yr) to GLYPH<12> / GLYPH<24> 0.6 dex at the lowest ˙ Macc regimes ( GLYPH<24> 10 GLYPH<0> 10 M yr). GLYPH<12> /
This di GLYPH<11> erence between the two conversions is significantly reduced if we adopt, in our approach, a constant spot temperature of 10 000 K, an assumption closer to the uniform correction, at T GLYPH<24> 10 000 K, that was introduced in Gullbring et al.'s method. Indeed, individual T spot estimates adopted in our study cover a wide range of values, with a mean around GLYPH<24> 6500 K, a spread of GLYPH<24> 2000-3000 K at a given stellar temperature and nominal T spot that can reach up to GLYPH<24> 9000-11 000 K and down to GLYPH<24> 5000 K. As described earlier, spot temperatures, in our approach, are inferred case by case by fitting simultaneous optical ( r -band) and UV ( -band) variability amplitudes with spot models. Hence, u these correspond to the color temperatures that best reproduce
Fig. 14. L acc -L exc u calibration relationship. The black solid line traces the relationship derived in this study, while the orange dashed line represents the relationship by Gullbring et al. (1998). The data points represent the u -band excess luminosity and the accretion luminosity estimates inferred on an individual basis for a sample of 44 CTTS in our survey (see text). The error bars reflect the uncertainty on the individual T spot estimates. The black dashed-dotted line shows the calibration line that would be inferred, with the procedure followed in this study, in the assumption T spot = 10 000 K.
the observed, GLYPH<21> -dependent contrast of the spot distribution with the stellar reference emission level (which is the e GLYPH<11> ect we aim at accounting for when introducing a bolometric correction). As the peak of the emission of a blackbody in the u -band occurs around 10 000 K, lower T spot estimates naturally imply that a larger correction factor is needed in order to recover the total flux emitted by the spot. While, for a typical photosphere (T GLYPH<24> 4000 K), 12% of the excess emission of a 10 000 K spot is observed in the u -band, this percentage reduces to GLYPH<24> 10% for a 7000 K spot and to less than 8% for a 6000 K spot. In order to evaluate how much of the discrepancy could actually be due to this e GLYPH<11> ect, we repeated our procedure assuming a constant T spot = 10 000 K over the whole subsample of objects; as shown in Fig. 14, this indeed would allow us to mostly cancel the o GLYPH<11> set between the two calibrations.
We are aware of the simplified nature of the blackbody approximation for stellar and spot fluxes; at the same time, we stress that the results inferred from this description are not inconsistent with those obtained from more sophisticated pictures. The discrepancy, albeit systematic, between L acc estimates from Eq. 13 and those from Gullbring et al. (1998)'s calibration is smaller than, or comparable to, the usual estimates of the uncertainty a GLYPH<11> ecting the accretion rate measurements ( GLYPH<24> 0.5 dex), and a non-negligible contribution to this o GLYPH<11> set may actually derive from the di GLYPH<11> erent assumption on the correction factors adopted across the sample of objects considered in each study. Fig. 10 of the theoretical study performed by Calvet & Gullbring (1998), though it provides full endorsement of Gullbring et al.'s relationship, yet depicts the complexity of achieving a detailed physical representation of the accretion shock. The range of predictions from model configurations they explored would lie, on Fig. 14 of our work, across the region delimited by our (Eq. 13) and Gullbring et al. (1998)'s relationship.
Considering this, and the fact that each model has its own limitations, we believe it beneficial to explore whether, and to which extent, information deduced from data might actually be sensitive to di GLYPH<11> erent model assumptions. We therefore adopt the calibration in Eq. 13 to estimate the total L acc from the measured u -band luminosity excess, and will refer at the same time to Gullbring et al.'s, where relevant, for comparison purposes.
If we assume that the accretion energy is reprocessed entirely into the accretion continuum (cf. Herczeg & Hillenbrand 2008), the mass accretion rate ˙ Macc can be derived from L acc as
$$\begin{array} { c } \Big | & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & \\ & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & && & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & &
& & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & - & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & ; & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & } & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & &. & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & _ & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & \ & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & + & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & = & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & &, & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & ^ & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & b & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & | & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & &.. & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & &$$
where M GLYPH<3> and R GLYPH<3> are the parameters of the central star, R in is the inner disk radius and we are assuming that the accretion funnel originates at the truncation radius of the disk, at R in GLYPH<24> 5 R GLYPH<3> (Gullbring et al. 1998).
Fig. 15 compares the ˙ Macc distributions inferred from each of the two UV derivations described at the beginning of Sect. 4. The diagram reports the ˙ Macc determinations for every accreting object, in the sample, that displays a UV excess according to the identification procedure previously described. The two distributions are on average consistent, within a small mass-dependent o GLYPH<11> set likely reflecting a residual overestimation of the ( u GLYPH<0> g ) color excess from Fig. 9 (see discussion around Eq. 8). Variability is likely to a GLYPH<11> ect, at least partly, the scatter observed within GLYPH<6> 0.25 dex around the fitting line (see Sect. 4.2).
Fig. 16 shows the mass accretion rate distribution inferred for a population of 236 high-confidence NGC 2264 members, as a function of stellar mass, whose range extends down to GLYPH<24> 0.1 M GLYPH<12>
Fig. 15. ˙ Macc values obtained with the two methods described in the text. ˙ Macc values on the y-axis are inferred from u g r snapshot photometry, while ˙ Macc values on the x-axis correspond to the median UV excess detected during the ur monitoring. Colors and sizes of symbols are scaled according to stellar mass M . The solid line marks the equality GLYPH<3> line; the linear regression to the point distribution is traced as a dashed line.
and up to GLYPH<24> 1.5 M GLYPH<12> . These objects have been classified as CTTS, i.e., accreting objects, as opposed to WTTS among the PMS population analyzed so far, based on spectroscopic criteria (H GLYPH<11> EW, H GLYPH<11> width at 10% intensity) and or photometric criteria (signifi-/ cant UV excess from the CFHT sample, GLYPH<11> IRAC value consistent with Class II sources from the data of Teixeira et al. 2012, large variability from the CFHT photometry; see Venuti et al., in prep., for this last point). The accretion parameters for these objects are reported in Table 4. The nominal values of the accretion rates are computed from the photometry corresponding to the median UV excess detected during the CFHT MegaCam 2-week long mon-/ itoring and are estimated to be accurate within a factor of GLYPH<24> 3 typically.
A confidence detection threshold for ˙ Macc has been computed by evaluating the average scatter of the WTTS around the reference color sequence and testing the corresponding level of 'noise' on the UV excess - and consequently accretion rate - determination. Namely, the magnitude-dependent rms scatter of WTTS around the reference sequence has been measured to compute a (magnitude-dependent) minimum UV excess level to be detected in order to be confident that accretion is indeed the dominant source of excess. This allowed us to trace a conservative boundary separating the objects with an unambiguous ˙ Macc detection from the objects for which it is not possible, a priori, to evaluate the relevance of spurious contributions (i.e., chromospheric activity) to the apparent UV excess. For the accreting objects for which the actually measured UV excess is less than the corresponding boundary value, only an upper limit at the detection threshold has been reported for ˙ Macc .
Little extensive investigation of mass accretion rates in NGC 2264 has been reported in the literature prior to the survey we are currently performing. Here we refer again to the study of Rebull et al. (2002). Those authors reported ˙ Macc estimates for about 75 CTTS in the region; their accretion rates are derived from the measured UV excess luminosities by adopting Gullbring et al. (1998)'s relationship to obtain the total L acc values. Results of the comparison of our ˙ Macc estimates with theirs, for the few tens of sources in common (that cover nonetheless about 2 orders of magnitude in ˙ Macc ), are quite consistent with what deduced from the comparison of the measured L exc UV (Fig. 13). When using the same L exc u -L acc calibration, ˙ Macc estimates from the two studies distribute around the equality line, with an rms scatter of about 0.5 dex, pretty consistent with the average amount of ˙ Macc variability we detect on week timescales during our monitoring (see Sect. 4.2).
Some important features can be observed on Fig. 16. The ˙ Macc distribution globally traces a mass-dependent trend, showing an average increase of the mass accretion rates with stellar mass. The existence of such a trend has been investigated from observations over the last decade, albeit with a large uncertainty on the quantitative estimate of the actual relationship, which is likely to be dependent, among other factors, upon the probed stellar mass range and the mean age and age spread across the cluster (cf., e.g., Hartmann et al. 2006 and references therein, Rigliaco et al. 2011, Manara et al. 2012). Scattering of objects at a given stellar mass (see discussion later in the Section) also contributes to increasing the uncertainty on the actual relationship. Another important point to this respect is to understand the actual role played by detection biases in the observed mass-˙ Macc trend. As previously discussed, the statistical sample of accretion rates is limited at the lower ˙ Macc end (Fig. 16), due to the impossibility of an accurate detection below a certain threshold; for this group of objects, only an upper limit to the actual ˙ Macc value can be inferred. Contrast e GLYPH<11> ects favor the detection of smaller accretion rates on cooler, i.e. lower-mass stars over higher-mass stars (as can be see in Fig. 16), thus unavoidably introducing a mass dependence. It is thus of interest to assess the degree of disentanglement between the observed mass-˙ Macc dependence and the e GLYPH<11> ects of censoring in the data.
Astatistical approach that allows us to infer a robust measure of correlation in a given sample, in presence of multiple censoring (both ties, here points at the same x-value but with di GLYPH<11> erent y-values, and non-detections, i.e. upper limits), is a generalization of Kendall's GLYPH<28> test for correlation (see Feigelson & Babu 2012; Helsel 2012). The test consists in pairing the data points (measurements and upper limits) in all possible configurations and, for each pair, measuring the slope (positive or negative) of the line connecting the two points. A pair of data points having the same x-value will be counted as an indeterminate relationship, likewise a pair of upper limits; upper limits will uniquely contribute a definite relationship when paired with actual detections at higher y-value. The number of times positive slopes occur is then compared to the number of negative slopes, and their di GLYPH<11> erence weighted against the total number of available pairs. This defines the statistical correlation coe GLYPH<14> cient, GLYPH<28> . ln this picture, upper limits have the e GLYPH<11> ect of lowering the likelihood of a correlation, if this is present in the data, as they introduce a number of indeterminate relationships among the tested pairs. Conversely, no correlation will be found in a pure sample of upper limits, even though these trace a well-defined trend, since the number of pairs with definite relationship will be zero. In the null hypothesis of no correlation, GLYPH<28> is expected to follow a normal distribution centered around zero; by measuring the deviation from zero of the actually found value, in terms of GLYPH<27> , it is thus possible to assess a confidence level for the presence of correlation in a given sample.
Fig. 16. ˙ Macc distribution as a function of stellar mass for the population of NGC 2264 accreting members observed at CFHT. Upper limits are shown for those objects that fall below the estimated confidence threshold for accretion detection (see text). For some objects, no significant ˙ Macc has been detected at the median state of the system, but they do show a significant accretion activity (i.e., above the detection level) at the brightest state; in these cases, an upper limit is placed at the detection threshold, while a cross marks the maximum ˙ Macc actually detected. Orange dots and green triangles mark two subgroups of objects dominated respectively by stochastic accretion bursts and variable extinction from a rotating inner disk warp (Stau GLYPH<11> er et al. 2014).
Table 4. UV excess, u -band excess luminosity, ˙ Macc and ˙ Macc variability estimates for NGC 2264 accreting members.
| Mon-ID | ( u GLYPH<0> g ) exc. | ( u GLYPH<0> r ) exc. 1 | log L exc u / L GLYPH<12> 1 | log ˙ M ( u GLYPH<0> g ) acc | log ˙ M ( u GLYPH<0> r ) acc 1 | log ˙ M max = ˙ M med 2 | log ˙ M med = ˙ M min 3 |
|------------|-------------------------|---------------------------|-------------------------------|--------------------------------|----------------------------------|---------------------------|---------------------------|
| Mon-000007 | -0.16 | -0.65 | -1.50 | -7.17 | -7.22 | 0.32 | |
| Mon-000011 | -0.97 | -1.95 | -0.88 | -7.53 | -6.73 | 0.24 | 0.19 |
| Mon-000017 | 0.03 | -0.27 | -2.14 | | -8.24 * | 0.02 | |
| Mon-000028 | -1.79 | -1.4 | -3.38 | -8.90 | -9.13 | 0.40 | 0.59 |
| Mon-000040 | -0.46 | -0.34 | -3.89 | -9.24 | -9.37 | 0.20 | 0.55 |
| Mon-000042 | -0.17 | -0.01 | -5.08 | -9.34 | -9.48 * | | |
| Mon-000053 | -0.35 | -0.11 | -4.31 | -9.06 | -9.46 | 0.33 | |
| Mon-000056 | 0.04 | 0.01 | | | -8.24 * | | |
| Mon-000059 | -1.91 | -1.11 | -3.32 | -8.36 | -8.91 | 0.26 | 0.57 |
| Mon-000063 | -0.53 | -1.03 | -2.56 | -8.62 | -8.21 | 0.15 | |
Notes. A full version of the Table is available in electronic form at the CDS. A portion is shown here for guidance regarding its form and content. ( 1 ) Value measured at the median luminosity state of the system.
( 2,3 ) Variability range detected around the median ˙ Macc level during the 2 week-long ur monitoring. If no accretion activity is detected above the detection limit for the object at the minimum median luminosity level, but some significant accretion is detected at the brightest state, only the / upper variability bar is reported (i.e., log ˙ Mmax = ˙ Mmed upper ( ) ); if the object is a non-detection in accretion, no variability measurement is reported. ( * ) Upper limit.
The application of this statistical tool to our data allowed us to establish the presence of a correlation ( GLYPH<28> GLYPH<24> 0 28) that appears : to hold across the whole mass range studied here with a confidence of more than 6 GLYPH<27> . The robustness of this result was tested against a similar search for correlation in randomly generated distributions of ˙ Macc in the log range [-10.5 , -6.5] for the same stellar population with the same individual detection thresholds. The GLYPH<28> distribution inferred from 100 iterations is peaked around GLYPH<28> = 0.00 (no correlation) with a GLYPH<27> of 0.04; this suggests that indeed an intrinsic correlation is observed in our data to a significance of > 6 GLYPH<27> . We then inferred a statistical estimate for the slope following the approach of Akritas-Theil-Sen nonparametric regression (see Feigelson & Babu 2012):
- 1. we derived a first guess for the slope from a least-squares fit to the data distribution and explored a range of GLYPH<6> 0.5 around this first estimate with a step of 0.005;
- 2. for each value x , we subtracted the x M trend from the initial GLYPH<3> ˙ Macc distribution and repeated the Kendall's GLYPH<28> computation procedure on the distribution of residues thus inferred.
The best fitting trend is the one that, subtracted to the point distribution, produces GLYPH<28> = 0, while an error bar can be inferred corresponding to the interval of values that produce GLYPH<28> < j GLYPH<27> j . We applied this procedure to both the mass-˙ Macc distribution inferred from the u GLYPH<0> r excess distribution (see discussion around Eq. 9) and the one inferred from the u GLYPH<0> g excess distribution (see discussion around Eq. 8), obtaining respectively:
$$\dot { M } _ { a c c } & \in M _ { * } ^ { 1. 5 \pm 0. 2 } & ( 1 5 ) & \text{negligibl} \\ & \text{cretion } t$$
$$\dot { M } _ { a c c } \in M _ { * } ^ { 1. 3 \pm 0. 2 } & & ( 1 6 ) \quad \text{hand, } m _ { \substack { m } { \shortmid } \in \lambda \end{m}$$
The two trends are consistent within 1 GLYPH<27> ; the smaller exponent in Eq. 16 compared to Eq. 15 may reflect the small, mass-dependent o GLYPH<11> set between the ˙ Macc distributions inferred from the two methods (cf. Fig. 15). A slope of 1.7 GLYPH<6> 0.2, instead of the estimate in Eq. 15, would be inferred if we converted u GLYPH<0> r excesses to L acc values following Gullbring et al. (1998). The two estimates are still consistent within 1 GLYPH<27> ; this comparison illustrates that a (small) range in values around the true slope may be induced by external factors such as the L exc u -L acc conversion.
The analysis of correlation described above refers to the homogeneous sample of Fig. 16 as a whole. While the relationship we infer seems to be robust across the whole sample, this likely provides a general, average information on the global trend of ˙ Macc with mass, not a punctual description of the trend. We notice, for instance, that little mass dependence is observed in the upper envelope of the ˙ Macc distribution above M GLYPH<3> GLYPH<24> 0.25 M GLYPH<12> . We attempted a more detailed investigation of the observed ˙ Macc vs. M relationship by probing separately two di GLYPH<3> GLYPH<11> erent, similarly populated mass bins, M GLYPH<3> GLYPH<20> 0.3 M GLYPH<12> and M GLYPH<3> > 0.3 M GLYPH<12> . In both subgroups, we found some evidence of correlation, albeit with different values and significance levels: a correlation with a slope of 3.3 GLYPH<6> 0.7 was inferred, to the 4 GLYPH<27> level, in the lower-mass group, while a correlation with a slope of 0.9 GLYPH<6> 0.4 was obtained for the higher-mass group with a significance of 2.4 GLYPH<27> . These results might suggest that the dependence of ˙ Macc on M GLYPH<3> is not uniform across the whole M - ˙ GLYPH<3> Macc range, but shallower at higher masses and higher accretion rates; on the other hand, a closer investigation of the M GLYPH<3> ˙ Macc relationship from separate, small subsamples is necessarily more uncertain than the assessment of a general correlation trend observed across the whole sample.
Another remarkable feature on Fig. 16 is the large dispersion in the ˙ Macc values observed at each stellar mass, covering a range of GLYPH<24> 2 to 3 dex. Similar results have been inferred from previous statistical surveys of accretion in a given cluster (see, e.g., the recent studies of Rigliaco et al. 2011 on GLYPH<27> Ori and of Manara et al. 2012 on the ONC). This implies that only the average behavior of the actual trend of ˙ Macc with M GLYPH<3> can be deduced, and suggests that di GLYPH<11> erent accretion regimes may co-exist within the same young stellar population. To this respect, we highlight in Fig. 16 the accretion properties of two, morphologically well-distinct, classes of YSOs in NGC 2264, both actively accreting. The first corresponds to the newly identified (Stau GLYPH<11> er et al. 2014) class of objects whose light curves are dominated by accretion bursts. The second class includes objects whose light curves show periodic or quasi-periodic flux dips likely resulting from a rotating inner disk warp partly occulting the stellar emission (Bouvier et al. 2007a; Alencar et al. 2010). As can be seen in Fig. 16, both classes of objects show a level of accretion on average larger than the mean level of accretion activity detected across the population of NGC 2264; however, the two classes are well distinguished, with the first showing a mean accretion rate about three times larger than the second.
## 4.2. Mid-term ˙ Macc variability
The scatter in Fig. 16 could in principle partly arise from the huge photometric variability exhibited by T Tauri stars, both on short-term (hours) and mid-term (days) timescales (e.g., Ménard & Bertout 1999). Short-term variability can a GLYPH<11> ect the ˙ Macc estimates inferred for single objects, but its contribution is likely negligible for our purposes (i.e., for a statistical mapping of accretion throughout the population of the cluster). On the other hand, mid-term variability, comprising the geometric e GLYPH<11> ects linked with stellar rotation and the intrinsic accretion variability (timescales relevant for hot spots), might e GLYPH<11> ectively blur the ˙ Macc distribution inferred from the mapping of the region, since each object is observed at an arbitrary phase.
In order to assess the contribution of mid-term variability to the ˙ Macc spread, we probed the variability of the detected ˙ Macc , over timescales relevant to stellar rotation, by measuring the UV excess and correspondingly computing the mass accretion rate from each observing epoch during the CFHT u -band and r -band monitoring. On average, 16-17 points distributed over the 2-week long survey have been considered to probe variability. This procedure allowed us to robustly associate a range of variability to the individual average ˙ Macc , inferred for each object as described in Sect. 4.1.
Fig. 17 shows the results inferred from this analysis; each variability bar encompasses all values of ˙ Macc detected for the corresponding object during the monitoring (i.e., it traces the di GLYPH<11> erence between the highest and the lowest detected ˙ Macc ). Objects for which only an upper limit to the average ˙ Macc had been derived have not been considered for this step of the analysis; for objects whose nominal ˙ Macc value would fall below the detection threshold (Sect. 4.1) at certain epochs, an upper limit to the lowest apparent ˙ Macc has been drawn.
As can be observed on Fig. 17, variability properties are not uniform across the sample. No clear trends emerge with stellar mass or mass accretion rates; the geometry of individual systems might have a more important contribution in determining the apparent ˙ Macc variability on week timescales, as suggested by the very few points on the diagram, maybe observed in a pole-on configuration, that show a negligible variation in the measured mass accretion rate. The (a)symmetry of individual bars, albeit potentially a GLYPH<11> ected by the specific temporal sampling, may reflect the way accretion proceeds onto the central object, as well
Fig. 17. Variability of the mass accretion rates observed for NGC 2264 members over the 2-week long CFHT monitoring. Black dots correspond to the median ˙ Macc measured for each object (see Fig. 16). For each object, the relevant variability bar is displayed, corresponding to the di GLYPH<11> erence between the maximum and the minimum ˙ Macc detected during the monitoring. A typical variability bar is shown in red.
as the dominant features of the system: a strongly asymmetric bar with the median ˙ Macc point close to the lower end can identify an object showing sudden, short-lived accretion bursts, while the opposite case well describes a system whose typical luminosity state is interspersed by short duration flux dips. These properties are indeed observed for some of the objects marked in Fig. 16.
The detected amplitudes of variability in ˙ Macc range from small fractions to GLYPH<24> 1 order of magnitude. In order to better visualize the average e GLYPH<11> ects, we subdivided the sample of objects in Fig. 17 in three broad mass intervals (M GLYPH<3> < 0 4 M : GLYPH<12> ; 0 4 M : GLYPH<12> GLYPH<20> M GLYPH<3> GLYPH<20> 1 M ; M GLYPH<12> GLYPH<3> > 1 M ) and for each of them comGLYPH<12> puted the mean ˙ Macc and amplitude of variability. These results are reported in Table 5, while a typical variability bar is represented in red in the lower right part of Fig. 17. On average, a variability of GLYPH<24> 0.5 dex in ˙ Macc is observed over a couple of weeks (which correspond to GLYPH<24> 2-3 rotational cycles for most of the objects; see A GLYPH<11> er et al. 2013), against a typical ˙ Macc spread of GLYPH<24> 2 dex. This comparison clearly shows that the observed ˙ Macc spread at each mass is significantly larger than what can be accounted for by variability on week timescales, be it intrinsic (non-steady accretion) or geometric (rotational modulation).
## 4.3. Accretion variability: intrinsic vs. modulated
As discussed in Sect. 4.2 (see also Sect. 5.2), an average variability of GLYPH<24> 0.5 dex is derived when monitoring the observed ˙ Macc for individual objects over days-to-weeks timescales. This amount of variability is expected to incorporate both the intrinsic variability associated with the accretion process and the geometric e GLYPH<11> ect of varying accretion shock projection along the line of sight as the star rotates.
An illustration of this is shown in Fig. 18. The underlying
Fig. 18. Phased diagram of the variability of the UV excess monitored over a baseline varying from a few hours to a few rotational cycles for an NGC 2264 accreting member (M GLYPH<3> = 1.13 M ; GLYPH<12> ˙ Macc = 5.98 GLYPH<2> 10 GLYPH<0> 9 M yr; GLYPH<12> / P rot = 4.767 days, from A GLYPH<11> er et al. 2013). The phase is computed starting from the epoch of the first measurement; the UV excess at each epoch is computed as described in Eq. 9. Di GLYPH<11> erent symbols correspond to di GLYPH<11> erent rotational cycles.
sinusoidal profile describes the geometric modulation of the accretion spot linked with stellar rotation, which is reflected in the measured UV excess and, consequently, in the value of ˙ Macc inferred at a given phase. Two additional e GLYPH<11> ects contribute to the variability picture: the intrinsic variability of accretion on days timescales, reflected in the variation of the UV excess measured at the same phase in two di GLYPH<11> erent cycles, and the intrinsic variability of accretion on hours timescales, reflected in the rms variation of the UV excess measured within the same rotational cycle around a given phase (i.e., measurements obtained a few hours apart during the same night).
In order to probe the relative significance of these di GLYPH<11> erent contributions to the monitored ˙ Macc variability and characterize the intrinsic accretion variability over hours-to-days timescales, we selected a subsample of 35 accreting members of NGC 2264, subject to the following conditions:
- 1. being an actual detection in ˙ Macc (i.e., not an upper limit);
- 2. displaying a detectable periodicity, known from the study of A er et al. (2013); GLYPH<11>
- 3. having rotational period small enough to be able to detect at least a partial superposition of di GLYPH<11> erent cycles in the phased diagram.
A er et al. (2013)'s study of rotation in NGC 2264 is based on GLYPH<11> a 23 day-long optical monitoring of the star-forming region per-
Table 5. Average variability in ˙ Macc displayed, on week timescales, by di GLYPH<11> erent, mass-sorted, groups of accreting members of NGC 2264.
| M GLYPH<3> group (M GLYPH<12> ) : | < 0.4 | 0.4-1 | > 1 |
|-------------------------------------------|-------------------|------------------|------------------|
| < M GLYPH<3> > (M GLYPH<12> ) | 0.26 | 0.60 | 1.20 |
| < log( ˙ M med acc ) > (M GLYPH<12> / yr) | -8.36 | -7.92 | -7.58 |
| < GLYPH<1> log ˙ M acc 1 > (dex) | 0.50 | 0.46 | 0.52 |
| < log bar + bar GLYPH<0> 2 > | -0.1 GLYPH<6> 0.3 | 0.0 GLYPH<6> 0.3 | 0.1 GLYPH<6> 0.2 |
Notes. Estimates only take into account objects for which a detection, and not an upper limit, is available for the lowest ˙ Macc phase. ( 1 ) log ˙ M max GLYPH<0> log ˙ M min acc acc ( 2 ) Index probing the symmetry of the variability bars around ˙ M med acc : bar + = log ˙ M max acc GLYPH<0> log ˙ M med acc ; bar GLYPH<0> = log ˙ M med acc GLYPH<0> log ˙ M min acc .
formed with the CoRoT satellite in March 2008. Accreting stars with detected rotational modulation amount to about 16% of the CTTS in our sample. These are distributed over the whole ˙ Macc range at all masses in Fig. 16, except at the lowest ˙ Macc regimes ( . 5 GLYPH<2> 10 GLYPH<0> 10 M yr), typically populated by objects fainter than GLYPH<12> / 17 in r and hence not attainable with CoRoT.
For each of these objects selected as described above, we phased the light curve of the UV excess and measured independently the average rms variation of detections obtained within the same observing night and the average rms variation between the average UV excess measured in a given phase bin of 0.05 at di GLYPH<11> erent rotational cycles.
The average peak-to-peak variation in the color excess throughout the sample amounts to GLYPH<24> 0.47 mag, which corresponds to a variation of GLYPH<24> 0.52 dex in ˙ Macc , consistent with what we found in Sect. 4.2. 50% of the objects show an average intrinsic rms variation of < 0.1 mag at a given phase from cycle to cycle (80% at GLYPH<20> 0.15 mag and 90% at GLYPH<20> 0.25 mag). Hence, on average a ratio of GLYPH<24> 0.25 between the intrinsic rms variation on day timescales and the peak-to-peak variation can be inferred. The average rms variation on hour timescales is smaller, amounting to GLYPH<20> 0.05 mag. On the assumption that the two contributions (accretion variability on hours vs. days timescales) are mutually independent, we conclude that these two sources of variability together contribute on average just GLYPH<24> 28% of the observed peakto-peak variation in the UV excess. For a typical GLYPH<1> ˙ Macc of 0.52 dex, intrinsic accretion variability is thus expected to contribute for about 0.15 dex, while a major contribution arises from the geometric modulation of the accretion shock.
Interestingly, in the picture of modulation-dominated variability and assuming a homogeneous phase sampling, we would expect to statistically observe symmetric variability bars around the average value of ˙ Macc ; this is indeed consistent with the results reported in Sect. 4.2 and synthetized in Table 5.
## 5. Discussion
Accretion is a key ingredient in early stellar evolution: it regulates the star-disk interaction over the first few million years, with a major impact on the dynamical evolution of both the central object and the protoplanetary disk. Inferring a complete picture of accretion within large, well-characterized samples of young stars allows us to explore the accretion properties over a variety of parameters (e.g., stellar mass, age, disk properties), and hence represents a crucial issue for understanding how accretion evolves on an individual vs. statistical basis.
## 5.1. The M GLYPH<3> GLYPH<0> ˙ Macc relationship
Understanding what relationship links disk accretion rates and the mass of central objects has been a major focus for studies of accretion in YSOs over the last years. A prime motivation for this lies in that the M GLYPH<3> - ˙ Macc relationship likely reflects the actual mechanisms governing the accretion process.
Hartmann et al. (2006) reviewed a number of di GLYPH<11> erent mechanisms which may be relevant to disk accretion and its variability and to the M GLYPH<3> ˙ Macc relationship. As noted by those authors, several unrelated mechanisms may contribute to establishing this relationship, and those mechanisms may act di GLYPH<11> erently in di GLYPH<11> erent mass regimes. A number of previous studies have attempted to better understand the mass dependence of the M GLYPH<3> ˙ Macc relationship (Vorobyov & Basu 2008; Rigliaco et al. 2011; Fang et al. 2013); these analyses suggest a diminution of the steepness of the ˙ Macc -M dependence as M GLYPH<3> GLYPH<3> increases from a few tenths or hundredths of solar mass to a few solar masses. This is consistent with what we observe here for NGC 2264; on the other hand, the overall trend observed in the subsolar-to-solar mass regimes appears to be significantly shallower than that observed in the intermediate (1-10 M GLYPH<12> ) mass regime (Ercolano et al. 2014).
In this study, we examined the distribution of mass accretion rates over mass for a homogeneous population of 236 confirmed, accreting members in NGC 2264, covering the mass range GLYPH<24> 0.1-1.5 M GLYPH<12> . We inferred the presence of a correlation between ˙ Macc and M GLYPH<3> and further showed that this result is not significantly a GLYPH<11> ected by a mass-dependence in the ˙ Macc detection limits. The same fraction of accreting stars over the total young population ( GLYPH<24> 40%) is roughly observed at lower ( < 0.4 M GLYPH<12> ) and higher ( > 1 M ) masses; unless the true fraction GLYPH<12> of accreting objects is considerably larger at higher masses than at lower masses, this attests that no significant selection biases towards lower-mass objects a GLYPH<11> ect our accretion survey. Hence, we obtain ˙ Macc / M , with GLYPH<11> GLYPH<3> GLYPH<11> GLYPH<24> 1.4 GLYPH<6> 0.3 (Eqs. 15-16). This exponent is smaller than the GLYPH<11> = 2 dependence inferred by Muzerolle et al. (2003) over the mass range 0.04-1 M GLYPH<12> ; the trend they obtained, however, is strongly influenced by the substellar component of the PMS population, which is not probed in our study. Indeed, results similar to Muzerolle et al.'s findings have been subsequently inferred from studies probing a comparable mass range in the substellar down to planetary mass regimes (e.g., Mohanty et al. 2005 for a composite sample of members from di GLYPH<11> erent star-forming regions, Natta et al. 2006 in GLYPH<26> Ohiuchi, Herczeg & Hillenbrand 2008 in Taurus, Alcalá et al. 2014 in Lupus). On the other end, studies addressing more specifically the T Tauri mass regime have recently proposed somewhat lower estimates for the quantitative dependence of ˙ Macc on M . Rigliaco et al. (2011) GLYPH<3> probed a mass range, in GLYPH<27> Ori, similar to the one investigated in Muzerolle et al.'s study (0.06-1 M GLYPH<12> ) and inferred a value of GLYPH<11> = 1 6 : GLYPH<6> 0 4. Barentsen et al. (2011) studied a population of 158 : accreting stars, covering the mass range 0.2-2 M GLYPH<12> , in IC 1396, and inferred a M - ˙ GLYPH<3> Macc relationship with GLYPH<11> = 1 1 : GLYPH<6> 0 2. : All these results are quite consistent with the estimate of slope here inferred. The range of GLYPH<11> from these studies may in part reflect the inhomogeneous nature of the methodologies and stellar samples; however, taken at face value, the results suggest a possible dependence of GLYPH<11> on mass, with the higher mass regime showing a shallower slope.
## 5.2. Accretion variability: what contribution to the ˙ Macc spread at a given mass?
A ubiquitous result of the studies of ˙ Macc distributions for large samples of young stars is the significant spread observed in ˙ Macc at a given mass, enveloping the average trend over 2 to 3 orders of magnitude. CTTS are known to display a strong variability over di GLYPH<11> erent timescales; this takes contribution both from geometric e GLYPH<11> ects linked with the rotational modulation of surface starspots and disk features (Herbst et al. 1994) and from the intrinsic variability of the accretion process. Variability could thus be partly responsible for the observed scatter.
In order to probe this e GLYPH<11> ect, we monitored the UV excess and ˙ Macc variability for about 150 NGC 2264 accreting members over two full weeks, with typically 16-17 epochs for each object; this allowed us to show that variability on week timescales determines on average a variation of the detected ˙ Macc over GLYPH<24> 0.5 dex, significantly smaller than the extent of the average ˙ Macc scatter.
This study complements the results inferred from recent studies that explored the variability in mass accretion rates
on longer timescales. Nguyen et al. (2009) analyzed the ˙ Macc variability of a sample of 40 members in Taurus-Auriga and Chamaeleon I, from multi-epoch optical spectra distributed over GLYPH<24> 10 months, with typically 4 epochs per object on a baseline varying from hours to months. They probed the accretion properties from H GLYPH<11> 10% width and Ca II flux and inferred a median variability estimate amounting respectively to 0.65 dex and 0.35 dex. Fang et al. (2013) probed the ˙ Macc variability of several tens of members in L1641, monitored on timescales of 1, 10 and 22 months; measuring the amount of accretion from the full width of the H GLYPH<11> line at 10% intensity, the authors inferred a typical ˙ Macc variability of GLYPH<24> 0.6 dex.
A recent spectroscopic survey of the ˙ Macc variability in T Tauri and Herbig Ae stars, addressing shorter ( . hour to days) timescales, has been performed by Costigan et al. (2014). The authors probed accretion properties and their variability from H GLYPH<11> EW measurements for a sample of 14 objects; targets have been monitored over . 1 hour blocks, in some cases iterated within a single night, and repeated over a few nights. Combining the results of this short-term variability monitoring with multiyear information for a few objects, as well as with results from di GLYPH<11> erent surveys, the authors found that the dominant contribution to the observed variability in ˙ Macc arises from the days timescale, with a spread in accretion rates ranging from 0.04 to 0.4 dex.
All these results robustly show that variability on day-tomonth timescales does not impact significantly on the large spread observed in ˙ Macc around the average ˙ Macc -M GLYPH<3> trend; hence, the spread is real and possibly linked to the di GLYPH<11> erent evolutionary stages of individual objects (see Sect. 5.3). Additionally, a strong overlap in the age distributions for the populations of accreting (CTTS) and non-accreting (WTTS) members seems to hold; modulo the issue of an accurate age determination for young stars, this suggests that an intrinsically large range in ˙ Macc exists at a given mass and age, which may reflect various other parameters (like, e.g., the properties of the stellar magnetic field or the initial mass of the disk).
Remarkably, the order-of-magnitude estimates for the ˙ Macc variability inferred on day-to-week timescales (this study; Costigan et al. 2014) and on month-to-year timescales (Nguyen et al. 2009; Fang et al. 2013) are quite consistent; this suggests that the same mechanisms dominate variability over these baselines, with a major contribution arising from the mid-term variability component. This picture is supported by the results of the comparison, shown in Fig. 13, between the L exc UV measurements obtained from ours and Rebull et al. (2002)'s survey of NGC 2264, respectively; what we observe in this case is that, indeed, UV excess luminosities measured at the two epochs are globally consistent, with an rms scatter, about the equality line, of the same order of magnitude as the average amount of variability detected during our 2 week-long CFHT monitoring.
## 5.3. What is the origin of the intra-cluster spread in ˙ Macc ?
A star-to-star variety in the evolutionary stage and evolutionary scenario may provide an important contribution to the interpretation of the large range of accretion properties observed within the region. The cluster shows a hierarchical structure (see Dahm 2008 and references therein), with regions of active, current star formation embedded in a more widespread population of somewhat older stars (Sung et al. 2009). Several episodes of star formation may have occurred, as proposed by Adams et al. (1983). Despite the uncertainty on a quantitative estimate, there is a general consensus about an age spread of up to several Myr within
Fig. 19. Evolution of the accretion properties as a function of stellar age for NGC 2264 accreting members. Three di GLYPH<11> erent mass groups are compared: M GLYPH<3> < 0 4 : M GLYPH<12> (filled circles); 0 4 : M GLYPH<12> GLYPH<20> M GLYPH<3> GLYPH<20> 1 M GLYPH<12> (open squares); M GLYPH<3> > 1 M GLYPH<12> (crosses).
the population of NGC 2264. It is thus of interest to attempt a characterization of the accretion properties relative to age indicators and disk evolutionary stages.
Looking at how points distribute on the HR diagram of the cluster (Fig. 12) and comparing this to model isochrones provides a debated indication on nominal ages. In order to probe the evolution of accretion properties with stellar age, we inferred an age estimate for each source from isochrone fitting, adopting the models of Siess et al. (2000). The results for accreting sources are displayed vs. the ˙ Macc estimates in Fig. 19. Only objects which are actual detections in ˙ Macc and whose age estimate from models is between GLYPH<24> 10 6 yr and 10 7 yr have been retained for the comparison.
An overall decreasing trend of the average ˙ Macc with increasing stellar ages is traced in Fig. 19, consistently with previous results regarding the average evolution of accretion with stellar age (e.g. Hartmann et al. 1998; Sicilia-Aguilar et al. 2010; Manara et al. 2012). The anticorrelation trend is well described in the M GLYPH<3> < 1 M GLYPH<12> regime, reaching a significance of over 5 GLYPH<27> according to a Spearman's rank order test (Press et al. 1992). A linear regression to this group of objects yields
$$\dot { M } _ { a c c } \infty \, t ^ { - \eta }, \, \eta \simeq 1. 5 1,$$
quite consistent with the GLYPH<17> = 1 5 estimate inferred by Hartmann : et al. (1998). Little information can be achieved on the accretion properties of the higher-mass group (M GLYPH<3> > 1 M ) from our UV GLYPH<12> excess analysis.
The actual ˙ Macc -age relationship may vary depending on the mass range probed, as suggested by the looser correlation that can be inferred from the least massive group of objects (M GLYPH<3> < 0.4 M GLYPH<12> ) compared to the 0.4 - 1 M GLYPH<12> group. This might reflect truly di GLYPH<11> erent evolutionary timescales, but also be affected by uncertainties on the age estimates inferred from models. Indeed, a clear-cut decreasing trend is observed on the lowerleft envelope of the data point distribution in Fig. 19, with the
youngest group being among the most luminous sources in the sample. While limits on the detection of small accretion rates in luminous stars might somewhat a GLYPH<11> ect the observed trend, a more significant bias here is likely introduced by the model age estimates. We notice that lower-mass stars appear to be systematically older than higher-mass stars, based on model ages. If this is not a physical e GLYPH<11> ect, but rather an artifact driven by systematics in the model, the actual anticorrelation trend that can be derived from Fig. 19 is, at best, doubtful.
The reliability of such time evolution analyses of accretion is subject to the assumption that the interpretation of the luminosity spread for a given PMS population on the HR diagram in terms of a true age spread is overall correct. However, this interpretation is subject to a severe controversy. Indeed, recent studies have questioned the accuracy of individual age estimates from the stellar luminosity. Bara GLYPH<11> e et al. (2009) claimed that the luminosity spread observed on the HR diagram of a given starforming region does not correspond to an actual age spread, but merely reflects the individual episodic accretion history, whose dynamics may mimic an age spread of up to a few Myr for coeval stars. While no consensus has obviously been achieved on this issue, an intrinsic age spread of the order of Myr, if present, is likely to be reflected in di GLYPH<11> erent properties of the region, such as the spatial distribution of members. This point is discussed in Sect. 5.4.
As mentioned in Sect. 3.1, information on the circumstellar disk morphology, hence on the evolutionary status, is conveyed by the mid-IR slope of the SED of the system. In Fig. 20, the accretion properties for three di GLYPH<11> erent mass groups of members are compared to the GLYPH<11> IRAC classification from Teixeira et al. (2012). Smaller values of GLYPH<11> IRAC correspond to more evolved disks; the average accretion rates decrease as disks become more evolved, albeit within a significant spread for each mass group.
These comparisons show that several parameters, beyond stellar mass, regulate the accretion evolution of individual systems and eventually contribute to shape the complex picture of a star-forming region such as we may infer from an extensive accretion survey.
## 5.4. A spatial mapping of accretion properties in NGC 2264
Characterizing the spatial distribution of accreting members according to their accretion properties is a useful tool to investigate the evolution dynamics of the region.
Fig. 21 shows a spatial mapping of accretion in NGC 2264. Most accretors are projected onto the cluster; a part of the population of accreting or mildly accreting members are instead located on the peripheral regions. Some interesting features can be observed: the strongest accretors tend to be concentrated around the two known active sites of star formation within the cloud, a few parsecs apart, while the population of more moderate accretors tends to be more evenly distributed throughout the whole cluster. The halo of members is spread over a few parsecs around the star-forming sites.
This di GLYPH<11> erential distribution of mass accretion rates may be the product of a sequential star formation process: the youngest stars, likely the most actively accreting, are indeed expected to be found close to their birth sites, while dynamical evolution over a few Myr (the average age of the cluster) can explain displacements up to a few parsecs relative to the original location where stars were formed. If this is the case, the distribution of ˙ Macc also reflects the presence of an intrinsic age spread within the region, hence corroborating the interpretation in terms of a time evolution over di GLYPH<11> erent ages.
Fig. 20. ˙ Macc -GLYPH<11> IRAC relationship. The GLYPH<11> IRAC -based disk morphology classification follows Table 2 of Teixeira et al. (2012). Three di GLYPH<11> erent mass groups are compared: M GLYPH<3> < 0 4 : M GLYPH<12> (filled circles); 0 4 : M GLYPH<12> GLYPH<20> M GLYPH<3> GLYPH<20> 1 M GLYPH<12> (open squares); M GLYPH<3> > 1 M GLYPH<12> (crosses).
We attempted to pursue further this scenario by investigating the spatial distributions of distinct, equal-sized groups of objects at the two age extremities in Fig. 19. If our interpretation is correct, we would expect the presumed younger member group to be spatially more compact than the older one. A statistical method to probe spatial compactness is the minimum spanning tree (MST) method (Prim 1957). This (see also Allison et al. 2009; Parker et al. 2011) consists in computing the minimum path-length required to connect all points of a given sample in a network of direct point-to-point links with no closed loops. Shorter MST lengths will thus identify, to a certain degree of confidence, more compact populations. The significance of the result can be tested by randomly selecting two groups of objects of the same size and belonging to the same population as the two groups of objects under study, and computing the MST of the first random group, the MST of the second random group and the ratio between the two. The iteration of this procedure allows us to reconstruct the normal distribution of MST1 / MST2 values when no significant di GLYPH<11> erence exists between the spatial distributions of two given groups of objects selected among the population of interest.
For our population of accreting objects, sampled in random groups of 20 to 30 elements, we derived a normal distribution of MST ratios centered on 1.0 (homogeneous spatial distribution) with a GLYPH<27> of 0.2. Little evidence for an actual di GLYPH<11> erence in the spatial distributions of 'younger' vs. 'older' members in Fig. 19 can be inferred when comparing the result of their MST test to this distribution. Somewhat smaller values than the mean of 1.0 are obtained from the MST y oun g er / MST older ratio, oscillating around a significance of 1.5 GLYPH<27> that this di GLYPH<11> erence is truly meaningful. This might suggest that the younger population is to some extent more compact than the older population; however, no conclusive evidence can be drawn from this analysis, and the small statistics at lower and higher ages in Fig. 19 yields some dependence of the specific result on the specific selection
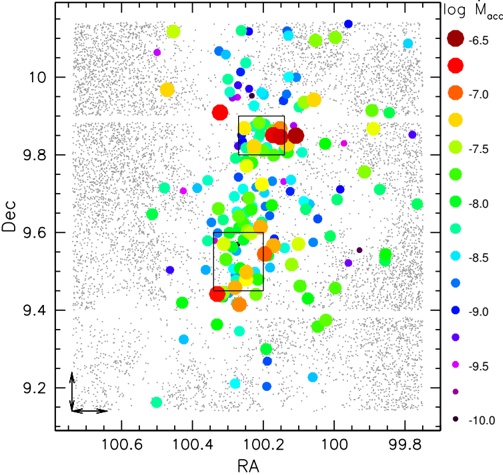
a complete picture of accretion in the cluster and monitored its variability over a few rotational cycles. A broad interval of ˙ Macc values has been inferred within the region, ranging from GLYPH<24> 10 GLYPH<0> 7 to a few GLYPH<2> 10 GLYPH<0> 10 M yr; at any given stellar mass M , a large GLYPH<12> / GLYPH<3> spread in ˙ Macc values, typically extending over 2 orders of magnitude, is observed.
The average ˙ Macc shows a statistically significant correlation with M ; more uncertain is the functional form of this depenGLYPH<3> dence, which in turn appears to be mass-dependent and likely time-evolving, as highlighted by the results inferred from previous studies for various young stellar populations. A statistical slope of 1.4 GLYPH<6> 0.3 for the log ˙ Macc over log M GLYPH<3> relationship is here derived for NGC 2264 in the mass sample probed; while the absence of the lower-mass ( < 0.1 M GLYPH<12> ) stellar component may contribute to explain this less steep dependence than the value of GLYPH<24> 2 proposed in several studies, the large spread of ˙ Macc values observed at a given mass attests the mere indicative value of such a relationship, which weighs the contributions of several trends as well as of undetected regimes.
-10.0
Fig. 21. Spatial mapping of accretion properties in NGC 2264. Small grey dots indicate the distribution of field stars, large dots indicate accreting cluster members. Only objects with an actual ˙ Macc detection are shown. Symbol colors and sizes are scaled according to the value of ˙ Macc . The black boxes mark the regions of maximum stellar density in the cluster (from Lamm et al. 2004). Double arrows mark a physical distance of 1.5 parsecs.
of objects for the two groups. On the other hand, the complexity of the cluster, with its clumpy structure, the presence of at least two separated poles of star formation, the association with several massive OB stars, intrinsically translates to a non-linearity in the cluster evolution and, consequently, to a certain degree of ambiguity in the information provided by the spatial distribution of more evolved members.
## 6. Conclusions
Wehave performed an extensive photometric investigation of accretion in the young open cluster NGC 2264. Our sample, homogeneous in the dataset and in the characterization of individual properties, includes GLYPH<24> 750 members, spanning in mass the range GLYPH<24> 0.1-2 M GLYPH<12> ; of these, about 40% show ongoing accretion. Accretion activity has been traced from the detection and monitoring of the u -band excess emission relative to non-accreting young stars; we showed that this excess is a reliable indicator of accretion, matching the properties observed at di GLYPH<11> erent wavelengths (H GLYPH<11> emission, IR excess), with the advantage of providing alone a direct proxy to the accretion luminosity.
We re-examined the membership of the cluster from an accretion-related perspective, exploring a wider area around the spatial distribution of currently known members within the starforming region. This allowed us to expand the census of accreting members, with the identification of 50 new candidates based on their accretion signatures at short wavelengths. We detected UV color excess ranging from a few tenths of a mag to GLYPH<24> 3 mag, with a sensitivity of GLYPH<24> 0.2 mag deriving from the definition of the reference color locus from the properties of non-accreting young stars. Following a new empirical prescription for the conversion of the UV excess into accretion luminosity, we inferred
Little contribution to the spread in the ˙ Macc vs. M GLYPH<3> distribution arises from ˙ Macc variability, which is found to amount to GLYPH<24> 0.5 dex on the average, at least on days to months timescales; hence, this spread is physically relevant and provides valuable insight on the complexity of the accretion and evolutionary picture for a given stellar population. A di GLYPH<11> erential distribution of evolutionary stages among members, such as we may deduce from the HR diagram of the cluster and or from disk evolution / tracers ( GLYPH<11> IRAC ), would naturally impact the global accretion picture we may infer for the cluster as a whole. Indeed, ˙ Macc is shown to anticorrelate with such intrinsic evolutionary age in-/ dicators, although these trends are in turn not exempt from a large amount of scatter. The detected spread in ˙ Macc may thus reflect the dynamics of cluster evolution and the presence of a non-negligible age spread among its members, be it the result of sequential star formation episodes and or of a multiplicity / of evolutionary patterns. Moreover, a diversity in the accretion regimes at play, from episodic, short-lived accretion bursts to steadier, funnel-flow accretion, may concur to shape the features of di GLYPH<11> erent stellar groups and result in a range of observed accretion rates, from the upper envelope of the ˙ Macc vs. M GLYPH<3> distribution to lower accretion rate regimes.
An important contribution toward the achievement of a complete physical picture of the accretion process is provided by a detailed analysis of the variability properties. Geometric e GLYPH<11> ects constitute an important filter to the e GLYPH<11> ective variability profile for a given system, contributing up to 75%, on the average, of the detected ˙ Macc variability; however, much information on the underlying physics is conveyed by the specific photometric signatures of this variability, and a comparative analysis over intrinsically di GLYPH<11> erent stellar groups may be of remarkable interest to discern di GLYPH<11> erent scenarios. This aspect will be fully addressed for the young stellar population of NGC 2264 in a forthcoming paper (Venuti et al., in prep.); this is intended to provide a complete characterization of the accretion process and its impact onto the dynamics of the cluster.
Acknowledgements. We would like to thank Christian Veillet, former director of CFHT, for granting discretionary time to perform the mapping survey in December 2010, and the Terapix center at Institut d'Astrophysique de Paris, and in particular Yannick Mellier, for the prompt processing of the MegaCam images obtained during this run. We also thank Nadine Manset and Jim Thomas at CFHT for e GLYPH<14> cient run scheduling and data retrieval procedures. We warmly thank Luisa Rebull for retrieving for us the L acc values she derived for her 2002 paper on disk-bearing objects in NGC 2264. We thank Kevin Covey for discussions on SDSS dwarf sequences and Lynne Hillenbrand for discussions on bolometric corrections scales; we also acknowledge useful discussion on the ˙ Macc -
M relationship with Beate Stelzer. This publication makes use of data products GLYPH<3> from the Sloan Digital Sky Survey and the Two Micron All Sky Survey. This project was in part supported by the grant ANR 2011 Blanc SIMI5-6 020 01. SHPA and APS acknowledge support from CNPq, CAPES and Fapemig.
## References
Abazajian, K., Adelman-McCarthy, J. K., Agüeros, M. A., et al. 2004, AJ, 128, 502
- Abazajian, K. N., Adelman-McCarthy, J. K., Agüeros, M. A., et al. 2009, ApJS, 182, 543
- Adams, M. T., Strom, K. M., & Strom, S. E. 1983, ApJS, 53, 893
- A er, L., Micela, G., Favata, F., Flaccomio, E., & Bouvier, J. 2013, MNRAS, GLYPH<11> 430, 1433
- Alcalá, J. M., Natta, A., Manara, C. F., et al. 2014, A&A, 561, A2
Alencar, S. H. P., Teixeira, P. S., Guimarães, M. M., et al. 2010, A&A, 519, A88
Allison, R. J., Goodwin, S. P., Parker, R. J., et al. 2009, MNRAS, 395, 1449
- Annis, J., Soares-Santos, M., Strauss, M. A., et al. 2011, ArXiv e-print 1111.6619 Armitage, P. J. 2011, ARA&A, 49, 195
- Bara GLYPH<11> e, I., Chabrier, G., & Gallardo, J. 2009, ApJ, 702, L27
Barentsen, G., Vink, J. S., Drew, J. E., et al. 2011, MNRAS, 415, 103
Bertin, E. 2011, in Astronomical Society of the Pacific Conference Series, Vol.
442, Astronomical Data Analysis Software and Systems XX, ed. I. N. Evans,
A. Accomazzi, D. J. Mink, & A. H. Rots, 435
Bertin, E. & Arnouts, S. 1996, A&AS, 117, 393
Bessell, M. S., Castelli, F., & Plez, B. 1998, A&A, 333, 231
- Boulade, O., Charlot, X., Abbon, P., et al. 2003, in Society of Photo-Optical Instrumentation Engineers (SPIE) Conference Series, ed. M. Iye & A. F. M. Moorwood, Vol. 4841, 72-81
Bouvier, J., Alencar, S. H. P., Boutelier, T., et al. 2007a, A&A, 463, 1017
- Bouvier, J., Alencar, S. H. P., Harries, T. J., Johns-Krull, C. M., & Romanova, M. M. 2007b, Protostars and Planets V, 479
- Bouvier, J., Cabrit, S., Fernandez, M., Martin, E. L., & Matthews, J. M. 1993, A&A, 272, 176
- Calvet, N. & Gullbring, E. 1998, ApJ, 509, 802
- Camenzind, M. 1990, in Reviews in Modern Astronomy, ed. G. Klare, Vol. 3, 234-265
- Cauley, P. W., Johns-Krull, C. M., Hamilton, C. M., & Lockhart, K. 2012, ApJ, 756, 68
- Cody, A. M., Stau GLYPH<11> er, J., Baglin, A., et al. 2014, AJ, 147, 82
- Cody, A. M., Stau GLYPH<11> er, J. R., Micela, G., Baglin, A., & CSI 2264 Team. 2013, Astronomische Nachrichten, 334, 63
Cohen, M. & Kuhi, L. V. 1979, ApJS, 41, 743
- Costigan, G., Vink, J. S., Scholz, A., Ray, T., & Testi, L. 2014, MNRAS, 440, 3444
Covey, K. R., Ivezi´ c, Ž., Schlegel, D., et al. 2007, AJ, 134, 2398
Covey, K. R., Lada, C. J., Román-Zúñiga, C., et al. 2010, ApJ, 722, 971
- Dahm, S. E. 2008, in Handbook of Star Forming Regions, Volume I, ed. B. Reipurth, 966
Dahm, S. E. & Simon, T. 2005, AJ, 129, 829
Dullemond, C. P., Natta, A., & Testi, L. 2006, ApJ, 645, L69
- Ercolano, B., Mayr, D., Owen, J. E., Rosotti, G., & Manara, C. F. 2014, MNRAS Fang, M., Kim, J. S., van Boekel, R., et al. 2013, ApJS, 207, 5
Feigelson, E. D. & Babu, G. J. 2012, Modern Statistical Methods for Astronomy, Cambridge University Press
F˝ urész, G., Hartmann, L. W., Szentgyorgyi, A. H., et al. 2006, ApJ, 648, 1090
Finlator, K., Ivezi´, Ž., Fan, X., et al. 2000, AJ, 120, 2615 c
Fiorucci, M. & Munari, U. 2003, A&A, 401, 781
Flaccomio, E., Micela, G., & Sciortino, S. 2006, A&A, 455, 903
Fukugita, M., Ichikawa, T., Gunn, J. E., et al. 1996, AJ, 111, 1748
Gillen, E., Aigrain, S., McQuillan, A., et al. 2014, A&A, 562, A50
Guarcello, M. G., Prisinzano, L., Micela, G., et al. 2007, A&A, 462, 245
Gullbring, E., Hartmann, L., Briceno, C., & Calvet, N. 1998, ApJ, 492, 323
Haisch, Jr., K. E., Lada, E. A., & Lada, C. J. 2001, ApJ, 553, L153
Hartmann, L., Calvet, N., Gullbring, E., & D'Alessio, P. 1998, ApJ, 495, 385
Hartmann, L., D'Alessio, P., Calvet, N., & Muzerolle, J. 2006, ApJ, 648, 484
Helsel, D. R. 2012, Statistics for Censored Environmental Data, Wiley
- Herbig, G. H. & Bell, K. R. 1988, Third Catalog of Emission-Line Stars of the Orion Population : 3 : 1988
Herbst, W., Herbst, D. K., Grossman, E. J., & Weinstein, D. 1994, AJ, 108, 1906 Herczeg, G. J. & Hillenbrand, L. A. 2008, ApJ, 681, 594
Hillenbrand, L. A. 2005, ArXiv astro-ph 0511083
/
Joy, A. H. 1945, ApJ, 102, 168
Königl, A. 1991, ApJ, 370, L39
Kraus, A. L. & Hillenbrand, L. A. 2007, AJ, 134, 2340
Lada, C. J. 1987, in IAU Symposium, Vol. 115, Star Forming Regions, ed. M. Peimbert & J. Jugaku, 1-17
Lada, C. J., Muench, A. A., Luhman, K. L., et al. 2006, AJ, 131, 1574
Article number, page 22 of 24
- Lamm, M. H., Bailer-Jones, C. A. L., Mundt, R., Herbst, W., & Scholz, A. 2004,
- A&A, 417, 557 Lenz, D. D., Newberg, J., Rosner, R., Richards, G. T., & Stoughton, C. 1998, ApJS, 119, 121 Luhman, K. L., Stau GLYPH<11> er, J. R., Muench, A. A., et al. 2003, ApJ, 593, 1093 Manara, C. F., Robberto, M., Da Rio, N., et al. 2012, ApJ, 755, 154 Ménard, F. & Bertout, C. 1999, in NATO ASIC Proc. 540: The Origin of Stars and Planetary Systems, ed. C. J. Lada & N. D. Kylafis, 341 Meyer, M. R., Calvet, N., & Hillenbrand, L. A. 1997, AJ, 114, 288 Mohanty, S., Jayawardhana, R., & Basri, G. 2005, ApJ, 626, 498 Muzerolle, J., Hillenbrand, L., Calvet, N., Briceño, C., & Hartmann, L. 2003, ApJ, 592, 266 Natta, A., Testi, L., & Randich, S. 2006, A&A, 452, 245 Nguyen, D. C., Scholz, A., van Kerkwijk, M. H., Jayawardhana, R., & Brandeker, A. 2009, ApJ, 694, L153 Parker, R. J., Bouvier, J., Goodwin, S. P., et al. 2011, MNRAS, 412, 2489 Pecaut, M. J. & Mamajek, E. E. 2013, ApJS, 208, 9 Press, W. H., Teukolsky, S. A., Vetterling, W. T., & Flannery, B. P. 1992, Numerical recipes in C. The art of scientific computing Prim, R. C. 1957, Bell Syst. Tech. J., 36, 1389 Ramírez, S. V., Rebull, L., Stau GLYPH<11> er, J., et al. 2004, AJ, 127, 2659 Rebull, L. M., Makidon, R. B., Strom, S. E., et al. 2002, AJ, 123, 1528 Regnault, N., Conley, A., Guy, J., et al. 2009, A&A, 506, 999 Rigliaco, E., Natta, A., Randich, S., Testi, L., & Biazzo, K. 2011, A&A, 525, A47 Sicilia-Aguilar, A., Henning, T., & Hartmann, L. W. 2010, ApJ, 710, 597 Siess, L., Dufour, E., & Forestini, M. 2000, A&A, 358, 593 Skrutskie, M. F., Cutri, R. M., Stiening, R., et al. 2006, AJ, 131, 1163 Stau GLYPH<11> er, J., Cody, A. M., Baglin, A., et al. 2014, AJ, 147, 83 Sung, H., Bessell, M. S., Chun, M.-Y., Karimov, R., & Ibrahimov, M. 2008, AJ, 135, 441 Sung, H., Bessell, M. S., & Lee, S.-W. 1997, AJ, 114, 2644 Sung, H., Stau GLYPH<11> er, J. R., & Bessell, M. S. 2009, AJ, 138, 1116 Taylor, M. B. 2005, in Astronomical Society of the Pacific Conference Series, Vol. 347, Astronomical Data Analysis Software and Systems XIV, ed. P. Shopbell, M. Britton, & R. Ebert, 29 Teixeira, P. S., Lada, C. J., Marengo, M., & Lada, E. A. 2012, A&A, 540, A83 Vorobyov, E. I. & Basu, S. 2008, ApJ, 676, L139 Walker, M. F. 1956, ApJS, 2, 365
White, R. J. & Basri, G. 2003, ApJ, 582, 1109
Appendix A: Accretion-oriented revision of the census of NGC 2264 members: new CTTS candidate members and possible field contaminants
Table A.1. List of new candidate members from the accretion-based census of the population of NGC 2264.
| Mon-ID | RA | Dec | Selection criteria | Additional information 1 |
|--------------|----------|----------|-----------------------|---------------------------------------------------|
| Mon-001428 | 100.193 | 9.71302 | UV, var I | likely CTTS based on IRAC light curve |
| Mon-005009 | 100.541 | 9.79834 | var II, lc | irregular IRAC / CoRoT light curves |
| Mon-005278 | 100.648 | 9.43207 | UV, var II | IR excess |
| Mon-005326 | 100.621 | 9.4455 | UV | |
| Mon-005385 | 100.354 | 9.75632 | UV, var I | flat IRAC light curve |
| Mon-005455 | 100.215 | 9.37313 | UV | flat IRAC light curve |
| Mon-005596 | 100.516 | 9.45916 | var I | flat IRAC light curve |
| Mon-005664 | 100.227 | 9.15885 | UV | spotted-like CoRoT light curve |
| Mon-005745 | 100.518 | 9.16134 | UV | |
| Mon-005807 | 100.282 | 9.23241 | UV, var I | |
| Mon-005836 | 100.371 | 9.3043 | UV | flat IRAC light curve |
| Mon-006037 * | 99.8723 | 9.72772 | var II, lc | spotted-like CoRoT light curve |
| Mon-006079 | 99.8713 | 9.7107 | UV, var I, var II | eclipsing binary / very short period binary |
| Mon-006144 | 99.9284 | 9.55441 | UV | flat IRAC light curve |
| Mon-006183 | 99.972 | 9.82939 | UV, var II | flat IRAC light curve |
| Mon-006286 | 100.126 | 9.19233 | UV | |
| Mon-006324 | 99.9531 | 9.29308 | UV | |
| Mon-006325 | 100.06 | 9.22705 | UV, var II | |
| Mon-006369 | 99.8757 | 9.29094 | varI, var II | |
| Mon-006398 | 99.8103 | 9.61444 | UV, var II | flat IRAC light curve |
| Mon-006409 | 99.8134 | 9.64136 | UV | flat IRAC light curve |
| Mon-006429 | 99.7954 | 9.53839 | UV, var I, var II | strong IR excess; IRAC light curve of YSO |
| Mon-006465 | 99.8548 | 9.54391 | UV, var I, var II | eclipsing binary |
| Mon-006491 | 99.8563 | 9.5276 | UV, var II, lc | IR excess; CoRoT light curve of CTTS |
| Mon-006498 | 99.8275 | 9.39888 | UV | flat IRAC light curve |
| Mon-006515 | 99.7764 | 9.66813 | UV | |
| Mon-006873 | 99.7924 | 9.15089 | var I, var II | |
| Mon-006902 | 99.7511 | 9.23571 | var I, var II | |
| Mon-006930 | 99.767 | 9.27055 | var II, lc | likely CTTS based on CoRoT light curve |
| Mon-006950 | 99.7792 | 9.85195 | UV, var II | |
| Mon-006985 | 99.7794 | 10.1191 | UV, var II | |
| Mon-006986 | 99.7915 | 10.0869 | UV, var I, var II, lc | likely CTTS based on CoRoT light curve |
| Mon-006991 | 99.8417 | 10.1065 | var II, lc | likely CTTS based on CoRoT light curve; IR excess |
| Mon-006999 | 99.8665 | 10.0635 | var I | |
| Mon-007004 | 99.8581 | 10.0854 | UV | |
| Mon-007018 | 99.9725 | 10.1093 | var I, var II | |
| Mon-007402 | 100.625 | 9.94183 | var I | |
| Mon-007418 | 100.576 | 10.0519 | UV | |
| Mon-007461 | 100.241 | 10.1179 | UV, var II | probable MIPS 24 mexcess |
| Mon-007496 | 100.515 | 10.0884 | var I, var II | GLYPH<22> |
| Mon-007845 | 99.8919 | 9.40008 | UV | |
| Mon-008139 | 99.7565 | 10.0797 | UV | |
| Mon-008140 | 99.8043 | 9.61337 | UV, var II | |
| Mon-008141 | 100.665 | 9.67704 | UV | |
| Mon-008142 | 99.7682 | 9.69662 | UV, var I, var II | |
| Mon-014132 | 99.7648 | 9.27109 | var II, lc | AA Tau-type CoRoT light curve; IR excess |
| Mon-020662 | 100.211 | 10.0384 | UV | |
| Mon-021771 | 100.518 | 9.57561 | var I, var II | flat IRAC light curve |
| Mon-025015 | 99.967 | 9.40013 | UV | |
| Mon-025101 | 99.8522 | 9.92528 | UV, var II | |
| Mon-124054 | 100.391 | 9.92262 | UV, var I | |
Notes. Selection criteria: UV = UV excess; var I = multi-year variability; var II = mid-term variability (i.e., on week timescales); lc = light curve morphology.
- ( 1 ) From Spitzer IRAC and or CoRoT monitoring obtained during the CSI 2264 campaign (and or additional IR photometry), when available. / /
( * ) WTTS candidate member
Table A.2. List of NGC 2264 members, with no apparent accretion activity from previous surveys, reclassified as CTTS from this accretion-based census of the population of NGC 2264.
| Mon-ID | RA | Dec | Selection criteria | Additional information 1 |
|------------|----------|----------|----------------------|---------------------------------------------------------------------------------------------------------------------------------------------------------------|
| Mon-000293 | 100.252 | 9.68758 | UV | |
| Mon-000316 | 100.232 | 9.64025 | UV | IR excess; likely CTTS based on IRAC light curve flat IRAC light curve flat IRAC light curve; possible 8 mexcess |
| Mon-000340 | 100.483 | 9.67968 | UV | IR excess; likely CTTS based on IRAC light curve flat IRAC light curve flat IRAC light curve; possible 8 mexcess |
| Mon-000507 | 100.261 | 9.85702 | UV | GLYPH<22> |
| Mon-000685 | 100.189 | 9.8195 | UV | flat IRAC light curve |
| Mon-000718 | 100.267 | 9.34567 | UV | flat IRAC light curve |
| Mon-000750 | 100.327 | 9.52487 | UV | IRAC light curve; possible 8 GLYPH<22> |
| Mon-000823 | 100.209 | 9.95111 | UV | IR excess; likely CTTS based on IRAC light curve flat IRAC light curve flat IRAC light curve; possible 8 mexcess |
| Mon-000914 | 100.216 | 9.6322 | UV | very strong IR excess |
| Mon-000957 | 100.19 | 9.20354 | UV | IR excess |
| Mon-000959 | 100.188 | 9.2685 | var | IR excess |
| Mon-001060 | 100.128 | 10.0008 | UV | IR excess; likely CTTS based on IRAC light curve IR excess |
| Mon-001211 | 99.9598 | 9.52143 | UV | IR excess; likely CTTS based on IRAC light curve IR excess |
| Mon-001224 | 100.07 | 9.67295 | UV | IR excess; likely CTTS based on IRAC light curve IR excess |
| Mon-001241 | 100.141 | 9.81216 | UV | IR excess; likely CTTS based on IRAC light curve strong IR excess; IRAC light curve of YSO strong IR excess strong MIPS 24 GLYPH<22> mexcess strong IR excess |
| Mon-001267 | 100.143 | 9.42142 | var | IR excess; likely CTTS based on IRAC light curve strong IR excess; IRAC light curve of YSO strong IR excess strong MIPS 24 GLYPH<22> mexcess strong IR excess |
| Mon-001280 | 99.9177 | 9.30604 | UV | IR excess; likely CTTS based on IRAC light curve strong IR excess; IRAC light curve of YSO strong IR excess strong MIPS 24 GLYPH<22> mexcess strong IR excess |
| Mon-001576 | 100.133 | 10.119 | UV | IR excess; likely CTTS based on IRAC light curve strong IR excess; IRAC light curve of YSO strong IR excess strong MIPS 24 GLYPH<22> mexcess strong IR excess |
| Mon-001582 | 100.499 | 10.0638 | UV | IR excess; likely CTTS based on IRAC light curve strong IR excess; IRAC light curve of YSO strong IR excess strong MIPS 24 GLYPH<22> mexcess strong IR excess |
Notes. Selection criteria: UV = UV excess; var = multi-year variability.
( 1 ) From Spitzer IRAC monitoring obtained during the CSI 2264 campaign (and or additional IR photometry), when available. / /
Table A.3. Objects with questioned membership from the CFHT UV-census.
| Mon-ID | RA | Dec | u | g | r | i | Membership criteria |
|--------------|----------|----------|--------|--------|--------|--------|-----------------------|
| Mon-000003 | 100.439 | 9.78583 | 20.46 | 18.204 | 16.924 | 16.206 | P, X |
| Mon-000004 | 100.561 | 9.84104 | 17.808 | 15.998 | 15.075 | 14.594 | P, RV |
| Mon-000025 | 100.511 | 9.97441 | 18.025 | 16.134 | 15.193 | 14.69 | P, RV |
| Mon-000031 | 100.555 | 9.76763 | 17.801 | 16.118 | 15.307 | 14.888 | P, RV |
| Mon-000387 | 100.455 | 9.68496 | 20.53 | 18.408 | 17.273 | 16.681 | X |
| Mon-000414 | 100.559 | 9.59579 | 18.446 | 16.44 | 15.431 | 14.944 | P, RV |
| Mon-000593 * | 100.257 | 9.35157 | 17.793 | 15.822 | 15.077 | 14.836 | P, RV |
| Mon-000600 * | 100.205 | 9.98095 | 22.567 | 19.684 | 18.106 | 17.212 | X |
| Mon-000696 * | 100.337 | 9.5717 | 20.309 | 19.512 | 19.589 | 18.516 | h |
| Mon-000820 | 100.481 | 9.50528 | 19.538 | 17.513 | 16.49 | 15.902 | X |
| Mon-000944 | 100.458 | 9.68479 | 20.258 | 18.274 | 17.185 | 16.629 | X |
| Mon-000946 * | 100.202 | 9.99424 | 21.252 | 18.81 | 17.472 | 16.715 | II |
| Mon-000966 | 100.196 | 9.30923 | 17.729 | 15.882 | 14.942 | 14.415 | P, RV |
| Mon-000976 | 100.433 | 9.15588 | 21.325 | 19.108 | 17.798 | 17.058 | X |
| Mon-000983 | 100.242 | 9.30085 | 16.047 | 14.663 | 14.206 | 14.042 | RV |
| Mon-000988 | 100.088 | 9.98401 | 20.823 | 18.249 | 16.758 | 15.93 | P, RV |
| Mon-001043 * | 100.064 | 9.71678 | 21.746 | 19.149 | 17.695 | 16.854 | P, II / III |
| Mon-001046 | 99.9849 | 9.72542 | 15.811 | 14.455 | 14.048 | 13.881 | RV |
| Mon-001086 | 99.8899 | 9.86127 | 18.279 | 16.524 | 15.639 | 15.144 | P, RV |
| Mon-001192 | 100.162 | 9.36066 | 17.954 | 15.866 | 15.079 | 14.799 | RV |
| Mon-001207 | 99.9804 | 9.98644 | 21.113 | 18.345 | 16.911 | 16.009 | h |
| Mon-001283 * | 99.861 | 9.51055 | 21.364 | 18.75 | 17.59 | 17.012 | RV |
| Mon-001289 | 99.8527 | 9.37588 | 16.778 | 15.082 | 14.379 | 14.084 | P, RV |
| Mon-001293 | 99.8972 | 9.54233 | 18.331 | 16.315 | 15.239 | 14.681 | P, RV |
| Mon-001311 | 99.8151 | 9.65357 | 18.014 | 16.134 | 15.181 | 14.684 | P, RV |
| Mon-001393 | 100.552 | 9.98531 | 17.072 | 15.373 | 14.609 | 14.195 | P, RV |
| Mon-006019 * | 100.142 | 9.42022 | 19.511 | 17.507 | 16.217 | 15.507 | P |
| Mon-007454 | 100.129 | 10.0801 | 17.799 | 16.099 | 15.494 | 15.14 | P |
Notes. Membership criteria, in the literature, for the listed objects: P = photometric member (i.e., located on a cluster sequence in the R vs. R-I diagram); X = X-ray emitter, from Sung et al. (2009); RV = radial velocity member, from F˝ urész et al. (2006); h = H GLYPH<11> emission candidate, from Sung et al. (2009); II = Class II object, from Sung et al. (2009); II III / = Class II III object, from Sung et al. (2009). /
( * ) More uncertain cases | 10.1051/0004-6361/201423776 | [
"Laura Venuti",
"Jérôme Bouvier",
"Ettore Flaccomio",
"Silvia H. P. Alencar",
"Jonathan Irwin",
"John R. Stauffer",
"Ann Marie Cody",
"Paula S. Teixeira",
"Alana P. Sousa",
"Giuseppina Micela",
"Jean-Charles Cuillandre",
"Giovanni Peres"
] | 2014-08-02T23:01:15+00:00 | 2014-08-02T23:01:15+00:00 | [
"astro-ph.SR"
] | Mapping accretion and its variability in the young open cluster NGC 2264: a study based on u-band photometry | We aim at characterizing the accretion properties of several hundred members
of the star-forming cluster NGC 2264 (3 Myr). We performed a deep u,g,r,i
mapping and a simultaneous u+r monitoring of the region with CFHT/MegaCam in
order to directly probe the accretion process from UV excess measurements.
Photometric properties and stellar parameters are determined homogeneously for
about 750 monitored young objects, spanning the mass range 0.1-2 Mo. About 40%
are classical (accreting) T Tauri stars, based on various diagnostics (H_alpha,
UV and IR excesses). The remaining non-accreting members define the
(photospheric+chromospheric) reference UV emission level over which flux excess
is detected and measured. We revise the membership status of cluster members
based on UV accretion signatures and report a new population of 50 CTTS
candidates. A large range of UV excess is measured for the CTTS population,
varying from a few 0.1 to 3 mag. We convert these values to accretion
luminosities and obtain mass accretion rates ranging from 1e-10 to 1e-7 Mo/yr.
Taking into account a mass-dependent detection threshold for weakly accreting
objects, we find a >6sigma correlation between mass accretion rate and stellar
mass. A power-law fit, properly accounting for upper limits, yields M_acc
$\propto$ M^{1.4+/-0.3}. At any given stellar mass, we find a large spread of
accretion rates, extending over about 2 orders of magnitude. The monitoring of
the UV excess on a timescale of a couple of weeks indicates that its
variability typically amounts to 0.5 dex, much smaller than the observed
spread. We suggest that a non-negligible age spread across the cluster may
effectively contribute to the observed spread in accretion rates at a given
mass. In addition, different accretion mechanisms (like, e.g., short-lived
accretion bursts vs. more stable funnel-flow accretion) may be associated to
different M_acc regimes. |
1408.0433v2 | ## Flow-induced nonequilibrium self-assembly in suspensions of stiff, apolar, active filaments
Ankita Pandey, 1 P. B. Sunil Kumar, 1 and R. Adhikari 2
1 Indian Institute of Technology, Madras, Chennai 600036, India 2 The Institute of Mathematical Sciences, CIT Campus, Chennai 600113, India (Dated: August 20, 2015)
Active bodies in viscous fluids interact hydrodynamically through self-generated flows. Here we study spontaneous aggregation induced by hydrodynamic flow in a suspension of stiff, apolar, active filaments. Lateral hydrodynamic attractions in extensile filaments lead, independent of volume fraction, to anisotropic aggregates which translate and rotate ballistically. Lateral hydrodynamic repulsion in contractile filaments lead, with increasing volume fractions, to microstructured states of asters, clusters, and incipient gels where, in each case, filament motion is diffusive. Our results demonstrate that the interplay of active hydrodynamic flows and anisotropic excluded volume interactions provides a generic nonequilibrium mechanism for hierarchical self-assembly of active soft matter.
Filamentous structures along which chemical energy is converted to mechanical motion are found in many biological contexts such as actin filaments, molecular motors walking on microtubules, flagellar bundles and ciliary hairs. These cellular components maintain structure, influence signaling, and provide motile forces. Much recent effort has been directed at synthesising biomimetic analogues of such components. Motor-microtubule mixtures [1] and self-assembled motor-microtubules bundles capable of motility [2] are two examples where dynamic structures remarkably similar to those occurring in vivo have been synthesized in the laboratory. These emergent structures are maintained by nonequilibrium 'active' forces generated by the consumption of chemical energy. Hydrodynamic flow provides a way of transmitting nonequilibrium forces and its role in creating and maintaining dynamic structures remains relatively unexplored.
Our present theoretical understanding of hydrodynamics in nonequilibrium energy-converting systems is based largely on continuum [3] or kinetic [4] theories that prescribe, respectively, the spatiotemporal evolution of coarse-grained fields or distribution functions. These theories predict long wavelength collective phenomena like instabilities [5, 6], the onset of flows [7] through spontaneous symmetry breaking [8] and the continuous generation of topological defects [9]. The complementary domain of short wavelength phenomena where near-field hydrodynamics, the shape of the active body and excluded volume interactions are important, has been much less studied [10, 11]. This domain is relevant in situations where particle numbers are not thermodynamically large and a hydrodynamic limit is not necessarily attained, as for example in the cell. Theoretical descriptions that do not presume the existence of continuum and hydrodynamic limits, then, are required to provide insight into the physics of short wavelength phenomena in active matter.
In this Letter we study short wavelength aggregation phenomena in suspensions of stiff, apolar, active filaments using a description that resolves individual filaments and includes their hydrodynamic and excluded volume interactions. Our model for an active filament consists of rigidly connected active beads that produce force-free, torque-free flows in the fluid [10]. We approximate the active flow of each bead by its slowest decaying component, the irreducible stresslet [12]. The stresslet principal axis is always aligned along the filament tangent and the principal values are either positive (extensile) or negative (contractile). This ensures that an isolated straight filament produces active flows but does not actively translate or rotate and is, thus, individually apolar. However, as we show, translational and rotational motion is possible in the combined flow of two or more stiff, apolar filaments. This inherently collective and nonequilibrium source of motion, when constrained by the anisotropic excluded volume interactions between filaments, leads to non-trivial states of aggregation in suspension.
The apolar filament suspension is an example of a system where forces that break time reversal invariance, and which are usually associated with dissipation and the cessation of motion, drive the system and lead to nonquilibrium steady states (NESS) with non-zero fluxes. A wellknown paradigm of NESS is the driven dissipative system, where external forces at the system boundary produce nonequlibrium. In contrast, here internal forces distributed continuously within the system boundary produce nonequilibrium. Therefore, apolar active suspensions are novel model systems for studying NESS both theoretically and experimentally. Many recent developments in the statistical physics of NESS, such as fluctuation theorems, macroscopic fluctuation theory, and motility-induced phase separation can be tested in the system we study here.
Our results are as follows. We find distinct fixed points for the non-linear dynamics of pairs of filaments translating and rotating in their mutual flow. Extensile fila-
FIG. 1. (Color online) Self-assembly of extensile filaments. (a) Flow field of two extensile filaments producing lateral attraction. (b) Lateral attraction drive rapid dimerization at early times. (c) Coagulation of k -mers at intermediate times. (d) Aggregation of k -mers into a single cluster at late times. The background color indicates the magnitude of the velocity normalized by its maximum. Snapshot b-d are for a φ = 0 05 system taken at . t = 0 1 . τ e , t = 0 2 . τ e and t = 1 8 . τ e respectively.
ments, driven by dominant lateral attractions, join into stable rotating dimers. Contractile filaments, driven by dominant perpendicular attractions, join into translating and rotating T-shaped dimers. Extensile filament suspensions are always unstable and show a two-step aggregation kinetics. A rapid initial growth of small clusters is followed by a slower merging of these clusters into large, dynamic aggregates which translate and rotate ballistically. Contractile filament suspensions remain homogeneous and isotropic but develop short wavelength microstructure that depends on volume fraction. We observe such microstructures in a sequence of states of asters, clusters, and incipient gels with increasing volume fraction. The centres of mass of the filaments show a non-thermal diffusion which decreases with increasing volume fraction. We describe these results in detail below and then discuss their significance.
Active Zimm model: We briefly describe our model for an active filament [10]. We consider N b spherical active beads of radius a centred at r n . These are acted on by elastic forces F n = -∂U ( r 1 , . . . , r N b ) /∂ r n derived from the potential U ( r 1 , . . . , r N b ) which bonds neighbouring beads into a connected filament, penalises filament curvature, and enforces volume exclusion between beads. The equilibrium bond length is b . Each bead has a stresslet S n = S 0 ( t n t n -1 3 I ) aligned along the local tangent t n . The beads move in response to the elastic forces acting on them and the hydrodynamic flow which results, at low Reynolds numbers and small bead size, in the following equation of motion glyph[negationslash]
$$\dot { \mathbf r } _ { n } = \mu \mathbf F _ { n } + \sum _ { m \neq n } \left [ G ( \mathbf r _ { n } - \mathbf r _ { m } ) \cdot \mathbf F _ { m } + \nabla \mathbf G ( \mathbf r _ { n } - \mathbf r _ { m } ) \cdot \mathbf S _ { m } \right ]. \\ \mathbf r _ { \dots \cdots } \cdot \mathbf C / \dots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \\ \mathbf r _ { \dots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \dots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \ddots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots.$$
Here, G r ( ) is a Green function of the Stokes equation, µ is the bead mobility and S 0 is the principal value of the stresslet. The flow produced by a single bead is extensile or contractile when S 0 is, respectively, positive or negative. The stresslet self-term is absent as it cannot produce translational motion in an unbounded domain. These equations of motions may be thought of as a generalization, to active filaments, of the Zimm model of polymer dynamics where hydrodynamic interactions are treated at the level of the Kirkwood-Risemann superposition approximation. The accuracy of this approximation is ( a/b ) 3 for monopolar flows and, by an extension of the original study, ( a/b ) 4 for dipolar flows. With the choice of parameters made here, we make no more than 6% error in computing hydrodynamic interactions using the superposition approximation. We simulate a suspension of N such filaments using the lattice Boltzmann method to compute the active flows, as described in detail in [10].
Activity induced dimerization : As a prelude to collective dynamics we study the motion of a pair of ac-
FIG. 2. (Color online) Growth kinetics in extensile filaments. The mean of the k -mer distribution function 〈 k 〉 as a function of time t , for varying filament numbers N . Dimerization dominates the rapid growth for t glyph[lessmuch] τ e while coagulation of k -mers dominates the slow growth for t glyph[greatermuch] τ e . These regimes correspond, respectively, to panels (b) and (c) of Fig.(1).
FIG. 3. (Color online) Self-assembly of contractile filaments. (a) Flow field of two contractile filaments producing perpendicular attraction. Microstructured steady states of asters at volume fraction φ = 0 11 in (b), clusters at . φ = 0 15 in (c) and incipient . gel at φ = 0 34 in (d). . A typical aster configuration is circled in (b). The background color indicates the magnitude of the velocity normalized by its maximum.
tive filaments in their mutual hydrodynamic flow. The flow points outwards along the long-axis for extensile filaments but inwards for contractile filaments. More generally, contractile flow is obtained from extensile flow by reversing all streamlines [10]. Extensile filament pairs attract laterally as is clear from the streamlines around a proximate pair shown in Fig.(1a). Extensile filament pairs repel perpendicularly as is clear from the reversed streamlines of Fig.(3a). The lateral attraction drives parallel filaments towards each other till steric forces prevent further motion. The shear flow along the filament long axis causes a small lateral motion, thus forming a stable rotating dimer (see movie in [13]). This is the stable state for a pair of extensile filaments and is independent of the special initial condition chosen in the simulation. Streamlines around a contractile filament flow in a direction opposite to that of extensile filaments. Thus, contractile filament pairs repel laterally and attract perpendicularly in their mutual flow as is clear from the streamlines in Fig.(1a) and Fig.(3a). The perpendicular attraction, combined with steric repulsion, drives contractile filaments to form T -shaped dimers which translate and rotate (see movie in [13]). Again, this stable state is independent of the initial condition used to generate it.
The dimerization described above is an essentially nonequilibrium phenomenon mediated by the active hydrodynamic flow. Although the microscopic processes that give rise to activity-induced flows and result in the dimerization phenomenon might vary greatly in origin and function, the resultant hydrodynamic flows and interactions can be completely parametrised using the irreducible expansion of the active flow [12], the leading term of which is retained in this analysis. This makes the nonequilibrium dimerisation both robust and generic.
Aggregation of extensile filaments : The nonequilibrium flow-induced forces described above produce selfassembled structures in suspensions of filaments which depend crucially on the sign of the stresslet. In exten- sile filaments, the lateral hydrodynamic attraction destabilises the homogeneous isotropic state of the suspension. Dimer pairs form rapidly and further aggregate to form k -mers. Asymptotically, the individual clusters collapse into a single dynamic cluster which translates and/or rotates according to its final shape. The qualitative features of the aggregation kinetics is shown in the panels (b-d) of Fig.1 and in the movie in [13].
To quantitatively understand the aggregation kinetics we compute the distribution P k, t ( ) of k -mers, which we define as k filaments that are within half a filament length of each other. The distribution is computed over an ensemble of 50 simulations with different initial conditions. The first moment 〈 k 〉 ( ) t = ∑ ∞ k =1 k P ( k, t ) provides a measure of the mean size of the aggregates and this quantity is plotted in Fig.(2). There is a rapid initial growth of the mean size for a duration τ e followed by a slower growth at later times. We estimate τ e from the intersection of a pair of straight lines that best fit the data. From this, we find that the duration τ e of rapid growth is weakly dependent or, possibly, independent of volume fraction while the duration of slow growth to saturation increases with volume fraction.
The nonequilibrium aggregation proceeds through a frequent coagulation process in which k -mers join j -mers to form ( k + )-mers and a rare fragmentation process j in which ( k + )-mers break into j j -mers and k -mers. A careful observation of the kinetics reveals a hierarchy of rates: dimerization is the most rapid process, followed by single filaments joining k -mers (with k ≥ 3), then dimers joining k -mers and, finally, k -mers joining j -mers (with j ≥ 3). The fragmentation rates show an opposite hierarchy: the breaking of a ( k + )-mer into j k -mers and j -mers with k ≈ j is the most rapid process, followed the breaking of dimers and, finally, monomers from ( k + )-mers. These rates are determined by the hydrodyj namic flow due to k -mers and j -mers and is sensitive to their shape. A direct calculation of the coagulation and
(a) Stationary cluster size distribution
(b) Filament center of mass diffusion
FIG. 4. (Color online) (a) Steady state k -mer distribution function P glyph[star] ( k ) with varying volume fraction φ . The distribution shows two qualitative changes at φ = 0 15 and . φ = 0 34. . (b) Filament diffusion coefficient D as a function of volume fraction φ and mean square displacement (MSD) as a function of time t (inset). D is non-dimensionalised by L /τ 2 c , where L = ( N b -1) b is the filament length and τ c the typical time taken to reach stationarity from initially ordered states.
fragmentation rates is, therefore, a formidable problem. Nonetheless, constructing a tractable theoretical model for the rates of hydrodynamic coagulation and fragmentation is desirable as the rates can then be employed in a Smoluchowski-like mean-field description of aggregation kinetics.
Microstructure of contractile filaments: Nonequilib- rium self-assembly in contractile filaments proceeds in a manner very different from extensile filaments. Here, perpendicular hydrodynamic attraction induces dynamic microstructure in initially homogeneous and isotropic states of the suspension. Averaged over long times and large lengths, the suspension remains homogeneous and isotropic, but any instantaneous configuration reveals both positional inhomogeneities and orientational anisotropies. Three distinct microstructures emerge as a function of volume fraction, as shown in panels (bd) of Fig.(3). At the lowest volume fractions, filaments transiently cluster into star-shaped k -mers reminscent of asters (panel b). These k -mers frequently break and reform while their centers of mass diffuse as shown in the movie in [13]. Through this dynamics, the spatiotemporally averaged position and orientation become, respectively, uniform and isotropic. With an increase in volume fraction, the steric constraints limit the dynamic joining and breaking of k -mers and their diffusion (panel c). A percolating network of filaments is formed which, at short time scales, may present a solid-like response by being able to support forces and torques. With further increase in volume fraction, this network gets sterically constrained to a great extent and thus shows greatly reduced positional and orientational dynamics. States that are initially inhomogeneous and have a preferred orientation are unstable and evolve, rapidly, into homogeneous, isotropic microstructured states shown in the movie [13].
In order to distinguish between the distinct microstructural states, we compute the stationary k -mer distribution P glyph[star] ( k ) = lim t →∞ P k, t ( ) for different filament volume fractions and plot it in Fig. (4a). Asters correspond to φ = 0 05 0 11 0 15, clusters to . , . , . φ = 0 21 0 24 and the . , . incipient gel to φ = 0 34. . The distribution shows qualitatively different shapes for each microstructure and the rapid change in shape around φ = 0 3 provides a signa-. ture of gelation. The motion of individual filaments is diffusive in all three microstructured states as the linear variation of the mean square displacement with time shows in the inset of Fig.(4b). The diffusive constant D decreases with volume fraction as Fig.(4b) shows. The parallel hydrodynamic repulsion between filaments enhances their effective volume which increases the steric hindrance and so constrains filament motion, leading to smaller diffusion. It is important to emphasise that the diffusive motion occurs in the absence of thermal fluctuations and consequently D does not obey a Stokes-Einstein relation.
Discussion: Hierarchical self-assembly in thermodynamic equilibrium is driven by a competition between energy and entropy. In contrast, the self-assembly mechanism reported here is an essentially nonequilibrium phenomenon driven by dissipative, hydrodynamic flow produced by active processes. The relative translation of pairs of particles, which contributes to microstructure formation, is possible to due the absence of Onsager sym-
metry of the mobility matrix that prevents such motion in passive hydrodynamic flow. This short wavelength physics is resolved by our particle picture of active flow but is beyond the reach of current long wavelength continuum and kinetic theories.
Several recent experiments report dynamic selfassembly of anisotropic particles in hydrodynamic flow. The formation of 'living' colloidal crystals on planar substrates [14] bears a striking similarity with the aggregation of extensile filaments into liquid crystalline clusters. We suggest that extensile, dipolar hydrodynamic flows, modified by the presence of a no-slip boundary to induce attraction, play a crucial role in the self-assembly of such 'living' crystals. The dimerization of polar bi-metallic catalytic nanomotors [15] is, again, strikingly similar to the dimerization we report here. To directly verify some of our predictions we suggest experiments on apolar active particles made by adding a third metallic stripe of gold or platinum to bi-metallic catalytic nanomotors. Finally, we note that our work suggest a new nonequilibrium mechanism with which to control and manipulate hierarchical self-assembly of soft matter.
Computing resources through HPCE, IIT Madras and Annapurna, IMSc are gratefully acknowledged. RA thanks the Indo-US Science and Technology Foundation for a fellowship. The authors thank M. E. Cates, P. Chaikin, S. Ghose, A. Laskar, T. E. Mallouk, H. Masoud, D. Pine, M. Shelley and R. Singh for helpful discussions, S. Ghose for help with figures and R. Manna for sharing simulation data on filament pairs.
- [1] F. J. N´d´ elec, e T. Surrey, A. C. Maggs, and S. Leibler, Nature 389 , 305 (1997).
- [2] T. Sanchez, D. Chen, S. DeCamp, M. Heymann, and Z. Dogic, Nature 491 , 431 (2012).
- [3] M. C. Marchetti, J. F. Joanny, S. Ramaswamy, T. B. Liverpool, J. Prost, M. Rao, and R. A. Simha, Rev. Mod. Phys. 85 , 1143 (2013).
- [4] D. Saintillan and M. J. Shelley, Comptes Rendus Physique 14 , 497 (2013).
- [5] R. A. Simha and S. Ramaswamy, Phys. Rev. Lett. 89 , 058101 (2002).
- [6] D. Saintillan and M. J. Shelley, Phys. Rev. Lett. 100 , 178103 (2008).
- [7] F. G. Woodhouse and R. E. Goldstein, Physical review letters 109 , 168105 (2012).
- [8] E. Tjhung, D. Marenduzzo, and M. E. Cates, Proceedings of the National Academy of Sciences 109 , 12381 (2012).
- [9] L. Giomi, M. J. Bowick, X. Ma, and M. C. Marchetti, Physical review letters 110 , 228101 (2013).
- [10] G. Jayaraman, S. Ramachandran, S. Ghose, A. Laskar, M. Saad Bhamla, P. B. Sunil Kumar, and R. Adhikari, Phys. Rev. Lett. 109 , 158302 (2012); A. Laskar, R. Singh, S. Ghose, G. Jayaraman, P. S. Kumar, and R. Adhikari, Scientific reports 3 (2013), 10.1038/srep01964.
- [11] R. Chelakkot, A. Gopinath, L. Mahadevan, and M. F. Hagan, Journal of The Royal Society Interface 11 , 20130884 (2014); H. Jiang and Z. Hou, Soft Matter 10 , 1012 (2014).
- [12] S. Ghose and R. Adhikari, Phys. Rev. Lett. 112 , 118102 (2014).
- [13] See Supplemental Material on YouTube for movies showing aggregation kinetics and microstructure formation and attached Supplementary Information for theoretical estimates of the flow-induced motion, and suggested designs of apolar nanorods.
- [14] J. Palacci, S. Sacanna, A. P. Steinberg, D. J. Pine, and P. M. Chaikin, Science 339 , 936 (2013).
- [15] W. Wang, W. Duan, A. Sen, and T. E. Mallouk, Proc. Natl. Acad. Sci. 110 , 17744 (2013). | null | [
"Ankita Pandey",
"P. B. Sunil Kumar",
"R. Adhikari"
] | 2014-08-02T23:19:45+00:00 | 2015-08-19T16:59:29+00:00 | [
"cond-mat.soft",
"physics.chem-ph",
"physics.flu-dyn"
] | Flow-induced nonequilibrium self-assembly in suspensions of stiff, apolar, active filaments | Active bodies in viscous fluids interact hydrodynamically through
self-generated flows. Here we study spontaneous aggregation induced by
hydrodynamic flow in a suspension of stiff, apolar, active filaments. Lateral
hydrodynamic attractions in extensile filaments lead, independent of volume
fraction, to anisotropic aggregates which translate and rotate ballistically.
Lateral hydrodynamic repulsion in contractile filaments lead, with increasing
volume fractions, to microstructured states of asters, clusters, and incipient
gels where, in each case, filament motion is diffusive. Our results demonstrate
that the interplay of active hydrodynamic flows and anisotropic excluded volume
interactions provides a generic nonequilibrium mechanism for hierarchical
self-assembly of active soft matter. |
1408.0434v1 | ## The Buckling of Single-Layer MoS 2 Under Uniaxial Compression
Jin-Wu Jiang ∗
Shanghai Institute of Applied Mathematics and Mechanics, Shanghai Key Laboratory of Mechanics in Energy Engineering, Shanghai University, Shanghai 200072, People's Republic of China
(Dated: August 5, 2014)
## Abstract
Molecular dynamics simulations are performed to investigate the buckling of single-layer MoS 2 under uniaxial compression. The strain rate is found to play an important role on the critical buckling strain, where higher strain rate leads to larger critical strain. The critical strain is almost temperature-independent for T < 50 K, and it increases with increasing temperature for T > 50 K owning to the thermal vibration assisted healing mechanism on the buckling deformation. The length-dependence of the critical strain from our simulations is in good agreement with the prediction of the Euler buckling theory.
PACS numbers: 63.22.Np, 62.25.Jk, 62.20.mq
Keywords: Molybdenum Disulphide, Buckling, Uniaxial Compression
## I. INTRODUCTION
Molybdenum Disulphide (MoS ) is a semiconductor with a bulk bandgap above 1.2 eV, 2 1 which can be further manipulated by changing its thickness, 2 or through application of mechanical strain. 3-6 This finite bandgap is a key reason for the excitement surrounding MoS 2 as compared to graphene as graphene has a zero bandgap. 7-9 Because of its direct bandgap and also its well-known properties as a lubricant, MoS 2 has attracted considerable attention in recent years. 10,11 For example, Radisavljevic et al. 12 demonstrated the application of single-layer MoS 2 (SLMoS ) as a good transistor. The strain and the electronic noise effects 2 were found to be important for the SLMoS 2 transistor. 5,13-15
Besides the electronic properties, several recent works have addressed the thermal and mechanical properties of SLMoS 2 16-25 Recently, we have parametrized the Stillinger-Weber potential for SLMoS . 2 26 Based on this Stillinger-Weber potential, we derived an analytic formula for the elastic bending modulus of the SLMoS , where the importance of the finite 2 thickness effect was revealed. 27 We have also shown that the MoS 2 resonator has much higher quality factor than the graphene resonator. 28
As an important mechanical phenomenon, the buckling of graphene has attracted lots of attention in past few years. 29-40 Compared to graphene, the bending modulus of SLMoS 2 is higher by a factor of seven due to its finite thickness, 27 yet the in-plane bending stiffness in SLMoS 2 is smaller than graphene by a factor of five. 26 As a result, the SLMoS 2 should be more difficult to be buckled than graphene, according to the Euler buckling theory, which says that the buckling critical strain is proportional to the bending modulus to inplane stiffness ratio. 41 This advantage would benefit for the application of SLMoS 2 in some mechanical devices, where the avoidance of buckling is desirable. However, the study of the buckling for the SLMoS 2 is still lacking, and is thus the focus of the present work.
In this paper, we study the buckling of the SLMoS 2 under uniaxial compression via molecular dynamics (MD) simulations. We find that the critical buckling strain increases linearly with the increase of the strain rate, and this strain rate effect becomes more important for longer SLMoS . 2 The critical strain is almost temperature-independent in low-temperature regions, but it increases considerably with increasing temperature for temperatures above 50 K, because the buckling deformation is repaired by the thermal vibration at higher temperatures. We show that the critical strain depends on the length ( L ) as /epsilon1 c ∝ 40 6 . /L 2 , which
is in good agreement with the prediction of /epsilon1 c ∝ 43 52 . /L 2 from the Euler buckling theory.
## II. EULER BUCKLING THEORY
We first present some basic knowledge for the Euler buckling theory. Similar as the visual displacement method used in Ref. 41, let's assume that the buckling happens by exciting one normal (phonon) mode ( m,n ) in SLMoS ; i.e. 2 the system is deformed into the shape corresponding to one of its normal mode,
$$w \, = \, w _ { m n } = a _ { m n } \sin \frac { m \pi x } { L _ { x } } \sin \frac { n \pi y } { L _ { y } },$$
where a mn is the amplitude. L x and L y are the length in x and y directions. Integers m , n =0, 2, 4, ... for periodic boundary condition. Because the buckling mode is in close relation with the normal mode, we show the first two lowest-frequency normal modes with integers ( m,n ) = (2,0) and (0,2) in the top and bottom panels in Fig. 1. The periodic boundary condition is applied in x and y directions. The eigen vector is obtained by diagonalizing the dynamical matrix K ij = ∂ V/∂x ∂x 2 i j , which is obtained numerically by calculating the energy change after a small displacement of the i -th and j -th degrees of freedom.
After some simple algebra, we get the general strain energy corresponding to a general mode ( m,n ) as
$$V _ { S } \, & = \, \frac { 1 } { 2 } \int \int \left [ N _ { x } \left ( \frac { \partial w } { \partial x } \right ) ^ { 2 } + N _ { y } \left ( \frac { \partial w } { \partial y } \right ) ^ { 2 } + 2 N _ { x y } \frac { \partial w } { \partial x } \frac { \partial w } { \partial y } \right ] d x d y \\ & = \, \frac { \pi ^ { 2 } } { 8 } L _ { x } L _ { y } N _ { x } m ^ { 2 } \frac { a _ { m n } ^ { 2 } } { L _ { x } ^ { 2 } }, \\ \cdot \quad \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \,.$$
where N x is the force in the x direction. The bending energy corresponding to the mode ( m,n ) is
$$V _ { D } \, & = \, \frac { D } { 2 } \int \int \left \{ \left ( \frac { \partial ^ { 2 } w } { \partial x ^ { 2 } } + \frac { \partial ^ { 2 } w } { \partial y ^ { 2 } } \right ) ^ { 2 } - 2 \, ( 1 - \nu ) \left [ \frac { \partial ^ { 2 } w } { \partial x ^ { 2 } } \frac { \partial ^ { 2 } w } { \partial y ^ { 2 } } - \left ( \frac { \partial ^ { 2 } w } { \partial x \partial y } \right ) ^ { 2 } \right ] \right \} d x d y \\ & = \, \frac { \pi ^ { 4 } L _ { x } L _ { y } } { 8 } D a _ { m n } ^ { 2 } \left [ \left ( \frac { m } { L _ { x } } \right ) ^ { 2 } + \left ( \frac { n } { L _ { y } } \right ) ^ { 2 } \right ] ^ { 2 }, \\ \text{where $\nu$ is the Poisson ratio and $D$ is the bending modulus.}$$
where ν is the Poisson ratio and D is the bending modulus.
Within the configuration just before buckling, the strain energy is maximum and there is no bending energy. After buckling, this maximum strain energy is fully converted into the
bending energy; i.e. V S = V B . From this equation, we get the critical force for buckling
$$N _ { x } \, = \, - \frac { \pi ^ { 2 } D } { L _ { y } ^ { 2 } } \left ( \frac { m L _ { y } } { L _ { x } } + \frac { n ^ { 2 } L _ { x } } { m L _ { y } } \right ) ^ { 2 }.$$
Recall that N x = C 11 /epsilon1 with C 11 as the in-plane stiffness, we get the critical strain for buckling,
$$\epsilon _ { c } \, = \, - \frac { \pi ^ { 2 } D } { C _ { 1 1 } L _ { y } ^ { 2 } } \left ( \frac { m L _ { y } } { L _ { x } } + \frac { n ^ { 2 } L _ { x } } { m L _ { y } } \right ) ^ { 2 }.$$
Obviously, the minimum value of /epsilon1 c is chosen at ( m,n ) = (2 0); i.e. , the buckling happens by deforming the SLMoS 2 into the shape of the first lowest-frequency normal mode shown in the top panel of Fig. 1. We note that the choose of m = 2 instead of m = 1 here is the result of the constraint from the periodic boundary condition applied in the x direction. The Stillinger-Weber potential gives a bending modulus 27 D = 9 61 eV and the in-plane tension . stiffness 26 C 11 = 139 5 Nm . -1 for the SLMoS . Using these two quantities, we get an explicit 2 formula for the critical strain of SLMoS , 2
$$\epsilon _ { c } = - \frac { 4 \pi ^ { 2 } D } { C _ { 1 1 } L _ { x } ^ { 2 } } = - \frac { 4 3. 5 2 } { L _ { x } ^ { 2 } } \equiv - \frac { 4 3. 5 2 } { L ^ { 2 } }.$$
Hereafter, we will use L to denote the length of the SLMoS 2 instead of L x .
## III. RESULTS AND DISCUSSIONS
After the representation of the Euler buckling theory, we are now performing MD simulations to study the buckling of SLMoS . All MD simulations in this work are performed using 2 the publicly available simulation code LAMMPS 42,43 , while the OVITO package was used for visualization in this section 44 . The standard Newton equations of motion are integrated in time using the velocity Verlet algorithm with a time step of 1 fs. The interaction within MoS 2 is described by the Stillinger-Weber potential, where the parameters for this potential have been fitted to the phonon dispersion of single-layer and bulk MoS . 2 26 The phonon dispersion is closely related to some mechanical quantities like Young's modulus and some thermal properties, so this parameter set can give a good description for the mechanical and thermal properties of the single-layer MoS . 2 Periodic boundary conditions are applied in the two in-plane directions, and the free boundary condition is applied in the out-of-plane direction. Our simulations are performed as follows. First, the Nos´-Hoover e 45,46 thermostat
is applied to thermalize the system to a constant pressure of 0, and a constant temperature of 1.0 K within the NPT (i.e. the particles number N, the pressure P and the temperature T of the system are constant) ensemble, which is run for 100 ps. The SLMoS 2 is then compressed in the x-direction within the NPT ensemble, which is also maintained through the Nos´ e-Hoover thermostat. The SLMoS 2 is compressed unaxially along the x direction by uniformly deforming the simulation box in this direction, while it is allowed to be fully relaxed in lateral directions during the compression.
We shall examine the strain rate effect on the critical strain. Fig. 2 shows the stress strain relation under compression for SLMoS 2 with length 60 ˚ and width 40 ˚ at 1.0 K A A low temperature. The buckling phenomenon happens when the SLMoS 2 is compressed with the critical strain /epsilon1 c , which corresponds to a sharp drop in the curve. The critical strain /epsilon1 c = 0 00939, 0.01073, and 0.01141 correspond to the strain rate of . ˙ /epsilon1 = 1 0 . µ s -1 , 10.0 µ s -1 , and 100.0 µ s -1 . The critical strain increases with increasing strain rate. It is because the system is compressed so fast that the relaxation time is not long enough for the occurrence of the buckling phenomenon.
Fig. 3 shows the configuration evolution for the SLMoS . 2 The SLMoS 2 is compressed at a strain rate ˙ /epsilon1 = 1 0 . µ s -1 . The buckling happens at /epsilon1 = 0 00939. . The first normal mode buckling is observed at the critical strain, as this mode has the lowest exciting energy. The figure shows that MoS 2 is further deformed with more strain applied. However, the deformation always follows the shape of the first normal mode, and no high-order normal mode is observed. It indicates that the strain energy stored in the buckled SLMoS 2 (with first normal mode buckling) is not large enough to jump from the first normal mode to highorder normal mode. It is because this jumping requires the reverse of a ripple (with large bending curvature) in the first normal mode, which is forbidden by high potential threshold. It is quite interesting that the structure transforms from sinuous into zigzag at /epsilon1 = 0 249, . due to stress concentration at the two valleys of the sinuous shape.
To further examine the strain rate effect on the critical strain, we perform systematic simulations for the buckling of the SLMoS 2 under compression with different strain rate. Fig. 4 shows the critical strain for SLMoS 2 with width 40 ˚ at 1.0 K. The length of the A SLMoS 2 is 60 ˚ in panel (a) and 120 ˚ in panel (b). A A In both systems, the critical strain increases linearly with increasing strain rate. The simulation data are fitted to a linear function y = a + bx , where the coefficient a = 9 4 . × 10 -3 and 2 4 . × 10 -3 can be regarded as
the exact value (with ˙ /epsilon1 → 0 0) for the critical strain in these two SLMoS . . 2 Using a strain rate of 1.0 µ s -1 , we get the critical strains 0.00938 and 0.00252 for SLMoS 2 with L = 60 ˚ A and 120 ˚ . As a result, the error due to using a finite strain rate of 1.0 A µ s -1 is 0.2% and 5% for these two SLMoS . 2 For the coefficient b , this slope of the fitting line in the shorter system in panel (a) is 2 7 . × 10 -5 µ s, which is only a quarter of the slope of 1 0 . × 10 -4 µ s in the longer MoS 2 in panel (b). It indicates that the strain rate has stronger effect for longer SLMoS , because the frequency of the buckling mode (first lowest-frequency normal mode) 2 is lower in longer system, leading to longer response time. That is the buckling mode in a longer SLMoS 2 requires longer relaxation time for its occurrence.
Fig. 5 shows the length dependence of the critical strain in SLMoS 2 with width 40 ˚ . A This set of simulations are performed at a low temperature of 1.0 K, so that it can be consistent with the static Euler buckling theory. The system is compressed at the strain rate of 1.0 µ s -1 (red squares), 10.0 µ s -1 (blue triangles), and 100.0 µ s -1 (black circles). According to the Euler buckling theory, the critical strain is inversely proportional to the square of the length of the SLMoS , so we fit simulation data to function 2 y = a + bx -2 . The coefficient b increases with increasing strain rate. In particular, the coefficient of b = 40 6 ˚ . A 2 for ˙ /epsilon1 = 1 0 . µ s -1 agrees quite well with (error 6.7%) the prediction from the Euler buckling theory of b = 4 π D/C 2 11 = 43 52 ˚ , where . A 2 D is the bending modulus and C 11 is the in-plane stiffness for SLMoS . 2 Furthermore, for the strain rate ˙ /epsilon1 = 1 0 . µ s -1 , the other coefficient a is pretty small and there is almost no fluctuation between simulation data, both of which validate the usage of the small strain rate, ˙ /epsilon1 = 1 0 . µ s -1 . The critical strain for the shortest SLMoS 2 ( L = 60 ˚ ) deviates from the fitting curve in all of the three situations. A It is due to the linear nature of the Euler buckling theory, while the nonlinear effect becomes important in the short system. The critical strain does not depend on the width of the SLMoS , 2 because the shape of the buckling mode is uniform in the width direction. Hence, the strain energy is the same in SLMoS 2 of different widths. That is why the width parameter does not present in the Euler buckling formula Eq. (5).
Fig. 6 shows the temperature effect on the critical strain for SLMoS 2 with width 40 ˚ at A strain rate 1.0 µ s -1 . Panel (a) is the temperature dependence of the relative critical strain versus for SLMoS 2 with L = 60 and 120 ˚ . The relative critical strain is scaled by the value A at 1.0 K; i.e. 0.00939 and 0.00252 for L = 60 and 120 ˚ respectively. A Lines are guided to the eye. The critical strain in both systems keeps almost a constant at temperatures bellow
50 K. It increases linearly with increasing temperature for temperatures above 50 K, and the critical strain increases faster in longer SLMoS . 2 This is due to strong thermal vibration at high temperatures. Panel (b) shows the maximum thermal vibration amplitude versus temperature for SLMoS 2 with L = 60 (black circles) and 120 ˚ (red squares). A According to the equipartition theorem, the maximum thermal vibration amplitude can be fitted to function y = ax 0 5 . . Lines are the fitting results. The maximum vibration amplitude increases with increasing temperature. At higher temperatures (above 50 K), the maximum vibration amplitude is so large that it can disturb the buckling mode; i.e. the strong thermal vibration is able to heal the buckling-induced deformation in the SLMoS . 2 At the initial buckling stage, atoms are displaced from its original position (following the buckling mode, i.e first lowest-frequency normal mode), but atoms are involved in a strong thermal vibration in the mean time. This large thermal vibration amplitude blurs the buckling deformation and the original configuration of the SLMoS . 2 In other words, the thermal vibration introduces a healing mechanism for the buckling deformation at the initial buckling stage. Similar thermal healing mechanism has also been observed in the thermal treatment for defected carbon materials. 47,48 Hence, larger compression strain is in need to intrigue the buckling phenomenon at higher temperatures.
We end by noting that the present atomistic simulation actually has practical impact, although we emphasized the importance of the strain rate and temperature effects on the buckling of the SLMoS , which are technique aspects. MoS 2 2 and graphene have complementary physical properties, so it is natural to investigate the possibility of combining graphene and MoS 2 in specific ways to create heterostructures that mitigate the negative properties of each individual constituent. For example, graphene/MoS /graphene heterostructures have 2 better photon absorption and electron-hole creation properties, because of the enhanced light-matter interactions by the single-layer MoS . 2 49 It has been shown that the buckling critical strain for a graphene of 19.7 ˚ in length is around 0.0068. A 29 From Euler buckling theorem, it can be extracted that the buckling critical strain for a graphene of 60.0 A in ˚ length is around 0.00073. Our simulations have shown that the buckling critical strain for SLMoS 2 of the same length is 0.0094, which is one order higher than graphene. It indicates that the SLMoS 2 can sustain stronger compression than graphene. The higher buckling critical strain for the SLMoS 2 is helpful for the graphene/MoS 2 heterostructure to protect from buckling damage.
## IV. CONCLUSION
In conclusion, we have performed MD simulations to investigate the buckling of the SLMoS 2 under uniaxial compression. In particular, we examine the importance of the strain rate and temperature effects on the critical buckling strain. The critical strain increases linearly with increasing strain rate, and it keeps almost a constant at low temperatures. The critical strain increases with increasing temperature at temperatures above 50 K, because the strong thermal vibration is able to repair the buckling-induced deformation. The length dependence for the critical strain is in good agreement with the Euler buckling theory.
Acknowledgements The work is supported by the Recruitment Program of Global Youth Experts of China and the start-up funding from the Shanghai University.
∗ Email address: [email protected]
1 K. K. Kam and B. A. Parkinson, Journal of Physical Chemistry 86 , 463 (1982).
- 2 K. F. Mak, C. Lee, J. Hone, J. Shan, and T. F. Heinz, Physical Review Letters 105 , 136805 (2010).
- 3 J. Feng, X. Qian, C. . Huang, and J. Li, Nature Photonics 6 , 866 (2012).
- 4 P. Lu, X. Wu, W. Guo, and X. C. Zeng, Phys. Chem. Chem. Phys. 14 , 13035 (2012).
- 5 H. J. Conley, B. Wang, J. I. Ziegler, R. F. Haglund, S. T. Pantelides, and K. I. Bolotin, Nano Letters 13 , 3626 (2013).
- 6 T. Cheiwchanchamnangij, W. R. L. Lambrecht, Y. Song, and H. Dery, Physical Review B 88 , 155404 (2013).
- 7 K. S. Novoselov, A. K. Geim, S. V. Morozov, D. Jiang, M. I. Katsnelson, I. V. Grigorieva, S. V. Dubonos, and A. A. Firsov, Nature 438 , 197 (2005).
- 8 A. H. Castro Neto, F. Guinea, N. M. R. Peres, K. S. Novoselov, and A. K. Geim, Rev. Mod. Phys. 81 , 109 (2009).
- 9 V. M. Pereira and A. H. Castro Neto, Physical Review Letters 103 , 046801 (2009).
- 10 Q. H. Wang, K. Kalantar-Zadeh, A. Kis, J. N. Coleman, and M. S. Strano, Nature Nanotechnology 7 , 699 (2012).
- 11 M. Chhowalla, H. S. Shin, G. Eda, L. . Li, K. P. Loh, and H. Zhang, Nature Chemistry 5 , 263
(2013).
- 12 B. Radisavljevic, A. Radenovic, J. Brivio, V. Giacometti, and A. Kis, Nature Nanotechnology 6 , 147 (2011).
- 13 V. K. Sangwan, H. N. Arnold, D. Jariwala, T. J. Marks, L. J. Lauhon, and M. C. Hersam, Nano Letters 13 , 4351 (2013).
- 14 M. Ghorbani-Asl, N. Zibouche, M. Wahiduzzaman, A. F. Oliveira, A. Kuc, and T. Heine, Scientific Reports 3 , 2961 (2013).
- 15 T. Cheiwchanchamnangij, W. R. L. Lambrecht, Y. Song, and H. Dery, Physical Review B 88 , 155404 (2013).
- 16 W. Huang, H. Da, and G. Liang, Journal of Applied Physics 113 , 104304 (2013).
- 17 J.-W. Jiang, X.-Y. Zhuang, and T. Rabczuk, Scientific Reports 3 , 2209 (2013).
- 18 V. Varshney, S. S. Patnaik, C. Muratore, A. K. Roy, A. A. Voevodin, and B. L. Farmer, Computational Materials Science 48 , 101 (2010).
- 19 S. Bertolazzi, J. Brivio, and A. Kis, ACS Nano 5 , 9703 (2011).
- 20 R. C. Cooper, C. Lee, C. A. Marianetti, X. Wei, J. Hone, and J. W. Kysar, Physical Review B 87 , 035423 (2013).
- 21 R. C. Cooper, C. Lee, C. A. Marianetti, X. Wei, J. Hone, and J. W. Kysar, Physical Review B 87 , 079901 (2013).
- 22 X. Liu, G. Zhang, Q.-X. Pei, and Y.-W. Zhang, Applied Physics Letters 103 , 133113 (2013).
- 23 A. Castellanos-Gomez, M. Poot, G. A. Steele, H. S. J. van der Zant, N. Agrait, and G. RubioBollinger, Advanced Materials 24 , 772 (2012).
- 24 A. Castellanos-Gomez, R. Roldan, E. Cappelluti, M. Buscema, F. Guinea, H. S. J. van der Zant, and G. A. Steele, Nano Letters 13 , 5361 (2013).
- 25 A. Castellanos-Gomez, M. Poot, G. A. Steele, H. S. J. van der Zant, N. Agrat, and G. RubioBollinger, Nanoscale Res Lett 7 , 1 (2012).
- 26 J.-W. Jiang, H. S. Park, and T. Rabczuk, Journal of Applied Physics 114 , 064307 (2013).
- 27 J.-W. Jiang, Z. Qi, H. S. Park, and T. Rabczuk, Nanotechnology 24 , 435705 (2013).
- 28 J.-W. Jiang, H. S. Park, and T. Rabczuk, Nanoscale 6 , 3618 (2013).
- 29 Q. Lu and R. Huang, International Journal of Applied Mechanics 1 , 443 (2009).
- 30 W. J. Patrick, Journal of Computational and Theoretical Nanoscience 7 , 2338 (2010).
- 31 A. Sakhaee-Pour, Computational Materials Science 45 , 266 (2009).
- 32 S. C. Pradhan and T. Murmu, Computational Materials Science 47 , 268 (2009).
- 33 S. C. Pradhan, Physics Letters, Section A: General, Atomic and Solid State Physics 373 , 4182 (2009).
- 34 O. Frank, G. Tsoukleri, J. Parthenios, K. Papagelis, I. Riaz, R. Jalil, K. S. Novoselov, and C. Galiotis, ACS Nano 4 , 3131 (2010).
- 35 A. Farajpour, M. Mohammadi, A. R. Shahidi, and M. Mahzoon, Physica E: Low-dimensional Systems and Nanostructures 43 , 1820 (2011).
- 36 V. Tozzini and V. Pellegrini, Journal of Physical Chemistry C 115 , 25523 (2011).
- 37 S. Rouhi and R. Ansari, Physica E: Low-dimensional Systems and Nanostructures 44 , 764 (2012).
- 38 G. I. Giannopoulos, Computational Materials Science 53 , 388 (2012).
- 39 M. Neek-Amal and F. M. Peeters, Applied Physics Letters 100 , 101905 (2012).
- 40 H. . Shen, Y. . Xu, and C. . Zhang, Applied Physics Letters 102 , 131905 (2013).
- 41 S. Timoshenko and S. Woinowsky-Krieger, Theory of Plates and Shells, 2nd ed (McGraw-Hill, New York, 1987).
- 42 S. J. Plimpton, Journal of Computational Physics 117 , 1 (1995).
- 43 Lammps, http://www.cs.sandia.gov/ ∼ sjplimp/lammps.html (2012).
- 44 A. Stukowski, Modelling and Simulation in Materials Science and Engineering 18 , 015012 (2010).
- 45 S. Nose, Journal of Chemical Physics 81 , 511 (1984).
- 46 W. G. Hoover, Physical Review A 31 , 1695 (1985).
- 47 Y. A. Kim, H. Muramatsu, T. Hayashi, M. Endo, M. Terrones, and M. S. Dresselhaus, Chemical Physics Letters 398 , 87 (2004).
- 48 J.-W. Jiang and J.-S. Wang, Journal of Applied Physics 108 , 054303 (2010).
- 49 L. Britnell, R. M. Ribeiro, A. Eckmann, R. Jalil, B. D. Belle, A. Mishchenko, Y.-J. Kim, R. V. Gorbachev, T. Georgiou, S. V. Morozov, A. N. Grigorenko, A. K. Geim, C. Casiraghi, A. H. C. Neto, and K. S. Novoselov, Science 340 , 1311 (2013).
FIG. 1: (Color online) The two lowest-frequency phonon normal modes in the SLMoS 2 of dimension 100 × 80 ˚ , with periodic boundary condition in both A x and y directions. The position of atom i plotted in the figure is /vector r i = /vector R i + C/vector u i , where /vector R i is the equilibrium position, /vector u i is the component of atom i in the eigen vector of the normal mode. C is a scaling factor for the convenience of illustration. The eigen vector is /vector u i = /vector e z sin 2 πx L x for the first lowest-frequency mode in the top panel, and /vector u i = /vector e z sin 2 πy L y for the second lowest-frequency mode in the bottom panel.
FIG. 2: (Color online) Stress strain relation under compression for SLMoS 2 with length 60 ˚ and A width 40 ˚ at 1.0 K. The curve drops sharply at a critical strain A /epsilon1 c = 0 00939 when the SLMoS . 2 is compressed at a strain rate ˙ /epsilon1 = 1 0 . µ s -1 .
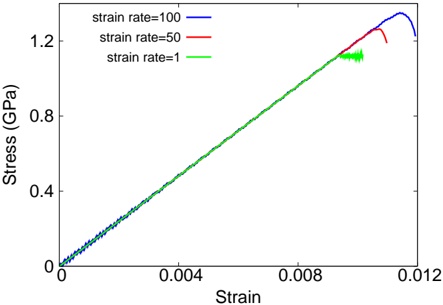
FIG. 3: (Color online) The structure evolution for SLMoS 2 with length 60 A and width 40 ˚ ˚ A at 1.0 K. The SLMoS 2 is compressed at a strain rate ˙ /epsilon1 = 1 0 . µ s -1 . The buckling happens at /epsilon1 = 0 00939. . The structure transforms from sinuous into zigzag at /epsilon1 = 0 249. .
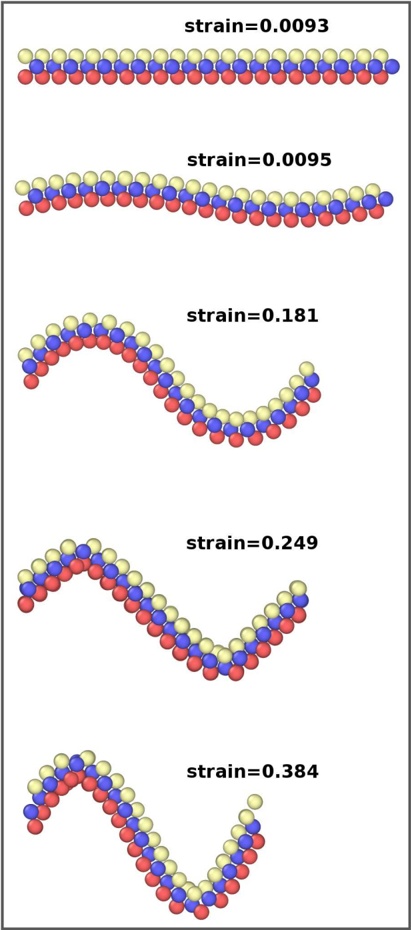
FIG. 4: (Color online) The strain rate effect on the critical strain for SLMoS 2 with width 40 ˚ A at 1.0 K. The critical strain increases linearly with increasing strain rate for SLMoS 2 with length L = 60 ˚ in (a) and A L = 120 ˚ in (b). A Note that the slope (2 7 . × 10 -5 µ s) of the fitting line in the shorter system in (a) is only a quarter of the slope of 1 0 . × 10 -4 µ s in the longer MoS 2 in (b), which implies that the strain rate has stronger effect for longer MoS 2 .
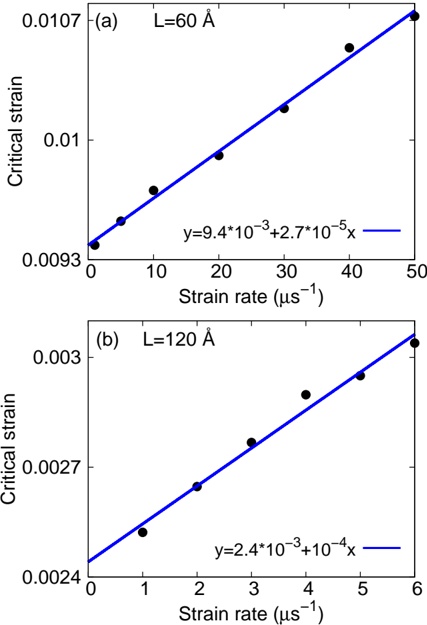
FIG. 5: (Color online) The length dependence of the critical strain in SLMoS 2 with width 40 ˚ A at 1.0 K. The system is compressed at the strain rate of 1.0 µ s -1 (red squares), 10.0 µ s -1 (blue triangles), and 100.0 µ s -1 (black circles). Lines are the fitting to function y = a + bx -2 , where the coefficient b increases with increasing strain rate. In particular, the coefficient of b = 40 6 ˚ . A 2 for ˙ /epsilon1 = 1 0 . µ s -1 is only 6.7% smaller than the prediction from the Euler buckling theory of b = 4 π D/C 2 11 = 43 52 ˚ , where . A 2 D is the bending modulus and C 11 is the in-plane stiffness for SLMoS . 2
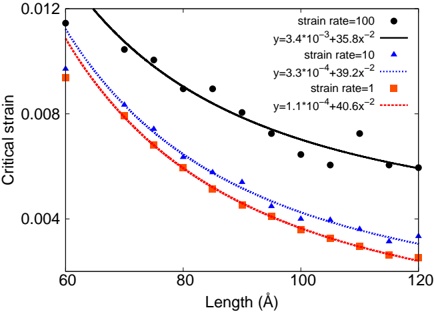
FIG. 6: (Color online) The temperature effect on the critical strain for SLMoS 2 with width 40 ˚ A at strain rate 1.0 µ s -1 . (a) Relative critical strain versus temperature for SLMoS 2 with L = 60 and 120 ˚ . The relative critical strain is scaled by the value at 1.0 K; i.e. A 0.00939 and 0.00252 for L = 60 and 120 ˚ respectively. A Lines are guided to the eye. (b) The maximum thermal vibration amplitude versus temperature for SLMoS 2 with L = 60 (black circles) and 120 A (red squares). ˚ Lines are fitting to function y = ax 0 5 . .
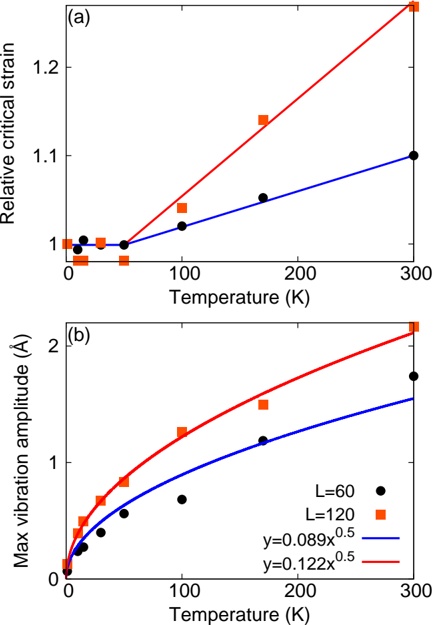 | 10.1088/0957-4484/25/35/355402 | [
"Jin-Wu Jiang"
] | 2014-08-02T23:20:29+00:00 | 2014-08-02T23:20:29+00:00 | [
"cond-mat.mtrl-sci"
] | The Buckling of Single-Layer MoS2 Under Uniaxial Compression | Molecular dynamics simulations are performed to investigate the buckling of
single-layer MoS2 under uniaxial compression. The strain rate is found to play
an important role on the critical buckling strain, where higher strain rate
leads to larger critical strain. The critical strain is almost
temperature-independent for T<50 K, and it increases with increasing
temperature for T>50 K owning to the thermal vibration assisted healing
mechanism on the buckling deformation. The length-dependence of the critical
strain from our simulations is in good agreement with the prediction of the
Euler buckling theory. |
1408.0436v1 | ## A Fast Uniaxial Compression of the Single-Layer MoS 2
Jin-Wu Jiang ∗
Shanghai Institute of Applied Mathematics and Mechanics, Shanghai Key Laboratory of Mechanics in Energy Engineering, Shanghai University, Shanghai 200072, People's Republic of China (Dated: August 5, 2014)
The Euler buckling theorem states that the buckling critical strain is an inverse square function of the length for a thin plate in the static compression process. However, the suitability of this theorem in the dynamical process is unclear, so we perform molecular dynamics simulations to examine the applicability of the Euler buckling theorem in case of a fast compression of the single-layer MoS 2 . We find that the Euler buckling theorem is not applicable in such dynamical process, as the buckling critical strain becomes a length-independent constant in the buckled system with many ripples. However, the Euler buckling theorem can be resumed in this dynamical process after restricting the theorem to an individual ripple in the buckled structure.
PACS numbers: 63.22.Np, 62.25.Jk, 62.20.mq Keywords: Molybdenum Disulphide, Euler Buckling Theorem, Strain Rate
Molybdenum Disulphide (MoS ) has attracted consid2 erable attention in recent years on its electronic, thermal, or mechanical properties, 1-16 as it is one of the useful two-dimensional materials. Different two-dimensional materials (eg. graphene and MoS ) have complementary 2 physical properties. Therefore, experimentalists have combined graphene and MoS2 in specific ways to create heterostructures that mitigate the negative properties of each individual constituent. 17 However, the temperature change will lead to some mechanical compression/tension on the heterostructure, because of different thermal expansion coefficient of graphene and MoS . 2 18 This thermal-induced mechanical compression will intrigue the buckling of some layers in the sandwich structure, as the buckling critical strain is usually very low for layered materials. Hence, it is important to investigate the buckling phenomenon, including the single-layer MoS 2 (SLMoS ). 2
The buckling critical strain of a thin plate can be captured by the Euler buckling theorem, i.e., /epsilon1 c = -4 π D 2 C 11 L 2 , where D is the bending modulus and C 11 is the in-plane tension stiffness. L is the length of the plate. The Euler buckling theorem is developed for static compression processes. The static compression process is equivalent to molecular dynamics (MD) simulations with extremely low strain rates. Although this theorem has been widely used in static mechanical processes, it is still unclear whether the Euler buckling theorem is applicable in dynamical compression processes, where the strain rate has important effect on the compression/tension behavior of the system. 19 For instance, it is crucial to apply mechanical strain at a very low strain rate for the study of structure transitions, so that the system has enough time to relax its structure. We thus examine in present work whether the Euler buckling theorem is applicable in the dynamical compression process.
In this letter, we perform MD simulations to examine the applicability of the Euler buckling theorem in the dynamical compression of SLMoS 2 at different strain rates.
It turns out that the Euler buckling theorem is not applicable for longer SLMoS 2 at higher strain rate, in which the buckling critical strain becomes length independent. However, the Euler buckling theorem will become applicable after restricting it to individual ripples in the buckled SLMoS . 2
The SLMoS 2 can be constructed by duplicating a rectangular unit cell of (5.40, 3.12) ˚ in the two-dimensional A plane. The number of unit cell is ( n , n x y ) in the armchair and zigzag directions. The length of the SLMoS 2 is 5 40 . × n x , and its width is 3 12 . × n y . We fix n y = 10 for all simulations in present work. The free boundary condition is applied in the out-of-plane direction. We apply the fixed boundary condition in armchair direction and periodic boundary condition in zigzag direction. The SLMoS 2 is compressed unaxially along the armchair direction. The zigzag direction is kept stress free during compression.
All MD simulations in this work are performed using the publicly available simulation code LAMMPS 20 , while the OVITO package was used for visualization. 21 The standard Newton equations of motion are integrated in time using the velocity Verlet algorithm with a time step of 1 fs. The interaction within MoS 2 is described by the Stillinger-Weber potential. 14 All simulations are performed at 1.0 K low temperature, so that our MD simulations are more comparable with the Euler buckling theorem, which does not consider the temperature effect. The SLMoS 2 is thermalized using the Nos´ e-Hoover 22,23 thermostat for 100 ps within the NPT (i.e. the number of particles N, the pressure P and the temperature T of the system are constant) ensemble. After thermalization, the SLMoS 2 is compressed unaxially along the armchair direction, while the system is allowed to be fully relax in the zigzag direction. NPT ensemble is applied also applied in the compression step.
Fig. 1 shows the stress-strain relation for the SLMoS 2 with n x = 100, which is compressed at strain rates of ˙ /epsilon1 = 10 , 10 , and 10 9 8 7 s -1 , respectively. A value for the
FIG. 1: (Color online) Strain rate effect on the buckling critical strain of SLMoS . 2 Insets (from top to bottom) illustrate the buckling mode of the SLMoS 2 at strain rates of 10 9 , 10 , 8 and 10 7 s -1 , respectively. The size of a single buckling ripple is enclosed by rectangulars.
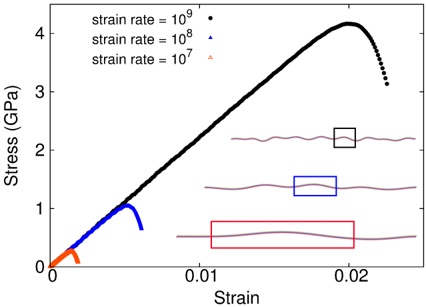
thickness is required for the computation of the stress. However thickness is not a well-defined quantity in oneatomic thick layered materials such as SLMoS . 2 Hence, we have assumed the thickness of the SLMoS 2 to be the space between two neighboring MoS 2 layers in the threedimensional bulk MoS . 2 That is the thickness is 6.09 ˚ A for SLMoS . 2 The x-axis is the absolute value for the compression strain. The SLMoS 2 buckles at the critical strain, at which the stress within the system starts to drop. The critical strain is sensitive to the strain rate, and the buckling critical strain increases sharply with increasing strain rate.
Insets (from top to bottom) of Fig. 1 illustrate the buckling mode of the SLMoS , which is compressed with 2 strain rates of ˙ /epsilon1 = 10 , 10 , and 10 9 8 7 s -1 , respectively. An individual ripple in the buckling mode is enclosed by rectangular. The length of the ripple decreases quickly with increasing strain rate. Normally, the buckling mode follows the shape of the first bending phonon mode in the system, in which only one ripple occurs after buckling. However, if the system is compressed very fast (i.e. with high strain rate), the buckling mode does not follow the shape of the first bending phonon mode of the SLMoS , 2 and there will be more than one ripple in the buckling SLMoS . 2 In other words, higher-energy bending modes are actuated by the fast compression. This phenomenon has also been observed in the compression of graphene. 24
This strain rate effect can be interpreted in terms of the relaxation time for each bending mode. The first bending modes has the longest relaxation time (or oscillation period), τ = 2 π/ω , due to its lowest angular frequency ω . It means that the longest response time is needed for the appearance of the first bending mode during the compression of the SLMoS . When the system is compressed 2 very fast, the response time is too short for the occurrence of the first bending mode. Instead, higher-energy
ε
FIG. 2: (Color online) Length dependence (log-log) of the buckling critical strain for the SLMoS 2 at strain rates of 10 9 , 10 , and 10 8 7 s -1 , respectively. Simulated data are fitted to functions /epsilon1 c = a + bn -2 x , which becomes a length-independent constant a in the limit of n x → + ∞ .
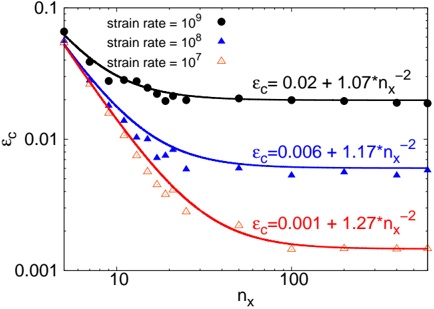
bending modes have shorter relaxation, and is able to be actuated by buckling when the SLMoS 2 is subjected to a fast compression.
Fig. 2 shows the buckling critical strain for SLMoS 2 of different length. The system is compressed at three different strain rates. The simulation data are fitted to the function /epsilon1 c = a + bn -2 x . The second term n -2 x obeys the Euler buckling theorem, which says the critical strain is an inverse quadratic function of the system length. 25 It means that the Euler buckling theorem is valid for short systems. However, in the limit of n x → + ∞ , the critical strain becomes a length-independent constant a = 0.0198, 0.0060, and 0.0015 for strain rates of 10 , 9 10 , 8 and 10 7 s -1 , respectively. This saturating phenomenon clearly demonstrates that the Euler buckling theorem is not applicable in such dynamical process. For ˙ /epsilon1 = 10 7 s -1 , the critical strain is almost saturate when n x > 100. For higher strain rates, the saturation of the critical strain happens at shorter length. That is, the critical strain becomes a constant when n x > 50 for ˙ /epsilon1 = 10 8 s -1 , and n x > 15 for ˙ = 10 /epsilon1 9 s -1 . The fitting parameter a becomes closer to zero for lower strain rate, as the dynamical process is more similar as a static process when the strain rate is lower.
To explore the origin for the inapplicability of the Euler buckling theorem, we examine the ripples in the buckling mode. We first count the number of ripples in the buckling mode. For ˙ /epsilon1 = 10 7 s -1 , there is only one ripple in the buckled SLMoS 2 with n x < 100. For ˙ /epsilon1 = 10 8 s -1 , the buckled SLMoS 2 has only one ripple if n x < 50. For ˙ /epsilon1 = 10 9 s -1 , there is only one ripple in the buckled SLMoS 2 with n x < 15, and more than one ripple is observed for longer systems with n x > 15. For instance, the insets of Fig. 1 show that there are many ripples in the buckled SLMoS 2 with n x = 100, when this system is compressed at a strain rate of 10 9 s -1 . These ripples are
FIG. 3: (Color online) The length dependence of the average ripple size ( λ ) for SLMoS 2 compressed by strain rates of 10 9 , 10 , and 10 8 7 s -1 , respectively. Inset shows the distribution of the ripple size for a buckling SLMoS 2 with n x = 600, which is compressed at ˙ = 10 /epsilon1 8 s -1 . Twenty good ripple samples have been picked out from the buckled SLMoS 2 for the production of this histogram plot. The averaged ripple size from the histogram figure is λ = 90 7 . ± 3 3 ˚ . . A Lines are guide to the eye.
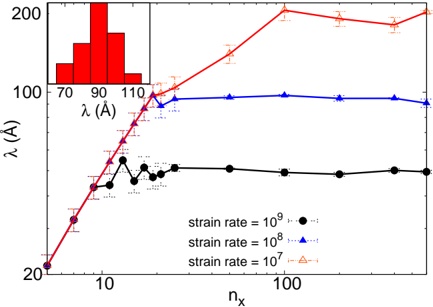
ε
FIG. 4: (Color online) Buckling critical strain versus buckling ripple size for SLMoS 2 compressed by strain rates of 10 9 , 10 , 8 and 10 7 s -1 , respectively. The solid line is the prediction of the Euler buckling theorem. All simulation data are close to the solid line, which validates the Euler buckling theorem.
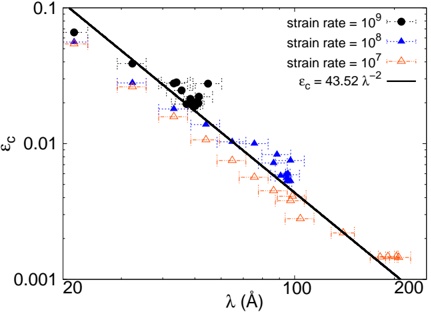
utilized to get the averaged ripple size. It should be noted that, for short systems with only one ripple in the buckling mode, the length of the SLMoS 2 will be regarded as the averaged ripple size, and the error is simply chosen as 10% of the length in this situation.
Fig. 3 shows the length dependence of the averaged ripple size for SLMoS 2 compressed at different strain rates. Fig. 3 inset shows the distribution of the ripple size for a buckling SLMoS 2 with n x = 600, which is compressed at ˙ /epsilon1 = 10 8 s -1 . Twenty good ripple samples have been picked out from the buckled SLMoS 2 for the production of this histogram plot. The averaged ripple size from the histogram figure is λ = 90 7 . ± 3 3 . ˚. Fig. 3 shows an A interesting phenomenon that the averaged ripple size is almost saturated for longer systems with larger n x , where more than one ripple occurs. For higher strain rate, the averaged ripple size becomes saturated at smaller length. This saturation phenomenon is similar as the length dependence of the buckling critical strain shown in Fig. 2, which has demonstrated the inapplicability of the Euler buckling theorem.
Intrigued by the saturation phenomena in both Figs. 2 and 3, we find that the Euler buckling theorem is closely related to the number of ripples in the buckling mode. It is valid in case of only one ripple in the buckling mode. However, the Euler buckling theorem becomes invalid when more than one ripple occurs. The Euler buckling theory says, 25
$$\epsilon _ { c } = - \frac { 4 \pi ^ { 2 } D } { C _ { 1 1 } L ^ { 2 } } = - \frac { 4 3. 5 2 } { L ^ { 2 } }, \text{ \quad \ \ } ( 1 )$$
where L is the length of the system. We have used the Stillinger-Weber potential to extract the bending modulus 15 D = 9 61 . eV and the in-plane tension stiffness 14 C 11 = 139 5 Nm . -1 for the SLMoS . 2 We note an important fact that only one ripple is assumed in the buckling mode during the derivation of Eq. (1). However, Fig. 3 discussed the suitability of the Euler buckling theorem based on regarding L as the total length of the system. It seems that a more proper way is to treat L as the size of an individual ripple in the buckling mode with many ripples. We thus show the buckling critical strain v.s averaged ripple size in Fig. 4. The prediction of the Euler buckling theorem is also plotted in the figure (black solid line) for comparison. We find that all simulation data (calculated with different strain rates) are closely distributed around the line for the Euler buckling theorem. In other words, the Euler buckling theorem is applicable and is independent of the strain rate, after we have treated L in Eq. (1) as the averaged ripple size. The merit of using lower strain rate (10 7 s -1 ) is to extend the examination of the Euler buckling theorem to larger ripple size.
We have performed MD simulations to investigate whether the Euler buckling theorem is applicable for dynamical processes, in which the SLMoS 2 is compressed at high strain rates. We found that the theorem is not applicable in the presence of more than one ripple in the buckling mode, where the buckling critical strain becomes a length-independent constant. However, we have also showed that the Euler buckling becomes applicable if this theorem is applied to a single ripple in the buckled SLMoS . 2
Acknowledgements The work is supported by the Recruitment Program of Global Youth Experts of China and the start-up funding from Shanghai University. The author thanks T.-Z. Zhang and X.-M. Guo for insightful discussions.
- ∗ Email address: [email protected]
- 1 K. K. Kam and B. A. Parkinson, Journal of Physical Chemistry 86 , 463 (1982).
- 2 Q. H. Wang, K. Kalantar-Zadeh, A. Kis, J. N. Coleman, and M. S. Strano, Nature Nanotechnology 7 , 699 (2012).
- 3 M. Chhowalla, H. S. Shin, G. Eda, L. . Li, K. P. Loh, and H. Zhang, Nature Chemistry 5 , 263 (2013).
- 4 A. Castellanos-Gomez, M. Poot, G. A. Steele, H. S. J. van der Zant, N. Agrait, and G. Rubio-Bollinger, Advanced Materials 24 , 772 (2012).
- 5 A. Castellanos-Gomez, M. Poot, G. A. Steele, H. S. J. van der Zant, N. Agrat, and G. Rubio-Bollinger, Nanoscale Res Lett 7 , 1 (2012).
- 6 W. Huang, H. Da, and G. Liang, Journal of Applied Physics 113 , 104304 (2013).
- 7 S. Bertolazzi, J. Brivio, and A. Kis, ACS Nano 5 , 9703 (2011).
- 8 R. C. Cooper, C. Lee, C. A. Marianetti, X. Wei, J. Hone, and J. W. Kysar, Physical Review B 87 , 035423 (2013).
- 9 R. C. Cooper, C. Lee, C. A. Marianetti, X. Wei, J. Hone, and J. W. Kysar, Physical Review B 87 , 079901 (2013).
- 10 V. Varshney, S. S. Patnaik, C. Muratore, A. K. Roy, A. A. Voevodin, and B. L. Farmer, Computational Materials Science 48 , 101 (2010).
- 11 X. Liu, G. Zhang, Q.-X. Pei, and Y.-W. Zhang, Applied Physics Letters 103 , 133113 (2013).
- 12 A. Castellanos-Gomez, R. Roldan, E. Cappelluti, M. Buscema, F. Guinea, H. S. J. van der Zant, and G. A. Steele, Nano Letters 13 , 5361 (2013).
- 13 J.-W. Jiang, X.-Y. Zhuang, and T. Rabczuk, Scientific Reports 3 , 2209 (2013).
- 14 J.-W. Jiang, H. S. Park, and T. Rabczuk, Journal of Applied Physics 114 , 064307 (2013).
- 15 J.-W. Jiang, Z. Qi, H. S. Park, and T. Rabczuk, Nanotechnology 24 , 435705 (2013).
- 16 J.-W. Jiang, H. S. Park, and T. Rabczuk, Nanoscale 6 , 3618 (2013).
- 17 L. Britnell, R. M. Ribeiro, A. Eckmann, R. Jalil, B. D. Belle, A. Mishchenko, Y.-J. Kim, R. V. Gorbachev, T. Georgiou, S. V. Morozov, A. N. Grigorenko, A. K. Geim, C. Casiraghi, A. H. C. Neto, and K. S. Novoselov, Science 340 , 1311 (2013).
- 18 W. Bao, F. Miao, Z. Chen, H. Zhang, W. Jang, C. Dames, and C. N. Lau, Nature Nanotechnology 4 , 562 (2009).
- 19 J.-W. Jiang, A. M. Leach, K. Gall, H. S. Park, and T. Rabczuk, Journal of the Mechanics and Physics of Solids 61 , 1915 (2013).
- 20 S. J. Plimpton, Journal of Computational Physics 117 , 1 (1995).
- 21 A. Stukowski, Modelling and Simulation in Materials Science and Engineering 18 , 015012 (2010).
- 22 S. Nose, Journal of Chemical Physics 81 , 511 (1984).
- 23 W. G. Hoover, Physical Review A 31 , 1695 (1985).
- 24 M. Neek-Amal and F. M. Peeters, Physical Review B 82 , 085432 (2010).
- 25 S. Timoshenko and S. Woinowsky-Krieger, Theory of Plates and Shells, 2nd ed (McGraw-Hill, New York, 1987). | 10.1038/srep07814 | [
"Jin-Wu Jiang"
] | 2014-08-02T23:32:25+00:00 | 2014-08-02T23:32:25+00:00 | [
"cond-mat.mtrl-sci"
] | A Fast Uniaxial Compression of the Single-Layer MoS2 | The Euler buckling theorem states that the buckling critical strain is an
inverse square function of the length for a thin plate in the static
compression process. However, the suitability of this theorem in the dynamical
process is unclear, so we perform molecular dynamics simulations to examine the
applicability of the Euler buckling theorem in case of a fast compression of
the single-layer MoS2. We find that the Euler buckling theorem is not
applicable in such dynamical process, as the buckling critical strain becomes a
length-independent constant in the buckled system with many ripples. However,
the Euler buckling theorem can be resumed in this dynamical process after
restricting the theorem to an individual ripple in the buckled structure. |
1408.0437v3 | ## Graphene Versus MoS : a Mini Review 2
Jin-Wu Jiang ∗
Shanghai Institute of Applied Mathematics and Mechanics, Shanghai Key Laboratory of Mechanics in Energy Engineering, Shanghai University, Shanghai 200072, People's Republic of China (Dated: April 14, 2015)
Graphene and MoS 2 are two well-known quasi two-dimensional materials. This review is a comparative survey of the complementary lattice dynamical and mechanical properties of graphene and MoS . This comparison facilitates the study of graphene/MoS 2 2 heterostructures, which is expected to mitigate the negative properties of each individual constituent.
PACS numbers: 68.65.-k, 63.22.-m, 62.20.-x Keywords: Graphene, Molybdenum Disulphide, Lattice Dynamics, Mechanical Properties
## Contents
I.
Introduction
- II. Structure and Interatomic Potential
- III. Phonon Dispersion
- IV. Mechanical Properties
- V. Nanomechanical Resonators
- VI. Thermal Conductivity
- VII. Electronic Band structure
- VIII. Optical Absorption
1 2 3 4 5 6 7 7 other materials in this family. For example, the mechanical properties of single-layer MoS 2 (SLMoS ) were suc2 cessfully measured using the same nanoindentation platform as graphene. 3,4 In the theoretical community, many theorems or approaches, initially developed to study graphene, are also applicable to other Q2D materials. Some of the extensions may turn out to be trivial because of the common two-dimensional nature of these materials. However, the extensions may bring about new findings as these Q2D materials have different microscopic structures. For example, the bending modulus of SLMoS 2 can be derived using a similar analytic approach as graphene. The bending modulus of SLMoS 2 is about seven times larger than that of graphene, owing to its trilayer structure (one Mo layer sandwiched between two S layers). 5-9 Another example is the puckered micro structure of black phosphorus, which leads to a negative Poisson's ratio in the out-of-plane direction. 10
- IX. Graphene/MoS 2 Heterostructure
- X. Conclusions
References
7
9
9
## I. INTRODUCTION
From the above, we found that graphene is attracting ongoing research interest from both the academic and applied communities. Many review articles have been devoted to graphene. 1,11-19 Addition, more and more researchers have begun examining possible applications of other Q2D materials, using the knowledge gained from graphene. In particular, MoS 2 has attracted considerable research interest. Many review articles have also been published on MoS . 2 20-24
Quasi two-dimensional (Q2D) materials have many novel properties and have attracted intensive research interest over the past decades. The size of the family of Q2D materials keeps expanding. The Q2D family currently contains the following materials: graphene, hexagonal boron nitride, 2D honeycomb silicon, layered transition metal dichalcogenides (MoS , WS , ...), black phos2 2 phorus and 2D ZnO. Graphene is the most well-known material among the Q2D family of materials. Novoselov and Geim were awarded the Nobel prize in physics for graphene in 2010. 1
The investigations on graphene are extensive but not exhaustive. 2 They are helpful for the whole Q2D family because many of the experimental set ups (initially for graphene) can be used to perform measurements on
The present review focusses on a detailed comparison of the mechanical properties of graphene and SLMoS . 2 This comparison makes it clear as to what the positive/negative properties for graphene and MoS 2 are, highlighting the possible advanced features and drawbacks of graphene/MoS 2 heterostructures. 25 These heterostructures were expected to mitigate the negative properties of each individual constituent. For example, graphene/MoS /graphene heterostructures have efficient 2 photon absorption and electron-hole creation properties, because of the enhanced light-matter interactions in the SLMoS 2 layer. 25 Another experiment recently showed that MoS 2 can be protected from radiation damage by coating it with graphene layers. 26 This design exploits the outstanding mechanical properties of graphene.
In this review, we introduce and compare the follow-
FIG. 1: (Color online) Top view of the structures of (a) graphene and (b) SLMoS . 2 The red rhombus encloses the unit cell in each structure. The numbers are the lattice constant ( a ) and the bond length ( ) in ˚ . b A
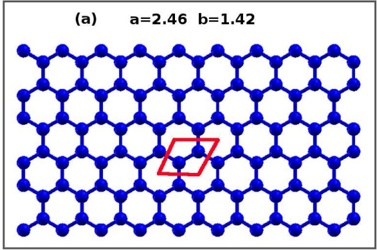
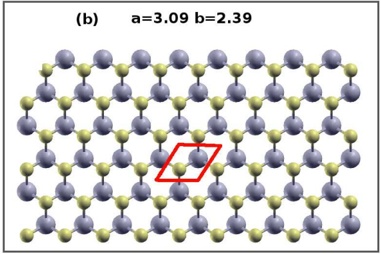
ing properties for graphene and the SLMoS ; the struc2 ture, interatomic potential, phonon dispersion, Young's modulus, yield stress, bending modulus, buckling phenomenon, nanomechanical resonator, thermal conductivity, electronic band structure, optical absorption, and the graphene/MoS 2 heterostructure. This article ends up with a table that lists the major results for all of the properties that are compared in the article.
## II. STRUCTURE AND INTERATOMIC POTENTIAL
Structure. First, the structures of graphene and SLMoS 2 are compared. Fig. 1 (a) shows that graphene has a honeycomb lattice structure with a D 6 h point group. There are two inequivalent carbon atoms in the unit cell. These two carbon atoms are reflected onto each other by the inverse symmetry operation from the D 6 h point group. The lattice constant is a = 2 46 ˚ and the . A C-C bond length is b = a/ √ 3 = 1 42 ˚ . . A 27
Figure 1 (b) shows the top view of the SLMoS 2 structure. SLMoS 2 has a trilayer structure with one Mo atomic layer sandwiched between two outer S atomic layers. The small yellow balls represent the projection of the outer two S atomic layers onto the Mo atomic layer. The point group for SLMoS 2 is D 3 h . The R π rotation sym- metry is broken in SLMoS . There are two S atoms and 2 one Mo atom in the unit cell. The lattice constant for the in-plane unit cell is a = 3 09 ˚ and the Mo-S bond . A length is b = 2 39 ˚ . These values were computed using . A the Stillinger-Weber (SW) potential. 28 They agree with the first-principles calculations 29 and the experiments. 30
Interatomic potential. The interactions between the carbon atoms in graphene can be calculated using four different computation cost levels. The first principles calculation is the most expensive approach to compute the interatomic energy of graphene. Many existing simulation packages can be used for such calculations, including the commercial Vienna Ab-initio Simulation Package (VASP) 31 and the freely available Spanish Initiative for Electronic Simulations with Thousands of Atoms (SIESTA) package. 32 To save on the computation cost, Brenner et al. developed an empirical potential for carbon-based materials, including graphene. 33 The Brenner potential takes the form of the bond-order Tersoff potential 34 and is able to capture most of the linear properties and many of the nonlinear properties of graphene. For instance, it can describe the formation and breakage of bonds in graphene, providing a good description of its structural, mechanical and thermal properties. The Tersoff potential 34 or the SW potential 35,36 provides reasonable predictions for some of the nonlinear and linear properties of graphene. These two empirical potentials have fewer parameters than the Brenner potential, thus they are faster than the Brenner potential. Last, the linear part of the C-C interactions in graphene can be captured using valence force field models (VFFMs). 37 The VFFMs have the most inexpensive computation cost and can be used to efficiently compute some of the linear properties.
The potentials of these four computation levels can also be used for SLMoS . 2 First principles calculations can also be used for SLMoS . 2 In 2009, Liang et al. parameterized a bond-order potential for SLMoS , 2 38 which was based on the bond order concept underlying the Brenner potential. 33 This Brenner-like potential was recently further modified to study the nanoindentations in SLMoS 2 thin films using a molecular statics approach. 39 Recently, we parameterized the SW potential for SLMoS , where potential parameters were fit2 ted to the phonon spectrum. 28 This potential could easily be used in some of the popular simulation packages, such as the General Utility Lattice Program (GULP) 40 and the Large-Scale Atomic/Molecular Massively Parallel Simulator (LAMMPS). 41 In 1975, Wakabayashi et al. 30 developed a VFFM to calculate the phonon spectrum in bulk MoS . 2 This linear model has been used to study the lattice dynamical properties of some MoS 2 based materials. 42-44
FIG. 2: (Color online) Phonon dispersion of graphene along the high symmetry ΓKM lines in the Brillouin zone. The interactions between the carbon atoms were determined by the Brenner potential. The inset shows the first Brillouin zone for the hexagonal lattice structure.
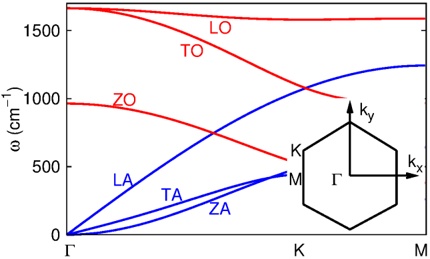
FIG. 3: (Color online) Eigenvectors for the six phonon modes at the Γ point in the first Brillouin zone of graphene. The arrow attached to each atom represents the vibration component of the atom in the eigenvector. The numbers are the frequencies of each phonon mode with units of cm -1 .
## III. PHONON DISPERSION
A phonon is a quasiparticle in reciprocal space. Each phonon mode describes a particular type of collective vibrations for all of the atoms in the real lattice space. The symmetry of the vibration morphology follows an irreducible representation of the space group of the system. These irreducible representations are denoted by the wave vector /vector k . The phonon modes are denoted by the wave vector /vector k and the branch index τ , where /vector k is the inter-cell degree of freedom and τ corresponds to the intra-cell degree of freedom. Each phonon mode has a specific angular frequency ( ω τ k ) and eigenvector ( /vector ξ τ k ). For graphene and SLMoS , each degree of freedom in the real 2 lattice space can be indicated as ( l 1 2 l sα ). l 1 and l 2 denote the position of the unit cell. s describes the different atoms in the unit cell and α = x, y, z is the direction of the axis. The frequency and the eigenvector of the
FIG. 4: (Color online) Phonon dispersion of SLMoS 2 along the high symmetry ΓKM lines in the Brillouin zone. The interactions are described by the SW potential. The inset shows the first Brillouin zone for the hexagonal lattice structure.
phonon mode can be obtained through the diagonalization of the following dynamical matrix,
$$D _ { s \alpha ; s ^ { \prime } \beta } \left ( \vec { k } \right ) = \frac { 1 } { \sqrt { m _ { s } m _ { s ^ { \prime } } } } \sum _ { l _ { 1 } = 1 } ^ { N _ { 1 } } \sum _ { l _ { 2 } = 1 } ^ { N _ { 2 } } K _ { 0 0 s \alpha ; l _ { 1 } l _ { 2 } s ^ { \prime } \beta } e ^ { i \vec { k } \cdot \vec { R } _ { l _ { 1 } l _ { 2 } } } ;$$
$$\sum _ { s ^ { \prime } \beta } D _ { s \alpha ; s ^ { \prime } \beta } \left ( \vec { k } \right ) \xi _ { \beta } ^ { ( \tau ^ { \prime } ) } ( \vec { k } | 0 0 s ^ { \prime } ) = \omega ^ { ( \tau ) 2 } ( \vec { k } ) \xi _ { \alpha } ^ { ( \tau ^ { \prime } ) } ( \vec { k } | 0 0 s ).$$
The force constant matrix K 00 sα l ; 1 2 l s β ′ stores the information on the interactions between the two degrees of freedom, (00 sα ) and ( l 1 2 l s β ′ ). N 1 × N 2 gives the total number of unit cells. For the short-range interactions, a summation over ( l 1 , l 2 ) can be truncated to the summation over the neighboring atoms.
Figure 2 shows the phonon dispersion of graphene along the high symmetry ΓKM lines in the first Brillouin zone. The force constant matrix was constructed using the Brenner potential. 33 The inset shows the first Brillouin zone for the hexagonal lattice structure. There are six phonon branches in graphene according to the two inequivalent carbon atoms in the unit cell. These branches (from bottom to top) are the z-directional acoustic (ZA), transverse acoustic (TA), longitudinal acoustic (LA), zdirectional optical (ZO), transverse optical (TO), and longitudinal optical (LO) branches. The three blue curves in the lower frequency range correspond to the three acoustic branches, while the upper three red curves correspond to the optical branches. The eigenvectors of the six phonon modes at the Γ point in the first Brillouin zone of graphene are displayed in Fig. 3. In the top panel, the three acoustic phonon modes have zero frequency, indicating that the interatomic potential did not vary during the rigid translational motion. In the bottom panel, the two in-plane optical phonon modes have almost the same frequency, revealing the isotropic phonon properties for the two in-plane directions in graphene. 45
Figure 4 shows the phonon dispersion of SLMoS 2
FIG. 5: (Color online) Eigenvectors for the nine phonon modes at the Γ point in the first Brillouin zone of SLMoS 2 . There are three acoustic phonon modes, two intra-layer optical modes, two intra-layer shearing modes and two intra-layer breathing modes. The arrows attached to each atom represent the vibration component of the atom in the eigenvector.
along the high symmetry ΓKM lines in the first Brillouin zone. The atomic interactions are described by the SW potential. 28 The inset shows the same first Brillouin zone as graphene. Each unit cell has one Mo atom and two S atoms, thus there are nine branches in the phonon spectrum. The three lower blue curves correspond to the three acoustic branches, while the six upper curves correspond to the optical branches. Fig. 5 shows the eigenvectors for the nine phonons at the Γ point in the first Brillouin zone of SLMoS 2 . There are two interesting shear-like phonon modes and two inter-layer breathinglike phonon modes, as shown in the second raw. 46
From the phonon dispersion of graphene and SLMoS , 2 it is difficult to determine which material has better phonon properties. Yet, there are two obvious differences in their phonon dispersions. First, the spectrum of graphene is overall higher than that of SLMoS 2 by about a factor of three. As a result, the phonon modes in graphene can carry more energy than those in SLMoS 2 in the thermal transport phenomenon, leading to the stronger thermal transport ability of graphene. Second, there is a distinct energy band gap between the acoustic and optical branches in SLMoS . 2 This band gap forbids many phonon-phonon scattering channels; thus it protects the acoustic phonon modes from being interrupted by the high-frequency optical phonons in SLMoS . 2 47 As a result, SLMoS 2 nanoresonators have a higher quality (Q)factor than graphene, since the resonant oscillations in SLMoS 2 (related to the ZA mode) are affected by weaker thermal vibrations.
## IV. MECHANICAL PROPERTIES
The mechanical properties for both graphene and SLMoS 2 have been extensively investigated. 48-60 Here, several of the basic mechanical properties, including the Young's modulus, yield stress, bending modulus and buckling phenomenon will be discussed. These mechanical properties are fundamental for the application of graphene or SLMoS 2 in nano-devices. A good mechanical stability is essential in nanoscale devices, as they are sensitive to external perturbations because of their high surface to volume ratio.
Young's modulus. Here, the effective Young's modulus ( E 2 D ), which is thickness independent, is discussed. The Young's modulus is related to this quantity through Y = E 2 D /h , where h is the film thickness. The thicknesses were chosen to be 3.35 ˚ and 6.09 ˚ for graphene A A and SLMoS , 2 respectively. The nanoindentation experiments measured the effective Young's modulus of graphene to be around 335.0 Nm -1 3 . This value could be reproduced using a simple approach, in which the nonlinear interactions are estimated from the Tersoff-Brenner potential. 61
For SLMoS , similar nanoindentation experiments ob2 tained an average value for the effective Young's modulus of 180 ± 60 Nm -1 in the experiment by Bertolazzi et al., 62 and 120 ± 30 Nm -1 , measured by Cooper et al. 4,63 Recently, Liu et al. performed similar nanoindentation experiments on chemical vapor deposited SLMoS , obtain2 ing an effective Young's modulus of about 170 Nm -1 64 . The nanoindentation set up has also been used to study the Young's modulus of thicker MoS 2 films. 65 The theoretical prediction of the effective Young's modulus is 139.5 Nm -1 for SLMoS , based on the SW potential. 2 28
Yield stress. The nanoindentation measurements can also determine the yield stress ( σ int , the maximum of the stress-strain curve). Lee et al. determined the yield stress to be 42 ± 4 Nm -1 for graphene. 3 The yield stresses obtained with the continuum elasticity theory were 42.4 Nm -1 using a tight-binding atomistic model, 66 and 44.4 Nm -1 using the Brenner potential. 67 While the elasticity continuum simulation gave an isotropic value for the yield stress in graphene, microscopic atomic models have predicted the yield stress to be chirality dependent in graphene. The first-principles calculations predicted the yield stress to be 40.5 Nm -1 in the zigzag direction and 36.9 Nm -1 in the armchair direction in graphene. 48 Molecular mechanics simulations obtained a yield stress of 36.9 Nm -1 in the zigzag direction and 30.2 Nm -1 in the armchair direction in graphene. 68 Both of the atomic models showed that graphene has a higher yield stress in the zigzag direction than in the armchair direction. Note that the definition of the armchair/zigzag direction is the opposite in Refs. 48 and 68. We have retained the definition from Ref. 68, where the armchair direction is along the direction of the carbon-carbon bonds.
In SLMoS , nanoindentation experiments found that 2 the yield stress was 15 ± 3 Nm -1 , determined by Bertolazzi et al., 62 and 16 5 . ± Nm -1 , determined by Cooper et al. 4,63 In the first-principles calculations, the yield stress was predicted to be 17.5 Nm -1 under a biaxial strain in SLMoS . 2 69 While the work on the yield stress in SLMoS 2 is limited at the present stage, considerable attention has been paid to the novel structure transition in SLMoS . 2 70-73 In this structure transition, the outer two S atomic layers are shifted relative to each other,
leading to abrupt changes in the electronic and phonon properties in SLMoS . 2 This structure transition is the result of the trilayer configuration of SLMoS 2 and is not observed in graphene.
Bending modulus. Graphene is extremely soft in the out-of-plane direction, owing to its one-atom-thick structure. 74-78 Graphene is so thin that it has an extremely small bending modulus, which can be explained by the well-known relationship in the shell theorem, D = E 2 D h / 2 (12(1 -ν 2 )), where h is the thickness and ν is Poisson's ratio. The bending modulus of graphene has been derived analytically from two equivalent approaches; it was 1.17 eV using the geometric approach with the interactions described by the VFFM, 5,6 and 1.4 eV from the exponential Cauchy-Born rule using the Brenner potential. 7,8 Note that these two approaches are equivalent to each other and the difference in the bending modulus mainly comes from the different potentials used in these two studies.
A similar analytic approach was used to derive the bending modulus of SLMoS 2 using the SW potential. 9 The bending modulus of SLMoS 2 is 9.61 eV, which is larger than that of graphene by a factor of seven. The large bending modulus of SLMoS 2 is due to its trilayer atomic structure, which results in more interaction terms inhibiting the bending motion. The bending modulus can be calculated using:
$$D \, = \, \frac { \partial ^ { 2 } W } { \partial \kappa ^ { 2 } }, \quad \quad ( 1 )$$
where W is the bending energy density and κ is the bending curvature. For SLMoS , the bending energy can be 2 written as: 9
$$D \ = \ \sum _ { q } \frac { \partial ^ { 2 } W } { \partial r _ { q } ^ { 2 } } \left ( \frac { \partial r _ { q } } { \partial \kappa } \right ) ^ { 2 } + \sum _ { q } \frac { \partial ^ { 2 } W } { \partial \theta _ { q } ^ { 2 } } \left ( \frac { \partial \theta _ { q } } { \partial \kappa } \right ) ^ { 2 }, \ \ ( 2 ) \quad \text{for with} \\ \text{sensi}.$$
where r q and θ q are the geometrical parameters in the empirical potential expressions. This formula is substantially different from the bending modulus formula for graphene. 79 Specifically, the first derivatives, ∂r q ∂κ and ∂θ q ∂κ , are nonzero, owing to the trilayer structure of SLMoS . 2 As a result, the bending motion in SLMoS 2 will counteract with an increasing amount of cross-plane interactions.
Buckling phenomenon. The buckling phenomenon can be a disaster in electronic devices, but it can also be useful in some situations. 80-83 The Euler buckling theorem states that the buckling critical strain can be determined from the effective Young's modulus and the bending modulus through following formula: 84
$$\epsilon _ { c } = - \frac { 4 \pi ^ { 2 } D } { E ^ { 2 D } L ^ { 2 } }, \quad \text{ at } \left ( 3 \right ) \, \text{ at } \text{ } \text{ } \text{ } \text{ } \text{ } \text{ } \text{ } \text{ } \text{ } \text{ } \text{ } \text{ } \text{ } \text{ } \text{ } \text{ } \text{ } \text{ } \text{ } \text{ } \text{ } \text{ } \text{ } \text{ } \text{ } \text{ } \text{ } \text{ } \text{ } \text{ } \text{ } \text{ } \text{ } \text{ } \text{ } \text{ } \text{ } \text{ } \text{ } \text{ } \text{ } \text{ } \text{ } \text{ } \text{ } \text{ } \text{ } \text{ } \text{ } \text{ } \text{\ } \text{ } \text{ } \text{ } \text{ } \text{ } \text{ } \text{ } \text{ } \text{ } \text{ } \text{ } \text{ } \text{ } \text{ } \text{ } \text{ } \text{ } \text{ } \text{ } \text{ } \text{ } \text{ } \text{ } \text{ } \text{ } \text{ } \text{ } \text{ } \text{ } \text{ } \text{ } \text{ } \text{ } \text{ } \text{ } \text{ } \text{ } \text{ } \text{ } \text{ } \text{ } \text{ } \text{ } \text{ } \text{ } \text{ } \text{ } \text{ } \text{ } \text$$
where L is the length of the system. For graphene, E 2 D = 335 Nm -1 and D = 1 4 eV, found from the above .
discussions, giving the explicit formula for the buckling critical strain:
$$\epsilon _ { c } = - \frac { 2. 6 4 } { L ^ { 2 } }.$$
The length ( L ) has units of ˚ . A
For SLMoS , 2 E 2 D = 139 5 Nm . -1 and D = 9 61 eV . were determined from the above discussions. The explicit formula for the buckling critical strain can is:
$$\epsilon _ { c } = - \frac { 4 3. 5 2 } { L ^ { 2 } }. \quad \quad \quad ( 5 )$$
The buckling critical strain for SLMoS 2 is twenty times larger than graphene, for samples of the same length; i.e., it is difficult to buckle SLMoS 2 under external compression. This phenomenon has been examined with both MD simulations and phonon analysis. 71,85
We have discussed and compared the mechanical properties of graphene and SLMoS . 2 Graphene has a larger Young's modulus and a larger yield stress and is more flexible than SLMoS . 2 However, SLMoS 2 has a higher bending modulus and does not buckle as readily under external compression as graphene. Hence, in terms of the mechanical properties, it is more advantageous for graphene and SLMoS 2 to be used together in a heterostructure, to mitigate the negative mechanical properties of each constitute.
## V. NANOMECHANICAL RESONATORS
Nanoresonators based on two-dimensional materials such as graphene and SLMoS 2 are promising candidates for ultra-sensitive mass sensing and detection because of their large surface areas and small masses. 86-94 For sensing applications, it is important that the nanoresonator exhibits a high Q-factor because the sensitivity of a nanoresonator is inversely proportional to its Qfactor. 95 The Q-factor is a quantity that records the total number of oscillation cycles of the resonator before its resonant oscillation decays considerably. Hence, a weaker energy dissipation leads to a higher Q-factor.
For graphene nanoresonators, the Q-factor increases exponentially with a decreasing temperature 96,97 , T -α . Zande et al. 96 found that the exponent α =0 35 . ± 0 05 for . temperatures below 40 K. For temperatures above 40 K, α = 2 3 . ± 0 1. . Chen et al. 97 observed a similar transition in the Q-factor. This continuous transition for the temperature dependence of the Q-factor is attributed to the diffusion of adsorbs in the out-of-plane direction on the surface of the graphene layer. 98,99 The MD simulations also predicted a discontinuous transition in the Q-factor at the low temperature of 7.0 K, caused by the in-plane diffusion of adsorbs on the graphene surface. 98 A very high Q-factor has been achieved in the laboratory at low temperatures. Bunch et al. observed a Q-factor of 9000 for a graphene nanoresonator at 10 K. 96 . Chen et al. also
found that the Q-factor increased with decreasing temperature, reaching 10 4 at 5 K 97 . Eichler et al. 100 found that the Q-factor of a graphene nanoresonator reached 10 5 at 90 mK.
For SLMoS , 2 two recent experiments demonstrated the nanomechanical resonant behavior in SLMoS 2 101 and few-layer MoS 2 102 . Castellanos-Gomez et al. found that the figure of merit, i.e., the frequency-Q-factor product is f 0 × Q ≈ 2 × 10 9 Hz for SLMoS . 2 101 Lee et al. found that few-layer MoS 2 resonators exhibit a high figure of merit of f 0 × Q ≈ 2 × 10 10 Hz. 102 The high Q-factor of SLMoS 2 was attributed to the energy band gap in the phonon dispersion of SLMoS , which protects the resonant os2 cillations from being scattered by thermal vibrations. 47 As a result, it was predicted that the Q-factor of SLMoS 2 nanoresonators will be higher than the graphene nanoresonators by at least a factor of four.
Although it has been theoretically predicted that MoS 2 will have better mechanical resonance behavior than graphene, experiments on MoS 2 nanoresonators are limited. More measurements are needed to examine their properties, such as the mass sensitivity. Furthermore, the sensor application of the nanoresonators depends on the level of low frequency 1/f noise, which is a limiting factor for the communication applications and the sensor sensitivity and selectivity for the graphene and MoS 2 nanoresonators. 103-109
## VI. THERMAL CONDUCTIVITY
The thermal transport phenomenon occurs when there is a temperature gradient in a material. The thermal energy can be carried by phonons or electrons. The electronic thermal conductivity is important for metals. For graphene, the thermal conductivity is mainly contributed to by phonons, while the electronic thermal conductivity is less than 1% of the overall thermal conductivity in graphene. 110,111 Thus, only the phonon (lattice) thermal conductivity will be discussed for the graphene. The thermal transport is in the ballistic regime at low temperature with weak phonon-phonon scattering. 112,113 For ballistic transport, the thermal conductivity ( κ ) is proportional to the length ( L ) of the system, κ ∝ L . At high temperature, the phonon-phonon scattering is strong, so the thermal transport is in the diffusive regime. For diffusive transport, the thermal conductivity is related to the thermal current density ( J ) and the temperature gradient ( /triangleinv T ) through the Fourier law, κ = -/triangleinv T/J .
In bulk materials, the room temperature thermal conductivity is normally a constant that is size independent. Graphene has high thermal conductivity, 49,114-124 which behaves irregularity with the length in Q2D graphene; i.e., the in-plane thermal conductivity is not constant and increases with an increasing sample length. 125-133 For 10 nm long graphene, the room temperature thermal conductivity from the MD simulation is on the order of 134 60 Wm -1 K -1 . It in- creased quickly with an increasing length and reached 250 Wm -1 K -1 for 300 nm long graphene. 129 For a length of 4.0 µ m, graphene had a thermal conductivity around 135 2500 Wm -1 K -1 . For graphene samples larger than 10 µ m, the thermal conductivity varies in the range from 1500 Wm -1 K -1 to 5000 Wm -1 K -1 depending on the sample size and quality. 129,136,137 The highest value of 5000 Wm -1 K -1 was achieved for the 20 µ m sample by Balandin et al. These studies show that the thermal conductivity in graphene increases with an increasing dimension, although the sample size is larger than the phonon mean free path. 137 However, there is still no universally accepted fact on the underlying mechanism for the size dependence of the thermal conductivity in graphene. 127,132,138-141 In the out-of-plane direction, it has been shown that the thermal conductivity for graphene decreases with increasing layer number, as there are more phonon-phonon scattering channels in thicker few-layer graphene. 138,142-149
For MoS , 2 a recent experiment by Sahoo et al. found that few-layer MoS 2 has a thermal conductivity around 150 52 Wm -1 K -1 , which is much lower than that in thick graphene layers (1000 Wm -1 K -1 ). 142 Although there are currently no measurements on the thermal conductivity of SLMoS , this topic 2 has attracted increasing interest in the theoretical community. 151-153 In 2010, Varshney et al. performed force-field based MD simulations to study the thermal transport in SLMoS . 2 151 In 2013, two first-principles calculations were performed to investigate the thermal transport in SLMoS 2 in the ballistic transport regime. 152,153 The predicted room temperature thermal conductivity in the ballistic regime was below 800 Wm -1 K -1 for a 1.0 µ m long SLMoS 2 sample. 153 This value is considerably lower than the ballistic thermal conductivity of 5000 Wm -1 K -1 for a graphene sample with the same length. 154 The smaller thermal conductivity of SLMo 2 in the ballistic regime was caused by the lower phonon spectrum in SLMoS , which is lower 2 than that of graphene by a factor of three. Each phonon mode in SLMoS 2 carries less thermal energy than in graphene. In 2013, we performed MD simulations to predict the room temperature thermal conductivity of SLMoS , which was 6.0 Wm 2 -1 K -1 for a 4.0 nm-long system. 28 More recently, the size dependence of the thermal conductivity in SLMoS 2 was studied with MD simulations. The value obtained was below 2.0 Wm -1 K -1 for a system with a length shorter than 120.0 nm. 155
The above discussions have established that graphene has a much higher thermal conductivity than SLMoS . 2 The high thermal conductivity of graphene is useful for transporting heat out of the electronic transistor devices, so graphene can be used to enhance the thermal transport capability of some composites. 156-164 Current transistors operate at very high speeds and are damaged by the inevitable Joule heating if the generated heat energy is not pumped out effectively. In this sense, graphene has better thermal conductivity properties than SLMoS . 2
## VII. ELECTRONIC BAND STRUCTURE
The electronic band structure is fundamental for electronic processes, such as the transistor performance. In particular, the value of the electronic band gap determines whether the material is metallic (zero band gap), semiconductor (moderate band gap), or insulator (large band gap).
Graphene has a nice electronic properties. 165 Electrons in graphene have a linear energy dispersion near the Brillouin zone corner, which are massless Dirac fermions with 1/300 the speed of light. 166,167 The Dirac fermion was found to be closely related to the mirror plane symmetry in the AB-stacked few-layer graphene; i.e. Dirac fermions present in AB-stacked few-layer graphene with an odd number of layers and the electronic spectrum becomes parabolic in AB-stacked few-layer graphene with an even number of layers. 168 Interestingly, Dirac fermions present again in twisted bilayer graphene. 169 It is due to the effective decoupling of the two graphene layers by the twisting defect; i.e., the mirror plane symmetry is effectively recovered in the twisted bilayer graphene. The Dirac cone at the Brillouin zone corner has a zero band gap in graphene, that is mainly contributed by free π electrons. 170 For electronic device, like transistors, a finite band gap is desirable, so various techniques have been invented to open an electronic band gap in graphene. The strain engineering can generate finite band gap of 0.1 eV for a 24% uniaxial strain. 171 Guinea et al. applied tirangular symmetric strains to generate a band gap over 0.1 eV, which is observable at room temperature. 172 A finite band gap can also be opened by confining the graphene structure in a nanoribbon form, where the band gap increases with decreasing ribbon width. 173
Electrons in SLMoS 2 are normal fermions with parabolic energy dispersion, and it is a semiconductor with a direct band gap above 1.8 eV. 174-177 This finite band gap endorses SLMoS 2 to work as a transistor. 178,179 Similar as graphene, the band gap in SLMoS 2 can also be modulated by strain engineering. First principles calculations predict a semiconductor-to-metal transition in SLMoS 2 by both biaxial compression or tension. 180 The experiment by Eknapakul et al. shows that an uniaxial tensile mechanical strain of 1.5% can produce a direct-toindirect band gap transition. 181 With increasing number of layers, the electronic band gap for few-layer MoS 2 undergoes a direct-to-indirect transition, and decreases to a value of 1.2 eV for bulk MoS . 2 182
From these comparisons, we find that SLMoS 2 possesses a finite band gap prior to any gap-opening engineering. Consequently, it may be more competitive than graphene for applications in transistor, optoelectronics, energy harvesting, and other nano-material fields.
## VIII. OPTICAL ABSORPTION
Optical properties of Q2D materials are important for their applications in photodetector, phototransitor, or other photonic nanodevices. The photocarriers in these Q2D materials may have quite different behavior from conventional semiconductors, due to their particular configuration.
Graphene has a Dirac cone electron band structure with zero band gap. 166,167 Relating to this unique band structure, graphene can absorb about 2% of incident light over a broad wavelength, which is strong considering its one-atom-thick nature. 183 Xia et al. demonstrated an ultra fast photodetector behavior for graphene, where the photoresponse did not degrade for optical intensity modulations up to 40 GHz, and the intrinsic band width was estimated to be above 500 GHz. 184 However, the photoresponsivity for graphene is low due to zero bandgap.
SLMoS 2 has a direct band gap about 1.8 eV. 174,175 This optical-range band gap lead to high absorption coefficient for incident light, so the SLMoS 2 have very high sensitivity in photon detection. 182 Lopez-Sanchez et al. found that the photoresponsivity of the SLMoS 2 can be as high as 880 AW -1 for an incident light at the wavelength of 561 nm, and the photoresponse is in the 400680 nm. 185 This high photoresponsivity together with its fast light emission enables SLMoS 2 to be an ultra sensitive phototransistors with good device mobility and large ON current. In phototransistors, the electron-hole pair can be efficiently generated by photoexcition in doped SLMoS , which joins the doping-induced charges to form 2 a bound states of two electrons and one hole. As a result, the carrier effective mass is considerably increased, and the photoconductivity can be decreased. 186
For optical properties, graphene is very fast in the photo detection, while SLMoS 2 is very sensitive in this photo detection application. Considering this complementary property, it may be fruitful for the cooperation of these two materials.
## IX. GRAPHENE/MOS 2 HETEROSTRUCTURE
Thus far, we have focused on comparing several of the properties of graphene and SLMoS . 2 The remainder of the article is devoted to studies on the close relationship between these two materials. As graphene and SLMoS 2 have complementary physical properties, it is natural to combine graphene and SLMoS 2 in specific ways to create heterostructures that mitigate the negative properties of each individual constituent. 25,26,187-197
There have been some experiments investigating the advanced properties of graphene/MoS 2 heterostructures. Britnell et al. found that graphene/MoS 2 heterostructures have high quality photon absorption and electronhole creation properties, because of the enhanced lightmatter interactions by the SLMoS 2 layer. 25 Graphene has outstanding mechanical properties. These properties
TABLE I: The properties that have been compared for graphene and SLMoS 2 in the present review article.
| properties | graphene | SLMoS 2 |
|----------------------|-----------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------|----------------------------------------------------------------------------------------------------------------------------------|
| structrue | D 6 h ; a = 2 . 46 ˚; A b = 1 . 42 ˚ A (Ref. 27) | D 3 h ; a = 3 . 09 ˚; A b = 2 . 39 ˚ A (Ref. 28) |
| interaction | ab initio; Brenner; SW; VFFM | ab initio; Brenner; SW; VFFM |
| phonon dispersion | ω op ≈ 1664 . 5 cm - 1 ; ω gap = 0 | ω op ≈ 478 . 8 cm - 1 ; ω gap = 25 . 0 cm - 1 |
| Young's modulus | E 2 D = 335 . 0 Nm - 1 (Ref. 3) | E 2 D = 180 ± 60 Nm - 1 (Ref. 62) E 2 D = 120 ± 30 Nm - 1 (Ref. 4) E 2 D = 170 Nm - 1 (Ref. 64) E 2 D = 139 . 5 Nm - 1 (Ref. 28) |
| yield stress | σ int = 42 ± 4 Nm - 1 (Ref. 3) σ int = 42 . 4 Nm - 1 (Ref. 66) σ int = 44 . 4 Nm - 1 (Ref. 67) σ zig int = 40.5 Nm - 1 , σ arm int =36.9 Nm - 1 (Ref. 48) σ zig int = 36 . 9 Nm - 1 , σ arm int =30.2Nm - 1 (Ref. 68) | σ int = 15 ± 3 Nm - 1 (Ref. 62) σ int = 16 . 5 Nm - 1 (Refs. 4,63) σ int = 17 . 5 Nm - 1 (Ref. 69) |
| bending modulus | D = 1 . 17 eV (Refs. 5,6), 1.4 eV (Refs. 7,8) | D = 9 . 61 eV(Ref. 9) |
| buckling strain | /epsilon1 c = - 2 . 64 L 2 | /epsilon1 c = - 43 . 52 L 2 |
| nanoresonator | f 0 × Q = 6 . 3 × 10 11 Hz (10 K, Ref. 96) f 0 × Q = 1 . 82 × 10 12 Hz (5 K, Ref. 97) f 0 × Q = 1 . 56 × 10 13 Hz (90 mK, Ref. 100) | f 0 × Q ≈ 2 × 10 9 Hz (300 K, Ref. 101) |
| nanoresonator | f 0 × Q = 6 . 4 T - 1 . 2 × 10 3 THz (Ref. 47) | f 0 × Q = 2 . 4 T - 1 . 3 × 10 4 THz (Ref. 47) |
| thermal conductivity | 5000 Wm - 1 K - 1 (ballistic, L = 1 µm , Ref. 154) | 800 Wm - 1 K - 1 (ballistic, L = 1 µm , Refs. 152,153) |
| thermal conductivity | 60 Wm - 1 K - 1 ( L = 10 nm, Ref. 134) 250 Wm - 1 K - 1 ( L = 300 nm, Ref. 129) κ > 1500 Wm - 1 K - 1 ( L > 4 µ m, Refs. 129,135-137) | 6 Wm - 1 K - 1 ( L = 4 nm, Ref. 28) 2 Wm - 1 K - 1 ( L = 120 nm, Ref. 155) |
| thermal conductivity | 1000 Wm - 1 K - 1 (thick graphene layers, Ref. 142) | 52 Wm - 1 K - 1 (thick MoS 2 layers, Ref. 150) |
| electronic band | Dirac cone; E gap = 0 (Refs. 166,167) | parabolic; E gap ≈ 1 . 8 eV (direct, Refs. 174,175) |
| optical absorption | fast photoresponse (Ref. 184) large band width (Ref. 184) low photoresponsivity (0.5 mAW - 1 Ref. 184) | high photoresponsivity (880 AW - 1 , Ref. 185) |
have been used to protect the MoS 2 films from radiation damage. 26 Recently, Larentis et al. measured the electron transport in graphene/MoS 2 heterostructures and observed a negative compressibility in the MoS 2 component. 191 This surprising phenomenon was interpreted based on the interplay between the Dirac and parabolic bands for graphene and MoS , 2 respectively. Yu et al. fabricated high-performance electronic circuits based on the graphene/MoS 2 heterostructure, with MoS 2 as the transistor channel and graphene as the contact electrodes and the circuit interconnects. 198
Although experimentalists have shown great interest in graphene/MoS 2 heterostructures, the corresponding theoretical efforts have been limited until recently. First-principle calculations predicted that the interlayer space and binding energy for the heterostructure are -21.0 meV and 3.66 ˚ in A Ref. 199 and -23.0 meV and 3.32 A in ˚ Ref. 197. Using these two quantities, 200 a set of Lennard-Jones potential parameters were determined as /epsilon1 =3.95 meV and σ =3.625 ˚ , A with a cutoff of 10.0 ˚. A These potential parameters were used to study the tension-induced structure transition of the graphene/MoS /graphene heterostruc2
ture. It was shown that the Young's modulus of the graphene/MoS /graphene heterostructure could be pre2 dicted by the following rule of mixtures, based on the arithmetic average, 201
$$Y _ { \text{GMG} } = Y _ { G } f _ { G } + Y _ { M } f _ { M },$$
where Y GMG , Y G and Y M are the Young's moduli of the heterostructure, graphene and SLMoS , respectively. 2 f G = 2 V G / (2 V G + V M ) = 0 524 is the volume fraction for . the two outer graphene layers in the heterostructure and f M = V M / (2 V G + V M ) = 0 476 is the volume fraction . for the inner SLMoS 2 layer. The thicknesses were 3.35 ˚ A and 6.09 ˚ for single-layer graphene and SLMoS , respecA 2 tively. At room temperature, the Young's modulus was 859.69 GPa for graphene and 128.75 GPa for SLMoS . 2 From this mixing rule, the upper-bound of the Young's modulus for the heterostructure was 511.76 GPa.
As another important mechanical property, the total strain of the graphene/MoS /graphene heterostructure 2 was about 0.26, which is much smaller than the value of 0.40 for SLMoS . 2 200 Under large mechanical tension, the heterostructure collapsed from the buckling of the outer graphene layers. These graphene layers were com-
pressed in the lateral direction by the Poisson-induced stress, when the heterostructure was stretched in the longitudinal direction.
## X. CONCLUSIONS
We have compared the mechanical properties of graphene and SLMoS . 2 The main results are listed in
- ∗ Email address: [email protected]; [email protected]
- 1 Geim, A.K., Novoselov, K.S.. The rise of graphene. Nature Materials 2007;6(3):183-191.
- 2 Neto, A.H.C., Novoselov, K.. New directions in science and technology: two-dimensional crystals. Rep Prog Phys 2011;74(8):082501.
- 3 Lee, C., Wei, X., Kysar, J.W., Hone, J.. Measurement of the elastic properties and intrinsic strength of monolayer graphene. Science 2008;321:385.
- 4 Cooper, R.C., Lee, C., Marianetti, C.A., Wei, X., Hone, J., Kysar, J.W.. Nonlinear elastic behavior of two-dimensional molybdenum disulfide. Physical Review B 2013;87:035423.
- 5 Ou-Yang., Z.C., bin Su, Z., Wang, C.L.. Coil formation in multishell carbon nanotubes: Competition between curvature elasticity and interlayer adhesion. Physical Review Letters 1997;78(21):4055.
- 6 Tu, Z.C., Ou-Yang, Z.C.. Single-walled and multiwalled carbon nanotubes viewed as elastic tubes with the effective youngs moduli dependent on layer number. Physical Review B 2002;65:233407.
- 7 Arroyo, M., Belytschko, T.. An atomistic-based nite deformation membrane for single layer crystalline films. Journal of the Mechanics and Physics of Solids 2001;50:1941-1977.
- 8 Lu, Q., Arroyo, M., Huang, R.. Elastic bending modulus of monolayer graphene. Journal of Physics D: Applied Physics 2009;42:102002.
- 9 Jiang, J.W., Qi, Z., Park, H.S., Rabczuk, T.. Elastic bending modulus of single-layer molybdenum disulphide (mos ): 2 Finite thickness effect. Nanotechnology 2013;24:435705.
- 10 Jiang, J.W., Park, H.S.. Negative poisson's ratio in single-layer black phosphorus. Nature Communications 2014;5:4727.
- 11 Ferrari, A.C.. Raman spectroscopy of graphene and graphite: Disorder, electron-phonon coupling, doping and nonadiabatic effects. Solid State Communications 2007;143:47-57.
- 12 Castro Neto, A.H., Guinea, F., Peres, N.M.R., Novoselov, K.S., Geim, A.K.. The electronic properties of graphene. Rev Mod Phys 2009;81(1):109-162.
- 13 Geim, A.K.. Graphene: Status and prospects. Science 2009;324(5934):1530-1534.
- 14 Malard, L.M., Pimenta, M.A., Dresselhaus, G., Dresselhaus, M.S.. Raman spectroscopy in graphene. PHYSICS REPORTS-REVIEW SECTION OF PHYSICS LETTERS 2009;473:51-87.
- 15 Rao, C.N.R., Sood, A.K., Subrahmanyam, K.S., Govin-
Table I. This table serves as a resource for the prediction of corresponding properties for the graphene/MoS 2 heterostructure.
Acknowledgements This work was supported by the Recruitment Program of Global Youth Experts of China and start-up funding from Shanghai University.
- daraj, A.. Graphene: The new two-dimensional nanomaterial. Angewandte Chemie - International Edition 2009;48(42):7752-7777.
- 16 Allen, M.J., Tung, V.C., Kaner, R.B.. Honeycomb carbon: A review of graphene. CHEMICAL REVIEWS 2010;10(1):132-145.
- 17 Bonaccorso, F., Sun, Z., Hasan, T., Ferrari, A.C.. Graphene photonics and optoelectronics. Nature Photonics 2010;4(9):611-622.
- 18 Schwierz, F.. Graphene transistors. Nature Nanotechnology 2010;5(7):487-496.
- 19 Balandin, A.A.. Thermal properties of graphene and nanostructured carbon materials. Nature Materials 2011;10:569-581.
- 20 Wang, Q.H., Kalantar-Zadeh, K., Kis, A., Coleman, J.N., Strano, M.S.. Electronics and optoelectronics of two-dimensional transition metal dichalcogenides. Nature Nanotechnology 2012;7(11):699-712.
- 21 Chhowalla, M., Shin, H.S., Eda, G., Li, L.., Loh, K.P., Zhang, H.. The chemistry of two-dimensional layered transition metal dichalcogenide nanosheets. Nature Chemistry 2013;5(4):263-275.
- 22 Xu, M., Liang, T., Shi, M., Chen, H.. Graphenelike two-dimensional materials. Chemical Reviews 2013;113(5):3766-3798.
- 23 Butler, S., Hollen, S., Cao, L., Cui, Y., Gupta, J., Gutirrez, H., et al. Progress, challenges, and opportunities in two-dimensional materials beyond graphene. ACS Nano 2013;7(4):2898-2926.
- 24 Huang, X., Zeng, Z., Zhang, H.. Metal dichalcogenide nanosheets: preparation, properties and applications. CHEMICAL SOCIETY REVIEWS 2013;42(5):19341946.
- 25 Britnell, L., Ribeiro, R.M., Eckmann, A., Jalil, R., Belle, B.D., Mishchenko, A., et al. Strong light-matter interactions in heterostructures of atomically thin films. Science 2013;340(6138):1311-1314.
- 26 Zan, R., Ramasse, Q.M., Jalil, R., Georgiou, T., Bangert, U., Novoselov, K.S.. Control of radiation damage in mos2 by graphene encapsulation. ACS Nano 2013;7(11):10167-10174.
- 27 Saito, R., Dresselhaus, G., Dresselhaus, M.S.. Physical Properties of Carbon Nanotubes. Imperial College, London; 1998.
- 28 Jiang, J.W., Park, H.S., Rabczuk, T.. Molecular dynamics simulations of single-layer molybdenum disulphide (mos ): 2 Stillinger-weber parametrization, mechanical properties, and thermal conductivity. Journal of Applied Physics 2013;114:064307.
- 29 Molina-S´nchez, a A., Wirtz, L.. Phonons in single-
- layer and few-layer mos 2 and ws . 2 Physical Review B 2011;84(15):155413.
- 30 Wakabayashi, N., Smith, H.G., Nicklow, R.M.. Lattice dynamics of hexagonal mos 2 studied by neutron scattering. Physical Review B 1975;12(2):659-663.
- 31 Kresse, G., Furthmuller, J.. Efficient iterative schemes for ab initio total-energy calculations using a plane-wave basis set. Physical Review B 1996;54:11169.
- 32 Soler, J.M., Artacho, E., Gale, J.D., Garcia, A., Junquera, J., Ordejon, P., et al. The siesta method for ab initio order-n materials simulation. Journal of Physics: Condensed Matter 2002;14(11):2745. Code available from http://www.icmab.es/dmmis/leem/siesta/.
- 33 Brenner, D.W., Shenderova, O.A., Harrison, J.A., Stuart, S.J., Ni, B., Sinnott, S.B.. A second-generation reactive empirical bond order (REBO) potential energy expression for hydrocarbons. Journal of Physics: Condensed Matter 2002;14:783-802.
- 34 Tersoff, J.. Empirical interatomic potential for carbon, with applications to amorphous carbon. Physical Review Letters 1988;61(25):2879-2882.
- 35 Stillinger, F.H., Weber, T.A.. Computer simulation of local order in condensed phases of silicon. Physical Review B 1985;31(8):5262.
- 36 Abraham, F.F., Batra, I.P.. Theoretical interpretation of atomic force microscope images of graphite. Surf Sci 1989;209:L125.
- 37 Aizawa, T., Souda, R., Otani, S., Ishizawa, Y.. Bond softening in monolayer graphite formed on transition-metal carbide surfaces. Physical Review B 1990;42(18):11469-11478.
- 38 Liang, T., Phillpot, S.R., Sinnott, S.B.. Parametrization of a reactive many-body potential for mo-s systems. Physical Review B 2009;79(24):245110.
- 39 Stewart, J.A., Spearot, D.E.. Atomistic simulations of nanoindentation on the basal plane of crystalline molybdenum disulfide (mos ). Modelling and Simulation in Ma2 terials Science and Engineering 2013;21:045003.
- 40 Gale, J.D.. Gulp: A computer program for the symmetry-adapted simulation of solids. J Chem Soc, Faraday Trans 1997;93(4):629-637. Code available from https://projects.ivec.org/gulp/.
- 41 Lammps, . http://wwwcssandiagov/ ∼ sjplimp/lammpshtml 2012;.
- 42 Jimenez Sandoval, S., Yang, D., Frindt, R.F., Irwin, J.C.. Raman study and lattice dynamics of single molecular layers of mos 2 . Physical Review B 1991;44(8):39553962.
- 43 Dobardzic, E., Milosevic, I., Dakic, B., Damnjanovic, M.. Raman and infrared-active modes in ms2 nanotubes (m=mo,w). Physical Review B 2006;74(3):033403.
- 44 Damnjanovic, M., Dobardzic, E., Miloeevic, I., Virsek, M., Remskar, M.. Phonons in mos 2 and ws 2 nanotubes. Materials and Manufacturing Processes 2008;23:579-582.
- 45 Wang, H., Wang, Y., Cao, X., Feng, M., Lan, G.. Vibrational properties of graphene and graphene layers. Journal of Raman Spectroscopy 2009;40(12):1791-1796.
- 46 Zhang, X., Han, W.P., Wu, J.B., Milana, S., Lu, Y., Li, Q.Q., et al. Raman spectroscopy of shear and layer breathing modes in multilayer mos . 2 Physical Review B 2013;87:115413.
- 47 Jiang, J.W., Park, H.S., Rabczuk, T.. Mos 2 nanoresonators: Intrinsically better than graphene? Nanoscale 2013;6:3618.
- 48 Liu, F., Ming, P., Li, J.. Ab initio calculation of ideal strength and phonon instability of graphene under tension. Physical Review B 2007;76:064120.
- 49 Hao, F., Fang, D., Xu, Z.. Mechanical and thermal transport properties of graphene with defects. Applied Physics Letters 2011;99(4):041901.
- 50 Ni, Z., Bua, H., Zoub, M., Yia, H., Bia, K., Chen, Y.. Anisotropic mechanical properties of graphene sheets from molecular dynamics. Physica B: Condensed Matter 2009;405(5):1301-1306.
- 51 Gao, Y., Hao, P.. Mechanical properties of monolayer graphene under tensile and compressive loading. Physica E: Low-dimensional Systems and Nanostructures 2009;41(8):1561-1566.
- 52 Guo, Y., Jiang, L., Guo, W.. Opening carbon nanotubes into zigzag graphene nanoribbons by energy-optimum oxidation. Physical Review B 2010;82:115440.
- 53 Zheng, Y., Wei, N., Fan, Z., Xu, L., Huang, Z.. Mechanical properties of grafold: a demonstration of strengthened graphene. Nanotechnology 2011;22(40):405701.
- 54 Wei, Y., Wu, J., Yin, H., Shi, X., Yang, R., Dresselhaus, M.. The nature of strength enhancement and weakening by pentagonheptagon defects in graphene. Nature Materials 2012;11:759-763.
- 55 Zhang, Y., Pan, C.. Measurements of mechanical properties and number of layers of graphene from nanoindentation. Diamond and Related Materials 2012;24:1-5.
- 56 Yue, Q., Kang, J., Shao, Z., Zhang, X., Chang, S., Wang, G., et al. Mechanical and electronic properties of monolayer mos2 under elastic strain. Physics Letters A 2012;376:1166-1170.
- 57 Huang, Y., Wu, J., Hwang, K.C.. Thickness of graphene and single-wall carbon nanotubes. Physical Review B 2006;74:245413.
- 58 Shen, L., Shen, H.S., Zhang, C.L.. Temperaturedependent elastic properties of single layer graphene sheets. Materials & Design 2010;31(9):4445-4449.
- 59 Han, T., He, P., Luo, Y., Zhang, X.. Research progress in the mechanical properties of graphene. Advances in Mechanics 2011;41(3):279-293.
- 60 Xu, L., Wei, N., Zheng, Y., Fan, Z., Wang, H.Q., Zheng, J.C.. Graphene-nanotube 3d networks: intriguing thermal and mechanical properties. Journal of Materials Chemistry 2012;22(4):1435-1444.
- 61 Jiang, J.W., Wang, J.S., Li, B.. Elastic and nonlinear stiffness of graphene: a simple approach. Physical Review B 2010;81(7):073405.
- 62 Bertolazzi, S., Brivio, J., Kis, A.. Stretching and breaking of ultrathin mos 2 . ACS Nano 2011;5(12):9703-9709.
- 63 Cooper, R.C., Lee, C., Marianetti, C.A., Wei, X., Hone, J., Kysar, J.W.. Erratum: Nonlinear elastic behavior of two-dimensional molybdenum disulfide (physical review b - condensed matter and materials physics(2013) 87 (035423)). Physical Review B 2013;87(7):079901.
- 64 Liu, K., Yan, Q., Chen, M., Fan, W., Sun, Y., Suh, J., et al. Elastic properties of chemical-vapor-deposited monolayer mos2, ws2, and their bilayer heterostructures. Preprint at http://arxivorg/abs/14072669 2014;.
- 65 Castellanos-Gomez, A., Poot, M., Steele, G.A., van der Zant, H.S.J., Agrait, N., Rubio-Bollinger, G.. Elastic properties of freely suspended mos 2 nano sheets. Advanced Materials 2012;24:772-775.
- 66 Cadelano, E., Palla, P.L., Giordano, S., Colombo, L..
- Nonlinear elasticity of monolayer graphene. Physical Review Letters 2009;102(23):235502.
- 67 Reddy, C.D., Rajendran, S., Liew, K.M.. Equilibrium configuration and continuum elastic properties of finite sized graphene. Nanotechnology 2006;17(3):864.
- 68 Zhao, H., Min, K., Aluru, N.R.. Size and chirality dependent elastic properties of graphene nanoribbons under uniaxial tension. Nano Letters 2009;9(8):3012-3015.
- 69 Tao, P., Guo, H., Yang, T., Zhang, Z.. Strain-induced magnetism in mos2 monolayer with defects. Journal of Applied Physics 2014;115:054305.
- 70 Lin, Y.C., Dumcenco, D.O., Huang, Y.S., Suenaga, K.. Atomic mechanism of phase transition between metallic and semiconducting mos 2 single-layers. Nature Nanotechnology 2014;9:391-396.
- 71 Jiang, J.W.. Phonon bandgap engineering of strained monolayer mos2. Nanoscale 2014;6:8326.
- 72 Kan, M., Wang, J.Y., Li, X.W., Zhang, S.H., Li, Y.W., Kawazoe, Y., et al. Structures and phase transition of a mos 2 monolayer. Journal of Physical Chemistry C 2014;118(3):1515-1522.
- 73 Dang, K.Q., Simpsona, J.P., Spearot, D.E.. Phase transformation in monolayer molybdenum disulphide (mos2) under tension predicted by molecular dynamics simulations. Scripta Materialia 2014;76:41-44.
- 74 Wei, Y., Wang, B., Wu, J., Yang, R., Dunn, M.L.. Bending rigidity and gaussian bending stiffness of singlelayered graphene. Nano Letters 2013;13(1):26-30.
- 75 Xin, Z., Jianjun, Z., Ou-Yang, Z.C.. Strain energy and young's modulus of single-wall carbon nanotubes calculated from electronic energy-band theory. Physical Review B 2000;62(20):13692-13696.
- 76 Ma, T., Li, B., Chang, T.. Chirality- and curvaturedependent bending stiffness of single layer graphene. Applied Physics Letters 2011;99:201901.
- 77 Shen, Y., Wu, H.. Interlayer shear effect on multilayer graphene subjected to bending. Applied Physics Letters 2012;100(10):101909.
- 78 Shi, X., Peng, B., Pugno, N.M., Gao, H.. Stretchinduced softening of bending rigidity in graphene. Applied Physics Letters 2012;100:191913.
- 79 Arroyo, M., Belytschko, T.. Finite crystal elasticity of carbon nanotubes based on the exponential cauchy-born rule. Physical Review B 2004;69:115415.
- 80 Wang, Y., Yang, R., Shi, Z., Zhang, L., Shi, D., Wang, E., et al. Super-elastic graphene ripples for flexible strain sensors. ACS Nano 2011;5(5):3645-3650.
- 81 Zhang, J., Xiao, J., Meng, X., Monroe, C., Huang, Y., Zuo, J.M.. Free folding of suspended graphene sheets by random mechanical stimulation. Physical Review Letters 2010;104:166805.
- 82 Shi, J.X., Ni, Q.Q., Lei, X.W., Natsuki, T.. Nonlocal elasticity theory for the buckling of double-layer graphene nanoribbons based on a continuum model. Computational Materials Science 2011;50(11):3085-3090.
- 83 Wang, C., Lan, L., Tan, H.. The physics of wrinkling in graphene membranes under local tension. Phys Chem Chem Phys 2013;15(8):2764-2773.
- 84 Timoshenko, S., Woinowsky-Krieger, S.. Theory of Plates and Shells, 2nd ed. McGraw-Hill, New York; 1987.
- 85 Jiang, J.W.. The buckling of single-layer mos 2 under uniaxial compression. Nanotechnology 2014;25:355402.
- 86 Zhou, M., Zhai, Y., Dong, S.. Electrochemical sensing and biosensing platform based on chemically reduced
- graphene oxide. Analytical Chemistry 2009;81(14):56035613.
- 87 Xu, Y., Chen, C., Deshpande, V.V., DiRenno, F.A., Gondarenko, A., Heinz, D.B., et al. Radio frequency electrical transduction of graphene mechanical resonators. Applied Physics Letters 2010;97:243111.
- 88 He, X.Q., Kitipornchai, S., Liew, K.M.. Resonance analysis of multi-layered graphene sheets used as nanoscale resonators. Nanotechnology 2005;16:2086-2091.
- 89 Liu, Y., Xu, Z., Zheng, Q.. The interlayer shear effect on graphene multilayer resonators. Journal of the Mechanics and Physics of Solids 2011;59(8):1613-1622.
- 90 Wang, J., He, X., Kitipornchai, S., Zhang, H.. Geometrical nonlinear free vibration of multi-layered graphene sheets. Journal of Physics D: Applied Physics 2011;44(13):135401.
- 91 Xu, Y., Yan, S., Jin, Z., Wang, Y.. Quantum-squeezing effects of strained multilayer graphene nems. Nanoscale Res Lett 2011;6:355.
- 92 Gu, F., Zhang, J.H., Yang, L.J., Gu, B.. Molecular dynamics simulation of resonance properties of strain graphene nanoribbons. ACTA Physica Sinica 2011;60(5):056103.
- 93 Shen, Z.B., Tang, H.L., Li, D.K., Tang, G.J.. Vibration of single-layered graphene sheet-based nanomechanical sensor via nonlocal kirchhoff plate theory. Computational Materials Science 2012;61:200-205.
- 94 Zhou, S.M., Sheng, L.P., Shen, Z.B.. Transverse vibration of circular graphene sheet-based mass sensor via nonlocal kirchhoff plate theory. Computational Materials Science 2014;86:73-78.
- 95 Ekinci, K.L., Roukes, M.L.. Nanoelectromechanical systems. Rev Sci Instrum 2005;76:061101.
- 96 van der Zande, A.M., Barton, R.A., Alden, J.S., Ruiz-Vargas, C.S., Whitney, W.S., Pham, P.H.Q., et al. Large-scale arrays of single-layer graphene resonators. Nano Letters 2010;10(12):4869-4873.
- 97 Chen, C., Rosenblatt, S., Bolotin, K.I., Kalb, W., Kim, P., Kymissis, I., et al. Performance of monolayer graphene nanomechanical resonators with electrical readout. Nature Nanotechnology 2009;4:861.
- 98 Jiang, J.W., Wang, B.S., Park, H.S., Rabczuk, T.. Adsorbate migration effects on continuous and discontinuous temperature-dependent transitions in the quality factors of graphene nanoresonators. Nanotechnology 2014;25(2):025501.
- 99 Edblom, C., Isacsson, A.. Diffusion-induced dissipation and mode coupling in nanomechanical resonators. Preprint at http://arxivorg/abs/14061365v1 2014;.
- 100 Eichler, A., Moser, J., Chaste, J., Zdrojek, M., WilsonRae, I., Bachtold, A.. Nonlinear damping in mechanical resonators made from carbon nanotubes and graphene. Nature Nanotechnology 2011;6:339.
- 101 Castellanos-Gomez, A., van Leeuwen, R., Buscema, M., van der Zant, H.S.J., Steele, G.A., Venstra, W.J.. Single-layer mos 2 mechanical resonators. Advanced Materials 2013;25(46):6719-6723.
- 102 Lee, J., Wang, Z., He, K., Shan, J., Feng, P.X.L.. High frequency mos 2 nanomechanical resonators. ACS Nano 2013;7(7):6086-6091.
- 103 Balandin, A.A.. Low-frequency 1/f noise in graphene devices. Nature Nanotechnology 2013;8:549.
- 104 Lin, Y.M., Avouris, P.. Strong suppression of electrical noise in bilayer graphene nanodevices. Nano Letters
2008;8:2119-2125.
- 105 Pal, A.N., Ghosh, A.. Resistance noise in electrically biased bilayer graphene. Physical Review Letters 2009;102:126805.
- 106 Cheng, Z., Li, Q., Li, Z., Zhou, Q., Fang, Y.. Suspended graphene sensors with improved signal and reduced noise. Nano Letters 2010;10:1864-1868.
- 107 Rumyantsev, S., Liu, G., Stillman, W., Shur, M., Balandin, A.A.. Electrical and noise characteristics of graphene field-effect transistors: ambient effects, noise sources and physical mechanisms. Journal of Physics: Condensed Matter 2010;22:395302.
- 108 Liu, G., Rumyantsev, S., Shur, M., Balandin, A.A.. Graphene thickness-graded transistors with reduced electronic noise. Applied Physics Letters 2012;100:033103.
- 109 Hossain, M.Z., Roumiantsev, S.L., Shur, M., Balandin, A.A.. Reduction of 1/f noise in graphene after electron-beam irradiation. Applied Physics Letters 2013;102:153512.
- 110 Saito, K., Nakamura, J., Natori, A.. Ballistic thermal conductance of a graphene sheet. Physical Review B 2007;76(11):115409.
- 111 Yi˘en, g S., Tayari, V., Island, J.O., Porter, J.M., Champagne, A.R.. Electronic thermal conductivity measurements in intrinsic graphene. Physical Review B 2013;87(24):241411.
- 112 Wang, J.S., Wang, J., L¨, u J.T.. Quantum thermal transport in nanostructures. Eur Phys J B 2008;62(4):381-404. 113 Wang, J.S., Agarwalla, B.K., Li, H., Thingna, J.. Nonequilibrium greens function method for quantum thermal transport. Front Phys 2013;:DOI:10.1007/s11467-013-0340-x.
- 114 Chen, S., Wu, Q., Mishra, C., Kang, J., Zhang, H., Cho, K., et al. Thermal conductivity of isotopically modified graphene. Nature Materials 2012;11:203-207.
- 115 Guo, Z., Zhang, D., Gong, X.G.. Thermal conductivity of graphene nanoribbons. Applied Physics Letters 2009;95(16):163103.
- 116 Xu, Y., Chen, X., Gu, B.L., Duan, W.. Intrinsic anisotropy of thermal conductance in graphene nanoribbons. Applied Physics Letters 2009;95(23):233116.
- 117 Chen, S., Moore, A.L., Cai, W., Suk, J.W., An, J., Mishra, C., et al. Raman measurements of thermal transport in suspended monolayer graphene of variable sizes in vacuum and gaseous environments. ACS Nano 2011;5(1):321-328.
- 118 Wei, N., Xu, L., Wang, H.Q., Zheng, J.C.. Strain engineering of thermal conductivity in graphene sheets and nanoribbons: a demonstration of magic flexibility. Nanotechnology 2011;22(10):105705.
- 119 Wei, Z., Ni, Z., Bi, K., Chen, M., Chen, Y.. In-plane lattice thermal conductivities of multilayer graphene films. Carbon 2011;49(8):2653-2658.
- 120 Xie, Z.X., Chen, K.Q., Duan, W.. Thermal transport by phonons in zigzag graphene nanoribbons with structural defects. Journal of Physics: Condensed Matter 2011;23(31):315302.
- 121 Zhai, X., Jin, G.. Stretching-enhanced ballistic thermal conductance in graphene nanoribbons. Europhysics Letters 2011;96(1):16002.
- 122 Peng, X.F., Wang, X.J., Gong, Z.Q., Chen, K.Q.. Ballistic thermal conductance in graphene nanoribbon with double-cavity structure. Applied Physics Letters 2011;99(23):233105.
- 123 Ma, F., Zheng, H.B., Sun, Y.J., Yang, D., Xu, K.W., Chu, P.K.. Strain effect on lattice vibration, heat capacity, and thermal conductivity of graphene. Applied Physics Letters 2012;101:111904.
- 124 Guo, Z.X., Ding, J.W., Gong, X.G.. Substrate effects on the thermal conductivity of epitaxial graphene nanoribbons. Physical Review B 2012;85(23):235429.
- 125 Mingo, N., Broido, D.A.. Carbon nanotube ballistic thermal conductance and its limits. Physical Review Letters 2005;95(9):096105.
- 126 Mingo, N., Broido, D.A.. Length dependence of carbon nanotube thermal conductivity and the 'problem of long waves'. Nano Letters 2005;5(7):1221-1225.
- 127 Nika, D.L., Pokatilov, E.P., Askerov, A.S., Balandin, A.A.. Phonon thermal conduction in graphene: Role of umklapp and edge roughness scattering. Physical Review B 2009;79:155413.
- 128 Nika, D.L., Askerov, A.S., Balandin, A.A.. Anomalous size dependence of the thermal conductivity of graphene ribbons. Nano Letters 2012;12(6):3238-3244.
- 129 Xu, X., Pereira, L.F., Wang, Y., Wu, J., Zhang, K., Zhao, X., et al. Length-dependent thermal conductivity in suspended single-layer graphene. Nature Communications 2014;5:3689.
- 130 Nika, D.L., Pokatilov, E.P., Balandin, A.A.. Theoretical description of thermal transport in graphene: The issues of phonon cut-off frequencies and polarization branches. Phys Status Solidi B 2011;248(11):2609-2614.
- 131 Wang, J., Wang, X.M., Chen, Y.F., Wang, J.S.. Dimensional crossover of thermal conductance in graphene nanoribbons: a first-principles approach. Journal of Physics: Condensed Matter 2012;24:295403.
- 132 Nika, D.L., Balandin, A.A.. Two-dimensional phonon transport in graphene. Journal of Physics: Condensed Matter 2012;24(23):233203.
- 133 Li, N., Ren, J., Wang, L., Zhang, G., H¨nggi, a P., Li, B.. Phononics: Manipulating heat flow with electronic analogs and beyond. Rev Mod Phys 2012;84(3):10451066.
- 134 Jiang, J.W., Lan, J., Wang, J.S., Li, B.. Isotopic effects on the thermal conductivity of graphene nanoribbons: Localization mechanism. Journal of Applied Physics 2010;107(5):054314.
- 135 Cai, W., Moore, A.L., Zhu, Y., Li, X., Chen, S., Shi, L., et al. Thermal transport in suspended and supported monolayer graphene grown by chemical vapor deposition. Nano Letters 2010;10:1645-1651.
- 136 Balandin, A.A., Ghosh, S., Bao, W., Calizo, I., Teweldebrhan, D., Miao, F., et al. Superior thermal conductivity of single-layer graphene. Nano Letters 2008;8(3):902-907.
- 137 Ghosh, S., Calizo, I., Teweldebrhan, D., Pokatilov, E.P., Nika, D.L., Balandin, A.A., et al. Extremely high thermal conductivity of graphene: Prospects for thermal management applications in nanoelectronic circuits. Applied Physics Letters 2008;92(15):151911.
- 138 Lindsay, L., Broido, D.A., Mingo, N.. Flexural phonons and thermal transport in multilayer graphene and graphite. Physical Review B 2011;83:235428.
- 139 Aksamija, Z., Knezevic, I.. Lattice thermal conductivity of graphene nanoribbons: Anisotropy and edge roughness scattering. Applied Physics Letters 2011;98:141919.
- 140 Chen, L., Kumar, S.. Thermal transport in graphene supported on copper. Journal of Applied Physics
- 141 Wei, Z., Yang, J., Bi, K., Chen, Y.. Mode dependent lattice thermal conductivity of single layer graphene. Journal of Applied Physics 2014;116:153503.
- 142 Ghosh, S., Bao, W., Nika, D.L., Subrina, S., Pokatilov, E.P., Lau, C.N., et al. Dimensional crossover of thermal transport in few-layer graphene. Nature Materials 2010;9:555-558.
- 143 Singh, D., Murthy, J.Y., Fisher, T.S.. Mechanism of thermal conductivity reduction in few-layer graphene. Journal of Applied Physics 2011;110(4):044317.
- 144 Zhang, G., Zhang, H.. Thermal conduction and rectification in few-layer graphene y junctions. Nanoscale 2011;3:4604.
- 145 Zhong, W.R., Ai, M.P.Z.B.Q., Zheng, D.Q.. Chirality and thickness-dependent thermal conductivity of fewlayer graphene: A molecular dynamics study. Applied Physics Letters 2011;98(11):113107.
- 146 Zhong, W.R., Huang, W.H., Deng, X.R., Ai, B.Q.. Thermal rectification in thicknessasymmetric graphene nanoribbons. Applied Physics Letters 2011;99(19):193104.
- 147 Rajabpour, A., Allaei, S.M.V.. Tuning thermal conductivity of bilayer graphene by inter-layer sp3 bonding: A molecular dynamics study. Applied Physics Letters 2012;101(5):053115.
- 148 Cao, H.Y., Guo, Z.X., Xiang, H., Gong, X.G.. Layer and size dependence of thermal conductivity in multilayer graphene nanoribbons. Physics Letters A 2012;376(9):525-528.
- 149 Sun, T., Wang, J., Kang, W.. Van der waals interactiontuned heat transfer in nanostructures. Nanoscale 2013;5:128.
- 150 Sahoo, S., Gaur, A.P.S., Ahmadi, M., Guinel, M.J.F., Katiyar, R.S.. Temperature dependent raman studies and thermal conductivity of few layer mos . 2 Journal of Physical Chemistry C 2013;.
- 151 Varshney, V., Patnaik, S.S., Muratore, C., Roy, A.K., Voevodin, A.A., Farmer, B.L.. Md simulations of molybdenum disulphide (mos ): 2 Force-field parameterization and thermal transport behavior. Computational Materials Science 2010;48(1):101-108.
- 152 Huang, W., Da, H., Liang, G.. Thermoelectric performance of mx 2 (m=mo, w; x=s, se) monolayers. Journal of Applied Physics 2013;113:104304.
- 153 Jiang, J.W., Zhuang, X.Y., Rabczuk, T.. Orientation dependent thermal conductance in single-layer mos . Sci2 entific Reports 2013;3:2209.
- 154 Jiang, J.W., Wang, J.S., Li, B.. Thermal conductance of graphene and dimerite. Physical Review B 2009;79(20):205418.
- 155 Liu, X., Zhang, G., Pei, Q.X., Zhang, Y.W.. Phonon thermal conductivity of monolayer mos2 sheet and nanoribbons. Applied Physics Letters 2013;103:133113.
- 156 Yan, Z., Liu, G., Khan, J.M., Balandin, A.A.. Graphene quilts for thermal management of high-power gan transistors. Nature Communications 2012;3:827.
- 157 Goyal, V., Balandin, A.A.. Thermal properties of the hybrid graphene-metal nano-micro-composites: Applications in thermal interface materials. Applied Physics Letters 2012;100(7):073113.
- 158 Shahil, K.M.F., Balandin, A.A.. Graphenemultilayer graphene nanocomposites as highly efficient thermal interface materials. Nano Letters 2012;12:861-867.
- 159 Goli, P., Legedza, S., Dhar, A., Salgado, R., Renteria, J., Balandin, A.A.. Graphene-enhanced hybrid phase change materials for thermal management of li-ion batteries. Journal of Power Source 2014;248(15):37-43.
- 160 Malekpour, H., Chang, K.H., Chen, J.C., Lu, C.Y., Nika, D.L., Novoselov, K.S., et al. Thermal conductivity of graphene laminate. Nano Letters 2014;14:5155.
- 161 Song, P., Caob, Z., Caib, Y., Zhaob, L., Fangb, Z., Fu, S.. Fabrication of exfoliated graphene-based polypropylene nanocomposites with enhanced mechanical and thermal properties. Polymer 2011;52(18):4001-4010.
- 162 Yu, W., Xie, H., Bao, D.. Enhanced thermal conductivities of nanofluids containing graphene oxide nanosheets. Nanotechnology 2010;21(5):055705.
- 163 Yu, W., Xie, H., Chen, W.. Experimental investigation on thermal conductivity of nanofluids containing graphene oxide nanosheets. Journal of Applied Physics 2010;107(9):094317.
- 164 Yua, W., Xie, H., Wang, X., Wang, X.. Significant thermal conductivity enhancement for nanofluids containing graphene nanosheets. Physics Letters A 2011;375(10):1323-1328.
- 165 Wang, Y., Shi, Z., Huang, Y., Ma, Y., Wang, C., Chen, M., et al. Supercapacitor devices based on graphene materials. Journal of Physical Chemistry C 2009;113:13103013107.
- 166 Novoselov, K.S., Geim, A.K., Morozov, S.V., Jiang, D., Katsnelson, M.I., Grigorieva, I.V., et al. Twodimensional gas of massless dirac fermions in graphene. Nature 2005;438(7065):197-200.
- 167 Zhou, S.Y., Gweon, G.H., Graf, J., Fedorov, A.V., Spataru, C.D., Diehl, R.D., et al. First direct observation of dirac fermions in graphite. Nature Physics 2006;2:595599.
- 168 Partoens, B., Peeters, F.M.. Normal and dirac fermions in graphene multilayers: Tight-binding description of the electronic structure. Physical Review B 2007;75:193402.
- 169 Hass, J., Varchon, F., Millan-Otoya, J.E., Sprinkle, M., Sharma, N., de Heer, W.A., et al. Why multilayer graphene on 4h-sic 000 ¯ 1 behaves like a single sheet of graphene. Physical Review Letters 2008;100:125504.
- 170 Reich, S., Maultzsch, J., Thomsen, C., Ordejon, P.. Tight-binding description of graphene. Physical Review B 2002;66:035412.
- 171 Pereira, V.M., Neto, A.H.C., Peres, N.M.R.. Tightbinding approach to uniaxial strain in graphene. Physical Review B 2009;80:045401.
- 172 Guinea, F., Katsnelson, M.I., Geim, A.K.. Energy gaps and a zero-field quantum hall effect in graphene by strain engineering. Nature Physics 2010;6(1):30-33.
- 173 Nakada, K., Fujita, M., Dresselhaus, G., Dresselhaus, M.S.. Edge state in graphene ribbons: Nanometer size effect and edge shape dependence. Physical Review B 1996;54:17954.
- 174 Kam, K.K., Parkinson, B.A.. Detailed photocurrent spectroscopy of the semiconducting group vi transition metal dichalcogenides. Journal of Physical Chemistry 1982;86(4):463-467.
- 175 Eknapakul, T., King, P.D.C., Asakawa, M., Buaphet, P., He, R.H., Mo, S.K., et al. Electronic structure of a quasi-freestanding mos 2 monolayer. Nano Letters 2014;14(3):1312-1316.
- 176 Li, Y., Zhou, Z., Zhang, S., Chen, Z.. Mos 2 nanoribbons: High stability and unusual electronic and magnetic
- properties. Journal of the American Chemical Society 2008;130(49):16739-16744.
- 177 Lu, P., Wu, X., Guo, W., Zeng, X.C.. Strain-dependent electronic and magnetic properties of mos 2 monolayer, bilayer, nanoribbons and nanotubes. Phys Chem Chem Phys 2012;14(37):13035-13040.
- 178 Radisavljevic, B., Radenovic, A., Brivio, J., Giacometti, V., Kis, A.. Single-layer moS 2 transistors. Nature Nanotechnology 2011;6:147.
- 179 Sangwan, V.K., Arnold, H.N., Jariwala, D., Marks, T.J., Lauhon, L.J., Hersam, M.C.. Low-frequency electronic noise in single-layer mos 2 transistors. Nano Letters 2013;13(9):4351-4355.
- 180 Scalise, E., Houssa, M., Pourtois, G., Afanasev, V., Stesmans, A.. Strain-induced semiconductor to metal transition in the two-dimensional honeycomb structure of mos . Nano Research 2012;5(1):43-48. 2
- 181 Conley, H.J., Wang, B., Ziegler, J.I., Haglund, R.F., Pantelides, S.T., Bolotin, K.I.. Bandgap engineering of strained monolayer and bilayer mos . 2 Nano Letters 2013;13(8):3626-3630.
- 182 Mak, K.F., Lee, C., Hone, J., Shan, J., Heinz, T.F.. Atomically thin MoS : 2 A new direct-gap semiconductor. Physical Review Letters 2010;105(13):136805.
- 183 Nair, R.R., Blake, P., Grigorenko, A.N., Novoselov, K.S., Booth, T.J., Stauber, T., et al. Fine structure constant defines visual transparency of graphene. Science 2008;320(5881):1308.
- 184 Xia, F., Mueller, T., ming Lin, Y., Valdes-Garcia, A., Avouris, P.. Ultrafast graphene photodetector. Nature Nanotechnology 2009;4:839-843.
- 185 Lopez-Sanchez, O., Lembke, D., Kayci, M., Radenovic, A., Kis, A.. Ultrasensitive photodetectors based on monolayer mos . Nature Nanotechnology 2013;8:497501. 2
- 186 Lui, C.H., Frenzel, A.J., Pilon, D.V., Lee, Y.H., Ling, X., Akselrod, G.M., et al. Trion induced negative photoconductivity in monolayer mos . arXiv:14065100 2014;. 2
- 187 Roya, K., Padmanabhana, M., Goswamia, S., Saia, T.P., Kaushalb, S., Ghosh, A.. Optically active heterostructures of graphene and ultrathin mos 2 . Solid State Communications 2013;175-176:35-42.
- 188 Algara-Siller, G., Kurasch, S., Sedighi, M., Lehtinen, O., Kaiser, U.. The pristine atomic structure of mos2 monolayer protected from electron radiation damage by graphene. Applied Physics Letters 2013;103:203107.
- 189 Myoung, N., Seo, K., Lee, S.J., Ihm, G.. Large current modulation and spin-dependent tunneling of
- vertical graphene/mos2 heterostructures. ACS Nano 2013;7(8):7021-7027.
- 190 Bertolazzi, S., Krasnozhon, D., Kis, A.. Nonvolatile memory cells based on mos2/graphene heterostructures. Nano Letters 2013;7(4):3246-3252.
- 191 Larentis, S., Tolsma, J.R., Fallahazad, B., Dillen, D.C., Kim, K., MacDonald, A.H., et al. Band offset and negative compressibility in graphene-mos2 heterostructures. Nano Letters 2014;14(4):20392045.
- 192 Zhang, W., Chuu, C.P., Huang, J.K., Chen, C.H., Tsai, M.L., Chang, Y.H., et al. Ultrahigh-gain photodetectors based on atomically thin graphene-mos 2 heterostructures. Scientific Reports 2014;4:3826.
- 193 Xia, F., Hu, X., Sun, Y., Luo, W., Huang, Y.. Layerby-layer assembled moo2graphene thin film as a highcapacity and binder-free anode for lithium-ion batteries. Nanoscale 2012;4:4707-4711.
- 194 Zhang, W., Chuu, C.P., Huang, J.K., Chen, C.H., Tsai, M.L., Chang, Y.H., et al. Ultrahigh-gain photodetectors based on atomically thin graphene-mos 2 heterostructures. Scientific Reports 2013;4:3826.
- 195 Xu, H., He, D., Fu, M., Wang, W., Wang, H.W.Y.. Optical identification of mos /graphene heterostructure 2 on sio 2 /si substrate. Optics Express 2014;22(13):15969.
- 196 Wang, L.F., Ma, T.B., Hu, Y.Z., Zheng, Q., Wang, H., Luo, J.. Superlubricity of two-dimensional fluorographene/mos 2 heterostructure: a first-principles study. Nanotechnology 2014;25(38):385701.
- 197 Ma, Y., Dai, Y., Guo, M., Niu, C., Huang, B.. Graphene adhesion on mos2 monolayer: An ab initio study. Nanoscale 2011;3(9):3883-3887.
- 198 Yu, L., Lee, Y.H., Ling, X., Santos, E.J.G., Shin, Y.C., Lin, Y., et al. Graphene/mos 2 hybrid technology for large-scale two-dimensional electronics. Nano Letters 2014;14(6):3055-3063.
- 199 Miwa, R.H., Scopel, W.L.. Lithium incorporation at the mos2/graphene interface: an ab initio investigation. Journal of Physics: Condensed Matter 2013;25:445301.
- 200 Jiang, J.W., Park, H.S.. Mechanical properties of mos /graphene heterostructures. Applied Physics Letters 2 2014;105:033108.
- 201 Karkkainen, K.K., Sihvola, A.H., Nikoskinen, K.I.. Effective permittivity of mixtures: Numerical validation by the fdtd method. IEEE TRANSACTIONS ON GEOSCIENCE AND REMOTE SENSING 2000;38(3):1303. | 10.1007/s11467-015-0459-z | [
"Jin-Wu Jiang"
] | 2014-08-02T23:36:21+00:00 | 2015-04-13T01:15:58+00:00 | [
"cond-mat.mtrl-sci"
] | Graphene Versus MoS2: a Short Review | Graphene and MoS2 are two well-known quasi two-dimensional materials. This
review is a comparative survey of the complementary lattice dynamical and
mechanical properties of graphene and MoS2. This comparison facilitates the
study of graphene/MoS2 heterostructures, which is expected to mitigate the
negative properties of each individual constituent. |
1408.0438v2 | ## Evidence against a mean-field description of short-range spin glasses revealed through thermal boundary conditions
Wenlong Wang ∗
Department of Physics, University of Massachusetts, Amherst, Massachusetts 01003, USA
## Jonathan Machta †
Department of Physics, University of Massachusetts, Amherst, Massachusetts 01003, USA and Santa Fe Institute, 1399 Hyde Park Road, Santa Fe, New Mexico 87501, USA
## Helmut G. Katzgraber
Department of Physics and Astronomy, Texas A&M University, College Station, Texas 77843-4242, USA Materials Science and Engineering Program, Texas A&M University, College Station, Texas 77843, USA and Santa Fe Institute, 1399 Hyde Park Road, Santa Fe, New Mexico 87501, USA
A theoretical description of the low-temperature phase of short-range spin glasses has remained elusive for decades. In particular, it is unclear if theories that assert a single pair of pure states, or theories that are based on infinitely many pure states-such as replica symmetry breaking-best describe realistic short-range systems. To resolve this controversy, the three-dimensional EdwardsAnderson Ising spin glass in thermal boundary conditions is studied numerically using population annealing Monte Carlo. In thermal boundary conditions all eight combinations of periodic vs antiperiodic boundary conditions in the three spatial directions appear in the ensemble with their respective Boltzmann weights, thus minimizing finite-size corrections due to domain walls. From the relative weighting of the eight boundary conditions for each disorder instance a sample stiffness is defined, and its typical value is shown to grow with system size according to a stiffness exponent. An extrapolation to the large-system-size limit is in agreement with a description that supports the droplet picture and other theories that assert a single pair of pure states. The results are, however, incompatible with the mean-field replica symmetry breaking picture, thus highlighting the need to go beyond mean-field descriptions to accurately describe short-range spin-glass systems.
## I. INTRODUCTION
A plethora of problems across disciplines and, in particular, a wide variety of optimization problems map onto spin-glass-like Hamiltonians [1-6]. As such, despite the fact that only a selected class of disordered magnets, such as LiHoF 4 or Au Fe x 1 -x show this intriguing state of matter, spin glasses have been of great importance across multiple fields including condensed matter physics, evolutionary biology, neuroscience and computer science. Most recently spin glasses have played a pivotal role in the development of new computing prototypes based on quantum bits in both a theoretical, as well as device-centered role. For example, the stability of topologically protected quantum computing proposals [7-9] against different error sources-recently implemented experimentally [10]-heavily relies on spin-glass physics [11-13]. Similarly, the native benchmark problem currently used to gain a deeper understanding of state-of-the-art quantum annealing machines is based on a spin-glass Hamiltonian [14-17]. Given this recent renaissance of spin glasses to benchmark novel algorithms, as well as to develop cutting-edge computing paradigms, it is unsettling that no consensus exists as to whether
∗ Electronic address: [email protected]
† Electronic address: [email protected]
mean-field theory, also known as replica symmetry breaking theory (RSB) [2, 3, 18-21], accurately describes the low-temperature phase of these systems.
Spin-glass models are well understood in the meanfield regime where infinite-range interactions dominate. However, in finite space dimensions spin glasses are still poorly understood and have been the subject of a long-standing controversy. In this paper we seek to help resolve this controversy. Using numerical methods, we study the low-temperature phase of the threedimensional Edwards-Anderson (EA) spin glass [22]. In so doing, we introduce two methods that promise to be useful in the study of other disordered systems-thermal boundary conditions and sample stiffness extrapolation.
The controversy concerning the EA model is between two competing classes of theories as to the nature of the low-temperature phase. One proposal, championed by Parisi and collaborators [2, 3, 18-21, 23], is that finitedimensional EA spin glasses behave like the mean-field Ising spin glass, known as the Sherrington-Kirkpatrick (SK) model [24]. Parisi analytically studied the SK model [18-20] and found that the low-temperature phase is characterized by an unusual form of symmetry breaking called replica symmetry breaking (RSB). This RSB solution of the SK model predicts that there is an infinity of pure thermodynamic states and that the overlap distribution of these pure states is not self-averaging. Many features of Parisi's RSB solution of the SK model have now been verified by rigorous mathematical methods [25].
The mean-field or RSB picture for finite-dimensional EA spin glasses asserts that the qualitative features of the SK model also hold for finite-dimensional models so that, in particular, there are infinitely many pure states in the thermodynamic limit.
In contrast to the RSB picture, the main competing class of theories for the three-dimensional (3D) EA model assume that the low-temperature phase consists simply of a single pair of pure states related by the spin-reversal symmetry of the Hamiltonian. The earliest and most widely accepted of these theories is the 'droplet picture' developed by McMillan [26], Bray and Moore [27], and Fisher and Huse [28-30]. The droplet picture asserts that the low lying excitations of the pure states are compact droplets with energies that scale as a power of the size of the droplet. By contrast, the low lying excitations in the RSB picture are space filling objects.
Several features of the original RSB picture for finitedimensional EA models have been mathematically ruled out in a series of papers by Newman and Stein [31-35]. These authors provide two alternative theories for finitedimensional EA models, both of which have infinitely many pure states. The first is a nonstandard RSB picture, similar to the original RSB picture but with a selfaveraging thermodynamic limit. Newman and Stein give heuristic arguments against the nonstandard RSB picture but do not rule it out. On the other hand, the nonstandard RSB picture is promoted as a viable theory for finite-dimensional EA models in Ref. [36]. The second is the 'chaotic pairs' picture. Here there are infinitely many pure states but they are organized in such a way that in each finite volume only a single pair of states related by a global spin flip is seen.
In the following we refer to all pictures that display a single pair of pure states in each large finite volume as two-state pictures. Therefore, the droplet and chaotic pairs pictures are both two-state pictures within this definition. Note that for the droplet model it is the same pair of states in every volume while for chaotic pairs a different pair of states is manifest in each volume.
Parallel to these analytical efforts, many computational studies have been aimed at distinguishing between the two classes of theories (see, for example, Refs. [3745]). Unfortunately, computational methods have been difficult to apply to spin glasses. The fundamental questions concern the limit of large system sizes, however, attempts to extrapolate to large sizes have not been conclusive because the range of sizes accessible to simulations at low temperatures is quite small and, for fixed size, the variance between samples for many observables is quite large. Thus, a straightforward extrapolation to large sizes based on mean values of observables can be misleading. Computational studies have yielded a confusing mixture of results: Some point to the RSB picture, some to a two-state picture, and some to a mixed scenario, known as the the 'trivial nontrivial' (TNT) picture described in Refs. [38, 42, 46]. Recently, there have been efforts to analyze statistics other than simple disorder averages [44, 47-51] but these methods have not been definitive either and so the controversy continues.
Here we introduce two related innovations to more effectively extrapolate from small system sizes to the large system-size limit. First, we employ thermal boundary conditions instead of the usual periodic boundary conditions. In d space dimensions, thermal boundary conditions allow the 2 d combinations of periodic or antiperiodic boundary conditions each to appear with the correct Boltzmann weights. The idea is to let the system choose boundary conditions that minimize the presence of domain walls and thus finite-size effects. Second, based on thermal boundary conditions, we define a spin stiffness measure for each sample. We show, as expected for a low-temperature phase, that the sample stiffness becomes large as the system size becomes large. We then study the behavior of the system in the limit of large sample stiffness and relate the system's behavior for large sample stiffness to the large system-size limit. During this process we also obtain new measurements of the spin stiffness exponent at nonzero temperatures. These generic techniques promise to be of broad utility in understanding disordered systems in statistical mechanics, not just the EA spin-glass model. Furthermore, using this approach we conclude that a two-state picture best describes the low-temperature phase of the threedimensional Edwards-Anderson Ising spin glass.
The paper is structured as follows. In Sec. II we introduce the studied model, as well as thermal boundary conditions. Section III describes the implementation of population annealing Monte Carlo used in this study, followed by the measured quantities in Sec. IV. Results are presented in Sec. V, followed by a discussion in Sec. VI and concluding remarks.
## II. THE EDWARDS-ANDERSON MODEL IN THERMAL BOUNDARY CONDITIONS
## A. Edwards-Anderson model
We study the three-dimensional Edwards-Anderson Ising spin-glass model [22]. The model is defined by the Hamiltonian
$$\mathcal { H } = - \sum _ { \langle i, j \rangle } J _ { i j } S _ { i } S _ { j },$$
where S i ∈ {± } 1 are Ising spins and the sum is over nearest neighbors on a cubic lattice of linear size L . The random couplings J ij are chosen from a Gaussian distribution with zero mean and unit variance. A set of couplings J = { J ij } defines a disorder realization or 'sample.'
## B. Thermal boundary conditions
Most Monte Carlo simulations of spin systems are performed with periodic boundary conditions (PBC) be-
cause it is often assumed that periodic boundary conditions yield the mildest finite-size correction. Free boundary conditions are sometimes also employed [39] as are antiperiodic boundary conditions in one direction for the purpose of measuring spin stiffness. In this work we consider thermal boundary conditions (TBC). Thermal boundary conditions include the set of all 2 d choices of periodic or antiperiodic boundary conditions in d spatial dimensions. This means that for three space dimensions ( d = 3) we have 8 possible choices. For example, one of the 8 elements in the set of boundary conditions is 'periodic in the x -direction and antiperiodic in the y and z directions.' For each boundary condition ζ , there is a free energy F ζ and the probability distribution for spin states in TBC is the weighted mixture of the eight boundary conditions with weights e -βF ζ . An equivalent way to describe thermal boundary conditions is to say that the eight boundary conditions are annealed so that each spin configuration together with a boundary condition appears with its proper Boltzmann weight.
The motivation for using thermal boundary conditions for spin glasses can be explained by considering two simpler examples-the ferromagnetic and antiferromagnetic Ising models on a square lattice with lattice size L an odd number. For the ferromagnetic Ising model periodic boundary conditions in all directions are natural and appropriate because they do not induce domain walls in the ordered phase. However, for the antiferromagnetic Ising model, periodic boundary conditions will induce domain walls and the observables for finite systems will have strong finite-size corrections. The natural boundary conditions for the antiferromagnet with L odd are antiperiodic in all directions. Now, suppose we are asked to simulate an Ising model but we are not told whether it is a ferromagnet or antiferromagnet. If we use thermal boundary conditions then we will automatically choose the natural boundary conditions independent of which model we have been given, namely periodic in all directions if the system is a ferromagnet and antiperiodic in all directions if the system is an antiferromagnet. The other boundary conditions will induce domain walls and therefore have higher free energies. The difference in free energy between thermal boundary conditions and any of the domain-wall-inducing boundary conditions scales as L θ where θ is the spin stiffness exponent. For the Ising model (either ferromagnetic or antiferromagnetic) in the low-temperature phase, θ = d -1 ≥ 0, and, even for modest system sizes, thermal boundary conditions are essentially the same as the single natural boundary condition because all unfavorable choices are suppressed.
While one can a priori determine the optimal boundary conditions for simple systems such as ferromagnets and antiferromagnets, the same is not true for spin glasses. For a given sample, a single boundary condition such as PBC may induce domain walls and induce large finite-size effects. The motivation for using thermal boundary conditions is thus the same as for the simple (anti)ferromagnetic example discussed above. Because we do not know which of the eight periodic/antiperiodic boundary conditions fits the sample best, we simply let the system choose by minimizing the free energy.
At zero temperature, thermal boundary conditions correspond to selecting from among the 2 d boundary conditions those with the lowest energy ground states. These boundary conditions have been employed with exact algorithms for finding ground states of two-dimensional spin glasses [52, 53]. Thomas and Middleton [53] call thermal boundary conditions 'extended' boundary conditions and argue, as we do, that these boundary conditions minimize finite-size effects. Similar ideas but using periodic and antiperiodic boundary conditions in a single direction are discussed in [54-57].
For the mathematical statistical physicist the difficulties produced by spurious domain walls are avoided by using 'windows:' Consider a very large system of linear size L and a large window inside this system of linear size glyph[lscript] such that 1 glyph[lessmuch] glyph[lscript] glyph[lessmuch] L . Then any domain walls induced by the 'bad' boundary conditions will almost surely lie outside the window and observables measured within the window will not be influenced by the domain wall. By collecting data only inside the window the results are then independent of the boundary conditions. Unfortunately, the computational statistical physicist does not have the luxury of collecting equilibrated data in this way for spin glasses where attainable system sizes deep within the low-temperature phase do not exceed, for example, L ≈ 10 in three space dimensions.
Thermal boundary conditions may also be used to measure the spin stiffness exponent θ by comparing the free energy of TBC with other boundary conditions. For example, for spin glasses it is sufficient to compare the free energy for TBC with that for PBC. This approach is expected to yield the same exponent but a different prefactor for the spin stiffness as compared to the standard method of taking the absolute value of the free energy difference between periodic and antiperiodic boundary conditions.
## III. METHODS
We use population annealing Monte Carlo [58-60] to simulate the EA model. The most common method for large-scale spin-glass simulations is parallel tempering Monte Carlo [61], however, parallel tempering Monte Carlo is not well suited to thermal boundary conditions and is not easily used to measure free energies. In contrast, population annealing is able to simulate TBC and accurately measure free energies in a straightforward way.
Population annealing is related to simulated annealing where the temperature of the system is lowered in a step-wise fashion following a predefined annealing schedule. In each annealing step a Markov chain Monte Carlo algorithm is applied to the system at the current temperature in the schedule. In population annealing a large population of replicas of the system are simultaneously
annealed from high to low temperature. However, simulated annealing is designed for finding only ground states and it does not correctly sample equilibrium states at the temperatures traversed during the annealing schedule. Population annealing corrects this deficiency by adding a resampling step that ensures that the population of replicas at every temperature is a Gibbs ensemble at that temperature. Population annealing is an example of a sequential Monte Carlo algorithm [62] and it converges to the correct equilibrium distribution as the population size increases. It is thus well suited to parallel computation and our implementation uses OpenMP.
The algorithm works as follows. Let R 0 be the initial size of the population of replicas of the system. In our implementation of population annealing, each replica is initialized independently at infinite temperature T ( β = 1 /T = 0). Each replica has the same set of couplings. For thermal boundary conditions, 1 / 8 of the replicas are assigned to each of the 8 boundary conditions. The temperature of the population is now cooled from β = 0 in a sequence of steps to a target temperature β 0 . The annealing step from β to β ′ ( β ′ > β ) consists of two stages: The first stage is resampling and the second stage is the application of the Metropolis algorithm at inverse temperature β ′ . In the resampling step, some replicas are eliminated and others are duplicated. For TBC, when a replica is copied, its boundary condition is copied with it.
The resampling step works as follows. Suppose we have ˜ R β replicas that represent an equilibrium ensemble at inverse temperature β and we want to lower the temperature to β ′ > β . The ratio of the statistical weight at β to β ′ for replica j , with energy E j is exp[ -( β ′ -β E ) j ]. In principle this factor should represent how many copies to make of the system. However, this ratio is typically larger than unity. In order to keep the population size roughly fixed we need to normalize the ratio. First compute normalized weights τ j ( β, β ′ ) whose sum over the ensemble is R 0 ,
$$\tau _ { j } ( \beta, \beta ^ { \prime } ) = \left ( \frac { R _ { 0 } } { \tilde { R } _ { \beta } } \right ) \frac { \exp { [ - ( \beta ^ { \prime } - \beta ) E _ { j } ] } } { Q ( \beta, \beta ^ { \prime } ) }, \quad ( 2 ) \quad \text{when} \quad \text{that} \quad \text{$\quad$}$$
where Q is the normalization given by
$$Q ( \beta, \beta ^ { \prime } ) = \frac { \sum _ { j = 1 } ^ { \tilde { R } _ { \beta } } \exp \left [ - ( \beta ^ { \prime } - \beta ) E _ { j } \right ] } { \tilde { R } _ { \beta } }. \quad \ \ ( 3 ) \quad \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \$$
The new population at temperature β ′ is obtained by differential reproduction. The number of copies n j of replica j is either the floor (greatest integer less than) glyph[floorleft] τ j glyph[floorright] or ceiling glyph[ceilingleft] τ j glyph[ceilingright] with probabilities glyph[ceilingleft] τ j glyph[ceilingright] -τ j and τ j -glyph[floorleft] τ j glyph[floorright] , respectively. Note that this choice ensures that the expectation of n j is τ j . It also minimizes the variance of n j among all integer probability distributions with this expectation. (Note that it is possible to have n j = 0 for replica j .) In our implementation, the size of the population at each temperature ˜ R β is variable but stays close to the target
TABLE I: Parameters of the numerical simulations for different system sizes L and periodic (PBC), as well as thermal (TBC) boundary conditions. R 0 represents the number of replicas, 1 /β 0 is the lowest temperature simulated, N T the number of temperatures used in the annealing schedule, N S the number of sweeps per temperature, and M the number of samples. M PBC is the number of hard samples for periodic boundary conditions and M TBC the number of hard samples for thermal boundary conditions.
| L | R 0 PBC | R 0 TBC | 1 /β 0 | N T | N S | M | M PBC | M TBC |
|-----|-----------|-----------|----------|-------|-------|------|---------|---------|
| 4 | 5 10 4 | 5 10 4 | 0 . 200 | 101 | 10 | 4941 | 0 | 0 |
| 6 | 2 10 5 | 2 10 5 | 0 . 200 | 101 | 10 | 4959 | 0 | 0 |
| 8 | 5 10 5 | 5 10 5 | 0 . 200 | 201 | 10 | 5099 | 5 | 33 |
| 10 | 10 6 | 2 10 6 | 0 . 200 | 301 | 10 | 4945 | 286 | 291 |
| 12 | 10 6 | 3 10 6 | 0 . 333 | 301 | 10 | 5000 | 533 | 386 |
value R 0 . In the next stage of the annealing step, every member of the new population is subject to N S sweeps of the Metropolis algorithm at inverse temperature β ′ . Our implementation of population annealing follows a schedule of N T inverse temperatures β that are evenly spaced between β = 0 and β 0 . The system sizes and temperatures in the simulations, together with the parameters of the population annealing simulations are shown in Table I. The definition of hard samples is given below. Note that although the number of sweeps per temperature N S is small, the total number of sweeps, R N N 0 S T , is large and comparable to the number of sweeps performed in parallel tempering simulations. In population annealing, equilibration results from large values of R 0 and is guaranteed in the limit R 0 →∞ for fixed N S and N T .
The free energy can be estimated [59] from the normalization factors Q β,β ( ′ ) defined in Eq. (2) according to
$$- \, \beta _ { k } \tilde { F } ( \beta _ { k } ) = \sum _ { \ell = N _ { T } - 1 } ^ { k + 1 } \ln Q ( \beta _ { \ell }, \beta _ { \ell - 1 } ) + \ln \Omega, \quad ( 4 )$$
where Ω is the number of configurations of the system so that for N Ising spins, Ω = 2 N for PBC and Ω = 2 ( N + ) d for TBC in d dimensions.
Because population annealing has not been used before for large-scale simulations in statistical physics, we did a careful comparison to data previously obtained using parallel tempering [44, 63]. We measured observables for the same set of samples studied in Refs. [44, 63], comprising approximately 5000 samples for each system size L with periodic boundary conditions. We found no statistical difference between population annealing and parallel tempering for any disorder averaged observable (see Sec. V B for a comparison of one observable). A detailed comparison between population annealing and parallel tempering will be presented in a subsequent publication [64].
The convergence to equilibrium of population annealing for each sample can be quantified using the family
entropy . Define family i as the set of replicas at some low temperature that are descended from replica i at the highest temperature. In practice most families are empty sets. Let η i be the fraction of the population in family i , i.e., the fraction of the population at the low temperature that is descended from replica i in the initial, high-temperature population. Then the family entropy S f is given by
$$S _ { f } = - \sum _ { i } \eta _ { i } \log \eta _ { i }. \quad \ \ ( 5 ) \stackrel { \dashv \dashv } { \text{ref} } \\ \stackrel { \text{sta} } { \text{sct} }$$
The exponential of S f is an effective number of families. For example, if there are k surviving families all of the same size then η i = 1 /k for each surviving family and e S f = k . In practice, the family sizes are exponentially distributed.
Since each family has an independent history during the simulation, e -S / f 2 is a conservative measure of statistical errors. As discussed in Ref. [64], e -S f is a reasonable measure of systematic errors. In our simulations, we require that e -S f < 0 01 for every disorder sample. . For hard samples that do not meet this requirement with the standard population size given in Table I we increased the population size until this equilibration criterion was met. The numbers of hard samples M PBC and M TBC for periodic and thermal boundary conditions, respectively, are given in Table I. Most hard samples were equilibrated using 5 runs with R 0 = 3 × 10 , which were then com6 bined using weighted averaging [59] for a total population of 1 5 . × 10 . 7 For the hardest samples of size L = 10 and 12, population sizes up to 10 8 were required to meet the equilibration criterion.
## IV. MEASURED QUANTITIES
## A. Free energy, ground-state energy and spin stiffness
Using Eq. (4) we measure the free energies, F TBC J and F PBC J , for each sample J in thermal (TBC) and periodic (PBC) boundary conditions, respectively. We also measure the ground-state energies E TBC J and E PBC J for each sample in both TBC and PBC, respectively. We compute the ground-state energy by taking the minimum energy in the population at the lowest temperature ( T = 0 2 . glyph[lessmuch] T c ). We report on a careful study of the ground-state calculation in a separate paper [65]. There we show that the average ground-state energy agrees with other methods, that multiple runs always yield the same ground state, and that for a small number of the hardest samples we find agreement with exact branch and bound methods.
The traditional measure of spin stiffness is the difference between the free energy, or at zero temperature, the ground-state energy of two different boundary conditions-usually periodic and antiperiodic in a single direction with periodic boundary conditions in all other directions. For spin glasses, this quantity may be of either sign and the absolute value must be taken before performing the disorder average. Here we consider the free energy (ground-state energy) difference between thermal boundary conditions and periodic boundary conditions. This quantity is nonnegative because periodic boundary conditions are contained in the TBC ensemble of boundary conditions so no absolute value needs to be taken. We refer to ∆ F as the disorder average free energy (groundstate energy) difference between TBC and PBC. The scaling of ∆ F with system size L defines the stiffness exponent θ ,
$$\Delta F \sim L ^ { \theta }.$$
We measure θ at T = 0, 0 2, and 0 42 by fitting to this . . equation.
The free energy for each boundary condition in the TBC ensemble can be measured using an analog of Eq. (4) by partitioning Q into its 8 boundary condition components but we did not collect data to do this measurement. Instead, we estimate the ratio of the free energy of the dominant boundary condition to the free energy of all the other boundary conditions combined. Let f J be the fraction of the population in the boundary condition with the largest population in sample J . The quantity λ J ,
$$\lambda _ { \mathcal { J } } = \log \frac { f _ { \mathcal { J } } } { ( 1 - f _ { \mathcal { J } } ) },$$
is an estimator of the free-energy difference (times -β ) between the dominant boundary condition and all other boundary conditions in sample J . Note that λ J is a measure of the stiffness of sample J . If only one boundary condition dominates the ensemble of boundary conditions it means that inserting a domain wall is very costly and the sample is stiff while if λ J is small, the domain walls induced by changing boundary conditions have little cost and the sample is not stiff. Note that, in principle, all boundary conditions could have equal weight so λ ≥ -log 7.
## B. Order parameter distribution
The order parameter for spin glasses is obtained from the spin overlap, q defined by
$$q = \frac { 1 } { N } \sum _ { i } S _ { i } ^ { ( 1 ) } S _ { i } ^ { ( 2 ) },$$
where the superscripts '(1)' and '(2)' indicate two statistically independent spin configurations chosen from the Gibbs distribution. Let P J ( q ) be the overlap distribution for sample J and let P q ( ) be the disorder average of the overlap distribution. In population annealing, the pairs of independent spin configurations used in Eq. (8)
are chosen randomly from the population of replicas with the restriction that the two replicas are from different families. This ensures that the spin configurations are independent.
Two-state pictures make very different predictions from the RSB picture for P J ( q ) for the low-temperature phase of the EA model in the infinite-volume limit. If there is a single pair of pure states then P J ( q ) consists of two δ functions at ± q EA and, of course, P q ( ) after disorder averaging is the same. Here q EA is the EdwardsAnderson order parameter. In the RSB picture, P J ( q ) consists of a countable infinity of δ functions of varying weights densely filling the range between ± q EA while P q ( ) is a smooth function between ± q EA with delta functions at ± q EA . Thus, one can, in principle, distinguish between the two classes of pictures by examining P q ( ) near the origin (and thus away from q EA ). A measure of the weight near the origin of the overlap distribution is I J ( q ),
$$I _ { \mathcal { J } } ( q ) = \int _ { - q _ { 0 } } ^ { + q _ { 0 } } d q P _ { \mathcal { J } } ( q ). \quad \quad ( 9 ) \quad \text{TA} \quad \text{diff}$$
We refer to the disorder average of I J ( q ) as I ( q ). The choice q 0 = 0 2 . has been used in many past studies [38, 44] to distinguish the RSB and two-state pictures and, in this work, we investigate the statistics of I J ( q 0 = 0 2). . In the following, we use the symbols I J and I L as abbreviations for I J (0 2) and its disorder av-. erage I (0 2) for size . L , respectively.
## V. RESULTS
In this section, we present results for the spin stiffness (VA), the order parameter distribution near zero, I J (VB) and the correlation of I J and λ J (VC). The main result of this section is that λ J increases with system size and that stiff samples have small values of I J .
## A. Spin stiffness
Figure 1 shows the free-energy difference or, for T = 0, ground-state energy difference ∆ F between TBC and PBC for temperatures T = 0, 0 2, . and 0 42 as a func-. tion of system size L . The straight lines are best fits to the functional form ∆ F ∼ aL θ . The fits for θ are shown in Table II. The result θ T ( = 0) = 0 197 . ± 0 017 . is in reasonable agreement though at the low end of previous measurements of θ carried out at zero temperature [37, 66-68]. Note that the stiffness exponent has not previously been measured at nonzero temperature. We see that θ decreases as temperature increases. Presumably, this is a finite-size effect because θ is expected to have a single asymptotic value throughout the low-temperature phase [30].
Next consider the sample stiffness measure λ J , defined in Eq. (7). Let G L ( λ ) be the cumulative distribution
FIG. 1: Free-energy change ∆ F vs system size L for T = 0, 0 2, . and 0 42. . The straight lines are fits of the form ∆ F ∼ aL θ .
TABLE II: Estimates of the stiffness exponents θ and θ λ for different temperatures T .
| T | 0 | 0 . 2 | 0 . 42 |
|-----|-------------|-------------|-------------|
| θ | 0 . 197(17) | 0 . 189(17) | 0 . 169(12) |
| θ λ | - | 0 . 290(30) | 0 . 268(20) |
function for λ . The left panel of Fig. 2 is a log plot of 1 -G L ( λ ), the complementary cumulative distribution function, for λ at T = 0 42, and sizes 4 through 12. . The nearly straight line behavior of log(1 -G L ( λ )) is indicative of a nearly exponential tail and suggests a data collapse if λ is scaled by a characteristic λ char ( L ) given by the slope of the line. Since the tail is not perfectly straight, we instead define λ char ( L ) in terms of medianlike quantities. If the distribution were exactly exponential then 1 -G λ ( ) = e -λ/λ char and 1 -G λ ( char log b ) = 1 /b for any b . If the distribution is not perfectly exponential, λ char depends on b so there is some ambiguity in the definition. We choose b such that λ char is obtained from the tail of the distribution but not so far into the tail that the statistics are poor. For T = 0 2 we choose . b = 2 so λ char is defined as the median divided by log 2. For T = 0 42 we choose . b = 10 to ensure that λ char is obtained from the tail of the distribution. The right panels of Figs. 2 and 3 show 1 -G L ( λ/λ char ( L )) for T = 0 42 . and T = 0 2, respectively, and reveal that all of the cu-. mulative distributions collapse onto the same curve when scaled by λ char ( L ).
Figure 4 shows λ char ( L ) vs log L for T = 0 2 and . T = 0 42. . Since λ char ( L ) is a stiffness measure, we can extract a new stiffness exponent θ λ from a fit to the form,
$$\lambda _ { \text{char} } ( L ) \sim a L ^ { \theta _ { \lambda } }. \quad \quad \quad ( 1 0 )$$
The values of θ λ , given in Table II, are larger than θ obtained from the average free energy difference but close to the value, 0 27, found in Ref. [67] using aspect ratio .
scaling. Presumably, the asymptotic values of θ and θ λ are the same. We prefer the larger value, θ λ because it is obtained from the tail of the stiffness distribution so we believe it reflects the large-size behavior more accurately than the average free energy difference that defines θ . Aspect ratio scaling is an independent way to minimize finite-size effects and it is interesting that these two approaches yield the same answer within error bars.
It seems clear that λ char ( L ) →∞ as L →∞ . At least on a coarse scale, the full distribution G L ( λ ) also scales with λ char ( L ). A closer look at G near the head of the distribution for T = 0 42 shows that the data collapse is . not perfect and there are significant finite-size corrections near λ = 0. Figure 5 shows 1 -G L ( λ/λ char ( L )) vs λ in the region near λ = 0 for T = 0 42. . Note that curves do not collapse perfectly and that 1 -G L ( λ/λ char ( L )) appears to be increasing with L . Figure 6 is the same plot for T = 0 2. Because . G L (0) is so small for T = 0 2, the error . bars are too large to discern whether there is a trend with L . A reasonable hypothesis is that there is an asymptotic L →∞ scaling function G ∞ ( z ) where z = λ/λ char such that G L ( λ ) → G ∞ ( λ/λ char ( L )). The straight line behavior of log(1 -G ∞ ( z )) for large z and increasing trend with L for small z suggests that G ∞ (0) = 0 and G ∞ ( z ) is exponential for z glyph[greatermuch] 1. In more physical terms, if G ∞ ( z ) exists and is zero for z → 0 + , it means that a single boundary condition dominates the TBC ensemble almost surely, i.e., the dominant boundary condition almost always has a much lower free energy than the other seven boundary conditions. A more complicated possibility is that G ∞ (0 + ) > 0. The consequences of these possibilities for the RSB vs two-state pictures are discussed in Sec. VI.
It is noteworthy that for the system sizes accessible to simulations, λ char ( L ) is sufficiently small that the TBC ensemble contains a mixture of several competing boundary conditions for a substantial fraction of samples. The disorder average I L is dominated by these samples and is therefore not characteristic of the largeL behavior when λ char ( L ) is expected to be large. In what follows we circumvent this difficulty by extrapolating first in λ and then in L , making use of the fact our data contain a relatively large dynamic range in λ .
## B. Order parameter near q = 0
Figure 7 shows I L , the disorder average of the integrated order parameter distribution with | q | < 0 2, as a . function of size L for temperatures T = 0 2 and 0 42, as . . well as for both PBC and TBC. For both boundary conditions, I L is, within error bars, independent of system size. The results for PBC are identical to those obtained using parallel tempering Monte Carlo [38, 44]. In fact, in Fig. 8 we show a scatter plot of I J computed both with population annealing and parallel tempering Monte Carlo. The data are strongly correlated and both methods yield the same results within statistical errors.
FIG. 2: (Left panel) Linear-log plot of 1 -G L ( λ ) (the complementary cumulative distribution function) vs λ for sizes L = 4 through 12 at T = 0 42. (Right panel) 1 . -G L ( λ/λ char ( L )) vs λ/λ char ( L ).
FIG. 3: (Left panel) Linear-log plot of 1 -G L ( λ ) (the complementary cumulative distribution function) vs λ for sizes L = 4 through 10 at T = 0 2. . (Right panel) 1 -G L ( λ/λ char ( L )) vs λ/λ char ( L ).
The constancy of I L has been taken as strong evidence for the RSB picture because the two-state picture predicts I L should decrease as L -θ . However, in what follows we argue that in TBC ultimately I L → 0 for very large L . On first glance the results for TBC are surprising since I TBC L is larger by more than a factor of two than I PBC L . The explanation is that for many samples the TBC ensemble contains several boundary conditions with significant weight and the overlap between spin configurations with different boundary conditions will tend to have small values of q due to the existence of a relative domain wall. We shall return to this important point in Sec. VI.
## C. Order parameter near q = 0 vs spin stiffness
Figure 9 is a scatter plot showing many of the disorder samples at T = 0 42 (left panel) and . T = 0 2 (right panel) . for all the sizes studied using TBC. Each point on the plot represents a sample J . The x coordinate of the point is λ J = log [ f J / (1 -f J )] and the y coordinate is I J .
FIG. 4: Log-log plot of λ char ( L ) vs L for T = 0 2 and . T = 0 42. . The straight lines represent fits of the form λ char ( L ) ∼ aL θ λ .
FIG. 5: (Left panel) 1 -G L ( λ ) vs λ for system sizes L = 4 through 12 at T = 0 42 in the region near . λ = 0. (Right panel) 1 -G L ( λ/λ char ( L )) vs λ/λ char ( L ). Note that 1 -G L (0) increases slowly with L .
Figure 10 is the same as Fig. 9 but with each system size on a separate plot for T = 0 2. The qualitative features of . the plots are the same for each size although, as described above, the distribution of λ 's shifts to larger values for larger L . These figures together with the behavior of the λ distribution constitute the main results of our paper and motivate our conclusion that I J → 0 almost surely as L →∞ in thermal boundary conditions.
Samples J for which I J or 1 -f J are exactly zero within the precision of the simulations are not shown on these log-log plots since log I J = -∞ or λ J = ∞ . The fractions of such samples are given in Table III. Note that actual values of I J or 1 -f J are are never exactly zero for finite systems; zeros correspond to values smaller than can be represented by the finite population sizes used in the simulations. It is important to note that the trends shown in Fig. 9 continue to hold for the large values of λ that are omitted from this figure. Including all sizes, there are 216 samples with 1 -f J = 0 for T = 0 42 . and 2996 such samples for T = 0 2. . Of these, only seven
FIG. 6: (Left panel) 1 -G L ( λ ) vs λ for system sizes L = 4 through 10 at T = 0 2 in the region near . λ = 0. (Right panel) 1 -G L ( λ/λ char ( L )) vs λ/λ char ( L ).
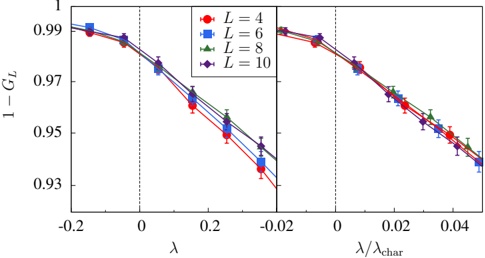
FIG. 7: I L vs L for PBC and TBC at temperature T = 0 42 (left . panel) and T = 0 2 (right panel). . The data seem independent of system size, suggesting an RSB interpretation of the data.
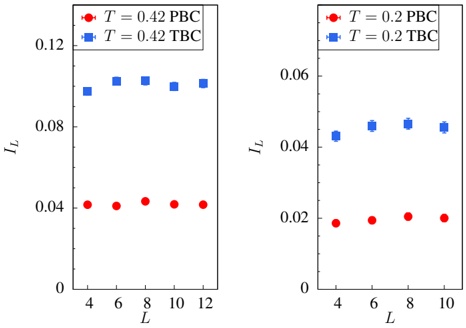
samples for T = 0 42 and 38 for . T = 0 2 are measured . to have nonzero values of I J . The average value of I for only those samples with 1 -f J = 0 are 2 5 . × 10 -8 and 10 -4 for T = 0 42 and . T = 0 2, respectively. .
A striking feature of Figs. 9 and 10 is that there is a bounding curve that becomes a straight line for large λ with most samples lying below that curve. Why are there two classes of samples, with most samples below the curve and a few above it? We speculate that the samples below the curve have nonzero values of I J as a result of the overlap between spin configurations with different boundary conditions. The contribution to the overlap between different boundary conditions in the TBC ensemble cannot exceed 2 f (1 -f ) in the limit f → 1, so that if this is the primary mechanism producing small overlaps in sample J then log I J < ( -λ J + log 2). The straight lines in Fig. 9 are defined by log I = ( -λ +log 2). Thus, for most samples, we believe that the primary contribution to I J comes from the overlap between different boundary conditions. For the rare samples above the bounding curve,
FIG. 8: Log-log scatter plot of I J for PBC for each sample at temperature T = 0 20 and . L = 10 computed with parallel tempering Monte Carlo (PT, vertical axis) and population annealing Monte Carlo (PA, horizontal line). The data show both methods yields the same result for each sample within statistical errors.
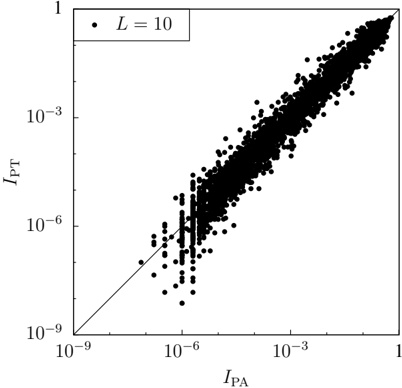
TABLE III: Fraction of samples with I J = 0 and f J = 1 for different sizes, temperatures, and boundary conditions.
| PBC | PBC | PBC | PBC | PBC | PBC |
|-----------------------------------|-------|-------|-------|-------|-------|
| System size L | 4 | 6 | 8 | 10 | 12 |
| Fraction I J = 0 ( T = 0 . 42) | 0.21 | 0.19 | 0.16 | 0.16 | 0.19 |
| Fraction of I J = 0 ( T = 0 . 2) | 0.60 | 0.57 | 0.55 | 0.54 | - |
| Fraction of f J = 1 ( T = 0 . 42) | - | - | - | - | - |
| Fraction of f J = 1 ( T = 0 . 2) | - | - | - | - | - |
| TBC | TBC | TBC | TBC | TBC | TBC |
|-----------------------------------|-------|-------|-------|--------|-------|
| System size L | 4 | 6 | 8 | 10 | 12 |
| Fraction I J = 0 ( T = 0 . 42) | 0.05 | 0.04 | 0.03 | 0.03 | 0.03 |
| Fraction of I J = 0 ( T = 0 . 2) | 0.35 | 0.33 | 0.3 | 0.28 | - |
| Fraction of f J = 1 ( T = 0 . 42) | 0.009 | 0.009 | 0.008 | 0.008 | 0.010 |
| Fraction of f J = 1 ( T = 0 . 2) | 0.15 | 0.16 | 0.15 | 0.15 | - |
the primary contribution to I J must come from small overlaps within the dominant boundary condition.
Asecond important feature of Figs. 9 and 10 is that the rare samples above the bounding curve have I J roughly uniformly distributed on a logarithmic scale between the bounding curve and 1. On a linear scale this means that for large λ almost all of these samples have small values of I J . Let ρ x y ( | ) be the conditional probability density for x = I J conditioned on y = λ J . If this distribution is exactly log uniform above the bounding line then the part of the distribution above the line would take the
FIG. 9: (Color online) Scatter plots showing all disorder realizations for all system sizes at T = 0 42 (left . panel) and T = 0 2 (right . panel). Each point represents a sample J located at x coordinate λ J and y coordinate I J . Red diamonds represent L = 4, blue crosses L = 6, green squares L = 8, purple triangles L = 10, and orange plus symbols L = 12.
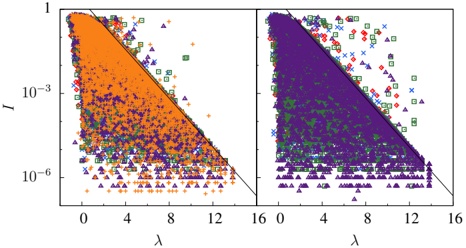
FIG. 10: (Color online) Same as Fig. 9 but for each system size in a separate panel and T = 0 2. . Again, red diamonds represent L = 4, blue crosses L = 6, green squares L = 8, and purple triangles L = 10.
form,
$$- \quad \rho ( x | y ) = \frac { 1 - w ( y ) } { x y } \quad \text{for} \quad x > 2 \exp ( - y ), \ \ ( 1 1 )$$
where w y ( ) is the fraction samples below the bounding line. Figure 11 shows histograms of I J values of the samples of all sizes that lie above the bounding line for the two temperatures. The position α along the horizontal axis is the scaled logarithmic distance between the bounding line and one. That is, α J = -log I J / λ [ -log(2)] so that zero corresponds to large values, I J ≈ 1 while one corresponds to I J on the bounding line. For T = 0 2 the distribution is indeed relatively uniform on . a logarithmic scale while for T = 0 42 it is skewed to a . small value of I .
)
α
(
N
30
20
10
0
0
0.2
0.4
0.6
0.8
1
α
FIG. 11: Histogram N ( α ) for α J = log( I J ) / [ -λ J +log(2)] for T = 0 42 (left panel) and . T = 0 2 (right panel). . α = 1 corresponds to the small values of I at the bounding line.
## VI. DISCUSSION
Three salient features of the data are apparent from Figs. 4, 9, and 11.
- I. Typical values of the sample stiffness λ J increase with system sizes L , as described by λ char ( L ).
- II. Most samples have I J less than a bounding curve described by 2 e -λ for large λ .
- III. Samples with I J above the bounding curve have I J distributed more or less uniformly in log I between the bounding curve and one.
We conjecture that these features hold for arbitrarily large L and all temperatures in the low-temperature phase. Assuming the above statements are asymptotically correct, we can draw some strong conclusions about how I L behaves for sufficiently large L that λ char ( L ) glyph[greatermuch] 1. Note that these system sizes are far larger than are accessible in our simulations but, given the large dynamic range in λ we can extrapolate to these sizes by first extrapolating in λ . For large L λ , J is nearly always large according to Statement (I). Furthermore, due to Statements (II) and (III), I J is, almost always small when λ J is large. Thus I J is nearly always small when L is large. This conclusion is the main result of our analysis. It is consistent with two-state pictures but not consistent with the RSB picture.
In addition to being consistent with our data, these conjectures are quite plausible. Statement (I) asserts that λ J is a measure of sample stiffness and that in the low-temperature phase, almost all samples become stiff for large system sizes. As discussed above, Statement (II) asserts that in TBC large values of I J arise mostly from the overlap between two different boundary conditions. Statement (III) asserts that the free-energy cost of a large excitation in the dominant boundary condition is more or less uniformly distributed between λ/β and 0.
We can make the arguments more quantitative using a simple model of how the disorder average I L will behave for large L . Let ρ x y ( | ) be the conditional probability density for I J = x conditioned on λ J = y . Based on statements (II) and (III) we propose the form,
$$\mathfrak { P } \, \Big | \quad & \rho ( x | y ) = w ( y ) \delta [ x, 2 \exp ( - y ) ] + \frac { 1 - w ( y ) } { x y } \theta [ x - 2 \exp ( - y ) ], \\ & \quad \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \ dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots.$$
where w y ( ) is the fraction of samples at fixed λ below the bounding curve, and θ x ( ) and δ x, y ( ) are the Heaviside function and the δ -function, respectively. The first term conservatively places all the samples below the bounding curve on the curve itself. The second term represents the samples above the bounding curve with the conservative assumption that the distribution of I J above the curve is uniform on a log scale as in Eq. (11). For purposes of the following calculation we assume that w is a constant independent of y but the qualitative conclusions do not depend on this assumption. Finally, we assume that the distribution of λ obeys a size independent form G ∞ ( z ) for the scaled variable z = λ/λ char ( L ). Note that we have assumed that the dependence of I L on L is entirely through λ char ( L ) and that the conditional probability ρ x y ( | ) is independent of L . These assumptions yield an explicit expression for I L as a function of λ char ( L ),
$$\ r v e \quad & I _ { L } = \frac { 1 } { \lambda _ { \text{char} } ( L ) } \int _ { 0 } ^ { \infty } d G _ { \infty } ( z ) \int _ { 0 } ^ { \infty } d x \ x \rho ( x | z \lambda _ { \text{char} } ( L ) ). \\ I _ { \tau } \quad & \text{d} \dots \dots \colon \colon = \colon = \colon = \colon = \colon = \colon = \colon = \colon = \colon = \colon = \colon = \colon = \colon = \colon = \colon = \colon = \colon = \colon = \colon = \colon = \colon = \colon = \colon = \colon = \colon = \colon = \colon = \colon = \colon = \colon = \colon = \colon = \colon = \colon = \colon = \colon = \colon = \colon = \colon = \colon = \colon = \colon = \colon = \colon = \colon = \colon = \colon = \colon = \colon = \colon = \colon$$
Plugging in the ansatz of Eq. (12) and an exponential form for the scaled λ distribution, 1 -G ∞ ( z ) = e -z , yields a somewhat complex expression involving exponential integrals whose asymptotic large λ behavior is,
$$\overset { \circ } { \cdot } \\ \cdot \\ \cdot \\ \cdot \\ \cdot \\ \cdot \\ \cdot \\ \cdot \\ \cdot \\ \cdot \\ \cdot \\ \cdot \\ \cdot \\ \cdot \\ \cdot \\ \cdot \\ \cdot \\ \cdot \\ \cdot \\ \cdot \\ \cdot \\ \cdot \\ \cdot \\ \cdot \\ \cdot \\ \cdot \\ \cdot \\ \cdot \\ \cdot \\ \cdot \\ \cdot \\ \cdot \\ \cdot \\ \cdot \\ \cdot \\ \cdot \\ \cdot \\ \cdot \\ \cdot \\ \cdot \\ \cdot \\ \cdot \\ \cdot \\ \cdot \\ \cdot \\ \cdot \\ \cdot \\ \cdot \\ \cdot \\ \cdot \\ \cdot \\ \cdots \\ \cdots \\ \cdots \\ \cdots \\ \cdots \\ \cdots \\ \cdots \\ \cdots \\ \cdots \\ \cdots \\ \cdots \\ \cdots \\ \cdots \\ \cdots \\ \cdots \\ \cdots \\ \cdots \\ \cdots \\ \cdots \\ \cdots \\ \cdots \\ \cdots \\ \cdots \\ \cdots \\ \cdots \\ \cdots \\ \cdots \\ \cdots \\ \cdots \\ \cdots \\ \cdots \\ \cdots \\ \cdots \\ \cdots \\ \cdots \\ \cdots \\ \cdots \\ \cdots \\ \cdots \\ \cdots \\ \cdots \\ \cdots \\ \cdots \\ \cdots \\ \cdots \\ \cdots \\ \cdots \\ \cdots \\ \cdots \\ \cdots \\ \cd� \\ \cd� \\ \cd� \\ \cd� \\ \cd� \\ \cd� \\ \cd� \\ \cd� \\ \cd� \\ \cd� \\ \cd� \\ \cd� \\ \cd� \\ \cd� \\ \cd� \\ \cd� \\ \cd� \\ \cd� \\ \cd� \\ \cd� \\ \cd� \\ \cd� \\ \cd� \\ \cd� \\ \cd� \\ \cd� \\ \cd� \\ \cd� \\ \cd� \\ \cd� \\ \cd� \\ \cd� \\ \cd� \\ \cd� \\ \cd� \\ \cd� \\ \cd� \\ \cd� \\ \cd� \\ \cd� \\ \cd� \\ \cd� \\ \cd� \\ \cd� \\ \cd� \\ \cd� \\ \cd� \\ \cd� \\ \cd� \\ \cd� \\ \cd� \\ \cd� \\ \cd� \\ \cd� \\ \cd� \\ \cd� \\ \cd� \\ \cd� \\ \cd� \\ \cd� \\ \cd� \\ \cd� \\ \cd� \\ \cd� \\ \cd� \\ \cd� \\ \cd� \\ \cd� \\ \cd� \\ \cd� \\ \cd� \\ \cd� \\ \cd� \\ \cd� \\ \cd� \\ \cd� \\ \cd� \\ \cd� \\ \cd� \\ \cd� \\ \cd� \\ \cd� \\ \cd� \\ \cd� \\ \cd� \\ \cd� \\ \cd� \\ \cd� \\ \cd� \\ \cd� \\ \cd� \\ \cd� \\ \cd� \\ \cd� \\ \cd� \\ \cd� \\ \cd� \\ \cd� \\ \cd� \\ \cd� \\ \cd� \\ \cd� \\ \cd� \\ \cd� \\ \cd� \\ \cd� \\ \cd� \\ \cd� \\ \cd� \\ \cd� \\ \cd� \\ \cd� \\ \cd� \\ \cd� \\ \cd� \\ \cd� \\ \cd� \\ \cd� \\ \cd� \\ \cd� \\ \cd� \\ \cd� \\ \cd� \\ \cd� \\ \cd� \\ \cd� \\ \cd� \\ \cd� \\ \cd� \\ \cd� \\ \cd� \\ \cd� \\ \cd� \\ \cd� \\ \cd� \\ \cd� \\ \cd� \\ \cd� \\ \cd� \\ \cd� \\ \cd� \\ \cd� \\ \cd� \\ \cd� \\ \cd� \\ \cd� \\ \cd� \\ \cd� \\ \cd� \\ \cd� \\ \cd. \\ \cd� \\ \cd� \\ \cd� \\ \cd� \\ \cd� \\ \cd� \\ \cd� \\ \cd� \\ \cd� \\ \cd� \\ \cd� \\ \cd� \\ \cd� \\ \cd� \\ \cd� \\ \cd� \\ \cd� \\ \cd� \\ \cd� \\ \cd� \\ \cd� \\ \cd� \\ \cd� \\ \cd� \\ \cd� \\ \cd� \\ \cd� \\ \cd� \\ \cd� \\ \cd� \\ \cd� \\ \cd� \\ \cd� \\ \cd� \\ \cd� \\ \cd� \\ \cd� \\ \cd� \\ \cd� \\ \cd� \\ \cd� \\ \cd� \\ \cd� \\ \cd� \\ \cd� \\ \cd� \\ \cd� \\ \cd� \\ \cd� \\ \cd. \\ \cd� \\ \cd� \\ \cd� \\ \cd� \\ \cd� \\ \cd� \\ \cd� \\ \cd� \\ \cd� \\ \cd� \\ \cd� \\ \cd� \\ \cd� \\ \cd� \\ \cd� \\ \cd� \\ \cd� \\ \cd� \\ \cd� \\ \cd� \\ \cd� \\ \cd� \\ \cd� \\ \cd� \\ \cd� \\ \cd� \\ \cd� \\ \cd� \\ \cd� \\ \cd� \\ \cd� \\ \cd� \\ \cd� \\ \cd� \\ \cd� \\ \cd� \\ \cd� \\ \cd� \\ \cd� \\ \cd� \\ \cd� \\ \cd� \\ \cd� \\ \cd� \\ \cd� \\ \cd� \\ \cd� \\ \cd� \\ \cd� \\ \cdk \\ \cd� \\ \cd� \\ \cd� \\ \cd� \\ \cd� \\ \cd� \\ \cd� \\ \cd� \\ \cd� \\ \cd� \\ \cd� \\ \cd� \\ \cd� \\ \cd� \\ \cd� \\ \cd� \\ \cd� \\ \cd� \\ \cd� \\ \cd� \\ \cd� \\ \cd� \\ \cd� \\ \cd� \\ \cd� \\ \cd� \\ \cd� \\ \cd� \\ \cd� \\ \cd� \\ \cd� \\ \cd� \\ \cd� \\ \cd� \\ \cd� \\ \cd� \\ \cd� \\ \cd� \\ \cd� \\ \cd� \\ \cd� \\ \cd� \\ \cd� \\ \cd� \\ \cd� \\ \cd� \\ \cd� \\ \cd� \\ \cd� \\ \cdj \\ \cd� \\ \cd� \\ \cd� \\ \cd� \\ \cd� \\ \cd� \\ \cd� \\ \cd� \\ \cd� \\ \cd� \\ \cd� \\ \cd� \\ \cd� \\ \cd� \\ \cd� \\ \cd� \\ \cd� \\ \cd� \\ \cd� \\ \cd� \\ \cd� \\ \cd� \\ \cd� \\ \cd� \\ \cd� \\ \cd� \\ \cd� \\ \cd� \\ \cd� \\ \cd� \\ \cd� \\ \cd� \\ \cd� \\ \cd� \\ \cd� \\ \cd� \\ \cd� \\ \cd� \\ \cd� \\ \cd� \\ \cd� \\ \cd� \\ \cd� \\ \cd� \\ \cd� \\ \cd� \\ \cd� \\ \cd� \\ \cd� \\ \cdjs \\ \cd� \\ \cd� \\ \cd� \\ \cd� \\ \cd� \\ \cd� \\ \cd� \\ \cd� \\ \cd� \\ \cd� \\ \cd� \\ \cd� \\ \cd� \\ \cd� \\ \cd� \\ \cd� \\ \cd� \\ \cd� \\ \cd� \\ \cd� \\ \cd� \\ \cd� \\ \cd� \\ \cd� \\ \cd� \\ \cd� \\ \cd� \\ \cd� \\ \cd� \\ \cd� \\ \cd� \\ \cd� \\ \cd� \\ \cd� \\ \cd� \\ \cd� \\ \cd� \\ \cd� \\ \cd� \\ \cd� \\ \cd� \\ \cd� \\ \cd� \\ \cd� \\ \cd� \\ \cd� \\ \cd� \\ \cd� \\ \cd� \\ \cd� \\ \cd� \\ \cd� \\ \cd� \\ \cd� \\ \cd� \\ \cd� \\ \cd� \\ \cd� \\ \cd� \\ \cd� \\ \cd� \\ \cd� \\ \cd� \\ \cd� \\ \cd� \\ \cd� \\ \cd� \\ \cd� \\ \cd� \\ \cd� \\ \cd� \\ \cd� \\ \cd� \\ \cd� \\ \cd� \\ \cd� \\ \cd� \\ \cd� \\ \cd� \\ \cd� \\ \cd� \\ \cd� \\ \cd� \\ \cd� \\ \cd� \\ \cd� \\ \cd� \\ \cd� \\ \cd� \\ \cd� \\ \cd� \\ \cd� \\ \cd� \\ \cd� \\ \cd� \\ \cd� \\ \cd� \\ \cd� \\ \cd� \\ \cdJ \\ \cd� \\ \cd� \\ \cd� \\ \cd� \\ \cd� \\ \cd� \\ \cd� \\ \cd� \\ \cd� \\ \cd� \\ \cd� \\ \cd� \\ \cd� \\ \cd� \\ \cd� \\ \cd� \\ \cd� \\ \cd� \\ \cd� \\ \cd� \\ \cd� \\ \cd� \\ \cd� \\ \cd� \\ \cd� \\ \cd� \\ \cd� \\ \cd� \\ \cd� \\ \cd� \\ \cd� \\ \cd� \\ \cd� \\ \cd� \\ \cd� \\ \cd� \\ \cd� \\ \cd� \\ \cd� \\ \cd� \\ \cd� \\ \cd� \\ \cd� \\ \cd� \\ \cd� \\ \cd� \\ \cd� \\ \cd� \\ \cd� \\ \cd� \\ \cd� \\ \cd� \\ \cd� \\ \cd� \\ \cd� \\ \cd� \\ \cd� \\ \cd� \\ \cd� \\ \cd� \\ \cd� \\ \cd� \\ \cd� \\ \cd� \\ \cd� \\ \cd� \\ \cd� \\ \cd� \\ \cd� \\ \cd� \\ \cd� \\ \cd� \\ \cd� \\ \cd� \\ \cd� \\ \cd� \\ \cd� \\ \cd� \\ \cd� \\ \cd� \\ \cd� \\ \cd� \\ \cd� \\ \cd� \\ \cd� \\ \cd� \\ \cd� \\ \cd� \\ \cd� \\ \cd� \\ \cd� \\ \cd� \\ \cd� \\ \cd� \\ \cd� \\ \cd� \\ \cd� \\ \cd� \\ \cd� \\ \cd� \\ \cd� \\ \cd� \\ \cd� \\ \cd� \\ \cd� \\ \cd� \\ \cd� \\ \cd� \\ \cd� \\ \cd� \\ \cd� \\ \cd� \\ \cd� \\ \cd� \\ \cd� \\ \cd� \\ \cd� \\ \cd� \\ \cd� \\ \cd� \\ \cd� \\ \cd� \\ \cd� \\ \cd� \\ \cd� \\ \cd� \\ \cd� \\ \cd� \\ \cd� \\ \cd� \\ \cd� \\ \cd� \\ \cd� \\ \cd� \\ \cd� \\ \cd� \\ \cd� \\ \cd� \\ \cd� \\ \cd� \\ \cd� \\ \cd� \\ \cd� \\ \cd� \\ \cd� \\ \cd� \\ \cd� \\ \cd� \\ \cd� \\ \cd3 \\ \cd� \\ \cd� \\ \cd� \\ \cd� \\ \cd� \\ \cd� \\ \cd� \\ \cd� \\ \cd� \\ \cd� \\ \cd� \\ \cd� \\ \cd� \\ \cd� \\ \cd� \\ \cd� \\ \cd� \\ \cd� \\ \cd� \\ \cd� \\ \cd� \\ \cd� \\ \cd� \\ \cd� \\ \cd� \\ \cd� \\ \cd� \\ \cd� \\ \cd� \\ \cd� \\ \cd� \\ \cd� \\ \cd� \\ \cd� \\ \cd� \\ \cd� \\ \cd� \\ \cd� \\ \cd� \\ \cd� \\ \cd� \\ \cd� \\ \cd� \\ \cd� \\ \cd� \\ \cd� \\ \cd� \\ \cd� \\ \cd� \\ \cd1 \\ \cd� \\ \cd� \\ \cd� \\ \cd� \\ \cd� \\ \cd� \\ \cd� \\ \cd� \\ \cd� \\ \cd� \\ \cd� \\ \cd� \\ \cd� \\ \cd� \\ \cd� \\ \cd� \\ \cd� \\ \cd� \\ \cd� \\ \cd� \\ \cd� \\ \cd� \\ \cd� \\ \cd� \\ \cd� \\ \cd� \\ \cd� \\ \cd� \\ \cd� \\ \cd� \\ \cd� \\ \cd� \\ \cd� \\ \cd� \\ \cd� \\ \cd� \\ \cd� \\ \cd� \\ \cd� \\ \cd� \\ \cd� \\ \cd� \\ \cd� \\ \cd� \\ \cd� \\ \cd� \\ \cd� \\ \\
\\$$
Using Eq. (10) and assuming that asymptotically θ λ = , θ we recover the prediction of the two-state picture that I L ∼ L -θ , however, with a logarithmic correction that arises from the assumption of a log-uniform distribution for I J .
While the above assumptions lead to an explicit asymptotic expression for I L as a function L , this expression should not be taken too seriously. However, the qualitative conclusion that I J → 0 for almost all samples as L →∞ is robust and depends only on the asymptotic validity of statements (I) - (III) above.
Given that λ char ( L ) is increasing with L and that I decreases with increasing λ , why is I L nearly constant for the sizes studied in our TBC simulations of the 3D EA model? We believe this conundrum can be explained, at least in part, by the fact that the main contribution to I L comes from samples with small values of λ . For T = 0 2, . more than half the contribution to I L comes from samples with λ < 1 and more than 80% from λ < 2,
and these fractions are even higher for T = 0 42. . The head of the λ distribution, has very little dependence on L , as can be seen in Figs. 2 and 3. Furthermore, the bounding curves in Fig. 9 are nearly flat in the small λ region. Thus several effects come into play in keeping I L nearly independent of L . First, the main contribution to I L is from samples with small stiffness. Second, the fraction of samples with small stiffness decreases by only a small amount for the sizes studied and, finally, I does not depend much on λ for small λ . One would have to go to much larger sizes before I L would decrease according to the predicted asymptotic power law L -θ .
In the foregoing, we have assumed that G L (0) → 0 as L → ∞ or, equivalently, if G ∞ ( z ) exists, G ∞ (0 + ) = 0. We now consider the consequences of an alternate assumption that λ char ( L ) → ∞ and G ∞ ( z ) exists but G ∞ (0 + ) > 0. This possibility cannot be ruled out by the data although if it holds, it appears that G ∞ (0 + ) is quite small. In physical terms G ∞ (0 + ) > 0 means that even for very large sizes, a fraction G ∞ (0 + ) of samples has a mixed ensemble of boundary conditions in TBC while the remaining samples have only a single boundary condition in the TBC ensemble. This scenario would imply that the 3D EA model in TBC is divided into two classes of disorder realizations, one of which, with weight (1 -G ∞ (0 + )), has I L = 0 and the other, with weight G ∞ (0 + ), has I L > 0. This possibility seems unlikely but is not contradicted by the data. It has no straightforward explanation in either two-state or RSB pictures.
Our hypothesis is that thermal boundary conditions and periodic boundary conditions have the same behavior in the limit of large system sizes. We use thermal boundary conditions as a tool to improve the extrapolation to large system sizes from the very small system sizes accessible in simulations. It is known that coupling dependent boundary conditions are not equivalent to periodic boundary conditions and are not suitable for understanding properties of the spin glass phase because they could be used to select a single pure state even if coupling independent boundary conditions admit many pure states. The status of thermal boundary conditions with regard to coupling dependence is not clear. On the one hand, the TBC ensemble contains different mixtures of boundary conditions for different choices of couplings. On the other hand, the particular mixture of the 8 boundary conditions is chosen by the system itself and is not imposed externally. As discussed in Sec. II B, our intuition is that TBC minimizes finite size effects rather than introducing spurious physics but this question requires further investigation. In any case, we have provided compelling evidence that the 3D EA model in thermal boundary conditions is best described by a picture with a single pair of pure states in each finite volume.
## VII. SUMMARY
We have introduced two techniques with the aim of extrapolating to the large system-size behavior of finitedimensional spin glasses at low temperature. First, we use thermal boundary conditions to minimize the effect of domain walls induced by boundary conditions. Second, we use a natural measure of sample stiffness defined within thermal boundary conditions and extrapolate to large values of the sample stiffness. By noting that the sample stiffness increases with system size we then obtain an extrapolation in system size. The dynamic range in sample stiffness in the data is sufficiently large that a qualitative extrapolation is readily apparent. The conclusion is that nearly all large samples will have essentially no weight in the overlap distribution near zero overlap. The analysis also explains why this qualitative behavior cannot be seen using a direct extrapolation in system size for the small sizes studied. Our conclusions are consistent with two-state pictures but are inconsistent with the mean field, replica symmetry breaking picture.
Our results hold for thermal boundary conditions. We believe that thermal boundary conditions are equivalent to other coupling independent boundary conditions so that our conclusions about the infinite volume limit also apply to the more familiar periodic boundary conditions. However, it is important to investigate the equivalence of thermal and periodic boundary conditions.
Our numerical simulations used population annealing. This Monte Carlo algorithm has not been used before for large-scale studies in statistical physics. We found that it is an effective computational tool with several advantages over parallel tempering, the standard computational method in the field. We believe that population annealing will be useful for other hard problems in statistical physics and related fields. Similarly, thermal boundary conditions and extrapolating in sample stiffness are general methods that should be useful in studying other finite-dimensional disordered systems.
## Acknowledgments
H.G.K. acknowledges support from the NSF (Grant No. DMR-1151387) and would like to thank Georg Schneider & Sohn for creating TAP4. J.M. and W.W. acknowledge support from NSF (Grant No. DMR1208046). We are grateful to Alan Middleton, Dan Stein, and Chuck Newman for reading an early version of the manuscript and for useful discussions. We acknowledge the contribution of Burcu Yucesoy in providing comparison data from parallel tempering simulations and for useful discussions. We thank the Texas Advanced Computing Center (TACC) at The University of Texas at Austin for providing HPC resources (Stampede Cluster), ETH Zurich for CPU time on the Brutus and Euler clusters, and Texas A&M University for access to their Eos and Lonestar clusters. We especially thank O. Byrde for beta
- [1] K. Binder and A. P. Young, Spin glasses: Experimental facts, theoretical concepts and open questions , Rev. Mod. Phys. 58 , 801 (1986).
- [2] M. M´ ezard, G. Parisi, and M. A. Virasoro, Spin Glass Theory and Beyond (World Scientific, Singapore, 1987).
- [3] A. P. Young, ed., Spin Glasses and Random Fields (World Scientific, Singapore, 1998).
- [4] A. K. Hartmann and H. Rieger, New Optimization Algorithms in Physics (Wiley-VCH, Berlin, 2004).
- [5] D. L. Stein and C. M. Newman, Spin Glasses and Complexity , Primers in Complex Systems (Princeton University Press, 2013).
- [6] A. Lucas, Ising formulations of many NP problems , Front. Physics 12 , 5 (2014).
- [7] M. H. Freedman, A. Y. Kitaev, M. J. Larsen, and Z. Wang, Topological Quantum Computation (2002), (arXiv:quant-ph/0101025).
- [8] A. Y. Kitaev, Fault-tolerant quantum computation by anyons , Ann. Phys. 303 , 2 (2003).
- [9] H. Bombin and M. A. Martin-Delgado, Topological Quantum Distillation , Phys. Rev. Lett. 97 , 180501 (2006).
- [10] D. Nigg, M. Mueller, E. A. Martinez, P. Schindler, M. Hennrich, T. Monz, M. A. Martin-Delgado, and R. Blatt, Experimental Quantum Computations on a Topologically Encoded Qubit , Science 345 , 302 (2014).
- [11] E. Dennis, A. Kitaev, A. Landahl, and J. Preskill, Topological quantum memory , J. Math. Phys. 43 , 4452 (2002).
- [12] H. G. Katzgraber, H. Bombin, and M. A. MartinDelgado, Error Threshold for Color Codes and Random 3-Body Ising Models , Phys. Rev. Lett. 103 , 090501 (2009).
- [13] H. Bombin, R. S. Andrist, M. Ohzeki, H. G. Katzgraber, and M. A. Martin-Delgado, Strong Resilience of Topological Codes to Depolarization , Phys. Rev. X 2 , 021004 (2012).
- [14] N. G. Dickson, M. W. Johnson, M. H. Amin, R. Harris, F. Altomare, A. J. Berkley, P. Bunyk, J. Cai, E. M. Chapple, P. Chavez, et al., Thermally assisted quantum annealing of a 16-qubit problem , Nat. Comm. 4 , 1903 (2013).
- [15] S. Boixo, T. Albash, F. M. Spedalieri, N. Chancellor, and D. A. Lidar, Experimental signature of programmable quantum annealing , Nat. Comm. 4 , 2067 (2013).
- [16] H. G. Katzgraber, F. Hamze, and R. S. Andrist, Glassy Chimeras Could Be Blind to Quantum Speedup: Designing Better Benchmarks for Quantum Annealing Machines , Phys. Rev. X 4 , 021008 (2014).
- [17] T. F. Rønnow, Z. Wang, J. Job, S. Boixo, S. V. Isakov, D. Wecker, J. M. Martinis, D. A. Lidar, and M. Troyer, Defining and detecting quantum speedup , Science 345 (2014).
- [18] G. Parisi, Infinite number of order parameters for spinglasses , Phys. Rev. Lett. 43 , 1754 (1979).
- [19] G. Parisi, The order parameter for spin glasses: a function on the interval 0 -1, J. Phys. A 13 , 1101 (1980).
- [20] G. Parisi, Order parameter for spin-glasses , Phys. Rev. Lett. 50 , 1946 (1983).
- [21] R. Rammal, G. Toulouse, and M. A. Virasoro, Ultra-
- metricity for physicists , Rev. Mod. Phys. 58 , 765 (1986).
- [22] S. F. Edwards and P. W. Anderson, Theory of spin glasses , J. Phys. F: Met. Phys. 5 , 965 (1975).
- [23] G. Parisi, Some considerations of finite dimensional spin glasses , J. Phys. A 41 , 324002 (2008).
- [24] D. Sherrington and S. Kirkpatrick, Solvable model of a spin glass , Phys. Rev. Lett. 35 , 1792 (1975).
- [25] D. Panchenko, The Sherrington-Kirkpatrick model: An overview , J. Stat. Phys. 149 , 362 (2012).
- [26] W. L. McMillan, Domain-wall renormalization-group study of the two-dimensional random Ising model , Phys. Rev. B 29 , 4026 (1984).
- [27] A. J. Bray and M. A. Moore, Scaling theory of the ordered phase of spin glasses , in Heidelberg Colloquium on Glassy Dynamics and Optimization , edited by L. Van Hemmen and I. Morgenstern (Springer, New York, 1986), p. 121.
- [28] D. S. Fisher and D. A. Huse, Ordered phase of short-range Ising spin-glasses , Phys. Rev. Lett. 56 , 1601 (1986).
- [29] D. S. Fisher and D. A. Huse, Absence of many states in realistic spin glasses , J. Phys. A 20 , L1005 (1987).
- [30] D. S. Fisher and D. A. Huse, Equilibrium behavior of the spin-glass ordered phase , Phys. Rev. B 38 , 386 (1988).
- [31] C. M. Newman and D. L. Stein, Multiple states and thermodynamic limits in short-ranged Ising spin-glass models , Phys. Rev. B 46 , 973 (1992).
- [32] C. M. Newman and D. L. Stein, Non-mean-field behavior of realistic spin glasses , Phys. Rev. Lett. 76 , 515 (1996).
- [33] C. M. Newman and D. L. Stein, Simplicity of state and overlap structure in finite-volume realistic spin glasses , Phys. Rev. E 57 , 1356 (1998).
- [34] C. M. Newman and D. L. Stein, The state(s) of replica symmetry breaking: Mean field theories vs short-ranged spin glasses , J. Stat. Phys. 106 , 213 (2002).
- [35] C. M. Newman and D. L. Stein, TOPICAL REVIEW: Ordering and broken symmetry in short-ranged spin glasses , J. Phys.: Condensed Matter 15 , 1319 (2003).
- [36] N. Read, Short-range Ising spin glasses: the metastate interpretation of replica symmetry breaking , Phys. Rev. E 90 , 032142 (2014).
- [37] M. Palassini and A. P. Young, Triviality of the ground state structure in Ising spin glasses , Phys. Rev. Lett. 83 , 5126 (1999).
- [38] H. G. Katzgraber, M. Palassini, and A. P. Young, Monte Carlo simulations of spin glasses at low temperatures , Phys. Rev. B 63 , 184422 (2001).
- [39] H. G. Katzgraber and A. P. Young, Monte Carlo simulations of spin-glasses at low temperatures: Effects of free boundary conditions , Phys. Rev. B 65 , 214402 (2002).
- [40] R. Alvarez Ba˜os, A. Cruz, L. A. Fernandez, J. M. Giln Narvion, A. Gordillo-Guerrero, M. Guidetti, A. Maiorano, F. Mantovani, E. Marinari, V. Martin-Mayor, et al., Nature of the spin-glass phase at experimental length scales , J. Stat. Mech. P06026 (2010).
- [41] J. Houdayer, F. Krzakala, and O. C. Martin, Large-scale low-energy excitations in 3-d spin glasses , Eur. Phys. J. B. 18 , 467 (2000).
- [42] F. Krzakala and O. C. Martin, Spin and link overlaps in 3-dimensional spin glasses , Phys. Rev. Lett. 85 , 3013
(2000).
- [43] H. G. Katzgraber and A. P. Young, Monte Carlo studies of the one-dimensional Ising spin glass with power-law interactions , Phys. Rev. B 67 , 134410 (2003).
- [44] B. Yucesoy, H. G. Katzgraber, and J. Machta, Evidence of Non-Mean-Field-Like Low-Temperature Behavior in the Edwards-Anderson Spin-Glass Model , Phys. Rev. Lett. 109 , 177204 (2012).
- [45] A. Billoire, A. Maiorano, E. Marinari, V. Martin-Mayor, and D. Yllanes, The cumulative overlap distribution function in realistic spin glasses , Phys. Rev. B 90 , 094201 (2014).
- [46] M. Palassini and A. P. Young, Nature of the spin glass state , Phys. Rev. Lett. 85 , 3017 (2000).
- [47] A. Billoire, L. A. Fernandez, A. Maiorano, E. Marinari, V. Martin-Mayor, G. Parisi, F. Ricci-Tersenghi, J. J. Ruiz-Lorenzo, and D. Yllanes, Comment on 'Evidence of Non-Mean-Field-Like Low-Temperature Behavior in the Edwards-Anderson Spin-Glass Model' , Phys. Rev. Lett. 110 , 219701 (2013).
- [48] B. Yucesoy, H. G. Katzgraber, and J. Machta, Yucesoy, Katzgraber, and Machta reply: , Phys. Rev. Lett. 110 , 219702 (2013).
- [49] A. A. Middleton, Extracting thermodynamic behavior of spin glasses from the overlap function , Phys. Rev. B 87 , 220201 (2013).
- [50] C. Monthus and T. Garel, Typical versus averaged overlap distribution in spin glasses: Evidence for droplet scaling theory , Phys. Rev. B 88 , 134204 (2013).
- [51] A. Billoire, A. Maiorano, E. Marinari, V. Martin-Mayor, and D. Yllanes, The cumulative overlap distribution function in realistic spin glasses , ArXiv e-prints (2014), 1406.1639.
- [52] J. W. Landry and S. N. Coppersmith, Ground states of two-dimensional ± J Edwards-Anderson spin glasses , Phys. Rev. B 65 , 134404 (2002).
- [53] C. K. Thomas and A. A. Middleton, Matching Kasteleyn cities for spin glass ground states , Phys. Rev. B 76 , 220406(R) (2007).
- [54] K. Hukushima, Domain-wall free energy of spin-glass models: Numerical method and boundary conditions , Phys. Rev. E 60 , 3606 (1999).
- [55] M. Sasaki, K. Hukushima, H. Yoshino, and H. Takayama, Temperature Chaos and Bond Chaos in EdwardsAnderson Ising Spin Glasses: Domain-Wall Free-Energy
- Measurements , Phys. Rev. Lett. 95 , 267203 (2005).
- [56] M. Sasaki, K. Hukushima, H. Yoshino, and H. Takayama, Scaling Analysis of Domain-Wall Free Energy in the Edwards-Anderson Ising Spin Glass in a Magnetic Field , Phys. Rev. Lett. 99 , 137202 (2007).
- [57] M. Hasenbusch, Monte-Carlo simulation with fluctuating boundary-conditions , Physica A 197 , 423 (1993).
- [58] K. Hukushima and Y. Iba, in THE MONTE CARLO METHOD IN THE PHYSICAL SCIENCES: Celebrating the 50th Anniversary of the Metropolis Algorithm , edited by J. E. Gubernatis (AIP, 2003), vol. 690, pp. 200-206.
- [59] J. Machta, Population annealing with weighted averages: A Monte Carlo method for rough free-energy landscapes , Phys. Rev. E 82 , 026704 (2010).
- [60] J. Machta and R. Ellis, Monte Carlo methods for rough free energy landscapes: Population annealing and parallel tempering , J. Stat. Phys. 144 , 541 (2011).
- [61] K. Hukushima and K. Nemoto, Exchange Monte Carlo method and application to spin glass simulations , J. Phys. Soc. Jpn. 65 , 1604 (1996).
- [62] A. Doucet, N. de Freitas, and N. Gordon, eds., Sequential Monte Carlo Methods in Practice (Springer-Verlag, New York, 2001).
- [63] B. Yucesoy, J. Machta, and H. G. Katzgraber, Correlations between the dynamics of parallel tempering and the free-energy landscape in spin glasses , Phys. Rev. E 87 , 012104 (2013).
- [64] W. Wang, J. Machta, and H. G. Katzgraber, Population annealing for large scale spin glass simulations (2014), in preparation.
- [65] W. Wang, J. Machta, and H. G. Katzgraber, Finding ground states of Ising spin glasses using population annealing Monte Carlo (2014), in preparation.
- [66] A. K. Hartmann, Scaling of stiffness energy for threedimensional ± J Ising spin glasses , Phys. Rev. E 59 , 84 (1999).
- [67] A. C. Carter, A. J. Bray, and M. A. Moore, Aspect-ratio scaling and the stiffness exponent θ for Ising spin glasses , Phys. Rev. Lett. 88 , 077201 (2002).
- [68] S. Boettcher, Stiffness exponents for lattice spin glasses in dimensions d = 3 , . . . , 6, The European Physical Journal B - Condensed Matter and Complex Systems 38 , 83 (2004). | 10.1103/PhysRevB.90.184412 | [
"Wenlong Wang",
"Jonathan Machta",
"Helmut G. Katzgraber"
] | 2014-08-02T23:42:14+00:00 | 2014-11-13T01:54:08+00:00 | [
"cond-mat.dis-nn"
] | Evidence against a mean field description of short-range spin glasses revealed through thermal boundary conditions | A theoretical description of the low-temperature phase of short-range spin
glasses has remained elusive for decades. In particular, it is unclear if
theories that assert a single pair of pure states, or theories that are based
infinitely many pure states-such as replica symmetry breaking-best describe
realistic short-range systems. To resolve this controversy, the
three-dimensional Edwards-Anderson Ising spin glass in thermal boundary
conditions is studied numerically using population annealing Monte Carlo. In
thermal boundary conditions all eight combinations of periodic vs antiperiodic
boundary conditions in the three spatial directions appear in the ensemble with
their respective Boltzmann weights, thus minimizing finite-size corrections due
to domain walls. From the relative weighting of the eight boundary conditions
for each disorder instance a sample stiffness is defined, and its typical value
is shown to grow with system size according to a stiffness exponent. An
extrapolation to the large-system-size limit is in agreement with a description
that supports the droplet picture and other theories that assert a single pair
of pure states. The results are, however, incompatible with the mean-field
replica symmetry breaking picture, thus highlighting the need to go beyond
mean-field descriptions to accurately describe short-range spin-glass systems. |
1408.0440v1 | ## Contagious Synchronization and Endogenous
## Network Formation in Financial Networks ∗
Christoph Aymanns, Co-Pierre Georg † ‡
July 1, 2014
## Abstract
When banks choose similar investment strategies the financial system becomes vulnerable to common shocks. We model a simple financial system in which banks decide about their investment strategy based on a private belief about the state of the world and a social belief formed from observing the actions of peers. Observing a larger group of peers conveys more information and thus leads to a stronger social belief. Extending the standard model of Bayesian updating in social networks, we show that the probability that banks synchronize their investment strategy on a state non-matching action critically depends on the weighting between private and social belief. This effect is alleviated when banks choose their peers endogenously in a network formation process, internalizing the externalities arising from social learning.
∗ We would like to thank Toni Ahnert, Jean-Edouard Colliard, Jens Krause, Tarik Roukny, three anonymous referees, seminar participants at ECB, Bundesbank, as well as the 2013 INET Plenary Conference in Hong Kong, and the VIII Financial Stability Seminar organized by the Banco Central do Brazil for helpful discussions and comments. This paper has been prepared under the Lamfalussy Fellowship Program sponsored by the ECB whose support is gratefully ackonwledged. The views expressed in this paper do not necessarily reflect the views of Deutsche Bundesbank, the ECB, or the ESCB.
† Mathematical Institute, University of Oxford and Institute for New Economic Thinking at the Oxford Martin School. E-Mail: [email protected] .
‡ Deutsche Bundesbank and University of Cape Town Graduate School of Business. E-Mail: [email protected] .
Keywords: social learning, endogenous financial networks, multiagent simulations, systemic risk
JEL Classification:
G21, C73, D53, D85
## 1 Introduction
When a large number of financial intermediaries choose the same investment strategy (i.e. their portfolios are very similar) the financial system as a whole becomes vulnerable to common shocks. A case at hand is the financial crisis of 2007/2008 when many banks invested into mortgage backed securities in anticipation that the underlying mortgages-many of which being US subprime mortgages-would not simultaneously depreciate in value. This assumption turned out to be incorrect resulting in one of the largest financial crises since the great depression. How could so many banks choose a non-optimal investment strategy despite the fact that they carefully monitor both economic fundamentals and the actions of other banks?
This paper presents a simple agent-based model in which financial intermediaries synchronize their investment strategy on a state non-matching action despite informative private signals about the state of the world. In a countable number of time-steps N agents, representing financial intermediaries (banks for short), choose one of two actions. There are two states of the world which are revealed at the end of the simulation. A bank's action is either state-matching, in which case the bank receives a positive payoff if the state is revealed, or it is state-non-matching in which case the bank receives zero. Banks are connected to a set of peers in a financial network of mutual lines of credit resembling the interbank market. They receive a private signal about the state of the world and observe the previous actions of banks with whom they are connected via a mutual line of credit, but not of other banks. Based on both signals banks form a belief about the state of the world and choose their action accordingly.
Our model differs from the existing literature along two dimensions. First and foremost we develop an agent-based model of the financial system with strategic interaction amongst agents. This differs from existing models (see,
for example, Poledna et al. (2014), Bluhm et al. (2013), Georg (2013), and Ladley (2013)) where agent behaviour is myopic. Agents in myopic models react to the state of the world but when choosing an optimal action they do not take into account how other agents will react to their choice. Thus, the notion of equilibrium in myopic models is a rather mechanical. Strategic interaction amongst agents arises in our model from the fact that agents learn about their neighbors' actions, i.e. via the social belief. All the aforementioned papers furthermore use an exogenous network structure as starting point for the agent-based simulation, while our model uses an endogenous network formation process to arrive at a pairwise stable network structure that maximizes expected utility from social learning.
Second, while our model is mildly boundedly rational it shares a number of assumptions with the literature on Bayesian learning in social networks. The main difference to this literature (see, for example, Acemoglu et al. (2011), Gale and Kariv (2003)) is that we model an externality that is not present in the standard model of Bayesian learning in social networks. We assume that banks receive more information about the actions of other banks than they can computationally use. This assumption seems natural in a financial system that is increasingly complex. 1 The underlying assumption is that banks cannot adjust their actions (i.e. their investment strategy) as fast as they receive information from their peers and thus have to aggregate over potentially large amounts of information. 2 The social belief in our model is formed not just from observing one neighbor at a time, but rather from observing a set of neighbors simultaneously. It is thus reasonable to assume that receipt of more information, i.e. observing the actions of a larger subset of agents, will create a stronger social belief than the receipt of less information. We model this by allowing for different weights of the social
1 See, for example, Haldane and Madouros (2012) for a discussion of increasing complexity in financial regulation.
2 This assumption renders the agents boundedly rational, albeit mildly so, as for example DeMarzo et al. (2003) argue.
and private belief.
The other key difference to the existing literature on Bayesian learning in social networks is that we allow agents to endogenously form links based on the utility they get from an improved social belief in a first stage of the model. In the second stage of the model agents then learn about the state of the world and take their investment decisions. To the best of our knowledge, the only other paper considering endogenously formed social networks in a Bayesian learning setup is Acemoglu et al. (2014) who develop a two-stage game similar to ours. Acemoglu et al. (2014) model endogenous network formation via a communication cost matrix where some agents (in a social clique ) can communicate at low costs, while others communicate at high cost. The main difference to our model is that we endogenously obtain a decreasing marginal value of additional links. We obtain a resulting endogenous network structure which is pairwise stable in the sense of Jackson and Wolinsky (1996).
We obtain two sets of results, one for networks with exogenous network structure, and one for endogenously formed networks. First, we analyze different ways of weighting private and social belief. In particular, we compare the standard equal weighting scenario in which agents place equal weights on their private and social belief, with two scenarios where agents place more weight on the social belief when they have a larger neighborhood. In the neighborhood size scenario the social belief is weighted with the size of the neighborhood, i.e. the private signal is weighted equal to every observed neighbor action. In the relative neighborhood scenario agents put more weight on the social belief when the neighborhood constitutes a larger share of the overall network. For completely uninformative signals there is no difference between these weighting functions. For informative signals, however, the weighting function has an impact on the probability that agents synchronize their investment decisions on a state non-matching ac-
tion, i.e. for the probability that choosing a state-non-matching action is contagious. 3 Contagion is, very generally, understood as the transmission of adverse effects from one agent to another and is more likely if agents place greater weight on their social belief and depends on the density of the underlying exogenous network structure. 4 The probability of contagion increases by a factor of 200 in the neighborhood size scenario compared to the equal weighting scenario, which highlights the importance of understanding the learning dynamics when agents place different weight on their social belief, depending on the size of their neighborhood.
We show that contagious synchronization occurs even if private signals are informative and if agents are initialized with an action that is on average state matching. The probability of contagion depends non-monotonously on the density of the network. For small network densities ρ glyph[lessorsimilar] 0 1 . the probability of contagion increases sharply and then decreases slowly for larger network densities. We confirm the robustness of our results by conducting 2 000 , independent simulations where we observe the average final action as a function of the average initial action with varying network densities.
This result is of particular interest for policy makers as it relates two sources of systemic risk: common shocks and interbank market freezes. When the network density is too small, for example in the aftermath of an interbank market freeze, banks are unable to fully incorporate the information about their peers' actions. This effect is empirically tested by Caballero (2012), who documents a higher correlation amongst various asset classes in the world in the aftermath of the Lehman insolvency, i.e. during times of extreme stress on interbank markets and heightened uncertainty about the state of the world. This can be understood as a contagious synchronization
3 Such informational cascades are a well-documented empirical phenomenon. See, for example, Alevy et al. (2007), Bernhardt et al. (2006), Chang et al. (2000), Chiang and Zheng (2010), and Cipriani and Guarino (2014).
4 For a more thorough discussion of the different forms of contagion, see for example Bandt et al. (2009).
of bank's investment strategies for which our model provides a simple rationale.
Second, turning to the extension of endogenously formed networks, we show that endogenous link formation in the first stage of our model can significantly improve the speed of learning and reduce the probability of contagious synchronization relative to random networks. When private signals are less informative, the additional utility from forming a link is smaller and the endogenously formed network is less dense. This in turn can increase the probability of contagious synchronization in the second stage of the model. Heightened uncertainty about the state of the world, i.e. a less informative signal, does therefore not only directly increase the probability of contagious synchronization, but also indirectly because agents have less incentives to endogenously form links. If agents are heterogenous in the informativeness of their private signals, i.e. if some agents receive signals with higher precision than others, we show that the resulting endogenous network structure is of a core-periphery type. The structure of real-world interbank markets is often of this particular type, as for example Craig and von Peter (2014) show. Naturally, these endogenously formed networks transfer information more effectively from highly informed agents to less informed agents than simple random networks.
This paper relates to three strands of literatures. First and foremost, the paper develops a financial multi-agent simulation in which agents learn not only from private signals, but also via endogenously formed interbank links. This is in contrast with existing multi-agent models of the financial system which include Nier et al. (2007) and Iori et al. (2006) who take a fixed network and static balance sheet structure. 5 Slight deviations from these
5 Closely related is the literature on financial networks. See, for example, Allen and Gale (2000), and Freixas et al. (2000) for an early model of financial networks. The vast majority of models in this literature consider a fixed network structure only (see, amongst various others, Battiston et al. (2012)).
models can be found, for example, in Bluhm et al. (2013), Ladley (2013), and Georg (2013) who employ different equilibrium concepts. The main contribution this paper makes is to develop a sufficiently simple model of a financial system with a clear notion of equilibrium that allows to be implemented on a computer and tested against analytically tractable special cases.
Second, this paper relates to the literature on endogenous network formation pioneered by Jackson and Wolinsky (1996) and Bala and Goyal (2000). Few papers on endogenous network formation in interbank markets, exist, however. Notable exceptions are Castiglionesi and Navarro (2007) who study the formation of endogenous networks in a banking network with microfounded banking behaviour. Unlike Castiglionesi and Navarro (2007), however, our paper uses a starkly simplified model of social learning to describe the behaviour of banks. This allows the introduction of informational spillovers from one bank to another, a mechanism not present in the work of Castiglionesi and Navarro (2007).
Finally, our paper is closely related to the literature on Bayesian learning in social networks. The paper closest to ours in this literature is Acemoglu et al. (2014) who study a model of sequential learning in an endogenously formed social network where each agent receives a private signal about the state of the world and observe past actions of their neighbors. We contribute to this literature by allowing agents to place more weight on their social belief when their neighborhood is larger. Other related papers in this literature include Banerjee (1992), Bikhchandani et al. (1992), Bala and Goyal (1998), and Gale and Kariv (2003) who, however, all consider static networks only.
The remainder of this paper is organized as follows. The next section develops the baseline model and presents the results in the limiting case of an
exogenous network structure. Section 3 generalizes the model by allowing agents to endogenously form links in a first stage of the model. Section (4) concludes.
## 2 Contagious Synchronization with Fixed Network Structure
## 2.1 Model Description and Timeline
There is a countable number of dates t = 0 1 , , . . . , T and a fixed number i = 1 , . . . , N of agents A i which represent financial institutions and are called banks for short. By a slight abuse of notation the model parameter θ is sometimes called the state of the world and we assume it can take two values θ ∈ { 0 1 , } . The probability that the world is in state θ is denoted as P ( θ ) and we assume that each state of the world is obtained with equal probability 1 2 . At each point in time t bank i chooses one of two investment strategies x i t ∈ { 0 1 , } which yields a positive return if the state of the world is revealed and matches the investment strategy chosen, and nothing otherwise. Agents take an action by choosing a certain investment strategy. Taking an action and switching between actions is costless. The utility of bank i from investing is given as:
$$u ^ { i } ( x ^ { i }, \theta ) = \begin{cases} \ 1 & \text{if $x^{i}=\theta$} \\ \ 0 & \text{else} \end{cases}$$
The state of the world is unknown ex-ante and revealed at time T . This setup captures a situation where the state of the world is revealed less often (e.g. quarterly) than banks take investment decisions (e.g. daily). 6
6 In an alternative setup the state of the world is fixed throughout and an agent collects information and takes an irreversible decision at time t , but receives a payoff that is discounted by a factor e -κt . Both formulations incentivize agents to take a decision in finite time instead of collecting information until all uncertainty is eliminated.
Banks can form interconnections in the form of mutual lines of credit. The set of banks is denoted N = { 1 2 , , . . . , n } and the set of banks to which bank i is directly connected is denoted K i ⊆ N . Bank i thus has k i = | K i | direct connections called neighbors. This implements the notion of a network of banks g which is defined as the set of banks together with a set of unordered pairs of banks called (undirected) links L = ∪ n i =1 { ( i, j ) : j ∈ K i } . A link is undirected since lines of credit are mutual and captured in the symmetric adjacency matrix g of the network. Whenever a bank i and j have a link, the corresponding entry g ij = 1 , otherwise g ij = 0 . When there is no risk of confusion in notation, the network g is identified by its adjacency matrix g . For the remainder of this section, I assume that the network structure is exogenously fixed and does not change over time. I assume that banks monitor each other continuously when granting a credit line and thus observe their respective actions.
In this section, the network g is exogenously fixed throughout the simulation. In t = 0 there is no previous decision of agents. Thus, each bank decides on its action in autarky. Banks receive a signal about the state of the world and form a private belief upon which they decide about their investment strategy x i t =0 . The private signal received at time t is denoted s i t ∈ S where S is a Euclidean space. Signals are independently generated according to a probability measure F θ that depends on the state of the world θ . The signal structure of the model is thus given by ( F 0 , F 1 ) . I assume that F 0 and F 1 are not identical and absolutely continuous with respect to each other. Throughout this paper I will assume that F 0 and F 1 represent Gaussian distributions with mean and standard deviation ( µ , σ 0 0 ) and ( µ , σ 1 1 ) respectively.
In t = 1 , . . . bank i again receives a signal s i t but now also observes the t -1 actions x j t -1 of its neighbors j ∈ K i . The model outlined in this section is implemented in a multi-agent simulation where banks are the agents. Date
t = 0 in the model timeline is the initialization period. Subsequent dates t = 1 , . . . , T are the update steps which are repeated until the state of the world is being revealed in state T . Once the state is revealed, returns are realized and measured. In the simulation results discussed in Section 2.2 the state of the world was revealed at the end of the simulation after the system has reached a steady state in which agents do not change their actions any more. 7
Banks form a private belief at time t based on their privately observed signal s i t and a social belief based on the observed actions x j t -1 their neighboring banks took in the previous period. The first time banks choose an action is a special case of the update step with no previous decisions being taken. The information set I i t of a bank i at time t is given by the private signal s i t , the set of banks connected to bank i in t -1 , K i t -1 , and the actions x j t -1 of connected banks j ∈ K i t -1 . Formally:
$$I ^ { i } _ { t } = \left \{ s ^ { i } _ { t }, K ^ { i } _ { t - 1 }, x ^ { j } _ { t - 1 } \forall j \in K ^ { i } _ { t - 1 } \right \}$$
The set of all possible information sets of bank i is denoted by I i . A strategy for bank i selects an action for each possible information set. Formally, a strategy for bank i is a mapping σ i : I i → x i = { 0 1 , } . The notation σ -i = { σ , . . . , σ 1 i -1 , σ i +1 , σ n } is used to denote the strategies of all banks other than i .
A strategy profile σ = { σ i } i ∈ 1 ,...,n is a pure strategy equilibrium of this game of social learning for a bank i 's investment, if σ i maximizes the bank's expected pay-off, given the strategies of all other banks σ -i . Acemoglu et al.
7 In practice this is ensured by having many more update steps than it takes the system to reach a steady state.
(2011) show that the strategy decision of bank i , x i t = σ i ( I i t ) is given as:
$$x ^ { i } = \begin{cases} 1 & \text{if $\mathbb{P}_{\sigma}(\theta=1|s_{t}^{i})+\mathbb{P}_{\sigma}(\theta=1|x_{t-1}^{j}},j\in K_{t-1}^{i})>1$} \\ 0 & \text{if $\mathbb{P}_{\sigma}(\theta=1|s_{t}^{i})$} \\ \text{private belief $p$} \end{cases} } + \underbrace { \mathbb { P } _ { \sigma }(\theta=1|s_{t-1}^{j}},j\in K_{t-1}^{i}$} } _ { \text{social belief $q$} } < 1$$
and x i ∈ { 0 1 , } otherwise. The first term on the right-hand side of Equation 3 is the private belief, the second term is the social belief, and the threshold is fixed to 1 2 . This equation can be generalized when introducing weights on the private and social belief. In its most general form, it can be written as:
$$x ^ { i } = \begin{cases} 1 & \text{if $t(p^{i},q^{i})>\frac{1}{2}$} \\ 0 & \text{if $t(p^{i},q^{i})<\frac{1}{2}$} \end{cases}$$
where t ( p , q i i ) is a weighting function depending on the private and social belief. A simple weighting function
$$t ( p ^ { i }, q ^ { i } ) = \begin{cases} \frac { 1 } { 2 } ( p ^ { i } + q ^ { i } ) & \text{if $|K^{i}|>0$,} \\ p ^ { i } & | K ^ { i } | = 0, \end{cases}$$
implements the model of Acemoglu et al. (2011) where agents place equal weight on their private and social belief (we denote this weighting function as the equal weighting scenario).
The simple weighting function is appropriate in a setting where agents receive two signals at a time only: their private signal and the signal of their direct predecessor in the social network. In our setting, however, banks receive multiple signals, only one of which is their private signal. It is thus natural to allow for more general weighting functions which, however, have to satisfy two conditions: (i) In the case with no social learning ( K i t -1 = ∅ ), the weighting should reduce to the simple case t ( p , q i i ) = p i in which the agent will select action x i = 1 whenever it is more likely that the state of
the world is θ = 1 and zero otherwise; and (ii) With social learning the weighting should depend on the number of neighboring signals, i.e. the size of the neighborhood k i t -1 = | K i t -1 | . The underlying assumption is that the agent will place a higher weight on the social belief when the neighborhood is larger. We consider two different scenarios for the weighting function: (i) The private signal and each observed action are equally weighted (called the neighborhood size scenario):
$$t ( p ^ { i }, q ^ { i } ) = \left ( \frac { 1 } { k _ { t - 1 } ^ { i } + 1 } \right ) p ^ { i } + \left ( \frac { k _ { t - 1 } ^ { i } } { k _ { t - 1 } ^ { i } + 1 } \right ) q ^ { i }$$
And (ii) Observed actions are weighted with the relative size of the neighborhood (called the relative neighborhood scenario):
$$t ( p ^ { i }, q ^ { i } ) = \left ( 1 - \frac { k _ { t - 1 } ^ { i } } { N - 1 } \right ) p ^ { i } + \left ( \frac { k _ { t - 1 } ^ { i } } { N - 1 } \right ) q ^ { i }$$
The private belief of bank i is denoted p i = P ( θ = 1 | s i ) and can easily be obtained using Bayes' rule. It is given as:
$$p ^ { i } = \left ( 1 + \frac { d \mathbb { F } _ { 0 } } { d \mathbb { F } _ { 1 } } ( s _ { t } ^ { i } ) \right ) ^ { - 1 } = \left ( 1 + \frac { f _ { 0 } ( s _ { t } ^ { i } ) } { f _ { 1 } ( s _ { t } ^ { i } ) } \right ) ^ { - 1 }$$
where f 0 and f 1 are the densities of F 0 and F 1 respectively. Bank i is assumed to form a social belief q i by simply averaging over the actions of all neighbors j ∈ K i t -1 :
$$q ^ { i } = \mathbb { P } _ { \sigma } ( \theta = 1 | K ^ { i } _ { t }, x ^ { j }, j \in K ^ { i } _ { t - 1 } ) = 1 / k ^ { i } _ { t - 1 } \sum _ { j \in K ^ { i } _ { i - 1 } } x ^ { j } _ { t - 1 }$$
Given these private and social beliefs, agents choose an action according to equation (4).
Averaging over the actions of neighbors is a special case of DeGroot (1974) who introduces a model where a population of N agents is endowed with initial opinions p (0) . Agents are connected to each other but with varying
levels of trust, i.e. their interconnectedness is captured in a weighted directed n × n matrix T . A vector of beliefs p is updated such that p t ( ) = Tp t ( -1) = T p t (0) . DeMarzo et al. (2003) point out that this process is a boundedly rational approximation of a much more complicated inference problem where agents keep track of each bit of information to avoid a persuasion bias (effectively double-counting the same piece of information). Therefore, the model this paper develops is also boundedly rational. 8
The model in this section can be formulated as an agent-based model. Banks are agents a i who choose one of two actions x i ∈ { 0 1 , } . Variables determined in the model internally are given by the private and social belief of agent i at time t , p , q i t i t and the only exogenously given parameter is the state of the world θ which is identical for all agents i . Each agent has an information set I i given by Equation (2). Agents receive utility (1) and decide on their optimal strategy given in Equation (3). The interaction of agents is captured in a network structure g , encapsulated in an agent i 's information set. Equations (8) and (9) specify how agents take their decisions and choose an optimal strategy.
## 2.2 Herding with Exogenous Network Structures
Our interest is to understand under which conditions agents in the model with an exogenously fixed network structure coordinate on a state nonmatching action. Before analyzing the full model, we build some intuition by discussing useful benchmark cases. Let the state of the world be θ = 0 and assume that f 0 = mf 1 . For m = 1 the signal is completely uninformative. For m > 1 the signal is informative and more so the larger m is. In the equal weighting scenario, equation (3) together with equations (8) and (9)
8 This bounded rationality can be motivated analogously to DeMarzo et al. (2003) who argue that the amount of information agents have to keep track of increases exponentially with the number of agents and increasing time, making it computationally impossible to process all available information.
yields:
$$\frac { 1 } { 2 } ( 1 + m ) ^ { - 1 } + \frac { 1 } { 2 } \frac { 1 } { k } \sum _ { j \in K ^ { i } _ { t - 1 } } x ^ { j } _ { t - 1 } > \frac { 1 } { 2 } \Leftrightarrow \sum _ { j \in K ^ { i } _ { t - 1 } } x ^ { j } _ { t - 1 } > k \left [ 1 - \frac { 1 } { ( 1 + m ) } \right ] \quad ( 1 0 )$$
For completely uninformative signals, m = 1 , equation (10) implies that an agent will always follow the majority of her neighbors. For very informative signals, m glyph[greatermuch] 1 , equation (10) implies that an agent will only ignore her private signal if she receives a strong social signal. The required strength of the social signal increases with the precision of the private signal. Now consider the neighborhood size scenario. The equation analogous to (10) for this scenario reads:
$$\left ( \frac { 1 } { k _ { t - 1 } ^ { i } + 1 } \right ) ( 1 + m ) ^ { - 1 } + \left ( \frac { k _ { t - 1 } ^ { i } } { k _ { t - 1 } ^ { i } + 1 } \right ) \frac { 1 } { k _ { t - 1 } ^ { i } } \sum _ { j \in K _ { t - 1 } ^ { i } } x _ { t - 1 } ^ { j } > \frac { 1 } { 2 } \\ \cdot \quad \, \cdot \quad \, \cdot \quad \, \cdot \quad \, \cdot \quad \, \cdot \quad \, \cdot \quad \, \cdot \quad \, \cdot \quad \, \cdot \quad \, \cdot \quad \, \cdot \quad \, \cdot \quad \, \cdot \quad \, \cdot \quad \, \cdot \quad \, \cdot \quad \, \cdot \quad \, \cdot \quad \, \cdot \quad \, \cdot \quad \, \cdot \quad \, \cdot \quad \, \cdot \quad \, \cdot \quad \, \cdot \quad \, \cdot \quad \, \cdot \quad \, \cdot \quad \, \cdot$$
$$\Leftrightarrow \sum _ { j \in K _ { t - 1 } ^ { i } } x _ { t - 1 } ^ { j } > \frac { k _ { t - 1 } ^ { i } } { 2 } + \left [ \frac { 1 } { 2 } - \frac { 1 } { 1 + m } \right ] \quad \ \ ( 1 2 )$$
For completely uninformative signals m = 1 this condition reduces to the equal weighting scenario. For highly informative signals, m glyph[greatermuch] 1 , however, the agent is almost as willing to follow her neighbors as in the uninformative equal weighting scenario. The neighborhood scenario thus captures the situation where the agent is aware not only of her own private signal informativeness, but also of that of her neighbors. In the relative neighborhood scenario equation (10) reads:
$$\left ( 1 - \frac { k _ { t - 1 } ^ { i } } { N - 1 } \right ) ( 1 + m ) ^ { - 1 } + \left ( \frac { k _ { t - 1 } ^ { i } } { N - 1 } \right ) \frac { 1 } { k _ { t - 1 } ^ { i } } \sum _ { j \in K _ { t - 1 } ^ { i } } x _ { t - 1 } ^ { j } > \frac { 1 } { 2 } \quad \ \ ( 1 3 )$$
$$\Leftrightarrow \sum _ { j \in K _ { t - 1 } ^ { i } } x _ { t - 1 } ^ { j } > ( N - 1 ) \left [ \frac { 1 } { 2 } - \frac { 1 } { 1 + m } \right ] + \frac { k _ { t - 1 } ^ { i } } { 1 + m } \quad \ \ ( 1 4 )$$
Again, for completely uninformative signals this equation reduces to the equal weighting case. For highly informative signals, m glyph[greatermuch] 1 , this equation reduces to ∑ j ∈ K i t -1 x j t -1 > 1 2 ( N -1) if the neighborhood is sufficiently
small m glyph[greatermuch] k i t -1 . An agent will thus ignore her private signal and follow the majority of her neighbors, if her neighborhood is larger than half of the network. The central node in a star network will thus always follow the majority of the spokes and spokes will always follow their private signal.
We can gain further insights into the model dynamics by resorting to a mean-field approximation in which we consider the simplified action dynamics of a representative agent. Given the adjacency matrix g of a network g , the social belief q of the representative agent is given as q = g x /k where x is the vector of all agent's actions. The social belief in the mean-field approximation is simply the average action of the population:
$$q = \Pr ( x = 0 \ | \ q = q ) \cdot 0 + \Pr ( x = 1 \ | \ q = q ) \cdot 1 = \Pr ( x = 1 \ | \ q = q ) \ \ ( 1 5 )$$
which yields a self-consistency relation for the social belief and hence for the average action of the population. The equilibrium average action q ∗ is implicitely given by the solution to the self-consistency condition:
$$q ^ { * } = \Pr ( x = 1 \ | \ q = q ^ { * } ) = \int _ { 1 - q * } ^ { 1 } p _ { P } ( p \ | \ \theta = 0 ) d p.$$
Note that Pr( x = 1 | q = 0) = 0 and Pr( x = 1 | q = 1) = 1 . Since Pr( x = 1 | q = q ∗ ) is the cumulative distribution function of the bell shaped private belief it will have a sigmoid shape. Therefore the self consistency equation will have three solutions: q 1 = 0 , q 2 = 1 and some q 3 ∈ (0 , 1) . We illustrate this in figure 4. q 1 , q 2 are stable fixed points while q 3 is unstable (this can be seen graphically in figure 4 and is a direct result from the specified learning dynamics). q 3 defines the 'critical' social belief beyond which the system synchronizes on the state non-matching action.
These exercises show that the impact of the weighting function on agents' strategies is easily understood in the case of completely uninformative and fully informative signals or in a mean field approximation. But what hap-
pens in the more realistic interim region? Are densely connected networks more conducive for agents to coordinate on state non-matching actions or sparse networks? And how does the fraction of nodes that coordinate on a state non-matching action depend on the initial conditions? We address these questions in an agent-based simulation for three cases. In the case (I) of informed agents the distance between the mean of the two signals µ 1 -µ 0 = 0 6 . -0 4 = 0 2 . . while in the case (U) of uninformed agents the distance between the mean of the two signals is µ 1 -µ 0 = 0 51 . -0 49 = 0 02 . . . In both cases we use a standard deviation of σ 0 1 , = √ 0 1 . . 9 We conduct our simulations with N = 100 agents and update T = 100 times. To analyze the impact of the network structure on the probability of coordination on a state non-matching action, we vary the network density ρ of a random (Erdös-Rényi) graph within ρ = [0 0 . , 0 95] . in 20 steps. Each simulation is repeated S = 1 000 , times to account for stochasticity. For all simulations we assume that the state of the world is θ = 0 . An overview of the parameters used can be found in Table 1.
Figure (1) shows the average final action of the system after T = 100 update steps for a random graph with varying densities in the informed and uninformed case for the equal weighting, neighborhood size, and relative neighborhood scenario. When the network density is very low, agents effectively act on the basis of their private signal only and the fraction of agents that choose a state non-matching action is proportional to the signal informativeness. With increasing network density, social learning sets in and the fraction of agents with a state non-matching action is reduced. With an informative signal and equal weighting there is almost no agent that chooses a state non-matching action after T = 100 update steps. In the neighborhod size scenario agents are more likely to follow their neighbors than in the equal weighting scenario. The initial conditions of the simu-
9 Alarger standard deviation would make the signal less informative, without changing our results qualitatively.
lation thus have a stronger effect on an agent's decision. It will therefore take a longer time for agents to choose a state matching action. As long as the signal is not fully informative, equation (11) implies that an agent i will only choose action x i = 1 if more than half of her neighbors chose that action. With increasing network density the dependence on the initial conditions will become more important, which explains the increase in the fraction of agents choosing a state non-matching action with increasing network density in the center-left panel of Figure (1). Note that this effect is not present for uninformative signals as can be seen in the right panel of Figure (1). Finally, agent i in the relative neighborhood scenario chooses x i = 1 only if a relatively large fraction of her neighbors also chooses this action. The threshold for this is independent of the size of the neighborhood and only depends on the total network size.
The initial conditions become more important in the case of informative signals for the neighborhood size scenario. In order to understand how exactly our results depend on the initial conditions, Figure (2) shows the probability that a large fraction ( > 80% ) of agents coordinate on a state non-matching action for three cases: (1) For a full sample of S = 1 000 , simulations; (2) conditional on agents starting on average with a state matching action: ˆ = x ∑ i x i (0) /N < 1 2 ; (3) conditional on agents starting on average with a state non-matching action: ˆ x > 1 2 . As expected, the probability that agents coordinate on a state non-matching action drastically increases when agents initially start with a state non-matching action. However, less so in the equal weighting scenario because agents place less weight on their social beliefs and private signals are informative. A comparison of the left-center with the left-top panel in Figure (2) shows that the probability of contagion increases by a factor of roughly 200 in the neighborhood size scenario compared to the equal weighting scenario. Again, for uninformative signals this effect is not present.
While Figure (2) shows the existence of contagion even for initial actions that are state matching, the relationship between average initial and average final action is not yet quantified. Therefore, in Figure (3) we plot the average final action versus the average initial action in a density plot. We conducted a total of S = 1 000 , × 20 simulations and show the resulting pair of average initial and average final action as a dot with the respective coordinates. The left side of Figure (3) is for an informative signal and we draw initial actions according to the (informative) private signal. The mean of initial distributions is thus ˆ x I < 0 5 . , i.e. informative on average. In the right panel we show the same results for an uninformative signal and the mean of initial distributions is thus much closer to ˆ x I = 1 2 . Contagion is shown in the upper right quadrant of each subfigure. For the equal weighting scenario (top), only very few simulations yield a final average action that is state non-matching. A similar picture can be seen for the relative neighborhood (bottom) scenario. In the neighborhood size (center) scenario, however, a substantial number of simulations with an initially state matching average action yield a final state non-matching average action, confirming the existence of a contagious regime.
## 3 Contagious Synchronization in Endogenously Formed Networks
Banks form interbank networks endogenously. The decision whether or not two banks engage in interbank lending, e.g. in the form of agreeing on a mutual line of credit, depends in reality on many factors, including liquidity needs and counterparty risk. In the previous section we analyzed how one bank can learn about an underlying state of the world by observing the action of another bank to which it has issued an interbank credit. This additional information can create a benefit for the loan-issuing bank that constitutes a, possibly positive, externality for the lending decision. When banks coordinate on a state non-matching information, however, 'learning'
about a neighboring bank's action constitutes a negative externality. The net effect of both externalities determines whether two banks are willing to engage in interbank lending. We compute the value of an additional link in three steps. First, we compute the probability that an agent chooses a state matching action, given her signal structure, private beliefs and neighbors' actions. Given this probability, we compute, second, an agent's expected utility conditional on her social belief which depends on her strategic choice to establish a link. Once an agent's expected utility with and without a link is computed, we can use the concept of pairwise stable networks to determine the equilibrium network structure.
## 3.1 The Probability that Agents Choose a State Matching Action
Based on the signal structure, the update of private beliefs, and neighbors' action choice we can derive the probability that an agent i chooses a state matching action. To see this, we first derive the distribution of private beliefs. The private signal structure is given as:
$$f _ { 0 } ( s ) & = \frac { 1 } { \sqrt { 2 \pi } \sigma _ { 0 } } \exp \left ( \frac { - ( s - \mu _ { 0 } ) ^ { 2 } } { 2 \sigma _ { 0 } ^ { 2 } } \right ) \\ f _ { 1 } ( s ) & = \frac { 1 } { \sqrt { 2 \pi } \sigma _ { 1 } } \exp \left ( \frac { - ( s - \mu _ { 1 } ) ^ { 2 } } { 2 \sigma _ { 1 } ^ { 2 } } \right )$$
and we assume that σ 0 = σ 1 = σ . Denote the probability distribution of agent i 's private belief p i as f p ( p i ) . We can then state the following:
Proposition 1 For θ ∈ { 0 1 , } the probability that agent i chooses a state matching action x i = θ , given a social belief q i = q and private belief p i , is given by:
$$\Pr ( x ^ { i } = \theta \, | \, q ^ { i } = q ) = \int _ { 0 } ^ { 1 - q } f _ { p } ( p ^ { i } \, | \, \theta = 0 ) d p ^ { i } = \int _ { 1 - q } ^ { 1 } f _ { p } ( p ^ { i } \, | \, \theta = 1 ) d p ^ { i }, \ ( 1 8 )$$
where the distribution f p ( p i | θ = 0) of agent i 's private belief is given as:
$$f _ { p } ( p ^ { i } \, | \, \theta = 0 ) = \frac { \left ( \left ( - \frac { 1 - p } { p ^ { 2 } } - \frac { 1 } { p } \right ) p \sigma ^ { 2 } \right ) \exp \left ( - \frac { \left ( ( \mu _ { 0 } - \mu _ { 1 } ) ^ { 2 } - 2 \sigma ^ { 2 } \log \left ( \frac { 1 } { p } - 1 \right ) \right ) ^ { 2 } } { 8 \sigma ^ { 2 } ( \mu _ { 0 } - \mu _ { 1 } ) ^ { 2 } } \right ) } { \left ( \sqrt { 2 \pi } \sigma \right ) \left ( ( 1 - p ) ( \mu _ { 0 } - \mu _ { 1 } ) \right ) }.$$
and similarly for f p ( p i | θ = 1) .
$$\text{Proof, see Appendix (C).}$$
In the absence of maturity, liquidity and counterparty risk, the value of an interbank loan, is proportional to the probability that the newly connected neighbor chooses a state-matching action and thus proportional to (18).
## 3.2 Agents' Expected Utility
Recall that an agent i 's utility u i is given as:
glyph[negationslash]
$$u ^ { i } ( x ^ { i } ) = \begin{cases} 1 & \text{if $x^{i}=\theta$} \\ 0 & \text{if $x^{i} \neq \theta$} \end{cases}$$
The expected utility of agent i conditional on her social belief q i is thus:
$$\overline { u } ^ { i } ( x ^ { i } \, | \, q ^ { i } ) = \Pr ( x ^ { i } = \theta \, | \, q ^ { i } = q ).$$
The value of a link is given by the marginal utility from establishing a link, which in turn depends on the change in the social belief q . An agent can thus influence her social belief by strategically choosing neighbors. The probability that a neighbor takes a state matching action depends in turn on the social belief that this neighbor forms about her neighbors, which leads to complex higher-order effects which we neglect in this paper. Rather, we assume that an agent i has constant beliefs about her neighbors' social beliefs q ′ . An agent who ignores the effect of second-nearest neighbors (i.e. neighbors of neighbors) on the social beliefs of nearest neighbors will simply assume that her neigbhors' social belief is q ′ = 1 2 . This amounts to assuming
that the neighbors' actions are independent of each other. The expected utility of agent i conditional on a given q ′ and neighborhood K i is given as:
$$\overline { u } ^ { i } ( q ^ { \prime }, K ^ { i } ) = \sum _ { a \in Q ^ { i } } \Pr ( q ^ { i } = a \, | \, q ^ { \prime } ) \Pr ( x ^ { i } = \theta \, | \, q ^ { i } = a ),$$
i
where Q is the set of all possible values of the social belief of agent i . The first term on the right-hand side of equation (22) is the probability that agent i has a certain social belief given the social belief of her neighbors. The second term is the probability of choosing a state matching action given that social belief and given by equation (18). For a given size of the agent's neighborhood k i , Q i is simply Q i = { n/k i | n ∈ Z , 0 ≤ n ≤ k i } . The probability of a particular social belief can be computed by summing over the probabilities of combinations of actions chosen by the neighbors of agent i . Define the set of feasible action vectors of i 's neighbors conditional on agent i having a social belief q i = a :
$$X ^ { a i } = \{ \mathbf x \, | \, \sum _ { j } x _ { j } = a, x _ { j } \in \{ 0, 1 \}, j \in K _ { i } \}.$$
i.e. X ai is the set of all action vectors that are compatible with a social belief q i = a . Then the probability of agent i having a private belief of q i = a given the social beliefs of all i 's neighbors, q ′ , is given as:
$$\Pr ( q ^ { i } = a \, | \, q ^ { \prime } ) = \sum _ { y \in X ^ { a i } } \prod _ { j \in K ^ { i } } \Pr ( x ^ { j } = y ^ { j } \, | \, q ^ { j } = q ^ { \prime } ).$$
Now define the probability that neighbor j chooses a state matching action as:
$$z ^ { j } = \Pr ( x ^ { j } = \theta \, | \, q ^ { j } = q ^ { \prime } ) = \int _ { 0 } ^ { 1 - q ^ { j } } f _ { p } ( p ^ { j } \, | \, \theta = 0 ) d p$$
Note, that f p ( p j | θ = 0) depends on the signal structure of neighbor j .
We can write for the probability of agent i having a private belief of q i = a
in equation (24):
$$\Pr ( x ^ { j } = y ^ { j } \ | \ q ^ { j } = q ^ { \prime } ) = \begin{cases} z ^ { j } & \text{if $y^{j}=0$} \\ 1 - z ^ { j } & \text{if $y^{j}=1$} \end{cases}$$
j
If z = z ∀ j the distribution in 24 would be a simple binomial distribution. In general, however, this is not the case and we need to resort to numerical methods to compute the equilibrium network structures.
## 3.3 The Network Formation Process
We now have all necessary ingredients to compute the expected utility of an agent i given her neighborhood K i and expectations about her neighbors' social belief q ′ . In the endogenous network formation process the agent will seek to maximize her utility by changing her neighborhood while holding q ′ fixed. In this section we outline an algorithm for endogenous network formation that ensures a pairwise stable network in the sense of Jackson and Wolinsky (1996):
Definition 1 A network defined by an adjacency matrix g is called pairwise stable if
- (i) For all banks i and j directly connected by a link, l ij ∈ L : u i ( g ) ≥ u i ( g -l ij ) and u j ( g ) ≥ u j ( g -l ij )
- (ii) For all banks i and j not directly connected by a link, l ij glyph[owner] L : u i ( g + l ij ) < u i ( g ) and u j ( g + l ij ) < u j ( g )
where the notation g + l ij denotes the network g with the added link l ij and g -l ij the network with the link l ij removed. When maintaining a link is costly, there will be some network density that depends on the cost c > 0 per link. The marginal utility of an additional link decreases with the number of links because the expected utility is bounded by 1 (the pay-off is 1 and the probability of choosing the correct action is less than, or equal to, 1 ).
The algorithm to ensure a pairwise stable equilibrium starts by choosing a random agent i from the set of agents N . Then, choose a second agent j from the set of agents N \ K i that are not yet neighbors of i . Agents are chosen with the following probability:
$$w ^ { j } = \exp ( \beta E ^ { j } ) / Z,$$
where Z = ∑ k w k is a normalization constant and E j = | 1 2 -µ j 0 | is a proxy for agent j 's signal strength. For β = 0 i chooses the new agent with equal probability. While this makes it more likely that agent i considers forming a link with agent j when j has a higher signal strength, it does not imply that such a link is actually formed. This decision is solely based on the utility that both i and j obtain from establishing the link.
Now, let K ′ i = K i ∪ j , i.e. the neigborhood of agent i after adding adding agent j , and similarly K ′ j = K j ∪ i . The marginal utilities of adding j and i to the respective neighborhoods are then:
$$\Delta \bar { u } ^ { i } ( q ^ { \prime }, K ^ { i }, K ^ { i } ) & = \bar { u } ^ { i } ( q ^ { \prime }, K ^ { i } ) - \bar { u } ^ { i } ( q ^ { \prime }, K ^ { i } ) \\ \Delta \bar { u } ^ { j } ( q ^ { \prime }, K ^ { \prime j }, K ^ { j } ) & = \bar { u } ^ { j } ( q ^ { \prime }, K ^ { \prime j } ) - \bar { u } ^ { j } ( q ^ { \prime }, K ^ { i } )$$
Given the marginal utilities of agents i and j and their cost of maintaining link c i and c j the agents will form a link if ∆¯ ( u i q , K ′ ′ i , K i ) > c i and ∆¯ ( u j q , K ′ ′ j , K j ) > c j . If ∆¯ ( u i q , K ′ ′ i , K i ) > c i and ∆¯ ( u j q , K ′ ′ j , K j ) < c j , the algorithm selects the least informative agent in the neighborhood of j :
$$l = \underset { m \in K ^ { j } } { \arg \min } E ^ { m }.$$
Now, define K ′′ j = K ′ j \ k . If ∆¯ ( u i q , K ′ ′ i , K i ) > c i and ∆¯ ( u j q , K ′ ′′ j , K j ) > c j , form the link l ij and remove the link l jk (and similarly for i → j and j → i ). Otherwise, don't form the link. If ∆¯ ( u i q , K ′ ′ i , K i ) < c i and ∆¯ ( u j q , K ′ ′ j , K j ) < c j repeat the previous step, i.e. consider removing the
least informative neighbor and re-evaluate the utilities.
## 3.4 Equilibrium Networks
The endogenously formed network in an economy with identically informed agents and positive cost c of maintaining a link is a simple Erdös-Rényi network with a network density depending on the signal structure and link cost. To analyze more realistic situations, we can harvest the strengths of multi-agent simulations. In the following we therefore assume that agents are heterogenously informed about the underlying state of the world: a few 'informed' agents have relatively precise signals and low costs of maintaining a link, while many 'uninformed' agents have relatively imprecise signals and higher cost of maintaining a link. Table 2 summarizes the parameters we are using for the rest of this section.
In order to compare the dynamics on the endogenous networks to the ER networks we run the following simulations. We first create 1 000 , networks using the network formation algorithm described above. Then, we run the social learning algorithm described in Section 2 while holding the network structure constant throughout. The underlying assumption is that banks are updating their investment decisions faster than the network structure changes. This can be empirically corroborated by looking at the term structure of interbank lending. While 90% of the turnover in interbank markets is overnight, about 90% of exposures between banks stems from the term segments.
We also run the social learning algorithm with an initialization bias in which we set the initial action of all agents to some pre-defined value. To assess the efficiency of the endogenous network formation, we compare the performance of the endogenously formed networks to the performance of ErdösRényi networks. All simulations in this section are conducted using the equal weighting scenario. An example of a resulting network structure can
be found in Figure 5 and the degree distribution of the endogenously formed networks in 1 000 , is shown in Figure 6. The degree distribution of the endogenously formed networks is clearly bimodal. One peak corresponds to the uninformed nodes with small degree while the second peak corresponds to the informed nodes with high degree. Figure 7 shows the distribution of the final action for the 1 000 , simulations conducted. A clear improvement over the Erdös-Rényi networks can be seen, highlighting the importance of core banks with more precise private signals. Since core banks are highly interconnected, there is a higher chance that they are in the neighborhood of a peripheral bank (as opposed to a peripheral bank being in the neighborhood of another peripheral bank) which increases the precision of peripheral banks' social belief.
To further understand the difference between endogenously formed and random networks, we analyze the time it takes learning to converge. We assume the learning has converged at time t if:
$$\sum _ { i } | x _ { i } ( t ) - x _ { i } ( t + \Delta t ) | / N < 0. 0 5, \text{ where } \Delta t = 1 5.$$
It can be seen from Figure (8) that, except for very long convergence times, the system always converges faster in the endogenous network case than in the Erdös-Rényi case. Note, that this simulation was conducted without initialization bias, i.e. with average initial action of 1 2 . Finally, the probability of contagion as a function of an initialization bias, i.e. as a function of average initial action is shown in Figure (9). Again, the picture is unanimously showing that the probability of contagion, i.e. the probability that more than 80% of agents coordinate on a state non-matching action is significantly smaller in the endogenous network case than in the case of a random Erdös-Rényi graph.
## 4 Conclusion
This paper develops a model of contagious synchronization of bank's investment strategies. Banks are connected via mutual lines of credit and endogenously choose an optimal network structure. They receive a private signal about the state of the world and observe the strategies of their counterparties. When banks observe the actions of more peers they put more weight on their social belief. We compare three scenarios of weighting functions. First, in the equal weighting scenario, agents place equal weights on their private and social belief. Second, in the neighborhood scenario agents place proportionately more weight on the social signal when the size of the neighborhood increases. Third, in the relative neighborhood scenario agents place more weight on the social belief if their neighborhood constitutes a larger fraction of the overall network. Social learning increases the probability of choosing a state matching action and thus agents' utility. When agents strategically choose their neighbors they take the additional utility from learning into account. The more neighbors a given agent has, the lower is the marginal utility from another link and the network endogenously reaches an equilibrium configuration.
We obtain two results which are policy relevant. First, in a complex financial system where agents cannot take the action of all their peers into account when taking an investment decision, the probability of contagious synchronization depends on two things: (i) the weighting between the private and social belief; and (ii) the density of the financial network. Our model thus relates two empirically relevant sources of systemic risk: common shocks interbank market freezes. Second, the probability of contagious synchronization is substantially reduced when agents internalize the positive effects of social learning in a strategic decision with whom to form a link. The benefit from learning is reduced when the private signals about the state of the world are less informative.
The model has a number of interesting extensions. One example is the case with two different regions that can feature differing states of the world. Such an application could capture a situation in which banks in two countries (one in a boom, the other in a bust) can engage in interbank lending within the country and across borders. This would provide an interesting model for the current situation within the Eurozone. The model so far features social learning but not individual learning. Another possible extension would be to introduce individual learning and characterize the conditions under which the contagious regime exists. Finally, the model can be applied to real-world interbank network and balance sheet data to test for the interplay of contagious synchronization and endogenous network structure.
One drawback of the model is that there is no closed-form analytical solution for the benefit a bank obtains through learning from a peer that takes into account higher order effects. This benefit will depend on whether or not a neighboring bank chose a state matching on state non-macthing action in the previous period and thus on the social belief of neighboring banks. In the former case, the benefit will be positive, while in the latter case it will be negative. Agents have ex ante no way of knowing what action a neighboring bank selected until the state of the world is revealed ex post. Finding such a closed-form solution is beyond the scope of the present paper which focuses on the application in an agent-based model, but would provide a fruitful exercise for future research.
## References
Acemoglu, D., Bimpikis, K., Ozdaglar, A., 2014. Dynamics of information exchange in endogenous social networks. Theoretical Economics 9, 41 97.
Acemoglu, D., Dahleh, M.A., Lobel, I., Ozdaglar, A., 2011. Bayesian learning in social networks. Review of Economic Studies 78, 1201-1236.
Alevy, J.E., Haigh, M.S., List, J., 2007. Information cascades: Evidence from an experiment with financial market professionals. The Journal of Finance 67, 151-180.
Allen, F., Gale, D., 2000. Financial contagion. Journal of Political Economy 108, 1-33.
Bala, V., Goyal, S., 1998. Learning from neighbors. The Review of Economic Studies 65, 559-621.
Bala, V., Goyal, S., 2000. A noncooperative model of network formation. Econometrica 68, 1181-1231.
Bandt, O., Hartmann, P., Peydró, J.L., 2009. Systemic Risk in Banking: An Update. The Oxford Handbook of Banking (Oxford University Press, UK) .
Banerjee, A., 1992. A simple model of herd behaviour. The Quarterly Journal of Economics 107, 797-817.
Battiston, S., Gatti, D.D., Gallegati, M., Greenwald, B.C., Stiglitz, J., 2012. Liaisons dangereuses: Increasing connectivity, risk sharing, and systemic risk. Journal of Economic Dynamics and Control 36, 1121-1141.
Bernhardt, D., Campello, M., Kutsoati, E., 2006. Who herds? Journal of Financial Economics 80, 657-675.
Bikhchandani, S., Hirshleifer, D., Welch, I., 1992. A theory of fads, fashion, custom, and cultural change as informational cascades. Journal of Political Economy 100, 992-1026.
Bluhm, M., Faia, E., Krahnen, J.P., 2013. Endogenous Banks' Networks, Cascades, and Systemic Risk. SAFE Working Paper 12. Goethe University Frankfurt.
Caballero, R., 2012. A Macro Tragedy Waiting to Happen (in a VaR sense). Keynote Speech, TCMB Conference 2012. Turkiye Cumhuriyet Merkez Bankasi.
Castiglionesi, F., Navarro, N., 2007. Fragile Financial Networks. CentER Discussion Paper No. 2007-100. Tilburg University.
Chang, E.C., Cheng, J.W., Khorana, A., 2000. An examination of herd behavior in equity markets: An international perspective. Journal of Banking and Finance 24, 1651-1679.
- Chiang, T.C., Zheng, D., 2010. An empirical analysis of herd behavior in global stock markets. Journal of Banking and Finance 34, 1911-1921.
Cipriani, M., Guarino, A., 2014. Estimating a structural model of herd behavior in financial markets. The American Economic Review 104, 224251.
Craig, B., von Peter, G., 2014. Interbank tiering and money center banks. Journal of Financial Intermediation In press.
DeGroot, M., 1974. Reaching a consensus. Journal of the American Statistical Association 69, 118-121.
DeMarzo, P., Vayanos, D., Zwiebel, J., 2003. Persuasion bias, social influence, and unidimensional opinions. Quarterly Journal of Economics 118, 909-968.
Freixas, X., Parigi, B.M., Rochet, J.C., 2000. Systemic risk, interbank relations, and liquidity provision by the central bank. Journal of Money, Credit and Banking 32, 611-38.
Gale, D., Kariv, S., 2003. Bayesian learning in social networks. Games and Economic Behaviour 45, 329-346.
Georg, C.P., 2013. The effect of the interbank network structure on contagion and common shocks. Journal of Banking and Finance 37, 2216-2228.
Haldane, A.G., Madouros, V., 2012. The Dog and the Frisbee. Speech. Federal Reserve Bank of Kansas City's 36th Economic Policy Symposium, "The Changing Policy Landscape" , Jackson Hole, Wyoming.
Iori, G., Jafarey, S., Padilla, F., 2006. Systemic risk on the interbank market. Journal of Economic Behavior & Organization 61, 525-542.
- Jackson, M.O., Wolinsky, A., 1996. A strategic model of social and economic networks. Journal of Economic Theory 71, 44-74.
Ladley, D., 2013. Contagion and risk sharing on the interbank market. Journal of Economic Dynamics and Control 37, 1384-1400.
Nier, E., Yang, J., Yorulmazer, T., Alentorn, A., 2007. Network models and financial stability. Journal of Economic Dynamics and Control 31, 2033-2060.
Poledna, S., Thurner, S., Farmer, J.D., Geanakoplos, J., 2014. Leverageinduced systemic risk under basle ii and other credit risk policies. Journal of Banking and Finance 42, 199-212.
## A Tables
| Variable | Description | Value | Value | Value |
|------------|----------------------------------------|--------------|--------------|-----------------|
| Variable | Description | 1 - (I) | 2 - (U) | 3 - (H) |
| N | Number of agents | 100 | 100 | 100 |
| µ 0 | Average signal for θ = 0 | 0 . 4 | 0 . 49 | 0 . 3 |
| µ 1 | Average signal for θ = 1 | 0 . 6 √ | 0 . 51 √ | 0 . 7 |
| σ 0 | Standard deviation of signal for θ = 0 | 0 . 1 √ | 0 . 1 √ | √ 0 . 1 √ |
| σ 1 | Standard deviation of signal for θ = 1 | 0 . 1 | 0 . 1 | 0 . 1 |
| T | Number of iterations of updater | 100 | 100 | 100 |
| ρ | Density of ER network | [0 , 0 . 95] | [0 , 0 . 95] | 0 . 5 |
| p | Probability of being informed | NA | NA | [0 . 1 , 0 . 9] |
| S | # of simulations per param. config. | 1000 | 1000 | 1000 |
Table 1: Parameters for runs for the case of informed (I), uninformed (U), and heterogeneous (H) agents.
| Notation | Description | Value |
|------------|--------------------------------------------------------------|---------|
| N | Number of agents | 30 |
| N I | Number of informed agents | 4 |
| N U | Number of unformed agents | 26 |
| µ 0 I | Average signal for θ = 0 for informed agents | 0 . 3 |
| µ 1 I | Average signal for θ = 1 for informed agents | 0 . 7 √ |
| σ 0 I | Standard deviation of signal for θ = 0 for informed agents | 0 . 1 √ |
| σ 1 I | Standard deviation of signal for θ = 1 for informed agents | 0 . 1 |
| µ 0 U | Average signal for θ = 0 for uninformed agents | 0 . 4 |
| µ 1 U | Average signal for θ = 1 for uninformed agents | 0 . 7 √ |
| σ 0 U | Standard deviation of signal for θ = 0 for uninformed agents | 0 . 1 √ |
| σ 1 U | Standard deviation of signal for θ = 1 for uninformed agents | 0 . 1 |
| c I | Cost per link for informed agent | 0 |
| c U | Cost per link for informed agent | 0 . 1 |
| T C | Number of iterations of network algorithm | 400 |
| q ′ | Agent's belief of average action of neighbors of neighbors | 0 . 5 |
| β | Intensity of choice in agent selection | 30 |
| T | Number of iterations of action updater | 100 |
| n | Number of endogenously formed networks used for simulation | 1000 |
| S | Number of simulations per parameter configuration | 100 |
| ρ | Average density of ER networks | 0 . 08 |
Table 2: Parameters for network formation and runs with endogenous networks.
## B Figures
Figure 1: Average final action of agents as a function of the network density rho of a random graph for the informed (left) and uninformed (right) case. Top: Equal weighting scenario; Center: Neighborhood size scenario; Bottom: relative neighborhood scenario.
Figure 2: Fraction of simulations per parameter configuration S (1000) in which agents synchronize on the state non matching action (more than 80% of agents choose state non-matching action) as a function of network density rho of a random graph for the informed (left) and uninformed (right) case. Top: Equal weighting scenario; Center: Neighborhood size scenario; Bottom: relative neighborhood scenario. We distinguish three cases: (1) unconditional: we compute the fraction based on the full sample S . (2) conditional ˆ x ≤ 1 2 : we compute the fraction based on the sub-set of simulations in which the average initial action ˆ = x ∑ i x i (0) /N ≤ 1 2 , i.e. when the agents start with a state matching action. (3) conditional ˆ x > 1 2 : we compute the fraction based on the sub-set of simulations when the agents start with a state non matching action.
Figure 3: Average final action ˆ x F = ∑ i x i ( T /N ) versus the average initial action ˆ x I = ∑ i x i (0) /N for the informed (left) and uninformed (right) case. Top: Equal weighting scenario; Center: Neighborhood size scenario; Bottom: relative neighborhood scenario. Data points are averages over S = 1000 simulations and all network densities ρ (20 values equally distributed over the interval [0 , 0 95] . ). The color code indicates the frequency with which a point occurs in the sample (total size 20 × 1000 ), the scale of the color code is logarithmic of base 10.
Figure 4: Probability of choosing state matching action (equivalent to average social belief and average action in mean field) given that the state of the world is θ = 0 , f p ( p i | θ = 0) for µ 0 = 0 4 . . Furthermore we use µ 1 = 1 -µ 0 and σ 2 = 0 1 . . The intersections between the probability function and the diagonal mark the fixed points of the dynamical system.
Figure 5: Example network from ensemble of n = 1000 endogenously formed networks. Black nodes are 'informed' agents, while white nodes are 'uninformed'.
Figure 6: Degree distribution of ensemble of n = 1000 endogenously formed networks compared to ER networks with same average density.
Figure 7: Distribution of final action in ER networks vs. endogenous networks. This is without bias, i.e. the initial action is random based on the private belief only.
Figure 8: Distribution of convergence time ER networks vs. endogenous networks. This is without bias, i.e. the initial action is random based on the private belief only.
Figure 9: Probability of contagion vs. initialization bias. Missing values correspond to zero frequency.
## C Proofs
Proof of Proposition (1) . We use the notation f P ( p i | θ = 0) to indicate that the functional form of the probability distribution of the private belief p i has be derived assuming that θ = 0 . Now, let s p ( i ) be the inverse of the private belief:
$$s ( p ^ { i } ) = \frac { \mu _ { i } ^ { 2 } - \mu _ { 1 } ^ { 2 } + 2 \sigma ^ { 2 } \log \left ( \frac { 1 - p ^ { i } } { p ^ { i } } \right ) } { 2 ( \mu _ { 0 } - \mu _ { 1 } ) }$$
The distribution of the private belief can be computed as follows:
$$f _ { p } ( p ^ { i } ) = \frac { \partial s ( p ^ { i } ) } { \partial p ^ { i } } f _ { s } ( s ( p ^ { i } ) ).$$
where the probability density function for signal s is given as:
$$f _ { s } ( s ) = \frac { 1 } { \sqrt { 2 \pi } \sigma } \exp \left ( \frac { - ( s - \mu _ { 0 } ) ^ { 2 } } { 2 \sigma ^ { 2 } } \right )$$
and the private belief p i ( s ) is given by Equation (8). Substituting in the expression for s p ( i ) and computing the partial derivative we obtain:
$$f _ { p } ( p ^ { i } \, | \, \theta = 0 ) = \frac { \left ( \left ( \frac { 1 - p ^ { i } } { p ^ { i } } - 1 \right ) \sigma ^ { 2 } \right ) \exp \left ( - \frac { \left ( ( \mu _ { 0 } - \mu _ { 1 } ) ^ { 2 } - 2 \sigma ^ { 2 } \log \left ( \frac { 1 } { p ^ { i } } - 1 \right ) \right ) ^ { 2 } } { 8 \sigma ^ { 2 } ( \mu _ { 0 } - \mu _ { 1 } ) ^ { 2 } } \right ) } { \left ( \sqrt { 2 \pi } \sigma \right ) \left ( ( 1 - p ^ { i } ) ( \mu _ { 0 } - \mu _ { 1 } ) \right ) }$$
Example distributions of the private belief are shown in Figure (10). We have µ 1 = 1 -µ 0 and σ 2 = 0 1 . . Note, that the majority of the probability density of the private belief is to the left of 0 5 . in all cases. Therefore, the private signal tends to produce private beliefs that yield the state matching action. If we increase the | µ 0 -0 5 . | the distribution becomes more skewed towards the actual state of the world. Hence the private belief becomes more informative.
Now that we have defined the pdf of the private belief we can compute the
Figure 10: Probability density function of the private belief given that the state of the world is θ = 0 f P ( p | θ = 0) for three values of µ 0 ∈ { 0 3 . , 0 4 . , 0 48 . } .
probability that the agent chooses x i = 0 given some social belief q = q i as:
$$\Pr ( x ^ { i } = 0 \, | \, q ^ { i } = q ) = \int _ { 0 } ^ { 1 - q } f _ { p } ( p ^ { i } \, | \, \theta = 0 ) d p ^ { i },$$
where we use the notation f p ( p i | θ = 0) to indicate that the functional form of f p has be derived assuming that θ = 0 . This result generalizes to all θ due to the symmetry of the signal structure. It can be shown that:
$$\Pr ( x ^ { i } = \theta \, | \, q ^ { i } = q ) = \int _ { 0 } ^ { 1 - q } f _ { p } ( p ^ { i } \, | \, \theta = 0 ) d p ^ { i } = \int _ { 1 - q } ^ { 1 } f _ { p } ( p ^ { i } \, | \, \theta = 1 ) d p ^ { i }. \ \ ( 3 6 )$$
Therefore we have derived an expression for the probability of choosing the correct action that does not depend on the actual state of the world but only on the signal structure and the social belief. | 10.1016/j.jbankfin.2014.06.030 | [
"Christoph Aymanns",
"Co-Pierre Georg"
] | 2014-08-03T00:02:00+00:00 | 2014-08-03T00:02:00+00:00 | [
"q-fin.EC",
"q-fin.CP",
"q-fin.GN"
] | Contagious Synchronization and Endogenous Network Formation in Financial Networks | When banks choose similar investment strategies the financial system becomes
vulnerable to common shocks. We model a simple financial system in which banks
decide about their investment strategy based on a private belief about the
state of the world and a social belief formed from observing the actions of
peers. Observing a larger group of peers conveys more information and thus
leads to a stronger social belief. Extending the standard model of Bayesian
updating in social networks, we show that the probability that banks
synchronize their investment strategy on a state non-matching action critically
depends on the weighting between private and social belief. This effect is
alleviated when banks choose their peers endogenously in a network formation
process, internalizing the externalities arising from social learning. |
1408.0441v1 | The Origin and Non-quasiparticle Nature of Fermi Arcs in Bi2Sr2CaCu2O8+δ
T. J. Reber , N. C. Plumb , Z. Sun , Y. Cao , Q. Wang , K. McElroy , H. Iwasawa , M. 1 1 1 1 1 1 2 Arita , J. S. Wen , Z. J. Xu , G. Gu , Y. Yoshida , H. Eisaki , Y. Aiura , and D. S. Dessau 2 3 3 3 4 4 4 1
1 Dept. of Physics, University of Colorado, Boulder, 80309-0390, USA
2 Hiroshima Synchrotron Radiation Center, Hiroshima University, Higashi-Hiroshima, Hiroshima 739-0046, Japan
3 Condensed Matter Physics and Materials Science Department, Brookhaven National Labs, Upton, New York, 11973 USA
4 AIST Tsukuba Central 2, 1-1-1 Umezono, Tsukuba, Ibaraki 3058568, Japan
A Fermi arc 1,2 is a disconnected segment of a Fermi surface observed in the pseudogap phase 3,4 of cuprate superconductors. This simple description belies the fundamental inconsistency in the physics of Fermi arcs, specifically that such segments violate the topological integrity of the band . Efforts to resolve this contradiction of experiment and 5 theory have focused on connecting the ends of the Fermi arc back on itself to form a pocket, with limited and controversial success 6,7,8,9 . Here we show the Fermi arc, while composed of real spectral weight, lacks the quasiparticles to be a true Fermi surface . To 5 reach this conclusion we developed a new photoemission-based technique that directly probes the interplay of pair-forming and pair-breaking processes with unprecedented precision. We find the spectral weight composing the Fermi arc is shifted from the gap edge to the Fermi energy by pair-breaking processes 10 . While real, this weight does not form a true Fermi surface, because the quasiparticles, though significantly broadened, remain at the gap edge. This non-quasiparticle weight may account for much of the unexplained behavior of the pseudogap phase of the cuprates.
In a solid the behavior of the electrons is most fully described in terms of the electron Green's function, the poles of which map the energy vs. momentum dependence of the electronic quasiparticles (the dressed electronic states) . The locus of poles at the Fermi energy, EF, defines 5 the Fermi surface of the material, from which almost all of the electronic properties of a material emanate. For a single continuous band, the Fermi surface should form a continuous loop. Consequently, the broken segments of Fermi surface known as Fermi arcs apparently require a major rethinking of some of the basic tenets of condensed matter physics.
One approach to resolving this problem is completely discarding the notion of electron quasiparticles, and with it almost all of the understanding of solids built up from generations of condensed matter physicists. Much support for this line of reasoning came from angle resolved photoemission spectroscopy (ARPES), which is unique in its ability to directly probe the electronic excitations as a function of energy and momentum, i.e. the quasiparticles. Earlier ARPES studies found that the ARPES peaks were either anomalously broad or vanishingly weak 11,12,13 especially in the underdoped 'pseudogap' regime of the cuprates - aspects that were widely taken as evidence for the lack of electron-quasiparticles. The recent introduction of laser
and low energy ARPES 14 made tremendous advances in the peak sharpness and spectral weight at EF, handicapping this line of argument. We for example now see sharp nodal quasiparticle-like peaks for all doping levels of Bi2Sr2CaCu2O8+δ (Bi2212) studied (down to moderately underdoped x=.10 samples - see Fig. 3b black), in contrast to recent studies which were unable to observe peaks below x=0.20 13 . Therefore other ideas are needed to understand the origin of the unusual non-Fermi liquid behavior in the cuprates. Here we show that regardless of whether the peaks are sharp enough to be considered quasiparticles, these states do not reach the Fermi energy and so cannot dominate the transport and thermodynamics the way that regular quasiparticle states normally would. This finding drops the relevance of the question of whether these states are sharp enough to be quasiparticles. Instead, we argue that a more relevant issue for understanding the nature of the non-Fermi liquid behavior is whether these excitations reach the Fermi energy at all.
In addition to its ability to measure quasiparticle peaks, the momentum-resolution of ARPES makes it a preferred tool to study gaps and Fermi surfaces, and therefore Fermi arcs. Despite its great power and directness, ARPES has lacked appropriate quantitative analysis techniques, which can also significantly affect the qualitative picture that emerges. For example, gap values have been predominantly measured using the approximate 'midpoint of leading edge' 15 or 'peak separation of symmetrized spectra' 1,2 techniques, each of which is known to fail in many limits. Phenomenological models 16 have also been used to fit gapped energy distribution curves (EDCs) 17 , but since the EDC lineshape is not yet understood 18 , these fittings are not obviously better than the approximate measures.
To avoid the difficulties inherent in the traditional techniques of analyzing ARPES spectra, we have developed and employed a new method, the tomographic density of states (TDoS), the creation of which is illustrated in Fig 1, with more details in the supplementary materials. Briefly, the TDoS is a one-dimensional momentum-sum of the coherent electronic spectral weight (black curve in D), which is then normalized to a similar but ungapped reference momentum-sum along the node (black curve in B), with some similarities to the proposal by Vehkter & Varma 19 . The resulting TDoS (panel F) represents the density of states and is in many ways equivalent to a typical Giaever tunneling curve of an s-wave superconductor 20 , except that it is localized to a single slice through the band structure (hence the name tomographic, meaning
sliced or sectioned). This unique advantage is indispensible when electron interactions are strongly momentum dependent (e.g. in a d-wave superconductor).
To analyze the TDoS, we use the formula first proposed by Dynes to explain tunneling spectra from strongly coupled s-wave superconductors:
$$I _ { T D o S } \left ( \omega \right ) = \rho _ { _ { D y n e s } } \left ( \omega \right ) = \text{Re} \frac { \omega - i \Gamma _ { _ { T D o S } } } { \sqrt { \left ( \omega - i \Gamma _ { _ { T D o S } } \right ) ^ { 2 } - \Delta ^ { 2 } } }$$
(1)
where ω is the energy relative to EF, Γ TDoS is the pair-breaking scattering rate and Δ is the superconducting gap 21,22 . This formula is essentially a simple BCS density of states with gap broadened by the parameter ΓTDoS, which is interpreted as the rate of pair-breaking. This formula has been extensively tested on conventional superconductors 23 , and while initially phenomenological, it has been derived from the Eliashberg theory 22 . Since each TDoS is specific to a single location on the Fermi surface the gap magnitude is single valued, allowing us to use Dynes' original form even in d-wave superconductors. An example fit of a TDoS to (1) is shown in panel F, with the extracted superconducting gap value =5.9±0.1 meV and scattering rate TDoS=2.6±0.1 meV. The TDoS values extracted here are consistent with what has been measured by tunneling 24 and optics 25 , though previous ARPES-based methods to extract electronic scattering rates relied on the EDC or MDC widths that give values roughly an order of magnitude larger 26 - see for example the EDCs of panel A that have widths of order 20 meV. This difference arises because TDoS is only sensitive to pair-breaking interactions while the EDCs and MDCs are sensitive to all electronic scattering processes (see Fig SM3).
Taking advantage of the momentum selectivity of the TDoS, Figure 2 details the evolution of the TDoS along the Fermi surface in the near-nodal regime from an optimally doped (Tc=91K) Bi2212 sample. By fitting to the Dynes formula (eqn 1), we find the gap is linear and symmetric about the node as expected for a d-wave gap (Fig. 2E). In this near-nodal regime, TDoS is essentially isotropic and of the scale of 2-3 meV, which is counter to earlier ARPES observations in which was large (of the order of 20-30 meV) and grew rapidly away from the node 26 .
In Fig. 2F, we compare the TDoS gap measurements with the EDC leading edge 15 technique (data in panel C) and symmetrized EDC 1,2 technique (panel D), all of which came from the identical ARPES data sets. We show ΔTDoS is roughly the average of the 'standard' techniques away from the node. However the other methods both fail in proximity to the node. Specifically, both the EDC leading edge method and the symmetrized EDC methods have a short 'arc' near the node in which the extracted gap value is either zero or negative (which is often artificially set to zero). Directly observing the sharp cusp of the d-wave gap so near the node confirms the findings of other probes such as thermal conductivity 27 . By comparing Figs. 2e and 2f we see that the threshold for the artificial zero gap in the conventional techniques is when ΓTDoS≈Δ. This zero gap regime is what previously would have been considered a Fermi arc, i.e. the zero gap regime would have indicated the presence of a real portion of Fermi surface . 2
To study the Fermi arc in greater detail we move to an underdoped sample (TC=65K) with finely gridded momentum maps in the superconducting state (T=10K) and the normal (i.e. pseudogap and/or prepairing) state (T=75K) (Fig. 3). The formation of the Fermi arc is evident in the Fermi surface maps (Fig. 3A). The symmetrized EDCs show a small (2°) Fermi arc at 10K but a much larger one at 75K, with a gap from this method (determined by the depression of weight at zero energy) only definitively present at 10° and beyond (Fig. 3B). However the TDoS paint a different picture, showing a smooth evolution of the gap rather than a discrete change at any one angle (Fig. 3C). Our observation of a finite near-nodal gap above TC is only possible if there are pre-formed superconducting pairs in the pseudogap state 28,29 .
Assuming a simple d-wave Δ and an isotropic ΓTDoS, we can fit the entire momentum dependence of the TDoS at once (Fig. 3D). Both the superconducting and pseudogap states are well fit with this form. While ΔMax has shrunk by 30% from the superconducting state to the normal state, ΓTDoS has more than doubled, completely filling in the gap for states close to the node. These filled-in states are the source of previous observations of a Fermi arc and should be considered a manifestation of superconductive pre-pairing in the pseudogap state. The extremely short arc in the superconducting state is most likely due to in-plane impurity scattering (e.g. Cu vacancies). 30,31 However, the growth of the arc with temperature cannot be explained by static disorder. Instead, a dynamical process must lead to the increased pair-breaking rate that causes the arc to grow as was first proposed by Norman et al. 10
A more complete temperature dependence of the Fermi arc is shown in Fig. 4A, for a similarly underdoped sample (TC=67K). The growth of the Fermi arc with temperature can be 2 accurately simulated with an electron Green's function which utilizes a tight-binding band structure obtained from experiment, a simple d-wave gap (ΔMax=38meV), and a scattering rate TDoS which is constant across the Fermi surface (Fig. 2E) but which varies strongly with temperature. The values of the electron scattering rate are directly obtained from the Dynes fits up to 110K. At higher temperatures the fits become less reliable, so we have extrapolated those values. While the gap is seen to close slightly with increasing temperature (Fig. 3D), it was held constant in Fig. 4 for simplicity. The observed growth of the Fermi arc with increased temperature can be understood with the schematic of Fig. 4B. As the dominant effect of raising temperature is to increase ΓTDoS, the threshold of ΓTDoS=Δ moves away from the node increasing the arc length.
The notion of discontinuous Fermi arcs put forward from the previous ARPES experiments is unphysical within the context of standard condensed matter theory, because Fermi surfaces must be topologically connected. Therefore, significant effort has been expended to observe if and how these arcs close to form a Fermi pocket. For example, recent ARPES experiments 6,7 have presented evidence for arc closures, though many of these have been met with skepticism for reasons including potential contamination from shadow bands, superstructure bands , or extended extrapolations. With the understanding presented here, there is no physical 9 reason why the arc would need to be closed because it is not a real locus of quasiparticle states. In this light, the difficulty in observing the 'back' side of the arc is completely natural - that is, the arc is actually arc-like, as opposed to only being the front side of a small hole pocket.
High magnetic field quantum oscillation studies in the cuprates have found evidence for a small Fermi surface pocket , with these pockets potentially related to the pockets discussed in 8 some of the ARPES experiments. However, Hall effect measurements indicate that the pockets hold electrons instead of holes , making it clear that the pockets observed in the quantum 8 oscillation experiments are inconsistent with the ARPES Fermi arc with back-side closure. Additionally, new evidence from NMR indicates that the high-magnetic fields used in the quantum oscillation experiments cause a reconstruction of the Fermi surface that can create the small pockets observed in those experiments 32 .
Within the conventional analysis method of symmetrized EDCs, the Fermi arcs are considered loci of quasiparticle states at the Fermi level that grow with increasing temperature. Instead, the above simulations and data argue that the arcs are a result of the interplay between Δ(k,T) and TDoS (k,T) , which we find is dominated by Δ(k) and TDoS (T). Importantly, this result indicates that the arcs are not composed of true quasiparticles because, even though the quasiparticles exist, they are not at at E - rather the pole locations are the gap values, Δ(k) (Fig F 4C). Rather than a true Fermi surface of quasiparticle poles, the arcs are regions where real spectral weight has been scattered inside the d-wave gap, with this incoherent non-quasiparticle weight varying with Fermi surface angle and temperature (Fig. 4C). Aside from the single quasiparticle state at the node, this non-quasiparticle weight comprises the only states available to contribute to the low energy transport and thermodynamic properties. Therefore, these states are strong candidates to explain the unusual transport, heat capacity, and other thermodynamic properties in the pseudogap state of the cuprates 33 .
Acknowledgements. We thank G. Arnold, A. Balatsky, I. Mazin, S. Golubov and M. Hermele for valuable conversations and D. H. Lu and R. G. Moore for help at SSRL. SSRL is operated by the DOE, Office of Basic Energy Sciences. ARPES experiments at the Hiroshima Synchrotron Radiation Center were performed under proposal 09-A-48. Funding for this research was provided by DOE Grant No. DE-FG02-03ER46066 (Colorado) and DE-AC02-98CH10886 (Brookhaven) with partial support from the NSF EUV ERC and from Kakenhi (10015981 and 19340105).
## Contributions
T. R., N. P., Z. S., Y. C., Q. W., M. A. and H. I. performed the ARPES measurements. J. W., Z. X., G. G., Y. Y. , H. E. and Y. A. grew and prepared the samples. T.R. analysed the ARPES data. T.R and D.D. developed the TDoS technique and wrote the paper with suggestions and comments by N.P., Z. S. and K. M. ARPES simulations were done by T. R. D.D. is responsible for project direction, planning and infrastructure.
.
Correspondence and requests for materials should be addressed to D. D. ([email protected])
Fig 1: Creation and Fitting of the Tomographic density of states (TDoS). a) Nodal spectrum of optimally doped (TC =92K) Bi2212 at T=50K. b) (colored) 7 out of a total of 170 individual energy distribution curves (EDCs) taken along the horizontal colored lines of panel a. The green EDC corresponds to k=kF. The sum of all 170 individual EDCs gives the spectral weight curve (black). c) Slightly (6°) off nodal spectra taken along the red cut in the inset. d) EDCs and the corresponding spectral weight for the data of panel C showing the superconducting gap at EF as well as additional spectral weight above EF due to the Bogoliubov quasiparticles. e) Off-nodal spectra normalized to nodal spectral weight (color scale data) and the spectral weight curves from panels B and D (orange and red curves, respectively). The red curve is normalized to the orange curve to create the tomographic density of states or TDoS curve (Yellow). f) Fit of the TDoS (red circles) to the Dynes tunneling formula (green line).
Fig 2: Angular dependence of the TDOS and comparison to conventional ARPES analysis techniques from an optimal TC=91K Bi2212 sample at T=50K. a) Angle dependence of ARPES spectra. b) TDoS curves vs. angle. c) EDC's at kF vs. angle. d) Symmetrized EDC's at kF vs. angle, all from the same data set. e) ΔTDoS and ΓTDoS for angles very near the node. Error bars are ±σ returned from fits to the data of panel B. f) ΔTDoS near the node compared to Δ's measured by the other two methods. These other methods show a short but artificial 'arc' of zero gapped states near the node, while ΔTDoS extrapolates to 0 meV only at the node.
Fig 3: Comparing the TDoS and Symmetrized EDCs when determining a Fermi Arc, for an underdoped (TC=65K ) sample. a) Spectral weight at EF both in the superconducting (T=10K, top) and pseudogap (T=75K, bottom) states. b) Symmetrized EDCs from which one would determine a finite range of gapless states at EF that grows with increasing temperature. c) Measured TDoS spectra as a function of angle away from the node. d) Two parameter fits (ΓTDoS and ΔMax) for each entire set of spectra, with parameters listed on the panels. Δmax is the max of the d-wave gap, occurring at the antinode, with the k-dependence of the gap forced to maintain the simple d-wave form. ΓTDoS is held to a constant value throughout k-space, consistent with the results of fig 2E.
Fig 4: Simulating the observed temperature dependence of the Fermi arc from a Tc=67K underdoped Bi2Sr2CaCu2O8 sample. a) The unusual temperature-dependent arc length is seen in both the data and simulations. The main inputs to the simulations are an experimentally determined tight binding band structure, a simple d wave gap (both below and above Tc) with independently measured d-wave gap maximum 40 meV, and a temperature dependent scattering rate ΓTDoS (shown) with units of meV. The majority of these ΓTDoS values (<110K) are also independently experimentally determined. b) Simple picture for the temperature dependence of the Fermi arc length. The arc is approximately the region where ΓTDoS > Δ, which grows rapidly with temperature as ΓTDoS grows. c) Cartoon showing change in spectral weight (red) along the Fermi surface due to increasing ΓTDOS between the superconducting and normal states as determined by the TDoS (green)
Figure 1
Figure 2
Figure 3
## Supplemental Methods
Samples and experimental equipment. The samples studied in this letter were high quality Bi2Sr2CaCu2O8+ single crystals cleaved in ultra-high vacuum. All data were taken with a Scienta R4000 analyzer using 7 eV photons. The Scienta electron detection systems have a noticeable nonlinearity as a function of counting rate that can be up to a 30% increase 34,35 . To our knowledge this effect has so far been ignored in the analysis of ARPES spectra though it can play a significant role, especially near the Fermi edge where spectral weight is rapidly decreasing. We have calibrated and corrected for this effect. All other methods of experimentation are standard for the field. TDoS's do not require very high angular resolution, though high energy resolution is important because we will be studying superconducting gaps of the order of a few meV. For this reason we use low energy photons (7 eV), giving an experimental resolution of approximately 4 meV FWHM.
## Data treatment- background removal and spectral weight determination.
We find it is very helpful to isolate the weight of the dispersive states from that of the background non-dispersive states. We have done that here by analyzing each spectrum via momentum distribution curves (MDCs). We fit each MDC to a Lorentzian with a constant offset, taking the area of the Lorentzian to be the dispersive spectral weight and the offset to be the background. Figure SI1a shows a sample MDC from a nodal cut at 50K (red), its fit (teal), the background weight (blue) and the band weight (green). The energy dependence of these various spectral weights is shown in Fig SI1b, while the effect of the background removal on the overall spectrum is shown in Fig SI1c. The BG-removed spectrum looks essentially identical to the original spectrum, except that some of the haze around the dispersive band-like states is missing.
## Including Energy Resolution in Fitting the TDoS,
Though small in low energy ARPES, the energy resolution is finite and for the most accurate fits we need to include it. To properly include the energy resolution we can't simply convolve the Dynes formula with a Gaussian with the width of the energy resolution. That method fails to consider the effect of the rapidly decreasing weight from the Fermi Edge. Instead we must consider how the experimental resolution affects the data prior to the normalization procedure. Consequently, we use the formula:
$$\ F i t ( \omega ) = \frac { \left ( F ( \omega ) \, \rho _ { _ { D y n e s } } ( \omega ) \right ) \otimes R ( \omega ) } { F ( \omega ) \otimes R ( \omega ) }$$
Where F(ω) is the Fermi Function, ρDynes(ω) is the Dynes formula, R(ω) is the experimental resolution. The main effect of including the resolution is the deviation from the expected 'U' shape inside the gap to the 'V' shape of our TDoS. Once the energy resolution is included the quality of the fits is excellent as shown in Fig. SI2, where we have reprinted the TDoS from Fig 2b (Fig. SI2).
## Comparing ΓTDoS to ΓMDC
The standard ARPES method for determining the scattering rate, momentum distribution curve (MDC) widths 36 , gives static values ΓMDC( =0,T~0) nearly an order of magnitude larger than the associated values for ΓTDOS. Note that this data is from low photon energy ARPES, which as first shown by Koralek et al. returns ΓMDC significantly lower than standard ARPES experiments[ 37 ]. Furthermore, while the TDoS method returns almost identical scattering rates from many samples (Fig. SI3a), the ΓMDC's from the same exact samples vary by more than a factor of 2 (Fig. SI3b). This wide variation in MDC widths without a similar variation in the TC indicates that the MDCs (and EDCs) are subject to scattering processes that do not affect the TDoS's (or the pairing). These results show that the physical processes that are responsible for
the MDC broadening ΓMDC are different from (or in addition to) those that are responsible for the TDoS broadening ΓTDoS.
To understand the difference between the ΓMDC and ΓTDoS, we plot the effect of increasing ΓTDoS on density of states using Dynes formula, in Fig. SI3c. The dominant effect of increasing Γ is to shift weight from the peak at Δ up to EF. Since we are restoring weight to the Fermi energy, we argue ΓTDoS represents only the scattering processes that can break pairs while ΓMDC represents all scattering processes. For example, In a d-wave superconductor we expect pairbreaking scattering to be those scattering events with a q=k'-k which change the phase of the order parameter, whereas non-pair-breaking scattering would not change the phase and are likely related to highly prevalent forward scattering events 38 . Figure SI3d schematically illustrates both a pair-breaking (blue) and non-pair-breaking scattering event (red). We imagine that out-ofplane disorder would be well screened and would predominantly cause forward scattering and not break the pairs, while in-plane disorder (e.g. Cu vacancies) would give the large q scattering necessary for pair breaking 39,40 .
## Simulating Nodal and Off-Nodal Spectra
Using the electron Green's function, it is simple, in principle, to recreate our observed ARPES spectra. Including the Fermi Edge, energy dependent self-energy and experimental resolution, the ARPES spectra can be written:
$$I _ { \text{ARPES} } \left ( \omega, k \right ) = \left ( F ( \omega ) \times - \frac { 1 } { \pi } \text{Im} G ( \omega, k ) \right ) \otimes R ( \omega, k )$$
Where F(ω) is the Fermi function R(ω,k) is the experimental resolution and the Green's function is written:
$$G ( \omega, k ) = \frac { \omega + \Sigma - \varepsilon _ { k } } { \left ( \omega + \Sigma \right ) ^ { 2 } - \left ( \varepsilon _ { k } \right ) ^ { 2 } - \Delta _ { k } ^ { 2 } }$$
where Σ is the complex self energy and εk is the bare band and Δ is the gap magnitude. For these simulations, we used a reasonable interpretation that Im(Σ) linear and symmetric about EF with a step at 70 meV and the minimum value as determined from the MDC width (20 meV). We took the Kramers-Kronig transform of Im(Σ) to extract the Re(Σ). We assumed a linear bare band with vBB = 2.9 eV/Å and kF = .42 1/Å. Finally, we set T to 50K and the energy resolution at 4 meV. For the nodal (Δ=0) case this simulation does an excellent job of recreating the observed spectrum as shown in Fig SI4. To simulate the slightly off-nodal spectra we should only have to add the presence of a small but finite Δ. However, the addition of a finite Δ has no observable effect on the on the simulation, even though the gap is clearly resolvable in the data. We find that the minimum Im(Σ) is just too large to achieve a significant depreciation in weight at the Fermi energy for the off-nodal spectrum. We can achieve the expected reduction in spectral weight by drastically reducing the minimum Im(Σ) by an order of magnitude. However the band's width would be dramatically too narrow if we only used ΓTDoS. Instead, we can compensate by broadening the spectrum as if the MDC width was dominated by extrinsic final state effects by convolving a Lorentzian in momentum with the spectrum. The resulting simulation matches the observed spectra quite well for both the gapped and ungapped cases. This result further supports our conclusion that ΓTDoS more accurately describes the superconducting state scattering rates than ΓMDC.
## Creating and Simulating the Fermi Surface Maps
To create a Fermi surface map that is representative of the coherent spectral weight at EF and thus the Fermi arc, we found it necessary to remove the incoherent background and correct
for the photon energy dependent matrix elements. We removed the background as described previously for each individual angle. For 7 eV photons, the suppression of spectral weight due to matrix elements is dramatic beyond 10° from the node. If left uncorrected this effect would artificially shrink the observed Fermi arcs. To compensate, we normalize the coherent spectral weight for each angle over the range -30 to -70 meV, well below the region of the gap.
To simulate the Fermi surface maps in Fig. 4, rather than the spectral function, we started
## with electron Green's function of the form
$$G ( \omega, k _ { x }, k _ { y } ) = \frac { \omega + i \Gamma _ { T D o S } - \varepsilon _ { k } } { \left ( \omega + i \Gamma _ { T D o S } \right ) ^ { 2 } - \left ( \varepsilon _ { k } \right ) ^ { 2 } - \Delta _ { k } ^ { 2 } }$$
Where ΓTDoS is the pair-breaking scattering rate, Δk is a d-wave gap of the form
$$\Delta _ { k } = \frac { \Delta _ { 0 } } { 2 } \left ( \cos k _ { x } - \cos k _ { y } \right )$$
And εk is the band structure, a tight binding model of the form
$$\varepsilon _ { k } = u - 2 t _ { 0 } \left ( \cos k _ { x } + \cos k _ { y } \right ) - 4 t _ { 1 } \left ( \cos k _ { x } \cos k _ { y } \right ) - 2 t _ { 2 } \left ( \cos 2 k _ { x } + \cos 2 k _ { y } \right ) \\ - 4 t _ { 3 } \left ( \cos 2 k _ { x } \cos k _ { y } + \cos k _ { x } \cos 2 k _ { y } \right ) - 4 t _ { 4 } \left ( \cos 2 k _ { x } \cos 2 k _ { y } \right )$$
Extracting just the imaginary part, we recover the spectral function A(ω,kx,ky) which ARPES actually measures. To account for the large MDC widths, we broaden the spectra as previously discussed for the 2-D simulations, but along both kx and ky for the 3-D case.
## Supplemental Discussion
## Mathematical Comparison of TDoS to Normal ARPES and Tunneling
As the TDoS is a merger of ARPES data with tunneling analysis, we find illustrative to directly compare how ARPES, tunneling and the TDoS measure the spectral function A(k,ω). Rather than the usual kx and k y , we define two orthogonal momenta, kll and k , where kll is the
momentum parallel to the Fermi surface while k is normal to the Fermi surface, though still in the xy plane ( kz would be the out-of plane direction). A(k, ) is the spectral function, M 2 (k, ) is the ARPES or tunneling matrix element, and f( ) is the Fermi function.
The intensity measured by ARPES (ignoring experimental resolution) is:
$$I ( k, \omega ) _ { \text{ABS} } = A ( k, \omega ) M ^ { 2 } ( k, \omega ) f ( \omega )$$
While (k, ) ARPES contains the most detail, the pairing processes can be swamped by nonthermodynamic scattering processes like forward scattering. Tunneling experiments integrate over all momenta such that:
$$I ( \omega ) _ { \iota u m e l i n g } = \int _ { k _ { \perp } } \int _ { k _ { l l } } A ( k, \omega ) M ^ { 2 } ( k, \omega ) d ^ { 2 } k$$
While tunneling is sensitive to the pairing processes , I( ) tunneling is complicated by strong variation along kll such as to the d-wave superconducting gap, the van-Hove singularity near the antinode, etc. However to create the TDoS we integrate over the momentum, k :
$$I ( k _ { i l, } \omega ) _ { T D o S } = \int _ { k _ { \perp } } A ( k, \omega ) M ^ { 2 } ( k \, \omega ) f ( \omega ) d k _ { \perp }$$
By normalizing the spectra properly we obtain the simple functional as shown below,
$$\cong \int _ { k _ { \perp } } A ( k, \omega ) d k _ { \perp }$$
This form allows us to probe the thermodynamic pair-forming and pair-breaking processes with the use of well developed tunneling analysis techniques for a simple (i.e. s-wave) gap 41 , even though the gap varies as a function of kll due to the d-wave nature of the order parameter.
Fig SI1: Removing the Background, a) Sample MDC (red) 100 meV from EF, its fit (teal), background weight (blue), and band weight (Green). The MDC at EF (dashed) is shown for comparison. b) Energy dependence of spectral weights for a nodal spectrum at 50K. c) Comparison of the original nodal spectrum and with the background removed.
Fig SI2: Experimental TDoS spectra and Fits. TDoS and fits as a function of angle near the node used in figure 2.
Fig SI3: Broadening mechanisms for MDC curves not present in TDoS spectra. a) TDoS spectra at θ=6° from 3 different samples, including extracted parameters Δ and ΓTDoS. b) Nodal MDCs at EF from the same three samples as studied in panel a, showing the significant deviation in MDC widths from sample to sample. The extracted broadening parameters ΓMDC are shown in a. c) Illustration of how increasing Γ TDoS shifts weight from the peak to EF d) Diagram of the Fermi surface detailing the difference between non-pair-breaking forward scattering (red) and pair-breaking unitary scattering (blue).
## Figure SI4: Simulations of Nodal and Off-Nodal Spectra from the Electron Green's
Function. The first column shows experimental data in the superconducting state for the node (top and slightly off-node (bottom). The second column shows simulations using Eq. S2 and S3 with a Γ=20 meV (obtained from MDC analysis). While nodal case closely matches the experimental data, the off-nodal simulation cannot recreate the gap. Instead we must lower Γ by an order of magnitude to achieve the observed depletion of weight at EF (third column). To recover the experimental MDC widths, we then broaden the spectra by convolving a Lorentzian with a width, Γk, in momentum (fourth column).
Figure SI1
Figure SI2
a
Figure SI3
1
## Data
## Simulations
Figure SI4 Momentum

1 Norman, M. et al. Destruction of the Fermi surface in underdoped high-TC superconductors. Nature 392 , 157(1998)
- 2 Kanigel, A. et al. Evolution of the pseudogap from Fermi arcs to the nodal liquid. Nature Physics 2 , 447 (2006).
- 3 Loeser, A. G. et al., Excitation gap in the normal state of underdoped Bi Sr CaCu2O8+δ Science 2 2 273 , 325 (1996).
- 4 Ding, H. et al., Spectroscopic evidence for a pseudogap in the normal state of underdoped high-TC superconductors Nature 382 , 51 (1996)
- 5 Pines, P. & Nozieres, P., The Theory of Quantum Liquids , W.A. Benjamin Inc., New York (1966)
- 6 Yang, H.-B., et al. Emergence of preformed Cooper pairs from the doped Mott insulating state in Bi2Sr2CaCu2O8+δ. Nature 456 ,77 (2008)
- 7 Meng, J. et al. Coexistence of Fermi arcs and Fermi pockets in a highT c copper oxide superconductor. Nature (London) 462 , 335 (2009)
- 8 Doiron-Leyraud, N. et al. Quantum oscillations and the Fermi surface in an underdoped highT c superconductor. Nature 447 , 565 (2007)
- 9 King, P.D.C. et al, Structural origin of apparent Fermi surface pockets in angle-resolved photoemission of Bi2 Sr2-x LaxCuO6+d. Phys. Rev. Lett. 106 , 127005 (2011).
- 10 Norman, M. R., Kanigel, A. Randeria M., Chatterjee, U. & Campuzano, J. C. Modeling the Fermi arc in underdoped cuprates Phys. Rev. B 76 , 174501 (2007)
- 11 Damascelli, A. Hussain, Z. & Shen, Z-X Angle-resolved photoemission studies of the cuprate superconductors. Review of Modern Physics 75 , 473 (2003).
- 12 Laughlin, R.B. Evidence for Quasipartile Decay from Photoemission in Underdoped Cuprates, Phys. Rev. Lett 79, 1726 (1997)
- 13 Fournier, D. et al, Loss of nodal quasiparticle integrity in underdoped YBa2Cu3O6+ x Nature Physics 6 , 905-911 (2010)
- 14 Koralek, J.D. et al, Laser Based Angle-Resolved Photoemission, the Sudden Approximation, and Quasiparticle-Like Spectral Peaks in Bi2Sr2CaCu2O8+d Phys. Rev. Lett. 96, 017005 (2006)
- 15 Shen, Z.-X. et al. Anomalously Large Gap Anisotropy in the a-b plane of Bi 2 Sr 2 CaCu 2 O 8+ Phys. Rev. Lett. 70 , 1553 (1993).
- 16 Norman, M. R., Randeria, M., Ding, H. & Campuzano, J. C. Phenomenology of the low-energy spectral function in high-TC superconductors. Phys. Rev. B 57 , R11093-R11096 (1998).
- 17 Lee, W.S. et al., Abrupt onset of a second energy gap at the superconducting transition of underdoped Bi2212. Nature 450 , 81-84 (2007).
- 18 Casey, P. A., Koralek, J. D., Plumb, N. C., Dessau, D.S. & Anderson, P. W. Accurate theoretical fits to laser-excited photoemission spectra in the normal phase of high temperature superconductors. Nature Physics 4 , 210 (2008).
- 19 Vehkter, I. & Varma C. M. Proposal to Determine the Spectrum of Pairing Glue in High-Temperature Superconductors, Phys. Rev. Lett. 90 , 237003 (2003)
- 20 Giaever, I., Hart, H. R. , & Mergele, K. Tunneling into superconductors at temperatures below 1 degree K Phys. Rev. 126 , 941-948 (1962).
- 21 Dynes, R. C., Narayanamurti, V., Garno, J.P., Direct Measurement of Quasiparticle-Lifetime Broadening in a Strong-Coupled Superconductor. Phys. Rev. Lett. 41 ,1509-1512 (1978)
- 22 Mikhailovsky, A. A., Shulga, S. V., Karakozov, A. E., Dolgov, O. V., & Maksimov, E. G. Thermal pair-breaking in superconductors with strong electron-phonon interaction. Solid State Communications 80 ,7 (1991)
- 23 Wolf, E.L. Principles of Electron Tunneling Spectroscopy, Oxford University Press, USA (1989)
- 24 Pasupathy, A. et al. Electronic Origin of the Inhomogeneous Pairing Interaction in the High-Tc Superconductor Bi2Sr2CaCu2O8+δ. Science 320 , 196 (2008).
25 Hwang, J., Timusk, T. & Gu G. D. High-transition-temperature superconductivity in the absence of the magnetic-resonance mode. Nature 427 , 6976 (2004)
- 26 Valla, T. et al. Temperature Dependent Scattering Rates at the Fermi Surface of Optimally Doped Bi2Sr2CaCu2 O 8+ δ . Phys. Rev. Lett. 85 , 828 (2000).
- 27 Sutherland, M. et al. Thermal conductivity across the phase diagram of cuprates: Low-energy quasiparticles and doping dependence of the superconducting gap. Phys. Rev. B 67 , 174520 (2003).
- 28 Emery, V.J. & Kivelson, S.A. Importance of phase fluctuations in superconductors with small superfluid density. Nature 374 , 434(1995)
- 29 Y. Wang, L. Li, and N. P. Ong, Nernst Effect in High TC Superconductors Phys. Rev. B 73 , 024510 (2006)
- 30 Fehrenbacher, R. Effect of nonmagnetic impurities on the gap of a dx^2-y^2 superconductor as seen by angle-resolved photo-emission Phys. Rev. B 54 6632 (1996)
- 31 Haas, S., Balatsky, A. V., Sigrist, M. & Rice, T. M. Extended gapless regions in disordered dx^2-y^2 wave superconductors Phys. Rev. B 56 5108 (1997)
- 32 Wu, T. et al., Magnetic-field-induced charge-stripe order in the high-temperature superconductor YBa2Cu3Oy. Nature 477 , 191 (2011)
- 33 Varma, C.M., Littlewood, P. B., Schmitt-Rink, S., Abrahams, E. & Ruckenstein, A. E. Phenomenology of the normal state of Cu-O high-temperature superconductors. Phys. Rev Lett. 63 , 1996 (1989)
- 34 Kay, A. W. et al. Multiatom resonant photoemission Phys. Rev. B 63 , 115119 (2001)
- 35 Manella, N. et al. Correction of Non-linearity Effects in Detectors for Electron Spectroscopy Jour. of Elec. Spec. and Rel. Phen. 141 , 45 (2004)
- 36 T. Valla et al., Evidence for quantum critical behavior in the optimally doped cuprate Bi Sr CaCu2O8+δ 2 2 Science 285 , 2110 (1999)
- 37 Koralek, J.D. et al, Laser Based Angle-Resolved Photoemission, the Sudden Approximation, and Quasiparticle-Like Spectral Peaks in Bi2Sr2CaCu2O8+d Phys. Rev. Lett. 96, 017005 (2006)
- 38 Dahm, T., Hirschfeld, P.J., Scalapino, D. J., & Zhu, L. Nodal quasiparticles in the cuprate superconductors Phys. Rev. B 72 , 214512 (2005)
- 39 Haas, S., Balatsky, A. V., Sigrist, M. & Rice, T. M. Extended gapless regions in disordered dx^2-y^2 wave superconductors Phys. Rev. B 56 5108 (1997)
- 40 Fehrenbacher, R. Effect of nonmagnetic impurities on the gap of a dx^2-y^2 superconductor as seen by angle-resolved photo-emission Phys. Rev. B 54 6632 (1996)
- 41 Dynes, R. C., Narayanamurti, V., and Garno, J. P. Direct Measurement of Quasiparticle-Lifetime Broadening in a Strong-Coupled Superconductor. Phys. Rev. Lett. 41 1509 (1978) | 10.1038/nphys2352 | [
"T. J. Reber",
"N. C. Plumb",
"Z. Sun",
"Y. Cao",
"Q. Wang",
"K. McElroy",
"H. Iwasawa",
"M. Arita",
"J. S. Wen",
"Z. J. Xu",
"G. Gu",
"Y. Yoshida",
"H. Eisaki",
"Y. Aiura",
"D. S. Dessau"
] | 2014-08-03T00:09:56+00:00 | 2014-08-03T00:09:56+00:00 | [
"cond-mat.supr-con"
] | The Origin and Non-quasiparticle Nature of Fermi Arcs in Bi$_2$Sr$_2$CaCu$_2$O$_{8+δ}$ | A Fermi arc is a disconnected segment of a Fermi surface observed in the
pseudogap phase of cuprate superconductors. This simple description belies the
fundamental inconsistency in the physics of Fermi arcs, specifically that such
segments violate the topological integrity of the band. Efforts to resolve this
contradiction of experiment and theory have focused on connecting the ends of
the Fermi arc back on itself to form a pocket, with limited and controversial
success. Here we show the Fermi arc, while composed of real spectral weight,
lacks the quasiparticles to be a true Fermi surface. To reach this conclusion
we developed a new photoemission-based technique that directly probes the
interplay of pair-forming and pair-breaking processes with unprecedented
precision. We find the spectral weight composing the Fermi arc is shifted from
the gap edge to the Fermi energy by pair-breaking processes. While real, this
weight does not form a true Fermi surface, because the quasiparticles, though
significantly broadened, remain at the gap edge. This non-quasiparticle weight
may account for much of the unexplained behavior of the pseudogap phase of the
cuprates. |
1408.0442v1 | ## Power Distribution in Randomized Weighted Voting: the Effects of the Quota
Joel Oren 1 , Yuval Filmus 2 , Yair Zick 3 , and Yoram Bachrach 4
- 1 Department of Computer Science, University of Toronto, Canada
[email protected]
- 2 Institute of Advanced Study Princeton University, USA
[email protected]
- 3 School of Computer Science
Carnegie-Mellon University, USA
[email protected]
- 4 Microsoft Research, UK
[email protected]
Abstract. We study the Shapley value in weighted voting games. The Shapley value has been used as an index for measuring the power of individual agents in decision-making bodies and political organizations, where decisions are made by a majority vote process. We characterize the impact of changing the quota (i.e., the minimum number of seats in the parliament that are required to form a coalition) on the Shapley values of the agents. Contrary to previous studies, which assumed that the agent weights (corresponding to the size of a caucus or a political party) are fixed, we analyze new domains in which the weights are stochastically generated, modeling, for example, elections processes.
We examine a natural weight generation process: the Balls and Bins model, with uniform as well as exponentially decaying probabilities. We also analyze weights that admit a super-increasing sequence, answering several open questions pertaining to the Shapley values in such games.
## 1 Introduction
Weighted voting is a common method for making group decisions. This is the method used in parliaments: one can think of the political parties in a parliament as weighted agents , where an agent's weight is the number of seats it holds in the parliament.
Power dynamics in electoral systems have been the focus of academic study for several decades. One important observation is that the weight of a party is not necessarily equal to its electoral power. For example, consider a parliament that has three parties, two with 50 seats, and one with 20 seats. Assuming that a majority of the votes is required in order to pass a bill, all three parties have the same decision-making power: no single party can pass a bill on its own, whereas any two parties can. This contrasts the fact that one of the parties has significantly less weight than the other two. One of the
most prominent measures of voting power is the Shapley-Shubik power index (also referred to as the Shapley value); it has played a central role in the analysis of real-life voting systems, such as the US electoral college [1, 2], the EU council of members [3, 4, 5], and the UN security council [6].
Empirical studies of weighted voting present an interesting phenomenon: changes to the quota (i.e., the number of votes required in order to pass a bill, also called the threshold) can dramatically affect agent voting power. Changes to the quota have been proposed as a way to correct power imbalance in the EU council of members [4]; this is because quota changes are perceived as a preferable alternative to changes to agent weights (as is proposed by [7]), and were thus argued for in [4, 8].
The objective of this paper is to study the effects of changes to the quota on electoral power as measured by the Shapley-Shubik power index. Previous analytical studies of power indices as a function of the quota have mostly focused on the following question: given a set of weights, what would be the effect of changes to the quota on voting power?
As mentioned, the effect that changing the quota has on the Shapley value has been studied to some extent. However, as these studies show, relatively little can be said about these effects in general. Instead of studying arbitrary weight vectors, we assume that weights are sampled from certain natural distributions. Modeling a parliamentary election process, we think of voters as casting their ballots according to a prescribed distribution, that determines the number of seats each party will hold. Using natural weight generation processes, we analyze the expected behavior of the Shapley value as a function of the quota. For example, some of our results show that even when weights are likely to be very similar, some choices of a quota will cause significant differences in voting power.
Our Contributions Our work focuses on the Balls and Bins model -a model that has received considerable recent attention in the computer science community [9, 10, 11]. Informally, in this iterative process, in each round a ball is thrown into one of several bins according to a fixed probability distribution.
In Section 4, we study a simple model, where each ball lands in one of the n bins uniformly at random. We identify a repetitive fluctuation pattern in the Shapley values, with cycles of length m n . We show that if the quota is sufficiently bounded away from the borders of its lengthm n cycle, then the Shapley values of all agents are likely to be very close to each other. On the other hand, we show that due to noise effects, when the quota is situated close enough to small multiples of m n , the highest Shapley value can be roughly double than that of the smallest one. In other words, even if one expects that candidate weights are identical with high probability, choosing a quota near a multiple of m n may result in a great difference between Shapley values.
To complement our findings for the uniform case, in Section 5 we consider the case in which the probabilities decay exponentially, with a decay factor no larger than 1 / 2 . We show that analyzing this case essentially boils down to characterizing the Shapley values in a game where weights are a super-increasing sequence (Section 6). Our results significantly strengthen previous results obtained for this case in [12]: we fully characterize the Shapley value as a function of the quota for the super-increasing case.
In addition to giving a closed-form formula for the Shapley values, we also provide conditions for the equality of consecutive agents.
## 1.1 Related Work
Weighted voting games (WVGs) have been studied extensively, two classic power measures proposed by [13] and by [6, 14] being the main object of analysis (see [5], [15] and [16] for expositions). From an economic point of view, the appeal of the Shapley value is that it is the only division rule that satisfies certain desirable axioms [6]. Computing Shapley values in WVGs has also been the focus of several studies: power indices have been shown to be computationally intractable (see [17] for a detailed overview), but easily approximable. Randomized sampling has been employed in order to efficiently approximate the Shapley value, with the earliest examples of this technique appears in [1], with subsequent analysis in [18, 19]. However, this type of analysis employs the inherent probabilistic nature of power indices, rather than inducing randomness in the weighted voting game itself.
If one makes no assumptions on weight distributions, very little can be said about the effects of the quota on WVGs. Indeed, as demonstrated in [20, 21, 12], power measures are highly sensitive to varying quota values. While [21] presents some preliminary results on the effects of the quota when weights are sampled from a given distribution, our work takes a more principled approach to the matter.
Several works have studied the effects of randomization on weighted voting games from a theoretical, computational and empirical perspective. The earliest study of randomization and its effects on voting power is due to [7], who shows that the Banzhaf power index scales as the square root of players' weight when weights are drawn from bounded distributions. 5 [23] shows certain convergence results for power indices, when players are sampled from some distributions; [24] show that when weights are sampled from the uniform distribution, the expected Shapley value of a player is proportional to its weight, assuming that the quota is 50%. [21] considers a model where the quota is sampled from a uniform distribution, and bounds the variance of the Shapley value in this setting, both for general weights and for weights sampled from certain distributions. The effects of changes to the quota have also been studied empirically, mostly in the context of the EU council of members [8, 3, 4].
## 2 Preliminaries
General notation Given a vector x ∈ R n and a set S ⊆ { 1 , . . . , n } , let x S ( ) = ∑ i ∈ S x i . For a random variable X , we let E [ X ] be its expectation, and Var[ X ] be its variance. For a set S , we denote by [ S k ] the collection of subsets of S of cardinality k . The notation T ∈ R [ S k ] means that the set T is chosen uniformly at random from [ S k ] . We let B( n, p ) denote the binomial distribution with n trials and success probability p . We let N ( µ, σ 2 ) denote the normal distribution with mean µ and variance σ 2 . We let U a, b ( ) denote the uniform distribution on the interval [ a, b ] .
5 The results shown by Penrose predate the work by Banzhaf, but can be applied directly to his work; see [22] for details.
We let O p ( ) · denote the usual big-O notation, conditioned on a fixed value of p . In other words, having f ( n ) = O p ( g n ( )) means that there exist functions K ( ) · , N ( ) · , such that for n ≥ N p ( ) , f ( n ) ≤ K p ( ) · g n ( ) .
Finally, for a distribution D over R , and some event E , we simplify our notation by letting Pr[ E ( D )] = Pr x ∼ D [ E ( x )] . For example, for a > 0 , we can write Pr[B( n, p ) ≤ a ] = Pr x ∼ B( n,p ) [ x ≤ a ] .
Weighted voting games A weighted voting game (WVG) is given by a set of agents N = { 1 , . . . , n } , where each agent i ∈ N has a positive weight w i , and a quota (or threshold ) q . Unless otherwise specified, we assume that the weights are arranged in non-decreasing order, w 1 ≤ ·· · ≤ w n . For a subset of agents S ⊆ N , we define w S ( ) = ∑ i ∈ S w i .
A subset of agents S ⊆ N is called winning (has value 1 ) if w S ( ) ≥ q and is called losing (has value 0 ) otherwise.
The Shapley value Let Sym n be the set of all permutations of N . Given some permutation σ ∈ Sym n and an agent i ∈ N , we let P i ( σ ) = { j ∈ N : σ j ( ) < σ i ( ) } ; P i ( σ ) is called the set of i 's predecessors in σ . Let us write m S i ( ) to be v S ( ∪ { } i ) -v S ( ) ; in other words, m S i ( ) = 1 if and only if v S ( ) = 0 but v S ( ∪ { } i ) = 1 . If m S i ( ) = 1 , we say that i is pivotal for S ; similarly, we write m σ i ( ) = m P σ i ( i ( )) , and say that i is pivotal for σ ∈ Sym n if i is pivotal for P i ( σ ) . The Shapley-Shubik power index (often referred to as as the Shapley value in the context of WVG's) is simply the probability that i is pivotal for a permutation σ ∈ Sym n selected uniformly at random. More explicitly,
$$\varphi _ { i } = \frac { 1 } { n! } \sum _ { \sigma \in S y m _ { n } } m _ { i } ( \sigma ).$$
Since σ -1 ( ) i is distributed uniformly when σ is chosen at random from Sym n , we also have the alternative formula
$$\varphi _ { i } = \frac { 1 } { n } \sum _ { \ell = 0 } ^ { n - 1 } \underset { S \in _ { R } [ \overset { N } { \lambda } \times \{ i \} } { \mathbb { E } } } { \mathbb { m } } _ { i } ( S ).$$
Properties of the Shapley value For WVGs, it is not hard to show that w i ≤ w j implies ϕ i ≤ ϕ j , and so if the weights are arranged in non-decreasing order, the minimal Shapley value is ϕ 1 and the maximal one is ϕ n . Another useful property that follows immediately from the definitions is that ∑ i ∈ N ϕ i = 1 , assuming 0 < q ≤ ∑ i ∈ N w i . When we want to emphasize the role of the quota q , we will think of the Shapley values as functions of q : ϕ i ( q ) .
## 3 An Overview of our Results
We begin by briefly presenting our three major contributions.
The Balls and Bins Distribution: the Uniform Case In this work, we study the effects of the quota on agents' voting power, when agent weights are sampled from the balls and bins distribution. This distribution is appealing, as it can naturally model election dynamics under plurality voting: consider an election where m voters vote for n parties; the weight of each party is determined by the number of votes it receives. If we assume that each voter will vote for party i with probability p i , party seats are distributed according to the balls and bins distribution with the probability vector p . We first study the case where balls are thrown into bins uniformly at random; that is, voters choose parties uniformly at random (the impartial culture assumption).
(a) The Shapley values of agents 1, 10, 20 and 30 in a 30-agent WVG where weights were drawn from a balls and bins distribution with m = 10000 balls.
(b) The Shapley values as a function of the quota in a 10-agent game where agent i 's weight is 2 i -1 .
When weights are drawn from a uniform balls and bins distribution with m balls and n bins, Shapley values follow a rather curious fluctuation pattern as the quota varies (see Figure 1a). Note that the fluctuation is quite regular, with power disparity occurring at regular intervals (these intervals are of length m n ). Our first result (Theorem 4.1) shows that when we select a quota that is sufficiently far from an integer multiple of m n , all agents' Shapley values tend to be the same. When the quota is an integer multiple of m n , we distinguish between two cases; when the quota is far from the 50% mark, power disparity is likely to occur, with the weakest agent's voting power sinking to less than half that of the strongest (Theorem 4.2). However, disparity is mitigated when the quota is near the 50% mark (Theorem 4.3). These results indicate that even if weights are likely to be similar (as is the case for the uniform balls and bins distribution), power disparity is likely in certain quotas.
The Balls and Bins Distribution: the Exponential Case In Section 5, we explore the case where the voting probabilities are exponentially increasing, i.e. p i p i +1 = ρ for some fixed constant 0 < ρ < 1 2 . In this case, we show (Theorem 5.1) that agents' weights are very likely to be super-increasing (super-increasing weights were first studied by [12]). Thus, in order to understand the expected behavior of voting power as a function of
the quota in the exponential setting, it suffices to characterize the Shapley value for weighted voting games with super increasing weights.
Super-Increasing Weights Following the crucial observation made in Theorem 5.1, we complete characterize voting power in WVGs with super-increasing weights in Section 6. First we show that in order to compute the Shapley value of an agent under a super-increasing sequence, it suffices to know his Shapley value when weights are powers of 2 (Lemma 6.2). This connection leads to a closed-form formula for the Shapley value when weights are super-increasing (Theorem 6.1). Employing our formula, we are able to derive some interesting properties of the Shapley values as functions of the quota for super-increasing sequences. These results generalize those found in [12], providing a clear understanding of the mechanics of power distribution and the quota for the case of super-increasing sequences.
We conclude our study with an interesting analysis of ϕ i ( q ) when weights are finite prefixes of the sequence (2 m ) ∞ m =0 . The analysis explains in many ways the fractal shape of ϕ i ( q ) when weights are powers of two, and shows when voting power will increase or decrease.
## 4 The Balls and Bins Distribution: the Uniform Case
We now consider a generative stochastic process called the Balls and Bins process. In its most general form, given a set of n bins and a distribution represented by a vector p ∈ [0 , 1] n such that ∑ n i =1 p i = 1 , the process unfolds in m steps. At every step, a ball is thrown into one of the bins based on the probability vector p . The resulting weights are then sorted in non-decreasing order w 1 ≤ · · · ≤ w n .
We begin our study of the balls and bins process by considering the most commonly studied version of the balls and bins model, in which each ball is thrown into one of the bins with equal probability, i.e., p i = 1 /n , for all i ∈ N .
As Figure 1a shows for the case of n = 30 , the behavior of the Shapley values demonstrates an almost perfect cyclic pattern, with intervals of length m/n . As can be seen in the figure, for quota values that are sufficiently distant from the interval endpoints, all of the Shapley values tend to be equal (as the Shapley values of the highest and lowest agents are equal in these regions). As the number of balls grows, all of the bins tend to have nearly the same number of balls in them; however, low weight discrepancy does not immediately translate to low power discrepancy: we can guarantee nearly equal voting power in some quotas, but not in others.
We begin by providing a formula for the differences between two Shapley values.
Lemma 4.1 For all agents i, j ∈ N ,
$$| \varphi _ { j } - \varphi _ { i } | = \frac { 1 } { n - 1 } \sum _ { \ell = 0 } ^ { n - 2 } \Pr _ { S \in R [ \stackrel { N \subset ( i, j ) } { \ell } ] } [ q - \max ( w _ { i }, w _ { j } ) \leq w ( S ) < q - \min ( w _ { i }, w _ { j } ) ].$$
We now give a theoretical justification for the near-identity of Shapley values for quotas that are well-away from integer multiples of m n .
Theorem 4.1. Let M = m 3 n 3 . Suppose that | q -glyph[lscript]m n | > 1 √ M n m for all integers glyph[lscript] . Then with probability 1 -2( 2 e ) n , all Shapley values are equal to 1 /n .
glyph[negationslash]
The idea of the proof is the following. Suppose that w i ≤ w j . According to Lemma 4.1, ϕ i = ϕ j only if for some S ⊆ N \ { i, j } , we have q -w j ≤ w S ( ) < q -w i . For a fixed set of agents | S | ∈ [ N \{ i,j } k ] we have S ∼ B( m,k/n ) - as each ball enters into one of the bins corresponding to S with probability k/n . As a result, w S ( ) is concentrated around the mean km/n . On the other hand q -w , q j -w i ≈ q -m n . Therefore, if q is far away from ( k +1) m n for all 0 ≤ k ≤ n -2 , then the probability that q -w j ≤ w S ( ) < q -w i is very small. The details can be found in the appendix.
Returning to our voting setting, the interpretation of Theorem 4.1 is that if the voter population is much larger than the number of candidates, and the votes are assumed to be cast uniformly at random (i.e., a totally neutral distribution of preferences), then choosing a quota that is well away from a multiple of m n , will most probably lead to an even distribution of power among the elected representatives (e.g., political parties).
## 4.1 How Weak Can the Weakest Agent Get in the Uniform Case?
As Theorem 4.1 demonstrates, if the quota is sufficiently bounded away from any integral multiple of m n , then the distribution of power tends to be even among the agents. When the quota is close to an integer multiple of m n , it may very well be that the resulting weighted voting game may not display such an even distribution of power, as a result of weight differences, as a result of the intrinsic 'noise' of the process. Figure 1a provides an empirical validation of this intuition. Motivated by these observations, we now proceed to study the expected Shapley value of the weakest agent, ϕ 1 (recall that we assume that the weights are given in non-decreasing order).
We now present two contrasting results. Let q = glyph[lscript] · m n , for an integer glyph[lscript] . When glyph[lscript] = o (log n ) , we show that the expected minimal Shapley value is roughly 1 2 n , and so it is at least half the maximal Shapley value (in expectation).
Theorem 4.2. Let q = glyph[lscript] · m n for some integer glyph[lscript] = o (log n ) . For m = Ω n ( 3 log n ) , E [ ϕ 1 ] = 1 2 n + ( o 1 n ) .
In contrast, when glyph[lscript] = Ω n ( ) , this effect disappears.
$$\begin{array} { l } \text{Theorem } 4. 3. \ L e t \ q = \ell \cdot \frac { m } { n } \text{ for } \ell \in \{ 1, \dots, n \} \text{ such that } \gamma \leq \frac { \ell } { n } \leq 1 - \gamma \text{ for some} \\ \text{constant } \gamma > 0. \ T h e n \text{ for } m = \Omega ( n ^ { 3 } ), \mathbb { E } [ \varphi _ { 1 } ] \geq \frac { 1 } { n } - O _ { \gamma } \left ( \sqrt { \frac { \log n } { n ^ { 3 } } } \right ). \end{array}$$
The idea behind the proof of both theorems is the formula for ϕ 1 given in Lemma 4.2. In this formula and in the rest of the section, the probabilities are taken over both the displayed variables and the choice of weights.
Lemma 4.2 Let q = glyph[lscript] · m n , where glyph[lscript] ∈ { 1 , . . . , n - } 1 . For m = Ω n ( 3 log n ) ,
$$\mathbb { E } [ \varphi _ { 1 } ] = \frac { 1 } { 2 ( n - \ell ) } - \frac { \ell } { n ( n - \ell ) } + \frac { 1 } { n - \ell } \Pr _ { A \in _ { R } [ ^ { N } _ { \ell - 1 } ) ] } [ w ( A ) + w _ { 1 } \geq q ] \pm O \left ( \frac { 1 } { n ^ { 2 } } \right ).$$
The full details of the proof appear in the appendix.
In order to estimate the expression Pr A ∈ R [ N \{ } 1 glyph[lscript] -1 ] [ w A ( ) + w 1 ≥ q ] , we need a good estimate for w 1 . Such an estimate is given by the following lemma.
$$L e m m a { 4. 3 } \ W i t h p r o b a b i l i y { 1 - 2 / n, w e h a v e t h a t } \, \sqrt { \frac { m \log n } { 3 n } } \leq \frac { m } { n } - w _ { 1 } \leq \sqrt { \frac { 4 m \log n } { n } }.$$
We obtain this bound by applying the Poisson approximation technique to the Balls and Bins process, which we now roughly describe. Consider the case of a random event, defined with respect to the weight distribution induced by the process. The probability of the event can be well-approximated by the probability of an analogous event, defined with respect to n i.i.d. Poisson random variables, assuming the event is monotone in the number of balls.
We can now prove Theorem 4.2.
Proof (of Theorem 4.2). Lemma A.3 (a simple technical result proved in the appendix) shows that
$$\Pr _ { A \in R [ \begin{smallmatrix} N \times ( 1 ) \\ \ell - 1 \end{smallmatrix} \rangle ] } [ w ( A ) + w _ { 1 } \geq q ] \leq \frac { n } { n - \ell + 1 } \Pr [ B ( m, \frac { \ell - 1 } { n } ) \geq q - w _ { 1 } ].$$
The concentration bound on w 1 (Lemma 4.3) shows that with probability 1 -2 /n , q -w 1 ≥ ( glyph[lscript] -1) m n + √ m log n 3 n . Assuming this, a Chernoff bound gives
$$\Pr [ B ( m, \frac { \ell - 1 } { n } ) \geq q - w _ { 1 } ] \leq \Pr [ B ( m, \frac { \ell - 1 } { n } ) \geq \frac { ( \ell - 1 ) m } { n } + \sqrt { \frac { m \log n } { 3 n } } ] \leq e ^ { - \frac { m \log n / ( 3 n ) } { 3 ( \ell - 1 ) m / n } } = o ( 1 ),$$
using glyph[lscript] = (log o n ) . Accounting for possible failure of the bound on q -w 1 , we obtain
$$\Pr _ { A \in R [ \begin{smallmatrix} N \bigcup ( 1 ) \\ \ell - 1 \end{smallmatrix} ] } [ w ( A ) + w _ { 1 } \geq q ] \leq \left ( 1 - \frac { 2 } { n } \right ) \cdot o \left ( \frac { n } { n - \ell } \right ) + \frac { 2 } { n } \cdot 1 = o ( 1 ),$$
using glyph[lscript] = (log o n ) . Lemma 4.2 therefore shows that
$$\mathbb { E } [ \varphi _ { 1 } ] \leq \frac { 1 } { 2 ( n - \ell ) } + o \left ( \frac { 1 } { n - \ell } \right ) + O \left ( \frac { 1 } { n ^ { 2 } } \right ) = \frac { 1 } { 2 n } + o \left ( \frac { 1 } { n } \right ),$$
since glyph[lscript] = (log o n ) implies 1 n -glyph[lscript] = 1 n + glyph[lscript] n n ( -glyph[lscript] ) = 1 n + ( o 1 n ) . Lemma 4.2 also implies a matching lower bound:
$$\mathbb { E } [ \varphi _ { 1 } ] \geq \frac { 1 } { 2 ( n - \ell ) } - \frac { \ell } { n ( n - \ell ) } - O \left ( \frac { 1 } { n ^ { 2 } } \right ) \geq \frac { 1 } { 2 n } - o \left ( \frac { 1 } { n } \right ).$$
In the regime of glyph[lscript] addressed by Theorem 4.2, Pr A ∈ R [ N \{ } 1 glyph[lscript] -1 ] [ w A ( ) + w 1 ≥ q ] was negligible. In contrast, in the regime of glyph[lscript] addressed by Theorem 4.3, Pr A ∈ R [ N \{ } 1 glyph[lscript] -1 ] [ w A ( )+ w 1 ≥ q ] ≈ 1 / 2 , as the following lemma, which is proved in the appendix using the Berry-Esseen theorem, shows.
Lemma 4.4 Suppose q = glyph[lscript] m n for an integer glyph[lscript] satisfying γ ≤ glyph[lscript] -1 n ≤ 1 -γ , and let
$$t _ { \varepsilon } = \Pr _ { A \in _ { R } [ \substack { N \times ( 1 ) \\ \ell - 1 } ] } \left [ w ( A ) + w _ { 1 } \geq q \colon w _ { 1 } = \frac { m } { n } - \varepsilon \sqrt { \frac { m \log n } { n } } \right ].$$
Then for m ≥ 4 n 3 ,
$$t _ { \varepsilon } \geq \frac { 1 } { 2 } - \frac { \varepsilon } { 2 \pi \gamma } \sqrt { \frac { \log n } { n } } - \frac { 1 } { n }.$$
As Lemma 4.3 shows, 1 / 3 ≤ ε ≤ 4 with probability 1 -2 /n , which explains the usefulness of this bound. We can now prove Theorem 4.3.
Proof (of Theorem 4.3). Lemma 4.3 shows that with probability 1 -2 /n w , 1 = m n -ε √ m log n n for some 1 / 3 ≤ ε ≤ 4 , in which regime Lemma 4.4 shows that t ε ≥ 1 2 -2 πγ √ log n n -1 n . Accounting for the case in which ε is out of bounds,
$$\Pr _ { A \in _ { R } [ ^ { N \times ( 1 ) } _ { \ell - 1 } ] } [ w ( A ) + w _ { 1 } \geq q ] \geq \left ( 1 - \frac { 2 } { n } \right ) \left ( \frac { 1 } { 2 } - \frac { 2 } { \pi \gamma } \sqrt { \frac { \log n } { n } } - \frac { 1 } { n } \right ) \geq \frac { 1 } { 2 } - \frac { 2 } { \pi \gamma } \sqrt { \frac { \log n } { n } } - \frac { 3 } { n }.$$
Substituting this in Lemma 4.2, we obtain
$$& \stackrel { \text{-\dots} } { \mathbb { E } } [ \varphi _ { 1 } ] \geq \frac { 1 } { 2 ( n - \ell ) } - \frac { \ell } { n ( n - \ell ) } + \frac { 1 } { n - \ell } \left ( \frac { 1 } { 2 } - \frac { 2 } { \pi \gamma } \sqrt { \frac { \log n } { n } } - \frac { 3 } { n } \right ) - O \left ( \frac { 1 } { n ^ { 2 } } \right ) \\ & \quad = \frac { 1 } { n - \ell } - \frac { \ell } { n ( n - \ell ) } - \frac { 1 } { n - \ell } O _ { \gamma } \left ( \sqrt { \frac { \log n } { n } } \right ) - O \left ( \frac { 1 } { n ^ { 2 } } \right ) = \frac { 1 } { n } - O _ { \gamma } \left ( \sqrt { \frac { \log n } { n ^ { 3 } } } \right ).$$
## 5 The Balls and Bins Distribution: the Exponential Case
In Section 4, we show that even when the distribution is not inherently biased towards any agent, substantial inequalities may arise due to random noise. We now turn to study the case in which the distribution is strongly biased. Returning to our formal definition of the general balls and bins process, we assume that the probabilities in the vector p are ordered in increasing order and p i p i +1 = ρ , for some ρ < 1 / 2 . We observe that as m approaches ∞ , the weight vector follows a power law with probability 1 , where for each i = 1 , . . . , n -1 , w i w i +1 = ρ . A closely related family of weight vectors that we will refer to is the family of super-increasing weight vectors:
Definition 5.1. A series of positive weights w = ( w , . . . , w 1 n ) is said to be superincreasing (SI) if for every i = 1 , . . . , n , ∑ i -1 j =1 w < w j i .
The following three results (Lemma 5.1, Lemma 5.2 and Theorem 5.1) show that for a sufficiently large value of m , estimating the Shapley values in WVGs where the weights are sampled from an exponential distribution can be reduced to the study of Shapley values in a game with a prescribed (fixed) SI weight vector; Section 6 studies power distribution in WVGs with SI weights. The following lemma gives a characterization of the necessary size of the voter population, so as to make the weight vector super-increasing, if the voters vote according to the above exponential distribution.
Lemma 5.1 Assume that m voters submit the votes according to the exponential distribution over candidates, such that for ρ ∈ (0 , 1 2 ) , and the probability that voter j votes for candidate i is proportional to ρ n -i . There is a constant C > 0 such that if m ≥ Cρ -n (2 ρ -1) -2 log n then the resulting weight vector is super-increasing with probability 1 -O ( 1 n ) . Furthermore, as m →∞ , the probability approaches 1 .
The proof of the lemma uses a standard concentration bound (see Appendix B). Before we proceed, it would be helpful to provide some intuition about the behavior of the Shapley values. Assuming that agent weights are given by an n -length (increasing) sequence w of real-values, consider the set of all distinct subset sums of the weights S ( w ) = { s : ∃ P ⊆ [ n ] s.t. s = ∑ i ∈ P w n +1 -i } (we use w n +1 -i instead of w i to make some formulas below nicer). Furthermore, suppose that the subset sums are ordered in increasing order; i.e., S ( w ) = { s j } t j =1 , such that s j < s j +1 for 1 ≤ j < t . It is easy to show, using the definition of the Shapley value, that for any quota q ∈ ( s , s j j +1 ] , for 1 ≤ j < t , the Shapley values of every agent i ∈ N remain constant at some value ϕ i ( j ) , defined for the j 'th interval. We formalize this intuition in Section 6, where we give a formula for ϕ i ( j ) .
glyph[negationslash]
Before we state the formula (Proposition 5.2 below), we need some notation. For each P ⊆ N , let ˜( w P ) = ∑ i ∈ P w n +1 -i . For some j , ˜( w P ) = s j , where s j ∈ S . If P = N then j < t and so s j +1 = ˜( w P + ) for some P + ⊆ N . Write I w P = ( ˜( w P ,w P ) ˜( + )] . Then by definition, the intervals I w P partition the interval (0 , w ( N )] . We can now state the formula for ϕ i ( j ) . Given a weight vector w , let ϕ w i ( q ) denote the Shapley value of player i when the quota is q and the weights are given by w .
Proposition 5.2. Suppose that w = ( w , . . . , w 1 n ) is a SI sequence of weights, and suppose that q ∈ (0 , w ( N )] , say q ∈ I w P for some P ⊆ N . Write P = { j 0 , . . . , j r } in increasing order. If i / P ∈ then ϕ w n +1 -i ( q ) = ∑ t ∈{ 0 ,...,r } : j t >i 1 j t ( j t -1 t ) . If i ∈ P , say i = j s , then ϕ w n +1 -i ( q ) = 1 j s ( j s -1 s ) -∑ t ∈{ 0 ,...,r } : j t >i 1 j t ( j t -1 t -1 ) .
Suppose that w is generated using a Balls and Bins process with probabilities p , where p is a SI sequence; then it stands to reason that if a sufficiently large number of balls is tossed (i.e., m is large enough), then voting power distribution under w will be very close to power distribution under the weight vector p . This intuition is captured in the following lemma, which is proved in the appendix.
Lemma 5.2 Suppose that p = ( p , . . . , p 1 n ) is a SI sequence summing to 1 , and let w , . . . , w 1 n be obtained by sampling m times from the distribution p , . . . , p 1 n .
Suppose that T ∈ (0 1] , , say T ∈ I p ( P ) for some P ⊆ { 1 , . . . , n } . If the distance of T from the endpoints ˜( p P ) , p ˜( P + ) of I p ( P ) is at least ∆ = √ log( nm /m ) then with probability 1 -2 ( nm ) 2 it holds that if w is SI then for all i ∈ N ϕ , w i ( mT ) = ϕ p i ( T ) .
Combining both lemmas, we obtain our main result on the exponential case of the Balls and Bins distribution.
Theorem 5.1. Assume that m voters submit the votes according to the exponential distribution over candidates, such that for ρ ∈ (0 , 1 2 ) , and the probability that voter j votes for candidate i is proportional to ρ n -i . Assume further that m ≥ Cρ -n (2 ρ -1) -2 log n , where C > 0 is some global constant.
Suppose that T ∈ (0 1] , , say T ∈ I p ( P ) for some P ⊆ { 1 , . . . , n } . If the distance of T from the endpoints ˜( p P ) , p ˜( P + ) of I p ( P ) is at least ∆ = √ log( nm /m ) then with probability 1 -O (1 /n ) it holds that for all i ∈ { 1 , . . . , n } , ϕ w i ( mT ) = ϕ p i ( T ) .
Furthermore, for all but finitely many values of T ∈ (0 , 1] , the probability that ϕ w i ( mT ) = ϕ p i ( T ) tends to 1 as m →∞ .
Proof. Lemma 5.1 gives a constant C > 0 such that if m ≥ Cρ -n (2 ρ -1) -2 log n then w is SI with probability 1 -O (1 /n ) . Hence the first part of the theorem follows from Lemma 5.2.
For the second part, Lemma 5.1 shows that as m →∞ , the probability that w is SI approaches 1 . Suppose now that T is not of the form ˜( p P ) (these are the finitely many exceptions). When m is large enough, the conditions of Lemma 5.2 are satisfied, and so as m → ∞ , the error probability in that lemma goes to 0 . The second part of the theorem follows. glyph[intersectionsq] glyph[unionsq]
The theorem shows that in the case of the exponential distribution, if the number of balls is large enough then we can calculate with high probability the Shapley values of the resulting distribution based on the Shapley values of the original exponential distribution (without sampling). It therefore behooves us to study the Shapley values of an exponential distribution, or indeed any SI sequence.
## 6 Super-increasing sequences
In Section 5, we have shown that when the number of voters is large, studying the distribution of Shapley values when weights are drawn from an exponential balls and bins distribution boils down to the study of the Shapley values where weights are superincreasing. This section constitutes a thorough analysis of power distribution when weights are super-increasing; in particular, we provide strong generalizations of the results by [20] and [12].
Up to this point, we assumed that the weights are arranged in non-decreasing order. In order to simplify our formulas, we will somewhat abuse our definitions by assuming that the weights are rather ordered in non-increasing order, w 1 > w 2 > · · · > w n > 0 . We also assume that w is a super-increasing sequence; that is, a sequence satisfying w > i ∑ n j = +1 i w j for all i ∈ N .
When considering different weight vectors, we will use ϕ w i ( q ) for the Shapley value of agent i under weight vector w and quota q .
## 6.1 Reducing super-increasing weight vectors to the case of a power law of 2
While not every quota in the range (0 , w ( N )] can be expanded as a sum of members of { w , . . . , w 1 n } , there are certain naturally defined intervals that partition (0 , w ( N )] . For a subset C ⊆ N , define β C ( ) = ∑ i ∈ C 2 n -i . Intuitively, we think of β C ( ) as the value resulting from the binary characteristic vector of the set of agents C . The purpose of the following two lemmas is to reduce every super-increasing weight vector to the case where the weights obey a power-law distribution, with a power of 2 .
$$\text{Lemma} \, 6. 1 \, \text{ Let } C _ { 1 }, C _ { 2 } \subseteq N. \, \text{ Then } \beta ( C _ { 1 } ) < \beta ( C _ { 2 } ) \, \text{if and only if } w ( C _ { 1 } ) < w ( C _ { 2 } ).$$
Proof. In order to prove the claim, it suffices to observe adjacent sets C , C 1 2 ⊆ N , i.e., ones satisfying β C ( 2 ) = β C ( 1 ) + 1 . Let glyph[lscript] = max( N \ C 1 ) , and define C = C 1 ∩ { 1 , . . . , glyph[lscript] - } 1 . Then C 1 = C ∪ { glyph[lscript] + 1 , . . . , n } and C 2 = C ∪ { } glyph[lscript] . Therefore w C ( 2 ) -w C ( 1 ) = w glyph[lscript] -w ( { glyph[lscript] +1 , . . . , n } ) > 0 , since w , . . . , w 1 n is super-increasing. glyph[intersectionsq] glyph[unionsq]
For a non-empty set of agents C ⊆ N , we let P -⊆ N be the unique subset of agents satisfying β P ( -) = β P ( ) -1 . Lemma 6.1 shows that every quota q ∈ (0 , w ( N )] belongs to a unique interval ( w P ( -) , w ( P )] ; we denote P by A q ( ) . We think of A q ( ) as an increasing sequence a , . . . , a 0 r depending on q , for some value of r which also depends on q . Whenever we write P = { a , . . . , a 0 r } , we will always assume that a 0 < · · · < a r .
Lemma 6.2 For all agents i ∈ N and quotas q ∈ (0 , w ( N )] , ϕ w i ( q ) = ϕ b i ( β A q ( ( ))) , where b = (2 n -1 , . . . , 1) .
Proof. Let σ be a random permutation in Sym n , and recall that P i ( σ ) is the set of agents appearing before agent i in σ . The Shapley value ϕ w i ( q ) is the probability that w P ( i ( σ )) ∈ [ q -w , q i ) , or equivalently, that q ∈ ( w P ( i ( σ )) , w ( P i ( σ )) + w i ] . Since the intervals ( w C ( -) , w ( C )] partition (0 , w ( N )] , q is in ( w P ( i ( σ )) , w ( P i ( σ )) + w i ] if and only if w P ( i ( σ )) ≤ w A q ( ( ) -) and w A q ( ( )) ≤ w P ( i ( σ ) ∪{ } i ) . Lemma 6.1 shows that this is equivalent to checking whether β P ( i ( σ )) ≤ β A q ( ( ) -) and β A q ( ( )) ≤ β P ( i ( σ ) ∪ { } i ) . Now, note that β A q ( ( ) -) = β A q ( ( )) -1 , so the above condition simply states that i is pivotal for σ under b when the quota is β A q ( ( )) . glyph[intersectionsq] glyph[unionsq]
Lemma 6.2 implies that for any super-increasing w , if we wish to compute ϕ w i ( q ) , it is only necessary to find A q ( ) . However, finding A q ( ) is easy; a greedy algorithm can find A q ( ) in linear time (see Appendix C.1). In the special case in which w i = d n -i for some integer d , there is a particularly simple formula described in Appendix C.2.
We now present a closed-form formula for the Shapley values, whose proof is given in the appendix. The resulting Shapley values are illustrated in Figure 1.
$$& \text{Theorem $6.1$. $ Consider an agent $i\in N$ and $a$ prescribed quota value $q\in (0,w(N)$].} \\ & \text{Let $A(q) = \{a_{0},\dots,a_{r} \}$. $If $i\notin A(q)$ then $\varphi_{i}(q)=\sum_{t\in \{0,\dots,r\} \colon \frac{1}{a_{t\{a_{t-1}}\}}$. $If $i\in A(q),} \\ & \text{say $i=a_{s}$, then $\varphi_{i}(q)=\frac{1}{a_{s}\{a_{s}-1\}$} \, - \sum_{t\in \{0,\dots,r\} \colon \frac{1}{a_{t\{a_{t-1}}\}$}.}$$
(c) Shapley values for n = 5 , w i = 2 -i . Values ϕ i ( q ) for different i are slightly nudged to show the effects of Lemma 6.3.
(d) Shapley values ϕ 1 ( q ) for n = 5 , w i = 2 -i compared to the limiting case n = ∞ .
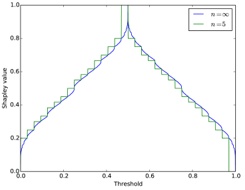
(e) Shapley values in the limiting case, w i = 2 -i .
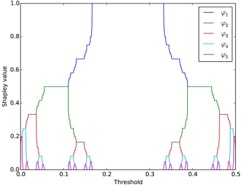
(f) Shapley values in the limiting case, w i = 3 -i .
Fig. 1: Examples of several Shapley values corresponding to super-increasing sequences.
## 6.2 Properties of the Shapley values
Zuckerman et al. [12] provide a nice characterization of super-increasing sets:
Theorem 6.2 ([12]). If the weights w are super-increasing then for every quota q ∈ (0 , w ( N )] , either ϕ 1 ( q ) = ϕ 2 ( q ) or ϕ 2 ( q ) = ϕ 3 ( q ) .
In this section, we further generalize this result, using Theorem 6.1. Specifically, as a consequence of the theorem, we can determine in which cases ϕ i ( q ) = ϕ i +1 ( q ) . The results are summarized in the following lemma, which is proved in the appendix. Given a set S ⊆ N , let Ψ i ( S ) be the indicator variable of i ∈ S ; that is, Ψ i ( S ) = 1 if i ∈ S , and is 0 otherwise.
Lemma 6.3 Given a quota q ∈ (0 , w ( N )] , let A q ( ) = { a , . . . , a 0 r } . For each i ∈ N \ { n } , if Ψ i ( A q ( )) = Ψ i +1 ( A q ( )) then ϕ i ( q ) = ϕ i +1 ( q ) . If Ψ i ( A q ( )) = 0 and Ψ i +1 ( A q ( )) = 1 then ϕ i ( q ) ≥ ϕ i +1 ( q ) , with equality if and only if i + 1 = a r . If Ψ i ( A q ( )) = 1 and Ψ i +1 ( A q ( )) = 0 then ϕ i ( q ) > ϕ i +1 ( q ) .
For each i ∈ N , let Ψ i be the truth value of i ∈ A q ( ) . Lemma 6.3 shows that if Ψ i = Ψ i +1 then ϕ i ( q ) = ϕ i +1 ( q ) . Since there are only two possible truth values, for
each i ∈ N \ { 1 , n } , either ϕ i -1 ( q ) = ϕ i ( q ) or ϕ i ( q ) = ϕ i +1 ( q ) . This generalizes Theorem 6.2.
Since the Shapley values are constant in the interval ( w P ( -) , w ( P )] , it follows that in order to analyze the behavior of ϕ i ( q ) , one need only determine the rate of increase or decrease at quotas of the form w P ( ) for P ⊆ N . These are given by the following lemma, proved in the appendix.
Lemma 6.4 Let P ⊆ N be a non-empty set of agents, and let i ∈ N be an agent. If i / P ∈ -then ϕ i ( w P ( -)) < ϕ i ( w P ( )) . If i ∈ P -then ϕ i ( w P ( -)) > ϕ i ( w P ( )) .
Moreover, | ϕ i ( w P ( )) -ϕ i ( w P ( -)) | ≤ 1 n ; this inequality is tight only if a ) P = { n } . b ) i < n and P = { 1 , . . . , i } or P = { i, n } , or c ) i = n and P = { n -1 } . Otherwise, | ϕ i ( w P ( )) -ϕ i ( w P ( -)) | ≤ 1 n n ( -1) .
## 6.3 Limiting case
In what follows, we briefly discuss some interesting properties of the Shapley value for weight vectors that are finite prefixes of an infinite super-increasing sequence. The full details can be found in Appendix C.6. Section 6.2 shows that the Shapley value be easily expressed and analyzed when weights are super-increasing. It is in fact useful to think of classes of super-increasing weights that are finite prefixes of an infinite superincreasing sequence; one example of such a sequence is ( 2 -i ) ∞ i =0 . Given an infinite super-increasing weight sequence w , we refer to the first m elements of w as w | m . Given an infinite super-increasing sequence w , we can use the closed-form formula we define for the Shapley value in the finite case in order to derive a value for the infinite case. We can then define a value for agent i under an infinite sequence w : ϕ w i ( q ) . We show that the two formulas are closely related; one can derive ϕ w | m i ( q ) using ϕ w i ( q ) (the connection is illustrated in Figure 1); moreover, we show that ϕ w i ( q ) is continuous in q , and that it takes values of 0 when q approaches 0, and when q approaches ∑ ∞ i =0 w i .
## 7 Conclusions and Future Work
We have studied the Shapley value as a function of the quota under a number of natural weight distributions. Assuming that weights are drawn from balls and bins distributions allows us to reason rigourously about the effect of quota changes. We were also able to completely characterize the case where weights are super-increasing, strongly generalizing previous work. The take-home message from our work is that changes to the quota matter, even when weights are nearly identical. Given the relative success of this analysis, it would be interesting to study other natural weight distributions (the case of i.i.d. bounded weights is studied in an extended version of this paper [25]). Moreover, our results show that employing probabilistic approaches to cooperative games (beyond the case of WVGs) may be a useful research avenue.
## Bibliography
- [1] Mann, I., Shapley, L.: Values of large games IV : Evaluating the electoral college by montecarlo techniques. Technical report, The RAND Corporation (1960)
- [2] Mann, I., Shapley, L.: Values of large games VI : Evaluating the electoral college exactly. Technical report, The RAND Corporation (1962)
- [3] Leech, D.: Designing the voting system for the council of the european union. Public Choice 113 (2002) 437-464 10.1023/A:1020877015060.
- [4] Słomczy´ nski, W., Zyczkowski, K.: Penrose voting system and optimal quota. Acta ˙ Physica Polonica B 37 (11) (2006) 3133-3143
- [5] Felsenthal, D.S., Machover, M.: The Measurement of Voting Power: Theory and Practice, Problems and Paradoxes. Edward Elgar Publishing (November 1998)
- [6] Shapley, L.: A value for n -person games. In: Contributions to the Theory of Games, vol. 2. Annals of Mathematics Studies, no. 28. Princeton University Press, Princeton, N. J. (1953) 307-317
- [7] Penrose, L.: The elementary statistics of majority voting. Journal of the Royal Statistical Society 109 (1) (1946) 53-57
- [8] Leech, D., Machover, M.: Qualified majority voting: the effect of the quota. LSE Research Online (2003)
- [9] Mitzenmacher, M., Richa, A.W., Sitaraman, R.: The power of two random choices: A survey of techniques and results. In: in Handbook of Randomized Computing, Kluwer (2000) 255-312
- [10] Mitzenmacher, M., Upfal, E.: Probability and computing - randomized algorithms and probabilistic analysis. Cambridge University Press (2005)
- [11] Raab, M., Steger, A.: Balls into bins: A simple and tight analysis. In Luby, M., Rolim, J., Serna, M., eds.: Randomization and Approximation Techniques in Computer Science. Volume 1518 of Lecture Notes in Computer Science. Springer Berlin Heidelberg (1998) 159-170
- [12] Zuckerman, M., Faliszewski, P., Bachrach, Y., Elkind, E.: Manipulating the quota in weighted voting games. Artificial Intelligence 180-181 (2012) 1-19
- [13] Banzhaf, J.: Weighted voting doesn't work: a mathematical analysis. Rutgers Law Review 19 (1964) 317
- [14] Shapley, L., Shubik, M.: A method for evaluating the distribution of power in a committee system. The American Political Science Review 48 (3) (1954) 787-792
- [15] Maschler, M., Solan, E., Zamir, S.: Game Theory. Cambridge Unversity Press (2013)
- [16] Peleg, B., Sudh¨ olter, P.: Introduction to the Theory of Cooperative Games. Second edn. Volume 34 of Theory and Decision Library. Series C: Game Theory, Mathematical Programming and Operations Research. Springer, Berlin (2007)
- [17] Chalkiadakis, G., Elkind, E., Wooldridge, M.: Computational Aspects of Cooperative Game Theory. Morgan and Claypool (2011)
- [18] Bachrach, Y., Markakis, E., Resnick, E., Procaccia, A., Rosenschein, J., Saberi, A.: Approximating power indices: theoretical and empirical analysis. Autonomous Agents and Multi-Agent Systems 20 (2) (2010) 105-122
| 16 | Joel Oren, Yuval Filmus, Yair Zick, and Yoram Bachrach |
|------|--------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------|
| [19] | Fatima, S., Wooldridge, M., Jennings, N.: A linear approximation method for the shapley value. Artificial Intelligence 172 (14) (2008) 1673-1699 |
| [20] | Zick, Y., Skopalik, A., Elkind, E.: The shapley value as a function of the quota in weighted voting games. In: Proceedings of the Twenty-Second International Joint Conference on Artificial Intelligence (IJCAI-11). (2011) 490-495 |
| [21] | Zick, Y.: On random quotas and proportional representation in weighted voting games. In: Proceedings of the 23rd International Joint Conference on Artificial Intelligence (IJCAI-13). (2013) 432-438 |
| [22] | Felsenthal, D., Machover, M.: Voting power measurement: a story of misreinven- tion. Social choice and welfare 25 (2) (2005) 485-506 |
| [23] | Lindner, I.: Power measures in large weighted voting games. PhD thesis, Univ. of Hamburg (2004) |
| [24] | Tauman, Y., Jelnov, A.: Voting power and proportional representation of voters. Dept. of Econs. Working Papers 12-04, Stony Brook Univ. (2012) |
| [25] | Oren, J., Filmus, Y., Zick, Y., Bachrach, Y.: On the effects of priors in weighted voting games. In: Proceedings of the 5th International Workshop on Computa- tional Social Choice (COMSOC'14). (2014) |
Appendix
## A Missing Proofs from Section 4
## A.1 Proof of Lemma 4.1
We now provide the complete proof of Lemma 4.1
Lemma 4.1 For all agents i, j ∈ N ,
$$| \varphi _ { j } - \varphi _ { i } | = \frac { 1 } { n - 1 } \sum _ { \ell = 0 } ^ { n - 2 } \Pr _ { S \in R [ \stackrel { N \langle i, j \rangle } { \ell } ] } [ q - \max ( w _ { i }, w _ { j } ) \leq w ( S ) < q - \min ( w _ { i }, w _ { j } ) ].$$
Proof. Assume without loss of generality that w j ≥ w i , and so ϕ j ≥ ϕ i . For σ ∈ Sym n , let T ij ( σ ) be the permutation obtained by exchanging agents i and j . Then by the definition of the Shapley value and by linearity of expectations:
$$\varphi _ { j } - \varphi _ { i } & = \underset { \sigma \in \text{Sym} _ { n } } { \mathbb { E } } ( m _ { j } ( \sigma ) - m _ { i } ( \sigma ) ) \\ & = \underset { \sigma \in \text{Sym} _ { n } } { \mathbb { E } } m _ { j } ( \sigma ) - \underset { \sigma \in \text{Sym} _ { n } } { \mathbb { E } } m _ { i } ( \sigma ) = \underset { \sigma \in \text{Sym} _ { n } } { \mathbb { E } } ( m _ { j } ( T _ { i j } ( \sigma ) ) - m _ { i } ( \sigma ) ).$$
glyph[negationslash]
We proceed to evaluate m T j ( ij ( σ )) -m σ i ( ) . Suppose first that agent i precedes agent j in σ , so that σ = S i R j U and T ij ( σ ) = S j R i U (where S, R , and U form a partition of N \ { i, j } ). In this case m T j ( ij ( σ )) -m σ i ( ) = 0 precisely when w S ( ) + w < q i ≤ w S ( ) + w j , in which case m T j ( ij ( σ )) -m σ i ( ) = 1 ; we can rewrite the condition as w S ( ) ∈ [ q -w , q j -w i ) .
glyph[negationslash]
When agent j precedes agent i in σ , we can write σ = S j R i U and T ij ( σ ) = S i R j U . In this case m T j ( ij ( σ )) -m σ i ( ) = 0 precisely when w S ( ) + w i + w R ( ) < q ≤ w S ( ) + w j + w R ( ) , in which case m T j ( ij ( σ )) -m σ i ( ) = 1 ; we can rewrite the condition as w S ( ∪ R ) ∈ [ q -w , q j -w i ) .
In order to unify both conditions together, define P ′ i ( σ ) = P i ( σ ) \ { j } . Using this definition, we see that m T j ( ij ( σ )) -m σ i ( ) is the indicator of the event w P ( ′ i ( σ )) ∈ [ q -w , q j -w i ) . The cardinality | P ′ i ( σ ) | is exactly the position of agent i in the permutation σ ′ obtained by removing agent j from σ , minus one. Since σ is a uniformly random permutation of N σ , ′ is a uniformly random permutation of N \ { j } , and so | P ′ i ( σ ) | is distributed randomly among { 0 , . . . , n - } 2 . Given | P ′ i ( σ ) | , the set P i ( σ ) is chosen randomly among all subsets of N \ { i, j } of the specified size, yielding our formula.
## A.2 Proof of Theorem 4.1
We give the full proof of the following theorem.
Theorem 4.1. Let M = m 3 n 3 . Suppose that | q -glyph[lscript]m n | > 1 √ M n m for all integers glyph[lscript] . Then with probability 1 -2( 2 e ) n , all Shapley values are equal to 1 /n .
In this section, we do not assume that the weights w , . . . , w 1 n are ordered, in order to maintain the fact that the weights are independent random variables.
The idea of the proof is to use the following criterion, which is a consequence of Lemma 4.1:
Proposition A.1. Suppose that for all agents i, j ∈ N and for all subsets S ⊆ N \ { i, j } , we have q / ∈ ( w S ( ∪ { } i ) , w ( S ∪ { } j )] . Then all Shapley values are equal to 1 /n .
glyph[negationslash]
Proof. We show that under the assumption on q , all Shapley values are equal, and so all must equal 1 /n . Suppose that for some agents i = j , we have ϕ i < ϕ j (and so w < w i j ). Lemma 4.1 implies the existence of a set S ⊆ N \{ i, j } satisfying q -w j ≤ w S ( ) < q -w i , or in other words w S ( ) + w < q i ≤ w S ( ) + w j . This is exactly what is ruled out by the assumption on q .
Next, we show that the weights w S ( ) are concentrated around points of the form glyph[lscript] m n .
Lemma A.1 Suppose that m > 3 n 2 . With probability 1 -2( 2 e ) n , the following holds: for all S ⊆ N , | w S ( ) -| S m | n | ≤ √ 3 nm .
glyph[negationslash]
Proof. The proof uses a straightforward Chernoff bound. We can assume that S = ∅ (as otherwise the bound is trivial). For each non-empty set S ⊆ N , the distribution of w S ( ) is B( m, | S | n ) . Therefore for 0 < δ < 1 ,
$$\Pr \left [ \left | w ( S ) - \frac { | S | m } { n } \right | > \delta \frac { | S | m } { n } \right ] \leq 2 e ^ { - \frac { \delta ^ { 2 } | S | m } { 3 n } }.$$
Choosing δ = √ 3 n 2 | S m | < 1 , we obtain
$$\Pr \left [ \left | w ( S ) - \frac { | S | m } { n } \right | > \sqrt { 3 | S | m } \right ] \leq 2 e ^ { - n }.$$
Since there are 2 n possible sets S , a union bound implies that | w S ( ) -| S m | n | ≤ √ 3 nm with probability at least 1 -2( 2 e ) n .
This immediately implies Theorem 4.1, as we now show.
Proof (of Theorem 4.1). First, note that M < 1 , as otherwise, it would imply that for all glyph[lscript] = 1 , . . . , n , | q -glyph[lscript]m/n | ≥ m/n , which is impossible, as every quota in the range (0 , m ] is within some integral multiple of m/n . Thus, having M > 1 , implies that m> n 3 3 ≥ 3 n 2 , as required by Lemma A.1.
Lemma A.1 shows that with probability 1 -2( 2 e ) n , for all sets S we have | w S ( ) -| S m | n | ≤ √ 3 nm . Condition on this event. Suppose, for the sake of obtaining a contradiction, that ϕ < ϕ i j for some agents i, j . Then Proposition A.1 shows that there must exist some S ⊆ N \{ √ i, j } such that q ∈ ( w S ( ∪{ } i ) , w ( S ∪{ } j )] . Since both w S ( ∪{ } i ) and w S ( ∪{ } j ) are 3 nm -close to ( | S | +1) m n , this implies that | q -( | S | +1) m n | ≤ √ 3 nm = 1 √ M · m n , contradicting our assumption on q . We conclude that all agents have the same Shapley value 1 /n .
## A.3 Proof of Lemma 4.2
We prove the following lemma.
Lemma 4.2 Let q = glyph[lscript] · m n , where glyph[lscript] ∈ { 1 , . . . , n - } 1 . For m = Ω n ( 3 log n ) ,
$$\mathbb { E } [ \varphi _ { 1 } ] = \frac { 1 } { 2 ( n - \ell ) } - \frac { \ell } { n ( n - \ell ) } + \frac { 1 } { n - \ell } \Pr _ { A \in \L _ { R } \left [ ^ { N \times ( 1 ) } _ { \ell - 1 } \right ] } [ w ( A ) + w _ { 1 } \geq q ] \pm O \left ( \frac { 1 } { n ^ { 2 } } \right ).$$
The proof closely follows the proof sketch in Section 4.1.
We will need the fact that with high probability, w 1 is close to m/n .
Lemma A.2 With probability at least 1 -1 /n ,
$$\frac { m } { n } - \sqrt { \frac { 4 m \log n } { n } } \leq w _ { 1 } \leq \frac { m } { n }.$$
Proof. Clearly w 1 ≤ m/n always, so we only need to address the lower bound on w 1 . Let w , . . . , w ′ 1 ′ n be the loads of the bins before sorting them. The loads w ′ i are independent random variables with distribution B( m, 1 /n ) . For each index i , Chernoff's bound shows that
$$\text{ra} \, \text{Pr} \left [ w _ { i } ^ { \prime } < \frac { m } { n } - \sqrt { \frac { 4 m \log n } { n } } \right ] \leq e ^ { - \frac { 4 m \log n / n } { 2 m / n } } = \frac { 1 } { n ^ { 2 } }.$$
A union bound shows that with probability 1 -1 /n , all i ∈ N satisfy w ′ i ≥ m n -√ 4 m log n n , and so w 1 ≥ m n -√ 4 m log n n .
Below we will be interested in bounding probabilities of the form Pr A ∈ R [ N \{ } 1 k ] [ P w A ( ( ))] for predicates P . The following lemma shows how to bound these probabilities from above.
Lemma A.3 For a weight vector w and S ⊆ N , let E ( w S ( )) be a random event (i.e., some predicate on w S ( ) ), and let 0 ≤ k ≤ n -1 . Then
$$\Pr _ { A \in _ { R } [ ^ { N \times ( 1 ) } _ { k } ] } [ \mathcal { E } ( w ( A ) ) ] \leq \frac { n } { n - k } \Pr [ \mathcal { E } ( B ( m, \frac { k } { n } ) ) ].$$
Also,
$$\Pr _ { A \in _ { R } [ _ { k } ^ { N } ] } [ \mathcal { E } ( w ( A ) ) ] = \Pr [ \mathcal { E } ( B ( m, \frac { k } { n } ) ) ].$$
Proof. First, we have
$$\text{First, we have} \\ A \in _ { R } [ ^ { N \underset { k } { \langle 1 \rangle } } ] ^ { \left [ \mathcal { E } ( w ( A ) ) \right ] } & = \frac { 1 } { \binom { n - 1 } { k } } \sum _ { A \in [ ^ { N \underset { k } { \langle 1 \rangle } } ] } \Pr [ \mathcal { E } ( w ( A ) ) ] \\ & \leq \frac { 1 } { \binom { n - 1 } { k } } \sum _ { A \in [ ^ { N } { k } ] } \Pr [ \mathcal { E } ( w ( A ) ) ] \\ & = \frac { n } { n - k } \Pr _ { A \in _ { R } [ ^ { N } { k } ] } [ \mathcal { E } ( w ( A ) ) ].$$
Consider the last expression. Since the probability is over all subsets of N of size k , the same value is obtained from the unsorted Balls and Bins process (without sorting the loads). Under this process, w A ( ) ∼ B( m, k n ) for all A ∈ [ N k ] , and so
$$\Pr _ { A \in _ { R } [ _ { k } ^ { N } ] } [ \mathcal { E } ( w ( A ) ) ] = \Pr _ { w \sim B ( m, \frac { k } { n } ) } [ \mathcal { E } ( w ) ].$$
This implies the lemma.
Let p k = Pr A ∈ R [ N \{ } 1 k ] [ q -w 1 ≤ w A ( ) < q ] , and recall that formula (1) shows that ϕ 1 = 1 n ∑ n -1 k =0 p k . We start by showing that the only non-negligible p k are p glyph[lscript] -1 and p glyph[lscript] , using a Chernoff bound. The idea is that when k ≥ glyph[lscript] +1 , it is highly unlikely that w A ( ) < q , and when k ≤ glyph[lscript] -1 , it is highly unlikely that w A ( ) ≥ q -w 1 .
Lemma A.4 Suppose that m ≥ 9 n 2 log n . Then for k ∈ { 1 , . . . , n } \ { glyph[lscript] -1 , glyph[lscript] } we have p k ≤ 1 /n 2 , and so
$$0 \leq \mathbb { E } [ \varphi _ { 1 } ] - \frac { p _ { \ell - 1 } + p _ { \ell } } { n } \leq \frac { 1 } { n ^ { 2 } }.$$
Proof. Let k ∈ N . Lemma A.3 shows that
$$p _ { k } \leq n \Pr [ q - w _ { 1 } \leq B ( m, \frac { k } { n } ) < q ].$$
Suppose first that k ≥ glyph[lscript] +1 . Chernoff's bound shows that
$$\Pr [ q - w _ { 1 } \leq B ( m, \frac { k } { n } ) < q ] \leq \Pr [ B ( m, \frac { k } { n } ) < \frac { k m } { n } - \frac { m } { n } ] \leq e ^ { - \frac { ( m / n ) ^ { 2 } } { 3 k m / n } } = e ^ { - m / ( 3 n k ) } \leq \frac { 1 } { n ^ { 3 } }.$$
Suppose next that k ≤ -glyph[lscript] 2 . Since w 1 ≤ m/n , another application of Chernoff's bound gives
$$\Pr [ q - w _ { 1 } \leq B ( m, \frac { k } { n } ) < q ] & \leq \Pr [ B ( m, \frac { k } { n } ) \geq \frac { ( \ell - 1 ) m } { n } ] \\ & \leq \Pr [ B ( m, \frac { k } { n } ) \geq \frac { k m } { n } + \frac { m } { n } ] \\ & \leq e ^ { - \frac { ( m / n ) ^ { 2 } } { 3 k m / n } } = e ^ { - m / ( 3 n k ) } \leq \frac { 1 } { n ^ { 3 } }. \\ _ { \cdot }$$
Therefore p k ≤ 1 /n 2 for all k ∈ N \ { glyph[lscript] -1 , glyph[lscript] } . The estimate for E [ ϕ 1 ] follows from formula (1).
The next step is to consider the following estimates for p glyph[lscript] -1 , p glyph[lscript] :
$$p _ { \ell - 1 } ^ { \prime } & = \Pr _ { A \in _ { R } \binom { N \cup \{ 1 \} } { \ell - 1 } } [ q - w _ { 1 } \leq w ( A ) ], \\ p _ { \ell } ^ { \prime } & = \Pr _ { A \in _ { R } \binom { N \cup \{ 1 \} } { \ell } } [ w ( A ) < q ].$$
The following lemma shows that p ′ glyph[lscript] -1 ≈ p glyph[lscript] -1 and p ′ glyph[lscript] ≈ p glyph[lscript] .
Lemma A.5 Suppose that m ≥ 24 n 2 log n . Then p glyph[lscript] -1 ≤ p ′ glyph[lscript] -1 ≤ p glyph[lscript] -1 + 1 n and p glyph[lscript] ≤ p ′ glyph[lscript] ≤ p glyph[lscript] + 2 n , and so
$$- \frac { 3 } { n ^ { 2 } } \leq \mathbb { E } [ \varphi _ { 1 } ] - \frac { p _ { \ell - 1 } ^ { \prime } + p _ { \ell } ^ { \prime } } { n } \leq \frac { 1 } { n ^ { 2 } }.$$
Proof. Clearly p glyph[lscript] -1 ≤ p ′ glyph[lscript] -1 and p glyph[lscript] ≤ p ′ glyph[lscript] . First,
$$p _ { \ell - 1 } ^ { \prime } - p _ { \ell - 1 } \leq \Pr _ { A \in \L _ { R } \binom { N \langle 1 \rangle } { \ell - 1 } } [ w ( A ) \geq q ] \leq n \Pr [ \mathsf B ( m, \frac { \ell - 1 } { n } ) \geq q ],$$
using Lemma A.3. Chernoff's bound shows that
$$\Pr [ B ( m, \frac { \ell - 1 } { n } ) \geq \frac { ( \ell - 1 ) m } { n } + \frac { m } { n } ] \leq e ^ { - \frac { ( m / n ) ^ { 2 } } { 3 ( \ell - 1 ) m / n } } = e ^ { - m / ( 3 n ( \ell - 1 ) ) } \leq \frac { 1 } { n ^ { 2 } }.$$
Similarly,
$$p _ { \ell } ^ { \prime } - p _ { \ell } \leq \Pr _ { A \in \L _ { R } [ \Lambda ^ { N \vee ( 1 ) } _ { \ell } ] } [ w ( A ) < q - w _ { 1 } ] \leq n \Pr [ B ( m, \frac { \ell } { n } ) < q - w _ { 1 } ].$$
Wenowneed the lower bound on w 1 given by Lemma A.2, which holds with probability 1 -1 /n :
$$q - w _ { 1 } \leq \frac { \ell m } { n } - \left ( \frac { m } { n } - \sqrt { \frac { 4 m \log n } { n } } \right ) \leq \frac { \ell m } { n } - \frac { m } { 2 n },$$
the latter inequality following from m ≥ 24 n 2 log n > 16 n log n . Assuming the lower bound on w 1 ,
$$\Pr [ B ( m, \frac { \ell } { n } ) < q - w _ { 1 } ] \leq e ^ { - \frac { ( m / ( 2 n ) ) ^ { 2 } } { 3 ( \ell - 1 ) m / n } } = e ^ { - m / ( 1 2 n ( \ell - 1 ) ) } \leq \frac { 1 } { n ^ { 2 } }.$$
Therefore
$$p _ { \ell } ^ { \prime } - p _ { \ell } \leq \left ( 1 - \frac { 1 } { n } \right ) \cdot \frac { 1 } { n ^ { 2 } } + \frac { 1 } { n } \cdot 1 < \frac { 2 } { n }.$$
The formula for E [ ϕ 1 ] follows from Lemma A.4.
It remains to relate p ′ glyph[lscript] -1 and p ′ glyph[lscript] .
Lemma A.6 Suppose that m ≥ 24 n 3 log n . Then
$$\left | p _ { \ell } ^ { \prime } - \left ( \frac { n } { 2 ( n - \ell ) } - \frac { \ell } { n - \ell } ( 1 - p _ { \ell - 1 } ^ { \prime } ) \right ) \right | \leq \frac { 1 } { n },$$
and so
$$a \, s \upsilon \\ - \frac { 4 } { n ^ { 2 } } \leq \mathbb { E } [ \varphi _ { 1 } ] - \left ( \frac { 1 } { 2 ( n - \ell ) } - \frac { \ell } { n ( n - \ell ) } + \frac { p _ { \ell - 1 } ^ { \prime } } { n - \ell } \right ) \leq \frac { 2 } { n ^ { 2 } }.$$
## Proof. We have
$$\text{Proof} \ \text{We have} \\ p _ { \ell } ^ { \prime } & = \Pr _ { \ell ^ { N } \{ 1 \} } [ w ( A ) < q ] \\ & = \frac { 1 } { \binom { n - 1 } { \ell } } \sum _ { A \in [ N ^ { N } \{ 1 \} } \Pr [ w ( A ) < q ] \\ & = \frac { 1 } { \binom { n - 1 } { \ell } } \sum _ { A \in [ N ^ { N } ] } \Pr [ w ( A ) < q ] - \frac { 1 } { \binom { n - 1 } { \ell } } \sum _ { A \in [ N ^ { N } \ell ^ { - 1 } _ { 1 } ] } \Pr [ w ( A ) + w _ { 1 } < q ] \\ & = \frac { n } { n - \ell } \Pr _ { A \in R [ N ^ { N } ] } \Pr [ w ( A ) < q ] - \frac { \ell } { n - \ell } \left ( 1 - \Pr _ { A \in R [ N ^ { N } \langle 1 \rangle } [ w ( A ) + w _ { 1 } \geq q ] \right ) \\ & = \frac { n } { n - \ell } \Pr [ B ( m, \frac { \ell } { n } ) < q ] - \frac { \ell } { n - \ell } ( 1 - p _ { \ell - 1 } ^ { \prime } ), \\ \text{where the final equality follows from the second part of Lemma A.3. We proceed to} \\ \text{estimate} \Pr [ B ( m, \frac { \ell } { \ell } ) < q ] \, \text{using the Berry-Esseen theorem. The normalized binomial}$$
where the final equality follows from the second part of Lemma A.3. We proceed to estimate Pr[B( m, glyph[lscript] n ) < q ] using the Berry-Esseen theorem. The normalized binomial B( m, glyph[lscript] n ) -q is a sum of m independent copies of the random variable X with Pr[ X = 1 -glyph[lscript] n ] = glyph[lscript] n and Pr[ X = -glyph[lscript] n ] = 1 -glyph[lscript] n . The Berry-Esseen theorem states that
$$| \Pr [ B ( m, \frac { \ell } { n } ) - q < 0 ] - \Pr [ \mathcal { N } ( 0, \sigma ^ { 2 } ) < 0 ] | < \frac { \rho } { \sigma ^ { 3 } \sqrt { m } },$$
where σ 2 = E [ X 2 ] = glyph[lscript] n (1 -glyph[lscript] n ) 2 + (1 -glyph[lscript] n )( glyph[lscript] n ) 2 = glyph[lscript] n (1 -glyph[lscript] n ) and ρ = E [ | X | 3 ] = glyph[lscript] n (1 -glyph[lscript] n ) 3 +(1 -glyph[lscript] n )( glyph[lscript] n ) 3 = glyph[lscript] n (1 -glyph[lscript] n )[( glyph[lscript] n ) 2 +(1 -glyph[lscript] n ) 2 ] . Since Pr[ N (0 , σ 2 ) < 0] = 1 / 2 , we conclude that
$$\left | \Pr [ B ( m, \frac { \ell } { n } ) - q < 0 ] - \frac { 1 } { 2 } \right | < \frac { 1 } { \sqrt { m } } \frac { ( \frac { \ell } { n } ) ^ { 2 } + ( 1 - \frac { \ell } { n } ) ^ { 2 } } { \sqrt { \frac { \ell } { n } } \left ( 1 - \frac { \ell } { n } \right ) } \leq 2 \sqrt { \frac { n } { m } },$$
since the denominator is at least √ 1 n (1 -1 n ) , and the numerator is at most 2(1 -1 n ) 2 ≤ 2 √ 1 -1 n . Since m ≥ 24 n 3 log n ≥ 4 n 3 , we further have 2 √ n m ≤ 1 n . The formula for E [ ϕ 1 ] follows from Lemma A.5.
Lemma A.6 is simply a reformulation of Lemma 4.2.
## A.4 Proof of Lemma 4.3
Let us recall Lemma 4.3.
$$L e m m a { 4. 3 } \ W i t h p r o b a b i l i t y { 1 - 2 / n, w e h a v e t h a t } \, \sqrt { \frac { m \log n } { 3 n } } \leq \frac { m } { n } - w _ { 1 } \leq \sqrt { \frac { 4 m \log n } { n } }.$$
Wealready proved the upper bound in Lemma A.2, using a simple union bound. The lower bound (corresponding to an upper bound on w 1 ) is much more difficult, because of the dependence between the individual bins. One way to overcome this difficulty is to use the Poisson approximation, given by the following theorem.
Theorem A.1 ([10]). Let w , . . . , w 1 n be sampled according to the Balls and Bins distribution with m balls, and let X ,. . . , X 1 n be n i.i.d. random variables sampled from the distribution Pois( m n ) . Let f : R n → { 0 1 , } be a boolean function over the weight vector, such that the probability p w , . . . , w ( 1 n ) = Pr[ f ( w , . . . , w 1 n ) = 1] is monotonically increasing or decreasing with the number of balls. Then p w , . . . , w ( 1 n ) ≤ 2 p X , . . . , X ( 1 n ) .
The following lemma completes the proof of Lemma 4.3, since calculation shows that for all n ≥ 1 ,
$$\frac { m } { n } \sqrt { \frac { \log ( n / \log ( 2 n ) ) } { m / n } } = \sqrt { \frac { m \log ( n / \log ( 2 n ) ) } { n } } \geq \sqrt { \frac { m \log n } { 3 n } }.$$
(In fact, the minimum of log( n/ log(2 n )) log n is obtained for n = 3 , in which case it is roughly 0 47 . .)
$$\text{Lemma} \, \text{A.7} \, \text{Let} \, \lambda = \frac { m } { n }. \, \text{For any} \, \varepsilon \leq \sqrt { \frac { \log \left ( \frac { n } { \log ( 2 n ) } \right ) } { \lambda } }, \, \text{Pr} [ w _ { 1 } > \lambda ( 1 - \varepsilon ) ] \leq \frac { 1 } { n }.$$
Proof. We define n i.i.d random variables X ,. . . , X 1 n , sampled from the distribution Pois( λ ) . We first derive a concentration bound on min i X i , after which we will make use of Theorem A.1 to obtain the desired result. By the definition of the Poisson distribution, glyph[negationslash]
$$\Pr [ \min _ { i } X _ { i } > t ] = \Pr [ X _ { 1 } > t ] ^ { n } \leq \Pr [ X _ { 1 } \neq t ] ^ { n } \leq \left ( 1 - e ^ { - \lambda } \frac { \lambda ^ { t } } { t! } \right ) ^ { n } \leq \left ( 1 - e ^ { - \lambda } \left ( \frac { e \lambda } { t } \right ) ^ { t } \right ) ^ { n }.$$
The last inequality is due to the fact that t ! ≥ ( t e ) t , by Stirling's approximation. Setting t = (1 -ε λ ) , we get
$$= ( 1 - \varepsilon ) \lambda, \, \text{we get} \\ \Pr [ \min _ { i } X _ { i } > ( 1 - \varepsilon ) \lambda ] & \leq \left ( 1 - e ^ { - \lambda } \left ( \frac { e \lambda } { ( 1 - \varepsilon ) \lambda } \right ) ^ { ( 1 - \varepsilon ) \lambda } \right ) ^ { n } \\ & = \left ( 1 - e ^ { - \lambda } \left ( \frac { e } { 1 - \varepsilon } \right ) ^ { ( 1 - \varepsilon ) \lambda } \right ) ^ { n } \\ & \leq \left ( 1 - e ^ { - \varepsilon \lambda } e ^ { ( 1 - \varepsilon ) \varepsilon \lambda } \right ) ^ { n } \\ & = \left ( 1 - e ^ { - \varepsilon ^ { 2 } \lambda } \right ) ^ { n } \leq e ^ { - n e ^ { - \varepsilon ^ { 2 } \lambda } }. \\ \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \colon \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \end{matrix}$$
The second inequality follows from the inequality 1 1 -x ≥ e x , for | x | < 1 . The third inequality follows from the inequality 1 -x ≤ e -x .
$$\sum _ { \substack { \alpha \cdot \\ \text{Now, for any} } } \varepsilon \leq \sqrt { \frac { \log \left ( \frac { n } { \log ( 2 n ) } \right ) } { \lambda } }, \, \text{we have} } ^ { \quad \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \$$
$$e ^ { - n e ^ { - \epsilon ^ { 2 } \lambda } } \leq e ^ { - n e ^ { - \log \left ( \frac { n } { \log ( 2 n ) } \right ) } } = e ^ { - \log ( 2 n ) } = \frac { 1 } { 2 n }.$$
.
Asimple coupling argument shows that Pr[min i w > i (1 -ε λ ) ] is monotone increasing in the number of balls (here, f ( w , . . . , w 1 n ) is 1 if and only if min i w i > (1 -ε λ ) ). Therefore Theorem A.1 holds, and we have
$$\Pr [ \min _ { i } w _ { i } > ( 1 - \varepsilon ) \lambda ] \leq 2 \Pr [ \min _ { i } X _ { i } > ( 1 - \varepsilon ) \lambda ] \leq \frac { 1 } { n },$$
which concludes the proof.
## A.5 Proof of Lemma 4.4
Lemma 4.4 Suppose q = glyph[lscript] m n for an integer glyph[lscript] satisfying γ ≤ glyph[lscript] -1 n ≤ 1 -γ , and let
$$t _ { \varepsilon } = \Pr _ { A \in _ { R } [ \stackrel { N \times ( 1 ) } { \ell - 1 } ] } \left [ w ( A ) + w _ { 1 } \geq q \colon w _ { 1 } = \frac { m } { n } - \varepsilon \sqrt { \frac { m \log n } { n } } \right ].$$
Then for m ≥ 4 n 3 ,
$$t _ { \varepsilon } \geq \frac { 1 } { 2 } - \frac { \varepsilon } { 2 \pi \gamma } \sqrt { \frac { \log n } { n } } - \frac { 1 } { n }.$$
Proof. The idea of the proof is to replace w A ( ) by the weight of a random set of size glyph[lscript] -1 . A simple coupling argument shows that
$$\cdots \cdots \cdots _ { r } \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \\ t _ { \varepsilon } & \geq \Pr _ { A \in _ { R } \left [ _ { \ell - 1 } ^ { N } \right ] } \left [ w ( A ) + w _ { 1 } \geq q \colon w _ { 1 } = \frac { m } { n } - \varepsilon \sqrt { \frac { m \log n } { n } } \right ] \\ & = \Pr \left [ B ( m, \frac { \ell - 1 } { n } ) \geq \frac { ( \ell - 1 ) m } { n } + \varepsilon \sqrt { \frac { m \log n } { n } } \right ],$$
using the second part of Lemma A.3.
As in the proof of Lemma A.6, since m ≥ 4 n 3 , we can use the Berry-Esseen theorem to estimate the latter expression up to an additive error of 1 n :
$$t _ { \varepsilon } & \geq \Pr \left [ \mathsf B ( m, \frac { \ell - 1 } { n } ) \geq \frac { ( \ell - 1 ) m } { n } + \varepsilon \sqrt { \frac { m \log n } { n } } \right ] \\ & \geq \Pr \left [ \mathcal { N } ( \frac { ( \ell - 1 ) m } { n }, \frac { ( \ell - 1 ) m } { n } ( 1 - \frac { \ell - 1 } { n } ) ) \geq \frac { ( \ell - 1 ) m } { n } + \varepsilon \sqrt { \frac { m \log n } { n } } \right ] - \frac { 1 } { n }.$$
In order to estimate the latter probability, we use the bound Pr[ N (0 1) , ≥ x ] ≥ 1 / 2 -x √ 2 π (for x ≥ 0 ), which follows from Pr[ N (0 1) , ≥ 0] = 1 2 / and the fact that the density of N (0 1) , is bounded by 1 / √ 2 π . In our case,
$$x = \varepsilon \sqrt { \frac { m \log n } { n } } \Big / \sqrt { \frac { ( \ell - 1 ) m } { n } } ( 1 - \frac { \ell - 1 } { n } ) \leq \varepsilon \sqrt { \frac { m \log n } { n } } \Big / \sqrt { \gamma ^ { 2 } m } = \varepsilon \sqrt { \frac { \log n } { \gamma ^ { 2 } n } }.$$
Therefore
$$t _ { \varepsilon } \geq \frac { 1 } { 2 } - \frac { \varepsilon } { 2 \pi \gamma } \sqrt { \frac { \log n } { n } } - \frac { 1 } { n }.$$
## B Missing Proofs From Section 5
## B.1 Proof of Lemma 5.1
Lemma 5.1 Assume that m voters submit the votes according to the exponential distribution over candidates, such that for ρ ∈ (0 , 1 2 ) , and the probability that voter j votes for candidate i is proportional to ρ n -i . There is a constant C > 0 such that if m ≥ Cρ -n (2 ρ -1) -2 log n then the resulting weight vector is super-increasing with probability 1 -O ( 1 n ) . Furthermore, as m →∞ , the probability approaches 1 .
Proof. The proof uses Bernstein's inequality with a subsequent application of the union bound. Consider a sequence w 1 ≤ w 2 ≤ ·· · ≤ w n . The sequence is clearly superincreasing if for every i = 2 , . . . , n , w /w i i -1 ≥ 2 , and w 1 > 0 . We now lower bound the probability of this event, by upper-bounding the probability of the following bad events: E i is the event that w i < 2 w i -1 (for i = 2 , . . . , n ), and E 1 is the event that w 1 = 0 . A union bound shows that the sequence w is super-increasing with probability at least 1 -∑ n i =1 Pr[ E i ] .
First note that the probability that voter j votes for candidate i is equal to
$$p _ { i } = \frac { \rho ^ { n - i } } { \sum _ { i = 1 } ^ { n } \rho ^ { n - i } } = \frac { \rho ^ { n - i } ( 1 - \rho ) } { 1 - \rho ^ { n } } = \Theta ( \rho ^ { n - i } ).$$
Bounding the probability of E 1 is easy:
$$\Pr [ E _ { 1 } ] = ( 1 - p _ { 1 } ) ^ { m } \leq e ^ { - p _ { 1 } m } = e ^ { - \Theta ( \rho ^ { n - 1 } m ) }.$$
glyph[negationslash]
In order to bound the probability of E i for i = 1 , consider the random variable X = 2 w i -1 -w i . This random variable is a sum of m i.i.d. random variables X (1) , . . . , X ( m ) corresponding to the different voters with the following distribution:
$$X ^ { ( j ) } = \begin{cases} 2 & \text{w.p.} \, p _ { i - 1 }, \\ - 1 & \text{w.p.} \, p _ { i }, \\ 0 & \text{w.p.} \, 1 - p _ { i - 1 } - p _ { i }. \end{cases}$$
Using the identity p i -1 = ρp i , the moments of X are
$$\mathbb { E } [ X ] = m \, \mathbb { E } [ X ^ { ( j ) } ] = ( 2 \rho - 1 ) p _ { i } m = \Theta ( ( 2 \rho - 1 ) \rho ^ { n - i } m ),$$
Var[ X ] = m ( E [ X ( j )2 ] -E [ X ( j ) ] 2 ) = (4 ρ +1) p m i -(2 ρ -1) 2 p m 2 i = O ρ ( n -i m . )
Since | X ( j ) -E [ X ( j ) ] | = O (1) , Bernstein's equality gives
$$\lambda _ { [ \lambda _ { i } } = 1 & = \mathcal { \langle } / \mathcal { \rangle }, \mathcal { \rangle } \, \mathcal { \rangle } \, \mathcal { \rangle } \, \mathcal { \rangle } \, \mathcal { \rangle } \, \mathcal { \rangle } \, \mathcal { \rangle } \, \mathcal { \rangle } \, \mathcal { \rangle } \, \mathcal { \rangle } \, \mathcal { \rangle } \, \mathcal { \rangle } \, \mathcal { \rangle } \, \mathcal { \rangle } \, \mathcal { \rangle } \, \mathcal { \rangle } \, \mathcal { \rangle } \, \mathcal { \rangle } \, \mathcal { \rangle } \, \mathcal { \rangle } \, \mathcal { \rangle } \quad \mathcal { \rangle } \, \mathcal { \rangle } \, \mathcal { \rangle } \, \mathcal { \rangle } \, \mathcal { \rangle } \, \mathcal { \rangle } \, \mathcal { \rangle } \, \mathcal { \rangle } \, \mathcal { \rangle } \, \mathcal { \rangle } \, \mathcal { \rangle } \, \mathcal { \rangle } \, \mathcal { \rangle } \, \mathcal { \rangle } \, \mathcal { \rangle } \, \mathcal { \rangle } \, \mathcal { \rangle } \, \mathcal { \rangle } \, \mathcal { \rangle } \, \mathcal { \rangle } \ \mathcal { \rangle } \, \mathcal { \rangle } \, \mathcal { \rangle } \, \mathcal { \rangle } \, \mathcal { \rangle } \, \mathcal { \rangle } \, \mathcal { \rangle } \, \mathcal { \rangle } \, \mathcal { \rangle } \, \mathcal { \rangle } \, \mathcal { \rangle } \, \mathcal { \rangle } \, \mathcal { \rangle } \, \mathcal { \rangle } \, \mathcal { \rangle } \, \mathcal { \rangle } \, \mathcal { \rangle } \, \mathcal { \rangle } \, \mathcal { \rangle } \, \mathcal { \rangle } \ \mathcal { \rangle } \, \mathcal { \rangle } \, \mathcal { \rangle } \, \mathcal { \rangle } \, \mathcal { \rangle } \, \mathcal { \rangle } \, \mathcal { \rangle } \, \mathcal { \rangle } \, \mathcal { \rangle } \, \mathcal { \rangle } \, \mathcal { \rangle } \, \mathcal { \rangle } \, \mathcal { \rangle } \, \mathcal { \rangle } \, \mathcal { \rangle } \, \mathcal { \rangle } \, \mathcal { \rangle } \, \mathcal { \rangle } \, \mathcal { \rangle } \, \mathcal { \rangle } \
\Pr [ E _ { i } ] & = \Pr [ X > 0 ] \\ & \leq \exp - \frac { \frac { 1 } { 2 } \, \mathbb { E } [ X ] ^ { 2 } } { \mathbb { Z } [ X ] + O ( \mathbb { E } [ X ] ) } \\ & = \exp - \frac { \Theta ( ( 2 \rho - 1 ) ^ { 2 } \rho ^ { 2 ( n - i ) } m ^ { 2 } ) } { O ( \rho ^ { n - i } m ) } \\ & = \exp - \Omega ( ( 2 \rho - 1 ) ^ { 2 } \rho ^ { n - i } m ).$$
Summarizing,
$$\sum _ { i = 1 } ^ { n } \Pr [ E _ { i } ] \leq e ^ { - \Theta ( \rho ^ { n - 1 } m ) } + \sum _ { i = 2 } ^ { n } e ^ { - \Omega ( ( 2 \rho - 1 ) ^ { 2 } \rho ^ { n - i } m ) }.$$
When m ≥ Cρ -n (2 ρ -1) -2 log n for an appropriate C , all the terms are O (1 /n 2 ) , and so the total error probability is O (1 /n ) , proving the first part of lemma. As m → ∞ , all the terms tend to 0 , and so the total error probability tends to 0 , proving the second part of the lemma.
## B.2 Proof of Lemma 5.2
Lemma 5.2 Suppose that p = ( p , . . . , p 1 n ) is a SI sequence summing to 1 , and let w , . . . , w 1 n be obtained by sampling m times from the distribution p , . . . , p 1 n .
Suppose that T ∈ (0 1] , , say T ∈ I p ( P ) for some P ⊆ { 1 , . . . , n } . If the distance of T from the endpoints ˜( p P ) , p ˜( P + ) of I p ( P ) is at least ∆ = √ log( nm /m ) then with probability 1 -2 ( nm ) 2 it holds that if w is SI then for all i ∈ N ϕ , w i ( mT ) = ϕ p i ( T ) .
Proof. Suppose that w is super-increasing. Lemma 6.1 implies that I w ( P ) = ( ˜( w P ,w P ) ˜( + )] , since both p and w are super-increasing (a priori, it could be that P + would have different values when defined with respect to p and to w ). The idea of the proof is to show that with high probability, mT ∈ I w ( P ) , and then the lemma follows from Proposition 5.2. We do that by upper-bounding the probability of the following two bad events: ˜( w P ) ≥ mT and ˜( w P + ) < mT .
The random variable ˜( w P ) is a sum of m i.i.d. indicator random variables which are 1 with probability ˜( p P ) . Therefore E [ ˜( w P )] = mp P ˜( ) . Hoeffding's inequality shows that
$$\dots \Pr [ \tilde { w } ( P ) \geq m T ] \leq \Pr [ \tilde { w } ( P ) \geq \mathbb { E } [ \tilde { w } ( P ) ] + m \Delta ] \leq e ^ { - 2 \Delta ^ { 2 } m }.$$
Similarly Pr[ ˜( w P + ) < mT ] ≤ e -2 ∆ m 2 . When ∆ ≥ √ log n/m , both error probabilities are at most 1 / nm ( ) 2 .
## C Missing Proofs from Section 6
## C.1 A Greedy Algorithm for Finding A q ( )
Given a point q ∈ (0 , w ( N )] and a vector of super-increasing weights w , it is possible to find A q ( ) in time O n ( ) .
Lemma C.1 Algorithm 1 calculates A q ( ) in linear time.
Proof. As stated, the algorithm does not in fact run in linear time, but it is easy to modify it so that it does run in linear time. It remains to prove that it calculates A q ( ) correctly.
Let A q ( ) = a , . . . , a 0 r , so that A q ( ) -= a , . . . , a 0 r -1 , a r +1 , . . . , n . Denote by A i the value of A in the algorithm after i iterations of the loop. We prove by induction on i
that A i = A q ( ) ∩{ 1 , . . . , i } , which shows that the algorithm returns A q ( ) . The inductive claim trivially holds for i = 0 . Assuming that A i -1 = A q ( ) ∩ { 1 , . . . , i - } 1 , we now prove that A i = A q ( ) ∩ { 1 , . . . , i } . We consider two cases: i / A q ∈ ( ) and i ∈ A q ( ) . If i / A q ∈ ( ) then q ≤ w A q ( ( )) = w A ( i -1 ) + w A q ( ( ) ∩{ i, . . . , n } ) ≤ w A ( i -1 ) + w ( { i + 1 , . . . , n } ) , and so line 5 does not get executed. Suppose now that i ∈ A q ( ) . If a r = i then q > w A q ( ( ) -) = w A ( i -1 ) + w ( { i +1 , . . . , n } ) , and so line 5 gets executed. If a r > i then q > w A q ( ( ) -) ≥ w A ( i -1 ) + w > w A i ( i -1 ) + w ( { i +1 , . . . , n } ) , since w is super-increasing, and so line 5 gets executed in this case as well.
## Algorithm 1 An algorithm for finding A q ( )
```
Algorithm 1 An algorithm for finding A(q)
1: procedure FIND-SET(w, q)
2: A \leftarrow \emptyset
3: for i \leftarrow 1 to n do
4: if q > w(A \cup \{i + 1, \dots, n\}) then
5: A \leftarrow A \cup \{i}
6: end if
7: end forreturn A
8: end procedure
```
## C.2 Finding A q ( ) when Weights are w i = d n -i
Lemma C.2 Suppose w i = d n -i for some integer d ≥ 2 , and let q ∈ (0 , w ( N )] . Write glyph[ceilingleft] q glyph[ceilingright] in base d : glyph[ceilingleft] q glyph[ceilingright] = ( t 1 . . . t n d ) . If the base d representation only consists of the digits 0 and 1 then A q ( ) = { i ∈ N : t i = 1 } . Otherwise, let glyph[lscript] be the minimal index such that t glyph[lscript] > 1 , and let k < glyph[lscript] be the maximal index less than glyph[lscript] satisfying t k = 0 (the proof shows that such an index exists). Then A q ( ) = { i ∈ { 1 , . . . , k - } 1 : t i = 1 } ∪ { k } .
glyph[negationslash]
Proof. Suppose first that t i ∈ { 0 1 , } for all i ∈ N , and let Q q ( ) = { i ∈ N : t i = 1 } . Since glyph[ceilingleft] q glyph[ceilingright] ≥ 1 , Q q ( ) = ∅ . Lemma 6.1 shows that w Q q ( ( ) -) < w Q q ( ( )) and so q = w Q q ( ( )) ∈ ( w Q q ( ( ) -) , w ( Q q ( ))] , showing that A q ( ) = Q q ( ) .
Suppose next that glyph[lscript] is the minimal index such that t glyph[lscript] > 1 . If t k = 1 for all k < glyph[lscript] then
$$q > \lceil q \rceil - 1 \geq \sum _ { j = 1 } ^ { \ell - 1 } w _ { j } + 2 w _ { \ell } - 1 \geq w ( N ), \\. \quad. \quad. \quad. \quad. \quad. \quad.$$
since the fact that the w i are integral and super-increasing implies that
$$w _ { \ell } \geq \sum _ { j = \ell + 1 } ^ { n } w _ { j } + 1.$$
We conclude that the maximal index k < glyph[lscript] satisfying t k = 0 exists. Let Q q ( ) = { i ∈ { 1 , . . . , k - } 1 : t i = 1 } ∪ { k } . On the one hand,
$$q \leq \lceil q \rceil \leq \sum _ { j \in Q ( q ) \langle \{ k \} } w _ { j } + ( d - 1 ) \sum _ { j = k + 1 } ^ { n } w _ { j } < w ( Q ( q ) ).$$
On the other hand,
$$\Phi \text{sounds}, \\ q > \lceil q \rceil - 1 & \geq \sum _ { j \in Q ( q ) \langle k \} } w _ { j } + \sum _ { j = k + 1 } ^ { \ell - 1 } w _ { j } + 2 w _ { \ell } - 1 \\ & \geq \sum _ { j \in Q ( q ) \langle k \} } w _ { j } + \sum _ { j = k + 1 } ^ { n } w _ { j } = w ( Q ( q ) ^ { - } ). \\ \Phi \text{sounds} \quad \sim \partial \ \partial \ \partial \$$
Therefore A q ( ) = Q q ( ) .
## C.3 Proof of Theorem 6.1
First, we recall the statement of Theorem 6.1.
Theorem 6.1. Consider an agent i ∈ N and a prescribed quota value q ∈ (0 , w ( N )] . Let A q ( ) = { a , . . . , a 0 r } . If i / A q ∈ ( ) then ϕ i ( q ) = ∑ t ∈{ 0 ,...,r } : a >i t 1 a t ( a t -1 t ) . If i ∈ A q ( ) , say i = a s , then ϕ i ( q ) = 1 a s ( as -1 s ) -∑ t ∈{ 0 ,...,r } : a >i t 1 a t ( a t -1 t -1 ) .
Proof. Lemma 6.2 shows that ϕ w i ( q ) = ϕ b i ( β A q ( ( ))) , where b = 2 n -1 , . . . , 1 . Therefore we can assume without loss generality that w = 2 n -1 , . . . , 1 , i.e., w i = 2 n -i , and that q = ∑ j ∈ A q ( ) w j .
Recall that ϕ i ( q ) is the probability that w P ( i ( π )) ∈ [ q -w , q i ) , where π is chosen randomly from Sym n , and P i ( π ) is the set of predecessors of i in π . The idea of the proof is to consider the maximal τ ∈ { 1 , . . . , r +1 } such that a t ∈ P i ( π ) for all t < τ . We will show that when i / ∈ A q ( ) , each possible value of τ ( π ) corresponds to one summand in the expression for ϕ i ( q ) . When i ∈ A q ( ) , say i = a s , we will show that the events that i is pivotal with respect to q and that i is pivotal with respect to q -w i are disjoint, and their union is an event having probability 1 /a s ( a s -1 s ) .
Suppose that i is pivotal for π and τ ( π ) = τ . We start by showing that τ ≤ r , ruling out the case τ = r +1 . If τ = r +1 then by definition
$$w ( P _ { i } ( \pi ) ) \geq \sum _ { j \in A ( q ) } w _ { j } = q,$$
contradicting the assumption w P ( i ( π )) < q . Therefore τ ≤ r , and so a τ is welldefined. We claim that if k ∈ P i ( π ) for some agent k < a τ then k ∈ A q ( ) . Indeed, otherwise
$$w ( P _ { i } ( \pi ) ) \geq \sum _ { t = 0 } ^ { \tau - 1 } w _ { a _ { t } } + w _ { k } \geq \sum _ { t = 0 } ^ { \tau - 1 } w _ { a _ { t } } + w _ { a _ { \tau } - 1 } > \sum _ { t = 0 } ^ { \tau - 1 } w _ { a _ { t } } + \sum _ { j = a _ { \tau } } ^ { n } w _ { j } \geq q,$$
again contradicting w P ( i ( π )) < q (the third inequality made use of the fact that w is super-increasing).
Furthermore, we claim that a τ ≥ i . Otherwise,
$$w ( P _ { i } ( \pi ) ) \leq \sum _ { t = 0 } ^ { \tau - 1 } w _ { a _ { t } } + \sum _ { j = a _ { \tau } + 1 } ^ { n } w _ { j } - w _ { i } < \sum _ { t = 0 } ^ { \tau } w _ { a _ { t } } - w _ { i } \leq q - w _ { i },$$
contradicting the assumption w P ( i ( π )) ≥ q -w i .
Summarizing, we have shown that τ ≤ r , a τ ≥ i and
$$P _ { i } ( \pi ) \cap \{ 1, \dots, a _ { \tau } \} = \{ a _ { 0 }, \dots, a _ { \tau - 1 } \}.$$
Denote this event E τ , and call a τ ≤ r satisfying a τ ≥ i legal .
Suppose first that i / ∈ A q ( ) . We have shown above that if i is pivotal then E τ happens for some legal τ . We claim that the converse is also true. Indeed, given E τ defined with respect to a permutation π , and for some legal τ , the weight of P i ( π ) can be bounded as follows.
$$\sum _ { t = 0 } ^ { \tau - 1 } w _ { a _ { t } } \leq w ( P _ { i } ( \pi ) ) \leq \sum _ { t = 0 } ^ { \tau - 1 } w _ { a _ { t } } + \sum _ { j = a _ { \tau } + 1 } ^ { n } w _ { j } < \sum _ { t = 0 } ^ { \tau } w _ { a _ { t } }.$$
The second inequality follows from the definition of τ , whereas the third inequality follows as before from the definition of a super-increasing sequence. The upper bound is clearly at most q , and the lower bound satisfies
$$\sum _ { t = 0 } ^ { \tau - 1 } w _ { a _ { t } } \geq q - \sum _ { j = a _ { \tau } } ^ { n } w _ { j } > q - w _ { a _ { \tau } - 1 } \geq q - w _ { i },$$
since i < a τ .
It remains to calculate Pr[ E τ ] . The event E τ states that the restriction of π to { 1 , . . . , a τ } consists of the elements { a , . . . , a 0 τ -1 } in some order, followed by i (recall that i ≤ a τ ). For each of the τ ! possible orders, the probability of this is 1 /a τ · · · ( a τ -τ ) = ( a τ -τ -1)! /a τ ! , and so
$$\Pr [ E _ { \tau } ] = \frac { \tau! ( a _ { \tau } - \tau - 1 )! } { a _ { \tau }! } = \frac { 1 } { a _ { \tau } \binom { a _ { \tau } - 1 } { \tau } }.$$
Summing over all legal τ , we obtain the formula in the statement of the theorem. This completes the proof in the case i / A q ∈ ( ) .
Suppose next that i ∈ A q ( ) , say i = a s . Since a τ ≥ a s = i while i / P ∈ i ( π ) , we deduce that τ = s . Therefore the event E s happens. Conversely, when E s happens,
$$w ( P _ { i } ( \pi ) ) \leq \sum _ { t = 0 } ^ { s - 1 } w _ { a _ { t } } + \sum _ { j = a _ { s } + 1 } ^ { n } w _ { j } < \sum _ { t = 0 } ^ { s } w _ { a _ { t } } \leq q.$$
Therefore i is pivotal (with respect to q ) if and only if E s happens and w P ( i ( π )) ≥ q -w i .
It is easy to check that A q ( -w i ) = A q ( ) \ { } i = a , . . . , a 0 s -1 , a s +1 , . . . , a r . The argument above shows that if i is pivotal with respect to q -w i then for some τ ′ ≥ s +1 ,
$$P _ { i } ( \pi ) \cap \{ 1, \dots, a _ { \tau ^ { \prime } } \} = \{ a _ { 0 }, \dots, a _ { s - 1 }, a _ { s + 1 }, \dots, a _ { \tau ^ { \prime } - 1 } \}.$$
In particular, the event E s happens. Conversely, when E s happens,
$$w ( P _ { i } ( \pi ) ) \geq \sum _ { t = 0 } ^ { s - 1 } w _ { a _ { t } } \geq q - w _ { a _ { s } } - \sum _ { j = a _ { s } + 1 } ^ { n } w _ { j } > ( q - w _ { a _ { s } } ) - w _ { a _ { s } }.$$
Therefore i is pivotal with respect to q -w i if and only if E s happens and w P ( i ( π )) < q -w i . We conclude that
Pr[ w i is pivotal with respect to q ] = Pr[ E s ] -Pr[ w i is pivotal with respect to q -w . i ]
Above we have calculated Pr[ E s ] = 1 /a s ( a s -1 s ) , and we obtain the formula in the statement of the theorem.
## C.4 Proof of Lemma 6.3
To prove Lemma 6.3, we will need some combinatorial identities.
Lemma C.3 Let p, t be integers satisfying p > t ≥ 1 . Then
$$\frac { 1 } { p \binom { p - 1 } { t } } + \frac { 1 } { p \binom { p - 1 } { t - 1 } } = \frac { 1 } { ( p - 1 ) \binom { p - 2 } { t - 1 } }.$$
Proof. The proof is a simple calculation:
$$\frac { 1 } { p \binom { p - 1 } { t } } + \frac { 1 } { p \binom { p - 1 } { t - 1 } } = \frac { t! ( p - t - 1 )! + ( t - 1 )! ( p - t )! } { p! }$$
$$= \frac { ( t - 1 )! ( p - t - 1 )! [ t + ( p - t ) ] } { p! } = \frac { ( t - 1 )! ( p - t - 1 )! } { ( p - 1 )! } = \frac { 1 } { ( p - 1 ) \binom { p - 2 } { t - 1 } }.$$
$$p ( \bar { \ } _ { t } ^ { r } \bar { \ } _ { t } ^ { \ } ) \quad p ( \bar { \ } _ { t - 1 } ^ { r } ) & p! \\ & = \frac { ( t - 1 )! ( p - t - 1 )! [ t + ( p - t ) ] } { n! } = \frac { ( t - 1 )! ( p - t - 1 )! } { ( p - 1 )! } = \frac { 1 } { ( n - 1 )! ( p - 2 ) }.$$
Lemma C.4 Let p, t, k be integers satisfying p > t ≥ 0 and k ≥ 0 . Then
$$\frac { 1 } { p \binom { p - 1 } { t } } - \sum _ { \ell = 1 } ^ { k } \frac { 1 } { ( p + \ell ) \binom { p + \ell - 1 } { t + \ell - 1 } } = \frac { 1 } { ( p + k ) \binom { p + k - 1 } { t + k } }.$$
In particular,
$$\frac { 1 } { p \binom { p - 1 } { t } } = \sum _ { \ell = 1 } ^ { \infty } \frac { 1 } { ( p + \ell ) \binom { p + \ell - 1 } { t + \ell - 1 } }.$$
Proof. The proof is by induction on k . If k = 0 then there is nothing to prove. For k > 0 we have
$$\frac { 1 } { p ( p ^ { - 1 } _ { t } ) } - \sum _ { \ell = 1 } ^ { k } \frac { 1 } { ( p + \ell ) \binom { p + \ell - 1 } { t + \ell - 1 } } = \frac { 1 } { ( p + k - 1 ) \binom { p + k - 2 } { t + k - 1 } } - \frac { 1 } { ( p + k ) \binom { p + k - 1 } { t + k - 1 } } = \frac { 1 } { ( p + k ) \binom { p + k - 1 } { t + k } },$$
using Lemma C.3. The second expression of the lemma follows from rearranging the first formula and taking the limit k →∞ .
We are now ready to prove Lemma 6.3. First, recall the statement of the lemma.
Lemma 6.3 Given a quota q ∈ (0 , w ( N )] , let A q ( ) = { a , . . . , a 0 r } . For each i ∈ N \ { n } , if Ψ i ( A q ( )) = Ψ i +1 ( A q ( )) then ϕ i ( q ) = ϕ i +1 ( q ) . If Ψ i ( A q ( )) = 0 and Ψ i +1 ( A q ( )) = 1 then ϕ i ( q ) ≥ ϕ i +1 ( q ) , with equality if and only if i + 1 = a r . If Ψ i ( A q ( )) = 1 and Ψ i +1 ( A q ( )) = 0 then ϕ i ( q ) > ϕ i +1 ( q ) .
Proof. For the first item, since i +1 / A q ∈ ( ) then a t > i iff a t > i +1 , and so
$$\varphi _ { i } ( q ) = \sum _ { \substack { t \in \{ 0, \dots, r \} \colon \\ a _ { t } > i } } \frac { 1 } { a _ { t } \binom { a _ { t } - 1 } { t } } = \sum _ { \substack { t \in \{ 0, \dots, r \} \colon \\ a _ { t } > i + 1 } } \frac { 1 } { a _ { t } \binom { a _ { t } - 1 } { t } } = \varphi _ { i + 1 } ( q ).$$
For the second item, suppose that i +1 = a s . We have
$$\varphi _ { i } ( q ) - \varphi _ { i + 1 } ( q ) & = \sum _ { t = s } ^ { r } \frac { 1 } { a _ { t } \binom { a _ { t } - 1 } { t } } - \left [ \frac { 1 } { a _ { s } \binom { a _ { s } - 1 } { s } } - \sum _ { t = s + 1 } ^ { r } \frac { 1 } { a _ { t } \binom { a _ { t } - 1 } { t - 1 } } \right ] \\ & = \sum _ { t = s + 1 } ^ { r } \left [ \frac { 1 } { a _ { t } \binom { a _ { t } - 1 } { t } } + \frac { 1 } { a _ { t } \binom { a _ { t } - 1 } { t - 1 } } \right ] = \sum _ { t = s + 1 } ^ { r } \frac { 1 } { ( a _ { t } - 1 ) \binom { a _ { t } - 2 } { t - 1 } }, \\ \dots \dots \pi \dots \pi \nu \tau \dots \dots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots.$$
using Lemma C.3. Therefore ϕ i ( q ) ≥ ϕ i +1 ( q ) , with equality if and only if s = r . For the third item, suppose that i = a s . We have
$$\varphi _ { i } ( q ) - \varphi _ { i + 1 } ( q ) & = \frac { 1 } { a _ { s } \binom { a _ { s } - 1 } { s } } - \sum _ { t = s + 1 } ^ { r } \frac { 1 } { a _ { t } \binom { a _ { t } - 1 } { t - 1 } } - \sum _ { t = s + 1 } ^ { r } \frac { 1 } { a _ { t } \binom { a _ { t } - 1 } { t } } \\ & = \frac { 1 } { a _ { s } \binom { a _ { s } - 1 } { s } } - \sum _ { t = s + 1 } ^ { r } \frac { 1 } { ( a _ { t } - 1 ) \binom { a _ { t } - 2 } { t - 1 } }, \\ \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \colon$$
using Lemma C.3. The same lemma also implies that the expression 1 /p ( p t -1 ) is decreasing in p . Since i + 1 / A q ∈ ( ) , if a s +1 exists then a s +1 ≥ a s + 2 , and in general a s + glyph[lscript] ≥ a s + glyph[lscript] +1 . Therefore
$$\varphi _ { i } ( q ) - \varphi _ { i + 1 } ( q ) \geq \frac { 1 } { a _ { s } \binom { a _ { s } - 1 } { s } } - \sum _ { \ell = 1 } ^ { r - s } \frac { 1 } { ( a _ { s } + \ell ) \binom { a _ { s } + \ell - 1 } { s + \ell - 1 } } = \frac { 1 } { ( a _ { s } + r - s ) \binom { a _ { s } + r - s - 1 } { r } } > 0,$$
using Lemma C.4.
For the fourth item, suppose that i = a s . We have
$$\varphi _ { i } ( q ) - \varphi _ { i + 1 } ( q ) & = \left [ \frac { 1 } { a _ { s } \binom { a _ { s } - 1 } { s } } - \sum _ { t = s + 1 } ^ { r } \frac { 1 } { a _ { t } \binom { a _ { t } - 1 } { t - 1 } } \right ] - \left [ \frac { 1 } { a _ { s + 1 } \binom { a _ { s + 1 } - 1 } { s + 1 } } - \sum _ { t = s + 2 } ^ { r } \frac { 1 } { a _ { t } \binom { a _ { t } - 1 } { t - 1 } } \right ] \\ & = \frac { 1 } { a _ { s } \binom { a _ { s } - 1 } { s } } - \frac { 1 } { a _ { s + 1 } \binom { a _ { s + 1 } - 1 } { s + 1 } } - \frac { 1 } { a _ { s + 1 } \binom { a _ { s + 1 } - 1 } { s } } = 0, \\ \intertext { s u s e l i n d e n d i t h e e n d i t h e e n d i t h e e n d i t h e e n d i t h e e n d i t h e e n d i t h e e n d i t h e e n d i t h e e n d i t h e e n d i t h e e n d i t h e e n d i t h e e n d i t h e e n d i t h e e n d i t h e e n d i t h e e n d i t h e e n d i t h e e n d i t h e e n d i t h e e n d i t h e e n d i t h e e n d i t h e e n d i t h e e n d i t h e e n d i t h e e n d i t h e e n d i t h e e n d e n d i t h e e n d i t h e e n d i t h e e n d i t h e e n d i t h e e n d i t h e e n d i t h e e n d i t h e e n d i t h e e n d i t h e e n d i t h e e n d i t h e e n d i t h e e n d i t h e e n d i t h e e n d i t h e e n d i t h e e n d i t h e e n d i t h e e n d i t h e e n d i t h e e n d i t h e e n d i t h e e n d i t h e e n d i t h e e n d i t h e e n d i t h e e n d i t h e e e n d i t h e e n d i t h e e n d i t h e e n d i t h e e n d i t h e e n d i t h e e n d i t h e e n d i t h e e n d i t h e e n d i t h e e n d i t h e e n d i t h e e n d i t h e e n d i t h e e n d i t h e e n d i t h e e n d i t h e e n d i t h e e n d i t h e e n d i t h e e n d i t h e e n d i t h e e n d i t h e e n d i t h e e n d i t h e e n d i t h e e n d i t h e e n d i t h e e n n d i t h e e n d i t h e e n d i t h e e n d i t h e e n d i t h e e n d i t h e e n d i t h e e n d i t h e e n d i t h e e n d i t h e e n d i t h e e n d i t h e e n d i t h e e n d i t h e e n d i t h e e n d i t h e e n d i t h e e n d i t h e e n d i t h e e n d i t h e e n d i t h e e n d i t h e e n d i t h e e n d i t h e e n d i t h e e n d i t h e e n d i t h e e n d i t h e e n d i n t h e e n d i t h e e n d i t h e e n d i t h e e n d i t h e e n d i t h e e n d i t h e e n d i t h e e n d i t h e e n d i t h e e n d i t h e e n d i t h e e n d i t h e e n d i t h e e n d i t h e e n d i t h e e n d i t h e e n d i t h e e n d i t h e e n d i t h e e n d i t h e e n d i t h e e n d i t h e e n d i t h e e n d i t h e e n d i t h e e n d i t h e e n d i t h e e n d i t h e t e n d i t h e e n d i t h e e n d i t h e e n d i t h e e n d i t h e e n d i t h e e n d i t h e e n d i t h e e n d i t h e e n d i t h e e n d i t h e e n d i t h e e n d i t h e e n d i t h e e n d i t h e e n d i t h e e n d i t h e e n d i t h e e n d i t h e e n d i t h e e n d i t h e e n d i t h e e n d i t h e e n d i t h e e n d i t h e e n d i t h e e n d i t h e e n d i t h e e n d ie n d i t h e e n d i t h e e n d i t h e e n d i t h e e n d i t h e e n d i t h e e n d i t h e e n d i t h e e n d i t h e e n d i t h e e n d i t h e e n d i t h e e n d i t h e e n d i t h e e n d i t h e e n d i t h e e n d i t h e e n d i t h e e n d i t h e e n d i t h e e n d i t h e e n d i t h e e n d i t h e e n d i t h e e n d i t h e e n d i t h e e n d i t h e e n d i t h e e n d i g e n d i t h e e n d i t h e e n d i t h e e n d i t h e e n d i t h e e n d i t h e e n d i t h e e n d i t h e e n d i t h e e n d i t h e e n d i t h e e n d i t h e e n d i t h e e n d i t h e e n d i t h e e n d i t h e e n d i t h e e n d i t h e e n d i t h e e n d i t h e e n d i t h e e n d i t h e e n d i t h e e n d i t h e e n d i t h e e n d i t h e e n d i t h e e n d i t h e e n d is t h e e n d i t h e e n d i t h e e n d i t h e e n d i t h e e n d i t h e e n d i t h e e n d i t h e e n d i t h e e n d i t h e e n d i t h e e n d i t h e e n d i t h e e n d i t h e e n d i t h e e n d i t h e e n d i t h e e n d i t h e e n d i t h e e n d i t h e e n d i t h e e n d i t h e e n d i t h e e n d i t h e e n d i t h e e n d i t h e e n d i t h e e n d i t h e e n d i t h e n d i t h e e n d i t h e e n d i t h e e n d i t h e e n d i t h e e n d i t h e e n d i t h e e n d i t h e e n d i t h e e n d i t h e e n d i t h e e n d i t h e e n d i t h e e n d i t h e e n d i t h e e n d i t h e e n d i t h e e n d i t h e e n d i t h e e n d i t h e e n d i t h e e n d i t h e e n d i t h e e n d i t h e e n d i t h e e n d i t h e e n d i t h e e n d i t h e e n d ier t h e e n d i t h e e n d i t h e e n d i t h e e n d i t h e e n d i t h e e n d i t h e e n d i t h e e n d i t h e e n d i t h e e n d i t h e e n d i t h e e n d i t h e e n d i t h e e n d i t h e e n d i t h e e n d i t h e e n d i t h e e n d i t h e e n d i t h e e n d i t h e e n d i t h e e n d i t h e e n d i t h e e n d i t h e e n d i t h e e n d i t h e e n d i t h e e n d i t h e i n d e n d i t h e e n d i t h e e n d i t h e e n d i t h e e n d i t h e e n d i t h e e n d i t h e e n d i t h e e n d i t h e e n d i t h e e n d i t h e e n d i t h e e n d i t h e e n d i t h e e n d i t h e e n d i t h e e n d i t h e e n d i t h e e n d i t h e e n d i t h e e n d i t h e e n d i t h e e n d i t h e e n d i t h e e n d i t h e e n d i t h e e n d i t h e e n d i t h e n d i n t h e e n d i t h e e n d i t h e e n d i t h e e n d i t h e e n d i t h e e n d i t h e e n d i t h e e n d i t h e e n d i t h e e n d i t h e e n d i t h e e n d i t h e e n d i t h e e n d i t h e e n d i t h e e n d i t h e e n d i t h e e n d i t h e e n d i t h e e n d i t h e e n d i t h e e n d i t h e e n d i t h e e n d i t h e e n d i t h e e n d i t h e e n d i t h e e n n d i t h o n d e n d e n d e n d e n d e n d e n d e n d e n d e n d e n d e n d e n d e n d e n d e n d e n d e n d e n d e n d e n d e n d e n d e n d e n d e n d e n d e n d e n d e n d e n d e n d e n d e n d e n d e n d e n d e n d e n d e n d e n d e n d e n d e n d e n d e n d e n d e n d e n d e n d e n d e n d e n d e n d e n d e n d e n d e n d e n d e n d e n d e n d e n d e n d e n d e n d e n d e n e d e n d e n d e n d e n d e n d e n d e n d e n d e n d e n d e n d e n d e n d e n d e n d e n d e n d e n d e n d e n d e n d e n d e n d e n d e n d e n d e n d e n d e n d e n d e n d e n d e n d e n d e n d e n d e n d e n d e n d e n d e n d e n d e n d e n d e n d e n d e n d e n d e n d e n d e n d e n d e n d e n d e n d e n d e n d e n d e n d e n d e n d e n d e n d e n d e n d e n d i t h e e n d e n d e n d e n d e n d e n d e n d e n d e n d e n d e n d e n d e n d e n d e n d e n d e n d e n d e n d e n d e n d e n d e n d e n d e n d e n d e n d e n d e n d e n d e n d e n d e n d e n d e n d e n d e n d e n d e n d e n d e n d e n d e n d e n d e n d e n d e n d e n d e n d e n d e n d e n d e n d e n d e n d e n d e n d e n d e n d e n d e n d e n d e n d e n d e n d e n d e e n d e n d e n d e n d e n d e n d e n d e n d e n d e n d e n d e n d e n d e n d e n d e n d e n d e n d e n d e n d e n d e n d e n d e n d e n d e n d e n d e n d e n d e n d e n d e n d e n d e n d e n d e n d e n d e n d e n d e n d e n d e n d e n d e n d e n d e n d e n d e n d e n d e n d e n d e n d e n d e n d e n d e n d e n d e n d e n d e n d e n d e n d e n d e n d e n d e n d ier { s u s e n d e { s u s e n d e { s u s e n d e { s u s e n d e } } }$$
using Lemma C.3 together with a s +1 = a s +1 .
## C.5 Proof of Lemma 6.4
First, let us recall the statement of Lemma 6.4.
Lemma 6.4 Let P ⊆ N be a non-empty set of agents, and let i ∈ N be an agent. If i / P ∈ -then ϕ i ( w P ( -)) < ϕ i ( w P ( )) . If i ∈ P -then ϕ i ( w P ( -)) > ϕ i ( w P ( )) .
Moreover, | ϕ i ( w P ( )) -ϕ i ( w P ( -)) | ≤ 1 n ; this inequality is tight only if a ) P = { n } . b ) i < n and P = { 1 , . . . , i } or P = { i, n } , or c ) i = n and P = { n - } 1 . Otherwise, | ϕ i ( w P ( )) -ϕ i ( w P ( -)) | ≤ 1 n n ( -1) .
Proof. Define ϕ + = ϕ i ( w P ( )) and ϕ -= ϕ i ( w P ( -)) . Let P = a , . . . , a 0 r . We have P -= a , . . . , a 0 r -1 , a r +1 , . . . , n .
Suppose first that i > a r , and let s be the index of i in the sequence P -. According to Theorem 6.1, ϕ + = 0 and
$$\varphi _ { - } = \frac { 1 } { i \binom { i - 1 } { s } } - \sum _ { \ell = 1 } ^ { n - i } \frac { 1 } { ( i + \ell ) \binom { i + \ell - 1 } { s + \ell - 1 } } = \frac { 1 } { n \binom { n - 1 } { s + n - i } }.$$
Wesee that i ∈ P -and ϕ -> ϕ + . Furthermore, | ϕ + -ϕ -| ≤ 1 n n ( -1) unless s + n - ∈ i { 0 , n -1 } . If s + n -i = 0 then s = 0 and i = n , implying P -= { n } and so P = { n - } 1 . If s + n -i = n -1 then s = i -1 and so P -= 1 , . . . , n , which is impossible.
Suppose next that i = a r . According to the theorem,
$$\varphi _ { + } - \varphi _ { - } = \frac { 1 } { i \binom { i - 1 } { r } } - \sum _ { \ell = 1 } ^ { n - i } \frac { 1 } { ( i + \ell ) \binom { i + \ell - 1 } { r + \ell - 1 } } = \frac { 1 } { n \binom { n - 1 } { r + n - i } }.$$
Wesee that i / P ∈ -and ϕ + > ϕ -. Furthermore, | ϕ + -ϕ -| ≤ 1 n n ( -1) unless r + n - ∈ i { 0 , n - } 1 . If r + n -i = 0 then r = 0 and i = n , and so P = { n } . If r + n -i = n then r = i -1 and so P = 1 , . . . , i .
Finally, suppose that i < a r . If i / P ∈ then
$$\varphi _ { + } - \varphi _ { - } = \frac { 1 } { a _ { r } \binom { a _ { r } - 1 } { r } } - \sum _ { \ell = 1 } ^ { n - a _ { r } } \frac { 1 } { ( a _ { r } + \ell ) \binom { a _ { r } + \ell - 1 } { r + \ell - 1 } } = \frac { 1 } { n \binom { n - 1 } { r + n - a _ { r } } }.$$
We see that i / P ∈ -and ϕ + > ϕ -. Furthermore, | ϕ + -ϕ -| ≤ 1 n n ( -1) unless r + n -a r ∈ { 0 , n - } 1 . If r + n -a r = 0 then r = 0 and a r = n , and so P = { n } . If r + n -a r = n -1 then a r = r +1 , which implies P = 1 { , . . . , r +1 } . However, this contradicts the assumption i / P ∈ .
If i < a r and i ∈ P then
$$\varphi _ { - } - \varphi _ { + } = \frac { 1 } { a _ { r } \binom { a _ { r } - 1 } { r - 1 } } - \sum _ { \ell = 1 } ^ { n - a _ { r } } \frac { 1 } { ( a _ { r } + \ell ) \binom { a _ { r } + \ell - 1 } { r + \ell - 2 } } = \frac { 1 } { n \binom { n - 1 } { r + n - a _ { r } - 1 } }.$$
We see that i ∈ P -and ϕ -> ϕ + . Furthermore, | ϕ + -ϕ -| ≤ 1 n n ( -1) unless r + n -a r -1 ∈ { 0 , n - } 1 . If r + n -a r -1 = 0 then r = 1 and a r = n , and so P = { i, n } . If r + n -a r -1 = n -1 then a r = r , which is impossible.
## C.6 A Note on the Limiting Behavior of the Shapley Value under Super-Increasing Weights
Given a super-increasing sequence w , . . . , w 1 n (where again, w 1 > w 2 > · · · > w n ) and some m ∈ N , let us write w | m for ( w , . . . , w 1 m ) and [ m ] for { 1 , . . . , m } . We write ϕ w | m i ( q ) for the Shapley value of agent i ∈ [ m ] in the weighted voting game in which
the set of agents is [ m ] , the weights are w | m , and the quota is q . We also write A | m ( q ) for the set P ⊆ [ m ] such that q ∈ ( w | m ( P -) , w | m ( P )] .
The following lemma relates ϕ w i ( q ) and ϕ w | m i ( q ) .
Lemma C.5 Let m ∈ N and i ∈ [ m ] , and let q ∈ (0 , w ([ m ])] . Then
$$\varphi _ { i } ^ { w | _ { m } } ( q ) = \varphi _ { i } ^ { w } ( w ( A | _ { m } ( q ) ) ).$$
Proof. Theorem 6.1 provides a function Φ such that ϕ w | m i ( q ) = Φ A ( | m ( q )) and ϕ w i ( w A ( | m ( q ))) = Φ A w A ( ( ( | m ( q )))) = Φ A ( | m ( q )) . We conclude that the Shapley values coincide.
Therefore the plot of ϕ w | m i can be readily obtained from that of ϕ w i . This suggests looking at the limiting case of an infinite super-increasing sequence ( w i ) ∞ i =1 , which is a sequence satisfying w > i 0 and w i ≥ ∑ ∞ j = +1 i w j for all i ≥ 1 . The super-increasing condition implies that the sequence sums to some value w ( ∞ ≤ ) 2 w 1 . Lemma C.5 suggests how to define ϕ i in this case: for q ∈ (0 , w ( ∞ )) and i ≥ 1 , let
$$\varphi _ { i } ^ { ( \infty ) } ( q ) = \lim _ { n \to \infty } \varphi _ { i } ^ { w | _ { n } } ( q ).$$
We show that the limit exists by providing an explicit formula for it, as given in Theorem C.1, which is proved in the appendix. In the theorem, we consider possibly infinite subsets P = { a , . . . , a 0 r } of the positive integers, ordered in increasing order; when r = ∞ , the subset is infinite. Also, the notation { a, . . . , ∞} (or { a, . . . , r } when r = ∞ ) means all integers larger than or equal to a .
## Theorem C.1. Let q ∈ (0 , w ( ∞ )) and let i be a positive integer.
- (a) There exists a non-empty subset of the positive integers P = { a , . . . , a 0 r } such that either q = w P ( ) or P is finite and q ∈ ( w P ( -) , w ( P )] , where P -= { a , . . . , a 0 r -1 } ∪ { a r +1 , . . . , ∞} .
- (b) The limit ϕ ( ∞ ) i ( q ) = lim n →∞ ϕ w | n i ( q ) exists. When i / P ∈ ,
$$\varphi _ { i } ^ { ( \infty ) } ( q ) = \sum _ { \substack { t \in \{ 0, \dots, r \} \colon \\ a _ { t } > i } } \, \frac { 1 } { a _ { t } \binom { a _ { t } - 1 } { t } },$$
and when i ∈ P , say i = a s , then
$$\varphi _ { i } ^ { ( \infty ) } ( q ) = \frac { 1 } { a _ { s } \binom { a _ { s } - 1 } { s } } - \sum _ { \substack { t \in \{ 0, \dots, r \} \colon \\ a _ { t } > i } } \, \frac { 1 } { a _ { t } \binom { a _ { t } - 1 } { t - 1 } }.$$
Lemma C.5 easily extends to the case n = ∞ .
Lemma C.6 Let m ≥ 1 be an integer, let i ∈ [ m ] , and let q ∈ (0 , w ([ m ])] . Then ϕ w | m i ( q ) = ϕ ( ∞ ) i ( w A ( | m ( q ))) .
Proof. Lemma C.5 shows that for n ≥ m ϕ , w | m i ( q ) = ϕ w | n i ( w A ( | m ( q ))) , and therefore ϕ w | m i ( q ) = lim n →∞ ϕ w | n i ( w A ( | m ( q ))) = ϕ ( ∞ ) i ( w A ( | m ( q ))) .
We conclude by showing that the limiting functions ϕ ( ∞ ) i are continuous (see appendix for the proof).
Theorem C.2. Let i be a positive integer. The function ϕ ( ∞ ) i is continuous on (0 , w ( ∞ )) , and lim q → 0 ϕ ( ∞ ) i ( q ) = lim q → w ( ∞ ) ϕ ( ∞ ) i ( q ) = 0 .
Summarizing, we can extend the functions ϕ w | n i to a continuous function ϕ ( ∞ ) i which agrees with ϕ w | n i on the points w P ( ) for P ⊆ { 1 , . . . , n } . When w i = 2 -i then the plot of ϕ ( ∞ ) has no flat areas, but when w i = d -i for d > 2 , the limiting function is constant on intervals ( w P ( -) , w ( P )] . This is reflected in Figure 1.
## C.7 Proof of Theorem C.1
We start with some preliminary lemmas. For a (possibly infinite) subset P of the positive integers, define
$$\beta _ { \infty } ( P ) = \sum _ { i \in P } 2 ^ { - i }.$$
We have the following analog of Lemma 6.1.
Lemma C.7 Suppose P , P 1 2 are two subsets of the positive integers. Then β ∞ ( P 1 ) ≤ β ∞ ( P 2 ) if and only if w P ( 1 ) ≤ w P ( 2 ) . Furthermore, if β ∞ ( P 1 ) < β ∞ ( P 2 ) then w P ( 1 ) < w P ( 2 ) .
glyph[negationslash]
Proof. Suppose that β ∞ ( P 1 ) ≤ β ∞ ( P 2 ) and P 1 = P 2 . Let i = min( P 2 \ P 1 ) . Then
$$w ( P _ { 2 } ) - w ( P _ { 1 } ) \geq w _ { i } - \sum _ { j = i + 1 } ^ { \infty } w _ { j } \geq 0.$$
Equality is only possible if max P 2 = i and P 1 = P 2 \{ }∪{ i i +1 , . . . , ∞} . However, in that case β ∞ ( P 1 ) = β ∞ ( P 2 ) .
glyph[negationslash]
There is a subtlety involved here: we can have β ∞ ( P 1 ) = β ∞ ( P 2 ) for P 1 = P 2 . This is because dyadic rationals (numbers of the form A 2 B ) have two different binary expansions. For example, 1 2 = (0 1000 . . . . ) 2 = (0 0111 . . . . ) 2 . The lemma states (in this case) that w ( { 1 } ) ≥ w ( { 2 3 4 , , , . . . } ) , but there need not be equality.
In the sequel, we will use the fact that each real r ∈ (0 1) , has a binary expansion with infinitely many 0 s (alternatively, a set P such that β ∞ ( P ) = r and there are infinitely many n / P ∈ ), and a binary expansion with infinitely many 1 s (alternatively, a set P such that β ∞ ( P ) = r and there are infinitely many n ∈ P ). If r is not dyadic, then it has a unique binary expansion which has infinitely many 0 s and 1 s. If r is dyadic, say r = 1 2 , then it has one expansion (0 1000 . . . . ) 2 with infinitely many 0 s and another expansion (0 0111 . . . . ) 2 with infinitely many 1 s.
The following lemma, which forms the first part of Theorem C.1, describes the analog of the intervals ( w P ( -) , w ( P )] in the infinite case.
Lemma C.8 Let q ∈ (0 , w ( ∞ )) . There exists a non-empty subset P of the positive integers such that either q = w P ( ) or P = { a , . . . , a 0 r } is finite and q ∈ ( w P ( -) , w ( P )] , where P -= { a , . . . , a 0 r -1 } ∪ { a r +1 , . . . , ∞} .
↦
Proof. Since q < w ( ∞ ) , for some m we have q ≤ w m ([ ]) . For n ≥ m , let A | n = A | n ( q ) . Let Q | n be the subset of [ n ] preceding A | n , and let R | n be the subset of [ n + 1] preceding A | n ; here 'preceding' is in the sense of X → X -. The interval ( w Q ( | n ) , w ( A | n )] splits into ( w Q ( | n ) , w ( R | n )] ∪ ( w R ( | n ) , w ( A | n )] , and so A | n +1 ∈ { R | n , A | n } . Also β ∞ ( A | n +1 ) ≤ β ∞ ( A | n ) , with equality only if A | n +1 = A | n .
We consider two cases. The first case is when for some integer M , for all n ≥ M we have A | n = A = { a , . . . , a 0 r } . In that case for all n ≥ M ,
$$\sum _ { t = 0 } ^ { r - 1 } w _ { a _ { t } } + \sum _ { t = a _ { r } + 1 } ^ { n } w _ { t } < q \leq \sum _ { t = 0 } ^ { r } w _ { a _ { t } },$$
and taking the limit n →∞ we obtain q ∈ ( w A ( -) , w ( A )] .
The other case is when A | n never stabilizes. The sequence β ∞ ( A | n ) is monotonically decreasing, and reaches a limit b satisfying b < β ∞ ( A | n ) for all n . Since w A ( | m ) ∈ ( w Q ( | n ) , w ( A | n )] for all integers m ≥ n ≥ 1 , Lemma C.7 implies that b ∈ [ β ∞ ( Q | n ) , β ∞ ( A | n )) .
Let L be a subset such that b = β ∞ ( L ) and there are infinitely many i / L ∈ , and define L | n = L ∩ [ n ] . We have b ∈ [ β ∞ ( L | n ) , β ∞ ( L | n ) + 2 -n ) . Therefore Q | n = L | n , and so q > w Q ( | n ) = w L ( | n ) . Taking the limit n →∞ , we deduce that q ≥ w L ( ) .
If n / L ∈ then A | n = Q | n ∪ { n } , and so q ≤ w A ( | n ) = w L ( | n ) + w n . Since there are infinitely many such n , taking the limit n →∞ we conclude that q ≤ w L ( ) and so q = w L ( ) .
We can now give an explicit formula for ϕ ( ∞ ) i .
Theorem C.1. Let q ∈ (0 , w ( ∞ )) and let i be a positive integer.
(a) There exists a non-empty subset of the positive integers P = { a , . . . , a 0 r } such that either q = w P ( ) or P is finite and q ∈ ( w P ( -) , w ( P )] , where P -= { a , . . . , a 0 r -1 } ∪ { a r +1 , . . . , ∞} .
- (b) The limit ϕ ( ∞ ) i ( q ) = lim n →∞ ϕ w | n i ( q ) exists. When i / P ∈ ,
$$\varphi _ { i } ^ { ( \infty ) } ( q ) = \sum _ { \substack { t \in \{ 0, \dots, r \} \colon \\ a _ { t } > i } } \, \frac { 1 } { a _ { t } \binom { a _ { t } - 1 } { t } },$$
and when i ∈ P , say i = a s , then
$$\varphi _ { i } ^ { ( \infty ) } ( q ) = \frac { 1 } { a _ { s } \binom { a _ { s } - 1 } { s } } - \sum _ { \substack { t \in \{ 0, \dots, r \} \colon \\ a _ { t } > i } } \, \frac { 1 } { a _ { t } \binom { a _ { t } - 1 } { t - 1 } }.$$
We comment that the convergence of the sums in the theorem is guaranteed by Lemma C.4.
Proof. The first part has been proved as Lemma C.8, and it remains to prove the second part.
Suppose first that P is finite P and either q = w P ( ) or q ∈ ( w P ( -) , w ( P )] . For all n ≥ max P , P | n ( q ) = P , and so Lemma C.5 shows that ϕ w | n i ( q ) = ϕ w | max P i ( q ) . Therefore the limit exists and equals the stated formula, which is the same as the one given by Theorem 6.1.
Suppose next that P is infinite and q = w P ( ) . Consider first the case in which we can also write q = w Q ( ) for some finite Q , say Q = { q 0 , . . . , q u } . Then P = { q 0 , . . . , q u -1 } ∪ { q u +1 , q u +2 , . . . , ∞} . We now consider several cases.
If i < q u and i / P ∈ then i / Q ∈ and
$$\varphi _ { i } ^ { ( \infty ) } ( q ) = \sum _ { \substack { t \in \{ 0, \dots, u \} ; \\ q _ { t } > i } } \frac { 1 } { q _ { t } \binom { q _ { t } - 1 } { t } } = \sum _ { \substack { t \in \{ 0, \dots, u - 1 \} ; \\ q _ { t } > i } } \frac { 1 } { q _ { t } \binom { q _ { t } - 1 } { t } } + \sum _ { \ell = 1 } ^ { \infty } \frac { 1 } { ( q _ { u } + \ell ) \binom { q _ { u } + \ell - 1 } { t + \ell - 1 } },$$
using Lemma C.4. The right-hand side is the expression we gave for ϕ ( ∞ ) i ( w P ( )) .
If i < q u and i ∈ P , say i = q s , then i ∈ Q and
$$\varphi _ { i } ^ { ( \infty ) } ( q ) = \frac { 1 } { i \binom { i - 1 } { s } } - \sum _ { \substack { t \in \{ 0, \dots, u \} ; \\ q _ { t } > i } } \frac { 1 } { q _ { t } \binom { q _ { t } - 1 } { t } } = \frac { 1 } { i \binom { i - 1 } { s } } - \sum _ { \substack { t \in \{ 0, \dots, u - 1 \} ; \\ q _ { t } > i } } \frac { 1 } { q _ { t } \binom { q _ { t } - 1 } { t } } - \sum _ { \ell = 1 } ^ { \infty } \frac { 1 } { ( q _ { u } + \ell ) \binom { q _ { u } + \ell - 1 } { t + \ell - 1 } } },$$
using Lemma C.4. The right-hand side is the expression we gave for ϕ ( ∞ ) i ( w P ( )) .
If i = q u then i ∈ Q and i / P ∈ . In that case
$$\varphi _ { i } ^ { ( \infty ) } ( q ) = \frac { 1 } { i \binom { i - 1 } { u } } = \sum _ { \ell = 1 } ^ { \infty } \frac { 1 } { ( i + \ell ) \binom { i + \ell - 1 } { u + \ell - 1 } },$$
using Lemma C.4. The right-hand side is the expression we gave for ϕ ( ∞ ) i ( w P ( )) .
Finally, if i > q u then i / Q ∈ and i ∈ P . Suppose that i is the v th member in P . In that case
$$\varphi _ { i } ^ { ( \infty ) } ( q ) = 0 = \frac { 1 } { i \binom { i - 1 } { v } } - \sum _ { \ell = 1 } ^ { \infty } \frac { 1 } { ( i + \ell ) \binom { i + \ell - 1 } { v + \ell - 1 } },$$
using Lemma C.4. The right-hand side is the expression we gave for ϕ ( ∞ ) i ( w P ( )) .
It remains to consider the case in which q cannot be written as q = w Q ( ) for finite Q . In that case, there are infinitely many positive integers n such that n ∈ P and infinitely many such that n / P ∈ . This implies that for every positive integer n , q ∈ ( w P ( ∩ [ n ]) , w ( P ∩ [ n ]) + w n ) , and so P | -n ( q ) = P ∩ [ n ] . Lemma 6.4 shows that | ϕ n ( q ) -ϕ n ( w P ( ∩ [ n ])) | ≤ 1 n . On the other hand, Theorem 6.1 readily implies that ϕ n ( w P ( ∩ [ n ])) tends to the expression we gave for ϕ ( ∞ ) i ( w P ( )) . We conclude that ϕ n ( q ) tends to the same expression.
## C.8 Proof of Theorem C.2
First, we recall the statement of Theorem C.2.
Theorem C.2. Let i be a positive integer. The function ϕ ( ∞ ) i is continuous on (0 , w ( ∞ )) , and lim q → 0 ϕ ( ∞ ) i ( q ) = lim q → w ( ∞ ) ϕ ( ∞ ) i ( q ) = 0 .
Proof. Let q ∈ (0 , w ( ∞ )) . We start by showing that ϕ ( ∞ ) i is continuous from the right at q . Lemma C.8 shows that we can find a subset P such that either q = w P ( ) or q ∈ ( w P ( -) , w ( P )] . If q < w P ( ) then since ϕ ( ∞ ) i is constant on ( w P ( -) , w ( P )] according to Theorem C.1, clearly ϕ ( ∞ ) i is continuous from the right at q . Therefore we can assume that q = w P ( ) . Since q < w ( ∞ ) , we can further assume that there are infinitely many n / P ∈ .
Suppose that we have a sequence q j tending to q strictly from the right. For each j we can find a subset P j such that either q j = w P ( j ) or q j ∈ ( w P ( -j ) , w ( P j )] . We can assume that the second case doesn't happen by replacing q j with w P ( -j ) ; the new sequence still tends to q strictly from the right. So we can assume that q j = w P ( j ) > w P ( ) . Let k j ( ) = min( P j \ P ) , and let l ( j ) > k j ( ) be the smallest index larger than k j ( ) such that l ( j ) / P ∈ . Then
$$q _ { j } - q = w ( P _ { j } ) - w ( P ) \geq w _ { k ( j ) } - \left ( \sum _ { t = k ( j ) + 1 } ^ { \infty } w _ { t } - w _ { l ( j ) } \right ) \geq w _ { l ( j ) }.$$
As j → ∞ , l ( j ) → ∞ and so k j ( ) → ∞ . Therefore we can assume without loss of generality that k j ( ) > i for all j . Theorem C.1 then implies that
$$| \varphi _ { i } ^ { ( \infty ) } ( q _ { j } ) - \varphi _ { i } ^ { ( \infty ) } ( q ) | \leq \sum _ { s = 0 } ^ { \infty } \frac { 1 } { ( k ( j ) + s ) \binom { k ( j ) + s - 1 } { s } } = \frac { 1 } { k ( j ) - 1 },$$
using Lemma C.4. Since k j ( ) →∞ , ϕ ( ∞ ) i ( q j ) → ϕ ( ∞ ) i ( q ) .
We proceed to show that ϕ ( ∞ ) i is continuous from the left at q . Lemma C.8 shows that we can find a subset P such that either q = w P ( ) or q ∈ ( w P ( -) , w ( P )] . In the second case, since ϕ ( ∞ ) i is constant on ( w P ( -) , w ( P )] according to Theorem C.1, clearly ϕ ( ∞ ) i is continuous from the left at q . Therefore we can assume that q = w P ( ) . Since q > 0 , we can further assume that there are infinitely many n ∈ P .
Suppose that we have a sequence q j tending to q strictly from the left. For each j we can find a subset P j such that either q j = w P ( j ) or q j ∈ ( w P ( -j ) , w ( P j )] , and in both cases q j ≤ w P ( j ) < w P ( ) . Let k j ( ) = min( P \ P j ) , and let l ( j ) > k j ( ) be the smallest index larger than k j ( ) such that l ( j ) ∈ P . Then
$$q - q _ { j } \geq w ( P ) - w ( P _ { j } ) \geq w _ { k ( j ) } + w _ { l ( j ) } - \sum _ { t = k ( j ) + 1 } ^ { \infty } w _ { t } \geq w _ { l ( j ) }.$$
At this point we can prove that ϕ ( ∞ ) i ( q j ) → ϕ ( ∞ ) i ( q ) as in the preceding case.
It remains to show that lim q → 0 ϕ ( ∞ ) i ( q ) = lim q → w ( ∞ ) ϕ ( ∞ ) i ( q ) = 0 . We start by showing that lim q → 0 ϕ ( ∞ ) i ( q ) = 0 . Let q j be a sequence tending to 0 strictly from the right. As before, we can assume that q j = w P ( j ) for each j . Let k j ( ) = min P j . Since q j ≥ w k j ( ) , k j ( ) →∞ . Therefore we can assume without loss of generality that k j ( ) > i for all j . Theorem C.1 then implies that
$$\varphi _ { i } ^ { ( \infty ) } ( q _ { j } ) \leq \sum _ { s = 0 } ^ { \infty } \frac { 1 } { ( k ( j ) + s ) \binom { k ( j ) + s - 1 } { s } } = \frac { 1 } { k ( j ) - 1 },$$
using Lemma C.4. Since k j ( ) →∞ , ϕ ( ∞ ) i ( q j ) → 0 .
We finish the proof by showing that lim q → w ( ∞ ) ϕ ( ∞ ) i ( q ) = 0 . Let q j be a sequence tending to M strictly from the left. As before, we can find subsets P j such that q j ≤ w P ( j ) and ϕ ( ∞ ) i ( q j ) = ϕ ( ∞ ) i ( w P ( j )) . Let k j ( ) be the minimal k / P ∈ j . Since q j ≤ w ( ∞ -) w k j ( ) , k j ( ) → ∞ . Therefore we can assume without loss of generality that k j ( ) > i for all j . Theorem C.1 implies that
$$\varphi _ { i } ^ { ( \infty ) } ( q _ { j } ) \leq \frac { 1 } { i \binom { i - 1 } { i - 1 } } - \sum _ { \ell = 1 } ^ { k ( j ) - 1 - i } \frac { 1 } { ( i + \ell ) \binom { i + \ell - 1 } { i + \ell - 2 } } = \frac { 1 } { k ( j ) - 1 },$$
using Lemma C.4. Since k j ( ) →∞ , ϕ ( ∞ ) i ( q j ) → 0 . | null | [
"Joel Oren",
"Yuval Filmus",
"Yair Zick",
"Yoram Bachrach"
] | 2014-08-03T00:15:02+00:00 | 2014-08-03T00:15:02+00:00 | [
"cs.GT"
] | Power Distribution in Randomized Weighted Voting: the Effects of the Quota | We study the Shapley value in weighted voting games. The Shapley value has
been used as an index for measuring the power of individual agents in
decision-making bodies and political organizations, where decisions are made by
a majority vote process. We characterize the impact of changing the quota
(i.e., the minimum number of seats in the parliament that are required to form
a coalition) on the Shapley values of the agents. Contrary to previous studies,
which assumed that the agent weights (corresponding to the size of a caucus or
a political party) are fixed, we analyze new domains in which the weights are
stochastically generated, modelling, for example, elections processes.
We examine a natural weight generation process: the Balls and Bins model,
with uniform as well as exponentially decaying probabilities. We also analyze
weights that admit a super-increasing sequence, answering several open
questions pertaining to the Shapley values in such games. |
1408.0443v1 | ## Ranking the Economic Importance of Countries and Industries
Wei Li, Dror Y. Kenett, and H. Eugene Stanley
Center for Polymer Studies and Department of Physics, Boston University, Boston, USA
## Kazuko Yamasaki
Department of Environmental Sciences, Tokyo University of Information Sciences, Japan
## Shlomo Havlin
Department of Physics, Bar-Ilan University, Israel
(Dated: August 5, 2014)
## Abstract
In the current era of worldwide stock market interdependencies, the global financial village has become increasingly vulnerable to systemic collapse. The recent global financial crisis has highlighted the necessity of understanding and quantifying interdependencies among the world's economies, developing new effective approaches to risk evaluation, and providing mitigating solutions. We present a methodological framework for quantifying interdependencies in the global market and for evaluating risk levels in the world-wide financial network. The resulting information will enable policy and decision makers to better measure, understand, and maintain financial stability. We use the methodology to rank the economic importance of each industry and country according to the global damage that would result from their failure. Our quantitative results shed new light on China's increasing economic dominance over other economies, including that of the USA, to the global economy.
## INTRODUCTION
The growth of technology, globalization, and urbanization has caused world-wide human social and economic activities to become increasingly interdependent [1-13]. From the recent financial crisis it is clear that components of this complex system have become increasingly susceptible to collapse. Integrated models, currently in use, have been unable to predict instability, provide scenarios for future stability, or control or even mitigate systemic failure. Thus, there is a need of new ways of quantifying complex system vulnerabilities as well as new strategies for mitigating systemic damage and increasing system resiliency [14, 15]. Achieving this would also provide new insight into such key issues as financial contagion [16, 17] and systemic risk [18-20] and would provide a way of maintaining economic and financial stability in the future.
It is clear from the recent crisis that different sectors of the economy are strongly interdependent. The housing bubble in the USA caused a liquidity freeze in the international banking system, which in turn triggered a massive slowdown of the real economy costing many trillions of dollars and threatening the financial integrity of the European Union. This demonstrates the high level of dependence between different components in the world economic system. Because strong nonlinearities and feedback loops make economic systems highly vulnerable, we need to understand the behavior of the interacting networks that comprise the economy. How do they interact with each other, and what are their vulnerabilities? One may consider an industry in two countries respectively, for example, electrical equipment industry in China and the USA, and ask which industry is more important to economic stability, electrical equipment in China or that in the USA? Is electrical equipment in China more critical for global economy stability when the production in electrical equipment in China is reduced, and how it will impact the industries within the country and industries abroad.
To answer these questions, we employ recent advances in the theory of cascading failures in interdependent networks [21-23]. In the case of interdependent networks, a malfunction of only a few components can lead to cascading failures and to a sudden collapse of the entire system. This is in contrast to single isolated networks, which tend to collapse gradually [24]. These recent results indicate the central importance of interconnectivity and interdependency to the stability of the entire system. There have been studies of the complex set
of coupled economic networks [25-28]. However, the importance of countries and industries in the stability of the global economy have not been analyzed, and there is a need for useful methods to quantify and rank their economic importance and influence.
The input-output (IO) model is a technique that quantifies interdependency in interconnected economic systems. Wassily Leontief [29] first introduced the IO model in 1951, for which he received the Nobel Prize in Economics in 1973. It can be used to study the effect of consumption shocks on interdependent economic systems [30-36]. Analysis of IO data is performed using such techniques as the hypothetical extraction method (HEM) [37, 38]. Although HEM can measure the relative stimulative importance of a given industry by calculating output with and without the industry being examined, it does not quantify each industry's full spectrum of importance to the stability of global economic system. For example, if an industry in a given country collapses completely due to natural disaster or civil unrest it will no longer be able to consume products supplied by other industries. This can cause cascading failure in the economic system if the other industries cannot function when the cash flow from the failed industry is removed. By measuring how widely the damage spreads, we will rank here an industry's importance within the world-wide economic system.
In this paper we examine the interdependent nature of economies between and within 14 countries and the rest of the world (ROW). We use an 'input-output table' [39] and focus on economic activity during the period 1995-2011. From the table we analyze data from 14 countries (Australia, Brazil, Canada, China, Germany, Spain, France, UK, India, Italy, Japan, Korea, Russia, and USA) and from the rest of the world (ROW). The economic activity in each country is divided into 35 industrial classifications. Each cell in the table shows the output composition of each industry to all other 525 industries and its final demand and export to the rest of the world (see Ref. [40]). We construct an output network using the 525 industries as nodes and the output product values as weighted links based on the input-output table, and focus on the output product value for each industry.
Our goal is to introduce a methodology for quantifying the importance of a given industry in a given country to global economic stability with respect to other industries in countries that are related to this industry. Thus, we study the inflow and outflow of money between each set of 35 industries and the ROW in each of the 14 countries (see the Data section for more detail). We use the theory of cascading failures in interdependent networks to gain valuable information on the local and global influence on global stability of different
economic industries, a methodology that can provide valuable new insights and information to present-day policy and decision makers.
## WORLD INPUT-OUTPUT TABLE DATA
The database we use in this study is the World Input-Output Table (WIOT) [40]. It provides data for 27 European countries, 13 other countries, and the rest of the world (ROW) for the period 1995-2011. For our sample, we select the 14 countries with the largest domestic input and the largest import in production in 2011 and also the ROW (adding the remaining 26 countries into the ROW). Using this sample, we construct a new input-output industry-by-industry table. For sake of simplicity, we assume that each industry produces only one unique product. In the WIOT, the column entries represent an industry's inputs and the row entries represent an industry's outputs. The rows in the upper sections indicate the intermediate or final use of products. A product is intermediate when it is used in the production of other products (intermediate use). The final use category includes domestic use (private or government consumption and investment) and exports. The final element in each row indicates the total use of each product. The industry columns in the WIOT contain information on the supply of each product. The columns indicate the values of all intermediate, labor, and capital inputs used in production. Total supply of the product in the economy is determined by domestic input plus final demand. The IO table contains negative numbers as outputs for various reasons [39], but their fraction is fairly small and their values are small as well. For simplicity, we set these negative numbers as zero in our analysis.
Based on the supply of the product for each industry, it is possible to construct a directed product supply network. Then we reverse the direction of the links in the network (see schematic representation in Fig. 1), and the network represents the money outflow from one industry to another; e.g., electrical equipment industry is pointing to machinery industry because electrical equipment industry buys a product from machinery industry. The links are weighted according to the value of products from machinery industry as its output electrical equipment industry as its input.
## INDUSTRY TOLERANCE
In order to quantify and rank the influence of industries in the stability of this global network, we perform a cascading failure tolerance analysis [21]. Our model is described as follows. Suppose industry A fails, other industries can no longer sell their products to industry A and thus they lose that revenue. The revenue industry B is reduced by a fraction p ′ , which is defined as industry B's revenue reduction caused by the failure of industry A divided by that industry B's total revenue. The tolerance fraction p is the threshold above which an industry fails. This occurs when reduced revenue fraction p ′ is larger than tolerance fraction p . Here we assume that (i) p is the same for all industries and that every industry fails when its p ′ > p and (ii) the failure of an industry in country A does not reduce the revenue of the other industries in the same country A because they are able to quickly adjust to the change.
The methodology can be schematically illustrated as follows: In step 1, industry A in country i fails. This causes other industries in other countries to fail if their p ′ > p . Assume that in step 2 industries B C , , and D fail. The failure of these industries in step 2 will reduce other industries' revenue and cause more industries including those in country i to have a reduced fraction p ′ . Thus in step 3 there is an increased number of industries whose p ′ > p . Eventually the system reaches a steady state in which no more industries fail. The surviving industries will all have a reduced revenue fraction that is smaller than the tolerance fraction, i.e., p ′ ≤ p . Figure 1 demonstrates this process, and the subfigures show the steps in the cascading failure.
To determine how much the failure of each industry would impact the stability of the economic network, we change the tolerance fraction p from 0 to 1 and measure the fraction of surviving industries left in the network. When the tolerance fraction approaches 0, any revenue reduction caused by the failure of one industry can easily destroy almost all the other industries in the network, and the network will collapse. When the tolerance fraction approaches 1, all the industries can sustain a large reduction of revenue and the failure of one industry will not affect the others.
Figure 2(a) shows the failures of electrical equipment industry in China and energy industry in the United States for the 2009 WIOT and shows the fraction of the largest cluster of connected and functional industries as a function of the tolerance fraction p after
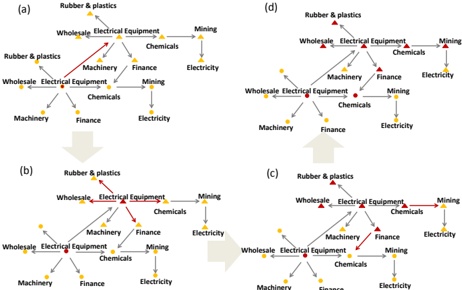
Finance
FIG. 1: Schematic representation of each step in the cascading failure propagation in the world economic network. We present an example of two countries, where circle nodes represent country 1, and triangles represent country 2. Both countries have the same industries, and the arrow between two nodes points in the direction of money flow. (a) There is a failure in electrical equipment industry in Country 1 (circle) which causes a failure of electrical equipment industry in Country 2. In (b) the failure of electrical equipment industry in Country 2 will cause rubber and plastics, wholesale, finance and chemicals in Country 2 to fail. (c) Shows mining in Country 2 and chemicals in Country 1 to fail further. (d) The network reached a steady state. The red nodes represent the failing industries and the yellow nodes stand for the surviving industries.
the Chinese electrical equipment industry becomes malfunction and is removed from the network due to a large shock to this industry. The shock could result from different causes, such as natural environmental disaster, government policy changes, insufficient financial capability. The removal of China electrical equipment industry will cause revenue reduction in other industries because China electrical equipment industry is not able to buy products and provide money to other industries. When p is small, the industries are fragile and sensitive to the revenue reduction, causing most of the industries fail, and the number of the surviving industries is very small. When p is large, the industries can tolerate large revenue reduction and are more robust when revenue decreases. The number of the surviving industries tends to increase abruptly at a certain p = p c value as p increases. Figure 2(b) shows the number of cascading steps that elapse before a stable state is reached as a function of tolerance fraction p after removing the Chinese electrical equipment industry or the USA
## China Electrical Equipment
## USA Energy
FIG. 2: Typical examples of industry tolerance threshold p c . Tolerance threshold p c shows the importance of each industry in the international industry networks. In (a) the black curve shows the fraction of surviving industries as a function of tolerance threshold for the case when the electrical equipment industry in China fails in year 2009 and the red curve represents the case of the failure of energy industry in 2009 in the USA. (b) Shows the number of failure steps as a function of p corresponding to (a). The total number of steps is the number of cascades it takes for the network to reach a steady state after certain initial failure. The peaks in (b) are corresponding to the abrupt jumps in (a), which means that large numbers of cascade steps are associated at p c with a dramatic failures in the industry network. Each step in the cascading process in (b) is demonstrated in Figure 1.
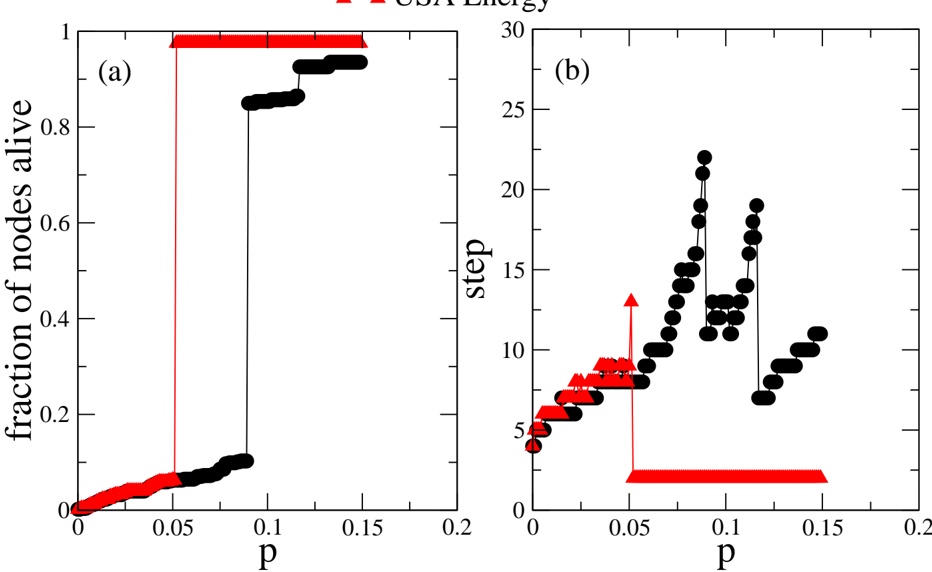
energy industry. The number of steps reaches a peak when p approaches criticality p c [24].
Here we analyze for each of the 525 industries this important parameter, the critical tolerance threshold p c . Our goal is to determine the threshold p c at which global network subject to collapse becomes stable and most of the industries in the network survive after initial failures. To this end, we assume that the p c is the critical threshold below which less
than 30% of industries survive. When p > p c , more than 30% of the remaining industries survive after the failure cascade in the system is over. When p < p c , the survival rate of the remaining industries is 30% or less. The higher this threshold, the higher the impact of a failing industry will be on the vulnerability of the global network. Without losing generalization, we also take different fraction of surviving industries to set p c in simulations. For example, when the p c is the threshold below which 50% of industries survive, the importance of industries and countries maps are shown as in supplementary information. The correlation of p c values in simulations using 50% fraction of surviving industries and 30% surviving industries is 1 and the p c are identical in both scenarios. Thus, we find that the critical threshold p c is not sensitive to the chosen fraction in this industry network, for values below 50%. The following p c in this study is defined as the critical threshold below which less than 30% of industries survive.
We use this methodology to test how the failure of an individual industry in a given country impacts the stability of the entire system. Thus, p c of an industry is our measure of the importance of this industry in the global economic network.
Using the tolerance threshold p c , we can quantify and rank the economic importance of each industry. We measure the tolerance threshold of 35 industries in 14 countries between 1995 and 2011. We calculate the tolerance of each industry according to how much it affects the entire network, i.e., all 35 industries in all 14 countries.
## IMPORTANCE OF COUNTRY AND INDUSTRY
The proposed methodology provides the means to quantify and rank the importance of each industry to the stability of the global economic network or the importance of each country in the global economic network.
We define the importance of each country by averaging all the 35 industries p c within the country for a specific year,
$$I _ { c o u n t r y } ( i ) \equiv \frac { 1 } { n } \sum _ { k = 1 } ^ { n } p _ { c } ( i, k )$$
where n is the number of industries. To rank the importance of a given country, we average the tolerance across industries as shown in Eq. 1.
Figure 3(a) shows the importance of all countries for different years where the average in
FIG. 3: Ranking the importance of individual industries or countries. (a) Map of averaging industry tolerances for each country, I country . The average tolerance p c is calculated by averaging the largest four p c for each country in one year. The color represents the strength of the tolerance, ranging from blue for low tolerance, to red for high tolerance. (b) Averaging industry tolerance over 17 years (1995-2011). The average tolerance p c is calculated by averaging the industry tolerance over 17 years for each country (for presentation sake, we plot only the top 20 industries with respect to their I industry value).
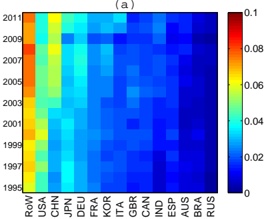
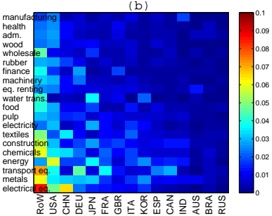
The values are represented using the same color code.
Eq. 1 is taken over the four largest p c values, in order to consider the strongest industries. Note that the rest of the world (RoW) is the most important 'country' since it includes many countries other than the 14 countries included in the sample. Countries in RoW provide products that are crucial inputs to these 14 countries and their industries. We also define the importance of the individual industries in terms of the average of their p c ,
$$I _ { i n d u s t r y } ( i ) \equiv \frac { 1 } { T } \sum _ { j = 1 } ^ { T } p _ { c } ( i, t ),$$
where T denotes years. Figure 3(b) shows the average tolerance of industry over all years (1995-2011) for the individual countries. For the sake of clarity, we plot only the top 20 industries with respect to the average of I industry values for all the countries. Note that the electrical equipment industry is the most important when we average the tolerance fraction p c across 17 years. The energy industry p c in the United States, for example, is relatively high because the United States is the world's largest energy consumer.
## ROBUSTNESS AND STABILITY OF ECONOMIC STRUCTURE
We use the critical tolerance threshold p c to measure the importance of each industry in the global economic network. We can also rank each industry according to their tolerance p c ( i, k ) for each separate country-the tolerance of industry i in country k . By comparing industry order rankings for different years, we can study the similarity in economic environment across a period of 17 years.
To do this we use the Kendall τ coefficient [41], which measures rank correlation, i.e., the similarity in data orderings when ranked by each quantity. Let ( x , y 1 1 ) , ( x , y 2 2 ) , . . . , ( x , y n n ) be a set of observations of the random variables X and Y respectively. Any pair of observations ( x i ) and ( y i ) is concordant if the ranks for both elements agree, that is if x i < x j and y i < y j or if x i > x j and y i > y j . Otherwise the pair is discordant. If x i = x j or y i = y j , the pair is neither concordant nor discordant. The Kendall τ coefficient is defined as
$$\tau = \frac { n _ { + } - n _ { - } } { \frac { 1 } { 2 } n ( n - 1 ) },$$
where n + is the number of concordant pairs and n -is the number of discordant pairs. The coefficient τ is in the range -1 ≤ τ ≤ 1. When the agreement between the two rankings is perfect, the coefficient is 1. When the disagreement between the two rankings is perfect, the coefficient is -1. If X and Y are independent, the coefficient is approximately zero.
We use the Kendall τ to investigate the evolution of the economic structure of each country in our sample. For each year, we rank the industries in each country according to their tolerance values, and calculate the Kendall τ for every year pair. Figure 4 shows the values of the Kendall τ for all pairs of years, for China (Fig. 4(a)), USA (Fig. 4(b)), and Germany (Fig.4(c)), using a color code ranging from blue, for low similarity, to red, for high similarity (see Supplementary Information for all other countries). For these three countries, we find different behaviors in terms of the stability and consistency of the economic structures. For the case of China, we observe that the structure changes significantly, with high values of the Kendal correlation (represented using red) only presenting for previous 2 ∼ 3 years (as can be observed from the diagonal of elements of Fig. 4(a)). However, in the case of the USA, it is possible to observe three periods in terms of stability of the economic structure: 1995-1999, 2000-2007, and 2008-2011 (see Fig. 4(b)). The first marks the period leading to the 'dot.com' crisis, which was followed by a significant change in the
FIG. 4: Kendall correlation coefficient heat map shows the industry rank correlation coefficient between each pair of years from 1995 -2011. Using Kendall correlation coefficient τ , we investigate the evolution of the economic structure of the investigated countries. For each year, we rank the industries in each country according to their tolerance values, and then calculate the Kendall τ for every pairs of years. We plot the values of the Kendall τ for all pairs of years, for China (top), USA (middle), and Germany (bottom), using a color code ranging from blue, for low similarity, to red, for high similarity (see Supplementary Information for all other countries).
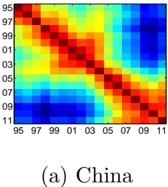
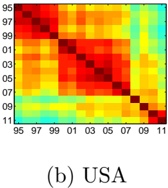
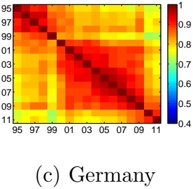
US market structure. The second marks the period leading unto the financial crisis, which again was followed by a significant change in the US market structure. Finally, the third marks the period following the financial crisis, which shows no stable period in terms of market structure. Finally, in the case of Germany, we observe only two periods: 1995-1999, and 2000-2011 (see Fig. 4(c)). The first period can be also attributed to that apparent in the case of the USA, however possibly to a lesser extent and also resulting from the introduction of the Euro currency. However, in the case of Germany we do not observe a change in structure following the recent financial crisis, which highlights the degree of stability in the German economy.
## THE RISE OF CHINA
Due to the fact that economic influence is dynamic across time, we ask whether the methodology presented here can provide new information on the increase or decline of economic importance. In each year we calculate the individual industry tolerance as described above. We then calculate the average tolerance of each country for a given year. Figure 5 shows the average of p c of country for the 17-year period investigated. In Figure 5(a), we show the largest tolerance p c in China, the USA and Germany along 17 years. Figure 5(b)
shows the average of 4 largest industries p c , and Figure 5(c) shows the average of 8 largest p c in each country.
We find that the average tolerance p c of China becomes larger than that of the USA after 2003, which is most pronounced in Figure 5(b). The USA tolerance p c first increases from 1995 to 2000, then decreases from 2000 to 2009, with a slight increase in 2010-2011. Germany's tolerance p c in general increase in the investigated period and shows certain fluctuations between 2000 and 2005. Note that for the USA the change across time is minor but that the economic importance of China increases significantly. The economic importance of China relative to that of the USA shows a consistent increase from year to year, illustrating how the economic power structure in the world's economy has been changing during time.
To further validate these results, we compare the total product output (see Figure 6, red triangle) and average tolerance p c (see Figure 6, black circles) for China, USA, and Germany, as a function of time. The product output (see Figure 6, red triangle) value is the total money flow a country supplies to the other countries plus value added in the products, which also indicates its total trade impact on foreign countries. Studying Figure 6, we find that generally speaking the total outputs of the three investigated countries grows throughout time, with that of the USA and China being higher in value than that of Germany (see Figure 6, right y-axis). However, by comparing the tolerance p c , we find three different behaviors. First, for the case of China (Figure 6(a)), we find that both the tolerance p c and total outputs are growing in time, and observe that in the early 2000's there was a jump in the tolerance p c , following by a sharp increase in the total output. Secondly, for the case of the USA (Figure 6(b)), we find that while the total output is increasing in time, the tolerance p c is in a decreasing trend. Finally, for the case of Germany (Figure 6(c)), we find that while the total import is increasing in time, the tolerance p c is rather stable with small fluctuations.
This provides further evidence into the change in influence of these three important economies - that of China is increasing, that of the US is declining, and that of Germany is rather constant across time. Comparing the total output to the tolerance p c provides further evidence that the tolerance measurement of country's impact reveals the underlying economic evolving dependencies which is not obvious from the simple measurement of total output capability.
FIG. 5: Tolerance p c changes of China, the USA and Germany for 17 years. We show that the average tolerance p c increases from 1995 to 2011. In (a), we shows the largest tolerance p c in China, the USA and Germany along 17 years. (b) Shows the average of 4 largest p c in each country. We can see the p c of China becomes larger than the USA after 2003. (c) Shows the average of 8 largest p c in each country. The difference between the average p c of China and that of the USA is smaller compared to that in (b) in years 2005-2011. This is because the average includes more industries with small p c and mainly the importance of large industries increase. The USA tolerance p c first increases from 1995 to 2000, then slightly decreases from 2000 to 2009, with a small increase in 2010-2011. Germany's tolerance p c in general slightly increases in the 17-year period and shows small fluctuations between 2000 and 2005.
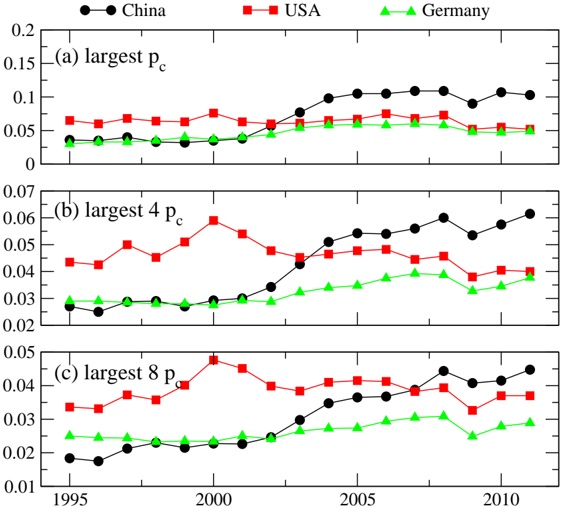
## CONCLUSIONS
We developed a framework to quantify interdependencies in the world industrial network and measure risk levels in global markets. We use the methodology to rank the economic importance of each industry and country according to the global damage that would result from their failures. Using network science to investigate input-output data of money flows between different economic industries, it becomes possible to stress test the global economic
FIG. 6: Tolerance p c of China, the USA and Germany comparing to the total product output value. For each country, the p c is an average of the largest four industry p c of this country (black circles). The product output (red triangle) value is the money flow a country supplies to the rest of the countries, which also indicates its impact to foreign countries. In (a) and (c), the trends of the p c and output value are similar, which indicate that China and Germany become more influential to the world economy. In (b), the p c of the USA increases in the period of year 1995 to year 2000, and decreases from 2000 to 2011, while the output value increases from 1995 to 2011 in general.
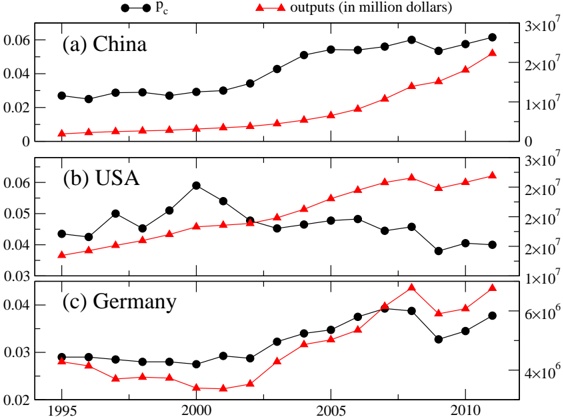
network and identify vulnerabilities and sources of systemic risk. Our quantitative results shed new light on China's increasing economic influence over other economies, including that of the USA. The resulting information will enable policy and decision makers to better measure, understand, and maintain financial stability.
We would like to thank the European Commission FET Open Project FOC 255987 and FOC-INCO 297149 for financial support. We wish to thank the ONR, DTRA, DFG, EU project, Multiplex and LINC, EU projects, the Keck Foundation, and the Israel Science Foundation for financial support.
[1] D. Helbing and S. Balietti. Fundamental and real-world challenges in economics. Science and Culture , 76(9-10):1680262, 2010.
- [2] S. Havlin, D. Y. Kenett, E. Ben-Jacob, A. Bunde, R. Cohen, H. Hermann, JW Kantelhardt, J. Kert´sz, S. Kirkpatrick, J. Kurths, et al. e Challenges in network science: Applications to infrastructures, climate, social systems and economics. European Physical Journal-Special Topics , 214(1):273, 2012.
- [3] M. San Miguel, J.H. Johnson, J. Kertesz, K. Kaski, A. D´ ıaz-Guilera, R.S. MacKay, V. Loreto, P. Erdi, and D. Helbing. Challenges in complex systems science. The European Physical Journal Special Topics , 214:245-271, 2012.
- [4] D. Helbing. Systemic risks in society and economics. Social Self-Organization , pages 261-284, 2012.
- [5] David Lazer, Alex Sandy Pentland, Lada Adamic, Sinan Aral, Albert Laszlo Barabasi, Devon Brewer, Nicholas Christakis, Noshir Contractor, James Fowler, Myron Gutmann, et al. Life in the network: the coming age of computational social science. Science (New York, NY) , 323(5915):721, 2009.
- [6] G. King. Ensuring the data-rich future of the social sciences. Science , 331(6018):719, 2011.
- [7] Jan Lorenz, Heiko Rauhut, Frank Schweitzer, and Dirk Helbing. How social influence can undermine the wisdom of crowd effect. Proceedings of the National Academy of Sciences , 108(22):9020-9025, 2011.
- [8] Kazuko Yamasaki, Takeshi Fujiwara, Kousuke Yoshizawa, Shuhei Miyake, Zeyu Zheng, Xiang Gao, and Naoko Sakurai. The complex network study of money and co2 emission flows between industrial sectors in asian countries using input-output table. In Proceedings of International Conference on Business Management & IS , number 1, 2012.
- [9] Bo Meng and Satoshi Inomata. Production networks and spatial economic interdependence: An international input-output analysis of the asia-pacific region. 2009.
- [10] Steven Rinaldi, James Peerenboom, and Terrence Kelly. Identifying, understanding, and analyzing critical infrastructure interdependencies. Control Systems , IEEE 21(6): 11-25, 2001.
- [11] S. Solomon, and M. Levy. Pioneers on a New Continent: Physics and Economics, Quantitative Finance , 3, 1, 12-16, 2003.
- [12] M. Levy. Scale-Free Human Migration and the Geography of Social Networks, Physica A , 389, 4913-4917, 2010.
- [13] P. Klimek, R. Hausmann, and S. Thurner. Empirical confirmation of creative destruction from world trade data. PLoS One , 7(6) 2012.
- [14] J. Doyne Farmer and Duncan Foley. The economy needs agent-based modelling. Nature , 460(7256):685-686, 2009.
- [15] T. Lux and F. Westerhoff. Economics crisis. Nature Physics , 5(1):2-3, 2009.
- [16] Kristin Forbes and Roberto Rigobon. Measuring contagion: conceptual and empirical issues. In International financial contagion, pages 43-66. Springer, 2001.
- [17] Kristin J Forbes and Roberto Rigobon. No contagion, only interdependence: measur- ing stock market comovements. The Journal of Finance, 57(5):2223-2261, 2002.
- [18] Z. Bodie, A. Kane, and A. J. Marcus. Investments . McGraw-Hill/Irwin, 2002.
- [19] Monica Billio, Mila Getmansky, Andrew W Lo, and Loriana Pelizzon. Econometric measures of systemic risk in the finance and insurance sectors. Technical report, National Bureau of Economic Research, 2010.
- [20] Dimitrios Bisias, Mark Flood, Andrew Lo, and Stavros Valavanis. A survey of systemic risk analytics. US Department of Treasury, Office of Financial Research, (0001), 2012.
- [21] S.V. Buldyrev, R. Parshani, G. Paul, H.E. Stanley, and S. Havlin. Catastrophic cascade of failures in interdependent networks. Nature , 464(7291):1025-1028, 2010.
- [22] J. Gao, S.V. Buldyrev, H.E. Stanley, and S. Havlin. Networks formed from interdependent networks. Nature Physics , 8(1):40-48, 2011.
- [23] Wei Li, Amir Bashan, Sergey V Buldyrev, H Eugene Stanley, and Shlomo Havlin. Cascading failures in interdependent lattice networks: The critical role of the length of dependency links. Physical Review Letters , 108(22):228702, 2012.
- [24] Roni Parshani, Sergey V Buldyrev, and Shlomo Havlin. Interdependent networks: reducing the coupling strength leads to a change from a first to second order percolation transition. Physical review letters , 105(4):048701, 2010.
- [25] A. Garas, P. Argyrakis, C. Rozenblat, M. Tomassini, and S. Havlin. Worldwide spreading of economic crisis. New journal of Physics , 12(11):113043, 2010.
- [26] F. Schweitzer, G. Fagiolo, D. Sornette, F. Vega-Redondo, A. Vespignani, and D.R. White. Economic networks: The new challenges. Science , 325(5939):422-425, 2009.
- [27] X. Huang, I. Vodenska, S. Havlin, H.E. Stanley Cascading failures in bi-partite graphs: model for systemic risk propagation. Scientific reports , 3, 2013.
- [28] C. Hidalgo, and R. Hausmann. A Network View of Economic Development. Developing Alternatives , 12(1), 5-10, 2008.
- [29] Wassily W Leontief, Erik Dietzenbacher, and Michael L Lahr. Wassily Leontief and inputoutput economics . Cambridge University Press, 2004.
- [30] Walter Isard. Methods of regional analysis: an introduction to regional science. Technical report, 1960.
- [31] Michael L Lahr and Erik Dietzenbacher. Input-output analysis: frontiers and extensions . Palgrave, 2001.
- [32] Thijs Ten Raa. The economics of input-output analysis . Cambridge University Press, 2005.
- [33] Ronald E Miller and Peter D Blair. Input-output analysis: foundations and extensions . Cambridge University Press, 2009.
- [34] Joost R Santos. Inoperability input-output modeling of disruptions to interdependent economic systems. Systems Engineering , 9(1):20-34, 2006.
- [35] Vladimir N Pokrovskii. Econodynamics: the theory of social production , volume 12. Springer, 2012.
- [36] Wassily Leontiev. Input output economics . Oxford University Press, 1986.
- [37] Ronald E Miller and Michael Lahr. A taxonomy of extractions. Regional Science Perspectives In Economic Analysis: A Festschrift In Memory of Benjamin H. Stevens, Michael L. Lahr, Ronald E. Miller, eds., Elsevier Science, pages 407-441, 2001.
- [38] Umed Temurshoev. Identifying optimal sector groupings with the hypothetical extraction method. Journal of Regional Science, 50(4):872-890, 2010.
- [39] Marcel Timmer and AA Erumban. The world input-output database (wiod): Contents, sources and methods. WIOD Background document available at www. wiod. org , 2012.
- [40] World input-output data table, http://www.wiod.org.
- [41] Maurice G Kendall. A new measure of rank correlation. Biometrika, 30:81-93, 1938. | null | [
"Wei Li",
"Dror Y. Kenett",
"Kazuko Yamasaki",
"H. Eugene Stanley",
"Shlomo Havlin"
] | 2014-08-03T00:19:50+00:00 | 2014-08-03T00:19:50+00:00 | [
"q-fin.GN",
"physics.soc-ph"
] | Ranking the Economic Importance of Countries and Industries | In the current era of worldwide stock market interdependencies, the global
financial village has become increasingly vulnerable to systemic collapse. The
recent global financial crisis has highlighted the necessity of understanding
and quantifying interdependencies among the world's economies, developing new
effective approaches to risk evaluation, and providing mitigating solutions. We
present a methodological framework for quantifying interdependencies in the
global market and for evaluating risk levels in the world-wide financial
network. The resulting information will enable policy and decision makers to
better measure, understand, and maintain financial stability. We use the
methodology to rank the economic importance of each industry and country
according to the global damage that would result from their failure. Our
quantitative results shed new light on China's increasing economic dominance
over other economies, including that of the USA, to the global economy. |
1408.0445v1 | ## The physical limit of logical '>' operation
PAN Feng , ZHANG Heng-liang , QI Jie 1 2 1
- (1. School of Information Science and Technology, Donghua University, Shanghai 200051, China;
- 2. School of Power and Mechanical Engineering, Wuhan University, Wuhan 430072, China)
Abstract : In this paper two connected Szilard single molecule engines (with different temperature) model of Maxwell's demon are used to demonstrate and analysis the logical compare operation. The logical and physical complexity of '>' operations are both showed to be kTln2. Then this limit was used to prove the time complexity lower bound of sorting problem. It confirmed the proposed way to measure the complexity of a problem, provided another evidence of the equivalence between information theoretical and thermodynamic entropies.
PACS number: 89.70.-a
## Ⅰ . INTRODUCTION
There are already many ways of measuring complexity in the field of complex systems. These measures of complexity are divided into four categories by Lloyd [1]. Computational complexity is a particularly important objective to us in complex systems [2]. Certain amount of resources is necessary in order to solve any given problems. For instance, space (memory), time and energy are all essential to run an algorithm on a computer. We proposed a definition to measure the complexity of a problem: the minimum energy required to solve it [3]. This measure was based on entropy reduction (negentropy) between the entropy before the problem was solved and after, which is interesting because the definition of information is also negentropy.
As computers are firstly physical systems: the laws of physics dictate what they can and cannot do [4,5]. Or in other words, information is physical [6]. The physics of information told us everything in the universe is doing computation. Physical objects might be thought of as being made of information [7]. The position and velocity of an atom in a gas register information. As pointed out by Fredkin and Toffoli [8,9], each atomic collision performs AND, OR, NOT, or COPY operations on suitably defined input and output bits. In this way, the second law of thermodynamics is a statement about information processing: the underlying physical dynamics of the universe preserve bits and prevent their number from decreasing [7].
Discussion on the relationship between energy and information can be traced back to the Maxwell demon which is proposed by Maxwell in 1867. The demon is a construct that can distinguish the velocities of individual gas molecules and then separate hot and cold molecules into two domains of a container, after that the two domains will have different temperature [10]. The result seems to contradict the second law of thermodynamics. Maxwell demon can be expressed by entropy which is the most influential concept to arise from statistical mechanics. The definition of entropy is: S k lnW = ⋅ . In which k is Boltzmann constant, W is the number of all possible microstate (complexion) which give the same macrostate.
To exorcise the Mawell's demon, at the beginning, it's generally believed that the demon needs to cost energy in the measurement, eg. in order to locate the molecules it needs to illuminate them [11]. However, Rolf Landauer [12], the pioneer of the physics of information and Charlies Bennett [13] show that the measurement process can, in principle, be performed without energy expenditure. In fact, this measurement can be performed by a CNOT gate which is reversible with no energy cost [14]. They finally succeeded in finding the right answer which is now the famous Landauer's principle [12]: the results of the measurement must be stored in the demon's memory. The demon will need to erase his memory for new measurement as his memory is finite. There is energy dissipation associated with this erasure.
Shizume[15] and Piechocinska [16] provides examples and proofs of Landauer's principle in the domains of both classical and quantum mechanics. This erasure principle has been verified experimentally recently [17]. It can be represented in several ways.
Physical dynamics preserve information: Any process that erases a bit in one place must transfer that same amount of information somewhere else.
The connection between information and energy: In order to acquire a bit information you need to consume at least kTln2 energy.
Szilard devised in 1929 a one-molecule engine model which captured the essence and the significance of information in the thermodynamics [18]. After that it became a standard model in the physics of information research field [10]. The Landauer principle of information erasure can be explained by the standard Szilard engine model [19].
The classical computer, which is based on irreversible gates (AND gate, OR gate), is intrinsically dissipative. In contrast, reversible computer is based on reversible gates (Toffoli gate, Fredkin gate [8]). As was shown by Bennett [20], in principle, there is no energy dissipation in reversible computer.
'The required computation can be performed, print the result and run the computation backward, again using reversible gates, to recover the initial state of the computer without any energy consumption'.
As we understand it, the above reversible computer is not truly, completely reversible because you still have to record the computation result in memory ('print the result' in the above description) which need energy consumption according to Landauer principle. In fact, this specific amount of energy consumption is very important and is exactly what we use to measure the complexity of a problem [3].
In previous studies, the emphasis was still put on the basic logic gates which constitute the computer [21]. But these AND, OR, NOR gates are too subtle and useless in the analysis of practical problems (eg: sorting problem). In this paper we'll concentrate on a simple problem: logical compare operations (eg: '>'). These operations are the most basic logical operation in any computer language and in the same time an important operation to many practical algorithms. We'll try to measure its logical and physical complexity and show their equivalence.
This paper is organized as the follows. In Sec. Ⅱ we focus on the logical complexity of '>' problem. In Sec. Ⅲ we map this problem into Szilard model and derive its physical complexity. In Sec. Ⅳ we apply this limit to prove the time complexity lower bound of the sorting problem. Section Ⅴ is devoted to summary and discussions.
## Ⅱ .LOGICAL COMPLEXITY OF '>' PROBLEM
In the following we'll take the '>' operation as the example of compare operation. The method used by Landauer [12] was chosen.
Table 1. The truth table of one bit '>' operator
| First bit | Second bit | '>' result | State |
|-------------|--------------|--------------|---------|
| 0 | 0 | 0 | A |
| 0 | 1 | 0 | B |
| 1 | 0 | 1 | C |
| 1 | 1 | 0 | D |
Table 1 is the truth table of one bit '>' operator. As for the entropy reduction of one bit '>' operator, the problem space is 3 bit. There are eight possible initial states, in which the result is random distributed because the operation is not performed (before) and in thermal equilibrium they will occur with equal probability. The result will be determined after the computation. How much entropy reduction will occur before and after the operation is performed? The initial and final machine states are shown in Table 2. State A, B, C and D occur with a probability of 1/4 each.
Table 2. One bit '>' operator which maps eight possible states onto only four different states
| Before | Before | Before | After | After | After | Final state |
|----------|----------|----------|---------|---------|---------|---------------|
| bit | bit | result | bit | bit | result | Final state |
| 0 | 0 | 0 | 0 | 0 | 0 | A |
| 0 | 0 | 1 | 0 | 0 | 0 | A |
| 0 | 1 | 0 | 0 | 1 | 0 | B |
| 0 | 1 | 1 | 0 | 1 | 0 | B |
| 1 | 0 | 0 | 1 | 0 | 1 | C |
| 1 | 0 | 1 | 1 | 0 | 1 | C |
| 1 | 1 | 0 | 1 | 1 | 0 | D |
| 1 | 1 | 1 | 1 | 1 | 0 | D |
The initial entropy was
$$S _ { i } = k \, l n W = - k \sum \rho l n \, \rho = - k \sum \frac { 1 } { 8 } l n \frac { 1 } { 8 } = 3 k \, l n \, 2$$
The final entropy was
$$S _ { f } = - k \sum \rho l n \, \rho = - k \cdot 4 \cdot ( \frac { 1 } { 4 } l n \frac { 1 } { 4 } ) = 2 k l n 2$$
The difference 1 2 2 S S k ln -=
If the '>' operator was tested against two M bit string, it can be easily deduced that the entropy reduction will still be 2. To our surprise, the complexity of '>' k ln operator has nothing to do with the length of string been tested. This result can be easily expanded to other basic compare operators: '<','<=','>=','=','!='. Their complexities are all 2that have nothing to do with the length of string been tested. k ln
In the same time, our method of reasoning gives no guarantee that this minimum is in fact, even in principle, physical achievable. It should be mentioned that the algorithm with the above minimum energy consumption is still not available now. For classical computer we may never find such algorithm (because it has to perform the operation one bit by one bit). But we believe in the possibility in other kind of computers and try to map it into physical world with Szilard single molecule engine model.
## Ⅲ . THERMAL COMPLEXITY OF '>' PROBLEM
The Szilard engine consists of a one-dimensional cylinder, whose volume is V , containing s single-molecule gas and a partition that works as a movable piston. The operator (a demon) of the engine inserts the partition into the cylinder, measures the position of the molecule, and connects to the partition a string with a weight at its end. These actions by the demon are optimally performed without energy consumption [13,19].
In order to get the physical resource limit of '>' operation, we must first map the logical '>' operation into physical world. The main idea is to use two connected Szilard single atom engines with different temperature. The demon's memory is also modeled as a single-molecule gas in a box with a partition in the middle. The one bit information (0 or 1) is represented by the position (left or right) of the molecule in the box.
The following is the protocol to get the information of comparison result (see Fig.1). In the beginning, the two molecules move freely over the volume V .
Step 1: There were two same cylinders (their length are both 2 L ) each with a molecule in it. But the velocity ( 1 v , 2 v ) of the two molecules are different. As
2 1 3 2 2 mv kT =
and the Szilard engine is one dimension.
$$\frac { 1 } { 2 } m v _ { 1 } ^ { 2 } = \frac { 1 } { 2 } k T _ { 1 } \quad \ \frac { 1 } { 2 } m v _ { 2 } ^ { 2 } = \frac { 1 } { 2 } k T _ { 2 }$$
The '>' can be considered as been performed between two different velocity, kinetic energy or temperature in this way.
Step 2: The demon measures the location of the molecule. Then two partitions are inserted at the center of two cylinders. The first molecule was put on the right side of the first cylinder and the second molecule was put on the left side.
There is only one particle, the probabilities that particle belongs to the two sides After are both 1/2, the corresponding entropy is: 1 1 1 2 2 2 . 2 2 S k ln k ln k ln = + =
separation, suppose the particle was limited to the left side. The probability that particle belongs to the left domain is 1 and the probability belongs to the right domain is 0. The corresponding entropy is: 2 1 1 0. According to the second law of S k ln = =
thermodynamics, the minimum energy required by the demon is 1 2 ( ) 2 . T S S kT ln -=
This is exactly the Landauer principle. The demon has to 'borrow' 1 2 2 2 kT ln kT ln + energy from out system in this step.
FIG.1: The protocol to get the information of comparison result
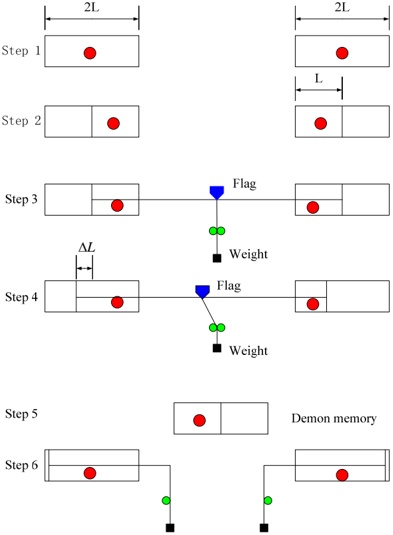
Step 3. The demon connects to the two partitions a string with a weight at its middle. The weight is very small and the string won't shrink or elongate. There is a flag in a certain position on the string.
Step 4. Then release it, the two molecules will push the partitions. Suppose 1 2 v v > , the two partitions will move toward left until new balance is established. The distance moved is L Δ . According to the ideal gas function (one molecule version),
will be in direct proportion to pV kT = and in the one dimension case, The V length. Before the movement of two partitions, we'll have
$$p _ { _ { 1 } } L = k T _ { _ { 1 } }, \ \ p _ { _ { 2 } } L = k T _ { _ { 2 } }$$
After the movement of two partitions (new balance),
$$p ( \, L + \Delta L \, ) = k T _ { 1 }, \ \ p ( \, L - \Delta L \, ) = k T _ { 2 }$$
Then
$$\Delta L = \frac { T _ { 1 } - T _ { 2 } } { T _ { 1 } + T _ { 2 } } L$$
In the process of step 4, the weight is elevated. The amount of work extracted by the engine is:
$$\int _ { L _ { 1 } } ^ { L _ { 2 } } p d V = \int _ { L _ { 1 } } ^ { L _ { 2 } } \frac { k T } { V } d V = k T \, l n \frac { L _ { 2 } } { L _ { 1 } }$$
The work done by the left engine is 1 L L kT ln L +Δ , while the work done by the right
$$\text{engine is } k T _ { 2 } \, l n \frac { L - \Delta L } { L } \,.$$
Step 5: The demon measures the location the flag and records the measurement outcome in his memory. 1 2 v v > (or 1 2 T T > ) is true. The demon will cost energy 2 according to Landauer principle. kT ln
Step 6: Connect to the two partitions two different strings each with a weight at its end then release it. The left engine will do work 1 2 L kT ln L L +Δ and the right engine
2 2 L kT ln L L -Δ . The sum of the work done by the two engines (step 4 plus step 6) will be:
$$k T _ { 1 } l n \frac { L + \Delta L } { L } + k T _ { 2 } l n \frac { L - \Delta L } { L } + k T _ { 1 } l n \frac { 2 L } { L + \Delta L } + k T _ { 2 } l n \frac { 2 L } { L - \Delta L } = k T _ { 1 } l n 2 + k T _ { 2 } l n 2 \ \ ( 6 )$$
Which equals to the energy 'borrowed' by the demon in step 2 and can be 'pay back' to the out system.
In the whole process, the total energy consumed by demon to fulfill the '>' operation is 2(step 5). kT ln
## Ⅳ . THE APPLICATION OF '>' LIMIT
We will use this physical limit to prove the time complexity lower bound of sorting problem as an application. This lower bound has been proved in computer science long ago [2], but we'll rethink this problem from physical view.
Suppose there are N particles with different velocities in one container. The demon knows the information of their velocity but not the information of their positions. The container was first divided into N equal parts. The demon then separates these N particles into the N left-to-right positions according to their velocities. If these N particles were treated as N variables, and their velocities as the corresponding variable's values, through this mapping the demon can be treated as a special purpose computer that deals with the problem of sorting.
The entropy before separation is:
$$S _ { 1 } = k \, l n \, W _ { 1 } = k \, l n \, N ^ { N } = k N \, l n \, N$$
The entropy after separation is 0 and the minimum energy required to solve this problem was kTN ln N .
There are two kind of sorting algorithm: Comparison and not Comparison. In any specific comparison sort algorithm, the main structure is usually circulation. The following statements (in C language) or like are expected to execute in one cycle.
…
$$<_C_> ...
if (x[i]>x[j])$$
…
According to Landauer principle, the three assignment operation (determinacy operation, sentences 2,3,4) need not consume energy in principle. The one need energy to operate is the branch statement (sentence 1 which is a kind of uncertainty operation). The operation it performs is '>', with the lower bound of energy consumption as 2 kT ln
Then the time complexity lower bound of sorting is:
$$\frac { k N \, l n \, N } { \ k \, l n \, 2 } = N \, l o g _ { _ { 2 } } \, N$$
As for not comparison sorting algorithm (eg. radix sort), their time complexity is ( ) , but it needs extra data structure called bucket (at least O N N buckets) compared with comparison sort, each bucket needs at least 2 log N bit. In each of N cycle, the radix sort need to write one bucket, this will cost 2 2 kT ln log N kT ln N ⋅ = energy according to Landauer principle. Even radix sort cannot exceed the above energy lower bound. We show the equivalence (energy cost) between comparison and not comparison sorting algorithm, which has not yet been discovered in computer science.
## Ⅴ . SUMMARY AND DISCUSSION
In this paper we verified the definition of problem complexity been proposed with a specific, simple '>' problem, provided new and profound understanding of computation complexity from the physics of information view.
We show how to measure the complexity of compare operation and demonstrated only the theoretical feasibility in physics. The idea we propose to explain the thermal limit of '>' operation, its key point is first to generate a signal (the result of '>' operation) by using two connected Szilard engine. The important conclusion we got is that this signal generation process is energy free. The second process is to measure the above signal and record the result in one bit.
There are certainly other different ways to realize this compare operation physically and some definitely can be experimental verified like the Landauer principle.
## REFERENCE
- 1. Lloyd, S. (2001). Measures of complexity: a nonexhaustive list. IEEE Control Systems Magazine, 21(4), 7 8. -
- 2. Christos, H. P. (1994). Computational complexity. New York: Addision Wesley -Publishing Company, 50 60. -
- 3. Feng, P., Heng liang, -Z., & Jie, Q. (2013). Problem Complexity Research from Energy Perspective. arXiv preprint arXiv:1309.3975.
- 4. Lloyd, S. (2000). Ultimate physical limits to computation. Nature, 406(6799), 1047 1054. -
- 5. Landauer, R. (1988). Dissipation and noise immunity in computation and communication. Nature, 335(6193), 779 784. -
- 6. Landouer, R. (1991). Information is physical. Physics Today, 25.
- 7. Lloyd, S. (2006). Programming the universe: a quantum computer scientist takes on the cosmos: Random House LLC.
- 8. Fredkin, E., & Toffoli, T. (2002). Conservative logic: Springer.
- 9. Feynman, R. P., Hey, J., & Allen, R. W. (1998). Feynman lectures on computation: Addison Wesley Longman Publishing Co., Inc. -
- 10. Leff, H., & Rex, A. F. (2010). Maxwell's Demon 2 Entropy, Classical and Quantum Information, Computing: CRC Press.
- 11. Brillouin, L. (1951). Maxwell's demon cannot operate: Information and entropy. I. Journal of Applied Physics, 22(3), 334 337. -
- 12. Landauer, R. (1961). Irreversibility and heat generation in the computing process. IBM journal of Research and Development, 5(3), 183 191. -
- 13. Bennett, C. H. (1982). The thermodynamics of computation-a review. International Journal of Theoretical Physics, 21(12), 905 940. -
- 14. Benenti, G., Strini, G., & Casati, G. (2004). Principles of quantum computation and information: World scientific.
- 15. Shizume, K. (1995). Heat generation required by information erasure. Physical Review E,
## 52(4), 3495.
16. Piechocinska, B. (2000). Information erasure. Physical Review A, 61(6), 062314.
Shizume, K. (1995). Heat generation required by information erasure. Physical Review E, 52(4), 3495.
17. Bérut, A., Arakelyan, A., Petrosyan, A., Ciliberto, S., Dillenschneider, R., & Lutz, E. (2012). Experimental verification of Landauer's principle linking information and thermodynamics. Nature, 483(7388), 187 189. -
18. Szilard, L. (1923). On the decrease of entropy in a thermodynamic system by the intervention of intelligent beings. Maxwell's Demon 2: Entropy, Classical and Quantum Information, Computing, 110 119. -
19. Hosoya, A., Maruyama, K., & Shikano, Y. (2011). Maxwell's demon and data compression. Physical Review E, 84(6), 061117.
- 20. Bennett, C. H. (1973). Logical reversibility of computation. IBM journal of Research and Development, 17(6), 525 532. -
- 21. Maroney, O. J. (2005). The (absence of a) relationship between thermodynamic and logical reversibility. Studies in History and Philosophy of Science Part B: Studies in History and Philosophy of Modern Physics, 36(2), 355 374. - | null | [
"Feng Pan",
"Heng-Liang Zhang",
"Jie Qi"
] | 2014-08-03T01:13:52+00:00 | 2014-08-03T01:13:52+00:00 | [
"physics.data-an",
"cond-mat.stat-mech",
"cs.CC"
] | The physical limit of logical compare operation | In this paper two connected Szilard single molecule engines (with different
temperature) model of Maxwell's demon are used to demonstrate and analysis the
logical compare operation. The logical and physical complexity of compare
operations are both showed to be kTln2. Then this limit was used to prove the
time complexity lower bound of sorting problem. It confirmed the proposed way
to measure the complexity of a problem, provided another evidence of the
equivalence between information theoretical and thermodynamic entropies. |
1408.0446v3 | ## SUPERNOVAE DRIVEN TURBULENCE IN THE INTERSTELLAR MEDIUM
FREDERICK ARMSTRONG GENT
Thesis submitted for the degree of Doctor of Philosophy

School of Mathematics & Statistics Newcastle University Newcastle upon Tyne United Kingdom
November 2012
My son, Declan. Wherever you're going may you always enjoy the journey . . .
## Acknowledgements
I would like to thank my supervisors - Prof. Anvar Shukurov, Dr. Graeme Sarson and Dr. Andrew Fletcher - who have provided a collaborative and stimulating environment in which to work. They have been constructive in their criticism and very supportive both with resources and advice. They have provided opportunities for me to participate in the broader research community in this country and internationally. I have always felt that they valued and were generally interested in our project and have enjoyed the freedom to think and work autonomously.
Further I thank my host in Helsinki - Dr. Maarit Mantere, her family and her colleagues, amongst them Dr. Petri K¨ aply¨, Dr. a Thomas Hackmann and Dr. Jorma Harju - who has provided invaluable guidance in the application and understanding of the use of the pencil-code and in particular principles of numerical modelling and specifically modelling the ISM. She, and they, also made my visits to Finland for work an extremely pleasurable social and cultural experience.
In addition I feel privileged to have shared offices with a fabulous group of friends, who have filled my experience of post graduate life with amusement, drama and insight. In particular I thank my ever present room mates Timothy Yeomans, Donatello Gallucci, Dr. Joy Allen and Anisah Mohammed. Other graduate students and Post Docs who have made memorable contributions to my experience during my graduate studies are: Dr. Sam James, Dr. Pete Milner, Dr. Jill Johnson, Dr. Andrew Baggaley, Dr. James Pickering, Dr. Kevin Wilson, Dr. Daniel Maycock, Dr. David Elliot, Dr. Drew Smith, Dr. Paul McKay, Dr. Angela White, Nathan Barker, Nuri Badi, Matt Buckley, Christian Perfect, Alix Leboucq, Rob Pattinson, Holly Ainsworth, Rute Vieira, Kavita Gangal, Nina Wilkinson, Asghar Ali, Gavin Whitaker, Stacey Aston, Lucy Sherwin, Jamie Owen, David Cushing, Tom Fisher.
I wish to thank the school computing support officers, Dr. Anthony Youd and Dr. Michael Beaty, and administrative staff Jackie Williams, Adele Fleck, Jackie Martin and Helen Green, plus Andrea Carling in MathsAid and Gail de-Blaquiere of the SAgE Faculty Office. I also thank Prof. Carlo Barenghi, Prof. Ian Moss, Prof. David Toms, Prof. Robin Johnson, Dr. Paul Bushby, Dr. Nikolaos Proukakis, Dr. Nicholas Parker, Prof. John Matthews, Prof. Robin Henderson, Dr. Peter Avery, Dr. Colin Gillespie, Dr. Phil Ansel, Dr. David Walshaw, Dr. Jian Shi, Dr. Zinaida Lykova, Prof. Peter Jorgensen, Dr. Rafael Bocklandt and Dr. Alina Vdovina for their general practical and intellectual assistance during my research and previously.
I owe a special debt of gratitude to Dr. James Ford and Dr. Bill Foster, who enabled meto successfully apply for a place on the degree programme in 2004, leading me towards a new scientific vocation.
I wish to express my gratitude and respect for my hosts at the Inter University Centre for Astronomy and Astrophysics, in Pune, India, where I spent a stimulating, effective and enjoyable month, writing up my thesis, and investigating some new material: Prof. Kandu Subramanian, Luke Charmandy, Pallavi Bhatt, Nishant Singh and Dr. Pranjal Trivedi.
I acknowledge the support of the staff and resources from; the Center for Science and Computing, Espoo, Finland, where the bulk of my simulations were computed; the HPC-Europa II programme, which funded my research visits to Finland; UKMHD, who provided computing on the UK MHD Cluster, St. Andrews, Scotland and support for attendance at UKMHD conferences; Nordita, Stockholm, Sweden, and in particular Prof. Axel Brandenburg, who provided financial and practical support for attendance at conferences and development of the simulation code; the International Space Science Institute, Berne, Switzerland support for attending their workshop and publishing; my funding research council the Engineering and Physical Sciences Research Council; the Science and Technology Facilities Council for additional support; and the pencil-code developers, among them Prof. Axel Brandenburg, Dr. Antony Mee, Dr. Wolfgang Dobler, Dr. Boris Dintrans, Dr. Dhrubaditya Mitra, Dr. Matthias Rheinhardt.
In addition to those who have contributed directly to my research I would like to thank many, who have communicated informally, either by email or in person, and in particular: Prof. Miguel de Avillez and Dr. Oliver Gressel for advice arising from their previous experiences of similar modelling; Dr. Greg Eyink, Dr. Eric Blackman and Prof. Russell Kulsrud for their insights into volume averaging, magnetic helicity and cosmic rays; the anonymous reviewers of my submitted articles to Monthly Notices for their conscientious and constructive assessment of the work; for informal international discussions Dr. Marijke Haverkorn, Dr. Dominik Schleicher, Dr. Reiner Beck, Dr. Simon Calderesi, Dr. Gustavo Guerrero, Dr. J¨ orn Warnecke, Dr. Sharanya Sur, Anne Liljstr¨hm, Nadya Cheso nok, Prof. Sridhar Seshadri; and visitors to my department Dr. Michele Sciacco, Luca Galantucci, Alessandra Spagniolli, Carl Schneider, Dr. Mike Garrett, Brendan Mulkerin and Dr. Rodion Stepanov.
In conclusion I thank my internal examiner, Dr. Paul Bushby, and my external examiner Prof. James Pringle for an interesting, intelligent and rigorous viva.
Finally I thank my parents and family for their patience and support throughout my academic studies.
## Abstract
I model the multi-phase interstellar medium (ISM) randomly heated and shocked by supernovae (SN), with gravity, differential rotation and other parameters we understand to be typical of the solar neighbourhood. The simulations are in a 3D domain extending horizontally 1 × 1 kpc 2 and vertically 2 kpc , symmetric about the galactic mid-plane. They routinely span gas number densities 10 -5 -10 2 cm -3 , temperatures 1010 8 K , speeds up to 10 3 kms -1 and Mach number up to 25. Radiative cooling is applied from two widely adopted parameterizations, and compared directly to assess the sensitivity of the results to cooling.
There is strong evidence to describe the ISM as comprising well defined cold, warm and hot regions, typified by T ∼ 10 2 , 10 4 and 10 6 K , which are statistically close to thermal and total pressure equilibrium. This result is not sensitive to the choice of parameters considered here. The distribution of the gas density within each can be robustly modelled as lognormal. Appropriate distinction is required between the properties of the gases in the supernova active mid-plane and the more homogeneous phases outside this region. The connection between the fractional volume of a phase and its various proxies is clarified. An exact relation is then derived between the fractional volume and the filling factors defined in terms of the volume and probabilistic averages. These results are discussed in both observational and computational contexts.
The correlation scale of the random flows is calculated from the velocity autocorrelation function; it is of order 100 pc and tends to grow with distance from the mid-plane. The origin and structure of the magnetic fields in the ISM is also investigated in nonideal MHD simulations. A seed magnetic field, with volume average of roughly 4 nG , grows exponentially to reach a statistically steady state within 1.6 Gyr. Following Germano (1992), volume averaging is applied with a Gaussian kernel to separate magnetic field into a mean field and fluctuations. Such averaging does not satisfy all Reynolds rules, yet allows a formulation of mean-field theory. The mean field thus obtained varies in both space and time. Growth rates differ for the mean-field and fluctuating field and there is clear scale separation between the two elements, whose integral scales are about 0 7 kpc . and 0 3 kpc . , respectively.
Analysis of the dependence of the dynamo on rotation, shear and SN rate is used to clarify its mean and fluctuating contributions. The resulting magnetic field is quadrupolar, symmetric about the mid-plane, with strong positive azimuthal and weak negative radial orientation. Contrary to conventional wisdom, the mean field strength increases away from the mid-plane, peaking outside the SN active region at | z | glyph[similarequal] 300 pc . The strength of the field is strongly dependent on density, and in particular the mean field is mainly organised in the warm gas, locally very strong in the cold gas, but almost absent in the hot gas. The field in the hot gas is weak and dominated by fluctuations.
## Contents
| Outline of the content . . . . . . . . . . . . . . . . . . . . . . . . . . | | |
|-----------------------------------------------------------------------------------------------------------------------------------------------|-----|-------|
| Structure and contents . . . . . . . . . . . . . . . . . . . . . . . | | |
| 1.1.2 | | |
| brief description of galaxies . . . . . . . . . . . . . . . . . . . . . . . | | 1.2 A |
| 1.2.1 Classification . . . . . . . . . . . . . . . . . . . . . . . . . . . . | | |
| 1.2.2 The interstellar medium . . . . . . . . . . . . . . . . . . . . . . | | |
| Introduction . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . | | 2.1 |
| Star formation and condensation of molecular clouds . . . . . . . . . . . | | 2.2 |
| Discs and spiral arms . . . . . . . . . . . . . . . . . . . . . . . . . . . . | | 2.3 |
| The multi-SNe environment . . . . . . . . . . . . . . . . . . . . . . . . | | 2.4 |
| The stratified interstellar medium . . . . . . . . . . . . . . . . . Compressible flows and shock handling . . . . . . . . . . | | 2.4.1 |
| . . . . | | 2.4.2 |
| Distribution and modelling of SNe . . . . . . . . . . . . . . . | | |
| . | | 2.4.3 |
| Solid body and differential rotation . . . . . . . . . . . . . . . . | | 2.4.4 |
| 2.4.5 Radiative cooling and diffuse heating . . . . . . . . . . . . . . . | | |
| 2.4.6 Magnetism . . . . . . . . . . . . . . . . . . . . . . . . . . . . . | | |
| Cosmic Rays . . . . . . . . . . . . . . . . . . . . . . . . . . . . | | |
| 2.4.7 2.4.8 . . | | |
| Diffusivities . . . . . . . . . . . . . . . . . . . . . . . . . . 2.4.9 The galactic fountain . . . . . . . . . . . . . . . . . . . . . . . . | | |
| 2.4.10 Spiral arms . . . . . . . . . . . . . . . . . . . . . . . . . . . . . | | |
| . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . | | 2.5 |
| Summary . | | |
| Modelling the interstellar medium | | |
| equations and their numerical implementation | | |
| Basic equations . . . . . . . . . . . . . . . . . . . . . . . . . . . . . | | |
| Modelling supernova activity . . . . . . . . . . . . . . . . . . . . . | | |
| . | | |
| . | | |
| . | | |
| . | | |
| . | | |
| 3 Basic | | |
| 3.1 | | |
| | 3.2 | |
| 3.3 | photoelectric | Radiative cooling and heating . . . . . . . . . . . . . . . . | 29 |
|---------------------------------------------------|------------------------------------------------------|-------------------------------------------------------------------------------|------|
| 3.4 Numerical methods | . . . . . . | . . . . . . . . . . . . . . . . . . . . . . . | 31 |
| 3.5 Boundary conditions | . . . . . | . . . . . . . . . . . . . . . . . . . . . . . | 33 |
| 3.6 Initial conditions | . . . . . . . | . . . . . . . . . . . . . . . . . . . . . . . | 37 |
| 3.7 Simulation vs. 'realised' time, and geometry | 3.7 Simulation vs. 'realised' time, and geometry | . . . . . . . . . . . . . . . . | 38 |
| Models explored | Models explored | | 42 |
| 4.1 Summary of models | . . . . . . | . . . . . . . . . . . . . . . . . . . . . . . | 42 |
| 4.2 Model data summary | . . . . . | . . . . . . . . . . . . . . . . . . . . . . . | 44 |
| Multiphase description of the interstellar medium | Multiphase description of the interstellar medium | 47 | |
| Is the ISM multi-phase? | Is the ISM multi-phase? | | |
| | | . . | 48 |
| 5.2 | The filling factor and fractional volume | . . . . . . . . . . . . . . . . . . | 57 |
| | 5.2.1 | Filling factors: basic concepts . . . . . . . . . . . . . . . . . . . | 57 |
| | 5.2.2 | Homogeneous-phase and lognormal approximations . . . . . . . | 58 |
| | 5.2.3 | Application to simulations . . . . . . . . . . . . . . . . . . . . . | 60 |
| | 5.2.4 | Observational implications . . . . . . . . . . . . . . . . . . . . . | 63 |
| 5.3 | Three-phase structure defined using specific entropy | . . . . . . . . . . . . | 64 |
| 5.4 | Further results . . . . . . . . . | . . . . . . . . . . . . . . . . . . . . . . . | 66 |
| 5.5 | Summary . . . . . . . . . . . | . . . . . . . . . . . . . . . . . . . . . . . | 69 |
| Structure of the velocity field | Structure of the velocity field | | 71 |
| Gas flow to and from the mid-plane | Gas flow to and from the mid-plane | . . . . . . . . . . . . . . . . . . . . | 72 |
| 6.1 | The correlation scale of the random flows | . | 73 |
| 6.2 6.3 | Summary . . . . . . . . . . . | . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . | 77 |
| | | | 78 |
| Sensitivity to model parameters | Sensitivity to model parameters | | |
| 7.1 | Sensitivity to the cooling function | . . . . . . . . . . . . . . . . . . . . . | 78 |
| 7.2 | Sensitivity to rotation, shear and | SN rate . . . . . . . . . . . . . . . . . . | 87 |
| 7.3 | Summary . . . . . . . . . . . | . . . . . . . . . . . . . . . . . . . . . . . | 90 |
| Galactic magnetism: mean field and fluctuations | Galactic magnetism: mean field and fluctuations | 91 | |
| Mean field in anisotropic turbulence | Mean field in anisotropic turbulence | | 92 |
| 8.1 The mean magnetic field | . . . | . . . . . . . . . . . . . . . . . . . . . . . | 94 |
| 8.2 | Scale separation . . . . . . . . | . . . . . . . . . . . . . . . . . . . . . . . | 98 |
| 8.3 | Evaluation of the method . . . | . . . . . . . . . . . . . . . . . . . . . . . | 100 |
| 8.4 | Summary . . . . . . . . . . . | . . . . . . . . . . . . . . . . . . . . . . . | 102 |
| | | | Contents |
|----|----------------------------------------------|----------------------------------------------|------------|
| V | The galactic dynamo and magnetic structure | The galactic dynamo and magnetic structure | 103 |
| 9 | The magnetic field | The magnetic field | 104 |
| | 9.1 | The magnetic dynamo . . . . . . | . . . 104 |
| | 9.2 | Mean and fluctuating field composition | . . . 110 |
| | 9.3 | Three-phase structure of the Field | . . . 112 |
| | 9.4 | Structure of the Field . . . . . . | . . . 116 |
| | 9.5 | Summary . . . . . . . . . . . . | . . . 118 |
| VI | Summary of results and future investigation | Summary of results and future investigation | 119 |
| 10 | | | 120 |
| | Summary of results | Summary of results | |
| | 10.1 | Multi-phase ISM results . . . . | . . . 120 |
| | 10.2 | Magnetized ISM results . . . . | . . . 122 |
| | 10.3 | Future investigation and experiments | . . . 123 |
| | 10.4 | Review . . . . . . . . . . . . . | . . . 126 |
| A | Evolution of an individual supernova remnant | Evolution of an individual supernova remnant | 128 |
| | A.1 | The snowplough test . . . . . . | . . . 128 |
| | A.2 | Cooling-heating in the shocks . | . . . 131 |
| | A.3 | The structure of the SN remnant | . . . 132 |
| B | Stability | criteria | 134 |
| | B.1 | Courant criteria . . . . . . . . . | . . . 134 |
| | B.2 | Thermal Instability . . . . . . . | . . . 136 |
| C | Mass sensitivity and mass conservation | Mass sensitivity and mass conservation | 138 |
| D | Dimensional units | Dimensional units | 143 |
## List of Figures
| 1.1 | Hubble classification diagram . . . . . . . . . . . . . . . . . . . . . . | 5 |
|-------|-----------------------------------------------------------------------------|-----|
| 1.2 | Revised kinematic galaxy classification diagram . . . . . . . . . . . . | 5 |
| 1.3 | Images of galaxies . . . . . . . . . . . . . . . . . . . . . . . . . . . | 6 |
| 3.1 | The cooling functions . . . . . . . . . . . . . . . . . . . . . . . . . . | 31 |
| 3.2 | Geometry of shearing box. . . . . . . . . . . . . . . . . . . . . . . . | 39 |
| 3.3 | Statistical vs. real time diagram . . . . . . . . . . . . . . . . . . . . . | 40 |
| 5.1 | Volume plots of density and temperature for Model WSWa . . . . . . | 49 |
| 5.2 | Horizontal averages u z , T , and ρ for Model WSWa(WSWb) . . . . . | 50 |
| 5.3 | Total volume probability distributions for Model WSWa . . . . . . . | 51 |
| 5.4 | 2D probability distribution of n and T for Model WSWa . . . . . . . | 52 |
| 5.5 | Probability phase distributions Model WSWa . . . . . . . . . . . . . | 53 |
| 5.6 | Lognormal fit to n probability distributions Model WSWa . . . . . . . | 54 |
| 5.7 | Probability distributions for pressure of Model WSWa . . . . . . . . . | 55 |
| 5.8 | Horizontal averages of density and pressure of Model WSWa . . . . . | 56 |
| 5.9 | Filling factors for Model WSWa as function of z . . . . . . . . . . . | 61 |
| 5.1 | 2D n and T distribution for Model WSWaover plotted with specific entropy | 65 |
| 5.11 | Probability distributions by phase for Model WSWa via specific entropy | 66 |
| 5.12 | Volume and mass fractions for Model WSWa and WSWah - function of | 67 |
| 5.13 | Volume snapshots of ρ by phase for Model WSWa . . . . . . . . . . . | 69 |
| 6.1 | Volume snapshots of the velocity for Model WSWa . . . . . . . . . . | 71 |
| 6.2 | Contour plots u z ( z ) for Model WSWaby phase . . . . . . . . . . . . | 72 |
| 6.3 | Structure function of velocity . . . . . . . . . . . . . . . . . . . . . . | 74 |
| 6.4 | Autocorrelation function of velocity . . . . . . . . . . . . . . . . . . | 75 |
| 7.1 | 2D probability distribution of n and T for Model WSWb . . . . . . . | 79 |
| 7.2 | 2D probability distribution of n and T for Model RBN . . . . . . . . | 80 |
| 7.3 | 2D probability distribution of mid-plane n and T . . . . . . . . . . . | 81 |
| 7.4 | Comparison of energy density in HD models . . . . . . . . . . . . . . | 82 |
| 7.5 | Fractional volumes by z for Models RBN and WSWb . . . . . . . . . | 83 |
| 7.6 | Total volume probability distributions for Models RBN and WSWb . | 84 |
| 7.7 | Horizontal averages for n from Models RBN and WSWb . . . . . . . | 85 |
glyph[negationslash]
| 7.8 | Probability distributions by phase for Models RBN and WSWb . . . . . . 86 |
|-------|---------------------------------------------------------------------------------------------|
| 7.9 | Horizontal averages of n and P for Models B1Ω ∗ and B1ΩSh . . . . . . 88 |
| 7.10 | Horizontal averages of n and P for Models B1Ω ∗ and B1ΩSN . . . . . . 90 |
| 8.1 | Growth of energy densities for Model B2Ω . . . . . . . . . . . . . . . . 95 |
| 8.2 | Mean and fluctuating e B for Model B2Ω . . . . . . . . . . . . . . . . . . 96 |
| 8.3 | Volume snapshot of mean and fluctuating B . . . . . . . . . . . . . . . . 97 |
| 8.4 | Power spectra of mean and fluctuating B , glyph[lscript] = 50 pc . . . . . . . . . . . . 98 |
| 8.5 | Power spectra of mean and fluctuating B , glyph[lscript] = 50 pc . . . . . . . . . . . . 99 |
| 8.6 | Growth of e B for Model B2Ω . . . . . . . . . . . . . . . . . . . . . . . . 100 |
| 9.1 | Magnetic energy for MHDmodels . . . . . . . . . . . . . . . . . . . . . 104 |
| 9.2 | Horizontal averages for B x and B y in Model B2Ω . . . . . . . . . . . . . 106 |
| 9.3 | Horizontal averages for magnetic helicity in Model B2Ω . . . . . . . . . 108 |
| 9.4 | Separation into mean and fluctuating magnetic energy for Model B1Ω . . 110 |
| 9.5 | Exponential fits for magnetic growth rates . . . . . . . . . . . . . . . . . 111 |
| 9.6 | Total volume probability distributions for Model B1Ω and H1Ω . . . . . . 112 |
| 9.7 | Horizontal averages of n and P for Model B1Ω and H1Ω . . . . . . . . . 113 |
| 9.8 | Probability distributions by phase for n and T . . . . . . . . . . . . . . . 114 |
| 9.9 | 2D probability distribution of n and T for Models B1Ω and H1Ω . . . . . 114 |
| 9.10 | 2D mid-plane probability distribution for Models B1Ω and H1Ω . . . . . 115 |
| 9.11 | 2D probability distribution of n, B and B,T for Model B1Ω . . . . . . . 115 |
| 9.12 | Volume snapshots of B by phase for Model B1Ω . . . . . . . . . . . . . 116 |
| 9.13 | Pitch angles for MHDmodels . . . . . . . . . . . . . . . . . . . . . . . 117 |
| A.1 | SN radial expansion . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 129 |
| A.2 | 1D slices of remnant structure . . . . . . . . . . . . . . . . . . . . . . . 132 |
| C.1 | Vertically oscillating disc . . . . . . . . . . . . . . . . . . . . . . . . . . 141 |
## List of Tables
| 3.1 | The RBN cooling function . . . . . . . . . . . . . . . . . . | . . . . 29 |
|-------|-------------------------------------------------------------------|--------------|
| 3.2 | The WSWcooling function . . . . . . . . . . . . . . . . . . | . . . . 29 |
| 4.1 | List of models . . . . . . . . . . . . . . . . . . . . . . . . . | . . . . 42 |
| 4.2 | Model results . . . . . . . . . . . . . . . . . . . . . . . . . | . . . . 45 |
| 5.1 | Filling factors for Model WSWa . . . . . . . . . . . . . . . | . . . . 62 |
| 5.2 | Fractional volumes for Model RBN and WSWb as function of | . . . . 67 |
| 6.1 | Correlation scale of l turb . . . . . . . . . . . . . . . . . . . | . . . . 76 |
| 7.1 | Key to multiple temperature bands . . . . . . . . . . . . . . | . . . . 83 |
| 8.1 | Growth rates of B for Model B2Ω . . . . . . . . . . . . . . | . . . . 100 |
| 9.1 | Magnetic helicity in MHDmodels . . . . . . . . . . . . . . | . . . . 109 |
| 9.2 | Magnetic field growth rates . . . . . . . . . . . . . . . . . . | . . . . 110 |
| B.1 | Thermally unstable wavelengths . . . . . . . . . . . . . . . | . . . . 137 |
| D.1 | Specified units . . . . . . . . . . . . . . . . . . . . . . . . . | . . . . 143 |
| D.2 | Derived units . . . . . . . . . . . . . . . . . . . . . . . . . | . . . . 144 |
## Part I
Motivation and outline: magnetism and the interstellar medium in galaxies
## Chapter 1
## How to shed some light on galaxies?
## 1.1 Outline of the content
## 1.1.1 Motivation behind this work
As we look into the sky, for generations mankind has been captivated by its beauty, awestruck by the spectacular (aurora, comets), and reassured by its familiarity and constancy over the centuries. The combination of improved observations and measurements, mathematics and validated theory have transformed our understanding of the objects populating our own solar system and the most distant of galaxies. In doing so the universe has grown to fill spaces and time so vast our minds cannot easily conceive them. We have discovered new entities (black holes, supernovae, jets and pulsars, etc) that have been so vast or alien, that they are a challenge to describe. To do so has required combining theories about the very large (general relativity) and the very small (bosons, cosmic rays, quantum mechanics, etc). Hence, in contrast to the constant and familiar, astronomy and astrophysics have instead continually challenged our preconceptions and uncovered shocking and surprising discoveries.
In more recent years it has even become possible to visit space and to devise machines that enable us to peer further into space, and also to view the universe in wavelengths invisible to the human eye, the radio spectrum, x-rays, infrared, etc. The rate of discovery and understanding has accelerated. It has become apparent that magnetic fields are ubiquitous, with many planets and stars generating their own magnetic fields. Of interest to this study, it has also been discovered that the tenuous gas between the stars is magnetized and in many galaxies, including our own, these magnetic fields are organized on a galactic scale. Scientific controversy surrounds these structures, which cannot easily be explained with what we know so far about magnetism.
Despite all the advances in technology, even with instruments in orbit, observational data is effectively constrained to line of site measurements. On galactic time scales, we are also in effect viewing a freeze frame of the sky, and any understanding of motion and evolution has to be inferred by comparing differences between galaxies at different
stages of development. Assumptions and estimates must be invoked about the composition and distribution of the gas along these lines of measurement. If we can accurately model astrophysical objects in three dimensions with numerical simulations, these can be used to assess the best methods of estimating the 3D composition. The movement and structure of the astrophysical models can be investigated more easily and inexpensively than the galaxies directly, and be used to motivate useful and effective targets for future observations and investigation.
## 1.1.2 Structure and contents
In the rest of the Introduction, I provide a brief description of galaxy structure, some of the primary mysteries of interest here and how this research might address these. Section 2 reviews some of the progress made to date with similar models and discusses the significant differences between what is and is not included within the various models.
The most substantial result of my research has been the construction of a robust and versatile numerical model capable of simulating a 3D section of a spiral galaxy. The system is extremely complicated physically and also, inevitably, numerically. The simulations need to evolve over weeks or months and overcoming numerical problems has taken a large proportion of my research time. However the most interesting outcomes are not numerical, but the results and analysis obtained from the simulations. I therefore reserve my comments on some of the critical numerical insights to the Appendices. These may be of interest to others interested in numerical modelling, but less so to the wider scientific community. However, I think it is important not to brush these issues under the carpet for at least two reasons. First, it is important to be clear and honest about the deficits in one's model, so that the reader may be able to understand how robustly the model may capture various features of the interstellar medium. Secondly, sharing the experiences may help to improve the models of others.
However, so that the reader may reasonably understand the outcomes, in Part II I fully describe the model. I state what physical components are included, and discuss the implications of any necessary numerical limitations or exclusions. In Parts III-V I describe and explain in detail the new results I have obtained. These include data from two sets of simulations, conducted over a period exceeding 12 months. They differ in that the second set include the addition of a seed magnetic field. Rather than discuss each simulation or set separately, I describe various characteristics of the ISM and consider to what extent these depend on any model parameters. Part VI contains a summary of my work, conclusions and discussion of the future of this research approach.
## Collaborative and previously available content
Some of the work presented in this thesis is the result of collaboration, which has been submitted for publication. A review of previous related numerical work has appeared in
a published chapter (Gent, 2012), which will form part of a book from the International Space Science Institute (ISSI). Chapter 2 covers similar subject matter, but has been substantially revised. The thesis contains material, submitted to MNRAS (Gent, Shukurov, Sarson, Fletcher and Mantere, 2013; Gent, Shukurov, Fletcher, Sarson and Mantere, 2013), in which I am lead author with co-authors Prof. A. Shukurov, Dr. A. Fletcher, Dr. G. R. Sarson and Dr. M. Mantere. The latter article forms the basis of Chapter 8, with some additional new work in Section 8.3. Material from the former article is included in Chapters 3, 5 and 6, plus Sections 7.1 and 10.1, and Appendices A and B. All numerical simulation code refinement, testing and running was performed by myself.
## 1.2 A brief description of galaxies
The largest dynamically bound structures in the universe so far observed are galaxy clusters. These collections of multiple galaxies of various types interact gravitationally and also contain an intergalactic magnetic field among other features. They occupy regions of space spanning order of 10 - 100 mega-parsecs (Mpc). Within clusters galaxies may collide, merge or accrete material from one to another. Groups of galaxies, typically spanning order 1 Mpc, contain a few dozen gravitationally bound galaxies. Our own galaxy, the Milky Way, belongs to the Local Group containing about 40 galaxies. We refer to the Galaxy (capitalised), to denote the Milky Way, to distinguish it from galaxies in general (lower case).
## 1.2.1 Classification
The next largest category in the hierarchy of such structures are the galaxies. All galaxies will interact with the intergalactic material surrounding them to a greater or lesser extent. Nevertheless they generally contain powerful internal forces and structure, which may govern the internal dynamics irrespective of the external environment. An early attempt to identify the different categories of galaxies was made by Edwin Hubble in the 1920s, illustrated in Fig. 1.1.
The classification of galaxies turned out to be more complicated than Hubble could have envisaged. In the Hubble classification galaxies are elliptical (E) or spiral (S). Spirals also include barred galaxies where the spiral arms emerge from the tips of an elongated central layer, rather than the central bulge. It may not always be certain whether a galaxy, which appears elliptical as viewed from our solar system, is not in fact a spiral, viewed face on. Subsequently van den Bergh (1976) revised Hubble's morphological classification of galaxies, but more recently Cappellari et al. (2011), using the ATLAS 3D astronomical survey, proposed a more physical classification based on the kinematic properties of galaxies. Their revised classification diagram is shown in Fig. 1.2.
Considering the kinematic properties of the galaxies improves the consistency of classification and reduces the reliance for identification on our viewing angle. It also helps
Figure 1.1: Hubble's traditional tuning fork classification diagram for galaxies. Courtesy of the European Space Agency (ESA) http://www.spacetelescope.org/images/ heic9902o/ Galaxies are defined as elliptical (E) or spiral (s) with further division of spirals into normal or barred (Sb)
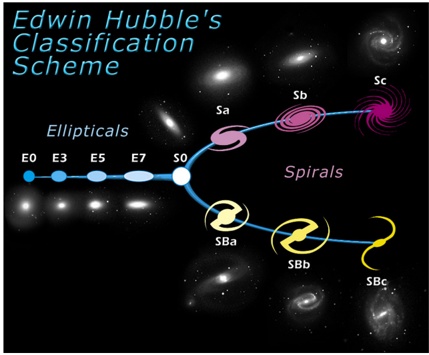
Figure 1.2: The revised galaxy classification diagram of Cappellari et al. (2011) using the ATLAS 3D astronomical survey. Galaxies are categorized as slow rotators, corresponding to elliptical shapes and fast rotators, which become increasingly flattened with smaller central bulge as a result of higher angular momentum.
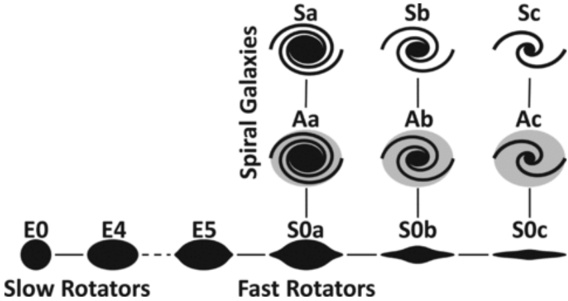
us to understand the underlying cause for the variation in morphology. Disc galaxies rotate faster and, significantly, about a single axis of rotation. In some cases elliptical galaxies exhibit very weak rotation. In others the shape is the result of multiple axes of rotation, with angular momentum acting in two or three transverse directions. This action counteracts the tendency to flatten perpendicular to an axis of rotation.
Cappellari et al. (2011) found only a very small proportion of galaxies are actually elliptical (about 4% in most clusters) and the rate of rotation as well as stellar density is very important to the morphology the strength of the magnetic field. It is my long term aim to model the ISM in any class of galaxy, although the current model is constructed to simulate spiral galaxies. The most comprehensive data pertains to the Galaxy, so as a first iteration with which we can verify the relevance of the model, it is convenient to use parameters matching the Galaxy in the solar neighbourhood and compare the outcomes
with what we understand of the real Galaxy.
The Galaxy is estimated to have a stellar disc of radius approximately 16 kiloparsecs (kpc) with atomic hydrogen HI up to 40 kpc, and the Sun, is estimated to be 7 - 9 kpc from the Galactic centre. (Here capitalised Sun denotes our own star.) Most of the mass in the Galaxy is in the form of non-interacting dark matter and stars, with stars accounting for about 90% of the visible mass with gas and dust the other 10%. There is a large central bulge and although hard to identify from our position inside the Galaxy, it is likely that we live in a barred galaxy. Away from the centre most of the mass is contained within a thin disc ± 200 parsecs (pc) of the mid-plane (Kulkarni and Heiles, 1987; Clemens, Sanders and Scoville, 1988; Bronfman et al., 1988; Ferri` ere, 2001) over a Galactocentric radius of about 4 - 12 kpc. Either side of the disc is a region referred to as the galactic halo with height of order 10 kpc. Halo gas is generally more diffuse and hotter gas in the disc.
Figure 1.3: Images of spiral galaxies M81 (a), Whirlpool (b), and the barred spiral galaxy NGC 1300 (c) from http://hubblesite.org/gallery/album/galaxy/ The image in panel (d) represents the typical location of the simulation region, superimposed as a blue box, orbiting the galaxy within the mid-plane of the disc. It extends above and below the mid-plane.




Figure 1.3 shows examples of disc galaxies, in panels (a - c). Panel d indicates the typical location and size of the simulation region in a galaxy, which will be described in Part II. Here the disc is rotating around the axis at about 230 km s -1 (for the Galaxy in the solar neighbourhood). As the ISM nearer to the centre of a galaxy travels a shorter orbit, differential rotation induces a shear through the ISM in the azimuthal direction, with the ISM trailing further away from the galactic centre. Rotation and shear vary between different galaxies, and also over different radii within each galaxy. These features can affect the classification of a galaxy and appear to be important to the strength and organization of the magnetic field.
## 1.2.2 The interstellar medium
The space between the stars is filled with a tenuous gas, the interstellar medium (ISM), which is mainly hydrogen (90.8% by number [70.4% by mass]) and helium (9.1% [28.1%]), with much smaller amounts of heavier elements also present and a very small proportion of the hydrogen in molecular form (Ferri` ere, 2001). The density of the ISM in the thin disc is on average below 1 atom cm -3 . (In air at sea level the gas number density is about 10 27 cm -3 .) The ISM contains gas with a huge range in density and temperature, and can be described as a set of phases each with distinct characteristics.
The multi-phase nature of the ISM affects all of its properties, including its evolution, star formation rate, galactic winds and fountains, and behaviour of the magnetic fields, which in turn feed back into the cosmic rays. In a widely accepted picture (Cox and Smith, 1974; McKee and Ostriker, 1977), most of the volume is occupied by the hot ( T glyph[similarequal] 10 6 K ), warm ( T glyph[similarequal] 10 4 K ) and cold ( T glyph[similarequal] 10 2 K ) phases. The concept of the multi-phase ISM in pressure equilibrium has endured with modest refinement (Cox, 2005). Perturbed cold gas is quick to return to equilibrium due to short cooling times, while warm diffuse gas with longer cooling times has persistent transient states significantly out of thermal pressure balance (Kalberla and Kerp, 2009, and references therein). Dense molecular clouds, while containing most of the total mass of the interstellar gas, occupy a negligible fraction of the total volume and are of key importance for star formation (e.g. Kulkarni and Heiles, 1987, 1988; Spitzer, 1990; McKee, 1995). Gas that does not form one of the three main, stable phases but is in a transient state, may also be important in some processes. The main sources of energy maintaining this complex structure are supernova explosions (SNe) and stellar winds (Mac Low and Klessen, 2004, and references therein). The clustering of SNe in OB associations facilitates the escape of the hot gas into the halo thus reducing the volume filling factor of the hot gas in the disc, perhaps down to 10% at the mid-plane (Norman and Ikeuchi, 1989). The energy injected by the SNe not only produces the hot gas but also drives compressible turbulence in all phases, as well as driving outflows from the disc associated with the galactic wind or fountain, as first suggested by Bregman (1980). Thus turbulence, the multi-phase structure, and the dischalo connection are intrinsically related features of the ISM.
Although accounting for only about 10% of the total visible mass in galaxies, the turbulent ISM is nevertheless important to their dynamics and structure. Heavy elements are forged by successive generations of stars. These are recycled into the ISM by SN feedback and transported by the ISM around the galaxy to form new stars. The ISM supports the amplification and regulation of a magnetic field, which also affects the movement of gas and subsequent location of new stars. Heating and shock waves within the ISM, primarily driven by supernovae, results in thermal and turbulent pressure alongside magnetic and cosmic ray pressure, which supports the disc against gravitational collapse.
## Chapter 2
## A brief review of interstellar modelling
## 2.1 Introduction
Work to produce a comprehensive description of the complex dynamics of the multiphase ISM has been significantly advanced by numerical simulations in the last three decades, starting with Chiang and Prendergast (1985), followed by many others including Rosen, Bregman and Norman (1993); Rosen and Bregman (1995); V´ azquez-Semadeni, Passot and Pouquet (1995); Passot, V´ azquez-Semadeni and Pouquet (1995); Rosen, Bregman and Kelson (1996); Korpi, Brandenburg, Shukurov, Tuominen and Nordlund (1999); Gazol-Pati˜ no and Passot (1999); Wada and Norman (1999); de Avillez (2000); Wada and Norman (2001); de Avillez and Berry (2001); de Avillez and Mac Low (2002); Wada, Meurer and Norman (2002); de Avillez and Breitschwerdt (2004); Balsara et al. (2004); de Avillez and Breitschwerdt (2005 a b , ); Slyz et al. (2005); Mac Low et al. (2005); Joung and Mac Low (2006); de Avillez and Breitschwerdt (2007); Wada and Norman (2007); Gressel et al. (2008 a ); Hill et al. (2012).
Numerical simulations of this type are demanding even with the best computers and numerical methods available. The self-regulation cycle of the ISM includes physical processes spanning enormous ranges of gas temperature and density, as well as requiring a broad range of spatial and temporal scales. It involves star formation in the cores of molecular clouds, assisted by gravitational and thermal instabilities at larger scales, which evolve against the global background of transonic turbulence, in turn, driven by star formation and subsequent SNe (Mac Low and Klessen, 2004). It is understandable that none of the existing numerical models cover the whole range of parameters, scales and physical processes known to be important.
Two major approaches in earlier work focus either on the dynamics of diffuse gas or on dense molecular clouds. In this chapter I will review a range of previous and current models, relating them to the physical features they include or omit. As with the general structure of the thesis, it is the extent to which physical processes are investigated that is of most interest, therefore I shall consider the physical problems and detail how various numerical approaches have been applied to these.
## 2.2 Star formation and condensation of molecular clouds
I shall not explicitly consider star formation. This occurs in the most dense clouds, which form from compressions in the turbulent ISM. As densities and temperatures attain critical levels in the clouds the effects of self-gravity and thermal instability may accelerate the collapse of regions within the clouds to form massive objects, which eventually ignite under high pressures to form stars.
The clouds themselves typically occupy regions spanning only a few parsecs. The final stages of star formation occurs on scales many magnitudes smaller than that, which may be regarded as infinitesimal by comparison to the dynamics of the galactic rotation and disc-halo interaction. Bonnell et al. (2006) model star formation by identifying regions of self gravitating gas of number density above 10 5 cm -3 and size ≤ 0 5 pc . . To track the evolution of even one star, requires very powerful computing facilities, and a time resolution well below 1 year. Currently this excludes the possibility of simultaneously modelling larger scale interstellar dynamics.
Modelling on the scale of molecular clouds, incorporating subsonic and supersonic turbulence and self-gravity is reported in Klessen, Heitsch and Mac Low (2000) and Heitsch, Mac Low and Klessen (2001) with and without magnetic field. These authors investigated the effect of various regimes of turbulence on the formation of multiple high density regions, which may then be expected to form stars. The subsequent collapse into stars was beyond the resolution of these models. Magnetic tension inhibited star formation, but this was subordinate to the effect of supersonic turbulence, which enhanced the clustering of gas within the clouds. These clusters provide the seed for star formation. In these models, supersonic turbulence was imposed by a numerical prescription. Physically the primary drivers of turbulence are SNe, and these evolve on scales significantly larger than the computational domain, so it would be difficult to include SNe and the fine structure of molecular clouds in the same model.
In addition to compression and self-gravity, thermal instability may also accelerate the formation of high density structures within the ISM. Brandenburg, Korpi and Mee (2007) investigated the effects of turbulence and thermal instability, including scales below 1 pc. Their analysis concluded that turbulent compression dominated that of thermal instability in the formation of the densest regions. The minimum cooling times were far longer than the typical turnover time of the turbulence.
Slyz et al. (2005) included star formation and a thermally unstable cooling function with a numerical domain spanning 1.28 kpc. The typical resolution was 10 or 20 pc. As previously stated, the dynamics of compression at higher resolution substantially dominate those of self-gravity and thermal instability. At this resolution, maximum density was about 10 2 cm -3 and minimum temperatures were above 300. They found a sensitivity in their results to the inclusion or exclusion of self-gravity, which Heitsch, Mac Low and Klessen (2001), with higher resolution, found to be subordinate to the effects of turbulence on the density profile. I would argue that this indicates that including self-gravity at
such large scales may therefore produce artificial numerical rather than physical effects. The gravitational effect of the ISM on scales greater than 1 pc are negligible, compared to stellar gravity and other dynamical effects.
In summary, modelling star formation and molecular clouds in the ISM necessitates a resolution significantly less than 1 pc. Self-gravity within the ISM is significant only for dense structures inside molecular clouds. Such gravitation is proportional to l -2 , where l denotes the distance from some mass sink, so is a highly localised phenomenon. Star formation in large scale modelling can therefore at best be parametrized by the removal of mass from the ISM based on the distribution of dense mass structures and self-gravity neglected.
## 2.3 Discs and spiral arms
To model a whole spiral galaxy requires a domain radius of order 10 kpc and potentially double that in height to include the halo. Often to avoid excessive computation, when modelling scales spanning the whole disc some authors either adopt a 2D horizontal approach (Slyz, Kranz and Rix, 2003), or adopt a very low vertical extent in 3D (Dobbs and Price, 2008; Hanasz, W´ olta´ski and Kowalik, 2009; Kulesza- ˙ ydzik et al., 2009; Dobbs n Z and Pringle, 2010). Given the mass, energy and turbulence are predominantly located within a few hundred parsecs of the mid-plane, some progress can be made with this approach.
A number of important physical features of the ISM must be neglected at this resolution. An important factor in the self-regulation of the ISM is the galactic fountain, in which over-pressured hot gas in the disc is convected into the halo, where it cools and rains back to the disc. How this affects star-formation and SNe rates is poorly understood.
The multi-phase ISM cannot currently be resolved at these scales. The cold diffuse gas exists in clumpy patches of at most a few parsecs. Even the hot bubbles of gas, generated at the disc by SNe and clusters of SNe are typically less than a few hundred parsecs across. The resolution of these global models is of order 100 pc, which is insufficient to include the separation of scales of about 10 3 between the hot and the warm gas. Generally these models apply an isothermal ISM. Dobbs and Price (2008) include a multiphase medium, by defining cold and warm particles, with fixed temperature and density, but must exclude any interaction between the phases.
The random turbulence driven by SNe must also be neglected or weakly parametrized. Dobbs and Price (2008) exclude SNe with the effect of significantly reducing the disc height between the spiral arms. Hanasz, W´ olta´ski and Kowalik (2009) neglect the thern mal and kinetic energy and inject energy only through current rings of radius 50 pc and 1% of the total SN energy. Slyz, Kranz and Rix (2003) use forced supersonic random turbulence to generate density perturbations.
These models can reproduce structures similar to spiral arms and, where a magnetic
field is included, an ordered field on the scale of the spiral arms. These can be related to different rates of rotation and for various density profiles. Even in 3D however these only describe the flat 2D structure of the disc and spiral arms. Both the velocity and the magnetic fields are vectors and subject to non-trivial transverse effects. The effect of asymmetry on these vectors in the vertical direction cannot be well represented with this geometry.
Features such as the vertical density distribution of the ISM, the thermal properties and turbulent velocities cannot be understood from these models. They must be introduced as model parameters, derived from observational measurements or smaller scale simulations. On the other hand structures such as spiral arms are too large to generate in more localised simulations. The global simulations may help to identify suitable parameters for introducing spiral arms into local models, such as the scale of the density fluctuations, orientation of the arms, typical width of the arms, how the strength or orientation of the magnetic field varies between the arm and interarm regions.
## 2.4 The multi-SNe environment
This thesis concerns modelling the ISM in a domain larger than the size of molecular clouds (Sect 2.2) and much smaller than a galaxy, or even just the disc (Sect 2.3). Models on this scale were introduced by Rosen, Bregman and Norman (1993), in 2D with much lower resolution, and without SNe. Nonetheless these already were able to identify features of the galactic fountain and the multiphase structure of the ISM. Individual SNe were investigated numerically by Cowie, McKee and Ostriker (1981). Extensive high resolution simulations led to the refinement of the classic Sedov-Taylor solution (Sedov, 1959; Taylor, 1950) and subsequent snowplough describing the evolution of an expanding blast wave (Ostriker and McKee, 1988; Cioffi, McKee and Bertschinger, 1998). The modelling of multiple SNe in the form of superbubbles within a stratified ISM was advanced by Tomisaka (1998). The first 3D simulations of SNe driven turbulence in the ISM were by Korpi, Brandenburg, Shukurov, Tuominen and Nordlund (1999) and, independently, de Avillez (2000). In this section I consider the key physical and numerical elements of these and subsequent similar models, and the extent to which their inclusion or omission improves or hinders the results.
## 2.4.1 The stratified interstellar medium
From the images in Fig.1.3 and the profiles illustrated in Fig. 1.2 it can be seen that the matter in spiral galaxies is substantially flattened into a disc. This morphology strongly depends on the rate and form of rotation of the galaxy. Towards the centre of these galaxies is a bulge, where the density structure and dynamics differ substantially from those in the disc. In elliptical galaxies the structure may involve asymmetries that are complicated to model. I shall defer consideration of the central region and elliptical galaxies to
elsewhere and confine this thesis to the investigation of the disc region of fast rotating galaxies.
Along the extended plane of the disc in fast rotators the dense region of gas may reasonably be approximated as unstratified to within about a few hundred parsecs of the mid-plane depending on the galaxy. The thickness of the disc away from the central bulge can, in many cases, to first approximation be regarded as constant, although it does usually increase exponentially away from the galactic centre. Thus, towards the outer galaxy, even over relatively short distances the flat disc approximation breaks down. Providing the model domain remains sufficiently within the thickness of the disc, some progress can be made by ignoring stratification, (eg Balsara et al., 2004; Balsara and Kim, 2005).
Important to the dynamics of the interstellar medium is its separation into characteristic phases in apparent pressure equilibrium. Is this separation a real physical effect, or just a statistical noise? What are the thermodynamical properties of the gas, what are the filling factors, typical motions and, if the phases do in fact differ qualitatively, how do they interact? The answers to these questions are critically different when considering the ISM to be stratified or not. Balsara et al. (2004) investigated the effect of increasing rates of supernovae on the composition of the ISM. With initial density set to match the mid-plane of the Galaxy, increasing the rate of energy injection resulted in increased proportions of cold dense and hot diffuse gas and correspondingly less warm gas. The typical radius of SN remnant shells in such a dense medium remained below 50 pc before being absorbed into the surrounding turbulence. The result of increased SNe is higher pressures and eventually overheating of the ISM.
However when a stratified ISM is included, the increased pressure from SNe near the mid-plane is released away from the disc, by a combination of diffuse convection and blow outs of hot high pressure bubbles. Korpi, Brandenburg, Shukurov and Tuominen (1999); de Avillez (2000); de Avillez and Berry (2001) included stratification. They found superbubbles, which combine multiple SNe merging or exploding inside existing remnants in the disc and then breaking out into the more diffuse layers, where they transport the hot gas away. They also had individual SNe exploding at distances > ∼ 500 pc from the mid-plane, where the ambient ISM is very diffuse and the remnants of these SNe extend to a radius of a few hundred parsecs. This also has an effect on the typical pressures, turbulent velocities and mixing scales. Instead of the cold gas and hot gas becoming more abundant at the mid-plane, the hot gas is transported away and the thickness of the disc expands reducing the mean density and mean temperature at the mid-plane.
Due to the gravitational potential, dominated by stellar mass near the mid-plane, there is a vertical density and pressure gradient. This will vary depending on the galaxy, but in most simulations of this nature it is useful to adopt the local parameters, since data relating to the solar neighbourhood is generally better understood, and therefore is convenient for benchmarking the results of numerical simulations.
There is a natural tendency for cold dense gas to be attracted to the mid-plane and
hot diffuse gas to rise and cool. Estimates from observations in the solar vicinity place the Gaussian scale height of the cold molecular gas at about 80 pc and the neutral atomic hydrogen about 180 pc (Ferri`re, 2001). The warm gas is estimated to have an exponential e scale height of 390 -1000 pc . Observationally hot gas is more difficult to isolate and estimates vary for the exponential scale height; ranging from as low as 1 kpc to over 5 kpc. Hence to reasonably produce the interaction between the cold and warm gas, we at least need to extend ± 1 kpc vertically. de Avillez (2000) with a vertical extent of ± 4 kpc found the ISM above about 2.5 kpc to be 100% comprised of hot gas, and this vertical extent was not high enough to observe the cooling and recycling of the hot gas back to the disc. Subsequent models (including de Avillez and Mac Low, 2001; de Avillez and Berry, 2001; de Avillez and Mac Low, 2002; Joung and Mac Low, 2006; Joung, Mac Low and Bryan, 2009; Hill et al., 2012) use an extended range in z of ± 10 kpc and find the volume above about ± 2 5 kpc . almost exclusively occupied by the hot gas for column densities and SNe rates comparable to the solar vicinity. Many of these models exclude the magnetic field and all exclude cosmic rays so the models have somewhat thinner discs than expected from observations. With the inclusion of magnetic and cosmic ray pressure, we expect the disc to be somewhat thicker and the scale height of the hot gas to increase.
The build up of thermal and turbulent pressure by SNe near the mid-plane generates strong vertical flows of the hot gas towards the halo. With vertical domain | z | = 10kpc de Avillez and Breitschwerdt (2004) are able to attain an equilibrium with hot gas cooling sufficiently to be recycled back to the mid-plane, replenishing the star forming regions and subsequently SNe. Such recycling may be expected to occur in the form of a galactic fountain. However Korpi, Brandenburg, Shukurov and Tuominen (1999); Korpi, Brandenburg, Shukurov, Tuominen and Nordlund (1999) found the correlation scale in the warm gas of the velocity field remained quite consistently about 30 pc independent of z location, but in the hot gas it increased from about 20 pc at the mid-plane to over 150 pc at | z | glyph[similarequal] 300 pc and increasing with height. Other authors report correlation scales similar near the mid-plane, but the vertical dependence of correlation lengths requires further investigation. If there is an increase in the correlation length of the velocity field with height, as | z | → 1 kpc the scale of the turbulent structures of the ISM can become comparable to the typical size of the numerical domain. Consequently in extending the z -range to include the vertical dimension of the hot gas, its horizontal extent may exceed the width of too narrow a numerical box. With a vertical extent of only ± 1 kpc , or with Gressel et al. (2008 a ) ± 2 kpc , there is a net outflow of gas. Without a mechanism for recycling the hot gas, net losses eventually exhaust the disc and the model parameters cease to be useful. Korpi, Brandenburg, Shukurov, Tuominen and Nordlund (1999) found this restriction limited the useful time frame to a few hundred Myr. It is difficult to combine in one model the detailed dynamics of the SNe driven turbulence about the mid-plane with a realistic global mechanism for the recycling of the hot gas.
There has also been some discussion on the effect of magnetic tension inhibiting these
outflows. Using 3D simulations of a stratified but non-turbulent ISM with a purely horizontal magnetic field Tomisaka (1998) placed an upper bound on this confinement. When the ISM is turbulent the magnetic field becomes disordered, the ISM contains pockets of diffuse gas, and the opportunity for hot gas blow outs increases substantially (see e.g. Korpi, Brandenburg, Shukurov and Tuominen, 1999; de Avillez and Breitschwerdt, 2004, 2005 b ).
## 2.4.2 Compressible flows and shock handling
The ISM is highly compressible, with much of the gas moving at supersonic velocities. The most powerful shocks are driven by SNe. Accurate modelling of a single SNe in 3D requires high resolution and short time steps (Ostriker and McKee, 1988). On the scales of interest here, hundreds or thousands of SNe are required and this constrains the time and resolution available to model the SNe. Approximations need to be made, which retain the essential characteristics of the blast waves and structure of the remnants at the minimum physical scales resolved by the model.
Shock handling is optimised (by e.g. de Avillez, 2000; Balsara et al., 2004; Mac Low and Klessen, 2004; Joung and Mac Low, 2006; Gressel et al., 2008 a ) through adaptive mesh refinement (AMR), where increased resolution is applied locally for regions containing the strongest contrasts in density, temperature or flow. With increased spatial resolution the time step must also be much smaller, so there are considerable computational overheads to the procedure. Many of the codes utilising AMR do not currently include modelling of differential rotation, although Gressel et al. (2008 a ) does apply shear using the Nirvana 1 code. An alternative approach is to apply enhanced viscosities where there are strong convergent flows (by e.g. Korpi, Brandenburg, Shukurov, Tuominen and Nordlund, 1999). This broadens the shock profiles and removes discontinuities, so care needs to be taken that essential physical properties are not compromised.
## 2.4.3 Distribution and modelling of SNe
There are a number of different types of supernovae, with different properties and origin. Type Ia SNe arise from white dwarfs, which are older stars that have used up most of their hydrogen and comprise mainly of heavier elements oxygen and carbon. If, through accretion or other mechanisms, their mass exceeds the Chandrasekhar limit (Chandrasekhar, 1931) of approximately 1 38 . M glyph[circledot] they become unstable and explode. Type Ia are observed in all categories of galaxy and can have locations isolated from other types of SNe.
Type II SNe are produced by massive, typically more than 10 M glyph[circledot] , relatively young hot stars, which rapidly exhaust their fuel and collapse under their own gravity before exploding. Type Ib and Ic are characterized by the absence of hydrogen lines in their spectrum and, for Ic, also their helium, which has been stripped by either stellar winds
1 http://nirvana-code.aip.de/
or accretion, before the more dense residual elements collapse to form SNe. Otherwise Type II, Ib and Ic SNe are very similar, located only in fast rotating galaxies and populating mainly the star forming dense gas clouds near the mid-plane of the disc. For the remainder of this thesis I shall collectively denote these as Type CC (core collapsing) and Type I shall refer only to Type Ia. Type CC SNe are more strongly correlated in space and time than Type I, because they form in clusters, evolve over a few million years and explode in rapid succession.
In many disc galaxies, including the Milky Way, Type CC SNe are much more prolific than Type I. Both types effectively inject 10 51 erg into the ISM (equivalent to 10 40 modern thermo-nuclear warheads exploded simultaneously). Type CC also contribute 4 -20 M glyph[circledot] as ejecta at supersonic speeds of a few thousand kms -1 . Mainly located in the most dense region of the disc, Type CC SNe energy can be more rapidly absorbed and explosion sites reach a radius of typically 50 pc before becoming subsonic, while some Type I explode in more diffuse gas away from the mid-plane and can expand to a radius of a few hundred parsecs. Because Type CC are correlated in location and time, many explode into or close to existing remnants and form superbubbles of hot gas, which help to break up the dense gas shells of SN remants and increase the turbulence. Heating outside the mid-plane by Type I SNe helps to disrupt the thick disc and increase the circulation of gas from within.
A common prescription for location of SNe in numerical models, is to locate them randomly, but uniformly in the horizontal plane and to apply a Gaussian or exponential random probability distribution in the vertical direction, with its peak at the mid-plane z = 0 . Having determined the location, an explosion is then modelled by injecting a roughly spherical region containing mass, energy and/or a divergent velocity profile. The sphere needs to be large enough, that for the given resolution, the resulting thermal and velocity gradients are numerically resolved. This means that for typical resolution of a few pc the radius of the injection site will be several parsecs and indicative of the late Sedov-Taylor or early snowplough phase (See Section 3.2 and Appendix A.1) some thousands of years after the explosion. Subsequently gas is expelled by thermal pressure or kinetic energy from the interior to form an expanding supersonic shell, which drives turbulent motions and heats up the ambient ISM. Problems have been encountered with modelling the subsequent evolution of these remnants. Cooling can dissipate the energy before the remnant shell is formed. Using kinetic rather than thermal energy to drive the SNe evolution is hampered by the lack of resolution.
As well as being physically consistent, clustering of SNe mitigate against energy losses by ensuring they explode in the more diffuse, hot gas where they are subject to lower radiative losses. To achieve clustering for the Type CC SNe Korpi, Brandenburg, Shukurov and Tuominen (1999) selected sites with a random exponential distribution in z , excluded sites in the horizontal plane with density below average for the layer and then applied uniform random selection. de Avillez (2000) apply a more rigorous prescription to locate 60% of Type CC in superbubbles, in line with observational estimates (Cowie,
Songaila and York, 1979). In addition to a simplified clustering scheme Joung and Mac Low (2006) and Joung, Mac Low and Bryan (2009) also adjust the radii of their SNe injection sites to enclose 60 M glyph[circledot] of ambient gas. This appears to optimise the efficiency of the SNe modelling; avoiding high energy losses at T > 10 8 K with a smaller injection site or avoiding too large an injection site, which dissipates the energy before the snowplough phase can be properly reproduced.
The critical features of the SNe modelling must ensure that the SNe are sufficiently energetic and robust to stir and heat the ambient ISM. It is unlikely that the individual remnants can be accurate in every detail, given the constraints on time and space resolution, but the growth of the remnants should be physically consistent, producing remnants and bubbles of multiple remnants at the appropriate scale. In particular we can expect about 10% of the energy to be output into the ISM in the form of kinetic energy when the remnant merges with the ambient ISM. Spitzer (1978) estimates this to be 3% and Dyson and Williams (1997) to be 30%.
## 2.4.4 Solid body and differential rotation
To understand the density and temperature composition of the ISM the inclusion of the rotation of the galaxy is not essential. Even an appreciation of the characteristic velocities and Mach numbers associated with the regions of varying density or temperature can be obtained without rotation. Balsara et al. (2004); Balsara and Kim (2005); Mac Low et al. (2005) and de Avillez and Breitschwerdt (2005 a ) investigate the magnetic field in the ISM without rotation or shear, the latter in the vertically extended stratified ISM, otherwise in an unstratified (200 pc) 3 section. The latter two models impose a uniform B of between 2 -5 µ G . The turbulence breaks up the ordered field (mean denoted B 0 ) and with modest amplification of the total magnitude B , although the simulations last only a few hundred Myr. Over a longer period, it would be expected that B 0 would continue to dissipate in the absence of any restoring mechanism (rotation). They analyze the distribution with respect to density and temperature of the fluctuations, b , and mean parts of the field, and their comparative strengths.
Balsara et al. (2004) and Balsara and Kim (2005) investigate the fluctuation dynamo, introducing a seed field of order 10 -3 µ G and increasing it to 10 -1 µ G over 40 Myr. This is insufficiently long to saturate and there is no mean field, but they do examine the turbulent structure of b and the dynamo process.
However galactic differential rotation is a defining feature of the global characteristics of disc galaxies and is felt locally by the Coriolis effect and shearing in the azimuthal direction. There is observational evidence that the magnetic field in disc galaxies, which is heavily randomised by turbulence, is also strongly organized along the direction of the spiral arms (e.g. Patrikeev et al., 2006; Tabatabaei et al., 2008; Fletcher et al., 2011). Differential rotation is responsible for the spiral structure, so must be included to understand the source of the mean field in the galaxy.
There is also considerable controversy over the nature and even the existence of the the galactic dynamo. A fluctuation dynamo can be generated by turbulence alone, but it is not clear that it can be sustained indefinitely. The mean field dynamo cannot be generated without anisotropic turbulence and large scale systematic flows.
Gressel et al. (2008 a ); Gressel et al. (2008 b ) include differential rotation and by introducing a small seed field, are able to derive a mean field dynamo for a stratified ISM. The dynamo is only sustained in their model for rotation 4 Ω 0 , where Ω 0 ≈ 230 km s -1 is the angular velocity of the Galaxy in the solar vicinity. Otherwise they apply parameters the same as or similar to the local Galaxy. Gressel (2008) also considered solid body rotation and found no dynamo, but concluded that shear, without rotation, cannot support the galactic dynamo. Without rotation diamagnetic pumping is too weak to balance the galactic wind. The resolution of the model at (8 pc) 3 limits the magnetic Reynolds numbers available, which may explain the failure to find a dynamo with rotation of Ω 0 . For a comprehensive understanding of the galactic magnetic field differential rotation should not be neglected.
## 2.4.5 Radiative cooling and diffuse heating
The multi-phase structure of the ISM would appear to be the result of a combination of the complex effects of supersonic turbulent compression, randomized heating by SNe and the differential cooling rates of the ISM in its various states. Although excluding SNe, and having a low resolution, Rosen, Bregman and Norman (1993) generated a multiphase ISM with just diffuse stellar heating from the mid-plane and non-uniform radiative cooling.
Radiative cooling depends on the density and temperature of the gas and different absorption properties of various chemicals within the gas on the molecular level. For models such as the ones discussed here detailed analysis of these effects and estimates of the relative abundances of these elements in different regions of the ISM (see e.g. Wolfire et al., 1995) need to be adapted to fit a monatomic gas approximation. Stellar heating varies locally, on scales far below the resolution of these models, due to variations in interstellar cloud density and composition as well ambient ISM temperature sensitivities.
Subtle variations in the application of these cooling and heating approximations may have very unpredictable effects, due to the complex interactions of the density and temperature perturbations and shock waves. In particular thermal instability is understood to be significant in accelerating the gravitational collapse of dense clouds, by cooling the cold dense gas more quickly than the ambient diffuse warm gas.
Different models have used radiative cooling functions which are qualitatively as well as quantitatively distinct, making direct comparison uncertain. V´ azquez-Semadeni, Gazol and Scalo (2000) compared their thermally unstable model to a different model by Scalo et al. (1998) who used a thermally stable cooling function. They concluded that thermal instability on 1 pc scales is insufficient to account for the phase separation of the ISM,
but in the presence of other instabilities increases the tendency towards thermally stable temperatures. Similarly, de Avillez and Breitschwerdt (2004) and Joung and Mac Low (2006) compared results obtained with different cooling functions, but comparing models with different algorithms for the SN distribution and control of the explosions. In the absence of SNe driven turbulence the ISM does separate into two phases with reasonable pressure parity and in the presence of background turbulence this separation persists (S´ anchez-Salcedo, V´ azquez-Semadeni and Gazol, 2002; Brandenburg, Korpi and Mee, 2007). Although the pressure distribution broadens, the bulk of both warm and cold gases broadly retain pressure parity.
An additional complexity is advocated by de Avillez and Breitschwerdt (2010). Generally it is assumed that ionization through heating and recombination of atoms by cooling are in equilibrium. However recombination time scales lag considerably, so that cooling is not just dependent on temperature and density. Cooler gas which had been previously heated to T > 10 6 K will remain more ionized than gas of equivalent density and temperature which has not been previously heated. de Avillez and Breitschwerdt (2010) show that this significantly affects the radiation spectra of the gas, therefore they use a cooling function which varies locally, depending on the thermal history of the gas.
The choice of cooling and heating functions has a quantitative effect on the results of ISM models and there is evidence that the inclusion or exclusion of thermal instability in various temperature ranges has a qualitative impact on the structure of the ISM. However uncertainty remains over whether the adopted cooling functions are indeed faithfully reproducing the physical effects. There is also uncertainty over how critical the differences between various parameterizations are to the results, once SNe, magnetic fields and other processes are considered. It is certain, however, that differential radiative cooling is an essential feature of the ISM.
## 2.4.6 Magnetism
Estimates of the strength of magnetic fields indicate that the magnetic energy density has the same order of magnitude as the kinetic and thermal energy densities of the ISM. Including magnetic pressure substantially increases the thickness of the galactic disc compared to the purely hydrodynamic regime. Magnetic tension and the Lorentz force will affect the velocities and density perturbations in the ISM. Ohmic heating and electrical conductivity will affect the thermal composition of the ISM. Hydrodynamical models provide an excellent benchmark, but to accurately model the ISM and be able to make direct comparisons with observations the magnetic field should be included.
Comparisons between MHD and HD models have been made (Korpi, Brandenburg, Shukurov and Tuominen, 1999; Balsara et al., 2004; Balsara and Kim, 2005; Mac Low et al., 2005; de Avillez and Breitschwerdt, 2005 a ). These either impose a relatively strong initial mean field or contain only a random field, and are evolved over a comparatively short time frame. So the composition of the field cannot reliably be considered authentic.
Ideally it would be useful to understand the dynamo mechanism; are there minimum and maximum rates of rotation conducive to magnetic fields? How does the SNe rate or distribution affect the magnetic field? What is the structure of the mean field, how do the mean and fluctuating parts of the field compare and how is the magnetic field related to the multi-phase composition of the ISM? To ensure the field is the product of the ISM dynamics the mean field needs to be generated consistently with the key ingredients of differential rotation and turbulence, from a very small seed field. The time over which the model evolves must be sufficiently long that no trace of the seed field properties persist.
## 2.4.7 Cosmic Rays
Cosmic rays are high energy charged particles, travelling at relativistic speeds. Their trajectories are strongly aligned to the magnetic field lines (Kulsrud, 1978). It is speculated that, amongst other potential sources, they are generated and accelerated in shock fronts around supernovae. They also occur in solar mass ejections, some of which are caught in the Earth's magnetosphere. The polar aurora result from these travelling along the field lines and heating the upper atmosphere as they collide.
Cosmic rays are of interest in themselves, but also are estimated to make a similar contribution to the energy density and pressures in the ISM as each of the magnetic field, the kinetic and the thermal energies (Parker, 1969). As such their inclusion can be expected to significantly affect the global properties of the ISM.
Although a substantial component of the ISM is not charged the highly energized cosmic rays strongly affect the bulk motion of the gas. The interaction between cosmic rays and the ISM is highly non-linear, but can be considered in simplified form by a diffusion-advection equation,
$$\frac { \partial e _ { \text{cr} } } { \partial t } + \nabla ( e _ { \text{cr} } u ) = - p _ { \text{cr} } \nabla u + \nabla ( \hat { K } \nabla e _ { \text{cr} } ) + Q _ { \text{cr} } \,,$$
$$p _ { \text{cr} } = ( \gamma _ { \text{cr} } - 1 ) e _ { \text{cr} } \,,$$
where e cr and p cr are the cosmic ray energy and pressure respectively, and ˆ K the cosmic ray diffusion tensor, γ cr the cosmic ray ratio of specific heats, and Q cr a cosmic ray source term such as SNe. u is the ISM gas velocity.
Hanasz et al. (2004, 2005, 2006, 2011) use cosmic rays in a magnetized isothermal simulation to perturb the magnetic field and drive the dynamo in their global disc galaxy simulations. None of the thermodynamic, stratified models of the ISM have yet included cosmic rays.
## 2.4.8 Diffusivities
The dimensionless parameters characteristic of the ISM, such as the kinetic and magnetic Reynolds numbers (reflecting the relative importance of gas viscosity and electrical
resistivity) and the Prandtl number (quantifying thermal conductivity) are too large to be obtainable with current computers. Lequeux (2005) estimates the Reynolds number Re glyph[similarequal] 10 7 for the cold neutral medium, with viscosity ν glyph[similarequal] 3 × 10 17 cm s 2 -1 . Uncertainty applies to these estimates in the various phases and also to thermal and magnetic diffusivities, but physical Re and Rm (magnetic Reynolds number) are far larger and diffusivities far smaller than can be resolved numerically. Given the very low physical diffusive co-efficients in the ISM some models approximate them as zero. Applying ideal MHDwhere electrical resistivity is ignored (e.g. de Avillez, 2000; Mac Low et al., 2005; Joung and Mac Low, 2006; Li, Mac Low and Klessen, 2005, and their subsequent models) the magnetic field is modelled as frozen in to the fluid. Although magnetic diffusion is not explicitly included in their equations, it exists through numerical diffusion which is determined by the grid scale. In models with adaptive mesh refinement, the diffusion varies locally with the variations in resolution.
In fact, within the turbulent environment of the ISM, although the diffusivity is very low, shocks and compressions can create conditions, in which the time scales of the diffusion are comparable with other time scales such as the diffusion of heat, charge and momentum. Korpi, Brandenburg, Shukurov, Tuominen and Nordlund (1999) and Gressel et al. (2008 a ) include bulk diffusivity in their equations, which are some orders of magnitude larger than those typical of the ISM. These are constrained by the minimum that can be resolved with the numerical resolution available, but ensure the level of diffusion is consistent throughout.
Although, the maximum effective Reynolds numbers are much lower than estimates for the real ISM, there is considerable consistency in structures derived by models on the meso-scales, e.g., thickness of the disc, size of remnant structures and super bubbles, typical velocities, densities and temperatures. Uncertainties are greater in describing the fine structures; remnant shells, condensing clouds, and dispersions of velocity, density and temperature.
## 2.4.9 The galactic fountain
It is reasonable to conclude from what we understand from observations and the work of de Avillez and Mac Low (2002) and their subsequent models, that the modelling of the galactic fountain requires a scale height of order ± 10 kpc . They found z = ± 5 kpc was insufficient to establish a duty cycle with hot gas condensing and recycling back to the disc. Gressel et al. (2008 a ) model the ISM to z = ± 2 kpc and throughout their model there is a net outflow across the outer horizontal surfaces.
Less clear is how large a horizontal span is required. Korpi, Brandenburg, Shukurov, Tuominen and Nordlund (1999) found the correlation length of the velocity of the hot gas increased from about 20 pc at z = 0 to about 150 pc at | z | = 300pc and the scale of the box at | z | = 850pc . This indicates that as height increases above 1 kpc the size of the physical structures of the hot gas may well exceed the model. As such reliable modelling
of the galactic fountain may well require a substantially larger computational domain in all directions. de Avillez and Mac Low (2002) model large | z | with much lower resolution than the mid-plane, to manage the computational demands. It may be that the scale of the task may necessitate sacrificing resolution throughout to expand the range of the models to investigate the galactic fountain.
## 2.4.10 Spiral arms
Only models on the larger scales previously described (Slyz, Kranz and Rix, 2003; Dobbs and Price, 2008; Hanasz et al., 2004, and subsequent models) have reproduced features similar to the spiral arms in rotating galaxies. It is unlikely that the dynamics of the spiral arms can be understood from models in the scale of 1-2 kpc in the horizontal, because they are structures typical of the full size of the galaxy. Rather than an outcome of such models, they could perhaps be included as an input in the form of a density wave through the box at appropriate intervals, with other associated effects, such as fluctuations in SNe rates.
## 2.5 Summary
Many models have been used, some to describe different astrohpysical features or alternative approaches to the same environment. Direct comparison of results is consequently difficult. All models must omit ingredients and approximate or parameterize some of the challenging dynamics. Computational power restricts resolution, domain size and physical components, so each model must be adapted to match the requirements of the particular astrophysics under investigation; e.g. star formation permits only a small domain, enables high resolution, requires thermal instability; spiral arms impose the requirement of a global domain, restrict resolution or turbulence. A comprehensive understanding requires a heirarchy of models, spanning an overlapping range of scales, encompassing the all the critical physical features.
## Part II
## Modelling the interstellar medium
## Chapter 3
## Basic equations and their numerical implementation
## 3.1 Basic equations
I solve numerically a system of equations using the PENCIL CODE 1 , which is designed for fully nonlinear, compressible magnetohydrodynamic (MHD) simulations. I do not currently include cosmic rays, which will be considered elsewhere subsequently.
The basic equations include the mass conservation equation, the Navier-Stokes equation (written here in the rotating frame), the heat equation and the induction equation:
$$\frac { D \rho } { D t } \, = \, - \nabla \cdot ( \rho \boldsymbol u ) \, + \, \dot { \rho } _ { \text{SN} },$$
$$\frac { D \rho } { D t } & = - \nabla \cdot ( \rho u ) + \dot { \rho } _ { \text{SN} }, & ( 3. 1 ) \\ \frac { D u } { D t } & = - \rho ^ { - 1 } \nabla \sigma _ { \text{SN}, \text{in} } - c _ { s } ^ { 2 } \nabla \left ( s / c _ { p } + \ln \rho \right ) - \nabla \Phi - S u _ { x } \hat { y } - 2 \Omega \times u \\ & \quad + \rho ^ { - 1 } j \times B + \nu \left ( \nabla ^ { 2 } u + \frac { 1 } { 3 } \nabla \nabla \cdot u + 2 \mathbf W \cdot \nabla \ln \rho \right ) + \zeta _ { \nu } \left ( \nabla \nabla \cdot u \right ), \quad ( 3. 2 ) \\ \rho T \frac { D s } { D t } & = \dot { \sigma } _ { \text{SN}, t } + \rho \Gamma - \rho ^ { 2 } \Lambda + \nabla \cdot \left ( c _ { p } \rho \chi \nabla T \right ) + \eta \mu _ { 0 } \dot { j } ^ { 2 } \\ & \quad + 2 \rho \nu \left | \mathbf W \right | ^ { 2 } + \zeta _ { \chi } \left ( \rho T \nabla ^ { 2 } s + \nabla \ln \rho T \cdot \nabla s \right ) + \rho T \nabla \zeta _ { \chi } \cdot \nabla s, & ( 3. 3 ) \\ \frac { \partial A } { \partial t } & = u \times B - S A _ { y } \hat { x } - S x \frac { \partial A } { \partial y } \\ & \quad + \left ( \eta + \zeta _ { \eta } \right ) \nabla ^ { 2 } A + \nabla \cdot A ( \nabla \eta + \nabla \zeta _ { \eta } ), & ( 3. 4 ) \\ \end{cases}$$
where ρ , T and s are the gas density, temperature and specific entropy, respectively, u is the deviation of the gas velocity from the background rotation profile (here called the velocity perturbation ), and B and A are the magnetic field and magnetic potential, respectively, such that B = ∇× A . Also j is the current density, c s is the adiabatic speed of sound, c p is the heat capacity at constant pressure, S is the velocity shear rate associated with the Galactic differential rotation at the angular velocity Ω (see below), assumed to be aligned with the z -axis. The Navier-Stokes equation includes the viscous term with
1 http://code.google.com/p/pencil-code
the viscosity ν and the rate of strain tensor W whose components are given by
$$2 W _ { i j } = \frac { \partial u _ { i } } { \partial x _ { j } } + \frac { \partial u _ { j } } { \partial x _ { i } } - \frac { 2 } { 3 } \delta _ { i j } \nabla \cdot { \boldsymbol u },$$
as well as the shock-capturing viscosity ζ ν and the Lorentz force, ρ -1 j × B . The implementation of shock-capturing is discussed in Section 3.4
The system is driven by SN energy injection per unit volume, at rates ˙ σ SN kin , in the form of kinetic energy in Eq. (3.2) and thermal energy ( ˙ σ SN th , ) in Eq. (3.3). Energy injection is confined to the interiors of SN remnants, and the total energy injected per supernova is denoted E SN . The mass of the SN ejecta is included in Eq. (3.1) via the source ˙ ρ SN . The forms of these terms are specified and further details are given in Section 3.2.
The heat equation also contains a thermal energy source due to photoelectric heating ρΓ , energy loss due to optically thin radiative cooling ρ Λ 2 , heat conduction with the thermal diffusivity χ , viscous heating (with | W | the determinant of W ), Ohmic heating ηµ 0 j 2 , and the shock-capturing thermal diffusivity ζ χ . K = c p ρχ is the thermal conductivity and µ 0 is vacuum permeability.
The induction equation includes magnetic diffusivity η and shock-capturing magnetic diffusivity ζ η .
The advective derivative,
$$\frac { D } { D t } = \frac { \partial } { \partial t } + ( U + u ) \cdot \nabla,$$
includes transport by an imposed shear flow U = (0 , Sx, 0) in the local Cartesian coordinates (taken to be linear across the local simulation box), with the velocity u representing a deviation from the overall rotational velocity U . As discussed later, the perturbation velocity u consists of two parts, a mean flow and a turbulent velocity. A mean flow is considered using kernel averaging techniques (e.g. Germano, 1992) applying a Gaussian kernel:
$$\langle u \rangle _ { \ell } ( x ) & = \int _ { V } u ( x ^ { \prime } ) G _ { \ell } ( x - x ^ { \prime } ) \, \mathrm d ^ { 3 } x ^ { \prime }, \\ G _ { \ell } ( x ) & = \left ( 2 \pi \ell ^ { 2 } \right ) ^ { - 3 / 2 } \exp \left [ - x ^ { 2 } / ( 2 \, \ell ^ { 2 } ) \right ],$$
where, as discussed in Chapter 8, glyph[lscript] glyph[similarequal] 50 pc is determined to be an appropriate smoothing scale. The random flow u turb is then u -〈 〉 u glyph[lscript] . The differential rotation of the galaxy is modelled with a background shear flow along the local azimuthal ( y ) direction, U y = Sx . The shear rate is S = r ∂ Ω/ r ∂ in terms of galactocentric distance r , which translates into the x -coordinate for the local Cartesian frame. In this thesis I consider models with rotation and shear relative to those in the solar neighbourhood, Ω 0 = -S = 25kms -1 kpc -1 .
The ISM is considered an ideal gas, with thermal pressure given by
$$p = \frac { k _ { \text{B} } } { \mu m _ { \text{p} } } \rho T,$$
where k B is the Boltzmann constant, m p is the proton mass. I have assumed the gas to have the Solar chemical composition and the level of ionization to be uniform 2 adopting a value of µ = 0 62 . for the mean molecular weight. The calculation does not explicitly solve for temperature nor pressure, but for entropy. Due to its complexity ions and electrons are not modelled directly, however even without this it is reasonable to consider different states of ionization for gas depending on temperature. Expressions including T in Eq. 3.3 are reformulated in terms of s and ρ for the calculation. However the equation of state and the effect of µ is applied indirectly through the specific heat capacities c v and c p and via the temperature dependent radiative cooling. In future simulations and analysis we could consider applying µ , which varies according to the temperature and its corresponding level of ionization. As a result the thermal pressure might reduce for the cold and warm gas, and increase for the hot gas, when compared to the analysis presented in this thesis. Further clarification is included in Appendix D.
In Eq. (3.2), Φ is the gravitational potential produced by stars and dark matter. For the Solar vicinity of the Milky Way, Kuijken and Gilmore (1989) suggest the following form of the vertical gravitational acceleration (see also Ferri`re, 2001): e
$$g _ { z } = - \frac { \partial \Phi } { \partial z } = - \frac { a _ { 1 } z } { \sqrt { z _ { 1 } ^ { 2 } + z ^ { 2 } } } - a _ { 2 } \frac { z } { z _ { 2 } },$$
with a 1 = 4 4 . × 10 -14 kms -2 , a 2 = 1 7 . × 10 -14 kms -2 , z 1 = 200pc and z 2 = 1kpc . Self-gravity of the interstellar gas is neglected because it is subdominant at the scales of interest.
If self-gravity were included it applies on scales below the Jeans length
$$\lambda _ { \text{J} } \approx \sqrt { \frac { k _ { \text{B} } T r ^ { 3 } } { G M \mu } },$$
where the gravitational energy GMµ/r of the total mass M enclosed within a radius of r exceeds the thermal energy per particle k B T within r . If the density of cold gas increases sufficiently such that locally λ J becomes less than the grid length ∆ then it can no longer be resolved. Dobbs, Burkert and Pringle (2011) exclude this in their models by locating SNe where the the ISM becomes sufficiently self-gravitating, thus preventing the process exceeding the grid resolution. This is also used to regulate the SN rate.
2 I thank Prof. J. Pringle for helping me during my viva to derive an appreciation for the determination of µ appropriately for the distinct ionized states of different ISM phases.
## 3.2 Modelling supernova activity
I include both Type CC and Type I SNe in these simulations, distinguished only by their frequency and vertical distribution. The SNe frequencies are those in the Solar neighbourhood (e.g. Tammann, L¨ offler and Schr¨der, 1994). Type CC SNe are introduced at a o rate, per unit surface area, of ν II = 25kpc -2 Myr -1 ( 0 02 yr . -1 in the whole Galaxy), with fluctuations of the order of 10 -4 yr -1 at a time scale of order 10 Myr . Such fluctuations in the SN II rate are natural to introduce; there is some evidence that they can enhance dynamo action in MHD models (Hanasz et al., 2004; Balsara et al., 2004). The surface density rate of Type I SNe is ν I = 4kpc -2 Myr -1 (an interval of 290 years between SN I explosions in the Galaxy).
Unlike most other ISM models of this type, the SN energy in the injection site is split between thermal and kinetic parts, in order to further reduce temperature and energy losses at early stages of the SN remnant evolution. Thermal energy density is distributed within the injection site as exp[ -( r/r SN ) 6 ] , with r the local spherical radius and r SN the nominal location of the remnant shell (i.e. the radius of the SN bubble) at the time of injection. Kinetic energy is injected by adding a spherically symmetric velocity field u r ∝ exp[ -( r/r SN ) 6 ] ; subsequently, this rapidly redistributes matter into a shell. To avoid a discontinuity in u at the centre of the injection site, the centre is simply placed midway between grid points. I also inject 4 M glyph[circledot] as stellar ejecta, with density profile exp[ -( r/r SN ) 6 ] . Given the turbulent environment, there are significant random motions and density inhomogeneities within the injection regions. Thus, the initial kinetic energy is not the same in each region, and, injecting part of the SN energy in the kinetic form results in the total kinetic energy varying between SN remnants. I therefore record the energy added for every remnant so I can fully account for the rate of energy injection. For example, in Model WSWa I obtain the energy per SN in the range
$$0. 5 < E _ { \text{SN} } < 1. 5 \times 1 0 ^ { 5 1 } \text{erg},$$
with the average of 0 9 . × 10 51 erg .
The SN sites are randomly distributed in the horizontal coordinates ( x, y ) . Their vertical positions are drawn from normal distributions with scale heights of h II = 0 09 kpc . for SN II and h I = 0 325 kpc . for Type I SNe. Thus, Eq. (3.1) contains the mass source of 4 M glyph[circledot] per SN,
$$\mathring { \rho } _ { \text{SN} } \simeq 4 M _ { \odot } \left ( \frac { \nu _ { \text{II} } } { 2 h _ { \text{II} } } + \frac { \nu _ { \text{I} } } { 2 h _ { \text{I} } } \right ) [ M _ { \odot } \text{kpc} ^ { - 3 } \text{Myr} ^ { - 1 } ],$$
whereas Eqs. (3.2) and (3.3) include kinetic and thermal energy sources of similar strength adding up to approximately E SN per SN:
$$\dot { \sigma } _ { \text{SN,kin} } \simeq \dot { \sigma } _ { \text{SN,th} } = \frac { 1 } { 2 } E _ { \text{SN} } \left ( \frac { \nu _ { \text{II} } } { 2 h _ { \text{II} } } + \frac { \nu _ { \text{I} } } { 2 h _ { \text{I} } } \right ) [ \text{erg kpc} ^ { - 3 } \text{ Myr} ^ { - 1 } ].$$
The only other constraints applied when choosing SN sites are to reject a site if an SN explosion would result in a local temperature above 10 10 K or if the local gas number density exceeds 2 cm -3 . The latter requirement ensures that the thermal energy injected is not lost to radiative cooling before it can be converted into kinetic energy in the ambient gas. More elaborate prescriptions can be suggested to select SN sites (Korpi, Brandenburg, Shukurov and Tuominen, 1999; de Avillez, 2000; Joung and Mac Low, 2006; Gressel et al., 2008 a ); I found this unnecessary for the present purposes.
Arguably the most important feature of SN activity, in the present context, is the efficiency of evolution of the SNe energy from thermal to kinetic energy in the ISM, a transfer that occurs via the shocked, dense shells of SN remnants. Given the relatively low resolution of this model (and most, if not all, other models of this kind), it is essential to verify that the dynamics of expanding SN shells are captured correctly: inaccuracies in the SN remnant evolution would indicate that the modelling of the thermal and kinetic energy processes was unreliable. Therefore, I present in Appendix A detailed numerical simulations of the dynamical evolution of an individual SN remnant at spatial grid resolutions in the range ∆ = 1 4 pc -. The SN remnant is allowed to evolve from the Sedov-Taylor stage (at which SN remnants are introduced in these simulations) for t ≈ 3 5 Myr . . The remnant enters the snowplough regime, with a final shell radius exceeding 100 pc , and the numerical results are compared with the analytical solution of Cioffi, McKee and Bertschinger (1998). The accuracy of the numerical results depends on the ambient gas density n 0 : larger n 0 requires higher resolution to reproduce the analytical results. I show that agreement with Cioffi, McKee and Bertschinger (1998) in terms of the shell radius and speed is very good at resolutions ∆ ≤ 2 pc for n 0 glyph[similarequal] 1 cm -3 , and excellent at ∆ = 4pc , for n 0 ≈ 0 1 . and 0 01 cm . -3 .
Since shock waves in the immediate vicinity of an SN site are usually stronger than anywhere else in the ISM, these tests also confirm that this handling of shock fronts is sufficiently accurate and that the shock-capturing diffusivities that are employed do not unreasonably affect the shock evolution.
The standard resolution is 4 pc. To be minimally resolved, the initial radius of an SN remnant must span at least two grid points. Because the origin is set between grid points, a minimum radius of 7 pc for the energy injection volume is sufficient. The size of the energy injection region in the model must be such that the gas temperature is above 10 6 K and below 10 8 K : at both higher and lower temperatures, energy losses to radiation are excessive and adiabatic expansion cannot be established. Following Joung and Mac Low (2006), I adjust the radius of the energy injection volume to be such that it contains 60 M glyph[circledot] of gas. For example, in Model WSWa this results in a mean r SN of 35 pc , with a standard deviation of 25 pc and a maximum of 200 pc . The distribution of radii appears approximately lognormal, so r SN > 75 pc is very infrequent and the modal value is about 10 pc ; this corresponds to the middle of the Sedov-Taylor phase of the SN expansion. Unlike Joung and Mac Low (2006), I found that mass redistribution within the injection
site was not necessary. Therefore I do not impose uniform site density, particularly as it may lead to unexpected consequences in the presence of magnetic fields.
## 3.3 Radiative cooling and photoelectric heating
Table 3.1: The cooling function of Rosen, Bregman and Norman (1993), labelled RBN in the text (and in the labels of the numerical models), with Λ = 0 for T < 10 K .
| T k [ K] | Λ k erg g - 2 s - 1 cm 3 K - β k ] | β k |
|------------|--------------------------------------|-----------|
| 10 | 9 . 88 × 10 5 | 6.000 |
| 300 | 8 . 36 × 10 15 | 2.000 |
| 2000 | 3 . 80 × 10 17 | 1.500 |
| 8000 | 1 . 76 × 10 12 | 2.867 |
| 10 5 | 6 . 76 × 10 29 | - 0 . 650 |
| 10 6 | 8 . 51 × 10 22 | 0.500 |
I consider two different parameterizations of the optically thin radiative cooling appearing in Eq. (3.3), both of the piecewise form Λ = Λ T k β k within a number of temperature ranges T k ≤ T < T k +1 , with T k and Λ k given in Tables 3.2 and 3.1. Since this is just a crude (but convenient) parameterization of numerous processes of recombination and ionization of various species in the ISM, there are several approximations designed to describe the variety of physical conditions in the ISM. Each of the earlier models of the SN-driven ISM adopts a specific cooling curve, often without explaining the reason for the particular choice or assessing its consequences. In Section 7.1 I discuss the sensitivity of results to the choice of the cooling function.
Table 3.2: The cooling function of Wolfire et al. (1995) at T < 10 5 K , joined to that of Sarazin and White (1987) at higher temperatures, with Λ = 0 for T < 10 K . This cooling function is denoted WSW in the text (and in the labels of the numerical models).
| T k | Λ k | β k |
|---------------|-------------------------------------------------|----------|
| [ K] 10 | [ erg g - 2 s - 1 cm 3 K - β k ] 3 . 70 × 10 16 | 2.12 |
| 141 | 9 . 46 × 10 18 | 1.00 |
| 313 | 1 . 18 × 10 20 | 0.56 |
| 6102 | 1 . 10 × 10 10 | 3.21 |
| 10 5 | 1 . 24 × 10 27 | - 0 . 20 |
| 2 . 88 × 10 5 | 2 . 39 × 10 42 | - 3 . 00 |
| 4 . 73 × 10 5 | 4 . 00 × 10 26 | - 0 . 22 |
| 2 . 11 × 10 6 | 1 . 53 × 10 44 | - 3 . 00 |
| 3 . 98 × 10 6 | 1 . 61 × 10 22 | 0.33 |
| 2 . 00 × 10 7 | 9 . 23 × 10 20 | 0.50 |
One parameterization of radiative cooling, labelled WSW and shown in Table 3.2, consists of two parts. For T < 10 5 K , the cooling function fitted by S´ anchez-Salcedo,
V´ azquez-Semadeni and Gazol (2002) to the 'standard' equilibrium pressure-density relation of Wolfire et al. (1995, Fig. 3b therein) is used. For higher temperatures, the cooling function of Sarazin and White (1987) is adopted. This part of the cooling function (but extended differently to lower temperatures) was used by Slyz et al. (2005) to study star formation in the ISM. The WSW cooling function was also used by Gressel et al. (2008 a ). It has two thermally unstable ranges: at 313 < T < 6102 K , the gas is isobarically unstable ( β k < 1 ); at T > 10 5 K , some gas is isochorically or isentropically unstable ( β k < 0 and β k < -1 5 . , respectively).
Results obtained with the WSW cooling function are compared with those using the cooling function of Rosen, Bregman and Norman (1993), labelled RBN, whose parameters are shown in Table 3.1. This cooling function has a thermally unstable part only above 10 5 K . Rosen, Bregman and Norman (1993) truncated their cooling function at T = 300K . Instead of an abrupt truncation, I have smoothly extended the cooling function down to 10 K . This has no palpable physical consequences as the radiative cooling time at these low temperatures becomes longer than other time scales in the model, so that adiabatic cooling dominates. The minimum temperature reported in the model of Rosen, Bregman and Norman (1993) is about 100 K . Here, with better spatial resolution, the lowest temperature gas is at times below 10 K , with some gas at 50 K present most of the time.
I took special care to accurately ensure the continuity of the cooling functions, as small discontinuities may affect the performance of the code; hence the values of Λ k in Table 3.2 differ slightly from those given by S´ anchez-Salcedo, V´ azquez-Semadeni and Gazol (2002). The two cooling functions are shown in Fig. 3.1. The cooling function used in each numerical model is identified with a prefix RBN or WSW in the model label (see Table 4.1). The purpose of Models RBN and WSWb is to assess the impact of the choice of the cooling function on the results (Section 7.1). Other models employ the WSWcooling function.
I also include photoelectric heating in Eq. (3.3) via the stellar far-ultraviolet (UV) radiation Γ , following Wolfire et al. (1995), and allowing for its decline away from the Galactic mid-plane with a length scale comparable to the scale height of the stellar disc near the Sun (cf. Joung and Mac Low, 2006):
$$\Gamma ( z ) = \Gamma _ { 0 } \exp \left ( - | z | / 3 0 0 \, \text{pc} \right ), \quad \Gamma _ { 0 } = 0. 0 1 4 7 \, \text{erg} \, \text{g} ^ { - 1 } \, \text{s} ^ { - 1 }.$$
This heating mechanism is smoothly suppressed at T > 2 × 10 4 K , since the photoelectric effect due to UV photon impact on PAHs (Polycyclic Aromatic Hydrocarbons) and small dust grains is impeded at high temperatures (Wolfire et al., 1995).
Figure 3.1: The cooling functions WSW (solid, black) and RB (red, dash-dotted), with parameters given in Tables 3.2 and 3.1, respectively.
## 3.4 Numerical methods
The model occupies a relatively small region within the galactic disc and lower halo with parameters typical of the solar neighbourhood. Using a three-dimensional Cartesian grid, the results have been obtained for a region 1 024 . × 1 024 . × 2 240 kpc . 3 in size ( 1 024 . × 1 024 . × 2 176 kpc . 3 for the MHD models), with 1 024 kpc . in the radial and azimuthal directions and 1 120 kpc . ( 1 088 kpc . ) vertically on either side of the galactic mid-plane. Assuming that the correlation length of the interstellar turbulence is l 0 glyph[similarequal] 0 1 kpc . , it might be expected that the computational domain encompass about 2,000 turbulent cells, so the statistical properties of the ISM should be reliably captured. Testing individual SNe in diffuse ISM and snapshot sampling over various runs confirms the computational domain is sufficiently broad to accommodate comfortably even the largest SN remnants at large heights, so as to exclude any self-interaction of expanding remnants through the periodic boundaries.
Vertically, the reference model accommodates ten scale heights of the cold HI gas, two scale heights of diffuse HI (the Lockman layer), and one scale height of ionized hydrogen (the Reynolds layer). The vertical size of the domain in the reference model is insufficient to include the scale height of the hot gas and the Galactic halo. Therefore, it may be desirable to increase its vertical extent in future work. Note, however, that the size of SN remnants, and the correlation scale of the flow above a few hundred parsec height may approach the horizontal size of the numerical domain and may even exceed it at greater heights (Korpi, Brandenburg, Shukurov, Tuominen and Nordlund, 1999). The periodic boundary conditions exclude divergent flows at scales comparable to the horizontal size of the box, suggesting that an increase in height may necessitate an appropriate increase in the horizontal dimensions to reliably capture the dynamics of the flow, and remain consistent with the assumptions of the (sheared) periodic boundary conditions in x and y .
The standard resolution (numerical grid spacing) is ∆x = ∆y = ∆z = ∆ = 4pc . The grid is 256 × 256 × 560 (excluding 'ghost' boundary zones) for the HD models, slightly reduced to 256 × 256 × 544 for the MHD models. One model at doubled resolution, ∆ = 2pc , has a grid 512 × 512 × 1120 in size. A sixth-order finite difference scheme for spatial vector operations and a third-order Runge-Kutta scheme for time stepping are applied.
The spatial and temporal resolutions attainable impose lower limits on the kinematic viscosity ν and thermal conductivity K , which are, unavoidably, much higher than any realistic values. These limits result from the Courant-Friedrichs-Lewy (CFL) condition which requires that the numerical time step must be shorter than the crossing time over the mesh length ∆ for each of the transport processes involved. It is desirable to avoid unnecessarily high viscosity and thermal diffusivity. The cold and warm phases have relatively small perturbation gas speeds (of order 10 km s -1 ), so ν and χ are prescribed to be proportional to the local speed of sound, ν = ν c /c 1 s 1 and χ = χ c /c 1 s 1 . To ensure the maximum Reynolds and P´ eclet numbers based on the mesh separation ∆ are always less than unity throughout the computational domain (see Appendix B.1), ν 1 ≈ 4 2 . × 10 -3 kms -1 kpc , χ 1 ≈ 4 1 . × 10 -4 kms -1 kpc and c 1 = 1kms -1 . This gives, for example, χ = 0 019 km s . -1 kpc at T = 10 5 K and 0 6 km s . -1 kpc at T = 10 8 K .
Numerical handling of the strong shocks widespread in the ISM needs special care. To ensure that they are always resolved, shock-capturing diffusion of heat, momentum and induction are included, with the diffusivities ζ χ , ζ ν and ζ η , respectively, defined as
$$\zeta _ { \chi } = \begin{cases} c _ { \chi } \Delta x ^ { 2 } \max _ { 5 } | \nabla \cdot u |, & \text{if $\nabla \cdot u < 0$,} \\ 0, & \text{otherwise,} \end{cases}$$
(and similarly for ζ ν or ζ η , but with coefficients c ν or c η ), where max 5 denotes the maximum value occurring at any of the five nearest mesh points (in each coordinate). Thus, shock-capturing diffusivity is proportional to the maximum divergence of the velocity in the local neighbourhood, and are confined to the regions of convergent flow. Here, c χ = c ν = c η is a dimensionless coefficient which has been adjusted empirically to 10. This prescription spreads a shock front over sufficiently many (usually, four) grid points. Detailed test simulations of an isolated expanding SN remnant in Appendix A confirm that this prescription produces quite accurate results, particularly in terms of the most important goal: the conversion of thermal to kinetic energy in SN remnants.
With a cooling function susceptible to thermal instability, thermal diffusivity χ has to be large enough as to allow us to resolve the most unstable normal modes:
$$\chi \geq \frac { 1 - \beta } { \gamma \, \tau _ { \text{cool} } } \left ( \frac { \Delta } { 2 \pi } \right ) ^ { 2 },$$
where β is the cooling function exponent in the thermally unstable range ( β = 0 56 . in the WSWmodel), τ cool is the radiative cooling time, and γ = 5 3 / is the adiabatic index. From
the contours of constant cooling time plotted in Fig. 7.1 of Chapter 7, it is evident that for these models τ cool is typically in excess of 1 Myr in the thermally unstable regime. Further details can be found in Appendix B.2 where it is demonstrated that, with the parameters chosen in my models, thermal instability is well resolved by the numerical grid.
The shock-capturing diffusion broadens the shocks and increases the spread of density around them. An undesirable effect of this is that the gas inside SN remnants cools faster than it should, thus reducing the maximum temperature and affecting the abundance of the hot phase. Having considered various approaches while modelling individual SN remnants in Appendix A, a prescription is adopted which is numerically stable, reduces gas cooling within SN remnants, and confines extreme cooling to the shock fronts. Specifically, the term ( Γ -ρΛ T ) -1 in Eq. (3.3) is multiplied by
$$\xi = \exp ( - C | \nabla \zeta _ { \chi } | ^ { 2 } ),$$
where ζ χ is the shock diffusivity defined in Eq. (3.9). Thus ξ ≈ 1 almost anywhere in the domain, but reduces towards zero in strong shocks, where |∇ ζ χ | 2 is large. The value of the additional empirical parameter, C ≈ 0 01 . , was chosen to ensure numerical stability with minimum change to the basic physics. It has been verified that, acting together with other artificial diffusion terms, this does not prevent accurate modelling of individual SN remnants (see Appendix A for details).
## 3.5 Boundary conditions
Given the statistically homogeneous structure of the ISM in the horizontal directions at the scales of interest (neglecting arm-interarm variations), I apply periodic boundary conditions in the azimuthal ( y ) direction. Differential rotation is modelled using the shearingsheet approximation with sliding periodic boundary conditions (Wisdom and Tremaine, 1988) in x , the local analogue of cylindrical radius.
Unlike the horizontal boundaries of the computational domain, where periodic or sliding-periodic boundary conditions may be adequate (within the constraints of the shearing box approximation), the boundary conditions at the top and bottom of the domain are more demanding. The vertical size of the galactic halo is of order of 10 kpc, and nontrivial physical processes occur even at that height, especially when galactic wind and cosmic ray escape are important. Within a few kiloparsecs of the mid-plane, SN heating induces a flow of hot gas towards the halo. The results of e.g., de Avillez and Breitschwerdt (2007, and references therein) suggest that in excess of ± 5 kpc is required for the hot gas to cool and return to the mid-plane. Their vertical extent ( z = ± 10 kpc ) excludes significant mass loss from the system, but at considerable numerical expense. Because MHD runs may require simulation times exceeding 1 Gyr, it is desirable to restrict resources to the region, which can be reliably modelled with the minimum vertical extent. Gressel et al. (2008 a ) applied double the height modelled here, but with half the resolution, hence re-
quiring a quarter of the resources. In adopting ± 1 kpc for the vertical boundary, there is no physical mechanism for adequate cooling and return of the hot gas, so care must be taken to address potential mass loss. For the HD runs, which require only a few Myr to acquire a statistically steady turbulent state, this is not too problematic. For the MHD runs mass must be replaced, and this is addressed in Appendix C.
It is also important to formulate boundary conditions at the top and bottom of the domain that admit the flow of matter and energy, while minimising any associated artefacts that might affect the interior. Stress-free, open vertical boundaries would seem to be the most appropriate, requiring that the horizontal stresses vanish, while gas density, entropy and vertical velocity have constant first derivatives on the top and bottom boundaries. These are implemented numerically using 'ghost' zones; i.e., three outer grid planes that allow derivatives at the boundary to be calculated in the same way as at interior grid points. The interior values of the variables are used to specify their ghost zone values.
Shocks occur ubiquitously within the ISM and handling these is particularly problematic as they approach the boundary. Within the computational domain and on the periodic boundaries, shocks are absorbed into the ambient medium, placing a finite limit on the magnitude of the momentum or energy associated with the shock. When a sharp structure approaches the vertical boundary, however, the strong gradients may be extrapolated into the ghost zones. This artificially enhances the prominence of such a structure, and may cause the code to crash. Here I describe how these boundary conditions have been modified to ensure the numerical stability of the model.
## Mass
To prevent artificial mass sources in the ghost zones, I impose a weak negative gradient of gas density in the ghost zones. Thus, the density values are extrapolated to the ghost zones from the boundary point as
$$\rho ( x, y, \pm Z \pm k \Delta ) = ( 1 - \Delta / 0. 1 \text{kpc} ) \rho ( x, y, \pm Z \pm ( k - 1 ) \Delta )$$
for all values of the horizontal coordinates x and y , where the boundary surfaces are at z = ± Z , and the ghost zones are at z = ± Z ± k∆ with k = 1 2 3 , , . The upper (lower) sign is used at the top (bottom) boundary. This ensures that gas density gradually declines in the ghost zones.
## Temperature
To prevent a similar artificial enhancement of temperature spikes in the ghost zones, gas temperature there is kept equal to its value at the boundary,
$$T ( x, y, \pm Z \pm k \Delta ) = T ( x, y, \pm Z ) \,,$$
so that temperature is still free to fluctuate in response to the interior processes. This prescription is implemented in terms of entropy, given the density variation described above.
## Velocity
Likewise, the vertical velocity in the ghost zones is kept equal to its boundary value if the latter is directed outwards,
$$u _ { z } ( x, y, \pm Z \pm k \Delta ) = u _ { z } ( x, y, \pm Z ) \,, \quad u _ { z } ( x, y, \pm Z ) \gtrless 0 \,.$$
However, when gas cools rapidly near the boundary, pressure can decrease and gas would flow inwards away from the boundary. To avoid suppressing inward flows, where
$$u _ { z } ( x, y, \pm Z ) \leqslant 0$$
the following is applied:
$$\text{if} \ \ | u _ { z } ( x, y, \pm Z \mp \Delta ) | < | u _ { z } ( x, y, \pm Z ) |,$$
set otherwise, set
$$u _ { z } ( x, y, \pm Z \pm \Delta ) = 2 u _ { z } ( x, y, \pm Z ) - u _ { z } ( x, y, \pm Z \mp \Delta ) \,.$$
In both cases, in the two outer ghost zones ( k = 2 3 , ), set
$$u _ { z } ( x, y, \pm Z \pm k \Delta ) = 2 u _ { z } ( x, y, \pm Z \pm ( k - 1 ) \Delta ) - u _ { z } ( x, y, \pm Z \pm ( k - 2 ) \Delta ) \,,$$
so that the inward velocity in the ghost zones is always smaller than its boundary value. This permits gas flow across the boundary in both directions, but ensures that the flow is dominated by the interior dynamics, rather than by anything happening in the ghost zones.
For the horizontal components of the velocity at the vertical boundaries, symmetrical conditions are applied to exclude horizontal stresses, so
$$u _ { x } ( x, y, \pm Z \pm k \Delta ) = u _ { x } ( x, y, \pm Z \mp k \Delta ) \,,$$
and similarly for u y .
$$u _ { z } ( x, y, \pm Z \pm \Delta ) = \frac { 1 } { 2 } \left [ u _ { z } ( x, y, \pm Z ) + u _ { z } ( x, y, \pm Z \mp \Delta ) \right ] \, ;$$
## Magnetic field
For the MHD models, two alternative sets of vertical boundary conditions are considered: vertical field and open. The objective with the vertical field condition is to exclude external flux. Any flux across the horizontal periodic boundaries conserves the magnetic energy. To identify a genuine dynamo process, the addition of magnetic energy due to non-physical boundary effects can be excluded by ensuring zero vertical flux on the upper and lower surfaces. For the horizontal components of the vector potential
$$A _ { x } ( x, y, \pm Z \pm k \Delta ) = A _ { x } ( x, y, \pm Z \mp k \Delta )$$
and similarly for A y , and for the vertical component
$$A _ { z } ( x, y, \pm Z \pm k \Delta ) = - A _ { z } ( x, y, \pm Z \mp k \Delta ) \,,$$
ensuring on the boundary that
$$\frac { \partial A _ { x } } { \partial z } = \frac { \partial A _ { y } } { \partial z } = A _ { z } = 0 = B _ { x } = B _ { y } \,.$$
B z can differ from zero.
Such an approach creates a boundary layer, in which the non-zero horizontal fields near the surfaces, which may be significant close to z ± = 1kpc , must vanish nonphysically.
The alternative open boundary conditions do not exclude external flux, but preserve the physical structure of the field up to the boundary. Gressel et al. (2008 a ) applied these with a domain up to ± 2 kpc in z , and argue the external magnetic flux was negligible. It is reasonable to expect, given the dominant flow of gas is outward in these simulations, that the outward magnetic flux might exceed the inward flux, so that artificial growth of the magnetic field due to boundary effects may be discounted. The vertical component of the Poynting flux on the boundary is monitored with these boundary conditions and the total flux outwards is 2 orders of magnitude greater than the total flux inwards. For the vertical component
$$A _ { z } ( x, y, \pm Z \pm k \Delta ) = A _ { z } ( x, y, \pm Z \mp k \Delta ) \,,$$
and for the horizontal components
$$A _ { x } ( x, y, \pm Z \pm k \Delta ) = 2 A _ { x } ( x, y, \pm Z \pm ( k - 1 ) \Delta ) - A _ { x } ( x, y, \pm Z \pm ( k - 2 ) \Delta )$$
and similar for A y , such that
$$\frac { \partial ^ { 2 } A _ { x } } { \partial z ^ { 2 } } = \frac { \partial ^ { 2 } A _ { y } } { \partial z ^ { 2 } } = \frac { \partial A _ { z } } { \partial z } = 0 = \frac { \partial B _ { x } } { \partial z } = \frac { \partial B _ { y } } { \partial z } \,.$$
The constraint on ∂B /∂z z is automatically satisfied since ∇· B = 0 .
## 3.6 Initial conditions
An initial density distribution is adopted corresponding to isothermal hydrostatic equilibrium in the gravity field of Eq. (3.7):
$$\rho ( z ) = \rho _ { 0 } \exp \left [ a _ { 1 } \left ( z _ { 1 } - \sqrt { z _ { 1 } ^ { 2 } + z ^ { 2 } } - \frac { a _ { 2 } } { 2 a _ { 1 } } \, \frac { z ^ { 2 } } { z _ { 1 } } \right ) \right ].$$
Since some models do not contain magnetic fields and none contain cosmic rays, which provide roughly one quarter each of the total pressure in the ISM (the remainder being thermal and turbulent pressures), the gas scale heights can be expected to be smaller that those observed. Given the limited spatial resolution of the simulations, and the correspondingly weakened thermal instability and neglected self-gravity, it is not quite clear in advance whether the gas density used in the model should include molecular hydrogen or, otherwise, include only diffuse gas.
ρ 0 = 3 5 . × 10 -24 g cm -3 is used for Models RBN and WSWb, corresponding to gas number density, n 0 = 2 1 cm . -3 at the mid-plane. This is the total interstellar gas density, including the part confined to molecular clouds. These models, discussed in Section 7.1, exhibit unrealistically strong cooling. Therefore, all other subsequent models have a smaller amount of matter in the computational domain (a 17% reduction), with ρ 0 = 3 0 . × 10 -24 g cm -3 , or n 0 = 1 8 cm . -3 , accounting only for the atomic gas (see also Joung and Mac Low, 2006).
As soon as the simulation starts, because of density-dependent heating and cooling the gas is no longer isothermal, so ρ z ( ) given in Eq. (3.11) is not a hydrostatic distribution. To avoid unnecessarily long initial transients, a non-uniform initial temperature distribution is imposed so as to be near static equilibrium:
$$T ( z ) = \frac { T _ { 0 } } { z _ { 1 } } \left ( \sqrt { z _ { 1 } ^ { 2 } + z ^ { 2 } } + \frac { a _ { 2 } } { 2 a _ { 1 } } \frac { z ^ { 2 } } { z _ { 2 } } \right ),$$
where T 0 is obtained from
$$\Gamma ( 0 ) = \rho _ { 0 } \Lambda ( T _ { 0 } ) \approx 0. 0 1 4 7 \, \text{erg} \, g ^ { - 1 } \, s ^ { - 1 }.$$
The value of T 0 therefore depends on ρ 0 and the choice of the cooling function.
For the models that include a magnetic field, the initial seed field B = (0 , B I n z , ( ) 0) . I use B I = 0 05 . µ Gcm 3 and n 0 = 1 8 cm . -3 , such that 〈 B rms 〉 glyph[similarequal] 0 001 . µ G with 〈·〉 indicating the average over the computational domain.
Due to differential cooling and heating in the vertically stratified gas the initial setup is in an unstable equilibrium, resulting in collapse and subsequent oscillations. A new equilibrium requires the gradual build up of thermal and turbulent pressure, followed by
an extended period while the oscillations of the disc dissipate and the disc becomes statistically steady. Gressel et al. (2008 b ) eliminate these transients by adjusting the vertical heating profile to balance exactly the initial cooling. While heating may be only marginal to the long term dynamics of the model, this does add a long term unphysical ingredient. Analternative approach, for future reference, may be to begin without heating and cooling in isothermal, hydrostatic equilibrium. This would be a stable equilibrium, and the heating and cooling terms could be switched on after the thermal and turbulent pressures are sufficiently developed to support the gas against gravitational collapse. This may reduce the duration, and hence numerical expense, of the initial transients.
## 3.7 Simulation vs. 'realised' time, and geometry
For this model, as with other models of this type, the unperturbed initial conditions, which cannot be expected to exist in nature, require an extended period of simulation time to reach a quasi-steady turbulent state. Joung and Mac Low (2006) allow 40 Myr for the initial transients to be subsumed by turbulence, while using a similar model de Avillez and Breitschwerdt (2007) argue this should be more like 200 Myr. The initial conditions are not in equilibrium due to the heating and cooling terms, and in the absence of thermal stability there is a large scale collapse of the disc. The thickness of the disc is gradually expanded by the build up of both thermal and ram pressure by the injection of SNe. There remain large scale vertical oscillations from the initial collapse, which require longer to settle. In my model the regular systematic oscillations dissipate over a timescale of at least 100 Myr, but not more than 200 Myr, although random fluctuations occur at later times.
The quasi-steady turbulent state then needs to be tracked over a few hundred Myr to provide reliable statistics for a robust analysis. For models tracing the galactic dynamo, with the relatively low magnetic Reynolds numbers available in the model, it is necessary to run them for up to 2 Gyr to see the magnetic field grow to saturation. Is it then reasonable to assume that the models have a time independent statistically steady state? Tutukov, Shustov and Wiebe (2000) model the lifetime evolution of the Galaxy. They suggest significant variation of star formation and SN rates occur in timescales of a few hundred Myr, with associated changes to the ISM mass and thickness of the disc. On the scale of 1 Gyr, qualitative as well as quantitative effects might be expected to occur. These scales are based on highly simplified premises and are only indicative of galactic trends. Nevertheless it is reasonable to question whether a steady hydrodynamical state should persist over such long timescales.
Consider also the effect of time on the geometry of the numerical domain. Nominally the box is differentially rotating around the Galactic centre. Due to the differential rotation in the azimuthal direction the boundary nearest to the galactic centre moves ahead of the corresponding outer boundary, and this is realised in the model by the sliding periodic
Figure 3.2: Illustration of the preservation of horizontal geometry of the simulation domain using the shearing box approximation. An arbitrary starting location for the orbit of the numerical box about the galactic centre is indicated by the rectangular box bottom left. Differential rotation is represented by the inner boundary moving ahead of the outer ( 2 nd position). The dotted arrows denote the angular velocity of the box. The rectangular geometry of the box is maintained by substituting statistically identical gas in the blue triangle ahead of the box for the gas in the trailing grey triangle. Arbitrary positions on the outer boundary subject to some velocity, are indicated by the solid arrows, grey arrows for an original section and blue for a section of the substituted edge and its substitute. Corresponding arrows on the inner boundary indicate the offset postitions. The offset from the original edge increases, while the offset from the substitute edge decreases ( 3 rd position). By the time the sliding boundaries have been offset by their full length ( 4 th position) the inner and outer edges are in exact correspondence. Thus the blue rectangle in the 4 th postion becomes a new arbitrary starting postion and the process repeats.
boundary conditions. The numerical domain therefore is elongated in the azimuthal direction over time as illustrated in Fig. 3.2. The rectangular box in the bottom left follows the orbit about the galactic centre, being increasingly distorted as shown. If we regard the sliding boundaries to be forever moving apart in this way, as the simulation box completes several orbits, the geometry would rapidly cease to resemble a rectangle and be stretched much like an elastic band.
However to first approximation let us suppose the ISM in the neighbourhood of our box in the horizontal directions to be statistically homogeneous to that within the box. Consider the position of the 2 nd box in Fig. 3.2, with the inner boundary in advance of the outer, illustrated by dotted grey lines. Statistically there is little to distinguish gas within the triangular region bounded by the rear blue edge and the trailing corner from that bounded by the leading and outer blue edges and leading dotted line. Preserving the geometry of the box (blue) as it orbits the galaxy, gas in the trailing triangle is replaced by equivalent gas occupying an identical region of the ISM previously just ahead of the box. Some typical flow, denoted by the solid blue arrows, identifies the identical conditions on the trailing and substitute gas near the outer edge, and the corresponding position on the
Figure 3.3: Illustration of the distinction between simulation time and realised time, as explained in the text.
inner edge ( 2 nd and 3 rd positions). The solid grey arrows denote such flow across original sections. The offset between the black arrows increases with the shear, and the offset between the blue arrows reduces, until the offset for the original edges is the full length of the boundary ( 4 th position). At this point the inner and outer edges are no longer offset and the process is repeated from this new starting geometry (indistinguishable from the 1 st position).
With respect to the time, the total simulation time might be considered independent of the physical time to which it is scaled. Only the physical processes inside the calculation are actually tracking real time. Supernova remnants, the advection time of the hot gas from the disc to the boundary, the life times of superbubbles containing multiple SNe have simulation times matching the corresponding physical times. The superbubbles have the longest duration of all the locally coherent physical features in the simulation domain. The premise of the periodic boundary conditions is that horizontally the properties of the ISM in the neighbourhood are statistically identical to first approximation. Thus as one superbubble dissipates and a new one evolves, rather than regarding the new event as occurring later in time it is reasonable to regard it as occurring at the same time in some random location in the neighbourhood. From this conception the entire simulation can be regarded as occurring simultaneously in the quasi-steady state, whose physical time frame need only match the simulation time of the longest lasting superbubble.
In Fig. 3.3 this principle is illustrated. Consider an arbitrary starting time for the simulation in the statistically steady state to correspond to the initial position of the black box. It orbits for 60-100 Myr as shown. The simulation continues, but could be considered now to be modelling an entirely different part of the orbit, shown in blue, but regarded
in the realised time frame to be concurrent with the part just modelled in black. Hence, 120-200 Myr of simulation time has elapsed, but only 60-100 Myr of realised time need be considered to have elapsed. Given the statistical homogeneity of the ISM within the neighbourhood of the orbit, even a nearby parcel of ISM, indicated by the orange box, could be regarded as statistically independent of the original sample. In this way each segment of 60-100 Myr may be considered as repeated sampling of the independent sections of the ISM in the same orbit over the same time period, irrespective of how long the simulation lasts. Similarly, the extended simulation time may be considered in terms of ensemble sampling from appropriate neighbourhoods within multiple galaxies, where the common parameters apply.
The only feature that is modelled here that has a structure larger than the local box, and evolves over time scales exceeding the longest lasting superbubbles, is the mean magnetic field. However, the large scale structure of the mean field, is in reality also a statistical property of the random magnetic field on the local scale. Rather than single field lines extending azimuthally over kpc scales, the field lines are highly scattered, but with a preferential orientation in the direction of shear. The large scale organization of the field in the model is therefore not due to any physical superstructures, but to alignment within the random small scale structures.
Finally, the large time scales required to follow the growth of the magnetic dynamo may contravene the assumption of a quasi-steady state. In this case the magnetic Reynolds numbers in the simulations are far smaller than in the real ISM, so it may be expected that the growth rates would be much slower in the simulations. Also here, however, it would be an error to regard the tracing of the dynamo as a physically continuous process. Instead, the appropriate interpretation of time in the dynamo runs, is that each 100-300 Myr of the simulation represents statistical sampling of hydrodynamically similar galaxies with magnetic fields at various stages of maturity.
## Chapter 4
## Models explored
## 4.1 Summary of models
I consider five numerical models which do not include magnetic fields (HD), and five which do (MHD), and these are named in Table 4.1 Column 1, together with some of the more important input parameters. Some significant statistical outcomes describing the results for each model are displayed in Table 4.2. The HD models are labelled with prefix RBN or WSW to denote the cooling function used (as described in Section 3.3). All the MHDmodels use the WSW cooling function, so WSW is dropped and labels identify the other key parameters applied.
Table 4.1: Selected input parameters of the numerical models explored in this paper, named in Column (1). Column: (2) numerical resolution; (3) galactic rotation rate Ω ; (4) galactic shear rate S ; (5) galactic supernovae rate ˙ σ ; (6) initial mid-plane gas number density n 0 ; (7) magnetic field B ; (8) vertical boundary condition on magnetic potential A (Sect. 3.1); (9) Section where particular model is considered. The estimates for the solar neighbourhood of mean angular velocity Ω 0 and rate of SN explosions ˙ σ 0 (Sect. 3.1 and 3.2).
glyph[negationslash]
| (1) | (2) | (3) | (4) | (5) | (6) | (7) | (8) | (9) |
|-------|--------|-----------|-----------|---------------|----------------|-------|------------|-----------|
| Model | ∆ [pc] | Ω [ Ω 0 ] | S [ Ω 0 ] | ˙ σ [ ˙ σ 0 ] | n 0 [ cm - 3 ] | B = 0 | bc z ( A ) | Section |
| WSWa | 4 | 1 | -1 | 1 | 1.8 | no | - | 5, 6, B.2 |
| WSWah | 2 | 1 | -1 | 1 | 1.8 | no | - | 5.1 |
| RBN | 4 | 1 | -1 | 1 | 2.1 | no | - | 7.1, C |
| WSWb | 4 | 1 | -1 | 1 | 2.1 | no | - | 7.1, C |
| H1Ω | 4 | 1 | -1 | 1 | 1.8 | no | - | 7.2, 9 |
| B1Ω | 4 | 1 | -1 | 1 | 1.8 | yes | vertical | 7.1, 9 |
| B1ΩO | 4 | 1 | -1 | 1 | 1.8 | yes | open | 9 |
| B2Ω | 4 | 2 | -2 | 1 | 1.8 | yes | vertical | 8, 9, C |
| B1ΩSN | 4 | 1 | -1 | 0.8 | 1.8 | yes | vertical | 7.2, 9 |
| B1ΩSh | 4 | 1 | -1.6 | 1 | 1.8 | yes | vertical | 7.2, 9 |
For the MHD models, B1Ω and B1ΩO denote models with parameters matching the solar neighbourhood, but with alternative vertical boundary conditions, as described in Section 3.5; all models (HD also) have a rate and distribution of supernova explosions equivalent to the solar neighbourhood estimates ˙ σ 0 , as explained in Section 3.2, except for B1ΩSN at 0 8 ˙ . σ 0 ; B2Ω has galactic rotation Ω and shearing -S double the value Ω 0 = 25kms -1 kpc -1 introduced in Section 3.1; and B1ΩSh has a shearing rate -1 6 . Ω 0 . The primary motivation for these variations is to investigate the sensitivity of the dynamo to the parameters.
Some adjustments to the model are implemented for the MHD runs, to stabilize the disc and to recycle mass, which is transported across the vertical boundaries over the extended duration required for the dynamo. These are detailed in Appendix C. To assist direct comparison with the HD models, Model WSWa is repeated with these adjustments applied, and labelled in Table 4.1 as H1Ω .
Column 2 of Table 4.1 lists the resolution applied in each model. The standard resolution is (4 pc) 3 , with only one model, WSWah, having (2 pc) 3 . The latter model is applied to assess the sensitivity of the models to resolution. The starting state for this model is obtained by remapping a snapshot at t = 600 Myr from the standard-resolution Model WSWa (when the system has settled to a statistically steady state) onto a grid 512 × 512 × 1120 in size. Resolutions of (1 pc) 3 , (2 pc) 3 and (4 pc) 3 were tested for separate analysis of single remnant models in uniform monotonic ambient ISM of various densities (see Appendix A.1), prior to conducting these comprehensive simulations.
The initial conditions, described in Section 3.6, are intended to be transient, with the statistically steady state into which the models evolve being independent of the initial state within 2-4 Myr of the start. Subsequent evolution however is not independent of the initial density profile, and to facilitate comparison of my results with theory and observations, it is important that the density profile in the evolved state should be close to the estimated values for the solar neighbourhood. In the HD models, we would expect the combined thermal and RAM pressure supporting the gas against gravitational acceleration to be weaker than the observed ISM, due to the absence of magnetic and cosmic ray pressure. Cosmic ray pressure is absent from all models. Since the model resolution does not resolve the dense molecular clouds, it is not clear in advance whether to include this contribution to the ISM density. Models RBN and WSWb are initialised with the contribution from molecular hydrogen included, while all other models exclude it, as listed in Column 6.
The parameters of rotation, shear and supernova rate are listed in Columns 3, 4 and 5 of Table 4.1. Column 7 indicates whether a magnetic field is included, and Column 8 indicates which boundary conditions apply to the vector potential A on the upper and lower surfaces, which are described in Section 3.5. Column 9 lists the Sections of this thesis in which the results for each model are described.
These models are computationally demanding. The standard resolution models re-
quire parallel processing on around 280 nodes and consume around 100 000 cpu hours for 100 Myr of simulation. Therefore, to maximise the results from the available resources, only three models have been run from the initial conditions at t = 0 yr. These were Models RBN, WSWb and B1Ω , which were evolved until the systems were in the hydrodynamical steady turbulent state, at about 200 Myr, and then continued to at least 600 Myr.
Model WSWa was initialised from a turbulent snapshot of WSWb at 400 Myr, but had the gas density at every point reduced by about 17%, so that the revised density profile corresponded to the estimated rates for the solar neighbourhood, excluding molecular hydrogen. It was then continued to 675 Myr, sufficient for any transients arising from the adjustment to subside. Model WSWah was initialised by remeshing a snapshot from Model WSWa at about 600 Myr, and was continued to 650 Myr. Due to the reduced grid spacing and the improved resolution of gradients in all variables, the iterative time step reduces substantially to satisfy the Courant-Friedrichs-Lewy (CFL) condition. The impact is an increase of 10-30 times in the computational demands to advance the simulation each Myr. Consequently, only about 50 Myr were completed for this model, which may perhaps yield insufficient statistics for the steady state of this simulation.
For the magnetic runs, B1Ω was run to 400 Myr, and then all of these models were continued from this snapshot with the revised parameters as listed in Table 4.1. It becomes apparent from the rates of growth that if the dynamo is successful, it would require in excess of 2 Gyr for the magnetic field to grow to saturation. Each is run for another several hundred Myr, enough to identify the presence of a dynamo and provide a basis for comparisons between the models. To investigate the dynamo process to saturation, Model B2Ω , with the fastest growing dynamo, is continued to 1.7 Gyr. The dynamo saturates at about 1.1 Gyr and then continues with the system in a statistically steady state. For comparisons in the saturated regime, models B1ΩO and B1Ω are restarted from a snapshot of B2Ω at 1.2 Gyr and 1.4 Gyr respectively, and continued for a further 400 Myr each.
## 4.2 Model data summary
In Table 4.2 some indicative data from the various models identified in Table 4.1 are displayed. Here angular brackets denote averages over the whole volume, taken from eleven snapshots (10 for WSWah) within the statistical steady state. The standard deviations (in brackets) are spatial fluctuations for the combined snapshots. The time span, ∆t , is given in Column 18, normalised by τ = L / u x 〈 turb 〉 , where u turb is the root-mean-square random velocity and L x ≈ 1 kpc is the horizontal size of the computational domain. For the HD models, this refers to the steady state. For the MHD models the system has been in a hydrodynamically steady state much longer than the ∆t as listed. For B1Ω B1ΩO , and B2Ω , ∆t refers to the latter period when the magnetic field is also in a statistical steady
Table 4.2: Column (1) lists the models from Table 4.1 with some indicative results: (10) average sound speed 〈 c s 〉 ; (11) average kinematic viscosity 〈 ν 〉 ; (12) average Reynolds number defined at the grid spacing 〈 Re ∆ 〉 ; (13) average r.m.s. perturbation velocity 〈 u rms 〉 ; (14) turbulent velocity 〈 u turb 〉 ; (15) thermal energy density 〈 e th 〉 ; (16) kinetic energy density 〈 e kin 〉 ; (17) magnetic energy density 〈 e B 〉 ; and (18) time span over which the models have been in steady state ( τ is the typical horizontal crossing time); Standard deviation over volume using eleven composite snapshots (ten for WSWah) per model are given in brackets.
| ∆t [ τ ] | 3.9 0.5 2.7 | 1.5 1.9 2.0 | 4.8 | 4.5 2.5 3.6 |
|------------------------------|-----------------------------------|--------------------------|---------|-------------------------------------------|
| 〈 e B 〉 [ E SN kpc - 3 ] | - - - | 5 (8) 3 (5) 7 (10) | | 0 . 1 (0 . 4) 0 . 1 (0 . 4) 0 . 1 (0 . 4) |
| 〈 e kin 〉 [ E SN kpc - 3 ] | 13 (34) 10 (50) 9 (25) 13 (46) | 5 (13) 6 (15) 5 (15) | 9 (19) | 10 (26) 7 (16) 7 (24) |
| 〈 e th 〉 [ E SN kpc - 3 ] | 30 (87) 19 (59) 25 (115) 29 (85) | 25 (93) 25 (96) 26 (102) | 26 (74) | 25 (66) 23 (75) 29 (94) |
| 〈 u turb 〉 [kms - 1 ] | 26 (27) 34 (37) 18 (22) 20 (22) | 5 (6) 6 (8) 5 (6) | 12 (16) | 15 (19) 6 (8) 7 (10) |
| 〈 u rms 〉 [kms - 1 ] | 76 (85) 103 (124) 37 (42) 45 (49) | 12 (11) 13 (14) 11 (9) | 33 (45) | 38 (47) 18 (13) 20 (18) |
| 〈 Re ∆ 〉 | 0 . 88 0 . 85 1 . 18 0 . 97 | 0 . 64 0 . 65 0 . 59 | 0 . 95 | 0 . 88 1 . 01 0 . 96 |
| 〈 ν 〉 | 0 . 44 0 . 77 0 . 24 0 . 27 | 0 . 09 0 . 09 0 . 09 | 0 . 17 | 0 . 24 0 . 09 0 . 10 |
| c s 〉 [kms - 1 ] | (113) (207) (118) (75) | (25) (22) (21) | (65) | (75) (23) (32) |
| | 108 186 58 65 | 23 23 21 | 41 | 58 21 24 |
| Model | WSWa WSWah RBN | B1Ω B1ΩO B2Ω | H1Ω | B1Ω ∗ B1ΩSN B1ΩSh |
state. For B1ΩSN and B1ΩSh , the field is still growing and ∆t refers only to how long the system has been hydrodynamically steady. Results are also taken from Model B1Ω during the kinematic stage, for comparison with the latter models; these are listed in the table as B1Ω ∗ . As ν is set proportional to the speed of sound c s (Column 10) it is variable, and the table presents its average value 〈 ν 〉 = ν 1 〈 c s 〉 as Column 11, where ν 1 = 0 004 . in all models.
The numerical resolution is sufficient when the mesh Reynolds number, Re ∆ = u∆/ν , does not exceed a certain value (typically between 1 and 10) anywhere in the domain. The indicative parameter values of the mesh Reynolds number in Table 4.2 Column 12 are averages, 〈 Re ∆ 〉 = ∆ u 〈 turb /c s 〉 /ν 1 , where ∆ is the grid spacing (4 pc for all models, except for Model WSWah, where ∆ = 2pc ). Although Re ∆ is typically close to 1 in all models, for some locations this could be much greater. However, u∆/ν < 5 , is ensured through the combination of temperature dependent bulk diffusion and shock enhanced diffusion.
Other quantities shown in Table 4.2 have been calculated as follows. In Column 13 〈 u rms 〉 is derived from the total perturbation velocity field u , which excludes only the overall galactic rotation U . In Column 14 〈 u turb 〉 is obtained from the turbulent velocity only, with the mean flows 〈 u 〉 glyph[lscript] , defined in Eq. (3.6), deducted from u . In Columns 15 and 16, e th = 〈 ρe 〉 and e kin = 〈 1 2 ρu 2 〉 are the average thermal and kinetic energy densities respectively; the latter includes the perturbed velocity u , and both are normalised by the SN energy E SN = 10 51 erg . In Column 17 e B = 〈 B / 2 8 π 〉 is the average magnetic energy density, also normalised by E SN . For the magnetic runs, the energies are given for the stage after the magnetic field has saturated, except for Models B1ΩSN B1ΩSh , and B1Ω ∗ , for which data is only available for the kinematic stage.
## Part III
## Multiphase description of the interstellar medium
## Chapter 5
## Is the ISM multi-phase?
As explained in Section 1.2.2 the ISM has been described as comprising dynamically distinct regions of hot, warm and cold gas (Cox and Smith, 1974; McKee and Ostriker, 1977), which co-exist in relative pressure equilibrium. This was postulated theoretically; due to differential cooling rates of the gas at various states (temperature and density composition, which here I shall refer to as phases ) compared to the rate of thermal conductivity in the ISM, it could be expected that the phases would settle to pressure equilibrium far faster than they diffuse into a thermal equilibrium. Since observations confirm gas exists at temperatures typical of the cold at T glyph[similarequal] 10 2 K , warm at T glyph[similarequal] 10 4 K and hot at T glyph[similarequal] 10 6 K this picture of phases in pressure balance would appear to be inevitable.
However the description becomes less convincing once the highly turbulent nature of the ISM is considered. The continual shocks and heating produced by SNe create bubbles of extremely hot gas surrounded by ballistically propelled cold dense shells. It cannot be excluded that in fact these phases are merely transitory features of a violently perturbed medium with a broad spectrum of randomly distributed pressures, where gases of different temperatures merely occupy part of the continuum of a qualitatively homogeneous gas ( ? , discussion on The controversy ).
In this chapter I report how my results address this issue using the model which most closely resembles the Milky Way, WSWa. The observational data and our understanding of the ISM is strongest for the solar neighbourhood and this also provides a good basis for assessing the accuracy of my model. If a distinction between the phases can be justified it may be useful in interpreting observations. Trying to make sense of observations and statistical inferences from data, with such huge scale separation of 6 to 10 orders of magnitude, is highly unreliable. If separation into phases is valid then it permits observers and theoreticians to make inferences on more discrete data sets, with better defined characteristics in terms of for example mass, velocity, temperature and magnetic field distributions.
Model WSWa is taken as a hydrodynamic (HD) reference model, because it has rotation corresponding to a flat rotation curve with the Solar angular velocity, and gas density comparable to the solar neighbourhood, but excluding the molecular clouds (See Appendix C for a discussion of the effect of this change of total mass).
Figure 5.1: A three-dimensional rendering of (a) temperature and (b) density distributions in Model WSWa at t = 551Myr . Cold, dense gas is mostly located near the mid-plane, whereas hot gas extends towards the upper and lower boundaries. To facilitate visualisation of the 3D structure, warm gas ( 10 3 < T < 10 6 K ) and diffuse gas ( n < 10 -2 cm -3 ) are plotted with high transparency, so that extreme temperatures, and dense structures are emphasized.
Figure 5.1 shows typical temperature and density distributions at t = 551Myr (i.e., 151 Myr from the start of run WSWa). Supernova remnants appear as irregularly shaped regions of hot, dilute gas. A hot bubble breaking through the cold gas layer extends from the mid-plane towards the lower boundary, visible as a vertically stretched region in the temperature snapshot near the ( x, z ) -face. Another, smaller bubble can be seen below the mid-plane near the ( y, z ) -face. Cold, dense structures are restricted to the mid-plane and occupy a small part of the volume. Very hot and cold regions exist in close proximity.
Horizontally averaged quantities, as functions of height and time, are plotted in Fig. 5.2 for Model WSWb at t < 400 Myr , and WSWa at later times, showing the effect of reducing the total mass of gas at the transition time. This figure shows the vertical velocity (panel a), temperature (b) and gas density (c). Average quantities may have limited physical significance, because the multi-phase gas structure encompasses an extremely wide range of conditions. For example panel (b) shows that the average temperature near the mid-plane, | z | < . ∼ 0 35 pc , is, perhaps unexpectedly, generally higher than that at the larger heights. This is due to SN II remnants, which contain very hot gas with T > ∼ 10 8 K and are concentrated near the mid-plane; even though their total volume is small, they significantly affect the average temperature.
Nevertheless these average conditions help to illustrate some global properties of the simulations. Before the system settles into a quasi-stationary state at about t = 250 Myr , it undergoes a few large-scale transient oscillations involving quasi-periodic vertical motions. The periodicity of approximately 100 Myr, is consistent with the breath-
Figure 5.2: Horizontal averages of (a) the vertical velocity, (b) temperature and (c) gas density as functions of time for Model WSWa (Model WSWb up to 0.4 Gyr).
ing modes identified by Walters and Cox (2001) in 1D models with vertical perturbations, attributable to the gravitational acceleration. Gas falling from altitude will pass through the mid-plane, where the net vertical gravity is zero and so continues its trajectory until the increasing gravity with height again reverses it. Turbulent pressure and gas viscosity dampen these modes. At later times, a systematic outflow develops with an average speed of about 100 km s -1 ; we note that the vertical velocity increases very rapidly near the mid-plane and varies much less at larger heights. The result of the reduction of gas density at t ≈ 400 Myr is clearly visible, as it leads to higher mean temperatures and a stronger and more regular outflow, together with a less pronounced and more disturbed layer of cold gas.
## 5.1 Identification of a multi-phase structure
All models described in this thesis, including the HD reference Model WSWa, have a well-developed multi-phase structure apparently similar to that observed in the ISM. Since the ISM phases are not genuine, thermodynamically distinct phases ( ? ), their definition is tentative, with the typical temperatures of the cold, warm and hot phases usually set at T glyph[similarequal] 10 2 K 10 , 4 -10 5 K and 10 6 K , respectively.
From inspection of the total volume probability density distributions shown in Fig. 5.3 it is not necessarily apparent that such a description is justified. The black solid lines refer to Model WSWa and the blue dashed lines refer to Model WSWah, which differs only in
Figure 5.3: Volume weighted probability distributions of gas number density (a) , temperature (b) and thermal pressure (c) for models WSWa (black, solid) and WSWah (blue, dashed) for the total numerical domain | z | ≤ 1 12 kpc . .
its doubly enhanced resolution and against which the sensitivity to resolution may be measured. In panel (b) there are clearly three distinct peaks in the temperature, corresponding roughly to the conventional definitions. For the gas density and temperature probability distributions (Fig. 5.3a and b) the minima in the distributions appear independent of resolution (at density 10 -2 cm -3 , and at temperatures 10 2 and 3 × 10 5 K). The distributions are most consistent in the thermally unstable range 313 - 6102 K. The minimum about the unstable range above 10 5 K is more pronounced with the higher resolution, because the hotter gas has reduced losses to thermal conduction. The modal temperatures of the cold gas ( 100 K) and warm gas ( 10 4 K) are consistent. In Fig. 5.3 for Model WSWah (blue, dashed lines) the bimodal structure of the density distribution (a) and the trimodal structure of the temperature distribution (b) are more pronounced. From Table 4.2 Column 15, note that the average thermal energy density for Model WSWah is less than Model WSWa. This indicates that the higher temperatures are associated with even more diffuse gas, and the dense structures are even colder, reducing the overall thermal energy in the system.
However the plots are not inconsistent with an alternative description. de Avillez and Breitschwerdt (2005 a ) conclude, from very similar results, that the ISM gas density and temperature have a broad continuum of values, out of thermal pressure equilibrium. In panel (c), apart from a reduction of approximately one half for the higher resolution, the probability distributions of thermal pressure are almost indistinguishable. They have a broad distribution, varying across about three orders of magnitude for probability density above 0.001. This is markedly narrow, however, when contrasted to the five to six orders of magnitude across which density and temperature vary.
The probability distribution of gas number density and temperature is shown in Fig. 5.4 (model WSWa). While it is evident that there are large regions of pressure disequilibrium, there is clear evidence of three well defined phases, in which the pressure is perturbed about a line of constant thermal pressure, described by,
$$\log n = - \log T + \text{constant}.$$
There are three distinct peaks at ( T [ K] , n [ cm -3 ]) glyph[similarequal] (10 2 , 10) (10 , 4 , 10 -1 ) and (10 6 , 10 -3 ) . The lines intersecting the maxima for the cold, warm and hot distributions at (log T, log n ) = (2 , 1 2) . , (4 , -0 8) . , (6 , -2 8) . , respectively, correspond to p = k B nT = 10 -12 7 . dyncm -2 .
Figure 5.4: Total volume probability distributions of gas by temperature T and density n . Eleven snapshots of Model WSWa in the interval t = 634 to 644 Myr were used, with the system in a statistical steady state.
A reasonable identification of the boundaries between these phases is via the minima at about 500 K and 5 × 10 5 K .
Having divided the gas along these boundaries, the probability distributions within each phase of gas number density n , turbulent r.m.s. velocity u turb , Mach number M , thermal pressure p and total pressure P are displayed in Fig. 5.5, from Model WSWa.
The overlap in the gas density distributions (Fig. 5.5a) is small. The modal densities that typify each of the hot, warm and cold gas are 10 -3 , 10 -1 and 10 cm -3 , respectively. Cold, dense clouds are formed through radiative cooling facilitated by compression; the latter, however, is truncated at the grid scale of 4 pc, preventing compression to the higher densities in excess of about 10 2 cm -3 . From the comparison with the higher resolution Model WSWah in Fig. 5.3, it is evident that the separation into phases is more distinct with increased numerical resolution and that the anti-correlation between temperature and density is stronger. Hence the distinction between the density distributions evident in Fig. 5.5a, is even more pronounced when applied to high resolution.
The velocity probability distributions in Fig. 5.5b reveal a clear connection between the magnitude of the turbulent velocity of gas and its temperature: the r.m.s. velocity in each phase scales with its speed of sound. This is confirmed by the Mach number distributions in Fig. 5.5c: both warm and hot phases are transonic with respect to their sound speeds. The cold gas is mostly supersonic, having speeds typically under 10 km s -1 . The double peak in velocity (Fig. 5.5b) is a robust feature, not dependent on the temperature boundary. This likely includes ballistic gas in SN remnants, as well as bulk transport by ambient gas at subsonic or transonic speed with respect to the warm gas.
Figure 5.5: Total volume probability distribution of (a) density, (b) turbulent velocity, u turb (c) Mach number (defined with respect to the local speed of sound and u turb ), (d) thermal pressure, and (e) total pressure, for each phase of Model WSWa, using eleven snapshots spanning t = 634 to 644 Myr . The phases are: cold T < 500 K (black, solid line), warm 500 ≤ T < 5 × 10 5 K (blue, dashed), and hot T ≥ 5 × 10 5 K (red, dash-dotted).
Probability densities of thermal pressure, shown in Fig. 5.5d, are notable for their relatively narrow spread: one order of magnitude, compared to a spread of six orders of magnitude in gas density. Moreover, the three phases have overlapping distributions, suggesting that the system is in statistical thermal pressure balance. However, thermal pressure is not the only part of the total pressure in the gas. In the Galaxy, contributions to the pressure also arise from the turbulent pressure associated with the random motions and the cosmic ray and magnetic pressures. The turbulent pressure, p turb = 1 3 ρu 2 turb is included in P for Fig. 5.5e. The random motions | u turb | 2 are derived by subtracting the mean flows 〈| u | 2 〉 glyph[lscript] from the total | u | 2 (see Chapter 8 for explanation with respect to B ). In Model WSWa the cosmic ray and magnetic pressures are absent.
The total pressure distribution for the hot gas differs little from the thermal pressure. The modal warm pressure increases only by about 25% at around 3 × 10 -13 dyncm -2 . For the cold gas the modal pressure increases about ten fold from 2 × 10 -13 dyncm -2 to
2 × 10 -12 dyncm -2 . The cold gas appears over pressured as a result. It becomes apparent (cf. below Fig. 5.7) that this is due to the vertical pressure gradient. All the cold gas occupies the higher pressure mid-plane, while the warm and hot gas distributions mainly include lower pressure regions away from the disc.
Theoretically, it might be expected that the densities of a gas subjected to multiple shocks may adopt a lognormal distribution rather than a normal distribution (Kevlahan and Pudritz, 2009). The probability distributions for density in Fig. 5.5a can be reasonably approximated by lognormal distributions, of the form
$$\mathcal { P } ( n ) = \Lambda ( \mu _ { n }, s _ { n } ) \equiv \frac { 1 } { n s _ { n } \sqrt { 2 \pi } } \exp \left ( - \frac { ( \ln n - \mu _ { n } ) ^ { 2 } } { 2 s _ { n } ^ { 2 } } \right ).$$
The quality of the fits is good, but less so for the hot gas. This is improved when the hot gas is subdivided into that near the mid-plane ( | z | ≤ 200 pc ) and that at greater heights ( | z | > 200 pc ); the former dominated by very hot gas in the interior of SN remnants, the latter predominantly more diffuse gas in the halo. These fits are illustrated in Fig. 5.6, using 500 data bins in the range 10 -4 8 . < n < 10 2 5 . cm -3 , where the warm gas has also been subdivided by height; the best-fit parameters are given in Table 5.1.
Figure 5.6: Density probability distributions for model WSWa, together with the best-fit lognormal distributions (dotted) for the cold (black, solid), warm and hot gas. The warm/hot gas have been divided into regions | z | ≤ 200 pc (blue/red, dashed/dash-3dotted) and | z | > 200 pc (light blue/orange, dash-dotted/long dashed) respectively.
The two types of hot gas have rather different density distributions, and separating them in this way significantly improves the quality of the lognormal fits. The warm gas distributions remain very similar, with identical variance but shifted to lower density above | z | = 200 pc . It therefore appears justified to consider the two hot gas components separately, where it appears strongly affected by its proximity to the SN activity. The structure of the warm gas appears independent of the SN activity, and merely exhibits a dependence on the global density gradient, so it make sense to consider the warm gas as
a single distribution. All distributions are fitted to lognormals at or above the 95% level of significance applying the Kolmogorov-Smirnov test. Although the warm gas density is well described by a lognormal distribution, there is the appearance of power law behaviour (Fig. 5.6) in its low density tail.
Probability distributions of the pressure, displayed in Fig. 5.7, show that although the thermal pressure of the cold gas near the mid-plane is out of equilibrium with the other phases the total pressures are all much closer to equilibrium. The gas at | z | > 200 pc (dotted lines) are in both thermal and total pressure balance. Thus by including the effect of the global pressure gradient, there is even stronger evidence to support the concept of pressure equilibrium between the phases.
Figure 5.7: Probability distributions for (a) thermal pressure p and (b) total pressure P in Model WSWa, separately for the cold (black, solid), warm and hot gas. The warm/hot gas have been divided into regions | z | ≤ 200 pc (blue/red, dashed/dash-3dotted) and | z | > 200 pc (light blue/orange, dash-dotted/long dashed) respectively.
The broad lognormal distribution of P for the cold gas is consistent with multiple rarefaction and compression due to shocks. The hot and warm gas pressure distributions however appear to follow a power law. Away from the mid-plane their pressure distributions have a similar shape, but slightly narrower. The density distribution for the hot gas is also narrower for | z | > 200 pc , although not so the warm gas. This indicates that the gas away from the SN active mid-plane is, understandably, more homogeneous.
The time-averaged vertical density profiles obtained under the different numerical resolutions are shown in Fig. 5.8. Although the density distribution in Fig. 5.3a reveals higher density contrasts with increased resolution, there is little difference in the z -profiles of the models. The mean gas number density at the mid-plane n (0) , which with the coarse grid resolution excludes the contribution from HII, is about 2 2 cm . -3 , double the observation estimates summarised in Ferri` ere (2001). This might be expected in the absence of the magnetic and cosmic ray components of the ISM pressure, to support the gas against the gravitational force.
However the vertical pressure distributions are consistent with the models of Boulares and Cox (1990, their Fig. 1 and 2), which include the weight of the ISM up to | z | = 5kpc . The total pressure P (0) glyph[similarequal] 2 5 (2 0) . . × 10 -12 dyncm -2 for the standard (high) resolution model is slightly above their estimate of about 1.9 for hot, turbulent gas. For the turbulent
Figure 5.8: Horizontal averages of gas number density, n z ( ) (a) , and total pressure, P z ( ) (b) , for Model WSWa (solid, black), and Model WSWah (dashed, blue). Each are time-averaged using six and ten snapshots respectively, spanning 633 to 638 Myr. The vertical lines indicate standard deviation within each horizontal slice. The thermal p z ( ) (dotted) and ram p turb ( z ) (fine dashed) pressures are also plotted (b) .
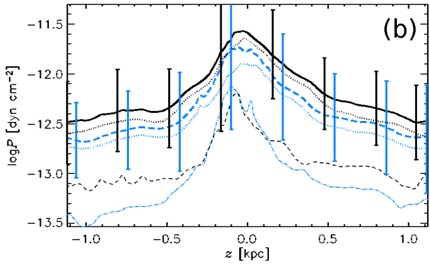
pressure alone p turb (0) glyph[similarequal] 6 3 (7 9) . . × 10 -13 dyncm -2 falling to 1 0 (0 6) . . for | z | = 500 pc and then reasonably level. Together with the narrower pressure and density distributions for gas at | z | > 200 pc , discussed above, this indicates that the pressure gradient above 500 pc is weak and this gas remains relatively homogeneous in comparison to gas near the mid-plane. The pressures are generally slightly reduced with increased resolution, except for p turb near the mid-plane. Small scales are better resolved, so the turbulent structures are a stronger component of the SN active region. These pressures are consistent with Boulares and Cox (1990) even though our model does not explicitly include the pressure contributions from the ISM above 1 kpc .
Comparing the thermal pressure distribution (Fig. 5.3c) with de Avillez and Breitschwerdt (2004, their Fig. 4a) and Joung, Mac Low and Bryan (2009, their Fig. 2) the peaks are at 3.16, 1.3 and 4 1 . × 10 -13 dyncm -2 , respectively. The model of de Avillez and Breitschwerdt (2004) include the gas up to | z | = 10kpc and resolution up to 1.25 pc, and has the lowest modal pressure. Joung, Mac Low and Bryan (2009) model up to | z | = 10kpc , but include only gas within 125 pc of the mid-plane for the pressure distribution, and have the highest modal value. Data in Fig. 5.3c is for the total volume within | z | = 1kpc , having a modal pressure between the other two models.
It is reasonable to conclude that the main effects of the increased resolution are confined to the very hot interiors and to the thin shells of SN remnants; the interiors become hotter and the SN shell shocks become thinner with increased resolution (see Appendix A). Simultaneously, the higher density of the shocked gas enhances cooling, producing more cold gas and reducing the total thermal energy. Otherwise, the overall structure of the diffuse gas is little affected: the probability distributions of thermal pressure are almost indistinguishable, with the standard resolution having a fractionally higher pressure (Fig. 5.3c). We can conclude that the numerical resolution of the reference model, ∆ = 4pc , is sufficient to model the diffuse gas phases reliably. This choice of the working numerical resolution is further informed by tests described in Appendix A.
To summarise: the system is close to a state of statistical pressure equilibrium, with the total pressure having similar values and similar probability distributions in each phase. Joung, Mac Low and Bryan (2009) also conclude from their simulations that the gas is in both thermal and total pressure balance. This could be expected, since the only significant deviation in the statistical dynamic equilibrium of the system is the vertical outflow of the hot gas and entrained warm clouds (see Section 6.1).
## 5.2 The filling factor and fractional volume
## 5.2.1 Filling factors: basic concepts
The fractional volume of the ISM occupied by the phase i is given by
$$f _ { V, i } = \frac { V _ { i } } { V }$$
where V i is the volume occupied by gas in the temperature range defining phase i and V is the total volume. How the gas is distributed within a particular phase is described by the phase filling factor
$$\phi _ { i } = \frac { \overline { n _ { i } } ^ { 2 } } { \overline { n _ { i } ^ { 2 } } }$$
where the over bar denotes a phase average , i.e., an average only taken over the volume occupied by the phase i . φ i describes whether the gas density of a phase is homogeneous φ i = 1 or clumpy φ < i 1 . Both of these quantities are clearly important parameters of the ISM, allowing one to characterise, as a function of position, both the relative distribution of the phases and their internal structure. As discussed below, the phase filling factor is also directly related to the idea of an ensemble average, an important concept in the theory of random functions and so φ i provides a useful connection between turbulence theory and the astrophysics of the ISM. Both f V,i and φ i are easy to calculate in a simulated ISM by simply counting mesh-points.
In the real ISM, however, neither f V nor φ i can be directly measured. Instead the volume filling factor can be derived (Reynolds, 1977; Kulkarni and Heiles, 1988; Reynolds, 1991),
$$\Phi _ { i } = \frac { \langle n _ { i } \rangle ^ { 2 } } { \langle n _ { i } ^ { 2 } \rangle },$$
for a given phase i , where the angular brackets denote a volume average , i.e., taken over the total volume. Most observational work in this area to-date has concentrated on the diffuse ionized gas (or warm ionized medium) since the emission measure of the free electrons EM ∝ n 2 e and the dispersion measure of pulsars DM ∝ n e , allowing Φ to be estimated along many lines-of-sight (e.g. Reynolds, 1977; Kulkarni and Heiles, 1988; Reynolds, 1991; Berkhuijsen, Mitra and Mueller, 2006; Hill et al., 2008; Gaensler et al., 2008).
In terms of the volume V i occupied by phase i ,
$$\overline { n _ { i } } = \frac { 1 } { V _ { i } } \int _ { V _ { i } } n _ { i } \, d V,$$
whilst
$$\langle n _ { i } \rangle = \frac { 1 } { V } \int _ { V } n _ { i } \, d V = \frac { 1 } { V } \int _ { V _ { i } } n _ { i } \, d V \,,$$
the final equality holding because n i = 0 outside the volume V i by definition. Since the two types of averages differ only in the volume over which they are averaged, they are related by the fractional volume:
$$\langle n _ { i } \rangle = \frac { V _ { i } } { V } \overline { n _ { i } } = f _ { V, i } \overline { n _ { i } },$$
and
$$\langle n _ { i } ^ { 2 } \rangle = \frac { V _ { i } } { V } \overline { n _ { i } ^ { 2 } } = f _ { V, i } \overline { n _ { i } ^ { 2 } }.$$
Consequently, the volume filling factor Φ n,i and the phase filling factor φ n,i are similarly related:
$$\Phi _ { i } = \frac { \langle n _ { i } \rangle ^ { 2 } } { \langle n _ { i } ^ { 2 } \rangle } = f _ { V, i } \frac { \overline { n _ { i } } ^ { 2 } } { \overline { n _ { i } ^ { 2 } } } = f _ { V, i } \phi _ { i }.$$
Thus the parameters of most interest, f V,i and φ n,i , characterizing the fractional volume and the degree of homogeneity of a phase respectively, are related to the observable quantity Φ n,i by Eq. (5.9). This relation is only straightforward when the ISM phase can be assumed to be homogeneous or if one has additional statistical knowledge, such as the probability density function, of the phase. In next sub-section we discuss some simple examples to illustrate how these ideas can be applied to the real ISM and also how the properties of our simulated ISM compare to earlier observations.
As with the density filling factors introduced above, filling factors of temperature and other variables can be defined similarly to Eqs. (5.3) and (5.4). Thus φ T,i = T i 2 /T 2 i , etc.
## 5.2.2 Homogeneous-phase and lognormal approximations
To clarify the physical significance of the various quantities defined above, the relations between them are discussed in more detail. Consider Eqs. (5.2), (5.3) and (5.4) for an idealised two-phase system, where each phase is homogeneous. (The arguments can be generalised to an arbitrary number of homogeneous phases.) This scenario is often visualised in terms of discrete clouds of one phase, of constant density and temperature, being embedded within the other phase, of different (but also constant) density and temperature. The two phases might be, for example, cold clouds in the warm gas or hot regions coexisting with the warm phase. Let one phase have (constant) gas number density N 1 and occupy volume V 1 , and the other N 2 and V 2 , respectively. The total volume of the system is V = V 1 + V 2 .
The volume-averaged density of each phase, as required for Eq. (5.4), is given by
$$\langle n _ { i } \rangle = \frac { N _ { i } V _ { i } } { V } = f _ { V, i } N _ { i }.$$
where i = 1 2 , . Similarly, the volume average of the squared density is
$$\langle n _ { i } ^ { 2 } \rangle & = \frac { N _ { i } ^ { 2 } V _ { i } } { V } = f _ { V, i } N _ { i } ^ { 2 }.$$
The fractional volume of each phase can then be written as
$$f _ { V, i } = \frac { \langle n _ { i } \rangle ^ { 2 } } { \langle n _ { i } ^ { 2 } \rangle } = \frac { \langle n _ { i } \rangle } { N _ { i } } = \Phi _ { n, i },$$
with f V, 1 + f V, 2 = 1 , and Φ n, 1 + Φ n, 2 = 1 . The volume-averaged quantities satisfy 〈 n 〉 = 〈 n 1 〉 + 〈 n 2 〉 = f V, 1 N 1 + f V, 2 N 2 and 〈 n 2 〉 = 〈 n 2 1 〉 + 〈 n 2 2 〉 = f V, 1 N 2 1 + f V, 2 N 2 2 , with the density variance σ 2 ≡ 〈 n 2 〉 - 〈 n 〉 2 = f V, 1 f V, 2 ( N 1 -N 2 ) 2 .
In contrast, the phase-averaged density of each phase, as required for Eq. (5.3), is simply n i = N i , and the phase average of the squared density is n 2 i = N 2 i , so that the phase filling factor is φ n,i = 1 . This ensures that Eq. (5.9) is consistent with Eq. (5.12). Thus, the phase filling factor is unity for each phase of a homogeneous-phase medium, and these filling factors clearly do not sum to unity in the case of multiple phases. This filling factor can therefore be used as a measure of the homogeneity of the phase (with a value of unity corresponding to homogeneity). On the contrary, the fractional volumes must always add up to unity, ∑ i f V,i = 1 .
Thus for homogeneous phases, the volume filling factor and the fractional volume of each phase are identical to each other, Φ n,i = f V,i , and both sum to unity when considering all phases; in contrast, the phase-averaged filling factor is unity for each phase, φ n,i = 1 . If a given phase occupies the whole volume (i.e., we have a single-phase medium), then all three quantities are simply unity: φ n,i = Φ n,i = f V,i = 1 .
Apart from the limitations arising from the inhomogeneity of the ISM phases, an unfortunate feature of the above definition of the volume filling factor (5.4), which hampers comparison with theory, is that the averaging involved is inconsistent with that used in the theory of random functions. In the latter, the calculation of volume (or time) averages is usually complicated or impossible and, instead, ensemble averages (over the relevant probability distribution functions) are used; the ergodicity of the random functions is relied upon to ensure that the two averages are identical to each other (Section 3.3 in Monin and Yaglom, 2007; Tennekes and Lumley, 1972). But the volume filling factors above are not compatible with such a comparison, as they are based on averaging over the total volume, despite the fact that each phase occupies only a fraction of it. In contrast, the phase averaging is performed only over the volume of each phase, and so should correspond better to results from the theory of random functions.
To illustrate this distinction, first note that, for the lognormal distribution, P ( n i ) ∼
Λ µ ( n,i , s n,i ) , Eq. (5.1), the mean and mean-square densities are given by the following phase ('ensemble') averages:
$$\overline { n _ { i } } = e ^ { \mu _ { n, i } + s _ { n, i } ^ { 2 } / 2 }, \ \sigma _ { i } ^ { 2 } = \overline { ( n _ { i } - \overline { n _ { i } } ) ^ { 2 } } = \overline { n _ { i } } ^ { 2 } \left ( e ^ { s _ { n, i } ^ { 2 } } - 1 \right ),$$
where σ 2 i is the density variance around the mean n i , so that
$$\phi _ { n, i } = \frac { \overline { n _ { i } } ^ { 2 } } { \overline { n _ { i } ^ { 2 } } } = \frac { \overline { n _ { i } } ^ { 2 } } { \sigma _ { i } ^ { 2 } + \overline { n _ { i } } ^ { 2 } } = \exp ( - s _ { n, i } ^ { 2 } ).$$
With the filling factor thus defined, φ n,i = 1 only for a homogeneous density distribution, σ i = 0 (or equivalently, s n,i = 0 ). This makes it clear that this filling factor, defined in terms of the phase average, is quite distinct from the fractional volume, but rather quantifies the degree of homogeneity of the gas distribution within a given phase. Both describe distinct characteristics of the multi-phase ISM, and, if properly interpreted, can yield rich information about the structure of the ISM.
## 5.2.3 Application to simulations
The definitions of filling factors and fractional volumes from Equations (5.2), (5.4) and (5.3) are applied to the phases identified in Section 5.1 for the HD reference model (WSWa). These are presented as horizontal averages in Fig. 5.9. Volumes are considered as discrete 4 pc thick slices spanning the full horizontal area. The cold, warm and hot phases are T < 5 × 10 2 K 5 , × 10 2 K < T < 5 × 10 5 K and T > 5 × 10 5 K , respectively.
The hot gas (Fig. 5.9c) accounts for about 60% of the volume at | z | glyph[similarequal] 1 kpc and about 50% near the mid-plane. The local maximum of the fractional volume of the hot gas at | z | < ∼ 200 pc is due to the highest concentration of SN remnants there. A conspicuous contribution to various diagnostics - especially within 200 pc of the mid-plane, where most of the SNe are localised - comes from the very hot gas within SN remnants. Regarding its contribution to integrated gas parameters, it should perhaps be considered as a separate phase.
glyph[negationslash]
Now how robust are results based on the assumption that each phase is homogeneous? How strongly does the inhomogeneity of the ISM phases affect the results? Note immediately that, unlike the fractional volumes, the filling factors do not add up to unity, ∑ i Φ n,i = 1 , if any phase i is not homogeneous. Figure 5.9b displays the vertical profiles of the density filling factors Φ n,i = 〈 n i 〉 2 / n 〈 2 i 〉 computed for each phase in the reference model, as in Eq. (5.4). (As these are functions of z , the averaging here is in two dimensions, over horizontal planes; the distinction between the total plane and that part of the plane occupied by the relevant phase remains relevant, however.) This should be compared with the fractional volumes shown in Fig. 5.9c. For all three phases, the values of Φ n,i are smaller than f V,i and the peak near the mid-plane evident for the hot gas in f V,i is absent in Φ n,i . The volume density filling factors in Fig. 5.9a are closest to unity for
Figure 5.9: Horizontal averages for cold (black, solid line), warm (blue, dashed) and hot (red, dash-dotted) of the gas density (a) phase-averaged filling factors φ n , (b) volume-averaged filling factors Φ n and (c) fractional volumes f V . Results plotted are from 21 snapshots in the interval 636 to 646 Myr for Model WSWa.
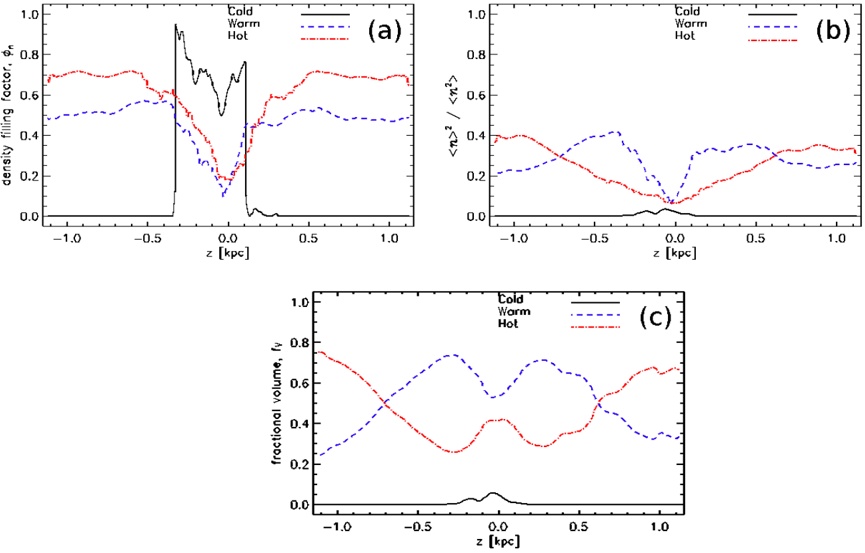
the cold gas (near the mid-plane, where such gas is abundant), indicating that this phase is more homogeneous than the other phases.
Table 5.1 illustrates the meaning and significance of the quantities introduced above. The first part, (A), presents results for the actual density distribution from Model WSWa. The volume filling factors Φ n for the hot gas have been adjusted for the whole volume, since they are calculated over only 0.2 and 0.8 of the total volume, respectively. Thus, the hot gas at | z | ≤ 0 2 kpc . ( | z | > 0 2 kpc . ) occupies 0 275 . ( 0 410 . ) of that volume, but 0 055 . ( 0 331 . ) of the total volume.
Part (A) of the table allows confirmation, by direct calculation of the the quantities involved, that Eq. (5.9) is satisfied to high accuracy, i.e., φ f n V /Φ n = 1 for each phase. Because the statistical parameters involved are averaged over time, this relation is not exact, but is satisfied exactly for each snapshot. Similarly, φ n = n 2 ( σ 2 + n 2 ) only approximately, whereas the equality is satisfied very accurately for each snapshot.
Part (B) of the table provides the parameters, µ n and s n , of the best-fit lognormal approximations to the probability distributions of the gas density shown in Fig. 5.6. Using Eq. (5.13), n and σ are derived and then Eq. (5.14) is used to determine each φ n . f V is taken directly from the simulation data, i.e. from Part (A), and Eq. (5.9) is used to calculate Φ n .
The accuracy of the lognormal approximation to the density PDFs is characterized by the values of the mean density n , its standard deviation σ and the two filling factors, as
Table 5.1: Statistical parameters of the distribution of gas number density n in various phases for Model WSWa, and their lognormal and homogeneous-phase approximations. Figures in Part (A) have been calculated directly from a composite of 11 simulation snapshots, those in (B) and (C) represent the best-fit lognormal and homogeneous-phase approximations to the data in (A), respectively: µ n and s n are defined in Eq. (5.1); n and σ are the mean and standard deviation of n ; φ n , f V and Φ n are the phase filling factor, the fractional volume and the volume filling factor, respectively, as defined in Section 5.2.1. The lower ( Q 1 ) and upper ( Q 3 ) quartiles and the median of the density distributions are given in the last three columns. Standard deviation for each mean between the simulation snapshots as % of n is shown in brackets.
| Q 3 | [cm ] 14 . 2 0 . 16 0 . 0066 | 0 . 0017 13 . 9 0 . 14 | 0 . 0069 0 . 0016 | 12 . 6 0 . 14 0 . 0062 0 . 0013 |
|-------------|--------------------------------------------------|----------------------------------------------------|--------------------------------------------------------------|---------------------------------------|
| Median | [cm ] 7 . 1 0 . 049 0 . 0032 | 0 . 00097 7 . 5 0 . 048 0 . 0031 | 0 . 00094 12 . 6 | 0 . 14 0 . 0062 0 . 0013 |
| Q 1 | [cm ] 3 . 9 0 . 019 0 . 0013 0 . 00057 | 4 . 1 0 . 017 0 . 0014 | 0 . 00056 12 . 6 | 0 . 14 0 . 0062 0 . 0013 |
| φ n f V Φ n | 1 . 000 0 . 999 0 . 178 0 . 819 | 1 1 | 0 . 179 0 . 821 1 | 1 0 . 179 0 . 821 |
| Φ n | 0 . 0016 0 . 0486 0 . 0039 0 . 1850 | 0 . 0016 ∗ 0 . 0486 ∗ 0 . 0039 ∗ | 0 . 1850 ∗ 0 . 0016 ∗ 0 . 0486 ∗ | 0 . 0039 ∗ 0 . 1850 ∗ |
| f V | 0 . 004 0 . 608 0 . 057 | 0 . 331 each phase 0 . 004 0 . 422 0 . 003 | 0 . 276 0 . 002 0 . 049 | 0 . 007 0 . 152 |
| φ n | 0 . 384 0 . 080 0 . 124 0 . 457 | in 0 . 43 0 . 115 0 . 24 | 0 . 55 1 1 | 1 1 |
| σ | [cm ] 15 . 90 0 . 48 0 . 019 0 . 0016 | distribution 13 . 3 0 . 39 0 . 011 | 0 . 0011 0 0 | 0 0 |
| n | [cm ] . 6 (9%) 14 (3%) 0062 (13%) 0013 (10%) | density probability 11 . 5 0 . 14 0 . 0063 | 0 . 0013 | 12 . 6 0 . 14 0 . 0062 0 . 0013 |
| s n | [ln cm ] 12 0 . 0 . | 0 . (5.1) to the gas 0 . 92 1 . 47 | 1 . 20 0 . 77 approximation | |
| µ n | [ln cm ] from the simulation | approximation 2 . 02 - 3 . 03 | pc ) - 5 . 78 - 6 . 96 phase | ( | z | ≤ 200 pc ) ( | z | > 200 pc ) |
| Phase | (A) Gas density Cold Warm Hot ( | z | ≤ 200 pc ) | Hot ( | z | > 200 pc ) (B) The lognormal Cold Warm | Hot ( | z | ≤ 200 Hot ( | z | > 200 pc ) (C) The homogeneous | Cold Warm Hot Hot |
∗ indicates a fixed value, taken from part (A)
compared to the corresponding quantities in (A). The approximation is quite accurate for the mean density and σ . The median (Q ) and the lower and upper quartiles (Q 2 1 and Q ) 3 of the density distribution, are derived
$$Q _ { 2 } = e ^ { \mu _ { n } }, \ \ Q _ { 1, 3 } = e ^ { \mu _ { n } \pm 0. 6 7 s _ { n } }$$
and shown in the last three columns, are also reasonably consistent between Parts (A) and (B). The most significant disparity is apparent in the cold gas, where the skew in the real distribution is stronger than evident in the lognormal approximation. Even here the differences are modest, and for the warm and hot gas the agreement is excellent.
Finally, Part (C) allows one to assess the consequences of an assumption of homogeneousphases, where φ n = 1 and f V = Φ n for each phase by definition. The values of Φ n obtained under this approximation are very significantly in error (by a factor 3-10). The last two columns of the table suggest the reason for that: perhaps unexpectedly, this approximation is strongly biased towards higher densities for all phases, except for the cold gas (which occupies negligible volume), so that the gas density within each phase obtained with this approximation is very close to the upper quartile of the probability distribution and thus misses significant amounts of a relatively rarefied gas in each phase.
In conclusion the lognormal approximation to the gas density distribution provides much more accurate estimates of the fractional volume than the homogeneous-phase approximation, at least for the model ISM. This should be borne in mind when observational data are interpreted in terms of filling factors.
Comparing the gas density distribution shown in Fig. 5.3a with the higher resolution run Model WSWah, the mean warm gas density ( 0 14 cm . -3 ) and the minimum in the distribution ( 10 -2 cm -3 ) appears to be independent of the resolution. However the natural log mean µ n glyph[similarequal] -8 for the hot gas within and without 200 pc of the mid-plane, but with larger standard deviation for the gas near the mid-plane. This compares with -6.96 and -5.78 in Table 5.1 for 4 pc resolution, i.e. about 1/3. This reflects the improved resolution of low density in the remnant interior.
## 5.2.4 Observational implications
Here I consider how these results might be used to interpret observational results. Observations can be used to estimate the volume-averaged filling factor Φ n,i , defined in Eq. (5.4), for a given ISM phase. On its own, this quantity is of limited value in understanding how the phases of the ISM are distributed: of more use are the fractional volume occupied by the phase f V,i , defined in Eq. (5.2), and its degree of homogeneity which is quantified by φ n,i , defined by Eq. (5.3). Knowing Φ n,i and φ n,i , f V,i follows via Eq. (5.9):
$$f _ { V, i } & = \frac { \Phi _ { n, i } } { \phi _ { n, i } }.$$
This formula is exact, but its applicability in practise is limited if φ n,i is unknown. However φ n,i can be deduced from the probability distribution of n i : for example if the density probability distribution of the phase can be approximated by the lognormal, then φ n,i can be estimated from Eq. (5.14).
Berkhuijsen, Mitra and Mueller (2006) and Berkhuijsen and M¨ uller (2008) estimated Φ n, DIG for the diffuse ionized gas (DIG) in the Milky Way using dispersion measures of pulsars and emission measure maps. In particular, Berkhuijsen, Mitra and Mueller (2006) obtain Φ n, DIG glyph[similarequal] 0 24 . towards | z | = 1kpc , and Berkhuijsen and M¨ uller (2008) find the smaller value Φ n, DIG glyph[similarequal] 0 08 . for a selection of pulsars that are closer to the Sun than the sample of Berkhuijsen, Mitra and Mueller (2006). On the other hand, Berkhuijsen and Fletcher (2008) and Berkhuijsen and Fletcher (2012) used similar data for pulsars with known distances to derive PDFs of the distribution of DIG volume densities which are well described by a lognormal distribution; the fitted lognormals have s DIG glyph[similarequal] 0 22 . at | b | > 5 deg (Table 1 in Berkhuijsen and Fletcher, 2012). Using Eqs. (5.14) and (5.15), this implies that the fractional volume of DIG, with allowance for its inhomogeneity, is about
$$f _ { V, \text{DIG} } \simeq 0. 1 { - 0. 2 }.$$
In other words these results imply that the DIG is approximately homogeneous. Berkhuijsen and Fletcher (2008) also fitted lognormal distributions to the volume densities of the warm HI along lines-of-sight to 140 stars (although no filling factors could be calculated for this gas): they found s HI glyph[similarequal] 0 3 . , again suggesting that this phase of the ISM is approximately homogeneous. Corrections for the inhomogeneity in the fractional volume only become significant when s i > . ∼ 0 5 ; by a factor of 1.3 for s i = 0 5 . and a factor of 2 for s i = 0 8 . .
## 5.3 Three-phase structure defined using specific entropy
In Section 5.1 the three phase medium was defined according to temperature bands. This definition unfortunately precludes any statistically meaningful description of the temperature distribution of each phase, as these are effectively just the total temperature distribution split into three disjoint segments. It is evident that there is likely to be some overlap in the distribution of temperatures between the phases; considering the similarities between the cold phase and colder gas in the warm phase, and between the hot phase and the hotter gas in the warm phase, as described in Section 5.4.
With reference to Fig. 5.4, where the probability distribution of T, n is displayed as 2D contours, the gas is spread across regions out of pressure equilibrium about a line of constant thermal pressure, corresponding to p glyph[similarequal] k B nT = 10 -12 7 . dyncm -2 . This is reproduced in Fig. 5.10. The minima of the probability distribution may be considered to be aligned roughly perpendicular to the line of constant pressure, intersecting at log T glyph[similarequal] 2 75 K . and log T glyph[similarequal] 5 25 K . .
Figure 5.10: PDF contour plot by volume of log n vs log T for Model S Ω , averaged over 200 Myr. The lines of constant specific entropy s = 3 7 . · 10 8 and 23 2 . · 10 8 erg g -1 K -1 indicate where the phases are defined as cold for s ≤ 3 7 . and as hot for s > 23 2 . .
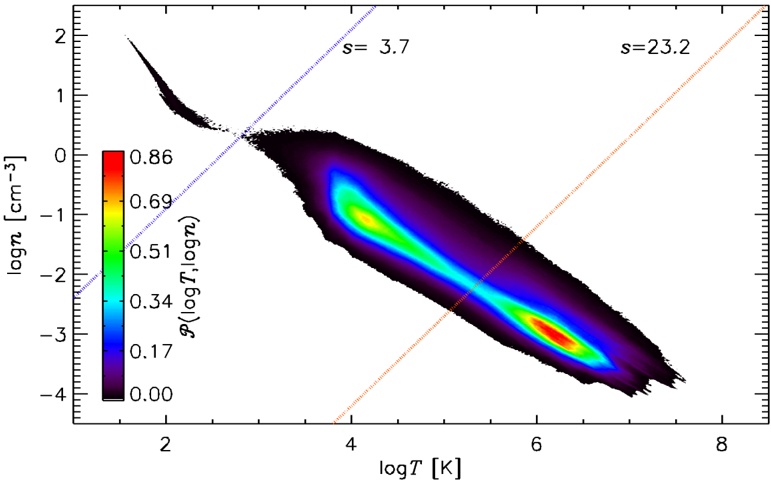
Specific entropy is related to temperature and density by
$$s = \, c _ { \nu } \left [ \ln T - \ln T _ { 0 } - ( \gamma - 1 ) ( \ln \rho - \ln \rho _ { 0 } ) \right ],$$
with c v denoting the specific heat capacity of the gas at constant volume and γ = 5 3 / the adiabatic index. Note that s = 0 when both T = T 0 and ρ = ρ 0 . Lines of constant specific entropy in Fig. 5.10 take the form log n -1 5 log . T = constant. The dotted lines plotted identify the cold phase as occurring where s < 3 7 . · 10 8 erg g -1 K -1 (blue) and hot occurring where s > 23 2 . · 10 8 erg g -1 K -1 (orange). Although these are not necessarily observable quantities, they can be calculated directly for the simulated data, and the various probability distributions determined, including the temperatures.
In Fig. 5.11 the probability distributions for each phase defined by specific entropy from Model WSWa are displayed for ρ T , , p and P in panels (a - d) respectively, where p is thermal pressure and P is total pressure, as described in Section 5.1, so that it excludes cosmic ray and magnetic pressures, but include turbulent pressure.
The distribution of n for the hot gas is slightly narrower, but the modal density remains 10 -3 cm -3 . The warm gas distribution is however bi-modal with peaks at and more disjoint. The peaks in the distributions are consistent with the definitions in Section 5.1 at 10 -3 , 10 -1 and 10 cm -3 for hot, warm and cold respectively.
From panels (c) and (d) we can see that the peaks of the distributions are consistent with the line of constant pressure at p = 10 -12 7 . erg cm -3 referred to in Fig. 5.10. There is little change in the distributions of p , compared to Fig. 5.5. The differences in P between
Figure 5.11: Distributions of entropy defined phases for Model WSWa: cold (black, solid), warm (blue, dashed) and hot (red, dash-dotted) for ρ , T , p , and P (Panels a - d, respectively). Eleven snapshots are used spanning t = 634 to 644 Myr . Error bars indicate the 95% confidence interval accounting for deviations over time. The cold phase is defined to exist where specific entropy s < 3 7 . · 10 8 erg g -1 K -1 , hot where s > 23 2 . · 10 8 erg g -1 K -1 and the warm phase in between.
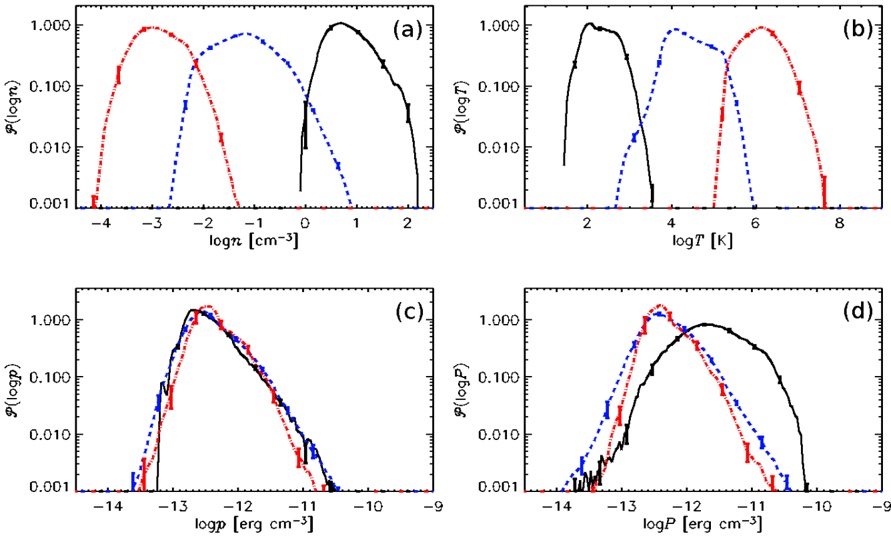
the cold gas and the rest can be accounted for by the vertical pressure gradient as explained with reference to Fig. 5.7.
With this approach we can obtain credible probability distributions for temperature T shown in panel (b). These distributions may help to qualify the characteristics of a region of the ISM from measurements of temperature, as the means and variances can be well defined for each phase and the regions of intersection are small.
## 5.4 Further results
In this section the distribution of the gas is explored more closely. The temperature of the ISM is more finely identified with a set of narrower bands as detailed in Table 5.2. As with the phases in Eq. (5.2) the fractional volume of each temperature range i at a height z can be given by
$$f _ { V, i } ( z ) = \frac { V _ { i } ( z ) } { V ( z ) } = \frac { N _ { i } ( z ) } { N ( z ) },$$
where N z i ( ) is the number of grid points in the temperature range T i, min ≤ T < T i, max , with T i, min and T i, max given in Table 5.2, and N z ( ) is the total number of grid points at
## that height. The fractional mass is similarly calculated as
$$f _ { M, i } ( z ) = \frac { M _ { i } ( z ) } { M ( z ) },$$
where M z i ( ) is the mass of gas within temperature range i at a given z , and M z ( ) is the total gas mass at that height.
Table 5.2: Key to Figs. 5.12 and 7.5, defining the gas temperature bands used there.
| Temperature band | Line style | Phase |
|-----------------------------|-------------------|---------|
| T < 5 × 10 1 K | | cold |
| 5 × 10 1 K ≤ T < 5 × 10 2 K | · - · - · - · - · | cold |
| 5 × 10 2 K ≤ T < 5 × 10 3 K | - - - - - | warm |
| 5 × 10 3 K ≤ T < 5 × 10 4 K | - - - - | warm |
| 5 × 10 4 K ≤ T < 5 × 10 5 K | -- · - · - - | warm |
| 5 × 10 5 K ≤ T < 5 × 10 6 K | - · · · - · | hot |
| T ≥ 5 × 10 6 K | · · · · · · | hot |
Figure 5.12: Vertical profiles of (a) the fractional volume (Eq. 5.16) and (b) the fractional mass (Eq. 5.17) for Model WSWa, calculated for the temperature ranges given, along with the figure legend, in Table 5.2. Data from 21 snapshots were used spanning 636 to 646 Myr . Fractional volume (c) for Model WSWa and (d) for Model WSWah. Direct comparison from 6 (10) snapshots for Model WSWa (WSWah) in the reduced interval 633 to 638 Myr .
Note that the relative abundances of the various phases in these models might be affected by the unrealistically high thermal conductivity adopted. The coldest gas (black, solid), with T < 50 K , is largely confined within about 200 pc of the mid-plane. Its fractional volume (Fig. 5.12a) is small even at the mid-plane, but it provides more than half
of the gas mass at z = 0 (Fig. 5.12b). Gas in the next temperature range, 50 < T < 500 K (purple, dash-dotted), is similarly distributed in z . Models WSWa and WSWah differ only in their resolution, using 2 and 4 pc, respectively. Model WSWah is a continuation of the state of WSWa after 600 Myr of evolution. With higher resolution the volume fraction of the coldest gas is significantly enhanced (Fig. 5.12d compared to b), but it is similarly distributed.
Gas in the range 5 × 10 2 < T < 5 × 10 3 K (dark blue, dashed) has a similar profile to the cold gas for both the fractional mass and the fractional volume, and this is insensitive to the model resolution. This is identified with the warm phase, but exists in the thermally unstable temperature range. It accounts for about 10% by volume and 20% by mass of the gas near the mid-plane. Heiles and Troland (2003) estimate at least 48% of the WNM to be in the thermally unstable range 500 K < T < 5000 K , and that the WNM accounts for 50% of the volume filling fraction at | z | = 0 . From Fig. 5.12a, assuming the WMN corresponds to the two bands within 500 K < T < 50 000 K , in the model this account for roughly 50% of the total volume fraction for | z | < 400 pc , and about 40% at | z | glyph[similarequal] 0 , with only a third of this in the unstable range. So the WMN is consistent with observation, although the model may slightly under represent the thermally unstable abundance. It is negligible away from the supernova active regions.
The two bands with T > 5 × 10 5 K (red, dotted and orange, dash-3dotted) behave similarly to each other, occupying similar fractional volumes for | z | < . ∼ 0 75 kpc , and with f V,i increasing above this height (more rapidly for the hotter gas). In contrast the fractional masses in these temperature bands are negligible for | z | < . ∼ 0 75 kpc , and increase above this height (less rapidly for the hotter gas). The temperature band 5 × 10 4 < T < 5 × 10 5 K (green/black, dash-3dotted) is identified with the warm phase, based on the minimum in the combined density and temperature distribution at T glyph[similarequal] 5 × 10 5 K in Fig. 5.4. However as a function of z it is similarly distributed to the hotter gas (orange) in all profiles. This indicates it is likely a transitional range of mainly hot gas cooling, which accounts for a relatively small mass fraction of the warm gas. The dramatic effect of increased resolution (Fig. 5.12d compared to c) is the significant increase in the very hot gas (red, dotted), particularly displacing the hotter gases (orange and green) but also to some degree the warm gas (blue, dashed). This reflects the reduced cooling due to the better density contrasts resolved, associating the hottest temperatures to the most diffuse gas.
The middle temperature range 5 × 10 3 < T < 5 × 10 4 K has a distinctive profile in both fractional volume and fractional mass, with minima near the mid-plane and maxima at about | z | glyph[similarequal] 400 pc , being replaced as the dominant component by hotter gas above this height. The fractional volume and vertical distribution of this gas is quite insensitive to the resolution.
A three dimensional rendering of a snapshot of the density distribution from the reference model (WSWa) is illustrated in Fig. 5.13, showing the typical location and density composition of each phase separately. In panel a the cold gas is located near the mid-
Figure 5.13: 3D snapshots, from Model WSWa, of gas number density in (a) the cold gas, (b) the warm gas, and (c) the hot gas. In each plot regions that are clear (white space) contain gas belonging to another phase. The phases are separated at temperatures 500 K and 5 × 10 5 K . The colour scale for log n is common to all three plots.
plane, apparently in layers with some more isolated fragments. The location and filling fraction of the warm (panel b) and hot (panel c) gas appear similar, although the hot gas has density typically 1/100 that of the warm gas density. The density of the gas is more roughly correlated with z , with the stongest fluctuations in the structure of the hot gas, including very diffuse regions scattered about the mid-plane as well as near the vertical boundaries.
The analysis of the warm gas density distribution within and outside the supernova active mid-plane in Section 5.1 indicated that its shape and standard deviation is fairly robust, and is merely shifted with respect to mean density, a predictable consequence of balancing the global pressure gradient. On the other hand the gas density distributions of the hot gas have been found to be quite different within and outside the mid-plane. In particular the distribution of hot gas near the mid-plane has a larger standard deviation, as well as increased mean. This is reflected in the pockets of very diffuse gas near the mid-plane, amongst the most dense hot gas.
The significance of these features to observations, are that the effects of the warm gas are more predictable, with consistent standard deviation, independent of height and in principle a predictable trend in the mean with respect to the pressure balance to the gravitational potential. For the hot gas observations along a line-of-sight above the supernova active region | z | glyph[similarequal] 300 pc will also have consistent standard deviation and trend in the mean. The structure of the hot gas near the mid-plane is significantly more complex and subject to strong local effects.
## 5.5 Summary
The ISM is reasonably described by separation into phases. The boundaries between the phases can be identified by the minima in the volume weighted probability distributions
of the gas temperature. An alternative representation in terms of specific entropy for the phase boundaries also yields statistically meaningful phase temperature PDFs. The phases are well described by statistical thermal and total pressure balance. The phase PDFs for the gas density are lognormal, and applying these fits provides a better determination of the fractional volume from the phase filling factor than the assumption of homogeneous phases.
## Chapter 6
## Structure of the velocity field
Figure 6.1: The perturbation velocity field u in Model WSWa at t = 550Myr . The colour bar indicates the magnitude of the velocity depicted in the volume shading, with rapidly moving regions highlighted with shades of red. The low velocity regions, shaded blue, also have reduced opacity to assist visualisation. Arrow length of vectors (a) is proportional to the magnitude of u , with red (blue) arrows corresponding to u z > 0 ( u z < 0 ) and independent of the colour bar. Trajectories of fluid elements (b) are also shown, indicating the complexity of the flow and its pronounced vortical structure.
Understanding the nature of the flows in the ISM is important for appreciating many other inter-related properties of the ISM. What are the systematic vertical flows? Can they be characterized as a wind sufficient to escape the gravitational potential of the galaxy and hence deplete the gas content or are they characteristic of a galactic fountain, in which case the gas is recycled? How does the velocity correlate with the density and hence contribute to kinetic energy and the energy balance in the galaxy, against thermal, magnetic and cosmic ray contributions? How is the velocity field divided between a mean
flow and fluctuations? To what extent do these properties vary by phase? Over what scales are the turbulent eddies of the ISM correlated, and how do they depend on phase or vary as a function of height? What is the vortical structure of the ISM and what contributions do various features of the velocity field bring to the magnetic dynamo? In this section some of the general features of the velocity field are described and some characteristics of the flow by phase are considered. The correlation scales as a function of height are measured for the total ISM.
In Fig. 6.1 aspects of the velocity field in 3D for the reference Model WSWa are displayed. The volume rendering shows the regions of high speed. Speeds below about 300 km s -1 are transparent to aid visualisation. Velocity vectors are illustrated (panel a) using arrows, size indicating speed and colour the z -component. These indicate that flows away from the mid-plane are dominant. Red patches are indicative of recent SNe and there is a strongly divergent flow close to middle on the xz -face. In addition stream lines (b) display the presence of many small scale vortical flows near the mid-plane.
## 6.1 Gas flow to and from the mid-plane
Figure 6.2: Contour plots of the probability distributions P ( z, u z ) for the vertical velocity u z as a function of z in Model WSWa from eleven snapshots 634-644 Myr. The cold ( T < 500 K) , warm (500 K ≤ T < 5 × 10 5 K) and hot ( T ≥ 5 × 10 5 K) are shown in panels (a) to (c) , respectively. The horizontal averages of the vertical velocity u z in each case are over plotted (red, dashed) as well as the mid-plane position (black, dotted).
The mean vertical flow is dominated by the hot gas, so it is instructive to consider the velocity structure of each phase separately. Figure 6.2 shows plots of the probability distributions P ( z, u z ) as functions of z and u z from eleven snapshots of Model WSWa, separately for the cold (a), warm (b) and hot gas (c).
The cold gas is mainly restricted to | z | < 300 pc and its vertical velocity varies within ± 20 km s -1 for | z | ≶ 0 . On average, the cold gas moves towards the mid-plane, presumably after cooling at larger heights. The warm gas is involved in a weak net vertical outflow above | z | = 100 pc , of order ± 10 km s -1 . This might be an entrained flow within the hot gas. However, due to its skewed distribution, the modal flow is typically towards the mid-plane. The hot gas has large net outflow speeds, accelerating to about 100 km s -1 within | z |± 200 pc , but with small amounts of inward flowing gas at all heights. The mean hot gas outflow increases at an approximately constant rate to a speed of over 100 km s -1 within ± 100 pc of the mid-plane, and then decreases with further distance from the midplane, at a rate that gradually decreases with height for | z | > . ∼ 0 5 kpc . This is below the escape velocity associated with a galactic wind.
Asignificant effect of increased resolution is the increase in the magnitude of the perturbed velocity, from 〈 u rms 〉 = 76kms -1 in Model WSWa to 103 km s -1 in Model WSWah (Table 4.2 Column 13) and temperatures ( 〈 c s 〉 increases from 150 to 230 km s -1 ); both 〈 u rms 〉 and the random velocity 〈 u 0 〉 are increased by a similar factor of about 1.3. However, the thermal energy e th is reduced by a factor of 0.6 with the higher resolution, while kinetic energy e K remains about the same. This suggests that in the higher-resolution model, the higher velocities and temperatures are associated with lower gas densities.
## 6.2 The correlation scale of the random flows
The correlation length of the random velocity u at a single time step of the Model WSWa, has been estimated by calculating the second-order structure functions D ( ) l of the velocity components u x , u y and u z , where
$$\mathcal { D } ( l ) = \langle [ u ( x + l ) - u ( x ) ] ^ { 2 } \rangle,$$
with x the position in the ( x, y ) -plane and l a horizontal offset. The offsets in the z -direction have not been included because of the systematic outflows and expected variation of the correlation length with z . The aggregation of the squared differences by | l | , presumes that the flow is statistically-isotropic horizontally. I will consider more detailed analysis of the three-dimensional properties of the random flows, including the degree of anisotropy and its dependence on height and phase in future work.
D ( ) l was measured at five different heights, ( z = 0 100 , , -100 , 200 and 800 pc ). Averaging over six adjacent slices in the ( x, y ) -plane, each position corresponds to a layer of thickness 20 pc. The averaging took advantage of the periodic boundaries in x and y ; for simplicity choosing a simulation snapshot at a time for which the offset in
Figure 6.3: The second-order structure functions calculated using Eq. (6.1), for the layer -10 < z < 10 pc, of the velocity components u x (black, solid line), u y (blue, dashed) and u z (red, dashdot). The offset l is confined to the ( x, y ) -plane only.
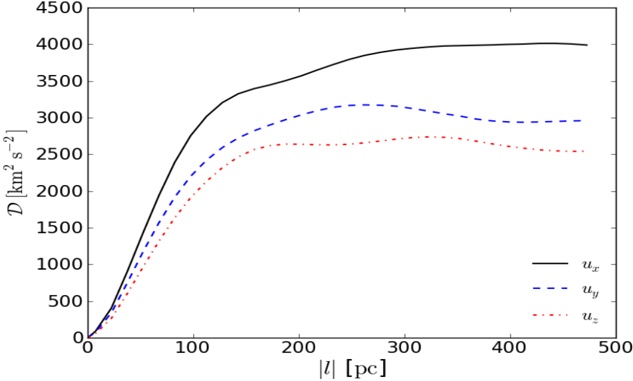
the y -boundary, due to the shearing boundary condition, was zero. The structure function for the mid-plane ( -10 < z < 10 pc ) is shown in Fig. 6.3.
The correlation scale can be estimated from the form of the structure function since velocities are uncorrelated if l exceeds the correlation length l turb , so that D becomes independent of l , D l ( ) ≈ 2 u 2 rms for l glyph[greatermuch] l turb . Precisely which value of D ( ) l should be chosen to estimate l turb in a finite domain is not always clear; for example, the structure function of u y in Fig. 6.3 allows one to make a case for either the value at which D ( ) l is maximum or the value at the greatest l . This uncertainty can give an estimate of the systematic uncertainty in the values of l turb obtained. Alternatively, and more conveniently, one can estimate l turb via the autocorrelation function C ( ) l , related to D ( ) l by
$$\mathcal { C } ( l ) = 1 - \frac { \mathcal { D } ( l ) } { 2 u _ { r m s } ^ { 2 } }.$$
In terms of the autocorrelation function, the correlation scale l turb is defined as
$$l _ { \text{turb} } = \int _ { 0 } ^ { \infty } \mathcal { C } ( l ) \, \text{d} l,$$
and this provides a more robust method of deriving l turb in a finite domain. Of course, the domain must be large enough to make C ( ) l negligible at scales of the order of the domain size; this is a nontrivial requirement, since even an exponentially small tail can make a finite contribution to l turb . In such estimates we are, of course, limited to the range of C ( ) l within the computational domain, so that the upper limit in the integral of Eq. (6.3) is equal to L x = L y , the horizontal box size; this is another source of uncertainty in the estimates of l turb .
Figure 6.4 shows C ( ) l for five different heights in the disc, where u rms was taken
Figure 6.4: Autocorrelation functions for the velocity components u x (black, solid line), u y (blue, dashed) and u z (red, dash-dot) for 20 pc thick layers centred on five different heights, from top to bottom: -10 < z < 10 pc , 90 < z < 110 pc , -110 < z < -90 pc , 190 < z < 210 pc and 790 < z < 810 pc .
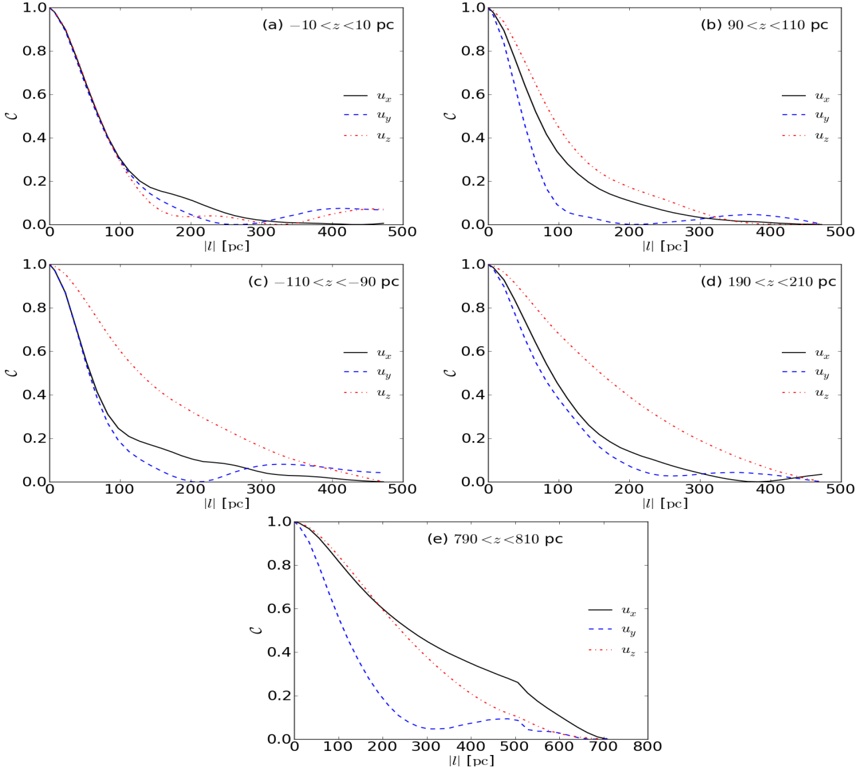
to correspond to the absolute maximum of the structure function, u 2 rms = max( D ) / 2 , from Eq. (6.2). The autocorrelation function of the vertical velocity varies with z more strongly than, and differently from, the autocorrelation functions of the horizontal velocity components; it broadens as | z | increases, meaning that the vertical velocity is correlated over progressively greater horizontal distances. Already at | z | ≈ 200 pc , u z is coherent across a significant horizontal cross-section of the domain and at | z | ≈ 800 pc so is u x . An obvious explanation for this behaviour is the expansion of the hot gas streaming away from the mid-plane, which thus occupies a progressively larger part of the volume as it flows towards the halo.
Table 6.1 shows the rms velocities derived from the structure functions for each component of the velocity at each height, and the correlation lengths obtained from the autocorrelation functions. Note that these are obtained without separation into phases. The uncertainties in u rms due to the choices of local maxima in D ( ) l are less than 2 km s -1 . However, these can produce quite large systematic uncertainties in l turb , as small changes
in u rms can lead to C ( ) l becoming negative in some range of l (i.e. a weak anti-correlation), and this can significantly alter the value of the integral in Eq. (6.3). Such an anticorrelation at moderate values of l is natural for incompressible flows; the choice of u rms is thus not straight forward. Other choices of u rms in Fig. 6.3 can lead to a reduction in l turb by as much as 30 pc . Better statistics, derived from data cubes for a number of different time-steps, will allow for a more thorough exploration of the uncertainties, but this analysis shall also be deferred to later work.
Table 6.1: The correlation scale l turb and rms velocity u rms at various distances from the midplane.
| | u rms [ kms - 1 ] | u rms [ kms - 1 ] | u rms [ kms - 1 ] | l turb [ pc ] | l turb [ pc ] | l turb [ pc ] |
|-------|---------------------|---------------------|---------------------|-----------------|-----------------|-----------------|
| z | u x | u y | u z | u x | u y | u z |
| 0 | 45 | 40 | 37 | 99 | 98 | 94 |
| 100 | 36 | 33 | 43 | 102 | 69 | 124 |
| - 100 | 39 | 50 | 46 | 95 | 87 | 171 |
| 200 | 27 | 20 | 63 | 119 | 105 | 186 |
| 800 | 51 | 21 | 107 | 320 | 158 | 277 |
The rms velocities given in Table 6.1 are compatible with the global values of u rms and u turb for the reference run W Ω shown in Table 4.1 (within their uncertainties). The increase in the root-mean-square value of u z with height, from about 40 km s -1 at z = 0 to about 60 km s -1 at z = 200 pc , reflects the systematic outflow with a speed increasing with | z | . There is also an apparent tendency for the root-mean-square (rms) values of u x and u y to decrease with increasing distance from the mid-plane. This is understandable, as the rate of acceleration from SN forcing will decline from the mid-plane. However it is not excluded that these rms values might increase again at heights substantially away from the mid-plane, where the gas is hotter and gas speeds are generally higher in all directions.
The correlation scale of the random flow is very close to 100 pc in the mid-plane, and this value has been adopted for l turb elsewhere in the thesis. This estimate is in good agreement with the hydrodynamic ISM simulations of Joung and Mac Low (2006), who found that most kinetic energy is contained by fluctuations with a wavelength (i.e. 2 l turb in our notation) of 190 pc . In the MHD simulations of Korpi, Brandenburg, Shukurov, Tuominen and Nordlund (1999), l turb for the warm gas was 30 pc at all heights, but that of the hot gas increased from 20 pc in the mid-plane to 60 pc at | z | = 150pc . de Avillez and Breitschwerdt (2007) found l turb = 73pc on average, with strong fluctuations in time. As in Korpi, Brandenburg, Shukurov, Tuominen and Nordlund (1999), there is a weak tendency for l turb of the horizontal velocity components to increase with | z | in my simulations, but this tendency remains tentative, and must be examined more carefully to confirm whether it is robust. The correlation scale of the vertical velocity, which has a systematic part due to the net outflow of hot gas, grows from about 100 pc at the midplane to nearly 200 pc at z = 200pc . Due to the increase of the fractional volume of the hot gas with distance from the mid-plane, this scale might be expected also to increase
further.
## 6.3 Summary
The heating and shocking induced by SNe produce a mean outflow of gas from the disc of up to 200 km s -1 within | z | < ∼ 500 pc , which slows to 100 km s -1 within | z | < ∼ 1 kpc , which is mainly comprised of hot gas. These velocities are below the escape velocity, that would be associated with a galactic wind, so represents only the outward part of the galactic fountain. The horizontal correlation scale of the turbulent flow is of order 100 pc near the mid-plane. The correlation length increases with height, reaching 200 -300 pc for | z | glyph[similarequal] 800 pc , and likely to continue to increase above this.
## Chapter 7
## Sensitivity to model parameters
## 7.1 Sensitivity to the cooling function
An important factor in the persistence of a multi-phase ISM is the action of differential cooling. Radiative cooling and UV-heating rates in the ISM are dependent on a variety of localised factors, such as gas density, the presence and abundance of helium, heavier elements and metals, filtering by dust grains, and the temperature and ionization of the gas (Wolfire et al., 1995). In simulations of this kind, where the gas is usually modelled as a single fluid with a mean molecular weight, the cooling and heating processes are heavily parametrized. Many authors adopt alternative cooling profiles, with little effort to establish the utility of their choice. Some comparisons have been recorded between cooling functions, but using alternative numerical methods or modelling indirectly related physical problems. de Avillez and Breitschwerdt (2010) use a time dependent cooling function, which recognises the delay in recombination of previously ionized gas, and demonstrates that there is a substantial variation in the resulting cooling. There are inevitably overheads associated with this refinement. So far, the extent to which this affects the primary global properties of the ISM (temperature, density, velocity distributions) has not been clarified.
Here two models, RBN and WSWb, with parameters given in Table 4.1, are compared directly to assess how the specific choice of the cooling functions affect the results. Apart from different parameterizations of the radiative cooling, the two models share identical parameters, except as follows: because of the sensitivity of the initial conditions to the cooling function (Section 3.6), the value of T 0 was slightly higher in Model RBN. (The density, heating and gravity profiles were the same.)
One consideration with the inclusion of a thermally unstable branch for the WSW cooling function, used in Model WSWa, is that the cooling times must be adequately resolved (see Section 3.4 and Appendix B.2). From Eq. (3.3), the net cooling rate due to the diffuse heating and cooling terms is
$$\frac { D s } { D t } = - \left ( \frac { \rho \Gamma ( z ) - \rho ^ { 2 } \Lambda } { \rho T } \right ) ; \ \ [ ( \text{in cgs units} ) \ \text{erg} \, g ^ { - 1 } \, K ^ { - 1 } \, s ^ { - 1 } ].$$
Figure 7.1: (a) The total volume probability distributions by gas number density n and temperature T . Eleven snapshots of Model WSWb in the interval t = 305 to 325 Myr were used, with the system in a statistical steady state. Contours of constant cooling time ( 10 5 , 10 6 , 10 7 and 10 8 yr) are over plotted to indicate where the gas may be subject to rapid radiative cooling. These are drawn from the contour plot of cooling time τ cool (b) , given in Eq. (7.1) with diffuse heating Γ (0) as applied at the mid-plane z = 0 . The solid red patch at T < ∼ 10 4 K is a region where heating exceeds cooling so τ cool is not defined. In (c) and (d) the contours again as (a) and (b) respectively, but for Γ z ( ) at | z | = 1kpc .
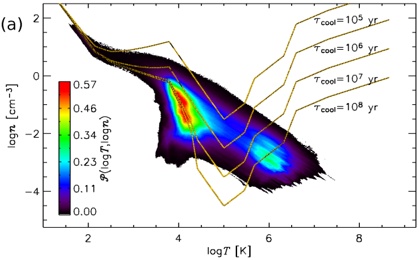
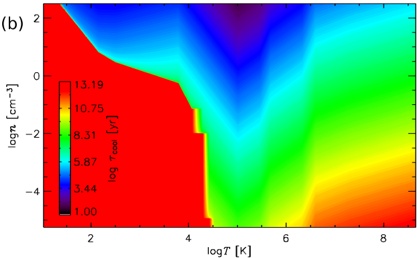
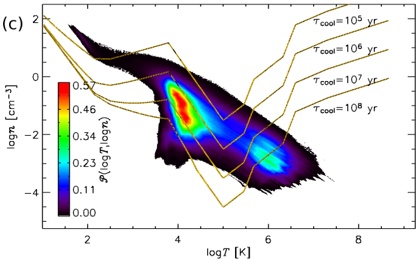
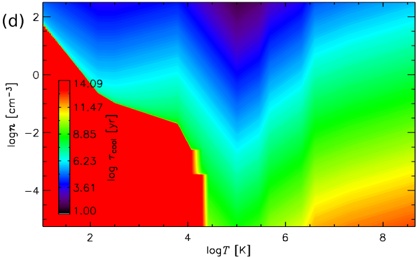
The cooling time τ cool is then given by
$$\tau _ { \text{cool} } = \frac { c _ { \text{v} } T } { \rho \Lambda - \Gamma ( z ) } \quad [ s ],$$
where Λ and Γ are the radiative cooling and ultra violet heating respectively, as described in Section 3.3, and c v is the specific heat capacity of the gas at constant volume.
In Fig. 7.1a the combined probability distributions of the gas number density and temperature in Model WSWb are overplotted with contours of constant cooling time τ cool , from the WSW cooling function and with the heating as it is applied at the mid-plane. Alongside this (Fig. 7.1b) are the contours of τ cool for the same range of temperature and density as in panel a. Note that the distribution in panel a is considerably broader than that for Model WSWa, displayed in Fig 5.4; i.e. there is greater pressure dispersion associated with the additional mass included in Models WSWb and RBN.
The heating Γ z ( ) is a maximum at the mid-plane and reduces with | z | . Ultra violet heating only applies at temperatures up to about 2 · 10 4 K , so τ cool is independent of z above these temperatures. Below T glyph[similarequal] 10 4 K there are densities where heating exceeds cooling, so the cooling time is undefined, indicated by the solid red regions in the con-
tour plot (b). From (a) it is apparent that the distribution of the cold gas is bounded by this region, suggesting that gas cannot remain cold as it is reheated very quickly. The very narrow distribution of the cold gas is in part explained by the equivalently narrow 'corridor' between the rapid heating (red) and the rapid cooling (blue) bounding it.
The effect of reduced heating with height is illustrated by the revised contours of τ cool (Fig. 7.1 c,d) for | z | = 1kpc . The corridor between rapid heating and rapid cooling shifts well below the location of the cold gas in panel (c). It is also the case that the density of the gas reduces with height. Therefore negligible quantities of gas in the thermally unstable range 313 -6102 K will be subject to this faster cooling and longer cooling times near the mid-plane will apply.
Only warm gas T glyph[similarequal] 10 5 K is significantly subject to cooling times less than 10 5 yr . There exists a substantial distribution of warm gas T glyph[similarequal] 10 4 K inside the (red) region where Γ (0) > ρΛ (panel a), but not so for Γ (1) (b). From inspection of the distribution of gas near the mid-plane (Fig. 7.3a below) it is clear that very little gas occupies the region of net heating (solid, red). Some gas below 10 4 K does spread into this region indicating that adiabatic cooling due to compression and expansion is dominant here.
Figure 7.2: (a) The total volume probability distributions by gas number density n and temperature T for Model RBN. Contours of constant cooling time ( 10 5 , 10 6 , 10 7 and 10 8 yr) are over plotted to indicate where the gas may be subject to rapid radiative cooling. These are drawn from the contour plot of cooling time τ cool (b) , given in Eq. (7.1) with diffuse heating Γ (0) as applied at the mid-plane z = 0 . The solid red patch at T < ∼ 10 4 K is a region where heating exceeds cooling so τ cool is not defined.
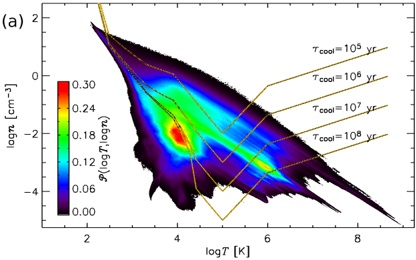
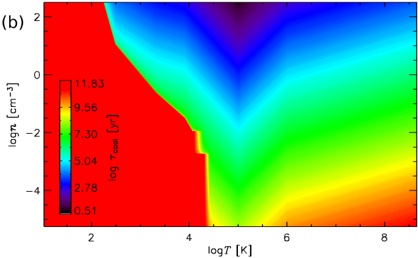
In Fig. 7.2, panels a and b of Fig. 7.1 are reproduced for Model RBN. There is far more gas in the temperature range around 10 3 K , due to the absence of a thermally unstable branch between 313 and 6102 K . The distribution of the cold gas near log n glyph[similarequal] log T glyph[similarequal] 2 is very similar to Model WSWb (Fig. 7.1a,c), although in this case it is not aligned with the narrow corridor between rapid heating (red) and rapid cooling (blue, panel b). This indicates that the composition of the cold gas is strongly dependent on the adiabatic shocks, rather than the balance between heating and cooling processes. The corresponding contours of τ cool extend to much lower densities in the temperature range above 10 6 K , so cooling times are much shorter for RBN cooling. Yet there is a greater abundance of very hot gas than with Model WSWb, which is explained by the much lower density of this
gas, which mitigates against the tendency for rapid cooling.
The distributions of gas near the mid-plane (within 100 pc ) for both models are displayed in Fig. 7.3. From these it is evident that the low temperature - low density boundary of the distributions aligns quite strongly with the region of net heating (red in Fig. 7.1b and Fig. 7.2b), although there is limited dispersion into this region. Both models have distributions with extended peaks along this boundary below 10 3 K , corresponding to the most thermally stable location. This extends to higher temperature for RBN cooling than for WSW, through the range which is unstable for the latter. However the most significant alignment, common to both models, is along the line of constant thermal pressure. Note that the colour scale differs between the plots, such that these peaks contain a similar proportion of the gas in both models. The cold dense tip of the RBN distribution extends into the region ( log n glyph[similarequal] log T glyph[similarequal] 2 ) where net heating should make it unstable, yet lies on the line of constant pressure through the peaks of warm and hot gas. This is associated with the equilibrium pressure between the phases, which is slightly lower at the mid-plane for WSW cooling than for RBN. In contrast to the case for the total volumes, Model WSWb has more gas near the mid-plane at higher temperature and lower density than Model RBN. Beyond this the cooling function has only a weak effect on the distribution for the gas with T > ∼ 10 3 K .
Figure 7.3: The mid-plane probability distributions ( | z | < 100 pc ) by gas number density n and temperature T for (a) Model WSWb and (b) Model RBN. Contours of constant cooling time ( 10 5 , 10 6 , 10 7 and 10 8 yr) are over plotted to indicate where the gas may be subject to rapid radiative cooling.
The volume-averaged thermal and kinetic energy densities, the latter due to the perturbed motions alone, are shown in Fig. 7.4 as functions of time. The averages for each are shown in Columns 15 and 16, respectively of Table 4.2, using the appropriate steady state time intervals given in Column 18. Models reach a statistically steady state, with mild fluctuations around a well defined mean value, very soon (within 60 Myr of the start of the simulations). The effect of the cooling function is evident: both the thermal and kinetic energies in Model RBN are about 60% of those in Model WSWb. This is understandable as Model RBN has a stronger cooling rate than Model WSWb, only dropping below the WSW rate in the range T < 10 3 K (see Fig. 3.1).
Interestingly, both models are similar in that the thermal energy is about 2 5 . times
Figure 7.4: Evolution of volume-averaged thermal (black: Model WSWb, blue: Model WSWa, purple: Model WSWah, red: Model RBN) and kinetic energy density (lower lines) in the statistically steady regime, normalised to the SN energy E SN kpc -3 . Models WSWb (black) and RBN (red) essentially differ only in the choice of the radiative cooling function.
the kinetic energy. These results are remarkably consistent with results by Balsara et al. (2004, their Fig. 6) and Gressel (2008, Fig. 3.1). Gressel (2008) applies WSW cooling and has a model very similar to Model WSWa, but with half the resolution and | z | ≤ 2 kpc . He reports average energy densities of 24 and 10 E SN kpc -3 (thermal and kinetic, respectively) with SN rate ˙ σ SN , comparable to 29 and 13 E SN kpc -3 obtained here for ModelWSWa.
Balsara et al. (2004) simulate an unstratified cubic region 200 pc in size, driven at SN rates of 8, 12 and 40 times the Galactic rate, with resolution more than double that of Model WSWa. For SN rates 12˙ σ SN and 8˙ σ SN , they obtain average thermal energy densities of about 225 and 160 E SN kpc -3 , and average kinetic energy densities of 95 and 60 E SN kpc -3 , respectively (derived from their energy totals divided by the [200 pc] 3 volume).
To allow comparison with models here, where the SNe energy injection rate is 1˙ σ SN , we divide their energy densities by 12 and 8, respectively, to obtain energy densities of 19 and 20 E SN kpc -3 (thermal), and 8 and 7.5 E SN kpc -3 (kinetic). These are slightly smaller than our results with RBN cooling (25 and 9 E SN kpc -3 ) and those with WSW (29 and 13 E SN kpc -3 for WSWa, as given above). Since Balsara et al. (2004) used an alternative cooling function (Raymond and Smith, 1977), leading to some additional uncertainty over the net radiative energy losses, the results appear remarkably consistent.
While cooling and resolution may marginally affect the magnitudes, it appears that the thermal energy density may consistently be expected to be about 2 5 . times the kinetic energy density, independent of the model. It also appears, from comparing the stratified and unstratified models, that the ratio of thermal to kinetic energy is not strongly dependent on height, at least between the mid-plane and ± 2 kpc .
Figure 7.5: Vertical profiles of the fractional volumes occupied by the various temperature ranges, with the key shown in Table 7.1. (a) Model WSWb, using 21 snapshots spanning 305 to 325 Myr. (b) Model RBN, using 21 snapshots spanning 266 to 286 Myr.
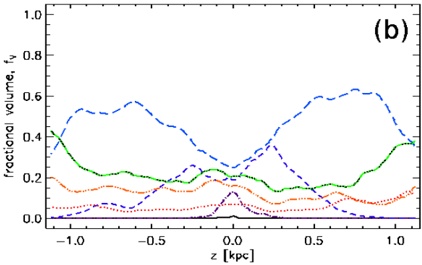
Table 7.1: Key to Figs. 5.12 and 7.5, defining the gas temperature bands used there (same as Table 5.2).
| Temperature band | Line style | Phase |
|-----------------------------|-------------------|---------|
| T < 5 × 10 1 K | | cold |
| 5 × 10 1 K ≤ T < 5 × 10 2 K | · - · - · - · - · | cold |
| 5 × 10 2 K ≤ T < 5 × 10 3 K | - - - - - | warm |
| 5 × 10 3 K ≤ T < 5 × 10 4 K | - - - - | warm |
| 5 × 10 4 K ≤ T < 5 × 10 5 K | -- · - · - - | warm |
| 5 × 10 5 K ≤ T < 5 × 10 6 K | - · · · - · | hot |
| T ≥ 5 × 10 6 K | · · · · · · | hot |
Figure 7.5, which plots the horizontal fractional volumes f V,i ( z ) defined in Eq. (5.16), helps reveal how the thermal gas structure depends on the cooling function. Model WSWb, panel (a), has significantly more very cold gas ( T < 50 K ; black, solid) than RBN, panel (b), but slightly warmer cold gas ( T < 500 K ; purple, dash-dotted) is more abundant in RBN. The warm and hot phases ( T > 5 × 10 3 K ) have roughly similar distributions in both models, although Model RBN has less of both phases. Apart from relatively minor details, the effect of the form of the cooling function thus appears to be straightforward and predictable: stronger cooling means more cold gas, and vice versa. What is less obvious, however, is that the very hot gas is more abundant near ± 1 kpc in Model RBN than in WSWb, indicating that the typical densities must be much lower. This, together with the greater abundance of cooler gas near the mid-plane, suggest that there is less stirring with RBN cooling.
The two models are further compared in Fig. 7.6, where separate probability distributions are shown for the gas density, temperature and thermal pressure. With both cooling functions, the most probable gas number density is around 3 × 10 -2 cm -3 ; the most probable temperatures are also similar, at around 3 × 10 4 K . With the RBN (blue, dashed) cooling function, the density range extends to smaller densities than with WSWb (black, solid); on the other hand, the temperature range for WSWb extends both lower and higher than for RBN. It is evident that the isobarically unstable branch of WSW cooling signifi-
cantly reduces the amount of gas in the 313-6102 K temperature range (dark blue, dashed in Fig. 7.5) and increases the amount below 100 K. However this is not associated with higher densities than RBN. This may be indicative that multiple compressions, rather than thermal instability, dominate the formation of dense clouds. The most probable thermal pressure is lower in Model RBN than in WSWb, consistent with the lower thermal energy content of the former, and with the differences between the 2D plots in Fig. 7.1a (WSW) and Fig. 7.2a (RBN). However, in contrast, the pressure at the mid-plane (Fig. 7.3) is higher for Model RBN than for Model WSWb.
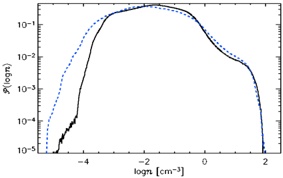
Figure 7.6: Volume weighted probability distributions for (a) gas density, (b) temperature and (c) thermal pressure, for Model RBN (blue, dashed) and Model WSWb (black, solid), in a statistical steady state, each averaged over 21 snapshots spanning 20 Myr (RBN: 266 to 286 Myr , and WSWb: 305 to 325 Myr ) and the total simulation domain | z | ≤ 1 12 kpc . .
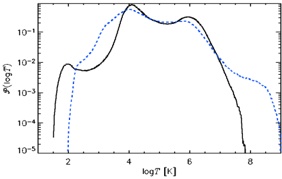
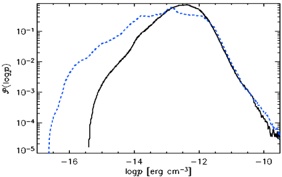
The density and temperature probability distributions for WSWb are similar to those obtained by Joung and Mac Low (2006, their Fig. 7), who used a similar cooling function, despite the difference in the numerical methods (adaptive mesh refinement down to 1 95 pc . in their case). With slightly different implementation of the cooling and heating processes, again with adaptive mesh refinement down to 1 25 pc . , de Avillez and Breitschwerdt (2004, their Fig. 3) found significantly more cool, dense gas. It is noteworthy that the maximum densities and lowest temperatures obtained in my study with a nonadaptive grid are of the same order of magnitude as those from AMR-models, where the local resolution is up to three times higher. At 4 pc resolution, the mean minimum temperature is 34 K , within the range 15 -80 K for 0.6252 5 pc . (de Avillez and Breitschwerdt, 2004, their Fig. 9). For mean maximum gas number, my value of 122 cm -3 is within their range 288 -79 cm -3 .
In Fig 7.7 the horizontal averages of the gas number density n are plotted for Models WSWb (black) and RBN (blue). The density scale height is lower for Model RBN, indicative that the stronger cooling is inhibiting the circulation of hot gas away from the mid-plane.
The probability distributions of Fig. 7.6 do not show clear separations into phases (cf. the distributions shown by Joung and Mac Low (2006); de Avillez and Breitschwerdt (2004)); thus division into three phases would arguably only be conventional, if based on these distributions alone. Based on the analysis described in Section 5.1, however the assertion that the complicated thermal structure can indeed be reasonably described in terms of three phases remains justified.
Distributions of density obtained for the individual phases from Models WSWb and
Figure 7.7: Horizontal averages of gas number density, n z ( ) , for Model WSWb (solid, black) and Model RBN (dashed, blue). Each are time-averaged using eleven snapshots. The vertical lines indicate standard deviation within each horizontal slice.
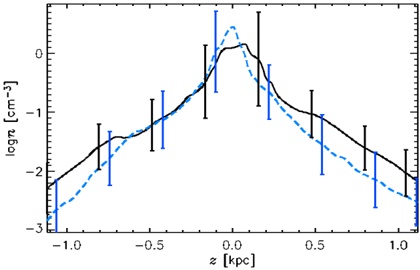
RBN, shown in Fig. 7.8a and f respectively, confirm the clear phase separation in both cases. This is also clear from the perturbation velocity in Fig 7.8b and g. Here the same borderline temperatures are defined for individual phases as for Model WSWa (Fig. 5.5). Despite minor differences between the corresponding panels in Figs. 5.5 and 7.8, the peaks in the gas density probability distributions are close to 10 1 , 3 × 10 -2 and 10 -3 cm -3 in all models. The similarity in the properties of the cold gas suggests that the radiative cooling (different in Models RBN and WSW) is less important than adiabatic cooling at these scales. Given the extra cooling of hot gas and reduced cooling of cold gas with the RBN cooling function, more of the gas resides in the warm phase in Model RBN. The probability distribution for the Mach number in the warm gas extends to higher values with the RBN cooling function, perhaps because more shocks reside in the more widespread warm gas, at the expense of the cold phase. It is useful to remember that, although each distribution in this figure is normalised to unit underlying area, the fractional volume of the warm gas is about a hundred times that of the cold.
The thermal pressure distribution in the hot gas reveals the two 'types' (see the end of section 5.1), which are mostly found within | z | < ∼ 200 pc (high pressure hot gas within SN remnants) and outside this layer (diffuse, lower pressure hot gas). The broader pressure distributions in both models, as compared to Fig. 5.5, indicate that the enhanced mass, particularly in the SN active regions, adds resistance to the release of hot gas from the mid-plane through blow outs and convection. The pressure builds up at the mid-plane without release to the halo, leading to a stronger vertical pressure gradient. This is also evident in the MHD models (Sections 7.2 and 9), where the circulation of hot gas out of the disc is partially inhibited by the presence of a predominantly horizontal magnetic field. Note that the location of the cold gas thermal pressure (Fig. 7.8i) is offset from the hot pressure peak, but for total pressure (panel j) they are well aligned.
In conclusion, the properties of the cold and warm phases are not strongly affected by the choice of the cooling function. The main effect is that the RBN cooling function produces slightly less hot gas, but extended to higher temperatures with significantly lower
Figure 7.8: Total volume phase probability distributions for Model WSWb (left column) and Model RBN (right column): gas number density n (a) (f) , ; turbulent velocity u turb (b) (g) , ; Mach number defined with respect to local sound speed and u turb (c) (h) , ; thermal pressure (d) (i) , ; and total pressure (e) (j) , . Cold phase T < 500 K (black, solid), warm 500 < T < 5 × 10 5 K (blue, dashed) and hot T > 5 × 10 5 K (red, dash-dotted). Eleven snapshots have been used for averaging, spanning t = 266 to 286 Myr for Model RBN and t = 305 to 325 Myr for Model WSWb.
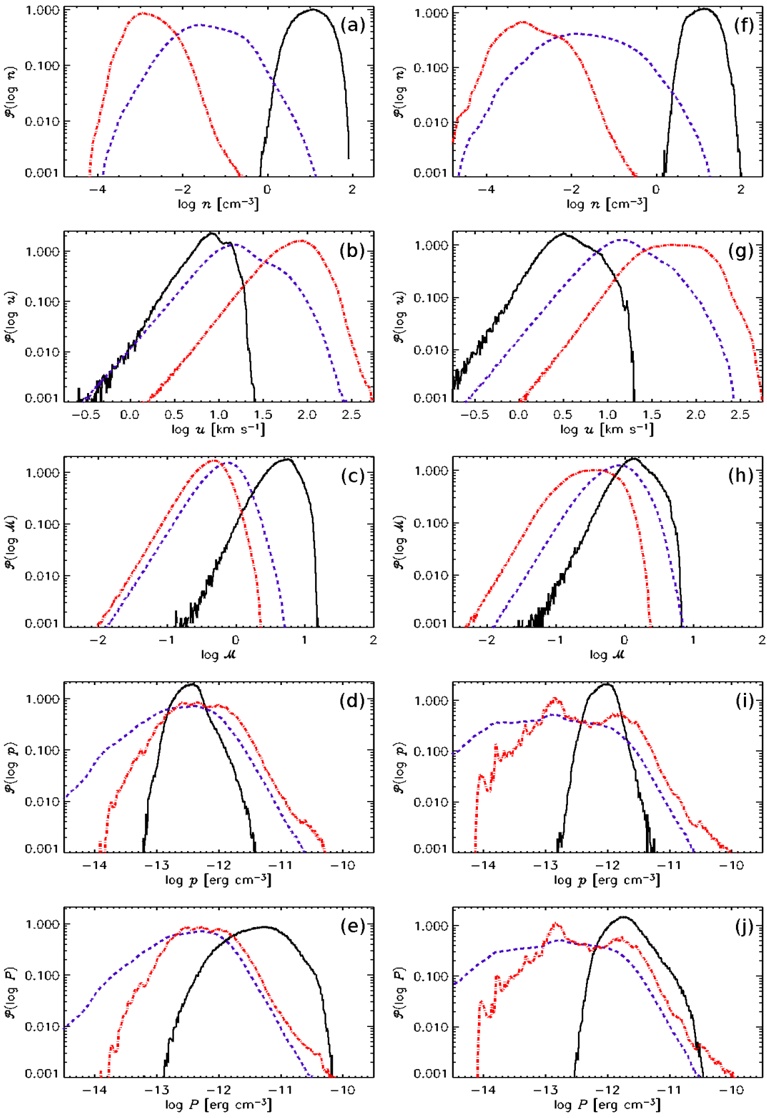
pressures. This can readily be understood, as this function provides significantly stronger cooling at T > ∼ 10 3 K .
## 7.2 Sensitivity to rotation, shear and SN rate
More thorough analysis of the effects of the other model parameters included here will need to follow in future work. Direct comparison between Models B2Ω and B1Ω in the saturated state may be used to consider the effect of rotation, but further studies with reduced rotation and a range of rotation rates would be more informative. The effects of shear and supernova rate can only be directly considered in the kinematic stage for the MHD runs with Models B1ΩSN and B1ΩSh , and it would also be helpful to consider a range of these parameters, to get a fuller appreciation of their effects.
From Table 4.2, it is evident that even in the kinematic stages there are significant differences between the HD and MHD models, so that the presence of a weak magnetic field cannot be ignored. For example in Column 10 of the table, the sound speeds 〈 c s 〉 of the MHD models are between one quarter and one half those of the HD models, indicating that the mean temperatures are much lower for MHD. Yet the thermal energies 〈 e th 〉 (15) are very similar. The velocities for the MHD models, both perturbation 〈 u rms 〉 (13) and turbulent 〈 u turb 〉 (14), are around one fifth those of the HD models. The kinetic energy 〈 e kin 〉 (16) is also reduced, even in the kinematic stage, to about one half to one third of the HD values.
Two significant changes to the models were included for the MHD runs. The location algorithm for the SNe was corrected to eliminate unphysical oscillation of the disc, and a numerical patch to replace physical mass loss was applied (see Appendix C for details of both). The former may indicate that 〈 u rms 〉 and 〈 e kin 〉 have been exaggerated in the HD runs. This also has the effect of stabilising the disc, so that the most dense gas remains near the mid-plane and SN energy will be more readily absorbed. This may also help to explain the reduced temperatures, without loss of thermal energy, and also the greatly reduced velocities, without a commensurate loss of kinetic energy. Similar models (de Avillez and Breitschwerdt, 2004; Joung and Mac Low, 2006; Gressel et al., 2008 a ) have found clustering of SNe necessary to generate large enough bubbles of hot gas to blow out from the disc. It would appear to be necessary to include this, especially for the MHD models where the thickness of the disc increases. There may also be some unintended effect of replacing the mass. For a direct comparison, an HD model labelled H1Ω was run with the same parameters as Model WSWa, but with these two changes implemented (see Section 9.3). Without the magnetic field, temperatures are substantially higher with 〈 c s 〉 glyph[similarequal] 44 km s -1 , but still much lower than before the numerical adjustments. The thermal energy 〈 e th 〉 remains similar. The velocities are larger than with MHD, but substantially reduced from the original HD runs. There is some reduction in 〈 e kin 〉 compared to the original HD runs, but remains slightly higher than for MHD.
In conclusion, the MHD models probably understate the temperature differentials, with cold gas and hot gas under represented, because a lack of clustering prevents adequate blowouts of hot gas. Due to the improved stability of the disc, however, the velocity and in particular the are kinetic energy is probably more accurately reproduced, and the higher values in the earlier HD models are unphysical manifestations of the vertical disc oscillations. The vertical density distribution in Model H1Ω is similar to that of Model WSWa, suggesting that the numerical recycling of mass is not strongly distorting the dynamics.
## Rotation
Comparing the results in Table 4.2 Column 10, 〈 c s 〉 glyph[similarequal] 23 km s -1 for Model B1Ω is slightly higher than 21 km s -1 for Model B2Ω . However the thermal energy 〈 e th 〉 glyph[similarequal] 25 E SN kpc -3 (Column 15) is lower than 26 E SN kpc -3 for Model B2Ω . The velocities (Columns 13 and 14) are very similar, as is the kinetic energy 〈 e kin 〉 (16). The total energy is even higher for Model B2Ω with the doubled rotation, when the magnetic energy 〈 e B 〉 (17) is included.
The probability distributions of the various quantities (density, temperature, pressure, etc.) do not differ greatly as a result of rotation, although the higher rotation inhibits very hot or cold gas. The horizontal averages of density, temperature and pressure are also very similar. So the dominant effect appears to be in the detailed structure of the velocity field, particularly the extent of vorticity. For Model B1Ω 〈|∇ × u |〉 = 194kms -1 kpc -1 and 〈|∇ · u |〉 = 185 km s -1 kpc -1 , while these are 178 and 144 km s -1 kpc -1 respectively for Model B2Ω . So although there is more vorticity in Model B1Ω , the ratio of the stream function to potential flow is greater for Model B2Ω .
## Shear
Figure 7.9: Horizontal averages of (a) gas number density, n z ( ) , and (b) total pressure, P z ( ) , for Model B1Ω ∗ (solid, black), and Model B1ΩSh (dashed, blue). Each is time-averaged using eleven snapshots spanning 600 to 700 Myr. The vertical lines indicate standard deviation within each horizontal slice. The thermal p z ( ) (dotted) and ram p turb ( z ) (fine dashed) pressures are also plotted (b) . The magnetic pressure p B is also plotted (fine, dash-3dotted).
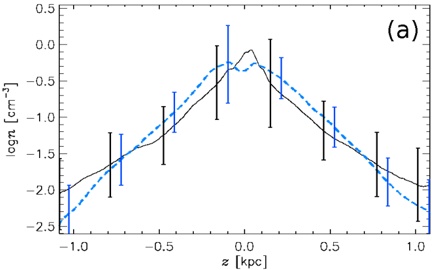
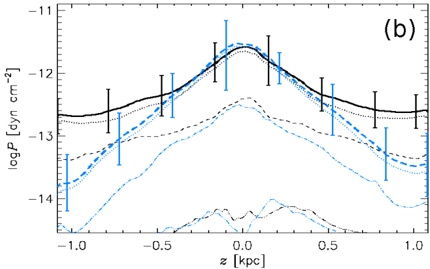
The effect of increasing the shear (Model B1ΩSh ) can be seen from the comparisons with the results for Model B1Ω ∗ , for the kinematic stage only. Temperatures are reduced, with 〈 c s 〉 glyph[similarequal] 24 km s -1 against 〈 c s 〉 glyph[similarequal] 58 km s -1 , although in line with the other MHD models following the saturation of the dynamo, and also with B1ΩSN for the kinematic stage only. However thermal energy 〈 e th 〉 glyph[similarequal] 29 E SN kpc -3 is enhanced compared to Model B1Ω ∗ . The velocities are almost half that of Model B1Ω ∗ , with kinetic energy only slightly diminished, and matching that of Model B1ΩSN .
Otherwise shear appears to make little difference to the hydrodynamics. The probability distributions for the density, temperature, thermal and turbulent pressures are insensitive to the shear, except that the hot gas extends to significantly lower densities than for the other models. However, the shear does affect the vertical structure of the model, unlike the effect of increased rotation. In Fig. 7.9 the horizontal averages of density and pressure are plotted for Models B1Ω ∗ (black, taken from its kinematic period) and B1ΩSh (blue). The scale height of the density (panel a) is narrower for Model B1Ω ∗ , with a higher density at the mid-plane. Given the twin peaks in the density profile for Model B1ΩSh , the higher scale height appears to be an indirect effect of the magnetic field, rather than of the shear itself. As discussed in Chapter 9, the regular part of the magnetic field is strongest just outside of the SN active region, and can affect the location of the gas. This is evident in the twin peaks of the magnetic pressure (panel b, blue, dashtriple-dotted). The total pressure near the mid-plane is about the same for both models, but falls more rapidly away from the mid-plane for Model B1ΩSh . So increased shear enhances the vertical pressure gradient. For Model B1ΩSh 〈|∇ × u |〉 = 342kms -1 kpc -1 and 〈|∇ · u |〉 = 188kms -1 kpc -1 . Although the potential flow is similar to Model B1Ω , and stronger than Model B2Ω after saturation of the dynamo, for Model B1Ω ∗ in the kinematic stage 〈|∇ × u |〉 = 737kms -1 kpc -1 and 〈|∇ · u |〉 = 295kms -1 kpc -1 . So the magnitude of the flows and the ratio of rotational to irrotational flow (1.8) are smaller than for Model B1Ω ∗ (2.5).
## Supernova Rate
The reduction in SN rate in Model B1ΩSN predictably reduces the temperatures 〈 c s 〉 and the thermal energy 〈 e th 〉 , but velocities and kinetic energy are similar to Model B1ΩSh , also in the kinematic stage (see Table 4.2).
There is more cold gas than for the other models, and there is less very diffuse gas. Otherwise the distributions of gas density, temperature and pressure, and the multi-phase structure are not strongly affected.
However the vertical distribution of the gas is affected by the SN rate. Similar to the increased shear, the reduced SN rate in Model B1ΩSN increases the scale height of the gas density (Fig. 7.10a blue, dashed). Unlike Model B1ΩSN , there is a distinctive peak in density at the mid-plane. For Model B1ΩSN 〈|∇ × u |〉 = 251kms -1 kpc -1 and 〈|∇ · u |〉 = 153kms -1 kpc -1 . The potential flow is predictably reduced compared
Figure 7.10: Horizontal averages of (a) gas number density, n z ( ) , and (b) total pressure, P z ( ) , for Model B1Ω ∗ (solid, black), and Model B1ΩSN (dashed, blue). Each are time-averaged using eleven snapshots spanning 600 to 700 Myr. The vertical lines indicate standard deviation within each horizontal slice. The thermal p z ( ) (dotted) and ram p turb ( z ) (fine dashed) pressures are also plotted (b) . The magnetic pressure p B is also plotted (fine, dash-3dotted).
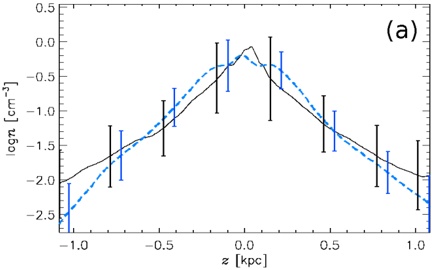
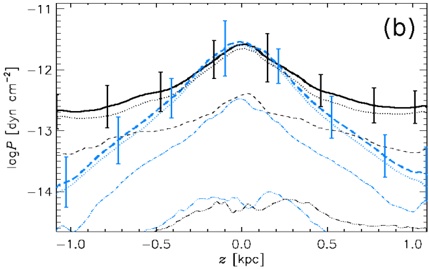
to Model B1Ω ∗ , and also to Model B1ΩSh . The ratio of rotational to irrotational flow is also reduced, at 1.6. The scale height of the gas density may be related to this ratio, given the similarities of Models B1ΩSN and B1ΩSh , with 1.6 and 1.8 respectively, and the similarities of Models B1Ω ∗ and B2Ω , with 1.0 and 1.2 respectively. Alternatively there could be independent causes: the strong alignment of the magnetic field in the case of Model B1ΩSh and the reduced hot gas circulation induced by the SN forcing in Model B1ΩSN .
## 7.3 Summary
The cooling function affects the detail of the multi-phase structure, particularly the abundance of gas in the thermally unstable range, and the overall energy, because of differences in the cumulative cooling effect. However the separation into phases is not strongly sensitive to the form of the cooling function. Typical density, velocity and modal temperatures are quite consistent for each phase, independent of the cooling function. Supernova rate affects the thermodynamic properties, so reduced SNe produces cooler, less turbulent gas, given the same gas surface density. The perturbation and turbulent velocities, as well as the temperature are not sensitive to the rotation or shearing rate. However the relative vorticity of the system is affected by changes to any of these parameters.
## Part IV
## Galactic magnetism: mean field and fluctuations
## Chapter 8
## Mean field in anisotropic turbulence
The ISM of spiral galaxies is extremely inhomogeneous, with SNe driving highly compressible, transonic turbulent motions, yet it supports magnetic fields at a global scale of a few kiloparsecs. Mean-field dynamo models have proven successful in modelling galactic magnetic fields, and offer a useful framework to study them and to interpret their observations (e.g., Beck et al., 1996; Shukurov, 2007). Turbulent dynamo action involves two distinct mechanisms. The fluctuation dynamo relies solely on the random nature of the fluid flow to produce random magnetic fields at scales smaller than the integral scale of the random motions. The mean-field dynamo produces magnetic field at a scale significantly larger than the integral scale, and requires rotation and stratification to do so. For any dynamo mechanism, it is important to distinguish the kinematic stage when magnetic field grows exponentially as it is too weak to affect fluid motions, and the nonlinear stage when the growth is saturated, and the system settles to a statistically steady state.
The scale of the mean field produced by the dynamo is controlled by the properties of the fluid flow. For example, in the simplest α 2 -dynamo in a homogeneous, infinite domain, the most rapidly growing mode of the mean magnetic field has scale of order 4 π η turb /α , where α can be understood as the helical part of the random velocity and η turb is the turbulent magnetic diffusivity (Sokoloff, Shukurov and Ruzmaikin, 1983). For any given α and η turb , this scale is finite and the mean field produced is, of course, not uniform.
In galaxies, the helical turbulent motions and differential rotation drive the so-called αω -dynamo, where the mean field has a radial scale of order ∆r glyph[similarequal] 3 |D| -1 3 / ( hR ) 1 2 / at the kinematic stage (Starchenko and Shukurov, 1989), with D the dynamo number, h glyph[similarequal] 0 5 kpc . the half-thickness of the dynamo-active layer and R glyph[similarequal] 3 kpc the scale of the radial variation of the local dynamo number. For |D| = 20 , this yields ∆r glyph[similarequal] 1 3 kpc . .
These estimates refer to the most rapidly growing mode of the mean magnetic field in the kinematic dynamo; it can be accompanied by higher modes that have a more complicated structure. Magnetic field in the saturated state can be even more inhomogeneous due to the local nature of dynamo saturation. The mean magnetic field can have a nontrivial, three-dimensional spatial structure, and any analysis of global magnetic structures must start with the separation of the mean and random (fluctuating) parts. However, many nu-
merical studies of mean-field dynamos define the mean magnetic field as a uniform field obtained by averaging over the whole volume available; or in the case of fields showing non-trivial variations in a certain direction, as planar averages, e.g., over horizontal planes for systems that show z -dependent fields (e.g., Brandenburg and Subramanian, 2005).
The mean and random magnetic fields are assumed to be separated by a scale, λ , of order the integral scale of the random motions, l turb ; λ is not necessarily precisely equal to l turb , however, and must be determined separately for specific dynamo systems. The leading large-scale dynamo eigenmodes themselves have extended Fourier spectra, both at the kinematic stage and after distortions by the dynamo nonlinearity. Thus, both the mean and random magnetic fields are expected to have a broad range of scales, and their spectra can overlap in wavenumber space. It is therefore important to develop a procedure to isolate a mean magnetic field without unphysical constraints on its spectral content. This problem is especially demanding in the multi-phase ISM, where the extreme inhomogeneity of the system can complicate the spatial structure of the mean magnetic field.
The definition of the mean field as a horizontal average may be appropriate in some simplified numerical models, where the vertical component of the mean magnetic field, B z , vanishes because of periodic boundary conditions applied in x and y ; otherwise, ∇ · B = 0 cannot be ensured. An alternative averaging procedure that retains threedimensional spatial structure within the averaged quantities is volume averaging with a kernel G glyph[lscript] ( r -r ′ ) , where glyph[lscript] is the averaging length: 〈 f ( r ) 〉 glyph[lscript] = ∫ V f ( r ′ ) G glyph[lscript] ( r -r ′ ) d 3 r ′ , for a scalar random field f .
## Reynolds rules
A difficulty with kernel volume averaging, appreciated early in the development of turbulence theory, is that it does not obey the Reynolds rules of the mean (unless glyph[lscript] → ∞ ); i.e.
glyph[negationslash]
$$\langle \langle f \rangle _ { \ell } g \rangle _ { \ell } \neq \langle f \rangle _ { \ell } \langle g \rangle _ { \ell } \quad \text{ and } \quad \langle \langle f \rangle _ { \ell } \rangle _ { \ell } \neq \langle f \rangle _ { \ell }$$
glyph[negationslash]
(Sect. 3.1 in Monin and Yaglom, 2007). If instead glyph[lscript] → ∞ and the mean is simply computed over the whole volume, then the total field can be decomposed into the mean and random parts, B = B 0 + b , where B 0 = B and b = 0 . The decomposition for the magnetic energies then follows conveniently as
$$\overline { B ^ { 2 } } = \overline { ( B _ { 0 } + b ) ^ { 2 } } = \overline { B _ { 0 } ^ { 2 } + 2 B _ { 0 } \cdot b + b ^ { 2 } } = \overline { B _ { 0 } ^ { 2 } + \overline { b ^ { 2 } } }$$
Horizontal averaging represents a special case with glyph[lscript] → ∞ in two dimensions, or alternatively can be considered an average over the total 'volume' of each horizontal slice, and thus satisfies the Reynolds rules; however, the associated loss of a large part of the spatial structure of the mean field limits its usefulness. Kernel volume averaging retains the spatial structure, but critically 〈 b 〉 glyph[lscript] in general does not equal 0 . The decomposition of
the total magnetic energy B 2 into mean and fluctuating energies cannot so conveniently be recovered from the quadratic terms 〈 B 〉 2 glyph[lscript] and b 2 . An alternative formulation must be devised.
## Germano approach to turbulence
Germano (1992) suggested a consistent approach to volume averaging which does not rely on the Reynolds rules. A clear, systematic discussion of these ideas is provided by Eyink (2012, Chapter 2), and an example of their application can be found in Eyink (2005). The averaged Navier-Stokes and induction equations remain unaltered, independent of the averaging used, if the mean Reynolds stresses and the mean electromotive force are defined in an appropriate, generalised way. The equations for the fluctuations naturally change, and care must be taken for their correct formulation. An important advantage of averaging with a Gaussian kernel (Gaussian smoothing) is its similarity to astronomical observations, where such smoothing arises from the finite width of a Gaussian beam, or is applied during data reduction.
In this chapter, I consider the magnetic field B produced by the rotational shear and random motions in Model B2Ω with Ω = -S = 2 Ω 0 . Ω 0 = 25kms -1 kpc -1 is the angular velocity in the Solar vicinity. This model has the fastest dynamo of all the magnetic runs in Table 4.1, so was adopted pragmatically to allow me to follow the dynamo process from early in the kinematic stage through to saturation and beyond. All of the magnetic models included in this thesis, however, appear to have produced a dynamo, so this analysis would be equally valid for all cases, were there sufficient resources to track them fully to the non-linear stage.
Using Gaussian smoothing, an approach is suggested, below, to determine the appropriate length glyph[lscript] , and then obtain the mean magnetic field B glyph[lscript] . The procedure ensures that ∇· B glyph[lscript] = 0 . The random magnetic field b is then obtained as b = B -B glyph[lscript] . The Fourier spectra of the mean and random magnetic fields overlap in wavenumber space, but their maxima are well separated.
## 8.1 The mean magnetic field
Figure 8.1 demonstrates the approximately exponential growth of magnetic energy density against the (relatively) stationary background of turbulent motions and thermal structure. As the average magnetic energy density 〈 e B 〉 = 〈| B | 2 〉 / 8 π becomes comparable to the average kinetic energy density 〈 e u 〉 at t > 1 Gyr , the latter shows a modest reduction, as expected for the conversion of the kinetic energy of random motions to magnetic energy. The use of 〈〉 without subscript indicates averaging over the total numerical domain, analogous to the use of overbar in Eq. (8.2). For t > 1 4 Gyr . , the magnetic field settles to a statistically steady state with 〈 e B 〉 ≈ 2 5 . × 10 -13 erg cm -3 , somewhat larger than 〈 e u 〉 ≈ 1 6 . × 10 -13 erg cm -3 , while the thermal energy density 〈 e T 〉 ≈ 10 -12 erg cm -3 ap-
Figure 8.1: Evolution of energy densities averaged over the whole computational domain; thermal 〈 e T 〉 (red), kinetic 〈 e u 〉 (blue) and magnetic 〈 e B 〉 (black). Guide line (purple, dotted) indicates exp(7 5 . t Gyr -1 ) .
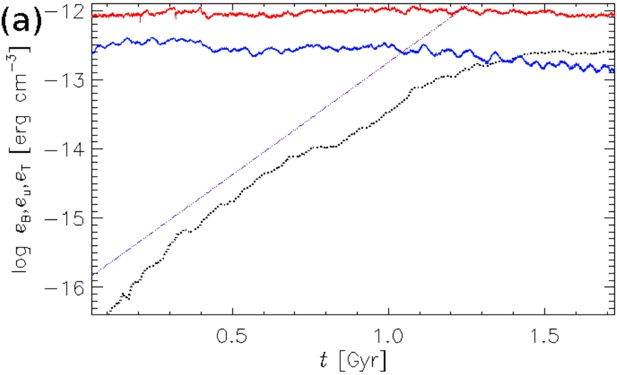
pears only weakly affected. Due to changes to the flow and thermodynamic composition, Ohmic heating is offset by reduced viscous heating or more efficient radiative cooling.
Magnetic field B can be decomposed into B glyph[lscript] , the part averaged over the length scale glyph[lscript] , and the complementary fluctuations b ,
$$B = B _ { \ell } + b, \quad B _ { \ell } = \langle B \rangle _ { \ell }, \quad b = B - B _ { \ell },$$
using volume averaging with a Gaussian kernel:
$$\langle B \rangle _ { \ell } ( x ) & = \int _ { V } B ( x ^ { \prime } ) G _ { \ell } ( x - x ^ { \prime } ) \, \mathfrak { d } ^ { 3 } x ^ { \prime }, \\ G _ { \ell } ( x ) & = \left ( 2 \pi \ell ^ { 2 } \right ) ^ { - 3 / 2 } \exp \left [ - x ^ { 2 } / ( 2 \, \ell ^ { 2 } ) \right ],$$
where V is the volume of the computational domain. This operation preserves the solenoidality of both B glyph[lscript] and b , and retains their three-dimensional structure. For computational efficiency, the averaging was performed in the Fourier space where the convolution of Eq. (8.4) reduces to the product of Fourier transforms.
$$\hat { B } _ { \ell } ( k, \ell ) = \hat { B } ( k ) \exp \left \{ - 2 ( \ell \pi ) ^ { 2 } k \cdot k \right \} \,,$$
where ˆ B k ( ) = F [ B x ( )] and ˆ B k glyph[lscript] ( , glyph[lscript] ) = F [ B x glyph[lscript] ( , glyph[lscript] )] .
Since the averaging (8.4) does not obey the Reynolds rules for the mean, the definitions of various averaged quantities should be generalised as suggested by Germano (1992). In particular, the local energy density of the fluctuation field is given by
$$e _ { b } ( x ) = \frac { 1 } { 8 \pi } \int _ { V } | B ( x ^ { \prime } ) - B _ { \ell } ( x ) | ^ { 2 } G _ { \ell } ( x - x ^ { \prime } ) \, \mathrm d ^ { 3 } x ^ { \prime },$$
while
$$\langle e _ { B } ( x ) \rangle _ { \ell } = & \frac { 1 } { 8 \pi } \int _ { V } | B ( x ^ { \prime } ) | ^ { 2 } G _ { \ell } ( x - x ^ { \prime } ) \mathrm d ^ { 3 } x ^ { \prime } \\ e _ { B \ell } ( x ) = & \frac { 1 } { 8 \pi } | B _ { \ell } ( x ) | ^ { 2 }$$
This ensures that 〈 e B glyph[lscript] 〉 = e B glyph[lscript] + e b .
Expanding B x ( ′ ) in a Taylor series around x , and using
$$\int _ { V } G _ { \ell } ( x - x ^ { \prime } ) \, \mathrm d ^ { 3 } x ^ { \prime } = 1$$
(normalisation), and
$$\int _ { V } ( x - x ^ { \prime } ) G _ { \ell } ( x - x ^ { \prime } ) \, \mathrm d ^ { 3 } x ^ { \prime } = 0$$
(symmetry of the kernel), it can be shown that e b = | b | 2 / (8 π ) + O glyph[lscript]/L ( ) 2 , where L is the scale of the averaged magnetic field, defined as L 2 = | B glyph[lscript] | / |∇ 2 B glyph[lscript] | in terms of the characteristic magnitude of B glyph[lscript] and its second derivatives. Thus the difference between the ensemble and volume averages rapidly decreases as the averaging length decreases, glyph[lscript]/L → 0 , or if the averaging is performed over the whole space, L →∞ ; this quantifies the deviations from the Reynolds rules for finite glyph[lscript]/L .
Figure 8.2: (a) Energy densities at t = 1 2 Gyr . of mean, 〈 e B glyph[lscript] 〉 (black, solid), and fluctuating, 〈 e b 〉 (blue, dashed), magnetic fields as functions of the averaging length glyph[lscript] , normalised by 〈〈 e B 〉 〉 glyph[lscript] and averaged over the region | z | < 0 5 kpc . ; also 〈 e B glyph[lscript] 〉 at t = 0 8 Gyr . (dotted) and t = 1 6 Gyr . (dash-triple-dotted). Values of glyph[lscript] sampled are indicated by red crosses. (b) Derivative of 〈 e b 〉 from Panel (a) with respect to glyph[lscript] , with the same line types.
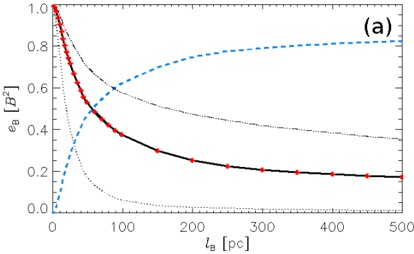
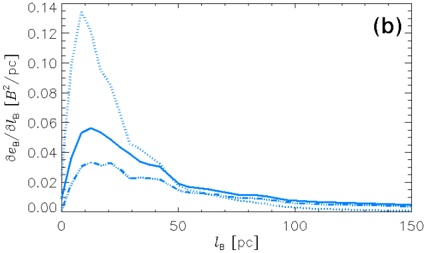
The appropriate choice of glyph[lscript] is not obvious. The decomposition into B glyph[lscript] and b was considered, through applying the averaging over a range 0 < glyph[lscript] < 500 pc to 37 snapshots of the magnetic field between t = 0 8 . and 1.7 Gyr. The results for t = 0 8 . , 1.2 and 1 6 Gyr . are shown in Fig. 8.2. The smaller is glyph[lscript] , the closer the correspondence between the averaged field and the original field (since the average is effectively sampling a smaller local volume), and hence the smaller the part of the total field considered as the fluctuation. Hence 〈 B 2 glyph[lscript] 〉 is a monotonically decreasing function of glyph[lscript] , whereas 〈 b 2 〉 monotonically increases (Fig. 8.2a). The curves for t = 0 8 . and 1.6 Gyr merely demonstrate that as the
field grows over time, the mean field becomes more dominant. There is a corresponding shift downward with time of the curve for 〈 e b 〉 , so that the length glyph[lscript] B , where they are in equipartition, increases. A length scale defining the mean would not be expected to vary, at least in the kinematic stage.
It may be helpful to identify that value of glyph[lscript] where the variation of B glyph[lscript] and b with glyph[lscript] becomes weak enough. To facilitate this, consider the rate of change of the relevant quantities with glyph[lscript] , shown in Fig. 8.2b (note the different scale of the horizontal axis in this panel). The length glyph[lscript] ≈ 50 pc is clearly distinguished: all the curves in Panel (b) are rather featureless for glyph[lscript] > 50 pc . The values in Fig. 8.2 have been obtained from the part of the domain with | z | < 0 5 kpc . , where most of the gas resides and where dynamo action is expected to be most intense. The results, however, remain quite similar if the whole computational domain | z | ≤ 1 kpc is used. While this value of glyph[lscript] has been estimated in a rather heuristic and approximate manner, the analysis of the magnetic power spectra in Section 8.2 confirms that glyph[lscript] = 50pc is close to the optimal choice.
To put the estimate glyph[lscript] ≈ 50 pc into context, note that it is about half the integral scale of the random motions, l turb , estimated in Section 6.2. Simulations of a single SN remnant in an ambient density similar to that at z = 0 (Appendix A.1) also show that the expansion speed of the remnant reduces to the ambient speed of sound when its radius is 50-70 pc.
Figure 8.3: Field lines of (a) the total magnetic field B , (b) its averaged part B glyph[lscript] , (c) the fluctuations b , obtained by averaging with glyph[lscript] = 50pc , for t = 1 625 Gyr . . Field directions are indicated by arrows. The colour of the field lines indicates the field strength (colour bar on the left), whereas the vectors are coloured according to the strength of the azimuthal ( y ) component (colour bar on the right).
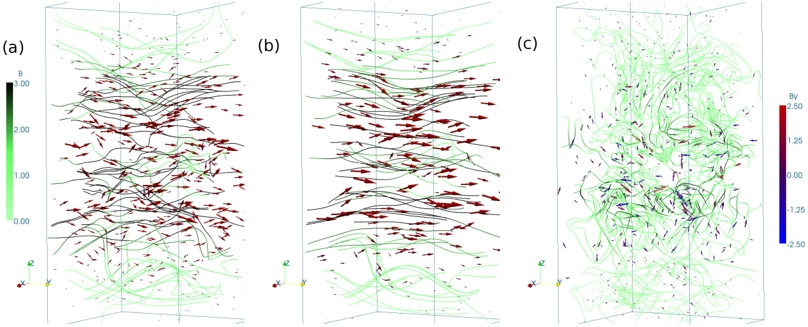
Figure 8.3 illustrates the total, mean and random magnetic fields thus obtained. For this saturated state, the field has a very strong uniform azimuthal component and a weaker radial component. The orientation of the field is the same above and below the mid-plane ( B > y 0 and B x < 0 ), with maxima located at | z | ≈ 0 2 kpc . ; the results will be reported in greater detail in Part V.
## 8.2 Scale separation
Scale separation between the mean and random magnetic fields in natural and simulated turbulent dynamos remains a controversial topic. The signature of scale separation sought for is a pronounced minimum in the magnetic power spectrum at an intermediate scale, larger than the energy-range scale of the random flow and smaller than the size of the computational domain. The power spectrum for B is M k ( ) = k -2 〈|F ( k ) |〉 k , for spherical shells of thickness δk at radius k = | k | , from F ( k ) = ∫ V B x ( ) exp( -2 πi k · x )d 3 x . The spectra of the mean and random magnetic fields obtained by Gaussian smoothing, shown in Fig. 8.4, have maxima at significantly different wavenumbers. Note however that the spectrum of the total magnetic field does not have any noticeable local minima and, with the standard approach (e.g., based on horizontal averages), the system would be considered to lack scale separation.
Figure 8.4: Power spectra of total (black, dotted), mean (red, dash-dotted) and fluctuating (blue, dashed) magnetic fields, for Gaussian smoothing with glyph[lscript] = 50pc , at t = 1 05Gyr . . Vertical red (dash-dotted) line marks the averaging wavenumber 2 π glyph[lscript] -1 and vertical black (dotted) line indicates the Nyquist wave number π ∆ -1 . Short vertical segments mark the energy-range scales 2 π L -1 glyph[lscript] and 2 π L -1 b of the mean and random magnetic fields, respectively, obtained from Eq. (8.6).
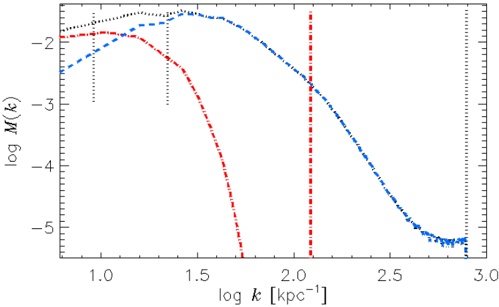
figure 8.4 shows the magnetic power spectra of B B , glyph[lscript] and b . Note that glyph[lscript] is not located between the maxima in the power spectra of B glyph[lscript] and b ; in fact, the spectral density of the mean field is negligible for k glyph[similarequal] 2 π glyph[lscript] -1 . This can be understood from the transform of the kernel G glyph[lscript] ( x ) , i.e. ̂ G glyph[lscript] ( k ) = exp( -glyph[lscript] 2 k 2 / 2) ; this kernel would divide a purely sinusoidal field equally into the mean and random parts at the wavelength λ eq = √ 2 / ln 2 π glyph[lscript] . For glyph[lscript] = 50pc , λ eq = 0 27 kpc . , and the latter figure is a better guide to the expected separation scale. The separation of scales is immediately apparent in the spectra of the mean and random fields, M k glyph[lscript] ( ) and M k b ( ) , with the former having a broad absolute maximum at about 0 56 kpc . , and the latter a broad maximum near 0 2 kpc . . The effective separation scale λ ≈ 0 48 kpc . can be identified where M k glyph[lscript] ( ) = M k b ( ) , i.e. where the curves cross at log k glyph[similarequal] 1 1 . .
Figure 8.5: As Fig. 8.4, but for (a) glyph[lscript] = 20pc and (b) glyph[lscript] = 100pc .
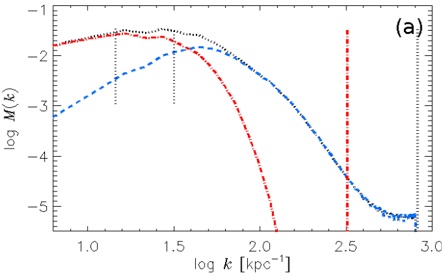
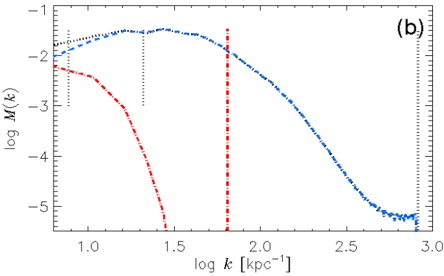
The integral scales of B glyph[lscript] and b can be obtained from their spectral densities as
$$\mathcal { L } _ { \ell } = \frac { \pi } { 2 } \int _ { 2 \pi / D } ^ { \pi / \Delta } k ^ { - 1 } M ( k ) \, \mathrm d k \left [ \int _ { 2 \pi / D } ^ { \pi / \Delta } M ( k ) \, \mathrm d k \right ] ^ { - 1 },$$
where ∆ is the numerical grid separation and D is the size of the domain (Section 12.1, Monin and Yaglom, 2007). This yields L glyph[similarequal] glyph[lscript] 0 67 kpc . and L glyph[similarequal] b 0 28 kpc . for B glyph[lscript] and b , respectively (Fig. 8.4).
As the magnetic field strength grows, the magnitudes of the spectral densities change but the characteristic wavenumbers vary rather weakly. L glyph[lscript] remains close to 0 7 kpc . throughout the kinematic phase, increasing only beyond 1.1 Gyr to about 0 9 kpc . . L b increases from 0 23 . to 0 28 kpc . during the kinematic phase, but rises to 0 4 kpc . after the system saturates. The stability of L glyph[lscript] is consistent with the eigenmode amplification of the mean magnetic field as expected for a kinematic dynamo, and supports glyph[lscript] ≈ 50 pc as a reasonable choice of the averaging scale.
Figure 8.5 presents magnetic energy spectra obtained using glyph[lscript] = 20pc and 100 pc . In the former, the effective separation scale λ ≈ 0 16 kpc . is less than L b glyph[similarequal] 0 21 kpc . . This is inconsistent, implying that energy at scales about L b lies predominantly within B glyph[lscript] . For glyph[lscript] = 100 pc , λ ≥ 1 kpc is greater than L glyph[similarequal] glyph[lscript] 0 81 kpc . , which is also inconsistent. Significantly, applying glyph[lscript] = 50pc satisfies L b < λ < L glyph[lscript] . Hence the scale λ , at which the dominant energy contribution switches between the mean and fluctuating parts, is here consistent only with glyph[lscript] glyph[similarequal] 50 pc .
As well as different spatial scales, the mean and random magnetic field energies have different exponential growth rates (Fig. 8.6), given in Table 8.1. The growth for the mean field component of the total magnetic energy is denoted by Γ e and the growth of the random field energy by γ e . Results from horizontal averaging are also given; they differ from those obtained with Gaussian smoothing, especially for the mean field. The growth rate Γ e of the mean-field energy is controlled by the shear rate, mean helicity of the random flow, and the turbulent magnetic diffusivity. Any mean magnetic field is accompanied by a random field, which is part of the mean-field dynamo mechanism (as any large-scale
Table 8.1: Exponential growth rates of energy in the mean and random magnetic fields, Γ e and γ e , respectively, with associated values of reduced χ 2 . From exponential fits to the corresponding curves in Fig. 8.6, for 0 8 . < t < 1 05 Gyr . . (Growth for t < 0 8 Gyr . is similar to this interval see Fig. 8.1.)
| | Γ e [Gyr - 1 ] | χ 2 | γ e [Gyr - 1 ] | χ 2 |
|----------------------|------------------|--------|------------------|--------|
| Gaussian smoothing | 10 . 9 | 1 . 00 | 5.5 | 1 . 15 |
| Horizontal averaging | 13 . 6 | 0 . 25 | 6 . 2 | 0 . 25 |
magnetic field is tangled by the random flow); the energy of this part of the small-scale field should grow at the same rate Γ e as the mean energy. The fluctuation dynamo produces another part of the random field whose energy growth rate depends on the turbulent kinematic time scale l/u , and the magnetic Reynolds and Mach numbers. The difference between Γ e and γ e obtained suggests that both mean-field and fluctuation dynamos are present in our model. The growth rate of the mean magnetic energy is roughly double that of the random field for both types of averaging. This is opposite to what is usually expected, plausibly because of the inhibition of the fluctuation dynamo by the strongly compressible nature of the flow and low Reynolds numbers available at this resolution. We would expect the fluctuation dynamo to be stronger with more realistic Reynolds numbers.
Figure 8.6: Evolution of magnetic energy densities, averaged for full domain: total magnetic field (black, dotted), mean (black, solid), and random (blue, dashed) obtained from Gaussian smoothing with glyph[lscript] = 50pc . Energy densities of mean and random magnetic fields obtained from horizontal averaging are shown long-dashed (black and blue, respectively).
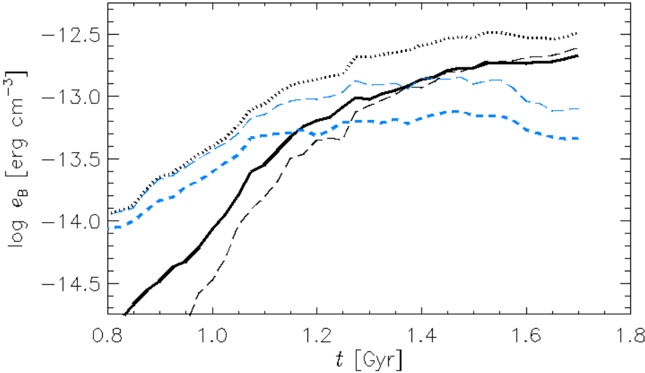
## 8.3 Evaluation of the method
The approach used here to identify the appropriate averaging length glyph[lscript] (and thus the effective separation scale λ ) is simple (but not oversimplified); glyph[lscript] can in fact depend on position,
and it may remain constant in time only at the kinematic stage of all the dynamo effects involved. Wavelet filtering may prove to be more efficient than Gaussian smoothing in assessing the variations of glyph[lscript] .
At the kinematic stage, the spectral maximum of the mean field is already close to the size of the computational domain, and it cannot be excluded that the latter is too small to accommodate the most rapidly growing dynamo mode. These results should therefore be considered as preliminary with respect to the mean field; simulations in a bigger domain are clearly needed.
The physically motivated averaging procedure used here, producing a mean field with three-dimensional structure, may facilitate fruitful comparison of numerical simulations with theory and observations. Although Gaussian smoothing does not obey all the Reynolds rules, it is possible that a consistent mean-field theory can be developed, e.g. in the framework of the τ -approximation (see e.g. Brandenburg and Subramanian, 2005, and references therein). This approach does not rely upon solving the equations for the fluctuating fields, and hence only requires the linearity of the average and its commutation with the derivatives. The properly isolated mean field is likely to exhibit different spatial and temporal behaviour than the lower-dimensional magnetic field obtained by two-dimensional averaging.
Brandenburg and Subramanian (2005, Ch.11.5) include estimates for the strength of the mean field dynamo in rapidly rotating galaxies. Here I apply their method to Model B2Ω , to compare their estimates with the simulation results. The turnover time is given by τ = l turb /u turb . From Section 6.2, l turb glyph[similarequal] 0 1 kpc . . The estimates assume incompressibility, so I shall use the upper bound of the subsonic turbulence. The mean field dynamo grows primarily in the warm gas, as is detailed in Part V. From Fig. 5.11, the modal temperature of the warm gas is 10 4 K , which equates to c s glyph[similarequal] 15 km s -1 , the upper bound for u turb . Hence τ glyph[similarequal] 1 150 Gyr / .
The turbulent resistivity is η turb = 1 3 u turb turb l glyph[similarequal] 0 5 km s . -1 kpc . From Fig. 9.2 in Part V, it is apparent that the scale height of the dynamo active region may be as high as h glyph[similarequal] 0 6 kpc . . So α = τ 2 Ω u ( 2 turb /h ) glyph[similarequal] 5 / 6 km s -1 . The αΩ -dynamo has two control parameters: C Ω = Sh /η 2 turb glyph[similarequal] -36 and C α = αh/η turb glyph[similarequal] 1 , so the dynamo number D = C C Ω α glyph[similarequal] -36 .
If | D > D | crit , a critical dynamo number which the authors expect to be in the range 6 -10 , then exponential growth of the magnetic field is possible during the kinematic stage. The growth rate exponent Γ can be estimated by
$$\Gamma \approx \frac { \eta _ { \text{turb} } } { h ^ { 2 } } \left ( \sqrt { | D | } - \sqrt { D _ { \text{cr} i t } } \right )$$
So for Model B2Ω , the expected growth rate of the magnetic field Γ is of order 4-5 Gyr -1 .
Note the growth rates Γ e shown in Table 8.1 refer to the magnetic energy, so Γ e = 2 Γ as estimated here. For Gaussian smoothing Γ e = 10 9 Gyr . -1 , while for horizontal averaging it is 13 6 Gyr . -1 . Although the analytic estimates apply to incompressible flow and
there is considerable uncertainty over the choices of l turb , u turb , h and D crit , a reasonable upper bound for this model is Γ = 6Gyr -1 . In addition, given the complexity of the system, other mean field dynamo processes could be present in addition to the shear dynamo to which the analytics refer. Nevertheless, the agreement of theory and experiment is very encouraging.
## 8.4 Summary
Using kernel smoothing to identify the mean field permits separation of the fluctuations from the systematic part of the magnetic field, while preserving its basic structure. The departure from the Reynolds rules is addressed by redefining how the magnetic energy terms are derived. A heuristic approach has been adopted to determine the appropriate smoothing scale, which appears to correctly identify the separation between the mean and random parts of the field. This allows us to examine the growth of the mean and random field, and a mean field dynamo has been modelled, with growth consistent with the analytic estimates for the galactic shear dynamo. In the remainder of this thesis, the method described in this chapter is applied to determine the mean B field and the mean flow u whenever they are required.
## Part V
## The galactic dynamo and magnetic structure
## Chapter 9
## The magnetic field
In this chapter the magnetic field generated dynamically in the various MHD models is investigated in some detail. All the models in this section show sustained amplification of the magnetic field, and evident organisation into a mean field. Of interest to theorists is what is driving the dynamo, and where the dynamo or dynamos are acting. Of general interest is the general shape and structure of the magnetic field, to what extent is it ordered or fluctuating, and how strongly correlated is it to the density or temperature in the ISM. The vertical magnetic structure of the ISM is particularly difficult to observe, so how the simulated field varies with distance from the mid-plane is of great interest. How does the magnetic field interact with the velocity field, and to what extent are the properties of the ISM, such as distributions of temperature, pressure and density, or various filling factors, affected by the magnetic field? These issues will be considered by comparing the MHD models with each other and with the non-magnetic models.
## 9.1 The magnetic dynamo
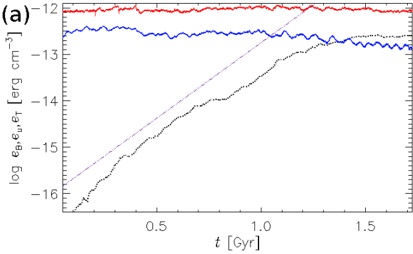
Figure 9.1: (a) Time evolution for the log of thermal (red, top jagged), kinetic (blue, 2 nd top jagged) and magnetic (black, dotted) energy densities from Model B2Ω , averaged over the total volume. The dotted line indicates 6 6 Gyr . -1 . (b) 〈 B rms 〉 as a function of time for Models B1Ω (solid, black), B2Ω (dashed, purple), B1ΩO (dash-dotted, blue), B1ΩSh (long dashed, orange), and B1ΩSN (dash-3dotted, red). The later continuations of Models B1Ω from 1.4 Gyr and B1ΩO from 1.2 Gyr are Model B2Ω continued with parameters amended.
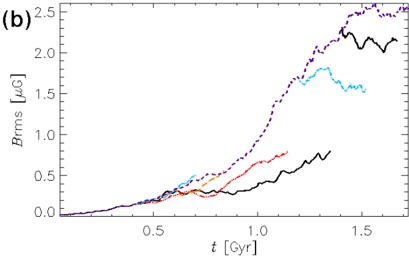
In Fig. 9.1a the time evolution of magnetic (purple), kinetic (blue) and thermal (red) log energy density is plotted for Model B2Ω . The growth in kinetic energy density from rest, and thermal energy due to SN heating, is near instantaneous. The growth in 〈 B rms 〉 is much slower and irregular, intermittently exponential, linear and even occasionally exhibiting decay. Dynamo theory anticipates that, as magnetic energy density ( e B = 1 2 µ 0 | B | 2 ) approaches that of the kinetic energy density ( e kin = 1 2 ρ | u | 2 ), the magnetic field saturates to a steady state, with kinetic and magnetic energy near equipartition. The Lorentz Force feeds back onto the velocity field suppressing the kinematic dynamo. In Fig. 9.1a 〈 e B 〉 and 〈 e kin 〉 intersect at about 1.3 Gyr corresponding to 〈 B rms 〉 glyph[similarequal] 2 5 . µ G . This is remarkably consistent with the observed estimates of the field strength in the solar neighbourhood.
The thermal energy density ( e th = ρ c v T ), with c v the specific heat capacity at constant volume) is quite insensitive to 〈 e B 〉 , as is 〈 e kin 〉 up to 1 Gyr, with 〈 e th 〉 glyph[similarequal] 9 × 10 -13 and 〈 e kin 〉 glyph[similarequal] 3 × 10 -13 erg cm -3 . However around 1.1 Gyr, when 〈 e B 〉 grows to within half of 〈 e kin 〉 , kinetic energy is transferred to magnetic energy. There is also a slight reduction in 〈 e th 〉 after 1.4 Gyr, such that total energy density is roughly conserved, with 〈 e B 〉 glyph[similarequal] 2 5 . × 10 -13 , 〈 e kin 〉 glyph[similarequal] 1 5 . × 10 -13 and 〈 e th 〉 glyph[similarequal] 8 × 10 -13 erg cm -3 .
In Fig. 9.1b the time evolution of 〈 B rms 〉 is plotted for the MHD models. It is evident that all the models exhibit periods of exponential growth. At 400 Myr B1Ω is in quasisteady hydrodynamic turbulence with negligible magnetic energy and the other models are initialised using this snapshot. Subsequently the lowest growth rate appears to apply for B1Ω . However B1ΩO , plotted in blue dash-dotted in Fig. 9.1a, differs only in the open vertical boundary condition, and appears to attain stronger growth. For this model the Poynting flux is monitored on the boundary and the net outflow of magnetic energy throughout this phase is consistently of order 10 2 times the inflow or greater. The growth would appear therefore to be driven by the internal dynamics, and potentially assisted by the flux of magnetic helicity outward.
In their models matching these parameters, Gressel et al. (2008 a ) found no dynamo. Only with differential galactic rotation ≥ 4 Ω 0 did they observe a mean field dynamo. They resolved a grid of ∆ = 8pc , while here ∆ = 4pc , and I also use temperature dependent viscosity and thermal conductivity, which permit much larger Reynolds numbers. Consistent with their results, however, I do find the strongest dynamo corresponds to the higher rotation rate (plotted in purple, dashed in Fig. 9.1a).
Increasing the shear alone in Model B1ΩSh (plotted in orange, long dashes) also enhances magnetic field growth relative to Model B1Ω . For spiral galaxies, which often have nearly flat rotation curves with respect to the galactocentric radius r , with angular velocity of the form Ω ∝ r -1 , the shear parameter S = -Ω . It is convenient to introduce the ratio of the shear rate to the rotation rate:
$$q = - \frac { S } { \Omega } = - \frac { d \ln \Omega } { d \ln r }.$$
Flat rotation curves correspond to q = 1 . Such rotation laws are known to be hydrodynamically stable, as the Rayleigh instability only sets in for q > 2 . To exclude additional Rayleigh instability effects -S/Ω < 2 is required, so S = -40 km s -1 kpc -1 = -1 6 . Ω 0 is adopted, yielding q = 1 6 . . There may however remain a contribution of magnetorotational instability (MRI), which has an instability condition of q > 0 . There is evidence, however, that this effect is suppressed in the presence of SN turbulence (Korpi, K¨ apyl¨ a and V¨ ais¨l¨, 2010; Piontek and Ostriker, 2007; Balbus and Hawley, 1991). Future work, a a comparing a model in which the sign of S or Ω is reversed (so that q < 0 ) to a standard model, may help to isolate the influence of MRI from the shear dynamo. Such a run, with the outer disc modelled to rotate faster than the inner disc, would not be relevent for any known galaxies, but other than a sign change in the mean horizontal components of the flow and the mean magnetic field, the ISM temperature, density and pressure distributions should be retained. The turbulent structure should be unaffected, at least in the kinematic stage.
Figure 9.2: Time evolution of the horizontal averages for (a) B x and (b) B y for Model B2Ω , with galactic rotation twice Ω 0 and parameters otherwise typical of the Galaxy in the solar neighbourhood. The maximum strength of the seed field is B < y 0 01 . µ G .
In Fig. 9.2 the time evolution of B x and B y , averaged horizontally, are plotted against z for Model B2Ω . Horizontally averaged B z glyph[similarequal] 0 for all z , although the random fluctuations are typically stronger than for B x and B y . It is evident that a strong mean field is generated, that it is dominated by the azimuthal ( y ) component, and that the magnitudes of both B y and B x vary with z and are roughly symmetric about the mid-plane.
That 〈 B z 〉 glyph[similarequal] 0 is not a physical result, but imposed by the periodic and sliding periodic boundary conditions applied horizontally to all three components of the magnetic potential. Given the divergence free condition on the magnetic field in the galaxy, it is reasonable to expect that the mean radial field, which is oriented inwards on both sides of the mid-plane throughout the simulation, cannot meet at the centre of the galaxy. Towards
the centre of the galaxy, there must be a significant mean vertical component. Of course for small galactic radius, the shearing box approximation breaks down anyway. Nevertheless in future work horizontal boundary conditions, which permit the free movement of the field lines, may reveal non trivial vertical field structure.
Reducing the supernova rate by 20% with Model B1ΩSN (plotted in red, dash-dotted) also drives a stronger dynamo than B1Ω . As discussed in Section 7.1, the investigation by Balsara et al. (2004) with SN rates of 8 σ 0 to 40 σ 0 indicates that as SN rates exceed some critical level, the amplification of the small scale field is quenched. The critical rate will be at least above 12 σ 0 , based on their periodic box calculations, and will likely be higher, given the release of hot gas away from the mid-plane in the stratified ISM. It may also be reasonable to expect a minimum SN rate, below which the dynamo cannot operate. Gressel (2008) also found that the strength of the magnetic field increased for lower SN rates over a range from 0 25 . σ 0 to σ 0 .
The strongest ordered field corresponds to the layers between 200 and 600 pc away from the mid-plane in Fig. 9.2. Although the ordering of the field is stronger in Model B2Ω , all the MHD models share this structure. The weaker mean field near the mid-plane may be a result of the scrambling of the field lines by SN turbulence. The strongest mean field occurs where the filling factors of the warm gas are highest, and outside the most active SN layer. This is consistent with the loss of field amplification as SN rates increase.
To understand what is driving the dynamo, it may help to look at the kinetic and magnetic helicity. The growth of magnetic helicity may suppress the dynamo. In Fig. 9.3, horizontal averages from Model B2Ω as a function of z and evolving in time are displayed for (panel a) kinetic helicity ( u · ω ) and (panel b) current helicity J · B , a proxy for the magnetic helicity ( A B · ), but gauge invariant. J = c 4 π ∇× B in the time independent electric field. Hence, J ∼ L -2 A , where L is some integral scale of the magnetic potential, can be used to indicate the evolving structure without the requirement to deduct the contribution of the arbitrary gauge ∇ Φ from A . Fig. 9.3c shows J · B , normalised by the time dependent 〈 B rms 2 〉 , the relative current helicity, of use for comparing the kinematic stage with the saturated state.
From the first two plots it appears that the saturation of the dynamo beyond 1 Gyr coincides with the transfer of mean helicity from kinetic to magnetic form. This transfer is present in the saturated stages for Models B1Ω and B1ΩO also. In (a), the kinetic helicity either side of the mid-plane is of opposite sign, negative in the south and positive in the north, as would be expected. What is surprising is that there is another sign change at | z | glyph[similarequal] 0 3 . ∼ 0 5 kpc . . The pattern is most clearly revealed for Model B2Ω , but is common to all of the MHD models and is also a consistent feature of the HD models. In the saturated stage the magnetic helicity appears to exhibit strong mean structures, and there is some tendency for sign asymmetry about the mid-plane, although this is fragmented. The sign of 〈 B y 〉 is quite consistently positive in the latter stages, so the intermittent reversals in helicity are primarily due to the fluctuations in 〈 B x 〉 .
Figure 9.3: Time evolution from Model B2Ω of horizontal averages for (a) kinetic helicity ( u ω · ), and (b) the current helicity J · B , a gauge invariant proxy for magnetic helicity. In (c) the relative current helicity J · B normalised by 〈 B rms 2 〉 ( ) t is displayed. Regions of black (white) indicate values above (below) the colour bar range.
The stronger current helicity at later times, however, is primarily only a weak effect of a much stronger field. In Fig. 9.3c, where the normalised J · B is plotted, it is evident that the peak relative helicity occurs prior to field saturation up to 1 1 Gyr . . Throughout the simulation the net J · B is negative. The normalised 〈 J · B / B 〈 2 〉〉 = -6 0 Gyr . -1 before saturation, where 〈〉 indicates averaging over the whole volume and the over-bar here refers to averaging over time, 0 4 . < t < 1 1 Gyr . , and -0 6 Gyr . -1 post-saturation. Further details of this quantity are given in Table 9.1 for all the MHD models.
The initial condition has a very weak purely azimuthal magnetic field, which has zero helicity. For the models with a vertical field boundary condition there can be no net flux of helicity into or out of the domain as A · B = 0 on the upper and lower surfaces, and flux across the periodic boundaries sums to zero. Therefore the generation of net magnetic helicity (Table 9.1a) in these models is only possible through the electrical resistivity present in the induction equation, Eq. (3.4). For Model B1ΩO helicity is free to be transported across the vertical boundary, and although net helicity can be also gener-
Table 9.1: For each MHD model the time and total volume averaged J · B normalised by the time dependent | B | 2 are listed [ Gyr -1 ] . 〈〉 S N ( ) indicates averaging over the total volume below (above) the mid-plane. ∆t is the period to which the averages relate [ Gyr] . Part ( a ) applies to the models prior to the field saturating and ( b ) to the models afterwards. Standard deviations are given in brackets.
| | B1Ω | B1ΩO | B1ΩSN | B2Ω | B1ΩSh |
|----------------------------|----------------------------|----------------------------|----------------------------|----------------------------|----------------------------|
| ( a ) The kinematic phase | ( a ) The kinematic phase | ( a ) The kinematic phase | ( a ) The kinematic phase | ( a ) The kinematic phase | ( a ) The kinematic phase |
| 〈 J · B 〉 | - 7 . 3 (484) | - 48 . 0 (404) | - 8 . 1 (183) | - 6 . 0 (170) | - 6 . 0 (210) |
| 〈 J · B 〉 S | +9 . 3 | - 17 . 0 | - 13 . 5 | +7 . 0 | - 20 . 7 |
| 〈 J · B 〉 N | - 23 . 8 | - 78 . 0 | - 2 . 7 | - 19 . 1 | +8 . 6 |
| ∆t | 0 . 0 - 0 . 6 | 0 . 4 - 0 . 7 | 0 . 4 - 1 . 1 | 0 . 4 - 1 . 1 | 0 . 4 - 0 . 9 |
| ( b ) The non-linear phase | ( b ) The non-linear phase | ( b ) The non-linear phase | ( b ) The non-linear phase | ( b ) The non-linear phase | ( b ) The non-linear phase |
| 〈 J · B 〉 | +0 . 2 ( 4 . 2 ) | - 1 . 2 ( 9 . 8 ) | | - 0 . 6 (6 . 4 ) | |
| 〈 J · B 〉 S | - 0 . 04 | - 0 . 6 | | +1 . 4 | |
| 〈 J · B 〉 N | +0 . 46 | - 1 . 8 | | - 2 . 7 | |
| ∆t | 1 . 4 - 1 . 7 | 1 . 2 - 1 . 7 | | 1 . 2 - 1 . 7 | |
ated through resistive transfer, it is clear that significant vertical transport does occur, with |〈 J · B 〉| = 48Gyr -1 being much larger than 6 -8 Gyr -1 for the other models. Given that 〈 J · B 〉 is negative, it appears that positive helicity is being preferentially transported out of the domain, and this enhances the dynamo.
In all cases, the fluctuations (standard deviation) in helicity, shown in brackets in Table 9.1, are 1-2 orders of magnitude larger than the net values. With such large fluctuations, the case could be made that the net helicity does not significantly differ from zero. However even the small net changes in helicity may be sufficient to influence the dynamo, given the efficiency of Model B1ΩO compared to Model B1Ω . The standard deviation is about the same, but the signature of the faster dynamo is stronger.
After saturation, when the field has grown by an order of 10 2 , the relative helicity is reduced to order unity in all models. From Fig 9.3b, for the unnormalised magnetic helicity, it is evident that the net helicity at this stage can switch sign, so in fact over a sufficiently long period it would appear that the net relative helicity fluctuates around zero. For the dynamo in the rotating galaxy, the removal of positive helicity is required. Where the net helicity is of opposite sign in the North and South, (as in B1Ω B2Ω , and B1ΩSN Table 9.1a), the positive side can be in either half. There is evidence from Fig 9.3c, for the normalised magnetic helicity, that the sign alternates in both hemispheres during the kinematic phase also for Model B2Ω . Given that helicity cannot be transported away, this may be the positive helicity, being transported back and forth within the domain, whereas for Model B1ΩO both hemispheres are strongly negative as the positive helicity can be transported completely out of the domain. Of course, substantial positive helicity persists in both hemispheres as a result of the powerful fluctuations.
## 9.2 Mean and fluctuating field composition
Applying the approach in Section 8.1 to Model B1Ω yields a similar outcome to the plot in Fig. 8.2 for Model B2Ω . As displayed in Fig. 9.4, the dependence of the separation of the total field into mean and fluctuating parts is very similar to Model B2Ω . The appropriate choice of glyph[lscript] glyph[similarequal] 50 pc for the smoothing length appears independent of model, and instead closely related to the typical SN remnant scale. This choice is applied to all the MHD models and analysis of the resulting mean and fluctuating fields are presented in Table 9.2 and Fig. 9.5.
Figure 9.4: For Model B1Ω at t = 0 49 Gyr . (a) the proportion of 〈 e B 〉 contribution from B glyph[lscript] and b depending on glyph[lscript] B and (b) ∂ 〈 e B 〉 / ∂ glyph[lscript] B . Compare with Fig. 8.2 for Model B2Ω .
The growth rates of the mean and fluctuating parts of the magnetic energy from the MHDmodels are listed in Table 9.2. The plots of the actual growth together with the fitted exponentials are displayed in Fig. 9.5. These can be compared to the growth rates of the total field energy shown in Fig. 9.1b, which includes the whole simulation period. The table data and the plots in Fig. 9.5 are derived over a time interval of about 400 Myr , and strong temporal fluctuations are evident, even over so long a time frame. This time frame is chosen because it is well within the kinematic regime for analysis of the dynamo, and because there is snapshot data for all models during this period. From the steady growth in Models B1ΩO and B2Ω (panels a and b) it is clear that they can be well approximated as
Table 9.2: Growth rate for the mean ( Γ e ) and fluctuating ( γ e ) magnetic energy during a portion of the kinematic stage for each model. ˆ Γ is the estimated growth rate of the mean magnetic field using the approximation described in Section 8.3. ∆t is the period analysed, and N is the number of snapshots used. The fit of the sum of both exponentials to the total measured field energy is indicated by the reduced χ 2 .
| Model | 2 ˆ Γ [ Gyr - 1 ] | Γ e [ Gyr - 1 ] | γ e [ Gyr - 1 ] | ∆t [ Gyr ] | χ 2 | N |
|---------|---------------------|-------------------|-------------------|--------------|-------|-----|
| B1Ω | 0 - 1.4 | 2.1 | 2.6 | 0.4 - 0.83 | 0.42 | 31 |
| B1ΩO | 0 - 1.4 | 10.1 | 9 | 0.4 - 0.70 | 0.01 | 16 |
| B1ΩSN | 0 - 1.4 | 4.2 | 2.4 | 0.4 - 0.82 | 0.43 | 36 |
| B2Ω | 8 - 10 | 5.5 | 5.1 | 0.4 - 0.84 | 0.04 | 37 |
| B1ΩSh | 1.8 - 3.8 | 5.8 | 5.3 | 0.4 - 0.82 | 0.1 | 36 |
exponential. This is less clear from the other models (in panels c and d), which have more pronounced dips and plateaux. However from Fig. 9.1 it is evident that further exponential growth follows. There would be greater certainty over the parameters derived for Γ e and γ e if resources permitted the extension of these models for at least another 400 Myr , and preferably up to saturation.
Figure 9.5: Growth of the mean ( (a) and (c) ) and fluctuating ( (b) and (d) ) field. Models B1ΩO (light blue, dashed) and B2Ω (purple, dash-dotted) are shown in panels (a) and (b); Models B1Ω (black, solid), B1ΩSN (red, dash-3dotted) and B1ΩSh (orange, long-dashed) in panels (c) and (d). Plotted with the actual growth rates are the exponential fits for each model (matching color, dotted). The parameters of the fits are detailed in Table 9.2.
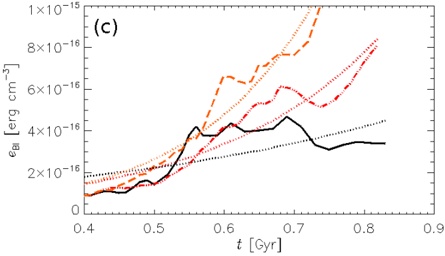
The estimate ˆ Γ is derived using Eq.(8.7) from Section 8.3. The estimates included are l turb = 0 1 kpc . , u turb = 15 km s -1 , h = 0 6 kpc . and D crit = 6 ∼ 10 . From the location of the strongest field in Fig. 9.2 it may be that for the mean field dynamo, the active region is 0 2 . < z < ∼ | | ∼ 0 6 . with the mid-plane more active for the fluctuation dynamo. The height of the strongest mean field in Model B1ΩSN appears slightly lower, h < ∼ 0 4 kpc . , from its equivalent plot to Fig. 9.2. This might be expected as the reduced SN activity will not inflate the disc as much. Otherwise h appears quite consistent across the models. l turb would not appear to be dependent upon the parameters, but on the size of the remnants. Again, it might be expected to be somewhat smaller for Model B1ΩSN , because increased density in the most SN active region could restrict typical remnant size. Since the gas in all models is transonic, the characteristic turbulent velocity is likely to be around the speed of sound for the gas. u turb may therefore vary modestly and it will be worth obtaining improved approximations.
Comparing the model fitted growth rates Γ e to the estimates for the growth rates
from the shear dynamo ˆ Γ all of the actual growth rates exceed the estimates, except for Model B2Ω . In Section 8.3 this model was analysed for a later period in its evolution and Γ e = 10 9 Gyr . -1 obtained is comparable to 2 ˆ Γ = 8 ∼ 10 Gyr -1 . Perhaps there remains significant transients from the Model B1Ω snapshot at 400 Myr from which this model is initialised. Otherwise the model growth rates are only slightly above the upper estimates, except for Model B1ΩO with Γ e = 10 1 Gyr . -1 much larger than the upper estimate of 1.4. This model has the open vertical boundary condition for the magnetic field and the efficiency of the dynamo may benefit from the advection of helicity.
Also of interest, the model growth rates γ e for the fluctuating field energy are generally smaller than for the mean field energy. This is not the case for Model B1Ω where Γ e = 2 1 Gyr . -1 is less than γ e = 2 6 Gyr . -1 . As can be seen from Fig. 9.5c and d, the growth of this model had stalled temporarily, so this might not be significant over the longer times scales. For Model B1ΩSN the relative difference between γ e = 2 4 Gyr . -1 and Γ e = 4 2 Gyr . -1 is somewhat larger than in the other models. This could also be due to the short term dip in the total magnetic energy, but may indicate a higher SN rate contributes to the fluctuation dynamo. In both cases further extended analysis in the kinematic phase is required.
## 9.3 Three-phase structure of the Field
The total volume probability distributions for gas number density n , temperature T and thermal pressure p are displayed in Fig. 9.6 from Models B1Ω (black, solid) and H1Ω (blue, dashed). Note that Model H1Ω includes the correction to the SN distribution, which stabilises the disc against unphysical cyclic oscillations, although it is still subject to natural random vertical fluctuations. Hence the mean density in the SN active region remains consistently higher than in Model WSWa.
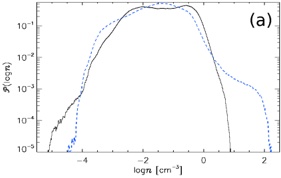
Figure 9.6: Volume weighted probability distributions of gas number density (a) , temperature (b) and thermal pressure (c) for models H1Ω (black, solid) and B1Ω (blue, dashed) for the total numerical domain | z | ≤ 1 12 kpc . .
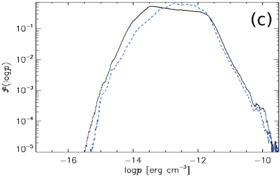
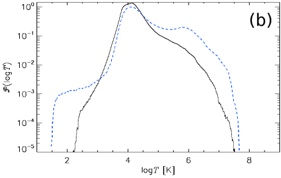
Although the three phase temperature distribution is still visible for this model in Fig. 9.6b, it is less pronounced than the results from Model WSWa shown in Fig. 5.3b. However the three phase structure for the MHD Model B1Ω is not at all apparent in panel b, with a significantly narrower range of temperatures. The bulk of the density distributions (a) are quite similar between the HD and MHD models, except that the high
densities are not as well resolved in the MHD models. The thermal pressure distributions are very similar, but with the HD modal pressure approximately one third the MHD modal pressure.
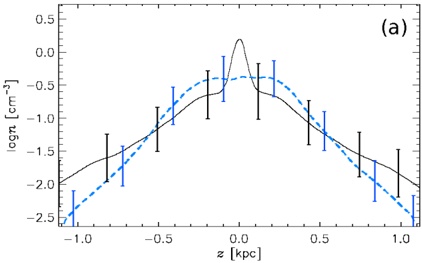
Figure 9.7: Horizontal averages of gas number density, n z ( ) (a) , and total pressure, P z ( ) (b) , for Model B1Ω (solid, black), and Model H1Ω (dashed, blue). Each are time-averaged using eleven snapshots respectively, spanning 100 Myr. The vertical lines indicate standard deviation within each horizontal slice. The thermal p z ( ) (dotted) and ram p turb ( z ) (fine dashed) pressures are also plotted (b) . For Model WSWah the magnetic pressure p B is also plotted (fine, dash-3dotted).
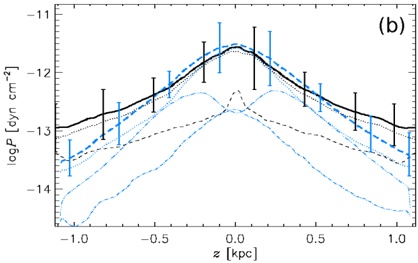
As discussed in Section 7.2 the stability of the disc reduces the effectiveness of the SNe to generate and circulate hot gas, in the absence of SN clustering. Hence Model H1Ω has a slightly thicker disc, with less hot gas than Model WSWa. On top of this the effect of the magnetic pressure in Model B1Ω is to expand the thick disc even further and this is illustrated in Fig. 9.7a, where the horizontal averages of gas number density n z ( ) are plotted against z for both models. The strong peak in the density at the mid-plane is evident for Model H1Ω (black, solid), while for Model B1Ω (blue, dashed) there is a broad plateau in the density, extending to | z | glyph[similarequal] 300 pc , where the mean magnetic field is strongest.
The horizontal averages of the pressure are plotted in Fig. 9.7b for both models. There is a strong peak at the mid-plane in the turbulent pressure for the HD model (black, dashed), but a much weaker profile for the MHD model (blue, dash-dotted). There are two peaks in the magnetic pressure (blue, dash-3dotted) near | z | glyph[similarequal] 200 pc , which supports the extended density profile. Another possible effect, which might constrain the circulation of the hot gas, and hence enhance the pressure at the mid-plane, is the strong horizontal orientation of the field. As mentioned in Section 9.1 the periodic boundary conditions exclude a non-zero vertical component to the mean field, so the magnetic tension predominantly acts against the vertical flows. Some understanding of the multi-phase structure of the magnetised ISM is still possible from these models, but the extreme temperatures and densities are significantly under represented. To improve this in future work it will be desirable to allow unrestricted evolution of vertical field and to apply realistic clustering of the SNe to generate more supperbubbles (composite multiple SN remnants forming a single superstructure) or chimneys (plumes venting hot gas from the disc towards the halo).
Figure 9.8: Probability distributions by phase: cold (blue, dashed), warm (black, solid) and hot (red, dash-dotted) for gas number density ( n (a), (b) ) and temperature ( T (c), (d) ) for Model B1Ω ( (a), (c) ) and Model H1Ω ( (b), (d) ). 95% confidence intervals for temporal deviation are shown as error bars.
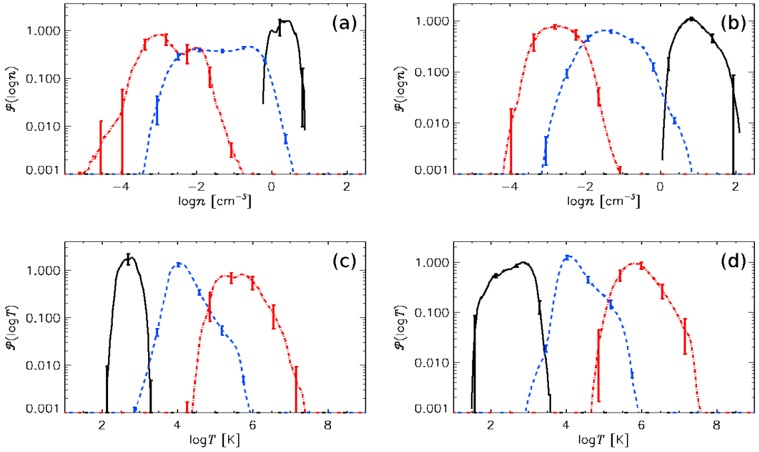
Results for separation of the ISM into three phases using the method detailed in Section 5.3 are shown for Models B1Ω and H1Ω in Fig 9.8 with total volume probability distributions. The phases are defined using entropy s such that for cold s < 4 4 . · 10 8 erg g -1 K -1 and hot s > 23 2 . · 10 8 erg g -1 K -1 with warm in between. Apart from the higher densities for the cold phase with the HD model (panel b), anticipated by the volume distributions (Fig. 9.6), the warm and hot distributions for the MHD density (panel a) are broad, with a bimodal structure to the hot gas. The distributions for the warm gas (panels c and d) are very similar and for the cold (hot) distributions the MHD model does not extend to as low (high) temperatures.
Figure 9.9: Probability contour plot by volume of log n vs log T for Model B1Ω (a) and Model H1Ω (b) . The lines of constant entropy s = 4 4 . · 10 8 and 23 2 . · 10 8 erg g -1 K -1 indicate where the phases are defined as cold for s ≤ 4 4 . and as hot for s > 23 2 . .
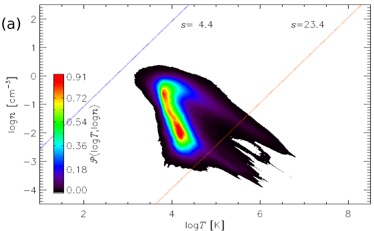
Comparing the combined probability distribution of density and temperature for both of these models in Fig. 9.9 with those of Model WSWa in Fig. 5.4 the spread is more broad and not obviously aligned along a line of constant pressure. The HD distribution
here is less compact than with MHD. However when considering only the mid-plane distributions, as displayed in Fig. 9.10 the distributions match better with Model WSWa and the pressure alignment is evident. So the broad distributions for the total volumes are explained by the stronger gradient in the pressure distribution, due to the reduced stirring of the hot gas. The thermal pressure at the mid-plane is also very similar in both models, reflected also in the agreement of the total and thermal pressure near the midplane in the plot of horizontal averages (Fig 9.7b). The magnetic and turbulent pressure in Model B1Ω combine to match the mid-plane turbulent pressure alone of Model H1Ω . For the temperature in Model B1Ω the hot gas has two modes, evident in Fig. 9.9a at 10 5 K and 10 6 K , but at the mid-plane there only the single 10 3 K mode. The structure of the ISM at the mid-plane is therefore common to both models with modes at 10 6 K , 10 -2 cm -3 and 10 4 K 1cm , -3 . The cold gas is insufficiently resolved in Model B1Ω for comparison.
Figure 9.10: The mid-plane probability distributions ( | z | < 100 pc ) by gas number density log n and temperature log T for (a) Model B1Ω and (b) Model H1Ω .
There is no evident dependence in the probability distributions between the MHD models differing in rotation, shear or SN rate. The models in the kinematic stage extend to lower densities and higher temperatures than either the HD Model H1Ω or the MHD models in the dynamo saturated state, and also extend to lower pressures.
Figure 9.11: Total volume probability distributions ( | z | < 100 pc ) by gas number density log n and magnetic field strength log | B | (a) and temperature log | T | and magnetic field strength log | B | (b) for Model B1Ω .
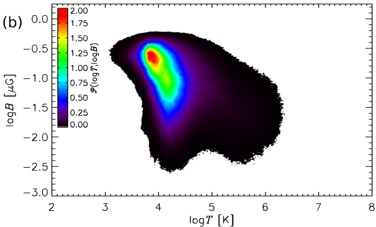
In Fig. 9.11a the joint probability distributions of gas number density with magnetic field strength is shown and in Fig. 9.11b of temperature with magnetic field strength for Model B1Ω . From (a) it is clear there is a strong positive correlation between magnetic
field strength and density and from (b) a weak negative correlation between temperature and field strength. The T, B distribution has very strong peak at T = 10 4 K .
Figure 9.12: Vector plots of the magnetic field B (a) in the cold phase (b) the warm phase and (c) the hot phase. Field directions are indicated by arrows and strength by their thickness. The colour of the arrows indicates the strength of the azimuthal ( y ) component (colour bar on the right). The background shading illustrates the density of the ISM.
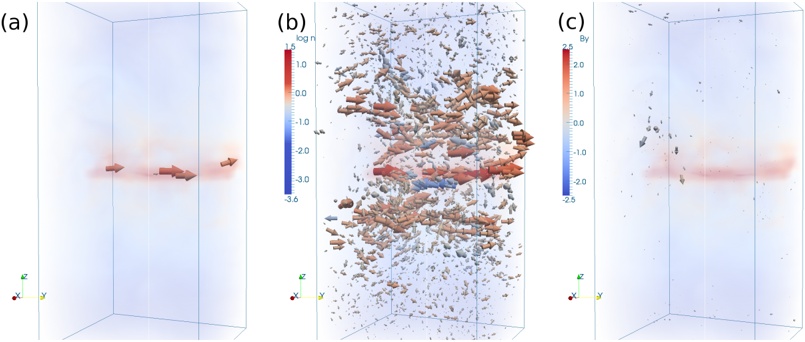
For Model B1Ω the ISM for a single snapshot is decomposed into the three phases and the magnetic field for each plotted separately in Fig. 9.12. In panel a the cold gas occupies only a limited volume near the mid-plane, but the magnetic field is very strong and organised in alignment with the mean field surrounding it in the warm gas. This is represented by the length and thickness of the vector arrows. The colour of the arrows emphasises that the alignment has a strong azimuthal component. No arrows are present away from the mid-plane, because the cold gas is absent there. In panel b the warm gas is present throughout the numerical volume. Field vectors are present almost throughout and the field is highly aligned, mainly in the azimuthal direction. The strength of the field increases towards the mid-plane. The presence of some vectors in blue or grey indicates that there are significant perturbations where the field includes reversals, some of these strong. Some of the field exhibits significant vertical orientation, but it is mainly horizontal. In panel (c) the hot gas is also present throughout the volume, although in smaller amounts near the mid-plane. Despite this there is very little magnetic field. What field there is generally weak and lacks much systematic alignment, although any orientation tends to be vertical, consistent with the field lines being stretched by the gas flowing away from the mid-plane. Effectively the hot gas has a very weak field, which is highly disordered. Most of the magnetic field, and particularly the mean field, occupies the warm gas. Detailed quantitative analysis of the structure of the gas will be deferred to future work.
## 9.4 Structure of the Field
In future work the structure of the magnetic field shall be analysed in more depth for the total field as well as each phase individually. The correlation of the field in the kinematic
Figure 9.13: Total volume weighted probability distributions of magnetic field pitch angles in models B1Ω (black, solid), B1ΩO (blue, dashed), B2Ω (red, dash-dotted), B1ΩSN (green, dash3dotted) and B1ΩSh (orange, long-dashed). Composite data for eleven snapshots each spanning 100 Myr from the saturated dynamo (kinematic stage) for the first three (latter two).
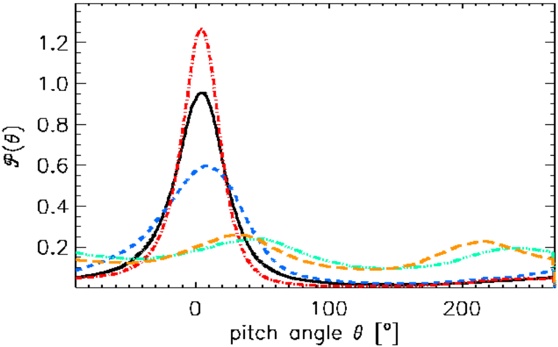
stage and once the dynamo has saturated shall be measured, with attention to how it varies with height.
As a preliminary inspection the pitch angles, arctan( B /B x y ) , for the total volume have been calculated for each model using eleven snapshots spanning 100 Myr and the probability distributions plotted in Fig. 9.13. As the dynamo evolves the magnetic field becomes increasingly ordered, with the orientation close to the azimuthal. Model B2Ω (red,dash-dotted), with the double rotation rate, predictably has the most regular field, with the smallest standard deviation and smallest modal pitch angle of θ glyph[similarequal] 3 ◦ , close to the azimuthal direction. Increased rotation will increase the laminar tendency of the flow, whereas Models B1Ω (black, solid) and B1ΩO (blue, dashed) have higher perturbation velocities relative to their rotation. So although the modal pitch angles are also close to azimuthal, 4 ◦ and 9 ◦ respectively, their standard deviations are higher. With open boundaries Model B1ΩO the field is more irregular than Model B1Ω .
In the kinematic stage for Models B1ΩSN (green, dash-3dotted) and B1ΩSh (orange, long-dashed) the fields are clearly less organised and the modal pitch angles are further from the azimuthal with θ glyph[similarequal] 50 ◦ and 32 ◦ respectively. There are also significant modes in almost the reverse directions, at θ glyph[similarequal] 240 ◦ and 216 ◦ respectively. This is consistent with the higher magnitude of the relative helicity during the dynamo growth stage, as there is likely to be reduced tangling of the field lines if they have the same horizontal orientation. It may be, however, that the highly ordered field in these simulations is enhanced by the reduced motions of the hot gas. The lack of clustering in the SNe, now that the mass in the disc is more stable, and the constraint for the mean magnetic field to have zero vertical component, due to the periodic boundary conditions (Sections 7.2 and 9.1), mitigate against the transport of hot gas away from the disc. However the pitch angles may be expected to align within the range 9 ◦ to 32 ◦ , assuming more scattering than in the
saturated stage with Model B1ΩO for the former and more ordering than in the kinematic stage for Model B1ΩSh for the latter angle.
## 9.5 Summary
All of the models investigated have produced a galactic mean field dynamo. In general the simulation dynamo grows more rapidly than the analytic predictions, so there would appear to be an additional elements in the theoretical model required to explain the dynamo. The efficiency of the dynamo is improved if positive magnetic helicity can be removed, either by vertical transport or resistive diffusion. The magnitude of the magnetic field is strongly aligned to the density of the ISM and indirectly the warm and cold phases. More particularly the mean field is stronger in the warm and cold gas, with the hot gas containing a more random field. The mean magnetic field and the magnetic energy is strongest at | z | glyph[similarequal] 300 pc , just outside the SNe active region. The fluctuating dynamo is likely to be strongest in this SNe active region, but due to the low magnetic Reynolds numbers in the simulations, it is likely that the field and energy is significantly weaker in the simulations than might be expected.
## Part VI
## Summary of results and future investigation
## Chapter 10
## Summary of results
## 10.1 Multi-phase ISM results
The multi-phase gas structure obtained in these simulations appears robust, relatively insensitive to the physical parameters included: total gas density or prescription of radiative cooling (Section 7.1), SN rates, or rates of rotation and shear (Section 9.3). Previous studies (e.g. Mac Low et al., 2005; Joung and Mac Low, 2006) indicate that the existence of such a multi-phase structure does not have as a prerequisite either rotation, shear or stratification. Its morphology, however, would strongly be affected by the latter. Only SN rates close to the Milky Way estimates have been considered here, so whether there are upper and lower rates where a multi-phase structure may be excluded, remains to be investigated.
The parameterization of the radiative cooling is especially important for the hot phase of the ISM. Apart from the obvious effect that there is more hot gas with the cooling function WSW, which has weaker cooling than RBN at T > ∼ 10 3 K (Fig. 3.1), regions of low thermal and total pressure are more widespread with RBN (Fig. 7.8). For the same reason, the WSW cooling function produces an ISM which has three times more thermal and kinetic energy than RBN (Fig. 7.4). However, with either cooling function, thermal energy is about twice the kinetic energy due to perturbation velocities; more work is needed to decide if the relation E th glyph[similarequal] 2 E kin is of a general character.
Examination of the 2D probability distribution of T and n , as described in Section 5.3, permits a physically motivated identification of natural boundaries of the major phases. Further refinement, distinguishing the SN active region | z | < ∼ 200 pc from the more homogeneous strata | z | > ∼ 200 pc (Section 5.1) improves the quality of the statistical modelling of each phase. The probability distribution of the density of each phase is approximated to high quality by lognormal fits.
Considering that probability densities for gas temperature and number density, calculated for individual phases, are clearly separated, it is significant that probability densities for both thermal and total pressure - the sum of thermal, magnetic (for MHD) and turbulent pressures - are not segregated at all. Despite its complex thermal and dynamical
structure, the gas is in statistical pressure equilibrium. Since the SN-driven ISM is random in nature, both total and thermal pressure fluctuate strongly in both space and time (albeit with significantly smaller relative fluctuations than the gas density, temperature and perturbation velocity), so the pressure balance is also statistical in nature. These might appear to be obvious statements, since a statistically steady state (i.e., not involving systematic expansion or compression) must have such a pressure balance. However, alternative conclusions may be drawn that the broadness of the pressure distribution in itself, irrespective of the convergence of modal pressures, indicates thermal pressure disequilibrium and a single phase ISM. Systematic deviations from pressure balance may be associated with the vertical outflow of the hot gas (leading to lower pressures), and with the compression of the cold gas by shocks and other converging flows (leading to somewhat increased pressures). If we allow for the global vertical pressure gradient (cf. Fig. 5.7) it is evident that locally phases are in total pressure equilibrium and a multiphase description is useful for analysis of the ISM.
A direct relationship between various methods of estimating the filling factor or fractional volume from observations is presented in Section 5.2. If an appropriate means of relating the observable filling factor to the filling factor derived from the statistical properties of the distributions can be found - perhaps by applying the simulation model fits then a more accurate estimate of the fractional volume of the various phases may emerge. This represents an improvement upon the assumption of locally homogeneous gas, the primary analytical tool used to date in determinations of the fractional volumes of the phases.
The modal properties of density, temperature, velocity, magnetic field, Mach number and pressure have been calculated for each phase separately. In particular there is confirmation that the phases, with quantifiable small intersections in terms of thermal and density distributions, are close to both thermal and total statistical pressure balance. Statistical modelling, as used for the density, is also possible for any magnetohydrodynamic variable. This provides the opportunity to identify regions of the ISM with diagnostics other than temperature or density, which may help to characterize the dominant phase within observations.
The correlation scale of the random flows is obtained in Section 6.2, from the autocorrelation functions of the velocity components. Within 200 pc of the mid-plane, the horizontal velocity components have a consistent correlation scale of about 100 pc . In contrast, the scale of the vertical velocity (which has a systematic part due to the galactic outflow of hot gas) grows from about 100 pc at the mid-plane to nearly 200 pc at z = 200 pc , and further at larger heights. This is due to the increase of the fractional volume of the hot gas with distance from the mid-plane. Near to | z | glyph[similarequal] 1 kpc (and beyond), most of the volume is occupied by the hot gas. Further measurements of the correlation scale above 500 pc are required to assess to what extent such flows may reliably be modelled within a numerical domain with horizontal dimensions of 1 kpc .
There is clear indication of cold gas falling back towards the mid-plane at speeds of a few km/s, hot gas involved in vigorous outflow away from the mid-plane, and some warm gas entrained in this outflow (Section 6.1). The outflow speed of the hot gas increases up to 100 km s -1 within 100 pc of the mid-plane, and then slowly decreases. In contrast, the mean vertical velocity of the warm gas increases linearly with | z | , up to 20 km s -1 at | z | = 1kpc .
## 10.2 Magnetized ISM results
The strongest result from the MHD models is the successful generation of a mean field dynamo for all the parameters considered, including parameters matching the local Galaxy (Section 9.1). A fluctuating dynamo may also be present, but further analysis is required. In addition, an effective approach for identifying appropriately the mean and random elements of the magnetic field has been identified, in terms of local volume averaging (Section 8). The growth rates of the mean field and the fluctuating field for each model have been compared with analytic estimates for the shear dynamo appropriate for the parameters in each case, and the simulation results either match or exceed these estimates. The growth rates obtained exclude neither the possibility of a primordial field, nor a randomly seeded field via a Biermann battery. However the persistent orientation of the resultant mean field, without reversals in the azimuthal direction, is consistent with the hypothesis that galactic magnetic fields are generated through a dynamo, with the same alignment above and below the mid-plane and independent of galactic longitude (i.e. quadrupolar).
In these simulations the presence of positive magnetic helicity appears to limit the dynamo growth. Model B1ΩO , with open vertical boundary conditions, had more rapid growth magnetic field than the otherwise equivalent Model B1Ω , with the vertical field condition on these boundaries. Although the former vents net magnetic energy through the external boundaries, which should slow the dynamo, it also expels significant positive magnetic helicity, which appears to enhance the dynamo. Otherwise all models generate net negative magnetic helicity on the resistive time-scale during the kinematic phase; this process is reversed as the dynamo saturates, reverting to a net relative helicity of approximately zero. The vertical transport of the magnetic field lines, and the associated sign dependent helicity, is therefore a persistent feature of the galactic dynamo; and significantly, the sign of the outward helicity flux is common to both sides of the mid-plane.
Analysis of the multiphase structure of the magnetic field indicates that the strength of the magnetic field is closely connected with the density, and by association the warm and cold phases of the ISM. Examination of the structure of this field in each phase reveals that the weak field in the hot gas is predominantly random. There is a very strong regular component to the field in the cold gas, organised and amplified in alignment with the ambient warm gas. Most of the mean field is present within the warm gas.
## 10.3 Future investigation and experiments
An important technical aspect of simulations of this kind is the minimum numerical resolution ∆ required to capture the basic physics of the multi-phase ISM. As with all other simulations of the SN-driven ISM, a host of numerical tools (such as shock-capturing diffusivity) need to be employed to handle the extremely wide dynamical range (e.g. 10 2 < T < ∼ ∼ 10 8 K in terms of gas temperature and 10 -4 < n < ∼ ∼ 10 2 cm -3 gas number density within the model) and widespread shocks characteristic of the multi-phase ISM driven by SNe (detailed in Section 3.4). ∆ = 4pc has been demonstrated to be sufficient with the numerical methods employed here, and results shown to be consistent with those obtained by other authors using adaptive mesh refinement with maximum resolutions of 2 pc and 1 25 pc . (Section 5.1). The numerical method has been carefully tested by reproducing, quite accurately, the Sedov-Taylor and snowplough analytical solutions for individual SN remnants (Appendix A). Progress has been made in describing the multi-phase ISM structure and modelling the galactic dynamo in the vicinity close to the mid-plane. The relatively low vertical boundary, with carefully applied vertical boundary conditions, has adequately captured the critical features of the SN-driven ISM.
From the data already available through these simulations, considerable additional analysis would prove interesting. The distribution of the gas number density and its description in terms of lognormal fits has been considered, and a similar treatment of other measurables, such as temperature, gas speed and pressure should also be possible. Some analysis of the total velocity correlation scales has been reported, but it would be useful to conduct this analysis of the gas velocity by individual phases, to identify the correlation scale for each. It would also be useful to investigate the correlation of time and position of the velocity field. The forcing by SN turbulence against a background of stratification and differential rotation induces a combination of vortical and divergent velocity. How these are decomposed within the velocity field, and how their interaction is affected by changing the rates of SN injection, or galactic rotation, might help to understand how the galactic dynamo operates.
Simulated line-of-sight observation from any location within a simulation, considering local bubbles, and taking into account changes in elevation, would permit us to compare simulated observational measurements with direct data measurements, and extend the ways in which observational measurements might be interpreted, with regard to underlying processes. This would be particularly useful in terms of Faraday rotation measures for the magnetic field. All of the models so far have parameters close to the solar neighbourhood, so the statistics could be readily identified with observational data.
Building upon the existing model, a number of future extensions present themselves.
## Parameter Sweep
To understand the effects of various parameters requires each parameter to be considered for a range of values; at least three each, and preferably more. So the rates of SN injection, rotation and shear need to be varied separately to identify how these affect the properties of the ISM.
The model need not be restricted to galaxies similar to the Milky Way. Galaxies at higher redshift (young galaxies) could be investigated using different stellar gravitational potentials and higher proportions of ISM to stars.
## Supernova Rates
Currently the models are constructed with the SN rates imposed as a parameter, based on a multiple of the observed SN rates. The Schmidt-Kennicutt Law (Kennicutt, 1998) defines a relationship between the gas surface density of the galactic disc with an SN rate, which is a reasonable fit to the data from observations. Some numerical models on the scale of galaxies have successfully reproduced star-formation and feedback rates which reasonably match this relationship dynamically, rather than by imposition (e.g. Dobbs, Burkert and Pringle, 2011). At the local level, however, how the distribution of gas within cold clouds (rather than the bulk volume of the gas in the warm ISM) is related to the supernova rate is highly non-trivial.
Nevertheless it would be preferable to derive a method of SN feedback, which responds to the mass available for star formation, and the distribution of the gas between the cold and warm phases; i.e a system in which the SN rate is self-regulating, slowing down if SN activity burns aways the gas, and speeding up as gas cools into clouds and star formation increases. Such an experiment may require a reasonably well modelled galactic fountain and an appropriate scheme for including realistic clustering of the SNe, to facilitate the venting of the hot gas from the disc as discussed in Section 7.2. Given the rarefaction of the gas density across the disc, due to spiral arms and other effects, it is not immediately apparent how such locally determined supernova rates might relate to the Schmidt-Kennicutt Law, applicable to the whole galaxy. However, experiments with a range of gas density distributions representative of the spiral arm (inter arm) regions could be considered, in which the Schmidt-Kennicutt relations might be a lower (upper) bound against which to assess the algorithm. An effective self-regulating method, which is reasonably consistent with the Schmidt-Kennicutt Law, would then be a useful analytical tool to apply in galaxies with a broad range of parameters, which may differ significantly from the local Galaxy.
## Vertical Magnetic Field
As discussed in Section 9.1, the contraint that 〈 B z 〉 = 0 is a construct of the periodic boundary conditions rather than a physical result. To explore the natural evolution of
the vertical structure of the magnetic field, which is poorly understood due to difficulty in deriving observational measurements, alternative horizontal boundary conditions are required. Keeping the horizontal boundary condition on A z periodic or sheared would not affect B z , but will contribute to the horizontal components and retain the effect of shear on B x . With appropriate care to handle shocks crossing the boundary, setting the first or second derivatives for A x and A y to zero, should permit B z to evolve naturally.
Allowing the mean field to have a vertical component will also relax the horizontal magnetic tension and allow greater, more physical circulation of gas between the disc and halo. Given that the objective here will be to understand the structure of the field, the net flow of magnetic energy across the boundaries is of less concern, so the open field condition on the vertical boundary should be employed, as applied for Model B1ΩO , so as not to constrain B x and B y nonphysically.
## Cosmic Rays
Cosmic rays are estimated to account for about one quarter of the pressure in the ISM, and are strongly aligned with the magnetic field. Including them effectively will allow results from the simulations to be much more directly compared with observational estimates, including the vertical distribution of density, temperature and pressure, and fitted values of the probability distributions of these variables. The interaction of cosmic rays with thermodynamics and hydrodynamics has not previously been explored on these scales, so subtle or even dramatic effects may be revealed.
In addition, synchrotron emissions are an important tool for observations, and modelling these directly via simulated line-of-sight measurements will improve the comparison with the real observations. We shall also be able to compare the simulated observations with the direct measurements, to assess how robust the observational assumptions are.
## Galactic Fountain
de Avillez and Breitschwerdt (2007) and similar models have sufficient vertical extent with | z | = 10kpc for hot gas to cool and recycle naturally to the mid-plane. With their limited horizontal aspect, however, we cannot know enough about the true scales of the galactic fountain. With the grid scale ∆ varying in the vertical direction and increasing the horizontal range of the model, I intend to explore the physical and time scales of the galactic fountain. Due to the damping effect of the magnetic field, it may paradoxically be numerically more efficient to include magnetism for this project, and possibly also cosmic rays, rather than to model a purely hydrodynamic regime.
## Spiral Arms
The range of models included so far assume the gas is located in an inter arm region of the galaxy. There are no density waves encountered as the numerical box orbits the galactic centre. How the formation of stars, generation and orientation of the magnetic field reacts within and between the spiral arms is not well understood. Within this model, spiral arms could be modelled with an additional gravitational potential which passes through the box at set times during its orbit.
## Parker and Magnetorotational Instability and SN Quenching
Parker instabilities occur in plasma subject to gravitational forces, and magnetorotational instabilities occur in differentially rotating plasma. These instabilities are postulated to be damped by the turbulence generated by SNe. These models could be used to test this postulation by simulating a system in which either or both of these instabilities are present. Repeating the experiment in each case, with and without SN driven turbulence included, it would be possible to identify whether the instabilities are in fact suppressed.
## 10.4 Review
In conclusion, such models are highly complex in their construction, and in the results they generate. The results reported in this thesis are the product of several revised sets of calculations, possible only after many sets of simulations that preceded them. Changes take hundreds of thousands of iterations to unfold, and it is not always immediately apparent which outcomes are robust physical effects and which are numerical artifacts. Given that the observational data and theoretical framework is far from complete, it is also not always obvious whether the numerical results, which appear to match our expectations of the ISM, are in fact true, or results which appear to conflict with our expectations are nevertheless correct.
The more the results have been analysed, the better our understanding of the model and the causes of various effects. It would be desirable to be able to run all the simulations with exactly the same numerical ingredients, but such is the expense in resources and time that as improvements and corrections are revealed they are implemented on the fly, and cannot often be applied retrospectively. Hence there are considerable algorithmic differences between the HD models and the MHD models; and even within the sets of simulations, some numerical ingredients differ, beyond the physical parameters which are under investigation.
This is a new model and with each set of simulations, better experience is garnered on how best to interpret and report the results. It is now a very rich numerical resource, which has the potential to unlock far more secrets of the ISM than have been listed in this thesis. I hope to have the opportunity to extend this model in the directions described
above, and in the process to shed new light on the structure and dynamics of galaxies.
## Appendix A
## Evolution of an individual supernova remnant
## A.1 The snowplough test
The thermal and kinetic energy supplied by SNe drives, directly or indirectly, all the processes discussed in this thesis. It is therefore crucial that the model captures correctly the energy conversion in the SN remnants and its transformation into the thermal and kinetic energies of the interstellar gas. As discussed in Section 3.2, the size of the region where the SN energy is injected corresponds to the adiabatic (Sedov-Taylor) or snowplough stage. Given the multitude of artificial numerical effects required to model the extreme conditions in the multi-phase ISM, it is important to verify that the basic physical effects are not affected, while sufficient numerical control of strong shocks, rapid radiative cooling, supersonic flows, etc., is properly ensured. Another important parameter to be chosen is the numerical resolution.
Before starting the simulations of the multi-phase ISM reported in this thesis, I have carefully verified that the model can reproduce, to sufficient accuracy, the known realistic analytical solutions for the late stages of SN remnant expansion, until merger with the ISM. The minimum numerical resolution required to achieve this in this model is ∆ = 4pc . In this Appendix, I consider a single SN remnant, initialised as described in Section 3.2, that expands into a homogeneous environment. All the numerical elements of the model are in place, but here periodic boundary conditions are used in all dimensions.
The parameters χ 1 and ν 1 are as applied in Model WSWa for ∆ = 4pc , but reduced here proportionally for ∆ = 2 and 1 pc . The constant C ≈ 0 01 . used in Eq. (3.10) to suppress cooling around shocks is unchanged. This may allow excess cooling at higher resolution, evident in the slightly reduced radii in Fig. A.1. For Model WSWah, χ 1 and ν 1 were just as in Model WSWa; for future reference, they should be appropriately adjusted, as should C , to better optimise higher resolution performance.
Figure A.1: The shell radius R of an SN remnant versus time, shown in (a) linear and (b) logarithmic scales; (c) the corresponding expansion speed ˙ R . Frame columns 1-3 are for different ambient gas densities, ρ / 0 10 24 g cm -3 = (1 0 0 1 0 01) . , . , . from left to right. Numerical results obtained under three numerical resolutions are shown: ∆ = 4pc (black, solid), 2 pc (green, dashed) and 1 pc (orange, dash-dotted). Dotted lines are for the standard snowplough solution (A.2) (dark blue) and its modification by Cioffi, McKee and Bertschinger (1998) (light blue). The horizontal line in Panels ( c1 )-( c3 ) shows the sound speed in the ambient ISM.
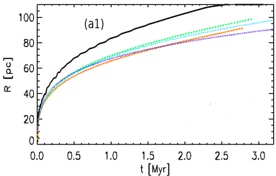
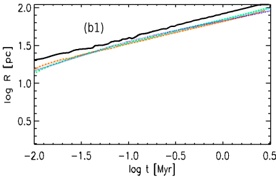
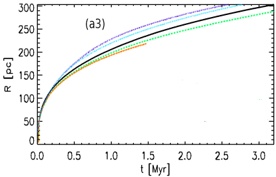
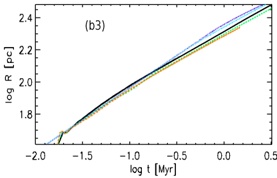
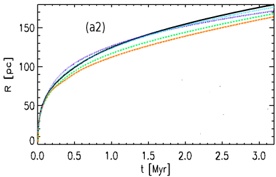
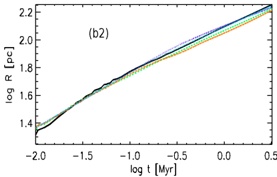
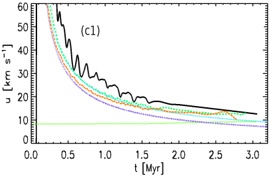
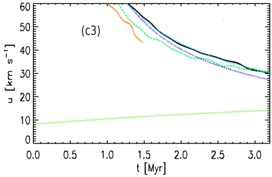
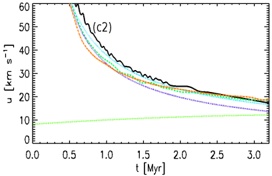
## The adiabatic and snowplough stages
The Sedov-Taylor solution,
$$\dots \dots, \\ R = \left ( \kappa \frac { E _ { \text{SN} } } { \rho _ { 0 } } \right ) ^ { 1 / 5 } t ^ { 2 / 5 },$$
is accurately reproduced with this code at the resolution ∆ = 4pc or higher. Here R is the remnant radius, E SN the explosion energy, ρ 0 the ambient gas density, and dimensionless parameter κ ≈ 2 026 . for γ = 5 3 / (Ostriker and McKee, 1988).
Modelling even a single remnant becomes more challenging when radiative cooling becomes important. Here numerical results are compared with two analytic solutions for an SN remnant expanding into a perfect, homogeneous, monatomic gas at rest. The standard momentum-conserving snowplough solution for a radiative SN remnant has the form
$$R = R _ { 0 } \left [ 1 + 4 \frac { \dot { R } _ { 0 } } { R _ { 0 } } ( t - t _ { 0 } ) \right ] ^ { 1 / 4 },$$
where R 0 is the radius of the SN remnant at the time t 0 of the transition from the adiabatic stage, and ˙ R 0 is the shell expansion speed at t 0 . The transition time is determined by
Woltjer (1972) as that when half of the SN energy is lost to radiation; this happens when
$$\dot { R } _ { 0 } = 2 3 0 \, \text{km} \, s ^ { - 1 } \left ( \frac { n _ { 0 } } { 1 \, \text{cm} ^ { - 3 } } \right ) ^ { 2 / 1 7 } \left ( \frac { E _ { \text{SN} } } { 1 0 ^ { 5 1 } \, \text{erg} } \right ) ^ { 1 / 1 7 } ;$$
the transitional expansion speed thus depends very weakly on parameters.
## Pressure driven and momentum driven snowplough
Cioffi, McKee and Bertschinger (1998) obtained numerical and analytical solutions for an expanding SN remnant with special attention to the transition from the Sedov-Taylor stage to the radiative stage. These authors adjusted an analytical solution for the pressuredriven snowplough stage to fit their numerical results to an accuracy of within 2% and 5% in terms of R and ˙ R , respectively. (Their numerical resolution was 0 1 pc . in the interstellar gas and 0 01 pc . within ejecta.) They thus obtained
$$R = R _ { \mathrm p } \left ( \frac { 4 } { 3 } \frac { t } { t _ { \mathrm p } } - \frac { 1 } { 3 } \right ) ^ { 3 / 1 0 },$$
where the subscript p denotes the radius and time for the transition to the pressure driven stage. The estimated time of this transition is
$$t _ { \text{p} } \simeq 1 3 \, \text{Myr} \left ( \frac { E _ { \text{SN} } } { 1 0 ^ { 5 1 } \text{erg} } \right ) ^ { 3 / 1 4 } \left ( \frac { n _ { 0 } } { 1 \, \text{cm} ^ { - 3 } } \right ) ^ { - 4 / 7 }.$$
For ambient densities of ρ 0 = (0 01 0 1 1) . , . , × 10 -24 g cm -3 , this yields transition times t p ≈ (25 6 6 , . , 1 8) . × 10 4 yr and shell radii R p ≈ (130 48 18) pc , , , respectively, with speed ˙ R p = (213 296 412) km s , , -1 .
This continues into the momentum driven stage with
$$\left ( \frac { R } { R _ { \text{p} } } \right ) ^ { 4 } = \frac { 3. 6 3 \, \left ( t - t _ { \text{m} } \right ) } { t _ { \text{p} } } \left [ 1. 2 9 - \left ( \frac { t _ { \text{p} } } { t _ { \text{m} } } \right ) ^ { 0. 1 7 } \right ] + \left ( \frac { R _ { \text{m} } } { R _ { \text{p} } } \right ) ^ { 4 },$$
where subscript m denotes the radius and time for this second transition,
$$t _ { \text{m} } \simeq 6 1 \, t _ { \text{p} } \left ( \frac { \dot { R } _ { \text{ej} } } { 1 0 ^ { 3 } \, \text{km} \, s ^ { - 1 } } \right ) ^ { 3 } \left ( \frac { E _ { \text{SN} } } { 1 0 ^ { 5 1 } \, \text{erg} } \right ) ^ { - 3 / 1 4 } \left ( \frac { n _ { 0 } } { 1 \, \text{cm} ^ { - 3 } } \right ) ^ { - 3 / 7 },$$
where ˙ R ej glyph[similarequal] 5000 km s -1 is the initial velocity of the 4 M glyph[circledot] ejecta. For each ρ 0 = (0 01 . , 0 1 . , 1 0) . × 10 -24 g cm -3 , the transitions occur at t m = (168 16 8 1 68) Myr , . , . , and R m = (1014 281 78) pc , , , respectively. The shell momentum in the latter solution tends to a constant, and the solution thus converges with the momentum-conserving snowplough (A.2); but, depending on the ambient density, the expansion may become subsonic and the remnant merge with the ISM before Eq. (A.2) becomes applicable.
The simulation results are compared with the momentum-conserving snowplough so-
lution and those of Cioffi, McKee and Bertschinger in Fig. A.1, testing the model with numerical resolutions ∆ = 1 , 2 and 4 pc for the ambient gas densities ρ 0 = (0 01 0 1 1 0) . , . , . × 10 -24 g cm -3 . Shown in Fig. A.1 are: a linear plot of the remnant radius R versus time, to check if its magnitude is accurately reproduced; a double logarithmic plot of R t ( ) , to confirm that the scaling is right; and variation of the expansion speed with time, to help assess more delicate properties of the solution. There is good agreement with the analytical results for all the resolutions investigated when the ambient gas number density is below 1 cm -3 . For ∆ = 4pc , the remnant radius is accurate to within about 3% for ρ 0 = 10 -25 g cm -3 and underestimated by up to 6% for ρ 0 = 10 -26 g cm -3 . At higher numerical resolutions, the remnant radius is underestimated by up to 7% and 11% for ρ 0 = 10 -25 g cm -3 and 10 -26 g cm -3 , respectively. For ρ 0 = 10 -24 g cm -3 , excellent agreement is obtained for the higher resolutions, ∆ = 1 and 2 pc ; simulations with ∆ = 4pc overestimate the remnant radius by about 20-25% in terms of R and ˙ R at t = 2Myr . Note that a typical SN explosion site in the models described in the main part of the thesis has an ambient density n 0 < 1 cm -3 so that ∆ = 2 or 4 pc produce a satisfactory fit to the results, despite the much finer resolution of the simulations of Cioffi, McKee and Bertschinger.
The higher than expected expansion speeds into dense gas can be explained by the artificial suppression of the radiative cooling within and near to the shock front as described by Eq. (3.10). Our model reproduces the low density explosions more accurately because the shell density is lower, and radiative cooling is therefore less important.
## A.2 Cooling-heating in the shocks
In code units, the applied net (heating or) cooling ([ Γ -ρΛ T ] -1 ) has amplitudes much greater than 1, and of opposite sign in close proximity. Perturbations to Γ or Λ are particularly vulnerable to instability when acted upon by shocks, and can lead to purely numerical thermal spikes, which can cause the code to crash. Therefore some form of suppression of net cooling within the shock profile is essential for code stability.
In addition, the method of enhanced diffusion coefficients for handling shocks has the effect of broadening the shock profiles and increasing the density spread. High density ISM inside the remnants cool faster, thus diffusing the hot phase ISM more rapidly than would occur within the unresolvable thin shock fronts that exist physically.
Having considered various approaches, a prescription is adopted which is stable, consistent with the snowplough, reduces cooling in the remnant shell interior, and applies cooling to the peak shell density. The net diffuse heating/cooling [ Γ -ρΛ T ] -1 is multiplied by ξ = e -C ( ∇ ζ ) 2 , where ζ is the shock diffusivity, defined in Eq. (3.9). Therefore, ξ is unity through most of our domain, but reduces towards zero in strong shocks, where ( ∇ ζ ) 2 is non-zero. C is another numerical factor, the value of which is chosen to guarantee code stability without altering the basic physics; these constraints are normally
fulfilled with C glyph[similarequal] 0 01 . .
## A.3 The structure of the SN remnant
Figure A.2: One-dimensional cuts through the origin of an SN remnant expanding into gas of a density ρ 0 = 10 -25 g cm -3 , simulated with the numerical resolution ∆ = 4pc . The variables shown are (a1)-(c1) gas density, (a2)-(c2) temperature, and (a3)-(c3) velocity. The shock viscosity profile of Eq. (3.9) (scaled to fit the frame, black, dotted) is shown in the temperature and velocity panels; the net cooling, log( -T -1 ( Γ -ρΛ ) ), only where ρΛ ≥ Γ , from Eq. (3.3) (blue, dashed) is included in the temperature panel; and the ambient sound speed (pink, dashed) is also shown with the velocity. Panels in the top row (a) show the injection profiles used to initialise the remnant at t = 0 ; the lower panel rows are for the later times (b) t = 0 72 Myr . and (c) t = 1 02 Myr . .
Cuts through the simulated SN remnant are shown in Fig. A.2 for gas density, temperature and velocity, obtained for resolution ∆ = 4pc and with ambient density ρ 0 = 10 -25 g cm -3 . In the temperature and velocity panels, the profile of the shock viscosity from Eq. (3.9) is also included (black dotted line), scaled to fit each plot. The temperature panels also show where net cooling is applied to the remnant, T -1 ( Γ -ρΛ ) < 0 from Eq. (3.3) (blue dashed line), while the velocity panels also show the ambient sound speed (pink dashed lines). The top panel depicts the initial distributions, at t = 0 , with which the mass of 4 M glyph[circledot] and 5 × 10 50 erg each of thermal and kinetic energy are injected. The other panels are for t = 0 72 . and 1 02 Myr . after the start of the evolution, from top to bottom, respectively; the actual simulation continued to t = 1 32 Myr . , when the remnant radius reached 130 pc .
The position of the peak of the density profile is used to determine the shell radius shown in Fig. A.1. The Rankine-Hugoniot jump conditions are not very well satisfied with the numerical parameters used here. This is due to our numerical setup, essentially designed to control the shocks by spreading them sufficiently to be numerically resolvable in production runs that contain many interacting shocks and colliding SN shells. Better shock front profiles have been obtained with other choices of parameters and cooling control, and with better resolution. The density and temperature contrasts across the shock fronts are reduced by the shock smoothing, which inhibits the peak density and enhances gas density behind the shocks. In an isolated remnant, the peak gas number density does not exceed 10 cm -3 , but in the full ISM simulation densities in excess of 100 cm -3 are obtained, as a result of interacting remnants and highly supersonic flows.
The interior of the SN remnant, if more dense due to numerical smoothing about the shock profile, would cool unrealistically rapidly, so that the SN energy would be lost to radiation rather than agitate the ambient ISM. The centre panels in Fig. A.1 clarify how the cooling suppression described in Eq. (3.10) reduces the cooling rate in the relatively homogeneous interior of the remnant, while still allowing rapid cooling in the dense shell where the gradient of the shock viscosity is small. It is evident from the temperature cuts that the remnant still contains substantial amounts of hot gas when its radius reaches 100 pc, so it would be merging with the ISM in the full simulation.
The panels in the right column of Fig. A.2 demonstrate that the interior gas velocity can be more than twice the shell speed. Due to the high interior temperature, this flow is subsonic, while the remnant shell expands supersonically with respect to its ambient sound speed. The enhanced viscosity in the hotter interior (with viscosity proportional to the sound speed; see Section 3.4) inhibits numerical instabilities that could arise from the high velocities. In fact, accurate modelling of the SN interiors is not essential in the present context (where the main interest is in a realistic description the multi-phase ISM), as long as the interaction of the remnant with the ambient gas is well described, in terms of the energy conversion and transfer to the ISM, the scales and energy of turbulence, and the properties of the hot gas.
## Appendix B
## Stability criteria
## B.1 Courant criteria
## Time step control
To achieve numerical stability with the explicit time stepping used, the Courant-FriedrichsLewy conditions have to be amply satisfied. For example, for advection terms, the numerical time step should be selected such that
$$\Delta t < \kappa \frac { \Delta } { \max ( c _ { s }, u, U ) },$$
where c s is the speed of sound, u = | u | is the amplitude of the perturbed velocity, i.e., the deviation from the imposed azimuthal shear flow U , and κ is a dimensionless number, determined empirically, which often must be significantly smaller than unity. Apart from the velocity field, other variables also affect the maximum time step, e.g., those associated with diffusion, cooling and heating, so that the following inequalities also have to be satisfied:
$$\Delta t < \frac { \kappa _ { 1 } \Delta ^ { 2 } } { \max ( \nu, \gamma \chi, \eta ) } \,, \quad \Delta t < \frac { \kappa _ { 2 } } { H _ { \max } } \,,$$
where κ 1 and κ 2 are further empirical constants and
$$H _ { \max } = \max \left ( \frac { 2 \nu | \mathbf W | ^ { 2 } + \zeta _ { \nu } ( \nabla \cdot u ) ^ { 2 } + \zeta _ { \chi } ( \nabla \cdot u ) ^ { 2 } } { c _ { \nu } T } \right ) \,.$$
κ = κ 1 = 0 25 . and κ 2 = 0 025 . are used. The latter, more stringent constraint has a surprisingly small impact on the typical time step, but a large positive effect on the numerical accuracy. Whilst the time step may occasionally decrease to below 0.1 or 0.01 years following an SN explosion, the typical time step is more than 100 years.
## Minimum diffusivity
Numerical stability also requires that the Reynolds and P´ eclet numbers defined at the resolution length ∆ , as well as the Field length, are sufficiently small. These mesh P´clet e
and Reynolds numbers are defined as
$$\text{Pe} _ { \Delta } = \frac { u \Delta } { \chi } \leq \frac { u _ { \max } \Delta } { \chi } \,, \quad \text{Re} _ { \Delta } = \frac { u \Delta } { \nu } \leq \frac { u _ { \max } \Delta } { \nu } \,,$$
where u max is the maximum perturbed velocity and ∆ is the mesh length. For stability these must not exceed some value, typically between 1 and 10.
In numerical modelling of systems with weak diffusivity, ν and χ are usually set constant, close to the smallest value consistent with the numerical stability requirements. This level strongly depends on the maximum velocity, and hence is related to the local sound speed, which can exceed 1500 km s -1 in the ISM models. To avoid unnecessarily strong diffusion and heat conduction in the cold and warm phases, the corresponding diffusivity is scaled with gas temperature, as T 1 2 / . As a result, the diffusive smoothing is strongest in the hot phase (where it is most required). This may cause reduced velocity and temperature inhomogeneities within the hot gas, and may also reduce the temperature difference between the hot gas and the cooler phases.
The effect of thermal instability is controlled by the Field length,
$$\lambda _ { \text{F} } \simeq \left ( \frac { K T } { \rho ^ { 2 } \Lambda } \right ) ^ { 1 / 2 } \simeq 2. 4 \, \text{pc} \left ( \frac { T } { 1 0 ^ { 6 } \, K } \right ) ^ { \frac { 7 } { 4 } } \left ( \frac { n } { 1 \, \text{cm} ^ { - 3 } } \right ) ^ { - 1 } \left ( \frac { \Lambda } { 1 0 ^ { - 2 3 } \, \text{erg} \, \text{cm} ^ { 3 } \, s ^ { - 1 } } \right ) ^ { - \frac { 1 } { 2 } },$$
where any heating has been neglected. To avoid unresolved density and temperature structures produced by thermal instability, it is required that λ F > ∆ , and so the minimum value of the thermal conductivity χ follows as
$$\chi _ { \min } = \frac { 1 - \beta } { \gamma \tau _ { \text{cool} } } \left ( \frac { \Delta } { 2 \pi } \right ) ^ { 2 },$$
where τ cool is the minimum cooling time, and β is the relevant exponent from the cooling function (e.g. as in Table 3.2 for WSW cooling). In the single remnant simulations of Appendix A, τ cool glyph[greaterorsimilar] 0 75 Myr . . In the full ISM simulations, minimum cooling times as low as 0 05 Myr . were encountered. χ min has maxima corresponding to β = 0 56 . , -0 2 . , -3 , . . . for T = 313 10 , 5 , 2 88 . × 10 5 K . . . . All of these, except for that at T = 313K , result in χ min < 4 × 10 -4 kms -1 kpc at c s = c 1 = 1kms -1 , so are satisfied by default for any χ 1 sufficiently high to satisfy the Pe ∆ ≤ 10 requirement. For T = 313K , at c s = c 1 , then χ min = 6 6 . × 10 -4 kms -1 kpc > χ 1 . Thus if cooling times as short as 0.05 Myr were to occur in the cold gas, λ F < ∆ , and the model would be marginally under-resolved. Analysis of the combined distribution of density and temperature from Fig. (7.1), however, indicates that cooling times this short occur exclusively in the warm gas.
With χ 1 ≈ 4 1 . × 10 -4 kms -1 kpc , as adopted in Section 3.4, then Pe ∆ ≤ 10 is near the limit of numerical stability. (The choice of thermal diffusivity is discussed further in Appendix B.2.) As a result, the code may occasionally crash (notably when hot gas is
particularly abundant), and has to be restarted. When restarting, the position or timing of the next SN explosion is modified, so that the particularly troublesome SN that causes the problem is avoided. In extreme cases, it may be necessary to increase χ temporarily (for only a few hundred time steps), to reduce the value of Pe ∆ during the period most prone to instability, before the model can be continued with the normal parameter values.
## B.2 Thermal Instability
One of the two cooling functions employed in this thesis, WSW, supports isobaric thermal instability in the temperature range 313 < T < 6102 K where β < 1 . (Otherwise, for the RBN cooling function or outside this temperature range for WSW cooling, β ≥ 1 or Γ glyph[lessmuch] ρΛ , so the gas is either thermally stable or has no unstable equilibrium.)
Under realistic conditions for the ISM, thermal instability can produce very small, dense gas clouds which cannot be captured with the resolution ∆ = 4pc used here. Although the efficiency of thermal instability is questionable in the turbulent, magnetized ISM, where thermal pressure is just a part of the total pressure (V´zquez-Semadeni, Gazol a and Scalo, 2000; Mac Low and Klessen, 2004, and references therein), this instability is purposely suppressed in my model. However, this is done not by modifying the cooling function, but rather by enhancing thermal diffusivity so as to avoid the growth of perturbations at wavelengths too short to be resolved by the numerical grid.
Following Field (1965), consider the characteristic wave numbers
$$k _ { \rho } = \frac { \mu ( \gamma - 1 ) \rho _ { 0 } \mathcal { L } _ { \rho } } { \mathcal { R } c _ { s } T _ { 0 } }, \ \ k _ { T } = \frac { \mu ( \gamma - 1 ) \mathcal { L } _ { T } } { \mathcal { R } c _ { s } }, \ \ k _ { K } = \frac { \mathcal { R } c _ { s } \rho _ { 0 } } { \mu ( \gamma - 1 ) K },$$
where R is the gas constant, and the derivatives L T ≡ ( ∂ L / ∂ T ) ρ and L ρ ≡ ( ∂ L / ∂ ρ ) T are calculated for constant ρ and T , respectively. The values of temperature and density in these equations, T 0 and ρ 0 , are those at thermal equilibrium, L ( T , ρ 0 0 ) = 0 with L = ρΛ -Γ . Isothermal and isochoric perturbations have the characteristic wave numbers k ρ and k T , respectively, whereas thermal conductivity K is characterized by k K . The control parameter of the instability is ϕ = k /k ρ K .
The instability is suppressed by heat conduction, with the largest unstable wave numbers given by (Field, 1965)
$$k _ { \text{cc} } = [ k _ { K } ( k _ { \rho } - k _ { T } ) ] ^ { 1 / 2 }$$
$$k _ { \text{cw} } = \left [ - k _ { K } \left ( k _ { T } + \frac { k _ { \rho } } { \gamma - 1 } \right ) \right ] ^ { 1 / 2 } \,,$$
for the condensation and wave modes, respectively, whereas the most unstable wave num-
Table B.1: The unstable wavelengths of thermal instability, according to Field (1965), at thermally unstable equilibria ( T , ρ 0 0 ) with the WSW cooling function.
| T 0 [K] | ρ 0 [ 10 - 24 g / cm 3 ] | ϕ | λ ρ [pc] | λ cc [pc] | λ mc [pc] | λ cw [pc] | λ mw [pc] |
|-----------|----------------------------|------|------------|-------------|-------------|-------------|-------------|
| 313 | 4.97 | 1.91 | 2 | 5 | 5 | 2 | 4 |
| 4000 | 1.2 | 0.04 | 101 | 32 | 84 | 14 | 74 |
| 6102 | 0.94 | 0.02 | 192 | 44 | 136 | 20 | 120 |
## bers are
$$k _ { \text{mc} } = \left [ \frac { ( 1 - \beta ) ^ { 2 } } { \gamma ^ { 2 } } + \frac { \beta ( 1 - \beta ) } { \gamma } \right ] ^ { 1 / 4 } ( k _ { \rho } k _ { \text{cc} } ) ^ { 1 / 2 } \,,$$
$$k _ { \text{mw} } = \stackrel { \mu } { \left | \frac { \beta - 1 } { \gamma } } \, k _ { \rho } k _ { \text{cw} } \right | ^ { 1 / 2 } \,.$$
Table B.1 contains the values of these quantities for the parameters of the reference Model WSWa, presented in terms of wavelengths λ = 2 π /k , rather than of wave numbers k . The unstable wavelengths of thermal instability are comfortably resolved at T 0 = 6102 K and 4000 K , with the maximum unstable wavelengths λ cc = 44pc and 32 pc , respectively, being much larger than the grid spacing ∆ = 4pc . The shortest unstable wavelength of the condensation mode in the model, λ cc = 5pc at T ≈ 313 K is marginally resolved at ∆ = 4pc ; gas at still lower temperatures is thermally stable. Unstable sound waves with λ cw = 2pc at T = 313K are shorter than the numerical resolution of the reference model. However, for these wave modes to be unstable, the isentropic instability criterion must also be satisfied, which is not the case for β > 0 , so these modes remain thermally stable.
Thus, there can be confidence that the parameters of these models (most importantly, the thermal diffusivity) have been chosen so as to avoid any uncontrolled development of thermal instability, even when only the bulk thermal conductivity is accounted for. Since much of the cold gas, which is most unstable, has high Mach numbers, thermal instability is further suppressed by the shock capturing diffusivity.
## Appendix C
## Mass sensitivity and mass conservation
## Effect of molecular mass
The two Models RB & WSWb have about 117% of the ISM mass of the reference Model WSWa, the difference corresponding to the abundance of molecular hydrogen. The difference is apparent comparing the lower panel of Fig. 7.5 with the upper panel of Fig. 5.12. Including the molecular gas, the abundance of hot gas reduces with height, contrary to observation, while otherwise it increases with height. Its inclusion appears to produce unrealistically strong cooling, as evident in the altered profiles of velocity and temperature in the horizontal averages of Fig. 5.2 from t = 400Myr , after the transition from Model WSWb to Model WSWa.
Therefore all the other models presented in this thesis match the mass in Model WSWa, assuming that the cloudy molecular component is concentrated in very small scales, not resolved by the coarse grid. Comparing the lower panels of Fig. 7.8 for WSWb with Fig. 5.5 for WSWa, the higher end of all three total pressure distributions are very similar, but for the warm and hot gas the distributions extend to much longer tails of low pressure gas. When molecular gas is included it appears that much of the gas is under pressured and out of equilibrium. Otherwise, comparing Fig. 7.8 with Fig. 5.5, the probability distributions for density, velocity and Mach numbers are very similar. The density distributions without the molecular hydrogen are narrower, but the peaks match, so aside from the pressures, the phase structure appears to be independent of the disc surface density.
## Numerical mass diffusion
The Pencil code is non-conservative, so that gas mass is not necessarily conserved; this can be a problem due to extreme density gradients developing with widespread strong shocks. In general, solving Eq. (3.1) in terms of log density rather than linear density is numerically more efficient. However solving for ρ , rather than ln ρ is more accurate, and applying a numerical diffusion to the equation of mass resolves the problem of numerical dissipation in the snowplough test cases described in Appendix A.1, with mass then being
conserved to within machine accuracy. Eq. (3.1) thus becomes
$$\frac { D \rho } { D t } \, = \, - \nabla \cdot ( \rho \mathfrak { u } ) \, + \, \dot { \rho } _ { \mathbb { S N } }, + ( \mathcal { V } + \zeta _ { \mathcal { V } } ) \nabla ^ { 2 } \rho + \nabla \zeta _ { \mathcal { V } } \cdot \nabla \rho,$$
in which constant V ≈ 4 1 . × 10 -3 kms -1 kpc is the unphysical mass diffusion coefficient and ζ V is as defined in Eq. (3.9), but with coefficient c V = 1 . A correction term is then required for mass conservation for each of Eq. (3.2) and (3.3).
$$\frac { D u } { D t } \longrightarrow \frac { D u } { D t } - \rho ^ { - 1 } \frac { \mathcal { V } \nabla ^ { 2 } \rho } { 2 } u \,, \quad \rho T \frac { D s } { D t } \longrightarrow \rho T \frac { D s } { D t } - \frac { \mathcal { V } \nabla ^ { 2 } \rho } { c _ { \text{p} } }.$$
However for the full model, once the ISM becomes highly turbulent, there remains some numerical mass loss. A comparison of mass loss through the vertical boundaries to the total mass loss in the volume indicates that numerical dissipation accounts for much less than 1% per Gyr . The rate of physical loss, due to the net vertical outflow, is of order 15% per Gyr .
## Boundary mass loss
In such a demanding simulation of this nature, it is inevitable that some heavily parameterized processes, approximations and numerical patches must be employed: cooling functions, supernova injection, boundary conditions and shock capturing viscosity amongst others, all of which have been explained and hopefully satisfactorily justified. Perhaps the most physically compromising numerical fix, which is necessary to maintain the mass in the long MHD runs, relates to the issue of physical boundary losses.
The general net outflow of gas through the vertical boundaries is a genuine physical process and consequence of sustained SN activity. Even if we were able to incorporate the galactic fountain and recycle this gas to the mid-plane, the loss of mass from the ISM would be entirely expected over a period of a few hundred Myr, never mind a Gyr. The natural evolution of a galaxy as it ages would see an increasing proportion of the gas in the disc locked into stellar mass and more of the residual gas escaping the gravitational potential in galactic winds. As discussed in Section 3.7, however, we may reasonably consider the simulation time merely to be a statistically steady representation of time interval being modelled. Therefore, to maintain a statistically steady hydrodynamical state, it is important to retain a steady density composition of the ISM, after the system first settles into such a state, within the first 2-4 Myr or so.
de Avillez and Breitschwerdt (2010) and Joung, Mac Low and Bryan (2009), and references within both, achieve mass conservation by extending the boundary to | z | = 10 kpc , which I prefer not to do to preserve numerical resources. Some mass is recycled in the form of 4 M glyph[circledot] of ejecta per SN. While this has useful diagnostic properties in plotting the expanding remnant profiles in the single SN experiments from Appendix A.1, it is negligible in relation to the ambient mass of the ISM. Given that mass losses from the
ISM to support star formation are not included, I would be inclined to exclude ejecta mass in future simulations, thus making the SN feedback process mass neutral. The option of using ejecta to artificially replenish the boundary mass losses would require at least a ten fold increase in the current rate of ejecta, and this would have dramatic consequences for the accuracy of the SN energy injection and would also strongly affect the local dynamics unphysically.
The potentially controversial solution I have adopted is to calculate the total net mass loss through the boundary and to regularly redistribute it everywhere in the model, proportional to the local density. Given the replacement rate is of order 10 -7 of the ISM mass on each occasion, and the local ratios of gas density are preserved, there should be minimal impact on the local dynamics throughout the simulation. Similarly the local structures of energy, temperature, velocity, etc. should be minimally affected. The effect of this solution is to preserve the simulation for as long as required, with no perceptible difference between the statistical properties of the hydrodynamics of the model before and after its implementation.
## Sensitivity to SNe location
Kennicutt (1998) postulates a relationship between the surface gas density in star-forming galaxies and the supernova rate. The estimates are very much approximations to first order on the global galactic parameters. The self-regulating mechanism, by which the amount of gas in the star forming regions diminishes with increasing SN activity, and the SN activity decreases with diminishing gas density, is complex and not well understood. In this model no attempt has yet been made to probe this relationship, and SN rates are applied purely as a parameter with a particular rate and distribution for each model, and not sensitive to the fluctuations in the gas density.
The majority of Type CC SN are clustered in OB associations of young stars emerging from the star forming clouds of molecular hydrogen, which are located close to the galactic mid-plane. It would therefore seem desirable to model these with a distribution which prefers locations associated with these dense regions. My early prescription for Type CC location involved a quite complex calculation to determine the mass distribution of the ISM each time a Type CC was required, and then randomly selected, the location with a probability proportional to density.
Two problems emerged with this method. The first was numerical. Given the analysis described in Appendix A.1, because the error in the approximation of cooling in the evolution of an SN remnant is higher with density, these SNe lost too much of their initial energy before their evolution into the snowplough stage was completed. Hence the ISM did not produce enough hot gas, and the turbulence was also inefficient at generating cold dense structures. The hot gas was confined to the mid-plane, where it was cooled, and substantial blow outs into the lower halo could not be sustained. Hence the gas near the boundary remained cool at about 10 4 K , instead of nearer 10 6 K . The second problem
was in the physics. Although the stars are formed in the dense molecular clouds, after the first few SN in an OB association explode they sweep away the dense gas, so that subsequent SN occur in the relatively diffuse gas in the wake of previous SN. So in fact the dependence on SN location with density is less direct.
The method used to locate Type I SN is to assume that ( x, y, z ) belong to random distributions ( X,Y,Z ) such that X,Y ∼ U ( -0 512 0 512) . , . and Z ∼ N (0 , h 2 I ) . This simple prescription was also applied to Type CC SN, but with h II for the scale height, resulting in an improvement in the numerical approximation of the SN remnants and also an increase in the formation of both hot and cold gas, and the advection of the hot gas from the disc to the lower halo.
Figure C.1: Time evolution (a) of horizontal averages of gas density for Model B2Ω with vertical distribution of Type CC SN from Z ∼ N (0 , h 2 II ) , and (b) with vertical distribution of Type CC SN from Z ∼ N z ,h ( h 2 II ) , where z h corresponds to the horizontal location with the largest total mass at the time of the SN explosion.
A new problem emerges with this method, however. There is a tendency for oscillations in the disc to be amplified over time, if the vertical distribution is fixed to vary about z = 0kpc . This is an unphysical effect, because one would expect the location of SNe in general to follow the star forming regions if they stray from the mid-plane. This might be overlooked for the rather shorter duration hydrodynamic simulations, but when it becomes necessary to extend runs beyond 1 Gyr to trace the dynamo, this effect not only interferes with the physical integrity of the models, it actually leads to the bulk of the gas being blown out of the model, and the simulation crashing. In Fig C.1a the horizontal averages for density from Model B1Ω are plotted against time. It can be seen that the disc oscillates from early on. This is natural, as intermittently one would expect the distribution of SNe to be greater above or below the disc. It is not natural, however, that the periodicity of the oscillations should be so regular nor should the amplitude be amplified.
From panel (a) the initial oscillations are somewhat chaotic, and the disc fragments, with several strands of dense gas out of phase. From about 500 Myr the fragments align and the bulk of the disk mass oscillates with period ∼ 200 Myr , and the displacement grows to as much as 500 pc by 1 2 Gyr . .
This is corrected by tracking the vertical position of the peak horizontal average gas density and adjusting the location of the SN distribution to match. To be explicit, if the horizontal slice with the highest gas density is located at z = z h when a Type CC SN site is being selected, then the vertical location of the site will be selected from an N z , h ( h II ) random distribution, rather than as previously N (0 , h II ) . In fig. C.1b the simulation has been restarted from about 600 Myr with the revised vertical distribution. Because the SNe are now distributed symmetrically about the disc mass, the systematic oscillations are damped within 300 Myr. The perturbations to the position of the disc are more natural and are no longer unstable. In the latter stages, beyond 1.2 Gyr, the disc density distribution broadens, but this is due to the saturation of the magnetic field and the additional magnetic pressure supporting the gas against gravity.
## Appendix D
## Dimensional units
Mee (2007, Appendix C) outlines how the system of dimensionless units for a simulation using the Pencil-code are uniquely specified by the definition of a set of fundamental units in the centimetres, grams and seconds (cgs) system. Here I clarify how these are specified, which units are currently actually defined in the code and the relation to the derived units.
The base units are length, speed and density, which are listed in Table D.1. It is desirable in numerical modelling to satisfy the constraint of finite precision that variables should not differ greatly from unity. By specifying two from three units of length, time and speed, the third unit follows. The selection of Myr or Gyr for time are natural, and with a gas speed in the ISM typically measured in kms -1 , it follows that unit length should be of order pc or kpc, respectively.
Because 1 Gyr = 3 15570 . × 10 16 s and 1 kpc = 3 08573 . × 10 31 cm , to use unit speed as 10 5 kms -1 I choose to approximate unit length = 3 15570 . × 10 21 cm ≈ 1 kpc . The mean number density of atomic hydrogen near the mid-plane of the Galaxy is estimated to be about 1 cm -3 . With the proton mass about 1 6728 . × 10 -24 g , unit density = 10 -24 g cm -3 is a convenient base unit to use.
Table D.1: Specified units
| Quantity | Symbol | Unit |
|------------|----------|------------------------------|
| Length | [ L ] | 3 . 15570 × 10 21 cm ≈ 1 kpc |
| Velocity | [ u ] | 10 5 cms - 1 = 1 kms - 1 |
| Density | [ ρ ] | 1 × 10 - 24 g cm - 3 |
It is also possible to define separately units for temperature and magnetic field strength, but one should be aware that specifying a value which conflicts with the three fundamental units may lead to code instability or numerical errors. These options are necessary, to permit specification where models neglect physics such as density or velocity, but it is important to be aware that no more than three fundamental units may be specified independently, so the derived determination for magnetic field strength and temperature is required and not an arbitrary choice.
Some of the main derived units referred to in this thesis and their construction in terms of the fundamental units are listed in Table D.2. Because it is less evident how the unit of temperature and magnetic field are dependent on the specification of the fundamental units, their derivation is described explicitly below.
Table D.2: Derived units
| Quantity | Symbol | Typical Derivation | Unit |
|---------------------------------------------------------------------------------|---------------------------------------------------------|-------------------------------------------------------------------------------------------------------------------------------------------------------|------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------|
| Time Temperature Mass Energy Energy density Pressure Magnetic field diffusivity | [ t ] [ T ] [ m [ E [ e V [ p ] [ B [ ν ] [ χ ] [ η ] ] | [ L ][ u ] - 1 µ [ u ] 2 γ - 1 R - [ ρ ][ L ] 3 [ ρ ][ L ] 3 [ u ] 2 [ ρ ][ u ] 2 [ ρ ][ u ] 2 √ µ 0 [ ρ ] 1 2 [ u ] [ L ][ u ] [ L ][ u ] [ L ][ u ] | 3 . 15570 × 10 16 s = 1 Gyr 44 . 74127 K 3 . 14256 × 10 40 g 3 . 14256 × 10 50 erg 1 × 10 - 14 erg cm - 3 1 × 10 - 14 dyncm - 2 3 . 54491 × 10 - 7 G 3 . 15570 × 10 26 erg s g - 1 3 . 15570 × 10 26 erg s g - 1 3 . 15570 × 10 26 erg s g - 1 |
| | | 1 | |
| | ] | | |
| | ] | | |
| | ] | | |
| | ] | | |
| Kinematic viscosity | | | |
| Thermal | | | |
| Magnetic diffusivity | | | |
| Specific entropy | [ s | [ u ] 2 [ T ] - 1 | 2 . 23507 × 10 8 erg g - 1 K - 1 |
## Unit temperature and ionization
In cgs units the Boltzmann constant k B glyph[similarequal] 1 38 . × 10 -16 erg K -1 and the atomic mass unit m u = 1 66 . × 10 -24 g . From the equation of state
$$c _ { \mathrm s } ^ { \, 2 } = \gamma \frac { p } { \rho } = \gamma \frac { k _ { \mathrm B } } { m _ { u } \mu } T,$$
where the Boltzmann constant k B = 1 380658 . × 10 -16 erg K -1 , the atomic mass unit m u = 1 6605402 . × 10 -24 g , the ratio of specific heats γ = 5 3 / and the mean molecular weight µ = 0 62 . . Hence unit temperature T 0 is derived from the unit sound speed c s0 , which is 1 km s -1 , as
$$T _ { 0 } = \frac { \mu } { \gamma R } c _ { s _ { 0 } } ^ { \, 2 } = 4 4. 7 4 1 2 7 \, K,$$
where the gas constant R = k /m B u .
As is discussed in Section 3.1 in relation to Eq. 3.1 the mean molecular weight µ depends on the degree of ionization of the gas, due to the presence of free electrons. It could also depend on the presence of molecular hydrogen, but as concluded for these models, this is not resolved, so only the atomic particles contribute to µ .
Assuming the gas to be fully ionized then we would have one each of hydrogen ions and electrons for each atom and for each helium atom one ion and two electrons. If X is the proportion of the number of hydrogen atoms and Y the proportion of helium atoms, then the total number of particles in the ISM, comprised purely of these two elements is
given by
$$N = & \frac { X _ { i } \rho } { m _ { p } } + \frac { X _ { e } \rho } { m _ { p } } + \frac { Y _ { i } \rho } { 4 m _ { p } } + \frac { 2 Y _ { e } \rho } { 4 m _ { p } } \\ = & \frac { \rho } { m _ { p } } \left ( \frac { 4 X _ { i } + 4 X _ { e } + Y _ { i } + 2 Y _ { e } } { 4 } \right ) \\ \mu ^ { - 1 } = & \left ( \frac { 8 X + 3 ( 1 - X ) } { 4 } \right ) = \left ( \frac { 5 X + 3 } { 4 } \right ).$$
Given the estimates X = 0 908 . and Y = 0 092 . stated in Section 1.2.2 then for the fully ionized gas µ = 0 531 . . For the fully neutral gas, with X e = Y e = 0 then µ = 1 074 . . It may be reasonable to approximate the cold gas as neutral and the hot gas as fully ionized, and to apply an appropriate temperature dependent transition between them in the warm gas, without all the additional complexity of modelling ions and electrons. Care would then need to be taken to ensure the unit of temperature is appropriate to the value of µ = 0 531 . .
## Unit magnetic field strength
Similarly, in cgs units magnetic field energy density is defined as B / 2 (2 µ 0 ) where the magnetic field is specified in Gauss [ G] and the magnetic vacuum permeability µ 0 = 4 π G cm erg 2 3 -1 . The factor of one half is required for parity with the formulation of the thermal and kinetic energy densities. So 1 G = ( µ 0 erg cm -3 ) 1 2 .
## Bibliography
Balbus, S. A. and J. F. Hawley. 1991. 'A powerful local shear instability in weakly magnetized disks. I - Linear analysis. II - Nonlinear evolution.' ApJ 376:214-233.
Balsara, D. S. and J. Kim. 2005. 'Amplification of Interstellar Magnetic Fields and Turbulent Mixing by Supernova-driven Turbulence. II. The Role of Dynamical Chaos.' ApJ 634:390-406.
Balsara, D. S., J. Kim, M.-M. Mac Low and G. J. Mathews. 2004. 'Amplification of Interstellar Magnetic Fields by Supernova-driven Turbulence.' ApJ 617:339-349.
Beck, R., A. Brandenburg, D. Moss, A. Shukurov and D. Sokoloff. 1996. 'Galactic Magnetism: Recent Developments and Perspectives.' ARA&A 34:155-206.
Berkhuijsen, E. M. and A. Fletcher. 2008. 'Density probability distribution functions of diffuse gas in the Milky Way.' MNRAS 390:L19-L23.
Berkhuijsen, E. M. and A. Fletcher. 2012. Density PDFs of diffuse gas in the Milky Way. In EAS Publications Series , ed. M. A. de Avillez. Vol. 56 of EAS Publications Series pp. 243-246.
Berkhuijsen, E. M., D. Mitra and P. Mueller. 2006. 'Filling factors and scale heights of the diffuse ionized gas in the Milky Way.' Astron. Nachr. 327:82-96.
Berkhuijsen, E. M. and P. M¨ uller. 2008. 'Densities and filling factors of the diffuse ionized gas in the Solar neighbourhood.' A&A 490:179-187.
Bonnell, I. A., C. L. Dobbs, T. P. Robitaille and J. E. Pringle. 2006. 'Spiral shocks, triggering of star formation and the velocity dispersion in giant molecular clouds.' MNRAS 365:37-45.
Boulares, A. and D. P. Cox. 1990. 'Galactic hydrostatic equilibrium with magnetic tension and cosmic-ray diffusion.' ApJ 365:544-558.
Brandenburg, A. and K. Subramanian. 2005. 'Astrophysical magnetic fields and nonlinear dynamo theory.' Phys. Rep. 417:1-209.
Brandenburg, Axel, Maarit J. Korpi and Antony J. Mee. 2007. 'Thermal Instability in Shearing and Periodic Turbulence.' ApJ 654:945-954.
Bregman, J. N. 1980. 'The galactic fountain of high-velocity clouds.' ApJ 236:577-591.
Bronfman, L., R. S. Cohen, H. Alvarez, J. May and P. Thaddeus. 1988. 'A CO survey of the southern Milky Way - The mean radial distribution of molecular clouds within the solar circle.' ApJ 324:248-266.
- Cappellari, M., E. Emsellem, D. Krajnovi´ c, R. M. McDermid, P. Serra, K. Alatalo, L. Blitz, M. Bois, F. Bournaud, M. Bureau, R. L. Davies, T. A. Davis, P. T. de Zeeuw, S. Khochfar, H. Kuntschner, P.-Y. Lablanche, R. Morganti, T. Naab, T. Oosterloo, M. Sarzi, N. Scott, A.-M. Weijmans and L. M. Young. 2011. 'The ATLAS 3 D project - VII. A new look at the morphology of nearby galaxies: the kinematic morphology-density relation.' MNRAS 416:1680-1696.
- Chandrasekhar, S. 1931. 'The highly collapsed configurations of a stellar mass.' MNRAS 91:456-466.
- Chiang, W.-H. and K. H. Prendergast. 1985. 'Numerical study of a two-fluid hydrodynamic model of the interstellar medium and population I stars.' ApJ 297:507-530.
- Cioffi, Denis F, Christopher F. McKee and Edmund Bertschinger. 1998. 'Dynamics of Radiative Supernova Remnants.' ApJ 334:252-265.
- Clemens, D. P., D. B. Sanders and N. Z. Scoville. 1988. 'The large-scale distribution of molecular gas in the first Galactic quadrant.' ApJ 327:139-155.
- Cowie, L. L., A. Songaila and D. G. York. 1979. 'Orion's Cloak - A rapidly expanding shell of gas centered on the Orion OB1 association.' ApJ 230:469-484.
- Cowie, L. L., C. F. McKee and J. P. Ostriker. 1981. 'Supernova remnant revolution in an inhomogeneous medium. I - Numerical models.' ApJ 247:908-924.
Cox, D. P. 2005. 'The Three-Phase Interstellar Medium Revisited.' ARA&A 43:337-385.
- Cox, D. P. and B. W. Smith. 1974. 'Large-Scale Effects of Supernova Remnants on the Galaxy: Generation and Maintenance of a Hot Network of Tunnels.' ApJ 189:L105.
- de Avillez, M. A. 2000. 'Disc-halo interaction - I. Three-dimensional evolution of the Galactic disc.' MNRAS 315:479-497.
- de Avillez, M. A. and D. Breitschwerdt. 2004. 'Volume filling factors of the ISM phases in star forming galaxies. I. The role of the disk-halo interaction.' A&A 425:899-911.
- de Avillez, M. A. and D. Breitschwerdt. 2005 a . 'Global dynamical evolution of the ISM in star forming galaxies. I. High resolution 3D simulations: Effect of the magnetic field.' A&A 436:585-600.
- de Avillez, M. A. and D. Breitschwerdt. 2005 b . 'Testing Global ISM Models: A Detailed Comparison of O VI Column Densities with FUSE and Copernicus Data.' ApJ 634:L65-L68.
- de Avillez, M. A. and D. Breitschwerdt. 2007. 'The Generation and Dissipation of Interstellar Turbulence: Results from Large-Scale High-Resolution Simulations.' ApJ 665:L35-L38.
- de Avillez, M. A. and D. Breitschwerdt. 2010. The Evolution of the Large-Scale ISM: Bubbles, Superbubbles and Non-Equilibrium Ionization. In Astronomical Society of the Pacific Conference Series , ed. R. Kothes, T. L. Landecker, & A. G. Willis. Vol. 438 of Astronomical Society of the Pacific Conference Series p. 313.
- de Avillez, M. A. and D. L. Berry. 2001. 'Three-dimensional evolution of worms and chimneys in the Galactic disc.' MNRAS 328:708-718.
- de Avillez, M. A. and M.-M. Mac Low. 2001. 'Mushroom-shaped Structures as Tracers of Buoyant Flow in the Galactic Disk.' ApJ Letters 551:L57-L61.
- de Avillez, M. A. and M.-M. Mac Low. 2002. 'Mixing Timescales in a Supernova-driven Interstellar Medium.' ApJ 581:1047-1060.
- Dobbs, C. L., A. Burkert and J. E. Pringle. 2011. 'The properties of the interstellar medium in disc galaxies with stellar feedback.' MNRAS 417:1318-1334.
- Dobbs, C. L. and D. J. Price. 2008. 'Magnetic fields and the dynamics of spiral galaxies.' MNRAS 383:497-512.
- Dobbs, C. L. and J. E. Pringle. 2010. 'Age distributions of star clusters in spiral and barred galaxies as a test for theories of spiral structure.' MNRAS 409:396-404.
- Dyson, J. E. and R. J. Williams. 1997. second ed. Dirac House, Temple Back, Bristol, BS1 6BE: IOP Publishing Ltd.
Eyink, G. L. 2005. 'Locality of turbulent cascades.' Physica D 207:91-116.
Eyink, G. L. 2012. 'Turbulence Theory.' Turbulence Theory (Course Notes), John Hopkins Univ., http://www.ams.jhu.edu/ ∼ eyink/Turbulence/ .
Ferri` ere, K. M. 2001. 'The interstellar environment of our galaxy.' Rev. Mod. Phys. 73:1031-1066.
Field, G. B. 1965. 'Thermal Instability.' ApJ 142:531-567.
Fletcher, A., R. Beck, A. Shukurov, E. M. Berkhuijsen and C. Horellou. 2011. 'Magnetic fields and spiral arms in the galaxy M51.' MNRAS 412(4):2396-2416.
URL: http://dx.doi.org/10.1111/j.1365-2966.2010.18065.x
| Gaensler, B M, G J Madsen, S Chatterjee and S A Mao. 2008. 'The Vertical Structure of Warm Ionised Gas in the Milky Way.' Publications of the Astronomical Society of Australia 25:184-200. |
|-------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------|
| Gazol-Pati˜o, n A. and T. Passot. 1999. 'A Turbulent Model for the Interstellar Medium. III. Stratification and Supernova Explosions.' ApJ 518:748-759. |
| Gent, F. A. 2012. 'Galaxies in a Box: A Simulated View of the Interstellar Medium.' Space Sci. Rev. 166:281-291. |
| Gent, F. A., A. Shukurov, A. Fletcher, G. R. Sarson and M. J. Mantere. 2013. 'The supernova-regulated ISM - I. The multiphase structure.' MNRAS 432:1396-1423. |
| Gent, F. A., A. Shukurov, G. R. Sarson, A. Fletcher and M. J. Mantere. 2013. 'The supernova-regulated ISM - II. The mean magnetic field.' MNRAS 430:L40-L44. |
| Germano, M. 1992. 'Turbulence - The filtering approach.' J. Fluid Mech. 238:325-336. |
| Gressel, O., D. Elstner, U. Ziegler and G. R¨diger. u 2008 a . 'Direct simulations of a supernova-driven galactic dynamo.' A&A 486:L35-L38. |
| Gressel, O., D. Elstner, U. Ziegler and G R¨diger. u 2008 b . 'Dynamo coefficients from local simulations of the turbulent ISM.' AN 329:619-624. |
| Gressel, Oliver. 2008. Supernova-driven Turbulence and Magnetic Field Amplification in Disk Galaxies PhD thesis Astrophysikalisches Institut Potsdam. |
| Hanasz, M., D. W´lta´ski o n and K. Kowalik. 2009. 'Global Galactic Dynamo Driven by Cosmic Rays and Exploding Magnetized Stars.' ApJ 706:L155-L159. |
| Hanasz, M., D. W´ltanski, o K. Kowalik and H. Kotarba. 2011. Cosmic-ray driven dy- namo in galaxies. In IAU Symposium , ed. A. Bonanno, E. de Gouveia Dal Pino, & A. G. Kosovichev. Vol. 274 of IAU Symposium pp. 355-360. |
| Hanasz, M., G. Kowal, K. Otmianowska-Mazur and H. Lesch. 2004. 'Amplification of Galactic Magnetic Fields by the Cosmic-Ray-driven Dynamo.' ApJ Letters 605:L33- L36. |
| Hanasz, M., H. Lesch, K. Otmianowska-Mazur and G. Kowal. 2005. Cosmic ray driven dynamo in galactic disks. In The Magnetized Plasma in Galaxy Evolution , ed. K. T. Chyzy, K. Otmianowska-Mazur, M. Soida and R.-J. Dettmar. pp. 162-170. |
| Hanasz, M., K. Otmianowska-Mazur, G. Kowal and H. Lesch. 2006. 'Cosmic ray driven dynamo in galactic disks: effects of resistivity, SN rate and spiral arms.' Astronomische Nachrichten 327:469. |
| Heiles, C. and T. H. Troland. 2003. 'The Millennium Arecibo 21 Centimeter Absorption- Line Survey. II. Properties of the Warm and Cold Neutral Media.' ApJ 586:1067-1093. |
|------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------|
| Heitsch, F., M.-M. Mac Low and R. S. Klessen. 2001. 'Gravitational Collapse in Turbu- lent Molecular Clouds. II. Magnetohydrodynamical Turbulence.' ApJ 547:280-291. |
| Hill, A. S., M. R. Joung, M.-M. Mac Low, R. A. Benjamin, L. M. Haffner, C. Klingenberg and K. Waagan. 2012. 'Vertical Structure of a Supernova-driven Turbulent, Magnetized Interstellar Medium.' ApJ 750:104-122. |
| Hill, Alex S, Robert A Benjamin, Grzegorz Kowal, Ronald J Reynolds, L Matthew Haffner and Alex Lazarian. 2008. 'The Turbulent Warm Ionized Medium: Emission Measure Distribution and MHDSimulations.' ApJ 686:363-378. |
| Joung, M. K. Ryan and M.-M. Mac Low. 2006. 'Turbulent Structure of a Stratified Supernova-Driven Interstellar Medium.' ApJ 653:1266-1279. |
| Joung, M. K. Ryan, M.-M. Mac Low and Greg L. Bryan. 2009. 'Dependence of Inter- stellar Turbulent Pressure on Supernova Rate.' ApJ 704:137-149. |
| Kalberla, P. M. W. and J. Kerp. 2009. 'The Hi Distribution of the Milky Way.' ARA&A 47:27-61. |
| Kennicutt, Jr., R. C. 1998. 'The Global Schmidt Law in Star-forming Galaxies.' ApJ 498:541-552. |
| Kevlahan, N. and R. E. Pudritz. 2009. 'Shock-generated Vorticity in the Interstellar Medium and the Origin of the Stellar Initial Mass Function.' ApJ 702:39-49. |
| Klessen, R. S., F. Heitsch and M.-M. Mac Low. 2000. 'Gravitational Collapse in Turbu- lent Molecular Clouds. I. Gasdynamical Turbulence.' ApJ 535:887-906. |
| Korpi, M. J., A. Brandenburg, A. Shukurov and I. Tuominen. 1999. 'Evolution of a superbubble in a turbulent, multi-phased and magnetized ISM.' A&A 350:230-239. |
| Korpi, M. J., A. Brandenburg, A. Shukurov, I. Tuominen and ˚ A. Nordlund. 1999. 'A supernova-regulated interstellar medium: simulations of the turbulent multiphase medium.' ApJ 514:L99-L102. |
| Korpi, M. J., P. J. K¨pyl¨ a a and M. S. V¨is¨l¨. a a a 2010. 'Influence of Ohmic diffusion on the excitation and dynamics of MRI.' Astronomische Nachrichten 331:34. |
| Kuijken, K. and G. Gilmore. 1989. 'The Mass Distribution in the Galactic Disc - II - Determination of the Surface Mass Density of the Galactic Disc Near the Sun.' MNRAS 239:605-649. |
| Kulesza-Zydzik, ˙ B., K. Kulpa-Dybeł, K. Otmianowska-Mazur, G. Kowal and M. Soida. 2009. 'Formation of gaseous arms in barred galaxies with dynamically important mag- netic field: 3D MHDsimulations.' A&A 498:L21-L24. |
|-------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------|
| Kulkarni, S. R. and C. Heiles. 1987. The atomic component. In Interstellar Processes , ed. D. J. Hollenbach and H. A. Thronson Jr. Vol. 134 of Astrophysics and Space Science Library pp. 87-122. |
| Kulkarni, S. R. and C. Heiles. 1988. Neutral hydrogen and the diffuse interstellar medium. In Galactic and Extragalactic Radio Astronomy , ed. K. I. Kellermann and G. L. Ver- schuur. Berlin and New York, Springer-Verlag pp. 95-153. |
| Kulsrud, R. M. 1978. Propagation of cosmic rays through a plasma. In Astronomical Papers Dedicated to Bengt Stromgren , ed. A. Reiz &T. Andersen. pp. 317-326. |
| Lequeux, J. 2005. The Interstellar Medium . |
| Li, Yuexing, M.-M. Mac Low and Ralf S. Klessen. 2005. 'Control of Star Formation in Galaxies by Gravitational Instability.' ApJ 620:L19-22. |
| Mac Low, M.-M., D. S. Balsara, J. Kim and M. A. de Avillez. 2005. 'The Distribution of Pressures in a Supernova-driven Interstellar Medium. I. Magnetized Medium.' ApJ 626:864-876. |
| Mac Low, M.-M. and R. S. Klessen. 2004. 'Control of star formation by supersonic turbulence.' Rev. Mod. Phys. 76:125-194. |
| McKee, C. F. 1995. The Phases of the Interstellar Medium,. In Physics of the Interstellar Medium and Intergalactic Medium , ed. A. Ferrara, C. F. McKee, C. Heiles and P. R. Shapiro. Vol. 80 Astron. Soc. Pacific, San Francisco p. 292. |
| McKee, C. F. and J. P. Ostriker. 1977. 'A theory of the interstellar medium - Three components regulated by supernova explosions in an inhomogeneous substrate.' ApJ 218:148-169. |
| Mee, Antony James William. 2007. Studies of interstellar hydromagnetic turbulence PhD thesis Newcastle University, School of Mathematics and Statistics. |
| Monin, A. S. and A. M. Yaglom. 2007. Statistical Fluid Mechanics, Vol. I, Dover . |
| Norman, C. A. and S. Ikeuchi. 1989. 'The disk-halo interaction - Superbubbles and the structure of the interstellar medium.' ApJ 345:372-383. |
| Ostriker, J. P. and C. F. McKee. 1988. 'Astrophysical blastwaves.' Rev. Mod. Phys. 60:1- 68. |
| Parker, E. N. 1969. 'Galactic Effects of the Cosmic-Ray Gas.' Space Sci. Rev. 9:651-712. |
| Passot, T., E. V´zquez-Semadeni a and A. Pouquet. 1995. 'A Turbulent Model for the Interstellar Medium. II. Magnetic Fields and Rotation.' ApJ 455:536-555. |
|-------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------|
| Patrikeev, I., A. Fletcher, R. Stepanov, R. Beck, E. M. Berkhuijsen, P. Frick and C. Horel- lou. 2006. 'Analysis of spiral arms using anisotropic wavelets: gas, dust and magnetic fields in M51.' A&A 458:441-452. |
| Piontek, R. A. and E. C. Ostriker. 2007. 'Models of Vertically Stratified Two-Phase ISM Disks with MRI-Driven Turbulence.' ApJ 663:183-203. |
| Raymond, J. C. and B. W. Smith. 1977. 'Soft X-ray spectrum of a hot plasma.' ApJ 35:419-439. |
| Reynolds, RJ. 1977. 'Pulsar dispersion measures and H-alpha emission measures - Limits on the electron density and filling factor for the ionized interstellar gas.' ApJ 216:433- 439. |
| Reynolds, R. J. 1991. 'Line integrals of N E and (n Es - squared ) at high Galactic latitude.' ApJ Letters 372:L17-L20. |
| Rosen, A. and J. N. Bregman. 1995. 'Global Models of the Interstellar Medium in Disk Galaxies.' ApJ 440:634-665. |
| Rosen, A., J. N. Bregman and D. D. Kelson. 1996. 'Global Models of the Galactic Interstellar Medium: Comparison to X-Ray and H i Observations.' ApJ 470:839-857. |
| Rosen, Alexander, Joel N. Bregman and Michael L. Norman. 1993. 'Hydrodynamcal Simulations of Star-Gas Interactions in the Interstellar Medium with an External Grav- itational Potential.' ApJ 413:137-149. |
| S´nchez-Salcedo, a F. J., E. V´zquez-Semadeni a and A. Gazol. 2002. 'The Nonlinear Devel- opment of the Thermal Instability in the Atomic Interstellar Medium and Its Interaction with Random Fluctuations.' ApJ 577:768-788. |
| Sarazin, C. L. and R. E. White, III. 1987. 'Steady state cooling flow models for normal elliptical galaxies.' ApJ 320:32-48. |
| Scalo, J., E. V´zquez-Semadeni, a D. Chappell and T. Passot. 1998. 'On the Probability Density Function of Galactic Gas. I. Numerical Simulations and the Significance of the Polytropic Index.' ApJ 504:835-853. |
| Sedov, L. I. 1959. Similarity and Dimensional Methods in Mechanics . New York: Aca- demic Press. |
| Shukurov, A. 2007. In Mathematical Aspects of Natural Dynamos, , ed. E. Dormy and A. M. Soward. Chapman &Hall/CRC pp. 313-359. |
| Slyz, A. D., J. E. G. Devriendt, G. Bryan and J. Silk. 2005. 'Towards simulating star formation in the interstellar medium.' MNRAS 356:737-752. |
|---------------------------------------------------------------------------------------------------------------------------------------------------------------------------|
| Slyz, A. D., T. Kranz and H.-W. Rix. 2003. 'Exploring spiral galaxy potentials with hydrodynamical simulations.' MNRAS 346:1162-1178. |
| Sokoloff, D., A. Shukurov and A. Ruzmaikin. 1983. 'Asymptotic solution of the α 2 - dynamo problem.' Geophys. Astrophys. Fluid Dyn. 25:293-307. |
| Spitzer, Jr., L. 1990. 'Theories of the hot interstellar gas.' ARA&A 28:71-101. |
| Spitzer, L. 1978. Physical processes in the interstellar medium . |
| Starchenko, S. V. and A. M. Shukurov. 1989. 'Observable parameters of spiral galaxies and galactic magnetic fields.' A&A 214:47-60. |
| Tabatabaei, F. S., M. Krause, A. Fletcher and R. Beck. 2008. 'High-resolution radio continuum survey of M33. III. Magnetic fields.' A&A 490:1005-1017. |
| Tammann, G. A., W. L¨ffler o and A. Schr¨der. o 1994. 'The Galactic supernova rate.' ApJS 92:487-493. |
| Taylor, G. 1950. 'The Formation of a Blast Wave by a Very Intense Explosion. I. Theo- retical Discussion.' Royal Society of London Proceedings Series A 201:159-174. |
| Tennekes, H. and J. L. Lumley. 1972. First Course in Turbulence . Cambridge: MIT Press. |
| Tomisaka, K. 1998. 'Superbubbles in magnetized interstellar media: blowout or confine- ment?' MNRAS 298:797-810. |
| Tutukov, A. V., B. M. Shustov and D. S. Wiebe. 2000. 'The Stellar Epoch in the Evolution of the Galaxy.' Astronomy Reports 44:711-718. |
| van den Bergh, S. 1976. 'A new classification system for galaxies.' ApJ 206:883-887. |
| V´zquez-Semadeni, a E., A. Gazol and J. Scalo. 2000. 'Is Thermal Instability Significant in Turbulent Galactic Gas?' ApJ 540:271-285. |
| V´zquez-Semadeni, a E., T. Passot and A. Pouquet. 1995. 'A turbulent model for the inter- stellar medium. 1: Threshold star formation and self-gravity.' ApJ 441:702-725. |
| Wada, K. and C. A. Norman. 1999. 'The Global Structure and Evolution of a Self- Gravitating Multiphase Interstellar Medium in a Galactic Disk.' ApJ 516:L13-L16. |
| Wada, K. and C. A. Norman. 2001. 'Numerical Models of the Multiphase Interstellar Matter with Stellar Energy Feedback on a Galactic Scale.' ApJ 547:172-186. |
Wada, K. and C. A. Norman. 2007. 'Density Structure of the Interstellar Medium and the Star Formation Rate in Galactic Disks.' ApJ 660:276-287.
Wada, K., G. Meurer and C. A. Norman. 2002. 'Gravity-driven Turbulence in Galactic Disks.' ApJ 577:197-205.
Walters, M. A. and D. P. Cox. 2001. 'Models of Vertical Disturbances in the Interstellar Medium.' ApJ 549:353-376.
Wisdom, J. and S. Tremaine. 1988. 'Local simulations of planetary rings.' AJ 95:925940.
Wolfire, M. G., D. Hollenbach, C. F. McKee, A. G. G. M. Tielens and E. L. O. Bakes. 1995. 'The neutral atomic phases of the interstellar medium.' ApJ 443:152-168.
Woltjer, L. 1972. 'Supernova Remnants.' ARA&A 10:129-158. | 10.10443/1755 | [
"Frederick Gent"
] | 2014-08-03T01:17:41+00:00 | 2017-03-08T00:39:04+00:00 | [
"astro-ph.GA"
] | Supernovae Driven Turbulence In The Interstellar Medium | I model the multi-phase interstellar medium (ISM) randomly heated and shocked
by supernovae, with gravity, differential rotation and other parameters we
understand to be typical of the solar neighbourhood. The simulations are 3D
extending horizontally 1 x 1 kpc squared and vertically 2 kpc, symmetric about
the galactic mid-plane. They routinely span gas number densities 1/10000 to 100
per cubic cm, temperatures 100 to 100 MK, speeds up to 10000 km/s and Mach
number up to 25. Radiative cooling is applied from two widely adopted
parameterizations, and compared directly to assess the sensitivity of the
results to cooling. There is strong evidence to describe the ISM as comprising
well defined cold, warm and hot regions, which are statistically close to
thermal and total pressure equilibrium. This result is not sensitive to the
choice of parameters considered here. The distribution of the gas density
within each can be robustly modelled as lognormal. Appropriate distinction is
required between the properties of the gases in the supernova active mid-plane
and the more homogeneous phases outside this region. The connection between the
fractional volume of a phase and its various proxies is clarified. An exact
relation is then derived between the fractional volume and the filling factors
defined in terms of the volume and probabilistic averages. These results are
discussed in both observational and computational contexts. The correlation
scale of the random flows is calculated from the velocity autocorrelation
function; it is of order 100 pc and tends to grow with distance from the
mid-plane. The origin and structure of the magnetic fields in the ISM is also
investigated in non-ideal MHD simulations. A seed magnetic field, with volume
average of roughly 4 nG, grows exponentially to reach a statistically steady
state within 1.6 Gyr. |
1408.0448v1 | ## Holomorphic Poisson Cohomology
Zhuo Chen Daniele Grandini Yat-Sun Poon August 5, 2014
∗ † ‡
## Abstract
Holomorphic Poisson structures arise naturally in the realm of generalized geometry. A holomorphic Poisson structure induces a deformation of the complex structure in a generalized sense, whose cohomology is obtained by twisting the Dolbeault ∂ -operator by the holomorphic Poisson bivector field. Therefore, the cohomology space naturally appears as the limit of a spectral sequence of a double complex. The first sheet of this spectral sequence is simply the Dolbeault cohomology with coefficients in the exterior algebra of the holomorphic tangent bundle. We identify various necessary conditions on compact complex manifolds on which this spectral sequence degenerates on the level of the second sheet. The manifolds to our concern include all compact complex surfaces, K¨hler manifolds, and nilmanifolds with abelian a complex structures or parallelizable complex structures.
## 1 Introduction
The algebraic geometry of Poisson brackets over complex manifolds were studied for some time [21]. In recent years, there are significant interests on holomorphic
∗ Address: Department of Mathematical Sciences, Tsinghua University, Beijing, P.R.C.
† Address: Department of Mathematics, University of New Mexico at Albuquerque, Albuquerque, NM 87131, U.S.A.
‡ Address: Department of Mathematics, University of California at Riverside, Riverside, CA 92521, U.S.A.. Email: [email protected].
Poisson structures due to their emergence in generalized complex geometry [11] [12] [13]. As such, one could consider their deformations either as complex analytic objects [6] [8] [14], or as generalized complex objects [9]. On the other hand, there are classifications of holomorphic Poisson structures on algebraic surfaces [2], and computations of their related cohomology theory [16].
A holomorphic Poisson structure consists of a holomorphic bi-vector field Λ on a complex manifold such that [ [Λ , Λ] ] = 0. It is demonstrated in [9] that the deformation of such structure as a generalized complex structure is dictated by the cohomology space ⊕ k H k Λ of the differential operator ∂ Λ = ∂ + [ [Λ , -] ]. This observation motivates the authors' desire to find a way to compute the cohomology spaces H k Λ . Since this space is naturally the limit of a spectral sequence of a double complex due to the operators ∂ and [ [Λ , -] ], it is an obvious question on when and how fast this spectral sequence could degenerate. We will see that the first sheet of this spectral sequence is the Dolbeault cohomology on the manifold with coefficients in the holomorphic polyvectors. As this is a classical object, it becomes desirable to identify the conditions under which the spectral sequence will degenerate at its second level.
In this paper, we identify three situations in which the spectral sequence of the holomorphic Poisson double complex degenerates at its second level. In the next chapter, we will explain the role of holomorphic Poisson structures in generalized geometry, and then set up our computation of cohomology in the context of Lie bi-algebroids and their dual differentials [17]. Our reference for differential calculus of Lie algebroids is the book [18]. We will then set up the holomorphic Poisson double complex and its related spectral sequence.
We will make observation on three very different kinds of complex manifolds: complex parallelizable, nilmanifolds with abelian complex structures, and K¨hlerian a manifolds.
On complex parallelizable manifolds, we have the following result.
Theorem 1. Let M be a complex parallelizable manifold with an invariant holomorphic Poisson structure Λ . Let g 1 0 , be the vector space of holomorphic vector fields on M . Let H q ∂ ( g ∗ (0 1) , ) be the Chevalley-Eilenberg cohomology for the conjugation
algebra g 0 1 , , and H p ad Λ ( g 1 0 , ) the cohomology of the operator ad Λ = [ [Λ , -] ] on the exterior algebra of g 1 0 , , then
$$H _ { \Lambda } ^ { k } ( M ) = \oplus _ { p + q = k } H _ { \overline { \partial } } ^ { q } ( \mathfrak { g } ^ { * ( 0, 1 ) } ) \otimes H _ { \text{ad} _ { \Lambda } } ^ { p } ( \mathfrak { g } ^ { 1, 0 } ).$$
This result will appear as Theorem 3 in this text. The proof of this result is not hard except for an application of Sakane's work [25] on Dolbeault cohomology on complex parallelizable manifolds because the holomorphic tangent bundle is trivial in this case. A typical example is the complex three-dimensional Iwasawa manifold.
The analysis of nilmanifolds takes significantly more effort. Much are based on our experience with computation of various cohomology on nilmanifolds, starting from Nomizu's work on de Rham cohomology [20], its generalization to Dolbeault cohomology [3] [5] and their generalizations to cohomology with coefficients in holomorphic vector fields [9] [10] [19]. In this paper, we need to deal with cohomology with coefficients in holomorphic poly-vector fields. The result below generalizes what was known for Kodaira surface [22].
Theorem 2. Suppose that M = G/ Γ is a 2-step nilmanifold with an abelian complex structure. Suppose that the center of g is real two-dimensional, then for any invariant holomorphic Poisson structure Λ , the Poisson spectral sequence degenerates on the second sheet.
This theorem will appear as Theorem 2. In view of the work in [4] and [24], we expect much room to generalize this theorem. There are also lots of examples.
Finally, to deal with K¨hlerian manifolds, we adopt an idea from Hitchin in his a paper [14] (see also [8]) when he uses a contraction of the holomorphic bivector field Λ to pass a problem at hand to a consideration on Dolbeault cohomology. This contraction yields a homomorphism of double complex. Based on it, we prove the following result.
Theorem 3. Suppose that X is a holomorphic Poisson manifold with complex dimension n . If the Fr¨hlicher spectral sequence of its complex structure degenerates o at the E 1 -level, then its holomorphic Poisson spectral sequence degenerates at the
E n -level.
This theorem will appear as Theorem 6. Note that it is well known that the Fr¨hlicher spectral sequence on a compact complex surface always degenerates [1]. o The last theorem could be applied to all compact complex surfaces as well as all compact K¨ ahlerian manifolds [27].
## 2 Holomorphic Poisson Double Complex
## 2.1 Holomorphic Poisson Structures as Generalized Complex Structures
A generalized complex manifold [11] [12] is a smooth (2 n )-dimensional manifold M equipped with a subbundle L of the bundle T = ( TM ⊕ T M ∗ ) C such that
- · L and its conjugate bundle L are transversal;
- · L is maximally isotropic with respect to the natural pairing on ( TM ⊕ T M ∗ ) C ;
- · and the space of sections of L is closed respective to the Courant bracket.
Equivalently, it is determined by a bundle automorphism J on TM ⊕ T M ∗ such that J ◦ J = -identity, J is orthogonal with respect to the natural pairing, and the space of sections of the + -eigenbundle with respect to i J is closed with respect to the Courant bracket.
Typical examples of generalized complex structures are classical complex structures and symplectic structures on a manifold. For a classical complex structure, the corresponding bundle L as a generalized complex structure is T 1 0 , M ⊕ T ∗ (0 1) , M , the direct sum of the bundle of type (1,0)-vectors and the bundle of type (0,1)-forms.
Suppose that a manifold M is equipped with a complex structure J . A holomorphic Poisson structure on ( M,J ) is a holomorphic bi-vector field Λ such that with respect to the Schouten bracket, [ [Λ , Λ] ] = 0. It follows that for any number t , the map
$$\mathcal { J } _ { t \Lambda } = \left ( \begin{array} { c c } J & \text{Im} ( t \Lambda ) \\ 0 & - J ^ { * } \end{array} \right )$$
determines a generalized complex structure. Here by J α ∗ where α is a 1-form, we mean ( J α X ∗ ) = α JX ( ) for any vector field X .
At t = 0, one recovers the generalized complex structure determined by the classical complex structure J on the manifold M . This is an example of deformation of generalized complex structures.
The corresponding bundles as generalized complex structure for J t Λ is the pair of bundles of graphes L t Λ and L t Λ where
$$\overline { L } _ { t \Lambda } = \{ \overline { \ell } + t \Lambda ( \overline { \ell } ) \, \colon \overline { \ell } \in \overline { L } \}.$$
## 2.2 Holomorphic Poisson Cohomology
Given a generalized complex structure, the pair of bundles L and L makes a Lie bialgebroid. Via the canonical non-degenerate pairing on the bundle T , the bundle L is complex linearly identified to the dual of L . Therefore, the Lie algebroid differential of L acts on L . It extends to a differential on the exterior algebra of L . For the calculus of Lie bialgebroids, we follow the conventions in [18]. In particular, let ρ be the anchor map on the Lie algebroid L . For any element Γ in C ∞ ( M, ∧ k L ) and elements a , . . . , a 1 k +1 in C ∞ ( M, ∧ k L ), the differential of Γ is
$$( \overline { \partial } _ { L } \Gamma ) ( a _ { 1 }, \dots, a _ { k + 1 } ) & = \sum _ { r = 1 } ^ { k + 1 } ( - 1 ) ^ { r + 1 } \rho ( a _ { r } ) ( \Gamma ( a _ { 1 }, \dots, \hat { a } _ { r }, \dots, a _ { k + 1 } ) ) \\ & \quad + \sum _ { r < s } ( - 1 ) ^ { r + s } \Gamma ( \left [ a _ { r }, a _ { s } \right ], a _ { 1 }, \dots, \hat { a } _ { r }, \dots, \hat { a } _ { s }, \dots, a _ { k + 1 } ). \\ \quad \text{For example if $L$ comes from a commlex structure $L = T^{1,0} M \oplus T^{*(0,1)} M$ The}$$
For example, if L comes from a complex structure, L = T 1 0 , M ⊕ T ∗ (0 1) , M . The differential is
$$\overline { \partial } \colon C ^ { \infty } ( T ^ { 1, 0 } M \oplus T ^ { * ( 0, 1 ) } M ) \to C ^ { \infty } ( ( T ^ { 1, 0 } M \otimes T ^ { * ( 0, 1 ) } M ) \oplus T ^ { * ( 0, 2 ) } M ). \quad \ \ ( 3 )$$
Obviously, when ω is a (0 , 1)-form, then ∂ω is the classical ∂ -operator in Dolbeault theory. When X is a (1 , 0)-vector field, Y a (0 , 1)-vector field and ω a (1 , 0)-form, then
$$( \overline { \partial } X ) ( \omega, \overline { Y } ) = - \overline { Y } \omega ( X ) - X ( [ \omega, \overline { Y } ] ) = - \overline { Y } \omega ( X ) + ( \mathcal { L } _ { \overline { Y } } \omega ) ( X ) = \omega ( [ X, \overline { Y } ] ). \quad ( 4 )$$
Therefore, ∂X is identical to the so-called Riemann-Cauchy operator as in [7]. For future reference, we note the following observation, which could be proved by treating ∂ as a Lie algebroid differential with respect to the Lie algebroid L as we did in the calculus in equation (4) above.
Lemma 1 For any (2 , 0) -field Λ (1 0) , , -forms ω , γ and (0 , 1) -vector field Z ,
$$( \overline { \partial } \Lambda ) ( \omega, \gamma, \overline { Z } ) = - \overline { Z } ( \Lambda ( \omega, \gamma ) ) - \omega ( [ \overline { Z }, \Lambda \gamma ] ) + \gamma ( [ \overline { Z }, \Lambda \omega ] ).$$
## 2.3 Poisson Double Complex
We have seen that a holomorphic Poisson structure Λ could be treated as a deformation of the complex structure J . While the pair of bundles L Λ and L Λ form a Lie bi-algebroid, so does the pair L and L Λ [17].
Proposition 1 [9] The Lie algebroid differential of L Λ acting on L is given by
$$\overline { \partial } _ { \Lambda } = \overline { \partial } + \text{ad} _ { \Lambda } \, \colon C ^ { \infty } ( T ^ { 1, 0 } M \oplus T ^ { * ( 0, 1 ) } M ) \to C ^ { \infty } ( \wedge ^ { 2 } ( T ^ { 1, 0 } M \oplus T ^ { * ( 0, 1 ) } M ) ), \quad ( 5 )$$
where by definition ad Λ ( v + ω ) = [ [Λ , v + ω ] ] when v is a smooth section of T 1 0 , M and ω is a smooth section of T ∗ (0 1) , M .
The operator ∂ Λ extends to act on the exterior algebra of T 1 0 , M ⊕ T ∗ (0 1) , M :
$$\overline { \partial } _ { \Lambda } \, \colon K ^ { n } \to K ^ { n + 1 }, \quad \text{where} \quad K ^ { n } = C ^ { \infty } ( \wedge ^ { n } ( T ^ { 1, 0 } M \oplus T ^ { * ( 0, 1 ) } M ) ). \quad \text{ (6)}$$
Since Λ is a holomorphic Poisson structure, ∂ Λ ◦ ∂ Λ = 0. Therefore, one has a complex with ∂ Λ being a differential. Starting with k = 0, one has the k -th cohomology of this complex. It is denoted by H k Λ ( M ). This cohomology space is called the k -th holomorphic Poisson cohomology of Λ; or simply Poisson cohomology.
Since Λ is holomorphic Poisson, it follows that
$$\overline { \partial } \circ \overline { \partial } = 0, \quad \overline { \partial } \circ \text{ad} _ { \Lambda } + \text{ad} _ { \Lambda } \circ \overline { \partial } = 0, \quad \text{ad} _ { \Lambda } \circ \text{ad} _ { \Lambda } = 0.$$
Define A p,q = C ∞ ( M, ∧ p T 1 0 , M ⊗∧ q T ∗ (0 1) , M ), then
$$\overline { \partial } \, \colon A ^ { p, q } \to A ^ { p, q + 1 } ; \quad \text{and} \quad \text{ad} _ { \Lambda } \, \colon A ^ { p, q } \to A ^ { p + 1, q }.$$
Therefore, we obtain a double complex.
$$\begin{array} { c c c c c c } A ^ { p, q + 1 } & \longrightarrow & A ^ { p + 1, q + 1 } & & \\ \overline { \partial } & \uparrow & & \uparrow &. \\ A ^ { p, q } & \longrightarrow & A ^ { p + 1, q } & & \\ & a d _ { \Lambda } & & & \\ \end{array}$$
.
For the double complex ( A ∗ ∗ , , ad Λ , ∂ ) , its associated single complex is K n = ⊕ p + = q n A p,q and the differential is
$$\overline { \partial } _ { \Lambda } = \overline { \partial } + \text{ad} _ { \Lambda } \, \colon K ^ { n } \longrightarrow K ^ { n + 1 }.$$
Lemma 2 The triples ( A ∗ ∗ , , ad Λ , ∂ ) form a double complex. Its total cohomology is the holomorphic Poisson cohomology.
The bi-grading yields two spectral sequences abutting to the Poisson cohomology. We focus on the case when the filtration is given by
$$F ^ { p } K ^ { n } = \oplus _ { p ^ { \prime } + q = n, p ^ { \prime } \geq p } A ^ { p ^ { \prime }, q }.$$
Equivalently, the zero-th sheet of this spectral sequence E p,q 0 is precisely A p,q . Since ∂ Λ = ∂ + ad Λ and ad Λ does not raise the second index in the bi-degree ( p, q ), the restriction of the differential on the 0-th sheet is
$$\overline { \partial } \colon A ^ { p, q } \rightarrow A ^ { p, q + 1 }.$$
Therefore, the first sheet of this spectral sequence is the Dolbeault cohomology
$$E _ { 1 } ^ { p, q } = H ^ { q } ( M, \Theta ^ { p } )$$
where Θ p is the p -th exterior power of the holomorphic tangent bundle of the complex manifold M .
It follows that the next sheet of this spectral sequence is given by the cohomology of the differential
$$d _ { 1 } ^ { p, q } = \text{ad} _ { \Lambda } \, \colon H ^ { q } ( M, \Theta ^ { p } ) \rightarrow H ^ { q } ( M, \Theta ^ { p + 1 } )$$
for all p + q ≥ 0, and the second sheet of this spectral sequence is
$$E _ { 2 } ^ { p, q } = \frac { \text{kernel of ad} _ { \Lambda } \, \colon H ^ { q } ( M, \Theta ^ { p } ) \rightarrow H ^ { q } ( M, \Theta ^ { p + 1 } ) } { \text{image of ad} _ { \Lambda } \, \colon H ^ { q } ( M, \Theta ^ { p - 1 } ) \rightarrow H ^ { q } ( M, \Theta ^ { p } ) }.$$
To facilitate further computation, we recall that the differential d p,q 2 is computed as follows. Suppose that ' v ' represents a class in H q ( M, Θ ) and ad p Λ v represents a zero class in H q ( M, Θ p +1 ), it represents an element in E p,q 2 . As ad Λ v represents a zero class, there exists ' w ' a section of T p +1 0 , M ⊗ T ∗ (0 ,q -1) M such that ∂w = ad Λ v . Since
$$\overline { \partial } { \text{ad} } _ { \Lambda } w = - { \text{ad} } _ { \Lambda } \overline { \partial } w = - { \text{ad} } _ { \Lambda } { \text{ad} } _ { \Lambda } v = 0,$$
ad Λ w represents a class in E p +2 ,q -1 2 . By definition, it is the image of the class of v via the map d p,q 2 .
## 2.4 Complex Projective Spaces as Examples
Let Λ be any non-trivial holomorphic section of the bundle Θ 2 of the complex projective space M = CP n . Assume that [ [Λ , Λ] ] = 0 so that Λ is a holomorphic Poisson structure. Since H q ( M, Θ ) vanishes for all p q ≥ 1, the first sheet of the holomorphic Poisson double complex is reduced to its zero-th row:
$$H ^ { 0 } ( M, \mathcal { O } ) \stackrel { d _ { 1 } ^ { 0, 0 } = a d _ { \Lambda } } { \longrightarrow } H ^ { 0 } \left ( M, \Theta \right ) \stackrel { d _ { 1 } ^ { 1, 0 } = a d _ { \Lambda } } { \longrightarrow } H ^ { 0 } \left ( M, \Theta ^ { 2 } \right ) \longrightarrow \ \cdots \cdot$$
It is apparent that d 1 is not identically equal to zero. It is also apparent that d 2 is identically equal to zero.
## 2.5 Hopf Manifolds M = S 1 × S 2 n -1
Consider C n with coordinates z = ( z , . . . , z 1 n ). Let λ > 1 be a real number. It generates a one-parameter group of automorphism on C n . The quotient of C n \{ } 0 with respect this group is diffeomorphic to the manifold M = S 1 × S 2 n -1 . The complex structure on C n descends onto M to define an integrable complex structure. As a complex manifold, it is a principal elliptic fibration over the complex projective space N = CP n -1 :
$$\pi \, \colon M = S ^ { 1 } \times S ^ { 2 n - 1 } \rightarrow N = \mathbb { C P } ^ { n - 1 }.$$
Denote the fiber by F and the holomorphic vertical vector field by V . We have the following exact sequence of holomorphic vector bundles over the Hopf manifold M :
$$0 \to \mathcal { O } _ { X } ( V ) \to \Theta _ { M } \to \pi ^ { * } \Theta _ { N } \to 0,$$
where O X ( V ) denote the vertical bundle of the projection π . It is also a bundle trivialized by the vector field V . Explicitly the vector field V is simply the holomorphic vector field generated by the group of dilations.
$$V = z _ { 1 } \frac { \partial } { \partial z _ { 1 } } + \dots + z _ { n } \frac { \partial } { \partial z _ { n } }.$$
For all 1 ≤ p ≤ n -1, the exact sequence (14) generates
$$0 \to \mathcal { O } _ { X } ( V ) \otimes \pi ^ { * } \Theta _ { N } ^ { p - 1 } \to \Theta _ { M } ^ { p } \to \pi ^ { * } \Theta _ { N } ^ { p } \to 0.$$
We also have O X ( V ) ⊗ π ∗ Θ n -1 N ∼ = Θ n M . Let ω = ∂ ln | z | 2 . It is a global ∂ -closed (0 , 1)-form on the Hopf manifold M .
## Proposition 2 On the Hopf manifold M ,
- · for all p ≥ 0 and q ≥ 2 , H q ( M, Θ p M ) = 0 .
- · H 0 ( M, O M ) = 〈 1 〉 , and H 1 ( M, O M ) = 〈 ω 〉 .
- · H 0 ( M, Θ n M ) = 〈 V 〉 ⊗ H 0 ( N, Θ n -1 N ) , H 1 ( M, Θ n M ) = 〈 ω ∧ V 〉 ⊗ H 0 ( N, Θ n -1 N ) .
- · For all 1 ≤ p ≤ n -1 ,
$$H ^ { 0 } ( M, \Theta _ { M } ^ { p } ) \ & = \ & H ^ { 0 } ( N, \Theta _ { N } ^ { p } ) \oplus \langle V \rangle \otimes H ^ { 0 } ( N, \Theta _ { N } ^ { p - 1 } ), \\ H ^ { 1 } ( M, \Theta _ { M } ^ { p } ) \ & = \ & \langle \overline { \omega } \rangle \otimes H ^ { 0 } ( M, \Theta _ { M } ^ { p } ) \\ & = \ & \langle \overline { \omega } \rangle \otimes H ^ { 0 } ( N, \Theta _ { N } ^ { p } ) \oplus \langle \overline { \omega } \wedge V \rangle \otimes H ^ { 0 } ( N, \Theta _ { N } ^ { p - 1 } ).$$
$$\Psi, \nabla _ { N } \oplus \{ \omega / \vee \vee \psi \, \{ \Psi, \nabla _ { N } \, \}.$$
The proof of this proposition is a straight-forward application of the Leray spectral sequence with respect to the fiberation π . Similar computation could be found in [10] and [15]. Below we outline a proof. First of all, by virtue of the dimension of the fiber and the global (0 , 1)-form ω on the manifold M , one proves that the direct image sheaves of R π q ∗ O M = 0 for q ≥ 2, and
$$R ^ { 0 } \pi _ { * } \mathcal { O } _ { M } \cong \mathcal { O } _ { N }, \ \ R ^ { 1 } \pi _ { * } \mathcal { O } _ { M } \cong \mathcal { O } _ { N } ( \overline { \omega } ).$$
By the Projective Formula, for all k ≥ 0, R π π q ∗ ∗ Θ k N = 0 for q ≥ 2, and
$$R ^ { 0 } \pi _ { * } \pi ^ { * } \Theta _ { N } ^ { k } \cong \Theta _ { N } ^ { k }, \ \ R ^ { 1 } \pi _ { * } \pi ^ { * } \Theta _ { N } ^ { k } \cong \mathcal { O } _ { N } ( \overline { \omega } ) \otimes \Theta _ { N } ^ { k }.$$
As the second sheet of the Leray spectral sequence for π ∗ Θ k N is
$$E _ { 2 } ^ { p, q } ( \pi ^ { * } \Theta _ { N } ^ { k } ) = H ^ { p } ( N, R ^ { q } \pi _ { * } \pi ^ { * } \Theta _ { N } ^ { k } ).$$
E p,q 2 = 0 for all q ≥ 2. Moreover,
$$E _ { 2 } ^ { p, 0 } ( \pi ^ { * } \Theta _ { N } ^ { k } ) = H ^ { p } ( N, \Theta _ { N } ^ { k } ), \ \ E _ { 2 } ^ { p, 1 } ( \pi ^ { * } \Theta _ { N } ^ { k } ) = \langle \overline { \omega } \rangle \otimes H ^ { p } ( N, \Theta _ { N } ^ { k } ).$$
Recall that N is the complex projective space CP n -1 . Therefore, the above cohomology spaces vanish except when p = 0. It follows immediately the differential d p,q 2 is identically zero, and hence the Leray spectral sequence degenerates to ⊕ p + = q m E p,q 2 ( π ∗ Θ ) = k N H m ( M,π ∗ Θ ). In particular, k N
$$H ^ { 0 } ( M, \pi ^ { * } \Theta _ { N } ^ { k } ) \cong H ^ { 0 } ( N, \Theta _ { N } ^ { k } ), \ \ H ^ { 1 } ( M, \pi ^ { * } \Theta _ { N } ^ { k } ) \cong \langle \overline { \omega } \rangle \otimes H ^ { 0 } ( N, \Theta _ { N } ^ { k } ). \quad ( 1 7 )$$
By the exact sequence (16), one concludes immediately, that for all p ≥ 0 and q ≥ 2, H q ( M, Θ p M ) = 0. By chasing diagram, one could actually show that the induced long exact sequence of (16) splits. The claim in the proposition above follows.
Given the proposition above, one notes that the non-zero terms of the first sheet of the Poisson double complex with respect to any holomorphic Poisson structure on the Hopf manifold are contained in the zero-th and the first rows only. To compute the differential on the second sheet explicitly, note that the first sheet is given by
$$\langle \overline { \omega } \rangle \ \stackrel { a d } { \rightarrow } \ \langle \overline { \omega } \rangle \otimes H ^ { 0 } ( M, \Theta _ { M } ) \ \stackrel { a d } { \rightarrow } \ \langle \overline { \omega _ { M } } \rangle \otimes H ^ { 0 } ( M, \Theta _ { M } ^ { 2 } ) \ \stackrel { a d } { \rightarrow } \ \langle \overline { \omega } \rangle \otimes H ^ { 0 } ( M, \Theta _ { M } ^ { 3 } ) \ \stackrel { a d } { \rightarrow }$$
$$\langle 1 \rangle \ \stackrel { a d } { \to } \quad H ^ { 0 } ( M, \Theta _ { M } ) \quad \stackrel { a d } { \to } \quad H ^ { 0 } ( M, \Theta _ { M } ^ { 2 } ) \quad \stackrel { a d } { \to } \quad H ^ { 0 } ( M, \Theta _ { M } ^ { 3 } ) \quad \stackrel { a d } { \to }$$
To prepare our computation, note that when we treat CP n -1 as a homogeneous space, then its space of holomorphic vector fields is sl ( n, C ). They are generated by linear action of SU n ( ) on C n .
Let A ∈ sl ( n, C ), and define on C n the function
$$f _ { A } ( z ) = \frac { 1 } { | z | ^ { 2 } } \overline { z } ^ { T } A z.$$
.
By homogeneity, this function is well-defined on the Hopf manifold M . It is straightforward to show that L A ω = ∂f A and L V f A = 0 .
Consider the bi-vector field Λ = V ∧ A. Since A and V commute, Λ is a holomorphic Poisson structure. We claim that its associated Poisson double complex degenerates at the E 2 -level.
Since the only non-trivial elements in the first sheet of the double complex are in the zero-th and the first row, E p,q 2 vanishes except possibly when ( p, q ) = ( p, 0) and ( p, q ) = ( p, 1) . Therefore, the only possibly non-trivial differential on the second sheet are d p, 1 2 . According to the structure of the cohomology spaces, each term in E p, 1 2 is represented by an element of the form ω ∧ Γ for some Γ in H 0 ( M, Θ ). Since p L V ( ω ) = 0 and L V (Γ) = 0,
$$& \left [ V \wedge A, \overline { \omega } \wedge \Gamma \right ] = V \wedge \left [ A, \overline { \omega } \wedge \Gamma \right ] = V \wedge \mathcal { L } _ { A } \overline { \omega } \wedge \Gamma + ( - 1 ) ^ { p } V \wedge \left [ A, \Gamma \right ] \wedge \overline { \omega } \\ = \ & V \wedge \overline { \partial } f _ { A } \wedge \Gamma + ( - 1 ) ^ { p } V \wedge \left [ A, \Gamma \right ] \wedge \overline { \omega } = - \overline { \partial } \left ( f _ { A } V \wedge \Gamma \right ) + ( - 1 ) ^ { p } V \wedge \left [ A, \Gamma \right ] \wedge \overline { \omega }.$$
So, ad Λ ( ω ∧ Γ) represents the zero class in 〈 ω 〉 ⊗ H 0 ( M, Θ p +1 ) if and only if [ [ A, Γ] ] is equal to zero. Under this condition, ad Λ ( ω ∧ Γ) = -∂ ( f A V ∧ Γ), and d p, 1 2 ( ω ∧ Γ) is represented by
$$- \text{ad} _ { \Lambda } ( f _ { \Lambda } V \wedge \Gamma ) = - [ V \wedge A, f _ { \Lambda } V \wedge \Gamma ] = A \wedge [ V, f _ { \Lambda } V \wedge \Gamma ] - V \wedge [ A, f _ { \Lambda } V \wedge \Gamma ] \\ = \ A \wedge ( \mathcal { L } _ { V } f _ { \Lambda } ) V \wedge \Gamma + A \wedge f _ { \Lambda } [ V, V \wedge \Gamma ] - V \wedge ( \mathcal { L } _ { A } f _ { \Lambda } ) V \wedge \Gamma - V \wedge f _ { \Lambda } [ A, V \wedge \Gamma ].$$
Note that the first summand is equal to zero because L V f A = 0. The second summand is equal to zero because V commutes with every element in H 0 ( M, Θ ). p The third summand is equal to zero by skew-symmetry of exterior multiplication. The last summand is equal to zero because as noted above when the term [ [ad Λ , ω ∧ Γ] ] represents the zero class in H 1 ( M, Θ p +1 ), [ [ A, Γ] ] = 0 . Therefore, d p, 1 2 = 0 for all p .
In the rest of this article, we investigate the degeneracy of holomorphic Poisson spectral sequence in various special settings.
## 3 Nilmanifolds
A compact manifold M is called a nilmanifold if there exists a simply-connected nilpotent Lie group G and a lattice subgroup Γ such that M is diffeomorphic to G/ Γ. We denote the Lie algebra of G by g , and the center of g by Z ( g ). The step of the nilmanifold is the nilpotence of the Lie algebra g . A left-invariant complex structure J on G is said to be abelian if on the Lie algebra g , it satisfies the conditions J ◦ J = -identity and [ [ JA,JB ] ] = [ [ A, B ] ] for all A and B in the Lie algebra g . If one complexifies the algebra g and denotes the + i and -i eigen-spaces of J respectively by g 1 0 , and g 0 1 , , then the invariant complex structure J being abelian is equivalent to the complex algebra g 1 0 , being abelian.
Denote ∧ k g 1 0 , and ∧ k g ∗ (0 1) , respectively by g k, 0 and g ∗ (0 ,k ) .
## 3.1 Cohomology of Nilmanifolds
Now assume that the Lie algebra g is 2-step nilpotent, i.e. [ g g , ] ⊂ Z ( g ). In such a case, we call M = G/ Γ a 2-step nilmanifold [19].
On the nilmanifold M , we consider g k, 0 as invariant ( k, 0)-vector fields, and g ∗ (0 ,k ) as invariant (0 , k )-forms. It yields an inclusion map
$$\mathfrak { g } ^ { p, 0 } \otimes \mathfrak { g } ^ { * ( 0, q ) } \hookrightarrow C ^ { \infty } ( M, \wedge ^ { p } T ^ { 1, 0 } M \otimes \wedge ^ { q } T ^ { * ( 0, 1 ) } M ).$$
When the complex structure is also invariant, ∂ sends g p, 0 ⊗ g ∗ (0 ,q ) to g p, 0 ⊗ g ∗ (0 ,q +1) .
The concerned cohomology is
$$H ^ { q } ( \mathfrak { g } ^ { p, 0 } ) = \frac { \text{kernel of } \overline { \partial } \, \colon \mathfrak { g } ^ { * ( 0, q ) } \otimes \mathfrak { g } ^ { p, 0 } \to \mathfrak { g } ^ { * ( 0, q + 1 ) } \otimes \mathfrak { g } ^ { p, 0 } } { \text{image of } \overline { \partial } \, \colon \mathfrak { g } ^ { * ( 0, q - 1 ) } \otimes \mathfrak { g } ^ { p, 0 } \to \mathfrak { g } ^ { * ( 0, q ) } \otimes \mathfrak { g } ^ { p, 0 } }.$$
The inclusion map yields an inclusion of cohomology:
$$H ^ { q } ( \mathfrak { g } ^ { p, 0 } ) \hookrightarrow H ^ { q } ( M, \Theta ^ { p } ).$$
Theorem 1 On a 2-step nilmanifold M with an invariant abelian complex structure, the inclusion g p, 0 ⊗ g ∗ (0 ,q ) in C ∞ ( M, ∧ p T 1 0 , M ⊗ ∧ q T ∗ (0 1) , M ) induces an isomorphism of cohomology. In other words,
$$H ^ { q } ( \mathfrak { g } ^ { p, 0 } ) \cong H ^ { q } ( M, \Theta ^ { p } ).$$
We need some preparations before we give a proof for this theorem.
Let C be the center of G and ψ : G → G/C the quotient map. Since G is 2-step nilpotent, G/C is abelian. Consider M = G/ Γ and N = ψ G /ψ ( ) (Γ). We have a holomorphic fibration Ψ : M → N whose fiber is isomorphic to F = C/ C ( ∩ Γ).
Let c = Z ( g ), t = g /Z ( g ). Below are some facts shown in Sections 2 and 3 of [19]. Since g is 2-step nilpotent, t is abelian. As a vector space, g 1 0 , = t 1 0 , ⊕ c 1 0 , , and g ∗ (1 0) , = t ∗ (1 0) , ⊕ c ∗ (1 0) , . The only nontrivial Lie brackets in g 1 0 , ⊕ g 0 1 , are of the form [ t 1 0 , , t 0 1 , ] ⊂ c 1 0 , ⊕ c 0 1 , .
Explicitly, there exists a real basis { X , JX k k : 1 ≤ k ≤ n } for t and { Z , JZ /lscript /lscript : 1 ≤ /lscript ≤ m } a real basis for c . The corresponding complex bases for t 1 0 , and c 1 0 , are respectively composed of the following elements:
$$T _ { k } = \frac { 1 } { 2 } ( X _ { k } - i J X _ { k } ), \quad \text{and} \quad W _ { \ell } = \frac { 1 } { 2 } ( Z _ { \ell } - i J Z _ { \ell } ).$$
The structure equations of g are determined by
$$\lambda _ { 1 } \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \ dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots\dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \delta \delta \delta \delta \delta \delta \delta \delta \delta \delta \delta \delta \delta \delta \delta \delta \delta \delta \delta \delta \delta \delta \delta \delta \delta \delta \delta \delta \delta \delta \delta \delta \delta \delta \delta \delta \delta \delta \delta \delta \delta \delta \delta \delta \delta \delta \delta \delta \delta \delta \delta \delta \delta \delta \delta \delta \delta \delta \delta \delta \delta \delta \delta \delta \delta \delta \delta \ delta \delta \delta \delta \delta \delta \delta \delta \delta \delta \delta \delta \delta \delta \delta \delta \delta \delta \delta \delta \delta \delta \delta \delta \delta \delta \delta \delta \delta \delta \delta \delta \delta \delta \delta \delta \delta \delta \delta \delta \delta \delta \delta \delta \delta \delta \delta \delta \delta \delta \delta \delta \delta \delta \delta \delta \delta \delta \delta \delta \delta \delta \delta \delta \delta \delta \delta delta \delta \delta \delta \delta \delta \delta \delta \delta \delta \delta \delta \delta \delta \delta \delta \delta \delta \delta \delta \delta \delta \delta \delta \delta \delta \delta \delta \delta \delta \delta \delta \delta \delta \delta \delta \delta \delta \delta \delta \delta \delta \delta \delta \delta \delta \delta \delta \delta \delta \delta \delta \delta \delta \delta \delta \delta \delta \delta \delta \delta \delta \delta \delta \delta \delta \d� \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \sigma \delta \delta \delta \delta \delta \delta \delta \delta \delta \delta \delta \delta \delta \delta \delta \delta \delta \delta \delta \delta \delta \delta \delta \delta \delta \delta \delta \delta \delta \delta \delta \delta \delta \delta \delta \delta \delta \delta \delta \delta \delta \delta \delta \delta \delta \delta \delta \delta \delta \delta \delta \delta \delta \delta \delta \delta \delta \delta \delta \delta \delta \delta \delta \delta \delta \delta \Delta \delta \delta \delta \delta \delta \delta \delta \delta \delta \delta \delta \delta \delta \delta \delta \delta \delta \delta \delta \delta \delta \delta \delta \delta \delta \delta \delta \delta \delta \delta \delta \delta \delta \delta \delta \delta \delta \delta \delta \delta \delta \delta \delta \delta \delta \delta \delta \delta \delta \delta \delta \delta \delta \delta \delta \delta \delta \delta \delta \delta \delta \delta \delta \delta \delta \delta$$
for some constants E /lscript kj . Let { ω k : 1 ≤ k ≤ n } be the dual basis for t ∗ (1 0) , , and let { ρ /lscript : 1 ≤ /lscript ≤ m } be the dual basis for c ∗ (1 0) , . By formula (4),
$$\widehat { \partial } & \Gamma _ { j } = \sum _ { k, \ell } E _ { k j } ^ { \ell } \overline { \omega } ^ { k } \wedge W _ { \ell }, \\ \widehat { \partial } & \Gamma _ { j } = \sum _ { k, \ell } E _ { k j } ^ { \ell } \overline { \omega } ^ { k } \wedge W _ { \ell },$$
The dual structure equations for (20) are
$$\Phi _ { \Phi } ^ { \ell } = \sum _ { i, j } E ^ { \ell } _ { j i } \omega ^ { i } \wedge \overline { \omega } ^ { j }.$$
Equivalently,
It follows that
$$d \overline { \rho } ^ { \ell } = - \sum _ { i, j } \overline { E } ^ { \ell } _ { j i } \omega ^ { j } \wedge \overline { \omega } ^ { i }.$$
$$[ T _ { j }, \overline { \rho } ^ { \ell } ] = \mathcal { L } _ { T _ { j } } \overline { \rho } ^ { \ell } = - \sum _ { i } \overline { E } ^ { \ell } _ { j i } \overline { \omega } ^ { i }. \\ \therefore \text{ operator } d = \partial + \bar { \partial } \text{ satisfies}$$
In summary, the operator d = ∂ + ¯ satisfies ∂
$$\partial \tilde { t } ^ { * ( 1, 0 ) } = 0, \quad \bar { \partial } \tilde { t } ^ { * ( 1, 0 ) } = 0, \quad \partial \tilde { c } ^ { * ( 1, 0 ) } = 0, \quad \bar { \partial } \tilde { c } ^ { * ( 1, 0 ) } \subset \mathfrak { t } ^ { * ( 1, 1 ) }. \quad ( 2 5 )$$
Moreover, the co-boundary operator ¯ : ∂ g 1 0 , → g ∗ (0 1) , ⊗ g 1 0 , satisfies
$$\bar { \partial } \mathfrak { c } ^ { 1, 0 } = 0, \quad \bar { \partial } \mathfrak { t } ^ { 1, 0 } \subset \mathfrak { t } ^ { * ( 0, 1 ) } \otimes \mathfrak { c } ^ { 1, 0 }.$$
Lemma 3 Let Θ N be the tangent sheaf of N , the quotient manifold. Then R q Ψ ( ∗ ∧ l Ψ Θ ∗ N ) = c ∗ (0 ,q ) ⊗∧ l Θ N .
Proof: By Lemma 4 in [19], we have R q Ψ ( ∗ O M ) = c ∗ (0 ,q ) ⊗ O N . Thus, by the projective formula,
$$R ^ { q } \Psi _ { * } ( \wedge ^ { l } \Psi ^ { * } \Theta _ { N } ) = R ^ { q } \Psi _ { * } ( \Psi ^ { * } \wedge ^ { l } \Theta _ { N } ) = R ^ { q } \Psi _ { * } ( \mathcal { O } _ { M } ) \otimes \wedge ^ { l } \Theta _ { N } = \mathfrak { c } ^ { * ( 0, q ) } \otimes \wedge ^ { l } \Theta _ { N }.$$
$$\text{Lemma } 4 \ H ^ { k } ( N, \wedge ^ { l } \Theta _ { N } ) = \mathfrak { t } ^ { * ( 0, k ) } \otimes \mathfrak { t } ^ { l, 0 }, \text{ and } H ^ { k } ( M, \wedge ^ { l } \Psi ^ { * } \Theta _ { N } ) = \mathfrak { g } ^ { * ( 0, k ) } \otimes \mathfrak { t } ^ { l, 0 }.$$
Proof: The proof is essentially the same as that of Lemma 5 in [19]. Here we give a sketch. First note that N is an abelian variety. It follows that Θ N is holomorphically trivial, and is isomorphic to t 1 0 , . Therefore, H k ( N, ∧ l Θ ) = N t ∗ (0 ,k ) ⊗ t l, 0 .
To compute H k ( M, ∧ l Ψ Θ ∗ N ), we use the standard Leray spectral sequence for the fibration Ψ. By the previous lemma, the second sheet is given by
$$E _ { 2 } ^ { p, q } & = H ^ { p } ( N, R ^ { q } \Psi _ { * } ( \wedge ^ { l } \Psi ^ { * } \Theta _ { N } ) ) = H ^ { p } ( N, \mathfrak { c } ^ { * ( 0, q ) } \otimes \wedge ^ { l } \Theta _ { N } ) \\ & = \mathfrak { c } ^ { * ( 0, q ) } \otimes H ^ { p } ( N, \wedge ^ { l } \Theta _ { N } ) = \mathfrak { c } ^ { * ( 0, q ) } \otimes \mathfrak { t } ^ { * ( 0, p ) } \otimes \mathfrak { t } ^ { l, 0 }.$$
Thus d 2 : E p,q 2 → E p +2 ,q -1 2 is a map
$$\mathfrak { c } ^ { * ( 0, q ) } \otimes \mathfrak { t } ^ { * ( 0, p ) } \otimes \mathfrak { t } ^ { l, 0 } \to \mathfrak { c } ^ { * ( 0, q - 1 ) } \otimes \mathfrak { t } ^ { * ( 0, p + 2 ) } \otimes \mathfrak { t } ^ { l, 0 }.$$
But d 2 is essentially given by ¯ . ∂ Equalities (25) and (26) imply that d 2 = 0. It follows that
$$H ^ { k } ( M, \wedge ^ { l } \Psi ^ { * } \Theta _ { N } ) & = \oplus _ { p + q = k } E _ { 2 } ^ { p, q } = \oplus _ { p + q = k } \mathfrak { c } ^ { * ( 0, q ) } \otimes \mathfrak { t } ^ { * ( 0, p ) } \otimes \mathfrak { t } ^ { l, 0 } \\ & = \mathfrak { g } ^ { * ( 0, k ) } \otimes \mathfrak { t } ^ { l, 0 }.$$
## Lemma 5 Suppose that
$$0 \to Z \to E \stackrel { \rho } { \longrightarrow } Q \to 0$$
is an exact sequence of holomorphic vector bundles. Then there induces a series of exact sequences
$$0 \to E ^ { ( 1 ) } \to \wedge ^ { l } E \to \wedge ^ { l } Q ; \\ 0 \to E ^ { ( 2 ) } \to E ^ { ( 1 ) } \to \wedge ^ { l - 1 } Q \otimes Z ; \\ \dots \dots \dots \\ 0 \to E ^ { ( r + 1 ) } \to E ^ { ( r ) } \to \wedge ^ { l - r } Q \otimes \wedge ^ { r } Z ; \\ \dots \dots \dots \\ 0 \to E ^ { ( l ) } \to E ^ { ( l - 1 ) } \to Q \otimes \wedge ^ { l - 1 } Z,$$
where E ( ) l = ∧ l Z .
Proof: For any m ≥ 0 and n ≥ 0, we define a derivative operator D ρ : ∧ m Q ⊗∧ n E → ∧ m +1 Q ⊗∧ n -1 E by
Now consider
$$& D _ { \rho } ( q _ { 1 } \wedge \cdots \wedge q _ { m } \otimes e _ { 1 } \wedge \cdots \wedge e _ { n } ) \\ = & \sum _ { i = 1 } ^ { n } ( - 1 ) ^ { i - 1 } q _ { 1 } \wedge \cdots \wedge q _ { m } \wedge \rho ( e _ { i } ) \otimes e _ { 1 } \wedge \cdots \widehat { e } _ { i } \cdots \wedge e _ { n }. \\ \text{consider} & \quad \mathcal { D } ^ { l } \. \ \wedge ^ { l } \mathcal { E } \ \ \cdots \ \wedge ^ { l } \mathcal { O }$$
$$D _ { \rho } ^ { l } \colon \wedge ^ { l } E \rightarrow \wedge ^ { l } Q.$$
Let E (1) = Ker D l ρ . Similarly, for each r = 1 , · · · , l , we consider
$$D _ { \rho } ^ { r } \colon \wedge ^ { l } E \to \wedge ^ { l + r } Q \otimes \wedge ^ { l - r } E,$$
and let E ( l -r +1) = Ker D r ρ . It is obvious that ∧ l Z = E ( ) l ⊂ E ( l -1) ⊂ · · · ⊂ E (1) . The fact that E ( r ) /E ( r +1) ∼ = ∧ l -r Q ⊗∧ r Z is also easily seen.
Proof: [of Theorem 1] Let E = Θ M , Z = O M ⊗ c 1 0 , , Q = Ψ Θ ∗ N . Then we have the following exact sequence of holomorphic vector bundles:
$$0 \to Z \to E \stackrel { \rho } { \longrightarrow } Q \to 0.$$
By Lemma 5, we have a filtration of ∧ l E = ∧ l Θ M :
$$\mathcal { O } _ { M } \otimes \mathfrak { c } ^ { l, 0 } = \wedge ^ { l } Z = E ^ { ( l ) } \subset E ^ { ( l - 1 ) } \subset \cdots \subset E ^ { ( 1 ) } \subset E ^ { ( 0 ) } = \wedge ^ { l } E = \wedge ^ { l } \Theta _ { M }.$$
Moreover, the associated graded spaces are:
$$G ^ { 0 } = E ^ { ( 0 ) } / E ^ { ( 1 ) } \cong \wedge ^ { l } Q = \Psi ^ { * } ( \wedge ^ { l } \Theta _ { N } ) ;$$
$$G ^ { 0 } = E ^ { ( 0 ) } / E ^ { ( 1 ) } \cong \wedge ^ { l } Q = \Psi ^ { * } ( \wedge ^ { l } \Theta _ { N } ) ; \\ G ^ { 1 } = E ^ { ( 1 ) } / E ^ { ( 2 ) } \cong \wedge ^ { l - 1 } Q \otimes Z = \Psi ^ { * } ( \wedge ^ { l - 1 } \Theta _ { N } ) \otimes \mathfrak { c } ^ { 1, 0 } ;$$
· · · · · · · · ·
$$G ^ { r } = E ^ { ( r ) } / E ^ { ( r + 1 ) } = \wedge ^ { l - r } Q \otimes \wedge ^ { r } Z = \Psi ^ { * } ( \wedge ^ { l - r } \Theta _ { N } ) \otimes \mathfrak { c } ^ { r, 0 } ; \\ \cdots \cdots \cdots$$
$$G ^ { l - 1 } = E ^ { ( l - 1 ) } / E ^ { ( l ) } \cong Q \otimes \wedge ^ { l - 1 } Z = \Psi ^ { * } ( \Theta _ { N } ) \otimes \mathfrak { c } ^ { l - 1, 0 }.$$
Accordingly, we have a filtration of the co-chain complex C · = T ∗ (0 , · ) ⊗∧ l Θ M :
$$T ^ { * ( 0, \bullet ) } \otimes \mathfrak { c } ^ { l, 0 } = \mathcal { F } ^ { ( l ) } C ^ { \bullet } \subset \mathcal { F } ^ { ( l - 1 ) } C ^ { \bullet } \subset \cdots \subset \mathcal { F } ^ { ( 1 ) } C ^ { \bullet } \subset \mathcal { F } ^ { ( 0 ) } C ^ { \bullet } = C ^ { \bullet },$$
where F ( r ) C · = T ∗ (0 , · ) ⊗ E ( r ) . Thus there associates a spectral sequence: E p,q r , which starts with
$$E _ { 0 } ^ { p, q } = \mathcal { F } ^ { ( p ) } C ^ { p + q } / \mathcal { F } ^ { ( p + 1 ) } C ^ { p + q } = T ^ { * ( 0, \bullet ) } \otimes G ^ { p } \cong T ^ { * ( 0, \bullet ) } \otimes \Psi ^ { * } ( \wedge ^ { l - p } \Theta _ { N } ) \otimes \mathfrak { c } ^ { p, 0 }$$
and d 0 = ¯ . ∂ It follows from Lemma 4 that we have
$$E _ { 1 } ^ { p, q } = H ^ { p + q } ( G ^ { p } ) = H ^ { p + q } ( \Psi ^ { * } ( \wedge ^ { l - p } \Theta _ { N } ) \otimes \mathfrak { c } ^ { p, 0 } ) = \mathfrak { g } ^ { * ( 0, p + q ) } \otimes \mathfrak { t } ^ { l - p, 0 } \otimes \mathfrak { c } ^ { p, 0 }.$$
The associated d 1 : E p,q 1 → E p +1 ,q 1 should be exactly
$$\bar { \partial } \colon \mathfrak { g } ^ { * ( 0, p + q ) } \otimes \mathfrak { t } ^ { ( l - p, 0 ) } \otimes \mathfrak { c } ^ { ( p, 0 ) } \to \mathfrak { g } ^ { * ( 0, p + 1 + q ) } \otimes \mathfrak { t } ^ { ( l - p - 1, 0 ) } \otimes \mathfrak { c } ^ { ( p + 1, 0 ) }.$$
Here we use the fact that g is 2-step nilpotent, namely the relations in (25) and (26). Hence
$$E _ { 2 } ^ { p, q } = H _ { d _ { 1 } } ^ { p + q } ( E ^ { p, q } \to E ^ { p + 1, q } ) = \frac { \text{Ker} ( \bar { \partial } ) \cap \mathfrak { g } ^ { * ( 0, p + q ) } \otimes \mathfrak { t } ^ { ( l - p, 0 ) } \otimes \mathfrak { c } ^ { ( p, 0 ) } } { \bar { \partial } ( \mathfrak { g } ^ { * ( 0, p - 1 + q ) } \otimes \mathfrak { t } ^ { ( l - p + 1, 0 ) } \otimes \mathfrak { c } ^ { ( p - 1, 0 ) } ) }.$$
The operator d 2 : E p,q 2 → E p +2 ,q -1 2 is essentially that of ¯ . ∂ So the previous expression implies that d 2 = 0. So E p,q 2 = E p,q ∞ . Therefore, one has
$$\begin{array} { c } \dashrightarrow \substack { r \choose r \choose \cdots } \substack { \cdot \, - } _ { 2 } \cdot \, - \, \cdot \, - \, \cdot \, - \, \cdot \, - \, \cdot \, - \, \cdot \, - \, r \choose \cdots } \, r \choose \cdots \\ \text{expression implies that } d _ { 2 } = 0. \ \text{So } E _ { 2 } ^ { p, q } = E _ { \infty } ^ { p, q }. \ \text{Therefore, one has} \\ \\ H ^ { k } ( \wedge ^ { l } \Theta _ { M } ) = H _ { \theta } ^ { k } ( C ^ { \bullet } ) \cong \bigoplus _ { p + q = k } E _ { 2 } ^ { p, q } \\ \\ = \ \bigoplus _ { p + q = k } \frac { \text{Ker} ( \bar { \partial } ) \cap \mathfrak { g } ^ { * ( 0, p + q ) } \otimes t ^ { l - p, 0 } \otimes \mathfrak { c } ^ { p, 0 } } { \partial ( \mathfrak { g } ^ { * ( 0, p - 1 + q ) } \otimes t ^ { l - p + 1, 0 } \otimes \mathfrak { c } ^ { p - 1, 0 } ) } = \bigoplus _ { p } \frac { \text{Ker} ( \bar { \partial } ) \cap \mathfrak { g } ^ { * ( 0, k ) } \otimes t ^ { l - p, 0 } \otimes \mathfrak { c } ^ { p, 0 } } { \partial ( \mathfrak { g } ^ { * ( 0, k - 1 ) } \otimes t ^ { l - p + 1, 0 } \otimes \mathfrak { c } ^ { p - 1, 0 } ) } \\ \\ = \ \overline { \text{Ker} ( \bar { \partial } ) \cap ( \bigoplus _ { p } \mathfrak { g } ^ { * ( 0, k ) } \otimes t ^ { l - p, 0 } \otimes \mathfrak { c } ^ { p, 0 } ) } = \ \text{Ker} ( \bar { \partial } ) \cap \mathfrak { g } ^ { * ( 0, k ) } \otimes \mathfrak { g } ^ { l, 0 } } { \partial ( \mathfrak { g } ^ { * ( 0, k - 1 ) } \otimes \mathfrak { g } ^ { l, 0 } ) } \\ = \ H _ { \theta } ^ { k } ( \mathfrak { g } ^ { l, 0 } ), \\ \end{array}$$
as required.
## 3.2 Degeneracy of Holomorphic Poisson Double Complex
As a consequence of Theorem 1,
$$E _ { 2 } ^ { p, q } = \frac { \text{kernel of ad} _ { \Lambda } \, \colon H ^ { q } ( \mathfrak { g } ^ { p, 0 } ) \rightarrow H ^ { q } ( \mathfrak { g } ^ { p + 1, 0 } ) } { \text{image of ad} _ { \Lambda } \, \colon H ^ { q } ( \mathfrak { g } ^ { p - 1, 0 } ) \rightarrow H ^ { q } ( \mathfrak { g } ^ { p, 0 } ) }$$
where H q ( g p, 0 ) is given in (18).
As an application, we consider the case when the nilmanifold is 2-step with real two-dimensional center. Since
$$\mathfrak { g } ^ { 1, 0 } = \mathfrak { t } ^ { 1, 0 } \oplus \mathfrak { c } ^ { 1, 0 } \quad \text{and} \quad \mathfrak { g } ^ { * ( 0, 1 ) } = \mathfrak { t } ^ { * ( 0, 1 ) } \oplus \mathfrak { c } ^ { * ( 0, 1 ) },$$
and the complex dimension of c 1 0 , is equal to one,
$$\mathfrak { g } ^ { p, 0 } = \mathfrak { t } ^ { p, 0 } \oplus \mathfrak { t } ^ { p - 1, 0 } \otimes \mathfrak { c } ^ { 1, 0 }, \quad \mathfrak { g } ^ { * ( 0, q ) } = \mathfrak { t } ^ { * ( 0, q ) } \oplus \mathfrak { t } ^ { * ( 0, q - 1 ) } \otimes \mathfrak { c } ^ { * ( 0, 1 ) }.$$
Lemma 6 g ∗ (0 1) , c 1 0 , and t 1 0 , t ∗ (0 1) , c 1 0 , .
$$\text{Lemma} & \, 6 \, \mathfrak { g } ^ { * ( 0, 1 ) } \oplus \mathfrak { c } ^ { 1, 0 } \subseteq \ker \overline { \partial } \ a n d \ \overline { \partial } \mathfrak { t } ^ { 1, 0 } \subseteq \mathfrak { t } ^ { * ( 0, 1 ) } \otimes \mathfrak { c } ^ { 1, 0 }. \ M o r e o v e r, \\ & \, \overline { \partial } ( \mathfrak { t } ^ { * ( 0, a ) } \otimes \mathfrak { c } ^ { * ( 0, b ) } \otimes \mathfrak { t } ^ { k, 0 } \otimes \mathfrak { c } ^ { \ell, 0 } ) \subseteq \mathfrak { t } ^ { * ( 0, a + 1 ) } \otimes \mathfrak { c } ^ { * ( 0, b ) } \otimes \mathfrak { t } ^ { k - 1, 0 } \otimes \mathfrak { c } ^ { \ell + 1, 0 }.$$
In subsequent presentation, we suppress the notations for the vector spaces, and simply keep track of the quadruple of indices to indicate the components. With this notation, the statement above is summarized as
$$\overline { \partial } ( a, b ; k, \ell ) \subseteq ( a + 1, b ; k - 1, \ell + 1 ).$$
Due to dimensional assumption on c 1 0 , , when /lscript ≥ 1, then the space ( a + 1 , b ; k -1 , /lscript +1) is trivial.
Next, we turn our attention to the effect of an invariant holomorphic Poisson structure. Given the dimension restriction on c 1 0 , , g 2 0 , = c 1 0 , ⊗ t 1 0 , ⊕ t 2 0 , . With regard to this decomposition, any Λ in g 2 0 , is the sum of Λ 1 and Λ 2 where, Λ 1 = W ∧ T with W ∈ c 1 0 , , T ∈ t 1 0 , , and Λ 2 is in t 2 0 , .
Since the complex structure is abelian, [ [Λ , g 1 0 , ] ] = 0. One could also see from the structure equations (22) that [ [Λ , ω k ] ] = 0. By (24),
$$[ \Lambda _ { 1 }, \overline { \rho } ] = W \wedge [ T, \overline { \rho } ] \subseteq \mathfrak { t } ^ { * ( 0, 1 ) } \otimes \mathfrak { c } ^ { 1, 0 }.$$
Lemma 7 When Λ = Λ 1 +Λ 2 , then ad Λ ( g 1 0 , ) = 0 , ad Λ ( t ∗ (0 1) , ) = 0 , and
$$\ a d _ { \Lambda _ { 1 } } ( \mathfrak { c } ^ { * ( 0, 1 ) } ) \subseteq \mathfrak { t } ^ { * ( 0, 1 ) } \otimes \mathfrak { c } ^ { 1, 0 }, \quad a d _ { \Lambda _ { 2 } } ( \mathfrak { c } ^ { * ( 0, 1 ) } ) \subseteq \mathfrak { t } ^ { * ( 0, 1 ) } \otimes \mathfrak { t } ^ { 1, 0 }.$$
As a consequence of the above lemma, ad Λ 1 ( t ∗ (0 ,a ) ⊗ c ∗ (0 ,b ) ⊗ t k, 0 ⊗ c /lscript, 0 ) is contained in t ∗ (0 ,a +1) ⊗ c ∗ (0 ,b -1) ⊗ t k, 0 ⊗ c /lscript +1 0 , , and ad Λ 2 ( t ∗ (0 ,a ) ⊗ c ∗ (0 ,b ) ⊗ t k, 0 ⊗ c /lscript, 0 ) is contained in t ∗ (0 ,a +1) ⊗ c ∗ (0 ,b -1) ⊗ t k +1 0 , ⊗ c /lscript, 0 . Using our shorthand notations, we have
$$a d _ { \Lambda _ { 1 } } ( a, b ; k, \ell ) = ( a + 1, b - 1 ; k, \ell + 1 ), \ \ a d _ { \Lambda _ { 2 } } ( a, b ; k, \ell ) = ( a + 1, b - 1 ; k + 1, \ell ). \ ( 3 2 )$$
As the range of ad Λ 1 and ad Λ 2 are in different spaces,
$$\ker \text{ad} _ { \Lambda } = \ker \text{ad} _ { \Lambda _ { 1 } } \cap \ker \text{ad} _ { \Lambda _ { 2 } }.$$
Theorem 2 Suppose that M = G/ Γ is a 2-step nilmanifold with an abelian complex structure. Suppose that the center of g is real two-dimensional, then for any invariant holomorphic Poisson structure Λ , the Poisson spectral sequence degenerates on the second sheet.
We need to prove that d p,q 2 ≡ 0 for all p, q . Given the dimension assumption on c 1 0 , , Using our shorthand notations, the space g ∗ (0 ,q ) ⊗ g p, 0 decomposes into four components:
$$( q, 0 ; p, 0 ) ; \ \ ( q - 1, 1 ; p, 0 ) ; \ \ ( q, 0 ; p - 1, 1 ) ; \ \ ( q - 1, 1 ; p - 1, 1 ).$$
Suppose that A is in g ∗ (0 ,q ) ⊗ g p, 0 and ∂A = 0. Consider ad Λ ( A ) = ad Λ 1 A + ad Λ 2 A . By (32), ( q, 0; p, 0), ( q, 0; p -1 1) and ( , q -1 1; , p -1 1) are in ker , ad Λ 1 , and
$$a d _ { \Lambda _ { 1 } } ( A ) \in a d _ { \Lambda _ { 1 } } \mathfrak { g } ^ { * ( 0, q ) } \otimes \mathfrak { g } ^ { p, 0 } = a d _ { \Lambda _ { 1 } } ( q - 1, 1 ; p, 0 ) \subseteq ( q, 0 ; p, 1 ).$$
Similarly, ( q, 0; p, 0) and ( q, 0; p -1 1) are in ker , ad Λ 2 , and
$$& \ a d _ { \Lambda _ { 2 } } ( A ) \in a d _ { \Lambda _ { 2 } } \mathfrak { g } ^ { * ( 0, q ) } \otimes \mathfrak { g } ^ { p, 0 } \\ = & \ \ a d _ { \Lambda _ { 2 } } ( q - 1, 1 ; p, 0 ) \oplus a d _ { \Lambda _ { 2 } } ( q - 1, 1 ; p - 1, 1 ) \subseteq ( q, 0 ; p + 1, 0 ) \oplus ( q, 0 ; p, 1 ).$$
ad Λ ( A ) represents a zero class in H q ( g p +1 ) if and only if there exists B such that ad Λ ( A ) = ∂B . By (29), the image of ∂ is contained in the components ( a, b ; k, 1) for some a, b, k . From the above observation on ad Λ 1 ( A ) + ad Λ 2 ( A ), such B exists only if ad Λ ( A ) ∈ ( q, 0; p, 1). Furthermore by (29) again, B is contained in the component ( q -1 0; , p +1 0); which is contained in , t ∗ (0 ,q -1) ⊗ t p +1 0 , . Then d A 2 is represented by ad Λ ( B ). However, by Lemma 7, ( q -1 0; , p +1 0) is in the kernel of both , ad Λ 1 and ad Λ 2 . Therefore, d 2 ≡ 0 as claimed.
## 3.3 Examples
We consider examples of holomorphic Poisson structures that satisfies the conditions in Theorem 2. In particular, let W be an element in c 1 0 , and T an element in t 1 0 , . Define Λ = W ∧ T . Since ∂ (0 , 0; 1 , 1) ⊆ (1 , 0; 0 , 2) by (29), the dimension restriction implies that Λ is holomorphic. As the complex structure is abelian, Λ is Poisson.
The first example of non-abelian nilmanifold is the Kodaira surface. As a nilmanifold, it is covered by the product of the real three-dimensional Heisenberg group H 3 and the one-dimensional trivial additive group R 1 . Computation on this manifold was done extensively in [22]. It is known to have an invariant holomorphic symplectic structure. Using the usual transformation from symplectic structure to Poisson structure, one obtains a holomorphic Poisson structure on such a Kodaira surface such that the Poisson bi-vector field is of the type W ∧ T , and hence satisfies the conditions in Theorem 2. We skip the details for this case, and refer readers to [22].
Six-dimensional 2-step nilmanifolds with abelian complex structures were studied extensively in [5] [19] [26]. The underlying algebraic structure is classified. In particular, let R n denotes the n -dimensional abelian group and H n the n -dimensional real Heisenberg group, then the 2-step nilpotent groups with abelian complex structures are R 6 , H 3 × R 3 , H 5 × R 1 , H 3 × H 3 , the real six-dimensional Iwasawa group W 6 and one additional group P 6 which we will describe with a little more details below. Since R 6 is abelian and H 3 × R 3 covers the product of a Kodaira surface and an elliptic curve, they are not new examples in a strict sense. We consider the four remaining cases in their respective series in all admisssible dimensions, namely H 2 n +1 × R 1 , H 2 n +1 × H 2 m +1 , W 4 n +2 and P 4 n +2 . We demonstrates that they will each provide an example for Theorem 2.
## 3.3.1 H 2 n +1 × R 1
Let { X , Y , Z , Z k k 1 2 : 1 ≤ k ≤ n } be a basis of a (2 n +2)-dimensional vector space g . Define a Lie bracket by
$$[ X _ { k }, Y _ { k } ] = - [ Y _ { k }, X _ { k } ] = Z _ { 1 }, \ \ [ X _ { k }, Z _ { 1 } ] = [ Y _ { k }, Z _ { 1 } ] = 0, \\ [ X _ { k }, Z _ { 2 } ] = [ Y _ { k }, Z _ { 2 } ] = [ Z _ { 1 }, Z _ { 2 } ] = 0$$
for all k . Then { X , Y , Z k k 1 : 1 ≤ k ≤ n } span the (2 n +1)-dimensional Heisenberg algebra h 2 n +1 . With Z 2 , g is the one-dimensional trivial extension of the Heisenberg algebra. Its center is spanned by Z 1 and Z 2 . Now, define a linear map by
$$J X _ { k } = Y _ { k }, \ \ J Y _ { k } = - X _ { k }, \ \ J Z _ { 1 } = Z _ { 2 }, \ \ J Z _ { 2 } = - Z _ { 1 }.$$
It defines an abelian complex structure.
$$3. 3. 2 \ \ H _ { 2 n + 1 } \times H _ { 2 m + 1 }$$
Let { X , Y , Z k k 1 : 1 ≤ k ≤ n } be a basis for the (2 n + 1)-dimensional Heisenberg algebra h 2 n +1 as in (33). Let { U , V , Z /lscript /lscript 2 : 1 ≤ /lscript ≤ m } be a basis for a 2 m + 1dimensional Heisenberg algebra h 2 m +1 so that [ [ U , V /lscript /lscript ] ] = Z 2 for all /lscript . On h 2 n +1 ⊕ h 2 m +1 , its center is spanned by Z 1 and Z 2 . Consider the linear map
$$J X _ { k } = Y _ { k }, \ \ J Y _ { k } = - X _ { k }, \ \ J U _ { \ell } = V _ { \ell }, \ \ J V _ { \ell } = - U _ { \ell }, \ \ J Z _ { 1 } = Z _ { 2 }, \ \ J Z _ { 2 } = - Z _ { 1 }.$$
It defines an abelian complex structure.
## 3.3.3 W 4 n +2
It is a 4 n +2-dimensional nilpotent group. On Lie algebra level, let
$$\{ Z _ { 1 }, Z _ { 2 }, X _ { 4 k + 1 }, X _ { 4 k + 2 }, X _ { 4 k + 3 }, X _ { 4 k + 4 } \colon 0 \leq k \leq n - 1 \}$$
be a basis such that the non-zero structure equations are given by
$$& \left [ X _ { 4 k + 1 }, X _ { 4 k + 3 } \right ] = - \frac { 1 } { 2 } Z _ { 1 }, \quad \left [ X _ { 4 k + 1 }, X _ { 4 k + 4 } \right ] = - \frac { 1 } { 2 } Z _ { 2 }, \\ & \left [ X _ { 4 k + 2 }, X _ { 4 k + 3 } \right ] = - \frac { 1 } { 2 } Z _ { 2 }, \quad \left [ X _ { 4 k + 2 }, X _ { 4 k + 4 } \right ] = \frac { 1 } { 2 } Z _ { 1 }.$$
We obtain an abelian complex structure if we insist J 2 = -identity, and
$$J X _ { 4 k + 1 } = X _ { 4 k + 2 }, \ \ J X _ { 4 k + 3 } = - X _ { 4 k + 4 }, \ \ J Z _ { 1 } = - Z _ { 2 }.$$
## 3.3.4 P 4 n +2
It is again a 4 n + 2-dimensional nilpotent group. On Lie algebra level, it is a degeneration of the structure in (35). In particular, with respect to the basis as given in (34), the non-zero structure equations are given by
$$\left [ X _ { 4 k + 1 }, X _ { 4 k + 2 } \right ] = - \frac { 1 } { 2 } Z _ { 1 }, \ \left [ X _ { 4 k + 1 }, X _ { 4 k + 4 } \right ] = - \frac { 1 } { 2 } Z _ { 2 }, \ \left [ X _ { 4 k + 2 }, X _ { 4 k + 3 } \right ] = - \frac { 1 } { 2 } Z _ { 2 }.$$
An abelian complex structure is defined by the requirements in (36).
## 4 Complex Parallelizable Nilmanifolds
A nilmanifold is complex parallelizable if there is an invariant complex structure J such that for all X,Y in g ,
$$[ X, J Y ] = J [ X, Y ].$$
In this case, g is the underlying real Lie algebra of a complex Lie algebra, and
$$[ \mathfrak { g } ^ { 1, 0 }, \mathfrak { g } ^ { 1, 0 } ] \subseteq \mathfrak { g } ^ { 1, 0 }, \ \ [ \mathfrak { g } ^ { 1, 0 }, \mathfrak { g } ^ { 0, 1 } ] = \{ 0 \}.$$
Dually, when ∂ is the Chevalley-Eilenberg differential on g ∗ (1 0) , , then ( ⊕ g ∗ (1 0) , , ∂ ) forms an exterior differential algebra. So is the conjugate. Let H q ∂ ( g ∗ (0 1) , ) denote
the q -th cohomology of the differential algebra ( ⊕ g ∗ (0 ,q ) , ∂ ). It is proved in [25] that the Dolbeault cohomology H p,q ( M ) is isomorphic to the H q ∂ ( g ∗ (0 1) , ) ⊗ g ∗ ( p, 0) .
Since the holomorphic tangent bundle for a complex parallelizable manifold is trivialized by the complex vector fields of the algebra g 1 0 , ,
$$H ^ { q } ( M, \Theta ^ { p } ) \cong H ^ { 0, q } ( M ) \otimes \mathfrak { g } ^ { p, 0 } \cong H ^ { q } _ { \overline { \partial } } ( \mathfrak { g } ^ { * ( 0, 1 ) } ) \otimes \mathfrak { g } ^ { p, 0 }.$$
Suppose that Λ is an invariant holomorphic Poisson structure on M . The above observation implies that the first sheet of the Poisson double complex is given by
$$E _ { 1 } ^ { p, q } = H _ { \frac { q } { \partial } ( \mathfrak { g } ^ { * ( 0, 1 ) } ) } \otimes \mathfrak { g } ^ { p, 0 }.$$
Since the exterior differential of g ∗ (0 1) , is contained in g ∗ (0 2) , , ad Λ ( ω ) = 0 for all ω ∈ g ∗ (0 1) , . If ∑ j Ω j ⊗ θ j represents an element in H q ∂ ( g ∗ (0 1) , ) ⊗ g p, 0 where Ω j for appropriate number of j forms a basis for H q ∂ ( g ∗ (0 1) , ), and θ j ∈ g p, 0 , then
$$\hat { \Phi } _ { \Lambda } ( \sum _ { j } \overline { \Omega } ^ { j } \otimes \theta _ { j } ) = \sum _ { j } ( - 1 ) ^ { q } \overline { \Omega } ^ { j } \otimes \text{ad} _ { \Lambda } ( \theta _ { j } ). \quad \hat { \Phi } _ { \Lambda } \quad \hat { \Phi } _ { \Lambda } \quad \hat { \Phi } _ { \Lambda } \quad \hat { \Phi } _ { \Lambda } \quad \hat { \Phi } _ { \Lambda } \quad \hat { \Phi } _ { \Lambda } \quad \hat { \Phi } _ { \Lambda } \quad \hat { \Phi } _ { \Lambda } \quad \hat { \Phi } _ { \Lambda } \quad \hat { \Phi } _ { \Lambda } \quad \hat { \Phi } _ { \Lambda } \quad \hat { \Phi } _ { \Lambda } \quad \hat { \Phi } _ { \Lambda } \quad \hat { \PhPhi } _ { \Lambda } \quad \hat { \Phi } _ { \Lambda } \quad \hat { \Phi } _ { \Lambda } \quad \hat { \Phi } _ { \Lambda } \quad \hat { \Phi } _ { \Lambda } \quad \hat { \Phi } _ { \Lambda } \quad \hat { \Phi } _ { \Lambda } \quad \hat { \Phi } _ { \Lambda } \quad \hat { \Phi } _ { \Lambda } \quad \hat { \Phi } _ { \Lambda } \quad \hat { \Phi } _ { \Lambda } \quad \hat { \Phi } _ { \Lambda } \quad \hat { \Phi } _ { \Lamda } \quad \hat { \Phi } _ { \Lambda } \quad \hat { \Phi } _ { \Lambda } \quad \hat { \Phi } _ { \Lambda } \quad \hat { \Phi } _ { \Lambda } \quad \hat { \Phi } _ { \Lambda } \quad \hat { \Phi } _ { \Lambda } \quad \hat { \Phi } _ { \Lambda } \quad \hat { \Phi } _ { \Lambda } \quad \hat { \Phi } _ { \Lambda } \quad \hat { \Phi } _ { \Lambda } \quad \hat { \Phi } _ { \Lambda } \quad \hat { \Phi } _ { \Lambda } \quad \hat { p } _ { \Lambda } \quad \hat { p } _ { \Lambda } \quad \hat { p } _ { \Lambda } \quad \hat { p } _ { \Lambda } \quad \hat { p } _ { \Lambda } \quad \hat { p } _ { \Lambda } \quad \hat { p } _ { \Lambda } \quad \hat { p } _ { \Lambda } \quad \hat { p } _ { \Lambda } \quad \hat { p } _ { \Lambda } \quad \hat { p } _ { \Lambda } \quad \hat { p } _ { \Lambda } \quad \hat { p } _ { \Lambda } \quad \hat { p } _ { \Lambda } \quad \hat { p } _ { p } \quad \hat { p } _ { \Lambda } \quad \hat { p } _ { \Lambda } \quad \hat { p } _ { \Lambda } \quad \hat { p } _ { \Lambda } \quad \hat { p } _ { \Lambda } \quad \hat { p } _ { \Lambda } \quad \hat { p } _ { \Lambda } \quad \hat { p } _ { \Lambda } \quad \hat { p } _ { \Lambda } \quad \hat { p } _ { \Lambda } \quad \hat { p } _ { \Lambda } \quad \hat { p } _ { \Lambda } \quad \hat { p } _ { \Lambda } \quad \hat { p } _ { \Lambda } \quad p _ { \Lambda } \quad \hat { p } _ { \Lambda } \quad \hat { p } _ { \Lambda } \quad \hat { p } _ { \Lambda } \quad \hat { p } _ { \Lambda } \quad \hat { p } _ { \Lambda } \quad \hat { p } _ { \Lambda } \quad \hat { p } _ { \Lambda } \quad \hat { p } _ { \Lambda } \quad \hat { p } _ { \Lambda } \quad \hat { p } _ { \Lambda } \quad \hat { p } _ { \Lambda } \quad \hat { p } _ { \Lambda } \quad \hat { p } _ { \Lambda } \quad \hat { p } _ { \langle \Phi } _ { \Lambda } \quad \hat { p } _ { \Lambda } \quad \hat { p } _ { \Lambda } \quad \hat { p } _ { \Lambda } \quad \hat { p } _ { \Lambda } \quad \hat { p } _ { \Lambda } \quad \hat { p } _ { \Lambda } \quad \hat { p } _ { \Lambda } \quad \hat { p } _ { \Lambda } \quad \hat { p } _ { \Lambda } \quad \hat { p } _ { \Lambda } \quad \hat { p } _ { \Lambda } \quad \hat { p } _ { \Lambda } \quad \hat { p } _ { \Lambda } \quad \hat { p. } \quad \hat { p } _ { \Lambda } \quad \hat { p } _ { \Lambda } \quad \hat { p } _ { \Lambda } \quad \hat { p } _ { \Lambda } \quad \hat { p } _ { \Lambda } \quad \hat { p } _ { \Lambda } \quad \hat { p } _ { \Lambda } \quad \hat { p } _ { \Lambda } \quad \hat { p } _ { \Lambda } \quad \hat { p } _ { \Lambda } \quad \hat { p } _ { \Lambda } \quad \hat { p } _ { \Lambda } \quad \hat { p } _ { \Lambda } \quad \hat { p } _ { \Lambda } \quad 0 \quad \hat { \Phi } _ { \Lambda } \quad \hat { p } _ { \Lambda } \quad \hat { p } _ { \Lambda } \quad \hat { p } _ { \Lambda } \quad \hat { p } _ { \Lambda } \quad \hat { p } _ { \Lambda } \quad \hat { p } _ { \Lambda } \quad \hat { p } _ { \Lambda } \quad \hat { p } _ { \Lambda } \quad \hat { p } _ { \Lambda } \quad \hat { p } _ { \Lambda } \quad \hat { p } _ { \Lambda } \quad \hat { p } _ { \Lambda } \quad \hat { p } _ { \Lambda } \ \hat { p } _ { \Lambda } \quad \hat { p } _ { \Lambda } \quad \hat { p } _ { \Lambda } \quad \hat { p } _ { \Lambda } \quad \hat { p } _ { \Lambda } \quad \hat { p } _ { \Lambda } \quad \hat { p } _ { \Lambda } \quad \hat { p } _ { \Lambda } \quad \hat { p } _ { \Lambda } \quad \hat { p } _ { \Lambda } \quad \hat { p } _ { \Lambda } \quad \hat { p } _ { \Lambda } \quad \hat { p } _ { \Lambda } \quad \hat { p } _ { \Lambda } \quad \hat { \Phi } _ { \Lambda } \quad \hat { p } _ { \Lambda } \quad \hat { p } _ { \Lambda } \quad \hat { p } _ { \Lambda } \quad \hat { p } _ { \Lambda } \quad \hat { p } _ { \Lambda } \quad \hat { p } _ { \Lambda } \quad \hat { p } _ { \Lambda } \quad \hat { p } _ { \Lambda } \quad \hat { p } _ { \Lambda } \quad \hat { p } _ { \Lambda } \quad \hat { p } _ { \Lambda } \quad \hat { p } _ { \Lambda } \quad \hat { p }_ { \Lambda } \quad \hat { p } _ { \Lambda } \quad \hat { p } _ { \Lambda } \quad \hat { p } _ { \Lambda } \quad \hat { p } _ { \Lambda } \quad \hat { p } _ { \Lambda } \quad \hat { p } _ { \Lambda } \quad \hat { p } _ { \Lambda } \quad \hat { p } _ { \Lambda } \quad \hat { p } _ { \Lambda } \quad \hat { p } _ { \Lambda } \quad \hat { p } _ { \Lambda } \quad \hat { p } _ { \Lambda } \quad \hat { p } _ { \Lambda } \quad \hat { p } _ { \Langle \Phi } _ { \Lambda } \quad \hat { p } _ { \Lambda } \quad \hat { p } _ { \Lambda } \quad \hat { p } _ { \Lambda } \quad \hat { p } _ { \Lambda } \quad \hat { p } _ { \Lambda } \quad \hat { p } _ { \Lambda } \quad \hat { p } _ { \Lambda } \quad \hat { p } _ { \Lambda } \quad \hat { p } _ { \Lambda } \quad \hat { p } _ { \Lambda } \quad \hat { p } _ { \Lambda } \quad \hat { p } _ { \Lambda } \quad \hat { p } _ { \Lambda } \quad \hat { \Phi }_ { \Lambda } \quad \hat { p } _ { \Lambda } \quad \hat { p } _ { \Lambda } \quad \hat { p } _ { \Lambda } \quad \hat { p } _ { \Lambda } \quad \hat { p } _ { \Lambda } \quad \hat { p } _ { \Lambda } \quad \hat { p } _ { \Lambda } \quad \hat { p } _ { \Lambda } \quad \hat { p } _ { \Lambda } \quad \hat { p } _ { \Lambda } \quad \hat { p } _ { \Lambda } \quad \hat { p } _ { \Lambda } \quad \hat { p } _ { \Lambda } \quad \hat { p } _ { p } _ { \Lambda } \quad \hat { p } _ { \Lambda } \quad \hat { p } _ { \Lambda } \quad \hat { p } _ { \Lambda } \quad \hat { p } _ { \Lambda } \quad \hat { p } _ { \Lambda } \quad \hat { p } _ { \Lambda } \quad \hat { p } _ { \Lambda } \quad \hat { p } _ { \Lambda } \quad \hat { p } _ { \Lambda } \quad \hat { p } _ { \Lambda } \quad \hat { p } _ { \Lambda } \quad \hat { p } _ { \Lambda } \quad \hat { p } _ { \Lambda } \quad \hat { p }_ { \Lambda } \quad \hat { p } _ { p } \quad \hat { p } _ { \Lambda } \quad \hat { p } _ { \Lambda } \quad \hat { p } _ { \Lambda } \quad \hat { p } _ { \Lambda } \quad \hat { p } _ { \Lambda } \quad \hat { p } _ { \Lambda } \quad \hat { p } _ { \Lambda } \quad \hat { p } _ { \Lambda } \quad \hat { p } _ { \Lambda } \quad \hat { p } _ { \Lambda } \quad \hat { p } _ { \Lambda } \quad \hat { p } _ { \Lambda } \quad \hat { p } _ { \Lambda } 0 \quad \hat { \Phi } _ { \Lambda } \quad \hat { p } _ { \Lambda } \quad \hat { p } _ { \Lambda } \quad \hat { p } _ { \Lambda } \quad \hat { p } _ { \Lambda } \quad \hat { p } _ { \Lambda } \quad \hat { p } _ { \Lambda } \quad \hat { p } _ { \Lambda } \quad \hat { p } _ { \Lambda } \quad \hat { p } _ { \Lambda } \quad \hat { p } _ { \Lambda } \quad \hat { p } _ { \Lambda } \quad \hat { p } _ { \Lambda } \quad \hat { p } _ { \Lambda } 0 \quad \hat { \Phi } _ { \Lambda _ { \Lambda } \quad \hat { p } _ { \Lambda } \quad \hat { p } _ { \Lambda } \quad \hat { p } _ { \Lambda } \quad \hat { p } _ { \Lambda } \quad \hat { p } _ { \Lambda } \quad \hat { p } _ { \Lambda } \quad \hat { p } _ { \Lambda } \quad \hat { p } _ { \Lambda } \quad \hat { p } _ { \Lambda } \quad \hat { p } _ { \Lambda } \quad \hat { p } _ { \Lambda } \quad \hat { p } _ { \Lambda } \quad \hat { p } _ { \Lambda } \quad \hat { p } _ { \rangle } 0 \quad \hat { \Phi } _ { \Lambda } \quad \hat { p } _ { \Lambda } \quad \hat { p } _ { \Langle \Phi } \quad \hat { \Phi } _ { \Lambda } \quad \hat { p } _ { \Langle \Phi }$$
Therefore, it represents a zero class in H q +1 ∂ ( g ∗ (0 1) , ) ⊗ g p, 0 if and only if ad Λ ( θ j ) = 0 for each j . It follows that d p,q 2 ≡ 0. Moreover, ( g p, 0 , ad Λ ) form a complex. Let H p ad Λ ( g 1 0 , ) be the p -th cohomology, then
$$E _ { 2 } ^ { p, q } = H _ { \overline { \partial } } ^ { q } ( \mathfrak { g } ^ { * ( 0, 1 ) } ) \otimes H _ { \text{ad} _ { \Lambda } } ^ { p } ( \mathfrak { g } ^ { 1, 0 } ).$$
Due to the degeneracy, H k Λ ( M ) = ⊕ p + = q k H q ∂ ( g ∗ (0 1) , ) ⊗ H p ad Λ ( g 1 0 , ) . In summary, we have
Theorem 3 Let M be a complex parallelizable manifold with an invariant holomorphic Poisson structure Λ . Let g 1 0 , the vector space of invariant holomorphic vector fields on M . Let H q ∂ ( g ∗ (0 1) , ) be the Chevalley-Eilenberg cohomology for the conjugation algebra g 0 1 , , and H p ad Λ ( g 1 0 , ) the cohomology of the operator ad Λ = [ [Λ , -] ] on the exterior algebra of g 1 0 , , then
$$H _ { \Lambda } ^ { k } ( M ) = \oplus _ { p + q = k } H _ { \overline { \partial } } ^ { q } ( \mathfrak { g } ^ { * ( 0, 1 ) } ) \otimes H _ { \text{ad} _ { \Lambda } } ^ { p } ( \mathfrak { g } ^ { 1, 0 } ).$$
## 4.1 Complex Three-dimensional Iwasawa Manifolds
Let G be the complex Heisenberg group of 3 × 3 matrices of the form
$$z \coloneqq \left ( \begin{array} { c c c } 1 & z _ { 1 } & z _ { 2 } \\ 0 & 1 & z _ { 3 } \\ 0 & 0 & 1 \end{array} \right ).$$
Let H be the co-compact lattice of matrices whose entries are Gaussian integers. As a complex manifold, G /similarequal C 3 . Let ∂ ∂z 1 , ∂ ∂z 2 , ∂ ∂z 3 be the corresponding coordinate global vector fields. Viewed as matrices,
$$& \text{global vector fields. Viewed as matrices,} \\ & \frac { \partial } { \partial z _ { 1 } } = \left ( \begin{array} { c c c } 0 & 1 & 0 \\ 0 & 0 & 0 \\ 0 & 0 & 0 \end{array} \right ), \quad \frac { \partial } { \partial z _ { 2 } } = \left ( \begin{array} { c c c } 0 & 0 & 1 \\ 0 & 0 & 0 \\ 0 & 0 & 0 \end{array} \right ), \quad \frac { \partial } { \partial z _ { 3 } } = \left ( \begin{array} { c c c } 0 & 0 & 0 \\ 0 & 0 & 1 \\ 0 & 0 & 0 \end{array} \right ). \\ & \text{Then, $g^{1,0}$ is spanned by the vector fields}$$
Then, g 1 0 , is spanned by the vector fields
$$W _ { 1 } = \frac { \partial } { \partial z _ { 1 } }, \quad W _ { 2 } = \frac { \partial } { \partial z _ { 2 } }, \quad W _ { 3 } = \frac { \partial } { \partial z _ { 3 } } + z _ { 1 } \frac { \partial } { \partial z _ { 2 } }$$
which are all holomorphic. Their dual basis is given by
$$\omega _ { 1 } = d z _ { 1 }, \quad \omega _ { 2 } = d z _ { 2 } - z _ { 1 } d z _ { 3 }, \quad \omega _ { 3 } = d z _ { 3 }$$
and ∂ω 1 = ∂ω 3 = 0 , ∂ω 2 = -ω 1 ∧ ω . 3 Therefore,
$$E _ { 1 } ^ { 0, 0 } = \langle 1 \rangle, \ \ E _ { 1 } ^ { 0, 1 } = \langle \overline { \omega } _ { 1 }, \overline { \omega } _ { 3 } \rangle \ \ E _ { 1 } ^ { 0, 2 } = \langle \overline { \omega } _ { 1 } \wedge \overline { \omega } _ { 2 }, \overline { \omega } _ { 2 } \wedge \overline { \omega } _ { 3 } \rangle, \ \ E _ { 1 } ^ { 0, 3 } = \langle \overline { \omega } _ { 1 } \wedge \overline { \omega } _ { 2 } \wedge \overline { \omega } _ { 3 } \rangle.$$
Also note that
$$[ W _ { 1 }, W _ { 2 } ] = [ W _ { 2 }, W _ { 3 } ] = 0, \ \ [ W _ { 1 }, W _ { 3 } ] = W _ { 2 }$$
and [ W,ω i j ] = 0 . By direct computation, the invariant holomorphic Poisson structures are given by
$$\Lambda = a W _ { 1 } \wedge W _ { 2 } + b W _ { 2 } \wedge W _ { 3 },$$
for some constants a, b ∈ C . Moreover, as we get ad Λ = 0, d 1 = 0:
Proposition 3 Let M be the Iwasawa manifold, equipped with the usual parallelizable complex structure. If Λ is any invariant holomorphic Poisson structure on M , then the corresponding spectral sequence degenerates at the first step, and H k Λ ( M ) = ⊕ p + = q k H q ∂ ( g ∗ (0 1) , ) ⊗ g 1 0 , .
## 5 Lichnerowicz Homomorphism
On any complex manifold, there is a well known double complex, the Dolbeault bi-complex. Recall that d = ∂ + ∂ . Define
$$B ^ { p, q } = C ^ { \infty } ( M, \wedge ^ { p } T ^ { * ( 1, 0 ) } M \otimes \wedge ^ { q } T ^ { * ( 0, 1 ) } M ).$$
Due to the integrability of the complex structure, we have the double complex
$$\begin{array} { c c c c c } B ^ { p, q + 1 } &$$
.
Recall that A p,q = C ∞ ( M, ∧ p T (1 0) , M ⊗∧ q T ∗ (0 1) , M ). Given a holomorphic Poisson structure Λ, contraction with -Λ defines a map from B 1 0 , to A 2 0 , . We extend to the map φ : B p,q → A p,q as follows.
- 1. φ ω ( ) = -(Λ ω ) for all ω in B 1 0 , .
- 2. φ ω ( ) = ω for all ω in B 0 1 , .
- 3. φ =identity on B 0 0 , .
- 4. Extend φ to B p,q for p, q ≥ 1 by φ A ( ∧ B ) = φ A ( ) ∧ φ B ( ).
By construction, it is apparent that φ maps B p,q to A p,q . The rest of this section is to prove the following observation.
Theorem 4 The map φ is a homomorphism from the Dolbeault double complex to the Poisson double complex.
$$\overline { \partial } \circ \phi = \phi \circ \overline { \partial$$
It suffices to verify the above identities on B 0 0 , , B 1 0 , and B 0 1 , . For any function f , ∂ ◦ φf = ∂f . As ∂f is a (0 , 1)-form, it is clear that φ ◦ ∂f = ∂f . To work on the
other identity, we do it locally, and there exists (1 , 0) holomorphic vector fields X j and Y j such that at least locally, Λ = ∑ j X j ∧ Y j . Then
$$\begin{array} {$$
On the other hand,
$$\text{ad} _ { \Lambda } ( \phi f ) = \sum _ {$$
Therefore, the identities in (41) are satisfied when they are applied to smooth functions on the manifold.
Next, we test the identities (41) against (0 , 1)-forms, say ω . Since the map φ is the identity map when it is restricted to the bundle of (0 , q )-forms. Therefore, the identity ∂ ◦ φ ω ( ) = φ ∂ω ( ) is obviously satisfied.
Lemma 8 For any (2 , 0) -form Ω , (1 , 0) -forms γ and δ , φ (Ω)( γ, δ ) = Ω(Λ γ, Λ ) δ . For any (1 , 1) -form Γ , (1 , 0) -form γ and (0 , 1) -vector Z , φ (Γ)( γ, Z ) = Γ(Λ γ, Z ) .
Proof: By linearity, it suffices to consider the case when Ω = α ∧ β where α and β are (1 , 0)-forms. In this case, it is just a matter of definition of φ because,
$$& \phi ( \alpha \wedge \beta ) ( \gamma, \delta ) =$$
The proof of the second statement is similar.
Suppose that γ and Z are as given in the last lemma, then
$$& \phi ( \partial \overline { \omega } ) ( \gamma, \overline { Z } ) = \partial \overline { \omega } ( \Lambda \gamma, \overline { Z } ) \\ = & \ \ ( \Lambda \gamma ) ( \overline { \omega } ( \overline { Z } ) - \overline { Z } ( \overline { \omega } ( \Lambda \gamma ) ) - \overline { \omega } ( [ \Lambda \gamma, \overline { Z } ] ) = \mathcal { L } _ { \Lambda \gamma } \overline { \omega } ( \overline { Z } ) - \overline { \omega } ( \mathcal { L } _ { \Lambda \gamma } \overline { Z } ) = ( \mathcal { L } _ { \Lambda \gamma } \overline { \omega } ) \overline { Z }.$$
It is equal to Z ([ [Λ γ, ω ] ]) = ad Λ ( ω )( γ, Z ) as a consequence of the observation of the next lemma.
Lemma 9 [23, Lemma 4, Page 10] For any (1 , 0) -vector field X , (0 , 1) -vector field Z , (0 , 1) -form ω and (1 , 0) -forms γ , and δ ,
$$[ \Lambda, X ] ( \gamma, \delta ) & \ = \ - \Lambda ( \omega ) ( \gamma ( \Lambda \delta ) ) - \gamma ( [ \Lambda \delta, X ] ) + \delta ( [ \Lambda \gamma, X ] ), \\ [ \Lambda, \overline { \omega } ] ( \gamma, \overline { Z } ) & \ = \ \overline { Z } ( [ \Lambda \gamma, \overline { \omega } ] ).$$
Since the identities (41) holds when they are tested on (0 , 1)-forms, we next test them on a (1 0)-form , ω . In particular, for any (1 , 0)-forms ω , γ , and δ ,
$$& \phi ( \partial \omega ) ( \gamma, \delta ) = ( \partial \omega ) ( \Lambda \gamma, \Lambda \delta ) \\ = & \ ( \Lambda \gamma ) ( \omega ( \Lambda \delta ) ) - ( \Lambda \delta ) ( \omega ( \Lambda \gamma ) ) - \omega ( \left [ \Lambda \gamma, \Lambda \delta \right ].$$
Recall the following observation.
Lemma 10 [23, Lemma 18, Page 31] Let Λ be a bi-vector field. For any (1 , 0) -forms ω , γ , and δ ,
$$\begin{array} { c c } & \frac { 1 } { 2 } [ \Lambda, \Lambda ] ( \omega, \gamma, \delta ) = \omega ( [ \Lambda \gamma, \Lambda \delta ] ) - ( \Lambda \omega ) ( \Lambda ( \gamma, \delta ) ) \\ + & \gamma ( [ \Lambda \delta, \Lambda \omega ] ) - ( \Lambda \gamma ) ( \Lambda ( \delta, \omega ) ) + \delta ( [ \Lambda \omega, \Lambda \gamma ] ) - ( \Lambda \delta ) ( \Lambda ( \omega, \gamma ) ). \end{array}$$
Since the bivector field Λ is Poisson, [ [Λ , Λ] ] = 0. By the last lemma, the identity (42) is equal to
$$- ( \Lambda \omega ) ( \Lambda ( \gamma, \delta ) ) + \gamma ( \left [ \Lambda \delta, \Lambda \omega \right ] ) + \delta ( \left [ \Lambda \omega, \Lambda \gamma \right ] ).$$
By Lemma 9, it is equal to -[ [Λ , Λ ]]( ω γ, δ ). By definition of φ , it is equal to ad Λ ( φ ω ( ))( γ, δ ). As this is true for all γ and δ , ad Λ ( φ ω ( )) = φ ∂ω ( ) as needed.
By Lemma 8, for any (1 0)-forms , ω , γ and (0 1)-vector field , Z ,
$$& \phi ( \overline { \partial } \omega ) ( \gamma, \overline { Z } ) = ( \overline { \partial } \omega ) ( \Lambda \gamma, \overline { Z } ) = ( d \omega ) ( \Lambda \gamma, \overline { Z } ) \\ = \ & ( \Lambda \gamma ) \omega ( \overline { Z } ) - \overline { Z } ( \omega ( \Lambda \gamma ) ) - \omega ( [ \Lambda \gamma, \overline { Z } ] ) = - \overline { Z } ( \Lambda ( \gamma, \omega ) ) - \omega ( [ \Lambda \gamma, \overline { Z } ] ) \\ = \ & \overline { Z } ( \Lambda ( \omega, \gamma ) ) + \omega ( [ \overline { Z }, \Lambda \gamma ] ).$$
On the other hand, we treat ∂ as the Lie algebroid differential for the bundle L ,
then
$$& ( \overline { \partial } \phi \omega ) ( \gamma, \overline { Z } ) = - ( \overline { \partial } ( \Lambda \omega ) ) ( \gamma, \overline { Z } ) \\ & = \quad - \rho ( \omega ) ( ( \Lambda \omega ) ( \overline { Z } ) ) + \rho ( \overline { Z } ) \omega ( \Lambda \omega ) + \Lambda \omega ( [ \omega, \overline { Z } ] ) \\ & = \quad \overline { Z } ( \omega ( \Lambda \omega ) ) - ( \mathcal { L } _ { \overline { Z } } \omega ) \Lambda \omega = \overline { Z } ( \omega ( \Lambda \omega ) ) - \overline { Z } ( \omega ( \Lambda \omega ) ) + \omega ( ( \overline { [ Z }, \Lambda \omega ] ) \\ & = \quad \omega ( \left [ \overline { Z }, \Lambda \omega \right ] ). \\. & \quad \, \kappa \quad \dots \quad. \quad. \quad. \quad. \quad. \quad.$$
As a consequence of Lemma 1 and the assumption that Λ is holomorphic, for any (1 0)-forms , ω , γ and (0 1)-vector field , Z ,
$$\overline { Z } ( \Lambda ( \omega, \gamma ) ) + \omega ( [ \overline { Z }, \Lambda \gamma ] ) = \gamma ( [ \overline { Z }, \Lambda \omega ] ).$$
By (43) and (44), we conclude that the identifies in (41) holds when it is tested against any (1 , 0)-forms.
The proof of Theorem 4 is now complete.
## 5.1 Applications
The first identity in (41) implies that the bundle map φ induces a complex linear homomorphism
$$\phi \colon H ^ { q } \left ( X, \Omega ^ { p } \right ) \longrightarrow H ^ { q } \left ( X, \Theta ^ { p } \right ).$$
The second identity implies that this homomorphism fits into the following commutative diagram:
$$\text{ram} \colon & & & \\ & & d _ { 1 } ^ { p, q } = a d _ { \Lambda } & & \\ & H ^ { q } \left ( X, \Theta ^ { p } \right ) & \longrightarrow & H ^ { q } \left ( X, \Theta ^ { p + 1 } \right ) & \\ \phi & \uparrow & \uparrow & \uparrow & \phi \, \\ & H ^ { q } \left ( X, \Omega ^ { p } \right ) & \longrightarrow & H ^ { q } \left ( X, \Omega ^ { p + 1 } \right ) & \\ & & d _ { 1 } ^ { p, q } = \partial & \\ s \text{ the holomorphic bundle of } ( n. 0 ) \text{-forms. } The man is define}$$
where Ω p is the holomorphic bundle of ( p, 0)-forms. The map is defined so that when p = 0, φ is an identity map.
Lemma 11 Suppose that X is holomorphic Poisson manifold such that the Fr¨hlicher o spectral sequence degenerates at the E 1 -level, then for spectral sequence of the holomorphic Poisson double complex
$$E _ { n } ^ { 0, q } = E _ { 1 } ^ { 0, q } = H ^ { q } \left ( X, \mathcal { O } \right ),$$
and d 0 ,q n ≡ 0 for all q and for all n ≥ 2 .
Proof: As noted above, when p = 0, the homomorphism φ is an isomorphism. The E 0 ,q 1 -term for the Fr¨hlicher spectral sequence is o H q ( X, O ). When d p,q 1 = ∂ is identically equal to zero on it, then d 0 ,q 1 = ad Λ is identically equal to zero on the E 0 ,q 1 -term for the Poisson spectral sequence, which is H q ( X, O ) as well. It follows that E 0 ,q 2 = H q ( X, O ) .
Suppose that ω is a ∂ -closed (0 , q )-form representing an element in H q ( X, O ) . Since d ω 1 represents the zero element in H q ( X, Θ), there exists a section A of A 1 ,q -1 such that
$$a d _ { \Lambda } \left ( \overline { \omega } \right ) = \overline { \partial } A.$$
By definition, d 0 ,q 2 [ ω ] is represented by ad Λ A. This is an element in A 2 ,q -1 , representing a class in H q -1 ( X, Θ ) 2 . However, since φ ω ( ) = ω , we also have
$$\overline { \partial } A = \text{ad} _ { \Lambda } \left ( \overline { \omega } \right ) = \text{ad} _ { \Lambda } \left ( \phi \left ( \overline { \omega } \right ) \right ) = \phi \left ( \partial \overline { \omega } \right ) = 0.$$
It follows that ad Λ ( ω ) = ∂A = 0. By choosing A = 0, we find that d 0 ,q 2 [ ω ] is represented by zero. Therefore, d 0 ,q 2 ≡ 0 for all q .
For n ≥ 2 and for all q , since
$$E _ { n + 1 } ^ { 0, q } = \ker d _ { n } ^ { 0, q } \colon E _ { n } ^ { 0, q } \rightarrow E _ { n } ^ { n, q - n + 1 }.$$
It is now apparent that by induction, E 0 ,q n +1 = E 0 ,q n . After all, we have seen that if ω is in H q ( X, O ), then under the current assumption, ∂ω +ad ( Λ ω ) = 0.
Theorem 5 The holomorphic Poisson spectral sequence on any compact holomorphic Poisson surface degenerates at E 2 -level.
Proof: The first sheet of the holomorphic Poisson spectral sequence of a compact complex surface is:
$$H ^ { 2 } \left ( \mathcal { O } \right ) \ \stackrel { d _ { 1 } ^ { 0, 2 } } { \longrightarrow } \ H ^ { 2 } \left ( \Theta \right ) \ \stackrel { d _ { 1 } ^ { 1, 2 } } { \longrightarrow } \ H ^ { 2 } \left ( \Theta ^ { 2 } \right ) \ \longrightarrow \ 0$$
$$H ^ { 1 } \left ( \mathcal { O } \right ) \ \stackrel { d _ { 1 } ^ { 0, 1 } } { \longrightarrow } \ H ^ { 1 } \left ( \Theta \right ) \ \stackrel { d _ { 1 } ^ { 1, 1 } } { \longrightarrow } \ H ^ { 1 } \left ( \Theta ^ { 2 } \right ) \ \longrightarrow \ 0 \ \cdot$$
$$H ^ { 0 } ( \mathcal { O } ) \ \stackrel { d _ { 1 } ^ { 0, 0 } } { \longrightarrow } \ H ^ { 0 } \left ( \Theta \right ) \ \stackrel { d _ { 1 } ^ { 1, 0 } } { \longrightarrow } \ H ^ { 0 } \left ( \Theta ^ { 2 } \right ) \ \longrightarrow \ 0$$
Since the Fr¨hlicher spectral sequence degenerates at o E 1 -level on any compact complex surface, the previous lemma is applicable. Therefore, the second sheet of the holomorphic Poisson spectral sequence is given as below.
$$\text{sso spectral sequence is given as below.} \\ H ^ { 2 } ( \mathcal { O } ) & = E _ { 2 } ^ { 0, 2 } \quad \ E _ { 2 } ^ { 1, 2 } \quad E _ { 2 } ^ { 2, 2 } \quad 0 \\ H ^ { 1 } ( \mathcal { O } ) & = E _ { 2 } ^ { 0, 1 } \quad \ E _ { 2 } ^ { 1, 1 } \quad E _ { 2 } ^ { 2, 1 } \quad 0 \. \\ H ^ { 0 } ( \mathcal { O } ) & = E _ { 2 } ^ { 0, 0 } \quad \ E _ { 2 } ^ { 1, 0 } \quad E _ { 2 } ^ { 2, 0 } \quad 0 \\ \text{ion restriction. the only non-trivial differential on t}$$
Due to a dimension restriction, the only non-trivial differential on the second sheet are
$$d _ { 2 } ^ { 0, 1 } \, \colon H ^ { 1 } \left ( \mathcal { O } \right ) = E _ { 2 } ^ { 0, 1 } \longrightarrow E _ { 2 } ^ { 2, 0 } \quad \text{and} \quad d _ { 2 } ^ { 0, 2 } \, \colon H ^ { 2 } \left ( \mathcal { O } \right ) = E _ { 2 } ^ { 0, 2 } \longrightarrow E _ { 2 } ^ { 2, 1 }.$$
By the second part of the previous lemma, these two maps are identically zero. Therefore, d p,q 2 ≡ 0 for all ( p, q ) .
Theorem 6 Suppose that X is holomorphic Poisson manifold with complex dimension n . If the Fr¨hlicher spectral sequence of its complex structure degenerates at the o E 1 -level, then its holomorphic Poisson spectral sequence degenerates at the E n -level.
Proof: Similar to the case when n = 2, on a complex manifold with dimension n , the only non-trivial terms at the top sheet are
$$d _ { n } ^ { 0, n - 1 } \colon E _ { n } ^ { 0, n - 1 } \longrightarrow E _ { n } ^ { n, 0 } \text{ \ and \ } d _ { n } ^ { 0, n } \coloneqq E _ { n } ^ { 0, n } \longrightarrow E _ { n } ^ { n, 1 }.$$
Acknowledgment. D. Grandini and Y.-S. Poon thank the Mathematical Sciences Center, Tsinghua University, for hospitality during their visits in summer 2012.
## References
- [1] W. Barth, C. Peters & A. Van de Ven, Compact Complex Surfaces , Ergebnisse der Mathematik und ihrer Grenzgebiete, Springer-Verlag (1984) Berlin.
- [2] C. Bartocci & E Marci, Classification of Poisson surfaces , Commun. Contemp. Math. 7 (2005) 89-95.
- [3] S. Console & A. Fino, Dolbeault cohomology of compact nilmanifolds , Transform. Groups. 6 (2001), 111-124.
- [4] S. Console, A. Fino, & Y. S. Poon, Stability of abelian complex structures , International J. Math. 17 (2006), 401-416.
- [5] L. A. Cordero, M. Fern´ndez, A. Gray & L. Ugarte, a Compact nilmanifolds with nilpotent complex structures: Dolbeault cohomology , Trans. Amer. Math. Soc., 352 (2000), 5405-5433.
- [6] D. Fiorenza & M. Manetti, Formality of Koszul brackets and deformations of holomorphic Poisson manifolds , preprint, arXiv:1109.4309v2.
- [7] P. Gauduchon, Hermitian connections and Dirac operators , Bollettino U.M.I. 11B (1997), 257-288.
- [8] R.Goto, Deformations of generalized complex and generalized K¨hler structures a , J. Differential Geom. 84 (2010), 525-560.
- [9] D. Grandini, Y.-S. Poon, & B. Rolle, Differential Gerstenhaber algebras of generalized complex structures , Asia J. Math. 18 (2014) 191-218.
- [10] G. Grantcharov, C. McLaughlin, H. Pedersen, & Y. S. Poon, Deformations of Kodaira manifolds , Glasgow Math. J. 46 (2004), 259-281.
- [11] M. Gualtieri, Generalized complex geometry , Ann. of Math. 174 (2011), 75-123.
- [12] N. J. Hitchin, Generalized Calabi-Yau manifolds , Quart. J. Math. 54 (2003), 281-308.
- [13] N. J. Hitchin, Instantons, Poisson structures, and generalized K¨hler geometry a , Commun. Math. Phys. 265 (2006), 131-164.
- [14] N. J. Hitchin, Deformations of holomorphic Poisson manifolds , Mosc. Math. J. 669 (2012), 567-591.
- [15] T. H¨ ofer, Remarks on principal torus bundles , J. Math. Kyoto U., 33 (1993), 227-259.
- [16] W. Hong, & P. Xu, Poisson cohomology of Del Pezzo surfaces , J. Algebra 336 (2011), 378-390.
- [17] Z. J. Liu, A. Weinstein, & P. Xu, Manin triples for Lie bialgebroids , J. Differential Geom. (1997), 547-574.
- [18] K. C. H. Mackenzie, General Theory of Lie Groupoids and Lie Algebroids , London Math. Soc. Lecture Notes Series 213 , Cambridge U Press, 2005.
- [19] C. Maclaughlin, H. Pedersen, Y. S. Poon, & S. Salamon, Deformation of 2-step nilmanifolds with abelian complex structures , J. London Math. Soc. 73 (2006) 173-193.
- [20] K. Nomizu, On the cohomology of compact homogenous spaces of nilpotent Lie groups , Ann. Math. 59 (1954), 531-538.
- [21] A. Polishchuk, Algebraic geometry of Poisson brackets , J. Math. Sci. (New York) 84 (1997), 1413-1444.
- [22] Y. S. Poon, Extended deformation of Kodaira surfaces , J. reine angew. Math. 590 (2006), 45-65.
- [23] B. Rolle, Construction of weak mirrir pairs by deformations , Ph.D. Thesis, University of California at Riverside. (2011).
- [24] S. Rollenske, Lie algebra Dolbeault cohomology and small deformations of nilmanifolds , J. London. Math. Soc. (2) 79 (2009), 346-362.
- [25] Y. Sakane, On compact complex parallelisable solvmanifolds , Osaka J. Math. 13 (1976), 187-212.
- [26] S. M. Salamon, Complex structures on nilpotent Lie algebras , J. Pure Appl. Algebra 157 (2001), 311-333.
- [27] C. Voisin, Hodge Theory and Complex Algebraic Geometry, I , Cambridge studies in advanced mathematics 76 (2004), Cambridge University Press. | null | [
"Zhuo Chen",
"Daniele Grandini",
"Yat-Sun Poon"
] | 2014-08-03T01:46:29+00:00 | 2014-08-03T01:46:29+00:00 | [
"math.DG",
"math.SG",
"Primary 53D18, Secondary: 16E45, 22E25, 32G05, 53D17"
] | Holomorphic Poisson Cohomology | A holomorphic Poisson structure induces a deformation of the complex
structure as Hitchin's generalized geometry. Its associated cohomology
naturally appears as the limit of a spectral sequence of a double complex. The
first sheet of this spectral sequence is the Dolbeault cohomology with
coefficients in the exterior algebra of the holomorphic tangent bundle. We
identify various necessary conditions on compact complex manifolds on which
this spectral sequence degenerates on the level of the second sheet. The
manifolds to our concern include all compact complex surfaces, K\"ahler
manifolds, and nilmanifolds with abelian complex structures or complex
parallelizable manifolds. |
1408.0449v1 | ## Thermopower enhancement by fractional layer control in 2D oxide superlattices
Woo Seok Choi 1,2,3* , Hiromichi Ohta 4 , and Ho Nyung Lee 1**
1 Materials Science and Technology Division, Oak Ridge National Laboratory, Oak Ridge, TN 37831, USA
2 Department of Physics, Sungkyunkwan University, Suwon, Gyeonggi-do 440-746, Korea 3 IBS Center for Integrated Nanostructure Physics, Institute of Basic Science (IBS), Sungkyunkwan University, Suwon, Gyeonggi-do 440-746, Korea
4 Research Institute for Electronic Science, Hokkaido University, N20W10, Sapporo 001-0020, Japan * e-mail: [email protected].
** e-mail: [email protected].
We have investigated two-dimensional thermoelectric properties in transition metal oxide heterostructures. In particular, we adopted an unprecedented approach to direct tuning of the 2D carrier density using fractionally δ -doped oxide superlattices. By artificially controlling the carrier density in the 2D electron gas that emerges at a La Sr x 1x TiO3 δ -doped layer, we demonstrate that a thermopower as large as 408 μ V K -1 can be reached. This approach also yielded a power factor of the 2D carriers 117 μ Wcm -1 K -2 , which is one of the largest reported values from transition metal oxide based materials. The promising result can be attributed to the anisotropic band structure in the 2D system, indicating that δ -doped oxide superlattices can be a good candidate for advanced thermoelectrics.
Thermoelectric phenomenon is indispensable in understanding the transport nature of itinerant charge carriers and their interaction with the crystal lattice. In practical sense, it is utilized to convert heat into electric power (Seebeck effect) or to generate temperature gradient from electricity (Peltier effect). Therefore, thermoelectric power generation is considered as one of the most important technologies for sustainable energy. The thermoelectric efficiency is often quantified by the thermoelectric figure of merit ZT = ( S 2 σ κ / ) T , where S , σ , κ , and T are the Seebeck coefficient or thermopower, the electrical conductivity, the thermal conductivity, and the absolute temperature, respectively. In order to achieve a high ZT value, the prerequisites of materials are large S and σ , and low κ . However, phenomenologically, S and log σ are inversely proportional to each other, which poses difficulty in maximizing the ZT value. [1] Moreover, σ and κ are linearly proportional to each other if the thermal transport is dominated by charge carriers instead of phonons, again limiting the controllability of ZT . Therefore, in most cases, achieving a delicate balance among S , σ , and κ is the key to achieving the maximum ZT value.
Until recently, the majority of the research on thermoelectric materials has been devoted to the conventional semiconductors such as Bi Te and PbTe, partially owing to their high efficiency. 2 3 [1] However, their volatile nature especially at high temperatures and the use of toxic elements (such as Pb, Sb, Se, and Te) prevented these materials from being a ubiquitous choice. On the other hand, recent studies reported that transition metal oxides (TMOs) can be a promising candidate for highly efficient thermoelectrics with high | S | and σ , and hence, the high power factor ( PF = S 2 σ ). [2, 3] More importantly, in most cases, the strong correlation uniquely found in TMOs can be a useful tool for developing new thermoelectric materials. For example, Na CoO showed a large x 2 | S | due to a strong electronic correlation, [4] and low dimensional Nb-doped SrTiO exhibited an 3 unexpectedly large PF [5-7] by a dimensional crossover of the polaronic behavior. [8, 9] More
recently, it has also been shown that TMO superlattices can have minimized thermal conductivity due to the crossover from incoherent to coherent phonon scattering, suggesting that it can be beneficial for thermoelectric applications. [10] Owing to the versatile physical properties of the TMOs, the thermoelectric properties can be further investigated in terms of complex electronic and crystallographic structures, such as disproportionate band structure, effective mass anisotropy, dimensionality, and formation of heterointerfaces. [2, 3] We further emphasize that the additional degree of freedom in TMOs (i.e., charge, spin, orbital, and lattice) and strong coupling among them could lead to an unprecedented thermoelectric behavior with novel physical origins. [11]
In addition to the selection of appropriate materials system, the geometry of samples also plays a critical role in determining the thermoelectric efficiency. [12, 13] In particular, a large | S | could be achieved due to the modified electronic structure near the Fermi level ( E F ) in low dimensional structures. For example, quantum confinement effect on the thermoelectric property was observed in a PbTe/Pb 1x Eu Te multiple quantum well structure, x [12] and enhancement of | S | due to the electron filtering effect was observed in InGaAs based superlattices. [14] More recently, SrTiO 3 based 2D structures also exhibited an interesting low-dimensional effect. [5, 6] As recent technical advances in synthesizing oxide heterostructures provide an unprecedented opportunity for realizing various low dimensional structures with the atomic precision, we can use such structures as a test bed for enhancing the thermoelectric properties.
In order to develop highly efficient, low dimensional TMO thermoelectrics, we focus on the strongly correlated 2D perovskite oxide materials. In particular, previous studies found the interface between the Mott insulator LaTiO (LTO) and the band insulator SrTiO (STO) bears a 3 3 two-dimensional electron gas (2DEG). The 2D system exhibited intriguing transport and optical
properties including electronic reconstruction, [15, 16] anomalous T -dependent metallic behavior, [17] multi-carrier/multi-channel conduction, [18-20] 2D superconductivity and quantum critical behavior. [21-23] More interestingly, it has been recently shown that the carrier density could be effectively controlled by a selective band filling through controlled doping of the 2DEG layer. [20]
In this paper, we present carrier-density-tuned 2D thermoelectric phenomena for a direct comparison with the 3D case for a wide range of carrier densities. As shown in Fig. 1, this could be achieved by fabricating fractional superlattices (SLs) using pulsed laser epitaxy (PLE). We carefully modified the carrier concentration in the LSTO ( δ -doped) layer by incorporating different concentrations of La 3+ ions within the layer. Using the deliberate crystal design, we could achieve a precise control on the carrier density ( n ) of LSTO as was previously achieved in the 3D case. [24] Furthermore, we observed a large enhancement of | S | due to the 2D confinement effect, for the same n , without sacrificing much of the electron mobility in TMO SLs. The enhancement of | S | resulted in a 300% enhancement in power factor for a moderate value of n , suggesting that the low dimensional effect together with the controllability of n is an important factor to be considered in oxide thermoelectric materials.
Fractional δ -doping method was used to fabricate [(La Sr x 1x TiO3) /(SrTiO ) 1 3 10 ] 10 (LSTO/STO, x = 0.25, 0.50, 0.75, and 1.00) SLs. Note that the SLs were adopted to amplify the effect from each 2DEG layer. The number of 2DEG layers in each sample was fixed to 10. Details on the PLEbased controlled δ -doping method can be found elsewhere. [20] To measure the transport properties of the SLs, we made a direct Ohmic contact with indium to the metallic 2D LSTO layers in the van der Pauw geometry using ultrasonic soldering. Temperature- ( T -) dependent S was measured by conventional steady-state method (Δ T ~2 K) using a cryogenic refrigerator. Other transport
properties were characterized using a physical property measurement system (Quantum Design Inc.).
The transport properties of the SLs are shown in Fig. 2 as a function of x . The value of S at room T was extracted from linear fitting of the Δ V -Δ T curves as shown in the lower left inset of Fig. 2a. For all the samples, S revealed a negative value indicating n -type conduction. The values of | S | were comparable to those reported from Nb:STO/STO SLs. [5, 6] With increasing La 3+ incorporation within the δ -doped layer ( x ), | S | gradually decreased. The T -dependent S curves shown in the upper right inset indicate that | S | decreases with decreasing T . In slightly doped bulk LSTO ( ≤ 0.1), x T 2 -dependence was observed for | S |-T curves which could be later attributed to the enhancement of the electron-phonon coupling with the decrease in n . [25] For our SLs, however, we could not observe any characteristic T -dependent behavior (other than the typical linear T -dependence observed for diffusion thermoelectricity) that could be attributed to unconventional physical mechanism. The room T carrier density ( n ) and mobility ( μ ) values of the SLs (corresponding to the 2D layers) are shown in Fig. 2b. Here, n is normalized by the nominal total thickness of the 2D layers as discussed below. The linear increase of n with x is clearly observed as expected, while μ does not show any considerable x -dependence.
Conventionally, the ZT value is calculated based on bulk (3D) σ , and thus, an effective thickness of the 2D layer is required to calculate n in cm -3 . In this way, the thermoelectric properties of low dimensional materials could be properly understood. While it is practically impossible to experimentally obtain the exact thickness of the 2D layer in LSTO/STO SLs, [5, 6] one may consider the well-studied transport property of the SLs in order to estimate the thickness. LTO/STO and LSTO/STO interfacial systems at low T (< ~50K) have to be understood in terms
of multi-carrier or multi-channel transport. [18-20] According to magnetic field dependent Hall resistance measurements, the so-called 'low-density-high-mobility carriers' located in STO, i.e. , away from the interface, become active at low T . This is due to enhanced dielectric screening of carriers assisted by the largely enhanced dielectric constant of STO especially at low T . [26] On the other hand, at room T , 'high-density-low-mobility carriers' located at the interface (or the LSTO layer) play a dominant role in the transport property. The dielectric constant of STO is an order of magnitude smaller at room T than that at low T , suggesting a minimized spill-over effect of conduction electrons into the STO sides. In addition, oxygen vacancies have been carefully removed throughout the SLs, and we believe that the STO spacing layers remain insulating. Therefore, to understand the room T carrier dynamics of the δ -doped SLs, we have considered only the high-density-low-mobility carriers confined at the LSTO layer, with the nominal thickness of 1 u.c. (~4 Å).
The linear dependence of n with x was observed in 3D LSTO, [24, 25] where each La 3+ ion ideally adds one electron to the system by modifying Ti 4+ ( d 0 ) into Ti 3+ ( d 1 ) (0 < x ≤ 0.95). Note that if all Sr 2+ ions are substituted by La 3+ (LaTiO ), the bulk sample becomes a Mott insulator, although 3 one would expect 1.68×10 22 cm -3 of carrier density from simple reasoning. For the 2D δ -doped layer, such trend in bulk, i.e. , linear increase of n with x , was similarly observed. However, the SL does not become insulating even in the case of x = 1, possibly due to the smearing out of a small number of carriers even at room T . The measured n of our LTO/STO SL (corresponding to the 2D layers) is 8.1×10 21 cm -3 , suggesting that only half of the electrons compared to the bulk contribute to the actual conduction in 2D. Note that such decrease in n can also be attributed to the surface/interface depletion of the carriers. [27]
The decrease in x (or n ) yields an increase in | S | in 2D. This behavior coincides with the phenomenological behavior for 3D thermoelectric materials, suggesting that this phenomenological model can be universally applied for the lower dimensional cases as well. Note that such a direct comparison study could only be realized due to the fabrication of fractional SLs. For x = 0.25 SL, | S | increased up to 408 μ V K -1 , which is ~2.5 times larger compared to x = 1.00 SL, indicating that tuning n in 2D system is an effective method to enhance the | S | value.
For more detailed analyses, we directly compared the transport property of LSTO for 3D and 2D (filled blue circles) cases, as summarized in Fig. 3 and Fig. 4. The data for 3D bulk LSTO (empty squares) for systematic n values is taken from a previous study by Okuda et al . [25] First, we note that the electrical conductivity is rather lower in our SLs than that in the bulk LSTO (Fig. 3a) for the same n . This is mainly due to the reduced μ which could be attributed to the reduced dimensional or confinement effect. On the other hand, μ has a completely different tendency for bulk and SL samples, as shown in Fig. 3b. For the 3D case, the decrease of μ with decreasing n was observed and attributed to the tendency of localization of the carriers, possibly due to the enhanced electron-phonon coupling at lower n as previously discussed. [25] Similar decrease in μ with decreasing n at room T has also been observed in another study on La doped STO bulk. [28] Note that the values of μ at room T were similar for other electron dopants in STO such as Nb or oxygen vacancies, [5, 6] although the decreasing trend with decreasing n was less evident. [29] In our 2D LSTO case, however, we did not find any distinct n -dependent behavior, which suggests that such an n -dependent localization effect does not prevail for a very wide range of n . Nevertheless, the dimensional confinement induced localization seems to affect the carrier transport for all the SLs. Indeed, even scattering with La 3+ ions does not seem to play a large role at room T , as μ is almost constant and independent of n (or x ). This might be attributed to the fact that for a δ -doped
layer, electron-phonon coupling does not depend on n anymore, due to the atomic confinement of 2D carriers. [10]
The most important observation regarding the thermoelectric effect in the 2D oxide SLs is the enhancement of | S | due to the reduced dimensionality. We first note that the qualitative trend, i.e. , the increase of | S | with the decrease of n , is the same for both 3D and 2D. While a phenomenological trend has been also observed in heavily Nb-doped STO, [2] our direct and deliberate control of n through fractional layer structuring reported here for the first time can open a door to novel TMO thermoelectric heterostructures.
More interestingly, | S | of our SLs is much larger than that of the bulk samples for the same n values (Fig. 4a). In particular, more persistent | S | is observed as the n is increased over a wide range, as compared to the bulk samples. To estimate the enhancement by the dimensional crossover over a wide range of n (which was not accessible in bulk), we adopted the curve (grey line), which was used to theoretically explain the n -dependence of | S | in heavily Nb-doped STO bulk. [2] Note that this curve was a modification of the Jonker relationship and explains the 3D data by Okuda et al . quite well especially for low n . [30] Based on this estimation of | S | in 3D, S 2D / S 3D was calculated (empty diamond symbols in red). S 2D / S 3D shows a drastic increase for x = 0.50 compared to x = 0.25 SLs. Above x = 0.50, it more or less saturates. However, it should be noted that the estimation of | S | in 3D overestimates the last few data points by Okuda et al. , suggesting that S 2D / S 3D can be even much larger than what shown here, for higher n values ( x = 0.75 and 1.00 SLs). In addition to the orbital degeneracy of the Ti 3 d t -2 g band and strong correlation attributed to the large | S | in oxide single crystals, the reduced dimensionality enforces disproportionate (anisotropic) band structure, which further enhances | S |. The structural
anisotropy becomes larger as n increases, which should most probably lead to an increased anisotropy of the carrier transport ( e.g. , the in-plane conductivity linearly increases with increasing x , while there is no linear relationship for the out-of-plane conductivity), [18] and the deviation of the | S | values between 2D and 3D also increases with increasing n . Such a large enhancement of | S | for large n values increases the PF of the SLs substantially as shown in Fig. 4b. Compared to the largest value for 3D LSTO (35 μ Wcm -1 K -2 ), the PF value corresponding to the 2D layers reaches up to 117 μ Wcm -1 K -2 for x = 0.75 SL, which is more than a 300% enhancement over the values reported from the bulk samples. Moreover, this PF value is larger than that for most of the oxide heterostructures reported up to date (shown in triangles in Fig. 4b), [8, 28, 31-33] which can be mostly explained by 3D thermoelectric calculations, [2] especially at high n . This is mainly due to the 2D confinement effect together with a wide n control. We again emphasize that such a large PF value could be achieved uniquely through systematic fabrication of δ -doped SLs with controlled doping. Finally, since the thermal conductivity of the 2D layer could not be measured, we estimated it from the bulk value of 10 W K -1 m -1 at room T , [2, 25] and obtained ZT values corresponding to the 2D layers ranging from 0.08 ( x = 0.25) to 0.35 ( x = 0.75).
In summary, we have shown that a highly efficient thermoelectric material can be designed by superlattice approach, in which the delicate balance between carrier density and thermopower is controlled by fractional control of 2D carriers. The general trend in the thermoelectric property of 3D transition metal oxides is still valid for the 2D SLs, and the maximum S value can be achieved when n is at the lowest limit of conduction. However, | S | clearly increases in 2D compared to 3D, and one can achieve much larger PF values with 2D superlattices. The results demonstrated here indicate that modifying the dimension of carrier conduction is a way to tuning the thermoelectric properties of oxide materials beyond what the bulk counterpart can perform.
## Acknowledgements
We appreciate valuable discussion with J. H. Han and V. R. Cooper. This work was supported by the U.S. Department of Energy, Basic Energy Sciences, Materials Sciences and Engineering Division. WSC was supported by Samsung Research Fund, Sungkyunkwan University, 2013. HO is supported by JSPS-KAKENHI (25246023, 25106007).
## Figure legends
Figure 1 | Schematics of fractionally-doped transition metal oxide superlattices. [(La Sr x 1x TiO3) /(SrTiO ) 1 3 10 ] 10 superlattice samples with controlled chemical compositions have been fabricated to detail the carrier conduction for controlling thermopower. As the portion of La in the 2DEG layer increases, both 2D carrier density and conductivity also increase, while 2D thermopower decreases.
Figure 2 | Transport properties of fractional superlattices. a , S as a function of x . As x decreases, | S | increases, reaching over 400 μ V K -1 for x = 0.25. The lower left inset shows the potential difference as a function of T gradient at 300 K. The upper right inset shows the T -dependence of | S |, which increases with increasing T . b , n and μ as a function of x at 300 K. n has been normalized to the total effective thickness of the 2D layers. n is linearly proportional to x , while μ does not exhibit any systematic change.
Figure 3 | Electronic transport behaviors of 2D and 3D thermoelectric oxides. a , σ and b , μ as a function of n for bulk samples (empty squares) and fractional SLs (filled blue circles). The reduced σ is mainly due to the reduced μ .
Figure 4 | Thermoelectric properties of 2D and 3D thermoelectric oxides. a , S and b , PF as a function of n for bulk samples (empty squares) and fractional SLs (filled circles). While the general n -dependence is maintained, the fractional superlattices show highly enhanced thermoelectric properties, mainly due to the increased anisotropy. The thick grey line in a represents results from a theoretical calculation of the 3D data based on Jonker relationship. [2, 30] Right red axis in a is data for S 2D / S 3D , which are represented with the empty diamonds in red.
Various PF values for bulk (green triangles), [28] film (orange and cyan triangles), [31, 32] and superlattices (purple triangles) [8] are shown for comparison in b . The thick grey line represents data from a theoretical calculation for 3D. [2]
## References
- [1] G. J. Snyder, E. S. Toberer, Nat. Mater. 2008 , 7 , 105.
- [2] H. Ohta, K. Sugiura, K. Koumoto, Inorg. Chem. 2008 , 47 , 8429.
- [3] K. Koumoto, I. Terasaki, R. Funahashi, MRS Bull. 2006 , 31 , 206.
- [4] I. Terasaki, Y. Sasago, K. Uchinokura, Phys. Rev. B 1997 , 56 , R12685.
- [5] H. Ohta, S. Kim, Y. Mune, T. Mizoguchi, K. Nomura, S. Ohta, T. Nomura, Y. Nakanishi,
- Y. Ikuhara, M. Hirano, H. Hosono, K. Koumoto, Nat. Mater. 2007 , 6 , 129.
- [6] Y. Mune, H. Ohta, K. Koumoto, T. Mizoguchi, Y. Ikuhara, Appl. Phys. Lett. 2007 , 91 .
- [7] P. Delugas, A. Filippetti, M. J. Verstraete, I. Pallecchi, D. Marré, V. Fiorentini, Phys. Rev. B 2013 , 88 , 045310.
- [8] W. S. Choi, H. Ohta, S. J. Moon, Y. S. Lee, T. W. Noh, Phys. Rev. B 2010 , 82 , 024301.
- [9] A. S. Alexandrov, A. M. Bratkovsky, Phys. Rev. B 2010 , 81 , 153204.
- [10] J. Ravichandran, A. K. Yadav, R. Cheaito, P. B. Rossen, A. Soukiassian, S. J. Suresha, J.
- C. Duda, B. M. Foley, C.-H. Lee, Y. Zhu, A. W. Lichtenberger, J. E. Moore, D. A. Muller, D. G.
- Schlom, P. E. Hopkins, A. Majumdar, R. Ramesh, M. A. Zurbuchen, Nat. Mater. 2014 , 13 , 168.
- [11] H. Y. Hwang, Y. Iwasa, M. Kawasaki, B. Keimer, N. Nagaosa, Y. Tokura, Nat. Mater. 2012 , 11 , 103.
- [12] L. D. Hicks, T. C. Harman, X. Sun, M. S. Dresselhaus, Phys. Rev. B 1996 , 53 , R10493.
- [13] L. D. Hicks, M. S. Dresselhaus, Phys. Rev. B 1993 , 47 , 12727.
- [14] J. M. O. Zide, D. Vashaee, Z. X. Bian, G. Zeng, J. E. Bowers, A. Shakouri, A. C. Gossard, Phys. Rev. B 2006 , 74 , 205335.
- [15] A. Ohtomo, D. A. Muller, J. L. Grazul, H. Y. Hwang, Nature 2002 , 419 , 378.
- [16] S. Okamoto, A. J. Millis, Phys. Rev. B 2004 , 70 , 241104.
- [17] S. S. A. Seo, W. S. Choi, H. N. Lee, L. Yu, K. W. Kim, C. Bernhard, T. W. Noh, Phys. Rev. Lett. 2007 , 99 , 266801.
- [18] J. S. Kim, S. S. A. Seo, M. F. Chisholm, R. K. Kremer, H. U. Habermeier, B. Keimer, H. N. Lee, Phys. Rev. B 2010 , 82 , 201407.
- [19] R. Ohtsuka, M. Matvejeff, K. Nishio, R. Takahashi, M. Lippmaa, Appl. Phys. Lett. 2010 , 96 , 192111.
- [20] W. S. Choi, S. Lee, V. R. Cooper, H. N. Lee, Nano Lett. 2012 , 12 , 4590.
- [21] J. Biscaras, N. Bergeal, A. Kushwaha, T. Wolf, A. Rastogi, R. C. Budhani, J. Lesueur, Nat. Commun. 2010 , 1 , 89.
- [22] J. Biscaras, N. Bergeal, S. Hurand, C. Grossetête, A. Rastogi, R. C. Budhani, D. LeBoeuf, C. Proust, J. Lesueur, Phys. Rev. Lett. 2012 , 108 , 247004.
- [23] J. Biscaras, N. Bergeal, S. Hurand, C. Feuillet-Palma, A. Rastogi, R. C. Budhani, M. Grilli, S. Caprara, J. Lesueur, Nat. Mater. 2013 , 12 , 542.
- [24] Y. Tokura, Y. Taguchi, Y. Okada, Y. Fujishima, T. Arima, K. Kumagai, Y. Iye, Phys. Rev. Lett. 1993 , 70 , 2126.
- [25] T. Okuda, K. Nakanishi, S. Miyasaka, Y. Tokura, Phys. Rev. B 2001 , 63 , 113104.
- [26] M. A. Saifi, L. E. Cross, Phys. Rev. B 1970 , 2 , 677.
- [27] A. Ohtomo, H. Y. Hwang, Appl. Phys. Lett. 2004 , 84 , 1716.
- [28] S. Ohta, T. Nomura, H. Ohta, K. Koumoto, J. Appl. Phys. 2005 , 97 , 034106.
- [29] A. Spinelli, M. A. Torija, C. Liu, C. Jan, C. Leighton, Phys. Rev. B 2010 , 81 , 155110.
- [30] G. H. Jonker, Philips Res. Rep. 1968 , 23 , 131.
- [31] B. Jalan, S. Stemmer, Appl. Phys. Lett. 2010 , 97 , 042106.
- [32] J. Ravichandran, W. Siemons, M. L. Scullin, S. Mukerjee, M. Huijben, J. E. Moore, A. Majumdar, R. Ramesh, Phys. Rev. B 2011 , 83 , 035101.
- [33] M. L. Scullin, C. Yu, M. Huijben, S. Mukerjee, J. Seidel, Q. Zhan, J. Moore, A.
Majumdar, R. Ramesh, Appl. Phys. Lett. 2008 , 92 .
Figure 1. Choi et al.
-1
Figure 2. Choi et al.
Figure 3. Choi et al.
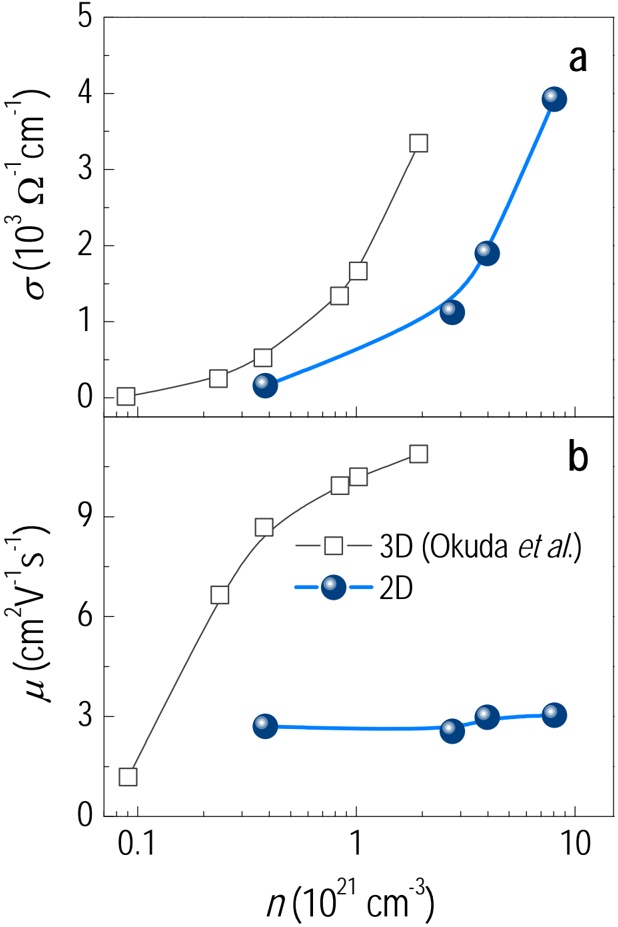
Figure 4. Choi et al.
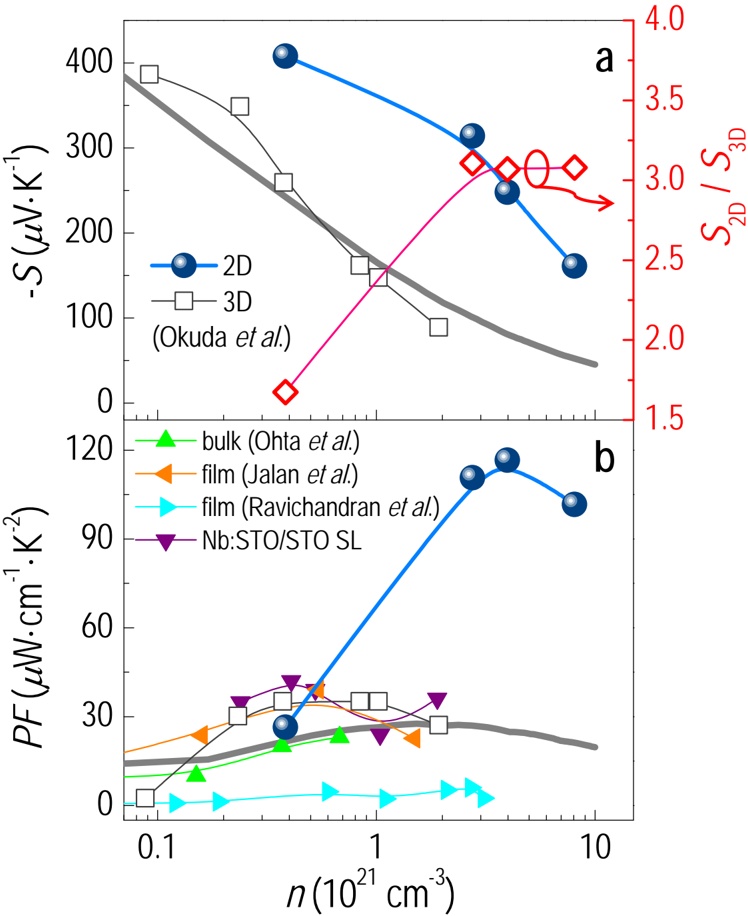 | 10.1002/adma.201401676 | [
"Woo Seok Choi",
"Hiromichi Ohta",
"Ho Nyung Lee"
] | 2014-08-03T01:47:58+00:00 | 2014-08-03T01:47:58+00:00 | [
"cond-mat.str-el",
"cond-mat.mes-hall",
"cond-mat.mtrl-sci"
] | Thermopower enhancement by fractional layer control in 2D oxide superlattices | We have investigated two-dimensional thermoelectric properties in transition
metal oxide heterostructures. In particular, we adopted an unprecedented
approach to direct tuning of the 2D carrier density using fractionally
{\delta}-doped oxide superlattices. By artificially controlling the carrier
density in the 2D electron gas that emerges at a LaxSr1-xTiO3 {\delta}-doped
layer, we demonstrate that a thermopower as large as 408 {\mu}V K-1 can be
reached. This approach also yielded a power factor of the 2D carriers 117
{\mu}Wcm-1K-2, which is one of the largest reported values from transition
metal oxide based materials. The promising result can be attributed to the
anisotropic band structure in the 2D system, indicating that {\delta}-doped
oxide superlattices can be a good candidate for advanced thermoelectrics. |
1408.0450v2 | ## Correction of Wall Adhesion Effects in the Centrifugal Compression of Strong Colloidal Gels
Richard Buscall 1,2,* and Daniel R Lester 3,4
- 1 MSACT Research & Consulting, 34 Maritime Court, Haven Road, Exeter, EX2 8GP, UK.
2 Particulate Fluids Processing Centre, Dept of Chemical & Biomolecular Engineering, University of Melbourne, Parkville, VIC 3052, Australia. 3 CSIRO Mathematics, Informatics & Statistics, Graham Rd, Highett VIC 3190, Australia.
- 4 School of Civil, Environmental & Chemical Engineering, Royal Melbourne Institute of Technology, Melbourne, VIC 3001, Australia.
*Author to whom correspondence should be addressed at [email protected].
## Abstract
Several methods for measuring the compressive strength of strong particulate gels are available, including the centrifuge method, whereby the strength as a function of volumefraction is obtained parametrically from the dependence of equilibrium sediment height upon acceleration. The analysis used conventionally due to Buscall & White (1987) ignores the possibility that the particulate network might adhere to the walls of the centrifuge tube, even though many types of cohesive particulate gel can be expected to. The neglect of adhesion is justifiable when the ratio of the shear to compressive strength is small, which it can be for many systems away from the gel-point, but never very near it. The errors arising from neglect of adhesion are investigated theoretically and quantified by synthesising equilibrium sediment height versus acceleration data for various degrees of adhesion and then analysing them in the conventional manner. Approximate correction factors suggested by dimensionless analysis are then tested. The errors introduced by certain other approximations made routinely in order to render the data-inversion practicable are analysed too. For example, it shown that the error introduced by treating the acceleration vector as approximately one-dimensional is minuscule for typical centrifuge dimensions, whereas making this assumption renders the data inversion tractable.
## Introduction
Aggregated colloidal particles form compressible sediments and filter-cakes, hence the compressive strength of the particulate phase is an important property of such systems, which are sometimes called attractive or cohesive particulate gels these days. Strongly cohesive particulate gels, by which is meant systems where the interparticle attraction is strong enough to arrest activated processes such as coarsening, creep and delayed collapse, show selflimiting sedimentation and filtration, whereby the application of a given acceleration or load will lead to the formation of a stable sediment or filter-cake with a stable density profile. The scaled well-depth -U min / k T B , and hence the activation energy for particle escape and diffusion, can be very large for strongly-flocculated and coagulated colloidal particles. Hence it is found that sediments of low volume-fraction can be stable for years or even decades, as reflected by the exponential dependence of the KramersÕ time upon well-depth. Under such circumstances it is meaningful to speak of equilibrium sediment heights and filter cakes thicknesses and to attempt to calculate the curve of compressive strength as a function particulate volume-fraction ( φ ) from curves of equilibrium filter-cake thickness (or sediment thickness) versus load (or centrifugal acceleration).
Several methods have been used to measure the compressive strength as a function of density. The most direct in concept is pressure-filtration, whereby the equilibrium filter cake volume is measured for a series of applied pressure in carefully-controlled and instrumented pressurefilters [1-8]. The analysis of this test is trivial, or at least it is provided that the possibility of adhesion of the particulate network to the side-walls of the filter can be neglected, as it can be provided that 4 h τ w PD << 1 , where τ w is the adhesive shear strength, P the compressive strength, and h and D are the thickness and diameter of the cake respectively [9]. τ w is taken to be the yield stress in shear at the wall and hence it can be determined independently in principle by using, say, a suitable rheometer, fitted with smooth tools made of similar material to that the walls of the filter. Alternatively, one might simply use the true yield stress of the suspension as an upper bound estimate of the adhesive strength, since it has been found in practice that whereas τ y > τ w, it is generally of similar order, with values of τ w/ τ y in the range 0.2 to 0.6 being typical of coagulated systems [8,10-13]. Another option perhaps would be to use several different filter diameters and extrapolate the results to infinite diameter, although this might not be too convenient in practice, since it requires a set of pressure filtration cells and a rather large amount of sample overall. The other three methods commonly used rely on sedimentation-equilibrium in one way or another:
- (i) Measure the equilibrium sediment height in a series of batch settling columns of increasing initial sediment height under normal gravity [1,8,14-16].
- (ii) Measure the equilibrium height likewise in a laboratory centrifuge fitted with either a swing-out (preferably) or a horizontal rotor for a series of accelerations [1,8, 10, 16-22].
- (iii) Determine the concentration versus depth profile in a tall equilibrium sediment; tall so that there is significant compression towards the bottom [8,23-29,31,32].
The principle behind each of these methods is that the unbuoyed self-weight,
$$w ( h ) = \Delta \rho g \int _ { h } ^ { h _ { \text{eq} } } \phi ( z ) d z \,, \, \text{at any height $h$ in a sediment of total equilibrium height $h_{\text{eq}$ is}$$
balanced by the compressive strength P ( φ { h }), where Δρ is the suspension inter-phase density difference, g gravitational or centrifugal acceleration, φ (h) the local volume-. This assumption only holds exactly in the absence of adhesion, where the approximate 1D force balance [9,35]
$$\frac { d P } { d z } = \Delta \rho g \phi - \frac { 4 \tau _ { _ { w } } } { D } \,,$$
shows wall adhesion effects can only be neglected when
$$\frac { 4 \tau _ { w } [ \phi ( 0 ) ] } { D \Delta \rho g \phi ( 0 ) } < < 1$$
Methods (i) and (ii) are very similar in basis, clearly: the prime reason for distinguishing between them is that adhesion affects them differently as the magnitude of the acceleration g is very different between centrifugation and batch settling. A secondary reason is that whereas the raw data in case (i) of h eq versus h 0 can be inverted exactly to obtain P ( φ ) when adhesion is negligible, one of the corresponding pair of equations used to invert centrifuge data, that for the pressure, is now approximate. The approximation used prior to this work introduced an systematic error of ca. 5% or thereabouts, typically [18]. It is however possible to do better and render the data inversion for the centrifuge method significantly more accurate, as will be shown later in the paper.
Like pressure filtration, method (iii), concentration-profiling, is fairly direct in the absence of adhesion since integration of the concentration profile gives the pressure at any height z above the base of the column, such that,
$$\Delta \rho g \int _ { z } ^ { h _ { z q } } \phi ( z ^ { \prime } ) d z ^ { \prime } \rightarrow P ( \phi [ z ] ) \,.$$
It has however been shown recently [27,28] that the method is rather sensitive to any adhesion to the walls of the tube, to the point where, by using two or more columns of different diameter [27], it is possible to invert the data and determine both the compressive and the shear strength functions fairly accurately.This method is too computationally intensive to be used routinely, however a simple correction method has been recently developed [35] based upon an approximate 1D force balance, assuming the functional form of Py ( φ ) is known.. The essential problem with the profiling method is that the errors coming from any adhesion accumulate up the φ ( z ) profile [27], as per equation (2). This can be shown clearly by consideration of (2), where the shear yield strength τ w increases nonlinearly with φ , whilst the denominator of (2) increases linearly. Hence for any tall column of modest diameter, then increasing solids volume fraction with bed depth will eventually lead to the violation of (2) and divergence of the predicted compressive yield strength somewhere down the column. Thus, the apparent or uncorrected compressive strength can appear to diverge well below the jamming limit (sometimes called point-J) when adhesion is significant in this sense [27]. The basic problem with the profiling method then is, that in order to determine P ( φ ) over a significant range of concentration, the column needs to be tall in order to obtain significant compression near the bottom. This however means working at large 4 heq / D which just amplifies errors coming from adhesion. Method (i), whereby the sediment is compressed more and more by increasing h 0 must can suffer significantly from this problem as gravitational acceleration g in (2) is relatively small, order 10 [m/s ]. Conversely, method (ii), 2 centrifugation, involves much larger acceleration, where g= ω 2 R, can be varied over the range 10 -10 [m s 2 6 -2 ], or more, depending upon the centrifuge. Here ω is the angular rotation rate and R distance from the axis of rotation to the bottom of the centrifuge tube. Furthermore, whilst increasing initial height h0 is required in sedimentation to achieve greater compressive stress in batch settling, greater pressures in centrifugation are achieved by increasing the rotation rate ω , and hence acceleration g . Hence any errors coming from the neglect of adhesion now decrease going up the P ( φ ) curve, simply because the sediment is shrinking and hence the area in contact with the wall reduces. The same is true for pressure-filtration. The other significant advantage of the centrifuge method is its large dynamic range, since four or
even five decades of acceleration and thus strength can be covered given a suitable centrifuge or set of centrifuges. Its main disadvantage is that it can be difficult to get close to the gelpoint since control of speed becomes a problem at very low speeds. It is likewise difficult to get close to the gel-point with pressure-filtration method because of the problem of applying and controlling small pressures.
A word needs to be said about adhesion versus cohesion perhaps. There are at least a dozen different types of interparticle attraction, or mechanisms of flocculation, known (e.g Van der Waals, depletion, liquid-bridging, incipient flocculation, charge-patch, bridging, and so on [30]). Many of these are indiscriminate inasmuch that they can produce an attraction between particles and any bounding surface too, even if the strength of attraction might depend upon the nature of the material in some cases (cf. Van der Waals), if not others (e.g. depletion). The Derjaguin approximation [30] suggests that the particle-wall force should be ca. twice the particle-particle force for spheres, everything else being equal. This could be taken to imply that the adhesive shear strength could perhaps be higher than the bulk shear strength, everything else being equal, although this has never been observed in experimentally to the best of our knowledge [8,10-13]. The two can be measured rheometrically by determining the shear yield stress twice, first using smooth shearing surfaces and then again with suitably roughened tools. An alternative is to use a vane tool and two smooth outer cylinders, one to give a narrow gap, such that yield occurs prematurely at the outer wall, and the second to give a wide gap such that yield then occurs at the vane [13]. Such data as there is in the literature is typical, supposing that the limited published data is
suggests that reasonably representative [8,10-13]. 0.2 ≤ τ w τ y ≤ 0.7
## Constitutive relationships and modelling
Quantitative constituitive relationship were needed in order to generate synthetic sedimentation-equilibrium data. More specifically, the continuum model described in detail by Lester et al. [27] requires the compressive yield stress and wall shear functions P y ( φ ) and τ w ( φ ) as input. Following Lester et al. [27], the functional form used for P y ( φ ) is
$$P ( \phi ) = k \left [ \left ( \frac { \phi } { \phi _ { g } } \right ) ^ { n } - 1 \right ] ; \ \phi > \phi _ { g }$$
This form captures the experimentally-observed rapid increase in compressive strength at solids concentrations above gel-point, along with the progression towards power-law behaviour seen typically at higher concentrations. The power-law index n has been found to be ca. 4 typically for electrolyte-flocculated systems [8,10, 16-22,35 ] and somewhat higher for (e.g.) strongly polymer-flocculated calcium carbonate, as used in [27]. Numerical data was thus generated for both n = 4 and n = 5.
Again, following Lester et al. [27] and guided by experimental data [11], it was assumed that τ w ( φ ) ≤τ y ( φ ) = γ c G ( φ ) and, in turn, that the linear shear modulus G ( φ ) = 5/3 K ( φ ) = 5/3 d P ( φ )/dln φ . It should be emphasised that here γ c is merely a parameter: it is not the true shear strain, rather it is an apparent critical strain defined by γ c ≡τ w / G . The reason for doing so is that it is commonly found that the yield stress and modulus have similar, and in some cases identical concentration dependencies [8,10-12,19-21], meaning that the apparent yield strain, so defined, varies only weakly with volume-fraction at worst, making it a convenient parameter. Hence in the simulations, the amount of wall adhesion can be varied conveniently by changing the value of the apparent critical shear strain γ c , defined as above, The latter has been found to vary widely in practice from one material to another. For electrolyte aggregated systems values from 0.00005 to 0.025 have been reported [8,10-12,1921] with, 0.0001 to 0.002 being more typical perhaps. Apparent critical strains of ca. 0.02 have been reported for strongly polymer flocculated suspensions and a value of ~ 0.01 has been found enough to give strong wall effects in gravity-settling even in quite large diameter tubes [27]. From considerations of the nature of colloidal inter-particle forces the critical strain might be expected to vary inversely with particle size but only weakly if at all with volume-fraction. Published data are reasonably consistent with these notions, so far as the data go [8,10,11,21]. The functional forms used for the compressive strength combine to cause the ratio of the two, τ w ( φ ) / Py ( φ ) to decay rapidly from unity at the gel-point to an asymptotic value of 5 3 γ c at high volume-fraction, as shown in fig.1. The rate of decrease is such that the ratio of shear to compressive stress is approximately constant over most of the range, which is what is seen experimentally. On the other hand the ratio has to approach unity at the gel-point from theoretical considerations and, furthermore, the expected wall-adhesive effects have been observed experimentally near the gel-point [27,28]. Indeed, the constitutive forms used here were used to fit experimental data for CaCO3 flocculated using three different polymeric flocculants in [27].
To generate synthetic data for analysis, sedimentation curves were generated using the functional form (4) for (apparent) critical strains γ c of 0.0002, 0.002 and 0.02. The gel-point
and starting volume-fraction was taken to be 0.1, the initial column height h 0 was 0.075m and the tube diameter was 0.01m in most of the runs, latter dimensions being fairly typical of centrifuge testing.
Fig.
1 Input
material
functions:
compressive
strength
and
wall
stress,
the
latter
for
three values
of
the
apparent
critical
shear
strain.
The
ratio
of
wall
stress
to
compressive
is
plotted for
the
largest
strain.
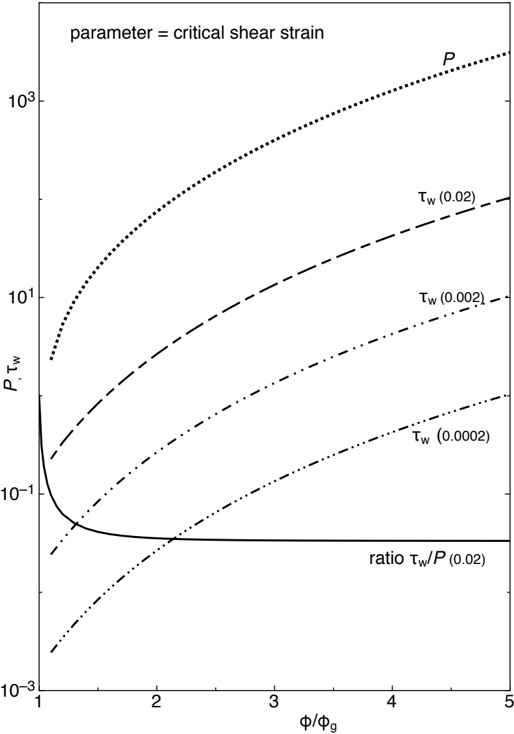
Fig. 2 Schematic
illustration
of
the
geometry
of
the
centrifuge
test.
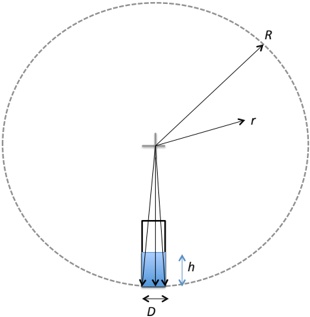
In any real centrifuge the acceleration g = ω 2 r varies with radial distance away from the axis of rotation and hence also varies down the column of suspension. It is useful to define maximum and mean values of the magnitude of the acceleration thus, (cf. Fig. 2) ,
$$g _ { \max } = \omega ^ { 2 } R ; \ \overline { g } = \omega ^ { 2 } ( R - h _ { e q } / 2 ) \,,$$
where the spatial mean represents the acceleration per unit mass for a perfectly incompressible suspension, whereas the maximum acceleration does so in the opposite limit of zero rigidity.
As we seek a simple robust means of data inversion, in most of this work the effect of wall adhesion will be explored in the uniform g limit, since effects of spatially-varying acceleration are typically negligible. In the case of uniform g and negligible wall adhesion effects, the equilibrium curve of h versus g can be inverted exactly using the simple formulae [18],
$$P _ { y } ( \phi _ { b } ) = \Delta \rho g h _ { 0 } \phi _ { 0 } ; \quad \phi _ { b } = \frac { h _ { 0 } \phi _ { 0 } } { h _ { e q } + d h _ { e q } / d \ln g }$$
It can be seen that in this case the compressive strength then depends parametrically only upon g plus three known constants, which means that any errors coming from the neglect of wall adhesion can only affect the apparent concentration at the tube bottom φ b .
In the case of radially varying g the data can only be inverted approximately even when adhesion is absent or ignored [18]. The approximation suggested by Buscall & White [18] which has been used by most workers to date reads,
$$P ( \phi _ { b } ) = \Delta \rho \overline { g } \phi _ { 0 } h _ { 0 }$$
$$\begin{array} { c } \mu \times \tau _ { b } \nu \quad - r \circ \tau _ { 0 } \cdot \tau \\ \\ \phi _ { b } = \frac { \phi _ { 0 } h _ { 0 } \left [ 1 - \frac { 1 } { 2 R } \left ( h _ { e q } + \frac { d h _ { e q } } { d \ln g _ { \max } } \right ) \right ] } { \left [ \left ( h _ { e q } + \frac { d h _ { e q } } { d \ln g _ { \max } } \right ) \left ( ( 1 - \frac { h _ { e q } } { R } \right ) + \frac { h _ { e q } ^ { 2 } } { 2 R } \right ] } \end{array}$$
This approximation was derived by acknowledging the radial increase of g down the tube axis, but by supposing otherwise that the g vector field within the tube is parallel to the column walls, and equal in magnitude at any height h . This Òparallel-gÓ approximation, valid for D/2 π R <<1, simplifies the analysis of the test very considerably by rendering the analysis 1dimensional. D /2 π R is of order 0.01 in a typical benchtop centrifuge and the error introduced by the use of the parallel-g approximation is be expected from the geometry to be of order 1cos( D R / ) ~ ( D R / ) . It will be shown later via a direct comparison of simulated data for parallel 2 and true vector g , that the error is indeed negligible to all intents and purposes for small ( D /2 π R ). Furthermore, if both D/ 2 π R << 1 and h/R << 1, then the acceleration can be regarded as both parallel and approximately uniform (as per eqn 5), and the validity of this approximation for small but finite ( D /2 π R ) will be tested also.
The numerical calculations required to generate synthetic sedimentation-equilibrium curves in , can be executed efficiently via plasticity theory, centrifugation, i.e. although the usual problems associated with spurious slip-lines are encountered [27]. Rather, it is preferable to resolve the deviatoric stresses below the yield stress by incorporating solidlike viscoelasticity sub-yield. For materials brittle in shear (small critical strain) and for the purposes of calculating sedimentation equilibrium, the results are insensitive to the precise behaviour sub-yield and so small-strain linear elasticity suffices to regularize solutions given by plasticity theory, as has been discussed elsewhere [27]. The reader is referred to ref. [27] for details of the method employed to simulate equilibrium sedimentation curves. The values of the various constants and variables used are shown in table 1 below. ( Py ( φ ), τ w ( φ )) → ( h eq , g )
Table 1: Values of key quantities used in the simulations
| quantity | value |
|------------|---------|
| φ g
=
φ 0 | 0.10 |
| k | 5
Pa |
| n | 4,
5 |
| Δρ | 2000
kg
m --3 |
| D | 5,
10,
15
mm |
| h 0 | 0.075m |
| R | 0.175m |
## True radial versus parallel versus uniform acceleration.
Simulated equilibrium height versus acceleration curves calculated for true vectorial g and constant, parallel g are plotted in fig. 2 for D/ 2 π R = 0.009 (D=10mm) and h/R ~ 1/3 and a power-law index n= 4.0. It can be seen that even for h/R as large as 1/3, the radial variation of acceleration makes little difference to the predicted equilibrium curve, provided that the heights from the vector simulation are plotted against the mean magnitude of the acceleration and not its maximum value. This implies that for h R ≤ 1 3 the simpler eqn (6) can be used to invert real centrifuge data rather than (7), even though both are equally easy to use. The main difficulty in the application of either of these equations to experimental data is the calculation of the slope d heq /dln g which needs to be evaluated as accurately as possible. Fortunately, empirical observations suggest that h eq as a function of ln(g) has only weak curvature (arising from power-law behaviour of Py ( φ )), facilitating 1 st order piece-wise fitting for the purpose of smoothing and differentiation. Since uniform g and true vector g differ only slightly, then parallel g and true vector g must differ by an even smaller amount, as shown in Fig. 3. The error introduced by the parallel-g approximation is negligible, in spite of previous criticisms regarding its use [33,34]. It is clear from the simulated data though that the parallel-g assumption is an accurate approximation for real laboratory centrifuges.
Fig. 3 Synthesised
equilibrium
height
versus
acceleration
data
for
constant g
equal
in magnitude
to
the
mean
acceleration ω 2 (R--h/2) compared
with
centrifugal
acceleration
for n= 4, D= 15mm and h eq /R < 1/3 .
Fig. 4 Synthesised
equilibrium
height
versus
acceleration
data
for
vector
centrifugal g compared
with
the
parallel-g for
15mm
internal
dia.
Tubes
and n =
4.
The
figures
in
brackets show
the
fractional
error
of
the
parallel--g
approximation
at
each
end
of
the
curve.
## Effect of adhesion
A set of synthetic equilibrium height data for both n =5 and n= 4 is shown in fig. 5. Whilst the effect of increasing the critical strain from 0.0002 to 0.002 is barely discernible, that of going from 0.002 to 0.02 is more significant. For the model suspensions used here the corresponding yield stress ratio, , decreases rapidly from ca. unity at the gelpoint toward the asymptotic value of 5/3 at high concentrations. A small stress ratio does not necessarily equate to a small effect though since wall effects are amplified by a geometric factor of 4 h eq /D [9, 27]. τ w ( φ ) / Py ( φ ) γ c
The synthetic data were inverted using (6), and some sample output is plotted in fig. 6. The large initial error introduced by neglect or ignorance of adhesion decreases rapidly with increasing volume-fraction. This decrease has two components, the first of which is the decrease of the ratio 4 τ w( φ (0))/D Δρ φ g (0) with increasing g, the second of which come from s the constitutive behaviour where the wall-adhesion to compressive strength ratio decreasing rapidly with volume-fraction. This behaviour is consistent with various experiments [11, loc. Cit.] and consistent too with the notion that
Fig. 5 Synthesised
equilibrium
height
versus
acceleration
data
for
constant g ,
10mm internal
diameter
tubes,
two
values
of
the
power--law
index
and
for
three
different
levels
of wall
adhesion
as
parameterised
by
the
critical
shear
strain.
The
effect
of
adhesion
is
just discernible
at
0.002
and
significant
at
0.02.
The
result
for
zero
shear
strain
(not
shown)
is indistinguishable
from
the
curve
for
0.0002.
The
inset
semi--log
plot
illustrates
the
slow change
in
the
gradient
term
used
in
eqns
(7)
or
(6).
cohesive particulate networks are short in shear but exhibit ratchet poroelastic and strainhardening in compression [11,31,32,36,37]. Similar results for n = 4 are shown in fig. 6. The same pattern can be seen, large errors due neglect of adhesion for a critical strain of 0.02 near the gel-point, but with convergence on the correct result at high concentration.
Since rheological characterisation will often involve determination of the either or both of the adhesive or true shear yield stresses, it is pertinent to ask whether the results of applying eqns (2) or (3) be corrected, using a set of shear yield stress data measured separately using some sort of rheometer. An overall momentum balance on the sediment of the type first described by Michaels and Bolger [9] motivates the testing of corrections of the form,
$$P _ { c o r r. } ( \phi ) = P _ { a p p } ( \phi ) - 4 \tau _ { _ { w } } ( \phi ) \frac { h _ { 0 } } { D } f ( h _ { e q } )$$
wherein f(h eq)
represents
an
approximate
or
average
way
of
accounting
for
the
effect
of the
consolidation
of
the
sediment
on
the
total
adhesion.
Thus,
the
following
simple forms
are
suggested
as
likely
over--corrections,
Fig. 6 Apparent
compressive
strength
for
critical
adhesive
shear
strain
=
0.02
obtained
by applying
eqns
3
to
the
data
in
fig.
5
(points)
compared
with
the
true
curve
(heavy
line).
Also shown
are
the
results
of
applying
the
suggested
under
and
over
corrections f 1 to f 4 to
the points.
Guessed
corrections
of
this
type
cause
the
result
to
become
negative
below
ca.
1.3 times
the
gel--point.
Below
that
only
iteration
of
the
data
via
retrodiction
and
correction
will do.
$$f _ { 1 } ( h _ { e q } ) = \frac { h _ { e q } } { h _ { 0 } } \quad \text{or}, \ f _ { 2 } ( h _ { e q } ) = \frac { \phi _ { 0 } } { \phi } \$$
whereas
the
following
pair
are
likely
to
be
under--corrections
$$f _ { 3 } ( h _ { e q } ) = \left ( \frac { h _ { e q } } { h _ { 0 } } \right ) ^ { 2 } \quad \text{or}, \ f _ { 4 } ( h _ { e q } ) = \left ( \frac { \phi _ { 0 } } { \phi } \right ) ^ { 2 } \ \.$$
These candidate upper and lower bound corrections applied to the data for critical strain of 0.02 are compared with the true curve in figs. 6 and 7. The corrected curves bracket the true curve except near the gel-point where no simple correction term is ever going to eliminate the errors coming from unacknowledged or unknown adhesion, since it contributes hugely near the gel-point. The difficult region looks to be where iteration may be required order to recover the true curve, either that or go to wider tubes, the discriminator though is the φ / φ g ≤ 1.3
Fig. 7 As
for
fig.
6
but
for
a
power--law
index
of n =
4.
Reducing
the
power--law
from
5
to
4 reduces
the
errors
coming
from
adhesion
a
little,
but
otherwise
the
picture
is
much
the
same.
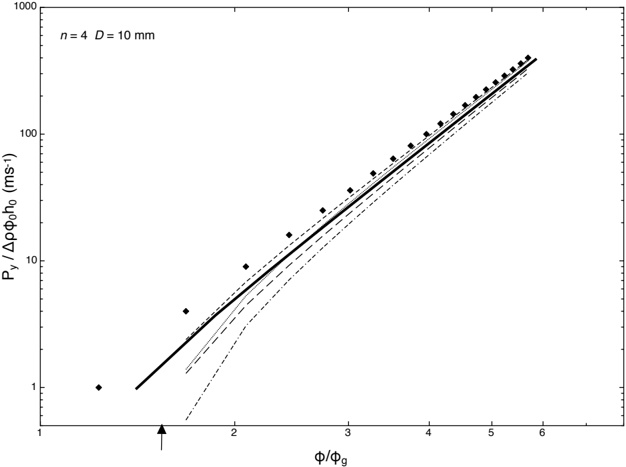
factor . If the latter is significantly less than unity, then the lower-bound correction f 4 4 τ W h 0 Py , app. D
should be good, as the errors are then always fractional.
Fig. 8 Data
of
Zhou
et
al.
(replotted
from
ref.
10,
see
also
ref.
8,
fig.
3)
and
corrected according
to
eqn
6
with
corrections f 1 and f 3 from
eqns
9
and
10
using
the
fit (shown)
to
the
shear
data.
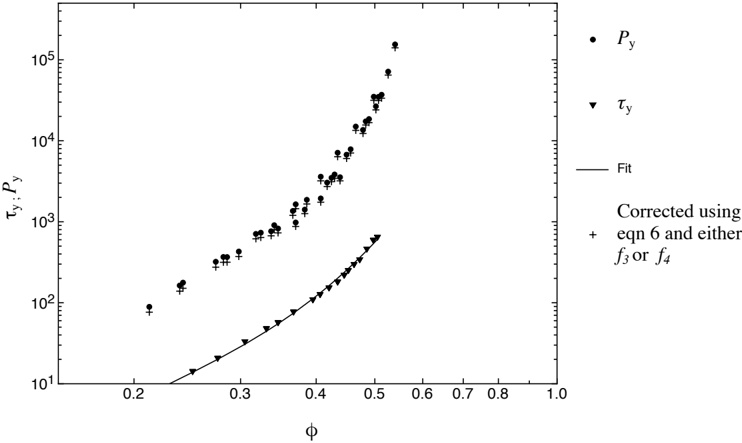
A data set taken from the literature is re-plotted in fig. 8, together with the lower-bound corrections calculated from the shear yield stress data shown. The latter were measured using a cruciform cross-sectioned vane and hence they are true yield stress values, and hence overestimates of the adhesive or wall stress needed, which, in [8] is estimated as being ca. 30% of the true value for this material from a comparison of rheometric data taken from the literature [10, 21, 23]. This almost certainly means that the corrections are systematically too large, not that it would seem to matter too much in this case as they rather small anyway, since the yield stress ratio is > 10.
What if one does not have a means of generating independent shear-stress data? Or does not wish to undertake the workload (the centrifuge generates the complete curve, whereas for the shear rheometry one needs a whole series of samples spanning the concentration range and to be sure that the structure is preparation or history independent). It is fairly obvious that an alternative would be to use several values of column height and tube diameter and extrapolate each point on the sedimentation curve to . It should be possible in principle to determine both strength functions by this means too, although the analysis could be rather tedious perhaps. The real problem with this method though is that one can only realistically vary by a factor of about 5 even in the most accommodating of centrifuges whereas a decade or more would probably be needed to extract reliable values for the shear strength. On h 0 / D → 0 h 0 / D
the other hand, varying by just two or three can and has been used to confirm that adhesion is negligible for various materials, including coagulated latex [16-20]. h 0 / D
The simulated effect of diameter is illustrated in fig. 9 for the most adhesive case studied here, i.e. critical strain = 0.02 and for three different values of tube diameter at fixed h 0 = 0.075m. The tube diameters were 5, 10, 15mm, but also shown is the datum for infinite diameter at each acceleration. The effect of diameter decreases with increasing acceleration as expected and for the two higher accelerations, and hence well away from the gel-point, the extrapolation to 1/ D = 0 is sensibly linear, whereas at g =5 it is curved away from the abscissa somewhat, implying that the use of three narrow centrifuge tubes might not be quite good enough for the most adhesive cases near the gel-point. It is always possible though to augment centrifuge data with gravity-settling data of course, where it is much easier to cover a wide a range of , unless perhaps the amount of material available is very limited for some reason. h 0 / D
Fig. 9 Simulated
height
data
for
a
critical
strain
of
0.02
for
three
tube
diameters.
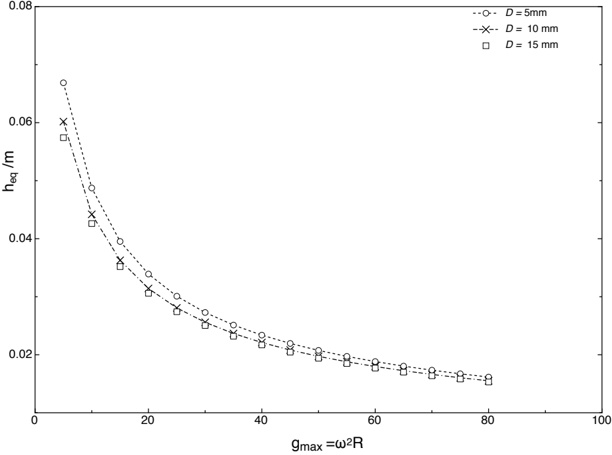
Fig. 10 Extrapolation
of
simulated
height
data
for
a
critical
strain
of
0.02
to
infinite
tube diameter
for
three
accelerations
measured
in
units
of
normal
gravity
g.
Here
the
points
for infinite D are
known.
At
the
lowest
g,
near
the
gel--point
the
plot
is
slightly
convex
to
the abscissa
implying
that
several
tube
diameters
would
be
needed
in
practice
for
a
good extrapolation.
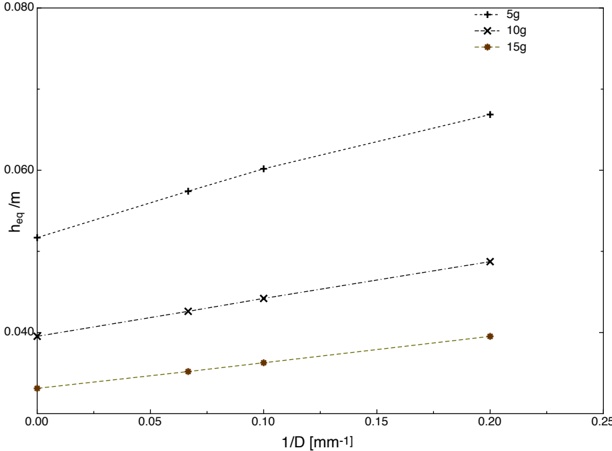
## Concluding remarks
The approximate equations used conventionally for estimating the compressive strength curve for cohesive particulate gels from raw centrifuge data ignore the possibility of adhesion to the walls and furthermore are based on the assumption that the acceleration vector field inside the tube is everywhere parallel to the tube axis. The validity of these two assumptions has been explored and tested using simulated test data, as have some simple corrections for adhesion suggested by dimensional analysis. Corrections to the Òparallel gÓ assumption are not needed as this approximation turns out produce negligible error.
Adhesion was parameterised in terms of a critical shear strain for shear yielding at the wall. This was done simply for convenience because the ratio of the shear yield stress to compressive strength itself is expected in practice to decrease rapidly with increasing volumefraction near the gel-point, before becoming more or less constant, whereas the critical shear strain has been found to be at worst only weakly concentration-dependent. Critical shear strains are known to vary from one material to another and with particle size, hence critical
strains of 0, 0.0002, 0.002 and 0.02 were used in order to cover the range reported in the literature, where values of << 0.01 have been reported for many electrolyte coagulated or flocculated suspensions, including polystyrene latex and a range of minerals, whereas values of order 0.02 have been reported for one electrolyte flocculated mineral system [27]. Aside from that study, critical strain values of order 0.01 or more have only been reported for mineral suspensions strongly-flocculated using high polymers and for water-treatment sludges. A particular form for the dependence of the shear and compressive strength on volume-fraction had to be assumed and this again was motivated by published experimental data. The dependence of the resulting adhesive to compressive strength ratio on volumefraction and critical strain on volume-fraction and critical strain is plotted in Fig 1 in order to illustrate the parameter space covered. Small strength ratios alone do not necessarily mean a negligible effect of adhesion in the centrifuge since the relative effect of adhesion is given by the ratio 4 τ w( φ (0))/D Δρ φ g (0), hence experimental parameters such as g and D play a significant role.
The simulations herein suggest that adhesion can be usually neglected in centrifuge testing for volume-fractions well above the gel-point, by which is meant > 3 φ g , and otherwise where the apparent critical shear strain << 0.01. Otherwise, the following tactics might be considered:
- 1. The adhesive shear strength could be measured independently in a rheometer fitted with appropriate tools and a correction applied using (6) or (7)and (8). The simple corrections suggested here will always fail very near the gel-point though.
- 2. Make measurements using several different values of the ratio of initial height h 0 to tube diameter D and extrapolate to h 0 / D. This method may or may not be practicable, depending upon the design of the centrifuge. The range of h 0 / D covered should be at least three-fold and preferably five-fold, as should the number of points, although it rather depends upon the strength of the effect. Fewer points would needed to demonstrate that adhesion is insignificant, where it is, than would be needed to perform a good extrapolation, where it is not.
- 3. Complement the centrifuge data with data from gravity-settling for a set of column chosen so as to vary h 0 / D by a factor of at least five and better ten, with h 0 and D each varied by at least three. One could also complement centrifuge data with that coming from an instrumented pressure-filter, in principle, since the construction of these is usually such that h 0 / D is small, except that pressure-filtration does not
normally work near the gel-point because of the difficulty in applying the necessary small pressures. This method has however been used to validate and complement the centrifuge method at higher volume-fraction [8, 10, 21, 23].
The centrifuge method has been used recently to examine the effect of temperature on the stability of incipiently flocculated polystyrene latices [36], but without taking the possibility of adhesion into account. It has been used also to measure the compressibility of microgels, albeit using inclined rather than horizontal or swing-out rotors which adds complication to the analysis. Wall shear-stresses were ignored, which could well be reasonable for microgels in good solvents, perhaps [37].
## References
- 1. Grace H P, Chemical Engineering Progress, 47 (1953) 303-318.
- 2. Callaghan I C and Ottewill R H, J.Chem. Soc. Faraday Disc., 57 (1974) 110- 118.
- 3. Meeten G H, Chem. Eng. Sci., 48 (1993) 2391-2398.
- 4. Sherwood J D and Meeten G H, J. Petrol. Sci. & Eng., 18 (1997) 73-81.
- 5. Miller K T, Melant R M and Zukoski C F, J. Am Ceram. Soc., 79 (1996) 25452556.
- 6. Green M D, Eberl M, Landman K L and White L R, AIChE J., 42 (1996) 23082318.
- 7. Green M D, Landman K A, de Kretser R G and Boger D V, Ind. Eng. Chem. Research, 37 (1998) 4152-4156.
- 8. R. G. de Kretser, D. V. Boger and P. J. Scales, Rheology Rev. BSR (2003), pp 125 -165.
- 9. A. S. Michaels and J. C. Bolger, Ind. Eng. Chem. Fundamentals 1, 211 (1962).
- 10. Zhou Z, Scales P J and Boger D V, Chem. Eng. Sci., 56 (2001) 2901-2920;
- 11. R. Buscall, arXiv:0903.0970v1 [cond-mat.soft] (2009).
- 12. A. L. Tindley, The effect of electrolytes on the properties of titanium dioxide dispersions, Ph.D. thesis, University of Leeds, Engineering Faculty (2007).
- 13. Stickland, A.D., Kumar, A., Kusuma, T., Scales, P.J., Tindley, A., Biggs, S., & Buscall, R., The Effect of Vane-in-Cup Gap Width on Creep Testing of StronglyFlocculated Suspensions, (submitted to Rheol. Acta, July 2014). http://arxiv:1408.0069.
- 14. K. Been & G.C. Stills, Self-weight consolidation of soft soils, Geotechnique, 1981, 31, 519-535.
- 15. Tiller F M and Khatib Z, J. Colloid Int. Sci. 100 (1984) 55-67.
- 16. Buscall R, Colloids & Surfaces, 5, 269 (1982).
- 17. Buscall R, Stewart R F and Sutton D, Filt. Sep., 21 (1984) 183-188.
- 18. Buscall R and White L R, J. Chem. Soc. Faraday Trans. I, 83 (1987) 873-891.
- 19. R. Buscall, I. J. McGowan, P. D. A. Mills, R. F. Stewart, D. Sutton, L. R. White, and G. E. Yates, Journal of Non-Newtonian Fluid Mechanics 24, 183 (1987).
- 20. R. Buscall, P. D. A. Mills, J. W. Goodwin, and D. W. Lawson, Journal of the Chemical Society: Faraday Transactions I84, 4249 (1988).
- 21. Channell G M and Zukoski C F, AIChE J, 43 (1997) 1700-1708.
- 21. Green M D and Boger D V, Ind. Eng. Chem. Research, 36 (1997) 4984-4992.
- 23. Channell G M, Miller K T and Zukoski C F, AIChE J., 46 (2000) 72-78.
- 24. Auzerais F M, Jackson R, Russel W B and Murphy W F, J Fluid Mech, 211 (1990) 613-639.
- 26. Bergstrom L, J. Chem. Soc. Faraday Trans., 88 (1992) 3201-211.
- 26. Sherwood J D, Meeten G H, Farrow C A and Alderman N J, J. Chem. Soc. Faraday Transactions, 87 (1991) 611-618.
- 27.Lester, D.R., Buscall, R., A.D. Stickland, P. J. Scales, Wall Adhesion and Constitutive Modelling of Strong Colloidal Gels, J. Rheol., 58(5):1247Ð1276, (2014)..
- 28. The role of solid friction in the sedimentation of strongly attractive colloidal gels, Jean-Michel Condre, Christian Ligoure and Luca Cipelletti J. Stat. Mech. (2007) P02010 doi: 10.1088/1742-5468/2007/02/P02010.
- 29. S. Manley, J.M. Skotheim, L. Mahadevan, D.A. Weitz, Phys. Rev. Lett. 94, 218302 (2005).
- 30. ÒColloidal DispersionsÓ, W. B. Russel, D. A. Saville and W. R. Schowalter, Cambridge University Press (1989).
- 31. C. Kim, Y. Lui, A. Kuhnle, S. Hess, S. Viereck, T. Danner, L. Mahadevan and D. A. Weitz., Phys. Rev. Lett., 2007, 99, 028303.
- 32 J.J. LiŽtor-Santos , C. Kim, P.J. Lu, A. Fern‡ndez-Nieves, and D.A. Weitz, Eur. Phys. J. E 28, 159 (2009)
- 33. R. Burger, F. Concha, Settling velocities of particulate systems: 12. Batch centrifugation of flocculated suspensions, Internat. J. Mineral Process. 63 (2001) 115Ð 145.
- 34. Berres, S., R. Burger & R. Garces, Drying Technology, 28: 858Ð870, 2010.
- 35. D.R. Lester, R. Buscall, Correction of Wall Adhesion Effects in Batch Settling of Strong Colloidal Gels, (submitted, JNNFM, September 2014). http://arxiv.org/abs/1408.0450.
- 36. Yow, H. N., and S. Biggs, Probing the stability of sterically-stabilized polystyrene particles by centrifugal sedimentation, Soft Matter, 2013, 9 , 10031-10041.
- 37. Nordstrom, K. N. , E. Verneuil, W. G. Ellenbroek, T. C. Lubensky, J. P. Gollub,
and D. J. Durian, Phys. Rev. E 82 , 041403 (2010).
Note: One of us is sometimes asked what ÔMSACTÕ in ÔMSACT Research & ConsultingÕ. It is short for ÔMud, Sludge and Custard TamedÕ, although this is more of an ambition than an claim. | null | [
"Richard Buscall",
"Daniel R. Lester"
] | 2014-08-03T03:13:29+00:00 | 2014-10-09T10:46:47+00:00 | [
"cond-mat.soft"
] | Correction of Wall Adhesion Effects in the Centrifugal Compression of Strong Colloidal Gels | Several methods for measuring the compressive strength of strong particulate
gels are available, including the centrifuge method, whereby the strength as a
function of volume-fraction is obtained parametrically from the dependence of
equilibrium sediment height upon acceleration. The analysis used conventionally
due to Buscall & White (1987) ignores the possibility that the particulate
network might adhere to the walls of the centrifuge tube, even though many
types of cohesive particulate gel can be expected to. The neglect of adhesion
is justifiable when the ratio of the shear to compressive strength is small,
which it can be for many systems away from the gel-point, but never very near
it. The errors arising from neglect of adhesion are investigated theoretically
and quantified by synthesising equilibrium sediment height versus acceleration
data for various degrees of adhesion and then analysing them in the
conventional manner. Approximate correction factors suggested by dimensionless
analysis are then tested. The errors introduced by certain other approximations
made routinely in order to render the data-inversion practicable are analysed
too. For example, it shown that the error introduced by treating the
acceleration vector as approximately one-dimensional is minuscule for typical
centrifuge dimensions, whereas making this assumption renders the data
inversion tractable. |
1408.0451v2 | ## GENERALIZED TRAPEZOIDAL WORDS
## AMYGLENANDFLORENCELEVÉ
ABSTRACT. The factor complexity function Cw ( n ) of a finite or infinite word w counts the number of distinct factors of w of length n for each n ≥ 0. A finite word w of length | w | is said to be trapezoidal if the graph of its factor complexity Cw n ( ) as a function of n (for 0 ≤ n ≤ | w | ) is that of a regular trapezoid (or possibly an isosceles triangle); that is, Cw n ( ) increases by 1 with each n on some interval of length r , then Cw n ( ) is constant on some interval of length s , and finally Cw n ( ) decreases by 1 with each n on an interval of the same length r . Necessarily Cw ( 1 ) = 2 (since there is one factor of length 0, namely the empty word ), so any trapezoidal word is on a binary alphabet. Trapezoidal words were first introduced by de Luca (1999) when studying the behaviour of the factor complexity of finite Sturmian words , i.e., factors of infinite 'cutting sequences', obtained by coding the sequence of cuts in an integer lattice over the positive quadrant of R 2 made by a line of irrational slope. Every finite Sturmian word is trapezoidal, but not conversely. However, both families of words (trapezoidal and Sturmian) are special classes of socalled rich words (also known as full words ) - a wider family of finite and infinite words characterized by containing the maximal number of palindromes - studied in depth by the first author and others in 2009.
In this paper, we introduce a natural generalization of trapezoidal words over an arbitrary finite alphabet A , called generalized trapezoidal words (or GT-words for short). In particular, we study combinatorial and structural properties of this new class of words, and we show that, unlike the binary case, not all GT-words are rich in palindromes when |A| ≥ 3, but we can describe all those that are rich.
## 1. INTRODUCTION
Given a finite or infinite word w , let Cw n ( ) (resp. Pw ( n ) ) denote the factor complexity function (resp. the palindromic complexity function ) of w , which associates with each integer n ≥ 0 the number of distinct factors (resp. palindromic factors) of w of length n . The well-known infinite Sturmian words are characterized by both their factor complexity and palindromic complexity. In 1940 Morse and Hedlund [11] established that an infinite word w is Sturmian if and only if C w ( n ) = n + 1 for each n ≥ 0. Almost half a century later, in 1999, Droubay and Pirillo [7] showed that an infinite word w is Sturmian if and only if P w ( n ) = 1 whenever n is even, and P w ( n ) = 2 whenever n is odd. In the same year, de Luca [4] studied the factor complexity function of finite words and showed, in particular, that if w is a finite Sturmian word (meaning a factor of an infinite Sturmian word), then the graph of Cw n ( ) as a function of n (for 0 ≤ n ≤ | w | , where | w | denotes the length of w ) is that of a regular trapezoid (or possibly an isosceles triangle). That is, Cw n ( ) increases by 1 with each n on some interval of length r , then Cw n ( ) is constant on some interval of length s , and finally Cw n ( ) decreases by 1 with each n on an interval of the same size r . Such a word is said to be trapezoidal . Since Cw ( 1 ) = 2, any trapezoidal word is necessarily on a binary alphabet.
In this paper, we study combinatorial and structural properties of the following natural generalization of trapezoidal words over an arbitrary finite alphabet.
Date : Submitted August 2014; Revised February 2015.
2000 Mathematics Subject Classification. 68R15.
Key words and phrases. word complexity; trapezoidal word; Sturmian word; palindrome; rich word.
Corresponding author: Amy Glen.
Note: Preliminary work on this new class of words was presented in talks by the first author at the 35th Australasian Conference on Combinatorial Mathematics & Combinatorial Computing (35ACCMCC) in December 2011 and at a workshop on Outstanding Challenges in Combinatorics on Words at the Banff International Research Station (BIRS) in February 2012.
Definition 1. A finite word w with alphabet Alph ( w ) : = A |A| ≥ , 2, is said to be a generalized trapezoidal word (or GT-word for short) if there exist positive integers m M , with m ≤ M such that the factor complexity funtion Cw n ( ) of w increases by 1 for each n in the interval [ 1, m ] , is constant for each n in the interval [ m M , ] , and decreases by 1 for each n in the interval [ M w , | | ] . That is, w is a GT-word if there exist positive integers m M , with m ≤ M such that Cw satisfies the following:
$$\begin{array} { c c c c } \tilde { \nu } & \cdot$$
So if a finite word w consisting of at least two distinct letters is a GT-word then the graph of its factor complexity Cw n ( ) as a function of n (for 0 ≤ n ≤ | w | ) forms a regular trapezoid (or possibly an isosceles triangle when m = M ) on the interval [ 1, | w | - |A| + ] 1 , as shown in Figure 1 below. In the case of a 2-letter alphabet, the GT-words are precisely the (binary) trapezoidal words studied by de Luca [4].
FIGURE 1. Graph of the factor complexity function Cw n ( ) of a GT-word w .
Remark 2. In what follows, any finite word w with | Alph w ( ) | = 1 (e.g., w = aaaa) will also be classed as a generalized trapezoidal word since the complexity function of such a word, being constant on the interval [ 1, | w , satisfies the 'trapezoidal conditions' in Definition 1 with m | ] = 1 and M = | w . |
Let w be a finite word with alphabet Alph ( w ) : = A |A| ≥ , 2. A right special factor u of w is one that can be extended to the right by at least two different letters and still remains a factor of w , i.e., ux is a factor of w for at least two different letters x ∈ A . Let Rw ( = R ) denote the smallest positive integer r such that w has no right special factor of length r and let Kw ( = K ) denote the length of the shortest unrepeated suffix of w (i.e., the shortest suffix of w that occurs only once in w ). In [4, Proposition 4.7], de Luca proved that a finite word w is a binary trapezoidal word if and only if | w | = Rw + Kw .
Example 3. The binary word w = aaabb of length 5 has complexity sequence { Cw n ( ) } n ≥ 0 = 1, 2, 3, 3, 2, 1, so w is clearly a trapezoidal word and we see that Rw = 3, Kw = 2, and indeed | w | = Rw + Kw .
Every finite Sturmian word w , being a binary trapezoidal word, satisfies the condition | w | = Rw + Kw , but not conversely, i.e., there exist non-Sturmian binary trapezoidal words. For instance, the binary trapezoidal word aaabb in Example 3 is not Sturmian because it contains two palindromes,
aa and bb , of even length 2. All non-Sturmian trapezoidal words were classified by D'Alessandro [3] in 2002.
/negationslash
It is natural to wonder if there is an analogous combinatorial characterization in terms of R and K for generalized trapezoidal words. One might guess, for instance, that GT-words are, perhaps, the finite words w that satisfy the condition | w | = Rw + Kw + | Alph ( w ) | -2. But whilst it is true that any word satisfying this 'RK-condition' is a GT-word (see Corollary 6 later), the converse does not hold. For example, the GT-word u = ababadac of length 8 with complexity sequence { Cu ( n ) } n ≥ 0 = 1, 4, 5, 5, 5, 4, 3, 2, 1 has Ru = 4 and Ku = 1, but Ru + Ku + 2 = 8. However, we see that | u | = Rv + Kv + | Alph ( u ) | -2 where v is the so-called 'heart' of u (see Definition 11); namely, the factor v = ababada (with Rv = 4, Kv = 2) obtained from u by deleting its last letter c that occurs only once in u . It turns out that the condition | w | = Rv + Kv + | Alph ( w ) | -2, where v is the heart of w , does indeed characterize generalized trapezoidal words (see Theorem 17 later).
In the next section, we prove some combinatorial properties of GT-words, particularly with respect to the parameters R and K , followed by our main results in Section 3 where we prove some characterizations of GT-words (see Theorem 17, Corollary 20, and Theorem 21) and describe all the GT-words that are rich in palindromes (see Theorem 27). We use standard terminology and notation for combinatorics on words, as in the book [10], for instance.
## 2. PRELIMINARY RESULTS
The following result of de Luca [4], which describes the graph of the complexity function of any given word w , will be needed in what follows.
Proposition 4. [4, Proposition 4.2] Let w be a finite word with | Alph w ( ) | ≥ 2 and let m = min { Rw Kw , } , M = max { Rw Kw , } . The factor complexity function Cw of w is strictly increasing on the interval [ 0, m , is ] non-decreasing on the interval [ m M , and is strictly decreasing on the interval , ] [ M w . Moreover, for all , | | ] n ∈ [ M w , one has Cw , | | ] ( n + ) = 1 Cw n ( ) -1 . If Rw < Kw, then Cw is constant on the interval [ m M . , ]
As a first step towards obtaining a combinatorial characterization of generalized trapezoidal words, we describe, in the following theorem, the finite words w satisfying the so-called RK-condition | w | = Rw + Kw + | Alph ( w ) | -2.
Theorem 5. Suppose w is a finite word with Alph ( w ) : = A |A| ≥ , 2 . Then | w | = Rw + Kw + |A| 2 if and only if the factor complexity function Cw of w satisfies:
$$\begin{array} {$$
where m = min { Kw , Rw } and M = max { Kw , Rw } . Moreover, Cw ( Rw ) = Cw Kw ( ) and the maximal value of Cw is m + |A| 1 .
Proof. ( ⇒ ): Suppose that | w | = Rw + Kw + |A| 2. We first consider the case Rw ≤ Kw so that m = Rw and M = Kw . By Proposition 4, we know that Cw is strictly increasing on the interval [ 0, Rw ] and is constant on the interval [ Rw Kw , ] , and then strictly decreasing on the interval [ Kw , | w | ] ; in particular,
$$C _ { w } ( i + 1 ) = C _ { w } ( i ) - 1 \$$
It remains to show that Cw i ( ) = |A| + i -1 for i ∈ [ 1, Rw ] . Since Cw ( 1 ) = |A| , we have Cw i ( ) ≥ |A| + i -1 for i ∈ [ 1, Rw ] , so Cw ( Rw ) ≥ |A| + Rw -1, and in fact, we have Cw ( Rw ) = |A| + Rw -1.
Indeed, from Equation (1) and the hypothesis | w | = Rw + Kw + |A| 2, we deduce that
$$1 = C _ { w } ( | w | ) = C _ { w } ( K _ {$$
Hence, since Cw Kw ( ) = Cw ( Rw ) , it follows that Cw ( Rw ) = |A| + Rw -1. This implies that Cw i ( ) = |A| + i -1 for i ∈ [ 1, Rw ] . For if not, then there exists an r < Rw such that Cw r ( ) > |A| + r -1 and Cw r ( + ) n ≥ Cw r ( ) + n for n = 1, 2, . . . , Rw -r (e.g., see [4]) implying that
$$C _ { w } ( R _ { w } ) \geq C _ { w } ( r$$
which is impossible because Cw ( Rw ) = |A| + Rw -1.
Nowlet us consider the case Kw < Rw , so that m = Kw and M = Rw . By Proposition 4, we know that Cw is strictly increasing on the interval [ 0, Kw ] and is non-decreasing on the interval [ Kw Rw , ] , and then strictly decreasing on the interval [ Rw , | w | ] ; in particular,
$$C _ { w } ( i + 1 ) = C _ { w } ( i ) - 1 \text{ \ for } i \in [ R _ { w }, | w | ].$$
Moreover, by the hypothesis | w | = Rw + Kw + |A| 2, it is easy to see that the maximal value of the complexity is Cw ( Rw ) = | w | -Rw + 1 = Kw + |A| 1. But since Kw < Rw , we have Cw Kw ( ) ≥ Kw + |A| 1, and therefore, Cw ( Rw ) = Cw Kw ( ) = |A| + Kw -1. Using a similar argument to that used in the previous case, it follows that Cw i ( ) = |A| + i -1 for i ∈ [ 1, Kw ] .
( ⇐ ): To prove the converse statement, let us first suppose that Kw < Rw . Then by assumption, Cw i ( ) = |A| + i -1 for i ∈ [ 1, Kw ] , and so Cw Kw ( ) = |A| + Kw -1. Moreover, since Cw i ( + ) = 1 Cw i ( ) for i ∈ [ Kw Rw , -1 , it follows that ] Cw Kw ( ) = Cw ( Rw ) . Furthermore, by the condition Cw i ( + ) = 1 Cw i ( ) -1 for i ∈ [ Rw , | w | ] , we have Cw ( Rw ) = | w | -( Rw -1 ) = | w | -Rw + 1. Hence, | w | -Rw + 1 = Kw + |A| 1, i.e., | w | = Rw + Kw + |A| 2. On the other hand, if we suppose now that Kw ≥ Rw , we easily deduce from the hypothesis that Cw ( Rw ) = Rw + |A| 1 = Cw Kw ( ) = | w | -Kw + 1, and therefore | w | = Rw + Kw + |A| 2. /square
Corollary 6. Suppose w is a non-empty finite word. If | w | = Rw + Kw + | Alph w ( ) | -2 , then w is a GT-word.
Proof. In the case when | Alph ( w ) | ≥ 2, the result follows immediately from Theorem 5. It remains to consider the case when | Alph ( w ) | = 1. Any such word has length equal to Rw + Kw + | Alph ( w ) | -2 where Rw = 1 and Kw = | w | , and clearly all such words are GT-words since the graphs of their complexity functions, being constant, satisfy the trapezoidal property (see Remark 2). /square
It should be noted here that we are using a slightly different convention for Rw compared to [4]; in that paper, a power of a letter had Rw = 0, not 1, since the empty word was considered to be a factor that is not right special in such a word. However, our convention (defining Rw to be the smallest positive integer such that w does not have a right special factor of length Rw ) allows us to view single-letter words as GT-words satisfying the RK-condition.
Let w be a finite word with Alph ( w ) : = A |A| ≥ , 2. A factor u of w is said to be right-extendable if there exists a letter x ∈ A such that ux is a factor of w and u is said to have right-valence j ≥ 0 if u is right-extendable in w by j distinct letters (e.g., see [4]). Left special factors , left-extendable factors , and left-valences are all similarly defined. A factor of w is said to be bispecial if it is both left and right special. Clearly, any left (resp. right) special factor has left (resp. right) valence at least 2. In the case when |A| = 2, left and right special factors have valences equal to 2 since any factor of a word is only extendable to the left or right in at most two different ways.
For the subset of GT-words satisfying the RK-condition, we have the following consequence of Theorem 5 and Proposition 4.
Proposition 7. Suppose w is a finite word with | Alph w ( ) | ≥ 2 . Then | w | = Rw + Kw + | Alph w ( ) | -2 if and only if there exists exactly one right special factor of w of length i for every (non-negative) integer i < Rw and each non-empty right special factor of w has right-valence 2 .
Proof. ( ⇒ ): Let | w | = Rw + Kw + | Alph ( w ) | -2, m = min { Rw Kw , } , and M = min { Rw Kw , } . Suppose w contains two distinct right special factors of the same length i for some i < Rw . If i < m , then since each factor of w of length less than m is right-extendable in w , we would have Cw i ( + ) 1 -Cw i ( ) > 1, contradicting the fact that Cw n ( + ) 1 -Cw n ( ) = 1 for each n ∈ [ 1, m -1 ] by Theorem 5. On the other hand, if m ≤ i < Rw (in which case m = Kw and M = Rw ), then there being two distinct right special factors of length i implies that Cw i ( + ) 1 -Cw i ( ) ≥ 1. Indeed, since all factors of length i of w , except the suffix of w of length i , are right-extendable in w , the two different right special factors of length i would increase the complexity of w by at least 1 when going from factors of length i to factors of length i + 1. But this contradicts that fact that Cw must be constant on the interval [ Kw , Rw ] by Theorem 5. So w contains exactly one right special factor of each length i < Rw . Furthermore, using similar reasoning as above, we deduce that all non-empty right special factors of w must have right-valence 2.
( ⇐ :) Conversely, if w contains exactly one right special of each length i < Rw with each non-empty right special factor having right-valence 2, then using Proposition 4, we deduce that Cw must satisfy the conditions in Theorem 5, and hence | w | = Rw + Kw + | Alph ( w ) | -2. /square
/negationslash
Recall that binary trapezoidal words are precisely those that satisfy | w | = Rw + Kw (see [3, 4]), so Proposition 7 (above) applies to all binary trapezoidal words, but it is not true in general for all GTwords w with | Alph ( w ) | > 2 (only those that satisfy the RK-condition). For instance, the GT-word w = abbac does not satisfy the RK-condition (since Rw = 2, Kw = 1, and Rw + Kw + | Alph ( w ) | -2 = 4 = | w | ) and it has two different right special factors of length 1 (namely the letters a and b ). We also note that GT-words that do not satisfy the RK-condition can also contain right special factors with right-valences greater than 2 (and also left special factors with left-valences greater than 2). For example, in the GT-word u = ababadac (which does not satisfy the RK-condition), the letter a is a right special factor with right-valence 3. The letters b and d are each right-extendable only by the letter a in u , whereas the letter c is not right-extendable as a factor of u , so there is only a jump of 1 between Cu ( 1 ) = 4 and Cu ( 2 ) = 5.
As introduced by de Luca [4], one can define two parameters, Lw and Hw , analogous to Rw and Kw , when considering left factors instead of right factors. Specifically, for a given finite word w with | Alph ( w ) | ≥ 2, Lw is defined to be the smallest positive integer /lscript such that w has no left special factor of length /lscript and Hw is the shortest unrepeated prefix of w . In [4, Proposition 4.6], de Luca proved that any finite word w satisfies | w | ≥ Rw + Kw and also | w | ≥ Lw + Hw . Moreover, Cw ( Rw ) = Cw ( Lw ) and max { Rw Kw , } = max { Lw , Hw } [4, Corollary 4.1].
Using the dual of Proposition 4, in which Rw is replaced by Lw and Kw is replaced by Hw (see [4]), we can prove (in a symmetric way) the corresponding dual of Theorem 5, and subsequently we have the following dual of Proposition 7.
Proposition 8. Suppose w is a finite word with | Alph w ( ) | ≥ 2 . Then | w | = Lw + Hw + | Alph w ( ) | -2 if and only if there exists exactly one left special factor of w of length i for every (non-negative) integer i < Lw and each non-empty left special factor of w has left-valence 2 . /square
The following useful result of de Luca [4] concerns the structure of right and left special factors of maximal length of a given word w with respect to the parameters Rw , Kw , Lw , and Hw .
Proposition 9. [4, Proposition 4.5] Suppose w is a word and u is a right (left) special factor of w of maximal length. Then u is either a prefix (suffix) of w or bispecial. If Rw > Hw (Lw > Kw), then u is bispecial.
The next result is a refinement of [4, Proposition 4.6].
Proposition 10. Suppose w is a non-empty finite word. Then
$$| w | \geq R _ { w } + K _ { w } + | A l p h ( w ) | - 2 \ \ a n d \ \ | w | \geq L _ { w } + H _ { w } + | A l p h ( w ) | - 2.$$
Proof. We will prove only the first inequality since the second one is proved by a symmetric argument. If | Alph ( w ) | = 1, then Rw = 1 and Kw = | w | , so | w | = Rw + Kw + | Alph ( w ) | -2. Now suppose that | Alph ( w ) | ≥ 2 and let m = min { Rw Kw , } , M = max { Rw Kw , } . Since Cw ( 1 ) = | Alph ( w ) | , it follows from Proposition 4 that Cw i ( ) ≥ | Alph ( w ) | + i -1 for i = 1, 2, . . . , m , and so Cw m ( ) ≥ | Alph ( w ) | + m -1. Moreover, since Cw i ( + ) 1 ≥ Cw i ( ) for all integers i ∈ [ m M , -1 , ] we have Cw ( M ) ≥ Cw m ( ) . Furthermore, by Proposition 4, we have Cw i ( + ) = 1 Cw i ( ) -1 for all integers i ∈ [ M w , | | ] , and therefore Cw ( M ) = | w | -( M -1 ) = | w | -M + 1. Hence
$$\text{cores} \, & \mathcal { C } _ { w } \, \mathcal { U } _ { J } - \mathcal { U } _ { J } - \mathcal { U } _ { J } - \mathcal { U } _ { J } - \mathcal { U } _ { J } \, \mathcal { T } \\ | w | & = C _ { w } ( M ) + M - 1 \\ & \geq C _ { w } ( m ) + M - 1 \\ & \geq | \text{Alph} ( w ) | + m - 1 + M - 1 \\ & = | \text{Alph} ( w ) | + m + M - 2 \\ & = | \text{Alph} ( w ) | + R _ { w } + K _ { w } - 2.$$
/square
Let | w x | denote the number of occurrences of a letter x in a non-empty finite word w .
Definition 11 (Heart) . Let w be a non-empty finite word. Suppose that r is the longest (possibly empty) prefix of w such that | w x | = 1 for all x ∈ Alph ( r ) and that s is the longest (possibly empty) suffix of w such that | w x | = 1 for all x ∈ Alph ( s ) . If | w | > | Alph ( w ) | , then there exists a unique (non-empty) word v with | v | < | w | such that w = rvs and we call v the heart of w . Otherwise, if | w | = | Alph ( w ) | , then r = s = w and we define the heart of w to be itself.
Note. Roughly speaking, for any finite word w with | w | > | Alph ( w ) | (i.e., for any finite word w that contains at least two occurrences of some letter), the heart of w is defined to be the unique (nonempty) factor of w that remains if we delete the longest prefix and the longest suffix of w that contain letters only occurring once in w .
Equivalently, the heart of a non-empty finite word w is the unique (non-empty) factor v of w such that w = rvs where rv is the longest prefix of w such that Krv > 1 and vs is the longest suffix of w such that Hvs > 1, i.e., ˜ vs is the longest prefix of ˜ w such that Kvs ˜ > 1 (where ˜ u denotes the reversal of a given word u ).
Example 12. Consider the word w = ebbacbadf . By deleting from w the longest prefix and the longest suffix that contain letters only occurring once in w , we determine that the heart of w is v = bbacba . We also observe that w can be expressed as w = rvs with r = e , s = df , and where rv = ebbacba is the longest prefix of w such that Krv > 1 and vs = bbacbadf is the longest suffix of w such that Hvs > 1. Note that the word w is a generalized trapezoidal word with Rw = 3 and Kw = 1, and we see that | w | = Rv + Kv + | Alph ( w ) | -2 (where Rv = 2 and Kv = 3); in fact, this condition characterizes GT-words (see Theorem 17 in the next section).
Remark 13. All binary trapezoidal words are equal to their own hearts, except those of the form a n b or ab n where a, b are distinct letters and n > 1 is an integer. Such (binary) trapezoidal words have hearts of the form x n for some letter x ∈ { a b , } . We also note that any word w with | w | = | Alph w ( ) | , i.e., any word w that is a product of mutually distinct letters, is a GT-word (such a word w has Rw = 1 and Kw = 1 and therefore satisfies the RK-condition).
The next result generalizes [4, Proposition 4.8].
Proposition 14. Let w be a non-empty finite word with heart v. If | w | = Rv + Kv + | Alph w ( ) | -2 , then
$$\min \{ R _ { v }, K _ { v } \} = \min \{ L _ { v }, H _ { v } \} \ \ a n d \ \ | w | = L _ { v } + H _ { v } + | A l p h ( w ) | - 2.$$
Proof. We first observe that if | w | = Rv + Kv + | Alph ( w ) | -2, then | v | = Rv + Kv + | Alph ( v ) | -2 because, by definition of the heart v of w , | w | - | v | = | Alph ( w ) | - | Alph ( v ) | , i.e., | v | = | w | -| Alph ( w ) | + | Alph ( v ) | . The result is trivial if | Alph ( v ) | = 1 because, in this case, Rv = Lv = 1 and Kv = Hv = | v | . So we will henceforth assume that | Alph ( v ) | ≥ 2.
By [4, Corollary 4.1], Cv ( Rv ) = Cv ( Lv ) and max { Rv , Kv } = max { Lv , Hv } . Hence, since any finite word v satisfies | v | ≥ Lv + Hv + | Alph ( v ) | -2 (by Proposition 10), we deduce that min { Lv , Hv } ≤ min { Rv , Kv } . Indeed, we have
$$\dots \dots ( \cdots v, \cdots v _ { 1 } ) \cdots \dots \dots \dots \\ | v | & = R _ { v } + K _ { v } + | \text{Alph} ( v ) | - 2 \\ & = \min \{ R _ { v }, K _ { v } \} + \max \{ R _ { v }, K _ { v } \} + | \text{Alph} ( v ) | - 2 \\ & = \min \{ R _ { v }, K _ { v } \} + \max \{ L _ { v }, H _ { v } \} + | \text{Alph} ( v ) | - 2 \\ & \geq L _ { v } + H _ { v } + | \text{Alph} ( v ) | - 2 \\ \tau \cup \cdots \dots \cdots \tau n \quad \nu \ \, \cdots$$
and thus min { Lv , Hv } ≤ min { Rv , Kv } .
Suppose that Lv ≤ Hv . Then, by [4, Corollary 4.1], Hv = max { Rv , Kv } , and thus, since min { Lv , Hv } ≤ min { Rv , Kv } , we have Lv ≤ min { Rv , Kv } . Furthermore, since Lv ≤ Hv , it follows from Theorem 5 and the dual statement of Proposition 4 (with Lv and Hv instead of Rv and Kv ) that Cv ( Lv ) = Cv ( Hv ) = Cv ( Rv ) = Cv ( Kv ) = min { Rv , Kv } + | Alph ( v ) | -1. This implies that min { Rv , Kv } ≤ Lv ≤ max { Rv , Kv } because Cv ( ) i ≥ | Alph ( v ) | + i -1 for i = 1, 2, . . . , min { Rv , Kv } . But, as deduced above, Lv ≤ min { Rv , Kv } ; thus we must have Lv = min { Rv , Kv } , and hence min { Lv , Hv } = min { Rv , Kv } .
Let us now suppose that Hv < Lv = max { Lv , Hv } (= max { Rv , Kv } ) . Then, since min { Lv , Hv } ≤ min { Rv , Kv } , we have Hv ≤ min { Rv , Kv } . We wish to show that Hv = min { Rv , Kv } . Suppose not, i.e., suppose Hv < min { Rv , Kv } . Let m = min { Rv , Kv } . Since v is a (generalized trapezoidal) word satisfying the RK-condition, it follows from Proposition 7 that there exists exactly one right special factor of v of length i for every non-negative integer i < m , with each right special factor having right-valence 2. Likewise, there must exist exactly one left special factor of v of length i for every non-negative integer i < m (where Hv < m ≤ Lv ), with each left special factor having left-valence 2. But this implies that Cv ( m ) = Cv ( m -1 , contradicting the fact that the complexity function of ) v satisfies Cv ( m ) = Cv ( m -1 ) + 1 by Theorem 5. Hence we must have Hv = min { Rv , Kv } .
Finally, since we have min { Lv , Hv } = min { Rv , Kv } and also max { Lv , Hv } = max { Rv , Kv } , it easily follows that | v | = Lv + Hv + | Alph ( v ) | -2, and hence | w | = Lv + Hv + | Alph ( w ) | -2. /square
We have the following easy consequence of Proposition 14.
Corollary 15. Let w be a non-empty finite word with heart v. Then | w | = Rv + Kv + | Alph w ( ) | -2 if and only if | w | = Lv + Hv + | Alph w ( ) | -2 . /square
/negationslash
Note. If a word w satisfies the RK -condition | w | = Rw + Kw + | Alph ( w ) | -2 (with Rw and Kw instead of Rv and Kv ), it is not necessarily true that | w | = Lw + Hw + | Alph ( w ) | -2 (and vice versa). For example, the word u = abbcc of length | u | = 5 is a GT-word with complexity sequence { Cu ( n ) } n ≥ 0 = 1, 3, 4, 3, 2, 1. This GT-word has Ru = 2, Ku = 2, and Ru + Ku + 1 = | u | . On the other hand, Lu = 2, Hu = 1, and Lu + Ku + 1 = | u | . However, we see that | u | = Rv + Kv + 1 and | u | = Lv + Hv + 1 where v = bbcc is the heart of u with Rv = Lv = Kv = Hv = 2.
In [4, Corollary 5.3], de Luca proved that the minimal period length π w of any finite word w satisfies π w ≥ Rw + 1, and moreover, if π w = Rw + 1, then | w | = Rw + Kw . The following proposition gives a refinement of that result.
Proposition 16. Suppose w is a non-empty finite word with minimal period length π w. Then π w ≥ Rw + | Alph w ( ) | -1 . Moreover, if π w = Rw + | Alph w ( ) | -1 , then | w | = Rw + Kw + | Alph w ( ) | -2 .
Proof. For any finite word w with minimal period length π w , we have π w ≥ | w | -Kw + 1 [4, Proposition 5.1], and by Proposition 10, Rw ≤ | w | -Kw -| Alph ( w ) | + 2. Hence π w ≥ Rw + | Alph ( w ) | -1. Furthermore, if π w = Rw + | Alph ( w ) | -1, then it follows from [4, Proposition 5.1] that | w | ≤ Rw + Kw + | Alph ( w ) | -2, and therefore | w | = Rw + Kw + | Alph ( w ) | -2 by Proposition 10. /square
We are now ready to prove our main results about GT-words.
## 3. MAIN RESULTS
## 3.1. Characterizations of GT-words.
Theorem 17. Suppose w is a non-empty finite word with heart v. Then w is a GT-word if and only if | w | = Rv + Kv + | Alph w ( ) | -2 .
Example 18. The GT-word w = ababadac does not satisfy the RK -condition, but it does satisfy the following condition in terms of its heart v :
$$| w | = R _ { v } + K _ { v } + | \text{Alph} ( w ) | - 2.$$
Indeed, v = ababada with Rv = 4, Kv = 2, and | w | = 4 + 2 + 2 = 8.
The following lemma is needed for the proof of Theorem 17.
Lemma 19. Suppose w is a non-empty finite word with heart v. Then w is a GT-word if and only if v is a GT-word. Moreover, when w (or equivalently v) is a GT-word, the maximal interval [ mw Mw , ] on which Cw is constant is equal to the maximal interval [ mv , Mv ] on which Cv is constant, i.e., mw = mv and Mw = Mv.
/negationslash
/negationslash
Proof. If v = w , we are done. So suppose v = w . Then | w | > | Alph ( w ) | ≥ 2 and we have w = rvs where r and s are maximal such that | w x | = 1 for all x ∈ Alph ( r ) ∪ Alph ( s ) . We distinguish three cases: w = vs (where s is non-empty), w = rv (where r is non-empty), or w = rvs (where both r and s are non-empty). The latter two cases (when w = rv or w = rvs ) are proved similarly to the first case (when w = vs ), so we consider only that case. By definition of v and s , there exist distinct letters a 1 , . . . , aj ∈ Alph ( v ) such that s = a 1 · · · aj (i.e., w = va 1 · · · aj ) where j = | w | - | v | . Hence, Cw i ( ) = Cv ( ) + i j for i = 1, 2, . . . , | v | .
Now suppose w is a GT-word. Let [ mw Mw , ] be the maximal interval on which Cw is constant and let [ mv , Mv ] be the maximal interval on which Cv is constant. Then since Cv ( ) i = Cw i ( ) -j for i = 1, 2, . . . , | v | , we see that Cv increases by 1 with each n in the interval [ 1, mw ] , is constant on the interval
[ mw Mw , ] , and decreases by 1 with each n in the interval [ Mw , | v | ] . So v is a GT-word, and moreover mv = mw and Mv = Mw .
Conversely, suppose v is a GT-word. Then since Cw i ( ) = Cv ( ) + i j for i = 1, 2, . . . , | v | , we see that Cw increases by 1 with each n in the interval [ 1, mv ] , is constant on the interval [ mv , Mv ] , and decreases by 1 with each n in the interval [ Mv , | v | ] . Moreover, by Proposition 4, Cw must continue to decrease by 1 with each n in the interval [ | v | + 1, | w | ] . Thus, w is a GT-word and mw = mv , Mw = Mv . /square
Proof of Theorem 17. ( ⇐ ): First suppose that | w | = Rv + Kv + | Alph ( w ) | -2 where v is the heart of w . By definition of v , | w | - | v | = | Alph ( w ) | - | Alph ( v ) | , so | v | = Rv + Kv + | Alph ( v ) | -2. Hence, v is a GT-word by Corollary 6, and therefore w is also a GT-word by Lemma 19.
( ⇒ ): Conversely, suppose w is a GT-word. If | w | = | Alph ( w ) | (i.e., if w is a product of mutually distinct letters), then w = v (by Definition 11) and such a GT-word has Rv = Rw = 1 and Kv = Rw = 1; whence | w | = | v | = Rv + Kv + | Alph ( w ) | -2. So we will henceforth assume that | w | > | Alph ( w ) | , in which case Kv > 1.
Since w is a GT-word, so too is v by Lemma 19. It suffices to show that | v | = Rv + Kv + | Alph ( v ) | -2 because it follows from this equality that | w | = Rv + Kv + | Alph ( w ) | -2 by noting that | w | - | v | = | Alph ( w ) | - | Alph ( v ) | .
/negationslash
/negationslash
If | Alph ( v ) | = 1, then Rv = 1 and Kv = | v | , and hence | v | = Rv + Kv + | Alph ( v ) | -2. Now suppose that | Alph ( v ) | ≥ 2 and let [ mv , Mv ] denote the maximal interval on which Cv is constant. If Rv < Kv , then by Proposition 4 (and the fact that v is a GT-word), the complexity Cv of v satisfies the conditions of Theorem 5 with m = mv = Rv and M = Mv = Kv ; whence | v | = Rv + Kv + | Alph ( v ) | -2. On the other hand, if Rv ≥ Kv , then Mv = Rv (by Proposition 4 again) and we claim that mv = Kv . Suppose not, i.e., suppose that mv = Kv . If mv < Kv then Cv ( mv ) = Cv ( mv + ) 1 . But since each factor of v of length mv is right-extendable in v , this implies that v has no right special factor of length mv ; a contradiction (since mv < Kv ≤ Rv ). Now suppose mv > Kv . Then we have Cv ( Kv + ) = 1 Cv ( Kv ) + 1. Let s denote the suffix of v of length Kv . Since all factors of v of length Kv except s are right-extendable in v , the equality Cv ( Kv + ) = 1 Cv ( Kv ) + 1 implies that v contains either two different right special factors of length Kv , each with right-valence 2, or only one right special factor of length Kv with right-valence 3. But then so too would any GT-word w ′ with heart v and Kw ′ = 1 (e.g., w ′ = vx where x ∈ Alph ( v ) ). And since s is right-extendable in any such w ′ , it follows that Cw ′ ( Kv + ) = 1 Cw ′ ( Kv ) + 2; a contradiction. Thus mv = Kv , and so by Proposition 4 (and the fact that v is a GT-word), the complexity Cv of v satisfies the conditions of Theorem 5 with m = mv = Kv and M = Mv = Rv . Hence | v | = Rv + Kv + | Alph ( v ) | -2. /square
In view of Corollary 15, we have the following straightforward consequence of Theorem 17.
Corollary 20. Suppose w is a non-empty finite word with heart v. Then w is a GT-word if and only if | w | = Lv + Hv + | Alph w ( ) | -2 . /square
The next result describes the generalized trapezoidal words w that are 'triangular' in the sense that the graphs of their factor complexity functions are triangles on the interval [ 1, | w | - |A| + ] 1 where A = Alph ( w ) .
Theorem 21. Let w be a finite word with | Alph w ( ) | ≥ 2 and suppose v is the heart of w. Then the graph of the factor complexity Cw ( n ) of w as a function of n ( 0 ≤ n ≤ | w | ) is a triangle on the interval [ 1, | w | - | Alph w ( ) | + ] 1 if and only if Kv = Rv.
Proof. ( ⇐ ): If Kv = Rv , then the graph of the factor complexity function Cv of v is clearly a triangle on the interval [ 1, | v | - | Alph ( v ) | + ] 1 by Proposition 4. Hence, by Lemma 19, the graph of Cw is a triangle on the interval [ 1, | w | - | Alph ( w ) | + ] 1 .
( ⇒ ): Suppose the graph of Cw is a triangle on the interval [ 1, | w | - | Alph ( w ) | + ] 1 . More precisely, suppose Cw increases by 1 with each n in the interval [ 1, m ] and decreases by 1 with each n in the interval [ m w , | | - | Alph ( w ) | + ] 1 for some positive integer m .
Let us first consider the case Rv ≥ Kv . By Proposition 4, Cv increases by 1 with each n in the interval [ 1, Kv ] , is non-decreasing on the interval [ Kv , Rv ] , and decreases by 1 with each n in the interval [ Rv , | v | ] . But by Lemma 19, since the graph of Cw is a triangle, so too is the graph of Cv ; in particular, Cv increases by 1 with each n in the interval [ 1, m ] and decreases by 1 with each n in the interval [ m w , | | - | Alph ( w ) | + ] 1 where m is the same as above. Hence m = Kv = Rv . Similarly, when considering the case Rv ≤ Kv , we deduce that m = Kv = Rv . /square
We end this section by noting that the set of all GT-words is factorial (i.e., closed by taking factors) and is also closed under reversal.
Proposition 22. The set of all GT-words is closed by factors.
/negationslash
/negationslash
Proof. Let w be a GT-word. If | Alph ( w ) | = 1, then clearly all of its factors are GT-words too (see Remark 2). So let us now assume that | Alph ( w ) | ≥ 2. By Lemma 19, it suffices to consider the heart v of w . Suppose, by way of contradiction, that there exists a factor u of v (and hence w ) that is not a GTword. Then the heart v ′ of u is not a GT-word (by Lemma 19 again), so | v ′ | = Rv ′ + Kv ′ + | Alph ( v ′ ) | -2 by Theorem 17 . Hence, by Proposition 7, v ′ contains two different right special factors of the same length or a right special factor with right-valence greater than 2. But then the same would be true for the heart v of w , and therefore | v | = Rv + Kv + | Alph ( v ) | -2 by Proposition 7, contradicting the fact that v is a GT-word (by Theorem 17). /square
Proposition 23. A finite word w is a GT-word if and only if w is a GT-word. ˜ Proof. The result follows immediately from the definition of a GT-word (Definition 1) by observing that, for any word w , its reversal w has the same complexity as w . /square
/negationslash
˜ Example 24. The word abbcc and its reversal are both GT-words with complexity sequence { C n ( ) } n ≥ 0 = 1, 3, 4, 3, 2, 1. We note, however, that abbcc satisfies the RK-condition, but its reversal ccbba does not because it has K = 1, R = 2, and R + K + 1 = 5. So the set of all words satisfying the RK-condition is not closed under reversal, whereas the set of all GT-words is closed under this involution.
3.2. Palindromically-Rich GT-words. In the case when |A| = 2, the first author, together with de Luca and Zamboni [5], have shown that the set of all palindromic (binary) trapezoidal words coincides with the set of all Sturmian palindromes. Moreover, if w is a (binary) trapezoidal word, then w contains exactly | w | + 1 distinct palindromes (including the empty word ε ). That is, (binary) trapezoidal words (and hence finite Sturmian words) are rich in palindromes in the sense that they contain the maximum possible number of distinct palindromic factors since, as shown in [6], a finite word of length n contains at most n + 1 distinct palindromic factors (including ε ). More precisely, a finite word w is said to be rich if and only if it has | w | + 1 distinct palindromic factors, and an infinite word is rich if all of its factors are rich [8]. So, roughly speaking, a finite or infinite word is rich if and only if a new palindrome is introduced at each position in the word (see Proposition 26 below).
The family of rich words was studied in depth by the first author and others in [8]. Such words were also independently considered in 2004 by Brlek, Hamel, Nivat, and Reutenauer [1] who called them
full words . Amongst various properties of rich words, we have the following characterization in terms of so-called complete returns . Let u be a non-empty factor of a finite or infinite word w . A factor of w having exactly two occurrences of u , one as a prefix and one as a suffix, is called a complete return to u in w .
Proposition 25. [8] A finite or infinite word w is rich if and only if, for each non-empty palindromic factor u of w, every complete return to u in w is a palindrome.
In short, w is rich if and only if all complete returns to palindromes are palindromes in w . We also have the following characterization of rich words that will be useful in what follows. Note that a factor u of a word w is said to be unioccurrent in w if u has exactly one occurrence in w .
Proposition 26. [6, Proposition 3] A word w is rich if and only if all of its prefixes have a unioccurrent palindromic suffix (called a ups for short). Similarly, w is rich if and only if all of its suffixes have a unioccurrent palindromic prefix.
Note. The ups of a rich word w is necessarily the longest palindromic suffix of w .
Whilst it is true that all binary trapezoidal words are rich [5], the converse does not hold; for example, the binary word aabbaa is rich, but not trapezoidal because its complexity jumps by 2 from C ( 1 ) = 2 to C ( 2 ) = 4. Moreover, unlike in the binary case, not all generalized trapezoidal words are rich. For instance, the word aabca is a non-rich GT-word. However, it is easy to see, for instance, that all GTwords w with | Alph ( w ) | = 3 and Kw = 1 are rich since any such word is simply a binary GT-word (which is rich) followed by a new letter (its ups). More generally, our next result describes all the rich GT-words.
Theorem 27. Let w be a GT-word and suppose that its heart v has longest palindromic prefix p and longest palindromic suffix q. Then w is rich if and only if one of the following conditions is satisfied.
- (i) p and q are unseparated in v (i.e., either v = pq, v = p = q, or p and q overlap in v).
/negationslash
- (ii) v = pxq where Alph ( p ) ∩ Alph q ( ) = ∅ and x ∈ Alph p ( ) ∪ Alph q . ( )
- (iii) v = puq where Alph ( p ) ∩ Alph q ( ) = ∅ and u = u Zu 1 2 where u , u , Z are words (at least one of 1 2 which is non-empty) such that Alph ( u 1 ) ⊆ Alph ( p , Alph ) ( u 2 ) ⊆ Alph q , and Z contains no letters ( ) in common with p and q.
## Examples
- /trianglerightsld Rich GT-word: abacabade has complexity sequence { C n ( ) } n ≥ 0 = 1, 5, 6, 6, 6, 5, 4, 3, 2, 1 with heart v = p = q = abacaba (a palindrome).
- /trianglerightsld Rich GT-word: ababadac has complexity sequence { C n ( ) } n ≥ 0 = 1, 4, 5, 5, 5, 4, 3, 2, 1 with heart v = ababada , p = ababa , and q = ada ( p and q overlap).
- /trianglerightsld Rich GT-word: aaabab has complexity sequence { C n ( ) } n ≥ 0 = 1, 2, 3, 4, 3, 2, 1 with heart v = pq where p = aaa and q = bab ( v is a product of p and q ).
- /trianglerightsld Rich GT-word: bacabacac has complexity sequence { C n ( ) } n ≥ 0 = 1, 3, 4, 5, 5, 5, 4, 3, 2, 1 with heart v = paq where p = bacab and q = cac . Here Alph ( q ) ⊂ Alph ( p ) and p , q are separated by a letter in Alph ( p ) .
- /trianglerightsld Rich GT-word: acacbcb has complexity sequence { C n ( ) } n ≥ 0 = 1, 3, 4, 5, 4, 3, 2, 1 with heart v = pcq where p = aca and q = bcb . Here | Alph ( p ) ∪ Alph ( q ) | > | Alph ( p ) ∩ Alph ( q ) | ≥ 1 and p , q are separated by a letter in Alph ( p ) ∩ Alph ( q ) .
- /trianglerightsld Rich GT-word: aabcc has complexity sequence { C n ( ) } n ≥ 0 = 1, 3, 4, 3, 2, 1 with heart v = puq where p = aa , u = b , and q = cc . Here Alph ( p ) ∩ Alph ( q ) = ∅ and p , q are separated by a letter not in Alph ( p ) ∪ Alph ( q ) .
- /trianglerightsld Rich GT-word: aaadcbcb has complexity sequence { C n ( ) } n ≥ 0 = 1, 4, 5, 6, 5, 4, 3, 2, 1 with heart v = puq where p = aaa , u = dc , and q = bcb . Here Alph ( p ) ∩ Alph ( q ) = ∅ and p , q are separated by the word dc where the letter d is not in Alph ( p ) ∪ Alph ( q ) and c ∈ Alph ( q ) .
- /trianglerightsld Non-Rich GT-word: ababadbc has complexity sequence { C n ( ) } n ≥ 0 = 1, 4, 5, 5, 5, 4, 3, 2, 1 with heart v = pdq where p = ababa and q = b . Here Alph ( q ) ⊂ Alph ( p ) and p , q are separated by a letter not in Alph ( p ) . Note that v ends with a non-palindromic complete return to b .
- /trianglerightsld Non-Rich GT-word: abacbab has complexity sequence { C n ( ) } n ≥ 0 = 1, 3, 4, 5, 4, 3, 2, 1 with heart v = pcq where p = aba and q = bab . Here Alph ( p ) = Alph ( q ) and p , q are separated by a letter that they do not contain. Note that v contains non-palindromic complete returns to each of the letters a and b .
- /trianglerightsld Non-Rich GT-word: dcdbacdc has complexity sequence { C n ( ) } n ≥ 0 = 1, 4, 5, 6, 5, 4, 3, 2, 1 with heart v = puq where p = dcd , u = ba , and q = cdc . Here Alph ( p ) = Alph ( q ) and p , q are separated by a product of two distinct letters, neither of which they contain themselves. Note that v contains non-palindromic complete returns to each of the letters c and d .
- /trianglerightsld Non-Rich GT-word: aaaaaadebcad has complexity sequence { C n ( ) } n ≥ 0 = 1, 5, 6, 7, 7, 7, 7, 6, 5, 4, 3, 2, 1 with heart v = puq where p = aaaaaa , u = debca , q = d . Here Alph ( p ) ∩ Alph ( q ) = ∅ and p , q are separated by a product of mutually distinct letters, with last letter in Alph ( p ) and first letter in Alph ( q ) . Note that v begins with a nonpalindromic complete return to a and also ends with a non-palindromic complete return to d .
- /trianglerightsld Non-Rich GT-word: abcedabceded has complexity sequence { C n ( ) } n ≥ 0 = 1, 5, 6, 7, 7, 7, 7, 6, 5, 4, 3, 2, 1 with heart v = puq where p = a , u = bcedabce , q = ded . Here Alph ( p ) ∩ Alph ( q ) = ∅ and p , q are separated by a word containing letters in Alph ( p ) and Alph ( q ) , but beginning with a letter not in Alph ( p ) . Note that v begins with a non-palindromic complete return to the letter a and also contains non-palindromic complete returns to each of the other letters b , c , d , and e .
The proof of Theorem 27 requires several lemmas (Lemmas 30-35, to follow), but first we show that, in the case of a binary alphabet, every trapezoidal word has unseparated p and q . This result allows us to give an alternative proof of the fact that all binary trapezoidal words are rich, originally proved in [5] (see Corollary 29 below).
Proposition 28. Suppose w is a binary trapezoidal word. Then the longest palindromic prefix p and longest palindromic suffix q of w are unseparated in w.
Proof. Let Alph ( w ) = { a b , } . We first observe that if w takes the form x n y or xy n where { x y , } = { a b , } and n ∈ N + , then w is simply a product of its longest palindromic prefix and longest palindromic suffix.
Let us now suppose, on the contrary, that w is a binary trapezoidal word (not of the form x n y or xy n ) of minimal length such that its longest palindromic prefix p and longest palindromic suffix q are separated, i.e., such that w = puq where u is a non-empty word. Clearly, w cannot be a palindrome; otherwise w would itself be its longest palindromic prefix and suffix (i.e., w = p = q ).
/negationslash
We first show that p = q . Suppose not, i.e., suppose w = pup . Then u must be a non-palindromic word because w is not a palindrome. If p has an occurrence in w that is neither a prefix nor a suffix of
/negationslash
/negationslash w , then w would begin with a complete return to p (shorter than w ), which cannot be a palindrome because otherwise w would begin with a palindrome longer than p (its longest palindromic prefix). So w would begin with a non-palindromic complete return to p (shorter than w ) of the form pUp where U is a non-palindromic word. Let s = pUp . Since any factor of w is a (binary) trapezoidal word (by Proposition 22 or [3, Proposition 8]), the proper prefix s = pUp of w is a binary trapezoidal word. But this contradicts the minimality of w as a binary trapezoidal word (of shortest length) having separated longest palindromic prefix and suffix. Therefore p occurs only twice in w , as a prefix and as a suffix. That is, w = pup is itself a non-palindromic complete return to p . If p were a letter, say p = a , then w = aua where Alph ( u ) = { } b (since w is a complete return to p ), which implies that u = b n for some integer n ≥ 1. However, this is not possible because u is not a palindrome. So | p | ≥ 2. If p = aa , then w = aauaa where u begins and ends with the letter b . In this case, the letter a is bispecial, so b cannot be left or right special by Propositions 7 and 8. In particular, bb cannot a factor of u nor can aa because w is a complete return to aa . Hence, we deduce that u = ( ba ) n b for some integer n ≥ 1; a contradiction (since u is not a palindrome). Thus p = aa , and likewise it can be shown that p = bb . Hence | p | ≥ 3. Let us write p = xPx where x ∈ { a b , } and P is a palindrome. Then we have w = xPxuxPx . Let w ′ be the prefix of w obtained from w by removing its last letter x , i.e., w ′ = wx -1 = xPxuxP = puxP and let S = PxuxP so that w ′ = xS and w = w x ′ = xSx . Clearly p = xPx is the longest palindromic prefix of w ′ . Let q ′ denote the longest palindromic suffix of w ′ . By the minimality of w as binary trapezoidal word (of shortest length) having separated longest palindromic prefix and suffix, p and q ′ cannot be separated in w ′ . Hence | uxP | ≤ | q ′ | < | w ′ | . If | q ′ | = | uxP | , then w ′ (and hence w ) begins with the palindrome xPxPx longer than p . Therefore | uxP | < | q ′ | < | w ′ | and the prefix Px of q ′ overlaps with a suffix of the prefix xPx of w ′ . Hence w ′ either begins with the palindrome xPPx (if | q ′ | = | uxP | + 1) or begins with a palindrome Q having xP as a prefix (and Px as a suffix) with | xPx | < | Q | < | 2 P | + 2 (since P , being a palindrome, overlaps with itself in a palindrome). Neither case is possible because p = xPx is the longest palindromic prefix of w ′ . Thus p = q .
We now claim that p and q are both unioccurrent in w . Indeed, if p occurs more than once in w , then w would begin with a complete return to p (shorter than w ), which cannot be a palindrome because otherwise w would begin with a palindrome longer than p (its longest palindromic prefix). So w begins with a non-palindromic complete return to p (shorter than w ) of the form pUp with p being its longest palindromic prefix and suffix. But since pUp is trapezoidal (by Proposition 22 or [3, Proposition 8]), this contradicts the minimality of w as a binary trapezoidal word (of shortest length) having separated longest palindromic prefix and suffix. Likewise, we deduce that q occurs only once (as a suffix) in w . So Hw ≤ | p | and Kw ≤ | q | . Moreover, since w is a binary trapezoidal word, we have | w | = Rw + Kw and | w | = Lw + Hw .
/negationslash
If Rw > Hw , then by Proposition 9, the right special factor r of w of maximal length | r | = Rw -1 is bispecial, so r occurs at least twice in w . In particular, w contains either both ara and brb or both arb and bra . Let P be the shortest prefix of w that contains both arx and bry where { x y , } = { a b , } . Without loss of generality, we may assume that P ends with a factor S of the form S = arxS ′ = S bry ′′ . In particular, S = aEy where E is a complete return to r . Let p ′ (resp. q ′ ) denote the longest palindromic prefix (resp. suffix) of P = P S ′ = P aEy ′ . If | q ′ | > | S | = | aEy | , then P would have a proper prefix containing yEa ˜ , of which yrb ˜ and xra ˜ are factors. So ˜ r would be a bispecial factor of P (and hence of w ) of length | r | , and therefore ˜ r = r by Propositions 7 and 8. Moreover, we deduce that E must be palindromic complete return to (the palindrome) r ; otherwise, reasoning as above, we would reach a contradiction. It follows that y = a and x = b , and so we see that w has a prefix shorter than P that contains both arx = arb and bry = bra , contradicting the minimality of P . Thus | q ′ | ≤ | aEy | . If | ry | < | q ′ | < | aEy | , then E contains yr ˜ , which implies ˜ r = r (since E is a complete return to r ). Furthermore, E cannot contain xr ˜ ; otherwise ˜ r would be a left special factor of length | r | different
/negationslash
/negationslash from r , which is not possible by Proposition 8. So E contains a factor X of the form X = rxX ′ = X yr ′′ ˜ that contains only one occurrence of r (as a prefix) and only one occurrence of ˜ r (as a suffix). Such a factor cannot be a palindrome (since x = y ) and it follows that the longest palindromic prefix and longest palindromic suffix of X each have length less than | r | and therefore they must be the same palindrome, Q say. But then X would be a non-palindromic complete return to Q , contradicting the minimality of w . So either | q ′ | ≤ | ry | or | q ′ | = | S | = | aEy | . In the former case, one can use similar reasoning as above to deduce that p ′ and q ′ are separated in P , again contradicting the minimality of w . In the latter case (when | q ′ | = | S | = | aEy | ), S = aEy is a palindrome, which implies that y = a (and hence x = b ) and that ˜ r = r (i.e., r is a palindrome). So w = P aEaQ ′ ′ where E is a palindromic complete return to r beginning with rb and ending with br . Reasoning as above, we deduce that | p | < | P ar ′ | and | q | < | raQ ′ | (for if not, we reach a contradiction to either the minimality of P or the fact that E is a complete return to r ). Let w ′ denote the prefix of w obtained from w by removing the last letter of w , i.e., let w ′ = wz -1 = P aEaQ z ′ ′ -1 where z is the last letter of w . Then, since | p | < | P ar ′ | , we see that p (the longest palindromic prefix of w ) is also the longest palindromic prefix of w ′ , and using similar arguments as above, we deduce that the longest palindromic suffix q ′′ of w ′ has length | q ′′ | < | raQ ′ | -1. Hence, just as p and q are separated in w , we see that the longest palindromic prefix and longest palindromic suffix of w ′ (namely p and q ′′ ) are separated in w ′ ; a contradiction (yet again) to the minimality of w as a binary trapezoidal word (of shortest length) having separated longest palindromic prefix and suffix. Thus Rw ≤ Hw , and similarly we deduce that Lw ≤ Kw .
If Rw = Hw , then | w | = | p | + | u | + | q | ≥ Rw + | u | + Kw > Rw + Kw (because Rw = Hw ≤ | p | , Kw ≤ | q | , and | u | ≥ 1); a contradiction. So Rw < Hw , and using similar reasoning, we deduce that Lw < Kw too. Hence it follows that Rw = Lw and Kw = Hw since max { Rw Kw , } = max { Lw , Hw } and min { Rw Kw , } = min { Lw , Hw } by [4, Corollary 4.1] and Proposition 14. This implies that | pu | ≤ Rw since | pu | = | w | - | q | where | w | = Rw + Kw and Kw ≤ | | q . However, by Proposition 9, the right special factor r of w of maximal length | r | = Rw -1 is a prefix of w , which occurs at least twice in w , and therefore p (which is a prefix of r since | pu | ≤ Rw = | r | + 1) occurs more than once in w ; a contradiction. Thus p and q are unseparated in w . /square
Corollary 29. All binary trapezoidal words are rich.
Proof. If w is a binary trapezoidal word, but not rich, then w contains a non-palindromic complete return to a palindrome p of the form pup where u is a non-palindromic word. Let r = pup . Clearly p is both the longest palindromic prefix and the longest palindromic suffix of r and these occurrences of p in r are separated. But this yields a contradiction because r , being a factor of w , must be a binary trapezoidal word (by Proposition 22 or [3, Proposition 8]), and therefore its longest palindromic prefix and suffix cannot be separated (by Proposition 28). /square
Lemma 30. A GT-word w is rich if and only if the heart of w is rich.
Proof. Let w be a GT-word. If w is rich, then clearly the heart of w is rich too since any factor of a rich word is rich.
/negationslash
/negationslash
Conversely, suppose that the heart v of w is rich. If v = w , we are done. So suppose that v = w . Then | w | > | Alph ( w ) | ≥ 2 and we have w = rvs where r and s are maximal such that | w x | = 1 for all x ∈ Alph ( r ) ∪ Alph ( s ) . Moreover, since v = w , at least one of the factors r and s is non-empty. If r is non-empty, then | r | = | Alph ( r ) | and it is easy to see that each prefix of r has a unioccurrent palindromic suffix - just the last letter of each prefix. Likewise, if s is non-empty, each prefix of s has a ups. Moreover, since v is rich, each prefix of v has a ups, by Proposition 26. Thus, since the alphabets Alph ( v ) , Alph ( r ) , and Alph ( s ) are mutually disjoint sets, we see that each prefix of w = rvs has a ups, and thus w is rich, by Proposition 26 again. /square
Lemma 31. Let w be a GT-word and suppose that its heart v has longest palindromic prefix p and longest palindromic suffix q. If v = puq for some non-empty word u, then one of the following conditions holds:
- (i) p = ( ax ) n a, u = x, q = ( bx ) m b for some n , m ∈ N + where a, b, and x are mutually distinct letters;
- (ii) Alph ( p ) ⊆ Alph q ( ) or Alph ( q ) ⊆ Alph ( p ; )
- (iii) Alph ( p ) ∩ Alph q ( ) = ∅ .
Moreover, if condition (i) is satisfied, then w is rich.
/negationslash
In other words, the above lemma says that if v is the heart of a GT-word with separated p and q such that the alphabets of p and q are not disjoint and neither alphabet is a subset of the other, then v takes the form given by condition (i). All other hearts of the form v = puq ( u = ε ) are such that the alphabets of p and q are disjoint or one is a subset of the other.
Remark 32. For a given letter x, let ϕ x denote the morphisms defined as follows:
↦
↦
$$\iota \iota \iota _ { x }, \iota \iota _ { x } \, \iota \iota _ { y } \, \iota \iota \iota _ { y } \, \iota \iota _ { y } \, \iota \iota _ { y } \, \iota \iota _ { y } \, \iota \iota _ { y } \, \iota \iota _ { y } \, \iota \iota _ { y } \, \iota \iota _ { y } \, \iota \iota _ { y } \, \iota \iota _ { y } \, \iota \iota _ { y } \, \iota \iota _ { y } \, \iota \iota _ { y } \, \iota \iota _ { y } \, \iota \iota _ { y } \, \iota \iota _ { y } \, \iota \iota _ { y } \, \iota \iota _{ y } \, \iota \iota _ { y } \, \iota \iota _ { y } \, \iota \iota _ { y } \, \iota \iota _ { y } \, \iota \iota _ { y } \, \iota \iota _ { y } \, \iota \iota _ { y } \, \iota \iota _ { y } \, \iota \iota _ { y } \, \iota \iota _ { y } \, \iota \iota _ { y } \, \iota \iota _ { y } \, \iota \iota _ { y } \, \iota \iota _ { y } \, \iota \iota _ { y } \, \iota \iota _ { y } \, \iota _ { y } \, \iota \iota _ { y } \, \iota \iota _ { y } \, \iota \iota _ { y } \, \iota \iota _ { y } \, \iota \iota _ { y } \, \iota \iota _ { y } \, \iota \iota _ { y } \, \iota \iota _ { y } \, \iota \iota _ { y } \, \iota \iota _ { y } \, \iota \iota _ { y } \, \iota \iota _ { y } \, \iota \iota _ { y } \, \iota \iota _ { y } \, \iota \iota _ { y } \, \iota \iota _ { y } \\ \varphi _ { x } \, \colon & \begin{cases} x \mapsto x \\ y \mapsto y x \end{cases} & \text{for all letters $y \neq x$},$$
/negationslash
/negationslash i.e., ϕ x maps the letter x to itself and inserts the letter x to the right of all other letters different from x. A word v satisfying condition (i) in Lemma 31 can be expressed as v = ϕ x ( a n + 1 b m ) b, i.e., v is obtained from the binary trapezoidal word a n + 1 b m + 1 by inserting the letter x ∈ { a b , } to the right of each letter except the last. The shortest such word takes the form ϕ x ( aab b. )
Proof of Lemma 31. Wefirst observe that, for any word v with longest palindromic prefix p and longest palindromic suffix q , the alphabets of p and q satisfy one of the following three conditions.
/negationslash
- (A) Alph ( p ) ∩ Alph ( q ) = ∅ and neither alphabet is a subset of the other.
- (B) Alph ( p ) ⊆ Alph ( q ) or Alph ( q ) ⊆ Alph ( p ) (i.e., one alphabet is a subset of the other).
- (C) Alph ( p ) ∩ Alph ( q ) = ∅ .
/negationslash
Furthermore, we observe that there exist hearts v of GT-words of the form v = puq ( u = ε ) with p and q satisfying these conditions. For example, the GT-word acacbcb has heart v = acacbcb = puq (itself) where p = aca , u = c , q = bcb with the alphabets of p and q satisfying condition (A). Condition (B) is satisfied, for instance, by the GT-word ababadbc which has heart v = ababadb = puq where p = ababa , u = d , q = b with Alph ( q ) ⊂ Alph ( p ) . We also observe that the reversal of v = ababadb (which is also a GT-word by Proposition 23) is such that the alphabet of its longest palindromic prefix (namely b ) is contained in the alphabet of its longest palindromic suffix (namely ababa ). An example of a heart of a GT-word of the form v = puq satisfying condition (B) with Alph ( p ) = Alph ( q ) is abacbab . And lastly, condition (C) is satisfied, for example, by the GT-word aabcc , which has heart v = aabcc = puq (itself) where p = aa , u = b , q = cc .
Now suppose, more generally, that v is the heart of a GT-word of the form v = puq where u is a non-empty word. Then | Alph ( v ) | ≥ 3. Indeed, if | Alph ( v ) | = 1, then v = x n for some letter x and positive integer n , in which case v = p = q (i.e., p and q are unseparated). And if | Alph ( v ) | = 2 then p and q cannot be separated by a non-empty word in v by Proposition 28. We also note that if | w | = | Alph ( w ) | , then w = v and such a word is simply a product of mutually distinct letters with its first and last letters being its longest palindromic prefix and longest palindromic suffix, respectively, and therefore it satisfies condition (iii) in the statement of the lemma. So we will henceforth assume that | w | > | Alph ( w ) | , in which case the heart v of w satisfies Kv > 1 and Hv > 1. This means, in particular, that each letter in Alph ( v ) is both left and right extendable in v .
/negationslash
/negationslash
We showed above that there exist hearts v of GT-words of the form v = puq ( u = ε ) with p and q satisfying conditions (ii) and (iii) in the statement of the lemma (which correspond to conditions (B) and (C) above). So let us now suppose that v satisfies neither of those two conditions. Then v satisfies condition (A) above, i.e., Alph ( p ) ∩ Alph ( q ) = ∅ and there exist at least two distinct letters a and c such that a ∈ Alph ( p ) \ Alph ( q ) and c ∈ Alph ( q ) \ Alph ( p ) . We now show that p , q , and u must take the form given in condition (i) of the lemma.
/negationslash
/negationslash
/negationslash
/negationslash
Let us first note that the palindrome p (resp. q ) must contain at least two distinct letters - at least one letter in Alph ( p ) ∩ Alph ( q ) and at least one in Alph ( p ) \ Alph ( q ) (resp. Alph ( q ) \ Alph ( p ) ). Hence the palindromes p and q each have length at least three. Now, p contains a letter x ∈ Alph ( q ) such that xa is a factor of v for some letter a ∈ Alph ( p ) \ Alph ( q ) . Since q is a palindrome, the letter x will occur at least twice in q , except if q has odd length and x occurs only once as its central letter. In any case, x will be right-extendable in q by a letter b = a (since a ∈ Alph ( q ) ). So xa and xb are factors of v (where a = x and a = b ), and therefore x is a right special factor of v of length 1. On the other hand, q contains a letter y ∈ Alph ( p ) such that yc is a factor of v for some letter c ∈ Alph ( q ) \ Alph ( p ) . Since p is a palindrome, the letter y will occur at least twice in p , except if p has odd length and y occurs only once as its central letter. In any case, y will be right-extendable in p by a letter d = c (since c ∈ Alph ( p ) ). So yc and yd are factors of v (where c = y and c = d ), and therefore y is a right special factor of v of length 1. We have thus shown that the letters x and y are right special factors of v . But since v is a GT-word (with | v | = Rv + Kv + | Alph ( v ) | -2 by Theorem 17), it contains at most one right special factor of each length (see Proposition 7), and so we must have x = y . Therefore xa , xb , xc , and xd are all factors of v where a = b , c = d , and moreover, a = c since a ∈ Alph ( p ) \ Alph ( q ) and c ∈ Alph ( q ) \ Alph ( p ) . If a = d or b = c , then x would have right-valence at least 3 in v , which is not possible by Proposition 7. (Alternatively, we observe that since each distinct letter in v is right-extendable in v because Kv > 1, the letter x having right-valence at least 3 would imply that Cv ( 2 ) ≥ | Alph ( v ) | + 2, i.e., Cv ( 2 ) ≥ Cv ( 1 ) + 2, contradicting the hypothesis that v is a GT-word.) Hence we must have a = d and b = c . It follows that the only factors of p of length 2 are xa and ax and the only factors of q of length 2 are xb and bx . So we deduce that p takes the form p = ( xa ) n x or p = ( ax ) n a for some n ∈ N + and that q takes the form q = ( xb ) m x or q = ( bx ) m b for some m ∈ N + . Moreover, we note that xa , ax , bx , and xb are the only factors of length 2 of v . Indeed, x must always be preceded or followed by either a or b , otherwise x would have right or left valence greater than 2, and also each of the letters a and b must always be preceded or followed by the letter x in v , otherwise we would have another left or right special factor of length 1 in addition to x (which is bispecial), contradicting the hypothesis that v is a GT-word. So the word u that separates p and q in v = puq cannot contain any letters different from a , b , or x , and any factor of u of length 2 (if | u | ≥ 2) must be one of the words ax , xa , bx , xb .
/negationslash
/negationslash
/negationslash
/negationslash
/negationslash
Wenowseparately consider the two possible forms of each of p and q with respect to the 'separating word' u .
Case 1: p = ( ax ) n a for some n ∈ N + . In this case, if u begins with the letter a , then a would be a right special factor of length 1; a contradiction. So u must begin with the letter x . If u = x , then v satisfies condition (i) in the statement of lemma. Otherwise, if | u | ≥ 2, then u must begin with xa or xb since x must be followed by either a or b in v . But if u begins with xa , then v begins with the palindrome ( ax ) n axa longer than p . Thus u begins with xb .
Case 2: p = ( xa ) n x for some n ∈ N + . In this case, u must begin with the letter a or b since x can only be followed and preceded by one of these letters. If u begins with the the letter a (which must always be followed by the letter x ), then v would begin with the palindrome ( xa ) n xax = ( xa ) n + 1 x longer than p , which is not possible. So u must begin with the letter b . If u = b , then q must begin with x
/negationslash
/negationslash
/negationslash
/negationslash
(not b ), and so q takes the form q = ( xb ) m x for some m ∈ N + , in which case v would end with the palindrome xb xb ( ) m x longer than q . So | u | ≥ 2 and u begins with bx .
Case 3: q = ( bx ) m b for some m ∈ N + . Using similar reasoning as in Case 1, we deduce that either v satisfies condition (i) or that u must end with ax .
Case 4: q = ( xb ) m x for some m ∈ N + . Using similar reasoning as in Case 2, we deduce that u must end with xa .
From the above considerations, we see that either v satisfies condition (i), or u takes one of the following forms:
$$u = x b u ^ { \prime } a x, \ \ u = x b u ^ { \prime } x a, \ \ u = b x u ^ { \prime } a x, \ \ u = b x u ^ { \prime } x a, \ \ \text{or} \ \ u = b x a.$$
But if u takes any of the above forms, we see that v contains the following 6 factors of length 3: axa , xax , axb , bxa , bxb , xbx . This means that the complexity of v jumps by 2 from Cv ( 2 ) = 4 to Cv ( 3 ) = 6, contradicting the hypothesis that v is a GT-word.
Hence we have shown that v must satisfy one of the conditions (i)-(iii).
Lastly, it is easily verified that if v satisfies condition (i), then each prefix of v has a unioccurrent palindromic suffix, and hence v is rich by Proposition 26. Thus w is rich by Lemma 30. /square
Lemma 33. Let w be a GT-word with heart v having longest palindromic prefix p and longest palindromic suffix q. Suppose v = pxq where x is a letter and Alph ( p ) ⊆ Alph q ( ) or Alph ( q ) ⊆ Alph ( p . Then w is rich ) if and only if x ∈ Alph ( p ) ∪ Alph q . ( )
/negationslash
Proof. We first note that | w | > | Alph ( w ) | because if | w | = | Alph ( w ) | , then w = v and v would be a product of mutually distinct letters which does not take the assumed form. Hence Kv > 1 and Hv > 1. It is also easy to see that p = q and | Alph ( v ) | = 1. Furthermore, if | Alph ( v ) | = 2 then p and q cannot be separated by a non-empty word in v (by Proposition 28). Hence | Alph ( v ) | ≥ 3.
/negationslash
/negationslash
/negationslash
( ⇒ ): Suppose w is rich, then v is rich (by Lemma 30). By way of contradiction, let us suppose that x ∈ Alph ( p ) ∪ Alph ( q ) . Without loss of generality, we will assume that Alph ( q ) ⊆ Alph ( p ) . Since p and q contain at least one letter in common, there exists a letter a = x such that p = p ap ′ ′′ and q = q ′′ aq ′ where p ′′ and q ′′ are (possibly empty) words that contain no letters in common. But ap ′′ xq ′′ a is a complete return to a , so it must be a palindrome (since v is rich), which implies that p ′′ = q ′′ = ε . So v = p axaq ′ ′ where p ′ = ˜ q ′ because v is not a palindrome. Moreover, both p ′ and q ′ must be nonempty. Indeed, if p ′ = ε , then v = axaq ′ and we see that v begins with the palindrome axa which is longer than p = a ; a contradiction. Likewise, if q ′ = ε , we reach a contradiction. Now, since both p ′ and q ′ are non-empty, there exists a letter y ∈ Alph ( p ′ ) and a letter z ∈ Alph ( q ′ ) (with y = x and z = x ) such that ya and az are factors of v . But then, since xa and ax are also factors of v , we see that the letter a is a bispecial factor of v of length 1. Moreover, since Kv > 1, each letter in Alph ( v ) is rightextendable in v , and therefore the letter a must always be followed by either x or z in v . For if not, then a would have right-valence greater than 2 in v , which would imply that Cv ( 2 ) ≥ | Alph ( v ) | + 2, i.e., Cv ( 2 ) ≥ Cv ( 1 ) + 2, contradicting the hypothesis that v is a GT-word (also see Proposition 7). Likewise, the letter a can only be preceded by the letter x or y in v by Proposition 8. Since p is a palindrome containing ya , we see that ay is a factor of p . Similarly, since q is a palindrome containing az , we see that za must be a factor of q . We thus deduce that y = z . So the only factors of v of length 2 are za , az , ax , and xa . If z = a , then p = a m and q = a n for some m n , ∈ N + , in which case v = a m xa n , contradicting the hypothesis that the longest palindromic prefix and longest palindromic suffix of v are separated. So z = a and we deduce that p takes the form p = ( az ) m a for some m ∈ N + and q takes the form q = ( az ) n a for some n ∈ N + . But then v = ( az ) m ax ( az ) n a , in which case either v is a
/negationslash
/negationslash
/negationslash
/negationslash
palindrome (if m = n ) or the longest palindromic prefix and longest palindromic suffix of v overlap in v ; a contradiction. Hence x ∈ Alph ( p ) ∪ Alph ( q ) .
/negationslash
( ⇐ ): Conversely, suppose x ∈ Alph ( p ) ∪ Alph ( q ) . We will show that v (and hence w ) is rich by determining the possible forms of p and q in v . Without loss of generality, we will assume that Alph ( q ) ⊆ Alph ( p ) . Then Alph ( p ) = Alph ( v ) , and so p contains at least three distinct letters (since | Alph ( v ) | ≥ 3); in particular, p contains the letter x and at least two other distinct letters a and b (different from x ). We first observe that v cannot contain the square of a letter. Indeed, if yy were a factor of v for some letter y , then y would be a factor of p (since Alph ( p ) = Alph ( q ) ), and therefore y would be preceded and followed by some letter z = y (since | Alph ( p ) | ≥ 3). But then yy would be bispecial and y can only ever be preceded (and followed) by itself and z in v , otherwise y would have left or right valence more than 2, which is impossible by Propositions 7 and 8. Likewise, the letter z can only ever be preceded and followed by the letter y in v , which implies that v is a binary word; a contradiction. So v does not contain the square of a letter. Moreover, using similar arguments as in the proof of Lemma 31 (with the aid of Propositions 7-8 again), we deduce that p (and hence v ) contains only two distinct letters different from x and that p and q must take the following forms:
$$p = [ b ( x a ) ^ { m } x ] ^ { k } b \text{ \ and \ } q = ( a x ) ^ { n } a$$
where a and b are distinct letters (different from x ) and k m n , , ∈ N + with n ≥ m . That is,
$$v = p x q = [ b ( x a ) ^ { m } x ] ^ { k } b ( x a ) ^ { n + 1 }$$
with | v | = | p | + | q | + 1 = Rv + Kv + | Alph ( v ) | -2 where Rv = | p | and Kv = | q | . (Note that when Alph ( p ) ⊆ Alph ( q ) the forms of p and q are opposite to those given above.) It is easy to see that every prefix of any such v has a unioccurrent palindromic suffix. Hence v is rich (by Proposition 25), and thus w is rich by Lemma 30. /square
Lemma 34. Let w be a GT-word with heart v having longest palindromic prefix p and longest palindromic suffix q. If v = puq where | u | ≥ 2 and Alph ( p ) ⊆ Alph q ( ) or Alph q ( ) ⊆ Alph ( p , then Alph ) ( u ) is not contained in Alph ( p ) ∪ Alph q . Moreover, w is not rich. ( )
Proof. As in the proof of Lemma 33, we first note that | w | > | Alph ( w ) | because if | w | = | Alph ( w ) | , then w = v and v would be a product of mutually distinct letters which does not take the assumed form. Hence Kv > 1 and Hv > 1. We must also have | Alph ( v ) | ≥ 3, because if | Alph ( v ) | = 1 then v would be a palindrome (i.e., v = p = q ), and if | Alph ( v ) | = 2, then p and q cannot be separated by a non-empty word in v by Proposition 28.
Without loss of generality, we will assume that Alph ( q ) ⊆ Alph ( p ) . Suppose on the contrary that v is a heart of a GT-word of minimal length such that v = puq where | u | ≥ 2 and the alphabet of u is contained in Alph ( p ) ∪ Alph ( q ) (where Alph ( q ) ⊆ Alph ( p ) ).
/negationslash
Using very similar reasoning as in the proof of Proposition 28 (and keeping in mind that any left/right special factor of v has left/right valence 2 by Propositions 7 and 8), we deduce that p = q and that both p and q are unioccurrent in v . Hence Hv ≤ | p | and Kv ≤ | | q . Moreover, one can also show (using much the same reasoning as in the proof of Proposition 28) that Rv ≤ Hv and Lv ≤ Kv , from which it follows that Rv = Lv and Kv = Hv since max { Rv , Kv } = max { Lv , Hv } and min { Rv , Kv } = min { Lv , Hv } by [4, Corollary 4.1] and Proposition 14. This implies that | pu | ≤ Rv + | Alph ( v ) | -2 since | pu | = | v | - | q | where | v | = Rv + Kv + | Alph ( v ) | -2 (by Theorem 17) and Kv ≤ | q | . Moreover, since Alph ( u ) ⊆ Alph ( p ) , we have Kpu > 1 and Hpu > 1, and therefore pu is (the heart of) a GT-word (by Proposition 22). Hence | pu | = Lpu + Hpu + Alph ( pu ) -2 (by Corollary 20), where Alph ( pu ) = Alph ( v ) and Hpu = Hv = Kv since Hv ≤ | p | . Therefore
$$| p u | = L _ { p u } + H _ { v } + | \text{Alph} ( v ) | - 2 \leq R _ { v } + | \text{Alph} ( v ) | - 2,$$
i.e., Lpu + Hv ≤ Rv . But Rv ≤ Hv . This implies that Rv = Hv and Lpu = 0, which is impossible.
Thus Alph ( u ) is not contained in Alph ( p ) ∪ Alph ( q ) ; in particular, u contains a letter not in Alph ( p ) ∪ Alph ( q ) . Suppose that u also contains a letter in common with p or q . Then, using the fact that v contains at most one left (resp. right) special factor of each length, with any such factor having left (resp. right) valence 2 (Propositions 7 and 8), it can be (tediously) shown that v must take one of the following forms ( cf. arguments in the proofs of Lemmas 31 and 33).
/negationslash
- /trianglerightsld Type 1: v = aZ aZ a 1 2 where a is a letter, each Zi is a product of at least two mutually distinct letters different from a (i.e., | Zi | = | Alph ( Zi ) | ≥ 2 and a ∈ Alph ( Zi ) for i = 1, 2), and Alph ( Z 1 ) ∩ Alph ( Z 2 ) = ∅ .
/negationslash
- /trianglerightsld Type 2: v = ( ab ) m + 1 Z ab ( ) n -1 a where a , b are distinct letters, m n , ∈ N + , and Z is a product of mutually distinct letters (possibly just a single letter) different from a and b (i.e., | Z | = | Alph ( Z ) | and a b , ∈ Alph ( Z ) ).
- /trianglerightsld Type 3: The reverse of Type 2.
Note that hearts v of Type 1 have p = q = a and u = Z aZ 1 2 (e.g., abcadea ); hearts of Type 2 have p = ( ab ) m a , u = bZ q , = ( ab ) n -1 a (e.g., ababcaba ); and hearts of Type 3 have p = ( ab ) n -1 a , u = Zb , q = ( ab ) m a (e.g., adcbaba ). It is easy to see that any such word is not rich. Indeed, if v is of Type 1, then v contains two non-palindromic complete returns to the letter a (namely aZ a 1 and aZ a 2 ). On the other hand, if v is of Type 2 (or similarly Type 3), then v contains the non-palindromic complete return abZa (or aZba ) to the letter a .
It remains to show that if u has no letters in common with p and q , then v (and hence w ) is not rich. We distinguish two cases, as follows.
Case 1: u is not a palindrome . Since Alph ( q ) ⊆ Alph ( p ) , the first letter a of q is a factor of p and we can write p = p ap ′ ′′ and q = aq ′ where p ′′ is a (possibly empty) word not containing the letter a . That is, v = p ap ′ ′′ uaq ′ where ap ′′ ua is a non-palindromic complete return to the letter a . Thus v is not rich.
/negationslash
/negationslash
/negationslash
Case 2: u is a palindrome . If p = q then v ( = pup ) would be a palindrome. But this is absurd because if v were a palindrome, then we would necessarily have v = p = q by definition of p and q . Therefore p = q . Let x denote the last letter of u . Since | u | ≥ 2, there exists a letter y (possibly equal to x ) such that xy and its reversal yx are factors of u . Moreover, if /lscript is the last letter of p and f is the first letter of q , then /lscript x and xf are factors of v where { /lscript , f } ∩ { x y , } = ∅ since u contains no letters in common with p and q . So the letter x is a bispecial factor of v of length 1. This means that neither p nor q contains a left or right special factor, otherwise v would contain another left or right special factor different from x , which is not possible by Propositions 7 and 8. So either p = a m for some letter a and m ∈ N + or p = ( ab ) m a where a , b are distinct letters and m ∈ N + . Likewise, since q has no left or right special factor of length 1 and Alph ( q ) ⊆ Alph ( p ) , it follows that q must take the form a n , ( ab ) n a or ( ba ) n b for some n ∈ N + . If p = a m , then q = a n where n = m (since p = q and Alph ( q ) ⊆ Alph ( p ) ). However, if this was the case, then v would begin (or end) with a palindrome of the form a k ua k longer than p (or q ). So p must take the form ( ab ) m a for some m ∈ N + . If q also takes the form ( ab ) n a for some n ∈ N + , then v would begin (or end) with a palindrome of the form ( ab ) k au ab ( ) k a longer than p (or q ). So q must take the form ( ba ) n b . But then v = ( ab ) m au ( ba ) m b which contains the nonpalindromic complete return baub to the letter b (and also the non-palindromic complete return auba to the letter a ). Thus v is not rich. /square
Lemma 35. Let w be a GT-word with heart v having longest palindromic prefix p and longest palindromic suffix q. Suppose v = puq where u is a non-empty word and Alph ( p ) ∩ Alph q ( ) = ∅ . Then v is rich if and only if there exist words u 1 , u , and Z (at least one of which is non-empty) such that u 2 = u Zu 1 2 where Alph u ( 1 ) ⊆ Alph ( p , Alph ) ( u 2 ) ⊆ Alph q , and Z contains no letters in common with p and q. Moreover, ( ) | Z | = | Alph Z ( ) | and there exist mutually distinct letters a, b, x, y and positive integers m , n such that one of the following conditions is satisfied:
- (i) p = ( ab ) m a, u = Zx, q = ( yx ) n y;
- (ii) p = ( ba ) m b, u = aZx, q = ( yx ) n y;
- (iii) p = a m + 1 , u = Zx, q = ( yx ) n y;
- (iv) p = ( ab ) m a, u = Z, q = x n + 1 ;
- (v) p = ( ab ) m a, u = Z, q = ( xy ) n x;
- (vi) p = a m , u = Z, q = x n ;
- (vii) the forms of p and q are the opposite of those satisfying one of the conditions (i)-(vi) with the reversal of the corresponding u separating them.
Note. The word Z must be non-empty in conditions (iv)-(vi).
Proof. Clearly we have | Alph ( v ) | ≥ 3, because if | Alph ( v ) | = 1 then v would be a palindrome (i.e., v = p = q ), and if | Alph ( v ) | = 2, then p and q cannot be separated by a non-empty word in v by Proposition 28. We also observe that if | w | = | Alph ( w ) | , then w = v and such a word is simply a product of mutually distinct letters with its first and last letters being its longest palindromic prefix and longest palindromic suffix, respectively. Such a word v has p , u , and q satisfying condition (vi) with m = n = 1. So we will now assume that | w | > | Alph ( w ) | , in which case the heart v of w satisfies Kv > 1 and Hv > 1. This means, in particular, that each letter in Alph ( v ) is both left and right extendable in v .
( ⇒ :) Suppose v is rich. Then we must have | p | ≥ 2 and | q | ≥ 2. Indeed, if p = a for some letter a , then since Hv > 1, p occurs at least twice in v , and therefore v begins with a palindromic complete return to p that is longer than p (its longest palindromic prefix), which is not possible. Likewise, we deduce that | q | ≥ 2. We distinguish two cases, as follows.
/negationslash
/negationslash
Case 1: Alph ( u ) ⊆ Alph ( p ) ∪ Alph ( q ) . Suppose x is the left-most letter in u that is not in the alphabet of p . Then v = pu xu q 1 2 where u 1 , u 2 are (possibly empty) words with Alph ( pu 1 ) = Alph ( p ) . Let a denote the last letter of pu 1 . Then a occurs in p (since Alph ( pu 1 ) = Alph ( p ) ), and moreover, since | p | ≥ 2, there exists a letter b = x such that ba and ab are factors of p . Since ax is also a factor of v , we see that a is a right special factor of v of length 1. Moreover, the letter x is left special in v because x ∈ Alph ( q ) and so there exists a letter y ∈ Alph ( q ) such that xy and also yx is a factor of q ; whence ax and yx are factors of v where y = a . We thus deduce that p contains no left or right special factor of length 1. Indeed, the right special letter a can only be followed by b (not x ) in p ; otherwise a would have right-valence greater than 2, which implies that Cv ( 2 ) ≥ Cv ( 1 ) + 2 (since each letter in Alph ( v ) is right-extendable in v ). But this is impossible because v is a GT-word (also see Proposition 7). We also note that the letter a can be preceded by only the letter b in p ; otherwise a would be another left special factor of v of length 1 (in addition to the letter x ) which is not possible by Proposition 8. So pu 1 takes one of the following forms:
/negationslash
$$\ p u _ { 1 } = a ^ { m + 1 } \, ( a = b, u _ { 1 } = \varepsilon ), \ \ p u _ { 1 } = ( a b ) ^ { m } a \, ( a \neq b, u _ { 1 } = \varepsilon ), \ \text{ or } \ \ p u _ { 1 } = ( b a ) ^ { m } b a \, ( a \neq b, u _ { 1 } = a )$$
/negationslash for some m ∈ N + . Furthermore, we observe that the letters a and b cannot occur to the right of x in v ; otherwise one of those letters would be left special. But the only letter that can be left special in v is
/negationslash
˜ ˜ Case 2: Alph ( u ) contains a letter not in Alph ( p ) ∪ Alph ( q ) . Using very similar reasoning as in Case 1, we deduce that v satisfies one of the conditions (i)-(vi) where Z is a non-empty word containing no letters in common with p and q , and the reversal of any such v (namely, ˜ v = qup ˜ , which is also a GT-word by Proposition 23) satisfies condition (vii). Moreover, we note that | Z | = | Alph ( Z ) | , i.e., Z is a product of mutually distinct letters. Indeed, Z has no left or right special factor of length 1 because the letters a and x are, respectively, the unique right and left special factors of v of length 1. This implies that Z is either a product of mutually distinct letters (possibly just a single letter), or Z takes one of the following forms:
x , by the fact that | v | = Lv + Hv + | Alph ( v ) | -2 (by Corollary 20) together with Proposition 8. Hence Alph ( xu q 2 ) = Alph ( q ) , and using similar reasoning as for pu 1 , we observe that xu q 2 has no left or right special factor of length 1. Therefore xu q 2 = x yx ( ) n y for some n ∈ N + where x = y (and u 2 = ε ). We have thus shown that v satisfies one of the conditions (i)-(iii) with Z = ε , and the reversal of any such v (namely, v = qup , which is also a GT-word by Proposition 23) satisfies condition (vii).
$$Z = ( c d ) ^ { k } c, \ \ Z = ( c d ) ^ { k + 1 }, \ \ \text{or} \ \ Z = c ^ { k + 1 } \ \ \text{for some} \, k \in \mathbb { N } ^ { + },$$
where c and d are distinct letters. But none of the above forms are possible because in each case the letter c would be a left special factor of v of length 1 (different from x ). Thus Z must be a product of mutually distinct letters.
( ⇐ ): Conversely, suppose u = u Zu 1 2 where u 1 , u 2 , and Z are words such that Alph ( u 1 ) ⊆ Alph ( p ) , Alph ( u 2 ) ⊆ Alph ( q ) , and Z contains no letters in common with p and q . Then, using the same reasoning as above, we deduce that v satisfies one of the conditions (i)-(vii) and it is easy to see that every prefix of any such word has a unioccurrent palindromic suffix; whence v is rich. /square
Proof of Theorem 27. ( ⇒ ): Suppose w is rich. Then the heart v of w is clearly rich too since any factor of a rich word is rich (see Lemma 30). Suppose, by way of contradiction, that v is the (rich) heart of a rich GT-word w such that v satisfies none of the conditions (i)-(iii) in the statement of the theorem. Then, by Lemmas 31, 33, and 35, the only possibility is that v takes the form v = puq where | u | ≥ 2 and Alph ( p ) ⊆ Alph ( q ) or Alph ( q ) ⊆ Alph ( p ) . However, by Lemma 34, all such v are not rich. Hence one of the conditions (i)-(iii) must hold.
( ⇐ ): Conversely, suppose that v satisfies one of the conditions (i)-(iii) in the statement of the theorem. To prove that w is rich, it suffices to prove that v is rich (by Lemma 30). We first observe that if v satisfies either of the conditions (ii) or (iii), then v is rich (by Lemmas 31, 33, and 35). So let us now assume that v satisfies condition (i) and suppose, on the contrary, that v is a heart of a GT-word of minimal length satisfying that condition but v is not rich. Then, by Proposition 25, v contains a non-palindromic complete return to some non-empty palindrome P , say r = PUP where U is a nonpalindromic word. If r = PUP is a factor of p , then p would be a non-rich (heart of a) GT-word shorter than v satisfying condition (i), contradicting the minimality of v as a heart of a GT-word of shortest length satisfying condition (i), but not rich. So r = PUP is not a factor of p , and likewise, r is not a factor of q . Therefore r = PUP is not wholly contained in either of the palindromes p and q . Hence, we have v = p rq ′ ′ = p PUPq ′ ′ where p ′ is prefix of p and q ′ is a suffix of q . Note that at least one of the words p ′ and q ′ is non-empty; otherwise v = PUP where P = p = q and | U | ≥ 2, in which case v does not satisfy either of the conditions (i) or (ii). We distinguish three cases, as follows.
/negationslash
Case 1: The first occurrence of P in r is not contained in p. In this case, q = P UPq ′ ′ where P ′ is a (possibly empty) suffix of P with P ′ = P (i.e., P ′ is a proper suffix of P ) because, by assumption, q does not contain r = PUP as a factor. Let S = PUPq ′ . This proper suffix of v is (the heart of) a GT-word (by Proposition 22) and its longest palindromic prefix is P . Indeed, if S had a palindromic prefix longer than P , but shorter than r = PUP , then P would occur more than twice in r (i.e., P would
occur as an interior factor of r ), which is impossible because r is a complete return to P . On the other hand, if S had a palindromic prefix Z longer than r = PUP , then the palindrome Z (which begins with r = PUP ) would be a non-rich (heart of a) GT-word shorter than v satisfying condition (i), contradicting the minimality of v . So we see that the longest palindromic prefix of S (namely P ) and the longest palindromic suffix of S (namely q ) are unseparated in S . Hence S is a non-rich (heart of a) GT-word (shorter than v ) satisfying condition (i), contradicting the minimality of v again.
Case 2: The second occurrence of P in r is not contained in q. Using the same reasoning as in Case 1 we reach a contradiction.
Case 3: The first occurrence of P in r is contained in p and the second occurrence of P in r is contained in q . In this case, p ends with PU ′ where U ′ is a proper prefix of UP and q begins with U P ′′ where U ′′ is a proper suffix of PU . Let S = PUPq ′ where q ′ is a suffix of q . We observe that S has longest palindromic suffix q , and using the same reasoning as in Case 1, we deduce that the longest palindromic prefix of S is P . Moreover, P and q must be unseparated in S . Otherwise, if P and q were separated by a letter or word of length at least 2 in S , then the same would be true of p and q in v , which is impossible because v satisfies condition (i). Hence S is a non-rich (heart of a) GT-word (shorter than v ) satisfying condition (i), contradicting the minimality of v .
In each of the above three cases we have reached a contradiction. Hence v (and therefore w ) must be rich. /square
## 4. CLOSING REMARKS
In this paper we have introduced a new class of words that encompass the (original) binary trapezoidal words and have studied combinatorial and structural properties of these so-called generalized trapezoidal words. We have also proved some characterizations of these words and have described all those that are rich in palindromes. A nice (direct) consequence of our characterization of rich GTwords is that all GT-words with palindromic hearts are rich. In the case of binary trapezoidal words, we have independently proved that the longest palindromic prefix and longest palindromic suffix of any such word must be 'unseparated', from which it follows that all binary trapezoidal words are rich, originally proved in a different way in [5]. Further work-in-progress concerns the enumeration of generalized trapezoidal words, as has recently been considered in the binary case [2] (see also [9] in which an enumeration formula for binary trapezoidal words was independently obtained).
## 5. ACKNOWLEDGEMENTS
We thank very much the two anonymous referees for their thoughtful comments and suggestions which greatly helped to improve the paper. The first author would also like to thank members of the Laboratoire MIS and Equipe SDMA at the Université de Picardie Jules Verne for their kind hospitality during her 1-month visit in mid 2011 when some of the preliminary work on this paper was done. She also gratefully acknowledges the funding provided by the Université de Picardie Jules Verne for her visit to Amiens.
## REFERENCES
- [1] S. Brlek, S. Hamel, M. Nivat, C. Reutenauer, On the palindromic complexity of infinite words, Internat. J. Found. Comput. Sci. 15 (2004) 293-306.
- [2] M. Bucci, A. De Luca, G. Fici, Enumeration and structure of trapezoidal words, Theoret. Comput. Sci. 468 (2013) 12-22.
- [3] F. D'Alessandro, A combinatorial problem on trapezoidal words, Theoret. Comput. Sci. 273 (2002) 11-33.
- [4] A. de Luca, On the combinatorics of finite words, Theoret. Comput. Sci. 218 (1999) 13-39.
- [5] A. de Luca, A. Glen, L.Q. Zamboni, Rich, Sturmian, and trapezoidal words, Theoret. Comput. Sci. 407 (2008) 569-573.
- [6] X. Droubay, J. Justin, G. Pirillo, Episturmian words and some constructions of de Luca and Rauzy, Theoret. Comput. Sci. 255 (2001) 539-553.
- [7] X. Droubay, G. Pirillo, Palindromes and Sturmian words, Theoret. Comput. Sci. 223 (1999), p. 73-85.
- [8] A. Glen, J. Justin, S. Widmer, L.Q. Zamboni, Palindromic richness, European J. Combin. 30 (2009) 510-531.
- [9] A. Heinis, On low-complexity bi-infinite words and their factors, J. Théor. Nombres Bordeaux 13 (2001) 421-442.
- [10] M. Lothaire, Algebraic Combinatorics on Words, Encyclopedia of Mathematics and its Applications , vol. 90, Cambridge University Press , UK, 2002.
- [11] M. Morse, G. A. Hedlund, Symbolic dynamics II. Sturmian trajectories, Amer. J. Math. 62 (1940) 1-42.
AMY GLEN
SCHOOL OF ENGINEERING & INFORMATION TECHNOLOGY MURDOCH UNIVERSITY 90 SOUTH STREET MURDOCH WA 6150 AUSTRALIA
E-mail address :
[email protected]
FLORENCE LEVÉ LABORATOIRE MIS UNIVERSITÉ DE PICARDIE JULES VERNE 33 RUE SAINT LEU 80039 AMIENS FRANCE
E-mail address :
[email protected] | null | [
"Amy Glen",
"Florence Levé"
] | 2014-08-03T03:18:45+00:00 | 2015-02-24T06:40:38+00:00 | [
"math.CO",
"cs.DM",
"68R15"
] | Generalized trapezoidal words | The factor complexity function $C_w(n)$ of a finite or infinite word $w$
counts the number of distinct factors of $w$ of length $n$ for each $n \ge 0$.
A finite word $w$ of length $|w|$ is said to be trapezoidal if the graph of its
factor complexity $C_w(n)$ as a function of $n$ (for $0 \leq n \leq |w|$) is
that of a regular trapezoid (or possibly an isosceles triangle); that is,
$C_w(n)$ increases by 1 with each $n$ on some interval of length $r$, then
$C_w(n)$ is constant on some interval of length $s$, and finally $C_w(n)$
decreases by 1 with each $n$ on an interval of the same length $r$. Necessarily
$C_w(1)=2$ (since there is one factor of length $0$, namely the empty word), so
any trapezoidal word is on a binary alphabet. Trapezoidal words were first
introduced by de Luca (1999) when studying the behaviour of the factor
complexity of finite Sturmian words, i.e., factors of infinite "cutting
sequences", obtained by coding the sequence of cuts in an integer lattice over
the positive quadrant of $\mathbb{R}^2$ made by a line of irrational slope.
Every finite Sturmian word is trapezoidal, but not conversely. However, both
families of words (trapezoidal and Sturmian) are special classes of so-called
"rich words" (also known as "full words") - a wider family of finite and
infinite words characterized by containing the maximal number of palindromes -
studied in depth by the first author and others in 2009.
In this paper, we introduce a natural generalization of trapezoidal words
over an arbitrary finite alphabet $\mathcal{A}$, called generalized trapezoidal
words (or GT-words for short). In particular, we study combinatorial and
structural properties of this new class of words, and we show that, unlike the
binary case, not all GT-words are rich in palindromes when $|\mathcal{A}| \geq
3$, but we can describe all those that are rich. |
1408.0452v1 | ## Methodology for Detection of QRS Pattern using Secondary Wavelets
## ARAMCO Endowed chair-Technology
T.R.Gopalakrishnan Nair PMU,KSA Vice President, RIIC Dayananda Sagar Institutions Bangalore, India [email protected]
Geetha A P Advanced Signal & Image Processing Group, RIIC Dayananda Sagar Institutions Bangalore, India [email protected]
Asharani Dept.of E&C JNTUHEC Hyderabad,India [email protected]
AbstractApplications of wavelet transform to the field of health care signals have paved the way for implementing revolutionary approaches in detecting the presence of certain abnormalities in human health patterns. There were extensive studies carried out using primary wavelets in various signals like Electrocardiogram (ECG), sonogram etc. with a certain amount of success. On the other hand analysis using secondary wavelets which inherits the characteristics of a set of variations available in signals like ECG can be a promise to detect diseases with ease. Here a method to create a generalized adapted wavelet is presented which contains the information of QRS pattern collected from an anomaly sample space. The method has been tested and found to be successful in locating the position of R peak in noise embedded ECG signal.
Keywords - ECG, CWT, pattern adapted wavelet
## I. INTRODUCTION
Wavelet transform is an efficient mathematical tool for local analysis of nonstationary and transient signals. Application of wavelet transform to estimate, characterize and identify properties of signals has been successful in many fields like astronomy, nuclear engineering, signal and image processing and fractals.
The wavelet analysis procedure is to adopt a wavelet prototype function, called an analyzing wavelet or mother wavelet function. A large section of localized waveforms can be employed as wavelet provided that they satisfy predefined mathematical criteria. The continuous wavelet transform (CWT) of a signal x(t) is defined as
$$( 1 )$$
where is the complex conjugate of the analyzing wavelet function ψ(t), parameters a and b is the dilation and location parameter of the wavelet respectively. However for a function to be classified as a wavelet, it has to satisfy certain mathematical criteria such as
$$i ) \ \ I t \ \ h a s \ \text{to} \ \text{poses finite energy}$$
$$( 2 )$$
$$\text{ii} ) \text{ \ } If \, \mathcal { P } ( f ) \text{ is the Fourier transform of $\psi(t), i.e.}$$
$$( 3 )$$
then the necessary condition is
$$( 4 )$$
Criterion (ii) implies that the wavelet has no zero frequency components. This criterion is known as admissibility condition and is the admissibility constant [1].
Wavelet transform can be considered as the projection of a signal x(t) into a family of functions that are the normalized, dilated and translated versions of a prototype function (the wavelet). Wavelet transforms can comprise an infinite set of possible basis functions. Primary wavelets or the adapted wavelets are used as basis functions. There are many primary wavelet bases designed for general applications such as Meyer, Mexican hat, Haar, Daubechies etc [1].
This paper provides an analysis of ECG signal in order to accurately identify QRS complex peak. ECG records the electrical activity of heart over a period of time as detected by electrodes attached to the outer surface of the skin and recorded by a device external to the body. Initial part of the waveform P wave, represents activity of the atria. The following part is the QRS complex which is produced by the contraction of ventricles. The subsequent return of the ventricular mass to a rest state -re-polarization produces the T wave. R wave detectors are extremely useful tools for the analysis of ECG signals. Making an algorithm for detection of R-peak in QRS complex is a difficult task. This is due to the variability of ECG patterns caused by noise and artifacts [2].
Since the quality of performance of an automated ECG analysis system depends highly on the reliable detection of Rpeaks, the aim of this research work is to locate R peaks accurately. Heart rate variability measures rely heavily on the accuracy of the QRS feature detection on the digitized ECG signal [3]. QRS detection is difficult due to the physiological variability of the QRS complex. Other ECG components such as the P or T wave which look similar to QRS complexes often lead to wrong detections. Noise that is embedded within the ECG signal makes the detection of R-peak more complex. Noise sources include muscle noise, artifacts due to electrode motion, power-line interference and baseline wander.
Analyzing an ECG waveform using pattern adapted wavelets gives a better method for accurate analysis because of the rhythmic nature of the signal. Here, we have considered a set of signal patterns for adapted wavelet formation by considering typical variations in QRS complex. These adapted wavelets are used to bring out an accurate and easy method for the detection of R-peak in an ECG signal.
## II. RESEARCH BACKGROUND
An adapted wavelet is the best basis function designed for a given signal representation. There are several methods to construct pattern-adapted wavelets. Authors Chapa and Rao worked on the (bi)orthogonal relations to construct pattern adapted wavelet and have used it for target detection [4]. Akram Aldroubi, Patrice Abry, and Michael Unser used Projection based methods for generating pattern adapted wavelet [5]. Gupta et al. have suggested a method to construct wavelets that are matched to a given signal in the statistical sense [6]. Lifting scheme introduced by Wim Sweldens can be used to construct wavelets custom designed for certain applications [7].
Misiti et al. have used the method of least square optimization for generating pattern adapted wavelet. The principle for designing a new wavelet for CWT is to approximate a given pattern, using least squares optimization under constraints, leading to an admissible wavelet compatible for the pattern detection [8]. In our research work, we have used this method to generate adapted wavelet.
Detection of QRS complex in noisy ECG signal is not easy because of its varying nature. There are several methods developed to determine the accurate location of QRS peak using primary wavelets. Senhadji et al. has made a comparison on the ability of three different wavelets namely Daubechies, spline and Morlet to recognize and describe isolated cardiac beats [9]. Kadambe et al. applied DWT-based QRS detection algorithm. In their approach a specific spline wavelet, suitable for the analysis of QRS complexes, was designed and the scales were chosen adaptively based on the signal [10]. Li et al. suggested a method based on finding the modulus maxima larger than a threshold obtained from the pre-processing of preselected initial beats [11]. A quadratic spline wavelet with compact support was used in their analysis. The local maxima of the WT modulus at different scales were used to locate the sharp variation points of ECG signals.
Authors in [12] introduces a supervised learning algorithm which learns the optimal scales for each dataset using the annotations provided by physicians on a small training set. For each record, this method allows a specific set of non consecutive scales to be selected, based on the record's characteristics and along with a hard thresholding rule was used to label the R spikes. However pattern adapted wavelet for detection of R-peak in QRS complex provides a better performance in comparison with the above specified methods.
## III. RESEARCH METHODOLOGY
If we observe ECG waveforms we can find a set of variations of QRS complex. In order to study these variations data has been collected from www.physionet.org/physiobank. MIT-BIT Arrhythmia Database is used for performance comparison. Having analyzed the databank for many cases, typical five variation of QRS complex was selected. Using these five patterns five adapted wavelets was generated. CWT of these adapted wavelets with the practical QRS complexes provides maximum matching. This matching of QRS waveform with an adapted wavelet can maximize the coefficients in wavelet transform.
Pattern adapted wavelets are designed using least squares optimization method under certain constraints. The generated adapted wavelets were used in CWT analysis. The algorithm consists of two phases. The first phase of the algorithm decides the best matching wavelet for the QRS complex in the given ECG signal. For this purpose 250 points (approximately one cycle) of the ECG signal to be analyzed is extracted. This portion of the signal under consideration was transformed using CWT for each of the five pattern adapted wavelets. The maximum value of coefficients in each case will be compared. The adapted wavelet which gives maximum coefficients is selected for further analysis of ECG waveform.
In the second phase using the selected adapted wavelet, CWT of the given ECG signal is computed. From the coefficient matrix of CWT the position and scale of each peak is extracted. The peak values corresponding to P and T waves are removed to avoid false detection.
## IV. IMPLEMENTATION
From the physiobank, MIT-BIT Arrhythmia Database is used for selection of typical patterns. Five typical variations of QRS patterns are selected. A wavelet was adapted for each pattern using Matlab® Wavelet toolbox command 'pat2cwav', i.e. 'pattern to continuous wave'. The function gives an approximation to the given pattern in the interval [0 1] by least squares fitting a projection on the space of functions orthogonal to constants.
Fig. 1 through fig. 5 depicts the five adapted wavelets used for analysis. These adapted wavelets were used for the CWT analysis of ECG waveforms from the databank. A portion of ECG signal (approximately 250 points) is considered at the beginning. Using each wavelet, CWT is calculated for the signal under consideration. The adapted wavelet which gives maximum coefficient of CWT analysis is then considered for further analysis. In the second phase, by means of the best matched adapted wavelet the given ECG signal under goes a second time CWT analyzes. By further inspection of coefficient matrix of CWT R-peaks of ECG signal was extracted. One possibility of false detection is the peak of Twave. After finding one QRS peak the searching for next QRS peak has to begin after an absolute refractory period. The important aspect is that it helps in preventing a T-wave being identified as an R-wave. The value used for absolute refractory period is 192milli seconds. Using these wavelets it was possible to find the QRS peaks accurately.
Figure 1. Adapted wavelet 1
Figure 2. Adapted wavelet 2
Figure 3. Adapted wavelet 3
Figure 4. Adapted wavelet 4
Figure 5. Adapted wavelet 5
## V. RESULT
Using adapted wavelet it was possible to find out R-peaks very accurately which is an important task in ECG analysis. Different ECG waveforms from the database have been tested and R-peak detection was accurate. Data from different ECG electrode has been tested and even the negative R- peaks were detected correctly. Even in the presence of baseline drift and high T-wave the detection was good. The adapted wavelets used with different waveforms are listed in table1. Fig. 6 to fig. 8 shows the R- peaks detected using adapted wavelets. R-peaks are represented using circles.
Figure 6. ECG waveform 103m analysed
Figure 7. ECG waveform 105m analysed
Figure 8. ECG waveform 123m analysed
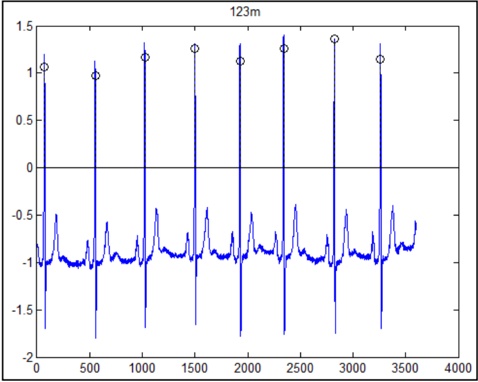
TABLE I. ADAPTED WAVELET USED IN ANALYSIS
| Sl.No | Sample waveform | Adapted wavelet used |
|---------|-------------------|------------------------|
| 1 | 102m V5 | ADW3 |
| 2 | 105m MLII | ADW5 |
| 3 | 103m MLII | ADW2 |
| 4 | 107m V1 | ADW1 |
| 5 | 123 V1 | ADW4 |
## CONCLUSION
In this research work we have used secondary wavelets for the evaluation of CWT. This adaptive wavelet transform technique has successfully identified the R-peaks in most of the cases. Many researchers have worked with wavelet transforms as means of analyzing ECG signals. The methods used by them have been different and of varying effectiveness. All of them used primary wavelets for their analyzes and this paper shows a clear advancement on the efficacy of analyzing ECG signals with varational symptoms. The next step in this research will be to fine tune the algorithm to make it statistically successful across a wide variety of variations.
## ACKNOWLEDGEMENT
The authors are grateful to Dr.Suma for her suggestions and comments on this paper.
## REFERENCES
- [1] Mallat, S. 'A Wavelet Tour of Signal Processing. In: Wavelet Analysis and Its Applications,' 2nd edn. IEEE Computer Society Press, San Diego 1999
- [2] Paul S Addison 'Wavelet transforms and the ECG:A Review,' Cardio Digital Ltd, Elvingston Science Centre, East Lothian, EH33 1EH, UK.
- [3] Jiapu pan and Willis J. Tompkins,'A Real-Time QRS Detection Algorithm,' IEEE, IEEE Transactions on Biomedical Engineering, vol. BME-32, no. 3, March 1985
- [4] Joseph O. Chapa and Raghuveer M. Rao 'Algorithms for Designing Wavelets to Match a Specified Signal, ' IEEE transactions on signal processing, vol. 48, no. 12, December 2000
- [5] Akram Aldroubi, Patrice Abry, and Michael Unser 'Construction of Biorthogonal Wavelets Starting from Any Two Multiresolutions,' IEEE transactions on signal processing, vol. 46, no. 4, April 1998
- [6] Gupta, A. Joshi, S.D. Prasad, S. 'A new approach for estimation of statistically matched wavelet' IEEE Transactions on Signal Processing,vol.53 no.5 May 2005
- [7] Wim Sweldens , Peter schroder 'Building Your Own Wavelets at Home,' Technical report Industrial Mathematics initiative. Department of mathematics, University of South Carolina 1995.
- [8] Misiti, Y. Misiti, G. Oppenheim, J.M. Poggi, Hermes, "Les ondelettes et leurs applications,' M, 2003.
- [9] Senhadji L, Carrault G, Bellanger J J and Passariello G 'Comparing wavelet transforms for recognizing cardiac patterns,' IEEE Trans. Med. Biol. 13 167-73, 1995
- [10] Kadambe S,Murray R and Boudreaux-Bartels G F 'Wavelet transformbased QRS complex detector,' IEEE Trans.Biomed. Eng. 46 83848,1999
- [11] Li C, Zheng C and Tai C 'Detection of ECG characteristic points using wavelet transforms,' IEEE Trans. Biomed.Eng. 42 21-8 1995.
- [12] A. Fred, J. Filipe, and H. Gamboa 'A Supervised Wavelet Transform Algorithm for R Spike Detection in Noisy ECGs,' Biostec, CCIS 25, pp. 256-264, c Springer-Verlag Berlin Heidelberg 2008 | null | [
"T. R. Gopalakrishnan Nair",
"A. P. Geetha",
"Asharani"
] | 2014-08-03T03:43:28+00:00 | 2014-08-03T03:43:28+00:00 | [
"cs.CV"
] | Methodology For Detection of QRS Pattern Using Secondary Wavelets | Applications of wavelet transform to the field of health care signals have
paved the way for implementing revolutionary approaches in detecting the
presence of certain abnormalities in human health patterns. There were
extensive studies carried out using primary wavelets in various signals like
Electrocardiogram (ECG), sonogram etc. with a certain amount of success. On the
other hand analysis using secondary wavelets which inherits the characteristics
of a set of variations available in signals like ECG can be a promise to detect
diseases with ease. Here a method to create a generalized adapted wavelet is
presented which contains the information of QRS pattern collected from an
anomaly sample space. The method has been tested and found to be successful in
locating the position of R peak in noise embedded ECG signal. |
1408.0453v1 | ## ADAPTIVE WAVELET BASED IDENTIFICATION AND EXTRACTION OF PQRST COMBINATION IN RANDOMLY STRETCHING ECG SEQUENCE
T.R Gopalakrishnan Nair
RIIC, DSI Bangalore, India
Geetha A P RIIC, DSI Bangalore, India
Asharani M Dept.of ECE,JNTUHEC Hyderabad , India
## ABSTRACT
Cardiovascular system study using ECG signals have evolved tremendously in the domain of electronics and signal processing. However, there are certain floating challenges unresolved in the analysis and detection of abnormal performances of cardiovascular system. As the medical field is moving towards more automated and intelligent systems, wrong detection or wrong interpretations of ECG waveform of abnormal conditions can be quite fatal. Since the PQRST signals vary their positions randomly, the process of locating, identifying and classifying each feature can be cumbersome and it is prone to errors. Here we present an automated scheme using adaptive wavelet to detect prominent R-peak with extreme accuracy and algorithmically tag and mark the coexisting peaks P, Q, S, and T with almost same accuracy. The adaptive wavelet approach used in this scheme is capable of detecting R-peak in ECG with 99.99% accuracy along with the rest of the waveforms.
line when there is no electrical activity in heart. The first deflection shown in the ECG is the P-wave. It results from depolarization of the atria. QRS complex corresponds to the ventricular depolarization. The T-wave represents ventricular repolarisation. In few individuals a U- wave may be visible after T-wave which is caused by the afterpotentials that are probably generated by mechanicalelectric feedback [1]. The amplitude and relative position of different waves P-Q-R-S-T give valuable information about the functioning of heart. There are various methods adapted for the detection and identification of waveform features.
Index TermsECG, PQRST signal, adaptive wavelet, CWT, Baseline drift removal
## 1. INTRODUCTION
One of the non-invasive methods to register the electrical activity of heart is ECG. The changes in electrical potential during depolarization and repolarisation of the myocardial fibres are recorded by electrodes positioned on the surface of the body. The normal ECG recordings have a number of different morphologies depending of the patient, type of the lead used for recording etc. So it is hard to build a universal tool for automatic ECG analysis. Computational intelligence can bring forward a number of conceptually and computationally appealing methods for ECG signal processing, classification and interpretation. The noninvasive method of recording and analyzing the ECG signal has made it popular as a routine part of any complete medical evaluation.
The normal clinical features of the electrocardiogram, which include wave amplitudes and inter-wave timings, are shown in Fig 1. The iso-electric line on ECG is a horizontal
Fig. 1 A normal ECG waveform
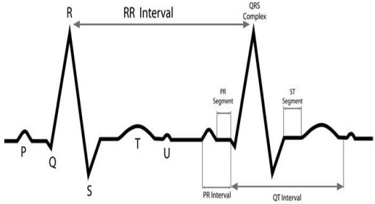
Automatic detection of ECG features depends mainly on the accurate detection of R- peak. R-peak detection using slope- amplitude analysis [2], digital filters [3-6], difference operation method [7] and transformed domains [8] were the first few developed methods. Artificial Neural Networks [9, 10], Genetic Algorithm [11], Hidden Markov Model [12] and Support Vector Machines [13], Shannon energy envelope (SEE) estimator[14] were also used for the QRS detection. Wavelet transform has emerged over recent years as a powerful tool for de-noising and detection of QRS complex.
For the detection of characteristic points of ECG waveforms, Li et al. had introduced an algorithm based on discrete wavelet transform (DWT) [15]. Identifying the singularity points using Lipschitz exponent at different scales was the adapted method. Kadambe et al. also used the DWT analysis using Spline wavelet as they are insensitive to non-stationarity in the QRS complex and robust to noise [16]. Mahmoodabadi et al. analysed ECG signals from Modified Lead II using two filters D4 and D6 and compared their performance. In order to delineate the ECG waveform Martínez et al. used a quadratic spline wavelet with adaptive threshold levels [17]. Sivanarayana and Reddy have used biorthogonal wavelet transform for ECG parameters estimation [18]. Virgilio et al. detected characteristic points by comparing the coefficients of the discrete WT on selected scales against fixed thresholds [19]. Romero et al. had used Continuous Wavelet Modulus Maxima for R-wave detection [20]. A relative performance analysis about the different wavelet transform analysis method for the QRS detection was presented by Senhadji et al. [21].
All the attempts hitherto undoubtedly were a step forward in accurate detection of R peak. Many of the methods used 4 to 6 scales of resolution to find the characteristic points. Algorithm was tested with one database and obtained accuracy varying from 95 % to 995. In our study we have used a QRS-pattern adaptive wavelet for continuous wavelet transform analysis of ECG signals to bring out high accuracy R-peak detection. Once the R-peaks are marked other characteristic points P-Q-S-T are identified accurately in time domain analysis.
Continuous wavelet transform (CWT) is preferable over DWT for signal analysis, feature extraction and detection tasks, for it provide a description that is truly shift invariant. CWT performs a correlation analysis, so that it gives maximum when the input signal resemble to the mother wavelet. The continuous wavelet transform (CWT) of a signal x (t) is defined as
$$( 1 )$$
where is the complex conjugate of the analysing wavelet function ψ(t), parameters a and b is the dilation and location parameter of the wavelet respectively. Here x (t) is decomposed into a set of basis functions Ψ(t) called the wavelets, along the new dimensions, scale and translation. The most important properties of wavelets are the admissibility and the regularity conditions. The admissibility condition can be used to first analyze and then reconstruct a signal without loss of information. Regularity conditions state that the wavelet function should have some smoothness and concentration in both time and frequency domains. In other words it should have finite energy.
Wavelet transforms can comprise an infinite set of possible basis functions. Primary wavelets or the adaptive wavelets are used as basis functions. Most of the ECG analysis were carried out using primary wavelets such as spline, Mexican hat, Haar, Daubechies etc. As CWT performs a correlation study, using a pattern adaptive wavelet can give a better analysis. Even in the presence of noise an adaptive wavelet can give a better correlation. For our study we developed an adaptive wavelet matching to the QRS complex of a typical ECG waveform. This paper brings out an accurate method to identify ECG characteristic points using adaptive wavelet.
## 2. RESEARCH BACKGROUND
Any clinical analysis of ECG waveform starts from identifying the QRS complex, its amplitude and width as well as its regularity. This will be followed by P-wave and T- wave analysis, and the analysis of various intervals, P- R, R-R, S-T and Q-T segments. The primary objective of any digital analysis of ECG wave is to locate the R-peak accurately. ECG waveforms are usually contaminated by noise and artifacts such as power line interference, contact noise, patient- electrode motion artifacts, electromyographic noise, baseline drift etc. [1]. Accurate identification of Rpeak and other characteristic points still remain a challenging task because of the presence of noise and the varying morphologies of ECG waves.
Time-frequency analysis techniques of WT have been applied for ECG analysis, to take advantage of the nonstationary nature of the cardiac cycle. But most of the analysis of ECG waves were mainly carried out using DWT. Romero et al. used CWT using Mexican hat for ECG signal time-frequency analysis. In CWT as there is no discretization of scales, it can provide a better resolution. Using a high resolution in wavelet space allows individual maxima to be followed accurately across scales.
In this paper, we have overcome the difficulties experienced in the earlier works like low detection sensitivity in the presence of noise, computational complexity associated with the requirement to calculate wavelet transform over many scales etc. We used CWT analysis of the ECG signal using an adaptive wavelet designed for QRS complex detection. An adaptive wavelet is the best basis function designed for a given signal representation. There are several methods to construct pattern-adaptive wavelets. Bi-orthogonal method [22], Projection based methods [23], statistical method [24], Lifting scheme [25] etc. Misiti et al. have used the method of least square optimization for generating pattern adaptive wavelet [26]. The principle for designing a new wavelet for CWT is to approximate a given pattern, using least squares optimization under constraints, leading to an admissible wavelet compatible for the pattern detection. In our research work, we have used this method with a polynomial approximation of order 4 to generate the adaptive wavelet. Using adaptive wavelet R-peaks were detected accurately.
Many of the previous studies were mainly focused on the QRS complex detection. Abed et al. has developed an algorithm to detect P, QRS and T waves. Authors have used Haar wavelet for QRS detection and later DB2 wavelet was used for P and T detection [27]. Chouhan and Mehta employed a modified definition of slope of ECG signal, as the feature for detection of ECG wave components [28]. For myocardial ischemia analysis Ranjit et al. considered WT up to four scales and the scale 2 to 4 was used to locate T- and P-waves using maxima minima method [29]. In our study once the R- peaks were detected using adaptive wavelet, QS-P-T points were identified with high accuracy in time domain analysis.
## 3. RESEARCH METHODOLOGY
After analysing various ECG signals from the database [30] a typical bipolar QRS waveform was selected. Using the method of least square optimization, a pattern adaptive wavelet was generated [28]. The adaptive wavelet is shown in Fig. 3. A wavelet was adapted for the pattern using Matlab® Wavelet toolbox command 'pat2cwav', i.e. 'pattern to continuous wave'. The function gives an approximation to the given pattern in the interval [0 1] by least squares fitting, a projection within the space of functions orthogonal to constants. This adaptive wavelet is used for the CWT analysis of the ECG signals.
Fig. 2 Adaptive wavelet
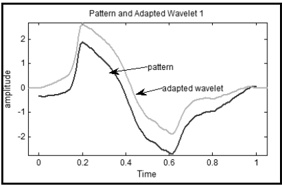
ECG signals required for analysis were collected from global data source where annotated ECG signals are available [30]. MIT-BIH Arrhythmia and PTB diagnostic database were used for the testing of algorithm.
## 3.1 Baseline Drift Removal
Any ECG signal analysis requires a pre-processing to remove the noise artifacts. For computerized detection of QRS complexes based on threshold detection the main affecting noise factor will be baseline drift. The frequency content of the baseline wander is usually in a range well below 0.5Hz. This baseline drift can be eliminated using median filters (200-ms and 600-ms) [30]. The original ECG signal was processed with a median filter of 200-ms width to filter QRS complexes and P waves. The resulting signal was then processed with a median filter of 600-ms width to remove T waves. The signal resulting from the second filter operation contained the baseline of the ECG signal, which was then subtracted from the original signal to produce the baseline corrected ECG signal. The baseline corrected signal for the ECG signal 108 V1 lead is shown in Fig 3. The intermediate results of unravelling QRS & P-wave as well as T-waves are also shown in fig 3.
3.2 De-noising the ECG Wave
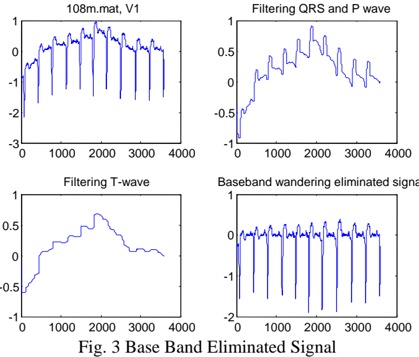
Another factor which can affect the peak detection process is the low frequency noise. Detection of R peak will not be affected by the presence of noise as the peak amplitude is high. But the P, Q, S and T wave detection will be affected by the noise as these waves are of low amplitude. Stationary wavelet transform with DB1 is used for the noise removal. De-noised signal is shown in fig. 4.
## 3.3 Suppressing T-Wave
Since high T-wave can lead to false detection it is better to suppress the T-wave before the QRS detection. From the de-noised signal, T-wave can be suppressed using the median filter of 600ms width. A suppressed T-wave waveform is shown in Fig. 5 for the ECG signal 102, V2 lead.
Fig. 4 De-noised signal
Before finding out the R-peaks using adaptive wavelet the signal is squared. Squaring of the signal allows us to use the same adaptive wavelet for all waveforms for all the different leads from which the ECG signal is being taken. That means for analysing 'bipolar signal', 'only negative amplitude signal' OR 'only positive amplitude signal', the same adaptive signal can be used. It also enhances the R-peak by reducing the P-wave effect as shown in Fig 5. The high frequency components in the signal related to the QRS complex are further enhanced. Squaring of signal also helps in analysing waveforms of very low signal to noise ratio. Following are the major steps involved in finding the Rpeaks.
- 1. Calculate continuous wavelet transform of the given ECG signal up to two levels using the adaptive wavelet.
- 2. Detect a series of maximum- minimum pair in the first and second level.
- 3. Remove those maximum - minimum pairs whose absolute values are less than the threshold. Threshold value is selected as the 30% of the maximum of CWT coefficients as shown in Fig. 5. Statistical and heuristic estimation methods were used to arrive at the threshold value. Threshold value less than 30% results in higher false detection, whereas threshold value greater than 30% results in more number of misses in peak detection.
- 4. Detect the zero - crossing point between a pair of maximum and minimum points.
- 5. Decrease the false detections by removing peaks which are occurring within less than 120ms.
- 6. Verify second level coefficients in a similar manner and compare the R-peak positions to avoid false detection.
- 7. Previously rejected events are re-evaluated using a reduced threshold when a significant time has passed without finding a QRS complex. For ECG signals with R\_R peak variability, reducing the time limit for less than120ms may be required.
8. From R-peak point, moving to the left and right to the extent of 15% (of RR interval) find the first trough/peak (if R-peak is positive, find the trough, if R- peak is negative find the peak) to locate the Q and S respectively. Q and S points should be a point after crossing the iso-electric line. Positions of P and T waves come approximately within 40% of RR interval from Q and S points. From Q moving to the left find the first maximum point to fix P- point and from S moving to the right the first peak gives T point. If there is a negative occurrence of T wave it is detected by comparing the negative and positive peak within the 40% RR interval. The Fig. 6 shows an ECG wave with all these points marked.
Fig. 5 Intermediate processed ECG signal
Fig.6 PQRST marked ECG signal
## 4. RESULT
The proposed algorithm was tested on two different sets of data, MIT-BIH arrhythmia database and PTB diagnostic database. For MIT-BIH database the sampling frequency was 360Hz with 2- channels and for PTB database the sampling frequency was 1 KHz with 16 channels. In both databases it was possible to detect all the characteristic peaks PQRST. For few signals (like 101 and 106 waveform from MIT-BIH), the noise level was very high, where only R detection was possible and other peaks were not distinguishable. Inverted T -waves were also detected with high accuracy. Cases of atrial fibrillation were not considered for testing as only R -peaks are present in the signal. Special cases of missed or merged P-waves were analysed separately by taking the relative positions of P, T and R-waves to avoid false P-detection.
## 5. CONCLUSION
Adaptive wavelet approach has provided an R-peak detection accuracy of 99.9% by making use of just 2 levels of resolution. Same accuracy of detection was obtained for both databases having different sampling rates. With the effective baseline correction and noise removal, other characteristic points viz P-Q-S-T were also detected with high accuracy.
The algorithm has not incorporated the automatic detection of atrial fibrillation (AF). The research can be extended to incorporate the automatic detection of AF. The research uses currently available databases, analysing real time signals and providing real time results will be the next challenge.
## 5. REFERENCES
- [1] Gari D. Clifford, Francisco Azuaje, Patrick E. McSharry, Advanced Methods and Tools for ECG Data Analysis
- [2] Jiapu Pan and Willis J. Tompkins, 'A Real-Time QRS Detection Algorithm, IEEE Transactions on Biomedical Engineering,' Vol. BME-32, No. 3, March 1985
- [3] M.L. Ahlstrom and W.J. Tompkins, 'Digital filters for real time ECG signal processing using microprocessors,' IEEE Trans. Biomed. Eng., vol. BME-32, no. 9, pp. 708-713, Sept. 1985.
- [4] G. Tremblay and A.R. LeBlanc, 'Near-optimal signal preprocessor for positive cardiac arrhythmia identification,' IEEE Trans. on Biomed. Engg., vol.32, no.2, pp.141-151, Feb. 1985.
- [5] Q. Xue, Y.H. Hu and W.J. Tompkins, 'Neural-network based adaptive matched filtering for QRS detection,' IEEE Trans. Biomed. Eng., vol. 39, no. 4, pp. 317-329, April 1992.
- [6] S. Suppappola and Sun Ying, 'Nonlinear transforms of ECG signals for digital QRS detection: a quantitative analysis,' IEEE Trans. Biomed. Eng., vol. 41, pp. 397-400, April 1994.
- [7] Yun-Chi Yeha,c, Wen-June Wang, ' QRS complexes detection for ECG signal: The Difference Operation Method,' computer methods and programs in biomedicine ( 2008 ) 245
[8] I.S.N. Murthy and G.S.S.D. Prasad, 'Analysis of ECG from pole-zero models,' IEEE Trans. on Biomed. Engg., vol.39,no.7, pp.741-751, July 1992
- [9] Hu YH, Tompkins WJ, Urrusti JL, Afonso VX., 'Applications of artificial neural networks for ECG signal detection and classification.,' J Electrocardiology. 1993; Suppl:66-73.
- [10] Y. Suzuki, 'Self-organizing QRS-wave recognition in ECG using neural networks,' IEEE Trans. Neural Networks, vol. 6, pp. 1469-1477, 1995.
- [11] R. Poli, S. Cagnoni and G. Valli, 'Genetic design of optimum linear and nonlinear QRS detectors,' IEEE Trans. Biomed. Eng., vol. 42, no. 11, pp. 1137-1141, Nov. 1995.
- [12] D.A. Coast, R.M. Stern, G.G. Cano and S.A. Briller, 'An Approach to Cardiac Arrhythmia Analysis Using Hidden Markov Models,' IEEE Transactions on Biomedical Engineering, vol. 37, no. 9, pp. 826-836, Sept. 1990.
- [13] Mehta SS, Lingayat NS., 'Detection of QRS complexes in electrocardiogram using support vector machine,' J Med Eng Technol. 2008 May-June;32(3):206-15.
- [14] M.Sabarimalai, Manikandana, K.P.Soman, 'A novel method for detecting R-peaks in electrocardiogram(ECG) signal,' Biomedical Signal Processing and Control (2011)
- [15] Cuiwei Li, Chongxun Zheng, and Changfeng Tai, 'Detection of ECG Characteristic Points using Wavelet Transforms,' IEEE Transactions on Biomedical Engineering, Vol. 42, No. 1, pp. 2128, 1995.
- [16] Kadambe S, Murray R and Boudreaux-Bartels G F, 'Wavelet transform-based QRS complex detector,' IEEE Trans. Biomed. Eng. 46 838-48, 1999
- [17] Martin´ez JP, Almeida R, Olmos S 'A Wavelet-Based ECG Delineator Evaluation on Standard Databases,' IEEE Trans Biomed Eng 2004; 51(4):570-581.
- [18] N. Sivannarayana, D. C. Reddy, 'Biorthogonal wavelet transforms ELSEVIER 1999; 21:167-174.
- [19] V. Di-Virgilio, C. Francaiancia, S. Lino, and S. Cerutti, 'ECG fiducial points detection through wavelet transform,' in 1995 IEEE Eng. Med. Biol. 17th Ann. Conf. 21st Canadian Med. Biol. Eng. Conf., Montreal, Quebec, Canada, 1997, pp. 1051-1052.
- [20] Romero Legarreta, PS Addison, N Grubb,GR Clegg, CE Robertson, KAA Fox , JN Watson, 'R-wave Detection Using Continuous Wavelet Modulus Maxima,' IEEE Computers in Cardiology 2003;30:565-568.
- [21] Senhadji L, Carrault G, Bellanger J J and Passariello G 'Comparing wavelet transforms for recognizing cardiac patterns,' IEEE Trans. Med. Biol. 13 167-73, 1995
- [22] Joseph O. Chapa and Raghuveer M. Rao 'Algorithms for Designing Wavelets to Match a Specified Signal,' IEEE transactions on signal processing, vol. 48, no. 12, December 2000
- [23] Akram Aldroubi, Patrice Abry, and Michael Unser 'Construction of Biorthogonal Wavelets Starting from Any Two Multiresolutions,' IEEE transactions on signal processing, vol. 46, no. 4, April 1998
- [24] Gupta, A. Joshi, S.D. Prasad, S. 'A new approach for estimation of statistically matched wavelet,' IEEE Transactions on Signal Processing,vol.53 no.5 May 2005
- [25] Wim Sweldens , Peter schroder 'Building Your Own Wavelets at Home,' Technical report Industrial Mathematics initiative. Department of Mathematics, University of South Carolina 1995.
- [26] Misiti, Y. Misiti, G. Oppenheim, J.M. Poggi, Hermes, "Les ondelettes et leurs applications,' M, 2003.
- [27] Abed Al Raoof Bsoul, Soo-Yeon Ji, Kevin Ward, and Kayvan Najarian, 'Detection of P, QRS, and T Components of ECG Using Wavelet Transformation,' Complex Medical Engineering, 2009 CME, ICME, International
- [28] V.S. Chouhan† and S.S. Mehta, 'Threshold-based Detection of P and T-wave in ECG using New Feature Signal,' IJCSNS International Journal of Computer Science and Network security, Vol.8 No.2, February 2008
- [29] P. Ranjith, P.C. Baby, P. Joseph, 'ECG analysis using wavelet transform: Application to Myocardial Ischemia Detection,' IRBM, Elsevier Volume 24, Issue 1, February 2003, Pages 44-47. [30] www.physionet.org/physiobank | 10.1109/ChinaSIP.2013.6625344 | [
"T. R. Gopalakrishnan Nair",
"A. P. Geetha",
"M. Asharani"
] | 2014-08-03T03:49:36+00:00 | 2014-08-03T03:49:36+00:00 | [
"cs.CV"
] | Adaptive Wavelet Based Identification and Extraction of PQRST Combination in Randomly Stretching ECG Sequence | Cardiovascular system study using ECG signals have evolved tremendously in
the domain of electronics and signal processing. However, there are certain
floating challenges unresolved in the analysis and detection of abnormal
performances of cardiovascular system. As the medical field is moving towards
more automated and intelligent systems, wrong detection or wrong
interpretations of ECG waveform of abnormal conditions can be quite fatal.
Since the PQRST signals vary their positions randomly, the process of locating,
identifying and classifying each feature can be cumbersome and it is prone to
errors. Here we present an automated scheme using adaptive wavelet to detect
prominent R-peak with extreme accuracy and algorithmically tag and mark the
coexisting peaks P, Q, S, and T with almost same accuracy. The adaptive wavelet
approach used in this scheme is capable of detecting R-peak in ECG with 99.99%
accuracy along with the rest of the waveforms. |
1408.0454v2 | ## Probing the Antisymmetric Fano Interference Assisted by a Majorana Fermion
- F. A. Dessotti , L. S. Ricco 1 1 , M. de Souza 2 , F. M. Souza , and A. C. Seridonio 3 1 2 ,
1 Departamento de F´ ısica e Qu´ ımica, Unesp - Univ Estadual Paulista, 15385-000, Ilha Solteira, SP, Brazil 2 IGCE, Unesp - Univ Estadual Paulista, Departamento de F´ ısica, 13506-900, Rio Claro, SP, Brazil 3
Instituto de F´ ısica, Universidade Federal de Uberlˆndia, 38400-902, Uberlˆndia, MG, Brazil a a
As the Fano effect is an interference phenomenon where tunneling paths compete for the electronic transport, it becomes a probe to catch fingerprints of Majorana fermions lying on condensed matter systems. In this work we benefit of this mechanism by proposing as a route for that an AharonovBohm-like interferometer composed by two quantum dots, being one of them coupled to a Majorana bound state, which is attached to one of the edges of a semi-infinite Kitaev wire within the topological phase. By changing the Fermi energy of the leads and the symmetric detuning of the levels for the dots, we show that opposing Fano regimes result in a transmittance characterized by distinct conducting and insulating regions, which are fingerprints of an isolated Majorana quasiparticle. Furthermore, we show that the maximum fluctuation of the transmittance as a function of the detuning is half for a semi-infinite wire, while it corresponds to the unity for a finite system. The setup proposed here constitutes an alternative experimental tool to detect Majorana excitations.
PACS numbers: 85.35.Be, 73.63.Kv, 85.25.Dq
## I. INTRODUCTION
In the field of high-energy Physics, Ettore Majorana proposed, almost a century ago, the existence of fermions that form their own antiparticles. In condensed matter Physics, such fermions emerge as quasiparticle excitations [1]. Remarkably, two distant Majorana quasiparticles can define a single nonlocal regular fermion, which provides a protected qubit, free of the environment and immune to the decoherence phenomenon. Such a bit thus can be considered as the fundamental unity for the achievement of a quantum computer. For this reason, in the last decade, the run for devices based on Majoranas started in the field of quantum information [2, 3]. In this scenario, the superconducting state is the most promising environment for the feasibility of Majorana fermions, in particular, the p -wave and spinless type.
The Kitaev wire within the topological phase [4] is an example, since Majorana fermions emerge as zero-energy modes bounded to the edges of such a system. From the experimental point of view, the realization of p -wave superconductivity can be performed by putting an s -wave superconductor close to a semiconducting nanowire with strong spin-orbit interaction placed perpendicular to a huge magnetic field. In such conditions, p -wave superconductivity is induced on the nanowire due to the socalled proximity effect [5-7].
In the context of quantum transport [8-19], in particular for a single quantum dot (QD) hybridized with a Majorana bound state (MBS), a zero-bias anomaly (ZBA) [11, 12] in the conductance is predicted to appear, given by G = 0 5 . G 0 , where G 0 = e /h 2 is the quantum of conductance. The ZBA has been observed experimentally in conductance measurements through a nanowire of indium antimonide merged to gold and niobium titanium nitride [16]. In this system, Majoranas are supposed to exist as a result of the ZBA that persists to large magnetic fields and gate voltages. Such a robustness of the
Figure 1. (Color online) Aharonov-Bohm-like interferometer with MBSs hosted by a Kitaev wire within the topological phase: two leads are coupled to two QDs hybridized with a MBS 1; the half-electron state is represented by the semisphere in the left side of the wire. The tunneling parameters between the QDs and the leads are V and the leadlead coupling is V BT . The symmetric detuning in the QDs is ∆ ε = ε 2 -ε , 1 where ε 1 = -∆ ε 2 and ε 2 = ∆ ε 2 represent the energy levels of the QDs. The coupling strength of the QD 1 with the MBS 1 is λ . ε M couples the MBS 1 to the MBS 2 (the semi-sphere in the right side of the wire). The bias ϕ of the setup approaches zero.
ZBA has also been observed in the setup of a superconductor of aluminium close to a nanowire of indium arsenide [17].
In this work we follow the strategy of electronic interferometry to probe signatures arising from Majorana fermions. To that end, the Fano interference [20] is the proper way to accomplish the aforementioned goal. As such a phenomenon is due to the competition between paths of itinerant electrons that travel directly through an energy continuum (an electronic reservoir of a metallic lead for instance) and those that are discrete as found within QDs, patterns of interference then record im-
prints of Majorana excitations on transmittance profiles. Thereby we explore the manifestation of the Fano effect in the quantum transport through an Aharonov-Bohmlike interferometer formed by two QDs [21, 22], in which one of them is coupled to a MBS hosted by a semi-infinite Kitaev wire within the topological phase.
By calculating the transmittance of this device, we have found that the Fano interference exhibits an antisymmetric feature: the Green's functions ˜ G d d j j and ˜ G d d j l for the QDs cannot be determined by the exchange of the indexes j ↔ l in ˜ G d d l l and ˜ G d d l j , respectively, with l, j = 1 ... 2 . We propose that such a feature can be captured experimentally by performing measurements of the zero-bias conductance as a function of the Fermi energy of the leads and the symmetric detuning ∆ ε = ε 2 -ε 1 in the QDs, where ε 1 = -∆ ε 2 and ε 2 = ∆ ε 2 represent the energy levels of the QDs [23]. As a result, contrasting Fano limits reveal distinct conducting and insulating regions, which are signatures of an isolated Majorana quasiparticle.
Moreover, we have determined that the symmetric Fano effect is recovered when electrons travel only through the QDs and the Fermi energy of the leads is in resonance with the Majorana zero mode. As a consequence, the transmittance as a function of the symmetric detuning exhibits a maximum fluctuation of half for the semi-infinite Kitaev wire, contrasting with the unity variation observed in the case of a finite system. In the former situation, the maximum fluctuation of the transmittance is halved due to the half fermion nature of the isolated MBS, while the latter represents the situation where two MBSs displaced far apart are coupled and thus forming a nonlocal Dirac fermion delocalized over the wire edges.
This paper is organized as follows: in Sec. II we develop the theoretical model for the system sketched in Fig. 1 by deriving the expression for the transmittance through such a device and the Green's functions of the QDs. The results are present in Sec. III and in Sec. IV, we summarize our concluding remarks.
## II. THE MODEL
In order to mimic the system outlined in Fig. 1, we employ the Hamiltonian proposed by Liu et al. [11], taking two QDs into account,
$$\mathcal { H } & = \sum _ { \alpha k } \tilde { \varepsilon } _ { \alpha k } c _ { \alpha k } ^ { \dagger } c _ { \alpha k } + \sum _ { j } \varepsilon _ { j } d _ { j } ^ { \dagger } d _ { j } + V \sum _ { \alpha k j } ( c _ { \alpha k } ^ { \dagger } d _ { j } + \text{H.c.} ) \\ & + V _ { B T } \sum _ { k p } ( c _ { B k } ^ { \dagger } c _ { T p } + \text{H.c.} ) + \mathcal { H } _ { \text{MBSs} }, \quad ( 1 ) \quad \text{where}$$
where the electrons in the lead α = B,T (bottom/top) are described by the operator c † αk ( c αk ) for the creation (annihilation) of an electron in a quantum state labeled by the wave number k and energy ˜ ε αk = ε k -µ α , with µ α as the chemical potential. Here we adopt the gauge µ B =
∆ µ and µ T = -∆ , with µ µ B -µ T = 2∆ µ = eϕ as the bias between the leads, being e > 0 the electron charge and ϕ the bias-voltage. For the QDs, d † j ( d j ) creates (annihilates) an electron in the state ε j , with j = 1 2. , V is the hybridization of the QDs with the leads, V BT is the lead-lead coupling and
$$\mathcal { H } _ { \text{MBSs} } = i \varepsilon _ { M } \Psi _ { 1 } \Psi _ { 2 } + \lambda ( d _ { 1 } - d _ { 1 } ^ { \dagger } ) \Psi _ { 1 } \quad \ \ ( 2 )$$
for the Kitaev wire within the topological phase. In particular for j = 1, the QD 1 is coupled to the MBS 1 described by the operator Ψ † 1 = Ψ . 1 The strength of this coupling is λ . The MBS 2 given by Ψ † 2 = Ψ 2 is connected to the MBS 1 via the coefficient ε M ∼ e -L/ξ , with L as the distance between the MBSs and ξ as a coherence length. In what follows we derive the Landauer-B¨ttiker u formula for the zero-bias conductance G [24]. Such a quantity is a function of the transmittance T ( ε ) as follows:
$$G = \frac { e ^ { 2 } } { h } \int d \varepsilon \left ( - \frac { \partial f _ { F } } { \partial \varepsilon } \right ) \mathcal { T } ( \varepsilon ). \quad \quad ( 3 )$$
We begin with the transformations c Bk = 1 √ 2 ( c ek + c ok ) and c Tk = 1 √ 2 ( c ek -c ok ) on the Hamiltonian of Eq. (1), which depends on the even and odd conduction operators c ek and c ok , respectively. These definitions allow us to express Eq. (1) as H = H e + H o + ˜ H tun = H ϕ =0 + ˜ H tun , where
$$\stackrel { \sim } { \text{user} } \quad \text{ where } \\ \text{ie sit} _ { \text{uled} } \quad \mathcal { H } _ { e } & = \sum _ { k } \varepsilon _ { k } c _ { e k } ^ { \dagger } c _ { e k } + \sum _ { j } \varepsilon _ { j } d _ { j } ^ { \dagger } d _ { j } + \sqrt { 2 } V \sum _ { j k } ( c _ { e k } ^ { \dagger } d _ { j } + \text{H.c.} ) \\ \text{ice de} _ { \text{$\mathbb{ }$\mathbb{ }$\mathbb{ }$\mathbb{ }$\mathbb{ }$\mathbb{ }$\mathbb{ }$\mathbb{ }$\mathbb{ }$\mathbb{ }$\mathbb{ }$\mathbb{ }$\mathbb{ }$\mathbb{ }$\mathbb{ }$\mathbb{ }$\mathbb{ }$\mathbb{ }$\mathbb{ }$\mathbb{ }$\mathbb{ }$\mathbb{ }$\mathbb{ }$\mathbb{ }$\mathbb{ }$\mathbb{ }$\mathbb{ }$\mathbb{ }$\mathbb{ }$\mathbb{ }$\mathbb{ }$\mathbb{ }$\mathbb{ }$\mathbb{ }$ \mathbb{ }$\mathbb{ }$\mathbb{ }$\mathbb{ }$\mathbb{ }$\mathbb{ }$\mathbb{ }$\mathbb{ }$\mathbb{ }$\mathbb{ }$\mathbb{ }$\mathbb{ }$\mathbb{ }$\mathbb{ }$\mathbb{ }$\mathbb{ }$\mathbb{ }$\mathbb{ }$\mathbb{ }$\mathbb{ }$\mathbb{ }$\mathbb{ }$\mathbb{ }$\mathbb{ }$\mathbb{ }$\mathbb{ }$\mathbb{ }$\mathbb{ }$\mathbb{ }$\mathbb{ }$\mathbb{ }$\mathbb{ }$\mathbb{ }$\mathBB{ }$\mathbb{ }$\mathbb{ }$\mathbb{ }$\mathbb{ }$\mathbb{ }$\mathbb{ }$\mathbb{ }$\mathbb{ }$\mathbb{ }$\mathbb{ }$\mathbb{ }$\mathbb{ }$\mathbb{ }$\mathbb{ }$\mathbb{ }$\mathbb{ }$\mathbb{ }$\mathbb{ }$\mathbb{ }$\mathbb{ }$\mathbb{ }$\mathbb{ }$\mathbb{ }$\mathbb{ }$\mathbb{ }$\mathbb{ }$\mathbb{ }$\mathbb{ }$\mathbb{ }$\mathbb{ }$\mathbb{ }$\mathbb{ }$\mathbb{ \end{ \quad \text{$\mathbb{ }$\mathbb{ }$\mathbb{ }$\mathbb{ }$\mathbb{ }$\mathbb{ }$\mathbb{ }$\mathbb{ }$\mathbb{ }$\mathbb{ }$\mathbb{ }$\mathbb{ }$\mathbb{ }$\mathbb{ }$\mathbb{ }$\mathbb{ }$\mathbb{ }$\mathbb{ }$\mathbb{ }$\mathbb{ }$\mathbb{ }$\mathbb{ }$\mathbb{ }$\mathbb{ }$\mathbb{ }$\mathbb{ }$\mathbb{ }$\mathbb{ }$\mathbb{ }$\mathbb{ }$\mathbb{ }$\mathbb{ }$\mathbb{\ }$\mathbb{ }$\mathbb{ }$\mathbb{ }$\mathbb{ }$\mathbb{ }$\mathbb{ }$\mathbb{ }$\mathbb{ }$\mathbb{ }$\mathbb{ }$\mathbb{ }$\mathbb{ }$\mathbb{ }$\mathbb{ }$\mathbb{ }$\mathbb{ }$\mathbb{ }$\mathbb{ }$\mathbb{ }$\mathbb{ }$\mathbb{ }$\mathbb{ }$\mathbb{ }$\mathbb{ }$\mathbb{ }$\mathbb{ }$\mathbb{ }$\mathbb{ }$\mathbb{ }$\mathbb{ }$\mathbb{ }$\mathbb{ }$\mathbb{ }$, \quad \text{$\mathbb{ }$\mathbb{ }$\mathbb{ }$\mathbb{ }$\mathbb{ }$\mathbb{ }$\mathbb{ }$\mathbb{ }$\mathbb{ }$\mathbb{ }$\mathbb{ }$\mathbb{ }$\mathbb{ }$\mathbb{ }$\mathbb{ }$\mathbb{ }$\mathbb{ }$\mathbb{ }$\mathbb{ }$\mathbb{ }$\mathbb{ }$\mathbb{ }$\mathbb{ }$\mathbb{ }$\mathbb{ }$\mathbb{ }$\mathbb{ }$\mathbb{ }$\mathbb{ }$\mathbb{ }$\mathbb{ }$\mathbb{ }$\text{ \quad \text{$\mathbb{ }$\mathbb{ }$\mathbb{ }$\mathbb{ }$\mathbb{ }$\mathbb{ }$\mathbb{ }$\mathbb{ }$\mathbb{ }$\mathbb{ }$\mathbb{ }$\mathbb{ }$\mathbb{ }$\mathbb{ }$\mathbb{ }$\mathbb{ }$\mathbb{ }$\mathbb{ }$\mathbb{ }$\mathbb{ }$\mathbb{ }$\mathbb{ }$\mathbb{ }$\mathbb{ }$\mathbb{ }$\mathbb{ }$\mathbb{ }$\mathbb{ }$\mathbb{ }$\mathbb{ }$\mathbb{ }$\mathbb{ }$\extract \colon = \text{$\mathbb{ }$\mathbb{ }$\mathbb{ }$\mathbb{ }$\mathbb{ }$\mathbb{ }$\mathbb{ }$\mathbb{ }$\mathbb{ }$\mathbb{ }$\mathbb{ }$\mathbb{ }$\mathbb{ }$\mathbb{ }$\mathbb{ }$\mathbb{ }$\mathbb{ }$\mathbb{ }$\mathbb{ }$\mathbb{ }$\mathbb{ }$\mathbb{ }$\mathbb{ }$\mathbb{ }$\mathbb{ }$\mathbb{ }$\mathbb{ }$\mathbb{ }$\mathbb{ }$\mathbb{ }$\mathbb{ }$\mathbb{ }$\mathbb
\text{$\mathbb{ }$\text{$\mathbb{ }$\text{$\mathbb{ }$\text{$\mathbb{ }$\text{$\mathbb{ }$\text{ \text{$\mathbb{ }$\text{ \text{$\mathbb{ }$\text$ }
$\mathbb{ }$$
represents the Hamiltonian part of the system coupled to the QDs via an effective hybridization √ 2 V , while
$$\mathcal { H } _ { o } = \sum _ { k } \varepsilon _ { k } c _ { o k } ^ { \dagger } c _ { o k } - V _ { B T } \sum _ { k p } c _ { o k } ^ { \dagger } c _ { o p } \quad \quad ( 5 )$$
is the decoupled one. However, they are connected to each other by the tunneling Hamiltonian ˜ H tun = -∆ µ ∑ k ( c † ek c ok + c † ok c ek ) .
As in the zero-bias regime ∆ µ → 0, due to ϕ → 0, ˜ H tun is a perturbative term and the linear response theory ensures that
$$\mathcal { T } \left ( \varepsilon \right ) = ( 2 \pi V _ { B T } ) ^ { 2 } \tilde { \rho } _ { e } ( \varepsilon ) \tilde { \rho } _ { o } ( \varepsilon ), \text{ \quad \ \ } \text{(6)}$$
where ˜ ( ) = ρ e ε -1 π Im ( ˜ G ψ ψ e e ) is the local density of states (LDOS) for the Hamiltonian of Eq. (4) and
$$\mathcal { G } _ { \Psi _ { e } \Psi _ { e } } = - \frac { i } { \hbar } \theta \left ( t \right ) \text{Tr} \{ \varrho _ { e } [ \Psi _ { e } \left ( t \right ), \Psi _ { e } ^ { \dagger } \left ( 0 \right ) ] _ { + } \} \quad \left ( 7 \right )$$
gives the retarded Green's function in the time domain t , where θ t ( ) is the Heaviside step function, glyph[rho1] e is the density-matrix for Eq. (4), Ψ e = f e + ( π ∆ ρ 0 ) 1 / 2 q ∑ j d j
is a field operator, with f e = ∑ p c ep , the Anderson parameter ∆ = 2 πV 2 ρ 0 and q = ( πρ 0 ∆) -1 / 2 ( √ 2 V 2 V BT ) .
To calculate Eq. (7) in the energy domain ε , we should employ the equation-of-motion (EOM) method [24, 25] summarized as follows
$$( \varepsilon + i 0 ^ { + } ) \tilde { \mathcal { G } } _ { \mathcal { A B } } = [ \mathcal { A }, \mathcal { B } ^ { \dagger } ] _ { + } + \tilde { \mathcal { G } } _ { [ \mathcal { A }, \mathcal { H } _ { i } ] \mathcal { B } } \quad \ ( 8 ) \quad \ \frac { \cdot \cdot \cdot } { \lambda ^ { \prime } }$$
for the retarded Green's function ˜ G AB , with A and B as fermionic operators belonging to the Hamiltonian H i . By considering A = B = Ψ e and H i = H e , we find
$$\tilde { \mathcal { G } } _ { \Psi _ { e } \Psi _ { e } } & = \tilde { \mathcal { G } } _ { f _ { e } f _ { e } } + ( \pi \rho _ { 0 } \Delta ) q ^ { 2 } \sum _ { j l } \tilde { \mathcal { G } } _ { d _ { j } d _ { l } } + 2 ( \pi \rho _ { 0 } \Delta ) ^ { 1 / 2 } q \\ & \times \sum _ { j } \tilde { \mathcal { G } } _ { d _ { j } f _ { e } }. & ( 9 ) \quad \text{Dirac} \\ & \Psi _ { 2 } =$$
From Eqs. (4), (8) with A = B = f e and (9), we obtain
$$\tilde { \mathcal { G } } _ { f _ { e } f _ { e } } & = \frac { \pi \rho _ { 0 } ( \bar { q } - i ) } { 1 - \sqrt { x } ( \bar { q } - i ) } + \pi \rho _ { 0 } \Delta \left [ \frac { ( \bar { q } - i ) } { 1 - \sqrt { x } ( \bar { q } - i ) } \right ] ^ { 2 } \\ & \times \sum _ { j l } \tilde { \mathcal { G } } _ { d _ { j } d _ { l } } \left ( \varepsilon \right ) & ( 1 0 )$$
and the mixed Green's function
$$\tilde { \mathcal { G } } _ { d _ { j } f _ { e } } = \sqrt { \pi \Delta \rho _ { 0 } } \frac { ( \bar { q } - i ) } { 1 - \sqrt { x } ( \bar { q } - i ) } \sum _ { l } \tilde { \mathcal { G } } _ { d _ { j } d _ { l } }, \quad ( 1 1 ) \quad \text{ and }$$
determined from Eq. (8) by considering A = d j , B = f e and H i = H e , with the parameter x = ( πρ V 0 BT ) 2 and ¯ = q 1 πρ 0 ∑ k ε 1 -ε k .
Additionally, for the Hamiltonian of Eq. (5) we have the LDOS ˜ ( ) = ρ o ε -1 π Im ( ˜ G f o f o ) , with
$$\mathcal { G } _ { f _ { o } f _ { o } } = - \frac { i } { \hbar } \theta \left ( t \right ) \text{Tr} \{ \varrho _ { o } [ f _ { o } \left ( t \right ), f _ { o } ^ { \dagger } \left ( 0 \right ) ] _ { + } \} \quad \left ( 1 2 \right ) \quad \text{the } \colon$$
and f o = ∑ ˜ q c oq ˜ . We notice that ˜ G f o f o is decoupled from the QDs. Thereby, from Eqs. (5) and (12), we take A = B = f o and H i = H o in Eq. (8) and we obtain
$$\tilde { \mathcal { G } } _ { f _ { o } f _ { o } } = \frac { \pi \rho _ { 0 } ( \bar { q } - i ) } { 1 + \sqrt { x } ( \bar { q } - i ) }. \quad \quad ( 1 3 )$$
Thus the substitution of Eqs. (9), (11), and (13) in Eq. (6), leads to
$$\mathcal { T } \left ( \varepsilon \right ) & = \mathcal { T } _ { b } + \sqrt { \mathcal { T } _ { b } \mathcal { R } _ { b } } \tilde { \Delta } \sum _ { j \tilde { j } } \text{Re} \{ \tilde { \mathcal { G } } _ { d _ { j } d _ { \tilde { j } } } \left ( \varepsilon \right ) \} \quad \text{ as t} \\ & - \left ( 1 - 2 \mathcal { T } _ { b } \right ) \frac { \tilde { \Delta } } { 2 } \sum _ { j \tilde { j } } \text{Im} \{ \tilde { \mathcal { G } } _ { d _ { j } d _ { \tilde { j } } } \left ( \varepsilon \right ) \}, \quad \text{ (14)}$$
where ∆ = ˜ ∆ 1+ x is an effective dot-lead coupling, T b = 4 x (1+ x ) 2 represents the background transmittance and
R b = 1 - T b = (1 -x ) 2 (1+ x ) 2 is the corresponding reflectance, both in the absence of the QDs and MBSs.
We emphasize that Eq.(14) is the generalization of Eq. (2) found in Ref. [26] for an Aharonov-Bohm-like device of a single QD, but without an applied magnetic field. Yet, in Ref. [26] the authors introduce q b = √ R b T b = (1 -x ) 2 √ x as the Fano parameter. Here we focus on two cases: the case q b →∞ , which we call by regime of weak coupling lead-lead due to the background transmittance T b = 0, and the strong coupling limit q b = 0 characterized by T b = 1.
glyph[negationslash]
We calculate the Green's functions ˜ G d d j l within the wide-band limit. To obtain them, we first express the Majorana operators Ψ 1 and Ψ 2 in terms of a nonlocal Dirac fermion state η as follows: Ψ 1 = 1 √ 2 ( η † + η ) and Ψ 2 = i 1 √ 2 ( η † -η , ) with η = η † and { η, η † } = 1. We verify that Eq. (2) transforms into
$$\mathcal { H } _ { \text{MBS} s } & = \varepsilon _ { M } ( \eta ^ { \dagger } \eta - \frac { 1 } { 2 } ) + \frac { \lambda } { \sqrt { 2 } } ( d _ { 1 } \eta ^ { \dagger } + \eta d _ { 1 } ^ { \dagger } ) \\ & + \frac { \lambda } { \sqrt { 2 } } ( d _ { 1 } \eta - d _ { 1 } ^ { \dagger } \eta ^ { \dagger } ).$$
By applying the EOM on
$$\mathcal { G } _ { d _ { j } d _ { l } } = - \frac { i } { \hbar } \theta \left ( t \right ) \text{Tr} \{ \varrho _ { \text{e} } [ d _ { j } \left ( t \right ), d _ { l } ^ { \dagger } \left ( 0 \right ) ] _ { + } \}, \quad \left ( 1 6 \right )$$
and changing to the energy domain ε , we obtain the following relation:
glyph[negationslash]
$$\underset { \text{leave} } { \text{aau} } ( \varepsilon - \varepsilon _ { j } - \Sigma - \delta _ { j 1 } \Sigma _ { \text{MBS1} } ) \tilde { \mathcal { G } } _ { d _ { j } d _ { l } } = \delta _ { j l } + \Sigma \sum _ { \tilde { l } \neq j } \tilde { \mathcal { G } } _ { d _ { l } d _ { l } }, \ ( 1 7 )$$
with Σ = -( √ x + ) i 1+ x ∆ and Σ MBS1 = λ K 2 (1 + λ K 2 ˜ ) as the self-energy due to the MBS 1 coupled to the QD 1, K = 1 2 ( 1 ε -ε M + 0 i + + 1 ε + ε M + 0 i + ) and ˜ K = K ε + ε 1 +¯ Σ -λ K 2 have the same forms as found in Ref. [11], where Σ is the ¯ complex conjugate of Σ. Thus the solution of Eq. (17) provides
$$\tilde { \mathcal { G } } _ { d _ { 1 } d _ { 1 } } = \frac { 1 } { \varepsilon - \varepsilon _ { 1 } - \Sigma - \Sigma _ { \text{MBS1} } - \mathcal { C } _ { 2 } }$$
as the Green's function of the QD 1, with C j = Σ 2 ε -ε j -Σ as the self-energy due to the presence of the j th QD.
For C 2 = 0, we highlight that Eq. (18) is reduced to the Green's function of the single QD system found in Ref. [11]. In the case of the QD 2, we have
$$\tilde { \mathcal { G } } _ { d _ { 2 } d _ { 2 } } = \frac { 1 - \tilde { \mathcal { G } } _ { d _ { 1 } d _ { 1 } } ^ { 0 } \Sigma _ { \text{MBS1} } } { \varepsilon - \varepsilon _ { 2 } - \Sigma - \frac { \tilde { \mathcal { G } } _ { d _ { 1 } d _ { 1 } } ^ { 0 } } { \tilde { \mathcal { G } } _ { d _ { 2 } d _ { 2 } } ^ { 0 } } \Sigma _ { \text{MBS1} } - \mathcal { C } _ { 1 } }, \quad ( 1 9 )$$
where ˜ G 0 d d 1 1 = 1 ( / ε -ε 1 -Σ) and ˜ G 0 d d 2 2 = 1 ( / ε -ε 2 -Σ) represent the corresponding Green's functions for the single QD system without Majoranas. The mixed Green's functions are
$$\tilde { \mathcal { G } } _ { d _ { 2 } d _ { 1 } } = \frac { \Sigma } { \varepsilon - \varepsilon _ { 2 } - \Sigma } \tilde { \mathcal { G } } _ { d _ { 1 } d _ { 1 } } \quad \quad ( 2 0 ) \quad \begin{pmatrix} 0 \\ 0 \\ 0 \end{pmatrix}$$
and
$$\tilde { \mathcal { G } } _ { d _ { 1 } d _ { 2 } } = \frac { \Sigma } { \varepsilon - \varepsilon _ { 1 } - \Sigma - \Sigma _ { \text{MBS1} } } \tilde { \mathcal { G } } _ { d _ { 2 } d _ { 2 } }. \quad \ ( 2 1 )$$
glyph[negationslash]
By inspecting Eqs. (18), (19), (20) and (21), we verify that the functions ˜ G d d 1 1 and ˜ G d d 1 2 can be found by the exchange of the indexes 1 ↔ 2 in ˜ G d d 2 2 and ˜ G d d 2 1 , respectively, just in the case of Σ MBS1 = 0 . Nevertheless, in the opposite situation, namely for Σ MBS1 = 0, this symmetry is not verified, which corresponds to the Kitaev wire coupled to the interferometer as outlined in Fig. 1.
Following Ref. [11], we compare the aforementioned symmetry breaking with the one that arises from a Regular Fermionic (RF) zero mode attached to the interferometer instead of the MBS 1. In such a case, one can show that Σ MBS1 is replaced by Σ RF = λ 2 ε + 0 i + in the Green's functions above. Thus the comparison proposed will allow us to isolate exclusively Majorana signatures from those due to a standard QD side-coupled to the interferometer.
It is worth mentioning that the Green's functions for the QDs derived in this work are exact as expected since the Hamiltonian of Eq. (1) is quadratic. From the experimental point of view this feature can be feasible by keeping the two QDs far apart in such a way that the interdots Coulomb repulsion U becomes negligible to ensure the applicability of the present approach, otherwise the term Ud d d d † 1 1 † 2 2 should be added to Eq. (1). In this situation, an interacting self-energy Σ U enters in the Green's functions and leads to a dephasing rate -Im(Σ U ) / glyph[planckover2pi1] that competes with -Im(Σ) / glyph[planckover2pi1] , -Im(Σ MBS1 ) / glyph[planckover2pi1] and -Im( C j ) / glyph[planckover2pi1] . Particularly if U is relevant in the regime of extremely low temperatures, it will be possible to induce a Kondo effect [27] and a ZBA determined by the interplay between such a phenomenon and the Majorana zero mode should appear. To avoid the emergence of the Kondo resonance in the ZBA of the transmittance we thereby assume two QDs far apart to fulfill the assumption U = 0.
## III. RESULTS AND DISCUSSION
Below we investigate the antisymmetric feature of the Green's functions by employing the expression for the transmittance (Eq. (14)) with λ = 4∆ in the case of the Kitaev wire coupled to the interferometer. By varying ε in Eq. (14), the transmittance T becomes a function of the Fermi energy ε = µ T = µ B of the leads [9, 10]. According to Eq. (3), this transmittance can be obtained experimentally via the conductance G in units of G 0 = e /h 2
Figure 2. (Color online) Density plot of the transmittance (Eq. (14)) as a function of the symmetric detuning ∆ ε for the QDs and the Fermi energy ε in units of ∆ within the Fano regime x = 0 ( q b → ∞ ): (a) The Aharonov-Bohm-like interferometer is decoupled from the Kitaev wire leading to a symmetric Fano effect. (b) The interferometer is hybridized with a semi-infinite Kitaev wire via the QD 1: the Fano effect is antisymmetric. The central structure at ε = 0 gives the ZBA due to the MBS 1. In both panels the orange color denote a perfect insulating behavior.
for temperatures T → 0 just by attaching gate voltages to the metallic leads in order to tune the Fermi level. Additionally, we estimate the symmetric detuning ∆ ε, the Fermi energy ε and ε M in units of the Anderson parameter ∆ .
In Fig. 2, the density plot of the transmittance is presented as a function of the symmetric detuning ∆ ε and the Fermi level ε for the Fano regime x = 0 ( q b → ∞ ). The panel (a) exhibits the situation in which the Kitaev wire is decoupled from the interferometer, thus leading to the symmetric Fano interference arising from symmetric Green's functions by the permutation of the indexes in the parameters of the QDs. As a result, the density plot is characterized by specular regions with respect to the dotted-black line labeled as symmetry line.
On the other hand, for a semi-infinite Kitaev wire ( ε M = 10 -7 ) attached to the interferometer, the specular feature is not observed as the aftermath of the Green's functions ˜ G d d j j and ˜ G d d j l for the QDs, which cannot be determined by the exchange of the indexes j ↔ l in ˜ G d d l l and ˜ G d d l j , respectively, with l, j = 1 ... 2 . Such a hallmark is shown in the panel (b) of Fig. 2, where we clearly visualize the distortion of the pattern found in panel (a): the antisymmetric Fano effect for the limit x = 0 ( q b →∞ ) assisted by the isolated MBS 1 can be recognized by the current antisymmetric pattern of (b). In the latter, the central region is the ZBA due to the MBS 1, which occurs for ε = 0 and any value of ∆ . ε
Fig. 3 exhibits the opposite Fano regime, which is determined by x = 1 ( q b = 0) . In this limit, the tunneling of electrons through the leads is dominant with respect to that via the QDs. In panel (a) of Fig. 3 for the Kitaev wire removed, we observe the specular feature as the corresponding found in Fig. 2(a), but with the regime of
Figure 3. (Color online) Density plot of the transmittance (Eq. (14)) as a function of the symmetric detuning ∆ ε for the QDs and the Fermi energy ε in units of ∆ for the opposite Fano regime x = 1 ( q b = 0): the central structure at ε = 0 gives the reversed ZBA due to the MBS 1. In panels (a) and (b) the red regions denote a perfect conducting behavior, which is the reversed of that found in Fig. 2.
Figure 4. (Color online) Density plot of the transmittance (Eq. (14)) as a function of the symmetric detuning ∆ ε for the QDs and the Fermi energy ε in units of ∆ for a RF zero mode coupled to the interferometer in opposite Fano regimes: (a) x = 0 ( q b →∞ ) and (b) x = 1 ( q b = 0) .
interference reversed: note that the orange color regions become replaced by the red type. This swap indicates that a perfect insulating behavior changes to a conducting one as pointed out in Fig. 3(a).
In the presence of a semi-infinite Kitaev wire, the reversed pattern of Fig. 2(b) is given by Fig. 3(b), where the antisymmetric Fano effect manifests itself via the antisymmetric upper and lower parts of this figure. As a result, the difference between panels (a) and (b) of Figs. 2 and 3 reveals that the emergence of new insulating and conduction regions with respect to those found in panels (a) of both figures can be considered as fingerprints of an isolated MBS. Additionally, the ZBA due to the MBS 1 is also reversed. It is worth mentioning that the remaining diagonals in Figs. 2(b) and 3(b) are due to the QD 2, which even decoupled from the MBS 1 is still sensitive to it as Eq. (19) ensures via the self-energy Σ MBS1 = λ K 2 (1 + λ K . 2 ˜ ) As we can notice, such a de-
Figure 5. (Color online) Transmittance of Eq. (14) as a function of the symmetric detuning ∆ ε with Fermi energy ε = 0 in units of ∆ within the symmetric Fano regime x = 0 for different lengths L of the Kitaev wire given by the parameter ε M ∼ e -L/ξ in Eq. (2) as well as for the case of a RF zero mode.
pendence yields a slight change in the slopes of these diagonals with respect to those observed in Figs. 2(a) and 3(a) obtained with Σ MBS1 = 0 .
Fig. 4 shows the analysis of the transmittance for the Fano limits x = 0 and x = 1 in the case of a RF zero mode coupled to the interferometer via QD 1. As we can verify, the symmetry breaking is distinct with respect to that observed in the situation of a Kitaev wire present: the patterns of Figs. 2(b) and 3(b) do not match with those found in Figs. 4(a) and (b), respectively. Consequently, this difference ensures that the patterns of Figs. 2(b) and 3(b) constitute robust signatures due to an isolated MBS. In which concerns on the remaining diagonals of the QD 2 for the RF zero mode, the change in the slopes are weaker than for the MBS 1, since in the RF situation the self-energy Σ RF is just proportional to λ . 2
In Fig. 5, we present the transmittance through the interferometer for the leads in resonance with the MBS 1 for the case of weak coupling lead-lead characterized by x = 0 ( q b → ∞ ). This regime corresponds to the situation whereby electrons travel exclusively via the QDs, which are also in resonance with the MBS 1. Two distinct wire lengths are analyzed: (i) the semi-infinite Kitaev wire and (ii), the case of a finite system. For the setup (i) given by ε M = 10 -7 , it is possible to notice in the red lineshape that the transmittance approaches half for | ∆ ε | → ∞ , while it evolves towards the unity in the limit | ∆ ε | → 0.
The unitary value of the transmittance occurs for the QDs in resonance with the MBS 1 (∆ ε = 0), thus leading to the maximum transmittance, since the two QDs and the MBS 1 allow a perfect resonant tunneling through the Fermi level of the leads. Away from ∆ ε = 0 , the transmittance becomes half the unity as a result of the isolated MBS 1, which is a half-electron state (see the semi-sphere in the left side of the Kitaev wire of Fig. 1) and the only piece of the system in resonance with the Fermi level of the leads. For 0 < | ∆ ε | < ∞ , the resonant
Transmittance
Transmittance
Figure 6. (Color online) Transmittance determined by Eq. (14) as a function of the Fermi energy ε in units of ∆ in the Fano regime x = 0 ( q b →∞ ) for the double QD setup of Fig. 1 with ε M = 10 -7 . In panel (a) we use ∆ ε = 8∆: the solid-green lineshape is for the situation of the MBS 1 present, while the blue curve corresponds to the free interferometer in which the Kitaev wire is absent. Panel (b): for the reversed detuning ∆ ε = -8∆ only the pronounced satellite , peaks of the QDs in the free case (solid-blue lineshape) and the ZBA in the solid-red lineshape remain placed at the same positions with respect to those found in panel (a). In both panels a Majorana peak (ZBA) rises characterized by an amplitude nearby 1 / 2. Such a central structure is robust against the gates swap in contrast to the pronounced satellite peaks of the QDs when the Kitaev wire is side-coupled to one of these dots.
tunneling due to the QDs is not perfect and the transmittance stays within the range 1 / 2 < T < 1 . For the setup (ii), an unitary fluctuation in the transmittance as a function of ∆ ε emerges in opposite to the value of half observed in the system (i): see the curves given by the blue and green colors, respectively for ε M = 10 -3 and ε M = 10 -2 . In both profiles, we verify that the transmittance reaches the unity for ∆ ε = 0 , but it vanishes as we increase | ∆ ε . |
The variation of the maximum value of the transmittance has a simple physical origin: it arises from the presence of the MBS 2 (see the semi-sphere in the right side of the Kitaev wire of Fig. 1), which combines with the MBS 1 in order to form the regular and delocalized fermionic state η as Eq. (15) shows. Such a regular fermion adds an extra factor of half to the fluctuation of T and provides the unitary suppression of the trans- mittance for | ∆ ε | →∞ . Additionally, the bigger ε M the shorter the length of the Kitaev wire according to the term ε M ∼ e -L/ξ in Eq. (2) and sharper the widths of the profiles of the transmittance as a function of ∆ ε (notice that the green line is sharper than the corresponding blue one).
In situations (i) and (ii), the Fano effect is symmetric since the left and right sides of Fig. 5 are specular. We also show in Fig. 5 the interferometer hybridized with a RF zero mode instead of a MBS 1. Such a curve is given by the black-circle lineshape, in which we can notice that the fluctuation of the transmittance is still one as expected from the regular nature of the electronic state of the QD. However, the width of the resonance differs from those found in the finite wires analyzed as the aftermath of the functional form of the self-energy Σ RF , which is size independent in opposite to Σ MBS1 .
In Fig. 6 we analyze the profiles of the transmittance as a function of the Fermi energy for fixed detunings ∆ ε within the Fano limit x = 0 ( q b → ∞ ) in the situations of the semi-infinite Kitaev wire ( ε M = 10 -7 ) present and absent. To that end we account two distinct scenarios: (a) ∆ ε > 0 and (b) ∆ ε < 0 . The features of the former are printed in panel (a) where we can clearly visualize a couple of pronounced satellite peaks both in the solid-blue and green lineshapes, which are due to the imposed detuning ∆ ε = 8∆ for the QDs. Note that in the MBS 1 case (solid-green lineshape) the detuning is bigger than that observed in the free case (solid-blue lineshape of panel (a)) as expected due to the renormalization of the level ε 1 = -4∆ of the QD 1 hybridized with the Kitaev wire, since the QD 2 with ε 2 = 4∆ is decoupled from it as outlined in Fig. 1. For panel (b) in which ∆ ε = -8∆, the positions of the pronounced satellite peaks in the transmittance for the free interferometer (blue curve) as well as that of the ZBA in the solid-red lineshape (MBS 1 case) persist as those observed in panel (a). On the other hand, the pronounced satellite peaks in presence of the MBS 1 (red curve) do not as a result of the symmetry-breaking feature previously discussed for the system Green's functions. We stress that the ZBA is then immune against the swapping of gates thus revealing the robustness of the MBS 1, being characterized by a transmittance amplitude close to 1 / 2.
Fig. 7 contrasts the transmittance patterns of Fig. 6. The Fano regime x = 1 ( q b = 0) replaces the resonances in Fig. 6 by the antiresonances of Fig. 7 as can be seen in panels (a) and (b) of the same figure. Thus the ZBA is a Majorana dip that drops to above or below 1 / 2 depending on the sign of ∆ ε. A detailed discussion on the mechanism of such a fluctuation is addressed in Ref. [13] for an analogous Scanning Tunneling Microscope system. To remove this instability of the Majorana fingerprint the QD 2 should be discarded by keeping ε M = 10 -7 as shown in Fig. 8(a) and (b): in the single QD setup the dip of the transmittance stabilizes at 1 / 2 both for ε 1 = -4∆ and ε 1 = 4∆. The independence of this hallmark with the gate voltage for a single QD also occurs in the oppo-
Transmittance
Figure 7. (Color online) Transmittance determined by Eq. (14) as a function of the Fermi energy ε in units of ∆ in the Fano regime x = 1 ( q b = 0) for the double QD setup of Fig. 1 with ε M = 10 -7 . Panels (a) and (b): reversed patterns of panels (a) and (b) of Fig. 6.
site Fano limit x = 0 ( q b →∞ ) as widely treated in Ref. [12].
Additionally, we can conclude from Fig. 8 that the single QD setup avoids the manifestation of the symmetrybreaking feature in the system Green's functions, which are present in the double QD version of the interferometer as we have demonstrated in this work. Thus the methodology proposed here to pursuit Majorana bound states is not feasible by considering only one dot: the employment of a couple of QDs allows us to explore how the aforementioned symmetry is broken in distinct scenarios as those with a free interferometer, a side-coupled regular fermion and a Kitaev wire within the topological phase. Each one breaks the symmetry by its own way and the differences between these cases reveal the Majorana way of symmetry breaking: the signature of a Majorana is not restricted to the vicinity of the ZBA due to the zero mode nature of such an excitation, it spreads over the entire space spanned by ε and ∆ ε in the density plots of panels (b) for Figs. 2 and 3. Panels (a) of Figs. 2 and 3 as well as Fig. 4 exhibit non Majorana fingerprints due to distinguished ways of breaking the symmetry property under consideration.
Transmittance
Figure 8. (Color online) Transmittance determined by Eq. (14) as a function of the Fermi energy ε in units of ∆ in the Fano regime x = 1 ( q b = 0) for the situation without the QD 2 in the setup of Fig. 1 by considering ε M = 10 -7 . In panel (a) we use ε 1 = -4∆: the solid-green lineshape is for the situation of the MBS 1 present, while the blue curve corresponds to the free interferometer in which the Kitaev wire is absent. Panel (b): For the reversed QD level ε 1 = 4∆ , the pronounced satellite dip of the QD 1 in the free case (solidblue lineshape) appears above the Fermi level of the leads as expected and the ZBA in the solid-red lineshape persists as observed in panel (a). Thus in both panels a Majorana dip (ZBA) emerges characterized by an amplitude of 1 / 2.
## IV. CONCLUSIONS
In summary, we have explored theoretically a semiinfinite Kitaev wire within the topological phase coupled to a double QD system. Our analysis reveal that the Green's functions of the QDs are antisymmetric under the permutation of the indexes that label the parameters of these dots. We propose that such a feature can be probed experimentally just by measuring the zero-bias conductance as a function of the Fermi energy of the leads and the symmetric detuning of the QDs levels.
Thereby, our results reveal a strong dependence of the transmittance on contrasting Fano regimes of interference, where conducting and insulating regions emerge as signatures of a single Majorana fermion excitation. We have demonstrated that the symmetric Fano interference is recovered in particular for the electron tunneling only via the QDs and with the metallic leads in resonance with the Majorana zero mode, thus resulting in a fluctuation
of the transmittance given by half or unity, respectively for a semi-infinite or finite Kitaev wire. The former situation corresponds to an isolated Majorana excitation, while the latter represents the bounding of two distant Majoranas and the formation of a nonlocal Dirac fermion. Both scenarios can be helpful to guide experiments whose purpose is to pursuit the existence of a single Majorana fermion or a pair formed by such a quasiparticle in condensed matter systems.
- [1] J. Alicea, Rep. Prog. Phys. 75 , 076501, (2012).
- [2] K. Flensberg, Phys. Rev. Lett. 106 , 090503 (2012).
- [3] M. Leijnse, and K. Flensberg, Phys. Rev. Lett. 107 , 210502 (2012).
- [4] A.Y. Kitaev, Phys. Usp. 44 , 131 (2001).
- [5] A.A. Zyuzin, D. Rainis, J. Klinovaja, and D. Loss, Phys. Rev. Lett. 111 , 056802 (2013).
- [6] D. Rainis, J. Klinovaja, L. Trifunovic, and D. Loss, Phys. Rev. B 87 , 024515 (2013).
- [7] A. Zazunov, P. Sodano, and R. Egger, New J. Phys 15 , 035033 (2013).
- [8] Y. Cao, P. Wang, G. Xiong, M. Gong, and X.-Q. Li, Phys. Rev. B 86 , 115311 (2012).
- [9] Y.-X. Li, and Z.M. Bai, J. Appl. Phys. 114 , 033703 (2013).
- [10] N. Wang, S. Lv, and Y. Li, J. Appl. Phys. 115 , 083706 (2014).
- [11] D.E. Liu, and H.U. Baranger, Phys. Rev. B 84 , 201308(R) (2011).
- [12] E. Vernek, P.H. Penteado, A.C. Seridonio, and J.C. Egues, Phys. Rev. B 89 , 165314 (2014).
- [13] A.C. Seridonio, E. C. Siqueira, F.A. Dessotti, R.S. Machado, and M. Yoshida, J. Appl. Phys. 115 , 063706 (2014).
- [14] A. Ueda and T. Yokoyama, Phys. Rev. B 90 , 081405(R) (2014).
- [15] C.-H. Lin, J. D. Sau, and S. Das Sarma, Phys. Rev. B 86 , 224511 (2012).
- [16] V. Mourik, K. Zuo, S.M. Frolov, S.R. Plissard, E.P.A.M. Bakkers, and L.P. Kouwenhoven, Science 336 , 1003 (2012).
## ACKNOWLEDGMENTS
This work was supported by the Brazilian agencies CNPq, CAPES, FAPEMIG, PROPe/UNESP and 2014/14143-0 S˜ ao Paulo Research Foundation (FAPESP). A. C. Seridonio and F. A. Dessotti are grateful to P. Sodano for valuable discussions.
- [17] A. Das, Y. Ronen, Y. Most, Y. Oreg, M. Heiblum, and H. Shtrikman, Nature Phys. 8 , 887 (2012).
- [18] E.J.H. Lee, X. Jiang, M. Houzet, R. Aguado, C.M. Lieber, and S. De Franceschi, Nature Nanotechnology 9 , 79 (2014).
- [19] E.J.H. Lee, X. Jiang, R. Aguado, G. Katsaros, C.M. Lieber, and S. De Franceschi, Phys. Rev. Lett. 109 , 186802 (2012).
- [20] U. Fano, Phys. Rev. 124 , 1866 (1961).
- [21] A. W. Holleitner, C. R. Decker, H. Qin, K. Eberl, and R. H. Blick, Phys. Rev. Lett. 87 , 256802 (2001).
- [22] T. Hatano, T. Kubo, Y. Tokura, S. Amaha, S. Teraoka, and S. Tarucha, Phys. Rev. Lett. 106 , 076801 (2011).
- [23] The current lack of symmetry in the system Green's functions was verified previously in an STM system with adatoms [13], but for a Fermi energy in resonance with the Majorana zero mode. In the case of a setup composed by QDs as the proposed in this manuscript, the Fermi level is an experimentally tunnable parameter thus allowing the feasibility of a situation away from the resonance condition.
- [24] H. Haug and A.P. Jauho, Quantum Kinetics in Transport and Optics of Semiconductors, Springer Series in SolidState Sciences 123 (Springer, New York, 1996).
- [25] The EOM method can be found in great deal in K. Flensberg Phys. Rev. B 82 180516(R) (2010) and within its supplementary material.
- [26] W. Hofstetter, J. K¨ onig, and H. Schoeller, Phys. Rev. Lett. 87 , 156803 (2001).
- [27] Q. F. Sun and H. Guo, Phys. Rev. B 66 , 155308 (2002). | 10.1063/1.4898776 | [
"F. A. Dessotti",
"L. S. Ricco",
"M. de Souza",
"F. M. Souza",
"A. C. Seridonio"
] | 2014-08-03T03:51:26+00:00 | 2014-11-08T20:21:20+00:00 | [
"cond-mat.mes-hall"
] | Probing the Antisymmetric Fano Interference Assisted by a Majorana Fermion | As the Fano effect is an interference phenomenon where tunneling paths
compete for the electronic transport, it becomes a probe to catch fingerprints
of Majorana fermions lying on condensed matter systems. In this work we benefit
of this mechanism by proposing as a route for that an Aharonov-Bohm-like
interferometer composed by two quantum dots, being one of them coupled to a
Majorana bound state, which is attached to one of the edges of a semi-infinite
Kitaev wire within the topological phase. By changing the Fermi energy of the
leads and the symmetric detuning of the levels for the dots, we show that
opposing Fano regimes result in a transmittance characterized by distinct
conducting and insulating regions, which are fingerprints of an isolated
Majorana quasiparticle. Furthermore, we show that the maximum fluctuation of
the transmittance as a function of the detuning is half for a semi-infinite
wire, while it corresponds to the unity for a finite system. The setup proposed
here constitutes an alternative experimental tool to detect Majorana
excitations. |
1408.0455v1 | ## Quantized CSI-Based Tomlinson-Harashima Precoding in Multiuser MIMO Systems
Liang Sun, Member , IEEE and Ming Lei
## Abstract
This paper considers the implementation of Tomlinson-Harashima (TH) precoding for multiuser MIMO systems based on quantized channel state information (CSI) at the transmitter side. Compared with the results in [1], our scheme applies to more general system setting where the number of users in the system can be less than or equal to the number of transmit antennas. We also study the achievable average sum rate of the proposed quantized CSI-based TH precoding scheme. The expressions of the upper bounds on both the average sum rate of the systems with quantized CSI and the mean loss in average sum rate due to CSI quantization are derived. We also present some numerical results. The results show that the nonlinear TH precoding can achieve much better performance than that of linear zero-forcing precoding for both perfect CSI and quantized CSI cases. In addition, our derived upper bound on the mean rate loss for TH precoding converges to the true rate loss faster than that of zeroforcing precoding obtained in [2] as the number of feedback bits becomes large. Both the analytical and numerical results show that nonlinear precoding suffers from imperfect CSI more than linear precoding does.
## Index Terms
Tomlinson-Harashima precoding, QR decomposition, random vector quantization, zero-forcing, Givens transformation.
## I. INTRODUCTION
Since the pioneering work [3] and [4], multiple-input multiple-output (MIMO) communication systems have been extensively studied in both academic and industry communities and becomes the key technology of most emerging wireless standards. It is shown that significantly enhanced spectral efficiency and link reliability can be achieved compared with conventional single antenna
systems [3, 5]. In the downlink multiuser MIMO systems, multiple users can be simultaneously served by exploiting the spatial multiplexing capability of multiple transmit antennas, rather than trying to maximize the capacity of a single-user link.
The performance of a MIMO system with spatial multiplexing is severely impaired by the multi-stream interference due to the simultaneous transmission of parallel data streams. To reduce the interference between the parallel data streams, both the processing of the data streams at the transmitter (precoding) and the processing of the received signals (equalization) can be used. Precoding matches the transmission to the channel. Accordingly, linear precoding schemes with low complexity are based on zero-forcing (ZF) [6] or minimum mean-squareerror (MMSE) criteria [7] and their improved version of channel regularization [8]. In spite of very low complexity, the linear schemes suffer from capacity loss. Nonlinear processing at either the transmitter or the receiver provides an alternative approach that offers the potential for performance improvements over the linear approaches. This kind of approaches includes schemes employing linear precoding combined with decision feedback equalization (DFE) [5, 9], vector perturbation [10], Tomlinson-Harashima (TH) precoding [1, 11], and ideal dirty paper coding [12, 13] which is too complex to be implemented in practice. Vector perturbation has been proposed for multiuser MIMO channel model and can achieve rate near capacity [10]. It has superior performance to linear precoding techniques, such as zero-forcing beamforming and channel inversion, as well as TH precoding [10]. However, this method requires the joint selection of a vector perturbation of the signal to be transmitted to all the receivers, which is a multi-dimensional integer-lattice least-squares problem. The optimal solution with an exhaustive search over all possible integers in the lattice is complexity prohibited. Although some suboptimal solutions, such as sphere encoder [14], exist, the complexity is still much higher than TH precoding.
TH precoding can be viewed as a simplified version of vector perturbation by sequential generation of the integer offset vector instead of joint selection. This technique employs modulo arithmetic and has a complexity comparable to that of linear precoders. It was originally proposed to combat inter-symbol interference in highly dispersive channels [15] and can readily be extended to MIMO channels [1, 16]. Although it was shown in [10] that TH precoding does not perform nearly as well as vector perturbation for general SNR regime, it can achieve significantly
better performance than the linear pre-processing algorithm, since it limits the transmitted power increase while pre-eliminating the inter-stream interference [11]. Thus, it provides a good choice of tradeoff between performance and complexity and has recently received much attention [1, 11]. Note that TH precoding is strongly related to dirty paper coding. In fact, it is a suboptimal implementation of dirty paper coding proposed in [17].
As many precoding schemes, the major problem for systems with TH precoding is the availability of the channel state information (CSI) at the transmitter. In time division duplex systems, since the channel can be assumed to be reciprocal, the CSI can be easily obtained from the channel estimation during reception. In frequency division duplex (FDD) systems, the transmitter cannot estimate this information and the CSI has to be communicated from the receivers to the transmitter via a feedback channel. In this paper, we will focus on the implementation of TH precoding in FDD systems. In this context, for linear precoding, there have been extensive research results for MIMO systems with quantized CSI at the transmitter [2, 18, 19]. However, as far as we know, there has been very few works directed at the design of TH precoding based on the quantized CSI at the transmitter side. In this respect, the previous design in [20] is based on MMSE criteria. Since the MSE is a function of both statistics (moments) of the channels and the statistics of the channel quantization error, the computation of the MSE requires the exact distribution of the channels which can be very difficult to obtain in practical systems. In addition, even if the exact distribution function of channels could be obtained, the statistics of quantization error can be very difficult to obtain for more general channel fading other than uncorrelated Rayleigh fading even with simple random vector quantization (RVQ) codebook. Instead, we aim to design low complexity method which can be easily implemented in practical systems with arbitrary channel fading. Our scheme employs a more direct method which only depends on the quantized CDI of user channels.
In this paper, we design a multiuser spatial TH precoding based on quantized CSI and ZF criteria. As in [1], we focus on high spectral efficiency, in particular non-binary modulation alphabets and correspondingly we assume high signal-to-noise ratios (SNRs). In contrast to [1] where perfect CSI is at the transmitter side, we assume only quantized CDI is available at the transmitter. The feedforward filter as well as the feedback filter are computed at the transmitter only based on the available quantized CDI at the transmitter side. In addition, our scheme also
Fig. 1 . TH precoding for multiuser MIMO downlink with quantized CSI feedback.
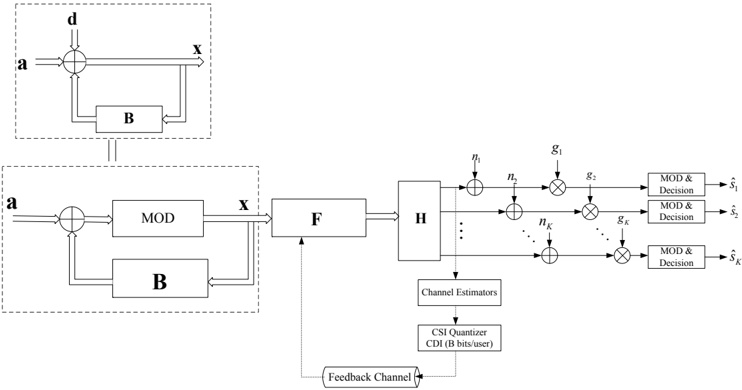
generalizes the results in [1] to more general system setting where the number of users K in system can be less than or equal to the number of transmit antennas n T . We also study the achievable average sum rate of the proposed quantized CSI-based TH precoding scheme by analytically characterizing the average sum rate and the rate loss due to quantized CSI as functions of the number of feedback bits per user. Our derived upper bound for TH precoding tracks the true rate loss quite closely and appears to converge faster than the upper bound for ZF precoding obtained in [2] as the number of feedback bits becomes large.
## II. SYSTEM MODEL
As shown in Fig. 1, we consider the multi-user downlink systems where TH precoding [15] is used at the transmitter for multi-user interference pre-subtraction. The transmitter is equipped with n T transmit antennas and K decentralized users each has a single antenna such that K ≤ n T . Let the vector s = [ s , 1 · · · , s K ] T ∈ C K × 1 represent the modulated signal vector for all users, where s k is the k -th modulated symbol stream for user k . Here we assume that an M -ary square constellation ( M is a square number) is employed in each of the parallel data streams and the constellation set is A = { s I + js Q | s , s I Q ∈ ± 1 √ 3 2( M -1) , ± 3 √ 3 2( M -1) , · · · , ± √ M √ 3 2( M -1) } .
In general, the average transmit symbol energy is normalized, i.e. E {| s k | 2 } = 1 . s is fed to the precoding unit, which consists of a backward square matrix B and a nonlinear operator MOD τ ( ) · which acts independently over the real and imaginary parts of its input as follows
$$\text{MOD} _ { \tau } ( x ) = x - \tau \left \lfloor \frac { x + \tau } { 2 \tau } \right \rfloor,$$
where τ = √ M √ 3 2( M -1) , /floorleft z /floorright is the largest integer not exceeding z . B must be strictly lower triangular to allow data precoding in a recursive fashion [1]. The construction of B will depend on the level of CSI of the supported users available at the transmitter side. If we temporarily neglect the nonlinear operator MOD τ ( ) · in Fig. 1, the channel signal vector x = [ x , 1 · · · , x K ] T can be generated as
$$x _ { 1 } = s _ { 1 },$$
$$x _ { k } = s _ { k } - \sum _ { l = 1 } ^ { k - 1 } [ \mathbf B ] _ { k, l } x _ { l }, \ k = 2, \cdots, K. \quad \quad \quad$$
In this way, if b = ( I + B ) -1 s become large in the presence of deep fading the transmit power can be greatly increased. TH precoding modulo (1) reduces the transmit symbols into the boundary square region of R = { x + jy x, y | ∈ ( -τ, τ ) } . With (1) and (2) the channel signals are equivalently given as
$$x _ { k } = s _ { k } + d _ { k } - \sum _ { l = 1 } ^ { k - 1 } [ \mathbf B ] _ { k, l } x _ { l }, \ k = 2, \cdots, K, \\ \$$
where d k ∈ { 2 τ ( p I + jp Q ) | p , p I Q ∈ Z } is properly selected to ensure the real and imaginary parts of x k are constrained into R [1]. The constellation of the modified data symbols v k = s k + d k is simply the periodic extension of the original constellation along the real and imaginary axes. Equivalently, the effective data symbols v k ( k = 2 , · · · , K ) are passed into B , which is implemented by the feedback structure. Thus, we have
$$\mathbf v = \mathbf C \mathbf x,$$
where v = [ v , v 1 2 , · · · , v K ] T and
$$C = B + I.$$
We will make the standard observation that the elements of x are almost uncorrelated and uniformly distributed over the Voronoi region of the constellation R , and that such a model becomes more precise as n T increases [11, Theorem 3.1]. With E { ss H } = I , the covariance of x can be accurately approximated as R x = M M -1 I [11]. Moreover, the induced shaping loss by the non-Gaussian signaling leads to the fact that the achievable rate can be up to 1 53 . dB from the channel capacity [21]. However, as indicated in [1], the so-called shaping loss can be bridged by higher-dimensional precoding lattices. A scheme named 'inflated lattice' precoding has been proved to be capacity-achieving in [22]. Thus, following [1], we will ignore the shaping gap in this work.
A spatial channel pre-equalization is performed at the transmitter side using a feedforward precoding matrix F ∈ C n T × K . Throughout this work, we assume equal power allocation to all supported users. Then the received signal can be written as
$$r = \sqrt { \frac { P } { \kappa } } \text{HF} x + \text{n},$$
where H = [ h T 1 , · · · , h T K ] T is the compact flat fading channel matrix consisting of all users's channel vectors and h k ∈ C n T × 1 is the channel from the transmitter to user k 1 . κ is used for transmit power normalization. F ∈ C n T × K satisfies transmit power constraint P κ Tr { FR F x H } = P κ M M -1 Tr { FF H } = P . As for B F , is also designed based on the level of CSI available to the transmitter. We assume n is the white additive noise at all the receivers with the covariance R n = I without loss of generality. Each receiver compensates for the channel gain by dividing by a factor g k prior to the modulo operation as follows:
$$y = G \left ( \sqrt { \frac { P } { \kappa } } \text{HF} x + \text{n} \right ),$$
where G = diag ( g 1 1 , , · · · , g K,K ) .
Throughout this work, we assume each receiver can obtain perfect CSI of his own through channel estimation and feeds back this information to the transmitter via a zero-delay feedback link with possible rate-constraints. In this part, we assume this feedback information is perfect
1 The ordering of the users' channel vectors in H will affect the precoding order of the users' information signals and further affect the performance of each user. However, at this stage we assume the user channel vectors are randomly ordered. Thus the TH precoding order of the users is 1 2 , , · · · , K .
at the transmitter. The design of TH precoding for MU MIMO systems with perfect CSI has been studied in [1] where, for simplicity, the authors restrict the work to the systems with equal number of transmit antennas and users. In this part, we review and extend that construction for systems with arbitrary number of users no more that of the transmit antennas.
With perfect CSI at the transmitter, let the QR decomposition of the compact channels be H = RQ , where R = [ r i,j ] ∈ C K × K is a lower left triangular matrix and Q ∈ C K × n T is a semiunitary matrix with orthonormal rows which satisfies QQ H = I . Then the precoding matrix F is given as F = Q H , the scaling matrix G is given as G = √ κ P ∆ with ∆ = diag ( r -1 1 1 , , · · · , r -1 K,K ) and the feedback matrix reads B = ∆HF -I = ∆R -I . According to the transmit power constraint P κ M M -1 K = P , we have κ = M M -1 K . With the processing, the effective received data symbols y corrupted by additive noise can be written as [1]
$$y = v + G n.$$
At the receivers, each symbol in y is firstly modulo reduced into the boundary region of the signal constellation A . A quantizer of the original constellation will follow the modulo operation to detect the received signals. The SNR ξ k for receiver k can be written as
$$\xi _ { k } = \frac { P } { \kappa } | r _ { k, k } | ^ { 2 }.$$
In the following part, we will describe how to implement the precoding with quantized CSI obtained at the transmitter.
## III. SYSTEM WITH QUANTIZED TRANSMIT CSI
In practical systems, perfect CSI is never available at the transmitter. For example, in a FDD system, the transmitter obtains CSI for the downlink through the limited feedback of B bits by each receiver. Following the studies of quantized CSI feedback in [2, 19], channel direction vector is quantized at each receiver, and the corresponding index is fed back to the transmitter via an error and delay-free feedback channel. Given the quantization codebook W = { w 1 , · · · , w n } ( w i ∈ C 1 × n T ), which is known to both the transmitter and all the receivers, the k -th receiver
selects the quantized channel direction vector of its own channel as follows:
$$\hat { h } _ { k } = \arg \max _ { w _ { i } \in \mathbb { W } } \{ | \bar { h } _ { k } w _ { i } | ^ { 2 } \},$$
where ¯ h k = h k ‖ h k ‖ is the channel direction vector of user k .
In this work, we use RVQ codebook, in which the n quantization vectors are independently and isotropically distributed on the n T -dimensional complex unit sphere. Although RVQ is suboptimal for a finite-size system, it is very amenable to analysis and also its performance is close to the optimal quantization [2]. Using the result in [2], for user k we have
$$\bar { h } _ { k } = \hat { h } _ { k } \cos \theta _ { k } + \tilde { h } _ { k } \sin \theta _ { k },$$
where cos 2 θ k = | ¯ h h k ˆ H k | 2 , ˜ h k ∈ C 1 × n T is a unit norm vector isotropically distributed in the orthogonal complement subspace of ˆ h k and independent of sin θ k . Then H can be written as
$$H = \Gamma \left ( \Phi \hat { H } + \Omega \tilde { H } \right ), \quad \quad \quad ( 1 2 ) \\. \quad. \quad.. \. \. \. \. \. \. \. \. \. \.$$
/negationslash
With the quantized CDI at the transmitter side, the transmitter obtains the feedforward precoding matrix F and feedback matrix B through the QR decomposition of compact channel matrix ˆ H in the same way as the QR decomposition of matrix H , i.e. ˆ H = ˆ ˆ RQ , where the matrices ˆ R and ˆ Q have the same structure as the matrices R and Q respectively. Then we have F = ˆ Q H and B = ( diag { ˆ R }) -1 ˆ R -I . In addition, the scaling matrix at the receivers now becomes where Γ = diag ( ρ , 1 · · · , ρ K ) with ρ k = ‖ h k ‖ , Φ = diag (cos θ , 1 · · · , cos θ K ) and Ω = diag ( sin θ , 1 · · · , sin θ K ) , ˆ H = [ ˆ h T 1 , · · · , ˆ h T K ] T and ˜ H = [ ˜ h T 1 , · · · , ˜ h T K ] T . For simplicity of analysis, in this work we consider the quantization cell approximation used in [19, 23], where each quantization cell is assumed to be a Voronoi region of a spherical cap with surface area approximately equal to 1 n of the total surface area of the n T -dimensional unit sphere. For a given codebook W , the actual quantization cell for vector w i , R i = { ¯ : h | ¯ hw i | 2 ≥ | ¯ hw j | 2 , ∀ i = j } , is approximated as ˜ R ≈ i { ¯ : h | ¯ hw i | ≥ 1 -δ } , where δ = 2 -B n T -1 .
$$G = \sqrt { \frac { \kappa } { P } } \left ( \Gamma \Phi \text{ diag} \left \{ \hat { R } \right \} \right ) ^ { - 1 }. \\.. \. \. \. \. \. \. \. \ \. \ \.$$
Using the same operation at the receiver side as that in perfect CSI case to detect the received
signals, the detected signal vector ˆ y can be further written as
$$\text{signs, use usereceipts} \, \text{$y$ can we runen when as} \\ \hat { y } & = G \left ( \sqrt { \frac { P } { \kappa } } \text{H} F x + n \right ) \\ & = G \sqrt { \frac { P } { \kappa } } \Gamma \left ( \hat { \Phi } \hat { H } + \Omega \tilde { H } \right ) F x + G n \\ & = v + \left ( \Phi \, \text{diag} \left \{ \hat { R } \right \} \right ) ^ { - 1 } \Omega \tilde { H } \hat { Q } ^ { H } x + \sqrt { \frac { \kappa } { P } } \left ( \Gamma \Phi \, \text{diag} \left \{ \hat { R } \right \} \right ) ^ { - 1 } n, \\ \text{where we have used the relationship} \, v = \left ( \text{diag} \left \{ \hat { R } \right \} \right ) ^ { - 1 } \hat { R } x. \, \text{In} \, ( 14 ), \, \text{the first term is the useful}$$
where we have used the relationship v = ( diag { ˆ R }) -1 ˆ Rx . In (14), the first term is the useful signal vector for all the users and the second term is interference signal caused by the quantized CSI.
According to (14), the output signal-to-interference-plus-noise ratio (SINR) γ k for receiver k can be written as
$$\gamma _ { k } & = \frac { 1 } { \frac { \sin ^ { 2 } \theta _ { k } } { | \hat { r } _ { k, k } | ^ { 2 } \cos ^ { 2 } \theta _ { k } } } \| \tilde { \mathbf h } _ { k } \hat { Q } ^ { H } \| ^ { 2 } + \frac { \kappa } { P } \frac { 1 } { \rho _ { k } ^ { 2 } | \hat { r } _ { k, k } | ^ { 2 } \cos ^ { 2 } \theta _ { k } } } \\ & = \frac { \frac { P } { \kappa } \rho _ { k } ^ { 2 } | \hat { r } _ { k, k } | ^ { 2 } \cos ^ { 2 } \theta _ { k } } { \frac { P } { \kappa } \rho _ { k } ^ { 2 } \| \tilde { \mathbf h } _ { k } \hat { Q } ^ { H } \| ^ { 2 } \sin ^ { 2 } \theta _ { k } + 1 }. \\ \text{AVERAGE SUM RATE ANALYSIS UNDER QUANTIZED CSI FEEDBACK}$$
## IV. AVERAGE SUM RATE ANALYSIS UNDER QUANTIZED CSI FEEDBACK
In this section we will study the achievable average sum rate of the proposed quantized CSI feedback TH precoding scheme. Although the exact distribution of each term in the expression of the output SINR γ k in (15) can be obtained (see for the detailed information), these terms are located at both the numerator and the denominator in (15) . Thus, to obtain the exact closed-form expression of the distribution of output SINR γ k can be very difficult if not impossible, not to mention the exact closed-form expression of the average sum rate. Thus, to simplify analysis, we have appealed to studying some bounds of the average sum rate and the average sum rate loss instead of exact results. For tractability, throughout this section we assume each user's channel is Rayleigh-faded. In the following subsection, we will first study the statistical distribution of the power of interference signal at each user caused by quantized CSI.
## A. Interference Part
In this subsection, assuming Rayleigh fading channel and RVQ for quantized CSI feedback, we will derive the statistical distribution of interference part P κ ρ 2 k ‖ ˜ h Q k ˆ H ‖ 2 sin 2 θ k in (15). It is
well known that ρ 2 k has a χ 2 2 n T distribution and the distribution of sin 2 θ k is given in [2, 18]. However, since ˜ h k ⊥ ˆ h k ( k = 1 , · · · , K ) and ˆ Q is determined by ˆ h k ( k = 1 , · · · , K ), ˜ h k for k = 1 , · · · , K are not independent of ˆ Q . The distribution of the term ‖ ˜ h Q k ˆ H ‖ 2 is still unknown and to obtain the exact result is not trivial. The following lemma presents the exact distribution of this interference term. It is one of the key contributions of this paper.
Lemma 1: For 1 < K < n T , the random variables ε k = ‖ ˜ h Q k ˆ H ‖ 2 for k = 1 , · · · , K follow the same beta distribution with shape ( K -1) and ( n T -K ) which is denoted as ε k ∼ Beta( K -1 , n T -K ) . In addition, the probability density function (p.d.f.) of ε k is given as
$$f _ { \varepsilon _ { k } } ( x ) & = \frac { 1 } { \beta ( K - 1, n _ { T } - K ) } x ^ { K - 2 } ( 1 - x ) ^ { n _ { T } - K - 1 }. \\.$$
where β a, b ( ) = ∫ 1 0 t a -1 t b -1 d t is beta function [24]. Specially, when K = 1 there is no interference term. When K = n T , ε k = ‖ ˜ h Q k ˆ H ‖ 2 is equal to 1 which is a constant.
## Proof: See Appendix A.
Lemma 1 implies a very interesting result that, with randomly ordered user channel vectors, the signal of the user which is precoded ahead suffers from the same interference signal power as the signals of the users which are precoded afterwards. In the following we will only focus on the general situation that 1 < K < n T . However, it is easy to check that all the obtained results also apply to the special cases of K = 1 and K = n T .
The expectation of the logarithm of the interference term ε k , which is shown to be useful in the following theorems, is obtained in the following lemma.
Lemma 2: The expectation of the logarithm of the interference term ε k is given by
$$\mathbb { E } _ { \mathbf h, \mathbf w } & \left [ - \log _ { 2 } \left ( \| \tilde { \mathbf h } _ { k } \hat { Q } ^ { \mathbf \mu } \| ^ { 2 } \right ) \right ] = \log _ { 2 } e \sum _ { m = K - 1 } ^ { n _ { T } - 2 } \sum _ { l = 0 } ^ { n _ { T } - m - 2 } \frac { ( n _ { T } - 2 )! } { m! \ l! \ ( n _ { T } - m - 2 - l )! } ( - 1 ) ^ { l } \frac { 1 } { m + l } \quad ( 1 7 ) \\ \mathfrak { s } \quad \ e \ \circ \quad \ e \quad \ e \quad \ e \quad \ e \quad \ e \quad \ e \quad \ e \quad \ e \quad \ e \quad \ e \quad \ e \quad \ e \quad \ e \quad \ e \quad \ e \quad \ e \quad \ e \quad \ e \quad \ e \quad \ e \quad \ e \quad \ e \quad \ e \quad \ e \quad \ e \quad \ e \quad \ e \quad \ e \quad \ e \quad \ e \quad \ e \quad \ e \quad \ e \quad \ e \quad \ e \quad \ e \quad \ e \quad \ e \quad \ e \quad \ e \quad \ e \quad \ e \quad \ e \quad \ e \quad \ e \quad \ e \quad \ e \quad \ e \quad \ e \quad \ e \quad \ a c e \quad \ e \quad \ e \quad \ e \quad \ e \quad \ e \quad \ e \quad \ e \quad \ e \quad \ e \quad \ e \quad \ e \quad \ e \quad \ e \quad \ e \quad \ e \quad \ e \quad \ e \quad \ e \quad \ e \quad \ e \quad \ e \quad \ e \quad \ e \quad \ e \quad \ e \quad \ e \quad \ e \quad \ e \quad \ e \quad \ e \quad \ e \quad \ e \quad \ e \quad \ e \quad \ e \quad \ e \quad \ e \quad \ e \quad \ e \quad \ e \quad \ e \quad \ e \quad \ e \quad \ e \quad \ e \quad \ e \quad \ e \quad \ e \quad \ e \quad e \quad \ e \quad \ e \quad \ e \quad \ e \quad \ e \quad \ e \quad \ e \quad \ e \quad \ e \quad \ e \quad \ e \quad \ e \quad \ e \quad \ e \quad \ e \quad \ e \quad \ e \quad \ e \quad \ e \quad \ e \quad \ e \quad \ e \quad \ e \quad \ e \quad \ e \quad \ e \quad \ e \quad \ e \quad \ e \quad \ e \quad \ e \quad \ e \quad \ e \quad \ e \quad \ e \quad \ e \quad \ e \quad \ e \quad \ e \quad \ e \quad \ e \quad \ e \quad \ e \quad \ e \quad \ e \quad \ e \quad \ e \quad \ e \quad \ e \quad 0 \quad \ e \quad \ e \quad \ e \quad \ e \quad \ e \quad \ e \quad \ e \quad \ e \quad \ e \quad \ e \quad \ e \quad \ e \quad \ e \quad \ e \quad \ e \quad \ e \quad \ e \quad \ e \quad \ e \quad \ e \quad \ e \quad \ e \quad \ e \quad \ e \quad \ e \quad \ e \quad \ e \quad \ e \quad \ e \quad \ e \quad \ e \quad \ e \quad \ e \quad \ e \quad \ e \quad \ e \quad \ e \quad \ e \quad \ e \quad \ e \quad \ e \quad \ e \quad \ e \quad \ e \quad \ e \quad \ e \quad \ e \quad \ e \quad \ e \quad \ u n e \quad \ e \quad \ e \quad \ e \quad \ e \quad \ e \quad \ e \quad \ e \quad \ e \quad \ e \quad \ e \quad \ e \quad \ e \quad \ e \quad \ e \quad \ e \quad \ e \quad \ e \quad \ e \quad \ e \quad \ e \quad \ e \quad \ e \quad \ e \quad \ e \quad \ e \quad \ e \quad \ e \quad \ e \quad \ e \quad \ e \quad \ e \quad \ e \quad \ e \quad \ e \quad \ e \quad \ e \quad \ e \quad \ e \quad \ e \quad \ e \quad \ e \quad \ e \quad \ e \quad \ e \quad \ e \quad \ e \quad \ e \quad \ e \quad \ e \quad$$
Proof:
$$\gamma \colon \text{See Appendix B}.$$
## B. Upper Bounds on the Average Sum Rate Loss and Sum Rate
The instantaneous achievable rates for user k with perfect CSI and quantized CSI feedback are given as
$$R _ { P, k } = \log _ { 2 } \left ( 1 + \xi _ { k } \right )$$
and
$$R _ { Q, k } = \log _ { 2 } ( 1 + \gamma _ { k } ),$$
respectively. The following theorem quantifies the average sum rate performance degradation as a function of the feedback rate.
Theorem 1: With B feedback bits per user, the average sum rate loss of user k due to quantized CSI feedback can be upper bounded by 2
$$\Delta R _ { k } & = \mathbb { E } _ { \mathbf H, W } \{ R _ { P, k } - R _ { Q, k } \} \\ & \leq \Delta R = \log _ { 2 } \left ( 1 + c P \ 2 ^ { - \frac { B } { n _ { T } - 1 } } \right ) + \frac { \log _ { 2 } ( e ) } { n _ { T } - 1 } \sum _ { \colon, \, \cdot } ^ { n _ { T } - 1 } \beta \left ( n, \frac { i } { n _ { T } - 1 } \right ),$$
$$\leq \Delta R = \log _ { 2 } \left ( 1 + c P \ 2 ^ { - \frac { B } { n _ { T } - 1 } } \right ) + \frac { \log _ { 2 } ( e ) } { n _ { T } - 1 } \sum _ { i = 1 } ^ { n _ { T } - 1 } \beta \left ( n, \frac { i } { n _ { T } - 1 } \right ), \\ \left ( \tau _ { - 1 } \aleph _ { - } \right ) \,. \quad. \quad. \quad. \quad. \quad. \quad.$$
where c = ( K -1) n T κ n ( T -1) and n = 2 B is the size of codebook.
Proof:
$$\gamma \colon \text{See Appendix C.}$$
According to the results in [2, Theorem 1 ], the average sum rate loss due to quantized feeback for ZF precoding is upper bounded by ∆ R zf < log 2 ( 1 + P 2 -B n T -1 ) . We find the first term at the right hand side (RHS) of (20) can be approximated as log 2 ( 1 + P 2 -B n T -1 ) with high order constellation, large number of transmit antennas and large number of supported users. Thus, the second term at the RHS of (20) can be seen as the sum rate degradation of nonlinear precoding compared with that of linear precoding when only quantized CSI is available at the transmitter side. In addition, similar to the results for the linear ZF beamforming in [2], the rate loss for nonlinear precoding is also an increasing function of the system SNR ( P ). Thus, the system with fixed feedback rate is interference-limited at high SNR regime, which is shown in the following theorem.
Theorem 2: The average sum rate of user k achieved by quantized CSI-based TH precoding with B feedback bits per user is bounded as
$$R _ { Q, k } & \leq \log _ { 2 } e \left ( \sum _ { m = K - 1 } ^ { n _ { T } - 2 } \sum _ { l = 0 } ^ { n _ { T } - m - 2 } \frac { ( n _ { T } - 2 )! } { m! \ l! \ ( n _ { T } - m - 2 - l )! } ( - 1 ) ^ { l } \frac { 1 } { m + l } + \frac { 1 } { n _ { T } - 1 } \sum _ { l = 1 } ^ { n } \frac { 1 } { l } \right ), \quad ( 2 1 ) \\. & \quad \. \. \. \. \. \. \.$$
where n = 2 B is the size of codebook.
2 Note that, in contrast to ZF precoding, for TH precoding different users have different average sum rate loss. Interestingly, simulation results show that, for finite SNR, the users precoded earlier will suffer from greater sum rate loss. However, in this work will adopt the average sum rate loss over all supported users.
## Proof: See Appendix D.
We can see from this theorem that, with fixed feedback bits per user, as the interference and signal power both increase linearly with P , the system becomes interference-limited and the average sum rate converges to an upper bound. These can also be observed from the simulation results in Fig. 3.
In the context of linear ZF precoding in [2], the author showed the interference-limited scenario can be avoided by scaling the feedback rate linearly with the SNR P dB (in decibels). Particularly, it is showed in [2, Theorem 3] that in order to maintain a constant average sum rate loss no greater than log 2 b bits per user between the system with perfect CSI and the system with finite-rate feedback, it is sufficient to scale the number of feedback bits per user according to
$$B = ( n _ { T } - 1 ) \frac { \log _ { 2 } 1 0 } { 1 0 } P _ { d \mathrm B } - ( n _ { T } - 1 ) \log _ { 2 } ( b - 1 ).$$
However, for nonlinear TH precoding, the explicit relationship between the feedback rate and the SNR to maintain a constant average sum rate loss cannot be easily obtained. This is mainly due to the fact that the expression of average sum rate loss in (20) is a much more complex function of n ( B ) than the corresponding expression for linear ZF precoding given in [2, Theorem 1]. In the following we will derive a corresponding relationship for the system employing TH precoding. First, in Appendix E we show that the second term at the RHS of (20) can be bounded by a decreasing function of n for a fixed n T . In addition, this upper bound approaches zero as n → ∞ . Thus, as n scales linearly with SNR (in decibels), for an arbitrary given constant 0 < ε < 1 , we can always find a positive integer N ε ( ) such that, whenever n ≥ N ε ( ) ,
$$\Delta R \leq \log _ { 2 } \left ( 1 + c P \ 2 ^ { - \frac { B } { n _ { T } - 1 } } \right ) + \varepsilon. \\ \dots \dots \dots \dots \dots \dots$$
To characterize a sufficient condition of the scaling of feedback rate, we set the RHS of (23) to be the maximum allowable gap of log 2 b . After some simple manipulations, we get
$$B & = ( n _ { T } - 1 ) \log _ { 2 } P - \log _ { 2 } ( b - 2 ^ { \varepsilon } - 1 ) + \log _ { 2 } c \\ & = ( n _ { T } - 1 ) \frac { \log _ { 2 } 1 0 } { 1 0 } P _ { \text{dB} } - \log _ { 2 } ( b - 2 ^ { \varepsilon } - 1 ) + \log _ { 2 } c.$$
Fig. 2 . 4 × 4 system with increasing number of feedback bits.
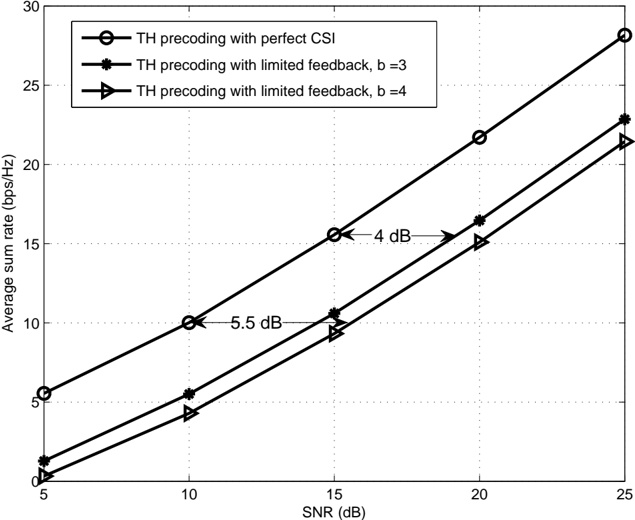
In Fig. 2, the average sum rate curves are shown for a system with n T = 4 and K = 4 . The feedback rate is assumed to scale according to the relationship given in (24). Notice that, since ε can be set to be a small number when B is large enough, in the simulation we set ε = 0 to get a stronger condition than (24). Quantized CSI-based TH precoding is seen to perform within around 4 dB and 5 5 . dB of TH precoding with perfect CSI for b = 3 and b = 4 respectively.
## V. NUMERICAL RESULTS
In this section we present some numerical results. We assume n T = K = 4 . Here the SNR of the systems is defined to be equal to P .
Fig. 3 shows the average sum rate performance of TH precoding and linear ZF precoding with both perfect CSI and quantized CSI, and 4 8 , and 15 feedback bits per user. We can see TH precoding performs better than linear precoding in both perfect CSI and quantized CSI cases. When the SNR is small and moderate, the average sum rate achieved by quantized CSI-based TH precoding can even be better than that of perfect CSI-based linear ZF precoding.
Fig. 3 . The average sum rate performance of TH precoding and ZF precoding for both perfect CSI and quantized CSI.
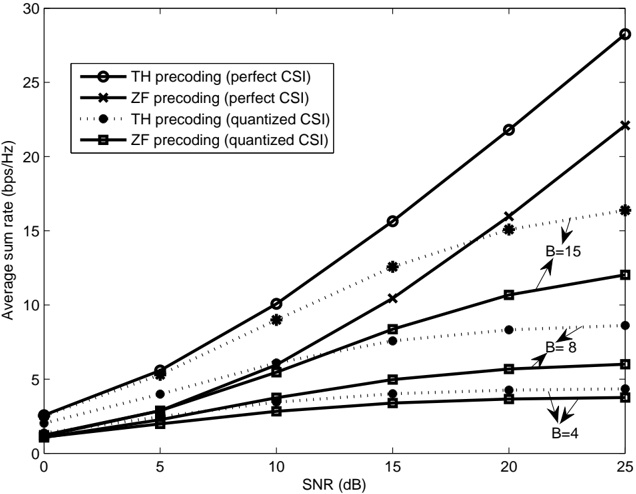
Fig. 4 plots the average sum rate loss per user as a function of the number of feedback bits for both ZF precoding and TH precoding in a system at an SNR of 25 dB. We also plot the upper bound from Theorem 1 in this paper and the upper bound from Theorem 1 in [2]. From the figure we can see that nonlinear precoding suffers from imperfect CSI more than linear precoding does. However, the performance of nonlinear precoding can still be better than linear precoding when SNR is not large or the feedback quantization resolution is high enough. In addition, we notice that the upper bound for TH precoding tracks the true rate loss quite closely, and appears to converge faster than the upper bound for linear precoding obtained in [2] as B increases.
## VI. CONCLUSION
In this paper, we have investigated the implementation of TH precoding in the downlink multiuser MIMO systems with quantized CSI at the transmitter side. In particular, our scheme generalized the results in [1] to more general system setting where the number of users K in the systems can be less than or equal to the number of transmit antennas n T . In addition,
Fig. 4 . The average sum rate loss per user and corresponding upper bounds against the number of feedback bits. P = 25 dB.
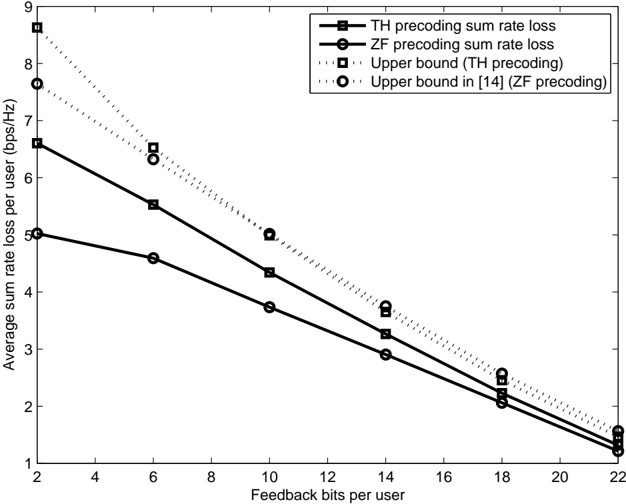
we studied the achievable average sum rate of the proposed scheme by deriving expressions of upper bounds on both the average sum rate and the mean loss in sum rate due to CSI quantization. Our numerical results showed that the nonlinear TH precoding could achieve much better performance than that of linear zero-forcing precoding for both perfect CSI and quantized CSI cases. In addition, our derived upper bound for TH precoding converged to the true rate loss faster than the upper bound for zero-forcing precoding obtained in [2] as the number of feedback bits increased.
## APPENDIX A
## PROOF OF Lemma 1
The results for the special cases that K = 1 and n T are trivial. In the following we will consider the cases that 1 < K < n T . Since the user channel vectors in H are unordered, so are the quantized channel direction vectors in ˆ H = [ ˆ h T 1 , · · · , ˆ h T K ] T . According to the QR
decomposition of ˆ H we have
$$\hat { h } _ { k } & = \sum _ { l = 1 } ^ { k } \hat { r } _ { k, l } \hat { q } _ { l }, \\ + \quad \nu \quad \alpha \colon \alpha \dots \dots \colon \dots \dots \dots \dots$$
If we require ˆ r i,i > 0 for i = 1 , · · · , K , this decomposition is unique . Particularly, we have ˆ r 1 1 , = 1 and ˆ q 1 = ˆ h 1 . In addition, ˜ h k is isotropically distributed in the null space of ˆ h k [2]. Thus, for k = 1 we have ˜ h 1 ⊥ ˆ q 1 or equivalently ˜ h 1 is an isotropically distributed unit vector in the null space of ˆ q 1 .
With the assumption of RVQ, the quantized channel direction vectors ˆ h k ( k = 1 , · · · , K ) are independently and isotropically distributed on the n T -dimensional complex unit sphere due to the assumption of i.i.d. Rayleigh fading. Thus we can conclude that the orthonormal basis ˆ q 1 , · · · , ˆ q K of the subspace spanned by quantized channel vectors ˆ h k ( k = 1 , · · · , K ) have no preference of direction, i.e., [ ˆ q T 1 , · · · , ˆ q T K ] T is isotropically distributed in the K × n T semiunitary space. Thus, to derive the distribution of ε 1 = ‖ ˜ h Q 1 ˆ H ‖ 2 , we can assume ˆ q i = e i for i = 1 , · · · , K without loss of generality, where e i is the i -th row of the identity matrix I n T . Recall that ˜ h 1 ⊥ ˆ q 1 , thus the random vector ˜ h 1 can be written in the form of ˜ h 1 = [0 , v ] , where the vector v = [ v , v 1 2 , · · · , v n T -1 ] is isotropically distributed on the ( n T -1) -dimensional complex unit sphere. Then ε 1 = ‖ ˜ h Q 1 ˆ H ‖ 2 = ∑ K -1 l =1 | v l | 2 . Let t l = | v l | 2 . It has been obtained in [25] that the joint p.d.f. of t 1 , · · · , t K -1 is
$$f ( t _ { 1 }, \dots, t _ { K - 1 } ) = \begin{cases} \begin{array} { c c } \frac { \Gamma ( n _ { T - 1 } ) } { \Gamma ( n _ { T } - K ) } \left ( 1 - \sum _ { i = 1 } ^ { K - 1 } t _ { i } \right ) ^ { n _ { T } - K - 1 }, & t _ { i } \geq 0 \text{ for } i = 1, \cdots, K - 1, \sum _ { i = 1 } ^ { K - 1 } t _ { i } = 1 \\ 0, & \text{ otherwise } \end{array}. \end{cases}$$
Now we want to obtain the distribution of u 1 = ∑ K -1 l =1 t l . We define the following transformation of variables
$$u _ { 1 } = \sum _ { l = 1 } ^ { K - 1 } t _ { l }, \ \ u _ { i } = t _ { i } \quad \text{for $i=2,\cdots,K-1$.} \\ \dots \quad \dots \quad \dots \quad \dots \quad \dots \quad \dots \quad \dots \quad \dots \quad \dots \quad \dots \quad \dots \quad \dots \quad \dots \quad \dots \quad \dots \quad \dots \quad \dots \quad \dots \quad \dots \quad \dots \quad \dots \quad \dots \quad \dots \quad \dots \quad \dots \quad \dots \quad \dots \quad \dots \quad \dots \quad \dots \quad \dots \quad \dots \quad \dots \quad \dots \quad \dots \quad \dots \quad \dots \quad \dots \quad \dots \quad \dots \quad \dots \ \dots \quad \dots \quad \dots \quad \dots \quad \dots \quad \dots \quad \dots \quad \dots \quad \dots \quad \dots \quad \dots \quad \dots \quad \dots \quad \dots \quad \dots \quad \dots \quad \dots \quad \dots \quad \dots \quad \dots \quad \dots \quad \dots \quad \dots \quad \dots \quad \dots \quad \dots \quad \dots \quad \dots \quad \dots \quad \dots \quad \dots \quad \dots \quad \dots \quad \dots \quad \dots \quad \dots \quad \dots \quad \dots \quad \dots \quad \dots \cdots \quad \dots \quad \dots \quad \dots \quad \dots \quad \dots \quad \dots \quad \dots \quad \dots \quad \dots \quad \dots \quad \dots \quad \dots \quad \dots \quad \dots \quad \dots \quad \dots \quad \dots \quad \dots \quad \dots \quad \dots \quad \dots \quad \dots \quad \dots \quad \dots \quad \dots \quad \dots \quad \dots \quad \dots \quad \dots \quad \dots \quad \dots \quad \dots \quad \dots \quad \dots \quad \dots \quad \dots \quad \dots \quad \dots \quad \dots \quad \ dots \quad \dots \quad \dots \quad \dots \quad \dots \quad \dots \quad \dots \quad \dots \quad \dots \quad \dots \quad \dots \quad \dots \quad \dots \quad \dots \quad \dots \quad \dots \quad \dots \quad \dots \quad \dots \quad \dots \quad \dots \quad \dots \quad \dots \quad \dots \quad \dots \quad \dots \quad \dots \quad \dots \quad \dots \quad \dots \quad \dots \quad \dots \quad \dots \quad \dots \quad \dots \quad \dots \quad \dots \quad \dots \quad \dots \quad \dots \quad \ Dots \quad \dots \quad \dots \quad \dots \quad \dots \quad \dots \quad \dots \quad \dots \quad \dots \quad \dots \quad \dots \quad \dots \quad \dots \quad \dots \quad \dots \quad \dots \quad \dots \quad \dots \quad \dots \quad \dots \quad \dots \quad \dots \quad \dots \quad \dots \quad \dots \quad \dots \quad \dots \quad \dots \quad \dots \quad \dots \quad \dots \quad \dots \quad \dots \quad \dots \quad \dots \quad \dots \quad \dots \quad \dots \quad \dots \quad \dots \quad \Dots \quad \dots \quad \dots \quad \dots \quad \dots \quad \dots \quad \dots \quad \dots \quad \dots \quad \dots \quad \dots \quad \dots \quad \dots \quad \dots \quad \dots \quad \dots \quad \dots \quad \dots \quad \dots \quad \dots \quad \dots \quad \dots \quad \dots \quad \dots \quad \dots \quad \dots \quad \dots \quad \dots \quad \dots \quad \dots \quad \dots \quad \dots \quad \dots \quad \dots \quad \dots \quad \dots \quad \dots \quad \dots \quad \dots \quad \dots \quad \frown \dots \quad \dots \quad \dots \quad \dots \quad \dots \quad \dots \quad \dots \quad \dots \quad \dots \quad \dots \quad \dots \quad \dots \quad \dots \quad \dots \quad \dots \quad \dots \quad \dots \quad \dots \quad \dots \quad \dots \quad \dots \quad \dots \quad \dots \quad \dots \quad \dots \quad \dots \quad \dots \quad \dots \quad \dots \quad \dots \quad \dots \quad \dots \quad \dots \quad \dots \quad \dots \quad \dots \quad \dots \quad \dots \quad \dots \quad \dots \ { \dots \quad \dots \quad \dots \quad \dots \quad \dots \quad \dots \quad \dots \quad \dots \quad \dots \quad \dots \quad \dots \quad \dots \quad \dots \quad \dots \quad \dots \quad \dots \quad \dots \quad \dots \quad \dots \quad \dots \quad \dots \quad \dots \quad \dots \quad \dots \quad \dots \quad \dots \quad \dots \quad \dots \quad \dots \quad \dots \quad \dots \quad \dots \quad \dots \quad \dots \quad \dots \quad \dots \quad \dots \quad \dots \quad \dots \quad \dots \$$
It is easy to obtain the corresponding Jacobian is J = 1 . Thus the joint p.d.f. of u , 1 · · · , u K -1 is
$$f _ { u _ { 1 }, \dots, u _ { K - 1 } } \left ( x _ { 1 }, \cdots, x _ { K - 1 } \right ) & = \frac { \Gamma ( n _ { T } - 1 ) } { \Gamma ( n _ { T } - K ) } \left ( 1 - x _ { 1 } \right ) ^ { n _ { T } - K - 1 }. \\ & \quad \,. \.$$
Since 0 ≤ t i ≤ 1 , we have 0 ≤ t 1 = u 1 -∑ K -1 i =2 u i ≤ 1 . The region of the random variables after transformation can be obtained as D = ( u , 1 · · · , u K -1 ) | 0 ≤ K -1 l =2 u l ≤ u 1 ≤ 1 0 , ≤
.
u i ≤ 1 for i = 2 , · · · , K -1 } . Then the marginal distribution of u 1 can be obtained as
$$- \quad \cdot \quad \cdot \quad, \quad \Lambda \quad \cdot \\ f _ { u _ { 1 } } ( x ) \quad = \int \dots \int _ { \mathcal { D } } f ( x, x _ { 2 } \dots, x _ { K - 1 } ) \, \mathrm d x _ { 2 } \dots \mathrm d x _ { K - 1 } \\ = \int \dots \int _ { \mathcal { D } } \frac { \Gamma ( n _ { T } - 1 ) } { \Gamma ( n _ { T } - K ) } \left ( 1 - x _ { 1 } \right ) ^ { n _ { T } - K - 1 } \, \mathrm d x _ { 2 } \dots \mathrm d x _ { K - 1 } \\ \stackrel { ( a ) } { = } \frac { \Gamma ( n _ { T } - 1 ) } { \Gamma ( n _ { T } - K ) } ( 1 - x ) ^ { n _ { T } - K - 1 } \frac { x ^ { K - 2 } } { ( K - 2 )! } \\ \text{ich is given by (16), where in (a) we have used the identity } \, \int \, \dots \int \, \mathrm d t _ { 1 } \cdots \, \mathrm d t _ { n } =$$
which is given by (16), where in (a) we have used the identity ∫ ∫ · · · ∫ ∑ n i =1 t i ≤ h t 1 ≥ 0 , ··· ,t n ≥ 0 d t 1 · · · d t n = h n n ! [24]. We find that ε 1 = u 1 follows beta distribution with shape ( K -1) and ( n T -K ) . In the following we will prove ε k s have the same distribution.
Let π be an arbitrary and channel-independent permutation of (1 , 2 , · · · , K ) . P π = [ 1 π (1) , · · · , 1 π ( K ) ] T is the permutation matrix corresponding to π and 1 π ( ) i is the π ( ) i -th column of identity matrix. We denote ˆ H π = P H π ˆ = [ h T π (1) , · · · , h T π ( K ) ] T the matrix obtained by permutating the row vector of matrix ˆ H according to the permutation π . Then the QR decomposition of ˆ H π can be written as ˆ H π = P RQ π ˆ ˆ = ˆ R Q π ˆ π . With the assumption that ˆ R π has positive diagonal elements, the above QR decomposition of ˆ H π is unique. Using Givens transformation, there is a series of Givens matrices G 1 , · · · , G K -1 ∈ C K × K which satisfy P RG π ˆ 1 · · · G K -1 = ¯ R π [26], where ¯ R π ∈ C K × K is a lower triangular matrix with positive diagonal elements. Since Givens matrix is unitary, we have G 1 · · · G K -1 G H K -1 · · · G H 1 = I . So ˆ H π can be written as ˆ H π = ¯ R G π H K -1 · · · G Q H 1 ˆ . Let ¯ Q π = G H K -1 · · · G Q H 1 ˆ . Then we have ˆ H π = ¯ R Q π ¯ π where ¯ Q π is unitary. Thus ˆ H π = ¯ R Q π ¯ π is also a QR decomposition of ˆ H π . Using the uniqueness of QR decomposition, we conclude that ¯ Q π = ˆ Q π and ¯ R π = ˆ R π . Thus we have
$$\varepsilon _ { k } & = \| \tilde { h } _ { k } \hat { Q } ^ { H } \| ^ { 2 } \\ & = \| \tilde { h } _ { k } \hat { Q } ^ { H } _ { \pi } G ^ { H } _ { K - 1 } \cdots G ^ { H } _ { 1 } \| ^ { 2 } \\ & \stackrel { ( b ) } { = } \| \tilde { h } _ { k } \bar { Q } ^ { H } _ { \pi } \| ^ { 2 },$$
where ( b ) is due to the fact that the matrix G i is unitary for i = 1 , · · · , K -1 . If we let π (1) = k , ˆ h k will be the first row of ˆ H π . According to the previous derivation in the proof, we know ε k for k = 2 , · · · , K -1 have the same distribution as ε 1 whose p.d.f. is give by (16).
## APPENDIX B
## PROOF OF Lemma 2
Let Y = ‖ ˜ h Q k ˆ H ‖ 2 . As shown in Lemma 1, Y follows the beta distribution with shape ( K -1) and ( n T -K ) and the cumulative distribution function (c.d.f.) is given by Pr ( Y ≤ y ) = I x ( K -1 , n T -K ) , where I x ( · , · ) is the regularized incomplete beta function. Using the facts that
$$I _ { x } \left ( a, b \right ) & = \sum _ { m = a } ^ { a + b - 1 } \frac { ( a + b - 1 )! } { m! ( a + b - m - 1 )! } x ^ { m } ( 1 - x ) ^ { a + b - m - 1 }, \\ \intertext { r \infty } \varepsilon \quad \varepsilon \quad \varepsilon \quad \cdot \quad \varepsilon \quad \cdot \quad \cdot \quad \cdot \quad \cdot \quad \cdot \quad \cdot \quad \cdot \quad \cdot \quad \cdot \quad \cdot \quad \cdot \quad \cdot \quad \cdot \quad \cdot \quad \cdot \quad \cdot \quad \cdot \quad \cdot \quad \cdot \quad \cdot \quad \cdot \quad \cdot \quad \cdot \quad \cdot \quad \cdot \quad \cdot \quad \cdot \quad \cdot \quad \cdot \quad \cdot \quad \cdot \quad \cdot \quad \cdot \quad \cdot \quad \cdot \quad \cdot \quad \cdot \quad \cdot \quad \cdot \quad \cdot \quad \cdots$$
E [ X ] = ∫ ∞ 0 Pr ( X ≥ x ) d x for nonnegative random variables and binomial expansion, we have
$$\mathbb { E } [ X ] = \int _ { 0 } ^ { \infty } \Pr \left ( X \geq x \right ) d x & \text{ for nonnegative random variables and binomial expansion, we have } \\ \mathbb { E } \left [ - \ln Y \right ] & = \int _ { 0 } ^ { \infty } \Pr \left ( Y \leq e ^ { - x } \right ) d x \\ & = \int _ { 0 } ^ { \infty } I _ { e - x } ( K - 1, n _ { T } - K ) d x \\ & = \int _ { 0 } ^ { \infty } \left \{ \sum _ { m = K - 1 } ^ { n _ { T } - 2 } \frac { ( n _ { T } - 2 )! } { m! ( n _ { T } - 2 - m )! } e ^ { - m x } ( 1 - e ^ { - x } ) ^ { n _ { T } - 2 - m } \right \} d x \\ & = \int _ { 0 } ^ { \infty } \left \{ \sum _ { m = K - 1 } ^ { n _ { T } - 2 } \frac { ( n _ { T } - 2 )! } { m! ( n _ { T } - 2 - m )! } e ^ { - m x } \sum _ { l = 0 } ^ { n _ { T } - 2 } \binom { n _ { T } - m - 2 } { l } ( - 1 ) ^ { l } e ^ { - l x } \right \} d x \\ & = \sum _ { m = K - 1 } ^ { n _ { T } - 2 } \sum _ { l = 0 } ^ { n _ { T } - m - 2 } \frac { ( n _ { T } - 2 )! } { m! ( n _ { T } - 2 - m )! } \binom { n _ { T } - m - 2 } { l } ( - 1 ) ^ { l } \frac { 1 } { m + l }. \\ & = \sum _ { m = K - 1 } ^ { n _ { T } - 2 } \sum _ { l = 0 } ^ { n _ { T } - m - 2 } \frac { ( n _ { T } - 2 )! } { m! \, l! \, ( n _ { T } - m - 2 - l )! } ( - 1 ) ^ { l } \frac { 1 } { m + l }.$$
Thus (17) is proved.
## APPENDIX C
## PROOF OF Theorem 1
First we will prove the fact that | r k,k | 2 and ρ 2 k | ˆ r k,k | 2 have the same distribution. Let the QR decomposition of matrix ˇ H = ΦH ˆ be ˇ ˇ QR . It is easy to see | ˇ r k,k | 2 = ρ 2 k | ˆ r k,k | 2 , where ˇ r k,k is the k -th diagonal element of ˇ R . Since we assume using RVQ, ˇ H has the same distribution as H . Thus ρ 2 k | ˆ r k,k | 2 has the same distribution as | r k,k | 2 .
Using (9), (15) (18) and (19), we can write
$$\text{Using (9), (15) (18) and (19), we can write } \\ \Delta R _ { k } & = \mathbb { E } _ { \mathbb { H }, w } \left \{ \log _ { 2 } \left ( 1 + \frac { P } { \kappa } | _ { r _ { k }, k } | ^ { 2 } \right ) - \log _ { 2 } \left ( 1 + \frac { \frac { P } { \kappa } \rho _ { k } ^ { 2 } | \tilde { r } _ { k, k } | ^ { 2 } \cos ^ { 2 } \theta _ { k } } { \frac { \kappa } { \kappa } \rho _ { k } ^ { 2 } \| \hbar { k } } \right ) \right \} \\ & = \mathbb { E } _ { \mathbb { H }, w } \left \{ \log _ { 2 } \left ( 1 + \frac { P } { \kappa } | _ { r _ { k }, k } | ^ { 2 } \right ) \right \} - \mathbb { E } _ { \mathbb { H }, w } \left \{ \log _ { 2 } \left ( \frac { P } { \kappa } \rho _ { k } ^ { 2 } \left ( | \tilde { r } _ { k, k } | ^ { 2 } \cos ^ { 2 } \theta _ { k } + \| \tilde { h } _ { k } \tilde { Q } ^ { \theta } \| ^ { 2 } \sin ^ { 2 } \theta _ { k } \right ) + 1 \right ) \right \} \\ & \quad + \mathbb { E } _ { \mathbb { H }, w } \left \{ \log _ { 2 } \left ( \frac { P } { \kappa } \rho _ { k } ^ { 2 } \| \hbar { k } \tilde { Q } ^ { \theta } \| ^ { 2 } \sin ^ { 2 } \theta _ { k } \right ) \right \} \\ & \quad \leq \mathbb { E } _ { \mathbb { H }, w } \left \{ \log _ { 2 } \left ( 1 + \frac { P } { \kappa } | _ { r _ { k }, k } | ^ { 2 } \right ) \right \} - \mathbb { E } _ { \mathbb { H }, w } \left \{ \log _ { 2 } \left ( 1 + \frac { P } { \kappa } \rho _ { k } ^ { 2 } | \tilde { r } _ { k, k } | ^ { 2 } \cos ^ { 2 } \theta _ { k } \right ) \right \} \\ & \quad + \mathbb { E } _ { \mathbb { H }, w } \left \{ \log _ { 2 } \left ( 1 + \frac { P } { \kappa } \rho _ { k } ^ { 2 } \| \tilde { h } _ { k } \tilde { Q } ^ { \theta } \| ^ { 2 } \sin ^ { 2 } \theta _ { k } \right ) \right \} \\ & \quad \approx - \mathbb { E } _ { \mathbb { H }, w } \left \{ \log _ { 2 } \left ( \cos ^ { 2 } \theta _ { k } \right ) \right \} + \mathbb { E } _ { \mathbb { H }, w } \left \{ \log _ { 2 } \left ( 1 + \frac { P } { \kappa } \rho _ { k } ^ { 2 } \| \tilde { h } _ { k } \tilde { Q } ^ { \theta } \| ^ { 2 } \sin ^ { 2 } \theta _ { k } \right ) \right \}$$
$$\leq \log _ { 2 } \left ( 1 + \frac { P } { \kappa } \mathbb { E } _ { \mathbf H, W } \left \{ \rho _ { k } ^ { 2 } \| \tilde { \mathbf h } _ { k } \hat { Q } ^ { H } \| ^ { 2 } \sin ^ { 2 } \theta _ { k } \right \} \right ) - \mathbb { E } _ { \mathbf H, W } \left \{ \log _ { 2 } \left ( \cos ^ { 2 } \theta _ { k } \right ) \right \}. \\ \intertext { H a r a t i n d e w a l i m i n t a n d t h a n o n a n o t i v a t i m c i l h. } \| \tilde { \mathbf h }. \hat { \mathbf A } ^ { H \| ^ { 2 } \sin ^ { 2 } A. \ i n t h a c o n d t. }$$
$$& - \stackrel { - \mathcal { M }, \mathcal { N } } { \Phi } \left \{ \stackrel { - \mathcal { M } } { \mathcal { M } } ^ { \mathcal { M } } \stackrel { \mathcal { M }, \mathcal { K }, \mathcal { K } } { \Phi } \right \} \right \} \stackrel { - \mathcal { M }, \mathcal { N } } { \Phi } \stackrel { \mathcal { M }, \mathcal { K } } { \Phi } \stackrel { \mathcal { M } } { \Phi } \right \} \right \} \\ & \quad + \mathbb { E } _ { \mathbf H, W } \left \{ \log _ { 2 } \left ( 1 + \frac { P } { \kappa } \rho _ { k } ^ { 2 } \| \tilde { \mathbf h } _ { k } \hat { Q } ^ { H } \| ^ { 2 } \sin ^ { 2 } \theta _ { k } \right ) \right \} \\ & \quad \approx - \mathbb { E } _ { \mathbf H, W } \left \{ \log _ { 2 } \left ( \cos ^ { 2 } \theta _ { k } \right ) \right \} + \mathbb { E } _ { \mathbf H, W } \left \{ \log _ { 2 } \left ( 1 + \frac { P } { \kappa } \rho _ { k } ^ { 2 } \| \tilde { \mathbf h } _ { k } \hat { Q } ^ { H } \| ^ { 2 } \sin ^ { 2 } \theta _ { k } \right ) \right \} \\ & \quad \leq \log _ { 2 } \left ( 1 + \frac { P } { \kappa } \mathbb { E } _ { \mathbf H, W } \left \{ \rho _ { k } ^ { 2 } \| \tilde { \mathbf h } _ { k } \hat { Q } ^ { H } \| ^ { 2 } \sin ^ { 2 } \theta _ { k } \right \} \right ) - \mathbb { E } _ { \mathbf H, W } \left \{ \log _ { 2 } \left ( \cos ^ { 2 } \theta _ { k } \right ) \right \}. \\ \quad \longrightarrow \quad \dots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots.$$
Here (31) holds by eliminating the non-negative terms ‖ ˜ h Q k ˆ H ‖ 2 sin 2 θ k in the second term of (30). (32) follows by using high SNR approximation and the fact that | r k,k | 2 and ρ 2 k | ˆ r k,k | 2 have the same distribution which has been proved above. (33) follows by applying Jensen's inequality.
Since the norm of the channel vector ρ k and the direction of channel vector ¯ h k are independent and sin 2 θ k and ˜ h k ( ˆ h k ) are also independent with each other [2], we have
$$\mathbb { E } _ { \mathbf H, W } \left \{ \rho _ { k } ^ { 2 } \| \tilde { \mathbf h } _ { k } \hat { Q } ^ { \mathcal { H } } \| ^ { 2 } \sin ^ { 2 } \theta _ { k } \right \} = \mathbb { E } _ { \mathbf H, W } \left \{ \rho _ { k } ^ { 2 } \right \} \mathbb { E } _ { \mathbf H, W } \left \{ \| \tilde { \mathbf h } _ { k } \hat { Q } ^ { \mathcal { H } } \| ^ { 2 } \right \} \mathbb { E } _ { \mathbf H, W } \left \{ \sin ^ { 2 } \theta _ { k } \right \}. \quad \text{(34)} \\ \text{Each the main of this and this of $2\partial\cos_{bosh_{used_recommend{cases}$\theta$} \, \text{$a$} \, \text{$a$} \, \text{$a$} \, \text{$a$} \, \text{$a$} \, \text{$a$} \, \text{$a$} \, \text{$a$} \, \text{$a$} \, \text{$a$} \, \text{$a$} \, \text{$a$} \, \text{$a$} \, \text{$a$} \, \text{$a$} \, \text{$a$} \, \text{$a$} \, \text{$a$} \, \text{$a$} \, \text{$a$} \, \text{$a$} \, \text{$a$} \, \text{$a$ } \, \text{$a$} \, \text{$a$} \, \text{$a$} \, \text{$a$} \, \text{$a$} \, \text{$a$} \, \text{$a$} \, \text{$a$} \, \text{$a$} \, \text{$a$} \, \text{$a$} \, \text{$a$} \, \text{$a$} \, \text{$a$} \, \text{$a$} \, \text{$a$} \, \text{$a$} \, \text{$a$} \, \text{$a$} \, \text{$a$} \, \text{$a$} \, \text{$a$} \. \text{$a$} \, \text{$a$} \, \text{$a$} \, \text{$a$} \, \text{$a$} \, \text{$a$} \, \text{$a$} \, \text{$a$} \, \text{$a$} \, \text{$a$} \, \text{$a$} \, \text{$a$} \, \text{$a$} \, \text{$a$} \, \text{$a$} \, \text{$a$} \, \text{$a$} \, \text{$a$} \, \text{$a$} \, \text{$a$} \, \text{$a$} \, \text{$a$} \, \end{$$
Each term of right hand side of (34) can be obtained respectively as follows.
$$\mathbb { E } _ { \mathbf H, W } \left \{ \rho _ { k } ^ { 2 } \right \} & = \mathbb { E } _ { \mathbf H, W } \left \{ \chi _ { 2 n _ { T } } ^ { 2 } \right \} = n _ { T }, & \\ \int _ { \left \| \tilde { K } _ { \mathbf H } \right \| 2 } \right \| _ { \mathbb { P } } \quad \int _ {$$
$$\mathbb { E } _ { \mathrm H, W } \left \{ \| \tilde { \mathbf h } _ { k } \hat { \mathbf Q } ^ { H } \| ^ { 2 } \right \} & = \mathbb { E } _ { \mathrm H, W } \left ( \text{Beta} \left ( K - 1, n _ { T } - 1 \right ) \right ) = \frac { K - 1 } { n _ { T } - 1 }, \\ & \quad \quad \quad$$
$$\mathbb { E } _ { \mathrm H, W } \left \{ \sin ^ { 2 } \theta _ { k } \right \} & \leq 2 ^ { - \frac { B } { M - 1 } }, \\ \intertext { a b t i n d k i n s o n d f o m i n d f o m i n d f o m i n d f o m i n d f o m i n d f o m i n d f o m i n d f o m i n d f o m i n d f$$
where (36) can be easily obtained by using p.d.f. result in (16) and (37) is given in [18] and [2, Lemma 1] respectively. In [27], the second term in (33) was obtained as
$$\mathbb { E } _ { \mathbf H, W } \left \{ \log _ { 2 } \left ( \cos ^ { 2 } \theta _ { k } \right ) \right \} = \log _ { 2 } ( e ) \sum _ { i = 1 } ^ { n } \binom { n } { i } ( - 1 ) ^ { i } \sum _ { l = 1 } ^ { i ( n _ { T } - 1 ) } \frac { 1 } { l },$$
and (38) is rewritten in [28] as
$$\mathbb { E } _ { \mathbf H, W } \left \{ \log _ { 2 } \left ( \cos ^ { 2 } \theta _ { k } \right ) \right \} = - \frac { \log _ { 2 } ( e ) } { n _ { T } - 1 } \sum _ { i = 1 } ^ { n _ { T } - 1 } \beta \left ( n, \frac { i } { n _ { T } - 1 } \right ). \\ \intertext { n a t r e c t f o$$
The final result follows by combing (34)-(39) .
## APPENDIX D
PROOF OF Theorem 2
The average sum rate for user k can be upper bounded as
$$\text{$ne average sum rate for user $\kappa$ can be upper nounae as} \\ \\ \mathbb { E } _ { \text{H}, w } \left \{ R _ { Q, k } \right \} & = \mathbb { E } _ { \text{H}, w } \left \{ \log _ { 2 } \left ( 1 + \frac { \underline { P } _ { \kappa } \rho _ { k } ^ { 2 } | \hat { r } _ { k, k } | ^ { 2 } \cos ^ { 2 } \theta _ { k } } { \underline { P } _ { \kappa } ^ { 2 } \| \tilde { h } _ { k } \tilde { Q } ^ { H } \| ^ { 2 } \sin ^ { 2 } \theta _ { k } + 1 } \right ) \right \} \\ & \leq \mathbb { E } _ { \text{H}, w } \left \{ \log _ { 2 } \left ( 1 + \frac { | \hat { r } _ { k, k } | ^ { 2 } \cos ^ { 2 } \theta _ { k } } { \| \tilde { h } _ { k } \tilde { Q } ^ { H } \| ^ { 2 } \sin ^ { 2 } \theta _ { k } } \right ) \right \} \\ & = \mathbb { E } _ { \text{H}, w } \left \{ \log _ { 2 } \left ( \frac { | \hat { r } _ { k, k } | ^ { 2 } \cos ^ { 2 } \theta _ { k } + \| \tilde { h } _ { k } \tilde { Q } ^ { H } \| ^ { 2 } \sin ^ { 2 } \theta _ { k } } { \| \tilde { h } _ { k } \tilde { Q } ^ { H } \| ^ { 2 } \sin ^ { 2 } \theta _ { k } } \right ) \right \} \\ & \leq - \mathbb { E } _ { \text{H}, w } \left \{ \log _ { 2 } \left ( \| \tilde { h } _ { k } \tilde { Q } ^ { H } \| ^ { 2 } \sin ^ { 2 } \theta _ { k } \right ) \right \}, \\ \\ \text{where (40) is obtained using the facts that $|\hat { r } _ { k, k } | ^ { 2 } \leq 1$ and $|\tilde { h } _ { k } \tilde { Q } ^ { H } \| ^ { 2 } \leq 1.$ By using [2, Lemma$} \\ \mathbb { A } \stackrel { \sim } { \sim } \mathbb { P } _ { \text{H} } \quad \text{$\mathbb { A } \stackrel { \sim } { \sim } \mathbb { A } \stackrel { \sim } { \sim } \mathbb { A } \stackrel { \sim } { \sim } \mathbb { A } \stackrel { \sim } { \sim } \mathbb { A } \stackrel { \sim } { \sim }$$
where (40) is obtained using the facts that | ˆ r k,k | 2 ≤ 1 and ‖ ˜ h Q k ˆ H ‖ 2 ≤ 1 . By using [2, Lemma 3] and (36), E H , W { R Q,k } can be upper bounded as
$$\mathbb { E } _ { \mathrm H, W } \left \{ R _ { Q, k } \right \} \leq - \mathbb { E } _ { \mathrm H, W } \left \{ \log _ { 2 } \left ( \left \| \tilde { \mathbf h } _ { k } \hat { Q } ^ { H } \right \| ^ { 2 } \right ) \right \} - \mathbb { E } _ { \mathrm H, W } \left \{ \log _ { 2 } \left ( \sin ^ { 2 } \theta _ { k } \right ) \right \}. \quad \, \quad \, ( 4 1 ) \\ \intertext { T h a n d } \mathbb { m } ( \mathcal { U } \colon \, \text{all some $t$ machine $t$ machine $t$ machine $t$ machine $t$ machine $t$ machine $t$ machine $t$ machine $t$ machine $t$ machine $t$ machine $t$ machine $t$ machine $t$ machine $t$ machine $t$ machine $t$ machine $t$ machine $t$ machine $t$ machine $t$ machine $t$ machine $t$ machine $t$ machine $t$ machine $t$ machine $t$ machine $t$ machine $t$ machine $t$ machine $t$ machine $t$ machine $t$ machine $t$ machine $t$ machine $t$ machine $t$ machine $t$ machine $t$ machine $t$ machine $t$ machine $t$ machine $t$ machine $t$ machine $t$ machine $t$ machine $t$ machine $t$ machine $t$ machine $t$ machine $t$ machines $t$ machine $t$ machine $t$ machine $t$ machine $t$ machine $t$ machine $t$ machine $t$ machine $t$ machine $t$ machine $t$ machine $t$ machine $t$ machine $t$ machine $t$ machine $t$ machine $t$ machine $t$ machine $t$ machine $t$ machine $t$ machine $t$ machine $t$ machine $t$ machine $t$ machine $t$ machine $t$ machine $t$ machine $t$ machine $t$ machine $t$ machine $t$ machine $t$ machine $t$ machine $t$ machine $t$ machine $t$ machine $t$ machine $t$ machine $t$ machine $t$ machine $t$ machine $t$ machine $t$ machine $t$ machine $t$ machine $t$ machine $t$ machine $t$ machine $t$ Machine $t$ machine $t$ machine $t$ machine $t$ machine $t$ machine $t$ machine $t$ machine $t$ machine $t$ machine $t$ machine $t$ machine $t$ machine $t$ machine $t$ machine $t$ machine $t$ machine $t$ machine $t$ machine $t$ machine $t$ machine $t$ machine $t$ machine $t$ machine $t$ machine $t$ machine $t$ machine $t$ machine $t$ machine $t$ machine $t$ machine $t$ machine $t$ machine $t$ machine $t$ machine $t$ machine $t$ machine $t$ machine $t$ machine $t$ machine $t$ machine $t$ machine $t$ machine $t$ machine $t$ machine $t$ machine $t$ machine $t$ machine $t$ machine $t$ machine $t$machine $t$ machine $t$ machine $t$ machine $t$ machine $t$ machine $t$ machine $t$ machine $t$ machine $t$ machine $t$ machine $t$ machine $t$ machine $t$ machine $t$ machine $t$ machine $t$ machine $t$ machine $t$ machine $t$ machine $t$ machine $t$ machine $t$ machine $t$ machine $t$ machine $t$ machine $t$ machine $t$ machine $t$ machine $t$ machine $t$ machine $t$ machine $t$ machine $t$ machine $t$ machine $t$ machine $t$ machine $t$ machine $t$ machine $t$ machine $t$ machine $t$ machine $t$ machine $t$ machine $t$ machine $t$ machine $t$ machine $t$ machine $t$ machine $t$ machine $t$Machine $t$ machine $t$ machine $t$ machine $t$ machine $t$ machine $t$ machine $t$ machine $t$ machine $t$ machine $t$ machine $t$ machine $t$ machine $t$ machine $t$ machine $t$ machine $t$ machine $t$ machine $t$ machine $t$ machine $t$ machine $t$ machine $t$ machine $t$ machine $t$ machine $t$ machine $t$ machine $t$ machine $t$ machine $t$ machine $t$ machine $t$ machine $t$ machine $t$ machine $t$ machine $t$ machine $t$ machine $t$ machine $t$ machine $t$ machine $t$ machine $t$ machine $t$ machine $t$ machine $t$ machine $t$ machine $t$ machine $t$ machine $t$ machine $t$ machine $t$ engine $t$ engine $t$ engine $t$ engine $t$ engine $t$ engine $t$ engine $t$ engine $t$ engine $t$ engine $t$ engine $t$ engine $t$ engine $t$ engine $t$ engine $t$ engine $t$ engine $t$ engine $t$ engine $t$ engine $t$ engine $t$ engine $t$ engine $t$ engine $t$ engine $t$ engine $t$ engine $t$ engine $t$ engine $t$ engine $t$ engine $t$ engine $t$ engine $t$ engine $t$ engine $t$ engine $t$ engine $t$ engine $t$ engine $t$ engine $t$ engine $t$ engine $t$ engine $t$ engine $t$ engine $t$ engine $t$ engine $t$ engine $t$ engine $t$ engine $t$ Engine $t$ engine $t$ engine $t$ engine $t$ engine $t$ engine $t$ engine $t$ engine $t$ engine $t$ engine $t$ engine $t$ engine $t$ engine $t$ engine $t$ engine $t$ engine $t$ engine $t$ engine $t$ engine $t$ engine $t$ engine $t$ engine $t$ engine $t$ engine $t$ engine $t$ engine $t$ engine $t$ engine $t$ engine $t$ engine $t$ engine $t$ engine $t$ engine $t$ engine $t$ engine $t$ engine $t$ engine $t$ engine $t$ engine $t$ engine $t$ engine $t$ engine $t$ engine $t$ engine $t$ engine $t$ engine $t$ engine $t$ engine $t$ engine $t$ engine $t$Engine $t$ engine $t$ engine $t$ engine $t$ engine $t$ engine $t$ engine $t$ engine $t$ engine $t$ engine $t$ engine $t$ engine $t$ engine $t$ engine $t$ engine $t$ engine $t$ engine $t$ engine $t$ engine $t$ engine $t$ engine $t$ engine $t$ engine $t$ engine $t$ engine $t$ engine $t$ engine $t$ engine $t$ engine $t$ engine $t$ engine $t$ engine $t$ engine $t$ engine $t$ engine $t$ engine $t$ engine $t$ engine $t$ engine $t$ engine $t$ engine $t$ engine $t$ engine $t$ engine $t$ engine $t$ engine $t$ engine $t$ engine $t$ engine $t$ engine $t$ engines $t$ engine $t$ engine $t$ engine $t$ engine $t$ engine $t$ engine $t$ engine $t$ engine $t$ engine $t$ engine $t$ engine $t$ engine $t$ engine $t$ engine $t$ engine $t$ engine $t$ engine $t$ engine $t$ engine $t$ engine $t$ engine $t$ engine $t$ engine $t$ engine $t$ engine $t$ engine $t$ engine $t$ engine $t$ engine $t$ engine $t$ engine $t$ engine $t$ engine $t$ engine $t$ engine $t$ engine $t$ engine $t$ engine $t$ engine $t$ engine $t$ engine $t$ engine $t$ engine $t$ engine $t$ engine $t$ engine $t$ engine $t$ engine $t$ engine $t$ machine $t$ engine $t$ engine $t$ engine $t$ engine $t$ engine $t$ engine $t$ engine $t$ engine $t$ engine $t$ engine $t$ engine $t$ engine $t$ engine $t$ engine $t$ engine $t$ engine $t$ engine $t$ engine $t$ engine $t$ engine $t$ engine $t$ engine $t$ engine $t$ engine $t$ engine $t$ engine $t$ engine $t$ engine $t$ engine $t$ engine $t$ engine $t$ engine $t$ engine $t$ engine $t$ engine $t$ engine $t$ engine $t$ engine $t$ engine $t$ engine $t$ engine $t$ engine $t$ engine $t$ engine $t$ engine $t$ engine $t$ engine $t$ engine $t$ engines $t$ engines $t$ engine $t$ engine $t$ engine $t$ engine $t$ engine $t$ engine $t$ engine $t$ engine $t$ engine $t$ engine $t$ engine $t$ engine $t$ engine $t$ engine $t$ engine $t$ engine $t$ engine $t$ engine $t$ engine $t$ engine $t$ engine $t$ engine $t$ engine $t$ engine $t$ engine $t$ engine $t$ engine $t$ engine $t$ engine $t$ engine $t$ engine $t$ engine $t$ engine $t$ engine $t$ engine $t$ engine $t$ engine $t$ engine $t$ engine $t$ engine $t$ engine $t$ engine $t$ engine $t$ engine $t$ engine $t$ engine $t$ engine $t$ engine $t$ engines $t$Engine $t$ engine $t$ engine $t$ engine $t$ engine $t$ engine $t$ engine $t$ engine $t$ engine $t$ engine $t$ engine $t$ engine $t$ engine $t$ engine $t$ engine $t$ engine $t$ engine $t$ engine $t$ engine $t$ engine $t$ engine $t$ engine $t$ engine $t$ engine $t$ engine $t$ engine $t$ engine $t$ engine $t$ engine $t$ engine $t$ engine $t$ engine $t$ engine $t$ engine $t$ engine $t$ engine $t$ engine $t$ engine $t$ engine $t$ engine $t$ engine $t$ engine $t$ engine $t$ engine $t$ engine $t$ engine $t$ engine $t$ engine $t$ engine $t$ engines $t$ Engine $t$ engine $t$ engine $t$ engine $t$ engine $t$ engine $t$ engine $t$ engine $t$ engine $t$ engine $t$ engine $t$ engine $t$ engine $t$ engine $t$ engine $t$ engine $t$ engine $t$ engine $t$ engine $t$ engine $t$ engine $t$ engine $t$ engine $t$ engine $t$ engine $t$ engine $t$ engine $t$ engine $t$ engine $t$ engine $t$ engine $t$ engine $t$ engine $t$ engine $t$ engine $t$ engine $t$ engine $t$ engine $t$ engine $t$ engine $t$ engine $t$ engine $t$ engine $t$ engine $t$ engine $t$ engine $t$ engine $t$ engine $t$ engine $t$ engines $t$engine $t$ engine $t$ engine $t$ engine $t$ engine $t$ engine $t$ engine $t$ engine $t$ engine $t$ engine $t$ engine $t$ engine $t$ engine $t$ engine $t$ engine $t$ engine $t$ engine $t$ engine $t$ engine $t$ engine $t$ engine $t$ engine $t$ engine $t$ engine $t$ engine $t$ engine $t$ engine $t$ engine $t$ engine $t$ engine $t$ engine $t$ engine $t$ engine $t$ engine $t$ engine $t$ engine $t$ engine $t$ engine $t$ engine $t$ engine $t$ engine $t$ engine $t$ engine $t$ engine $t$ engine $t$ engine $t$ engine $t$ engine $t$ engine $t$ engine $t$engine $t$ engine $t$ engine $t$ engine $t$ engine $t$ engine $t$ engine $t$ engine $t$ engine $t$ engine $t$ engine $t$ engine $t$ engine $t$ engine $t$ engine $t$ engine $t$ engine $t$ engine $t$ engine $t$ engine $t$ engine $t$ engine $t$ engine $t$ engine $t$ engine $t$ engine $t$ engine $t$ engine $t$ engine $t$ engine $t$ engine $t$ engine $t$ engine $t$ engine $t$ engine $t$ engine $t$ engine $t$ engine $t$ engine $t$ engine $t$ engine $t$ engine $t$ engine $t$ engine $t$ engine $t$ engine $t$ engine $t$ engine $t$ engine $t$ engines $t$ legging _ \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \ \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \$$
Then (21) follows by using Lemma 2 and [2, Lemma 3].
## APPENDIX E
THE PROOF THAT THE RHS OF (20) CAN BE BOUNDED BY A DECREASING FUNCTION OF n FOR A FIXED n T
$$\text{Let } \mathcal { J } \coloneqq \frac { \log _ { 2 } ( e ) } { n _ { T } - 1 } \sum _ { i = 1 } ^ { n _ { T } - 1 } \beta \left ( n, \frac { i } { n _ { T } - 1 } \right ). & \beta \left ( n, \frac { i } { n _ { T } - 1 } \right ) \text{ can be written as} \\ \quad \_ \int \quad i \quad \bigvee \quad \Gamma ( n ) \Gamma ( \frac { i } { n _ { T } - 1 } )$$
$$\beta \left ( n, \frac { i } { n _ { T } - 1 } \right ) = \frac { \Gamma ( n ) \Gamma ( \frac { i } { n _ { T } - 1 } ) } { \Gamma \left ( n + \frac { i } { n _ { T } - 1 } \right ) }.$$
By applying Kershaw's inequality for the gamma function [29],
$$\begin{array} { c c c } & & \frac { \Gamma ( x + s ) } { \Gamma \left ( x + 1 \right ) } < \left ( x + \frac { s } { 2 } \right ) ^ { s - 1 }, \forall x > 0, 0 \leq s \leq 1. \\ & & \\. & \colon &. &. \end{array} \quad.$$
With x = n -1 + i n T -1 and s = 1 -i n T -1 , we have
$$\frac { \Gamma ( n ) } { \Gamma \left ( n + \frac { i } { n _ { T } - 1 } \right ) } \leq \left ( n - \frac { 1 } { 2 } + \frac { i } { 2 ( n _ { T } - 1 ) } \right ) ^ { - \frac { i } { n _ { T } - 1 } } \leq \left ( n - \frac { 1 } { 2 } \right ) ^ { - \frac { i } { n _ { T } - 1 } }. \\ \text{Thus, $\mathcal{J}$ can be upper bounded as}$$
Thus, J can be upper bounded as
$$\mathcal { J } \leq \sum _ { i = 1 } ^ { n _ { T } - 1 } \Gamma ( \frac { i } { n _ { T } - 1 } ) \left ( n - \frac { 1 } { 2 } \right ) ^ { - \frac { i } { n _ { T } - 1 } }, \\ \intertext { w a d e d i n d e d e d e d e d e d e d e d e d e d e d e d e d e d e d e d e d e d e d e d e d e d e d e d e d e d e d e d e d e d e d e d e d e d e d e d e d e d e d e d e d e d e d e d e d e d e d e d e d e d e d e d e d e d e d e d e d e d e d e d e d e d e d e d e d e d e d e d e d e d e d e d e d e d e d e d e d e d e d e d e d e d e d e d e d e d e d e d e d e d e d e d e d e d e d e d e d e d e d e d e d d e d e d e d e d e d e d e d e d e d e d e d e d e d e d e d e d e d e d e d e d e d e d e d e d e d e d e d e d e d e d e d e d e d e d e d e d e d e d e d e d e d e d e d e d e d e d e d e d e d e d e d e d e d e d e d e d e d e d e d e d e d e d e d e d e d e d e d e d e d e d e d e d e d e d e d e d e d e d e d e d e d e d e d e d e d e d e d e d e d e d e d e d e d e d e d e d e d e d e d o d e d e d e d e d e d e d e d e d e d e d e d e d e d e d e d e d e d e d e d e d e d e d e d e d e d e d e d e d e d e d e d e d e d e d e d e d e d e d e d e d e d e d e d e d e d e d e d e d e d e d e d e d e d e d e d e d e d e d e d e d e d e d e d e d e d e d e d e d e d e d e d e d e d e d e d e d e d e d e d e d e d e d e d e d e d e d e d e d e d e d e d e d e d e d e d e d e d e d e d t e d e d e d e d e d e d e d e d e d e d e d e d e d e d e d e d e d e d e d e d e d e d e d e d e d e d e d e d e d e d e d e d e d e d e d e d e d e d e d e d e d e d e d e d e d e d e d e d e d e d e d e d e d e d e d e d e d e d e d e d e d e d e d e d e d e d e d e d e d e d e d e d e d e d e d e d e d e d e d e d e d e d e d e d e d e d e d e d e d e d e d e d e d e d e d e d e d e d e d e e d e d e d e d e d e d e d e d e d e d e d e d e d e d e d e d e d e d e d e d e d e d e d e d e d e d e d e d e d e d e d e d e d e d e d e d e d e d e d e d e d e d e d e d e d e d e d e d e d e d e d e d e d e d e d e d e d e d e d e d e d e d e d e d e d e d e d e d e d e d e d e d e d e d e d e d e d e d e d e d e d e d e d e d e d e d e d e d e d e d e d e d e d e d e d e d e d e d e d e d e d e d e d e d e d e d e d e d e d e d e d e d e d e d e d e d e d e d e d e d e d e d e d e d e d e d e d e d e d e d e d e d e d e d e d e d e d e d e d e d e d e d e d e d e d e d e d e d e d e d e d e d e d e d e d e d e d e d e d e d e d e d e d e d e d e d e d e d e d e d e d e d e d e d e d e d e d e d e d e d e d e d e d e d e d e d e d e d e d e d e d e d e d e d e d e d e d e d e d e d e d e d e d e d e d e d e d e d e d e d e d e d e d e d e d e d e d e d e d e d e d e d e d e d e d e d e d e d e d e d e d e d e d e d e d e d e d e d e d e d e d e d e d e d e d e d e d e d e d e d e d e d e d e d e d e d e d e d e d e d e d e d e d e d e d e d e d e d e d e d e d e d e d e d e d e d e d e d e d e d e d e d e d e d e d e d e d e d e d e d e d e d e d e d e d e d e d e d ed e d e d e d e d e d e d e d e d e d e d e d e d e d e d e d e d e d e d e d e d e d e d e d e d e d e d e d e d e d e d e d e d e d e d e d e d e d e d e d e d e d e d e d e d e d e d e d e d e d e d e d e d e d e d e d e d e d e d e d e d e d e d e d e d e d e d e d e d e d e d e d e d e d e d e d e d e d e d e d e d e d e d e d e d e d e d e d e d e d e d e d e d e d e d e d e d e d e d e d e s t e n t e n t e n t e n t e n t e n t e n t e n t e n t e n t e n t e n t e n t e n t e n t e n t e n t e n t e n t e n t e n t e n t e n t e n t e n t e n t e n t e n t e n t e n t e n t e n t e n t e n t e n t e n t e n t e n t e n t e n t e n t e n t e n t e n t e n t e n t e n t e n t e n t e n t e n t e n t e n t e n t e n t e n t e n t e n t e n t e n t e n t e n t e n t e n t e n t e n t e n t i n t e n t e n t e n t e n t e n t e n t e n t e n t e n t e n t e n t e n t e n t e n t e n t e n t e n t e n t e n t e n t e n t e n t e n t e n t e n t e n t e n t e n t e n t e n t e n t e n t e n t e n t e n t e n t e n t e n t e n t e n t e n t e n t e n t e n t e n t e n t e n t e n t e n t e n t e n t e n t e n t e n t e n t e n t e n t e n t e n t e n t e n t e n t e n t e n t e n t e n s t e n t e n t e n t e n t e n t e n t e n t e n t e n t e n t e n t e n t e n t e n t e n t e n t e n t e n t e n t e n t e n t e n t e n t e n t e n t e n t e n t e n t e n t e n t e n t e n t e n t e n t e n t e n t e n t e n t e n t e n t e n t e n t e n t e n t e n t e n t e n t e n t e n t e n t e n t e n t e n t e n t e n t e n t e n t e n t e n t e n t e n t e n t e n t e n t e n t e n s s t e n t e n t e n t e n t e n t e n t e n t e n t e n t e n t e n t e n t e n t e n t e n t e n t e n t e n t e n t e n t e n t e n t e n t e n t e n t e n t e n t e n t e n t e n t e n t e n t e n t e n t e n t e n t e n t e n t e n t e n t e n t e n t e n t e n t e n t e n t e n t e n t e n t e n t e n t e n t e n t e n t e n t e n t e n t e n t e n t e n t e n t e n t e n t e n t e n t e n e s s t e n t e n t e n t e n t e n t e n t e n t e n t e n t e n t e n t e n t e n t e n t e n t e n t e n t e n t e n t e n t e n t e n t e n t e n t e n t e n t e n t e n t e n t e n t e n t e n t e n t e n t e n t e n t e n t e n t e n t e n t e n t e n t e n t e n t e n t e n t e n t e n t e n t e n t e n t e n t e n t e n t e n t e n t e n t e n t e n t e n t e n t e n t e n t e n t e n t e s s t e n t e n t e n t e n t e n t e n t e n t e n t e n t e n t e n t e n t e n t e n t e n t e n t e n t e n t e n t e n t e n t e n t e n t e n t e n t e n t e n t e n t e n t e n t e n t e n t e n t e n t e n t e n t e n t e n t e n t e n t e n t e n t e n t e n t e n t e n t e n t e n t e n t e n t e n t e n t e n t e n t e n t e n t e n t e n t e n t e n t e n t e n t e n t e n t e n t i n t t e n t e n t e n t e n t e n t e n t e n t e n t e n t e n t e n t e n t e n t e n t e n t e n t e n t e n t e n t e n t e n t e n t e n t e n t e n t e n t e n t e n t e n t e n t e n t e n t e n t e n t e n t e n t e n t e n t e n t e n t e n t e n t e n t e n t e n t e n t e n t e n t e n t e n t e n t e n t e n t e n t e n t e n t e n t e n t e n t e n t e n t e n t e n t e n t e n t e n t u n t e n t e n t e n t e n t e n t e n t e n t e n t e n t e n t e n t e n t e n t e n t e n t e n t e n t e n t e n t e n t e n t e n t e n t e n t e n t e n t e n t e n t e n t e n t e n t e n t e n t e n t e n t e n t e n t e n t e n t e n t e n t e n t e n t e n t e n t e n t e n t e n t e n t e n t e n t e n t e n t e n t e n t e n t e n t e n t e n t e n t e n t e n t e n t e n t e n t e n e n t e n t e n t e n t e n t e n t e n t e n t e n t e n t e n t e n t e n t e n t e n t e n t e n t e n t e n t e n t e n t e n t e n t e n t e n t e n t e n t e n t e n t e n t e n t e n t e n t e n t e n t e n t e n t e n t e n t e n t e n t e n t e n t e n t e n t e n t e n t e n t e n t e n t e n t e n t e n t e n t e n t e n t e n t e n t e n t e n t e n t e n t e n t e n t e n t e n t e s s s t e n t e n t e n t e n t e n t e n t e n t e n t e n t e n t e n t e n t e n t e n t e n t e n t e n t e n t e n t e n t e n t e n t e n t e n t e n t e n t e n t e n t e n t e n t e n t e n t e n t e n t e n t e n t e n t e n t e n t e n t e n t e n t e n t e n t e n t e n t e n t e n t e n t e n t e n t e n t e n t e n t e n t e n t e n t e n t e n t e n t e n t e n t e n t e n t e n t e e n t e n t e n t e n t e n t e n t e n t e n t e n t e n t e n t e n t e n t e n t e n t e n t e n t e n t e n t e n t e n t e n t e n t e n t e n t e n t e n t e n t e n t e n t e n t e n t e n t e$$
where the RHS is a decreasing function of n for a fixed n T .
## REFERENCES
- [1] C. Windpassinger, R. F. H. Fischer, T. Vencel, and J. B. Huber, 'Precoding in multiantenna and multiuser communications,' IEEE Trans. Wireless Commun. , vol. 3, no. 4, pp. 1305-1316, Jul. 2004.
- [2] N. Jindal, 'MIMO broadcast channels with finite-rate feedback,' IEEE Trans. Inform. Theory , vol. 52, pp. 5045-5060, Nov. 2006.
- [3] ˙ . I E. Telatar, 'Capacity of multi-antenna Gaussian channels,' Europ. Trans. Commun. , pp. 585-595, Nov.-Dec. 1999.
- [4] G. J. Foschini and J. E. Hall, 'Layered space-time architecture for wireless communication in a fading environment when using multi-element antennas,' Bell Labs Tech. J. , pp. 41-59, 1996.
- [5] P. W. Wolniansky, G. J. Foschini, G. D. Golden, and R. A. Valenzuela, 'V-BLAST: An architecture for realizing very high data rates over the rich-scattering wireless channel,' in Proc. URSI Int. Symposium on Signals, Systems, and Electronics , pp. 295-300, Pisa, Italy 1998.
- [6] T. Haustein, C. von Helmolt, E. Jorswieck, V. Jungnickel, and V. Pohl, 'Performance of MIMO systems with channel inversion,' in Proc. 55th IEEE Veh. Technol. Conf. , pp. 35-39, Birmingham, AL, May 2002.
- [7] M. Joham, K.Kusume, M. H. Gzara, and W. Utschick, 'Transmit Wiener filter for the downlink of TDD DS-CDMA systems,' in Proc. IEEE 7th Symp. Spread-Spectrum Technol., Applicat. , pp. 9-13, Prague, Czech Republic, Sep. 2002.
- [8] C. B. Peel, B. M. Hochwald, and A. L. Swindlehurst, 'A vector-perturbation technique for near-capacity multiantenna multi-user communication -Part I: Channel inversion and regularization,' IEEE Trans. Commun. , vol. 53, no. 1, pp. 195-202, Jan. 2005.
- [9] J. Yang and S. Roy, 'Joint transmitter-receiver optimization for multi-input multi-output systems with decision feedback,' IEEE Trans. Inform. Theory , vol. 40, no. 5, pp. 1334-1347, Sep. 1994.
- [10] B. M. Hochwald, C. B. Peel, and A. L. Swindlehurst, 'A vector-perturbation technique for near-capacity multiantenna multiuser communication - Part II: Perturbation,' IEEE Trans. Commun. , vol. 53, no. 3, pp. 537-544, Mar. 2005.
- [11] R. F. H. Fischer, Precoding and Signal Shaping for Digital Transmission , 1st ed. USA: New York: Wiley, 2002.
- [12] M. Costa, 'Writing on dirty paper,' IEEE Trans. Inform. Theory , vol. 29, no. 1, pp. 439-441, May 1983.
- [13] H. Weingarten, Y. Steinberg, and S. Shamai (Shitz), 'The capacity region of the Gaussian multiple-input multiple-output broadcast channel,' IEEE Trans. Inform. Theory , vol. 52, no. 9, pp. 3936-3964, Sep. 2006.
- [14] M. O. Damen, A. Chkeif, and J.-C. Belfiore, 'Lattice code decoder for space-time codes,' IEEE Commun. Lett. , vol. 4, pp. 161-163, May. 2000.
- [15] H. Harashima and H. Miyakawa, 'Matched-transmission technique for channels with intersymbol interference,' IEEE Trans. Commun. , vol. 20, pp. 774-780, Aug. 1972.
- [16] A. A. D'Amico, 'Tomlinson-Harashima precoding in MIMO systems: A unified approach to transceiver optimization based on multiplicative schur-convexity,' IEEE Trans. Signal Process. , vol. 56, no. 8, pp. 3662-3677, Aug. 2008.
- [17] G. Caire and S. Shamai (Shitz), 'On the achievable throughput of a multi-antenna Gaussian broadcast channel,' IEEE Trans. Inform. Theory , vol. 49, no. 7, pp. 1691-1706, Jul. 2003.
- [18] C. K. Au-Yeung and D. J. Love, 'On the performance of random vector quantization limited feedback beamforming in a MISO system,' IEEE Trans. Wireless Commun. , vol. 6, pp. 458-462, Feb. 2007.
- [19] T. Yoo, N. Jindal, and A. Goldsmith, 'Multi-antenna downlink channels with limited feedback and user selection,' IEEE J. Sel. Areas Commun. , vol. 25, no. 7, pp. 1478-1491, Sep. 2007.
- [20] I. Slim, A. Mezghani, and J. A. Nossek, 'Quantized CDI based Tomlinson Harashima precoding for broadcast channels,' in Proc. IEEE Int. Conf. on Commun. (ICC) , Jun. 2011, pp. 1-5.
- [21] R. D. Wesel and J. M. Cioffi, 'Achievable rates for Tomlinson-Harashima precoding,' IEEE Trans. Inform. Theory , vol. 44, no. 2, pp. 824-831, Mar. 1998.
- [22] U. Erez and R. Zamir, 'Achieving 1 2 / log (1 + SNR ) on the AWGN channel with lattice encoding and decoding,' IEEE Trans. Inform. Theory , vol. 50, no. 10, pp. 2293-2314, Oct. 2004.
- [23] K. K. Mukkavilli, A. Sabharwal, E. Erkip, and B. Aazhang, 'On beamforming with finite rate feedback in multiple antenna systems,' IEEE Trans. Inform. Theory , vol. 50, no. 10, pp. 2562-2579, Oct. 2003.
- [24] I. S. Gradshteyn and I. M. Ryzhik, Table of Integrals, Series, and Products , 6th ed. New York: Academic, 2000.
- [25] L. Sun and M. R. McKay, 'Eigen-based transceivers for the MIMO broadcast channel with semi-orthogonal user selection,' IEEE Trans. Signal Process. , vol. 58, no. 10, pp. 5246-5261, Oct. 2010.
- [26] G. H. Golub and C. F. V. Loan, Matrix Computations , 3rd ed. Baltimore: Johns Hopkins Univ. Press, 1996.
- [27] R. Bhagavatula and J. R. W. Heath, 'Adaptive limited feedback for sum-rate maximizing beamforming in cooperative multicell systems,' IEEE Trans. Signal Process. , vol. 59, no. 2, pp. 800-811, Feb. 2011.
- [28] R. Bhagavatula and R. W. Heath, 'Adaptive bit partitioning for multicell intercell interference nulling with delayed limited feedback,' IEEE Trans. Signal Process. , vol. 59, no. 8, pp. 3824-3836, Aug. 2011.
- [29] D. Kershaw, 'Some extensions of W. Gautschi's inequalities for the gamma function,' Math. Comput. , vol. 41, no. 164, pp. 607-611, Oct. 1983. | null | [
"Liang Sun",
"Ming Lei"
] | 2014-08-03T04:33:02+00:00 | 2014-08-03T04:33:02+00:00 | [
"cs.IT",
"math.IT"
] | Quantized CSI-Based Tomlinson-Harashima Precoding in Multiuser MIMO Systems | This paper considers the implementation of Tomlinson-Harashima (TH) precoding
for multiuser MIMO systems based on quantized channel state information (CSI)
at the transmitter side. Compared with the results in [1], our scheme applies
to more general system setting where the number of users in the system can be
less than or equal to the number of transmit antennas. We also study the
achievable average sum rate of the proposed quantized CSI-based TH precoding
scheme. The expressions of the upper bounds on both the average sum rate of the
systems with quantized CSI and the mean loss in average sum rate due to CSI
quantization are derived. We also present some numerical results. The results
show that the nonlinear TH precoding can achieve much better performance than
that of linear zero-forcing precoding for both perfect CSI and quantized CSI
cases. In addition, our derived upper bound on the mean rate loss for TH
precoding converges to the true rate loss faster than that of zeroforcing
precoding obtained in [2] as the number of feedback bits becomes large. Both
the analytical and numerical results show that nonlinear precoding suffers from
imperfect CSI more than linear precoding does. |
1408.0456v1 | 
Nuclear Physics A

Nuclear Physics A 00 (2014) 1-8
## Theory of Jet Quenching in Ultra-Relativistic Nuclear Collisions
Guang-You Qin
Institute of Particle Physics and Key Laboratory of Quark and Lepton Physics (MOE), Central China Normal University, Wuhan, 430079, China
## Abstract
We present a short overview of recent progress in the theory of jet quenching in ultra-relativistic nuclear collisions, including phenomenological studies of jet quenching at RHIC and the LHC, development in NLO perburbative QCD calculation of jet broadening and energy loss, full jet evolution and modification, medium response to jet transport, and lattice QCD and AdS CFT / studies of jet quenching.
Keywords: relativistic nuclear collisions, quark-gluon plasma, jet quenching
## 1. Introduction
One of main goals of ultra-relativistic nuclear collisions, such as those performed at the Relativistic Heavy-Ion Collider (RHIC) and the Large Hadron Collider (LHC), is to create a novel state of matter, called quark-gluon plasma (QGP), and study its various properties. Large transverse momentum quarks and gluons, produced from early stage hard scatterings, have been regarded as very useful probes of such highly excited nuclear matter. These hard partonic jets interact with medium constituents during their propagation through the QGP medium before fragmenting into hadrons. The interaction with medium usually causes partons to lose energy, therefore observables associated with jets are modified as compared to the vacuum jets such as the case in elementary nucleon-nucleon collisions.
The basic framework for studying jet production in ultra-relativistic nuclear collisions is perburbative QCD factorization paradigm, i.e., processes involving large transverse momentum ( pT ) transfer may be factorized into longdistance and short-distance pieces. For example, the cross section of single inclusive high pT hadron production in elementary nucleon-nucleon collisions may be obtained as follows:
$$d \sigma _ { h } \approx \sum _ { a b j d } f ( x _ { a } ) \otimes f ( x _ { b } ) \otimes d \sigma _ { a b \to j d } \otimes D _ { j \to h } ( z _ { j } ).$$
In the above factorized formula, f ( xa ), f ( xb ) are parton distributions functions (PDF) and D zj ( ) is fragmentation functions (FF). These non-perturbative long-distance quantities are universal and usually obtained from global fitting to various experimental measurements, such as e + e GLYPH<0> and deep-inelastic scattering (DIS) experiments, etc. The partonic scattering cross sections d GLYPH<27> ab ! jd are short-distance quantities involving large pT transfer, and thus may be calculated using perturbative QCD techniques.
In phenomenological studies of jet energy loss and jet quenching ultra-relativistic heavy-ion collisions, the above formula needs some modification due to the presence of hot and dense QGP:
$$d \tilde { \sigma } _ { h } \approx \sum _ { a b j j ^ { \prime } d } f ( x _ { a } ) \otimes f ( x _ { b } ) \otimes d \sigma _ { a b \to j d } \otimes P _ { j \to j ^ { \prime } } \otimes D _ { j ^ { \prime } \to h } ( z ^ { \prime } _ { j } ).$$
The additional piece Pj ! 0 j is to take into account the interaction between the hard partons j and the QGP medium before fragmenting into high pT hadrons. Often one combines parton-medium interaction function Pj ! 0 j and vacuum fragmentation function to define so-called medium-modified fragmentation function ˜ Dj ! h GLYPH<25> P j 0 Pj ! 0 j GLYPH<10> Dj 0 ! h ; one may also define medium-modified parton cross section by combining parton-medium interaction with vacuum cross section. Although the above factorized formula have been widely used in phenomenological studies of jet modification and energy loss, no formal proof of factorization is available yet for ultra-relativistic heavy-ion collisions.
## 2. Radiative and Collisional Jet Energy Loss
In the study of jet quenching in ultra-relativistic heavy-ion collisions, two di GLYPH<11> erent medium-induced mechanisms are usually considered for jet energy loss: elastic collisions with medium constituents and induced bremsstrahlung processes. The energy loss occurred in binary elastic collisions is usually referred to as collisional jet energy loss. The scatterings between hard partonic jets with medium constituents usually induce additional radiation which carry away part of the parent parton's energy; such mechanism is called radiative energy loss.
During last decades, much e GLYPH<11> ort has been focused on studying radiative jet energy loss. A number of approaches have been developed in the literature. Based on the assumptions made in di GLYPH<11> erent formalisms when calculating single gluon emission spectrum, they may be cast into two categories: multiple soft scatterings, such as Baier-DokshitzerMueller-Peigne-Schi GLYPH<11> -Zakharov (BDMPS-Z), [1, 2], Amesto-Salgado-Wiedemann (ASW) [3] and Arnold-MooreYa GLYPH<11> e (AMY) [4] formalisms, versus few hard scatterings, such as Gyulassy-Levai-Vitev (GLV) [5] and higher twist (HT) [6] formalisms. Recently, various improvements have been done to the original jet energy loss formalisms. For example, AMY formalism has been developed to include finite medium length e GLYPH<11> ect [7]. GLV formalism has been extended to finite dynamical medium, and recently the e GLYPH<11> ect of non-zero magnetic mass was also included [8, 9]. HT formalism has been extended to incorporate multiple scatterings [10].
In addition to the di GLYPH<11> erence in single gluon emission spectrum, di GLYPH<11> erent evolution schemes have been used when calculating multiple gluon emissions. One popular method is Poisson convolution which assumes that multiple gluon emissions are independent. This method has been widely used in BDMPS, ASW and GLV formalisms, to get the probability distribution P ( GLYPH<1> E ) of parton energy loss [11, 12, 13]:
$$P ( \Delta E ) = \sum _ { n = 0 } ^ { \infty } \frac { e ^ { - ( N _ { \varepsilon } ) } } { n! } \left [ \prod _ { i = 1 } ^ { n } \int d \omega \frac { d I ( \omega ) } { d \omega } \right ] \delta \left ( \Delta E - \sum _ { i = 1 } ^ { n } \omega _ { i } \right ),$$
where dI = d ! is the spectrum for single gluon emission. In AMY formalism, the coupled rate equations have been used to obtain the time evolution of quark and gluon jet momentum distribution f ( p ) = dN p ( ) = dp [14, 15]. The rate equations can be schematically written as:
$$\frac { d f ( p, t ) } { d t } = \int d k \left [ f ( p + k, t ) \frac { d \Gamma ( p + k, k, t ) } { d k d t } - f ( p, t ) \frac { d \Gamma ( p, k, t ) } { d k d t } \right ],$$
where d GLYPH<0> ( p k t ; ; ) = dkdt is the rate for a parton with momentum p to lose momentum k . HT formalism is based on perturbative QCD power expansion; it solves DGLAP-like evolution equations to obtain the medium-modified fragmentation function ˜ ( D z Q ; 2 ) [16, 17]:
$$\frac { \partial \tilde { D } ( z, Q ^ { 2 } ) } { \partial \ln Q ^ { 2 } } = \frac { \alpha _ { s } } { 2 \pi } \int \frac { d y } { y } P ( y ) \int d \zeta ^ { - } K ( \zeta ^ { - }, Q ^ { 2 } ) \tilde { D } ( z / y, Q ^ { 2 } ),$$
where K ( GLYPH<16> GLYPH<0> ; Q 2 ) is the kernel for parton-medium scattering which induces additional radiation in the medium. A systematic comparison of di GLYPH<11> erent jet energy loss models has been performed in the framework of a 'brick' of QGP in Ref. [18].
Collisional jet eneergy loss was first studied by Bjorken in 1982 [19]. Compared to radiative component of jet energy loss, collisions energy loss is usually considered to be small for light flavor (leading) partons, especially when jet energy is su GLYPH<14> ciently large. But in realistic calculation of nuclear suppression factor RAA at RHIC and the LHC kinematics, collisional energy loss may give sizable contribution [13, 15, 20]. The contribution of collisional energy loss is more prominent for heavy flavor partons. Taking bottom quarks as a example, it has been shown in Ref. [21]
Figure 1. (Color online) The extracted values of scaled jet transport parameter ˆ q T = 3 by using single inclusive hadron suppression factor RAA at both RHIC and LHC. The shown values are for a quark jet with initial energy of 10 GeV at the center of the most central A-A collisions and at an initial proper time GLYPH<28> 0 = 0 6 fm c. The figure is taken from Ref. [34] done by JET Collaboration. : /
that below around 15 GeV collisional energy loss dominates while at high energy radiative component dominates. Collisional energy loss is also a very important ingredient when studying full jet evolution and energy loss [22], and the response of medium to jet transport [23, 24] as will be discussed Sec. (5,6).
## 3. Phenomenological Studies at RHIC and the LHC
The main purpose of jet quenching study is to figure out the detailed interaction mechanisms between jets and the QGP medium, and to improve our knowledge of hot and dense nuclear matter. One important way to achieve this is to perform systematic studies of jet quenching observables and compare to a wealth of available experimental measurements. Various phenomenological studies have been performed in the literature for a wealth of jet quenching observables, such as the suppression of single inclusive high pT hadron production, dihadron suppression and photonhadron correlations in relativistic nucleus-nucleus collisions [25, 26, 27, 28, 29, 30]. Recently, much interest has been shifted to the quantitative extraction of various jet transport coe GLYPH<14> cients. These transport coe GLYPH<14> cients can generally be written as the correlations of gluon fields, thus may provide much insight into the internal structure and the properties of QGP matter that hard jets traverse. One of the most important jet quenching parameters is ˆ [1], q
$$\hat { q } = \frac { 1 } { L } \int \frac { d ^ { 2 } k } { ( 2 \pi ) ^ { 2 } } k _ { \perp } ^ { 2 } P ( \vec { k } _ { \perp }, L ) \approx \frac { 4 \pi \alpha _ { s } C _ { s } } { N _ { c } ^ { 2 } - 1 } \int d y ^ { - } \langle F ^ { \mu + } ( 0 ) F _ { \mu } ^ { + } ( y ^ { - } ) \rangle,$$
where P k ( ~ ? ) is the probability distribution of transverse momentum transfer between the propagating partons and medium. This parameter not only quantifies the transverse momentum broadening of the jet [31, 32], but also controls the size of medium-induced radiative energy loss. As has been pointed out in Ref. [33], the precise determination of ˆ q T = 3 combined with the knowledge of shear viscosity over entropy ratio GLYPH<17>= s can provide important clues to our understanding of QGP properties, e.g., when and at what scale a weakly-coupled quark gluon system at su GLYPH<14> ciently high temperatures changes to a strongly-coupled fluid at RHIC and the LHC energies.
Very recently a collaborative e GLYPH<11> ort have been performed to quantitatively extract jet quenching parameter ˆ within q the framework of JET Collaboration [34] by a few jet quenching groups: McGill-AMY [15], Martini-AMY [35], HTM[16], HT-BW [36], DGLV-CUJET [37]. In this work, the space-time evolutions of the bulk QGP matter produced in heavy-ion collisions at RHIC and the LHC are described utilizing realistic viscous hydrodynamics simulations. By
comparing the calculations from five di GLYPH<11> erent energy loss models to experimental measurements, the values of jet quenching parameter ˆ have been extracted. q
One important result from such collaborative e GLYPH<11> ort is shown in Fig. 1. The range of ˆ values as constrained by q the measured single hadron nuclear modification factors RAA at both RHIC and LHC are obtained as:
$$\frac { \hat { q } } { C _ { s } T ^ { 3 } } = \begin{cases} \ 3. 5 \pm 0. 9, & T \approx 3 7 0 \, \text{MeV} \, ( \text{at RHC} ), \\ 2. 8 \pm 1. 1, & T \approx 4 7 0 \, \text{MeV} \, ( \text{at the LHC} ). \end{cases}$$
This translates into ˆ q GLYPH<25> 1.2-1.9 GeV 2 fm for a quark jet at the highest temperatures reached in the most central Au + Au collisions at RHIC and Pb + Pb collisions at LHC.
One may clearly see that the scaled dimensionless quantity ˆ q T = 3 is temperature dependent. In the future, it is of great importance to map out the temperature dependence of jet quenching parameter by extending the current study to the future higher energy Pb-Pb collisions at the LHC and lower energy collisions at RHIC. The expected values of ˆ q in A-A collisions at other collision energies (0.063 ATeV, 0.130 ATeV and 5.5 ATeV) are shown by dashed boxes. We can see that the values of ˆ in hot QGP matter are much higher than those of cold nuclei (the value of ˆ q qN = T 3 e GLYPH<11> in cold nuclei constrained from DIS experiments is indicated by the triangle in the figure). The result from next-to-leading order (NLO) Super-Yang-Mills (SYM) calculation [38] is also shown by two arrows on the right axis of the figure.
We also note some other recent phenomenological studies of jet quenching observables at RHIC and the LHC energies, such as those based on DGLV formalism [9], dE dx = model [39], and soft-collinear e GLYPH<11> ective theory (SCET) [40], etc. In the future, we may include more studies in the JET collaboration framework to fully take into account the systematic uncertainties. Also more experimental observables should be utilized to get tighter constraints on jet energy loss models and jet quenching parameters.
## 4. Developments in Next-to-Leading Order Calculations
In phenomenological studies of jet quenching in ultra-relativistic heavy-ion collisions, leading-order formalisms of jet energy loss have been applied so far. In Ref. [18], it is found that much of model di GLYPH<11> erence can be attributed to specific approximations made in the model calculations, (such as eikonal, soft and collinear approximations. To better constrain the models, it is important to investigate the e GLYPH<11> ects of di GLYPH<11> erent approximations or to relax these approximations when building up jet quenching formalisms. One such e GLYPH<11> ort was performed in Ref. [41], where the e GLYPH<11> ect of non-eikonal large angle scatterings is studied and it is found to be small for partons with energies larger than 10-15 GeV. In Ref. [42], the medium-induced radiation is re-studied by going beyond eikonal approximation, and the finite energy e GLYPH<11> ect has been taken into account.
To achieve a systematic estimation of the errors made in leading-order calculation, we need build a fully next-toleading order (NLO) framework for calculating jet quenching and jet energy loss. The first e GLYPH<11> ort along this direction was performed in Ref. [43, 44], where NLO correction to parton transverse momentum broadening was studied in the framework of BDMPS formalism. The correction due to medium-induced radiation is found to be sizable; in particular parton transverse momentum broadening receives a double logarithmic contribution ln ( 2 L l = 0 ), with L the length of the medium and l 0 the scale associated with medium constituents. Recently, it was argued in Ref. [45, 46] that such double logarithmic correction may be absorbed by a redefinition renormalization of jet quenching parameter / ˆ. q In Ref. [45, 46], the scale evolution of ˆ q was further studied. It is found that when the medium size L is large, parton transverse momentum broadening as well as parton energy loss receive additional medium-length dependence, GLYPH<1> E / ˆ q L 0 2 + GLYPH<13> with GLYPH<13> = 2 p GLYPH<11> s Nc =GLYPH<25> , as compared to traditional BDMPS jet energy loss formalism.
The renormalization of jet quenching parameter ˆ has also been studied in Ref. [47], where NLO QCD corrections q to the transverse momentum broadening are computed in the framework of hadron production semi-inclusive deepinelastic scattering and lepton pair production in p-A collisions. In this work, a factorization formula is derived for k 2 ? -weighted cross section; the collinear divergence is absorbed into the redefinitioon of nonpertubative PDF and twist4 quark-gluon correlation functions. The factorization leads to a DGLAP evolution equation for parton distribution function, as well as a new QCD evolution equation for twist-4 quark-gluon correlation functions. From this new QCD evolution equation, the scale GLYPH<22> dependence of jet quenching parameter ˆ( q GLYPH<22> 2 ) may be obtained if the momentum and spatial correlations of two nucleons inside the nucleus are neglected.
Figure 2. (Color online) A schematic illustration of the evolution of full jet, and di GLYPH<11> erent medium-induced processes that contribute to full jet energy loss and modification in a quark-gluon plasma.
## 5. Full Jet Evolution and Modification
In recent years, full jets have been extensively studied in ultra-relativistic heavy-ion collisions. With the large kinematics available at the LHC, we now have the opportunity to investigate medium e GLYPH<11> ects on jets with transverse energies over a hundred GeV. The basic idea of reconstructing full jets is to recombine final state hadron fragments and to infer the information about the original hard partons and the medium e GLYPH<11> ect on them. Since both leading and sub-leading fragments are included, full jets are expected to provide more discriminative power than leading hadron observables [48]. One big challenge in studying full jets in relativistic heavy-ion collision as compared to elementary collisions is the contamination from the fluctuating hydrodynamic background. Sophisticated experimental techniques have been developed and utilized to disentangle jets from fluctuating background.
The first jet measurement from the LHC heavy-ion program was the momentum imbalance asymmmetry of cor-/ related back-to-back jet pairs [49, 50]. We observe a strong modification of dijet momentum imbalance distribution in Pb-Pb collisions as compared to p-p collisions at the LHC, while the the angular distribution is largely unchanged. Similar observations have been obtained for full jets correlated with high pT direct photons in Pb-Pb collisions at the LHC[51]. These results indicate that the away-side subleading jets experience significant amount of energy loss when propagating through the produced QGP. Various model calculations based on jet energy loss have been performed to explain the observed dijet and GLYPH<13> -jet momentum imbalance [22, 52, 53, 54, 55, 56, 57, 58, 59, 60, 61].
The evolution of full jets in QGP medium is schematically illustrated in Fig. 2, where the thick solid arrow through the center of jet cone represents the leading parton of the jet, and other lines represent the accompanying gluons. Compared to leading hadron observables, a few additional ingredients need be taken into account when studying full jets in QGP medium. The radiated gluons may lose energy or get deflected by interacting with the medium constituents; some of the gluons may be kicked out of the jet cone. These ingredients can be encoded by solving the following Boltzmann transport equation [22]:
$$\frac { d f _ { g } ( \omega, k _ { \perp }, t ) } { d t } = - \hat { e } \frac { \partial f _ { g } } { \partial \omega } + \frac { 1 } { 4 } \hat { q } \nabla _ { k _ { \perp } } ^ { 2 } f _ { g } + \frac { d N _ { g } ^ { \text{md} } } { d \omega d k _ { \perp } ^ { 2 } d t },$$
where f g ( !; k ? ; t ) is the momentum distribution of the accompanying gluons of the full jets. In the equation, the first and second terms represent the collisional energy loss and transverse momentum broadening due to interacting with medium constituents, and the last term denotes the gluon radiation induced by the medium.
By solving the above evolution equation, we may obtain the information of full jets after propagating through the medium. In particular, the energy of the original full jet may be decomposed as:
$$E _ { j \text{t} } & = E _ { \text{in} } + E _ { \text{lost} } = E _ { \text{in}, \text{rad} } + E _ { \text{out}, \text{rad} } + E _ { \text{th}, \text{coll} }.$$
Interestingly, the last term, i.e., the medium absorption or the thermalization of the soft radiations, is found to give the largest contribution to full jet energy loss. This is not a surprising result since the medium modification of soft components of the jet or accompanying gluons at large angles are expected to easier than the inner hard core of the jet.
The picture is often referred to as jet collimation: soft partons of the jet are stripped o GLYPH<11> when they propagate through the hot and dense nuclear medium [52].
Similar results have also been obtained in Ref. [58, 62, 63, 64] where it is argued that if medium color field varies over jet transverse size, the shower partons of the full jets will lose color coherence due to their interaction with the surrounding medium. Such color decoherence e GLYPH<11> ect will open up the phase space for soft and large angle gluon radiation, as compared to traditional BDMPS formalism. Utilizing rate equation to study multiple gluons emissions, it is found that the energy of jets can be rapidly degraded into many soft gluons which carry energies of medium temperature. In terms of radiated gluons, there are three di GLYPH<11> erent phase spaces separated by two scales, x 0 and x th . The total energy of the original jet may be decomposed as:
$$E _ { j \text{t} } = E _ { \text{in} } + E _ { \text{lost} } = E _ { \text{in} } ( x > x _ { 0 } ) + E _ { \text{out} } ( x _ { \text{th} } < x < x _ { 0 } ) + E _ { \text{flow} } ( x < x _ { 0 } ). & & ( 1 0 )$$
The radiated gluons with x > x 0 are inside the jet cone and thus part of final reconstructed jet. For x < x 0 , the radiation is outside jet cone. The radiation with x < x th is soft and thus quickly thermalized and flows into the medium.
The substructures or fragmentation profiles are also of great interest in full jet study as they may provide additional information about jet-medium interaction [48]. Both longitudinal and transverse jet fragmentation profiles have been measured ATLAS and CMS Collaborations for Pb-Pb collisions at the LHC [65, 66, 67]. For transverse directions, little change is observed at small radius r compared to p-p collisions, while there is a significant excess at large r accompanied by a depletion at intermediate r . For the momentum (fraction) distribution of jet fragments, there is an excess at both small and large z ( pT ), and a depletion in the fragmentation profiles (functions) is observed at intermediate z ( pT ).
There are some challenges and complications in the study of full jet observables due to their sensitivity to various details of jet-medium interaction and experimental setups. For example, di GLYPH<11> erent treatments of recoiled partons may lead to di GLYPH<11> erent pictures of jet energy loss, and may results in di GLYPH<11> erent jet internal structures in the final state [61]. In Ref. [68], it has been shown that fragmentation and recombination mechanisms may lead to di GLYPH<11> erent jet fragmentation profiles. It is also very important to take into account all experimental jet finding conditions when comparing model calculations of jet substructures with experimental measurements [69].
## 6. Medium Response to Jet Transport
Jets lose energy during their propagating through QGP medium; some of the lost energy is deposited into the medium and make medium excitations. One way to study the medium response to jet propagation is to solve the following hydrodynamic equation,
$$\partial _ { \mu } T ^ { \mu \nu } ( x ) = J ^ { \nu } ( x )$$
where the source term represents the jet energy and momentum deposition profiles which may be calculated from jet quenching calculations.
The study of medium response and collective excitations is very interesting and important since it may provide a direct probe to the speed of sound cs of the QGP medium. Also it is a necessary ingredient of jet-medium interaction and helpful for understanding many observables associated with jets, e.g., where the lost energy manifests in the final state. In Ref. [70], the medium response to the lost energy from two back-to-back partons is studied using a (3 + 1)-dimentional ideal hydrodynamics, and the redistribution of the lost energy after hydrodynamic evolution is also calculated. The finding from this study is qualitatively consistent with the measurements by CMS Collaboration, i.e., the lost energy from the jet are carried by soft particles at large angles [50].
It should be noted that the energy deposition profiles for full jets are quite di GLYPH<11> erent from single partons due to the fact that the radiated partons may serve as additional sources depositing energy and momentum into medium and significantly increase the length dependence of energy deposition rate [23, 24]. Jet energy deposition profiles are also sensitive to some details in the model calculations, such as the cuto GLYPH<11> energy often applied to determine which part of radiation is treated as thermalized and flows to the medium [23, 24, 71, 72]. The spatial distribution of the jet energy momentum deposition profiles is also important for studying the response of medium to jet transport. / For example, it is found in Ref. [73] that collinear radiation may produce very nice cone-like structure of medium response, but a wide spatial distribution of energy deposition profiles expected from large angle radiation may destroy such cone-like structure.
## 7. Jet Quenching from Lattice QCD and AdS CFT /
While perturbative QCD based jet energy models have been very successful in studying jet quenching in relativistic heavy-ion collisions, there exist many model discrepancies due to specific approximations applied in model [18, 34]. Lattice QCD calculation can provide some guideline and constraints on our jet quenching studies, e.g., the values of various jet transport coe GLYPH<14> cients that are typically obtained from phenomenological calculations. In Ref. [74], jet quenching parameter ˆ q was first computed within the framework finite temperature lattice gauge theory. The calculation was carried out in quenched SU (2), and extrapolated to the case of SU (3) with 2 flavors of quarks, yielding a value of ˆ q = 1.3-3.3 GeV 2 / fm for a gluon jet at a temperature T = 400 MeV. Recently within the framework of a dimensionally reduced e GLYPH<11> ective theory (electrostatic QCD), the contribution from soft QGP modes to jet quenching parameter ˆ q was evaluated numerically, and a value of ˆ q = 6 GeV 2 / fm is obtained for RHIC energies [75]. A first principle calculation of collisional kernel C k ( ? ) was also carried out in Ref. [76] and the shape of the collision kernel k 3 ? C k ( ? ) is found to be consistent with Gaussian at small k ? .
AdS CFT correspondence provides another non-perturbative approach and reference for studying jet quenching in / a strongly-coupled plasma. A recent study utilizing more realistic shooting string description of energetic quarks could achieve better agreement with experiment data [77]. A NLO calculation which takes into account the corrections from finite t'Hooft coupling produces a value of jet quenching parameter ˆ much closer to these extracted from perturbative q QCD-based phenomenological studies. The substructure of full jets was studied in Ref. [78], where it is found that jets emerging from the plasma look almost like vacuum jets, but with reduced energy and larger opening angle.
## 8. Summary
We have provided a short review of the recent development in theoretical and phenomenological studies of jet quenching in ultra-relativistic heavy-ion collisions. While significant progresses have been achieved in various directions, such as the quantitative extraction of jet quenching parameter, full jet energy loss and substructures, medium response to jet transport, and so on, there are still many open questions and a lot to be improved. More detailed phenomenological studies are needed in order to map out the temperature dependence of various jet transport coefficients. A fully next-to-leading order framework for studying jet energy loss and modification is still unavailable. It is important to build a framework which allows for simultaneous simulation of jet transport and medium response by combining realistic hydrodynamic models and jet energy loss deposition calculations. The detailed thermalization / mechanisms for jet deposited energy momentum is not fully understood. Complications exist in both theoretical and / experimental studies of full jets and their detailed substructures. The e GLYPH<11> ort along these and other directions will further improve our knowledge of jet-medium interaction, and help us to achieve more comprehensive understanding of the novel properties of hot and dense QGP produced in high energy nuclear collisions.
## 9. Acknowledgments
This work was supported in part by the Natural Science Foundation of China under grant no 11375072.
## References
- [1] R. Baier, Y. L. Dokshitzer, A. H. Mueller, S. Peigne, and D. Schi GLYPH<11> , Nucl.Phys. B483 , 291 (1997), arXiv:hep-ph 9607355. /
- [2] B. Zakharov, JETP Lett. 63 , 952 (1996), arXiv:hep-ph 9607440. /
- [3] U. A. Wiedemann, Nucl.Phys. B588 , 303 (2000), arXiv:hep-ph 0005129. /
- [4] P. B. Arnold, G. D. Moore, and L. G. Ya GLYPH<11> e, JHEP 0111 , 057 (2001), arXiv:hep-ph 0109064. /
- [5] M. Gyulassy, P. Levai, and I. Vitev, Nucl.Phys. B571 , 197 (2000), arXiv:hep-ph 9907461. /
- [6] X.-N. Wang and X.-f. Guo, Nucl.Phys. A696 , 788 (2001), arXiv:hep-ph 0102230. /
- [7] S. Caron-Huot and C. Gale, Phys.Rev. C82 , 064902 (2010), arXiv:1006.2379.
- [8] M. Djordjevic and U. W. Heinz, Phys.Rev.Lett. 101 , 022302 (2008), arXiv:0802.1230.
- [9] M. Djordjevic and M. Djordjevic, Phys.Lett. B709 , 229 (2012), arXiv:1105.4359.
- [10] A. Majumder, Phys.Rev. D85 , 014023 (2012), arXiv:0912.2987.
- [11] C. A. Salgado and U. A. Wiedemann, Phys.Rev. D68 , 014008 (2003), arXiv:hep-ph 0302184. /
- [12] T. Renk, J. Ruppert, C. Nonaka, and S. A. Bass, Phys.Rev. C75 , 031902 (2007), arXiv:nucl-th 0611027. /
- [13] S. Wicks, W. Horowitz, M. Djordjevic, and M. Gyulassy, Nucl. Phys. A784 , 426 (2007), arXiv:nucl-th 0512076. /
- [14] S. Jeon and G. D. Moore, Phys.Rev. C71 , 034901 (2005), arXiv:hep-ph 0309332. /
- [15] G.-Y. Qin et al. , Phys. Rev. Lett. 100 , 072301 (2008), arXiv:0710.0605.
- [16] A. Majumder and C. Shen, Phys.Rev.Lett. 109 , 202301 (2012), arXiv:1103.0809.
- [17] G.-Y. Qin and A. Majumder, Phys.Rev.Lett. 105 , 262301 (2010), arXiv:0910.3016.
- [18] N. Armesto et al. , Phys.Rev. C86 , 064904 (2012), arXiv:1106.1106.
- [19] J. D. Bjorken, FERMILAB-PUB-82-059-THY.
- [20] B. Schenke, C. Gale, and G.-Y. Qin, Phys.Rev. C79 , 054908 (2009), arXiv:0901.3498.
- [21] S. Cao, G.-Y. Qin, and S. A. Bass, Phys.Rev. C88 , 044907 (2013), arXiv:1308.0617.
- [22] G.-Y. Qin and B. Muller, Phys.Rev.Lett. 106 , 162302 (2011), arXiv:1012.5280.
- [23] G. Y. Qin, A. Majumder, H. Song, and U. Heinz, Phys. Rev. Lett. 103 , 152303 (2009), arXiv:0903.2255.
- [24] R. B. Neufeld and B. Muller, Phys. Rev. Lett. 103 , 042301 (2009), arXiv:0902.2950.
- [25] S. A. Bass et al. , Phys. Rev. C79 , 024901 (2009), arXiv:0808.0908.
- [26] N. Armesto, M. Cacciari, T. Hirano, J. L. Nagle, and C. A. Salgado, J. Phys. G37 , 025104 (2010), arXiv:0907.0667.
- [27] X.-F. Chen, C. Greiner, E. Wang, X.-N. Wang, and Z. Xu, Phys. Rev. C81 , 064908 (2010), arXiv:1002.1165.
- [28] H. Zhang, J. F. Owens, E. Wang, and X.-N. Wang, Phys. Rev. Lett. 98 , 212301 (2007), arXiv:nucl-th 0701045. /
- [29] T. Renk, Phys. Rev. C78 , 034904 (2008), arXiv:0803.0218.
- [30] G.-Y. Qin, J. Ruppert, C. Gale, S. Jeon, and G. D. Moore, Phys.Rev. C80 , 054909 (2009), arXiv:0906.3280.
- [31] A. Majumder and B. Muller, Phys. Rev. C77 , 054903 (2008), arXiv:0705.1147.
- [32] G.-Y. Qin and A. Majumder, Phys.Rev. C87 , 024909 (2013), arXiv:1205.5741.
- [33] A. Majumder, B. Muller, and X.-N. Wang, Phys.Rev.Lett. 99 , 192301 (2007), arXiv:hep-ph 0703082. /
- [34] K. M. Burke et al. , (2013), arXiv:1312.5003.
- [35] C. Young, B. Schenke, S. Jeon, and C. Gale, Phys.Rev. C86 , 034905 (2012), arXiv:1111.0647.
- [36] X.-F. Chen, T. Hirano, E. Wang, X.-N. Wang, and H. Zhang, Phys.Rev. C84 , 034902 (2011), arXiv:1102.5614.
- [37] J. Xu, A. Buzzatti, and M. Gyulassy, (2014), arXiv:1402.2956.
- [38] Z.-q. Zhang, D.-f. Hou, and H.-c. Ren, JHEP 1301 , 032 (2013), arXiv:1210.5187.
- [39] B. Betz and M. Gyulassy, (2014), arXiv:1404.6378.
- [40] Z.-B. Kang, R. Lashof-Regas, G. Ovanesyan, P. Saad, and I. Vitev, (2014), arXiv:1405.2612.
- [41] R. Abir, Phys.Rev. D87 , 034036 (2013), arXiv:1301.1839.
- [42] L. Apolin¢rio, N. Armesto, G. Milhano, and C. A. Salgado, (2014), arXiv:1404.7079.
- [43] B. Wu, JHEP 1110 , 029 (2011), arXiv:1102.0388.
- [44] T. Liou, A. Mueller, and B. Wu, Nucl.Phys. A916 , 102 (2013), arXiv:1304.7677.
- [45] E. Iancu, (2014), arXiv:1403.1996.
- [46] J.-P. Blaizot and Y. Mehtar-Tani, (2014), arXiv:1403.2323.
- [47] Z.-B. Kang, E. Wang, X.-N. Wang, and H. Xing, Phys.Rev.Lett. 112 , 102001 (2014), arXiv:1310.6759.
- [48] I. Vitev and B.-W. Zhang, Phys. Rev. Lett. 104 , 132001 (2010), arXiv:0910.1090.
- [49] Atlas Collaboration, G. Aad et al. , Phys.Rev.Lett. 105 , 252303 (2010), arXiv:1011.6182.
- [50] CMS Collaboration, S. Chatrchyan et al. , Phys.Rev. C84 , 024906 (2011), arXiv:1102.1957.
- [51] CMS Collaboration, S. Chatrchyan et al. , (2012), arXiv:1205.0206.
- [52] J. Casalderrey-Solana, J. G. Milhano, and U. A. Wiedemann, J.Phys.G G38 , 035006 (2011), arXiv:1012.0745.
- [53] I. Lokhtin, A. Belyaev, and A. Snigirev, Eur.Phys.J. C71 , 1650 (2011), arXiv:1103.1853.
- [54] C. Young, B. Schenke, S. Jeon, and C. Gale, Phys.Rev. C84 , 024907 (2011), arXiv:1103.5769.
- [55] Y. He, I. Vitev, and B.-W. Zhang, Phys.Lett. B713 , 224 (2012), arXiv:1105.2566.
- [56] T. Renk, Phys.Rev. C85 , 064908 (2012), arXiv:1202.4579.
- [57] K. C. Zapp, F. Krauss, and U. A. Wiedemann, JHEP 1303 , 080 (2013), arXiv:1212.1599.
- [58] J.-P. Blaizot, F. Dominguez, E. Iancu, and Y. Mehtar-Tani, JHEP 1406 , 075 (2014), arXiv:1311.5823.
- [59] W. Dai, I. Vitev, and B.-W. Zhang, Phys.Rev.Lett. 110 , 142001 (2013), arXiv:1207.5177.
- [60] G.-Y. Qin, (2012), arXiv:1210.6610.
- [61] X.-N. Wang and Y. Zhu, Phys.Rev.Lett. 111 , 062301 (2013), arXiv:1302.5874.
- [62] N. Armesto, H. Ma, Y. Mehtar-Tani, C. A. Salgado, and K. Tywoniuk, JHEP 1201 , 109 (2012), arXiv:1110.4343.
- [63] J. Casalderrey-Solana, Y. Mehtar-Tani, C. A. Salgado, and K. Tywoniuk, Phys.Lett. B725 , 357 (2013), arXiv:1210.7765.
- [64] Y. Mehtar-Tani and K. Tywoniuk, (2014), arXiv:1401.8293.
- [65] CMS Collaboration, S. Chatrchyan et al. , JHEP 1210 , 087 (2012), arXiv:1205.5872.
- [66] CMS Collaboration, S. Chatrchyan et al. , Phys.Lett. B730 , 243 (2014), arXiv:1310.0878.
- [67] ATLAS Collaboration, G. Aad et al. , (2014), arXiv:1406.2979.
- [68] G.-L. Ma, Phys.Rev. C88 , 021902 (2013), arXiv:1306.1306.
- [69] R. Perez-Ramos and T. Renk, Phys.Rev. D90 , 014018 (2014), arXiv:1401.5283.
- [70] Y. Tachibana and T. Hirano, (2014), arXiv:1402.6469.
- [71] T. Renk, Phys.Rev. C88 , 044905 (2013), arXiv:1306.2739.
- [72] S. Floerchinger and K. C. Zapp, (2014), arXiv:1407.1782.
- [73] R. Neufeld and I. Vitev, Phys.Rev. C86 , 024905 (2012), arXiv:1105.2067.
- [74] A. Majumder, Phys.Rev. C87 , 034905 (2013), arXiv:1202.5295.
- [75] M. Panero, K. Rummukainen, and A. Sch0Ł1fer, Phys.Rev.Lett. 112 , 162001 (2014), arXiv:1307.5850.
- [76] M. Laine and A. Rothkopf, (2013), arXiv:1310.2413.
- [77] A. Ficnar, S. S. Gubser, and M. Gyulassy, (2013), arXiv:1311.6160.
- [78] P. M. Chesler and K. Rajagopal, (2014), arXiv:1402.6756. | 10.1016/j.nuclphysa.2014.09.004 | [
"Guang-You Qin"
] | 2014-08-03T04:57:40+00:00 | 2014-08-03T04:57:40+00:00 | [
"nucl-th",
"hep-ph"
] | Theory of Jet Quenching in Ultra-Relativistic Nuclear Collisions | We present a short overview of recent progress in the theory of jet quenching
in ultra-relativistic nuclear collisions, including phenomenological studies of
jet quenching at RHIC and the LHC, development in NLO perburbative QCD
calculation of jet broadening and energy loss, full jet evolution and
modification, medium response to jet transport, and lattice QCD and AdS/CFT
studies of jet quenching. |
1408.0457v1 | ## Tidal radii and destruction rates of globular clusters in the Milky Way due to bulge-bar and disk shocking
Edmundo Moreno , B´ arbara Pichardo 1 1 and H´ ector Vel´zquez a 2
## ABSTRACT
We calculate orbits, tidal radii, and bulge-bar and disk shocking destruction rates for 63 globular clusters in our Galaxy. Orbits are integrated in both an axisymmetric and a non-axisymmetric Galactic potential that includes a bar and a 3D model for the spiral arms. With the use of a Monte Carlo scheme, we consider in our simulations observational uncertainties in the kinematical data of the clusters. In the analysis of destruction rates due to the bulge-bar, we consider the rigorous treatment of using the real Galactic cluster orbit, instead of the usual linear trajectory employed in previous studies. We compare results in both treatments. We find that the theoretical tidal radius computed in the nonaxisymmetric Galactic potential compares better with the observed tidal radius than that obtained in the axisymmetric potential. In both Galactic potentials, bulge-shocking destruction rates computed with a linear trajectory of a cluster at its perigalacticons give a good approximation to the result obtained with the real trajectory of the cluster. Bulge-shocking destruction rates for clusters with perigalacticons in the inner Galactic region are smaller in the non-axisymmetric potential, as compared with those in the axisymmetric potential. For the majority of clusters with high orbital eccentricities ( e > 0 5), . their total bulge+disk destruction rates are smaller in the non-axisymmetric potential.
Subject headings: galaxy: halo - galaxy: kinematics and dynamics - globular clusters: general
## 1. Introduction
In two previous papers (Allen et al. 2006, 2008, hereafter Papers I and II) tidal radii and destruction rates due to bulge and disk shocking were computed for 54 globular clusters
1 Instituto de Astronom´ ıa, Universidad Nacional Aut´noma de M´ exico, o Apdo. Postal 70-264, 04510, M´ exico, D. F., M´xico. e
2 Observatorio Astron´mico Nacional, Universidad Nacional Aut´noma de M´ exico, Apdo. o o Postal 877, 22800 Ensenada, M´ exico.
in our Galaxy, using axisymmetric and non-axisymmetric Galactic potentials. In Paper I the non-axisymmetric Galactic potential included the Galactic bar, and in Paper II the additional effect of three dimensional (3D) spiral arms was also analyzed. The models for these non-axisymmetric components given by Pichardo et al. (2003, 2004) were employed in those computations. The absolute proper motion data needed to compute the Galactic orbits of the globular clusters were obtained from the extensive studies of Dinescu et al. (1997, 1999a,b, 2000, 2001, 2003) and Casetti-Dinescu et al. (2007), who have computed the proper motions for a good fraction of the total number of globular clusters; for other clusters, Dinescu et al. (1999b) have compiled the proper motion data from various sources. Lately, Casetti-Dinescu et al. (2010) have given the absolute proper motions of other nine globular clusters, and Casetti-Dinescu et al. (2013) present new absolute proper motions of NGC 6397, NGC 6626, and NGC 6656; thus now we dispose of absolute proper motion data for a total of 63 globular clusters in our Galaxy.
For the new sample of 63 globular clusters, we compute again their tidal radii and destruction rates due to bulge and disk shocking, now with some improvements. We use axisymmetric and non-axisymmetric Galactic potentials, the later including both the spiral arms and the Galactic bar models of Pichardo et al. (2003, 2004), as in Paper II. A first part of our improvements has to do with this Galactic potential, the initial orbital conditions of the globular clusters, and the uncertainties in the computed quantities: (a) the Galactic potential is now rescaled to recent values of the galactocentric distance and rotation velocity of the local standard of rest, as found by Brunthaler et al. (2011), (b) we use the solar velocity obtained by Sch¨nrich et al. (2010), (c) the late compilation of clusters properties o given by Harris (2010) is used to update other parameters employed in our computations, and (d) we make Monte Carlo simulations to estimate the uncertainties in the tidal radii and destruction rates, and compare with estimates in Papers I and II.
The second part of our improvements refers to the procedure to compute destruction rates. In Papers I, II and in previous studies of tidal heating due to the interaction with the Galactic bulge and heating by disk shocking (e.g., Aguilar et al. 1988; Gnedin & Ostriker 1997, 1999), the impulse approximation and a straight-path cluster trajectory have been employed. Here we relax the straight-path approximation and follow the more rigorous treatment given by Gnedin et al. (1999a), who employ a fit to the tidal acceleration along the true Galactic orbit of the cluster. In this paper this procedure is undertaken in our nonspherical Galactic potentials, as opposed to the spherical potential used by Gnedin et al. (1999a). The results are compared with those obtained using the usual straight-path aproximation.
In § 2 we give the globular cluster data employed in our study. The Galactic potential
and its parameters are presented in § 3. In § 4 some properties of the Galactic orbits in both the axisymmetric and non-axisymmetric potentials are tabulated, and for some clusters we show their meridional orbits. The tidal radii are analyzed in § 5. The needed formulism of destruction rates using the real trajectories of globular clusters is summarized in § 6, and our results are presented in § 8. In § 9 we present our conclusions.
## 2. Employed data for the globular clusters
In Table 1 we list the cluster parameters employed in our study. Equatorial coordinates ( α, δ ), are given in columns 2 and 3. The distance r and radial velocity v r , in columns 4 and 5, are taken from the recent compilation by Harris (2010). The absolute proper motions, µ x = µ α cos δ , µ y = µ δ , in columns 6 and 7, are the values given by Dinescu et al. (1997, 1999a,b, 2000, 2001, 2003) and Casetti-Dinescu et al. (2007, 2010, 2013), except for 47 Tuc (NGC 104) and M4 (NGC 6121) whose values are taken from Anderson & King (2003) and Bedin et al. (2003), respectively. As in Papers I and II, the mass of a cluster, M c , given in column 8, is computed using a mass-to-light ratio ( M/L ) V = 2 M /L /circledot /circledot . In § 5 we also employ for some clusters their M c computed with dynamical mass-to-light ratios given by McLaughlin & van der Marel (2005) . The observed tidal radius r td (we call r td = r K if this radius is computed with a King model (King 1962)) is not listed by Harris (2010), but as he points out, it can be computed with his listed values for the concentration, c , and core radius, r c , only for those clusters with a noncollapsed core. For clusters with a collapsed core, Harris suggests to take r td estimated by McLaughlin & van der Marel (2005) and Peterson & King (1975). For this type of clusters, and listed in Table 1, McLaughlin & van der Marel (2005) give r td for NGC 362, NGC 1904, NGC 6266, and NGC 6723; we take their r td for a King model, which is the model we use in our computations. For other clusters in Table 1, Peterson & King (1975) estimate r td in NGC 6397, NGC 6752, NGC 7078, and NGC 7099. These values of r td from McLaughlin & van der Marel (2005) and Peterson & King (1975) are transformed according to the distances r given by Harris (2010). For NGC 6284, NGC 6293, NGC 6342, and NGC 6522, we take r td from Harris' previous compilation, transformed with his new listed distances. Column 9 gives the final r td = r K employed values, and column 10 the half-mass radius, r h , in each cluster.
## 3. The Galactic potential
In our analysis we employ axisymmetric and non-axisymmetric models for the Galactic gravitational potential. The axisymmetric model is based on the Galactic model of Allen & Santill´n (1991), which gives a circular rotation speed on the Galactic plane Θ a 0 ≈ 220 km/s at its assumed Sun's Galactocentric distance R 0 = 8.5 kpc. This model is scaled to the new Galactic parameters Θ , 0 R 0 given by Brunthaler et al. (2011): Θ = 239 0 ± 7 km/s, R 0 = 8.3 ± 0.23 kpc.
The non-axisymmetric Galactic model is built from the scaled axisymmetric model. First, all the mass in the spherical bulge component in this axisymmetric model is employed to built the Galactic bar. In Papers I and II, where only 70% of the bulge mass was employed to built the bar, we have mentioned some properties of the model used for this bar component. We use the third bar model given by Pichardo et al. (2004) (the model of superposition of ellipsoids), which approximates the boxy COBE/DIRBE brightness profiles shown by Freudenreich (1998).
We also consider a 3D gravitational potential to represent the spiral arms. The model used for these arms, called PERLAS, is given by Pichardo et al. (2003), and has already been employed in Paper II. The total mass of the 3D spiral arms is taken as a small fraction of the mass in the disk component of the scaled axisymmetric model. We take M arms /M disk = 0.04 ± 0.01, considered by Pichardo et al. (2012) in their analysis of the maximum value on the Galactic plane of the parameter Q T (Sanders & Tubbs 1980; Combes & Sanders 1981), which, as a function of Galactocentric distance, is the ratio of the maximum azimuthal force of the spiral arms to the radial axisymmetric force at a given distance.
The mass density at the center of the spiral arms falls exponentially with Galactocentric distance, and we take its corresponding radial scale length equal to the one of the Galactic exponential disk modeled by Benjamin et al. (2005): H = 3.9 ± 0.6 kpc, using R 0 = 8.5 kpc, scaled now with the new value of R 0 .
Other properties of the Galactic bar and the Galactic spiral arms, have been collected in Pichardo et al. (2012). We use the following parameters in our computations: a) the present angle between the bar's major axis and the Sun-Galactic center line is taken as 20 , b) the ◦ angular velocity of the bar is in the range ≈ 55 ± 5 kms -1 kpc -1 , c) we consider the pitch angle of the spiral arms in the range ≈ 15.5 ± 3.5 , d) the range for the angular velocity of ◦ the spiral arms is ≈ 24 ± 6 kms -1 kpc -1 .
Table 2 summarizes all the parameters employed in our Galactic models, along with the Solar velocity ( U, V, W ) /circledot obtained by Sch¨nrich et al. (2010) (here o U is taken negative towards the Galactic center) and its uncertainties estimated by Brunthaler et al. (2011).
## 4. Properties of the Galactic orbits
For the computation of the Galactic orbits we have employed the Bulirsch-Stoer algorithm given by Press et al. (1992), and also the Runge-Kutta algorithm of seventh-eight order elaborated by Fehlberg (1968). In our problem both algorithms give practically the same results, and due to the complicated mathematical forms of the gravitational potentials of the non-axisymmetric Galactic components (bar and 3D spiral arms), we have favored the Runge-Kutta algorithm to reduce the computing time, specially in the Monte Carlo calculations. The Bulirsch-Stoer algorithm is employed mainly in the computations with the axisymmetric potential.
In Table 3 we give for each cluster some orbital parameters obtained with the nonaxisymmetric (first line) and axisymmetric (second line) potentials. Except for the data given in columns 8 and 9, whose associated time interval is commented in the next section, the data presented in this table correspond to a backward time integration of 5 × 10 9 yr in the axisymmetric case, and from 10 9 to 3 × 10 9 yr in the non-axisymmetric case, depending on the cluster. The second, third, and fourth columns show the average perigalactic distance, the average apogalactic distance, and the average maximum distance from the Galactic plane, respectively. The fifth column gives the average orbital eccentricity, this eccentricity defined as e = ( r max -r min ) / r ( max + r min ), with r min and r max successive perigalactic and apogalactic distances. Columns 6 and 7 give the orbital energy per unit mass, E , and the z-component of angular momentum per unit mass, h , only in the axisymmetric potential, where these two quantities are constants of motion. Columns 8 and 9 list tidal radii, which are discussed in the next section.
In Figures 1 and 2 we show meridional orbits for some clusters, whose NGC number is given. In each pair of columns the orbit in the axisymmetric potential is shown in the left frame, and that in the non-axisymmetric potential in the right frame. We choose this sample of clusters to illustrate how strong the effect of the non-axisymmetric Galactic components can be. The most conspicuous difference between the computations in both potentials is the orbital radial extent. This has important consequences in the clusters tidal radii, as shown in the next section.
Figures 3, 4, and 5 show the comparison in both Galactic potentials of the average perigalactic distance, average apogalactic distance, and average maximum distance from the Galactic plane, given respectively in the second, third, and fourth columns of Table 3. Values in the axisymmetric potential (with a subindex 'ax') and non-axisymmetric potential (with a subindex 'nax') are given in the horizontal and vertical axes, respectively. The uncertainties shown in these figures are estimated with the differences from corresponding quantities
obtained in the minimum and maximum energy orbits in each cluster, according to the uncertainties in the cluster radial velocity, distance, and proper motions.
## 5. Tidal radii
## 5.1. Comparison of theoretical and observed tidal radii in the axisymmetric and non-axisymmetric Galactic potentials
## 5.1.1. Comparison with observed King tidal radii r K
As in Papers I and II, for each globular cluster, and in both axisymmetric and non-axisymmetric Galactic potentials employed in our analysis, we compute a theoretical tidal radius using two expressions. The first is King's formula (King 1962)
$$r _ { K _ { t } } = \left [ \frac { M _ { c } } { M _ { g } ( 3 + e ) } \right ] ^ { 1 / 3 } r _ { m i n },$$
where M c is the mass of the cluster, M g is an effective galactic mass, e is the orbital eccentricity as defined in the previous section, and r min is the perigalactic distance. The mass M g is taken as the equivalent central mass point which gives an acceleration at the given perigalactic position with a magnitude equal to the magnitude of the actual acceleration at this point in the corresponding Galactic potential.
The second expression is the one proposed in Paper I, computed at the perigalactic position
$$r _ { * } = \left [ \frac { G M _ { c } } { \left ( \frac { \partial F _ { x ^ { \prime } } } { \partial x ^ { \prime } } \right ) _ { r ^ { \prime } = 0 } + \dot { \theta } ^ { 2 } + \dot { \varphi } ^ { 2 } \sin ^ { 2 } \theta } \right ] ^ { 1 / 3 }, \\ \text{mponent of the Galactic acceleration along the line $x^{\prime}$ joining the cluster with}$$
with F x ′ the component of the Galactic acceleration along the line x ′ joining the cluster with the Galactic center, and its partial drivative evaluated at the given perigalactic point. The angles ϕ and θ are angular spherical coordinates of the cluster in an inertial galactic frame.
In Paper I these two expressions for a theoretical tidal radius gave similar values. For a given Galactic potential, this result is maintained in the present computations. Columns 8 and 9 in Table 3 give the average values <r K t > <r > , ∗ of r K t and r ∗ , over the last 10 9 yr (in some clusters this time interval is extended to have a few perigalactic points).
In this and next sections of § 5 we make some comparisons using r K t given by Eq. (1). The first comparison is r K t with the observed tidal radius (also called the limiting radius) r td = r K listed in Table 1, estimated with a King model (King 1962). In Figures 6 and 7 we show with big filled squares this comparison in the axisymmetric and non-axisymmetric Galactic potentials. These points have two marks: clusters in which the tidal radius <r K t > computed with the non-axisymmetric potential is greater than <r K t > computed with the axisymmetric potential, are marked with encircled points; crossed points correspond to clusters in which <r K t > computed with the non-axisymmetric potential is less than <r K t > computed with the axisymmetric potential. These marks are shown in both figures. Thus, encircled and crossed points in Figure 6 will move upwards and downwards, respectively, to give the corresponding Figure 7. As in Papers I and II, the uncertainty in <r K t > , or <r > ∗ , is estimated in each cluster by computing <r K t > in the minimum and maximum energy orbits, according to the uncertainties in the cluster radial velocity, distance, and proper motions. The small empty squares and empty triangles in Figures 6 and 7 show the values of <r K t > in these minimum and maximum energy orbits, respectively.
From these figures we note that <r K t > computed in the non-axisymmetric potential compares better with r K : many clusters whose points lie below the line of coincidence in Figure 6, are closer to this line in Figure 7; these are the encircled points. Likewise, several clusters with points (now the crossed points) above the line of coincidence in Figure 6, are closer to this line in Figure 7. The rearrangement of the encircled points is the most conspicuous.
In Figure 6 a sample of eight clusters has been selected, represented by encircled points numbered from 1 to 8, and correspond to NGC 362, NGC 5139, NGC 5897, NGC 5986, NGC 6287, NGC 6293, NGC 6342, and NGC 6584, respectively. For these clusters, in Figure 8 we give the values of their perigalactic distance, r min , as a function of time, over the last 10 9 yr; black dots joined by black lines show the values in the axisymmetric potential, and the dots and lines in red correspond to the non-axisymmetric potential. The black and red horizontal dotted lines show the corresponding average value of r min in the given interval of time. Each frame shows the cluster name and also the identification number in Figure 6. Except for NGC 6293, Figure 8 partly explains why in the case of encircled points, <r K t > increases using the non-axisymmetric potential: in these clusters, the average value of r min obtained with the non-axisymmetric potential (red horizontal dotted lines) is greater than the corresponding average in the axisymmetric potential (black horizontal dotted lines).
The other factor which helps to understand the rearrangement of encircled
points from Figure 6 to Figure 7 (at least those in the considered sample) is the value of the effective galactic mass M g employed in King's formula Eq. (1). As stated in § 3, the original concentrated spherical bulge in the axisymmetric potential was employed to built the bar; thus, due to the less mass concentration of the non-axisymmetric potential in the inner Galactic region (see upper frame in figure 7 in Paper I), the contribution of the bar to M g computed at a given perigalactic distance in this inner region is expected to decrease compared with the contribution of the spherical bulge in the axisymmetric potential. In general, the value of M g in the non-axisymmetric potential will depend on the position of the perigalactic point relative to the axes of the Galactic bar, because this bar generates a non-axisymmetric force field. In addition, M g has also the effect of the spiral arms with their relative orientation to the axes of the bar at the time of occurrence of the perigalactic point. Thus, the value of M g depends on the specific perigalactic point.
To illustrate these comments, in Figure 9 we give values of M g computed on the Galactic plane as a function of distance to the Galactic center. The black line corresponds to the axisymmetric potential; the continuous red and blue lines show values of M g due to the axisymmetric background (i.e. disk and spherical dark halo) plus the Galactic bar, along the major and minor axes of the bar, respectively. The dashed red and blue lines show values of M g along these major and minor axes with the addition of the spiral arms, i.e. considering all the mass components in the non-axisymmetric potential, taking in particular the major axis of the bar as the line where the spiral arms originate in the inner Galactic region. Thus, note the smaller values that M g can take in the inner Galactic region in the non-axisymmetric potential.
Figure 10 shows the values of M g at the perigalactic points in Figure 8. The correspondence of colors in this figure is that given in Figure 8. The horizontal dotted lines show the average values of M g over the last 10 9 yr; these lines are not plotted in NGC 6293 to avoid confusion in the lower continuous red line. The average values of M g in the axisymmetric and non-axisymmetric potentials almost coincide in the clusters NGC 5897, NGC 5986, NGC 6287, NGC 6342, and NGC 6584; thus in these clusters the increase of the average value of r min in the non-axisymmetric potential explains the corresponding increase of <r K t > . For the remaining clusters in this sample, NGC 362, NGC 5139, and NGC 6293, the average value of M g is sensibly smaller in the non-axisymmetric potential, specially in NGC 6293. This result combined with the increase of r min , gives a net increase of <r K t > for NGC 362 and NGC 5139 in the non-axisymmetric potential.
On the other hand, in NGC 6293 the strong decrease of the average value of M g in the non-axisymmetric potential compared with that in the axisymmetric potential, counteracts the corresponding slight decrease of the average value of r min shown in Figure 8, giving a net increase of <r K t > in the non-axisymmetric potential.
## 5.1.2. Comparison with improved observed limiting radii
Recently Miocchi et al. (2013) have derived the radial stellar density profiles of 26 Galactic globular clusters from resolved star counts, using high-resolution HubbleSpaceTelescope observations. In particular, they derive the limiting radius r l , what we call the observed tidal radius, employing King and Wilson (Wilson 1975) models. Considering the clusters in common between our sample and their 26 clusters, we have taken their best fits given by the least value of the reduced χ 2 in the third column of their table 2, and compare our theoretical tidal radii r K t with their corresponding limiting radii r l .
We give this comparison in Figure 11, in particular in the non-axisymmetric potential. The black points with their uncertainties are points already plotted in Figure 7 with corresponding King tidal radii r K employed in that figure. The red points are the comparison between r K t with r l ; the uncertainties in r l are computed with data in table 2 of Miocchi et al. (2013) using distances given in our Table 1. Thus these points are displaced in the horizontal axis with respect to the black points. The displacements are shown with dotted blue lines. Red crossed points correspond to clusters in which a Wilson model gives the best fit to the density profile. The comparison between r K t with r l is almost the same as r K t vs r K in Figure 7, except for the five red crossed points, where r l is about a factor of 2-3 greater than r K and r K t . These five points correspond to NGC 288, NGC 5024 (M53), NGC 5272 (M3), NGC 5466, and NGC 5904 (M5). As commented in Paper I, the last three clusters appear to be dissolving (Leon et al. 2000; Odenkirchen & Grebel 2004; Belokurov et al. 2006); also, NGC 288 has extended tails (Grillmair et al. 2004), and NGC 5024 is possibly an accreted cluster (Mackey & Gilmore 2004). Thus in these five clusters r l will be an upper bound for the tidal radius; some stars contributing to r l may be already escaping from the cluster.
## 5.1.3. Comparison with improved cluster masses
In their study of structural properties of massive star clusters, McLaughlin & van der Ma (2005) have obtained dynamical mass-to-light ratios ( M/L ) V for 57 Galactic globular clusters. In this part we compute r K t for clusters in common between our sample and those listed in their table 13, now with the cluster mass M c computed with their ( M/L ) V , instead of ( M/L ) V = 2 M /L /circledot /circledot employed in our study. With these new values of r K t , we compare r K t vs r K in the non-axisymmetric potential.
Figure 12 shows this comparison. The black points are points from Figure 7, using ( M/L ) V = 2 M /L /circledot /circledot ; the red points employ the ( M/L ) V values of McLaughlin & van der Marel (2005) with their uncertainties. For clarity in the figure, these red points are slightly displaced to the right of the black points. Thus, there is no much difference with respect to the comparison made in Figure 7, and the standard ( M/L ) V = 2 M /L /circledot /circledot is a convenient test in our analysis.
## 5.2. Tidal radii with Monte Carlo computations
The comparison of theoretical and observed tidal radii made in the last section was repeated, now using Monte Carlo simulations. The uncertainties in the cluster distance, radial velocity, and proper motions, listed in Table 1, plus the uncertainties of the Galactic parameters listed in Table 2, were considered as 1 σ variations in a Gaussian Monte Carlo sampling. For each cluster we computed a few hundreds of orbits. In each sampled cluster orbit computed backward in time, we found the average <r K t > over the last 10 9 yr, and in turn, with all these values in a given cluster, determined its corresponding global average, denoted by 〈 r K t 〉 , and its 1 σ variation.
Figures 13 and 14 show the comparison of 〈 r K t 〉 with r K in the axisymmetric and nonaxisymmetric Galactic potentials. The error bars in both figures correspond to the computed 1 σ variation. With these Monte Carlo calculations we obtain nearly the same comparisons shown in Figures 6 and 7; thus, again our conclusion is that 〈 r K t 〉 compares better with r K employing the non-axisymmetric potential. These Figures 13 and 14 also show that the estimate of the uncertainty in <r K t > done in § 5.1 using the minimum and maximum energy orbits, is acceptable.
An additional plotted point in Figures 13 and 14, which does not appear in Figures 6 and 7, is the one corresponding to the cluster Pal 3, the upper point in these figures. This cluster has an unbounded orbit computed with its mean distance, radial velocity, and proper motions listed in Table 1, and the mean Galactic parameters in Table 2. In the Monte Carlo
simulations we have picked out its bounded orbits.
## 5.3. Overfilling excess of predicted tidal radius?
Webb et al. (2013) have considered observed limiting radii of Galactic globular clusters, given by a King model, r K , and their theoretical tidal radius, r t , computed at their perigalactic distance in the axisymmetric Galactic potential used by Johnston et al. (1995), but r t obtained as if the Galactic potential were spherically symmetric. They take the ratio of the difference ( r K -r t ) to the average ( r K + )/2, and plot this ratio against the perigalacr t tic distance. Clusters with this ratio greater than zero, overfill their predicted theoretical tidal radius; underfilling occurs in clusters which have this ratio less than zero. Webb et al. (2013) show in their figure 1 that the majority of clusters are overfilling their predicted tidal radius. Through N -body simulations of star clusters moving on the plane of symmetry of a given axisymmetric Galactic potential, they find an analytical correction to be applied to r t computed at perigalacticon, to obtain a better estimate of the cluster limiting radius r L . With this value of r L employed instead of r t in the computation of the ratio mentioned above, Webb et al. (2013) find that the overfilling excess disappears, and there is a stronger agreement between theory and observations.
To compare with the results of Webb et al. (2013), in our axisymmetric and nonaxisymmetric Galactic potentials we compute the theoretical tidal radius at perigalacticon with King's formula Eq. (1) (or alternatively with r ∗ in Eq. (2)), take the average values of r K t over the last 10 9 yr listed in column 8 of Table 3, take the ratio of the difference ( r K -<r K t > ) to the average ( r K + <r K t > )/2 ( r K is listed in Table 1) and plot this ratio against the logarithm of the average perigalactic distance in these last 10 9 yr. We do the same taking only the last perigalacticon, and its distance to the Galactic center.
Figure 15 shows our results. The two upper frames (a),(c) correspond to the last 10 9 yr, and the two lower frames (b),(d) to the last perigalacticon. The frames on the left (a),(b) give results in the axisymmetric Galactic potential, and the frames on the right (c),(d) in the nonaxisymmetric Galactic potential. At first sight, there is no evident overfilling nor underfilling excess of predicted theoretical tidal radius; the points scatter approximately around zero value in the ratio 2( r K -<r K t > )/( r K + <r K t > ). This holds in both the axisymmetric and non-axisymmetric Galactic potentials, thus the main point in the discrepance of our results with those of Webb et al. (2013) seems to be the different ways in which the theoretical tidal radius is computed at perigalactic distance.
If we apply the correction given by Webb et al. (2013) in their equation 8 to our r K t
computed at perigalacticon, this leads to a new cluster limiting radius r LK . To compute this limiting radius we take in each cluster an average of r K t , the orbital eccentricity, and the orbital phase, over the last 10 9 yr. We determine the ratio of the difference ( r K -r LK ) to the average ( r K + r LK )/2, and plot this ratio against the logarithm of the average perigalactic distance in these last 10 9 yr. This is shown in Figure 16 only for the non-axisymmetric Galactic potential. The error bars shown in this figure are obtained using the the minimum and maximum energy orbits, mentioned in § 5.1. We find a strong underfilling excess; there is a systematic shifting towards negative values in comparison with the initial approximately zero excess found in Figure 15. Then our conclusion is that in our computations we do not need to apply the correction given by Webb et al. (2013). This issue needs a further study.
## 6. Bulge-shocking destruction rates taking the real trajectory of a cluster
In Paper I we have listed some relations needed to compute destruction rates of globular clusters due to bulge and disk shocking. Those corresponding to bulge shocking employ the impulse approximation, along with adiabatic corrections, and a linear trajectory of the cluster when passing at a given perigalactic point. In this section we give relations to compute destruction rates due to bulge shocking employing the real trajectory of a globular cluster, maintaining the impulse approximation.
Let F ( r ) be the Galactic gravitational acceleration at the position r in an inertial reference system with origin at the Galactic center. In particular, in the following we consider this acceleration due to the spherical bulge component in the used axisymmetric model, and due to the bar in the non-axisymmetric model, in which all the bulge is represented by this bar, as mentioned in § 3.
With r c the position of the center of a globular cluster, and r ′ the position of a star in the cluster with respect to the cluster center, then r = r c + r ′ is the position of the star in the inertial frame, and we define F r ( ′ ) with the relation F ( r ) ≡ F ( r c + r ′ )= F r ( ′ ).
Then, up to linear terms in r ′ and at the cluster position r c , the tidal acceleration M r ( ′ ) on the star is (with a sum over a repeated index)
$$M \left ( r ^ { \prime } \right ) = F \left ( r ^ { \prime } \right ) - F \left ( r ^ { \prime } = 0 \right ) \simeq J \cdot r ^ { \prime } = e _ { i } x _ { j } ^ { \prime } \left ( \frac { \partial F _ { x _ { i } ^ { \prime } } } { \partial x _ { j } ^ { \prime } } \right ) _ { r ^ { \prime } = 0 }.$$
The coordinates x ′ i , i = 1, 2, 3, are Cartesian coordinates of r ′ ; this vector written in the inertial base of unitary vectors ( e 1 , e 2 , e 3 ). The matrix J is given by
$$J = \left ( \begin{array} { c c c } \frac { \partial F _ { x ^ { \prime } } } { \partial x ^ { \prime } } & \frac { \partial F _ { x ^ { \prime } } } { \partial y ^ { \prime } } & \frac { \partial F _ { x ^ { \prime } } } { \partial z ^ { \prime } } \\ \frac { \partial F _ { y ^ { \prime } } } { \partial x ^ { \prime } } & \frac { \partial F _ { y ^ { \prime } } } { \partial y ^ { \prime } } & \frac { \partial F _ { y ^ { \prime } } } { \partial z ^ { \prime } } \\ \frac { \partial F _ { + ^ { \prime } } } { \partial x ^ { \prime } } & \frac { \partial F _ { - ^ { \prime } } } { \partial y ^ { \prime } } & \frac { \partial F _ { + ^ { \prime } } } { \partial z ^ { \prime } } \end{array} \right ) _ { r ^ { \prime } = 0 }.$$
To obtain the stellar velocity change due to M , we integrate d v ′ /dt = M in the inertial frame, taking two successive apogalactic points in the cluster's orbit. The stellar velocity v ′ is measured in the inertial frame. Using the impulse approximation, the change in the ith component of the stellar velocity between these two successive apogalactic points is (there is a sum over the index j )
$$\Delta v _ { i } ^ { \prime } = x _ { j } ^ { \prime } \int _ { t _ { a p 1 } } ^ { t _ { a p 2 } } \left ( \frac { \partial F _ { x _ { i } ^ { \prime } } } { \partial x _ { j } ^ { \prime } } \right ) _ { \mathbf r ^ { \prime } = 0 } d t = x _ { j } ^ { \prime } I _ { i j },$$
with I ij defined by the integral, and the integration done numerically along the real orbit of the cluster, under the whole used Galactic potential, between successive apogalactic points occurring at times t ap 1 , t ap 2 , i.e. an apogalactic period.
The change of stellar energy per unit mass is ∆ E = v ′ · ∆ v ′ + (1/2)(∆ v ′ ) 2 . Thus, with Eq. (5), assuming spherical symmetry in the cluster, and an isotropic stellar velocity distribution within the cluster depending only on distance r ′ = | r ′ | from the center of the cluster, we have the two local (i.e. averaged on a spherical surface of radius r ′ ) diffusion coefficients due to the interaction with the bulge
$$< ( \Delta E ) _ { b } > _ { l o c } = \frac { 1 } { 2 } < ( \Delta \mathfrak { v } ^ { \prime } ) ^ { 2 } > _ { l o c } = \frac { 1 } { 6 } r ^ { \prime 2 } \sum _ { i, j } I _ { i j } ^ { 2 },$$
$$< ( \Delta E ) _ { b } ^ { 2 } > _ { l o c } \approx < ( v ^ { \prime } \cdot \Delta v ^ { \prime } ) ^ { 2 } > _ { l o c } = \frac { 1 } { 9 } r ^ { \prime 2 } v ^ { \prime 2 } ( r ^ { \prime } ) ( 1 + \chi _ { r ^ { \prime }, v ^ { \prime } } ( r ^ { \prime } ) ) \sum _ { i, j } I _ { i j } ^ { 2 }, \quad \quad ( 7 ) \\ \dots \quad r ^ { \prime \prime } \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot$$
with v ′ ( r ′ ) the rms velocity within the cluster at distance r ′ , and the position-velocity correlation function χ r ,v ′ ′ ( r ′ ) given by Gnedin & Ostriker (1999). The sum in these equations gives nine squared coefficients I 2 ij .
To take into account the stellar motion within the cluster during its interaction with the Galactic bulge or bar in an apogalactic period, adiabatic correction factors η 1 ( x ), η 2 ( x ) are introduced in Eqs. (6) and (7), having the forms (Gnedin & Ostriker 1999)
$$\eta _ { 1 } ( x ( r ^ { \prime } ) ) = ( 1 + x ^ { 2 } ( r ^ { \prime } ) ) ^ { - \gamma _ { 1 } },$$
$$\eta _ { 2 } ( x ( r ^ { \prime } ) ) = ( 1 + x ^ { 2 } ( r ^ { \prime } ) ) ^ { - \gamma _ { 2 } },$$
with x r ( ′ ) = ω r ( ′ ) τ ; ω r ( ′ ) is angular velocity of stars inside the cluster at distance r ′ , and as in Paper I, the angular velocity in circular motion at distance r ′ is considered to represent this ω r ( ′ ). The factor τ is an effective interaction time with the Galactic bulge or bar in an apogalactic period. The exponents γ 1 , γ 2 depend on the ratio between τ and the cluster's inner dynamical time evaluated at the half-mass radius, t dyn,h = ( π r 2 h 3 / 2 GM c ) 1 2 / (the halfmass radius r h and the mass of the cluster M c are listed in Table 1). The values of γ 1 , γ 2 are those considered in Paper I, based on Table 2 of Gnedin & Ostriker (1999).
In the usual procedure employed in the impulse approximation with a linear trajectory of the cluster passing at a given perigalactic point, the effective interaction time τ is estimated as τ = | r p | / | v p | , with r p , v p the position and velocity of the cluster at this point with respect to the Galactic inertial frame. For the real trajectory of the cluster considered in this section, we follow the treatment of Gnedin et al. (1999a) to estimate τ . Gnedin et al. (1999a) consider a potential with spherical symmetry and estimate τ making a Gaussian fit of the form e -t 2 /τ 2 to the tidal acceleration in the z-direction. In our Galactic potentials we make a similar fit to the rms total tidal acceleration.
From Eq. (3), the local averaged square tidal acceleration is
$$< M ^ { 2 } > _ { l o c } = \frac { 1 } { 3 } r ^ { \prime 2 } \sum _ { i, j } \left ( \frac { \partial F _ { x ^ { \prime } _ { i } } } { \partial x ^ { \prime } _ { j } } \right ) _ { \mathbf r ^ { \prime } = 0 } ^ { 2 } \\ \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \colon$$
Taking an average over the cluster, the Gaussian fit in an apogalactic period is made on the rms tidal acceleration given by
$$\left ( < M ^ { 2 } > \right ) ^ { 1 / 2 } & = \left \{ \frac { 1 } { 3 } < r _ { c } ^ { 2 } > \sum _ { i, j } \left ( \frac { \partial F _ { x _ { i } ^ { \prime } } } { \partial x _ { j } ^ { \prime } } \right ) _ { r ^ { \prime } = 0 } ^ { 2 } \right \} ^ { 1 / 2 }, \quad \right ) ^ { ( 1 1 ) } \\ \omega _ { \cdot } \quad. \quad. \quad. \quad. \quad. \quad. \quad. \quad. \quad. \quad.$$
where <r > 2 c is the mean square cluster radius, computed below. The resulting value of τ given by the fit is employed in Eqs. (8) and (9).
In the axisymmetric potential the tidal acceleration ( < M 2 > ) 1 2 / has one maximum in every apogalactic period. However, in the non-axisymmetric potential, and in some clusters,
this acceleration may have a complicated behavior in some apogalactic periods, showing more than one maximum. Figure 17 shows as an example some apogalactic periods in a run in the cluster NGC 6266. The black dots give the positions in time of apogalactic points; the black curve is ( < M 2 > ) 1 2 / and the red curves show the typical approximate fits made to the main acceleration peaks in cases like this.
Including the adiabatic correction factors, the averages of Eqs. (6) and (7) over the cluster are
$$< ( \Delta E ) _ { b } > = \frac { 1 } { 6 } < r ^ { \prime 2 } \eta _ { 1 } ( x ( r ^ { \prime } ) ) > \sum _ { i, j } I _ { i j } ^ { 2 },$$
$$< ( \Delta E ) _ { b } ^ { 2 } > \approx \frac { 1 } { 9 } < r ^ { \prime 2 } v ^ { \prime 2 } ( r ^ { \prime } ) ( 1 + \chi _ { r ^ { \prime }, v ^ { \prime } } ( r ^ { \prime } ) ) \eta _ { 2 } ( x ( r ^ { \prime } ) ) > \sum _ { i, j } I _ { i j } ^ { 2 },$$
with
$$< r ^ { \prime 2 } \eta _ { 1 } ( x ( r ^ { \prime } ) ) > = \frac { 4 \pi } { M _ { c } } \int _ { 0 } ^ { r _ { K } } \rho _ { c } ( r ^ { \prime } ) \eta _ { 1 } ( x ( r ^ { \prime } ) ) r ^ { \prime 4 } d r ^ { \prime },$$
$$< r ^ { \prime 2 } v ^ { \prime 2 } ( r ^ { \prime } ) ( 1 + \chi _ { r ^ { \prime }, \nu ^ { \prime } } ( r ^ { \prime } ) ) \eta _ { 2 } ( x ( r ^ { \prime } ) ) > = \frac { 4 \pi G } { M _ { c } } \int _ { 0 } ^ { r _ { K } } \rho _ { c } ( r ^ { \prime } ) M _ { c } ( r ^ { \prime } ) \eta _ { 2 } ( x ( r ^ { \prime } ) ) ( 1 + \chi _ { r ^ { \prime }, \nu ^ { \prime } } ( r ^ { \prime } ) ) r ^ { \prime 3 } d r ^ { \prime },$$
and <r > 2 c in Eq. (11)
$$< r _ { c } ^ { 2 } > = < r ^ { \prime 2 } > = \frac { 4 \pi } { M _ { c } } \int _ { 0 } ^ { r _ { K } } \rho _ { c } ( r ^ { \prime } ) r ^ { \prime 4 } d r ^ { \prime },$$
r K is the tidal radius of the cluster (listed in Table 1), M c is its total mass, ρ c ( r ′ ) is its spatial density, obtained with a King (1966) model, and M r c ( ′ ) is the mass of the cluster within radius r ′ . As in Paper I, we approximate the rms velocity v ′ ( r ′ ) with the corresponding circular velocity at that r ′ .
With E c /similarequal -0 2 . GM /r c h the mean binding energy per unit mass of the cluster, and if the cluster has a dominant maximum of the tidal acceleration ( < M 2 > ) 1 2 / in a given apogalactic period, bulge shock timescales in this period are defined as (Gnedin & Ostriker 1997)
$$t _ { b u l g e, 1 } = \left ( \frac { - E _ { c } } { < ( \Delta E ) _ { b } > } \right ) P _ { o r b },$$
$$t _ { b u l g e, 2 } = \left ( \frac { E _ { c } ^ { 2 } } { < ( \Delta E ) _ { b } ^ { 2 } > } \right ) P _ { o r b },$$
with P orb the apogalactic period. If the cluster has more than one maximum of ( < M 2 > ) 1 2 / in the given apogalactic period, as in Figure 10, instead of P orb we use in each main fitted peak the corresponding interval of time taken in the fit. In each case the total destruction rate due to bulge shocking is
$$\frac { 1 } { t _ { b u l g e } } = \frac { 1 } { t _ { b u l g e, 1 } } + \frac { 1 } { t _ { b u l g e, 2 } }.$$
## 7. Disk and spiral arms shocking
The treatment for disk shocking remains the same as in Paper I. The corresponding expressions to Eqs. (12) and (13) for disk shocking are obtained averaging equations (1) and (2) in Gnedin et al. (1999b), resulting in
$$< ( \Delta E ) _ { d } > = \frac { 2 g _ { m } ^ { 2 } } { 3 v _ { z } ^ { 2 } } < r ^ { \prime 2 } \eta _ { 1 } ( x ( r ^ { \prime } ) ) >,$$
$$< ( \Delta E ) _ { d } ^ { 2 } > = \frac { 4 g _ { m } ^ { 2 } } { 9 v _ { z } ^ { 2 } } < r ^ { \prime 2 } v ^ { \prime 2 } \eta _ { 2 } ( x ( r ^ { \prime } ) ) ( 1 + \chi _ { r ^ { \prime }, v ^ { \prime } } ( r ^ { \prime } ) ) >.$$
In both, the axisymmetric and non-axisymmetric Galactic potentials, | g m | is the maximum acceleration produced by the corresponding axisymmetric disk component in its perpendicular z-direction, on the perpendicular line to the plane of the disk passing at the position where the cluster crosses the disk, and | v z | is the z-velocity of the cluster at this point. Here τ in x r ( ′ ) = ω r ( ′ ) τ is given by τ = | z m | / v | z | , with | z m | the z-distance at which | g m | is reached.
With n crossings of the cluster orbit with the Galactic plane, disk shock timescales and corresponding total destruction rate are given by
$$t _ { d i s k, 1 } = \left ( \frac { - E _ { c } } { < ( \Delta E ) _ { d } > } \right ) \frac { P _ { o r b } } { n },$$
$$t _ { d i s k, 2 } = \left ( \frac { E _ { c } ^ { 2 } } { < ( \Delta E ) _ { d } ^ { 2 } > } \right ) \frac { P _ { o r b } } { n },$$
$$\frac { 1 } { t _ { d i s k } } = \frac { 1 } { t _ { d i s k, 1 } } + \frac { 1 } { t _ { d i s k, 2 } }.$$
In the non-axisymmetric potential, the spiral arms represent a plane mass distribution, analogous to the axisymmetric disk component, and also produce a shock on a cluster crossing the Galactic plane, with corresponding averaged diffusion coefficients < (∆ E ) arms > and < (∆ E ) 2 arms > . At a given crossing point, the ratios < (∆ E ) arms > / < (∆ E ) d > , < (∆ E ) 2 arms > / < (∆ E ) 2 d > between averaged diffusion coefficients due to the spiral arms and axisymmetric disk, will depend on the squared ratio of corresponding maximum accelerations ( | g m arms | / g | m disk | ) 2 . The velocity | v z | has the same value in both type of diffusion coefficients, as this velocity, as well as the orbit itself, is computed under the whole Galactic potential, i.e. including the axisymmetric (disk and dark halo) and non-axisymmetric (bar and spiral arms) components. There will be also a dependence of these ratios on the corresponding | z m | given by the spiral arms, through the dependence of η 1 and η 2 on τ .
Figures 18 and 19 show the azimuth-averaged ratios ( | g m arms | / g | m disk | ) 2 and | z m arms | / z | m disk | as functions of the distance R to the Galactic center of the point where a cluster orbit crosses the Galactic plane. The squared ratio ( | g m arms | / g | m disk | ) 2 is important only in the region of the spiral arms (2-12 kpc) and of order 10 -2 -10 -3 . In this region | z m arms | / z | m disk | is close to unity. Thus, in our analysis we ignore the spiral arms shocking, which compared with the one of the disk will be two or three orders of magnitude lower.
## 8. Destruction rates. Results
In this section we present bulge-shocking destruction rates obtained with the formulism given in the last section, using the real trajectories of globular clusters in the employed Galactic potentials, and compare with corresponding values obtained with the usual linear trajectory approximation used in Paper I. The disk-shocking destruction rates are also computed and compared in the axisymmetric and non-axisymmetric potentials. All the computations are done with Monte Carlo simulations.
Table 4 shows our results. Bulge-shocking destruction rates averaged over the last 10 9
yr in a cluster's orbit (this time is increased in some clusters) and their lower, σ -, and upper, σ + , uncertainties, are listed according to the linear (columns 2-4) or real (columns 5-7) employed cluster's trajectory. Columns 8-10 give the disk-shocking destruction rates. For each cluster, the first line gives values in the non-axisymmetric potential, and the second line in the axisymmetric potential.
With the data given in Table 4, Figures 20 and 21 show separately the comparison of bulge-shocking total destruction rates in the axisymmetric and non-axisymmetric Galactic potentials. Values obtained with the real trajectory of the cluster are shown in the vertical axis, and in the horizontal axis those with the linear trajectory. The error bars in these and following figures are given by the σ -and σ + values in Table 4. The conclusion from these two figures is that the use of the linear trajectory, along with the associated effective interaction time estimated as τ = | r p | / | v p | , gives a good approximation to compute destruction rates due to the bulge, in the axisymmetric and non-axisymmetric Galactic potentials.
To see how much the computed destruction rates can change if we take the cluster mass-to-light ratio ( M/L ) V different from the assumed ( M/L ) V =2 M /L /circledot /circledot , we consider, as in Figure 12, dynamical mass-to-light ratios ( M/L ) V obtained by McLaughlin & van der Marel (2005). For clusters in common between our sample and in table 13 of McLaughlin & van der Marel (2005), the new cluster mass M c is computed, and in Figure 22 we show the comparison of bulge-shocking total destruction rates in particular in the axisymmetric potential, comparing values using the real (vertical axis) and linear (horizontal axis) trajectory. The black points with their uncertainties are points from Figure 20, obtained with the assumed ( M/L ) V = 2 M /L /circledot /circledot . The red points are obtained with the dynamical mass-to-light ratios given by McLaughlin & van der Marel (2005). The correspondig shifts between black and red points in a cluster are shown with blue lines. Thus, the destruction rates do not change too much, specially those with high values, and the standard ( M/L ) V = 2 M /L /circledot /circledot is a convenient test value.
Taking the real trajectories, Figure 23 shows the comparison of bulge-shocking total destruction rates in the non-axisymmetric (vertical axis) and axisymmetric (horizontal axis) Galactic potentials. Here we note important differences between both potentials, specially in the region of high destruction rates, where values obtained with the non-axisymmetric potential are smaller than those with the axisymmetric potential. As noted in § 3, in the non-axisymmetric potential all the bulge is represented by the Galactic bar; thus, there is no remnant of the original concentrated spherical bulge in the axisymmetric potential, whose mass is now distributed over the bar, with less central concentration (see upper frame in figure 7 in Paper I) and thus less dangerous for clusters crossing its region. This explains
the behavior in the high destruction rate region in Figure 23. In § 5.1.1 we saw a related decrease of tidal radii in the inner Galactic region in the non-axisymmetric potential; see discussion of Figure 8 in that section. Our conclusion is that the more appropriate non-axisymmetric Galactic potential employed in our computations, reduces the destruction rates due to the bulge (bar, in this case) for clusters with perigalacticons in the inner Galactic region.
Disk-shocking destruction rates in the non-axisymmetric and axisymmetric potentials are compared in Figure 24. Practically these destruction rates are the same in both potentials. Comparing this figure with Figure 23, we note that the disk dominates the destruction rate for clusters in the low destruction rate region, i.e. clusters with perigalacticons relatively distant from the Galactic center.
Adding the bulge-shocking total destruction rate obtained with the real trajectory of the cluster, and the disk-shocking destruction rate, results in the total bulge+disk destruction rate. Figure 25 shows the comparison of these total values in the non-axisymmetric (vertical axis) and axisymmetric (horizontal axis) Galactic potentials. In Figure 26 we show the same Figure 25 but now without the error bars. Empty and black squares correspond to clusters with orbital eccentricity e ≤ 0 5 and . e > 0 5, respectively. . The points marked with a circle show the clusters whose mass is less than 10 5 M /circledot . The position of some clusters are marked with their NGC and Pal numbers.
As in Figure 23, in these last figures we note that in the region of high destruction rates, dominated by the bulge, the total destruction rates obtained with the non-axisymmetric potential are smaller than those resulting with the axisymmetric potential. Figure 26 shows that the majority of clusters with high eccentricities ( e > 0 5), have smaller destruction rates . in the non-axisymmetric potential.
With the non-axisymmetric Galactic potential employed in our analysis, along with the more appropriate Monte Carlo simulations, we see from Figure 26 that seven clusters have particularly high destruction rates at the present time, due to bulge and disk shocking: Pal 5, NGC 6144, NGC 6121, NGC 6342, NGC 5897, NGC 6293, and NGC 6522. In Paper I, using only the Galactic bar in the non-axisymmetric potential, we found that NGC 6528 had the greatest destruction rate; now with the present non-axisymmetric Galactic model and the Monte Carlo simulations, this cluster has a low destruction rate, as shown in Figure 26.
## 9. Conclusions
We have employed the available 6-D data (positions and velocities) of 63 globular clusters in our Galaxy to analyze their Galactic orbits and compute their tidal radii, as well as their bulge and disk shocking destruction rates. This analysis has been made in axisymmetric and non-axisymmetric Galactic potentials; in particular, the used non-axisymmetric potential is a very detailed model which includes both the Galactic bar and a 3D model for the spiral arms. Our analysis is made using Monte Carlo simulations, to take into account the several uncertainties in the kinematical data of the clusters. For the computation of destruction rates due to the bulge in both Galactic potentials, we have employed the rigorous treatment of considering the real Galactic cluster orbit, instead of the usual linear trajectory employed in previous studies.
Our first result is that the theoretical tidal radius computed in the non-axisymmetric Galactic potential compares better with the observed tidal radius than that computed in the axisymmetric potential. This result leaves an open question with a recent study made by Webb et al. (2013), who propose a correction to be applied to the theoretical tidal radius computed at perigalacticon, to have a better comparison with the observed tidal radius. In our computations we do not need to introduce this correction.
The first conclusion from our results of bulge-shocking destruction rates is that the usual linear trajectory of the cluster considered at perigalacticon, gives a good approximation to the result obtained taking the real trajectory of the cluster. This conclusion holds in both the axisymmetric and non-axisymmetric potentials.
Our second conclusion is that the bulge-shocking destruction rates for clusters with perigalacticons in the inner Galactic region, turn out to be smaller in the non-axisymmetric potential, as compared with those in the axisymmetric one. The majority of clusters with high orbital eccentricities ( e > 0 5) have . smaller total bulge+disk destruction rates in the non-axisymmetric potential.
Weacknowledge financial support from UNAM DGAPA-PAPIIT through grant IN114114.
## REFERENCES
Aguilar, L., Hut, P., & Ostriker, J. P. 1988, ApJ, 335, 720
Allen, C., Moreno, E., & Pichardo, B. 2006, ApJ, 652, 1150 (Paper I)
Allen, C., Moreno, E., & Pichardo, B. 2008, ApJ, 674, 237 (Paper II)
Allen, C., & Santill´n, A. 1991, Rev. Mexicana Astron. Astrofis., 22, 255 a Anderson, J., & King, I. R. 2003, AJ, 126, 772 Bedin, L. R., Piotto, G., King, I. R., & Anderson, J. 2003, AJ, 126, 247 Belokurov, V., Evans, N. W., Irwin, M. J., Hewett, P. C., & Wilkinson, M. I. 2006, ApJ, 637, L29 Benjamin, R. A., et al. 2005, ApJ, 630, L149 Brunthaler, A., et al. 2011, AN, 332, No. 5, 461 Casetti-Dinescu, D. I., Girard, T. M., Herrera, D., van Altena, W. F., L´ opez, C. E., & Castillo, D. J. 2007, AJ, 134, 195 Casetti-Dinescu, D. I., Girard, T. M., Korchagin, V. I., van Altena, W. F., & L´pez, C. E. o 2010, AJ, 140, 1282 Casetti-Dinescu, D. I., Girard, T. M., J´ ılkov´, L., van Altena, W. F., Podest´, F., & L´pez, a a o C. E. 2013, AJ, 146, 33 Combes, F., & Sanders, R. H. 1981, A&A, 96, 164 Dinescu, D. I., Girard, T. M., van Altena, W. F., M´ndez, R. A., & L´pez, C. E. 1997, AJ, e o 114, 1014 Dinescu, D. I., van Altena, W. F., Girard, T. M., & L´pez, C. E. 1999a, AJ, 117, 277 o Dinescu, D. I., Girard, T. M., & van Altena, W. F. 1999b, AJ, 117, 1792 Dinescu, D. I., Majewski, S. R., Girard, T. M., & Cudworth, K. M. 2000, AJ, 120, 1892 Dinescu, D. I., Majewski, S. R., Girard, T. M., & Cudworth, K. M. 2001, AJ, 122, 1916 Dinescu, D. I., Girard, T. M., van Altena, W. F., & L´pez, C. E. 2003, AJ, 125, 1373 o Drimmel, R. 2000, A&A, 358, L13 Fehlberg, E. 1968, NASA TR R-287 Freudenreich, H. T. 1998, ApJ, 492, 495 Gerhard, O. 2002, ASP Conf. Ser., 273, 73 Gerhard, O. 2011, Mem. Soc. Astron. Italiana Suppl., Vol. 18, 185
Gnedin, O. Y., & Ostriker, J. P. 1997, ApJ, 474, 223 Gnedin, O. Y., & Ostriker, J. P. 1999, ApJ, 513, 626 Gnedin, O. Y., Hernquist, L., & Ostriker, J. P. 1999, ApJ, 514, 109 Gnedin, O. Y., Lee, H. M., & Ostriker, J. P. 1999, ApJ, 522, 935 Grillmair, C. J., Jarrett, T. H., & Ha, A. C. 2004, ASP Conf. Ser., 327, 276 Harris, W. E. 1996, AJ, 112, 1487 Harris, W. E. 2010, arXiv:1012.3224v1 Johnston, K. V., Spergel, D. N., & Hernquist, L. 1995, ApJ, 451, 598 King, I. R. 1962, AJ, 67, 471 King, I. R. 1966, AJ, 71, 64 Leon, S., Meylan, G., & Combes, F. 2000, A&A, 359, 907 Mackey, A. D., & Gilmore, G. F. 2004, MNRAS, 355, 504 McLaughlin, D. E., & van der Marel, R. P. 2005, ApJS, 161, 304 Miocchi, P., Lanzoni, B., Ferraro, F. R., Dalessandro, E., Vesperini, E., Pasquato, M., Beccari, G., Pallanca, C., & Sanna, N. 2013, ApJ, 774, 151 Odenkirchen, M., & Grebel, E. K. 2004, ASP Conf. Ser., 327, 284 Peterson, C. J. & King, I. R. 1975, AJ, 80, 427 Pichardo, B., Martos, M., & Moreno, E. 2004, ApJ, 582, 230 Pichardo, B., Martos, M., Moreno, E., & Espresate, J. 2003, ApJ, 582, 230 Pichardo, B., Moreno, E., Allen, C., Bedin, L. R., Bellini, A., Pasquini, L. 2012, AJ, 143, 73 Press, W. H., Teukolsky, S. A., Vetterling, W. T., & Flannery, B. P. 1992, Numerical Recipes in Fortran 77: The Art of Scientific Computing (2nd ed.; Cambridge: Cambridge Univ. Press) Sanders, R. H., & Tubbs, A. 1980, AJ, 235, 803 Sch¨ onrich, R., Binney, J., & Dehnen, W. 2010, MNRAS, 403, 1829
Webb, J. J., Harris, W. E., Sills, A., & Hurley, J. R. 2013, ApJ, 764, 124 Wilson, C. P. 1975, AJ, 80, 175
This preprint was prepared with the AAS LT E X macros v5.2. A
Table 1. Globular Clusters Data
| Cluster | α 2000 ( deg ) | δ 2000 ( deg ) | r ( kpc ) | v r ( km/s ) | µ x ( mas ) | µ y ( mas ) | M c ( M /circledot ) | r K ( pc ) | r h ( pc ) |
|-----------|------------------|------------------|-------------|----------------|----------------|----------------|------------------------|--------------|--------------|
| NGC 104 | 6.02363 | - 72.08128 | 4.5 ± 0.45 | - 18.0 ± 0.1 | 5.64 ± 0.20 | - 2.02 ± 0.20 | 1e+06 | 55.37 | 4.15 |
| NGC 288 | 13.1885 | - 26.58261 | 8.9 ± 0.89 | - 45.4 ± 0.2 | 4.67 ± 0.42 | - 5.62 ± 0.23 | 86000 | 34.15 | 5.77 |
| NGC 362 | 15.8094 | - 70.84878 | 8.6 ± 0.86 | 223.5 ± 0.5 | 5.07 ± 0.71 | - 2.55 ± 0.72 | 400000 | 26.61 | 2.05 |
| NGC 1851 | 78.5282 | - 40.04655 | 12.1 ± 1.21 | 320.5 ± 0.6 | 1.28 ± 0.68 | 2.39 ± 0.65 | 370000 | 22.95 | 1.8 |
| NGC 1904 | 81.0462 | - 24.52472 | 12.9 ± 1.29 | 205.8 ± 0.4 | 2.12 ± 0.64 | - 0.02 ± 0.64 | 240000 | 30.9 | 2.44 |
| NGC 2298 | 102.248 | - 36.00531 | 10.8 ± 1.08 | 148.9 ± 1.2 | 4.05 ± 1.00 | - 1.72 ± 0.98 | 57000 | 23.36 | 3.08 |
| NGC 2808 | 138.013 | - 64.86350 | 9.6 ± 0.96 | 101.6 ± 0.7 | 0.58 ± 0.45 | 2.06 ± 0.46 | 970000 | 25.35 | 2.23 |
| Pal 3 | 151.383 | 0.07167 | 92.5 ± 9.25 | 83.4 ± 8.4 | 0.33 ± 0.23 | 0.30 ± 0.31 | 32000 | 107.81 | 17.49 |
| NGC 3201 | 154.403 | - 46.41247 | 4.9 ± 0.49 | 494.0 ± 0.2 | 5.28 ± 0.32 | - 0.98 ± 0.33 | 160000 | 36.13 | 4.42 |
| NGC 4147 | 182.526 | 18.54264 | 19.3 ± 1.93 | 183.2 ± 0.7 | - 1.85 ± 0.82 | - 1.30 ± 0.82 | 50000 | 34.16 | 2.69 |
| NGC 4372 | 186.439 | - 72.65900 | 5.8 ± 0.58 | 72.3 ± 1.2 | - 6.49 ± 0.33 | 3.71 ± 0.32 | 220000 | 58.91 | 6.6 |
| NGC 4590 | 189.867 | - 26.74406 | 10.3 ± 1.03 | - 94.7 ± 0.2 | - 3.76 ± 0.66 | 1.79 ± 0.62 | 150000 | 44.67 | 4.52 |
| NGC 4833 | 194.891 | - 70.87650 | 6.6 ± 0.66 | 200.2 ± 1.2 | - 8.11 ± 0.35 | - 0.96 ± 0.34 | 320000 | 34.14 | 4.63 |
| NGC 5024 | 198.23 | 18.16817 | 17.9 ± 1.79 | - 62.9 ± 0.3 | 0.50 ± 1.00 | - 0.10 ± 1.00 | 520000 | 95.64 | 6.82 |
| NGC 5139 | 201.697 | - 47.47958 | 5.2 ± 0.52 | 232.1 ± 0.1 | - 5.08 ± 0.35 | - 3.57 ± 0.34 | 2.2e+06 | 73.19 | 7.56 |
| NGC 5272 | 205.548 | 28.37728 | 10.2 ± 1.02 | - 147.6 ± 0.2 | - 1.10 ± 0.51 | - 2.30 ± 0.54 | 610000 | 85.22 | 6.85 |
| NGC 5466 | 211.364 | 28.53444 | 16.0 ± 1.60 | 110.7 ± 0.2 | - 4.65 ± 0.82 | 0.80 ± 0.82 | 110000 | 72.98 | 10.7 |
| Pal 5 | 229.022 | - 0.11161 | 23.2 ± 2.32 | - 58.7 ± 0.2 | - 1.78 ± 0.17 | - 2.32 ± 0.23 | 20000 | 51.17 | 18.42 |
| NGC 5897 | 229.352 | - 21.01028 | 12.5 ± 1.25 | 101.5 ± 1.0 | - 4.93 ± 0.86 | - 2.33 ± 0.84 | 130000 | 36.88 | 7.49 |
| NGC 5904 | 229.638 | 2.08103 | 7.5 ± 0.75 | 53.2 ± 0.4 | 5.07 ± 0.68 | - 10.70 ± 0.56 | 570000 | 51.55 | 3.86 |
| NGC 5927 | 232.003 | - 50.67303 | 7.7 ± 0.77 | - 107.5 ± 0.9 | - 5.72 ± 0.39 | - 2.61 ± 0.40 | 230000 | 37.45 | 2.46 |
| NGC 5986 | 236.512 | - 37.78642 | 10.4 ± 1.04 | 88.9 ± 3.7 | - 3.81 ± 0.45 | - 2.99 ± 0.37 | 410000 | 24.15 | 2.96 |
| NGC 6093 | 244.26 | - 22.97608 | 10.0 ± 1.00 | 8.1 ± 1.5 | - 3.31 ± 0.58 | - 7.20 ± 0.67 | 330000 | 20.88 | 1.77 |
| NGC 6121 | 245.897 | - 26.52575 | 2.2 ± 0.22 | 70.7 ± 0.2 | - 12.50 ± 0.36 | - 19.93 ± 0.49 | 130000 | 33.16 | 2.77 |
| NGC 6144 | 246.808 | - 26.02350 | 8.9 ± 0.89 | 193.8 ± 0.6 | - 3.06 ± 0.64 | - 5.11 ± 0.72 | 94000 | 86.35 | 4.22 |
| NGC 6171 | 248.133 | - 13.05378 | 6.4 ± 0.64 | - 34.1 ± 0.3 | - 0.70 ± 0.90 | - 3.10 ± 1.00 | 120000 | 35.33 | 3.22 |
| NGC 6205 | 250.422 | 36.45986 | 7.1 ± 0.71 | - 244.2 ± 0.2 | - 0.90 ± 0.71 | 5.50 ± 1.12 | 450000 | 43.39 | 3.49 |
| NGC 6218 | 251.809 | - 1.94853 | 4.8 ± 0.48 | - 41.4 ± 0.2 | 1.30 ± 0.58 | - 7.83 ± 0.62 | 140000 | 24.13 | 2.47 |
| NGC 6254 | 254.288 | - 4.10031 | 4.4 ± 0.44 | 75.2 ± 0.7 | - 6.00 ± 1.00 | - 3.30 ± 1.00 | 170000 | 23.64 | 2.5 |
| NGC 6266 | 255.303 | - 30.11372 | 6.8 ± 0.68 | - 70.1 ± 1.4 | - 3.50 ± 0.37 | - 0.82 ± 0.37 | 800000 | 23.1 | 1.82 |
| NGC 6273 | 255.657 | - 26.26797 | 8.8 ± 0.88 | 135.0 ± 4.1 | - 2.86 ± 0.49 | - 0.45 ± 0.51 | 770000 | 37.3 | 3.38 |
| NGC 6284 | 256.119 | - 24.76486 | 15.3 ± 1.53 | 27.5 ± 1.7 | - 3.66 ± 0.64 | - 5.39 ± 0.83 | 260000 | 102.72 | 2.94 |
| NGC 6287 | 256.288 | - 22.70836 | 9.4 ± 0.94 | - 288.7 ± 3.5 | - 3.68 ± 0.88 | - 3.54 ± 0.69 | 150000 | 19.02 | 2.02 |
| NGC 6293 | 257.543 | - 26.58208 | 9.5 ± 0.95 | - 146.2 ± 1.7 | 0.26 ± 0.85 | - 5.14 ± 0.71 | 220000 | 39.32 | 2.46 |
| NGC 6304 | 258.634 | - 29.46203 | 5.9 ± 0.59 | - 107.3 ± 3.6 | - 2.59 ± 0.29 | - 1.56 ± 0.29 | 140000 | 22.74 | 2.44 |
| NGC 6316 | 259.155 | - 28.14011 | 10.4 ± 1.04 | 71.4 ± 8.9 | - 2.42 ± 0.63 | - 1.71 ± 0.56 | 370000 | 22.97 | 1.97 |
| NGC 6333 | 259.797 | - 18.51594 | 7.9 ± 0.79 | 229.1 ± 7.0 | - 0.57 ± 0.57 | - 3.70 ± 0.50 | 260000 | 18.39 | 2.21 |
| NGC 6341 | 259.281 | 43.13594 | 8.3 ± 0.83 | - 120.0 ± 0.1 | - 3.30 ± 0.55 | - 0.33 ± 0.70 | 330000 | 30.05 | 2.46 |
| NGC 6342 | 260.292 | - 19.58742 | 8.5 ± 0.85 | 115.7 ± 1.4 | - 2.77 ± 0.71 | - 5.84 ± 0.65 | 63000 | 36.74 | 1.8 |
| NGC 6356 | 260.896 | - 17.81303 | 15.1 ± 1.51 | 27.0 ± 4.3 | - 3.14 ± 0.68 | - 3.65 ± 0.53 | 430000 | 41.01 | 3.56 |
| NGC 6362 | 262.979 | - 67.04833 | 7.6 ± 0.76 | - 13.1 ± 0.6 | - 3.09 ± 0.46 | - 3.83 ± 0.46 | 100000 | 30.73 | 4.53 |
| NGC 6388 | 264.072 | - 44.73550 | 9.9 ± 0.99 | 80.1 ± 0.8 | - 1.90 ± 0.45 | - 3.83 ± 0.51 | 990000 | 19.43 | 1.5 |
| NGC 6397 | 265.175 | - 53.67433 | 2.3 ± 0.23 | 18.8 ± 0.1 | 3.69 ± 0.29 | - 14.88 ± 0.26 | 77000 | 29.79 | 1.94 |
| NGC 6441 | 267.554 | - 37.05144 | 11.6 ± 1.16 | 16.5 ± 1.0 | - 2.86 ± 0.45 | - 3.45 ± 0.76 | 1.2e+06 | 24.11 | 1.92 |
| NGC 6522 | 270.892 | - 30.03397 | 7.7 ± 0.77 | - 21.1 ± 3.4 | 6.08 ± 0.20 | - 1.83 ± 0.20 | 200000 | 36.82 | 2.24 |
Table 1-Continued
| Cluster | α 2000 ( deg ) | δ 2000 ( deg ) | r ( kpc ) | v r ( km/s ) | µ x ( mas ) | µ y ( mas ) | M c ( M /circledot ) | r K ( pc ) | r h ( pc ) |
|-----------|------------------|------------------|-------------|----------------|---------------|----------------|------------------------|--------------|--------------|
| NGC 6528 | 271.207 | - 30.05628 | 7.9 ± 0.79 | 206.6 ± 1.4 | - 0.35 ± 0.23 | 0.27 ± 0.26 | 73000 | 9.45 | 0.87 |
| NGC 6553 | 272.323 | - 25.90869 | 6.0 ± 0.60 | - 3.2 ± 1.5 | 2.50 ± 0.07 | 5.35 ± 0.08 | 220000 | 13.37 | 1.8 |
| NGC 6584 | 274.657 | - 52.21578 | 13.5 ± 1.35 | 222.9 ± 15.0 | - 0.22 ± 0.62 | - 5.79 ± 0.67 | 200000 | 30.13 | 2.87 |
| NGC 6626 | 276.137 | - 24.86978 | 5.5 ± 0.55 | 17.0 ± 1.0 | 0.63 ± 0.67 | - 8.46 ± 0.67 | 310000 | 17.96 | 3.15 |
| NGC 6656 | 279.1 | - 23.90475 | 3.2 ± 0.32 | - 146.3 ± 0.2 | 7.37 ± 0.50 | - 3.95 ± 0.42 | 430000 | 29.7 | 3.13 |
| NGC 6712 | 283.268 | - 8.70611 | 6.9 ± 0.69 | - 107.6 ± 0.5 | 4.20 ± 0.40 | - 2.00 ± 0.40 | 170000 | 17.12 | 2.67 |
| NGC 6723 | 284.888 | - 36.63225 | 8.7 ± 0.87 | - 94.5 ± 3.6 | - 0.17 ± 0.45 | - 2.16 ± 0.50 | 230000 | 30.2 | 3.87 |
| NGC 6752 | 287.717 | - 59.98456 | 4.0 ± 0.40 | - 26.7 ± 0.2 | - 0.69 ± 0.42 | - 2.85 ± 0.45 | 210000 | 40.48 | 2.22 |
| NGC 6779 | 289.148 | 30.18347 | 9.4 ± 0.94 | - 135.6 ± 0.9 | 0.30 ± 1.00 | 1.40 ± 0.10 | 160000 | 28.86 | 3.01 |
| NGC 6809 | 294.999 | - 30.96475 | 5.4 ± 0.54 | 174.7 ± 0.3 | - 1.42 ± 0.62 | - 10.25 ± 0.64 | 180000 | 24.07 | 4.45 |
| NGC 6838 | 298.444 | 18.77919 | 4.0 ± 0.40 | - 22.8 ± 0.2 | - 2.30 ± 0.80 | - 5.10 ± 0.80 | 30000 | 10.35 | 1.94 |
| NGC 6934 | 308.547 | 7.40447 | 15.6 ± 1.56 | - 411.4 ± 1.6 | 1.20 ± 1.00 | - 5.10 ± 1.00 | 160000 | 33.83 | 3.13 |
| NGC 7006 | 315.372 | 16.18733 | 41.2 ± 4.12 | - 384.1 ± 0.4 | - 0.96 ± 0.35 | - 1.14 ± 0.40 | 200000 | 52.37 | 5.27 |
| NGC 7078 | 322.493 | 12.16700 | 10.4 ± 1.04 | - 107.0 ± 0.2 | - 0.95 ± 0.51 | - 5.63 ± 0.50 | 810000 | 63.23 | 3.03 |
| NGC 7089 | 323.363 | - 0.82325 | 11.5 ± 1.15 | - 5.3 ± 2.0 | 5.90 ± 0.86 | - 4.95 ± 0.86 | 700000 | 41.65 | 3.55 |
| NGC 7099 | 325.092 | - 23.17986 | 8.1 ± 0.81 | - 184.2 ± 0.2 | 1.42 ± 0.69 | - 7.71 ± 0.65 | 160000 | 37.43 | 2.43 |
| Pal 12 | 326.662 | - 21.25261 | 19.0 ± 1.90 | 27.8 ± 1.5 | - 1.20 ± 0.30 | - 4.21 ± 0.29 | 10000 | 105.56 | 9.51 |
| Pal 13 | 346.685 | 12.77200 | 26.0 ± 2.60 | 25.2 ± 0.3 | 2.30 ± 0.26 | 0.27 ± 0.25 | 5400 | 16.59 | 2.72 |
Table 2. Galactic parameters
| Parameter | Value | References |
|------------------------|---------------------------------------------------|--------------|
| R 0 | 8.3 ± 0.23 kpc | 1 |
| Θ 0 | 239 ± 7 km/s | 1 |
| ( U, V, W ) /circledot | ( - 11 . 1 ± 1.2,12.24 ± 2.1,7.25 ± 0.6) km s - 1 | 2,1 |
| Galactic Bar | Galactic Bar | Galactic Bar |
| position of major axis | 20 ◦ | 3 |
| angular velocity | 55 ± 5 kms - 1 kpc - 1 | 4 |
| Spiral Arms | Spiral Arms | Spiral Arms |
| M arms /M disk | 0.04 ± 0.01 | 5 |
| scale length ( H ) | 3.9 ± 0.6 kpc ( R 0 = 8.5 kpc) | 6 |
| pitch angle | 15.5 ± 3.5 ◦ | 7 |
| angular velocity | 24 ± 6 kms - 1 kpc - 1 | 4 |
References. - 1) Brunthaler et al. (2011). 2) Sch¨ onrich et al. (2010).
3) Gerhard (2002). 4) Gerhard (2011).
5) Pichardo et al. (2012).
6) Benjamin et al. (2005). 7) Drimmel (2000).
Table 3. Orbital parameters with the non-axisymmetric and axisymmetric potentials
| Cluster | <r min > ( kpc ) | <r max > ( kpc ) | < | z | max > ( kpc ) | <e> | E (10 kms - 1 ) 2 | h (10 kms - 1 kpc ) | <r K t > ( pc ) | <r ∗ > ( pc ) |
|-----------|--------------------|--------------------|-------------------------|-------------|---------------------|-----------------------|-------------------|-----------------|
| NGC 104 | 5.78 | 8.30 | 3.13 | 0.177 | | | 91.6 | 102.9 |
| NGC 104 | 6.25 | 7.57 | 3.16 | 0.095 | - 1482 . 12 | 134.55 | 98.3 | 112.4 |
| NGC 288 | 2.60 | 12.38 | 6.40 | 0.654 | | | 23.6 | 22.8 |
| NGC 288 | 2.78 | 12.25 | 6.70 | 0.632 | - 1384 . 68 | - 46 . 38 | 24.5 | 23.5 |
| NGC 362 | 1.39 | 9.28 | 3.85 | 0.736 | | | 24.3 | 20.7 |
| NGC 362 | 0.74 | 11.09 | 2.16 | 0.877 | - 1492 . 42 | - 12 . 56 | 17.1 | 15.9 |
| NGC 1851 | 6.66 | 33.28 | 7.61 | 0.667 | | | 70.1 | 68.2 |
| NGC 1851 | 6.73 | 31.75 | 7.59 | 0.650 | - 939 . 52 | 238.99 | 71.5 | 69.5 |
| NGC 1904 | 5.25 | 18.85 | 5.54 | 0.563 | | | 51.4 | 51.4 |
| NGC 1904 | 5.19 | 20.52 | 5.37 | 0.596 | - 1137 . 89 | 173.68 | 52.0 | 51.6 |
| NGC 2298 | 3.18 | 20.38 | 11.49 | 0.731 | | | 22.0 | 20.8 |
| NGC 2298 | 3.20 | 17.90 | 9.52 | 0.698 | - 1212 . 81 | - 56 . 36 | 22.7 | 21.3 |
| NGC 2808 | 2.27 | 10.74 | 2.39 | 0.649 | | | 46.0 | 43.4 |
| NGC 2808 | 2.73 | 12.74 | 2.59 | 0.647 | - 1395 . 39 | 94.19 | 53.3 | 51.4 |
| NGC 3201 | 9.00 | 16.86 | 4.54 | 0.304 | | | 67.5 | 72.3 |
| | 8.99 | 17.12 | 4.52 | 0.311 | - 1151 . 30 | - 251 . 56 | 67.8 | 72.5 |
| NGC 4147 | 3.89 | 27.33 | 13.97 | 0.750 | | | 25.0 | 22.8 |
| | 3.78 | 28.64 | 14.73 | 0.766 | | 66.83 | 25.4 | 22.8 |
| | 2.39 | 5.30 | 1.57 | 0.386 | - 1001 . 35 | | 30.4 | 33.2 |
| NGC 4372 | 3.19 | 7.41 | 1.60 | 0.397 | - 1624 . 75 | 95.34 | 37.7 | 39.9 |
| NGC 4372 | 9.60 | 30.81 | 11.86 | 0.525 | | | 67.5 | 68.6 |
| NGC 4590 | 9.57 | 30.40 | | 0.521 | - 932 . 42 | 264.42 | 68.0 | 68.6 |
| | 1.04 | 8.41 | 11.82 1.54 | 0.778 | | | 22.1 | 18.3 |
| NGC 4833 | 0.98 | 7.43 | 1.93 | 0.767 | - 1685 . 97 | 26.11 | | 17.3 |
| NGC 4833 | 16.43 | 36.30 | 24.34 | 0.377 | | | 18.3 155.4 | 161.6 |
| NGC 5024 | 16.44 | 36.46 | 24.44 | 0.379 | - 811 . 52 | 143.90 | 155.7 | 161.9 |
| NGC 5024 | 1.49 | 5.81 | | 0.592 | | | | |
| NGC 5139 | | | 1.16 | 0.737 | | | 47.5 | 47.4 |
| | 0.98 | 6.45 | 1.69 | | - 1770 . 34 | - 34 . 25 | 36.7 | 35.5 |
| NGC 5272 | 5.61 | 13.28 | 8.77 | 0.404 | | | 76.3 | 80.2 |
| | 5.60 | 14.22 | 8.99 | 0.435 | - 1267 . 90 | 79.36 | 76.7 | 79.4 |
| NGC 5466 | 6.81 | 60.45 | 36.45 | 0.797 | | - 32 . 56 | 48.8 | 44.1 |
| NGC 5466 | 6.85 | 60.20 | 36.33 | 0.796 | - 663 . 05 | | 49.1 | 44.2 |
| Pal 5 | 3.80 | 18.74 | 10.93 | 0.663 | | | 19.2 | 18.5 |
| | 3.97 | 18.88 | 10.92 | 0.653 | - 1179 . 26 | | 19.6 | 18.7 |
| NGC 5897 | 1.89 | 7.95 | | | | 54.78 | 23.4 | |
| NGC 5897 | | 8.94 | 5.09 | 0.621 | | | | 22.5 |
| NGC 5904 | 1.48 2.65 | 36.80 | 4.49 | 0.719 | - 1552 . 41 | 23.18 | 17.5 | 16.6 |
| | | | 17.89 | 0.866 | | | 46.5 | 40.4 |
| | 2.76 | 37.35 | 18.11 | 0.863 | - 888 . 65 | 40.12 | 46.6 | 40.5 48.8 |
| NGC 5927 | 3.44 | 4.64 | 0.80 | 0.150 | | | 41.4 48.7 | 57.3 |
| NGC 5986 | 4.50 1.05 | 5.45 3.97 | 0.79 1.33 | 0.095 0.562 | - 1693 . 39 | 110.15 | 24.7 | 24.6 |
| NGC 5986 | 0.46 | | | | | | | |
| | | 4.90 | 1.31 | 0.831 | - 1904 . 82 | 1.51 | 12.9 | 12.4 |
| NGC 6093 | 2.07 | 3.11 | 3.02 | 0.201 | | | 34.1 | 37.0 |
| | 2.01 | 3.78 | 3.14 | 0.311 | - 1867 . 55 | 10.18 | 31.7 | 32.8 |
Table 3-Continued
| Cluster | <r min > ( kpc ) | <r max > ( kpc ) | < | z | max > ( kpc ) | <e> | E (10 kms - 1 ) 2 | h (10 kms - 1 kpc ) | <r K t > ( pc ) | <r ∗ > ( pc ) |
|-----------|--------------------|--------------------|-------------------------|-------------|---------------------|-----------------------|-------------------|-----------------|
| NGC 6121 | 0.39 | 5.95 | 0.49 | 0.874 | | | 11.6 | 7.7 |
| NGC 6121 | 0.55 | 5.47 | 2.11 | 0.827 | - 1824 . 59 | - 1 . 58 | 9.8 | 8.7 |
| NGC 6144 | 2.14 | 2.99 | 2.64 | 0.166 | | | 22.2 | 24.9 |
| NGC 6144 | 2.08 | 2.66 | 2.33 | 0.123 | - 1981 . 75 | - 20 . 51 | 22.1 | 23.3 |
| NGC 6171 | 2.28 | 3.14 | 2.34 | 0.157 | | | 25.1 | 28.4 |
| NGC 6171 | 2.70 | 3.31 | 2.41 | 0.104 | - 1886 . 70 | 39.42 | 28.3 | 31.2 |
| NGC 6205 | 5.35 | 21.93 | 13.90 | 0.609 | | | 67.7 | 67.2 |
| NGC 6205 | 5.30 | 22.61 | 14.22 | 0.621 | - 1087 . 59 | - 30 . 31 | 67.1 | 66.4 |
| NGC 6218 | 2.76 | 5.94 | 2.21 | 0.363 | | | 30.0 | 32.1 |
| NGC 6218 | 2.73 | 5.32 | 2.56 | 0.323 | - 1744 . 69 | 59.13 | 29.5 | 31.2 |
| NGC 6254 | 3.86 | 5.84 | 2.43 | 0.204 | | | 38.8 | 43.5 |
| NGC 6254 | 3.46 | 4.93 | 2.40 | 0.175 | - 1737 . 04 | 71.23 | 37.3 | 41.9 |
| NGC 6266 | 1.52 | 2.63 | 0.83 | 0.276 | | | 37.2 | 43.6 |
| NGC 6266 | 1.41 | 2.22 | 0.85 | 0.223 | - 2167 . 78 | 33.20 | 32.8 | 34.9 |
| NGC 6273 | 1.28 | 2.40 | 1.28 | 0.304 | | | 34.4 | 38.4 |
| NGC 6273 | 1.35 | 1.83 | 1.60 | 0.153 | - 2169 . 73 | - 11 . 81 | 32.0 | 33.2 |
| NGC 6284 | 6.34 | 8.52 | 2.78 | 0.147 | | | 62.2 | 69.7 |
| | 6.40 | 8.10 | 2.68 | 0.117 | - 1461 . 17 | 148.72 | 64.3 | 73.3 |
| | 0.91 | 5.03 | 2.82 | 0.707 | | | 16.3 | 14.2 |
| NGC 6287 | 0.87 | 4.30 | 2.44 | 0.671 | | - 3 . 07 | 8.7 | 7.7 |
| NGC 6287 | 0.32 | 3.34 | 0.46 | 0.826 | - 1895 . 79 | | 14.2 | 8.9 |
| NGC 6293 | | | | | | | 8.6 | 7.7 |
| NGC 6293 | 0.37 | 2.67 | 1.19 | 0.756 | - 2168 . 38 | - 3 . 58 | | |
| NGC 6304 | 1.90 | 3.25 | 0.53 | 0.276 | | | 23.7 | 27.4 |
| NGC 6304 | 1.84 | 3.09 | 0.57 | 0.253 | - 2054 . 85 | 48.88 | 22.8 | 24.3 |
| NGC 6316 | 0.72 | 3.07 | 1.18 | 0.626 | | | 19.9 | 19.2 |
| NGC 6316 | 0.96 | 2.59 | 0.83 | 0.460 | - 2170 . 75 | - 26 . 10 | 18.2 | 19.0 |
| NGC 6333 | 1.44 | 5.32 | 1.53 | 0.582 | | | 21.5 | 21.5 |
| | 1.02 | 4.37 | 1.34 | 0.623 | - 1937 . 01 | 27.83 | 15.3 | 15.1 |
| NGC 6341 | 1.20 | 10.43 | 2.43 | 0.793 | | | 22.9 | 20.6 |
| | 1.30 | 10.86 | 2.59 | 0.786 | - 1496 . 54 | 30.29 | 21.6 | 20.1 |
| NGC 6342 | 1.29 | 2.09 | 1.37 | 0.245 | | | 14.9 | 17.1 |
| | 0.73 | 1.68 | 1.13 | 0.401 | - 2304 . 73 | 10.92 | 8.3 | 8.6 |
| NGC 6356 | 2.45 | 7.94 | 2.08 | 0.528 | | | 38.2 | 39.6 |
| | 2.30 | 7.74 | 1.98 | 0.542 | - 1637 . 01 | 67.45 | 37.3 | 37.8 |
| NGC 6362 | 2.31 | 5.05 | 1.98 | 0.374 | | | 22.4 | 24.0 |
| | 2.28 | 5.80 | 1.70 | 0.436 | - 1760 . 08 | 62.23 | 23.4 | 24.4 |
| | 0.70 | 3.03 | 1.10 | 0.627 | | | 27.6 | 26.1 |
| NGC 6388 | 0.53 | 2.95 | 0.88 | 0.696 | - 2148 . 65 | - 13 . 57 | 16.2 | 16.2 |
| NGC 6397 | 2.53 | 5.12 | 1.46 | 0.344 | | | 23.1 | 25.4 |
| | 3.33 | 6.42 | 1.66 | 0.317 | | | 27.4 | 29.7 |
| NGC 6441 | 0.57 | 3.97 | 0.87 | 0.751 | - 1672 . 42 | 91.10 | | 22.5 |
| NGC 6441 | | | | | | | 27.6 | |
| | 0.48 | 3.15 | 1.45 | 0.742 | - 2082 . 24 | - 2 . 77 | 16.9 | 15.7 |
| NGC 6522 | 0.37 0.81 | 3.87 2.23 | 0.57 1.16 | 0.831 0.471 | - 2199 . 97 | 18.26 | 13.4 13.2 | 8.9 13.4 |
Table 3-Continued
| Cluster | <r min > ( kpc ) | <r max > ( kpc ) | < | z | max > ( kpc ) | <e> | E (10 kms - 1 ) 2 | h (10 kms - 1 kpc ) | <r K t > ( pc ) | <r ∗ > ( pc ) |
|-----------|--------------------|--------------------|-------------------------|-------------|---------------------|-----------------------|-------------------|-----------------|
| NGC 6528 | 0.81 | 2.85 | 1.20 | 0.571 | | | 12.5 | 12.0 |
| NGC 6528 | 0.57 | 1.51 | 0.77 | 0.454 | - 2399 . 18 | 14.31 | 7.3 | 7.6 |
| NGC 6553 | 2.09 | 8.75 | 0.33 | 0.615 | | | 28.9 | 28.1 |
| NGC 6553 | 2.31 | 12.02 | 0.52 | 0.677 | - 1445 . 87 | 97.14 | 30.2 | 28.0 |
| NGC 6584 | 1.38 | 12.43 | 4.43 | 0.804 | | | 21.7 | 19.4 |
| NGC 6584 | 1.06 | 12.20 | 3.11 | 0.843 | - 1434 . 63 | 24.27 | 15.3 | 14.5 |
| NGC 6626 | 1.03 | 2.82 | 0.85 | 0.472 | | | 21.7 | 24.0 |
| NGC 6626 | 0.74 | 3.09 | 0.88 | 0.613 | - 2111 . 49 | 21.96 | 14.2 | 14.3 |
| NGC 6656 | 2.85 | 7.96 | 1.18 | 0.472 | | | 42.9 | 45.1 |
| NGC 6656 | 3.10 | 9.18 | 1.28 | 0.495 | - 1542 . 68 | 105.56 | 45.7 | 46.8 |
| NGC 6712 | 0.60 | 5.56 | 1.14 | 0.809 | | | 15.9 | 13.6 |
| NGC 6712 | 0.91 | 6.34 | 1.86 | 0.749 | - 1767 . 49 | 13.60 | 12.9 | 12.5 |
| NGC 6723 | 2.00 | 3.25 | 3.03 | 0.242 | | | 29.1 | 31.4 |
| NGC 6723 | 2.06 | 2.66 | 2.65 | 0.127 | - 1969 . 12 | - 0 . 19 | 30.1 | 30.8 |
| NGC 6752 | 4.65 | 6.71 | 1.75 | 0.180 | | | 45.8 | 52.7 |
| NGC 6752 | 4.74 | 5.81 | 1.72 | 0.102 | - 1640 . 42 | 109.14 | 48.9 | 56.8 |
| NGC 6779 | 0.62 | 12.52 | 0.77 | 0.906 | | | 15.2 | 10.7 |
| NGC 6779 | 0.84 | 12.49 | 2.44 | 0.875 | - 1428 . 17 | - 24 . 15 | 11.7 | 10.5 |
| NGC 6809 | 1.98 | 5.95 | 3.87 | 0.508 | | | 25.5 | 26.1 |
| NGC 6809 | 1.78 | 5.61 | 3.59 | 0.526 | - 1741 . 44 | 19.74 | 22.9 | 22.7 |
| NGC 6838 | 5.01 | 6.56 | 0.33 | 0.131 | | | 25.2 | 29.4 |
| | 4.88 | 6.98 | 0.29 | 0.177 | - 1599 . 94 | 134.92 | 25.8 | 29.6 |
| NGC 6934 | 6.88 | 34.87 | 20.35 | 0.670 | | | 54.6 | 52.3 |
| NGC 6934 | 6.83 | 35.12 | 20.60 | 0.674 | - 892 . 95 | - 56 . 25 | 54.6 | 52.4 |
| NGC 7006 | 17.89 | 79.15 | 26.93 | 0.631 | | | 115.4 | 111.1 |
| NGC 7006 | 17.90 | 79.32 | 26.97 | 0.632 | - 514 . 26 | 572.52 | 115.7 | 111.4 |
| NGC 7078 | | | | | - . | | 91.5 | |
| | 6.12 | 10.89 | 5.25 | 0.281 | 1347 69 | | | 98.5 |
| | 6.48 | 11.00 | 5.45 | 0.259 | | 139.60 | 94.4 | 103.1 78.9 |
| NGC 7089 | 6.10 6.14 | 33.12 34.19 | 18.03 18.77 | 0.689 0.695 | - 908 . 90 | - 67 . 44 | 83.4 84.1 | 79.3 |
| NGC 7089 | 3.16 | 6.91 | 4.20 | 0.373 | | | 32.6 | 35.0 |
| NGC 7099 | | | | | | | | |
| Pal 12 | 3.09 | 7.38 | 4.70 | 0.412 | - 1584 . 65 | - 46 . 62 | 32.9 | 34.0 |
| Pal 12 | 15.25 | 19.64 | 15.76 | 0.128 | | | 40.3 | 44.7 |
| | 15.19 | 19.86 | 15.90 | 0.131 | - 1010 . 08 | 165.80 | 40.4 | 44.8 |
| | 11.86 | 88.13 | 38.24 | 0.763 | | | 25.5 | 23.6 |
| Pal 13 | 11.84 | 88.01 | 38.03 | 0.763 | - 485 . 90 | - 329 . 53 | 25.4 | 23.5 |
Table 4. Destruction Rates of globular clusters in the non-axisymmetric and axisymmetric potentials, obtained with Monte Carlo simulations
| | ---- Linear Trajectory | ---- Linear Trajectory | ---- Linear Trajectory | | | | | | |
|----------------------------|-------------------------------------------------------------|-----------------------------------------------------------------------|-----------------------------------------|---------------------------------------------------|-------------------------------------------------------------|-------------------------------------------------------------|-----------------------------------------|-------------------------------------------------------------|---------------------------------------------------|
| Cluster | < 1 /t bulge > ( yr - 1 ) | σ - ( yr - 1 ) | ---- σ + ( yr - 1 ) | ----Real < 1 /t bulge > ( yr - 1 ) | Trajectory σ - ( yr - 1 ) | ---- σ + ( yr - 1 ) | < 1 /t disk > ( yr - 1 ) | σ - ( yr - 1 ) | σ + ( yr - 1 ) |
| NGC 104 | 0.321E-15 | 0.191E-15 | 0.962E-14 | 0.286E-14 | 0.225E-14 | 0.650E-14 | 0.146E-12 | 0.359E-13 | 0.616E-13 |
| | 0.806E-16 | 0.304E-16 | 0.497E-16 | 0.466E-15 | 0.104E-15 | 0.165E-15 | 0.148E-12 | 0.281E-13 | 0.352E-13 |
| NGC 288 | 0.750E-10 | 0.669E-10 | 0.289E-09 | 0.157E-09 | 0.129E-09 | 0.408E-09 | 0.809E-11 | 0.440E-11 | 0.563E-11 |
| | 0.621E-09 | 0.585E-09 | 0.538E-08 | 0.542E-09 | 0.516E-09 | 0.496E-08 | 0.899E-11 | 0.493E-11 | 0.842E-11 |
| NGC 362 | 0.365E-11 0.767E-10 | 0.259E-11 0.580E-10 0.495E-16 | 0.134E-09 0.227E-14 | 0.228E-11 0.390E-10 0.248E-15 0.488E-16 | 0.144E-11 0.301E-10 0.236E-15 0.466E-16 0.126E-12 | 0.244E-11 | 0.128E-12 0.170E-12 | 0.383E-13 0.528E-13 | 0.439E-13 0.614E-13 |
| | | | 0.445E-11 | | 0.704E-12 | 0.672E-10 0.703E-14 0.523E-14 | 0.777E-15 | 0.642E-15 | |
| NGC 1851 | 0.540E-16 0.145E-15 0.127E-12 0.105E-11 | 0.138E-15 0.123E-12 0.104E-11 0.741E-11 0.743E-10 0.383E-14 0.171E-14 | 0.146E-13 0.306E-11 0.866E-10 | | 0.889E-11 0.544E-10 0.666E-14 0.510E-15 | 0.126E-11 0.639E-10 | 0.860E-15 0.628E-13 0.635E-13 0.835E-12 | 0.723E-15 0.506E-13 0.512E-13 0.668E-12 | 0.332E-14 0.419E-14 |
| NGC 1904 | 0.506E-15 0.163E-14 0.903E-16 0.895E-16 0.320E-11 0.219E-10 | 0.161E-14 0.221E-16 0.212E-16 0.308E-11 0.213E-10 0.697E-10 0.167E-11 | 0.302E-16 0.300E-10 0.669E-09 0.463E-09 | 0.300E-11 0.217E-10 0.670E-10 0.238E-11 0.147E-15 | 0.345E-16 0.276E-11 0.213E-10 0.458E-10 0.106E-11 0.655E-16 | 0.174E-14 0.779E-16 0.209E-10 0.685E-09 0.234E-09 0.136E-11 | 0.109E-13 0.466E-12 0.519E-12 0.792E-10 | 0.129E-14 0.483E-14 0.504E-14 0.505E-14 0.384E-12 0.427E-12 | 0.164E-12 |
| Pal 3 NGC 3201 NGC 4147 | 0.910E-10 0.352E-11 0.299E-15 | 0.499E-15 0.149E-15 0.145E-15 0.408E-10 0.326E-09 | 0.469E-10 0.834E-09 0.201E-13 | 0.135E-12 0.714E-12 0.983E-11 | 0.149E-14 | 0.645E-09 0.459E-13 0.636E-14 | | | 0.176E-12 0.151E-11 0.133E-13 0.984E-12 0.164E-11 |
| NGC 2298 NGC 2808 | 0.789E-11 0.769E-10 0.498E-14 | | 0.210E-13 | 0.819E-14 0.672E-15 | | | 0.727E-14 0.537E-14 | 0.289E-14 0.220E-14 | 0.182E-11 |
| | | | | 0.562E-10 | | 0.465E-10 | 0.989E-12 | 0.768E-12 | |
| | 0.225E-14 | | | | | | | | 0.406E-14 |
| | | | 0.331E-16 | 0.168E-15 0.801E-16 | | 0.556E-13 | 0.132E-14 0.107E-13 | | 0.328E-14 0.203E-13 0.241E-12 0.125E-13 |
| | | | 0.830E-14 0.826E-13 | 0.154E-14 0.107E-14 | 0.106E-14 0.999E-16 | 0.239E-13 | 0.490E-14 | | |
| NGC 4372 NGC 4590 | 0.295E-15 | | 0.213E-11 0.337E-15 0.351E-15 0.792E-10 | 0.112E-15 0.160E-09 0.264E-09 0.487E-12 | 0.590E-16 0.189E-09 0.484E-12 0.291E-12 | 0.258E-15 0.154E-15 0.597E-10 0.104E-09 | 0.436E-10 0.151E-13 0.162E-13 | 0.327E-10 | 0.567E-10 0.171E-10 0.223E-13 |
| NGC 4833 NGC 5024 NGC 5139 | 0.661E-10 0.454E-09 0.188E-12 | 0.187E-12 0.305E-12 | 0.106E-08 0.415E-10 0.937E-10 0.443E-10 | 0.292E-12 0.958E-10 0.108E-09 | 0.878E-10 | 0.144E-09 0.633E-09 | 0.389E-11 0.422E-11 0.491E-13 | 0.137E-10 0.887E-14 0.951E-14 | 0.247E-13 0.152E-11 0.126E-11 |
| | 0.307E-12 0.371E-10 | 0.187E-10 0.992E-10 | 0.320E-09 0.718E-11 | | 0.546E-10 0.754E-10 | 0.105E-09 0.241E-09 | 0.561E-13 0.639E-11 0.746E-11 | 0.107E-11 0.100E-11 0.475E-13 | 0.138E-11 0.151E-11 |
| NGC 5272 | 0.156E-09 0.438E-12 | 0.377E-12 | 0.441E-10 0.136E-09 | 0.170E-11 0.661E-12 | 0.161E-11 0.609E-12 0.153E-10 0.392E-11 | 0.221E-10 0.481E-10 | 0.127E-11 | 0.539E-13 0.151E-11 0.618E-12 0.681E-12 | 0.189E-11 0.124E-11 0.132E-11 |
| NGC 5466 | 0.854E-12 0.538E-11 0.495E-11 | 0.770E-12 0.503E-11 0.462E-11 | 0.208E-09 | 0.171E-10 0.417E-11 | 0.393E-12 0.104E-12 | 0.247E-09 0.221E-09 | 0.118E-11 | 0.157E-11 | 0.184E-11 0.113E-10 |
| NGC 5897 | 0.250E-09 0.434E-08 | 0.402E-08 0.244E-12 | 0.218E-07 0.853E-12 | 0.499E-12 | | 0.170E-11 | 0.189E-12 | 0.976E-13 | 0.190E-12 |
| | 0.350E-12 | | | 0.149E-12 | | | | | |
| | | | 0.631E-12 | | | | | 0.102E-12 | 0.280E-10 |
| NGC 5904 | | 0.208E-12 | | | 0.118E-11 | 0.342E-12 | 0.246E-10 | | |
| | | 0.467E-11 | | 0.142E-11 | | | | 0.220E-11 | 0.324E-11 |
| | | | 0.473E-10 | | | | | 0.445E-12 0.144E-12 | 0.564E-12 |
| | | | | | | 0.108E-08 0.198E-07 | 0.307E-11 | 0.245E-11 0.227E-11 | 0.516E-09 0.172E-08 |
| | | | | 0.406E-09 | 0.354E-08 | | 0.461E-09 | 0.428E-09 0.113E-10 | |
| | 0.345E-08 0.304E-07 | 0.312E-08 0.289E-07 | 0.149E-07 0.300E-06 | 0.110E-07 0.399E-07 | 0.950E-08 0.383E-07 | 0.445E-07 0.406E-06 | 0.288E-11 | 0.317E-09 | 0.101E-10 |
| | | 0.220E-09 | 0.625E-09 | | 0.366E-09 | | 0.616E-09 | | |
| Pal 5 | | | | | | | | | |
| | | | | 0.378E-08 | | | 0.196E-10 | 0.146E-10 | 0.154E-10 |
| | 0.302E-12 | | | | | | 0.198E-12 | | 0.192E-12 |
| NGC 5927 | | | | | | | | | |
| NGC 5986 | 0.535E-11 0.255E-14 | 0.146E-14 | 0.506E-14 0.187E-10 | 0.116E-13 | | 0.106E-10 | 0.483E-11 | | |
| | 0.222E-10 | 0.121E-10 | | 0.233E-10 | 0.395E-14 0.151E-10 | 0.620E-14 0.204E-10 | 0.156E-11 0.523E-12 | | 0.172E-12 |
| | 0.640E-09 | 0.437E-09 | 0.564E-09 | 0.228E-09 | | 0.174E-09 | 0.605E-12 | 0.147E-12 | |
| | | | | | 0.155E-09 | | | | 0.171E-12 |
Table 4-Continued
| | ---- Linear Trajectory ---- | ---- Linear Trajectory ---- | ---- Linear Trajectory ---- | Trajectory | Trajectory | Trajectory | | | |
|----------|-------------------------------|-------------------------------|-------------------------------|------------------------------------|----------------|---------------------|--------------------------|----------------|----------------|
| Cluster | < 1 /t bulge > ( yr - 1 ) | σ - ( yr - 1 ) | σ + ( yr - 1 ) | ----Real < 1 /t bulge > ( yr - 1 ) | σ - ( yr - 1 ) | ---- σ + ( yr - 1 ) | < 1 /t disk > ( yr - 1 ) | σ - ( yr - 1 ) | σ + ( yr - 1 ) |
| NGC 6093 | 0.194E-11 | 0.180E-11 | 0.735E-11 | 0.248E-11 | 0.232E-11 | 0.900E-11 | 0.128E-12 | 0.743E-13 | 0.872E-13 |
| NGC 6093 | 0.140E-09 | 0.136E-09 | 0.332E-09 | 0.487E-10 | 0.474E-10 | 0.116E-09 | 0.156E-12 | 0.873E-13 | 0.112E-12 |
| NGC 6121 | 0.286E-09 | 0.144E-09 | 0.167E-09 | 0.676E-09 | 0.310E-09 | 0.786E-09 | 0.176E-10 | 0.416E-11 | 0.651E-11 |
| NGC 6121 | 0.252E-08 | 0.147E-08 | 0.219E-08 | 0.215E-08 | 0.125E-08 | 0.180E-08 | 0.137E-10 | 0.288E-11 | 0.372E-11 |
| NGC 6144 | 0.126E-08 | 0.678E-09 | 0.206E-08 | 0.304E-08 | 0.161E-08 | 0.575E-08 | 0.325E-09 | 0.986E-10 | 0.862E-10 |
| NGC 6144 | 0.226E-08 | 0.157E-08 | 0.182E-07 | 0.495E-08 | 0.249E-08 | 0.272E-07 | 0.472E-09 | 0.128E-09 | 0.176E-09 |
| NGC 6171 | 0.206E-10 | 0.135E-10 | 0.468E-10 | 0.229E-10 | 0.140E-10 | 0.840E-10 | 0.170E-10 | 0.450E-11 | 0.486E-11 |
| NGC 6171 | 0.897E-10 | 0.840E-10 | 0.188E-08 | 0.866E-10 | 0.775E-10 | 0.189E-08 | 0.177E-10 | 0.470E-11 | 0.604E-11 |
| NGC 6205 | 0.325E-14 | 0.241E-14 | 0.300E-13 | 0.388E-13 | 0.342E-13 | 0.577E-12 | 0.611E-13 | 0.331E-13 | 0.931E-13 |
| NGC 6205 | 0.277E-14 | 0.198E-14 | 0.156E-13 | 0.920E-15 | 0.662E-15 | 0.542E-14 | 0.657E-13 | 0.354E-13 | 0.813E-13 |
| NGC 6218 | 0.260E-11 | 0.219E-11 | 0.183E-10 | 0.140E-11 | 0.115E-11 | 0.141E-10 | 0.136E-11 | 0.549E-12 | 0.870E-12 |
| NGC 6218 | 0.280E-12 | 0.216E-12 | 0.323E-11 | 0.126E-12 | 0.889E-13 | 0.142E-11 | 0.123E-11 | 0.332E-12 | 0.454E-12 |
| NGC 6254 | 0.821E-12 | 0.737E-12 | 0.714E-11 | 0.315E-12 | 0.258E-12 | 0.544E-11 | 0.777E-12 | 0.424E-12 | 0.679E-12 |
| NGC 6254 | 0.127E-13 | 0.100E-13 | 0.859E-13 | 0.228E-13 | 0.157E-13 | 0.587E-13 | 0.584E-12 | 0.206E-12 | 0.308E-12 |
| NGC 6266 | 0.594E-12 | 0.470E-12 | 0.341E-11 | 0.245E-12 | 0.158E-12 | 0.268E-12 | 0.781E-13 | 0.290E-13 | 0.418E-13 |
| NGC 6266 | 0.130E-11 | 0.118E-11 | 0.760E-10 | 0.865E-12 | 0.705E-12 | 0.136E-10 | 0.900E-13 | 0.421E-13 | 0.726E-13 |
| NGC 6273 | 0.214E-10 | 0.154E-10 | 0.553E-10 | 0.152E-10 | 0.863E-11 | 0.339E-10 | 0.208E-11 | 0.656E-12 | 0.765E-12 |
| NGC 6273 | 0.148E-10 | 0.104E-10 | 0.108E-09 | 0.216E-10 | 0.153E-10 | 0.546E-10 | 0.262E-11 | 0.892E-12 | 0.994E-12 |
| NGC 6284 | 0.898E-10 | 0.871E-10 | 0.100E-08 | 0.144E-09 | 0.136E-09 | 0.212E-08 | 0.557E-10 | 0.451E-10 | 0.162E-09 |
| NGC 6284 | 0.215E-09 | 0.209E-09 | 0.883E-08 | 0.342E-09 | 0.333E-09 | 0.172E-07 | 0.556E-10 | 0.450E-10 | 0.188E-09 |
| NGC 6287 | 0.188E-10 | 0.981E-11 | 0.141E-10 | 0.264E-10 | 0.136E-10 | 0.181E-10 | 0.493E-12 | 0.132E-12 | 0.195E-12 |
| NGC 6287 | 0.721E-09 | 0.443E-09 | 0.553E-09 | 0.323E-09 | 0.195E-09 | 0.234E-09 | 0.758E-12 | 0.266E-12 | 0.325E-12 |
| NGC 6293 | 0.487E-09 | 0.242E-09 | 0.240E-09 | 0.334E-09 | 0.146E-09 | 0.319E-09 | 0.295E-10 | 0.106E-10 | 0.107E-10 |
| NGC 6293 | | | | | | | 0.364E-10 | 0.140E-10 | 0.183E-10 |
| | 0.107E-07 | 0.684E-08 | 0.105E-07 | 0.118E-07 | 0.769E-08 | 0.122E-07 | | | |
| NGC 6304 | 0.130E-10 | 0.100E-10 | 0.428E-10 | 0.100E-10 | 0.779E-11 | 0.203E-09 | 0.349E-11 | 0.173E-11 | 0.220E-11 |
| NGC 6304 | 0.945E-11 | 0.842E-11 | 0.247E-09 | 0.139E-10 | 0.126E-10 | 0.364E-09 | 0.358E-11 | 0.162E-11 | 0.316E-11 |
| NGC 6316 | 0.872E-11 | 0.687E-11 | 0.178E-10 | 0.396E-11 | 0.268E-11 | 0.826E-11 | 0.461E-12 | 0.174E-12 | 0.281E-12 |
| NGC 6316 | 0.128E-09 | 0.113E-09 | 0.566E-09 | 0.818E-10 | 0.732E-10 | 0.399E-09 | 0.710E-12 | 0.309E-12 | 0.659E-12 |
| NGC 6333 | 0.243E-11 | 0.192E-11 | 0.785E-11 | 0.321E-11 | 0.273E-11 | 0.895E-11 | 0.170E-12 | 0.577E-13 | 0.931E-13 |
| NGC 6333 | 0.154E-10 | 0.113E-10 | 0.878E-10 | 0.501E-11 | 0.370E-11 | 0.341E-10 | 0.222E-12 | 0.757E-13 | 0.929E-13 |
| NGC 6341 | 0.668E-11 | 0.449E-11 | 0.108E-10 | 0.627E-11 | 0.482E-11 | 0.135E-10 | 0.472E-12 | 0.114E-12 | 0.144E-12 |
| NGC 6341 | 0.462E-10 | 0.395E-10 | 0.203E-09 | 0.280E-10 | 0.247E-10 | 0.126E-09 | 0.501E-12 | 0.107E-12 | 0.133E-12 |
| NGC 6342 | 0.586E-09 | 0.347E-09 | 0.675E-09 | 0.620E-09 | 0.324E-09 | 0.406E-09 | 0.109E-09 | 0.325E-10 | 0.344E-10 |
| NGC 6342 | 0.445E-08 | 0.252E-08 | 0.321E-08 | 0.856E-08 | 0.491E-08 | 0.608E-08 | 0.144E-09 | 0.372E-10 | 0.363E-10 |
| NGC 6356 | 0.179E-10 | 0.157E-10 | 0.747E-10 | 0.244E-10 | 0.225E-10 | 0.153E-09 | 0.223E-11 | 0.154E-11 | 0.232E-11 |
| NGC 6356 | 0.139E-09 | 0.132E-09 | 0.171E-08 | 0.101E-09 | 0.971E-10 | 0.130E-08 | 0.231E-11 | 0.154E-11 | 0.283E-11 |
| NGC 6362 | 0.417E-10 | 0.281E-10 | 0.145E-09 | 0.135E-10 | 0.104E-10 | 0.110E-09 | 0.212E-10 | 0.611E-11 | 0.782E-11 |
| NGC 6362 | 0.683E-11 | 0.385E-11 | 0.906E-11 | 0.349E-11 | 0.183E-11 | 0.543E-11 | 0.178E-10 | 0.320E-11 | 0.396E-11 |
| NGC 6388 | 0.122E-11 | 0.883E-12 | 0.186E-11 | 0.166E-12 | 0.120E-12 | 0.512E-12 | 0.125E-13 | 0.366E-14 | 0.507E-14 |
| NGC 6388 | 0.408E-10 | 0.299E-10 | 0.639E-10 | 0.572E-11 | 0.409E-11 | 0.780E-11 | 0.179E-13 | 0.457E-14 | 0.684E-14 |
| NGC 6397 | 0.131E-10 | 0.108E-10 | 0.699E-10 | 0.438E-11 | 0.345E-11 | 0.206E-10 | 0.115E-10 | 0.479E-11 | 0.714E-11 |
| NGC 6397 | 0.237E-12 | 0.114E-12 | 0.279E-12 | 0.176E-12 | 0.724E-13 | 0.153E-12 | 0.667E-11 | 0.145E-11 | 0.185E-11 |
| NGC 6441 | 0.379E-11 | 0.270E-11 | 0.586E-11 | 0.584E-12 | 0.401E-12 | 0.115E-11 | 0.331E-13 | 0.113E-13 | 0.196E-13 |
| NGC 6441 | 0.142E-09 | 0.107E-09 | 0.366E-09 | 0.274E-10 | 0.204E-10 | 0.694E-10 | 0.500E-13 | 0.185E-13 | 0.314E-13 |
Table 4-Continued
| | ---- Linear Trajectory ---- | ---- Linear Trajectory ---- | ---- Linear Trajectory ---- | ----Real Trajectory | ----Real Trajectory | ----Real Trajectory | | | |
|-------------------|-----------------------------------------------------------------------------------------------------|---------------------------------------------------------------------------------------------------------------|-------------------------------------------------------------------------------------------|-------------------------------------------------------------------------------------------|-----------------------------------------------------------------------------------------------------|-------------------------------------------------------------------------------------------|-----------------------------------------------------------------------|---------------------------------------------------------------------------------|-----------------------------------------|
| Cluster | < 1 /t bulge > ( yr - 1 ) | σ - ( yr - 1 ) | σ + ( yr - 1 ) | < 1 /t bulge > ( yr - 1 ) | σ - ( yr - 1 ) | σ + ( yr - 1 ) | < 1 /t disk > ( yr - 1 ) | σ - ( yr - 1 ) | σ + ( yr - 1 ) |
| NGC 6522 | 0.211E-09 | 0.142E-09 | 0.213E-09 | 0.285E-09 | 0.200E-09 | 0.328E-09 | 0.154E-10 | 0.569E-11 | 0.842E-11 |
| | 0.450E-08 | 0.403E-08 | 0.145E-07 | 0.528E-08 | 0.480E-08 | 0.168E-07 | 0.277E-10 | 0.143E-10 | 0.203E-10 |
| NGC 6528 | 0.296E-11 | 0.213E-11 | 0.492E-11 | 0.355E-12 | 0.249E-12 | 0.144E-11 | 0.377E-13 | 0.130E-13 | 0.161E-13 |
| | 0.935E-10 | 0.800E-10 | 0.506E-09 | 0.221E-10 | 0.185E-10 | 0.782E-10 | 0.948E-13 | 0.557E-13 | 0.827E-13 |
| NGC 6553 | 0.103E-12 | 0.954E-13 | 0.210E-11 | 0.894E-13 | 0.792E-13 | 0.475E-12 | 0.643E-14 | 0.345E-14 | 0.853E-14 |
| NGC 6584 | 0.247E-12 0.163E-10 | 0.240E-12 0.139E-10 | 0.405E-10 0.356E-10 | 0.582E-13 0.252E-10 | 0.563E-13 0.211E-10 | 0.909E-11 0.545E-10 | 0.422E-14 0.944E-12 | 0.220E-14 0.554E-12 | 0.776E-14 0.865E-12 |
| NGC 6712 NGC 6723 | 0.640E-11 0.113E-09 0.151E-12 0.885E-14 0.140E-10 0.886E-10 0.121E-10 0.572E-11 0.241E-11 0.535E-14 | 0.422E-11 0.943E-10 0.133E-12 0.399E-14 0.950E-11 0.740E-10 0.433E-11 0.229E-11 0.330E-14 0.244E-10 0.272E-09 | 0.152E-10 0.569E-09 0.328E-11 0.990E-14 0.199E-10 0.591E-09 0.776E-10 0.113E-13 0.536E-10 | 0.999E-12 0.333E-10 0.972E-13 0.322E-14 0.124E-10 0.279E-10 0.394E-12 0.198E-13 0.722E-10 | 0.594E-12 0.273E-10 0.746E-13 0.140E-14 0.904E-11 0.232E-10 0.474E-11 0.311E-12 0.834E-14 0.473E-10 | 0.160E-11 0.132E-09 0.344E-12 0.345E-14 0.208E-10 0.150E-09 0.361E-11 0.215E-13 0.868E-10 | 0.290E-12 0.328E-12 0.244E-12 0.164E-12 0.640E-11 0.415E-11 0.272E-11 | 0.896E-13 0.118E-12 0.488E-13 0.130E-12 0.131E-12 0.126E-11 0.137E-11 0.207E-11 | 0.139E-12 0.173E-12 0.241E-12 |
| | | | | | | 0.167E-09 | 0.466E-11 | | 0.767E-13 0.581E-11 |
| NGC 6626 NGC 6656 | | 0.823E-11 | 0.470E-10 0.470E-09 | 0.238E-10 0.890E-11 | 0.186E-10 | 0.853E-10 | 0.423E-12 0.475E-12 | 0.906E-13 | 0.191E-12 0.155E-12 0.134E-11 0.162E-11 |
| NGC 6752 | 0.367E-10 0.353E-09 | 0.187E-10 | 0.746E-09 | 0.233E-09 | 0.179E-09 0.232E-10 | 0.485E-09 | 0.229E-11 | 0.749E-12 0.809E-12 | 0.101E-11 0.958E-12 |
| NGC 6779 | | | 0.638E-10 | 0.309E-10 | | 0.551E-10 | 0.222E-11 0.228E-11 | 0.666E-12 0.612E-12 | 0.750E-12 |
| NGC 6809 | 0.245E-10 0.756E-11 | 0.405E-11 | 0.153E-10 | 0.371E-11 | 0.228E-11 | 0.795E-11 | 0.231E-11 | 0.515E-12 | 0.969E-12 |
| NGC 6838 | | 0.487E-13 | 0.150E-11 0.436E-16 | 0.653E-14 0.198E-15 | 0.539E-14 0.489E-16 | 0.367E-12 | | | 0.642E-12 |
| NGC 6934 | 0.493E-13 0.905E-16 | 0.276E-16 | 0.161E-10 | 0.277E-12 | 0.264E-12 0.114E-11 | 0.662E-16 0.524E-11 | 0.948E-13 | 0.633E-14 | 0.135E-12 0.870E-14 |
| NGC 7078 | 0.415E-12 0.148E-11 0.175E-13 | 0.405E-12 0.138E-11 0.159E-13 | 0.112E-09 0.734E-12 | 0.641E-13 0.131E-11 0.956E-14 | 0.631E-13 0.130E-11 0.832E-14 | 0.271E-11 0.305E-09 0.168E-12 | 0.895E-13 0.429E-13 0.536E-13 0.246E-12 | 0.812E-13 0.769E-13 0.418E-13 0.523E-13 0.183E-12 | 0.439E-12 0.740E-12 0.156E-11 0.689E-12 |
| NGC 7006 | 0.203E-12 0.138E-11 | 0.146E-11 0.201E-12 | 0.244E-10 0.303E-09 | 0.115E-11 | | 0.961E-10 | 0.380E-13 0.241E-13 | 0.182E-13 | 0.436E-12 |
| NGC 7099 | 0.243E-13 0.515E-12 | 0.272E-11 0.246E-11 | 0.133E-10 0.172E-10 | 0.409E-11 0.163E-11 | 0.315E-11 0.136E-11 | 0.246E-10 0.117E-10 | 0.296E-11 0.312E-11 | 0.138E-11 | 0.144E-11 |
| | 0.322E-11 | 0.510E-12 | 0.697E-10 | 0.330E-12 | 0.328E-12 | 0.484E-10 | | 0.132E-11 | |
| | 0.296E-11 | | | | | | | | |
| | | | | | | | | | 0.155E-11 |
| NGC 7089 | | 0.235E-13 | 0.130E-11 | 0.324E-13 | 0.308E-13 | 0.636E-12 | 0.204E-13 0.231E-13 | 0.168E-13 0.191E-13 | 0.772E-13 0.989E-13 |
| Pal 12 | 0.205E-11 0.214E-11 | 0.160E-11 | 0.218E-10 | 0.109E-10 | 0.782E-11 | 0.528E-10 | 0.270E-10 | 0.204E-10 | 0.982E-10 |
| | | | 0.423E-10 | 0.101E-10 | 0.785E-11 | 0.668E-10 | | 0.210E-10 | 0.115E-09 |
| Pal 13 | 0.135E-13 | 0.167E-11 0.126E-13 | 0.764E-12 | 0.568E-13 0.512E-14 | 0.519E-13 | 0.238E-11 | 0.281E-10 0.718E-13 | 0.645E-13 | 0.705E-12 |
| | | | | | | | | 0.611E-13 | |
| | | | | | 0.481E-14 | | | | |
| | 0.982E-14 | 0.910E-14 | 0.542E-12 | | | 0.381E-12 | 0.679E-13 | | 0.714E-12 |
Fig. 1.- Meridional Galactic orbits for a sample of globular clusters. Each pair of columns shows the orbits with the axisymmetric (left) and non-axisymmetric (right) Galactic potentials. The cluster NGC number is given.
Fig. 2.- As in Figure 1.
Fig. 3.- Comparison of the cluster average perigalactic distance, second column in Table 3, in the axisymmetric potential (denoted with a subindex 'ax') and in the non-axisymmetric potential (with a subindex 'nax'). The plotted line is the line of coincidence.
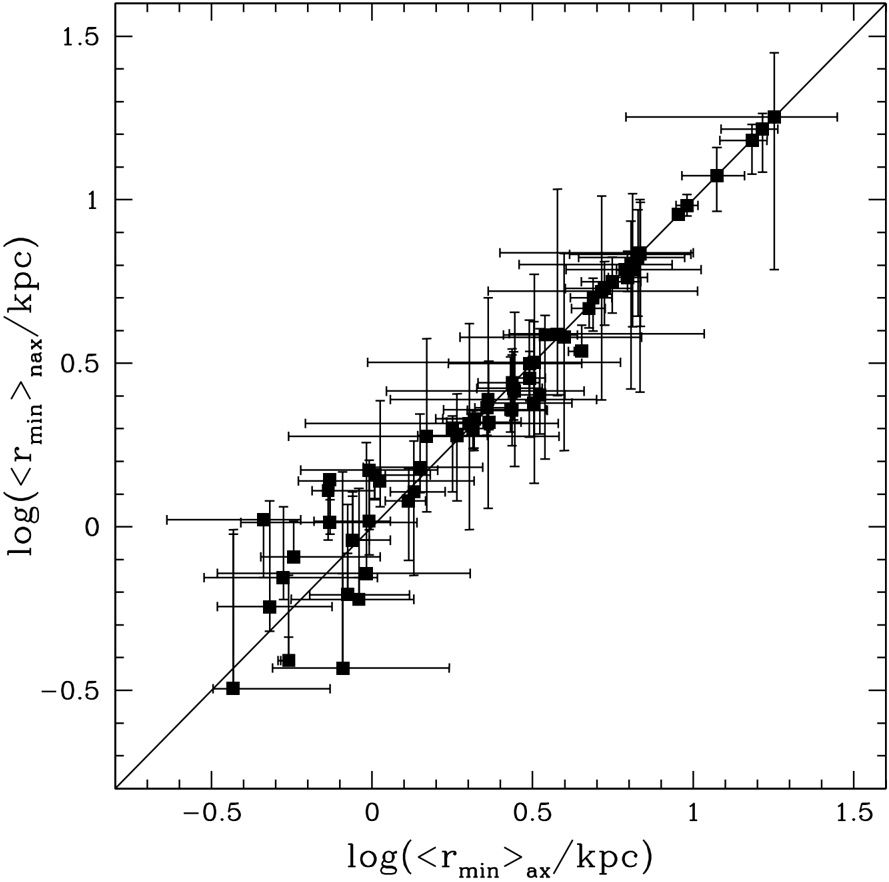
Fig. 4.- Comparison of the cluster average apogalactic distance, third column in Table 3, in the axisymmetric potential (with a subindex 'ax') and in the non-axisymmetric potential (with a subindex 'nax'). The plotted line is the line of coincidence.
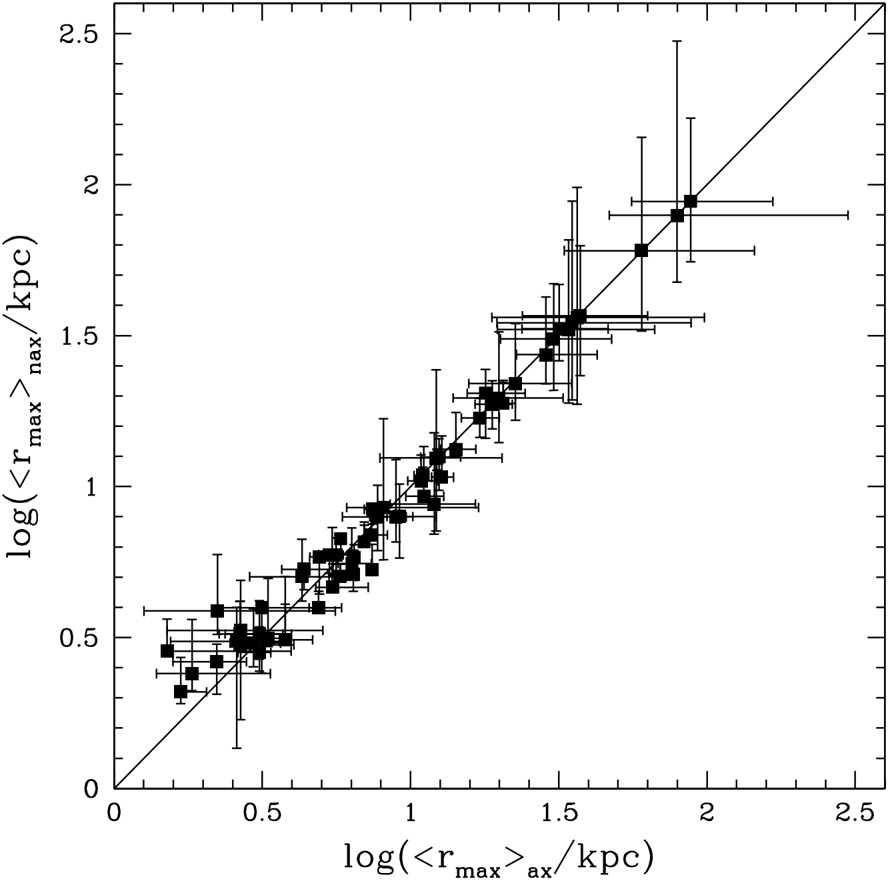
Fig. 5.- Comparison of the cluster maximum distance from the Galactic plane, fourth column in Table 3, in the axisymmetric potential (with a subindex 'ax') and in the nonaxisymmetric potential (with a subindex 'nax'). The plotted line is the line of coincidence.
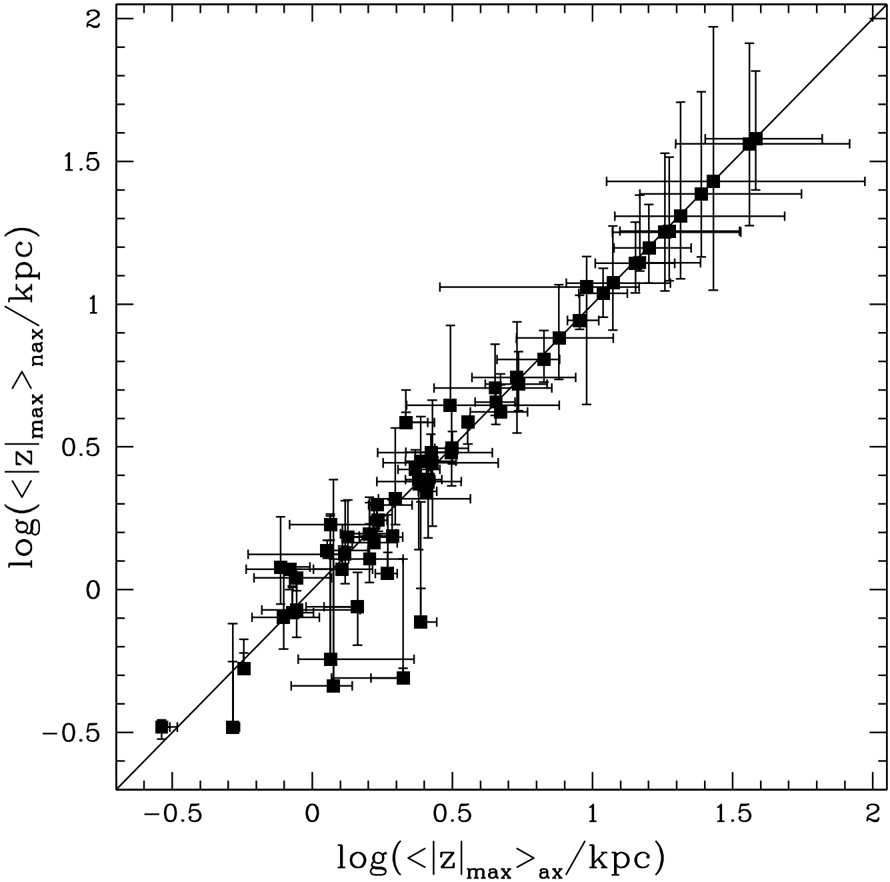
Fig. 6.- Comparison of the theoretical tidal radius r K t computed in the axisymmetric potential, averaged over the last 10 9 yr in each cluster orbit, and the observed tidal radius r K . Encircled and crossed points correspond, respectively, to clusters in which <r K t > in this axisymmetric potential, is less or greater than <r K t > computed in the non-axisymmetric potential. See next Figure 7. The small empty squares and triangles give <r K t > in the minimum and maximum energy orbits. The continuous line is the line of coincidence. The numbered encircled points are considered in Figure 8.
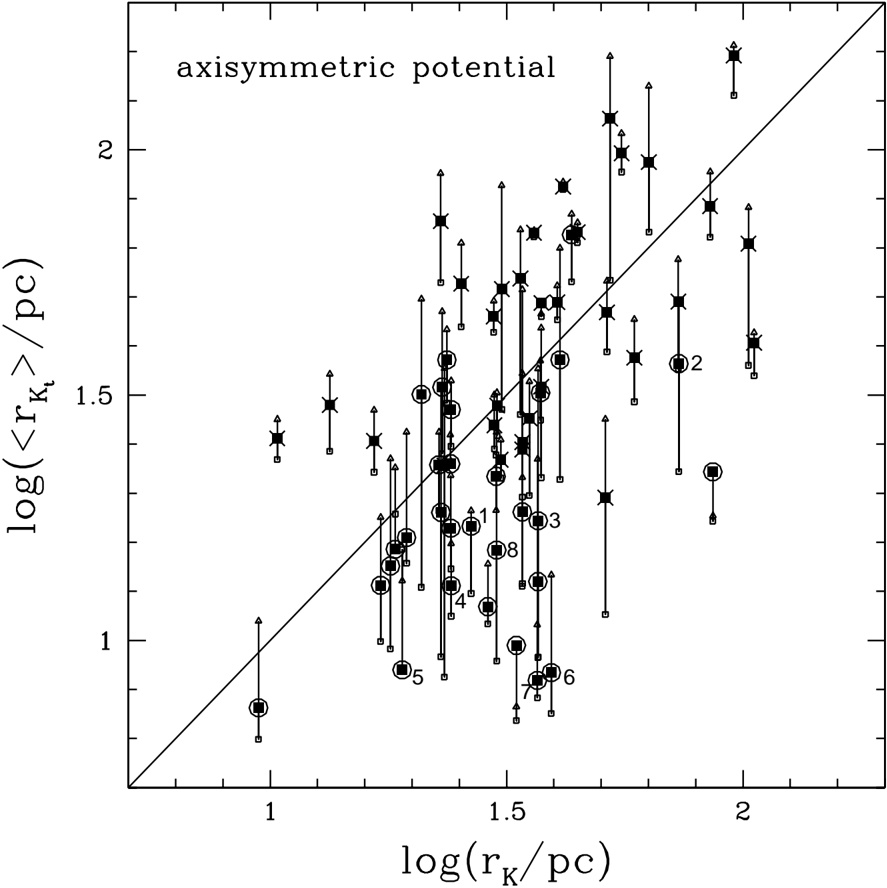
Fig. 7.- Comparison of the averaged theoretical tidal radius r K t computed in the nonaxisymmetric potential and the observed tidal radius r K . The marks in the points maintain the corresponding meaning given in Figure 6.
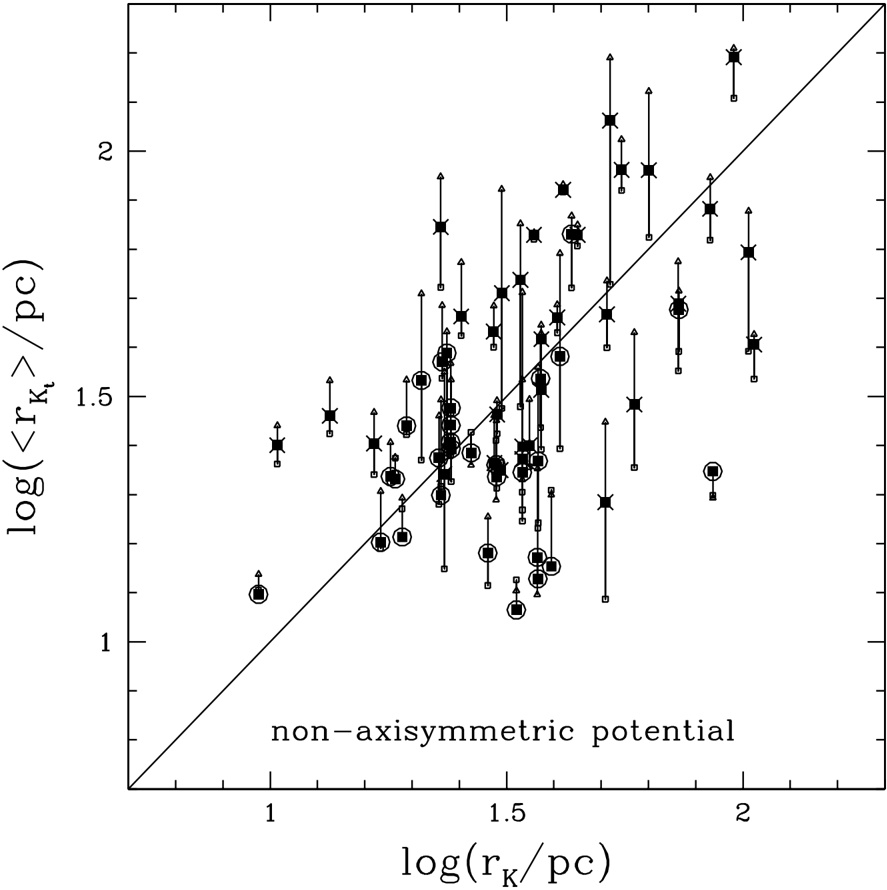
Fig. 8.- Perigalactic distance as a function of time over the last 10 9 yr for the sample of globular clusters with numbered encircled points in Figure 6. Black dots joined with black lines show the values in the axisymmetric potential; those in red correspond to the nonaxisymmetric potential. The horizontal dotted lines show the corresponding average values. In each frame the cluster name and its identification number in Figure 6 are given.
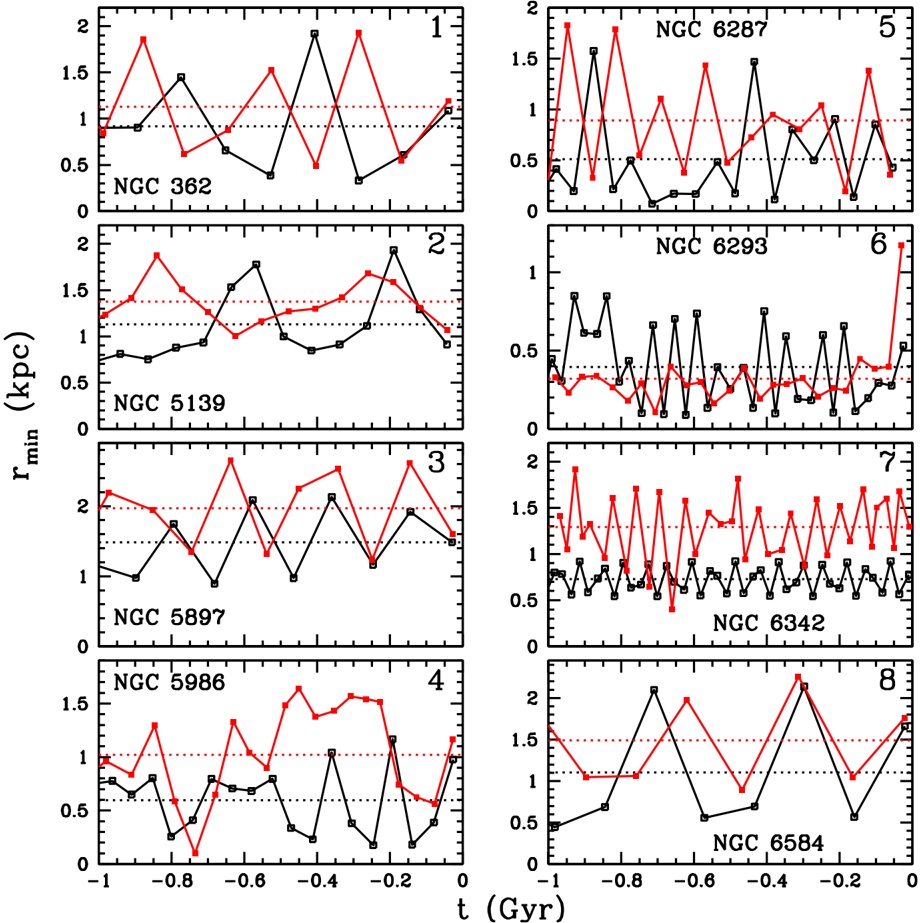
Fig. 9.M g computed on the Galactic plane as a function of distance to the Galactic center. Values in the axisymmetric potential are shown with the black line; the continuous and dashed red and blue lines show values in the non-axisymmetric potential, along the major (red) and minor (blue) axes of the bar. The continuous red and blue lines show the contribution of the axisymmetric background and Galactic bar in this potential, and the corresponding dashed lines includes the spiral arms with a particular orientation (see main text).
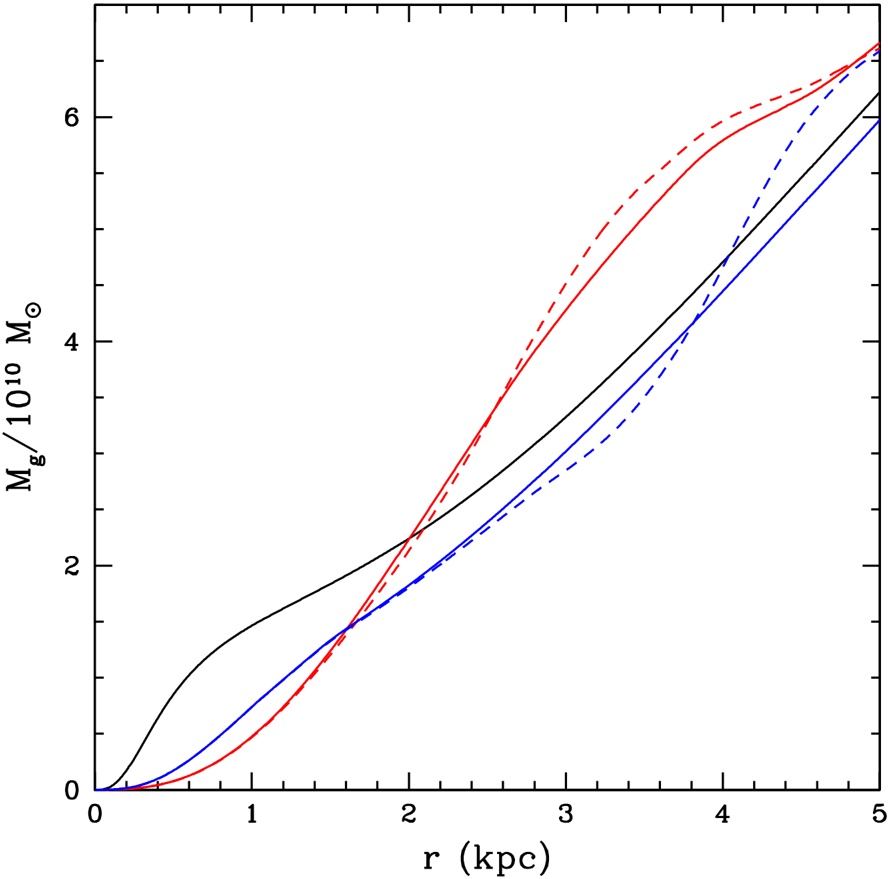
Fig. 10.- Effective galactic mass M g employed in Eq. (1) as a function of time over the last 10 9 yr for the clusters in Figure 8. The correspondence of colors is the same as in Figure 8. The horizontal dotted lines (not plotted in NGC 6293) show the average values of M g .
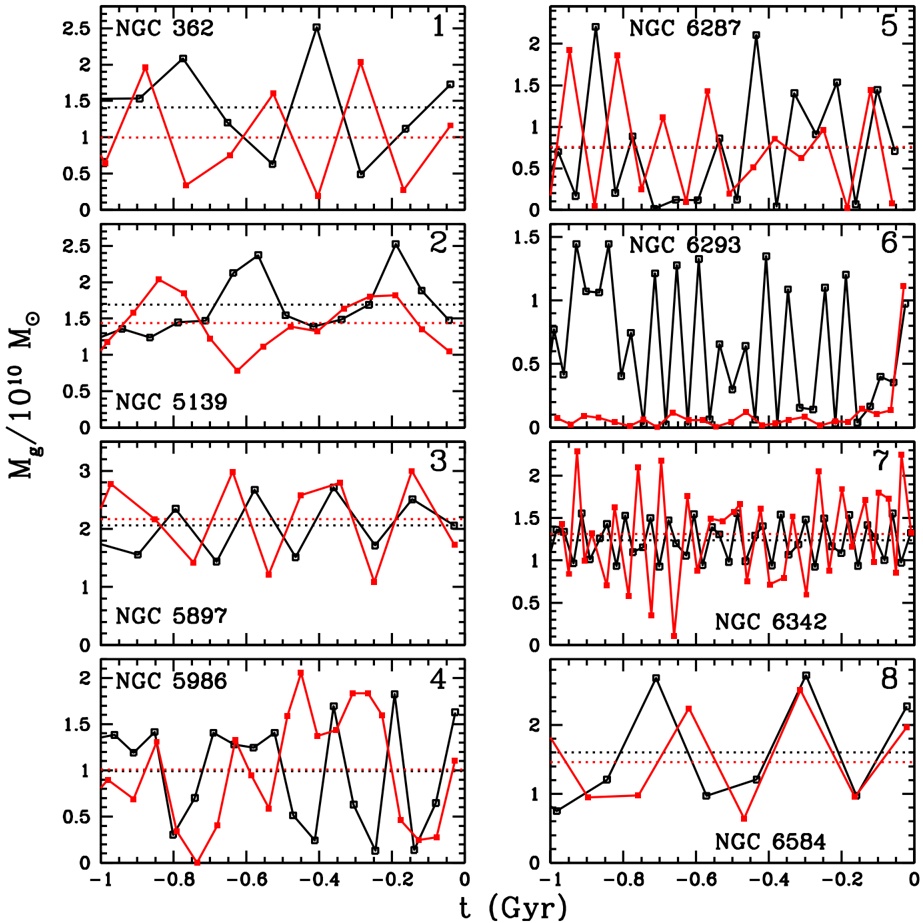
Fig. 11.- Red points: comparison between r K t and the limiting radius r l obtained by Miocchi et al. (2013) for some clusters in our sample. The comparison is made in the nonaxisymmetric potential. Black points are corresponding points from r K t vs r K in Figure 7. Horizontal displacements between red and black points are shown with dotted blue lines. Red crossed points correspond to clusters in which a Wilson model gives the best fit.
Fig. 12.Red points: comparison of r K t vs r K in the non-axisymmetric potential computing the cluster mass M c with dynamical mass-to-light ratios given by McLaughlin & van der Marel (2005). Black points: corresponding points from Figure 7 using ( M/L ) V = 2 M /L /circledot /circledot . For clarity, the red points are slightly displaced to the right of the black points.
Fig. 13.- Comparison of the Monte Carlo theoretical tidal radius global average 〈 r K t 〉 computed with the axisymmetric potential over the last 10 9 yr, and the observed tidal radius r K . Compare this figure with Figure 6.
Fig. 14.- As in Figure 13, here we show the results in the non-axisymmetric potential. In this case compare with Figure 7.
Fig. 15.- Frames (a),(c): ratio of the difference between r K in Table 1 and <r K t > in column 8 of Table 3 for the last 10 9 yr in the orbital computation, to their average ( r K + <r K t > )/2, plotted against the logarithm of the average perigalactic distance in this time interval. Frames (b),(d): the same comparison, but with r K t computed only in the last perigalacticon, and the logarithm of its corresponding distance to the Galactic center. Frames (a),(b) show results in the axisymmetric Galactic potential, and (c),(d) in the non-axisymmetric Galactic potential.
Fig. 16.- As in Figure 15 in the non-axisymmetric Galactic potential over the last 10 9 yr, but now applying to r K t computed at perigalacticon the correction given by Webb et al. (2013) in their equation 8, which results in the average limiting radius r LK . This new limiting radius is used instead of <r K t > in the ratio plotted in the ordinate axis of Figure 15.
Fig. 17.- An example in the non-axisymmetric potential of the Gaussian fits to ( < M 2 > ) 1 2 / in some apogalactic periods, where this tidal acceleration has more than one maximum in a given period. The black dots show the positions of the apogalactic points, and the red curves the approximate fits to the main peaks in the tidal acceleration.
Fig. 18.- Azimuth-averaged squared ratio of maximum z-accelerations due to the spiral arms and axisymmetric disk component in the non-axisymmetric potential, as a function of the distance R to the Galactic center of an orbital crossing point with the Galactic plane.
Fig. 19.- Azimuth-averaged ratio of distances from the Galactic plane where maximum z-accelerations of the spiral arms and axisymmetric disk are reached, as a function of the distance R to the Galactic center of an orbital crossing point with the Galactic plane.
Fig. 20.- Comparison of bulge-shocking total destruction rates in the axisymmetric potential, employing the real and linear trajectories in each cluster. Corresponding values are shown in the vertical and horizontal axes. The plotted line is the line of coincidence.
Fig. 21.- As in Figure 20, here the comparison is made in the non-axisymmetric potential.
Fig. 22.Comparison of bulge-shocking total destruction rates in the axisymmetric potential, employing the real and linear trajectories in each cluster. Here the cluster mass M c is computed with dynamical mass-to-light ratios ( M/L ) V given by McLaughlin & van der Marel (2005). Black points are points from Figure 20, and red points are the new points obtained with the dynamical mass-to-light ratios. Corresponding shifts between black and red points in a cluster are shown with blue lines.
Fig. 23.- Comparison of bulge-shocking total destruction rates employing the real trajectory in each cluster. Values obtained in the non-axisymmetric potential (denoted with a subindex 'nax') and axisymmetric potential (with a subindex 'ax') are shown in the vertical and horizontal axes, respectively. The plotted line is the line of coincidence.
Fig. 24.- Comparison of disk-shocking destruction rates obtained in the non-axisymmetric potential (vertical axis) with those obtained in the axisymmetric potential (horizontal axis). The plotted line is the line of coincidence.
Fig. 25.- Total bulge+disk destruction rates employing the real trajectory of the cluster. Values obtained in the non-axisymmetric potential and in the axisymmetric potential are shown in the vertical and horizontal axes, respectively. The plotted line is the line of coincidence.
Fig. 26.- This is Figure 25 without the error bars. Points shown with empty squares correspond to clusters with orbital eccentricity e ≤ 0 5, . and those with black squares to clusters with e > 0 5. . The squares with a circle correspond to clusters with a mass less than 10 5 M /circledot . The position of the cluster Pal 5 is shown, and also other clusters with their NGC numbers.
 | 10.1088/0004-637X/793/2/110 | [
"Edmundo Moreno",
"Barbara Pichardo",
"Hector Velazquez"
] | 2014-08-03T04:58:18+00:00 | 2014-08-03T04:58:18+00:00 | [
"astro-ph.GA"
] | Tidal radii and destruction rates of globular clusters in the Milky Way due to bulge-bar and disk shocking | We calculate orbits, tidal radii, and bulge-bar and disk shocking destruction
rates for 63 globular clusters in our Galaxy. Orbits are integrated in both an
axisymmetric and a non-axisymmetric Galactic potential that includes a bar and
a 3D model for the spiral arms. With the use of a Monte Carlo scheme, we
consider in our simulations observational uncertainties in the kinematical data
of the clusters. In the analysis of destruction rates due to the bulge-bar, we
consider the rigorous treatment of using the real Galactic cluster orbit,
instead of the usual linear trajectory employed in previous studies. We compare
results in both treatments. We find that the theoretical tidal radius computed
in the nonaxisymmetric Galactic potential compares better with the observed
tidal radius than that obtained in the axisymmetric potential. In both Galactic
potentials, bulge-shocking destruction rates computed with a linear trajectory
of a cluster at its perigalacticons give a good approximation to the result
obtained with the real trajectory of the cluster. Bulge-shocking destruction
rates for clusters with perigalacticons in the inner Galactic region are
smaller in the non-axisymmetric potential, as compared with those in the
axisymmetric potential. For the majority of clusters with high orbital
eccentricities (e > 0.5), their total bulge+disk destruction rates are smaller
in the non-axisymmetric potential. |
1408.0458v3 | ## Is d ∗ a candidate of hexaquark-dominated exotic state?
F. Huang, 1 Z.Y. Zhang, 2, 3 P.N. Shen, 2, 3, 4 and W.L. Wang 5
1
School of Physical Sciences, University of Chinese Academy of Sciences, Beijing 101408, China 2 Institute of High Energy Physics, Chinese Academy of Sciences, Beijing 100049, China 3 Theoretical Physics Center for Science Facilities, CAS, Beijing 100049, China 4 College of Physics and Technology, Guangxi Normal University, Guilin 541004, China 5 School of Physics and Nuclear Energy Engineering, Beihang University, Beijing 100191, China (Dated: March 16, 2015- dstar˙v7)
We confirm our previous prediction of a d ∗ state with I ( J P ) = 0(3 + ) [Phys. Rev. C 60 , 045203 (1999)] and report for the first time based on a microscopic calculation that d ∗ has about 2/3 hidden color (CC) configurations and thus is a hexaquark-dominated exotic state. By performing a more elaborate dynamical coupled-channels investigation of the ∆∆-CC system within the framework of resonating group method (RGM) in a chiral quark model, we found that the d ∗ state has a mass of about 2 38 . -2 42 GeV, a root-mean-square radius (RMS) of 0 76 . . -0 88 fm, and a CC fraction . of 66% -68%. The last may cause a rather narrow width to d ∗ which, together with the quantum numbers and our calculated mass, is consistent with the newly observed resonance-like structure ( M ≈ 2380 MeV, Γ ≈ 70 MeV) in double-pionic fusion reactions reported by WASA-at-COSY Collaboration.
PACS numbers: 14.20.Pt, 13.75.Cs, 12.39.Jh, 24.10.Eq
The ABC effect has drawn physicists' great attention since its observation in 1961 in the pd reaction [1]. In recent years, much experimental progress in exploring the nature of the ABC effect has been made. In 2009, the CELSIUS/WASA Collaboration measured the most basic double-pionic fusion reaction pn → dπ π 0 0 with an incident proton energy of 1.03 GeV and 1.35 GeV [2], and found significant enhancements in the ππ invariant mass spectrum at ππ invariant mass below 0.32 GeV 2 and also in the dπ invariant mass spectrum at ∆ resonance region. To accommodate these data as well as the energy dependence of the total cross section at √ s < 2 5 . GeV, the conventional t -channel ∆∆ intermediate state is found to be not sufficient, and a new structure, namely an s -channel resonance with mass of about 2.36 GeV and width of about 80 MeV, is expected. In 2011, the WASA-at-COSY Collaboration further measured the pn → dπ π 0 0 reaction with the beam energies of 1 0 . -1 4 GeV which cover the transition region of the con-. ventional t -channel ∆∆ process [3]. They found that neither the t -channel ∆∆ process nor the Roper resonance process can explain the data, and an s -channel resonance with quantum numbers of I ( J P ) = 0(3 + ), mass of about 2.37 GeV and width of about 70 MeV is indeed needed to describe the data. Recently, the WASA-at-COSY Collaboration measured the polarized /vector np scattering through the quasi-free process /vector dp → p spectator np [4, 5]. By incorporating the newly measured A y data into the SAID analysis, they obtained a pole in the 3 D 3 -3 G 3 waves at (2380 ± 10)+ (40 i ± 5) MeV, which again supports the existence of a resonance, called d ∗ , as mentioned in Ref. [3]. Further evidence of this resonance has also been reported in the quasi-free np → npπ π 0 0 reaction [6]. Since its mass is above the threshold of ∆ Nπ channel, while its width is much smaller than the decay width of ∆, this resonance must be a very interesting state involving new physical mechanisms and it is obviously worthwhile investigating.
Theoretically, the possibility of the existence of dibaryon states was first proposed in 1964 by Dyson and Xuong based on SU(6) symmetry [7]. Since then, extensive efforts have been given in exploring the possible existence of a ∆∆ dibaryon on hadronic degrees of freedom. However, no convincing results have ever been released yet. Since the birth of quark model, dramatic progresses on this aspect were pouring in. In 1980, by analyzing the characteristics of the one-gluon-exchange (OGE) interaction between quarks, Oka and Yazaki pointed out that in all non-strange baryon-baryon (BB) systems, the ∆∆ system with I ( J P ) = 0(3 + ) is the only one in which the effective BB interaction induced by OGE shows an attractive feature [8]. In the following years, by including the interaction between the quark field and chiral field into the constituent quark model, one successfully reproduced the data of the nucleon-nucleon (NN) interaction and the binding energy of the deuteron [9], which would provide a much reliable platform to predict the structures of dibaryons in the quark degrees of freedom. In 1999, we carefully performed a dynamical study of the ∆∆ system in the quark degrees of freedom within the framework of Resonating Group Method (RGM), with the hidden color (CC) channel being properly taken into account [10]. Where, by employing the chiral SU(3) quark model with a set of reasonable model parameters which can reproduce the NN scattering phase shifts at relatively lower energies and the binding energy of deuteron, we found that the quark-exchange effect in the ∆∆ system with quantum number I ( J P ) = 0(3 + ) is so important (see also Ref. [11]) that the system should be bound in nature with a binding energy of about 20 -50 MeV in a single ∆∆ channel calculation. The coupling to the CC
channel was also intensively studied and found to play an important role in the binding behavior of the system. It offers an additional binding energy of over 20 MeV to the system, and thus the binding energy of d ∗ , relative to the threshold of ∆∆ channel, would run up to 40 -80 MeV. Unexpectedly, our predicted mass and quantum numbers are quite close to the new observation released recently by WASA-at-COSY Collaboration [4].
In this work, we perform a further elaborate investigation of the ∆∆ -CC system within the framework of RGM in a chiral quark model. Besides the binding energy, we concentrate on a detailed study of the relative wave function of the ∆∆ -CC system, which is crucial to the understanding of the structure and decay property of d ∗ . We find for the first time based on a microscopic calculation that the d ∗ has a CC component of about 2/3, which indicates that d ∗ is a hexaquark-dominated exotic state. The large CC configuration is quite helpful for us to understand that d ∗ , although locating above the thresholds of ∆ Nπ and NNππ channels, has a relatively narrow width as will be discussed later in more detail. In the most recent experimental papers by WASA-at-COSY Collaboration and SAID Data Analysis Center [5, 6], our scenario for d ∗ present here has been cited as a plausible explanation of the resonance observed in the doublepionic fusion reaction, as both our calculated binding energy and the expected width from our picture of d ∗ are in agreement with the experimental findings.
The interaction between i -th quark and j -th quark in our chiral quark model reads
$$V _ { i j } = V _ { i j } ^ { \text{OGE} } + V _ { i j } ^ { \text{conf} } + V _ { i j } ^ { \text{ch} }, \quad \quad ( 1 )$$
where V OGE ij is the OGE interaction which describes the short-range perturbative QCD behavior, and V conf ij the confinement potential describing the long-range nonperturbative QCD effects. V ch ij is the chiral field induced quark-quark interaction which provides the mediumrange non-perturbative QCD effects, and to test the model dependence of our results, we employ two different models for this interaction. In the chiral SU(3) quark model, V ch ij reads
$$V _ { i j } ^ { \text{ch} } = \sum _ { a = 0 } ^ { 8 } \left ( V _ { i j } ^ { \sigma _ { a } } + V _ { i j } ^ { \pi _ { a } } \right ), \quad \ \ ( 2 ) \quad 0 ( 3 )$$
and in the extended chiral SU(3) quark model, V ch ij reads
$$V _ { i j } ^ { \text{ch} } = \sum _ { a = 0 } ^ { 8 } \left ( V _ { i j } ^ { \sigma _ { a } } + V _ { i j } ^ { \pi _ { a } } + V _ { i j } ^ { \rho _ { a } } \right ), \quad \ \ ( 3 ) \quad \text{$\mathrm RM$} \quad \text{$the$} \\ \text{$to 2$} \\ \text{$\mathrm fm$.}$$
with σ a , π a and ρ a ( a = 0 1 , , · · · , 8) being the scalar, pseudo-scalar and vector nonet fields, respectively. Note that the OGE will be largely reduced when vector-meson exchanges are included, i.e. the short-range interaction
TABLE I. Binding energy, root-mean-square radius (RMS) of 6 quarks, and fraction of channel wave function for deuteron in chiral SU(3) quark model and extended chiral SU(3) quark model with ratio of tensor coupling to vector coupling f/g=0 and f/g=2/3 for vector meson fields.
| | SU(3) | Ext. SU(3) | Ext. SU(3) |
|------------------------|---------|--------------|--------------|
| | | (f/g=0) | (f/g=2/3) |
| Binding energy (MeV) | 2.09 | 2.24 | 2.20 |
| RMS of 6 q (fm) | 1.38 | 1.34 | 1.35 |
| Fraction (NN) L =0 (%) | 93.68 | 94.66 | 94.71 |
| Fraction (NN) L =2 (%) | 6.32 | 5.34 | 5.29 |
mechanisms are quite different in these two models. We refer readers to Refs. [9, 12] for further details.
The parameters of both models are fixed by fitting the energies of the octet and decuplet baryon ground states, the NN scattering phase shifts in the low energy region ( √ s /lessorequalslant 2 m N +200 MeV) and the binding energy of deuteron [9, 12]. See Table I for the binding energy, root-mean-square radius (RMS) of 6 q , and the fraction of each partial wave for deuteron obtained from our models. They are all quite reasonable.
With all the parameters being properly fixed, we are eager to a investigation for the properties of the ∆∆-CC system without introducing any new adjustable parameters. Here the hidden color channel CC with isospin I = 0 and spin S = 3 is built as
$$\kappa \, \ln \, \left ( \lambda \right ) \, \lambda \, \cdots \, \cdots \, \cdots \, \cdots \, \cdots \, \cdots \, \cdots \, \cdots \, \\ ( 1 ) \, \left ( \lambda \right ) \, \right ) _ { I S = 0 3 } \equiv - \frac { 1 } { 2 } \left | \Delta \Delta \right \rangle _ { I S = 0 3 } + \frac { \sqrt { 5 } } { 2 } \mathcal { A } ^ { s f c } \left | \Delta \Delta \right \rangle _ { I S = 0 3 }, \ ( 4 )$$
with A sfc being the antisymmetrizer in spin-flavor-color space. We dynamically calculate the binding energy of this system by solving the RGM equation for a bound state problem, and then discuss the structure of this bound state via a systematic analysis of fractions of each channel in the resultant relative wave function. The results obtained in chiral SU(3) quark model and the extended chiral SU(3) quark model with the ratios of the tensor coupling to vector coupling f/g=0 and f/g=2/3 for vector meson fields are listed in Table II, where the values for RMS of 6 quarks are also shown.
One sees from Table II that the ∆∆ state with I ( J P ) = 0(3 + ) has a binding energy of about 30 -60 MeV and a RMS of about 0 80 . -0 96 fm in a ∆∆ ( . L = 0 2) double-, channel calculation. The coupling to the CC channel will further result in an increment of about 20 MeV to the binding energy and a considerable decrement of the RMS, and finally, the mass of this bound state will reach to 2 38 . -2 42 GeV and the RMS will shrink to 0 76 . . -0 88 . fm. This clearly shows that d ∗ is a ∆∆-CC deeply bound and compact state where the coupling to the CC channel plays a significant role.
Apart from the RMS, more information about the 'size' of d ∗ can be acquired from its spacial distribu-
TABLE II. Binding energy, root-mean-square radius (RMS) of 6 quarks, and fraction of channel wave function for d ∗ in chiral SU(3) quark model and extended chiral SU(3) quark model with ratio of tensor coupling to vector coupling f/g=0 and f/g=2/3 for vector meson fields.
| | ∆∆ ( L = 0 , 2) | ∆∆ ( L = 0 , 2) | ∆∆ ( L = 0 , 2) | ∆∆ - CC ( L = 0 , 2) | ∆∆ - CC ( L = 0 , 2) | ∆∆ - CC ( L = 0 , 2) |
|------------------------|-------------------|--------------------|----------------------|------------------------|------------------------|------------------------|
| | SU(3) | Ext. SU(3) (f/g=0) | Ext. SU(3) (f/g=2/3) | SU(3) | Ext. SU(3) (f/g=0) | Ext. SU(3) (f/g=2/3) |
| Binding energy (MeV) | 28.96 | 62.28 | 47.90 | 47.27 | 83.95 | 70.25 |
| RMS of 6 q (fm) | 0.96 | 0.80 | 0.84 | 0.88 | 0.76 | 0.78 |
| Fraction (∆∆) L =0 (%) | 97.18 | 98.01 | 97.71 | 33.11 | 31.22 | 32.51 |
| Fraction (∆∆) L =2 (%) | 2.82 | 1.99 | 2.29 | 0.62 | 0.45 | 0.51 |
| Fraction (CC) L =0 (%) | | | | 66.25 | 68.33 | 66.98 |
| Fraction (CC) L =2 (%) | | | | 0.02 | 0.00 | 0.00 |
/s32
/s32
/s32
/s32
FIG. 1. Relative wave functions in the extended chiral SU(3) quark model with f/g=0 for deuteron (left) and d ∗ (right).
tion feature as shown in Fig. 1, where the partial-wave projected relative wave function in physical basis as a function of the distance between two physical states in the extended chiral SU(3) quark model with f/g=0 is plotted. The results in other two models are similar. For comparison, the results for deuteron are also plotted. Here the relative wave function in physical basis, namely the channel wave function in the quark cluster model, is defined in the usual way as [13-15]
$$\psi _ { \text{BB} } ( \boldsymbol r ) \equiv \langle \phi _ { \text{B} } ( \boldsymbol \xi _ { 1 }, \boldsymbol \xi _ { 2 } ) \, \phi _ { \text{B} } ( \boldsymbol \xi _ { 4 }, \boldsymbol \xi _ { 5 } ) \, | \, \Psi _ { 6 q } \rangle \,, \quad ( 5 ) \quad \text{loca} ^ { 1 }$$
with B standing for ∆ or C and Ψ 6 q being the six-quark wave function from RGM calculation,
In Eqs. (5) and (6), φ B is the antisymmetrized internal wave function for cluster B, with ξ i ( i = 1 2 4 5) , , , being the internal Jacobi coordinates for corresponding cluster; A is the antisymmetrizer for quarks from different clusters required by Pauli exclusion principle; and η BB ( r ) is the relative wave function between two clusters of B, which in present investigation is completely determined by the interacting dynamics of the whole sixquark system. From Fig. 1 one sees that d ∗ is rather narrowly distributed and it has a maximal distribution located around 0 7 fm for ∆∆ ( . L = 0) and 0 4 fm for . CC ( L = 0), respectively. While deuteron is widely distributed with a maximal distribution located around 1 4 . fm.
$$\Psi _ { 6 q } = \sum _ { B = \Delta, C } \mathcal { A } \left [ \phi _ { B } ( \xi _ { 1 }, \xi _ { 2 } ) \, \phi _ { B } ( \xi _ { 4 }, \xi _ { 5 } ) \, \eta _ { B B } ( r ) \right ]. \quad ( 6 ) \quad \text{thing} \\ \text{relati}$$
It should be mentioned that an even more interesting thing in this investigation is to study the fractions of relative wave functions for each individual channel, which
will help us get a further understanding of the structure of d ∗ . Our extracted fractions of relative wave functions for ∆∆ and CC channels are tabulated in Table II. Of great interest is that one observes that the fraction of the CC channel in d ∗ is about 66% -68%. Note according to symmetry, a pure hexaquark state of ∆∆-CC system with isospin I = 0 and spin S = 3 reads
$$[ 6 ] _ { o r b } [ 3 3 ] _ { I S = 0 3 } = \sqrt { \frac { 1 } { 5 } } \left | \Delta \Delta \right \rangle _ { I S = 0 3 } + \sqrt { \frac { 4 } { 5 } } \left | \CC \right \rangle _ { I S = 0 3 }, \ ( 7 ) \quad \text{$\text{and} \,m$} \\ \text{partial partial}$$
which indicates that the fraction of CC channel in a pure hexaquark state is 80%. It is thus fair to say that d ∗ is a hexaquark-dominated state as it has a CC configuration of 66% -68%. This finding is of great interest. It helps us to understand that d ∗ , although locating above the thresholds of the ∆ Nπ and NNππ channels, has a relatively narrow width since the CC component cannot subject to a direct break-up decay. Actually, it can only decay to colorless hadrons via the re-combination processes of six color quarks together with quark-antiquark pair creation processes, which are highly suppressed and have much lower probability than those direct break-up decay processes. A conjecture that d ∗ should have an unconventional origin and the CC configuration will suppress its decay width has also been proposed by Bashkanov, Brodsky and Clement in Ref. [16]. Our microscopic calculation presented here supports their argument and our dynamical results show that d ∗ has about 2/3 hiddencolor configurations. However, a detailed calculation of the decay width of d ∗ needs to take into account both the kinematic effects and the effects from the dynamical structure of d ∗ . In the literature the former has been considered by using a simple momentum dependent prescription for d ∗ s decay width [17]. Now an investigation of the later also becomes possible, because the relative wave functions of d ∗ is available in the present paper. Our work along this line is in progress.
It should particularly be stressed that the abovementioned features of d ∗ are due to both the quark exchange effect and the short-range interaction being attractive in the ∆∆-CC system. As we have pointed out in Ref. [11], the quark exchange effect is highly dependent on the quantum numbers of the system. Opportunely, the ∆∆ system with I ( J P ) = 0(3 + ) is one of the few systems which have strong quark exchange effect that drags two baryons together to form a compact state. As for the interaction property, Oka and Yazaki claimed in 1980 that in all the non-strange two-baryon systems, the ∆∆ system with I ( J P ) = 0(3 + ) is the only one in which the OGE provides strong attraction in short range [8]. In our chiral SU(3) quark model, the OGE indeed provides strong short-range attraction. In the extended chiral SU(3) quark model, although the OGE is largely reduced, the short-range interaction is still attractive and the attraction is even much stronger, as the vector meson exchanges (VMEs) are also strongly attrac- tive in short range. Considering both mentioned facts, the ∆∆ system with I ( J P ) = 0(3 + ) is certainly deeply bound and it would couple to the CC channel strongly as two interacting ∆s are dragged closer enough by strong attraction. As a comparison, the NN 3 S 1 partial wave has a rather different feature. In this partial wave, the quark exchange effect is very week (almost negligible), and moreover, the short-range interaction stemming from OGE and VMEs are all repulsive. Therefore, the NN 3 S 1 partial wave can only get attraction in the medium- and long-range through σ and π meson exchanges, and as a result, the deuteron is loosely bound and hardly couples to CC channel. We emphasize that the ∆∆ system with I ( J P ) = 0(3 + ) is a highly special system where both the quark exchange effect and the short-range interaction are attractive, which makes this system deeply bound and promotes a strong coupling to the CC channel.
In summary, it is the first time one finds based on a microscopic calculation with no additional parameters besides those fixed already in the study of NN scattering phase shifts that d ∗ has about 2/3 hidden-color configurations and thus tends to be a hexaquark-dominated exotic state. It has a mass of about 2 38 . -2 42 GeV, a root-. mean-square radius of 0 76 . -0 88 fm, and a CC fraction of . 66% -68% which may cause a relatively narrow width of d ∗ . Our findings are consistent with the newly observed resonance-like structure ( M ≈ 2380 MeV, Γ ≈ 70 MeV) in double-pionic fusion reactions reported by WASA-atCOSY Collaboration. We mention that if its character can be further verified, the d ∗ will be the first hexaquarkdominated exotic state we have ever found, and it may open a door to new physical phenomena.
In literature there are several other interpretations of the recent WASA-at-COSY experiment. Gal et al. carried out a πN ∆ three-body-calculation [18] and found the D 03 state as a dynamically generated pole at the right mass and slightly larger width (see Ref. [5] for a comment of the width). Huang et al. performed a coupled-channel quark model calculation and obtained an energy close to the observed value, but their calculated width is still too large [17].
The πN ∆ three-body resonance scenario proposed by Gal et al. [18] might have a relatively larger RMS than that from our picture. While measuring the 'size' of d ∗ is rather involved, experiments in future might reach d ∗ by electromagnetic transitions, which will give information about d ∗ form factor and further tell us the real structure of the observed resonance [19]. We look forward to experimental progresses along this line.
We are grateful for constructive discussions with Prof. H. Clement and Prof. R. L. Workman.
This work is partly supported by the National Natural Science Foundation of China under grants Nos. 11475181, 11105158, 11035006 and 11165005, the Keyproject by the Chinese Academy of Sciences under project No. KJCX2-EW-N01. F.H. is grateful to the
support of the One Hundred Person Project of the University of Chinese Academy of Sciences.
- [1] N. E. Booth et al. , Phys. Rev. Lett. 7 , 35 (1961).
- [2] M. Bashkanov et al. , Phys. Rev. Lett. 102 , 052301 (2009).
- [3] P. Adlarson et al. (WASA-at-COSY Collaboration), Phys. Rev. Lett. 106 , 242302 (2011).
- [4] P. Adlarson et al. (WASA-at-COSY Collaboration & SAID DAC), Phys. Rev. Lett. 112 , 202301 (2014).
- [5] P. Adlarson et al. (WASA-at-COSY Collaboration & SAID DAC), Phys. Rev. C 90, 035204 (2014).
- [6] P. Adlarson et al. (WASA-at-COSY Collaboration),
- arXiv:1409.2659 [nucl-ex].
- [7] F. J. Dyson and N. H. Xuong, Phys. Rev. Lett. 13 , 815 (1964).
- [8] M. Oka and K. Yazaki, Phys. Lett. B 90 , 41 (1980).
- [9] Z. Y. Zhang et al. , Nucl. Phys. A 625 , 59 (1997).
- [10] X. Q. Yuan et al. , Phys. Rev. C 60 , 045203 (1999).
- [11] Q. B. Li et al. , Nucl. Phys. A 683 , 487 (2001).
- [12] L. R. Dai et al. , Nucl. Phys. A 727 , 321 (2003).
- [13] A. M. Kusainov et al. , Phys. Rev. C 44 , 2343 (1991).
- [14] L. Ya. Glozman, V. G. Neudatchin, and I. T. Obukhovsky, Phys. Rev. C 48 , 389 (1993).
- [15] Fl. Stancu, S. Pepin, and L. Ya. Glozman, Phys. Rev. C 56 , 2779 (1997).
- [16] M. Bashkanov, S.J. Brodsky, and H. Clement, Phys. Lett. B 727 , 438 (2013).
- [17] H. X. Huang et al. , Phys. Rev. C 89 , 034001 (2014).
- [18] A. Gal et al. , Phys. Rev. Lett. 111 , 172301 (2013).
- [19] H. Clement, private communication. | null | [
"F. Huang",
"Z. Y. Zhang",
"P. N. Shen",
"W. L. Wang"
] | 2014-08-03T05:16:54+00:00 | 2015-03-13T10:59:34+00:00 | [
"nucl-th",
"hep-ph",
"nucl-ex"
] | Is $d^*$ a candidate of hexaquark-dominated exotic state? | We confirm our previous prediction of a $d^*$ state with $I(J^P)=0(3^+)$
[Phys. Rev. C 60, 045203 (1999)] and report for the first time based on a
microscopic calculation that $d^*$ is a hexaquark dominated exotic state as it
has about 2/3 hidden color (CC) configurations. By performing a more elaborate
dynamical coupled-channels investigation of the $\Delta\Delta$-CC system within
the framework of resonating group method (RGM) in a chiral quark model, we
found that the $d^*$ state has a mass of about 2.38-2.42 GeV, a
root-mean-square radius (RMS) of 0.76-0.88 fm, and a CC fraction of 66%-68%.
The last ensures that the $d^*$ has a rather narrow width which, together with
the quantum numbers and our calculated mass, is consistent with the newly
observed resonance-like structure ($M\approx 2380$ MeV, $\Gamma\approx 70$ MeV)
in double-pionic fusion reactions reported by WASA-at-COSY Collaboration. |
1408.0459v1 | 1
## Mirror symmetry breaking in He isotopes and their mirror nuclei
Takayuki Myo ∗ 1, 2 and Kiyoshi Kat¯ o † 3
General Education, Faculty of Engineering, Osaka Institute of Technology, Osaka, Osaka 535-8585, Japan 2 Research Center for Nuclear Physics (RCNP), Osaka University, Ibaraki 567-0047, Japan 3 Nuclear Data Centre, Faculty of Science, Hokkaido University, Sapporo 060-0810, Japan (Dated: August 5, 2014)
We study the mirror symmetry breaking of 6 He- Be and 6 8 He- C using the 8 4 He + XN ( X = 2, 4) cluster model. The many-body resonances are treated for the correct boundary condition using the complex scaling method. We find that the ground state radius of 8 C is larger than that of 8 He due to the Coulomb repulsion in 8 C. On the other hand, the 0 + 2 resonances of the two nuclei exhibit the inverse relation; the 8 C radius is smaller than the 8 He radius. This is due to the Coulomb barrier of the valence protons around the 4 He cluster core in 8 C, which breaks the mirror symmetry of the radius in the two nuclei. A similar variation in the radius is obtained in the mirror nuclei, 6 He and 6 Be. A very large spatial extension of valence nucleons is observed in the 0 + 2 states of 8 He and 8 C. This property is related to the dominance of the ( p 3 / 2 ) 2 ( p 1 / 2 ) 2 configuration for four valence nucleons, which is understood from the reduction in the strength of the couplings to other configurations by involving the spatially extended components of valence nucleons.
PACS numbers: 21.60.Gx, 21.10.Dr, 21.10.Sf, 27.20.+n
## I. INTRODUCTION
Unstable nuclei have often been observed in unbound states beyond the particle thresholds due to the weak binding nature of valence nucleons. Resonance spectroscopy of unbound states in unstable nuclei has been developed using radioactive-beam experiments [1]. In addition to the energies and decay widths of resonances, information on their configurations and spatial properties is important in understanding the structures of unstable nuclei. In proton-rich and neutron-rich nuclei, the correlations between valence nucleons and between a valence nucleon and a core nucleus lead to the exotic nuclear properties in resonances as well as in the weakly bound states that are currently beyond our standard understanding of stable nuclei. The comparison of the structures between proton-rich and neutron-rich nuclei is related to the mirror symmetry in unstable nuclei with a large isospin.
The results of certain experiments on proton-rich 8 C have recently been reported [2]. The 8 C nucleus is an unbound system beyond the proton drip line. Currently, only the ground state is observed in 8 C. This resonance is located at 2 MeV above the 6 Be + 2 p threshold energy and close to the 7 B + p threshold [2]. The excited states of 8 C can decay not only to a two-body 7 B + p channel, but also to the many-body channels of 6 Be + 2 , p 5 Li + 3 p and 4 He + 4 , in which p 5 Li, 6 Be, and 7 B are also unbound systems. Large decay widths for multi-particle decays make it difficult to identify the excited states of 8 C experimentally.
The mirror nucleus of 8 C is 8 He with isospin T = 2.
∗ [email protected]
† [email protected]
Thus far, many experiments on 8 He have been reported [3-5]. Its ground state is weakly bound, and it has a neutron skin structure consisting of four valence neutrons around 4 He with a separation energy of 3.1 MeV. As regards the excited states of 8 He, most of these states are observed above the 4 He + 4 n threshold energy. Therefore, the resonances of 8 He can decay into many channels including 7 He + n , 6 He + 2 n , 5 He + 3 n , and 4 He + 4 n , similar to 8 C. The multi-particle decays of 8 He are related to the Borromean nature of 6 He, which decays into 4 He + 2 n with a small excitation energy. With this background information on He isotopes and their mirror nuclei, we remark that most of the states appearing in these nuclei can exist as many-body resonances. It is important to understand the characteristics of these resonances as many-body states beyond the simple two-body resonance, considering the couplings with the continuum states of various decay channels into subsystems. The proper treatment of boundary conditions for the resonant and continuum states is inevitable to obtain reliable results of the resonance properties.
The comparison of the structures of protonand neutron-rich nuclei is interesting from the viewpoint of mirror symmetry. In this study we compare the structures of 8 He and 8 C and also those of 6 He and 6 Be. It is interesting to examine the effect of the Coulomb interaction on the mirror symmetry of these nuclei. The structures of resonances and weakly bound states are generally influenced by the open channels of particle emissions. Hence, the mirror symmetry of unstable nuclei can be related to the coupling behavior between the open channels and the continuum states.
In the theoretical analysis to investigate the unbound states of 8 He and 8 C, it is necessary to describe the 4 He + 4 n /4 p five-body unbound states. In this analysis, we employ the cluster-orbital shell model (COSM) [6-14] that has been successfully used to describe the 4 He+4 N five-
body system. In COSM, we adopt single particle wave functions of non-restricted radial forms, which are optimized by solving the many-body Schr¨dinger equation. o In addition, the effects of all the open channels are taken into account explicitly in the COSM, and therefore we can treat the many-body decaying phenomena. In our previous works [10, 12, 13], we have successfully described the He isotopes and their mirror, proton-rich nuclei. We have obtained many-body resonances using the complex scaling method (CSM) [15-17] under the correct boundary conditions for all decay channels. In CSM, the resonant wave functions are described using the L 2 basis functions without any approximation. Using the combined COSM and CSM we describe the many-body resonances and also the decaying process of the states. The application of CSM to nuclear physics has been extensively carried out for resonance spectroscopy, transition strengths into unbound states, and nuclear reaction problems [9, 10, 17-22].
In the previous analyses [11], we have discussed the mirror symmetry of 7 He and 7 B with the 4 He + 3 N model. It is found that the mirror symmetry is broken in their ground states where the mixing of 6 Be(2 + 1 ) in 7 B is larger than that of 6 He(2 + 1 ) in 7 He. This result concerns the relative energies between the states of A = 7 nuclei and the channels of the (2 + 1 state of A = 6 nuclei)+ N . In Refs. [12, 13], we investigated the five-body resonances of 8 C with the 4 He + 4 p model. We found that the configurations of 8 He and 8 C are similar; the ground 0 + states are mainly described by the ( p 3 / 2 ) 4 configuration for four valence nucleons as a sub-closed nature, and the excited 0 + 2 states are strongly dominated by the 2p2h configuration of ( p 3 / 2 ) 2 ( p 1 / 2 ) 2 .
In this study, we proceed with our analysis of 8 He and 8 C and concentrate on the spatial properties of the 0 + states of the two nuclei. Recently, the dineutron-cluster model [23] has been used to demonstrate the possibility of viewing dineutron clustering in 8 He(0 + 2 ) as like 4 He-core plus two dineutrons. This model is based on the boundstate approximation. On the other hand, our results for the 0 + 2 states of 8 He and 8 C show a single configuration of ( p 3 / 2 ) 2 ( p 1 / 2 ) 2 of valence nucleons with the correct treatment for resonances. It is important to clarify the reason for the single configuration of the 0 + 2 states in relation to the boundary condition of resonances and also to the spatial extension of valence nucleons because the 0 + 2 states are resonances decaying into five-body constituents. In addition, we compare the radii of 8 He and 8 C to understand the effect of the Coulomb interaction on the spatial distribution of the valence protons in 8 C, which was partially carried out in the previous study [12]. In this study we examine the mirror symmetry in the spatial properties of the two nuclei. The Coulomb interaction provides a repulsive effect on the system, which is naively expected to enlarge the radius of the system. In fact, we have shown that the ground state radius of 8 C is larger than that of 8 He [12, 13]. We perform the same analysis for the 0 + 2 resonances of the two nuclei. The comparison between mirror nuclei is also discussed for the A = 6 nuclei, 6 He and 6 Be using the 4 He + 2 N model.
This paper is organized as follows. In Sect. II, we explain the COSM wave function and the complex scaling method. In Sect. III, we present the results of the mirror symmetry relations of 8 He- C and that of 8 6 He- Be. 6 A summary is provided in Sect. IV.
## II. COMPLEX-SCALED CLUSTER ORBITAL SHELL MODEL
We use the COSM of the 4 He + 4 N system for 8 He and 8 C, and the 4 He + 2 N system for 6 He and 6 Be. The Hamiltonian is the same as that used in the previous studies [11, 12],
$$\begin{array} { c c c } \begin{array} { c } \\ \\ \\$$
$$= \, \sum _ { i = 1 } ^ { X } \left [ \frac { p$$
where X denotes the valence nucleon number around 4 He, and the mass number is given by 4 + X . The terms t i and T G denote the kinetic energies of each particle ( 4 He and N ) and of the center of mass of the total system, respectively. The operator p i denotes the relative momentum between 4 He and N . The reduced mass µ is 4 m/ 5 described using the nucleon mass m . The 4 HeN interaction V αN is given by the microscopic KKNN potential [17, 24] for the nuclear part, in which the tensor correlation of 4 He is renormalized. For the Coulomb part, we use the folded Coulomb potential using the density of 4 He as the (0 s ) 4 configuration. The NN interaction V NN is given by the Minnesota potential [25] for the nuclear part in addition to the point Coulomb interaction between protons. These interactions reproduce the lowenergy scatterings of the 4 HeN and the N N -systems, respectively.
For the wave function of 4 He, we assume a (0 s ) 4 configuration of a harmonic oscillator wave function with length parameter of 1.4 fm. We expand the relative wave functions of the 4 He + XN system ( X = 2 4) using the , COSM basis states [6]. In the COSM, the total wave function Ψ J with spin J is represented by the superposition of the configuration Ψ J c as
$$\Psi ^ { J } \, = \, \sum _ { \substack { c$$
$$\Psi _ { c } ^ { J } \, = \, \prod _ { i$$
where the vacuum | 0 〉 represents the 4 He ground state. The creation operator a † α corresponds to the singleparticle state of a valence nucleon above 4 He with the quantum number α = { n, /lscript, j } in the jj -coupling scheme.
FIG. 1: Sets of the spatial coordinates in COSM.
The index n represents the different radial components. In this study, the valence nucleons are assumed to be protons only or neutrons only. The index c represents a set of α i values for valence nucleons as c = { α , . . . , α 1 X } . We obtain a summation over the available configurations in Eq. (3) with a total spin J . The amplitudes { C J c } in Eq. (3) are determined variationally with respect to the total wave function Ψ J by the diagonalization of the Hamiltonian matrix elements.
The coordinate representation of the single-particle state for a † α is given as ψ α ( r ) as a function of the relative coordinate r between 4 He and a valence nucleon, as shown in Fig. 1. We employ a sufficient number of bases to expand ψ α ( r ) for the description of the spatial extension of valence nucleons, in which the ψ α ( r ) terms are normalized. In this model, the radial part of ψ α ( r ) is expanded with the Gaussian basis functions for each orbit [7, 17] as
$$\psi _ { \alpha } ( r ) \ = \ \sum _ { k = 1 }$$
$$\phi _ { \ell j } ^ { k } ( r, b _ { \ell j } ^ { k }$$
The index k corresponds to the Gaussian basis function with the length parameter b k /lscriptj . The normalization factor of the basis and basis number are given by N and N /lscriptj , respectively, and k = 1 , . . . , N /lscriptj . The coefficients { d k α } in Eq. (5) are determined using the Gram-Schmidt orthonormalization. Hence, the basis states ψ α ( r ) are orthogonal to each other, as indicated by Eq. (7). The radial bases ψ α ( r ) are distinguished by the index n , which is indexed up to the basis number N /lscriptj . The same method using Gaussian basis functions for a single-particle state is employed in the tensor-optimized shell model [19, 2628]. The Pauli principle between a valence nucleon and 4 He is treated using the orthogonality condition model [29], in which the single-particle state ψ α ( r ) is imposed to be orthogonal to the 0 s state occupied by 4 He. The length parameters b k /lscriptj are chosen in geometric progression [17]. We use at most 17 Gaussian basis functions by setting b k /lscriptj to range from 0.2 fm to around 40 fm typically. The large value of b k /lscriptj plays an important role in accounting for the continuum state of a valence nucleon. To obtain the Hamiltonian matrix elements of multi-nucleon systems in the COSM, we employ the j -scheme technique of the shell-model calculation.
For the model space of the COSM, the angular momenta of the single-particle states are taken as /lscript ≤ 2 [10, 12]. We fit the two-neutron separation energy of 6 He to the experiment of 0.975 MeV by taking the 173.7 MeV of the repulsive strength of the Minnesota potential from the original value of 200 MeV [25].
We briefly review the CSM to describe the resonances and nonresonant continuum states. In the CSM, we transform the relative coordinates as U θ ( ) r i = r i e iθ for i = 1 , . . . , X , as shown in Fig. 1, where U θ ( ) denotes the operator for transformation with a scaling angle θ . The Hamiltonian in Eq. (2) is transformed into the complexscaled Hamiltonian H θ = U θ HU θ ( ) ( ) -1 , and the corresponding complex-scaled Schr¨dinger equation is given o as
$$H _ { \theta } \Psi _ { \theta } ^ { J } \ = \ E \Ps$$
The eigenstates Ψ J θ = U θ ( )Ψ J are obtained by solving the eigenvalue problem of H θ . In the CSM, all the energy eigenvalues E of the bound and unbound states are located on a complex energy plane, according to the ABC theorem [15, 16]. In this theorem, it is proved that the boundary condition of the resonances is transformed into damping behavior at the asymptotic region. This condition is the same as that of the bound states. For a finite value of θ , every Riemann branch cut starting from different particle thresholds is commonly rotated down by 2 θ in the complex energy plane. In contrast, bound states and resonances are obtainable as stationary solutions with respect to θ . We can identify the pole of resonances as Gamow states with complex eigenvalues, E = E r -iΓ / 2, where E r and Γ denote the resonance energies and decay widths, respectively. In the wave function, the θ -dependence is included in the amplitudes in Eq. (3) as { C J c ( θ ) } . The optimal angle θ is determined to locate the stationary point of each resonance in the complex energy plane [17].
In the CSM, resonances are precisely described as eigenstates expanded in terms of L 2 basis functions such as Gaussian basis functions. It is noted that the amplitude { C J c ( θ ) } of resonances becomes a complex number, while the resonances are normalized to obey the relation ∑ ( c C J c ( θ ) ) 2 = 1 [8, 30, 31]. For amplitudes, when the imaginary part is a relatively small value, it is reasonable to discuss the physical meaning of the real part of the amplitudes. In the present study, we also discuss the radius of resonances being a complex number. When the radius exhibits an imaginary part relatively smaller than the real one, we consider that the real part of the radius is regarded as a reference providing the information on the spatial size of the resonances. Recently, the complex radius has been used to estimate the size of hadronic resonances such as those observed in the ¯ KN system [32, 33].
The Hermitian product is not applied due to the biorthogonal eigenstates of the non-Hermitian H θ [30, 34,
TABLE I: Energy eigenvalues of the 0 + 1 2 , states of 6 He and 6 Be measured from the 4 He + N + N threshold with the experimental values. Units are in MeV.
| | 6 He | 6 He | 6 Be | 6 Be |
|-------|---------|--------|---------|--------|
| | Energy | Γ | Energy | Γ |
| 0 + 1 | - 0.975 | - | 1 . 383 | 0.041 |
| exp. | - 0.975 | - | 1 . 370 | 0.092 |
| 0 + 2 | 3.88 | 8.76 | 5 . 95 | 11.21 |
TABLE II: Energy eigenvalues of the 0 + 1 2 , states of 8 He and 8 C measured from the 4 He + N + N + N + N threshold with the experimental values [2]. Units are in MeV.
| | 8 He | 8 He | 8 C | 8 C |
|-------|--------|--------|-----------|-----------|
| | Energy | Γ | Energy | Γ |
| 0 + 1 | - 3.22 | - | 3.32 | 0.072 |
| exp. | - 3.11 | - | 3.449(30) | 0.130(50) |
| 0 + 2 | 3.07 | 3.19 | 8.88 | 6.64 |
35]. The matrix elements of a physical quantity ˆ for resO onant states are calculated using the amplitudes { C J c ( θ ) } and are independent of the angle θ , as evidenced from the following relation
$$\mu _ { \begin{array} {$$
The properties of the resonances are uniquely determined as the Gamow states [17, 36]. In the CSM, it is not necessary to obtain the original solution of resonances by using the inverse transformation of the complex scaling, which is the so-called back-rotation. This is because the matrix elements of the resonances are uniquely obtained in Eq. (9).
## III. RESULTS
## A. Energy spectra
We discuss the structures of the 0 + states of 8 He and 8 C, and also those of 6 He and 6 Be. The energy eigenvalues of these states have been obtained in a previous analysis [12], and here, we discuss the mirror symmetry of these nuclei. We summarize the energy properties in Tables I and II, which values are measured from the 4 He + N + N (+ N + N ) thresholds. For 8 He and 8 C, the 0 + 2 states are obtained as five-body resonances. The systematic energy spectra for He isotopes and their mirror nuclei have been presented in previous studies [10, 12]. The results well reproduce the observed energy levels and predict several resonances. The matter and charge radii of 6 He and 8 He obtained in the COSM also agree with the observations [10]. This agreement indicates that the spatial distributions of the valence neutrons are described well to explain the neutron halo and skin structures in the weakly bound states. In the following section, we discuss the various radii values corresponding to the ground and resonant states to investigate the spatial properties of valence nucleons in relation to the mirror symmetry.
## B. Effect of spatial extension of valence nucleons in 8 He and 8 C
We discuss the effect of the spatial extension of valence nucleons on the configuration mixing of the singleparticle states in 8 He and 8 C. This analysis is important to understand the reason for the dominance of a single configuration in the 0 + 2 resonances of the two nuclei. In the COSM, we expand the wave function of the valence nucleons using the Gaussian basis functions given in Eq. (6) with a length parameters { b k /lscriptj } . The spatial extension is considered in a superposition of the Gaussian basis functions with the large value of b k /lscriptj . To investigate the effect of spatial extension, we restrict the motion of valence nucleons in which the relative distance between 4 He and a valence nucleon becomes smaller than 6 fm. The distance of 6 fm is determined to retain the properties of the configuration mixing of the 8 He ground state. Since 8 He has a bound state, the four valence neutrons of 8 He are considered to be distributed not very far from 4 He. The restriction for the spatial extension of the COSM wave functions is placed with the maximum lengths of { b k /lscriptj } in Eq. (6) for a valence nucleon. The maximum lengths of { b k /lscriptj } are determined for the Gaussian basis functions so as to satisfy the matrix elements of the relative distance between a nucleon and 4 He (Fig. 1) to be 6 fm. In this treatment, the energy of 8 He is obtained as -3 14 MeV as measured from the . 4 He + 4 n threshold, which is still close to the value of -3 22 MeV . obtained without the restriction [10].
The result of the configuration mixing with the spatial restriction for valence nucleons is listed in Table III for the ground states of 8 He and 8 C. We list the dominant configurations with their squared amplitudes ( C J c ) 2 as given in Eq. (3). The states of 8 He and 8 C show similar values of mixing, in which the ( p 3 / 2 ) 4 configuration commonly dominates the total wave functions. The 8 C state is described under the bound-state approximation in a manner similar to that for 8 He, because the spatial restriction does not treat the boundary condition for resonances correctly. For comparison, the results without the restriction are listed in Table IV [12]. For 8 He, it is found that the mixing values of each configuration do not strongly depend on the restriction of the spatial extension. For 8 C, the mixing values with the restriction (Table III) are also close to the real parts of the values without the restriction (Table IV). These results indicate
TABLE III: Squared amplitudes ( C J c ) 2 of the ground states of 8 He and 8 C with spatial restriction of valence nucleons.
| Configuration | 8 He(0 + 1 ) | 8 C(0 + 1 ) |
|------------------------------|----------------|---------------|
| ( p 3 / 2 ) 4 | 0.858 | 0.854 |
| ( p 3 / 2 ) 2 ( p 1 / 2 ) 2 | 0.069 | 0.071 |
| ( p 3 / 2 ) 2 (1 s 1 / 2 ) 2 | 0.006 | 0.01 |
| ( p 3 / 2 ) 2 ( d 3 / 2 ) 2 | 0.008 | 0.008 |
| ( p 3 / 2 ) 2 ( d 5 / 2 ) 2 | 0.043 | 0.041 |
| other 2p2h | 0.011 | 0.01 |
TABLE IV: Squared amplitudes ( C J c ) 2 of the ground states of 8 He and 8 C without spatial restriction.
| Configuration | 8 He(0 + 1 ) | 8 C(0 + 1 ) |
|------------------------------|----------------|--------------------|
| ( p 3 / 2 ) 4 | 0.86 | 0 . 878 - 0 . 005i |
| ( p 3 / 2 ) 2 ( p 1 / 2 ) 2 | 0.069 | 0 . 057 +0 . 001i |
| ( p 3 / 2 ) 2 (1 s 1 / 2 ) 2 | 0.006 | 0 . 010 +0 . 003i |
| ( p 3 / 2 ) 2 ( d 3 / 2 ) 2 | 0.008 | 0 . 007 +0 . 000i |
| ( p 3 / 2 ) 2 ( d 5 / 2 ) 2 | 0.042 | 0 . 037 +0 . 000i |
| other 2p2h | 0.011 | 0 . 008 +0 . 000i |
that the spatial extension does not have a significant effect in the ground states of 8 He and 8 C.
In a manner similar to the above discussion, we discuss the effect of spatial extension on the configuration mixing of the 0 + 2 states of 8 He and 8 C. In the previous analysis [12], it was obtained that the ( p 3 / 2 ) 2 ( p 1 / 2 ) 2 configuration commonly dominates the total wave functions of 8 He and 8 C. We restrict the spatial extension in the 0 + 2 states in the same manner as done for the ground states. The results are listed in Table V. We find that the configuration mixing values of the 0 + 2 states of 8 He and 8 Care very similar. The dominant configurations are retained as ( p 3 / 2 ) 2 ( p 1 / 2 ) 2 with about 0.8 of the squared amplitudes in both nuclei. The residual components are distributed among other configurations such as ( p 3 / 2 ) 4 and ( p 3 / 2 ) 2 (1 s 1 / 2 ) 2 . As regards the results without the restriction, the dominant configurations of the valence neutron/protons are listed in Table VI, in which a nearly pure ( p 3 / 2 ) 2 ( p 1 / 2 ) 2 configuration is obtained with very large squared amplitudes of about 0.93 -0.97 for the real parts. The differences in the results between Tables V and VI indicate that the spatial extension of the valence nucleons plays an important role in reducing the coupling strengths between the configurations in the 0 + 2 states, which is not observed in the ground states of 8 He and 8 C. The reduction in the coupling strength is related to the motion of valence nucleons. Without the spatial extension, the four valence nucleons cannot be distributed widely. In this situation, the strengths of the couplings between the different configurations generally increase because the amplitudes of the wave function are confined in the interaction region. When the spatial ex-
TABLE V: Squared amplitudes ( C J c ) 2 of the 0 + 2 states of 8 He and 8 C with spatial restriction of valence nucleons.
| Configuration | 8 He(0 + 2 ) | 8 C(0 + 2 ) |
|------------------------------|----------------|---------------|
| ( p 3 / 2 ) 4 | 0.069 | 0.051 |
| ( p 3 / 2 ) 2 ( p 1 / 2 ) 2 | 0.806 | 0.796 |
| ( p 3 / 2 ) 2 (1 s 1 / 2 ) 2 | 0.042 | 0.086 |
| ( p 3 / 2 ) 2 ( d 3 / 2 ) 2 | 0.018 | 0.013 |
| ( p 3 / 2 ) 2 ( d 5 / 2 ) 2 | 0.007 | 0.003 |
| other 2p2h | 0.003 | 0.0005 |
TABLE VI: Squared amplitudes ( C J c ) 2 of the 0 + 2 states of 8 He and 8 C without spatial restriction.
| Configuration | 8 He(0 + 2 ) | 8 C(0 + 2 ) |
|------------------------------|----------------------|---------------------|
| ( p 3 / 2 ) 4 | 0 . 020 - 0 . 009i | 0 . 044 +0 . 007i |
| ( p 3 / 2 ) 2 ( p 1 / 2 ) 2 | 0 . 969 - 0 . 011i | 0 . 934 - 0 . 012i |
| ( p 3 / 2 ) 2 (1 s 1 / 2 ) 2 | - 0 . 010 - 0 . 001i | - 0 . 001 +0 . 000i |
| ( p 3 / 2 ) 2 ( d 3 / 2 ) 2 | 0 . 018 +0 . 022i | 0 . 020 +0 . 003i |
| ( p 3 / 2 ) 2 ( d 5 / 2 ) 2 | 0 . 002 +0 . 000i | 0 . 002 +0 . 001i |
tension is realized in the 0 + 2 states of 8 He and 8 C, their wave functions can be distributed widely and most of the amplitudes of valence nucleons penetrate from the interaction region. As a result, the coupling strengths between the configurations decrease and the single configuration of ( p 3 / 2 ) 2 ( p 1 / 2 ) 2 survives dominantly in the 0 + 2 states.
It is noted that the spatial extension of valence nucleons can also affect the diagonal energies of the singleparticle configurations, particularly with the higher orbits, because of the release of the kinetic energies of the configurations by the spatial extension of nucleons. This effect is considered to enhance the configuration mixing because the diagonal energies of the configurations approach each other, as opposed to the case of a reduction in the coupling matrix elements between the configurations. The present calculation of 8 He and 8 C includes both effects simultaneously, and the obtained results indicate that the effect of the reduction in coupling is fairly strong.
The dineutron model calculation [23] has recently been used to determine the two-dineutron enhanced states in 8 He(0 + 2 ) under the bound-state approximation. In general, the dineutron is a kind of spatial localization of two neutrons, such as a cluster, and it corresponds to the configuration mixing of various single-particle states in the mean field picture. In fact, for 6 He, the mixing of various orbits of the two valence neutrons enhances the dineutron formation [17, 37, 38]. In the present calculations of 8 He and 8 C, when the spatial extension is restricted within the bound-state approximation, the configuration mixing in the 0 + 2 states increase in strength in comparison with the resonance solution of the CSM. This feature in the bound-state approximation can be related to the
enhancement of the dineutron/diproton (dinucleon) components. However, the 0 + 2 states in the CSM calculations for 8 He and 8 C are described as the five-body resonances and are dominated by the single ( p 3 / 2 ) 2 ( p 1 / 2 ) 2 configuration of four valence nucleons. This result indicates that the states in the CSM calculations can have the different properties from the dinucleon enhanced ones.
## C. Spatial properties of 8 He and 8 C
It is important to understand the roles of the Coulomb interaction on the spatial properties of 8 C in comparison with 8 He. This is related to the examination of the mirror symmetry in the two nuclei. For this purpose, we investigate the various radii sizes of 8 He and 8 C, which reflect the motion of valence nucleons. It is shown that the effect of the motion of valence nucleons on the configuration mixing depends on the state. It is interesting to discuss the case of the radius. We noted that the radius of Gamow resonances is obtained as a finite complex number, because Gamow states have complex eigen-energies and complex amplitudes. In the present analyses, most of the radii of resonances exhibit imaginary parts that are relatively smaller than the real ones, similar to case of the squared amplitudes listed in Tables IV and VI. Hence, we discuss the spatial size of resonances using the real part of the complex radii. The explicit form of the operator for the various radii in the COSM is provided in Ref. [6], in which the case of He isotopes is given.
The results of the radii of the 0 + 2 states in 8 He and 8 C are obtained as listed in Table VII in addition to the 0 + 1 results obtained in the previous study [12, 13]. We calculate the matter ( R m ), proton ( R p ), neutron ( R n ), and charge ( R ch ) radii, and the mean relative distances between 4 He and a single valence nucleon ( r c -N ) and between 4 He and the center of mass of the four valence nucleons ( r c 4 -N ). For the 0 + 1 states, the matter radius of 8 C is larger than that of 8 He by about 12% for the real part. A similar calculation for the ground states of 8 He and 6 He with a 4 He core was performed using the Gamow shell model approach [39] in which the ground-state properties obtained for two nuclei agree with our calculation [10]. The neutron-neutron correlation between two nuclei has also been investigated. The most recent experimental value of the charge radius of 8 He(0 + 1 ) is reported as 1.959(16) fm [40], which is close to our result of 1.92 fm.
For 0 + 2 states, all the values of radii are complex numbers because of the resonances in the two nuclei. The imaginary parts are fairly large for 8 He(0 + 2 ), but still smaller than the real ones. The values for 8 C exhibit small imaginary parts and the bound-state properties still survive in this state, in spite of the higher energy of 8.88 MeV from the lowest threshold. In the two nuclei, the various radii of the 0 + 2 states are larger than the corresponding values of their ground 0 + 1 states. This is consistent with the significant effect of the spatial extension of valence nucleons in the 0 + 2 states, as discussed
TABLE VII: Various radii of the 0 + 1 2 , states of 8 He and 8 C in units of fm.
| | 8 He(0 + 1 ) | 8 C(0 + 1 ) | 8 He(0 + 2 ) | 8 He(0 + 2 ) | 8 He(0 + 2 ) | 8 C(0 + 2 ) | 8 C(0 + 2 ) | 8 C(0 + 2 ) |
|-----------|----------------|------------------|----------------|----------------|----------------|---------------|---------------|---------------|
| R m | 2.52 | 2 . 81 - 0 . 08i | 7.56 | + | 2.04i | 4.87 | + | 0.13i |
| R p | 1.8 | 3 . 06 - 0 . 10i | 3.15 | + | 0.69i | 5.46 | + | 0.15i |
| R n | 2.72 | 1 . 90 - 0 . 01i | 8.53 | + | 2.32i | 2.36 | + | 0.05i |
| R ch | 1.92 | 3 . 18 - 0 . 09i | 3.22 | + | 0.67i | 5.53 | + | 0.15i |
| r c - N | 3.55 | 4 . 05 - 0 . 12i | 11.03+ | | 3.11i | 7.21 | + | 0.21i |
| r c - 4 N | 2.05 | 2 . 36 - 0 . 03i | 5.60 | + | 1.55i | 3.68 | + | 0.13i |
FIG. 2: Real parts of matter, proton, and neutron radii of the ground states (upper panel) and the 0 + 2 states (lower panel) of 8 He and 8 C in units of fm. Circles with error bars indicate experimental data of the matter radius of 8 He [3, 41, 42].
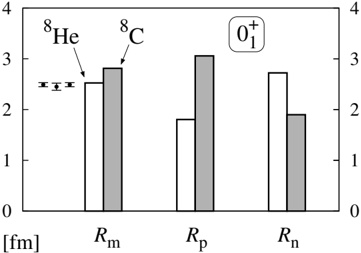
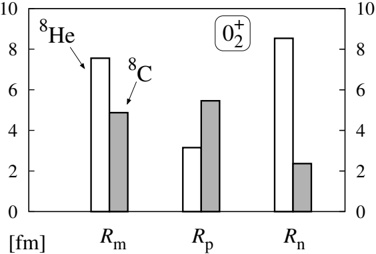
already.
It is interesting that the matter radius of 8 C is smaller than that of 8 He in the 0 + 2 states. The proton radius of 8 C can be compared with the neutron radius of 8 He. The results indicate that the proton radius of 8 C is smaller than the neutron radius of 8 He. This relation is opposite to that observed for the ground states of 8 He and 8 C. To understand this difference clearly, we plot the real parts of the matter, proton, and neutron radii for 0 + 1 2 . in Fig. 2. For 8 He(0 + 2 ), the observed large matter radius originates from the large neutron radius. For 8 C(0 + 2 ), the large matter radius is due to the large proton radius, which is smaller than the neutron radius of 8 He.
We conclude that the relation of the spatial properties between 8 He and 8 C depends on the states, which can be explained in terms of the Coulomb interaction. The Coulomb interaction acts repulsively, thereby shifting the entire energy of 8 C upward with respect to the 8 He energy. In the ground state of 8 C, this repulsion extends the distances between 4 He and a valence proton and between valence protons. On the other hand, the Coulomb interaction makes the barrier above the particle threshold in 8 C and the 0 + 2 resonance is affected by this barrier, the effect of which prevents the wave function of valence protons of 8 C from extending spatially. In 8 He, there is no Coulomb barrier for the four valence neutrons and the neutrons can extend to a large distance in the resonances. This role of the Coulomb interaction leads to the radius of 8 C(0 + 2 ) being smaller than that of 8 He(0 + 2 ).
For the ground states of 8 He and 8 C, two states have different boundary conditions for the bound and resonant states. This difference can affect the radius in addition to the Coulomb repulsion. Naively, the unbound condition on 8 C is considered to enhance the 8 C radius in comparison with the case of the bound state. In the present calculation, the effect of the boundary condition on the radius is automatically included along with the Coulomb repulsion. The decomposition of the two effects, while being meaningful, may be difficult to achieve.
## D. Spatial properties of 6 He and 6 Be
For comparison with the A = 8 nuclei, it is interesting to investigate the effect of the Coulomb interaction in 6 He and 6 Be, in which the spatial distributions of the two valence nucleons are involved. Table VIII lists the various radii of 6 He and 6 Be for the 0 + 1 2 , states. In these states, only the ground state of 6 He is bound, and the other 0 + states are three-body resonances located above the 4 He + N + N threshold. In Table VIII, we list the matter ( R m ), proton ( R p ), neutron ( R n ), charge ( R ch ) radii, the relative distances between 4 He and a valence nucleon ( r c -N ), between valence nucleons ( r NN ), and between the 4 He core and the center of mass of the two valence nucleons ( r c 2 -N ). As regards the charge radius of 6 He(0 + 1 ), the latest experimental value is reported as 2.060(8) fm [40], which is close to our result of 2.01 fm.
As regards the radii of the 0 + 2 states in Table VIII, the imaginary parts of the radii increase to values larger than the real parts for certain neutron-radii related values for 6 He. This indicates that the coupling to the continuum states is larger in the 0 + 2 states of the A = 6 nuclei than in the case of their ground states and also the A = 8 cases. In a manner similar to the case of the A = 8 nuclei, we examine the mirror symmetry of the spatial
It is found that the radii values for 6 Be(0 + 1 ) are mostly real, and therefore we use the real parts to estimate the radius. The matter radius of 6 Be(0 + 1 ) is larger than that of 6 He(0 + 1 ) by 18%, which percentage is larger than the A = 8 (0 + 1 ) case for which the corresponding value is 12%.
TABLE VIII: Various radii of the 0 + 1 2 , states of 6 He and 6 Be in units of fm.
| | 6 He(0 + 1 ) | 6 Be(0 + 1 ) | 6 He(0 + 2 ) 6 | 6 He(0 + 2 ) 6 | 6 He(0 + 2 ) 6 | Be(0 + 2 ) | Be(0 + 2 ) | Be(0 + 2 ) |
|-----------|----------------|----------------|------------------|------------------|------------------|--------------|--------------|--------------|
| R m | 2.37 | 2.80 + 0.17i | 3.94 | + | 4.12i | 2.88 | + | 1.93i |
| R p | 1.82 | 3.13 + 0.20i | 2.24 | + | 1.71i | 3.31 | + | 2.33i |
| R n | 2.6 | 1.96 + 0.08i | 4.57 | + | 4.91i | 1.74 | + | 0.69i |
| R ch | 2.01 | 3.25 + 0.21i | 2.34 | + | 1.63i | 3.39 | + | 1.93i |
| r NN | 4.82 | 6.06 + 0.35i | 9.38 | | +10.97i | 7.4 | + | 5.10i |
| r c - N | 3.96 | 4.90 + 0.40i | 7.46 | + | 8.06i | 5.1 | + | 3.97i |
| r c - 2 N | 3.15 | 3.85 + 0.37i | 5.82 | + | 5.91i | 3.53 | + | 3.07i |
FIG. 3: Real parts of matter, proton, and neutron radii of the ground states (upper panel) and the 0 + 2 states (lower panel) of 6 Be and 6 He in units of fm. Circles with error bars indicate the experimental data of the matter radius of 6 He [3, 41, 42].
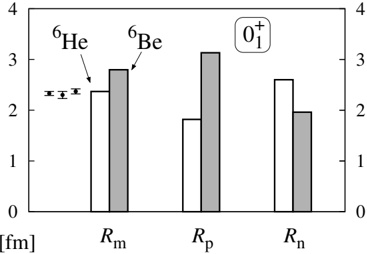
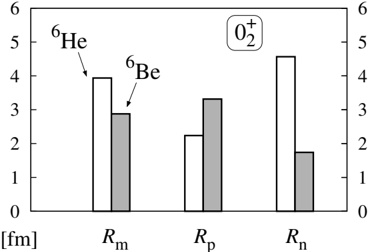
properties of the 0 + 2 state in A = 6 systems by studying the real parts of the various radii. It is found that in the 0 + 2 state, the 6 Be radii values are smaller than the 6 He radii values, which is a common feature observed in the A = 8 systems. We also plot the real parts of the matter, proton, and neutron radii (Fig. 3) to examine the differences in the two nuclei. In the ground state, the proton radius of 6 Be is larger than the neutron radius of 6 He due to the Coulomb repulsion from the two valence protons of 6 Be. In the 0 + 2 state, the proton radius of 6 Be is smaller than the neutron radius of 6 He due to the Coulomb barrier effect in 6 Be. These results are due to a
situation similar to that observed in the case of 8 He and 8 C.
From the analyses of the radius of the 0 + 1 2 , states for A = 6 and 8 nuclei, we conclude that the Coulomb interaction breaks the mirror symmetry as regards the spatial properties of neutron-rich and proton-rich nuclei. This breaking depends on the states; spatial enhancement occurs in the 0 + 1 states due to the Coulomb repulsion, and the shrinkage effect influences the 0 + 2 resonances due to the Coulomb barrier. The latter effect on the radius can also be seen in the 3 α Hoyle state in 12 C, which is located immediately above the 3 α threshold energy (Y. Funaki, private communication). This resonance is affected by the Coulomb barrier of α particles, which stabilizes the Hoyle state with a fairly narrow decay width [43]. There have recently been several interesting results concerning the radii of resonances in terms of both experimental [44] and theoretical aspects [11, 12, 45] An effect similar to the Coulomb interaction on the stabilization of the resonances has also been reported in Ref. [46], in which the s -and p -wave resonances are investigated in the mirror nuclei of 10 Li and 10 N using the core + N model. In 10 Li, the s -wave state exists as a virtual state. On the other hand, the corresponding mirror state in 10 N transforms into a resonant state because of the presence of the Coulomb barrier.
## IV. SUMMARY
In summary, we investigated the spatial properties of the mirror nuclei 8 He- C, and 8 6 He- Be using the 6 4 He + XN ( X =2, 4) cluster model. The boundary condition for resonances is accurately treated using the complex scaling method. We found that the relation of the radii
- [1] I. Tanihata, H. Savajols, and R. Kanungo, Prog. Part. Nucl. Phys. 68 , 215 (2013).
- [2] R. J. Charity et al. , Phys. Rev. C 84 , 014320 (2011).
- [3] I. Tanihata et al. , Phys. Lett. B289 , 261 (1992).
- [4] F. Skaza et al. , Nucl. Phys. A788 , 260c (2007), and references therein.
- [5] M.S. Golovkov et al. , Phys. Lett. B 672 , 22 (2009).
- [6] Y. Suzuki and K. Ikeda, Phys. Rev. C 38 , 410 (1988).
- [7] H. Masui, K. Kat¯ o and K. Ikeda, Phys. Rev. C 73 , 034318 (2006).
- [8] T. Myo, K. Kat¯ and K. Ikeda, o Phys. Rev. C 76 , 054309 (2007).
- [9] T. Myo, R. Ando and K. Kat¯, o Phys. Rev. C 80 , 014315 (2009).
- [10] T. Myo, R. Ando and K. Kat¯ o, Phys. Lett. B 691 , 150 (2010).
- [11] T. Myo, Y. Kikuchi and K. Kat¯ o, Phys. Rev. C 84 , 064306 (2011).
- [12] T. Myo, Y. Kikuchi and K. Kat¯ o, Phys. Rev. C 85 , 034338 (2012).
- [13] T. Myo, Y. Kikuchi, and K. Kat¯ o, Phys. Rev. C 87 ,
between 8 He and 8 C is different in their ground 0 + states and the 0 + 2 states. In the ground states, the Coulomb interaction in 8 Crepulsively enlarges the radius to a value larger than that of 8 He. In the 0 + 2 states, which are five-body resonances in both nuclei, the radius of 8 C is smaller than that of 8 He due to the Coulomb barrier generated from four valence protons with the 4 He core in 8 C. For 8 He there is no Coulomb barrier, which enhances the spatial distribution of the valence neutrons in the resonance. These roles of the Coulomb interaction break the mirror symmetry of the radius in 8 He and 8 C. A similar set of variations in the radius is observed in 6 He and 6 Be.
We also investigated the properties of the configuration mixing of the single-particle states in the 0 + 2 resonances of 8 He and 8 C. For this purpose, we focused on the effect of the spatial extension of valence nucleons on the states. The spatial extension of the valence nucleons plays a role in reducing the strength of the couplings between the configurations in the 0 + 2 resonances. This leads to the dominance of the single ( p 3 / 2 ) 2 ( p 1 / 2 ) 2 configuration in the 0 + 2 resonances of 8 He and 8 C.
## Acknowledgments
This work was supported by a Grant-in-Aid for Young Scientists from the Japan Society for the Promotion of Science (Grant No. 24740175). Numerical calculations were performed on a supercomputer (NEC SX9) at RCNP, Osaka University.
## References
049902 (2013).
- [14] W. Horiuchi, Y. Suzuki and K. Arai, Phys. Rev. C 85 , 054002 (2012).
- [15] J. Aguilar and J. M. Combes, Commun. Math. Phys. 22 , . (1971269.
- [16] E. Balslev and J. M. Combes, Commun. Math. Phys. 22 , 2 (1971)80)
- [17] S. Aoyama, T. Myo, K. Kat¯ and K. Ikeda, o Prog. Theor. Phys. 116 , 1 (2006).
- [18] T. Myo, K. Kat¯, S. Aoyama and K. Ikeda, o Phys. Rev. C 63 , 054313 (2001).
- [19] T. Myo, K. Kat¯ o, H. Toki and K. Ikeda, Phys. Rev. C 76 , 024305 (2007).
- [20] A. T. Kruppa, R. Suzuki and K. Kat¯, o Phys. Rev. C 75 , 044602 (2007).
- [21] Y. Kikuchi, T. Myo, K. Kat¯ and K. Ikeda o Phys. Rev. C 87 , 034606 (2013).
- [22] K. Ogata, T. Myo, T. Furumoto, T. Matsumoto and M. Yahiro, Phys. Rev. C 88 , 024616 (2013).
- [23] F. Kobayashi and Y. Kanada-En'yo, Phys. Rev. C 88 , 034321 (2013).
- [24] H. Kanada, T. Kaneko, S. Nagata and M. Nomoto, Prog. Theor. Phys. 61 , 1327 (1979).
- [25] Y. C. Tang, M. LeMere and D. R. Thompson, Phys. Rep. 47 , 167 (1978).
- [26] T. Myo, H. Toki and K. Ikeda, Prog. Theor. Phys. 121 , 511 (2009).
- [27] T. Myo, A. Umeya, H. Toki and K. Ikeda, Phys. Rev. C 84 , 034315 (2011).
- [28] T. Myo, A. Umeya, H. Toki and K. Ikeda, Phys. Rev. C 86 , 024318 (2012).
- [29] S. Saito, Prog. Theor. Phys. Suppl. 62 , 11 (1977).
- [30] M. Homma, T. Myo and K. Kat¯ o, Prog. Theor. Phys. 97 , 561 (1997).
- [31] T. Berggren, Phys. Lett. B 373 , 1 (1996).
- [32] A. Dot´ e, T. Inoue and T. Myo, Nucl. Phys. A912 , 66 (2013).
- [33] T. Sekihara and T. Hyodo, Phys. Rev. C 87 , 045202 (2013).
- [34] T. Berggren, Nucl. Phys. A109 , 265 (1968).
- [35] T. Myo, A. Ohnishi and K. Kat¯, o Prog. Theor. Phys. 99 , 801 (1998).
- [36] W. J. Romo, Nucl. Phys. A116 , 617 (1968).
- [37] S. Aoyama, S. Mukai, K. Kat¯ o, and K. Ikeda, Prog. Theor. Phys. 93 , 99 (1995).
- [38] K. Hagino and H. Sagawa, Phys. Rev. C 72 , 044321 (2005).
- [39] G. Papadimitriou, A. T. Kruppa, N. Michel, W. Nazarewicz, M. P/suppressoszajczak, l and J. Rotureau, Phys. Rev. C 84 , 051304 (2011).
- [40] M. Brodeur et al. , Phys. Rev. Lett. 108 , 052504 (2012).
- [41] G. D. Alkhazov et al. , Phys. Rev. Lett. 78 , 2313 (1997).
- [42] O. A. Kiselev et al. , Eur. Phys. J. A 25 , Suppl. 1 , 215 (2005).
- [43] T. Yamada and P. Schuck, Phys. Rev. C 69 , 024309 (2004).
- [44] A. N. Danilov, T. L. Belyaeva, A. S. Demyanova, S.A. Goncharov, A. A. Ogloblin, Phys. Rev. C 80 , 054603 (2009).
- [45] Y. Funaki, A. Tohsaki, H. Horiuchi, P. Schuck, G. R¨ oepke, Eur. Phys. J. A24 , 321 (2005).
- [46] S. Aoyama, K. Kat¯, and K. Ikeda, o Phys. Lett. B 414 , 13 (1997). | 10.1093/ptep/ptu112 | [
"Takayuki Myo",
"Kiyoshi Kato"
] | 2014-08-03T05:17:27+00:00 | 2014-08-03T05:17:27+00:00 | [
"nucl-th",
"nucl-ex"
] | Mirror symmetry breaking in He isotopes and their mirror nuclei | We study the mirror symmetry breaking of $^6$He-$^6$Be and $^8$He-$^8$C using
the $^4$He + $X$N ($X$=2, 4) cluster model. The many-body resonances are
treated for the correct boundary condition using the complex scaling method. We
find that the ground state radius of $^8$C is larger than that of $^8$He due to
the Coulomb repulsion in $^8$C. On the other hand, the $0^+_2$ resonances of
the two nuclei exhibit the inverse relation; the $^8$C radius is smaller than
the $^8$He radius. This is due to the Coulomb barrier of the valence protons
around the $^4$He cluster core in $^8$C, which breaks the mirror symmetry of
the radius in the two nuclei. A similar variation in the radius is obtained in
the mirror nuclei, $^6$He and $^6$Be. A very large spatial extension of valence
nucleons is observed in the $0^+_2$ states of $^8$He and $^8$C. This property
is related to the dominance of the $(p_{3/2})^2(p_{1/2})^2$ configuration for
four valence nucleons, which is understood from the reduction in the strength
of the couplings to other configurations by involving the spatially extended
components of valence nucleons. |
1408.0461v3 | ## The standard sign conjecture on algebraic cycles: the case of Shimura varieties
Sophie Morel and Junecue Suh
September 18, 2014
## 1 Introduction
First we recall the standard sign conjecture, its origin, statement and significance.
Let k be a field and fix a Weil cohomology theory H ∗ on the category of smooth projective varieties over k with coefficients in a field F of characteristic zero ( cf. [3] 3.3.1). Denote by M hom ( k ) F the category of homological motives over k associated with H ∗ , and by M num ( k ) F the category of numerical motives over k , both with coefficients in F ( cf. [3] 4.1). The functor H ∗ defines a realization functor from M hom ( k ) F to the category of graded F -vector spaces, that we will denote by H ∗ ( cf. [3] 4.2.5).
The K¨ unneth standard conjecture (cf. [3] 5.1.1) states tha t, for every smooth projective variety X/k , the K¨ unneth projectors p i X onto the direct factor H ( i X ) of H ( ∗ X ) are given by algebraic cycles. In the classical theory of motives (of Grothendieck), one uses it to modify the sign in the commutativity constraints in the ⊗ -structure in order to get the Tannakian category of homological motives.
For classical cohomology theories, the conjecture would be a consequence of the Hodge conjecture over the complex numbers and the Tate conjecture over finitely generated fields. Namely, as noted by Grothendieck (see [25] p.99), the projectors (and any linear combination thereof) clearly are morphisms of Hodge structures and commute with the Galois action, and these cohomology classes make natural test cases for the Hodge and Tate conjectures.
/negationslash
The strongest evidence for the K¨ unneth conjecture is givenby Katz and Messing ([15], Theorem 2): It is true when k is algebraic over a finite field and H ∗ is either the /lscript -adic cohomology for a prime /lscript = char( k ) , or the crystalline cohomology.
For the purpose of modifying the commutativity constraints and getting the Tannakian category, one needs somewhat less, and the necessary weakening is called the standard 'sign' conjecture (terminology proposed by Jannsen; cf. [3] 5.1.3 for the formulation and see [3] 6.1.2.1 for obtaining the Tannakian category):
Conjecture 1.1 For every M ∈ Ob M hom ( k ) F , there exists a decomposition M = M + ⊕ M -such that H ( ∗ M + ) (resp. H ( ∗ M -) ) is concentrated in even (resp. odd) degrees.
Equivalently, for every smooth projective X/k , the sum p + X (resp. p -X ) of the even (resp. odd) K¨ unneth projectors on H ( ∗ X ) is given by an algebraic cycle. Note that such a decomposition is necessarily unique (up to unique isomorphism).
This conjecture has, in addition to the consequences in terms of the category of homological motives and the algebraicity of (Hodge or Tate) cohomology classes, also the following interesting consequence, due to Andr´ e and Kahn. Recall that the numerical and the homological equivalences on algebraic cycles on projective smooth varieties are conjectured to be the same.
Theorem 1.2 ([3] 9.3.3.3) Let M be an additive ⊗ -subcategory of M hom ( k ) F and let M num be its image in M num ( k ) F . If the sign conjecture is true for every object of M , then the functor M -→ M num admits a section compatible with ⊗ , unique up to ⊗ -isomorphism.
Next we turn to the main geometric objects of this paper, Shimura varieties. In this paper, we will take for k a subfield of C , and for H ∗ the cohomology theory that sends a smooth projective variety X over k to the Betti cohomology of X ( C ) with coefficients in number fields F .
Let ( G , X , h ) be pure Shimura data (cf [11] 2.1.1 or [22] 3.1), E ⊂ C the reflex field and K a neat open compact subgroup of G ( A f ) . Denote by S K the Shimura variety at level K associated to ( G , X , h ) ; it is a smooth quasi-projective variety over E . Assume that E ⊂ k . If S K is projective, denote by M S ( K ) the image of S K in M hom ( k ) Q .
For a general connected reductive group G over Q , we say that G satisfies condition (C), if
- (i) Arthur's conjectures (cf section 3) are known for G ,
- (ii) the cohomological Arthur parameters for G satisfy a certain condition that will be spelled out at the end of section 3 (roughly, that what happens at the finite places determines the parameter) and
- (iii) the classification of cohomological representations of G ( R ) giv en by Adams and Johnson in [1] agrees with the classification given by Arthur's conjectures.
Given the current state of knowledge of (C) (see below), we will also consider a weaker condition. We say that G satisfies condition (C´), if there exists a Q -algebraic subgroup G ′ of G which contains the derived group G der and satisfies (C).
The goal of this paper is to prove the following theorem :
Theorem 1.3 Let ( G , X , h ) be simple PEL Shimura data. Assume that G is anisotropic over Q modulo its center (so that S K is projective and smooth) and that it satisfies condition (C´).
Then M S ( K ) ∈ M hom ( k ) Q satisfies the sign conjecture.
If G is not anisotropic modulo its center, then S K is not projective, so we can not talk about its homological motive. A possible generalization is the motive representing the intersection cohomology of the minimal compactification of S K . Such a motive is not known to exist for general varieties (though we certainly expect that it does), but in the case of minimal compactifications of Shimura varieties it has been constructed by Wildeshaus, even in the category of Chow motives over E (cf [27] Theorems 0.1 and 0.2). We then have the following generalization of the previous theorem :
Theorem 1.4 Let ( G , X , h ) be simple PEL Shimura data, and assume that G satisfies condition (C´). Denote by IM S ( K ) the 'intersection motive' of the minimal compactification of S K .
Then IM S ( K ) satisfies the sign conjecture.
We actually have versions of these two theorems for motives with coefficients in smooth motives (whose Betti realizations are automorphic local systems), see Theorem 2.3.
We will deduce Theorems 1.3 and 1.4 from another result that we need some more notation to state. Let G be a connected reductive group over Q , A G the maximal Q -split torus in the center of G , K ∞ a maximal compact subgroup of G ( R ) , K ′ ∞ = A ( G R ) ◦ K ∞ , and X = G ( R ) / K ′ ∞ . We assume that X is a Hermitian symmetric domain; this is satisfied by the group G in any Shimura data, and also by any subgroup thereof as in condition (C´).
With the notation and under this assumption, the double coset space
$$S ^ { K } = G ( \mathbb { Q } ) \, \wedge \, ( \mathcal { X } \times G ( \mathbb { A } _ { f } ) / K )$$
still makes sense for open compact subgroups K of G ( A f ) , and is a finite disjoint union of quotients of Hermitian symmetric domains by arithmetic subgroups of G ( Q ) . In particular, it is a disjoint union of locally symmetric Riemannian manifolds if K is neat. Moreover, by a theorem of Baily and Borel (cf [7] Theorem 10.11), S K is a quasi-projective complex algebraic variety, smooth if K is neat.
Let H K = C ∞ c (K \ G ( A f ) / K , Q ) be the algebra of functions K \ G ( A f ) / K -→ Q that are locally constant and have compact support, with multiplication given by the convolution product.
Let j : S K -→ S K be the embedding of S K in its minimal compactification. Let W be an irreducible algebraic representation of G defined over a field F , and denote by F W the associated F -local system on S K (cf [18], p 113). Let d be the dimension of S K (as an algebraic variety). The intersection complex of S K with coefficients in F W (or W ) is the complex
$$\text{IC} _ { W } ^ { \text{K} } \coloneqq ( j _ {! * } ( \mathcal { F } _ { W } [ d ] ) ) [ - d ].$$
The intersection cohomology of S K with coefficients in F W (or W ) is
$$I H ^ { * } ( S ^ { K }, W ) \coloneqq H ^ { * } ( \overline { S } ^ { K }, I C _ { W } ^ { K } ).$$
It admits an F -linear action of H K ⊗ Q F (cf [18] p 122-123).
We write
$$I H ^ { i } ( S ^ { K }, W ) \otimes _ { F } \mathbb { C } = \bigoplus _ { \pi _ { f } } \pi _ { f } ^ { K } \otimes \sigma ^ { i } ( \pi _ { f } ),$$
where the sum is over all irreducible admissible representations π f of G ( A f ) , π K f is the space of K -invariant vectors in π f (a representation of H K ⊗ C ) and the σ i ( π f ) are finite-dimensional C -vector spaces. Then :
Theorem 1.5 Assume that G satisfies (C) and let π f be as above. Then, either σ i ( π f ) = 0 for every i even, or σ i ( π f ) = 0 for every i odd.
/negationslash
Remark 1.6 In general, for π f fixed, there can be several degrees i with σ i ( π f ) = 0 (as is clear on the formula for IH i in section 4). Hence the methods of this paper cannot be used to prove the full K¨ unneth conjecture.
This is also clear from the fact that the Lefschetz operator on IH ∗ commutes with the action of the Hecke operators. Note that the action of C × on the IH i that gives the pure Hodge structure (whose existence follows from M. Saito's theory of mixed Hodge modules) also commutes with the action of the Hecke operators (and with the Lefschetz operator). See page 8 of Arthur's review paper [5] for a more precise version of these two statements.
Here is the present state of knowledge about condition (C) :
- (i) Arthur's conjectures (with substitute parameters) are known for split symplectic and quasisplit special orthogonal groups, by the book [6] of Arthur, modulo the stabilization of the twisted trace formula and a local theorem at the archimedean place (see the end of the introduction of [6]). They are also known for quasi-split unitary groups by work of Mok ([21]) and for their inner forms by work of Kaletha-Minguez-Shin-White ([14]), modulo the same hypotheses. Finally, still assuming the same hypotheses, the conjectures are known for tempered representations of split general symplectic and quasi-split general orthogonal groups, by work of Bin Xu ([28]). 1
- (ii) This condition, in the cases where Arthur's conjectures are (almost) known, follows easily from strong multiplicity one for the groups GL n .
- (iii) The agreement of the classifications of Arthur and Adams-Johnson for cohomological representations of G ( R ) is still open, though it should be accessible.
1 Note that we only need condition (C') for theorem 1.4, so Arthur's results already allow us to get theorem 1.4 for the Shimura varieties of split general symplectic groups.
Remark 1.7 In the case of even special orthogonal groups, Arthur's methods don't allow to distinguish between a representation and its conjugate under the orthogonal group. This doesn't affect the methods of this paper and thus is not a problem for us, see the end of section 4.
In the final section, we discuss the possibility of using finite correspondences to attack the standard K¨ unneth (or sign) conjecture for general project ive smooth varieties.
Acknowledgments We thank Pierre Deligne for helpful discussions, especially regarding the material on finite correspondences in the final section. We also thank Colette Moeglin for pointing out some misconceptions about Arthur's conjectures in a previous version of this article.
## 2 Reduction to Theorem 1.5
First, we review the motivic constructions of coefficient systems and intersection motives, by Ancona and Wildeshaus. This will allow us to state Theorem 2.3 with coefficients, which, together with Theorem 1.5, implies both 1.3 and 1.4. We then make certain reduction steps necessary for passing from PEL Shimura varieties to the associated connected Shimura varieties. Finally we prove Theorem 2.3, modulo Theorem 1.5.
## 2.1 Review of motivic constructions
Let F be a number field and let W be a finite dimensional algebraic representation of G F .
One applies Th´ eor` eme 4.7 and Remarque 4.8 of [2] to get a Chow motive ˜( µ W ) over S K , whose Betti realization over S K ( C ) is the local system corresponding to W . By construction, it is a direct sum of Tate twists of direct summands in the motives
$$\pi _ { * } ^ { ( r ) } { \mathbf 1 } _ { A ^ { r } }$$
where r ≥ 0 and π ( r ) : A r -→ S K is the r th power of the Kuga-Sato abelian scheme.
Then one applies 2 the main result of [27] (Theorems 0.1 and 0.2 and Corollary 0.3) to obtain the intermediate extension j ! ∗ ˜( µ W ) on the minimal compactification S K , whose Betti realization is naturally isomorphic to the intersection complex.
Finally, by taking the direct image of j ! ∗ ˜( µ W ) under the structure morphism m : S K -→ Spec k , one gets the intersection motive IM S ( K , W ) whose Betti realization is
2 Wildeshaus' construction requires a condition, which he names (+) and is the same as (3.1.5) in [22], on the central torus in the Shimura data. It is satisfied by any PEL Shimura data: See for instance the analysis of the maximal torus quotient of G in § 7 of [17].
canonically isomorphic to the intersection cohomology IH ( ∗ S K ( C ) , W ) . 3
Also constructed in [27] (Theorem 0.5) is an endomorphism KgK of IM S ( K , W ) , for each double coset KgK ∈ K \ G ( A f ) / K , whose Betti realization coincides with the usual action of the Hecke operator for the coset on the intersection cohomology. The construction uses the compatibility of the motivic middle extension and the 'change of level' maps [ h · ] ∗ , see Theorem 0.4 of [27].
To avoid possible confusion, we will use the notation ˜ KgK for the endomorphisms of IM S ( K , W ) . 4
## 2.2 Sign conjecture with coefficients
Now we are ready to state a version with coefficients.
Let W be an irreducible algebraic representation of G over a number field F . We denote by IH + (resp. IH -) the direct sum of IH ( i S K ( C ) , W ) for i even (resp. odd), and denote by p + W = p + W,F (resp. p -W = p -W,F ) the corresponding projector on IH ( ∗ S K ( C ) , W ) .
Theorem 2.3 Assume that the group G in the simple PEL data satisfies condition (C´), so that there exists a subgroup G ′ which contains G der and satisfies condition (C).
Then there exists an endomorphism ˜ p + W (resp. ˜ p -W ) of the image of IM S ( K , W ) in M hom ( k ) F whose Betti realization is p + W (resp. p -W ). It follows that the image of IM S ( K , W ) in M hom ( k ) F admits a decomposition
$$I M ( S ^ { K }, W ) _ { h o m } = I M ( S ^ { K }, W ) _ { h o m } ^ { + } \oplus I M ( S ^ { K }, W ) _ { h o m } ^ { - }$$
such that H ( ∗ IM S ( K , W ) + hom ) = IH + and H ( ∗ IM S ( K , W ) -hom ) = IH -are concentrated in even and odd degrees, respectively.
## 2.4 Reduction steps
Change of base field : First, we reduce to the case where k = C . For this, note that the vector spaces of algebraic correspondences modulo an adequate equivalence that is coarser than the algebraic equivalence (in particular the homological equivalence) are invariant under the change of ground field from ¯ k to C . Then use the fact that the even and odd projectors are invariant under the action of Gal( ¯ k/k ) .
3 Strictly speaking, Wildeshaus' construction works only for direct factors N of π ( r ) ∗ 1 A r . Given a Tate twist N m ( ) , one takes the m th Tate twist of IM S ( K , N ) , which has Betti realization IH ( ∗ S K ( C ) , N ( m )) .
4 Wildeshaus does not construct an action of the Hecke algebra on IM S ( K , W ) . One expects, but does not know at the moment, that there is a canonical choice of ˜ KgK .
Connected components : As the minimal compactification S K is normal by construction, its connected components and irreducible components coincide. Thus the even projector for S K is the sum of the even projectors for the connected components, and the sign conjecture is true for S K and W iff it is true for each of its connected components.
Raising the level : Finally, we may pass from a neat level subgroup K to any level subgroup K ′ ⊂ K . It suffices to show that IM S ( K , W ) is a direct factor of IM S ( K ′ , W ) in M hom ( C ) F . Take a connected component X of S K , with X = X ∩ S K . The change of level map f := [1 ] · : S K ′ -→ S K is a finite etale surjection that extends to a finite surjection ´ f : S K ′ -→ S K . Let Y be the inverse image f -1 ( X ) and Y := Y ∩ S K ′ = f -1 ( X ) .
Over X we have the adjunction map for direct image and the trace map:
$$\text{adj} _ { f } \colon \mathcal { F } _ { W } \longrightarrow f _ { * } \mathcal { F } _ { W } \text{ and } \text{ Tr} _ { f } \colon f _ { * } \mathcal { F } _ { W } \longrightarrow \mathcal { F } _ { W }.$$
Since f is finite, these maps extend to
$$\overline { \text{adj} _ { f } } \colon j _ {! * } \mathcal { F } _ { W } \longrightarrow \overline { f } _ { * } ( j _ {! * } \mathcal { F } _ { W } ) \text{ and } \overline { \text{Tr} _ { f } } \colon \overline { f } _ { * } ( j _ {! * } \mathcal { F } _ { W } ) \longrightarrow j _ {! * } \mathcal { F } _ { W }$$
(here j ! ∗ F W means j ! ∗ ( F W [dim X ])[ -dim X ] ). In Betti cohomology, these maps give rise to
/d47
$$I H ^ { i } ( S ^ { K }, W ) \overset { \text{adj} } { \longrightarrow } I H ^ { i } ( S ^ { K ^ { \prime } }, W ) \overset { \text{Tr} } { \longrightarrow } I H ^ { i } ( S ^ { K }, W )$$
/d47
/d47
/d47
Lemma 2.4.1 The composite map is equal to multiplication by deg( f ) .
Proof. We may replace Y (hence Y ) with any connected component, denoting the restriction of f (also f ) by the same letter. It suffices to show that
$$\overline { \text{Tr} _ { f } } \circ \overline { \text{adj} _ { f } } = \deg ( f ) \ \text{ on } j _ {! * } \mathcal { F } _ { W }.$$
By construction F = F W is a semisimple local system, and we may replace it with a direct summand and assume it is irreducible. Then j ! ∗ F is a simple perverse sheaf ( cf. Th´ eor`me e 4.3.1(ii) of [8]), and it suffices to show the equality over the dense open subset X . This last follows from Th´ eor`me 2.9 (Var 4) (I), expos´ XVIII, SGA4 . e e /square
As we have recalled, Wildeshaus constructs [1 ] · ∗ between intersection motives; see also the construction leading up to Corollary 8.8 in [27]. Thus IM S ( K , F W ) is a direct factor of IM S ( K ′ , F W ) , modulo homological equivalence.
## 2.5 Proof of Theorem 2.3 modulo Theorem 1.5
By the previous reduction steps, we may pass to the connected Shimura varieties, see 2.1.2, 2.1.7 and 2.1.8 in [11]: The projective system of connected locally symmetric varieties depend
only on the triple ( G ad , G der , X + ) . The motivic constructions of the coefficient systems and the intersection cohomology can be therefore transferred to the connected locally symmetric varieties attached to the subgroup G ′ , for all small enough level subgroups.
## Lemma 2.6 If Theorem 1.5 is true for W , then there exist elements
$$h _ { W, F } ^ { \pm } \in \mathcal { H } _ { \mathbf K } \otimes _ { \mathbb { Q } } F$$
which act as p ± W on IH ( ∗ S K ( C ) , W ) .
Proof of Lemma. First we prove the statement over the field of coefficients F ′ = C . Let Σ be the finite set consisting of the irreducible admissible representations π f that have nonzero contribution to the right hand side of (1) for some i . Then as representations of the Hecke algebra H K ⊗ Q C , ( π K f ) π f ∈ Σ are irreducible and pairwise inequivalent. By Jacobson's density theorem, for each π f ∈ Σ there exists an element h π f ∈ H K ⊗ Q C that acts as 1 on π K f and as 0 on π ′ K f for every other π ′ f in Σ .
By Theorem 1.5, Σ is the disjoint union of two subsets Σ ± , consisting of those π f ∈ Σ that have contribution in even or odd degrees, respectively. Therefore
$$\lambda _ { \mathbb { M } ^ { \pm } _ { W, \mathbb { C } } } = \sum _ { \pi _ { f } \in \Sigma ^ { \pm } } h _ { \pi _ { f } } \in \mathcal { H } _ { \mathbb { K } } \otimes _ { \mathbb { Q } } \mathbb { C }$$
acts as p ± W, C = p ± W,F ⊗ F 1 C .
To conclude the proof, use the fact: If f : H -→ E is an F -linear map of F -vector spaces and F ′ is an extension field of F , then an element p ∈ E lies in the image of f iff p ⊗ 1 F ′ is in the image of f ⊗ F 1 F ′ . /square
Now Theorem 2.3 follows easily from the lemma: Writing
$$\dot { h } _ { W, F } ^ { \pm } = \sum _ { g \in K \overline { \text{G} } ( \mathbb { A } _ { f } ) / K } c _ { g } ^ { \pm } \, [ 1 _ { K g K } ], \ \ c _ { g } ^ { \pm } \in F$$
the endomorphism of IM S ( K , W ) in M rat ( C ) F and also its image in M hom ( C ) F
$$\tilde { p } _ { W } ^ { \pm } \coloneqq \sum c _ { g } ^ { \pm } \widetilde { K g K }$$
has Betti realization p ± W .
In the case W is the trivial representation defined over Q , we get Theorems 1.3 and 1.4.
Remark 2.7 We have focused on PEL Shimura varieties, in order to apply the known constructions. However, the deduction via Lemma 2.6 of the sign conjecture from Theorem 1.5 is valid for more general varieties.
First, for the trivial coefficient system, the motivic construction of coefficient systems is unnecessary, and we do not need to restrict to PEL types.
Then for compact Shimura varieties (that is, in case the group is anisotropic over Q modulo center), we do not need Wildeshaus' construction of intersection motives, and the Shimura data do not need to satisfy his condition (+) on its central torus.
Over the complex numbers (or even over Q , see [12]), the sign conjecture can be verified for the locally symmetric varieties considered in Theorem 1.5. Through the work of Shimura, Deligne, Milne, and others we have a complete theory of canonical models of Shimura varieties over reflex fields, and the sign conjecture holds for these models.
Finally, if we know the sign conjecture for the varieties attached to a Q -anisotropic semisimple group G , we also know it for the varieties attached to any isogenous quotient group of G . For any variety of the latter kind admits a finite ´tale covering from a variety of the former kind, and e we can apply an argument similar to the one in 2.4.
Of course, Theorem 1.5 is essential in all these generalizations.
## 3 Arthur's conjectures
Wefollow the presentation of Kottwitz in section 8 of [16]. As before, G is a connected reductive group over Q .
Let ξ : A ( G R ) ◦ -→ C × be a character of A ( G R ) ◦ . Let L 2 G be the space of functions f : G ( Q ) \ G ( A ) -→ C such that :
- · f ( zg ) = ξ ( z f ) ( g ) ∀ z ∈ A ( G R ) ◦ , g ∈ G ( A ) ;
- · f is square-integrable modulo A ( G R ) ◦ .
(Cf. the beginning of section 2 of [4].)
Then G ( A ) acts on L 2 G by right multiplication on the argument of the function. We say that an irreducible representation π of G ( A ) is discrete automorphic if it appears as a direct summand in the representation L 2 G . In that case, we write m π ( ) for the multiplicity of π in L 2 G ; it is known to be finite. We denote by Π disc ( G ) the set of equivalence classes of discrete automorphic representations of G ( A ) and by L 2 G ,disc the discrete part of L 2 G (ie the completed direct sum of the isotypical components of the π ∈ Π disc ( G ) ).
Arthur conjectured that
$$L _ { \text{G}, d i s c } ^ { 2 } \simeq \bigoplus _ { \psi } \bigoplus _ { \Pi _ { \psi } } m ( \psi, \pi ) \pi,$$
where the ψ are equivalence classes of global Arthur parameters, the Π ψ are sets of (isomorphism classes of) smooth admissible representations of G ( A ) called Arthur packets and m ψ,π ( ) are
nonnegative integers that we will define later. Note that we are not saying that the representations π are irreducible. (They are not in general.)
The traditional statement of Arthur's conjectures involves the conjectural Langlands group L Q of Q , and Arthur parameters are morphisms L Q × SL 2 ( C ) -→ L G , where L G = ̂ G /multicloseright W Q is the Langlands dual group of G . In some cases, it is possible to use instead substitute parameters defined in terms of cuspidal automorphic representations of general linear groups. This is the point of view that is taken in the proofs of Arthur's conjectures by Arthur for symplectic and orthogonal groups (cf [6]) and by Mok in the case of quasi-split unitary groups (cf [21]). In any case, a global Arthur parameter ψ gives rise to :
- · a character ξ ψ : A ( G R ) ◦ -→ C × ;
- · a reductive subgroup S ψ of ̂ G such that S ◦ ψ ⊂ Z ( ̂ G ) Γ ⊂ S ψ , where Γ = Gal( Q Q / ) ;
In the sum above, we only take the parameters ψ such that ξ ψ = ξ .
- · a character ε ψ of the finite group S ψ := S /Z ψ ( ̂ G ) Γ S ◦ ψ with values in {± } 1 .
↦
Part of Arthur's conjectures is that there should be a map π 0 -→ 〈 ., π 0 〉 from the set of isomorphism classes of irreducible constituents of elements of Π ψ to ̂ S ψ , such that 〈 ., π 0 〉 = 〈 ., π 1 〉 if π 0 and π 1 are two irreducible constituents of the same π ∈ Π ψ , and that the multiplicity m ψ,π ( ) is given by the following formula :
$$\psi _ { m } ( \psi, \pi ) = m ( \psi, \pi ^ { 0 } ) \coloneqq | \mathfrak { S } _ { \psi } | ^ { - 1 } \sum _ { x \in \mathfrak { S } _ { \psi } } \varepsilon _ { \psi } ( x ) \langle x, \pi ^ { 0 } \rangle,$$
if π 0 is an irreducible constituent of π .
We can now state part (ii) of condition (C). It says that, for every irreducible admissible representation π f of G ( A f ) , there is at most one Arthur parameter ψ such that π f is the finite part of an irreducible constituent of an element of Π ψ .
There are also local versions of Arthur's conjectures involving local Arthur parameters and local Arthur packets. We will not give details here (see for example chapter I of Arthur's book [6]).
## 4 Proof of Theorem 1.5
We use the notation of Theorem 1.5 and of section 3, and we take for ξ : A ( G R ) ◦ -→ C × the inverse of the character by which A ( G R ) ◦ acts on W ( R ) .
If π is an irreducible representation of G ( A ) , we can write π = π f ⊗ π ∞ , where π f (resp. π ∞ ) is an irreducible representation of G ( A f ) (resp. G ( R ) ).
Let g be the complexified Lie algebra of G ( R ) . If π ∞ is an irreducible representation of G ( R ) ,
we write H ( ∗ g , K ; ′ ∞ π ∞ ⊗ W ) for the ( g , K ) ′ ∞ -cohomology of the space of K ′ ∞ -finite vectors in π ∞ ⊗ W (cf chapter I of [10]).
It follows from Zucker's conjecture (a theorem of Looijenga ([20]), Saper-Stern ([24]) and Looijenga-Rapoport([19])) and from Matsushima's formula (proved by Matsushima for S K compact and by Borel and Casselman in the general case, cf Theorem 4.5 of [9]) that there is a H K ⊗ C -equivariant isomorphism, for every k ∈ Z ,
$$\cdot \quad \begin{array} { c } \cdot \\ \quad \text{IH} ^ { k } ( S ^ { K }, W ) \simeq \bigoplus _ { \pi \in \Pi _ { d i s c } ( \mathbf G ) } \pi _ { f } ^ { K } \otimes \mathbf H ^ { k } ( \mathfrak g, K _ { \infty } ^ { \prime } ; \pi _ { \infty } \otimes W ) ^ { m ( \pi ) } \end{array}$$
(see also (2.2) of Arthur's article [4]).
If π f is an irreducible representation of G ( A f ) , let Π ∞ ( π f ) be the set of equivalence classes of irreducible representations π ∞ of G ( R ) such that π := π f ⊗ π ∞ ∈ Π disc ( G ) . Then, for every irreducible admissible representation π f of G ( A f ) and every k ∈ Z ,
$$\dot { \ } \dim \sigma ^ { k } ( \pi _ { f } ) = \sum _ { \pi _ { \infty } \in \Pi _ { \infty } ( \pi _ { f } ) } m ( \pi _ { f } \otimes \pi _ { \infty } ) \dim H ^ { k } ( \mathfrak { g }, K ^ { \prime } _ { \infty } ; \pi _ { \infty } \otimes W ).$$
/negationslash
Vogan and Zuckerman have classified all the admissible representations π ∞ of G ( R ) such that H ( ∗ g , K ; ′ ∞ π ∞ ⊗ W ) = 0 in [26], and Adams and Johnson have constructed local Arthur packets for these representations in [1]. (It is part of our assumptions that their construction is compatible with the local and global Arthur conjectures of section 3.) We will follow Kottwitz's exposition of their results in section 9 of [16].
Let θ be the Cartan involution of G ( R ) that is the identity on K ∞ . For every real reductive group H , let q H ( ) = 1 2 dim( H/K H ) , where K H is a maximal compact-modulo-center subgroup of H .
/negationslash
/negationslash
Fix π f such that Π ∞ ( π f ) = ∅ . By part (ii) of condition (C), π f determines a global Arthur parameter ψ , and we write ψ ∞ for the local Arthur parameter of G R defined by ψ . The set Π ∞ ( π f ) is a subset of the local Arthur packet associated to ψ ∞ . If π ∞ ∈ Π ∞ ( π f ) and π = π f ⊗ π ∞ , then the character 〈 ., π 〉 of S ψ factors as 〈 ., π f 〉〈 ., π ∞ 〉 , where both factors are characters of S ψ , and the first (resp. second) factor depends only on π f (resp. π ∞ ). By the multiplicity formula in section 3, the fact that m π ( ) = m ψ,π ( ) = 0 means that the character 〈 ., π ∞ 〉 of S ψ is uniquely determined by π f . 5
Let π ∞ ∈ Π ∞ ( π f ) . Then there is a relevant pair ( L, Q ) such that π ∞ comes by cohomological induction from a 1-dimensional representation of L , cf pages 194-195 of [16]. Here Q is a parabolic subgroup of G C and L is a Levi component of Q that is defined over R . By proposition 6.19 of [26], π ∞ ⊗ W can only have ( g , K ) ′ ∞ -cohomology in degrees belonging to R +2 N , with
5 〈 , .π ∞ 〉 is actually a character of the bigger group S ψ ∞ , but its values on S ψ ∞ are not determined by π f , otherwise Π ∞ ( π f ) would be a singleton, and this is not the case in general (cf case 3 on page 90 of Rogawski's paper [23] for a counterexample if G = GU (2 , 1) ).
R = dim ( C u ∩ p ) , where u is the Lie algebra of the unipotent radical of Q and p is the -1 -eigenspace for θ acting on g . Let l be the (complex) Lie algebra of L . As l and u are invariant under θ (by construction of L and Q ), we see easily that
$$\dim _ { \mathbb { C } } ( \mathfrak { p } ) = 2 R + \dim _ { \mathbb { C } } ( \mathfrak { l } \cap \mathfrak { p } ),$$
hence R = ( q G R ) -q L ( ) . So the parity of R is determined by the parity of q L ( ) .
Now lemma 9.1 of [16] says that
$$( - 1 ) ^ { q ( L ) } = \langle \lambda _ { \pi _ { \infty } }, s _ { \psi } \rangle,$$
where s ψ ∈ S ψ is determined by the global parameter ψ (if we see global parameters as morphisms ψ : L Q × SL 2 ( C ) -→ L G , then s ψ is the image by ψ of the nontrivial central element of SL 2 ( C ) ) and λ π ∞ is the character of S ψ ∞ ⊃ S ψ defined on page 195 of [16]. But lemma 9.2 of [16] implies that the product λ π ∞ 〈 ., π ∞ 〉 is independent of π ∞ in the Arthur packet of ψ ∞ , so the restriction of λ π ∞ to S ψ depends only on π f . This implies that the parity of R depends only on π f , which gives Theorem 1.5.
We have to be a bit careful if G is a quasi-split even special orthogonal group, because in that case Arthur proved his conjectures only up to conjugacy by the quasi-split even orthogonal group G ′ ⊃ G . But, if π ∞ is a representation of G ( R ) with nonzero ( g , K ) ′ ∞ -cohomology, then the integer R associated to π ∞ as above does not change if we replace π ∞ by a G ′ ( R ) -conjugate (because the relevant pair ( L, Q ) is just replaced by a G ′ ( R ) -conjugate). So the proof above still applies.
## 5 K¨ unneth conjecture and finite correspondences
From the proofs of the theorem of Katz and Messing and that of ours, one may wonder if the K¨ unneth conjecture or the sign conjecture can be proved for more general projective smooth varieties, only using finite correspondences. More precisely, consider the Q -subspace
$$Z _ { \text{fin}, \text{H} ^ { * } } ^ { d } \subseteq \text{H} ^ { 2 d } ( X \times _ { k } X ) ( d )$$
spanned by the cohomology classes of all the cycles of codimension d on X × k X , that are finite in both projections to X (where d = dim X ).
Conjecture 5.1 For every projective smooth variety X/k and every i ∈ Z , the K¨nneth projector u π i X (resp. the projector π + X ) belongs to Z d fin H , ∗ .
This is a priori stronger than the K¨nneth (resp. the sign) c onjecture. It turns out that the apparent u strength is only illusory, if either (a) k is algebraically closed or (b) k is perfect and H ∗ is a classical Weil cohomology theory. The case (a) is a consequence of the following proposition.
Proposition 5.2 Suppose that k is an algebraically closed field. Then the abelian group
$$Z _ { \text{fin}, \sim _ { \text{rat} } } ^ { d } \subseteq Z _ { \sim _ { \text{rat} } } ^ { d }$$
generated by the cycles mapping finitely to X in both projections, in the group of codimension d cycles on X modulo rational equivalence, is in fact equal to the whole Z d ∼ rat .
Proof. It is enough to prove that any irreducible closed subscheme of codimension d on X × k X is rationally equivalent to a cycle that is finite in both projections. Because a proper quasi-finite map is finite, it is the matter of finding a cycle in the rational equivalence class, that meets all the closed fibres over k -rational points in both projections properly, that is, in dimension at most zero. This follows from the generalized moving lemma [13] of Friedlander and Lawson: In any fixed projective embedding, all the fibres of the first (resp. second) projection have the same degree, as they are all algebraically equivalent. /square
Now, in the case (b), let k be a perfect field, and suppose that Z is an algebraic cycle of codimension d on X × k X . If H ∗ is a classical Weil cohomology theory, then we have a corresponding cohomology theory H ∗ /k ′ for every algebraic extension k ′ of k , compatible with the cycle class maps in an obvious sense.
Let k be an algebraic closure of k . By Proposition 5.2, Z ⊗ k k is rationally - hence homologically - equivalent to a cycle Z ′ which is finite over X ⊗ k k in both projections. Let k ′ be a finite Galois extension of k over which Z ′ is defined. Taking the 'average' of the Gal( k /k ′ ) -translates of Z ′ (which requires Q -coefficients), one gets a cycle Z ′ 0 on X , defined over k , that is finite in both projections and has the same cohomology class as Z .
This means that, in the two cases, if the K¨nneth conjectureis true for u X/k , then each π i X is in fact a linear combination of the cohomology classes of finite correspondences over X . Finding enough such finite correspondences for general X/k (which can be turned into the problem of finding certain finite extensions of the function field k X ( ) ) seems to be an interesting open problem.
## References
- [1] Jeffrey Adams and Joseph F. Johnson. Endoscopic groups and packets of nontempered representations. Compositio Math. , 64(3):271-309, 1987.
- [2] Giuseppe Ancona. D´ ecomposition du motif d'un sch´ ema a b´lien universel. e Ph.D. thesis , 2013.
- [3] Yves Andr´ e. Une introduction aux motifs (motifs purs, motifs mixtes, p´ eriodes) , volume 17 of Panoramas et Synth` eses [Panoramas and Syntheses] . Soci´ et´ e Math´ ematique de France, Paris, 2004.
| [4] | James Arthur. The L 2 -Lefschetz numbers of Hecke operators. Invent. Math. , 97(2):257- 290, 1989. |
|-------|------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------|
| [5] | James Arthur. L 2 -cohomology and automorphic representations. In Canadian Mathemati- cal Society. 1945-1995, Vol. 3 , pages 1-17. Canadian Math. Soc., Ottawa, ON, 1996. |
| [6] | James Arthur. The endoscopic classification of representations.Orthogonal and symplectic groups , volume 61 of American Mathematical Society Colloquium Publications . American Mathematical Society, Providence, RI, 2013. |
| [7] | W. L. Baily, Jr. and A. Borel. Compactification of arithmetic quotients of bounded sym- metric domains. Ann. of Math. (2) , 84:442-528, 1966. |
| [8] | A. A. Be˘linson, ı J. Bernstein, and P. Deligne. Faisceaux pervers. In Analysis and topology on singular spaces, I (Luminy, 1981) , volume 100 of Ast´ erisque , pages 5-171. Soc. Math. France, Paris, 1982. |
| [9] | A. Borel and W. Casselman. L 2 -cohomology of locally symmetric manifolds of finite vol- ume. Duke Math. J. , 50(3):625-647, 1983. |
| [10] | A. Borel and N. Wallach. Continuous cohomology, discrete subgroups, and representa- tions of reductive groups , volume 67 of Mathematical Surveys and Monographs . American Mathematical Society, Providence, RI, second edition, 2000. |
| [11] | Pierre Deligne. Vari´t´s e e de Shimura: interpr´tati e on modulaire, et techniques de construc- tion de mod`les e canoniques. In Automorphic forms, representations and L -functions (Proc. Sympos. Pure Math., Oregon State Univ., Corvallis, Ore., 1977), Part 2 , Proc. Sympos. Pure Math., XXXIII, pages 247-289. Amer. Math. Soc., Providence, R.I., 1979. |
| [12] | G. Faltings. Arithmetic varieties and rigidity. In Seminar on number theory, Paris 1982- 83 (Paris, 1982/1983) , Progress in Mathematics, pages 63-77. Birkh¨user a Boston , Boston, MA, 1984. |
| [13] | E. Friedlander and H. Lawson. Moving algebraic cycles of bounded degree. Invent. Math. 132(1):91-119, 1998. |
| [14] | Tasho Kaletha, Alberto Minguez, Sug Woo Shin, and Paul-James White. Endoscopic clas- sification of representations : inner forms of unitary groups. http://arxiv.org/abs/1409.3731, 2014. |
| [15] | Nicholas M. Katz and William Messing. Some consequences of the Riemann hypothesis for varieties over finite fields. Invent. Math. , 23:73-77, 1974. |
| [16] | Robert E. Kottwitz. Shimura varieties and λ -adic representations. In Automorphic forms, Shimura varieties, and L -functions, Vol. I (Ann Arbor, MI, 1988) , volume 10 of Perspect. Math. , pages 161-209. Academic Press, Boston, MA, 1990. |
| [17] | Robert E. Kottwitz. Points on some Shimura varieties over finite fields. J. Amer. Math. Soc. , 5(2):373-444, 1992. |
| [18] | Robert E. Kottwitz and Michael Rapoport. Contribution of the points at the boundary. In The zeta functions of Picard modular surfaces , pages 111-150. Univ. Montr´al, e Montreal, QC, 1992. |
|--------|-------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------|
| [19] | E. Looijenga and M. Rapoport. Weights in the local cohomology of a Baily-Borel compact- ification. In Complex geometry and Lie theory (Sundance, UT, 1989) , volume 53 of Proc. Sympos. Pure Math. , pages 223-260. Amer. Math. Soc., Providence, RI, 1991. |
| [20] | Eduard Looijenga. L 2 -cohomology of locally symmetric varieties. Compositio Math. , 67(1):3-20, 1988. |
| [21] | Chung Pang Mok. Endoscopic classification of representations of quasi-split unitary groups. http://arxiv.org/pdf/1206.0882v3, 2013. |
| [22] | Richard Pink. On l -adic sheaves on Shimura varieties and their higher direct images in the Baily-Borel compactification. Math. Ann. , 292(2):197-240, 1992. |
| [23] | Jonathan D. Rogawski. Analytic expression for the number of points mod p . In The zeta functions of Picard modular surfaces , pages 65-109. Univ. Montr´al, e Montreal, QC, 1992. |
| [24] | Leslie Saper and Mark Stern. L 2 -cohomology of arithmetic varieties. Ann. of Math. (2) , 132(1):1-69, 1990. |
| [25] | John T. Tate, Jr. Algebraic cycles and poles of zeta functions. In Arithmetical algebraic geometry (Proc. Conf. Purdue Univ., 1963) , pages 93-110. Harper &Row, NewYork, 1965. |
| [26] | David A. Vogan, Jr. and Gregg J. Zuckerman. Unitary representations with nonzero coho- mology. Compositio Math. , 53(1):51-90, 1984. |
| [27] | J¨rg o Wildeshaus. Intermediate extension of chow moti ves of abelian type. http://arxiv.org/abs/1211.5327, 2013. |
| [28] | Bin Xu. Endoscopic classification of tempered representations: quasi-split general even orthogonal group and general symplectic group. http://arxiv.org/abs/1211.5327, 2013. | | null | [
"Sophie Morel",
"Junecue Suh"
] | 2014-08-03T06:20:08+00:00 | 2014-09-17T14:34:46+00:00 | [
"math.AG",
"math.NT"
] | The standard sign conjecture on algebraic cycles: the case of Shimura varieties | We show how to deduce the standard sign conjecture (a weakening of the
K\"unneth standard conjecture) for Shimura varieties from some statements about
discrete automorphic representations (Arthur's conjectures plus a bit more). We
also indicate what is known (to us) about these statements. |
1408.0462v1 | ## SHRINKAGE PRIORS FOR LINEAR INSTRUMENTAL VARIABLE MODELS WITH MANY INSTRUMENTS
## P. RICHARD HAHN 1 AND HEDIBERT LOPES 2
Abstract. This paper addresses the weak instruments problem in linear instrumental variable models from a Bayesian perspective. The new approach has two components. First, a novel predictor-dependent shrinkage prior is developed for the many instruments setting. The prior is constructed based on a factor model decomposition of the matrix of observed instruments, allowing many instruments to be incorporated into the analysis in a robust way.
Second, the new prior is implemented via an importance sampling scheme, which utilizes posterior Monte Carlo samples from a first-stage Bayesian regression analysis. This modular computation makes sensitivity analyses straightforward.
Two simulation studies are provided to demonstrate the advantages of the new method. As an empirical illustration, the new method is used to estimate a key parameter in macroeconomic models: the elasticity of inter-temporal substitution. The empirical analysis produces substantive conclusions in line with previous studies, but certain inconsistencies of earlier analyses are resolved.
## 1. Introduction
This paper considers the practically important problem of how to undertake an instrumental variables analysis when the instrumental variables may be only weakly predictive of the endogenous regressor. This problem is illustrated via an applied problem from monetary policy theory: estimating the elasticity of inter-temporal substitution (EIS). The EIS is a central parameter in the theoretically optimal consumption rule. The weak instruments problem is addressed by including an array of instruments which-in aggregate-alleviate the weak instruments phenomenon. In adding these many auxiliary instruments, care must
1. Booth School of Business, University of Chicago.
2. INSPER - Institute of Education and Research.
The first author thanks the Booth School of Business for supporting this research.
be taken to avoid over-fitting, which will be achieved through a powerful shrinkage prior based on ideas from factor analysis. Using Bayesian factor models for the purpose of inducing a regression can prove problematic [Hahn et al., 2013]: if the dominant factor structure apparent in the instruments does not predict the endogenous regressor, estimates of the first stage regression can be strongly biased to zero, exacerbating the identification problem the instruments were intended to resolve. What is required instead is a prior over the first-stage regression coefficients which is biased towards any obvious factor structure, but which does not collapse sharply to zero if the evident structure in the instruments appears not to be predictive of the endogenous regressor. It is demonstrated that a prior built on this principle can be constructed in terms of an approximate low-rank decomposition of the instruments matrix. Finally, an importance resampling approach is developed to implement the new prior in the instrumental variables setting.
1.1. Overview. The balance of this paper introduces a factor shrinkage prior and explores its many relations to previous methods and its application to instrumental variable models with many instruments. Specifically, Section 2 lays out the background and notation of Bayesian linear IV, Gaussian linear factor models, and predictor-dependent priors for linear regression.
Despite this rich context, the basic intuition behind the new prior is quite straightforward, and is worth delineating at the outset. Begin with a linear model for a scalar response variable x i :
$$x _ { i } = z _ { i } ^ { t } \delta + \epsilon _ { i } ; \quad \epsilon _ { i } \stackrel { \text{iid} } { \sim } N ( 0, \sigma ^ { 2 } ).$$
Afactor shrinkage prior over the vector of regression coefficients δ is induced via the following three steps.
- (1) First, suppose that cov(z) = BB t + Ψ 2 is known, for Ψ 2 diagonal and rank( B ) glyph[lessmuch] dim(z). That is, suppose that the factor structure of the predictor variables is known.
- (2) Next, create an over-complete dictionary by decomposing Z into i) its projection onto the column space of B and ii) the residuals arising from this projection. Specifically,
$$& \text{define} \, \tilde { Z } = \begin{pmatrix} \tilde { B } ^ { \prime } Z \\ ( I - \tilde { B } \tilde { B } ^ { t } ) Z \end{pmatrix}, \, \text{where} \, \tilde { B } \text{ is an orthonormalization of } B. \text{ Note that the} \\ & \text{span of} \, \tilde { Z } \text{ is the same as for } Z. \end{pmatrix}$$
- (3) Redefine the likelihood in terms of ˜: z x i = ˜ z t i ˜ + δ glyph[epsilon1] i glyph[epsilon1] i iid ∼ N(0 , σ 2 ) . Proceed with Bayesian inference under one's preferred shrinkage prior over ˜ . δ
The intuition behind this method is simply that if the derived variables ˜ B Z t are strong predictors of x , the shrinkage prior on ˜ δ should allow to spot this strong signal; at the same time, if these derived variables are not by themselves adequate, the residual predictors ( I -˜ ˜ BB Z t ) have still been retained. In the former case, one has relied on the factor structure of the predictor variables to construct an approximately sparse regression problem with p + k predictors, of which k are dominant. In the latter case, one has only added k glyph[lessmuch] p predictors and so one is essentially not much worse off than if fitting the unmodified regression.
This sketch has omitted many details. For example, in practice, the factor structure is not known exactly and so must be inferred or approximated and one must choose what prior to use once ˜ Z and ˜ δ have been defined. Section 3 fills in these details and demonstrates the prior's performance via a small simulation study. Finally, one must determine how to implement this prior within an instrumental variable analysis; Section 4 introduces an efficient importance sampler for this purpose.
Section 5 then turns to the empirical analysis and Section 6 concludes with a brief discussion.
## 2. Background
2.1. The Bayesian linear instrumental variables model. This section describes a simple re-parametrization of the usual Gaussian instrumental variables (IV) model. This representation will underpin the computational approach taken later.
The starting point of Bayesian approaches to endogenous regressors is the structural equation model
$$y _ { i } & = \beta x _ { i } + \epsilon _ { y } \\ x _ { i } & = z _ { i } ^ { t } \delta + \epsilon _ { x }.$$
where ( glyph[epsilon1] x , glyph[epsilon1] y ) are jointly Gaussian with mean zero and covariance
$$\text{cov} \begin{pmatrix} \epsilon _ { x } \\ \epsilon _ { y } \end{pmatrix} \equiv \text{S} = \begin{pmatrix} \sigma _ { x } ^ { 2 } & \sigma _ { x y } \\ \sigma _ { y x } & \sigma _ { y } ^ { 2 } \end{pmatrix}.$$
The variable x i is referred to as the treatment variable, y i is the response variable and z i is a vector of instruments . The unknown parameters in this model are β , δ , σ 2 x , σ 2 y and σ xy = σ yx ; the parameter of interest is β . Because of the implied covariance between x i and glyph[epsilon1] y , valid estimates of β cannot be obtained from just a regression of y i onto x i .
The joint distribution of the observables can be found by substitution
$$x _ { i } & = z _ { i } ^ { t } \delta + \epsilon _ { x }, \\ y _ { i } & = z _ { i } ^ { t } \delta \beta + \beta \epsilon _ { x } + \epsilon _ { y }.$$
A further reparametrization yields
$$x _ { i } & = z _ { i } ^ { t } \delta + \nu _ { x }, \\ y _ { i } & = z _ { i } ^ { t } \delta \beta + \nu _ { y },$$
with
$$\text{cov} \binom { \nu _ { x } } { \nu _ { y } } = \Omega = \text{ASA} ^ { t }$$
where A = 1 0 β 1 . Equation (3) is referred to as the 'reduced form' equations, in contrast to (1), the 'structural' equations. These various formulations invite a host of possible prior specifications. For a discussion of common specifications, see Lopes and Polson [2014].
The focus in this paper will be on priors for δ when the number of instruments p is large relative to the number of available observations n . Priors over the remaining parameters are
determined by a factorization of the likelihood based on glyph[epsilon1] y | glyph[epsilon1] x ∼ N( αglyph[epsilon1] x , ξ 2 ), where
$$\alpha = \frac { \sigma _ { y } } { \sigma _ { x } } \rho ; \ \xi ^ { 2 } = ( 1 - \rho ^ { 2 } ) \sigma _ { y } ^ { 2 },$$
with ρ ≡ σ xy σ σ x y . The matrix Ω can be written in terms of β , α ξ , 2 and σ 2 x ,
$$\Omega = \begin{pmatrix} \sigma _ { x } ^ { 2 } & ( \beta + \alpha ) \sigma _ { x } ^ { 2 } \\ ( \beta + \alpha ) \sigma _ { x } ^ { 2 } & ( \beta + \alpha ) ^ { 2 } \sigma _ { x } ^ { 2 } + \xi ^ { 2 } \end{pmatrix},$$
which in turn corresponds to the following factorization of the joint likelihood over observables ( x, y ):
$$f ( x, y \, | \, z ) = f ( y \, | \, x, z ) f ( x \, | \, z )$$
$$( 6 )$$
$$= N _ { y | x } ( x \beta + \alpha ( x - z ^ { t } \delta ), \xi ^ { 2 } ) \times \\ N _ { x } ( z ^ { t } \delta, \sigma _ { x } ^ { 2 } ).$$
The appearance of δ in both factors on the right-hand side means that observations of ( y , i z ) i allow one to disentangle β and α . It is concievable, of course, that in a given applied problem one instead has
$$f ( 7 ) \quad \ f ( x, y \, | \, z ) = f ( y \, | \, x, z ) f ( x \, | \, z ) = N _ { y | x } ( x \beta + \alpha ( x - z ^ { t } \delta ), \xi ^ { 2 } ) N _ { x } ( z ^ { t } \tilde { \delta }, \sigma _ { x } ^ { 2 } ),$$
glyph[negationslash]
with ˜ = δ δ . The assumption that ˜ = δ δ is referred to as the instrument exclusion restriction and in general is untestable. See Conley et al. [2012] and Chan and Tobias [2014] for approaches which weaken this assumption, yielding only partial identification of β . In this paper, the exclusion restriction will be assumed.
Bayesian linear IV has been studied for many years now [Lindley and El-Sayed, 1968, Dreze, 1976, Geweke, 1996, Chamberlain and Imbens, 1996, Chao and Phillips, 1998] and remains an active area of research [Kleibergen and Zivot, 2003]. For a textbook treatment, chapter 7 of Rossi et al. [2006] is a nice resource. The basic approach outlined above can be modified to consider non-Gaussian error terms [Conley et al., 2008]. In the empirical illustration considered in Section 5, y i is the quarterly change in consumption in the United States, x i is the real interest rate and β denotes the elasticity of inter-temporal substitution.
The instrument vector z i consists of a battery of macroeconomic indicators, twice-lagged. This formulation of the economic problem follows from a linearization of an Euler equation; see Yogo [2004] section II (and references therein) for details.
2.2. Gaussian factor regression models. Given a p -byk matrix B and a k -by-1 vector f , i a linear factor model for the p -dimensional vector z i takes the form
$$z _ { i } = \mathbf B f _ { i } + \epsilon _ { i }$$
where glyph[epsilon1] i is a p -dimensional, independent, additive error term (referred to as idiosyncratic errors ). Conditional on the factors f , the data may be viewed as realizations of an indei pendent and identically distributed random variable. However, the latent factor scores f i are not observable, rather they are given a prior distribution. Integrating over the latent factors induces a dependence structure among the observed data, in particular
$$\text{Cov} ( z _ { i } ) = \text{BCov} ( f _ { i } ) \text{B} ^ { t } + \Psi ^ { 2 },$$
where Cov( glyph[epsilon1] i ) = Ψ 2 is assumed diagonal.
When the priors over the latent factors and the idiosyncratic errors are both Gaussian, f i iid ∼ N(0 , I k ) and glyph[epsilon1] i iid ∼ N(0 , Ψ 2 ), the marginal distribution of z i is also normally distributed,
$$z _ { i } & \sim N ( 0, \text{BB} ^ { t } + \Psi ^ { 2 } ),$$
and the model is called a Gaussian factor model.
Factor models have been a topic of research for more than 100 years. A seminal reference is Spearman [1904] and Bartholomew and Moustaki [2011] is an excellent contemporary reference. Bayesian factor models continue to see new developments, for example Lopes et al. [2008] and Murray et al. [2013]. Recent work considering the use of factor models in the many instruments context include Groen and Kapetanios [2009], Ng and Bai [2009], Hahn and Hansen [2011] and Kapetanios and Marcellino [2010]. Much of this previous work on factor models for IV analysis is non-Bayesian and the Bayesian treatments tend to focus specifically on asymptotic analysis under non-informative priors. The present paper differs
from these earlier approaches in considering predictor dependent priors and an importance sampling implementation.
2.2.1. Weak factors and weak instruments. Factor models can be useful in a regression context owing to their ability to leverage 'side information'. To observe this phenomenon, consider a factor regression model specified as:
$$x _ { i } = z _ { i } ^ { t } \delta + \epsilon _ { i } ; \quad \epsilon _ { i } \sim N ( 0, \sigma ^ { 2 } ) ; \quad \delta = \theta B ^ { t } ( \text{BB} ^ { t } + \Psi ^ { 2 } ) ^ { - 1 }.$$
Suppose that z i follows the distribution in (10) and that many observations are available from this distribution, whereas only a limited number of x observations are available. In this case, inference concerning δ still benefits, because the 'unlabeled' draws from (10) permit reliable inference concerning B and Ψ 2 , which reduces the p -dimensional regression in (11) to the problem of learning the k -dimensional vector θ . (For a more general discussion of this idea, see Liang et al. [2007].)
However, if the assumption in (11) relating δ to B and Ψ 2 fails, the factor regression strategy can backfire, leading to insidious bias; in particular the true but unknown δ need not live in the span of B BB t ( t + Ψ 2 ) -1 . Inferences made under an incorrect assumption of this form tend to exhibit a strong zero-bias when priors on θ are centered at the origin. A similar phenomenon has long been recognized in the area of principal component analysis, where it is referred to as the 'least eigenvalue problem' [Jolliffe, 1982, Cox, 1968]. The illustration of this weak factor problem in the Bayesian linear factor model context is the topic of Hahn et al. [2013].
In the IV context, the weak factor problem relates intimately to the 'weak instrument' problem. Note that when δ = 0 the likelihood in (4) is non-unique in terms of the parameters β and α , with any combination having the same sum β + α giving equivalent likelihood evaluations. The weak instruments problem refers then to cases where δ is small (but not zero), so that the likelihood is nearly flat for many combinations of α and β . Therefore, strong zero-bias in δ due to the weak factor problem will directly impact inferences concerning β by inducing a weak instrument scenario. A natural way to avoid this difficulty is to work
with a 'pure regression model', dealing only with a conditional model for ( x i | z ) i rather than for ( x , i z ) jointly. i It is therefore natural to ask how evident structure in the predictor matrix might be incorporated into a prior of the regression coefficients.
In the applied context of this paper, factor structure in the instrument vector is plausible if one posits macroeconomic trends underlying joint movement of the various indicators.
2.3. Predictor-dependent priors. The idea of specifying a prior distribution over a set of regression coefficients in a way that depends on the observed matrix of predictor variables goes back at least to Zellner [1986], where the so-called g -prior was introduced:
$$( \delta \, | \, \sigma ^ { 2 }, g ) \sim N ( 0, g \sigma ^ { 2 } ( \mathbf Z \mathbf Z ^ { t } ) ^ { - 1 } ).$$
The g -prior continues to be a popular choice in the Bayesian variable selection literature [Liang et al., 2008, Maruyama and George, 2011], due largely to the convenient closed form marginal likelihood it implies. The g -prior can be motivated by specifying a regression problem in the de-correlated predictor space and using independent priors in that representation. That is, supposing cov(z) ≡ Σ = LL t is known and defining w i ≡ L -1 z i gives that
$$w _ { i } \sim N ( 0, \mathbf I ) ; \ \ x _ { i } \sim N ( w _ { i } ^ { t } \eta, \sigma ^ { 2 } ) ; \ \ \eta \sim N ( 0, g \mathbf I ),$$
implies
$$x _ { i } \sim N ( z _ { i } ^ { t } \delta, \sigma ^ { 2 } ) ; \quad \delta = \mathbf L ^ { - t } \eta ; \quad \delta \sim N ( 0, g \Sigma ^ { - 1 } ).$$
Zellner's g -prior follows from using an empirical plug-in estimate of Σ -1 . The general idea of working in a rotated predictor representation has been fruitful in many contexts, for example in a model averaging capacity [Clyde et al., 1996]. West [2003] introduces generalized-singular g -priors as a way to formally tie factor models to principal component regression, essentially by letting the prior on each ψ 2 j approach a degenerate distribution at 0, so that 'the latent factors explain essentially all the variation in the predictors'. With no additive error, the observed data is assumed to arise as Z = BF and B can be computed (non-uniquely) via a
generalized inverse. (In practice the eigenvalues of B will all be positive, but small values are set to zero.)
While West [2003] expresses concern that 'a basic modelling issue arises from the explicit design-, and sample size-, dependence of the empirical factor model,' the insight connecting factor models and g -priors can be applied 'in reverse' to ask: is it possible to specify a predictor-dependent prior that allows for non-zero idiosyncratic variances? That is, instead of using a dimension reduced design matrix based on the singular-value decomposition (SVD) of Z , it should be possible to use a true factor decomposition of n -1 ZZ t . Such a prior would benefit from the substantive bias that the response variable should associate more strongly with the communalities than the idiosyncratic errors, while directly avoiding the 'weak factor' problem by working with a pure regression model rather than a joint model.
The next section lays out the mechanics of producing such a decomposition and describes how to use this decomposition to construct a robust factor shrinkage prior.
## 3. Factor shrinkage priors
If it were possible to extract latent factors governing the correlation structure in a vector of instruments, one might suppose that these factors would make 'strong' instruments. However, such an approach is at risk of extracting the 'wrong' latent factors with respect to the desired regression, which could worsen the weak instruments problem. This section builds a prior designed to nudge the regression towards apparent factor structure in the instruments matrix, without committing to the assumption that the endogenous regressor is independent of the instruments conditional on the factors.
The new factor shrinkage prior is built on two ideas, the Frisch decomposition of a matrix and a robust shrinkage prior called the horseshoe prior. Sections 3.1 and 3.2 provide the details of this work. Section 3.3 defines the new prior and section 3.4 conducts a small simulation study.
- 3.1. The Frisch decomposition. The notion of 'shared factors' among vectors of measurements can be characterized in terms of an optimization problem motivated by the early
work of Ragnar Frisch on 'confluence analysis' [Frisch, 1934]. Specifically, given a covariance matrix Σ , consider the following rank minimization problem :
$$\min _ { D } \ \ r a n k ( \Sigma - D )$$
$$\text{s.t.} \ \text{D diagonal},$$
$$D \text{ diagonal,} \\ \Sigma - D \geq 0.$$
If D ∗ is a solution to (15), denote a matrix pair ( Ψ B 2 , ) a Frisch decomposition of Σ , if
$$\Psi ^ { 2 } = D ^ { * } ; \ \ B B ^ { t } = \Sigma - D ^ { * }.$$
By assuming Σ known, this problem is non-statistical in nature, yet it readily captures an intuition about what makes factor models appealing as descriptions of data. Factor models are popular not merely because they decomposes covariance structure into a common component and an independent (diagonal) component, but because it is anticipated that this decomposition can be done parsimoniously. Indeed, any p -byp covariance matrix has a p -1 dimensional factor representation (let Ψ 2 = ι p I for ι p the smallest eigenvalue of the SVD), whereas the Frisch decomposition demands that we have the most concise of all such descriptions.
Alas, solving (15) is quite difficult. Fortunately, high quality approximations are available using a surrogate objective function based on the matrix trace [Fazel, 2002]:
$$\begin{matrix} \end{matrix}$$
$$( 1 7 )$$
$$\min _ { D } & \quad \text{trace} ( \Sigma - D ) \\ \text{s.t.} & \quad D \text{ diagonal}, \\ & \quad \Sigma - D \geq 0.$$
The trace approximation is convex and can be routinely solved by readily available software [Grant and Boyd, 2013, 2008]. The specifics of this approximation are beyond the scope of this paper; see Ning et al. [2013] for an excellent overview with many references. The trace approximation serves to extract a 'sharper' set of eigenvectors, in the sense of having a more rapidly decaying set of eigenvalues, as seen in Figure 1, which overlays the eigenvalues
Figure 1. An illustration of how the eigenvalues of a full covariance matrix Σ can be flatter than the eigenvalues of the trace-heuristic derived loadings matrix Σ -D ∗ . This occurs when Σ has an underlying factor structure with relatively large idiosyncratic variances.
of an example covariance matrix Σ and Σ -D ∗ , where D ∗ solves (17). In this sense, the trace heuristic still isolates 'commonalities'. Henceforth, whenever a Frisch decomposition is referred to, it is to be understood that it is computed approximately using the feasible trace formulation in (17).
3.2. The horseshoe prior. The 'horseshoe' prior of Carvalho et al. [2010] is defined as a scale mixture of normals, with representation
$$\pi ( \delta _ { j } ) = \int N ( \delta _ { j } | 0, \lambda _ { j } ^ { 2 } ) \pi ( \lambda _ { j } ^ { 2 } ) d \lambda _ { j }.$$
To motivate this representation, consider the 'intercept only model', ( z j | δ j ) ∼ N( δ , j 1). Then, for ( δ j | λ j ) ∼ N(0 , λ 2 j ), the posterior mean of δ j may be expressed as
$$E ( \delta _ { j } \, | \, z _ { j } ) = \{ 1 - E ( \kappa _ { j } \, | \, z _ { j } ) \} z _ { j },$$
where κ j = 1 (1 + / λ 2 j ). The prior gets its name from the fact that a half-Cauchy prior λ j ∼ C (0 1) yields + , a U-shaped Beta ( 1 2 , 1 2 ) distribution over the 'shrinkage factor' κ ,
expressing the anticipation that shrinkage ought to be either severe ( κ ≈ 1) or minimal ( κ ≈ 0), and less likely to be at intermediate levels ( κ ≈ 1 / 2).
The horseshoe and its relatives (such as Griffin and Brown [2012] and Polson and Scott [2012]) make good default priors for regression coefficients because they lack hyper-parameters and have been observed empirically to successfully shrink irrelevant coefficients strongly to zero without similarly attenuating the magnitude of relevant coefficients.
3.3. A factor shrinkage horseshoe prior. The factor shrinkage horseshoe prior arises as the implied prior on δ when a horseshoe prior is placed on the regression coefficients corresponding to an augmented predictor matrix. This enriched predictor matrix is constructed using the Frisch decomposition of ˆ Σ = n -1 ZZ t (the hat denoting that this can be thought of as a point estimate of cov(z) = Σ ). The enriched predictor set is defined as follows. Let ( B Ψ , 2 ) denote the Frisch decomposition of ˆ Σ and denote by k the rank of B . Let ˜ B denote the orthonormalization of B . The enriched matrix is then defined as
$$\tilde { Z } = \begin{pmatrix} \tilde { B } ^ { t } Z \\ ( I - \tilde { \mathrm B } \tilde { \mathrm B } ^ { t } ) Z \end{pmatrix}.$$
Note that ˜ Z is dimension ( p + k )-byn . Complete the regression model via
$$x _ { i } & = \tilde { z } _ { i } ^ { t } \tilde { \delta } + \epsilon _ { i } \quad \epsilon _ { i } ^ { \text{iId} } \sim N ( 0, \sigma ^ { 2 } ) \\ \tilde { \delta } & \sim N ( 0, s ^ { 2 } \Lambda ^ { 2 } ), \quad \lambda _ { j } \sim C ^ { + } ( 0, 1 ), \quad s \sim C ^ { + } ( 0, 1 ).$$
The matrix Λ is diagonal with local shrinkage factors λ j , j = 1 , . . . , p + k . Denote by Λ f the upper k -byk block of Λ , associated with the derived factors, and Λ r the lower p -byp block associated with the residuals.
3.3.1. Local shrinkage and over-complete dictionaries. It may appear that nothing has been gained via working with the augmented design matrix. Indeed, the implied prior over δ under (20) is mostly similar to a typical regression prior. In the special case where Λ f = I k
and Λ r = I p are considered fixed, the prior on δ is simply a standard normal:
$$Z ^ { t } \delta = Z ^ { t } \tilde { \mathbf B } \tilde { \delta } _ { f } + Z ^ { t } ( \mathbf I - \tilde { \mathbf B } \tilde { \mathbf B } ^ { t } ) \tilde { \delta } _ { r },$$
$$\delta = \tilde { \mathbf B } \tilde { \delta } _ { f } + ( \mathbf I - \tilde { \mathbf B } \tilde { \mathbf B } ^ { t } ) \tilde { \delta } _ { r },$$
$$\delta \sim N ( 0, \tilde { B } \tilde { B } ^ { t } + ( I - \tilde { B } \tilde { B } ^ { t } ) ( I - \tilde { B } \tilde { B } ^ { t } ) ^ { t } ) = N ( 0, I ).$$
The last line follows from the idempotence of I -˜ ˜ BB t .
However, the models are in fact quite different when the local hyper-variances are taken into account. The over-parametrized augmented matrix ˜ Z allows an expansion of what it means to be 'local', by creating new composite predictors that are themselves linear combinations of the original predictors. In this enriched set, the composite predictors may be found to represent the large signals, allowing more of the original predictor coefficients to be severely zero-shrunk.
The factor shrinkage prior construction suggests that local shrinkage priors combined with over-complete dictionaries could be a powerful general method for constructing novel priors for regression models.
3.3.2. Computational details. For completeness, note two additional details concerning the implemented Frisch decomposition. First, the solution to (15) is invariant to row and column scaling operations, while (17) is not. This observation has motivated weighted minimum trace approximations that attempt to define and compute an optimal weight matrix [Shapiro, 1982, Ning et al., 2013]. As a crude heuristic, the approach taken here is to solve (17) applied to the sample correlation matrix as opposed to the sample covariance matrix.
Similarly, because Σ is only known up to an empirical estimate, the actual rank of B will tend not to be reduced. Accordingly, ˜ is constructed by approximating Z B (respectively, ˜ ) B by its first few dominate eigenvectors. This approximation entails that the associated Ψ 2 will not be perfectly diagonal, but only 'nearly' diagonal.
These two approximations determine the precise specification of the prior in (22), but do not change the underlying motivation and intuition. Moreover, the next section demonstrates
that they do not demonstrably affect the qualitative behavior of the resulting posterior estimator.
3.4. Comparison study. This section compares the performance of the new prior to that of a full factor model and a pure regression model. Two regimes were considered, both with p = 30 and n = 60. In both cases data z i is drawn from a factor model with parameters B and Ψ 2 generated as follows. For j = 1 , . . . , p and g = 1 , . . . , k
$$\text{and} \, \text{$\text{generate as norows. for $j=1,\dots,p$ and $g=1,\dots,\kappa$} \\ a _ { j, g } \sim N ( 0, 1 ) \\ w _ { g } \equiv 1 + | \epsilon _ { g } |, \text{ s.t. } | w _ { g } | \geq | w _ { g ^ { \prime } } | \text{ if $g<g^{\prime}} \\ ( 2 3 ) \quad & \epsilon _ { g } \sim t ( 0, d f = 5 ), \\ B \equiv AW, \\ \psi _ { j } = \sqrt { b _ { j } b _ { j } ^ { \prime } } / u _ { j }, \text{ } u _ { j } \sim \text{Unif} ( 1 / 2, 7 / 4 ), \\ \text{where} \, W \text{ is a $k$-by-k$ diagonal matrix with diagonal elements $w_{g}$. The respor}$$
where W is a k -byk diagonal matrix with diagonal elements w g . The response variable x i is then generated from the factor model (11) with σ = 1 5. This gives a signal-to-noise ratio / of 5-to-1 conditional on f , representing a quite strong signal if the factors were observable. i From this basic procedure, two regimes are considered. In the first regime, k = 3, and the first and most dominant factor (in the sense of | w g,g | being largest) is solely predictive of x i : θ = (1 0 0). , , In the second regime, k = 10, and the least dominant factor is the one which is solely predictive of x i : θ = (0 0 , , . . . , 1) . Simulations under each regime consisted of 500 replications. Performance was judged using root mean square prediction error (RMSE), scaled by the theoretically best possible generalization error as determined by the simulated parameter values:
$$R M S E = \frac { \sqrt { \sigma ^ { 2 } + n ^ { - 1 } \sum _ { i } \left ( | z _ { i } ^ { t } ( \delta - \hat { \delta } ) | ^ { 2 } \right ) } } { \sigma }.$$
Under the simulation protocol described, σ = √ 1 -m +1 25 where / m denotes the (1 1) , entry of M = B BB t ( t + Ψ 2 ) -1 B under the first regime and the (10 10) entry under the , second.
Intuitively, the first regime is favorable to a factor model, because x i associates strongly with the dominant factor and n = 60 observations ought to provide information about this dominant trend of covariation. Conversely, the second regime should prove challenging for a factor model, as x i is not associated with the dominant factors; in this regime one might expect a pure regression approach to perform better. The results in Tables 1 and 2 show that indeed these intuitions are borne out. The factor shrinkage approach matches the better performing method in each case. Figure 2 illustrates the benefits of the factor shrinkage in the favorable regime; not only is the average error better as reported in the tables, but it is more often the better performing method as well, indicated by the majority of the plotted points lying above the diagonal.
Table 1. Case one: when the dominant factor structure is highly predictive of the response, the factor shrinkage prior performs on par with the full factor model regression. Reported numbers are given as percent of the theoretical optimal RMSE
| Method | RMSE |
|------------------|--------|
| Factor shrinkage | 1.09 |
| Factor model | 1.09 |
| Regression model | 1.13 |
Table 2. Case two: when the factor structure is less predictive of the response, the factor shrinkage approach performs on par with the pure regression model (both with horseshoe priors), while the full factor model over-shrinks. Reported numbers are given as percent of the theoretical optimal RMSE.
| Method | RMSE |
|------------------|--------|
| Factor shrinkage | 1.17 |
| Factor model | 1.28 |
| Regression model | 1.17 |
## 4. An importance resampler for Bayesian IV
Importance sampling a Bayesian IV models proceeds analogously to two-stage least squares in that one first fits a model for x i | z i to obtain estimates of δ . Given δ , estimates for β , α
Figure 2. The RMSE as a percentage of the optimal. When factor structure lay beneath idiosyncratic noise, the factor shrinkage prior dominates the unmodified horseshoe prior.
and ξ 2 follow straightforwardly from a regression analysis. However, unlike two-stage least squares, which disregards the contribution of f ( x | y ) in forming the first-stage estimate, a Bayesian sampling approach can account for both parts of the likelihood when obtaining posterior draws of δ . Integrating α, β and ξ 2 from the model a priori yields
$$\pi ( \delta, \sigma _ { x } ^ { 2 } \, | \, { \mathbf x }, { \mathbf y }, { \mathbf Z } ) \in \pi ( \delta, \sigma _ { x } ^ { 2 } \, | \, { \mathbf x }, { \mathbf Z } ) f ( { \mathbf y } \, | \, { \mathbf x }, { \mathbf Z }, \delta ),$$
which reveals that one can obtain posterior draws from π ( δ , σ 2 x | x y Z , , ) by first sampling from π ( δ , σ 2 x | x Z , ) as if y were not observed, and then resampling with weights proportional to f ( y | x Z , , δ ). Draws of ( α, β, ξ 2 ) are then obtain compositionally, conditional on a given value of δ .
In the following, assume a normal-inverse-Gamma prior is used for ( α, β, ξ 2 ), with prior mean E( α ) = E( β ) = 0, covariance of c I , and Gamma shape parameter of s/ 2 and scale parameter of v/ 2. Define ˜ x i ≡ ( x , x i i -z i δ ). Let M = c -1 I +˜ ˜, x x t b = s + y y t -y xM t ˜ -1 ˜ x y t , and a = n + . Note that ˜, v x M , a and b depend implicitly on δ ; in particular, let subscript j denote dependence on the j th sample of δ .
- (1) Draw N samples of δ from π ( δ , σ 2 x | x Z , ) using the sampler described in Carvalho et al. [2009] (though any regression model of choice will suffice here).
- (2) Resample with weights proportional to f ( y | δ , x Z , ). Under the conjugate prior described above, y i | z , x , i i δ , α, β, σ 2 y x | ∼ N( x β i + ( α x i -z t i δ ) , σ 2 y x | ), for each i implies that marginally over ( α, β, σ 2 y x | ) the n -vector of responses has a multivariate t -distribution: y | x Z , , δ ∼ t( a, M ). Therefore the resampling weights are determined for draw δ ( j ) as w j ∝ det( M j ) -1 2 b -a j 2 j .
- (3) Finally, sample ( α, β, σ 2 x ) given δ from π α, β, σ ( 2 x , ξ 2 | x Z y , , , δ ), which is a conjugate Gaussian regression with predictor vector ˜. x More specifically, draw σ 2 x from an inverse-Gamma distribution with shape parameter b/ 2 and scale parameter a/ 2, then draw ( α, β ) as a vector with mean M x y -1 ˜ t and covariance σ 2 x M -1 .
- 4.1. Synthetic example. This section demonstrates the efficacy of the new approach using synthetic data where the true parameters are known for post-analysis evaluation. The intent of this exercise is not to argue that the factor shrinkage prior is better than alternatives in any absolute sense; the goal is rather to illustrate the role played by predictor-induced bias in posterior inferences in an IV problem.
The parameters of this demonstration are set to mimic the applied analysis in the following section: α = -0 08 and . β = 0 2. . The instruments are generated from a k = 3 factor model as in the previous simulation. For this demonstration, p = 20 and n = 60.
Two priors for the 'first stage' regression coefficients δ are compared, the horseshoe priors and the new factor shrinkage prior. In the instrumental variables regression context mean squared prediction error is not the primary focus, rather it is inferences concerning the structural parameter β that are relevant. To reflect this inferential focus, the simulation study considers the coverage and size of the 95% intervals produced by the two models over 250 simulated data sets.
The upshot of the study is that the two regression methods have identical coverage of 94.8% (237 out of 250) that is very nearly identical to the nominal coverage. However,
Figure 3. A kernel density plot of the ratio between the posterior 95% interval widths of the horseshoe IV regression versus the factor shrinkage IV regression. The factor shrinkage intervals are smaller on 71% of simulated data sets with an average decrease in interval length of 6%.
the factor shrinkage prior is, on average, 6% smaller. Figure 3 profiles this difference via a smoothed histogram of this ratio across simulated data sets.
## 5. Empirical study: the elasticity of inter-temporal substitution
Yogo [2004] considers estimating the elasticity of inter-temporal substitution via a linearization of the Euler equation, using macroeconomic data and an instrumental variable analysis. Ng and Bai [2009] extend this analysis by incorporating many additional macro variables (detailed in Ludvigson and Ng [2007]) as instruments and consolidating them into factors using a boosting approach. This section mimics that analysis for comparative purposes, focusing on the 1970:3 to 1998:4 quarterly data for the United States. The complete set of factors use by Ng and Bai [2009] was unobtainable; of their 209 macro-variables a subset of 82 are used here, listed by variable code in the appendix. A representative subset of these macro-variables includes, for example, gross domestic purchases, fixed investment in durable equipment, assets abroad, and net exports.
It is a practically relevant question as to whether or not (lagged) macroeconomic indicators serve as valid instruments in the sense of satisfying the exclusion restriction. On the one hand, under a causal interpretation it seems reasonable to assert that past indicators should only relate to the present economy via the more recent indicators-a sort of Markov property. On the other hand, this narrative falls apart when one considers latent common causes that serve to induce dependence between today's indicators, yesterdays indicators, and today's response variable. Such shared common causes clearly violate the desired exclusion restriction. That said, this possibility will not be discussed further here; rather, a narrow comparison is drawn with the results of Ng and Bai [2009], who assume the validity of the macro indicators as instruments.
For reference, the model being fit is as in (6): f ( x, y | z) = N y x | ( xβ + ( α x -z t δ ) , ξ 2 )N (z x t δ , σ 2 x ), where y i is the quarterly consumption growth (i.e., the change in consumption) in the United States, x i is the real interest rate and β denotes the elasticity of inter-temporal substitution (EIS). The instrument vector z i consists of aforementioned macroeconomic indicators (twice lagged), in addition to the original instruments used inYogo [2004]: twice lagged nominal interest rate, inflation, consumption growth, and log dividend-price ratio. See Yogo [2004] section II for a theoretical justification of this model.
One goal of estimating EIS centers around the hypothesis that it is precisely 1, which corresponds to the theoretical proposition that an investors optimal consumption level is a constant proportion of wealth. If β < 1 is less than 1, the investors optimal consumptionwealth ratio is increasing in expected returns, if β > 1 it is decreasing.
Additionally, a statistical puzzle was laid out by Yogo concerning testing the hypothesis that EIS is small. One can estimate EIS via two distinct linearizations of the Euler equation. Denote the estimand EIS by ψ . One can estimate this directly, as described above, so that β ≡ ψ . Alternatively, one may interchanging the response variable (consumption growth) and the regressor (real interest rate), whence ψ ≡ 1 /β . When comparing these two approaches, one often finds that both ψ and 1 /ψ are estimated to be insignificantly different than zero, which gives an apparent contradiction.
To estimate this model, a factor shrinkage prior is placed on δ and the conjugate normalinverse-gamma prior described in Section 4 is used for ( α, β, ξ 2 ), with parameters s = 1, v = 1, and c = 25.
Using the direct form of the linearization, so that β ≡ ψ , the partial factor shrinkage IV model gives a posterior mean rate of inter-temporal substitution of approximately 16%, with 95% credible interval of (1 4% . , 30 8%). This is notably higher than the earlier analyses and . the credible interval safely excludes 1. Figures 4 and 5 summarize the posterior inference concerning ψ ≡ β . Table 3 compares the estimates and standard errors/posterior uncertainty for various estimation methods. Bayesian IV with the factor shrinkage prior is the only approach which gives an estimate of β ≡ ψ greater than the OLS estimate (0.16 versus 0.12 respectively); in particular this arises due to a posterior mean estimate of -0 10 for . α .
Using the inverted form of the linearization, so that β ≡ 1 /ψ , the partial factor IV model gives a posterior mean for ψ of 0.41, with 95% credible interval of (18% 63%). , Although these estimates differ markedly from the direct regression (it is a distinct model with distinct priors), notice that no paradox emerges. In both cases, ψ is estimated to be below 1 and 1 /ψ is estimated to be above 1. As shown in Figure 6, however, this form of the regression has much weaker signal-to-noise ratio, which results in a multimodal posterior.
Table 3. Estimates of the elasticity of intertemporal substitution using the direct regression ( β ≡ ψ ), by various methods: ordinary least squares (OLS), two-stage least squares (TSLS) for Yogo's original four instruments and for the augmented vector including the 82 macro indicators , Bayesian IV with factor shrinkage prior (FSP), and the boosted factor IV of Ng and Bai [2009], Table 7b (FIV ). b Standard errors for Bayesian models are given as the posterior standard deviation. All figures are have been rounded to two decimal places for comparison.
| Method | ˆ ψ ≡ ˆ β | standard error |
|-------------|-------------|------------------|
| OLS | 0.12 | 0.05 |
| TSLS (Yogo) | 0.06 | 0.09 |
| TSLS (full) | 0.23 | 0.1 |
| FSP | 0.16 | 0.08 |
| FIV b | 0.09 | 0.06 |
Figure 4. Posterior draws of ( α, β ).
## 6. Discussion
The factor shrinkage prior leverages an atypical matrix decomposition to create a prior that favors regression coefficients consistent with factor structure underlying the matrix of instruments. In the language of factor analysis, this prior asserts that the treatment variable is more likely to depend on the communalities of the instrument matrix than on the idiosyncrasies. A resampling approach is implemented which allows efficient computation and hence straightforward sensitivity analysis. Specifically, the resampling weights only require computing the determinant of a d +1 dimensional matrix, where d is the dimension of the treatment variable (typically one), irrespective of the number of instruments.
Analysis on synthetic data reveals that the new prior performs according to intuition: when factor structure predictive of the treatment is apparent in the matrix of instruments, this concordance with the prior yields tighter inference concerning the treatment effect of interest ( β ). Meanwhile, working with a pure regression model sidesteps the least-eigenvalue
Figure 5. The marginal posterior of the coefficient for elasticity of demand (here β = ψ ). The 90% posterior credible interval does not include 1.
problem that plagues direct factor modeling. Moreover, the new prior can be used even when the instruments are not jointly Gaussian, such as many binary instruments. More generally, the efficacy of the factor shrinkage prior speaks to the possibilities of combining local shrinkage priors with over-complete dictionaries.
## References
- D. Bartholomew and I. Moustaki. Latent Variable models and Factor Analysis: A Unified Approach . Wiley, third edition, 2011.
- C. Carvalho, N. Polson, and J. Scott. The horseshoe estimator for sparse signals. Biometrika , 97:465-480, 2010.
- C. M. Carvalho, N. G. Polson, and J. G. Scott. Handling sparsity via the horseshoe. In International Conference on Artificial Intelligence and Statistics , pages 73-80, 2009.
- G. Chamberlain and G. Imbens. Hierarchical Bayes models with many instrumental variables, 1996.
- J. Chan and J. Tobias. Priors and posterior computation in linear endogenous variable models with imperfect instruments. Journal of Applied Econometrics , 2014.
Figure 6. The marginal posterior of the coefficient for elasticity of demand using the inverted regression. The 90% posterior credible interval for ψ still does not include 1. The multimodal posterior is typical of horseshoe-based posteriors in low signal-to-noise ratio problems.
- J. C. Chao and P. C. Phillips. Posterior distributions in limited information analysis of the simultaneous equations model using the Jeffreys prior. Journal of Econometrics , 87(1): 49-86, 1998.
- M. Clyde, H. Desimone, and G. Parmigiani. Prediction via orthogonalized model mixing. Journal of the American Statistical Association , 91(435):1197-1208, 1996.
- T. G. Conley, C. B. Hansen, R. E. McCulloch, and P. E. Rossi. A semi-parametric Bayesian approach to the instrumental variable problem. Journal of Econometrics , 144(1):276-305, 2008.
- T. G. Conley, C. B. Hansen, and P. E. Rossi. Plausibly exogenous. Review of Economics and Statistics , 94(1):260-272, 2012.
- D. Cox. Notes on some aspects of regression analysis. Journal of the Royal Statistical Society Series A , 131:265-279, 1968.
- J. H. Dreze. Bayesian limited information analysis of the simultaneous equations model. Econometrica: Journal of the Econometric Society , pages 1045-1075, 1976.
- M. Fazel. Matrix rank minimization with applications . PhD thesis, Stanford University, 2002.
- R. Frisch. Statistical confluence analysis by means of complete regression systems. Technical Report 5, University of Oslo, Economic Institute, 1934.
- J. Geweke. Bayesian reduced rank regression in econometrics. Journal of Econometrics , 75 (1):121-146, 1996.
- M. Grant and S. Boyd. Graph implementations for nonsmooth convex programs. In V. Blondel, S. Boyd, and H. Kimura, editors, Recent Advances in Learning and Control , Lecture
Notes in Control and Information Sciences, pages 95-110. Springer-Verlag Limited, 2008. M. Grant and S. Boyd. CVX: Matlab software for disciplined convex programming, version 2.0 beta. http://cvxr.com/cvx , Sept. 2013.
- J. Griffin and P. Brown. Structuring shrinkage: some correlated priors for regression. Biometrika , 99:481-487, 2012.
- J. J. Groen and G. Kapetanios. Parsimonious estimation with many instruments. Federal Reserve Bank of New York, Staff Report , (386), 2009.
- J. Hahn and K. Hansen. Parameter orthogonalization and Bayesian inference with many instruments. Economics Letters , 112(2):207-209, 2011.
- P. Hahn, C. M. Carvalho, and S. Mukherjee. Partial factor modeling: predictor-dependent shrinkage for linear regression. Journal of the American Statistical Association , 108(503): 999-1008, 2013.
- I. T. Jolliffe. A note on the use of principal components in regression. Journal of the Royal Statistical Society, Series C , 31(3):300-303, 1982.
- G. Kapetanios and M. Marcellino. Factor-GMM estimation with large sets of possibly weak instruments. Computational Statistics & Data Analysis , 54(11):2655-2675, 2010.
- F. Kleibergen and E. Zivot. Bayesian and classical approaches to instrumental variable regression. Journal of Econometrics , 114(1):29-72, 2003.
- F. Liang, S. Mukherjee, and M. West. The use of unlabeled data in predictive modeling. Statistical Science , 22(2):189-205, 2007.
- F. Liang, R. Paulo, G. Molina, M. Clyde, and J. Berger. Mixtures of g priors for Bayesian variable selection. Journal of the American Statistical Association , 103:410-423, 2008.
- D. Lindley and G. El-Sayed. The Bayesian estimation of a linear functional relationship. Journal of the Royal Statistical Society. Series B , 30:190-202, 1968.
- H. F. Lopes and N. G. Polson. Bayesian instrumental variables: priors and likelihoods. Econometric Reviews , 33(1-4):100-121, 2014.
- H. F. Lopes, E. Salazar, and D. Gamerman. Spatial dynamic factor analysis. Bayesian Analysis , 3(4):759-792, 2008.
- S. C. Ludvigson and S. Ng. The empirical risk-return relation: A factor analysis approach. Journal of Financial Economics , 83(1):171-222, 2007.
- Y. Maruyama and E. I. George. Fully Bayes factors with a generalized g-prior. The Annals of Statistics , 39(5):2740-2765, 2011.
- J. S. Murray, D. B. Dunson, L. Carin, and J. E. Lucas. Bayesian Gaussian copula factor models for mixed data. Journal of the American Statistical Association , 108(502):656-665, 2013.
- S. Ng and J. Bai. Selecting instrumental variables in a data rich environment. Journal of Time Series Econometrics , 1(1), 2009.
- L. Ning, T. T. Georgiou, A. Tannenbaum, and S. P. Boyd. Linear models based on noisy data and the Frisch scheme. arXiv preprint arXiv:1304.3877 , 2013.
- N. Polson and J. Scott. Local shrinkage rules, Levy processes and regularized regression. Journal of the Royal Statistical Society, B , 74(2):287-311, 2012.
- P. E. Rossi, G. M. Allenby, and R. McCulloch. Bayesian statistics and marketing . Series in Probability and Statistics. Wiley, 2006.
- A. Shapiro. Weighted minimum trace factor analysis. Psychometrika , 47(3):243-264, 1982.
- C. Spearman. General intelligence, objectively determined and measured. American Journal of Psychology , 15:201-293, 1904.
- M. West. Bayesian factor regression models in the 'large p, small n' paradigm. In J. M. Bernardo, M. Bayarri, J. Berger, A. Dawid, D. Heckerman, A. Smith, and M. West, editors, Bayesian Statistics 7 , pages 723-732. Oxford University Press, 2003.
- M. Yogo. Estimating the elasticity of intertemporal substitution when instruments are weak. Review of Economics and Statistics , 86(3):797-810, 2004.
- A. Zellner. On assessing prior distributions and Bayesian regression analysis with g-prior distributions. In Bayesian Inference and Decision Techniques: Essays in Honor of Bruno de Finetti , pages 233-243. Amsterdam: North-Holland, 1986.
## Appendix A. Data description
The table below lists the macroeconomic indicators used in our instruments matrix by mnemonic and accompanied by brief abbreviated descriptions. These data came originally from the now-defunct DRI-Global Insight, Basic Economics Database which has been subsumed by the IHS Economics & Country Risk database. Compare to the table in Appendix A.1 in Ludvigson and Ng [2007], of which our list is a subset (some of the series are no longer kept). Following those authors, we apply the following data transformations (DT), indicated by: 1=no transformation; 2 = first difference; 3 = log first difference.
| Category/Name FX | DT | Description |
|--------------------|------|-----------------------------------------------------------------------|
| BPAUS | 2 | U.S. ASSETS ABROAD (NET) |
| BPB | 2 | BALANCE ON MERCHANDISE TRADE |
| GDFXFC | 3 | CHAIN-TYPE QUANTITY INDEX - EXPORTS OF GOODS AND SERV |
| GNET | 2 | NET EXPORTS OF GOODS AND SERV |
| GRFIW | 3 | RECEIPT FACTOR INCOME FROM REST OF WORLD |
| GXIM | 1 | % CHG FRM PRECEDING PERIOD: IMPORTS |
| GXMDQF | 3 | EXPORTS-DURABLE GOODS |
| GXMNQF | 3 | EXPORTS-NONDURABLE GOODS |
| GXMQF | 3 | EXPORTS-GOODS |
| GDFMFC | 3 | CHAIN-TYPE QUANTITY INDEX - IMPORTS OF GOODS AND SERV |
| Consumption | | |
| GDFCDC | 3 | CHAIN-TYPE QUANTITY INDEX - PCE, DURABLE GOODS |
| GXDAQF | 3 | AUTO OUTPUT-EXPORTS |
| GXPC | 1 | % CHG FROM PRECEDING PERIOD:PERSONAL CONSUMPTION EXPENDS |
| GDFCFC | 3 | CHAIN-TYPE QUANTITY INDEX - PERSONAL CONSUMPTION EXPENDITURES |
| Prices | | |
| GD | 3 | IMPLICIT PR DEFLATOR: GROSS NATIONAL PRODUCT |
| GDC | 3 | IMPLICIT PR DEFLATOR: PERSONAL CONSUMPTION EXPENDITURES |
| GDCD | 3 | IMPLICIT PR DEFLATOR: DURABLE GOODS,PCE |
| GDCN | 3 | IMPLICIT PR DEFLATOR: NONDURABLE GOODS,PCE |
| GDCS | 3 | IMPLICIT PR DEFLATOR: SERVICES, PCE |
| GDEX | 3 | IMPLICIT PR DEFLATOR: EXPORTS OF GDS & SERV |
| GDEXIM | 3 | TERMS OF TRADE |
| GDFCC | 3 | CHAIN-TYPE PRICE INDEX - PERSONAL CONSUMPTION EXPENDITURES |
| GDFCNC | 3 | CHAIN-TYPE PRICE INDEX - PCE, NONDURABLE GOODS |
| GDFCSC | 3 | CHAIN-TYPE PRICE INDEX - PCE, SERVICES |
| GDFDCF | 3 | CHAIN-TYPE PRICE INDEX - NATL DEFENSE EXPENDITURES & GROSS INVESTMENT |
| GDFDFC | 3 | CHAIN-TYPE PRICE INDEX - PCE, DURABLE GOODS |
| GDFDPC | 3 | CHAIN-TYPE PRICE INDEX- PRODUCERS' DURABLE EQUIPMENT |
| GDFEXC | 3 | CHAIN-TYPE PRICE INDEX - EXPORTS OF GOODS AND SERVICES |
| GDFGEC | 3 | CHAIN-TYPE PRICE INDEX - GOVT CONSUMPTION EXPENDITURES & GROSS INV |
| GDFGFC | 3 | CHAIN-TYPE PRICE INDEX - FED CONSUMPTION EXPEND & GROSS INVESTMENT |
| GDFGOC | 3 | CHAIN-TYPE PRICE INDEX - NONDEF CONS EXPENDITURES & GROSS INVESTMENT |
| GDFGSC | 3 | CHAIN-TYPE PRICE INDEX - S&L CONSUMPTION EXPEND & GROSS INVESTMENT |
| GDFICF | 3 | CHAIN-TYPE PRICE INDEX - PRIVATE FIXED INVESTMENT |
| GDFIMC | 3 | CHAIN-TYPE PRICE INDEX - IMPORTS OF GOODS AND SERV |
| GDFIRC | 3 | CHAIN-TYPE PRICE INDEX - RESIDENTIAL |
| GDFISC | 3 | CHAIN-TYPE PRICE INDEX - NONRESIDENTIAL STRUCTURES |
| GDFNRC | 3 | CHAIN-TYPE PRICE INDEX - NONRESIDENTIAL |
| GDGF | 3 | IMPLICIT PR DEFLATOR: FED GOV'T PURCH OF GDS & SERV |
| GDIS | 3 | IMPLICIT PR DEFLATOR: PRIVATE NONRESINDENTIAL STRUCTURES |
| LBGDPU | 3 | IMPLICIT PRICE DEFLATOR: NONFARM BUSINESS |
| Fixed Investment | | |
| GFINO | 3 | FIXED INVEST:PRODUCER DURABLE EQUIP |
| GXIFN | 1 | % CHG FRM PRECEDING PERIOD:NONRESIDENTIAL FIXED INVESTMENT |
| GXIFR | 1 | % CHG FRM PRECEDING PERIOD:RESIDENTIAL FIXED INVESTMENT |
| GXIPD | 1 | % CHG FRM PRECEDING PERIOD: NONRESID PRODUCERS' DUR EQUIP |
|---------|-----|---------------------------------------------------------------|
| GXIS | 1 | % CHG FRM PRECEDING PERIOD: NONRESIDENTIAL STRUCTURES |
| GXPI | 1 | % CHG FRM PRECEDING PERIOD:GROSS PRIV DOM INVESTMENT |
| GDFFIC | 3 | CHAIN-TYPE QUANTITY INDEX - PRIVATE FIXED INVESTMENT |
| GDFIFC | 3 | CHAIN-TYPE QUANTITY INDEX - GROSS PRIVATE DOMESTIC INVESTMENT |
## Output & Income
| GDFDEC | 3 | CHAIN-TYPE QUANTITY INDEX - NATL DEF EXPENDITURES & GROSS INVESTMENTS |
|----------|-----|-------------------------------------------------------------------------|
| GDFEOC | 3 | CHAIN-TYPE QUANTITY INDEX - NONDEF CONS EXPEND & GROSS INVESTMENT |
| GDFFGC | 3 | CHAIN-TYPE QUANTITY INDEX - FED CONSUMPTION EXPEND & GROSS INVESTMENT |
| GDFGGC | 3 | CHAIN-TYPE QUANTITY INDEX - GOVT CONSUMPTION EXPENDITURES & GROSS |
| GDFGLC | 3 | CHAIN-TYPE QUANTITY INDEX - S&L CONSUMPTION EXPEND & GROSS INVESTMENT |
| GDFINC | 3 | CHAIN-TYPE QUANTITY INDEX - NONRESIDENTIAL |
| GDFNFC | 3 | CHAIN-TYPE QUANTITY INDEX - PCE, NONDURABLE GOODS |
| GDFPDC | 3 | CHAIN-TYPE QUANTITY INDEX - PRODUCERS' DURABLE EQUIPMENT |
| GDFRFC | 3 | CHAIN-TYPE QUANTITY INDEX - RESIDENTIAL |
| GDFSFC | 3 | CHAIN-TYPE QUANTITY INDEX - PCE, SERVICES |
| GDFSTC | 3 | CHAIN-TYPE QUANTITY INDEX - NONRESIDENTIAL STRUCTURES |
| GPY | 3 | PERSONAL INCOME, TOTAL |
| GWY | 3 | NAT'L INCOME: WAGES AND SALARIES |
| GXNP | 1 | % CHANGE FROM PRECEDING PERIOD, GNP |
| GXSAV | 3 | PERSN'L INCOME: PERS SAVING RATE, GPSAV AS % OF GYD |
| GXYD | 1 | % CHG FRM PRECEDING PERIOD: DISP. PERSONAL INCOME |
| GYDPCQ | 3 | DISPOSABLE PERSONAL INCOME PER CAPITA IN CHAINED |
| GYFIR | 3 | GY BY IND DIV: FINANCE, INSUR AND REAL ESTATE |
| GYGGE | 3 | GY BY IND DIV: GOV'T AND GOV'T ENTERPRISES |
| GYM | 3 | GY BY IND DIV: MANUFACTURING INDUSTRY |
| GYMD | 3 | GY BY IND DIV: DURABLE GOODS MANUFACTURING INDUSTRY |
| GYMN | 3 | GY BY IND DIV: NONDURABLE GOODS MANUFACTURING INDUSTRY |
| GYS | 3 | GY BY IND DIV: SERVICE INDUSTRIES |
| GYT | 3 | GY BY IND DIV: TRANSPORTATION INDUSTRY |
| GYUT | 3 | GY BY IND DIV: ELECTRIC, GAS AND SANITARY SEW INDUSTRY |
## Sales, Orders, Purchases
| GXNPD | 1 | GROSS DOM PURCH |
|---------|-----|-----------------------------------------------|
| GXNS | 1 | FINAL SALES OF DOM PROD |
| GXNSD | 1 | FINAL SALE TO DOM PURCH |
| LBOUT | 3 | OUTPUT PER HOUR ALL PERSONS |
| LBOUTU | 3 | OUTPUT PER HOUR ALL PERSONS: NONFARM BUSINESS | | null | [
"P. Richard Hahn",
"Hedibert Lopes"
] | 2014-08-03T06:50:05+00:00 | 2014-08-03T06:50:05+00:00 | [
"stat.ME"
] | Shrinkage priors for linear instrumental variable models with many instruments | This paper addresses the weak instruments problem in linear instrumental
variable models from a Bayesian perspective. The new approach has two
components. First, a novel predictor-dependent shrinkage prior is developed for
the many instruments setting. The prior is constructed based on a factor model
decomposition of the matrix of observed instruments, allowing many instruments
to be incorporated into the analysis in a robust way.
Second, the new prior is implemented via an importance sampling scheme, which
utilizes posterior Monte Carlo samples from a first-stage Bayesian regression
analysis. This modular computation makes sensitivity analyses straightforward.
Two simulation studies are provided to demonstrate the advantages of the new
method. As an empirical illustration, the new method is used to estimate a key
parameter in macro-economic models: the elasticity of inter-temporal
substitution. The empirical analysis produces substantive conclusions in line
with previous studies, but certain inconsistencies of earlier analyses are
resolved. |
1408.0463v1 | ## Stability analysis of a model gene network links aging, stress resistance, and negligible senescence
Valeria Kogan 1 2 , , Ivan Molodtcov 1 2 , , Leonid I. Menshikov 2 3 , , Robert J. Shmookler Reis 4 5 6 , , and Peter Fedichev 1 2 , 1) Moscow Institute of Physics and Technology, 141700,
Institutskii per. 9, Dolgoprudny, Moscow Region, Russian Federation
2) Quantum Pharmaceuticals, Ul. Kosmonavta Volkova 6A-606, 125171, Moscow, Russian Federation
Northern (Arctic) Federal University, 163002, Severnaya Dvina Emb.
17, Arkhangelsk, Russian Federation
4)
McClellan VA Medical Center, Central Arkansas Veterans Healthcare System, Little Rock, AR, USA
5) Department of Biochemistry and Molecular Biology,
University of Arkansas for Medical Sciences, Little Rock, AR, USA and
6) Department of Geriatrics, University of Arkansas for Medical Sciences, Little Rock, AR, USA
Several animal species are considered to exhibit what is called negligible senescence, i.e. they do not show signs of functional decline or any increase of mortality with age, and do not have measurable reductions in reproductive capacity with age. Recent studies in Naked Mole Rat (NMR) and longlived sea urchin showed that the level of gene expression changes with age is lower than in other organisms. These phenotypic observations correlate well with exceptional endurance of NMR tissues to various genotoxic stresses. Therefore, the lifelong transcriptional stability of an organism may be a key determinant of longevity. However, the exact relation between genetic network stability, stress-resistance and aging has not been defined. We analyze the stability of a simple geneticnetwork model of a living organism under the influence of external and endogenous factors. We demonstrate that under most common circumstances a gene network is inherently unstable and suffers from exponential accumulation of gene-regulation deviations leading to death. However, should the repair systems be sufficiently effective, the gene network can stabilize so that gene damage remains constrained along with mortality of the organism, which may then enjoy a remarkable degree of stability over very long times. We clarify the relation between stress-resistance and aging and suggest that stabilization of the genetic network may provide a mathematical explanation of the Gompertz equation describing the relationship between age and mortality in many species, and of the apparently negligible senescence observed in exceptionally long-lived animals. The model may support a range of applications, such as systematic searches for therapeutics to extend lifespan and healthspan.
The Naked Mole Rat is an example from a growing list of animal species with no signs of aging or reduction in reproductive capacity with age. On the other hand, the age-dependent increase in death rate for most species, including humans, follows the Gompertz equation, which describes an exponential increase in mortality with age. In this work we construct a mathematical model of a gene network, described by a few differential equations with unstable and stable solutions, corresponding to normal and 'neglible' senesecence. For this purpose, we define aging as an exponential accumulation of epigenetic dysregulation errors, and show that the Gompertz 'law' is a direct consequence of the inherent genetic instability of the network. On the organism level this leads to the loss of stress resistance, the onset of age-related diseases, and finally to death. We suggest and analyze several strategies for gene network stabilization, which can be exploited for future life-extending therapeutics.
## Introduction
Aging in most species studied, including humans, leads to an exponential increase of mortality with age, primarily from a variety of age-related diseases. Agrowing number of animal species are recognized to exhibit what is called negligible senescence, i.e. they do not show mea- surable reductions with age, in their reproductive ability or functional capacities [1]. Death rates in negligibly senescent animals do not increase with age as they do in senescent organisms. One negligibly senescent species is the ocean quahog clam, which lives about 400 years in the wild [2] and is the longest-living non-colonial animal. Its extreme longevity is associated with increased resistance to oxidative stress in comparison with short-lived clams [3]. No noticeable signs of aging were found in a few turtle species, such as Blanding's turtle, whose lifespan is over 75 years [4], and the painted turtle, which was documented to live at least 61 years. Studies showed that these turtles increase offspring quality with age, so they are considered to be negligibly senescent [5]. The archetypical example of negligible senescence is the Naked Mole Rat (NMR), which has been documented to live in captivity for as long as 28 years [6] with no signs of increasing mortality, little or no age-related decline in physiological functions, sustained reproductive capacity, and no reported instances of cancer throughout their long lives [7]. These phenotypic observations correlate well with exceptional resistance of NMR tissues to diverse genotoxic stresses [8, 9]. Even more examples of negligibly senescent organisms may be found in the AnAge database [10].
In contrast, aging in most species studied, including humans, follows the Gompertz equation [11] describing
3)
an exponential increase of mortality with age, a possible signature of underlying instability of key regulatory networks. Recent studies of gene expression levels in the Naked Mole Rat and long-lived sea urchin [12] showed that the frequency of gene expression changes is lower in negligibly senescent animals than in other animal species [2-4, 12-14]. Therefore, the lifelong stability of the transcriptome may be a key determinant of longevity, and improving the maintenance of genome stability may be a sound strategy to defend against numerous age-related diseases. In this work we propose and analyze a simple mathematical model of a genetic network, and investigate the stability of gene expression levels in response to environmental or endogenous stresses. We show that under a very generic set of assumptions there exist two distinctly different classes of aging dynamics, separated by a sharp transition depending on the genome size, regulatory-network connectivity, and the efficiency of repair systems. If the repair rates are sufficiently high or the connectivity of the gene network is sufficiently low, then the regulatory network is very stable and mortality is time-independent in a manner similar to that observed in negligibly senescent animals. Should the repair systems display inadequate efficiency, a dynamic instability emerges, with exponential accumulation of genomeregulation errors, functional declines and a rapid aging process. The two regimes also show dramatically different dynamics of stress-resistance with age: stable genetic networks are more robust against noise, and the efficacy of stress defenses does not decline with age. In contrast, the stress responses of 'normally aging' animals deteriorate exponentially.
## Genetic-network stability analysis
A living body, the organism, is an interacting system containing the genome and the expressome, defined as all the molecules (the transcriptome, proteome, metabolome) produced according to the genetic program and for which expression levels are regulated by genes and their epigenetic states (see Figure 1). Likewise the expression states of the genes are regulated by the components of the expressome. For the sake of model simplicity, but without loss of generality, we will specifically talk about the genes expressing as, and being regulated by, proteins. However, other levels of description such as the metabolome could also be viewed as relevant aspects of the expressome, similarly impacted by both endogenous and exogenous (environmental) factors. We start from the organism in an initially 'normal' state, i.e. the state where all genes have youthful/healthy expression profiles. With the passage of time, t , most of the genes, g t ( ) genes in total, retain 'normal' expression profiles, while a few genes, e g ( ) t genes in total, subsequently become either physically damaged or (epigenetically) dysregulated and represent a few 'defects' or 'errors' in the genetic program. The genes are translated into the pro-
Figure 1: The minimum stability analysis model for a gene network. At any given time the genome consists of a number of normally expressed and dysregulated genes . The proteome accumulates 'defects', the proteins expressed by dysregulated genes, which are removed via the protein quality-control or turnover systems. DNA repair machinery controls epigenetic states of the genes and restores normal expression levels. On top of this, interactions with the environment damage both the proteome and the genome subsystems, increasing the load on the protein-turnover and DNA-repair components. Parameters f , β , p and c appear in Eqs. (1) and (2), and are interpreted below.
teome, including its 'defects', at a certain translation rate p .
Next, we assume that the initial state of the genome is mostly stable, meaning that the number of improperly expressed genes is small relative to the total genome size, e g glyph[lessmuch] G and, therefore, the number of improperly produced proteins, e p ( ) t , is also small. This means that the interaction between the defects in the genome and the proteome can be neglected. Therefore, the most general model describing the dynamics of the interacting defects in the genome and in the proteome can be described by the following equations:
$$\dot { e } _ { p } = p e _ { g } - c e _ { p } + f _ { p },$$
$$\dot { e } _ { g } = \beta G K e _ { p } - \delta e _ { g } + G f _ { g }, \text{ \quad \ \ } ( 2 )$$
where β is the coupling rate constant characterizing the regulation of the gene expression by the proteins. The constant K is the average number of genes regulated by
any single protein and here represents a simple measure of the overall connectivity of the genetic network (See the section below on Strategies for stabilization of genetic networks). The constant c reflects the combined efficiency of proteolysis and heat shock response systems, mediating degradation and refolding of misfolded proteins, respectively, whereas δ characterizes the DNA repair rate. Furthermore, the model includes the force terms, f p ( ) t and f g ( ) t , which characterize the proteome and genome damage rates, respectively. The 'forces' can represent any of a number of things, including oxidative stress (metabolic), temperature, gamma-radiation (environmental), that are imperfectly compensated by protective mechanisms.
Eqs. (1) and (2) can only hold in their simple linearized form if defects do not interfere with the repair machinery or any other rare essential subsystems of the gene network. As we will see below if, for example, a defect alters a DNA repair system-associated gene or protein, the repair rate drops, the system becomes unstable and may quickly diverge from its normal state [15, 16]. To avoid the complications from introducing such nonlinearities, we adopt a simple hypothesis as to how defects in the evolving gene network could be responsible for the demise of a cell or organism. Specifically, we assume that mortality at any time is dependent on the probability of a defect to 'land' on and damage or dysregulate an essential gene. Because any gene in the model can be dysregulated for a short time (brief relative to lifespan) and then 'repaired', a gene is considered essential if the disruption of its expression, even for a limited time, is lethal to the cell in which it was disrupted. The suggested picture is quite general, however, and is easily extended to multicellular/metazoan animals, since the stability boundaries are the same - only the exponents will be reduced because some threshold fraction of cells must die (in some most-vulnerable tissue compartment) to produce organism lethality. In this case the population dynamics of a set of gene networks representing N t ( ) organisms can be represented by:
$$\dot { N } ( t ) = - M \left ( t \right ) N ( t ), \quad \ \ \ ( 3 ) \quad s l o _ { \cdot \cdot }$$
where M t ( ) = ωe /G g is the mortality rate, proportional to the fraction of mis-regulated genes, e /G g , and ω is an empirical factor, roughly a measure of the (small) fraction of genes in the whole genome that are essential. The presented model is, obviously, an extreme simplification. Nevertheless it can be rigorously derived as a limiting case for the dynamics of a more complex genetic regulatory network, where the number of dysregulated genes is sufficiently large [17].
Since aging is a slow process, Eqs. (1)-(3) can be further simplified by neglecting second derivatives with respect to time,
$$\dot { M } ( t ) = \Lambda M ( t ) + \omega F ( t ), \quad \quad ( 4 ) \quad \quad \,,$$
where F = f/ c ( + ) δ is a combined measure of genotoxic stress, f = βKf p + cf g + ˙ f g , and Λ = ( βpGK -cδ / c ) ( + ) δ
is the exponent characterizing genetic-network stability, which is precisely the propagation rate of geneexpression-level perturbations. In the long run, stress levels can be averaged out and presumed to be timeindependent, f p,g ( ) = const t , which yields the following expression for the age-dependent mortality rate:
$$M ( t ) = \frac { \omega F } { \Lambda } ( \exp \Lambda t - 1 ).$$
The nature of the solution is very different depending on the sign of the exponent Λ . Whenever the combined efficiency of all repair systems is lower than a measure of the defect proliferation rate,
$$R _ { 0 } = \frac { \beta p G } { c \delta } K > 1,$$
the gene network becomes inherently unstable, Λ > 0 , and the number of regulatory errors (defects) grows exponentially, M t ( ) ∼ exp(Λ ) t , which is identical to the well-known Gompertz law [11]. The average lifespan does not depend on the initial population size,
$$t _ { l e } \approx \frac { 1 } { \Lambda } \ln \left ( 1 + \frac { 1 } { \gamma } + \sqrt { \frac { \pi } { 2 \gamma } } \right ), \quad \quad ( 7 )$$
but depends on both the exponent Λ and on the genotoxic stress level through the parameter γ = ωF/ Λ 2 , which is typically very small. Therefore in the limit, when the life expectancy is large, the average lifespan can be approximated by t le ≈ Λ -1 log(1 /γ ) .
A considerably more intriguing situation occurs when the genome is stable, Λ < 0 ( R 0 < 1 ), and the gene network may remain stable under reasonable stress conditions for a very long time. The fractions of dysregulated genes and of misexpressed proteins will then stabilize at constant levels, as will the mortality rate itself, M ∞ = ωF/ | Λ | . Constant mortality means that the population of animals dies off exponentially rather than age-dependently: N t ( ) = N 0 exp( -M t ∞ ) , which is much slower than the prediction from the Gomperz law. We believe that the age-independent mortality observed in NMR experiments over a very long lifespan [6], together with exceptional stress resistance of NMR tissues [8], may be manifestations of this stable scenario. We predict that the gene networks of negligibly senescent animals are exceptionally robust, and the number of dysregulated genes will scarcely change with age. This argument is supported by the observations of [14], in which the number of genes differentially expressed with age was compared between NMR, mice and humans.
## Aging in a transcriptome of fruit flies
The model summarized by Eqs. (3) and (4) predicts that the number of gene regulatory errors will most often grow exponentially as animals age, as will the risk
Figure 2: Principal components analysis of gene expression profiles in aging flies (data from [18]), fed on control (ad lib) and calorically restricted diets. Every point represents a transcriptome for flies of a specific age and diet. As the animals age, the genetic network accumulates regulation errors and the transcription levels change in a single direction, up to a limit beyond which viability cannot be maintained.
of death (mortality). This means that gene expression levels (or metabolite levels, etc.) should change with age and deviate from their healthy/youthful states. To test this prediction, we reanalyzed gene expression of fruitflies from the data of reference [18]. The measurements were performed at 6 adult ages, for two groups of Drosophila melanogaster : normally ('ad lib') fed control flies and calorically restricted (CR) flies. Figure 2 is a Principal Components (PC) analysis plot, in which each point represents the state of gene expression for one combination of age and diet. The first/horizontal principal component, PC1, is the variance of an empirically derived cluster of 19 genes, which strongly correlates with the age of adult animals in either of the two diet groups. Points on the extreme left correspond to the youngest flies, and points for older age-groups are displaced progressively to the right.
Thus, deviation of the gene expression profile from the healthy young state increases with age, indicating that the number and extent of dysregulated genes increases along with mortality. However, no flies in either diet group were able to survive to the right of a certain boundary, beyond which the accumulation of gene-expression abnormalities becomes incompatible with survival of the organism.
Interestingly, the variance along the second principal component, PC2, creates a distinct separation between the ad lib (control) and CR-fed flies, based on expression variance in a different subset of 18 genes. This, of course, cannot be explained with the help of our basic model, but the proper generalization of that model is described in [17]. It is of great interest, nevertheless, that the entire range of variation in the PC1 dimension was less for CR flies than for control flies, despite spanning a much greater range of ages.
## Genetic-network stability and stress resistance
Extreme longevity has long been associated with exceptional resistance to a variety of stresses. And conversely, the decrease of stress resistance with age is one of the best-established indices of aging. These phenomena can be explained using our simplified model. To apply the model to experimental data, we reanalyzed data from reference [19], in which flies of varying age were exposed to radiation during an exposure time T 1 ∼ 0 1 . day and the median lethal dose LD 50 was measured, corresponding to 50% lethality of flies over a subsequent period of T = 2 days . To model the experiment, we assumed that the animals were subjected to an external genotoxic stress at age t = t 0 for a duration T that is small compared to the lifespan of the animals. We solve Eqs. (3), (4) and show that for 'normally' aging animals, in which Λ > 0 , the dose required to produce 50% mortality decreases exponentially with age:
$$D _ { 5 0 } \sim \frac { \ln 2 } { \omega T } - \frac { F _ { 0 } } { \Lambda } \exp ( \Lambda t _ { 0 } ),$$
in qualitative agreement with the experimental data [19]. We interpret this to mean that stress resistance of 'normally' aging animals decreases progressively with age, and the average lifespan roughly corresponds to the age at which endogenous (or common exogenous) stresses alone are sufficient to cause death. At late ages, Λ t 0 glyph[greaterorsimilar] 1 , the total accumulated error load, e g ( ) t , becomes so large that the linear model defined by Eq. (3) and (4) fails. A more comprehensive analysis shows that LD 50 remains positive, but shrinks exponentially at the most advanced ages [17]. Eq.(8) also implies that measures of stress resistance should constitute robust biomarkers of aging.
We suggest that negligibly senescent organisms correspond to Λ < 0 . That situation can be achieved only if the repair systems efficacies are relatively strong. Moreover, the model predicts no further decrease with age in the lethal-stress dosage LD 50 beyond a threshold age, | Λ | t 0 glyph[greaterorsimilar] 1 . Both predictions are well supported by experimental data. It is known that negligibly senescent organisms are more stress resistant than shorter-lived ones [8]. For example, a comparison of survival between negligibly senescent vs. short-lived clam tissues treated with tert-butyl hydroperoxide showed much higher resistance to oxidative stress in long-lived clams [3]. Also Oxygen Radical Absorbance Capacity (ORAC) was measured in young and old clams of both types. The experiment showed an age-related decline in ORAC for shorter-lived clams, whereas ORAC did not change with age in tissues of negligibly-senescent clams, which is exactly what the model predicts for a negligibly-senescent animal.
The proposed model may be considered as a general theory that subsumes previous 'error catastrophe' theories [15, 16] as special cases. It was long considered that error catastrophes had been disproved by the following experiment [20]. Drosophila adults in experimental groups were treated for 3 -5 days with a number of agents shown to increase misincorporation into protein or RNA, at doses leading to <20% mortality. Although these treatments produced error rates much higher than were seen during aging of control flies, the misincorporation rates subsequently returned to control (pre-treatment) levels, and the average lifespans of survivors were indistinguishable from controls [20]. Remarkably, this is exactly the prediction from our model. Since mortality follows first-order kinetics over time, the mortality increase from a stress depends only on the current value of the stress. Thus, the solutions of Eqs. (1)-(3) predict the same average lifespan of all animals surviving any stressful treatment as for controls (although the average lifespan of the entire treated group would obviously be shortened by inclusion of animals that died during treatment). Of course, stresses that induce appropriate defenses may cause hormesis, but this is beyond the intended scope of our simplified linear model.
## Strategies for stabilization of genetic networks
Eq. (6) implies many possibilities to stabilize a regulatory network and thus extend lifespan, as summarized in Table I. According to Eq. (7), a reduction in genotoxic stress levels by isolation of genes from the environment can protect from direct stresses but can only produce a weak (logarithmic) increase in lifespan. Much stronger effects could be achieved by interventions aimed at increasing gene-network stability and hence reducing Λ . This can be accomplished, for example, if genes and their epigenetic states were isolated from regulatory signals, which equates to a decrease in β . This could be the reason why silencing of most signalling pathways which initially involve kinase cascades but mostly terminate in transcription factors - accompanies extraordinary longevity and stress resistance in C. elegans [21, 22]. Such defensive strategies appear to have been utilized during the course of evolution, e.g., in protecting mitochondrial genes by their transfer to the nuclear genome, and by establishment of the nuclear envelope, considered a major factor leading to the emergence of multicellular life.
The relation between aging and the accumulation of defects is not limited to defects in the proteome, but can readily be extended to defects in the metabolome, including lipid metabolites, and the glycome (both of which are largely regulated by proteins, and thus under the indirect control of genes). It also encompasses Mobile Genetic Elements (MGE), genomic insertions of DNA ranging in size from hundreds to many thousands of basepairs, interspersed throughout every mammalian genome (see a recent review [23]). Although derived from ancient DNAand RNA viruses, very few of these elements encode an active 'transposase', and most have accumulated too many mutations to be transposed (i.e., to jump within or between chromosomes) even in the presence of an active transposase, which may be transiently provided by an exogenous retrovirus. However, some MGEs are still mobile and thus highly mutagenic, either passively or actively. Being essentially defects in the transcriptome and interacting with the genome, this type of mutation fits our model very well. MGEs are abundant, covering approximately 30-50% of the human genome, and have been implicated as responsible for over 100 human genetic disorders including some cancers [24, 25]. Transposition of MGEs can be either cell-toxic or mutagenic, since they can disrupt essential genes or activate adjacent ones, so they may account for a significant proportion of spontaneous genome damage. Considering that MGEs evidently evolved from viruses, it is not surprising that equations similar to Eqs. (1)-(3) and the stability criterion similar to (6) have been identified to describe infectious disease dynamics and stability of the virus-host system [26, 27]. The hypothesis that MGEs play a significant role in mutagenesis and genomic instability predicts that lifespan may be increased by strategies aimed at reducing either MGE transposition or recombination
Table I: Possible lifespan extension strategies with relation to the gene network stability model parameters, and possible examples of their evolutionary deployment.
| The model parameter | Biological embodiment |
|----------------------------------------------------|-------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------|
| Coupling rate, β | Protective nuclear wall; transfer of mitochondrial genes to the nuclear genome; inhibition of MGE(RT) |
| 'Effective' genome size, G | Epigenetic inactivation of genes; tissue differentiation and specialization; temporal restriction of gene expression |
| Expressome (proteome, metabolome) turnover rate, c | Turnover/repair of proteins and metabolites: their dilution via cell division, asymmetric division; chaperones, proteasomes, and autophagosomes; metabolome turnover/maintenance; apoptosis (in multi-celled organisms) |
| DNA repair rate, δ | DNA repair; defenses against viruses and mobile genetic elements |
| Genotoxic stress level, f | Isolation from environment; suppression of ROS; dietary preferences and avoidance of noxious biomaterials; development of nocireceptors and learned responses |
rates, p or β , by inhibiting the enzymes such as transposases and reverse transcriptases (RTs), which mediate their mobility. This prediction has been validated for at least some species [28].
context [33] with very similar conclusions.
Turnover of the proteome or metabolome, c , and repair efficiency, δ , are factors shown to modulate lifespan in several species. Indeed, DNA repair pathways are encoded by hundreds of genes [29], that are variously involved in detection of DNA damage, enzymatic manipulation of damaged DNA, and homologous recombination between DNA strands, often permitting complete restoration of the original sequence even when portions have been lost from one chromatid or chromosome homolog [23]. A somewhat more surprising result is that both the proteome and genome repair rates, c and δ respectively, formally contribute to the result on an equal footing. This means that increasing protein turnover may help protect against DNA damage and vice versa . Increased protein turnover rates, as can result from increased ubiquitin-proteasome activity, have been demonstrated to result in increased longevity in yeast. Enhanced proteasomal activity confers a 70% increase in median and maximum replicative lifespan, comparable to the longest lived single gene deletions identified, and greater than the extension observed by deletion of TOR1 or over-expression of SIR2 [30].
Recent data reveal that the NMR has highly efficient protein degrading machinery and thereby maintains high levels of protein quality control, constantly degrading misfolded and damaged proteins, thus maintaining uniform steady-state levels throughout life [31]. Our model predicts that DNA repair efficiency, δ , is as important for lifespan extension as increases in the protein turnover rate, c . These NMR results are interesting because their exceptional longevity occurs despite the presence of chronic oxidative stress even at young ages [8, 32]. Remarkably the stability of the proteome and its relationship to lifespan were previously analyzed in a related
Cell division is a trivial way to rebuild the cell components and dilute expressome defects in half (symmetric division) or more (asymmetric division), especially relevant to yeast and continuously dividing tissues. This simple dilution principle links the protein turnover rate to cell division frequency, so that decreasing the protein turnover rate c , by inhibiting cell-cycling or by other means, may be used as a gene-network destabilization strategy for anti-cancer and antibiotic treatments [34].
In differentiated organisms there appear even more ways to maintain stability of the gene network. Metazoan (multi-tissued) animals have the ability to eliminate cells that have sufficiently damaged or unstable genomes, in a process called apoptosis, and replace them with healthy, stem cell-derived cells. Thus the repair rates c and δ also cover the contributions of these apoptotic and regeneration pathways. Moreover, as cells divide and differentiate to form new tissues and cell types, resulting in many different epigenetically stable states of the same genome, all of the model constants can also vary depending on the tissue involved. Thus our model clearly permits the instability and aging rates of different tissues to vary. This does not, however, alter the outcomes, which will reflect the vulnerability of the most unstable tissue on which animal survival depends - most probably, the stem-cell subsystem corresponding to the most renewal-dependent tissue within the body.
According to the stability requirement (6), large genomes are difficult to maintain. There are multiple ways to increase system stability by keeping the size of the expressed genome under control. One such strategy, clearly of ancient origin, is differentiation, wherein only a small fraction of the full genome is expressed by any one cell type at any point in time. Another possible way to regulate the stability of the genetic network is by modulating the degree of network connectivity. The robustness of a simulated gene network with respect to
external noise was recently shown to be associated with the connectivity of the network [35]. This compares very well with our stability condition Eq.(6), which predicts that a gene network becomes stable if the characteristic measure of network connectivity becomes sufficiently small: K < K 0 = cδ/ pβG ( ) . A recent study of longlived Myotis brandtii genomes found a wide range of genetic abnormalities in the GH/IGF1 axis [36]. Ablation of growth hormone signaling may produce a reduction of the effective network connectivity K , which thus could be one of several possible explanations for the extreme life expectancy of long-lived bats. All the above strategies are mathematically equivalent and exist in nature; indeed, there are cases in which multiple strategies are employed to increase lifespan [36].
## Conclusions and Prospects
In summary, we have provided a mathematical explanation for the dramatic variance in lifespans seen in the animal kingdom, relating this variance to geneticnetwork stability and resistance to stresses. We developed a model, which lets us define Gompertzian or 'normal' aging as an exponential accumulation of generegulation abnormalities rooted in the inherent instability of gene networks occurring under most common circumstances, and causing a progressive loss of stress resistance with age. This, in turn, produces susceptibility to age-related diseases (or may even cause their onset), and leads to death of an organism. This seems consistent with previously reported experimental mouse data indicating that epigenetic dysregulation contributes far more (by up to two orders of magnitude) to the loss of geneexpression integrity than somatic mutations alone [37]. On the other hand, gene-networks of animals with better transcription fidelity or other mechanisms of genomemaintenance are not only more stress-resistant, but under specific conditions may become stable and produce negligible senescence phenotype [38]. An even more im-
- [1] Finch, C. E. Longevity, senescence, and the genome (University of Chicago Press, 1994).
- [2] Abele, D., Strahl, J., Brey, T. & Philipp, E. E. Imperceptible senescence: ageing in the ocean quahog arctica islandica. Free radical research 42 , 474-480 (2008).
- [3] Ungvari, Z. et al. Extreme longevity is associated with increased resistance to oxidative stress in arctica islandica, the longest-living non-colonial animal. The Journals of Gerontology Series A: Biological Sciences and Medical Sciences 66 , 741-750 (2011).
- [4] Congdon, J., Nagle, R., Kinney, O. & van Loben Sels, R. Hypotheses of aging in a long-lived vertebrate, blanding's turtle ( Emydoidea blandingii ). Experimental Gerontology 36 , 813-827 (2001).
- [5] Congdon, J. D. et al. Testing hypotheses of aging in long-
portant corollary is that the gene networks of extremely stress-resistant animals (extremophiles) can still be unstable, because network stability is determined by the value of the combined parameter R 0 given by Eq. (6), and not directly by high c and δ rates.
The most important results of this study are Eq. (4), phenomenologically describing aging of a gene network, and the concept of fundamental genomic instability described by Eq. (6). We show that the lifespan of a species is determined by the stability of its most vulnerable gene network, coupled with its expressome in a realistic environment. Mathematically, there exist two types of solutions to Eq. (4), implying the possibility of both stable and unstable phases. We posit that the stable phase corresponds to negligible senescence and is robust with respect to environmental or endogenous noise. Although unstable gene networks exponentially accumulate gene expression errors and eventually disintegrate, the growth exponent is nevertheless small. We believe that Eq. (6) represents the same phase boundary previously identified in [39]. The critical dynamics of gene networks is a natural way to bridge the 'hierarchy of scales' problem, which is to explain how lifespans can greatly exceed the time scales characterizing any of the constituent processes in living cells. The genetic networks of most animals are inherently unstable and this leads to their aging. Since stabilization of gene networks can be favored in multiple ways, further research has the clear potential to create novel therapies to protect against the most morbid ageassociated diseases, and perhaps even against aging itself.
## Acknowledgments
The authors are grateful to A. Tarkhov, M. Kholin and S. Filonov from Quantum Pharmaceuticals, and also to Dr. D. Podolsky and M. Konovalenko, for comments and stimulating discussions; and to Prof. A. Moskalev for extensive advice.
- lived painted turtles ( Chrysemys picta ). Experimental gerontology 38 , 765-772 (2003).
- [6] Buffenstein, R. The naked mole-rat: a new long-living model for human aging research. The Journals of Gerontology Series A: Biological Sciences and Medical Sciences 60 , 1369-1377 (2005).
- [7] Edrey, Y., Park, T., Kang, H., Biney, A. & Buffenstein, R. Endocrine function and neurobiology of the longestliving rodent, the naked mole-rat. Experimental gerontology 46 , 116-123 (2011).
- [8] Lewis, K., Mele, J., Hornsby, P. & Buffenstein, R. Stress resistance in the naked mole-rat: The bare essentials-a mini-review. Gerontology 58 , 453-462 (2012).
- [9] Andziak, B. et al. High oxidative damage levels in the longest-living rodent, the naked mole-rat. Aging cell 5 ,
463-471 (2006).
- [10] Tacutu, R. et al. Human ageing genomic resources: Integrated databases and tools for the biology and genetics of ageing. Nucleic acids research 41 , D1027-D1033 (2013).
- [11] Gompertz, B. On the nature of the function expressive of the law of human mortality, and on a new mode of determining the value of life contingencies. Philosophical transactions of the royal society of London 115 , 513-583 (1825).
- [12] Ebert, T. A. Longevity and lack of senescence in the red sea urchin Strongylocentrotus franciscanus . Experimental gerontology 43 , 734-738 (2008).
- [13] Jeannette Loram, A. B. Age-related changes in gene expression in tissues of the sea urchin Strongylocentrotus franciscanus . Mechanisms of Ageing and Development 133 , 338-347 (2012).
- [14] Kim, E. B. et al. Genome sequencing reveals insights into physiology and longevity of the naked mole rat. Nature 479 , 223-227 (2011).
- [15] Ohgkl, L. The maintenance of the accuracy of protein synthesis and its relevance to ageing. Fidelity of Protein Synthesis & Transfer RNA During Aging 2 , 55 (1974).
- [16] Orgel, L. E. The maintenance of the accuracy of protein synthesis and its relevance to aging. Science of Aging Knowledge Environment 2001 , 8 (2001).
- [17] Molodtsov, I., Kogan, V., Podolsky, D., Menshikov, L. & Fedichev, P. To be published.
- [18] Pletcher, S. D. et al. Genome-wide transcript profiles in aging and calorically restricted Drosophila melanogaster . Current Biology 12 , 712-723 (2002).
- [19] Parashar, V., Frankel, S., Lurie, A. G. & Rogina, B. The effects of age on radiation resistance and oxidative stress in adult drosophila melanogaster. Radiation research 169 , 707-711 (2008).
- [20] Reis, R. J. S. Enzyme fidelity and metazoan ageing. Interdiscip. Top. Gerontol 10 , 11-23 (1976).
- [21] Tazearslan, Ç., Ayyadevara, S., Bharill, P. & Reis, R. J. S. Positive feedback between transcriptional and kinase suppression in nematodes with extraordinary longevity and stress resistance. PLoS genetics 5 , e1000452 (2009).
- [22] Ayyadevara, S., Alla, R., Thaden, J. J. & Shmookler Reis, R. J. Remarkable longevity and stress resistance of nematode pi3k-null mutants. Aging cell 7 , 13-22 (2008).
- [23] Moskalev, A. et al. The role of dna damage and repair in aging through the prism of koch-like criteria. Ageing Research Reviews (2012).
- [24] Xing, J., Witherspoon, D., Ray, D., Batzer, M. & Jorde, L. Mobile dna elements in primate and human evolution. American journal of physical anthropology 134 , 219 (2007).
- [25] Belancio, V., Roy-Engel, A., Pochampally, R. & Deininger, P. Somatic expression of line-1 elements in human tissues. Nucleic acids research 38 , 3909-3922 (2010).
- [26] Perelson, A. Modelling viral and immune system dynamics. Nature Reviews Immunology 2 , 28-36 (2002).
- [27] Baccam, P., Beauchemin, C., Macken, C., Hayden, F. & Perelson, A. Kinetics of influenza a virus infection in humans. Journal of Virology 80 , 7590-7599 (2006).
- [28] Driver, C. J. & Vogrig, D. J. Apparent retardation of aging in drosophila melanogaster by inhibitors of reverse transcriptase. Annals of the New York Academy of Sciences 717 , 189-197 (1994).
- [29] Milanowska, K. et al. Repairoire -a database of dna repair pathways. Nucleic acids research 39 , D788-D792 (2011).
- [30] Kruegel, U. et al. Elevated proteasome capacity extends replicative lifespan in saccharomyces cerevisiae. PLoS genetics 7 , e1002253 (2011).
- [31] Pérez, V. I. et al. Protein stability and resistance to oxidative stress are determinants of longevity in the longestliving rodent, the naked mole-rat. Proceedings of the National Academy of Sciences 106 , 3059-3064 (2009).
- [32] Rodriguez, K., Edrey, Y., Osmulski, P., Gaczynska, M. & Buffenstein, R. Altered composition of liver proteasome assemblies contributes to enhanced proteasome activity in the exceptionally long-lived naked mole-rat. PloS one 7 , e35890 (2012).
- [33] Ryazanov, A. & Nefsky, B. Protein turnover plays a key role in aging. Mechanisms of ageing and development 123 , 207-213 (2002).
- [34] Dickson, M. & Schwartz, G. Development of cell-cycle inhibitors for cancer therapy. Current Oncology 16 , 36 (2009).
- [35] Peixoto, T. Emergence of robustness against noise: A structural phase transition in evolved models of gene regulatory networks. Phys. Rev. E 85 , 041908 (2012). Arxiv preprint arXiv:1108.4341.
- [36] Seim, I. et al. Genome analysis reveals insights into physiology and longevity of the brandt's bat myotis brandtii. Nature communications 4 (2013).
- [37] Li, W. & Vijg, J. Measuring genome instability in aging-a mini-review. Gerontology 58 , 129-138 (2012).
- [38] Azpurua, J. et al. Naked mole-rat has increased translational fidelity compared with the mouse, as well as a unique 28s ribosomal rna cleavage. Proceedings of the National Academy of Sciences 110 , 17350-17355 (2013).
- [39] Balleza, E. et al. Critical dynamics in genetic regulatory networks: examples from four kingdoms. PLoS One 3 , e2456 (2008). | 10.1038/srep13589 | [
"Valeria Kogan",
"Ivan Molodtcov",
"Leonid I. Menshikov",
"Robert J. Shmookler Reis",
"Peter Fedichev"
] | 2014-08-03T07:14:09+00:00 | 2014-08-03T07:14:09+00:00 | [
"q-bio.MN"
] | Stability analysis of a model gene network links aging, stress resistance, and negligible senescence | Several animal species are considered to exhibit what is called negligible
senescence, i.e. they do not show signs of functional decline or any increase
of mortality with age, and do not have measurable reductions in reproductive
capacity with age. Recent studies in Naked Mole Rat (NMR) and long- lived sea
urchin showed that the level of gene expression changes with age is lower than
in other organisms. These phenotypic observations correlate well with
exceptional endurance of NMR tissues to various genotoxic stresses. Therefore,
the lifelong transcriptional stability of an organism may be a key determinant
of longevity. However, the exact relation between genetic network stability,
stress-resistance and aging has not been defined. We analyze the stability of a
simple genetic- network model of a living organism under the influence of
external and endogenous factors. We demonstrate that under most common
circumstances a gene network is inherently unstable and suffers from
exponential accumulation of gene-regulation deviations leading to death.
However, should the repair systems be sufficiently effective, the gene network
can stabilize so that gene damage remains constrained along with mortality of
the organism, which may then enjoy a remarkable degree of stability over very
long times. We clarify the relation between stress-resistance and aging and
suggest that stabilization of the genetic network may provide a mathematical
explanation of the Gompertz equation describing the relationship between age
and mortality in many species, and of the apparently negligible senescence
observed in exceptionally long-lived animals. The model may support a range of
applications, such as systematic searches for therapeutics to extend lifespan
and healthspan. |
1408.0464v1 | ## DECOUPLING SHRINKAGE AND SELECTION IN BAYESIAN LINEAR MODELS: A POSTERIOR SUMMARY PERSPECTIVE
By P. Richard Hahn and Carlos M. Carvalho
Booth School of Business and McCombs School of Business
Selecting a subset of variables for linear models remains an active area of research. This paper reviews many of the recent contributions to the Bayesian model selection and shrinkage prior literature. A posterior variable selection summary is proposed, which distills a full posterior distribution over regression coefficients into a sequence of sparse linear predictors.
- 1. Introduction. This paper revisits the venerable problem of variable selection in linear models. The vantage point throughout is Bayesian: a normal likelihood is assumed and inferences are based on the posterior distribution, which is arrived at by conditioning on observed data.
In applied regression analysis, a 'high-dimensional' linear model can be one which involves tens or hundreds of variables, especially when seeking to compute a full Bayesian posterior distribution. Our review will be from the perspective of a data analyst facing a problem in this 'moderate' regime. Likewise, we focus on the situation where the number of predictor variables, p , is fixed.
In contrast to other recent papers surveying the large body of literature on Bayesian variable selection [Liang et al., 2008, Bayarri et al., 2012] and shrinkage priors [O'Hara and Sillanp¨¨, 2009, aa Polson and Scott, 2012], our review focuses specifically on the relationship between variable selection priors and shrinkage priors. Selection priors and shrinkage priors are related both by the statistical ends they attempt to serve (e.g., strong regularization and efficient estimation) and also in the technical means they use to achieve these goals (hierarchical priors with local scale parameters). We also compare these approaches on computational considerations.
Finally, we turn to variable selection as a problem of posterior summarization. We argue that if variable selection is desired primarily for parsimonious communication of linear trends in the data, that this can be accomplished as a post-inference operation irrespective of the choice of prior distribution. To this end, we introduce a posterior variable selection summary, which distills a full
Keywords and phrases: decision theory, linear regression, loss function, model selection, parsimony, shrinkage prior, sparsity, variable selection.
posterior distribution over regression coefficients into a sequence of sparse linear predictors. In this sense 'shrinkage' is decoupled from 'selection'.
We begin by describing the two most common approaches to this scenario and show how the two approaches can be seen as special cases of an encompassing formalism.
1.1. Bayesian model selection formalism. A now-canonical way to formalize variable selection in Bayesian linear models is as follows. Let M φ denote a normal linear regression model indexed by a vector of binary indicators φ = ( φ , . . . , φ 1 p ) ∈ { 0 1 , } p signifying which predictors are included in the regression. Model M φ defines the data distribution as
$$( 1 ) & & ( Y _ { i } | \mathcal { M } _ { \phi }, \beta _ { \phi }, \sigma ^ { 2 } ) \sim N ( X _ { i } ^ { \phi } \beta _ { \phi }, \sigma ^ { 2 } )$$
where X φ i represents the p φ -vector of predictors in model M φ . Given a sample Y = ( Y , . . . , Y 1 n ) and prior π β , σ ( φ 2 ), the inferential target is the set of posterior model probabilities defined by
$$p ( \mathcal { M } _ { \phi } \, | \, \mathbf Y ) = \frac { p ( \mathbf Y \, | \, \mathcal { M } _ { \phi } ) p ( \mathcal { M } _ { \phi } ) } { \sum _ { \phi } p ( \mathbf Y \, | \, \mathcal { M } _ { \phi } ) p ( \mathcal { M } _ { \phi } ) },$$
where p ( Y | M φ ) = ∫ p ( Y | M φ , β φ , σ 2 ) π β , σ ( φ 2 ) dβ dσ φ 2 is the marginal likelihood of model M φ and p ( M φ ) is the prior over models.
Posterior inferences concerning a quantity of interest ∆ are obtained via Bayesian model averaging (or BMA), which entails integrating over the model space
$$p ( \Delta \, | \, \mathbf Y ) = \sum _ { \phi } p ( \Delta \, | \, \mathcal { M } _ { \phi }, \mathbf Y ) p ( \mathcal { M } _ { \phi } \, | \, \mathbf Y ).$$
As an example, optimal predictions of future values of ˜ Y under squared-error loss are defined through
$$E ( \tilde { Y } \, | \, \mathbf Y ) \equiv \sum _ { \phi } E ( \tilde { Y } \, | \, \mathcal { M } _ { \phi }, \mathbf Y ) p ( \mathcal { M } _ { \phi } \, | \, \mathbf Y ).$$
An early reference adopting this formulation is Raftery et al. [1997]; see also Clyde and George [2004].
Despite its straightforwardness, carrying out variable selection in this framework demands attention to detail: priors over model-specific parameters must be specified, priors over models must be chosen, marginal likelihood calculations must be performed and a 2 -dimensional discrete space p must be explored. These concerns have animated Bayesian research in linear model variable selection for the past two decades.
Regarding model parameters, the consensus default prior for model parameters is π β , σ ( φ 2 ) = π β ( | σ 2 ) π σ ( 2 ) = N (0 , g Ω) × σ -1 . The most widely-studied choice of prior covariance is Ω = σ 2 ( X X t φ φ ) -1 , referred to as 'Zellner's g -prior' [Zellner, 1986], a ' g -type' prior or simply g -prior. Notice that this choice of Ω dictates that the prior and likelihood are conjugate normal-inversegamma pairs (for a fixed value of g ).
For reasons detailed in Liang et al. [2008], it is advised to place a prior on g rather than use a fixed value. Several recent papers describe priors p g ( ) that still lead to efficient computations of marginal likelihoods; see Liang et al. [2008], Maruyama and George [2011], and Bayarri et al. [2012]. Each of these papers (as well as the earlier literature cited therein) study priors of the form
$$p ( g ) \in g ^ { d } ( g + b ) ^ { - ( a + c + d + 1 ) }$$
with a > 0, b > 0, c > -1, and d > -1. (The support of g will be lower bounded by a function of the hyper parameter b .) Specific configurations of these hyper parameters recommended in the literature include: { a = 1 , b = 1 , d = 0 } [Cui and George, 2008], { a = 1 2 / , b = 1 ( b = n , c ) = 0 , d = 0 } [Liang et al., 2008], and { c = -3 4 / , d = ( n -5) / 2 -p φ / 2 + 3 / 4 } [Maruyama and George, 2011].
Bayarri et al. [2012] motivates the use of such priors from a formal testing perspective, using a variety of intuitive desiderata. Regarding prior model probabilities see Scott and Berger [2010], who recommend a hierarchical prior of the form φ j iid ∼ Ber( ), q q ∼ Unif(0 1). ,
1.2. Shrinkage regularization priors. Although the formulation above provides a valuable theoretical framework, it does not necessarily represent an applied statistician's first choice. To assess which variables contribute dominantly to trends in the data, the goal may be simply to mitigaterather than categorize-spurious correlations. Thus, faced with many potentially irrelevant predictor variables, a common first choice would be a powerful regularization prior .
Regularization - understood here as the intentional biasing of an estimate to stabilize posterior inference - is inherent to most Bayesian estimators via the use of proper prior distributions and is one of the often-cited advantages of the Bayesian approach. More specifically, regularization priors refer to priors explicitly designed with a strong bias for the purpose of separating reliable from spurious patterns in the data. In linear models, this strategy takes the form of zero-centered priors with sharp modes and simultaneously fat tails.
A well-studied class of priors fitting this description will serve to connect continuous priors to the model selection priors described above. Local scale mixture of normal distributions are of the
form
$$\pi ( \beta _ { j } \, | \, \lambda ) = \int N ( \beta _ { j } \, | \, 0, \lambda ^ { 2 } \lambda _ { j } ^ { 2 } ) \pi ( \lambda _ { j } ^ { 2 } ) d \lambda _ { j },$$
where different priors are derived from different choices for π λ ( 2 j ).
The last several years have seen tremendous interest in this area, motivated by an analogy with penalized-likelihood methods [Tibshirani, 1996]. Penalized likelihood methods with an additive penalty term lead to estimating equations of the form
$$\sum _ { i } h ( Y _ { i }, { \mathbf x } _ { i }, \beta ) + \alpha Q ( \beta )$$
where h and Q are positive functions and their sum is to be minimized; α is a scalar tuning variable dictating the strength of the penalty. Typically, h is interpreted as a negative log-likelihood, given data Y , and Q is a penalty term introduced to stabilize maximum likelihood estimation. A common choice is Q β ( ) = || β || 1 , which yields sparse optimal solutions β ∗ and admits fast computation [Tibshirani, 1996]; this choice underpins the lasso estimator, a mnemonic for 'least absolute shrinkage and selection operator'.
Park and Casella [2008] and Hans [2009] 'Bayesified' these expressions by interpreting Q β ( ) as the negative log prior density and developing algorithms for sampling from the resulting Bayesian posterior, building upon work of earlier Bayesian authors [Spiegelhalter, 1977, West, 1987, Pericchi and Walley, 1991, Pericchi and Smith, 1992]. Specifically, an exponential prior π λ ( 2 j ) = Exp( α 2 ) leads to independent Laplace (double-exponential) priors on the β j , mirroring expression (7).
This approach has two implications unique to the Bayesian paradigm. First, it presented an opportunity to treat the global scale parameter λ (equivalently the regularization penalty parameter α ) as a hyper parameter to be estimated. Averaging over λ in the Bayesian paradigm has been empirically observed to give better prediction performance than cross-validated selection of α (e.g., Hans [2009]). Second, a Bayesian approach necessitates forming point estimators from posterior distributions; typically the posterior mean is adopted on the basis that it minimizes mean squared prediction error. Note that posterior mean regression coefficient vectors from these models are nonsparse with probability one. Ironically, the two main appeals of the penalized likelihood methodsefficient computation and sparse solution vectors β ∗ -were lost in the migration to a Bayesian approach.
Nonetheless, wide interest in 'Bayesian lasso' models paved the way for more general local shrinkage regularization priors of the form (6). In particular, Carvalho et al. [2010] develops a
prior over location parameters that attempts to shrink irrelevant signals strongly toward zero while avoiding excessive shrinkage of relevant signals. To contextualize this aim, recall that solutions to glyph[lscript] 1 penalized likelihood problems are often interpreted as (convex) approximations to more challenging formulations based on glyph[lscript] 0 penalties. As such, it was observed that the global glyph[lscript] 1 penalty 'overshrinks' what ought to be large magnitude coefficients. The Carvalho et al. [2010] prior may be written as
$$\pi ( \beta _ { j } \ | \ \lambda ) & = N ( 0, \lambda ^ { 2 } \lambda _ { j } ^ { 2 } ), \\ \lambda _ { j } \stackrel { \text{ifId} } { \sim } C ^ { + } ( 0, 1 ).$$
with λ ∼ C + (0 1) or , λ ∼ C + (0 , σ 2 ). The choice of half-Cauchy arises from the insight that for scalar observations y j ∼ N ( θ , j 1) and prior θ j ∼ N (0 , λ 2 j ), the posterior mean of θ j may be expressed:
$$\mathbf E ( \theta _ { j } \ | \ y _ { j } ) = \{ 1 - \mathbf E ( \kappa _ { j } \ | \ y _ { j } ) \} y _ { j },$$
where κ j = 1 (1 + / λ 2 j ). The authors observe that U-shaped Beta(1/2,1/2) distributions (like a horseshoe) on κ j imply a prior over θ j with high mass around the origin but with polynomial tails. That is, the 'horseshoe' prior encodes the assumption that some coefficients will be very large and many others will be very nearly zero. This U-shaped prior on κ j implies the half-cauchy prior density π λ ( j ). The implied prior on β has Cauchy-like tails and a pole at the origin which entails more aggressive shrinkage than a Laplace prior.
Other choices of π λ ( j ) lead to different 'shrinkage profiles' on the ' κ scale'. Polson and Scott [2012] provides an excellent taxonomy of the various priors over β that can be obtained as scalemixtures of normals. The horseshoe and similar priors (e.g., Griffin and Brown [2012]) have proven empirically to be fine default choices for regression coefficients: they lack hyper parameters, forcefully separate strong from weak predictors, and exhibit robust predictive performance.
1.3. Model selection priors as shrinkage priors. It is possible to express model selection priors as shrinkage priors. To motivate this re-framing, observe that the posterior mean regression coefficient vector is not well-defined in the model selection framework. Using the model-averaging notion, the posterior average β may be be defined as:
$$E ( \beta \, | \, \mathbf Y ) \equiv \sum _ { \phi } E ( \beta \, | \, \mathcal { M } _ { \phi }, \mathbf Y ) p ( \mathcal { M } _ { \phi } \, | \, \mathbf Y ),$$
where E( β j | M φ , Y ) ≡ 0 whenever φ j = 0. Without this definition, the posterior expectation of β j is undefined in models where the j th predictor does not appear. More specifically, as the likelihood is constant in variable j in such models, the posterior remains whatever the prior was chosen to be.
To fully resolve this indeterminacy, it is common to set β j identically equal to zero in models where the j th predictor does not appear, consistent with the interpretation that β j ≡ ∂ E( Y ) /∂X j . A hierarchical prior reflecting this choice may be expressed
$$\pi ( \beta \, | \, \sigma ^ { 2 }, \phi ) = N ( 0, g \Lambda \Omega \Lambda ^ { t } )$$
where Λ ≡ diag(( λ , λ 1 2 , . . . , λ p )) and Ω is a positive semi-definite matrix that may depend on φ and/or σ 2 . When Ω is the identity matrix, one recovers (6). To fix β j = 0 when φ j = 0, let λ j ≡ φ s j j for s j > 0, so that when φ j = 0, the prior variance of β j is set to zero (with prior mean of zero). George and McCulloch [1997] develops this approach in detail, including the g -prior specification, Ω( φ ) = σ 2 ( X X t φ φ ) -1 .
Such priors imply that marginally (but not necessarily independently), for j = 1 , . . . , p ,
$$\pi ( \beta _ { j } \ | \ \phi _ { j }, \sigma ^ { 2 }, g, s _ { j } ) = ( 1 - \phi _ { j } ) \delta _ { 0 } + \phi _ { j } N ( 0, g s _ { j } ^ { 2 } \omega _ { j } ),$$
where δ 0 denotes a point mass distribution at zero. Hierarchical priors of this form are sometimes called 'spike-and-slab' priors ( δ 0 is the spike and the continuous full-support distribution is the slab) or the 'two-groups model' for variable selection. References for this specification include Mitchell and Beauchamp [1988] and Geweke et al. [1996], among others.
Note that the spike-and-slab approach can be expressed in terms of the prior over λ j , by integrating over φ :
$$\pi ( \lambda _ { j } \ | \ q ) & = ( 1 - q ) \delta _ { 0 } + q P _ { \lambda _ { j } },$$
where Pr( φ j = 1) = q , and P λ j is some continuous distribution on R + . Of course, q can be given a prior distribution as well; a uniform distribution is common. This representation transparently embeds model selection priors within the class of local scale mixture of normal distributions. An important paper exploring the connections between shrinkage priors and model selection priors is Ishwaran and Rao [2005], who consider a version of (11) via a specification of π λ ( j ) which is bimodal with one peak at zero and one peak away from zero. In many respects, this paper anticipated the work of Park and Casella [2008], Hans [2009], Carvalho et al. [2010], Griffin and Brown [2012], Polson and Scott [2012] and the like.
1.4. Computational issues in variable selection. Because posterior sampling is computationintensive and because variable selection is most desirable in contexts with many predictor variables,
computational considerations are important in motivating and evaluating the approaches above. The discrete model selection approach and the continuous shrinkage prior approach are both quite challenging in terms of posterior sampling.
In the model selection setting, for p > 30, enumerating all possible models (to compute marginal likelihoods, for example) is beyond the reach of modern capability. As such, stochastic exploration of the model space is required, with the hope that the unvisited models comprise a vanishingly small fraction of the posterior probability. George and McCulloch [1997] is frank about this limitation; noting that a Markov Chain run of length less than 2 p cannot have visited each model even once, they write hopefully that 'it may thus be possible to identify at least some of the high probability values'.
Garcia-Donato and Martinez-Beneito [2013] carefully evaluates methods for dealing with this problem and come to compelling conclusions in favor of some methods over others. Their analysis is beyond the scope of this paper, but we count it as required reading for anyone interested in the variable selection problem in large p settings. In broad strokes, they find that MCMC approaches based on Gibbs samplers (i.e., George and McCulloch [1997]) appear better at estimating posterior quantities-such as the highest probability model, the median probability model, etc-compared to methods based on sampling without replacement (i.e., Hans et al. [2007] and Clyde et al. [2011]).
Regarding shrinkage priors, there is no systematic study in the literature suggesting that the above computational problems are alleviated for continuous parameters. In fact, the results of Garcia-Donato and Martinez-Beneito [2013] (see section 6) suggest that posterior sampling in finite sample spaces is easier than the corresponding problem for continuous parameters, in that convergence to stationarity occurs more rapidly.
Moreover, if one is willing to entertain an extreme prior with π φ ( ) = 0 for || φ || 0 > M for a given constant M , model selection priors offer a tremendous practical benefit: one never has to invert a matrix larger than M × M , rather than the p × p dimensional inversions required of a shrinkage prior approach. Similarly, only vectors up to size M need to be saved in memory and operated upon. In extremely large problems, with thousands of variables, setting M = O √ ( p ) or M = O (log p ) saves considerable computational effort. For example, this approach is routinely applied to large scale internet data. Should M be chosen too small, little can be said; if M truly represents one's computational budget, the best model of size M will have to do.
1.5. Selection: from posteriors to sparsity. Identifying sparse models (subsets of non-zero coefficients) might be an end in itself, as in the case of trying to isolate scientifically important variables in the context of a controlled experiment. In this case, a prior with point-mass probabilities at the origin is unavoidable in terms of defining the implicit (multiple) testing problem. Furthermore, the use of Bayes factors is a well-established methodology for evaluating evidence in the data in favor of various hypotheses. Indeed, the highest posterior probability model (HPM) is optimal under 0-1 (classification) loss for the selection of each variable.
If the goal, rather than isolating all and only relevant variables (no matter their absolute size), is to accurately describe the 'important' relationships between predictors and response, then perhaps the model selection route is purely a means to an end. In this context, a natural question is how to fashion a sparse vector of regression coefficients which parsimoniously characterizes the available data. Leamer [1978] is a notable early effort advocating ad-hoc model selection for the purpose of human comprehensibility. Fouskakis and Draper [2008], Fouskakis et al. [2009] and Draper [2013] represent efforts to define variable importance in real-world terms using subject matter considerations. A more generic approach is to gauge predictive relevance [Gelfand et al., 1992].
A widely cited result relating variable selection to predictive accuracy is that of Barbieri and Berger [2004]. Consider mean squared prediction error (MSPE), n -1 E { ∑ i ( ˜ Y i -˜ ˆ ) X β i 2 } , and recall that the model-specific optimal regression vector is ˆ β φ ≡ E( β | M φ , Y ). Barbieri and Berger [2004] show that for X X t diagonal, the best predicting model according to MSPE is the model which includes all and only variables with marginal posterior inclusion probabilities greater than 1/2. This model is referred to as the median probability model (MPM). Their result holds both for a fixed design ˜ X of prediction points or for stochastic predictors with E { ˜ X X t ˜ } diagonal. However, the main condition of their theorem X X t diagonal - is almost never satisfied in practice. Nonetheless, they argue that the median probability model (MPM) tends to outperform the HPM on out-of-sample prediction tasks. Note that the HPM and MPM are often substantially different models, especially in the case of strong dependence among predictors.
George and McCulloch [1997] suggest an alternative approach, which is to specify a two-point shrinkage prior directly in terms of 'practical significance'. Specifically they propose
$$\Pr ( \lambda _ { j } = s _ { 1 } ) = q ; \ \Pr ( \lambda _ { j } = s _ { 2 } ) = ( 1 - q ),$$
where s 1 is a 'large' value reflecting vague prior information about the magnitude of β j , and s 2 is
a 'small' value which biases β j more strongly towards zero. They suggest setting s 1 and s 2 such that the prior (mean zero normal) densities are equal at a point d j = ∆ Y/ ∆ X j where '∆ Y is the size of an insignificant change in Y , and ∆ X i is the size of the maximum feasible change in X j .' This choice entails that the posterior probability Pr( λ j = s 2 | Y ) can be interpreted as the inferred probability that β j is practically significant. However, this approach does not provide a way to interpret the dependencies that arise in the posterior between the elements of λ , . . . , λ 1 p .
A similar approach, called hard thresholding , can be employed even if π λ ( j ) has a continuous density, by stating a classification rule based on posterior samples of β j and λ j . For example, Carvalho et al. [2010] suggest setting to zero those coefficients for which
$$\mathbf E ( \kappa _ { j } = 1 / ( 1 + \lambda _ { j } ^ { 2 } ) \, | \, \mathbf Y ) < 1 / 2.$$
Ishwaran and Rao [2005] discuss a variety of thresholding rules and relate them to conventional thresholding rules based on ordinary least squares estimates of β . As with the approach of George and McCulloch [1997], thresholding approaches do not account for dependencies between the various κ variables across predictors, as they are applied marginally. Indeed, as in Barbieri and Berger [2004], the theoretical results of Ishwaran and Rao [2005] treat only the orthogonal design case.
- 2. Posterior summary variable selection. None of the priors canvassed above, in themselves, provide sparse model summaries. To go from a posterior distribution to a sparse point estimate requires an additional step, regardless of what prior is used. Commonly studied approaches tend to neglect posterior dependencies between regression coefficients β , j j = 1 , . . . , p (equivalently, their associated scale factors λ j ).
In this section we describe a posterior summary based on an expected loss minimization problem. The loss function is designed to balance prediction ability (in the sense of mean square prediction error) and narrative parsimony (in the sense of sparsity). The new summary checks three important boxes:
- · it produces sparse vectors of regression coefficients for prediction,
- · it can be applied to a posterior distribution arising from any prior distribution,
- · it explicitly accounts for co-linearity in the matrix of prediction points and dependencies in the posterior distribution of β .
- 2.1. The cost of measuring irrelevant variables. Suppose that collecting information on individual covariates incurs some cost; thus the goal is to make an accurate enough prediction subject to
a penalty for acquiring predictively irrelevant facts.
Consider the problem of predicting an n -vector of future observables ˜ Y ∼ N ( ˜ X β, σ 2 I ) at a prespecified set of design points ˜ . Assume that a posterior distribution over the model parameters ( X β , σ 2 ) has been obtained via Bayesian conditioning, given past data Y and design matrix X ; denote the density of this posterior by π β, σ ( 2 | Y ).
It is crucial to note that ˜ X and X need not be the same. That is, the locations in predictor space where one wants to predict need not be the same points at which one has already observed past data. For notational simplicity, we will write X instead of ˜ X in what follows. Of course, taking ˜ X = X is a conventional choice, but distinguishing between the two becomes important in certain cases such as when p > n .
Define an optimal action as one which minimizes expected loss E( L ( ˜ Y , γ )), where the expectation is taken over the predictive distribution of unobserved values:
$$f ( \tilde { Y } ) & = \, \int f ( \tilde { Y } \, | \, \beta, \sigma ^ { 2 } ) \pi ( \beta, \sigma ^ { 2 } \, | \, \mathbf Y ) d ( \beta, \sigma ^ { 2 } ).$$
As a widely applicable loss function, consider
$$\mathcal { L } ( \tilde { Y }, \gamma ) & = \lambda | | \gamma | | _ { 0 } + n ^ { - 1 } | | \mathbf X \gamma - \tilde { Y } | | _ { 2 } ^ { 2 },$$
glyph[negationslash]
where || · || 0 = ∑ j 1 ( γ j = 0). This loss sums two components, one of which is a 'parsimony penalty' on the action γ and the other of which is the squared prediction loss of the linear predictor defined by γ . The scalar utility parameter λ dictates how severely we penalize each of these two components, relatively. Integrating over ˜ Y conditional on ( β, σ 2 ) (and overloading the notation of L ) gives
$$\mathcal { L } ( \beta, \sigma, \gamma ) \equiv \mathbb { E } ( \mathcal { L } ( \tilde { Y }, \gamma ) ) = \lambda | | \gamma | | _ { 0 } + n ^ { - 1 } | | \mathbf X \gamma - \mathbf X \beta | | _ { 2 } ^ { 2 } + \sigma ^ { 2 }.$$
Because ( β, σ 2 ) are unknown, an additional integration over π β, σ ( 2 | Y ) yields
$$\mathcal { L } ( \gamma ) \equiv \mathrm E ( \mathcal { L } ( \beta, \sigma, \gamma ) ) = \lambda | | \gamma | | _ { 0 } + \bar { \sigma } ^ { 2 } + n ^ { - 1 } \text{tr} ( \mathbf X ^ { t } \mathbf X \Sigma _ { \beta } ) + n ^ { - 1 } | | \mathbf X \bar { \beta } - \mathbf X \gamma | | _ { 2 } ^ { 2 },$$
where ¯ σ 2 = E( σ 2 ), ¯ = E( β β ) and Σ β = Cov( β ).
Dropping constant terms, one arrives at the 'decoupled shrinkage and selection' (DSS) loss function:
$$\mathcal { L } ( \gamma ) & = \lambda | | \gamma | | _ { 0 } + n ^ { - 1 } | | \mathbf X \bar { \beta } - \mathbf X \gamma | | _ { 2 } ^ { 2 }.$$
Optimization of the DSS loss function is a combinatorial programming problem depending on the posterior distribution via the posterior mean of β . The optimal solution of (19) therefore represents a 'sparsification' of ¯ , β which is the theoretically optimal action under pure squared prediction loss. In this sense, the DSS loss function explicitly trades off the number of variables in the linear predictor with its resulting predictive performance. Denote this optimal solution by
$$\beta _ { \lambda } \equiv \arg \min _ { \gamma } \ \lambda | | \gamma | | _ { 0 } + n ^ { - 1 } | | \mathbf X \bar { \beta } - \mathbf X \gamma | | _ { 2 } ^ { 2 }.$$
Note that the above derivation applies straightforwardly to the selection prior setting via expression (10) or (equivalently) via the hierarchical formulation in (12), which guarantee that ¯ is well β defined marginally across different models.
2.2. Analogy with high posterior density regions. Although orthographically (19) resembles expressions used in penalized likelihood methods, the better analogy is a Bayesian high posterior density (HPD) region. Like HPD regions, a DSS summary satisfies a 'comprehensibility criterion'; an HPD interval gives the shortest contiguous interval encompassing some fixed fraction of the posterior mass, while the DSS summary produces the sparsest linear predictor which still has reasonable prediction performance. Like HPD regions, DSS summaries are well defined under any given prior.
To amplify, the DSS optimization problem is well-defined for any posterior as long as ¯ exists. β Different priors may lead to very different posteriors, potentially with very different means. However, regardless of the precise nature of the posterior (e.g., the presence of multimodality), ¯ β is the optimal summary under squared-error prediction loss, which entails that expression (20) represents the sparsified solution to the optimization problem given in (16).
An important implication of this analogy is the realization that a DSS summary can be produced for a prior distribution directly, in the same way that a prior distribution has a high posterior density region. The DSS summary requires the user to specify a matrix of prediction points ˜ , but X conditional on this choice one can extract sparse linear predictors directly from a prior distribution.
In Section 3, we discuss strategies for using additional features of the posterior π β, σ ( 2 | Y ) to guide the choice of picking λ .
2.3. Computing and approximating β λ . The counting penalty || γ || 0 yields an intractable optimization problem for even tens of variables ( p ≈ 30). This problem has been addressed in recent
years by approximating the counting norm with modifications of the glyph[lscript] 1 norm, || γ || 1 = ∑ h | γ h | , leading to a surrogate loss function which is convex and readily minimized by a variety of software packages. Crucially, such approximations still yield a sequence of sparse actions (the solution path as a function of λ ), simplifying the 2 p dimensional selection problem to a choice between at most p alternatives. The goodness of these approximations is a natural and relevant concern. Note, however, that the goodness of approximation is entirely non-statistical-the statistical side of the problem has been separately addressed in the formation of the posterior distribution. This is what is meant by 'decoupled' shrinkage and selection.
More specifically, recall that DSS requires the evaluation of the optimal solution
$$\beta _ { \lambda } \equiv \arg \min _ { \gamma } \ \lambda | | \gamma | | _ { 0 } + n ^ { - 1 } | | \mathbf X \bar { \beta } - \mathbf X \gamma | | _ { 2 } ^ { 2 }.$$
The most simplistic and yet widely-used approximation is to substitute the glyph[lscript] 0 by the glyph[lscript] 1 norm, which leads to a convex optimization problem for which many implementations are available, in particular the lars algorithm (Efron et al. [2004]). Using this approximation, β λ can be obtained simply by running the lars algorithm using ¯ Y = X ¯ as the 'data'. See also Bondell and Reich β [2012] who similarly use an glyph[lscript] 1 penalty to define a sparse posterior point estimator.
It is well-known that the glyph[lscript] 1 approximation may unduly 'shrink' all elements of β λ beyond the shrinkage arising naturally from the prior over β . To avoid this potential 'double-shrinkage' it is possible to explicitly adjust the glyph[lscript] 1 approach towards the desired glyph[lscript] 0 target. Specifically, the local linear approximation argument of Zou and Li [2008] and Lv and Fan [2009] advises to solve a surrogate optimization problem (for any w j near the corresponding glyph[lscript] 0 solution)
$$\beta _ { \lambda } \equiv \arg \min _ { \gamma } \ \sum _ { j } \frac { \lambda } { | w _ { j } | } | \gamma _ { j } | + n ^ { - 1 } | | \mathbf X \bar { \beta } - \mathbf X \gamma | | _ { 2 } ^ { 2 }.$$
This approach yields a procedure analogous to the adaptive lasso of Zhou [2006] with ¯ Y = X ¯ β in place of Y . In what follows, we use w j = ¯ β j (whereas the adaptive lasso uses the least-squares estimate ˆ ). The β j lars package in R can then be used to obtain solutions to this objective function by a straightforward rescaling of the design matrix.
In our experience, this approximation successfully avoids double-shrinkage. In fact, as illustrated in the U.S. crime example below, this approach is able to un-shrink coefficients depending on which variables are selected into the model.
For a fixed value of λ , expression (19) uniquely determines a sparse vector β λ as its corresponding Bayes estimator. However, choosing λ to define this estimator is a non-trivial decision in its own
right. Section 3 considers how to use the posterior distribution π β, σ ( 2 | Y ) to illuminate the trade-offs implicit in the selection of a given value of λ .
3. Selection summary plots. How should one think about the generalization error across possible values of λ ? Consider first two extreme cases. When λ = 0, the solution to the DSS optimization problem is simply the posterior mean: β λ =0 ≡ ¯ . β Conversely, for very large λ , the optimal solution will be the zero vector, β λ = ∞ = 0, which will have expected prediction loss equal to the marginal variance of the response Y (which will depend on the predictor points in question). Letting λ depend on sample size so that λ n → 0 faster than the posterior distribution concentrates about the true parameter value, will give a consistent estimator [Bondell and Reich, 2012]. But in applied scenarios with finite samples, the sparsity of β λ depends directly on the choice of λ , making its selection an important consideration.
A sensible way to judge the goodness of β λ in terms of prediction is relative to the predictive performance of β -were it known-which is the optimal linear predictor under squared-error loss. The relevant scale for this comparison is dictated by σ 2 , which quantifies the best one can hope to do even if β were known. With these benchmarks in mind, one wants to address the question: how much predictive deterioration is a result of sparsification?
The remainder of this section defines three plots that can be used by a data analyst to visualize the predictive deterioration across various values of λ . The first plot concerns a measure of 'variation explained', the second plot considers the excess prediction loss on the scale of the response variable, and the final plot looks at the magnitude of the elements of β λ . Throughout, we will preprocess the outcome variable and covariates to be centered at zero and scaled to unit variance.
3.1. Variation explained of a sparsified linear predictor. Define the 'variation-explained' at design points X (perhaps different than those seen in the data sample used to form the posterior distribution) as:
$$\rho ^ { 2 } = \frac { n ^ { - 1 } | | \mathbf X \beta | | ^ { 2 } } { n ^ { - 1 } | | \mathbf X \beta | | ^ { 2 } + \sigma ^ { 2 } }.$$
Denote by
(24)
$$\rho _ { \lambda } ^ { 2 } = \frac { n ^ { - 1 } | | \mathbf X \beta | | ^ { 2 } } { n ^ { - 1 } | | \mathbf X \beta | | ^ { 2 } + \sigma ^ { 2 } + n ^ { - 1 } | | \mathbf X \beta - \mathbf X \beta _ { \lambda } | | ^ { 2 } }$$
the analogous quantity for the sparsified linear predictor β λ . The gap between β λ and β due to sparsification is tallied as a contribution to the noise term, which decreases the variation explained.
This quantity has the benefit of being directly comparable to the ubiquitous R 2 metric of model fit familiar to users of statistical software and least-squares theory.
Posterior samples of ρ 2 λ can be obtained as follows. First, solve (22) by applying the lars algorithm with inputs w j = ¯ β j and Y = X ¯ . β A single run of this algorithm will produce a sequence of solutions β λ for a range of λ values. (Obtaining draws of ρ 2 λ using a model selection prior requires posterior samples from ( β, σ 2 ) marginally across models.) Second, for each element in the sequence of β λ 's, convert posterior samples of ( β, σ 2 ) into samples of ρ 2 λ via definition (24). Finally, plot the expected value and 90% credible intervals of ρ 2 λ against the model size, || β λ || λ . The posterior mean of ρ 2 0 may be overlaid as a horizontal line for benchmarking purposes; note that even for λ = 0 (so that β λ =0 = ¯ ), the corresponding variation explained, β ρ 2 0 , will have a (non-degenerate) posterior distribution induced by the posterior distribution over ( β, σ 2 ).
Variation explained sparsity summary plots depict the posterior uncertainty of ρ 2 λ , thus providing a measure of confidence concerning the predictive goodness of the sparsified vector. In these plots, one often observes that the sparsified variation explained does not deteriorate 'statistically significantly' in the sense that the credible interval for ρ 2 λ overlaps the posterior mean of the unsparsified variation explained.
- 3.2. Excess error of a sparsified linear predictor. Define the 'excess error' of a sparsified linear predictor β λ as
$$\psi _ { \lambda } = \sqrt { n ^ { - 1 } | | { \mathbf X } \beta _ { \lambda } - { \mathbf X } \beta | | ^ { 2 } + \sigma ^ { 2 } } - \sigma.$$
This metric of model fit, while less widely used than variation explained, has the virtue of being on the same scale as the response variable. Note that excess error attains a minimum of zero precisely when β λ = β . As with the variation explained, the excess error is a random variable and so has a posterior distribution. By plotting the mean and 90% credible intervals of the excess error against model size (corresponding to increasing values of λ ), one can see at a glance the degree of predictive deterioration incurred by sparsification. Samples of ψ λ can be obtained analogously to the procedure for producing samples of ρ 2 λ , but using (25) in place of (24).
- 3.3. Coefficient magnitude plot. In addition to the two previous plots, it is instructive to examine which variables remain in the model at different levels of sparsification, which can be achieved simply by plotting the magnitude of each element of β λ as λ (hence model size) varies. However,
using λ or || β λ || 0 for the horizontal axis can obscure the real impact of the sparsification because the predictive impact of sparsification is non-constant. That is, the jump from a model of size 7 to one of size 6, for example, may correspond to a negligible predictive impact, while the jump from model of size 3 to a model of size 2 could correspond to considerable predictive deterioration. Plotting the magnitude of the elements of β λ against the corresponding excess error ψ λ gives the horizontal axis a more interpretable scale.
3.4. A heuristic for reporting a single model. The three plots described above achieve a remarkable consolidation of information hidden within the posterior samples of π β, σ ( 2 | Y ). They relate sparsification of a linear predictor to the associated loss in predictive ability, while keeping the posterior uncertainty in these quantities in clear view. Nonetheless, in many situations one would like a procedure that yields a single linear predictor.
For producing a single-model linear summary, we propose the following heuristic: report the sparsified linear predictor corresponding to the smallest model whose 90% ρ 2 λ credible interval contains E( ρ 2 0 ). In words, we want the smallest linear predictor whose predictive ability (practical significance) is not statistically different than the full model's.
This choice leans on convention, for example, to determine the 90% level (rather than say the 75% or 95%). However, this is true of alternative methods such as hard thresholding or examination of marginal inclusion probabilities, which both require similar conventional choices to be determined.
The DSS model selection heuristic offer a crucial benefit over these approaches, though-it explicitly includes a design matrix of predictors into its very formulation. Standard thresholding rules and methods such as the median probability model approach are instead defined on a one-by-one basis, which does not explicitly account for colinearity in the predictor space. (Recall that both the thresholding rules studied in Ishwaran and Rao [2005] and the median probability theorems of Barbieri and Berger [2004] restrict their analysis to the orthogonal design situation.)
In the DSS approach to model selection, dependencies in the predictor space appear both in the formation of the posterior and also in the definition of the loss function. In this sense, while the response vector Y is only 'used once' in the formation of the posterior, the design information may be 'used twice', both in defining the posterior and also in defining the loss function. Note that this is completely kosher in the sense that the model is conditional on X in the first place. Note also that the DSS loss function may be based on a predictor matrix different than the one used in the formation of the posterior.
Example: U.S. crime dataset ( p = 15 , n = 47 ). The U.S. crime data of Vandaele [1978] appears in Raftery et al. [1997] and Clyde et al. [2011] among others. The dataset consists of n = 47 observations on p = 15 predictors. As in earlier analyses we log transform all continuous variables. We produce DSS selection summary plots for three different priors: (i) the horseshoe prior, (ii) the robust prior of Bayarri et al. [2012] with uniform model probabilities, and (iii) a g -prior with g = n and model probabilities as suggested in Scott and Berger [2006]. With p = 15 < 30, we are able to evaluate marginal likelihoods for all models under the model selection priors (ii) and (iii).
We use these particular priors not to endorse them, but merely as representative examples of widely-used specifications.
Figures 1 and 2 show the resulting DSS plots under each prior. Notice that with this data set the prior choice has an impact; the resulting posteriors for ρ 2 are quite different. For example, under the horseshoe prior we observe a significantly larger amount of shrinkage, leading to a posterior for ρ 2 that concentrates around smaller values as compared to the results in Figure 2. Despite this difference, a conservative reading of the plots would lead to the same conclusion in either situation: the 7-variable model is essentially equivalent (in both suggested metrics, ρ 2 and ψ ) to the full model.
To use these plots to produce a single sparse linear predictor for the purpose of data summary, we employ the heuristic described in Section 3.4. Table 1 compares the resulting summary to the model chosen according to the median probability model criterion. Notably, the DSS heuristic yields the same 7-variable model under all three choices of prior. In contrast, the HPM is the full model, while the MPM gives either an 11-variable or a 7-variable model depending on which prior is used. Both the HPM and MPM under the robust prior choice would include variables with low statistical and practical significance.
Notice also that the MPM under the robust prior contains four variables with marginal inclusion probabilities near 1 2. / The precise numerics of these quantities is highly prior dependent and sensitive to search methods when enumeration is not possible. Accordingly, the MPM model in this case is highly unstable. By focusing on metrics more closely related to practical significance, the DSS heuristic provides more stable selection, returning the same 7-variable model under all prior specifications in this example. As such, this data set provides a clear example of statistical significance-as evaluated by standard posterior quantities-overwhelming practical relevance. The summary provided by a selection summary plot makes an explicit distinction between the two
notions of relevance, providing a clear sense of the predictive cost associated with dropping a predictor.
Finally, notice that there is no evidence of 'double-shrinkage'. That is, one might suppose that DSS penalizes coefficients twice, once in the prior and again in the sparsification process, leading to unwanted attenuation of large signals. However, double-shrinkage would not occur if the glyph[lscript] 0 penalty were being applied exactly, so any unwanted attenuation is attributable to the imprecision of the surrogate optimization in (22). In practice, we observe that the adaptive lasso-based approximation exhibits minimal evidence of double-shrinkage. Figure 3 displays the resulting values of β λ in the U.S. crime example plotted against the posterior mean (under the horseshoe prior). Notice that, moving from larger to smaller models, no double-shrinkage is apparent. In fact, we observe reinflation or 'unshrinkage' of some coefficients as one progresses to smaller models, as might be expected under the glyph[lscript] 0 norm.
| | DSS-HS (7) | DSS-Robust (7) | DSS- g -prior (7) | MPM (Robust) | MPM ( g -prior) |
|---------|--------------|------------------|---------------------|----------------|-------------------|
| M | • | • | • | 0.89 | 0.85 |
| So | - | - | - | 0.39 | 0.27 |
| Ed | • | • | • | 0.97 | 0.96 |
| Po1 | • | • | • | 0.71 | 0.68 |
| Po2 | - | - | - | 0.52 | 0.45 |
| LF | - | - | - | 0.36 | 0.22 |
| M.F | - | - | - | 0.38 | 0.24 |
| Pop | - | - | - | 0.51 | 0.40 |
| NW | • | • | • | 0.77 | 0.70 |
| U1 | - | - | - | 0.39 | 0.27 |
| U2 | • | • | • | 0.71 | 0.63 |
| GDP | - | - | - | 0.52 | 0.39 |
| Ineq | • | • | • | 0.99 | 0.99 |
| Prob | • | • | • | 0.91 | 0.88 |
| Time | - | - | - | 0.52 | 0.40 |
| R 2 MLE | 82.6% | 82.6% | 82.6% | 85.4% | 82.6% |
## Table 1
Selected models by different methods in the U.S. crime example. The MPM column displays marginal inclusion probabilities with the numbers in bold associated with the variables included in the median probability model. The R 2 mle row reports the traditional in-sample percentage of variation explained of the least-squares fit based on only the variables in a given column.
Example: Diabetes dataset ( p = 10 , n = 447 ). The diabetes data was used to demonstrate the lars algorithm in Efron et al. [2004]. The data consist of p = 10 baseline measurements on n = 442 diabetic patients; the response variable is a numerical measurement of disease progression. As in Efron et al. [2004], we work with centered and scaled predictor and response variables. In this example we only used the robust prior of Bayarri et al. [2012]. The goal is to focus on the sequence
Fig 1 . U.S. Crime Data: DSS plots under the horseshoe prior.
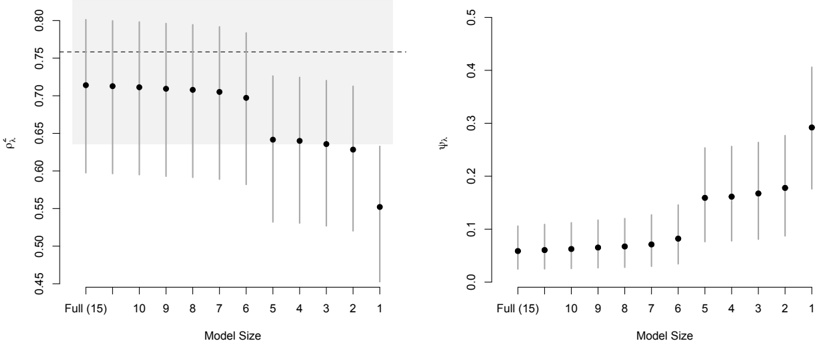
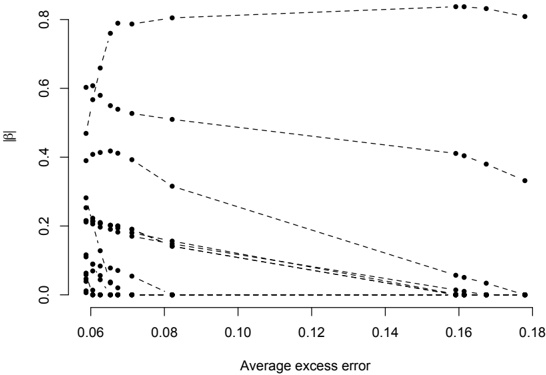
in which the variables are included and to illustrate how DSS provides an attractive alternative to the median probability model.
Table 2 shows the variables included in each model in the DSS path up to the 5-variable model. The DSS plots in this example (omitted here) suggest that this should be the largest model under consideration. The table also reports the median probability model.
Notice that marginal inclusion probabilities do not necessarily offer a good alternative to rank
variable importance, particularly in cases where the predictors are highly colinear. This is evident in the current example in the 'dilution' of inclusion probabilities of the variables with the strongest dependencies in this dataset: TC, LDL, HDL, TCH and LTG. It is possible to see the same effect in the rank of high probability models, as most models on the top of the list represent distinct combinations of correlated predictors. In the sequence of models from DSS, variables HDL and LTG are chosen as the representatives for this group.
Meanwhile, a variable such as Sex (highly correlated with BMI) appears with marginal inclusion
Fig 2 . U.S. Crime Data: DSS plot under the 'robust' prior of Bayarri et al. [2012] (top row) and under a g -prior with g = n (bottom row). All 2 15 models were evaluated in this example.
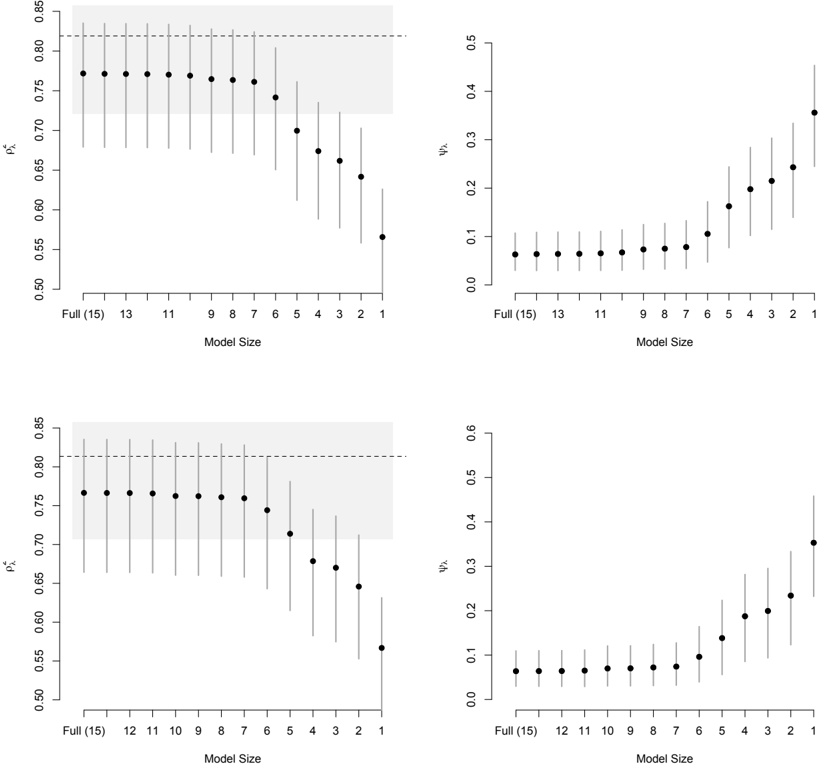
## dss model size: 15
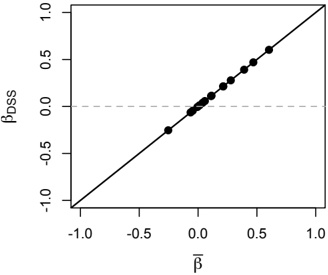
dss model size: 7
## dss model size: 9
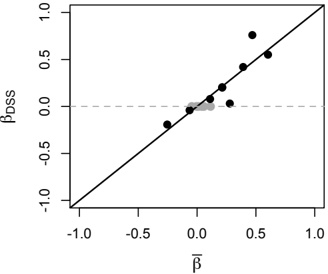
## dss model size: 2
Fig 3 . U.S. Crime data under the horseshoe prior: ¯ β refers to the posterior mean while β DSS is the value of β λ under different values of λ such that different number of variables are selected.
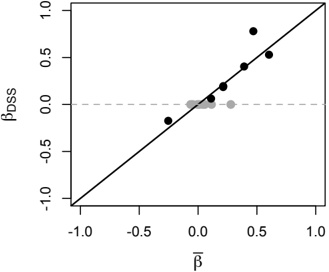
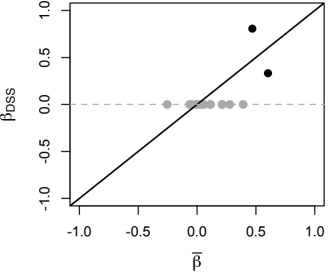
probability of 0.98, and yet its removal from DSS (five-variable) leads to only a minor increase in the model's predictive ability. Thus the diabetes data offer a clear example where statistical significance can overwhelm practical relevance if one looks only at standard Bayesian outputs. The summary provided by DSS makes a distinction between the two notions of relevance, providing a clear sense of the predictive cost associated with dropping a predictor.
Example: protein activation dataset ( p = 88 , n = 96 ). The protein activity dataset is from Clyde et al. [2011]. This example differs from the previous example in that with p = 88 predictors, the model space can no longer be exhaustively enumerated. In addition, correlation between the potential predictors is as high as 0.99, with 17 pairs of variables having correlations above 0.95. For
Table 2
| | DSS-Robust (5) | DSS-Robust (4) | DSS-Robust (3) | DSS-Robust (2) | DSS-Robust (1) | MPM ( Robust ) |
|---------|------------------|------------------|------------------|------------------|------------------|------------------|
| Age | - | - | - | - | - | 0.08 |
| Sex | • | - | - | - | - | 0.98 |
| BMI | • | • | • | • | • | 0.99 |
| MAP | • | • | • | - | - | 0.99 |
| TC | - | - | - | - | - | 0.66 |
| LDL | - | - | - | - | - | 0.46 |
| HDL | • | • | - | - | - | 0.51 |
| TCH | - | - | - | - | - | 0.26 |
| LTG | • | • | • | • | - | 0.99 |
| GLU | - | - | - | - | - | 0.13 |
| R 2 MLE | 50.8% | 49.2% | 48.0% | 45.9% | 34.4% | 51.3% |
Selected models by DSS and model selection prior in the Diabetes example. The MPM column displays marginal inclusion probabilities, and the numbers in bold are associated with the variables included in the median probability model.
this example, the horseshoe prior and the robust prior are considered. To search the model space, we use a conventional Gibbs sampling strategy as in Garcia-Donato and Martinez-Beneito [2013] (Appendix A), based on George and McCulloch [1997].
Figure 4 shows the DSS plots under the two priors considered. Once again, the horseshoe prior leads to smaller estimates of ρ 2 . And once again, despite this difference, the DSS heuristic returns the same (7) predictors under both priors. On this data set, the MPM under the Gibbs search (as well as the HPM and MPM given by BAS ) coincide with the DSS summary model.
Example: protein activation dataset ( p = 88 , n = 80 ). To explore the behavior of DSS in the p > n regime, we modify the previous example by randomly selecting a subset of n = 80 observations from the original dataset. These 80 observations are used to form our posterior distribution. To define the DSS summary, we take ˜ to be the entire set of 96 predictor values. For simplicity we only X use the robust model selection prior. Figure 5 shows the results; with fewer observations, smaller models don't give up as much in the ρ 2 and ψ scales as the original example. A conservative read of the DSS plots leads to the same 6-variable model, however, in this limited information situation, the models with 5 or 4 variables are competitive. One important aspect of Figure 5 is that even working in the p > n regime, DSS is able to evaluate the performance and provide a summary of models of any dimension up to the full model. This is accomplished even in this situations where by using the robust prior, the posterior was limited to models up to dimension n -1. In order for this to be achieved all DSS needs is the number of points in X to be larger than p . In situations where not enough points are available in the dataset, all the user needs to do is to add (arbitrary
Fig 4 . Protein Activation Data: DSS plots under model selection priors (top row) and under shrinkage priors (bottom row).
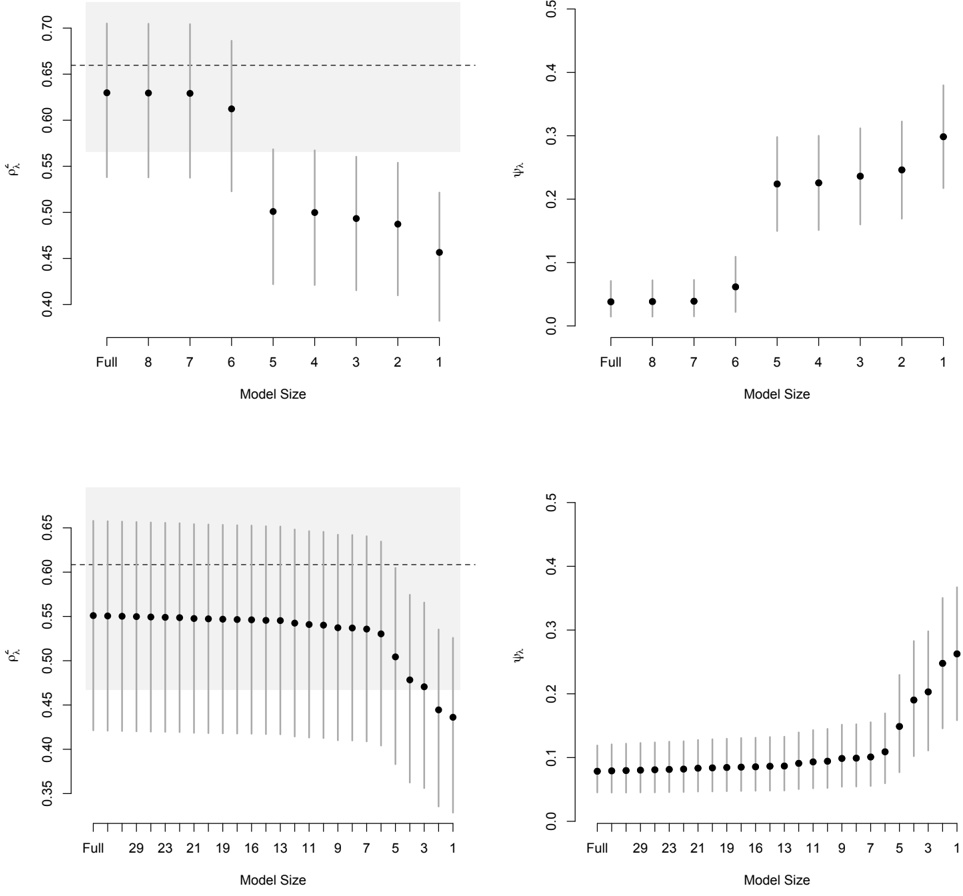
and without loss of generality) representative points in which to make predictions about potential Y .
- 4. Discussion. A detailed examination of the previous literature reveals that sparsity can play many roles in a statistical analysis-model selection, strong regularization, and improved
Fig 5 . Protein Activation Data ( p > n case): DSS plots under model selection priors
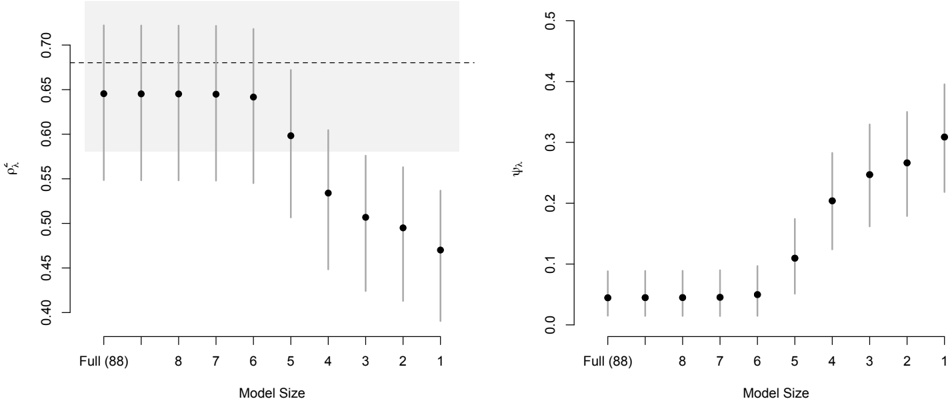
computation, for example. A central, but often implicit, virtue of sparsity is that human beings find fewer variables easier to think about.
When one desires sparse model summaries for improved comprehensibility, prior distributions are an unnatural vehicle for furnishing this bias. Instead, we describe how to use a decision theoretic approach to induce sparse posterior model summaries. Our new loss function resembles the popular penalized likelihood objective function of the lasso estimator, but its interpretation is very different. Instead of a regularizing tool for estimation, our loss function is a posterior summarizer with an explicit parsimony penalty. To our knowledge this is the first such loss function to be proposed in this capacity. Conceptually, its nearest forerunner would be high posterior density regions, which summarize a posterior density while satisfying a compactness constraint.
Unlike hard thresholding rules, our selection summary plots convey posterior uncertainty associated with the provided sparse summaries. In particular, posterior correlation between the elements of β impacts the posterior distribution of the sparsity degradation metrics ρ 2 and ψ . While the DSS approach does not 'automate' the problem of determining λ (and hence β λ ), they do manage to distill the posterior distribution into a graphical summary that reflects the posterior uncertainty in the predictive degradation due to sparsification. Furthermore, they explicitly integrate information about the possibly non-orthogonal design space in ways that standard thresholding rules and
marginal probabilities do not.
As a summary device, these plots can be used in conjunction with whichever prior distribution is most appropriate to the applied problem under consideration. As such, they complement recent advances in Bayesian variable selection and shrinkage estimation and will benefit from future advances in these areas.
We demonstrate how to apply the summary selection concept to logistic regression and Gaussian graphical models in a brief appendix.
## References.
- M. Barbieri and J. Berger. Optimal predictive model selection. Annals of Statistics , 32:870-897, 2004.
- M. Bayarri, J. Berger, A. Forte, and G. Garcia-Donato. Criteria for Bayesian model choice with application to variable selection. The Annals of Statistics , 40(3):1550-1577, 2012.
- H. Bondell and B. Reich. Consistent high-dimensional Bayesian variable selection via penalized credible regions. Journal of the American Statistical Association , 107:1610-1624, 2012.
- C. Carvalho, N. Polson, and J. Scott. The horseshoe estimator for sparse signals. Biometrika , 97:465-480, 2010.
- M. Clyde and E. George. Model uncertainty. Statistical Science , 19:81-94, 2004.
- M. Clyde, J. Ghosh, and M. Littman. Bayesian adaptive sampling for variable selection and model averaging. Journal of Computational and Graphical Statistics , 20:80-101, 2011.
- W. Cui and E. I. George. Empirical Bayes vs. fully Bayes variable selection. Journal of Statistical Planning and Inference , 138(4):888-900, 2008.
- D. Draper. Bayesian model specification: Heuristics and examples. In P. Damien, P. Dellaportas, N. Polson, and D. Stephens, editors, Bayesian Theory and Applications , pages 409-431. Oxford University Press, 2013.
- B. Efron, T. Hastie, I. Johnstone, and R. Tibshirani. Least angle regression. Annals of Statistics , 32:407-499, 2004.
- D. Fouskakis and D. Draper. Comparing stochastic optimization methods for variable selection in binary outcome prediction, with application to health policy. Journal of the American Statistical Association , 103(484):1367-1381, 2008.
- D. Fouskakis, I. Ntzoufras, and D. Draper. Bayesian variable selection using cost-adjusted BIC, with application to cost-effective measurement of quality of health care. Annals of Applied Statistics , 3:663-690, 2009.
- J. Friedman, T. Hastie, and R. Tibshirani. Sparse inverse covariance estimation with the graphical lasso. Biostatistics , 9(3):432-441, 2008.
- J. Friedman, T. Hastie, and R. Tibshirani. Regularization paths for generalized linear models via coordinate descent. Journal of Statistical Software , 33(1):1-22, 2010.
- G. Garcia-Donato and M. Martinez-Beneito. On sampling strategies in Bayesian variable selection problems with large model spaces. Journal of the American Statistical Association , 108:340-352, 2013.
- A. E. Gelfand, D. K. Dey, and H. Chang. Model determination using predictive distributions with implementation via sampling-based methods. Technical report, DTIC Document, 1992.
- E. George and R. McCulloch. Approaches for Bayesian variable selection. Statistica Sinica , 7:339-373, 1997.
- J. Geweke et al. Variable selection and model comparison in regression. In A. D. J.M. Bernardo, J.O. Berger and A. Smith, editors, Bayesian Statistics 5 , pages 609-620, New York, 1996. Oxford University Press.
- J. Griffin and P. Brown. Structuring shrinkage: some correlated priors for regression. Biometrika , 99:481-487, 2012.
- C. Hans. Bayesian lasso regression. Biometrika , 96:835-845, 2009.
- C. Hans, A. Dobra, and M. West. Shotgun stochastic search in regression with many predictors. Journal of the American Statistical Association , 102:507-516, 2007.
- H. Ishwaran and J. S. Rao. Spike and slab variable selection: frequentist and Bayesian strategies. The Annals of Statistics , 33(2):730-773, 2005.
- B. Jones, C. Carvalho, A. Dobra, C. Hans, C. Carter, and M. West. Experiments in stochastic computation for
high-dimensional graphical models. Statistical Science , 20:388-400, 2005.
- E. Leamer. Specification searches: ad hoc inference with nonexperimental data . Wiley series in probability and mathematical statistics. Wiley, 1978. ISBN 9780471015208. URL http://books.google.com/books?id=sYVYAAAAMAAJ .
- F. Liang, R. Paulo, G. Molina, M. Clyde, and J. Berger. Mixtures of g priors for Bayesian variable selection. Journal of the American Statistical Association , 103:410-423, 2008.
- J. Lv and Y. Fan. A unified approach to model selection and sparse recovery using regularized least squares. Annals of Statistics , 37:3498-3528, 2009.
- Y. Maruyama and E. I. George. Fully Bayes factors with a generalized g-prior. The Annals of Statistics , 39(5): 2740-2765, 2011.
- T. J. Mitchell and J. J. Beauchamp. Bayesian variable selection in linear regression. Journal of the American Statistical Association , 83(404):1023-1032, 1988.
- R. B. O'Hara and M. J. Sillanp¨¨. A review of Bayesian variable selection methods: what, how and which. aa Bayesian Analysis , 4(1):85-117, 2009.
- T. Park and G. Casella. The Bayesian lasso. Journal of the American Statistical Association , 103:681-686, 2008.
- L. Pericchi and A. Smith. Exact and approximate posterior moments for a normal location parameter. Journal of the Royal Statistical Society. Series B (Methodological) , pages 793-804, 1992.
- L. R. Pericchi and P. Walley. Robust Bayesian credible intervals and prior ignorance. International Statistical Review , pages 1-23, 1991.
- N. G. Polson and J. G. Scott. Local shrinkage rules, L´vy processes and regularized regression. e Journal of the Royal Statistical Society: Series B (Statistical Methodology) , 74(2):287-311, 2012.
- N. G. Polson, J. G. Scott, and J. Windle. Bayesian inference for logistic models using Polya-Gamma latent variables. Journal of the American Statistical Association , 108:1339-1349, 2013.
- A. Raftery, D. Madigan, and J. Hoeting. Bayesian model averaging for linear regression models. Journal of the American Statistical Association , 92:1197-1208, 1997.
- J. Scott and J. Berger. An exploration of aspects of Bayesian multiple testing. Journal of Statistical Planning and Inference , 136:2144-2162, 2006.
- J. G. Scott and J. O. Berger. Bayes and empirical-Bayes multiplicity adjustment in the variable-selection problem. The Annals of Statistics , 38(5):2587-2619, 2010.
- D. Spiegelhalter. A test for normality against symmetric alternatives. Biometrika , 64(2):415-418, 1977.
- R. Tibshirani. Regression shrinkage and selection via the lasso. Journal of the Royal Statistical Society, B , 58:267-288, 1996.
- W. Vandaele. In A. Blumstein, J. Cohen, and D. Nagin, editors, Deterrence and Incapacitation , pages 270-335. National Academy of Sciences Press, 1978.
- M. West. On scale mixtures of normal distributions. Biometrika , 74(3):646-648, 1987.
- A. Zellner. On assessing prior distributions and Bayesian regression analysis with g-prior distributions. In Bayesian Inference and Decision Techniques: Essays in Honor of Bruno de Finetti , pages 233-243. Amsterdam: NorthHolland, 1986.
- H. Zhou. The adaptive lasso and its oracle properties. Journal of the American Statistical Association , 101:1418-1429,
2006.
H. Zou and R. Li. One-step sparse estimates in nonconcave penalized likelihood models. Annals of Statistics , 36: 1509-1533, 2008.
## APPENDIX A: EXTENSIONS
A.1. Selection summary in logistic regression. Selection summary can be applied outside the realm of normal linear models as well. This section explicitly shows how to extend the approach to logistic regression and provides an illustration on real data.
Although one has many choices for judging predictive accuracy, it is convenient to note that squared prediction loss is precisely the negative log likelihood in the normal linear model setting, which suggests the following generalization of (16):
$$\mathcal { L } ( \tilde { Y }, \gamma ) = \lambda | | \gamma | | _ { 0 } - n ^ { - 1 } \log \left [ f ( \tilde { Y }, \mathbf X, \gamma ) \right ]$$
where f ( ˜ Y , γ ) denotes the likelihood of ˜ Y with 'parameters' γ .
In the case of a binary outcome vector using a logistic link function, the generalized DSS loss becomes
$$\mathcal { L } ( \tilde { Y }, \gamma ) & = \lambda | | \gamma | | _ { 0 } + n ^ { - 1 } \sum _ { i = 1 } ^ { n } \left ( \tilde { Y } _ { i } \mathbf X _ { i } \gamma - \log \left ( 1 + \exp \left ( \mathbf X _ { i } \gamma \right ) \right ) \right ).$$
Taking expectations yields
$$\mathcal { L } ( \tilde { Y }, \bar { \pi } ) = \lambda | | \gamma | | _ { 0 } + n ^ { - 1 } \sum _ { i = 1 } ^ { n } \left ( \bar { \pi } _ { i } \mathbf X _ { i } \gamma - \log \left ( 1 + \exp \left ( \mathbf X _ { i } \gamma \right ) \right ) \right ),$$
where ¯ π i is the posterior mean probability that ˜ Y i = 1. To help interpret this formula, note that it can be rewritten as a weighted logistic regression as follows. For each observed X i , associate a pair of pseudo-responses Z i = 1 and Z i + n = 0 with weights w i = ¯ π i and w i + n = 1 -¯ π i respectively. Then ¯ X π i i γ -log (1 + exp (X i γ )) may be written as
$$( 2 9 ) \quad \left \lceil w _ { i } Z _ { i } X _ { i } \gamma - w _ { i } \log \left ( 1 + \exp \left ( X _ { i } \gamma \right ) \right ) \right \rceil + \left \lceil w _ { i + n } Z _ { i + n } X _ { i } \gamma - w _ { i + n } \log \left ( 1 + \exp \left ( X _ { i } \gamma \right ) \right ) \right \rceil.$$
Thus, optimizing the DSS logistic regression loss is equivalent to finding the penalized maximum likelihood of a weighted logistic regression where each point in predictor space has a response Z i = 1, given weight ¯ , and a counterpart response π i Z i = 0, given weight 1 -¯ . The observed data π i determines ¯ π i via the posterior distribution. As before, if we replace (28) by the surrogate glyph[lscript] 1 norm
$$\mathcal { L } ( \tilde { Y }, \bar { \pi } ) = \lambda | | \gamma | | _ { 1 } + n ^ { - 1 } \sum _ { i = 1 } ^ { n } \left ( \bar { \pi } _ { i } \mathbf X _ { i } \gamma - \log \left ( 1 + \exp \left ( \mathbf X _ { i } \gamma \right ) \right ) \right ),$$
then an optimal solution can be computed via the R package GLMNet (Friedman et al. [2010]).
The DSS summary selection plot may be adapted to logistic regression by defining the excess error as
$$\psi _ { \lambda } = \sqrt { n ^ { - 1 } \sum _ { i } \pi _ { i } - 2 \pi _ { \lambda, i } \pi _ { i } + \pi _ { \lambda, i } ^ { 2 } } - \sqrt { n ^ { - 1 } \sum _ { i } \pi _ { i } ( 1 - \pi _ { i } ) }$$
where π i is the probability that ˜ y i = 1 given the true model parameters, and π λ,i is the corresponding quantity under the λ -sparsified model. This expression for the logistic excess error relates to the linear model case in that each expression can be derived from
$$\psi _ { \lambda } = \sqrt { n ^ { - 1 } \mathrm E \left ( | | \tilde { Y } - \hat { Y } _ { \lambda } | | ^ { 2 } \right ) } - \sqrt { n ^ { - 1 } \mathrm E \left ( | | \tilde { Y } - \mathrm E ( \tilde { Y } ) | | ^ { 2 } \right ) }$$
where the expectation is with respect to the predictive distribution of ˜ Y conditional on the model parameters, and ˆ Y λ denotes the optimal λ -sparse prediction. In particular, ˆ Y λ ≡ X β λ for the linear model and ˆ y λ,i ≡ π λ,i = (1+exp -X β i λ ) -1 for the logistic regression model. One notable difference between the expressions for excess error under the linear model and the logistic model is that the linear model has constant variance whereas the variance term depends on the predictor point in the logistic model as a result of the Bernoulli likelihood.
Example: German credit data ( n = 1000, p = 48). To illustrate selection summary in the logistic regression context, we use the German Credit data from the UCI repository, where n = 1000 and p = 48. In each record we have available covariates associated with a loan applicant, such as credit history, checking account status, car ownership and employment status. The outcome variable is a judgment of whether or not the applicant has 'good credit'. A natural objective when analyzing this data would be to develop a good model for assessing creditworthiness of future applicants. A default shrinkage prior over the regression coefficients is used, based on the ideas described in Polson et al. [2013] and the associated R package BayesLogit . The DSS selection summary plots (adapted to a logistic regression) are displayed in Figure 6. The plot suggests a high degree of 'pre-variable selection', in that all of the predictor variables appear to add an incremental amount of prediction accuracy, with no single predictor appearing to dominate. Nonetheless, several of the larger models (smaller than the full forty-eight variable model) do not give up much in excess error, suggesting that a moderately reduced model ( ≈ 35), may suffice in practice. Depending on the true costs associated with measuring those ten least valuable covariates, relative to the cost associated with an increase of 0.01 in excess error, this reduced model may be preferable.
λ
ψ
0.08
0.04
0.00
48
41
36
31
26
20
15
9
3
Model Size
Fig 6 . DSS plots for the German credit data. For this data, each included variable seems to add an incremental amount, as the excess error plot builds steadily until reaching the null model with no predictors.
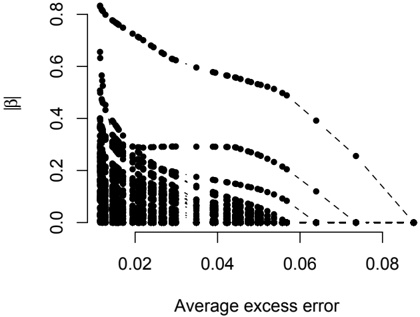
A.2. Selection summary for Gaussian graphical models. Covariance estimation is yet another area where a sparsifying loss function can be used to induce a parsimonious posterior summary.
Consider a ( p × 1) vector ( x , x 1 2 , . . . , x p ) = X ∼ N(0 , Σ ). Zeros in the precision matrix Ω = Σ -1 imply conditional independence among certain dimensions of X . As sparse precision matrices can be represented through a labelled graph, this modeling approach is often referred to as Gaussian graphical modeling. Specifically, for a graph G = ( V, E ), where V is the set of vertices and E is the set of edges, let each edge represent a non-zero element of Ω . See Jones et al. [2005] for a thorough overview. This problem is equivalent to finding a sparse representation in p separate linear models for X X j | -j , making the selection summary approach developed above directly applicable.
As with linear models, one has the option of modeling the entries in the precision matrix via shrinkage priors or via selection priors with point masses at zero. Regardless of the specific choice of prior, summarizing patterns of conditional independence favored in the posterior distribution remains a major challenge.
A DSS parsimonious summary can be achieved via a multivariate extension of (16) by once again leveraging the notion of 'predictive accuracy' as defined by the negative log likelihood:
$$\mathcal { L } ( \tilde { X }, \Gamma ) = \lambda | | \Gamma | | _ { 0 } - \log \det ( \Gamma ) - \text{tr} ( n ^ { - 1 } \tilde { X } \tilde { X } ^ { \prime } \Gamma )$$
where Γ represents the decision variable for Ω and || Γ || 0 represents the sum of non-zero entries in off-diagonal elements of Γ . Taking expectations with respect to the posterior predictive of ˜ X yields
$$\mathcal { L } ( \mathbf \Gamma ) = \mathbb { E } \left ( \mathcal { L } ( \tilde { \mathbf x }, \mathbf \Gamma ) \right ) = \lambda | | \mathbf \Gamma | | _ { 0 } - \log \det ( \mathbf \Gamma ) - \text{tr} ( \tilde { \mathbf S } \mathbf \Gamma )$$
where ¯ Σ represents the posterior mean of Σ .
As before, an approximate solution to the DSS graphical model posterior summary optimization problem can be obtained by employing the surrogate glyph[lscript] 1 penalty
$$\mathcal { L } ( \mathbf \Gamma ) = \mathbf E \left ( \mathcal { L } ( \tilde { \mathbf X }, \mathbf \Gamma ) \right ) = \lambda | | \mathbf \Gamma | | _ { 1 } - \log \det ( \mathbf \Gamma ) - \text{tr} ( \mathbf \Sigma \mathbf \Gamma ).$$
as developed by penalized likelihood methods such as the graphical lasso [Friedman et al., 2008]. | null | [
"P. Richard Hahn",
"Carlos M. Carvalho"
] | 2014-08-03T07:17:31+00:00 | 2014-08-03T07:17:31+00:00 | [
"stat.ME"
] | Decoupling shrinkage and selection in Bayesian linear models: a posterior summary perspective | Selecting a subset of variables for linear models remains an active area of
research. This paper reviews many of the recent contributions to the Bayesian
model selection and shrinkage prior literature. A posterior variable selection
summary is proposed, which distills a full posterior distribution over
regression coefficients into a sequence of sparse linear predictors. |
1408.0465v2 | ## CFAIR2: NEAR INFRARED LIGHT CURVES OF 94 TYPE IA SUPERNOVAE
Andrew S. Friedman 1,2 , W. M. Wood-Vasey 3 , G. H. Marion 1,4 , Peter Challis 1 , Kaisey S. Mandel 1 , Joshua S. Bloom 5 , Maryam Modjaz 6 , Gautham Narayan 1,7,8 , Malcolm Hicken 1 , Ryan J. Foley 9,10 , Christopher R. Klein 5 , Dan L. Starr 5 , Adam Morgan 5 , Armin Rest 11 , Cullen H. Blake 12 , Adam A. Miller 13 , Emilio E. Falco 1 , William F. Wyatt 1 , Jessica Mink 1 , Michael F. Skrutskie 14 , and Robert P. Kirshner 1
(Dated: September 3, 2015) submitted to The Astrophysical Journal Supplements
## ABSTRACT
CfAIR2 is a large homogeneously reduced set of near-infrared (NIR) light curves for Type Ia supernovae (SN Ia) obtained with the 1.3m Peters Automated InfraRed Imaging TELescope (PAIRITEL). This data set includes 4637 measurements of 94 SN Ia and 4 additional SN Iax observed from 20052011 at the Fred Lawrence Whipple Observatory on Mount Hopkins, Arizona. CfAIR2 includes JHK s photometric measurements for 88 normal and 6 spectroscopically peculiar SN Ia in the nearby universe, with a median redshift of z ∼ 0 021 for the normal SN Ia. . CfAIR2 data span the range from -13 days to +127 days from B -band maximum. More than half of the light curves begin before the time of maximum and the coverage typically contains ∼ 13-18 epochs of observation, depending on the filter. We present extensive tests that verify the fidelity of the CfAIR2 data pipeline, including comparison to the excellent data of the Carnegie Supernova Project. CfAIR2 contributes to a firm local anchor for supernova cosmology studies in the NIR. Because SN Ia are more nearly standard candles in the NIR and are less vulnerable to the vexing problems of extinction by dust, CfAIR2 will help the supernova cosmology community develop more precise and accurate extragalactic distance probes to improve our knowledge of cosmological parameters, including dark energy and its potential time variation.
Keywords: distance scale - supernovae: general, infrared observations, photometry
## 1. INTRODUCTION
Electronic address: [email protected], [email protected], [email protected], [email protected], [email protected], [email protected], [email protected], [email protected], [email protected], [email protected], [email protected], [email protected], [email protected], [email protected], [email protected], [email protected], [email protected], [email protected], [email protected], [email protected], [email protected]
- 2 Center for Theoretical Physics and Department of Physics, Massachusetts Institute of Technology, Cambridge, MA 02139, USA
1 Harvard-Smithsonian Center for Astrophysics, 60 Garden Street, Cambridge, MA 02138, USA
- 3 Department of Physics and Astronomy, University of Pittsburgh, 100 Allen Hall, 3941 O'Hara St, Pittsburgh, PA 15260, USA
- 5 Department of Astronomy, University of California Berkeley, Berkeley, CA 94720, USA
- 4 Astronomy Department, University of Texas at Austin, Austin, TX 78712, USA
- 6 Center for Cosmology and Particle Physics, New York University, Meyer Hall of Physics, 4 Washington Pl., Room 529, New York, NY 10003, USA
- 8 National Optical Astronomy Observatory, 950 N. Cherry Ave., Tucson, AZ 85719, USA
- 7 Physics Department, Harvard University, 17 Oxford Street, Cambridge, MA 02138, USA
- 9 Department of Astronomy, University of Illinois at UrbanaChampaign, 1002 W. Green St, Urbana, IL 61801, USA
- 11 Space Telescope Science Institute, STScI, 3700 San Martin Drive, Baltimore, MD 21218, USA
- 10 Department of Physics, University of Illinois at UrbanaChampaign, 1110 W. Green Street, Urbana, IL 61801, USA
- 12 University of Pennsylvania, Department of Physics and Astronomy, 209 South 33rd St., Philadelphia, PA 19104, USA
- 14 Department of Astronomy, P.O. Box 400325, 530 McCormick Road Charlottesville, VA 22904, USA
- 13 Jet Propulsion Laboratory, California Institute of Technology, Pasadena, CA 91125, USA, Hubble Fellow
Optical observations of Type Ia Supernovae (SN Ia) were crucial to the surprising 1998 discovery of the acceleration of cosmic expansion (Riess et al. 1998; Schmidt et al. 1998; Perlmutter et al. 1999). Since then, several independent cosmological techniques have confirmed the SN Ia results (see Frieman et al. 2008a; Weinberg et al. 2013 for reviews), while SN Ia provide increasingly accurate and precise measurements of extragalactic distances and dark energy (see Kirshner 2010; Goobar & Leibundgut 2011; Kirshner 2013 for reviews). Increasing evidence suggests that SN Ia observations at rest-frame NIR wavelengths yield more accurate and more precise distance estimates to SN Ia host galaxies than optical data alone (Krisciunas et al. 2004b, 2007; Wood-Vasey et al. 2008; Mandel et al. 2009, 2011; Contreras et al. 2010; Folatelli et al. 2010; Burns et al. 2011; Stritzinger et al. 2011; Phillips 2012; Kattner et al. 2012; BaroneNugent et al. 2012; Weyant et al. 2014; Mandel et al. 2014; Burns et al. 2014).
This work presents CfAIR2, a densely sampled, lowredshift photometric data set including 94 SN Ia NIR JHK s -band light curves (LCs) observed from 20052011 with the f/13.5 PAIRITEL 1.3-m telescope at the Fred Lawrence Whipple Observatory (FLWO) on Mount Hopkins, Arizona. Combining low-redshift NIR SN Ia data sets like CfAIR2 with higher redshift samples will play a crucial role in ongoing and future supernova cosmology experiments, from the ground and from space, which hope to reveal whether dark energy behaves like Einstein's cosmological constant Λ or some other phenomenon that may vary over cosmic history.
While SN Ia observed at optical wavelengths have been
shown to be excellent standardizeable candles using a variety of sophisticated methods correlating luminosity with LC shape and color, SN Ia are very nearly standard candles at NIR wavelengths, even before correction for LC shape or reddening (e.g., Wood-Vasey et al. 2008; Kattner et al. 2012; hereafter WV08 and K12). Compared to the optical, SN Ia in the NIR are both better standard candles and relatively immune to the effects of extinction and reddening by dust. Systematic distance errors from photometric calibration uncertainties, uncertain dust estimates, and intrinsic variability of unreddened SN Ia colors are outstanding problems with using SN Ia for precise cosmological measurements of dark energy with optical data alone (Wang et al. 2006; Jha et al. 2007; Conley et al. 2007; Guy et al. 2007; WoodVasey et al. 2007; Hicken et al. 2009a; Kessler et al. 2009; Guy et al. 2010; Conley et al. 2011; Campbell et al. 2013; Narayan 2013; Rest et al. 2014; Betoule et al. 2014; Scolnic et al. 2014a,b). By contrast, many of the systematic uncertainties and discrepancies between the most prominent optical LC fitting and distance estimation methods are avoided with the incorporation of NIR data (Mandel et al. 2011; hereafter M11; Folatelli et al. 2010; Burns et al. 2011; K12; Mandel et al. 2014). The most promising route toward understanding the dust in other galaxies and mitigating systematic distance errors in supernova cosmology comes from NIR observations.
CfAIR2 JHK s observations with PAIRITEL are part of a systematic multi-wavelength program of CfA supernova observations at FLWO. We follow up nearby supernovae as they are discovered to obtain densely sampled, high signal-to-noise ratio (S/N) optical and NIR LCs of hundreds of nearby low-redshift SN in UBVRIr i JHK ′ ′ s . Whenever possible, PAIRITEL NIR data were observed for targets with additional optical photometry at the FLWO 1.2-m, optical spectroscopy at the 1.5-m Tillinghast telescope with the FAST spectrograph, and/or late time spectroscopy at the MMT (Matheson et al. 2008; Hicken 2009; Hicken et al. 2009b; Blondin et al. 2012; Hicken et al. 2012). By obtaining concurrent optical photometry and spectroscopy for many objects observed with PAIRITEL, we considerably increase the value of the CfAIR2 data set. Of the 98 CfAIR2 objects, 92 have complementary optical observations from the CfA or other groups, including unpublished data. 15 Table 1 lists general properties of the 94 SN Ia.
It has only recently become understood that SN 2002cx-like objects, which we categorize as SN Iax (e.g., Foley et al. 2013), are significantly distinct both from normal SN Ia and spectroscopically peculiar SN Ia (Li et al. 2003; Branch et al. 2004; Chornock et al. 2006; Jha et al. 2006a; Phillips et al. 2007; Sahu et al. 2008;
15 All 10 spectroscopically peculiar SN Ia and SN Iax have optical data from the CfA or other groups, including unpublished CfA5 optical data. Of the 88 spectroscopically normal CfAIR2 SN Ia in Table 1, 64 have published optical data from the CfA or other groups, and 12 have unpublished CfA5 optical data. An additional 4 have CfA optical observations but no successfully reduced LCs yet: SN 2010jv, SN 2010ex, SN 2010ew, SN 2009fw. In addition, 2 objects have unpublished optical data from other groups PTF10icb (PTF: Parrent et al. 2011: only spectra included), PTF10bjs (PTF, CfA4: only natural system r i ). Six ob-′ ′ jects currently have no optical photometry, according to our search of the literature: SN 2010dl, SN 2009im, SN 2008hy, SN 2008fx, SN 2005ch, SN 2005ao.
Maund et al. 2010; McClelland et al. 2010; Narayan et al. 2011; Kromer et al. 2013; Foley et al. 2009, 2010a,b, 2013, 2014a,b, 2015; McCully et al. 2014b,a; Stritzinger et al. 2015). Throughout, we treat the 4 SN Iax included in CfAIR2 (SN 2005hk, SN 2008A, SN 2008ae, SN 2008ha) as a separate class of objects from SN Ia (see Table 2).
This work is a report on photometric data from PAIRITEL which improves upon and supersedes a previously published subset including 20 SN Ia JHK s LCs from (WV08; implicitly 'CfAIR1'), 1 SN Iax LC from WV08 (SN 2005hk), and 1 SN Iax LC from Foley et al. 2009 (SN 2008ha), along with work presented in Friedman 2012 (hereafter F12). 16 Data points for these 20 objects have been reprocessed using our newest mosaic and photometry pipelines and are presented as part of this CfAIR2 data release. The CfAIR1 (WV08) and CfAIR2 NIR data sets complement previous CfA optical studies of SN Ia (CfA1: Riess et al. 1999; CfA2: Jha et al. 2006b; CfA3: Hicken et al. 2009b; and CfA4: Hicken et al. 2012) and CfA5 (to be presented elsewhere). CfA5 will include optical data for at least 15 CfAIR2 objects and additional optical LCs for non-CfAIR2 objects.
The 4637 individual CfAIR2 JHK s data points represent the largest homogeneously observed and reduced set of NIR SN Ia and SN Iax observations to date. Simultaneous JHK s observing provided nightly cadence for the most densely sampled LCs and extensive time coverage, ranging from 13 days before to 127 days after the time of B -band maximum brightness ( t B max ). CfAIR2 data have means of 18, 17, and 13 observed epochs for each LC in JHK s , respectively, as well as 46 epochs for the most extensively sampled LC. CfAIR2 LCs have significant early-time coverage. Out of 98 CfAIR2 objects, 55% have NIR observations before t B max , while 34% have observations at least 5 days before t B max . The highest S/N LC points for each CfAIR2 object have median uncertainties of ∼ 0 032, 0 053, and 0 115 mag in . . . JHK s , respectively. The median uncertainties of all CfAIR2 LC points are 0 086, 0 122, and 0 175 mag in . . . JHK s , respectively.
Of the 98 CfAIR2 objects, 88 are spectroscopically normal SN Ia and 86 will be useful for supernova cosmology (SN 2006E and SN 2006mq were discovered late and lack precise t B max estimates). The 6 spectroscopically peculiar SN Ia and 4 SN Iax are not standardizable candles using existing LC fitting techniques, and currently must be excluded from Hubble diagrams.
## 1.1. Previous Results with NIR SN Ia
For optical SN Ia LCs, many sophisticated methods are used to reduced the scatter in distance estimates. These include ∆ m 15 ( B ) (Phillips 1993; Hamuy et al. 1996; Phillips et al. 1999; Prieto et al. 2006), multicolor lightcurve shape (MLCS; Riess et al. 1996, 1998; Jha et al. 2006b, 2007), 'stretch' (Perlmutter et al. 1997; Goldhaber et al. 2001), Bayesian Adapted Template Match (BATM; Tonry et al. 2003), color-magnitude intercept calibration (CMAGIC; Wang et al. 2003), spectral adaptive template (SALT; Guy et al. 2005; Astier et al. 2006; Guy et al. 2007), empirical methods (e.g., SiFTO; Conley et al. 2008), and BayeSN , a novel hierarchical Bayesian method developed at the CfA (M09, M11).
Table 1
## General Properties of 94 PAIRITEL SN Ia
| SN | RA a | DEC a | Host b | Morphology c | z helio d | σz helio d | z d | Discovery b | Discoverer(s) e | Type f | Type |
|---------------------------------|---------------------|-------------------|-------------------|----------------|-------------------|----------------|-------|---------------------|-------------------|---------------------|--------|
| Name | α (2000) | δ (2000) | Galaxy | | | | Ref. | Reference | | Reference | |
| SN 2005ao | 266.20653 | 61.90786 | NGC 6462 | SABbc | 0.038407 | 0.000417 | 1 | CBET 115 | POSS | IAUC 8492 | Ia |
| SN 2005bl | 181.05098 | 20.40683 | NGC 4070 | · · · | 0.02406 | 0.00008 | 1 | IAUC 8515 | LOSS, POSS | IAUC 8514 | Iap |
| SN 2005bo | 192.42099 | -11.09663 | NGC 4708 | SA(r)ab pec? | 0.013896 | 0.000027 | 1 | CBET 141 | POSS | CBET 142 | Ia |
| SN 2005cf | 230.38906 | -7.44874 | MCG -01-39-3 | S0 pec | 0.006461 | 0.000037 | 1 | CBET 158 | LOSS | IAUC 8534 | Ia |
| SN 2005ch | 215.52815 | 1.99316 | 1 | · · · | 0.027 | 0.005 | 3 | CBET 166 | ROTSE-III | CBET 167 | Ia |
| SN 2005el | 77.95316 | 5.19417 | NGC 1819 | SB0 | 0.01491 | 0.000017 | 1 | CBET 233 | LOSS | CBET 235 | Ia |
| SN 2005eq | 47.20575 | -7.03332 | MCG -01-9-6 | SB(rs)cd? | 0.028977 | 0.000073 | 1 | IAUC 8608 | LOSS | IAUC 8610 | Ia |
| SN 2005eu | 36.93011 | 28.17698 | 2 | · · · | 0.03412 | 0.000046 | 1 | CBET 242 | LOSS | CBET 244 | Ia |
| SN 2005iq | 359.63517 | -18.70914 | MCG -03-1-8 | Sa | 0.034044 | 0.000123 | 1 | IAUC 8628 | LOSS | CBET 278 | Ia |
| SN 2005ke | 53.76810 | -24.94412 | NGC 1371 | (R')SAB(r'l)a | 0.00488 | 0.000007 | 1 | IAUC 8630 | LOSS | IAUC 8631 | Iap |
| SN 2005ls | 43.56630 | 42.72480 | MCG +07-7-1 | Spiral | 0.021118 | 0.000117 | 1 | IAUC 8643 | Armstrong | CBET 324 | Ia |
| SN 2005na | 105.40287 | 14.13304 | UGC 3634 | SB(r)a | 0.026322 | 0.000083 | 1 | CBET 350 | POSS | CBET 351 | Ia |
| SN 2006D | 193.14111 | -9.77519 | MCG -01-33-34 | SAB(s)ab pec? | 0.008526 | 0.000017 | 1 | CBET 362 | BRASS | CBET 366 | Ia |
| SN 2006E | 208.36880 | 5.20619 | NGC 5338 | SB0 | 0.002686 | 0.000005 | 2 | CBET 363 | POSS, LOSS, CROSS | ATEL 690 | Ia |
| SN 2006N | 92.13021 | 64.72362 | MCG +11-8-12 | · · · | 0.014277 | 0.000083 | 1 | CBET 375 | Armstrong | IAUC 8661 | Ia |
| SN 2006X | 185.72471 | 15.80888 | NGC 4321 | SAB(s)bc | 0.00524 | 0.000003 | 1 | IAUC 8667 | Suzuki, CROSS | CBET 393 | Ia |
| SN 2006ac | 190.43708 | 35.06872 | NGC 4619 | SB(r)b pec? | 0.023106 | 0.000037 | 1 | IAUC 8669 | LOSS | CBET 398 | Ia |
| SN 2006ax | 171.01434 | -12.29156 | NGC 3663 | SA(rs)bc pec | 0.016725 | 0.000019 | 2 | CBET 435 | LOSS | CBET 437 | Ia |
| SN 2006cp | 184.81198 | 22.42723 | UGC 7357 | SAB(s)c | 0.022289 | 0.000002 | 1 | CBET 524 | LOSS | CBET 528 | Ia |
| SN 2006cz | 222.15254 | -4.74193 | MCG -01-38-2 | SA(s)cd? | 0.0418 | 0.000213 | 1 | IAUC 8721 | LOSS | CBET 550 | Ia |
| SN 2006gr | 338.09445 | 30.82871 | UGC 12071 | SBb | 0.034597 | 0.00003 | 1 | CBET 638 | LOSS | CBET 642 | Ia |
| SN 2006le | 75.17457 | 62.25525 | UGC 3218 | SAb | 0.017432 | 0.000023 | 1 | CBET 700 | LOSS | CBET 702 | Ia |
| SN 2006lf | 69.62286 | 44.03379 | UGC 3108 | S? | 0.013189 | 0.000017 | 2 | CBET 704 | LOSS | CBET 705 | Ia |
| SN 2006mq | 121.55157 | -27.56262 | ESO 494-G26 | SAB(s)b pec | 0.003229 | 0.000003 | 1 | CBET 721 | LOSS | CBET 724 | Ia |
| SN 2007S | 150.13010 | 4.40702 | UGC 5378 | Sb | 0.01388 | 0.000033 | 1 | CBET 825 | POSS | CBET 829 | Ia |
| SN 2007ca | 202.77451 | -15.10175 | MCG -02-34-61 | Sc pec sp | 0.014066 | 0.00001 | 1 | CBET 945 | LOSS | CBET 947 | Ia |
| SN 2007co | 275.76493 | 29.89715 | MCG +05-43-16 | · · · | 0.026962 | 0.00011 | 1 | CBET 977 | Nicolas | CBET 978 | Ia |
| SN 2007cq | 333.66839 | 5.08017 | 3 | · · · | 0.026218 | 0.000167 | 3 | CBET 983 | POSS | CBET 984 | Ia |
| SN 2007fb | 359.21827 | 5.50886 | UGC 12859 | Sbc | 0.018026 | 0.000007 | 2 | CBET 992 | LOSS | CBET 993 | Ia |
| SN 2007if | 17.71421 | 15.46103 | 4 | · · · | 0.0745 | 0.00015 | 5 | CBET 1059 | ROTSE-III | CBET 1059 | Iap |
| SN 2007le | 354.70186 | -6.52269 | NGC 7721 | SA(s)c | 0.006728 | 0.000002 | 1 | CBET 1100 | Monard | CBET 1101 | Ia |
| SN 2007nq | 14.38999 | -1.38874 | UGC 595 | E | 0.045031 | 0.000053 | 1 | CBET 1106 | ROTSE-III | CBET 1106 | Ia |
| SN 2007qe | 358.55408 | 27.40916 | 5 | · · · | 0.024 | 0.001 | 6 | CBET 1138 | ROTSE-III | CBET 1138 | Ia |
| SN 2007rx | 355.04908 | 27.42097 | 6 | · · · | 0.0301 | 0.001 | 7 | CBET 1157 | ROTSE-III | CBET 1157 | Ia |
| SN 2007sr | 180.46995 | -18.97269 | NGC 4038 UGC 3611 | SB(s)m pec | 0.005417 | 0.000017 | 2 | CBET 1172 | CSS | CBET 1173 | Ia |
| SN 2008C | 104.29794 | 20.43723 | | S0/a | 0.016621 | 0.000013 | 1 | CBET 1195 | POSS | CBET 1197 | Ia |
| SN 2008Z | 145.81364 | 36.28439 | 7 | · · · | 0.02099 | 0.000226 | 1 | CBET 1243 | POSS | CBET 1246 | Ia |
| SN 2008af | 224.86846 | 16.65325 | UGC 9640 | E | 0.033507 | 0.000153 | 1 | CBET 1248 | Boles | CBET 1253 | Ia |
| SNF20080514-002 SNF20080522-000 | 202.30350 204.19796 | 11.27236 5.14200 | UGC 8472 | S0 · · · | 0.022095 0.04526 | 0.00009 0.0002 | 1 9 | ATEL 1532 | SNF | ATEL 1532 B09 | Ia Ia |
| | | 4.90454 | SDSS? | | 0.03777 | 0.00006 | 9 | SNF | SNF | B09 | |
| SNF20080522-011 | 229.99519 | | SDSS? | · · · | | | | SNF | SNF | | Ia |
| SN 2008fr | 17.95488 | 14.64068 | 8 | · · · | 0.039 | 0.002 | 8 | CBET 1513 | ROTSE-III | CBET 1513 | Ia |
| SN 2008fv | 154.23873 | 73.40986 | NGC 3147 | SA(rs)bc | 0.009346 | 0.000003 | 1 | CBET 1520 | Itagaki | CBET 1522 | Ia Ia |
| SN 2008fx SN 2008gb | 32.89166 44.48821 | 23.87998 46.86566 | 9 | · · · | 0.059 0.037626 | 0.003 0.000041 | 3 3 | CBET 1523 CBET 1527 | CSS POSS | CBET 1525 CBET 1530 | Ia |
| SN 2008hm | 20.22829 51.79540 | 4.80531 | UGC 2427 UGC 881 | Sbc | 0.034017 0.019664 | 0.000077 | 1 | CBET 1586 | CHASE LOSS | CBET 1547 CBET 1594 | Ia Ia |
| SN 2008gl | 36.37335 | 46.94421 | 2MFGC 02845 | E Spiral | | 0.000117 | 1 | CBET 1545 | | | Ia |
| SN 2008hs | | 41.84311 | NGC 910 | E+ | 0.017349 | 0.000073 | 2 | CBET 1598 | LOSS | CBET 1599 | Ia |
| SN 2008hv | 136.89178 | 3.39240 | NGC 2765 | S0 | 0.012549 | 0.000067 | 1 | CBET 1601 | CHASE | CBET 1603 | |
| SN 2008hy | 56.28442 | 76.66533 | IC 334 | S? | 0.008459 | 0.000023 | 1 | CBET | POSS | CBET | Ia |
| | | | | | | | | 1608 | | 1610 | |
Note .
-
(a) SN RA, DEC positions [in decimal degrees] are best fit SN centroids appropriate for forced DoPHOT photometry at fixed coordinates.
- (b) Host Galaxy Names, discovery references, and discovery group/individual credits from NASA/IPAC Extragalactic Database (NED; http: //ned.ipac.caltech.edu/ ) and NASA/ADS ( http://adswww.harvard.edu/abstract\_service.html ). Also see IAUC List of Supernovae: http://www.cbat.eps.harvard.edu/lists/Supernovae.html . For SN Ia with non-standard IAUC names, we found the associated host galaxy from IAUC/CBET/ATel notices or the literature and searched for the recession velocity with NED. When the SN Ia is associated with a faint host not named in any major catalogs (NGC, UGC, . . . ) but named in a large galaxy survey (e.g., SDSS, 2MASS), we include the host name from the large survey rather than 'Anonymous'. However, to fit the table on a single page, long galaxy names are numbered.
- 1: APMUKS(BJ) B141934.25+021314.0 (SN 2005ch), 2: NSF J022743.32+281037.6 (SN 2005eu), 3: 2MASX J22144070+0504435 (SN 2007cq), 4: J011051.37+152739 (SN 2007if), 5: NSF J235412.09+272432.3 (SN 2007qe), 6: BATC J234012.05+272512.23 (SN 2007rx), 7: SDSS J094315.36+361709.2 (SN 2008Z), 8: SDSS J011149.19+143826.5 (SN 2008fr), 9: 2MASX J02113233+2353074 (SN 2008fx). The machine readable version of this table has full galaxy names.
- (c) Host galaxy morphologies taken from NED where available. Hosts with unknown morphologies denoted by
· · ·
- (d) Heliocentric redshift z helio , σ z helio references are from 1: NED Host galaxy name, 2: NED 21-cm or optical with smallest uncertainty, 3: CfA FAST spectrum on Tillinghast 1.5-m telescope, 4: Rest et al. 2014: PanSTARRS1, 5: Childress et al. 2011, 6: CBET 1176, 7: Hicken et al. 2009a, 8: CBET 1513, 9: Childress et al. 2013. For SN 2008fr, the NED redshift incorrectly lists the redshift of SN 2008fs (see CBET 1513). Heliocentric redshifts have not been corrected for any local flow models.
- (e) Discovery References/URLs: LOSS: Lick Observatory Supernova Search (see Li et al. 2000; Filippenko 2005, and references therein); Tenagra II ( http://www.tenagraobservatories.com/Discoveries.htm ); ROTSE-III (Quimby 2006); POSS: Puckett Observatory Supernova Search ( http://www.cometwatch.com/search.html ); BRASS: ( http://brass.astrodatabase.net ); SDSS-II: Sloan Digital Sky Survey II (Frieman et al. 2008b); CSS: Catalina Sky Survey ( http://www.lpl.arizona.edu/css/ ); SNF: Nearby Supernova Factory ( http: //snfactory.lbl.gov/ ); CHASE: CHilean Automatic Supernova sEarch ( http://www.das.uchile.cl/proyectoCHASE/ ); CRTS: Catalina RealTime Transient Survey ( http://crts.caltech.edu/ ); Itagaki ( http://www.k-itagaki.jp/ ); Boles: Coddenham Astronomical Observatory, U.K. ( http://www.coddenhamobservatories.org/ ); CROSS ( http://wwww.cortinasetelle.it/snindex.htm ); LSSS: La Sagra Sky Survey ( http://www.minorplanets.org/OLS/LSSS.html ); PASS: Perth Automated Supernova Search ( http://www.perthobservatory.wa.gov.au/ research/spps.html ); Williams 1997); PIKA: Comet and Asteroid Search Program ( http://www.observatorij.org/Pika.html ); PanSTARRS1: ( http://pan-starrs.ifa.hawaii.edu/public/ ); THCA Supernova Survey ( http://www.thca.tsinghua.edu.cn/en/index.php/TUNAS ) (f) Spectroscopic type reference. B09=Bailey et al. 2009.
- (g) Spectroscopic type of SN Ia = spectroscopically normal SN Ia. Spectroscopically peculiar SN Ia: including 91bg-like and 06gz-like objects.
Unlike optical SN Ia, which are standardizable candles after a great deal of effort, spectroscopically normal NIR SN Ia appear to be nearly standard candles at the ∼ 0 15-0 2 mag level or better, depending on the filter . . (Meikle 2000; Krisciunas et al. 2004a, 2005a, 2007; Folatelli et al. 2010; Burns et al. 2011; Phillips 2012; WV08; M09; M11; K12). Overall, SN Ia are superior standard candles and distance indicators in the NIR compared to optical wavelengths, with a narrow distribution of peak JHK s magnitudes and ∼ 5-11 times less sensitivity to reddening than optical B -band data alone.
Following Meikle (2000), pioneering work by Krisciunas et al. (2004a) (hereafter K04a) demonstrated that SN Ia have a narrow luminosity range in JHK s at t B max with smaller scatter than in B and V . Using 16 NIR SN Ia, K04a found no correlation between optical LC shape and intrinsic NIR luminosity. K04a measured JHK s absolute magnitude distributions with 1σ uncertainties of only σ J = 0 14, . σ H = 0 18, . and σ K s = 0 12 mag. . While K04a used a small, inhomogeneous, sample of 16 LCs, in WV08, we presented 1087 JHK s photometric observations of 21 objects (including 20 SN Ia and 1 SN Iax), the largest homogeneously observed lowz sample at the time. NIR data from WV08 and the literature strengthened the evidence that normal SN Ia are excellent NIR standard candles, especially in the H -band, where absolute magnitudes have an intrinsic root-mean-square (RMS) of 0 15-0 16 mag, . . without applying any reddening or LC shape corrections , comparable to the scatter in optical data corrected for both.
WV08 suggested that LC shape variation, especially in the J -band, might provide additional information for correcting NIR LCs and improving distance determinations. In M09, we applied a novel hierarchical Bayesian framework and a model accounting for variations in the J -band LC shape to NIR SN Ia data, constraining the marginal scatter of the NIR peak absolute magnitudes to 0 17, 0 11, and 0 19 mag, in . . . JHK s , respectively (see Fig. 9 of M09). Folatelli et al. 2010 obtained similar dispersions of 0 12-0 16 mag in . . Y JHK s , after correcting for NIR LC shape. Using 13 well-sampled, low extinction, normal NIR SN Ia LCs from the CSP, K12 find scatters in absolute magnitude of 0 12, 0 12, and 0 09 mag in . . . Y JH , respectively. K12 also confirm that NIR LC shape correlates with intrinsic NIR luminosity, finding evidence for a non-zero correlation between the peak absolute JH -maxima and the decline rate parameter ∆ m 15 , with only marginal dependence in Y . For a set of 12 SN Ia with JH LCs, Barone-Nugent et al. 2012 find a very small JH -band scatter of only 0 116 and 0 085 mag respectively, . . although their data set only includes 3-5 LC points for each of the 12 objects. Similarly, Weyant et al. 2014 use only 1-3 data points for each of 13 lowz NIR SN Ia to infer an H -band dispersion of 0.164 mag. Both BaroneNugent et al. 2012 and Weyant et al. 2014 use auxiliary optical data to estimate t B max . All of these results suggest that NIR data will be crucial for maximizing the utility of SN Ia as cosmological distance indicators.
## 1.2. Organization of Paper
This paper is organized as follows. In § 2, we discuss the current sample of nearby NIR SN Ia data including CfAIR2, describe the technical specifications of PAIRITEL, and outline our follow-up campaign. In § 3 we de- scribe the data reduction process, including mosaicked image creation, sky subtraction, host galaxy subtraction, and our photometry pipeline. In § 4, we present tests of PAIRITEL photometry, emphasizing internal calibration with 2MASS field star observations, tests for potential systematic errors, and external consistency checks for objects observed both by PAIRITEL and the CSP. Throughout § 2-4, we frequently reference F12, where many additional technical details can be found. In § 5, we present the principal data products of this paper, which include JHK s LCs of 94 SN Ia and 4 SN Iax. Further analysis of this data will be presented elsewhere. PAIRITEL and CSP comparison is discussed further in § 6. Conclusions and directions for future work are summarized in § 7. Additional details are included in a mathematical appendix (also see § 7 of F12).
## 2. OBSERVATIONS
In § 2.1, we provide recent historical context for CfAIR2 by describing the growing lowz sample of NIR SN Ia LCs. In § 2.2-2.4, we overview CfA NIR SN observations, describe PAIRITEL's observing capabilities, and detail our follow up strategy to observe SN Ia in JHK s .
## 2.1. Lowz NIR Light Curves of SN Ia
Technological advances in infrared detector technology have recently made it possible to obtain high quality NIR photometry for large numbers of SN Ia. Phillips (2012) provides an excellent recent review of the cosmological and astrophysical results derived from NIR SN Ia observations made over the past three decades. Early NIR observations of SN Ia were made by Kirshner et al. (1973); Elias et al. (1981, 1985); Frogel et al. (1987), and were particularly challenging as a result of the limited technology of the time. In addition, the flux contrast between the host galaxy and the SN Ia is typically smaller in the NIR than at optical wavelengths, making high S/N observations possible only for the brightest NIR objects with the detectors available in the 1970s and 1980s. While this situation has improved somewhat in the subsequent decades, NIR photometry is still significantly more challenging than at optical wavelengths. Elias et al. (1985) was the first to present a NIR Hubble diagram for 6 SN Ia. Although these 6 SN Ia LCs were not classified spectroscopically, Elias et al. (1985) was also the first to use what became the modern spectroscopic nomenclature of Type Ia instead of Type I to distinguish between Type Ia and Type Ib SN; SN Ib are now thought to be core collapse supernovae of stars that have lost their outer Hydrogen envelopes (see Modjaz et al. 2014 and references therein).
In the late 1990s and early 2000s, panoramic NIR arrays made it possible to obtain NIR photometry comparable in quantity and quality to optical photometry for nearby SN Ia. The first early-time NIR photometry with modern NIR detectors observed before t B max was presented for SN 1998bu (Jha et al. 1999; Hernandez et al. 2000). Since the first peak in the JHK s -band occurs ∼ 3-5 days before t B max , depending on the filter, SN Ia must generally be discovered by optical searches at least ∼ 5-8 days before t B max in order to be observed before the NIR maximum (F12; see § 2.4).
Pioneering early work was performed in the early 2000s in Chile at the Las Campanas Observatory (LCO) and
Table 1 General Properties of 94 PAIRITEL SN Ia (continued)
| SN | RA a | DEC a | Host b | Morphology c | z helio d | σz helio d | z d | Discovery b | Discoverer(s) e | Type f | Type |
|---------------------|---------------------|--------------------|-----------------------|------------------|-------------------|-------------------|-------|-----------------------|--------------------|---------------------|--------|
| Name | α (2000) | δ (2000) | Galaxy | | | | Ref. | Reference | | Reference | |
| SN 2009D | 58.59495 | -19.18194 | MCG -03-10-52 | Sb | 0.025007 | 0.000033 | 1 | CBET 1647 | LOSS | CBET 1647 | Ia |
| SN 2009Y | 220.59865 | -17.24675 | NGC 5728 | (R1)SAB(r)a | 0.009316 | 0.000026 | 2 | CBET 1684 | PASS, LOSS | CBET 1688 | Ia |
| SN 2009ad | 75.88914 | 6.66000 | UGC 3236 | Sbc | 0.0284 | 0.000005 | 1 | CBET 1694 | POSS | CBET 1695 | Ia |
| SN 2009al | 162.84201 | 8.57833 | NGC 3425 | S0 | 0.022105 | 0.00008 | 1 | CBET 1705 | CSS | CBET 1708 | Ia |
| SN 2009an | 185.69715 | 65.85145 | NGC 4332 | SB(s)a | 0.009228 | 0.000004 | 2 | CBET 1707 | Cortini+, Paivinen | CBET 1709 | Ia |
| SN 2009bv | 196.83538 | 35.78433 | MCG +06-29-39 | · · · | 0.036675 | 0.000063 | 1 | CBET 1741 | PIKA | CBET 1742 | Ia |
| SN 2009dc | 237.80042 | 25.70790 | UGC 10064 | S0 | 0.021391 | 0.00007 | 1 | CBET 1762 | POSS | CBET 1768 | Iap |
| SN 2009do | 188.74310 | 50.85108 | NGC 4537 | S | 0.039734 | 0.00008 | 1 | CBET 1778 | LOSS, POSS | CBET 1778 | Ia |
| SN 2009ds | 177.26706 | -9.72892 | NGC 3905 | SB(rs)c | 0.019227 | 0.000021 | 2 | CBET 1784 | Itagaki | CBET 1788 | Ia |
| SN 2009fw | 308.07711 | -19.73336 | ESO 597-6 | SA(rs)0-? | 0.028226 | 0.00011 | 1 | CBET 1836 | CHASE | CBET 1849 | Ia |
| SN 2009fv | 247.43430 | 40.81153 | NGC 6173 | E | 0.0293 | 0.00005 | 1 | CBET 1834 | POSS | CBET 1846 | Ia |
| SN 2009ig | 39.54843 | -1.31257 | NGC 1015 | SB(r)a | 0.00877 | 0.000021 | 1 | CBET 1918 | LOSS | CBET 1918 | Ia |
| SN 2009im | 53.34204 | -4.99903 | NGC 1355 | S0 sp | 0.0131 | 0.0001 | 1 | CBET 1925 | Itagaki | CBET 1934 | Ia |
| SN 2009jr | 306.60846 | 2.90889 | IC 1320 | SB(s)b? | 0.016548 | 0.00006 | 1 | CBET 1964 | Arbour | CBET 1968 | Ia |
| SN 2009kk | 57.43441 | -3.26447 | 2MFGC 03182 | · · · | 0.012859 | 0.00015 | 1 | CBET 1991 | CSS | CBET 1991 | Ia |
| SN 2009kq | 129.06316 | 28.06711 | MCG +05-21-1 | Spiral | 0.011698 | 0.00002 | 1 | CBET 2005 | POSS | ATEL 2291 | Ia |
| SN 2009le | 32.32152 | -23.41242 | ESO 478-6 | Sbc | 0.017792 | 0.000009 | 2 | CBET 2022 | CHASE | CBET 2025 | Ia |
| SN 2009lf | 30.41513 | 15.33290 | 10 | · · · | 0.045 | 0.002 | 3 | CBET 2023 | CSS | CBET 2025 | Ia |
| SN 2009na | 161.75577 | 26.54364 | UGC 5884 | SA(s)b | 0.020979 | 0.000006 | 2 | CBET 2098 | POSS | CBET 2103 | Ia |
| SN 2010Y | 162.76658 | 65.77966 | NGC 3392 | E? | 0.01086 | 0.000103 | 1 | CBET 2168 | Cortini | CBET 2168 | Ia |
| PS1-10w | 160.67450 | 58.84392 | Anonymous | · · · | 0.031255 | 0.0001 | 4 | R14 | PanSTARRS1 | R14 | Ia |
| PTF10bjs | 195.29655 | 53.81604 | MCG +09-21-83 | · · · | 0.030027 | 0.000073 | 1 | ATEL 2453 | PTF | ATEL 2453 | Ia |
| SN 2010ag | 255.97330 | 31.50152 | UGC 10679 | Sb(f) | 0.033791 | 0.000175 | 2 | CBET 2195 | POSS | CBET 2196 | Ia |
| SN 2010ai | 194.84999 | 27.99646 | 11 | E | 0.018369 | 0.000123 | 1 | CBET 2200 | ROTSE-III, Itagaki | CBET 2200 | Ia |
| SN 2010cr | 202.35442 | 11.79637 | NGC 5177 | S0 | 0.02157 | 0.000097 | 1 | CBET 2281 | Itagaki, PTF | ATEL 2580 | Ia |
| SN 2010dl | 323.75440 | -0.51345 | IC 1391 | · · · | 0.030034 | 0.00015 | 1 | CBET 2296 | CSS | CBET 2298 | Ia |
| PTF10icb | 193.70484 | 58.88198 | MCG +10-19-1 | · · · | 0.008544 | 0.000008 | 2 | ATEL 2657 | PTF | ATEL 2657 | Ia |
| SN 2010dw | 230.66775 | -5.92125 | 12 | · · · | 0.03812 | 0.00015 | 1 | CBET 2310 | PIKA | CBET 2311 | Ia |
| SN 2010ew | 279.29933 | 30.63026 | CGCG 173-018 | S | 0.025501 | 0.000127 | 1 | CBET 2345 | POSS | CBET 2356 | Ia |
| SN 2010ex | 345.04505 | 26.09894 | CGCG 475-019 | Compact | 0.022812 | 0.000005 | 1 | CBET 2348 | Ciabattari+ | CBET 2353 | Ia |
| SN 2010gn | 259.45832 | 40.88128 | 13 | Disk Gal | 0.0365 | 0.0058 | 1 | ATEL 2718 | PTF | CBET 2386 | Ia |
| SN 2010iw | 131.31205 | 27.82325 | UGC 4570 | SABdm | 0.021498 | 0.000017 | 1 | CBET 2505 | CSS | CBET 2511 | Ia? |
| SN 2010ju | 85.48321 | 18.49746 | UGC 3341 | SBab | 0.015244 | 0.000013 | 1 | CBET 2549 | LOSS | CBET 2550 | Ia |
| SN 2010jv | 111.86051 | 33.81143 | NGC 2379 | SA0 | 0.013469 | 0.000083 | 1 | CBET 2549 | LOSS | CBET 2550 | Ia |
| SN 2010kg | 70.03505 | 7.34995 | NGC 1633 | SAB(s)ab | 0.016632 | 0.000007 | 2 | CBET 2561 | LOSS | CBET 2561 | Ia |
| SN 2011B | 133.95016 | 78.21693 | NGC 2655 | SAB(s)0/a | 0.00467 | 0.000003 | 1 | CBET 2625 | Itagaki | CBET 262 | Ia |
| SN 2011K | 71.37662 | -7.34808 | 14 | · · · | 0.0145 | 0.001 | 3 | CBET 2636 | CSS | CBET 2636 | Ia |
| SN 2011aa | 114.17727 | 74.44319 | UGC 3906 | S | 0.012512 | 0.000033 | 2 | CBET 2653 | POSS | CBET 2653 | Iap? |
| SN 2011ae SN 2011ao | 178.70514 178.46267 | -16.86280 33.36277 | MCG -03-30-19 IC 2973 | · · · SB(s)d | 0.006046 0.010694 | 0.000019 0.000002 | 1 2 | CBET 2658 CBET 2669 | CSS POSS | CBET 2658 CBET 2669 | Ia Ia |
| SN 2011at | 142.23977 | -14.80573 | MCG -02-24-27 | SB(s)d | 0.006758 | 0.00002 | 1 | CBET 2676 | POSS | CBET 2676 | Ia |
| | | | | | | | | CBET 2708 | Jin+ | | Ia |
| SN 2011by | 178.93951 | 55.32592 | NGC 3972 | SA(s)bc | 0.002843 | 0.000005 | 1 | | POSS | CBET 2708 | Iap? |
| SN 2011de SN 2011df | 235.97179 291.89008 | 67.76196 54.38632 | UGC 10018 NGC 6801 | (R')SB(s)bc SAcd | 0.029187 0.014547 | 0.000017 0.000019 | 2 | CBET 2728 2 CBET 2729 | POSS | CBET 2728 CBET 2729 | Ia |
Note .
-
- (a) See caption in first part of Table 1.
- (b) Host Galaxy Names, discovery references, and discovery group/individual credits from NASA/IPAC Extragalactic Database (NED; http: //ned.ipac.caltech.edu/ ) and NASA/ADS ( http://adswww.harvard.edu/abstract\_service.html ). Also see IAUC List of Supernovae: http: //www.cbat.eps.harvard.edu/lists/Supernovae.html . For SN Ia with non-standard IAUC names, we found the associated host galaxy from IAUC/CBET/ATel notices or the literature and searched for the recession velocity with NED. When the SN Ia is associated with a faint host not named in any major catalogs (NGC, UGC, . . . ) but named in a large galaxy survey (e.g., SDSS, 2MASS), we include the host name from the large survey rather than 'Anonymous'. However, to fit the table on a single page, long galaxy names are numbered.
- 10: 2MASX J02014081+151952 (SN 2009lf), 11: SDSS J125925.04+275948.2 (SN 2010ai), 12: 2MASX J15224062-0555214 (SN 2010dw), 13: SDSS J171750.05+405252.5 (SN 2010gn), 14: CSS J044530.38-072054.7 (SN 2011K). The machine readable version of this table has full galaxy names.
- (c) -(e) See caption in first part of Table 1.
- (f) Spectroscopic type reference. R14=Rest et al. 2014.
- (g) Spectroscopic type of SN Ia = spectroscopically normal SN Ia. Spectroscopically peculiar SN Ia: including 91bg-like and 06gz-like objects. Uncertain spectroscopic types are denoted with a question mark (?): SN 2011de: classified as normal Ia in CBET 2728. But NIR LC morphology is consistent with a slow declining object (e.g., SN 2009dc-like). We classify it as Ia-pec.; SN 2011aa: classified as SN 1998aq-like normal Ia in CBET 2653. But Brown et al. 2014 identified it as a Super Chandrasekhar mass candidate, and NIR LC morphology is consistent with a slow declining object (e.g., SN 2009dc-like). We classify it as Ia-pec. SN 2010iw: classified as SN 2000cx-like, peculiar Ia in CBET 2511. But the NIR LC has the double peaked morphology of normal Ia. We classify it as a normal Ia.
Table 2 General Properties of 4 PAIRITEL SN Iax
| SN | RA a | DEC a | Host b | Morphology c | z helio d | σz helio d | z d | Discovery b | Discoverer(s) e | Type f | Type g |
|-----------|-----------|----------|-----------|----------------|-------------|--------------|--------|---------------|-------------------|-----------------------|----------|
| Name | α (2000) | δ (2000) | Galaxy | | | | Ref. | Reference | | Reference | |
| SN 2005hk | 6.96187 | -1.19819 | UGC 272 | SAB(s)d | 0.012993 | 0.000041 | 1 | IAUC 8625 | SDSS-II, LOSS | CBET 269; Ph07 | Iax |
| SN 2008A | 24.57248 | 35.37029 | NGC 634 | Sa | 0.016455 | 0.000007 | 2 CBET | 1193 | Ichimura | CBET 1198; F13; Mc14b | Iax |
| SN 2008ae | 149.01322 | 10.49965 | IC 577 | S? | 0.03006 | 0.000037 | 2 CBET | 1247 | POSS | CBET 1250; F13 | Iax |
| SN 2008ha | 353.71951 | 18.22659 | UGC 12682 | Im | 0.004623 | 0.000002 | 2 CBET | 1567 | POSS | CBET 1576; F09 | Iax |
Note .
-
- (a) -(e) See Table 1 caption.
- (f) Spectroscopic type reference, Ph07: Phillips et al. 2007; F09: Foley et al. 2009; F13: Foley et al. 2013; Mc14b: McCully et al. 2014b.
- (g) Spectroscopic type. Iax (Foley et al. 2013).
the Cerro Tololo Inter-American Observatory (CTIO), spearheaded by the work of Krisciunas et al. (2000, 2001, 2003, 2004b,c). K04a presented the largest Hubble diagram of its kind to date with 16 SN Ia. Before WV08 published 21 PAIRITEL NIR LCs observed by the CfA at FLWO, a handful of other NIR observations, usually for individual or small numbers of SN Ia or SN Iax of particular interest were presented in (Cuadra et al. 2002; Di Paola et al. 2002; Valentini et al. 2003; Candia et al. 2003; Benetti et al. 2004; Garnavich et al. 2004; Sollerman et al. 2004; Krisciunas et al. 2005a, 2006, 2007; Phillips et al. 2006, 2007; Pastorello et al. 2007b,a; Stritzinger & Sollerman 2007; Stanishev et al. 2007; Elias-Rosa et al. 2006, 2008; Pignata et al. 2008; Wang et al. 2008; Taubenberger et al. 2008). The largest NIR SN Ia sample prior to CfAIR2 was obtained by the Carnegie Supernova Project (CSP: Freedman & Carnegie Supernova Project 2005; Hamuy et al. 2006) at LCO, including observations of 59 normal and 14 peculiar NIR SN Ia LCs (Schweizer et al. 2008; Contreras et al. 2010; Stritzinger et al. 2010, 2011; Taubenberger et al. 2011). 17 Other SN Ia or SN Iax papers with published NIR data since WV08 include (Krisciunas et al. 2009; Leloudas et al. 2009; Yamanaka et al. 2009; Krisciunas et al. 2011; Barone-Nugent et al. 2012; Biscardi et al. 2012; Matheson et al. 2012; Taddia et al. 2012; Silverman et al. 2013; Stritzinger et al. 2014; Weyant et al. 2014; Cartier et al. 2014; Foley et al. 2014b; Amanullah et al. 2014; Goobar et al. 2014; Marion et al. 2015; Stritzinger et al. 2015). See Table 3 for a fairly comprehensive listing of SN Ia and SN Iax with NIR observations in the literature or presented in this paper.
Overall, while ∼ 1000 nearby SN Ia have been observed at optical wavelengths, prior to CfAIR2, only 147 total unique nearby objects have at least 1 NIR band of published Y JHK s data obtained with modern NIR detectors (from SN 1998bu onwards). These include 121 normal SN Ia, 22 peculiar SN Ia, and 4 SN Iax. CfAIR2 adds 66 new unique objects, including 62 normal SN Ia. By this measure, CfAIR2 increases the world published NIR sample of total unique objects by 66 / 147 ≈ 45% and normal SN Ia by 62 / 121 ≈ 51%. 12 additional CfAIR2 objects have new data which supersedes previously published PAIRITEL LCs and no data published by other groups. If we include these, CfAIR2 adds 78 total objects and 73 normal SN Ia to the literature. By this measure, CfAIR2 increases the world published sample of NIR objects by 78 / 135 ≈ 58% and the sample of normal SN Ia by 72 / 110 ≈ 65%. See Table 3.
## 2.2. PAIRITEL NIR Supernova Observations
Out of 121 total SN Ia and SN Iax observed from 20052011 by PAIRITEL, 23 are not included in CfAIR2. CfAIR2 includes improved photometry for 20 of 21 objects from WV08. For SN 2005cf, our photometry pipeline failed to produce a galaxy subtracted LC, so we include the WV08 LC for SN 2005cf in CfAIR2 and all applicable Figures or Tables. These 20 objects include additional observations not published in WV08, processed homogeneously using upgraded mosaic and photometry pipelines (see § 3). Table 1 lists general prop-
17 The CSP work did not yet distinguish SN Iax as a separate subclass from SN Ia.
Figure 1. Histogram of CfAIR2 Heliocentric Redshifts
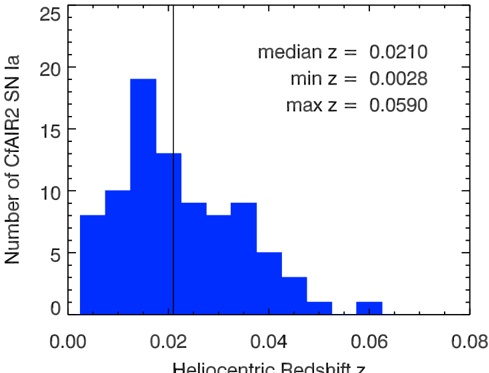
(Color online) Histogram of heliocentric redshifts z helio for 86 spectroscopically normal CfAIR2 SN Ia from Table 1 with t B max estimates accurate to within less than 10 days. Bin size ∆ z = 0 005. . Redshift statistics for the sample include: median (black vertical line, 0 0210), . minimum (0 0028), . and maximum (0 0590). . Heliocentric redshifts have not been corrected for any local flow models.
erties of the 94 CfAIR2 SN Ia and Table 2 lists these for the 4 CfAIR2 SN Iax.
Heliocentric galaxy redshifts are provided in Tables 1-2 and CMB frame redshifts are given in Table 9 to ease construction of future Hubble diagrams including NIR SN Ia data. 18 We obtained recession velocities from identified host galaxies as listed in the NASA/IPAC Extragalactic Database (NED). In cases where NED did not return a host galaxy or the host galaxy had no reported NED redshift, we either obtained redshift estimates from our own CfA optical spectra (Matheson et al. 2008; Blondin et al. 2012) or found redshifts reported in the literature. Fig. 1 shows a histogram of CfAIR2 heliocentric galaxy redshifts z helio for 86 normal SN Ia with t B max estimates accurate to within less than 10 days.
From 2005-2011, we also obtained extensive PAIRITEL NIR observations of 25 SN Ib/c (Bianco et al. 2014), and 20 SN II (to be presented elsewhere). Table 4 references all previously published and in preparation papers using PAIRITEL SN data, including multi-wavelength studies of individual objects (Tominaga et al. 2005; Kocevski et al. 2007; Modjaz et al. 2009; Wang et al. 2009; Foley et al. 2009; Sanders et al. 2013; Drout et al. 2013; Marion et al. 2014; Margutti et al. 2014; Fransson et al. 2014) and NIR/optical LC compilations for SN of all types (e.g., Modjaz 2007; WV08; F12; Bianco et al. 2014). The most recent of these papers (Sanders et al. 2013; Marion et al. 2014; Margutti et al. 2014; Fransson et al. 2014; Bianco et al. 2014) used the same mosaic and photometry pipelines also used to produce the CfAIR2 data for this paper (see § 3). For completeness, we also include information on all other types of SN with published PAIRITEL observations for both current and older pipelines.
18 However, note that none of the redshifts in Tables 1-2 or Table 9 have been corrected for local flow models. Objects with recession velocities glyph[lessorsimilar] 3000 km s -1 ( z glyph[lessorsimilar] 0 01) . must have their redshifts corrected with local flow models or other distance information before being included in Hubble diagrams.
Table 3
SN Ia and SN Iax with Published NIR Photometry
| SN Name | Type a | NIR Photometry b | SN Name | Type a | NIR Photometry | SN Name | Type a | NIR Photometry b |
|-------------------------------------------------|------------|-------------------------|---------------------|-----------|--------------------------|---------------------|---------------|--------------------|
| SN 2012Z | Iax | References S15 | SN 2007nq | Ia | References b CfAIR2; S11 | SN 2007as | Ia | References S11 |
| SN 2014J | Ia | A14; Go14; F14b | SN 2007le | Ia | CfAIR2; S11 | SN 2007ax | Ia-pec | S11 |
| SN 2013bh | Ia-pec | Si13 | SN 2007if | Ia-pec | CfAIR2; S11 | SN 2007ba | Ia-pec | S11 |
| SN 2011fe | Ia | M12 | SN 2007fb | Ia | CfAIR2 | SN 2007bc | Ia | S11 |
| SN 2010ae | Iax | S14 | SN 2007cq | Ia | CfAIR2; WV08 | SN 2007bd | Ia | S11 |
| SN 2008J | Ia | Ta12 | SN 2007co | Ia | CfAIR2 | SN 2007bm | Ia | S11 |
| SN 2011df SN 2011de | Ia Ia-pec? | CfAIR2 CfAIR2 | SN 2007ca SN 2007S | Ia Ia | CfAIR2; S11 CfAIR2; S11 | SN 2007hx SN 2007jg | Ia Ia | S11 S11 |
| SN 2011by | Ia | CfAIR2 | SN 2006mq | Ia | CfAIR2 | SN 2007on | Ia | S11 |
| | | CfAIR2 | SN 2006lf | Ia | CfAIR2; WV08 | SN 2008R | Ia | S11 |
| SN 2011at | Ia | | | | | | | |
| SN 2011ao | Ia | CfAIR2 | SN 2006le | Ia | CfAIR2; WV08 | SN 2008bc | Ia | S11 |
| SN 2011ae | Ia | CfAIR2 | SN 2006gr | Ia | CfAIR2; WV08 | SN 2008bq | Ia | S11 |
| SN 2011aa | Ia-pec? | CfAIR2 | SN 2006cz | Ia | CfAIR2 | SN 2008fp | Ia | S11 |
| SN 2011K | Ia | CfAIR2 | SN 2006cp | Ia | CfAIR2; WV08 | SN 2008gp | Ia | S11 |
| SN 2011B | Ia | CfAIR2 | SN 2006ax | Ia | CfAIR2; WV08; C10 | SN 2008ia | Ia | S11 |
| SN 2010kg | Ia | CfAIR2 | SN 2006ac | Ia | CfAIR2; WV08 | SN 2009F | Ia-pec | S11 |
| SN 2010jv | Ia | CfAIR2 | SN 2006X | Ia | CfAIR2; WV08; C10; WX08 | SN 2004eo | Ia | C10; Pa07b |
| SN 2010ju | Ia | CfAIR2 | SN 2006N | Ia | CfAIR2; WV08 | SN 2004S | Ia | K07 |
| SN 2010iw | Ia? | CfAIR2 | SN 2006E | Ia | CfAIR2 | SN 2003hv | Ia | L09 |
| SN 2010gn | Ia | CfAIR2 | SN 2006D | Ia | CfAIR2; WV08; C10 | SN 2003gs | Ia-pec | K09 |
| SN 2010ex | Ia | CfAIR2 | SN 2005na | Ia | CfAIR2; WV08; C10 | SN 2003du | Ia | St07 |
| SN 2010ew | Ia | CfAIR2 | SN 2005ls | Ia | CfAIR2 | SN 2003cg | Ia | ER06 |
| SN 2010dw | Ia | CfAIR2 | SN 2005ke | Ia-pec | CfAIR2; WV08; C10 | SN 2002fk | Ia | Ca14 |
| PTF10icb | Ia | CfAIR2 | SN 2005iq | Ia | CfAIR2; WV08; C10 | SN 2002dj | Ia | P08 |
| SN 2010dl | Ia | CfAIR2 | SN 2005hk | Iax | CfAIR2; WV08; Ph07 | SN 2002cv | Ia | ER08; DP02 |
| SN 2010cr | Ia | CfAIR2 | SN 2005eu | Ia | CfAIR2; WV08 | SN 2002bo | Ia | K04c; B04 |
| SN 2010ai | Ia | CfAIR2 | SN 2005eq | Ia | CfAIR2; WV08; C10 | SN 2001el | Ia | K03; S07 |
| SN 2010ag | Ia | CfAIR2 | SN 2005el | Ia | CfAIR2; WV08; C10 | SN 2001cz | Ia | K04c |
| PTF10bjs | Ia | CfAIR2 | SN 2005ch | Ia | CfAIR2; WV08 | SN 2001cn | Ia | K04c |
| PS1-10w | Ia | CfAIR2 | SN 2005cf | Ia | CfAIR2; WV08; Pa07a | SN 2001bt | Ia | K04c |
| SN 2010Y | Ia Ia | CfAIR2 | SN 2005bo | Ia Ia-pec | CfAIR2 | SN 2001ba | Ia | K04b |
| SN 2009na | | CfAIR2 | SN 2005bl | | CfAIR2; WV08 | SN 2001ay | Ia-pec | K11 |
| SN 2009lf | Ia | CfAIR2 | SN 2005ao | Ia | CfAIR2; WV08 | SN 2000cx | Ia-pec | Ca03; So04; K01 |
| SN 2009le SN | Ia Ia | CfAIR2 | SN 2004ef | Ia Ia | C10 | SN 2000ce | Ia Ia | K04b |
| 2009kq SN | | CfAIR2 | SN 2004ey | | C10 | SN 2000ca | Ia | K01 |
| 2009kk SN 2009jr | Ia Ia | CfAIR2 CfAIR2 | SN 2004gs SN 2004gu | Ia Ia-pec | C10 | SN 2000bk SN 2000bh | Ia | K04b |
| SN 2009im | Ia | CfAIR2 | | Ia | C10 C10 | SN 2000E | Ia | V03 |
| SN 2009ig | Ia | CfAIR2 | SN 2005A SN 2005M | Ia | | SN 1999gp | Ia | K01 |
| SN 2009fv | Ia | CfAIR2 | | | C10 | SN 1999ek | Ia | K04c |
| | | | SN 2005ag | Ia | C10 C10 | SN 1999ee | | |
| SN 2009fw SN 2009ds | Ia Ia | CfAIR2 CfAIR2 | SN 2005al SN 2005am | Ia Ia | C10 | SN 1999cp | Ia Ia | K04b K00 |
| SN 2009do | Ia | CfAIR2 CfAIR2; T11; Y09 | SN 2005hc | Ia | C10 C10 | SN 1999cl SN 1999by | Ia | K00 G04 |
| SN 2009dc SN 2009bv | Ia-pec Ia | CfAIR2 | SN 2005kc SN 2005ki | Ia Ia | | SN 1999ac | Ia-pec Ia-pec | Ph06 |
| SN 2009an | Ia | CfAIR2 | | Ia | C10 | SN 1999aa | Ia-pec | K00 |
| SN 2009al | Ia | CfAIR2 | SN 2006bh SN | Ia | C10 C10 | SN 1998bu | Ia | H00; J99 |
| | | | 2006eq | Ia-pec | | PTF09dlc | Ia | |
| SN 2009ad SN 2009Y | Ia Ia | CfAIR2 CfAIR2 | SN 2006gt SN | Ia-pec | C10 | PTF10hdv | Ia | BN12 |
| SN 2009D | Ia | | 2006mr SN | Ia | C10 S10 | PTF10mwb PTF10ndc | Ia | BN12 BN12 |
| SN | Ia | CfAIR2 CfAIR2 | 2006dd SN 2005hj | Ia | | | Ia | BN12 |
| 2008hy SN 2008hv | Ia | CfAIR2; | SN 2005ku | Ia | S11 S11 S11 | PTF10nlg PTF10qyx | Ia | BN12 |
| SN 2008hs | Ia | S11 CfAIR2 | SN 2006bd | Ia-pec | | PTF10tce | Ia | BN12 |
| SN | Ia | CfAIR2 | SN 2006br | Ia | | | Ia | BN12 |
| 2008hm SN 2008ha | Iax | CfAIR2; F09 | SN 2006bt | Ia-pec Ia | S11 S11 S11 | PTF10ufj | Ia | BN12 |
| SN 2008gl | Ia | CfAIR2 | SN 2006ej | | S11 | PTF10wnm | Ia | BN12 |
| SN 2008gb | Ia | CfAIR2 | SN 2006et | Ia Ia | S11 | PTF10wof PTF10xyt | Ia | BN12 |
| SN 2008fx | Ia | CfAIR2 | SN 2006ev | Ia | | | Ia | BN12 |
| SN 2008fv | Ia | CfAIR2; Bi12 | SN 2006gj | | S11 | SN 2011hr | Ia | W14 |
| SN 2008fr | Ia | CfAIR2 | SN 2006hb | Ia | | SN 2011gy | Ia | W14 |
| | Ia | CfAIR2 | SN 2006hx | Ia Ia | S11 S11 S11 | SN 2011hk | Ia-pec | W14 |
| | Ia | CfAIR2 | SN 2006is | Ia | | SN 2011fs | Ia Ia | W14 |
| SNF20080522-011 SNF20080522-000 SNF20080514-002 | Ia | CfAIR2 | SN 2006kf | Ia | S11 S11 | SN 2011gf SN 2011hb | | W14 |
| SN 2008af | Ia | CfAIR2 | SN 2006lu | Ia | | | Ia | W14 |
| SN 2008ae | Iax | | SN 2006ob | | | SN 2011io | Ia | W14 |
| SN 2008Z | Ia | CfAIR2 | SN 2006os | Ia | S11 S11 S11 | SN 2011iu | Ia | W14 |
| SN 2008C | Ia | CfAIR2 CfAIR2; | SN 2006ot | Ia-pec | | PTF11qri | Ia | W14 |
| SN 2008A | Iax | S11 CfAIR2 | SN 2007A | Ia | S11 S11 | PTF11qmo | Ia | W14 |
| SN 2007sr | Ia | CfAIR2; S08 | SN 2007N | Ia-pec | | PTF11qzq | Ia | W14 |
| | Ia | CfAIR2 | SN 2007af | Ia | | PTF11qpc | Ia | W14 |
| SN 2007rx | | | | | | | | |
| | | | SN 2007ai | | | Ia | | W14 |
| SN | | CfAIR2 | | Ia | | SN 2011ha | | |
| | | | | | S11 S11 | | | |
| | Ia | | | | | | | |
| 2007qe | | | | | | | | |
## Note .
-
(a) SN Spectroscopic Types: Ia = Normal SN Ia including 91T-like, 86G-like, and spectroscopically normal objects; Iap = Peculiar SN Ia including 91bg-like objects and extra-luminous, slow declining 06gz-like objects (Hicken et al. 2007); Iax = SN Iax including 02cx-like objects distinct from peculiar SN Ia (Li et al. 2003; Foley et al. 2013). Spectroscopic type references for CfAIR2 objects are in Tables 1-2, and in the references below for non-CfAIR2 objects with NIR photometry. SN with uncertain spectral types (SN 2011de, SN 2011aa, SN 2010iw) are denoted by a question mark (?) (see Table 1 caption).
(b) References for objects with at least 1 band of Y JHK s photometry. CfAIR2: this paper; WV08: Wood-Vasey et al. (2008); W14: Weyant et al. (2014); S15: Stritzinger et al. (2015); S14: Stritzinger et al. (2014); F14b: Foley et al. (2014b); Go14: Goobar et al. (2014); Ca14: Cartier et al. (2014); A14: Amanullah et al. (2014); Si13: Silverman et al. (2013); Ta12: Taddia et al. (2012); M12: Matheson et al. (2012); Bi12: Biscardi et al. (2012); BN12: Barone-Nugent et al. (2012); T11: Taubenberger et al. (2011); S11: Stritzinger et al. (2011); K11: Krisciunas et al. (2011); S10: Stritzinger et al. (2010); C10: Contreras et al. (2010); Y09: Yamanaka et al. (2009); L09: Leloudas et al. (2009); K09: Krisciunas et al. (2009); F09: Foley et al. (2009); WX08: Wang et al. (2008); T08: Taubenberger et al. (2008); S08: Schweizer et al. (2008); P08: Pignata et al. (2008); ER08: Elias-Rosa et al. (2008); S07: Stritzinger & Sollerman (2007); St07: Stanishev et al. (2007); Ph07: Phillips et al. (2007); Pa07b: Pastorello et al. (2007b); Pa07a: Pastorello et al. (2007a); K07: Krisciunas et al. (2007); Ph06: Phillips et al. (2006); ER06: Elias-Rosa et al. (2006); K05: Krisciunas et al. (2005b); So04: Sollerman et al. (2004); K04c: Krisciunas et al. (2004c); K04b: Krisciunas et al. (2004b); G04: Garnavich et al. (2004); B04: Benetti et al. (2004); V03: Valentini et al. (2003); K03: Krisciunas et al. (2003); Ca03: Candia et al. (2003); DP02: Di Paola et al. (2002); Cu02: Cuadra et al. (2002); K01: Krisciunas et al. (2001); K00: Krisciunas et al. (2000); H00: Hernandez et al. (2000); J99: Jha et al. (1999).
## 2.3. PAIRITEL 1.3-m Specifications
Dedicated in October 2004, PAIRITEL uses the Two Micron All Sky Survey (2MASS; Skrutskie et al. 2006) northern telescope together with the 2MASS southern camera. PAIRITEL is a fully automated robotic telescope with the sequence of observations controlled by an optimized queue-scheduling database (Bloom et al. 2003, 2006). Two dichroic mirrors allow simultaneous observing in JHK s (1.2, 1.6, and 2.2 µ m, respectively; Cohen et al. 2003; Skrutskie et al. 2006) with three 256 × 256 pixel HgCdTe NICMOS3 arrays. Figure 1 of WV08 shows a composite JHK s mosaicked image of SN 2006D (see § 3.1).
Since the observations are conducted with the instrument that defined the 2MASS JHK s system, we use the 2MASS point source catalog (Cutri et al. 2003) to establish photometric zero points. Typical 30-minute (1800second) observations (including slew overhead) reach 10σ sensitivity limits of ∼ 18 17 5 , . , and 17 mag for point sources in JHK s , respectively (F12). For fainter objects, 10σ point source sensitivities of 19 4, . 18 5, . and 18 mag are achievable with 1.5 hours (5400-seconds) of dithered imaging (Bloom et al. 2003) in JHK s , respectively. PAIRITEL thus observes significantly deeper than 2MASS, which used a 7.8-second total exposure time to achieve 10σ point source sensitivities of 15.8, 15.1, 14.3 in JHK s , respectively (Skrutskie et al. 2006; see § 4).
## 2.4. Observing Strategy
Automation of PAIRITEL made it possible to study SN with unprecedented temporal coverage in the NIR, by responding quickly to new SN and revisiting targets frequently (Bloom et al. 2006; WV08; F12). CfAIR2 followed up SN discovered by optical searches at δ glyph[greaterorsimilar] -30 degrees with V glyph[lessorsimilar] 18 mag, with significant discovery contributions from both amateur and professional astronomers (see Tables 1-2). SN candidates with a favorable observation window and airmass < 2 5 from Mount . Hopkins were considered for the PAIRITEL observation queue. We observed SN of all types but placed highest priority on the brightest SN Ia discovered early or close to maximum brightness. SN candidates meeting these criteria were often added to the queue before spectroscopic typing to observe the early time LC. Since many optically discovered SN of all types brighter than V < 18 mag are spectroscopically typed by our group at the CfA 19 or other groups within 1-3 days of discovery, we rarely spent more than a few observations on objects we later deactivated after typing. All CfA supernovae are spectroscopically classified using the SuperNova IDentification code (SNID; Blondin & Tonry 2007).
From 2005-2011, ∼ 20-30 SN per year were discovered that were bright enough to observe with the PAIRITEL 1.3-m, with ∼ 3-6 available on any given night from Mount Hopkins. Since we only perform follow-up NIR observations and are not conducting a NIR search to discover SN with PAIRITEL, we suffer from all the heterogeneous sample selection effects and biases incurred by each of the independent discovery efforts. A full analysis of the completeness of our sample is beyond the scope of this work. Overall, with ∼ 30% of the time on a robotic telescope available for supernova observations, effectively amounting to over 6 months on the sky, we observed over 2 / 3 of the candidate SN that met our follow-up criteria. We also observed galaxy template images (SNTEMP) for each SN to enable host subtraction (see § 3.4).
## 3. DATA REDUCTION
Since WV08, we have substantially upgraded our data reduction software, including both pipelines for combining the raw data into mosaics and for performing photometry on the mosaicked images. All CfAIR2 data were processed homogeneously with a single mosaicking pipeline (hereafter p3.6 ) that adds and registers PAIRITEL raw images into mosaics ( 3.1). § The mosaics, and their associated noise and exposure maps, were then fed to a single photometry pipeline (hereafter photpipe ), originally developed to handle optical data for the ESSENCE and SuperMACHO projects (Rest et al. 2005; Garg et al. 2007; Miknaitis et al. 2007) and modified to perform host galaxy subtraction and photometry on the NIR mosaicked images ( § 3.4-3.8). Earlier mosaic and photpipe versions have been used for previously published PAIRITEL SN LCs (see Table 4), with recent modifications by A. Friedman and W.M. Wood-Vasey to produce compilations of SN Ia and SN Iax (CfAIR2; this work) and SN Ib and SN Ic (Bianco et al. 2014). Photpipe now takes as input improved noise mosaics to estimate the noise in the mosaicked images ( 3.2), § registers the images to a common reference frame with SWarp (Bertin et al. 2002), subtracts host galaxy light at the SN position using reference images with HOTPANTS (Becker et al. 2004, 2007), and performs point-spread function (PSF) photometry using DoPHOT (Schechter et al. 1993). Photometry is extracted from either the unsubtracted or the subtracted images by forcing DoPHOT to measure the PSF-weighted flux of the object at a fixed position in pixel coordinates (see § 3.4; F12).
In § 3.1, we describe our p3.6 mosaic pipeline. In § 3.2, we describe sky subtraction and our improved method to produce noise mosaics corresponding to the mosaicked images. In § 3.3, we discuss the undersampling of the PAIRITEL NIR camera. In § 3.4-3.7 we detail the host galaxy subtraction process and describe our method for performing photometry on the subtracted or unsubtracted images. Major photpipe improvements are summarized in § 3.8. See F12 for additional details.
## 3.1. Mosaics
All CfAIR2 images were processed into mosaics at the CfA using p3.6 implemented in Python version 2.6. 20 F12 and references in Table 4 describe older mosaic pipelines. Klein & Bloom 2014 provide a more detailed description of p3.6 as used for PAIRITEL observations of RR Lyrae stars. Figs. 3-5 show sample p3.6 J -band mosaics for all 98 CfAIR2 objects.
Including slew overhead for the entire dither pattern, typical exposure times range from 600 to 3600 seconds,
20 p1.0 p3.6 -was developed at UC Berkeley and the CfA by J.S. Bloom, C. Blake, C. Klein, D. Starr, and A. Friedman.
Table 4 SN with Published or Forthcoming PAIRITEL Data
| Object or Compilation | Type(s) | Reference | Comments |
|-------------------------|---------------|------------------------------------------|----------------------------------------------------------------|
| SN 2005bf | Ic-Ib | Tominaga et al. 2005 | Unusual core-collapse object |
| SN 2006aj | Ic-BL | Modjaz et al. 2006; Kocevski et al. 2007 | Associated with GRB 060281 |
| SN 2006jc | Ib/c | Modjaz 2007 | Unusual core-collapse object; in M. Modjaz PhD Thesis |
| SN 2008D | Ib | Modjaz et al. 2009 | Associated with Swift X-ray transient XRT 080109 |
| SN 2005cf | Ia | Wang et al. 2009 | Normal SN Ia, significant multi-wavelength data |
| SN 2008ha | Iax | Foley et al. 2009 | Extremely low luminosity supernova Iax a |
| WV08 | Ia,Ia-pec,Iax | Wood-Vasey et al. 2008 | Compilation of 20 SN Ia and 1 SN Iax NIR LCs a |
| F12 | Ia,Ia-pec,Iax | Friedman 2012 | Compilation of SN Ia and SN Iax in A. Friedman PhD Thesis a |
| M07 | Ib,Ic | Modjaz 2007 | Compilation of SN Ib and SN Ic in M. Modjaz PhD Thesis b |
| PS1-12sk | Ibn | Sanders et al. 2013 | Pan-STARRS1 project observations |
| SN 2005ek | Ic | Drout et al. 2013 | Photometry from Modjaz 2007 PhD Thesis b |
| SN 2011dh | IIb | Marion et al. 2014 | SN in M51 |
| SN 2009ip | LBV | Margutti et al. 2014 | Luminous blue variable with outbursts. Not a supernova |
| SN 2010jl | IIn | Fransson et al. 2014 | Unusual core-collapse object |
| B14 | Ib,Ic | Bianco et al. 2014 | Compilation of PAIRITEL SN Ib and SN Ic b |
| CfAIR2 | Ia,Ia-pec,Iax | Friedman et al. 2015a | This paper. Compilation of PAIRITEL SN Ia, SN Ia-pec, SN Iax a |
| SN 2012cg | Ia | Marion et al. 2015b in prep. | Bright Ia with multi-wavelength data |
Note .
-
(a) Photometry in this paper supersedes PAIRITEL LCs from Wood-Vasey et al. 2008 (except SN 2005cf ), SN 2008ha LC in Foley et al. 2009, F12. (b) B14 supersedes M. Modjaz PhD Thesis.
yielding ∼ 50-150 raw images for mosaicking. Excluding slew overhead, effective exposure times are generally ∼ 40 -70% of the time on the sky, yielding typical actual exposure times of ∼ 250 to ∼ 2500 seconds. Raw images are obtained with standard double-correlated reads with the long exposure (7 8-second) minus short expo-. sure (51-millisecond) frames in each filter treated as the 'raw' frame input to p3.6 . These raw 256 × 256 pixel images are of ∼ 7 8-second duration with a plate scale . of 2 ′′ /pixel and a 8.53 ′ × 8.53 ′ field of view (FOV). To aid with reductions, the telescope is dithered after each set of three exposures with a step size < 2 ′ based on a randomized dither pattern covering a typical ∼ 12 ′ × 12 ′ FOV. The three raw images observed at each dither position are then added into 'triplestacks' before mosaicking. The p3.6 pipeline processes all raw images by flat correction, dark current and sky subtraction, registration, and stacking to create final JHK s mosaics using SWarp (Bertin et al. 2002). Bad pixel masks are created dynamically and flat fields - which are relatively stable - were created from archival images. Since the shorttimescale seeing also remains roughly constant in the several seconds of slew time between dithered images, we did not find it necessary to convolve the raw images to the seeing of a raw reference image before mosaicking. The seeing over long time periods (several months) remains relatively constant at 0.77-0.85 ′′ 21 . The raw images are resampled from a raw image scale of 2 ′′ /pixel into final mosaics with 1 ′′ /pixel sampling with SWarp (Bertin et al. 2002). The typical FWHM in the final PAIRITEL mosaics is ∼ 2 5-3 0 . . ′′ , consistent with the average image quality obtained by 2MASS (Bloom et al. 2003; Skrutskie et al. 2006).
The desired telescope pointing center for all dithered images is set to the SN RA and DEC coordinates from the optical discovery images. Unfortunately, as a result of various software and/or mechanical issues - for example problems with the RA drive - the PAIRITEL 1.3-m telescope pointing accuracy can vary by ∼ 1 -30
arcminutes from night to night. Catastrophic pointing errors can result in the SN being absent in all of the raw images and missing in the ∼ 12 ′ × 12 ′ mosaic FOV. More often, non-fatal pointing errors result in the SN being absent or off-center in some, but not all, raw images. In p2.0 used for WV08, the mosaic center was constrained to be the SN coordinates and the mosaic size in pixels was fixed. This resulted in a significant fraction of failed or low S/N mosaics using an insufficient number of raw images. For p3.0 p3.6 -, the constraint fixing the SN at the mosaic center was relaxed and the mosaic center was allowed to be the center of all imaging. This resulted in ∼ 15% more mosaic solutions than p2.0 . Mosaics that failed processing at intermediate photpipe stages were excluded from the LC automatically. Some mosaics that succeeded to the end of photpipe were excluded based on visual inspection or by identifying outlier LC points during post processing.
## 3.2. Sky Subtraction and Noise Maps
The PAIRITEL camera has no cold shutter, so dark current cannot be measured independently, and background frames include both sky and dark photons ('skark'). Fortunately, the thermal dark current counts across the raw frames, are negligible in JHK s for the NICMOS3 arrays on timescales comparable to the individual, raw, 7 8-second exposures (Skrutskie et al. 2006). . Furthermore, the dark current rate does not detectably vary across the 1.5 hours of the maximum dither pattern used in these observations. Background frames also include an electronic bias, characterized by shading in each of the four raw image quadrants which produces no noise, and amplifier glow, which peaks at the corners of the quadrants, and which, like thermal dark current, does produce Poisson noise. These intrinsic detector and sky noise contributions get smeared out over the mosaic dither pattern, producing characteristic patterns in the skark mosaics and mosaic noise maps (see Fig. 2). 22
22 The shading is an electronic bias which technically produces no noise. Shading was subtracted out as part of the skark counts
Figure 2. PAIRITEL Source, Skark, & Noise Mosaics

(Color online) Mosaics ( first row ), Skark Mosaics ( second row ), and Noise Mosaics ( third row ) for the PAIRITEL JHK s images of SN 2009an from 3/1/2009. The SN is marked with green circles (color online). Images are displayed in SAOimage ds9 with zscale scaling, in grayscale with counts increasing from black to white. The skark images contain the number of sky + dark current + bias counts (skark counts) subtracted from each mosaic pixel. Median skark counts for these images were ∼ 800, 6700 , and 19600 counts in JHK s , respectively, reflecting the sky noise increase towards longer NIR wavelengths which is worst in K s -band. The large scale patterns in the skark mosaics come from arcminute scale spatial variations in the sky brightness of the raw frames, and both thermal dark current and amplifier glow, which peak at the corners of each detector quadrant, and which both contribute Poisson noise. The skark mosaics also show signatures of the relatively stable electronic bias shading patterns in each quadrant of the raw JHK s detectors, which differ by bandpass. All of these contributions get smeared out over the mosaic dither pattern. Noise mosaics use source counts from the mosaic, skark counts from the skark mosaics, and noise from other sources (see § 7.1 of F12 for assumptions used to estimate the noise per pixel). The large scale patterns in the J -band skark and noise mosaics are dominated by the cumulative detector noise contributions, including thermal dark current, shading, and amplifier glow. By contrast, the H and K s skark and noise mosaics are dominated by sky counts and sky noise, respectively, which combine with the various detector imprints and spatiotemporal sky variation across the dither pattern to form the large scale patterns in those bandpasses.
PAIRITEL SN observations did not include on-off pointings alternating between the source and a nearby sky field, so skark frames were created for each raw image in the mosaic by applying a pixel-by-pixel average through the stack of a time series of unregistered raw frames, after removing the highest and lowest pixel values in the stack. The stack used a time window of 5 minutes before and after each raw image. This approximation assumes that the sky is constant on timescales less than 10 minutes. For reference, typical dithered image sequences have effective exposure times of 10-30 minutes. Fig. 2 shows that for J -band, where the sky counts are small compared to the various sources of detector noise, the for each corresponding raw image. However, the shading was included as a generic background contribution along with thermal dark current, amplifier glow, and sky counts, and thus effectively contributes to the noise mosaics in Fig. 2.
skark and noise mosaics are dominated by the cumulative effect of the intrinsic detector features over the entire dither pattern, including dark current, shading, and amplifier glow. 23 By contrast, the H and K s -band skark and noise mosaics in Fig. 2 are dominated by sky counts and sky noise, respectively, which combine with the various detector imprints and spatiotemporal sky variation to produce the large scale patterns smeared across the dither pattern.
Although the telescope is dithered ( < 2 ) ′ after three exposures at the same dither position, for host galaxies with large angular size glyph[greaterorsimilar] 2 -5 ′ (in the 8.53 ′ raw image FOV), host galaxy flux contamination introduces additional systematic uncertainty by biasing skark count estimates toward larger values, leading to over-subtraction of sky light in those pixels (F12). Still, the relatively large PAIRITEL 8.53 ′ FOV combined with a dither step size comparable or greater than the ∼ 1-2 ′ angular size of typical galaxies at z ∼ 0 02 allows us to safely estimate . the sky from the raw frames in most cases. This observing strategy also gives us more time on target compared to on-off pointing. While our approach can lead to systematic sky over-subtraction for SN and stars near larger galaxies, by testing the radial dependence of PAIRITEL photometry of 2MASS stars within 3 ′ of the SN (and close to the host galaxy), we estimate this systematic error to be negligible compared to our photometric errors, biasing SN photometry fainter by glyph[lessorsimilar] 0 01 mag in . JH and glyph[lessorsimilar] 0 02 in . K s (F12). By comparison, mean photometric errors for each of the highest S/N LC points from the set of SN in CfAIR2 are ∼ 0 03, 0 05, and 0 12 mag in . . . JHK s , respectively, (with larger mean statistical errors for all LC points of ∼ 0 09, 0 12, and 0 18 mag in . . . JHK s , respectively). We thus choose to ignore systematic errors from sky over-subtraction in this work.
Since three raw frames are taken at each dither position and co-added into triplestacks before mosaicking, p3.6 now also constructs 'tripleskarks', by co-adding the three associated skark frames taken at each dither position. To remove the estimated background counts, p3.6 now subtracts the associated tripleskark from each triplestack before creating final mosaics and new skark and noise mosaics (see Fig. 2). Since the estimated skark noise can vary by ∼ 10-100% across individual skark mosaics, modeling the noise in each pixel provides more reliable differential noise estimates at the positions of all 2MASS stars and the SN, although our absolute noise estimate is still underestimated since the noise mosaics do not model all sources of uncertainty (see § 7.1 of F12). To account for this, we also use 2MASS star photometry to empirically calculate inevitable noise underestimates, and correct for them in SN photometry on subtracted or unsubtracted images (see F12; § 4).
## 3.3. The PAIRITEL NIR Camera is Undersampled
The PAIRITEL Infrared camera is undersampled because the 2 ′′ detector pixels are larger than the atmospheric seeing disk at FLWO. This means we can not fully
- 23 For further information on these features of NICMOS arrays, also used on the Hubble Space Telescope, see
http://documents.stsci.edu/hst/nicmos/documents/handbooks/v10/c07\_detectors4.html or http://www.stsci.edu/hst/nicmos/documents/handbooks/DataHandbookv8/nic\_ch4.8. 3.html .
Figure 3. Gallery of 35 PAIRITEL J -band Mosaics
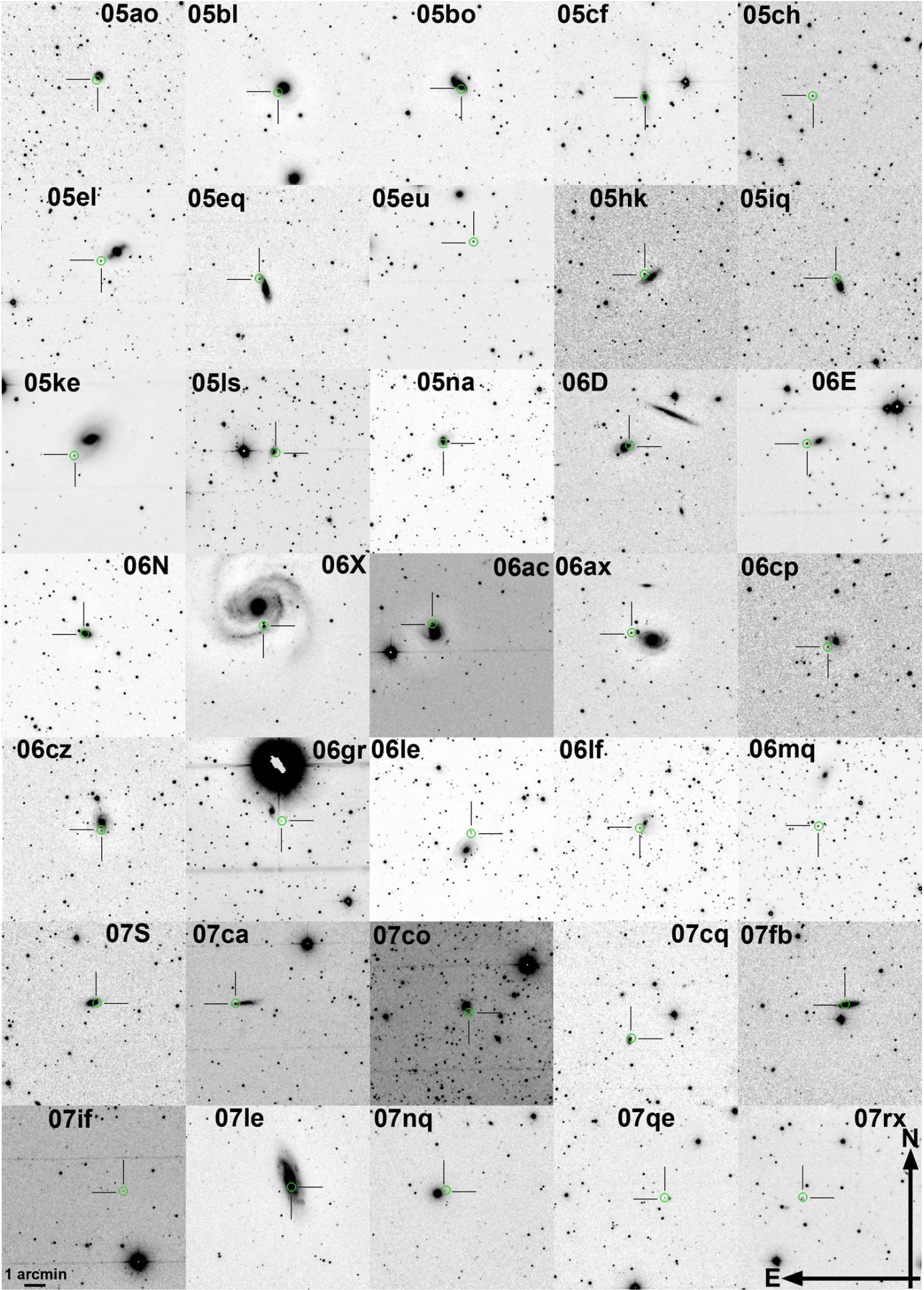
(Color online) A subset of 35 PAIRITEL J -band Mosaics from the set of 94 CfAIR2 SN Ia and 4 SN Iax observed with PAIRITEL from 2005-2011. SN Ia are marked by green circles (color online) and crosshairs. SN names are of the shortened form 06X = SN 2006X. North and East axes for all mosaics are indicated in the lower right corner of the figure.
Figure 4. Gallery of 35 PAIRITEL J -band Mosaics

(Color online) A subset of 35 PAIRITEL J -band Mosaics from the set of 94 CfAIR2 SN Ia and 4 SN Iax observed with PAIRITEL from 2005-2011. SN Ia are marked by green circles (color online) and crosshairs. SN names are of the shortened form 09an = SN 2009an. North and East axes for all mosaics are indicated in the lower left corner of the figure.
Figure 5. Gallery of 28 PAIRITEL J -band Mosaics

(Color online) A subset of 28 PAIRITEL J -band Mosaics from the set of 94 CfAIR2 SN Ia and 4 SN Iax observed with PAIRITEL from 2005-2011. SN Ia are marked by green circles (color online) and crosshairs. SN names are of the shortened form 06X = SN 2006X. North and East axes for all mosaics are indicated in the lower right corner of the figure. Non-IAUC SN Names include: 10bjs =PTF10bjs, 10icb =PTF10icb, snf02 =SNF20080514-002, snf00 =SNF20080522-000, snf01 =SNF20080522-011, ps10w =PS1-10w.
sample the point spread function (PSF) of the detected image. To achieve some sub-pixel sampling, PAIRITEL implements a randomized dither pattern. While dithering can help recover some of the image information lost from undersampling, large pixels with dithered imaging cannot fully replace a fully sampled imaging system (Lauer 1999; Fruchter & Hook 2002; Rowe et al. 2011), and in practice, dithering does not always reliably produce the desired sub-pixel sampling. When we subtract host galaxy light, which requires PSF matching SN and SNTEMP mosaics, undersampling leads to uncertainty in photometry for individual subtractions that can underestimate or overestimate the flux at the SN position. We correct for this by averaging many subtractions, and removing bad subtractions, when producing CfAIR2 LCs (see § 3.4-3.7).
## 3.4. Host Galaxy Subtraction
We obtain SNTEMP images after the SN has faded below detection for the PAIRITEL Infrared camera, typically glyph[greaterorsimilar] 6-12 months after the last SN observation. We use SNTEMP images to subtract the underlying host galaxy light at the SN position for each SN image that meets our image quality standards (see § 3.5-3.6). To limit the effects of variable observational conditions, sensitivity to individual template observations of poor quality, and to minimize the photometric uncertainty from individual subtractions, we try to obtain at least N T = 2, and as many as N T = 11 SNTEMP images that satisfy our image quality requirements (see § 3.7). In practice, we obtained medians of N T = 4, 4, and 3 usable SNTEMP images in JHK s , respectively (Fig. 6). In cases with only N T = 1 SNTEMP image, galaxy-subtracted LCs are deemed acceptable only for bright, well isolated SN that are consistent with the unsubtracted LCs (see § 3.5, § 4.2.2).
## 3.5. Forced DoPHOT on Unsubtracted Images
Forced DoPHOT photometry (Schechter et al. 1993) at a fixed position was performed on the unsubtracted SN images as an initial step for all PAIRITEL SN. Forced DoPHOT LCs on unsubtracted images provide an excellent approximation to the final galaxy-subtracted LCs for SN that were clearly separated from their host galaxy (F12). Approximately 30% of SN of all types observed by PAIRITEL are well isolated from the host galaxy and bright enough so that the measured galaxy flux at the SN position is glyph[lessorsimilar] 10% of the SN flux at peak brightness. We use 20 of these bright, well isolated SN to perform internal consistency checks to test for errors incurred from host galaxy subtraction (see § 4.2; F12).
## 3.6. Forced DoPHOT on Difference Images
We perform galaxy subtraction on all CfAIR2 objects to reduce the data with a homogeneous method. 24 We used subtraction-based photometry following Miknaitis et al. (2007). The SN flux in the difference images is measured with forced DoPHOT photometry at fixed pixel coordinates, determined by averaging SN centroids from
24 Only SN 2008A (and the SN 2005cf LC retained from WV08) use forced DoPHOT and no host subtraction. NNT failed for SN 2008A as a result of poor quality SNTEMP images (see § 3.7).
Figure 6. Histograms of JHK s SNTEMP Subtractions
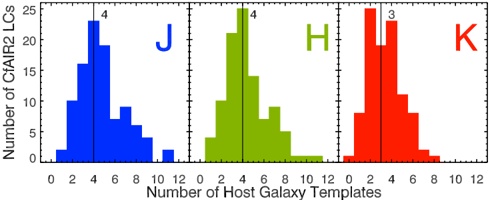
(Color online) Histogram of the number of host galaxy template images N T in each bandpass used for each SN. N T is the maximum number of SNTEMP subtractions used over all nights per LC and bandpass. Some subtractions fail during photpipe or are rejected as bad subtractions on individual nights during post-processing. We generally obtain > N T host galaxy images, but some images fail the mosaicking pipeline (especially in K s -band) prior to photpipe . We tried to obtain at least N T = 2, and as many as N T = 11 usable SNTEMP images, with medians of N T = 4, 4, and 3 SNTEMP images in JHK s , respectively. For some SN, only N T = 1 template images were usable and SN 2008A had no usable SNTEMP images.
J -band or CfA optical V -band difference images with photometric detections of the object that had a S/N > 5. SN centroids are typically accurate to within glyph[lessorsimilar] 0 2 . ′′ . Tests show no systematic LC bias for forced DoPHOT photometry as a result of SN astrometry errors if the SN centroid is accurate to within glyph[lessorsimilar] 0 5 . ′′ (F12). The RA and DEC values in Tables 1-2 show best fit SN centroid coordinates. These are typically more accurate than optical discovery coordinates from IAU/CBET notices, which may only be accurate to within glyph[lessorsimilar] 1 -2 ′′ . Forced DoPHOT photometry at this fixed position in the difference images employs the DoPHOT PSF calculated from standard stars in the un-convolved image. For the difference images the calibrated zero point from the template is used, with suitable correction for the convolution of the SNTEMP image as detailed by Miknaitis et al. (2007).
## 3.7. Averaging Subtractions: NNT Method
We use NNT, an alternative galaxy subtraction method for CfAIR2, which uses fewer individual subtractions than the NN2 method (Barris et al. 2005) used in WV08. With NNT, for each of the N SN mosaicked SN images, we subtract each of the usable N T SNTEMP images, yielding at most N NNT = N SN × N T individual subtractions. NNT yields N T realizations of the LC which can be combined into a final galaxy-subtracted LC with a night-by-night weighted flux average after robust 3σ rejection and manual checks to exclude individual bad subtractions. 25 SN or SNTEMP images that failed our image quality requirements were also excluded from NNT via automatic photpipe tests and manual checks, yielding fewer bad subtractions than the purely automated process used in WV08.
By obtaining 1 glyph[lessorsimilar] N T ≤ 11 usable SNTEMP images, including additional observations since WV08, most CfAIR2 SN Ia have N T glyph[greaterorsimilar] 4 SNTEMP images suitable for galaxy subtraction (see Fig. 6). NNT allowed us to
25 Weighted mean flux values on each night are weighted by the corrected DoPHOT uncertainties. A S/N > 1 cut is employed for individual subtractions before NNT. A S/N > 3 cut is employed for final LC points. N T can differ nightly and by bandpass and is often smallest in K s . See § 4.1.2, § 4.2.2, Table 6, and Appendix A.
exclude individual bad subtractions, average over variance across subtractions from different templates, and produce CfAIR2 SN Ia LCs with more accurate flux measurements compared to NN2 for WV08. We discuss the statistical and systematic uncertainty incurred from NNT host galaxy subtraction in § 4.2. CfAIR2 NNT LCs also show better agreement with CSP photometry for the same objects compared to WV08 (see § 4.3). 26
## 3.8. Photpipe Improvements
Since WV08, we have implemented several improvements to photpipe . Photpipe now takes p3.6 mosaics as input (see § 3.1). To use SN that are not in the p3.6 mosaic center, photpipe uses larger radius photometric catalogs and improved image masks (see F12). In WV08, our 'skark' noise estimate was assumed to be constant throughout the mosaic (see § 3.2). Figure 2 shows this is a bad approximation. Instead, p3.6 noise mosaics are used by photpipe and fed as inputs to DoPHOT (Schechter et al. 1993), our point source photometry module, and HOTPANTS (Becker et al. 2004, 2007), our difference imaging module (see § 3.4), leading to improved image subtraction. See F12 for details on the computational implementation of photpipe and p3.6 .
As a result of improvements discussed throughout § 3, CfAIR2 supersedes WV08 photometry for 20 out of 21 LCs (excluding SN 2005cf). CfAIR2 and WV08 photometry agree best for the brightest, well isolated, SN with little galaxy light at the SN position. Fainter SN that required significant host galaxy subtraction show the most disagreement between CfAIR2 and WV08 due mainly to the differences between NN2 and NNT (see § 4.3.1 of F12). Problems with WV08 NN2 photometry are most evident in the set of 9 WV08 SN also observed by the CSP, which are discussed in § 4.3. The improved agreement between CfAIR2 and CSP (see § 6) gives evidence that CfAIR2 photometry is superior to WV08.
Although individual LCs show differences between CfAIR2 and WV08 data, we do not expect the revised photometry to significantly affect the overall conclusions of WV08. Preliminary analysis, which will be presented elsewhere, will derive mean NIR LC templates and mean absolute magnitudes using only normal CfAIR2 SN Ia and compare these to mean templates derived using only 18 normal PAIRITEL SN Ia from WV08.
## 4. PHOTOMETRIC CALIBRATION AND VERIFICATION
We now discuss the methods used to calibrate PAIRITEL photometry and test the calibration, including internal consistency checks and comparison with external data sets with NIR photometry for the same objects. In § 4.1, we present PAIRITEL photometry for 2MASS stars which we use to test for systematic problems with PAIRITEL DoPHOT photometry. In § 4.2, we investigate potential systematic photometry errors from host galaxy subtraction. In § 4.3, we compute approximate color terms
26 Some fainter SN Ia LCs which used NN2 in WV08 showed significant systematic deviations from the published CSP photometry for the same objects. These discrepancies exceeded deviations expected from small bandpass differences without S-corrections (Contreras et al. 2010; M. Phillips - private communication).
describing offsets between PAIRITEL and CSP J and H bandpasses using 2MASS field stars observed by both groups. In § 4.4, we compare CfAIR2 data to an overlapping subset of CSP SN Ia photometry, demonstrating overall agreement between the data sets. Throughout, we refer to F12 for additional details.
## 4.1. Photometric Calibration
We organize § 4.1 as follows. In § 4.1.1, we present PAIRITEL mean photometric measurements and uncertainties for all 2MASS stars for 118 out of 121 SN Ia and SN Iax fields observed from 2005-2011. In § 4.1.2, we test whether DoPHOT is correctly estimating photometric uncertainties for PAIRITEL point sources. In § 4.1.3, we assess whether PAIRITEL DoPHOT photometry globally agrees with 2MASS star photometry. Overall, § 4.1.24.1.3 test the precision and accuracy of DoPHOT photometry on unsubtracted PAIRITEL images. We find no significant systematic differences with 2MASS.
## 4.1.1. PAIRITEL Photometry of 2MASS Standard Stars
For 121 PAIRITEL SN fields observed from 20052011, including 23 objects not in CfAIR2, we performed DoPHOT photometry on all 2MASS stars to measure the photometric zero point for each image. In a typical 12 ′ × 12 ′ p3.6 mosaic FOV, there were between 6 and 92 2MASS stars in each filter (see Figs. 3-5). While the exact coverage for a mosaic during a given night varies (see § 3.1), the majority of the 2MASS stars are covered by each observation of a given SN field. Fewer 2MASS stars are detected by DoPHOT as wavelength increases from J to H to K s . For all SN Ia or SN Iax fields with at least 5 mosaic images, the mean number of 2MASS stars was 39, 38, and 34 in JHK s , respectively (see Table 4.1 of F12).
We interpret the error on the weighted mean of the PAIRITEL photometric measurements to be the uncertainty in the measurement of the mean PAIRITEL magnitude for that 2MASS star (see § 4.1.2 and § 7.3 of F12 for mathematical details). Table 5 presents weighted mean PAIRITEL photometric measurements and uncertainties for all 2MASS stars in 118 SN fields observed by PAIRITEL. A global comparison of PAIRITEL and 2MASS star measurements is presented in § 4.1.2-4.1.3.
## 4.1.2. Photometric Precision
We assess the repeatability of DoPHOT measurements of 2MASS stars to quantify the photometric precision of PAIRITEL. This tests whether we have correctly estimated our uncertainties for point sources measured on individual nights. Although a small fraction of 2MASS stars are variable (Plavchan et al. 2008; Quillen et al. 2014), by averaging over glyph[greaterorsimilar] 4000 2MASS stars for each filter (see Table 5) and removing outlier points, we do not expect this to significantly affect our results. Assuming 2MASS stars have constant brightness, the measured scatter indicates if the PAIRITEL DoPHOT uncertainties are under or overestimated. Because we do not model all known sources of uncertainty in computing our noise mosaics (see § 3.2 and § 7.1 of F12), we expect to underestimate our photometric errors. Empirical tests using DoPHOT photometry of 2MASS stars in the unsubtracted images confirm we are underestimating our photometric
Table 5 PAIRITEL JHK s Photometry of 2MASS Standard Stars in SN Ia Fields
| SN | Star | α (2000) | δ (2000) | N J | m PTL J e | σ PTL mJ f | m 2M J g | σ m 2M J g | N H d | m PTL H e | σ PTL mH f | m 2M H g | σ m 2M H g | N K d | m PTL K [mag] e | σ PTL mK f | m 2M K g | σ m 2M K [mag] g |
|-----------|--------|-------------|--------------|-------|-------------|--------------|------------|--------------|---------|-------------|--------------|------------|--------------|---------|-------------------|--------------|------------|--------------------|
| a | b | c | c | d | [mag] | [mag] | [mag] | [mag] | | [mag] | [mag] | [mag] | [mag] | | | [mag] | [mag] | |
| SN 2005ak | 01 | 14:40:18.45 | +03:30:55.44 | 34 | 16.549 | 0.007 | 16.504 | 0.159 | 35 | 15.940 | 0.009 | 16.024 | 0.183 | 30 | 15.675 | 0.012 | 15.251 | 0.173 |
| SN 2005ak | 02 | 14:40:18.56 | +03:34:12.76 | 34 | 15.918 | 0.006 | 15.858 | 0.097 | 33 | 15.230 | 0.008 | 15.230 | 0.105 | 33 | 15.024 | 0.010 | 15.075 | 0.148 |
| SN 2005ak | 03 | 14:40:19.41 | +03:30:22.95 | 34 | 15.112 | 0.006 | 15.118 | 0.056 | 35 | 14.768 | 0.007 | 14.822 | 0.085 | 33 | 14.686 | 0.008 | 14.814 | 0.112 |
| SN 2005ak | 04 | 14:40:20.77 | +03:27:36.99 | 34 | 16.404 | 0.006 | 16.430 | 0.150 | 35 | 15.793 | 0.009 | 16.057 | 0.219 | 34 | 15.549 | 0.012 | 15.326 | 0.197 |
| SN 2005ak | 05 | 14:40:20.94 | +03:33:41.82 | 33 | 15.013 | 0.006 | 15.071 | 0.049 | 34 | 14.408 | 0.007 | 14.511 | 0.071 | 34 | 14.301 | 0.007 | 14.285 | 0.074 |
| SN 2005ak | 06 | 14:40:22.26 | +03:31:18.61 | 33 | 17.032 | 0.007 | 16.521 | 0.147 | 33 | 16.386 | 0.010 | 16.101 | 0.215 | 29 | 16.153 | 0.014 | 15.598 | 0.255 |
| SN 2005ak | 07 | 14:40:22.58 | +03:32:56.39 | 35 | 15.637 | 0.006 | 15.665 | 0.066 | 35 | 15.001 | 0.007 | 15.133 | 0.089 | 34 | 14.765 | 0.008 | 14.946 | 0.148 |
| SN 2005ak | 08 | 14:40:26.00 | +03:31:41.52 | 34 | 13.255 | 0.005 | 13.233 | 0.024 | 35 | 12.617 | 0.006 | 12.608 | 0.030 | 35 | 12.406 | 0.007 | 12.404 | 0.032 |
| SN 2005ak | 09 | 14:40:26.55 | +03:30:58.65 | 34 | 14.780 | 0.006 | 14.762 | 0.037 | 35 | 14.212 | 0.007 | 14.121 | 0.035 | 35 | 13.967 | 0.007 | 14.003 | 0.071 |
| SN 2005ak | 10 | 14:40:29.45 | +03:32:34.68 | 35 | 16.402 | 0.006 | 16.596 | 0.163 | 35 | 15.757 | 0.008 | 15.736 | 0.152 | 32 | 15.571 | 0.011 | 15.228 | 0.173 |
| SN 2005ak | 11 | 14:40:29.89 | +03:28:05.44 | 33 | 14.455 | 0.006 | 14.444 | 0.038 | 34 | 14.160 | 0.006 | 14.114 | 0.035 | 33 | 14.055 | 0.007 | 14.095 | 0.072 |
| SN 2005ak | 12 | 14:40:30.02 | +03:30:15.93 | 34 | 15.424 | 0.005 | 15.319 | 0.072 | 33 | 14.958 | 0.007 | 15.021 | 0.090 | 35 | 14.793 | 0.008 | 14.624 | 0.123 |
| SN 2005ak | 13 | 14:40:31.33 | +03:28:33.93 | 24 | 15.472 | 0.010 | 15.589 | 0.082 | 28 | 14.814 | 0.011 | 15.169 | 0.100 | 31 | 14.488 | 0.010 | 14.898 | 0.150 |
| SN 2005ak | 14 | 14:40:31.52 | +03:32:31.31 | 36 | 14.373 | 0.005 | 14.367 | 0.036 | 36 | 14.171 | 0.007 | 14.212 | 0.042 | 36 | 14.145 | 0.007 | 14.277 | 0.086 |
| SN 2005ak | 15 | 14:40:31.74 | +03:29:10.30 | 35 | 15.420 | 0.006 | 15.304 | 0.056 | 34 | 14.804 | 0.007 | 14.823 | 0.070 | 35 | 14.574 | 0.008 | 14.704 | 0.116 |
| SN 2005ak | 16 | 14:40:32.31 | +03:31:13.54 | 34 | 16.087 | 0.006 | 15.902 | 0.090 | 36 | 15.501 | 0.008 | 15.476 | 0.132 | · · · | · · · | · · · | · · · | · · · |
| SN 2005ak | 17 | 14:40:32.43 | +03:33:34.39 | 28 | 14.766 | 0.010 | 14.756 | 0.056 | 26 | 14.069 | 0.012 | 14.143 | 0.085 | 29 | 13.836 | 0.011 | 13.802 | 0.070 |
.
## Note
-
- ( A full machine-readable Table is available online in the electronic version of this paper. A portion is shown here for guidance ).
- (a) Tables like the above sample are provided online for 118 out of 121 SN Ia and SN Iax fields observed with PAIRITEL from 2005-2011 (SN 2005akSN 2011df), including 23 SN Ia without CfAIR2 photometry (e.g., SN 2005ak above). Tables include weighted mean PAIRITEL photometry and uncertainties for all 2MASS stars in each SN Ia field. 3 SN Ia are not included in Table 5 as a result of unresolved software errors: SN 2008fv, SN 2008hs (in CfAIR2), and SN 2011ay (not in CfAIR2).
- (b) Superscripts PTL and 2M denote PAIRITEL and 2MASS, respectively. Missing data is denoted by . . . .
- (c) RA ( α ) and DEC ( ) for Epoch 2000 in sexagesimal coordinates. δ
- (d) N X is the number of PAIRITEL SN images in band X = J, H, K with this standard star used to measure m PTL X and σ PTL mX .
- (e) PAIRITEL apparent brightness in magnitudes m PTL X is computed as the weighted mean PAIRITEL magnitude over all N X SN images with that 2MASS star.
- (f) PAIRITEL magnitude uncertainty σ PTL mX is computed as the error on the weighted mean of the N X measurements, each of which have already been corrected for DoPHOT uncertainty estimates as described in § 4.1.2 and F12. (see § 7.3 of F12).
- (f) The 2MASS magnitudes m 2M X and uncertainties σ 2M mX for each star are from the 2MASS point source catalog (Cutri et al. 2003).
magnitude uncertainties by factors of ∼ 1 5-3, depending . on the brightness of the point source and the filter (F12). We then multiply the uncorrected DoPHOT magnitude uncertainties ( σ do ) for individual points in the SN Ia LCs by this empirically measured, magnitude-dependent correction factor C . Corrected DoPHOT magnitude uncertainties are given by ˜ σ do = C × σ do (see § 4 of F12).
uncertainties. See § 4 of F12.
## 4.1.3. Photometric Accuracy
We test whether PAIRITEL and 2MASS star photometry are consistent within the estimated uncertainties after correcting the PAIRITEL DoPHOT uncertainties as discussed in § 4.1.2. This tests the photometric accuracy of PAIRITEL to identify any statistically significant systematic offsets from 2MASS. We expect mean PAIRITEL and 2MASS photometry to agree when averaged over many stars by construction , so this is a self-consistency check to rule out any glaring systematic problems with PAIRITEL DoPHOT photometry. For these tests, we measure the difference between the weighted mean PAIRITEL magnitudes for each star and the 2MASS catalog magnitudes in Table 5. Because PAIRITEL photometry goes deeper than 2MASS for each image and the weighted mean PAIRITEL magnitude of each 2MASS star is determined from measurements over many nights, we do not expect the 2MASS catalog magnitude and the weighted mean PAIRITEL magnitude to be strictly equal for all standard stars. We expect greatest agreement for the brightest 2MASS stars with decreasing agreement and increased scatter as the 2MASS catalog brightness decreases, consistent with measurements drawn from a distribution with Gaussian
Aggregated PAIRITEL-2MASS residuals for all 2MASS stars in 121 PAIRITEL SN fields yield weighted mean residuals of 0 0014 . ± 0 0006, 0 0014 . . ± 0 0007, and . -0 0055 . ± 0 0007 in . JHK s , respectively (uncertainties are standard errors of the mean). Thus, when averaging over thousands of stars observed over a 6-year span from 2005-2011, PAIRITEL and 2MASS agree to within a few thousandths of a magnitude in JHK s , with evidence for a small, but statistically significant PAIRITEL-2MASS offsets of ∼ 0 001, 0 001, and . . -0 006 mag in . JHK s , respectively, at the ∼ 2-3 σ level. If we correct for the slight underestimate of our uncertainties in the PAIRITEL2MASS residuals, we find that ∼ 68%, ∼ 95%, and ∼ 99% of the standard stars have PAIRITEL-2MASS residuals consistent within 0 to 1, 2, and 3σ respectively, as expected with correctly estimated Gaussian errors (see § 7.4 of F12).
## 4.2. Photometry Systematics
In § 4.2, we discuss internal consistency tests to assess other potential statistical and systematic errors with the photometry. In § 4.2.1-4.2.3, we evaluate our most important systematic and statistical uncertainty from the NNT host galaxy subtraction process, both for bright, well isolated objects and for objects superposed on the nucleus or spiral arms of host galaxies. See § 4 of F12 for discussions of systematic errors from sky subtraction and astrometric errors in the best fit SN centroid position.
Table 6 Computing NNT Errors
| N T | ˜ σ NNT mag error | S/N | Note |
|-------|--------------------------|---------------------|--------|
| 1 | max(0 . 25 mag , σ NNT ) | 3 < S / N < ∼ 4 . 2 | a |
| 2 | max(0 . 175 mag , σ NNT | 3 < S / N < ∼ 5 . 5 | b |
| 3+ | σ NNT | 3 < S / N | |
Note
.
-
(a) If N T = 1, σ NNT = ˜ σ do , the corrected DoPHOT error for a single subtraction.
(b) A S/N > 1 cut is used before NNT averaging. A S/N > 3 cut is placed on the final NNT LC points.
When subtracting SN and SNTEMP images observed under different seeing conditions, undersampling of the PAIRITEL NIR camera introduces uncertainties into both the estimates of the PSF and convolution kernel solution when attempting to transform the SN or SNTEMP image to the PSF of the other. This leads to flux being added or subtracted from photometry on individual subtractions. While NNT attempts to correct for this by averaging over many subtractions, there is always remaining uncertainty as a result of undersampling (see § 3).
For an individual night of photometry, we conservatively estimate the statistical uncertainty from NNT, σ NNT , as the error weighted standard deviation of the input flux measurements, weighted by the corrected DoPHOT flux uncertainties for each of the N T subtractions (for details see § 3 and Appendix A). For cases where only N T = 1 or 2 subtractions survive both the pipeline's cuts and any manual rejection, NNT flux estimates can be biased high or low and either the weighted standard deviation can not be computed or it is not a reliable estimate of the statistical uncertainty. To ensure accurate photometric uncertainties for these cases - at the expense of reduced photometric precision - we adopt a conservative systematic error floor of 0 25 mag or 0 175 . . mag for N T = 1 and N T = 2, respectively. Final galaxy subtracted uncertainties ˜ σ NNT are computed as in Table 6, which includes a final signal-to-noise cut of S/N > 3. Thus, when a given LC point has an uncertainty larger than its neighbors, either only 1 or 2 good subtractions were used or the scatter amongst the surviving 3+ subtractions was large.
In § 4.2.2-4.2.3, both for bright, well isolated objects and SN superposed on the host galaxy, NNT produces no net systematic bias given N T glyph[greaterorsimilar] 3-4 usable host galaxy templates. For fainter objects, SN superposed on the host galaxy nucleus, or SN with insufficient high quality SNTEMP images, the additional uncertainty from host galaxy subtraction can yield many LC points that are excluded based on S/N cuts, outlier rejection, or final quality checks, sometimes yielding LCs of insufficient quality for publication or cosmological analysis.
## 4.2.2. Galaxy Subtraction for Bright, well isolated Objects
To test if NNT biases the photometry, we first use SN that are well isolated from their host galaxy nuclei. In these cases, photometry on the unsubtracted images gives a good approximation to the final galaxy subtracted LC at most phases, providing an internal consistency check of NNT. We use bright SN for which the host galaxy flux at the SN position is a small fraction of the SN flux in the [ -10 50] day phase range, including ,
20 bright and/or well isolated SN of all types (see § 4 of F12). We test if the weighted mean residuals of the unsubtracted and subtracted LCs are consistent with zero to within the standard deviation of the residuals in this phase range, which are each only ∼ 0 001-0 002 . . mag, depending on the filter. After removing 3σ outliers and S/N < 3 points, the weighted means of the aggregated residuals for all 20 SN are consistent with 0 by this measure, with weighted means and standard deviations of the residuals of -0 0009 . ± 0 0016, 0 0006 . . ± 0 0019, and . 0 0007 . ± 0 0026 magnitudes in . JHK s , respectively. At least for bright, well isolated objects with sufficient host galaxy templates, NNT does not introduce a net bias in the photometry.
## 4.2.3. Galaxy Subtraction for Superposed SN
For SN superposed on the host galaxy, we can not make the same comparison in the absence of a suitable unsubtracted reference LC. In these cases, we test the subtraction process by performing forced DoPHOT NNT photometry on the galaxy subtracted difference images at positions near the host galaxy. We perform forced photometry on a 3 × 3 grid of positions with evenly spaced increments of 15 ′′ = 15 pixels centered around the SN position. At least some of these 9 grid positions are likely to be superposed on the galaxy. If the subtraction process is working correctly (no net bias), the difference image LCs should have a weighted mean of zero flux at all grid positions except for the central position with the SN, albeit with larger scatter for grid positions superposed on the galaxy (see § 4 of F12).
We performed this test for all SN fields. The standard deviation of the difference image flux values for each LC is used to estimate the uncertainty in the measured flux at each grid position. 27 For all CfAIR2 objects, grid positions offset from the SN showed weighted mean flux consistent with zero to within 1-3 standard deviations. Highly embedded SN fainter than J ∼ 18 -19 mag at the brightest LC point are often too faint for PAIRITEL, and NNT can yield LCs with inaccurate flux values that are not suitable for publication. However, if N T glyph[greaterorsimilar] 3 -4 host galaxy template images are obtained for sufficiently bright SN which reach J glyph[lessorsimilar] 18 mag, NNT galaxy subtraction yields a net bias of glyph[lessorsimilar] 0 01 mag even at positions . clearly superposed on host galaxies.
## 4.2.4. NNT vs. Forced DoPHOT Errors
NNT can lead to larger reported errors ( σ NNT ) compared to corrected DoPHOT point source photometry without galaxy subtraction ( ˜ ) for σ do cases with N T glyph[lessorsimilar] 2 -3, due primarily to our imposed systematic error floor for these cases (see Table 6). However, for cases with N T glyph[greaterorsimilar] 3 -4 templates, σ NNT glyph[lessorsimilar] ˜ σ do and NNT performs as well or better than DoPHOT without host subtraction as a result of the effective division by ∼ √ N T inside the error weighted standard deviation used to compute σ NNT (see Appendix A). Fig. 7 shows median magnitude uncertainties for both the highest S/N LC points for each SN and for all LC points for both forced DoPHOT and
27 The scatter also increases towards longer wavelength since the signal-to-noise ratio decreases from J to H to K as a result of the presence of additional contaminating sky noise (see § 3.2).
Figure 7. Forced DoPHOT and NNT Errors
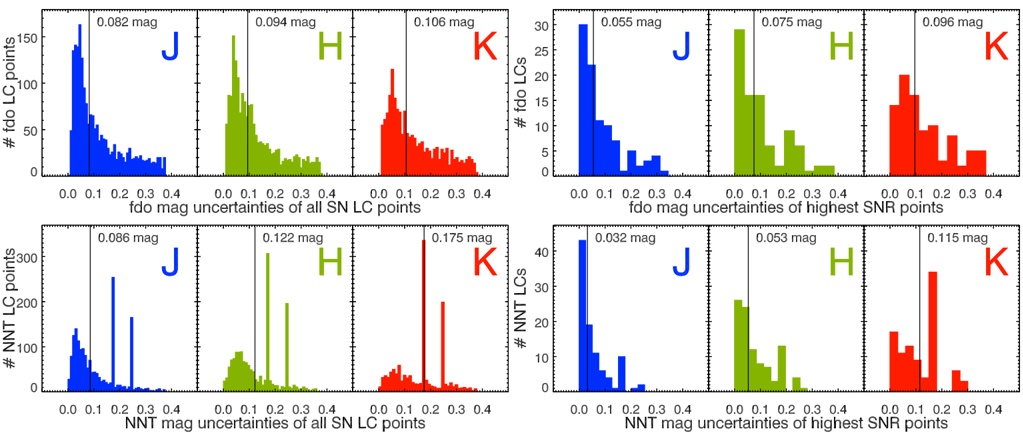
(Color online) Magnitude uncertainty histograms for ( Row 1 ) forced DoPHOT photometry (fdo) on unsubtracted images and ( Row 2 ) host galaxy subtracted photometry (NNT). Median values are indicated with vertical lines and plot annotations. Left columns show errors for all CfAIR2 LC points. Right columns show errors for only the highest S/N points for each CfAIR2 LC. Spikes at 0 25 and 0 175 mag (lower left . . figure), and at 0 175 mag (lower right figure) reflect the conservative systematic error floor imposed for cases with . N T = 1 or 2 usable subtractions (see Table 6). The highest S/N LC points have median uncertainties of ∼ 0 032, 0 053, and 0 115 mag in . . . JHK s , respectively (lower right plot). Even in these cases, the systematic error floor skews histograms toward larger median errors; for JHK s , there are ∼ 10 -35 LCs with only N T = 2 usable subtractions, leading to spikes at 0 175 mag. . All CfAIR2 NNT LC points have median uncertainties of 0 086, 0 122, and 0 175 mag in . . . JHK s , respectively (lower left plot). NNT errors are generally comparable to or less than forced DoPHOT errors on unsubtracted images provided N T glyph[greaterorsimilar] 3 -4. This again reflects the systematic error floor for N T = 1 or 2. For the highest S/N points for each LC, the median NNT photometric precision is smaller than forced DoPHOT for J and H , but not in K s , again as a result of the systematic error floor (see right column figures).
NNT photometry. The spikes in the NNT error distributions are artifacts of our systematic error floor chosen for cases with N T = 1-2 SNTEMP images.
decining object, 2 overluminous, slowly-declining objects, and 1 SN Iax. Of these, 9 had data published in WV08 and 9 are new to CfAIR2. See Table 7.
## 4.3. Comparing PAIRITEL and CSP Photometry
Comparing PAIRITEL CfAIR2 NNT LCs with published CSP photometry for the same SN Ia provides an important external consistency check. Although CfA and CSP observatories with NIR detectors are in the northern and southern hemispheres, respectively, an overlapping subset of 18 CfAIR2 objects in the declination range -24 94410 . < δ < 25 70778 were observed in . JHK s by both groups (see Table 7 and Figs. 10-12). 28 Similar to Tables 1-2 of this paper, Table 1 of Contreras et al. 2010 (hereafter C10) and Table 1 of Stritzinger et al. 2011 (hereafter S11) present general properties of 35 and 50 SN Ia observed by the CSP, respectively. Some CSP SN Ia had only optical observations and no NIR data. 29 The 18 CSP NIR objects independently observed by PAIRITEL include 14 normal SN Ia, 1 peculiar, fast-
28 The latitudes and longitudes of the PAIRITEL and CSP observatories are (FLWO: 31.6811 N, ◦ 110.8783 ◦ W) and (LCO: 29.0146 ◦ S, 70.6926 ◦ W), respectively. PAIRITEL observes objects with δ glyph[greaterorsimilar] -30 ◦ .
29 All PAIRITEL and CSP SN Ia with NIR overlap are included in CfAIR2 except SN 2006is (CSP NIR data in S11) and SN 2005mc (CSP optical data in C10), which had poor quality PAIRITEL LCs. Two other SN Ia (SN 2005bo, SN 2005bl) have PAIRITEL JHK s observations in CfAIR2 and CSP optical observations but no CSP NIR data (SN 2005bl: Taubenberger et al. 2008; SN 2005bo: C10), and are not included in the PAIRITEL and CSP NIR comparison set. SN 2005bl was also included in WV08.
## 4.3.1. CSP - PAIRITEL Offsets and Color Terms
Cohen et al. (2003) and Skrutskie et al. (2006) describe the 2MASS JHK s filter system while Carpenter (2001) and Leggett et al. (2006) provide color transformations from other widely used photometric systems to 2MASS. The PAIRITEL/2MASS JHK s bandpasses are very similar to the CSP JHK s filters, so it is a reasonable approximation to compare the LCs directly, without first attempting to transform the CSP data to the 2MASS system. However, to justify this approximation, following C10, we investigate whether there exist non-negligible zero point offsets or color terms between PAIRITEL and CSP NIR filters using 2MASS stars in fields observed by both groups. While C10 compared CSP measurements of 2MASS stars to the 2MASS point source catalog (Cutri et al. 2003), here we also compare CSP and PAIRITEL measurements of 2MASS stars from Table 5 to derive zero point estimates and color terms to approximately transform CSP natural system data to the 2MASS system. Although PAIRITEL is on the 2MASS natural system, PAIRITEL observations are deeper than 2MASS, so PAIRITEL measurements of 2MASS stars are more appropriate than 2MASS catalog data for estimating differences between PAIRITEL and CSP photometry.
C10 used CSP photometric measurements of 984 J and H -band 2MASS stars in their SN fields, finding these mean zero point offsets between the CSP Swope 1.0-m natural system and the 2MASS J and H filters:
$$J _ { \text{CSP} } - J _ { 2 M } = 0. 0 1 0 \pm 0. 0 0 3 \, \max \quad \ \ ( 1 ) \quad \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \
\quad H _ { \text{CSP} } - H _ { 2 M } = 0. 0 4 3 \pm 0. 0 0 3 \, \max \quad \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \
\quad J _ { \text{CSP} } - J _ { 2 M } = 0. 0 4 3 \pm 0. 0 0 3 \, \max \quad \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \
\quad I _ { \text{CSP} } - J _ { 2 M } = 0. 0 4 3 \pm 0. 0 0 3 \, \max \quad \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \
\quad I _ { \text{Eq} }$$
C10 did not derive zero point offsets in K s because they had only 41 CSP 2MASS star observations in K s .
For 19 objects observed by both PAIRITEL and CSP (including SN 2006is, which is not in CfAIR2), we obtained CSP standard star photometry for the local sequences for 16 objects from the literature (C10; S11; Taubenberger et al. 2011) and 3 additional objects from the CSP (M. Stritzinger - private communication; see § 4.33 of F12). In these 19 SN fields, we used 269, 264, and 24 2MASS stars observed both by PAIRITEL and CSP in JHK s , respectively, limited to the color range 0 2 . < ( J -H ) CSP < 0 7 . mag also used by C10. We compute CSP - PAIRITEL residuals for each 2MASS star in JHK s and interpret the weighted mean residuals and the error on the weighted mean as our estimate of the zero point offset and uncertainty between the CSP natural system ( JH Swope, K s duPont) and the PAIRITEL/2MASS JHK s system. Although column 6 of Table 5 reports uncertainties on the weighted mean PAIRITEL magnitudes of 2MASS stars as the error on the weighted mean, we follow the method reported by the CSP here and instead use the RMS to estimate our local sequence uncertainties (C10; S11), which yield larger, more conservative error estimates.
Figure 8. PAIRITEL and CSP JHK s Offsets
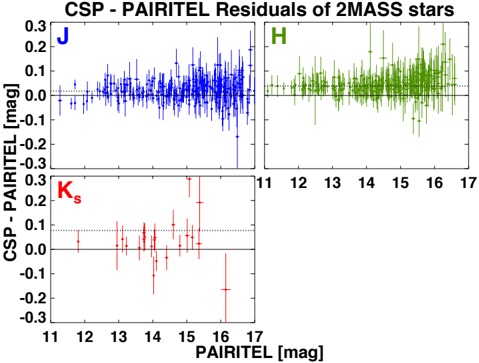
(Color online) For 19 NIR SN fields, we use 269, 264, and 24 2MASS stars observed by both PAIRITEL and the CSP in JHK s , respectively, in the color range 0 2 . < J ( -H ) CSP < 0 7 mag also used . by C10. Plots show CSP - PAIRITEL JHK s magnitude residuals on the y-axis versus the PAIRITEL star magnitude on the x-axis. Errors on the residuals are the quadrature sum of the quoted CSP errors and the PAIRITEL errors on the weighted mean magnitude of 2MASS stars, given by the RMS errors for PAIRITEL (not shown in Table 5; see § 4.3.1). The weighted mean zero-point offsets (dotted lines) in each panel are the values given in Eq. 2.
Using the RMS error for PAIRITEL measurements of
2MASS stars, we find zero point offsets of:
$$J _ { C S P } - J _ { P T L } = 0. 0 1 8 \pm 0. 0 0 2 \, \max \quad \ ( 2 ) \\ H _ { C S P } - H _ { P T L } = 0. 0 3 8 \pm 0. 0 0 3 \, \max \quad \ \\ K _ { s } _ { C S P } - K _ { s P T L } = 0. 0 7 7 \pm 0. 0 1 1 \, \max \quad \. \quad \.$$
The JHK s CSP - PAIRITEL zero point offsets from Eq. 2 are also shown in Fig. 8 and agree with those from C10 in Eq. 1 to within 2σ in J and 1σ in H . While C10 used ∼ 3-4 times as many 2MASS stars, Eq. 1 technically estimates the offsets between CSP and 2MASS, not the offsets between CSP and PAIRITEL given by Eq. 2. Since we are most interested in the latter, and since we do not consider the slight differences between Eq. 1 and Eq. 2 to be significant, we simply use our own offsets from Eq. 2 as needed. We do not consider the zero point offset for K s in Eq. 2 to be reliable, since it is based on only 24 2MASS stars measured by both groups.
## 4.3.3. CSP - PAIRITEL Color Terms
Considering only 2MASS stars in the color range 0 2 . < ( J -H ) CSP < . 0 7 mag, C10 obtained the following linear fits for the JH bands:
$$J _ { C S P } - J _ { 2 M } & = ( - 0. 0 4 5 \pm 0. 0 0 8 ) \times ( J - H ) _ { C S P } \ ( 3 ) \\ & + ( 0. 0 3 5 \pm 0. 0 6 7 ) \, \max \\ H _ { C S P } - H _ { 2 M } & = ( 0. 0 0 5 \pm 0. 0 0 6 ) \times ( J - H ) _ { C S P } \\ & + ( 0. 0 3 8 \pm 0. 0 8 0 ) \, \max \\.$$
C10 thus find some evidence for a small color term slope in J , a negligible color term in H , and do not attempt to derive any color terms involving K s .
Figure 9. PAIRITEL and CSP J -H Color Terms
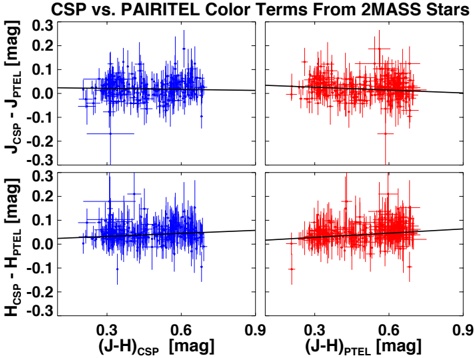
(Color online) Linear fits for JH color terms using 2MASS stars observed by PAIRITEL and CSP, given by Eq. 4. Following C10, we include only stars in the color range 0 2 . < J ( -H ) CSP < 0 7 mag, . yielding 263 2MASS stars with ( J -H ) CSP data (blue, left panels) and 259 stars with ( J -H ) PTL data (red, right panels). Error bars assume RMS errors for PAIRITEL (not shown in Table 5; see § 4.3.1). Linear fits have χ / 2 doF= χ 2 ν < 1 ( χ 2 ν = 0 79 0 35, . , . left panels and χ 2 ν = 0 79 0 33, right panels, both top to bottom). . , .
Following C10, we test for linear color terms between CSP and PAIRITEL filters using 263 2MASS stars with both J and H band data. We use the Carpenter 2001
color terms for K s . 30 We find the following JH linear color term fits using the RMS error for the PAIRITEL uncertainties of 2MASS stars (also see Fig. 9):
$$H,$$
$$J _ { C S P } - J _ { P T L } & = ( - 0. 0 1 4 \pm 0. 0 1 7 ) \times ( J - H ) _ { C S P } \ ( 4 ) \quad \frac { S ^ { 3 } } { S N \, 2 0 } \\ & + ( 0. 0 2 5 \pm 0. 0 0 9 ) \, \max \, \frac { S N \, 2 0 } { S N \, 2 0 } \\ H _ { C S P } - H _ { P T L } & = ( 0. 0 4 2 \pm 0. 0 2 2 ) \times ( J - H ) _ { C S P } \, \frac { S N \, 2 0 } { S N \, 2 0 } \\ & + ( 0. 0 2 0 \pm 0. 0 1 1 ) \, \max \, \frac { S N \, 2 0 } { S N \, 2 0 } \\ & \quad \, S N \, 2 0 }$$
Linear color term fits yield χ 2 ν < 1, indicating that while the fits are good, the errors are slightly overestimated by using the RMS. For all panels in Fig. 9, the probability that a correct model would give the observed χ 2 ν is ∼ 1. JH color term fits from Eq. 4 and from C10 in Eq. 3 agree in the slopes at 2σ and the intercepts at 1σ . Both fits also yield the same signs for the slopes and indicate at most small JH color terms.
Again, although the C10 fits used ∼ 3-4 times as many 2MASS stars, we consider the color terms from either Eqs. 3 or 4 to be equally reliable. For SN LCs with sufficient sampling to compute reliable colors, applying either set of color terms produced comparable results, since both color terms are small. In summary, either set of color terms (or no color terms) are reasonable choices to approximately put CSP data on PAIRITEL/2MASS system. Still, to compare CSP and CfAIR2 data on the same footing, for the analysis in § 4.4, we apply our own JH color terms from Eq. 4 and K s color terms from Carpenter 2001 as needed.
## 4.4. Comparing CfAIR2 and CSP LCs
Because CfAIR2 and CSP observations were generally performed at slightly different phases, it is usually not possible to compute direct LC data differences. We thus require a smooth model fit to interpolate from to compute residuals, which we apply to all 18 overlap objects. 31 The purpose of these model fits is not to estimate LC shape parameters, but merely to provide a baseline with which to compute residuals. Figs. 10-12 overplot all 18 example CfAIR2 and CSP SN Ia LCs for comparison. Applying either set of color terms from § 4.3.3 (or no color terms) had a negligible effect on the CSP LCs, model fits, and weighted mean residuals for the CSP-CfAIR2 data in Table 7.
For all CfAIR2 and color-term-corrected CSP LC points at similar phases, the scatter in the residuals arises
30 Carpenter 2001 find these fits for the Las Campanas Observatory (LCO) K s band using the Persson Standard stars:
Ks CSP -Ks 2M = ( -0 015 . ± 0 004) . × ( J -Ks ) CSP + (0 002 . ± 0 004) mag . . The Carpenter 2001 color transformations have been updated at http://www.astro.caltech.edu/˜{}jmc/2mass/ v3/transformations/ as of 2003. Carpenter 2001 find a fairly small color term for K s (the CSP K s filter is on the 2.5-m duPont telescope at LCO).
31 Model fits to joint CfAIR2+CSP data all use cubic splines, with some LCs using simple linear fits at late epochs glyph[greaterorsimilar] 30 days. All fits are boxcar-smoothed with a 5 day moving window. These steps avoid spline over-fitting. All fits to normal SN Ia use the WV08 normal SN Ia template LC to inform the fit for missing data, with data given greater weight than the template to account for intrinsic variation of the NIR LC shapes. Re-fitting the mean template LC using spectroscopically normal CfAIR2 SN Ia yielded very similar results to the WV08 template, so we did not find it necessary to construct a new mean template LC for the purposes of these LC fits. This will be presented elsewhere. Fits to peculiar SN Ia or SN Iax are direct fits to data only.
Table 7 18 NIR SN Ia Observed by PAIRITEL & CSP
| SN a | Type b | ∆ J [mag] c | ∆ H [mag] c | ∆ Ks [mag] c | Agree? d | CSP Refs e |
|-----------|----------|---------------------|---------------------|---------------------|------------|--------------|
| SN 2005el | Ia | 0 . 032 ± 0 . 026 | 0 . 042 ± 0 . 018 | 0 . 078 ± 0 . 024 | 234 | 1 |
| SN 2005eq | Ia | - 0 . 010 ± 0 . 030 | - 0 . 003 ± 0 . 024 | - 0 . 034 ± 0 . 030 | 112 | 1 |
| SN 2005hk | Iax | - 0 . 031 ± 0 . 027 | - 0 . 012 ± 0 . 028 | 0 . 050 ± 0 . 048 | 212 | 3 |
| SN 2005iq | Ia | - 0 . 025 ± 0 . 029 | 0 . 080 ± 0 . 060 | - 0 . 077 ± 0 . 045 | 122 | 1 |
| SN 2005ke | Iap | - 0 . 001 ± 0 . 014 | - 0 . 001 ± 0 . 014 | 0 . 010 ± 0 . 020 | 111 | 1 |
| SN 2005na | Ia | - 0 . 059 ± 0 . 030 | - 0 . 000 ± 0 . 023 | · · · | 21 | 1 |
| SN 2006D | Ia | 0 . 003 ± 0 . 011 | - 0 . 006 ± 0 . 014 | 0 . 000 ± 0 . 010 | 111 | 1 |
| SN 2006X | Ia | 0 . 009 ± 0 . 018 | 0 . 006 ± 0 . 011 | - 0 . 007 ± 0 . 010 | 111 | 1 |
| SN 2006ax | Ia | - 0 . 026 ± 0 . 014 | 0 . 003 ± 0 . 005 | 0 . 007 ± 0 . 018 | 211 | 1 |
| SN 2007S | Ia | 0 . 029 ± 0 . 023 | 0 . 015 ± 0 . 020 | 0 . 006 ± 0 . 024 | 211 | 2 |
| SN 2007ca | Ia | 0 . 004 ± 0 . 012 | 0 . 036 ± 0 . 025 | · · · | 12 | 2 |
| SN 2007if | Iap | 0 . 058 ± 0 . 033 | 0 . 053 ± 0 . 038 | · · · | 22 | 2 |
| SN 2007le | Ia | 0 . 015 ± 0 . 013 | 0 . 006 ± 0 . 008 | · · · | 21 | 2 |
| SN 2007nq | Ia | 0 . 004 ± 0 . 020 | 0 . 000 ± 0 . 054 | · · · | 11 | 2 |
| SN 2007sr | Ia | 0 . 022 ± 0 . 017 | 0 . 017 ± 0 . 012 | · · · | 22 | 4 |
| SN 2008C | Ia | - 0 . 004 ± 0 . 018 | - 0 . 001 ± 0 . 018 | · · · | 11 | 2 |
| SN 2008hv | Ia | 0 . 024 ± 0 . 024 | 0 . 011 ± 0 . 020 | · · · | 21 | 2 |
| SN 2009dc | Iap | - 0 . 004 ± 0 . 019 | - 0 . 006 ± 0 . 015 | - 0 . 002 ± 0 . 019 | 111 | 5 |
Note . - LCs use NNT galaxy subtraction (see (a) All SN § 3.7). The horizontal line in the middle of the table divides the 9 PAIRITEL SN with CfAIR2 data which supersedes WV08 data (top: SN 2005el-SN 2006ax) from the 9 SN with PAIRITEL data new to this work (bottom: SN 2007S-SN 2009dc).
- (b) Ia: spectroscopically normal. Iap: peculiar, under-luminous (SN 2005ke), peculiar over-luminous (SN 2007if, SN 2009dc). Iax: 02cx-like (SN 2005hk).
- (c) Weighted mean CSP - CfAIR2 residuals and 1σ errors, estimated by the error weighted standard deviation of the residuals divided by 3. Ks -band data not available for some CSP SN Ia.
(d) Do CSP - CfAIR2 weighted mean residuals agree within 1, 2, or ≥ 3σ for JHKs , respectively? For example, 132 would mean the NIR LCs agree in J within 1σ , H within ≥ 3σ , and Ks within 2σ . All 18 LCs in JH and all 8 in Ks agree within at least 3σ by this metric (Except for sn2005el, Ks , which agrees at 4σ ). (e) CSP References: (1) Contreras et al. 2010, (2) Stritzinger et al. 2011, (3) Phillips et al. 2007, (4) Schweizer et al. 2008, (5) Taubenberger et al. 2011
from both statistical photometric uncertainties and systematic uncertainties as a result of imperfect model fits, which can dominate, especially at late times. For individual SN Ia, we compute the weighted mean of the residuals about the joint model fit in the phase range [ -10 60] , days where the model fit is generally valid. To include systematic uncertainty from the joint model fit, we conservatively estimated the 1σ uncertainty on the weighted mean CSP - CfAIR2 residual as the error weighted standard deviation of the residuals, which we then divided by a factor of 3 to avoid overestimating the uncertainty. We then compute whether the mean CSP - CfAIR2 residuals are consistent with zero to within 1, 2 or ≥ 3σ in the selected phase range. We find that nearly all CfAIR2 and color term corrected CSP SN Ia LCs (18 JH and 8 K s LCs) are consistent to within 3σ by this metric. 32 See Figs. 10-12 and Table 7.
While this method is useful to compare entire LCs, we note that some CSP and CfAIR2 LCs in specific bands do show significant ∼ 0 1 . -0 4 mag deviations for individual . data points at similar phases or ranges of data points over smaller phase ranges, beyond what can be explained from poor model fits alone. For example, these discrepancies were noted: SN 2005iq, H < , 0 days; SN 2005na, H , 2040 days; SN 2007if, JH , 20-30 days; SN 2008hv, J , > 40 days; SN 2006D, H > , 40 days; SN 2005el, JH , > 40 days; SN 2007sr, H , 10-20 days. Nevertheless, many of these differences come from ∼ 1-2, individual outlier CfAIR2 data points, and most of the LCs show broad agreement by the above metric across a broad range of phases. See Figs. 10-12.
We can also test whether CfAIR2 and CSP are consistent for the entire overlap sample, rather than just individual objects. Fig. 13 shows aggregated residuals in the phase range [ -15 100] days after applying color terms ,
Figure 10. Comparing CfAIR2 to CSP Photometry
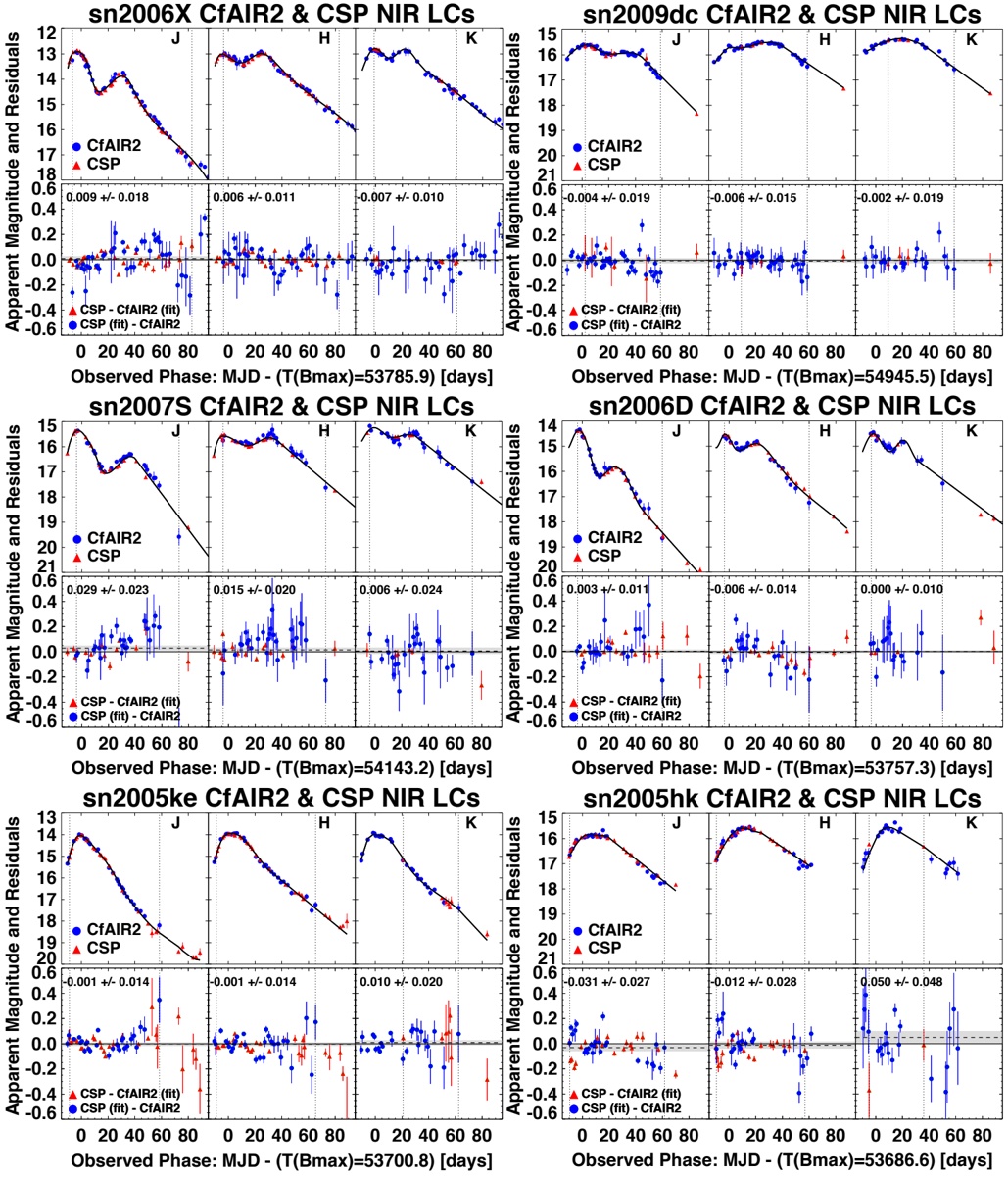
(Color online) (Top panels) Plot shows 6 example NIR SN Ia LCs out of the 18 CfAIR2 objects observed by both PAIRITEL and CSP. JHKs SN Ia LCs are shown from PAIRITEL CfAIR2 galaxy subtracted photometry (blue circles) and CSP LCs (red triangles) after applying color terms from Eq. 4 of this paper (see § 4.3.3). Vertical dotted lines show regions of temporal overlap for both LCs. The black line is a cubic spline model fit to the joint PAIRITEL+CSP data with a simple linear fit applied glyph[greaterorsimilar] 30-40 days in specific cases. For normal SN Ia, the WV08 mean template LC is used to help fit for missing data (not for Ia-pec or Iax: SN 2009dc, SN 2005ke, SN 2005hk).
(Bottom panels) CSP CfAIR2 residuals are computed as either (CSP data minus CfAIR2 joint model fit) or (CSP joint model fit -CfAIR2 data) for each epoch, using the same plot symbols as above for differences computed using CSP or CfAIR2 data. While the CSP (fit) - CfAIR2 residuals (blue circles) are above the zero residual line when the corresponding CfAIR2 data point has a larger magnitude value than the joint model fit in the top row panels, since we are computing CSP CfAIR2 residuals, the CSP - CfAIR2 (fit) (red triangles) residuals behave in the opposite sense. For example, when the CSP data has a larger magnitude than the joint model fit in the top row panels, the corresponding residual lies below the zero residual line. Weighted mean residuals and 1σ uncertainties for CSP - CfAIR2 data in the phase range [ -10 , 60] days, as listed in Table 7, are also shown in the upper left corner of each panel and indicated by the dashed line and the gray strip, respectively.
Figure 11. Comparing CfAIR2 to CSP Photometry
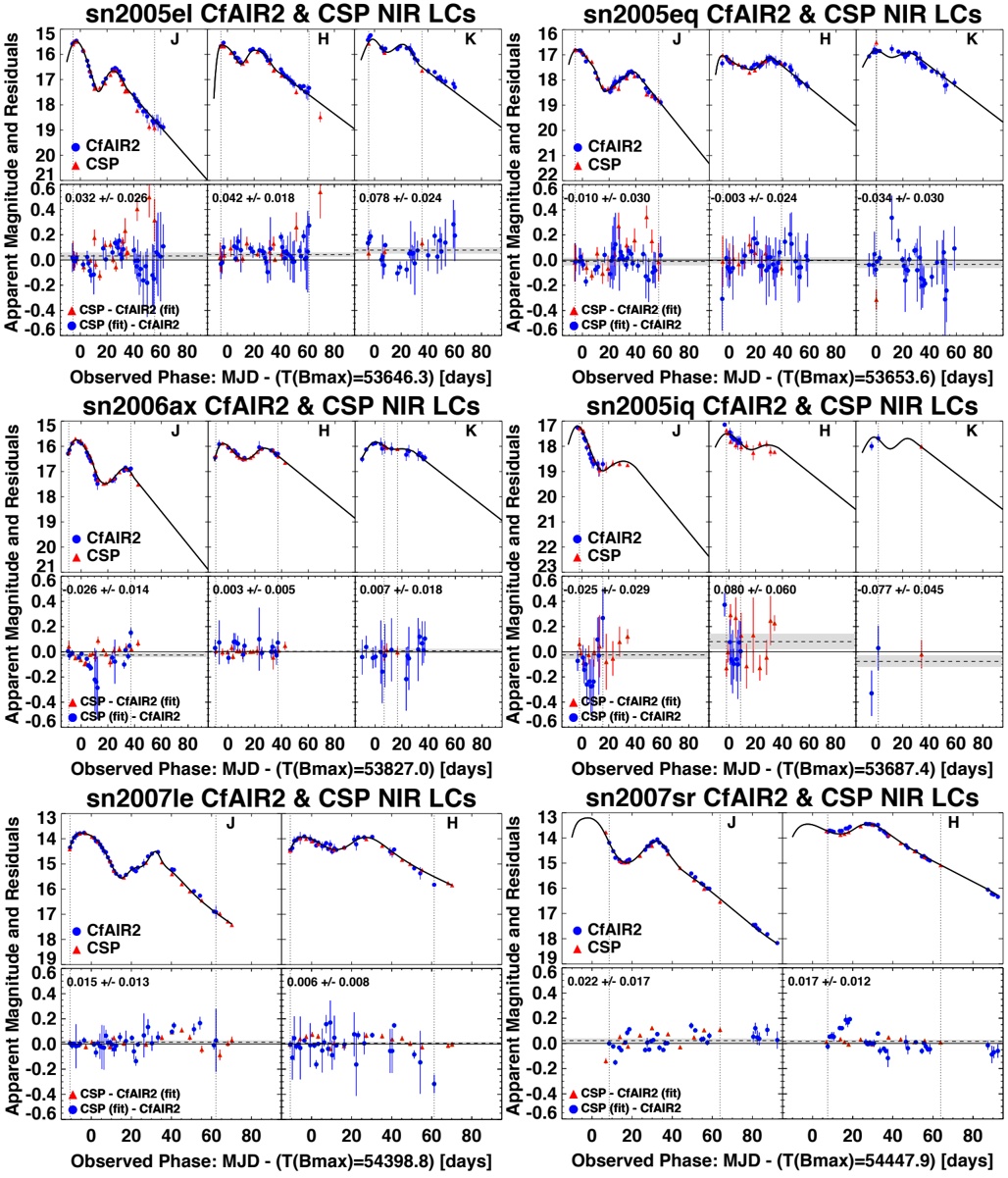
(Color online) (Top panels) Plot shows 6 example NIR SN Ia LCs out of the 18 CfAIR2 objects observed by both PAIRITEL and CSP. JHKs SN Ia LCs are shown from PAIRITEL CfAIR2 galaxy subtracted photometry (blue circles) and CSP LCs (red triangles) after applying color terms from Eq. 4 of this paper (see § 4.3.3). Vertical dotted lines show regions of temporal overlap for both LCs. The black line is a cubic spline model fit to the joint PAIRITEL+CSP data with a simple linear fit applied glyph[greaterorsimilar] 30-40 days in specific cases. For normal SN Ia, the WV08 mean template LC is used to help fit for missing data. CSP Ks -band is missing for some SN Ia (e.g., SN 2007le and SN 2007sr).
(Bottom panels) CSP CfAIR2 residuals are computed as either (CSP data minus CfAIR2 joint model fit) or (CSP joint model fit -CfAIR2 data) for each epoch, using the same plot symbols as above for differences computed using CSP or CfAIR2 data. While the CSP (fit) - CfAIR2 residuals (blue circles) are above the zero residual line when the corresponding CfAIR2 data point has a larger magnitude value than the joint model fit in the top row panels, since we are computing CSP CfAIR2 residuals, the CSP - CfAIR2 (fit) (red triangles) residuals behave in the opposite sense. For example, when the CSP data has a larger magnitude than the joint model fit in the top row panels, the corresponding residual lies below the zero residual line. Weighted mean residuals and 1σ uncertainties for CSP - CfAIR2 data in the phase range [ -10 , 60] days, as listed in Table 7, are also shown in the upper left corner of each panel and indicated by the dashed line and the gray strip, respectively.
Figure 12. Comparing CfAIR2 to CSP Photometry
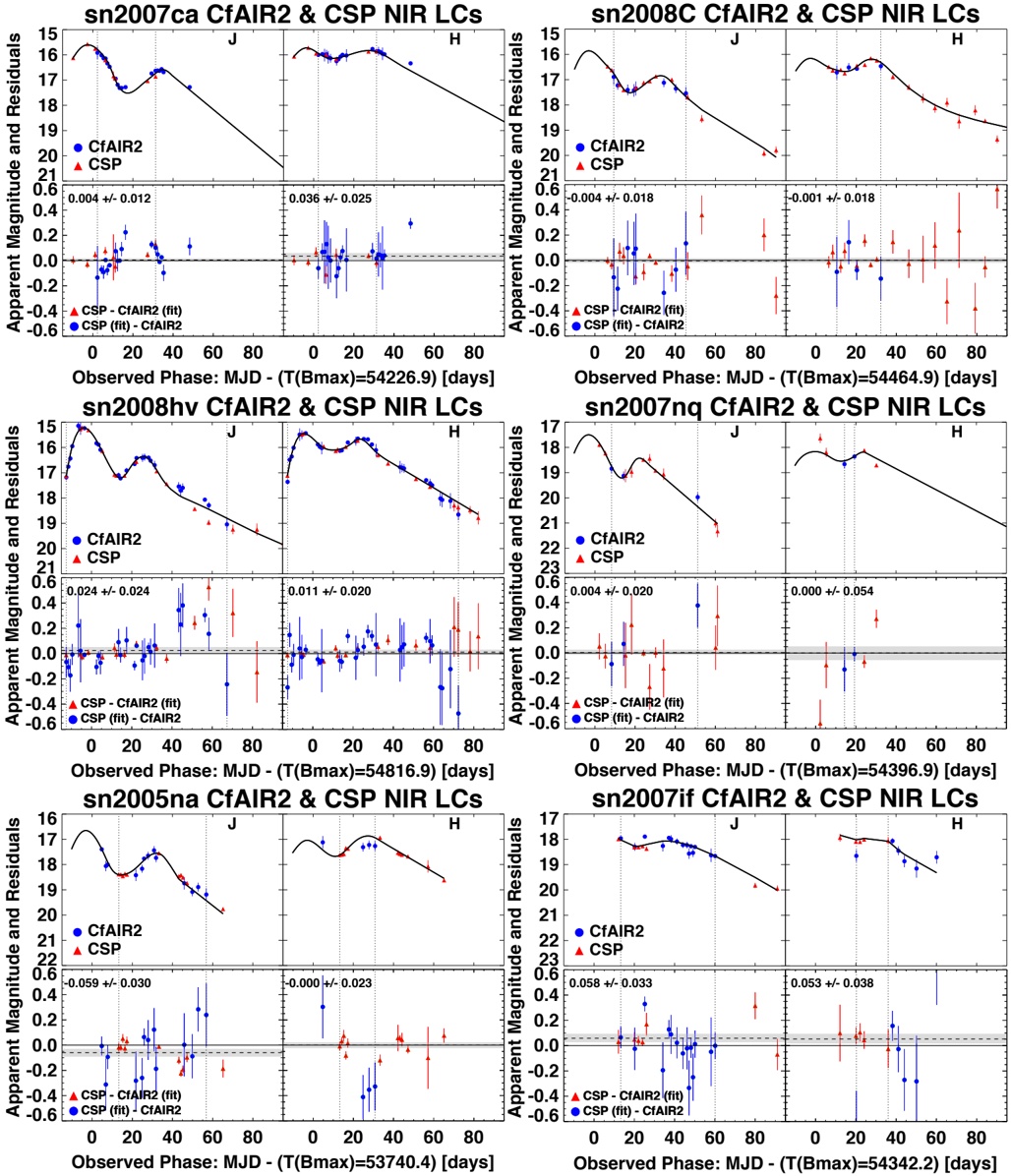
(Color online) (Top panels) Plot shows 6 example NIR SN Ia LCs out of the 18 CfAIR2 objects observed by both PAIRITEL and CSP. JHKs SN Ia LCs are shown from PAIRITEL CfAIR2 galaxy subtracted photometry (blue circles) and CSP LCs (red triangles) after applying color terms from Eq. 4 of this paper (see § 4.3.3). Vertical dotted lines show regions of temporal overlap for both LCs. The black line is a cubic spline model fit to the joint PAIRITEL+CSP data with a simple linear fit applied glyph[greaterorsimilar] 30-40 days in specific cases. For normal SN Ia, the WV08 mean template LC is used to help fit for missing data. CSP Ks -band is missing for all the above SN.
(Bottom panels) CSP CfAIR2 residuals are computed as either (CSP data minus CfAIR2 joint model fit) or (CSP joint model fit -CfAIR2 data) for each epoch, using the same plot symbols as above for differences computed using CSP or CfAIR2 data. While the CSP (fit) - CfAIR2 residuals (blue circles) are above the zero residual line when the corresponding CfAIR2 data point has a larger magnitude value than the joint model fit in the top row panels, since we are computing CSP CfAIR2 residuals, the CSP - CfAIR2 (fit) (red triangles) residuals behave in the opposite sense. For example, when the CSP data has a larger magnitude than the joint model fit in the top row panels, the corresponding residual lies below the zero residual line. Weighted mean residuals and 1σ uncertainties for CSP - CfAIR2 data in the phase range [ -10 , 60] days, as listed in Table 7, are also shown in the upper left corner of each panel and indicated by the dashed line and the gray strip, respectively.
Figure 13. CfAIR2/CSP Aggregated Residuals
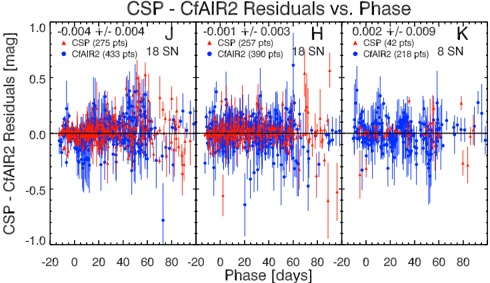
(Color online) Aggregated residuals and errors from LC model fits in § 4.4, Figs. 10-12, for CSP (red filled triangles) and CfAIR2 (blue filled circles) data from [ -15 100] days after applying the color , terms from Eq. 4 to CSP data. Outlier residuals from bad fits were removed with conservative 10σ clipping. There are 18 SN with joint JH data and 8 with K s data. Aggregated residuals include the following number of data points for CfAIR2: 433, 390, and 218, and CSP: 275, 257, and 42, in JHK s , respectively. The weighted means of the aggregated CSP - CfAIR2 residuals are -0 004 . ± 0 004, . -0 001 . ± 0 003, and 0 002 . . ± 0 009 for . JHK s , respectively. Applying the C10 color terms from Eq. 3 or applying no color terms had a negligible effect on the results. In all cases, differences between the JHK s CSP and CfAIR2 global weighted mean residuals have absolute values of only ∼ 0 001 . -0 004 mag, and are consistent with zero to . within 1σ , where the 1σ error is given by the standard error on the mean. PAIRITEL CfAIR2 data thus show excellent global agreement with CSP.
from Eq. 4 to the CSP data. Using 433, 390, and 218 CfAIR2 LC points, and 275, 257, and 42 CSP LC points, each in JHK s , respectively, we find the global weighted mean of the aggregated residuals is consistent with zero in each case (see Fig. 13). Applying color terms from C10 (or no color terms) did not affect the results. We conclude that both for individual LCs and for the global aggregated sample, PAIRITEL CfAIR2 photometry and CSP photometry show satisfactory overall agreement.
## 5. FINAL CfAIR2 DATA SET
Final, host galaxy subtracted JHK s LCs for 94 spectroscopically normal and peculiar CfAIR2 SN Ia and 4 SN Iax are presented in Fig. 14 and Table 8. 33 No K-corrections or Milky Way dust extinction corrections have been applied to the final CfAIR2 LCs (see § 6). PAIRITEL flux and magnitude measurements and errors are listed in Table 8 (see § 4.2.2). Fig. 15 shows CfAIR2 data for 2 peculiar SN Ia and 1 SN Iax with the WV08 mean LC template shown to emphasize how easily these objects can be distinguished from normal SN Ia using NIR LC shape alone. A new mean normal SN Ia NIR LC template using CfAIR2 and literature data will be presented elsewhere. Preliminary results show that the mean template using only CfAIR2 data is very similar to the WV08 template. We thus felt the WV08 template LC was sufficient for the purposes of this work, where it was used only to help fit PAIRITEL and CSP LCs for comparing normal SN Ia ( 4.3) and to provide a visual § comparison to peculiar objects (Fig. 15).
Table 9 shows fits of the observed JHK s properties for 88 CfAIR2 spectroscopically normal SN Ia. We de-
33 Only SN Iax SN 2008A and the SN 2005cf LC from WV08 used forced DoPHOT photometry, without galaxy subtraction.
Table 8 PAIRITEL CfAIR2 JHK s Photometry (Stub)
| SN | Type | Telescope | Band | Date MJD [days] a | f 25 b | σ f 25 c | JHKs σ [mag] d | JHKs [mag] d |
|-----------|--------|-------------|--------|---------------------|----------|------------|------------------|----------------|
| SN 2005ao | Ia | PAIRITEL | J | 2005Mar22 53451.48 | 227.592 | 17.306 | 19.11 | 0.08 |
| SN 2005ao | Ia | PAIRITEL | J | 2005Apr02 53462.51 | 255.056 | 21.694 | 18.98 | 0.09 |
| SN 2005ao | Ia | PAIRITEL | J | 2005Apr04 53464.39 | 263.369 | 29.603 | 18.95 | 0.12 |
| SN 2005ao | Ia | PAIRITEL | J | 2005Apr05 53465.39 | 266.528 | 72.947 | 18.94 | 0.3 |
| SN 2005ao | Ia | PAIRITEL | J | 2005Apr07 53467.39 | 311.257 | 40.449 | 18.77 | 0.14 |
| SN 2005ao | Ia | PAIRITEL | J | 2005Apr09 53469.42 | 341.932 | 12.23 | 18.67 | 0.04 |
| SN 2005ao | Ia | PAIRITEL | J | 2005Apr10 53470.38 | 343.194 | 25.402 | 18.66 | 0.08 |
| SN 2005ao | Ia | PAIRITEL | J | 2005Apr11 53471.38 | 395.464 | 65.052 | 18.51 | 0.18 |
| SN 2005ao | Ia | PAIRITEL | J | 2005Apr20 53480.35 | 259.901 | 17.128 | 18.96 | 0.07 |
| SN 2005ao | Ia | PAIRITEL | H | 2005Mar22 53451.48 | 535.15 | 44.485 | 18.18 | 0.09 |
| SN 2005ao | Ia | PAIRITEL | H | 2005Apr02 53462.51 | 416.466 | 50.697 | 18.45 | 0.13 |
| SN 2005ao | Ia | PAIRITEL | H | 2005Apr04 53464.39 | 393.065 | 120.604 | 18.51 | 0.34 |
| SN 2005ao | Ia | PAIRITEL | H | 2005Apr05 53465.39 | 475.528 | 75.989 | 18.31 | 0.18 |
| SN 2005ao | Ia | PAIRITEL | H | 2005Apr07 53467.39 | 526.212 | 113.705 | 18.2 | 0.24 |
| SN 2005ao | Ia | PAIRITEL | H | 2005Apr09 53469.42 | 596.101 | 72.917 | 18.06 | 0.13 |
| SN 2005ao | Ia | PAIRITEL | H | 2005Apr10 53470.38 | 695.897 | 83.084 | 17.89 | 0.13 |
| SN 2005ao | Ia | PAIRITEL | H | 2005Apr13 53473.36 | 713.816 | 114.068 | 17.87 | 0.18 |
| SN 2005ao | Ia | PAIRITEL | Ks | 2005Mar22 53451.48 | 833.517 | 126.88 | 17.7 | 0.17 |
| SN 2005ao | Ia | PAIRITEL | Ks | 2005Mar27 53456.43 | 723.626 | 127.287 | 17.85 | 0.19 |
| SN 2005ao | Ia | PAIRITEL | Ks | 2005Apr02 53462.51 | 622.584 | 126.942 | 18.01 | 0.22 |
| SN 2005ao | Ia | PAIRITEL | Ks | 2005Apr04 53464.39 | 550.997 | 88.049 | 18.15 | 0.18 |
| SN 2005ao | Ia | PAIRITEL | Ks | 2005Apr06 53466.39 | 862.798 | 125.926 | 17.66 | 0.16 |
| SN 2005ao | Ia | PAIRITEL | Ks | 2005Apr09 53469.42 | 871.012 | 138.486 | 17.65 | 0.17 |
| SN 2005ao | Ia | PAIRITEL | Ks | 2005Apr10 53470.38 | 1004.78 | 132.201 | 17.49 | 0.14 |
| SN 2005ao | Ia | PAIRITEL | Ks | 2005Apr11 53471.38 | 776.477 | 73.523 | 17.77 | 0.1 |
| SN 2005ao | Ia | PAIRITEL | Ks | 2005Apr13 53473.36 | 354.654 | 56.674 | 18.63 | 0.18 |
| SN 2005ao | Ia | PAIRITEL | Ks | 2005Apr20 53480.35 | 446.927 | 102.06 | 18.37 | 0.25 |
.
Note
-
(
A full machine-readable Table is available online in the electronic version of this paper.
A portion is shown here for guidance
).
(a)
Modified Julian Date.
- (b) f 25 : Flux normalized to a magnitude of 25. JHK s mag = -2 5 . log 10 ( f 25 ) + 25 mag.
- (c) σ f 25 : Symmetric 1σ error on f 25 , computed as the error weighted standard deviation of the flux measurements for each host galaxy subtraction on a given night, weighted by photometric errors corrected for DoPHOT underestimates. See Table 6 and Appendix A.
- σ JHKs mag = [ -2 5log . 10 ( f 25 -σ f 25 ) +2 5log . 10 ( f 25 + σ f 25 ) ]/2. (d) JHK s magnitude and 1σ uncertainty.
termined t B max and the LC shape parameter ∆ using MLCS2k2.v007 (Jha et al. 2007) fits to our own CfA optical CCD observations (Hicken 2009; Hicken et al. 2009a,b, 2012, CfA5 in prep. ) combined with other optical data from the literature where available (e.g., Ganeshalingam et al. 2010; C10; S11) and approximate t B max estimates from optical spectra in discovery and follow up notices as needed (See Table 9). Table 9 also lists the CMB frame redshift, z CMB , the JHK s apparent magnitudes at the brightest LC point, and the number of epochs in each LC.
Note that the JHK s magnitudes listed in Table 9 are not necessarily the apparent magnitudes at t B max or the relevant NIR first peaks, but simply the apparent magnitude of the brightest observed data point, which is very sensitive to data coverage. Also note that the z CMB values in Table 9 have not been corrected for any local flow models, which would provide more accurate redshift estimates for objects with z CMB glyph[lessorsimilar] 0 01 ( . glyph[lessorsimilar] 3000 km s -1 ). The apparent magnitudes and redshifts in Table 9 should thus not be naively used to estimate galaxy distances or naively combined with high-redshift data to estimate cosmological parameters.
## 6. DISCUSSION
The 94 CfAIR2 NIR SN Ia and 4 SN Iax LCs obtained in the northern hemisphere with PAIRITEL are matched only by the comparable, excellent quality, southern hemisphere CSP data set, which includes 72 SN Ia LCs (and 1 SN Iax) with at least 1 band of published Y JHK s data (see Table 10). The CfAIR2 and CSP data sets are
## Apparent Magnitude + constant
Observed Phase T - T(B max ) [days]
Figure 14. PAIRITEL CfAIR2 NIR LCs: 94 SN Ia and 4 SN Iax
(Color online) 94 CfAIR2 NIR SN Ia and 4 SN Iax LCs. Data points in magnitudes are shown for J (blue), H + 3 (green), and K s + 6 (red). Uncertainties are comparable to the sizes of the plot symbols. Plots are for the 88 spectroscopically normal SN Ia except for 6 peculiar SN Ia and 4 SN Iax (also see Fig. 15) marked in the lower right of each panel with Iap or Iax , which are displayed last starting with SN 2011de.
See notes below for the lower right corner of some LC plots:
- t : t B max estimated from optical spectra and cross checked with NIR LC features in lieu of early-time optical photometry (see Table 9).
- Iap : Peculiar objects, which clearly differ from the mean JHKs LC templates (see Fig. 15).
- Lt : SN 2006E and SN 2006mq were discovered late, so lack precise t B max estimates (see Table 9).
- Iax : See Foley et al. 2013 for a description of this distinct class of objects.
- wv : SN 2005cf is included in CfAIR2 but uses the same forced DoPHOT LC as in WV08, without host galaxy subtraction.
- do : SN 2008A used forced DoPHOT photometry, not the NNT host galaxy subtraction used for all other CfAIR2 LCs except SN 2005cf.
JHK s
Table 9 Light Curve Properties for 88 Spectroscopically Normal PAIRITEL CfAIR2 SN Ia
| SN | t B max a | σ t B a | Optical Ref. b | z CMB c | CMB c ∆ | d σ | ∆ d Jp e | σ Jp e | Hp e | σ Hp e | Kp e | σ Kp e | NJ f | NH f | NK f |
|---------------------------------|-------------------------|------------------|--------------------------------------|-------------------------|-----------------------------------------|-------------------------------|-----------------------------------|----------------------------|-------------------------|----------------|-------------------------------|---------------------|-------------|-------------|----------|
| SN2005ao | 53442 | 2 | IAUC 8492 | 0.03819 | 0.00099 · | · · · | · · 18.51 | 0.18 | 17.87 | 0.18 | 17.49 | 0.14 | 9 | 8 | 10 |
| SN2005bo SN2005cf | 53477.99 53533.56 | 0.53 0.11 | C10, G10 CfA3, Pa07a, WX09, G10 | 0.01502 0.00702 | 0.00108 0.00109 | 0.146 0.060 -0.108 | 16.33 0.032 13.83 | 0.04 0.04 | 15.55 13.96 | 0.07 0.02 | 15.53 13.97 | 0.12 0.02 | 15 17 | 16 17 | 13 15 |
| SN2005ch | 53536 | 3 | CBET 167 | 0.02782 | 0.00103 · 0.00100 | · · | · · · 17.02 | 0.03 | 16.79 | 0.08 | 16.05 | 0.06 | 13 | 11 | 8 |
| SN2005el | 53646.33 | 0.17 | CfA3, G10 | 0.01490 | · | 0.256 0.044 | 15.46 | 0.03 | 15.54 | 0.05 0.06 | 15.24 16.77 | 0.05 | 35 | 34 | 24 |
| SN2005eq SN2005eu | 53653.73 53659.70 | 0.19 0.16 | CfA3, G10 CfA3, G10 | 0.02837 0.03334 | 0.00098 0.00098 -0.153 | · · | · · · 16.83 0.039 17.14 | 0.03 0.07 | 17.08 16.96 | 0.10 | 16.81 | 0.18 31 0.17 23 | | 33 23 | 29 |
| SN2005iq | 53687.45 | 0.22 | CfA3, C10 | 0.03191 | 0.00097 | 0.157 | 0.049 17.26 | 0.08 | 17.14 | 0.09 | 17.68 | 0.18 12 | | 9 | 14 2 |
| SN2005ls SN2005na | 53714 53740.57 | 2 0.36 | CfA3 CfA3, C10, G10 | 0.02051 0.02683 | 0.00097 · 0.00102 · | · · · · | · · · 16.61 · · 17.40 | 0.17 0.07 | 15.85 17.12 | 0.25 0.25 | 15.67 | 0.25 0.26 | 21 13 | 19 4 | 19 |
| SN2006D | 53757.30 | 0.21 | CfA3, C10, G10 | 0.00965 | 0.00113 · | · · | · · · 14.34 | 0.02 | 14.61 | 0.04 | 16.80 14.45 | 0.06 | 23 | 21 | 10 17 |
| SN2006E | 53729 53760.44 | 10 0.50 | ATEL 690 CfA3 | 0.00364 0.01427 | 0.00134 0.00100 0.468 | · · · | · · · · 14.91 0.066 16.02 | 0.01 0.09 | 14.08 15.65 | 0.01 0.23 | 14.22 15.49 | 0.06 30 0.04 14 | | 29 12 | 25 |
| SN2006N SN2006X | 53785.90 | 0.11 | CfA3, C10, WX08, G10 | 0.00627 | 0.00121 0.00104 | -0.040 | 0.030 12.92 | 0.01 | 12.90 | 0.02 | 12.81 | | 45 | 44 | 37 |
| SN2006ac | 53781.38 | 0.30 | CfA3, G10 | 0.02412 | | 0.230 | 0.062 16.82 | 0.12 | 17.03 | 0.11 | 16.55 | 0.03 0.17 | 22 | 15 | 16 |
| SN2006ax SN2006cp | 53826.98 53896.76 | 0.14 0.14 | CfA3, C10 CfA3, G10 | 0.01797 0.02332 | 0.00107 · | · · -0.166 | · · · 15.82 0.048 16.96 | 0.01 15.92 0.08 16.84 | 0.17 0.08 | | 15.87 16.06 | 0.08 | 19 | 15 | 16 |
| SN2006cz | 53903 | 3 | CfA3, CBET 550 | 0.04253 | 0.00105 · | · · | · · · 17.63 | 0.06 | | 0.28 | 17.17 | 0.14 | 5 | 5 2 | 3 |
| SN2006gr | 54012.07 | 0.15 | CfA3, G10 | 0.03348 | 0.00102 0.00097 | -0.257 | 0.032 17.30 | 0.25 | 17.61 16.61 | 0.18 | 16.43 | 0.30 0.16 | 4 7 | 5 | 1 2 |
| SN2006le | 54047.36 | 0.14 | CfA3, G10 | 0.01727 | 0.00099 | -0.219 | 0.031 16.14 | 0.02 16.36 | | 0.08 | 16.04 | 0.08 | 39 | 36 | 31 |
| SN2006lf | 54044.79 | 0.13 | CfA3, G10 | 0.01297 | 0.00098 | 0.304 0.059 | 15.57 · | 0.17 | 15.53 12.78 | 0.06 | 15.35 | 0.25 0.00 | 40 | 41 | 28 |
| SN2006mq SN2007S | 54031 54143.25 | 10 0.17 | CBET 724, CBET 731 CfA3, S11 | 0.00405 0.01505 | 0.00125 · 0.00108 -0.303 | · · 0.028 | · · 13.82 15.36 | 0.01 0.02 | 15.32 | 0.01 0.25 | 12.81 15.18 | | 45 | 45 | 45 |
| SN2007ca | 54226.80 | 0.15 | CfA3, S11, G10 | 0.01511 | 0.00107 · | · · | · · · 15.92 | 0.25 15.77 | | 0.07 | 15.47 | 0.04 0.18 | 29 18 | 27 18 | 25 |
| SN2007co SN2007cq | 54264.61 54280.50 | 0.24 0.25 | CfA3, G10 CfA3, G10 | 0.02657 0.02503 | 0.00099 0.00095 · | -0.035 0.046 · · | 17.89 · · 16.40 | 0.17 | 17.57 16.70 | 0.18 0.19 | 16.50 15.29 | 0.22 0.25 | 7 6 | 6 6 | 10 5 |
| SN2007fb | 54287 | | CfA4, CBET 993 | 0.01681 | 0.00093 | 0.348 | · | 0.04 0.25 | 16.70 | | 17.03 | 0.28 | 2 | 2 | 6 1 |
| SN2007le | 54398.83 | 3 0.14 | CfA4, S11, G10 | 0.00551 | 0.00082 | 0.076 -0.111 0.033 | 16.58 13.76 | 0.02 | 13.91 | 0.18 0.01 | 13.76 | 0.18 | 35 | 31 | 25 |
| SN2007nq SN2007qe | 54396.94 54428.87 | 0.47 | CfA4, S11 CfA3, G10 | 0.04390 0.02286 | 0.00098 0.00095 | 0.361 -0.215 | 0.063 18.84 | 0.17 0.06 | | 0.06 0.05 | 17.76 | 0.19 | 3 8 | 2 8 | 3 7 |
| SN2007rx | 54441 | 0.15 | CfA4, CBET 1157 | 0.02890 | | 0.035 | 17.22 17.10 | | 18.36 16.71 16.56 | 0.06 | 16.91 16.45 | | 5 | 5 | 5 |
| SN2007sr | 54447.92 | 3 0.51 | CfA3, S08, G10 | 0.00665 | 0.00096 0.00122 | -0.249 0.080 0.040 | 14.06 | 0.07 | 13.44 | 0.03 | 13.39 | 0.17 0.08 0.03 | | 32 | 32 |
| SN2008C SN2008Z | 54464.79 54514.66 | 0.59 | CfA4, S11, G10 | 0.01708 | | -0.083 -0.038 -0.176 | 0.046 16.89 | 0.02 0.31 16.46 16.55 | | 0.17 0.18 | 14.89 16.16 | | 30 8 | 4 44 | 12 32 |
| SN2008af | 54500.47 | 0.19 1.02 | CfA4, G10 | 0.02183 | 0.00103 0.00104 | | 0.038 16.45 0.092 | 0.03 0.25 | | 0.25 | 0.25 0.10 0.25 | | 45 23 | 31 9 | 21 |
| SNf20080514-002 SNf20080522-000 | 54611.55 54621.28 | 0.42 0.48 | CfA3 G10 CfA4 | 0.03411 0.02306 | 0.00102 0.00104 0.00102 | 0.275 0.275 -0.137 | 18.16 | 0.11 0.17 | 17.24 16.61 17.17 | 0.12 0.25 | 17.01 | | 9 4 | 3 | 8 1 |
| SNf20080522-011 | 54617 | | CfA4 | 0.04817 | | 0.068 0.075 0.053 | 16.51 18.06 18.68 | 0.08 | 17.59 | | 16.47 16.79 | 0.18 0.30 | 8 | 9 | 2 |
| SN2008fr SN2008fv SN2008fx | 54732 54749.80 | 2 2 | CfA4 | 0.04026 0.04793 | 0.00101 -0.141 · | -0.126 0.046 · · · · | 17.72 · 14.91 | 0.05 | 18.18 14.98 | 0.12 0.32 0.25 | 17.24 16.68 14.84 17.50 | 0.18 0.17 0.25 0.18 | 5 3 6 | 6 3 5 | 6 3 5 |
| | 54729 | 0.20 3 | CfA5, Bi12 CBET 1525 | 0.00954 0.05814 | 0.00098 0.00102 0.00099 | · · | · · · 18.72 | 0.25 0.12 | 18.37 17.67 | 0.10 | 17.19 | 0.28 | 19 | 14 | 12 |
| SN2008gb SN2008gl | 54745.42 54768.13 | 1.09 0.27 | CfA4 CfA4 | 0.03643 0.03297 | · 0.00098 | -0.093 0.073 0.081 | 17.78 17.14 | 0.21 | 17.08 | 0.25 0.18 | 16.45 | | 9 26 | 12 22 21 | 10 23 |
| SN2008hs | 54804.33 54812.64 | 0.41 | CfA4 | 0.01918 | 0.00097 0.00098 | 0.311 -0.122 | 0.052 16.36 | 0.17 0.03 0.07 | 16.48 16.49 | 0.21 0.05 | 0.17 0.18 0.12 0.08 | | 20 | 29 | 17 24 |
| SN2008hm SN2008hv | 54816.91 | 0.15 0.11 | CfA4 CfA4, S11 | 0.01664 0.01359 | 0.00096 0.00108 | 0.927 | 0.070 16.37 0.051 | 0.25 | 15.44 | 0.04 | 16.06 16.17 15.15 14.68 | | 26 27 | 23 | 20 |
| SN2008hy SN2009D | 54803 54842 | 5 2 | AAVSO 392, CBET 1610 CfA4, CBET 1647 | 0.00821 | 0.00097 | 0.376 · · · | 15.14 · · · 15.67 0.058 16.31 | 0.03 0.01 | 14.72 16.78 16.93 | 0.02 | 0.06 16.29 0.25 0.25 | | 27 | 24 15 | 19 3 |
| SN2009Y SN2009ad | 54875.89 54886.05 | | CfA4 CfA4 | 0.02467 0.01007 0.02834 | 0.00099 | -0.106 · · | | 0.22 0.08 | 16.92 | 0.25 0.25 0.10 | 0.14 0.14 | | | 20 22 | 19 |
| SN2009al | 54896.41 | 0.48 0.24 0.31 | CfA4 | 0.02329 | 0.00108 0.00100 0.00105 | -0.116 · · · | 0.051 16.52 · · · 16.82 · · 16.52 | 0.03 | 16.55 15.08 | | 16.98 16.51 15.84 14.97 | 0.03 | 11 27 22 31 | 29 | 19 22 |
| SN2009an SN2009bv | 54898.21 54926.33 | 0.24 0.38 | CfA4 CfA4 | 0.00954 0.03749 | · 0.00104 0.00102 | 0.350 -0.180 | · 0.079 0.056 | 0.06 0.07 | 17.43 | 0.04 | 0.20 0.25 | | 13 | 13 9 | 8 |
| SN2009do | 54945 | 2 | CfA4, CBET 1778 | 0.04034 | | | 14.85 17.34 0.072 18.12 | 0.13 | 17.84 | 0.04 0.09 0.18 | 16.91 16.64 15.29 | 0.25 | 14 6 | 6 | 5 |
| SN2009ds SN2009fw SN2009fv | 54960.50 54993 54998 | 0.38 3 3 | CfA4 CBET 1849 CfA4, CBET 1846 | 0.02045 0.02739 0.02937 | 0.00102 0.00106 0.00097 · | 0.079 -0.120 · · | 0.056 16.22 · · · 15.94 | 0.23 0.09 0.16 | 16.20 15.65 15.90 | 0.17 0.25 0.25 | 14.27 15.57 14.72 | 0.18 0.26 0.25 | 6 | 5 5 9 | 3 5 3 |
| SN2009ig | 55079.43 | 0.25 | CfA4 CBET 1934 | 0.00801 0.01256 | 0.00100 0.00091 0.00096 | 0.238 -0.238 | 0.188 16.30 0.038 15.34 | 0.18 0.07 | 14.70 16.11 16.66 | 0.17 0.03 0.18 | 0.02 | | 6 11 9 | 11 | 7 |
| SN2009im SN2009jr | 55074 55119.83 | 3 | 0.01562 0.01244 | | · · -0.167 | · | · | 0.17 0.05 | 15.96 | | | | 11 17 | 14 17 11 | 6 11 |
| SN2009kk SN2009kq | 55125.83 55154.61 | 0.49 | CfA4 CfA4 CfA4 | 0.01236 | 0.00094 | · · 0.058 0.069 0.052 | 16.60 16.37 15.72 15.47 | | | 0.06 0.04 | 16.21 16.34 15.33 15.27 15.81 | 0.25 0.18 0.17 | 10 | 7 | 16 11 |
| SN2009le SN2009lf | 55165.41 55148 | 0.73 0.35 | CfA4 CBET | 0.01704 0.04409 | 0.00097 0.00107 | 0.237 -0.030 | 0.106 | 0.18 | 15.38 15.85 17.81 | 0.17 0.18 | | | 9 18 | 16 10 | 8 7 |
| SN2009na | 55201.31 | 0.23 2 | CfA4, 2025 CfA4 | 0.02202 | 0.00096 0.00098 0.00105 | -0.096 0.338 0.052 | 15.68 0.085 17.70 0.060 | 0.06 0.08 0.25 | 16.44 | | 17.86 | 0.18 0.36 0.17 0.23 | 11 15 | 10 | 8 12 |
| SN2010Y PS1-10w PTF10bjs | 55247.76 55248.01 | 0.28 | CfA4 R14 ATEL | 0.01126 0.03176 | 0.00103 0.00102 0.00102 | 0.826 · · · | 16.47 · · | | | 0.18 0.18 0.17 | 16.61 15.82 | 0.34 0.17 | | | 5 10 |
| SN2010ag | 55256 | 0.14 0.11 | CfA4 | 0.03055 0.03376 | · | 0.063 · · · · 0.051 | 15.23 17.00 · 16.95 | 0.02 0.06 0.06 0.01 | 15.20 17.34 17.09 17.14 | 17.35 | 0.25 | 10 | 10 | | 9 |
| SN2010ai | 55270.23 55276.84 55315 | 3 0.63 0.13 3 | CfA4, 2453 CfA4 CfA4, ATEL 2580 | 0.01927 0.02253 | | -0.249 0.358 · · · | · · | 0.04 0.01 | 16.67 | 0.07 | 16.48 16.50 16.49 | 0.10 0.17 | 11 15 22 15 | 12 15 17 12 | 17 8 |
| SN2010cr | | | CBET 2298 | | 0.00100 0.00105 0.00104 0.00096 | 0.074 · · · | 17.13 16.56 · | | 17.24 | 0.26 0.11 0.17 | 16.80 | 0.28 | | 3 12 | 5 |
| SN2010dl PTF10icb | 55341 55360 | 3 3 | Pa11 CfA4 | 0.02892 0.00905 | 0.00105 · · | · · | 16.65 · · · | 0.11 0.02 | | 0.18 | 16.59 14.58 | 0.25 0.25 | 5 12 6 | 6 4 | 7 4 4 |
| SN2010dw SN2010ew | 55357.75 55379 | 0.65 | CBET 2356 | 0.03870 0.02504 | -0.146 · · | · · · | 17.58 14.63 | 0.05 0.25 | 17.35 14.80 17.55 16.59 | | 16.66 15.39 | 0.25 0.17 | 5 2 | | |
| SN2010ex SN2010gn | 55386 55399 | 3 | CBET 2353 CBET | 0.02164 0.03638 | 0.00102 0.00098 | · 0.088 · · · · · 0.099 0.056 | 17.78 16.53 17.06 16.85 | | | 0.17 0.25 | 16.10 | 0.37 | | 2 3 18 | 2 2 13 |
| SN2010iw | 55492 | CfA5, CfA5, CBET | | 0.02230 | | · · | · | 16.79 17.42 16.41 | 0.25 0.23 0.23 0.10 | | 17.09 16.31 | | 0.17 | 3 18 21 | |
| SN2010ju | 55523.80 | 3 3 6 | 2386 2511 CfA5 | 0.01535 | 0.00095 0.00100 0.00104 0.00101 0.00104 | 0.023 · · · | · | 0.11 0.18 0.05 0.02 | 15.84 | 0.06 | 15.32 | 0.18 | 3 | 20 3 27 | 12 |
| SN2010jv | 55516 55543.48 | 0.44 3 0.13 | CBET 2550 CfA5 | 0.01395 0.01644 | -0.169 0.054 0.281 | 0.110 · 0.069 | 16.38 15.83 15.44 15.76 | 0.05 0.07 | 0.10 0.11 | | | 0.17 0.17 0.18 | 25 | | 37 |
| SN2010kg | | | CfA5 | | 0.00099 0.00101 | 0.142 | · | 15.42 15.86 | | | 14.82 15.71 | | 46 | 43 | 8 |
| SN2011B SN2011K SN2011ae | 55582.92 55578 55619 | 0.13 3 3 | CfA5, CBET 2636 CfA5 | 0.00474 0.01438 0.00724 | 0.00099 0.00120 -0.235 | 0.054 -0.138 0.076 | · 13.21 15.54 0.063 13.69 | 0.17 13.33 0.01 15.63 0.02 | 0.18 0.09 13.70 | 0.03 | 13.34 15.59 13.65 | 0.28 16 0.25 | 16 32 32 | 16 32 32 | 16 32 32 |
Note . - f (a) MJD o t B max and error from MLCS2k2.v007 (Jha et al. 2007) fits to B -band LCs from the CfA or the literature, where available. t B max fits from the literature are used for SN 2008fv (Biscardi et al. 2012), PS1-10w (Rest et al. 2014). For objects with no optical data or bad MLCS fits with reduced χ 2 > 3, t B max is estimated from any or all of: the MJD of the brightest point (rounded to the nearest day), optical spectra in listed CBET/IAUC/ATEL notices, and cross checked with fitted phases of NIR LC features, where possible (see F12). This applies to all SN in Table 9 with t B max and error rounded to the nearest day, with most assuming a ± -2 3 day uncertainty. Of these we observed SN 2009fw, SN 2010ew, SN 2010ex, and SN 2010jv at the CfA but do not have successfully reduced optical LCs for these objects, which are marked CfA? and may or may not be included in CfA5. 2 objects, SN 2006E, SN 2006mq were discovered several weeks after maximum and have only late time optical data, and only rough t B max estimates from optical spectra (these assume a ± 10 day uncertainty). Other objects with t B max from early optical data but with only late time NIR data where the first PAIRITEL observation is at a phase glyph[greaterorsimilar] 20 days after t B max include SN 2007qe, SN 2009ig, SN 2009im.
(b) Optical LC References: CfA5: in preparation; CfA4: Hicken et al. (2012); CfA3: Hicken et al. (2009b); CfA2: Jha et al. (2006b); CfA1: Riess et al. (1999); F09: Foley et al. (2009); R14: Rest et al. 2014; Br12: Bryngelson (2012); Bi12: Biscardi et al. (2012); S11: Stritzinger et al. (2011); Pa11: Parrent et al. (2011); C10: Contreras et al. (2010); G10: Ganeshalingam et al. (2010); WX09: Wang et al. (2009); WX08: Wang et al. (2008); S08: Schweizer et al. (2008).
(c) Redshift z CMB and error converted to CMB frame with apex vectors from Fixsen et al. 1996 (see NED: http://ned.ipac.caltech.edu/help/velc\_help.html ). Redshifts have not been corrected with any galactic flow models. Heliocentric redshifts (and references) and galactic coordinates are in Tables 1-2.
(d) ∆ parameter from MLCS2k2.v007 (Jha et al. 2007) fits to optical data from the CfA and/or the literature, where available. Only fits with reduced χ 2 < 3 are included. The following objects were not run through MLCS2k2 : PS1-10w (PanSTARRS1: t B max from SALT fit in Rest et al. 2014), SN 2008fv ( t B max in Biscardi et al. 2012). PTF10icb (Parrent et al. 2011, PTF) have unpublished optical data; PTF10bjs (PTF) has unpublished data and is in CfA4, but only in the r' i' natural system and not standard system magnitudes (Hicken et al. 2009b); SN 2006E (Bryngelson 2012) and SN 2006mq (CfA3) have only late time optical data.
- (e) Magnitudes and 1σ uncertainties in JHKs LCs at the brightest LC point (This is not necessarily the JHKs magnitude at the first NIR maximum or at t B max ). (f) Number of epochs w/ S/N > 3 in the JHKs lightcurves, respectively.
Figure 15. Peculiar SN Ia or SN Iax NIR LC Morphology
(Color online) CfAIR2 NIR LCs of 2 peculiar SN Ia (SN 2005ke, SN 2009dc), and 1 SN Iax (SN 2005hk) with the WV08 mean JHK s LC templates for spectroscopically normal SN Ia overplotted. Such objects can easily be distinguished from normal SN Ia based on NIR LC morphology alone.
quite complementary, observing mostly different objects with varying observation frequencies in individual NIR bandpasses (see § 4.3). CfAIR2 includes more than twice as many JH observations and more than ten times as many K s observations as CSP. By contrast, the CSP Y -band observations form a unique data set, since no CfA telescopes at FLWO currently have Y -band filters (see Table 10).
While CfAIR2 presents more total NIR SN Ia and SN Iax LCs than the CSP (98 vs. 73), more unique LCs (78 vs. 73), and includes ∼ 3-4 times the number of individual NIR observations, CSP photometric uncertainties are typically ∼ 2 -3 times smaller than for CfAIR2 (see Table 10), as a result of key differences between the NIR capabilities at CfA and CSP observing sites (see Table 2.1 of F12). These include better seeing at LCO vs. FLWO, a newer, higher resolution camera on the Swope 1.0-m telescope compared to the 2MASS south camera on the PAIRITEL-1.3m telescope, and CSP host galaxy template images sometimes taken with the 2.5-m du Pont telescope compared to CfAIR2 template images taken with the 1.3-m PAIRITEL using an undersampled camera. Overall, the CSP JHK s photometric precision for observations of the same objects at the brightest LC point is generally a factor of ∼ 2 -3 better than PAIRITEL, with median JHK s uncertainties of ∼ 0 01-0 02 . . mag for CSP and ∼ 0 02 . -0 05 mag for PAIRITEL (see . Table 10). More specifically, while CSP has fewer K s -band measurements, the peak photometric precision is ∼ 3 times better than PAIRITEL mainly because the CSP K s filter is on the duPont 2.5-m telescope, as compared to the PAIRITEL 1.3-m. What the CSP lacks in quantity compared to CfAIR2, it makes up for in quality.
However, unlike the CSP NIR data, since PAIRITEL photometry is already on the standard 2MASS JHK s system, no zero point offsets or color term corrections (e.g., Carpenter 2001; Leggett et al. 2006) or Scorrections based on highly uncertain NIR SN Ia SEDs (e.g., Stritzinger et al. 2002) are needed to transform CfAIR2 data to the 2MASS passbands. Avoiding ad-
Table 10 PAIRITEL and CSP NIR Data Census
| Project | SN a | NIR b | Y b | J b | H b | K s b | σ [mag] c |
|-----------|--------|---------|-------|-------|-------|---------|-------------|
| CfAIR2 | 98 | 4637 | 0 | 1733 | 1636 | 1268 | 0.02-0.05 |
| CSP | 73 | 2434 | 829 | 776 | 705 | 124 | 0.01-0.03 |
.
## Note
-
( a ) Number of SN Ia and SN Iax with NIR Y JH or K s observations in CfAIR2 (this paper) or CSP (C10; S11; Phillips et al. 2007; Schweizer et al. 2008; Taubenberger et al. 2011; Stritzinger et al. 2010).
- ( b ) Number of epochs of photometry.
( c ) Median magnitude uncertainties for CfAIR2 and CSP for same objects at the brightest LC pt.
ditional systematic uncertainty from S-corrections is a significant advantage for PAIRITEL CfAIR2 data, since the published spectral sample of only 75 NIR spectra of 33 SN Ia is still quite limited (Hsiao et al. 2007; Marion et al. 2009; Boldt et al. 2014). This advantage also applies to future cosmological uses of PAIRITEL data that would employ state-of-the-art NIR K-corrections to transform LCs to the rest-frame 2MASS filter system as the current world NIR spectral sample is increased. Even for relatively nearby z ∼ 0 08 objects, NIR K-corrections . in Y JHK s currently contribute uncertainties of ∼ 0 04-. 0 10 mag to distance estimates (Boldt et al. 2014). . Since NIR K-corrections at z ∼ 0 08 can themselves have val-. ues ranging from ∼ -0 8 . to ∼ 0 4 . mag, depending on the filter and phase, they can yield significant systematic distance errors if ignored (Boldt et al. 2014).
## 7. CONCLUSIONS
This work presents the CfAIR2 data set, including 94 NIR JHK s -band SN Ia and 4 SN Iax LCs observed from 2005-2011 with PAIRITEL. The 4637 individual CfAIR2 data points represent the largest homogeneously observed and reduced set of NIR SN Ia and SN Iax observations to date, nearly doubling the number of individual JHK s photometric observations from the CSP, surpassing the number of unique CSP objects, and increasing the total number of spectroscopically normal SN Ia with published NIR LCs in the literature by ∼ 65%. 34 CfAIR2 presents revised photometry for 20 out of 21 WV08 objects (and SN 2008ha from Foley et al. 2009) with more accurate flux measurements and increased agreement for the subset of CfAIR2 objects also observed by the CSP, as a result of greatly improved data reduction and photometry pipelines, applied nearly homogeneously to all CfAIR2 SN. 35
Previous studies have presented evidence that SN Ia are more standard in NIR luminosity than at optical wavelengths, less sensitive to dimming by host galaxy dust, and crucial to reducing systematic galaxy distance errors as a result of the degeneracy between intrinsic supernova color variation and reddening of light by dust, the most dominant source of systematic error in SN Ia cosmology (K04a; WV08; M09; F10; Burns et al. 2011; M11; K12; Burns et al. 2014). Combining PAIRITEL WV08 SN Ia data with optical and NIR data from the literature has already demonstrated that including NIR
34 Including revised photometry for 12 PAIRITEL objects with no CSP or other NIR data.
35 With the exception of SN 2005cf and SN 2008A (see § 3-4). SN of other types were also reduced using the same mosaicking and photometry pipelines as the CfAIR2 data set and are presented elsewhere (e.g., Bianco et al. 2014).
data helps to break the degeneracy between reddening and intrinsic color, making distance estimates less sensitive to model assumptions of individual LC fitters (M11; Mandel et al. 2014). CfAIR2 photometry will allow the community to further test these conclusions.
The addition of CfAIR2 to the literature presents clear new opportunities. A next step for the community is combine CfAIR2, CSP, and other NIR and optical low redshift SN Ia LC databases together using S-corrections, or color terms like those derived in this paper, to transform all the LCs to a common filter system. This optical and NIR data can be used to compute optical-NIR colors, derive dust and distance estimates, and construct optical and NIR Hubble diagrams for the nearby universe that are more accurate and precise than studies with optical data alone (e.g., M11). Empirical LC fitting and SN Ia inference methods that handle both optical and NIR data (e.g., BayeSN : M09; M11 and SNooPy : Burns et al. 2011) can be extended to utilize low and highz SN Ia samples to obtain cosmological inferences and dark energy constraints that take full advantage of CfAIR2, CSP and other benchmark NIR data sets.
Increasingly large, homogeneous, data sets like CfAIR2, raise hopes that SN Ia, especially in the restframe Y H bands, can be developed into the most precise and accurate of cosmological distance probes. This hope is further bolstered by complementary progress modeling SN Ia NIR LCs theoretically (e.g., Kasen 2006; Jack et al. 2012) and empirically (M09; M11; Burns et al. 2011). Combining future IJHY K s data with glyph[greaterorsimilar] 200 NIR SN Ia LCs from CfAIR2, the CSP, and the literature, will provide a growing lowz training set to study the intrinsic NIR properties of nearby SN Ia. This NIR data can better constrain the parent populations of host galaxy dust and extinction, elucidating the properties of dust in external galaxies, and allowing researchers to disentangle SN Ia reddening from dust and intrinsic color variation (M11).
CfAIR2 data should be further useful for a number of cosmological and other applications. Improved NIR distance measurements could also allow mapping of the local velocity flow independent of cosmic expansion to understand how peculiar velocities in the nearby universe affect cosmological inferences from SN Ia data (Turnbull et al. 2012; Davis et al. 2011). NIR data should also provide the best SN Ia set with which to augment existing optical measurements of the Hubble Constant (e.g., Riess et al. 2011). See Cartier et al. 2014 for a specific use of NIR SN Ia data to measure H 0 . Future work can compare NIR LC features and host-galaxy properties, which have been shown to correlate with Hubble diagram residuals for optical SN Ia (Kelly et al. 2010). Adding NIR spectroscopy to optical and infrared photometry can also help test physical models of exploding white dwarf stars (e.g., Kasen 2006; Jack et al. 2012), and investigate NIR spectral features that correlate with SN Ia luminosity, helping to achieve improved SN Ia distance estimates, similar to what has already been demonstrated with optical spectra (Bailey et al. 2009; Blondin et al. 2011; Mandel et al. 2014).
Our work emphasizing the intrinsically standard and relatively dust insensitive nature of NIR SN Ia has highlighted the rest-frame NIR as a promising wavelength range for future space based cosmological studies of
SN Ia and dark energy, where reducing systematic uncertainties from dust extinction and intrinsic color variation become more important than simply increasing the statistical sample size (e.g., Gehrels 2010; Beaulieu et al. 2010; Astier et al. 2011). Although ground-based NIR data can be obtained for low redshift objects, limited atmospheric transmission windows require that rest-frame NIR observations of high-z SN Ia be done from space. Currently, rest-frame SN Ia Hubble diagrams of highz SN Ia have yet to be constructed beyond the I band (Freedman & Carnegie Supernova Project 2005; Nobili et al. 2005; Freedman et al. 2009), with limited studies of SN Ia and their host galaxies conducted in the midinfrared with Spitzer (Chary et al. 2005; Gerardy et al. 2007). Our nearby NIR observations at the CfA with PAIRITEL have been recently augmented by RAISIN : Tracers of cosmic expansion with SN IA in the IR , an ongoing Hubble Space Telescope (HST) program (begun in Cycle 20) to observe ∼ 25 SN Ia at z ∼ 0 35 in the . rest-frame NIR with WFC3/IR.
Along with current and future NIR data, CfAIR2 will provide a crucial lowz anchor for future space missions capable of highz SN Ia cosmology in the NIR, including WFIRST (the Wide-Field Infrared Survey Telescope; a candidate for JDEM, the NASA/DOE Joint Dark Energy Mission; Gehrels 2010), The European Space Agency's EUCLID mission (Beaulieu et al. 2010), and the NASA James Webb Space Telescope (JWST; Clampin 2011). To fully utilize the standard nature of rest-frame SN Ia in the NIR and ensure the most precise and accurate extragalactic distances, the astronomical community should strongly consider space-based detectors with rest-frame NIR capabilities toward as long a wavelength as possible.
Until the launch of next generation NIR space instruments, continuing to observe SN Ia in the NIR from the ground with observatories like PAIRITEL and from space with HST programs like RAISIN is the best way to reduce the most troubling fundamental uncertainties in SN Ia cosmology as a result of dust extinction and intrinsic color variation. Ultimately, the CfAIR2 sample of nearby, low-redshift, NIR SN Ia will help lay the groundwork for next generation ground-based cosmology projects and space missions that observe very distant SN Ia at optical and NIR wavelengths to provide increasingly precise and accurate constraints on dark energy and its potential time variation over cosmic history. NIR SN Ia observations thus promise to play a critical role in elucidating the nature of one of the most mysterious discoveries in modern astrophysics and cosmology.
The Peters Automated Infrared Imaging Telescope (PAIRITEL) is operated by the Smithsonian Astrophysical Observatory (SAO) and was enabled by a grant from the Harvard University Milton Fund, the camera loan from the University of Virginia, and continued support of the SAO and UC Berkeley. Partial support for PAIRITEL operations and this work comes from National Aeronautics and Space Administration (NASA) Swift Guest Investigator grant NNG06GH50G ('PAIRITEL: Infrared Follow-up for Swift Transients'). PAIRITEL support and processing is conducted under the auspices of a DOE SciDAC grant (DE-FC0206ER41453), which provides support to J.S.B.'s group. J.S.B. thanks the Sloan Research Fellowship for partial support as well as NASA grant NNX13AC58G. We gratefully made use of the NASA/IPAC Extragalactic Database (NED). The NASA/IPAC Extragalactic Database (NED) Is operated by the Jet Propulsion Laboratory, California Institute of Technology, under contract with NASA. This publication makes use of data products from the 2MASS Survey, funded by NASA and the US National Science Foundation (NSF). IAUC/CBET were very useful. A.S.F. acknowledges support from an NSF STS Postdoctoral Fellowship (SES-1056580), a NSF Graduate Research Fellowship, and a NASA Graduate Research Program Fellowship. M.W.V. is funded by a grant from the US National Science Foundation (AST-057475). R.PK. acknowledges NSF Grants AST 12-11196, AST 09-097303, and AST 06-06772. M.M. acknowledges support in part from the Miller Institute at UC Berkeley, from Hubble Fellowship grant HST-HF-51277.01-A, awarded by STScI, which is operated by AURA under NASA contract NAS5-26555, and from
the NSF CAREER award AST-1352405. A.A.M. acknowledges support for this work by NASA from a Hubble Fellowship grant HST-HF-51325.01, awarded by STScI, operated by AURA, Inc., for NASA, under contract NAS 5-26555. Part of the research was carried out at the Jet Propulsion Laboratory, California Institute of Technology, under a contract with the National Aeronautics and Space Administration. A.S.F, R.P.K, and M.M. thank the Kavli Institute for Theoretical Physics at UC Santa Barbara, which is supported by the NSF through grant PHY05-51164. C.B. acknowledges support from the Harvard Origins of Life Initiative. Compu- tations in this work were run on machines supported by the Harvard Astronomy Computation Facility including the CfA Hydra cluster and machines supported by the Optical and Infrared Astronomy Division of the CfA. Other crucial computations were performed on the Harvard Odyssey cluster, supported by the Harvard FAS Science Division Research Computing Group. We thank the anonymous referee for a thorough and fair report that significantly helped to improve the paper.
Facilities: FLWO, PAIRITEL, 2MASS.
## APPENDIX
## NNT UNCERTAINTIES
We compute the estimated mean flux ˜ and uncertainty f σ NNT for a given night using the NNT host galaxy subtraction method in the following manner. For a night with N T successful host galaxy template subtractions, we have N T LC points with flux f i each with corrected DoPHOT flux uncertainties σ f do ,i , where i = { 1 2 , , . . . , N T } indexes the N T subtractions that are implicitly summed over for every summation symbol Σ below. The estimated flux on this night is simply given by the weighted mean:
$$\tilde { f } & = \frac { \Sigma f _ { i } w _ { f _ { i } } } { \Sigma w _ { f _ { i } } }$$
with weights given by w f i = 1 /σ 2 f do ,i . We choose to conservatively estimate the uncertainty on ˜ using the error f weighted sample standard deviation of the N T flux measurements, which has the advantage of being a function of both the input fluxes f i and corrected DoPHOT flux errors σ f do ,i via the weights w f i = 1 /σ 2 f do ,i , given by:
$$\sigma _ { \tilde { f } } & = \sqrt { \frac { \Sigma w _ { f _ { i } } ( f _ { i } - \tilde { f } ) ^ { 2 } } { \Sigma w _ { f _ { i } } } }$$
However, to correct bias as a result of small sample sizes, which is appropriate here, since N T ∼ 3 -12, we refine Eq. A2 and instead use an appropriate unbiased estimator of the weighted sample standard deviation, given by:
$$\sigma _ { \text{NNT} } = \sqrt { \left [ \frac { \Sigma w _ { f _ { i } } } { ( \Sigma w _ { f _ { i } } ) ^ { 2 } - \Sigma w _ { f _ { i } } ^ { 2 } } \right ] \Sigma w _ { f _ { i } } ( f _ { i } - \tilde { f } ) ^ { 2 } }$$
We use Eq. A3 to compute our final NNT error estimate σ NNT on the flux averaged over several subtractions on an individual night. To account for nights with only N T = 1 or 2 successful subtractions, we further implement a systematic error floor with a conservative magnitude cutoff as described in § 4.2.1 (see Table 6).
## REFERENCES
Bloom, J. S., Starr, D. L., Blake, C. H., Skrutskie, M. F., & Falco, E. E. 2006, in Astronomical Society of the Pacific Conference Series, Vol. 351, Astronomical Data Analysis Software and Systems XV, ed. C. Gabriel, C. Arviset, D. Ponz, & S. Enrique, 751
Amanullah, R., Goobar, A., Johansson, J., et al. 2014, ApJ, 788, L21
Astier, P., Guy, J., Pain, R., & Balland, C. 2011, A&A, 525, A7
Astier, P., Guy, J., Regnault, N., et al. 2006, A&A, 447, 31
Bailey, S., Aldering, G., Antilogus, P., et al. 2009, A&A, 500, L17
Barone-Nugent, R. L., Lidman, C., Wyithe, J. S. B., et al. 2012,
MNRAS, 425, 1007
- Barris, B. J., Tonry, J. L., Novicki, M. C., & Wood-Vasey, W. M. 2005, AJ, 130, 2272
- Beaulieu, J. P., Bennett, D. P., Batista, V., et al. 2010, in Astronomical Society of the Pacific Conference Series, Vol. 430, Pathways Towards Habitable Planets, ed. V. Coud´ e Du Foresto, D. M. Gelino, & I. Ribas, 266
- Becker, A. C., Rest, A., Miknaitis, G., Smith, R. C., & Stubbs, C. 2004, in Bulletin of the American Astronomical Society, Vol. 36, American Astronomical Society Meeting Abstracts, 108.12
- Becker, A. C., Silvestri, N. M., Owen, R. E., Ivezi´, Z., & Lupton, c ˇ R. H. 2007, PASP, 119, 1462
Benetti, S., Meikle, P., Stehle, M., et al. 2004, MNRAS, 348, 261
Bertin, E., Mellier, Y., Radovich, M., et al. 2002, in Astronomical
Society of the Pacific Conference Series, Vol. 281, Astronomical
Data Analysis Software and Systems XI, ed. D. A. Bohlender,
- D. Durand, & T. H. Handley, 228 Betoule, M., Kessler, R., Guy, J., et al. 2014, A&A, 568, A22 Bianco, F. B., Modjaz, M., Hicken, M., et al. 2014, ApJS, 213, 19 Biscardi, I., Brocato, E., Arkharov, A., et al. 2012, A&A, 537, A57
- Blondin, S., Mandel, K. S., & Kirshner, R. P. 2011, A&A, 526, A81
- Blondin, S., & Tonry, J. L. 2007, ApJ, 666, 1024
- Blondin, S., Matheson, T., Kirshner, R. P., et al. 2012, AJ, 143, 126
- Bloom, J. S., Caldwell, N., Pahre, M., & Falco, E. E. 2003, Proposal, 1
- Boldt, L. N., Stritzinger, M. D., Burns, C., et al. 2014, PASP, 126, 324
- Branch, D., Baron, E., Thomas, R. C., et al. 2004, PASP, 116, 903 Brown, P. J., Kuin, P., Scalzo, R., et al. 2014, ApJ, 787, 29 Bryngelson, G. 2012, PhD thesis, Clemson University
- Burns, C. R., Stritzinger, M., Phillips, M. M., et al. 2011, AJ, 141, 19
-. 2014, ApJ, 789, 32
- Campbell, H., D'Andrea, C. B., Nichol, R. C., et al. 2013, ApJ, 763, 88
- Candia, P., Krisciunas, K., Suntzeff, N. B., et al. 2003, PASP, 115, 277
- Carpenter, J. M. 2001, AJ, 121, 2851
Cartier, R., Hamuy, M., Pignata, G., et al. 2014, ApJ, 789, 89
Chary, R., Dickinson, M. E., Teplitz, H. I., Pope, A., &
Ravindranath, S. 2005, ApJ, 635, 1022
- Childress, M., Aldering, G., Aragon, C., et al. 2011, ApJ, 733, 3 Childress, M., Aldering, G., Antilogus, P., et al. 2013, ApJ, 770, 107
- Chornock, R., Filippenko, A. V., Branch, D., et al. 2006, PASP, 118, 722
- Clampin, M. 2011, in Society of Photo-Optical Instrumentation Engineers (SPIE) Conference Series, Vol. 8146, Society of Photo-Optical Instrumentation Engineers (SPIE) Conference Series, 814605
- Cohen, M., Wheaton, W. A., & Megeath, S. T. 2003, AJ, 126, 1090
- Conley, A., Carlberg, R. G., Guy, J., et al. 2007, ApJ, 664, L13 Conley, A., Sullivan, M., Hsiao, E. Y., et al. 2008, ApJ, 681, 482 Conley, A., Guy, J., Sullivan, M., et al. 2011, ApJS, 192, 1
- Contreras, C., Hamuy, M., Phillips, M. M., et al. 2010, AJ, 139, 519
- Cuadra, J., Suntzeff, N. B., Candia, P., Krisciunas, K., & Phillips, M. M. 2002, in Revista Mexicana de Astronomia y Astrofisica, vol. 27, Vol. 14, Revista Mexicana de Astronomia y Astrofisica Conference Series, ed. J. J. Claria, D. Garcia Lambas, & H. Levato, 121
- Cutri, R. M., Skrutskie, M. F., van Dyk, S., et al. 2003, 2MASS All Sky Catalog of point sources. (The IRSA 2MASS All-Sky Point Source Catalog, NASA/IPAC Infrared Science
- Archive. http://irsa.ipac.caltech.edu/applications/Gator/) Davis, T. M., Hui, L., Frieman, J. A., et al. 2011, ApJ, 741, 67 Di Paola, A., Larionov, V., Arkharov, A., et al. 2002, A&A, 393, L21
- Drout, M. R., Soderberg, A. M., Mazzali, P. A., et al. 2013, ApJ, 774, 58
- Elias, J. H., Frogel, J. A., Hackwell, J. A., & Persson, S. E. 1981, ApJ, 251, L13
- Elias, J. H., Matthews, K., Neugebauer, G., & Persson, S. E. 1985, ApJ, 296, 379
- Elias-Rosa, N., Benetti, S., Cappellaro, E., et al. 2006, MNRAS, 369, 1880
- Elias-Rosa, N., Benetti, S., Turatto, M., et al. 2008, MNRAS, 384, 107
- Filippenko, A. V. 2005, in Astronomical Society of the Pacific Conference Series, Vol. 332, The Fate of the Most Massive Stars, ed. R. Humphreys & K. Stanek, 33
- Fixsen, D. J., Cheng, E. S., Gales, J. M., et al. 1996, ApJ, 473, 576
- Folatelli, G., Phillips, M. M., Burns, C. R., et al. 2010, AJ, 139, 120
- Foley, R. J., Brown, P. J., Rest, A., et al. 2010a, ApJ, 708, L61 Foley, R. J., McCully, C., Jha, S. W., et al. 2014a, ApJ, 792, 29 Foley, R. J., Van Dyk, S. D., Jha, S. W., et al. 2015, ApJ, 798, L37
- Foley, R. J., Chornock, R., Filippenko, A. V., et al. 2009, AJ, 138, 376
- Foley, R. J., Rest, A., Stritzinger, M., et al. 2010b, AJ, 140, 1321 Foley, R. J., Challis, P. J., Chornock, R., et al. 2013, ApJ, 767, 57 Foley, R. J., Fox, O. D., McCully, C., et al. 2014b, MNRAS, 443, 2887
- Fransson, C., Ergon, M., Challis, P. J., et al. 2014, ApJ, 797, 118 Freedman, W. L., & Carnegie Supernova Project. 2005, in
Astronomical Society of the Pacific Conference Series, Vol. 339,
Observing Dark Energy, ed. S. C. Wolff & T. R. Lauer, 50
Freedman, W. L., Burns, C. R., Phillips, M. M., et al. 2009, ApJ,
704, 1036
Friedman, A. S. 2012, PhD thesis, Harvard University
- Frieman, J. A., Turner, M. S., & Huterer, D. 2008a, Ann. Rev. Astron. Astrophys., 46, 385
- Frieman, J. A., Bassett, B., Becker, A., et al. 2008b, AJ, 135, 338 Frogel, J. A., Gregory, B., Kawara, K., et al. 1987, ApJ, 315, L129 Fruchter, A. S., & Hook, R. N. 2002, PASP, 114, 144
- Ganeshalingam, M., Li, W., Filippenko, A. V., et al. 2010, ApJS, 190, 418
- Garg, A., Stubbs, C. W., Challis, P., et al. 2007, AJ, 133, 403 Garnavich, P. M., Bonanos, A. Z., Krisciunas, K., et al. 2004,
- ApJ, 613, 1120 Gehrels, N. 2010, arXiv:1008.4936, arXiv:1008.4936 [astro-ph.CO] Gerardy, C. L., Meikle, W. P. S., Kotak, R., et al. 2007, ApJ, 661, 995
- Goldhaber, G., Groom, D. E., Kim, A., et al. 2001, ApJ, 558, 359 Goobar, A., & Leibundgut, B. 2011, Annual Review of Nuclear and Particle Science, 61, 251
- Goobar, A., Johansson, J., Amanullah, R., et al. 2014, ApJ, 784, L12
- Guy, J., Astier, P., Nobili, S., Regnault, N., & Pain, R. 2005, A&A, 443, 781
- Guy, J., Astier, P., Baumont, S., et al. 2007, A&A, 466, 11 Guy, J., Sullivan, M., Conley, A., et al. 2010, A&A, 523, A7 Hamuy, M., Phillips, M. M., Suntzeff, N. B., et al. 1996, AJ, 112,
- 2438 Hamuy, M., Folatelli, G., Morrell, N. I., et al. 2006, PASP, 118, 2 Hernandez, M., Meikle, W. P. S., Aparicio, A., et al. 2000, MNRAS, 319, 223
- Hicken, M., Garnavich, P. M., Prieto, J. L., et al. 2007, ApJ, 669, L17
- Hicken, M., Wood-Vasey, W. M., Blondin, S., et al. 2009a, ApJ, 700, 1097
- Hicken, M., Challis, P., Jha, S., et al. 2009b, ApJ, 700, 331 Hicken, M., Challis, P., Kirshner, R. P., et al. 2012, ApJS, 200, 12 Hicken, M. S. 2009, PhD thesis, Harvard University
- Hsiao, E. Y., Conley, A., Howell, D. A., et al. 2007, ApJ, 663,
- 1187
- Jack, D., Hauschildt, P. H., & Baron, E. 2012, A&A, 538, A132 Jha, S., Branch, D., Chornock, R., et al. 2006a, AJ, 132, 189 Jha, S., Riess, A. G., & Kirshner, R. P. 2007, ApJ, 659, 122 Jha, S., Garnavich, P. M., Kirshner, R. P., et al. 1999, ApJS, 125, 73
- Jha, S., Kirshner, R. P., Challis, P., et al. 2006b, AJ, 131, 527 Kasen, D. 2006, ApJ, 649, 939
- Kattner, S., Leonard, D. C., Burns, C. R., et al. 2012, PASP, 124, 114
- Kelly, P. L., Hicken, M., Burke, D. L., Mandel, K. S., & Kirshner, R. P. 2010, ApJ, 715, 743
- Kessler, R., Becker, A. C., Cinabro, D., et al. 2009, ApJS, 185, 32 Kirshner, R. P. 2010, 'Foundations of supernova cosmology' in 'Dark Energy: Observational and Theoretical Approaches', ed.
P. Ruiz-Lapuente (Cambridge University Press), 151
Kirshner, R. P. 2013, in IAU Symposium, Vol. 281, IAU
Symposium, ed. R. Di Stefano, M. Orio, & M. Moe, 1
- Kirshner, R. P., Willner, S. P., Becklin, E. E., Neugebauer, G., & Oke, J. B. 1973, ApJ, 180, L97
- Klein, C. R., & Bloom, J. S. 2014, arXiv:1404.4870, arXiv:1404.4870 [astro-ph.SR]
- Kocevski, D., Modjaz, M., Bloom, J. S., et al. 2007, ApJ, 663, 1180
- Krisciunas, K., Hastings, N. C., Loomis, K., et al. 2000, ApJ, 539, 658
- Krisciunas, K., Phillips, M. M., & Suntzeff, N. B. 2004a, ApJ, 602, L81
- Krisciunas, K., Prieto, J. L., Garnavich, P. M., et al. 2006, AJ, 131, 1639
- Krisciunas, K., Phillips, M. M., Stubbs, C., et al. 2001, AJ, 122, 1616
- Krisciunas, K., Suntzeff, N. B., Candia, P., et al. 2003, AJ, 125, 166
- Krisciunas, K., Phillips, M. M., Suntzeff, N. B., et al. 2004b, AJ, 127, 1664
- Krisciunas, K., Suntzeff, N. B., Phillips, M. M., et al. 2004c, AJ, 128, 3034
- -. 2005a, AJ, 130, 350
- Krisciunas, K., Garnavich, P. M., Challis, P., et al. 2005b, AJ, 130, 2453
- Krisciunas, K., Garnavich, P. M., Stanishev, V., et al. 2007, AJ, 133, 58
- Krisciunas, K., Marion, G. H., Suntzeff, N. B., et al. 2009, AJ, 138, 1584
- Krisciunas, K., Li, W., Matheson, T., et al. 2011, AJ, 142, 74 Kromer, M., Fink, M., Stanishev, V., et al. 2013, MNRAS, 429, 2287
Lauer, T. R. 1999, PASP, 111, 227
- Leggett, S. K., Currie, M. J., Varricatt, W. P., et al. 2006, MNRAS, 373, 781
- Leloudas, G., Stritzinger, M. D., Sollerman, J., et al. 2009, A&A, 505, 265
- Li, W., Filippenko, A. V., Chornock, R., et al. 2003, PASP, 115, 453
- Li, W. D., Filippenko, A. V., Treffers, R. R., et al. 2000, in American Institute of Physics Conference Series, Vol. 522, American Institute of Physics Conference Series, ed. S. S. Holt & W. W. Zhang, 103
- Mandel, K. S., Foley, R. J., & Kirshner, R. P. 2014, ApJ, 797, 75 Mandel, K. S., Narayan, G., & Kirshner, R. P. 2011, ApJ, 731, 120
- Mandel, K. S., Wood-Vasey, W. M., Friedman, A. S., & Kirshner, R. P. 2009, ApJ, 704, 629
- Margutti, R., Milisavljevic, D., Soderberg, A. M., et al. 2014, ApJ, 780, 21
- Marion, G. H., H¨flich, P., Gerardy, C. L., et al. 2009, AJ, 138, o 727
- Marion, G. H., Vinko, J., Kirshner, R. P., et al. 2014, ApJ, 781, 69 Marion, G. H., Sand, D. J., Hsiao, E. Y., et al. 2015, ApJ, 798, 39 Matheson, T., Kirshner, R. P., Challis, P., et al. 2008, AJ, 135, 1598
- Matheson, T., Joyce, R. R., Allen, L. E., et al. 2012, ApJ, 754, 19 Maund, J. R., Wheeler, J. C., Wang, L., et al. 2010, ApJ, 722, 1162
- McClelland, C. M., Garnavich, P. M., Galbany, L., et al. 2010, ApJ, 720, 704
- McCully, C., Jha, S. W., Foley, R. J., et al. 2014a, Nature, 512, 54 -. 2014b, ApJ, 786, 134
- Meikle, W. P. S. 2000, MNRAS, 314, 782 Miknaitis, G., Pignata, G., Rest, A., et al. 2007, ApJ, 666, 674 Modjaz, M. 2007, PhD thesis, Harvard University Modjaz, M., Stanek, K. Z., Garnavich, P. M., et al. 2006, ApJ, 645, L21
- Modjaz, M., Li, W., Butler, N., et al. 2009, ApJ, 702, 226 Modjaz, M., Blondin, S., Kirshner, R. P., et al. 2014, AJ, 147, 99 Narayan, G., Foley, R. J., Berger, E., et al. 2011, ApJ, 731, L11 Narayan, G. S. 2013, PhD thesis, Harvard University Nobili, S., Amanullah, R., Garavini, G., et al. 2005, A&A, 437,
- 789
- Parrent, J. T., Thomas, R. C., Fesen, R. A., et al. 2011, ApJ, 732, 30
Pastorello, A., Mazzali, P. A., Pignata, G., et al. 2007a, MNRAS, 377, 1531
- Pastorello, A., Taubenberger, S., Elias-Rosa, N., et al. 2007b, MNRAS, 376, 1301
- Perlmutter, S., Gabi, S., Goldhaber, G., et al. 1997, ApJ, 483, 565 Perlmutter, S., Aldering, G., Goldhaber, G., et al. 1999, ApJ, 517, 565
Phillips, M. M. 1993, ApJ, 413, L105
-. 2012, PASA, 29, 434
- Phillips, M. M., Lira, P., Suntzeff, N. B., et al. 1999, AJ, 118, 1766 Phillips, M. M., Krisciunas, K., Suntzeff, N. B., et al. 2006, AJ, 131, 2615
- Phillips, M. M., Li, W., Frieman, J. A., et al. 2007, PASP, 119, 360
- Pignata, G., Benetti, S., Mazzali, P. A., et al. 2008, MNRAS, 388, 971
- Plavchan, P., Jura, M., Kirkpatrick, J. D., Cutri, R. M., & Gallagher, S. C. 2008, ApJS, 175, 191
- Prieto, J. L., Rest, A., & Suntzeff, N. B. 2006, ApJ, 647, 501 Quillen, A. C., Ciocca, M., Carlin, J. L., Bell, C. P. M., & Meng, Z. 2014, MNRAS, 441, 2691
- Quimby, R. M. 2006, PhD thesis, The University of Texas at Austin
Rest, A., Stubbs, C., Becker, A. C., et al. 2005, ApJ, 634, 1103 Rest, A., Scolnic, D., Foley, R. J., et al. 2014, ApJ, 795, 44 Riess, A. G., Press, W. H., & Kirshner, R. P. 1996, ApJ, 473, 88 Riess, A. G., Filippenko, A. V., Challis, P., et al. 1998, AJ, 116, 1009
- Riess, A. G., Kirshner, R. P., Schmidt, B. P., et al. 1999, AJ, 117, 707
- Riess, A. G., Macri, L., Casertano, S., et al. 2011, ApJ, 730, 119 Rowe, B., Hirata, C., & Rhodes, J. 2011, ApJ, 741, 46 Sahu, D. K., Tanaka, M., Anupama, G. C., et al. 2008, ApJ, 680,
- 580
- Sanders, N. E., Soderberg, A. M., Foley, R. J., et al. 2013, ApJ, 769, 39
- Schechter, P. L., Mateo, M., & Saha, A. 1993, PASP, 105, 1342 Schmidt, B. P., Suntzeff, N. B., Phillips, M. M., et al. 1998, ApJ, 507, 46
- Schweizer, F., Burns, C. R., Madore, B. F., et al. 2008, AJ, 136, 1482
- Scolnic, D., Rest, A., Riess, A., et al. 2014a, ApJ, 795, 45 Scolnic, D. M., Riess, A. G., Foley, R. J., et al. 2014b, ApJ, 780, 37
- Silverman, J. M., Vinko, J., Kasliwal, M. M., et al. 2013, MNRAS, 436, 1225
- Skrutskie, M. F., Cutri, R. M., Stiening, R., et al. 2006, AJ, 131,
- Sollerman, J., Lindahl, J., Kozma, C., et al. 2004, A&A, 428, 555 Stanishev, V., Goobar, A., Benetti, S., et al. 2007, A&A, 469, 645 Stritzinger, M., & Sollerman, J. 2007, A&A, 470, L1
- Stritzinger, M., Hamuy, M., Suntzeff, N. B., et al. 2002, AJ, 124, 2100
- Stritzinger, M., Burns, C. R., Phillips, M. M., et al. 2010, AJ,
- Stritzinger, M. D., Phillips, M. M., Boldt, L. N., et al. 2011, AJ,
- Stritzinger, M. D., Hsiao, E., Valenti, S., et al. 2014, A&A, 561,
- Stritzinger, M. D., Valenti, S., Hoeflich, P., et al. 2015, A&A, 573,
- Taddia, F., Stritzinger, M. D., Phillips, M. M., et al. 2012, A&A,
- Taubenberger, S., Hachinger, S., Pignata, G., et al. 2008, MNRAS, 385, 75
- Taubenberger, S., Benetti, S., Childress, M., et al. 2011, MNRAS, 412, 2735
- Tominaga, N., Tanaka, M., Nomoto, K., et al. 2005, ApJ, 633, L97 Tonry, J. L., Schmidt, B. P., Barris, B., et al. 2003, ApJ, 594, 1 Turnbull, S. J., Hudson, M. J., Feldman, H. A., et al. 2012,
- Valentini, G., Di Carlo, E., Massi, F., et al. 2003, ApJ, 595, 779 Wang, L., Goldhaber, G., Aldering, G., & Perlmutter, S. 2003, ApJ, 590, 944
- Wang, L., Strovink, M., Conley, A., et al. 2006, ApJ, 641, 50 Wang, X., Li, W., Filippenko, A. V., et al. 2008, ApJ, 675, 626
- Weinberg, D. H., Mortonson, M. J., Eisenstein, D. J., et al. 2013,
- Weyant, A., Wood-Vasey, W. M., Allen, L., et al. 2014, ApJ, 784,
- Williams, A. J. 1997, PASA, 14, 208
- Wood-Vasey, W. M., Miknaitis, G., Stubbs, C. W., et al. 2007,
- Wood-Vasey, W. M., Friedman, A. S., Bloom, J. S., et al. 2008, ApJ, 689, 377
- Yamanaka, M., Kawabata, K. S., Kinugasa, K., et al. 2009, ApJ,
1163 140, 2036 142, 156 A146 A2 545, L7 MNRAS, 420, 447 -. 2009, ApJ, 697, 380 Phys. Rep., 530, 87 105 ApJ, 666, 694 707, L118 | 10.1088/0067-0049/220/1/9 | [
"Andrew S. Friedman",
"W. M. Wood-Vasey",
"G. H. Marion",
"Peter Challis",
"Kaisey S. Mandel",
"Joshua S. Bloom",
"Maryam Modjaz",
"Gautham Narayan",
"Malcolm Hicken",
"Ryan J. Foley",
"Christopher R. Klein",
"Dan L. Starr",
"Adam Morgan",
"Armin Rest",
"Cullen H. Blake",
"Adam A. Miller",
"Emilio E. Falco",
"William F. Wyatt",
"Jessica Mink",
"Michael F. Skrutskie",
"Robert P. Kirshner"
] | 2014-08-03T07:28:41+00:00 | 2015-09-01T21:01:15+00:00 | [
"astro-ph.HE",
"astro-ph.CO",
"astro-ph.SR"
] | CfAIR2: Near Infrared Light Curves of 94 Type Ia Supernovae | CfAIR2 is a large homogeneously reduced set of near-infrared (NIR) light
curves for Type Ia supernovae (SN Ia) obtained with the 1.3m Peters Automated
InfraRed Imaging TELescope (PAIRITEL). This data set includes 4607 measurements
of 94 SN Ia and 4 additional SN Iax observed from 2005-2011 at the Fred
Lawrence Whipple Observatory on Mount Hopkins, Arizona. CfAIR2 includes JHKs
photometric measurements for 88 normal and 6 spectroscopically peculiar SN Ia
in the nearby universe, with a median redshift of z~0.021 for the normal SN Ia.
CfAIR2 data span the range from -13 days to +127 days from B-band maximum. More
than half of the light curves begin before the time of maximum and the coverage
typically contains ~13-18 epochs of observation, depending on the filter. We
present extensive tests that verify the fidelity of the CfAIR2 data pipeline,
including comparison to the excellent data of the Carnegie Supernova Project.
CfAIR2 contributes to a firm local anchor for supernova cosmology studies in
the NIR. Because SN Ia are more nearly standard candles in the NIR and are less
vulnerable to the vexing problems of extinction by dust, CfAIR2 will help the
supernova cosmology community develop more precise and accurate extragalactic
distance probes to improve our knowledge of cosmological parameters, including
dark energy and its potential time variation. |
1408.0466v1 | 
Nuclear Physics A

Nuclear Physics A 00 (2014) 1-4
## Systematic studies of the centrality dependence of soft photon production in Au + Au collision with PHENIX
Benjamin Bannier (for the PHENIX Collaboration) 1
Department of Physics and Astronomy, Stony Brook University, Stony Brook, NY 11794, USA
## Abstract
Since the earliest days of Heavy Ion Physics thermal soft photon radiation emitted during the reaction had been theorized as a smoking gun signal for formation of a quark-gluon plasma and as a tool to characterize its properties. In recent years the existence of excess photon radiation in heavy ion collisions over the expectation from initial hard interactions has been confirmed at both RHIC and LHC energies by PHENIX and ALICE respectively. There the radiation has been found to exhibit elliptic flow v 2 well above what can currently be reconciled with a picture of early emission from a plasma phase. During the 2007 and 2010 Au + Au runs PHENIX has measured a high purity sample of soft photons down to pT > 0 4 GeV : = c using an external conversion method. We present recent systematic studies by PHENIX from that sample on the centrality dependence of the soft photon yield, and elliptic and triangular flow v 2 and v 3 in Au + Au collisions which fill in the experimental picture and enable discrimination of competing soft photon production scenarios.
Keywords:
## 1. Introduction
Collisions of heavy ions create dense and hot states of hadronic medium like the Quark Gluon Plasma (QGP), for which direct photons, i.e. photons not produced in decays of hadrons, provide an excellent probe: they can be produced during all stages of the interaction, and leave the medium virtually undisturbed due their vanishing interaction cross section with the hadronic medium. They can thus probe the full space-time evolution of the system. Here photons with transverse momenta pT = q p 2 x + p 2 y glyph[greaterorsimilar] 2 5 GeV : = c are produced predominately in early, hard interactions and called hard photons, while photons with smaller transverse momentum are called soft and thought to be produced from the medium. The photon yield gives experimental access to the rates of their di GLYPH<11> erent production processes, and their correlation with the event geometry, i.e. their elliptical and triangular flow coe GLYPH<14> cients v 2 and v 3 , are sensitive to the dynamics of the medium. While direct photon yield and flow integrate over all production channels, both quantities measured together strongly constrain possible production scenarios.
Measurements of soft photons are notoriously di GLYPH<14> cult in electromagnetic calorimeters due to large contamination from misidentified hadrons and a deteriorating energy resolution. Instead we here reconstruct photons from external conversions to electrons and positrons. For the 2007 and 2010 RHIC runs the HBD detector was installed in the PHENIX detector providing spatially well-defined conversion locations on a cylindrical shell R = 60 cm from the beam pipe with X X = 0 = 2 to 3% [1]. We identify conversion pairs by their characteristic apparent pair masses
1 A list of members of the PHENIX Collaboration and acknowledgments can be found at the end of this issue.
(a) Correlation between pair mass assuming production of electron and positron at the nominal interaction point M cgl , and at the HBD shell M atm . The concentration of photons with 10 MeV = c 2 < M cgl < 15 MeV = c 2 and M atm < 5 MeV = c 2 corresponds to conversions in the HBD shell; the opposite concentration at 10 MeV = c 2 < M atm < 15 MeV = c 2 and M cgl < 5 MeV = c 2 is due to decay photons from GLYPH<25> 0 Dalitz decays, GLYPH<25> 0 ! GLYPH<13> ( ee ).
(b) R GLYPH<13> for di GLYPH<11> erent centrality classes from the 2007 and 2010 runs, compared to the virtual photon result from PHENIX [2]. Here and later statistical uncertainties are shown as bars, systematic uncertainties as boxes. Both results agree within uncertainties.
Figure 1.
(opening angles) at the nominal interaction vertex and at the HBD detector shell. Momenta of electrons and positrons can be calculated assuming they came from either the vertex or the HBD shell, and their invariant pair mass (opening angle) at the vertex and the HBD shell can be compared, see Fig. 1a. Applying a simultaneous selection on both mass variables allows a clean separation of electron-positron pairs from Dalitz decays and external photon conversions with the level of background < 1% in the conversion sample while maintaining a good photon momentum resolution.
## 2. Direct photon yield
While by selecting on the two apparent pair masses we have already arrived at a very pure photon sample its relation to the actual photon production rate Y incl GLYPH<13> depends on detector-specific quantities, namely the photon conversion probability p conv , the geometrical acceptance of the detector for electron-positron pairs aee , and the e GLYPH<14> ciency of the used experimental cuts " ee , with the exact values only known inside relatively large systematic uncertainties. Instead of attempting to accurately determine these correction factors we follow a di GLYPH<11> erent approach: in addition to the raw yield of photons N incl GLYPH<13> , we measure a raw yield of photons from the decay GLYPH<25> 0 ! GLYPH<13>GLYPH<13> , N GLYPH<25> 0 GLYPH<13> which we extract by pairing one photon reconstructed in a conversion pair with another photon reconstructed in the PHENIX calorimeters with very loose cuts and estimation of the combinatorial background with mixed-event photon-photon pairs. The raw GLYPH<25> 0 -tagged yield N GLYPH<25> 0 GLYPH<13> is related to the yield Y GLYPH<25> 0 GLYPH<13> by the same detector-dependent factors as the inclusive photon yield, and additionally a conditional acceptance factor h " f i quantifying the probability to reconstruct both photons from a GLYPH<25> 0 decay, given that one photon was already reconstructed in a conversion pair. Since we use only very loose cuts to select calorimeter photons we can trade less dependence on systematic uncertainties for reduced statistical significance via the signal-to-background ratio in the GLYPH<25> 0 -tagged sample. The shared factors then drop out in the ratio of both quantities so that we can formulate a quantity R GLYPH<13> ,
$$R _ { \gamma } = \frac { Y _ { \gamma } ^ { \text{incl} } } { Y _ { \gamma } ^ { \text{decay} } } = \frac { Y _ { \gamma } ^ { \text{incl} } / Y _ { \gamma } ^ { \text{n} ^ { 0 } } } { Y _ { \gamma } ^ { \text{decay} } / Y _ { \gamma } ^ { \text{n} ^ { 0 } } } = \frac { \frac { N _ { \gamma } ^ { \text{incl} } / P _ { \text{com} ^ { a _ { e _ { e _ { e _ { e _ { e _ { e _ { f } } } } } } } } } { Y _ { \gamma } ^ { \text{decay} } } } = \frac { \langle \varepsilon f \rangle \frac { N _ { \gamma } ^ { \text{incl} } } { N _ { \gamma } ^ { \text{n} ^ { 0 } } } } { Y _ { \gamma } ^ { \text{decay} } }$$
(a) Direct photon pT spectra for di GLYPH<11> erent centrality classes. The shaded bands indicate N coll -scaled fits to PHENIX pp data. While the direct photon yield varies over two orders of magnitude between centralities the shape shows little change, also see the text.
(b) The pT -integrated direct photon yield for di GLYPH<11> erent lower integration limits, note logarithmic axes. The dashed lines indicate independent fits to each set up measurements. The centrality-dependence of the integrated direct photon yield shows no dependence on the lower integration limit outside of uncertainties.
Figure 2. Direct photon yield
Here we have used the yield of photons from the decay of any hadron Y decay GLYPH<13> which can be calculated from the known hadron yields and their branching ratios to photons. The numerator of the RHS of Eq. (1) depends only on measured raw yields and the conditional acceptance h " f i which has to be determined in a Monte Carlo simulation of the detector; the denominator depends on known yields and branching ratios and can be calculate in e.g. a simple phase space simulation. With these definition any measurement R GLYPH<13> > 1 corresponds to a direct photon signal. Our results for R GLYPH<13> are show in Fig. 1b. We observe a substantial direct photon signal.
From R GLYPH<13> we can calculate the direct photon yield shown in Fig. 2a,
$$Y _ { \gamma } ^ { \text{direct} } = ( R _ { \gamma } - 1 ) Y _ { \gamma } ^ { \text{decay} }$$
and analyze its centrality-dependence. We find that the direct photon excess over the N coll -scaled pp yield has inverse slopes roughly independent of centrality, (239 GLYPH<6> 25 GLYPH<6> 7) MeV = c (0-20%), (260 GLYPH<6> 33 GLYPH<6> 8) MeV = c (20-40%), (225 GLYPH<6> 28 GLYPH<6> 6) MeV = c (40-60%), and (238 GLYPH<6> 50 GLYPH<6> 6) MeV = c (60-92%), and the pT -integrated yield of the excess over the N coll -scaled pp yield has a power-law dependence on the number of participants N part , N GLYPH<13> / N GLYPH<11> part with a power larger than that of hadrons, GLYPH<11> = 1 48 : GLYPH<6> 0 08(stat) : GLYPH<6> 0 04(syst), see Fig. 2b. :
## 3. Direct photon v 2 and v 3
The elliptical and triangular flow coe GLYPH<14> cients v 2 and v 3 of direct photons can be calculated from the raw inclusive photon flow coe GLYPH<14> cients v incl n , the expectation for photons from hadron decays v decay n , and the known composition of
v
Figure 3. The direct photon v 2 ( top ) and v 3 ( bottom ) as a function of the photon pT in di GLYPH<11> erent centrality classes. The results from this analysis are shown with circle markers, from a preliminary calorimeter analysis as squares. Both results are consistent within systematic uncertainties.
the inclusive photon sample quantified by R GLYPH<13> ,
$$v _ { n } ^ { \text{direct} } = \frac { R _ { \gamma } v _ { n } ^ { \text{incl} } - v _ { n } ^ { \text{decay} } } { R _ { \gamma } - 1 }$$
Here the vn can be calculated from the angles between the n -th order event plane measured at forward rapidities 1 0 : < GLYPH<17> j j < 2 8, : n , and the photon direction GLYPH<30> n with a Fourier decomposition, v 0 n = h cos 2( GLYPH<30> n GLYPH<0> n ) i . To obtain the actual vn we perform resolution corrections of the raw v 0 n with the 3-subevent method [3], taking the di GLYPH<11> erence to results from a 2-subevent resolution correction into account the systematic uncertainties. The v decay n can be calculated in a phase space simulation from the known vn and yields of the parent hadrons and their branching ratios to photons by measuring the decay photon GLYPH<30> n against the known event planes, i.e. with perfect resolution. Our result for the direct photon v 2 and v 3 are shown in Fig. 3. We observe markedly positive, non-zero coe GLYPH<14> cients which remain large down to low pT across all centralities.
## 4. Conclusions
We have extracted a high-purity sample of soft photons and simultaneously measured the direct photon yield and the direct photon elliptical and triangular flow coe GLYPH<14> cients v 2 and v 3 , and extended the measurements in the soft regime. We find a substantial direct photon signal consistent with an earlier measurement using virtual photons [2], and with pT -integrated yields growing with the number of participants N part faster than the yield of soft hadrons. The shape of the direct photon spectra shows no changes outside of uncertainties across centralities. The coe GLYPH<14> cients of the elliptical flow measured in the same direct photon sample show markedly positive values, consistent with results from a virtual photon analysis [4] and preliminary results from an analysis of photons measured in the PHENIX calorimeters. While as one might expected from the more eccentric collision geometry we find increasing v 2 values when going to more peripheral collision, the v 2 of direct photons appears to show less pT dependence than that of soft hadrons, even with an indication of flattening towards the smallest pT as already indicated by earlier measurements [5].
## References
- [1] W. Anderson, B. Azmoun, A. Cherlin, C. Chi, Z. Citron, et al., Nucl.Instrum.Meth. A646 , 35 (2011), 1103.4277 .
- [3] A. M. Poskanzer and S. Voloshin, Phys.Rev. C58 , 1671 (1998), nucl-ex/9805001
- [2] A. Adare et al. (PHENIX Collaboration), Phys.Rev.Lett. 104 , 132301 (2010), 0804.4168 .
- [4] A. Adare et al. (PHENIX Collaboration), Phys.Rev.Lett. 109 , 122302 (2012), 1105.4126 .
.
- [5] A. Drees (PHENIX collaboration), Nucl.Phys. A910-911 , 179 (2013). | 10.1016/j.nuclphysa.2014.08.034 | [
"Benjamin Bannier"
] | 2014-08-03T07:46:06+00:00 | 2014-08-03T07:46:06+00:00 | [
"nucl-ex"
] | Systematic studies of the centrality dependence of soft photon production in Au+Au collision with PHENIX | Since the earliest days of Heavy Ion Physics thermal soft photon radiation
emitted during the reaction had been theorized as a smoking gun signal for
formation of a quark-gluon plasma and as a tool to characterize its properties.
In recent years the existence of excess photon radiation in heavy ion
collisions over the expectation from initial hard interactions has been
confirmed at both RHIC and LHC energies by PHENIX and ALICE respectively. There
the radiation has been found to exhibit elliptic flow $v_2$ well above what can
currently be reconciled with a picture of early emission from a plasma phase.
During the 2007 and 2010 Au+Au runs PHENIX has measured a high purity sample of
soft photons down to $p_T>0.4\,\text{GeV}/c$ using an external conversion
method. We present recent systematic studies by PHENIX from that sample on the
centrality dependence of the soft photon yield, and elliptic and triangular
flow $v_2$ and $v_3$ in Au+Au collisions which fill in the experimental picture
and enable discrimination of competing soft photon production scenarios. |
1408.0467v2 | ## Online Pattern Matching for String Edit Distance with Moves /star
Yoshimasa Takabatake , Yasuo Tabei , and Hiroshi Sakamoto 1 2 1
1 Kyushu Institute of Technology { takabatake,hiroshi @donald.ai.kyutech.ac.jp } 2 PRESTO, Japan Science and Technology Agency [email protected]
Abstract. Edit distance with moves (EDM) is a string-to-string distance measure that includes substring moves in addition to ordinal editing operations to turn one string to the other. Although optimizing EDM is intractable, it has many applications especially in error detections. Edit sensitive parsing (ESP) is an efficient parsing algorithm that guarantees an upper bound of parsing discrepancies between different appearances of the same substrings in a string. ESP can be used for computing an approximate EDM as the L 1 distance between characteristic vectors built by node labels in parsing trees. However, ESP is not applicable to a streaming text data where a whole text is unknown in advance. We present an online ESP (OESP) that enables an online pattern matching for EDM. OESP builds a parse tree for a streaming text and computes the L 1 distance between characteristic vectors in an online manner. For the space-efficient computation of EDM, OESP directly encodes the parse tree into a succinct representation by leveraging the idea behind recent results of a dynamic succinct tree. We experimentally test OESP on the ability to compute EDM in an online manner on benchmark datasets, and we show OESP's efficiency.
## 1 Introduction
Streaming text data appears in many application domains of information retrieval. Social data analysis faces a problem for analyzing continuously generated texts. In computational biology, recent sequencing technologies enable us to sequence individual genomes in a short time, which resulted in generating a large collection of genome data. There is therefore a strong incentive to develop a powerful method for analyzing streaming texts on a large-scale.
Edit distance with moves (EDM) is a string-to-string distance measure that includes substring moves in addition to insertions and deletions to turn one string to the other in a series of editing operations. The distance measure is motivated in error detections, e.g., insertions and deletions on lossy communication channels [13], typing errors in documents [8] and evolutionary changes in biological sequences [9]. Computing an optimum solution of EDM is intractable,
/star This work was supported by JSPS KAKENHI(24700140,26280088) and the JST PRESTO program
Table 1. Summary of recent pattern matching methods for EDM. The table summaries upper bound for the approximation ratio of EDM, computation time and space for each method. The space for ESP and OESP is presented in bits. N is the length of an input string; σ is the alphabet size; n is the number of variables in CFG; α ∈ (0 , 1] is a parameter for a hash table; lg ∗ is the iterated logarithm; lg stands for log 2 .
| | Appro. ratio | Time | Space | Algorithm |
|------------------------------------------|-----------------------------------------------|--------------------------------------------------------|----------------------------------------------------------|-------------------------|
| SNN [16] Shapira and Storer [21] ESP [7] | O (lg N lg ∗ N ) O O (lg N ) O (lg N lg ∗ N ) | ( N O (1) + N polylog( N )) O ( N 2 ) O ( N lg ∗ N/α ) | O ( N O (1) ) O ( N lg N ) N lg σ + n ( α +3)lg( n + σ ) | Offline Offline Offline |
| OESP | O (lg 2 N ) | O ( N lg N lg n α lg lg n ) | n ( α +1)lg( n + σ ) + n lg ( αn ) +5 n + o ( n ) | Online |
since the problem is known to be NP-complete [16]. Therefore, researchers have paid considerable efforts to develop efficient approximation algorithms that are only applicable to an offline case where a whole text is given in advance (Table 1). Early results include the reversal model [12,1] which takes a substring of unrestricted size and replaces it by its reverse in one operation. Muthukrishnan and Sahinalp [16] proposed an approximate nearest neighbor considered as a sequence comparison with block operations. Recently, Shapira and Storer proposed a polylog time algorithm with O (lg N lg ∗ N ) approximation ratio for the length N of an input text.
Edit sensitive parsing (ESP) [7] is an efficient parsing algorithm developed for approximately computing EDM between strings in an offline setting. ESP builds from a given string a parse tree that guarantees upper bounds of parsing discrepancies between different appearances of the same substring, and then it represents the parse tree as a vector each dimension of which represents the frequency of the corresponding node label in a parse tree. L 1 distance between such characteristic vectors for two strings can approximate the EDM. Although ESP has an efficient approximation ratio O (lg N lg ∗ N ) and runs fast in O N ( lg ∗ N/α ) time for a parameter α ∈ (0 , 1] for hash tables, its applicability is limited to an offline case. For applications in web mining and Bioinformatics, computing an EDM of massive streaming text data has ever been an important task. An open challenge, which is receiving increased attention, is to develop a scalable online pattern matching for EDM.
We present an online pattern matching for EDM. Our method is an online version of ESP named online ESP (OESP) that (i) builds a parse tree for a streaming text in an online manner, (ii) computes characteristic vectors for a substring at each position of the streaming text and a query, and (iii) computes the L 1 distance between each pair of characteristic vectors. The working space of our method does not depend on the length of text but the size of a parse tree. To make the working space smaller, OESP builds a parse tree from a streaming text and directly encodes it into a succinct representation by leveraging the idea behind recent results of an online grammar compression [15,14] and a dynamic succinct tree [18]. Our representation includes a novel succinct representation of a tree named post-order unary degree sequence (POUDS) that is built by the post-order traversal of a tree and a unary degree encoding. To guarantee the approximate EDM computed by OESP, we also prove an upper bound of the approximation ratio between our approximate EDM and the exact EDM.
Experiments using standard benchmark texts revealed OESP's efficiencies.
## 2 Preliminaries
## 2.1 Basic notation
Let Σ be a finite alphabet forming texts, and σ = | Σ | . Σ ∗ denotes the set of all texts over Σ , and Σ /lscript denotes the set of all texts of length /lscript over Σ , i.e. Σ /lscript = { S ∈ Σ ∗ || S | = /lscript } . We assume a recursively enumerable set X of variables such that Σ ∩X = φ and all elements in Σ ∪X are totally ordered. A sequence of symbols from Σ ∪ X is called a string. The length of string S is denoted by | S | , and the cardinality of a set C is similarly denoted by | C | . A pair and triple of symbols from Σ ∪ X are called digram and trigram, respectively. Strings x and z are said to be the prefix and suffix of the string S = xyz , respectively, and x, y, z are called substrings of S . The i -th symbol of S is denoted by S i [ ] (1 ≤ i ≤ | S | ). For integers i and j with 1 ≤ i ≤ j ≤ | S | , the substring of S from S i [ ] to S j [ ] is denoted by S i, j [ ]. N denotes the length of a text S and it can be variable in an online setting.
## 2.2 Context-free grammar
A context-free grammar (CFG) is a quadruple G = ( Σ,V,D,Z s ) where V is a finite subset of X , D is a finite subset of V × ( V ∪ Σ ) ∗ of production rules, and Z s ∈ V represents the start variable. D is also called a phrase dictionary . Variables in V are called nonterminals. The set of strings in Σ ∗ derived from Z s by G is denoted by L G ( ). A CFG G is called admissible if for any Z ∈ X there is exactly one production rule Z → γ ∈ D . We assume | γ | = 2 or 3 for any production rule Z → γ .
The parse tree of G is represented as a rooted ordered tree with internal nodes labeled by variables in V and leaves labeled by elements in Σ , and the label sequence of its leaves are equal to an input string. Any internal node Z ∈ V in a parse tree corresponds to a production rule in the form of Z → γ in D . The height of Z is the height of the subtree whose root is Z .
## 2.3 Phrase and reverse dictionaries
For a set V of production rules, a phrase dictionary D is a data structure for directly accessing the phrase S ∈ ( Σ ∪ V ) ∗ for any given Z ∈ V if Z → S ∈ D . A reverse dictionary D -1 : ( Σ ∪ V ) ∗ → V is a mapping from a given sequence of symbols to a variable. D -1 returns a variable Z associated with a string S if Z → S ∈ D ; otherwise, it creates a new variable Z ′ / V ∈ and returns Z ′ . For example, if D = { Z 1 → abc, Z 2 → cd } , D -1 ( a, b, c ) returns Z 1 , while D -1 ( b, c ) creates Z 3 and returns it.
## 2.4 Problem definition
In order to describe our method we first review the notion of EDM. The EDM d S, Q ( ) between two strings S and Q is the minimum number of edit operations defined below to transform S into Q :
- 1. Insertion: A character a at position i in S is inserted, which generates S [1 , i -1] aS i S i [ ] [ +1 , N ],
- 2. Deletion: A character a at position i in S is deleted, which generates S [1 , i -1] S i [ +1 , N ],
- 3. Replacement: A character at position i is replaced by a , which generates S [1 , i -1] aS i [ +1 , N ],
- 4. Substring move: A substring S i, j [ ] is moved and inserted at the position k , which generates S [1 , i -1] S j [ +1 , k -1] S i, j S k, N [ ] [ ].
Problem 1 (Online pattern matching for EDM) For a streaming text S ∈ Σ ∗ , a query Q ∈ Σ ∗ , and a distance threshold k ≥ 0 , find all i ∈ [1 , | S | ] such that the EDM between a substring S i, i [ + | Q | ] and Q is at most k , i.e. d S i, i ( [ + | Q ,Q | ] ) ≤ k .
Cormode and Muthukrishnan [7] presented an offline algorithm for computing EDM. In their algorithm, a special type of derivation tree called ESP is constructed for approximately computing EDM. We present an online variant of ESP. Our algorithm approximately solves Problem 1 and is composed of two parts: (i) an online construction of a parse tree space-efficiently and (ii) an approximate computation of EDM from the parse tree. Although our method is an approximation algorithm, it guarantees an upper bound for the exact EDM. We now discuss the two parts in the next section.
## 3 Online Algorithm
OESP builds a special form of CFG and directly encodes it into a succinct representation in an online manner. Such a representation can be used as spaceefficient phrase/reverse dictionaries, which resulted in reducing the working space. In this section, we first present a simple variant of ESP in order to introduce the notion of alphabet reduction and landmark . We then detail OESP and approximate computations of the EDM in an online manner. In the next section, we present an upper bound of the approximate EDM for the exact EDM.
## 3.1 ESP
Given an input string S ∈ Σ ∗ , we decompose the current S into digrams WX or trigrams WXY associated with variables as production rules, and iterate this process while | S | > 1 for the resulting S .
In each iteration, ESP uniquely partitions S into maximal non-overlapping substrings such that S = S S 1 2 · · · S /lscript and each S i is categorized into one of three types, i.e., type1: a repetition of a symbol, type2: a substring not including a type1 substring and of length at least /ceilingleft lg | S |/ceilingright , and type3: a substring being neither type1 nor type2 substrings.
At one iteration of parsing S i , ESP builds two kinds of subtrees from digram WX and trigram WXY , respectively. The first type is a 2-tree corresponding to a production rule in the form of Z → WX . The second type is a 3-tree corresponding to Z → WXY .
ESP parses S i according to its type. In case S i is a type1 or type3 substring, ESP performs the left aligned parsing where 2-trees are built from left to right in S i and a 3-tree is built for the last three symbols if | S i | is odd, as follows:
- -If | S i | is even, ESP builds Z → S i [2 j -1 2 ], , j j = 1 , ..., | S i | / 2,
- -Otherwise, it builds Z → S i [2 j -1 2 ] for , j j = 1 , ..., ( /floorleft| S / i | 2 /floorright -1), and builds Z → S i [2 j -1 2 , j +1] for j = /floorleft| S / i | 2 . /floorright
In case S i is type2, ESP further partitions S i = s s ...s 1 2 /lscript (2 ≤ | s j | ≤ 3) by the alphabet reduction described below, and builds Z → s j for j = 1 , ..., /lscript .
After parsing all S i to S ′ i , ESP continues this process for the resulted string by concatenating all S ′ i ( i = 1 , . . . , /lscript ) at the next level.
Alphabet reduction: Alphabet reduction is a procedure for partitioning a string of type2 into digrams and trigrams. Given S of type2, consider each S i [ ] represented as binary integers. Let p be the position of the least significant bit in which S i [ ] differs from S i [ -1], and let bit ( p, S i [ ]) ∈ { 0 1 , } be the value of S i [ ] at the p -th position, where p starts at 0. Then, L i [ ] = 2 p + bit ( p, S i [ ]) is defined for any i ≥ 2. Since S contains no repetition (i.e., S is type2), the string L defined by L = L [2] L [3] . . . L [ | S | ] is also type2. We note that if the number of different symbols in S is m , denoted by [ S ] = m , clearly [ L ] ≤ 2 lg m . Then, S i [ ] is called landmark if (i) L i [ ] is maximal such that L i [ ] > max { L i [ -1] , L i [ +1] } or (ii) L i [ ] is minimal such that L i [ ] < min { L i [ -1] , L i [ +1] } and not adjacent to any other maximal landmark.
Because L is type2 and [ L ] ≤ lg | S | , any substring of S longer than lg | S | must contain at least one landmark. After deciding all landmarks, if S i [ ] is a landmark, we replace S i [ -1 , i ] by a variable X and update the current dictionary with X → S i [ -1 , i ]. After replacing all landmarks, the remaining substrings are replaced by the left aligned parsing.
## 3.2 Post-order CFG
OESP builds a post-order partial parse tree (POPPT) and directly encodes it into a succinct representation. A partial parse tree defined by Rytter [20] is the ordered tree formed by traversing a parse tree in a depth-first manner and pruning out all descendants under every node of nonterminal symbols appearing no less than twice.
Definition 1 (POPPT and POCFG [15]). A post-order partial parse tree (POPPT) is a partial parse tree whose internal nodes have post-order variables. A post-order CFG (POCFG) is a CFG whose partial parse tree is a POPPT.
Fig. 1. Example of a POCFG, the parse tree of a POCFG, a post-order partial parse tree (POPPT).
Note that the number of nodes in the POPPT is at most 3 n for a POCFG of n variables, because the right-hand sides consist of digrams or trigrams in the production rules and the numbers of internal nodes and leaves are n and at most 2 n , respectively.
Examples of a POCFG and POPPT are shown in Figure 1-i) and iii), respectively. The POPPT is built by traversing the parse tree in Figure 1-ii) in depth-first manner and pruning out all the descendants under the node having the second X 3 . The resulted POPPT in Figure 1-iii) consists of internal nodes having post-order variables.
Amajor advantage of POPPT is that we can directly encode it into a succinct representation which can be used as a phrase dictionary. Such a representation enables us to reduce the working space of OESP by using it in a combination with a reverse dictionary.
## 3.3 Online construction of a POCFG
OESP builds from a given input string a POCFG that guarantees upper bounds of parsing discrepancies between the same substrings in the string. The basic idea of OESP is to (i) start from symbols in an input text, (ii) replace as many as possible of the same digrams or trigrams in common substrings by the same nonterminal symbols, and (iii) iterate this process in a bottom-up manner until it generates a complete POCFG. The POCFG is built in an online manner and the POPPT corresponding to it consists of nodes having two or three children.
OESP builds two types of subtrees in a POPPT from strings XY and WXY . The first type is a 2-tree corresponding to a production rule in the form of Z → XY . The second type is a 3-tree corresponding to a production rule in the form of Z → WXY .
OESP builds a 2-tree or 3-tree from a substring of a limited length. Let u be a string of length m . A function L : ( Σ ∪ V ) m × [ m ] →{ 0 1 , } classifies whether or not the i -th position of u has a landmark, i.e., the i -th position of u has a landmark if L ( u, i ) = 1. L ( u, i ) is computed from a substring u i [ -1 , i + 2] of length four. OESP builds a 3-tree from a substring u i [ +1 , i +3] of length three if the i -th position of u does not have a landmark; otherwise, it builds a 2-tree from a substring u i [ + 2 , i + 3] of length two. The landmarks on a string are
Algorithm 1 Online construction of ESP. D is phrase dictionary, D -1 is reverse dictionary, and q k is queue at level k .
```
Algorithm 1 Online construction of ESP. D is phrase dictionary, D-1 is reverse
dictionary, and q_k is queue at level k.
1: function OESP
2: D := 0; initialize queues q_k
3: while reading a new character c from an input text do
4: PROCESSSYMBOL(q1, c)
5: end while
6: end function
7: function PROCESSSYMBOL(qk, X)
8: qk.enqueue(X)
9: if qk.size() = 4 then
10: if L(qk, 2) = 0 then
1: Z := D-1(qk[3], qk[4]); D := D \cup {Z \rightarrow qk[3]qk[4]}
12:
}
*/
*/
*/
```
decided such that they are synchronized in long common subsequences to make the parsing discrepancies as small as possible.
The algorithm uses a set of queues, q k , k = 1 , ..., m , where q k processes the string at k -th level of a parse tree of a POCFG and builds 2-trees and 3-trees at each k . Since OESP builds a balanced parse tree, the number m of these queues is bounded by lg N . In addition, landmarks are decided on strings of length at most four, and the length of each queue is also fixed to five. Algorithm 1 consists of the functions OESP and ProcessSymbol .
The main function is OESP which reads new characters from an input text and gives them to the function ProcessSymbol one by one. The function ProcessSymbol builds a POCFG in a bottom-up manner. There are two cases according to whether or not a queue q k has a landmark. For the first case of L ( q k , 2) = 0, i.e. q k does not have a landmark, the 2-tree corresponding to a production rule Z → q k [3] q k [4] in a POCFG is built for the third and fourth elements q k [3] and q k [4] of the k -th queue q k . For the other case, the 3-tree corresponding to a production rule Z → q k [3] q k [4] q k [5] is built for the third, fourth and fifth elements q k [3], q k [4] and q k [5] of the k -th queue q k . In both cases, the reverse dictionary D -1 returns a nonterminal symbol replacing a sequence of symbols. The generated symbol Z is given to the higher q k +1 , which enables the bottom-up construction of a POCFG in an online manner.
The computation time and working space depend on implementations of phrase and reverse dictionaries. The phrase dictionary for a POCFG of n variables can be implemented using a standard array of at most 3 n lg ( n + σ ) bits of space and O (1) access time. In addition, the reverse dictionary can be implemented using a chaining hash table and a phrase dictionary implemented as an array. Thus, the working space of OESP using these data structures is at most
Fig. 2. Succinct representation of a POCFG for a phrase dictionary.
n (4 + α ) lg ( n + σ ) bits. In the following subsections, we present space-efficient representations of phrase/reverse dictionaries.
## 3.4 Compressed phrase dictionary
OESP directly encodes a POCFG into a succinct representation that consists of bit strings B P , and a label sequence L . A bit string B is built by traversing a POPPTandputting c 0s and 1 for a node having c children in the post-order. The final 0 in B represents the super node. We shall call the bit string representation of a POPPT posterior order unary degree sequence (POUDS) . To dynamically build a tree and access any node in the POPPT, we index B by using the dynamic range min/max tree [18]. Our POUDS supports two tree operations: child B, i, j ( ) returns the j -th child of a node i ; num child B, i ( ) returns the number of children for a node i . They are computed in O (lg m/ lg lg m ) time while using 2 m + (1) o bits of space for a tree having m nodes.
A bit string P is built by traversing a POPPT and putting 1 for a leaf and 0 for an internal node in the post-order. P is indexed by the rank/select dictionary [10,17]. The label sequence L stores symbols of leaves in a POPPT.
We can access any element in L as a child of a node i in the following. First, we compute c = num child B, i ( ) and children nodes p = child B, i, j ( ) for j ∈ [1 , c ]. Then, we can compute the positions in L corresponding to the positions of these children as q = rank 1 ( P, p ) that returns the number of occurrences of 1 in P [0 , p ] in O (1) time. We obtain leaf labels as L q [ ]. For a POCFG of n nonterminal symbols, we can access the right-hand side of symbols from the lefthand side of a symbol of a production rule in O (lg n/ lg lg n ) time while using at most n lg ( n + σ ) + 5 n + ( ) bits of space. o n
## 3.5 Compressed reverse dictionary
We implement a reverse dictionary using a chaining hash table that has a load factor α ∈ (0 , 1] in a combination with a phrase dictionary. The hash table has αn entries and each entry stores a list of integers i representing the left-hand side X i of a rule. For the rule X i → S , the hash value is computed from the righthand side S . Then, the list corresponding to the hash value is scanned to search for X i while checking elements referred to as S in a phrase dictionary. Thus, the expected access time is O (1 /α ). The space for a POCFG with n nonterminal symbols is αn lg( n + σ ) bits for the hash table and n lg( n + σ ) bits for the lists, which resulted in n α ( +1)lg( n + σ ) bits in total.
A crucial observation in OESP is that indexes i for nonterminal symbols X i are created in a strictly increasing order. Thus, we can organize each list in a hash table as a strictly increasing sequence of the indexes of nonterminal symbols. We insert a new index i into a list in the hash table, and we append it at the end of the list. Each list in the hash table consists of a strictly increasing sequence of indexes. To make each index smaller, we compute the difference between an index i and the previous one j , and we encode it by the delta code, which resulted in the difference i -j being encoded in 1 + /floorleft lg ( i -j ) /floorright + 2 lg 1 + lg ( /floorleft /floorleft i -j ) /floorright/floorright bits. For all n nonterminal symbols, the space for the lists is upper bounded by n (1 + lg ( αn ) + 2 lg lg ( αn )). bits The space for the hash table is αn lg ( n + σ + n (1+lg( αn ) +2 lg lg ( αn )) bits in total, resulting in αn lg( n + )+ σ n (1+lg( αn )) bits by multiplying the original α by a constant.
Since the reverse dictionary is implemented using the chaining hash and the phrase dictionary, its total space is at most n α ( +1)lg( n + σ ) + n (5+lg ( αn )) + o n ( ) bits. We can obtain the following result.
Lemma 1. For a string length N , OESP builds a POCFG of n nonterminal symbols and its phrase/reverse dictionaries in O ( N lg n α lg lg n ) expected time using at most n α ( +1)lg( n + σ ) + n lg ( αn ) + 5 n + ( ) o n bits of space.
## 3.6 Online pattern matching with EDM
We approximately solve problem 1 by using OESP. First, the parse tree is computed from a query Q by OESP. Let T Q ( ) be a set of node labels in the parse tree for Q . We then compute a vector V ( Q ) each dimension V ( Q e )( ) of which represents the frequency of the corresponding node label e in T Q ( ).
OESP builds another parse tree for a streaming text S in an online manner. T S ( )[ i, i + | Q | ] is a set of node labels included in the subtree corresponding to a substring S i, i [ + | Q | ] from i to i + | Q | in T S ( ). V ( S )[ i, i + | Q | ] can be constructed for each i ∈ [1 , | S | - | Q | ] by adding the node labels corresponding to S i, i [ + | Q | ] and subtracting the node labels not included in T S ( )[ i, i + | Q | ] from V ( S )[ i, i + | Q ]], which can be performed in lg | S | time.
L 1 -distance approximates the EDM between V ( S )[ i, i + | Q | ] and V ( Q ), and it is computed as || V ( S )[ i, i + | Q | ] -V ( Q ) || = ∑ e ∈ ( T S ( )[ i,i + | Q | ∪ ] T Q ( )) | V ( S )[ i, i + | Q | ]( e ) -V ( Q e )( ) . | We obtain the results with respect to computational time and space for computing the L 1 distance from lemma 1 as follows.
Theorem 1. For a streaming text S of length N , OESP approximately solves the problem 1 in O ( N lg N lg n α lg lg n ) expected time using at most n α ( +1)lg( n + σ ) + n lg ( αn ) + 5 n + ( ) o n bits of space.
## 4 Upper Bound of Approximation
We present an upper bound of the approximate EDM in this section.
Fig. 3. Computation time in seconds for the length of text.
Theorem 2. || V ( S ) -V ( Q ) || = O (lg 2 m d S, Q ) ( ) for any S, Q ∈ Σ ∗ and m = max {| S , | | Q |} .
/negationslash
/negationslash
Proof. Let e , e 1 2 , . . . , e d be a shortest series of editing operations such that S k +1 = S k ( e k ) where S 1 = S , S d ( e d ) = Q , and d = d S, Q ( ). It is sufficient to prove the assumption: there exists a constant c such that || V ( S ) -V ( Q ) || ≤ c lg 2 m for R e ( ) = S S i . ( ) denotes the string resulted by the i -th iteration of ESP where S (0) = S . Let p , q i i be the smallest integers satisfying S i ( )[ p i ] = Q i ( )[ p i ] and S i ( )[ | S | ( ) i -q i ] = Q i ( )[ | Q i ( ) | -q i ], respectively. We show that q i -p i ≤ lg m +1 for each height i . This derives || V ( S ) -V ( Q ) || ≤ 2 lg m (lg m +1) because i ≤ lg m .
We begin with the case that e is an insertion of a symbol. Clearly, it is true for i = 0 since q 0 -p 0 ≤ 1. We assume the hypothesis on some height i . Let S i ( )[ p ′ ] be the closest landmark from S i ( )[ p i ] with p ′ < p i and S i ( )[ q ′ ] be the closest landmark from S i ( )[ q i ] with q i < q ′ . For the next height, let S i ( + 1) = S S S 1 2 3 such that the tail of S 1 derives S i ( )[ p i ] and the tail of S 2 derives S i ( )[ q i ], and let Q i ( +1) = Q Q Q 1 2 3 such that | Q 1 | = | S 1 | and | Q 3 | = | S 3 | . On any iteration of ESP, the left aligned parsing is performed from a landmark to its closest landmark. It follows that, for S 1 , S 1 [ j ] = Q j 1 [ ] except their tails, for S 2 , | S 2 | ≤ /floorleft 1 2 ( q i -p i ) /floorright ≤ /floorleft 1 2 (lg m +1) , and for /floorright S 3 , we can estimate S 3 [ j ] = Q j 3 [ ] for any j > /floorleft 1 2 lg m /floorright . Thus, q i +1 -p i +1 ≤ 1+ /floorleft 1 2 (lg m +1) + /floorright /floorleft 1 2 lg m /floorright ≤ lg m +1. Since d S, Q ( ) = d Q, S ( ), this bound is true for the deletion of any symbol. The case that e is a replacement is similar.
Moreover, the bound holds for the case of insertion or deletion of any string of length at most lg m . Using this, we can reduce the case of move operation of a substring u as follows. Without loss of generality, we assume u is a type2 substring and let u = xyz such that x/z are the shortest prefix/suffix of u that contain a landmark, respectively. Then, we note that the y inside of u is transformed to a same string for any occurrence of u . Therefore, the case of moving u from S to obtain Q is reduced to the case of deleting x, z at some positions and inserting them into other positions. Since | x , | | z | ≤ lg m , the case of moving u is identical to the case of inserting two symbols and deleting two symbols, i.e., || V ( S ) -V ( Q ) || ≤ 8 lg m (lg m +1).
From theorem 1 and 2, we obtain the following main theorem.
Theorem 3. EDM is O (lg 2 N ) -approximable by the proposed online algorithm with O ( N lg N lg n α lg lg n ) expected time and n α ( +1)lg( n + σ ) + n (5 + lg ( αn )) + o n ( ) bits of space.
length of text
Fig. 4. Working space of dictionary and hash table for the length of text.
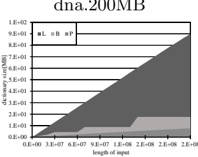
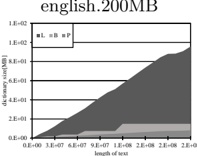
Fig. 5. Working space of a POUDS (B), a label sequence (L) and a bit string (P) which organizes a dictionary.
Fig. 6. The number of substrings whose EDM to a query is no more than each threshold.
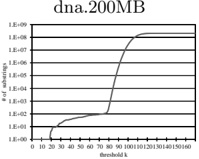
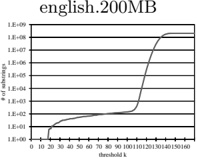
Proof. By the theorem 2, we obtain the bound || V ( S i, i [ + | Q | ] -V ( Q ) || = O (lg 2 | Q d S i, i | ) ( [ + | Q ,Q | ] ) for any i ∈ [1 , | S | - | Q | ]. The time complexity is proved by the theorem 1. Thus, for the strings S and Q with N = | S | ≥ | Q | , the result is concluded.
## 5 Experiments
We evaluated OESP on one core of an eight-core Intel Xeon CPU E7-8837 (2.67GHz) machine with 1024GB memory. We used two standard benchmark texts dna.200MB and english.200MB downloadable from http://pizzachili.dcc.uchile.cl/texts.html . We sampled texts of length 100 from these texts as queries. We also used computation time and working space as evaluation measures.
Figure 3 shows computation time for increasing the length of text. The computation time increased linearly for the length of text.
Figure 4 shows working space for increasing the length of text. The space of dictionary was much smaller than that of hash table. The dicionary used 115MB for dna.200MB and 121MB for english.200MB, while the hash table used 368MB for dna.200MB and 382MB for english.200MB.
Table 2. Space for POUDS B , label sequence P and bit string P organizing a dictionary on dna.200MB and english.200MB.
| L[MB] | | B[MB] | P[MB] |
|---------------|---------|---------|---------|
| dna.200MB | 89 . 95 | 17 . 62 | 7 . 73 |
| english.200MB | 95 . 72 | 14 . 99 | 8 . 22 |
Figure 5 shows space of a POUDS, a label sequence and a bit string organizing a dictionary for increasing the length of text. The space of dictionary and bit string was much smaller than that of the label sequence for dna.200MB and english.200MB. Table 2 details those space.
Figure 6 shows the number of substring whose EDM to a query is at most a threshold. There were thresholds where the number of substrings dramatically increases. The results showed the applicability of OESP to streaming texts.
## 6 Conclusion
We have presented an online pattern maching for EDM. Our method named OESP is an online version of ESP. A future work is to apply OESP to real world streaming texts.
## References
- 1. V. Bafna and P. A. Pevzner. Genome rearrangements and sorting by reversals. SIAM Jour. on Comp. , 25:272-289, 1996.
- 2. R. Clifford, K. Efremenko, B. Porat, and E. Porat. A black box for online approximate pattern matching. In CPM , pages 143-151, 2008.
- 3. R. Clifford, M. Jalsenius, E. Porat, and B. Sach. Pattern matching in multiple streams. In CPM , pages 97-109, 2012.
- 4. R. Clifford, M. Jalsenius, E. Porat, and B. Sach. Space lower bounds for online pattern matching. Theor. Comp. Sci. , 483:68-74, 2013.
- 5. R. Clifford and B. Sach. Online approximate matching with non-local distances. In CPM , pages 142-153, 2009.
- 6. R. Clifford and B. Sach. Pattern matching in pseudo real-time. JDA , 9:67-81, 2011.
- 7. G. Cormode and S. Muthukrishnan. The string edit distance matching problem with moves. TALG , 3:2:1-2:19, 2007.
- 8. M. Crochemore and W. Rytter. Text Algorithms . Oxford University Press, 1994.
- 9. R. Durbin, S. Eddy, A. Krogh, and G. Mitchison. Biological sequence analysis: probabilistic models of proteins and nucleic acids . Cambridge University Press, 1998.
- 10. G. Jacobson. Space-efficient static trees and graphs. In Proc. of FOCS , pages 549-554, 1989.
- 11. M. Jalsenius, B. Porat, and B. Sach. Parameterized matching in the streaming model. In STACS , pages 400-411, 2013.
- 12. J. D. Kececioglu and D. Sankoff. Exact and approximation algorithms for the inversion distance between two chromosomes. In Proc. of CPM , pages 87-105, 1993.
- 13. V. I. Levenshtein. Binary codes capable of correcting deletions, insertions and reversals. Soviet Physics Doklady , 10:707-710, 1996.
- 14. S. Maruyama and Y. Tabei. Fully-online grammar compression in constant space. In Proc. of DCC , pages 218-229, 2014.
- 15. S. Maruyama, Y. Tabei, H. Sakamoto, and K. Sadakane. Fully-online grammar compression. In Proc. of SPIRE , pages 218-229, 2013.
- 16. S Muthukrishnan and S. C. Sahinalp. Approximate nearest neighbors and sequence comparison with block operations. In Proc. of STOC , pages 416-424, 2000.
- 17. G. Navarro and E. Providel. Fast, small, simple rank/select on bitmaps. In Proc. of SEA , pages 295-306, 2012.
- 18. G. Navarro and K. Sadakane. Fully-functional static and dynamic succinct trees. TALG , 2012. Accepted. A preliminary version appeared in SODA 2010.
- 19. B. Porat and E. Porat. Exact and approximate pattern matching in the streaming model. In FOCS , pages 315-323, 2009.
- 20. W. Rytter. Application of Lempel-Ziv factorization to the approximation of grammar-based compression. Theor. Comp. Sci. , 302(1-3):211-222, 2003.
- 21. D. Shapira and J. A. Storer. Edit distance with move operations. JDA , 5:380-392, 2007. | null | [
"Yoshimasa Takabatake",
"Yasuo Tabei",
"Hiroshi Sakamoto"
] | 2014-08-03T07:48:52+00:00 | 2014-08-26T05:56:42+00:00 | [
"cs.DS"
] | Online Pattern Matching for String Edit Distance with Moves | Edit distance with moves (EDM) is a string-to-string distance measure that
includes substring moves in addition to ordinal editing operations to turn one
string to the other. Although optimizing EDM is intractable, it has many
applications especially in error detections. Edit sensitive parsing (ESP) is an
efficient parsing algorithm that guarantees an upper bound of parsing
discrepancies between different appearances of the same substrings in a string.
ESP can be used for computing an approximate EDM as the L1 distance between
characteristic vectors built by node labels in parsing trees. However, ESP is
not applicable to a streaming text data where a whole text is unknown in
advance. We present an online ESP (OESP) that enables an online pattern
matching for EDM. OESP builds a parse tree for a streaming text and computes
the L1 distance between characteristic vectors in an online manner. For the
space-efficient computation of EDM, OESP directly encodes the parse tree into a
succinct representation by leveraging the idea behind recent results of a
dynamic succinct tree. We experimentally test OESP on the ability to compute
EDM in an online manner on benchmark datasets, and we show OESP's efficiency. |
1408.0468v2 | ## On anti-de Sitter oscillators and de Sitter anti-oscillators
## Ion I. Cot˘escu a ∗
West University of Timi¸ soara, 4, RO-300223 Timi¸ soara, Romania
V. Pˆ arvan Ave.
August 12, 2014
## Abstract
We revisit the principal arguments for interpreting the free quantum fields on anti-de Sitter or de Sitter spacetimes of any dimensions as oscillators or respectively anti-oscillators. In addition, we point out that there exists a chart on the de Sitter background where the free Dirac field becomes a genuine anti-oscillator in the non-relativistic limit in the sense of special relativity.
Pacs: 04.62.+v
Keywords: de Sitter; anti-de Sitter; Dirac field; scalar field; oscillator; antioscillator.
∗ E-mail: [email protected]
The harmonic oscillators of frequency ω are among the most simple and popular classical or quantum systems. Changing ω → iω one obtains other systems that are called often anti-oscillators. For example, in the non-relativistic quantum mechanics on a d -dimensional Euclidean space of coordinates /vector x = ( x , x 1 2 , ..., x d ) the well-known Schr¨dinger equations of the harmonic isotropic o oscillator and its associated anti-oscillator of the same mass m read
$$\left [ - \frac { 1 } { 2 m } \Delta + \frac { m \omega ^ { 2 } } { 2 } \vec { x } ^ { 2 } \right ] \phi = i \partial _ { t } \phi \underset { \omega \to i \omega } { \longleftrightarrow } \left [ - \frac { 1 } { 2 m } \Delta - \frac { m \omega ^ { 2 } } { 2 } \vec { x } ^ { 2 } \right ] \phi = i \partial _ { t } \phi \,. \quad ( 1 )$$
In special relativity there are oscillating systems formed by scalar [1, 2, 3, 4] or spinor [5, 6] quantum fields but whose field equations are not covariant. Thus it seems that the natural relativistic oscillators are those of general relativity constituted by classical or quantum fields defined on anti-de Sitter (AdS) spacetimes [7, 8, 9, 10, 11]. Other systems simulating oscillatory motions in general relativity were studied in Refs. [12, 13]. Moreover, the terms of oscillator and anti-oscillator are used today even in cosmology related to actual models with positive or negative cosmological constants [14]. This suggests that typical system of general relativity are the AdS oscillators and the corresponding de Sitter (dS) anti-oscillators.
Under such circumstances we believe that it is worth reviewing the properties of the quantum fields defined on these spacetimes that emphasise their characters of oscillator or anti-oscillator. For this reason, we would like to revisit here the principal features of these systems considering the generalization to arbitrary dimensions [15, 16, 17] of some of our previous results [18, 19, 20]. In addition, we show that there exists a dS chart where the quantum fields behaves as genuine anti-oscillators in the non-relativistic limit. We focus on the free Dirac quantum field on the mentioned manifolds since this is the only quantum field having the same rest energy as in special relativity [21]. Why this property is important will be pointed out by comparing the Dirac field with the scalar one.
We discuss simultaneously both the manifolds under consideration here denoting the dS and AdS d -dimensional spacetimes by ( M /epsilon1 1+ d , g /epsilon1 ) understanding that /epsilon1 = 1 corresponds to the dS case and /epsilon1 = -1 to the AdS one. These spacetimes are hyperboloids embedded in the ( d + 2)-dimensional flat spacetimes, ( M /epsilon1 1+ +1 d , η /epsilon1 ), of coordinates z A , A,B,... = 0 1 2 , , , ..., d +1 and metric
$$\eta ^ { \epsilon } = \text{diag} ( 1, \underbrace { - 1, - 1, \dots, - 1 } _ { d }, - \epsilon ) \,.$$
︸ ︷︷ ︸ The equations η /epsilon1 AB z A ( x z ) B ( x ) = -/epsilon1 R 2 of the hyperboloids of radius R = 1 /ω , are solved by the functions z A ( x ) that introduce the coordinates x µ ( α, ...µ, ... = 0 1 2 , , , ..., d ) of the charts { x } on these manifolds.
On ( M /epsilon1 1+ d , g /epsilon1 ) one defines the static charts of Cartesian coordinates, { t, /vector x } (with t = x 0 ), given by the parametrization
$$\varphi \circ \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \\ z ^ { 0 } \ = \ \omega ^ { - 1 } \chi _ { \epsilon } ( r ) \begin{cases} \sinh \omega t & \text{if} \ \epsilon = 1 \\ \sin \omega t & \text{if} \ \epsilon = - 1 \end{cases}$$
$$z ^ { i } \ = \ x ^ { i }, \ \ i = 1, 2, \dots, d \quad & & ( 3 ) \\ z ^ { d } \ = \ \omega ^ { - 1 } \chi _ { \epsilon } ( r ) \begin{cases} \ \cosh \omega t & \text{if} \ \ \epsilon = 1 \\ \ \cos \omega t & \text{if} \ \ \epsilon = - 1 \end{cases} \\.. \,. \,. \,. \,. \,. \,. \,. \,. \,. \,. \,. \,. \,. \,. \,. \,. \,. \,. \,. \,. \,. \,. \,. \,. \,. \,. \,. \,. \,. \,. \,. \,. \,. \,. \,. \,. \,. \,. \,. \,. \,. \,. \,. \,. \,. \,. \,. \,. \,. \,. \,. \,. \,. \,. \,. \,. \,. \,. \,. \,. \,. \,. \,. \,. \,. \,. \,.. \,. \,. \,. \,. \,. \,. \,. \,. \,. \,. \,. \,. \,. \,. \,. \,. \,. \,. \,. \,. \,. \,. \,. \,. \,. \,. \,. \,. \,. \,. \,. \,. \,. \,. \,. \,. \,. \,. \,. \,. \,. \,. \,. \,. \,. \,. \,. \,. \,. \,. \,. \,. \,. \,. \,. \,. \,. \,. \,. \,. \,. \,. \,. \,. \,.$$
where we denote by r = | /vector x | the Euclidean norm of /vector x and
$$\chi _ { \epsilon } ( r ) & = \sqrt { 1 - \epsilon \, \omega ^ { 2 } r ^ { 2 } } \,. & ( 4 ) \\ \text{herical coordinates, } \vec { x } \to ( r, \theta _ { 1 }, \theta _ { 2 }, \dots, \theta _ { d - 1 } ), \, \text{defined as [22]}$$
In the associated spherical coordinates, /vector x → ( r, θ 1 , θ 2 , ..., θ d -1 ), defined as [22]
$$\begin{array} {$$
the line elements of these charts take the form
$$d s ^ { 2 } \ & = \ \eta _ { A B } ^ { \epsil$$
where d Ω 2 d -1 = dθ 1 2 + sin 2 θ dθ 1 2 2 + sin 2 θ 1 sin 2 θ dθ 2 3 2 + · · · is the usual line element on the sphere S d -1 [22]. The radial domains of these charts are D r = [0 , 1 /ω ) for the dS spacetimes and D r = [0 , ∞ ) for the AdS ones.
The Dirac theory in curved spacetimes can be built starting with spaces of 2 -dimensional spinors, k ψ , where one can define 2 k + 1 point-independent γ -matrices such that we must take k = d 2 when d is even or k = d +1 2 if d is odd [23, 24]. The Dirac equation for a free fermion of mass m , minimally coupled to the gravity of the background,
$$( i \gamma ^ { \mu } ( x ) \nabla _ { \mu }$$
is defined in local frames, { t, /vector x e ; } , given by the gauge fields (or 'vielbeins') e ˆ α and ˆ , labelled by the local indices e ˆ α ˆ α, ..., µ, .. ˆ , having the same range as the natural ones. The covariant derivatives having the action ∇ µ ψ = ( ∂ µ +Γ spin µ ) ψ depend on the spin connections denoted here as in Ref. [24].
The free Dirac equation on the central charts defined above can be brought in a simpler form by fixing the Cartesian gauge defined by the following 1-forms in Cartesian coordinates [16, 17]
$$\tilde { \omega } ^ { 0 } \ = \ \hat { e } _ {$$
$$\lambda \quad & \lambda ^ { \mu \nu \nu } \quad \Lambda$$
In this gauge the spherical variables of the free Dirac equation can be separated as in the spherical problems of special relativity, in terms of the angular spinors
φ κ, j ( ) ( θ ) defined in Ref.[25]. These depend only on the angular variables θ = ( θ , θ 1 2 , ..., θ d -1 ) and are determined by a set of weights ( j ) of an irreducible representation of the group Spin( d ) (i. e. the universal covering group of the group SO d ( )) and the eigenvalue κ = ±| κ | of an operator which concentrates all the angular operators of the Dirac one [16].
The separation procedure is complicated being different for even or odd values of d [25]. For odd d the particular solution of given energy, E , and positive frequency corresponding to the irreducible representation ( j ) may have the form
$$\psi _ { E, \kappa, ( j ) } ^ { \epsilon }$$
where κ can take positive or negative values. However, if d is even then there are pairs of associated irreducible representations, ( j 1 ) and ( j 2 ), giving the same eigenvalue of the first Casimir operator, among them one takes the first one for positive values of κ and the second one for the negative values, κ = -| κ | . Consequently, the particular solutions read
$$\psi _ {. }$$
It is remarkable that both these types of solutions involve the same type of radial wave functions that depend on E and
$$\begin{array} {$$
$$\kappa = \pm \left ( \frac { d - 1 } { 2 } + l \$$
where l is an auxiliary orbital quantum number related to the representations ( j ) or ( j 1 ) and ( j 2 ) [25]. These radial functions satisfy the system of radial equations
$$\left [ \pm \chi _ { \epsilon } ( r ) \frac { d }$$
that depend only on our function (4).
Thus we see that the free Dirac fields on dS or AdS spacetimes satisfy similar radial equations that can be transformed between themselves by replacing ω → iω . On the other hand, the energy eigenspinors on the AdS spacetime are square integrable corresponding to the discrete energy spectrum [16],
$$E _ { n } = m + \omega \left ( n + \frac { d } { 2 } \right ) \,, \quad n = 0, 1, 2, \dots \, \quad \text{(15)}$$
which, in our opinion, defines the ideal isotropic harmonic oscillator of general relativity. We remind the reader that the free massive scalar field of mass m minimally coupled to the AdS gravity has also equidistant energy levels [15],
$$E _ { n } ^ { s c } = M _ { A d S } + \omega \left ( n + \frac { d } { 2 } \right ) \,, \quad M _ { A d S } = \sqrt { m ^ { 2 } + \frac { d ^ { 2 } } { 4 } \omega ^ { 2 } } \,, \quad \quad ( 1 6 ) \\ \intertext { a l l } \Phi \,.$$
with the same energy quanta but having the ground state energy given by the effective AdS mass M AdS instead of m . This difference is due to the fact that in AdS spacetimes the free Dirac equation is no longer the square root of the Klein-Gordon equation with the same mass. Anyway, both these fields behave as oscillators such that it is natural to say that the corresponding fields on the dS spacetime behave as anti-oscillators.
Apart from this indirect argument, we can show that at least the free Dirac field on the dS spacetimes becomes a genuine anti-oscillator in the nonrelativistic limit. This can be done by changing the central dS chart { t, /vector x } into the de Sitter-Painlev´ one e { t , /vector ′ x } [26, 27] having the time
$$t ^ { \prime } = t + \frac { 1 } { 2 \omega } \ln ( 1 - \omega ^ { 2 } r ^ { 2 } )$$
and the line element
$$d s ^ { 2 } = ( 1 - \omega ^ { 2 } \vec { x } ^ { 2 } ) d t ^ { \prime \, 2 } + 2 \omega \vec { x } \cdot d \vec { x } d t ^ { \prime } - d \vec { x } ^ { 2 } \,.$$
Here we choose the Cartesian gauge defined by the 1-forms
$$\tilde { \omega } ^ { 0 } \ = \ d t ^ { \prime } \,,$$
$$\tilde { \omega } ^ { i } \ = \ d x ^ { i } - \omega x ^ { i } d t ^ { \prime } \,.$$
In this gauge the Dirac equation takes the Hamiltonian form,
$$\left [ - i \gamma ^ { 0 } \gamma ^ { i } \partial _ { i } + \gamma ^ { 0 } m + \mathcal { H } _ { i n t } \right ] \psi = i$$
having the traditional Minkowskian kinetic part and the specific interaction term with the gravitational field of the dS manifold that reads,
$$\mathcal { H } _ { i n t } = - i \omega \left ( x ^ { i } \partial _ { i } + \frac { d } { 2 } \right ) \,. \quad \quad \quad$$
Hereby we can derive the non relativistic limit (in the sense of special relativity) obtaining the Schr¨dinger equation o [ -1 2 m ∆+ H int ] φ = i∂ t ′ φ , of a nonrelativistic massive particle (of mass m ) freely moving on the dS spacetime. Furthermore, we observe that the substitution φ → e -i 2 mω/vector x 2 φ leads to Eq. (1b) of a genuine non-relativistic isotropic anti-oscillator.
In the same chart { t , /vector ′ x } , the example of the scalar field minimally coupled to the dS gravity is less convincing since the non-relativistic limit of the KleinGordon equation,
$$\left [ ( i \partial _ { t ^ { \prime } } - \mathcal { H } _ { i n t } ) ^ { 2 } + \Delta - m ^ { 2 } + \frac { d ^ { 2 } } { 4$$
is a Schr¨dinger equation of the form (1b) but depending on the effective dS o mass,
$$M _ { d S } & = \sqrt { m ^ { 2 } - \frac { d ^ { 2 } } { 4 } \omega ^ { 2 } } \,, & & ( 2 4 )$$
that does not make sense for m ≤ d 2 ω .
In other respects, we must specify that in the AdS geometries there are no charts similar to the de Sitter-Painlev´ one since this e might have a complex time resulted from the transformation (17) with iω instead of ω . Therefore the equation resulted in this case,
$$\left [ - i \gamma ^ { 0 } \gamma ^ { i } \partial _ { i } + \gamma ^ { 0 } m + \omega \left ( x ^ { i } \partial _ { i } + \frac { d } { 2 } \right ) \right ] \psi = i \partial _ { t ^ { \prime } } \psi \quad \quad \quad ( 2 5 ) \\. \quad. \. \. \. \. \. \. \. \. \. \. \. \.$$
remains a mere mathematical problem of academic interest but without a reasonable physical meaning (at least in this conjuncture).
The conclusion is that the crucial argument for defining the Dirac AdS oscillator is its discrete energy spectrum (15). The Dirac field on the dS spacetime can be considered as the corresponding anti-oscillator since these two problems transform into each other by changing ω → iω . Moreover, the dS Dirac antioscillator lays out its nature in the non relativistic limit. The scalar field has similar properties but with the difference that in this case the effective masses M AdS and M dS take over the role of the proper mass m .
Finally, we note that the Dirac oscillators of general relativity we discussed here are completely different from those of special relativity obeying Dirac equations with supplemental terms linear in space coordinates [5, 6]. The argument is that on AdS or dS backgrounds the fermions satisfy free Dirac equations that in the flat limit ( ω → 0) give the free Dirac quantum modes of special relativity, losing thus their oscillator or anti-oscillator properties.
## References
- [1] H. Yukawa, Phys. Rev. 91 , 416 (1953).
- [2] R. P. Feynman, M. Kislinger and F. Ravndal, Phys. Rev. D 3 , 2706 (1971).
- [3] Y. S. Kim and M. E. Noz, Am. J. Phys. 46 , 480 (1978).
- [4] Y. S. Kim and E. P. Wigner, Phys. Rev. A 38 , 1159 (1988).
- [5] D. Itˆ, K. Mori and E. Carrieri, o Nuovo Cimento 51A , 1119 (1967).
- [6] M. Moshinsky and A. Szczepaniak, J. Phys. A 22 , L817 (1989).
- [7] V. Aldaya and J. A. de Azcarraga, J. Math. Phys. 23 , 1297 (1982).
- [8] V. Aldaya, J. Bisquert and J. Navarro-Salas, Phys. Lett. A 156 , 315 (1991).
- [9] V. Aldaya, J. Bisquert, R. Loll and J. Navarro-Salas, J. Math. Phys. 33 , 3087 (1992).
- [10] C. Dullemond and E. van Beveren, Phys. Rev. D 28 , 1028 (1983).
- [11] D. J. Navarro and J. Navarro-Salas, J. Math. Phys. 37 , 6006 (1996).
- [12] I. I. Cot˘ aescu, Int. J. of Mod. Phys. A 12 , 3545 (1997).
- [13] I. I. Cot˘ aescu J. Math. Phys. 39 , 3043 (1998).
- [14] E. M. Barboza Jr. and N. A. Lemos Phys. Rev. D 78 , 023504 (2008).
- [15] I. I. Cot˘ aescu, Phys. Rev. D 60 , 107504 (1999)
- [16] I. I. Cot˘ aescu, Int. J. Mod. Phys. A 19 , 2117 (2004).
- [17] I. I. Cot˘ aescu, Rom. Journ. Phys. 50 , 19 (2005).
- [18] I. I. Cot˘ aescu, Mod. Phys. Lett. A 13 , 2923 (1998).
- [19] I. I. Cot˘ aescu, Mod. Phys. Lett. A 13 , 2991 (1998).
- [20] I. I. Cot˘ aescu, Phys. Rev. D 60 , 124006 (1999).
- [21] I. I. Cot˘ aescu, GRG 43 , 1639 (2011).
- [22] M. E. Taylor, Partial Differential Equations (Springer Verlag, New York 1996).
- [23] H. B. Lawson, Jr. and M.-L. Michelsohn, Spin Geometry (Princeton Univ. Press, 1989).
- [24] I. I. Cot˘ aescu and M. Visinescu, Symmetries and supersymmetries of the Dirac operators in curved spacetimes in Progress in General Relativity and Quantum Cosmology Research (Nova Science N.Y. 2007) pp.109-166; arXiv:hep-th/0411016.
- [25] X.-Y. Gu, Z.-Q. Ma and S.-H. Dong, Int. J. Mod. Phys. E 11 , 335 (2002); physics/0209039.
- [26] R. Gautreau, Phys. Rev. D 27 764 (1983).
- [27] M. K. Parikh, Physics Letters B 546 189 (2002); arXiv:hep-th/0204107v3. | null | [
"Ion I. Cotaescu"
] | 2014-08-03T07:50:55+00:00 | 2014-08-11T11:10:51+00:00 | [
"gr-qc",
"quant-ph"
] | On anti-de Sitter oscillators and de Sitter anti-oscillators | We revisit the principal arguments for interpreting the free quantum fields
on anti-de Sitter or de Sitter spacetimes of any dimensions as oscillators or
respectively anti-oscillators. In addition, we point out that there exists a
chart on the de Sitter background where the free Dirac field becomes a genuine
anti-oscillator in the non-relativistic limit in the sense of special
relativity. |
1408.0470v1 | ## ON BOUNDARY BEHAVIOR OF SPATIAL MAPPINGS
## DENIS KOVTONYUK AND VLADIMIR RYAZANOV
August 5, 2014
## Abstract
We show that homeomorphisms f in R n , n /greaterorequalslant 3 , of finite distortion in the OrliczSobolev classes W 1 ,ϕ loc with a condition on ϕ of the Calderon type and, in particular, in the Sobolev classes W 1 ,p loc for p > n -1 are the so-called lower Q -homeomorphisms, Q x ( ) = K 1 n -1 I ( x, f ) , where K x,f I ( ) is its inner dilatation. The statement is valid also for all finitely bi-Lipschitz mappings that a far-reaching extension of the well-known classes of isometric and quasiisometric mappings. This makes possible to apply our theory of the boundary behavior of the lower Q -homeomorphisms to all given classes.
2010 Mathematics Subject Classification: Primary 30C85, 30D40, 31A15, 31A20, 31A25, 31B25. Secondary 37E30.
## 1 Introduction
The problem of the boundary behavior is one of the central topics of the theory of quasiconformal mappings and their generalizations. At present mappings with finite distortion are studied, see many references in the monographs [12] and [30]. In this case, as it was earlier, the main geometric approach in the modern mapping theory is the method of moduli, see, e.g., the monographs [12], [30], [35], [43], [52], [53] and [55].
It is well-known that the concept of moduli with weights essentially due to Andreian Cazacu, see, e.g., [1]-[3], see also recent works [6]-[8] of her learner. At the present paper we give new modulus estimates for space mappings that essentially improve the corresponding estimates first obtained in the paper [23].
Here we apply our theory of the so-called lower Q -homeomorphisms first introduced in the paper [20], see also the monograph [30], that was motivated by the ring definition of quasiconformal mappings of Gehring, see [10]. The theory of lower Q -homeomorphisms has already found interesting applications to the theory of the Beltrami equations in the plane and to the theory of mappings of the classes of Sobolev and Orlich-Sobolev in the space, see, e.g., [17], [18], [23], [24], [25], [30] and [45].
Following Orlicz, see, e.g., paper [36], see also monograph [58], given a convex increasing function ϕ : R + → R + , ϕ (0) = 0 , denote by L ϕ the space of all functions f : D → R such that
$$\int _ { D } \varphi \left ( \frac { | f ( x ) | } { \lambda } \right ) \, d m ( x ) \, < \, \infty$$
for some λ > 0 where dm x ( ) corresponds to the Lebesgue measure in D . L ϕ is called the Orlicz space . In other words, L ϕ is the cone over the class of all functions g : D → R such that
$$\int _ { D } \varphi \left ( | g ( x ) | \right ) \, d m ( x ) \ < \ \infty$$
which is also called the Orlicz class , see [4].
The Orlicz-Sobolev class W 1 ,ϕ ( D ) is the class of all functions f ∈ L 1 ( D ) with the first distributional derivatives whose gradient ∇ f belongs to the Orlicz class in D f . ∈ W 1 ,ϕ loc ( D ) if f ∈ W 1 ,ϕ ( D ∗ ) for every domain D ∗ with a compact closure in D . Note that by definition W 1 ,ϕ loc ⊆ W 1 1 , loc . As usual, we write f ∈ W 1 ,p loc if ϕ t ( ) = t p , p /greaterorequalslant 1 . Later on, we also write f ∈ W 1 ,ϕ loc for a locally integrable vector-function f = ( f , . . . , f 1 m ) of n real variables x , . . . , x 1 n if f i ∈ W 1 1 , loc and
$$\int _ { D } \varphi \left ( | \nabla f ( x ) | \right ) \, d m ( x ) \, < \, \infty$$
where |∇ f ( x ) | = √ ∑ ( i,j ∂f i ∂x j ) 2 . Note that in this paper we use the notation W 1 ,ϕ loc for more general functions ϕ than in those classic Orlicz classes often giving up
the conditions on convexity and normalization of ϕ . Note also that the OrliczSobolev classes are intensively studied in various aspects at the moment, see, e.g., [24] and references therein.
In this connection, recall definitions which are relative to Sobolev's classes. Given an open set U in R n , n ≥ 2 , C ∞ 0 ( U ) denotes the collection of all functions ψ : U → R with compact support having continuous partial derivatives of any order. Now, let u and v : U → R be locally integrable functions. The function v is called the distributional (generalized) derivative u x i of u in the variable x i , i = 1 2 , , . . . , n , x = ( x , x , . . . , x 1 2 n ) , if
$$\int u \, \psi _ { x _ { i } } \, d m ( x ) = - \int v \, \psi \, d m ( x ) \quad \forall \, \psi \in C _ { 0 } ^ { \infty } ( U ) \.$$
u ∈ W 1 1 , loc if u x i exist for all i = 1 2 , , . . . , n . These concepts were introduced by Sobolev in R n , n /greaterorequalslant 2 , see [51], and at present it is developed under wider settings by many authors, see, e.g., [42] and further references in [24].
Recall also the following topological notion. A domain D ⊂ R n , n /greaterorequalslant 2 , is said to be locally connected at a point x 0 ∈ ∂D if, for every neighborhood U of the point x 0 , there is a neighborhood V ⊆ U of x 0 such that V ∩ D is connected. Note that every Jordan domain D in R n is locally connected at each point of ∂D , see, e.g., [57], p. 66.
Following [19] and [20], see also [30] and [44], we say that ∂D is weakly flat at a point x 0 ∈ ∂D if, for every neighborhood U of the point x 0 and every number P > 0 , there is a neighborhood V ⊂ U of x 0 such that
$$M ( \Delta ( E, F, D ) ) \, \geqslant P$$
for all continua E and F in D intersecting ∂U and ∂V . Here M is the modulus, see (3.5), and ∆( E,F,D ) the family of all paths γ : [ a, b ] → R n connecting E and F in D , i.e., γ a ( ) ∈ E γ b , ( ) ∈ F and γ t ( ) ∈ D for all t ∈ ( a, b ) . We say that the boundary ∂D is weakly flat if it is weakly flat at every point in ∂D .
We also say that a point x 0 ∈ ∂D is strongly accessible if, for every neighborhood U of the point x 0 , there exist a compactum E in D , a neighborhood V ⊂ U of x 0 and a number δ > 0 such that
$$M ( \Delta ( E, F, D ) ) \ \geqslant \ \delta$$
for all continua F in D intersecting ∂U and ∂V . We say that the boundary ∂D is strongly accessible if every point x 0 ∈ ∂D is strongly accessible.
It is easy to see that if a domain D in R n is weakly flat at a point x 0 ∈ ∂D , then the point x 0 is strongly accessible from D . Moreover, it was proved by us that if a domain D in R n is weakly flat at a point x 0 ∈ ∂D , then D is locally connected at x 0 , see, e.g., Lemma 5.1 in [20] or Lemma 3.15 in [30].
The notions of strong accessibility and weak flatness at boundary points of a domain in R n defined in [19], see also [20], are localizations and generalizations of the corresponding notions introduced in [28]-[29], cf. with properties P 1 and P 2 by V¨ ais¨l¨ a a in [53] and also with the quasiconformal accessibility and the quasiconformal flatness by N¨kki in [34]. a Many theorems on a homeomorphic extension to the boundary of quasiconformal mappings and their generalizations are valid under the condition of weak flatness of boundaries. The condition of strong accessibility plays a similar role for a continuous extension of the mappings to the boundary.
In the mapping theory and in the theory of differential equations, it is often applied the so-called Lipschitz domains whose boundaries are locally quasiconformal. Recall first that a map ϕ : X → Y between metric spaces X and Y is said to be Lipschitz provided dist( ϕ x ( 1 ) , ϕ ( x 2 )) /lessorequalslant M · dist( x , x 1 2 ) for some M < ∞ and for all x 1 and x 2 ∈ X . The map ϕ is called bi-Lipschitz if, in addition, M ∗ dist( x , x 1 2 ) /lessorequalslant dist( ϕ x ( 1 ) , ϕ ( x 2 )) for some M > ∗ 0 and for all x 1 and x 2 ∈ X. Later on, X and Y are subsets of R n with the Euclidean distance.
It is said that a bounded domain D in R n is Lipschitz if every point x 0 ∈ ∂D has a neighborhood U that can be mapped by a bi-Lipschitz homeomorphism ϕ onto the unit ball B n ⊂ R n in such a way that ϕ ∂D ( ∩ U ) is the intersection of B n with the a coordinate hyperplane and f ( x 0 ) = 0 , see, e.g., [35]. Note that a bi-Lipschitz homeomorphism is quasiconformal and the modulus is a quasiinvariant under such mappings. Hence the Lipschitz domains have weakly flat boundaries. In particular, smooth and convex bounded domains are so.
## 2 On BMO, VMO and FMO functions
The BMO space was introduced by John and Nirenberg in [16] and soon became one of the main concepts in harmonic analysis, complex analysis, partial differential equations and related areas, see, e.g., [13] and [40].
Let D be a domain in R n , n /greaterorequalslant 1 . Recall that a real valued function ϕ ∈ L 1 loc ( D ) is said to be of bounded mean oscillation in D , abbr. ϕ ∈ BMO( D ) or simply ϕ ∈ BMO , if
$$\| \varphi \| _ { * } = \sup _ { B \subset D } \quad \int _ { B } | \varphi ( z ) - \varphi _ { B } | \, d m ( z ) < \infty$$
where the supremum is taken over all balls B in D and
$$\varphi _ { B } = \underset { B } { \int } \varphi ( z ) \, d m ( z ) = \frac { 1 } { | B | } \underset { B } { \int } \varphi ( z ) \, d m ( z )$$
is the mean value of the function ϕ over B . Note that L ∞ ( D ) ⊂ BMO( D ) ⊂ L p loc ( D ) for all 1 /lessorequalslant p < ∞ , see, e.g., [40].
A function ϕ in BMO is said to have vanishing mean oscillation , abbr. ϕ ∈ VMO , if the supremum in (2.1) taken over all balls B in D with | B < ε | converges to 0 as ε → 0 . VMO has been introduced by Sarason in [50]. There are a number of papers devoted to the study of partial differential equations with coefficients of the class VMO, see, e.g., [5], [15], [31], [37] and [39].
Following [14], we say that a function ϕ : D → R has finite mean oscillation at a point z 0 ∈ D , write ϕ ∈ FMO( x 0 ) , if
$$\varliminf _ { \varepsilon \to 0 } \ \int _ { B ( z _ { 0 }, \varepsilon ) } | \varphi ( z ) - \tilde { \varphi } _ { \varepsilon } ( z _ { 0 } ) | \, d m ( z ) < \infty$$
where is the mean value of the function ϕ z ( ) over the ball B z , ε ( 0 ) . Condition (2.3) includes the assumption that ϕ is integrable in some neighborhood of the point z 0 . By the triangle inequality, we obtain the following statement.
$$\tilde { \varphi } _ { \varepsilon } ( z _ { 0 } ) = & \int _ { B ( z _ { 0 }, \varepsilon ) } \varphi ( z ) \, d m ( z ) \\ \intertext { two of the function } \tilde { \Lambda } \, \text{or the ball } R ( \tilde { \Lambda } \, \varepsilon \, \rangle \, \text{Condition } R \, \rangle$$
Proposition 2.1. If for some collection of numbers ϕ ε ∈ R , ε ∈ (0 , ε 0 ] ,
$$\varliminf _ { \varepsilon \to 0 } \, \int _ { B ( z _ { 0 }, \varepsilon ) } | \varphi ( z ) - \varphi _ { \varepsilon } | \, d m ( z ) < \infty \,, \\ \text{of finite mean as stillation at $z$} _ { \varepsilon$}$$
then ϕ is of finite mean oscillation at z 0 .
Choosing in Proposition 2.1 ϕ ε ≡ 0 , ε ∈ (0 , ε 0 ] , we have the following.
Corollary 2.1. If for a point z 0 ∈ D
$$\dot { \Phi } _ { \substack { \varepsilon \to 0 \\ \lim _ { \varepsilon \to 0 } } } \int _ { B ( z _ { 0 }, \varepsilon ) } ^ { \Phi } | \varphi ( z ) | \, d m ( z ) < \infty \,, \\ \intertext { i t e m e a n \ o s c i l l a t i o n \ a t \ z _ { \Lambda } }$$
then ϕ has finite mean oscillation at z 0 .
Recall that a point z 0 ∈ D is called a Lebesgue point of a function ϕ : D → R if ϕ is integrable in a neighborhood of z 0 and
$$\bar { \lim } _ { \varepsilon \to 0 } \, & \, \bar { \int } _ { B ( z _ { 0 }, \varepsilon ) } | \varphi ( z ) - \varphi ( z _ { 0 } ) | \, d m ( z ) = 0 \,. \\ m \, \text{ that almost every point in } D \text{ is a Elecose point for every function}$$
It is known that almost every point in D is a Lebesgue point for every function ϕ ∈ L 1 ( D ) . Thus, we have the following conclusion.
Corollary 2.2. Every function ϕ : D → R which is locally integrable, has a finite mean oscillation at almost every point in D .
Remark 2.1. Note that the function ϕ z ( ) = log(1 / z | | ) belongs to BMO in the unit disk ∆ , see, e.g., [40], p. 5, and hence also to FMO. However, ˜ (0) ϕ ε → ∞ as ε → 0 , showing that the condition (2.6) is only sufficient but not necessary for a function ϕ to be of finite mean oscillation at z 0 .
Clearly that BMO ⊂ FMO ⊂ L 1 loc but FMO is not a subset of L p loc for any p > 1 , see examples in Section 11.2 of the monograph [30], in comparison with BMO loc ⊂ L p loc for all p ∈ [1 , ∞ ) . Thus, FMO is essentially wider than BMO loc . The following lemma is key, see Corollary 2.3 in [14] and Corollary 6.3 in [30].
Lemma 2.1. Let D be a domain in R n , n /greaterorequalslant 2 , x 0 ∈ D , and let ϕ : D → R be a non-negative function of the class FMO( x 0 ) . Then
$$\dots \cdots \cdots \cdots _ { \mathcal { S } } \dots \cdots \cdots _ { \mathcal { S } } \dots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \\ \int _ { \varepsilon < | x - x _ { 0 } | < \varepsilon _ { 0 } } } \frac { \varphi ( x ) \, d m ( x ) } { \left ( | x - x _ { 0 } | \log \frac { 1 } { | x - x _ { 0 } | } \right ) ^ { n } } = O \left ( \log \log \frac { 1 } { \varepsilon } \right ) \quad a s \quad \varepsilon \to 0 \quad \quad ( 2. 8 ) \\ \text{for some } \varepsilon _ { 0 } \in ( 0, \delta _ { 0 } ) \text{ where } \delta _ { 0 } = \min ( e ^ { - e }, d _ { 0 } ), \, d _ { 0 } = \sup _ { \sim \sim 0 } | x - x _ { 0 } |.$$
for some ε 0 ∈ (0 , δ 0 ) where δ 0 = min( e -e , d 0 ) , d 0 = sup x ∈ D | x -x 0 | .
## 3 On lower Q -homeomorphisms
Let ω be an open set in R k , k = 1 , . . . , n -1 . Recall that a (continuous) mapping S : ω → R n is called a k -dimensional surface S in R n . The number of preimages
$$N ( S, y ) = \text{card} \, S ^ { - 1 } ( y ) = \text{card} \, \{ x \in \omega \, \colon S ( x ) = y \}, \ y \in \mathbb { R } ^ { n } \quad \ \ ( 3. 1 )$$
is said to be a multiplicity function of the surface S . It is known that the multiplicity function is lower semicontinuous, i.e.,
$$N ( S, y ) \geqslant \liminf _ { m \to \infty } \, N ( S, y _ { m } )$$
for every sequence y m ∈ R n , m = 1 2 , , . . . , such that y m → y ∈ R n as m →∞ , see, e.g., [38], p. 160. Thus, the function N S,y ( ) is Borel measurable and hence measurable with respect to every Hausdorff measure H k , see, e.g., [49], p. 52.
Recall that a k -dimensional Hausdorff area in R n (or simply area ) associated with a surface S : ω → R n is given by
$$\mathcal { A } _ { S } ( B ) = \mathcal { A } _ { S } ^ { k } ( B ) \coloneqq \int _ { B } N ( S, y ) \, d H ^ { k } y$$
for every Borel set B ⊆ R n and, more generally, for an arbitrary set that is measurable with respect to H k in R n , cf. 3.2.1 in [9] and 9.2 in [30].
If /rho1 : R n → R + is a Borel function, then its integral over S is defined by the equality
$$\int _ { \substack { \varrho \, d \mathcal { A } \\ S } } \varrho \, d \mathcal { A } \coloneqq \int _ { \mathbb { R } ^ { n } } \varrho ( y ) \, N ( S, y ) \, d H ^ { k } y \,. \quad \quad \quad$$
Given a family Γ of k -dimensional surfaces S , a Borel function /rho1 : R n → [0 , ∞ ] is called admissible for Γ , abbr. /rho1 ∈ admΓ , if
$$\int _ { S } \varrho ^ { k } \, d \mathcal { A } \geqslant 1$$
for every S ∈ Γ . The modulus of Γ is the quantity
$$M ( \Gamma ) = \inf _ { \varrho \in \text{adm} \, \Gamma } \int _ { \mathbb { R } ^ { n } } \varrho ^ { n } ( x ) \, d m ( x ) \,.$$
We also say that a Lebesgue measurable function /rho1 : R n → [0 , ∞ ] is extensively admissible for a family Γ of k -dimensional surfaces S in R n , abbr. /rho1 ∈ ext adm Γ , if a subfamily of all surfaces S in Γ , for which (3.4) fails, has the modulus zero.
Given domains D and D ′ in R n = R n ∪ {∞} , n /greaterorequalslant 2 , x 0 ∈ D \ {∞} , and a measurable function Q : R n → (0 , ∞ ) , we say that a homeomorphism f : D → D ′ is a lower Q -homeomorphism at the point x 0 if
$$M ( f \Sigma _ { \varepsilon } ) \geq \inf _ { \varrho \in \text{ext} \, \text{adm} \, \Sigma _ { \varepsilon } } \int _ { D \cap R _ { \varepsilon } } \, \frac { \varrho ^ { n } ( x ) } { Q ( x ) } \, d m ( x ) \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \ \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \end{cases}$$
for every ring R ε = { x ∈ R n : ε < | x -x 0 | < ε 0 } , ε ∈ (0 , ε 0 ) , ε 0 ∈ (0 , d 0 ) , where d 0 = sup x ∈ D | x -x 0 | , and Σ ε denotes the family of all intersections of the spheres S x , r ( 0 ) = { x ∈ R n : | x -x 0 | = r } , r ∈ ( ε, ε 0 ) , with D .
The notion of lower Q -homeomorphisms in the standard way can be extended to ∞ through inversions. We also say that a homeomorphism f : D → R n is a lower Q -homeomorphism on ∂D if f is a lower Q -homeomorphism at every point x 0 ∈ ∂D .
We proved the following significant statements on lower Q -homeomorphisms, see Theorem 10.1 (Lemma 6.1) in [20] or Theorem 9.8 (Lemma 9.4) in [30].
Proposition 3.1. Let D and D ′ be bounded domains in R n , n /greaterorequalslant 2 , Q : D → (0 , ∞ ) a measurable function and f : D → D ′ a lower Q -homeomorphism on ∂D . Suppose that the domain D is locally connected on ∂D and that the domain D ′ has a (strongly accessible) weakly flat boundary. If
$$\int _ { 0 } ^ { \delta ( x _ { 0 } ) } \frac { d r } { | | \, Q | | _ { n - 1 } ( x _ { 0 }, r ) } \ = \ \infty \quad \ \forall \ x _ { 0 } \in \partial D \quad \ \cdots \quad \cdots \quad \cdots \quad \cdots \quad \cdots \quad \cdots \quad \cdots \quad \cdots \quad \cdots \quad \cdots \quad \cdots \quad \cdots \quad \cdots \quad \cdots \quad \cdots \quad \cdots \quad \cdots \quad \cdots \quad \cdots \quad \cdots \quad \cdots \quad \cdots \quad \cdots \quad \cdots \quad \cdots \quad \cdots \quad \cdots \quad \cdots \quad \cdots \quad \cdots \quad \cdots \quad \cdots \quad \cdots \quad \cdots \quad \cdots \quad \cdots \quad \cdots \quad \cdots \quad \cdots \quad \cdots \quad \cdots \ \quad \cdots \quad \cdots \quad \cdots \quad \cdots \quad \cdots \quad \cdots \quad \cdots \quad \cdots \quad \cdots \quad \cdots \quad \cdots \quad \cdots \quad \cdots \quad \cdots \quad \cdots \quad \cdots \quad \cdots \quad \cdots \quad \cdots \quad \cdots \quad \cdots \quad \cdots \quad \cdots \quad \cdots \quad \cdots \quad \cdots \quad \cdots \quad \cdots \quad \cdots \quad \cdots \quad \cdots \quad \cdots \quad \cdots \quad \cdots \quad \cdots \quad \cdots \quad \cdots \quad \cdots \quad \cdots \quad \cdclots \quad \cdots \quad \cdots \quad \cdots \quad \cdots \quad \cdots \quad \cdots \quad \cdots \quad \cdots \quad \cdots \quad \cdots \quad \cdots \quad \cdots \quad \cdots \quad \cdots \quad \cdots \quad \cdots \quad \cdots \quad \cdots \quad \cdots \quad \cdots \quad \cdots \quad \cdots \quad \cdots \quad \cdots \quad \cdots \quad \cdots \quad \cdots \quad \cdots \quad \cdots \quad \cdots \quad \cdots \quad \cdots \quad \cdots \quad \cdots \quad \cdots \quad \cdots \quad \cdots \quad \cdots \quad \cdots \quad \ \cdots \quad \cdots \quad \cdots \quad \cdots \quad \cdots \quad \cdots \quad \cdots \quad \cdots \quad \cdots \quad \cdots \quad \cdots \quad \cdots \quad \cdots \quad \cdots \quad \cdots \quad \cdots \quad \cdots \quad \cdots \quad \cdots \quad \cdots \quad \cdots \quad \cdots \quad \cdots \quad \cdots \quad \cdots \quad \cdots \quad \cdots \quad \cdots \quad \cdots \quad \cdots \quad \cdots \quad \cdots \quad \cdots \quad \cdots \quad \cdots \quad \cdots \quad \cdots \quad \cdots \quad \cdots \quad \ \cdots\quad \cdots \quad \cdots \quad \cdots \quad \cdots \quad \cdots \quad \cdots \quad \cdots \quad \cdots \quad \cdots \quad \cdots \quad \cdots \quad \cdots \quad \cdots \quad \cdots \quad \cdots \quad \cdots \quad \cdots \quad \cdots \quad \cdots \quad \cdots \quad \cdots \quad \cdots \quad \cdots \quad \cdots \quad \cdots \quad \cdots \quad \cdots \quad \cdots \quad \cdots \quad \cdots \quad \cdots \quad \cdots \quad \cdots \quad \cdots \quad \cdots \quad \cdots \quad \cdots \quad \cdots \quad \cdots \quad \cdots\quad \cdots \quad \cdots \quad \cdots \quad \cdots \quad \cdots \quad \cdots \quad \cdots \quad \cdots \quad \cdots \quad \cdots \quad \cdots \quad \cdots \quad \cdots \quad \cdots \quad \cdots \quad \cdots \quad \cdots \quad \cdots \quad \cdots \quad \cdots \quad \cdots \quad \cdots \quad \cdots \quad \cdots \quad \cdots \quad \cdots \quad \cdots \quad \cdots \quad \cdots \quad \cdots \quad \cdots \quad \cdots \quad \cdots \quad \cdots \quad \cdots \quad \cdots \quad \cdots \quad \cdots \quad \cdots \ \cdots \quad \cdots \quad \cdots \quad \cdots \quad \cdots \quad \cdots \quad \cdots \quad \cdots \quad \cdots \quad \cdots \quad \cdots \quad \cdots \quad \cdots \quad \cdots \quad \cdots \quad \cdots \quad \cdots \quad \cdots \quad \cdots \quad \cdots \quad \cdots \quad \cdots \quad \cdots \quad \cdots \quad \cdots \quad \cdots \quad \cdots \quad \cdots \quad \cdots \quad \cdots \quad \cdots \quad \cdots \quad \cdots \quad \cdots \quad \cdots \quad \cdots \quad \cdots \quad \cdots \quad \cdots \quad \cdots
\quad \quad \quad$$
for some δ x ( 0 ) ∈ (0 , d ( x 0 )) where d x ( 0 ) = sup x ∈ D | x -x 0 | and
$$| | Q | | _ { n - 1 } ( x _ { 0 }, r ) = \left ( \int _ { D \cap S ( x _ { 0 }, r ) } Q ^ { n - 1 } ( x ) \, d \mathcal { A } \right ) ^ { \frac { 1 } { n - 1 } } \,, \\ \intertext { a n b e x t e n d e t o a ( c o n t i n u o u s ) \ h o m e o m o r p h i c \ m a p p i n g } \overline { f } \, \colon \overline { I }$$
then f can be extended to a (continuous) homeomorphic mapping f : D → D ′ .
## 4 A connection with the Orlicz-Sobolev classes
Given a mapping f : D → R n with partial derivatives a.e., recall that f ′ ( x ) denotes the Jacobian matrix of f at x ∈ D if it exists, J x ( ) = J x, f ( ) = det f ′ ( x ) is the Jacobian of f at x , and ‖ f ′ ( x ) ‖ is the operator norm of f ′ ( x ) , i.e.,
$$\| f ^ { \prime } ( x ) \| = \max \{ | f ^ { \prime } ( x ) h | \, \colon h \in \mathbb { R } ^ { n }, | h | = 1 \}.$$
We also let
$$l ( f ^ { \prime } ( x ) ) = \min \{ | f ^ { \prime } ( x ) h | \, \colon h \in \mathbb { R } ^ { n }, | h | = 1 \}.$$
The outer dilatation of f at x is defined by
/negationslash the inner dilatation of f at x by
$$K _ { O } ( x ) = K _ { O } ( x, f ) = \begin{cases} \begin{array} { c c } \| f ^ { \prime } ( x ) \| ^ { n } \\ \| J ( x, f ) | \end{array} & \text{if $J(x,f)\neq 0$,} \\ 1 & \text{if $f^{\prime}(x)=0$,} \\ \infty & \text{otherwise,} \end{cases} \\ \text{inner dilation of $f$ at $x$ by} \\ & \left ( \begin{array} { c c } \frac { | J ( x, f ) | } { \infty, f ) | } & \text{if $J(x-f)\neq 0$} \end{array} \end{cases}$$
/negationslash
Note that, see, e.g., Section 1.2.1 in [41],
$$K _ { I } ( x ) = K _ { I } ( x, f ) = \begin{cases} \frac { | J ( x, f ) | } { l ( f ^ { \prime } ( x ) ) ^ { n } } & \text{if } J ( x, f ) \neq 0, \\ 1 & \text{if } f ^ { \prime } ( x ) = 0, \\ \infty & \text{otherwise}, \end{cases} \\ \text{e that, see, e.g., Section 1.2.1 in [41], \quad \begin{matrix} 4. 4 \\ - \tilde { \nu } \ \ \sim \ \sim \ \sim \ \sim \ \sim \ \sim \ \sim \ \sim \ \sim \ \sim \ \sim \ \sim \ \sim \ \sim \ \sim \ \sim \ \sim \ \sim \ \sim \ \sim \ \sim \ \sim \ \sim \ \sim \ \sim \ \sim \ \sim \ \sim \ \sim \ \sim \ \sim \ \sim \ \sim \ \sim \ \sim \ \sim \ \sim \ \sim \ \sim \ \sim \ \sim \ \sim \ \sim \ \sim \ \sim \ \sim \ \sim \ \sim \ \sim \ \sim \ \sim \ \sim \ \sim \ \sim \ \sim \ \sim \ \sim \ \sim \ \sim \ \sim \ \sim \ \sim \ \sim \ \sim \ \sim \ \sim \ \sim \, \end{matrix}$$
$$K _ { O } ( x, f ) \leq K _ { I } ^ { n - 1 } ( x, f ) \quad \text{ and } \quad K _ { I } ( x, f ) \leq K _ { O } ^ { n - 1 } ( x, f ) \, \quad \text{ (4.5)}$$
in particular, K O ( x, f ) < ∞ a.e. if and only if K x,f I ( ) < ∞ a.e. The latter is equivalent to the condition that a.e. either det f ′ ( x ) > 0 or f ′ ( x ) = 0 .
Now, recall that a homeomorphism f between domains D and D ′ in R n , n /greaterorequalslant 2 , is called of finite distortion if f ∈ W 1 1 , loc and
$$\| f ^ { \prime } ( x ) \| ^ { n } \leqslant K ( x ) \cdot J _ { f } ( x )$$
with some a.e. finite function K . The term is due to Tadeusz Iwaniec. In other words, (4.6) just means that dilatations K O ( x, f ) and K x,f I ( ) are finite a.e.
In view of (4.5), the next statement says on a stronger modulus estimate than the obtained in [23], Theorem 4.1, in terms of the outer dilatation K O ( x, f ) . It is key for deriving consequences from our theory of lower Q -homeomorphisms.
Theorem 4.1. Let D and D ′ be domains in R n , n /greaterorequalslant 3 , and let ϕ : R + → R + be a nondecreasing function such that, for some t ∗ ∈ R + ,
$$\underset { t _ { * } } { \overset { \infty } { \int } } \left [ \frac { t } { \varphi ( t ) } \right ] ^ { \frac { 1 } { n - 2 } } d t < \infty \,.$$
Then each homeomorphism f : D → D ′ of finite distortion in the class W 1 ,ϕ loc is a lower Q -homeomorphism at every point x 0 ∈ D with Q x ( ) = [ K x,f I ( )] 1 n -1 .
/negationslash
Proof. Let B be a (Borel) set of all points x ∈ D where f has a total differential f ′ ( x ) and J f ( x ) = 0 . Then, applying Kirszbraun's theorem and uniqueness of approximate differential, see, e.g., 2.10.43 and 3.1.2 in [9], we see that B is the union of a countable collection of Borel sets B l , l = 1 2 , , . . . , such that f l = f | B l are bi-Lipschitz homeomorphisms, see, e.g., 3.2.2 as well as 3.1.4 and 3.1.8 in [9]. With no loss of generality, we may assume that the B l are mutually disjoint. Denote also by B ∗ the rest of all points x ∈ D where f has the total differential but with f ′ ( x ) = 0 .
By the construction the set B 0 := D \ ( B ⋃ B ∗ ) has Lebesgue measure zero, see Theorem 1 in [24]. Hence A S ( B 0 ) = 0 for a.e. hypersurface S in R n and, in particular, for a.e. sphere S r := S x , r ( 0 ) centered at a prescribed point x 0 ∈ D , see Theorem 2.11 in [21] or Theorem 9.1 in [30]. Thus, by Corollary 4 in [24] A S ∗ r ( f ( B 0 )) = 0 as well as A S ∗ r ( f ( B ∗ )) = 0 for a.e. S r where S ∗ r = f ( S r ) .
Let Γ be the family of all intersections of the spheres S r , r ∈ ( ε, ε 0 ) , ε 0 < d 0 = sup x ∈ D | x -x 0 | , with the domain D . Given /rho1 ∗ ∈ adm f (Γ) such that /rho1 ∗ ≡ 0 outside of f ( D ) , set /rho1 ≡ 0 outside of D and on D \ B and, moreover,
$$\varrho ( x ) \coloneqq \Lambda ( x ) \cdot \varrho _ { * } ( f ( x ) ) \quad \text{ for } x \in B$$
where
$$\text{where} \quad & \Lambda ( x ) \ \coloneqq \ \left [ \ J _ { f } ( x ) \cdot K _ { I } ^ { \frac { 1 } { n - 1 } } ( x, f ) \ \right ] ^ { \frac { 1 } { n } } \ = \ \left [ \ \frac { \det f ^ { \prime } ( x ) } { l ( f ^ { \prime } ( x ) ) } \ \right ] ^ { \frac { 1 } { n - 1 } } \ = \\ & \ = \ [ \ \lambda _ { 2 } \cdot \dots \cdot \lambda _ { n } \ ] ^ { \frac { 1 } { n - 1 } } \ \geq \ [ \ J _ { n - 1 } ( x ) \ ] ^ { \frac { 1 } { n - 1 } } \quad \text{ for a.e. } x \in B \ ;$$
here as usual λ n /greaterorequalslant . . . /greaterorequalslant λ 1 are principal dilatation coefficients of f ′ ( x ) , see, e.g., Section I.4.1 in [41], and J n -1 ( x ) is the ( n -1) -dimensional Jacobian of f | S r at x where r = | x -x 0 | , see Section 3.2.1 in [9].
Arguing piecewise on B l , l = 1 2 , , . . . , and taking into account Kirszbraun's theorem, by Theorem 3.2.5 on the change of variables in [9], we have that
$$\underset { S _ { r } } { \int } \varrho ^ { n - 1 } \, d \mathcal { A } \geqslant \underset { S _ { * } ^ { r } } { \overset { \lambda } { \int } } \varrho ^ { n - 1 } _ { * } \, d \mathcal { A } \geqslant 1$$
for a.e. S r and, thus, /rho1 ∈ ext adm Γ .
The change of variables on each B l , l = 1 2 , , . . . , see again Theorem 3.2.5 in [9], and countable additivity of integrals give also the estimate
$$\underset { D } { \omega } \, \infty \, \infty \, \infty \, \infty \, \infty \, \infty \, \infty \, \infty \, \infty \, \infty \, \infty \, \infty \, \infty \, \infty \, \infty \, \infty \, \infty \, \infty \, \infty \, \infty \, \infty \, \infty \, \infty \, \infty \, \infty \, \infty \, \infty \, \infty \, \infty \, \infty \, \infty \, \infty \, \infty \, \infty \, \infty \, \infty \, \infty \, \infty \, \infty \, \infty \, \incolon \\ \underset { D } { \int } \, \frac { \varrho ^ { n } ( x ) } { K _ { I } ^ { \frac { 1 } { n - 1 } } ( x ) } \, d m ( x ) \leqslant \underset { f ( D ) } { \int } \, \varrho _ { * } ^ { n } ( x ) \, d m ( x ) \, \\ \text{if is complete. } \, \square$$
and the proof is complete.
Corollary 4.1. Each homeomorphism f with finite distortion in R n , n /greaterorequalslant 3 , of the class W 1 ,p loc for p > n -1 is a lower Q -homeomorphism at every point x 0 ∈ D with Q = K 1 n -1 I .
## 5 Boundary behavior of Orlicz-Sobolev classes
In this section we assume that ϕ : R + → R + is a nondecreasing function such that, for some t ∗ ∈ R + ,
$$\mathbb { R } ^ { T }, \quad & \underset { t _ { * } } { \overset { \infty } { \int } } \left [ \frac { t } { \varphi ( t ) } \right ] ^ { \frac { 1 } { n - 2 } } d t < \infty \,.$$
The continuous extension to the boundary of the inverse mappings has a simpler criterion than for the direct mappings. Hence we start from the former. Namely, in view of Theorem 4.1, we have by Theorem 9.1 in [20] or Theorem 9.6 in [30] the next statement.
Theorem 5.1. Let D and D ′ be bounded domains in R n , n /greaterorequalslant 3 , D be locally connected on ∂D and ∂D ′ be weakly flat. Suppose that f is a homeomorphism of D onto D ′ in a class W 1 ,ϕ loc with condition (5.1) and K I ∈ L 1 ( D ) . Then f -1 can be extended to a continuous mapping of D ′ onto D .
However, as it follows from the example in Proposition 6.3 in [30], see also (4.5), any degree of integrability K I ∈ L q ( D ) , q ∈ [1 , ∞ ) , cannot guarantee the extension by continuity to the boundary of the direct mappings.
Also by Theorem 4.1, we have the following consequence of Proposition 3.1.
Theorem 5.2. Let D and D ′ be bounded domains in R n , n /greaterorequalslant 3 , D be locally connected on ∂D and ∂D ′ be (strongly accessible) weakly flat. Suppose that f : D → D ′ is a homeomorphism of finite distortion in W 1 ,ϕ loc with condition (5.1) such that
$$\int \frac { \delta ( x _ { 0 } ) } { | | K _ { I } | | ^ { \frac { 1 } { n - 1 } } ( x _ { 0 }, r ) } = \infty \quad \forall \ x _ { 0 } \in \partial D$$
for some δ x ( 0 ) ∈ (0 , d ( x 0 )) where d x ( 0 ) = sup x ∈ D | x -x 0 | and
$$| | K _ { I } | | ( x _ { 0 }, r ) = \underset { D \cap S ( x _ { 0 }, r ) } { \int } \, K _ { I } ( x, f ) \ d \mathcal { A } \.$$
Then f can be extended to a (continuous) homeomorphic map f : D → D ′ .
In particular, as a consequence of Theorem 5.2, we obtain the following generalization of the well-known theorems of Gehring-Martio and MartioVuorinen on a homeomorphic extension to the boundary of quasiconformal mappings between the so-called QED domains, see [11] and [32].
Corollary 5.1. Let D and D ′ be bounded domains in R n , n /greaterorequalslant 3 , D be locally connected on ∂D and ∂D ′ be (strongly accessible) weakly flat. Suppose that f : D → D ′ is a homeomorphism of finite distortion in the class W 1 ,p loc , p > n -1 . If (5.2) holds, then f can be extended to a (continuous) homeomorphic map f : D → D ′ .
Lemma 5.1. Let D and D ′ be bounded domains in R n , n /greaterorequalslant 3 , D be locally connected on ∂D and ∂D ′ be (strongly accessible) weakly flat. Suppose that f : D → D ′ is a homeomorphism of finite distortion in W 1 ,ϕ loc with condition (5.1) such that
$$\int _ { D ( x _ { 0 }, \varepsilon, \varepsilon _ { 0 } ) } K _ { I } ( x, f ) \cdot \psi _ { x _ { 0 }, \varepsilon } ^ { n } ( | x - x _ { 0 } | ) \, d m ( x ) = o ( I _ { x _ { 0 } } ^ { n } ( \varepsilon ) ) \text{ as } \varepsilon \rightarrow 0 \, \forall \, x _ { 0 } \in \partial D \text{ (5.3)}$$
where D x , ε, ε ( 0 0 ) = { x ∈ D : ε < | x -x 0 | < ε 0 } for some ε 0 ∈ (0 , δ 0 ) , δ 0 = δ x ( 0 ) = sup x ∈ D | x -x 0 | , and ψ x ,ε 0 ( ) t is a family of non-negative measurable
(by Lebesgue) functions on (0 , ∞ ) such that
$$0 \ < \ I _ { x _ { 0 } } ( \varepsilon ) \ = \ \underset { \varepsilon } { \int } \psi _ { x _ { 0 }, \varepsilon } ( t ) \ d t \ < \ \infty \quad \ \forall \ \varepsilon \in ( 0, \varepsilon _ { 0 } ) \. \quad \ \quad \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \$$
Then f can be extended to a (continuous) homeomorphic map f : D → D ′ .
Proof. Lemma 5.1 is an immediate consequence of Theorems 4.1 and 5.2 taking into account Lemma 3.7 in the work [46], see Lemma 7.4 in the monograph [30], and extending K x,f I ( ) by zero outside of D. ✷
Choosing in Lemma 5.1 ψ t ( ) = 1 ( / t log 1 /t ) and applying Lemma 2.1, we obtain the following result.
Theorem 5.3. Let D and D ′ be bounded domains in R n , n /greaterorequalslant 3 , D be locally connected on ∂D and ∂D ′ be (strongly accessible) weakly flat. Suppose that f : D → D ′ is a homeomorphism in W 1 ,ϕ loc with condition (5.1) such that
$$K _ { I } ( x, f ) \, \leqslant \, Q ( x ) \, \quad \text{ a.e. in } D$$
for a function Q : R n → R n , Q ∈ FMO( x 0 ) for all x 0 ∈ ∂D . Then f can be extended to a (continuous) homeomorphic map f : D → D ′ .
In the following consequences, we assume that K x,f I ( ) is extended by zero outside of D .
Corollary 5.2. In particular, the conclusions of Theorem 5.3 hold if
$$\varliminf _ { \varepsilon \to 0 } \, \int _ { B ( x _ { 0 }, \varepsilon ) } K _ { I } ( x, f ) \ d m ( x ) \ < \ \infty \quad \ \forall \ x _ { 0 } \in \partial D \.$$
Similarly, choosing in Lemma 5.1 the function ψ t ( ) = 1 /t , we come to the following more general statement.
Theorem 5.4. Let D and D ′ be bounded domains in R n , n /greaterorequalslant 3 , D be locally connected on ∂D and ∂D ′ be (strongly accessible) weakly flat. Suppose that f : D → D ′ is a homeomorphism in W 1 ,ϕ loc with condition (5.1) such that
$$\underset { \varepsilon < | x - x _ { 0 } | < \varepsilon _ { 0 } } { \int } \, K _ { I } ( x, f ) \, \frac { d m ( x ) } { | x - x _ { 0 } | ^ { n } } \ = \ o \left ( \left [ \log \frac { \varepsilon _ { 0 } } { \varepsilon } \right ] ^ { n } \right ) \quad \ \forall \ x _ { 0 } \in \partial D \quad \ \ ( 5. 7 )$$
as ε → 0 for some ε 0 ∈ (0 , δ 0 ) where δ 0 = δ x ( 0 ) = sup x ∈ D | x -x 0 | . Then f can be extended to a (continuous) homeomorphic map f : D → D ′ .
Corollary 5.3. The condition (5.7) and the assertion of Theorem 5.4 hold if
$$K _ { I } ( x, f ) \ = \ o \left ( \left [ \log \frac { 1 } { | x - x _ { 0 } | } \right ] ^ { n - 1 } \right ) \\ T h _ { \theta \ e a m \ e b e l d e l f }$$
as x → x 0 . The same holds if
$$k _ { f } ( r ) = o \left ( \left [ \log \frac { 1 } { r } \right ] ^ { n - 1 } \right )$$
as r → 0 where k f ( r ) is the mean value of the function K x,f I ( ) over the sphere | x -x 0 | = r .
Remark 5.1. Choosing in Lemma 5.1 the function ψ t ( ) = 1 ( / t log 1 /t ) instead of ψ t ( ) = 1 /t , we are able to replace (5.7) by and (5.9) by
$$\int _ { \varepsilon < | x - x _ { 0 } | < 1 } ^ { \cdot \cdot \cdot \cdot } \frac { k _ { I } ( x, f ) \ d m ( x ) } { \left ( | x - x _ { 0 } | \log \frac { 1 } { | x - x _ { 0 } | } \right ) ^ { n } } & = o \left ( \left [ \log \log \frac { 1 } { \varepsilon } \right ] ^ { n } \right ) \\ \intertext { d ( 5. 9 ) \, \text{by} }$$
$$k _ { f } ( r ) & = o \left ( \left [ \log \frac {$$
Thus, it is sufficient to require that
$$k _ { f } ( r ) = O \left ( \left [ \log \frac { 1$$
In general, we could give here the whole scale of the corresponding conditions in terms of log using functions ψ t ( ) of the form 1 / t ( log . . . log 1 /t ) .
Theorem 5.5. Let D and D ′ be bounded domains in R n , n /greaterorequalslant 3 , D be locally connected on ∂D and ∂D ′ be (strongly accessible) weakly flat. Suppose that f : D → D ′ is a homeomorphism in W 1 ,ϕ loc with condition (5.1) such that
$$\int _ { D } \Phi ( K _ { I } ( x, f ) ) \$$
for a non-decreasing convex function Φ : R + → R + . If, for some δ > Φ(0) ,
$$\begin{array} {$$
then f can be extended to a (continuous) homeomorphic map f : D → D ′ .
Indeed, by Theorem 3.1 and Corollary 3.2 in [48], (5.13) and (5.14) imply (5.2) and, thus, Theorem 5.5 is a direct consequence of Theorem 5.2.
Corollary 5.4. The conclusion of Theorem 5.5 holds if, for some α > 0 ,
$$\int _ { D } e ^ { \alpha K _ { I } ( x, f ) }$$
Remark 5.2. Note that by Theorem 5.1 and Remark 5.1 in [22] the conditions (5.14) are not only sufficient but also necessary for continuous extension to the boundary of f with the integral constraint (5.13).
Recall that by Theorem 2.1 in [48], see also Proposition 2.3 in [47], condition (5.14) is equivalent to a series of other conditions and, in particular, to the following condition
$$\int _ { \delta } ^ { \infty } \Phi ( t )$$
for some δ > 0 where 1 n ′ + 1 n = 1 , i.e., n ′ = 2 for n = 2 , n ′ is strictly decreasing in n and n ′ = n/ n ( -1) → 1 as n →∞ .
Finally, note that all these results hold, for instance, if f ∈ W 1 ,p loc , p > n -1 .
## 6 On finitely bi-Lipschitz mappings
Given an open set Ω ⊆ R n , n /greaterorequalslant 2 , following Section 5 in [21], see also Section 10.6 in [30], we say that a mapping f : Ω → R n is finitely bi-Lipschitz if
$$0 \ < \ l ( x, f ) \ \leqslant \ L ( x, f$$
where
$$L ( x, f ) \ = \ \lim _ { y \to x } \ \frac {$$
and
$$l ( x, f ) \ = \ \liminf _ { y \to x } \ \frac$$
/negationslash
By the classic Rademacher-Stepanov theorem, we obtain from the right hand inequality in (6.1) that finitely bi-Lipschitz mappings are differentiable a.e. and from the left hand inequality in (6.1) that J f ( x ) = 0 a.e. Moreover, such mappings have ( N ) -property with respect to each Hausdorff measure, see, e.g., either Lemma 5.3 in [21] or Lemma 10.6 [30]. Thus, the proof of the following theorems is perfectly similar to one of Theorem 4.1 and hence we omit it, cf. also similar but weaker Corollary 5.15 in [21] and Corollary 10.10 in [30] formulated in terms of the outer dilatation K O .
Theorem 6.1. Every finitely bi-Lipschitz homeomorphism f : Ω → R n , n /greaterorequalslant 2 , is a lower Q -homeomorphism with Q = K 1 n -1 I .
All results for finitely bi-Lipschitz homeomorphisms are perfectly similar to the corresponding results for homeomorphisms with finite distortion in the Orlich-Sobolev classes from the last section. Hence we will not formulate all them in the explicit form here in terms of inner dilatation K I .
We give here for instance only one of these results.
Theorem 6.2. Let D and D ′ be bounded domains in R n , n /greaterorequalslant 2 , D be locally connected on ∂D and ∂D ′ be (strongly accessible) weakly flat. Suppose that f : D → D ′ is a finitely bi-Lipschitz homeomorphism such that
$$\begin{array} {$$
for a non-decreasing convex function Φ : R + → R + . If, for some δ > Φ(0) ,
$$\Sigma \times \times \times \Sigma \times \Sigma \times \Sigma \times \Sigma \times \Sigma \times \Sigma \times \Sigma \times \Sigma \times \Sigma \times \Sigma \times \Sigma \times \Sigma \times \Sigma \times \Sigma \times \Sigma \times \Sigma \times \Sigma \times \Sigma \times \Sigma \times \Sigma \times \Sigma \times \Sigma \times \Sigma \times \Sigma \times \Sigma \times \Sigma \times \Sigma \times \Sigma \times \Sigma \times \Sigma \times \Sigma \times \Sigma \times \Sigma \times \Sigma \times \Sigma \times \Sigma \times \Sigma \times \Sigma \times \Sigma \times \Sigma \times \Smega \times \Sigma \times \Sigma \times \Sigma \times \Sigma \times \Sigma \times \Sigma \times \Sigma \times \Sigma \times \Sigma \times \Sigma \times \Sigma \times \Sigma \times \Sigma \times \Sigma \times \Sigma \times \Sigma \times \Sigma \times \Sigma \times \Sigma \times \Sigma \times \Sigma \times \Sigma \times \Sigma \times \Sigma \times \Sigma \times \Sigma \times \Sigma \times \Sigma \times \Sigma \times \Sigma \times \Sigma \times \Sigma \times \Sigma \times \Sigma \times \Sigma \times \Sigma \times \Sigma \times \Sigma \times \Sigma \times \Salpha \times \Sigma \times \Sigma \times \Sigma \times \Sigma \times \Sigma \times \Sigma \times \Sigma \times \Sigma \times \Sigma \times \Sigma \times \Sigma \times \Sigma \times \Sigma \times \Sigma \times \Sigma \times \Sigma \times \Sigma \times \Sigma \times \Sigma \times \Sigma \times \Sigma \times \Sigma \times \Sigma \times \Sigma \times \Sigma \times \Sigma \times \Sigma \times \Sigma \times \Sigma \times \Sigma \times \Sigma \times \Sigma \times \Sigma \times \Sigma \times \Sigma \times \Sigma \times \Sigma \times \Sigma \times \Sigma \times \Sappa \times \Sigma \times \Sigma \times \Sigma \times \Sigma \times \Sigma \times \Sigma \times \Sigma \times \Sigma \times \Sigma \times \Sigma \times \Sigma \times \Sigma \times \Sigma \times \Sigma \times \Sigma \times \Sigma \times \Sigma \times \Sigma \times \Sigma \times \Sigma \times \Sigma \times \Sigma \times \Sigma \times \Sigma \times \Sigma \times \Sigma \times \Sigma \times \Sigma \times \Sigma \times \Sigma \times \Sigma \times \Sigma \times \Sigma \times \Sigma \times \Sigma \times \Sigma \times \Sigma \times \Sigma \times \Sigma \times \Ssigma \times \Sigma \times \Sigma \times \Sigma \times \Sigma \times \Sigma \times \Sigma \times \Sigma \times \Sigma \times \Sigma \times \Sigma \times \Sigma \times \Sigma \times \Sigma \times \Sigma \times \Sigma \times \Sigma \times \Sigma \times \Sigma \times \Sigma \times \Sigma \times \Sigma \times \Sigma \times \Sigma \times \Sigma \times \Sigma \times \Sigma \times \Sigma \times \Sigma \times \Sigma \times \Sigma \times \Sigma \times \Sigma \times \Sigma \times \Sigma \times \Sigma \times \Sigma \times \Sigma \times \Sigma \times \Sigma \times \Lambda \Sigma \Sigma \Sigma \Sigma \Sigma \Sigma \Sigma \Sigma \Sigma \Sigma \Sigma \Sigma \Sigma \Sigma \Sigma \Sigma \Sigma \Sigma \Sigma \Sigma \Sigma \Sigma \Sigma \Sigma \Sigma \Sigma \Sigma \Sigma \Sigma \Sigma \Sigma \Sigma \Sigma \Sigma \Sigma \Sigma \Sigma \Sigma \Sigma \Sigma \Sigma \Sigma \Sigma \Sigma \Sigma \Sigma \Sigma \Sigma \Sigma \Sigma \Sigma \Sigma \Sigma \Sigma \Sigma \Sigma \Sigma \Sigma \Sigma \Sigma \Sigma \Sigma \Sigma \Sigma \Sigma \Sigma \Sigma \sigma \Sigma \Sigma \Sigma \Sigma \Sigma \Sigma \Sigma \Sigma \Sigma \Sigma \Sigma \Sigma \Sigma \Sigma \Sigma \Sigma \Sigma \Sigma \Sigma \Sigma \Sigma \Sigma \Sigma \Sigma \Sigma \Sigma \Sigma \Sigma \Sigma \Sigma \Sigma \Sigma \Sigma \Sigma \Sigma \Sigma \Sigma \Sigma \Sigma \Sigma \Sigma \Sigma \Sigma \Sigma \Sigma \Sigma \Sigma \Sigma \Sigma \Sigma \Sigma \Sigma \Sigma \Sigma \Sigma \Sigma \Sigma \Sigma \Sigma \Sigma \Sigma \Sigma \Sigma \Sigma \Sigma \Sigma
.. \quad \Sigma \quad \Sigma \quad \Sigma \quad \Sigma \quad \Sigma \quad \Sigma \quad \Sigma \quad \Sigma \quad \Sigma \quad \Sigma \quad \Sigma \quad \Sigma \quad \Sigma \quad \Sigma \quad \Sigma \quad \Sigma \quad \Sigma \quad \Sigma \quad \Sigma \quad \Sigma \quad \Sigma \quad \Sigma \quad \Sigma \quad \Sigma \quad \Sigma \quad \Sigma \quad \Sigma \quad \Sigma \quad \Sigma \quad \Sigma \quad \Sigma \quad \Sigma \quad \Sigma \quad \Sigma \quad \Sigma \quad \Sigma \quad \Sigma \quad \Sigma \quad \Sigma \quad \Sigma \quad \Smega \quad \Sigma \quad \Sigma \quad \Sigma \quad \Sigma \quad \Sigma \quad \Sigma \quad \Sigma \quad \Sigma \quad \Sigma \quad \Sigma \quad \Sigma \quad \Sigma \quad \Sigma \quad \Sigma \quad \Sigma \quad \Sigma \quad \Sigma \quad \Sigma \quad \Sigma \quad \Sigma \quad \Sigma \quad \Sigma \quad \Sigma \quad \Sigma \quad \Sigma \quad \Sigma \quad \Sigma \quad \Sigma \quad \Sigma \quad \Sigma \quad \Sigma \quad \Sigma \quad \Sigma \quad \Sigma \quad \Sigma \quad \Sigma \quad \Sigma \quad \Sigma \quad \Sigma \quad \Ss \quad \Sigma \quad \Sigma \quad \Sigma \quad \Sigma \quad \Sigma \quad \Sigma \quad \Sigma \quad \Sigma \quad \Sigma \quad \Sigma \quad \Sigma \quad \Sigma \quad \Sigma \quad \Sigma \quad \Sigma \quad \Sigma \quad \Sigma \quad \Sigma \quad \Sigma \quad \Sigma \quad \Sigma \quad \Sigma \quad \Sigma \quad \Sigma \quad \Sigma \quad \Sigma \quad \Sigma \quad \Sigma \quad \Sigma \quad \Sigma \quad \Sigma \quad \Sigma \quad \Sigma \quad \Sigma \quad \Sigma \quad \Sigma \quad \Sigma \quad \Sigma \quad \Sigma \quad \Sg \quad \Sigma \quad \Sigma \quad \Sigma \quad \Sigma \quad \Sigma \quad \Sigma \quad \Sigma \quad \Sigma \quad \Sigma \quad \Sigma \quad \Sigma \quad \Sigma \quad \Sigma \quad \Sigma \quad \Sigma \quad \Sigma \quad \Sigma \quad \Sigma \quad \Sigma \quad \Sigma \quad \Sigma \quad \Sigma \quad \Sigma \quad \Sigma \quad \Sigma \quad \Sigma \quad \Sigma \quad \Sigma \quad \Sigma \quad \Sigma \quad \Sigma \quad \Sigma \quad \Sigma \quad \Sigma \quad \Sigma \quad \Sigma \quad \Sigma \quad \Sigma \quad \Sigma \quad \Sig \quad \Sigma \quad \Sigma \quad \Sigma \quad \Sigma \quad \Sigma \quad \Sigma \quad \Sigma \quad \Sigma \quad \Sigma \quad \Sigma \quad \Sigma \quad \Sigma \quad \Sigma \quad \Sigma \quad \Sigma \quad \Sigma \quad \Sigma \quad \Sigma \quad \Sigma \quad \Sigma \quad \Sigma \quad \Sigma \quad \Sigma \quad \Sigma \quad \Sigma \quad \Sigma \quad \Sigma \quad \Sigma \quad \Sigma \quad \Sigma \quad \Sigma \quad \Sigma \quad \Sigma \quad \Sigma \quad \Sigma \quad \Sigma \quad \Sigma \quad \Sigma \quad \Sigma \quad \Sappa \quad \Sigma \quad \Sigma \quad \Sigma \quad \Sigma \quad \Sigma \quad \Sigma \quad \Sigma \quad \Sigma \quad \Sigma \quad \Sigma \quad \Sigma \quad \Sigma \quad \Sigma \quad \Sigma \quad \Sigma \quad \Sigma \quad \Sigma \quad \Sigma \quad \Sigma \quad \Sigma \quad \Sigma \quad \Sigma \quad \Sigma \quad \Sigma \quad \Sigma \quad \Sigma \quad \Sigma \quad \Sigma \quad \Sigma \quad \Sigma \quad \Sigma \quad \Sigma \quad \Sigma \quad \Sigma \quad \Sigma \quad \Sigma \quad \Sigma \quad \Sigma \quad \Sigma \quad \Sgo \quad \Sigma \quad \Sigma \quad \Sigma \quad \Sigma \quad \Sigma \quad \Sigma \quad \Sigma \quad \Sigma \quad \Sigma \quad \Sigma \quad \Sigma \quad \Sigma \quad \Sigma \quad \Sigma \quad \Sigma \quad \Sigma \quad \Sigma \quad \Sigma \quad \Sigma \quad \Sigma \quad \Sigma \quad \Sigma \quad \Sigma \quad \Sigma \quad \Sigma \quad \Sigma \quad \Sigma \quad \Sigma \quad \Sigma \quad \Sigma \quad \Sigma \quad \Sigma \quad \Sigma \quad \Sigma \quad \Sigma \quad \Sigma \quad \Sigma \quad \Sigma \quad \Sigma \quad \Sag \quad \Sigma \quad \Sigma \quad \Sigma \quad \Sigma \quad \Sigma \quad \Sigma \quad \Sigma \quad \Sigma \quad \Sigma \quad \Sigma \quad \Sigma \quad \Sigma \quad \Sigma \quad \Sigma \quad \Sigma \quad \Sigma \quad \Sigma \quad \Sigma \quad \Sigma \quad \Sigma \quad \Sigma \quad \Sigma \quad \Sigma \quad \Sigma \quad \Sigma \quad \Sigma \quad \Sigma \quad \Sigma \quad \Sigma \quad \Sigma \quad \Sigma \quad \Sigma \quad \Sigma \quad \Sigma \quad \Sigma \quad \Sigma \quad \Sigma \quad \Sigma \quad \Sigma \quad \S$$
then f can be extended to a (continuous) homeomorphic map f : D → D ′ .
Corollary 6.1. The conclusion of Theorem 6.2 holds if, for some α > 0 ,
$$\int _ { D } ^ { \lambda } \lambda ^ { \lambda } _ { I } ( x, f ) \ d m ( x ) \ < \ \infty \.$$
## References
- [1] Andreian Cazacu C., Influence of the orientation of the characteristic ellipses on the properties of the quasiconformal mappings, Proceedings of Romanian-Finnish Seminar on Teichm¨ller Spaces and Riemann Surfaces, Bucharest, 1971, 65-85. u
- [2] Andreian Cazacu C., Moduli inequalities for quasiregular mappings. Ann. Acad. Sci. Fenn. Math. 2 (1976), 17-28.
- [3] Andreian Cazacu C., On the length-area dilatation. Complex Var. Theory Appl. 50 (2005), no. 7-11, 765-776.
- [4] Birnbaum Z., Orlicz W. ¨ ber die Verallgemeinerungen des Begriffes der zueinauder konU jugierten Potenzen // Studia. Math. - 1931. 3 . - P. 1-67.
- [5] Chiarenza F., Frasca M., Longo P. W 2 ,p -solvability of the Dirichlet problem for nondivergence elliptic equations with VMO coefficients // Trans. Amer. Math. Soc. - 1993. 336 , no. 2. - P. 841-853.
- [6] Cristea M., Local homeomorphisms satisfying generalized modular inequalities. Complex Var. Elliptic Equ. 59 (2014), no. 10, 1363-1387.
- [7] Cristea M., On generalized quasiconformal mappings. Complex Var. Elliptic Equ. 59 (2014), no. 2, 232-246.
- [8] Cristea M., On generalized quasiregular mappings. Complex Var. Elliptic Equ. 58 (2013), no. 12, 1745-1764.
- [9] Federer H. Geometric Measure Theory. - Berlin: Springer-Verlag, 1969.
- [10] Gehring F.W. Rings and quasiconformal mappings in space // Trans. Amer. Math. Soc. - 1962. 103 , no. 3. - P. 353 - 393.
- [11] Gehring F.W., Martio O. Quasiextremal distance domains and extension of quasiconformal mappings // J. Anal. Math. - 1985. 45 . - P. 181-206.
- [12] Gutlyanskii V., Ryazanov V., Srebro U., Yakubov E. The Beltrami Equations: A Geometric Approach. - Developments in Math. 26 . - New York etc.: Springer, 2012.
- [13] Heinonen J., Kilpelainen T., Martio O. Nonlinear Potential Theory of Degenerate Elliptic Equations. - Oxford-New York-Tokio: Clarendon Press, 1993.
- [14] Ignat'ev A., Ryazanov V. Finite mean oscillation in the mapping theory // Ukr. Mat. Vis. - 2005. 2 , no. 3. - P. 395-417, 443 [in Russian]; transl. in Ukr. Math. Bull. - 2005. 2 , no. 3. - P. 403-424, 443.
- [15] Iwaniec T., Sbordone C. Riesz transforms and elliptic PDEs with VMO coefficients // J. Anal. Math. - 1998. 74 . - P. 183-212.
- [16] John F. and Nirenberg L.: On functions of bounded mean oscillation // Comm. Pure Appl. Math. - 1961. 14 . - P. 415-426.
- [17] Kovtonyuk D., Petkov I., Ryazanov V. On the boundary behaviour of solutions to the Beltrami equations // Complex Variables and Elliptic Equations. - 2013. 58 , no. 5. P. 647 - 663.
- [18] Kovtonyuk D.A., Petkov I.V., Ryazanov V.I., Salimov R.R. Boundary behavior and Dirichlet problem for Beltrami equations // Algebra and Analysis. - 2013. 25 , no. 4. P. 101-124 [in Russian]; transl in St. Petersburg Math. J. - 2014. 25 . - P. 587- 603.
- [19] Kovtonyuk D.A., Ryazanov V.I. On boundaries of space domains // Proc. Inst. Appl. Math. & Mech. NAS of Ukraine. - 2006. 13 . - P. 110 - 120.
- [20] Kovtonyuk D.A., Ryazanov V.I. Toward the theory of lower Q -homeomorphisms // Ukr. Mat. Visn. - 2008. 5 , no. 2. - P. 159 - 184 [in Russian]; transl. in Ukrainian Math. Bull. - 2008. 5 , no. 2. - P. 157 - 181.
- [21] Kovtonyuk D., Ryazanov V. On the theory of mappings with finite area distortion // J. Anal. Math. - 2008. 104 . - P. 291-306.
- [22] Kovtonyuk D., Ryazanov V. On the boundary behavior of generalized quasi-isometries // J. Anal. Math. - 2011. 115 . - P. 103-119.
- [23] Kovtonyuk D.A., Ryazanov V.I., Salimov R.R., Sevost'yanov E.A. On mappings in the Orlicz-Sobolev classes // Ann. Univ. Bucharest, Ser. Math - 2012. 3(LXI) , no. 1. P. 67-78.
- [24] Kovtonyuk D.A., Ryazanov V.I., Salimov R.R., Sevost'yanov E.A. Toward the theory of classes of Orlicz-Sobolev // Algebra and Analysis. - 2013. 25 , no. 6. - P. 49 101 [in Russian]; transl in St. Petersburg Math. J.
- [25] Kovtonyuk D.A., Salimov R.R., Sevost'yanov E.A. (ed. Ryazanov V.I.) Toward the Theory of Mappings in Classes of Sobolev and Orlicz-Sobolev. - Kiev: Naukova dumka, 2013 [in Russian].
- [26] Martio O., Rickman S., Vaisala J. Definitions for quasiregular mappings // Ann. Acad. Sci. Fenn. Ser. A1. Math. - 1969. 448 . - P. 1-40.
- [27] Martio O., Ryazanov V., Srebro U. and Yakubov E.: Mappings with finite length distortion // J. Anal. Math. - 2004. 93 . - P. 215-236.
- [28] Martio O., Ryazanov V., Srebro U. and Yakubov E.: Q -homeomorphisms // Contemporary Math. - 2004. 364 . - P. 193-203.
- [29] Martio O., Ryazanov V., Srebro U., Yakubov E.: On Q -homeomorphisms // Ann. Acad. Sci. Fenn. Ser. A1. Math. - 2005. 30 . - P. 49-69.
- [30] Martio O., Ryazanov V., Srebro U., Yakubov E. Moduli in Modern Mapping Theory. - Springer Monographs in Mathematics. - New York etc.: Springer, 2009.
- [31] Martio O., Ryazanov V., Vuorinen M. BMO and Injectivity of Space Quasiregular Mappings // Math. Nachr. - 1999. 205 . - P. 149-161.
- [32] Martio O., Vuorinen M. Whitney cubes, p -capacity and Minkowski content // Expo. Math. - 1987. 5 . - P. 17-40.
- [33] Maz'ya V. Sobolev Spaces. - Leningrad: Leningrad. Univ., 1985; transl. in Berlin: SpringerVerlag, 1985.
- [34] N¨ akki R.: Boundary behavior of quasiconformal mappings in n -space // Ann. Acad. Sci. Fenn. Ser. A1. Math. - 1970. 484 . - P. 1-50.
- [35] Ohtsuka M. Extremal Length and Precise Functions. - Tokyo: Gakkotosho Co., 2003.
- [36] Orlicz W. ¨ ber eine gewisse Klasse von R¨umen vom Typus B // Bull. Intern. de l'Acad. U a Pol. Serie A, Cracovie. - 1932.
- [37] Palagachev D.K. Quasilinear elliptic equations with VMO coefficients // Trans. Amer. Math. Soc. - 1995. 347 , no. 7. - P. 2481-2493.
- [38] Rado T., Reichelderfer P.V. Continuous Transformations in Analysis. - Berlin etc.: Springer, 1955.
- [39] Ragusa M.A. Elliptic boundary value problem in vanishing mean oscillation hypothesis // Comment. Math. Univ. Carolin. - 1999. 40 , no. 4. - P. 651-663.
- [40] Reimann H.M., Rychener T. Funktionen Beschr¨nkter Mittlerer Oscillation. - Lecture a Notes in Math. 487 . - Berlin etc.: Springer-Verlag, 1975.
- [41] Reshetnyak Yu.G. Space mappings with bounded distortion. - Novosibirsk: Nauka, 1982; transl. in Translations of Mathematical Monographs, 73 . - Providence, RI: Amer. Math. Soc., 1988.
- [42] Reshetnyak Yu.G.: Sobolev classes of functions with values in a metric space. Sibirsk. Mat. Zh. - 1997. 38 . - 657-675.
- [43] Rickman S. Quasiregular Mappings. - Berlin etc.: Springer-Verlag, 1993.
- [44] Ryazanov V.I., Salimov R.R. Weakly flat spaces and bondaries in the mapping theory // Ukr. Mat. Vis. - 2007. 4 , № 2. - P. 199 - 234 [in Russian]; transl. in Ukrainian Math. Bull. - 2007. 4 , no. 2. - P. 199 - 233.
- [45] Ryazanov V., Salimov R., Srebro U., Yakubov E. On Boundary Value Problems for the Beltrami Equations // Contemporary Math. - 2013. 591 . - P. 211-242.
- [46] V. Ryazanov and E. Sevost'yanov, Equicontinuous classes of ring Q-homeomorphisms // Sibirsk. Mat. Zh. - 2007. 48 , no. 6. - P. 1361-1376; translation in Siberian Math. J. 2007. 48 , no. 6. - P. 1093-1105.
- [47] Ryazanov V., Sevost'yanov E. Equicontinuity of mappings quasiconformal in the mean // Ann. Acad. Sci. Fenn. - 2011. 36 . - P. 231 - 244.
- [48] Ryazanov V., Srebro U., Yakubov E. On integral conditions in the mapping theory // Ukrainian Math. Bull. - 2010. 7 , no. 1. - P. 73-87.
- [49] Saks S. Theory of the Integral. - New York: Dover Publications Inc., 1964.
- [50] Sarason D. Functions of vanishing mean oscillation // Trans. Amer. Math. Soc. - 1975. 207 . - P. 391-405.
- [51] Sobolev S.L. Applications of functional analysis in mathematical physics. - Leningrad: Izdat. Gos. Univ., 1950; transl. in Providence, R.I.: Amer. Math. Soc., 1963.
- [52] Vasil'ev A. Moduli of Families of Curves for Conformal and Quasiconformal Mappings. Lecture Notes in Math. 1788 . - Berlin etc.: Springer-Verlag, 2002.
- [53] V¨ ais ¨ l ¨ a a J. Lectures on n -Dimensional Quasiconformal Mappings. - Lecture Notes in Math. 229 . - Berlin etc.: Springer-Verlag, 1971.
- [54] Vodop'yanov S. Mappings with bounded distortion and with finite distortion on Carnot groups // Sibirsk. Mat. Zh. - 1999. 40 , no. 4. - P. 764-804; transl. in Siberian Math. J. 1999. 40 , no. 4. - P. 644-677.
- [55] Vuorinen M. Conformal Geometry and Quasiregular Mappings. - Lecture Notes in Math. 1319 . - Berlin etc.: Springer-Verlag, 1988.
- [56] Whyburn G.Th. Analytic Topology. - Providence: AMS, 1942.
- [57] Wilder R.L. Topology of Manifolds. - New York: AMS, 1949.
- [58] Zaanen A.C. Linear analysis. - Noordhoff (1953).
## Denis Kovtonyuk and Vladimir Ryazanov,
Institute of Applied Mathematics and Mechanics, National Academy of Sciences of Ukraine, 74 Roze Luxemburg Str., Donetsk, 83114, Ukraine, denis [email protected], [email protected] | null | [
"Denis Kovtonyuk",
"Vladimir Ryazanov"
] | 2014-08-03T08:05:32+00:00 | 2014-08-03T08:05:32+00:00 | [
"math.CV",
"30C85, 30D40, 30C85, 30D40, 31A15, 31A20, 31A25, 31B25, 37E30"
] | On boundary behavior of spatial mappings | We show that homeomorphisms $f$ in ${\Bbb R}^n$, $n\geqslant3$, of finite
distortion in the Orlicz--Sobolev classes $W^{1,\varphi}_{\rm loc}$ with a
condition on $\varphi$ of the Calderon type and, in particular, in the Sobolev
classes $W^{1,p}_{\rm loc}$ for $p>n-1$ are the so-called lower
$Q$-homeomorphisms, $Q(x)=K^{\frac{1}{n-1}}_I(x,f)$, where $K_I(x,f)$ is its
inner dilatation. The statement is valid also for all finitely bi-Lipschitz
mappings that a far--reaching extension of the well-known classes of isometric
and quasiisometric mappings. This makes pos\-sib\-le to apply our theory of the
boundary behavior of the lower $Q$-homeomorphisms to all given classes. |
1408.0471v4 | ## D s ∗ 1 (2860) and D s ∗ 3 (2860) : Candidates for 1 D charmed-strange mesons
Qin-Tao Song 1 2 6 , , , Dian-Yong Chen 1 2 , ∗ † , Xiang Liu 2 3 , ‡ § , and Takayuki Matsuki 4 5 , ¶
1 Nuclear Theory Group, Institute of Modern Physics, Chinese Academy of Sciences, Lanzhou 730000, China 2 Research Center for Hadron and CSR Physics, Lanzhou University & Institute of Modern Physics of CAS, Lanzhou 730000, China 3 School of Physical Science and Technology, Lanzhou University, Lanzhou 730000, China 4 Tokyo Kasei University, 1-18-1 Kaga, Itabashi, Tokyo 173-8602, Japan 5 Theoretical Research Division, Nishina Center, RIKEN, Saitama 351-0198, Japan 6
University of Chinese Academy of Sciences, Beijing 100049, China
Newly observed two charmed-strange resonances, Ds ∗ 1 (2860) and Ds ∗ 3 (2860), are investigated by calculating their Okubo-Zweig-Iizuka allowed strong decays, which shows that they are suitable candidates for the 1 3 D 1 and 1 3 D 3 states in the charmed-strange meson family. Our study also predicts other main decay modes of Ds ∗ 1 (2860) and Ds ∗ 3 (2860), which can be accessible at the future experiment. In addition, the decay behaviors of the spin partners of Ds ∗ 1 (2860) and Ds ∗ 3 (2860), i.e., 1 D (2 -) and 1 D ′ (2 -), are predicted in this work, which are still missing at present. Experimental search for the missing 1 D (2 -) and 1 D ′ (2 -) charmed-strange mesons is an intriguing and challenging task for further experiment.
PACS numbers: 14.40.Lb, 12.38.Lg, 13.25.Ft
## I. INTRODUCTION
Very recently the LHCb Collaboration has released a new observation of an excess around 2.86 GeV in the ¯ 0 D K -invariant mass spectrum of Bs 0 → ¯ 0 D K -π + , which can be an admixture of spin-1 and spin-3 resonances corresponding to D s ∗ 1 (2860) and D s ∗ 3 (2860) [1, 2], respectively. As indicated by LHCb [1, 2], it is the first time to identify a spin-3 resonance. In addition, D s ∗ 2 (2573) also appears in the the ¯ 0 D K -invariant mass spectrum.
Before this observation, a charmed-strange state DsJ (2860) was reported by BaBar in the DK channel [3], where the mass and width are m = 2856 6 . ± 1 5 . ± 5 0 MeV and . Γ = 47 ± 7 ± 10 MeV [3], respectively, which was later confirmed by BaBar in the D K ∗ channel [4]. The DsJ (2860) has stimulated extensive discussions on its underlying structure. In Ref. [5], DsJ (2860) is suggested as a 1 3 D 3 cs ¯meson. This explanation was also supported by study of the e ff ective Lagrangian approach [6, 7], the Regge phenomenology [8], constituent quark model [9] and mass loaded flux tube model [10]. The ratio Γ ( DsJ (2860) → D K ∗ ) / Γ ( DsJ (2860) → DK ) was calculated as 0.36 [11] by the e ff ective Lagrangian method. However, the calculation by the QPC model shows that such a ratio is about 0.8 [12], which is close to the experimental value 1 10 . ± 0 15 . ± 0 19 [4]. . Thus, J P = 3 -assignment to DsJ (2860) is a possible explanation. In addition, DsJ (2860) as a mixture of charmed-strange states was given in Refs. [9, 12, 13]. DsJ (2860) could be a partner of Ds 1 (2710), where both DsJ (2860) and Ds 1 (2710) are a mixture of 2 3 S 1 and 1 3 D 1 cs ¯ states. By introducing such a mixing mechanism, the obtained ratio of D K DK ∗ / for DsJ (2860) and
∗ Corresponding author
† Electronic address: [email protected]
‡ Corresponding author
§ Electronic address: [email protected]
¶ Electronic address: [email protected]
Ds 1 (2710) [12] is consistent with the experimental data [4]. Reference [14] indicates that there exist two overlapping resonances (radially excited J P = 0 + and J P = 2 + cs ¯states) at 2.86 GeV. Besides the above explanations under the conventional charmed-strange meson framework, DsJ (2860) was explained as a multiquark exotic state [15]. DsJ (2860) as a J P = 0 + charmed-strange meson was suggested in Ref. [5]. However, this scalar charmed-strange meson cannot decay into D K ∗ [5], which contradicts the BaBar's observation of DsJ (2860) in its D K ∗ decay channel [3]. After the observation of DsJ (2860), DsJ (3040) was reported by BaBar in the D K ∗ channel [4], which can be explained as the first radial excitation of Ds 1 (2460) with J P = 1 + [16]. In addition, the decay behaviors of other missing 2 P charmed-strange mesons in experiment were given in Ref. [16].
Briefly reviewing the research status of DsJ (2860), we notice that more theoretical and experimental e ff orts are still necessary to clarify the properties of DsJ (2860). It is obvious that the recent precise measurement of LHCb [1, 2] provides us a good chance to identify higher radial excitations in the charmed-strange meson family.
The resonance parameters of the newly observed D s ∗ 1 (2860) and D s ∗ 3 (2860) by LHCb include [1, 2]:
$$m _ { D _ { s 1 } ^ { * } ( 2 8 6 0 ) } \ & = \ 2 8 5 9 \pm 1 2 \pm 6 \pm 2 3 \ \text{MeV}, \quad \quad ( 1 ) \\ \Gamma _ { \dots \ \dots \ \dots } \ & = \ 1 \leq 0 \, \pm \, \mathfrak { Z } \, \pm \, \mathfrak { Z } \, \pm \, \mathfrak { M } \omega \, \mathfrak { V } \quad \quad \quad \, \mathfrak { V } \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \ \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \cdots \, \quad \ \dots \, \quad \ \dots \, \quad \ \dots \, \quad \ \dots \, \quad \ \dots \, \quad \ \dots \, \quad \ \dots \, \quad \ \dots \, \quad \ \dots \, \quad \ \dots \, \quad \ \dots \, \quad \ \dots \, \quad \ \dots \, \quad \ \dots \, \quad \ \dots \, \quad \ \dots \, \quad \ \dots \, \quad \ \dots \, \quad \ \dots \, \quad \ \dots \, \quad \ \dots \, \quad \ \dots \, \quad \ \dots \, \quad \ \dots \, \quad \ \dots \, \quad \ \ dots \, \quad \ \dots \, \quad \ \dots \, \quad \ \dots \, \quad \ \dots \, \quad \ \dots \, \quad \ \dots \, \quad \ \dots \, \quad \ \dots \, \quad \ \dots \, \quad \ \dots \, \quad \ \dots \, \quad \ \dots \, \quad \ \dots \, \quad \ \dots \, \quad \ \dots \, \quad \ \dots \, \quad \ \dots \, \quad \ \dots \, \quad \ \dots \, \quad \ \dots \, \quad \ \dots \, \quad \ \dots \, \quad \ \dots \, \quad \ \dots \, \quad \ \ \dots \, \quad \ \dots \, \quad \ \dots \, \quad \ \dots \, \quad \ \dots \, \quad \ \dots \, \quad \ \dots \, \quad \ \dots \, \quad \ \dots \, \quad \ \dots \, \quad \ \dots \, \quad \ \dots \, \quad \ \dots \, \quad \ \dots \, \quad \ \dots \, \quad \ \dots \, \quad \ \dots \, \quad \ \dots \, \quad \ \dots \, \quad \ \dots \, \quad \ \dots \, \quad \ \dots \, \quad \ \dots \, \quad \ \dots \, \quad \ \dots \, \ \dots \, \quad \ \dots \, \quad \ \dots \, \quad \ \dots \, \quad \ \dots \, \quad \ \dots \, \quad \ \dots \, \quad \ \dots \, \quad \ \dots \, \quad \ \dots \, \quad \ \dots \, \quad \ \dots \, \quad \ \dots \, \quad \ \dots \, \quad \ \dots \, \quad \ \dots \, \quad \ \dots \, \quad \ \dots \, \quad \ \dots \, \quad \ \dots \, \quad \ \dots \, \quad \ \dots \, \quad \ \dots \, \quad \ \dots \, \quad \ \dots \, \cdots \, \quad \ \dots \, \quad \ \dots \, \quad \ \dots \, \quad \ \dots \, \quad \ \dots \, \quad \ \dots \, \quad \ \dots \, \quad \ \dots \, \quad \ \dots \, \quad \ \dots \, \quad \ \dots \, \quad \ \dots \, \quad \ \dots \, \quad \ \dots \, \quad \ \dots \, \quad \ \dots \, \quad \ \dots \, \quad \ \dots \, \quad \ \dots \, \quad \ \dots \, \quad \ \dots \, \quad \ \dots \, \quad \ \dots \, \quad \ \dots \,.$$
$$m _ { D _ { 3 } ^ { * } ( 2 8 6 0 ) } \ & = \ 2 8 6 0. 5 \pm 2. 6 \pm 2. 5 \pm 6. 0 \text{ MeV}, \quad ( 3 ) \\ \Gamma _ { \dots \dots \dots } \ & = \ \mathfrak { S } \, \pm 7 \, + \, \Lambda \, + \, \epsilon \, \text{ M} \, \partial \mathcal { V } \quad \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \$$
$$\Gamma _ { D _ { s 1 } ^ { * } ( 2 8 6 0 ) } \ & = \ 1 5 9 \pm 2 3 \pm 2 7 \pm 7 2 \ \text{MeV}, \quad \ \ ( 2 ) \\ \quad \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \$$
$$\Gamma _ { D _ { s 3 } ^ { * } ( 2 8 6 0 ) } \ = \ 5 3 \pm 7 \pm 4 \pm 6 \text{ MeV},$$
where the errors are due to statistical one, experimentally systematic e ff ects and model variations [1, 2], respectively.
At present, there are good candidates for the 1 S and 1 P states in the charmed-strange meson family (see Particle Data Group for more details [17]). Thus, two newly observed D s ∗ 1 (2860) and D s ∗ 3 (2860) can be categorized into the 1 D charmed-strange states when considering their spin quantum numbers and masses. Before observation of these two resonances, there were several theoretical predictions [18-21] of the mass spectrum of the 1 D charmed-strange meson fam-
ily, which are collected in Table I. Comparing the experimental data of D s ∗ 1 (2860) and D s ∗ 3 (2860) with the theoretical results, we notice that the masses of D s ∗ 1 (2860) and D s ∗ 3 (2860) are comparable with the corresponding theoretical predictions, which further supports that it is reasonable to assign D s ∗ 1 (2860) and D s ∗ 3 (2860) as the 1 D states of the charmedstrange meson family
TABLE I: Theoretical predictions for charmed-strange meson spectrum and comparison with the experimental data.
| J P ( 2 s + 1 L J ) | Expt. [17] | GI [18] | MMS [19] | PE [20] | EFG [21] |
|-----------------------|--------------|-----------|------------|-----------|------------|
| 0 - ( 1 S 0 ) | 1968 | 1979 | 1967 | 1965 | 1969 |
| 1 - ( 3 S 1 ) | 2112 | 2129 | 2110 | 2113 | 2111 |
| 0 + ( 3 P 0 ) | 2318 | 2484 | 2325 | 2487 | 2509 |
| 1 + (' 1 P 1 ') | 2460 | 2459 | 2467 | 2535 | 2536 |
| 1 + (' 3 P 1 ') | 2536 | 2556 | 2525 | 2605 | 2574 |
| 2 + ( 3 P 2 ) | 2573 [1, 2] | 2592 | 2568 | 2581 | 2571 |
| 1 - ( 3 D 1 ) | 2859 [1, 2] | 2899 | 2817 | 2913 | 2913 |
| 2 - (' 1 D 2 ') | - | 2900 | - | 2900 | 2931 |
| 2 - (' 3 D 2 ') | - | 2926 | 2856 | 2953 | 2961 |
| 3 - ( 3 D 3 ) | 2860 [1, 2] | 2917 | - | 2925 | 2871 |
Although both the mass spectrum analysis and the measurement of the spin quantum number support D s ∗ 1 (2860) and D s ∗ 3 (2860) as the 1 D states, we still need to carry out a further test of this assignment through study of their decay behaviors. This study can provide more detailed information on the partial decay widths, which is valuable for future experimental investigation of D s ∗ 1 (2860) and D s ∗ 3 (2860). In addition, there exist four 1 D states in the charmed-strange meson family. At present, the spin partners of D s ∗ 1 (2860) and D s ∗ 3 (2860) are still missing in experiment. Thus, we will also predict the properties of two missing 1 D states in this work.
This paper is organized as follows. In Section II, after some introduction we illustrate the study of decay behaviors of Ds 1 (2860) and Ds 3 (2860). In Sec. III, the paper ends with the discussion and conclusions.
## II. DECAY BEHAVIOR OF Ds 1 (2860) AND Ds 3 (2860)
Among all properties of these 1 D states, their two-body Okubo-Zweig-Iizuka (OZI)-allowed strong decays are the most important and typical properties. Hence, in the following we mainly focus on the study of their OZI-allowed strong decays. For the 1 D states studied in this work, their allowed decay channels are listed in Table II. Among four 1 D states in the charmed-strange meson family, there are two J P = 2 -states, which is a mixture of 1 1 D 2 and 1 3 D 2 states, i.e.,
$$\left ( \begin{array} { c } 1 D ( 2 ^ { - } ) \\ 1 ^ { D ^ { \prime } } ( 2 ^ { - } ) \end{array} \right ) = \left ( \begin{array} { c c } \cos \theta _ { 1 D } & \sin \theta _ { 1 D } \\ - \sin \theta _ { 1 D } & \cos \theta _ { 1 D } \end{array} \right ) \left ( \begin{array} { c } 1 ^ { 3 } D _ { 2 } \\ 1 ^ { 1 } D _ { 2 } \end{array} \right ), \quad ( 5 )$$
where θ 1 D is a mixing angle. In the heavy quark limit, a general mixing angle between 3 LL and 1 LL is θ L = arctan( √ L / ( L + 1)), which indicates θ 1 D = 39 ◦ [22].
TABLEII: The two-body OZI-allowed decay modes of 1 D charmedstrange mesons. Here, we use symbols, ◦ and -, to mark the OZIallowed and -forbidden decay modes, respectively. Ds ∗ 1 (2860) and Ds ∗ 3 (2860) are 1 3 D 1 and 1 3 D 3 states, respectively.
| Channels | D ∗ s 1 (2860) | 1 D (2 - ) 1 D ′ (2 - | D ∗ s 3 (2860) ) |
|------------------|------------------|-------------------------|--------------------|
| DK | ◦ | - | ◦ |
| D ∗ K | ◦ | ◦ | ◦ |
| D s η | ◦ | - | ◦ |
| D ∗ s η | ◦ | ◦ | ◦ |
| DK ∗ | ◦ | ◦ | ◦ |
| D ∗ 0 (2400) K | - | ◦ | - |
| D ∗ s 0 (2317) η | - | ◦ | - |
In the following, we apply the quark pair creation (QPC) model [23-29] to describe the OZI allowed two-body strong decays shown in Table II, where the QPC model was extensively adopted to study the strong decay of hadrons [5, 16, 3039]. In the QPC model, the quark-antiquark pair is created in QCDvacuumwith vacuumquantumnumber J PC = 0 ++ . For a decay process, i.e., an initial observed meson A decaying into two observed mesons B and C , the process can be expressed as
$$\langle B C | T | A \rangle = \delta ^ { 3 } ( \$$
where P B ( P C ) is the three-momentum of the final meson B C ( ) in the rest frame of A . MJi ( i = A B C , , ) denotes the orbital magnetic momentum. Additionally, M MJ A MJ B MJ C is the helicity amplitude. The transition operator T in Eq. (6) is written as [23-29]
$$T \ = \ - 3 \gamma \sum _ { m } \langle 1 m ; 1$$
which is introduced in a phenomenological way to reflect the property of quark-antiquark (denoted by indices 3 and 4) created from vacuum. Y lm ( p ) = | p | Ylm ( p ) is the solid harmonic. χ φ , , and ω are the general description of the spin, flavor, and color wave functions, respectively.
By the Jacob-Wick formula [40], the decay amplitude reads as
$$\begin{array} {$$
Finally, the general decay width is
$$\Gamma \ = \ \pi ^ { 2 } \frac { | \mathbf P _ {$$
where mA is the mass of the initial state A . In the following, the helicity amplitudes M MJ A MJ B MJ C of the OZI-allowed strong decay channels in Table II are calculated, which is the main task of the whole calculation. Here, we adopt the simple harmonic oscillator (SHO) wave function Ψ n ,/lscript m ( k ), where the value of a parameter R appearing in the SHO wave function can be obtained such that it reproduces the realistic root mean square (rms) radius, which can be calculated by the relativistic quark model [42] with a Coulomb plus linear confining potential as well as a hyperfine interaction term. In Table III, we list the R values adopted in our calculation. The strength of qq ¯is taken as γ = 6 3 [16] while the strength of . ss ¯satisfies γ s = γ/ √ 3. We need to specify our γ value adopted in the present work which is √ 96 π times larger than that adopted by other groups [41, 42], where the γ value as an overall factor can be obtained by fitting the experimental data (see Ref. [43] for more details of how to get the γ value). In addition, the constituent quark masses for charm, up down, and strange / quarks are 1.60 GeV, 0.33 GeV, and 0.55 GeV, respectively [42].
TABLE III: The R values (in units of GeV -1 ) [42] and masses (in units of MeV) [17] of the mesons involved in present calculation.
| States | R | mass | States | R | mass | States | R | mass |
|----------|------|--------|----------|------|--------|--------------|------|--------|
| D | 2.33 | 1867 | D ∗ | 2.7 | 2008 | D 0 (2400) | 3.13 | 2318 |
| D s | 1.92 | 1968 | D ∗ s | 2.22 | 2112 | D s 0 (2317) | 2.7 | 2318 |
| K | 2.17 | 494 | K ∗ | 3.13 | 896 | η | 2.12 | 548 |
With the above preparation, we obtain the total and partial decay widths of D s ∗ 1 (2860), D s ∗ 3 (2860) and their spin partners, and comparison with the experimental data [1, 2]. As shown in Table III, the R value of the P -wave charmed-strange meson is about 2.70 GeV -1 . For the D -wave state, the R value is estimated to be around 3.00 GeV -1 [42]. In present calculation, we vary the R value for the D -wave charmed-strange meson from 2.4 to 3.6 GeV -1 . In Fig. 1, we present the R dependence of the total and partial decay widths of Ds 1 (2860) and Ds 3 (2860).
## A. Ds 1 (2860)
The total width of Ds 1 (2860) as the 1 3 D 1 state is given in Fig. 1, where the total width is obtained as 128 ∼ 177 MeV corresponding to the selected R range, which is consistent with the experimental width of Ds 1 (2860) ( Γ = 159 ± 23 ± 27 ± 72 MeV [1, 2]). The information of the partial decay widths depicted in Fig. 1 also shows that DK is the dominant decay mode of the 1 3 D 1 charm strange meson, which explains why Ds 1 (2860) was experimentally observed in its DK decay channel [1, 2]). In addition, our study also indicates that the D K ∗ and DK ∗ channels are also important for the 1 3 D 1 state, which have partial widths 35 ∼ 44 MeV and 24 ∼ 40 MeV, respectively. The Ds η and Ds ∗ η channels have partial decay widths with several MeV, which is far smaller than the partial decay widths of the DK D K , ∗ and DK ∗ channels. This phenomena can be understood since the decays of the 1 3 D 1 state into Ds η and Ds ∗ η have the smaller phase space.
The above results show that Ds 1 (2860) can be a good candidate for the 1 3 D 1 charmed-strange meson.
Besides providing the partial decay widths, we also predict several typical ratios, i.e.,
$$\frac { \Gamma ( D _ { s 1 } ( 2 8 6 0 ) \to D$$
$$\stackrel { \theta \cdot \cdot \cdot \cdot } { \frac { \theta \cdot \cdot \cdot } { \Gamma ( D _ { s 1 } ( 2 8 6 0 ) \to D _ { s } \eta ) } } & \ = \ 0. 1 0 \sim 0. 1 4, \quad \ ( 1 2 ) \\ \cdot \cdot \quad \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot$$
$$\frac { \nu \nu _ { s 1 } \nu _ { \infty } \nu _ { \infty } \nu _ { \infty } } { \Gamma ( D _ { s 1 } ( 2 8 6 0 ) \to D K ^ { * } ) } \ = \ 0. 2 5 \sim 0. 8 5, \quad \ ( 1 1 ) \\ \Gamma ( D _ { s 1 } ( 2 8 6 0 ) \to D _ { s } \eta ) \quad \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \$$
which can be further tested in the coming experimental measurements.
The Belle Collaboration once reported Ds 1 (2710) in the DK invariant mass spectrum, which has mass 2708 ± 9 + 11 -10 MeV and width 108 ± 23 + 36 -31 MeV [44]. The analysis of angular distribution indicates that Ds 1 (2710) has the spin-parity J P = 1 -[44]. Later, the BaBar Collaboration confirmed Ds 1 (2710) in a new D K ∗ channel [4], where the ratio Γ ( D K ∗ ) / Γ ( DK ) = 0 91 . ± 0 13 . ± 0 12 for . Ds 1 (2710).
In Refs. [5, 11], the assignment of Ds 1 (2710) to the 1 3 D 1 charmed-strange meson was proposed. However, the obtained Γ ( D K ∗ ) / Γ ( DK ) = 0 043 [11] is . deviated far from the experimental data, which does not support the 1 3 D 1 charmedstrange assignment to Ds 1 (2710). Especially, the present study of newly observed Ds 1 (2860) shows that Ds 1 (2860) is a good candidate of the 1 3 D 1 charmed-strange meson.
If Ds 1 (2710) is not a 1 3 D 1 charmed-strange meson, we need to find the place in the charmed-strange meson family. In Ref. [5], the authors once indicated that Ds 1 (2710) as the 2 3 S 1 charmed-strange meson is not completely excluded . By 1 the e ff ective Lagrangian approach [11] and under the assignment of Ds 1 (2710) to the 2 3 S 1 charmed-strange meson, the Γ ( Ds 1 (2710) → D K ∗ ) / Γ ( Ds 1 (2710) → DK ) = 0 91 was ob-. tained, which is close to the experimental value [44]. We also notice the recent work of DsJ (2860) [45], where they also proposed that Ds 1 (2710) is the 2 3 S 1 cs ¯meson.
Besides the above exploration in the framework of a conventional charmed-strange meson, the exotic state explanation to Ds 1 (2710) was given in Ref. [15].
In the following, we include the mixing between 2 3 S 1 and 1 3 D 1 states to further discuss the mixing angle dependence of the decay behavior of Ds 1 (2860). Here, Ds 1 (2 S ) and Ds 1 (2860) are the mixtures of 2 3 S 1 and 1 3 D 1 states, which
1 We need to explain the reason why the 2 3 S 1 charmed-strange meson is not completely excluded in Ref. [5]. In Ref. [5], the total decay width of Ds 1(2710) as the 2 3 S 1 charmed-strange meson was calculated, which is 32 MeV. This value is obtained with the typical R = 3 2 GeV . -1 value. As shown in Fig. 4 (d) in [5], the total decay width is strongly dependent on the R value due to node e ff ects. If taking other typical R values which are not far away from 3 2 GeV . -1 , the total decay width can reach up to the lower limit of the experimental width of Ds 1(2710).
/s32
/s32
/s32
FIG. 1: (Color online). The total and partial decay widths of 1 3 D 1 (left panel) and 1 3 D 3 (right panel) charmed-strange mesons dependent on the R value. Here, the dashed lines with the yellow bands are the experimental widths of Ds ∗ 1 (2860) and Ds ∗ 3 (2860) from LHCb [1, 2].
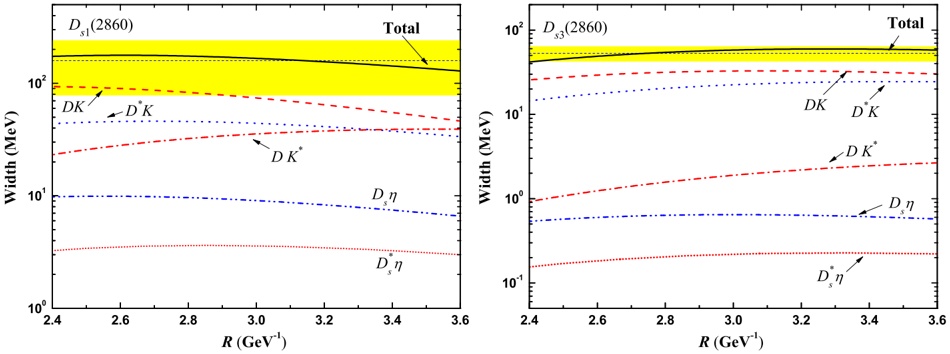
FIG. 2: (Color online). The total and partial decay widths (in units of MeV) of Ds 1 (2860) dependent on the R value. The solid, dashed and dotted curves correspond to the typical 2 S -1 D mixing angles θ = 0 , ◦ θ = 15 ◦ and θ = 30 , respectively. ◦ The band in the left-top panel is the total decay width with errors, which was reported by the LHCb Collaboration [1, 2].
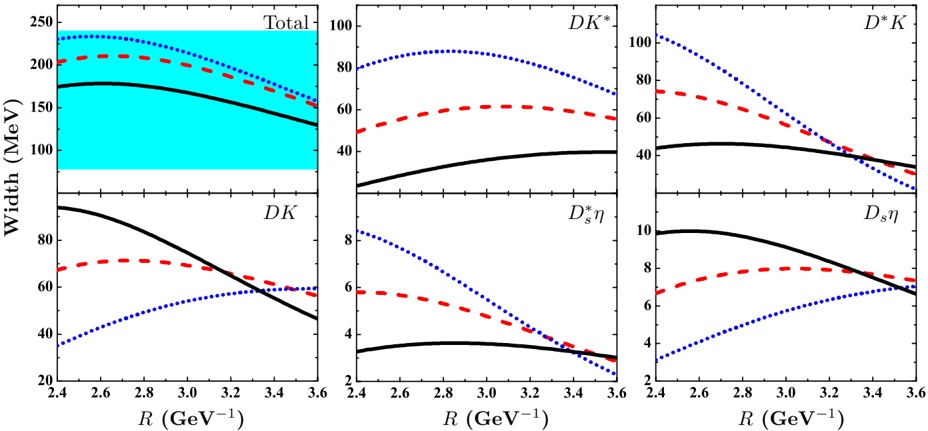
satisfy the relation below
$$\begin{pmatrix} | D _ { s 1 } ( 2 S ) \rangle \\ | D _ { s 1 } ( 2 8 6 0 ) \rangle \end{pmatrix} = \begin{pmatrix} \cos \theta & \sin \theta \\ - \sin \theta & \cos \theta \end{pmatrix} \begin{pmatrix} | 2 ^ { 3 } S _ { 1 } \rangle \\ | 1 ^ { 3 } D _ { 1 } \rangle \end{pmatrix}. \quad ( 1 3 ) \quad \text{with} \\ \text{The } 2 S - 1 D \, \text{mixing angle should be small due to the relative} \quad \text{while} \\ \text{even} \end{pmatrix}$$
The 2 S -1 D mixing angle should be small due to the relative large mass gap between 2 S and 1 D state, where we take some typical values θ = 0 , ◦ θ = 15 , and ◦ θ = 30 ◦ to present our results. θ = 0 ◦ denotes that there is no 2 S -1 D mixing. In Fig. 2, we present the total and partial decay widths, which depend on the R value, where we show the results with three di ff erent typical θ values. In the left-top panel of Fig. 2, we list the total decay width of Ds 1 (2860) and the comparison with the experimental data. When taking 2 4 GeV . -1 < R < 3 6 GeV . -1 , the calculated total decay width varies from 130 MeV to 235 MeV, which indicates the theoretically estimated total decay width of Ds 1 (2860) can overlap with the experimental measurement. In addition, we also notice that the partial decay widths for the Ds η and Ds ∗ η channels are less than 10 MeV, while for the DK , D K ∗ and DK ∗ decay modes, the corresponding partial decay widths vary from several 20 MeV to more than one hundred MeV, which strongly depend on the value of a mixing angle.
In Ref. [12], the authors adopted a di ff erent convention for the 2 S -1 D mixing, where their 2 S -1 D mixing angle has a sign opposite to our scenario. Taking the same R value and mixing angle for Ds 1 (2860), we obtain the partial decay widths of DK and D K ∗ are less than 10 MeV, while the calculated partial
decay width of DK ∗ is more than 20 MeV, which is consistent with the results in Ref. [12].
## B. Ds 3 (2860)
The two-body OZI-allowed decay behavior of Ds 3 (2860) as the 1 3 D 3 charmed-strange meson is presented in the right panel of Fig. 1, where the obtained total width can reach up to 42 ∼ 60 MeV, which overlaps with the LHCb's data (53 ± 7 ± 4 ± 6 MeV [1, 2]). This fact further reflects that Ds 3 (2860) is suitable for the 1 3 D 3 charmed-strange meson. Similar to Ds 1 (2860), the DK channel is also the dominant decay mode of Ds 3 (2860), where the partial decay width of Ds 3 (2860) → DK is 25 ∼ 30 MeV in the selected R value range. Additionally, we also calculate the partial decay width of Ds 3 (2860) → D K ∗ and Ds 3 (2860) → DK ∗ , which are 14 ∼ 24 MeV and 0 9 . ∼ 2 5 MeV, respectively. . The partial decay widths for Ds η and Ds ∗ η channel are of order of 0.1 MeV. The corresponding typical ratios for Ds 3 (2860) are
$$\frac { \Gamma ( D _ { s 3 } ( 2 8 6 0 ) \to D ^ { * } K ) } { \Gamma ( D _ { s 3 } ( 2 8 6 0 ) \to D K ) } \ = \ 0. 5 5 \sim 0. 8 0, \quad \ \ ( 1 4 ) \quad \ 8 7 ) \% \\ \Gamma ( D _ { s 3 } ( 2 8 6 0 ) \to D K ^ { * } ) \quad \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \$$
$$\stackrel { \theta \, \stackrel { s, \, \cdots, } { \Gamma ( D _ { s 3 } ( 2 8 6 0 ) \to D _ { s } \eta ) } } { \frac { \Gamma ( D _ { s 1 } ( 2 8 6 0 ) \to D K ) } { \Gamma ( D _ { s 1 } ( 2 8 6 0 ) \to D K ) } } \ = \ 0. 0 1 8 \sim 0. 0 2 0, \quad ( 1 6 ) \, \stackrel { \theta \, \stackrel { s, \, \cdots, } { \mathbb { W } } } { \cdots } \\ \cdots \ \, \cdots \ \, \cdots \ \, \cdots \ \,.$$
$$\frac { \Lambda \Lambda _ { s 3 } \Lambda \Lambda \Lambda \Lambda \Lambda \Lambda \Lambda \Lambda \Lambda \Lambda \Lambda \Lambda \Lambda \Lambda \Lambda \Lambda \Lambda \Lambda \Lambda \Lambda \Lambda \Lambda \Lambda \Lambda \Lambda \Lambda \Lambda \Lambda \Lambda \Lambda \Lambda \Lambda \Lambda \Lambda \Lambda \Lambda \Lambda \Lambda \Lambda \Lambda \Lambda \Lambda \Lambda \Lambda \Lambda \Lambda \Lambda \Lambda \Lambda \Lambda \Lambd } } { \Gamma ( D _ { s 3 } ( 2 8 6 0 ) \to D K ) } \ = \ 0. 0 3 \sim 0. 0 9, \quad \ ( 1 5 ) \quad \ \text{deca} \\ \Gamma ( D _ { s 3 } ( 2 8 6 0 ) \to D _ { s } \eta ) \quad \ \Lambda \Lambda \Lambda \Lambda \Lambda \Lambda \Lambda \Lambda \Lambda \Lambda \Lambda \Lambda \Lambda \Lambda \Lambda \Lambda \Lambda \Lambda \Lambda \Lambda \Lambda \Lambda \Lambda \Lambda \Lambda \Lambda \Lambda \Lambda \Lambda \Lambda \Lambda \Lambda \Lambda \Lambda \Lambda \Lambda \Lambda \Lambda \Lambda \Lambda \Lambda \Lambda \Lambda \Lambda \Lambda \Lambda \Lambda \Lambda \Lambda \Lambma \Lambda \Lambda \Lambda \Lambda \Lambda \Lambda \Lambda \Lambda \Lambda \Lambda \Lambda \Lambda \Lambda \Lambda \Lambda \Lambda \Lambda \Lambda \Lambda \Lambda \Lambda \Lambda \Lambda \Lambda \Lambda \Lambda \Lambda \Lambda \Lambda \Lambda \Lambda \Lambda \Lambda \Lambda \Lambda \Lambda \Lambda \Lambda \Lambda \Lambda \Lambda \Lambda \Lambda \Lambda \Lambda \Lambda \Lambda \Lambda \Lambda \Lamb Da \Lambda \Lambda \Lambda \Lambda \Lambda \Lambda \Lambda \Lambda \Lambda \Lambda \Lambda \Lambda \Lambda \Lambda \Lambda \Lambda \Lambda \Lambda \Lambda \Lambda \Lambda \Lambda \Lambda \Lambda \Lambda \Lambda \Lambda \Lambda \Lambda \Lambda \Lambda \Lambda \Lambda \Lambda \Lambda \Lambda \Lambda \Lambda \Lambda \Lambda \Lambda \Lambda \Lambda \Lambda \Lambda \Lambda \Lambda \Lambda \Lambda \Lambla \Lambda \Lambda \Lambda \Lambda \Lambda \Lambda \Lambda \Lambda \Lambda \Lambda \Lambda \Lambda \Lambda \Lambda \Lambda \Lambda \Lambda \Lambda \Lambda \Lambda \Lambda \Lambda \Lambda \Lambda \Lambda \Lambda \Lambda \Lambda \Lambda \Lambda \Lambda \Lambda \Lambda \Lambda \Lambda \Lambda \Lambda \Lambda \Lambda \Lambda \Lambda \Lambda \Lambda \Lambda \Lambda \Lambda \Lambda \Lambda \Lambda \LambDA \Lambda \Lambda \Lambda \Lambda \Lambda \Lambda \Lambda \Lambda \Lambda \Lambda \Lambda \Lambda \Lambda \Lambda \Lambda \Lambda \Lambda \Lambda \Lambda \Lambda \Lambda \Lambda \Lambda \Lambda \Lambda \Lambda \Lambda \Lambda \Lambda \Lambda \Lambda \Lambda \Lambda \Lambda \Lambda \Lambda \Lambda \Lambda \Lambda \Lambda \Lambda \Lambda \Lambda \Lambda \Lambda \Lambda \Lambda \Lambda \Lambda \Lamba \Lambda \Lambda \Lambda \Lambda \Lambda \Lambda \Lambda \Lambda \Lambda \Lambda \Lambda \Lambda \Lambda \Lambda \Lambda \Lambda \Lambda \Lambda \Lambda \Lambda \Lambda \Lambda \Lambda \Lambda \Lambda \Lambda \Lambda \Lambda \Lambda \Lambda \Lambda \Lambda \Lambda \Lambda \Lambda \Lambda \Lambda \Lambda \Lambda \Lambda \Lambda \Lambda \Lambda \Lambda \Lambda \Lambda \Lambda \Lambda \Lambda \LambDa \Lambda \Lambda \Lambda \Lambda \Lambda \Lambda \Lambda \Lambda \Lambda \Lambda \Lambda \Lambda \Lambda \Lambda \Lambda \Lambda \Lambda \Lambda \Lambda \Lambda \Lambda \Lambda \Lambda \Lambda \Lambda \Lambda \Lambda \Lambda \Lambda \Lambda \Lambda \Lambda \Lambda \Lambda \Lambda \Lambda \Lambda \Lambda \Lambda \Lambda \Lambda \Lambda \Lambda \Lambda \Lambda \Lambda \Lambda \Lambda \Lambda \Lamb D \Lambda \Lambda \Lambda \Lambda \Lambda \Lambda \Lambda \Lambda \Lambda \Lambda \Lambda \Lambda \Lambda \Lambda \Lambda \Lambda \Lambda \Lambda \Lambda \Lambda \Lambda \Lambda \Lambda \Lambda \Lambda \Lambda \Lambda \Lambda \Lambda \Lambda \Lambda \Lambda \Lambda \Lambda \Lambda \Lambda \Lambda \Lambda \Lambda \Lambda \Lambda \Lambda \Lambda \Lambda \Lambda \Lambda \Lambda \Lambda \Lambda \Lamb d \Lamb \Lamb \Lamb \Lamb \Lamb \Lamb \Lamb \Lamb \Lamb \Lamb \Lamb \Lamb \Lamb \Lamb \Lamb \Lamb \Lamb \Lamb \Lamb \Lamb \Lamb \Lamb \Lamb \Lamb \Lamb \Lamb \Lamb \Lamb \Lamb \Lamb \Lamb \Lamb \Lamb \Lamb \Lamb \Lamb \Lamb \Lamb \Lamb \Lamb \Lamb \Lamb \Lamb \Lamb \Lamb \Lamb \Lamb \Lamb \Lamb \Lamb \Lamb \Lamb \Lamb \Lamb \Lamb \Lamb \Lamb \Lamb \Lamb \Lamb \Lamb \Lamb \Lamb \Lamb \Lamb \Lamb \Lamb \lamb \Lamb \Lamb \Lamb \Lamb \Lamb \Lamb \Lamb \Lamb \Lamb \Lamb \Lamb \Lamb \Lamb \Lamb \Lamb \Lamb \Lamb \Lamb \Lamb \Lamb \Lamb \Lamb \Lamb \Lamb \Lamb \Lamb \Lamb \Lamb \Lamb \Lamb \Lamb \Lamb \Lamb \Lamb \Lamb \Lamb \Lamb \Lamb \Lamb \Lamb \Lamb \Lamb \Lamb \Lamb \Lamb \Lamb \Lamb \Lamb \Lamb \Lamb \Lamb \Lamb \Lamb \Lamb \Lamb \Lamb \Lamb \Lamb \Lamb \Lamb \Lamb \Lamb \Lamb \Lamb \Lamb \Lamb \Lamb \Lamb \Lamb \Lamb \Lamb \Lamb \Lamb \Lamb \Lamb \Lamb \Lamb \Lamb \Lamb \Lamb \Lamb \Lamb \Lamb \Lamb \Lamb \Lamb \Lamb \Lamb \Lamb \Lamb \Lamb \Lamb \Lamb \Lamb \Lamb \Lamb \Lamb \Lamb \Lamb \Lamb \Lamb \Lamb \Lamb \Lamb \Lamb \Lamb \Lamb \Lamb \Lamb \Lamb \Lamb \Lamb \Lamb \Lamb \Lamb \Lamb \Lamb \Lamb \Lamb \Lamb \Lamb \Lamb \Lamb \Lamb \Lamb \Lamb \Lamb \Lamb \Lamb \Lamb \Lamb \Lamb \ Lamb \Lamb \Lamb \Lamb \Lamb \Lamb \Lamb \Lamb \Lamb \Lamb \Lamb \Lamb \Lamb \Lamb \Lamb \Lamb \Lamb \Lamb \Lamb \Lamb \Lamb \Lamb \Lamb \Lamb \Lamb \Lamb \Lamb \Lamb \Lamb \Lamb \Lamb \Lamb \Lamb \Lamb \Lamb \Lamb \Lamb \Lamb \Lamb \Lamb \Lamb \Lamb \Lamb \Lamb \Lamb \Lamb \Lamb \Lamb \Lamb \Lamb \Lamb \Lamb \Lamb \Lamb \Lamb \Lamb \Lamb \Lamb \Lamb \Lamb \Lamb \Lamb \Lamb \Lamb \Lamb \Lamb \Lamb\Lamb \Lamb \Lamb \Lamb \Lamb \Lamb \Lamb \Lamb \Lamb \Lamb \Lamb \Lamb \Lamb \Lamb \Lamb \Lamb \Lamb \Lamb \Lamb \Lamb \Lamb \Lamb \Lamb \Lamb \Lamb \Lamb \Lamb \Lamb \Lamb \Lamb \Lamb \Lamb \Lamb \Lamb \Lamb \Lamb \Lamb \Lamb \Lamb \Lamb \Lamb \Lamb \Lamb \Lamb \Lamb \Lamb \Lamb \Lamb \Lamb \Lamb \Lamb \Lamb \Lamb \Lamb \Lamb \Lamb \Lamb \Lamb \Lamb \Lamb \Lamb \Lamb \Lamb \Lamb \Lamb \Lamb \L_{ \Lamb \Lamb \Lamb \Lamb \Lamb \Lamb \Lamb \Lamb \Lamb \Lamb \Lamb \Lamb \Lamb \Lamb \Lamb \Lamb \Lamb \Lamb \Lamb \Lamb \Lamb \Lamb \Lamb \Lamb \Lamb \Lamb \Lamb \Lamb \Lamb \Lamb \Lamb \Lamb \Lamb \Lamb \Lamb \Lamb \Lamb \Lamb \Lamb \Lamb \Lamb \Lamb \Lamb \Lamb \Lamb \Lamb \Lamb \Lamb \Lamb \Lamb \Lamb \Lamb \Lamb \Lamb \Lamb \Lamb \Lamb \Lamb \Lamb \Lamb \Lamb \Lamb \Lamb \Lamb \Lamb \Lamb \end{array}$$
which can be tested in future experiment.
In Ref. [5], the ratio Γ ( D K ∗ ) / Γ ( DK ) = 13 22 / = 0 59 . was given for DsJ (2860) observed by Belle as the 1 3 D 3 state, where the QPC model was also adopted and this ratio is obtained by taking a typical value R = 2 94 GeV . -1 . In the present work, we consider the range R = 2 4 . ∼ 3 6 GeV . -1 to present the D K DK ∗ / ratio for Ds 3 (2860). If comparing the ratio given in Eq. (14) with the corresponding one obtained in Ref. [5], we notice that their value Γ ( D K ∗ ) / Γ ( DK ) = 0 59 . [5] just falls into our obtained range Γ ( D K ∗ ) / Γ ( DK ) = 0 55 . ∼ 0 80. .
In addition, we need to make a comment on the experimental ratio Γ ( D K ∗ ) / Γ ( DK ) = 1 10 . ± 0 15 . ± 0 19 for . DsJ (2860), which was extracted by the BaBar Collaboration [3]. Since LHCb indicated that there exist two resonances Ds 1 (2860) and Ds 3 (2860) in the DK invariant mass spectrum [1, 2], the experimental ratio Γ ( D K ∗ ) / Γ ( DK ) for DsJ (2860) must be changed, which means that we cannot simply apply the old Γ ( D K ∗ ) / Γ ( DK ) data in Ref. [3] to draw a conclusion on the structure of DsJ (2860). We expect further experimental measurements of this ratio, which will be helpful to reveal the properties of the observed DsJ (2860) states.
$$C. \ 1 D ( 2 ^ { - } ) \text{ and } 1 D ^ { \prime } ( 2 ^ { - } )$$
In the following, we discuss the decay behaviors of two missing 1 D states in the present experiment, which is crucial to the experimental search for the 1 D (2 -) and 1 D ′ (2 -) states.
We first fix the mixing angle θ 1 D = 39 ◦ obtained in the heavy quark limit, and discuss the R value dependence of the total and partial decay widths of the two missing 2 -states in experiment, which are presented in Fig. 3. Since these two 1 D states have not yet been seen in experiment, we take the mass range 2850 ∼ 2950 MeV, which covers the theoretically predicted masses of the 1 D (2 -) and 1 D ′ (2 -) states from different groups listed in Table I, to discuss the decay behaviors of the 1 D (2 -) and 1 D ′ (2 -) states.
Additionally, as shown in Fig. 3, the 1 D (2 -) state can dominantly decay into D K ∗ , where B (1 D (2 -) → D K ∗ ) = (77 ∼ 87)%, and DK ∗ and Ds ∗ η are its main decay modes. Comparing D K ∗ , DK ∗ and Ds ∗ η with each other, Ds ∗ η is the weakest decay channel. Hence, we suggest experimental search for the 1 D (2 -) state firstly via the D K ∗ channel.
The total and partial decay width of 1 D (2 -) are present in the upper panel of Fig. 3. Here, two typical mass of 1 D (2 -) state, 2850 MeV and 2950 MeV, are considered, which are corresponding to the solid and dashed curved in Fig. 3. The estimated total decay width varies from 90 MeV to 190 MeV, which is due to the uncertainty of the predicted mass of the 1 D (2 -) state and the R value dependence as mentioned above. If the mass of the 1 D (2 -) state can be constrained by future experiment, the uncertainty of the total width for the 1 D (2 -) state can be further reduced. In any case, our study indicates that the 1 D (2 -) state has a broad width.
We also obtain two typical ratios, i.e.,
$$\frac { \Gamma ( 1 D ( 2 ^ { - } ) \to D K ^ { * } ) } { \Gamma ( 1 D ( 2 ^ { - } ) \to D ^ { * } K ) } & = 0. 1 1 \sim 0. 3 6 \quad \quad ( 1 7 ) \\ \Gamma ( 1 D ( 2 ^ { - } ) \to D _ { k } ^ { * } \eta ) \quad \dots \quad \dots \quad \dots \quad \dots$$
$$\stackrel { \bullet \, \mathcal { W } _ { \bullet } \, \mathcal { W } _ { \bullet } \, \mathcal { W } _ { \bullet } } { \frac { \Gamma ( 1 D ( 2 ^ { - } ) \to D _ { s } ^ { * } \eta ) } { \Gamma ( 1 D ( 2 ^ { - } ) \to D ^ { * } K ) } } = 0. 1 1 \sim 0. 1 8, \quad \ \ ( 1 8 ) \\ \text{s.m.s.s.s.s.s.s.s.s.s.s.s.s.s.s.s.s.s.s.s.s.s.s.s.s.s.s.s.s.s.s.s.s.s.s.s.s.s.s.s.s.s.s.s.s.s.s.s.s.s.s.s.s.s.s.s.s.s.s.s.s.s.s.s.s.s.s.s.s.s.s.s.s.s.s.s.s.s.s.s.s.s.s.s.s.s.s.s.s.s.s.s.s.s.s.s.s.s.s.s.s.t.s.s.s.s.s.s.s.s.s.s.s.s.s.s.s.s.s.s.s.s.s.s.s.s.s.s.s.s.s.s.s.s.s.s.s.s.s.s.s.s.s.s.s.s.s.s.s.s.s.s.s.s.s.s.s.s.s.s.s.s.s.s.s.s.s.s.s.s.s.s.s.s.s.s.s.s.s.s.s.s.s.s.s.s.s.s.s.s.s.s.s.s.s.s.s.s.s.s.s. s.s.s.s.s.s.s.s.s.s.s.s.s.s.s.s.s.s.s.s.s.s.s.s.s.s.s.s.s.s.s.s.s.s.s.s.s.s.s.s.s.s.s.s.s.s.s.s.s.s.s.s.s.s.s.s.s.s.s.s.s.s.s.s.s.s.s.s.s.s.s.s.s.s.s.s.s.s.s.s.s.s.s.s.s.s.s.s.s.s.s.s.s.s.s.s.s.s.s.s.n.s.s.s.s.s.s.s.s.s.s.s.s.s.s.s.s.s.s.s.s.s.s.s.s.s.s.s.s.s.s.s.s.s.s.s.s.s.s.s.s.s.s.s.s.s.s.s.s.s.s.s.s.s.s.s.s.s.s.s.s.s.s.s.s.s.s.s.s.s.s.s.s.s.s.s.s.s.s.s.s.s.s.s.s.s.s.s.s.s.s.s.s.s.s.s.s.s.s.s.ns.s.s.s.s.s.s.s.s.s.s.s.s.s.s.s.s.s.s.s.s.s.s.s.s.s.s.s.s.s.s.s.s.s.s.s.s.s.s.s.s.s.s.s.s.s.s.s.s.s.s.s.s.s.s.s.s.s.s.s.s.s.s.s.s.s.s.s.s.s.s.s.s.s.s.s.s.s.s.s.s.s.s.s.s.s.s.s.s.s.s.s.s.s.s.s.s.s.s.s.r.s.s.s.s.s.s.s.s.s.s.s.s.s.s.s.s.s.s.s.s.s.s.s.s.s.s.s.s.s.s.s.s.s.s.s.s.s.s.s.s.s.s.s.s.s.s.s.s.s.s.s.s.s.s.s.s.s.s.s.s.s.s.s.s.s.s.s.s.s.s.s.s.s.s.s.s.s.s.s.s.s.s.s.s.s.s.s.s.s.s.s.s.s.s.s.s.s.s.s.g.s.s.s.s.s.s.s.s.s.s.s.s.s.s.s.s.s.s.s.s.s.s.s.s.s.s.s.s.s.s.s.s.s.s.s.s.s.s.s.s.s.s.s.s.s.s.s.s.s.s.s.s.s.s.s.s.s.s.s.s.s.s.s.s.s.s.s.s.s.s.s.s.s.s.s.s.s.s.s.s.s.s.s.s.s.s.s.s.s.s.s.s.s.s.s.s.s.s.s.c.s.s.s.s.s.s.s.s.s.s.s.s.s.s.s.s.s.s.s.s.s.s.s.s.s.s.s.s.s.s.s.s.s.s.s.s.s.s.s.s.s.s.s.s.s.s.s.s.s.s.s.s.s.s.s.s.s.s.s.s.s.s.s.s.s.s.s.s.s.s.s.s.s.s.s.s.s.s.s.s.s.s.s.s.s.s.s.s.s.s.s.s.s.s.s.s.s.s.s.S.s.s.s.s.s.s.s.s.s.s.s.s.s.s.s.s.s.s.s.s.s.s.s.s.s.s.s.s.s.s.s.s.s.s.s.s.s.s.s.s.s.s.s.s.s.s.s.s.s.s.s.s.s.s.s.s.s.s.s.s.s.s.s.s.s.s.s.s.s.s.s.s.s.s.s.s.s.s.s.s.s.s.s.s.s.s.s.s.s.s.s.s.s.s.s.s.s.s.s.l.s.s.s.s.s.s.s.s.s.s.s.s.s.s.s.s.s.s.s.s.s.s.s.s.s.s.s.s.s.s.s.s.s.s.s.s.s.s.s.s.s.s.s.s.s.s.s.s.s.s.s.s.s.s.s.s.s.s.s.s.s.s.s.s.s.s.s.s.s.s.s.s.s.s.s.s.s.s.s.s.s.s.s.s.s.s.s.s.s.s.s.s.s.s.s.s.s.s.s.h.s.s.s.s.s.s.s.s.s.s.s.s.s.s.s.s.s.s.s.s.s.s.s.s.s.s.s.s.s.s.s.s.s.s.s.s.s.s.s.s.s.s.s.s.s.s.s.s.s.s.s.s.s.s.s.s.s.s.s.s.s.s.s.s.s.s.s.s.s.s.s.s.s.s.s.s.s.s.s.s.s.s.s.s.s.s.s.s.s.s.s.s.s.s.s.s.s.s.s.a.s.s.s.s.s.s.s.s.s.s.s.s.s.s.s.s.s.s.s.s.s.s.s.s.s.s.s.s.s.s.s.s.s.s.s.s.s.s.s.s.s.s.s.s.s.s.s.s.s.s.s.s.s.s.s.s.s.s.s.s.s.s.s.s.s.s.s.s.s.s.s.s.s.s.s.s.s.s.s.s.s.s.s.s.s.s.s.s.s.s.s.s.s.s.s.s.s.s.s.x.s.s.s.s.s.s.s.s.s.s.s.s.s.s.s.s.s.s.s.s.s.s.s.s.s.s.s.s.s.s.s.s.s.s.s.s.s.s.s.s.s.s.s.s.s.s.s.s.s.s.s.s.s.s.s.s.s.s.s.s.s.s.s.s.s.s.s.s.s.s.s.s.s.s.s.s.s.s.s.s.s.s.s.s.s.s.s.s.s.s.s.s.s.s.s.s.s.s.s.ss.s.s.s.s.s.s.s.s.s.s.s.s.s.s.s.s.s.s.s.s.s.s.s.s.s.s.s.s.s.s.s.s.s.s.s.s.s.s.s.s.s.s.s.s.s.s.s.s.s.s.s.s.s.s.s.s.s.s.s.s.s.s.s.s.s.s.s.s.s.s.s.s.s.s.s.s.s.s.s.s.s.s.s.s.s.s.s.s.s.s.s.s.s.s.s.s.s.s.s.is.s.s.s.s.s.s.s.s.s.s.s.s.s.s.s.s.s.s.s.s.s.s.s.s.s.s.s.s.s.s.s.s.s.s.s.s.s.s.s.s.s.s.s.s.s.s.s.s.s.s.s.s.s.s.s.s.s.s.s.s.s.s.s.s.s.s.s.s.s.s.s.s.s.s.s.s.s.s.s.s.s.s.s.s.s.s.s.s.s.s.s.s.s.s.s.s.s.s.s.i.s.s.s.s.s.s.s.s.s.s.s.s.s.s.s.s.s.s.s.s.s.s.s.s.s.s.s.s.s.s.s.s.s.s.s.s.s.s.s.s.s.s.s.s.s.s.s.s.s.s.s.s.s.s.s.s.s.s.s.s.s.s.s.s.s.s.s.s.s.s.s.s.s.s.s.s.s.s.s.s.s.s.s.s.s.s.s.s.s.s.s.s.s.s.s.s.s.s.s.e.s.s.s.s.s.s.s.s.s.s.s.s.s.s.s.s.s.s.s.s.s.s.s.s.s.s.s.s.s.s.s.s.s.s.s.s.s.s.s.s.s.s.s.s.s.s.s.s.s.s.s.s.s.s.s.s.s.s.s.s.s.s.s.s.s.s.s.s.s.s.s.s.s.s.s.s.s.s.s.s.s.s.s.s.s.s.s.s.s.s.s.s.s.s.s.s.s.s.s.d.s.s.s.s.s.s.s.s.s.s.s.s.s.s.s.s.s.s.s.s.s.s.s.s.s.s.s.s.s.s.s.s.s.s.s.s.s.s.s.s.s.s.s.s.s.s.s.s.s.s.s.s.s.s.s.s.s.s.s.s.s.s.s.s.s.s.s.s.s.s.s.s.s.s.s.s.s.s.s.s.s.s.s.s.s.s.s.s.s.s.s.s.s.s.s.s.s.s.s.
s.s.s.s.s.s.s.s.s.s.s.s.s.s.s.s.s.s.s.s.s.s.s.s.s.s.s.s.s$$
which can be accessible in experiment.
As for the 1 D ′ (2 -) state, the total and partial decay width are present in the lower panel of Fig. 3. we predict its total decay width ((80 ∼ 240) MeV), which shows that the 1 D ′ (2 -) state is also a broad resonance, where DK ∗ is its dominant decay mode with a branching ratio B (1 D ′ (2 -) → DK ∗ ) = (0 64 . ∼ 0 73)%. . Its main decay mode includes D K ∗ , while 1 D ′ → Ds ∗ η and 1 D ′ → D 0 (2400) K have small partial decay widths. Besides the above information, two typical ratios are listed as below
$$\frac { \Gamma ( 1 D ^ { \prime } ( 2 ^ { - } ) \to D ^ { * } K ) } { \Gamma ( 1 D ^ { \prime } ( 2 ^ { - } ) \to D K ^ { * } ) } & = 0. 3 6 \sim 0. 5 3, \quad \quad ( 1 9 ) \\ \Gamma ( 1 D ^ { \prime } ( 2 ^ { - } ) \to D ^ { * } \eta ) \quad \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \$$
$$\stackrel { \bullet \, \bullet \, \bullet \, \bullet \, \bullet \, \bullet \, \bullet \, \bullet \, \bullet \, \bullet \, \bullet \, \bullet \, \bullet \, \bullet \, \bullet \, \bullet \, \bullet \, \bullet \, \bullet \, \bullet \, \bullet \, \bullet \, \bullet \, \bullet \, \bullet \, \bullet \, \bullet \, \bullet \, \bullet \, \bullet \, \bullet \, \bullet \, \bullet \, \bullet \, \bullet \, \bullet \, \bullet \, \bullet \, \bullet \, \bullet \, \bullet \colon \, \bullet \, \bullet \, \bullet \, \bullet \, \bullet \, \bullet \, \bullet \, \bullet \, \bullet \, \bullet \, \bullet \, \bullet \, \bullet \, \bullet \, \bullet \, \bullet \, \bullet \, \bullet \, \bullet \, \bullet \, \bullet \, \bullet \, \bullet \, \bullet \, \bullet \, \bullet \, \bullet \, \bullet \, \bullet \, \bullet \, \bullet \, \bullet \, \bullet \, \bullet \, \bullet \, \bullet \, \bullet \, \bullet \, \bullet \, \bulLET \, \bullet \, \bullet \, \bullet \, \bullet \, \bullet \, \bullet \, \bullet \, \bullet \, \bullet \, \bullet \, \bullet \, \bullet \, \bullet \, \bullet \, \bullet \, \bullet \, \bullet \, \bullet \, \bullet \, \bullet \, \bullet \, \bullet \, \bullet \, \bullet \, \bullet \, \bullet \, \bullet \, \bullet \, \bullet \, \bullet \, \bullet \, \bullet \, \bullet \, \bullet \, \bullet \, \bullet \, \bullet \, \bullet \, \bullet \, \bul. \, \bullet \, \bullet \, \bullet \, \bullet \, \bullet \, \bullet \, \bullet \, \bullet \, \bullet \, \bullet \, \bullet \, \bullet \, \bullet \, \bullet \, \bullet \, \bullet \, \bullet \, \bullet \, \bullet \, \bullet \, \bullet \, \bullet \, \bullet \, \bullet \, \bullet \, \bullet \, \bullet \, \bullet \, \bullet \, \bullet \, \bullet \, \bullet \, \bullet \, \bullet \, \bullet \, \bullet \, \bullet \, \bullet \, \bullet \, \bullets \, \bullet \, \bullet \, \bullet \, \bullet \, \bullet \, \bullet \, \bullet \, \bullet \, \bullet \, \bullet \, \bullet \, \bullet \, \bullet \, \bullet \, \bullet \, \bullet \, \bullet \, \bullet \, \bullet \, \bullet \, \bullet \, \bullet \, \bullet \, \bullet \, \bullet \, \bullet \, \bullet \, \bullet \, \bullet \, \bullet \, \bullet \, \bullet \, \bullet \, \bullet \, \bullet \, \bullet \, \bullet \, \bullet \, \bullet \, \bulle \, \bullet \, \bullet \, \bullet \, \bullet \, \bullet \, \bullet \, \bullet \, \bullet \, \bullet \, \bullet \, \bullet \, \bullet \, \bullet \, \bullet \, \bullet \, \bullet \, \bullet \, \bullet \, \bullet \, \bullet \, \bullet \, \bullet \, \bullet \, \bullet \, \bullet \, \bullet \, \bullet \, \bullet \, \bullet \, \bullet \, \bullet \, \bullet \, \bullet \, \bullet \, \bullet \, \bullet \, \bullet \, \bullet \, \bullet \, \bul. \, \bullet \, \bullet \, \bullet \, \bullet \, \bullet \, \bullet \, \bullet \, \bullet \, \bullet \, \bullet \, \bullet \, \bullet \, \bullet \, \bullet \, \bullet \, \bullet \, \bullet \, \bullet \, \bullet \, \bullet \, \bullet \, \bullet \, \bullet \, \bullet \, \bullet \, \bullet \, \bullet \, \bullet \, \bullet \, \bullet \, \bullet \, \bullet \, \bullet \, \bullet \, \bullet \, \bullet \, \bullet \, \bullet \, \bullet \, \bul! \, \bullet \, \bullet \, \bullet \, \bullet \, \bullet \, \bullet \, \bullet \, \bullet \, \bullet \, \bullet \, \bullet \, \bullet \, \bullet \, \bullet \, \bullet \, \bullet \, \bullet \, \bullet \, \bullet \, \bullet \, \bullet \, \bullet \, \bullet \, \bullet \, \bullet \, \bullet \, \bullet \, \bullet \, \bullet \, \bullet \, \bullet \, \bullet \, \bullet \, \bullet \, \bullet \, \bullet \, \bullet \, \bullet \, \bullet \, \bulclon \, \bullet \, \bullet \, \bullet \, \bullet \, \bullet \, \bullet \, \bullet \, \bullet \, \bullet \, \bullet \, \bullet \, \bullet \, \bullet \, \bullet \, \bullet \, \bullet \, \bullet \, \bullet \, \bullet \, \bullet \, \bullet \, \bullet \, \bullet \, \bullet \, \bullet \, \bullet \, \bullet \, \bullet \, \bullet \, \bullet \, \bullet \, \bullet \, \bullet \, \bullet \, \bullet \, \bullet \, \bullet \, \bullet \, \bullet \, \boldlet \, \bullet \, \bullet \, \bullet \, \bullet \, \bullet \, \bullet \, \bullet \, \bullet \, \bullet \, \bullet \, \bullet \, \bullet \, \bullet \, \bullet \, \bullet \, \bullet \, \bullet \, \bullet \, \bullet \, \bullet \, \bullet \, \bullet \, \bullet \, \bullet \, \bullet \, \bullet \, \bullet \, \bullet \, \bullet \, \bullet \, \bullet \, \bullet \, \bullet \, \bullet \, \bullet \, \bullet \, \bullet \, \bullet \, \bullet \, \bold. \, \bullet \, \bullet \, \bullet \, \bullet \, \bullet \, \bullet \, \bullet \, \bullet \, \bullet \, \bullet \, \bullet \, \bullet \, \bullet \, \bullet \, \bullet \, \bullet \, \bullet \, \bullet \, \bullet \, \bullet \, \bullet \, \bullet \, \bullet \, \bullet \, \bullet \, \bullet \, \bullet \, \bullet \, \bullet \, \bullet \, \bullet \, \bullet \, \bullet \, \bullet \, \bullet \, \bullet \, \bullet \, \bullet \, \bullet \, \bold. \, \bullet \, \bullet \, \bullet \, \bullet \, \bullet \, \bullet \, \bullet \, \bullet \, \bullet \, \bullet \, \bullet \, \bullet \, \bullet \, \bullet \, \bullet \, \bullet \, \bullet \, \bullet \, \bullet \, \bullet \, \bullet \, \bullet \, \bullet \, \bullet \, \bullet \, \bullet \, \bullet \, \bullet \, \bullet \, \bullet \, \bullet \, \bullet \, \bullet \, \bullet \, \bullet \, \bullet \, \bullet \, \bullet \, \bullet \, \boldt \, \bullet \, \bullet \, \bullet \, \bullet \, \bullet \, \bullet \, \bullet \, \bullet \, \bullet \, \bullet \, \bullet \, \bullet \, \bullet \, \bullet \, \bullet \, \bullet \, \bullet \, \bullet \, \bullet \, \bullet \, \bullet \, \bullet \, \bullet \, \bullet \, \bullet \, \bullet \, \bullet \, \bullet \, \bullet \, \bullet \, \bullet \, \bullet \, \bullet \, \bullet \, \bullet \, \bullet \, \bullet \, \bullet \, \bullet \, \bult \, \bullet \, \bullet \, \bullet \, \bullet \, \bullet \, \bullet \, \bullet \, \bullet \, \bullet \, \bullet \, \bullet \, \bullet \, \bullet \, \bullet \, \bullet \, \bullet \, \bullet \, \bullet \, \bullet \, \bullet \, \bullet \, \bullet \, \bullet \, \bullet \, \bullet \, \bullet \, \bullet \, \bullet \, \bullet \, \bullet \, \bullet \, \bullet \, \bullet \, \bullet \, \bullet \, \bullet \, \bullet \, \bullet \, \bullet \, \boldclon \, \bullet \, \bullet \, \bullet \, \bullet \, \bullet \, \bullet \, \bullet \, \bullet \, \bullet \, \bullet \, \bullet \, \bullet \, \bullet \, \bullet \, \bullet \, \bullet \, \bullet \, \bullet \, \bullet \, \bullet \, \bullet \, \bullet \, \bullet \, \bullet \, \bullet \, \bullet \, \bullet \, \bullet \, \bullet \, \bullet \, \bullet \, \bullet \, \bullet \, \bullet \, \bullet \, \bullet \, \bullet \, \bullet \, \bullet \,\bullet \, \bullet \, \bullet \, \bullet \, \bullet \, \bullet \, \bullet \, \bullet \, \bullet \, \bullet \, \bullet \, \bullet \, \bullet \, \bullet \, \bullet \, \bullet \, \bullet \, \bullet \, \bullet \, \bullet \, \bullet \, \bullet \, \bullet \, \bullet \, \bullet \, \bullet \, \bullet \, \bullet \, \bullet \, \bullet \, \bullet \, \bullet \, \bullet \, \bullet \, \bullet \, \bullet \, \bullet \, \bullet \, \bullet \, \bullet \,\bul. \, \bullet \, \bullet \, \bullet \, \bullet \, \bullet \, \bullet \, \bullet \, \bullet \, \bullet \, \bullet \, \bullet \, \bullet \, \bullet \, \bullet \, \bullet \, \bullet \, \bullet \, \bullet \, \bullet \, \bullet \, \bullet \, \bullet \, \bullet \, \bullet \, \bullet \, \bullet \, \bullet \, \bullet \, \bullet \, \bullet \, \bullet \, \bullet \, \bullet \, \bullet \, \bullet \, \bullet \, \bullet \, \bullet \, \bullet \,\bulle \, \bullet \, \bullet \, \bullet \, \bullet \, \bullet \, \bullet \, \bullet \, \bullet \, \bullet \, \bullet \, \bullet \, \bullet \, \bullet \, \bullet \, \bullet \, \bullet \, \bullet \, \bullet \, \bullet \, \bullet \, \bullet \, \bullet \, \bullet \, \bullet \, \bullet \, \bullet \, \bullet \, \bullet \, \bullet \, \bullet \, \bullet \, \bullet \, \bullet \, \bullet \, \bullet \, \bullet \, \bullet \, \bullet \, \bullet \,\bul. \bullet \, \bullet \, \bullet \, \bullet \, \bullet \, \bullet \, \bullet \, \bullet \, \bullet \, \bullet \, \bullet \, \bullet \, \bullet \, \bullet \, \bullet \, \bullet \, \bullet \, \bullet \, \bullet \, \bullet \, \bullet \, \bullet \, \bullet \, \bullet \, \bullet \, \bullet \, \bullet \, \bullet \, \bullet \, \bullet \, \bullet \, \bullet \, \bullet \, \bullet \, \bullet \, \bullet \, \$$
It should be noticed that the threshold of D s ∗ 0 (2317) η is 2865 MeV and two 1 D charmed-strange mesons with J P = 2 -decaying into D s ∗ 0 (2317) η occur via D -wave. Thus, 1 D (2 -) / 1 D ′ (2 -) → D s ∗ 0 (2317) η is suppressed, which is supported by our calculation since the corresponding partial decay widths are of the order of a few keV for 1 D (2 -) → D s ∗ 0 η and of the order of 0.1 keV for 1 D ′ (2 -) → D s ∗ 0 η .
In Table IV, we fix the R value of 1 D (2 -) and 1 D ′ (2 -) to be 2.85 GeV -1 [42] and further discuss the total and partial decay widths dependent on the mixing angle θ 1 D , where three typical
FIG. 3: (Color online). The total and partial decay widths of 1 D (2 -) (upper row) and 1 D ′ (2 -) (lower row) charmed-strange mesons dependent on the R values. Here, a mixing angle of 39 ◦ is chosen. The solid and dashed curves correspond to two predicted masses of 2 -states, 2850 MeV and 2950 MeV, respectively.
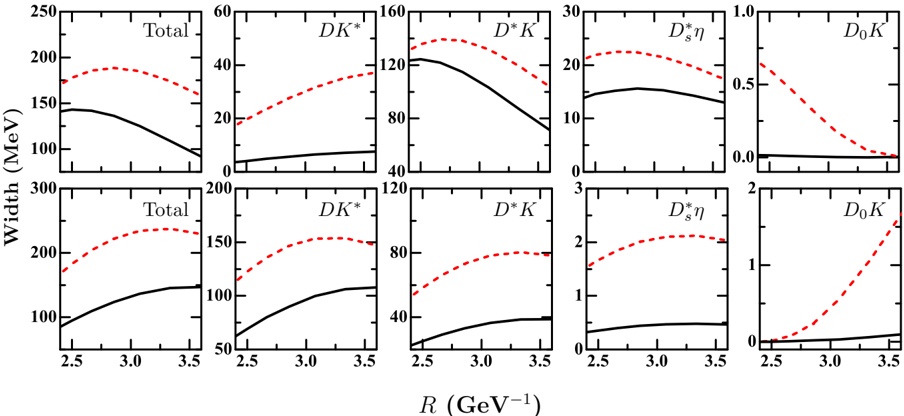
TABLE IV: The total and partial decay widths of two 2 -states (in units of MeV) dependent on the mixing angle θ 1 D (The typical values are θ 1 D = 20 ◦ , 30 ◦ and 50 ). Here, the ◦ R value of 1 D (2 -) and 1 D ′ (2 -) is fixed as R = 2 85 GeV . -1 [42].
| | M = 2850 MeV | M = 2850 MeV | M = 2850 MeV | M = 2850 MeV | M = 2850 MeV | M = 2850 MeV | M = 2950 MeV | M = 2950 MeV | M = 2950 MeV | M = 2950 MeV | M = 2950 MeV | M = 2950 MeV |
|----------------|----------------|----------------|----------------|----------------|----------------|----------------|----------------|----------------|----------------|----------------|----------------|----------------|
| | θ 1 D = 20 ◦ | θ 1 D = 20 ◦ | θ 1 D = 30 ◦ | θ 1 D = 30 ◦ | θ 1 D = 50 ◦ | θ 1 D = 50 ◦ | θ 1 D = 20 ◦ | θ 1 D = 20 ◦ | θ 1 D = 30 ◦ | θ 1 D = 30 ◦ | θ 1 D = 50 ◦ | θ 1 D = 50 ◦ |
| Channels | 1 D (2 - ) | 1 D ′ (2 - ) | 1 D (2 - ) | 1 D ′ (2 - ) | 1 D (2 - ) | 1 D ′ (2 - ) | 1 D (2 - ) | 1 D ′ (2 - ) | 1 D (2 - ) | 1 D ′ (2 - ) | 1 D (2 - ) | 1 D ′ (2 - ) |
| D ∗ K | 126.93 | 44.60 | 135.61 | 35.90 | 134.62 | 36.84 | 110.42 | 77.82 | 113.85 | 74.39 | 113.46 | 74.76 |
| DK ∗ | 26.06 | 70.04 | 13.54 | 82.59 | 1.99 | 94.18 | 56.19 | 118.06 | 38.58 | 135.69 | 22.34 | 152.00 |
| D ∗ s η | 13.93 | 2.08 | 15.17 | 0.83 | 15.03 | 0.97 | 20.23 | 4.21 | 21.91 | 2.54 | 21.72 | 2.72 |
| D ∗ 0 (2400) K | 0.012 | 0.011 | 0.008 | 0.015 | 0.002 | 0.022 | 0.50 | 0.08 | 0.42 | 0.16 | 0.22 | 0.36 |
| Total | 166.93 | 116.73 | 164.33 | 119.34 | 151.64 | 132.01 | 187.34 | 200.17 | 174.76 | 212.78 | 157.74 | 229.84 |
values θ 1 D = 20 , ◦ θ 1 D = 30 ◦ and θ 1 D = 50 ◦ are adopted. For 1 D (2 -) state, its total decay width varies from 152 MeV to 187 MeV, which indicates that the total decay width is weakly dependent on the mixing angle θ 1 D . Moreover, 1 D (2 -) state dominantly decays into D K ∗ , whose width varies from 110 MeV to 134 MeV caused by the uncertainty of the mass of 1 D (2 -) state and the di ff erent mixing angle θ 1 D . In addition, the ratio of 1 D (2 -) → Ds ∗ η and 1 D (2 -) → D K ∗ is estimated to be 0 11 . ∼ 0 19, which is consistent with that shown in Eq. . (18). However, the predicted partial decay width of 1 D (2 -) → DK ∗ is strongly dependent on the mixing angle, which varies from 2 MeV to 56 MeV.
## III. DISCUSSION AND CONCLUSIONS
The total decay width of 1 D ′ (2 -) varies from 117 MeV to 230 MeV depending on di ff erent predicted masses and mixing angles. Its dominant decay modes are D K ∗ and DK ∗ and the ratios of 1 D ′ (2 -) → D K ∗ and 1 D ′ (2 -) → DK ∗ are predicted to be 0 39 . ∼ 0 66. The partial decay widths of 1 . D ′ (2 -) → Ds ∗ η and 1 D ′ (2 -) → D 0 (2400) K are relatively small and are given by several MeV and less than 0.5 MeV, respectively.
With the observation of two charmed-strange resonances Ds 1 (2860) and Ds 3 (2860), which was recently announced by the LHCb Collaboration [1, 2], the observed charmed-strange states become more and more abundant. In this work, we have carried out a study of the observed Ds 1 (2860) and Ds 3 (2860), which indicates that Ds 1 (2860) and Ds 3 (2860) can be well categorized as 1 3 D 1 and 1 3 D 3 states in the charmed-strange meson family since the experimental widths of Ds 1 (2860) and Ds 3 (2860) can be reproduced by the corresponding calculated total widths of the 1 3 D 1 and 1 3 D 3 states. In addition, the result of their partial decay widths shows that the DK decay mode is dominant both for 1 3 D 1 and 1 3 D 3 states, which naturally explains why Ds 1 (2860) and Ds 3 (2860) were first observed in the DK channel. If Ds 1 (2860) and Ds 3 (2860) are the 1 3 D 1 and 1 3 D 3 states, respectively, our study also indicates that the D K ∗ and DK ∗ channels are the main decay mode of Ds 1 (2860) and Ds 3 (2860), respectively. Thus, we suggest for future exper-
iment to search for Ds 1 (2860) and Ds 3 (2860) in these main decay channels, which can not only test our prediction presented in this work but also provide more information of the properties of Ds 1 (2860) and Ds 3 (2860).
As the spin partners of Ds 1 (2860) and Ds 3 (2860), two 1 D charmed-strange mesons with J P = 2 -are still missing in experiment. Thus, in this work we also predict the decay behaviors of these two missing 1 D charmed-strange mesons. Our calculation by the QPC model shows that both 1 D (2 -) and 1 D ′ (2 -) states have very broad widths. For the 1 D (2 -) and 1 D ′ (2 -) states, their dominant decay mode is D K ∗ and DK ∗ , respectively. In addition, DK ∗ and D K ∗ are also the important decay modes of the 1 D (2 -) and 1 D ′ (2 -) states, respectively. This investigation provides valuable information when further experimentally exploring these two missing 1 D charmed-strange mesons.
In summary, the observed Ds 1 (2860) and Ds 3 (2860) provide us a good opportunity to establish higher states in the charmed-strange meson family. The following experimental and theoretical e ff orts are still necessary to reveal the underlying properties of Ds 1 (2860) and Ds 3 (2860). Furthermore, it is a challenging research topic for future experiment to hunt the two predicted missing 1 D charmed-strange mesons with J P = 2 . -
Before closing this section, we would like to discuss the threshold e ff ect or coupled-channel e ff ect, which was proposed to solve the puzzling lower mass and narrow widths for Ds 0 (2317) [46] and Ds 1 (2460) [47], and to understand the properties of X (3872). We notice that there exist several typical D K DK ∗ , ∗ , and D K ∗ ∗ thresholds, which are ∼ 2580 MeV, ∼ 2762 MeV, and ∼ 2902 MeV, respectively. Here, the observed Ds 1 (2860) and Ds 3 (2860) are near the D K ∗ ∗ threshold while Ds 1 (2715) is close to the DK ∗ threshold. This fact also shows that the threshold e ff ect or coupled-channel e ff ect is important to these observed charmed-strange states. For example, in Ref. [48], the authors studied the D K ∗ ∗ threshold e ff ect on D s ∗ 2 (2573). Thus, further theoretical study of Ds 1 (2860) and Ds 3 (2860) by considering the threshold e ff ect or coupledchannel e ff ect is an interesting research topic.
In addition, the results presented in this work are calculated by using the SHO wave functions with a rms radius obtained within a relativistic quark model [18], which can provide a quantitative estimate of the decay behavior of hadrons. However, the line shape of the SHO wave function is slightly different from the one obtained by the relativistic quark model. For example, the nodes may appear at di ff erent places for these two cases. Thus, adopting a numerical wave function from a relativistic quark model [18] may further improve the whole results, where we can compare the results obtained by using the SHO wave function and the numerical wave function, which is an interesting research topic 2 .
2 We would like to thank the anonymous referee for his her valuable sugges-/ tion.
## Acknowledgments
This project is supported by the National Natural Science Foundation of China under Grants No. 11222547, No. 11375240, No. 11175073, and No. 11035006, the Ministry of Education of China (SRFDP under Grant No. 2012021111000), and the Fok Ying Tung Education Foundation (No. 131006).
- [1] R. Aaij et al. [ LHCb Collaboration], arXiv:1407.7574 [hepex].
- [2] R. Aaij et al. [ LHCb Collaboration], arXiv:1407.7712 [hepex].
- [3] B. Aubert et al. [BaBar Collaboration], Phys. Rev. Lett. 97 , 222001 (2006) [hep-ex 0607082]. /
- [4] B. Aubert et al. [BaBar Collaboration], Phys. Rev. D 80 , 092003 (2009) [arXiv:0908.0806 [hep-ex]].
- [5] B. Zhang, X. Liu, W. -Z. Deng and S. -L. Zhu, Eur. Phys. J. C 50 , 617 (2007) [hep-ph 0609013]. /
- [6] P. Colangelo, F. De Fazio and S. Nicotri, Phys. Lett. B 642 , 48 (2006) [hep-ph 0607245]. /
- [7] P. Colangelo, F. De Fazio, F. Giannuzzi and S. Nicotri, Phys. Rev. D 86 , 054024 (2012) [arXiv:1207.6940 [hep-ph]].
- [8] D. -M. Li, B. Ma and Y. -H. Liu, Eur. Phys. J. C 51 , 359 (2007) [hep-ph 0703278 [HEP-PH]]. /
- [9] X. -H. Zhong and Q. Zhao, Phys. Rev. D 81 , 014031 (2010) [arXiv:0911.1856 [hep-ph]].
- [10] B. Chen, D. -X. Wang and A. Zhang, Phys. Rev. D 80 , 071502 (2009) [arXiv:0908.3261 [hep-ph]].
- [11] P. Colangelo, F. De Fazio, S. Nicotri and M. Rizzi, Phys. Rev. D 77 , 014012 (2008) [arXiv:0710.3068 [hep-ph]].
- [12] D. -M. Li and B. Ma, Phys. Rev. D 81 , 014021 (2010) [arXiv:0911.2906 [hep-ph]].
- [13] X. -h. Zhong and Q. Zhao, Phys. Rev. D 78 , 014029 (2008) [arXiv:0803.2102 [hep-ph]].
- [14] E. van Beveren and G. Rupp, Phys. Rev. D 81 , 118101 (2010) [arXiv:0908.1142 [hep-ph]].
- [15] J. Vijande, A. Valcarce and F. Fernandez, Phys. Rev. D 79 , 037501 (2009) [arXiv:0810.4988 [hep-ph]].
- [16] Z. -F. Sun and X. Liu, Phys. Rev. D 80 , 074037 (2009) [arXiv:0909.1658 [hep-ph]].
- [17] J. Beringer et al. [Particle Data Group Collaboration], Phys. Rev. D 86 , 010001 (2012).
- [18] S. Godfrey and N. Isgur, Phys. Rev. D 32 , 189 (1985).
- [19] T. Matsuki, T. Morii and K. Sudoh, Prog. Theor. Phys. 117 , 1077 (2007) [hep-ph 0605019]. /
- [20] M. Di Pierro and E. Eichten, Phys. Rev. D 64 (2001) 114004 [hep-ph 0104208]. /
- [21] D. Ebert, R. N. Faustov and V. O. Galkin, Eur. Phys. J. C 66 (2010) 197 [arXiv:0910.5612 [hep-ph]].
- [22] T. Matsuki, T. Morii and K. Seo, Prog. Theor. Phys. 124 (2010) 285 [arXiv:1001.4248 [hep-ph]].
- [23] L. Micu, Nucl. Phys. B 10 , 521 (1969).
- [24] A. Le Yaouanc, L. Oliver, O. Pene and J. C. Raynal, Phys. Rev. D 8 , 2223 (1973); Phys. Rev. D 9 , 1415 (1974); Phys. Rev. D 11 , 1272 (1975); Phys. Lett. B 72 , 57 (1977); Phys. Lett. B 71 ,
397 (1977).
- [25] A. Le Yaouanc, L. Oliver, O. Pene and J. C. Raynal, NEW YORK, USA: GORDON AND BREACH (1988) 311p
- [26] E. van Beveren, C. Dullemond and G. Rupp, Phys. Rev. D 21 , 772 (1980) [Erratum-ibid. D 22 , 787 (1980)].
- [27] E. van Beveren, G. Rupp, T. A. Rijken and C. Dullemond, Phys. Rev. D 27 , 1527 (1983).
- [28] R. Bonnaz, B. Silvestre-Brac and C. Gignoux, Eur. Phys. J. A 13 , 363 (2002) [hep-ph 0101112]. /
- [29] W. Roberts, B. Silvestre-Brac, Few Body Syst. 11 , 171 (1992).
- [30] X. Liu, Z. -G. Luo and Z. -F. Sun, Phys. Rev. Lett. 104 , 122001 (2010) [arXiv:0911.3694 [hep-ph]].
- [31] Z. -F. Sun, J. -S. Yu, X. Liu and T. Matsuki, Phys. Rev. D 82 , 111501 (2010) [arXiv:1008.3120 [hep-ph]].
- [32] J. -S. Yu, Z. -F. Sun, X. Liu and Q. Zhao, Phys. Rev. D 83 , 114007 (2011) [arXiv:1104.3064 [hep-ph]].
- [33] X. Wang, Z. -F. Sun, D. -Y. Chen, X. Liu and T. Matsuki, Phys. Rev. D 85 , 074024 (2012) [arXiv:1202.4139 [hep-ph]].
- [34] Z. -C. Ye, X. Wang, X. Liu and Q. Zhao, Phys. Rev. D 86 , 054025 (2012) [arXiv:1206.0097 [hep-ph]].
- [35] L. -P. He, X. Wang and X. Liu, Phys. Rev. D 88 , 034008 (2013) [arXiv:1306.5562 [hep-ph]].
- [36] Y. Sun, X. Liu and T. Matsuki, Phys. Rev. D 88 , no. 9, 094020 (2013) [arXiv:1309.2203 [hep-ph]].
- [37] Y. Sun, Q. -T. Song, D. -Y. Chen, X. Liu and S. -L. Zhu, Phys. Rev. D 89 , 054026 (2014) [arXiv:1401.1595 [hep-ph]].
- [38] C. -Q. Pang, L. -P. He, X. Liu and T. Matsuki, Phys. Rev. D 90 , 014001 (2014) [arXiv:1405.3189 [hep-ph]].
- [39] L. -P. He, D. -Y . Chen, X. Liu and T. Matsuki, arXiv:1405.3831 [hep-ph].
- [40] M. Jacob and G. C. Wick, Annals Phys. 7 , 404 (1959) [Annals Phys. 281 , 774 (2000)].
- [41] S. Godfrey and R. Kokoski, Phys. Rev. D 43 , 1679 (1991).
- [42] F. E. Close and E. S. Swanson, Phys. Rev. D 72 (2005) 094004 [hep-ph 0505206]. /
- [43] H. G. Blundell, hep-ph 9608473. /
- [44] J. Brodzicka et al. [Belle Collaboration], Phys. Rev. Lett. 100 , 092001 (2008) [arXiv:0707.3491 [hep-ex]].
- [45] S. Godfrey and K. Moats, arXiv:1409.0874 [hep-ph].
- [46] E. van Beveren and G. Rupp, Phys. Rev. Lett. 91 , 012003 (2003) [hep-ph 0305035]. /
- [47] E. van Beveren and G. Rupp, Eur. Phys. J. C 32 , 493 (2004) [hep-ph 0306051]. /
- [48] R. Molina, T. Branz and E. Oset, Phys. Rev. D 82 , 014010 (2010) [arXiv:1005.0335 [hep-ph]]. | 10.1140/epjc/s10052-015-3265-4 | [
"Qin-Tao Song",
"Dian-Yong Chen",
"Xiang Liu",
"Takayuki Matsuki"
] | 2014-08-03T08:26:42+00:00 | 2016-09-29T13:41:45+00:00 | [
"hep-ph",
"hep-ex"
] | $D_{s1}^*(2860)$ and $D_{s3}^*(2860)$: Candidates for $1D$ charmed-strange mesons | Newly observed two charmed-strange resonances, $D_{s1}^*(2860)$ and
$D_{s3}^*(2860)$, are investigated by calculating their Okubo-Zweig-Iizuka
allowed strong decays, which shows that they are suitable candidates for the
$1^3D_1$ and $1^3D_3$ states in the charmed-strange meson family. Our study
also predicts other main decay modes of $D_{s1}^*(2860)$ and $D_{s3}^*(2860)$,
which can be accessible at the future experiment. In addition, the decay
behaviors of the spin partners of $D_{s1}^*(2860)$ and $D_{s3}^*(2860)$, i.e.,
$1D(2^-)$ and $1D^\prime(2^-)$, are predicted in this work, which are still
missing at present. Experimental search for the missing $1D(2^-)$ and
$1D^\prime(2^-)$ charmed-strange mesons is an intriguing and challenging task
for further experiment. |
1408.0472v2 | ## Integrative multi-omics module network inference with Lemon-Tree
Eric Bonnet 1,2,3, ∗ , Laurence Calzone 1,2,3 and Tom Michoel 4, ∗
1 Institut Curie, 26 rue d'Ulm, 75248 Paris, France
2 INSERM U900, 75248 Paris, France
3 Mines ParisTech, 77300 Fontainebleau, France
4 Division of Genetics & Genomics, The Roslin Institute, The University of Edinburgh, Easter Bush, Midlothian, EH25 9RG, UK
∗ Corresponding authors, e-mail: [email protected], [email protected]
## Abstract
Module network inference is an established statistical method to reconstruct co-expression modules and their upstream regulatory programs from integrated multi-omics datasets measuring the activity levels of various cellular components across different individuals, experimental conditions or time points of a dynamic process. We have developed Lemon-Tree, an open-source, platform-independent, modular, extensible software package implementing state-of-the-art ensemble methods for module network inference. We benchmarked Lemon-Tree using large-scale tumor datasets and showed that Lemon-Tree algorithms compare favorably with state-of-the-art module network inference software. We also analyzed a large dataset of somatic copy-number alterations and gene expression levels measured in glioblastoma samples from The Cancer Genome Atlas and found that Lemon-Tree correctly identifies known glioblastoma oncogenes and tumor suppressors as master regulators in the inferred module network. Novel candidate driver genes predicted by Lemon-Tree were validated using tumor pathway and survival analyses. Lemon-Tree is available from http://lemon-tree.googlecode.com under the GNU General Public License version 2.0.
## Introduction
Recent years have witnessed a dramatic increase in new technologies for interrogating the activity levels of various cellular components on a genome-wide scale, including genomic, epigenomic, transcriptomic, and proteomic information [1]. It is generally acknowledged that integrating these heterogeneous datasets will provide more biological insights than performing separate analyses. For instance, in 2005, Garraway and colleagues combined SNP-based genetic maps and expression data to identify a novel transcription factor involved in melanoma progression [2]. More recently, international consortia such as The Cancer Genome Atlas (TCGA) or the International Cancer Genome Consortium (ICGC) have launched large-scale initiatives to characterize multiple types of cancer at different levels (genomic, transcriptomic, epigenomic, etc.) on several hundreds of samples. These integrative studies have already led to the identification of novel cancer genes [3,4].
Among the many ways to approach the challenge of data integration, module network inference is a statistically well-grounded method which uses probabilistic graphical models to reconstruct modules of co-regulated genes (or other biomolecular entities) and their upstream regulatory programs and which has been proven useful in many biological case studies [5, 6]. The module network model was introduced as a method to infer regulatory networks from large-scale gene expression compendia [5] and has subsequently been extended to integrate eQTL data [7,8], regulatory prior data [9], microRNA expression data [10], clinical data [11], copy number variation data [12] or protein interaction networks [13]. The original module network learning algorithm depended on a greedy heuristic, but subsequent work has extended this with alternative heuristics [14], Gibbs sampling [15] and ensemble methods [16]. Module network inference can be combined with gene-based network reconstruction methods [17,18] and recently a method has been developed to reconstruct module networks across multiple species simultaneously [19]. This methodological and algorithmic work has complemented studies that were solely focused on applying module network methods to provide new biological and biomedical insights [20-27].
Although the success of the module network method is indisputable, the various methodological innovations have been made available in a bewildering array of tools, written in a variety of programming languages, and, when source code has been released, it has never been with an OSI compliant license (Table 1). Here we present Lemon-Tree, a 'one-stop shop' software suite for module network inference based on previously validated algorithms where a community of developers and users can implement, test and use various methods and techniques. We benchmarked Lemon-Tree using large-scale datasets of somatic copynumber alterations and gene expression levels measured in glioblastoma samples from The Cancer Genome Atlas and found that Lemon-Tree compares favorably with existing module network softwares and correctly identifies known glioblastoma oncogenes and tumor suppressors as master regulators in the inferred module network. Novel candidate driver genes predicted by Lemon-Tree were validated using pathway enrichment and survival analysis.
## Design and Implementation
Lemon-Tree is a platform-independent command-line tool written in Java which implements previously validated algorithms for model-based clustering [15] and module network infer-
ence [16]. The principal design difference between Lemon-Tree and other module network softwares (e.g. Genomica [5] or CONEXIC [12]) consists of the separation of module learning and regulator assignment. We have previously shown that running a two-way clustering algorithm until convergence, and thereafter identifying the regulatory programs that give rise to the inferred condition clusterings for each gene module results in higher module network model likelihoods and reduced computational cost compared to the traditional approach of iteratively updating gene modules and regulator assignments [14,16]. Hence Lemon-Tree is run as a series of tasks , where each task represents a self-contained step in the module network learning and evaluation process and the output of one task forms the input of another (a work flow representation of the different steps is illustrated in Figure 1):
Task 'ganesh' Run one or more instances of a model-based Gibbs sampler [15] to simultaneously infer co-expression modules and condition clusters within each module from a gene expression data matrix.
Task 'tight clusters' Build consensus modules of genes that systematically cluster together in an ensemble of multiple 'ganesh' runs. Consensus modules are reconstructed by a novel spectral edge clustering algorithm which identifies densely connected sets of nodes in a weighted graph [28], with edge weight defined here as the frequency with which pairs of genes belong to the same cluster in individual 'ganesh' runs. Details about the tight clustering algorithm are provided in the Supplementary Methods.
Task 'regulators' Infer an ensemble of regulatory programs for a set of modules and compute a consensus regulator-to-module score. Regulatory programs take the form of a decision tree with the (expression level of) regulators at its internal nodes. The regulator score takes into account the number of trees a regulator is assigned to, with what score (posterior probability), and at which level of the tree [16]. An empirical distribution of scores of randomly assigned regulators is provided to assess significance. Regulator data need not come from the same data that was used for module construction but can be any continuous or discrete data type measured on the same samples. When multiple regulator types are considered, the 'regulators' task is run once for each of them.
Task 'experiments' For a fixed set of gene modules, cluster conditions separately for each module using a model-based Gibbs sampler [15] and store the resulting hierarchical condition trees in a structured XML file.
Task 'split reg' Assign regulators to a given range of one or more modules. This task allows parallelization of the 'regulators' task and needs the output of the 'experiments' task as an input.
Task 'figures' Draw publication-ready visualizations for a set of modules in postscript format, consisting of a heatmap of genes in each module, organized according to a consensus clustering of the samples, plus heatmaps of its top-scoring regulators, separated according to the regulator type (cf. Supplementary Figure 1).
Task 'go annotation' Calculate gene ontology enrichment for each module using the BiNGO [29] library.
While a typical run of Lemon-Tree will apply tasks 'ganesh', 'tight clusters' and 'regulators' in successive order, the software is designed to be flexible. For instance, the 'tight clusters' task can be equally well applied to build consensus clusters from the output of multiple third-party clustering algorithms, regulators can be assigned to the output of any clustering algorithm, etc. To facilitate this interoperability with other tools, input/output is handled via plain text files with minimal specification, the only exception being the storage of the regulatory decision trees which uses an XML format. Tasks also permit customization by changing the value of various parameters. We have purposefully provided default values for all parameters, based on our experience accrued over many years of developing and applying the software to a great variety of datasets from multiple organisms, and avoided mentioning any parameter settings in the Tutorial such that first-time users are presented with a simple workflow. Detailed instructions on how to integrate or extend (parts of) Lemon-Tree and a complete overview of all parameters and their default values are provided on the project website ( http://lemon-tree.googlecode.com/ ).
## Results
## Benchmark between Lemon-Tree and CONEXIC
We compared the performance of Lemon-Tree with CONEXIC (COpy Number and Expression In Cancer), a state-of-the-art module network algorithm designed to integrate matched copy number (amplifications and deletions) and gene expression data from tumor samples [12]. The general framework is the same for the algorithms, with modules of co-expressed genes associated to a list of regulators assigned via a probabilistic score. However, the probabilistic techniques used to build the modules and to assign regulators are different. We ran the two programs on the same large-scale reference data set to evaluate these differences. We used Gene Ontology (GO) enrichment and a reference network of protein-protein interactions to compare the co-expressed modules and the regulatory programs.
We downloaded gene expression and copy number glioblastoma datasets from the TCGA data portal [3] and we build an expression data matrix of 250 samples and 9,367 genes. We limited the number of samples for this benchmark study in order to save computational time. For the candidate regulators, we selected the top 1,000 genes that were significantly amplified or deleted as input genes for both CONEXIC and Lemon-Tree. To run CONEXIC, we followed the instructions of the manual and more specifically used the recommended bootstrapping procedure to get robust results. For Lemon-Tree, we generated an ensemble of two-way clustering solutions that were assembled in one robust solution by node clustering. Then we assigned the regulators using the same input list as with CONEXIC. A global score was calculated for each regulator and for each module and we selected the top 1% regulators as the final list (see Supplementary Methods). The total run-time for the two software programs on the benchmark dataset was quite similar, with a small advantage for Lemon-Tree (Supplementary Table S5).
To compare the Gene Ontology (GO) categories between Lemon-Tree and CONEXIC, we built a list of all common categories for a given p-value threshold and converted the corrected p-values to -log 10 (p-value) scores. We selected the highest score for each GO category and we counted the number of GO categories having a higher score for Lemon-Tree or
CONEXIC, and calculated the sum of scores for each GO category and each software. The results shown in Figure 2 indicate that Lemon-Tree clusters have a higher number of GO categories with lower p-values than CONEXIC (Figure 2A), and that globally the p-values are lower for Lemon-Tree clusters (Figure 2B). To benchmark the regulators' assignment of each software, we used a scoring scheme developed by Jornsten et al. [30]. For a given interaction distance in a reference protein-protein interaction network, we calculated the relative enrichment of known interactions in the networks inferred by Lemon-Tree and CONEXIC with respect to known interactions in networks where edges have been randomly re-assigned (see Supplementary Methods). Figure 2C shows the relative enrichments for interaction distances ranging from 1 (direct interaction) to 4. The Lemon-Tree inferred network is enriched for short or direct paths, a desired characteristic for well-estimated networks [30].
These results are consistent with a previous study conducted on bacteria and yeast data, where we showed a better performance in terms of enrichment in functional categories and known regulatory interactions of the algorithms underlying the Lemon-Tree software over Genomica (a software tool on which CONEXIC is based) [17]. Taken together, these results show that Lemon-Tree compares favorably with state-of-the-art module network inference algorithms.
## Integrative analysis of TCGA glioblastoma expression and copy-number data
Lemon-Tree can be used to integrate various types of 'omics' data and generate new biological and biomedical insights. Here, we exemplify how to integrate copy-number and expression data for a large dataset of glioblastoma tumor samples and show that the results are enriched in known key players of canonical tumor pathways as well as novel candidates. Malignant gliomas are the most common subtype of primary brain tumors and are very aggressive, highly invasive and neurologically destructive. Glioblastoma multiforme (GBM) is the most malignant form of gliomas, and despite intense investigation of this disease in the past decades, most patients with GBM die within approximately 15 months of diagnosis [31]. Somatic copy-number alterations (SCNA) are extremely common in cancer and affect a larger fraction of the genome than any other types of somatic genetic alterations. They have critical roles in activating oncogenes and inactivating tumor suppressor genes, and their study has suggested novel potential therapeutic strategies [32, 33]. However, distinguishing the alterations that drive cancer development from the passenger SCNAs that are acquired over time during cancer progression is a critical challenge. Here we use the module network framework implemented in the Lemon-Tree software tool to build a module network relating genes located in regions that are significantly amplified or deleted to modules of co-expressed genes. In other words, the module network selects and prioritizes copy-number altered genes that might play a role (direct or indirect) for clusters of co-expressed genes, performing important biological functions in glioblastoma. The resulting module network is used to prioritize SCNA genes that are amplified or deleted, and to provide novel hypotheses regarding drivers of glioblastoma.
We downloaded data from the TCGA project portal [3] and we selected 484 glioblastoma tumorsamples from different patients (representing 91% of the available samples). We selected 7,574 gene expression profiles and generated an ensemble of two-way clustering solutions that were assembled in one robust solution by node clustering, resulting in a set of 121 clusters composed of 5,423 genes (Supplementary Methods and Supplementary Table S1). We
assembled a list of genes amplified and deleted in glioblastoma tumors from the most recent GISTIC run of the Broad Institute TCGA Copy Number Portal on glioblastoma samples. GISTIC [34] is the standard software tool used for the detection of peak regions significantly amplified or deleted in a number of samples from copy-number profiles. We also included in the list a number of key genes amplified or deleted from previous studies [34-36]. The final list is composed of 353 amplified and 2,007 deleted genes (with all genes present on sex chromosomes excluded). We did not use extremely stringent statistical thresholds for the selection, to avoid the exclusion of potentially interesting candidates. From this list we built SCNA gene copy-number profiles using TCGA data and used those profiles as candidate regulators for the co-expressed gene clusters. We assigned regulators independently for amplified and deleted genes, and we selected the top 1% highest scoring regulators as the final list (a cutoff well above assignment of regulators expected by chance), with 92 amplified and 579 deleted selected genes (Supplementary Methods and Supplementary Tables S2 and S3). The resulting glioblastoma module network is composed of 121 clusters of co-expressed genes, together with associated prioritized lists of high-scoring SCNA genes (associated to amplified and deleted regions).
More than 60% of the clusters have a significant Gene Ontology (GO) enrichment (corrected p-value < 0.05, Table 2 and Supplementary Table S4). Several of those enriched clusters can be related to the hallmarks of cancers, ten distinctive and complementary capabilities that have been defined as the fundamental biological capabilities acquired during tumor development [37, 38]. For instance, we have 11 clusters enriched for GO categories related to cell cycle processes and regulation (p-value < 0.05), with three of them having very strong enrichment (corrected p-values 4 × 10 -18 , 6 × 10 -24 and 9 × 10 -71 , Table 2). The cell cycle is deregulated in most cancers and is at the heart of the 'sustaining proliferative signaling' hallmark. Eight clusters are enriched for categories related to immune response, with two of them displaying strong enrichment (corrected p-values 6 × 10 -33 and 6 × 10 -45 , Table 2). Most tumor lesions contain immune cells present at various degrees of density. Intense recent research has shown that this immune response is linked to two phenomena. First, it is obviously an attempt by the immune system to eradicate the tumor, but secondly, there is now a large body of evidence showing that immune cells also have strong tumor-promoting effects, and both aspects are categorized as part of the hallmarks of cancer [38]. For instance, microglia are a type of glial cells that act as macrophages of the brain and the spinal cord and thus act as the main form of immune response in the central nervous system. They constitute the dominant form of glioma tumor infiltrating immune cells, and they might promote tumor growth by facilitating immunosuppression of the tumor microenvironment [39]. The development of blood vessels (angiogenesis) is another crucial hallmark of cancer, providing sustenance in oxygen and nutrients and a way to evacuate metabolic wastes and carbon dioxide [38]. Glioblastoma multiforme is characterized by a striking and dramatic induction of angiogenesis [31]. There are seven clusters enriched for GO categories related to angiogenesis and blood vessel development, with two of them having strong enrichment (corrected p-values 4 × 10 -6 and 9 × 10 -16 , Table 2). A recent large-scale integrative study of hundreds of glioblastoma samples has shown that chromatin modifications could potentially have high biological relevance for this type of tumor [40]. Interestingly, we have a cluster highly enriched in chromatin assembly and organization (corrected p-value 5 × 10 -17 and 9 × 10 -24 , Table 2). Taken together, these results show that the clusters of co-expressed genes in the module network are representative of the molecular functions and biological
processes involved in tumor in general and more specifically in glioblastoma.
In the glioblastoma module network, we inferred a list of amplified and deleted SCNA genes linked to one or more clusters of co-expressed genes. Some of those SCNA genes are highly connected, representing potential master copy-number regulators for module activity. To identify and analyze those SCNA hub genes, we calculated for each high-scoring regulator the sum of the scores obtained in each module, and ranked them by decreasing score for amplified (Table 3) and deleted (Table 4) genes. Among these genes, we find many wellknown oncogenes and tumor supressors that are frequently amplified, deleted or mutated in glioblastoma. Those genes include EGFR PDGFRA FGFR3 PIK3CA MDM4 CDKN2A/B , , , , , , PTEN and are all members of the core alterated pathways in glioblastoma controlling key phenotypes such as proliferation, apoptosis and angiogenesis (Figure 3, [3,35,40,41]). Those genes and pathways are also frequently impaired in many other types of tumors [42-44]. In addition, we find in those lists of hub genes a number of interesting new candidates, both in amplified and deleted genes, that have not been associated with glioblastoma before. To better visualize the importance and role of both the well-known and novel SCNAs prioritized by Lemon-Tree, we represent those that are part of the three core pathways altered in glioblastoma as a network with edges representing activation or inhibition relationships, together with their levels of gene gains and losses in glioblastoma samples (Figure 3).
Within the list of amplified gene hubs (Table 3), we find a number of genes that have been rarely or never associated before with glioblastoma. INSR is a gene encoding for the insulin receptor, a transmembrane receptor activated by insuline and IGF factors, member of the tyrosine receptor kinase family, and playing a key role in glucose homeostasis. INSR is selected as a high-scoring regulator in 15 modules and ranked in third position in the list of amplified gene hubs. It is found to be amplified as low-level gain or higher in 39% of the samples (Table 3). Beyond its well-known role in glucose homeostasis, INSR stimulates cell proliferation (Figure 3) and migration and is often aberrantly expressed in cancer cells [45]. Consequently, amplification of INSR in glioblastoma may enhance proliferation. MYCN encodes a transcription factor (N-myc) highly expressed in fetal brain and critical for normal brain development. It is also a well-known proto-oncogene, and amplification of N-myc is associated with poor outcome in neuroblastoma [46]. MYCN is amplified as low-level gain or higher in 8% of the glioblastoma samples and is connected to 21 modules (Table 3). MYCN is part of the RB signaling pathway, and is also strongly connected to the RTK / PI3K and p53 pathways (Figure 3), with a direct influence on proliferation. For that reason, its amplification may also favor proliferation in glioblastoma. KRIT1 (also known as CCM1 ) is a gene crucial for maintaining the integrity of the vasculature and for normal angiogenesis. Loss of function of this gene is responsible for vascular malformations in the brain known as cerebral cavernous malformations [47, 48]. It is amplified as low-level gain or higher in 83% of the glioblastoma samples and it is listed in the top 10 hubs in our list (Table 3). The consequences of KRIT1 amplification are not completely clear, but we may hypothesize that it is required for proper angiogenesis development, which is a hallmark of glioblastoma [31], and that it may also help decrease apoptosis (Figure 3).
In the list of putative deleted genes, PAOX (polyamine oxidase) is ranked first, with a connection to 54 modules and the highest sum of scores value. It is classified as single loss (GISTIC call value of -1 or lower) in 89% of the samples. This is a very high value, comparable to the value obtained for the classical tumor suppressor CDKN2A (75%, Table 4). Amine oxidases are involved in the metabolism of polyamines, regulating their intracellular concentrations
and elimination. The products of this metabolism (e.g. hydrogen peroxyde) are cytotoxic and have been considered as a cause for apoptotic cell death. Amine oxidases are considered as biological regulators for cell growth and differentiation, and a primary involvement of amine oxidases in cancer growth inhibition and progression has been demonstrated [49]. Therefore, PAOX might have a tumor suppressor activity and its deletion in many glioblastoma samples could provide a selective advantage to glioblastoma tumor cells. Interestingly, amino acids metabolism is not part of the standard alterated pathways in glioblastoma (explaining why we did not represent PAOX on Figure 3), but targeting this pathway could lead to novel therapeutic treatments [50]. KLLN encodes a nuclear transcription factor and shares a bidirectional promoter with PTEN . It is activated by p53 and is involved in S phase arrest and apoptosis [51]. Recent studies show that KLLN has a tumor supressor effect and is associated with worse prognosis in prostate and breast carcinomas [52,53]. Consequently, the loss of KLLN that is observed in 88% of the glioblastoma samples (Table 4) would help the development of tumor cells by decreasing apoptosis and favoring proliferation (Figure 3).
To assess the biological relevance of the amplified and deleted gene hubs in the module network, we analyzed the prognosis value of the top gene hubs by survival analysis, using the clinical data available for TCGA samples (survival time and status of the patient). We constructed Kaplan-Meier estimates using GISTIC putative calls to define genes having single or deep copy loss (i.e. GISTIC call value ≤ -1) and genes having low-level gains or high-level amplifications (i.e. GISTIC call value ≥ 1). The differences between groups were formally tested and a total of 3 amplified genes and 18 deleted genes from the lists displayed in tables 3 and 4 have significant p-values < 0.05 (Figure 4 and Supplementary Table S6). Interestingly, among those genes we find the well-known glioblastoma oncogene EGFR and tumor suppressors CDKN2A and PTEN , but also novel candidates such as KRIT1 and PAOX described in the previous paragraph. Glioblastoma patients having copy-number alterations for those genes have a worse survival prognostic. This indicates the biological relevance of those genes that may be used as biomarkers.
## Availability and future directions
The Lemon-Tree software is hosted at Google Code ( http://lemon-tree.googlecode.com/ ). The source code, executables and documentation can be downloaded with no restrictions and no registration, and are released under the terms of the GNU General Public License (GPL) version 2.0. Developers and users can join the project by contacting the authors and there is a mailing list for discussions and news about module networks and the project. A step-by-step tutorial to learn how to install and use the software is available on the wiki section, together with the corresponding data sets.
In the future, we intend to extend Lemon-Tree's support for explicitly modelling causal relations between regulator types and to incorporate complementary algorithms available in the literature for integrating gene-based methods, physical interactions and cross-species data. Firstly, the current version of Lemon-Tree is able to associate co-expression modules to multiple 'regulator' types (e.g. expression regulators, structural DNA variants, phenotypic states, etc.) by assigning each of those independently as regulators of a module. We will extend the software with Bayesian methods to account for possible causal relations between
regulator types, e.g. when the association between a module and expression regulator can be partly explained by a structural DNA variant. Secondly, a key long-term objective of the Lemon-Tree project is to provide a general open-source repository for module network inference tools with a consistent user interface. As a first step, the current version of LemonTree implements algorithms previously developed by our group [14-17]. In the future, we intend to extend it with complementary algorithms developed by other groups, including algorithms to combine the strengths of module network methods with gene-based methods [18], to incorporate physical protein-protein or protein-DNA interactions as a prior in the regulator assignment procedure [13] or to infer module networks from multiple species simultaneously [19]. A document detailing guidelines to implement new functions in the Lemon-Tree Java codebase is available on the project wiki.
## Acknowledgments
This research was supported by Roslin Institute Strategic Grant funding from the BBSRC (TM). The research leading to these results has received funding from the European Communitys Seventh Framework Programme (FP7/2007-2013) under grant agreement number FP7-HEALTH-2010-259348 (ASSET project). EB and LC are members of the team 'Computational Systems Biology of Cancer', Equipe labellis´ ee par la Ligue Nationale Contre le Cancer.
## References
- 1. Hawkins RD, Hon GC, Ren B (2010) Next-generation genomics: an integrative approach. Nature Reviews Genetics 11: 476-486.
- 2. Garraway LA, Widlund HR, Rubin MA, Getz G, Berger AJ, et al. (2005) Integrative genomic analyses identify mitf as a lineage survival oncogene amplified in malignant melanoma. Nature 436: 117-122.
- 3. McLendon R, Friedman A, Bigner D, Van Meir EG, Brat DJ, et al. (2008) Comprehensive genomic characterization defines human glioblastoma genes and core pathways. Nature 455: 1061-1068.
- 4. Hudson TJ, Anderson W, Aretz A, Barker AD, Bell C, et al. (2010) International network of cancer genome projects. Nature 464: 993-998.
- 5. Segal E, Shapira M, Regev A, Pe'er D, Botstein D, et al. (2003) Module networks: identifying regulatory modules and their condition-specific regulators from gene expression data. Nat Genet 34: 166-167.
- 6. Friedman N (2004) Inferring cellular networks using probabilistic graphical models. Science 308: 799-805.
- 7. Lee S, Pe'er D, Dudley A, Church G, Koller D (2006) Identifying regulatory mechanisms using individual variation reveals key role for chromatin modification. Proc Natl Acad Sci USA 103: 14062-14067.
- 8. Zhang W, Zhu J, Schadt EE, Liu JS (2010) A Bayesian partition method for detecting pleiotropic and epistatic eQTL modules. PLoS Computational Biology 6: e1000642.
- 9. Lee SI, Dudley AM, Drubin D, Silver PA, Krogan NJ, et al. (2009) Learning a prior on regulatory potential from eqtl data. PLoS Genetics 5: e1000358.
- 10. Bonnet E, Tatari M, Joshi A, Michoel T, Marchal K, et al. (2010) Module network inference from a cancer gene expression data set identifies microRNA regulated modules. PLoS One 5: e10162.
- 11. Bonnet E, Michoel T, Van de Peer Y (2010) Prediction of a gene regulatory network linked to prostate cancer from gene expression, microRNA and clinical data. Bioinformatics 26: i683-i644.
- 12. Akavia UD, Litvin O, Kim J, Sanchez-Garcia F, Kotliar D, et al. (2010) An integrated approach to uncover drivers of cancer. Cell 143: 1005-1017.
- 13. Novershtern N, Regev A, Friedman N (2011) Physical module networks: an integrative approach for reconstructing transcription regulation. Bioinformatics 27: i177i185.
- 14. Michoel T, Maere S, Bonnet E, Joshi A, Saeys Y, et al. (2007) Validating module networks learning algorithms using simulated data. BMC Bioinformatics 8: S5.
- 15. Joshi A, Van de Peer Y, Michoel T (2008) Analysis of a Gibbs sampler for model based clustering of gene expression data. Bioinformatics 24: 176-183.
- 16. Joshi A, De Smet R, Marchal K, Van de Peer Y, Michoel T (2009) Module networks revisited: computational assessment and prioritization of model predictions. Bioinformatics 25: 490-496.
- 17. Michoel T, De Smet R, Joshi A, Van de Peer Y, Marchal K (2009) Comparative analysis of module-based versus direct methods for reverse-engineering transcriptional regulatory networks. BMC Syst Biol 3: 49.
- 18. Roy S, Lagree S, Hou Z, Thomson JA, Stewart R, et al. (2013) Integrated module and gene-specific regulatory inference implicates upstream signaling networks. PLoS Computational Biology 9.
- 19. Roy S, Wapinski I, Pfiffner J, French C, Socha A, et al. (2013) Arboretum: reconstruction and analysis of the evolutionary history of condition-specific transcriptional modules. Genome Research 23: 1039-1050.
- 20. Segal E, Sirlin CB, Ooi C, Adler AS, Gollub J, et al. (2007) Decoding global gene expression programs in liver cancer by noninvasive imaging. Nat Biotech 25: 675-680.
- 21. Zhu H, Yang H, Owen MR (2007) Combined microarray analysis uncovers selfrenewal related signaling in mouse embryonic stem cells. Syst Synth Biol 1: 171-181.
- 22. Li J, Liu Z, Pan Y, Liu Q, Fu X, et al. (2007) Regulatory module network of basic/helixloop-helix transcription factors in mouse brain. Genome Biol 8: R244.
- 23. Novershtern N, Itzhaki Z, Manor O, Friedman N, Kaminski N (2008) A functional and regulatory map of asthma. Am J Respir Cell Mol Biol 38: 324-336.
- 24. Amit I, Garber M, Chevrier N, Leite AP, Donner Y, et al. (2009) Unbiased reconstruction of a mammalian transcriptional network mediating pathogen responses. Science 326: 257.
- 25. Vermeirssen V, Joshi A, Michoel T, Bonnet E, Casneuf T, et al. (2009) Transcription regulatory networks in Caenorhabditis elegans inferred through reverse-engineering of gene expression profiles constitute biological hypotheses for metazoan development. Mol BioSyst 5: 1817-1830.
- 26. Novershtern N, Subramanian A, Lawton LN, Mak RH, Haining WN, et al. (2011) Densely interconnected transcriptional circuits control cell states in human hematopoiesis. Cell 144: 296-309.
- 27. Zhu M, Deng X, Joshi T, Xu D, Stacey G, et al. (2012) Reconstructing differentially coexpressed gene modules and regulatory networks of soybean cells. BMC Genomics 13: 437.
- 28. Michoel T, Nachtergaele B (2012) Alignment and integration of complex networks by hypergraph-based spectral clustering. Physical Review E 86: 056111.
- 29. Maere S, Heymans K, Kuiper M (2005) BiNGO: a Cytoscape plugin to assess overrepresentation of gene ontology categories in biological networks. Bioinformatics 21: 3448-3449.
- 30. J¨rnsten R, Abenius T, Kling T, Schmidt L, Johansson E, et al. (2011) Network modeling o of the transcriptional effects of copy number aberrations in glioblastoma. Molecular Systems Biology 7.
- 31. Maher EA, Furnari FB, Bachoo RM, Rowitch DH, Louis DN, et al. (2001) Malignant glioma: genetics and biology of a grave matter. Genes & Development 15: 1311-1333.
- 32. Beroukhim R, Mermel CH, Porter D, Wei G, Raychaudhuri S, et al. (2010) The landscape of somatic copy-number alteration across human cancers. Nature 463: 899-905.
- 33. Zack TI, Schumacher SE, Carter SL, Cherniack AD, Saksena G, et al. (2013) Pan-cancer patterns of somatic copy number alteration. Nature Genetics 45: 1134-1140.
- 34. Beroukhim R, Getz G, Nghiemphu L, Barretina J, Hsueh T, et al. (2007) Assessing the significance of chromosomal aberrations in cancer: methodology and application to glioma. Proceedings of the National Academy of Sciences 104: 20007-20012.
- 35. Parsons DW, Jones S, Zhang X, Lin JCH, Leary RJ, et al. (2008) An integrated genomic analysis of human glioblastoma multiforme. Science 321: 1807-1812.
- 36. Verhaak RG, Hoadley KA, Purdom E, Wang V, Qi Y, et al. (2010) Integrated genomic analysis identifies clinically relevant subtypes of glioblastoma characterized by abnormalities in PDGFRA, IDH1, EGFR, and NF1. Cancer Cell 17: 98-110.
- 37. Hanahan D, Weinberg RA (2000) The hallmarks of cancer. Cell 100: 57-70.
- 38. Hanahan D, Weinberg RA (2011) Hallmarks of cancer: the next generation. Cell 144: 646-674.
- 39. Yang I, Han SJ, Kaur G, Crane C, Parsa AT (2010) The role of microglia in central nervous system immunity and glioma immunology. Journal of Clinical Neuroscience 17: 6-10.
- 40. Brennan CW, Verhaak RG, McKenna A, Campos B, Noushmehr H, et al. (2013) The somatic genomic landscape of glioblastoma. Cell 155: 462-477.
- 41. Frattini V, Trifonov V, Chan JM, Castano A, Lia M, et al. (2013) The integrated landscape of driver genomic alterations in glioblastoma. Nature Genetics 45: 1141-1149.
- 42. Forbes SA, Bindal N, Bamford S, Cole C, Kok CY, et al. (2011) Cosmic: mining complete cancer genomes in the catalogue of somatic mutations in cancer. Nucleic Acids Research 39: D945-D950.
- 43. Vogelstein B, Papadopoulos N, Velculescu VE, Zhou S, Diaz LA, et al. (2013) Cancer genome landscapes. Science 339: 1546-1558.
- 44. Lawrence MS, Stojanov P, Mermel CH, Robinson JT, Garraway LA, et al. (2014) Discovery and saturation analysis of cancer genes across 21 tumour types. Nature 505: 495-501.
- 45. Belfiore A, Frasca F, Pandini G, Sciacca L, Vigneri R (2009) Insulin receptor isoforms and insulin receptor/insulin-like growth factor receptor hybrids in physiology and disease. Endocrine Reviews 30: 586-623.
- 46. Cheng JM, Hiemstra JL, Schneider SS, Naumova A, Cheung NKV, et al. (1993) Preferential amplification of the paternal allele of the n-myc gene in human neuroblastomas. Nature Genetics 4: 191-194.
- 47. W¨ ustehube J, Bartol A, Liebler SS, Br¨tsch R, Zhu Y, et al. (2010) Cerebral cavernous u malformation protein ccm1 inhibits sprouting angiogenesis by activating delta-notch signaling. Proceedings of the National Academy of Sciences 107: 12640-12645.
- 48. Guzeloglu-Kayisli O, Kayisli UA, Amankulor NM, Voorhees JR, Gokce O, et al. (2004) Krev1 interaction trapped-1/cerebral cavernous malformation-1 protein expression during early angiogenesis. Journal of Neurosurgery: Pediatrics 100: 481-487.
- 49. Toninello A, Pietrangeli P, De Marchi U, Salvi M, Mondov` ı B (2006) Amine oxidases in apoptosis and cancer. Biochimica et Biophysica Acta (BBA)-Reviews on Cancer 1765: 1-13.
- 50. Agostinelli E, Arancia G, Dalla Vedova L, Belli F, Marra M, et al. (2004) The biological functions of polyamine oxidation products by amine oxidases: perspectives of clinical applications. Amino Acids 27: 347-358.
- 51. Cho Yj, Liang P (2008) Killin is a p53-regulated nuclear inhibitor of dna synthesis. Proceedings of the National Academy of Sciences 105: 5396-5401.
- 52. Wang Y, Radhakrishnan D, He X, Peehl DM, Eng C (2013) Transcription factor klln inhibits tumor growth by ar suppression, induces apoptosis by tp53/tp73 stimulation in prostate carcinomas, and correlates with cellular differentiation. The Journal of Clinical Endocrinology & Metabolism 98: E586-E594.
- 53. Wang Y, He X, Yu Q, Eng C (2013) Androgen receptor-induced tumor suppressor, klln, inhibits breast cancer growth and transcriptionally activates p53/p73-mediated apoptosis in breast carcinomas. Human molecular genetics : ddt077.
## Figure and Tables
Figure 1. Flow chart for integrative module network inference with Lemon-Tree. This figure shows the general workflow for a typical integrative module network inference with Lemon-Tree. Blue boxes indicate the pre-processing steps that are done using third-party software such as R or user-defined scripts. Green boxes indicates the core module network inference steps done with the Lemon-Tree software package. Typical post-processing tasks (orange boxes), such as GO enrichment calculations, can be performed with Lemon-Tree or other tools. The Lemon-Tree task names are indicated in red (see main text for more details).
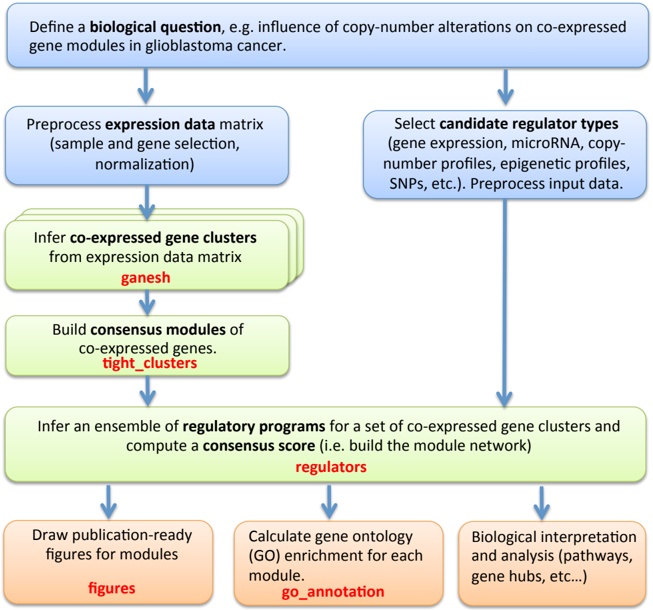
Figure 2. Comparison between Lemon-Tree and CONEXIC. Gene Ontology (GO) enrichment of the co-expressed gene clusters, indicated by counting the number of GO categories having a lower p-value (A) and by comparing the sum of the quantity -log10(p-value) (B) for different global p-value cutoff levels (x-axis). (C) Relative enrichment of inferred interactions by Lemon-Tree and CONEXIC to known molecular protein-protein interactions (PPI), for increasing interaction distances.
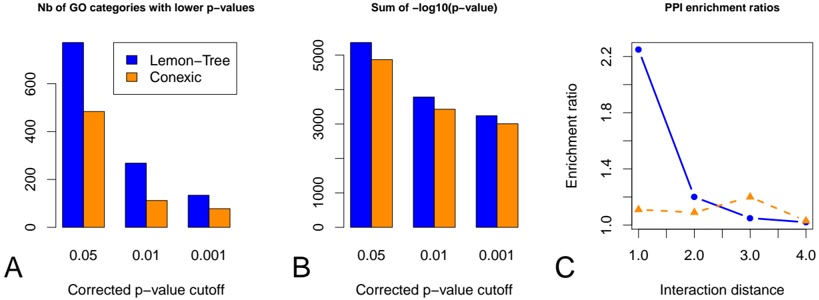

Figure 3. Glioblastoma signaling pathway alterations for top hub regulators. Copy number alterations for a selection of predicted hub regulators are indicated for canonical glioblastoma signaling pathways p53, RB and RTK/PI3K. Genes selected by the algorithm are indicated in black boxes, while light grey boxes depict genes that were not selected by the algorithm but are key factors for the pathway. Purple hexagons indicate phenotypes. Percentage of copy gain or loss is indicated by value and by color shades of red for gene gains and green for gene losses. The values are taken from GISTIC putative calls for low-levels gains or single-copy losses on 563 glioblastoma samples (data from the Broad institute).
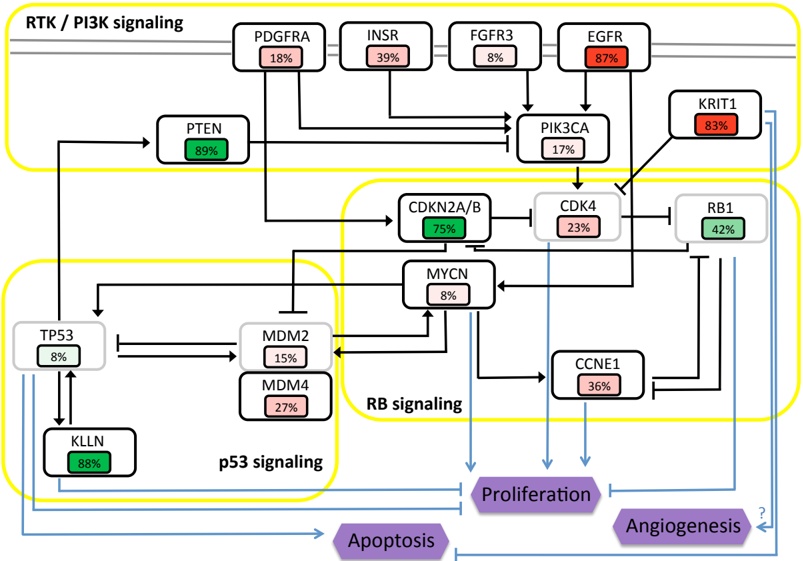
Figure 4. Kaplan-Meier survival curves for a selection of top hub glioblastoma genes predicted by the Lemon-Tree algorithm. The top three panels are genes having low-levels gains or high-level amplifications (magenta) compared to normal (blue), the bottom three panels are genes having single-copy loss or homozygous deletions (green) compared to normal (blue). All genes display significant differences between the groups (p < 0.05, see Supplementary Table S6 for a full list of p-values). Patient with putative gene gains or losses have significantly worse prognosis (lower values on the y-axis). The x-axis on all figures represent the time in number of days
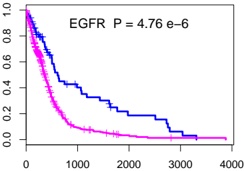
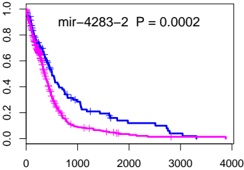
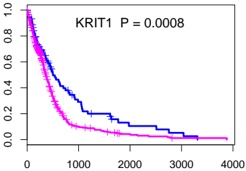
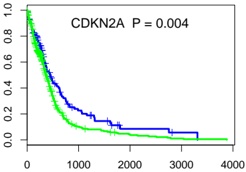
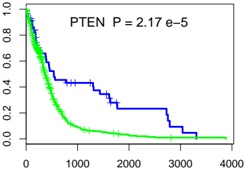
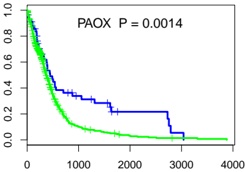

Table 1. Survey of module networks software tools, in chronological order by their first release date. I/O: g , graphical user interface; c , command line. Supported data integration: m , mRNA; mi , microRNA; e , eQTL; c , CNV; p , protein interactions; m-s , mRNA multiple species; any , any combination of discrete or continuous data types measured on the same samples. ( 1 ) Not OSI compliant. ( 2 ) No license provided. 3 GPL license.
Table 2. GO enrichment for glioblastoma modules
| Group | Module number | Module nb of genes | Corrected p-value | GOcategory |
|-------------------------|-----------------|----------------------|----------------------------------------------------------------------------------------------------------|------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------|
| Cell Cycle | 1 11 33 | 85 60 36 | 9 × 10 - 71 2 × 10 - 67 6 × 10 - 63 6 × 10 - 24 6 × 10 - 24 4 × 10 - 18 1 × 10 - 17 | cell cycle phase cell cycle process mitotic cell cycle cell cycle phase mitotic cell cycle cell cycle phase mitotic cell cycle |
| Immune response | 3 14 26 48 | 145 127 54 37 | 6 × 10 - 45 6 × 10 - 45 1 × 10 - 26 4 × 10 - 23 6 × 10 - 33 8 × 10 - 24 7 × 10 - 6 9 × 10 - 6 1 × 10 - 6 | immune response immune system process inflammatory response innate immune response response to type I interferon innate immune response defense response immune response immune system process |
| Vasculature | 27 37 | 40 81 | 4 × 10 - 16 2 × 10 - 15 7 × 10 - 13 3 × 10 - 10 9 × 10 - 6 | vasculature development blood vessel development angiogenesis extracellular matrix organization blood vessel development |
| Chromatin modifications | 70 | 12 | 9 × 10 - 24 8 × 10 - 24 5 × 10 - 17 | chromatin assembly nucleosome assembly chromatin organization |
Selection of clusters of co-expressed genes from the glioblastoma module network highly enriched for GO categories related to cancer hallmarks. Enriched categories are grouped into broader functional groups. Only a subset of the GO categories are displayed in this table. The full list is available as Supplementary Table 1.
Table 3. High-scoring amplified gene hubs detected by Lemon-Tree
| Symbol | Pathway | Band | Nm | Sum score | %amp. | M-list | P-list |
|------------|---------------------------------------------------|---------|------|-------------|---------|----------|----------|
| CHIC2 | | 4q12 | 32 | 5884 | 19 | x | x |
| EGFR | EGFR signalling | 7p11.2 | 24 | 5184 | 87 | x | x |
| INSR | EGFR signalling | 19p13.2 | 15 | 3918 | 39 | x | x |
| ASAP1 | Membrane cytoskeleton interactions, cell motility | 8q24.21 | 16 | 3119 | 11 | | |
| MYCN | Regulation of transcription | 2p24.3 | 21 | 3028 | 8 | x | |
| C1orf101 | | 1q44 | 19 | 2980 | 17 | | x |
| RHOB | Rho protein signal transduction | 2p24.1 | 19 | 2731 | 7 | | |
| KRIT1 | Small GTPase mediated signal transduction | 7q21.2 | 11 | 2242 | 83 | | |
| CCNE1 | Regulation of cell cycle | 19q12 | 14 | 1980 | 36 | x | x |
| SDCCAG8 | | 1q43 | 14 | 1973 | 17 | | x |
| ADCY8 | Intracellular signal transduction | 8q24.22 | 12 | 1949 | 11 | | |
| PDGFRA | Cell proliferation, signal transduction | 4q12 | 10 | 1874 | 18 | x | x |
| DDX1 | Regulation of translation | 2p24.3 | 16 | 1763 | 8 | | |
| MDM4 | p53 regulation | 1q32.1 | 9 | 1385 | 27 | x | x |
| mir-4283-2 | | 7q11.21 | 10 | 1374 | 80 | | |
| PRDM2 | Regulation of transcription | 1p36.21 | 8 | 1323 | 15 | | |
| FGFR3 | Cell growth | 4p16.3 | 5 | 1031 | 8 | x | x |
| SCIMP | Immune response, signal transduction | 17p13.2 | 8 | 1022 | 8 | | |
| GSDMC | Epithelial cell proliferation and apoptosis | 8q24.21 | 8 | 919 | 11 | | |
| COL4A1 | Angiogenesis | 13q34 | 2 | 743 | 5 | | x |
| PIK3CA | Cell signalling, cell growth | 3q26.3 | 7 | 743 | 17 | x | |
List of the top 20 amplified genes ordered by decreasing sum of score values. Nm: number of modules in which the gene is selected as a high-scoring regulator. % amp.: percentage of samples in which the gene is classified as low-level gain or high-level amplification (according to GISTIC putative calls). M-list: presence in a list of genes frequently mutated in cancer, compiled from [42-44]. P-list: presence in a list of genes recurrently amplified or deleted in 11 cancer types [33].
Table 4. High-scoring deleted genes detected by Lemon-Tree
| Symbol | Pathway | Band | Nb modules | Sum score | %del. | M-list | P-list |
|----------|-------------------------------------------|----------|--------------|-------------|---------|----------|----------|
| PAOX | Polyamine homeostasis, apoptosis | 10q26.3 | 54 | 7937 | 89 | x | x |
| CDKN2A | Negative regulation of cell proliferation | 9p21.3 | 31 | 4785 | 75 | | x |
| mir-3201 | | 22q13.32 | 21 | 3030 | 37 | | x |
| mir-340 | | 5q35.3 | 35 | 3030 | 10 | | x |
| mir-604 | | 10p11.23 | 49 | 2930 | 82 | | x |
| mir-938 | | 10p11.23 | 45 | 2921 | 82 | | |
| C9orf53 | | 9p21.3 | 29 | 2897 | 75 | | x |
| ATAD1 | | 10q23.31 | 55 | 2433 | 88 | | |
| KIAA0125 | | 14q32.33 | 30 | 2117 | 28 | | x |
| mir-548q | | 10p13 | 35 | 2017 | 81 | | |
| OMG | Cell adhesion | 17q11.2 | 21 | 1697 | 13 | | x |
| EVI2B | | 17q11.2 | 19 | 1629 | 13 | | x |
| KRTAP5-6 | | 11p15.5 | 18 | 1564 | 21 | | |
| SRGAP1 | Cell migration | 12q14.2 | 20 | 1397 | 14 | | |
| KLLN | Cell cycle arrest, apoptosis | 10q23.31 | 34 | 1374 | 88 | | x |
| FLT4 | Protein tyrosine kinase signalling | 5q35.3 | 12 | 1022 | 10 | | x |
| EFCAB4A | Metabolic process | 11p15.5 | 33 | 964 | 23 | | |
| HBD | | 11p15.4 | 38 | 964 | 20 | | |
| DMRTA2 | Regulation of transcription | 1p32.3 | 28 | 926 | 5 | | |
| TBC1D30 | | 12q14.3 | 15 | 791 | 13 | | |
| ART5 | Protein glycosylation | 11p15.4 | 11 | 785 | 21 | | |
| FAM19A5 | | 22q13.32 | 4 | 745 | 37 | | x |
| EVI2A | | 17q11.2 | 17 | 709 | 13 | | x |
| ARID2 | | 12q12 | 5 | 681 | 14 | x | |
| WDR37 | | 10p15.3 | 21 | 614 | 81 | | |
| MOB2 | Death receptor signalling | 11p15.5 | 15 | 599 | 23 | | |
| PTEN | EGFR signalling, AKT pathway | 10q23.31 | 19 | 593 | 89 | x | x |
| MUC4 | Cell matrix adhesion, transport | 3q29 | 10 | 588 | 11 | | |
| IDI1 | Isoprenoids synthesis | 10p15.13 | 23 | 569 | 81 | | |
| CSMD1 | | 8p23.2 | 8 | 566 | 12 | | x |
| CDKN2B | Negative regulation of cell proliferation | 9p21.3 | 19 | 565 | 75 | | x |
List of top 30 deleted genes ordered by decreasing sum of score values. % del.: percentage of samples in which the gene is classified as single-copy loss or deep loss (according to GISTIC putative calls). Nm, M-list and P-list: see Table 3.
## A Supplementary methods
## Tight clustering algorithm
Lemon-Tree uses a tight clustering step to extract consensus modules from an ensemble of clustering solutions. A novel spectral edge clustering algorithm [28] was implemented in Lemon-Tree for this purpose. This algorithm proceeds as follows:
## Pre-processing
First, let C k ( ) be the cluster assignment matrix for the k th ganesh run, i.e. C k ( ) is an N × Mk matrix where N is the number of genes and Mk the number of clusters in the k th run such that
$$C _ { i m } ^ { ( k ) } = \begin{cases} 1 & \text{if gene $i$ belongs to cluster $m$ in run $k$} \\ 0 & \text{otherwise} \end{cases}.$$
Ganesh clusters are non-overlapping and all genes belong to a cluster, i.e. GLYPH<229> m C ( k ) im = 1 for all i . Next, an N × N co-clustering matrix O k ( ) for the k th run is defined as
$$O _ { i j } ^ { ( k ) } = \begin{cases} 1 & \text{if gene $i$ and $j$ belong to the same cluster in run $k$} \\ 0 & \text{otherwise} \end{cases}.$$
O k ( ) is obtained from C k ( ) via the matrix multiplication
$$O ^ { ( k ) } = C ^ { ( k ) } ( C ^ { ( k ) } ) ^ { T }.$$
Averaging O k ( ) over all K runs gives the co-occurence frequency matrix
$$G = \frac { 1 } { K } \sum _ { k = 1 } ^ { K } O ^ { ( k ) }.$$
Entries of G close to 1 represent pairs of genes which robustly cluster together irrespective of the stochastic fluctuations introduced by the ganesh Gibbs sampling algorithm, whereas entries close to 0 represent noisy relations between gene pairs accidentally clustering together by random chance. We convert G to a sparse weighted adjacency matrix A by choosing a threshold e and setting
$$A _ { i j } = \begin{cases} G _ { i j } & \text{if $G_{ij} > \epsilon$} \\ 0 & \text{otherwise} \end{cases}.$$
In our experience, thresholds in the range e ∈ [ 0.2, 0.4 ] produce suitably sparse graphs while retaining all information about robust gene pairings. The default value is set to e = 0.25.
## Spectral clustering
Tight clusters are defined as subsets of genes X with a high total edge weight in the thresholded co-occurence frequency graph, as expressed by a score function
$$\mathcal { S } ( X ) = \frac { \sum _ { i, j \in X } A _ { i j } } { | X | },$$
where | X | denotes the number of elements in X . The spectral edge clustering algorithm iteratively searches for the set X which (approximately) maximizes S , removes X from the graph, and repeats the procedure until no more edges remain. Specifically:
- 1. Calculate the dominant eigenvector x corresponding to the largest eigenvalue of A x ; is normalized to have GLYPH<229> i x 2 i = 1, and by the Perron-Frobenius theorem, all its elements are positive xi ≥ 0.
- 2. Find the set X for which the vector uX with components uX i , = 1 for i ∈ X and 0 otherwise is as similar as possible to x , more precisely
$$X = \arg _ { Y } \max _ { Y } \frac { 1 } { | Y | ^ { 1 / 2 } } \sum _ { i \in Y } x _ { i }.$$
Since all xi ≥ 0, X must be of the form X = { i : xi > c } for some threshold value c and is easily found.
- 3. Store X and perform one of two alternatives
- (a) (Node clustering) Remove all nodes in X from the graph, i.e. set
$$A _ { i j } \leftarrow 0 \ \text{ if } i \in X \, \text{ OR } j \in X$$
- (b) (Edge clustering) Remove all edges in X from the graph, i.e. set
$$A _ { i j } \leftarrow 0 \ \text{ if } i \in X \, \text{AND} \, j \in X$$
- 4. Repeat 1 -3 until A = 0.
The solution for X in step 2 is an approximation to the real solution X = argmax Y S ( Y ) . However, because the dominant eigenvector x maximizes the quantity
$$x = \underset { y } { \arg } \max _ { y } \frac { \sum _ { i, j = 1 } ^ { N } A _ { i j } y _ { i } y _ { j } } { ( \sum _ { i = 1 } ^ { N } y _ { i } ^ { 2 } ) ^ { \frac { 1 } { 2 } } }. \\... \.. \..$$
over all possible choices of vectors y , including vectors of the form uY , it can be shown that the approximate solution is in some sense optimal. More precisely, the quantity maximized by x provides an upper bound to the (unknown) maximum value max Y S ( Y ) and numerical simulations on a variety of graphs have shown that the score of the approximate solution is always close to the upper bound, and therefore also to the true maximum. For more details, see [28].
Removal of nodes [step 3(a)] implies that every gene can belong to only one tight cluster whereas removal of edges [step 3(b)] results in possibly overlapping tight clusters. In module network applications, we always apply node clustering, because only non-overlapping clusters can be given a statistical interpretation in the form of an underlying Bayesian network model.
## Post-processing
The spectral clustering algorithm runs until all edges in the thresholded co-occurence frequency graph A have been removed, but not all clusters found represent well-supported tight clusters, particularly towards the end of the algorithm when tight clusters will consist of very few nodes and edges. We therefore apply a post-processing step whereby clusters that are too small or have too low value for the score function S are removed. The default values are to keep all tight clusters with minimum size of 10 genes and score value (i.e. weighted edge to node ratio) of 2. As a result, some genes may not belong to any tight cluster and are discarded from any subsequent analysis.
## Benchmark between Lemon-Tree and CONEXIC
We downloaded gene expression and copy number glioblastoma datasets from the Cancer Genome Atlas (TCGA, [3]) data portal and we selected a set of 250 samples that were matched for copy number and gene expression data. We built a matrix of gene expression ratios (normal/disease) and discarded genes having a flat profile (standard deviation < 0.25), keeping a total of 9,367 genes. To build a list of candidate regulators, we applied the program JISTIC on copy-number profiles to determine genes that were significantly amplified or deleted in the samples (with a default q-value cutoff of 0.25), and we selected the top 1,000 genes for each category as input for the candidate regulators for both CONEXIC and Lemon-Tree.
To run CONEXIC, we followed the instructions of the manual and more specifically used the recommended bootstrapping procedure to get robust results. For the Single Modulator step (initial grouping of genes into modules), we performed 100 bootstrap runs, with 10,000 permutations each. We selected the regulators that appear in at least 90% of the runs for the final Single Modulator run. We also performed 100 bootstrap runs for the Module Network step (learning the modulators that best fit the data and improving the grouping of genes into modules). We selected regulators appearing in at least 40% of the bootstrap files for the final Module Network run. The final network was composed of 281 modules and 6,292 genes.
For Lemon-Tree, we generated 150 two-way clustering solutions that were assembled in one robust solution by node clustering (minimum weight 0.33), resulting in a set of 257 clusters composed of 5,354 genes. Then we assigned the regulators using the same input list as with CONEXIC, with 10 hierarchical trees for each module. A global score was calculated for each regulator and for each module and we selected the top 1% regulators as the final list.
The GO enrichment for the CONEXIC and Lemon-Tree clusters were calculated using the built-in tool of the Lemon-Tree software package, which is based on the BiNGO Java library. The same list of reference genes, GO ontology file and annotation file were used for the two sets (see the latest version for the gene ontology file at http://geneontology. org/page/download-ontology , and the latest version for human gene association file at http://geneontology.org/page/download-annotations ). To compare the GO categories between Lemon-Tree and CONEXIC, we built a list of all common categories for a given pvalue threshold and converted the corrected p-values to converted the corrected p-values to -log 10 (p-value) scores. We selected the highest score for each GO category and we counted the number of GO categories having a higher score for Lemon-Tree or CONEXIC, and calculated the sum of scores for each GO category and each software.
We downloaded all the human protein-protein interactions (PPI) from Reactome, Intact and HPRDthroughthe Pathway Commons portal. The resulting network was composed of 9,599 genes and 168,117 interactions. We calculated the shortest paths between all pairs of genes in the network, using Dijkstra's algorithm from the JUNG library ( http://jung.sourceforge. org ). Interaction distances can be defined as the number of steps needed to 'walk' from one gene to another.
For a network G and interaction distance k , we followed [30] and calculated the enrichment ratio Er (as a relative proportion) as:
$$E r = \frac { P ( R _ { i j } = k | i \, \text{and} \, j \, \text{are connected in } G ) } { P ( R _ { i j } = k | i \, \text{and} \, j \, \text{are connected in } G _ { \text{permuted} } ) }$$
where Rij is the shortest path length in the PPI network between nodes i and j , and Gpermuted was generated by random permutations of the non-diagonal G elements (network edges).
## Integrative analysis of TCGA glioblastoma expression and copy-number data
We downloaded data from the Cancer Genome Atlas project portal (TCGA [3]) and we selected 484 glioblastoma tumor samples from different patients, matched for mRNA expression and copy-number data. The expression data was composed of a total of 12,042 genes. We selected genes differentially expressed (ttest p-value < 0.05, Benjamini-Hochberg correction, all calculations done with R) compared to normal tissue samples. We excluded genes having flat profiles (standard deviation < 0.3), resulting in an expression matrix of 7,574 genes that was centered, scaled and taken as input for Lemon-Tree. We generated 127 two-way clustering solutions that were assembled in one robust solution by node clustering (minimum weight 0.33, minimum size 10, minimum score 2), resulting in a set of 121 clusters composed of 5,423 genes (median cluster size of 34 genes, see complete list of genes and clusters in supplementary table S1).
We assembled a list of genes amplified and deleted in glioblastoma tumors from the most recent GISTIC run of the Broad Institute TCGA Copy Number Portal on glioblastoma samples ( http://www.broadinstitute.org/tcga/home ). GISTIC [34] is the standard software tool used for the detection of peak regions significantly amplified or deleted in a number of samples from copy-number profiles. We also included in the list a number of key genes amplified or deleted from previous studies [34-36]. The final list is composed of 353 amplified and 2,007 deleted genes (with all genes present on sex chromosomes excluded). To build the copy-number matrix profiles, we downloaded the segmented data (level 3 files) corresponding to Affymetrix Human SNP Array 6.0 hybridizations for all glioblastoma samples, and mapped all genes and miRNAs to the segments in each sample. Each gene is then assigned the copy-number value corresponding to the segment in which it is located or a missing value if there is no segment corresponding to the location of the gene. All the profiles were centered and scaled and used to infer the regulation programs. We assigned regulators independently for amplified and deleted genes lists, and we selected the top 1% highest scoring regulators as the final list (a cutoff well above assignment of regulators expected by chance), with 92 amplified and 579 deleted selected genes (see supplementary tables S2 and S3). | 10.1371/journal.pcbi.1003983 | [
"Eric Bonnet",
"Laurence Calzone",
"Tom Michoel"
] | 2014-08-03T08:39:37+00:00 | 2014-10-14T15:18:30+00:00 | [
"q-bio.GN"
] | Integrative multi-omics module network inference with Lemon-Tree | Module network inference is an established statistical method to reconstruct
co-expression modules and their upstream regulatory programs from integrated
multi-omics datasets measuring the activity levels of various cellular
components across different individuals, experimental conditions or time points
of a dynamic process. We have developed Lemon-Tree, an open-source,
platform-independent, modular, extensible software package implementing
state-of-the-art ensemble methods for module network inference. We benchmarked
Lemon-Tree using large-scale tumor datasets and showed that Lemon-Tree
algorithms compare favorably with state-of-the-art module network inference
software. We also analyzed a large dataset of somatic copy-number alterations
and gene expression levels measured in glioblastoma samples from The Cancer
Genome Atlas and found that Lemon-Tree correctly identifies known glioblastoma
oncogenes and tumor suppressors as master regulators in the inferred module
network. Novel candidate driver genes predicted by Lemon-Tree were validated
using tumor pathway and survival analyses. Lemon-Tree is available from
http://lemon-tree.googlecode.com under the GNU General Public License version
2.0. |
1408.0473v3 | ## Optimal Performance of Endoreversible Quantum Refrigerators
Luis A. Correa, 1, 2, GLYPH<3> Jos´ e P. Palao, 2, 3 Gerardo Adesso, 1 and Daniel Alonso 2,3
1 School of Mathematical Sciences, The University of Nottingham, University Park, Nottingham NG7 2RD, UK 2 IUdEA Instituto Universitario de Estudios Avanzados, Universidad de La Laguna, 38203 Spain 3 Departamento de F´ ısica, Universidad de La Laguna, 38204 Spain
(Dated: November 25, 2014)
The derivation of general performance benchmarks is important in the design of highly optimized heat engines and refrigerators. To obtain them, one may model phenomenologically the leading sources of irreversibility ending up with results which are model-independent, but limited in scope. Alternatively, one can take a simple physical system realizing a thermodynamic cycle and assess its optimal operation from a complete microscopic description. We follow this approach in order to derive the coe GLYPH<14> cient of performance at maximum cooling rate for any endoreversible quantum refrigerator. At striking variance with the universality of the optimal e GLYPH<14> ciency of heat engines, we find that the cooling performance at maximum power is crucially determined by the details of the specific system-bath interaction mechanism. A closed analytical benchmark is found for endoreversible refrigerators weakly coupled to unstructured bosonic heat baths: an ubiquitous case study in quantum thermodynamics.
PACS numbers: 05.70.Ln, 03.65.-w, 05.40.-a
## I. INTRODUCTION
Energy conversion systems, including heat engines and refrigerators, encompass a broad variety of devices which find widespread uses in the domestic, industrial and academic domains. Design optimization of such systems is crucial for their implementation to be cost-e GLYPH<14> cient, and the determination of general performance benchmarks to assess their 'optimality', is a very active research area [1, 2]. A familiar example of heat engine is a nuclear power station. The relevant figure of merit to benchmark its optimality is the output power rather than the e GLYPH<14> ciency of energy conversion [3]: In fact, capital costs are by far the dominant contribution to the price of the kWh, while the nuclear fuel itself is comparatively inexpensive. Hence, ideally, a nuclear energy station will be designed to operate at the maximum power output P GLYPH<3> corresponding to some heat input ˙ Q h ; GLYPH<3> , which defines an optimal e GLYPH<14> ciency GLYPH<17> GLYPH<3> GLYPH<17> GLYPH<0> P Q GLYPH<3> = ˙ h GLYPH<3> .
As a working assumption, one may treat a nuclear power station as a perfect Carnot engine running between heat reservoirs at temperatures Tc < T h 0 ( < Th ), where T h 0 is the effective temperature of the working fluid at the hot end of the cycle. This amounts to saying that the leading source of irreversibility in atomic power generation is the imperfect thermal contact of the working fluid with the reactor, to the point that internal friction and heat leaks may be completely disregarded. This is known as endoreversible approximation [2]. If one further assumes a simple Newtonian heat transfer law for the heat current ˙ Q h = Ch Th ( GLYPH<0> T h 0 ), where Ch is a constant, then the e GLYPH<11> ective temperature maximizing the power may be found to be the geometric mean of Th and Tc . Consequently, the optimal e GLYPH<14> ciency reads
$$\eta _ { * } = 1 - T _ { c } / T _ { h * } ^ { \prime } = 1 - \sqrt { T _ { c } / T _ { h } } = 1 - \sqrt { 1 - \eta _ { C } }, \quad ( 1 )$$
GLYPH<3> Electronic address: [email protected]
where GLYPH<17> C = 1 GLYPH<0> Tc = Th is the ultimate Carnot e GLYPH<14> ciency [4]. This formula, introduced by Yvon [5] and Novikov [3] in the mid 1950s in the context of atomic energy generation, was re-derived twenty years later by Curzon and Ahlborn [6] in their 1975 seminal paper 1 . In principle, it should be nothing but a crude approximation to optimality, but it turns out to be in good agreement with the observed e GLYPH<14> ciency of actual thermal power plants, and proves to be remarkably independent of the specific design [5]. Indeed, it agrees with the optimal e GLYPH<14> -ciency of any engine operating close to equilibrium [8, 9], and applies quite generally to symmetric low-dissipation engines [10], even if these are realized on a quantum mechanical support [11, 12]. Eq. (1) is, therefore, a useful design guideline, as it reliably benchmarks the optimal operation of a large class of heat engines. Besides, it is clearly model-independent.
In the last few decades, many attempts have been made to answer the fundamental question of whether a similar modelindependent benchmark can be obtained for optimal cooling. That would certainly be very useful in the design optimization of refrigerators, but unfortunately the straightforward endoreversible approach together with the assumption of a linear heat transfer law does not help in this case: The cooling rate ˙ Q c , which replaces P as figure of merit, is maximal only at vanishing coe GLYPH<14> cient of performance (COP) " GLYPH<17> ˙ Q P c = ˙ . This problem might be circumvented by resorting to alternative heat transfer laws, though these usually lead to involved (non-universal) formulas for the optimal COP, explicitly depending on phenomenological heat conductivities [13].
Benchmarks analogous to Eq. (1), may still be obtained by retaining the simple Newtonian ansatz and changing instead the definition of 'optimality'. Practical considerations may advise e.g. to pay the same attention to the COP and the cooling rate, so that the meaningful figure of merit would be
1 Interestingly, the origins of Eq. (1) can be traced back to a book by H. B. Reitlinger, first published in 1929 [7].
FIG. 1: Quantum tricycle: A quantum system selectively coupled through frequency filters to three heat baths (with temperatures Tw > Th > Tc ), embodies the prototype of any thermal device. Here, the direction of the heat currents (depicted as arrows) correspond to a refrigerator. Reversing them realizes a heat transformer heat engine. /
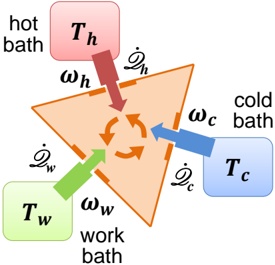
GLYPH<31> GLYPH<17> " ˙ Q c rather than ˙ Q c alone. In this case, one would find an optimal performance of " GLYPH<3> = p 1 + " C GLYPH<0> 1 [13], which holds in fact for any symmetric low-dissipation Carnot refrigerator [14]. Here, " C = Tc = ( Th GLYPH<0> Tc ) stands for the Carnot COP. Other criteria for optimality [15, 16] would lead, of course, to di GLYPH<11> erent performance benchmarks 2 .
In this paper, we analyze the COP at maximum cooling rate for endoreversible quantum refrigerators, generally modelled as tricycles [19]. We find that the details of the system-bath interaction mechanism place a tight upper bound on the cooling performance, which automatically precludes the derivation of any model-independent benchmarks. We then look into the paradigmatic case of a three-level compression refrigerator [20, 21] operating between unstructured bosonic heat baths, to obtain a simple closed expression for " GLYPH<3> ( " C ), which is further shown to bound and closely reproduce the optimal COP of any multi-stage endoreversible refrigerator within the same dissipative scheme. Our analysis unveils fundamental di GLYPH<11> erences between heat engines and refrigerators from the point of view of their optimal performance, and highlights the key importance of reservoir engineering in the optimization of technologically relevant quantum models.
This paper is structured as follows: The generic template of a quantum tricycle is briefly described Sec. II. Then, our main result, concerning the non-universality of the optimal cooling performance is derived in Sec. III and illustrated with a simple example in Sec. IV. Finally, in Sec. V we summarize and draw our conclusions. For the sake of clarity, the technical details of the derivation of quantum master equations for periodicallydriven systems are postponed until Appendix A.
2 Another option would be to relax the endoreversible approximation, allowing for heat leaks and internal friction, while keeping ˙ Q c as figure of merit, and a simple linear model for the heat currents [17, 18]. Generally, this also leads to model-dependent benchmarks.
## II. ENDOREVERSIBLE QUANTUM TRICYCLES
A generic energy conversion device may be thought of as a stationary black box in simultaneous thermal contact with three heat reservoirs at di GLYPH<11> erent temperatures Tw > Th > Tc or, alternatively, with two heat reservoirs Th > Tc and a work repository ( Tw ! 1 ), which, in principle, accounts for the case of a heat engine or a power-driven refrigerator (we shall elaborate more on this equivalence in an example below). This template, termed 'tricycle' [22], is suitable to describe averaged finite-time cycles or continuous processes, and is represented by the triple f ˙ Q w ; ˙ Q Q h ; ˙ c g of steady-state rates of incoming (positive) and outgoing (negative) energy flow in the system through each of the thermal contact ports. In order to comply with the first and second laws of thermodynamics, these must satisfy
$$\phi _ { w } + \phi _ { h } + \phi _ { c } = 0 \, \text{ \quad \ \ } \text{(a)}$$
$$\frac { \phi _ { w } } { T _ { w } } + \frac { \phi _ { h } } { T _ { h } } + \frac { \phi _ { c } } { T _ { c } } \equiv - \dot { S } \leq 0. \text{ \quad \ \ } ( 2 b )$$
If the black box encloses a quantum system, thermal contact with the heat reservoir may be selectively established through filters at frequencies !GLYPH<11> with GLYPH<11> 2 f w h c ; ; g . This is the distinctive feature of a quantum tricycle [19] (see Fig. 1). In absence of heat leaks or internal friction, a quantum tricycle exchanges quanta with all three baths at a single stationary rate I , i.e. ˙ Q GLYPH<11> = GLYPH<0> !GLYPH<11> I GLYPH<11> , with I h = GLYPH<0> I c = GLYPH<0> I w GLYPH<17> I (in what follows ~ = kB = 1). Thence, the fulfilment of the first law in Eq. (2a) demands to tune the filters in resonance so that ! w = ! h GLYPH<0> ! c .
Such 'ideal' devices have two complementary modes of operation compatible with Eq. (2b): The absorption compression refrigerator / f ˙ Q w > 0 ; ˙ Q h < 0 ; ˙ Q c > 0 g and the heat transformer heat engine / f ˙ Q w < 0 ; ˙ Q h > 0 ; ˙ Q c < 0 g [22, 23]. Let us consider for instance a compression refrigerator ( Tw !1 ) at fixed ! h , for which the inequality (2b) may be rewritten as ! c GLYPH<20> ! ; c rev GLYPH<17> ! h Tc = Th . As ! c ! ! ; c rev , the contact ports simultaneously reach local thermal equilibrium with their respective heat reservoirs, and the COP is maximized ( " ! " C ) [24]. In general, however, the e GLYPH<11> ective temperatures T 0 GLYPH<11> defined from the stationary state of the contacts, do not coincide with the corresponding equilibrium values T GLYPH<11> , and the COP is strictly smaller than " C .
The irreversibility hindering the cooling performance of ideal quantum tricycles might be thus understood as if only arising from imperfect thermal contact with the heat baths. It is in this sense that we refer to them as 'endoreversible'. Alternatively, ideal energy conversion systems may be tagged 'strongly coupled' [9, 25], referring to the fact that their energy fluxes remain at all times proportional to each other. This is a necessary prerequisite for any device to achieve maximum e GLYPH<14> ciency, although at vanishing energy-conversion rates [25].
## III. OPTIMAL COP FOR LARGE TEMPERATURES
Next, we shall tune the frequency filters of a generic endoreversible power-driven tricycle in the refrigerator configu-
ration, so as to maximize its cooling power in search for the optimal COP.
From Eq. (2b) it follows that the entropy production can be written as ˙ S = xh I h + xc I c , where the fluxes are I h = GLYPH<0> I c GLYPH<17> I , and their conjugate thermodynamic forces are given by x GLYPH<11> GLYPH<17> !GLYPH<11> = T GLYPH<11> . Note that refrigeration is achieved whenever xc < xh , according to Eq. (2b). Even though we shall concentrate on the dependence of the flux on the thermodynamic forces, it will generally be a function of other independent dimensionless combinations of parameters, describing the system-bath interactions and the spectrum of thermal fluctuations of the heat reservoirs.
The cold heat current writes as j ˙ Q c j = Tcxc I ( xh ; xc ) and its local maximization with respect to xc at fixed xh , follows from
$$x _ { c, * } \frac { \partial \mathcal { I } } { \partial x _ { c } } ( x _ { h }, x _ { c, * } ) + \mathcal { I } ( x _ { h }, x _ { c, * } ) = 0. \quad \ \ ( 3 ) \quad \text{ at\ } \\ \quad \ \text{ the 1}$$
Little more can be said without disclosing the full Hamiltonian of the tricycle, except if one restricts to a certain regime of parameters. Here, we shall take the high-temperature limit ( x GLYPH<11> ! 0), where e.g. symmetric quantum heat engines are known to operate at the Yvon-Novikov-Curzon-Ahlborn efficiency [26, 27], and where di GLYPH<11> erent models of absorption refrigerators achieve their maximal performance [28, 29].
We shall thus approximate I ( xh ; xc ) around x GLYPH<11> = 0, retaining only the first non-zero term in its Taylor expansion
$$\mathcal { I } ( x _ { h }, x _ { c } ) = \sum _ { i } \left ( \frac { \partial \mathcal { I } } { \partial x _ { i } } \right ) _ { \vec { 0 } } x _ { i } + \sum _ { i j } \left ( \frac { \partial ^ { 2 } \mathcal { I } } { \partial x _ { i } \partial x _ { j } } \right ) _ { \vec { 0 } } x _ { i } x _ { j } + \cdots, \ ( 4 ) \ \stackrel { \dots } { T _ { c } x _ { c } \mathcal { I } } } { \text{ yields} }$$
and express the optimal 'cold force' as xc ; GLYPH<3> ' Cxh , to first order in xh . The coe GLYPH<14> cient C may be obtained by substituting the approximated current of Eq. (4) into Eq. (3), and will thus depend explicitly on the partial derivatives of the stationary heat current evaluated in x GLYPH<11> = 0. Noting that the COP of an endoreversible refrigerator writes as
$$\varepsilon = \frac { \omega _ { c } } { \omega _ { h } - \omega _ { c } } = \left ( \frac { \varepsilon _ { C } + 1 } { \varepsilon _ { C } } \frac { x _ { h } } { x _ { c } } - 1 \right ) ^ { - 1 }, \quad \quad ( 5 ) \quad \quad \quad$$
the optimal performance, normalized by " C , is finally
$$\frac { \varepsilon _ { * } } { \varepsilon _ { C } } = \frac { C } { ( 1 - C ) \, \varepsilon _ { C } + 1 }. \quad \quad \ \ ( 6 ) \quad \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \$$
Here, C must be positive and upper-bounded by 1, so that 0 GLYPH<20> " GLYPH<3> GLYPH<20> " C . In general, it will be a function of parameters such as the dissipation rate ( GLYPH<13> ), ohmicity ( s ), high frequency cuto GLYPH<11> ( GLYPH<10> c ), dimensionality of the baths ( d ) or their equilibrium temperatures (through " C ). Thus, and unlike Eq. (1), " =" GLYPH<3> C converges to C ( " C = 0 ; GLYPH<13>; s ; GLYPH<10> c ; d ; GLYPH<1> GLYPH<1> GLYPH<1> ) as " C ! 0, rather than to a universal constant value.
The above discussion can be compared to the one done in Ref. [9] for a generic heat engine in the linear regime: There, the first order term in the expansion of the optimal force xc ; GLYPH<3> (in that case, around xc GLYPH<0> xh ! 0) contributed to GLYPH<17> GLYPH<3> =GLYPH<17> C with a universal constant value of 1 = 2, while the second order term added a correction, explicitly involving the first and second order partial derivatives of the heat current. In contrast, as we have just seen, the optimal cooling performance is already non-universal to the lowest order in xh .
In order to intuitively understand this fundamental di GLYPH<11> erence between engines and refrigerators, we remark that the useful e GLYPH<11> ect in a heat engine is sought at the interface of the working substance with an infinite-temperature heat reservoir, implying that the corresponding contact transitions will be saturated regardless of the details of the system-bath interaction. On the contrary, in a refrigerator, the useful e GLYPH<11> ect takes place in the interface with a bath at some finite temperature. Therefore, it is not so surprising that the spectral properties of the environmental fluctuations play a relevant role in establishing the optimal cooling performance.
Indeed, the situation resembles that of the maximization of the cooling power of endoreversible ('classical') refrigerators, for which the optimal performance is generally set by the heat conductivities, and depends critically on the specific heat transfer law assumed [13].
Finally, let us comment on the optimal COP in the complementary limit of " C ! 1 , that is, in the linear regime. Close to equilibrium, we may assume a linear relation between fluxes I GLYPH<11> and forces x GLYPH<11> , such that I h = L 11 xh + L 12 xc and I c = L 21 xh + L 22 xc . The Onsager coe GLYPH<14> cients Lij satisfy L 11 GLYPH<21> 0, L 22 GLYPH<21> 0, L 12 = L 21 and q 2 GLYPH<17> L 2 12 = L 11 L 22 . Here, the parameter GLYPH<0> 1 GLYPH<20> q GLYPH<20> 1 is stands for the tightness of the coupling between input and output fluxes [25], where q 2 ! 1 implies 'endoreversiblity'. We can maximize again j ˙ Q c j = Tcxc I c in xc for fixed xh , obtaining xc ; GLYPH<3> = GLYPH<0> L 21 xh = 2 L 22 . This yields an optimal COP of
$$\varepsilon _ { * } = \frac { q ^ { 2 } \varepsilon _ { C } } { ( 4 - 3 q ^ { 2 } ) \varepsilon _ { C } + ( 4 - 2 q ^ { 2 } ) }, \quad \quad ( 7 )$$
which converges to " GLYPH<3> = q 2 = (4 GLYPH<0> 3 q 2 ) as " C !1 . Hence, the ratio " =" GLYPH<3> C simply vanishes close to equilibrium, regardless of the magnitude of x GLYPH<11> and the details system-bath coupling.
## IV. EXAMPLE: UNSTRUCTURED BOSONIC BATHS
In order to get a closed expression for C ( " C ; GLYPH<13>; s ; GLYPH<10> c ; d ; GLYPH<1> GLYPH<1> GLYPH<1> ), specific instances have to be considered. Here we focus on a simple and paradigmatic endoreversible device, such as a three-level maser [20] subject to a weak periodic driving, in contact with unstructured bosonic baths (i.e. characterized by a flat spectral density) in d GLYPH<11> dimensions. Its Hamiltonian writes as
$$\text{enc} _ { \text{iii} } \quad H = \omega _ { c } \left | 2 \right \rangle \left \langle 2 \right | + \omega _ { h } \left | 3 \right \rangle \left \langle 3 \right | + \lambda \left ( e ^ { i \omega _ { w } t } \left | 2 \right \rangle \left \langle 3 \right | +$$
where GLYPH<21> is the intensity of the driving at the power input transition j 2 i $ j 3 . The remaining ones ( 1 i j i $ j 3 i and 1 j i $ j 2 ), i are linearly connected with the 'hot' and 'cold' heat reservoirs, through terms of the form GLYPH<27> GLYPH<11> GLYPH<10> B GLYPH<11> , where
$$\mathcal { B } _ { \alpha } \equiv \sum \nolimits _ { \mu } g _ { \alpha \mu } \left ( b _ { \alpha \mu } + b _ { \alpha \mu } ^ { \dagger } \right ) \, \text{ \quad \ \ } \text{(a)}$$
$$\sigma _ { h } \equiv \left | 1 \right \rangle \left \langle 3 \right | + \left | 3 \right \rangle \left \langle 1 \right | \text{ \quad \ \ } \text{(9b)}$$
$$\sigma _ { c } \equiv \left | 1 \right \rangle \left \langle 2 \right | + \left | 2 \right \rangle \left \langle 1 \right |.$$
The constants g GLYPH<11>GLYPH<22> / ( GLYPH<13> GLYPH<11> !GLYPH<22> ) 1 2 = indicate the intensity of the coupling between the mode !GLYPH<22> of bath GLYPH<11> and the corresponding contact transition of the working substance, and GLYPH<13> GLYPH<11> stands for the dissipation strength [28].
We shall assume very weak dissipation (i.e. GLYPH<13> GLYPH<11> GLYPH<28> T GLYPH<11> ) and parameters well into the quantum optical regime, so as to consistently derive a quantum master equation like ˙ % = P P P GLYPH<11> ! q 2 Z L GLYPH<11> !; q % , with dissipators L GLYPH<11> !; q of the LindbladGorini-Kossakowski-Sudarshan type [30, 31]. Their explicit form is given in Appendix A.
The non-equilibrium limit cycle state % 1 may be found from P P P GLYPH<11> ! q 2 Z L GLYPH<11> !; q % 1 = 0, while the corresponding (timeaveraged) heat currents are [32]
$$\mathcal { \hat { L } } _ { \alpha } = - T _ { \alpha } \sum _ { \omega } \sum _ { q \in \mathbb { Z } } \text{tr} \{ \mathcal { L } ^ { \alpha } _ { \omega, q } \varrho _ { \infty } \ln \tilde { \varrho } ^ { \alpha } _ { \omega, q } \}. \quad \text{ (10)}$$
The states ˜ % GLYPH<11> !; q are the unique local stationary states of each dissipator, i.e. L GLYPH<11> !; q ˜ % GLYPH<11> !; q = 0.
In general, a power-driven three-level maser does not realize a tricycle as it features closed performance characteristics, which is a clear indicator of irreversibility [19]. We shall take, however, the limit of weak driving, i.e. GLYPH<21> ! 0, in which the time averaged limit flux I reads
$$\mathcal { I } \simeq \frac { \Gamma _ { \omega _ { h } } \Gamma _ { - \omega _ { c } } - \Gamma _ { - \omega _ { h } } \Gamma _ { \omega _ { c } } } { \Gamma _ { \omega _ { h } } + \Gamma _ { \omega _ { c } } + 2 ( \Gamma _ { - \omega _ { h } } + \Gamma _ { - \omega _ { c } } ) }. \quad \quad ( 1 1 ) \quad \text{mar} \\ \text{that}$$
The excitation and relaxation rates GLYPH<0> GLYPH<6> !GLYPH<11> are given by GLYPH<0> !GLYPH<11> GLYPH<17> GLYPH<13> GLYPH<11> ! GLYPH<11> d [ N ( !GLYPH<11> ) + 1] and GLYPH<0> GLYPH<0> !GLYPH<11> = e GLYPH<0> !GLYPH<11> = T GLYPH<11> GLYPH<0> !GLYPH<11> , with N ( !GLYPH<11> ) GLYPH<17> ( e !GLYPH<11> = T GLYPH<11> GLYPH<0> 1) GLYPH<0> 1 . Here, d GLYPH<11> stands for the physical dimensionality of bath GLYPH<11> [33].
Taking now the high-temperature limit would result in GLYPH<0> !GLYPH<11> ' GLYPH<13> GLYPH<11> T GLYPH<11> ! GLYPH<11> d GLYPH<0> 1 GLYPH<11> and GLYPH<0> GLYPH<0> !GLYPH<11> ' GLYPH<13> GLYPH<11> T GLYPH<11> ! GLYPH<11> d GLYPH<0> 1 GLYPH<11> (1 GLYPH<0> x GLYPH<11> ), so that
$$\mathcal { I } \simeq \frac { \gamma _ { h } \gamma _ { c } } { 3 } T _ { c } \, \omega _ { c } ^ { d _ { c } - 1 } \frac { \omega _ { h } / T _ { h } - \omega _ { c } / T _ { c } } { \gamma _ { h } + \omega _ { c } ^ { d _ { c } - 1 } \omega _ { h } ^ { 1 - d _ { h } } \gamma _ { c } T _ { c } / T _ { h } }. \quad ( 1 2 ) \quad \text{man} \quad \text{the 1} \\ \text{me}$$
We shall discard the second term in the denominator of Eq. (12) by assuming that the coupling to the entropy sink is much stronger than the interaction with the cold bath (i.e. GLYPH<13> c GLYPH<28> GLYPH<13> h ). Setting up a comparatively e GLYPH<14> cient heat rejection mechanism is indeed very important for the maximization of the stationary flux in a refrigerator, which justifies this assumption as a first step towards optimality. Nonetheless, noting that Tc = Th = " C = " ( C + 1), we see that this would be justified anyway, as long as " C ! 0. The stationary flux may be thus written as
$$\mathcal { I } \simeq \mathcal { I } _ { 0 } ( x _ { c } ^ { d _ { c } - 1 } x _ { h } - x _ { c } ^ { d _ { c } } ), \quad \quad ( 1 3 ) \quad \text{anc}$$
with I 0 = GLYPH<13> c T dc c = 3. From here, it follows that C GLYPH<17> dc = ( dc + 1), i.e. xc ; GLYPH<3> = dc = ( dc + 1) ! h , which once substituted in Eq. (6) yields the following simple performance benchmark,
$$\frac { \varepsilon _ { * } } { \varepsilon _ { C } } = \frac { d _ { c } } { d _ { c } + 1 + \varepsilon _ { C } }. \quad \quad \ \ ( 1 4 ) \quad -$$
In Fig. 2, the optimal normalized COP of a large number of single- and multi-stage endoreversible absorption refrigerators [34] is compared with Eq. (14), considering unstructured
FIG. 2: (Blue dots) Optimal normalized COP versus " C for about 2 GLYPH<2> 10 5 n -stage endoreversible absorption refrigerators [34] with n 2 f 1 ; GLYPH<1> GLYPH<1> GLYPH<1> ; 10 , g and coupled to unstructured three-dimensional bosonic baths. All three temperatures T GLYPH<11> , dissipation rates GLYPH<13> GLYPH<11> and hot frequencies ! h were picked at random, and the COP was optimized in ! c so as to maximize the cooling power ˙ Q c in each case. Eq. (14) is plotted in solid gray.
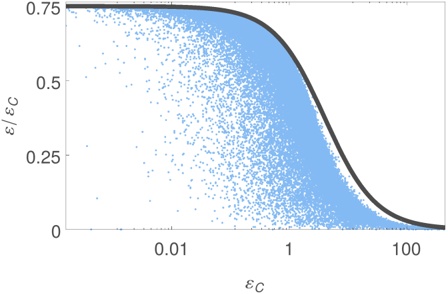
bosonic baths with dimensionality d GLYPH<11> = 3. We observe a remarkable agreement, especially at low " C . Notice, however, that Eq. (14) was obtained for a specific model of compression refrigerator 3 and under the assumption of asymmetric dissipation: There is, in principle, no reason, why it should remain tight nor an upper bound to the performance of other endoreversible models. Therefore, it should be thought-of just as a reasonable approximation to their generic behaviour. On a second thought, however, the excellent agreement observed may not be so surprising, provided that the optimal performance is set by the dissipative scheme alone. Solving for the limit cycle of a (weakly-driven) compression tree-level maser in di GLYPH<11> erent types of environment would be thus enough to come up with generally valid benchmarks for any endoreversible refrigerator in each case. This is one of the take-home messages of the present paper.
The optimal performance of single and multi-stage quantum absorption refrigerators is indeed known to be limited by " =" GLYPH<3> C GLYPH<20> d = ( d + 1) when attached to unstructured baths in d dimensions, with a saturation occurring precisely in the limit of large temperatures [29, 34]. Eq. (14) can be thus regarded for these models as a stronger bound which sharpens the one given in Ref. [34] for any finite " C . Remarkably, also another model of non-ideal refrigerator, with the same dissipative scheme, has been shown to have an optimal performance below " =" GLYPH<3> C = d = ( d + 1) [28]. Note, however that Eq. (14) should not be expected to hold quantitatively (and not even as a qualitative indicator of optimality) when moving away from endoreversibility.
3 Alternatively, we can consider an absorption three-level maser, driven by heat from a third reservoir at Tw [21] and then, take the limit Tw ! 1 . Eq. (12) would be thus exactly reproduced.
## V. CONCLUSIONS
To summarize and conclude, we have shown from first principles how the COP at maximum cooling power of endoreversible quantum tricycles is not universal in the hightemperature limit, but fundamentally constrained by the details of their interaction with the external heat reservoirs. For quantum refrigerators coupled to unstructured bosonic baths, we obtained a compact expression for their optimal performance, only dependent on the Carnot COP and the dimensionality of the baths.
Our results highlight the importance of reservoir engineering [35] in the design of quantum thermal devices: While squeezed-thermal and other types of engineered nonequilibrium environments are known to be capable of enhancing both the performance and power of heat engines and quantum refrigerators [29, 36-38], the exploration of more exotic and highly tunable reservoirs, such as cold atomic gases [39], might bring about new possibilities for the physical realization of super-e GLYPH<14> cient thermodynamic cycles, especially interesting for practical applications to quantum technologies.
## Acknowledgements
The authors are grateful to R. Uzdin and A. Levy for fruitful discussions and constructive criticism. This project was funded by COST Action MP1209, the Spanish MICINN (Grant No. FIS2010-19998), by the University of Nottingham through an Early Career Research and Knowledge Transfer Award and an EPSRC Research Development Fund Grant (PP-0313 36), and by the Brazilian funding agency CAPES / (Pesquisador Visitante Especial-Grant No. 108 2012). /
## Appendix A: Master equation for a periodically-driven three-level maser
In what follows, we shall derive a quantum master equation for a three-level maser weakly coupled to two unstructured bosonic reservoirs in d dimensions, and driven by a periodic perturbation. As already stated in the main text, the full Hamiltonian of system and baths (excluding their mutual interactions) is given by
$$& H _ { 0 } ( t ) = H ( t ) + H _ { B } = \omega _ { c } \left | 2 \right \rangle \left \langle 2 \right | + \omega _ { h } \left | 3 \right \rangle \left \langle 3 \right | + \\ & \lambda \left ( e ^ { i \omega _ { w } t } \left | 2 \right \rangle \left \langle 3 \right | + e ^ { - i \omega _ { w } t } \left | 3 \right \rangle \left \langle 2 \right | \right ) + \sum _ { \alpha = \left \{ h, c \right \} } \sum _ { \lambda } \omega _ { \lambda } b ^ { \dagger } _ { \alpha \lambda } b _ { \alpha \lambda }, \quad ( \text{A} 1 )$$
while the system-bath coupling writes as
$$H _ { I } = \sum _ { \alpha = \{ h, c \} } \sigma _ { \alpha } \otimes \left ( \sum _ { \lambda } g _ { \alpha \lambda } ( b _ { \alpha \lambda } + b _ { \alpha \lambda } ^ { \dagger } ) \right ). \quad ( A 2 ) \, \begin{array} { c } ( \omega _ { w } \\ \end{array} \, \text{Pl}$$
Recall that the 'thermal contact' operators GLYPH<27> GLYPH<11> were just GLYPH<27> h GLYPH<17> j 1 i h 3 j + j 3 i h 1 j and GLYPH<27> c GLYPH<17> j 1 i h 2 j + j 2 i h 1 . j The standard recipe to derive a Lindbland-Gorini-Kossakovsky-Sudarshan quantum master equation [33] demands to express the two GLYPH<27> GLYPH<11> in the interaction picture with respect to H 0 ( ), t and then, to suitably decompose them.
In the present case, the unitary evolution operator associated with H 0 ( ) t is formally given by the time-ordered exponential U 0 ( ) t = T exp n GLYPH<0> i R t 0 ds H 0 ( s ) o , and may be written as U 0 ( ) t = U 1 ( ) t U 2 ( ) t GLYPH<10> e GLYPH<0> iHBt , where
$$U _ { 1 } ( t ) \equiv \exp \left \{ - i t \left ( \omega _ { c } \left | 2 \right \rangle \left \langle 2 \right | + \omega _ { h } \left | 3 \right \rangle \left \langle 3 \right | \right ) \right \} \quad \ \left ( A 3 a \right )$$
$$U _ { 2 } ( t ) \equiv \exp \left \{ - i t \lambda \left ( | 2 \rangle \left \langle 3 \right | + \omega _ { h } \left | 3 \right \rangle \left \langle 2 \right | \right ) \right \}. \quad \ \ ( A 3 b )$$
This may be easily checked by noticing that d dt f U 1 ( ) t U 2 ( ) t g = GLYPH<0> iH t U ( ) 1 ( ) t U 2 ( ). t
A time-independent (or time-averaged) Hamiltonian ¯ H can be defined, that generates the same unitary dynamics as U t ( ) [i.e. e GLYPH<0> iHt ¯ GLYPH<17> U 1 ( ) t U 2 ( )]. For our three-level maser, this would t be
$$\bar { H } = \omega _ { c } \left ( | 2 \rangle \left \langle 2 | + | 3 \right \rangle \left \langle 3 | \right ) + \lambda \left ( | 2 \rangle \left \langle 3 | + | 3 \right \rangle \left \langle 2 | \right ), \quad \left ( A 4 \right )$$
with eigenvalues GLYPH<15> = f 0 ; ! c GLYPH<0> GLYPH<21>; ! c + GLYPH<21> g . Its corresponding set of positive Bohr quasi-frequencies ( GLYPH<15> j GLYPH<0> GLYPH<15> i > 0) is thus ¯ ! = f 0 2 ; GLYPH<21>; ! c GLYPH<6> GLYPH<21> g , where we have assumed without loss of generality that ! > GLYPH<21> c .
In general, we would have to resort now to Floquet theory [32, 40] in order to decompose the interaction picture thermal contact operators as
$$U ( t ) ^ { \dagger } \sigma _ { \alpha } U ( t ) = \sum _ { \tilde { \omega } } \sum _ { q \in \mathbb { Z } } A ^ { \alpha } _ { \tilde { \omega }, q } e ^ { - i ( \tilde { \omega } + q \omega _ { w } ) t }. \quad ( A 5 )$$
Fortunately for us, this may be done by mere inspection of the left-hand side of Eq. (A5), resulting in
$$A _ { \omega _ { c } + \lambda, 1 } ^ { h } = \frac { 1 } { 2 } \left ( \left | 1 \right \rangle \left \langle 3 \right | + \left | 1 \right \rangle \left \langle 2 \right | \right ) \text{ \quad \ \ } \left ( A 6 a \right )$$
$$A _ { \omega _ { c } - \lambda, 1 } ^ { h } = \frac { \bar { 1 } } { 2 } \left ( \left | 1 \right \rangle \left \langle 3 \right | - \left | 1 \right \rangle \left \langle 2 \right | \right ) \text{ \quad \ \ } \left ( A 6 b \right )$$
$$A _ { \omega _ { c } + \lambda, 0 } ^ { c } = \frac { 1 } { 2 } \left ( \left | 1 \right \rangle \left \langle 2 \right | + \left | 1 \right \rangle \left \langle 3 \right | \right ) \text{ \quad \ \ } \left ( A 6 c \right )$$
$$A _ { \omega _ { c } - \lambda, 0 } ^ { c } = \frac { \bar { 1 } } { 2 } \left ( \left | 1 \right \rangle \left \langle 2 \right | - \left | 1 \right \rangle \left \langle 3 \right | \right ) \text{ \quad \ \ } \left ( A 6 d \right )$$
$$A _ { - \bar { \omega }, - q } ^ { \alpha } = A _ { \bar { \omega }, q } ^ { \alpha \, \dagger }. \quad \quad \quad ( A 6 e )$$
There are, therefore, two open decay channels for each thermal contact, corresponding to frequencies !GLYPH<11> GLYPH<6> GLYPH<21> ( ! w = ! h GLYPH<0> ! c ).
Provided with the decomposition of Eq. (A6), we can now successively apply the Born, Markov and rotating-wave (or secular) approximations on the e GLYPH<11> ective equation of motion of the reduced density operator of the system in the interaction picture % ( ) [32, 33]. We thus arrive to a quantum master t
equation in the standard form:
$$\frac { d \varrho } { d t } = \sum _ { \alpha } \sum _ { \varpi } \sum _ { q \in \mathbb { Z } } \mathcal { L } _ { \varpi, q } ^ { \alpha } [ \varrho ] \\ \equiv \sum _ { \alpha } \sum _ { \varpi } \sum _ { q \in \mathbb { Z } } \left [ \Gamma _ { \varpi, q } ^ { \alpha } \left ( A _ { \varpi, q } ^ { \alpha } \varrho A _ { \varpi, q } ^ { \alpha } \, ^ { \dagger } - \frac { 1 } { 2 } \{ A _ { \varpi, q } ^ { \alpha } \, ^ { \dagger } A _ { \varpi, q } ^ { \alpha }, \varrho \} _ { + } \right ) + \\ \Gamma _ { - \varpi, - q } ^ { \alpha } \left ( A _ { \varpi, q } ^ { \alpha } \, ^ { \dagger } \varrho A _ { \varpi, q } ^ { \alpha } - \frac { 1 } { 2 } \{ A _ { \varpi, q } ^ { \alpha } A _ { \varpi, q } ^ { \alpha } \, ^ { \dagger }, \varrho \} _ { + } \right ) \right ]. \quad ( A 7 ) \quad \text{To sin} \, \mathbb { Z } \, \mathbb { Z } \, \text{and} \, is initial} \, \text{and} \, \text{in} \, \text{in} \, \text{in} \, \text{in} \, \text{in} \, \text{in} \, \text{in} \, \text{in} \, \text{in} \, \text{in} \, \text{in} \, \text{in} \, \text{in} \, \text{in} \, \text{in} \, \text{in} \, \text{in} \, \text{in} \, \text{in} \, \text{in} \, \text{in} \, \text{in} \, \text{in} \, \text{in} \, \text{in} \, \text{in} \, \text{in} \, \text{in} \, \text{in} \,\text{in} \, \text{in} \, \text{in} \, \text{in} \, \text{in} \, \text{in} \, \text{in} \, \text{in} \, \text{in} \, \text{in} \, \text{in} \, \text{in} \, \text{in} \, \text{in} \, \text{in} \, \text{in} \, \text{in} \, \text{in} \, \text{in} \, \text{in} \, \text{in} \, \text{in} \, \text{in} \, \text{in} \, \text{in} \, \text{in} \, \text{in} \, \text{in} \, \text{in } \, \text{in} \, \text{in} \, \text{in} \, \text{in} \, \text{in} \, \text{in} \, \text{in} \, \text{in} \, \text{in} \, \text{in} \, \text{in} \, \text{in} \, \text{in} \, \text{in} \, \text{in} \, \text{in} \, \text{in} \, \text{in} \, \text{in} \, \text{in} \, \text{in} \, \text{in} \, \text{in} \, \text{in} \, \text{in} \, \text{in} \, \text{in} \, \text{in} \, \tau \, \text{in} \, \text{in} \, \text{in} \, \text{in} \, \text{in} \, \text{in} \, \text{in} \, \text{in} \, \text{in} \, \text{in} \, \text{in} \, \text{in} \, \text{in} \, \text{in} \, \text{in} \, \text{in} \, \text{in} \, \text{in} \, \text{in} \, \text{in} \, \text{in} \, \text{in} \, \text{in} \, \text{in} \, \text{in} \, \text{in} \, \text{in} \, \text{in} \, \end{cases}$$
The assumption of factorized initial conditions between system and environmental degrees of freedom is implicit in the above, as is thermal equilibrium for the hot and cold heat reservoirs. Also note that the Lamb-shift term has been neglected in Eq. (A7).
The relaxation rates GLYPH<0> GLYPH<11> ! = 2Re nR 1 0 ds e i ! s h B GLYPH<11> ( ) t B GLYPH<11> ( t GLYPH<0> s ) i o are determined by the power spectrum of the environmental fluctuations, and satisfy the Kubo-Martin-Schwinger condition [41, 42] GLYPH<0> GLYPH<11> GLYPH<0> ! = e GLYPH<0> != T GLYPH<11> GLYPH<0> GLYPH<11> ! . Here, hGLYPH<1> GLYPH<1> GLYPH<1> i stands for equilibrium averaging. As already advanced in the main text, for our choice of the system-baths coupling scheme, i.e. bosonic baths with constant spectral density J GLYPH<11> ( ! ) GLYPH<24> GLYPH<13> GLYPH<11> , the relaxation rates are explicitly given by GLYPH<0> GLYPH<11> ! = GLYPH<13> GLYPH<11> ! GLYPH<11> d [ N GLYPH<11> ( ! ) + 1], with N GLYPH<11> ( ! ) GLYPH<17> ( e != T GLYPH<11> GLYPH<0> 1) GLYPH<0> 1 . Physically, this is compatible with weak coupling to the quantized electromagnetic field in thermal equilibrium, inside a d GLYPH<11> -dimensional box [33].
Equipped with Eqs. (A6) and (A7), we are now in the position of finding the limit cycle state % 1 , which is defined as
$$\sum _ { \alpha } \sum _ { \tilde { \omega } } \sum _ { q \in \mathbb { Z } } \mathcal { L } ^ { \alpha } _ { \tilde { \omega }, q } [ \varrho _ { \infty } ] = 0. \quad \quad ( A 8 )$$
The dissipators L GLYPH<11> ¯ !; q have local steady states (i.e. L GLYPH<11> ¯ !; q [ ˜ % GLYPH<11> ¯ !; q ] = 0) of the form ˜ % GLYPH<11> ¯ !; q = Z GLYPH<0> 1 exp n GLYPH<0> ¯ ! + q ! w ¯ ! ¯ H o [32]. Given their standard Lindblad form, each L GLYPH<11> ¯ !; q individually generates a fully contractive reduced dynamics towards ˜ % GLYPH<11> ¯ !; q , which is reflected in the monotonic decrease of the distance, as measured by the relative entropy, from any locally evolved state d dt % ( ) t = L GLYPH<11> ¯ !; q [ % ( )] t to ˜ % GLYPH<11> ¯ !; q [i.e. d dt S ( % ( ) t jj ˜ % GLYPH<11> !; q ) GLYPH<20> 0] [33, 43]. Such contractivity property applied to the actual steady state of the full Eq. (A7) eventually leads to the following inequality [32]
$$\sum _ { \alpha } \frac { 1 } { T _ { \alpha } } \left ( - T _ { \alpha } \sum _ { \tilde { \omega } } \sum _ { q \in \mathbb { Z } } \text{Tr} \, \mathcal { L } ^ { \alpha } _ { \tilde { \omega }, q } [ \varrho _ { \infty } ] \log \tilde { \varrho } ^ { \alpha } _ { \tilde { \omega }, q } \right ) \leq 0, \quad ( A 9 )$$
or equivalently
$$\sum _ { \alpha } \frac { 1 } { T _ { \alpha } } \left ( \sum _ { \tilde { \omega } } \sum _ { q \in \mathbb { Z } } \frac { \bar { \omega } + q \omega _ { w } } { \tilde { \omega } } \, \text{Tr} \, \bar { H } \mathcal { L } ^ { \alpha } _ { \tilde { \omega }, q } [ \varrho _ { \infty } ] \right ) \leq 0. \quad ( A 1 0 )$$
This can be understood as a statement of the second law of thermodynamics upon defining the limit cycle heat currents as ˙ Q GLYPH<11> GLYPH<17> P P ¯ ! q 2 Z ¯ ! + q ! w ¯ ! Tr f ¯ H L GLYPH<11> ¯ !; q [ % 1 g ] [32].
As it is probably useful for the interested reader, we now detail the specific form of the hot and cold dissipators. These are given by
$$\mathcal { L } ^ { \alpha } _ { \omega _ { a } + \lambda } [ \varrho ] \ & = \ \frac { \Gamma _ { \omega _ { a } + \lambda } } { 4 } \mathcal { D } _ { + + } [ \varrho ] \ + \ \frac { \Gamma _ { - \omega _ { a } - \lambda } } { 4 } \mathcal { D } _ { - - } [ \varrho ] \,, \\ \mathcal { L } ^ { \alpha } _ { \omega _ { a } - \lambda } [ \varrho ] \ & = \ \frac { \Gamma _ { \omega _ { a } - \lambda } } { 4 } \mathcal { D } _ { + - } [ \varrho ] \ + \ \frac { \Gamma _ { - \omega _ { a } + \lambda } } { 4 } \mathcal { D } _ { - + } [ \varrho ] \,, \ ( \text{A11} )$$
To simplify the notation, we have introduced the superoperators D , which act on % as
$$\text{$to$ simplify the notation, we have introduced the superopera-} \\ \text{tors $0$, which act on $g$ as} \\ \\ \text{$0_{++} [\varrho]$} \ = \ ( | 1 ) \langle 2 | + | 1 \rangle \langle 3 | ) \varrho ( | 2 \rangle \langle 1 | + | 3 \rangle \langle 1 | ) \\ \\ \quad \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \
\text{$- \frac{1}{2} \rangle \langle 2 | + | 2 \rangle \langle 3 | + | 3 \rangle \langle 2 | + | 3 \rangle \langle 3 | ) \varrho \\ \\ \quad \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \
\text{ $\n--[\varrho]$} \ = \ ( | 2 \rangle \langle 1 | + | 3 \rangle \langle 1 | ) \varrho ( | 1 \rangle \langle 2 | + | 1 \rangle \langle 3 | ) \\ \\ \quad \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \
\text{$- |\varrho]$} \ = \ ( | 1 \rangle \langle 2 | - | 1 \rangle \langle 3 | ) \varrho ( | 2 \rangle \langle 1 | - | 3 \rangle \langle 1 | ) \\ \\ \quad \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \
\text{$0_{++} [\varrho]$} \ = \ ( | 2 \rangle \langle 1 | - | 3 \rangle \langle 1 | ) \varrho ( | 1 \rangle \langle 2 | - | 1 \rangle \langle 3 | ) \\ \\ \quad \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \
\text{The populations of the limit cycle state $\varrho_{\infty}$ (expressed in} \\ \text{vector form as $n$ = \ln$. n$. n$. 1 ) $ \max be found by combining}$$
The populations of the limit cycle state % 1 (expressed in vector form as n = f n 1 ; n 2 ; n 3 g ) may be found by combining the relation M D L 3 GLYPH<1> n = 0 with the normalisation condition P i ni = 1. The coe GLYPH<14> cient matrix M D L 3 is given by
$$( i. e. \begin{array} { c c c c } M ^ { D 3 L } = \left ( \begin{array} { c c c c c } - 2 G _ { - \omega } ^ { + } + 2 \frac { G _ { \omega } ^ { - } G _ { - \omega } ^ { - } } { G _ { \omega } ^ { + } } & G _ { \omega } ^ { + } - \frac { G _ { \omega } ^ { - } G _ { \omega } ^ { - } } { G _ { \omega } ^ { + } } & G _ { \omega } ^ { + } - \frac { G _ { \omega } ^ { - } G _ { \omega } ^ { - } } { G _ { \omega } ^ { + } } \\ G _ { - \omega } ^ { + } - \frac { G _ { \omega } ^ { - } G _ { - \omega } ^ { - } } { G _ { \omega } ^ { + } } & - G _ { \omega } ^ { + } + \frac { G _ { \omega } ^ { - } G _ { \omega } ^ { - } } { 2 G _ { \omega } ^ { + } } & - G _ { \omega } ^ { + } \\ G _ { - \omega } ^ { + } - \frac { G _ { \omega } ^ { - } G _ { - \omega } ^ { - } } { G _ { \omega } ^ { + } } & \frac { G _ { \omega } ^ { - } G _ { \omega } ^ { - } } { 2 G _ { \omega } ^ { + } } & - G _ { \omega } ^ { + } + \frac { G _ { \omega } ^ { - } G _ { \omega } ^ { - } } { 2 G _ { \omega } ^ { + } } \end{array} \right ) \,, \\ \text{ usually} \quad \text{ where the constants } G _ { - \lambda } ^ { + } \, \text{ are defined as}$$
where the constants G GLYPH<6> are defined as
!
$$\begin{array} { l l l } G _ { \omega } ^ { + } & \equiv & \frac { \Gamma _ { \omega + A } ^ { S } + \Gamma _ { \omega - A } ^ { S } } { 4 } \,, & G _ { - \omega } ^ { + } & \equiv & \frac { \Gamma _ { - \omega - A } ^ { S } + \Gamma _ { - \omega + A } ^ { S } } { 4 } \,, \\ G _ { \omega } ^ { - } & \equiv & \frac { \Gamma _ { \omega + A } ^ { S } - \Gamma _ { - \omega - A } ^ { S } } { 4 } \,, & G _ { - \omega } ^ { - } & \equiv & \frac { \Gamma _ { - \omega - A } ^ { S } - \Gamma _ { - \omega + A } ^ { S } } { 4 } \,, \end{array}$$
and GLYPH<0> S GLYPH<6> ! GLYPH<21> GLYPH<6> GLYPH<17> GLYPH<0> GLYPH<11> GLYPH<6> ! h GLYPH<6> GLYPH<21> + GLYPH<0> GLYPH<11> GLYPH<6> ! c GLYPH<6> GLYPH<21> .
Finally, we also give the explicit form of the cycle-averaged stationary heat flows. In particular, ˙ Q h is given by
$$\text{ationary heat flows. In particular, } \mathcal { Q } _ { h } & \text{ is given by} \\ \mathcal { Q } _ { h } & \text{ = } \mathcal { Q } _ { \omega _ { h } + \lambda } + \mathcal { Q } _ { \omega _ { h } - \lambda } \text{,} \\ \mathcal { Q } _ { \omega _ { h } + \lambda } & \text{ = } \frac { \omega _ { h } + \lambda } { \omega _ { c } + \lambda } \text{ Tr} \{ \tilde { H } \mathcal { L } _ { \omega _ { h } + \lambda } [ \tilde { \rho } ] \} = \\ ( \omega _ { h } + \lambda ) \left [ \frac { \Gamma _ { - \omega _ { h } - \lambda } } { 2 } n _ { 1 } \text{ - } \frac { \Gamma _ { \omega _ { h } + \lambda } } { 4 } ( n _ { 2 } + n _ { 3 } + n _ { c } ) \right ] \text{,} \\ \mathcal { Q } _ { \omega _ { h } - \lambda } & \text{ = } \frac { \omega _ { h } - \lambda } { \omega _ { c } - \lambda } \text{ Tr} \{ \tilde { H } \mathcal { L } _ { \omega _ { h } - \lambda } [ \tilde { \rho } ] \} \text{ =} \\ ( \omega _ { h } - \lambda ) \left [ \frac { \Gamma _ { - \omega _ { h } + \lambda } } { 2 } n _ { 1 } \text{ - } \frac { \Gamma _ { \omega _ { h } - \lambda } } { 4 } ( n _ { 2 } + n _ { 3 } - n _ { c } ) \right ] \text{,}$$
and ˙ Q c writes as
$$& \mathcal { Q } _ { c } \, = \, \mathcal { Q } _ { \omega _ { c } + \lambda } \, + \, \mathcal { Q } _ { \omega _ { c } - \lambda } \,, \\ & \mathcal { Q } _ { \omega _ { c } + \lambda } \, = \, \underset { \_ - } { \text{Tr} } \{ \tilde { H } \mathcal { L } _ { \omega _ { c } + \lambda } [ \tilde { \rho } ] \} \,$$
$$= ( \omega _ { c } - \lambda ) \left [ \frac { \Gamma _ { - \omega _ { c } + \lambda } } { 2 } n _ { 1 } \, - \, \frac { \Gamma _ { \omega _ { c } - \lambda } } { 4 } ( n _ { 2 } + n _ { 3 } - n _ { c } ) \right ] \,.$$
$$& \mathcal { L } _ { c } \, = \, \mathcal { L } _ { \omega _ { c } + \lambda } \, + \, \mathcal { L } _ { \omega _ { c } - \lambda } \,, \\ & \mathcal { Q } _ { \omega _ { c } + \lambda } \, = \, \text{Tr} \{ \bar { H } \mathcal { L } _ { \omega _ { c } + \lambda } [ \tilde { \rho } ] \} \\ & = ( \omega _ { c } + \lambda ) \left [ \frac { \Gamma _ { - \omega _ { c } - \lambda } } { 2 } n _ { 1 } \, - \, \frac { \Gamma _ { \omega _ { c } + \lambda } } { 4 } ( n _ { 2 } + n _ { 3 } + n _ { c } ) \right ] \,, \\ & \mathcal { Q } _ { \omega _ { c } - \lambda } \, = \, \text{Tr} \{ \bar { H } \mathcal { L } _ { \omega _ { c } - \lambda } [ \tilde { \rho } ] \} \\ & = ( \omega _ { c } - \lambda ) \left [ \frac { \Gamma _ { - \omega _ { c } + \lambda } } { 2 } n _ { 1 } \, - \, \frac { \Gamma _ { \omega _ { c } - \lambda } } { 4 } ( n _ { 2 } + n _ { 3 } - n _ { c } ) \right ] \,.$$
- [1] B. Andresen, Angewandte Chemie International Edition 50 , 2690 (2011).
- [2] K. H. Ho GLYPH<11> mann, J. M. Burzler, and S. Schubert, J. Non-Equilib. Thermodyn 22 , 311 (1997).
- [3] I. Novikov, Atomic Energy 3 , 1269 (1957).
- [4] S. Carnot, Reflections on the Motive Power of Heat and on Machines Fitted to Develop That Power (J. Wiley & Sons (New York), 1890).
- [5] J. Yvon, in Proceedings of the International Conference on Peaceful Uses of Atomic Energy (United Nations, Geneva) (1955), p. 387.
- [6] F. Curzon and B. Ahlborn, Am. J. Phys. 43 , 22 (1975).
- [7] A. Vaudrey, F. Lanzetta, and M. Feidt, e-print arXiv:1406.5853.
- [8] C. Van den Broeck, Phys. Rev. Lett. 95 , 190602 (2005).
- [9] M. Esposito, K. Lindenberg, and C. Van den Broeck, Phys. Rev. Lett. 102 , 130602 (2009).
- [10] M. Esposito, R. Kawai, K. Lindenberg, and C. Van den Broeck, Phys. Rev. Lett. 105 , 150603 (2010).
- [11] M. Esposito, R. Kawai, K. Lindenberg, and C. Van den Broeck, Phys. Rev. E 81 , 041106 (2010).
- [12] E. Geva and R. Koslo GLYPH<11> , The Journal of chemical physics 96 , 3054 (1992).
- [13] Z. Yan and J. Chen, Journal of Physics D: Applied Physics 23 , 136 (1990).
- [14] C. de Tom´ as, A. C. Hern´ andez, and J. M. M. Roco, Phys. Rev. E 85 , 010104 (2012).
- [15] S. Velasco, J. M. M. Roco, A. Medina, and A. C. Hern´ andez, Phys. Rev. Lett. 78 , 3241 (1997).
- [16] B. Jim´ enez de Cisneros, L. A. Arias-Hern´ andez, and A. C. Hern´ andez, Phys. Rev. E 73 , 057103 (2006).
- [17] J. Chen, Journal of Physics A: Mathematical and General 27 , 6395 (1994).
- [18] Y. Apertet, H. Ouerdane, A. Michot, C. Goupil, and P. Lecoeur, EPL (Europhysics Letters) 103 , 40001 (2013).
- [19] R. Koslo GLYPH<11> and A. Levy, Anual Rev. Phys. Chem. 65 , 365 (2014).
- [20] H. E. D. Scovil and E. O. Schulz-DuBois, Phys. Rev. Lett. 2 , 262 (1959).
- [21] J. P. Palao, R. Koslo GLYPH<11> , and J. M. Gordon, Phys. Rev. E 64 ,
In these expressions, the constant nc is defined as
$$n _ { c } \, \equiv \, ( n _ { 2 3 } + n _ { 3 2 } ) \, = \, 2 \frac { G _ { - \omega } ^ { - } } { G _ { \omega } ^ { + } } \, n _ { 1 } \, - \, \frac { G _ { \omega } ^ { - } } { G _ { \omega } ^ { + } } ( n _ { 2 } + n _ { 3 } ) \,, \quad ( \text{A1} 5 )$$
where nij = h j i % 1j j i stands for steady-state coherences.
Getting the steady-state populations from Eq. (A13) and using the xpressions for the heat currents above, allows to check the validity of Eq. (11) in the limit of GLYPH<21> ! 0.
056130 (2001).
- [22] B. Andresen, P. Salamon, and R. S. Berry, The Journal of Chemical Physics 66 , 1571 (1977).
- [23] J. M. Gordon and K. C. Ng, Cool thermodynamics (Cambridge international science publishing Cambridge, 2000).
- [24] J. E. Geusic, E. O. Schulz-DuBios, and H. E. D. Scovil, Phys. Rev. 156 , 343 (1967).
- [25] O. Kedem and S. R. Caplan, Trans. Faraday Soc. 61 , 1897 (1965).
- [26] E. Geva and R. Koslo GLYPH<11> , J. Chem. Phys. 104 , 7681 (1996).
- [27] U. Raam and R. Koslo GLYPH<11> , e-print arXiv:1406.6788.
- [28] L. A. Correa, J. P. Palao, G. Adesso, and D. Alonso, Phys. Rev. E 87 , 042131 (2013).
- [29] L. A. Correa, J. P. Palao, D. Alonso, and G. Adesso, Sci. Rep. 4 (2014).
- [30] G. Lindblad, Comm. Math. Phys. 48 , 119 (1976).
- [31] V. Gorini, A. Kossakowski, and E. Sudarshan, J. Math. Phys. 17 , 821 (1976).
- [32] G. K. Robert Alicki, David Gelbwaser-Klimovsky (2012).
- [33] H. Breuer and F. Petruccione, The Theory of Open Quantum Systems (Oxford University Press, USA, 2002).
- [34] L. A. Correa, Phys. Rev. E 89 , 042128 (2014).
- [35] J. F. Poyatos, J. I. Cirac, and P. Zoller, Phys. Rev. Lett. 77 , 4728 (1996).
- [36] X. L. Huang, T. Wang, and X. X. Yi, Phys. Rev. E 86 , 051105 (2012).
- [37] O. Abah and E. Lutz, EPL (Europhysics Letters) 106 , 20001 (2014).
- [38] J. Roßnagel, O. Abah, F. Schmidt-Kaler, K. Singer, and E. Lutz, Phys. Rev. Lett. 112 , 030602 (2014).
- [39] S. McEndoo, P. Haikka, G. D. Chiara, G. M. Palma, and S. Maniscalco, EPL (Europhysics Letters) 101 , 60005 (2013).
- [40] K. Szczygielski, D. Gelbwaser-Klimovsky, and R. Alicki, Phys. Rev. E 87 , 012120 (2013).
- [41] R. Kubo, Journal of the Physical Society of Japan 12 , 570 (1957).
- [42] P. C. Martin and J. Schwinger, Phys. Rev. 115 , 1342 (1959).
- [43] H. Spohn, Journal of Mathematical Physics 19 , 1227 (1978). | 10.1103/PhysRevE.90.062124 | [
"Luis A. Correa",
"José P. Palao",
"Gerardo Adesso",
"Daniel Alonso"
] | 2014-08-03T08:55:35+00:00 | 2014-11-24T16:58:57+00:00 | [
"quant-ph",
"cond-mat.stat-mech"
] | Optimal performance of endoreversible quantum refrigerators | The derivation of general performance benchmarks is important in the design
of highly optimized heat engines and refrigerators. To obtain them, one may
model phenomenologically the leading sources of irreversibility ending up with
results which are model-independent, but limited in scope. Alternatively, one
can take a simple physical system realizing a thermodynamic cycle and assess
its optimal operation from a complete microscopic description. We follow this
approach in order to derive the coefficient of performance at maximum cooling
rate for \textit{any} endoreversible quantum refrigerator. At striking variance
with the \textit{universality} of the optimal efficiency of heat engines, we
find that the cooling performance at maximum power is crucially determined by
the details of the specific system-bath interaction mechanism. A closed
analytical benchmark is found for endoreversible refrigerators weakly coupled
to unstructured bosonic heat baths: an ubiquitous case study in quantum
thermodynamics. |
1408.0474v1 | ## Time
to
timestamp:
opportunistic
cooperative
localization from
reception
time
measurements
Fabio
Ricciato
Austrian
Institute
of
Technology
## Abstract
We
present
a
general
framework
for
improving
and
extending
GNSS--based
positioning
by leveraging
opportunistic
measurements
from
legacy
terrestrial
radio
signals.
The
proposed approach
requires
only
that
participating
nodes
collect
and
share reception
timestamps of incoming
packets
and/or
other
reference
signals
transmitted
by
other
fixed
or
mobile
nodes, with
no need
of inter--node
synchronization.
The
envisioned
scheme
couples
the
idea
of cooperative
GNSS
augmentation
with
recent
pioneering
work
in
the
field
of
time--based localization
in
asynchronous
networks.
In
this
contribution
we
present
the
fundamental principles
of the proposed
approach
and
discuss
the
system--level
aspects
that
make
it particularly
appealing
and
timely
for
Cooperative
ITS
applications,
with
the
goal
of
motivating further
research
and
experimentation
in
this
direction.
## 1. Introduction
&
motivations
In this paper
we
present
a
framework
approach
to
integrate
Global
Navigation
Satellite Systems
(GNSS)
and
legacy
terrestrial
wireless
networks
(short--range
and/or
long--range)
in order
to (1) improve
the
localization
accuracy
for
nodes
equipped
with
on--board
GNSS receiver
and
(2)
extend
the
localization
function
to
wireless
nodes
outside
GNSS
coverage and/or
without
onboard
GNSS
module.
The
proposed
approach
is
'opportunistic'
since
it
may exploit
legacy
wireless
communication
signals
from
fixed
infrastructure
and/or
between cooperating
mobile
nodes,
and
is particularly
appealing
for applications
in the field of Cooperative
Intelligent
Transportation
Systems
(C--ITS).
Our
approach
builds
upon
recent work
in
the
field
of
time--based
localization
in
asynchronous
network
[Nag11,Col14,Fac14], whose
principles
are
briefly
presented
hereafter,
combined
with
the
concept
of
cooperative positioning
[Gar12,Ami14].
The
requirements
for
practical
implementation
are
minimal:
we demand
only
that
the
participating
devices
are
capable
of
recording
reception
timestamps
for legacy
communication
signals,
and
that
have
the
means
to
share
these
data
along
with
their initial
position
(if
available)
as
provided
by
GNSS.
In
this
work
we
do
not
provide
a
single
ready--made
solution
for
a
specific
scenario
or
use-case,
but
rather
describe
a
more
general
reference
framework
and
the
underlying
principles of
the
proposed
solution
space.
Our
goal
is
twofold.
On
the
side
of
the
research
community,
we indicate a coherent research agenda aimed at attracting attention onto the (mostly unexplored
to
date)
field
of
opportunistic
and
cooperative time--based localization
between asynchronous nodes, highlighting some prominent directions for investigation and experimentation.
On
the
side
of
the
industry,
we
aim
at
drawing
attention
on
the
potential value
(in
terms
of
costs
vs.
benefits)
of
supporting
more
accurate
timing
measurement
in commercial--off--the--shelf
(COTS)
receivers
for
terrestrial
communication,
and
making
these measurements
available
via
standard
interfaces
to
system
integrators.
In
other
words,
we envision
the
future
'commoditization'
of
precise
receiver
timestamping
function
in
COTS
devices,
similarly
to
what
has
happened
for
the
Received
Signal
Strength
Indicator
(RSSI),
in order
to
unlock
the
potential
of
opportunistic
time--based
multi--radio
localization.
The
paper
is
organized
as
follows.
We
start
in
Sec.
2
by
representing
some
fundamental
trends in
wireless
systems
technology
that
collectively
motivate
the
appeal,
timeliness
and
practical viability
of
the
proposed
method
for
real--world
adoption.
In
Sec.
3
we
describe
in
a
tutorial manner
the
fundamental
principles
of
time--based
localization
in
asynchronous
networks. Along
the
way,
we
review
relevant
pioneering
work
and
highlight
a
number
of
relevant research
directions
for
the
scientific
community.
Finally,
in
Sec.
4
we
conclude
with
some simple
recommendations
for
industry
players.
## 2. Current
trends
## Trend
1:
Radios
coming
together
Generally
speaking,
radio
signals
can
be
used
to
perform
different
functions:
communication, localization
and navigation,
sensing
and
imaging,
to name
the most popular
nowadays. Historically,
the
vast
majority
of
radio
technologies
are
designed
to
serve
only
one
function, e.g. communication or localization.
Dedicated
single--function
radio
systems
are
easier
to design
and
allow
optimizing
each
component
(signal
format,
protocol,
device
etc.)
for
the function
of
interest.
However,
real--world
applications
and
use--cases
often
involve
a
blend
of multiple functions, for example communication and localization. The current dominant paradigm
is
to
use
multiple
single--function
systems:
for
example
in
the
field
of
C--ITS
one common
option
is
to
rely
on
a
GNSS
module
for
localization,
to
DSRC/IEEE
802.11p
module for
local--area
communication,
and
to
a
UMTS/LTE
module
for
wide--area
communication.
In this
way,
multiple
radio
modules
developed
independently
for
different
functions
end
up together,
co--located
in
the
same
On--Board
Unit
(OBU).
Similar
considerations
can
be
done
for smartphones.
Given
this
scenario,
it
is
quite
natural
to
ask
whether
some
form
of
tighter integration
or
inter--working
between
these
modules
could
be
exploited
to
improve
the overall
system
performance.
As
we
will
show
hereafter,
the
answer
is
positive
(at
least)
as
far as the positioning
accuracy
is concerned,
meaning
that
there
is a (mostly
unexplored) potential
to
improve
the
positioning
accuracy
through
clever
interworking
of
these
different systems.
## Trend
2:
Reusing
Radios
It
is
possible
that
in
the
mid--term
future
we
will
see
a
proliferation
of
wireless
technologies designed
natively
to
support
multiple
functions.
One
example
in
this
direction
is
given
by
the Ultra Wide Band (UWB) technology wherein the signal format, protocol and device architecture have been designed and standardized from the beginning to serve both communication
and
ranging
functions.
In
principle,
in
C--ITS
applications
one
could
develop systems
that
use
a
single
waveform
to
let
the
vehicle
sense
and
communicate
with
other vehicles.
However,
along
the
path
from
(current)
single--function
systems
towards
(future) multi--function
systems
there
are
opportunities
to
reuse
'opportunistically'
systems
that
were developed
for
some
'native'
function
X
in
order
to
perform
also
a
different
'supplementary' function
Y.
For
example,
certain
opportunistic
radars
(also
called
'green
radars')
exploit legacy signals from existing broadcasting towers. Of particular interest for practical applications
are
those
cases
where
the
supplementary
function
Y
can
be
performed
with
small or
null
adaptation
of
the
legacy
devices,
therefore
at
(almost)
zero
additional
cost.
The
most popular example is probably represented by radio localization methods based on the Received Signal Strength Indicator (RSSI) in WiFi, Bluethoot, IEEE 802.15.4 and other wireless
systems:
strictly
speaking,
RSSI
is
not
required
to
perform
the
native
function
of these systems, i.e., communication.
Nevertheless, RSSI is now a 'commodity'
function supported
by
most
(if
not
all)
commercial
devices,
and
that
has
enabled
the
implementation
of coarse localization
capabilities
in
these
systems.
Along
a
similar
line
of
reasoning,
we
claim here
that
timing
measurements
on
the
receiver
side,
i.e.,
accurate
timestamping,
is
a
small
but powerful
ingredient
holding
the
potential
to
introduce
more
accurate
localization
capabilities especially
in
multi--radio
nodes
(for
instance
smartphones
and
OBUs)
without
requiring
clock synchronization
between
them.
## Trend
3:
Cooperation
Before turning of the century the dominant paradigm for mobile radio systems was asymmetric and vertical: it would involve mobile end--terminals 'served' by fixed infrastructure
nodes
with
different
capabilities.
This
model
reflects
the
asymmetry
of
the traditional service--provisioning
model ,
wherein
provider
and
consumer
are
distinct
entities.
In the
last
decade
however,
the
peer--to--peer
paradigm
has
made
his
way,
first
in
computer applications
and
then
in
the
real
of
wireless
communications.
Systems
based
on
the
horizontal cooperation
between
peer
nodes
that collectively
build
the
service have
been
developed
and accepted.
In
many
scenarios,
and
prominently
in
the
C--ITS
field,
hybrid
radio
systems
are envisaged
to
include
a
combination
of
horizontal
and
vertical
components,
i.e.,
vehicle--to-vehicle
(V2V)
and
vehicle--to--infrastructure
(V2I).
The
application
of
the
peer--to--peer
concept for
GNSS
augmentation
has
been
proposed
earlier
in
[Gar12]
(see
also
[Ami14]
and
references therein) where it was shown that the fusion of initial GNSS positions and ranging measurements between
the
nodes
bears
the
potential
to improve the
position
estimates
(for GNSS--enabled
nodes)
and
at
the
same
time extend the
localization
function
to
non--GNSS-enabled
nodes.
However,
the
system
model
considered
in
those
papers
assumes
that nodes are
equipped
with
additional
ranging
capabilities . The
latter
can
be
delivered
by
external dedicated
sensors,
e.g. radar, or by implementing
dedicated
ranging
procedures
on
the wireless
communication
channel,
e.g.
two--way
Time--of--Arrival.
Instead,
we
are
interested
in methods
that
reuse
the
existing
communication
signals
that
are
anyway
available
over--the-air, without
requiring
additional
sensors,
protocols
or
signals. In principle, this can be achieved
by
resorting
to
RSSI--based
methods
from
received power measurements
associated to
the
communication
signals,
but
this
approach
is
known
to
be
very
inaccurate
in
practice and
would
unlikely
provide
any
accuracy
gain
over
plain
GNSS
technology
in
real
scenarios.
In this contribution we claim that cooperative (and opportunistic) localization can be implemented
from timing measurements,
by
exploiting
simply the receiver timestamps recorded
by
(legacy)
receivers
on
the
communication
signals
and
packets
transmitted
from other
mobile
and/or
fixed
nodes.
In
our
scheme,
a
set
of
timestamps
from
multiple
nodes
are transformed
into
a
set
of
pseudo--ranges,
and
the
latter
are
fused
with
initial
positions
to improve
and
extend
the
localization
function
without
any
need
of
additional
equipment, protocol
or
signal
for
ranging.
The
overall
dataflow
is
sketched
in
Fig.
1.
## 3. System
model
and
methodology
framework
## Reference
Scenario
We
envisage
a
cooperative
and
opportunistic
localization
system
where
a
subset
of
the participating
nodes
know
their
position
with
a
certain
initial
accuracy,
not
necessarily
equal for all nodes,
from
their
on--board
GNSS
module.
Furthermore,
each
node
communicates wireless
with
other
mobile
nodes
and/or
with
infrastructure
nodes,
for
other
purposes
than localization.
We
show
that
such
communication
signals
can
be
exploited
opportunistically
to collectively
improve
the
localization
accuracy
of
the
nodes.
To
achieve
this
goal,
it
is
only required
that
each
node
is
able
to
measure
the
reception
time
of
individual
packets
(in
case
of packet--oriented
protocols)
or
some
commonly
agreed
reference
signals
(in
case
of
continuous transmissions,
e.g.
frame
start
in
DVB--T)
according
to
its
local
clock,
and
that
it
is
able
to
share with
the
rest
of
the
system
the
recorded
reception
timestamps,
the
associated
packet/signal identifiers
and
its
initial
position
estimate
(if
available).
No
external
mechanism
is
required
to synchronize
the
clock
of
the
individual
receivers,
i.e.,
we
consider asynchronous
nodes . Also, we
do
not
make
any
assumption
on
the
transmission
time
of
every
packet
or
reference
signal, which
we
assume
uncontrolled
and
unknown.
In
this
way,
we
can
cope
with asynchronous transmissions . In fact, most data protocols
are indeed
completely
asynchronous,
and
in standard
COTS
devices
transmission
timestamps
(if
at
all
available)
are
less
accurate
than reception
timestamps.
However,
it
is
quite
straightforward
to
extend
the
method
presented here
to
make
use
of
any
additional
information
that
might
be
available
on
the
transmission times
(e.g.
in
case
of
periodic
transmissions).
Also,
for
the
sake
of
simplicity
we
consider
a basic
scenario
where
all
measured
data
are
somehow
gathered
at
a
centralized
entity
(server or
cloud)
in
charge
of
performing
the
computation,
and
we
do
not
consider
here
any
privacy or security
aspect.
Variations
of
the
proposed
method
to
perform
distributed,
secure
and privacy--preserving
computation
are
interesting
directions
for
progressing
the
research.
## Time--based
localization
with
asynchronous
nodes
In order
to
illustrate
the
principle
of
the
proposed
scheme,
we
need
first
to
introduce
a minimum
of
notation.
We
denote
by ti [ m ]
the
absolute
transmission
time
of
the
generic m th packet
sent
by
transmitting
node i , and
by rk [ m ] the absolute reception
time
of
the
same packet
by
the
receiving
node k .
Node k may
not
be
the
intended
destination
for
packet m and it
is
not
necessary
for k to
decode
the
whole
packet.
We
assume
only
that
node k overhears the
packet
and
decodes
the
minimum
set
of
control
information
(e.g.
the
header)
that
allow
to identify
the
source
node
(e.g.,
MAC
source
address)
and
to
discriminate
packet m from
other neighboring
packets
from
the
same
source.
Both
transmission
and
reception
times ti [ m ] and rk [ m ] are referred
to
an
ideal
absolute reference
clock
and
cannot
be
observed
directly.
What
can
be
measured
is
only
the local reception
timestamp ,
denoted
by sk [ m ],
according
to
the
local
clock
at
receiver k .
We
denote
by dik the
true
distance
between
transmitter
and
receiver i k .
We
consider
a
static
scenario
where the position of all nodes can be considered
fixed at the timescale of interest, leaving extensions
to
moving
nodes
as
a
prominent
direction
for
further
study.
When
nodes i and k are
in
direct
Line--of--Sight
(LOS),
the
transmit
and
reception
times
are linked
by
( c denoting
the
light
speed):
$$r _ { k } [ m ] = t _ { i } [ m ] + d _ { i k } [ m ] / c.$$
The
reception
timestamp
is
linked
to
the
absolute
arrival
time
by
the
following
relation:
$$s _ { k } [ m ] = a _ { k } + ( 1 + b _ { k } ) * r _ { k } [ m ] + h ( r _ { k } [ m ] ) + w _ { k } [ m ]$$
wherein ak and bk denote respectively
the clock bias (temporal
offset) and clock drift (frequency
offset)
of
receiving
clock k .
The
clock
drift
is
due
to
deviations
of
the
actual
clock frequency
from
its
nominal
value,
and
is
typically
limited
to
a
few
tens
of
ppm
for
commercial devices.
The
temporal
function hk(τ) ( τ denoting
a
generic
reception
instant)
accounts
for
any additional
slowly--varying
error
component,
possibly
non--linear,
caused
by
short--term
clock fluctuations.
This
error
component
is
highly
correlated
between
neighboring
packets
arriving at
the
same
receiver
within
a
small
interval.
Finally,
the
term wk m [ ] captures
the
residual measurement
error
component
associated
to
each
individual
reception
event
(including
e.g. clock
quantization,
timestamp
truncation
and
any
other
source
of
measurement
noise)
and can
be
modeled
as
an
independent
random
variable.
Note
that
eq.
(2)
focuses
exclusively
on clock
error
components.
We
are
not
considering
at
this
stage
additional
sources
of spatial measurement errors, like multipath and Non--Line--of--Sight (NLOS), which affect also synchronous
systems.
These
will
be
discussed
later
in
Sec.
4.
For
the
sake
of
illustration
simplicity,
consider
a
generic
scenario
with
multiple
nodes
in known
positions
('anchors')
and
a
single
node
('blind')
whose
position
is
unknown
and needs
to
be
determined.
Every
node
transmits
packets
that
are
overheard
and
timestamped by
other
nodes.
For
every
packet
traveling
from
node i to k we
can
write
one
equation
in
the form
of
(2),
resulting
in
a
system
of
equations
with
the
following
observables:
- ∞ Distances
between
pairs
of
anchor
nodes;
- ∞ Reception
timestamps sk [ m ];
and
the
following
types
of
of
unknowns:
- ∞ Clock
error
components: ak , bk and hk(τ) ;
- ∞ Transmission
times ti [ m ; ]
- ∞ Distances
(ranges)
between
the
blind
node
and
each
anchor
node;
In
order
to
locate
the
blind
node,
we
need
to
estimate
the
latter,
i.e.,
the
blind--anchor
ranges. It
turns
out
that
from
the
system
at
hand
we
cannot
obtain
direct
ranges
but
only pseudo-ranges , i.e., a set
of distances
defined
up
to
a
common
unknown
bias
term.
This
is
not
a problem
since
there
are
well--known
methods
for
computing
a
position
from
a
set
of
pseudo-ranges,
for
instance
the
standard
Iterative
Least
Squares
(ILS)
algorithm
used
in
GPS
[Tsu04].
In
order
to
obtain
pseudo--ranges
from
a
system
of
equations
of
the
form
(2)
we
need
to
deal with
the
other
unnecessary
unknowns
listed
above.
Generally
speaking,
each
unnecessary unknown
can
be
either eliminated upfront,
by
combining
(differentiating)
selected
equations, or
it
can
be estimated from
the
data
at
hand.
In
the
latter
case,
it
can
be
either
estimated jointly with
the
variables
of
interest
(i.e.
treated
as
a
nuisance
parameter)
or
it
can
be
estimated separately
and
then
compensated.
Therefore,
different
resolution
approaches
are
possible depending
on
how
each
unknown
is
treated.
Until
now,
only
a
few
pioneering
work
have started
to
formulate
and
investigate
some
of
these
methods.
One
of
the
intended
goals
of
the present
contribution
is
indeed
to
attract
further
research
to
explore
other
possible
solutions and
estimation
methods
for
the
problem
at
hand.
Some
previous
work
have
considered
a
simplified
clock
error
model
by
neglecting
the
clock drift bk and
the
slowly--varying
component hk(τ) .
In
this
case
eq.
(2)
simplifies
as
shown
in
Fig. 2--A.
One
possible
resolution
approach
is
to
differentiate
the
equations
relative
to
two
packets from
different
transmitters
arriving
at
the
same
receiver
in
order
to
get
rid
of
the
clock
bias ak (ref.
Fig
2--B)
then
treat
the
transmission
times
as
nuisance
parameters.
If
the
two
packets
are close
in
time,
such
a
differentiation
would
cancel
also
the
slowly--varying
component hk(τ) ,
if present.
Alternatively,
one
can
differentiate
the
equations
relative
to
reception
of
the
same packet
(from
a
single
transmitter)
arriving
at
two
different
receivers
in
order
to
get
rid
of
the transmission
times ti [ m ] (ref.
Fig
2--C)
then
treat
the
clock
bias
as
nuisance
parameter.
These , two
approaches
have
been
considered
recently
in
[Col14]
and
[Ban14]
respectively.
However, the
simplest
approach
is
to
apply
a double
differentiation on
the
four
equations
between
a
pair of
transmitters
and
a
pair
of
receivers,
as
shown
in
Fig.
2--D,
in
order
to
get
rid
of
both
types
of unknowns.
This
method
has
been
termed Differential Time--Difference
of
Arrival
(DTDoA)
and should
be
distinguished
from
the
classical
Time--Difference
of
Arrival
(TDoA)
adopted
in
GPS. The
requirement
that
anchor
nodes
(e.g.,
satellites)
be
synchronized
applies
to
TDoA
but
not to
DTDoA.
The DTDoA
equation
appeared
a
decade
ago
in
the
field of interferometric
localization [Mar05]
and
was
later
considered
in
systems
where
time--differences
are
measured
by
means of waveform correlators [Fan07]. The idea to use DTDoA with simple timestamp measurements
from
legacy
wireless
devices
was
presented
and
tested
only
recently
in [Nag11]
and
[Fac14],
where
different
approaches
were
adopted
to
estimate
and
compensate for
the
clock
drift,
among
other
methodological
differences.
Interestingly,
both
work
report experimental validation results with COTS IEEE 802.11b devices achieving sub--meter accuracy
in
LOS
conditions.
Further
work
is
needed
to
explore
more
advanced
estimation techniques,
however
the
early
result
in
[Nag11]
and
[Fac14]
indicate
that
sub--meter
accuracy is
at
reach
nowadays
with current COTS
equipment,
at
least
in
LOS
conditions.
## System
model
From
a
system--level
point
of
view
however,
the
closest
work
is
represented
by
[Col14].
The system
model
considered
therein
is
a
particular
case
of
the
more
general
scenario
envisioned here.
In
general,
we
consider
three
types
of
nodes:
- ∞ Fixed
stations :
terrestrial
infrastructure
nodes,
whose
positions
are
precisely
known,
i.e., with
negligible
positioning
error.
- ∞ Mobile
nodes
with
GNSS , whose
positions
are
known
only
approximately,
i.e.,
with
an initial
error
of
several
meters
that
we
aim
at
reducing.
- ∞ Mobile
node
without
GNSS (blind
node),
whose
position
is
completely
unknown
and needs
to
be
determined.
Depending on the radio technology, fixed stations can be transmit--only (e.g. DVB--T broadcasting
towers
or LTE beacons),
receive--only (e.g. passive WiFi sensors) or both transmitters and receivers, e.g. Road--Side Units (RSU) transceivers. The mobile nodes (vehicles)
are
assumed
to
be
equipped
with
terrestrial
communication
transceivers
and
able to
transmit
to
and
receive
from
other
nodes,
both
fixed
(V2I
links)
and/or
mobile
(V2V).
In [Col14]
the
authors
have
considered
a
particularized
scenario
where
fixed
stations
are transmit--only
and
the
single
blind node
is receive--only.
The
other
mobile
nodes,
called 'helpers'
therein,
know
their
position
with
certain
limited
accuracy,
and
these
(inaccurate) positions
are
given
in
input
to
the
localization
algorithm
along
with
the
reception
timestamps. In
other
words,
we
have
two
sources
of
uncertainty
(or
noise):
in
the
timing
measurement and
in
the
helper
position.
Remarkably,
the
simulation
results
presented
in
[Col14]
show
that, under
certain
conditions, the
final
error
on
the
blind
node
position
is
smaller
than
the
initial error
on
the
helper
node
positions . In
other
words,
the
output
position
(of
the
blind
node)
is more
accurate
than
the
input
positions
(of
the
helper).
The
'accuracy
gain'
is
obviously
due
to the
additional
information
contributed
by
the
terrestrial
timing
measurements.
This
result shows
that,
in
principle,
one
can
further
refine
the
initial
positions
of
the
helper
nodes (obtained
by
GNSS) by
exploiting
the
terrestrial
pseudo--ranges
information
embedded
in
the reception
timestamp
data -
instead
of
additional
direct
ranging
measurements
as
envisioned in
[Gar12].
As
noted
there,
the
positioning
refinement
process
can
be
performed sequentially , by
feeding
back
the
new
(more
accurate)
position
into
the
estimation
problem
in
order
to refine the position
of another
node
and
so on, or jointly , via more
compact
estimation procedures
that
seek
to
resolve
all
node
positions
jointly
at
once.
## 4. Next
steps
The
preliminary
simulation
result
presented
in
[Col14],
obtained
in
a
simplified
scenario, should
be
taken
as
a proof--of--concept
indicating
a
direction
for
further
experimentation rather
than
a
conclusive
point.
We
do
not
claim
at
this
stage
that
the
exploitation
of
terrestrial timestamp
data
by
means
of
asynchronous
localization
algorithms
will always improve
over initial GNSS
accuracy,
but we claim that it has the potential of doing so under
certain conditions .
The
research
question
for
the
academic
community
is
therefore:
- (1) Under
which
conditions
terrestrial
timestamp
measurements
complementing
GNSS can
improve
positioning
accuracy
down
to
sub--meter
level? And
for
the
industry:
- (2) What
can
be
done,
e.g.
on
the
side
of
radio
receiver
design,
to
facilitate
achieving
those conditions?
The goal of this contribution
is
to solicit academy
and
industry
to
pick
these
research questions as stimuli for progressing further with theoretical analysis and field experimentation.
Hereafter
we
indicate
some
desirable
action
points
for
both
communities.
## Commoditization
of
accurate
timestamping.
The
attractiveness
of
the
proposed
method
for
practical
applications
ultimately
depends
on the
quantitative
impact
of
measurement
errors
into
the
final
position
estimation.
Generally speaking,
we
can
identify
the
following
sources
of
errors:
- ∞ Clock
errors ,
due
e.g.
to
the
(in)stability
of
clock
frequencies
and
timestamp
quantization, among
other
factors.
- ∞ Multipath
errors in
Line--of--Sight
(LOS)
conditions.
- ∞ Non--Line--of--Sight
(NLOS)
errors .
Recall
that
only
clock
errors
were
considered
in
eq.
(2),
since
the
focus
there
was
to
show
that node
synchronization
can
be
effectively
replaced
by
timestamp
data
processing.
The
other two
error
components,
namely
multipath
and
NLOS,
can
be
modeled
as
further
additive
terms to
eq.
(2).
However,
it
should
be
noted
that
while
the
clock
error
components
vary
in time ,
the multipath
and
NLOS
components
vary
in space .
In
order
to
exploit
the
potential
of
cooperative
opportunistic
localization,
as
augmentation
of or
extension
to
GNSS
systems,
the
collective
effect
of
all
these
error
sources
must
be
kept
low.
We
have
shown
that,
in
principle,
clock
errors
can
be
counteracted
by
data
processing
in
the initial
estimation
phase
(ref.
Fig.
1).
This
is
achieved
by
considering
multiple
measurements
in temporal
diversity,
that
is,
averaging
over
multiple
packets.
However,
the
adoption
of
more stable
receiver
clock
and
more
accurate
timestamping
capabilities
would
reduce
the
power
of measurement
noise
in
input,
thus
facilitating
the
task
of
the
processing
stage
and
allowing
to use
a
lower
number
data
points
(i.e.,
packets),
with
beneficial
effect
also
on
the
estimation delay
and
computational
complexity.
When
a
GNSS
module
is
co--located
with
a
terrestrial wireless
receiver
(e.g.
in
OBU
or
smartphone),
the
GNSS
signal
can
be
passed
to
the
latter
in order
to
control
the
clock
signal
used
by
the
timestamping
function,
thus
improving
the timestamp
accuracy.
Similar
considerations
apply
for
the
multipath
error
that
is
encountered
in
LOS
links
due
to the
composition
of
multiple
signal
replicas
arriving
after
the
first
direct
path.
The
magnitude of
this
error
can
be
up
to
a
few
meters
for
each
individual
ranging
measurement
(see
e.g. [Exe12]).
It
can
be
counteracted
in
the
estimation
phase
by
leveraging spatial diversity
and redundancy,
i.e.,
considering
an
increased
number
of
anchors.
If
the
blind
node
is
in
motion, spatial diversity
is
transported
into temporal diversity,
and
the
same
goal
can
be
achieved
by considering
multiple
packets
from
the
same
(smaller)
set
of
anchors.
Also
in
this
case
it
would be beneficial
to
reduce ex ante the multipath
error
of
each
measurement
data
point
by adopting specific signal processing
techniques
in the receiver, e.g. to discriminate
and timestamp
the first arriving
signal
replica,
while
still
leaving
the
rest
of
the
receiver
chain tuning
on
the strongest replica
for
packet
decoding.
These
algorithms
have
been
well
studied in
the
realm
of
GPS
technology
and
could
be
reused
in
terrestrial
wireless
communication devices,
probably
with
a
relatively
minor marginal cost in terms
of
implementation
and resource
consumption.
We
remark
however
that
the
experimental
results
reported
by
[Nag11]
and
[Fac14],
obtained in LOS
conditions
with
COTS
WiFi
devices
that
do
not
implement
any
mitigation
strategy against multipath and/or clock errors, indicate that even without such additional improvements
sub--meter
accuracy
is
at
reach
nowadays
with
standard
devices.
## Robust
estimation
algorithms
for
NLOS
conditions
The
most
serious
source
of
error
in
our
scenario
is
undoubtedly
NLOS
reception.
In
ranging measurements NLOS paths introduce (possibly large) positive bias. NLOS mitigation strategies
are
an
active
field
of
research
and
already
cover
a
wide
range
of
approaches
(see e.g.
[Guv09],
[Vag13]
and
references
therein).
However,
most
previous
work
has
addressed NLOS
problem
in
the
context
of ranging techniques,
while
our
framework
is
based
on pseudo-ranges (or
equivalently,
range
differences).
Developing
robust
estimation
methods
that
can cope
with
NLOS
scenarios
is
definitely
one
of
the
most
compelling
research
challenges
in
the progress
of
this
work.
However,
in
certain
C--ITS
applications
one
can
expect
that
a
sufficient number
of
other
nodes
are
anyway
in
LOS
conditions,
e.g.
neighboring
vehicles
and
RSUs.
One
could
think
that
the
'commoditization'
of
more
accurate
receiver
timestamping,
i.e.,
the implementation
in
COTS
devices
of
clock
error
and
multipath
error
mitigation
techniques, would be irrelevant considering
that NLOS errors, which cannot be resolved by these techniques,
are the dominating
error
source
in practical settings. In other words, why attacking
the
'small'
errors
(clock
and
multipath)
while
the
'large'
ones
(NLOS)
are
there?
We
argue
instead
that
the
'commoditization'
of
accurate
receiver
timestamping
would
be beneficial
also
towards
the
goal
of
reducing
NLOS
errors.
First,
we
should
distinguish
between 'heavy
NLOS'
and
'moderate
NLOS'
conditions,
depending
on
whether
NLOS
links
are
the majority
or
not.
In
moderate
NLOS
scenarios
it
is
not
difficult
to
identify
and
exclude
the
few NLOS links with pure data--driven approaches. Furthermore, the reduction of the measurement
noise
for
LOS
links
will intrinsically
facilitate
the job of NLOS
mitigation techniques, as the subset of LOS measurement
will yield a higher degree of internal consistency,
making
it
easier
to
tell
apart
the
'outlier'
NLOS
data.
Third,
improving
the achievable
localization
accuracy
in
favorable
conditions
(LOS
or
moderate
NLOS)
down
to decimeter
level,
would
certainly
motivate
additional
experimentation
and
pilot
deployment
of communication
system
with
built--in
localization
functions.
This
in
turn
bears
the
potential
to attract more relevant research work on robust estimation methods in adverse NLOS conditions,
triggering
a
positive
virtuous
cycle.
## Extension
to
tracking
For
the
sake
of
simplicity
we
have
presented
the
fundamental
principles
of
the
proposed method
with
reference
to
a
static
scenario.
Extension
of
the
proposed
model
to
dynamic scenarios,
where
some
of
the
nodes
are
in
motion,
is
an
important
direction
for
further research.
Going
from
static
localization
to
dynamic
tracking
implies
certainly
an
increase
of computational
complexity,
as
pseudo--ranges
and
the
other
parameters
of
interest
vary
in time.
However,
since
node
mobility
increases
both
spatial
and
temporal
diversity,
it
should
be advantageous
in
terms
of
achievable
accuracy.
This
is
true
for
pure
GNSS--based
localization, and
a
fortiori
for
hybrid
GNSS/terrestrial
localization.
## 5. Conclusions
We
envision
an
increasing
level
of
integration
between
GNSS
positioning
and
terrestrial
radio localization,
with
the
latter
augmenting
and
complementing
the
former.
Given
the
ubiquitous presence
of
legacy
radio
signals
and
the
widespread
of
multi--radio
devices,
it
is
appealing
to devise
methods
to
reuse
available
signals
and
devices
for
localization
purposes.
We
have shown
that
this
can
be
achieved
in
principle
by
relying
simply
on
receiver
timestamps,
with no need of additional ranging methods or protocols. A few pioneering work have demonstrated
that
time--based
localization
in
asynchronous
networks
can
achieve
sub--meter accuracy.
Waiving
the
requirement
of
node
synchronization
is
an
important
step
towards unlocking
the
potential
for
opportunistic
and
cooperative
radio
localization
in
combination
to GNSS,
which
we
hope
will
motivate
further
research
and
experimentation
in
this
direction.
## Acknowledgments
The author would
like to thank (in alphabetical
order)
Angelo
Coluccia,
Nicoló Facchi, Francesco
Gringoli,
Giuseppe
Ricci
and
Andrea
Toma
for
several
fruitful
discussions
about resolution
approaches
for
time--based
localization
in
asynchronous
networks.
## References
[Tsu04]
J. B.--Y. Tsui. Fundamentals
of
Global
Positioning
System
Receivers:
A
Software Approach.
John
Wiley
&
Sons,
2004.
[Mar05]
M
Maroti,
B
Kusy,
and
G.
Balogh.
Radio
interferometric
geolocation.
ACM
SenSys, 2005.
[Fan07]
H.
Fan
and
C.
Yan.
Asynchronous
differential
TDOA
for
sensor
self--
localization.
IEEE ICASSP
2007.
[Guv09]
I.
Guvenc,
C.
C. Chong,
A
Survey
on
ToA
Based
Wireless
Localization
and
NLOS Mitigation
Techniques,
IEEE
Communications
Surveys
&
Tutorials,
11(3),
2009.
[Nag11]
A.
Nagy,
E.
Exel,
P.
Loschmidt,
G.
Gaderer,
Time--based
Localization
in
unsynchronized wireless
LAN
for
industrial
automation
systems.
IEEE
ETFA
2011.
[Gar12]
R.
Garello,
J.
Samson,
M.
Spirito,
H.
Wymeersch,
Peer--to--peer
cooperative
positioning. Part
II,
Hybrid
devices
with
GNSSS
&
Terrestrial
ranging
capabilities.
InsideGNSS,
July/August 2012.
[Exe12] R. Exel, Receiver Design for Time--based ranging with IEEE 802.11b Signals, International
Journal
of
Navigation
and
Observation,
2012.
[Vag13] R. M. Vaghefi, J. Schloemann, R. M. Buehrer, NLOS Mitigation in TOA--Based Localization
Using
Semidefinite
Programming.
IEEE
WPNC
2013.
[Col14] A. Coluccia, F. Ricciato, G. Ricci, Positioning with Signals of Opportunity,
IEEE Communications
Letter,
18(2),
February
2014.
[Ami14]
A.
Amini,
R.
M.
Vaghefi,
J.
M.
de
la
Garza,
R.
M.
Buehrer,
Improving
GPS--based
Vehicle Positioning
for Intelligent Transportation
Systems.
IEEE
Intelligent
Vehicles
Symposium 2014.
[Ban14]
F.
Bandiera,
A.
Coluccia,
G.
Ricci,
F.
Ricciato,
D.
Spano,
Time--based
localization
in asynchronous
WSN, 12th IEEE International Conference on Embedded
and Ubiquitous Computing
(EUC
2014),
Milano,
26--28
August
2014.
[Fac14]
N. Facchi,
F. Gringoli,
F. Ricciato,
A. Toma,
Emitter
Localization
from
Reception Timestamps
in
Asynchronous
Networks,
July
2014, arXiv:1407.8056 .
Figure
1
-
Conceptual
workflow
diagram
of
a
two--stage
localization
procedure
based
on
reception
timestamps.
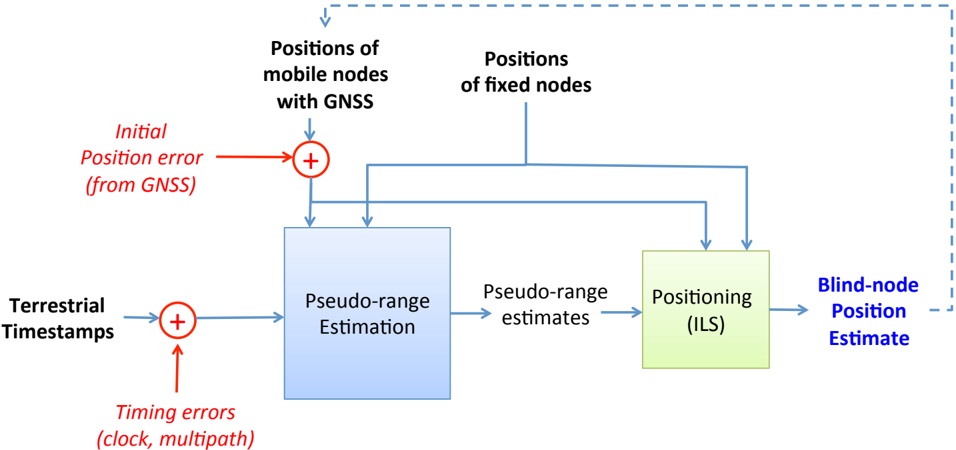
Figure
2
--
Compact
overview
of
different
approaches
for
asynchronous
time--based
localization
considered
in
recent literature.
The
DTDOA
procedures
presented
in
[Nag11]
and
[Fac14]
include
also
clock
drift
compensation
(not shown
in
the
equation).
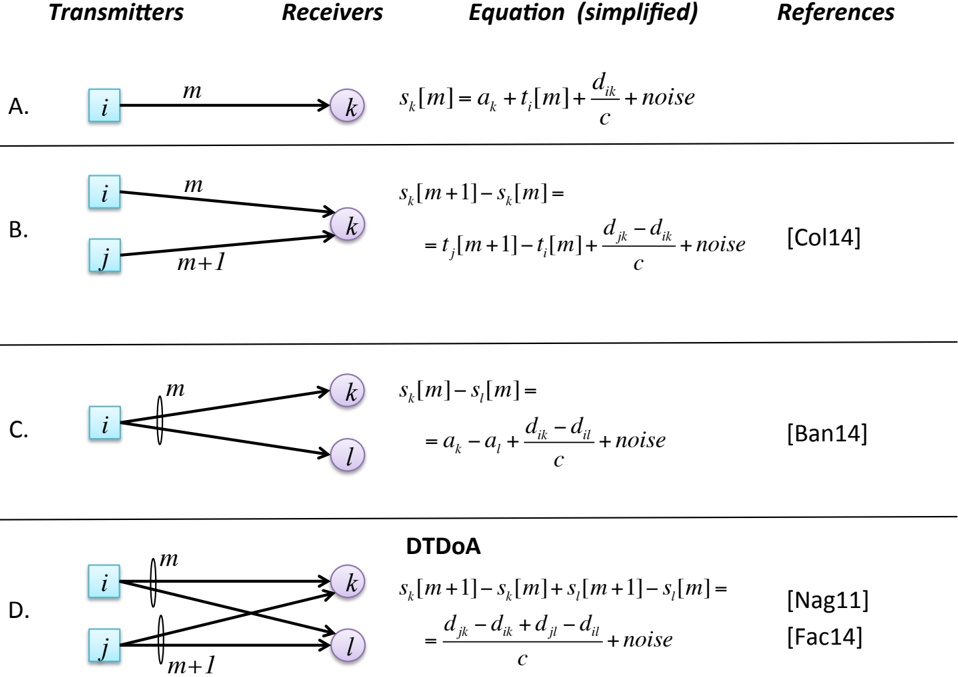
| | Transmi(ers* Receivers* | Equa1on**(simplified)* | References* |
|-----|---------------------------|----------------------------------------------------------------------------------------------------|-------------------|
| A.# | i ! k m ! | s k [ m ] = a k + t i [ m ] + d ik c + noise | |
| B.# | i ! j ! k m ! m+1 ! | s k [ m + 1] - s k [ m ] = = t j [ m + 1] - t i [ m ] + d jk - d ik c + noise | [Col14]# |
| C.# | k l i ! m ! | s k [ m ] - s l [ m ] = = a k - a l + d ik - d il c + noise | [Ban14]# |
| D.# | i ! j ! k l m+1 ! m ! | s k [ m + 1] - s k [ m ] + s l [ m + 1] - s l [ m ] = = d jk - d ik + d jl - d il c + noise DTDoA% | [Nag11]# [Fac14]# | | null | [
"Fabio Ricciato"
] | 2014-08-03T08:56:21+00:00 | 2014-08-03T08:56:21+00:00 | [
"cs.NI"
] | Time to timestamp: opportunistic cooperative localization from reception time measurements | We present a general framework for improving and extending GNSS-based
positioning by leveraging opportunistic measurements from legacy terrestrial
radio signals. The proposed approach requires only that participating nodes
collect and share reception timestamps of incoming packets and/or other
reference signals transmitted by other fixed or mobile nodes, with no need of
inter-node synchronization. The envisioned scheme couples the idea of
cooperative GNSS augmentation with recent pioneering work in the field of
time-based localization in asynchronous networks. In this contribution we
present the fundamental principles of the proposed approach and discuss the
system-level aspects that make it particularly appealing and timely for
Cooperative ITS applications, with the goal of motivating further research and
experimentation in this direction. |
1408.0476v1 | ## Quasi-two-dimensional Fermi gases at finite temperature
Andrea M. Fischer 1, 2 and Meera M. Parish 1, 2
1 Cavendish Laboratory, JJ Thomson Avenue, Cambridge, CB3 0HE, United Kingdom 2 London Centre for Nanotechnology, Gordon Street, London, WC1H 0AH, United Kingdom (Dated: August 5, 2014)
We consider a Fermi gas with short-range attractive interactions that is confined along one direction by a tight harmonic potential. For this quasi-two-dimensional (quasi-2D) Fermi gas, we compute the pressure equation of state, radio frequency spectrum, and the superfluid critical temperature T c using a mean-field theory that accounts for all the energy levels of the harmonic confinement. Our calculation for T c provides a natural generalization of the Thouless criterion to the quasi-2D geometry, and it correctly reduces to the 3D expression derived from the local density approximation in the limit where the confinement frequency ω z → 0. Furthermore, our results suggest that T c can be enhanced by relaxing the confinement and perturbing away from the 2D limit.
## I. INTRODUCTION
Two-dimensional (2D) Fermi systems are both of fundamental interest and technological importance. Classic examples include graphene [1], high-temperature superconductors [2], semiconductor interfaces [3], and layered organic superconductors [4]. In addition, it is now possible to confine cold gases of alkali atoms in a 1D optical lattice, leading to a series of quasi-2D layers [5, 6]. Here, the interlayer coupling can be tuned and indeed made negligible by increasing the lattice depth [7], thus allowing the investigation of single quasi-2D layers. Alternatively, interlayer tunnelling can be switched on and the behavior of simple layered systems investigated. Furthermore, the attractive short-range interactions between different fermionic species may be controlled using a magnetically tunable Feshbach resonance. All these scenarios serve to illustrate the high degree of experimental control available in cold atoms, thus making them ideal systems to study the behaviour of fermions in low dimensions.
ε B /ε F . In particular, many experiments in the BCS limit appear to be in the regime where ε F glyph[greaterorsimilar] glyph[planckover2pi1] ω z [11, 12, 14] and therefore one expects measurable deviations from 2D behavior [15, 16].
Experiments on quasi-2D atomic Fermi gases have thus far focussed on the behavior of a single quasi-2D gas. This is achieved by applying a sufficiently strong optical lattice so that interlayer tunnelling may be neglected, or by trapping the gas tightly in one direction (which we refer to as the z direction). In both cases, the confining potential for the layer can be approximated by a harmonic oscillator potential, i.e., V ( z ) = 1 2 mω z 2 z 2 , where m is the atom mass and ω z is the confinement frequency [37]. The gas is considered to be kinematically 2D provided the Fermi energy ε F and temperature T satisfy ε F , k B T glyph[lessmuch] glyph[planckover2pi1] ω z . In principle, the crossover from BCS pairing to tightly bound bosonic ↑↓ dimers can then be realized in 2D by increasing the attractive ↑ ↓ -interactions [8, 9], and this has been the subject of much investigation [7, 10-12]. Since a two-body bound state always exists in 2D for arbitrary attraction [13], the two-body binding energy, ε B , can be used to parameterize the interaction strength. In this manner, weak BCS pairing is achieved when ε B /ε F glyph[lessmuch] 1, while the Bose limit corresponds to ε B /ε F glyph[greatermuch] 1. However, in practice, it is difficult to remain strictly 2D when varying the parameter
In this work, we address the impact of confinement on a single, quasi-2D, two-component gas of fermions. Previously, we developed a mean-field theory of the quasi-2D system at zero temperature that allowed us to extrapolate to an infinite number of harmonic confinement levels [16]. Here, we extend our mean-field calculation to finite temperature and determine (i) the critical temperature for pair formation, T c ; (ii) the equation of state for the pressure; and (iii) the excitation spectrum obtained from radio frequency (RF) spectroscopy. An earlier mean-field study of the regime ε F glyph[greaterorsimilar] glyph[planckover2pi1] ω z considered RF spectra at finite temperature, but not the equation of state or T c [15]. The pressure of the quasi-2D gas has recently been measured experimentally [12], and a comparison with finite-temperature [17] and zero-temperature [18] calculations in 2D suggests that temperature noticeably increases the pressure in the BCS regime. We find here that confinement provides a competing effect, where an increase in ε F / glyph[planckover2pi1] ω z can reduce the pressure.
To date, there is no experimental observation of the superfluid phase in atomic 2D Fermi gases. However, our results show that k B T /ε c F is increased by relaxing the confinement and increasing ε F / glyph[planckover2pi1] ω z for constant ε B /ε F , thus raising the tantalizing possibility that superfluidity is most favorable when the gas lies between 2D and 3D. As far as we are aware, our work provides the first quasi2D generalization of the Thouless criterion for T c as we perturb away from the 2D limit.
## II. MODEL AND MEAN-FIELD THEORY
We consider a balanced two-component ( ↑ , ↓ ) gas of fermions strongly confined in the z -direction by a harmonic oscillator potential. Harmonic confinement within the x y -plane is not included, so the atoms possess a 2D momentum, k , in addition to an oscillator quantum number, n . The many-body grand-canonical Hamiltonian in
FIG. 1: (Color online) The momentum distribution η per spin component, for Fermi energy ε F = ω z and various binding energies ε B and temperatures T < T c . The momentum is scaled by the confinement length l z . The black dotted line is the momentum distribution for an ideal gas at zero temperature.
this case is
$$\hat { H } = & \sum _ { k, n, \sigma } \xi _ { k n } c _ { k n \sigma } ^ { \dagger } c _ { k n \sigma } & ( 1 ) \quad \text{$\text{$\text{$\text{$N=}$} } \\ & + \sum _ { \substack { k, n _ { 1 }, n _ { 2 } \\ k ^ { \prime }, n _ { 3 }, n _ { 4 } \\ q } } \langle n _ { 1 } n _ { 2 } | \hat { g } | n _ { 3 } n _ { 4 } \rangle c _ { k n _ { 1 } \uparrow } ^ { \dagger } c _ { q - k n _ { 2 } \downarrow } ^ { \dagger } c _ { q - k ^ { \prime } n _ { 3 } \downarrow } ^ { \dagger } c _ { k ^ { \prime } n _ { 4 } \uparrow }, \\ \quad \text{$\text{$\text{$\text{$n=}$} } } \text{$\text{$\text{$not$} } } \text{$\text{$to$ ren} } \\ \quad \text{$word$} \colon$$
where ξ k n = glyph[epsilon1] k n -µ , µ is the chemical potential, and glyph[epsilon1] k n = k / m 2 2 + nω z , corresponding to the single-particle energies relative to the zero-point energy ω / z 2. Here we set the system area Ω = 1 and glyph[planckover2pi1] = k B = 1. The shortrange 3D interaction ˆ is tuned by a broad g s -wave Feshbach resonance. The interaction matrix elements are most easily calculated using relative ( ν ) and center of mass ( N ) oscillator quantum numbers:
$$\langle n _ { 1 } n _ { 2 } | \hat { g } | n _ { 3 } n _ { 4 } \rangle & = g \sum _ { N, \nu, \nu ^ { \prime } } f _ { \nu } \langle n _ { 1 } n _ { 2 } | N \nu \rangle f _ { \nu ^ { \prime } } \langle N \nu ^ { \prime } | n _ { 3 } n _ { 4 } \rangle \\ & \equiv g \sum _ { N } V _ { N } ^ { n _ { 1 } n _ { 2 } } V _ { N } ^ { n _ { 3 } n _ { 4 } }. & ( 2 ) \\ & \text{withcon}.$$
Here, the function f ν = ( 2 π mω z ) 1 / 4 φ ν (0), with φ ν ( z ) being the ν -th harmonic oscillator eigenfunction. One can show that f 2 ν +1 = 0 and f 2 ν = ( -1) ν ν ! √ (2 ν )! 2 2 ν . The coefficients, 〈 n n 1 2 | Nν 〉 ∼ δ N + ν n 1 + n 2 , are determined in Ref. [19, 20]. The interaction strength g can be expressed as a function of the binding energy ε B of the two-body problem:
$$- \frac { 1 } { g } = \sum _ { \mathbf k, n _ { 1 }, n _ { 2 } } \frac { ( V _ { 0 } ^ { n _ { 1 } n _ { 2 } } ) ^ { 2 } } { \epsilon _ { \mathbf k n _ { 1 } } + \epsilon _ { \mathbf k n _ { 2 } } + \varepsilon _ { B } } \,. \quad \quad ( 3 ) \quad \ \langle \dot { I }$$
We can set N = 0 without loss of generality, since the center of mass motion decouples. An equation relating the binding energy ε B to the 3D scattering length a s [21, 22] may be obtained using Eq. (3) together with the renormalization condition 1 g = ml z √ 2 π ( 1 2 a s -Λ π ) , where l z = √ 1 /mω z and Λ is a UV momentum cutoff in 3D. Note that g differs from the usual definition of the 3D interaction strength by a factor of √ 2 πl z .
Following the approach in Ref. [16], we define the superfluid order parameter
$$\Delta _ { \mathbf q N } = g \sum _ { \mathbf k, n _ { 1 }, n _ { 2 } } V _ { N } ^ { n _ { 1 } n _ { 2 } } \langle c _ { \mathbf q - \mathbf k n _ { 2 } \downarrow } c _ { \mathbf k n _ { 1 } \uparrow } \rangle. \quad ( 4 )$$
Provided fluctuations around this are small, we can approximate Eq. (1) by the mean-field Hamiltonian
$$\text{spin} \\ \text{alend} \colon & \text{$\Gamma$} \colon \colon \colon \colon \colon \colon \colon \colon \colon \colon \colon \colon \colon \colon \colon \colon \colon \colon \colon \colon \colon \colon \colon \colon \colon \colon \colon \colon \colon \colon \colon \colon \colon \colon \colon \colon \colon \colon \colon \colon \colon \colon \colon \colon \colon \colon \colon \colon \colon \colon \colon \colon \colon \colon \colon \colon \colon \colon \colon \colon \colon \colon \colon \colon \colon \colon \colon \end{cases} \text{spin} \text{$\Gamma$} \text{$\Gamma$} \text{$\Gamma$} \text{$\Gamma$} \text{$\Gamma$} \text{$\Gamma$} \text{$\Gamma$} \text{$\Gamma$} \text{$\Gamma$} \text{$\Gamma$} \text{$\Gamma$} \text{$\Gamma$} \text{$\Gamma$} \text{$\Gamma$} \text{$\Gamma$} \text{$\Gamma$} \text{$\Gamma$} \text{$\Gamma$} \text{$\Gamma$} \text{$\Gamma$} \text{$\Gamma$} \text{$\Gamma$} \text{$\Gamma$} \\ \text{$\Gamma$} \text{$\Gamma$} \text{$\Gamma$} \text{$\Gamma$} \text{$\Gamma$} \text{$\Gamma$} \text{$\Gamma$} \text{$\Gamma$} \text{$\Gamma$} \text{$\Gamma$} \text{$\Gamma$} \text{$\Gamma$} \text{$\Gamma$} \text{$\Gamma$} \text{$\Gamma$} \text{$\Gamma$} \text{$\Gamma$} \text{$\Gamma$} \text{$\Gamma$} \text{$\Gamma$} \text{$\Gamma$} \text{$\Gamma$} \colon \colon \colon \colon \colon \colon \colon \colon \colon \colon \colon \colon \colon \colon \colon \colon \colon \colon \colon \colon \colon \colon \colon \colon \colon \colon \colon \colon \colon \colon \colon \colon \colon \colon \colon \colon \colon \colon \colon \colon \colon \colon \colon \colon \colon \colon \colon \colon \colon \colon \colon \colon \colon \colon \colon \colon \colon \colon \colon \colon \colon \colon \colon \text{$\Gamma$} \text{$\Gamma$} \text{$\Gamma$} \text{$\Gamma$} \text{$\Gamma$} \text{$\Gamma$} \text{$\Gamma$} \text{$\Gamma$} \text{$\Gamma$} \text{$\Gamma$} \text{$\Gamma$} \text{$\Gamma$} \text{$\Gamma$} \text{$\Gamma$} \text{$\Gamma$} \text{$\Gamma$} \text{$\Gamma$} \text{$\Gamma$} \text{$\Gamma$} \text{$\Gamma$} \text{$\Gamma$} \text{$\Gamma$} \end{cases}$$
Furthermore, we assume that ∆ q N = δ q0 δ N 0 ∆ . The as0 sumption of a completely uniform order parameter with N = 0 should be reasonable in the limit where the pairing is weak or ∆ 0 glyph[lessmuch] ε F . It also correctly captures the short-distance behavior between pairs, thus allowing us to renormalize the 3D contact potential in a straightforward manner. Equation (5) can then be diagonalized to give
$$\underset { \text{other-} } { \text{title} } \underset { \text{short-} } { \hat { H } } _ { \text{MF} } = \sum _ { \text{k,n} } ( \xi _ { \text{k} n } - E _ { \text{k} n } ) - \frac { \Delta _ { 0 } ^ { 2 } } { g } + \sum _ { \text{k,n,\sigma} } E _ { \text{k} n } \gamma _ { \text{k} n \sigma } ^ { \dagger } \gamma _ { \text{k} n \sigma }, \ ( 6 )$$
where E k n are the quasiparticle excitation energies. The quasiparticle creation and annihilation operators are given by
$$\gamma _ { \mathbf k n \uparrow } ^ { \dagger } = \sum _ { n ^ { \prime } } ( u _ { \mathbf k n ^ { \prime } n } c _ { \mathbf k n ^ { \prime } \uparrow } ^ { \dagger } + v _ { \mathbf k n ^ { \prime } n } c _ { - \mathbf k n ^ { \prime } \downarrow } ) \quad ( 7 )$$
$$\gamma _ { - { \mathbf k } n \downarrow } = \sum _ { n ^ { \prime } } ( u _ { { \mathbf k } n ^ { \prime } n } c _ { - { \mathbf k } n ^ { \prime } \downarrow } - v _ { { \mathbf k } n ^ { \prime } n } c _ { { \mathbf k } n ^ { \prime } \uparrow } ^ { \dagger } ), \quad ( 8 )$$
where the amplitudes u , v are assumed to be real, and they satisfy ∑ n ′ ( | u k n n ′ | 2 + | v k n n ′ | 2 ) = 1. Both the quasiparticle energies and amplitudes only depend on the momentum through its magnitude, k ≡ | k | .
The BCS ground state corresponds to the quasiparticle vacuum, but at finite temperature, quasiparticle states can be occupied and one must consider the mean-field grand potential:
$$( 3 ) \quad \langle \hat { H } _ { \text{MF} } \rangle = \sum _ { \mathbf k, n } \left [ \xi _ { \mathbf k n } - \frac { 2 } { \beta } \ln \left [ 2 \cosh ( \beta E _ { \mathbf k n } / 2 ) \right ] \right ] - \frac { \Delta _ { 0 } ^ { 2 } } { g } \ \ ( 9 )$$
where β ≡ T -1 . For fixed µ , the correct value of ∆ 0 is that which minimises 〈 ˆ H MF 〉 .
The Fermi energy in the quasi-2D system is defined to be the chemical potential of an ideal Fermi gas with the same particle density, i.e., one can write the particle density per spin as ρ ε ( F ) = m 2 π ( n h +1)( ε F -n ω / h z 2), where n h is the oscillator number of the highest occupied oscillator level for the non-interacting gas. The density ρ depends on the chemical potential through the quasiparticle amplitudes according to
$$\rho \equiv \sum _ { \mathbf k } \eta ( \mathbf k ) = \sum _ { \mathbf k, n _ { 1 }, n _ { 2 } } \frac { e ^ { \beta E _ { \mathbf k n _ { 1 } } } | v _ { \mathbf k n _ { 2 } n _ { 1 } } | ^ { 2 } + | u _ { \mathbf k n _ { 2 } n _ { 1 } } | ^ { 2 } } { 1 + e ^ { \beta E _ { \mathbf k n _ { 1 } } } } \ ( 1 0 ) \quad \quad 0$$
where η ( k ) is the in-plane momentum distribution per spin component.
The presence of discrete energy levels in the quasi2D confinement is clearly apparent in η ( k ) when ε F approaches ω z , as shown in Fig. 1. In particular, even when the gas is kinematically 2D at T = 0, with a clear 2D distribution, we see that interactions can populate the higher levels, resulting in additional weight in the distribution around k = 0. This feature is most pronounced when ε F = ω z , because here the Fermi energy touches the bottom of the next band at k = 0. A finite temperature also leads to occupation of the higher levels, and it can thus enhance the peak at k = 0. However, large T or large ε B eventually smears out the distorted Fermi distribution.
## Short-distance behavior
At large momentum values, η ( k ) is determined by the contact density C [23], which gives a measure of the density of pairs at short distances. Similarly to 2D and 3D [24], this can be derived from the adiabatic relation:
$$\mathcal { C } = \frac { m ^ { 2 } } { \hslash ^ { 4 } } \frac { \partial \langle \hat { H } _ { \text{MF} } \rangle } { \partial ( - 1 / g ) } \Big | _ { \Omega, \mu, T } \quad \quad \ \ ( 1 1 ) \quad \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \$$
However, the tail of the momentum distribution in quasi2D has a slightly modified behavior:
$$\eta ( { \mathbf k } ) \to \frac { \mathcal { C } } { 4 m ^ { 2 } } \sum _ { \nu } \frac { f _ { 2 \nu } ^ { 2 } } { \epsilon _ { { \mathbf k } \nu } ^ { 2 } } \quad \quad ( 1 2 ) \quad \quad \text{In}$$
Note that this yields the expected 2D behavior when ω z glyph[greatermuch] k / m 2 2 . In the quasi-2D mean-field approximation, the contact is simply related to the pairing order parameter: C = m 2 ∆ . This expression captures the monotonic 2 0 increase of C with increasing attraction, and it yields the correct two-body contact in the Bose limit. However, it is not quantitatively accurate in the BCS regime since the mean-field approach neglects interactions in the normal phase. Indeed, we see here that C = 0 above T c .
## III. CRITICAL TEMPERATURE
Within the mean-field approximation, pairing and superfluidity are destroyed simultaneously by thermal fluc-
FIG. 2: (Color online) Evolution of the critical temperature as the system is perturbed away from the 2D limit for fixed values of the interaction, ε B /ε F = 0 01 ( . ) and 0 05 ( . ). The dash-dotted lines are the leading order behavior in ε F /ω z from Eq. (20). Inset: The critical temperature at unitarity for large ε F /ω z . The horizontal dashed line corresponds to the 3D limit ε F /ω z →∞ (see text).
tuations, and the superfluid transition temperature corresponds to the point where ∆ 0 vanishes. Here, we focus on the BCS regime of weak interactions, where our approximation is expected to be most accurate and the mean-field T c is close to the superfluid BerezinskiiKosterlitz-Thouless (BKT) transition temperature [25]. First, we recall how to derive an expression for T c in the 2D limit. The relevant equations are (3) and (9) with all sums over quantum number n restricted to the n = 0 term. In this case, the quasiparticle energies are simply E k 0 = √ ξ 2 k 0 +∆ . 2 0 Substituting this into Eq. (9), and then using ∂ H 〈 ˆ MF 〉 /∂ ∆ = 0 and setting ∆ 2 0 0 = 0, yields the linearized gap equation for T c (or Thouless criterion):
$$\sum _ { k } \frac { 1 } { 2 \epsilon _ { k 0 } + \varepsilon _ { B } } = \sum _ { k } \frac { \tanh ( \beta _ { c } \xi _ { k 0 } / 2 ) } { 2 \xi _ { k 0 } } \,. \quad ( 1 3 )$$
In the weak-coupling limit ε B glyph[lessmuch] ε F , one can show that T c = e γ √ 2 ε B F ε /π , where γ ≈ 0 577 . is the Euler gamma constant [26]. The inclusion of Gor'kov-MelikBarkhudarov corrections predicts a critical temperature that is lower by a factor of e [27].
The situation is more complicated in the general quasi2D case. The gap equation is
$$- \, \frac { 1 } { g } = \sum _ { \mathbf k, n } \, \left ( \frac { \partial E _ { \mathbf k n } } { \partial \Delta _ { 0 } ^ { 2 } } \right ) \Big | _ { \Delta _ { 0 } = 0 } \tanh \left ( \beta _ { c } \xi _ { \mathbf k n } / 2 \right ) \quad ( 1 4 )$$
but there is no analytical expression for the quasiparticle energies. For fixed k , the E k n are the positive eigenvalues of the block matrix M = ( X D D † -X ) , where X ij = δ ij ξ k i and D ij = ∆ 0 V ij 0 . Hence, they are the solutions of the
characteristic equation, | M -E k n n I | = 0, where I n is the n × n identity matrix. Note that the determinant contains only even powers of ∆ . 0 Disregarding all terms of order greater than two, we obtain glyph[negationslash]
glyph[negationslash]
$$& \text{of order greater than two, we obtain} \quad \text{to inc} \\ & | M - E _ { \text{kn} } I _ { n } | = \prod _ { n _ { 1 } } \left ( E _ { \text{kn} } ^ { 2 } - \xi _ { \text{kn} _ { 1 } } ^ { 2 } \right ) \quad \text{fore} \ p \text{intera} \\ & - \Delta _ { 0 } ^ { 2 } \sum _ { n _ { 1 } } ( V _ { 0 } ^ { n _ { 1 } n _ { 1 } } ) ^ { 2 } \prod _ { n _ { 2 } \neq n _ { 1 } } \left ( E _ { \text{kn} } ^ { 2 } - \xi _ { \text{kn} _ { 2 } } ^ { 2 } \right ) \quad \text{express} \\ & + 2 \Delta _ { 0 } ^ { 2 } \sum _ { n _ { 1 } < n _ { 2 } } ( V _ { 0 } ^ { n _ { 1 } n _ { 2 } } ) ^ { 2 } \left ( \xi _ { \text{kn} } n _ { 1 } \xi _ { \text{kn} _ { 2 } } - E _ { \text{kn} } ^ { 2 } \right ) \\ & \times \prod _ { n _ { 3 } \neq n _ { 1 }, n _ { 2 } } \left ( E _ { \text{kn} } ^ { 2 } - \xi _ { \text{kn} _ { 3 } } ^ { 2 } \right ). \quad \text{(15)} \quad \text{Comb} \quad \varepsilon _ { B } / \omega _ { \text{tions} } \\ & \text{After differentiating the expression } | M - E _ { \text{kn} } I _ { n } | = 0 \text{ with} \quad \text{is fit.}$$
After differentiating the expression | M -E k n n I | = 0 with respect to ∆ 0 and letting ∆ 0 → 0, E k n → ξ k n , we find
$$\left ( \frac { \partial E _ { \mathbf k n } } { \partial \Delta _ { 0 } ^ { 2 } } \right ) \Big | _ { \Delta _ { 0 } = 0 } = \sum _ { n ^ { \prime } } \frac { \left ( V _ { 0 } ^ { n n ^ { \prime } } \right ) ^ { 2 } } { \xi _ { \mathbf k n } + \xi _ { \mathbf k n ^ { \prime } } }. \quad \left ( 1 6 \right ) \, \begin{array} { c } \text{extr} \\ \text{We} \\ \text{cont} \end{array}.$$
Hence, the linearized gap equation becomes
$$- \frac { 1 } { g } = \sum _ { \mathbf k, n _ { 1 }, n _ { 2 } } ( V _ { 0 } ^ { n _ { 1 } n _ { 2 } } ) ^ { 2 } \frac { \tanh \left ( \beta _ { c } \xi _ { \mathbf k n _ { 1 } } / 2 \right ) + \tanh \left ( \beta _ { c } \xi _ { \mathbf k n _ { 2 } } / 2 \right ) } { 2 ( \xi _ { \mathbf k n _ { 1 } } + \xi _ { \mathbf k n _ { 2 } } ) }, \quad \text{$1$. Mo.} \\ \text{which is a natural normalization of $two$ on some time} } ( 1 7 ) \quad \text{are dir} \quad \text{to the}$$
which is a natural generalization of the corresponding equation in 2D. This is one of the main results of this paper.
We extract the behaviour in the limit µ, ε B , T c glyph[lessmuch] ω z by reorganising Eq. (17):
$$& \frac { 1 } { g } + \sum _ { k, n _ { 1 }, n _ { 2 } } \frac { ( V _ { 0 } ^ { n _ { 1 } n _ { 2 } } ) ^ { 2 } } { \xi _ { \mathbf k n _ { 1 } } + \xi _ { \mathbf k n _ { 2 } } + i 0 } = \\ & \sum _ { \mathbf k, n _ { 1 }, n _ { 2 } } \frac { ( V _ { 0 } ^ { n _ { 1 } n _ { 2 } } ) ^ { 2 } } { \xi _ { \mathbf k n _ { 1 } } + \xi _ { \mathbf k n _ { 2 } } + i 0 } \left [ f ( \beta _ { c } \xi _ { \mathbf k n _ { 1 } } ) + f ( \beta _ { c } \xi _ { \mathbf k n _ { 2 } } ) \right ], \ \ ( 1 8 ) \\ \cdot \quad \vec { \lambda } \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \,.$$
where f ( x ) ≡ 1 / (1 + e x ) is the Fermi-Dirac distribution function. We see that the left hand side is inversely proportional to the quasi-2D T matrix at energy 2 µ , which can be readily expanded in 1 /ω z [28]. Expanding both sides up to linear order in 1 /ω z then yields
$$& \ln \left ( \frac { \varepsilon _ { B } } { 2 \mu } \right ) + \ln ( 2 ) \frac { 2 \mu + \varepsilon _ { B } } { \omega _ { z } } \simeq & \quad \text{For } \omega \\ & 2 \mathcal { P } \int _ { - \beta _ { c } \mu } ^ { \infty } d \epsilon \frac { f ( \epsilon ) } { \epsilon } + \frac { 4 \ln \left [ 4 ( 2 - \sqrt { 3 } ) \right ] } { \beta _ { c } \omega _ { z } } \ln ( 1 + e ^ { \beta _ { c } \mu } ), \ \ ( 1 9 ) \\ &. \quad \sim \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \end{array}$$
where P denotes the principle value. In the BCS weakcoupling limit ε B glyph[lessmuch] ε F , we have µ glyph[similarequal] ε F and β µ c →∞ . Thus, the integral term in Eq. (19) can be replaced by -2 ln (2 e γ β µ/π c ), and the whole equation can be simplified to give
$$\lambda _ { c } = \frac { e ^ { \gamma } } { \pi } \sqrt { 2 \varepsilon _ { B } \varepsilon _ { F } } \left [ 1 + \frac { \varepsilon _ { F } } { \omega _ { z } } \ln \left ( \frac { 7 + 4 \sqrt { 3 } } { 8 } \right ) \right ]. \quad ( 2 0 ) \quad \text{large} _ { \text{place} }$$
Therefore, for fixed interaction parameter ε B /ε F , we see that perturbing away from 2D actually increases T /ε c F .
To obtain results for larger values of ε F /ω z , we need to include multiple oscillator levels and we must therefore proceed numerically. Since the normal state is noninteracting in this approximation, we may determine the density (and ε F /ω z ) for a given β µ c and β ω c z using the expression:
$$\beta _ { c } \rho = \frac { 1 } { \pi } \sum _ { n } \ln \left ( e ^ { \beta _ { c } ( \mu - n \omega _ { z } ) } + 1 \right ). \quad \ \ ( 2 1 )$$
Combining this with Eqs. (3) and (17), we then solve for ε B /ω z as a function of β ω c z and ε F /ω z . The calculations are repeated for different numbers of levels, ε B /ω z is fitted as a function of the inverse number of levels, and the final value assigned to ε B /ω z is that obtained by extrapolating to an infinite number of levels.
The variation of T /ε c F with ε F /ω z is shown in Fig. 2. We clearly see that T /ε c F is enhanced by relaxing the confinement for fixed ε B /ε F , and the numerical results in the BCS regime are in excellent agreement with the analytical expression of Eq. (20) in the limit ε F /ω z glyph[lessmuch] 1. Moreover, the enhancement of T c becomes even more pronounced with increasing ε F /ω z . Interestingly, there are dips visible at low integer values of ε F /ω z . This is due to the single particle density of states having a step-like structure and being discontinuous at these points.
Increasing ε F /ω z further, we should eventually recover the result derived from treating the harmonic potential within the local density approximation (LDA), valid in the limit ε F /ω z → ∞ . In this case, it is easy to show that Eq. (21) reduces to
$$\frac { m } { 4 \pi } \frac { \varepsilon _ { F } ^ { 2 } } { \omega _ { z } } = \int d z \sum _ { { \mathbf k } _ { 3 \text{D} } } \frac { 1 } { 1 + e ^ { \beta _ { c } \left ( k _ { 3 \text{D} } ^ { 2 } / 2 m - \mu ( z ) \right ) } }, \quad ( 2 2 )$$
where k 3D is the momentum of the particles in 3D and µ z ( ) = µ -1 2 mω z 2 z 2 . To determine the behavior of the gap equation in this limit, we first rewrite Eq. (17) as
$$\text{when} \\ \text{$\text{ both}$} \\ - \frac { 1 } { g } = \sum _ { \mathbf k, \nu } \frac { f _ { 2 \nu } ^ { 2 } } { 2 \xi _ { \mathbf k \nu } } \sum _ { n _ { 1 } } | \langle n _ { 1 } \, 2 \nu - n _ { 1 } | 0 \, 2 \nu \rangle | ^ { 2 } \tanh \left ( \beta _ { c } \xi _ { \mathbf k n _ { 1 } } / 2 \right ).$$
For ω z → 0, we also require ν → ∞ to obtain a finite energy νω z . In this case, we can use Stirling's approximation for large values of ν to obtain
$$\frac { 1 } { \sqrt { 2 \pi } l _ { z } } \sum _ { \nu = 0 } ^ { \infty } \frac { f _ { 2 \nu } ^ { 2 } } { 2 \xi _ { \mathbf k \nu } } \simeq \frac { 1 } { 2 \pi } \int _ { - \infty } ^ { \infty } d k _ { z } \frac { 1 } { 2 ( \xi _ { \mathbf k 0 } + k _ { z } ^ { 2 } / 2 m ) },$$
where we have defined νω z = k / m 2 z 2 . We can also write |〈 n 1 2 ν -n 1 | 0 2 ν 〉| 2 = 1 2 2 ν ( 2 ν n 1 ) ≈ 1 √ πν e -( n 1 -ν ) 2 /ν , for large ν , so that ∑ 2 ν n 1 =0 |〈 n 1 2 ν -n 1 | 0 2 ν 〉| 2 may be replaced by ∫ 1 / 2 -1 / 2 dxδ x ( ), with n 1 = 2 νx + ν . Applying
FIG. 3: (Color online) Pressure of the quasi-2D gas for fixed Fermi energy ε F /ω z and temperature T/ε F = 0 1. . Note that T < T c for the parameter range considered here. The zerotemperature 2D mean-field pressure (dashed line) corresponds to that of an ideal 2D Fermi gas, P ideal . The displayed interval of interactions corresponds to a 2D √ ρ ≈ 1 (see text).
these approximations to Eq. (17) and using the renormalization condition for g finally gives
$$\frac { m } { 4 \pi a _ { s } } = \sum _ { { \mathbf k } _ { 3 \mathrm D } } \left [ \frac { m } { k _ { 3 \mathrm D } ^ { 2 } } - \frac { \tanh [ \beta _ { c } ( k _ { 3 \mathrm D } ^ { 2 } / 2 m - \mu ) / 2 ] } { 2 ( k _ { 3 \mathrm D } ^ { 2 } / 2 m - \mu ) } \right ] \,, \quad ( 2 3 ) \quad \text{where} \quad \text{cle.} \, C$$
which is exactly the LDA expression obtained by considering the Thouless criterion at the center of the trap ( z = 0). The fact that Eq. (17) reduces to the correct mean-field expression in the limit ω z → 0 may be regarded as a validation of our approach.
Solving the LDA equations at unitarity (1 /a s = 0) gives the value T /ε c F = 0 44, as indicated in the inset of . Fig. 2. As expected, our numerics converge to this value with increasing ε F /ω z . Note that it is lower than the corresponding mean-field value in the 3D uniform case, T 3D c /ε F = 0 5. .
## IV. PRESSURE
Below T c , we can determine the mean-field equation of state for the pressure directly from P = -〈 ˆ H MF 〉 , once ∆ 0 is known. Like before, all calculations are repeated with different numbers of harmonic levels and the resulting pressure values extrapolated to an infinite number of levels. In the 2D limit, the pressure at zero temperature corresponds to that of an ideal Fermi gas, P ideal = mε / π 2 F 2 , and is therefore independent of interactions. This artifact is due to the fact that mean-field theory in 2D predicts an effective dimer-dimer repulsion that is classically scale invariant (and thus only dependent on the density), rather than the correctly renormalized interaction expected for a quantum system [29, 30]. Once interactions beyond mean field are included, one finds that the pressure tends to zero with increasing attraction, ε B /ε F , since the system approaches a non-interacting Bose gas [12, 18].
Even though the mean-field approach is not accurate in pure 2D, we expect it to provide a reasonable estimate of the effect of confinement in the quasi-2D system, since mean-field theory becomes more reliable as we perturb away from 2D. Indeed, we see in Fig. 3 that once ω z is finite, the pressure in the plane decreases with increasing ε B /ε F , as expected. The interactions in quasi-2D may equivalently be parameterized by a 2D √ ρ , where the scattering length a 2D = √ π/Bl e z -√ π lz 2 a and B ≈ 0 905 . [21]. Increasing attraction and moving towards the Bose regime then corresponds to decreasing a 2D √ ρ . In the 2D limit, we have a 2D = √ 1 /mε B , but this is not true in general in quasi-2D. The interaction range displayed in Fig. 3 corresponds to the regime of strong interactions a 2D √ ρ ≈ 1 considered in a recent experiment [12]. Here, the pressure at finite temperature was observed to be lower than the 2D zero-temperature result. However, this appears at odds with thermodynamics, where the pressure is always expected to increase with temperature. Indeed, one can show for the 2D case that
$$\left ( \frac { \partial P } { \partial T } \right ) _ { N, \Omega } = \left ( \frac { \partial S } { \partial \Omega } \right ) _ { N, T } \in T \frac { \partial s } { \partial \tilde { T } } > 0 \,,$$
where ˜ = T T/ε F and s = S/N is the entropy per particle. On the other hand, we see from Fig. 3 that P/P ideal becomes increasingly reduced as we relax the confinement, and this reduction can be substantial even when ε F ≤ ω z . Therefore, for the densities considered in the experiment, where ε F ≈ 0 5 . ω z [12], we expect P/P ideal at low temperatures to lie below the 2D zero-temperature result. For weaker attraction, P/P ideal is increased until eventually the effect of temperature dominates and we have P/P ideal > 1. In this case, P/P ideal will be higher than the 2D T = 0 result, which is indeed what was observed [12].
## V. RADIO FREQUENCY SPECTRA
Radio frequency (RF) spectroscopy has been used in quasi-2D experiments to probe pairing and associated gaps in the energy spectrum [7, 11, 31, 32]. A pulse of RF laser light transfers atoms from one of the initial hyperfine states (say |↑〉 ) to a third one that is previously unoccupied (denoted | 3 ). 〉 The gas is then released from the trap and the atoms in different hyperfine states separated, so that the number of transferred atoms can be extracted. This is repeated over a range of different frequencies to determine the RF spectrum.
We calculate the transfer rate as a function of probe frequency using Fermi's golden rule. The perturbation to the Hamiltonian due to the RF pulse is
$$\delta \hat { H } \, \infty \, \sum _ { k, n } \left ( c _ { \mathbf k n 3 } ^ { \dagger } c _ { \mathbf k n \uparrow } + c _ { \mathbf k n \uparrow } ^ { \dagger } c _ { \mathbf k n 3 } \right ). \quad \ \ ( 2 4 )$$
Note that the initial and final state momenta are equal, owing to the long wavelength of the RF radiation. We also assume the ideal scenario where there are no final state interactions, which is reasonable for the case of 40 K atoms [32]. In general, such interactions can modify the high-frequency behavior of the RF spectrum [33].
There are two possible types of transition, as illustrated in the inset of Fig. 4(a). At zero temperature, the initial state is the BCS groundstate, | Ψ 0 〉 ∝ ∏ k nσ γ k nσ | 0 , where 〉 | 0 〉 is the vacuum for the operators c k nσ . One may think of | Ψ 0 〉 as a filled sea of 'quasiholes', each having energy -E k n + µ , with γ k nσ the creation operator for a quasihole. Transition (1) corresponds to a quasihole being destroyed and an atom created in a free state. Hence the final state is given by: | Ψ (1) F ( k , n 1 , n 2 ) 〉 = c † k n 1 3 γ † -k n 2 ↓ | Ψ I 〉 . At zero temperature, only transitions of type (1) are possible. However, at finite temperature, the initial state | Ψ I 〉 also contains some quasiparticles. Therefore, we can also have transition (2), where a quasiparticle is destroyed and an atom is created in a free state. The final state in this case is given by: | Ψ (2) F ( k , n 1 , n 2 ) 〉 = c † k n 1 3 γ k n 2 ↑ | Ψ I 〉 . Accounting for both of these bound-to-free transitions, the mean-field RF current or transition rate is then
$$I _ { \text{RF} } ( \omega ) \in \sum _ { \substack { k \\ n _ { 1 }, n _ { 2 } } } \left [ f ( - \beta E _ { \text{k} n _ { 2 } } ) \delta ( \xi _ { \text{k} n _ { 1 } } + E _ { \text{k} n _ { 2 } } - \omega ) | v _ { \text{k} n _ { 1 } n _ { 2 } } | ^ { 2 }$$
$$+ f ( \beta E _ { \mathbf k n _ { 2 } } ) \delta ( \xi _ { \mathbf k n _ { 1 } } - E _ { \mathbf k n _ { 2 } } - \omega ) | u _ { \mathbf k n _ { 1 } n _ { 2 } } | ^ { 2 } ] \,. \ ( 2 5 )$$
Here, the pulse frequency relative to the bare transition frequency between hyperfine states is denoted by ω .
We can gain insight into the RF spectrum by restricting the calculation to the two lowest harmonic oscillator levels, n = 0 1. , This two-level approximation provides a qualitative picture of the quasi-2D spectrum at finite temperature and has the advantage of yielding an analytical expression:
$$I _ { \text{RF} } ( \omega ) & \in \sum _ { n = 0, 1 } \frac { ( \Delta _ { 0 } V _ { 0 } ^ { n n } ) ^ { 2 } } { \omega ^ { 2 } } f \left ( - \beta \frac { \omega ^ { 2 } + ( \Delta _ { 0 } V _ { 0 } ^ { n n } ) ^ { 2 } } { 2 \omega } \right ) \, ( 2 6 ) \quad \text{two $p^{\prime}$} \quad \text{ due $tc$} \\ & \times \left [ \Theta \left ( \omega - \xi _ { n } - \sqrt { \xi _ { n } ^ { 2 } + ( \Delta _ { 0 } V _ { 0 } ^ { n n } ) ^ { 2 } } \right ) \, \quad \text{ set of} \quad \text{ ever}, \quad \\ & + \Theta \left ( - \omega \right ) \Theta \left ( \omega - \xi _ { n } + \sqrt { \xi _ { n } ^ { 2 } + ( \Delta _ { 0 } V _ { 0 } ^ { n n } ) ^ { 2 } } \right ) \, \right ], \quad \text{ shift $t$} \quad \text{prev}$$
where ξ n = nω z -µ . We see immediately that I RF scales with ∆ , and that there are contributions to the spec2 0 trum at both positive and negative frequencies once temperature is finite. Note there is no transition between the n = 0 and n = 1 levels, since parity must be conserved.
Figure 4 displays the numerical result for the RF spectra involving multiple harmonic levels. We focus on the regime ε F ≤ ω z where the spectrum has a simpler structure [16]. We have checked that the results have converged by varying the number of harmonic oscillator levels in the calculation of u k n n 1 2 and v k n n 1 2 . For the frequency range displayed here, we see that there are always
2
z
FIG. 4: (Color online) RF spectroscopy plots for the quasi-2D Fermi gas at T < T c . The RF current is scaled so that the largest peak is always has value 1. (a) RF spectra at various temperatures for ε B /ω z = 0 25, . ε F /ω z = 0 5. . The vertical dotted line marks ω = ε B . Inset: Different types of 'bound' [solid line] to free [dashed line] transitions (see text). (b) RF spectra at low temperature T/ε F = 0 1 for . ε F /ω z = 1 0 and . a range of binding energies.
two peaks at positive values of ω . The dominant peak is due to transitions of type (1) within the n = 0 oscillator level. The first term in Eq. (26) predicts a sharp onset of this peak at ω = ( glyph[epsilon1] k 0 + E k 0 -µ ) | k =0 = ε B . However, the numerical results show a confinement-induced shift to higher frequencies, consistent with what we found previously [16]. The second peak at higher ω is due to transitions of type (1) within the n = 1 oscillator level. As expected, it is much weaker when ω z is the largest energy scale. However, this secondary peak is enhanced for larger ε F and grows with increasing ε B , as shown in Fig. 4(b). At finite temperatures, two peaks also appear at negative ω values, due to type (2) transitions (see second term in Eq. (26)). In Fig. 4(a), the more rounded peak at lower frequency is from transitions in the n = 0 level and the sharper peak close to ω = 0 is from transitions in the n = 1 level.
We can investigate the behavior at large ε B /ε F by considering the two-body problem in quasi-2D. Using the dimer wave function φ n n 1 2 k ∝ V n n 1 2 0 / glyph[epsilon1] ( k n 1 + glyph[epsilon1] k n 2 + ε B )
with zero center-of-mass momentum in the plane, we obtain the simple expression
$$I _ { \text{RF} } ( \omega ) \in \frac { 1 } { \omega ^ { 2 } } \sum _ { \nu } f _ { 2 \nu } ^ { 2 } \Theta \left ( \omega - \varepsilon _ { B } - 2 \nu \omega _ { z } \right ) \quad ( 2 7 ) \quad \text{that} \\ \quad \text{tual} \\ T \circ \circ \circ \circ \circ \circ \circ \circ \circ \circ \circ \circ \circ \circ \circ \circ \circ \circ \circ \circ \circ \circ \circ \circ \circ \circ \circ \circ \circ \circ \circ \circ \circ \circ \circ \circ \circ \circ \circ \circ \circ \circ \circ \circ \circ \circ \circ \circ \circ \circ \circ \circ \circ \circ \circ \circ \circ \circ \circ \circ \circ \circ \circ \circ \circ \circ \circ \circ \circ \circ \circ \circ \circ \circ \circ \circ \circ \circ \circ \circ \circ \circ \circ \circ \circ \circ \circ \circ \circ \circ \circ \circ \circ \circ \circ \circ \circ \circ \circ \circ \OC \circ \circ \circ \circ \circ \circ \circ \circ \circ \circ \circ \circ \circ \circ \circ \circ \circ \circ \circ \circ \circ \circ \circ \circ \circ \circ \circ \circ \circ \circ \circ \circ \circ \circ \circ \circ \circ \circ \circ \circ \circ \circ \circ \circ \circ \circ \circ \circ \circ \circ \circ \circ \circ \circ \circ \circ \circ \circ \circ \circ \circ \circ \circ \circ \circ \circ \circ \circ \circ \circ \circ \circ \circ \circ \circ \circ \circ \circ \circ \circ \circ \circ \circ \circ \circ \circ \circ \circ \circ \circ \circ \circ \circ \circ \circ \circ \circ \circ \circ \ocolon$$
Thus, we see that we have peaks at ω = ε B +2 νω z , similar to the structure displayed in Fig. 4(b). The secondary peaks grow in size with increasing ε B /ω z until eventually one recovers I RF ( ω ) ∝ Θ( ω -ε B ) √ ω -ε B /ω 2 , the behavior expected in 3D [34].
## VI. CONCLUSION
We have considered the effect of a quasi-2D geometry on a Fermi gas at finite temperature. Such a study is important for ongoing experiments aimed at investigating the 2D BCS-Bose crossover, since many are in the regime where the confinement frequency ω z is a relevant energy scale. In particular, the pressure can be substantially reduced by increasing ε F /ω z , and this appears to be consistent with recent measurements [12]. Furthermore, once ε F glyph[greaterorsimilar] ω z or ε B glyph[greaterorsimilar] ω z , the discrete nature of the quasi-2D confinement should be clearly visible in the pairing properties even at finite temperature, as we can see from Figs. 2 and 4. A recent experiment at temperatures well above T c has already observed steps in the cloud aspect ratio for integer ε F /ω z [14].
- [1] A. H. Castro Neto et al. , Rev. Mod. Phys. 81 , 109 (2009).
- [2] C. C. Tsuei and J. R. Kirtley, Rev. Mod. Phys. 72 , 969 (2000).
- [3] D. L. Smith and C. Mailhiot, Rev. Mod. Phys. 62 , 173 (1990).
- [4] J. Singleton and C. Mielke, Contemporary Physics 43 , 63 (2002).
- [5] G. Modugno et al. , Phys. Rev. A 68 , 011601 (2003).
- [6] K. Martiyanov, V. Makhalov, and A. Turlapov, Phys. Rev. Lett. 105 , 030404 (2010).
- [7] A. T. Sommer et al. , Phys. Rev. Lett. 108 , 045302 (2012).
- [8] M. Randeria, J.-M. Duan, and L.-Y. Shieh, Phys. Rev. Lett. 62 , 981 (1989).
- [9] M. Randeria, J.-M. Duan, and L.-Y. Shieh, Phys. Rev. B 41 , 327 (1990).
- [10] M. Feld et al. , Nature 480 , 75 (2011).
- [11] Y. Zhang, W. Ong, I. Arakelyan, and J. E. Thomas, Phys. Rev. Lett. 108 , 235302 (2012).
- [12] V. Makhalov, K. Martiyanov, and A. Turlapov, Phys. Rev. Lett. 112 , 045301 (2014).
- [13] L. D. Landau and E. M. Lifshitz, Quantum Mechanics: Non-relativistic theory , Vol. 3 of Course of Theoretical Physics , 3rd ed. (Pergamon Press, Oxford; New York, 1989).
- [14] P. Dyke et al. , Phys. Rev. Lett. 106 , 105304 (2011).
- [15] J.-P. Martikainen and P. T¨rm¨ a, o Phys. Rev. Lett. 95 , 170407 (2005).
Rather than being an unwanted complication, the effects of confinement may provide a route to realizing superfluidity in quasi-2D Fermi gases. We have shown here that increasing ε F /ω z for fixed interaction ε B /ε F can actually increase T /ε c F ; thus it remains to be seen whether T c can be maximized with a geometry that lies between 2D and 3D. This requires a calculation that goes beyond mean-field theory and includes center-of-mass fluctuations of the pairs, since the size of T c eventually becomes too large to be determined only by pair breaking excitations.
In general, one will require approaches beyond the mean-field approximation in order to fully characterize the quasi-2D system. Normal-state interactions are an obvious omission in the theory and are expected to impact the RF spectra [35]. There is also the possibility of a pseudogap regime just above T c , where both bosonic pairs and Fermi statistics are present [10, 17, 36]. Nonetheless, our mean-field theory provides a major step towards including the effects of confinement.
## Acknowledgments
We gratefully acknowledge fruitful discussions with Selim Jochim, Michael K¨hl, Jesper Levinsen, and Stefan o Baur. This work was supported by the EPSRC under Grant No. EP/H00369X/2.
- [16] A. M. Fischer and M. M. Parish, Phys. Rev. A 88 , 023612 (2013).
- [17] M. Bauer, M. M. Parish, and T. Enss, Phys. Rev. Lett. 112 , 135302 (2014).
- [18] G. Bertaina and S. Giorgini, Phys. Rev. Lett. 106 , 110403 (2011).
- [19] Y. F. Smirnov, Nucl. Phys. 39 , 346 (1962).
- [20] R. Chasman and S. Wahlborn, Nuclear Physics A 90 , 401 (1967).
- [21] D. S. Petrov and G. V. Shlyapnikov, Phys. Rev. A 64 , 012706 (2001).
- [22] I. Bloch, J. Dalibard, and W. Zwerger, Rev. Mod. Phys. 80 , 885 (2008).
- [23] S. Tan, Annals of Physics 323 , 2971 (2008).
- [24] F. Werner and Y. Castin, Phys. Rev. A 86 , 013626 (2012).
- [25] S. S. Botelho and C. A. R. S´ de Melo, Phys. Rev. Lett. a 96 , 040404 (2006).
- [26] K. Miyake, Progr. Theor. Phys. 69 , 1794 (1983).
- [27] D. S. Petrov, M. A. Baranov, and G. V. Shlyapnikov, Phys. Rev. A 67 , 031601 (2003).
- [28] J. Levinsen and S. K. Baur, Phys. Rev. A 86 , 041602 (2012).
- [29] L. P. Pitaevskii and A. Rosch, Phys. Rev. A 55 , R853 (1997).
- [30] M. Olshanii, H. Perrin, and V. Lorent, Phys. Rev. Lett. 105 , 095302 (2010).
- [31] B. Fr¨hlich o et al. , Phys. Rev. Lett. 106 , 105301 (2011).
- [32] S. K. Baur et al. , Phys. Rev. A 85 , 061604 (2012).
- [33] C. Langmack, M. Barth, W. Zwerger, and E. Braaten, Phys. Rev. Lett. 108 , 060402 (2012).
- [34] R. Haussmann, M. Punk, and W. Zwerger, Phys. Rev. A 80 , 063612 (2009).
- [35] V. Pietil¨, Phys. Rev. A a 86 , 023608 (2012).
- [36] V. Ngampruetikorn, J. Levinsen, and M. M. Parish, Phys. Rev. Lett. 111 , 265301 (2013).
- [37] There is also a considerably weaker harmonic confinement in the x y , directions, with ω x = ω y glyph[lessmuch] ω z , which we will ignore here. However, one can map the properties of the uniform quasi-2D gas to the trapped gas using the local density approximation when the confinement is sufficiently weak. | 10.1103/PhysRevB.90.214503 | [
"Andrea M. Fischer",
"Meera M. Parish"
] | 2014-08-03T09:35:56+00:00 | 2014-08-03T09:35:56+00:00 | [
"cond-mat.quant-gas",
"cond-mat.supr-con"
] | Quasi-two-dimensional Fermi gases at finite temperature | We consider a Fermi gas with short-range attractive interactions that is
confined along one direction by a tight harmonic potential. For this
quasi-two-dimensional (quasi-2D) Fermi gas, we compute the pressure equation of
state, radio frequency spectrum, and the superfluid critical temperature $T_c$
using a mean-field theory that accounts for all the energy levels of the
harmonic confinement. Our calculation for $T_c$ provides a natural
generalization of the Thouless criterion to the quasi-2D geometry, and it
correctly reduces to the 3D expression derived from the local density
approximation in the limit where the confinement frequency $\omega_z \to 0$.
Furthermore, our results suggest that $T_c$ can be enhanced by relaxing the
confinement and perturbing away from the 2D limit. |
1408.0479v3 | ## Measurement of jet p T spectra and R AA in pp and Pb-Pb collisions at √ s NN = 2.76 TeV with the ALICE detector
## Salvatore Aiola (for the ALICE Collaboration)
E-mail:
[email protected]
Yale University, New Haven, CT 06520
Abstract. Hard-scattered partons provide an ideal probe for the study of the Quark-Gluon Plasma because they are produced prior to the formation of the QCD medium in heavy-ion collisions. Jet production is therefore susceptible to modifications induced by the presence of the medium ('jet quenching'). Both RHIC and LHC experiments have provided compelling evidence of jet quenching. Jets are reconstructed in ALICE utilizing the central tracking system for the charged constituents and the Electromagnetic Calorimeter for the neutral constituents. Jet spectra are reported for central (0-10%) and semi-central (10-30%) Pb-Pb events at √ s NN = 2 76 TeV. The nuclear modification factor, determined using a pp baseline measured . at the same collisional energy, shows a strong suppression of jet production in central Pb-Pb collisions with the expected centrality ordering. Observations are in qualitative agreement with medium-induced energy loss models. Furthermore, indication of a path-length dependence of jet suppression is inferred from measurements of the yields relative to the orientation of the event plane.
## 1. Introduction
The study of jets in ultra-relativistic heavy-ion collisions is intimately connected to the investigation of the properties of the Quark-Gluon Plasma (QGP). The QGP is a deconfined state of matter, in which the relevant degrees of freedom are those of strongly-interacting quarks and gluons. Simple quantum-mechanical considerations, based on the Heisenberg principle of indetermination, imply that hard-scattering processes, with a large momentum transfer, happen at a much smaller time scale as compared to that of the QGP formation, which is driven by many low momentum scatterings. The subsequent transport of the hard scattered parton through the medium and its fragmentation are expected to be considerably modified through elastic collisions and medium-induced radiation [1]. These phenomena are usually referred to as 'jet quenching'. Measurements at both RHIC [2, 3] and the LHC [4, 5, 6] have confirmed these predictions using a variety of observables. Jet reconstruction can take advantage of the more accurate estimate of the energy of the parton compared to high transverse momentum ( p T ) single hadron measurements, which are often used as proxies for jets.
In these proceedings we report measurements of the jet nuclear modification factor and charged jet v 2 performed by the ALICE experiment for Pb-Pb collisions at √ s NN = 2 76 TeV. . These results are based on data collected by ALICE in 2011 and extend previous measurements reported in Refs. [7, 8].
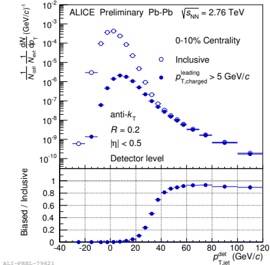
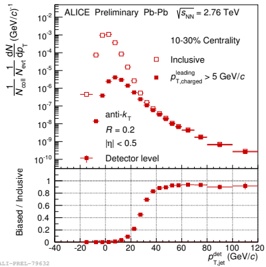
T
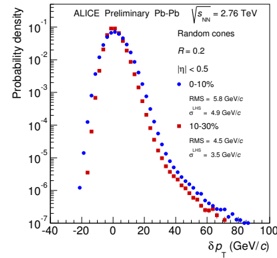
ALI-PREL-79202
(a) Jet p T spectra (0-10% centrality class).
(b) Jet p T spectra (10-30% centrality class).
(c) δp T distributions.
Figure 1: Jet p T spectra at detector level and δp T distributions in Pb-Pb collisions at √ s NN = 2 76 TeV at mid-rapidity. . Jets are reconstructed using the antik T algorithm with a resolution parameter R = 0 2 in two centrality ranges: . 0-10% (left) and 10-30% (middle). Spectra are normalized by the number of events and the number of binary collisions obtained in a Glauber MC calculation [9]. Both the inclusive spectra and the spectra biased by requiring a leading hadron with p T > 5 GeV/ c are shown. The bottom panels show the ratios of the biased over the inclusive spectra. The δp T distributions (right) are obtained using the random cone technique.
## 2. Experimental setup and analysis techniques
For a complete description of the ALICE detector and its performance see Refs. [10] and [11], respectively. The main sub-detectors used in the present measurement are the VZERO, the central tracking system and the Electromagnetic Calorimeter (EMCal). The VZERO detector consists of segmented scintillators covering the full azimuth at forward rapidity. It is used to measure the centrality of the Pb-Pb events and also provides the set of minimum bias and centrality triggers used to collect the presented data. The ALICE tracking system consists of the Inner Tracking System (ITS), a six-layer silicon detector, and a large Time Projection Chamber (TPC). The ITS provides a precise measurement of the first points of the tracks and a precise determination of the primary vertex. The tracking system allows reconstruction of charged tracks ranging from very low momentum ( p T ≈ 0 15 GeV/ ) to high momentum ( . c p T ≈ 100 GeV/ ), c with good momentum resolution and tracking efficiency. Tracks are reconstructed at midrapidity ( | η | < 0 9) and in full azimuth. . The EMCal is a Pb-scintillator sampling calorimeter, which covers mid-rapidity ( | η | < 0 7) . and partial azimuth (∆ φ = 100 ). ◦ In this analysis it is used to measure the decay photons of the neutral mesons, that are not detected by the tracking system. Energy deposition from charged particles, measured by the tracking system, is subtracted to avoid double counting their energy in the jet reconstruction. The details of this correction are outlined in Ref. [11].
The methods utilized in this analysis follow closely those used for the charged jet suppression measurement reported in Ref. [5] and for the pp jet cross section reported in Ref. [12]. The antik T jet finding algorithm [13] with a resolution parameter R = 0 2 has been employed in . its FastJet [14] implementation. Jets are required to be fully contained within the EMCal acceptance. Following the proposal in Ref. [15], the average background, ρ , is calculated, eventby-event, as the median of the p T density (jet p T over jet area) of the jets reconstructed by the k T algorithm. The average background is subtracted jet-by-jet: p reco T jet , = p raw T jet , -ρ × A jet , where p raw T jet , and A jet are respectively the transverse momentum and the area of the antik T jet
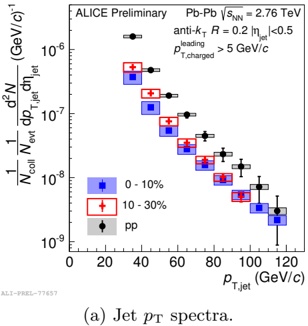
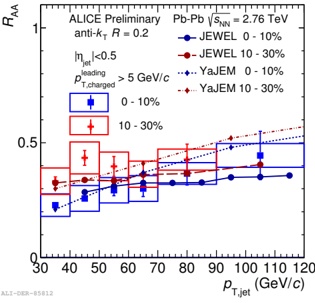
(b) Nuclear modification factor.
Figure 2: Jet p T spectra (left) and nuclear modification factor (right) at mid-rapidity for 0-10% and 10-30% centrality class Pb-Pb events at √ s NN = 2 76 TeV (color online). . The measured R AA is compared with two model predictions, YaJEM [16] and JEWEL [17], see text for details.
candidate. Figures 1a and 1b show the jet p T spectra at detector level, after the subtraction of the average background. Both the inclusive spectra and the spectra biased by requiring a leading hadron p T > 5 GeV/ c are shown. The bias is applied in order to suppress the combinatorial background. Background fluctuations are estimated using the random cone technique [18]. The root-mean-square widths of the δp T distributions, shown in Fig. 1c, are 5 8 GeV/ . c for the 0-10% centrality class and 4 5 GeV/ . c for the 10-30%. The response of the detector to jets has been quantified through a simulation which makes use of the PYTHIA6 event generator [19] and the GEANT3 transport code [20]. The results reported in Section 3 are obtained after correcting for both detector response and background fluctuations using standard regularized unfolding methods [21, 22].
## 3. Results
Figure 2a shows the antik T R = 0 2 jet . p T spectra at mid-rapidity for the 0-10% and the 10-30% centrality classes. In order to compare with the same measurement performed in pp collisions at the same √ s NN [12], the jet yield in Pb-Pb has been divided by the number of binary collisions calculated in a Monte Carlo Glauber model [9] that assumes independent binary nucleon-nucleon collisions. The systematic uncertainty is dominated by the tracking efficiency uncertainty and the unfolding regularization and is p T dependent, with a value of about 18% at p T jet , = 60 GeV/ c for the central events and only slightly smaller for the semi-central events.
The nuclear modification factor R AA is defined as the ratio of the Pb-Pb per-event yield over the pp cross section [12] multiplied by T AA = N coll /σ inel pp , obtained in the same Glauber calculation mentioned above. The measured R AA is shown in Fig. 2b. A strong suppression, with the expected centrality ordering, is observed and is in qualitative agreement with two energy loss model predictions, superimposed on the data. Both models use a combination of Glauber MC, perturbative QCD (pQCD) Leading Order (LO) calculations and PYTHIA, to describe the initial state, the hard scattering and the hadronization into final-state colorless particles. They both implement a hydrodynamic description of the medium. They differ in the specific way in which the interaction between the shower parton and the medium is modeled. In YaJEM [16] the energy loss mechanism is implemented through a pair of transport coefficients, one representing the increase of the parton's virtuality in the medium (radiative energy loss), and the other accounting for the collisional energy loss; in JEWEL [17] an average over a microscopic
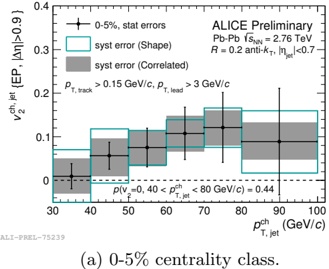
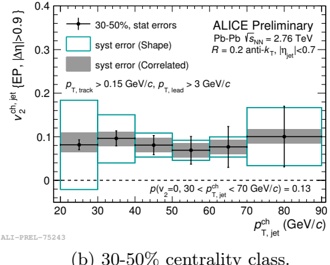
(b) 30-50% centrality class.
Figure 3: Charged jet v 2 in Pb-Pb collisions at √ s NN = 2 76 TeV at mid-rapidity. . Jets are required to have a leading hadron with p T > 3 GeV/ . c
description of the single parton-parton scatterings is implemented, using a MC model for the LPM interference.
The path-length dependence of the jet energy loss has been investigated by studying the charged jet yield with respect to the event plane orientation. The QGP formed in semi-central collisions is expected to take an ellipsoidal shape elongated in the direction perpendicular to the reaction plane, which has been confirmed by the measurement of the azimuthal anisotropy of low-momentum particle production [23]. High Q 2 partons produced out-of-plane are expected to be more heavily modified because they travel a longer path in the medium. The jet v 2 is defined as the second coefficient of the Fourier expansion of the jet yield with respect to the azimuthal angle between the jet axis and the event plane. For this measurement, the average background and the background fluctuations have been measured and subtracted differentially with respect to the angle with the event plane. The observed v 2 has been corrected for the finite event plane resolution by using a three sub-event technique [24]. Fig. 3 shows the charged jet v 2 for central (0-5%) and semi-central (30-50%) Pb-Pb events. In estimating the systematic uncertainties, the correlations between the in-plane and out-of-plane measurements have been taken into account. While we do not observe a significant indication for a non-zero jet v 2 in central events, the semi-central events shows a hint of a difference between the in- and out-ofplane nuclear modification factor, although the result is also still compatible with v 2 = 0 for jets.
## 4. Conclusions
In these proceedings we have reported new measurements of jet suppression performed by the ALICE experiment. The measured suppression for both central and semi-central events is in qualitative agreement with both the YaJEM and JEWEL models. In order to obtain a tighter constraint on the models the path-length dependence of the parton energy loss has been explored by measuring the charged jet v 2 , which shows hints of such an effect for semi-central events. ALICE has also measured jet yields in p-Pb collisions [25, 26], which show that cold nuclear matter effects in the initial state cannot account for the observed suppression in Pb-Pb collisions. These observations support the interpretation of the observed suppression as a medium-induced modification of the final state parton shower.
## References
- [1] R. Baier, Y. L. Dokshitzer, S. Peigne, D. Schiff, Phys.Lett. B345 (1995) 277-286 doi:10.1016/0370-2693(94) 01617-L .
- [2] STAR Collaboration, C. Adler, et al., Phys.Rev.Lett. 90 (2003) 082302 doi:10.1103/PhysRevLett.90. 082302 .
- [3] PHENIX Collaboration, S. S. Adler, et al., Phys. Rev. C69 (2004) 034910 doi:10.1103/PhysRevC.69. 034910 .
- [4] CMS Collaboration, S. Chatrchyan, et al., Phys. Rev. C 84 (2011) 024906 doi:10.1103/PhysRevC.84. 024906 .
- [5] ALICE Collaboration, B. Abelev, et al., JHEP 1403 (2014) 013 arXiv:1311.0633 , doi:10.1007/ JHEP03(2014)013 .
- [6] ATLAS Collaboration, G. Aad, et al., Phys.Lett. B719 (2013) 220-241 arXiv:1208.1967 , doi:10.1016/j. physletb.2013.01.024 .
- [7] S. Aiola (for the ALICE Collaboration), Journal of Physics: Conference Series 446 (2013) 012005 arXiv: 1304.6668 .
- [8] R. Reed (for the ALICE Collaboration), Journal of Physics: Conference Series 446 (2013) 012006 arXiv: 1304.5945 .
- [9] ALICE Collaboration, B. Abelev, et al., Phys.Rev. C88 (4) (2013) 044909 arXiv:1301.4361 , doi:10.1103/ PhysRevC.88.044909 .
- [10] ALICE Collaboration, K. Aamodt, other, Journal of Instrumentation 3 (2008) S08002 .
- [11] ALICE Collaboration, B. B. Abelev, et al. arXiv:1402.4476 .
- [12] ALICE Collaboration, B. Abelev, et al., Phys.Lett. B722 (2013) 262-272 arXiv:1301.3475 , doi:10.1016/ j.physletb.2013.04.026 .
- [13] M. Cacciari, G. Salam, G. Soyez, JHEP 04 (063) (2008) 063 .
- [14] M. Cacciari, G. P. Salam, G. Soyez, Eur.Phys.J. C72 (2012) 1896 arXiv:1111.6097 , doi:10.1140/epjc/ s10052-012-1896-2 .
- [15] M. Cacciari, G. Salam, Physics Letters B 659 (1-2) (2008) 119-126 .
- [16] T. Renk, Phys.Rev. C88 (1) (2013) 014905 arXiv:1302.3710 , doi:10.1103/PhysRevC.88.014905 .
- [17] K. C. Zapp, Physics Letters B 735 (2014) 157 - 163 arXiv:1312.5536 , doi:10.1016/j.physletb.2014.06. 020 .
- [18] ALICE Collaboration, B. Abelev, et al., JHEP 1203 (053) (2012) 053 .
- [19] T. Sj¨strand, S. Mrenna, P. Skands, Journal of High Energy Physics 5 (26) (2006) 1-581 . o
- [20] R. Brun, F. Carminati, S. Giani, CERN Program Library Long Write-up, W5013 .
- [21] A. Hocker, V. Kartvelishvili, NIM A372 (1996) 469-481 arXiv:hep-ph/9509307 , doi:10.1016/ 0168-9002(95)01478-0 .
- [22] G. D'Agostini, NIM 362 (1995) 487 .
- [23] ALICE Collaboration, K. Aamodt, et al., Phys. Rev. Lett. 105 (2010) 252302 doi:10.1103/PhysRevLett. 105.252302 .
- [24] A. M. Poskanzer, S. A. Voloshin, Phys. Rev. C 58 (1998) 1671-1678 doi:10.1103/PhysRevC.58.1671 .
- [25] R. Haake (for the ALICE Collaboration), PoS EPS-HEP2013 (2014) 176 arXiv:1310.3612 .
- [26] M. Connors (for the ALICE Collaboration), Nuclear Physics A 931 (2014) 1174 arXiv:1409.3468 , doi: 10.1016/j.nuclphysa.2014.09.092 . | 10.1016/j.nuclphysa.2014.08.033 | [
"Salvatore Aiola"
] | 2014-08-03T10:21:13+00:00 | 2014-12-08T16:03:22+00:00 | [
"nucl-ex"
] | Measurement of jet $p_{\rm T}$ spectra and $R_{\rm AA}$ in pp and Pb-Pb collisions at $\sqrt{s_{\rm NN}}$ = 2.76 TeV with the ALICE detector | Hard-scattered partons provide an ideal probe for the study of the
Quark-Gluon Plasma because they are produced prior to the formation of the QCD
medium in heavy-ion collisions. Jet production is therefore susceptible to
modifications induced by the presence of the medium ("jet quenching"). Both
RHIC and LHC experiments have provided compelling evidence of jet quenching.
Jets are reconstructed in ALICE utilizing the central tracking system for the
charged constituents and the Electromagnetic Calorimeter for the neutral
constituents. Jet spectra are reported for central (0-10%) and semi-central
(10-30%) Pb-Pb events at $\sqrt{s_{\rm NN}}=2.76$ TeV. The nuclear modification
factor, determined using a pp baseline measured at the same collisional energy,
shows a strong suppression of jet production in central Pb-Pb collisions with
the expected centrality ordering. Observations are in qualitative agreement
with medium-induced energy loss models. Furthermore, indication of a
path-length dependence of jet suppression is inferred from measurements of the
yields relative to the orientation of the event plane. |
1408.0480v2 | ## Demonstration of Entanglement-Enhanced Phase Estimation in Solid
Gang-Qin Liu, 1 Yu-Ran Zhang, 1 Yan-Chun Chang, 1 Jie-Dong Yue, 1 Heng Fan, 1,2, ∗ and Xin-Yu Pan 1,2, †
1 Beijing National Laboratory for Condensed Matter Physics, Institute of Physics, Chinese Academy of Sciences, Beijing 100190, China 2 Collaborative Innovation Center of Quantum Matter, Beijing 100190, China (Dated: April 9, 2015)
Precise parameter estimation plays a central role in science and technology. The statistical error in estimation can be decreased by repeating measurement, leading to that the resultant uncertainty of the estimated parameter is proportional to the square root of the number of repetitions in accordance with the central limit theorem. Quantum parameter estimation, an emerging field of quantum technology, aims to use quantum resources to yield higher statistical precision than classical approaches. Here, we report the first room-temperature implementation of entanglement-enhanced phase estimation in a solid-state system: the nitrogen-vacancy centre in pure diamond. We demonstrate a super-resolving phase measurement with two entangled qubits of different physical realizations: an nitrogen-vacancy centre electron spin and a proximal 13 Cnuclear spin. The experimental data shows clearly the uncertainty reduction when entanglement resource is used, confirming the theoretical expectation. Our results represent an elemental demonstration of enhancement of quantum metrology against classical procedure.
Information about the world is acquired by observation and measurement, the results of which are subject to error [1]. The classical approach to reduce the statistical error is to increase the number of resources for the measurement in accordance with the central limit theorem, however, this method sometimes seems undesirable and inefficient [2]. Quantum parameter estimation, the emerging field of quantum technology, aims to yield higher statistical precision of unknown parameters by harnessing entanglement and other quantum resources than purely classical approaches [3]. Since this quantum-enhanced measurement will benefit all quantitative science and technology, it has attracted a lot of attention as well as contention. Using N independent particles to estimate a parameter ϕ can achieve at best the standard quantum limit (SQL) or called shot noise limit scaling as δϕ ∝ 1 / √ N while it is believed that using N entangled particles and exotic states such as NOON states in principle is able to achieve the inviolable Heisenberg limit scaling as δϕ ∝ 1 /N [4, 5]. In such circumstances, there are many efforts using non-classical states and quantum strategy for sub-SQL phase estimation in different physical realizations, such as optical interferometry [2, 6-9], atomic systems [10, 11], and Bose-Einstein condensates [12, 13].
In this paper, we report the first room-temperature proofof-principle implementation of entanglement-enhanced phase estimation in a solid-state system: the nitrogen-vacancy (NV) centre in pure diamond single crystal. An individual NV center can be viewed as a basic unit of a quantum computer in which the nuclear spin with a long coherence time performs as the memory and the centre electron spin with a high control speed acts as the probe. This solid-state system is one of the most promising candidates for quantum information processing (QIP), and many coherent control and manipulation processes have been performed with this system [14-29]. Here, we demonstrate a super-resolving phase measurement with two entangled qubits of different physical realizations: a NV centre electron spin and a proximal 13 C nuclear spin. We are able to improve the phase sensitivity by factors close to √ 2 compared with the classical scheme, which conforms to the fundamental Heisenberg limit. As we have entangled two qubits with different physical realizations, our results represent a more generalized and elemental demonstration of enhancement of quantum metrology. Moreover, our system has overcomed the defects of post-selection in the most common optical systems which are fatal due to the fact that the measurement trials abandoned will eliminate the quantum advantage over classical strategy.
## Results
## System description
The phase estimation scheme is implemented by optically detected magnetic resonance (ODMR) [14, 16] technique on
FIG. 1: General scheme and system description. (a) Phase estimation schemes of the independent states and the electron-nuclear entangled state. By harnessing entanglement, quantum metrology yields higher statistical precision than classical approaches. (b) Energy levels and physical encoding of the two-bit system. The electron spin and a nearby 13 C nuclear spin of an NV center are employed to demonstrate the metrology scheme. At excited-state level anti-crossing (ESLAC), both spins can be polarized, manipulated and readout with high fidelity. Two-bit conditional quantum gates are implemented by applying selective microwave (MW) or (RF) pulses.
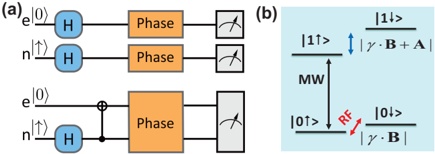
a home-built confocal microscope system. The description of the system can be found in [27]. The spin-1 electron spin of NV centre has triplet ground states with a zero-field splitting of ∆ ≈ 2 87 . GHz between the states | 0 〉 and | ± 1 〉 . As an external magnetic field of about 507 Gauss is applied along [111] direction of the diamond crystal, the degeneration of | ± 1 〉 states can be well relieved, and the first qubit is encoded on the | 0 〉 and | -1 〉 subspace ((hereinafter labelled as | 1 〉 )). The electron spin state can be initialized to | 0 〉 state by a short 532 nm laser pulse (3 µ s) and manipulated by resonant microwave (MW) pulses of tunable duration and phase. The electron spin state is readout by collecting the spin-dependent fluorescence. To enhance the fluorescence collection efficiency, a solid immersion lens (SIL) [30] is etched above the selected NV center, typical count rate in this experiment is 250 kps with SIL, see Methods for details.
The second qubit is encoded on the | ↑〉 and | ↓〉 states of a nearby 13 C nuclear spin. See Fig. 1(b) for the energy levels of the two qubit system. The coupling strength between the target nuclear spin and centre electron spin is 12.8 MHz, which indicates the 13 C atom sites on the third shell from the NVcentre [31]. The polarization and readout procedure of the nuclear spin is more complicated than that of a electron spin. The 507 Gauss magnetic field causes excited-state level anticrossing (ESLAC) of centre electron spin, in which the optical spin polarization of centre electron will transfer to nearby nuclear spins [32, 33]. So the host 14 N nuclear spin, the nearby 13 C nuclear spin as well as the center electron spin are polarized by the same laser pulse under this magnetic field. To readout the nuclear spin state, a mapping gate, which transfers nuclear spin state to electron spin, and a following optical readout of electron spin state are employed [17, 33], see Methods for details.
The nearby nuclear spin couples to the centre electron spin through strong dipolar interaction, which provides excellent conditions to implement two-qubit controlled gate. On the one hand, the resonant frequency of | 0 ↑〉 ⇔ | 1 ↑〉 transition and | 0 ↓〉 ⇔ | 1 ↓〉 transition are separated by 12.8 MHz from each other, so we can selectively manipulation one branch of nuclear spin with high fidelity while keep the other branch untouched (using weak MW pulses, see black arrow in Fig. 1(b)). On the other hand, the nuclear spin state evolution is strong affected by the state of electron spin: when electron spin is on the | 0 〉 state (or | -1 〉 state), the dynamics of the nuclear spin is dominated by the external magnetic filed (or the dipolar interaction, respectively), its Zeeman splitting between the | ↑〉 and | ↓〉 states is about 500 kHz, which is far away from the dipolar interaction strength of 12.8 MHz. Therefore, we can selectively manipulate nuclear spin state in one branch of electron spin, as well (using RF pulses, see red arrow in Fig. 1(b) and Supplementary Note 1).
## Phase preparation and measurement
Fig. 2(b) describes the pulse sequence to prepare and mea-
FIG. 2: Phase preparation and measurement (a) For each unknown state sitting on the equatorial plane of the Bloch sphere, we compare the amplitudes of the two Rabi signals from this state (under orthogonal microwave pulses driven) to extract the original phase information: ϕ = arctan( A /A x y ) . (b) Upper pane: pulse sequence to prepare and measure electron-nuclear spin entanglement state 1 √ 2 ( 1 | ↑〉 + e 2 iϕ | 0 ↓〉 ) . Lower pane: pulse sequence to prepare and measure nuclear spin superposition state 1 √ 2 ( 0 | ↑〉 + e iϕ | 0 ↓〉 ) . (c-e) Nuclear Rabi signals for phase measurement, with 0.1 M, 0.4 M and 2 M repetition of pulse sequence in (b) . The input phase ϕ is 30 ◦ . Solid circle with blue fitting line is driven by 0 ◦ RF pulse (X measurement), and square with red dash fitting line is driven by 90 ◦ RF pulse (Y measurement). (f) Dependence of measured phase and its standard deviation on repeat number.
sure the phase of a superposition state. Take nuclear spin for example, the qubit is defined in a rotating frame with frequency equalling to the energy splitting between | 0 ↑〉 and | 0 ↓〉 states. After polarized to | 0 ↑〉 by laser pulse, a resonant RF π 2 pulse brings the system to 1 √ 2 ( 0 | ↑〉 + e iϕ | 0 ↓〉 ) state. The phase of this state is determined by the relative phase of the applied RF pulse, which is tunable in experiment. The phase of electron superposition state is prepared in the same way, with resonant MW pulses.
The phase information of a superposition state is detected by converting it to population information of the spin qubits and a following optical readout. To eliminate the system error in long time measurement, we use a self-calibration measurement scheme as shown in Fig. 2(a). For each unknown state siting on the equatorial plane of the Bloch sphere, we measure the Rabi oscillations driven by two orthogonal microwave pulses (0 ◦ and 90 ◦ ), and compare the amplitudes of the two Rabi signal to extract the original phase information: ϕ = arctan A x A y , where A x and A y are the amplitudes of Rabi signals driven by 0 ◦ and 90 ◦ microwave pulses, respectively. Note that this is a single spin experiment, and we need to repeat the pulse sequence many times to get a reliable signal to noise ratio (SNR). Figs. 2(c-e) presents the nuclear Rabi signal of 0.1 M, 0.4 M and 2 M repeat of the pulse sequence in
FIG. 3: State tomography and phase relation. (a) The state tomography result of a nuclear spin superposition state 1 √ 2 ( | ↑〉 + | ↓〉 ) . (b) State tomography result of the electron-nuclear entangled state 1 √ 2 ( 1 | ↑〉 + 0 | ↓〉 ) . (c) Phase relation of an independent state. (d) Phase relation of an entangled state. Compared with independent state, the phase relation of entangled state has double frequency dependence on input phase, so a more precise phase estimation result can be achieved with entangled state.
Fig. 2(b), with an input phase of 30 ◦ . The error bar of the data point represent standard deviation (SD) of 10 repeat measurements. It is clear to see from Fig. 2(c) to Fig. 2(e) that the SNR is better as the measurement sequence is repeated more times. In Fig. 2(f), the decrease of phase estimation error can be well described by central limit theorem.
To improve phase estimation accuracy, one can increase the repeat number, which means longer measurement time is needed. An equivalent way is to employ more qubits. As mentioned before, the state of the multi-qubit system, independent or entanglement, determines the accuracy limit of phase estimation. For the investigated two-qubit system, the electron and nuclear spin can be prepared and measured independently. Fig. 3(a) plots the state tomography result of a nuclear spin superposition state. Using such independent state (either nuclear spin or electron spin) will get a phase relation as depicted in Fig. 3(c), the amplitude of Rabi signal has cosine dependence on the phase of input state.
The electron and nuclear spin can be prepared in entangled state by combination of MW and RF pulses. As shown in the upper pane of Fig. 2(b), after the first RF π 2 pulse (with phase ϕ ) brings the system to 1 √ 2 ( 0 | ↑〉 + e iϕ | 0 ↓〉 ) state, a selective MW π pulse of | 0 ↑〉 ⇔ | 1 ↑〉 transition, which has relative phase ϕ to the first RF pulse, brings the system to 1 √ 2 ( 1 | ↑〉 + e 2 iϕ | 0 ↓〉 ) state. The MW and RF channels are synchronized to the same clock reference and relative phase between them is calibrated before each measurement. Typical state tomography result of an electron-nuclear entangled state ( ϕ = 0 ◦ ) is depicted in Fig. 3(b). It is worth noting that
FIG. 4: Dependence of phase error on repeat number and input phases. (a) Standard deviations of the entangled state and independent state against repeat number. Single spin states (electron and nuclear) of the same input phase ϕ = 30 ◦ are prepared and measured independently, the phase extracted from each entangled state 'single measurement' is 2 ϕ = 60 ◦ . (b) The phase uncertainty is fitted by function δϕ = a/ √ ν + c for both single spin state and the entangled state, where ν corresponds to repeat number in unit of million (M). The curves show that the phase uncertainty, phase error represented by δϕ , of entanglement case is apparently lower than the case of single spin state. (c) The phase estimation results of different input phases including 0 ◦ , 5 ◦ , 10 ◦ , 15 ◦ , 20 ◦ , 25 ◦ and 30 ◦ , the repeat number is fixed to 1 M. (d) The phase error of different input phases, the repeat number is fixed to 1 M.
the dephasing time of electron spin (0.7 µ s, see Methods) is very short compared with the typical manipulation time (e.g. 10 µ s for a flip operation) of nuclear spin, which limits the QIP applications of this entangled state [22, 27, 33]. However, in our phase estimation application, the sensitive phase information is converted to population right after its generation and then only limited by T 1 of electron spin, which is about 5 ms. Meanwhile, the coherence of electron is less affected under microwave driving (see Methods), thus the phase of the entangled state is well preserved during the preparation and measurement. As shown in Fig. 3(d), the phase relation of the entangled state has double frequency dependence on the phase of input state, so the phase estimation using the entangled state of two qubit is more precise than that of using two state from independent single qubit.
## Entanglement-enhanced phase estimation
To demonstrate the merits of entangled state over independent state in phase estimation application, we compare their performances on different repeat number and different input phase, the measured results are summarized in Fig. 4. The experimental procedure is: firstly, single spin states (electron and nuclear) of the same input phase ( 30 ◦ ) are prepared and measured independently. Then the output phases extracted
from the same repeat number are counted together, no weight is added for either electron or nuclear spin states. For a fair comparison with entangled state, half of the statistic samples ( ν ) are extracted from electron spin states, and the other half ( ν ) are extracted from nuclear spin states. In the case of entangled state phase estimation, the entangled states are prepared and measured using the same repeat number ( ν ). Note the same MW and RF channels are used to prepare the independent and entangled states.
As shown in Fig. 4(a) and (c), the phase extracted from each entangled state measurement is 2 ϕ , so the phase error of input phase is just half of the standard deviation from ν sample statistic ( δϕ/ 2 ). For the independent-state input, the double sample number ( 2 ν ) only suppresses phase error to δϕ/ √ 2 level, which is larger than entanglement-state input.
Explicitly, we would expect that the phase uncertainty δϕ proportion respectively to 1 / √ νN and 1 / ( √ νN ) for single spin state and the entangled state with N being 2 in our experiment since two-qubit entanglement between electron spin and nuclear spin is used as the quantum resource. In Fig. 4(b), we consider that identical measurement is repeated ν times, then a general formulae, δϕ = a/ √ ν + c , is used to fit experimental data, where c is assumed to be a systematic error depending on specific experimental setup. The parameter a for scheme of entangled state should be smaller than that of the single spin scheme, corresponding to smaller uncertainty about the phase, if we assume that the single spin state and the entangled state are realized by the same physical state. Fig. 4(b) of the experimental data demonstrates clearly that the precision of phase estimation is enhanced by using entanglement which agrees well with theoretical expectation. Here the discrepancy between theory and experiment is possibly due to two related reasons: the electron spin state and the nuclear spin state are not the same, in particular for their decoherence time, while their similarity is assumed theoretically; the readout of NV centre system can only be by intensity of florescence of the electron spin. Besides the data processing method presented here, we have also tried linear fitting in the log-log scale for SD as well as variance (see Supplementary Note 2 and Supplementary Fig. 3 for detail). The obtained results are in good agreement with the results in Fig. 4(b), which confirms the validity of our conclusion.
Fig. 4(c) and (d) show the phase estimation results of different input phases. The phase error of entangled state is smaller than independent state in all input phases, which indicates the enhancement of phase estimation accuracy by entanglement is phase independent.
## Discussion
As summarized in Fig. 4 by different figures of merit quantifying the uncertainty of phase estimation, the entanglementenhanced precision is clearly shown by experimental data. This experiment demonstrates the advantage of the quantum metrology scheme. Practically by using quantum metrology, the measured physical quantity should have the same interaction on the probe system no matter it is prepared as a single qubit or entangled state. In our special designed experiment, the measured phases are artificially encoded to the probe state such that the enhancement of precision can be shown by entangled probe state. However in principle, the confirmation of theoretical expectation by experimental data provides a solid evidence that quantum phase estimation is applicable in this solid state system.
In this experiment, we use repeating measurement to overcome the low photon collection efficiency of NV center. The phase estimation accuracy can be further improved by employing single-shot measurement technique, which is now available in NV system [19, 20, 34]. Although the photon collection efficiency is not perfect ( < 20%, not every measurement is stored and counted), the following two facts guarantee the reliability of the demonstration: (1) we use the same scheme to measure single and entangled states, that is, the phase information is finally converted to fluorescence signal of NV center and detected. (2) The detection efficiency of the system is stable (though not perfect as single-shot readout) for all the measurement, so we can directly compare the measured phase noise of single and entangled states.
As the phase estimation accuracy is determined by the total number of entangled qubits, a straightforward way to improve the phase accuracy is increasing the involved spin number. The large amount of weakly coupled 13 C nuclear spins around NV center are one of the best candidates. With the assistance of dynamical decoupling on center electron spin, up to 6 13 C nuclear spins can be coherent manipulated [3537]. Multi-qubit application such as error correction has been demonstrated in this system [23, 24].
In conclusion, we report the first room-temperature implementation of entanglement-enhanced phase estimation in a solid-state system: the nitrogen-vacancy (NV) centre in pure diamond. We demonstrate a super-resolving phase measurement with two entangled qubits of different physical realizations: a NV centre electron spin and a proximal 13 C nuclear spin. Thus, our results represent a more generalized and elemental demonstration of enhancement of quantum metrology against classical procedure, which fully exploits the quantum nature of the system and probes.
## Methods
## Cram´ er-Rao bound and quantum Fisher information
In the simplest version of the typical quantum parameter estimation problem, we aim to recover the value of a unknown continuous parameter [say phase ϕ in Fig. 1(a)] encoded in a fixed set of states ρ ϕ of a quantum system [3]. We can obtain a single result ξ via performing a measurement on the system and it is useful to express the measurement in terms of set of POVM { ˆ E ξ } . With large number of measurements, it is possible to calculate the estimator ˜( ϕ ξ ) with the observation
conditional probability density function ( pdf ) of result ξ given the true values ϕ : p ξ ϕ ( | ) = Tr ( ˆ E ρ ξ ϕ ) . When the number of measurements ν is sufficiently large and the estimation is unbiased [38, 39], the root-mean square error for the statistical uncertainty can be shown to obey the well-known Cram´ er-Rao bound [40] given by
$$\delta \varphi \equiv \sqrt { \sum _ { \xi } [ \tilde { \varphi } ( \xi ) - \varphi ] ^ { 2 } p ( \xi | \varphi ) } \geq \frac { 1 } { \sqrt { \nu F ( \varphi ) } }, \quad ( 1 ) \quad \begin{array} { c } \frac { 1 } { \sigma } \\ \frac { 1 } { \sigma } \end{array} \right ) \text{where } F ( \varphi ) \equiv \sum _ { \varepsilon } p ( \xi | \varphi ) \left [ \partial _ { \varphi } \ln p ( \xi | \varphi ) \right ] ^ { 2 } \text{ is the Fisher infor-} \quad \begin{array} { c } \frac { 1 } { \sigma } \end{array}$$
where F ϕ ( ) ≡ ∑ ξ p ξ ϕ ( | ) [ ∂ ϕ ln p ξ ϕ ( | )] 2 is the Fisher information corresponding to the selected POVM and the conditional pdf of the result. Eq. (1) provides a lower bound for the achievable lower bound by choosing the optimal measurement expressed by some POVM { ˆ E opt ξ } that maximizes the Fisher information: F Q ( ϕ ) = max { ˆ E opt ξ } F ϕ ( ) which is known as the quantum Fisher information (QFI) [41].
For the classical scheme with separable probe state [( 0 | 〉 + e -iϕ | 1 ) 〉 / √ 2] ⊗ N , the lower bound at best leads to the SQL δϕ se ∝ 1 / √ νN . To implement the quantum counterpart of the Heisenberg limit δϕ en ∝ 1 / √ νN , we can choose the GHZ state ( 0 | 〉 ⊗ N + e -iNϕ | 1 〉 ⊗ N ) / √ 2 as the optimal probe state. Consider that the qubit number N = 2 , the two-qubit maximally entangled state will obtain a √ 2 advantage against the separable state.
## Sample preparation
High purity single crystal diamond (Element Six, N concentration < 5 ppb) is used for this experiment. There is almost no natural NV center in this diamond. NV centres are produced by electron implantation (7.5 Mev) and a following 2 hours vacuum annealing (at 800 ◦ C). Due to the random distribution of 13 C nuclear spins, the spin bath of individual NV center can be very different [31]. We choose NV centers with nearby 13 C nuclear spins, which can be identified by the extra splitting in ODMR signal, to implement the two-bit metrology scheme. Fig. 5(a) presents the physical structure of an NV center and a nearby 13 C nuclear spin. Fig. 5(c) is ODMR signal of this two-bit system. The coupling strength between electron spin and the selected 13 C nuclear is 12.8 MHz. Fig. 5(b) shows two dimensional fluorescence image of the FIB-etched SIL. The cross-cursor marked bright spot (blue) is the one used for this experiment.
## Coherence of electron spin and nearby nuclear spin
In this pure diamond, the coherence of NV electron spin is dominated by the randomly distributed 13 Cnuclear spins (natural abundance, 1.1%). The dephasing time of individual NV centres can be significantly different [42], from less than 1 µ s to nearly 10 µ s. From the free-induction decay signal of this NV center in Fig. 5(d), we extract the dephasing time ( T ∗ 2 ) of this electron spin, which is 0.72 µ s and much larger than the
FIG. 5: Characterization of the two-qubit system. (a) NV centre with a nearby 13 C nuclear spin. (b) 2D fluorescence scan of the FIB-etched solid immersion lens (SIL, 12 µ m diameter). The bright spot is the investigated NV centre. (c) ODMR of NV electron spin under magnetic field of 690 Gauss. The splitting is caused by the nearby 13 C nuclear spin. (d) Rabi oscillation and Free-induction decay (FID) of electron spin ( B = 507 Gauss). Due to the thermal fluctuation of the spin bath, centre electron spin picks up random phase during free precession and loses coherence. With the help of resonant MW pulses, electron spin can be flipped in short time, and is less affected by the bath noise.
time consumption of single manipulation on it (about 70 ns, see Rabi oscillation of electron spin in the same figure). It is worth noting that the dephasing time is not the direct limitation of electron manipulation duration. The latter is usually named T 1 ρ and can be characterized by the envelop decay time of electron spin Rabi oscillation [43]. The dephasing time of nuclear spin ( T ∗ 2 n = 270 µ s) is much longer than that of electron spin. Meanwhile, the used half π pulse of nuclear spin is only several microseconds, so the dephasing effect of nuclear spin can be ignored, See Supplementary Fig. 1 for the FID signal of the nearby nuclear spin.
## Coherent manipulation of electron spin and nuclear spin at ESLAC
As mentioned in the main text, we work at the excitedstate level anti-crossing (ESLAC) point to achieve fast and high fidelity initialization of the electron-nuclear two-qubit system. Under an external magnetic field of 507 Gauss (along the quantization axis of the selected NV) and laser excitation (532 nm), the electron and nuclear spins are polarized simultaneously. Fig. 6(a) shows ODMR spectrum of centre electron spin at such magnetic field. From the contrast difference of two peaks, which correspond to | ↑〉 and | ↓〉 states of 13 C nuclear spin, we estimate the polarization rate of this nuclear spin is about 85% (in | ↑〉 state). Furthermore, by measuring the pulse-ODMR spectrum of electron spin, we conclude that
the host 14 N nuclear spin is completely polarized under this magnetic field.
Fig. 6(b) shows the pulse sequence of electron and nuclear spin manipulation. After polarization with high fidelity, both spin states can be manipulated with resonant MW (or RF) pulses. For electron spin, the final state is readout by counting the fluorescence intensity of NV center, since | 0 〉 state is brighter than | 1 〉 state. For nuclear spin state, we use a mapping gate, which is composed by a weak pulse of | 0 ↑〉 ⇔ | 1 ↑〉 transition, to transfer the its state to electron spin and then readout optically. For example, an unknown nuclear spin state of | 0 〉 ⊗ ( α | ↑〉 + β | ↓〉 ) is transferred to α | 1 ↑〉 + β | 0 ↓〉 after applying the mapping gate. We carefully tuned the microwave power and pulse duration to maximum the flip efficiency while avoiding the unwanted non-resonant excitation. By comparing the Rabi amplitude of nuclear spin (Fig. 6(d), with mapping gate) and electron spin (Fig. 5(d), without mapping gate), we conclude that the mapping gate has transfer efficiency of more than 92%.
Figs. 6(c) and 6(d) present the pulse-ODMR spectrum and Rabi oscillation of the nearby nuclear spin when electron spin is at | 0 〉 state. The resonant frequency of this nuclear spin is 495 kHz, which is smaller than the Larmor frequency of 13 C nuclear spin under this magnetic field (542 kHz). We attribute this modification to the 'enhance effect' of center electron spin. As the nuclear spin is close to the electron spin, the nonsecular terms of their dipole interaction contribute some electronic character to the nuclear-spin levels and modify its magnetic moment [16]. The Rabi frequency of nuclear spin is about 100 kHz, which reaches 20% of the Zeeman splitting, such fast manipulation also benefits from the electron enhance effect. We discuss the validity of rotating wave approximation (RWA) in Supplementary Note 1.
## Synchronization of pulse generators and phase calibration
Synchronization of the MW and RF generators is one of the main challenges in this experiment. We use the same clock reference for all the generators. For each cable connection and pulse sequence, we measure the phase of prepared state as we scan the phase of input MW pulses. This gives us a phase relation between MW and RF channels, which is used to compensate the difference between the two rotating frames. We check the phase relation before and after each data acquisition. The phase drift of our system is about 2 ◦ in 2 hours measurement.
## Data normalization and state tomography
Since the population information of electron spin is the only directly measurable signal in NV system, we normalize all the data to the fluorescence intensity of electron spin | 0 〉 state. Specifically, we apply two readout pulses (300 ns) at the end of each measurement. See pulse sequences in Fig. 2(b) and
FIG. 6: Coherent manipulation of electron spin and nuclear spin at ESLAC (a) . ODMRspectrum of electron spin at B = 507 Gauss. (b) Pulse sequence to manipulate electron and nuclear spins at ESLAC. (c) ODMRspectrum and (d) Rabi oscillation of the nearby 13 C nuclear spin. At ESLAC, electron spin and nearby nuclear spins (including host 14 N nuclear spin and nearby 13 C nuclear spins) can be polarized by a short laser pulse. Then spin states are manipulated by resonant MW or RF pulses. Electron spin states are readout by counting the fluorescence intensity of NV centre; nuclear spin states are mapped to electron spin and readout in the same way. The resonant frequency of this nuclear spin is 495 kHz, which is slightly modified by centre electron spin.
Fig. 6(b). The first readout pulse gets the instant population information of NV electron spin, and the second readout pulse (1 µ s later) records a reference for the first one, as electron spin is polarized to | 0 〉 again after the 1 µ s laser excitation. The ratio between the first signal and the reference signal is used for further data analysis, such as phase estimation or state tomography.
To carry out state tomography, we adopt the method detailed in Ref. [18, 27]. Total three working transitions, | 0 ↑ 〉 ⇔ | 0 ↑〉 , | 0 ↑〉 ⇔ | 1 ↑〉 and | 0 ↓〉 ⇔ | 1 ↓〉 are selected. The real and imaginary parts of the matrix elements in each working transition are measured by using RF (or MW) pulses of 0 ◦ and 90 ◦ phases, respectively. Other three transitions are measured in the same way, but extra transfer pulses are added before Rabi measurement in the working transitions. The full procedure of state tomography can be found in Supplementary information (Supplementary Fig. 2).
Acknowledgement This work was supported by the National Basic Research Program of China ('973' Program under Grant Nos. 2014CB921402 and 2015CB921103), National Natural Science Foundation of China (under Grant No. 11175248), and the Strategic Priority Research Program of the Chinese Academy of Sciences (under Grant Nos. XDB07010300 and XDB01010000).
Author Contributions X.-Y.P. and H.F. designed the experiment. X.-Y.P. is in charge of experiment, H.F. is in charge of theory. G.-Q.L., Y.-C. C. and X.-Y.P. performed the experiment. Y.-R. Z. and J.-D. Y carried out the theoretical study.
- G.-Q.L. and Y.-R. Z. wrote the paper. All authors analysed the data and commented on the manuscript.
- Competing Interests The authors declare that they have no competing financial interests.
Correspondence Correspondence and requests for materials should be addressed to X.-Y.P or H.F.
- ∗ Electronic address: [email protected]
- † Electronic address: [email protected]
- [1] Helstron, C. W. Quantum detection and estimation theory. (Academic Press, New York, 1976).
- [2] Israel, Y ., Rosen, S. & Silberberg, Y . Supersensitive polarization microscopy using NOON states of light. Phys. Rev. Lett. 112 , 103604 (2014).
- [3] Giovannetti, V., Lloyd, S. & Maccone, L. Advances in quanum metrology. Nat. Photon. 5 , 222-229 (2011).
- [4] Giovannetti, V., Lloyd, S. & Maccone, L. Quantum metrology. Phys. Rev. Lett. 96 , 010401 (2006).
- [5] Giovannetti, V. & Maccone, L. Sub-Heisenberg estiamtion strategies are ineffective. Phys. Rev. Lett. 108 , 210404 (2012).
- [6] Nagata, T., Okamoto, R., O'Brien, J. L., Sasaki, K. & Takeuchi, S. Beating the standard quantum limit with four-entangled photons. Science 316 , 726-729 (2007).
- [7] Afek, I., Ambar, O. & Silberberg, Y. High-NOON quantum and classical light states by mixing quantum and classical light. Science 328 , 879-881 (2010).
- [8] Xiang, G. Y., Higgins, B. L., Berry, D. W., Wiseman, H. M. & Pryde G. J. Entanglement-enhanced measurement of a completely unknown optical phase. Nat. Photon. 5 , 43-47 (2011).
- [9] Higgins, B. L., Berry, D. W., Barlett, S. D., Wiseman, H. M. &Pryde, G. J. Entanglement-free Heisenberg-limited phase estimation. Nature 450 , 393-396 (2007).
- [10] Meyer, V., Rowe, M. A., Kielpinski, D., Sackett, C. A., Itano, W. M., Monroe, C., & Wineland, D. J. Experimental demonstration of entanglement-enhanced rotation angle estimation using trapped ions. Phys. Rev. Lett. 86 , 5870 (2001).
- [11] Schleier-Smith, M., Leroux, H. I. D. & Vuleti´ c, V . States of an ensemble of two-level atoms with reduced quantum uncertainty. Phys. Rev. Lett. 104 , 073604 (2010).
- [12] Jo, G. B. et al. Long phase coherence time and number squeezing of two Bose-Einstein condensates on an atom chip. Phys. Rev. Lett. 98 , 030407 (2007).
- [13] Sørensen, A., Duan, L. M., Cirac, J. I. & Zoller, P. Manyparticle entanglement with Bose-Einstein condensates. Nature 409 , 63-66 (2001).
- [14] Gruber, A., Dr¨ abenstedt, A., Tietz, C., Fleury, L., Wr achtrup, J. &von Borczyskowski, C. Scanning confocal optical microscopy and magnetic resonance on single defect centers. Science 276 , 2012-2014 (1997).
- [15] Jelezko, F., Gaebel, T., Popa, I., Domhan, M., Gruber, A. & Wrachtrup, J. Observation of coherent oscillation of a single nuclear spin and realization of a two-qubit conditional quantum gate. Phys. Rev. Lett. 93 , 130501 (2004).
- [16] Childress, L., Dutt, M. V. G., Taylor, J. M., Zibrov, A. S., Jelezko, F., Wrachtrup, J., Hemmer, P. R. & Lukin, M. D. Coherent dynamics of coupled electron and nuclear spin qubits in diamond. Science 314 , 281-285 (2006).
- [17] Gurudev Dutt, M. V., Childress, L., Jiang, L., Togan, E., Maze, J., Jelezko, F., Zibrov, A. S., Hemmer, P. R. & Lukin, M. D. Quantum register based on individual electronic and nuclear spin
- qubits in diamond. Science 316 , 1312-1316 (2007).
- [18] Neumann, P., Mizuochi, N., Rempp, F., Hemmer, P., Watanabe, H., Yamasaki, S., Jacques, V., Gaebel, T., Jelezko, F. & Wrachtrup, J. Multipartite entanglement among single spins in diamond. Science 320 , 1326-1329 (2008).
- [19] Neumann, P., Beck, J., Steiner, M., Rempp, F., Fedder, H., Hemmer, P. R., Wrachtrup, J. & Jelezko, F. Single shot readout of a single nuclear spin. Science 329 , 542-544 (2010).
- [20] Robledo, L., Childress, L., Bernien, H., Hensen, B., Alkemade, P. F. A. & Hanson, R. High-fidelity projective read-out of a solid state spin quantum register. Nature 477 , 574-578 (2011).
- [21] Maurer, P. C. et al. Room-temperature quantum bit memory exceeding one second. Science 336 , 1283-1286 (2012).
- [22] van der Sar, T. et al. Decoherence-protected quantum gates for a hybrid solid-state spin register. Nature 484 , 82-86 (2012).
- [23] Waldherr, G. et al. Quantum error correction in a solid-state hybrid spin register. Nature 506 , 204-207 (2014).
- [24] Taminiau, T. H., Cramer, J., van der Sar, T., Dobrovitski, V. V. & Hanson, R. Universal control and error correction in multi-qubit spin registers in diamond. Nat. Nanotech. 9 , 171-176 (2014).
- [25] Shi, F. Z. et al. Room-temperature implementation of the deutsch-jozsa algorithm with a single electronic spin in diamond. Phys. Rev. Lett. 105 , 040504 (2010).
- [26] Xu, X. K. et al. Coherence-protected quantum gate by continuous dynamical decoupling in diamond. Phys. Rev. Lett. 109 , 070502 (2012).
- [27] Liu, G. Q., Po, H. C., Du, J. F., Liu, R. B. & Pan, X. Y . Noise resilient quantum evolution steered by dynamical decoupling. Nat. Commun. 4 , 2254 (2013).
- [28] Pan, X. Y., Liu, G. Q., Yang, L. L. & Fan H. Solid-state optimal phase-covariant quantum cloning machine. Appl. Phys. Lett. 99 , 051113 (2011).
- [29] Chang, Y. C., Liu, G. Q., Liu, D. Q., Fan H. & Pan, X. Y . Room temperature quantum cloning machine with full coherent phase control in nanodiamond. Sci. Rep. 3 , 1498 (2013).
- [30] Hadden, J. P., Harrison, J. P., Stanley-Clarke, A. C., Marseglia, L., Ho, Y.-L. D., Patton, B. R., O'Brien, J. L. & Rarity, J. G. Strongly enhanced photon collection from diamond defect centers under microfabricated integrated solid immersion lenses. Appl. Phys. Lett. 97 , 241901 (2010).
- [31] Smeltzer, B., Childress, L. & Gali, A. 13 C hyperfine interactions in the nitrogen-vacancy centre in diamond. New J. Phys. 13 , 025021 (2011).
- [32] Jacques, V. et al. Dynamic polarization of single nuclear spins by optical pumping of nitrogen-vacancy color centers in diamond at room temperature. Phys. Rev. Lett. 102 , 057403 (2009).
- [33] Smeltzer, B., McIntyre, J. & Childress, L. Robust control of individual nuclear spins in diamond. Phys. Rev. A 80 , 050302(R) (2009).
- [34] Dr´ eau, A., Spinicelli, P., Maze, J. R., Roch, J.-F. & Jacques V . Single-shot readout of multiple nuclear spin qubits in diamond under ambient conditions. Phys. Rev. Lett. 110 , 060502 (2013).
- [35] Zhao, N. et al. Sensing single remote nuclear spins. Nat. Nanotech. 7 , 657-662 (2012).
- [36] Kolkowitz, S., Unterreithmeier, Q. P., Bennett, S. D. & Lukin, M. D. Sensing distant nuclear spins with a single electron spin. Phys. Rev. Lett. 109 , 137601 (2012).
- [37] Taminiau, T. H., Wagenaar, J. J. T., van der Sar, T., Jelezko, F., Dobrovitski, V. V. & Hanson, R. Detection and control of individual nuclear spins using a weakly coupled electron spin. Phys. Rev. Lett. 109 , 137602 (2012).
- [38] Zhang, Y. L., Zhang, Y. R., Mu, L. Z. & Fan, H. Criterion for remote clock synchronization with Heisenberg-scaling accuracy.
Phys. Rev. A 88 , 052314 (2013).
- [39] Zhang, Y. R., Jin, G. R., Cao, J. P., Liu, W. M. & Fan, H. Unbounded quantum Fisher information in two-path interferometry with finite photon number. J. Phys. A 46 , 035302 (2013).
- [40] Cram´ er, H. Mathematical Methods of Statistics. Ch. 32-34 (Princeton Univ., 1946).
- [41] Braunstein, S. L. & Caves, C. M. Statistical distance and the geometry of quantum states. Phys. Rev. Lett. 72 , 3439-3443 (1994).
- [42] Liu, G. Q., Pan, X. Y., Jiang, Z. F., Zhao, N. & Liu, R. B. Controllable effects of quantum fluctuations on spin free-induction decay at room temperature. Sci. Rep. 2 , 432 (2012).
- [43] Liu, G. Q. et al. Protection of centre spin coherence by dynamic nuclear spin polarization in diamond. Nanoscale 6 , 10134-10139 (2014).
## Supplementary Materials
## Supplementary Note 1: Validity of rotating wave approximation and coherence of nuclear spin
As mentioned in the main text, the achieved Rabi frequency of nuclear spin is not small compared with the energy gap ( | 0 ↑〉 → | 0 ↓〉 ), thus we need to evaluate whether rotating wave approximation (RWA) still works well under this circumstance. We measure nuclear pulse-ODMR spectrum and Rabi oscillation with RF pulses of different driven powers, as shown in Supplementary Fig. 1(a-b). The minimum Rabi fre-
FIG. S1: Coherence of nuclear spin. (a) Pulse-ODMR of 13 C nuclear spin with RF pulses of different driven power. The resonant frequencies are the same for all the measurement (evidence of weak driven). (b) Rabi oscillation of nuclear spin under weak RF driven. The measured Rabi frequency is about 10 kHz, with typical envelop decay time of T 1 ρ = 1 3 . ms. (c) FID of nuclear spin when electron spin is at m S = 0 state, with dephasing time of T ∗ 2 n ( m s = 0) = 270 s. (d) FID of nuclear spin when electron spin is at m S = -1 state, with dephasing time of T ∗ 2 n ( m s = -1) = 212 s. The square, circle and triangle are experiment data with detuning of 0 kHz, 5 kHz and 10 kHz, respectively. Solid lines are fitting to them.
quency is only 10 kHz with a RF power of -24 dBm(at signal generator), which is much less than the energy gap of nuclear spin and RWA works well at this power. We then choose π pulse of this RF power ( 49 µ s) to measure pulse-ODMR spectrum of nuclear spin. The resonant frequency between | 0 ↑〉 and | 0 ↓〉 transition is 495 kHz under this weak driven power. We find that the resonant frequencies are the same for all the measured RF pulses, including the one, which corresponds to a Rabi frequency of about 20% of nuclear spin energy gap. Therefore, we conclude that RWA works well for all the measurements in this experiment. This conclusion conforms with the results in Supplementary Ref. 1 and Supplementary Ref. 2, where RWA works well with a Rabi frequency less than half of the energy gap of two-level system (NV electron spin).
We then consider the coherence of nuclear spin. Supplementary Fig. 1(c) and (d) present the FID signals of nuclear spin under ESLAC, for both m S = 0 and m S = -1 states of electron spin. The dephasing time of nuclear spin ( T ∗ 2 n = 270 µ s for m S = 0 state and 210 µ s for m S = -1 state) is shorter than the result in Supplementary Ref. 3 This may be caused by the complicated spin bath of this NV center. However, similar to the case of electron spin, the dephasing time is not the limitation of nuclear manipulation duration. The Rabi envelope decay time of this nuclear spin ( T 1 ρ ) is more than 1 ms. The half π pulse, which is used to generate the superposition state of nuclear spin, is only 5 µ s and much shorter than the dephasing time. So we ignore the dephasing effect of nuclear spin in the metrology experiment.
FIG. S2: Procedure to carry out state tomography on electronnuclear two-qubit system. (a) The three solid arrows are selected working transitions, which can be driven by MW/RF pulse directly. The real and imaginary parts of the matrix elements in each working transition are measured by RF (or MW) pulses of 0 ◦ and 90 ◦ phases, respectively. (b) For the other three transitions (dash arrow), one or two pulses are applied to transfer the state information to working transition ( | 0 ↑〉 → | 0 ↓〉 ) before Rabi measurement. (c) Pulse duration and phase of state tomography. The diagonal elements of density matrix are measured three times, and the mean of these measurements are used.
FIG. S3: Data processing for standard deviation and variance of phase. (a) Linear fitting for standard deviation δϕ 2 against repeat number ν in the log-log scale with adjusted R-squares 0.967 and 0.881 for single state and entangled state. (b) Linear fitting for standard deviation subtracted the system error δϕ se in the log-log scale for single state and entangled state. Adjusted R-squares are 0.962 and 0.904. (c) The variance of phase is fitted by function δϕ 2 = a/ν + c where c represents the squared system error δϕ 2 . (d) Linear fitting for variance subtracted the squared system error in the log-log scale. Adjusted R-squares are 0.916 and 0.893 for single state and entangled state, respectively.
## Supplementary Note 2: Other data processing methods for standard deviation and variance
Regardless of system error, the variance of phase δϕ 2 with a sufficiently large number of measurements ν will be approximately normally distributed as δϕ 2 ∝ 1 /ν , which is based on the classical central limit theorem. This fact can also be explained by the additive property of Fisher information and is shown in Eq. (1) in the main text. Therefore, in Fig. 4(b) we set the exponent of ν as 0 5 . for standard deviation (SD) and a conclusive result is given. In Supplementary Fig. 3, we try other data processing methods for the presentation of the entanglement-enhanced metrology. In Supplementary Fig. 3(a), we use the linear fitting in the log-log scale to analyze the SD, δϕ 2 , against ν . Ideally the slope should be 0.5 and the intercept gives the value that represents the enhancement. However, there always exists the system error which will insult the linear analysis and give an inconclusive result for large number of measurement ν ∼ 1 M. We thus fix the slopes as 0.5 and give the enhancement by reading the intercepts in Supplementary Fig. 3(a). The adjusted R-square, ¯ R 2 , (ranging from 0 to 1 with larger number indicating better fitting) for single state and entangled state are 0.967 and 0.881, respectively. In Supplementary Fig. 3(b), the system error, δϕ se , read in Supplementary Fig. 3(c) is taken into consideration and subtracted out before analyzing, which leads to better adjusted R-squares: 0.962 and 0.904 for single state and en- tangled state, respectively. Therefore, we conclude that the data processing method we use in the main text for SD provides a better fitting to the experimental data. We also use the function δϕ 2 = a/ν + c to fit experimental data of variance, see results in Supplementary Fig. 3(c). Taking out the effect of squared system error δϕ 2 se , we use the linear fitting in the log-log scale and present the enhancement in Supplementary Fig. 3(d) with ¯ R 2 being 0.916 and 0.893 for single state and entangled state, respectively. It shows that the data processing method we use for SD in the main text is better than that for variance.
- ∗ Electronic address: [email protected]
- † Electronic address: [email protected]
- [S1] Fuchs, G. D., Dobrovitski, V. V., Toyli, D. M., Heremans, F. J. & Awschalom, D. D. Gigahertz Dynamics of a Strongly Driven Single Quantum Spin. Science 326 , 1520-1522 (2009).
- [S2] Scheuer, J. et al. Precise qubit control beyond the rotating wave approximation. New J. Phys. 16 , 093022 (2014).
- [S3] Dutt, M. V. G. et al. Quantum register based on individual electronic and nuclear spin qubits in diamond. Science 316 , 13121316 (2007). | 10.1038/ncomms7726 | [
"Gang-Qin Liu",
"Yu-Ran Zhang",
"Yan-Chun Chang",
"Jie-Dong Yue",
"Heng Fan",
"Xin-Yu Pan"
] | 2014-08-03T10:28:07+00:00 | 2015-04-08T05:47:54+00:00 | [
"quant-ph"
] | Demonstration of Entanglement-Enhanced Phase Estimation in Solid | Precise parameter estimation plays a central role in science and technology.
The statistical error in estimation can be decreased by repeating measurement,
leading to that the resultant uncertainty of the estimated parameter is
proportional to the square root of the number of repetitions in accordance with
the central limit theorem. Quantum parameter estimation, an emerging field of
quantum technology, aims to use quantum resources to yield higher statistical
precision than classical approaches. Here, we report the first room-temperature
implementation of entanglement-enhanced phase estimation in a solid-state
system: the nitrogen-vacancy centre in pure diamond. We demonstrate a
super-resolving phase measurement with two entangled qubits of different
physical realizations: an nitrogen-vacancy centre electron spin and a proximal
${}^{13}$C nuclear spin. The experimental data shows clearly the uncertainty
reduction when entanglement resource is used, confirming the theoretical
expectation. Our results represent an elemental demonstration of enhancement of
quantum metrology against classical procedure. |
1408.0481v3 | ## Neutrinos and dark energy after Planck and BICEP2: data consistency tests and cosmological parameter constraints
Jing-Fei Zhang, a Jia-Jia Geng, a Xin Zhang a,b, 1
a Department of Physics, College of Sciences, Northeastern University, Shenyang 110004, China
b Center for High Energy Physics, Peking University,
Beijing 100080, China
E-mail: [email protected], [email protected],
[email protected]
Abstract. The detection of the B-mode polarization of the cosmic microwave background (CMB) by the BICEP2 experiment implies that the tensor-to-scalar ratio r should be involved in the base standard cosmology. In this paper, we extend the ΛCDM+ +neutrino/dark rar diation models by replacing the cosmological constant with the dynamical dark energy with constant w . Four neutrino plus dark energy models are considered, i.e., the w CDM+ + r ∑ m ν , w CDM+ + r N eff , w CDM+ + r ∑ m ν + N eff , and w CDM+ + r N eff + m eff ν, sterile models. The current observational data considered in this paper include the Planck temperature data, the WMAP 9-year polarization data, the baryon acoustic oscillation data, the Hubble constant direct measurement data, the Planck Sunyaev-Zeldovich cluster counts data, the Planck CMB lensing data, the cosmic shear data, and the BICEP2 polarization data. We test the data consistency in the four cosmological models, and then combine the consistent data sets to perform joint constraints on the models. We focus on the constraints on the parameters w , ∑ m ν , N eff , and m eff ν, sterile .
1 Corresponding author.
## Contents
| 1 | Introduction | 1 |
|-----|-----------------------------------------------------------|-----|
| 2 | Methodology | 3 |
| 3 | Results and discussion | 5 |
| 3.1 | Data consistency tests | 5 |
| 3.2 | Constraints on dark energy, dark radiation, and neutrinos | 8 |
| 3.3 | Early-universe parameters and BICEP2 | 11 |
| 4 | Conclusion | 12 |
| A | Detailed constraint results | 14 |
## 1 Introduction
Discovery of neutrino oscillations has indicated that neutrinos have nonzero masses. Neutrino oscillation experiments can only place limits on the squared mass differences between the neutrino mass eigenstates: the solar and reactor experiments observed ∆ m 2 21 glyph[similarequal] 8 × 10 -5 eV , 2 and the atmospheric and accelerator beam experiments observed ∆ m 2 32 glyph[similarequal] 3 × 10 -3 eV . To measure the absolute masses of neutrinos, different experiments are needed. In fact, 2 cosmological data have been providing tight limits on the total mass of neutrinos.
The cosmic microwave background (CMB) observations have been used to constrain the neutrino mass and possibly the extra relativistic degrees of freedom (sometimes referred to as 'dark radiation') [1-3]. The latest CMB temperature power spectrum measured by the Planck satellite mission provided the tight limits on the total mass of active neutrinos, ∑ m ν , and the effective number of relativistic species, N eff [4]. For example, the Planck+WP+highL data combination (here, WP denotes the WMAP 9-year polarization data, and highL denotes the ACT and SPT temperature data) gives the 95% confidence level (CL) limits: ∑ m < ν 0 66 eV for the case of no extra relics ( . N eff = 3 046) and . N eff = 3 36 . +0 68 . -0 64 . for the case of minimal-mass normal hierarchy for the neutrino masses (only one massive eigenstate with m ν = 0 06 eV). Late-time geometric measurements can be used to help reduce some geometric . degeneracies and thus improve constraints. Therefore, the baryon acoustic oscillation (BAO) data are very useful in the parameter estimation. Note also that the BAO data are proven to be in good agreement with the Planck data, so one can always combine CMB data with BAO data without any question. The Planck+WP+highL+BAO data combination changes the above limits to: ∑ m < . ν 0 23 eV for the case of no extra relics and N eff = 3 30 . +0 54 . -0 51 . for the case of minimal-mass normal hierarchy model.
The measurements of the growth of large-scale structure also play a crucial role in constraining the neutrino mass. The Planck Collaboration reported a result of counts of rich clusters of galaxies by analyzing its sample of thermal Sunyaev-Zeldovich (SZ) clusters, σ 8 (Ω m / . 0 27) 0 3 . = 0 782 . ± 0 010 [5]. . And the weak lensing data can also give another combination of σ 8 and Ω m . The cosmic shear measurement provided by the CFHTLenS survey gave σ 8 (Ω m / . 0 27) 0 46 . = 0 774 . ± 0 040 [6]. . However, based on the six-parameter base ΛCDM cosmology, the Planck data predict more clusters than these astrophysical measurements
observe. The Planck+WP+highL data combination gives σ 8 (Ω m / . 0 27) 0 3 . = 0 87 . ± 0 02 and . σ 8 (Ω m / . 0 27) 0 46 . = 0 89 . ± 0 03, in tensions with the above two measurements at the 4.0 . σ and 2.3 σ levels, respectively. In fact, the tensions might just imply non-zero neutrino masses (see, e.g., Ref. [7]). Increasing neutrino masses could suppress the growth of structure below their free-streaming length, allowing σ 8 to be substantially lower.
On the other hand, the measurement of the Hubble constant H 0 is also very useful in breaking parameter degeneracies in cosmological constraints, but the direct measurement of H 0 is in tension with the Planck result based on the standard cosmology. The direct measurement gives H 0 = 73 8 . ± 2 4 km s . -1 Mpc -1 [8], but the six-parameter ΛCDM model fitting to Planck+WP+highL data gives H 0 = 67 3 . ± 1 2 km s . -1 Mpc -1 ; there is a tension at the 2.4 σ level between the two. One way of reducing the tension is to increase N eff [4]. Increasing the radiation density at fixed θ ∗ (to preserve the angular scales of the acoustic peaks) and fixed z eq (to preserve the early-ISW effect and so first-peak height) leads to the increase of the Hubble expansion rate before recombination and thus the decrease of the age of the universe. The angular scale of the photon diffusion length, θ D , is thus increased, thereby reducing the power in the CMB damping tail at a given multipole. The result is that N eff is positively correlated with H 0 .
Therefore, increasing both ∑ m ν and N eff could reconcile all the mentioned tensions between Planck and other astrophysical observations, and on the other hand the combination of these consistent data sets could determine these parameters more accurately. But in this case one has to assume the model in which the massive active neutrinos coexist with some extra radiation degrees of freedom. Actually, a more natural choice is to consider the model with light sterile neutrinos.
The existence of light massive sterile neutrinos is hinted by the anomalies of shortbaseline neutrino experiments [9-13]. There is evidence for oscillations at a ∆ m 2 of about 1 eV 2 from these experiments. Thus, additional neutrino masses are required. And the additional types of neutrino have to be sterile neutrinos so that they do not interact by the weak interaction and do not affect the width of Z 0 . Through their mixing with active neutrinos and their gravitational interactions, the sterile neutrinos could have a considerable effect on astrophysics and cosmology. Therefore, it is particularly important to search for cosmological evidence of sterile neutrinos through their gravitational effects on the large-scale structure formation and the evolution of the universe. When considering sterile neutrinos in a cosmological model, two extra parameters, N eff and m eff ν, sterile , are added. Hence, in a cosmological model with sterile neutrinos, the tensions of Planck with H 0 direct measurement, counts of Planck SZ clusters, and cosmic shear can be substantially relieved [7, 14, 15].
Recently, the BICEP2 Collaboration reported the detection of the B-mode polarization of the CMB [16]. If the treatment of the foreground model is correct, the BICEP2's result indicates the discovery of the primordial gravitational waves (PGWs). The frontiers of fundamental physics will be pushed forward in an unprecedented way as long as the BICEP2's result is confirmed by upcoming experiments. Adopting the ΛCDM+ r model, the fit to the observed B-mode power spectrum gives an unexpectedly large tensor-to-scalar ratio, r = 0 20 . +0 07 . -0 05 . , with r = 0 disfavored at the 7 σ level [16]. This result is in tension with the upper limit, r < 0 11 (95% CL), given by the fit to the combined Planck+WP+highL data [4]. . To explain and/or reduce this tension, numerous proposals have been put forward; see, e.g., Refs. [17-32]. An intriguing mechanism for relieving this tension is to involve a sterile neutrino species in the cosmological model with PGWs [33-38]. In Ref. [33], the model with PGWs and sterile neutrinos is called ΛCDM+ r + ν s model (or ΛCDM+ + r N eff + m eff ν, sterile model). It
was shown in Refs. [33, 34] that in the ΛCDM+ r + ν s model the tension between Planck and BICEP2 is well relieved, and meanwhile, the other tensions of Planck with other astrophysical observations, such as the H 0 direct measurement, the cluster counts, and the cosmic shear measurement, can all be significantly reduced. In addition, the current consistent cosmological data could provide independent evidence for the existence of sterile neutrino at high statistical significance, i.e., a joint analysis of current data prefer ∆ N eff ≡ N eff -3 046 . > 0 at the 2.7 σ level and a nonzero mass of sterile neutrino at the 3.9 σ level [33]. In Ref. [35], other typical models of neutrino and dark radiation were analyzed with the current observational data in detail.
In this paper, we investigate the effects of dynamical dark energy on the fits of models of neutrinos and dark radiation to the current observations. In Ref. [39], it was demonstrated that the tension between Planck and H 0 direct measurement might hint that dark energy is not the cosmological constant; once a dynamical dark energy is adopted, the tension of Planck with H 0 measurement could be well relieved. Also, it is known that due to the repulsive gravitational force, dark energy could suppress the growth of large-scale structure. Therefore, we wish to see if dark energy together with neutrinos could further reduce the tensions between Planck and other astrophysical observations. On the other hand, we will combine the consistent data sets to constrain the cosmological parameters concerning dark energy and neutrinos.
The paper is organized as follows. In Sec. 2, we briefly present the cosmological models and the observational data we use in this work. In Sec. 3, we test the data consistency for the models and present the fit results. Conclusion is given in Sec. 4. More detailed fit results are given in Appendix A.
## 2 Methodology
In this paper, we consider the extension of the ΛCDM cosmology to models in which dark energy has a constant w , i.e., the w CDM cosmology. Of course, since the PGWs are likely to have been detected by BICEP2, the basic framework should be the w CDM+ model. Further r extensions considered in this paper include: (i) active neutrinos with additional parameter ∑ m ν , (ii) extra dark radiation with additional parameter N eff , (iii) active neutrinos coexisting with extra relativistic degrees of freedom, with additional parameters ∑ m ν and N eff , and (iv) massive sterile neutrinos with additional parameters N eff and m eff ν, sterile .
The conventions used in this paper are consistent with those adopted by the Planck team [4], i.e., those used in the camb Boltzmann code. The base parameters for the basic eight-parameter w CDM+ r model are:
$$\{ \omega _ { b }, \, \omega _ { c }, \, 1 0 0 \theta _ { \text{MC} }, \, \tau, \, w, \, n _ { s }, \, \ln ( 1 0 ^ { 1 0 } A _ { s } ), \, r _ { 0. 0 5 } \},$$
where ω b ≡ Ω b h 2 and ω c ≡ Ω c h 2 are the baryon and cold dark matter densities today, respectively, θ MC is the approximation used in CosmoMC to r s ( z ∗ ) /D A ( z ∗ ) (the angular size of the sound horizon at the time of last-scattering), τ is the Thomson scattering optical depth due to reionization, w is the dark energy equation of state parameter, n s and A s are the power-law spectral index and power of the primordial curvature perturbations, respectively, and r 0 05 . is the tensor-to-scalar ratio at the pivot scale k 0 = 0 05 Mpc . -1 . Flat priors for the base parameters are used. Note also that the prior ranges for the base parameters are chosen to be much wider than the posterior in order not to affect the results of parameter
estimation. We use the CosmoMC package [40] to infer the posterior probability distributions of parameters.
Next, we describe the observational data sets used in this paper. Actually, this work is an extension of our previous works [33, 35] to the models of dark energy with constant w , thus we will use the same data sets to Refs. [33, 35] in order to be easier for a direct comparison. The data sets we use include the CMB (Planck+WP), BAO, H 0 , SZ, Lensing (CMB lensing + weak lensing), and BICEP2.
Planck+WP. We use the CMB TT angular power spectrum data from the first release of Planck [4], combined with the CMB large-scale TE and EE polarization power spectrum data form the 9-yr release of WMAP [3]. Note that in some occasions we also abbreviate Planck+WP to CMB for convenience.
BAO. We use the latest BAO measurements from the data release (DR) 11 of the Baryon Oscillation Spectroscopic Survey (BOSS) (part of SDSS-III): D V (0 32)( . r d, fid /r d ) = (1264 ± 25) Mpc and D V (0 57)( . r d, fid /r d ) = (2056 ± 20) Mpc, with r d, fid = 149 28 Mpc [41]. . Note also that there are some other BAO data sets, e.g., 6dFGS ( z = 0 1) [42], SDSS-DR7 . ( z = 0 35) [43], and WiggleZ ( . z = 0 44, 0.60, and 0.73) [44], where the three data from the . WiggleZ survey are correlated (with the inverse covariance matrix given by Ref. [44]). This work is in accordance with our previous papers [33, 35] for the use of the BAO data, i.e., we only use the latest two most accurate BAO data from the BOSS-DR11. This is sufficient for our purpose in breaking the CMB parameter degeneracies.
H . 0 We use the direct measurement of the Hubble constant from the Hubble Space Telescope (HST) observations, H 0 = (73 8 . ± 2 4) km s . -1 Mpc -1 [8].
SZ. We use the result of the counts of clusters of galaxies from the sample of Planck SZ clusters, σ 8 (Ω m / 0 27) . 0 3 . = 0 782 . ± 0 010 [5]. . Note that this result is derived by using the mass function given by Tinker et al. [45]; a different mass function given by Watson et al. [46] leads to a slightly different value, i.e., σ 8 (Ω m / 0 27) . 0 3 . = 0 802 . ± 0 014. . Moreover, the result also depends on the bias (1 -b ) that is assumed to account for all the possible observational biases including departure from hydrostatic equilibrium, absolute instrument calibration, temperature inhomogeneities, residual selection bias, etc. Numerical simulations taking into account of several ingredients of gas physics of clusters give the result of the bias of (1 -b ) = 0 8 . +0 2 . -0 1 . . Adopting the central value, (1 -b ) = 0 8, the Planck team found . that the constraints on Ω m and σ 8 are in good agreement with previous measurements using clusters of galaxies [5]. The result of σ 8 (Ω m / . 0 27) 0 3 . quoted in this paper is derived by fixing (1 -b ) = 0 8. . The result is changed to σ 8 (Ω m / . 0 27) 0 3 . = 0 764 . ± 0 025, if the bias is . allowed to vary in the range of [0 7 . , 1]. In Table 2 of Ref. [5], other values of σ 8 (Ω m / . 0 27) 0 3 . from various data combinations and analysis methods are also given. But in this paper, in accordance with previous works by us and by other authors, we choose to use the result of σ 8 (Ω m / . 0 27) 0 3 . = 0 78 . ± 0 01. .
Lensing. We use two kinds of lensing data, i.e., the CMB lensing power spectrum C φφ glyph[lscript] from the Planck mission [47] and the cosmic shear measurement of weak lensing from the CFHTLenS survey, σ 8 (Ω m / . 0 27) 0 46 . = 0 774 . ± 0 040 [6]. . Of course, they are two absolutely different, physically and observationally independent data sets.
BICEP2. We use the CMB angular power spectra (TT, TE, EE, and BB) data from the BICEP2 [16].
Since it has been proven that the Planck data are in good agreement with the BAO data, we can alway safely combine Planck+WP with BAO. So the Planck+WP+BAO combination is the basic data combination used in this paper. In the six-parameter base ΛCDM model, it
was shown that the Planck data are in tension with the H 0 direct measurement, the cluster counts, and the cosmic shear measurement at the 2-3 σ level [4]. In the seven-parameter ΛCDM+ r model, the Planck temperature data are also in tension with the BICEP2 polarization data [16]. It has been demonstrated that the ingredients such as dark energy, dark radiation, and neutrinos could help relieve these tensions to some extent [33-39]. Therefore, in this paper, we will test the data consistency in the cosmological models with dark energy, dark radiation, and neutrinos.
As mentioned above, we consider four models in this paper, i.e., (i) the w CDM+ + r ∑ m ν model, (ii) the w CDM+ + r N eff model, (iii) the w CDM+ + r ∑ m ν + N eff model, and (iv) the w CDM+ + r N eff + m eff ν, sterile model. We will constrain these models by using the Planck + WP + BAO data, and then compare the derived results with the observations of H 0 , SZ cluster counts, cosmic shear, and tensor-to-scalar ratio. This could test if in these models the Planck+WP+BAO data are consistent with these astrophysical observations. If these data sets are consistent, we can then combine these data together and use them to constrain the parameters concerning dark energy, dark radiation, neutrinos, and so on. But if the data are still in tension, the direct combination of different data sets is not appropriate. The subsequent data fits are based on this data consistency test analysis, and the fit results will be discussed in detail.
## 3 Results and discussion
## 3.1 Data consistency tests
We first constrain the four models using the Planck+WP+BAO data. Figure 1 shows the fit results in the Ω m -H 0 , Ω m -σ 8 , and n s -r 0 002 . planes. To exhibit the effects of dynamical dark energy, we also compare the results of w CDM + neutrino models with those of ΛCDM + neutrino models (purple contours vs. blue contours). The first-row panels are for the ΛCDM/ w CDM+ + r ∑ m ν models, the second-row panels are for the ΛCDM/ w CDM+ + r N eff models, the third-row panels are for the ΛCDM/ w CDM+ + r ∑ m ν + N eff models, and the fourth-row panels are for the ΛCDM/ w CDM+ + r N eff + m eff ν, sterile models. The gray bands are from the observational results, i.e., the HST result of Hubble constant H 0 = 73 8 . ± 2 4 km . s -1 Mpc -1 [8], the Planck result of SZ cluster counts σ 8 (Ω m / . 0 27) 0 3 . = 0 782 . ± 0 010 [5], and . the BICEP2 result of tensor-to-scalar ratio r = 0 20 . +0 07 . -0 05 . [16]. From the comparison of the contours from CMB+BAO with the bands from other astrophysical observations, one can directly test the consistency between different data sets.
First, we discuss the results of the ΛCDM/ w CDM+ + r ∑ m ν models (see the first-row panels). From the Ω m -H 0 plane, we clearly see that the tension on H 0 appearing in the ΛCDM-based model is greatly relieved once a dynamical dark energy is considered. But even in the w CDM-based model, Ω m and H 0 are still in strong degeneracy. Since w is anticorrelated with H 0 , we infer that a larger H 0 may prefer a phantom energy with w < -1. From the Ω m -σ 8 plane, we see that the consideration of dynamical dark energy amplifies the parameter space but nearly does not improve the reduction of the tension in the Ω m -σ 8 plane. Since w is anti-correlated with σ 8 but positively correlated with Ω m , the effect of w on σ 8 (Ω m / . 0 27) 0 3 . would be canceled a lot, leading to the fact that only ∑ m ν plays a significant role in relieving the tension between Planck CMB and SZ cluster counts. From the n s -r 0 002 . plane, we see that w could not affect the value of tensor-to-scalar ratio.
Next, we discuss the results of the ΛCDM/ w CDM+ + r N eff models (see the second-row panels). In the base ΛCDM model, the Planck prediction of H 0 is in tension with the direct
Figure 1 . The Planck+WP+BAO constraints in the Ω m -H 0 , Ω m -σ 8 , and n s -r 0 002 . planes for the ΛCDM/ w CDM+ + r ∑ m ν models (first-row panels), the ΛCDM/ w CDM+ + r N eff models (second-row panels), the ΛCDM/ w CDM+ + r ∑ m ν + N eff models (third-row panels), and the ΛCDM/ w CDM+ + r N eff + m eff ν, sterile models (fourth-row panels). The gray bands stand for the observational results, i.e., the HST result of Hubble constant H 0 = 73 8 . ± 2 4 km s . -1 Mpc -1 [8], the Planck result of SZ cluster counts σ 8 (Ω m / 0 27) . 0 3 . = 0 782 . ± 0 010 [5], . and the BICEP2 result of tensor-to-scalar ratio r = 0 20 . +0 07 . -0 05 . [16].
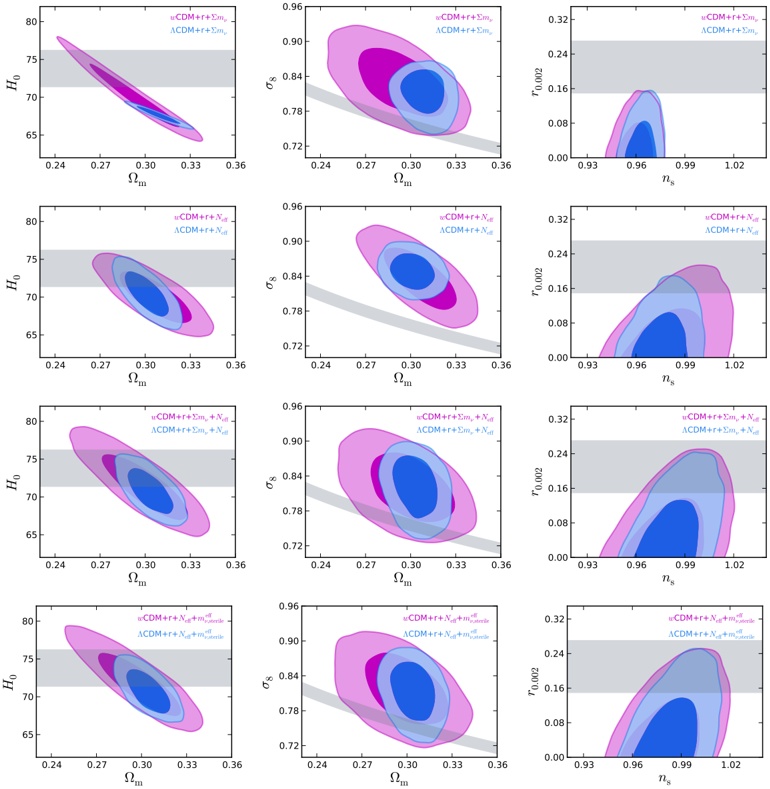
measurement of H 0 at about the 2.5 σ level, but once N eff is considered to be free, this tension could be relieved greatly, as shown by the blue contours in the Ω m -H 0 plane for the ΛCDM+ + r N eff model. Further introducing w does not lead to more impact on H 0 (as shown by the purple contours in the Ω m -H 0 plane), from which one can infer that the fit of this model to the CMB+BAO data would give the result of w around -1. In the Ω m -σ 8 plane, we can see that the parameter N eff does not help reduce the tension between Planck data and cluster data, but the parameter w could play a significant role in relieving this tension. Due to the repulsive gravitational force of dark energy, the growth of large-scale structure is suppressed by dark energy. Contrary to our intuition, larger w gives rise to more suppression
Table 1 . Predictions of the values of H 0 , σ 8 (Ω m / 0 27) . 0 3 . , σ 8 (Ω m / 0 27) . 0 46 . , and r 0 002 . given by the ΛCDM+ , ΛCDM+ + r r N eff + m eff ν, sterile , w CDM+ , and r w CDM+ + r N eff + m eff ν, sterile models under the constraints from Planck+WP+BAO. Quantified levels of the tensions with the observational results are also given.
| | ΛCDM+ r | ΛCDM+ r | ΛCDM+ r + N eff + m eff ν, sterile | ΛCDM+ r + N eff + m eff ν, sterile | w CDM+ r | w CDM+ r | w CDM+ r + N eff + m eff ν, sterile | w CDM+ r + N eff + m eff ν, sterile |
|---------------------------|----------------------------|-----------|--------------------------------------|--------------------------------------|----------------------------|------------|---------------------------------------|---------------------------------------|
| Parameter | 68% limits | tension | 68% limits | tension | 68% limits | tension | 68% limits | tension |
| H 0 | 67 . 80 +0 . 64 - 0 . 63 | 2 . 4 σ | 70 . 8 +1 . 7 - 2 . 1 | 1 . 0 σ | 69 . 0 +1 . 8 - 2 . 6 | 1 . 6 σ | 71 . 9 +2 . 3 - 3 . 2 | 0 . 6 σ |
| σ 8 (Ω m / 0 . 27) 0 . 3 | 0 . 857 ± 0 . 015 | 4 . 3 σ | 0 . 842 +0 . 038 - 0 . 029 | 2 . 0 σ | 0 . 868 ± 0 . 026 | 3 . 2 σ | 0 . 840 +0 . 039 - 0 . 034 | 1 . 7 σ |
| σ 8 (Ω m / 0 . 27) 0 . 46 | 0 . 876 +0 . 019 - 0 . 018 | 2 . 3 σ | 0 . 858 +0 . 038 - 0 . 030 | 1 . 7 σ | 0 . 882 +0 . 024 - 0 . 023 | 2 . 3 σ | 0 . 853 +0 . 041 - 0 . 033 | 1 . 5 σ |
| r 0 . 002 | < 0 . 12 (95%) | | < 0 . 20 (95%) | | < 0 . 11 (95%) | | < 0 . 20 (95%) | |
of the structure growth; in other words, larger w leads to smaller σ 8 (or, w and σ 8 are in the anti-correlation). The reason is that for larger w and fixed present dark energy density, dark energy comes to dominate earlier, causing the time of suppressing the growth of linear matter perturbation to be longer. Since w is positively correlated with Ω m , larger w would lead to larger Ω m . The effects of w on σ 8 and Ω m are contrary, and thus some offset happens for the quantity σ 8 (Ω m / . 0 27) 0 3 . , resulting in that increasing w still could not well relieve the tension (as shown by the purple contours in the Ω m -σ 8 plane). Since N eff is positively correlated with n s , and w is also positively correlated with n s , they can both contribute to enhance the value of r , but it seems that even in the w CDM+ + r N eff model the tension of r is still not well relieved.
At last, we discuss the results of both the ΛCDM/ w CDM+ + r ∑ m ν + N eff models and the ΛCDM/ w CDM+ + r N eff + m eff ν, sterile models (see the third-row and the last-row panels). Since the results of the two cases are very similar (see also Ref. [35]), we only focus on the case of sterile neutrino. We can see clearly that in the models involving sterile neutrinos all the tensions could be well relieved; see also Refs. [33-38]. In addition, when w is considered, the tensions will be further reduced, as shown by the Ω m -H 0 and the Ω m -σ 8 panels. In order to quantify how the data consistencies are improved by the sterile neutrino and dynamical dark energy, we give the fit results of H 0 , σ 8 (Ω m / . 0 27) 0 3 . , σ 8 (Ω m / . 0 27) 0 46 . , and r 0 002 . for the ΛCDM+ , the ΛCDM+ + r r N eff + m eff ν, sterile , the w CDM+ , and the r w CDM+ + r N eff + m eff ν, sterile models in Table 1. The levels of tensions between fit results and observational results are also given. Under the constraints from Planck+WP+BAO, considering sterile neutrino improves the tension with H 0 from 2.4 σ to 1.0 σ , the tension with SZ cluster counts from 4.3 σ to 2.0 σ , and the tension with cosmic shear from 2.3 σ to 1.7 σ , respectively; considering dynamical dark energy (with constant w ) improves the above levels of tensions to 1.6 σ , 3.2 σ , and 2.3 σ , respectively; simultaneous consideration of sterile neutrino and dynamical dark energy improves the tension levels to 0.6 σ , 1.7 σ , and 1.5 σ , respectively. But in this case dynamical dark energy nearly does not affect the fit result of r 0 002 . .
From the above analysis, we find that considering dynamical dark energy with constant w could further improve the data consistency. In the w CDM+ + r ∑ m ν model, the CMB+BAO data are basically consistent with H 0 , SZ cluster counts, and cosmic shear data, but still in tension with the BICEP2 data. In the w CDM+ + r N eff model, the CMB+BAO data are consistent with the H 0 measurement, but still in some tension with cluster data and BICEP2 data (though the previous tensions are further reduced to some extent). In the w CDM+ + r ∑ m ν + N eff model and the w CDM+ + r N eff + m eff ν, sterile model, the CMB+BAO data are consistent with all the data sets considered, and thus these data sets can be combined together to perform joint constraints on these two models almost without any question.
CDM+r+
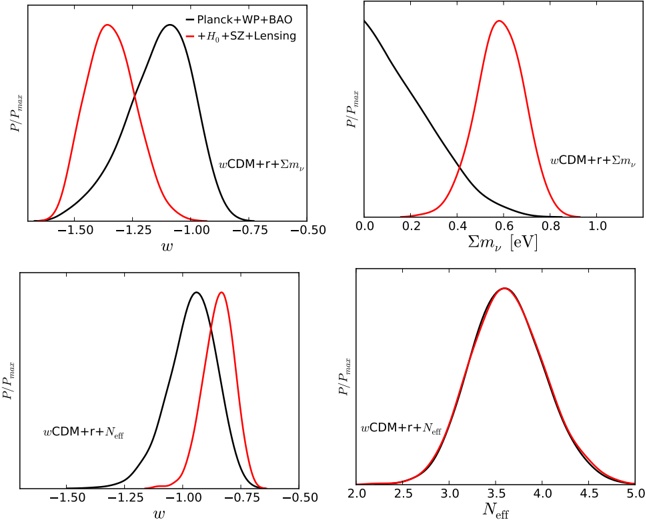
Σ
mν
Figure 2 . One-dimensional posterior distributions for the w CDM+ + r ∑ m ν model (upper) and the w CDM+ + r N eff model (lower).
## 3.2 Constraints on dark energy, dark radiation, and neutrinos
In this subsection, we give the fit results for the four models. Of course, we focus on the constraint results of dark energy, dark radiation, and neutrinos.
Figure 2 shows the fit results for the w CDM+ + r ∑ m ν model and the w CDM+ + r N eff model. In this figure, the one-dimensional posterior possibility distributions of w and ∑ m ν are plotted for the w CDM+ + r ∑ m ν model, and those of w and N eff are plotted for the w CDM+ + r N eff model. Black curves are from the Planck+WP+BAO constraints, and red curves are from the Planck+WP+BAO+ H 0 +SZ+Lensing constraints.
For the w CDM+ + r ∑ m ν model, the CMB+BAO data combination gives the constraint results:
$$w = - 1. 1 4 _ { - 0. 1 1 } ^ { + 0. 1 7 }, \\ \sum m _ { \nu } < 0. 4 8 \ e V.$$
Here, we show the ± 1 σ errors for w , and show the 95% CL upper limit for ∑ m ν . Note that throughout the paper we quote ± 1 σ errors, but when the parameters cannot be well constrained we only give the 2 σ upper limits for these parameters. The constraints on Ω m and H 0 are: Ω m = 0 293 . +0 021 . -0 018 . and H 0 = 70 1 . +2 3 . -3 2 . km s -1 Mpc -1 . Since the CMB+BAO data are basically consistent with the other astrophysical data (note that in this subsection we do not discuss BICEP2), one can also combine these data together. For convenience, hereafter we also use 'other' to denote the data combination of H 0 +SZ+Lensing. The
CMB+BAO+other data combination leads to:
$$w = - 1. 3 4 ^ { + 0. 1 0 } _ { - 0. 1 2 }, \\ \sum m _ { \nu } = 0. 5 8 ^ { + 0. 1 1 } _ { - 0. 1 0 } \, e V.$$
One can clearly see that once the other data sets are combined, the value of w becomes smaller. In fact, even though the consideration of dynamical dark energy could relieve the tension of H 0 , the strong degeneracy between Ω m and H 0 still exists; recall the discussion in the last subsection. So, when the other data sets are added, the Ω m -H 0 degeneracy is partly broken, resulting in that the Ω m becomes smaller and H 0 becomes larger: Ω m = 0 272 . +0 013 . -0 014 . and H 0 = 73 3 . ± 2 0 km s . -1 Mpc -1 . Since w and H 0 are in anti-correlation, larger H 0 leads to smaller w . This is why w becomes smaller in this case. In addition, the neutrino mass is sensitive to the cluster data, and so the combination with SZ and Lensing data could tighten the constraint on ∑ m ν .
For the w CDM+ + r N eff model, the CMB+BAO data combination gives:
$$w = - 0. 9 6 ^ { + 0. 1 2 } _ { - 0. 0 9 }, \\ N _ { \text{eff} } = 3. 6 3 ^ { + 0. 3 8 } _ { - 0. 4 2 }.$$
In this case, we also have Ω m = 0 306 . +0 017 . -0 015 . and H 0 = 70 1 . +2 0 . -2 4 . km s -1 Mpc -1 . From the discussion in the last subsection, we learn that the CMB+BAO data are not well consistent with the SZ cluster counts data, and so in principle it is not appropriate to combine them together. If we combine these data together (CMB+BAO+other), we get the results:
$$w = - 0. 8 5 ^ { + 0. 0 8 } _ { - 0. 0 6 }, \\ N _ { \text{eff} } = 3. 6 3 ^ { + 0. 3 9 } _ { - 0. 4 3 }.$$
We must keep in mind that the above results are from the tensioned data combination and thus are not reliable. Since the SZ cluster counts data give a lower σ 8 , we obtain a much higher w in this case (recall that w and σ 8 are in anti-correlation; see the relevant discussion in the last subsection). N eff is insensitive to the cluster and cosmic shear data, and so in this case the constraint on N eff is not changed. In this case, we have Ω m = 0 306 . ± 0 012 and . H 0 = 68 7 . ± 1 5 km s . -1 Mpc -1 .
Figure 3 summarizes the main results for the w CDM+ + r ∑ m ν + N eff model and the w CDM+ + r N eff + m eff ν, sterile model. In this figure, the two-dimensional posterior possibility distribution contours in the Ω m -w and ∑ m ν -N eff planes are plotted for the active neutrino model, and those in the Ω m -w and m eff ν, sterile -N eff planes are plotted for the sterile neutrino model. Purple contours are from the CMB+BAO constraints, and blue contours are from the CMB+BAO+other constraints. As discussed in the last subsection, in these two models the CMB+BAO data are consistent with the other observations considered in this paper, and thus the combination of these data sets is viewed as appropriate. In the following we report the fit results for the two models.
For the w CDM+ + r ∑ m ν + N eff model, the CMB+BAO data give the fit results:
$$w = - 1. 0 5 ^ { + 0. 1 7 } _ { - 0. 1 1 }, \\ \sum m _ { \nu } < 0. 6 5 1 \ e V, \quad N _ { \text{eff} } = 3. 6 8 ^ { + 0. 3 8 } _ { - 0. 4 5 }.$$
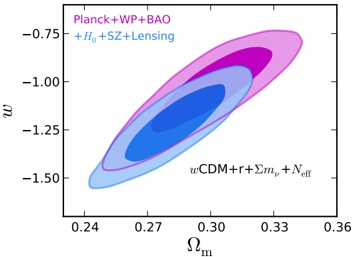
0.75
1.00
1.25
1.50
w
0.24
0.27
w
CDM+r+
0.30
mν, eff
sterile
0.33
eff
0.36
5.0
4.5
4.0
3.5
0.00
5.0
4.5
4.0
3.5
0.00
0.25
0.25
w
CDM+r+
0.50
Σ
mν
Σ
mν
0.75
[eV]
CDM+r+
w
0.50
mν,
0.75
+
N
eff
1.00
eff sterile
+
N
1.00
Ωm mν,
eff sterile
[eV]
Figure 3 . Two-dimensional joint, marginalized constraints for the w CDM+ + r ∑ m ν + N eff model (upper) and the w CDM+ + r N eff + m eff ν, sterile model (lower).
w CDM+r+ Σ mν + N eff In this case, we have Ω m = 0 299 . +0 021 . -0 016 . and H 0 = 71 6 . +2 4 . -3 2 . km s -1 Mpc -1 . Furthermore, the CMB+BAO+other data give the fit results:
$$w = - 1. 2 2 ^ { + 0. 1 4 } _ { - 0. 1 2 }, \\ \sum m _ { \nu } = 0. 6 9 ^ { + 0. 1 3 } _ { - 0. 1 5 } \, \text{eV}, \quad N _ { \text{eff} } = 3. 6 6 ^ { + 0. 3 5 } _ { - 0. 4 1 }.$$
In this case, we have Ω m = 0 283 . ± 0 015 and . H 0 = 74 1 . ± 2 0 km s . -1 Mpc -1 . From the upper panels of Fig. 3, one can see that the CMB+BAO data are well consistent with the other astrophysical data for this model.
For the w CDM+ + r N eff + m eff ν, sterile model, the CMB+BAO data combination gives the constraint results:
eff sterile
$$w = - 1. 0 6 ^ { + 0. 1 6 } _ { - 0. 1 1 },$$
mν,
+
N
eff
$$N _ { \text{eff} } = 3. 6 8 ^ { + 0. 3 8 } _ { - 0. 4 5 }, \quad m ^ { \text{eff} } _ { \nu, \text{sterile} } < 0. 7 0 \ e V.$$
In this case, we have Ω m = 0 298 . +0 020 . -0 017 . and H 0 = 71 9 . +2 3 . -3 2 . km s -1 Mpc -1 . Furthermore, the CMB+BAO+other data give the constraint results:
$$w = - 1. 2 0 \pm 0. 1 0, \\ N _ { \text{eff} } = 3. 5 6 ^ { + 0. 1 5 } _ { - 0. 3 3 }, \quad m _ { \nu, \text{steri} } ^ { \text{eff} } = 0. 7 0 \pm 0. 1 6 \ e V.$$
In this case, we have Ω m = 0 283 . +0 013 . -0 014 . and H 0 = 73 7 . ± 2 0 km s . -1 Mpc -1 . The same to the above active neutrino model, we also find from the lower panel of Fig. 3 that the CMB+BAO data are well consistent with the other observations for the sterile neutrino model.
+
N
eff
N
eff
N
eff
r
Figure 4 . Two-dimensional joint, marginalized constraints in the r 0 002 . -n s plane for the four models.
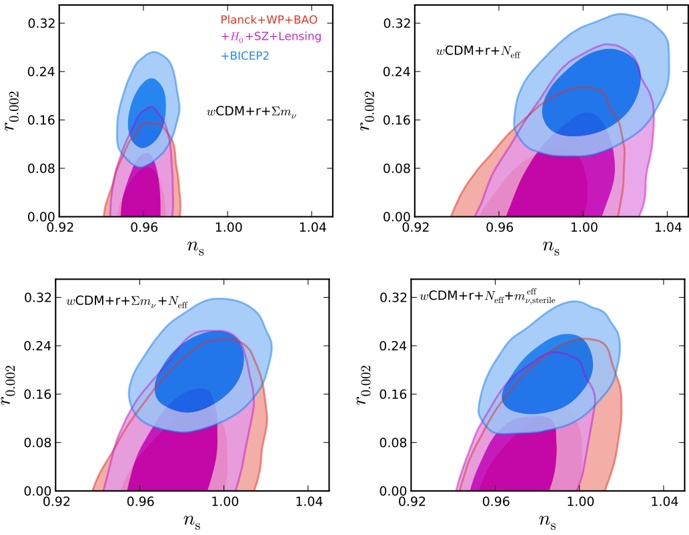
We find that the w CDM-based neutrino models fit the cosmological data much better than the corresponding ΛCDM-based models. The χ 2 min values of the w CDM-based models are given in Tables 2-5 in Appendix A, and those of the corresponding ΛCDM-based models can be found in Tables 1-4 of Ref. [35]. Note that in these tables actually the values of -ln L max = χ 2 min / 2 are given. Fits to the CMB+BAO+other data lead to an increase of ∆ χ 2 = -10 54 for the . w CDM+ + r ∑ m ν model, ∆ χ 2 = -3 64 for . the w CDM+ + r N eff model, ∆ χ 2 = -4 28 . for the w CDM+ + r ∑ m ν + N eff model, and ∆ χ 2 = -7 5 . for the w CDM+ + r N eff + m eff ν, sterile model, compared to the corresponding ΛCDM-based models. According to the Akaike information criterion, if χ 2 min improves by 2 or more with one additional parameter, its incorporation is justified. In this context, the performance of w CDM-based models (with only one more additional parameter beyond the corresponding ΛCDM-based models) improves χ 2 min significantly.
Furthermore, to see how the additional neutrino/dark radiation parameters improve the fits in the framework of w CDM, we report the χ 2 value of fitting the w CDM+ r model to the CMB+BAO+other data, χ 2 min = 9841 00. . Therefore, compared to this model, we get ∆ χ 2 = -18 12 for the . w CDM+ + r ∑ m ν model, ∆ χ 2 = -1 36 for the . w CDM+ + r N eff model, ∆ χ 2 = -18 42 for . the w CDM+ + r ∑ m ν + N eff model, and ∆ χ 2 = -22 02 for . the w CDM+ + r N eff + m eff ν, sterile model. It is clear to see that the neutrino mass plays a more important role than N eff in the fits.
## 3.3 Early-universe parameters and BICEP2
In this subsection we consider the constraints on n s and r and the BICEP2 data. Figure 4 shows the two-dimensional joint constraints on the four model in the n s -r 0 002 . plane. The
orange contours are for the CMB+BAO data, the purple ones are for the CMB+BAO+other data, and the blue ones are for the CMB+BAO+other+BICEP2 data.
For the w CDM+ + r ∑ m ν model and the w CDM+ + r N eff model, since the tension between Planck and BICEP2 cannot be greatly reduced, we are not interested in these two models for this aspect. We thus only give the 95% CL upper limits of r 0 002 . given by the CMB+BAO data for these two models: r 0 002 . < 0 125 for the . w CDM+ + r ∑ m ν model and r 0 002 . < . 0 165 for the w CDM+ + r N eff model.
In the w CDM+ + r ∑ m ν + N eff model and the w CDM+ + r N eff + m eff ν, sterile model, the tension of r between Planck and BICEP2 can be well relieved, and so we are interested in these two cases. For the w CDM+ + r ∑ m ν + N eff model, the CMB+BAO data give:
$$n _ { s } = 0. 9 8 3 ^ { + 0. 0 1 5 } _ { - 0. 0 1 7 }, \quad r _ { 0. 0 0 2 } < 0. 2 0 0.$$
Furthermore, the CMB+BAO+other+BICEP2 give the results:
$$n _ { s } = 0. 9 8 9 \pm 0. 0 1 3, \quad r _ { 0. 0 0 2 } = 0. 2 0 0 ^ { + 0. 0 3 9 } _ { - 0. 0 4 9 }.$$
For the w CDM+ + r N eff + m eff ν, sterile model, the CMB+BAO data give:
$$n _ { s } = 0. 9 8 4 ^ { + 0. 0 1 4 } _ { - 0. 0 1 7 }, \quad r _ { 0. 0 0 2 } < 0. 1 9 9.$$
Furthermore, the CMB+BAO+other+BICEP2 give the results:
$$n _ { s } = 0. 9 8 7 ^ { + 0. 0 1 4 } _ { - 0. 0 1 3 }, \quad r _ { 0. 0 0 2 } = 0. 1 9 3 ^ { + 0. 0 3 8 } _ { - 0. 0 5 0 }.$$
At last, we discuss the goodness of fits to the full data combination (with BICEP2 involved) for these two models. To see the role the parameter w plays in the fits, we take the ΛCDM-based models as references, and we obtain ∆ χ 2 = -1 78 for the . w CDM+ + r ∑ m ν + N eff model, and ∆ χ 2 = -3 04 . for the w CDM+ + r N eff + m eff ν, sterile model. Furthermore, to see how the two additional parameters relevant to neutrino/dark radiation improve the fits in the framework of w CDM, we choose the w CDM+ r model as a reference. In this case, we have χ 2 min = 9884 78 for the . w CDM+ r model. Therefore, we get ∆ χ 2 = -20 44 for . the w CDM+ + r ∑ m ν + N eff model, and ∆ χ 2 = -20 18 for the . w CDM+ + r N eff + m eff ν, sterile model.
## 4 Conclusion
Based on the standard ΛCDM cosmology, the Planck data are in good agreement with the BAO data, but are in tension with other astrophysical observations, such as the H 0 direct measurement, the SZ cluster counts, the cosmic shear measurement, and so on [4]. Some ingredients such as dark radiation, massive neutrinos, and dynamical dark energy were proposed to be considered in the cosmological model to reduce the tensions. In particular, extra sterile neutrino species, with additional parameters N eff and m eff ν, sterile , was used to resolve the tensions between Planck and other astrophysical observations. Then, after the detection of the B-mode polarization of the CMB by the BICEP2 experiment, which implies that the PGWs were possibly discovered, the base standard cosmology should at least be extended to the ΛCDM+ r model [16]. However, it was found that the BICEP2's result of r is in tension with the Planck's fit result. Again, it was proposed that the sterile neutrino can be used to reconcile the PGW results from BICEP2 and Planck [33, 34]. Other cases concerning neutrinos and dark radiation were also investigated in detail [35].
In this paper, we study the neutrino cosmological models in which the cosmological constant is replaced with the dynamical dark energy with constant w . Four cases are considered, i.e., the w CDM+ + r ∑ m ν model, the w CDM+ + r N eff model, the w CDM+ + r ∑ m ν + N eff model, and the w CDM+ + r N eff + m eff ν, sterile model. The observational data we consider in this paper include the Planck+WP, BAO, H 0 , Planck SZ cluster, Planck CMB lensing, cosmic shear, and BICEP2 data. We first tested the consistency of these data sets in the four cosmological models, and then performed joint constraints on the properties of dark energy and neutrinos.
For the w CDM+ + r ∑ m ν model, the consideration of dynamical dark energy is rather helpful in relieving the tension of H 0 , but even in this model Ω m and H 0 are still in strong degeneracy; the dark energy parameter w does not help much to reduce the tension between Planck and SZ cluster counts, and so only ∑ m ν plays a significant role in this aspect; also, w could not affect the value of r . Thus, the CMB+BAO data are basically consistent with other observations (except for BICEP2). The CMB+BAO constraint gives: w = -1 14 . +0 17 . -0 11 . and ∑ m < ν 0 48 eV. The CMB+BAO+ . H 0 +SZ+Lensing constraint gives: w = -1 34 . +0 10 . -0 12 . and ∑ m ν = 0 58 . +0 11 . -0 10 . eV.
For the w CDM+ + r N eff model, the dark energy parameter w does not lead to more impact on H 0 , but plays a significant role in reducing the tension of SZ cluster counts; larger w leads to smaller σ 8 and larger Ω m , so some offset happens for the quantity σ 8 (Ω m / 0 27) . 0 3 . , resulting in that the consideration of w still could not well relieve the tension between Planck and clusters; w can enhance the value of r in this case (it is positively correlated with n s ), but the tension of r still cannot be well relieved. The CMB+BAO data combination gives the results: w = -0 96 . +0 12 . -0 09 . , N eff = 3 63 . +0 38 . -0 42 . , and r 0 002 . < 0 165. .
The results of the active neutrinos plus dark radiation model and the sterile neutrino model are very similar. So we only took the sterile neutrino model as an example to analyze the data consistency. We found that in this model all the tensions considered are greatly reduced. Under the constraint from CMB+BAO, for the ΛCDM+ r model, the tensions with H 0 , SZ clusters, and cosmic shear are 2.4 σ , 4.3 σ , and 2.3 σ , respectively; for the w CDM+ + r N eff + m eff ν, sterile model, the above tensions are reduced to 0.6 σ , 1.7 σ , and 1.5 σ . The sterile neutrinos could well reconcile the r results from BICEP2 and Planck, and in this case dynamical dark energy does not further improve the r result.
For the w CDM+ + r ∑ m ν + N eff model, the CMB+BAO+ H 0 +SZ+Lensing constraint gives: w = -1 22 . +0 14 . -0 12 . , ∑ m ν = 0 69 . +0 13 . -0 15 . eV, and N eff = 3 66 . +0 35 . -0 41 . ; further adding the BICEP2 data, we have n s = 0 989 . ± 0 013 and . r 0 002 . = 0 200 . +0 039 . -0 049 . . For the w CDM+ + r N eff + m eff ν, sterile model, the CMB+BAO+ H 0 +SZ+Lensing data combination leads to: w = -1 20 . ± 0 10, . N eff = 3 56 . +0 15 . -0 33 . , and m eff ν, sterile = 0 70 . ± 0 16 eV. . Further adding the BICEP2 data gives: n s = 0 987 . +0 014 . -0 013 . and r 0 002 . = 0 193 . +0 038 . -0 050 . .
From our analysis, we found that both the w CDM+ + r ∑ m ν + N eff model and the w CDM+ + r N eff + m eff ν, sterile model are successful in relieving the tensions between Planck and other astrophysical observations. However, in the w CDM+ + r ∑ m ν + N eff model, one has to assume that the massive active neutrinos coexist with dark radiation, and thus we believe that the sterile neutrino model is more natural. To further tightly constrain the property of dark energy, accurate type Ia supernova data are needed. We leave the further analysis on the sterile neutrinos plus dark energy model in future work.
Table 2 . Fitting results for the w CDM+ + r ∑ m ν model. We quote ± 1 σ errors, but for the parameters that cannot be well constrained, we quote the 95% CL upper limits.
| | Planck+WP+BAO | Planck+WP+BAO | + H 0 +SZ+Lensing | + H 0 +SZ+Lensing | +BICEP2 | +BICEP2 |
|----------------|-----------------|----------------------------------|---------------------|----------------------------------|-----------|-------------------------------|
| Parameter | Best fit | 68% limits | Best fit | 68% limits | Best fit | 68% limits |
| Ω b h 2 | 0 . 02236 | 0 . 02202 +0 . 00027 - 0 . 00026 | 0 . 02215 | 0 . 02211 ± 0 . 00024 | 0 . 02200 | 0 . 02205 ± 0 . 00023 |
| Ω c h 2 | 0 . 1180 | 0 . 1193 ± 0 . 0023 | 0 . 1172 | 0 . 1171 +0 . 0013 - 0 . 0012 | 0 . 1176 | 0 . 1169 +0 . 0013 - 0 . 0012 |
| 100 θ MC | 1 . 04130 | 1 . 04124 ± 0 . 00059 | 1 . 04103 | 1 . 04136 +0 . 00055 - 0 . 00056 | 1 . 04119 | 1 . 04136 ± 0 . 00055 |
| τ | 0 . 098 | 0 . 090 +0 . 012 - 0 . 014 | 0 . 093 | 0 . 093 +0 . 012 - 0 . 014 | 0 . 092 | 0 . 093 +0 . 012 - 0 . 013 |
| Σ m ν | 0 . 039 | < 0 . 480 | 0 . 580 | 0 . 584 +0 . 111 - 0 . 097 | 0 . 545 | 0 . 581 +0 . 115 - 0 . 094 |
| w | - 1 . 01 | - 1 . 14 +0 . 17 - 0 . 11 | - 1 . 30 | - 1 . 34 +0 . 10 - 0 . 12 | - 1 . 35 | - 1 . 34 +0 . 10 - 0 . 12 |
| n s | 0 . 9651 | 0 . 9605 ± 0 . 0068 | 0 . 9632 | 0 . 9599 ± 0 . 0059 | 0 . 9623 | 0 . 9621 +0 . 0057 - 0 . 0058 |
| ln(10 10 A s ) | 3 . 100 | 3 . 086 +0 . 024 - 0 . 025 | 3 . 088 | 3 . 087 +0 . 023 - 0 . 025 | 3 . 084 | 3 . 086 +0 . 022 - 0 . 025 |
| r 0 . 05 | 0 . 010 | < 0 . 133 | 0 . 051 | < 0 . 152 | 0 . 180 | 0 . 181 +0 . 034 - 0 . 039 |
| Ω Λ | 0 . 701 | 0 . 707 +0 . 018 - 0 . 021 | 0 . 720 | 0 . 728 +0 . 014 - 0 . 013 | 0 . 730 | 0 . 730 ± 0 . 014 |
| Ω m | 0 . 299 | 0 . 293 +0 . 021 - 0 . 018 | 0 . 280 | 0 . 272 +0 . 013 - 0 . 014 | 0 . 270 | 0 . 270 ± 0 . 014 |
| σ 8 | 0 . 835 | 0 . 830 ± 0 . 037 | 0 . 780 | 0 . 786 ± 0 . 015 | 0 . 797 | 0 . 787 +0 . 015 - 0 . 016 |
| H 0 | 68 . 6 | 70 . 1 +2 . 3 - 3 . 2 | 72 . 0 | 73 . 3 ± 2 . 0 | 73 . 5 | 73 . 4 ± 2 . 0 |
| r 0 . 002 | 0 . 0094 | < 0 . 125 | 0 . 046 | < 0 . 143 | 0 . 171 | 0 . 173 +0 . 034 - 0 . 042 |
| - ln L max | 4904.82 | 4904.82 | 4911.44 | 4911.44 | 4934.33 | 4934.33 |
## Acknowledgments
We acknowledge the use of CosmoMC . We thank Yun-He Li for helpful discussion. JFZ is supported by the Provincial Department of Education of Liaoning under Grant No. L2012087. XZ is supported by the National Natural Science Foundation of China under Grant No. 11175042 and the Fundamental Research Funds for the Central Universities under Grant No. N120505003.
## A Detailed constraint results
In this appendix, we give the detailed constraint results for the four cosmological models considered in this paper. The one- and two-dimensional joint, marginalized posterior probability distributions of the parameters for the models are shown in Figs. 5-8. Detailed fit values for the cosmological parameters are given in Tables 2-5. In the tables, the ± 1 σ errors are quoted, but for the parameters that cannot be well constrained, only the 2 σ upper limits are given.
Figure 5 and Table 2 summarize the fit results for the w CDM+ + r ∑ m ν model. Figure 6 and Table 3 summarize the fit results for the w CDM+ + r N eff model. Figure 7 and Table 4 summarize the fit results for the w CDM+ + r ∑ m ν + N eff model. Figure 8 and Table 5 summarize the fit results for the w CDM+ + r N eff + m eff ν, sterile model.
## References
- [1] E. Komatsu et al. [WMAP Collaboration], 'Five-Year Wilkinson Microwave Anisotropy Probe (WMAP) Observations: Cosmological Interpretation,' Astrophys. J. Suppl. 180 , 330 (2009) [arXiv:0803.0547 [astro-ph]].
- [2] E. Komatsu et al. [WMAP Collaboration], 'Seven-Year Wilkinson Microwave Anisotropy Probe (WMAP) Observations: Cosmological Interpretation,' Astrophys. J. Suppl. 192 , 18 (2011) [arXiv:1001.4538 [astro-ph.CO]].
- [3] G. Hinshaw et al. [WMAP Collaboration], 'Nine-Year Wilkinson Microwave Anisotropy Probe (WMAP) Observations: Cosmological Parameter Results,' Astrophys. J. Suppl. 208 , 19 (2013) [arXiv:1212.5226 [astro-ph.CO]].
Figure 5 . Cosmological constraints on the w CDM+ + r ∑ m ν model.
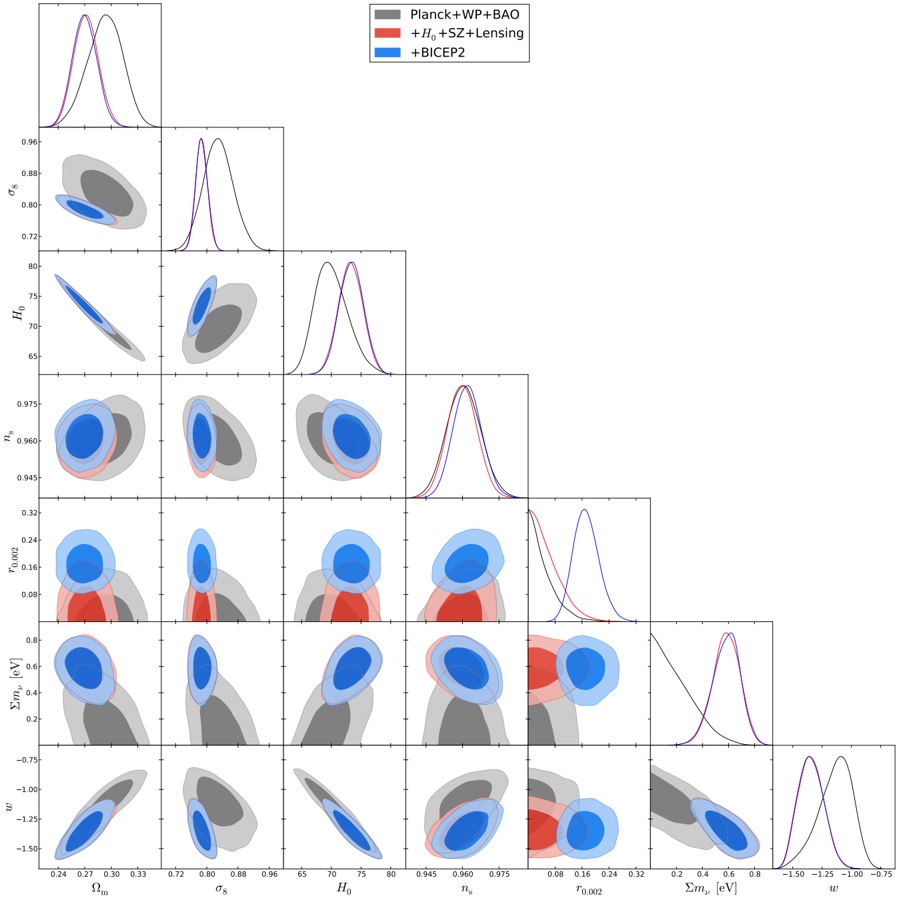
- [4] P. A. R. Ade et al. [Planck Collaboration], 'Planck 2013 results. XVI. Cosmological parameters,' arXiv:1303.5076 [astro-ph.CO].
- [5] P. A. R. Ade et al. [Planck Collaboration], arXiv:1303.5080 [astro-ph.CO].
- [6] J. Benjamin, L. Van Waerbeke, C. Heymans, M. Kilbinger, T. Erben, H. Hildebrandt, H. Hoekstra and T. D. Kitching et al. , arXiv:1212.3327 [astro-ph.CO].
- [7] R. A. Battye and A. Moss, 'Evidence for massive neutrinos from CMB and lensing observations,' Phys. Rev. Lett. 112 , 051303 (2014) [arXiv:1308.5870 [astro-ph.CO]].
- [8] A. G. Riess, L. Macri, S. Casertano, H. Lampeitl, H. C. Ferguson, A. V. Filippenko, S. W. Jha and W. Li et al. , 'A 3% Solution: Determination of the Hubble Constant with the Hubble
Figure 6 . Cosmological constraints on the w CDM+ + r N eff model.
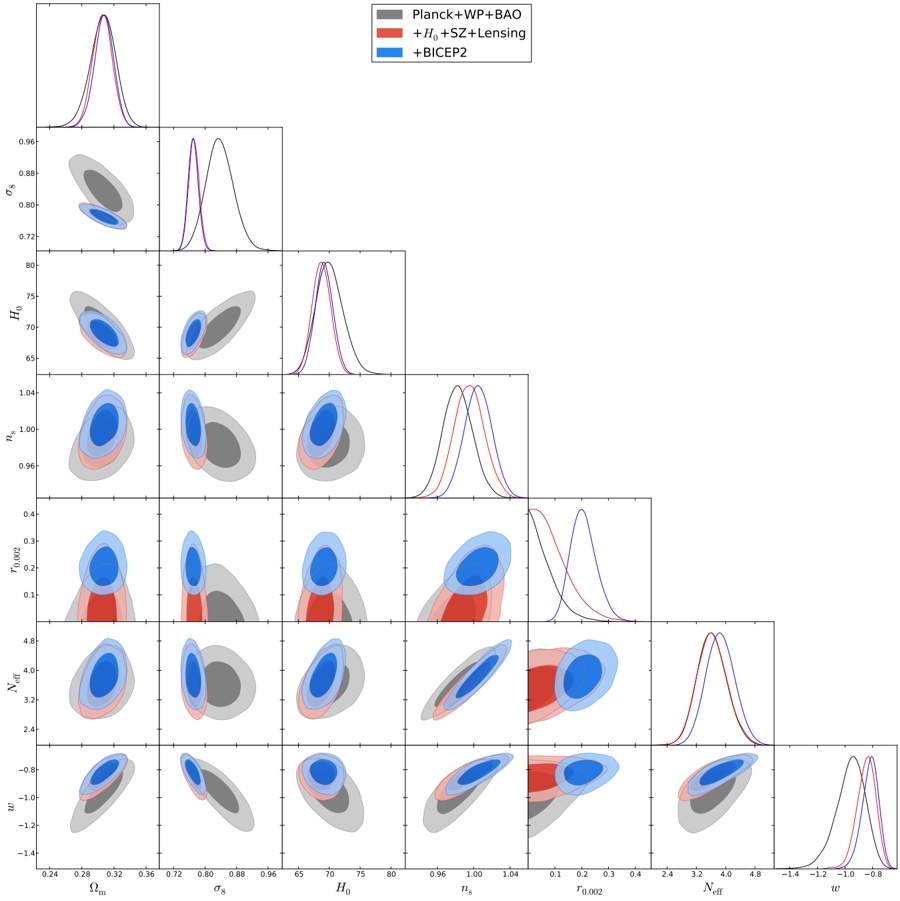
Space Telescope and Wide Field Camera 3,' Astrophys. J. 730 , 119 (2011) [Erratum-ibid. 732 , 129 (2011)] [arXiv:1103.2976 [astro-ph.CO]].
- [9] A. Aguilar-Arevalo et al. [LSND Collaboration], 'Evidence for neutrino oscillations from the observation of anti-neutrino(electron) appearance in a anti-neutrino(muon) beam,' Phys. Rev. D 64 , 112007 (2001).
- [10] A. A. Aguilar-Arevalo et al. [MiniBooNE Collaboration], 'Improved Search for ¯ ν µ → ¯ ν e Oscillations in the MiniBooNE Experiment,' Phys. Rev. Lett. 110 , 161801 (2013).
- [11] G. Mention, M. Fechner, T. .Lasserre, T. .A. Mueller, D. Lhuillier, M. Cribier and A. Letourneau, 'The Reactor Antineutrino Anomaly,' Phys. Rev. D 83 , 073006 (2011).
| | Planck+WP+BAO | Planck+WP+BAO | + H 0 +SZ+Lensing | + H 0 +SZ+Lensing | +BICEP2 | +BICEP2 |
|----------------|-----------------|----------------------------------|---------------------|----------------------------------|-----------|----------------------------------|
| Parameter | Best fit | 68% limits | Best fit | 68% limits | Best fit | 68% limits |
| Ω b h 2 | 0 . 02230 | 0 . 02245 +0 . 00037 - 0 . 0004 | 0 . 02278 | 0 . 02291 +0 . 00038 - 0 . 00037 | 0 . 02287 | 0 . 02302 ± 0 . 00036 |
| Ω c h 2 | 0 . 1238 | 0 . 127 +0 . 0054 - 0 . 0061 | 0 . 1179 | 0 . 1207 +0 . 0049 - 0 . 0053 | 0 . 1214 | 0 . 1234 ± 0 . 0048 |
| 100 θ MC | 1 . 04106 | 1 . 04057 +0 . 00073 - 0 . 00072 | 1 . 04095 | 1 . 04114 +0 . 00071 - 0 . 00072 | 1 . 04112 | 1 . 04092 +0 . 00068 - 0 . 00069 |
| τ | 0 . 098 | 0 . 095 +0 . 013 - 0 . 016 | 0 . 087 | 0 . 091 +0 . 014 - 0 . 016 | 0 . 081 | 0 . 093 +0 . 013 - 0 . 015 |
| w | - 0 . 974 | - 0 . 962 +0 . 120 - 0 . 087 | - 0 . 886 | - 0 . 847 +0 . 075 - 0 . 059 | - 0 . 832 | - 0 . 819 +0 . 067 - 0 . 053 |
| N eff | 3 . 4 | 3 . 63 +0 . 38 - 0 . 42 | 3 . 41 | 3 . 63 +0 . 39 - 0 . 43 | 3 . 66 | 3 . 86 +0 . 38 - 0 . 41 |
| n s | 0 . 975 | 0 . 983 +0 . 016 - 0 . 017 | 0 . 985 | 0 . 995 ± 0 . 016 | 0 . 996 | 1 . 005 ± 0 . 015 |
| ln(10 10 A s ) | 3 . 116 | 3 . 115 ± 0 . 032 | 3 . 082 | 3 . 094 +0 . 032 - 0 . 035 | 3 . 078 | 3 . 104 +0 . 03 - 0 . 034 |
| r 0 . 05 | 0 . 002 | < 0 . 158 | 0 . 024 | < 0 . 203 | 0 . 192 | 0 . 188 +0 . 034 - 0 . 042 |
| Ω Λ | 0 . 694 | 0 . 694 +0 . 015 - 0 . 017 | 0 . 701 | 0 . 694 ± 0 . 012 | 0 . 69 | 0 . 692 ± 0 . 011 |
| Ω m | 0 . 306 | 0 . 306 +0 . 017 - 0 . 015 | 0 . 299 | 0 . 306 ± 0 . 012 | 0 . 31 | 0 . 308 ± 0 . 011 |
| σ 8 | 0 . 838 | 0 . 838 +0 . 033 - 0 . 037 | 0 . 776 | 0 . 772 ± 0 . 013 | 0 . 763 | 0 . 77 ± 0 . 012 |
| H 0 | 69 . 3 | 70 . 1 +2 . 0 - 2 . 4 | 68 . 7 | 68 . 7 ± 1 . 5 | 68 . 4 | 69 . 2 ± 1 . 4 |
| r 0 . 002 | 0 . 002 | < 0 . 165 | 0 . 023 | < 0 . 224 | 0 . 205 | 0 . 207 +0 . 040 - 0 . 054 |
| - ln L max | 4903.64 | 4903.64 | 4919.82 | 4919.82 | 4940.82 | 4940.82 |
Table 3 . Fitting results for the w CDM+ + r N eff model. We quote ± 1 σ errors, but for the parameters that cannot be well constrained, we quote the 95% CL upper limits.
Table 4 . Fitting results for the w CDM+ + r ∑ m ν + N eff model. We quote ± 1 σ errors, but for the parameters that cannot be well constrained, we quote the 95% CL upper limits.
| | Planck+WP+BAO | Planck+WP+BAO | + H 0 +SZ+Lensing | + H 0 +SZ+Lensing | +BICEP2 | +BICEP2 |
|----------------|-----------------|----------------------------------|---------------------|----------------------------------|-----------|----------------------------------|
| Parameter | Best fit | 68% limits | Best fit | 68% limits | Best fit | 68% limits |
| Ω b h 2 | 0 . 02217 | 0 . 02245 +0 . 00038 - 0 . 00041 | 0 . 02244 | 0 . 02253 +0 . 00034 - 0 . 00037 | 0 . 02272 | 0 . 02261 +0 . 00034 - 0 . 00035 |
| Ω c h 2 | 0 . 1253 | 0 . 1274 +0 . 0054 - 0 . 0062 | 0 . 1224 | 0 . 1250 +0 . 0047 - 0 . 0055 | 0 . 1256 | 0 . 1276 +0 . 0048 - 0 . 0047 |
| 100 θ MC | 1 . 04043 | 1 . 04047 +0 . 00076 - 0 . 00075 | 1 . 04095 | 1 . 04060 +0 . 00071 - 0 . 00072 | 1 . 04089 | 1 . 04036 ± 0 . 00067 |
| τ | 0 . 096 | 0 . 095 +0 . 014 - 0 . 016 | 0 . 093 | 0 . 099 +0 . 013 - 0 . 016 | 0 . 104 | 0 . 102 +0 . 013 - 0 . 015 |
| Σ m ν | 0 . 052 | < 0 . 651 | 0 . 61 | 0 . 69 +0 . 13 - 0 . 15 | 0 . 60 | 0 . 72 +0 . 15 - 0 . 14 |
| w | - 0 . 99 | - 1 . 05 +0 . 17 - 0 . 11 | - 1 . 19 | - 1 . 22 +0 . 14 - 0 . 12 | - 1 . 11 | - 1 . 18 +0 . 14 - 0 . 11 |
| N eff | 3 . 51 | 3 . 68 +0 . 38 - 0 . 45 | 3 . 52 | 3 . 66 +0 . 35 - 0 . 41 | 3 . 73 | 3 . 87 ± 0 . 36 |
| n s | 0 . 979 | 0 . 983 +0 . 015 - 0 . 017 | 0 . 978 | 0 . 981 +0 . 014 - 0 . 015 | 0 . 988 | 0 . 989 ± 0 . 013 |
| ln(10 10 A s ) | 3 . 115 | 3 . 116 +0 . 031 - 0 . 036 | 3 . 102 | 3 . 119 +0 . 031 - 0 . 035 | 3 . 131 | 3 . 129 +0 . 03 - 0 . 032 |
| r 0 . 05 | 0 . 009 | < 0 . 188 | 0 . 047 | < 0 . 202 | 0 . 172 | 0 . 190 +0 . 035 - 0 . 04 |
| Ω Λ | 0 . 700 | 0 . 701 +0 . 016 - 0 . 021 | 0 . 720 | 0 . 717 ± 0 . 015 | 0 . 709 | 0 . 714 +0 . 015 - 0 . 016 |
| Ω m | 0 . 300 | 0 . 299 +0 . 021 - 0 . 016 | 0 . 280 | 0 . 283 ± 0 . 015 | 0 . 291 | 0 . 286 +0 . 016 - 0 . 015 |
| σ 8 | 0 . 847 | 0 . 820 ± 0 . 037 | 0 . 771 | 0 . 776 +0 . 015 - 0 . 017 | 0 . 774 | 0 . 773 +0 . 015 - 0 . 016 |
| H 0 | 70 . 3 | 71 . 6 +2 . 4 - 3 . 2 | 73 . 5 | 74 . 1 ± 2 . 0 | 72 . 9 | 74 . 3 +1 . 9 - 2 . 1 |
| r 0 . 002 | 0 . 009 | < 0 . 200 | 0 . 044 | < 0 . 213 | 0 . 177 | 0 . 200 +0 . 039 - 0 . 049 |
| - ln L max | 4904.45 | 4904.45 | 4911.29 | 4911.29 | 4932.17 | 4932.17 |
Table 5 . Fitting results for the w CDM+ + r N eff + m eff ν, sterile model. We quote ± 1 σ errors, but for the parameters that cannot be well constrained, we quote the 95% CL upper limits.
| | Planck+WP+BAO | Planck+WP+BAO | + H 0 +SZ+Lensing | + H 0 +SZ+Lensing | +BICEP2 | +BICEP2 |
|------------------|-----------------|----------------------------------|---------------------|----------------------------------|-----------|-------------------------------|
| Parameter | Best fit | 68% limits | Best fit | 68% limits | Best fit | 68% limits |
| Ω b h 2 | 0 . 02242 | 0 . 02248 +0 . 00033 - 0 . 00038 | 0 . 02232 | 0 . 02253 +0 . 00028 - 0 . 0003 | 0 . 02267 | 0 . 02261 ± 0 . 00029 |
| Ω c h 2 | 0 . 1242 | 0 . 1275 +0 . 0056 - 0 . 0061 | 0 . 1192 | 0 . 1228 +0 . 0035 - 0 . 005 | 0 . 1267 | 0 . 1265 +0 . 0047 - 0 . 0048 |
| 100 θ MC | 1 . 04065 | 1 . 04045 +0 . 00075 - 0 . 00074 | 1 . 04134 | 1 . 04075 +0 . 00066 - 0 . 00065 | 1 . 04035 | 1 . 04044 ± 0 . 00068 |
| τ | 0 . 095 | 0 . 096 +0 . 013 - 0 . 016 | 0 . 087 | 0 . 095 +0 . 013 - 0 . 016 | 0 . 099 | 0 . 100 +0 . 013 - 0 . 016 |
| m eff ν, sterile | 0 . 005 | < 0 . 701 | 0 . 67 | 0 . 70 ± 0 . 16 | 0 . 62 | 0 . 68 ± 0 . 15 |
| w | - 1 . 030 | - 1 . 060 +0 . 160 - 0 . 110 | - 1 . 210 | - 1 . 200 ± 0 . 100 | - 1 . 167 | - 1 . 170 +0 . 105 - 0 . 096 |
| N eff | 3 . 44 | 3 . 72 +0 . 31 - 0 . 45 | 3 . 33 | 3 . 56 +0 . 15 - 0 . 33 | 3 . 80 | 3 . 81 +0 . 28 - 0 . 35 |
| n s | 0 . 975 | 0 . 984 +0 . 014 - 0 . 017 | 0 . 962 | 0 . 974 +0 . 011 - 0 . 017 | 0 . 986 | 0 . 987 +0 . 014 - 0 . 013 |
| ln(10 10 A s ) | 3 . 111 | 3 . 119 +0 . 03 - 0 . 034 | 3 . 087 | 3 . 110 +0 . 028 - 0 . 034 | 3 . 122 | 3 . 126 +0 . 029 - 0 . 034 |
| r 0 . 05 | 0 . 007 | < 0 . 188 | 0 . 006 | < 0 . 179 | 0 . 203 | 0 . 186 +0 . 034 - 0 . 041 |
| Ω Λ | 0 . 709 | 0 . 702 +0 . 017 - 0 . 020 | 0 . 720 | 0 . 717 +0 . 014 - 0 . 013 | 0 . 716 | 0 . 713 +0 . 014 - 0 . 013 |
| Ω m | 0 . 291 | 0 . 298 +0 . 020 - 0 . 017 | 0 . 280 | 0 . 283 +0 . 013 - 0 . 014 | 0 . 284 | 0 . 287 +0 . 013 - 0 . 014 |
| σ 8 | 0 . 851 | 0 . 816 +0 . 038 - 0 . 041 | 0 . 773 | 0 . 773 ± 0 . 014 | 0 . 776 | 0 . 772 +0 . 014 - 0 . 015 |
| H 0 | 71 . 2 | 71 . 9 +2 . 3 - 3 . 2 | 73 . 0 | 73 . 7 ± 2 . 0 | 74 . 3 | 74 . 1 ± 2 . 0 |
| r 0 . 002 | 0 . 006 | < 0 . 199 | 0 . 006 | < 0 . 183 | 0 . 210 | 0 . 193 +0 . 038 - 0 . 050 |
| - ln L max | 4904.85 | 4904.85 | 4909.49 | 4909.49 | 4932.30 | 4932.30 |
Figure 7 . Cosmological constraints on the w CDM+ + r ∑ m ν + N eff model.
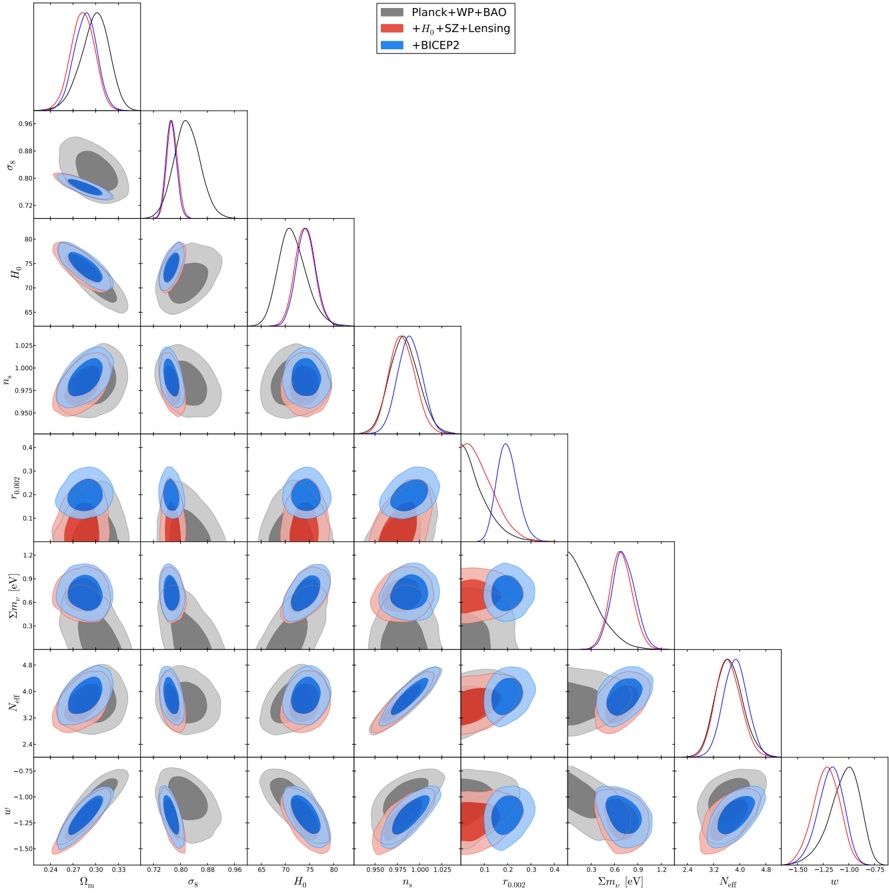
- [12] C. Giunti, M. Laveder, Y. F. Li, Q. Y. Liu and H. W. Long, 'Update of Short-Baseline Electron Neutrino and Antineutrino Disappearance,' Phys. Rev. D 86 , 113014 (2012) [arXiv:1210.5715 [hep-ph]].
- [13] C. Giunti, M. Laveder, Y. F. Li and H. W. Long, 'Pragmatic View of Short-Baseline Neutrino Oscillations,' Phys. Rev. D 88 , 073008 (2013) [arXiv:1308.5288 [hep-ph]].
- [14] M. Wyman, D. H. Rudd, R. A. Vanderveld and W. Hu, ' ν ΛCDM: Neutrinos help reconcile Planck with the Local Universe,' Phys. Rev. Lett. 112 , 051302 (2014) [arXiv:1307.7715 [astro-ph.CO]].
- [15] J. Hamann and J. Hasenkamp, 'A new life for sterile neutrinos: resolving inconsistencies using hot dark matter,' JCAP 1310 , 044 (2013) [arXiv:1308.3255 [astro-ph.CO]].
Figure 8 . Cosmological constraints on the w CDM+ + r N eff + m eff ν, sterile model.
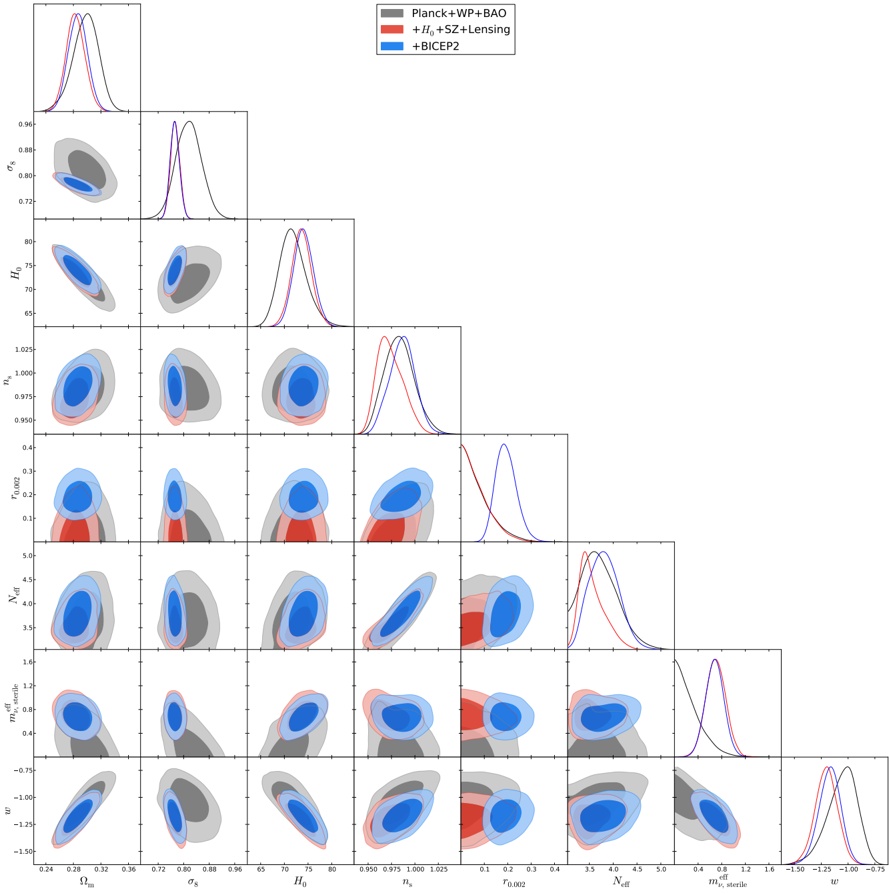
- [16] P. A. R. Ade et al. [BICEP2 Collaboration], 'Detection of B-Mode Polarization at Degree Angular Scales by BICEP2,' Phys. Rev. Lett. 112 , 241101 (2014) [arXiv:1403.3985 [astro-ph.CO]].
- [17] H. Liu, P. Mertsch and S. Sarkar, 'Fingerprints of Galactic Loop I on the Cosmic Microwave Background,' arXiv:1404.1899 [astro-ph.CO].
- [18] K. Harigaya and T. T. Yanagida, 'Discovery of Large Scale Tensor Mode and Chaotic Inflation in Supergravity,' arXiv:1403.4729 [hep-ph].
- [19] K. Nakayama and F. Takahashi, 'Higgs Chaotic Inflation and the Primordial B-mode Polarization Discovered by BICEP2,' arXiv:1403.4132 [hep-ph].
| [20] | R. H. Brandenberger, A. Nayeri and S. P. Patil, 'Closed String Thermodynamics and a Blue Tensor Spectrum,' arXiv:1403.4927 [astro-ph.CO]. |
|--------|---------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------|
| [21] | C. R. Contaldi, M. Peloso and L. Sorbo, 'Suppressing the impact of a high tensor-to-scalar ratio on the temperature anisotropies,' arXiv:1403.4596 [astro-ph.CO]. |
| [22] | V. c. Miranda, W. Hu and P. Adshead, 'Steps to Reconcile Inflationary Tensor and Scalar Spectra,' arXiv:1403.5231 [astro-ph.CO]. |
| [23] | M. Gerbino, A. Marchini, L. Pagano, L. Salvati, E. Di Valentino and A. Melchiorri, 'Blue Gravity Waves from BICEP2 ?,' arXiv:1403.5732 [astro-ph.CO]. |
| [24] | J. McDonald, 'Negative Running of the Spectral Index, Hemispherical Asymmetry and Consistency of Planck with BICEP2,' arXiv:1403.6650 [astro-ph.CO]. |
| [25] | D. K. Hazra, A. Shafieloo, G. F. Smoot and A. A. Starobinsky, 'Ruling out the power-law form of the scalar primordial spectrum,' arXiv:1403.7786 [astro-ph.CO]. |
| [26] | D. K. Hazra, A. Shafieloo, G. F. Smoot and A. A. Starobinsky, 'Whipped inflation,' arXiv:1404.0360 [astro-ph.CO]. |
| [27] | A. Kehagias and A. Riotto, 'Remarks about the Tensor Mode Detection by the BICEP2 Collaboration and the Super-Planckian Excursions of the Inflaton Field,' arXiv:1403.4811 [astro-ph.CO]. |
| [28] | D. H. Lyth, 'BICEP2, the curvature perturbation and supersymmetry,' arXiv:1403.7323 [hep-ph]. |
| [29] | C. Bonvin, R. Durrer and R. Maartens, 'Can primordial magnetic fields be the origin of the BICEP2 data?,' arXiv:1403.6768 [astro-ph.CO]. |
| [30] | J. Lizarraga, J. Urrestilla, D. Daverio, M. Hindmarsh, M. Kunz and A. R. Liddle, 'Can topological defects mimic the BICEP2 B-mode signal?,' arXiv:1403.4924 [astro-ph.CO]. |
| [31] | A. Moss and L. Pogosian, 'Did BICEP2 see vector modes? First B-mode constraints on cosmic defects,' arXiv:1403.6105 [astro-ph.CO]. |
| [32] | J. Chluba, L. Dai, D. Jeong, M. Kamionkowski and A. Yoho, 'Linking the BICEP2 result and the hemispherical power asymmetry through spatial variation of r ,' arXiv:1404.2798 [astro-ph.CO]. |
| [33] | J. -F. Zhang, Y. -H. Li and X. Zhang, 'Sterile neutrinos help reconcile the observational results of primordial gravitational waves from Planck and BICEP2,' arXiv:1403.7028 [astro-ph.CO]. |
| [34] | C. Dvorkin, M. Wyman, D. H. Rudd and W. Hu, 'Neutrinos help reconcile Planck measurements with both Early and Local Universe,' arXiv:1403.8049 [astro-ph.CO]. |
| [35] | J. -F. Zhang, Y. -H. Li and X. Zhang, 'Cosmological constraints on neutrinos after BICEP2,' Eur. Phys. J. C 74 , 2954 (2014) [arXiv:1404.3598 [astro-ph.CO]]. |
| [36] | Y. -H. Li, J. -F. Zhang and X. Zhang, 'Tilt of primordial gravitational wave spectrum in a universe with sterile neutrinos,' Sci. China Phys. Mech. Astron. 57 , 1455 (2014) [arXiv:1405.0570 [astro-ph.CO]]. |
| [37] | M. Archidiacono, N. Fornengo, S. Gariazzo, C. Giunti, S. Hannestad and M. Laveder, 'Light sterile neutrinos after BICEP-2,' JCAP 1406 , 031 (2014) [arXiv:1404.1794 [astro-ph.CO]]. |
| [38] | J. Bergstrm, M. C. Gonzalez-Garcia, V. Niro and J. Salvado, 'Statistical tests of sterile neutrinos using cosmology and short-baseline data,' arXiv:1407.3806 [hep-ph]. |
| [39] | M. Li, X. -D. Li, Y. -Z. Ma, X. Zhang and Z. Zhang, 'Planck Constraints on Holographic Dark Energy,' JCAP 1309 , 021 (2013) [arXiv:1305.5302 [astro-ph.CO]]. |
| [40] | A. Lewis and S. Bridle, 'Cosmological parameters from CMB and other data: A Monte Carlo approach,' Phys. Rev. D 66 , 103511 (2002) [astro-ph/0205436]. |
| [41] | L. Anderson et al. [BOSS Collaboration], 'The clustering of galaxies in the SDSS-III Baryon Oscillation Spectroscopic Survey: Baryon Acoustic Oscillations in the Data Release 10 and 11 galaxy samples,' arXiv:1312.4877 [astro-ph.CO]. |
|--------|----------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------|
| [42] | F. Beutler, C. Blake, M. Colless, D. H. Jones, L. Staveley-Smith, L. Campbell, Q. Parker and W. Saunders et al. , 'The 6dF Galaxy Survey: Baryon Acoustic Oscillations and the Local Hubble Constant,' Mon. Not. Roy. Astron. Soc. 416 , 3017 (2011) [arXiv:1106.3366 [astro-ph.CO]]. |
| [43] | W. J. Percival et al. [SDSS Collaboration], 'Baryon Acoustic Oscillations in the Sloan Digital Sky Survey Data Release 7 Galaxy Sample,' Mon. Not. Roy. Astron. Soc. 401 , 2148 (2010) [arXiv:0907.1660 [astro-ph.CO]]. |
| [44] | C. Blake, E. Kazin, F. Beutler, T. Davis, D. Parkinson, S. Brough, M. Colless and C. Contreras et al. , 'The WiggleZ Dark Energy Survey: mapping the distance-redshift relation with baryon acoustic oscillations,' Mon. Not. Roy. Astron. Soc. 418 , 1707 (2011) [arXiv:1108.2635 [astro-ph.CO]]. |
| [45] | J. L. Tinker, A. V. Kravtsov, A. Klypin, K. Abazajian, M. S. Warren, G. Yepes, S. Gottlober and D. E. Holz, 'Toward a halo mass function for precision cosmology: The Limits of universality,' Astrophys. J. 688 , 709 (2008) [arXiv:0803.2706 [astro-ph]]. |
| [46] | W. A. Watson, I. T. Iliev, A. D'Aloisio, A. Knebe, P. R. Shapiro and G. Yepes, 'The halo mass function through the cosmic ages,' Mon. Not. Roy. Astron. Soc. 433 , 1230 (2013) [arXiv:1212.0095 [astro-ph.CO]]. |
| [47] | P. A. R. Ade et al. [Planck Collaboration], 'Planck 2013 results. XVII. Gravitational lensing by large-scale structure,' arXiv:1303.5077 [astro-ph.CO]. | | 10.1088/1475-7516/2014/10/044 | [
"Jing-Fei Zhang",
"Jia-Jia Geng",
"Xin Zhang"
] | 2014-08-03T10:43:02+00:00 | 2014-10-17T15:53:14+00:00 | [
"astro-ph.CO",
"gr-qc",
"hep-ph",
"hep-th"
] | Neutrinos and dark energy after Planck and BICEP2: data consistency tests and cosmological parameter constraints | The detection of the B-mode polarization of the cosmic microwave background
(CMB) by the BICEP2 experiment implies that the tensor-to-scalar ratio $r$
should be involved in the base standard cosmology. In this paper, we extend the
$\Lambda$CDM+$r$+neutrino/dark radiation models by replacing the cosmological
constant with the dynamical dark energy with constant $w$. Four neutrino plus
dark energy models are considered, i.e., the $w$CDM+$r+\sum m_\nu$, $w$CDM+r +
$N_{\rm eff}$, $w$CDM+r + $\sum m_\nu$ + $N_{\rm eff}$, and $w$CDM+r + $N_{\rm
eff}$ + $m_{\nu,{\rm sterile}}^{\rm eff}$ models. The current observational
data considered in this paper include the Planck temperature data, the WMAP
9-year polarization data, the baryon acoustic oscillation data, the Hubble
constant direct measurement data, the Planck Sunyaev-Zeldovich cluster counts
data, the Planck CMB lensing data, the cosmic shear data, and the BICEP2
polarization data. We test the data consistency in the four cosmological
models, and then combine the consistent data sets to perform joint constraints
on the models. We focus on the constraints on the parameters $w$, $\sum m_\nu$,
$N_{\rm eff}$, and $m_{\nu,{\rm sterile}}^{\rm eff}$. |
1408.0482v1 | ## Green Broadcast Transmission in Cellular Networks: A Game Theoretic Approach
Cengis Hasan , Jean-Marie Gorce † † and Eitan Altman ‡
† Inria, University of Lyon, INSA-Lyon, 6 Avenue des Arts 69621 Villeurbanne Cedex, France ‡ Inria, 2004 Route des Lucioles, 06902 Sophia-Antipolis Cedex, France { cengis.hasan, eitan.altman } @inria.fr, { jean-marie.gorce } @insa-lyon.fr
Abstract -This paper addresses the mobile assignment problem in a multi-cell broadcast transmission seeking minimal total power consumption by considering both transmission and operational powers. While the large scale nature of the problem entails to find distributed solutions, game theory appears to be a natural tool. We propose a novel distributed algorithm based on group formation games, called the hedonic decision algorithm . This formalism is constructive: a new class of group formation games is introduced where the utility of players within a group is separable and symmetric being a generalized version of parity-affiliation games. The proposed hedonic decision algorithm is also suitable for any set-covering problem. To evaluate the performance of our algorithm, we propose other approaches to which our algorithm is compared. We first develop a centralized recursive algorithm called the hold minimum being able to find the optimal assignments. However, because of the NP-hard complexity of the mobile assignment problem, we propose a centralized polynomial-time heuristic algorithm called the column control producing near-optimal solutions when the operational power costs of base stations are taken into account. Starting from this efficient centralized approach, a distributed column control algorithm is also proposed and compared to the hedonic decision algorithm . We also implement the nearest base station algorithm which is very simple and intuitive and efficiently manage fastmoving users served by macro BSs. Extensive simulation results are provided and highlight the relative performance of these algorithms. The simulated scenarios are done according to Poisson point processes for both mobiles and base stations.
We consider broadcasting under a green-aware objective aiming at reducing the energy consumption which is an important issue in wireless environments[12]. Broadcasting may bring a strong improvement in wireless channels since a common resource (in frequency and/or time) may be used for all destinations. The transmission cost for a base station (BS) to reach all nodes in a multicast group is assumed to be proportional to the power needed to reach the worst mobile among the group, where the worst refers to the mobile receiving the weaker signal which relies on its distance and on additional shadowing effects. We thus consider the situation where there is one common information that every mobile m ∈ M is interested to receive, and which can be obtained from any one of n BSs. The objective is then to achieve a mobiles assignment which minimizes the total power consumption .
Index Terms -broadcast transmission, green networking, combinatorial optimization, game theory
## I. INTRODUCTION
Broadcast scenarios have been widely studied for video or audio broadcasting. More recently, the Multimedia Broadcast/Multicast Service (MBMS) [1] became a requirement of the Long-term Evolution (LTE) specifications to support the delivery of broadcast/multicast data in LTE systems. Broadcast and multicast downlink transmissions make no significant difference at the physical layer. Basically, broadcast services are available to all users without the need of subscribing to a particular service. Therefore, multicasting can thus be seen as 'broadcast via subscription', with the possibility of charging for the subscription [1]. MBMS is intended to be used for some content, such as streaming transmission of a sport or cultural event, but broadcasting may also be of interest to transmit some signalling such as a beacon for time synchronization or for power control purposes.
This work was supported by the ECOSCells project. It was done within the INRIA & Alcatel Lucent Bell-Labs joint research laboratory.
As mentioned above, this problem is relevant not only for streaming data transmission but also for signalling. A corollary question is indeed how many base stations should be kept active to ensure the signalling to a group of mobiles even when they are not transmitting. In low activity periods, such as during the night, it could be relevant to keep active only few BS ensuring the coverage of few active mobiles. Indeed, energy consumption and electromagnetic pollution are main societal and economical challenges that developed countries have to handle. The evolution of cellular networks toward smaller cells offering theoretically higher capacity could in turn lead to an unacceptable increase of the energy expenditure of wireless systems. When decreasing the cell size, the energy consumed for data transmission becomes lower compared to the operational power costs (e.g. power amplifiers, cooler, etc.) of a typical BS. Switching off a BS may then bring significant improvements in energy efficiency. Therefore, we take into account the switching on/off operation in the problem formulation. The overarching problem studied in the sequel is then finding energy-efficient broadcast transmission techniques to reduce spurious energy using distributed schemes.
The mobile assignment problem (MAP) in the context of broadcast transmission that we study in this work is actually a special case of the simple plant location problem (SPLP) [2]. SPLP lies within clustering problems . In the MAP, basically, the objective is to assign the points to at most k clusters so that the sum of all distances between points in the same cluster ( k -clustering) is minimized. In [3], the typical cost for a BS-mobile pair is assumed to be only a function of distance between the BS and the mobile, formulated as
∑ N j ∈C max i ∈ N j d α ij + P j 0 . Here, N j is a cluster of mobiles assigned to BS j , C is the set of clusters, d ij is the distance between mobile i and BS j , α is the path loss exponent and P j 0 is the operational power cost loaded to BS j . This formulation is modified in order to consider the effect of shadowing leading to the following total cost ∑ N j ∈C max i ∈ N j d α ij / Ψ ij + P j 0 where Ψ ij denotes the shadowing effect between mobile i and BS j . Thus, this modification turns the MAP into the SPLP.
While finding the global minimum of the MAP may be identified as an NP-hard problem from SPLP literature, the large scale nature of the cellular network further requires to solve it in a decentralized manner. Thus, game theory appears as a natural tool to cope with both features: distributed decision and NP-hardness. We address this problem by considering the mobiles as players being able to make strategic decisions and the BSs as the strategy identifiers: each mobile has to choose the best BS to be served.
## A. Related Work
Computational geometric approaches to the MAP can be found in [3], [4], [5], [6]. In [4], the authors examined the 1-dimensional version of the MAP, where the effects of shadowing and operational power cost are not taken into account. Polynomial time solutions via dynamic programming are proposed. In [5], authors suggested approximation algorithms (and an algebraic intractability result) for selecting an optimal line on which to place BSs to cover mobiles, and a proof of NP-hardness for any path loss exponent α > 1 .
The papers [7], [8], [9], [10] focused on source-initiated broadcasting of data in static all-wireless networks. Data are distributed from a source node to each node in a network. The main objective is to construct a minimum-energy broadcast tree rooted at the source node. Multi-hop routing is not the scope of our paper.
In [11], the combined problem of (i) deciding what subset of the mobiles would be assigned to each BS, and then (ii) sharing the BSs' cost of multicast among the mobiles is studied. The subset that is wished to assign to a given BS is said to be its target set of mobiles. This problem can be conceived as a coalitional pricing game played by mobiles which is called the association game of mobiles .
## B. Our Contribution
We propose algorithmic solutions for mobile assignment in the context of broadcasting, in order to minimize the overall energy consumption related to transmission and operational powers. In this context, switching off some fraction of BSs is considered to be a way of decreasing dramatically the total energy consumption. Note however that heterogeneous networks include macro and small-cells with or without coordination. It is reasonable to assume that small-cells are subject to switching off operation while macro-cells are always turned on. They can indeed serve moving mobiles in order to decrease the number of hand-offs. Further, since the small-cells are deployed intensively, their transmission power is lower than those of macro-cells, while their circuit power dominates.
Comparing the transmission power about few milliWatts with the operational power costs which may approach tens of Watts, turning off a fraction of BSs is appealing for reducing the total energy footprint of the network. The efforts for turning off some BSs will be concentrated on small-cells serving fixed mobiles[13].
The referred literature mostly concentrates on the geometric aspects of the MAP where basically, the coverage area of a BS is assumed to be a disc which issues from omnidirectional antenna pattern. However, the effect of shadowing , special designed antenna patterns as well as the operational power costs may impact the BS-mobile assignments. In this paper, we take into account these effects by introducing a power cost matrix containing all BS-mobile pairing power costs.
Furthermore, several papers working on coverage optimization deal with static optimization and planning from a centralized point of view. But the dynamic switching-off process associated to the large-scale nature of the network induces to find distributed solutions. To this end, we deal with this problem through a group formation game formulation. Subsequently, we introduce a new algorithm based on group formation games, called hedonic decision algorithm . This formalism is constructive: a new class of group formation games is introduced where the utility of players within a group is separable and symmetric. This is a generalization of parity affiliation games and this hedonic decision algorithm is in fact applicable for any set covering problem.
To prove the efficiency of this approach, we then derive four other methods allowing to solve the initial problem. First, we propose a recursive algorithm called the hold minimum algorithm which solves the considered problem optimally. However, the hold minimum algorithm operates in a centralized way since it requires the whole knowledge for each BSmobile pairing power cost. We then adapt an approach from the SPLP literature to the MAP: a centralized polynomial-time heuristic algorithm is proposed called the the column control which produces optimal assignments when taking into account the operational power cost. This algorithm is also extended to a distributed approach, where each mobile gathers the local information from the BSs located in its range. On the other hand, the nearest base station algorithm , a distributed greedy algorithm which runs in polynomial-time is also evaluated. This algorithm is not efficient if the operational power cost is large, but is very efficient for the fast-moving users served by macro BSs.
The rest of the paper is organized as follows. In section II, the MAP is formulated mathematically as a clustering problem and different formulations are then proposed. In section III, the game framework and the hedonic decision algorithm are proposed. In section IV, we derive other algorithmic solutions for the MAP and their complexity is anlayzed in section V. Finally, we present simulation results in section VI and we expose some conclusions in section VII.
## II. THE GENERIC MAP PROBLEM
We consider the coverage problem in the case of broadcast transmission in cellular networks. We assume that each BS
Fig. 1. Broadcast transmission in cellular networks.
transmits simultaneously to the mobiles. The distance between the mobile i and BS j is represented by d ij . The power needed to receive the transmission is given by P r . We consider basic signal propagation model capturing path loss as well as shadowing effect formulated as
$$P _ { i j } = P _ { r } \frac { d _ { i j } ^ { \alpha } } { \Psi _ { i j } }, \quad \quad \ \ ( 1 ) \quad \text{.}$$
where P ij and α denote transmitted power from BS j to mobile i and path loss exponent, respectively. The random variable Ψ is used to model slow fading effects and commonly follows a log-normal distribution.
The required transmission power depends on the mobile having the worst signal level from the BS (Figure 1). At this power level, all mobiles are guaranteed to receive a sufficient power. We also consider the operational power cost denoted as P j 0 which captures the energy expenditure of a typical BS j for operational costs (power amplifiers, cooler, etc.). So, the total power cost (transmission power + operational power cost) of a typical transmission between BS j and mobile i is denoted as
$$p _ { i j } = P _ { i j } + P _ { 0 } ^ { j }. \quad \ \ \ ( 2 ) \, \begin{array} { c } ( \text{see} \\ l o c a \end{array}$$
Let M = (1 , . . . , m ) and N = (1 , . . . , n ) be the sets of mobiles and BSs, respectively. Representing the power cost matrix P = ( p ij ) ∈ glyph[Rfractur] m n × , we assume p ij ∈ [0 , ∞ ) where if P ij > P max , then p ij = ∞ ( P max denotes a maximal power, for instance, in WiFi, it is 100 mW).
## A. The MAP as a Clustering Problem
Clustering is a rich branch of combinatorial problems which have been extensively studied in many fields including database systems, image processing, data mining, molecular biology, etc. [3]. Consider the set of mobiles M ; a cluster is any non-empty subset of M and a clustering is a partition of M . Many different clustering problems can be defined. The mostly studied problems are defined through their objective which is to assign the points to at most k clusters so that either:
- · k-centre : the maximum distance from any point to its cluster centre is minimized,
- · k-median : the sum of distances from each point to its closest cluster centre is minimized,
- · k-clustering : the sum of all distances between points in the same cluster is minimized.
The problem of clustering a set of points into a specific number of clusters so as to minimize the sum of cluster sizes is referred to as min-size k -clustering problem. In [3], the typical cost for a BS-mobile pair is assumed to be only a function of the BS-mobile distance and leads to the formulation: ∑ N j ∈C max i ∈ N j d α ij + P j 0 , where N j is a cluster of mobiles assigned to BS j , C is the set of clusters, d ij is the distance between mobile i and BS j , α is the path loss exponent, P j 0 is the operational power cost loaded to BS j . Since in this paper, we add the effect of shadowing to such a cost, the cost function becomes ∑ N j ∈C max i ∈ N j d α ij / Ψ ij + P j 0 . Note that the shadowing effect breaks the monotonicity with d ij (see Figure 1) and then shifts the problem to a simple plant location problem (SPLP) [2] formulated as follows:
- · Let have n potential facility locations. A facility can be opened in any location j ; opening a facility location has a non-negative cost corresponding to P j 0 in the MAP. Each open facility can provide an unlimited amount of commodity corresponding to unlimited number of mobiles served by a BS in the MAP;
- · there are m customers that require a service. The goal is to determine a subset of the set of potential facility locations, at which to open facilities and an assignment of all clients to these facilities so as to minimize the overall total cost.
However, the SPLP formulation presents a very high complexity, and we rather propose to turn out the problem as a set covering problem, starting from a binary integer formulation.
## B. Binary Integer Formulation
Note that there are at most 2 m -1 possible subsets of M . Each subset can be associated to any BS and the number of combinations is given by η = n (2 m -1) . We note S the collection of total possibilities. The index set of S is denoted by L = (1 , . . . , η ) . Let W = ( w kl ) ∈ glyph[Rfractur] ( m n + ) × η be a 0-1 matrix with w kl = 1 if the node k (i.e. mobile or BS) belongs to the set ( S l ; j ) . Let q = ( q l ) ∈ glyph[Rfractur] η be an η -dimensional vector. The value q l represents the optimal power of ( S l ; j ) ∈ S by which we denote a pair which consists of a set of mobiles S l assigned to BS j . Clearly
$$q _ { l } = \max _ { i \in S _ { l } } p _ { i j }. \quad \quad \quad ( 3 ) \quad \text{succeq} \quad \text{succeq}.$$
The formulation of this problem is given by
$$( P ) \quad & p = \min \sum _ { l \in L } q _ { l } x _ { l } & \quad \text{$\alpha$} \quad \text{$\alpha$} \quad \text{$\alpha$} \quad \text{$\text{of assc}$} \\ & \quad \text{s.t.} \quad \sum _ { l \in L } w _ { k l } x _ { l } = 1, \quad k \in M \cup N, \quad ( 4 ) \quad \text{turns t} \\ & \quad x _ { l } \in \{ 0, 1 \}, \quad l \in L \\ \cdot \quad \cdot \quad \sigma \quad \cdot \quad \cdot \quad \cdot \quad \sigma \quad \sigma \cdot \quad \text{and} \ ( 7$$
where the term ∑ l ∈ L w kl x l = 1 imposes that only one BS is associated to a mobile. By this way, we do not let a mobile to be assigned to several BSs. It follows that the optimal clustering is denoted as C ∗ ⊂ S such that C ∗ = { ( S ∗ ; j ∗ ) ∈ S ∀ , j ∈ N } where ( S ∗ ; j ∗ ) is the optimal pairing.
Thanks to this formulation, we can show that the MAP may be derived as a set partitioning problem. In the MAP, the set M is associated with another set N . Therefore, the collection S contains those subsets of M each of which is associated with every element of the set N . Consider the following example.
Example 2.1: Let us have a power cost matrix given by
$$P = \begin{bmatrix} 3 & 6 \\ 5 & 1 \end{bmatrix}.$$
The collection of total possibilities:
$$\mathcal { S } = \{ ( 1 ; 1 ), ( 2 ; 1 ), ( 1, 2 ; 1 ), ( 1 ; 2 ), ( 2 ; 2 ), ( 1, 2 ; 2 ) \}. \quad ( 6 ) \ \text{Then, } \varrho$$
Recall that ( S l ; j ) denotes the cluster of mobiles S l assigned to BS j . The optimal values for each possibility is given by q = ( q l ) = (3 5 5 6 1 6) , , , , , . Then, we define the following matrix:
$$\mathbf w = \begin{bmatrix} 1 & 0 & 1 & 1 & 0 & 1 \\ 0 & 1 & 1 & 0 & 1 & 1 \\ 1 & 1 & 1 & 0 & 0 & 0 \\ 0 & 0 & 0 & 1 & 1 & 1 \end{bmatrix}. \quad \quad ( 7 ) & \text{with} \\ \quad \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \$$
The optimal total power is thus calculated by the following binary integer program:
$$\text{may merge program.} & & \text{For ex} \\ p = & \min ( 3 x _ { 1 } + 5 x _ { 2 } + 5 x _ { 3 } + 6 x _ { 4 } + x _ { 5 } + 6 x _ { 6 } ) & & ( 1, 2, 3 \\ s. t. & x _ { 1 } + x _ { 3 } + x _ { 4 } + x _ { 6 } = 1, & & ( 2, 3 ; 1 \\ & x _ { 2 } + x _ { 3 } + x _ { 5 } + x _ { 6 } = 1, & & ( 8 ) & & ( 1 0, 2 7 \\ & x _ { 1 } + x _ { 2 } + x _ { 3 } = 1, & & ( 1, 3 ; 1 \\ & x _ { 4 } + x _ { 5 } + x _ { 6 } = 1, & & \text{Note} \\ & x _ { l } \in \{ 0, 1 \}, \quad l \in ( 1, \dots, 6 ). & & \text{is the ef}$$
The values x 1 = 1 and x 5 = 1 result in the optimal total power of the example scenario, i.e., p = 3 + 1 = 4 with the optimal clustering C ∗ = (1;1) (2; 2) { , } .
However, set partitioning problems are well known to be NP-hard [14]. Consequently, the MAP being a special set partitioning problem is also NP-hard.In the next section, we propose to reduce this complexity.
## C. The MAP as a Set Covering Problem
The previous formulation stated that a unique BS is allowed to serve a mobile. However in terms of pure coverage considerations, the optimal solution may feature some mobiles to be covered by several BS, no matter to which BS the mobile eventually associate with. We then relax the condition of associating only one BS to a cluster of mobiles in ( P ) such that it is now possible to have a cluster of mobiles covered by more than one BS: ∑ l ∈ L w kl x l ≥ 1 . Thus, this arrangement turns the MAP into so called set covering problem.
Consider a set of mobiles S assigned to BS j noted as ( S j ; ) . When a group of mobiles T ⊂ S deviates to another BS k then the cost due to S becomes additive. Let the cost of ( S j ; ) and ( T k ; ) be q S = max i ∈ ( S j ; ) p ij and q T = max i ∈ ( T k ; ) p ik , respectively. We denote the total cost before deviation of T as p and after deviation of T as p ′ , respectively 1 , which can be given by
$$p = p _ { r } + q _ { S },$$
$$p ^ { \prime } = p ^ { \prime } _ { r } + q _ { S \vee T } + q _ { T }, \text{ \quad \ \ } ( 1 0 )$$
where p r and p ′ r are the remaining costs before and after deviation, respectively. There is always a potential (probability) increasing the total cost when a deviation occurs, i.e. p ′ ≥ p . For better observation, let us consider the following power cost matrix:
$$\mathbf P = \begin{bmatrix} 1 0 & 1 5 & 2 5 \\ 2 7 & 2 0 & 3 3 \\ 3 2 & 3 1 & 3 0 \end{bmatrix}.$$
Let ( S j ; ) = (1 2 3; 1) , , and ( T k ; ) = (1 2; 3) , , respectively. Then, q S = max(10 27 32) = 32 , , , q T = max(25 33) = 33 , , and q S T \ = max(32) = 32 resulting in the following total costs:
$$p = 3 2$$
$$p ^ { \prime } = 3 2 + 3 3 = 6 5,$$
where p r = p ′ = 0
r . Utilizing this property, we delete from the collection S all those assignments ( S T j \ ; ) whenever the cost of ( S j ; ) is equal to the cost of ( S T j \ ; ) such that T ⊂ S .
For example, let us consider the last example where M = (1 , 2 3) , and N = (1 2 3) , , . For j = 1 , all possible assignments are (1; 1) , (2; 1) , (3; 1) , (1 2; 1) , , (1 3; 1) , , (2 , 3; 1) , (1 2 3; 1) , , corresponding to the cost vector q = (10 27 32 27 32 32 32) , , , , , , . Note that the cost of (3; 1) , (1 , 3; 1) , (2 , 3; 1) , (1 2 3; 1) , , are equal each other. Therefore,
1 Note that these costs are not optimal. We only would like to show what is the effect of deviation of a group of mobiles from theirs current BS.
we remove (3; 1) , (1 3; 1) , , (2 3; 1) , from the collection. The reduced collection of assignments becomes as following:
$$\mathcal { S } ^ { \prime } = \{ ( 1 ; 1 ), & ( 1, 2 ; 1 ), ( 1, 2, 3 ; 1 ), ( 1 ; 2 ), ( 1, 2 ; 2 ), & \stackrel { \circ } { \langle M, N ^ { n } } \\ & ( 1, 2, 3 ; 2 ), ( 1 ; 3 ), ( 1, 3 ; 3 ), ( 1, 2, 3 ; 3 ) \}. & ( 1 4 ) \quad \text{plays}$$
Note that this property is an extension of the geometric 'coverage range'. If the shadowing was not considered, this approach would reduced to defining the maximal coverage range. But with shadowing the mobile requiring the most power is not always the further one. Thus, the binary integer program of finding the solution of the problem is given by
$$p = & \min ( 1 0 x _ { 1 } + 2 7 x _ { 2 } + 3 2 x _ { 3 } + 1 5 x _ { 4 } + 2 0 x _ { 5 } + 3 1 x _ { 6 } + \int _ { \mathcal { W } } ^ { p \omega } \\ & 2 5 x _ { 7 } + 3 0 x _ { 8 } + 3 3 x _ { 9 } ) & \text{see 1}$$
$$( 1 5 )$$
$$& \varepsilon \omega _ { l } + \varepsilon \omega _ { 8 } + \varepsilon \omega _ { 9 l } & \quad \text{se} \, + \\ \text{s.t. } & x _ { 1 } + x _ { 2 } + x _ { 3 } + x _ { 4 } + x _ { 5 } + x _ { 6 } + x _ { 7 } + x _ { 8 } + x _ { 9 } \geq 1, & \quad \text{cond} \\ & x _ { 2 } + x _ { 3 } + x _ { 5 } + x _ { 6 } + x _ { 9 } \geq 1, & \quad \text{cond} \\ & x _ { 3 } + x _ { 6 } + x _ { 8 } + x _ { 9 } \geq 1, \\ & x _ { l } \in \{ 0, 1 \}, \quad l \in ( 1, \dots, 9 ). & \quad ( 1 5 )$$
The solution of this problem is found to be x 6 = 1 and x l = 0 , ∀ l ∈ (1 , . . . , 9) which fits to the optimal one.
By such an elimination, the size of the collection of assignments reduces from n (2 m -1) to nm . This prove that the set-covering formulation is much more efficient than the set-partitioning one.
## D. Brute-force Search Solution
Enumerating all possible solutions and choosing the one which produces the lowest cost is known as brute-force search or generate and test.
We represent by A = ( a ij ) ∈ glyph[Rfractur] m n × the assignment matrix where a ij ∈ (0 , 1) . If mobile i is assigned to BS j , then a ij = 1 , otherwise a ij = 0 . Notice that each row of the assignment matrix includes only unique '1' which means that a mobile is served by only one BS, i.e. ∑ j a ij = 1 . This is not in contradiction with our former remark about the possibility of having a mobile covered by several BS. Here now, we decide to associate a mobile to a BS. So if a mobile is covered by several BSs, the serving BS can be anyone of this covering set. Denoting the collection of the assignment matrices A , actually, we formalize the problem as following:
$$p = \min _ { \mathbf A \in \mathcal { A } } \left ( \sum _ { i \in M } \max _ { j \in N } \mathbf A \otimes \mathbf P \right ), \quad \quad ( 1 6 ) \, \stackrel { \text{alizat} } { T h } \,,$$
where ⊗ is the element-wise product. Note that the total number of possibilities of assignment matrices can be calculated as |A| = n m .
## III. DECENTRALIZED SOLUTION: THE HEDONIC DECISION (HD) ALGORITHM
We now turn to the study of decentralized methods for solving the MAP. Our approach is based on group formation game (see [19], [18], [20]).
A.
The Game Model
A group formation game is represented by a triple G = 〈 M,N m , ( u x x ) ∈ M 〉 where M = { 1 2 , , . . . , m } is the set of players (i.e. the mobiles), N is the set of strategies (i.e. the BSs) shared by all the players and u x : N m →glyph[Rfractur] is the utility function of player x ∈ M . Each player x ∈ M chooses exactly one element from the n alternatives in N . The choices of players are represented by σ = { s , s 1 2 . . . , s m } ⊆ N m which is called the strategy-tuple ( s x shows the strategy chosen by player x ). A partition of players according to strategy-tuple σ is denoted as Π( σ ) = { ( G σ j ) j ∈ N } where G σ j is the group of players choosing the strategy j .
We assume the two following conditions and we will see later how we can define the utilities to achieve these conditions:
- 1) Separability : The utility of any player in any group is said to be separable if its utility can always be split as a sum according to:
$$u _ { x } ( s _ { x }, \sigma _ { - x } ) = \sum _ { y \in G _ { s _ { x } } ^ { \sigma } } v _ { x } ( y ; s _ { x } ), \quad \ \ ( 1 7 )$$
where v x : { M N ; } → glyph[Rfractur] may be interpreted as the gain of player x from player y if x chooses strategy s x . Note that v x ( x s ; x ) is the utility of player x when it is the only player choosing strategy s x . Thus, the separability property states that utility transfers among a group of users sharing the same strategy is done such that the utility granted to one user is a sum of utilities granted individually by each partner in the group.
- 2) Symmetricity : The utility is said to be symmetric if the individual gain of x from y is equal to the gain of y from x when they both share the same strategy s :
$$v _ { x } ( y ; s ) = v _ { y } ( x ; s ), \ \forall x, y \in M. \quad ( 1 8 )$$
Therefore, this symmetric utility can be referred to as: v x ( y s ; ) = v y ( x s ; ) = v x, y ( ; s ) , ∀ x, y ∈ M v x,y s . ( ; ) is called the symmetric bipartite utility of player x and y while the common strategy is s .
Actually, the game defined above is a straightforward generalization of party affiliation games [23].
Theorem 3.1: G is a potential game.
Proof: A non-cooperative game is a potential game [21] whenever there exists a function Φ
$$\Phi ( s _ { x }, \sigma _ { - x } ) - \Phi ( s ^ { \prime } _ { x }, \sigma _ { - x } ) = u _ { x } ( s _ { x }, \sigma _ { - x } ) - u _ { x } ( s ^ { \prime } _ { x }, \sigma _ { - x } ), \ ( 1 9 )$$
meaning that when player x switches from strategy s x to s ′ x the difference of its utility can be given by the difference of a function Φ . This function is called a potential function .
The strategy-tuple that maximizes the potential function is a Nash equilibrium in the game.
Let us choose as following the potential function Φ :
glyph[negationslash]
glyph[negationslash]
$$\text{Le us conose as following one potential function } \Psi \colon \quad & \text{$b$. $sepa$} \\ \Phi ( \sigma ) & = \sum _ { j \in N } \left [ \sum _ { a \in G _ { j } ^ { \sigma } } v ( a, a ; j ) + \frac { 1 } { 2 } \sum _ { a \in G _ { j } ^ { \sigma } } \sum _ { b \in G _ { j } ^ { \sigma } ; b \neq a } v ( a, b ; j ) \right ] \quad & \text{Recal} \\ & = \sum _ { j \in N } \sum _ { a \in G _ { j } ^ { \sigma } } v ( a, a ; j ) + \frac { 1 } { 2 } \sum _ { j \in N } \sum _ { a \in G _ { j } ^ { \sigma } } \sum _ { b \in G _ { j } ^ { \sigma } ; b \neq a } v ( a, b ; j ). \quad & \text{groug C} \\ & = \text{motor} \\ \text{Aditalv here we take the sum of cinale lower initialec and}$$
Actually, here we take the sum of single player utilities and the half of total symmetric bipartite utilities. Let us rewrite the potential function as following:
glyph[negationslash]
$$\text{ne potential function as following:} \\ \Phi ( s _ { x }, \sigma _ { - x } ) = v ( x, x ; s _ { x } ) + \sum _ { y \in G _ { z } ^ { g } _ { x } } v ( x, y ; s _ { x } ) \\ + \underbrace { \sum _ { j \in N } \sum _ { a \in G _ { j } ^ { g } \vee x } v ( a, a ; j ) + \frac { 1 } { 2 } \sum _ { j \in N } \sum _ { a \in G _ { j } ^ { g } \vee x } \sum _ { b \in G _ { j } ^ { g } \vee x ; b \neq a } v ( a, b ; j ) } _ { I } \,. \quad \text{while} \quad \text{this, as:} \\ \text{When never } \tau \text{ such these from } \tau \text{ to } \tau ^ { \prime } \text{ the other lower} \quad.$$
When player x switches from σ x to σ ′ x (the other players do not change their strategies), then the strategy-tuple is transformed from σ to σ ′ , and the potential becomes glyph[negationslash]
$$& \text{transformed from $\sigma$ to $\sigma$}, and the potential becomes \\ & \Phi ( s ^ { \prime } _ { x }, \sigma _ { - x } ) = v ( x, x ; s ^ { \prime } _ { x } ) + \sum _ { y \in G ^ { \sigma } _ { s ^ { \prime } _ { x } } } v ( x, y ; s ^ { \prime } _ { x } ) } \quad \text{where $\theta$ is} \\ & + \underbrace { \sum _ { j \in N } \sum _ { a \in G ^ { \sigma } _ { j } ^ { \prime } \vee x } v ( a, a ; j ) + \frac { 1 } { 2 } \sum _ { j \in N } \sum _ { a \in G ^ { \sigma } _ { j } ^ { \prime } \vee x } \sum _ { b \in G ^ { \sigma } _ { j } ^ { \prime } \vee x \colon b \neq a } v ( a, b ; j ) } _ { I ^ { \prime } }. \text{system. $T$} \\ & \text{$given by $t$} \\ & \text{$u_{x}(j,$} \\ & \text{Note that $I=I^{\prime}$ since the total utility due to the other nlayers}$$
Note that I = I ′ since the total utility due to the other players is equal both in σ and σ ′ . Thus, the difference of potentials is given by
$$& \Phi ( s _ { x }, \sigma _ { - x } ) - \Phi ( s ^ { \prime } _ { x }, \sigma _ { - x } ) = v ( x, x ; s _ { x } ) - v ( x, x ; s ^ { \prime } _ { x } ) \\ & + \sum _ { y \in G ^ { \sigma } _ { s _ { x } } } v ( x, y ; s _ { x } ) - \sum _ { y \in G ^ { \sigma } _ { s ^ { \prime } _ { x } } } v ( x, y ; s ^ { \prime } _ { x } ). ( 2 3 ) \quad \text{symmet} \\ & \quad \text{express}$$
On the other hand, the difference of the utility of player x is calculated as
$$& u _ { x } ( s _ { x }, \sigma _ { - x } ) - u _ { x } ( s _ { x } ^ { \prime }, \sigma _ { - x } ) = v ( x, x ; s _ { x } ) - v ( x, x ; s _ { x } ^ { \prime } ) \\ & + \sum _ { y \in G _ { s _ { x } } ^ { \sigma } } v ( x, y ; s _ { x } ) - \sum _ { y \in G _ { s _ { x } ^ { \prime } } ^ { \sigma } } v ( x, y ; s _ { x } ^ { \prime } ). \quad & ( 2 4 ) \quad \text{Now, le} \\ & \dots \cdots.$$
By this result we conclude that
$$\Phi ( s _ { x }, \sigma _ { - x } ) - \Phi ( s _ { x } ^ { \prime }, \sigma _ { - x } ) = u _ { x } ( s _ { x }, \sigma _ { - x } ) - u _ { x } ( s _ { x } ^ { \prime }, \sigma _ { - x } ) \ ( 2 5 )$$
which proves that G is a potential game. Thus, G admits a Nash equilibrium in pure strategies σ ∗ which results in the partition Π( σ ∗ ) and which maximizes the potential function Φ .
Corollary 3.1: The proof 3.1 is constructive: any group formation game possessing separable and symmetric utility gain of players within a group always converges to a pure Nash equilibrium.
.
.
## B. Separable and Symmetric Gain Allocation
Recall that the required power for serving the group of mobiles G σ j by BS j is denoted as max x ∈ G σ j p xj . We represent by U G ( σ j ) = -max x ∈ G σ j p xj ≤ 0 , as a utility arising due to group G σ j . Note that U G ( σ j ) ≤ 0 , ∀ G σ j ⊆ M, ∀ j ∈ N is a monotonically decreasing function [16].
The clustering profit due to mobile x and y in BS j is given by
$$\Delta ( x, y ; j ) = U ( x, y ; j ) - [ U ( x ; j ) + U ( y ; j ) ] \quad ( 2 6 )$$
where U x j ( ; ) = -p xj is the utility of player x when is served alone in BS j . Therefore, ∆( x, y ; j ) = p xj + p yj -max( p xj , p yj ) = min( p xj , p yj ) .
Remark 3.1: Note that the clustering profit is a useful metric for evaluating a group of mobiles. Whenever a group of mobiles are near each other, then the clustering profit is high; thus, assigning this group to only one BS is almost always efficient.
To ensure separability and symmetricity, we propose to choose the symmetric bipartite utility according to:
glyph[negationslash]
$$v ( x, y ; j ) = \begin{cases} \theta \Delta ( x, y ; j ), & \text{if $x\neq y$} \\ - p _ { x j }, & \text{if $x=y$}, \end{cases} \quad ( 2 7 )$$
where θ is called as clustering weight which is a parameter that must be adjusted according to the environment. We will show later how it can impact the convergence point of the system. Thus, the utility function of any player x ∈ M is given by u x ( j, σ -x ) = ∑ y ∈ G σ j v x, y ( ; j ) then, glyph[negationslash]
$$\overline { \vdots 2 \rangle } \quad u _ { x } ( j, \sigma _ { - x } ) = \quad & \quad \ \ ( 2 8 ) \\ \underset { \text{is} } { \overline { \text{rs} } } \quad \begin{cases} \theta \sum _ { y \in G _ { j } ^ { \sigma } } \min ( p _ { x j }, p _ { y j } ) - p _ { x j }, & \text{if $G_{j}^{\sigma} \neq x$} \\ - p _ { x j }, & \text{if $G_{j}^{\sigma} = x$}. \end{cases}$$
## C. Interpretation of Clustering Weight
Let us rewrite the potential function according to defined symmetric bipartite utility. Then, using eq. (20), we may express the corresponding potential function which is equal to
$$\text{er } x \text{ is } \quad \Phi ( \sigma ) = \sum _ { j \in N } \left [ - \sum _ { a \in G _ { j } ^ { \sigma } } p _ { a j } + \frac { \theta } { 2 } \sum _ { a \in G _ { j } ^ { \sigma } } \sum _ { b \in G _ { j } ^ { \sigma } \wedge a } \min ( p _ { a j }, p _ { b j } ) \right ]. \\ \text{$(24)} \quad \text{Now let us consider that we can order the mobiles associated}$$
Now, let us consider that we can order the mobiles associated to BS j , according to the required power. The ordered set of mobiles related to BS j is represented by ˜ G σ j . Observe that we can now compute the potential function as following:
$$\text{its a} _ { \substack { \mathbf i t i o n \\ \text{in the} \\ \text{action} } } \quad \Phi ( \sigma ) = \sum _ { j \in N } \left [ - \sum _ { a \in \tilde { G } _ { j } ^ { \sigma } } p _ { a j } + \theta \sum _ { i = 1 } ^ { | \tilde { G } _ { j } ^ { \sigma } | - 1 } ( | \tilde { G } _ { j } ^ { \sigma } | - i ) p _ { i j } \right ]. \ \ ( 3 0 )$$
According to this result and the description of individual costs, we can state the following properties:
- 1) If θ is very small, i.e. the dominant term in the potential function and in the symmetric bipartite utility is the individual power p aj , then with a very low θ , each
mobile will privilege an association to the nearest BS. This is exactly the case when θ = 0 .
- 2) When θ increases a mobile may decide to leave its nearest neighbour if the lost in power is compensated by the second term. Suppose that the mobile wants to associate to a BS k , where all other mobiles currently associated with experience a better channel. Then the gain to associate to this second BS for this user will be θ ∑ p ij , i.e. the sum of all powers of mobiles already associated with this BS, weighted by θ . It is clear that the mobile will be joining either a cell having already strong power terms or a huge number of users.
- 3) If θ becomes very large, we can expect that all mobiles will converge to the same BS which means that only one BS is active.
## D. Network Topology as a Result of Best-reply Dynamics
Consider the setting in which only one player decides its strategy. It is called as best-reply dynamics when a player chooses the strategy which maximizes its utility. When there is no any player which can improve its utility, then this network topology, i.e. Π( σ glyph[star] ) , corresponds to a Nash equilibrium. Note that any local maximum in the potential function is a Nash equilibrium. Therefore, the network topology obtained by bestreply dynamics accounts for a local maximum of the potential function. Total power cost related to Π( σ glyph[star] ) can be given by
$$p = \sum _ { G _ { j } \in \Pi ( \sigma ^ { * } ) } \max _ { i \in G _ { j } } p _ { i j } \quad \quad ( 3 1 ) \quad \quad A. \ \, \mathcal { C }$$
where G j is the group of mobiles associated with BS j in the case of stable strategy-tuple σ glyph[star] .
Assuming that each mobile is capable to discover those BSs that can transmit to it, we can produce a scheduler in the following way: each BS generates a random clock-time for all those mobiles that it can transmit; then each mobile selects randomly a clock-time from those BSs that it can discover. We need to produce the clock-times by such a way that the collision of the turns of mobiles is minimal. In case of a collision, the clock-times of the corresponding mobiles are regenerated by corresponding BSs.
In Algorithm 1, the pseudo-code of the HD is given. Note that this is an algorithm performed in both BS and mobile sides by an exchange of the information in a separated channel.
Corollary 3.2: In the literature, the use of game models for set covering problems is called as set covering games [24], [25], [26]. The HD algorithm is a novel approach for set covering games. This algorithm is suitable for any set covering problem and facility activation problems where the agents are allowed to make strategic decisions
## IV. EFFICIENT ALGORITHMS FOR THE MAP
In this section, we propose different algorithmic solutions to evaluate and compare the efficiency of the distributed algorithm. Centralized algorithms exploit the set covering problem formulation since the search space is the smallest. However, binary integer linear programs are known to be NP-complete and thus we introduce two algorithms based on
## Algorithm 1 The Hedonic Decision
Base Station :
Check stability
while there is no stability do
Send information to each mobile about the current parti- tion
Check stability
end while
Mobile :
while there is no stability do
Determine the preferred BS according to eq. (28) Send information to the preferred BS
end while
dynamic programming: the hold minimum algorithm and the column control algorithm . Then, we develop the distributed version of the column control algorithm. A greedy solution of the problem is introduced as the nearest base station approach. The nearest BS and the column control are known and already used in the literature for SPLP problems. We adapt these algorithms to the MAP.
Because of the large scale nature of the collection set S , we rather develop the algorithms by making all operations on the power cost matrix. This approach foster the iterative removals of elements in the collection set, and ensure a faster convergence.
## A. Optimal Solution: The Hold Minimum (HM) Algorithm
The HM algorithm solves the problem optimally . We explain the algorithm by an example. Consider the power cost matrix which is given by
$$\begin{array} { c c c } y \\ & & P = \begin{bmatrix} 9 & 3 \\ 1 & 4 \\ 2 & 8 \end{bmatrix}. \quad & & ( 3 2 ) \end{array}$$
The power cost matrix can also be shown as P = ( p , p 1 2 , . . . , p n ) , where p j = ( p 1 j , p 2 j , . . . , p mj ) T . In each step, the algorithm removes a group of values p ij of the power cost matrix. Removing p ij means that we eliminate those clusters that include the mobile i and BS j from the collection set. The algorithm compares maximum n clusterings and holds only the clustering minimizing the total cost. Thus, it terminates in a step Q where each mobile is assigned to only one BS. In step s , the power cost matrix and collection set is denoted as P [ s ] = ( p 1 [ s , p ] 2 [ s , . . . , p ] n [ s ]) and S [ s ] , respectively.
Let us now turn to the example. In the initial step s = 0 , we assume that P [0] = P and S [0] = S given by
$$\mathcal { S } [ 0 ] = \{ ( 1 ; 1 ), ( 2 ; 1 ), ( 3 ; 1 ), ( 1, 2 ; 1 ), ( 1, 3 ; 1 ), ( 2, 3 ; 1 ), \\ ( 1, 2, 3 ; 1 ), ( 1 ; 2 ), ( 2 ; 2 ), ( 3 ; 2 ), ( 1, 2 ; 2 ), ( 1, 3 ; 2 ), \\ \text{ited}$$
Recall that assigning a cluster of mobiles S l to BS j has a cost max i ∈ S l p ij . Therefore, if we find the maximum value of p j , we obtain the total cost in case of all mobiles in column j are assigned to BS j . For example, max p 1 = max(9 1 2) = 9 , , .
This means that if all mobiles are assigned to BS 1, then the total cost is 9 .
The algorithm runs as following: in step s = 1 , we find the maximum value of each column of power cost matrix, then eliminate all values in power cost matrix except minimum of the calculated maximum values. Namely, max(9 1 2) , , = 9 and max(3 4 8) = 8 , , , then 9 is eliminated by putting an ∞
$$\mathbf P [ 1 ] = \begin{bmatrix} \infty & 3 \\ 1 & 4 \\ 2 & 8 \end{bmatrix}. \quad \begin{array} { c } \text{In e} \\ ( 3 4 ) & \text{pow} \\ \text{total} \\ \dots \end{array}$$
Thus, the collection set reduces to the following
$$\mathcal { S } [ 1 ] = \{ ( 2 ; 1 ), ( 3 ; 1 ), ( 2, 3 ; 1 ), ( 1 ; 2 ), ( 2 ; 2 ), ( 3 ; 2 ), ( 1, 2 ; 2 ), \quad & \text{exactly} \\ ( 1, 3 ; 2 ), ( 2, 3 ; 2 ), ( 1, 2, 3 ; 2 ) \}. \quad & ( 3 5 ) \quad & \frac { } { \text{$\text{$\text{$\text{$\text{$al$ori$it}$}$}$} } }$$
First column contains an ∞ which means that mobile 1 must be assigned to another BS (i.e. in this example, obviously BS 2 ). In fact, this represents the recursiveness of the algorithm where we run the algorithm for a sub power cost matrix. In this simple example, the sub power cost matrix is 3 . In general case, the algorithm does the following
$$P _ { j } [ s ] = \begin{cases} \ \max p _ { j } [ s ] + \mathfrak { h } ( \mathbf P _ { j } ^ { s u b } [ s ] ), & \text{if sub power cost matrix;} \\ \ \max p _ { j } [ s ], & \text{otherwise.} \end{cases} \quad \ \frac { \cdot } { \cdot }$$
(36)
where P j [ s ] represents the total cost if we assign all mobiles to BS j except those that can not be assigned to, and the optimal cost occurring due to sub power cost matrix P sub j [ s ] in step s . Here, h : glyph[Rfractur] m n × → {glyph[Rfractur] , A} is the function which gives the optimal value and assignments obtained by running HM algorithm.
For s = 2 , we calculate P 1 [2] = max(1 2)+ , h (3) = 2+3 = 5 , where P sub 1 [2] = (3) . On the other hand, we do not need to calculate P 2 [2] since it is kept in the memory. Therefore, P 2 [2] = P 2 [1] . Then, the algorithm holds minimum value of min( P 1 [2] , P 2 [2]) = P 1 [2] = 5 meaning that we remove 8 resulting in the following
$$\mathbf P [ 2 ] = \begin{bmatrix} \infty & 3 \\ 1 & 4 \\ 2 & \infty \end{bmatrix}, \quad \quad \ ( 3 7 ) \quad B. \ C \\ L _ { \Xi }$$
and
$$\mathcal { S } [ 2 ] = \{ ( 2 ; 1 ), ( 3 ; 1 ), ( 2, 3 ; 1 ), ( 1 ; 2 ), ( 2 ; 2 ), ( 1, 2 ; 2 ) \}. \ ( 3 8 ) \ \ P _ { 0 } \gg i$$
Then, for s = 3 , P 2 [3] = max(3 4) + , h (2) = 4 + 2 = 6 , where P sub 2 [3] = (2) , and P 1 [3] = P 1 [2] . We remove 4 , since min( P 1 [3] , P 2 [3]) = P 1 [3] . This gives the following matrix, collection set, assignments, and optimal total power,
$$\mathsf P [ 3 ] = \begin{bmatrix} \infty & 3 \\ 1 & \infty \\ 2 & \infty \end{bmatrix}, \quad \quad \quad ( 3 9 )$$
$$\mathcal { S } [ 3 ] = \{ ( 2 ; 1 ), ( 3 ; 1 ), ( 2, 3 ; 1 ), ( 1 ; 2 ) \} = \{ ( 2, 3 ; 1 ), ( 1 ; 2 ) \},$$
$$\mathfrak { h } ( \mathbf P ) \coloneqq \left \{ p = 5, \mathbf A = \begin{bmatrix} 0 & 1 \\ 1 & 0 \\ 1 & 0 \end{bmatrix} \right \}, \quad \begin{pmatrix} \mathfrak { m o u } \\ \mathfrak { w } ( 4 1 ) & | N _ { 3 } | \mathfrak { w } \\ \mathfrak { m o b i l } \mathfrak { w } \mathfrak { w } \mathfrak { w } \mathfrak { w } \mathfrak { w } \mathfrak { w } \mathfrak { w } \mathfrak { w } \mathfrak { w } \mathfrak { w } \mathfrak { w } \mathfrak { w } \mathfrak { w } \mathfrak { w } \mathfrak { w } \mathfrak { w } \mathfrak { w } \mathfrak { w } \mathfrak { w } \mathfrak { w } \mathfrak { w } \mathfrak { w } \mathfrak { w } \mathfrak { w } \mathfrak { w } \mathfrak { w } \mathfrak { w } \mathfrak { w } \mathfrak { w } \mathdag \mathfrak { w } \mathfrak { w } \mathfrak { w } \mathfrak { w } \mathfrak { w } \mathfrak { w } \mathfrak { w } \mathfrak { w } \mathfrak { w } \mathfrak { w } \mathfrak { w } \mathfrak { w } \mathfrak { w } \mathfrak { w } \mathfrak { w } \mathfrak { w } \mathfrak { w } \mathfrak { w } \mathfrak { w } \mathfrak { w } \mathfrak { w } \mathfrak { w } \mathfrak { w } \mathfrak { w } \mathfrak { w } \mathfrak { w } \mathfrak { w } \mathfrak { w } \mathfra \mathfrak { w } \mathfrak { w } \mathfrak { w } \mathfrak { w } \mathfrak { w } \mathfrak { w } \mathfrak { w } \mathfrak { w } \mathfrak { w } \mathfrak { w } \mathfrak { w } \mathfrak { w } \mathfrak { w } \mathfrak { w } \mathfrak { w } \mathfrak { w } \mathfrak { w } \mathfrak { w } \mathfrak { w } \mathfrak { w } \mathfrak { w } \mathfrak { w } \mathfrak { w } \mathfrak { w } \mathfrak { w } \mathfrak { w } \mathfrak { w } \mathfrak { w } \mathfro \mathfrak { w } \mathfrak { w } \mathfrak { w } \mathfrak { w } \mathfrak { w } \mathfrak { w } \mathfrak { w } \mathfrak { w } \mathfrak { w } \mathfrak { w } \mathfrak { w } \mathfrak { w } \mathfrak { w } \mathfrak { w } \mathfrak { w } \mathfrak { w } \mathfrak { w } \mathfrak { w } \mathfrak { w } \mathfrak { w } \mathfrak { w } \mathfrak { w } \mathfrak { w } \mathfrak { w } \mathfrak { w } \mathfrak { w } \mathfrak { w } \mathfrak { w } \mathfrum \mathfrak { w } \mathfrak { w } \mathfrak { w } \mathfrak { w } \mathfrak { w } \mathfrak { w } \mathfrak { w } \mathfrak { w } \mathfrak { w } \mathfrak { w } \mathfrak { w } \mathfrak { w } \mathfrak { w } \mathfrak { w } \mathfrak { w } \mathfrak { w } \mathfrak { w } \mathfrak { w } \mathfrak { w } \mathfrak { w } \mathfrak { w } \mathfrak { w } \mathfrak { w } \mathfrak { w } \mathfrak { w } \mathfrak { w } \mathfrak { w } \mathfrak { w } \mathfrig { \mathfrak { w } } \mathfrak { w } \mathfrak { w } \mathfrak { w } \mathfrak { w } \mathfrak { w } \mathfrak { w } \mathfrak { w } \mathfrak { w } \mathfrak { w } \mathfrak { w } \mathfrak { w } \mathfrak { w } \mathfrak { w } \mathfrak { w } \mathfrak { w } \mathfrak { w } \mathfrak { w } \mathfrak { w } \mathfrak { w } \mathfrak { w } \mathfrak { w } \mathfrak { w } \mathfrak { w } \mathfrak { w } \mathfrak { w } \mathfrak { w } \mathfrak { w } \mathfrak { w } \math frak { w } \mathfrak { w } \mathfrak { w } \mathfrak { w } \mathfrak { w } \mathfrak { w } \mathfrak { w } \mathfrak { w } \mathfrak { w } \mathfrak { w } \mathfrak { w } \mathfrak { w } \mathfrak { w } \mathfrak { w } \mathfrak { w } \mathfrak { w } \mathfrak { w } \mathfrak { w } \mathfrak { w } \mathfrak { w } \mathfrak { w } \mathfrak { w } \mathfrak { w } \mathfrak { w } \mathfrak { w } \mathfrak { w } \mathfrak { w } \mathfrak { w } \mathfrak { w
} _ . . " : - < +$$
respectively. The pseudo-code of this algorithm is given in Algorithm 2.
Theorem 4.1: The HM algorithm terminates in finite step. At this step, the total power cost is minimum.
Proof: The power cost matrix is transformed in each step by
$$\mathbf P [ 0 ] \to \mathbf P [ 1 ] \to \dots \to \mathbf P [ Q ]. \text{ \quad \ \ } ( 4 2 )$$
In each step, at least n -1 values are removed from the power cost matrix. Removed values are those that increase the total cost. The value that is held is the minimum one in the corresponding step. So, in the terminal step s = Q , it arrives to such a cost that is the lowest. Each mobile is assigned to exactly one BS in the terminal step.
## Algorithm 2 The Hold Minimum
$$\text{st} \quad \text{function $(p,A) = \mathfrak { h } ( \mathbf P )$$
while each row includes several ' 1 's in A do
k
←
1
for j = indices of columns of P not including all ∞ do V k ← maximum of column j except ∞
if any row in column
j
includes
∞
then sub
P
←
rows including
$$\begin{smallmatrix} \mu & \cdot & \cdot & \cdot &$$
end if
k
←
k
end for
(
i
min
, j min
Hold
V
+1
, V
min causing
min using
)
←
(
min
i
min
∞
of
V
, j min
P
ij
≥
V
min in
P
Put
0
in all indices causing
## end while
p
←
∑
max
A
⊗
P
end
The complexity of this algorithm is assessed in Section ?? .
B. Greedy Solution: The Column Control (CC) Algorithm
Let us denote the CC algorithm by c : glyph[Rfractur] m n × → {glyph[Rfractur] , A} . This algorithm exploits the assumption that the operational power cost P 0 is fairly higher than the transmitted power, i.e. P 0 glyph[greatermuch] P ij . The aim here is to assign many mobiles to only one BS. Recall that cluster N j (set of mobiles that can be assigned to BS j ) has the transmission cost max i ∈ N j P ij and the operational cost P j 0 . For better understanding, consider the following power cost matrix in which the operational power cost is assumed to be 12 W :
$$\begin{array} {$$
In such a scenario, we can assign | N 1 | = 3 mobiles to BS 1 with cost 12 50 . , | N 2 | = 4 mobiles to BS 2 with cost 12 45 . , | N 3 | = 4 mobiles to BS 3 with cost 12 43 . , and | N 4 | = 3 mobiles to BS 3 with cost 12 35 . .
P
)
and put ij
P
∞
in
≥
V
min in
A
all indices
The logic behind the CC algorithm is the following:
- 1) Find how many mobiles can be assigned to each BS
- 2) Choose the BS to which it can be assigned the most mobiles
- 3) If there are multiple BSs in the state of 2), then choose the BS which can serve the mobiles with minimal cost
Applying these rules to the last example, it turns out that BS 3 can cover the most mobiles | N 3 | = 4 which are N 3 = (1 , 2 3 4) , , with the lowest cost 12 43 . . Then, the algorithm assigns only a cluster of mobiles. In the following step, the CC algorithm performs the same rules to the remained mobiles which produces the sub power cost matrix P sub . In the last example, it is given by P sub = [ ∞ ∞ ∞ 12 29 . ] . This results in the assignment of mobile 5 to BS 4, because mobile 5 can not be assigned to other BSs. This shows the recursiveness of the CC algorithm. A pseudo-code is given in Algorithm 3.
Formally, in step s , we denote as following the set of mobiles assigned to BS j : R s [ ] = { Assigned mobiles in step s } . Thus, the collection set is reduced as following in step s :
$$\mathcal { S } [ s ] & = \{ \mathcal { S } [ s -$$
Considering the last example, in step s = 1 , R [1] = (1 , 2 3 4) , , . By assigning these mobiles to BS 3, the CC algorithm removes those assignments which include mobiles (1 2 3 4) , , , except ( S k ; ) = { (1 , 2 3 4) 3 , , , } . Thus, the total power and assignments are given by
$$\mathfrak { c } ( \mathbf P ) \coloneqq \left \{ p$$
Moreover, for any power cost matrix, we conclude that in a final step Q , the CC algorithm converges to the case where each mobile is assigned to one BS.
## Algorithm 3 The Column Control
function ( p, A ) = c ( P )
v
′
=
Find how many
v
min
∞
←
min
v
′
v
′′
=
Find which row of
v
′
is equal to
v
min for l = columns of P determined by | v ′′ | do
V
l
←
maximum value of column
l
of
P
end for
Find V min = min V l and the corresponding column l min if | v ′ | == 0 then
Put 1s to the column l min in A
else
A ′ ← Put 1s to the column l min in A
Find sub power cost matrix P sub which is composed by those mobiles that are not assigned
A
sub
←
Find assignments by running
c
(
P
sub
)
## end if
$$\mathbf A \leftarrow \text{Combine } \mathbf A ^ { s u b$$
$$p \leftarrow \sum \max \, \mathbf A \otimes \mathbf P$$
end has each column of
P
## C. Distributed Column Control (DCC) Algorithm
Assume that each BS broadcasts its own power vector and identities of mobiles that it can serve. Recall that we denote the power vector of BS j as p j . The power vector of BS 1 given in the power cost matrix of eq. (43) is p 1 = (12 50 12 30 12 20 . , . , . , ∞ ∞ , ) T . From a practical point of view, the BS broadcasts only the identity and associated costs of the mobiles which are associated with it. The infinity values are not broadcast. Therefore, the BS broadcasts the power vector as p 1 = (12 50 12 30 12 20) . , . , . T , and an identity vector represented as h j = ( h jk ) ∈ N | p j | . For example, h 1 = (1 2 3) , , T .
Moreover, each mobile receives power vectors from all BSs that can transmit to it. Then, each mobile generates the power cost matrix from received power vectors. For example, mobile 1 receives from BS 1, BS 2, and BS 3 the power vectors
$$p _ { 1 } = ( 1 2. 5 0, 1 2. 3 0, 1 2. 2 0 ) ^ { T },$$
$$p _ { 2 } = ( 1 2. 4 0, 1 2. 3 0, 1 2. 4 5, 1 2. 4 3 ) ^ { T },$$
and
$$p _ { 3 } = ( 1 2. 3 2, 1 2. 4 3, 1 2. 1 5, 1 2. 2 5 ) ^ { T }$$
with identity vectors h 1 = (1 2 3) , , T , h 2 = (1 2 3 4) , , , T , and h 3 = (1 2 3 4) , , , T , respectively. Mobile 1 decides that the power cost matrix is as following:
$$\begin{bmatrix} & & \hookrightarrow & & \\ 1 2. 5 0 & 1 2. 4 0 & 1 2. 3 2 \\ 1 2. 3 0 & 1 2. 3 0 & 1 2. 4 3 \\ 1 2. 2 0 & 1 2. 4 5 & 1 2. 1 5 \\ \infty & 1 2. 4 3 & 1 2. 2 5 \end{bmatrix}.$$
Note that mobile 1 realizes from h 2 and h 3 that BS 1 can not transmit to mobile 4. Therefore, it puts an infinite cost corresponding to mobile 4 and BS 1 in the power cost matrix.
By this rule each mobile determines its own power cost matrix. Thus, each mobile finds the assignments according to CC algorithm, and selects the BS from which it will receive data. For example, mobile 1 obtains the following assignment matrix by running CC algorithm
$$\begin{bmatrix} 0 & 0 & 1 \\ 0 & 0 & 1 \\ 0 & 0 & 1 \\ 0 & 0 & 1 \end{bmatrix}.$$
It turns out that mobile 1 chooses BS 3 for reception the broadcast data.
Remark 4.1: Through the advantage of the decentralization, the DCC algorithm makes possible the following: if the mobiles do not send any assignment information to a BS, then the corresponding BS is considered to be switched off . On the other hand, the CC algorithm is centralized, therefore, the network determines according to the assignments which BS is switched off .
## D. Greedy Solution: The Nearest BS (NBS) Algorithm
To solve the problem heuristically, the easiest way is to assign each mobile to the nearest BS. By 'nearness', we do not mean a geographical measure, instead, it is the lowest
power cost that the corresponding mobile needs from the corresponding BS. So, the mobile selects the BS transmitting with the lowest power. We assume that a mobile is capable to know the power costs corresponding to those BSs that can transmit to it.
Clearly, mobile i knows the vector p i = ( p i 1 , p i 2 , . . . , p in i ) where n i denotes the number of BSs that mobile i can be served. Then, mobile i only calculates the minimal value of p i , and chooses the corresponding BS,
$$a _ { i, j } = 1 \colon \ j = \arg \min _ { j } p _ { i },$$
where a i,j ∈ A is the BS that mobile i selects. Actually, this corresponds to remove from collection set S all assignments related to mobile i and the BSs being out BS j .
The NBS algorithm is very efficient and quick, and in most cases, it gives optimal assignments when the operational power cost P 0 is neglected (See Section VI).
## E. Greedy Set-Cover Algorithm (greedy-SC)
In [17], a greedy heuristic for the set covering problem is proposed by Chvatal. We utilize this algorithm in simulation results (section VI) to compare it with the proposed algorithms.
## V. TIME COMPLEXITY ANALYSIS
In this section, we estimate and compare the time complexity of the proposed algorithms.
Theorem 5.1: The time complexity of the HM algorithm is O m n ( 3 ) + ( n -1) ∑ m s =1 T m ( -s, n -1) + mO n ( ) .
Proof:
Note that at most n -1 operations are required to find the maximum value of a column of the power cost matrix in one step, and a single operation for finding the minimum of a vector having n values. In each step, there is at least one element in a column that is removed. At most m steps are needed until a convergence to the optimal case. Selection algorithms (finding maximum or minimum) have a time complexity in O n ( ) [27]. We can express as following the time complexity including the recursive property of the algorithm:
We also simulate the last recurrence resulting in the following graphical characteristics:
m
In the axis denoting T m ( ) , a log-scale is used. The figure illustrates that the complexity grows exponentially.
Theorem 5.2: The time complexity of the CC algorithm is O mn ( ) .
Proof: This result is known and a complete proof is available [28].
Theorem 5.3: The time complexity of the NBS algorithm is O n ( ) .
Proof: It is straightforward because the only operation that is performed in the NBS algorithm is to find the minimum value of a vector of power cost matrix having a dimension at most n . Therefore, the time complexity is O n ( ) .
Theorem 5.4: The time complexity of the HD algorithm is PLS-complete with ρ m,n mO n ( ) ( ) .
Proof: We denote by ρ m,n ( ) the rounds needed for converging to the Nash equilibrium. Note that this is a random variable. In each step, only one mobile performs a maximization operation which causes totally mO n ( ) complexity. This is repeated during ρ m,n ( ) rounds. So, the time required can be given by T m,n ( ) = ρ m,n mO n ( ) ( ) . Actually, the complexity of finding the Nash equilibria in a potential game is known to be PLS-complete, refer to [29].
Furthermore, the computational results achieved in next section highlight that the number of rounds grows logarithmically with respect to the number of mobiles and BSs (Figure 8).
## VI. SIMULATION RESULTS
## A. Downlink System Model
For small-cells, the cellular network model consists of BSs arranged according to an homogeneous Poisson point process Φ of intensity λ b ( points/m 2 ) in the Euclidean plane [30]. For macro-cells, we use the classical honeycomb model to represent a well structured network made of large cells.
$$T ( m, n ) = \sum _ { s = 1 } ^ { m } \left [ ( n - 1 ) \left ( O ( m - s ) + T ( m - s, n - 1 ) \right ) + O ( n ) \right ] \text{ For small} \\ ( 4 9 ) \text{ } \text{ } \text{ } \text{ } \text{ } \text{ } \text{ } \text{ } \text{ } \text{ } \text{ } \text{ } \text{ } \text{ } \text{ } \text{ } \text{ } \text{ } \text{ } \text{ } \text{ } \text{ } \text{ } \text{ } \text{ } \text{ } \text{ } \text{ } \text{ } \text{ } \text{ } \text{ } \text{ } \text{ } \text{ } \text{ } \text{ } \text{ } \text{ } \text{ } \text{ } \text{ } \text{ } \text{ } \text{ } \text{ } \text{ } \text{ } \text{ } \text{ } \text{ \text{ } \text{ } \text{ } \text{ } \text{ } \text{ } \text{ } \text{ } \text{ } \text{ } \text{ } \text{ } \text{ } \text{ } \text{ } \text{ } \text{ } \text{ } \text{ } \text{ } \text{ } \text{ } \text{ } \text{ } \text{ } \text{ } \text{ } \text{ } \text{ } \text{ } \text{ } \text{ } \text{ } \text{ } \text{ } \text{ } \text{ } \text{ } \text{ } \text{ } \text{ } \text{ } \text{ } \text{ } \text{ } \text{ } \text{ } \text{ } \text{ } \text{ \text{ } \text{ } \text{ } \text{ } \text{ } \text{ } \text{ } \text{ } \text{ } \text{ } \text{ } \text{ } \text{ } \text{ } \text{ } \text{ } \text{ } \text{ } \text{ } \text{ } \text{ } \text{ } \text{ } \text{ } \text{ } \text{ } \text{ } \text{ } \text{ } \text{ } \text{ } \text{ } \text{ } \text{ } \text{ } \text{ } \text{ } \text{ } \text{ } \text{ } \text{ } \text{ } \text{ } \text{ } \text{ } \text{ } \text{ } \text{ } \text{ } \text{} \text{ } \text{ } \text{ } \text{ } \text{ } \text{ } \text{ } \text{ } \text{ } \text{ } \text{ } \text{ } \text{ } \text{ } \text{ } \text{ } \text{ } \text{ } \text{ } \text{ } \text{ } \text{ } \text{ } \text{ } \text{ } \text{ } \text{ } \text{ } \text{ } \text{ } \text{ } \text{ } \text{ } \text{ } \text{ } \text{ } \text{ } \text{ } \text{ } \text{ } \text{ } \text{ } \text{ } \text{ } \text{ } \text{ } \text{ } \text{ } \text{ } \text{$$
(49)
where we assume that in each step s a sub-matrix occurs with complexity T m ( -s, n ) . Solving this kind of recurrence is tricky but further technical manipulations lead to following expression:
$$T ( m, n ) = O ( m ^ { 3 } n ) + ( n - 1 ) \sum _ { s = 1 } ^ { m } T ( m - s, n - 1 ) + m O ( n ). \begin{array} { c } \text{Poisson} \\ \text{in-med} \\ ( 50 ) & \text{non null} \end{array}$$
Also, we consider an independent collection of mobile users, located according to some independent homogeneous Poisson point process with intensity λ m ( points/m 2 ) . The main weakness of the Poisson model is that because of the independence of the Poisson point process, two BSs have a non null probability to be located very close to each other. This
weakness is balanced by two strengths: the natural inclusion of different cell sizes and shapes and the lack of edge effects, i.e. the network extends indefinitely in all directions [31]. The expected value of a homogeneous Poisson point process is E [Φ] = λA , where A ⊂ glyph[Rfractur] 2 denotes some area.
Moreover, the deployment scenario used to generate Figures 2, 3, 4, 6 corresponds to small-cells. We assume P r = -80 dBm , being the typical maximum received signal power of a wireless network as well as we set arbitrarily P ij = ∞ if P ij ≥ 20 dBm and we set the path loss exponent α = 3 . We also assume an equal operational power cost for all BS, P 0 = 12 W .
## B. Performance Results
We compare the proposed algorithms for different values of λ m and λ b . The average total power was calculated by Monte Carlo simulations by running the algorithms for different generated power cost matricesand taking the mean of the results.
We first start with macro-cells. As mentioned above, we use a honeycomb model with a cell radius equal to 4 km . Table I presents the optimal set-covering (SC) result as well as those obtained with the different proposed algorithms for different realization of power cost matrices and when the operational power cost is null, i.e. P 0 = 0 for all BSs. The transmission power P ij = ∞ if P ij ≥ 48 dBm . It turns out that the HD algorithm is very efficient and converges to nearly optimal assignments when operational power costs are neglected. This result indicates that switching off some BS does not decrease the total power significantly. The NBS algorithm also produces near optimal results in many examples. In these practical scenarios, the idea of switching off some BS is mostly interesting when the circuit power is dominant, which is not the case for macro-cells. Further, as fast moving users are associated with macro-cells in priority, it seems reasonable to keep all active. Therefore, the NBS algorithm is efficient and the gain achievable with any other optimal algorithm is marginal.
Table II compares the SC optimal results with all developed algorithms introduced in the paper for small-cells scenarios. The operational power cost is set to P 0 = 12 W and the BS density is increased. CC and DCC algorithms produce optimal assignments for almost all examples. However, the DCC algorithm naturally performs worse when the number of BSs increases. Moreover, the NBS algorithm exhibits worst results which highlights the interest of switching off some BSs when the operational power cost is higher than the transmission power cost.
Figure 2 illustrates the results achieved with the NBS algorithm, for different densities of BS and mobiles. This figure highlights an intuitive property of the NBS approach. When no operational cost is considered (see Figure 2), the power consumption decreases with the BS density, since the average distance between mobiles and BSs decreases accordingly. On the opposite, when an operational cost is considered, the NBS algorithm leads to an increased energy consumption since the number of active BS increases accordingly.
Let us now switch to the CC and DCC algorithms. Figure 3 focuses only on scenarios with circuit power, because they correspond to the more relevant cases. the upper curves show that the CC algorithm achieves much better results than NBS, especially when the BS density is high. This algorithm privileges solutions with larger cells. The distributed version DCC performs worst than the centralised one but still better than the NBS.
Figure 4 plots the change of the average total power with respect to the intensity of mobiles for small-cells scenario. The assumptions are as following: λ b = 1 11 . × 10 -5 points m 2 , θ = 0 002 . (in Figure 6, the optimal θ is found), and area A = 6 25 . km 2 . Note that the HD algorithm performs efficiently even though it is decentralized. For example, in case of λ m = 8 × 10 -8 , the average number of mobiles is given by 8 × 10 -8 · 6 25 . × 10 6 = 50 ; thus, the average power used per mobile is calculated as following: a) the HD algorithm: 63 50 = 1 26 / . W , b) the CC algorithm: 55 50 = 1 1 / . W , c) the greedy-SC algorithm: 50 50 = 1 / W , d) the SC algorithm: 43 83 . / 50 = 0 88 . W .
Figure 7 depicts the change of the average total power with respect to the intensity of mobiles for macro-cell deployment. λ b = 80 points 3600 km 2 , A = 3600 km 2 ( 60 km × 60 km area), and θ = 0 21 . (in Figure 7, we plot the change of average total power with respect to θ , and choose the optimal value). Here, we observe that the HD algorithm produces remarkable results. Calibrating θ properly is significant, otherwise the HD algorithm may not converge to the near optimal results. On the other hand, the NBS algorithm is also efficient in the macro-cell deployment. The drawback of greedy-SC algorithm reveals here since it works with a mechanism where the larger cells are privileged.
In Figures 6 and 7, the normalized average total power is plotted with respect to θ . From the figures and our observations in experiments performed in MATLAB, it might be considered that θ is mainly affected by the area over which the algorithm runs. For example, in Figure 7, the normalized average total power has a minimum in the same value of intensity of BSs, but it moves to a higher value when the area is enlarged from 2500 km 2 to 3600 km 2 .
Figure 8 shows the change of the average number of rounds of the HD algorithm for converging to a Nash equilibrium with respect to the area. The figure implies that the average number of rounds has a logarithmic characteristic. Moreover, when the operational power costs are zero, the average number of rounds increases since smaller cells are formed; therefore, the HD algorithm needs more rounds to converge to a Nash equilibrium.
## VII. CONCLUSION AND FUTURE WORKS
This paper addressed the MAP problem in the context of broadcast transmission. We introduced a novel decentralized solution based on group formation games, which we named the hedonic decision (HD) algorithm. This formalism is constructive: a new class of group formation games is introduced where the utility of players within a group is separable and symmetric being a generalization of party affiliation games. We proposed a centralized optimal recursive algorithm (the HM) as well as a centralized polynomial-time heuristic algorithm (the CC).
TABLE I A = 2500 km 2 , λ b = 6 points 2500 km 2 , λ m = 1 point 25 km 2 , P 0 = 0 W θ , = 0 11 . .
| Ex. i | m | n | | HM | SC | CC | DCC | NBS | HD |
|---------|-----|-----|----------|---------|---------|---------|---------|---------|---------|
| 1 | 54 | 6 | 10 - 7 × | 294.036 | 294.036 | 294.036 | 295.57 | 294.036 | 294.036 |
| 2 | 43 | 6 | 10 - 7 × | 299.816 | 299.816 | 323.619 | 352.166 | 299.816 | 299.816 |
| 3 | 46 | 6 | 10 - 7 × | 250.483 | 250.483 | 271.483 | 271.483 | 250.483 | 250.483 |
| 4 | 41 | 6 | 10 - 7 × | 270.442 | 270.442 | 302.815 | 287.968 | 284.574 | 283.074 |
| 5 | 51 | 6 | 10 - 7 × | 307.723 | 307.723 | 361.767 | 361.767 | 320.266 | 307.723 |
| 6 | 45 | 6 | 10 - 7 × | 278.521 | 278.521 | 317.509 | 317.509 | 278.521 | 278.521 |
| 7 | 41 | 6 | 10 - 7 × | 305.124 | 305.124 | 345.31 | 345.31 | 306.892 | 312.211 |
| 8 | 34 | 6 | 10 - 7 × | 221.568 | 221.568 | 236.717 | 236.717 | 256.074 | 221.568 |
| 9 | 58 | 6 | 10 - 7 × | 360.356 | 360.356 | 363.188 | 363.188 | 360.356 | 360.356 |
| 10 | 52 | 6 | 10 - 7 × | 310.072 | 310.072 | 310.072 | 310.072 | 332.074 | 332.074 |
| 11 | 44 | 6 | 10 - 7 × | 283.924 | 283.924 | 313.812 | 339.655 | 283.924 | 283.924 |
| 12 | 49 | 6 | 10 - 7 × | 312.972 | 312.972 | 312.972 | 312.972 | 325.58 | 337.994 |
| 13 | 53 | 6 | 10 - 7 × | 229.934 | 229.934 | 255.312 | 255.312 | 229.934 | 232.653 |
| 14 | 60 | 6 | 10 - 7 × | 308.6 | 308.6 | 308.6 | 308.6 | 320.206 | 320.206 |
| 15 | 57 | 6 | 10 - 7 × | 329.267 | 329.267 | 342.846 | 354.065 | 329.267 | 335.953 |
TABLE II A = 4 km 2 , λ b = 6 points 4 km 2 , λ m = 18 points 4 km 2 , P 0 = 12 W θ , = 0 003 . .
| Ex. i | m | n | HM | SC | CC | DCC | NBS | HD |
|---------|-----|-----|--------|--------|--------|--------|--------|--------|
| 1 | 14 | 4 | 24.153 | 24.153 | 24.153 | 24.153 | 48.183 | 24.153 |
| 2 | 14 | 7 | 24.14 | 24.14 | 36.226 | 36.226 | 72.139 | 24.152 |
| 3 | 23 | 7 | 36.138 | 36.138 | 48.177 | 48.275 | 84.042 | 48.185 |
| 4 | 16 | 7 | 36.195 | 36.195 | 36.195 | 36.257 | 72.208 | 48.204 |
| 5 | 19 | 4 | 24.109 | 24.109 | 24.109 | 36.174 | 48.126 | 36.184 |
| 6 | 7 | 3 | 12.07 | 12.07 | 12.07 | 12.07 | 24.073 | 12.07 |
| 7 | 15 | 8 | 36.178 | 36.178 | 36.178 | 36.222 | 84.241 | 36.222 |
| 8 | 15 | 7 | 24.11 | 24.11 | 24.11 | 24.144 | 72.101 | 24.154 |
| 9 | 18 | 9 | 36.099 | 36.099 | 36.148 | 36.253 | 84.042 | 36.148 |
| 10 | 24 | 6 | 36.111 | 36.111 | 36.191 | 36.191 | 60.134 | 36.191 |
| 11 | 21 | 3 | 24.149 | 24.149 | 24.149 | 24.149 | 36.162 | 24.149 |
| 12 | 18 | 10 | 36.111 | 36.111 | 36.111 | 48.141 | 84.053 | 48.152 |
| 13 | 23 | 5 | 36.105 | 36.105 | 36.105 | 48.143 | 60.218 | 36.105 |
| 14 | 13 | 4 | 24.082 | 24.082 | 24.104 | 24.104 | 48.123 | 24.11 |
| 15 | 17 | 8 | 36.19 | 36.19 | 36.19 | 36.217 | 60.217 | 36.19 |
TABLE III λ b = 0 10 . × 10 -3 points m 2 , λ m = 1 11 . × 10 -3 points m 2 , P 0 = 12 W , θ = 0 008 . .
| | Number of rounds | Number of rounds | Number of rounds | Number of rounds |
|----------------------|--------------------|--------------------|--------------------|--------------------|
| Example/Area( km 2 ) | 0 . 98 | 1 . 28 | 1 . 62 | 2 . 00 |
| 1 | 3 | 2 | 3 | 3 |
| 2 | 3 | 3 | 3 | 3 |
| 3 | 3 | 3 | 2 | 3 |
| 4 | 2 | 3 | 3 | 3 |
| 5 | 3 | 2 | 3 | 3 |
| 6 | 3 | 3 | 3 | 3 |
| 7 | 3 | 3 | 3 | 4 |
| 8 | 3 | 3 | 3 | 4 |
| 9 | 3 | 3 | 3 | 3 |
| 10 | 3 | 3 | 3 | 4 |
The results exhibit that the HD algorithm achieves very good results if the parameter θ is well chosen. The exact value of θ is not provided and may be used as a setting parameter.
The proposed HD algorithm is efficient and may be used in many other set covering problems. For instance, indoor wireless network planning has been studied for several years and the optimal BS activation is an important problem. The proposed HD algorithm could be used for planning purposes and thus optimizing the number of BS, but could also be used to optimize dynamically the number of active BS as a function of actives users. The provider may deploy a high density of BS and then could run dynamically the HD algorithm to optimize
Fig. 2. The NBS Algorithm: Average total power ¯ p with respect to intensity of BSs λ b for increasing values of intensity of mobiles λ m = (0 16 . , 0 25 0 44 1 00) . , . , . × 10 -4 points m 2 , A = 4 km 2 .
then number of active BSs.
Furthermore, it could be interesting to change the game parameters. One can define different clustering weights for each BS. That setting could provide better results. It is also possible to try different symmetric bipartite utility allocations.
## REFERENCES
- [1] S. Sesia, I. Toufik, and M. Baker, LTE The UMTS Long Term Evolution: From Theory to Practice . John Wiley & Sons, Ltd., 2009.
- [2] J. Krarup, P.M. Pruzan, 'The simple plant location problem: Survey and synthesis,' European Journal of Operational Research , vol. 12, pp. 3681, 1983.
- [3] V. Bil`, I. Caragiannis, C. Kaklamanis, and P. Kanellopoulos, 'Geometric o clustering to minimize the sum of cluster sizes,' In Proc. 13th European Symp. Algorithms, vol.3669 of LNCS , pp.460-471, 2005.
- [4] N. Lev-Tov and D. Peleg, 'Polynomial time approximation schemes for base station coverage with minimum total radii,' Computer Networks , vol.47, no.4, pp.489-501, Mar. 2005.
Fig. 3. Average total power ¯ p with respect to intensity of BSs λ b for increasing values of intensity of mobiles λ m = (0 16 0 25 0 44 1 00) . , . , . , . × 10 -4 points m 2 , A = 4 km 2 , P 0 = 12 W .
Fig. 4. Small cells: Change of the average total power ¯ p with respect to the intensity of mobiles.
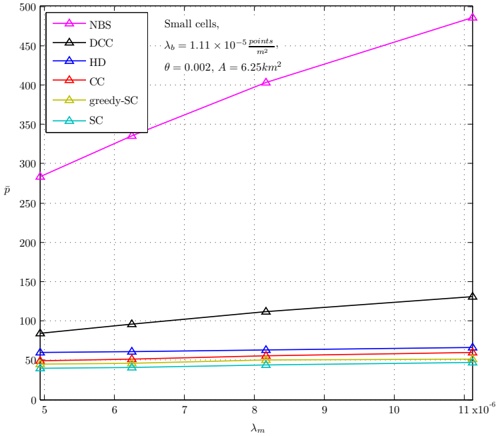
p
Fig. 5. Macro cells: Average total power ¯ p with respect to the intensity of mobiles.
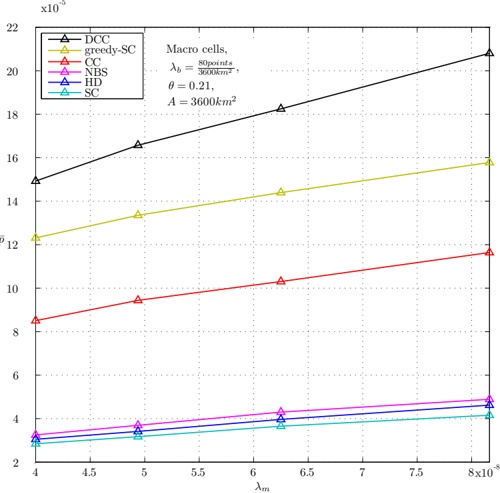
Fig. 6. Small cells: Normalized average total power with respect to θ .
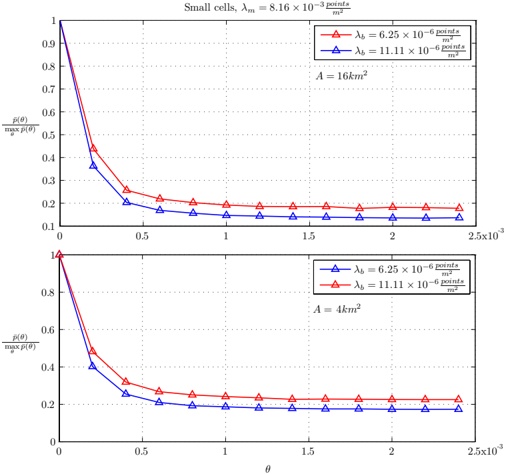
- [5] H. Alt, E. M. Arkin, H. Br¨ onnimann, J. Erickson, S. P. Fekete, C. Knauer, J. Lenchner, J. S. B. Mitchell, and K. Whittlesey, 'Minimum-cost coverage of point sets by disks,' In Proceedings of ACM Symposium on Computational Geometry (SCG '06) , pp. 449-458, New York, NY, USA, 2006.
- [6] S. Funke, S. Laue, Z. Lotker, and R. Naujoks, 'Power assignment problems in wireless communication: Covering points by disks, reaching few receivers quickly, and energy-efficient travelling salesman tours,' In Proceedings of Ad Hoc Networks , pp.1028-1035, 2011.
- [7] V. Rodoplu, T.H. Meng, 'Minimum energy mobile wireless networks,' IEEE Journal on Selected Areas in Communications , vol.17, no.8, pp.1333-1344, Aug. 1999.
- [8] J. E. Wieselthier, G. D. Nguyen, and A. Ephremides, 'On the construction of energy-efficient broadcast and multicast trees in wireless networks,'.
1
point
θ
Fig. 7. Macro cells: Normalized average total power with respect to θ .
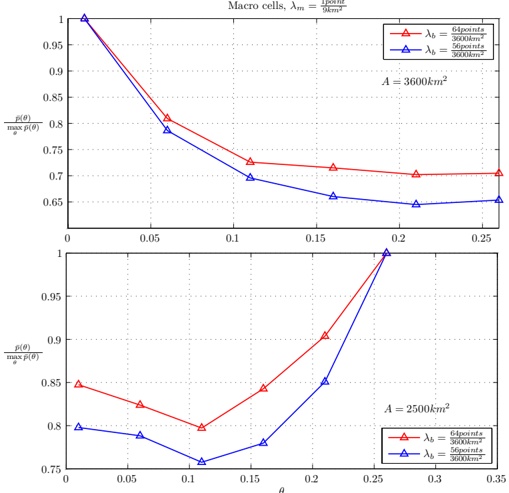
Fig. 8. Average number of rounds with respect to the area.
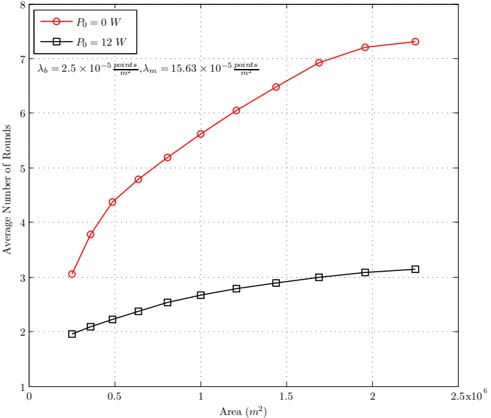
IEEE INFOCOM 2000 , pp.586-594, Tel Aviv, Israel, 2000.
- [9] ¨ . O E˘ gecio˘ glu, and T. Gonzalez, 'Minimum-energy broadcast in simple graphs with limited node power,' IASTED International Conference on Parallel and Distributed Computing and Systems (PDCS 2001) , pp.334338, Anaheim, CA, Aug. 2001.
- [10] M. Cagalj, J. P. Hubaux, and C. Enz, 'Minimum-energy broadcast in all-wireless networks: NP-completeness and distribution issues,' In Proceedings of ACM international conference on Mobile computing and networking (MobiCom) , New York, NY, USA, pp.172-182, 2002.
- [11] C. Hasan, E. Altman, and J.M. Gorce, 'A coalition game approach to the association problem of mobiles in broadcast transmission,' WiOpt 2011 pp.236-240, 9-13 May 2011.
- [12] A. P. Bianzino, C. Chaudet, D. Rossi, J. L. Rougier, 'A survey of green networking research,' IEEE Communications Surveys and Tutorials , vol.14, no.1, pp.3-20, 2012.
- [13] H. Claussen, 'The future of small cell networks,' IEEE COMMSOC MMTC E-Lett. [Online], pp.32-36, Sept. 2010. Available:
http://committees.comsoc.org/mmc/e-news/E-Letter-September10.pdf
- [14] E. Balas and M. W. Padberg, 'Set partitioning: A survey,' SIAM Review , vol.18, pp.710-760, 1976.
- [15] C. Lund, M. Yannakakis, 'On the hardness of approximating minimization problems,' Journal of the ACM vol.41, no.5, pp.960-981, Sept. 1994.
- [16] C. K. Singh and E. Altman, 'The wireless multicast coalition game and the non-cooperative association problem,' in 30th IEEE INFOCOM , Shanghai, China, 10-15, Apr. 2011.
- [17] Chv´ atal, V., 'A greedy heuristic for the set-covering problem,' Mathematics of Operations Research , vol. 4, no. 3, pp. 233-235, 1979.
- [18] G. Hollard, 'On the existence of a pure strategy Nash equilibrium in group formation games,' Elsevier Economics Letters , vol. 66, pp. 283287, 2000.
- [19] Konishi, H., Le Breton, M., Weber, S.,'Pure strategy Nash equilibrium in a group formation game with positive externalities,' Games and Economic Behavior vol. 21, 161-182.
- [20] I. Milchtaich, 'Stability and segregation in group formation,' Games and Economic Behavior , vol. 38, pp. 318-346, 2002.
- [21] D. Monderer and L. S. Shapley, 'Potential games,' Games and Economic Behavior vol. 14, pp. 124-143, 1996.
- [22] R. W. Rosenthal, 'A class of games possessing pure-strategy Nash equilibria,' International Journal of Game Theory vol. 2, 65-67, 1973.
- [23] J. H. Aldrich, W. T. Bianco, 'A game-theoretic model of party affiliation of candidates and office holders,' Mathematical and Computer Modelling , vol. 16, no. 8-9, pp. 103-116, Aug.-Sept., 1992.
- [24] D. Leibovic and E. Willett, 'Selfish set covering,' In Midstates Conference for Undergraduate Research in Computer Science and Mathematics , Nov. 2009.
- [25] X.-Y. Li, Z. Sun, W. Wang, 'Cost sharing and strategyproof mechanisms for set cover games,' Lecture Notes in Computer Science , vol. 3404, pp. 218-230, 2005.
- [26] X.-Y. Li, Z. Sun, W. Wang, X. Chu, S. J. Tang, P. Xu, 'Mechanism design for set cover games with selfish element agents,' Theoretical Computer Science , vol. 411, no. 1, pp. 174-187, 2010.
- [27] M. Blum, R. W. Floyd, V. Pratt, R. L. Rivest, and R. E. Tarjan, 'Time bounds for selection,' J. Comput. Syst. Sci. vol.7, no.4, pp.448-461, Aug. 1973.
- [28] T. Feder, and D. Greene, 'Optimal algorithms for approximate clustering,' Proceedings of the twentieth annual ACM symposium on Theory of computing , pp. 434-444, 1988.
- [29] A. Fabrikant, C. Papadimitriou, and K. Talwar, 'The complexity of pure Nash equilibria,' In Proceedings of the thirty-sixth annual ACM symposium on Theory of computing (STOC '04) , New York, NY, USA, 604-612, 2004.
- [30] F. Baccelli, and B. Błaszczyszyn, 'Stochastic geometry and wireless networks: volume I theory,' Foundations and Trends in Networking , vol.3, pp.249-449, 2009.
- [31] J. G. Andrews, F. Bacelli, and R. K. Ganti, 'A tractable approach to coverage and rate in cellular networks,' IEEE Trans. on Commun. , vol.59, no.11, pp.3122-3134, Nov. 2011.
- [32] J. Hoydis, M. Debbah, 'Green, cost-effective, flexible, small cell networks,' IEEE ComSoc MMTC E-Letter Special Issue on 'Multimedia Over Femto Cells' , 2010. | null | [
"Cengis Hasan",
"Jean-Marie Gorce",
"Eitan Altman"
] | 2014-08-03T10:47:17+00:00 | 2014-08-03T10:47:17+00:00 | [
"cs.NI",
"cs.GT"
] | Green Broadcast Transmission in Cellular Networks: A Game Theoretic Approach | This paper addresses the mobile assignment problem in a multi-cell broadcast
transmission seeking minimal total power consumption by considering both
transmission and operational powers. While the large scale nature of the
problem entails to find distributed solutions, game theory appears to be a
natural tool. We propose a novel distributed algorithm based on group formation
games, called \textit{the hedonic decision algorithm}. This formalism is
constructive: a new class of group formation games is introduced where the
utility of players within a group is separable and symmetric being a
generalized version of parity-affiliation games. The proposed hedonic decision
algorithm is also suitable for any set-covering problem. To evaluate the
performance of our algorithm, we propose other approaches to which our
algorithm is compared. We first develop a centralized recursive algorithm
called \textit{the hold minimum} being able to find the optimal assignments.
However, because of the NP-hard complexity of the mobile assignment problem, we
propose a centralized polynomial-time heuristic algorithm called \textit{the
column control} producing near-optimal solutions when the operational power
costs of base stations are taken into account. Starting from this efficient
centralized approach, a \textit{distributed column control algorithm} is also
proposed and compared to \textit{the hedonic decision algorithm}. We also
implement the nearest base station algorithm which is very simple and intuitive
and efficiently manage fast-moving users served by macro BSs. Extensive
simulation results are provided and highlight the relative performance of these
algorithms. The simulated scenarios are done according to Poisson point
processes for both mobiles and base stations. |
1408.0483v4 | ## ITERATED TORUS KNOTS AND DOUBLE AFFINE HECKE ALGEBRAS
## PETER SAMUELSON
Abstract. We give a topological realization of the (spherical) double affine Hecke algebra SH q,t of type sl 2 , and we use this to construct a module over SH q,t for any knot K ⊂ S 3 . As an application, we give a purely topological interpretation of Cherednik's 2-variable polynomials P n ( r, s ; q, t ) of type sl 2 from [Che13] (where r, s ∈ Z are relatively prime).
We then generalize the construction of these polynomials (for sl 2 ) from torus knots to all iterated cables of the unknot and prove they specialize to the colored Jones polynomials of the knot. Finally, in the Appendix we compare this construction to a later construction of Cherednik and Danilenko.
## Contents
| 1. | Introduction | 1 |
|-------------------------------------------------------|----------------------------------------------------------|-----|
| 2. | Background | 3 |
| 3. | A modified Kauffman bracket skein module | 14 |
| 4. | A topological interpretation of Cherednik's construction | 19 |
| 5. | Iterated cablings of the unknot | 22 |
| Appendix A. Comparing polynomials for iterated cables | Appendix A. Comparing polynomials for iterated cables | 25 |
References
27
## 1. Introduction
The (spherical) double affine Hecke algebra SH q,t ( g ) is a (noncommutative) algebra associated to a semisimple complex Lie algebra g and two parameters q, t ∈ C ∗ . These algebras were introduced by Cherednik to prove Macdonald's conjectures about Macdonald polynomials [Che95], and they have since found applications in many areas of mathematics (see, e.g. [Che05] and references therein). In this paper we give two new connections between DAHAs and knots - the first involves iterated cables of the unknot, and the second involves arbitrary knots.
- 1.1. Cables. In [AS15] (see also [AS12] and [AS11]), Aganagic and Shakirov used refined Chern-Simons theory and generalized Verlinde algebras to construct q, t versions of Reshetikhin-Turaev invariants for torus knots. In [Che13], Cherednik gave a construction of these polynomials using double affine Hecke algebras. More precisely, he used the representation theory of SH q,t ( g ) to construct polynomials P α,r,s ( q, t ) ∈ C [ q ± 1 , t ± 1 ], where α ∈ t ∗ is an integral dominant weight and r, s ∈ Z are relatively prime. He gave a number of conjectural properties of these polynomials - the conjecture which is relevant to us is that they specialize at t = q to the Reshetikhin-Turaev invariants of the ( r, s ) torus knot.
From now on we fix g = sl 2 . In this case, if we identify integral dominant weights with N , Cherednik proved the equality 1
$$& ( 1. 1 ) & & P _ { n, r, s } ( q, - q ^ { 2 } ) = J _ { n } ( K _ { r, s } ; q )$$
where the right hand side is the n th colored Jones polynomial of K r,s .
Date : August 3, 2017.
1 This equality is stated in our normalization conventions - the precise conversion is stated in Remark 4.3.
In this paper we extend the construction of the polynomials P n,r,s ( q, t ) from torus knots to all iterated cables of the unknot and show that these new polynomials specialize to the colored Jones polynomials. To do this, we provide a cabling formula that expresses the colored Jones polynomials of the cable K r,s of a knot K ⊂ S 3 in terms of those of K . Various versions of this formula are well-known and have appeared in the literature, but for completeness we prove skein-theoretic versions which are suited for our purposes in Section 2.1.5. We then show that the t = -q 2 specialization of the formula defining the polynomial P n ( r, s ; q, t ) is identical to the cabling formula when K is the unknot (in this case the cable K r,s is the ( r, s ) torus knot.)
We remark that the formula defining the polynomials P n ( r, s ; q, t ) (and our formula generalizing this to iterated torus knots) uses several structures associated to the DAHA SH q,t , and when this formula is identified with the skein-theoretic cabling formula, each of these structures has a natural topological interpretation. More precisely, Cherednik's construction uses the algebra SH q,t , an SL 2 ( Z ) action on SH q,t , an action of SH q,t on P = C [ x ] (called the polynomial representation), and a pairing P op ⊗ SH q,t P → C [ q ± 1 , t ± 1 ] (where P op is the twist of P by a certain anti-automorphism). In the t = -q 2 specialization the algebra SH q, -q 2 is the Kauffman bracket skein algebra of the torus, and the SL 2 ( Z ) action on SH q,t is induced by the action of the mapping class group of the torus. The polynomial representation corresponds to the skein module of a small neighborhood of a knot, which is a module over the algebra associated to its boundary torus. Finally, Cherednik's pairing corresponds to the decomposition of S 3 into the union of two unknotted solid tori, and the element on which he evaluates the pairing corresponds to the ( r, s ) torus knot, embedded in the common boundary of the two solid tori and colored with a Jones-Wenzl idempotent.
One advantage of using the cabling formula is that it applies to all knots. As mentioned above, this allows us to extend the definition of the polynomial P n,r,s from torus knots to all iterated cables of the unknot. More precisely, given a sequence r m = ( r 1 , . . . , r m ) and s m = ( s , . . . , s 1 m ) with r , s i i relatively prime integers, we define K ( r 1 , s 1 ) to be the ( r 1 , s 1 )-torus knot and K ( r m , s m ) to be the ( r m , s m ) cable of K ( r m -1 , s m -1 ). We then define a rational function P n ( r m , s m ; q, t ) ∈ C ( q ± 1 , t ± 1 ) for each n ∈ N (see Definition 5.7) and prove the following (see Theorem 5.8):
Theorem 1.1. If K ( r s , ) is a knot which is an iterated cable of the unknot, we have the equality
$$P _ { n } ( { \mathbf r }, { \mathbf s } ; q, t = - q ^ { 2 } ) = J _ { n } ( K ( { \mathbf r }, { \mathbf s } ) ; q )$$
If the sequences r m and s m are length 1, then K ( r s , ) is a torus knot and this theorem reproduces one of Cherednik's theorems in [Che11].
- 1.2. Arbitrary knots. It is natural to ask whether some similar construction can be used to produce 2-variable polynomial knot invariants for all knots. However, it seems likely that algebraic constructions using the polynomial representation can only 'see' iterated torus knots or links.
As a first step in this direction, in Section 3.3.2, for any knot K we define an SH q,t bimodule ¯ K q,t using a t -modification of the Kauffman bracket skein module construction. For the unknot, we show this bimodule is isomorphic to SH q,t itself. We further construct a canonical quotient K q,t of ¯ K q,t which is just a left module (see Definition 3.15), and we show that for the unknot this left module is the sign representation of SH q,t . We also show the following (see Proposition 3.16):
Theorem 1.2. The vector space K q,t is knot invariant which is a left module over SH q,t . If we specialize t = 1 then there is a natural surjective SH q,t =1 -module map
$$K _ { q, t = 1 } \twoheadrightarrow K _ { q } ( S ^ { 3 } \, \langle \, K ).$$
We remark that there have been a number of recent papers providing (or conjecturing) various connections between double affine Hecke algebras and certain classes of knots (e.g. [Che13], [GORS14], [EGL13], [GN15], [BS14]). However, to the best of our knowledge, the SH q,t -module K q,t is the only proven connection between DAHAs (with arbitrary parameters) and arbitrary knots.
To extract polynomial knot invariants from the classical skein module, one uses the C [ q ± 1 ]-linear map
$$\epsilon \, \colon K _ { q } ( S ^ { 3 } \, \searrow K _ { q } ( S ^ { 3 } ) = \mathbb { C } [ q ^ { \pm 1 } ]$$
induced by the inclusion S 3 \ K → S 3 -the key fact here is that K S q ( 3 ) is isomorphic to C [ q ± 1 ].
Question 1.3. For all t ∈ C ∗ , is there a canonical evaluation map ¯ K q,t → C [ q ± 1 , t ± 1 ]?
We give a positive answer to this question for the unknot in Corollary 3.21, but for other knots this seems to be a subtle question. In particular, the proof of Corollary 3.21 uses the PBW property for H q,t , which is a nontrivial fact. It is unclear whether an analogue of this PBW property can be proven for nontrivial knots. However, composing the surjection (1.2) with the evaluation map /epsilon1 gives a positive answer to this question when t = 1.
One might also ask if there is a similar topological construction of the (spherical) DAHA if g has rank greater than 1. Two versions of skein relations for g = sl n (and t = 1) appear in [Sik05] and [CKM14], and skein relations for g of rank 2 appear in [Kup96]. However, it is not clear whether the spherical subalgebra SH q,t ( g ) is a quotient of the g -skein module of the punctured torus, and the 'generators-and-relations' approach in this paper will be more difficult for higher rank g .
Some brief historical remarks are in order. After the first version of the present paper appeared, Cherednik and Danilenko (see [CD14]) gave a construction of certain polynomials for general g that are conjecturally related to iterated torus knots. For g = sl 2 we compare their construction to ours in an Appendix. After this, Morton and the author posted [MS14] (now [MS17]), which proved that the gl n polynomials defined in [CD14] specialized to the gl n Reshetikhin-Turaev invariants for iterated torus knots. Without further argument, this theorem doesn't directly imply the statement for sl 2 polynomials proved in this paper because the relationship between the q, t polynomials for gl 2 and sl 2 is not obvious.
A summary of the contents of the paper is as follows. In Section 2 we recall background material about the Kauffman bracket skein module and the double affine Hecke algebra, including two cabling formulas that are essential in later sections. In Section 3 we construct t -deformed versions of the Kauffman bracket skein module of a surface and of knot complements. We then use this to give a topological construction of Cherednik's polynomials in Section 4, and we give a topological proof that these polynomials specialize to the colored Jones polynomials of torus knots. We give an algebraic generalization of Cherednik's construction to iterated cables of the unknot in Section 5. Finally, in an Appendix we show that when g = sl 2 , the polynomials defined in [CD14] for iterated torus knots specialize to some constant times the colored Jones polynomial.
Acknowledgements: We would like to thank Yuri Berest for extensive explanations and discussions while advising the author's thesis [Sam12] (which contained the results in the first three subsections of Section 3), and for providing notes on which Section 2.2 was based. We would also like to thank I. Cherednik for helpful comments on an early version of this paper and discussions of [CD14], and G. Masbaum for several conversations, and in particular for explaining the sign in Corollary 2.15. We also thank D. Bar-Natan, E. Gorsky, A. Marshall, G. Muller, A. Oblomkov, M. Pabiniak, S. Shakirov, and D. Thurston for enlightening conversations. The author is grateful to the users of the website MathOverflow who have provided several helpful answers (see, e.g. [Ago]). Finally, several computations were done using Mathematica , and in particular using the packages KnotTheory and NCAlgebra .
## 2. Background
In this section we recall background material about Kauffman bracket skein modules and double affine Hecke algebras that will be used in the remainder of the paper.
- 2.1. Kauffman bracket skein modules. In this section we define the Kauffman bracket skein module and recall several of its properties. In particular, we describe its relation to the colored Jones polynomials and two resulting cabling formulas.
- 2.1.1. Knot complements. Recall that two maps f, g : M → N of manifolds are ambiently isotopic if they are in the same orbit of the identity component of the diffeomorphism group of N . This is an equivalence relation, and a knot in a 3-manifold M is the equivalence class of a smooth embedding K : S 1 ↪ → M .
Figure 1. Kauffman bracket skein relations
For an oriented knot K ⊂ S 3 there is a canonical identification T = S 1 × S 1 → ∂ S ( 3 \ K ). More precisely, let N K ⊂ S 3 be a closed tubular neighborhood of K , and let N c be the closure of its complement. Then the following lemma provides a unique (up to isotopy) identification of N K ∩ N c with S 1 × S 1 :
Lemma 2.1 ([BZ03, Ch. 3]) . There is a unique (up to isotopy) pair of simple loops (the meridian m and longitude l ) in T subject to the conditions
- (1) m is nullhomotopic in N K ,
- (2) l is nullhomologous in N c ,
- (3) m,l intersect once in T ,
- (4) in S 3 , the linking numbers ( m,K ) and ( l, K ) are 1 and 0, respectively.
2.1.2. Kauffman bracket skein modules. A framed link is an embedding of a disjoint union of annuli S 1 × [0 , 1] into an oriented 3-manifold M . (The framing refers to the [0 1] factor and is , a technical detail that will be suppressed when possible.) We will consider framed links to be equivalent if they are ambiently isotopic.
Let L ( M ) be the vector space spanned by the set of ambient isotopy classes of framed unoriented links in M (including the empty link). Let L ′ ( M ) be the smallest subspace of L ( M ) containing the skein expressions L + -qL 0 -q -1 L ∞ and L /unionsq © +( q 2 + q -2 ) L . The links L + , L 0 , and L ∞ are identical outside of a small 3-ball (embedded as an oriented sub-manifold of M ), and inside the 3-ball they appear as in Figure 1. (All pictures drawn in this paper will have blackboard framing. In other words, a line on the page represents a strip [0 , 1] × [0 , 1] in a tubular neighborhood of the page, and the strip is always perpendicular to the paper.)
Remark 2.2. Our constant q is the same as the constant A that is more commonly used in skein theory (e.g. in [BHMV95]). (We made this notational choice since we reserve the notation A for an algebra.)
Definition 2.3 ([Prz91]) . The Kauffman bracket skein module is the vector space K M q ( ) := L L / ′ . It contains a canonical element ∅ ∈ K M q ( ) corresponding to the empty link.
Remark 2.4. To shorten the notation, if M = F × [0 , 1] for a surface F , we will often write K F q ( ) for the skein module K F q ( × [0 , 1]).
Example 2.5. One original motivation for defining K M q ( ) is the isomorphism of vector spaces
↦
$$\mathbb { C } \stackrel { \sim } { \to } K _ { q } ( S ^ { 3 } ), \ \ 1 \mapsto \varnothing$$
↦
Kauffman proved that this map is an isomorphism and that the inverse image of a link is the Jones polynomial 2 of the link. The skein relations in Figure 1 can be used to remove crossings and trivial loops of a diagram of a link until the diagram is a multiple of the empty link, which shows that the vector space map C → K S q ( 3 ) sending α → α · ∅ is surjective. Showing it is injective is equivalent to showing the Jones polynomial of a link is well-defined.
2 More precisely, the image of the link is a number in C that depends polynomially on q ∈ C ∗ , and this (Laurent) polynomial is the Jones polynomial of the link, up to a normalization.
In general K M q ( ) is just a vector space - however, if M has extra structure, then K M q ( ) also has extra structure. In particular,
- (1) If M = F × [0 , 1] for some surface F , then K M q ( ) is an algebra (which is typically noncommutative). The multiplication is given by 'stacking links.'
- (2) If M is a manifold with boundary, then K M q ( ) is a module over K ∂M q ( ). The action is given by 'pushing links from the boundary into the manifold.'
- (3) An oriented embedding M ↪ → N of 3-manifolds induces a linear map K M q ( ) → K N q ( ).
- (4) If q = ± 1, then K M q ( ) is a commutative algebra (for any oriented 3-manifold M ). The multiplication is given by 'disjoint union of links,' which is well-defined because when q = ± 1, the skein relations allow strands to 'pass through' each other.
Remark 2.6. The third property may be interpreted as follows: let C be the category whose objects are oriented 3-dimensional manifolds and whose morphisms are oriented embeddings. Then K q ( -) is a functor 3 from C to the category of vector spaces. We also remark that the first two properties are a special case of the third. For example, there is an obvious map F × [0 , 1] /unionsq F × [0 , 1] → F × [0 , 1], and the product structure of K F q ( × [0 , 1]) comes from the application of the functor K q ( -) to this map.
Example 2.7. Let M = ( S 1 × [0 , 1]) × [0 , 1] be the solid torus. The skein relations can be applied to remove crossings and trivial loops in a diagram of any link, and the result is a sum of unions of parallel copies of the loop u generating π 1 ( M ). This shows that algebra map C [ u ] → K S q ( 1 × [0 , 1]) sending u n to n parallel copies of u is surjective, and it follows from [SW07] that this map is injective.
2.1.3. The Kauffman bracket skein module of the torus. We recall that the quantum torus is the algebra
$$A _ { q } \coloneqq \frac { \mathbb { C } \langle X ^ { \pm 1 }, Y ^ { \pm 1 } \rangle } { X Y - q ^ { 2 } Y X }$$
where q ∈ C ∗ is a parameter. There is a Z 2 action by algebra automorphisms on A q where the generator simultaneously inverts X and Y . We define e r,s = q -rs X Y r s ∈ A q , which form a linear basis for the quantum torus A q and satisfy the relations
$$e _ { r, s } e _ { u, v } = q ^ { r v - u s } e _ { r + u, s + v }$$
In this section we recall a beautiful theorem of Frohman and Gelca in [FG00] that gives a connection between skein modules and the invariant subalgebra A Z 2 q . First we establish some notation. Let T n ∈ C [ x ] be the Chebyshev polynomials defined by T 0 = 2, T 1 = x , and the relation T n +1 = xT n -T n -1 . If m,l are relatively prime, write ( m,l ) for the m,l curve on the torus (which is the simple curve wrapping around the torus l times in the longitudinal direction and m times in the meridian's direction). It is clear that the links ( m,l ) n span K T q ( 2 ), and it follows from [SW07] that this set is a basis. However, a more convenient basis is given by the elements ( m,l ) T = T d (( m d , l d )) (where d = gcd( m,l )). (We point out that since we are considering unoriented curves, ( m,l ) = ( -m, -l ).)
Theorem 2.8 ([FG00]) . The map f : K T q ( 2 ) → A Z 2 q given by f (( m,l ) T ) = e m,l + e -m, -l is an isomorphism of algebras.
(This theorem also follows from combining the results of [BP00] with Theorem 2.27.)
Remark 2.9. From the discussion in Section 2.1.1, if K is an oriented knot, then there is a canonical identification of S 1 × S 1 with the boundary of S 3 \ K , so K S q ( 3 \ K ) has a canonical A Z 2 q -module structure. (In fact, this module structure does not depend on the orientation of K , but we do not need this fact.)
3 To be pedantic, K q ( -) is functorial with respect to maps M → N that are oriented embeddings when restricted to the interior of M . In particular, if we identify a surface F with a boundary component of M and N , then the gluing map M /unionsq N → M /unionsq F N induces a linear map K q ( M ) ⊗ C K q ( N ) → K q ( M /unionsq F N ).
2.1.4. A topological pairing and the colored Jones polynomials. Let K ⊂ S 3 be a knot. If we identify the solid torus D 2 × S 1 with a neighborhood of K , then the embeddings D 2 × S 1 ↪ → S 3 and S 3 \ K ↪ → S 3 induce a C -linear map
$$K _ { q } ( D ^ { 2 } \times S ^ { 1 } ) \otimes _ { \mathbb { C } } K _ { q } ( S ^ { 3 } \, \sl \, K ) \to \mathbb { C }$$
If α is a link which is parallel to the boundary of D 2 × S 1 , it can be isotoped to a link inside D 2 × S 1 or a link inside S 3 \ K , and inside S 3 both these links are isotopic. Therefore, the map (2.1) descends to a pairing
$$( 2. 2 ) & & \langle -, - \rangle \colon K _ { q } ( D ^ { 2 } \times S ^ { 1 } ) \otimes _ { K _ { q } ( T ^ { 2 } ) } K _ { q } ( S ^ { 3 } \, \Lambda \, K ) \to K _ { q } ( S ^ { 3 } ) = \mathbb { C }$$
The colored Jones polynomials J n ( K q ; ) ∈ C [ q ± 1 ] of a knot K ⊂ S 3 were originally defined by Reshetikhin and Turaev in [RT90] using the representation theory of U q ( sl 2 ). (In fact, their definition works for any semisimple Lie algebra g , but we only deal with g = sl 2 .) Here we recall a theorem of Kirby and Melvin that shows that J n ( K q ; ) can be computed in terms of the pairing (2.2).
Let S n ∈ C [ u ] be the Chebyshev polynomials of the second kind, which satisfy the initial conditions S 0 = 1 and S 1 = u , and the recursion relation S n +1 = uS n -S n -1 .
Theorem 2.10 ([KM91]) . If ∅ ∈ K S q ( 3 \ K ) is the empty link, and y ∈ K T q ( 2 ) is the longitude, then
$$J _ { n } ( K ; q ) = \langle \varnothing \cdot S _ { n - 1 } ( y ), \varnothing \rangle$$
Remark 2.11. We remark that we avoid a common sign correction - in particular, for us, J n (unknot; q ) = ( -1) n -1 ( q 2 n -q -2 n ) / q ( 2 -q -2 ). Also, with this normalization, J 0 ( K q ; ) = 0 and J 1 ( K q ; ) = 1 for every knot K . Up to a sign, these conventions agree with the convention of labelling irreducible representations of U q ( sl 2 ) by their dimension. (The S n -1 are the characters of these irreducible representations.)
- 2.1.5. Two cabling formulas for colored Jones polynomials. In this section we describe how the colored Jones polynomials of a cable of a knot K can be computed from the skein module K S q ( 3 \ K ). There are two standard ways of defining the ( r, s ) cable of a knot, which we refer to as the topological and algebraic cablings, and each has its own cabling formula.
Remark 2.12. We make no claim to originality for the cabling formulas we give here - they are well known and have appeared in numerous places, including [FG00, Theorem 7.1], [van08], [Mor95], and [Tra14]. For the sake of completeness and self-containment we will provide precise statements.
2.1.5.1. Topological cabling.
Definition 2.13. Let K ⊂ S 3 be a framed knot with 0 framing and let r, s ∈ Z be relatively prime. Identify S 1 × S 1 with the boundary of a neighborhood of K such that the first copy of S 1 is a meridian of K and the second is the longitude determined by the framing. (We note that since K has 0 framing, its longitude is the same as the (unique) longitude given by Lemma 2.1). Then the ( r, s ) topological cable K top r,s of K is the knot which is the image of the ( r, s )-curve on T and which is given the 0 framing.
Let γ r,s ∈ SL ( 2 Z ) satisfy γ (0 , 1) = ( r, s ). The mapping class group of the torus T is SL ( 2 Z ), and this induces an action of SL ( 2 Z ) on K T q ( ). By construction, we have γ r,s ( y ) = ( r, s ) T , where ( r, s ) T is the ( r, s ) curve on the torus T and y is the longitude of K . We remark that the framing of ( r, s ) T is parallel to the torus T , and in particular the knot ( r, s ) T is not 0-framed in S 3 .
Definition 2.14. To give a precise statement, we give names to neighborhoods of K , its boundary torus, and its cable.
- (1) Let N r,s be a neighborhood of K top r,s , and identify K N q ( r,s ) = ∼ C [ u ] (as algebras) by setting the generator u to be equal to the 0-framed knot K top r,s .
- (2) Let N T be a neighborhood of T . Identify A Z 2 q with K N q ( T ) by identifying x = X + X -1 with the meridian and y = Y + Y -1 with the topological longitude of Lemma 2.1. Since K is 0-framed, the longitude y is the same as the longitude determined by the framing of K .
Figure 2. A cross-section of the neighborhoods N r,s and N T for ( r, s ) = (0 1). , The outer circle bounds N K .
- (3) Let N K be a neighborhood of K , and identify K N q ( K ) = ∼ C [ y ] (as algebras) by equating y with the 0-framed knot K . This is notationally consistent because the knot K is framed parallel to T , so it is the element Y + Y -1 ∈ A Z 2 q that we always call y .
The following tautological inclusions are illustrated in Figure 2:
$$\tau _ { 1 }, \ n r _ { 2 } \, \tilde { \mu } _ { 3 }$$
$$N _ { r, s } \overset { \iota } { \hookrightarrow } N _ { T } \overset { \mu } { \hookrightarrow } N _ { K }$$
We will write
$$\Gamma _ { r, s } ^ { \text{top} } \coloneqq \mu \circ \iota$$
$$\Gamma _ { r, s } ^ { \text{top} } \coloneqq \mu \circ \iota$$
for the composition of these inclusions. By functoriality of skein modules and the identifications above, the map Γ top r,s induces a C -linear map Γ top r,s : C [ u ] → C [ y ].
Lemma 2.15. The induced C -linear map Γ top r,s : C [ u ] → C [ y ] is given by
$$\Gamma _ { r, s } ^ { \text{top} } ( S _ { n - 1 } ( u ) ) = ( - q ) ^ { r s ( n ^ { 2 } - 1 ) } 1 _ { y } \cdot \gamma _ { r, s } ( S _ { n - 1 } ( y ) )$$
where 1 y ∈ C [ y ] is the empty link in the skein module of a neighborhood of K .
Proof. We first compute the image ι ( u ). By definition, ι ( u ) is the r, s curve on T , which is given the 0-framing in S 3 . The element γ r,s ( y ) ∈ K T q ( ) is, by definition, the same curve, but its framing is parallel to T . Now, the first sentence of the second paragraph of [MM08, pg. 323] says that since K has writhe 0 (i.e. framing 0), that the framing of γ r,s ( y ) in S 3 is rs . Therefore, ι ( u ) should be twisted by rs units of framing to be isotopic to γ r,s ( y ). Now S n -1 ( u ) is equal to the insertion of the n th Jones-Wenzl idempotent on u , which means that ι ( S n -1 ( u )) is equal to the n th Jones-Wenzl idempotent inserted on the framed curve γ r,s ( y ), which is then twisted by rs full twists.
Since the Jones-Wenzl idempotent annihilates cups and caps, the rs full twists simplify (under the skein relations) to the displayed power of -q . (For a reference for this final statement, see the first equation of the first diagram in the proof of [MV94, Thm. 3].) This shows ι ( S n -1 ( u )) = ( -q ) rs n ( 2 -1) γ r,s ( S n -1 ( y )).
Next, K N q ( K ) = C [ y ] is a right module over K N q ( T ). By the definition of this module structure, the linear map µ : K N q ( T ) → K N q ( K ) induced from µ : N T → N K is given by µ a ( ) = ∅ · a , where ∅ is the empty link. Under the identification C [ y ] = K N q ( k ) the empty link corresponds to 1, which shows that µ a ( ) = 1 · a . This completes the proof. /square
Corollary 2.16. The colored Jones polynomials of the cable K top r,s are computed by the formula
$$J _ { n } ( K _ { r, s } ^ { \text{top} } ; q ) = ( - q ) ^ { r s ( n ^ { 2 } - 1 ) } \langle \varnothing \cdot \gamma _ { r, s } ( S _ { n - 1 } ( y ) ), \varnothing \rangle _ { K }$$
where the pairing 〈- -〉 , K is the pairing associated to the knot K described in (2.2).
Proof. There are two tautological inclusions ι r,s : N r,s → S 3 and ι K : N K → S 3 . These are related to Γ top r,s via the formula ι r,s = ι K ◦ Γ top r,s . These inclusions all induce C -linear maps on skein modules, and we will abuse notation and denote the induced maps with the same notation.
Let 〈- -〉 , r,s : K N q ( r,s ) ⊗ K S q ( 3 \ K top r,s ) → C [ q ± 1 ] and 〈- -〉 , K : K N q ( K ) ⊗ K S q ( 3 \ K ) → C [ q ± 1 ] be the pairings described in (2.2). By definition, the evaluation 〈 f ( u , ) ∅ 〉 r,s is equal to ι r,s ( f ( u )) ∈ K S q ( 3 ) = C [ q ± 1 ]. Similarly, 〈 f ( y , ) ∅ 〉 K = ι K ( f ( y )).
Now if we combine these statements with Theorem 2.10 and Lemma 2.15, we obtain
$$\text{line these statements with itemsorem 2.10 and Lemma 2.10, we oodam} \\ J _ { n } ( K _ { r, s } ^ { \text{top} } ; q ) \ & = \ \langle S _ { n - 1 } ( u ), \varnothing \rangle _ { r, s } \\ & = \ \iota _ { r, s } ( S _ { n - 1 } ( u ) ) \\ & = \ \iota _ { K } ( \Gamma _ { r, s } ^ { \text{top} } ( S _ { n - 1 } ( u ) ) ) \\ & = \ ( - q ) ^ { r s ( n ^ { 2 } - 1 ) } \langle \varnothing \cdot \gamma _ { r, s } ( S _ { n - 1 } ( y ) ), \varnothing \rangle _ { K } \\ v follows from Theorem 2.10 because K ^ { \text{top} } \text{ is formed and the last ems}$$
The first equality follows from Theorem 2.10 because K top r,s is 0-framed, and the last equality follows from Lemma 2.15 and the definitions of ι K and 〈- -〉 , K . This completes the proof. /square
This corollary gives a formula for J n ( K top r,s ) in terms of the skein module of K . However, the typical cabling formula that appears in the literature gives an expression in terms of Jones polynomials of K -we next derive this from Corollary 2.16.
Corollary 2.17. The colored Jones polynomials of the cable K top r,s are given by the formula
$$J _ { n } ( K _ { r, s } ^ { \text{top} } ; q ) = ( - q ) ^ { r s ( n ^ { 2 } - 1 ) } \sum _ { j = ( - n + 1 ) / 2 } ^ { ( n - 1 ) / 2 } q ^ { - 4 r j ( s j + 1 ) } J _ { 2 s j + 1 } ( K ; q )$$
Proof. We need to expand 〈 ∅ · γ r,s ( S n -1 ( y )) , ∅ 〉 K in terms of the Jones polynomials of K . To do this, we will use a description of the right A Z 2 q -module K N q ( K ) from [BS14, Lemmas 5.4, 5.5].
$$f ( Y ) \cdot Y = Y f ( Y ), \ \ f ( Y ) \cdot X = - f ( q ^ { - 2 } Y ), \ \ f ( Y ) \cdot s = - f ( Y ^ { - 1 } )$$
$$\Delta _ { 1 } ^ { \dots \dots } \Delta _ { 2 } ^ { \dots } \Delta _ { 3 } ^ { \dots } \Delta _ { 4 } ^ { \dots } \Delta _ { 5 } ^ { \dots } \Delta _ { 6 } ^ { \dots } \Delta _ { 7 } ^ { \dots } \Delta _ { 8 } ^ { \dots } \Delta _ { 9 } ^ { \dots } \Delta _ { 9 } ^ { \dots } \Delta _ { 9 } ^ { \dots } \Delta _ { 9 } ^ { \dots } \Delta _ { 9 } ^ { \dots } \Delta _ { 9 } ^ { \dots } \Delta _ { 9 } ^ { \dots } \Delta _ { 9 } ^ { \dots } \Delta _ { 9 } ^ { \dots } \Delta _ { 9 } ^ { \dots } \Delta _ { 9 } ^ { \dots } \Delta _ { 9 } ^ { \dots } \Delta _ { 9 } ^ { \dots } \Delta _ { 9 } ^ { \dots } \Delta _ { 9 } ^ { \dots } \Delta _ { 9 } ^ { \dots } \Delta _ { 9 } ^ { \dots } \\ \text{Let $M=C[Y^{\pm1}]$} \rightarrow \Delta _ { 2 } ^ { \dots \dots \dots } \Delta _ { 3 } ^ { \dots \dots } \Delta _ { 4 } ^ { \dots \dots } \Delta _ { 5 } ^ { \dots \dots } \Delta _ { 6 } ^ { \dots \dots } \Delta _ { 7 } ^ { \dots \dots \dots } \Delta _ { 8 } ^ { \dots \dots \dots } \Delta _ { 9 } ^ { \dots \dots \dots \dots } \Delta _ { 9 } ^ { \dots \dots \dots \dots } \Delta _ { 9 } ^ { \dots \dots \dots \dots } \Delta _ { 9 } ^ { \dots \dots \dots \dots } \Delta _ { 9 } ^ { \dots \dots \dots \dots } \Delta _ { 9 } ^ { \dots \dots \dots \dots } \Delta _ { 9 } ^ { \dots \dots \dots \dots } \Delta _ { 9 } ^ { \dots \dots \dots \dots \dots } \Delta _ { 9 } ^ { \dots \dots \dots \dots \dots } \Delta _ { 9 } ^ { \dots \dots \dots \dots \dots } \Delta _ { 9 } ^ { \dots \dots \dots \dots \dots } \Delta _ { 9 } ^ { \dots \dots \dots \dots \dots } \Delta _ { 9 } ^ { \dots \dots \dots \dots \dots } \Delta _ { 9 } ^ { \dots \dots \dots \dots \dots } \Delta _ { 9 } ^ { \dots \dots \dots \dots \dots \dots } \Delta _ { 9 } ^ { \dots \dots \dots \dots \dots \dots \dots } \Delta _ { 9 } ^ { \dots \dots \dots \dots \dots \dots \dots } \Delta _ { 9 } ^ { \dots \dots \dots \dots \dots \dots \dots } \Delta _ { 9 } ^ { \dots \dots \dots \dots \dots \dots \dots \dots \dots } \Delta _ { 9 } ^ { \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots } \Delta _ { 9 } ^ { \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots } \Delta _ { 9 } ^ { \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots } \Delta _ { 9 } ^ { \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots } \Delta _ { 9 } ^ { \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots } \Delta _ { 9 } ^ { \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots } \Delta _ { 9 } ^ { \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \ dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots. \Delta _ { 9 } ^ { \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dts \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \sigma _ { 1 } } \rightarrow \Delta _ { 2 } } \rightarrow \Delta _ { 3 } } \rightarrow \Delta _ { 4 } } \rightarrow \Delta _ { 5 } } \rightarrow \Delta _ { 6 } } \rightarrow \Delta _ { 7 } } \rightarrow \Delta _ { 8 } } \rightarrow \Delta _ { 9 } } \rightarrow \Delta _ { 9 } } \rightarrow \Delta _ { 9 } } \rightarrow \Delta _ { 9 } } \rightarrow \Delta _ { 9 } } \rightarrow \Delta _ { 9 } } \rightarrow \Delta _ { 9 } } \rightarrow \Delta _ { 9 } } \rightarrow \Delta _ { 9 } } \rightarrow \Delta _ { 9 } } \rightarrow \Delta _ { 9 } } \rightarrow \Delta _ { 9 } } \rightarrow \Delta _ { 9 } } \rightarrow \Delta _ { 9 } } \rightarrow \Delta _ { 9 } } \rightarrow \Delta _ { 9 } } \rightarrow \Delta _ { 9 } } \rightarrow \Delta _ { 9 } } \rightarrow \Delta _ { 9 } } \rightarrow \Delta _ { 9 } } \rightarrow \Delta _ { 2 } } \rightarrow \Delta _ { 9 } } \rightarrow \Delta _ { 9 } } \rightarrow \Delta _ { 9 } } \rightarrow \Delta _ { 9 } } \rightarrow \Delta _ { 9 } } \rightarrow \Delta _ { 9 } } \rightarrow \Delta _ { 9 } } \rightarrow \Delta _ { 9 } } \rightarrow \Delta _ { 9 } } \rightarrow \Delta _ { 9 } } \rightarrow \Delta _ { 9 } } \rightarrow \Delta _ { 9 } } \rightarrow \Delta _ { 9 } } \rightarrow \Delta _ { 9 } } \rightarrow \Delta _ { 9 } } \rightarrow \Delta _ { 9 } } \rightarrow \Delta _ { 9 } } \rightarrow \Delta _ { 9 } } \rightarrow \Delta _ { 9 } } \rightarrow \Delta _ { 1 } } \rightarrow \Delta _ { 9 } } \rightarrow \Delta _ { 9 } } \rightarrow \Delta _ { 9 } } \rightarrow \Delta _ { 9 } } \rightarrow \Delta _ { 9 } } \rightarrow \Delta _ { 9 } } \rightarrow \Delta _ { 9 } } \rightarrow \Delta _ { 9 } } \rightarrow \Delta _ { 9 } } \rightarrow \Delta _ { 9 } } \rightarrow \Delta _ { 9 } } \rightarrow \Delta _ { 9 } } \rightarrow \Delta _ { 9 } } \rightarrow \Delta _ { 9 } } \rightarrow \Delta _ { 9 } } \rightarrow \Delta _ { 9 } } \rightarrow \Delta _ { 9 } } \rightarrow \Delta _ { 9 } } \rightarrow \Delta _ { 9 } } \rightarrow \Delta _ { 10 } } \rightarrow \Delta _ { 9 } } \rightarrow \Delta _ { 9 } } \rightarrow \Delta _ { 9 } } \rightarrow \Delta _ { 9 } } \rightarrow \Delta _ { 9 } } \rightarrow \Delta _ { 9 } } \rightarrow \Delta _ { 9 } } \rightarrow \Delta _ { 9 } } \rightarrow \Delta _ { 9 } } \rightarrow \Delta _ { 9 } } \rightarrow \Delta _ { 9 } } \rightarrow \Delta _ { 9 } } \rightarrow \Delta _ { 9 } } \rightarrow \Delta _ { 9 } } \rightarrow \Delta _ { 9 } } \rightarrow \Delta _ { 9 } } \rightarrow \Delta _ { 9 } } \rightarrow \Delta _ { 9 } } \rightarrow \Delta _ { 9 } } \rightarrow \Delta _ { 8 } } \rightarrow \Delta _ { 9 } } \rightarrow \Delta _ { 9 } } \rightarrow \Delta _ { 9 } } \rightarrow \Delta _ { 9 } } \rightarrow \Delta _ { 9 } } \rightarrow \Delta _ { 9 } } \rightarrow \Delta _ { 9 } } \rightarrow \Delta _ { 9 } } \rightarrow \Delta _ { 9 } } \rightarrow \Delta _ { 9 } } \rightarrow \Delta _ { 9 } } \rightarrow \Delta _ { 9 } } \rightarrow \Delta _ { 9 } } \rightarrow \Delta _ { 9 } } \rightarrow \Delta _ { 9 } } \rightarrow \Delta _ { 9 } } \rightarrow \Delta _ { 9 } } \rightarrow \Delta _ { 9 } } \rightarrow \Delta _ { 10 } } \rightarrow \Delta _ { 10 } } \rightarrow \Delta _ { 9 } } \rightarrow \Delta _ { 9 } } \rightarrow \Delta _ { 9 } } \rightarrow \Delta _ { 9 } } \rightarrow \Delta _ { 9 } } \rightarrow \Delta _ { 9 } } \rightarrow \Delta _ { 9 } } \rightarrow \Delta _ { 9 } } \rightarrow \Delta _ { 9 } } \rightarrow \Delta _ { 9 } } \rightarrow \Delta _ { 9 } } \rightarrow \Delta _ { 9 } } \rightarrow \Delta _ { 9 } } \rightarrow \Delta _ { 9 } } \rightarrow \Delta _ { 9 } } \rightarrow \Delta _ { 9 } } \rightarrow \Delta _ { 9 } } \rightarrow \Delta _ { 9 } } \rightarrow \Delta _ { 10 } } \rightarrow \Delta _ { 1 } } \rightarrow \Delta _ { 9 } } \rightarrow \Delta _ { 9 } } \rightarrow \Delta _ { 9 } } \rightarrow \Delta _ { 9 } } \rightarrow \Delta _ { 9 } } \rightarrow \Delta _ { 9 } } \rightarrow \Delta _ { 9 } } \rightarrow \Delta _ { 9 } } \rightarrow \Delta _ { 9 } } \rightarrow \Delta _ { 9 } } \rightarrow \Delta _ { 9 } } \rightarrow \Delta _ { 9 } } \rightarrow \Delta _ { 9 } } \rightarrow \Delta _ { 9 } } \rightarrow \Delta _ { 9 } } \rightarrow \Delta _ { 9 } } \rightarrow \Delta _ { 9 } } \rightarrow \Delta _ { 9 } } \rightarrow \Delta _ { 10 } } \rightarrow \Delta _ { 0 } \rightarrow \Delta _ { 9 } } \rightarrow \Delta _ { 9 } } \rightarrow \Delta _ { 9 } } \rightarrow \Delta _ { 9 } } \rightarrow \Delta _ { 9 } \rightarrow \Delta _ { 9 } \rightarrow \Delta _ { 9 } \rightarrow \Delta _ { 9 } \rightarrow \Delta _ { 9 } \rightarrow \Delta _ { 9 } \rightarrow \Delta _ { 9 } \rightarrow \Delta _ { 9 } \rightarrow \Delta _ { 9 } \rightarrow \Delta _ { 9 } \rightarrow \Delta _ { 9 } \rightarrow \Delta _ { 9 } \rightarrow \Delta _ { 9 } \rightarrow \Delta _ { 9 } \rightarrow \Delta _ { 9 } \rightarrow \Delta _ { 9 } \rightarrow \Delta _ { 9 } \rightarrow \Delta _ { 9 } \rightarrow \Delta _ { 9 } \rightarrow \Delta _ { 9 } \rightarrow \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \$$
By [BS14, Lemma 5.5], the right A Z 2 q -module K N q ( K ) is isomorphic to M e , where e = (1 + s / ) 2. Because of the sign in the action of s , the generator of M e is δ e := ( Y -Y -1 ) e , and under this isomorphism, δ is equal to the empty link ∅ ∈ K N q ( K ). In the following computation we use the identity S n -1 ( A + A -1 ) = ∑ ( n -1) / 2 j =( -n +1) 2 / A 2 j , which is a standard identity for Chebyshev polynomials.
Now since K is 0-framed, we can use Theorem 2.10 and Corollary 2.16 to conclude
$$\begin{array} {$$
$$J _ { n } ( K _ { r, s } ^ { \text{top} } )$$
Remark 2.18. Since both K top r,s and K are 0-framed, the equality in the final corollary is exact (up to an overall sign ( -1) n ), and is not just true up to a power of q . We also remark that under the substitutions q -4 ours = q theirs and n ours = 1 + b theirs , this last corollary agrees with [CD14, Eq. (4.31)], up to an overall sign. Iterating this formula also gives a formula which is exact up to overall sign because 2 sj +1 has the same parity for any j .
2.1.5.2. Algebraic cabling. The algebraic cabling procedure is similar to the topological one, but framing is dealt with differently. We will give a more abbreviated discussion that highlights the differences.
Definition 2.19. Let K ⊂ S 3 be a framed knot with any framing and let r, s ∈ Z be relatively prime. Identify S 1 × S 1 with the boundary of a neighborhood of K such that the first copy of S 1 is a meridian of K and the second is the longitude determined by the framing. (We note that since K has any framing, its longitude is not necessarily the same as the (unique) longitude given by Lemma 2.1). Then the ( r, s ) algebraic cable K alg r,s of K is the knot which is the image of the ( r, s )-curve on T and which is given the framing parallel to the torus T .
Let γ r,s ∈ SL ( 2 Z ) satisfy γ (0 , 1) = ( r, s ). The mapping class group of the torus T is SL ( 2 Z ), and this induces an action of SL ( 2 Z ) on K T q ( ). By construction, we have γ r,s ( y ) = ( r, s ) T , where ( r, s ) T is the ( r, s ) curve on the torus T and y is the longitude of K . We remark that the framing of ( r, s ) T is parallel to the torus T , so ( r, s ) T is isotopic to K alg r,s as a framed knot.
Definition 2.20. To give a precise statement, we give names to neighborhoods of K , its boundary torus, and its cable.
- (1) Let N r,s be a neighborhood of K alg r,s , and identify K N q ( r,s ) = ∼ C [ u ] (as algebras) by setting the generator u to be equal to the framed knot K alg r,s (which is not 0-framed).
- (2) Let N T be a neighborhood of T . Identify A Z 2 q with K N q ( T ) by identifying x = X + X -1 with the meridian and y = Y + Y -1 with the longitude in T which is given by the framing of K . (This is not the topological longitude given by Lemma 2.1.)
- (3) Let N K be a neighborhood of K , and identify K N q ( K ) = ∼ C [ y ] (as algebras) by equating y with the framed knot K . This means that the framing of the knot K is parallel to the torus T . (This is notationally consistent as before.)
The following tautological inclusions still hold:
$$N _ { r, s } \stackrel { \iota } { \hookrightarrow } N$$
We will write
$$\Gamma _ { r, s } ^ { \text{alg} } \coloneqq \$$
$$u$$
for the composition of these inclusions. By functoriality of skein modules and the identifications above, the map Γ alg r,s induces a C -linear map Γ alg r,s : C [ u ] → C [ y ].
Lemma 2.21. The induced C -linear map Γ alg r,s : C [ u ] → C [ y ] is given by
$$\Gamma _ { r, s } ^ { \text{alg} } ( S _ { n - 1 } ( u ) ) = 1 \cdot \gamma _ { r, s } ( S _ { n - 1 } ( y ) )$$
Proof. We first compute the image ι ( u ). By definition, ι ( u ) is the r, s curve on T which is given the framing parallel to T . As remarked above, the element γ r,s ( y ) ∈ K T q ( ) is isotopic to ι ( u ). This shows that ι ( S n -1 ( u )) = γ r,s ( S n -1 ( y )). The computation of the map µ is identical to the same computation in Lemma 2.15. /square
Corollary 2.22. The colored Jones polynomials of the cable K alg r,s are computed by the formula
$$J _ { n } ( K _ { r, s } ^ { \text{alg} } ; q ) = ( - q ) ^ { \bullet } \langle \varnothing \cdot \gamma _ { r, s } ( S _ { n - 1 } ( y ) ), \varnothing \rangle _ { K }$$
where the pairing 〈- -〉 , K is the pairing associated to the knot K described in (2.2). The exponent in ( -q ) · depends on n , r , s and the framing of K .
Proof. The only difference between the proof of this and the proof of Corollary 2.16 is that the knot K alg r,s is not 0-framed. However, since the Jones-Wenzl idempotent kills cups and caps, the evaluation 〈 S n -1 ( u , ) ∅ 〉 r,s will be a power of -q times the Jones polynomial J n ( K alg r,s ; q ). /square
- 2.2. The sl 2 double affine Hecke algebra. In this section we recall background about the double affine Hecke algebra H q,t of type A 1 that is required for Cherednik's construction and for our purposes later. The standard reference for the material in this section is [Che05].
- 2.2.1. The Poincar` e-Birkhoff-Witt property. We first give a presentation of the algebra H q,t .
Definition 2.23. Let H q,t be the algebra generated by X ± 1 , Y ± 1 , and T subject to the relations
$$( 2. 6 ) \quad \ \ T X T = X ^ { - 1 }, \ \ T Y ^ { - 1 } T = Y, \ \ X Y = q ^ { 2 } Y X T ^ { 2 }, \ \ ( T - t ) ( T + t ^ { - 1 } ) = 0$$
We remark that we have replaced the q that is standard in the third relation with q 2 to agree with the standard conventions for the skein relations in Figure 1. Also, the fourth relation implies that T is invertible, with inverse T -1 = T + t -1 -t . Finally, if we set t = 1, then the fourth relation reduces to T 2 = 1, and the third relation becomes XY = q 2 Y X . These imply that H q, 1 is isomorphic to the cross product A q /multicloseright Z 2 (where the generator of Z 2 acts by inverting X and Y ).
One of the key propeties of H q,t is the so-called PBW property, which says that, for all q, t ∈ C , the multiplication map yields a linear isomorphism
$$\mathbb { C } [ X ^ { \pm 1 } ] \otimes \mathbb { C } [ \mathbb { Z } _ { 2 } ] \otimes \mathbb { C } [ Y ^ { \pm 1 } ] \stackrel { \sim } { \to } H _ { q, t }$$
Another way of stating this property is that the elements { X T Y n ε m : m,n ∈ Z , ε = 0 , 1 } form a linear basis in H q,t . (See [Che05], Theorem 2.5.6(a).)
/negationslash
2.2.2. The spherical subalgebra. If t = ± i , the algebra H q,t contains the idempotent e := ( T + t -1 ) / t ( + t -1 ) (the identity e 2 = e is equivalent to the last relation in (2.6)). The spherical subalgebra of H q,t is
$$\text{SH} _ { q, t } \coloneqq e H _ { q, t } e$$
Note that SH q,t inherits its additive and multiplicative structure from H q,t , but the identity element of SH q,t is e , which is different from 1 ∈ H q,t . If t 2 q -2 -t -2 q 2 is invertible, then the next lemma shows that SH q,t is Morita equivalent to H q,t ; the mutually inverse equivalences are given by
↦
$$( 2. 8 ) \quad \text{Mod} \, H _ { q, t } \to \text{Mod} \, \text{SH} _ { q, t } \,, \, M \mapsto \text{e} M \ ; \quad \text{Mod} \, \text{SH} _ { q, t } \to \text{Mod} \, H _ { q, t } \,, \, M \mapsto \text{H} _ { q, t } \, \text{e} \otimes _ { \text{SH} _ { q, t } } M \.$$
↦
Lemma 2.24. If t 2 q -2 -t -2 q 2 is invertible, then H q,t e H q,t = H q,t .
Proof. Define a := t -1 X -tX -1 and π := Y T -1 . The statement then follows from the fact that Xπ is invertible and from the following identities:
$$\pi ^ { 2 } & = 1 \\ \pi X & = q ^ { 2 } X ^ { - 1 } \pi \\ a & = X \text{e} - \text{e} X ^ { - 1 } \\ \pi a + t ^ { - 2 } q ^ { 2 } a \pi & = - t ^ { - 1 } ( t ^ { 2 } q ^ { - 2 } - t ^ { - 2 } q ^ { 2 } ) X \pi \\ \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot$$
More precisely, let I be the two-sided ideal generated by e . Then the third identity shows a is in I , the final identity follows from the first two, and if ( t 2 q -2 -t -2 q 2 ) is a unit then I contains a unit because of the final identity. /square
↦
In the case t = 1, there is an isomorphism A Z 2 q ∼ = SH q, 1 given by w → e ¯ w e , where w ∈ A Z 2 q is a symmetric word in X,Y , and ¯ is the same word, viewed as an element of H w q,t . For later use we will need a presentation of SH q,t which we give here.
Definition 2.25. Let B ′ q be the algebra generated by x, y, z modulo the following relations:
$$( 2. 9 ) & [ x, y ] _ { q } = ( q ^ { 2 } - q ^ { - 2 } ) z, \ \ [ z, x ] _ { q } = ( q ^ { 2 } - q ^ { - 2 } ) y, \ \ [ y, z ] _ { q } = ( q ^ { 2 } - q ^ { - 2 } ) x$$
Also, define B q,t to be the quotient of B ′ q by the additional relation
$$q ^ { 2 } x ^ { 2 } + q ^ { - 2 } y ^ { 2 } + q ^ { 2 } z ^ { 2 } - q x y z = \left ( \frac { t } { q } - \frac { q } { t } \right ) ^ { 2 } + \left ( q + \frac { 1 } { q } \right ) ^ { 2 }$$
Remark 2.26. The element on the left hand side of (2.10) is central in B ′ q (see Corollary 3.7), so B q is the quotient of B ′ q by a central character.
Theorem 2.27 ([Ter13]) . There is an algebra isomorphism f : B q,t → SH q,t defined by the following formulas:
↦
↦
↦
$$x & \mapsto ( X + X ^ { - 1 } ) e \\ ( 2. 1 1 ) & y & \mapsto ( Y + Y ^ { - 1 } ) e \\ & z & \mapsto q ^ { - 1 } ( X Y T ^ { - 2 } + X ^ { - 1 } Y ^ { - 1 } ) e$$
Proof. The fact that (2.11) gives a well-defined algebra map can be checked directly, and the fact that it is an isomorphism is proved in [Ter13]. (See also [BS14, Thm. 2.20] for the precise conversion between Terwilliger's notation and ours.) /square
Remark 2.28. A-priori, it isn't obvious that the elements on the right hand side of (2.11) are contained in e H q,t e . However, short computations show that if we take a ∈ H q,t to be either X + X -1 , Y + Y -1 , or XYT -2 + X -1 Y -1 , then a e = e a , and this implies a e = e e a ∈ e H q,t e .
For later reference, we include a lemma that is useful for establishing isomorphisms of B ′ q -modules.
Lemma 2.29. Suppose that M and N are modules over B ′ q , and that as a C [ x ] -module M is generated by elements { m i ∈ M } . Furthermore, suppose that f : M → N is a morphism of C [ x ] -modules that satisfies f ( ym i ) = yf m ( i ) and f ( zm i ) = zf m ( i ) . Then f is a morphism of B ′ q -modules.
Proof. By definition, the elements x, y, z ∈ B ′ q satisfy the commutation relations (2.9). An arbitrary element of M can be written as m = ∑ n i =1 c p i i ( x m ) i , and using the C [ x ]-linearity of f and the commutation relations, powers of x in the expressions ym and zm can inductively be moved to the left. This shows that f ( ym ) = yf m ( ) and f ( zm ) = zf m ( ) for arbitrary m ∈ M , which completes the proof. /square
2.2.3. The standard and sign polynomial representation. Our definition of H q,t was in terms of generators and relations. However, H q,t can also be viewed as a family of subalgebras of End C ( C [ X,X -1 ]) using the construction we describe in this section. We first introduce the following linear operators on C [ X ± 1 ]:
$$\hat { x } [ f ( X ) ] \coloneqq X f ( X ) \, \ \hat { s } [ f ( X ) ] \coloneqq f ( X ^ { - 1 } ) \, \ \hat { y } [ f ( X ) ] \coloneqq f ( q ^ { - 2 } X )$$
Notice that these operators are invertible and satisfy the relations
$$\hat { s } ^ { 2 } = 1 \, \ \hat { s } \, \hat { x } = \hat { x } ^ { - 1 } \hat { s } \, \ \hat { s } \, \hat { y } = \hat { y } ^ { - 1 } \hat { s } \, \ \hat { x } \, \hat { y } = q ^ { 2 } \, \hat { y } \, \hat { x } \.$$
Thus, they define a representation of the crossed product A q /multicloseright Z 2 . The action of H q,t on C [ X ± 1 ] can be described by
↦
$$X \mapsto \hat { x } \, \ \ T \mapsto \hat { T } \coloneqq t \cdot \hat { s } + \frac { t - t ^ { - 1 } } { X ^ { 2 } - 1 } ( \hat { s } - 1 ) \, \ \ Y \mapsto \hat { y } \, \hat { s } \, \hat { T }$$
↦
↦
The operator ˆ is called the T Demazure-Lusztig operator (cf. [Che05], (1.4.26), (1.4.27)). Formally it is an operator on rational functions C ( X ), but it preserves the subspace C [ X ± 1 ] ⊂ C ( X ) because f ( X -1 ) -f ( X ) is always divisible (in C [ X ± 1 ]) by X 2 -1.
These assignments can be rephrased as follows: let D q be the localization of A q /multicloseright Z 2 with respect to the multiplicative set consisting of all nonzero polynomials in X . Then formulas (2.14) give an embedding
$$\Theta _ { q, t } \, \colon \, \mathsf H _ { q, t } \, \hookrightarrow \, \mathcal { D } _ { q }$$
The sign representation is defined similarly - we first define operators
$$\hat { x } [ f ( X ) ] \coloneqq X f ( X ) \, \ \hat { s } _ { - } [ f ( X ) ] \coloneqq - f ( X ^ { - 1 } ) \, \ \hat { y } _ { - } [ f ( X ) ] \coloneqq - f ( q ^ { - 2 } X )$$
These operators give C [ X ± 1 ] the structure of an A q /multicloseright Z 2 -module. We then define
↦
$$X \mapsto \hat { x } \, \ \ T \mapsto \hat { T } _ { - } \coloneqq - t ^ { - 1 } \cdot \hat { s } _ { - } + \frac { t - t ^ { - 1 } } { X ^ { 2 } - 1 } ( \hat { s } _ { - } + 1 ) \, \ \ Y \mapsto \hat { y } _ { - } \, \hat { s } _ { - } \, \hat { T } _ { - }$$
↦
↦
It can be checked directly that these assignments give an embedding Θ -q,t : H q,t →D q .
Definition 2.30. Let P + , P -:= C [ X ± 1 ] be the H q,t -modules given by formulas (2.14) and (2.17), respectively. We refer to these as the polynomial representation and the sign representation .
Remark 2.31. The modules P + and P -can also be viewed as induced modules as follows. Let H Y ⊂ H q,t be the subalgebra generated by Y ± 1 and T . Then H Y is the affine Hecke algebra (of type A 1 ) and it has two natural 1-dimensional modules, C t and C -t -1 . On the module C t both Y and T act by multiplication by t , and on C -t -1 they act by multiplication by -t -1 . Then P + and P -are the H q,t -modules which are induced from C t and C -t -1 , respectively.
2.2.4. The symmetric polynomial representation. Under the Morita equivalence (2.8), the H q,t -module P + corresponds to the SH q,t -module
$$\mathrm e P ^ { + } = \mathrm e H _ { q, t } / ( \mathrm e H _ { q, t } \left ( T - t \right ) + \mathrm e H _ { q, t } \left ( Y - t \right ) ) \cong \mathrm e \cdot \mathbb { C } [ X ^ { \pm 1 } ]$$
Now, note that the subspace e C [ X ± 1 ] ⊂ C [ X ± 1 ] is the image of the projector e = ( t -1 + T / t ) ( -1 + ) t and hence the kernel of 1 -e . By the Bernstein-Zelevinsky lemma (see [Che05], p. 202), the kernel of the operator T -t (acting on C [ X ± 1 ] as in (2.14)) is exactly C [ X ± 1 ] Z 2 = C [ X + X -1 ], the subspace of symmetric Laurent polynomials. Thus, for all parameters q, t ∈ C ∗ , the spherical algebra SH q,t acts on C [ X + X -1 ] via the identification
$$( 2. 1 8 ) \quad \mathbb { C } [ X + X ^ { - 1 } ] = e \cdot \mathbb { C } [ X ^ { \pm 1 } ] \cong e P ^ { + } \ \ f ( X + X ^ { - 1 } ) \leftrightarrow e f ( X + X ^ { - 1 } ) \leftrightarrow [ e f ( X + X ^ { - 1 } ) ]$$
Since Y + Y -1 commutes with e it preserves the subspace C [ X + X -1 ] ⊂ C [ X ± 1 ]. This operator is called the Macdonald operator , and it plays a fundamental role in the representation-theoretic approach to the theory of Macdonald polynomials. A computation shows that this operator can be written as
$$L _ { q, t } \coloneqq Y + Y ^ { - 1 } = \frac { t X ^ { - 1 } - t ^ { - 1 } X } { X ^ { - 1 } - X } \, \hat { y } + \frac { t ^ { - 1 } X ^ { - 1 } - t X } { X ^ { - 1 } - X } \, \hat { y } ^ { - 1 } \,.$$
Remark 2.32. Under the identification SH q,t =1 ∼ = K T q ( 2 ) in Theorem 2.8, the Macdonald operator is identified with the longitude of the torus.
2.2.5. Rank 1 Macdonald polynomials. We briefly review the definition of Macdonald polynomials of type A 1 (a.k.a. the Rogers or ( q, t )-ultraspherical polynomials, see [AI83]). This family of orthogonal polynomials depends on two parameters q, t ∈ C ∗ and forms a basis in the space C [ X + X -1 ] = C [ x ] of symmetric Laurent polynomials . 4 These polynomials can be naturally defined for an arbitrary root system; they possess some remarkable properties which were first conjectured by I. G. Macdonald and proved by Cherednik (see [Che05, Sect. 1.4] for a discussion of these polynomials and the Macdonald conjectures).
The Macdonald polynomials can be defined as solutions of the eigenvalue problem for the Macdonald operator:
$$L _ { q, t } [ \varphi ] = \left ( \lambda + \lambda ^ { - 1 } \right ) \varphi$$
4 The Macdonald polynomials of type A 1 constitute a subfamily of the four-parameter family of the so-called AskeyWilson polynomials , which is the most general family of orthogonal polynomials of one variable. The Askey-Wilson polynomials are controlled by the DAHA of type CC ∨ .
Theorem 2.33. There is a unique family of symmetric Laurent polynomials { p 0 ( x , p ) 1 ( x , . . . ) } ⊂ C [ X ± 1 ] Z 2 = C [ x ] , satisfying
$$( a ) \ L _ { q, t } [ p _ { n } ] = ( t q ^ { 2 n } + t ^ { - 1 } q ^ { - 2 n } ) \, p _ { n }$$
$$( b ) \ p _ { 0 } ( x ) = 1 \, \ \ p _ { n } ( x ) = X ^ { n } + X ^ { - n } + \sum _ { | m | < n } c _ { m } \, x ^ { m } \, \ n \geq 1$$
With this choice of normalization, the Macdonald polynomials depend rationally on q, t . For example, the first members of this family are
$$p _ { 0 } ( x ) = 1 \, \ \ p _ { 1 } ( x ) = X + X ^ { - 1 } \, \ \ p _ { 2 } ( x ) = X ^ { 2 } + X ^ { - 2 } + ( 1 - t ^ { 2 } ) ( 1 + q ^ { 4 } ) / ( 1 - t ^ { 2 } q ^ { 4 } )$$
2.2.6. The Dunkl-Cherednik pairing. Here we recall an important property of the polynomial representation which is analogous to the Shapovalov form from Lie theory. First we define an anti-automorphism of H q,t :
↦
$$\phi \colon \mathsf H _ { q, t } \to \mathsf H _ { q, t } \, \ \ X \mapsto Y ^ { - 1 } \, \ \ Y \mapsto X ^ { - 1 } \, \ \ T \mapsto T$$
↦
↦
We write φ P ( + ) for the twist of the module P + by this anti-automorphism.
Lemma 2.34. The vector space φ P ( + ) ⊗ H q,t P + is 1-dimensional.
Proof. This follows from the PBW property combined with some computations (see [Che05, Sec. 1.4.2]). /square
## Corollary 2.35. There are pairings
$$\langle -, - \rangle _ { q, t } \colon \phi ( P ^ { + } ) \otimes _ { H _ { q, t } } P ^ { + } \to \mathbb { C }, \ \, \ \langle -, - \rangle _ { q, t } \colon \phi ( P ^ { + } \text{e} ) \otimes _ { \text{SH} _ { q, t } } \text{e} P ^ { + } \to \mathbb { C }$$
and these pairings are both uniquely determined by the condition 〈 1 1 , 〉 = 1 .
Proof. The existence and uniqueness of the first pairing follows from Lemma 2.34. Since SH q,t and H q,t are Morita equivalent, the natural map φ P ( + e ) ⊗ SH q,t e P + → φ P ( + ) ⊗ H q,t P + is an isomorphism of vector spaces (see, e.g. [BS14, Lemma 5.2]). This shows the existence and uniqueness of the second pairing. /square
Remark 2.36. This pairing is very closely related to the topological pairing (2.2). More precisely, if the construction in this section is repeated for the sign representation P -, then this pairing at t = 1 is exactly the same as the pairing (2.2) when L is the unknot (see Lemma 4.5).
2.2.7. The sign representation. In this subsection we recall some facts about the sign representation P -of H q,t , which will be used in Section 3.4.
The symmetric sign representation e P -can be identified with C [ x ] as follows. First, we define
$$\delta _ { t } \coloneqq t X ^ { - 1 } - t ^ { - 1 } X$$
and note that in the sign representation we have e δ t = δ t and e · 1 = 0. Since T commutes with elements of C [ X + X -1 ] ⊂ H q,t , the -t -1 and t eigenspaces of T are
$$P ^ { - } = \mathbb { C } [ X + X ^ { - 1 } ] \oplus \mathbb { C } [ X + X ^ { - 1 } ] \delta _ { t }$$
Therefore, e kills the first factor in this decomposition, and we obtain
$$\text{(2.21)} & & \text{e} P ^ { - } = \mathbb { C } [ x ] \delta _ { t } \subset \mathbb { C } [ X ^ { \pm 1 } ]$$
where x = X + X -1 . As in the previous section, we write P -e for the right H q,t -module that is the twist of e P -by the anti-automorphism φ from (2.20).
Lemma 2.37. There is a well-defined pairing 〈- -〉 , : P -e ⊗ SH q,t e P -→ C , and this pairing is uniquely determined by the condition 〈 δ , δ t t 〉 = 1 .
Proof. The uniqueness of the claimed pairing follows from the decomposition (2.21) and from the fact that δ t is an eigenvector of e ( Y + Y -1 ) e . To show existence, we first note that there is an isomorphism f : H q,t → H q, -t -1 determined by
$$f ( X ) = X, \ \ f ( Y ) = Y, \ \ f ( T ) = T$$
The twist f ∗ ( P + ) of the standard polynomial representation by this isomorphism is the sign representation, and combining this with Lemma 2.34 shows that φ P ( -) ⊗ H q,t P -is one-dimensional. Then the claim follows using the same argument as in Corollary 2.35. /square
We will also need the analogues of the Macdonald polynomials for the sign representation.
Definition 2.38. We define the sign Macdonald polynomials by p -n ( x ) = p -n ( x q, t ; ) := p n ( x q, ; -t -1 ).
Remark 2.39. By the proof of Lemma 2.37, the polynomials p -n ( x δ ) t ∈ e P -are eigenvectors for the Macdonald operator Y + Y -1 .
## 3. A modified Kauffman bracket skein module
In this section we discuss deformations of skein modules to modules over the DAHA H q,t of type A 1 . We use a modification of the Kauffman bracket skein module to give a topological construction of the spherical subalgebra SH q,t . We also give a construction which associates an SH q,t -module to each knot in S 3 .
- 3.1. Modified KBSM for surfaces. Our goal in this section is to define a 2-parameter skein algebra K q,t ( F ) for a (connected) surface F . As we describe below, the algebra K q,t ( F ) will be a quotient of the skein module K F q ( \ { p } ) of the punctured surface by an ideal depending on the parameter t ∈ C ∗ . For general surfaces there is a surjection K q,t =1 ( F ) /dblarrowheadright K F q ( ), but the specialization K q,t =1 ( F ) is 'bigger' than K F q ( ). More precisely, the set of links with non-crossing, nontrivial components forms a (linear) basis of K F q ( ) but does not span K q,t =1 ( F ). However, if F is the torus T 2 , then this set is a linear basis for K q,t ( T 2 ) (for all t ). Therefore, K q,t ( T 2 ) can be viewed as a (flat) deformation of K T q ( 2 ). We will show that this deformation is the same as the algebraic deformation given by the spherical subalgebra SH q,t described previously.
Definition 3.1. We fix a point p ∈ F and define the following:
- (1) a vertical special strand is a homeomorphism [0 1] , →{ }× p [0 , 1] ⊂ F × [0 , 1],
- (2) a framed link with a vertical special strand is an isotopy class of embeddings [0 1] , /unionsq ( /unionsq n S 1 × [0 , 1] ) ↪ → F × [0 , 1], where n ≥ 0 and the isotopy class contains a representative whose embedding of [0 1] is a vertical special strand. , (The allowed isotopies must fix the boundary of the 3-manifold, and in particular the endpoints of the special strand are fixed.)
Let L q,t be the vector space spanned by framed links with a vertical special strand. (We remark that L q,t is isomorphic to the space spanned by framed links in a thickening of the punctured surface. However, we phrase the definition using 'special strands' because we will later want to extend this construction to 3-manifolds that are not thickened surfaces, and it seems less convenient to use the 'puncture' definition in this situation.)
Let L ′ q,t ⊂ C L q,t be the subspace generated by elements of the form
$$( 3. 1 ) \quad \ \ L _ { + } - q L _ { 0 } - q ^ { - 1 } L _ { \infty }, \ \ ( L \sqcup \circ ) + ( q ^ { 2 } + q ^ { - 2 } ) L, \text{ and } L _ { s } + ( q ^ { 2 } t ^ { - 2 } + q ^ { - 2 } t ^ { 2 } ) L ^ { \prime }$$
where L ,L ,L + 0 ∞ are links that are identical outside of a ball, and inside the ball appear as the first, second, and third terms of Figure 1 (respectively). Similarly, L , L s ′ are links which are identical outside a ball, and inside a ball appear as in Figure 3. (The dotted lines in Figure 3 represent the special strand, and the solid loop in L s is a component of a framed link in the skein module.) We note that the third relation in (3.1) doesn't require the special strand to be framed, since the relation doesn't use the framing of the special strand in any way.
Definition 3.2. The modified Kauffman bracket skein module K q,t ( F ) is the algebra C L q,t / L ′ q,t .
Figure 3. Skein relation for special strands
Figure 4. The generators for the punctured torus
Remark 3.3. In words, the first two relations in (3.1) say that the standard skein relations apply between links in F × [0 , 1]. The third relation (between L s and L ) is saying 'a loop around the special strand can be removed at the cost of a constant.' In other words, K q,t ( F ) is isomorphic to K F q ( \ p ) modulo the relation that says: if L p is a horizontally-framed loop encircling the puncture p , then L p = -q 2 t -2 -q -2 2 t .
The algebra structure is given by 'stacking links' as before. More precisely, given two links L , L 1 2 ⊂ F × [0 , 1], we take two copies of F × [0 , 1], each containing one of the L i , and glue F × { } 1 in one to F ×{ } 0 in the other via the identity map. Since each special strand begins and ends at p , the special strands glue together. The identity element of this algebra is the link with one special strand and no other components. We also remark that the identity component of the diffeomorphism group of a surface acts transitively, so different choices of p give isomorphic algebras. We therefore do not include the point p ∈ F in the notation.
Lemma 3.4. There is a natural surjective algebra map K q,t =1 ( F ) /dblarrowheadright K F q ( ) .
Proof. First, there is a natural map f : K F p q ( \ ) → K F q ( ). Let L p ∈ K F p q ( \ ) be the loop which encircles the puncture p . Under this map, L p is sent to a nullisotopic loop, which is equal to -q 2 -q -2 by the (standard) skein relations. Second, if t = 1, then L p = -q 2 t -2 -q -2 t 2 = -q 2 -q -2 in K q,t =1 ( F ). Third, by Remark 3.3, K q,t ( F ) is the quotient of K F q ( \ p ) by the relation L p = -q 2 t -2 -q -2 t 2 . Combining these three statements shows that if t = 1, then the map f : K F q ( \ p ) → K F q ( ) factors through to the quotient, so induces a map ˜ : f K q,t =1 ( F ) → K F q ( ). The map ˜ is surjective because f f is. /square
3.2. The torus. We now compute the algebra structure of K q,t ( T 2 ). We first recall a useful result from [BP00]. Let T ′ be the torus with one puncture, and let x ′ and y ′ be simple closed curves that intersect once, and let z ′ be the (simple closed) curve with the coefficient q in the resolution of the product x y ′ ′ . (See Figure 4.)
We also need the algebras B ′ q and B q,t from Section 2.2.2. We recall that B ′ q is the algebra generated by x, y, z modulo the following relations:
$$( 3. 2 ) & [ x, y ] _ { q } = ( q ^ { 2 } - q ^ { - 2 } ) z, \ \ [ z, x ] _ { q } = ( q ^ { 2 } - q ^ { - 2 } ) y, \ \ [ y, z ] _ { q } = ( q ^ { 2 } - q ^ { - 2 } ) x$$
and that B q,t is the quotient of B ′ q by the additional relation
$$q ^ { 2 } x ^ { 2 } + q ^ { - 2 } y ^ { 2 } + q ^ { 2 } z ^ { 2 } - q x y z = \left ( \frac { t } { q } - \frac { q } { t } \right ) ^ { 2 } + \left ( q + \frac { 1 } { q } \right ) ^ { 2 }$$
Theorem 3.5. [BP00, Thm 2.1] There is an algebra isomorphism B ′ q → K T q ( ′ ) induced by the assignments x → x ′ , y → y ′ , and z → z ′ .
↦
↦
↦
Remark 3.6. It is a general fact that if F is any surface and ∂ is a curve parallel to a boundary component of F , then ∂ is a central element in K F q ( ). This is true because if ∂ is 'on top of' a link L , then ∂ can be shrunk to be very close to the boundary, slid down the boundary until it is below L , and then expanded. In other words, the link ∂L is isotopic to the link L∂ .
## Corollary 3.7. The element w = q 2 x 2 + q -2 y 2 + q 2 z 2 -qxyz is central in B ′ q .
Proof. If we show that the element -w + q 2 + q -2 is the loop parallel to the boundary of T ′ , then the considerations in the previous remark apply to prove the claim. To see this identity we use [BP00, Eq. (2)]. Write δ for the loop around the puncture and α for the curve with coefficient q -1 in Figure 4. Then in our notation their identity is
$$\alpha z = q ^ { 2 } x ^ { 2 } + q ^ { - 2 } y ^ { 2 } - q ^ { 2 } - q ^ { - 2 } + \partial$$
Then the identity xy = qz + q -1 α of Figure 4 shows that
$$q x y z = q ^ { 2 } z ^ { 2 } + ( q ^ { 2 } x ^ { 2 } + q ^ { - 2 } y ^ { 2 } - q ^ { 2 } - q ^ { - 2 } + \partial )$$
This shows that -w + q 2 + q -2 = ∂ , as desired.
/square
It is clear that there is a surjection K T q ( ′ ) /dblarrowheadright K q,t ( T 2 ) induced topologically by 'filling in the puncture with the special strand.' This means that we can consider the loops x , y , z ′ ′ ′ as elements of K q,t ( T 2 ).
↦
↦
Corollary 3.8. There is an algebra isomorphism B q,t → K q,t ( T 2 ) induced by the assignments x → x ′ , y → y ′ , and z → z ′ .
↦
Proof. First we check that the composition f : B ′ q → K T q ( ′ ) → K q,t ( T 2 ) factors through the quotient B ′ q → B q,t . To do this we need to check that relation (2.10) holds, i.e. that f ( w ) = ( t q -q t ) 2 + ( q + 1 q ) 2 . If ∂ ∈ K T q ( ′ ) is the loop around the puncture in T ′ , then ∂ = -w + q 2 + q -2 ∈ K T q ( ′ ) (see the proof of Corollary 3.7). Then the third relation in (3.1) implies f ( ∂ ) = -q 2 t -2 -q -2 t 2 , and the calculation ( t/q -q/t ) 2 +( q + q -1 ) 2 = q 2 + q -2 + q 2 t -2 + q -2 t 2 shows the claim.
To show that f : B q,t → K q,t ( T 2 ) is injective, it suffices to show that the kernel of the map K T q ( ′ ) → K q,t ( T 2 ) is cyclic and is generated by δ + q 2 t -2 + q -2 t 2 , where δ is the loop in T ′ that encircles the puncture. This element is exactly the skein relation on the left of Figure 3, and any time this relation appears in a sum of links, we can slide the relation to the top of the manifold T ′ × [0 , 1]. In other words, any element a in the kernel of K T q ( ′ ) → K q,t ( T 2 ) can be written in the form a = a ′ ( δ + q 2 t -2 + q -2 t 2 ) for some a ′ ∈ K T q ( ′ ). This proves δ + q 2 t -2 + q -2 t 2 generates the kernel, as desired. /square
Corollary 3.9. The algebras SH q,t and K q,t ( T 2 ) are isomorphic.
Proof. Compose the isomorphism of Corollary 3.8 and Theorem 2.27.
/square
3.3. The deformation for 3-manifolds. We now define a deformed skein module ¯ K q,t ( M,f ) for a 3-manifold M with a boundary component F , a connected surface. The vector space ¯ K q,t ( M,f ) is actually a bimodule - it is a left module over K q,t ( F ) and a right module over K q,t ( T 2 ). The definition of ¯ K q,t ( M,f ) depends on some additional data (the map f , which is described below), but if M is a knot complement S 3 \ K , then we describe a canonical choice for this data.
For knot complements we also define a canonical quotient K q,t ( S 3 \ K ) of ¯ K q,t ( S 3 \ K ). This quotient destroys the right module structure, so K q,t ( S 3 \ K ) is just a left module over K q,t ( T 2 ). When K is the unknot this module has the 'right size' and can be viewed as a deformation of K S q ( 3 \ K ). However, it is not clear if this is true for other knots.
Figure 5. The 'tadpole' graph
3.3.1. General 3-manifolds. Let G be the 'tadpole' graph depicted in Figure 5, and let f : G → M be an embedding with f ( v 1 ) = p ∈ F ⊂ ∂M . (Here v 1 is the vertex of G that is not on the loop.) As before, the definition doesn't depend on the choice of p ∈ F , but it does depend on the choice of f .
Definition 3.10. A framed link compatible with f is an isotopy class of embeddings G /unionsq ( /unionsq n S 1 × [0 , 1]) ↪ → M containing a representative such that the embedding of G is given by the map f . (The isotopies we consider are those which fix the boundary of M .) The modified Kauffman bracket skein module ¯ K q,t ( M,f ) is the vector space of framed links compatible with f modulo the relations in Equation (3.1), where the third relation in (3.1) is only applied to the arc of the graph G , and not the loop of G .
Remark 3.11. Definition 3.10 could be rephrased as follows. Let M ′ := M \ (nbhd of f ( G )). Then ¯ K q,t ( M ) is the quotient of the skein module K M q ( ′ ) by the relation that says: if L is a loop in K M q ( ′ ) that is parallel to the loop on the boundary of M ′ that encircles the arc in G , then L = -q 2 t 2 -q -2 t -2 . This rephrasing shows that the definition of ¯ K q,t ( M,f ) is invariant under isotopies of the map f .
## Lemma 3.12. The space ¯ K q,t ( M,f ) is a left module over K q,t ( ∂M ) .
Proof. To see this, we note that there is a natural inclusion of the punctured surface ∂M p \ into M , which means that ¯ K q,t ( M,f ) is a (left) module over K q (( ∂M ) \ p ). By Remark 3.3, K q,t ( ∂M ) is a quotient by K q (( ∂M ) \ p ) by the relation L p = -q 2 t -2 -q -2 t 2 . By definition, this relation holds in ¯ K q,t ( M,f ), so the action of K q (( ∂M ) \ p ) factors through to an action of K q,t ( ∂M ) on ¯ K q,t ( M,f ). /square
If we thicken the loop in the graph G , then the boundary B of this thickened loop can be identified with the punctured torus T 2 \ p . Therefore, ¯ K q,t ( M,f ) is also a right module over K q,t ( T 2 ). However, in general this right module structure is not canonical - it depends on the identification of T 2 \ p with the boundary B (and also on the map f ).
3.3.2. Knot Complements. Let K ⊂ S 3 be a knot. In this section we describe a canonical choice of a map f : G → S 3 \ K (see Figure 6). We also describe a quotient K q,t ( K ) of ¯ K q,t ( S 3 \ K,f ) that is closely related to the classical skein module K S q ( 3 \ K ). In the next section we compute this module when K is the unknot.
If K is a knot in S 3 , then there is a unique (up to isotopy) choice of a longitude and meridian in the boundary of a tubular neighborhood of K . There is therefore a unique (up to isotopy) choice of curve C in S 3 \ K that is parallel to the meridian m . More precisely, C is a boundary component of an annulus whose other boundary component is the meridian of K . We pick a simple arc a in this annulus connecting C to the point p ∈ ∂ S ( 3 \ K ), and we define f : G → S 3 \ K to be the map given by the union of the embeddings of C and a . (See Figure 6.)
Definition 3.13. If K ⊂ S 3 is a knot, then ¯ K q,t ( K ) := ¯ K q,t ( S 3 \ K,f ), where the map f : G → S 3 \ K is the map described technically in the previous paragraph (and graphically in Figure 6).
Remark 3.14. There are many choices of an arc in an annulus connecting the two boundary components, but the definition does not depend on this choice because all such choices are isotopic (via an isotopy that does not fix the embedding of G ). Such isotopies are explicitly allowed in the definition of a 'framed link compatible with f ' (see the first sentence of Definition 3.10 and the last sentence of Remark 3.11).
Figure 6. The embedding of the graph G for a knot complement
As was mentioned in the previous section, the vector space ¯ K q,t ( K ) is a bimodule over K q,t ( S 1 × S 1 ). In general, the right module structure is non-canonical, but with our specific choice of f : G → S 3 \ K , there is a canonical choice for the right module structure.
In more detail, we let N G be a closed tubular neighborhood of the loop in the graph G , and we let T p be the boundary of N G (which is a punctured torus, where the puncture corresponds to the arc in the graph G ). Up to isotopy there is a unique loop m G in T p that is contractible in N G . By construction, there is a loop l G in T that is isotopic to the meridian of K , and up to isotopy this loop is unique. (The loops m G and l G are the meridian and longitude of G if G is viewed as the unknot inside of S 3 .) The choice of the (oriented) loops m G and l G gives an identification of S 1 × S 1 with T , and up to isotopy this identification is uniquely determined by the requirement that the first and second factors of S 1 × S 1 are sent to m G and l G , respectively.
We recall that for generic q , the algebra SH q,t is generated by elements x, y ∈ SH q,t , with x = ( X + X -1 ) e and y = ( Y + Y -1 ) e . Under the identifications in the previous paragraph, the elements x and y act on ¯ K q,t ( K ) on the left via m and l , respectively. The action of x and y on the right is given by l G and m G , respectively. (Note that the meridian m of K is isotopic to the longitude l G of G , so the element x ∈ SH q,t acts on the empty link 1 L ∈ ¯ K q,t ( K ) symmetrically on the left and on the right.) Let z G ∈ K q,t ( T 2 ) be the loop in the boundary of G that has the coefficient q in the resolution of the product l G m G , so that z ∈ SH q,t acts on ¯ K q,t ( K ) on the right by z G .
Definition 3.15. Let e P -be the symmetric sign representation, and define the left SH q,t -module
$$K _ { q, t } ( K ) \coloneqq \bar { K } _ { q, t } ( K ) \otimes _ { \text{SH} _ { q, t } } \text{e} P ^ { - }$$
The module K q,t ( K ) can equivalently be defined as the quotient of ¯ K q,t ( K ) by the left submodule generated by L m ( G + tq -2 + t -1 q 2 ) and L z ( G + tq -3 l G ), for all L ∈ ¯ K q,t ( K ). Topologically, this definition can be viewed as the t -analogue of 'filling in the graph G '. More precisely, we have the following lemma.
Proposition 3.16. If t = 1 , there is a natural surjection K q,t =1 ( K ) /dblarrowheadright K K q ( ) .
Proof. There are natural surjections from K S q ( 3 \ ( K ∪ G )) onto K q,t ( K ) and K K q ( ). When t = 1, all relations imposed in the definition of K q,t =1 ( K ) are also in the kernel of the map K S q ( 3 \ ( K ∪ G )) → K K q ( ). (This uses the fact that the specialization e P -q,t =1 is isomorphic to the skein module of the solid torus.) Therefore this map induces a map K q,t =1 ( K ) → K K q ( ). /square
Remark 3.17. The relations defining K q,t ( K ) can be viewed as skein relations in some sense, but an important difference is that they are not local. For example, any loop isotopic to the (1 , 1) curve in the torus T p that bounds the loop in G is declared to be equal to a loop isotopic to l G (which is isotopic to the meridian of K ), and this is not a local relation. This seems to make calculations involving K q,t ( K ) more difficult.
3.4. The unknot. In this section we compute the SH q,t -module K q,t ( K ), where K ⊂ S 3 is the unknot. We first compute the bimodule structure of ¯ K q,t ( K ). The key observation is the following lemma.
Lemma 3.18. Let U ⊂ S 3 be an open /epsilon1 -neighborhood of the union of the unknot K and the graph G . Then the complement S 3 \ U is diffeomorphic to ( T 2 \ p ) × [0 , 1] . Under this identification, the meridian m of K is isotopic to the longitude l G of G , and the longitude l of K is isotopic to the meridian m G of G .
Proof. If we write U a for U with the arc joining K and the loop in G removed, then U a is the Hopf link, so S 3 \ U a is the thickened torus T 2 × [0 , 1]. Since the arc a can be embedded in a vertical disc in T 2 × [0 , 1], it is isotopic to a vertical arc. Therefore, S 3 \ U is diffeomorphic to ( T 2 \ p ) × [0 , 1]. /square
Corollary 3.19. We have an isomorphism ¯ K q,t ( K ) = SH ∼ q,t of SH q,t -bimodules.
Proof. Let M ′ = ( S 3 \ K ) \ (nbhd of G ). By Lemma 3.18, there is a diffeomorphism ϕ : M ′ → ( T 2 \ p ) × [0 , 1]. By Remark 3.11, ¯ K q,t ( K ) is the quotient of K M q ( ′ ) by the relation that says: if L p is a loop around the arc A of the graph G , then L p = -q 2 t -2 -q -2 t 2 . Since this is exactly the relation defining K q,t ( T 2 ), this shows that ϕ induces an isomorphism of vector spaces, which implies ¯ K q,t ( K ) is isomorphic to SH q,t as vector spaces. The fact that ϕ respects the bimodule structure follows from the third sentence of Lemma 3.18 and the discussion following Remark 3.14. /square
Theorem 3.20. The left module K q,t ( K ) is isomorphic to e P -.
Proof. By Definition 3.15, K q,t ( K ) = ¯ K q,t ⊗ SH q,t e P -. Then Corollary 3.19 shows that K q,t ( K ) = SH q,t ⊗ SH q,t e P -, which completes the claim. /square
We write φ P ( -) for the twist of P -by the anti-automorphism φ defined in (2.20).
Corollary 3.21. If K is the unknot, the vector space φ P ( -) e ⊗ SH q,t ¯ K q,t ( K ) ⊗ SH q,t e P -is 1-dimensional.
Proof. By Corollary 3.19, there is a bimodule isomorphism ¯ K q,t ( K ) = SH ∼ q,t . By Lemma 2.37, the space of linear functions φ P ( -) e ⊗ SH q,t e P -→ C is 1-dimensional, which proves the claim. /square
Remark 3.22. It is natural to ask whether this corollary can be generalized to non-trivial knots. This seems like a subtle question in general - in particular, the proof in the case of the unknot relies on the existence and (essential) uniqueness of Cherednik's pairing (see Lemma 2.37), which is a non-trivial fact.
## 4. A topological interpretation of Cherednik's construction
In Section 2.1.5 we described how the colored Jones polynomials of a cable of a knot K can be computed from the skein module K S q ( 3 \ K ). In particular, the colored Jones polynomials of torus knots can be computed from the skein module of the unknot. In this section we use the topological construction of the previous sections to define polynomials J n,r,s ( q, t ) that satisfy
$$& ( 4. 1 ) & & J _ { n, r, s } ( q, t = 1 ) =$$
where K r,s is the ( r, s )-torus knot. (Technically, J n,r,s is a rational function of q and t , but this is because the Macdonald polynomials are rational functions of q and t .)
In [Che13], Cherednik used the double affine Hecke algebra of type g to construct 2-variable polynomials that specialize to the colored Jones polynomials of type g . We recall his construction for g = sl 2 and then show his polynomials are equal to the polynomials J n,r,s ( q, t ) (up to a renormalization).
Remark 4.1. It turns out that Cherednik's parameter t is slightly different than ours. To try to eliminate confusion, in this section we will write t c ∈ C ∗ for Cherednik's parameter and t ∈ C ∗ for ours. In general we will use a subscript c to indicate objects which depend on Cherednik's parameter.
4.1. Cherednik's construction. We first recall Cherednik's construction from [Che13]. Let P + c = C [ X ± 1 ] be the polynomial representation of H q,t c , and define the evaluation map
$$\epsilon _ { c } \colon P _ { c } ^ { + } \to \mathbb$$
In the notation of Section 2.35, we can write this evaluation map as /epsilon1 ( -) = 〈 1 , -〉 c , where the pairing on the right is defined in Corollary 2.35. If we identify e P + c ∼ = C [ x ] = C [ X + X -1 ] and restrict the evaluation map, for g x ( ) ∈ C [ x ] we obtain
(4.2)
$$\epsilon _ { c } \colon \text{e} P _ { c } ^ { + }$$
We recall Cherednik's construction of an SL ( 2 Z ) action on H q,t c via the following formulas:
(4.3)
↦
↦
$$\left [ \begin{array} {$$
Let γ r,s ∈ SL ( 2 Z ) be a matrix satisfying γ r,s (0 , 1) = ( r, s ), and let p n ∈ C [ X + X -1 ] ⊂ C [ X ± 1 ] be the Macdonald polynomial of Theorem 2.33. Cherednik then gives the following definition:
Definition 4.2 ([Che13]) . The nonreduced DAHA-Jones invariant is defined by
$$( 4. 4 ) & P _ { n, r, s } ( q, t _ { c } ) \$$
These polynomials do not depend on the choice of γ r,s (see Lemma 5.6).
Remark 4.3. The polynomials above are defined in [Che13, (2.18)], but we have changed the normalization by a power of -q . Note that his b is our n -1, so b b ( +2) = n 2 -1. Also, Cherednik's q 1 / 2 is our q 2 , and his t 1 / 2 is our t . Our Jones polynomials are normalized so that the n th colored Jones polynomial of the unknot is ( -1) n -1 ( q 2 n -q -2 n ) / q ( 2 -q -2 ).
- 4.2. The topological construction. We now give a topological interpretation of these polynomials (after establishing some notation). Let K be the unknot. Recall from (2.21) that as a C [ x ]-module we have K q,t ( K ) = C [ x δ ] t , and that by Theorem 3.20 the action of SH q,t is determined by
$$y \cdot \delta _ { t } = - ( t q ^ { - 2 } + t ^ { - 1 } q ^ { 2 } ) \delta _ { t }, \ \ z \cdot \delta _ { t } = - q ^ { - 3 } t ^ { - 1 } x \delta _ { t }$$
We first compare the module K q,t ( K ) to the classical skein module K K q ( ).
Lemma 4.4. When K is the unknot, the A Z 2 q -modules K K q ( ) and K q,t =1 ( K ) are isomorphic.
Proof. The formulas in (4.5) follow directly from Theorem 3.20. As a C [ x ]-module, the classical skein module K K q ( ) is freely generated by the empty link. If the formulas (4.5) are specialized to t = 1, then the action of y and z on δ t agrees with the action of y and z on the empty link. Then Lemma 2.29 shows that the C [ x ]-module isomorphism sending δ t =1 to the empty link is an isomorphism of A Z 2 q -modules. /square
We now need the analogue of the topological pairing in (2.2) which is provided by Lemma 2.37. We recall that this pairing is defined by
$$( 4. 6 ) & & \langle -, - \rangle _ { t } \colon \phi ( P ^ { - } ) e \otimes _ { \text{SH} _ { q, t } } K _ { q, t } ( K ) \to \mathbb { C }, \quad \langle \delta _ { t }, \varnothing \rangle = 1$$
(Recall that φ is the anti-automorphism defined in (2.20), and δ t = 1 · ( Y e ) is the generator of φ P ( -) e , and ∅ is the empty link in K q,t ( K ).)
Lemma 4.5. When t = 1 , the pairing 〈- -〉 , t =1 is the same as the topological pairing from (2.2).
↦
Proof. The topological pairing is uniquely determined by the requirement 〈 ∅ ∅ , 〉 = 1, and the algebraic pairing is uniquely determined by the requirement 〈 δ , δ t t 〉 t = 1. Furthermore, the isomorphism K q,t ( K ) → e P -satisfies ∅ → δ t , which completes the proof. /square
To simplify notation, we will view this pairing as a functional on K q,t ( K ):
$$\epsilon \, \colon K _ { q, t } ( K ) \to \mathbb { C }, \quad \epsilon ( u ) = \langle \delta _ { t }, u \rangle _ { t }$$
Lemma 4.6. We have the equality /epsilon1 ( f ( x )) = f ( -tq -2 -t -1 q 2 ) .
Proof. This follows from the identity y · δ t = -( tq -2 + t -1 q 2 ) δ t and the fact that φ x ( ) = y . /square
Definition 4.7. Let p -n ( x ) ∈ C [ x ] be the sign Macdonald polynomials of Definition 2.38, and let γ r,s ∈ SL ( 2 Z ) satisfy γ r,s (0 , 1) = ( r, s ). We then define
$$J _ { n, r, s } ( q, t ) \coloneqq ( - q ) ^ { r s ( n ^ { 2 } - 1 ) } \epsilon ( \gamma _ { r, s } ( p _ { n - 1 } ^ { - } ( y ) ) \cdot \mathbb { \varnothing } )$$
These polynomials do not depend on the choice of γ r,s by Lemma 5.6.
Remark 4.8. Lemma 4.5 shows that our pairing can be interpreted as the t -analogue of 'gluing the knot K into S 3 \ K to obtain S 3 .' Under this interpretation, the polynomials J n,r,s ( q, t ) can be interpreted (roughly) as the evaluations of parallels of the r, s torus knot embedded in S 3 \ (unknot ∪ G ).
4.3. The comparison. In this section we relate Cherednik's polynomials P n,r,s ( q, t c ) to the polynomials J n,r,s ( q, t ) that were constructed in the previous section using the cabling formula. We also relate these polynomials to the colored Jones polynomials J n ( K r,s ; q ) of the ( r, s ) torus knot.
Theorem 4.9. We have the following equalities
$$P _ { n, r, s } ( q, t _ { c } = - q ^ { 2 } t ^ { - 1 } ) & = J _ { n, r, s } ( q, t ) \\ J _ { n } ( K _ { r, s } ; q ) & = P _ { n, r, s } ( q, t _ { c } = - q ^ { 2 } ) = J _ { n, r, s } ( q, t = 1 )$$
Remark 4.10. The equality J n ( K r,s ; q ) = P n,r,s ( q, t = -q 2 ) in Theorem 4.9 was proved in [Che13, Thm. 2.8] by direct computation without relying on skein modules or the cabling formula. We also remark that the key fact used to prove the first equality is an isomorphism of algebras SH q,t = -q 2 ∼ = SH q,t =1 , and that the standard polynomial representation at t = -q 2 , when transferred along this isomorphism, becomes the sign representation. Then the second and third equalities are proved using the cabling formula, along with an identification of SH q,t =1 = A Z 2 q ∼ = K T q ( 2 ).
We begin with some lemmas which will be used in the proof. First, we recall the algebra B ′ q , which is generated by elements x, y, z subject to the relations
$$[ x, y ] _ { q } = ( q ^ { 2 } - q ^ { - 2 } ) z, \ \ [ z, x ] _$$
From Theorem 2.27, there is a surjection f : B ′ q → SH q,t given by
$$( 4. 9 ) \quad \ \ f ( x ) = ( X + X ^ { - 1 } ) e, \ \ f ( y ) = ($$
We first relate the SL 2 ( Z ) actions that are used in constructing both polynomials. The mapping class group SL ( 2 Z ) of T 2 \ p acts on K T q ( 2 \ p ), and we can transport this action to B ′ q using the isomorphism B ′ q = K T q ( 2 \ p ) of Theorem 3.5. We define two automorphisms τ ± : B ′ q → B ′ q :
↦
↦
$$( 4. 1 0 ) & \quad \left [ \begin{array} {$$
Lemma 4.11. The mapping class group SL ( 2 Z ) acts on B ′ q via formula (4.10). The induced action of SL ( 2 Z ) on SH q,t agrees with Cherednik's SL ( 2 Z ) action defined in (4.3).
Proof.
$$\text{Proof. These are all straightforward computations.}$$
We next relate the SH q,t c -module e c P + c used in Cherednik's construction to the module K q,t ( K ) = ∼ e t P -used in the topological construction. We consider both these modules as modules over B ′ q using the surjection f in (4.9). We will write e c ∈ H q,t c and e t ∈ H q,t for the idempotent ( T + t -1 ) / t ( + t -1 ). With this notation, we recall that we have the following equalities of C [ x ]-modules:
$$\mathbf e _ { c } P _ { c } ^ { + } = \mathbb { C } [ x ] 1 _ { c } \sub$$
The modules e c P + c and e t P -are isomorphic as C [ x ]-modules via the isomorphism
$$\varphi \colon \mathbf e _ { c } P _ { c } ^ { + } \to \mathbf e _ { t } P ^ { - }, \quad \varphi ( 1 _ { c } ) = \delta _ { t }$$
Lemma 4.12. If t c = -q 2 t -1 , then the map g : e c P + c → e t P -is an isomorphism of B ′ q -modules. This map satisfies ϕ p ( n ( x )) = p -n ( x δ ) t .
Proof. A short computation shows that
$$y \cdot 1 _ { c } = ( t _ { c } + t _ { c } ^ { - 1 } ) 1 _ { c }, \ \ z \cdot 1 _ { c } = q ^ { - 1 } t ^ { - 1 } x 1 _ { c }$$
Another short computation shows that
$$y \cdot \delta _ { t } = - ( t q ^ { - 2 } + t ^ { - 1 } q ^ { 2 } ) \delta _ { t }, \ z \cdot \delta _ { t } = - t q ^ { - 3 } x \delta _ { t }$$
If t c = -q 2 t -1 , then these formulas agree, and Lemma 2.29 gives the first claim. The second claim follows from the fact that the Macdonald polynomials p n ( x ) and p -n ( x ) are an eigenbasis for the operator y for the modules e c P + c and e t P -, respectively. /square
Finally, we relate the evaluation maps (4.2) and (4.7) that are used to define the polynomials P n,r,s and J n,r,s .
Lemma 4.13. If t c = -q 2 t -1 , then for all h x ( ) ∈ e c P + c we have
$$\epsilon _ { c } ( h ( x ) ) = \epsilon ( \varphi ( h ( x ) )$$
Proof. From (4.2), we have /epsilon1 c ( h x ( )) = h t ( c + t -1 c ). When t c = -q 2 t -1 this agree with the equality /epsilon1 ( h x ( )) = h ( -tq -2 -t -1 q 2 ) from (4.7). /square
We have now collected the facts needed to prove Theorem 4.9. We first recall the equalities claimed in the theorem:
$$P _ { n, r, s } ( q, t _ { c } = - q ^ { 2 } t ^ { - 1 } ) & = J _ { n, r, s } ( q, t ) \\ J _ { n } ( K _ { r, s } ; q ) & = P _ { n, r, s } ( q, t _ { c } = - q ^ { 2 } ) = J _ { n, r, s } ( q, t = 1 )$$
Proof. (of Theorem 4.9)
We recall that the polynomials P n,r,s ( q, t c ) and J n,r,s ( q, t ) are defined as follows:
$$P _ { n, r, s } ( q, t _ { c } ) \coloneqq ( - q ) ^ { r s ( n ^ { 2 } - 1 ) } \epsilon _ { c } ( \gamma _ { r, s } ( p _ { n - 1 } ( y ) ) \cdot 1 _ { c } )$$
$$J _ { n, r, s } ( q, t ) \coloneqq ( - q ) ^ { r s ( n ^ { 2 } - 1 ) } \epsilon ( \gamma _ { r, s } ( p _ { n - 1 } ^ { - } ( y ) ) \cdot \varnothing ) )$$
$$& ( - q ) ^ { r s ( n ^ { 2 } - 1 ) } \epsilon _ { c } ( \gamma _ { r, s } ( p _ { n - 1 } ( y ) ) \cdot 1 _ { c } ) \\ & ( - q ) ^ { r s ( n ^ { 2 } - 1 ) } \epsilon ( \gamma _ { r, s } ( p _ { n - 1 } ^ { - } ( y ) ) \cdot \varnothing ) )$$
↦
The empty link is denoted ∅ , and under the identification K q,t ( K ) = e t P -we have ∅ → δ t . By Lemma 4.12, we see that ϕ y ( · 1 ) c = y · ϕ (1 ) c = y · δ t . Then Lemma 4.11 shows that ϕ γ ( r,s ( p n ( y )) · 1 ) c = γ r,s ( p n ( y )) · δ t . Finally, Lemma 4.13 completes the proof of the first equality.
To complete the proof of the theorem, we first note that when t = 1, the module K q,t =1 ( K ) and the pairing 〈- -〉 , t are the same as the classical skein module K K q ( ) and the classical topological pairing. (These claims are Lemma 4.4 and 4.5, respectively.) The second equality in the statement of the theorem then follows from the cabling formula in Corollary 2.16. /square
## 5. Iterated cablings of the unknot
The key facts that allowed the comparison of Cherednik's polynomials to colored Jones polynomials of torus knots are that the colored Jones polynomials satisfy a cabling formula and that torus knots are cables of the unknot. However, the cabling formula applies to all knots, and in particular can be used to write colored Jones polynomials of iterated cables of the unknot in terms of colored Jones polynomials of the unknot. In this section we use this observation to extend Cherednik's construction.
More precisely, let r = ( r 1 , . . . , r m ) and s = ( s , . . . , s 1 m ) with r , s i i ∈ Z relatively prime, and write r k = ( r 1 , . . . , r k ) and similarly for s k .
Definition 5.1. Let K top ( r 1 , s 1 ) be the 0-framed ( r 1 , s 1 ) torus knot, and let K top ( r m , s m ) be the ( r m , s m ) topological cable of the knot K top ( r m -1 , s m -1 ). (See Definition 2.13 - in particular, each K top ( r k , s k ) is 0-framed.)
Below we will define 2-variable polynomials J n ( r s , ; q, t ) ∈ C [ q ± 1 , t ± 1 ], and we will show that they specialize to the colored Jones polynomials of the knot K top ( r s , ):
$$J _ { n } ( { \mathbf r }, { \mathbf s } ; q, t = - q ^ { 2 } ) = J _ { n } ( K ^ { \text{top} } ( { \mathbf r }, { \mathbf s } ) ; q )$$
When m = 1, this construction reproduces Cherednik's construction in [Che13].
Remark 5.2. As we learned in the last section, to produce Jones polynomials using the DAHA we can either use the sign representation and specialize to t = 1, or we can use the standard polynomial representation and specialize to t = -q 2 . In this section we will make the latter choice (since for higher rank DAHAs this specialization is more natural).
Before proceeding, we give an extension of Corollary 2.16 to iterated cables of the 0-framed unknot.
Remark 5.3. In Definition 2.14 the identification of the skein modules of the neighborhoods N K and N r,s of a knot K and its cable K r,s are the same since they are both 0-framed. We may therefore view the map Γ top r,s of equation (2.4) as a map Γ top r,s : C [ y ] → C [ y ] by identifying u = y .
Corollary 5.4. Given sequences r , s as above, let Γ top r s , = Γ top r 1 ,s 1 ◦ · · · ◦ Γ top r m ,s m : C [ y ] → C [ y ] , where Γ top r,s is defined in equation (2.4). Then we have the equality
$$J _ { n } ( K ^ { \text{top} } ( \mathbf r, \mathbf s ) ) = \langle \varnothing \cdot \Gamma ^ { \text{top} } _ { \mathbf r, \mathbf s } ( S _ { n - 1 } ( y ) ), \varnothing \rangle _ { u n k n o t }$$
Proof. This follows from the proof of Corollary 2.16 combined with a simple induction.
/square
5.1. Two variable polynomials for iterated cables. Let φ : H q,t → H q,t be the anti-automorphism from (2.20). Since φ T ( ) = T , this anti-automorphism restricts to the spherical subalgebra SH q,t . In terms of the generators x, y, z ∈ SH q,t from Theorem 2.27, we have
$$\phi ( x ) = y, \ \phi ( y ) = x, \ \phi ( z ) = z$$
Let P be the polynomial representation of H q,t defined in Section 2.2.3 twisted by the anti-automorphism φ , and let P e be its symmetrization. Explicitly, we may identify P e = C [ y ], where the action of SH q,t on P e is determined by the formulas
$$f ( y ) \cdot y = f ( y ) y, \ \ 1 \cdot x = ( t + t ^ { - 1 } ), \ \ 1 \cdot z = q ^ { - 1 } t ^ { - 1 } y$$
Recall that SL ( 2 Z ) acts on SH q,t via (4.3).
Definition 5.5. Given r, s ∈ Z relatively prime, let γ r,s ∈ SL ( 2 Z ) be such that
$$\gamma _ { r, s } \left ( \begin{array} { c } 0 \\ 1 \end{array} \right ) = \left ( \begin{array} { c } r \\ s \end{array} \right )$$
Lemma 5.6. The element γ r,s ( y ) ∈ SH q,t depends only on r, s and not on the choice of γ r,s .
Proof. The stabilizer of (0 , 1) T in SL ( 2 Z ) is the subgroup generated by τ -(see formula (4.3)). Since τ -( Y ) = Y , we have τ -( y ) = y , which proves the claim. /square
We let p n ( y ) ∈ P e be the standard Macdonald polynomials defined in Theorem 2.33. To define our polynomials we will need the map ι q,t of right C [ Y + Y -1 ]-modules and the evaluation map /epsilon1 q,t : P e → C :
$$( 5. 3 ) \quad \iota _ { q, t } \colon P e \to \text{SH} _ { q, t }, \quad \iota _ { q, t } ( f ( y ) ) = f ( y ), \quad \epsilon _ { q, t } ( v ) = \langle v \ | \ 1 \rangle _ { q, t }$$
where the pairing defining /epsilon1 q,t is the one from Corollary 2.35.
Figure 7. The (2 5) and (2 , , -5) cables of the (2 , 3) knot
Definition 5.7. Let r, s ∈ Z be relatively prime. Define a C -linear map Γ top r,s q,t ; : P e → P e by
$$\Gamma _ { r, s ; q, t } ^ { \text{top} } ( p _ { n - 1 } ( y ) ) \coloneqq ( - q ) ^ { r s ( n ^ { 2 } - 1 ) } 1 \cdot \gamma _ { r, s } ( \iota _ { q, t } ( p _ { n - 1 } ( y ) ) )$$
Given sequences r = ( r 1 , · · · , r m ) and s = ( s , 1 · · · , s m ) with r , s i i ∈ Z relatively prime, define
$$\Gamma ^ { \text{top} } _ { \text{r}, s ; q, t } \coloneqq \Gamma ^ { \text{top} } _ { r _ { 1 }, s _ { 1 } ; q, t } \circ \cdots \circ \Gamma ^ { \text{top} } _ { r _ { m }, s _ { m } ; q, t }, \quad J _ { n } ( \text{r}, s ; q, t ) \coloneqq \epsilon _ { q, t } ( \Gamma ^ { \text{top} } _ { \text{r}, s ; q, t } ( p _ { n - 1 } ( y ) ) )$$
Theorem 5.8. We have the equality
$$J _ { n } ( { \mathbf r }, { \mathbf s } ; q, t = - q ^ { 2 } ) = J _ { n } ( K ( { \mathbf r }, { \mathbf s } ) ; q )$$
Proof. By Theorem 2.27, the algebra SH q,t =1 and SH q,t = -q 2 are isomorphic, and by Lemma 4.11 this isomorphism is SL ( 2 Z )-equivarient. By Lemma 4.12 the right K T q ( 2 )-module K N q ( K ) is isomorphic to the right SH q,t = -q 2 -module P e . The inclusion maps ι q,t = -q 2 from (5.3) and ι from (2.3) agree, and when t = -q 2 the Macdonald polynomials p n ( y ) specialize to the Chebyshev polynomials S n ( y ). Therefore, the linear map Γ top r,s q,t ; = -q 2 is equal to the linear map Γ top r,s of (2.4), which implies that Γ top r s , ; q,t = -q 2 = Γ top r s , . Finally, /epsilon1 q,t = -q 2 ( a ) = 〈 a, ∅ 〉 unknot by Lemmas 4.5 and 4.13. This means that when t = -q 2 , the formula defining J n ( r s , ; q, t ) agrees exactly with the cabling formula for J n ( K top ( r s , )) in Corollary 5.4. This completes the proof of the theorem. /square
5.2. Examples. In this section we include example calculations of the polynomials constructed in the previous section. We first consider the case of the knot Kp := K ( r s , ) where r = (2 2) and , s = (3 5), , which is the (2 , 5) cable of the (2 , 3) knot (i.e. the trefoil). (We choose this example because it is the simplest example in which the ordering of the Γ r ,s i i matters.) To produce this knot and calculate its (normalized) colored Jones polynomial in Mathematica using the KnotTheory package, one inputs
$$\begin{smallmatrix} & & K p = \text{BR} [ 4, \{ 2, 1, 3, 2, 2, 1, 3, 2, 2, 1, 3, 2, - 1 \} ] \\ & & \text{ColouredJones} [ K p, 1 ] [ q ^ { 4 } ] ( q ^ { 4 } - q ^ { - 4 } ) / ( q ^ { 2 } - q ^ { - 2 } ) \\ & & q ^ { 1 4 } + q ^ { 1 8 } + q ^ { 2 2 } + q ^ { 2 6 } - q ^ { 4 2 } - q ^ { 4 6 } - q ^ { 5 0 } + q ^ { 5 8 } \end{smallmatrix}$$
The output of this is the first image in Figure 7 along with the polynomial displayed in (5.4). Similarly, for the (2 , -5) cable Km of the trefoil, the following produces the second image of Figure 7:
$$\begin{smallmatrix} & & K m = \text{BR} [ 4, \{ 2, 1, 3, 2, 2, 1, 3, 2, 2, 1, 3, 2, - 1, - 1, - 1, - 1, - 1, - 1, - 1, - 1, - 1, - 1, - 1 \} ] \\ & & \text{ColouredJones} [ K m, 1 ] [ q ^ { 4 } ] ( q ^ { 4 } - q ^ { - 4 } ) / ( q ^ { 2 } - q ^ { - 2 } ) \\ & & - q ^ { - 3 0 } + q ^ { - 6 } + q ^ { - 2 } + q ^ { 2 } + q ^ { 6 } + q ^ { 1 0 } - q ^ { 2 2 } - q ^ { 2 6 } - q ^ { 3 0 } + q ^ { 3 8 } \end{smallmatrix}$$
Remark 5.9. In the definition of the ( r, s ) cable of a knot K , one identifies the standard torus S 1 × S 1 with the boundary of a neighborhood N K of K . This identification is done using Lemma 2.1 - in other words, the longitude of the boundary torus of N K must have 0 linking number with the knot K . This explains why the first image in Figure 7 has 1 'negative' crossing at the right, instead of 5 'positive'
crossings (since 6 negative crossings must be added to correct for the framing/linking). Similarly, the second image of Figure 7 has 11 negative crossings instead of 5.
We have also implemented code to compute the polynomials of Definition 5.7 in Mathematica using the NCAlgebra package. Running this code produces the following polynomials:
$$\text{the NCAIgebra} \, \text{rank} \, \text{is} \, \text{code} \, \text{produces} \, \text{the following polynomials} \, \text{--} \\ ( 1 - q ^ { 4 } t ^ { 2 } ) J _ { 2 } ( K p ; q ; t ) \ = \ & q ^ { 3 2 } \left ( \frac { 1 } { t } - t ^ { 3 } \right ) + q ^ { 4 4 } \left ( - \frac { 1 } { t ^ { 1 3 } } - \frac { 1 } { t ^ { 1 3 } } \right ) + q ^ { 4 8 } \left ( \frac { 1 } { t ^ { 1 1 } } + \frac { 1 } { t ^ { 9 } } \right ) + q ^ { 5 2 } \left ( - \frac { 1 } { t ^ { 1 3 } } + \frac { 1 } { t ^ { 9 } } \right ) \, + \, \frac { 1 } { t ^ { 1 3 } } \right ) \, + \, \frac { 1 } { t ^ { 9 } } \right ) \, + \, \frac { 1 } { t ^ { 7 } } \right ) \, + \, \frac { 1 } { t ^ { 5 } } \right ) \, + \, \frac { 1 } { t ^ { 5 } } \right ) \, + \, \frac { 1 } { t ^ { 5 } } \right ) \, + \, \frac { 1 } { t ^ { 5 } } \right ) \, + \, \frac { 1 } { t ^ { 5 } } \right ) \, \text{--} \\ & q ^ { 5 6 } \left ( - \frac { 1 } { t ^ { 1 3 } } + \frac { 2 } { t ^ { 9 } } - \frac { 1 } { t ^ { 5 } } \right ) + q ^ { 6 0 } \left ( - \frac { 1 } { t ^ { 1 1 } } + \frac { 1 } { t ^ { 9 } } + \frac { 1 } { t ^ { 7 } } - \frac { 1 } { t ^ { 5 } } \right ) \, + \, \frac { 1 } { t ^ { 5 } } \right ) \, + \, \frac { 1 } { t ^ { 5 } } \right ) \, + \, \frac { 1 } { t ^ { 5 } } \right ) \, + \, \frac { 1 } { t ^ { 5 } } \right ) \, + \, \frac { 1 } { t ^ { 5 } } \right ) \, + \, \frac { 1 } { t ^ { 6 } } \left ( - \frac { 1 } { t ^ { 3 } } + t \right ) \, + \, \frac { 1 } { t ^ { 3 } } \left ( - \frac { 1 } { t ^ { 3 } } + t \right ) \, + \, \frac { 1 } { t ^ { 6 } } \left ( - \frac { 1 } { t ^ { 3 } } + t \right ) \, + \, \frac { 1 } { t ^ { 5 } } \right ) \, + \, \frac { 1 } { t ^ { 5 } } \right ) \, + \, \frac { 1 } { t ^ { 5 } } \right ) \, \text{--} \\ \text{For completeness, we also include the following polynomials for the trefoil} \, K _ { 2, 3 } \, \text{--} \\ J _ { 2 } ( K _ { 2, 3 } ; q ; t ) \ = \ & q ^ { 1 2 } \left ( \frac { 1 } { t } - t ^ { 3 } \right ) + q ^ { 4 } \left ( - \frac { 1 } { t ^ { 5 } } - \frac { 1 } { t ^ { 3 } } \right ) + q ^ { 8 } \left ( \frac { 1 } { t ^ { 4 } } + t \right ) \, + \, q ^ { 1 2 } \left ( - \frac { 1 } { t ^ { 3 } } + t \right ) \, + \, \frac { 1 } { t ^ { 5 } } \right ) \, + \, \frac { 1 } { t ^ { 5 } } \right )$$
For completeness, we also include the following polynomials for the trefoil K 2 3 , :
$$\text{For completeness, we also include the following polynomials for the trefoil } K _ { 2, 3 } \colon \\ J _ { 2 } ( K _ { 2, 3 } ; q, t ) \ & = \ q ^ { 1 2 } \left ( \frac { 1 } { t ^ { 5 } } + \frac { 1 } { t ^ { 3 } } \right ) + q ^ { 1 6 } \left ( \frac { 1 } { t ^ { 3 } } - t \right ) \\ ( 1 - q ^ { 4 } t ^ { 2 } ) J _ { 3 } ( K _ { 2, 3 } ; q, t ) \ & = \ q ^ { 2 4 } \left ( - \frac { 1 } { t ^ { 1 0 } } - \frac { 1 } { t ^ { 8 } } \right ) + q ^ { 3 2 } \left ( - \frac { 1 } { t ^ { 8 } } + \frac { 1 } { t ^ { 4 } } \right ) + q ^ { 2 8 } \left ( \frac { 1 } { t ^ { 6 } } + \frac { 1 } { t ^ { 4 } } \right ) + \\ & \ q ^ { 3 6 } \left ( - 1 - \frac { 1 } { t ^ { 8 } } + \frac { 2 } { t ^ { 4 } } \right ) + + q ^ { 4 0 } \left ( - 1 - \frac { 1 } { t ^ { 6 } } + \frac { 1 } { t ^ { 4 } } + \frac { 1 } { t ^ { 2 } } \right ) + \\ & \ q ^ { 4 4 } \left ( - 1 + \frac { 1 } { t ^ { 4 } } + \frac { 1 } { t ^ { 2 } } - t ^ { 2 } \right ) + q ^ { 4 8 } \left ( - 1 + t ^ { 4 } \right ) \\ \text{APPENDIX A. COMPARING POLYNOMIALS FOR ITERATED CABLES}$$
Appendix A. Comparing polynomials for iterated cables
After the first version of the present paper appeared, Cherednik and Danilenko gave a construction of certain polynomials for general g in [CD14]. For g = sl 2 , the constructions in [CD14] and in the present paper are similar but not quite identical. It turns out that in the specialization t = -q 2 , the differences can be explained by two different cabling procedures. Our construction for iterated torus knots involved the topological pairs ( r a , ) and uses the standard topological cabling K top r,a of a knot K (we refer to K top r,a as the topological cable of K ). However, the definition in [CD14] uses the Newton pairs ( r s , ), which are related to the topological pairs via equation (A.1). In Section 2.1.5 we described a slightly non-standard procedure for constructing a cable K alg r,s of a framed knot K , which we call the algebraic cable of K . Iterating these procedures (starting with the 0- framed unknot), we obtain two framed knots: K top r a , and K alg r s , . It turns out that these two knots are the same, up to an overall framing, and this implies their colored Jones polynomials are equal up to multiplication by a power of q .
Remark A.1. At this point we will not describe a precise relationship between the constructions for arbitrary t . However, it seems likely that the monomial in q in Definition 5.7 can be modified (to a rational function involving t and q ) in a way that would reproduce the polynomials defined in [CD14]. In particular, the constants appearing in our construction are (powers of) eigenvalues of the Dehn twist of the solid torus, which has Chebyshev polynomials as eigenvectors. This Dehn twist acts on the torus and on the solid torus, and it has a t -deformation which is the subgroup of lower-triangular matrices in SL 2 ( Z ) acting on the DAHA and its polynomial representation. This operator on the polynomial representation is diagonalized by Macdonald polynomials, with eigenvalues depending on q and t .
We first recall their construction when it is specialized to g = sl 2 after fixing some notation. Let r = ( r 1 , . . . , r m ) and s = ( s , . . . , s 1 m ) with r , s i i ∈ Z relatively prime be Newton pairs , and let a = ( a , . . . , a 1 m ) be determined by
$$( \text{A.1} ) & & a _ { 1 } = s _ { 1 }, \ \ a _ { i + 1 } = s _ { i + 1 } + r _ { i } r _ { i + 1 } a _ { i }$$
Remark A.2. The terminology 'Newton pairs' is used because they are the numbers produced by applying Newton's method to produce a multiplicative expansion of a Puiseux series describing an irreducible singularity of an algebraic planar curve. (See [EN85, Appendix 1A].)
Definition A.3. Given r s , we write K alg ( r s , ) for the iterated algebraic cable of the 0-framed unknot.
The algebraic cabling formula of Corollary 2.22 has a simple extension to iterated cables, where in the definition of Γ alg r,s in (2.5) we identify u = y as in Remark 5.3.
Corollary A.4. Given sequences r , s as above, let Γ alg r s , = Γ alg r 1 ,s 1 ◦ · · · ◦ Γ alg r m ,s m : C [ y ] → C [ y ] , where Γ alg r,s is defined in equation (2.5). Then we have the equality
$$J _ { n } ( K ^ { \text{alg} } ( \mathbf r, \mathbf s ) ) = q ^ { \bullet } \langle \varnothing \cdot \Gamma _ { \mathbf r, \mathbf s } ^ { \text{alg} } ( S _ { n - 1 } ( y ) ), \varnothing \rangle _ { u n k n o t }$$
where the exponent in q · depends on r , s , and n .
Proof. This follows from the proof of Corollary 2.22 combined with a simple induction. /square
Lemma A.5 ([EN85, Proposition 1A.1]) . Let a i be as defined in (A.1). Then the following iterated cables produce the same knot up to an overall framing twist:
$$K ^ { \text{top} } ( { \mathbf r }, { \mathbf a } ), \ \ K ^ { \text{alg} } ( { \mathbf r }, { \mathbf s } )$$
We now recall the definition of the polynomials JD r s , ( n q, t ; ) given in [CD14, Thm. 2.1] for g = sl 2 . We will use the notation of Section 4.1. Given r s , as above, let γ i ∈ SL ( 2 Z ) be such that
$$\gamma _ { i } \left ( \begin{array} { c } 0 \\ 1 \end{array} \right ) = \left ( \begin{array} { c } r _ { i } \\ s _ { i } \end{array} \right )$$
Write Γ c i : P e c → P e c for the C -linear map given by Γ ( c i f ( Y + Y -1 )) = 1 · γ i ( f ( Y + Y -1 )), and write Γ c r s , = Γ c 1 ◦ · · · ◦ Γ c m .
Definition A.6. Given r s , as above, [CD14] defines
$$\ J D _ { n, r, s } ( q, t ) \coloneqq \epsilon _ { c } ( \Gamma ^ { c } _ { r, s } ( p _ { n - 1 } ( Y + Y ^ { - 1 } ) ) )$$
Remark A.7. This definition has been rescaled by a constant so that it will specialize to our convention for the Jones polynomials. We have also used the fact that the pairing 〈- -〉 , c : P e c ⊗ e c P → C is symmetric.
Theorem A.8. We have the equality
$$J D _ { n, r, s } ( q, t = - q ^ { 2 } ) = q ^ { k } J _ { n } ( K ^ { \text{alg} } ( \mathbf r, s ) ) = q ^ { j } J _ { n } ( K ^ { \text{top} } ( \mathbf r, \mathbf a ) )$$
for some integers j, k that depend on r , s , and n .
Proof. We first remark that if we place a Jones-Wenzl idempotent on two different framings of a knot K and then evaluate in S 3 , the results will differ by a power of -q . (This is explained in the proof of Corollary 2.16.) This combined with Lemma A.5 shows the second equality. The arguments of Theorem 5.8 show that when t = -q 2 , the formula defining JD ( r s , ; q, t = -q 2 ) reproduces the algebraic cabling formula for iterated torus knots given in Corollary A.4, which proves the first equality. /square
## References
| [Ago] | Ian Agol, Complete knot invariant? , MathOverflow, URL:http://mathoverflow.net/q/35687 (version: 2010-08- 16). |
|-----------------|--------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------|
| [AI83] | R. Askey and Mourad E. H. Ismail, A generalization of ultraspherical polynomials , Studies in pure mathematics, Birkh¨user, a Basel, 1983, pp. 55-78. MR 820210 (87a:33015) |
| [AS11] | M. Aganagic and S. Shakirov, Knot Homology from Refined Chern-Simons Theory , ArXiv 1105.5117 (2011). |
| [AS12] | Mina Aganagic and Shamil Shakirov, Refined Chern-Simons theory and knot homology , String-Math 2011, Proc. Sympos. Pure Math., vol. 85, Amer. Math. Soc., Providence, RI, 2012, pp. 3-31. MR 2985324 |
| [AS15] | , Knot homology and refined Chern-Simons index , Comm. Math. Phys. 333 (2015), no. 1, 187-228. MR 3294947 |
| [BHMV95] | C. Blanchet, N. Habegger, G. Masbaum, and P. Vogel, Topological quantum field theories derived from the Kauffman bracket , Topology 34 (1995), no. 4, 883-927. MR 1362791 |
| [BP00] | Doug Bullock and J´zef o H. Przytycki, Multiplicative structure of Kauffman bracket skein module quantizations , Proc. Amer. Math. Soc. 128 (2000), no. 3, 923-931. MR 1625701 (2000e:57007) |
| [BS14] | Y. Berest and P. Samuelson, Double affine Hecke algebras and generalized Jones polynomials , ArXiv 1402.6032 (2014). |
| [BZ03] | Gerhard Burde and Heiner Zieschang, Knots , second ed., de Gruyter Studies in Mathematics, vol. 5, Walter de Gruyter & Co., Berlin, 2003. MR 1959408 (2003m:57005) |
| [CD14] | I. Cherednik and I. Danilenko, DAHA and iterated torus knots , arXiv 1408.4348 (2014). |
| [Che95] | Ivan Cherednik, Double affine Hecke algebras and Macdonald's conjectures , Ann. of Math. (2) 141 (1995), no. 1, 191-216. MR 1314036 (96m:33010) |
| [Che05] | , Double affine Hecke algebras , London Mathematical Society Lecture Note Series, vol. 319, Cambridge University Press, Cambridge, 2005. MR 2133033 (2007e:32012) |
| [Che11] | I. Cherednik, Jones polynomials of torus knots via daha , ArXiv 1111.6195 (2011). Ivan Cherednik, Jones polynomials of torus knots via DAHA , Int. Math. Res. Not. IMRN |
| [Che13] [CKM14] | (2013), no. 23, 5366-5425. MR 3142259 Sabin Cautis, Joel Kamnitzer, and Scott Morrison, Webs and quantum skew Howe duality , Math. Ann. 360 |
| [EGL13] | (2014), no. 1-2, 351-390. MR 3263166 P. Etingof, E. Gorsky, and I. Losev, Representations of Rational Cherednik algebras with minimal support and torus knots , arXiv 1304.3412 (2013). |
| [EN85] | David Eisenbud and Walter Neumann, Three-dimensional link theory and invariants of plane curve singular- ities , Annals of Mathematics Studies, vol. 110, Princeton University Press, Princeton, NJ, 1985. MR 817982 |
| [FG00] | (87g:57007) Charles Frohman and R˘zvan a Gelca, Skein modules and the noncommutative torus , Trans. Amer. Math. Soc. |
| [GN15] | (2000), no. 10, 4877-4888. MR MR1675190 (2001b:57014) Eugene Gorsky and Andrei Negut, Refined knot invariants and Hilbert schemes , J. Math. Pures Appl. (9) (2015), no. 3, 403-435. MR 3383172 |
| | 104 |
| [KM91] | Duke Math. J. 163 (2014), no. 14, 2709-2794. MR 3273582 Robion Kirby and Paul Melvin, The 3 -manifold invariants of Witten and Reshetikhin-Turaev for sl(2 , C ), |
| [Kup96] | Invent. Math. 105 (1991), no. 3, 473-545. MR 1117149 (92e:57011) Greg Kuperberg, Spiders for rank 2 Lie algebras , Comm. Math. Phys. 180 (1996), no. 1, 109-151. MR |
| [MM08] | 1403861 (97f:17005) H. R. Morton and P. M. G. Manch´n, o Geometrical relations and plethysms in the Homfly skein of the annulus , |
| [Mor95] | J. Lond. Math. Soc. (2) 78 (2008), no. 2, 305-328. MR 2439627 (2009h:57021) H. R. Morton, The coloured Jones function and Alexander polynomial for torus knots , Math. Proc. Cambridge Philos. Soc. 117 (1995), no. 1, 129-135. MR 1297899 (95h:57008) |
| [MS14] | H. Morton and P. Samuelson, The HOMFLYPT skein algebra of the torus and the elliptic Hall algebra , arXiv 1410.0859 (2014). |
| | Hugh Morton and Peter Samuelson, The HOMFLYPT skein algebra of the torus and the elliptic Hall algebra , |
| [MS17] | Duke Math. J. 166 (2017), no. 5, 801-854. MR 3626565 |
| [MV94] | G. Masbaum and P. Vogel, 3 -valent graphs and the Kauffman bracket , Pacific J. Math. 164 (1994), no. 2, 361-381. MR 1272656 (95e:57003) |
| [Prz91] | J´zef o H. Przytycki, Skein modules of 3 -manifolds , Bull. Polish Acad. Sci. Math. 39 (1991), no. 1-2, 91-100. MR 1194712 (94g:57011) |
| [Sam12] | Math. Phys. 127 (1990), no. 1, 1-26. MR 1036112 (91c:57016) Peter Samuelson, Kauffman bracket skein modules and the quantum torus , Ph.D. thesis, Cornell University, 2012. |
| [Sik05] | Adam S. Sikora, Skein theory for SU( n ) -quantum invariants , Algebr. Geom. Topol. 5 (2005), 865-897 (elec- tronic). MR 2171796 (2006j:57033) |
28
## PETER SAMUELSON
[SW07]
Adam S. Sikora and Bruce W. Westbury, Confluence theory for graphs , Algebr. Geom. Topol. 7 (2007), 439-478. MR 2308953 (2008f:57004)
[Ter13]
Paul Terwilliger, The universal Askey-Wilson algebra and DAHA of type ( C ∨ 1 , C 1 ), SIGMA Symmetry Integra- bility Geom. Methods Appl. 9 (2013), Paper 047, 40. MR 3116183
[Tra14]
A. T. Tran, The strong AJ conjecture for cables of torus knots , arXiv:1404.0331 (2014).
[van08] R. van der Veen, A cabling formula for the colored Jones polynomial , ArXiv 0807.2679 (2008).
Department of Mathematics, University of Edinburgh, Edinburgh, UK
E-mail address : [email protected] | 10.1093/imrn/rnx198 | [
"Peter Samuelson"
] | 2014-08-03T10:48:47+00:00 | 2017-08-01T18:30:45+00:00 | [
"math.QA",
"math.RT"
] | Iterated torus knots and double affine Hecke algebras | We give a topological realization of the (spherical) double affine Hecke
algebra $\mathrm{SH}_{q,t}$ of type $A_1$, and we use this to construct a
module over $\mathrm{SH}_{q,t}$ for any knot $K \subset S^3$. As an
application, we give a purely topological interpretation of Cherednik's
2-variable polynomials $P_n(r,s; q,t)$ of type $A_1$ from [Che13] (where $r,s
\in \mathbb{Z}$ are relatively prime), and we give a new proof that these
specialize to the colored Jones polynomials of the $r,s$ torus knot.
We then generalize Cherednik's construction (for $\mathcal{sl}_2$) to all
iterated cables of the unknot and prove the corresponding specialization
property. Finally, in the appendix we compare our polynomials associated to
iterated torus knots to the ones recently defined in [CD14], in the
specialization $t=-q^2$. |
1408.0485v1 | ## SIZE DEPENDENT CRUSH ANALYSIS OF LITHIUM ORTHOSILICATE PEBBLES GLYPH<3>
a ; y b c b b
School of Civil Engineering, The University of Sydney, NSW 2006, Australia y Corresponding author: [email protected]
R. K. Annabattula, M. Kolb, Y. Gan, R. Rolli and M. Kamlah a Department of Mechanical Engineering, Indian Institute of Technology Madras, Chennai - 600036, India b Institute for Applied Materials (IAM), Kalrsruhe Institute of Technology (KIT), 76344, Eggenstein-Leopoldshafen, Germany c
## ABSTRACT
Crushing strength of the breeder materials (lithium orthosilicate, Li4SiO4 or OSi) in the form of pebbles to be used for EU solid breeder concept is investigated. The pebbles are fabricated using a melt-spray method and hence a size variation in the pebbles produced is expected. The knowledge of the mechanical integrity (crush strength) of the pebbles is important for a successful design of breeder blanket. In this paper, we present the experimental results of the crush (failure) loads for spherical OSi pebbles of di GLYPH<11> erent diameters ranging from 250 GLYPH<22> mto 800 GLYPH<22> m. The ultimate failure load for each size shows a Weibull distribution. Furthermore, the mean crush load increases with increase in pebble diameter. It is also observed that the level of opacity of the pebble influences the crush load significantly. The experimental data presented in this paper and the associated analysis could possibly help us to develop a framework for simulating a crushable polydisperse pebble assembly using discrete element method.
## I. INTRODUCTION
Lithium Orthosilicate (Li4SiO4 or OSi) in the form of pebbles is the candidate breeder material for the Helium Cooled Pebble Bed (HCPB)
GLYPH<3> Published in Fusion Science and Technology, vol. 66, pages:136-141 (2014), doi:10.13182 FST13-737 /
breeder concept for European Union (EU) (Ref. 1). Thermo-mechanical integrity of the pebble bed is crucial for a safe and sustained fusion cycle. 2 Experimental and numerical investigations to assess the breeder material properties 3-9 and pebble bed packing structure 10-12 have been carried out in the past. It has also been shown that the pebble bed thermo-mechanical behaviour is strongly influenced by the individual pebble interactions and their packing structure in addition to the bulk material properties of the pebbles. 13-17 The fabricated OSi pebbles have a size distribution and the size distribution has not been taken into consideration in the previous numerical studies except in (Ref. 15). The e GLYPH<11> ect of pebble size distribution on the macroscopic behaviour has been studied using a polydisperse pebble assembly through Discrete Element Method (DEM) (Ref. 15). However, the study was focused on a non-crushable pebble assembly. But, under fusion relevant conditions, pebbles may fail possibly leading to termination of fusion fuel cycle. Recently, the studies on mechanics of a crushable pebble assembly have been reported albeit for a mono size pebble assembly. 14,16-18 For a more general understanding of the mechanics of pebble beds, the knowledge of the macroscopic response of a polydisperse crushable pebble assembly will be very useful in the design of pebble beds. However, such a study is not straight forward as in the case of mono size assemblies. We need a thorough understanding of crush (failure) load of individual pebbles as a func-

T
O
(a)
(b)
Fig. 1: (a) Optical images of a batch of OSi pebbles of size 250 GLYPH<22> mused for crush tests. (b) Zoomed view of the batch showing di GLYPH<11> erent transparency levels for pebbles. The transparent pebbles (marked 'T') fail at much lower load compared to opaque (or less transparent marked 'O') pebbles. Also, some of the pebbles are not completely spherical and hence the sphericity is also measured during the tests.
tion of pebble size which will be a necessary input for the numerical models mentioned in the foregoing discussion. Hence, in this paper we report the experimental details and the measured crush loads as a function of the pebble size for OSi pebbles.
## II. EXPERIMENTAL PROCEDURE
Crush experiments have been conducted on OSi pebbles of diameter in the range of 250 GLYPH<22> m 800 GLYPH<22> m at Fusion Materials Laboratory of Karlsruhe Institute of Technology (KIT), Germany. First, the pebbles are sieved into 10 di GLYPH<11> erent size groups with mean diameters of 250, 315, 355, 400, 450, 500, 560, 630, 710 and 800 (all in micrometer). Then, the as received OSi pebbles are heated up to 300 C for one hour in an inert gas (Nitroo gen) environment to remove any moisture present. Individual pebbles are compressed quasistatically using a table top uniaxial testing machine between two compression platens made of BK7 glass. BK7 glass is chosen as the material for compression platens to reduce the e GLYPH<11> ect of plastic deformation of platens on the failure load. 17 The crush experiments have been conducted in a glove box at room temperature and the compression platens contact the pebble at the top and bottom in all the experiments. The pebble size is measured before the crush test as the distance between the compression platens. The sphericity GLYPH<3> of the pebbles is measured through optical means by placing a layer of pebbles on a flat surface as shown in Fig. 1(a). The average sphericity of the pebbles is approximately 0.95 (see Table I.) and hence the pebble size measured as the distance between compression plates is a reasonable estimate. The spread of the pebble size for a particular mean size is very small (less than 5%) and hence in the results discussed in the following sections, only the mean size without error bars is considered. For each pebble size, 45 measurements have been made to take into account of the stochastic nature of the crush loads similar to the previous observations. 16 Furthermore, in Fig. 1(b) two types of pebble surface morphology may be observed. The pebbles which are more transparent are marked as 'T' while relatively opaque pebbles are marked 'O'. During the crush experiments, it has been observed that the transparent pebbles (marked 'T') show a very low
GLYPH<3> Sphericity in this study is defined as the ratio of minimum diameter to maximum diameter of a pebble measured in two orthogonal directions. The average of 60 measurements for each size is reported as the sphericity for the group shown in Table I.
TABLE I.: Average Form Factor (sphericity) as a function of pebble size measured for 60 samples each size.
| Mean Pebble Diameter ( GLYPH<22> m) | 250 | 315 | 355 | 400 | 450 | 500 | 560 | 630 | 710 | 800 |
|---------------------------------------|-------|-------|-------|-------|-------|-------|-------|-------|-------|-------|
| Form Factor (Sphericity) | 0.92 | 0.95 | 0.94 | 0.95 | 0.95 | 0.95 | 0.95 | 0.95 | 0.96 | 0.95 |
crush load while the opaque (marked 'O') pebbles show an average crush load with some distribution. Hence, in the data analysis, the crush loads of transparent pebbles (show negligibly small crush load) is discarded.
clean fracture surface (see Fig. 2(d)) without any steps as in region A . The crack propagates through the rest of the pebble at very high speed and the pebble breaks into few fragments.
## III. RESULTS AND DISCUSSION
In this section, we present the results obtained from the single pebble crush experiments followed by discussion. Fig. 2(a) shows the SEM image of a typical OSi pebble after failure. The details of the failure surface are delineated in Fig. 2(b), Fig. 2(c) and Fig. 2(d). Here, three typical regions A, B and C are highlighted each depicting a di GLYPH<11> erent failure mechanism.
Region A : In this region the cracking of the pebble seems to be advancing quite slowly and definitely not in a catastrophic manner as we can observe a stepped surface (see Fig. 2(c)) rather than a clean fracture surface typical of catastrophic failure. Although, such surfaces suggest some plastic deformation, it is not observed predominantly and hence plastic deformation may be ignored in these systems.
Region B : This type of micro structure is typical for OSi pebbles produced by a melt-spray process such as in this study. 19,20 Here the solidification of the melt leads to a flat void or pore within the pebble, compensating for the increase in density by crystallization. The void helps the crack to propagate resulting in a lower mechanical strength of the pebble.
Region C : This region shows the situation of a catastrophic failure of the pebble, i.e. the critical crack length is reached. We can observe a very
From the above discussion, it can be clearly seen that the OSi pebble failure is brittle in nature. Furthermore, the crush load data follows a Weibull distribution (see 16, 17) typical of brittle failure in materials. Details of the Weibull distribution for the experimental data is not presented here due to space limitations.
Fig. 3(a) shows the crush (failure) load y ( F ) as a function of pebble size. Each data point represents an average of 45 measurements with a standard deviation as shown in the figure. The crush load increases with increase in pebble size. Also note that the standard deviation also increases with increase in pebble size. This increase in standard deviation may be related to increase in number of defects and the size of defects with increase in pebble size. However, the data point corresponding to 355 GLYPH<22> mshows a lower crush load compared to the expected trend. This is due to the presence of large fraction of transparent pebbles (indicated by 'T' in Fig. 1(b)) for which the crush load is not very small unlike the cases in which such results are discarded as mentioned before. Fig. 3(b) shows the variation of a measure of crush stress z as a function of pebble size. Here, the crush stress is calculated by dividing the crush load with the area of a circle of same diameter as the pebble size. A size dependent crush stress that increases with decrease in pebble size can be observed. The data
y Crush load in the present analysis is defined as the point at which load suddenly drops in the load-displacement curve indicating the sudden fracture of pebbles.
z The crush stress here should be looked as crush load per unit surface area and not as stress in physical sense

(a)


(b)

(c)
(d)
Fig. 2: (a) SEM image of a typical failure surface of a OSi pebble. (b) Zoomed version of failure surface around top middle portion of the pebble shown in (a) describing various failure modes identified by region 'A' (slow crack growth), region 'B' (with voids) and region 'C' (clean fracture surface). (c) Surface details of region 'A' and (d) region 'C'.
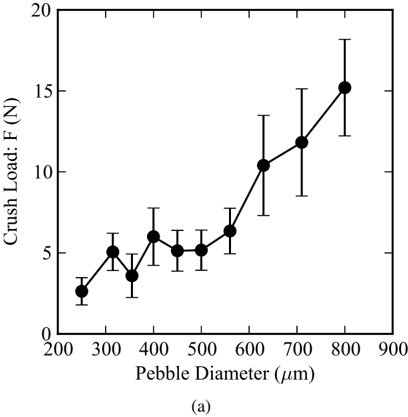
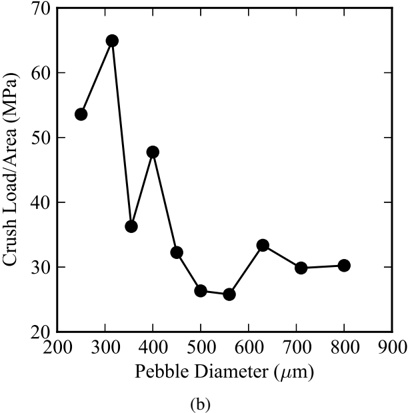
70
Fig. 3: (a) Crush Load and (b) Equivalent Crush Stress for OSi pebbles as a function of pebble size.
point corresponding to 355 GLYPH<22> mis an exception due to the presence of large number of transparent pebbles in the measurements as mentioned before. For characterizing the pebble failure a better measure is the critical failure energy, i.e. the stored elastic energy at the onset of failure of pebble during compression. 14,16,17 Critical failure energy ( Wc ) of a pebble in elastic contact is given by (Ref. 17)
$$W _ { c } = \sum _ { i = 1 } ^ { N _ { c } } \frac { 1 } { 5 } \left ( \frac { 9 F _ { i } ^ { 5 } } { 1 6 R _ { i } ^ { * } E ^ { * ^ { 2 } } } \right ) ^ { \frac { 1 } { 3 } } \quad ( 1 ) \quad \text{$tan$} \quad \text{(1)} \quad \text{the} \ \text{$Eq$}.$$
where Nc is the number of contacts, Fi is the normal contact force due to i th contact. The e GLYPH<11> ective elastic modulus ( E GLYPH<3> ) and e GLYPH<11> ective radius ( R GLYPH<3> ) are given by
$$E ^ { * } = \frac { 1 } { 2 } \left [ \frac { E _ { p } } { 1 - \nu _ { p } ^ { 2 } } + \frac { E _ { b k 7 } } { 1 - \nu _ { b k 7 } ^ { 2 } } \right ] ; \, \frac { 1 } { R ^ { * } } = \frac { 1 } { R _ { p } } + \frac { 1 } { R _ { b k 7 } }, \, \ ( 2 ) \text{ble} ^ { \text{(or)} } \,.$$
where, ( Ep ; Ebk 7) = (90 82) GPa and ( ; GLYPH<23> p ; GLYPH<23> bk 7) = (0 25 0 206) are the Young's modulus and Pois-: ; : son's ratio of the OSi pebble and BK7 glass materials, respectively. For the present case of a flat BK7 glass plate contacting OSi pebble, Rbk 7 = 1 and hence R GLYPH<3> = Rp . We also define another parameter critical failure energy per unit area ( Wc GLYPH<3> ) given by
(2) ble material. Hence, we assume The crush load experiments reported in this paper can be treated as mono-size pebbles with only a single contact pair. However, one needs to know the critical failure energy in order to predict a crush load versus pebble size variation as in Eq. 1. We hypothesise that the critical failure energy per unit area ( Wc GLYPH<3> ) of OSi pebbles doesn't depend on the size of the pebble and hence we can assume a constant mean failure energy per unit area to predict the crush load versus pebble size variation as in Eq. 1. We have already shown that the pebble failure is brittle (catastrophic) failure and there is no plastic deformation observed in these systems. Hence, the pebble fails when the strain energy release rate near the crack tip reaches the toughness (or critical failure energy per unit area) of the pebWc GLYPH<3> = 0 02 kJ : = m 2 for the present analysis x . Fig. 4 shows the crush load of all the pebbles (all sizes) plotted against the pebble size in filled circles. The line in the figure is the fitted curve for the data with Wc GLYPH<3> = 0 02 kJ : = m 2 showing good fit with the experimental data. Note that the figure is plotted on log-log scale and hence the linear relation between crush load and pebble
$$W _ { c } ^ { * } = \frac { W _ { c } } { \pi R ^ { 2 } } \quad \quad \ \ ( 3 ) \ \, \text{the} \quad \ \$$
x This is the mean critical failure energy per unit area of the pebble with a diameter of 500 GLYPH<22> m reported in previous studies by (Ref. 16)
Fig. 4: Crush load as a function of pebble size (filled circles) and an approximate fit to the data for a failure energy Wc GLYPH<3> = 0 02 kJ : = m 2 .
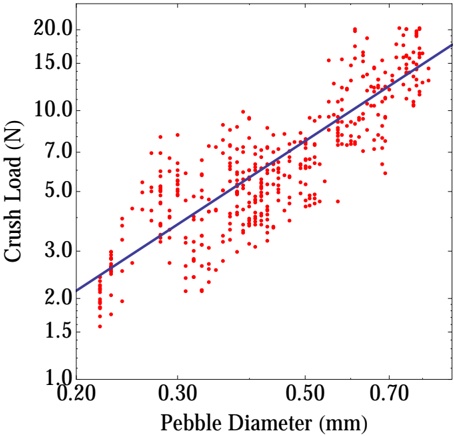
size should be understood in the right scale. Also, note that the critical failure energy reported for 500 GLYPH<22> mpebbles is a not a single value but follows a Weibull distribution 16 which is not taken into consideration in this analysis. The transition from lab scale analysis of experiments presented in this paper to real DEM simulations involving pebbles of di GLYPH<11> erent sizes in contact needs further work on which the authors are currently working.
## IV. CONCLUSIONS
The crush load data for pebbles of 10 di GLYPH<11> erent sizes has been reported. The crush data for each size shows a Weibull distribution similar to previous studies. The crush load increases with increase in pebble size. The standard deviation of crush load also increases with increase in pebble size. This may be attributed to increase in number of defects and size of defects with increase in pebble size. The pebble crush data for di GLYPH<11> erent pebble sizes can be fitted with a single curve with an assumption of critical failure energy per unit area. The critical failure energy per unit area of
0 02 kJ : = m 2 obtained for 500 GLYPH<22> mpebble from the previous studies shows a reasonable agreement with the data. Hence, such a trend may be incorporated in future DEM simulations for a crushable polydisperse pebble assembly which is expected to give new insights to pebble bed thermo-mechanics.
## REFERENCES
[1] L. BOCCACCINI, J.-F. SALAVY, O. BEDE, H. NEUBERGER, I. RICAPITO, P. SARDAIN, L. SEDANO, and K. SPLICHAL, 'The EU TBM systems: Design and development programme,' Fusion Engineering and Design , 84 , 2-6 , 333-337 (Jun. 2009).
[2] A. YING, J. REIMANN, L. BOCCACCINI, M. ENOEDA, M. KAMLAH, R. KNITTER, Y. GAN, J. G. VAN DER LAAN, L. MAGIELSEN, P. D. MAIO, G. DELLORCO, R. K. ANNABATTULA, J. T. VAN LEW, H. TANIGAWA, and S. VAN TIL, 'Status of ceramic breeder pebble bed thermomechanics R&D and impact on breeder ma-
terial mechanical strength,' Fusion Engineering and Design , 87 , 7-8 , 1130-1137 (Aug. 2012).
- [3] J. REIMANN, E. ARBOGAST, M. BEHNKE, S. MUELLER, and K. THOMAUSKE, 'Thermomechanical behaviour of ceramic breeder and beryllium pebble beds,' Fusion Engineering and Design , 49-50 , 1-4 , 643-649 (Nov. 2000).
- [4] G. PIAZZA, J. REIMANN, E. G ¨ NTHER, U R. KNITTER, N. ROUX, and J. LULEWICZ, 'Behaviour of ceramic breeder materials in long time annealing experiments,' Fusion Engineering and Design , 58-59 , 653-659 (Nov. 2001).
- [5] G. PIAZZA, J. REIMANN, E. G ¨ NTHER, U R. KNITTER, N. ROUX, and J. LULEWICZ, 'Characterisation of ceramic breeder materials for the helium cooled pebble bed blanket,' Journal of Nuclear Materials , 307-311 , 811816 (Dec. 2002).
- [6] L. B ¨ HLER and J. REIMANN, 'Thermal U creep of granular breeder materials in fusion blankets,' Journal of Nuclear Materials , 307311 , 807-810 (Dec. 2002).
- [7] Z. AN, A. YING, and M. ABDOU, 'Experimental & Numerical study of ceramic breeder pebble bed thermal deformation behavior,' Fusion Science and Technology , 47 , 4 , 1101 (2005).
- [8] J. REIMANN, G. PIAZZA, and H. HARSCH, 'Thermal conductivity of compressed beryllium pebble beds,' Fusion Engineering and Design , 81 , 1-7 , 449-454 (Feb. 2006).
- [9] R. KNITTER, B. ALM, and G. ROTH, 'Crystallisation and microstructure of lithium orthosilicate pebbles,' Journal of Nuclear Materials , 367-370 , 1387-1392 (Aug. 2007).
- [10] J. REIMANN, 'Influence of pebble bed dimensions and filling factor on mechanical
- pebble bed properties,' Fusion Engineering and Design , 69 , 1-4 , 241-244 (Sep. 2003).
- [11] J. REIMANN, R. PIERITZ, C. FERRERO, M. DIMICHIEL, and R. ROLLI, 'X-ray tomography investigations on pebble bed structures,' Fusion Engineering and Design , 83 , 7-9 , 1326-1330 (Dec. 2008).
- [12] Y. GAN, M. KAMLAH, and J. REIMANN, 'Computer simulation of packing structure in pebble beds,' Fusion Engineering and Design , 85 , 10-12 , 1782-1787 (Dec. 2010).
- [13] Y. GAN and M. KAMLAH, 'Discrete element modelling of pebble beds: With application to uniaxial compression tests of ceramic breeder pebble beds,' Journal of the Mechanics and Physics of Solids , 58 , 2 , 129-144 (Feb. 2010).
- [14] S. ZHAO, Y. GAN, and M. KAMLAH, 'Spherical ceramic pebbles subjected to multiple non-concentrated surface loads,' International Journal of Solids and Structures , 49 , 3-4 , 658-671 (Feb. 2012).
- [15] R. K. ANNABATTULA, Y. GAN, and M. KAMLAH, 'Mechanics of binary and polydisperse spherical pebble assembly,' Fusion Engineering and Design , 87 , 5-6 , 853858 (Aug. 2012).
- [16] R. K. ANNABATTULA, Y. GAN, S. ZHAO, and M. KAMLAH, 'Mechanics of a crushable pebble assembly using discrete element method,' Journal of Nuclear Materials , 430 , 1-3 , 90-95 (Nov. 2012).
- [17] S. ZHAO, Y. GAN, M. KAMLAH, T. KENNERKNECHT, and R. ROLLI, 'Influence of plate material on the contact strength of Li4SiO4 pebbles in crush tests and evaluation of the contact strength in pebblepebble contact,' Engineering Fracture Mechanics , 100 , 28-37 (Mar. 2013).
- [18] Y. GAN, M. KAMLAH, H. RIESCHOPPERMANN, R. ROLLI, and P. LIU, 'Crush probability analysis of ceramic
breeder pebble beds under mechanical stresses,' Journal of Nuclear Materials , 417 , 1-3 , 706-709 (2011).
- [19] R. KNITTER and B. LOBBECKE, 'Reprocessing of lithium orthosilicate breeder material by remelting,' Journal of Nuclear Materials , 361 , 1 , 104-111 (Mar. 2007).
- [20] M. KOLB, R. KNITTER, U. KAUFMANN, and D. MUNDT, 'Enhanced fabrication process for lithium orthosilicate pebbles as breeding material,' Fusion Engineering and Design , 86 , 9-11 , 2148 - 2151 (2011). | 10.13182/FST13-737 | [
"Ratna Kumar Annabattula",
"Matthias Kolb",
"Yixiang Gan",
"Rolf Rolli",
"Marc Kamlah"
] | 2014-08-03T10:59:14+00:00 | 2014-08-03T10:59:14+00:00 | [
"cond-mat.mtrl-sci",
"cond-mat.soft"
] | Size dependent crush analysis of lithium orthosilicate pebbles | Crushing strength of the breeder materials (lithium orthosilicate,
$\rm{Li_4SiO_4}$ or OSi) in the form of pebbles to be used for EU solid breeder
concept is investigated. The pebbles are fabricated using a melt-spray method
and hence a size variation in the pebbles produced is expected. The knowledge
of the mechanical integrity (crush strength) of the pebbles is important for a
successful design of breeder blanket. In this paper, we present the
experimental results of the crush (failure) loads for spherical OSi pebbles of
different diameters ranging from $250~\mu$m to $800~\mu$m. The ultimate failure
load for each size shows a Weibull distribution. Furthermore, the mean crush
load increases with increase in pebble diameter. It is also observed that the
level of opacity of the pebble influences the crush load significantly. The
experimental data presented in this paper and the associated analysis could
possibly help us to develop a framework for simulating a crushable polydisperse
pebble assembly using discrete element method. |
Subsets and Splits
No saved queries yet
Save your SQL queries to embed, download, and access them later. Queries will appear here once saved.